Урок 31. Синтаксический разбор предложения – конспект урока – Корпорация Российский учебник (издательство Дрофа – Вентана)
Разработки уроков (конспекты уроков)
Начальное общее образование
Линия УМК С. В. Иванова. Русский язык (1-4)
Русский язык
Внимание! Администрация сайта rosuchebnik.ru не несет ответственности за содержание методических разработок, а также за соответствие разработки ФГОС.
Задачи урока
- Закрепить навыки разбора предложений по членам и синтаксического разбора.
Виды деятельности
Находить грамматическую основу предложений. Соблюдать алгоритм проведения разбора по членам предложения и синтаксического разбора предложения. Осуществлять взаимный контроль и оказывать в сотрудничестве необходимую взаимопомощь, договариваться о последовательности действий и порядке работы в группах. Составлять предложения, удовлетворяющие заданным условиям.
Составлять предложения, удовлетворяющие заданным условиям.
Ключевые понятия
-
Синтаксис, грамматическая основа
| № | Название этапа | Методический комментарий |
|---|---|---|
| 1 | Словарная работа | — Найдите словарные слова, которые «спрятались», запишите в тетрадь. |
| 2 | Знакомство с темой урока | — Какую характеристику предложения предполагает синтаксический разбор предложения? — Проверьте свой ответ. |
| 3 | Работа по теме урока |
— Когда в предложении ставится двоеточие? — Какой частью речи может быть выражено сказуемое? — Работа с учебником.
|
| 4 | Закрепление изученного | — В каких предложениях пропущены запятые? — Докажите. |
| 5 | Рекомендации для самостоятельной работы дома | Составить три предложения с однородными членами и выполнить синтаксический разбор. |
Хотите сохранить материал на будущее? Отправьте себе на почту
в избранноеТолько зарегистрированные пользователи могут добавлять в избранное.
Войдите, пожалуйста.
Назад к методической помощи по линии Линия УМК С. В. Иванова. Русский язык (1-4)
Оценка разработки
Для оценки работы вам необходимо авторизоваться на сайте
Войти или зарегистрироваться
Ограничение доступа
Для доступа к материалу требуется регистрация на сайте
Войти или зарегистрироваться
Нужна помощь?
НЕПОЛНЫЙ СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА В ИНФОРМАЦИОННО-ПОИСКОВЫХ СИСТЕМАХ
НЕПОЛНЫЙ СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА В
ИНФОРМАЦИОННО-ПОИСКОВЫХ СИСТЕМАХ
А. Е. Ермаков
Е. Ермаков
ООО “Гарант-Парк-Интернет”
Ключевые слова: синтаксический разбор, разрешение омонимии, выделение именных групп, статистический анализ текста, информационный портрет текста.
Доклад посвящен опыту разработки неполного синтаксического анализатора русского языка и его внедрению в прикладные системы анализа полнотекстовых документов в компании “Гарант-Парк-Интернет”. Синтаксический разбор без учета глагольного управления на основе бесконтекстной грамматики позволяет выделять именные группы и разрешать морфологическую омонимию, не выходя за рамки допустимых ограничений на вычислительные ресурсы систем, работающих с большими массивами документов. Экспериментально показано, что использование такого анализатора на этапе предварительной обработки документа существенно повышает точность работы алгоритмов статистического анализа текста в прикладных системах.
1.
 Введение
Введение
Задаче компьютерного анализа текста на естественном языке посвящено множество теоретических и практических работ. Доступные сегодня вычислительные мощности позволили применить широкий класс математических методов анализа неструктурированных данных для обработки больших массивов документов, эффективно решая задачи поиска информации, классификации, кластерного анализа, выявления скрытых закономерностей и другие. Не последнее место в этом ряду занимают и наши собственные разработки в компании “Гарант-Парк-Интернет”, представленные на сайтеhttp://research.metric.ru.
К сожалению, внедрение математических методов в обработку текста проходит на фоне отсталости собственно лингвистической составляющей алгоритмов, что не позволяет достичь высокого качества работы прикладных систем. Ставший устойчивым уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика на время оказалась оставлена в стороне. Господствующего мнения, что лингвистические алгоритмы являются ненадежными, слабо масштабируемыми и чересчур медленными для решения реальных задач, до недавнего времени придерживались и автор в более ранних публикациях на эту тему [1,2].
Господствующего мнения, что лингвистические алгоритмы являются ненадежными, слабо масштабируемыми и чересчур медленными для решения реальных задач, до недавнего времени придерживались и автор в более ранних публикациях на эту тему [1,2].
Исследования, проведенные нами в последний год, заставили изменить сложившуюся точку зрения на место алгоритмов синтаксического разбора в структуре статистических анализаторов текста. Не претендуя на конкуренцию с разработчиками систем машинного перевода и оставаясь в рамках решения собственных задач, относимых скорее к разряду аналитических, мы начали успешно развивать синтаксическую обработку для внедрения в собственные продукты.
2. Синтаксический разбор в задачах автоматического анализа текста
Сложность реализации высокоточного анализатора связана с наличием тесной связи между синтаксисом и семантикой, присутствием в текстах русского языка большого количества синтаксически омонимичных конструкций, не допускающих однозначной интерпретации без привлечения знаний о семантической сочетаемости слов. Такова, например, проблема управления глагола предложно-падежными конструкциями. В синтаксически эквивалентных фразах “человек стрелял из ружья” и “человек стрелял из окна”, объект “ружье” представляет аргумент предиката “стрелять” в роли косвенного дополнения, а объект “окно” – обстоятельство места, которое является дополнительной характеристикой всей ситуации в целом.
Такова, например, проблема управления глагола предложно-падежными конструкциями. В синтаксически эквивалентных фразах “человек стрелял из ружья” и “человек стрелял из окна”, объект “ружье” представляет аргумент предиката “стрелять” в роли косвенного дополнения, а объект “окно” – обстоятельство места, которое является дополнительной характеристикой всей ситуации в целом.
Модель языка, призванная объединить синтаксическую и семантическую составляющие, известна под названием толково-комбинаторного словаря и призвана описать ограничения на сочетаемость лексических единиц в определенных синтаксических ролях, например, в форме известного аппарата лексических функций [6].
Однако, помимо колоссального объема необходимого ручного труда, разработку подобного словаря усложняет отсутствие достаточно полной и устоявшейся системы классификации типов синтагматических отношений (например, базиса лексических функций), а также парадигматической классификации лексики (тезауруса). Так, если описание синтагматики обязано декларировать, что аргумент предиката “стрелять”, представляющий орудие действия, должен относиться к классу “оружие”, то описание парадигматики призвано установить все имена, относимые к этому классу – “ружье”, “рогатка” и др.
Так, если описание синтагматики обязано декларировать, что аргумент предиката “стрелять”, представляющий орудие действия, должен относиться к классу “оружие”, то описание парадигматики призвано установить все имена, относимые к этому классу – “ружье”, “рогатка” и др.
Указанные проблемы привели к установившемуся мнению о нецелесообразности введения модуля синтаксического разбора в системы автоматического анализа текста. Однако оказалось, что, несмотря на ограниченную точность синтаксических анализаторов, их использование способно заметно повысить качество таких систем в случае комбинирования с известными статистическими методами [1,2], не выходя за рамки стандартных ограничений на вычислительные ресурсы.
Дело в том, что отдельные ошибки синтаксического анализатора поглощаются в дальнейшем при фильтрации статистическим анализатором, поскольку общее число “нормальных” языковых конструкций в тексте существенно превышает число “нестандартных”. Некоторые ошибки могут оказаться заметными при анализе текстов небольшого объема, однако стоит учесть, что статистическому анализу такие тексты вообще не поддаются.
Некоторые ошибки могут оказаться заметными при анализе текстов небольшого объема, однако стоит учесть, что статистическому анализу такие тексты вообще не поддаются.
Экспериментально проверенным фактом является также то, что для решения многих задач с приемлемым качеством не требуется полный синтаксический разбор, к которому призваны стремиться автоматические переводчики. Полный анализ всех возможных синтаксических связей, присутствующих во фразе, даже сейчас является непомерно долгим для нашего класса задач.
Основные задачи, решаемые сегодня системами анализа текста, следующие: формирование информационного портрета текста в терминах ключевых понятий, выявление смысловых связей между понятиями, автоматическое реферирование. Прикладные функции интеллектуальных систем, которые могут быть реализованы на основе этих результатов, были описаны в работах [3,4,5]. Важнейшей сопутствующей проблемой, решаемой исключительно средствами синтаксического анализа, является разрешение омонимии в тех случаях, когда грамматические формы различных слов совпадают (например, форма “стали” для существительного “сталь” и глагола “стать”).
3. Синтаксический разбор и разрешение омонимии
Целью синтаксического разбора является построение дерева синтаксических зависимостей между словами во фразе. В случае удачного разбора предложение сворачивается в полносвязное дерево с единственной корневой вершиной.
Поскольку одна словоформа может соответствовать нескольким грамматическим формам слова, в том числе формам различных слов, в ходе анализа необходимо производить свертку предложения для всех возможных вариантов грамматических форм. Те грамматические формы, которые обеспечивают максимальную свертку дерева (минимальное число висячих вершин), следует считать наиболее достоверными.
Как показала практика, для снятия большей части омонимии (около 90%) не требуется полный синтаксический анализ, обеспечивающий полную свертку дерева. Достаточным оказывается включение правил согласования слов в именных и глагольных группах, свертки однородных членов, согласования подлежащего и сказуемого, предложно-падежного управления и нескольких прочих – всего в пределах 20-ти правил, описываемых бесконтекстной грамматикой. Подробно ознакомиться со способами формального описания языка можно, например, в работе [7].
Подробно ознакомиться со способами формального описания языка можно, например, в работе [7].
Порядок применения правил управляется алгоритмом разбора, который на каждом шаге проверяет возможность применения очередного правила к очередному фрагменту фразы (паре-тройке слов, знаков препинания и т.п.) и, если удается, сворачивает фрагмент. Свертка фрагмента обычно заключается в его замене одним главным словом – удалением подчиненных слов, после чего разбор продолжается. В случае невозможности дальнейшего применения правил на любом из шагов совершается откат – последний свернутый фрагмент восстанавливается и делается попытка применить другие правила. Окончательным вариантом разбора следует считать такую последовательность применения правил, которая порождает максимальную свертку фразы.
Так, в ходе разбора фразы “усталые гуси и утки стали снижаться”, возникают следующие варианты:
( усталые -> ( гуси + утки ) ) ~> ( стали <- снижаться ),
( усталые -> гуси ) и ( утки ~> ( стали <- снижаться ) ),
( ( усталые -> гуси ) + ( утки <- стали ) ) снижаться,
и ряд других.
Здесь каждая пара скобок включает ряд слов, обработанных некоторым правилом на очередном шаге анализа. Прямая стрелка указывает отношение подчинения при свертке именных и глагольных групп, знак плюса – свертку равноправных однородных членов, а волнистая стрелка – связь подлежащего со сказуемым. Такое представление соответствует дереву зависимостей во фразе.
Очевидно, что только первый вариант соответствует полному разбору – полносвязному дереву с одной вершиной, представленной глагольной группой “стали снижаться”. Второй вариант не полон, но все установленные синтаксические связи являются правильными и позволяют правильно разрешить омонимию у глагола “стать”. В третьем варианте присутствует ошибка, вызванная наличием у существительного “сталь” формы “стали” в родительном падеже множественного числа – выделена именная группа “утки стали” (аналогично “полосы стали”, “ковка стали”).
Как видно, процессу разбора соответствует целое дерево вариантов свертки фразы, вследствие чего производительность алгоритма падает экспоненциально с ростом числа используемых правил и количества слов в предложении. Так, очень сложные предложения могут порождать десятки тысяч вариантов разбора. Эта вычислительная проблема является общей для всех синтаксических анализаторов, ввиду чего на практике целесообразно ограничивать допустимое число рассматриваемых вариантов, и выбирать из них субоптимальный вариант свертки.
Так, очень сложные предложения могут порождать десятки тысяч вариантов разбора. Эта вычислительная проблема является общей для всех синтаксических анализаторов, ввиду чего на практике целесообразно ограничивать допустимое число рассматриваемых вариантов, и выбирать из них субоптимальный вариант свертки.
Как показал опыт, влияние подобного ограничения сказывается лишь на разборе небольшого количества особенно сложных предложений. Однако для разрешения омонимии даже неполного разбора практически всегда оказывается достаточно. Положительной стороной этого момента является то, что точность анализа и его скорость (обратно пропорциональная полноте) регулируются одним числовым параметром, определяющим соотношение между ними. Так, начиная с некоторого момента, повышение точности разбора на один процент требует двукратного снижения производительности. В нашей реализации этот предел соответствует скорости обработки около 50 Мбайт текста в час (P-II, 400Мгц), что приемлемо для прикладных систем.
4. Информационный портрет текста и именные группы
Основной проблемой, возникающей при формировании информационного портрета текста, является проблема выделения именных групп — устойчивых словосочетаний, в которые входят существительные и согласованные с ними прилагательные (например, “развитие сельского хозяйства”). Именно цельные именные группы, а не отдельные слова, характеризуют содержание текста и могут служить для тематического индексирования, авторубрицирования и т.п. Сопутствующей задачей является их ранжирование по значимости в тексте – вычисление так называемого “тематического веса”, отражающего вклад соответствующего понятия в содержание текста (его информативность).
Синтаксические отношения в пределах именных групп могут быть описаны десятком правил бесконтекстной грамматики, которые учитывают лишь согласование грамматических форм.
В общем случае полезно привлечение словаря моделей управления существительных, типа “борьба с [кем,чем?]”, “борьба против [кого,чего?]”. Однако, в отличие от глаголов, лишь немногие существительные может участвовать в управлении, вследствие чего доля образуемых ими словосочетаний относительно мала (см., к примеру, [8]).
Однако, в отличие от глаголов, лишь немногие существительные может участвовать в управлении, вследствие чего доля образуемых ими словосочетаний относительно мала (см., к примеру, [8]).
В ходе полного синтаксического разбора фразы возможно установление синтаксических ролей именных групп в предложении, что позволяет ранжировать их с точки зрения важности для автора фразы. Так, наиболее важными являются слова из группы подлежащего, затем — сказуемого, прямого дополнения, косвенного дополнения, обстоятельства. В сочетании с алгоритмами статистического анализа эти факты способствуют более точному ранжированию понятий по значимости в информационном портрете документа.
Задача выявления дополнений и обстоятельств требует как минимум привлечения словаря моделей управления глаголов, который на данный момент отсутствует на рынке в объеме, достаточном для наших задач (в русском языке около 20 тысяч глаголов).
Задача выявления подлежащего в большинстве случаев решается достаточно просто и однозначно за счет введения соответствующих правил согласования существительного с глаголом.
Ниже приведен пример разбора нашим анализатором фразы:
(клинки,<- изготовленные) (великими->мастерами), становились
( (предметами <- (религиозного->поклонения) ), + (символами <- (гордости и+
( чести <- ( (живущих и+ будущих) -> (поколений<-японцев) ) ) ) ) )
После выбора наилучшего варианта разбора фразы включается обратный алгоритм синтеза, который проходит по дереву зависимостей и собирает все именные группы. Одновременно входящие в них слова ставятся в согласованные грамматические формы.
Полный список выделенных именных групп следующий:
100 КЛИНОК
50 СИМВОЛ ЧЕСТИ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
50 СИМВОЛ ЧЕСТИ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ
50 СИМВОЛ ЧЕСТИ ВЧЕРАШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
50 СИМВОЛ ЧЕСТИ ВЧЕРАШНЕГО ПОКОЛЕНИЯ
50 СИМВОЛ ЧЕСТИ
50 СИМВОЛ ГОРДОСТИ
50 СИМВОЛ
50 ПРЕДМЕТ РЕЛИГИОЗНОГО ПОКЛОНЕНИЯ
50 ПРЕДМЕТ
50 КЛИНОК
50 ВЕЛИКИЙ МАСТЕР ДРЕВНОСТИ
50 ВЕЛИКИЙ МАСТЕР
40 ЧЕСТЬ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
40 ЧЕСТЬ ВЧЕРАШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
37 ЧЕСТЬ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ
37 ЧЕСТЬ ВЧЕРАШНЕГО ПОКОЛЕНИЯ
33 РЕЛИГИОЗНОЕ ПОКЛОНЕНИЕ
33 МАСТЕР ДРЕВНОСТИ
30 СЕГОДНЯШНЕЕ ПОКОЛЕНИЕ ЯПОНЦА
30 ВЧЕРАШНЕЕ ПОКОЛЕНИЕ ЯПОНЦА
25 ЧЕСТЬ
25 СЕГОДНЯШНЕЕ ПОКОЛЕНИЕ
25 МАСТЕР
25 ГОРДОСТЬ
25 ВЧЕРАШНЕЕ ПОКОЛЕНИЕ
20 ПОКОЛЕНИЕ ЯПОНЦА
16 ПОКЛОНЕНИЕ
16 ДРЕВНОСТЬ
12 ПОКОЛЕНИЕ
10 ЯПОНЕЦ
Слева от каждой именной группы – понятия текста – указан его тематический вес, вычисляемый на основе синтаксической роли в предложении, а также места понятия в составе более сложной именной группы.
Так, если вес именной группы «предмет религиозного поклонения» равен 50 (не подлежащее), то веса входящих в нее понятий будут соответственно: 50 – для “предмет” (главного слова в группе), 50 * 2/3 = 33 для «религизное поклонение» (подчиненной группы длины 2 в группе длины 3) и 50 * 1/3 = 16 для «поклонение» (подчиненной группы длины 1 в группе длины 3).
Максимальный вес, равный 100, в данном примере имеет единственное понятие “клинок”, которое представляет подлежащее – главную тему фразы.
Заметим, что последняя часть разобранной фразы допускает второй, столь же полный вариант разбора:
(символами <-( (гордости и+ чести) <-
( (живущих и+ будущих) -> (поколений<-японцев) ) ) )
который порождает дополнительные именные группы:
гордость будущего поколения японца, гордость живущего поколения японца, символ гордости будущего поколения японца, символ гордости живущего поколения японца.
Наличие нескольких равноправных вариантов разбора есть явление синтаксической омонимии, разрешение которой невозможно без привлечения семантики, а иногда и прагматики, как в данном случае.
5. Заключение
Как показала практика, статистические методы анализа текста, на которых до настоящего времени были сконцентрированы усилия разработчиков интеллектуальных систем, достигли своего естественного предела. Дальнейшее усложнение математики без привлечения серьезной лингвистики не позволит заметно повысить качество подобных систем.
Несмотря на ограниченность синтаксических анализаторов текста, работающих без привлечения семантики, есть все основания утверждать, что их включение повышает точность работы статистических анализаторов, а также открывает качественно новые возможности, оставаясь в рамках разумных ограничений на вычислительные ресурсы.
Разработанный нами синтаксический анализатор русского языка, реализующий выделение именных групп и снятие омонимии, уже внедряется в очередную версию системы Russian Context Optimizer для СУБД Oracle [4]. С демонстрацией анализатора можно познакомиться на сайте http://research.metric.ru.
С демонстрацией анализатора можно познакомиться на сайте http://research.metric.ru.
Литература
- Ермаков А.Е. Тематический анализ текста с выявлением сверхфразовой структуры // Информационные технологии. — 2000. — N 11.
- Ермаков А.Е., Плешко В.В. Ассоциативная модель порождения текста в задаче классификации // Информационные технологии. — 2000. — N 12.
- Плешко В.В., Ермаков А.Е., Липинский Г.В. TopSOM: визуализация информационных массивов с применением самоорганизующихся тематических карт // Информационные технологии. — 2001. — N 8.
- Ермаков А.Е. Проблемы полнотекстового поиска и их решение // Мир ПК. – 2001. – N 5.
- Ермаков А.Е., Плешко В.В. Тематическая навигация в полнотекстовых базах данных // Мир ПК. – 2001. – N 8.
- Мельчук И.А Опыт теории лингвистических моделей “Смысл-Текст”. Семантика, синтаксис. — М.: Школа «Языки русской культуры», 1999.

- Гладкий А.В. Формальные грамматики и языки. — М.: Наука, 1973.
- Розенталь Д.Э. Управление в русском языке. Словарь-справочник. – М.: Книга, 1986.

Restricted syntactic analysis of text document in information retrieval systems
A. E. Ermakov
Key words: syntactic parsing, ambiguity resolution, noun-groups extracting, statistical text analysis, information text structure.
The report is devoted to development of restricted syntactic parser for Russian language and embedding it into full-text document analysis systems produced by «Garant-Park-Internet» Ltd. The simplified syntactic parsing that omits verb control is still capable to extract noun-groups and resolve morphological ambiguity. We designed such parser on the base of context-free grammar. Simplification of the parsing algorithm allows us to process large arrays of text documents in times suitable for use in information retrieval and text analyzing systems. Our experiments demonstrate that this parser could be used on document preprocessing stage in statistical text analysis algorithms to increase the precision of these systems.
Our experiments demonstrate that this parser could be used on document preprocessing stage in statistical text analysis algorithms to increase the precision of these systems.
Алгоритмы синтаксического анализа
— Дмитрий Сошников
Обзор курса
Синтаксический анализ или — один из первых этапов проектирования и реализации компилятора . Хорошо продуманный синтаксис вашего языка программирования — это большая мотивация, по которой пользователи предпочтут и выберут именно ваш язык.
Примечание: это класс по теории парсеров и алгоритмов разбора . Если вы заинтересованы в ручном практическом уроке синтаксического анализа, вы также можете рассмотреть [ Создание парсера с нуля ] где мы создаем парсер рекурсивного спуска.
Подробности смотрите в новостной ленте Hacker.
Проблема с «теорией синтаксических анализаторов» в классических школах компиляторов и книгах заключается в том, что эта теория часто считается «слишком продвинутой», уходящей прямо в сложные формальные описания из теории вычислений и формальных грамматик. В результате учащиеся могут потерять интерес к созданию компилятора уже на этапе разбора.
В результате учащиеся могут потерять интерес к созданию компилятора уже на этапе разбора.
Противоположной проблемой, часто встречающейся при описании синтаксического анализатора, является поверхностный подход, описывающий только ручной (обычно рекурсивный спуск) синтаксический анализ, в результате чего у учащихся возникают проблемы с пониманием реальных методов, стоящих за автоматическими синтаксическими анализаторами.
Я считаю, что это глубокое погружение в теорию парсинга должно сочетаться с практическим подходом , который идет параллельно и позволяет увидеть весь изученный теоретический материал на практике .
В классе Essentials of Parsing (он же Алгоритмы синтаксического анализа ) мы погружаемся в различные аспекты теории синтаксического анализа, подробно описывая синтаксические анализаторы LL и LR . Однако в то же время, чтобы сделать процесс обучения и понимания простым и увлекательным, мы параллельно строим автоматический анализатор для полного языка программирования, подобного JavaScript или Python, с нуля.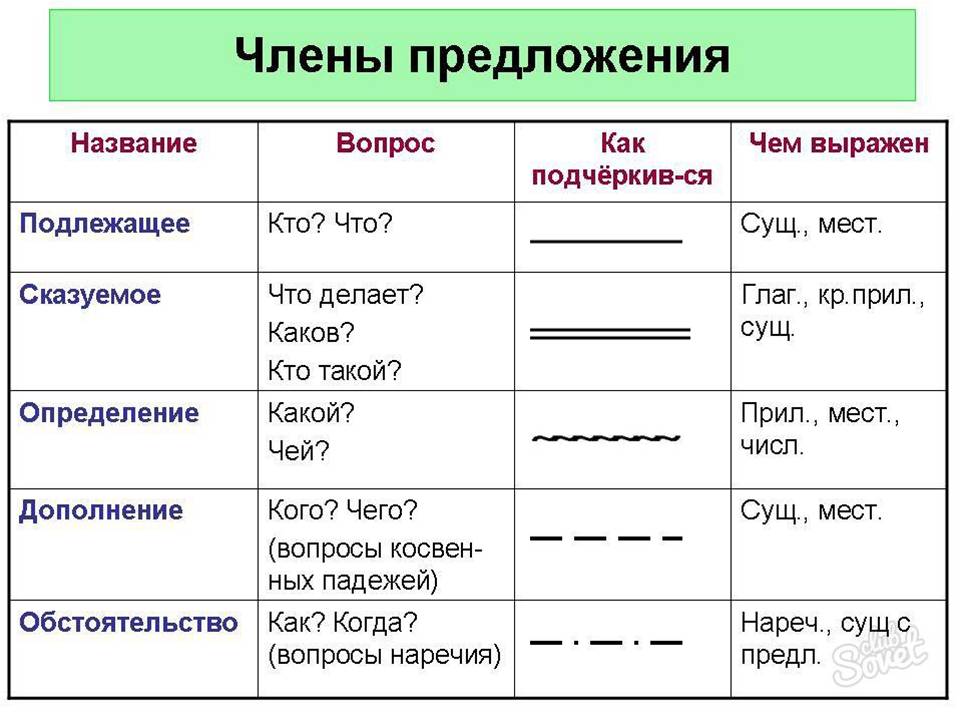
После этого занятия не только вы сможете использовать генератор синтаксических анализаторов для создания синтаксических анализаторов для языков программирования, но также понимать как генераторы синтаксических анализаторов работают под капотом.
Реализация синтаксического анализатора для языка программирования также сделает ваше практическое использование других языков программирования более профессиональным.
Как?
Вы можете просмотреть предварительные лекции, а также записаться на полный курс, описывающий алгоритмы парсинга LL и LR и рассказывающий о реализации автоматического парсера с нуля, в анимированном и аннотированном формате. Смотрите подробности ниже, что в курсе.
Доступные купоны:
|
Для кого этот курс?
Этот курс предназначен для любого любознательного инженера , который хотел бы получить навыки построения сложных систем (а создание парсера для языка программирования — довольно сложная инженерная задача!), и получить передаваемые знания для построения таких систем.
Если вас интересуют именно компиляторы, интерпретаторы и средства преобразования исходного кода, то этот курс также для вас.
Единственным условием для этого класса являются основные структуры данных и алгоритмы : деревья, списки, обход.
Если вы прошли или собираетесь пройти курс по созданию интерпретатора с нуля, класс синтаксических анализаторов может быть интерфейсом синтаксиса для интерпретатора, встроенного в этот класс.
Что используется для реализации?
Поскольку мы создаем язык, очень похожий по семантике на JavaScript или Python (два самых популярных языка программирования сегодня), мы используем именно JavaScript — его элегантную мультипарадигмальную структуру, которая сочетает в себе функциональное программирование, ООП на основе классов и прототипов. идеально подходит для этого.
Многие инженеры знакомы с JavaScript, поэтому сразу начать писать код будет проще. Для генерации автоматического парсера мы используем инструмент Syntax , который является независимым от языка генератором парсеров и поддерживает плагины для Python, Ruby, C#, PHP, Java, Rust и т. д. То есть реализация этого парсера может быть легко перенесена на любой другой язык по вашему выбору и вкусу.
д. То есть реализация этого парсера может быть легко перенесена на любой другой язык по вашему выбору и вкусу.
Примечание: мы хотим, чтобы наши учащиеся сами следовали, понимали и реализовывали каждую деталь парсера, а не просто копировали и вставляли окончательное решение. Полный исходный код языка доступен в видеолекциях, в которых показано и показано, как структурировать определенные модули.
Что особенного в этом классе?
Основные особенности этих лекций:
- Краткость и прямолинейность. Каждая лекция самодостаточна, лаконична и описывает информацию, непосредственно относящуюся к теме, не отвлекаясь на посторонние материалы или доклады.
- Анимированная презентация в сочетании с редактируемыми заметками . Это облегчает понимание темы и показывает, как (и , когда ) структуры объекта связаны. Статические слайды просто не работают для сложного контента.
- Сеанс живого кодирования сквозной с назначениями . Полный исходный код, начиная с нуля и до самого конца, представлен в видеолекциях класса .
Что в курсе?
Курс разделен на четыре части , всего 22 лекции и множество подтем в каждой лекции. Ниже оглавление и учебная программа .
Часть 1: Контекстно-свободные грамматики и языки
В этой части мы опишем различные конвейеры синтаксического анализа, поговорим о формальных грамматиках, деривациях, о том, что такое неоднозначная и неамбициозная грамматика, и начнем создавать наш язык программирования.
- Лекция 1: Формальные грамматики, контекстно-свободные
- Обзор курса
- Конвейер разбора
- Модуль токенизатора
- Модуль парсера
- AST: абстрактное синтаксическое дерево
- Парсеры, написанные вручную, и автоматические анализаторы
- Рекурсивный спуск
- Разбор LL и LR
- Формальные грамматики
- Терминалы, нетерминалы и производство
- Иерархия грамматики Хомского
- Контекстно-свободные грамматики
- Лекция 2: Грамматические производные
- Обозначение BNF (форма Бэкуса-Наура)
- Обозначение RegExp
- Токенизатор и парсер
- Процесс получения
- Самые левые и самые правые производные
- Разбор деревьев
- Обход в глубину — строка на листьях
- Неоднозначные грамматики
- Лекция 3: Неоднозначные грамматики
- Неоднозначные грамматики
- Левая и правая ассоциативность
- Приоритет оператора
- Левая рекурсия
- Нетерминальные уровни
- Однозначные грамматики
- Лекция 4: Синтаксический инструмент | Письмо
- Знакомство с инструментом синтаксиса
- Генераторы парсеров
- Грамматика БНФ
- Ассоциативность и приоритет
- Режим синтаксического анализа LALR(1)
- Буква языка программирования
- Лекция 5: Абстрактные синтаксические деревья
- CST: конкретное синтаксическое дерево (также известное как дерево синтаксического анализа)
- AST: абстрактное синтаксическое дерево
- Семантические действия
- Встроенный интерпретатор для простых DSL
- узлов AST поколения
- Выражение в скобках
Часть 2: Нисходящий анализ LL
В этой части мы подробно рассказываем о нисходящем анализе, описываем ручной рекурсивный анализатор и парсер с возвратом, а также углубляемся в алгоритм разбора LL(1).
- Лекция 6: Парсер с возвратом
- Нисходящие синтаксические анализаторы
- Синтаксические анализаторы снизу вверх, также известные как Shift-Reduce
- Левая рекурсия
- Анализатор рекурсивного спуска
- Парсер с возвратом
- Левый факторинг
- Лекция 7: Левая рекурсия и левая факторизация
- Общие правила префикса
- Почему откат выполняется медленно
- Левый факторинг
- Левая рекурсия
- Косвенная рекурсия
- Лекция 8. Анализатор прогнозирующего рекурсивного спуска
- Предиктивный анализ
- Концепция упреждающих токенов
- Анализатор рекурсивного спуска
- Наборы First & Follow
- Лекция 9: Анализ LL(1): наборы First & Follow
- Предиктивный анализ
- Концепция упреждающих токенов
- Структура парсера LL(1)
- Расчет первого набора
- Выполнить расчет набора
- Пример инструмента синтаксиса
- Лекция 10: Построение таблицы разбора LL(1)
- Упреждающие токены
- Структура синтаксического анализатора LL(1)
- Наборы First & Follow
- LL(1) таблица синтаксического анализа
- Набор прогнозов
- LL(1) конфликтов
- Лекция 11: Алгоритм разбора LL(1)
- Структура синтаксического анализатора LL(1)
- LL(1) таблица синтаксического анализа
- Разбор стека (автоматы с проталкиванием вниз)
- Крайний левый вывод
- Абстрактный алгоритм парсера LL(1)
Часть 3: Синтаксический анализ LR снизу вверх
В этой части мы опишем анализаторы снизу вверх и алгоритм анализа LR. Параллельно мы продолжаем строить наш язык программирования, анализируя конфликты Shift-Reduce и исправляем их.
- Лекция 12: Назад к практике: Заявления | Блоки
- Модуль включает: повторное использование вспомогательных функций
- Форматы AST: явный формат и формат S-выражения
- Выписки и списки выписок
- Программа: главная точка входа
- Блоки: группы операторов
- Лекция 13: Объявления функций
- Необязательные операторы
- Пустые блоки
- Объявления функций
- Операторы if-else
- Пример конфликта Shift-Reduce
- Лекция 14: Разбор LR: Canonical Collection LR-items
- Структура LR-парсера
- Canonical Collection предметов LR
- LR-предметы
- Операции закрытия и перехода
- DFA: детерминированные конечные автоматы (конечный автомат)
- КПК: Автоматы толкающего устройства
- Лекция 15: Таблица разбора LR: LR(0) и SLR(1)
- Таблица синтаксического анализа LR
- Действие и переход
- LR(0) режим синтаксического анализа
- Режим разбора SLR(1)
- Конфликты сдвига/уменьшения
- Уменьшить/Уменьшить конфликты
- Лекция 16: Анализ таблиц CLR(1) и LALR(1)
- LR(0) по сравнению с LR(1)
- Упреждающие наборы
- CLR(1) таблица синтаксического анализа
- Таблица синтаксического анализа LALR(1)
- Сравнение парсеров: LL и LR
- Лекция 17: Алгоритм разбора LR(1)
- Процесс синтаксического анализа LR(1)
- Алгоритм сдвига-уменьшения
- Правые ручки
- Анализ стека
- Описание абстрактного алгоритма LR
Часть 4: Практика и окончательный синтаксический анализатор
Заключительная часть курса полностью практическая, мы заканчиваем наш язык программирования Letter, создание переменных, функций, циклов, структур управления, объектно-ориентированное программирование и окончательный синтаксический анализатор .
- Лекция 18: Структуры управления: оператор If
- Оператор if
- Конфликт Shift-Reduce
- Выражение отношения
- Выражение равенства
- Логические литералы
- Лекция 19: Переменные | Назначение
- Логическое выражение И
- Логическое выражение ИЛИ
- Выражение присвоения
- Цепное назначение
- Объявление переменной
- Лекция 20: Вызовы функций | Унарное выражение
- Выражение вызова и вызовы функций
- Унарное выражение
- Цепные вызовы
- Список аргументов
- Лекция 21: Выражение члена | Итерация
- Выражение члена
- Доступ к собственности
- Индексы массива
- Строковые литералы
- Оператор итерации
- Пока, Делать, Для циклов
- Лекция 22: ООП | Конечный парсер
- Объектно-ориентированное программирование
- Объявление класса
- Супер звонки
- Новое выражение
- Генерация парсера
- Окончательный исполняемый файл
Надеюсь, вам понравится занятие, и вы будете рады обсудить любые вопросы и предложения в комментариях.
Практический алгоритм линейного времени с возвратом
Разбор Пакрата: Практический алгоритм линейного времени с возвратомАннотация
Разбор Packrat — новый и практичный метод для реализации парсеров с линейным временем для грамматик, определенных в языке синтаксического анализа сверху вниз (TDPL). Хотя TDPL изначально создавался как формальная модель для нисходящих парсеров с возможностью обратного отслеживания, этот тезис расширяет TDPL в мощную нотацию общего назначения для описания синтаксиса языка, предоставление привлекательной альтернативы к традиционным контекстно-свободным грамматикам (CFG). Общие синтаксические идиомы которые не могут быть представлены кратко в CFG легко выражаются в TDPL, такие как устранение неоднозначности с самым длинным совпадением и «синтаксические предикаты», сделать это возможным описать полный лексический и грамматический синтаксис практичного языка программирования в одной грамматике TDPL.
Парсинг Packrat — это адаптация 30-летнего табличного алгоритма парсинга. это никогда не применялось на практике до сих пор.
Парсер Packrat может распознать
любая строка, определенная грамматикой TDPL за линейное время,
обеспечивает мощность и гибкость
синтаксического анализатора рекурсивного спуска с возвратом
без сопутствующего риска экспоненциального времени синтаксического анализа.
Парсер packrat может распознавать любой язык LL( k ) или LR( k ),
а также многие языки, требующие неограниченного просмотра вперед
которые не могут быть проанализированы синтаксическими анализаторами сдвига/уменьшения.
Анализ Packrat также обеспечивает лучшие свойства композиции, чем анализ LL/LR,
что делает его более подходящим для динамических или расширяемых языков.
Основным недостатком синтаксического анализа packrat является его стоимость хранения,
который является постоянным множителем общего размера ввода
а не пропорционально глубине вложенности
синтаксических конструкций, появляющихся во входных данных.
Монадические комбинаторы и ленивые вычисления
включить элегантные и прямые реализации парсеров packrat
в последних языках функционального программирования, таких как Haskell. Три разных парсера packrat для языка Java
представлены здесь,
демонстрация построения парсеров packrat на Haskell
используя примитивное сопоставление с образцом, используя монадические комбинаторы,
и путем автоматической генерации из спецификации декларативного синтаксического анализатора.
Разработан прототип генератора парсера packrat для третьего случая
сам использует синтаксический анализатор packrat для чтения своих спецификаций синтаксического анализатора,
и поддерживает полную нотацию TDPL
расширенный с помощью «семантических предикатов»,
позволяя решениям синтаксического анализа зависеть от семантических значений
других синтаксических единиц.
Экспериментальные результаты показывают, что все эти парсеры packrat
надежно работать в линейном времени,
эффективно поддерживать парсинг «без сканера»
со встроенным лексическим анализом,
и предоставить удобные средства обработки ошибок
необходимо в практических приложениях.
Полная диссертация
В PDF или постскриптумPappy: генератор парсеров для Haskell
Полный исходный код Pappy, прототип генератора парсеров packrat, описанный в диссертации, доступен для просмотра в этом каталоге, или для загрузки в виде сжатого tar-файла. Ниже приводится краткая разбивка исходных файлов:- Поз.hs : Библиотечный модуль для отслеживания положения строки/столбца в текстовом файле.
- Parse.hs : Библиотека вспомогательных функций и монадических комбинаторов для использования в создании парсеров packrat. Вдохновленный Дааном Лейдженом библиотека Парсек, который был разработан для традиционных прогнозирующих парсеров и в основном прогнозирующие синтаксические анализаторы с возвратом в особом случае.
- ReadGrammar.hs : Монадный парсер packrat для спецификаций парсера Pappy.
- ReduceGrammar.hs : модуль сокращения грамматики, который переписывает леворекурсивные правила и операторы повторения (‘*’ и ‘+’) в примитивную праворекурсивную форму.
- SimplifyGrammar.hs : модуль упрощения грамматики, который оптимизирует грамматику и устраняет как можно больше нетерминалов.
- MemoAnalysis.hs :
Модуль анализа мемоизации,
что определяет множество нетерминалов
для запоминания парсером packrat.
- WriteParser.hs : Модуль генерации кода.
- Main.hs : Модуль управления верхнего уровня, который связывает все этапы компиляции вместе.
Пример анализаторов арифметических выражений
Ниже приведены полные версии примеров синтаксических анализаторов. для тривиального языка арифметических выражений, используемого в диссертации:- ArithRecurse.hs : Парсер рекурсивного спуска, описанный в Разделе 3.1.1, для тривиального языка арифметических выражений на рисунке 1.
- ArithPackrat.hs : Эквивалентный парсер packrat для того же тривиального языка, Раздел 3.1.4.
- ArithLeft.hs : Пример левой рекурсии для раздела 3.2.1, который расширяет вышеупомянутый парсер packrat с помощью собственно левоассоциативные операторы вычитания, деления и по модулю.
- ArithLex.hs :
Пример интегрированного лексического анализа для раздела 3.2.2,
который расширяет предыдущий синтаксический анализатор packrat
с поддержкой многозначных десятичных литералов
и необязательное заполнение пробелами
между литералами, операторами и пунктуацией.
- ArithMonad.hs : Пример парсера packrat, эквивалентного ArithLex.hs, но использование монадических комбинаторов для более краткого выражения функций синтаксического анализа и обеспечить поддержку для удобного обнаружения ошибок и создания отчетов. Обсуждается в разделах 3.2.3 и 3.2.4 диссертации. Требуются следующие два библиотечных модуля от Pappy:
- Ариф.паппи :
Спецификация парсера Pappy для парсера
эквивалентен ArithLex.hs и ArithMonad.hs.
Полученный автоматически сгенерированный парсер
доступен как Arith.hs.
- Поз.hs: Отслеживает позицию строки и столбца при сканировании вводимого текста.
- Parse.hs: Библиотека монадических комбинаторов для парсеров packrat.
Пример парсеров языка Java
Три полных и работающих синтаксических анализатора для языка Java, которые описаны в статье и используются для целей анализа и сравнения, доступны здесь:- JavaMonad.hs :
Парсер packrat для языка Java
который использует исключительно монадические комбинаторы
для определения функций синтаксического анализа, составляющих синтаксический анализатор. Оба «безопасных» комбинатора с постоянным временем
и «небезопасные» комбинаторы со скрытой рекурсией
используются в этом парсере,
это означает, что это не совсем парсер с линейным временем
хотя на практике это кажется довольно близким.
- JavaPat.hs : Версия вышеуказанного парсера изменено для использования прямого сопоставления с образцом Haskell для некоторых важных для производительности функций лексического анализа: пробелы, идентификаторы, ключевые слова, операторы, и целочисленные, символьные и строковые литералы. Остальная часть синтаксического анализатора, как и прежде, монадична, а также использует «небезопасные» комбинаторы.
- Java.pappy :
Спецификация парсера Pappy для языка Java.
Полученный автоматически сгенерированный парсер
доступен как Java.hs.
Поскольку Паппи переписывает операторы повторения,
этот синтаксический анализатор использует только примитивы с постоянным временем
и поэтому должен быть парсером строго линейного времени —
по крайней мере, в той степени, в которой доступ к памяти является постоянным
(что не совсем так
при наличии эффектов сборки мусора и кеша и тому подобного).