Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: самоуничтожением сейчас е с э н о т ц сейчас фюлонюмор 1 секунда назад майровский 1 секунда назад з с а к а р с 1 секунда назад тоаыгм 1 секунда назад я б о р д м 2 секунды назад тромбип 2 секунды назад с п р у т х 2 секунды назад липа нота животное 3 секунды назад п л о м б а е р 3 секунды назад корсет 4 секунды назад просветитель 4 секунды назад майдановка 4 секунды назад колосок 5 секунд назад
Как разобрать по составу слова ‘жесткий’ и ‘жесткость? Какой морфемный
образование
Какой морфемный разбор слов «жесткий» и «жесткость»?
Слово состоит из разных частей: приставки/ корень слова/ суффикс/ окончание. Давайте разберем слово «жесткий» по частям:
1 часть (приставка) — отсутствует;
2 часть (корень слова) — жестк;
3 часть (суффикс) — отсутствует;
4 часть (окончание) — ий;
Основа слова — жестк.
Жесткий — имя прилагательное (полное), качественное, неодушевленное, мужской род, единственное число, именительный/винительный падеж.
Давайте разберем слово «жесткость» по частям:
1 часть (приставка) — отсутствует;
2 часть (корень слова) — жестк;
3 часть (суффикс) — ость;
4 часть (окончание) — нулевое;
Основа слова — жесткость.
Жесткость — имя существительное, неодушевленное, женский род, единственное число, именительный/винительный падеж.
Давайте разберем слово «жесткий» по частям:
1 часть (приставка) — отсутствует;
2 часть (корень слова) — жестк;
3 часть (суффикс) — отсутствует;
4 часть (окончание) — ий;
Основа слова — жестк.
Жесткий — имя прилагательное (полное), качественное, неодушевленное, мужской род, единственное число, именительный/винительный падеж.
Давайте разберем слово «жесткость» по частям:
1 часть (приставка) — отсутствует;
2 часть (корень слова) — жестк;
3 часть (суффикс) — ость;
4 часть (окончание) — нулевое;
Основа слова — жесткость.
Жесткость — имя существительное, неодушевленное, женский род, единственное число, именительный/винительный падеж.
Слово Жесткий отвечает на вопрос Какой? и оказывается прилагательным мужского рода, которое обладает окончанием -ый: Жесткий-Жесткая-Жесткие.
Однокоренными словами оказываются: Жесткий-Жесткость-Жестковатый-Жестко.
Следовательно корнем слова будет морфема жестк-.
Аналогично выделим корень и в существительном Жесткость, которое оказывается однокоренным к прилагательному Жесткий. Это существительное женского рода (Жесткость — она моя) и следовательно отнесенное к третьему склонению будет обладать нулевым окончанием: Жесткость-Жесткости-Жесткостью.
В его составе выделим суффикс -ость.
Получаем: жестк-ий (корень-окончание), основа слова: жестк-
Получаем: жестк-ость_ (корень-суффикс-нулевое окончание), основа слова: жесткость.
Это существительное женского рода (Жесткость — она моя) и следовательно отнесенное к третьему склонению будет обладать нулевым окончанием: Жесткость-Жесткости-Жесткостью.
В его составе выделим суффикс -ость.
Получаем: жестк-ий (корень-окончание), основа слова: жестк-
Получаем: жестк-ость_ (корень-суффикс-нулевое окончание), основа слова: жесткость.
Жесткий — это прилагательное в форме мужского рода, единственного числа, именительного или винительного падежа. Показатель этих грамматических признаков — окончание -ий (ср.: жестк-ого, жестк-ому, жестк-им и др.).
Корень слова -жест- (однокоренные слова — жесть, жестокий, ужесточить, ужесточенный, ужесточавший, жесткость, жестковатый, жестковатость и др.).
Суффикс -к- (как в словах «жидкий», «вязкий», «редкий», «сладкий» и др.).
Основа жестк-.
Морфемная структура слова: корень\суффикс\окончание.
Слово «жесткость» производное от «жесткий». Кроме корня, оно «унаследовало» от него и суффикс -к-. Само же слово образовано с помощью суффикса -ость-.
Ветеранов , к сожалению, становится все меньше и меньше. Я недавно закончил школу, и могу сказать: так много как в первом классе,их больше небыло, приходилось вручать одному по три, по четыре букета. Но точную статистику вам никто не скажет, Нет такой организации, которая б считала ветеранов. П.С. Сначала я подумал имеется ввиду World of warcraft.
Больше ответов
Популярные вопросы из категории: образование
образование
Традиционная сдача экзамена или ЕГЭ — что лучше?…
образование
Зачем нужно было вводить ЕГЭ?…
образование
Гоголь только пересказывал сказку, так кто такой «Вий»?…
образование
Что такое Вальдорфское образование и чем знамениты Вальдорфские куклы?…
Вопросы по другим предметам:
Українська мова, 29.11.2021 10:30
Слово перекотиполе утворено:. ..
..
Литература, 29.11.2021 10:30
ответьте на вопрос «Мое время хорошее?» Развернутый ответ 20 предложений…
История, 29.11.2021 10:30
5 пословиц о обычии казахского народа!…
Математика, 29.11.2021 10:30
Докажите что произведение n положительных чисел с фиксированной суммой максимально когда они все равны между собой…
Українська мова, 29.11.2021 10:30
С.229-230 ..дібрати докази i висновок до тези: Перш ніж до дiла братися, треба поради спитатися….
Физика, 29.11.2021 10:30
Яку масу води можна перетворити на пару за рахунок 4,6МДж теплоти…
Химия, 29.11.2021 10:30
Установите последовательность химия 9 класс
…
Физика, 29.11.2021 10:30
R=40 ом, xL=80 Ом, xc=50Ом, пси=120 U=282В найти все токи, сопрот, проводимость?
Английский язык, 29.11.2021 10:30
2. 2. Finish up the following sentences using the phrases in brackets and referring their verbs to the future. 1. Tomorrow his brother and he … (to come to see us). 2. 2. In the mo…
1. Tomorrow his brother and he … (to come to see us). 2. 2. In the mo…
Физика, 29.11.2021 10:30
Задание 6 Определите КПД двигателя трактора, которому для выполнения работы 2,5 • 10⁷ Дж потребовалось 2 кг топлива с удельной теплотой сгорания 4,2-10⁷Дж/кг….
Синтаксический анализ сложен
Я пытался написать текстовый Scratch-редактор для лет сейчас. Мои ранние попытки не назывались «тош», а были прототипами той же идеи.
Самое сложное — превратить текст в блоки Scratch. Я должен сделать две вещи:
разработать синтаксис : как должен выглядеть текст?
Сначала я основывал свои прототипы на синтаксис скретчблоков, так как это было бы знаком моим пользователям.
реализует синтаксический анализатор : программа, которая извлекает структуру из текст, чтобы превратить его в блоки Scratch.
Вдохновленный синтаксическим анализом: решенная проблема, которая
не,
Я собираюсь описать различные подходы, которые я пробовал, и почему они
ужасный.
(Скоро я напишу больше о синтаксисе.)
Construct
Я написал Kurt, который позволяет вам манипулировать Scratch проектов с использованием кода Python. Проекты Scratch 1.4 имеют сумасшедший двоичный файл формате, поэтому Курт использует Construct чтобы сделать кодирование и декодирование намного проще.
Construct — это библиотека для разбора бинарных файлов, в которой она очень хороша.
Это декларативный формат, поэтому вы пишете описание двоичного формата, и он обрабатывает кодирование и декодирование для вас. Вот простая структура:
c = Struct("foo",
UBInt8 ("бар"),
SLInt16("квхх"),
LFloat32 ("гарпия"),
)
Construct также мог анализировать текст, что у него не очень хорошо получалось.
В FAQ сказано:
В чем Construct не силен?
Как упоминалось ранее, Construct не является хорошим выбором для разбора текста из-за к типичной сложности текстовых грамматик и относительной сложности правильного разбора Unicode.
Хотя Construct имеет набор специальных структур синтаксического анализа текста, он не предназначен для обработки текста и не является хорошим подходит для этих приложений.
 Хотя Construct имеет набор специальных
структур синтаксического анализа текста, он не предназначен для обработки текста и не является хорошим
подходит для этих приложений.
Хотя Construct имеет набор специальных
структур синтаксического анализа текста, он не предназначен для обработки текста и не является хорошим
подходит для этих приложений.Я все равно пытался его использовать. Взгляните на ужасное код если ты хочешь.
Для разбора текста нужно уметь работать с альтернативами. Конструкт имел Выберите класс для описания альтернатив. Это сработало, попробовав каждый
subconstruct по очереди и возвращая первый, который не вызвал ошибку.
Таким образом, вы можете написать что-то вроде:
c = Struct("foo",
Выбрать("вставить",
Последовательность("предикат",
Литерал ("<"),
предикат_блок,
Литерал ("> "),
),
Последовательность("репортер",
Литерал("("),
репортер_блок,
Литерал(")"),
),
)
Оказывается, это не лучший способ указать синтаксис языка.
Что-то не всегда работало, и код становился беспорядочным.
Брайс Бо предложил мне заглянуть в «lex/yacc», сказав мне это то, что использует большинство людей.
Теория синтаксического анализатора в четырехстах словах
Время для терминологии!
Разбор заключается в извлечении структуры из текста . Вот как Python
преобразует оператор типа print 2 + sin(6) * 4 в дерево синтаксического анализа который
выглядит примерно так:
Токенизация
В большинстве случаев перед
разбор. Он выполняет первый проход по тексту, разбивая его на список , если <(оценка) > (12)> , может стать следующим:
СИМВОЛ "если"
ЛАНГЛЕ "<"
ЛПАРЕН"("
СИМВОЛ "оценка"
РПАРЕН ")"
ЛАНГЛЕ "<"
ЛПАРЕН"("
ЦИФРА "12"
РПАРЕН ")"
ДИАПАЗОН ">"
Затем этот список токенов используется в качестве входных данных для синтаксического анализатора.
Не все анализаторы делают это. Некоторые парсеры пропускают стадию токенизации и работают на
список персонажей. Это называется разбором без сканера : он не
подходит для моего варианта использования, поэтому я никогда не использовал его.
Это называется разбором без сканера : он не
подходит для моего варианта использования, поэтому я никогда не использовал его.
Синтаксический анализ
Вы описываете синтаксис языка, используя контекстно-свободную грамматику , которая представляет собой набор правил, описывающих, как построить каждый узел в дереве синтаксического анализа.
Рассмотрим ввод и скажем "Привет!" на 10 секунд . Чтобы успешно разобрать это, нам нужно увидеть следующие токены:
- слово
сказать; - строка;
- слово
для; - номер;
- слово
сек.
Мы можем выразить это, используя следующее правило CFG:
блок -> "произнести "ТЕКСТ" за "ЧИСЛО" "сек"
Слева пишем название правила. Справа находится список
токены (или других правил ; мы увидим это через секунду). Это описывает, как
построить блок узел в дереве синтаксического анализа.
По соглашению имена в ПРОПИСНЫХ являются маркерами; имена в нижнем регистре относятся к
другие правила. Я пишу токены для словесных токенов типа «говорить» в кавычках, а не
верхний регистр.
Но это не совсем так. Мы хотим разрешить блоки репортеров внутри входных данных, т.к.
а также константы типа 10 . Давайте расширим нашу грамматику:
блок -> "произнести" текст "для" числа "сек"
текст -> ТЕКСТ
| "присоединиться" текст текст
номер -> НОМЕР
| номер "+" номер
Символ трубы | — это синтаксис для написания альтернатив: для построения текста узел, мы можем либо разобрать токен TEXT , либо токен "join" , за которым следуют два
больше текста узлов.
Теперь мы можем анализировать входные данные, такие как:
сказать присоединиться "Привет" "мир!" на 2 + 3 секунды
Построив таким образом более крупные правила из более мелких, мы можем описать
весь синтаксис языка.
Для получения дополнительной информации посетите страницу Википедии для ЕБНФ (который является способом определения контекстно-свободных грамматик).
PLY
lex — это токенизатор (или «лексер»). Чтобы использовать lex, вы сообщаете ему, что каждый вид жетон выглядит. Например, вы указываете, что числовые токены содержат один или больше цифр и может содержать точку.
yacc — генератор парсеров . Вы даете yacc CFG, и он выдает сильно оптимизированный парсер. Этот синтаксический анализатор принимает токены из lex в качестве входных данных и возвращает дерево разбора.
Я использовал PLY, Python выполнение. Вы можете увидеть полную парсер Я написал.
Проблема с yacc в том, что для большей эффективности он не принимает и контекстно-свободная грамматика. Грамматика должна быть в специальной форме под названием LALR . LALR трудно определить: лучшее определение — круговое, т.е. «Якк может разбирай»!
Это накладывает ограничения на типы продукционных правил, которые вы можете написать. Эти ограничения в основном искусственные: люди, естественно, не пишут LALR.
грамматики.
Эти ограничения в основном искусственные: люди, естественно, не пишут LALR.
грамматики.
Рекурсивный спуск
Рекурсивный спуск кажется, означает «написать синтаксический анализатор вручную». Вы должны определить функцию для разбора Каждое производственное правило. Их невероятно утомительно писать, и они могут проблемы с возвратом.
Несмотря на это, они, по сути, самые современные в синтаксическом анализе: большинство языки программирования, широко используемые сегодня, имеют рукописные синтаксические анализаторы. Это сумасшедший!
Некоторые языки даже не имеют формальной спецификации с использованием CFG, что является проблема при попытке реализовать новые парсеры для этих языков.
Я не пробовал рекурсивный спуск, потому что мне пришлось бы писать функцию для каждого блок в Scratch.
Новый синтаксис
В этот момент я понял, что синтаксис скретчблоков был плохой идеей. это неловко
писать, а также трудно разобрать. Вот почему я пытаюсь прояснить, что
тош не скретчблоки.
В основном меня вдохновил мой друг Натан из Интернета. Он написал:
Я написал синтаксический анализатор чистых блоков, достаточно хорошо умеющий определять, что вы имеете в виду без множества круглых скобок (например,
установите элемент 2 + 3 * 4 из positions + 10вместоустановить [a] на ((элемент ([2] + ([3] * [4])) из [позиция v]) + [10])) …
Итак, я изменил свой дизайн: я хотел свести к минимуму круглые скобки и сделать язык на самом деле приятно писать; сохраняя при этом идею, что вы можете писать код, как если бы вы читали блоки Scratch.
Конечно, этот новый язык еще труднее анализировать.
TDOP
Оператор сверху вниз приоритет аккуратный алгоритм синтаксического анализа, поэтому я попробовал это дальше. Может, это решит все мои проблемы?
TDOP напрямую не использует CFG; он прикрепляет логику синтаксического анализа непосредственно к каждому
токен. Как следует из названия, он хорошо справляется с приоритетами, поэтому работает хорошо.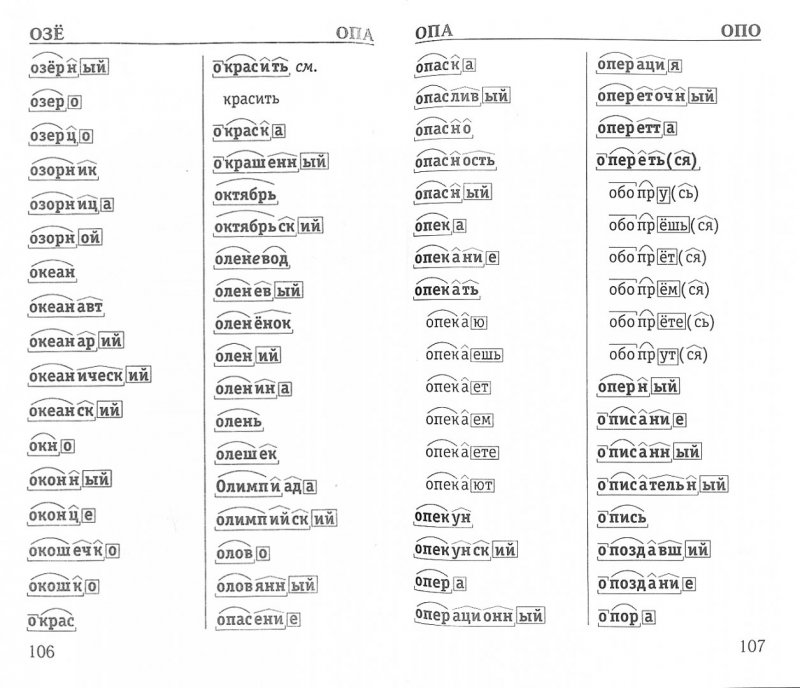 для грамматик инфиксных выражений.
для грамматик инфиксных выражений.
К сожалению, для моего прототипа это не сработало, так как токены слов вроде набор может иметь несколько значений. Я написал кучу кода, чтобы отслеживать
возможные блоки на основе токенов, которые мы видели до сих пор, но в итоге они выросли настолько
большой, он почти заменил часть TDOP.
Парсер на основе TDOP включен в Курт, а ты попробуй это с помощью инструмента Text Parser.
В основном это работает, но есть некоторые допустимые входные данные, которые он не может проанализировать. Его трудно решить, как это исправить, потому что трудно рассуждать о том, как код относится к грамматике.
Earley
Я упомянул, что синтаксический анализ не является решенной проблемой.
До сих пор мы видели:
- Двоичный синтаксический анализ плохо распространяется на текстовый синтаксический анализ (упс).
- CFG — хороший способ определения грамматик.
- yacc работает быстро, но накладывает ограничения на вашу грамматику.
- TDOP хорош, но его трудно понять.
- Рукописный код — это современный уровень техники.

Чего я действительно хотел, так это алгоритма, который мог бы принимать произвольные контекстно-независимые грамматику и анализировать ее эффективно. Я не хотел странных ограничений, таких как LALR-ность, и я не хотел писать код вручную.
К счастью, такие парсеры существуют! Одним из них является алгоритм Эрли. я обнаружил Эрли через моего друга Картика, который написал анализатор Эрли на Javascript.
Он также написал объяснение Эрли разбор. Парсинг Эрли будет быть очень важным для дальнейшего, так что я могу попытаться объяснить это сам.
Сколько предложений в абзаце и слов в абзаце?
Общий вопрос, который вы можете задать при написании эссе для задания, — сколько предложений вы должны включить в абзац. Это особенно важно, если вы пытаетесь достичь минимального количества слов или абзацев.
Содержание
Сколько предложений должно быть в абзаце? Как правило, абзацы должны состоять из 5-8 предложений. В этом случае, если вам нужно написать эссе из пяти абзацев, вам потребуется всего 25–40 предложений. Однако это не жесткое правило. В конце концов, вы не можете оценить хороший абзац словами или предложениями.
В этом случае, если вам нужно написать эссе из пяти абзацев, вам потребуется всего 25–40 предложений. Однако это не жесткое правило. В конце концов, вы не можете оценить хороший абзац словами или предложениями.
Итак, сколько предложений нужно написать в абзаце? Чтобы знать это, вам нужно определить, что ваши читатели хотят видеть в ваших работах, поскольку у разных читателей могут быть разные ожидания от вас.
Сколько слов в абзаце?Абзац обычно состоит из 75-160 слов. В среднем 15-20 слов в предложении и 5-8 предложений в абзаце, это примерно от 75 до 160 слов. Однако это будет зависеть от ожиданий вашей аудитории. В следующем разделе вы найдете информацию о том, что обычно рекомендуют учителя.
Многие учителя и воспитатели считают, что параграф должен содержать от 100 до 200 слов или не более 5-6 предложений. Это не зависит от размера шрифта и других стилистических решений.
Хорошее эмпирическое правило состоит в том, чтобы выразить свою идею в первом или двух предложениях, а в следующих 3-4 предложениях предоставить информацию, которая поддерживает вашу основную идею.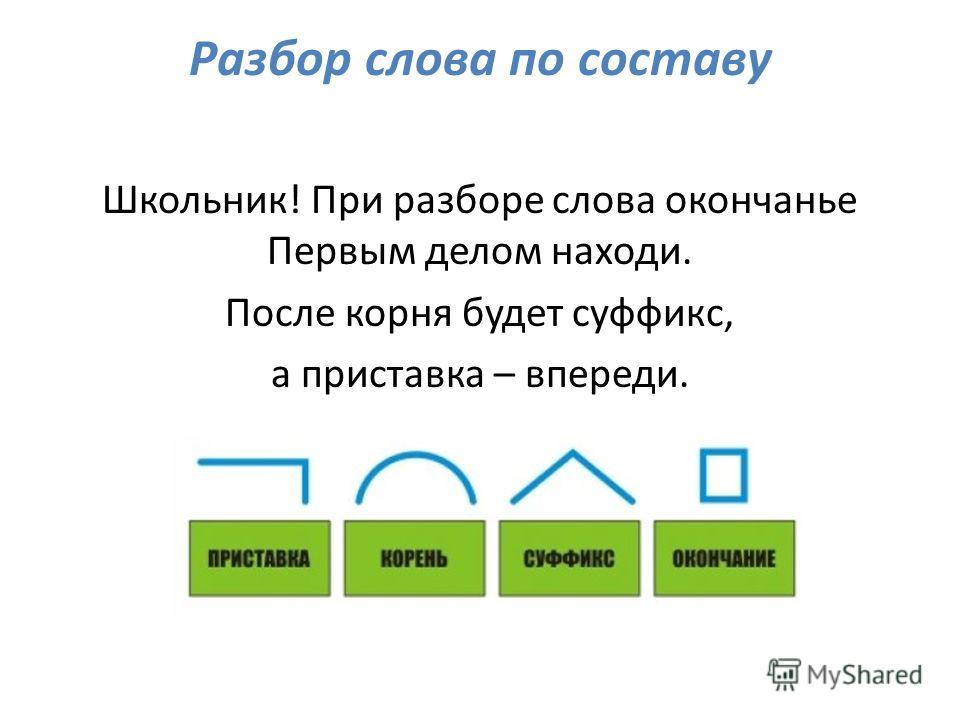 В последнем предложении сделайте осмысленный вывод.
В последнем предложении сделайте осмысленный вывод.
Как правило, учителя ожидают более длинных абзацев, потому что хотят посмотреть, обладаете ли вы необходимыми знаниями по предмету. Они знают, что вам будет не легче продемонстрировать свое понимание темы в одном-двух предложениях.
Сколько слов в предложении?Предложение обычно состоит в среднем из 15-20 слов. Таким образом, абзац из 5-6 предложений должен быть . Предложения длиннее этого должны быть разбиты на отдельные предложения. В противном случае они могут превратиться в повторяющиеся предложения.
Когда следует использовать более короткие абзацы? Короткий абзац состоит всего из двух или трех предложений. Более короткие абзацы, как правило, легче воспринимаются читателями и побуждают их бегло просматривать текст. Сплошные блоки текста часто трудно воспринимать и анализировать, особенно при быстром чтении. Возможно, поэтому в большинстве популярных книг короткие абзацы.
Новые авторы также предпочитают использовать более короткие абзацы в своих текстах. Это не только помогает им кратко предоставлять информацию, но также является отличным способом привлечь внимание читателей.
Коммерческие авторы предпочитают, чтобы длина абзаца не превышала трех-четырех предложений. Когда они пишут сообщение длиной от 1000 до 1500 слов, они используют множество подзаголовков, чтобы разделить абзацы и сделать их более точными.
Итак, если вы блогер или копирайтер, сокращайте абзацы своих постов, чтобы ваша целевая аудитория могла внимательно прочитать ваш пост и отдельные абзацы с четкими подзаголовками , чтобы читатели могли бегло просмотреть. Дополнительное пустое пространство, созданное разрывами абзацев и заголовками, позволяет читателю легко воспринимать важные части.
Независимо от размера вашего абзаца, он должен включать ключевые элементы, в том числе: единство, порядок, связность и завершенность.
Давайте кратко узнаем об этих элементах в следующем списке.
- Единство: В вашем абзаце должна быть одна законченная мысль, которую также следует соблюдать во всех его предложениях.
- Заказ: Это относится к методу, которым вы структурируете свои поддерживающие предложения. В соответствии с вашими требованиями вы можете следовать порядку важности или хронологическому порядку. Тем не менее, ваша конечная цель должна состоять в том, чтобы ваш абзац легко читался.
- Согласованность: Это качество делает ваш абзац легким для понимания. Предложения в вашем абзаце должны быть связаны и работать вместе как единое целое.
- Полнота: Полнота достигается, когда все абзацы легко поддерживают основную идею. Такие абзацы считаются завершенными.
Более короткие абзацы fo облегчают работу читателей, но длина вашего абзаца будет зависеть от типа письма. Академическое письмо будет отличаться от коммерческого письма, которое, в свою очередь, отличается от написания книги.
Во-первых, важно понять, что делает абзац хорошим? Помните, хороший абзац должен состоять из ключевого предложения, нескольких вспомогательных предложений и заключительной фразы.
Когда вы организуете свой отрывок в соответствии с этой структурой, ваш абзац дает вашим читателям ясное и краткое сообщение.
Ниже приведены несколько быстрых советов по написанию отличного абзаца.
Не оставляйте ни одно из ваших предложений позадиПри написании абзаца цель вашего первого предложения должна заключаться в том, чтобы заставить читателя прочитать следующее предложение.
К сожалению, многие начинающие писатели не обращают на это внимания. К четвертому и пятому предложениям их интерес начинает падать.
Быстро пересмотрите свой абзац, как только закончите его. Если в вашем отрывке есть предложение, которое не подталкивает читателей к следующей строке, немедленно исключите его.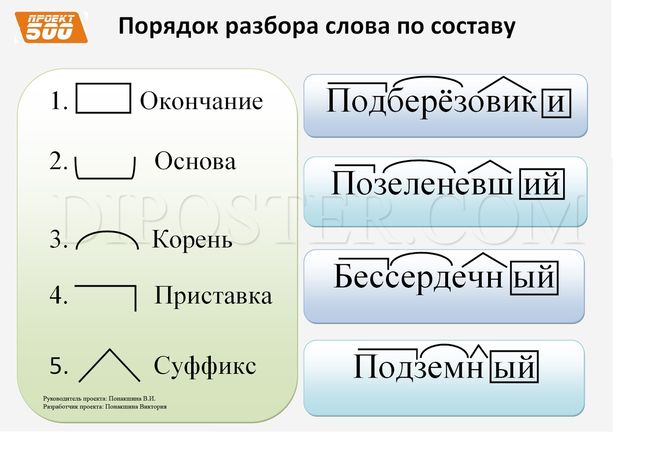 Это не принесет никакой пользы вашему абзацу.
Это не принесет никакой пользы вашему абзацу.
Установите связь между различными предложениями в вашем абзаце. Ваш абзац должен придерживаться одной точки от начала до конца. Когда вы начинаете новый абзац, не забудьте вернуться к последнему предложению предыдущего абзаца.
Осторожно начинайте новый абзацМногие начинающие писатели не понимают, когда им следует начинать новый абзац. Это просто. Каждый раз, когда вы начинаете новую идею или мысль, начинайте ее с нового абзаца. Однако ваш новый абзац должен охватывать основную цель вашей темы или предмета.
Завершение абзацаХороший абзац должен заканчиваться заключительным предложением, обобщающим основные идеи вашего абзаца. Ваше заключение должно подчеркивать суть абзаца, обеспечивая завершение.
Если вы пишете описательное эссе, в котором сравниваете или противопоставляете что-либо, вы должны использовать этот подход в заключительном предложении.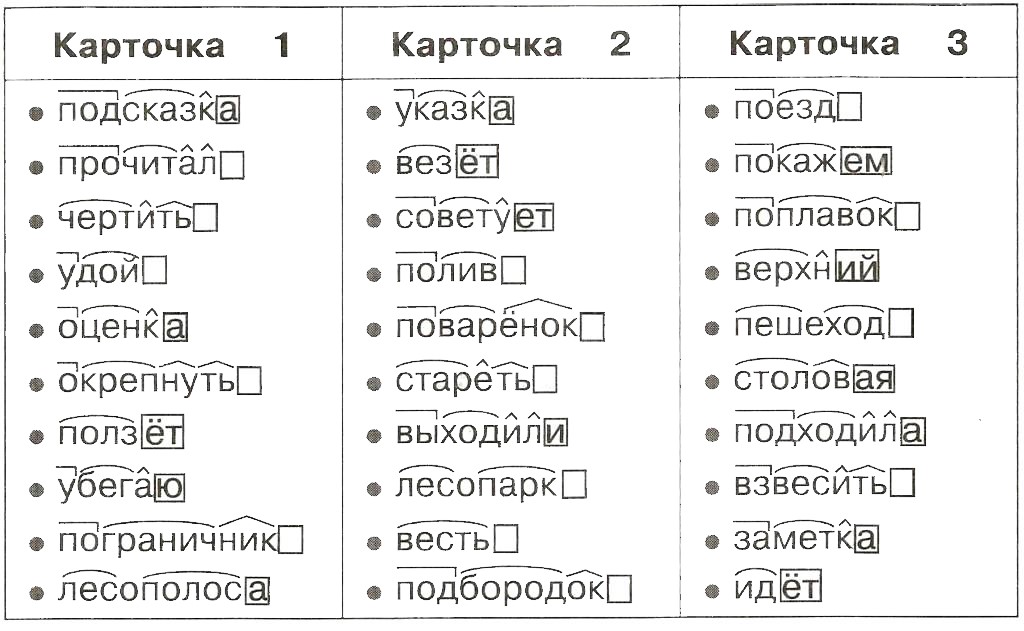
Несмотря на то, что разбивать большие куски текста на части, чтобы облегчить его усвоение читателями, полезно, не следует пренебрегать связями между предложениями. Переходные слова, такие как Следовательно, Соответственно, Следовательно, Следовательно, Таким образом, и т. д., помогут вам связать предложения с другими идеями в отрывке.
Кроме того, они позволяют вашим читателям понять ваши идеи и легко понять их. Переходные слова очень полезны для блоггеров, которые обычно сосредотачиваются на одной цели за раз.
Помимо переходов, вы также можете использовать местоимения, такие как «они» и «эти», чтобы улучшить плавность вашего письма.
Заключительные мысли Если вы посмотрите вокруг, вы обнаружите, что преобладает концепция абзацев с 5-8 предложениями. Тем не менее, до сих пор продолжаются дебаты. Некоторые эксперты говорят, что 2-3 предложения на отрывок оптимальны, в то время как другие говорят, что 5-7 предложений составляют идеальный абзац.