Разбор слова по составу Загустеет
А какие слова то
Например : Гладить-гладил основа н.ф глади прош.время гладил
Купить-купил
Сестра (корень сестр, окончание а) => Сестрица (корень сестр, суффикс иц, окончание а) => Сестрицын (корень сестр, суффикс иц, суффикс ын, окончание нулевое).
Я с раннего детства увлекаюсь музыкой, и большая заслуга в этом принадлежит моим родителям. Они сумели заинтересовать меня, привить любовь к музыке и научиться с вниманием и уважением относиться к различным музыкальным течениям.
Мои интересы в музыке разносторонни. Мне нравится классика, рок, этническая и медитативная музыка. Я считаю, что классическая и медитативная мелодии — лучший способ расслабиться, отдохнуть, почувствовать себя гармоничной личностью.
Музыка в моей жизни играет одну из ведущих ролей.Я обращаюсь к музыке регулярно. Когда мне плохо и больно, я включаю классические композиции, и все мои проблемы уходят на задний план. Когда мне нужно зарядиться энергией, мои наушники рвутся от рока.
Я считаю, что музыкальные пристрастия могут очень многое сказать о человеке, о его характере, воспитании и мировоззрении.
Люди не могут жить без музыки, она делает жизнь ярче, полнее и интереснее
П [п]-согласный,парный,глухой,твёрдый.
О [а]-гласный.
П [п]-согласный,парный,глухой,твёрдый.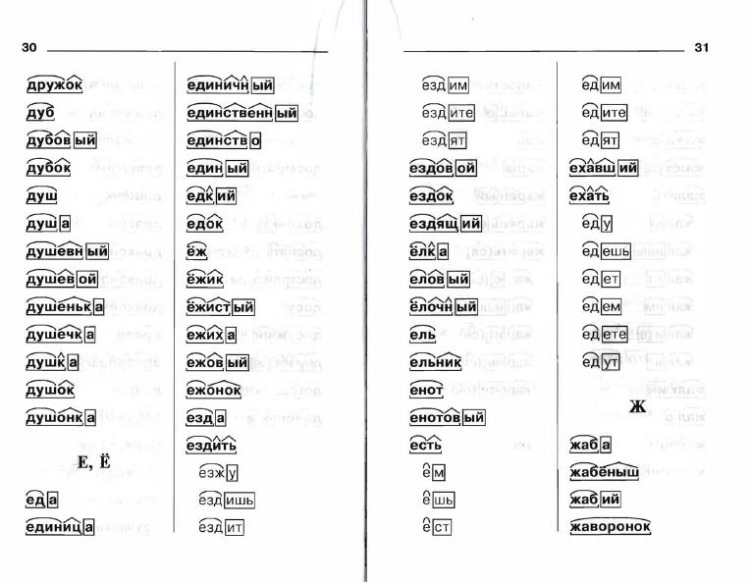
А [а]-гласный.
Д [д’]-согласный,парный,звонкий,мягкий.
Ь [ь]-
Я [й’]-согласный,непарный,звонкий,сонорный,мягкий.
[а]-гласный.
Подлежащее и сказуемое.
Подлежащее и сказуемое-друзья на веки. Что такое подлежащее и сказуемое? Это грамматическая основа. Подлежащее-это главный член предложения. Сказуемое-главный член предложения, обозначающий признак подлежащего. Подлежащее отвечает на вопросы-«Кто? Что?» Сказуемое отвечает на вопросы-«Что делает предмет? Что с ним происходит? Каков он? Что он такое? и на другие похожие вопросы. Пример : Ёлочка росла. Ёлочка -подлежащее, росла — сказуемое.
«Основа слова. Разбор слова по составу»
ФИО автора: Николаева Юлия Геннадьевна
Местоработы, должность: МОУ «ЛСОШ № 1» , учитель начальных классов.
Предмет: русский язык
Класс: 3
Тема урока: «Основа слова. Разбор слова по составу»
Базовыйучебник: русский языкВ.П. Канакина, В.Г. Горецкий (Страницы в учебнике: стр.73, 95-97,146)
Цель педагогической деятельности: формировать умения выделять основу в словах, разбирать слова по составу.
Задачи урока: — развивать умения находить в словах с однозначно выделяемыми морфемами основу (простые случаи), окончание, корень, приставку, суффикс; — развивать умения различать однокоренные слова и различные формы одного и того же слова
Тип урока: Изучение нового материала.
Формы работы учащихся:индивидуальная, парная, фронтальная.
Используемые технологии, активные формы обучения: системно – деятельностный подход, здоровьесберегающая технология
Необходимое техническое оборудование компьютер, мультимедиа проектор
СТРУКТУРА И ХОД УРОКА
№№
п/п
Этап урока
Деятельность учителя
Деятельность
обучающихся
Время
(в мин. )
)
1.
Самоопределение к учебной деятельности
— Сегодняплохих оценок не ставлю. У нас сейчас будет очень интересный урок. Я каждому раздам листы, и вы в конце урока напишете свои ощущения и поставите оценку себе, мне и его Величеству Уроку.
Игра «Крестики – нолики».
-Ребята, какой раздел мы с вами изучаем сейчас.
Япредлагаю вам вспомнить сейчас, что вы знаете о частях слова. В этом нам поможет игра «Крестики – нолики». Все, что нужно для игры, находится у каждого из вас на партах. А игра заключается в следующем: я буду читать вам утверждение и, если вы с ним согласны, в клеточке ставите
1.Родственные слова ещё называют однокоренными. (+)
2.Верно ли, что у слов сорока и сор одинаковый корень? (-)
3.Корень – это главная часть предложения. (-)
4.Окончание – изменяемая часть слова.(+)
5.Приставка – это часть речи.(-)
6.Корни в родственных словах пишутся одинаково. (+)
7.Окончание помогает образовывать новые слова. (-)
8.Суффикс – часть слова, которая стоит после корня . (+)
9.Окончание служит для связи слов в словосочетаниях и предложениях. (+)
-Проверим ваши ответы. Проверить ваши ответы будет легко. Сравните рисунок в вашей тетради с рисунком на экране. Проверяем правильность выполнения с помощью сигнальных карточек разного цвета.
-Если у вас получился такой же рисунок, значит, все ответы верные.
+
0
0
+
0
+
0
+
+
— Сегодня мы продолжим работать в рамках раздела «Состав слова» и познакомимсяещё с одной частью слова.
Отвечают на вопрос.
Выполняют задание.
Самопроверка
6мин
Актуализация знаний и фиксирование затруднения в пробном действии
Предлагает прочитать слова.
-Прочитайте, пожалуйста, слова и объедините каждый столбикодной темой.
леслесник лесалесной в лесулесовичок
-Что можно сказать о словах первого столбика?
-Как назовём слова второго столбика?
-Давайте выделим составные части слова лесник, прокомментируем и запишем в тетради.
— Ребята, скажите, сколько составных частей у вас получилось в слове?
— В этом слове есть еще одна составная часть, попробуйте найти её.
− Посмотрим результаты.
− Поднимите руки, кто не смог найти ещё одну часть слова.
Читают слова, предлагают варианты.
-Это однокоренные слова.
-Это разная форма одного и того же слова «лес».
Здесь изменяется только окончание.
Самостоятельно разбирают слова по составу.
(дети выделяют окончание и корень данных слов)
Отвечают. (Однокоренные или родственные слова). Приводят свои аргументы.
Записывают в тетрадь. Выделяют части слова.
-Три.
Ребята выполняют задание.
4 мин
3.
Выявление места и причины затруднения
− Какое задание выполняли?
− Как вы рассуждали?
− Где же возникло затруднение?
− Почему же вы не смогли справиться с этим заданием?
-Мы не знаем, какую часть надо найти и где она находится.
2 мин
4.
Построение проекта выхода из затруднения
Предлагает открытьучебник на странице 73, рассмотреть схему.
— Со всеми ли частями слова мы познакомились?
-Предлагает назвать часть слова, с которой мы еще не знакомы.
-Предлагает сформулировать тему урока и цель.
Мысегодня на уроке будем разбирать слова по составу, выделяя в них и основу, поэтому тема урока будет звучать так: «Основа слова. Разбор слова по составу».
-Вернемся к схеме на с.73,
— Из каких частейсостоит основа слова?
— Скажите, что нужно сделать, чтобы правильно выделить основу слова?
Рассматривают схему на с.73, находят часть слова, с которой не знакомились.
-Основа
Отвечают:
-Тема нашего урока «Основа слова»
Дети высказывают свои предположения и приходят к выводу:
-Основа– это составная часть слова, в которую входит корень, приставка, суффикс. Т.е. все слово без окончания и является основой.
-Отделитьсначала окончание.
3мин
5.Реализация построенного проекта
Учитель предлагает самостоятельновыделить основу услова « лесник», с проверкой по образцу, а затем у слова «лесной» с проверкой у доски.
Выделяют основу слова.
2 мин
6.
Первичное закрепление
Предлагает открытьучебник на странице 95 и прочитать правило тётушки Совы.
— Всё ли мы правильно сказали про основу слова? Что дополнительно сообщила нам тётушка Сова?
Работа у доски по одному с объяснением. Найдитеоснову слова и окончание в словах пушистый, снежинка, улетят.
Отвечают
-Мы сделали правильные выводы. Но тётушка Сова нас дополнила, что в основеслова заключено его лексическое значение.
Выполняют задание
5мин
7.
Физкультминутка
Руки кверху поднимаем,
А потом их опускаем.
А потом их развернем
И к себе скорей прижмем.
А теперь быстрей, быстрей
Хлопай, хлопай веселей.
Приседай скорей со мной,
Держим руки за спиной.
Встали прямо, руки вбок,
Влево — вправо поворот.
Все, закончили. Ура!
За занятия пора!
Выполняют упражнения
2 мин
7.
Самостоятельная работас взаимопроверкой
Организует самостоятельную работу упр.179.Задание: выписать слова с корнем ящер — и выделить в них основу и окончание.
Самостоятельная работа
спроверкой
по образцу на доске
8 мин
8.
Включение нового в систему знаний и повторение
(работа в парах)
− При выполнении каких заданий вы сможете использовать умения, приобретенные на уроке?
− Решите упр. 181, стр. 96.
Разбираем памятку на стр.146.
Затем, пользуясь образцом, разбираем слова по составу.
-При разборе слова по составу
Выполняют задание. Один ученик работает наоткидной доске
8 мин
9.
Рефлексия деятельности
-С какой частью слова познакомились на уроке, что о ней узнали.
— Что нужно сделать со словом, чтобы найти основу слова?
Предлагает выделить основу в словах на доске.
Сад, садовник, садовый.
− Оцените свою работу на уроке свои ощущенияи урок в целом.
— Составьте слово по подсказкам.
1. В слове есть окончание и основа. Она состоит из трёх частей
2. Корень тот же, что в словах: обмен, меняла, изменить.
3. В приставке две буквы «е».
4. Суффикс тот же, что в словах травка, шубка.
5. Окончание — первая буква алфавита.
Перемена
- А сейчас — перемена, урок окончен, отдыхайте.


-Мы узнали, что называется основой слова, и научились ее выделять в словах.
-Нужно отделить окончание.
Проверяют правильность выделения основы.
Оценивают на специальном оценочном листе.
Составляют слово
5 мин
Урок 36. состав числа 6. вычитание вида «6 – » — Математика — 1 класс
Математика, 1 класс
Урок 36. Состав числа 6. Вычитание вида: 6 – □
Перечень вопросов, рассматриваемых на уроке:
Определять состав числа шесть.
Определять место числа шесть на числовой прямой.
Решать примеры вида 6 минус число.
Находить число шесть в результате сложения.
Глоссарий по теме
Числовое выражение – это математические запись, в которой используются числа и знаки арифметических действий.
Состав числа – это слагаемые, которые в сумме дают это число.
Ключевые слова
Число шесть; состав числа 6; Числовые выражения
Основная и дополнительная литература по теме урока:
1. Моро М. И., Волкова С. И., Степанова С. В. Математика. Учебник. 1 кл. В 2 ч. М.: Просвещение, 2017. С.
2. Моро М. И., Волкова С. И. Математика. Рабочая тетрадь. 1 кл. В 2 ч. пособие для общеобразовательных организаций. — М: Просвещение, 201 . С.
На уроке мы узнаем, как получить число 6 из других чисел.
Научимся решать числовые равенства с числом 6.
Сможем соотносить число 6 с меньшими и большими числами.
Основное содержание урока
В какой-то день недели,
В шесть часов утра
Петухи пропели:
«В школу, детвора!»
Быстро собираемся,
Школьных дел не счесть…
Больше постараемся
Узнать про число … (шесть)
Состав числа (из двух меньших чисел) — это значит, что любое множество предметов можно получить сложением двух меньших множеств (двух слагаемых). Число 6 состоит из частей, которые надо запомнить.
Число 6 состоит из частей, которые надо запомнить.
На основе сделанного вывода о составе числа 6, можно записать
равенства:
1+5=6 | 2+4=6 | 3+3=6 |
5+1=6 | 4+2=6 | 6-3=3 |
6-1=5 | 6-2=4 | |
6-5=1 | 6-4=2 |
Решите задачу и выберите верный ответ
В тарелке 2 яблока, а груш — на 4 больше. Сколько груш в тарелке?
Названия файлов изображения к вопросу:
варианты для выбора ответа:
Решение задачи:
2 + 4 = 6
Подсказка: Вспомните состав числа 6.
Устный счёт
Родились у мамы-кошки
Шесть котят, такие крошки!
Как котята подрастали,
Их ребятам раздавали.
Лишь двоих оставили пока.
Остальных котят с утра
Разобрала детвора.
Сколько маленьких котят
Оставалось у ребят?
6 – 4 = 2
На лесной опушке сидят
Три зайчихи-старушки
Да тут же возле них
Пляшут трое молодых.
Сосчитайте поскорей
Сколько было всех зверей?
3 + 3 = 6
(В. Н. Савичев)
Решите примеры и заполните пропуски в таблице
6 — 4 =
6 — 2 =
6 — 0 =
6 — 3 =
Как можно прочитать состав числа 6 ?( Шесть – это три и три)
Дорисуем схему.
Впишите недостающие числа в пропуски
Заполните пустые клетки.
Вспомните состав числа 6. Вставьте нужные цифры в пустые окошки домика.
Решите задачу:
У Ксюши было 6 пирожных. 4 пирожных она отдал своей подруге. Сколько пирожных осталось у Ксюши?
Разбор типового тренировочного задания
Решите задачу и выберите верный ответ
В коробке было всего шесть щенков. С утра забрали 2 щенков, а потом пришли еще за 2.
Сколько щенков осталось в коробке?
Названия файлов с изображениями:
Тип вариантов ответов: Выберите вариант ответа (графический).
Решение: в коробке было всего 6 щенков, с утра забрали 2 щенков
6 — 2 = 4
Потом забрали еще 2
4 — 2 = 2
Правильный вариант/варианты (или правильные комбинации вариантов): 2 щенка осталось в коробке.
Второстепенный разбор слова по составу
План разбора слова второстепенный по составу с выделением корня и основы. Морфемный разбор со схемой и частями слова (морфемами) — корнем, суффиксом, окончанием.
втор о степен н ый
Часть речи — прилагательное , части слова — втор/о/степен/н/ый .
| втор | корень |
| о | соединительная гласная |
| степен | корень |
| н | суффикс |
| ый | окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Когда-нибудь я тоже научусь различать смыслы слов.
В каком смысле употребляется прилагательное вечный в отрывке:
Оказывается, совсем не страшно, что вечной любви не бывает и взаимной, по существу, тоже.
Ассоциации к слову «второстепенный»
Синонимы к слову «второстепенный»
Предложения со словом «второстепенный»
- Стаффаж — это фигуры людей и животных, изображённые в произведениях пейзажной живописи для оживления вида и имеющие второстепенное значение.
- Пусть будут знакомые и даже друзья, но пусть они кажутся второстепенными персонажами жизни, главный персонаж в духовном браке всегда один — это супруг.
- Решите, на каких правилах будете впредь настаивать, и усиленно проводите их в жизнь, закрывая глаза на второстепенные вопросы.
- (все предложения)
Сочетаемость слова «второстепенный»
Что (кто) бывает «второстепенным»
Значение слова «второстепенный»
ВТОРОСТЕПЕ́ННЫЙ, -ая, -ое. Не главный, не основной, менее существенный. Второстепенное дело. Второстепенная роль. □ В проекте не было главных и второстепенных задач. Все было важно. Галин, В Донбассе. || Не первый, не лучший по своим достоинствам; посредственный. Руководители театров иногда считают, что если в спектакле заняты один-два ведущих артиста труппы, то в остальных ролях можно занять второстепенных исполнителей. Н. Черкасов, Записки советского актера. ◊ Второстепенные члены предложения ( грамм.) — члены предложения, служащие для пояснения главных членов предложения. (Малый академический словарь, МАС)
Не главный, не основной, менее существенный. Второстепенное дело. Второстепенная роль. □ В проекте не было главных и второстепенных задач. Все было важно. Галин, В Донбассе. || Не первый, не лучший по своим достоинствам; посредственный. Руководители театров иногда считают, что если в спектакле заняты один-два ведущих артиста труппы, то в остальных ролях можно занять второстепенных исполнителей. Н. Черкасов, Записки советского актера. ◊ Второстепенные члены предложения ( грамм.) — члены предложения, служащие для пояснения главных членов предложения. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «второстепенный»
ВТОРОСТЕПЕ́ННЫЙ, -ая, -ое. Не главный, не основной, менее существенный. Второстепенное дело. Второстепенная роль. □ В проекте не было главных и второстепенных задач. Все было важно. Галин, В Донбассе. || Не первый, не лучший по своим достоинствам; посредственный. Руководители театров иногда считают, что если в спектакле заняты один-два ведущих артиста труппы, то в остальных ролях можно занять второстепенных исполнителей. Н. Черкасов, Записки советского актера. ◊ Второстепенные члены предложения ( грамм.) — члены предложения, служащие для пояснения главных членов предложения.
Предложения со словом «второстепенный»:
Стаффаж — это фигуры людей и животных, изображённые в произведениях пейзажной живописи для оживления вида и имеющие второстепенное значение.
Пусть будут знакомые и даже друзья, но пусть они кажутся второстепенными персонажами жизни, главный персонаж в духовном браке всегда один — это супруг.
Решите, на каких правилах будете впредь настаивать, и усиленно проводите их в жизнь, закрывая глаза на второстепенные вопросы.
Как выполнить разбор слова второстепенный по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, соединительная гласная, суффикс, окончание .
Схема разбора по составу: втор о степен н ый
Строение слова по морфемам: втор/о/степен/н/ый
Структура слова по морфемам: приставка/корень/суффикс/окончание
Конструкция слова по составу: корень [втор] + соединительная гласная [о] + корень [степен] + суффикс [н] + окончание [ый]
Основа слова: второстепенн
- втор — корень
- о — соединительная гласная
- степен — корень
- н — суффикс
- ый — окончание
- корень: 2
- окончание: 1
- соединительная гласная: 1
- суффикс: 1
Словообразование: производное, так как образовано 2 (двумя) способами, способы словообразования: суффиксальный.
Характеристики основы слова: непрерывная, сложная (более 1 корня), производная, членимая (есть словообразовательные афиксы) .
Состав смеси для улавливания: открытый машиночитаемый формат для представления смешанных веществ | Journal of Cheminformatics
Определение
Простейший вид Mixfile представляет собой смесь, которая по существу представляет собой отдельный компонент со значением чистоты, как показано на рис. 1. Единственный компонент описывается тремя частями информации: структурой бутена. производное, его название и концентрация ≥ 97%. Это представление требует только одного компонента, потому что примеси неизвестны и, следовательно, не указаны.Этот простой пример представляет собой невероятно распространенный вариант использования, особенно в каталогах реагентов.
Рис. 1Простая смесь с единственным известным компонентом, (S) -3-бутен-1,2-диолом, имеющая оценку чистоты
Другой очень распространенный вариант использования — когда активный ингредиент предоставляется в виде раствора, как показано на рис. 2. В этом случае задействуется иерархическая природа формата Mixfile. Корневой узел пуст, хотя его можно использовать для хранения вторичных метаданных о смеси в целом.В его состав входят два компонента: активный ингредиент и растворитель. Оба они представлены по имени и структуре. Активный ингредиент, триэтилалюминий , имеет 2 молярных количества. Концентрация растворителя, толуола , оставлена пустой, что по соглашению означает, что он составляет остаток смеси. Хотя было бы правильно рассчитать молярность растворителя и включить эту информацию, она излишняя, и для удобства и ясности представления ее лучше опустить.
Рис. 2Двухкомпонентная смесь с активным ингредиентом (триметилалюминий) известной концентрации, растворенным в растворителе (толуоле)
Иерархии Mixfile не имеют ограничений по глубине или высоте, и использование вложенности — удобный способ выразить смеси-смеси. Например, рассмотрим n — бутиллитий , растворенный в растворителе, который в просторечии называется гексаны , показанный на рис. 3.
Например, рассмотрим n — бутиллитий , растворенный в растворителе, который в просторечии называется гексаны , показанный на рис. 3.
Бутиллитий, растворенный в «гексанах», который сам по себе является смесь, состоящая из известных соединений в неопределенных пропорциях
Этот конкретный выбор иерархического описания ясно указывает на то, что описываемое вещество представляет собой смесь двух различных объектов : реагента и растворителя.Растворитель занимает один контейнерный узел, который описывается под названием гексаны . Поскольку он сам по себе является смесью, он не имеет структуры, и ему также не дается концентрация (поскольку подразумевается, что он составляет все, кроме реагента). Компонент гексаны имеет четыре назначенных ему подкомпонента, которые представляют собой основные изомеры C 6 , составляющие растворитель. Если бы относительные пропорции изомеров были известны, их можно было бы выразить в виде концентраций (например,грамм. как соотношение или объем / масса / молярные проценты), но в этом случае пропорция не указана производителем. Как таковой, он показывает, что формат Mixfile удобен для неполных данных, что важно, поскольку было бы неправильно настаивать на предоставлении информации, которая недоступна.
Одна очень практическая причина для описания веществ, таких как литийорганические реагенты, заключается в том, что безопасность и опасности зависят от состава. Рассмотрим родственный и гораздо более опасный третичный бутиллитиевый реагент , который показан на рис.4.
Рис. 4Трет-бутиллитий в пентане, для которого выбор растворителя особенно важен в целях безопасности
Знания только об активном ингредиенте ( t -бутиллитий) достаточно, чтобы убедиться, что этот материал является пирофорным, так как он имеет эту характеристику во всех своих формах. Однако для n -бутиллития растворы пирофорны только при более высоких концентрациях (примерно 10 моль / л и выше) [5]. Следовательно, возможность отслеживать концентрацию активного ингредиента и имеет важное значение для предоставления соответствующих рекомендаций по безопасности, обращению и утилизации.В случае этих двух литийорганических реагентов также важен состав растворителя, например t -бутиллитий обычно продается в виде растворов либо пентана, либо гептана, и эти растворители имеют резко разную летучесть, что является очень важной деталью для смеси, которая воспламеняется при контакте с воздухом. Любая база данных об опасностях будет неполной (и, возможно, опасной из-за пропусков) без возможности хранить и сопоставлять все эти факты.
Однако для n -бутиллития растворы пирофорны только при более высоких концентрациях (примерно 10 моль / л и выше) [5]. Следовательно, возможность отслеживать концентрацию активного ингредиента и имеет важное значение для предоставления соответствующих рекомендаций по безопасности, обращению и утилизации.В случае этих двух литийорганических реагентов также важен состав растворителя, например t -бутиллитий обычно продается в виде растворов либо пентана, либо гептана, и эти растворители имеют резко разную летучесть, что является очень важной деталью для смеси, которая воспламеняется при контакте с воздухом. Любая база данных об опасностях будет неполной (и, возможно, опасной из-за пропусков) без возможности хранить и сопоставлять все эти факты.
Еще одно важное соображение в отношении высокореактивных реагентов, таких как литийорганические растворы, заключается в том, что они со временем разлагаются и требуют титрования [6, 7] для повторного определения концентрации.Это означает, что недостаточно пометить образцы со ссылкой на свойства, которые они имели во время покупки, скорее, это должно быть записано с помощью структуры данных, которая может фиксировать изменяющуюся концентрацию, и в идеале делать это таким образом, чтобы полезно (например, в сочетании с программным обеспечением для планирования реакции для расчета объема, необходимого для стехиометрического использования).
Иерархия компонентов также может использоваться для представления смесей изомеров, что является обычным вариантом использования для результатов реакций, за которыми не следует эффективная стадия очистки, например.грамм. результат добавления Марковникова [8] брома, показанный на рис. 5.
Рис. 5Два изомера, образующиеся в результате бромирования пропена, представленные в виде смеси с указанием их относительных соотношений
Хотя некоторые виды изомеров могут быть эффективно представлены в структуре одного компонента (например, рацемические стереоизомеры), перечисление часто предпочтительнее, даже если есть альтернативы. Перечисление имеет некоторые преимущества по сравнению с более краткими вариантами кодирования, например.грамм. визуализация очень четкая, определение относительных концентраций простое и простая реализация.
Перечисление имеет некоторые преимущества по сравнению с более краткими вариантами кодирования, например.грамм. визуализация очень четкая, определение относительных концентраций простое и простая реализация.
Запись информации о свойствах смесей важна по очень многим причинам, не последней из которых является безопасность. Например, рассмотрим две коммерчески доступные формы четырехокиси осмия, показанные на рис. 6. Mixfile, представленный в (а), представляет собой твердую форму, которая в основном чиста, а (б) — тот же активный ингредиент, что и разбавленный раствор в воде. Оба эти материала чрезвычайно токсичны, но инструкции по хранению, обращению с ними и утилизации совершенно разные.Без четко определенного машиночитаемого формата для разграничения необработанного твердого вещества и разбавленного раствора выбор правильного паспорта безопасности материала будет зависеть от знаний и опыта ученого, выполняющего поиск. Другим ярким примером является азид натрия, который чрезвычайно токсичен в своей чистой твердой форме [9], но при растворении в воде при концентрациях ниже 0,1% он считается достаточно безвредным для использования в качестве пищевого консерванта [10].
Фиг.6Четырехокись осмия в двух формах: a чистый и b раствор, которые имеют очень разные профили безопасности
Описания смесей актуальны и за пределами химической лаборатории, поскольку существует бесчисленное множество потребительских товаров, которые могут выиграть от описания с подробными метаданными, как показано на рис. 7. Пример (a) описывает распространенную марку зубной пасты, тогда как (b ) представляет собой таблетированную форму для элетриптана [11]. Оба этих бытовых продукта имеют общие характеристики с точки зрения определения смесей: каждый из них имеет активный ингредиент ( фторид натрия и гидробромид элетриптана соответственно) и множество неактивных ингредиентов.Активные ингредиенты обычно находятся в центре внимания этих потребительских продуктов, но добавляемые дополнительные материалы очень важны: они обычно придают характеристики, которые влияют на стабильность, текстуру, вкус и эффективность. Они также являются частыми источниками беспокойства относительно токсичности и нежелательных побочных эффектов, поэтому сбор точных, полных и машиночитаемых данных по всем компонентам важен, не в последнюю очередь потому, что можно было бы быстро идентифицировать все такие потребительские товары с помощью любого конкретный компонент, о котором идет речь, когда есть проблемы со здоровьем.С точки зрения НИОКР составление лекарственного средства — это эмпирический процесс: точный состав и количество каждого вспомогательного вещества являются важной характеристикой таблетки лекарственного средства, и поэтому точная регистрация всех экспериментально определенных составов и сопоставление их с их эффективной эффективностью является важной частью продукта. дизайн.
Они также являются частыми источниками беспокойства относительно токсичности и нежелательных побочных эффектов, поэтому сбор точных, полных и машиночитаемых данных по всем компонентам важен, не в последнюю очередь потому, что можно было бы быстро идентифицировать все такие потребительские товары с помощью любого конкретный компонент, о котором идет речь, когда есть проблемы со здоровьем.С точки зрения НИОКР составление лекарственного средства — это эмпирический процесс: точный состав и количество каждого вспомогательного вещества являются важной характеристикой таблетки лекарственного средства, и поэтому точная регистрация всех экспериментально определенных составов и сопоставление их с их эффективной эффективностью является важной частью продукта. дизайн.
Две смеси, которые являются обычными предметами домашнего обихода: a марка зубной пасты и b состав элетриптана
Для потребительских товаров даже чаще, чем лабораторных реактивов, некоторая часть составляющих не может быть легко представлена одной или несколькими отдельными химическими структурами.Признание этого ограничения является ключевым моментом при проектировании Mixfile: в этих случаях должны быть предоставлены любые доступные метаданные. Обычно существует доступное имя в некоторой форме, а иногда и ссылки на внешние базы данных, которые содержат информацию о смесях, например Часто используется регистрационный номер Chemical Abstracts (CASRN) [12]. Эти ссылки не являются машиночитаемыми по своей сути, поэтому их следует рассматривать как заполнитель: облегчение неавтоматизированного отката предпочтительнее полного исключения информации, и часть будущей работы для этого проекта заключается в расширении возможности описания более сложных фрагменты структуры, подобные полимерам.
Программное обеспечение
Чтобы использовать формат Mixfile, мы создали простой редактор, который можно использовать для определения смесей.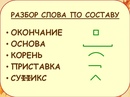 На рисунке 8 показано несколько панелей: главное окно редактора (а) представляет собой иерархическую схему смеси. Компоненты, составляющие это дерево, можно добавлять, удалять, перемещать, редактировать и т. Д. С помощью обычного меню, мыши и сочетаний клавиш. При редактировании отдельных компонентов открывается один из двух диалоговых окон: один для общих деталей (b), а другой — для эскиза конструкции (c).
На рисунке 8 показано несколько панелей: главное окно редактора (а) представляет собой иерархическую схему смеси. Компоненты, составляющие это дерево, можно добавлять, удалять, перемещать, редактировать и т. Д. С помощью обычного меню, мыши и сочетаний клавиш. При редактировании отдельных компонентов открывается один из двух диалоговых окон: один для общих деталей (b), а другой — для эскиза конструкции (c).
Скриншоты редактора смеси: a обзор смеси, b редактор компонентов, c эскиз структуры
Редактор смесей имеет возможность вызывать вычисление строк InChI для любой из составляющих структур, что выполняется с помощью стандартного инструмента командной строки (который устанавливается отдельно [13]). Как описано ниже, он также может создавать для смеси соответствующее производное обозначение MInChI.
По мере развития проекта Mixfile редактор будет постепенно улучшаться, а последние разработки будут по-прежнему доступны в виде программного обеспечения с открытым исходным кодом. Одним из примеров дополнительной служебной функции является возможность поиска структур по имени во внешней базе данных, показанной на рис. 9. Это удобный способ получения структур, для которых известно имя, чтобы избежать необходимости рисовать или находить -и вставляем соответствующий скетч. На момент отправки поддерживается только PubChem, хотя его можно легко расширить для поддержки других баз данных.
Рис. 9Снимок экрана функции поиска в базе данных
В то время как лучший сценарий для создания машиночитаемых метаданных состоит в том, чтобы они были созданы непосредственно исходящим ученым в формате, который может выражать все детали, факт заключается в том, что почти вся существующая информация о смеси выражается в виде текста. Эти текстовые описания обычно вполне понятны людям, хотя иногда выбранный синтаксис может быть неоднозначным даже для эксперта. Многие из этих текстовых описаний встречаются в длинных абзацах (например, в литературных публикациях), но они довольно часто абстрагируются с четко определенным началом и концом: это часто наблюдается в онлайн-каталогах поставщиков (например, Sigma-Aldrich [14] ThermoFisher [15] ] Alfa Aesar [16] и многие другие) и в специальных системах инвентаризации химических веществ.
Многие из этих текстовых описаний встречаются в длинных абзацах (например, в литературных публикациях), но они довольно часто абстрагируются с четко определенным началом и концом: это часто наблюдается в онлайн-каталогах поставщиков (например, Sigma-Aldrich [14] ThermoFisher [15] ] Alfa Aesar [16] и многие другие) и в специальных системах инвентаризации химических веществ.
Можно составить набор правил, которые могут интерпретировать большую часть смесей из такого набора данных. Рассмотрим простой пример, такой как « 1-Аза-12-корона-4 ≥ 97.0% ”, Который описывает одно известное соединение, составляющее большую часть материала, и, косвенно, некоторое количество неизвестных, составляющих остаток. Операцию анализа можно изобразить графически, как показано на рис. 10. Первое правило устанавливает, что 1 — Aza — 12 — корона — 4 — это имя химического объекта, который может быть отображен. к определению структуры. Второе правило определяет, что ≥ 97,0% является количественным определением, которое обеспечивает отношение , значение и единиц .
Рис. 10Этап синтаксического анализа для анализа смеси текста применяется к одному химическому названию с сопутствующей оценкой чистоты
Mixfiles, для которых явно определены несколько компонентов, требуют дополнительных шагов синтаксического анализа. Наиболее распространенными лабораторными примерами являются пары реагент-растворитель, выраженные с помощью текста, такого как «
Раствор триметил (трифторметил) силана 2
M в THF
”, Графически изображенная на рис.11. В этом случае правила синтаксического анализа должны найти границу между двумя компонентами и рекурсивно проанализировать их. К этому примеру применяется общее правило {определение растворенного вещества} в {определение растворителя}, хотя необходимо соблюдать осторожность, чтобы убедиться, что вхождение очень короткого ключевого слова в обрабатывается правильно.
Правила синтаксического анализа текста, применяемые к смеси, которая разделяется отдельно на активный ингредиент и растворитель
Как только граница определена, анализ продолжается: растворитель определяется как THF , что является общепринятым сокращением для тетрагидрофуран .Активный ингредиент требует еще нескольких шагов: суффикс 2 M считается количественным определением. Заглавная буква M в данном контексте обозначает молярный, поэтому концентрация интерпретируется как 2 моль / л. После обработки и удаления информации о количестве оставшийся текст необходимо дополнительно усечь: использование слова , решение является излишним и требует правила удаления. Как только это будет сделано, оставшийся текст — триметил (трифторметил) силан — станет допустимым химическим названием, которое можно проанализировать и преобразовать в структуру.
Эти два тематических исследования являются репрезентативными для большого количества общих текстовых описаний смесей лабораторных реагентов. В разделе «Методы» мы описываем краткое изложение нашей текущей работы по извлечению текста из смесей, а также доступность данных, которые мы уже сгенерировали. Коллекция из нескольких тысяч примеров смесей также включена в проект GitHub с открытым исходным кодом, все из которых были созданы с использованием нашего метода извлечения текста доказательства концепции, некоторые из которых показаны на рис.12.
Рис. 12Мозаика смешанных данных, извлеченных путем извлечения текста из коллекции каталогов
Распознавание текста в структуру, которое составляет ключевую часть процесса извлечения, может быть выполнено с использованием одного из нескольких доступных алгоритмов. Для практических целей необходимо объединить эту функциональность с поисковой таблицей, поскольку очень безопасно предположить, что ни один алгоритм не будет правильно интерпретировать все важные структуры в любой большой коллекции. Кроме того, бывают случаи, когда имя соотносится с субсмесью (например, когда-либо распространенные гексаны и ксилолы ), и с ними можно справиться, предоставив таблицу поиска с возможностью вставки ветви смеси.
Кроме того, бывают случаи, когда имя соотносится с субсмесью (например, когда-либо распространенные гексаны и ксилолы ), и с ними можно справиться, предоставив таблицу поиска с возможностью вставки ветви смеси.
Смеси InChI
Формат Mixfile, который мы описываем в этой статье, подходит для использования в качестве справочного контейнера, который подходит для подробных целей архивирования. Его можно легко визуализировать для создания визуального представления качества печати, и его можно расширить для хранения любых дополнительных метаданных, выходящих за рамки базовой спецификации.На разработку этого формата и связанных с ним инструментов сильно повлияло наше сотрудничество с IUPAC и предложенная ими нотация Mixtures InChI, сокращенно MInChI . По замыслу, представление контейнера Mixfile может использоваться в качестве исходного материала для генерации строки MInChI, которая включает в себя извлечение фундаментальной информации о компонентах и передачу им канонической стандартизации и мотива слоя, которые возникают при использовании InChI в качестве идентификатора структуры.
Как видно на рис. 13a, простая смесь, подобная этому примеру, где кофеин указан с определенной чистотой, соответствующая строка MInChI преобладает со структурным идентификатором из стандартного генератора InChI. Строка предваряется означающим, которое идентифицирует ее как совместимую со спецификацией MInChI, за ней следуют два дополнительных уровня: иерархия (которая в данном случае является одноэлементной) и концентрация, которая закодирована в краткой мнемонической форме.
Рис. 13Три все более сложных примера смесей, представленных в нотации MInChI: кофеин с оценкой чистоты; b трибромид бора, растворенный в хлористом метилене; c Диизопропиламид лития, растворенный в относительно сложной смеси растворителей
Пример (b) содержит два компонента, которые перечислены в разделе структуры. Блок иерархии указывает на смесь с плоской иерархией. В строке MInChI компонентный слой сортируется в алфавитном порядке по строкам InChI (который по совпадению имеет тот же порядок, что и в исходном Mixfile).Блок концентрации имеет одну секцию для каждого компонента, но вторая запись пуста, поскольку концентрация не указана (т.е. предполагается, что она составляет остаток смеси).
Блок иерархии указывает на смесь с плоской иерархией. В строке MInChI компонентный слой сортируется в алфавитном порядке по строкам InChI (который по совпадению имеет тот же порядок, что и в исходном Mixfile).Блок концентрации имеет одну секцию для каждого компонента, но вторая запись пуста, поскольку концентрация не указана (т.е. предполагается, что она составляет остаток смеси).
Пример (c) несколько более экзотичен, он представляет собой смесь нескольких наборов компонентов с 3 уровнями иерархии. Кроме того, у 3 узлов компонентов не указана структура. В этом случае порядок ветвлений отличается от того, который используется в Mixfile. Часть иерархической индексации строки MInChI обозначает форму дерева с помощью фигурных скобок.Три узла имеют заданные концентрации: ингредиент диизопропиламида лития имеет общую молярность, а составляющие ТГФ / гексаны выражены в виде пропорций, которые применяются конкретно к части иерархии (то есть фактическое определение гексанов в этом примере явно пронумерованы по своим структурам, и их приблизительные концентрации относительно друг друга определены в пределах их собственной ветви).
Хотя и Mixfiles, и MInChI используются для одних и тех же типов данных, они выполняют разные роли в общей инфраструктуре хеминформатики.Обозначение MInChI имеет некоторые ключевые преимущества по сравнению с исходным Mixfile:
краток, ограничен одной строкой, состоящей из символов ASCII, которыми можно легко манипулировать в электронной таблице или вставлять в одну строку ввода в веб-форме.
позволяет легко ссылаться на сравнение сходства: две смеси с одинаковыми составляющими будут идентичны до с индексом концентрации и секции
проверить наличие структуры в смеси чрезвычайно просто (например,грамм. содержится ли идентификатор запроса InChI в строке MInChI)
аналогично, структуры могут быть разделены и проиндексированы индивидуально по их кодам InChI
Относительно сложные сравнения состава и концентрации могут быть выполнены с помощью простых манипуляций со строками без необходимости в специальной библиотеке хеминформатики
Все эти характеристики актуальны для реализации в базе данных, где пользовательские поисковые запросы и операции индексации могут выполняться с использованием встроенных операторов или простых языков сценариев, для которых не всегда доступны удобные библиотеки хеминформатики. Предоставление возможности поиска отдельной структуры в любой смеси становится очень простым (достаточно любой реализации строки indexOf , если структура запроса может быть преобразована в идентификатор InChI).
Предоставление возможности поиска отдельной структуры в любой смеси становится очень простым (достаточно любой реализации строки indexOf , если структура запроса может быть преобразована в идентификатор InChI).
Сравнение смесей может быть выполнено с помощью некоторой относительно простой логики. Рассмотрим сценарий, когда в базе данных ведется поиск смесей, аналогичных запросу, показанному на рис. 14 (а), и рассматриваем (б) в качестве потенциального кандидата.Обе эти смеси представляют собой диметиламин в аналогичной концентрации, растворенный в двух разных растворителях. Сравнение двух цепочек MInChI может быстро установить, что каждая смесь состоит из двух компонентов, и у них есть один общий компонент. Общая структура, которая является активным ингредиентом (с фрагментом InChI C2H7 Н / с1-3-2 / ч4Н, 1-2х4 ), дается концентрация с обеих сторон: для (a) это конкретно 90 г / л, а для (b) — между 1.9 и 2,1 моль / л. Поскольку фрагмент идентификатора InChI начинается с молекулярной формулы, вычислить молекулярную массу несложно (используя очень простую таблицу поиска элементов и очень короткий блок кода). Это можно использовать, чтобы убедиться, что 90 г / л составляет приблизительно 2 моль / л, и поэтому обе эти смеси имеют общий ингредиент с общей концентрацией с различным растворителем.
Рис. 14Две очень похожие смеси и соответствующие им обозначения MInChI, подчеркивающие легкость, с которой они могут быть проанализированы с помощью базовой обработки строк
Как и в случае с автономным структурным идентификатором (InChI), обычно существуют веские причины для сохранения более подробной информации об источнике, например.грамм. Считайте строку MInChI нотацией композиции, которая восстанавливается из Mixfile, поскольку она не предназначена для использования в качестве основной записи данных. В процессе создания MInChI абстрагируются структурный идентификатор, концентрация и пропорциональные отношения компонентов, как указано в исходном описании. И строка MInChI, и составляющие ее идентификаторы InChI обратимы только в частичном смысле: преобразование вперед (например, Mixfile в MInChI или Molfile в InChI ) уменьшает степени свободы, чтобы повысить его полезность для конкретные цели.Любая заданная строка MInChI или InChI может соответствовать множеству различных, но эквивалентных выражений смеси или структуры, но при обращении преобразования обычно не восстанавливается исходный ввод. В случае идентификатора InChI это легко заметить, поскольку InChI не сохраняет координаты входных молекул, поэтому обратный процесс должен воссоздать их алгоритмически. Другие модификации, такие как выбор канонического таутомера, нормализация стереоцентров и разъединение связей с металлами, еще больше уменьшают корреляцию с исходной входной структурой.Кроме того, для преобразования Mixfile в MInChI такие свойства, как имена структур, вспомогательные идентификаторы и т. Д., Не сохраняются в нотации MInChI. Иногда их можно получить заново, но нет гарантии, что они будут такими же, как оригинал.
И строка MInChI, и составляющие ее идентификаторы InChI обратимы только в частичном смысле: преобразование вперед (например, Mixfile в MInChI или Molfile в InChI ) уменьшает степени свободы, чтобы повысить его полезность для конкретные цели.Любая заданная строка MInChI или InChI может соответствовать множеству различных, но эквивалентных выражений смеси или структуры, но при обращении преобразования обычно не восстанавливается исходный ввод. В случае идентификатора InChI это легко заметить, поскольку InChI не сохраняет координаты входных молекул, поэтому обратный процесс должен воссоздать их алгоритмически. Другие модификации, такие как выбор канонического таутомера, нормализация стереоцентров и разъединение связей с металлами, еще больше уменьшают корреляцию с исходной входной структурой.Кроме того, для преобразования Mixfile в MInChI такие свойства, как имена структур, вспомогательные идентификаторы и т. Д., Не сохраняются в нотации MInChI. Иногда их можно получить заново, но нет гарантии, что они будут такими же, как оригинал.
Это однонаправленное сокращение информации является ключом к практической ценности InChI и всех его производных: возможность рассматривать строку как уникальное и буквальное определение химического объекта делает множество сложных и ресурсоемких задач хеминформатики почти тривиально простыми. .Обозначение MInChI использует эти фундаментальные свойства InChI. Предостережение заключается в том, что системе архивирования рекомендуется также хранить данные в их первоначальной форме до любой первоначальной обработки, что является известным научным принципом (т. Е. Никогда не выбрасывайте оригинальную лабораторную записную книжку).
На момент написания спецификация MInChI приближается к завершению Фазы 1 и, как ожидается, будет официально выпущена позже в 2019 году. Обновления будут размещены на странице проекта IUPAC [17]. Если вы заинтересованы в реализации нотации MInChI в своих локальных системах, свяжитесь с авторами.
John MacFarlane — Beyond Markdown
Это эссе было первоначально размещено на https://talk.commonmark.org/t/beyond-markdown/2787 в апреле 2018 года.
При разработке Commonmark мы старались, насколько это было возможно, оставаться верными оригинальному описанию синтаксиса Markdown Джона Грубера. Мы отклонялись от него лишь изредка, в интересах устранения двусмысленности и повышения единообразия, а также с добавлением нескольких элементов синтаксиса, которые теперь практически повсеместны (например, изолированные блоки кода и ссылки на ярлыки).
Есть очень веские причины для такой консервативности. Но это уважение к прошлому сделало спецификацию CommonMark очень сложной задачей. Например, существует 17 принципов, управляющих акцентом, и эти правила по-прежнему оставляют вопросы нерешенными. Правила для элементов списка и блоков HTML также очень сложны. Все эти правила иногда приводят к неожиданным результатам, и они делают написание синтаксического анализатора для CommonMark сложным делом. Иногда я отчаиваюсь добраться до спецификации, которую стоит назвать 1.0.
Что, если бы мы не были привязаны к прошлому? Что, если бы мы попытались создать упрощенный синтаксис разметки, который сохранил бы то, что есть в Markdown, и при этом пересмотрел некоторые функции, которые привели к раздуванию и сложности в спецификации CommonMark?
Позвольте мне сразу прояснить, что я не предлагаю никаких изменений в целях проекта Commonmark. Если эти размышления к чему-то приведут, вероятно, это должен быть совершенно новый проект под новым названием. И если быть реалистом, то бремя поддержки обратной совместимости несущественно по сравнению с огромными практическими затратами на перевод существующих систем на новый облегченный язык разметки.Тем не менее… я думаю, это может быть полезно для мечтаний.
Далее я рассмотрю шесть функций Markdown, которые, по моему мнению, вызвали наибольшие трудности, и подскажу, как можно исправить каждую болевую точку.
1. Выделение
В Markdown акцент создается окружением текста * или _ символов, * вот так * . Сильный акцент создается путем их удвоения, ** вот так ** . Все это звучит очень просто, и визуально ясно, на каком из них делается сильный акцент.
К сожалению, этих простых операторов недостаточно для определения синтаксиса. Рассмотрим, например,
** этот * текст ** Наши простые правила согласуются с обоими этими значениями:
-
этот * текст -
этот текст *
Итак, чтобы полностью указать синтаксический анализ акцентов, нам нужны дополнительные правила. 17 обескураживающе сложных правил в спецификации CommonMark предназначены для принудительного толкования тех видов чтения, которые люди сочтут наиболее естественными.
Мне кажется, что использование сдвоенных символов для сильного выделения и возможность выделения даже части слова, как в fan * tas * tic , значительно усугубили проблему определения синтаксического анализа акцента, значительно увеличив неоднозначности, которые должна разрешить спецификация. В зависимости от контекста строка из трех *** в середине слова может быть любой из следующих:
- Символ
*, за которым следует начало сильного выделения. - Конец сильного выделения, за которым следует символ
*. - Конец обычного выделения, символ
*, затем начало обычного выделения. - Конец сильного акцента, за которым следует начало обычного акцента.
- Конец обычного акцента, за которым следует начало сильного акцента.
- Конец обычного выделения, за которым следует буквальный
**. - Литерал
**, за которым следует начало обычного выделения. - Литерал
***.

Как исправить упор
Чтобы значительно уменьшить двусмысленность, мы можем удалить удвоенные разделители символов для более сильного выделения. Вместо этого используйте один _ для регулярного выделения и один * для сильного выделения. Акцент теперь будет начинаться с левого, но не с правого фланга, и заканчиваться правым, но не левым разделителем того же типа.
Для выделения внутри слова нам потребуется специальный синтаксис:
вентилятор ~ _tas_ ~ tic Выделение внутри слова встречается крайне редко, так что это хороший компромисс, если немного усложнить его в обмен на упрощение правил (и концептуальной модели) для выделения акцента в целом.Специальный символ ~ здесь действует как пробел для целей синтаксического анализа (позволяя внутреннему слову _ выделять начало и конец), но не отображается как пробел. (Таким образом, он ведет себя так же, как экранированный пробел в reStructuredText.)
2. Ссылки
Обычная обработка ссылочных ссылок делает невозможным классифицировать какой-либо элемент синтаксиса до тех пор, пока не будет проанализирован весь документ. Например, рассмотрим
. [foo] [bar] [baz]
[bar]: url Это интерпретируется как
foo [baz]
Но предположим, что мы определяем ссылку для baz вместо bar :
[foo] [bar] [baz]
[baz]: url Тогда получаем:
[foo] bar
Итак, мы не можем определить, является ли [foo] буквальным текстом в квадратных скобках или ссылкой с описанием ссылки foo , пока мы не проанализируем весь документ.
Это очень затрудняет выделение синтаксиса, а также усложняет написание синтаксических анализаторов. Например, вы не можете анализировать ссылки, а затем разрешать ссылки в AST после анализа документа. — содержимое должно быть с отступом.
Это неплохое правило, но оно добавляет сложности: нужно отслеживать не только положение маркера списка, но и положение первого следующего за ним непространственного содержимого. Кроме того, нужны особые правила для таких случаев, как пустые элементы списка и элементы списка, которые начинаются с кода с отступом. Наконец, многих до сих пор удивляет, что, например, это не вложенный список:
- а
- б Таким образом, можно спросить: почему бы просто не потребовать, чтобы содержимое элемента списка было с отступом по крайней мере на один пробел после маркера списка? Это очевидное минимальное правило.Что блокирует это, так это наличие блоков кода с отступом. Если содержимое уровня блока под элементом списка начинается с отступа в один пробел после маркера списка, то код с отступом должен быть сдвинут на пять пробелов после маркера списка. Это не только несовместимо с восемью пробелами, указанными в исходном описании синтаксиса Markdown, но и приводит к ужасным результатам с более длинными маркерами списка:
99. Вот мой пункт списка.
И это код с отступом! Хотя это
соответствует абзацу выше! Подводя итог: большая часть сложности правил для элементов списка вызвана необходимостью иметь дело с блоками кода с отступом.
Как исправить отступы блоков кода и списков
Изолированные блоки кода теперь обычно предпочтительнее, чем блоки кода с отступом, потому что вы можете указать синтаксис для выделения, и вам не нужно делать отступы / отменять отступы при копировании и вставке кода. Поскольку мы изолировали блоки кода, нам не нужны блоки кода с отступом. Итак, мы можем просто избавиться от них.
Это освобождает отступ, чтобы его можно было более гибко использовать для обозначения вложенности списка, и мы можем принять простое, очевидное правило, согласно которому содержимое элемента списка должно иметь отступ как минимум на один пробел относительно маркера списка.
Еще одно преимущество удаления блоков кода с отступом состоит в том, что начальный отступ теперь можно игнорировать в целом, за исключением случаев, когда он влияет на списки.
4. Необработанный HTML
С самого начала вы могли вставлять необработанный HTML в документы Markdown, и он передавался дословно. Идея состоит в том, что вы можете вернуться к необработанному HTML для всего, что не может быть выражено в виде обычного текста.
Звучит проще, чем есть на самом деле. С самого начала Markdown.pl различает встроенный HTML-код и HTML-код блочного уровня.Встроенные HTML-теги передавались дословно, но их содержимое можно было интерпретировать как Markdown:
** привет ** даст вам
< sizeshi Было предусмотрено, что содержимое HTML на уровне блоков должно быть разделено пустыми строками, а начальный и конечный теги не должны иметь отступа. В таких HTML-блоках все будет передаваться дословно и не интерпретироваться как Markdown.Итак,
*Привет*
просто даст вам
*Привет*
Это вызвало несколько проблем. Во-первых, как мы идентифицируем контент на уровне блоков? Нужно ли нам жестко закодировать список элементов HTML, которые могут изменяться по мере развития HTML? А как насчет таких элементов, как , которые могут встречаться во встроенном или блочном контекстах?
Во-вторых, как насчет блочного HTML-кода, который не разделен должным образом и не имеет отступа?
привет
привет Должны ли парсеры просто обрабатывать его как встроенный HTML и генерировать недопустимый HTML?
В-третьих, как определить конец блока HTML? Учитывая, что теги могут быть вложенными, для этого требуется нетривиальный синтаксический анализ HTML.Выпущенная версия CommonMark для блоков HTML была разработана, чтобы упростить синтаксический анализ необработанных блоков HTML (без неопределенного упреждения или полной реализации синтаксического анализа HTML), а также дать авторам возможность включать содержимое CommonMark в теги HTML на уровне блоков, если они хотеть. Но результат довольно сложный: семь различных пар начальных и конечных условий.Правила встроенного HTML также сложны и содержат большое количество определений. Кроме того, поскольку Markdown стал полезен не только для создания HTML, но и для создания документов в различных форматах, то, как HTML выделяется для прямой передачи, стало казаться несколько произвольным. Те, кто пишет в других форматах, также выиграют от возможности передавать необработанный контент. Вместо передачи необработанного HTML мы должны ввести специальный синтаксис, который позволяет передавать необработанный контент любого формата.Для этого мы можем перегрузить наши существующие контейнеры для необработанных строк: интервалы кода и блоки кода: Но мы тоже можем сделать LaTeX: Мы могли даже передавать различный необработанный контент в разные форматы, например, включая HTML и LaTeX версии сложной фигуры. Может ли список прерывать абзац, как этот? Исходная документация по синтаксису Markdown не решает этого, а Однако было сделано одно исключение: когда текст абзаца сам является частью элемента списка, пустая строка не требуется. Если бы это исключение не было создано, мы не смогли бы распознать вложенный список в этом случае: Размышляя о спецификации CommonMark для элементов списка, мы поняли, что файл не содержит списка, значит не содержит подсписка. Мы считаем важным принцип единообразия. Действительно, это предполагает то, как мы указываем элементы списка и блочные кавычки.Это означает, что мы столкнулись с выбором: либо требовать пустую строку между текстом абзаца и следующим списком, либо разрешить спискам прерывать абзацы и рисковать случайной интерпретацией текста абзаца как списка. Мы выбрали первый вариант исключения из таблицы, поскольку в Markdown очень часто используются узкие подсписки без предшествующей пустой строки. Поэтому мы выбрали второй вариант, уменьшив ущерб с помощью уродливой эвристики (мы разрешаем упорядоченному списку прерывать абзац, только если номер списка равен Нам нужна пустая строка между текстом абзаца и списком. Всегда. То есть даже в подсписках. Итак, чтобы создать узкий список с подсписком, вы должны написать: Мы называем список узким, если он содержит хотя бы одну пару элементов без пустых строк между ними, поэтому в приведенном выше примере внутренний список узкий, а внешний — нет. Чтобы сжать оба списка: Markdown не предлагает общего способа добавления атрибутов (таких как классы или идентификаторы) к элементам. Это лишает его встроенного способа создания внутренних ссылок на разделы документа. (Во многих реализациях были введены слегка отличающиеся способы автоматической генерации идентификаторов из заголовков.) Это также лишает его естественного механизма расширения. В Markdown есть контейнеры для встроенных (например, выделение), блоков (например, цитаты), необработанного встроенного содержимого (фрагменты кода) и необработанного содержимого блока (блоки кода).Если бы к ним можно было прикрепить произвольные атрибуты, ими можно было бы управлять с помощью фильтров для получения очень гибкого вывода. Например, можно рассматривать цитату блока с классом «предупреждение» как предупреждение, или можно рассматривать блок кода с классом «точка» как точечную диаграмму graphviz, которая будет отображаться как изображение. Однако в настоящее время единственный способ прикрепить атрибуты к элементу — это перейти к необработанному HTML. Введите синтаксис для спецификации атрибута.После pandoc используйте для этого фигурные скобки Разрешить добавление атрибутов в строку перед для любого блочного элемента и непосредственно после после для любого встроенного элемента: Здесь идентификатор Спецификаторы атрибутов должны умещаться в одной строке, но можно использовать несколько (и затем они будут объединены): Возможно, было бы полезно добавить синтаксис для неукрашенных встроенных промежутков и изолированного универсального контейнера блока, как в pandoc. Но мы можем использовать выделение для встроенного контейнера и цитату блока для контейнера блока, поэтому в этом нет необходимости. Выделение Справочные ссылки Код Списки HTML Атрибуты Целью этого второго исследования пользователей является анализ того, насколько легко использовать SketchBench для рисования диаграмм классов по сравнению с традиционным инструментом WIMP UML CASE. Исследование удобства использования SketchBench было выполнено путем набора шестнадцати студентов бакалавриата из класса программной инженерии, которые не участвовали в исследовании распознавания. Все студенты были знакомы с обозначениями диаграмм классов UML, но у них не было опыта использования инструментов CASE (автоматизированная компьютерная разработка программного обеспечения) и интерфейсов на основе эскизов. Они взяли урок продолжительностью 15 минут, чтобы научиться принципам рисования по эскизам.Кроме того, мы познакомили их с основными функциями SketchBench, включили возможности распознавания многоштриховых символов и показали им, как рисовать схемы классов. Обратите внимание, что версия SketchBench, использованная в этом исследовании, поддерживала удаление любого штриха в процессе редактирования. Более того, они взяли урок продолжительностью 15 мин. чтобы изучить основные возможности ArgoUML для редактирования диаграмм классов. Студенты были разделены на две группы по восемь предметов (A и B), и каждый студент выполнял два задания (t1 и t2).Группа A использовала ArgoUML для решения t1 и SketchBench для t2, тогда как группа B решала t1 с помощью SketchBench и t2 с помощью ArgoUML. Каждая задача заключалась в создании диаграммы классов для программного обеспечения для бронирования отелей в соответствии с конкретным вариантом использования. В частности, вариантом использования для задачи t1 было «резервирование комнаты», тогда как вариантом использования для задачи t2 было «выписка из комнаты». На каждую задачу у студентов было двадцать минут, чтобы решить ее, используя только назначенный инструмент. Обратите внимание, что SketchBench еще не поддерживает распознавание текста, поэтому для поддержки пользователя в определении диаграммы классов, включая имена классов, объявления полей и методов и т. Д., Мы добавили в интерфейс кнопку для переключения с рисования. из режима в текстовый режим редактирования и наоборот.Штрихи, отредактированные в режиме редактирования текста, не отправлялись в распознаватель. В целом поставленные задачи были правильно выполнены 9 студентами, 5 из группы A и 4 из группы B. Два студента из группы A не смогли решить поставленную задачу: один использовал ArgoUML в задаче t1, а другой использовал SketchBench в задаче t2. Только в одном случае ученик не выполнил решение (для задачи t2) из-за неспособности SketchBench распознать часть диаграммы ученика. В группе B один студент не смог решить обе задачи, два студента не смогли решить задачу t2 с помощью ArgoUML, а один студент нарисовал неузнаваемый эскиз для задачи t1.Коробчатая диаграмма Напротив, нет значительной разницы во времени между двумя инструментами для задачи t2. Преимущества SketchBench, выделенные в t1, ослабляются из-за повышенной сложности диаграммы, которую нужно нарисовать. Действительно, мы заметили, что студенты столкнулись со многими трудностями при изменении эскизов и редактировании текстовых меток. Более того, некоторые возможности ArgoUML, такие как синтаксически управляемое редактирование, использовавшееся учениками группы A для решения t1, больше не были доступны для решения t2. Рейтинги за вопрос 1.1 показывают, что студенты считают SketchBench лучше, чем ArgoUML, при редактировании простых диаграмм классов. В частности, для задачи t1, даже если максимальная сложность редактирования одинакова для обоих инструментов, в среднем SketchBench лучше.Для задачи t2, для решения которой требуется больше символов, чем t1, SketchBench страдает от проблем распознавания неоднозначности, таких как перекрывающиеся и перерисованные символы, присущие плотным эскизам. Аналогичные оценки были получены по вопросам 1.2–1.5 относительно отредактированных символов диаграммы классов. В частности, для задачи t1 мы замечаем, что символы агрегирования и наследования труднее рисовать, поскольку они очень похожи, и SketchBench сбивает их распознавание. С другой стороны, для ArgoUML сложнее нарисовать агрегацию, поскольку она не включена в палитру символов, но ее можно определить, нарисовав символ ассоциации и задав его свойства через контекстное меню.Для задания t2 трудности рисования увеличиваются для всех символов; в основном это связано с расположением символов на листе. В частности, мы заметили, что, хотя ArgoUML обеспечивает поддержку макета символов, пользователи SketchBench постепенно рисуют символы на листе в соответствии со своим видением решения, что затрудняет процесс распознавания сложных эскизов. Ответы на вопрос 1.6 показывают, что оба инструмента дают предсказуемые результаты.Наконец, анализируя рейтинги вопросов 1.7 и 1.8, мы видим, что, когда задача несложная, SketchBench менее сложен в использовании и легче найти решение, чем ArgoUML. Действительно, при выполнении задания t2 небольшая практика учеников с зарисовками вызвала разочарование, из-за чего рисование диаграмм было трудно распознать. Рейтинги по вопросу 2.2 показывают, что SketchBench прост в использовании для разработки диаграмм классов UML. Однако сложность построения диаграмм влияет на эту меру. В частности, мы наблюдаем, что у студентов возникали трудности с исправлением ошибок распознавания, когда диаграммы содержали много символов. Выброс группы A соответствует студенту, который не смог создать узнаваемую диаграмму.Оценка за вопрос 2.3 показывает, что SketchBench очень приятен в использовании. Два выброса — это студенты, разочарованные неспособностью SketchBench распознать их эскизы. Рейтинги по вопросу 2.4 показывают, что использование SketchBench требует тех же умственных усилий, что и ArgoUML. Основные трудности, с которыми сталкиваются учащиеся при использовании SketchBench и отмеченные в ответах на вопрос 2.5, включают способ сообщения об ошибках в эскизах и их исправление, а также двухрежимный подход к рисованию, используемый для отделения рисунков от текста.Привлекательные особенности SketchBench, отмеченные ответами на вопрос 2.6, — это возможность рассуждать о решении непосредственно в инструменте, быстрота создания диаграммы без выбора символов из палитры и удовлетворение качества распознавания в SketchBench. В целом, ответы на вопросы показывают, что обе группы предпочитают SketchBench ArgoUML из-за простоты использования и приятности в использовании. Тем не менее, результаты этого исследования удобства использования должны быть дополнительно подтверждены путем рассмотрения других областей приложений и сравнения SketchBench с другими инструментами на основе эскизов. EnchantedLearning.com — это сайт, поддерживаемый пользователями. Пятибуквенные анаграммы Анаграмма — это слово или фраза, составленные путем перестановки букв другого слова или фразы.Например, стоп — это анаграмма горшков. Некоторые 5-буквенные анаграммы включают: Анаграммы Задания: Задание-головоломка с изображением животных анаграмм № 1 Животное анаграмма Картинка-головоломка. Рабочий лист № 2 Животное анаграмма Картинка-головоломка. Рабочий лист № 3 Задание-головоломка с изображением животного анаграммы № 4 Задание-головоломка с изображением анаграммы животных № 5 Задание-головоломка с изображением животного анаграммы № 6 Тело анаграммы Рисунок-головоломка Рабочий лист Одежда Анаграмма Рабочий лист головоломки с изображением Пищевая анаграмма Рабочий лист головоломки с изображением Рабочий лист анаграммы дома с изображением головоломки Математическая анаграмма Рабочий лист головоломки с изображением Музыкальная анаграмма Рабочий лист головоломки с изображением Анаграмма растений Рабочий лист головоломки с изображением Спортивная анаграмма Задание-головоломка с изображением Инструмент Анаграмма Рабочий лист головоломки с изображением Транспортная анаграмма Рабочий лист головоломки с картинками Анаграммы совпадений: Сопоставьте анаграммы животных # 1 Сопоставьте анаграммы животных # 2 Сопоставьте астрономические анаграммы Сопоставьте анаграммы тела Анаграммы сопоставления одежды Анаграммы сопоставления цветных слов Сопоставьте название страны Анаграммы Сопоставьте анаграммы фермы Сопоставьте анаграммы еды # 1 Сопоставьте анаграммы еды # 2 Соответствие географическим анаграммам Сопоставьте анаграммы, связанные с Хэллоуином Сопоставьте анаграммы, связанные с домом Анаграммы сопоставления вакансий Сопоставьте математические анаграммы Сопоставьте денежные анаграммы Сопоставьте музыкальные анаграммы Сопоставьте людей Анаграммы Сопоставьте анаграммы растений Сопоставьте школьные анаграммы Соответствие спортивным анаграммам Сопоставьте анаграммы Дня благодарения Сопоставление анаграмм инструмента Сопоставление анаграмм транспортных средств Сопоставление анаграмм погоды Сопоставьте анаграммы погоды Написать анаграмму: Задания-головоломки с анаграммами Задания-головоломки-анаграммы животных Apt Anagram Puzzle Worksheet Астрономический лист-головоломка с анаграммой Рабочий лист анаграммы тела Рабочий лист анаграммы одежды Название страны Лист анаграммы-головоломки Рабочий лист «Анаграмма еды» Географическая анаграмма. Рабочий лист Рабочий лист-головоломка «Домашняя и домашняя анаграмма» Задание Анаграммы Рабочий лист-головоломка Задание-головоломка с математической анаграммой Рабочий лист головоломки музыкальной анаграммы Рабочий лист анаграммы растений Школьная анаграмма. Рабочий лист Инструменты Анаграмма. Рабочий лист головоломки Рабочий лист анаграммы транспортного средства Напишите много анаграмм: Напишите много анаграмм # 1 Напишите много анаграмм # 2 Напишите много анаграмм # 3 Word Hunt Puzzle Рабочих листов: Рабочие листы-головоломки Word Hunt Пазлов Sprial Anagram (Их сложно решить!): Enchanted Learning ® Нажмите, чтобы прочитать нашу Политику конфиденциальности Авторские права © 2009-2018
EnchantedLearning.com —— Как процитировать веб-страницу ECMAScript 6, или 6-е издание стандарта ECMA-262, дает разработчикам JavaScript новые инструменты для написания более сжатого и модульного кода. В этой статье я расскажу, как мы можем использовать четыре из этих функций — итерируемые объекты, генераторы, толстые стрелки и Прежде чем перейти к более крупному примеру, мы рассмотрим некоторые более общие концепции. Функция высшего порядка — это нормальная функция, удовлетворяющая хотя бы одному из следующих условий: Если вы когда-либо писали прослушиватель событий или использовали Например, функция, которую мы передаем в Композиция функций — это комбинация простых функций для построения более сложных.Учитывая две функции Давайте посмотрим на пример. Нам поручено написать программу, которая принимает файл в качестве входных данных и возвращает массив количества появлений гласных в каждом слове в каждой строке. Есть много подходов к этой проблеме. Один из таких подходов — написать одну большую функцию, которая сделает все это. Монолитное решение ниже использует новую конструкцию Вышеупомянутое решение не расширяемо, не масштабируемо и не дает нам повторно используемых компонентов. Альтернативный подход — использовать функции и композицию высшего порядка. В приведенном выше коде Второй подход приводит к нескольким многократно используемым функциям, которые мы можем использовать во всей нашей кодовой базе и составлять вместе для решения более серьезных проблем. Таким образом, функции и композиция высшего порядка продвигают восходящий подход, который может привести к лаконичному и модульному коду. Так что — это ленивая оценка ? Ленивое вычисление — это стратегия, при которой вычисление фрагмента кода откладывается до тех пор, пока не потребуются его результаты. В этой статье я сосредоточусь на ленивом потреблении данных и построении ленивых конвейеров, которые нужно очищать вручную. Я , а не , собираюсь говорить о , как ленивое вычисление реализовано на уровне языка (без сокращения графа, нормальной формы и т. Д.). Давайте посмотрим на пример. Учитывая список целых чисел, возведите элементы этого списка в квадрат и выведите сумму первых четырех элементов в квадрате. Чтобы написать ленивую реализацию для этого, мы должны сначала вычислить , когда нам нужно что-то вычислить.В нашем случае, только когда мы хотим суммировать первые четыре элемента в квадрате, нам нужно предоставить элементы в квадрате. Поэтому мы можем отложить операцию возведения в квадрат, пока не начнем суммирование. Вооружившись этими знаниями, давайте реализуем ленивое решение. В реализации возведение элементов в квадрат мы начинаем только тогда, когда начинается суммирование. Следовательно, возводятся в квадрат только те элементы, которые суммируются.Это достигается за счет управления итерацией и способом получения значений. Реализован собственный протокол итераций, который выдает элементы один за другим и сигнализирует, когда у нас больше нет элементов для получения. Это очень похоже на то, что используют многие языки. Этот протокол инкапсулирован в объект-итератор. Объект итератора содержит одну функцию, Функция Реализация всего вышеперечисленного каждый раз, когда нам нужен итератор, может быть болезненной. К счастью, ES6 представил простой способ написания итераторов. Их называют генераторами. Генератор — это функция с приостановкой, которая может передавать значения вызывающей стороне, используя ключевое слово Объект Generator соответствует как итератору, так и итерируемому протоколу. Следовательно, его можно использовать с Теперь, когда мы немного знаем о ленивых вычислениях, функциях высшего порядка и композиции функций, давайте реализуем что-нибудь, чтобы увидеть, как использование этих трех подходов очищает наш код. Нам дан файл, который содержит имя пользователя в каждой строке.Файл потенциально может быть больше, чем доступная оперативная память. Нам дается функция, которая считывает следующий фрагмент с диска и дает нам фрагмент, который заканчивается новой строкой. Мы должны получить имена пользователей, которые начинаются с «A», «E» или «M». Затем мы должны делать запросы с именами пользователей к Пример содержимого файла: Давайте разделим проблему на более мелкие части, для которых мы можем написать отдельные функции. Один из подходов — использовать следующие функции: Вышеуказанные функции работают со значениями.Нам нужен способ применения этих функций к списку значений. Нам нужны функции высшего порядка, которые делают следующее: Весь этот подход может выиграть от ленивости, так что мы не будем делать сетевые запросы для всех имен пользователей, которые соответствуют нашим критериям, а только для первых Нам дается массив функций, которые должны выполняться с окончательными ответами, и функция, которая лениво дает нам следующий фрагмент. Нам нужна функция, которая лениво дает нам имена пользователей. Чтобы избежать лени, контролируя, когда достигаются ценности, давайте построим наши решения с помощью генераторов. Прежде чем писать следующий фрагмент нашего решения, давайте взглянем на ES6 Promises. Обещание — это заполнитель для будущего значения незавершенной операции.Интерфейс ES6 Promise позволяет нам определять, что должно выполняться после завершения или сбоя операции. Если операция прошла успешно, он вызывает обработчик успеха со значением операции. В противном случае он вызывает обработчик сбоя с ошибкой. Возвращаясь к нашему решению, давайте напишем функции, которые работают со значениями. Нам нужна функция, которая возвращает Теперь, когда у нас есть функции, которые работают со значениями, нам нужны функции, которые могут применять эти значения к ленивым спискам данных. Это будут функции высшего порядка. Они должны быть ленивыми и откладывать выполнение до тех пор, пока их явно не попросят выполнить. Похоже, это хорошее место для использования генераторов, поскольку нам нужны значения по запросу. Итак, теперь, когда у нас есть функции, которые нам понадобятся, давайте скомпонуем их для создания нашего решения. В результате у нас теперь есть многоразовые функции, которые работают со значениями, многократно используемые функции высшего порядка и способ скомбинировать все это вместе для написания лаконичного решения. В этой статье мы определили функции высшего порядка, композицию функций и отложенное вычисление.Затем мы рассмотрели примеры каждого из них.
Наконец, мы объединили все три подхода, чтобы написать ленивое, модульное и составное решение данной проблемы. По определению, шаблон стратегии определяет семейство алгоритмов и инкапсулирует каждый из них в вашем собственном классе, что позволяет менять стратегии местами. Другими словами, шаблон позволяет основному алгоритму изменяться независимо от клиентов, которые его используют. Он очень похож на шаблонный метод, но использует другой подход, предпочитая использовать композицию вместо наследования. Для начала представьте, что существует класс Решение, кажется, работает нормально, но использует Если нам нужно добавить новые (или многие другие) парсеры? Собираемся ли мы добавить много Нам нужен лучший подход, который позволит гибко добавлять новые парсеры без необходимости изменять существующий код. Шаблонный метод Шаблон стратегии предоставит нам хороший подход, который позволит избежать проблем, описанных выше, и будет соответствовать принципу открытости и закрытости от SOLID (о котором я планирую рассказать в следующей публикации). Во-первых, чтобы решить проблему и придать коду большую гибкость, метод Прежде всего, я создал класс Но поскольку Ruby - это динамический язык, который использует Duck Typing как подход к проверке, должно ли данное сообщение выполняться или нет для получателя, мы можем избавиться от этого базового класса и использовать только конкретные парсеры, результат должен быть тоже самое. При таком подходе действительно просто добавить новые поведения, например, если мне нужно добавить новый синтаксический анализатор, мне просто нужно создать новый код синтаксического анализатора, который реализует метод синтаксического анализа Кроме того, в паттерне стратегии предпочтение отдается использованию композиции, а не наследования, и код будет соответствовать принципу «открыто-закрыто». Ну вот и все, теперь вы можете создать сколько парсеров вам нужно. Вот как использовать шаблон стратегии с Ruby. Ознакомьтесь с полным исходным кодом. Самый простой способ установить ChemPy и его (необязательные) зависимости - использовать
менеджер пакетов conda: в настоящее время пакеты conda предоставляются только для Linux. В Windows и OS X
вместо этого вам нужно будет использовать pip: будет несколько тестов, которые будут пропущены из-за отсутствия некоторых дополнительных
бэкэнды в дополнение к таковым в SciPy (используются для решения систем нелинейных
уравнения и обыкновенные дифференциальные уравнения). Если вы все еще используете Python 2, вы можете использовать ветку долгосрочной поддержки 0.6.x
ChemPy, который продолжит получать исправления: Если вы использовали conda для установки ChemPy, вы можете пропустить этот раздел.
Но если вы используете pip, установка по умолчанию достигается путем написания: , вы можете пропустить флаг --user, если у вас есть права root.Возможно, вас заинтересует использование дополнительных бэкэндов (помимо тех, что предоставляются SciPy)
для решения ODE-систем и задач нелинейной оптимизации: Обратите внимание, что эта опция установит следующие библиотеки
(некоторые из которых требуют наличия дополнительных библиотек в вашей системе): , если вы хотите узнать, какие пакеты необходимо установить в системе на основе Debian, вы можете посмотреть это
Dockerfile. Если у вас установлен Docker, вы можете использовать его для размещения jupyter
ноутбук сервер: при первом запуске команды будут загружены некоторые зависимости. При установке
завершено, будет видна ссылка, которую вы можете открыть в своем браузере. Вы также можете запустить
набор тестов с использованием того же образа докера: будет несколько пропущенных тестов (из-за того, что некоторые зависимости не установлены по умолчанию) и
довольно много предупреждений. См. Демонстрационные скрипты в примерах /,
и несколько визуализированных блокнотов jupyter.{3-}, Fe (CN) 6 3- >>> print ('%. 3f'% ferricyanide.mass)
211,955 , как видите, в составе атомные номера (и 0 для заряда) используются как
ключи и количество каждого вида стали соответствующими значениями. ChemPy также может уравновешивать реакции, в которых реагирующие частицы более сложные и
лучше описываются другими терминами, чем их молекулярная формула. Глупо, но все же
наглядным примером может служить приготовление блинов без частично использованных упаковок: ChemPy может даже обрабатывать реакции с линейными зависимостями (недоопределенные системы), например.г .: , объект x1 выше является экземпляром SymPy’s Symbol. Если мы предпочитаем получить решение
с минимальными (ненулевыми) целыми коэффициентами мы можем передать underdetermined = None: , однако, обратите внимание, что хотя это решение в некотором смысле «каноническое»,
это просто одно из бесконечного числа решений (x1 из предыдущего может быть любым целым числом). Полезные функции и объекты
для работы с юнитами доступны из модуля chempy.units. Вот
пример того, как ChemPy может проверять согласованность единиц: прямо сейчас модуль .units оборачивает пакет количества некоторыми второстепенными
дополнения и обходные пути. Однако нет никакой гарантии, что основной
пакет не изменится в будущей версии ChemPy (есть много пакетов
для работы с юнитами в научной экосистеме Python). Если мы хотим предсказать pH раствора бикарбоната, нам просто нужны значения pKa и pKw: вот еще один пример для аммиака: ChemPy собирает уравнения и вспомогательные функции для работы с
такие понятия, как ионная сила: обратите внимание, как ChemPy извлекал заряды из названий веществ. Есть
также например доступны эмпирические уравнения и удобные классы для них, e.г .: , чтобы получить дополнительную информацию, например, о этого класса вы можете посмотреть в документации по API. Распространенной задачей при моделировании задач в химии является исследование временной зависимости
системы. Это направление обучения известно как
химическая кинетика, и ChemPy имеет
некоторые классы и функции для работы с такими задачами: Одна из фундаментальных задач науки - тщательный сбор данных о мире.
вокруг нас. ChemPy содержит постоянно растущую коллекцию параметризаций из научных
литература по химии. Вот как вы используете один из этих составов: Используя только веб-браузер (и подключение к Интернету), можно исследовать
записные книжки здесь: (любезно предоставлено людьми, стоящими за mybinder) Markdown.pl создала недопустимый HTML для двувложенного элемента Как исправить необработанный HTML
Это необработанный HTML: ` ` {= html}.
А вот блок HTML:
`` {= html}
` {= html}.
А вот блок HTML:
`` {= html}
"" {= латекс}
\ begin {tikzpicture}
\ node [внутренний sep = 0pt] (рассел) в точке (0,0)
{\ includegraphics [width = 0,25 \ textwidth] {bertrand_russell.jpg}};
\ node [inner sep = 0pt] (белая точка) в точке (5, -6)
{\ includegraphics [ширина =.25 \ textwidth] {alfred_north_whitehead.jpg}};
\ draw [<->, толстый] (russell.south east) - (whitehead.northwest)
узел [midway, fill = white] {Principia Mathematica};
\ end {tikzpicture}
`` 5. Списки и пустые строки
Абзац тест.
- Пункт один
- Товар второй Markdown.pl и его набор тестов требуют пустую строку между текстом абзаца и следующим списком. Как показывает набор тестов, это требование было введено, чтобы избежать случайного создания списков такими вещами, как:
Я думаю, он весил 200 фунтов, может быть, даже
220. Но он был не выше пяти футов ростом.
- Абзац первый
параграф второй
- элемент подсписка первый
- второй подпункт
- а
- б
- с
- d Markdown.Поведение pl нарушает то, что мы назвали принципом однородности , , который гласит, что содержимое элемента списка должно иметь то же значение, что и вне элемента списка. Этот принцип подразумевает, что если
а
- б
- с
- а
- б
- с
- d 1 ). Как исправить списки и пустые строки
- а
- б
- с
- d
- а
- б
- с
- d 6.Атрибуты
Как исправить атрибуты
{} . Идентификатор обозначается с помощью # . Простое слово рассматривается как класс (или может потребоваться начальное . , как в pandoc). Используйте = для произвольного атрибута ключ / значение.
{#myheader}
# * Синий заголовок * {синее положение = слева} myheader добавляется к блоку заголовка, а класс blue и атрибут ключ / значение position = left добавляются к выделенному тексту Blue Title .
{#mywarning}
{предупреждение}
> Не пытайтесь повторить это дома!
> Это может быть опасно. Сводка рекомендаций
~ ведут себя как пробел при синтаксическом анализе, но визуализируют как ничто. , теперь будут обрабатываться как обычный текст и экранироваться.
{= FORMAT} ; в контекстах блоков — изолированный блок кода с информационной строкой {= FORMAT} . {class #identifier key = value} . MTI | Бесплатный полнотекстовый | Многодоменное распознавание нарисованных от руки диаграмм с использованием иерархического анализа
7.2.1. Экспериментальная установка
7.2.2. Результаты и обсуждение
пятибуквенных анаграмм — Задания и рабочие листы: EnchantedLearning.com
Пятибуквенные анаграммы — Задания и рабочие листы: EnchantedLearning.com Рекламное объявление.
В качестве бонуса участники сайта получают доступ к версии сайта без баннерной рекламы с удобными для печати страницами.
Щелкните здесь, чтобы узнать больше.
(Уже зарегистрированы? Нажмите здесь.) способствует
наметать
бета
зверь
ударов акров
заботится
расы
напугать оповещение
изменить
позже ангел
угол
подобрать ascot
пальто
побережье
тако астра
оценки
пристально
электрошокер
слезы пекарь
тормоз
перерыв обнаженный
борода
хлеб
дебар начало
будучи
выпивка ниже
кишечник
колено расточки
халаты
трезвый накидки
шагов
пространство каретка
обслужить
ящик
след сидр
плакал
Дайсер хлопает в ладоши
застежка
кожа головы жестокий
lucre
язва датер
рейтинг
trade
протектор финики
насыщенный
вместо деист
диеты
правки
размещено
приливов приданое
хулиган
многословный ящик
перерисовать
награда
надзиратель
прирученный зарабатывает
около
более разумный
малый барабан земля
ненавистник
сердце излучает
предметы
клещи
поразить
раз сложный эфир
сброс
руль
лаконичный
деревья эфир
там
три заяц
слышит
реас
сошник
ножницы кучи
фаза
форма герои
лохи
лошадь
берег истечение срока
прыжки
бледность
раскаты
мольбы
чашелистик прыгнул
лепесток
тарелка
складка не менее
шифер
несвежий
украсть
сказки
бирюзовый лаймы
миль
слизь
улыбка литр
литр
релит
плиточник петли
поло
бассейны
шлюп
шпуля скока
столбы
уклон гривы
особняк
означает
имен товарищи
мясо
пар
приручает
команд заслуга
митра
переводить
таймер гвозди
убито
улитка noter
тонер
тенор ноты
начало
камень
тоны бледный
педаль
ходатайство панель
штраф
самолет пары
разобрать
груш
пожнет
запасной
копье запчасти
ремень
ловушки синтаксический анализ
запасной
копье паста
ленты
торф
септа
шпат шкуры
спали
пишется пирсы
священники
шпиль сосна
бекас
позвоночник пегая лошадь
крюк
точка поры
позер
проза
веревки
спора поводья
смола
полоскание
risen
сирена сбросить
руль
лаконичный
деревья обряды
ярусы
резина
попыток святой
сатин
морилка мазь
раб
вейлс
телятина служить
sever
veers
стих сухожилия
свиньи
вина
wisens коньки
кол
стейк
берет
тиков состояние
вкус
соски руль
сброс
деревья странный
проводной
шире
Напишите анаграммы (используя картинку в качестве подсказки):
На этом рабочем листе ученик пишет анаграмму животных для каждой Трехбуквенное слово — подсказка для каждой анаграммы дается по картинке.Анаграммы: акт / кошка, загар / муравей, смола / крыса, ода / лань, низкий / сова, ли / угорь, таб / летучая мышь, бог / собака, пи / овца. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму животных для каждого слова из 4 букв — картинка предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: голый / медведь, тростник / олень, штиль / моллюск, эль / тюлень, тога / коза, сердцевина / заяц, тетя / тунец, лапы / оса, поток / волк. Или перейдите к ответам.
На этом распечатанном рабочем листе ученик пишет анаграмму животных для каждого слова из 4 и 5 букв — изображение используется в качестве подсказки для каждой анаграммы.Анаграммы: бальзам / ягненок, поясница / лев, ушки / слизняк, берег / лошадь, лука / акула, кольчуга / улитка, гувернер / форель, торт / выдра, крад / змея. Или перейдите к ответам.
На этом распечатанном рабочем листе ученик пишет анаграмму животных для каждого слова, состоящего из 5+ букв — картинка предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: рожковое дерево / кобра, носер / цапля, петля / пудель, петухи / петух, прайд / паук, раптор / попугай, валик / лобстер, условно-досрочно освобожденный / леопард, эманат / ламантин.Или перейдите к ответам.
На этом листе для печати ученик пишет анаграмму животных для каждого слова — изображение используется в качестве подсказки для каждой анаграммы. Анаграммы: горох / обезьяна, приветствие / цапля, пошел / тритон, лист / блоха, куча / кобыла, одетый / барсук, настоящий / змей, морской берег / морской конек, заблудший / скат. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму животных для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы.Анаграммы: звезда / крысы, черт возьми / свиньи, мнения / пони, пистолет / гну, сок / жерех, милая / насекомое, крутейший / оцелоты, бург / личинка, медленный / совы. Или перейдите к ответам.
На этом распечатываемом листе ученик пишет анаграмму тела для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: челка / пальцы, баран / рука, пальцы / нос, слип / губы, гель / нога, область / ухо, ниже / локоть, запястья / запястье, кафе / лицо. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму одежды для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы.Анаграммы: ухмылка / кольцо, основа / бусы, узел / галстуки, удар / рукавицы, буст / ботинки, тако / пальто, шланги / туфли, супер / кошелек, жажда / футболка. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму еды для каждого слова — для каждой анаграммы используется картинка. Анаграммы: жатва / груша, пейджеры / виноград, кусок / слива, тунец / орех, бейн / фасоль, имитация / ветчина, дубы / стейк, дыня / лимон, стресс / десерты.Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму, относящуюся к дому, для каждого слова — изображение предоставляется как ключ к каждой анаграмме. Анаграммы: запах / дверь, ладонь / лампа, блеять / стол, ситар / лестница, вращается / тостер, сохранить / ваза, тупица / диван, голоса / плита, плоть / полка. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет математическую анаграмму для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы.Анаграммы: сеть / десять, буксир / два, папа / добавить, высота / восьмая, эвены / семь, там / три, изменение / треугольник, раздаточные материалы / тысяча, трещины / первая. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет музыкальную анаграмму для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: выпуклость / горн, вуаля / альт, упор / туба, изменение / треугольник, диез / арфы, тон / нота, тушь / маракасы, перезапись / рекордер, подпись / пение.Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму растения для каждого слова — изображение предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: дуб / бутон, блоха / лист, ступор / росток, вена / лоза, прыжок / лепесток, лампа / ладонь, кисть / куст, туловище / корни, язва / роза. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму спорта для каждого слова — для каждой анаграммы используется картинка.Анаграммы: табулатура / летучая мышь, десятка / сетка, поцелуй / лыжи, колья / коньки, скока / палки, ценность / бросок, степлер / ракетка, девица / медали, сердечники / счет. Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет инструментальную анаграмму для каждого слова — изображение предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: был / пила, убит / гвозди, чан / гайка, рилы / плоскогубцы, экипажи / винт, сыпь / ножницы, лонжерон / рашпиль, шланг / мотыги, лачуги / лопата. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет транспортную анаграмму для каждого слова — картинка предоставляется в качестве подсказки для каждой анаграммы. Анаграммы: океан / каноэ, дуга / автомобиль, суб / автобус, ранчо / якорь, бедра / корабль, пополнение запасов / ракеты, обряд / шина, панель / самолет, аилы / парус. Или перейдите к ответам.
Проведите линию от каждого слова животного до его анаграммы.Слова: сова / низкий, слизняк / ушки, свиньи / гоша, обезьяна / горох, летучие мыши / табы, цапля / приветствие, моллюск / спокойствие, коза / тога, корюшка / тает, тунец / тетя. Или перейдите к ответам.
Проведите линию от каждого слова животного до его анаграммы. Слова: блоха / лист, попугай / раптор, пудель / петля, лев / поясница, тюлень / продажа, ласточка / валятся, лошадь / берег, шершень / трон, комар / хвост, канна / груженый. Или перейдите к ответам.
Проведите линию от каждого связанного с астрономией слова до его анаграммы.Слова: Земля / сердце, планета / плита, вращается / тостер, космос / шаги, звезда / крысы, космос / комикс, туманность / неспособность, лунный / локтевой, солнечный / оральный, солнечные пятна / остановки. Или перейдите к ответам.
Проведите линию от каждого связанного с телом слова до его анаграммы. Слова: рука / баран, подбородок / дюйм, ухо / рука, бедра / корабль, ногти / улитка, позвоночник / сосны, талия / ожидание, кожа / родство, колено / острый, запястье / запястья. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с одеждой, до его анаграммы.Слова: сапоги / буст, туфли / мотыги, жилет / ветеринары, футболка / жажда, варежки / удар, накидка / темп, халат / босон, фартук / пастор, пальто / тако, серьга / злой. Или перейдите к ответам.
Проведите линию от каждого цветного слова до его анаграммы. Слова: синий / смазка, серебро / щепка, зеленый / жанр, загар / муравей, рубин / бери, бирюзовый / поздний, лимон / дыня, пурпурный / магнат, малиновый / микрон, алый / картели. Или перейдите к ответам.
Проведите линию от названия каждой страны до ее анаграммы.Слова: Иран / дождь, Лаос / также, Мали / почта, Оман / стон, Нигер / царствование, Йемен / враг, Китай / цепь, Ангола / аналог, Израиль / сериал, Перу / чистый. Или перейдите к ответам.
Проведите линию от каждого слова фермы до его анаграммы. Слова: подано / подано, жатва / груша, свиньи / гоша, конюшня / блеет, лошадь / берег, посевы / корпус, овца / пи, коровы / шалунья, гусак / сад, фермер / возделыватель. Или перейдите к ответам.
Проведите линию от каждого слова еды до его анаграммы.Слова: дыня / лимон, сидр / дайсер, чечевица / перемычка, лайм / миля, хэш / шах, капуста / озеро, хлеб / дебар, финики / насыщенный, булочки / курносый, тост / горностай. Или перейдите к ответам.
Проведите линию от каждого слова еды до его анаграммы. Слова: персик / дешево, тушеное мясо / запад, суп / опус, ямс / май, фасоль / банес, креп / крип, кола / уголь, петрушка / плейеры, ромэн / морена, сардина / песочное масло. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с географией, до его анаграммы.Слова: север / шип, юг / крик, восток / государство, запад / тушеное мясо, восток / ближайший, широта / высота, океан / каноэ, полюс / склон, пролив / художник, озера / слак. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с Хэллоуином, до его анаграммы. Слова: летучие мыши / удар, кошка / действие, напугать / заботы, монстр / наставники, упыри / слякоть, зелье / вариант, сова / низкий, ночь / вещь, угощение / дегустатор, тролли / прогулка. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с домом, до его анаграммы.Слова: комната / болото, лестница / ситары, лампа / ладонь, кухня / утолщение, портьеры / расстила, стол / блеять, полка / плоть, чердак / молчаливый, сад / опасность, двор / сарай. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с профессией, до его анаграммы. Слова: пекарь / тормоз, фермер / создатель, медсестра / руны, строитель / восстановитель, пехотинец / летчики, учитель / читер, рабочий / переделка, пилоты / испорченный, садовник / собравшийся, продавец / безымянный. Или перейдите к ответам.
Проведите линию от каждого связанного с математикой слова до его анаграммы.Слова: добавить / папа, десять / нетто, два / буксир, три / там, тысяча / раздаточных материалов, первый / трещины, семь / эвены, десятичный / востребованный, точка / пинто, решить / полевки. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с деньгами, до его анаграммы. Слова: центы / запах, оплата / треп, экономия / ваза, налоги / Техас, расходы / ожидание, цены / точность, десять центов / деизм, покупки / занято, кредит / прямой, торговля / рейтинг. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с музыкой, до его анаграммы.Слова: нота / тон, пение / знак, туба / абут, горн / выпуклость, гамма / шнурки, альт / вуаля, бит / абет, партитура / ядра, тенор / нотер, сольный концерт / статья. Или перейдите к ответам.
Проведите линию от каждого связанного с людьми слова до его анаграммы. Слова: сестра / сопротивление, родитель / ловушка, племя / кусачий, дети / занос, я / сосуд, родственник / чернила, приятель / колени, дамы / идеалы, друг / искатель, девица / медали. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с растением, до его анаграммы.Слова: росток / ступор, бутон / дуб, сад / опасность, лист / блоха, лепесток / прыжок, корни / туловище, сок / спа, саженец / плетение, лоза / жилка, сорняки / сшитые. Или перейдите к ответам.
Проведите линию от каждого связанного со школой слова до его анаграммы. Слова: читать / дорогой, учиться / почесать, слушать / молчать, наставник / форель, учить / жульничать, учиться / пыльный, учёный / хоровой, отчёт / носильщик, исследование / поисковик, тестирование / постановка. Или перейдите к ответам.
Проведите линию от каждого слова, связанного со спортом, до его анаграммы.Слова: дротик / дрот, поло / пул, игрок / повтор, поле / поле, игра / мега, гонки / акры, спорт / порты, бутсы / замок, медали / девица. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с Днем благодарения, до его анаграммы. Слова: подвиги / судьбы, подача / стих, есть / чай, поселенец / эстакада, друг / искатель, еда / хромой, выпечка / клюв, ямс / май, орехи / оглушение, десерт / десерты. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с инструментом, до его анаграммы.Слова: плоскогубцы / опасности, шлифовальный станок / сетка, клещи / принц, фрезеры / штаны, ножницы / сыпь, лопата / лачуги, тиски / тиски, суппорты / реплики, рашпиль / лонжерон, степлер / гипс. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с транспортным средством, до его анаграммы. Слова: автомобиль / дуга, трамвай / рынок, автобус / подводная лодка, лодки / хвастовство, кабины / струп, плот / братство, ракеты / пополнение запасов, грузовики / атака, кемперы / бегун, планер / пояс. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с погодой, до его анаграммы.Слова: мокрый снег / сталь, дождь / Иран, мороз / форты, роса / среда, снег / владение, спокойствие / моллюск, облако / мог, жара / ненависть, ураган / похабный, пасмурный / сверхъестественный. Или перейдите к ответам.
Проведите линию от каждого слова, связанного с погодой, до его анаграммы. Слова: холод / глыба, мокрый снег / сталь, мороз / форты, снег / владение, облако / мог, порыв / кишки, рукавицы / поражение, нагреватель / повторный нагрев, пасмурно / переохлаждение, пальто / тако. Или перейдите к ответам.
На этой серии заданий ученик пишет анаграмму для каждого слова.
Рабочий лист № 1 или ответы № 1
Рабочий лист № 2 или ответы № 2
Рабочий лист № 3 или ответы № 3
Рабочий лист № 4 или ответы № 4
Рабочий лист № 5 или ответы № 5
Рабочий лист № 6 или ответы № 6
Рабочий лист № 7 или ответы № 7
Рабочий лист № 8 или ответы № 8
Рабочий лист № 9 или ответы № 9
Рабочий лист № 10 или ответы № 10
Рабочий лист № 11 или ответы № 11
Рабочий лист № 12 или ответы № 12.
На этих распечатываемых листах ученик пишет анаграмму животных для каждого слова.
Рабочий лист № 1 или ответы № 1
Рабочий лист № 2 или ответы № 2
Рабочий лист № 3 или ответы № 3.
На этом распечатываемом рабочем листе ученик пишет соответствующую анаграмму для каждого слова. Или перейдите к ответам.
На этом распечатанном листе ученик пишет астрономическую анаграмму для каждого слова. Или перейдите к ответам.
На этом распечатанном рабочем листе ученик пишет анаграмму, относящуюся к телу, для каждого слова.Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму одежды для каждого слова. Или перейдите к ответам.
На этом листе для печати ученик записывает название страны для каждой анаграммы. Или перейдите к ответам.
На этом листе, который можно распечатать, ученик пишет анаграмму еды для каждого слова.
Рабочий лист № 1 или ответы № 1
Рабочий лист №2 или ответы №2.
На этом распечатанном рабочем листе ученик пишет географическую анаграмму для каждого слова. Или перейдите к ответам.
На этом распечатанном рабочем листе ученик пишет анаграмму, связанную с домом, для каждого слова. Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму, связанную с профессией, для каждого слова.Или перейдите к ответам.
На этом распечатываемом листе ученик пишет анаграмму по математике для каждого слова. Или перейдите к ответам.
На этом распечатанном рабочем листе ученик пишет анаграмму, связанную с музыкой, для каждого слова. Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму, связанную с растением, для каждого слова.Или перейдите к ответам.
На этом распечатываемом листе ученик пишет анаграмму, относящуюся к школе, для каждого слова. Или перейдите к ответам.
На этом рабочем листе, который можно распечатать, ученик пишет анаграмму, связанную с инструментами, для каждого слова. Или перейдите к ответам.
На этом распечатываемом рабочем листе ученик пишет анаграмму, связанную с транспортным средством, для каждого слова.Или перейдите к ответам.
Для каждого слова напишите как можно больше анаграмм. Слова: ест, оптс, бирюзовый, аминь, искусство, слизь, прыжок, тик, мерзость, смола, синтаксический анализ, чашелистик. Или перейдите к ответам.
Для каждого слова напишите как можно больше анаграмм. Слова: taser, scare, snug, spat, tame, mar, rapt, snap, dear, eta, emit, nets.Или перейдите к ответам.
Для каждого слова напишите как можно больше анаграмм. Слова: завязанный, вкладки, дорогой, планка, пробел, эфир, эсприт, мясо, поло, бледный, меса, мишура. Или перейдите к ответам.
На этой серии заданий ученик видит, сколько слов можно составить, используя буквы из различных слов и фраз.Это не совсем анаграммы, но они связаны.
Более 35 000 веб-страниц
Примеры страниц для потенциальных подписчиков или щелкните ниже Зачарованный поиск обучения
Найдите на веб-сайте Enchanted Learning:
Рекламное объявление.Рекламное объявление. Рекламное объявление. Ленивый, компонуемый и модульный JavaScript
вместо — в сочетании с функциями высшего порядка, композицией функций и отложенным вычислением, чтобы написать более понятный и понятный код. более модульный JavaScript. Функции высшего порядка
Array.prototype.map , значит, вы использовали функцию высшего порядка.Функции высшего порядка способствуют повторному использованию и модульности, отделяя способ применения операции от самой операции. Array.prototype.map, не знает ни о коллекциях, ни о том, как с ними работать. Все, что он знает, — это как оперировать ценностью. Следовательно, его можно повторно использовать в контексте как отдельных значений, так и коллекций. Функциональный состав
f и g , compose (f, g) дает нам новую функцию, которая возвращает f (g (x)) . Кроме того, поскольку результатом компоновки является функция, она может быть дополнительно скомпонована или передана функциям более высокого порядка. for-of для перебора значений в итерируемом цикле вместо обычного цикла for . Итерируемый объект — это контейнер, который реализует протокол итератора и может выдавать значения одно за другим (например, массивы, строки, генераторы и т. Д.).
function vowelCount (file) {
let contents = readFile (файл)
let lines = contents.split ('\ n') // разбить содержимое на массив строк
let result = [] // массив массивов, где каждый индекс отображается на строку
// и каждый индекс во внутреннем массиве сопоставляется с
// количество гласных для слова в этой строке
for (пусть строка из строк) {
let temp = []
пусть слова = строка.разделить (/ \ s + /)
for (пусть слово из слов) {
пусть vowelCount = 0
for (let char of word) {
если (
'a' === char || 'e' === char || 'i' === char || 'o' === char || 'u' === символ
) vowelCount ++
}
temp.push (vowelCount)
}
result.push (темп)
}
вернуть результат
}
// main.js
function vowelOccurrences (file) {
вернуть карту (слова => карта (vowelCount, words), listOfWordsByLine (читать (файл)))
}
function vowelCount (word) {
return reduce ((prev, char) => {
если (
'a' === char || 'e' === char || 'i' === char || 'o' === char || 'u' === символ
) return ++ пред.
иначе вернуться назад
}, 0, слово)
}
function listOfWordsByLine (строка) {
вернуть карту (строка => разделить (/ \ s + /, строка), разделить ('\ n', строка))
}
// многоразовые утилиты в util.js
функция reduce (fn, аккумулятор, список) {
возвращаться [].reduce.call (список, функция, аккумулятор)
}
function map (fn, list) {
return [] .map.call (список, fn)
}
функция split (splitOn, строка) {
вернуть string.split (splitOn)
}
listOfWordsByLine возвращает массив массивов, каждый элемент которого соответствует массиву слов, составляющих строку. Например:
let input = 'первая строка \ nстрока два'
listOfWordsByLine (input) // [['строка', 'один'], ['строка', 'два']]
vowelCount подсчитывает количество гласных в слове. vowelOccurrences использует vowelCount на выходе listOfWordsByLine для вычисления количества гласных на строку в слове. Ленивое вычисление
let squareAndSum = (iterator, n) => {
пусть результат = 0
while (n> 0) {
пытаться {
результат + = Math.pow (iterator.next (), 2)
п-
}
ловить(_) {
// длина списка была меньше, чем `n`, следовательно
// итератор.следующий бросил, чтобы сигнализировать, что он вне значений
перерыв
}
}
вернуть результат
}
let getIterator = (arr) => {
пусть я = 0
возвращаться {
next: function () {
if (i next , которая принимает нулевые параметры. Он возвращает следующий элемент, если он есть, и выбрасывает в противном случае. squareAndSum принимает в качестве входных данных объект-итератор и n , количество элементов для суммирования.Он извлекает из итератора n значений (вызывая .next () n раз), возводит в квадрат и затем суммирует их. getIterator дает нам итератор, который обертывает наш список (который мы называем итератором , поскольку мы можем перебирать его). Затем squareAndSumFirst4 использует getIterator и squareAndSum , чтобы получить сумму первых четырех чисел входного списка, лениво возведенную в квадрат. Хорошим побочным эффектом использования итераторов является то, что он позволяет нам реализовывать структуры данных, которые могут давать бесконечные значения. yield несколько раз во время выполнения. Генераторы при вызове возвращают объект Generator. Мы можем вызвать следующий для объекта Generator, чтобы получить следующее значение. В JavaScript мы создаем генераторы, определяя функцию с * .Вот пример.
// генератор, возвращающий бесконечный список последовательных
// целые числа начиная с 0
// обратите внимание на "*", чтобы сообщить парсеру, что это генератор
function * numbers () {
пусть я = 0
yield 'начальный бесконечный список чисел'
while (true) yield i ++
}
let n = numbers () // получаем итератор от генератора
n.next () // {значение: "начало бесконечного списка чисел", done: false}
n.next () // {значение: 0, выполнено: false}
n.next () // {значение: 1, выполнено: false}
// и так далее..
для для доступа к значениям, которые он дает.
for (let n of numbers ()) console.log (n) // напечатает бесконечный список чисел
Проблема
http://jsonplaceholder.typicode.com/users?username= . После этого мы должны запустить заданный набор из четырех функций для ответа на запрос для первых четырех запросов.
Брет
Антонетта
Саманта
Карианна
Камрен
Леопольдо - пробка
Элвин.Skiles
Maxime_Nienow
Дельфина
Мориа Стэнтон
getNextUsername ) filterIfStartsWithAEOrM ) makeRequest ) фильтр ) карта ) zip с с функцией сжатия) n , где n — количество функций, которые мы должны запускать ответы на запросы.
// функции, которые выполняются в ответе на запрос
пусть fnsToRunOnResponse = [f1, f2, f3, f4]
// имитирует получение следующего блока данных, прочитанных из файла
// * означает, что эта функция является генератором в JavaScript
function * getNextChunk () {
yield 'Брет \ nAntonette \ nSamantha \ nKarianne \ nKamren \ nLeopoldo_Corkery \ nElwyn.Скилз \ nMaxime_Nienow \ nDelphine \ nMoriah.Stanton \ n '
}
// getNextUsername принимает итератор, который возвращает следующий фрагмент, заканчивающийся новой строкой
// Сам по себе возвращает итератор, который выдает имена пользователей по одному за раз
function * getNextUsername (getNextChunk) {
for (пусть кусок getNextChunk ()) {
пусть строки = chunk.split ('\ n')
for (пусть l строк) if (l! == '') вывести l
}
}
true , если значение соответствует нашим критериям фильтра, и false в противном случае. Нам также нужна функция, которая возвращает URL-адрес при задании имени пользователя.Наконец, нам нужна функция, которая при получении URL-адреса делает запрос и возвращает обещание для этого запроса.
// эта функция возвращает истину, если имя пользователя соответствует нашим критериям
// и false в противном случае
let filterIfStartsWithAEOrM = username => {
let firstChar = имя пользователя [0]
вернуть 'A' === firstChar || 'E' === firstChar || 'M' === firstChar
}
// makeRequest делает запрос ajax к URL-адресу и возвращает обещание
// он использует новый API выборки и жирные стрелки из ES6
// это обычная функция, а не генератор
пусть makeRequest = url => fetch (url).затем (response => response.json ())
// makeUrl принимает имя пользователя и генерирует URL-адрес, который мы хотим запросить
пусть makeUrl = username => 'http://jsonplaceholder.typicode.com/users?username=' + имя пользователя
// фильтр принимает функцию (предикат), которая принимает значение и возвращает
// логическое значение и сам фильтр итератора возвращает, что итератор возвращает
// значение, если функция при применении к значению возвращает истину
function * filter (p, a) {
для (пусть x из a)
if (p (x)) дает x
}
// карта принимает функцию и итератор
// он возвращает новый итератор, который дает результат применения функции к каждому значению
// в итераторе, который был дан ему изначально
function * map (f, a) {
for (пусть x of a) дает f (x)
}
// zipWith принимает двоичную функцию и два итератора в качестве входных данных
// он возвращает итератор, который, в свою очередь, применяет данную функцию к значениям из каждого из
// итераторы и выдает результат.функция * zipWith (f, a, b) {
let aIterator = a [Symbol.iterator] ()
let bIterator = b [Symbol.iterator] ()
пусть aObj, bObj
while (true) {
aObj = aIterator.next ()
если (aObj.done) сломается
bObj = bIterator.next ()
если (bObj.done) сломается
yield f (aObj.value, bObj.value)
}
}
// execute заставляет отложенный итератор начать выполнение
// в основном он многократно вызывает `.next` на итераторе
// пока итератор не будет готов
выполнение функции (итератор) {
for (x of итератор) ;; // слить итератор
}
пусть filterUsernames = filter (filterIfStartsWithAEOrM, getNextUsername (getNextChunk)
let urls = map (makeUrl, filterUsernames)
пусть requestPromises = map (makeRequest, urls)
let applyFnToPromiseResponse = (fn, обещание) => обещание.then (response => fn (response))
пусть lazyComposedResult = zipWith (applyFnToPromiseResponse, fnsToRunOnResponse, requestPromises)
выполнить (lazyComposedResult)
lazyComposedResult — это ленивый конвейер составных приложений-функций.Ни один шаг в нашем конвейере не будет выполняться, пока мы не вызовем execute для окончательно скомпонованной части, то есть lazyComposedResult , чтобы запустить процесс. Следовательно, мы сделаем только четыре сетевых вызова, даже если наша пост-фильтрация набора результатов может содержать более четырех значений. Эпилог
Дополнительная литература
паттернов проектирования в Ruby: паттерн стратегии
Parser , который отвечает за синтаксический анализ текстов в различных форматах, изначально JSON и XML .
класс TextParser
attr_accessor: text,: parser
def инициализировать (текст, парсер)
@text = текст
@parser = парсер
конец
def parse
если парсер ==: json
"{текст: # {текст}}"
парсер elsif ==: xml
" , если , чтобы определить, какая стратегия для форматирования текста. Это не лучший подход по тем же причинам, которые я уже объяснял в публикации о методе шаблона. ifs для проверки каждого парсера? Я не масштабируюсь и не соблюдаю принцип открытости-закрытости Используйте правильную стратегию для рассмотрения множества синтаксических анализаторов
может решить эту проблему, но подход использования наследования не тот, который нам нужен. Наследование имеет определенные проблемы: TextParser # parse будет отвечать только за делегирование вызова метода синтаксического анализатора заданному классу, каждому из этих конкретных классов (JSONParser или XMLParser) будут содержать собственное поведение для реализации метода синтаксического анализа и будут внедряться через конструктор TextParser в качестве зависимости.
класс BaseParser
def parse (текст)
поднять "Надо реализовать!"
конец
конец
###
класс XMLParser BaseParser с абстрактным методом, который должен быть реализован подклассами, основная цель BaseParser здесь - «имитировать» интерфейс и гарантировать, что все подклассы будут требуется для реализации этого интерфейса.
класс XMLParser
def parse (текст)
" , и все будет продолжать работать:
класс ReverseParser
def parse (текст)
текст.обеспечить регресс
конец
конец
parser_xml = TextParser.new ('Мой текст', ReverseParser.new)
parser_xml.parse => "txeT yM"
Список литературы
чемпи · PyPI
$ conda install -c bjodah chempy pytest
$ pytest -rs -W ignore :: chempy.ChemPyDeprecationWarning --pyargs chempy
$ python3 -m pip install chempy pytest
$ python3 -m pytest -rs -W ignore :: chempy.ChemPyDeprecationWarning --pyargs chempy
$ python2 -m pip install "chempy <0.7"
Дополнительные зависимости
$ python3 -m pip install --user --upgrade chempy pytest
$ python3 -m pytest -rs --pyargs chempy
$ python3 -m pip install chempy [все]
Использование Docker
$./scripts/host-jupyter-using-docker.sh. 8888
$ ./scripts/host-jupyter-using-docker.sh. 0
Балансирующая стехиометрия химической реакции
>>> from chempy import balance_stoichiometry # Основная реакция в ракетах-носителях НАСА:
>>> reac, prod = balance_stoichiometry ({'Nh5ClO4', 'Al'}, {'Al2O3', 'HCl', 'h3O', 'N2'})
>>> из pprint import pprint
>>> pprint (dict (reac))
{'Al': 10, 'Nh5ClO4': 6}
>>> pprint (dict (prod))
{'Al2O3': 5, 'h3O': 9, 'HCl': 6, 'N2': 3}
>>> из chempy import mass_fractions
>>> для дробей на карте (mass_fractions, [reac, prod]):
... pprint ({k: '{0: .3g} wt%'. format (v * 100) для k, v в fractions.items ()})
...
{'Al': '27,7% масс.', 'Nh5ClO4': '72,3% масс'}
{'Al2O3': '52,3% мас.', 'H3O': '16,6% мас. ',' HCl ': '22,4% мас.', 'N2': '8,62% мас.}
>>> вещества = {s.name: s вместо s в [
... Вещество ('блины', состав = dict (яйца = 1, ложки_флора = 2, чашки_фамилка = 1)),
... Вещество ('яйца_6пак', состав = dict (яйца = 6)),
... Вещество ('коробка_молока', состав = dict (cups_of_milk = 4)),
... Вещество ('мешок_мучки', состав = dict (spoons_of_flour = 60))
...]}
>>> pprint ([dict (_) for _ in balance_stoichiometry ({'egg_6pack', 'milk_carton', 'mel_bag'},
... {'блин'}, вещества = вещества)])
[{'яйца_6пак': 10, 'мешок_мучки': 2, 'упаковка_молока': 15}, {'блинчик': 60}]
>>> pprint ([dict (_) for _ in balance_stoichiometry ({'C', 'O2'}, {'CO2', 'CO'})]) # doctest: + SKIP
[{'C': x1 + 2, 'O2': x1 + 1}, {'CO': 2, 'CO2': x1}]
>>> pprint ([dict (_) for _ in balance_stoichiometry ({'C', 'O2'}, {'CO2', 'CO'}, underdetermined = None)])
[{'C': 3, 'O2': 2}, {'CO': 2, 'CO2': 1}]
Балансирующие реакции
>>> из chempy import Equilibrium
>>> из символов импорта sympy
>>> K1, K2, Kw = символы ('K1 K2 Kw')
>>> e1 = Равновесие ({'MnO4-': 1, 'H +': 8, 'e-': 5}, {'Mn + 2': 1, 'h3O': 4}, K1)
>>> e2 = Равновесие ({'O2': 1, 'h3O': 2, 'e-': 4}, {'OH-': 4}, K2)
>>> coeff = Equilibrium.eliminate ([e1, e2], 'e-')
>>> коэфф
[4, -5]
>>> редокс = e1 * coeff [0] + e2 * coeff [1]
>>> печать (редокс)
32 H + + 4 MnO4- + 20 OH- = 26 h3O + 4 Mn + 2 + 5 O2; К1 ** 4 / К2 ** 5
>>> autoprot = Равновесие ({'h3O': 1}, {'H +': 1, 'OH-': 1}, кВт)
>>> n = редокс.отменить (автопрот)
>>> п
20
>>> редокс2 = окислительно-восстановительный потенциал + n * автопротекание
>>> print (redox2)
12 H + + 4 MnO4- = 6 h3O + 4 Mn + 2 + 5 O2; K1 ** 4 * кВт ** 20 / K2 ** 5
Работа с агрегатами
>>> от chempy import Реакция
>>> r = Reaction.from_string ("h3O -> H + + OH-; 1e-4 / M / s")
Отслеживание (последний вызов последний):
...
ValueError: невозможно преобразовать единицы измерения «1 / M» в «безразмерные».
>>> r = Reaction.from_string ("h3O -> H + + OH-; 1e-4 / s")
>>> from chempy.units import to_unitless, default_units as u
>>> to_unitless (r.param, 1 / ед. минута)
0,006
Химическое равновесие
>>> из коллекций import defaultdict
>>> из chempy.equilibria import EqSystem
>>> eqsys = EqSystem.from_string ("" "HCO3- = H + + CO3-2; 10 ** - 10,3
... h3CO3 = H + + HCO3-; 10 ** - 6,3
... h3O = H + + OH-; 10 ** - 14 / 55,4
... "" ") # pKa1 (h3CO3) = 6,3 (неявно включая CO2 (вод.)), pKa2 = 10,3 & pKw = 14
>>> arr, info, sane = eqsys.корень (defaultdict (float, {'h3O': 55.4, 'HCO3-': 1e-2}))
>>> conc = dict (zip (eqsys.substances, arr))
>>> из журнала импорта математики 10
>>> print ("pH:% .2f"% -log10 (conc ['H +']))
pH: 8,30
>>> из chempy import Equilibrium
>>> from chempy.chemistry import Species
>>> water_autop = Equilibrium ({'h3O'}, {'H +', 'OH-'}, 10 ** - 14) # принята молярная единица
>>> Ammonia_prot = Равновесие ({'Nh5 +'}, {'Nh4', 'H +'}, 10 ** - 9.24) # то же самое здесь
>>> субстанции = [Species.from_formula (f) for f in 'h3O OH- H + Nh4 Nh5 +'. split ()]
>>> eqsys = EqSystem ([water_autop, amia_prot], вещества)
>>> print ('\ n'.join (map (str, eqsys.rxns))) # "rxns" сокращение от "реакции"
h3O = H + + OH-; 1e-14
Nh5 + = H + + Nh4; 5,75e-10
>>> init_conc = defaultdict (float, {'h3O': 1, 'Nh4': 0.1})
>>> x, sol, sane = eqsys.root (init_conc)
>>> assert sol ['успех'] и здравомыслящий
>>> print (',' .join ('%.2g '% v для v в x))
1, 0,0013, 7,6e-12, 0,099, 0,0013
Концепции
>>> from chempy.electrolytes import ionic_strength
>>> ionic_strength ({'Fe + 3': 0,050, 'ClO4-': 0,150}) == .3
Правда
>>> из чемпы.генри импортный Генри
>>> kH_O2 = Генри (1.2e-3, 1800, ref = 'carpenter_1966')
>>> print ('%. 1e'% kH_O2 (298.15))
1.2e-03
Химическая кинетика (система обыкновенных дифференциальных уравнений)
>>> from chempy import ReactionSystem # Константы скорости ниже являются произвольными
>>> rsys = ReactionSystem.from_string ("" "2 Fe + 2 + h3O2 -> 2 Fe + 3 + 2 OH-; 42
... 2 Fe + 3 + h3O2 -> 2 Fe + 2 + O2 + 2 H +; 17
... H + + OH- -> h3O; 1e10
... h3O -> H + + OH-; 1e-4 "" ") #" [h3O] "= 1.0 (фактически 55,4 при RT)
>>> из chempy.kinetics.ode import get_odesys
>>> odesys, extra = get_odesys (rsys)
>>> из коллекций импортировать defaultdict
>>> импортировать numpy как np
>>> tout = sorted (np.concatenate ((np.linspace (0, 23), np.logspace (-8, 1))))
>>> c0 = defaultdict (float, {'Fe + 2': 0.05, 'h3O2': 0,1, 'h3O': 1,0, 'H +': 1e-2, 'OH-': 1e-12})
>>> result = odesys.integrate (tout, c0, atol = 1e-12, rtol = 1e-14)
>>> импортировать matplotlib.pyplot как plt
>>> fig, axes = plt.subplots (1, 2, figsize = (12, 5))
>>> для топора в осях:
... _ = result.plot (names = [k вместо k в rsys.substances, если k! = 'h3O'], ax = ax)
... _ = ax.legend (loc = 'best', prop = {'size': 9})
... _ = ax.set_xlabel ('Время')
... _ = ax.set_ylabel ('Концентрация')
>>> _ = оси [1] .set_ylim ([1e-13, 1e-1])
>>> _ = оси [1].set_xscale ('журнал')
>>> _ = оси [1] .set_yscale ('журнал')
>>> _ = fig.tight_layout ()
>>> _ = fig.savefig ('examples / kinetics.png', dpi = 72)
Недвижимость
>>> from Chempy import Substance
>>> от чемпы.properties.water_de density_tanaka_2001 импортировать water_de density как rho
>>> from chempy.units import to_unitless, default_units as u
>>> вода = Substance.from_formula ('h3O')
>>> для T_C в (15, 25, 35):
... концентрация_h3O = rho (T = (273,15 + T_C) * u.kelvin, units = u) /water.molar_mass (units = u)
... print ('[h3O] =% .2f M (при% d ° C)'% (to_unitless (концентрация_h3O, мкмоль), T_C))
...
[h3O] = 55,46 M (при 15 ° C)
[h3O] = 55,35 M (при 25 ° C)
[h3O] = 55,18 M (при 35 ° C)
Управляйте записными книжками с помощью скоросшивателя