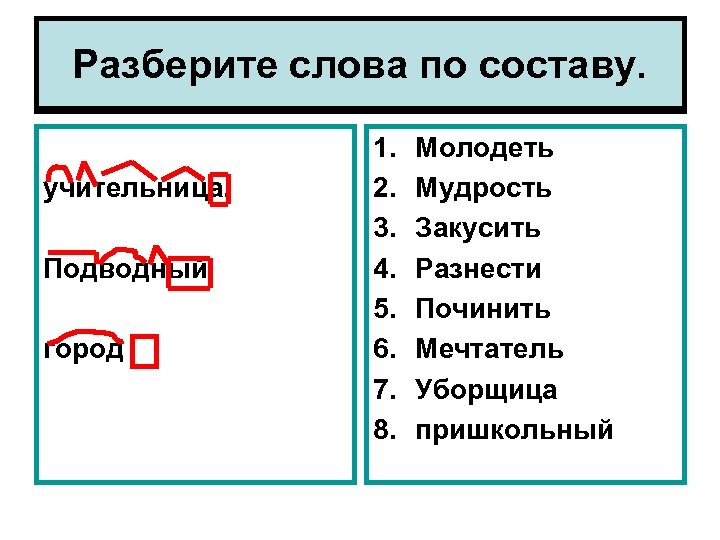
Смотреть, обидеть, видеть, дышать и ненавидеть..
- Форум
- Архив
- Подготовка домашних заданий.
Скажите, пожалуйста, почему правила В учебнике по русскому языку, 4 класс, гласят, что у глагола неопределенной формы, т.е начальной формы (без времени), как в названии темы, -ть это суффикс. Это правило.
А когда мы учим другое правило, как в названии темы, то эти же глаголы приобретают окончания —ать, -ять, -ить, -еть. По ним мы определяем спряжения глаголов, в том числе и исключения, как в названии темы.
Где правда? Окончание или суффикс?
Благодарю за пояснения.
это не окончания, а глаголы оканчивающиеся на ать ять.разные вещи
Да мне понятно, что разные.
Объяснить как?
А как разобрать по составу любой глагол из этих, неопределенной формы?
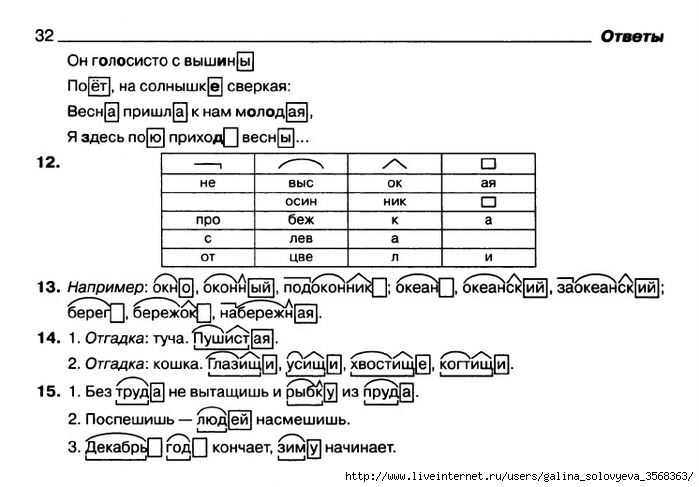
например, глаголы:
Салютовать
Приветствовать
Ненавидеть
Где суффикс? Где окончание?
1) салют/ова/ть — корень/суффикс/суффикс , салютова — основа, т.
 к. -ть — это формообразующий суффикс, он в основу не входит. Окончаний у глаголов неопределенной формы нет, даже нулевого.
к. -ть — это формообразующий суффикс, он в основу не входит. Окончаний у глаголов неопределенной формы нет, даже нулевого.2) привет/ств/ова/ть — корень/суффикс/суффикс/суффикс, приветствова — основа, окончания нет.
3) ненавид/е/ть — корень/суффикс/суффикс, ненавиде — основа, окончания нет.
Но в некоторых программах -ть выделяют как окончание. Что поделать, тогда нужно так и выделять.
Лично я придерживаюсь первого варианта, когда -ть — это суффикс, а окончания у инфинитива нет.
я так поняла, русисты сами еще не договорились. я лично просто говорю, что глагол оканчивается на -ять, дети, это НЕ окончание, квадратиком не выделяем, это просто такие буквы на конце.
Спасибо большое Вам! Я так и думала, основу только не знала, что -ть не входит. Вы обосновались очень доходчиво.
Нет, не преподаватель ))
это суффиксы, а не окончания
верно написали — не путайте «окончание» как часть слова со словосочетанием «оканчивается на . ..»
..»
почему такая хитрая формула — а потому что некоторые филологи и авторы справочников считают что -ть — окончание
и если так обозначить типа не должно считаться ошибкой
формулировка «оканчивается на …» позволяет избегать этой спорной тонкости
но основная школьная позиция — -ить и тд — суффиксы
-ить и т.п. — это два суффикса.
Продолжу тему.
Девочки, послушаю еще и Ваши коментарии.
Согласна, что мнений нет единогласных, и это печаль.. Но страдает ребенок, получая оценки и не получая правильные единые знания.
глаголы:
Уйти
Увести
В разных справочниках трактуются по-разному в подземном разборе. Каков ваш вариант?
Глагол
Искупался
Опять же..ну что сказать, дают тему, которую еще не изучали. Постфикс ребенок суффиксом отметил, нулевого окончания не поняв, конечно. Как и у автора, тоже 4 класс.
Спасибо всем заметившим мой вопрос.
Я к чему. Если, как пишет Марина, инфинитив не имеет окончания, то уйти и увести имеют суффиксы ти? Где мне взять это правило про суффиксы и окончания глаголов в неопр форме?
А простые глаголы в инфинитив
вернуть и мечтать -у- -а- в данном случае это еще один суффикс?
Лен, у неизменяемых слов нет окончаний, значит и у инфинитива его тоже нет.
Вернуть: вер — корень, ну — суффикс, ть — формообразующий суффикс, окончания нет, верну — основа.
Уйти: у — приставка, й — корень, ти — формообразующий суффикс, окончания нет, уй — основа.
Увести: у — приставка, вес — корень, ти — формообразующий суффикс, окончания нет, увес — основа.
Почитай про формообразующие суффиксы. Ну и про глагольные суффиксы вообще.
На счет нулевого окончания в глаголах прошедшего времени мужского рода. Чтобы понять, что окончание там есть, нужно поставить глагол в форму женского или среднего рода, тогда окончание появится.
Спасибо, Марина.
значит, надо обоснованно словообразующие суффиксы учителю показать? Ну, то есть я приду с вопросом, должен же быть адекватный с моей стороны момент в претензии. Буду искать информацию.
А постфикс как указывается схемой? Как приставка, но зеркально? А будет ли в данном случае окончание называться интерфикс?
Фото
Лен, все зависит от программы, которая именно в вашей школе. Если ваших детей учат, что -ть и -ти — глагольные окончания, то смысл тебе переть на рожон и доказывать, что это формообразующие суффиксы?
Если ваших детей учат, что -ть и -ти — глагольные окончания, то смысл тебе переть на рожон и доказывать, что это формообразующие суффиксы?
По поводу фото с выполненным заданием. Ошибки: не везде правильно выделяет основу (формообразующие суффиксы в основу не входят), не выделяет нулевые окончания, в глаголе пыталась, а, л являются отдельными суффиксами, первый — словообразующий, входит в основу, второй — формообразующий, в основу не входит (интересно, но ведь в глаголе поспешил он правильно суффиксы и, л отдельно выделил).
На счет постфикса. В принципе, да, он так и выделяется при разборе, как ты написала: как приставка, только наоборот. Но можно его выделять, как обычный суффикс. Но мне кажется, что постфиксы -ся, -сь являются формообразующими (возвратная форма) и тогда они в основу не входят. Но вот тут я не очень уверена, это, скорее, мои рассуждения.
Возвратные постфиксы входят в основу. Например, «умывать» и «умываться» — разные слово, а не формы одного и того же. Соответственно, основа в этих случаях прерывается: умыва…ся.
Например, «умывать» и «умываться» — разные слово, а не формы одного и того же. Соответственно, основа в этих случаях прерывается: умыва…ся.
Спасибо. Надо запомнить. Значит основа прерывается.
Интерфикс — это «асемантическая прокладка», то есть вставка, не имеющая никакого собственного значения (в отличие от морфем — в частности, окончания, которое интерфиксом являться не может).
Марина, спасибо.
У сына учителей по русскому языку несколько, точнее трое. Вот в этом проблема, наверное. Так сложились обстоятельства, не специально.
Я, в принципе, поняла суть ответа.

Спасибо. А интерфикс входит в основу? Он же в середине слова стоит.
Вы согласны, что глаголы в инфинитив не имеют выделяемого окончания, а -ть -ти это суффиксы, образующие форму глагола и не входящие в основу, потому как исключаются с изменением времени. Правильно?
Интерфикс входит в основу, поскольку не является формообразующей морфемой.
Насчёт -ть и -ти вам абсолютно верно ответила Марина — подход зависит от программы, поскольку этот вопрос русисты никак не разрешат окончательно. Сейчас эту вредную морфему чаще всего считают формообразующим суффиксом (точнее, постфиксом, но в школьную программу это понятие не включено), однако авторы учебника вправе придерживаться альтернативной точки зрения. В чем-то это проще для школьников: их же изначально учили, что с помощью окончания образуются формы слов, а с помощью суффикса — новые слова, и окончание — единственная изменяемая часть слова.
 Для средней школы уместно добавление: если вы выделите -ть как суффикс, это не будет ошибкой, но не забывайте, что он не входит в основу.
Для средней школы уместно добавление: если вы выделите -ть как суффикс, это не будет ошибкой, но не забывайте, что он не входит в основу.Спасибо за пояснение.
У вас «славка» с маленькой буквы написано? Это не имя?
Про глаголы так толково объяснили,а почему же «НА СЧЕТ нулевого окончания» раздельно написали?
Открыть тему в окнах
Знаменитости в тренде
Нормальный рост ребенка в четыре года
Она уничтожила себя: почему Ким Бейсингер потеряла карьеру и любовь
Юлия Высоцкая раскрыла секрет молодости
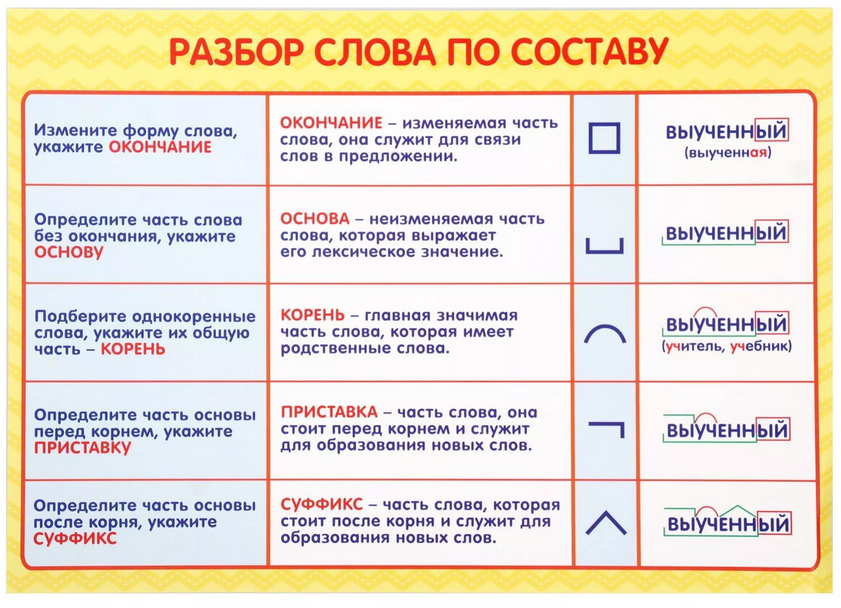
Как разобрать по составу слова: прочный|прочная|прочное?
Как выполнить морфемный разбор слов: прочный, прочная и прочное?
2
Azamatik
Ответы (7):
Share
3
Даже по словам, заданным в вопросе, уже без труда можно определить, что это одно и то же слово, но принадлежащее к разным родам: прочн/ый фундамент (мужской род), прочн/ая ткань (женский род) и прочн/ое основание (средний род).
Эти прилагательные имеют одно лексическое значение (все перечисленные предметы крепкие, их трудно разрушить),
но разные окончания -ый, -ая, -ое (они отделены от основы слова косой чертой).
Теперь постараемся определить основную значимую часть слов, в которой и заключено значение всех трех слов. И не только приведенных, но и других однокоренных, например: прочность, упрочнить, упрочнять, упрочнение, непрочно.
Легко видеть, что корень этих слов прочн-. Так же легко видеть, что все три слова имеют в своем составе только две морфемы: корень прочн- и окончания -ый, -ая, -ое соответственно.
Основа слов — прочн-.
Share
1
В этом вопросе нужно разобрать по составу слова: прочный, прочная, прочное.
Слово прочный. Основа данного слова ПРОЧН. Слово прочный является прилагательным. Оно состоит из корня  Получаем следующую схему: корень-окончание, а именно ПРОЧН — ЫЙ.
Получаем следующую схему: корень-окончание, а именно ПРОЧН — ЫЙ.
Слово прочная. Основа данного слова ПРОЧН. Слово прочная является прилагательным. Оно состоит из корня ПРОЧН и окончания АЯ. Получаем следующую схему: корень-окончание, а именно ПРОЧН — АЯ.
Слово прочное. Основа данного слова ПРОЧН. Слово прочное является прилагательным. Оно состоит из корня ПРОЧН и окончания ОЕ. Получаем следующую схему: корень-окончание, а именно ПРОЧН — ОЕ.
Данные слова однокоренные.
Share
Слово прочный — является прилагательным мужского рода, в единственном числе (во множественном числе будет — прочные), в именительном/винительном падеже.
Произведем разбор по составу слова Прочный:
Подберем для начала несколько однокоренных слов: прочность, прочно, упрочить и тд.
Корень слова -проч-.
Изменим это слово по родам (прочнАЯ, прочнОЕ) или же просклоняем слово по падежам (прочнОГО, к прочнОМУ и тд) и выделим окончание -ый-.
Слово образовано суффиксальным способом, при помощи суффикса -н-.
Основа слова -прочн-.
Прилагательное женского рода, единственного числа прочная разбирается по составу следующим образом:
Корень этого слова -проч- (прочно, упрочить).
Окончанием слова является -ая- (прочнОЙ, к прочнОЙ, прочнУЮ, прочнОЙ и о прочнОЙ).
Выделим еще одну морфему слова — это суффикс -н-.
Основой этого слова является -прочн-.
Слово прочное — является прилагательным среднего рода, единственного числа, в именительном и винительном падеже.
Сделаем разбор по составу слова Прочное:
Корнем слова является -проч-.
Окончанием слова является -ое-.
Суффикс слова -н-.
Основа этого слова -прочн-.
Готово.
Share
«Прочный, прочная, прочное» отвечают на вопросы — какой?, какая?, какое? значит это прилагательные, мужского, женского, среднего рода.
Сделаем разбор прилагательных по составу:
Прочный:
- приставка: отсутствует;
- корень слова: проч;
- суффикс: н;
- окончание: ый;
- основа слова: прочн.
Прочная:
- приставка: отсутствует;
- корень слова: проч;
- суффикс: н;
- окончание: ая;
- основа слова: прочн.
Прочное:
- приставка: отсутствует;
- корень слова: проч;
- суффикс: н;
- окончание: ое;
- основа слова: прочн.
Share
Прилагательное Прочная стоит в женском роде и окончание выделяется -АЯ, точно так же как в мужском роде окончанием будут -ЫЙ, а в среднем -ОЕ: Прочный фундамент-Прочная дружба-Прочное намерение.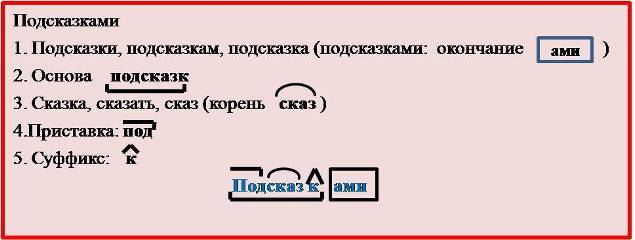 Однокоренными словами будут Прочность-Упрочить-Упрочнение-Прочнейший-Прочно. Корень слова ПРОЧ-. Также выделяем суффикс прилагательного -Н-.
Однокоренными словами будут Прочность-Упрочить-Упрочнение-Прочнейший-Прочно. Корень слова ПРОЧ-. Также выделяем суффикс прилагательного -Н-.
Получаем: ПРОЧ-Н-АЯ (ЫЙ,ОЕ) (корень-суффикс-окончание). Основа слова ПРОЧН-.
Share
Прочный, прочная, прочное — в данном случае эти однокоренные прилагательные, определим и другие однокоренные прочный, упрочить, прочность (отличать от существительного порочность), упрочненный.
Корень — проч-, суффикс -н-, Окончания отличаются -ый- прочный дом, -ая- прочная семья, -ое- прочное будущее.
Share
В словах: прочный, прочная, прочное — «проч» — корень, н — суффикс, -ый, -ая, -ое — окончания.
терминология — О термине «фрекентатив» при разборе слова «плавать» по составу
Вопрос задан
Изменён 1 год 3 месяца назад
Просмотрен 104 раза
Цитата из ответа: Таким образом в слове «пловец» суффикс: -в- остался от -ва-, образующего фрекентатив от «плы-ть».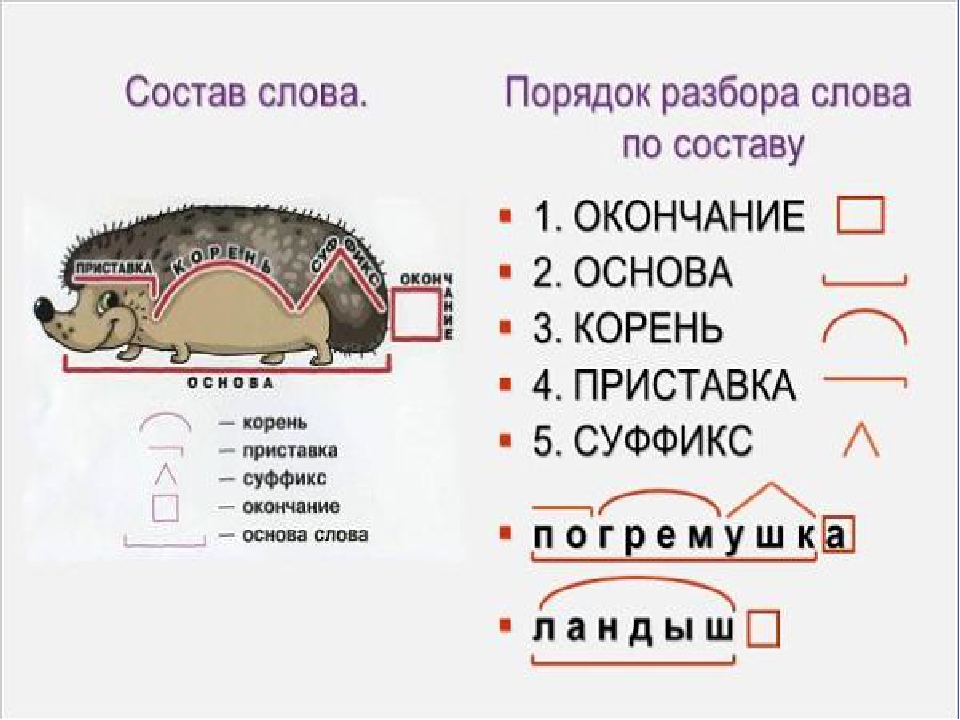 https://rus.stackexchange.com/questions/466692/Суффиксы-
https://rus.stackexchange.com/questions/466692/Суффиксы-
- Фрекентатив – это специальный лингвистический термин, актуальный в сравнительном языкознании.
Википедия: Фреквентатив – форма глагола , которая указывает на повторяющееся действие. Фреквентатив может рассматриваться как отдельный глагол, производный от исходного. Фреквентатив также есть в некоторых других языках, таких как латинский , балто-славянские ( польский , литовский ), финно-угорские ( финский , венгерский ), тюркские и т. д.
Применять его в школьном разборе слов по составу вроде бы нет особой необходимости, его значение указывается только в специальных словарях
Но есть еще термин «итератив», он обозначен в общих словарях:
Итератив (от лат. iterare — вторично делать, повторять; также многократный вид) — вид глагола, обозначающий многократное или повторяющееся действие.
- В русском языке форма фреквентатива образуется с помощью суффиксов -ыва , -ива, -ва, -а (слышивать, видывать, знавать и т.п.) и воспринимается носителями как устаревшая.
Как-то не очень похоже на плавать.
- И вопрос: Так плавать – это фрекентатив или итератив?
Корректно ли применять подобные термины в школьной практике? Стоит ли учащимся отвлекаться на подобную терминологию или лучше больше внимания уделять вопросам по существу?
- терминология
- морфемный-разбор
1
Погуглила. Хотя при исследовании «глагольной множественности», Дресслер, 1968, выделяет в своей работе различные итеративные нюансы, и среди них есть фреквентатив. Храковский 1989, так определяет «фреквантатив» как частный случай — «итератив с малыми интервалами между повторяющимися ситуациями», в целом их можно рассматривать как синонимичные и часто взаимозаменяемые. Особенно если мы не диссертацию пишем, а ищем, как объяснить школьникам, что -в- в слове пловец — суффикс, а не часть корня. Для чего это делать? Дала трем школьникам разобрать это слово — все выделяют корень плов, все удивляются, что -в- является отдельной морфемой и просят объяснений. Они перебирают в уме родственные слова, связанные с этим словом — и им кажется, что общая часть включает этот звук. Плавать, пловец, плывущий, плывет, заплыв и т.п. Когда они в 5 или 6 классе изучают чередование в корнях, им предлагают эти корни под видом «плав/плыв». Вот цитата с сайта Грамота.ру: «1. От места ударения в слове зависит написание корней ГОР/ГАР, КЛОН/КЛАН, ТВОР/ТВАР, ПЛОВ/ПЛАВ, ЗOР/ЗАР.» Когда детям объясняешь причину такого деления на морфемы, они начинают еще больше интересоваться русским языком, а когда говоришь, что они должны просто запомнить, потому что в словарях именно такой разбор, «исторически так сложилось», дети теряют интерес и не пытаются ни в чем самостоятельно разбираться.
Особенно если мы не диссертацию пишем, а ищем, как объяснить школьникам, что -в- в слове пловец — суффикс, а не часть корня. Для чего это делать? Дала трем школьникам разобрать это слово — все выделяют корень плов, все удивляются, что -в- является отдельной морфемой и просят объяснений. Они перебирают в уме родственные слова, связанные с этим словом — и им кажется, что общая часть включает этот звук. Плавать, пловец, плывущий, плывет, заплыв и т.п. Когда они в 5 или 6 классе изучают чередование в корнях, им предлагают эти корни под видом «плав/плыв». Вот цитата с сайта Грамота.ру: «1. От места ударения в слове зависит написание корней ГОР/ГАР, КЛОН/КЛАН, ТВОР/ТВАР, ПЛОВ/ПЛАВ, ЗOР/ЗАР.» Когда детям объясняешь причину такого деления на морфемы, они начинают еще больше интересоваться русским языком, а когда говоришь, что они должны просто запомнить, потому что в словарях именно такой разбор, «исторически так сложилось», дети теряют интерес и не пытаются ни в чем самостоятельно разбираться. Для них это и есть вопрос по существу.
Для них это и есть вопрос по существу.
4
In grammar, a frequentative form (abbreviated freq or fr) of a word is one that indicates repeated action, but is not to be confused with iterative aspect.
В грамматике фреквентативная форма… слова – это форма, которая указывает на повторяющееся действие, но её не следует путать с итеративным видом.
[ wikipedia.org ]
The iterative aspect (abbreviated iter), also called “semelfactive”, “event-internal pluractionality”, or “multiplicative”, is a grammatical aspect that expresses the repetition of an event observable on one single occasion, as in ‘he knocked on the door’, ‘he coughed’, ‘she is drumming’, etc. It is not to be confused with frequentative aspect and habitual aspect, which both signal repetition over more than one occasion.
Итеративный вид…, также называемый «полуактивным», «внутренней множественностью события» или «мультипликативным», представляет собой грамматический вид, который выражает повторение события, наблюдаемого в одном единственном случае, например, «он постучал по дверь», «он закашлялся», «она барабанит» и т.
д. Его не следует путать с фреквентативным и хабитуальным видами, которые оба указывают на повторение более чем однин раз.
[wikipedia.org]
 д. Его не следует путать
с фреквентативным и хабитуальным видами, которые оба указывают на
повторение более чем однин раз.
д. Его не следует путать
с фреквентативным и хабитуальным видами, которые оба указывают на
повторение более чем однин раз.Таким образом итератив в отличие от фрекфентатива – это повторение наблюдаемое в одном единственном случае.
«Он стучит в дверь» – можно рассматривать как итератив, потому что это повторение действия в одном случае, фактически это одно действие состоящее из повторяющихся действий (внутренняя множественность событий).
А пловец плавает не в данный момент, а плавает вообще периодически, такой у него род занятий.
4
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Некоторые проблемы методики проведения морфемного анализа в средней школе
Аннотация
Данная статья посвящена некоторым проблемам морфемного анализа в аспекте развития у обучающихся лингвистического мышления. Умение видеть границы между морфемами позволяет быстрее и точнее принимать и обрабатывать языковую информацию. Важнее анализировать такие слова, разбор которых может иметь варианты, позволяет исследовать их семантику и роль морфем в ее формировании, заглянуть в историческую глубину слова.
Умение видеть границы между морфемами позволяет быстрее и точнее принимать и обрабатывать языковую информацию. Важнее анализировать такие слова, разбор которых может иметь варианты, позволяет исследовать их семантику и роль морфем в ее формировании, заглянуть в историческую глубину слова.
Ключевые слова: лингвистическое мышление, морфемная структура, морфемный анализ, морфемы
Abstract
This article is devoted to some problems of morpheme analysis in the aspect of developing linguistic thinking among students. An ability to see the limits between morphemes allows to get and to work up language information more exactly and quicker. It is important to analyze such words which have variants in their analysis, this let study their semantics and the morphemes’ role in its forming, look into historical heart of the word.
Библиографическая ссылка на статью:
Кожарова А.А. Некоторые проблемы методики проведения морфемного анализа в средней школе // Современные научные исследования и инновации. 2016. № 2 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2016/02/64818 (дата обращения: 14.09.2022).
2016. № 2 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2016/02/64818 (дата обращения: 14.09.2022).
Морфемный анализ вызывает немалые сложности у школьников. Проблема заключается в том, что, действительно, во многих случаях при определении состава морфем конкретных слов трудно принимать однозначные решения. Более того даже словообразовательные словари могут по-разному описывать морфемную структуру одного и того же слова. Происходит это потому, что до сих пор ученые не могут прийти к согласию, какой из двух принципов выделения морфем является ведущим в случае их коллизии – принцип морфологической аналогии или принцип словообразовательной мотивации. Примером этому может служить известная дискуссия о слове буженина: в [Тихонов, 64] выделяется суффикс ин на основании аналогии с строганина, свинина, баранина, а в [Потиха, 34] ин интерпретируется как часть корня на том очевидном основании, что слово буженина в современном русском языке немотивированное и непроизводное и элемент бужен без ин ни в каком слове не встречается.
Эти споры – не каприз ученых, а отражение сложности, многоаспектности, эволюционного характера самих языковых фактов, которые естественным образом носителями языка по-разному осмысляются. В нашем примере, одни русскоговорящие попадают под воздействие закона аналогии и видят в ин суффикс как и в, например, свинина, не задумываясь об отсутствии его словообразовательной поддержки, другие наоборот реагируют прежде всего на отсутствие мотивации и не задумываются об аналогии со многими другими словами с суффиксом ин.
Актуальность темы статьи заключается в том, что одной из основных задач современной школы является развитие мышления обучающегося, умение находить связи и отношения между явлениями, видеть обусловленность одного факта другим. Морфемный анализ является тем видом упражнений, успешное выполнение которого целиком и полностью зависит от правильного установления словообразовательных отношений. Нет никакой необходимости в бесконечном, рутинном разборе словообразовательно очевидных слов. Гораздо интереснее анализировать такие слова, разбор которых может иметь варианты, позволяет исследовать их семантику и роль морфем в ее формировании, заглянуть в историческую глубину слова.
Гораздо интереснее анализировать такие слова, разбор которых может иметь варианты, позволяет исследовать их семантику и роль морфем в ее формировании, заглянуть в историческую глубину слова.
Морфемный анализ очень важен и в пользовательском аспекте. Морфем в языке на несколько порядков меньше, чем слов, поэтому в языках с морфологическим словообразованием, таких как русский, нет никакой необходимости удерживать в памяти большое количество производных слов: чтобы использовать производное слово достаточно знать значения производящей основы и словообразовательных морфем. Так дед и дедушка, старуха и старушка носители языка легко различают потому, что знают значение морфем дед, -стар-, – ушк-, – ух-. Наше языковое сознание в этом смысле устроено, образно говоря, как игрушка конструктор с инструкцией по сборке. В конструкторе из определенного набора деталей по определенным моделям можно собрать большое количество различных конструкций. Язык также состоит из «деталей» (фонем, морфем) и правил их сборки (словообразовательных и синтаксических моделей). Зная морфемы и правила их сборки, можно понимать даже впервые услышанные слова. Так, при проведении эксперимента дети на уроке без труда объяснили значение слова примарситься, хотя признались, что никогда его не слышали. Они все правильно сказали, что это значит “высадиться на Марс”. Происходит это потому, что в их сознании хранится информация о значении каждой из морфем в отдельности и модель словообразования, аналогичная уже известным словам приземлиться, прилуниться, приводниться. Регулярность модели сделала совсем простым понимание нового слова. Это на самом деле замечательный пример, который при обобщении дает ключ к пониманию того, как дети усваивают язык. В языке царствует аналогия и порядок, и все развитие языка – это процесс усиления этого порядка, вытеснения аномальных форм аналогичными (как, например, аномалия волк – волцы была вытеснена аналогией волк – волки). И это существенно облегчает и усвоение, и пользование языком. Конечно, и сейчас в русском языке хватает аномалий (языки не могут меняться быстро), с которыми приходиться мириться как с исключениями, но их несравнимо меньше, чем правильных аналогичных форм.
Зная морфемы и правила их сборки, можно понимать даже впервые услышанные слова. Так, при проведении эксперимента дети на уроке без труда объяснили значение слова примарситься, хотя признались, что никогда его не слышали. Они все правильно сказали, что это значит “высадиться на Марс”. Происходит это потому, что в их сознании хранится информация о значении каждой из морфем в отдельности и модель словообразования, аналогичная уже известным словам приземлиться, прилуниться, приводниться. Регулярность модели сделала совсем простым понимание нового слова. Это на самом деле замечательный пример, который при обобщении дает ключ к пониманию того, как дети усваивают язык. В языке царствует аналогия и порядок, и все развитие языка – это процесс усиления этого порядка, вытеснения аномальных форм аналогичными (как, например, аномалия волк – волцы была вытеснена аналогией волк – волки). И это существенно облегчает и усвоение, и пользование языком. Конечно, и сейчас в русском языке хватает аномалий (языки не могут меняться быстро), с которыми приходиться мириться как с исключениями, но их несравнимо меньше, чем правильных аналогичных форм. Именно поэтому очень важно сделать осмысленным морфемный анализ, потому что это развивает столь необходимое морфологическое видение слов.
Именно поэтому очень важно сделать осмысленным морфемный анализ, потому что это развивает столь необходимое морфологическое видение слов.
Сложности морфемного анализа также заключаются в вариативности установления мотивационных отношений между производным словом и производящей основой. В группе из 45 обучающихся был проведен эксперимент. Ученикам было предложено разобрать по составу слова дедушка и старушка. 98% испытуемых в обоих словах выделяли суффикс –ушк. Ошибка легко объясняется тем, что школьники не точно устанавливают словообразовательные отношения слова старушка с производящей основой. Они интуитивно мотивировали старушка основой слова старый, ошибочно перескакивая через словообразовательное звено старуха. Важно, чтобы ученики хорошо понимали, почему в слове дедушка суффикс –ушк, а старушка два суффикса –уш и –к.
Словообразовательные отношения – это отношения мотивации производного слова производящей основой того слова, от которого оно образовано. Есть материальная общность между производной и производящей основой, поскольку производное слово «наследует» производящую основу. Процесс словообразования реализуется присоединением к производящей основе словообразовательного аффикса – материального показателя словообразовательных отношений. В значении производной и производящей основ есть общие семантические компоненты. Например, в дом-домик, лес-лесник имеется общий семантический компонент «дом». Как видно из примера, словообразовательный аффикс –ик – не только показатель словообразовательного звена, но и носитель дополнительной информации. В первом случае он привносит уменьшительно-ласкательное значение, а во втором – значение лица по профессии.
Есть материальная общность между производной и производящей основой, поскольку производное слово «наследует» производящую основу. Процесс словообразования реализуется присоединением к производящей основе словообразовательного аффикса – материального показателя словообразовательных отношений. В значении производной и производящей основ есть общие семантические компоненты. Например, в дом-домик, лес-лесник имеется общий семантический компонент «дом». Как видно из примера, словообразовательный аффикс –ик – не только показатель словообразовательного звена, но и носитель дополнительной информации. В первом случае он привносит уменьшительно-ласкательное значение, а во втором – значение лица по профессии.
В школе существует два подхода к морфемному анализу слова: формальный и семантический. Формальный подход – это выделение морфем на основе их узнавания, то есть обучающиеся узнают морфему в том, случае, когда они ее встречали в той же позиции, но в других словах. В простых случаях, когда в слове есть один суффикс или приставка, формальный подход дает желаемый результат. Но в сложных случаях, когда в слове два и более суффикса или когда суффикс исторически стал частью корня и произошли изменения границ морфем, формальный подход может привести к ошибке. Например, в слове мешок формально можно выделить суффикс –ок, потому что этот суффикс встречается в других словах и легко узнается школьниками, но это приводит к ошибке, поскольку не учитывается, что произошла утрата мотивации (слово мешок в современном языке не мотивируется основой мех) и в результате корень поглотил суффикс.
Но в сложных случаях, когда в слове два и более суффикса или когда суффикс исторически стал частью корня и произошли изменения границ морфем, формальный подход может привести к ошибке. Например, в слове мешок формально можно выделить суффикс –ок, потому что этот суффикс встречается в других словах и легко узнается школьниками, но это приводит к ошибке, поскольку не учитывается, что произошла утрата мотивации (слово мешок в современном языке не мотивируется основой мех) и в результате корень поглотил суффикс.
Семантический подход учитывает словообразовательные отношения, позволяет правильно устанавливать границы между морфемами.
Алгоритм морфемного анализа может быть следующим:
1) выделить в слове формообразующие аффиксы:
— если слово изменяемое, то выписать несколько форм этого слова, чтобы определить окончание, то есть изменяемую часть слова;
— определить, есть ли в слове формообразующие суффиксы и определить основу слова.
2) установить, является ли основа производной или непроизводной. Например, основа слов дом и лес немотивированная, потому что мы не можем указать производящую основу для этих слов. В этом случае, как правило, основа равна корню (примером исключения, в частности, является отмеченное выше слово буженина, членение которого на морфемы подчиняется действию закона аналогии). Производная основа – это такая основа, для которой мы можем указать производящую основу, которая мотивирует производную. Основа слова домик мотивирована производящей основой дом. Для того чтобы показать, что анализируемая основа является мотивированной, нужно попытаться объяснить значение производного слова через значение производящей основы: домик – это маленький дом.
В процессе исторического развития структура морфем в слове может измениться. Вдумчивое выполнение морфемного анализа позволяет взглянуть на язык в диахронии, понять принципы исторических изменений в основе слова. Необходимо обсуждать, почему в слове мешок раньше выделялся корень мех, а в современном языке корень мешок, а в слове кустарник раньше выделяли два суффикса –ар и –ник, а сейчас один суффикс –арник.
Необходимо обсуждать, почему в слове мешок раньше выделялся корень мех, а в современном языке корень мешок, а в слове кустарник раньше выделяли два суффикса –ар и –ник, а сейчас один суффикс –арник.
Процесс утраты мотивации может быть связан не с внутриязыковыми причинами, а с внешними (экстралингвистическими). Например, слово чернила в историческом прошлом было производным, потому что мотивировалось словом черный. Изначально технология изготовления чернил была такова, что они могли быть только черного цвета. Когда чернила стали изготавливать разных цветов, то произошла утрата мотивации.
Очевидно, без учета исторических изменений внутри языка и в истории народа-носителя языка невозможно проводить морфемный анализ многих слов.
Кроме прагматической задачи правильно разобрать слово, есть еще и гуманитарная цель морфемного анализа – развитие у детей диахронического взгляда на язык, понимания того, что язык живой, развивающийся организм. Это воспитывает бережное и внимательное отношение к истории, которая фиксируется при помощи языка.
Это воспитывает бережное и внимательное отношение к истории, которая фиксируется при помощи языка.
Нужно прививать школьникам культуру пользования словарями, помогающими решать практические задачи и расширять лингвистический кругозор. Словообразовательный словарь – это результат глубокого, всестороннего научного исследования словообразовательной структуры слов. Применять такой словарь просто необходимо в случаях, вызывающих сомнения в установлении словообразовательных отношений. При этом учитель должен создавать ситуации, которые вынуждали бы обучающегося обратиться к словарю.
Поскольку морфемный анализ неотъемлемая часть курса русского языка в школе, проводится регулярно на протяжении многих лет, то нужно постоянно, от года к году усложнять материал для анализа. Важно подогревать интерес к морфемному анализу, предлагая для разбора слова, к которым хотелось бы «присмотреться». Как справедливо отмечает Я.Г. Балакай, «важно не то, чтобы учащиеся бойко членили слова по составу… важно то, чтобы делалось это осмысленно, вдумчиво, аргументированно» [Балакай, 86].
Чем более амбиционными будут цели учителя, тем больше оснований для интеллектуального развития обучающихся. Методика морфемного анализа и ее практическая реализация — это перспективная область профессиональной деятельности.
Библиографический список
- Балакай А.Г. Некоторые спорные вопросы морфемного анализа в вузе и в школе. «Русский язык в школе». – 1990. № 4. С. 81-86.
- Потиха З. А. Школьный словарь строения слов русского языка. – М.: Просвещение, 1999.
- Тихонов А.Н. Школьный словообразовательный словарь русского языка. – М.: Культура и традиции, 1996.
Количество просмотров публикации: Please wait
Все статьи автора «Кожарова Анна Араиковна»
Шоколадное программное обеспечение | Invantive(R) Composition for Word 22.0.187
Требуется модуль Puppet Chocolatey Provider. См. документацию по адресу https://forge.puppet.com/puppetlabs/chocolatey.
## 1. ТРЕБОВАНИЯ ## ### Вот требования, необходимые для обеспечения успеха. ### а. Настройка внутреннего/частного облачного репозитория ### #### Вам понадобится внутренний/частный облачный репозиторий, который вы можете использовать. Это #### вообще очень быстро настраивается и вариантов довольно много. #### Chocolatey Software рекомендует Nexus, Artifactory Pro или ProGet, поскольку они #### являются серверами репозиториев и дают вам возможность управлять несколькими #### репозитории и типы с одной установки сервера. ### б. Загрузите пакет Chocolatey и поместите во внутренний репозиторий ### #### Вам также необходимо загрузить пакет Chocolatey. #### См. https://chocolatey.org/install#organization ### в. Другие требования ### #### я. Требуется модуль puppetlabs/chocolatey #### См. https://forge.puppet.com/puppetlabs/chocolatey ## 2. ПЕРЕМЕННЫЕ ВЕРХНЕГО УРОВНЯ ## ### а. URL вашего внутреннего репозитория (основной). ### #### Должно быть похоже на то, что вы видите при просмотре #### на https://community.
 chocolatey.org/api/v2/
$_repository_url = 'URL ВНУТРЕННЕГО РЕПО'
### б. URL-адрес загрузки шоколадного nupkg ###
#### Этот URL-адрес должен привести к немедленной загрузке, когда вы перейдете к нему в
#### веб-браузер
$_choco_download_url = 'URL ВНУТРЕННЕГО РЕПО/package/chocolatey.1.1.0.nupkg'
### в. Центральное управление Chocolatey (CCM) ###
#### Если вы используете CCM для управления Chocolatey, добавьте следующее:
#### я. URL-адрес конечной точки для CCM
# $_chocolatey_central_management_url = 'https://chocolatey-central-management:24020/ChocolateyManagementService'
#### II. Если вы используете клиентскую соль, добавьте ее сюда.
# $_chocolatey_central_management_client_salt = "clientsalt"
#### III. Если вы используете служебную соль, добавьте ее здесь
# $_chocolatey_central_management_service_salt = 'сервисная соль'
## 3. УБЕДИТЕСЬ, ЧТО ШОКОЛАД УСТАНОВЛЕН ##
### Убедитесь, что Chocolatey установлен из вашего внутреннего репозитория
### Примечание: `chocolatey_download_url полностью отличается от обычного
### исходные местоположения.
chocolatey.org/api/v2/
$_repository_url = 'URL ВНУТРЕННЕГО РЕПО'
### б. URL-адрес загрузки шоколадного nupkg ###
#### Этот URL-адрес должен привести к немедленной загрузке, когда вы перейдете к нему в
#### веб-браузер
$_choco_download_url = 'URL ВНУТРЕННЕГО РЕПО/package/chocolatey.1.1.0.nupkg'
### в. Центральное управление Chocolatey (CCM) ###
#### Если вы используете CCM для управления Chocolatey, добавьте следующее:
#### я. URL-адрес конечной точки для CCM
# $_chocolatey_central_management_url = 'https://chocolatey-central-management:24020/ChocolateyManagementService'
#### II. Если вы используете клиентскую соль, добавьте ее сюда.
# $_chocolatey_central_management_client_salt = "clientsalt"
#### III. Если вы используете служебную соль, добавьте ее здесь
# $_chocolatey_central_management_service_salt = 'сервисная соль'
## 3. УБЕДИТЕСЬ, ЧТО ШОКОЛАД УСТАНОВЛЕН ##
### Убедитесь, что Chocolatey установлен из вашего внутреннего репозитория
### Примечание: `chocolatey_download_url полностью отличается от обычного
### исходные местоположения. Это прямо к голому URL-адресу загрузки для
### Chocolatey.nupkg, похожий на то, что вы видите при просмотре
### https://community.chocolatey.org/api/v2/package/chocolatey
класс {'шоколад':
шоколадный_download_url => $_choco_download_url,
use_7zip => ложь,
}
## 4. НАСТРОЙКА ШОКОЛАДНОЙ БАЗЫ ##
### а. Функция FIPS ###
#### Если вам нужно соответствие FIPS — сделайте это первым, что вы настроите
#### перед выполнением какой-либо дополнительной настройки или установки пакетов
#chocolateyfeature {'useFipsCompliantChecksums':
# убедиться => включено,
#}
### б. Применить рекомендуемую конфигурацию ###
#### Переместите расположение кеша, чтобы Chocolatey был очень детерминирован в отношении
#### очистка временных данных и доступ к локации для администраторов
шоколадный конфиг {'расположение кеша':
значение => 'C:\ProgramData\chocolatey\cache',
}
#### Увеличьте таймаут как минимум до 4 часов
шоколадный конфиг {'commandExecutionTimeoutSeconds':
значение => '14400',
}
#### Отключить прогресс загрузки при запуске choco через интеграции
Chocolateyfeature {'showDownloadProgress':
гарантировать => отключено,
}
### в.
Это прямо к голому URL-адресу загрузки для
### Chocolatey.nupkg, похожий на то, что вы видите при просмотре
### https://community.chocolatey.org/api/v2/package/chocolatey
класс {'шоколад':
шоколадный_download_url => $_choco_download_url,
use_7zip => ложь,
}
## 4. НАСТРОЙКА ШОКОЛАДНОЙ БАЗЫ ##
### а. Функция FIPS ###
#### Если вам нужно соответствие FIPS — сделайте это первым, что вы настроите
#### перед выполнением какой-либо дополнительной настройки или установки пакетов
#chocolateyfeature {'useFipsCompliantChecksums':
# убедиться => включено,
#}
### б. Применить рекомендуемую конфигурацию ###
#### Переместите расположение кеша, чтобы Chocolatey был очень детерминирован в отношении
#### очистка временных данных и доступ к локации для администраторов
шоколадный конфиг {'расположение кеша':
значение => 'C:\ProgramData\chocolatey\cache',
}
#### Увеличьте таймаут как минимум до 4 часов
шоколадный конфиг {'commandExecutionTimeoutSeconds':
значение => '14400',
}
#### Отключить прогресс загрузки при запуске choco через интеграции
Chocolateyfeature {'showDownloadProgress':
гарантировать => отключено,
}
### в. Источники ###
#### Удалить источник репозитория пакетов сообщества по умолчанию
Chocolateysource {'chocolatey':
гарантировать => отсутствует,
местоположение => 'https://community.chocolatey.org/api/v2/',
}
#### Добавить внутренние источники по умолчанию
#### Здесь может быть несколько источников, поэтому мы приведем пример
#### одного из них, использующего здесь переменную удаленного репо
#### ПРИМЕЧАНИЕ. Этот ПРИМЕР требует изменений
шоколадный источник {'internal_chocolatey':
обеспечить => настоящее,
местоположение => $_repository_url,
приоритет => 1,
имя пользователя => 'необязательно',
пароль => 'необязательно, не обязательно',
bypass_proxy => правда,
admin_only => ложь,
allow_self_service => ложь,
}
### б. Держите Chocolatey в курсе ###
#### Поддерживайте актуальность шоколада на основе вашего внутреннего источника
#### Вы контролируете обновления на основе того, когда вы отправляете обновленную версию
#### в ваш внутренний репозиторий.
Источники ###
#### Удалить источник репозитория пакетов сообщества по умолчанию
Chocolateysource {'chocolatey':
гарантировать => отсутствует,
местоположение => 'https://community.chocolatey.org/api/v2/',
}
#### Добавить внутренние источники по умолчанию
#### Здесь может быть несколько источников, поэтому мы приведем пример
#### одного из них, использующего здесь переменную удаленного репо
#### ПРИМЕЧАНИЕ. Этот ПРИМЕР требует изменений
шоколадный источник {'internal_chocolatey':
обеспечить => настоящее,
местоположение => $_repository_url,
приоритет => 1,
имя пользователя => 'необязательно',
пароль => 'необязательно, не обязательно',
bypass_proxy => правда,
admin_only => ложь,
allow_self_service => ложь,
}
### б. Держите Chocolatey в курсе ###
#### Поддерживайте актуальность шоколада на основе вашего внутреннего источника
#### Вы контролируете обновления на основе того, когда вы отправляете обновленную версию
#### в ваш внутренний репозиторий. #### Обратите внимание, что источником здесь является канал OData, аналогичный тому, что вы видите
#### при переходе на https://community.chocolatey.org/api/v2/
пакет {'шоколад':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
}
## 5. ОБЕСПЕЧЬТЕ ШОКОЛАД ДЛЯ БИЗНЕСА ##
### Если у вас нет Chocolatey for Business (C4B), вы можете удалить его отсюда.
### а. Убедитесь, что файл лицензии установлен ###
#### Создайте пакет лицензии с помощью сценария из https://docs.chocolatey.org/en-us/guides/organizations/organizational-deployment-guide#exercise-4-create-a-package-for-the-license
# TODO: добавить ресурс для установки/обеспечения пакета шоколадной лицензии
package {'шоколадная лицензия':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
}
### б. Отключить лицензионный источник ###
#### Лицензионный источник нельзя удалить, поэтому его необходимо отключить.
#### Это должно произойти после того, как лицензия была установлена пакетом лицензий.
#### Обратите внимание, что источником здесь является канал OData, аналогичный тому, что вы видите
#### при переходе на https://community.chocolatey.org/api/v2/
пакет {'шоколад':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
}
## 5. ОБЕСПЕЧЬТЕ ШОКОЛАД ДЛЯ БИЗНЕСА ##
### Если у вас нет Chocolatey for Business (C4B), вы можете удалить его отсюда.
### а. Убедитесь, что файл лицензии установлен ###
#### Создайте пакет лицензии с помощью сценария из https://docs.chocolatey.org/en-us/guides/organizations/organizational-deployment-guide#exercise-4-create-a-package-for-the-license
# TODO: добавить ресурс для установки/обеспечения пакета шоколадной лицензии
package {'шоколадная лицензия':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
}
### б. Отключить лицензионный источник ###
#### Лицензионный источник нельзя удалить, поэтому его необходимо отключить.
#### Это должно произойти после того, как лицензия была установлена пакетом лицензий. ## Отключенным источникам по-прежнему нужны все остальные атрибуты, пока
## https://tickets.puppetlabs.com/browse/MODULES-4449разрешено.
## Пароль необходим пользователю, но не гарантируется, поэтому он не должен
## независимо от того, что здесь установлено. Если у тебя когда-нибудь возникнут проблемы здесь,
## пароль - это GUID вашей лицензии.
Chocolateysource {'chocolatey.licensed':
гарантировать => отключено,
приоритет => '10',
пользователь => «клиент»,
пароль => '1234',
require => Package['chocolatey-license'],
}
### в. Убедитесь, что лицензионное расширение Chocolatey ###
#### Вы загрузили лицензионное расширение во внутренний репозиторий
####, так как вы отключили лицензированный репозиторий на шаге 5b.
#### Убедитесь, что у вас установлен пакет Chocolatey.extension (также известный как Лицензионное расширение Chocolatey)
пакет {'chocolatey.extension':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
#### Лицензионное расширение Chocolatey открывает все перечисленные ниже возможности, для которых также доступны элементы конфигурации/функции.
## Отключенным источникам по-прежнему нужны все остальные атрибуты, пока
## https://tickets.puppetlabs.com/browse/MODULES-4449разрешено.
## Пароль необходим пользователю, но не гарантируется, поэтому он не должен
## независимо от того, что здесь установлено. Если у тебя когда-нибудь возникнут проблемы здесь,
## пароль - это GUID вашей лицензии.
Chocolateysource {'chocolatey.licensed':
гарантировать => отключено,
приоритет => '10',
пользователь => «клиент»,
пароль => '1234',
require => Package['chocolatey-license'],
}
### в. Убедитесь, что лицензионное расширение Chocolatey ###
#### Вы загрузили лицензионное расширение во внутренний репозиторий
####, так как вы отключили лицензированный репозиторий на шаге 5b.
#### Убедитесь, что у вас установлен пакет Chocolatey.extension (также известный как Лицензионное расширение Chocolatey)
пакет {'chocolatey.extension':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
#### Лицензионное расширение Chocolatey открывает все перечисленные ниже возможности, для которых также доступны элементы конфигурации/функции. Вы можете посетить страницы функций, чтобы увидеть, что вы также можете включить:
#### - Конструктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-builder
#### - Package Internalizer - https://docs.chocolatey.org/en-us/features/paid/package-internalizer
#### - Синхронизация пакетов (3 компонента) - https://docs.chocolatey.org/en-us/features/paid/package-synchronization
#### - Редуктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-reducer
#### - Аудит упаковки - https://docs.chocolatey.org/en-us/features/paid/package-audit
#### – Пакетный дроссель — https://docs.chocolatey.org/en-us/features/paid/package-throttle
#### — Доступ к кэшу CDN — https://docs.chocolatey.org/en-us/features/paid/private-cdn
#### – Брендинг – https://docs.chocolatey.org/en-us/features/paid/branding
#### - Self-Service Anywhere (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.chocolatey.org/en-us/features/paid/self-service-anywhere
#### - Chocolatey Central Management (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.
Вы можете посетить страницы функций, чтобы увидеть, что вы также можете включить:
#### - Конструктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-builder
#### - Package Internalizer - https://docs.chocolatey.org/en-us/features/paid/package-internalizer
#### - Синхронизация пакетов (3 компонента) - https://docs.chocolatey.org/en-us/features/paid/package-synchronization
#### - Редуктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-reducer
#### - Аудит упаковки - https://docs.chocolatey.org/en-us/features/paid/package-audit
#### – Пакетный дроссель — https://docs.chocolatey.org/en-us/features/paid/package-throttle
#### — Доступ к кэшу CDN — https://docs.chocolatey.org/en-us/features/paid/private-cdn
#### – Брендинг – https://docs.chocolatey.org/en-us/features/paid/branding
#### - Self-Service Anywhere (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.chocolatey.org/en-us/features/paid/self-service-anywhere
#### - Chocolatey Central Management (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs. chocolatey.org/en-us/features/paid/chocolatey-central-management
#### - Другое - https://docs.chocolatey.org/en-us/features/paid/
### д. Обеспечение самообслуживания в любом месте ###
#### Если у вас есть настольные клиенты, в которых пользователи не являются администраторами, вы можете
#### чтобы воспользоваться преимуществами развертывания и настройки самообслуживания в любом месте
Chocolateyfeature {'showNonElevatedWarnings':
гарантировать => отключено,
}
шоколадная функция {'useBackgroundService':
убедиться => включено,
}
Chocolateyfeature {'useBackgroundServiceWithNonAdministratorsOnly':
убедиться => включено,
}
Chocolateyfeature {'allowBackgroundServiceUninstallsFromUserInstallsOnly':
убедиться => включено,
}
шоколадный конфиг {'backgroundServiceAllowedCommands':
значение => 'установить,обновить,удалить',
}
### е. Убедитесь, что центральное управление Chocolatey ###
#### Если вы хотите управлять конечными точками и составлять отчеты, вы можете установить и настроить
### Центральное управление.
chocolatey.org/en-us/features/paid/chocolatey-central-management
#### - Другое - https://docs.chocolatey.org/en-us/features/paid/
### д. Обеспечение самообслуживания в любом месте ###
#### Если у вас есть настольные клиенты, в которых пользователи не являются администраторами, вы можете
#### чтобы воспользоваться преимуществами развертывания и настройки самообслуживания в любом месте
Chocolateyfeature {'showNonElevatedWarnings':
гарантировать => отключено,
}
шоколадная функция {'useBackgroundService':
убедиться => включено,
}
Chocolateyfeature {'useBackgroundServiceWithNonAdministratorsOnly':
убедиться => включено,
}
Chocolateyfeature {'allowBackgroundServiceUninstallsFromUserInstallsOnly':
убедиться => включено,
}
шоколадный конфиг {'backgroundServiceAllowedCommands':
значение => 'установить,обновить,удалить',
}
### е. Убедитесь, что центральное управление Chocolatey ###
#### Если вы хотите управлять конечными точками и составлять отчеты, вы можете установить и настроить
### Центральное управление. Есть несколько частей для управления, так что вы увидите
### здесь раздел об агентах вместе с примечаниями по настройке сервера
### боковые компоненты.
если $_chocolatey_central_management_url {
package {'шоколадный агент':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
шоколадный конфиг {'CentralManagementServiceUrl':
значение => $_chocolatey_central_management_url,
}
если $_chocolatey_central_management_client_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
если $_chocolatey_central_management_service_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
Chocolateyfeature {'useChocolateyCentralManagement':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
Chocolateyfeature {'useChocolateyCentralManagementDeployments':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
}
Есть несколько частей для управления, так что вы увидите
### здесь раздел об агентах вместе с примечаниями по настройке сервера
### боковые компоненты.
если $_chocolatey_central_management_url {
package {'шоколадный агент':
обеспечить => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
шоколадный конфиг {'CentralManagementServiceUrl':
значение => $_chocolatey_central_management_url,
}
если $_chocolatey_central_management_client_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
если $_chocolatey_central_management_service_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
Chocolateyfeature {'useChocolateyCentralManagement':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
Chocolateyfeature {'useChocolateyCentralManagementDeployments':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
}
Анализ состава программного обеспечения: обзор и руководство по инструментам
Что такое Анализ состава программного обеспечения
По сути, решение SCA состоит из двух основных частей: каталога известных пакетов программного обеспечения и сканера, который просматривает артефакты сборки в поисках элементов из своего каталога. Каталог содержит больше, чем просто названия продуктов для каждой упаковки. Он также знает об опубликованных версиях, уязвимостях в каждой версии и типе требуемой лицензии, такой как Apache 2.0, MIT или GPL. Когда вы запускаете решение SCA, оно проверяет ваши файлы и создает список используемых вами сторонних продуктов. Для каждого продукта сканер сообщает поставщика продукта, имя, версию, тип лицензии и список уязвимостей, которые были обнаружены в продукте.
Каталог содержит больше, чем просто названия продуктов для каждой упаковки. Он также знает об опубликованных версиях, уязвимостях в каждой версии и типе требуемой лицензии, такой как Apache 2.0, MIT или GPL. Когда вы запускаете решение SCA, оно проверяет ваши файлы и создает список используемых вами сторонних продуктов. Для каждого продукта сканер сообщает поставщика продукта, имя, версию, тип лицензии и список уязвимостей, которые были обнаружены в продукте.
Зачем вам нужен SCA
Решения SCA должны распознавать большинство сторонних компонентов, как коммерческих, так и с открытым исходным кодом, но в целом решения SCA стали популярными, поскольку они устраняют риски, связанные с программным обеспечением с открытым исходным кодом. Большинство компаний используют по крайней мере некоторое программное обеспечение с открытым исходным кодом, и большинство приложений содержат по крайней мере некоторые уязвимости в используемом ими программном обеспечении с открытым исходным кодом. Кроме того, многие продукты с открытым исходным кодом являются частью сложной экосистемы, состоящей из нескольких отдельных компонентов или пакетов. Например, компании, использующие Linux, Docker, Apache или Node.js, скорее всего, имеют сотни или даже тысячи различных пакетов, каждый из которых имеет свои собственные лицензионные требования.
Кроме того, многие продукты с открытым исходным кодом являются частью сложной экосистемы, состоящей из нескольких отдельных компонентов или пакетов. Например, компании, использующие Linux, Docker, Apache или Node.js, скорее всего, имеют сотни или даже тысячи различных пакетов, каждый из которых имеет свои собственные лицензионные требования.
Несмотря на то, что последствия использования уязвимого программного обеспечения или неправильной лицензии могут быть серьезными, многие компании даже не знают, какое стороннее программное обеспечение у них есть.
Хотя технически возможно отслеживать все эти компоненты вручную, поддержание каталога в актуальном состоянии быстро становится чрезмерно утомительным. Отследить каждый новый пакет, который вы включаете, достаточно сложно в большой кодовой базе. Ситуация усугубляется, когда вы пытаетесь добавить в свой инвентарь версию и лицензию для каждого пакета. Пакеты часто поставляются со своими собственными зависимостями, что расширяет список. А отслеживание известных уязвимостей хуже. Вы, безусловно, можете найти уязвимости в общедоступной базе данных CVE в Mitre, но это означает ручной поиск и оценку результатов для каждого элемента в вашем инвентаре. И один раз поискать недостаточно. Что если кто-то обнаружит новую уязвимость в старом ПО? Вам придется периодически выполнять поиск снова, чтобы увидеть, могут ли недавно обнаруженные уязвимости повлиять на вас.
А отслеживание известных уязвимостей хуже. Вы, безусловно, можете найти уязвимости в общедоступной базе данных CVE в Mitre, но это означает ручной поиск и оценку результатов для каждого элемента в вашем инвентаре. И один раз поискать недостаточно. Что если кто-то обнаружит новую уязвимость в старом ПО? Вам придется периодически выполнять поиск снова, чтобы увидеть, могут ли недавно обнаруженные уязвимости повлиять на вас.
Очевидно, что эту работу можно автоматизировать. А поставщики, специализирующиеся на предоставлении услуг SCA, могут добиться лучших результатов, чем вы сами. Например, они могут дополнить свои списки известных уязвимостей данными из проприетарных источников или исследований.
Как работает SCA
Чтобы запустить сканер SCA, вы указываете его на свои файлы сборки. Они могут находиться на рабочем столе разработчика или промежуточном сервере, но чаще всего сканеры SCA считывают из каталога сборки в конвейере CI/CD.
Решения SCA распознают в вашей кодовой базе файлы, полученные от сторонних продуктов. Сканеры могут использовать несколько тактик для идентификации. Например, у них может быть список хэшей, предварительно вычисленных из файлов в известных программных продуктах. Хэш для каждого файла уникален. Когда сканер запускается, он вычисляет хэши для всех файлов вашего программного обеспечения и сопоставляет их со своим списком. Когда хэши совпадают, сканер знает, какой продукт и какая версия этого продукта у вас есть. Кроме того, многие сканеры могут анализировать исходные файлы, чтобы найти фрагменты проприетарного кода, включенные в ваш собственный код.
Сканеры могут использовать несколько тактик для идентификации. Например, у них может быть список хэшей, предварительно вычисленных из файлов в известных программных продуктах. Хэш для каждого файла уникален. Когда сканер запускается, он вычисляет хэши для всех файлов вашего программного обеспечения и сопоставляет их со своим списком. Когда хэши совпадают, сканер знает, какой продукт и какая версия этого продукта у вас есть. Кроме того, многие сканеры могут анализировать исходные файлы, чтобы найти фрагменты проприетарного кода, включенные в ваш собственный код.
Даже если ваш код никогда не меняется, вы можете получать разные результаты при каждом запуске сканера. Это связано с тем, что сканеры SCA часто обновляют свой список известных уязвимостей. Люди продолжают находить недостатки в программном обеспечении в течение многих лет после его выпуска, и хороший сканер часто обновляет свой список известных уязвимостей.
Что находит SCA?
Решения SCA производят несколько различных видов продукции, которые служат разным потребностям и могут использоваться разной аудиторией. Типичные отчеты SCA включают:
Типичные отчеты SCA включают:
Ведомость материалов
Список найденных сторонних пакетов. Знание того, какое программное обеспечение у вас есть, является первым шагом к обеспечению безопасности, а предоставление списка иногда является обязательным требованием.Список лицензий
Перечень лицензий на программное обеспечение, связанных со сторонними компонентами вашего программного обеспечения. Некоторые лицензии на ПО с открытым исходным кодом имеют очень строгие ограничения и могут создавать бизнес-риски. Юридические отделы часто устанавливают правила относительно того, каких лицензий должна избегать та или иная компания.Известные уязвимости
Список потенциально опасных уязвимостей в ваших сторонних программных компонентах. Как минимум такие списки показывают тип и серьезность каждой уязвимости, а также файлы, содержащие уязвимость.
SCA Challenges
Как и большинство средств тестирования, сканер SCA помогает находить проблемы.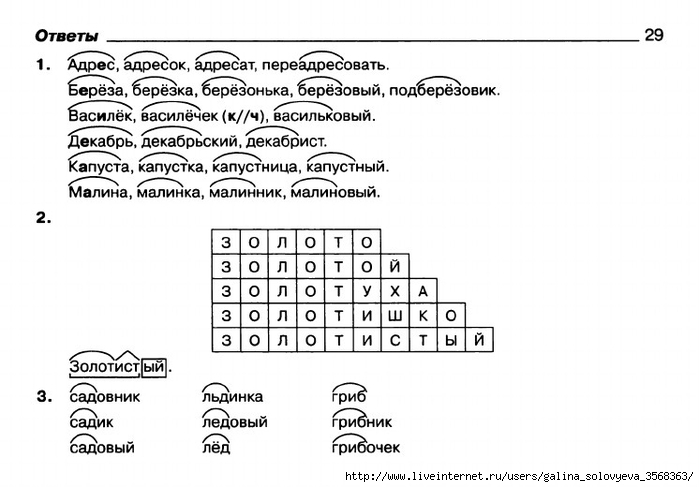 Ответ на то, что он находит, может представлять некоторые общие проблемы.
Ответ на то, что он находит, может представлять некоторые общие проблемы.
Оценка фактического риска
Знание того, что конкретная библиотека в вашей серверной части имеет определенную высокоприоритетную уязвимость, не всегда достаточно для того, чтобы группы разработчиков выбрали правильный ответ. Какой команде принадлежит эта библиотека? Какие части продукта зависят от него? Сколько потребуется регрессионного тестирования, если его заменят? В чем именно уязвимость? Ваш продукт когда-либо выполнял уязвимый путь кода? Можете ли вы безопасно игнорировать уязвимость? На эти вопросы не всегда легко ответить. При выборе решения SCA внимательно изучите отчеты об уязвимостях. Какой из них дает лучшую информацию?
Принятие риска
Вам нужно решить, кому разрешено определять, что конкретное обнаружение не нужно исправлять. Требование одобрения от группы безопасности может привести к надежно объективным решениям, но создает препятствие для разработчиков. Предоставление разработчикам возможности идти на риск ускоряет разработку кода, но требует мониторинга или аудита переопределений разработчиков.
Устранение технического долга
Если у вас большая база кода и вы не отслеживаете стороннее программное обеспечение, первое сканирование SCA, скорее всего, выявит тревожный технический долг. В вашем списке уязвимостей могут быть сотни элементов. Важно будет расставить приоритеты в работе. Какие уязвимости наиболее опасны? Какие компоненты на самом деле обрабатывают конфиденциальные данные? У кого больше всего уязвимостей? Какие из них проще или безопаснее обновить? Разделите работу на приоритетные части. Выделите определенное количество времени в каждом спринте для обработки результатов. Празднуйте новую победу после закрепления каждого куска.
Знать, что было упущено
Сканеры SCA могут не идентифицировать все компоненты сторонних производителей в вашем продукте. Они могут не распознать специализированные библиотеки, приобретенные у мелких поставщиков, или файлы с открытым исходным кодом, которые не получили широкого распространения. Некоторое количество ручного отслеживания все еще может быть необходимо.
Популярные решения SCA
Многие компании производят сканеры для анализа состава программного обеспечения. Вот некоторые из наиболее крупных и выдающихся претендентов, а также пару слов о каждом, чтобы показать, чем они отличаются.
Black Duck (by Synopsis) может похвастаться базой знаний, содержащей более 4 миллионов программных компонентов.
Функция просмотра зависимостей GitHub и «Сканирование зависимостей» GitLab генерируют оповещения об устаревших зависимостях в общедоступных репозиториях и создают запросы на включение для обновления вашего кода. Обзор зависимостей GitHub находится в стадии бета-тестирования на момент написания этой статьи (27.04.21). GitHub предоставляет сравнение функций здесь.
JFrog Xray доступен в облачной или автономной версиях и особенно хорошо интегрируется с продуктом JFrog Artifactory.
Snyk Open Source сканирует образы Docker, а также другие артефакты сборки. Он также извлекает выгоду из проприетарной базы данных уязвимостей программного обеспечения, поддерживаемой исследовательскими группами Snyk.
Nexus Intelligence от Sonatype делает упор на сокращение ложных срабатываний за счет более точного анализа артефактов сборки.
Veracode Software Composition Analysis строит графики вызовов, чтобы помочь вам определить, какие библиотеки с открытым исходным кодом фактически использует ваше приложение.
WhiteSource поддерживает более 200 языков программирования.

Как выбрать решение
Сначала соберите основные сведения о том, что вам нужно. Какие языки использует ваша кодовая база? Какие инструменты появляются в вашем пайплайне CI/CD? Кто в вашей компании хочет видеть отчеты SCA — разработчики? Безопасность? Юридический? Согласие? Какие проблемы он вам нужен для решения? Ответы помогут вам решить, какие из этих функций наиболее важны:
Комплексная идентификация компонентов
Чем больше сторонних компонентов распознает сканер, тем лучше. Сколько оно знает? Как часто обновляется список?Комплексная идентификация уязвимостей
Опять же, чем больше, тем лучше. Полагается ли сканер полностью на общедоступные источники, такие как Mitre, для получения данных об уязвимостях? Некоторые компании дополняют публичные списки собственными исследованиями.Возможности интеграции
На каком этапе процесса разработки программного обеспечения вы хотите провести сканирование? Если вы хотите, чтобы сканирование выполнялось автоматически, вам необходимо понять, как сканер интегрируется с вашей системой сборки.Скорость обратной связи с разработчиками
Как быстро разработчики смогут узнать, что сообщает сканер? Достаточно ли быстр сканер для запуска на каждой сборке? Могут ли разработчики увидеть результаты в своей собственной среде IDE? Генерирует ли сканер оповещения при обнаружении новых уязвимостей в продуктах, которые вы недавно не перестраивали?Пригодность отчетов
Возможности создания отчетов различаются. Разработчикам может быть трудно читать отчеты, предназначенные для сотрудников службы безопасности. Некоторые сканеры делают больше, чем другие, чтобы помочь вам понять, в чем заключается уязвимость и какие части вашего кода зависят от уязвимого компонента.Функции обеспечения соблюдения политик
Многие сканеры позволяют определять гибкие, учитывающие нюансы политики, которые будут блокировать сборки, содержащие неприемлемые лицензии или серьезные уязвимости.Ложные срабатывания
У сканеров SCA обычно не так много ложных срабатываний, как у сканеров DAST, но они случаются. Проверка концепции с использованием собственного кода — лучший способ оценить отношение сигнал/шум сканера.
 Полагается ли сканер полностью на общедоступные источники, такие как Mitre, для получения данных об уязвимостях? Некоторые компании дополняют публичные списки собственными исследованиями.
Полагается ли сканер полностью на общедоступные источники, такие как Mitre, для получения данных об уязвимостях? Некоторые компании дополняют публичные списки собственными исследованиями. Некоторые сканеры делают больше, чем другие, чтобы помочь вам понять, в чем заключается уязвимость и какие части вашего кода зависят от уязвимого компонента.
Некоторые сканеры делают больше, чем другие, чтобы помочь вам понять, в чем заключается уязвимость и какие части вашего кода зависят от уязвимого компонента.Рекомендации
Эти передовые методы помогут вам добиться успеха с любым решением SCA:
Безопасность выигрывает, когда это делают разработчики. Включите SCA на раннем этапе в свой SDLC. Предоставьте командам разработчиков возможность понимать риски и принимать ответственные решения.
Автоматизируйте сканирование SCA в конвейере CI/CD.
Неудачные сборки, содержащие серьезные уязвимости или запрещенные лицензии. Когда все уязвимости высокой степени серьезности будут устранены, рассмотрите возможность блокировки сборки для уязвимостей средней степени опасности.Обратитесь в юридический отдел, чтобы определить, какие лицензии неприемлемы для вашего бизнеса, и установите политики в своем решении SCA для принудительного исполнения этих решений.
Замените любой компонент, который больше не поддерживается его производителем. Сохранение программного обеспечения, которое никогда не будет получать обновления безопасности, опасно.
Убедитесь, что у разработчиков есть способ скрыть результаты сканирования, которые, как показывает исследование, не представляют реальной опасности в вашей среде. Периодически просматривайте набор скрытых результатов.
Убедитесь, что ваш сканер SCA часто обновляет данные о компонентах и уязвимостях.
Установить процесс проверки для принятия новых сторонних компонентов.
Убедитесь, что польза от использования компонента оправдывает любой связанный с ним риск. В процессе следует учитывать такие показатели риска, как надежность производителя, частота обновлений, история уязвимостей и усилия, необходимые для исправления.
 Неудачные сборки, содержащие серьезные уязвимости или запрещенные лицензии. Когда все уязвимости высокой степени серьезности будут устранены, рассмотрите возможность блокировки сборки для уязвимостей средней степени опасности.
Неудачные сборки, содержащие серьезные уязвимости или запрещенные лицензии. Когда все уязвимости высокой степени серьезности будут устранены, рассмотрите возможность блокировки сборки для уязвимостей средней степени опасности. Убедитесь, что польза от использования компонента оправдывает любой связанный с ним риск. В процессе следует учитывать такие показатели риска, как надежность производителя, частота обновлений, история уязвимостей и усилия, необходимые для исправления.
Убедитесь, что польза от использования компонента оправдывает любой связанный с ним риск. В процессе следует учитывать такие показатели риска, как надежность производителя, частота обновлений, история уязвимостей и усилия, необходимые для исправления.Дополнительная информация
OWASP — всегда отличный источник информации о безопасности приложений — содержит статью об анализе компонентов, в которой перечислены дополнительные сканеры SCA и указаны другие ресурсы. OWASP также спонсирует два собственных проекта с открытым исходным кодом, направленных на управление рисками от сторонних компонентов.
Заключение
Анализ состава программного обеспечения является стандартной, фундаментальной частью любого безопасного жизненного цикла разработки. Надежный конвейер CI/CD должен включать SCA, а также сканеры SAST и DAST. Раннее обнаружение проблем снижает затраты, повышает гибкость, делает программное обеспечение более безопасным и помогает разработчикам научиться включать безопасность в свои решения по планированию и проектированию.
Брайан Майерс | 26 мая 2021 г.
Нечеткий поиск — Когнитивный поиск Azure
- Статья
- 6 минут на чтение
Когнитивный поиск Azure поддерживает нечеткий поиск, тип запроса, который компенсирует опечатки и термины с ошибками во входной строке. Он делает это путем сканирования терминов, имеющих аналогичный состав. Расширение поиска, чтобы охватить почти совпадения, приводит к автоматическому исправлению опечатки, когда расхождение составляет всего несколько неуместных символов.
Что такое нечеткий поиск?
Это упражнение по расширению запроса, которое производит сопоставление терминов, имеющих сходный состав. Когда указан нечеткий поиск, поисковая система строит граф (на основе детерминированной теории конечных автоматов) терминов, составленных аналогичным образом, для всех терминов в запросе целиком. Например, если ваш запрос включает три термина «университет Вашингтона», диаграмма создается для каждого термина в запросе
Например, если ваш запрос включает три термина «университет Вашингтона», диаграмма создается для каждого термина в запросе search=university~ of~ вашингтон~ (в нечетком поиске стоп-слова не удаляются, поэтому «of» получается график).
График содержит до 50 расширений или перестановок каждого термина, фиксируя в процессе как правильные, так и неправильные варианты. Затем движок возвращает самые релевантные совпадения в ответе.
Для такого термина, как «университет», на графике может быть «университет, университет, университет, вселенная, инверсия». Любые документы, совпадающие с документами на графике, включаются в результаты. В отличие от других запросов, которые анализируют текст для обработки разных форм одного и того же слова («мыши» и «мышь»), сравнения в нечетком запросе принимаются за чистую монету без какого-либо лингвистического анализа текста. «Вселенная» и «инверсия», семантически разные, будут совпадать, потому что синтаксические расхождения невелики.
Совпадение считается успешным, если расхождения ограничены двумя или менее правками, где правкой является вставка, удаление, замена или транспонирование символа. Алгоритм коррекции строки, определяющий дифференциал, представляет собой метрику расстояния Дамерау-Левенштейна. Он описывается как «минимальное количество операций (вставок, удалений, замен или перемещений двух соседних символов), необходимых для замены одного слова другим».
В когнитивном поиске Azure:
Нечеткий запрос применяется к целым терминам, но вы можете поддерживать фразы с помощью конструкций AND. Например, «Университет~ из~ «Вшингтон~» будет соответствовать «Университету Вашингтона».
Расстояние редактирования по умолчанию равно 2. Значение
~ 0означает отсутствие расширения (совпадением считается только точный термин), но вы можете указать~ 1для одной степени различия или одного редактирования.Нечеткий запрос может расширить термин до 50 перестановок.
Это ограничение не настраивается, но вы можете эффективно уменьшить количество расширений, уменьшив расстояние редактирования до 1.Ответы состоят из документов, содержащих релевантное совпадение (до 50).
 Это ограничение не настраивается, но вы можете эффективно уменьшить количество расширений, уменьшив расстояние редактирования до 1.
Это ограничение не настраивается, но вы можете эффективно уменьшить количество расширений, уменьшив расстояние редактирования до 1.При обработке запроса нечеткие запросы не подвергаются лексическому анализу. Входные данные запроса добавляются непосредственно в дерево запросов и расширяются для создания графа терминов. Единственная трансформация — это нижний кожух.
В совокупности графики представляются как критерии соответствия маркерам в индексе. Как вы понимаете, нечеткий поиск по своей природе медленнее, чем другие формы запросов. Размер и сложность вашего индекса могут определить, достаточно ли преимуществ, чтобы компенсировать задержку ответа.
Примечание
Поскольку нечеткий поиск имеет тенденцию быть медленным, возможно, стоит изучить альтернативы, такие как индексирование n-грамм с его последовательностью коротких последовательностей символов (двух- и трехсимвольные последовательности для токенов биграмм и триграмм). В зависимости от вашего языка и поверхности запроса, n-gram может дать вам лучшую производительность. Компромисс заключается в том, что индексирование n-грамм требует очень много места для хранения и создает гораздо большие индексы.
В зависимости от вашего языка и поверхности запроса, n-gram может дать вам лучшую производительность. Компромисс заключается в том, что индексирование n-грамм требует очень много места для хранения и создает гораздо большие индексы.
Другой альтернативой, которую вы могли бы рассмотреть, если хотите обрабатывать только самые вопиющие случаи, была бы карта синонимов. Например, сопоставление «поиск» с «поиск, поиск, поиск» или «извлечение» с «извлечение».
Индексирование для нечеткого поиска
Строковые поля, которые атрибутированы как «доступные для поиска», являются кандидатами для нечеткого поиска.
Анализаторы не используются для создания графа расширения, но это не означает, что анализаторы следует игнорировать в сценариях нечеткого поиска. Анализаторы важны для токенизации во время индексации, когда токены в инвертированных индексах используются для сопоставления с графом.
Как всегда, если тестовые запросы не дают ожидаемых совпадений, поэкспериментируйте с другими анализаторами индексации. Например, попробуйте языковой анализатор, чтобы увидеть, получите ли вы лучшие результаты. Некоторым языкам, особенно языкам с мутациями гласных, могут быть полезны интонации и неправильные формы слов, генерируемые процессорами естественного языка Майкрософт. В некоторых случаях использование правильного языкового анализатора может повлиять на то, будет ли термин токенизирован таким образом, чтобы он был совместим со значением, предоставленным пользователем.
Например, попробуйте языковой анализатор, чтобы увидеть, получите ли вы лучшие результаты. Некоторым языкам, особенно языкам с мутациями гласных, могут быть полезны интонации и неправильные формы слов, генерируемые процессорами естественного языка Майкрософт. В некоторых случаях использование правильного языкового анализатора может повлиять на то, будет ли термин токенизирован таким образом, чтобы он был совместим со значением, предоставленным пользователем.
Как вызвать нечеткий поиск
Нечеткие запросы создаются с использованием полного синтаксиса запросов Lucene, с использованием полного синтаксического анализатора запросов Lucene и добавлением символа тильды ~ после каждого термина, введенного пользователем.
Вот пример запроса, который вызывает нечеткий поиск. Он включает четыре условия, два из которых написаны с ошибками:
POST https://[имя службы].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2020-06-30.
{
"search": "сиэтл~ набережная~ вид~ отель~",
"тип запроса": "полный",
"Режим поиска": "любой",
"searchFields": "Название отеля, Описание",
"select": "Название отеля, Описание, Адрес/Город,",
"количество": "правда"
}
Установите для типа запроса полный синтаксис Lucene (
queryType=full).Укажите строку запроса, в которой за каждым термином следует оператор тильды (
~) в конце каждого термина целиком (search=). Граф расширения будет создан для каждого термина во входных данных запроса.~ Включите необязательный параметр, число от 0 до 2 (по умолчанию), если вы хотите указать расстояние редактирования (
~1). Например, «синий~» или «синий~1» вернет «синий», «синий» и «клей».

При необходимости вы можете повысить производительность запроса, настроив запрос на определенные поля. Используйте параметр searchFields , чтобы указать поля для поиска. Вы также можете использовать свойство select , чтобы указать, какие поля возвращаются в ответе на запрос.
Тестирование нечеткого поиска
Для простого тестирования мы рекомендуем Search Explorer или Postman для повторения выражения запроса. Оба инструмента являются интерактивными, что означает, что вы можете быстро просмотреть несколько вариантов термина и оценить полученные ответы.
Когда результаты неоднозначны, выделение совпадений может помочь вам найти совпадение в ответе.
Примечание
Использование выделения совпадений для выявления нечетких совпадений имеет ограничения и работает только для базового нечеткого поиска. Если в вашем индексе есть профили оценки или если вы наслаиваете запрос с большим количеством синтаксиса, выделение совпадений может не определить совпадение.
Пример 1: нечеткий поиск с точным термином
Предположим, что в «Описании» существует следующая строка 9Поле 0233 в документе поиска: «Тестовые запросы со специальными символами, а также строки для MSFT, SQL и Java».
Начните с нечеткого поиска по «специальному» и добавьте выделение совпадений в поле «Описание»:
search=special~&highlight=Description
В ответе, поскольку вы добавили выделение совпадений, форматирование применяется к "специальному" как к соответствующему термину.
"@search.
 highlights": {
"Описание": [
«Тестовые запросы с специальными символами, а также строками для MSFT, SQL и Java».
]
highlights": {
"Описание": [
«Тестовые запросы с специальными символами, а также строками для MSFT, SQL и Java».
]
Повторите запрос, написав с ошибкой слово «специальный», убрав несколько букв («pe»):
search=scial~&highlight=Description
Пока никаких изменений в ответе. Используя расстояние по умолчанию в 2 градуса, удаление двух символов «pe» из «специального» по-прежнему позволяет успешно сопоставить этот термин.
"@search.highlights": {
"Описание": [
«Тестовые запросы с специальными символами, а также строками для MSFT, SQL и Java».
]
Попытка еще одного запроса, дальнейшее изменение поискового запроса, удаление одного последнего символа в общей сложности трех удалений (от «специального» до «масштабного»):
search=scal~&highlight=Description
Обратите внимание, что возвращается тот же ответ, но теперь вместо "специального" совпадения нечеткое совпадение находится в "SQL".
"@search.score": 0,4232868,
"@search.highlights": {
"Описание": [
"Сочетание специальных символов и строк для MSFT, SQL, 2019 г., Линукс, Ява».
]
Смысл этого расширенного примера в том, чтобы проиллюстрировать ясность, которую выделение совпадений может привести к неоднозначным результатам. Во всех случаях возвращается один и тот же документ. Если бы вы полагались на идентификаторы документов для проверки соответствия, вы могли бы пропустить переход от «специального» к «SQL».
См. также
- Как работает полнотекстовый поиск в Azure Cognitive Search (архитектура синтаксического анализа запросов)
- Проводник поиска
- Как сделать запрос в .NET
- Как сделать запрос в REST
КОД 128 и GS1-128 | Основы штрих-кодов | Информация о штрих-коде и советы
В мире существует около 100 видов штрих-кодов. Ниже представлено введение в штрих-коды CODE128 и GS1-128.
- КОД 128
- ГС1-128
CODE 128 — это штрих-код, разработанный Computer Identics Corporation (США) в 1981.
CODE 128 может представлять все 128 символов кода ASCII (цифры, прописные/строчные буквы, символы и управляющие коды). Поскольку он может представлять все символы (кроме японских кандзи, хираганы и катаканы), которые можно использовать с клавиатурой компьютера, этот штрих-код удобен для компьютера.
Основной состав следующий:
- А
- Стартовый код
- Б
- Контрольная цифра (Модуль 103)
- С
- Код остановки
- Существует 4 размера стержня.
- Один символ представлен 3 штрихами и 3 пробелами (всего шесть элементов).
- Начальный символ имеет три типа; «КОД-А», «КОД-В» и «КОД-С». Тип начального символа определяет состав последующих символов. (См. здесь таблицу состава символов. Например, когда CODE A используется в качестве начального символа, могут быть представлены символы в столбце CODE-A.)
 (См. здесь таблицу состава символов. Например, когда CODE A используется в качестве начального символа, могут быть представлены символы в столбце CODE-A.)
(См. здесь таблицу состава символов. Например, когда CODE A используется в качестве начального символа, могут быть представлены символы в столбце CODE-A.)- А
- Начните с кода C
- Б
- Изменить на КОД-А
- При использовании кода CODE-C двузначные числа могут быть представлены одним типом штрихового рисунка. Это обеспечивает очень высокую плотность данных.
- Когда используются символы набора кодов (КОД-A, КОД-B и КОД-C), штрих-код, начинающийся с начального символа КОДА-A, можно изменить, чтобы использовать символы в столбце КОД-B или КОД-C в середина обработки штрих-кода.
- При использовании "SHIFT" только один символ рядом с SHIFT может быть заменен на символ в следующем столбце (A на B, B на C, C на A). (Аналогично действию клавиши SHIFT на клавиатуре компьютера)
- «Модуль 103» используется как контрольная цифра.
Скачать
| Цифровой значение | КОД А | КОД В | КОД С | Стержневой узор |
|---|---|---|---|---|
| 0 | СП | СП | 00 | |
| 1 | ! | ! | 01 | |
| 2 | " | " | 02 | |
| 3 | # | # | 03 | |
| 4 | $ | $ | 04 | |
| 5 | % | % | 05 | |
| 6 | и | и | 06 | |
| 7 | ' | ' | 07 | |
| 8 | ( | ( | 08 | |
| 9 | ) | ) | 09 | |
| 10 | * | * | 10 | |
| 11 | + | + | 11 | |
| 12 | , | , | 12 | |
| 13 | - | - | 13 | |
| 14 | . | . | 14 | |
| 15 | / | / | 15 | |
| 16 | 0 | 0 | 16 | |
| 17 | 1 | 1 | 17 | |
| 18 | 2 | 2 | 18 | |
| 19 | 3 | 3 | 19 | |
| 20 | 4 | 4 | 20 | |
| 21 | 5 | 5 | 21 | |
| 22 | 6 | 6 | 22 | |
| 23 | 7 | 7 | 23 | |
| 24 | 8 | 8 | 24 | |
| 25 | 9 | 9 | 25 | |
| 26 | : | : | 26 | |
| 27 | ; | ; | 27 | |
| 28 | < | < | 28 | |
| 29 | = | = | 29 | |
| 30 | > | > | 30 | |
| 31 | ? | ? | 31 | |
| 32 | @ | @ | 32 | |
| 33 | А | А | 33 | |
| 34 | Б | Б | 34 | |
| 35 | С | С | 35 | |
| 36 | Д | Д | 36 | |
| 37 | Е | Е | 37 | |
| 38 | Ф | Ф | 38 | |
| 39 | Г | Г | 39 | |
| 40 | Х | Ч | 40 | |
| 41 | я | я | 41 | |
| 42 | Дж | Дж | 42 | |
| 43 | К | К | 43 | |
| 44 | л | л | 44 | |
| 45 | М | М | 45 | |
| 46 | Н | Н | 46 | |
| 47 | О | О | 47 | |
| 48 | Р | Р | 48 | |
| 49 | В | В | 49 | |
| 50 | Р | Р | 50 | |
| 51 | С | С | 51 | |
| 52 | Т | Т | 52 | |
| 53 | У | У | 53 | |
| 54 | В | В | 54 | |
| 55 | Вт | Вт | 55 | |
| 56 | х | х | 56 | |
| 57 | Д | Д | 57 | |
| 58 | З | З | 58 | |
| 59 | [ | [ | 59 | |
| 60 | \ | \ | 60 | |
| 61 | ] | ] 9 | 62 | |
| 63 | _ | _ | 63 | |
| 64 | НУЛ | 〝 | 64 | |
| 65 | СОХ | и | 65 | |
| 66 | СТХ | б | 66 | |
| 67 | ЕТХ | в | 67 | |
| 68 | ЕОТ | д | 68 | |
| 69 | ENQ | и | 69 | |
| 70 | ПОДТВЕРЖДЕНИЕ | ф | 70 | |
| 71 | бел | г | 71 | |
| 72 | БС | ч | 72 | |
| 73 | НТ | я | 73 | |
| 74 | ЛФ | и | 74 | |
| 75 | ВТ | к | 75 | |
| 76 | ФФ | л | 76 | |
| 77 | КР | м | 77 | |
| 78 | СО | и | 78 | |
| 79 | СИ | или | 79 | |
| 80 | ДЛЭ | р | 80 | |
| 81 | ДС1 | д | 81 | |
| 82 | ДС2 | р | 82 | |
| 83 | DC3 | с | 83 | |
| 84 | ДС4 | т | 84 | |
| 85 | НАК | и | 85 | |
| 86 | СИН | против | 86 | |
| 87 | ЭТБ | ш | 87 | |
| 88 | МОЖЕТ | х | 88 | |
| 89 | ЭМ | и | 89 | |
| 90 | SUB | по | 90 | |
| 91 | ЭСК | { | 91 | |
| 92 | ФС | ┘ | 92 | |
| 93 | ГС | } | 93 | |
| 94 | RS | ~ | 94 | |
| 95 | США | ДЕЛ | 95 | |
| 96 | ФНК 3 | ФНК 3 | 96 | |
| 97 | ФНК 2 | ФНК 2 | 97 | |
| 98 | СМЕНА | СМЕНА | 98 | |
| 99 | КОД С | КОД С | 99 | |
| 100 | КОД В | ФНК 4 | КОД В | |
| 101 | ФНК 4 | КОД А | КОД А | |
| 102 | FNC 1 | FNC 1 | FNC 1 | |
| 103 | ПУСК(КОД A) | |||
| 104 | СТАРТ (КОД B) | |||
| 105 | ПУСК(КОД С) | |||
| СТОП | ||||
Скачать
- Штрих-код CODE 128 может включать все 128 символов кода ASCII (включая управляющие коды, такие как [ESC], [STX], [ETX], [CR] и [LF]).
- Когда в качестве начального символа используется CODE-C, одна полоса может представлять собой двузначные числа. Это позволяет очень эффективно составлять штрих-коды. Если данные штрих-кода состоят из 12 или более цифр, CODE 128 обеспечивает меньший размер, чем ITF.
- Поскольку в CODE 128 используются 4 типа размера прутка, требуются принтеры с высоким качеством печати. CODE 128 не подходит для печати на матричных и струйных принтерах FA, а также для флексографской печати на гофрированном картоне.
Скачать
Использование CODE-C в качестве начального кода позволяет CODE 128 обеспечивать штрих-код с очень высокой плотностью данных, если обрабатываются только числа.
GS1-128 использует характеристики CODE 128 и в настоящее время используется во многих промышленных приложениях. При использовании GS1-128 в штрих-код включаются различные данные, такие как дата производства продукта, дата открытия, вес, размер, номер партии, пункт назначения, счет клиента и т.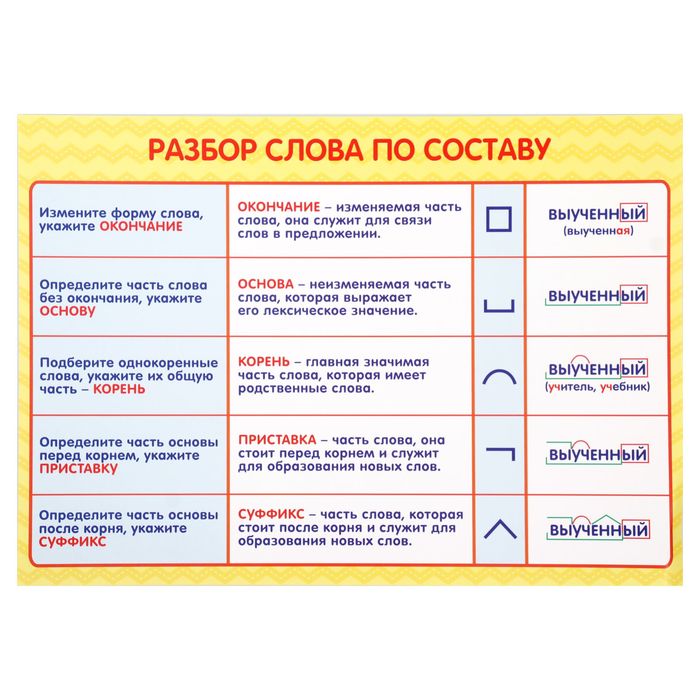 д.
д.
КОД 128 используется в следующих отраслях:
- Швейная промышленность США
- Пищевая промышленность США
- США Производство лекарств и медицинского оборудования
- Пищевая промышленность Австралии и Новой Зеландии
- Европейская фармацевтическая промышленность и производство медицинских инструментов
Скачать
GS1-128 — это штрих-код, который предоставляет различные данные, включая данные о распределении и бизнес-транзакциях, в дополнение к данным, предоставляемым кодом JAN и стандартным кодом распределения (ITF), доступным в настоящее время.
Следующие данные могут быть включены в штрих-код GS1-128:
- Номер упаковки
- Количество в упаковке
- Масса, грузоподъемность и кубатура
- Дата изготовления и подтверждение качества
- Номер лота
- Номер места (пункт назначения)
- Код счета клиента
- Номер заказа клиента
Необходимые данные используются для формирования этикетки со штрих-кодом для различных приложений.
Например, On-line покупка/заказ с использованием EDI (система обмена электронными данными между компаниями), управление открытой датой для продуктов питания, управление сроком годности лекарств, упрощение работы по проверке входящих продуктов, сортировка посылок по каждому пункту назначения и т. д. .. (Следующая этикетка представляет собой образец от производителя продуктов питания.)
- А
- Код изделия
- Б
- Срок действия качества (27 августа 1999 г.)
- С
- Количество поставки
- Д
- Вес нетто
- Э
- Номер лота
- Ф
- Серийный номер
Скачать
Код JAN и стандартный код распределения (ITF) являются штрих-кодами для обозначения самого продукта и его количества, а не для таких данных, как дата производства, номер упаковки, действительность качества и номер заказа.
Хотя CODE 39 позволяет включать такие данные в штрих-код, обмен такими данными между компаниями не допускается, поскольку определение и количество цифр данных различаются.
GS1-128 установлен как всемирный универсальный штрих-код для общего использования, при этом элементы и количество цифр данных, а также тип штрих-кода стандартизированы.
Скачать
Базовый состав ГС1-128 следующий:
- В качестве штрих-кода используется код 128.
- Чтобы разделить необходимые данные, такие как вес и открытые данные, добавляется «идентификатор приложения (AI)», за которым следуют данные. Если представлено несколько данных, все данные должны быть связаны.
- А
- А.И. указать код контейнера доставки
- Б
- А.И. для указания достоверности качества
- С
- А.И. указать объем поставки
Хотя идентификаторы приложений заключены в круглые скобки, они не включаются в данные штрих-кода. Они используются только для презентации.
Они используются только для презентации.
В приведенном выше примере после идентификатора приложения "01" присваивается 14-значный код для идентификации контейнера поставки (минимальная единица упаковки для коробок из гофрокартона). После идентификатора приложения «15» данные, отражающие достоверность качества (действительность потребления или действительность лекарственного средства), указывают на 27 августа 2099 г.5. После последнего идентификатора приложения «30» данные, представляющие количество поставки, приведены для отображения 3 штук.
Существует около 100 идентификаторов приложений, кроме указанных выше. Необходимые данные выбираются и включаются в штрих-коды пользователями.
GS1-128 не предназначен для представления фиксированных данных, но данные выбираются пользователем. Следовательно, для последовательного использования GS1-128 среди компаний стандарты для системы штрих-кода с доступными данными должны быть подготовлены соответствующей отраслью и участвующими группами компаний.
- Чтобы отличить GS1-128 от CODE 128, необходимо указать [FNC 1] (функция 1) после кода запуска (CODE-A до C).
- Даже если количество цифр для данных, следующих за идентификатором приложения, имеет переменную длину, [FNC 1] используется для разделения данных.
- А
- Код запуска C
- Б
- [FNC 1] для сигнала GS1-128
- С
- Данные 1 (фиксированной длины)
- Д
- Данные 2 (переменной длины)
- Э
- [FNC 1] для разделения данных
- Ф
- Данные 3 (переменной длины)
- Г
- Контрольная цифра
- Х
- Код остановки
- После добавления GS1-128 к коду EAN и стандартному коду распределения (ITF) его можно использовать в качестве кода для добавления дополнительных данных.
GS1-128 предназначен для представления идентификаторов приложений и относительных данных о продуктах или данных транзакций компаний, использующих CODE 128.
Другими словами, GS1-128 является стандартом для приложений, представляющих различные данные. CODE 128 является стандартом только для самого штрих-кода. Разница между GS1-128 и CODE 128 заключается в том, представляет ли он приложение или нет.
Поскольку GS1-128 использует состав штрих-кода CODE 128, любой считыватель штрих-кода, который может считывать CODE 128, может использоваться для считывания данных GS1-128.
Скачать
Существует 100 типов идентификаторов приложений, которые можно классифицировать следующим образом. Некоторые данные, следующие за каждым идентификатором приложения, имеют фиксированное количество цифр (стандартный идентификатор коробки, дата и единица измерения), в то время как другие имеют неопределенное количество цифр (номер партии, серийный номер, количество в упаковке, количество и номер заказа). ).
| Классификация | Контент | Идентификатор приложения |
|---|---|---|
| Тип упаковки |
| 00 "Стандартный идентификатор коробки" |
| Управление продуктами |
| 01 «Код контейнера доставки» |
| 20 | |
| 11~17 | |
| 10 | |
| 21 | |
| Индикатор измерения |
| 310~369 |
| Администрация |
| 400 |
| 401 | |
| 410~421 | |
| 90~99 |

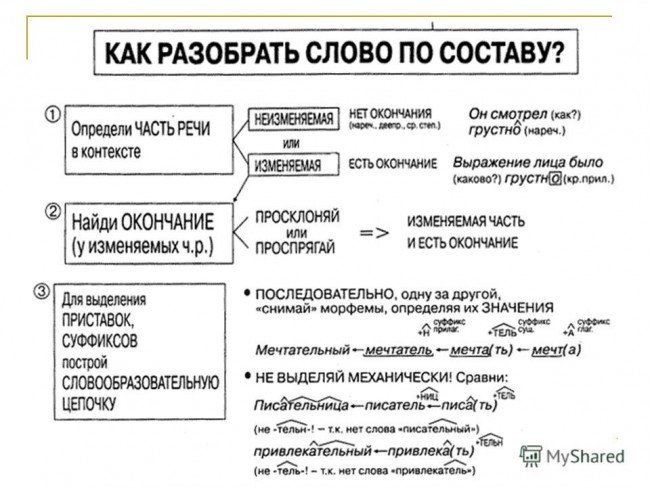
| Идентификатор приложения | Контент | Число цифр данных |
|---|---|---|
| 00 | Стандартная коробка ID | Числа с 18 цифрами |
"00" - это идентификатор, который дает серийный номер упаковки каждой коробке из гофрокартона и поддону для доставки. Поэтому каждой доставке присваивается разный номер.
Поэтому каждой доставке присваивается разный номер.
Данные состоят из 18 цифр следующего состава:
| Тип упаковки | 1 цифра |
| Универсальный код компании | 7 цифр |
| Серийный номер упаковки для каждой поставки | 9 цифр |
| Контрольная цифра (модуль 10/3 веса) | 1 цифра |
"Тип упаковки" выглядит следующим образом:
| Тип упаковки | |
|---|---|
| 0 | Футляр или коробка |
| 1 | Поддон (больше коробки и коробки) |
| 2 | Контейнер (больше поддона) |
| 3 | Любой тип упаковки, кроме указанного выше |
| 4 | По внутренним требованиям (для внутреннего пользования) |
| 5 | По взаимным требованиям заинтересованных компаний |
| 6~9 | Использование запрещено |
«Универсальный код компании» обозначается «код страны» + «код производителя» для компаний, зарегистрировавших JAN. Для компаний, которые не зарегистрировали JAN, необходимо получить универсальный код бизнес-счета.
Для компаний, которые не зарегистрировали JAN, необходимо получить универсальный код бизнес-счета.
«Стандартный идентификатор коробки» в Европе и Америке называется SSCC-18 (код серийного транспортного контейнера).
| Идентификатор приложения | Контент | Число цифр данных |
|---|---|---|
| 01 | Код контейнера доставки | Номера с 14 цифрами |
Тот же состав стандартного кода распределения (ITF) обычно применяется к «01». Он состоит из кода EAN упакованного продукта и индикатора упаковки, указывающего количество продукта.
| Индикатор упаковки | 1 цифра |
| Код EAN | 12 цифр |
| Контрольная цифра (Модуль 10/3 веса) | 1 цифра |
«Индикатор упаковки» выглядит следующим образом:
| Индикатор упаковки | |
|---|---|
| 0 | Коробки из гофрированного картона, содержащие смешанные продукты |
| 1~8 | Коробка из гофрированного картона для одного предмета в одинаковом количестве. Настройка в диапазоне от 1 до 8. Во многих случаях устанавливается 1. Настройка в диапазоне от 1 до 8. Во многих случаях устанавливается 1. |
| 9 | Коробка из гофрированного картона, содержащая разное количество для одной позиции |
Поскольку «код контейнера доставки» имеет тот же состав данных, что и код EAN и код стандартной дистрибуции, его можно использовать только при условии, что коды EAN и стандартной дистрибуции не печатаются на коробках из гофрокартона.
«Код контейнера доставки» называется SCC-14 (код контейнера доставки) в Европе и Америке.
- А
- Идентификатор (01 — код контейнера доставки.)
- Б
- Код контейнера доставки
- С
- Идентификатор (17 означает действительность для продажи.)
- Д
- Срок действия для продажи (30 августа 1998 г.)
- Э
- Идентификатор (10 — номер партии)
- Ф
- Номер партии
| Идентификатор приложения | Контент | Формат |
|---|---|---|
| 10 | Номер партии или номер партии | В пределах 20 буквенно-цифровых символов |
«10» — идентификатор приложения для указания номера партии и номера партии продукта. Доступно 20 буквенно-цифровых символов (переменной длины) или менее.
Доступно 20 буквенно-цифровых символов (переменной длины) или менее.
| Идентификатор приложения | Контент | Формат |
|---|---|---|
| 11 | Дата изготовления (ГГММДД) | Числа с 6 цифрами |
| 13 | Дата упаковки (ГГММДД) | Числа с 6 цифрами |
| 15 | Срок действия качества (ГГММДД) | Числа с 6 цифрами |
| 17 | Срок действия для продажи (ГГММДД) | Числа с 6 цифрами |
Указаны данные разных дат.
Для достоверности качества указаны важные данные, необходимые для управления. Например, «дата открытия» пищевых продуктов и «действительность лекарств» лекарств.
Например, «дата открытия» пищевых продуктов и «действительность лекарств» лекарств.
| Идентификатор приложения | Контент | Формат |
|---|---|---|
| 400 | Номер администрации (номер заказа клиента) | В пределах 30 буквенно-цифровых символов |
| 411 | Номер места (счетный код клиента) | Номера с 13 цифрами |
Это идентификаторы приложений для указания административных данных, таких как «номер заказа» клиентов и «код счета клиента».
| Идентификатор приложения | Контент | Формат |
|---|---|---|
| 410 | Номер места (код пункта назначения) | Номера с 13 цифрами |
| 420 | Номер места (почтовый индекс места назначения) | В пределах 9 буквенно-цифровых символов |
Используются для сортировки товаров по местам назначения. «410» — это идентификатор приложения, который позволяет сортировать каждую компанию с используемым кодом компании EAN.
«410» — это идентификатор приложения, который позволяет сортировать каждую компанию с используемым кодом компании EAN.
«420» — это идентификатор приложения, который позволяет выполнять сортировку для каждого пункта назначения доставки с использованием почтовых номеров.
Скачать
Основы штрих-кодов CODE 39 и Codabar
Основы двумерных кодов Индекс
ИНДЕКС
Angular Layout Composition полное руководство
В этой статье мы рассмотрим множество способов компоновки компоновки в angular.
Фото Глена Кэрри на Unsplash
Что такое компоновка макета?
Во многих отношениях планировка и композиция являются строительными блоками дизайна. Они придают вашей работе структуру и упрощают навигацию, от полей по бокам до содержимого между ними. Есть пять основных принципов, которые формируют композицию макета
Они придают вашей работе структуру и упрощают навигацию, от полей по бокам до содержимого между ними. Есть пять основных принципов, которые формируют композицию макета
- Близость
- Пробел
- Выравнивание
- Контраст
- Иерархия
Примечания: Я не буду объяснять здесь каждый принцип, так как это выходит за рамки нашей компетенции, но вы можете прочитать эту замечательную статью для получения дополнительной информации.
Как я могу сделать это в angular?
- Компонент должен отображаться в
{x:0, y:0} - Компонент
:хостстиль должен бытьдисплей: блокПочему это важно? чтобы внешнему компоненту было легко установить поля и ширину, если мы используем компонент внутри другого компонента. - Создавайте крошечные и многоразовые компоненты настолько кашеобразно, насколько это возможно.
Как я могу узнать, должна ли эта часть быть отделена как компонент? Компонент должен делать одно и только одно.

Что такое угловые методы композиции компоновки?
В этом посте рассматриваются различные способы комбинирования, смешивания и смешивания компонентов Angular, в том числе:
- Компоненты Content Projection внутри пользовательского элемента (компонент макета и стиля).
Что такое проецирование контента?
В Angular проекция контента используется для проецирования контента в компоненте (angular.io).
Почему мы его используем?
- Многие компоненты в вашем приложении используют одинаковую структуру и стиль, но отличаются по содержимому, другими словами Возможность повторного использования .
- Вы создаете компонент только для отображения, а другой компонент создан для обработки действий пользователя, другими словами Разделение концерна .
Как я могу его использовать?
Angular использует селекторы css, атрибуты html и элемент html для достижения композиции макета.
Однослотовый
По сути, вы просто добавляете в свой html, и он будет заменен содержимым вне компонента
<нг-контент>Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент>Войти в полноэкранный режимВыйти из полноэкранного режимаКонтент здесь
Многослотовый (Целевая проекция)
ng-contentпринимает атрибутselect, который позволяет нам установить конкретное имя селектора CSS для этого слота.
- Использование элемента(ов)
имя
Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент>Войти в полноэкранный режимВыйти из полноэкранного режимаКонтент для первого слота
Если вы используете его в обычной настройке angular cli, вы столкнетесь с ошибкой, если используете тег сейчас.
Отклонение необработанного обещания: ошибки синтаксического анализа шаблона: «slot-one» не является известным элементом, Angular не распознает тег
slot-one.slot-oneне является ни директивой, ни компонентом
Быстрый способ обойти эту ошибку — добавить свойство метаданных схемы в модуль, установить значение NO_ERRORS_SCHEMA в файле модуля.
// app.module.ts
импортировать {NgModule, NO_ERRORS_SCHEMA} из '@angular/core'; //
импортировать {BrowserModule} из '@angular/platform-browser';
импортировать {AppComponent} из './app.component';
импортировать { ContainerComponent } из './container-component';
@NgModule({
импортирует: [BrowserModule],
объявления: [AppComponent, ContainerComponent],
начальная загрузка: [AppComponent],
схемы: [NO_ERRORS_SCHEMA], // добавить эту строку
})
экспорт класса AppModule {}
Войти в полноэкранный режимВыйти из полноэкранного режима- Использование атрибута(ов)
[имя]|[имя][другое-имя]
Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент>Войти в полноэкранный режимВыйти из полноэкранного режимаКонтент для первого слота
Содержимое второго слота
- Использование атрибута со значением
[name="value"]
Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент>Войти в полноэкранный режимВыйти из полноэкранного режимаКонтент для первого слота
Контент для второго слота
- Использование класса(ов)
.| name .имя.другое-имя
 name
name Войти в полноэкранный режимВыйти из полноэкранного режима
<контейнер-компонент>Войти в полноэкранный режимВыйти из полноэкранного режимаКонтент для первого слота
Контент для первого и второго слота
- Без использования упаковки div
Как вы можете видеть в предыдущем примере, вы можете использовать целевой слот, обернув свой контент div или элементом и присоединив к нему селектор, но в некоторых случаях вы просто хотите поместить его туда.
Использование атрибута angular
ngProjectAsв теге ng-container или любом теге, который вы хотите
Войти в полноэкранный режимВыйти из полноэкранного режима
Войти в полноэкранный режимВыйти из полноэкранного режимаОчень важный текст с тегами. Очень важный текст с тегами.

Внутри
*ngДля // Компонент контейнера
@Составная часть({
...
шаблон: `
<контейнер-компонент [элементы]="данные">Войти в полноэкранный режимВыйти из полноэкранного режима{{ вещь }}
Обучение с помощью документации Python 2nd Edition
2.
 1. Значения и типы данных
1. Значения и типы данныхЗначение — это одна из фундаментальных вещей — как буква или число — которыми манипулирует программа. Значения, которые мы видели до сих пор, равны 2 (значение результат, когда мы добавили 1 + 1), и «Hello, World!».
Эти значения относятся к разным типам данных : 2 является целым числом , а "Привет, мир!" это строка , так называемая, потому что она содержит строку буквы. Вы (и интерпретатор) можете идентифицировать строки, потому что они заключено в кавычки.
Оператор печати также работает для целых чисел.
>>> напечатать 4 4
Если вы не уверены, какой тип имеет значение, интерпретатор может указать ты.
>>> type("Привет, мир!")
<тип 'строка'>
>>> тип(17)
<тип 'целое число'>
Неудивительно, что строки относятся к типу str , а целые числа относятся к типу
введите интервал . Менее очевидно, что числа с десятичной точкой принадлежат к типу
называется с плавающей запятой , потому что эти числа представлены в формате, называемом с плавающей запятой .
>>> тип(3.2) <тип 'плавающий'>
Как насчет таких значений, как "17" и "3,2"? Они похожи на числа, но они заключены в кавычки, как строки.
>>> тип("17")
<тип 'строка'>
>>> тип("3.2")
<тип 'строка'>
Это строки.
Строки в Python могут быть заключены либо в одинарные (‘), либо в двойные кавычки (""):
>>> type('Это строка.')
<тип 'строка'>
>>> type("И это тоже.")
<тип 'строка'>
Строки с двойными кавычками могут содержать внутри одинарные кавычки, как в «борода Брюса», а строки в одинарных кавычках могут иметь двойные кавычки. внутри них, как в «Рыцарях, говорящих «Ни!»».
Когда вы вводите большое целое число, у вас может возникнуть соблазн использовать запятые между группы из трех цифр, например, 1 000 000. Это не допустимое целое число в Python, но легально:
>>> напечатать 1 000 000 1 0 0
Ну, это совсем не то, что мы ожидали! Python интерпретирует 1 000 000 как
список из трех пунктов для печати. Так что не ставьте запятых в
целые числа.
Так что не ставьте запятых в
целые числа.
2.2. Переменные
Одной из самых мощных функций языка программирования является возможность управлять переменными . Переменная — это имя, которое ссылается на значение.
Оператор присваивания создает новые переменные и дает им значения:
>>> message = "Как дела, Док?" >>> n = 17 >>> пи = 3,14159
В этом примере выполняются три назначения. Первый присваивает строку «Что up, Doc?" в новую переменную с именем message. Вторая дает целое число 17 в n, а третий дает число с плавающей запятой 3,14159 в Пи.
Оператор присваивания , =, не следует путать со знаком равенства (хотя он использует тот же символ). Операторы присваивания связывают имя , слева от оператора со значением справа. Вот почему вы получите сообщение об ошибке, если введете:
>>> 17 = n
Обычный способ представить переменные на бумаге — написать имя со стрелкой. указывая на значение переменной. Такая цифра называется состоянием .
диаграмма , потому что она показывает, в каком состоянии находится каждая из переменных (подумайте об этом
как состояние ума переменной). На этой диаграмме показан результат
операторы присваивания:
указывая на значение переменной. Такая цифра называется состоянием .
диаграмма , потому что она показывает, в каком состоянии находится каждая из переменных (подумайте об этом
как состояние ума переменной). На этой диаграмме показан результат
операторы присваивания:
Оператор печати также работает с переменными.
>>> распечатать сообщение Что случилось док? >>> напечатать п 17 >>> напечатать пи 3.14159
В каждом случае результатом является значение переменной. Переменные также имеют виды; опять же, мы можем спросить переводчика, каковы они.
>>> тип(сообщение) <тип 'строка'> >>> тип(н) <тип 'целое число'> >>> тип (пи) <тип 'плавающий'>
Тип переменной — это тип значения, на которое она ссылается.
2.3. Имена переменных и ключевые слова
Программисты обычно выбирают для своих переменных осмысленные имена — они документируют, для чего используется переменная.
Имена переменных могут быть произвольно длинными. Они могут содержать как буквы, так и
цифры, но они должны начинаться с буквы. Хотя законно использовать
заглавные буквы, по соглашению мы этого не делаем. Если вы это сделаете, помните тот случай
имеет значение. Брюс и Брюс - разные переменные.
Они могут содержать как буквы, так и
цифры, но они должны начинаться с буквы. Хотя законно использовать
заглавные буквы, по соглашению мы этого не делаем. Если вы это сделаете, помните тот случай
имеет значение. Брюс и Брюс - разные переменные.
Символ подчеркивания (_) может появляться в имени. Он часто используется в названия, состоящие из нескольких слов, например my_name или price_of_tea_in_china.
Если вы дадите переменной недопустимое имя, вы получите синтаксическую ошибку:
>>> 76trombones = "большой парад" SyntaxError: неверный синтаксис >>> больше$ = 1000000 SyntaxError: неверный синтаксис >>> класс = "Информатика 101" SyntaxError: неверный синтаксис
76trombones является незаконным, потому что не начинается с буквы. больше$ является недопустимым, поскольку содержит недопустимый символ, знак доллара. Но что не так с классом?
Оказывается, этот класс является одним из Python ключевых слов . Ключевые слова определяют
правила и структура языка, и их нельзя использовать в качестве имен переменных.
Python имеет тридцать одно ключевое слово:
| и | как | утверждать | перерыв | класс | продолжить |
| по умолчанию | дел | Элиф | еще | кроме | исполнитель |
| наконец | для | из | глобальный | если | импорт |
| в | это | лямбда | не | или | пройти |
| печать | поднять | вернуть | попробовать | , а | с |
| выход |
Возможно, вы захотите держать этот список под рукой. Если переводчик жалуется на один
ваших имен переменных, и вы не знаете почему, посмотрите, есть ли они в этом списке.
2.5. Вычисление выражений
Выражение представляет собой комбинацию значений, переменных и операторов. если ты введите выражение в командной строке, интерпретатор вычислит его и отображает результат:
>>> 1 + 1 2
вычисление выражения выдает значение, поэтому выражения может появляться в правой части операторов присваивания. Значение по всем само по себе является простым выражением, как и переменная.
>>> 17 17 >>> х 2
Как ни странно, вычисление выражения — это не совсем то же самое, что печать ценность.
>>> message = "Как дела, Док?" >>> сообщение "Что случилось док?" >>> распечатать сообщение Что случилось док?
Когда оболочка Python отображает значение выражения, она использует тот же
формат, который вы использовали бы для ввода значения. В случае строк это означает, что
он включает кавычки. Но оператор печати печатает значение
выражение, которое в данном случае является содержимым строки.
В скрипте выражение само по себе является допустимым утверждением, но оно не Делать что-нибудь. Скрипт
17 3.2 "Привет, мир!" 1 + 1
вообще не выводит. Как бы вы изменили сценарий для отображения значения этих четырех выражений?
2.6. Операторы и операнды
Операторы — это специальные символы, которые представляют такие вычисления, как сложение и умножение. Используемые оператором значения называются операндами .
Ниже приведены все допустимые выражения Python, смысл которых более или менее очистить:
20+32 час-1 час*60+минута минута/60 5**2 (5+9)*(15-7)
Символы +, - и /, а также использование скобок для группировки, означают в Python то, что они означают в математике. Звездочка (*) означает знак умножения, а ** — знак возведения в степень.
Когда вместо операнда появляется имя переменной, оно заменяется на его значение до выполнения операции.
Сложение, вычитание, умножение и возведение в степень делают то, что вы
ожидать, но вы можете быть удивлены разделением. Следующая операция имеет
неожиданный результат:
Следующая операция имеет
неожиданный результат:
>>> минута = 59 >>> минут/60 0
Значение минуты равно 59, а 59, деленное на 60, равно 0,98333, а не 0. причина несоответствия в том, что Python выполняет целочисленное деление .
Если оба операнда являются целыми числами, результат также должен быть целым числом, и по соглашению целочисленное деление всегда округляет до против , даже в таких случаях где следующее целое число очень близко.
Возможным решением этой проблемы является вычисление процента, а не дробь:
>>> минут*100/60 98
Опять результат округляется в меньшую сторону, но хоть теперь ответ примерно правильный. Другой альтернативой является использование деления с плавающей запятой. мы увидим в глава 4, как преобразовать целые значения и переменные в числа с плавающей запятой ценности.
2.7. Порядок операций
Если в выражении встречается более одного оператора, порядок вычисления
зависит от правил приоритета . Python следует тому же приоритету
правила для своих математических операторов, которые делает математика. Аббревиатура ПЕМДАС
это полезный способ запомнить порядок операций:
Python следует тому же приоритету
правила для своих математических операторов, которые делает математика. Аббревиатура ПЕМДАС
это полезный способ запомнить порядок операций:
- P арензы имеют наивысший приоритет и могут использоваться для форсирования выражение для оценки в том порядке, в котором вы хотите. Поскольку выражения в скобки оцениваются первыми, 2 * (3-1) равно 4, а (1+1)**(5-2) равно 8. Вы также можете использовать круглые скобки, чтобы упростить чтение выражения, как в (минуты * 100) / 60, хотя это не меняет результат.
- E Возведение в степень имеет следующий наивысший приоритет, поэтому 2**1+1 равно 3 и не 4, а 3*1**3 равно 3, а не 27.
- M умножение и D ivision имеют одинаковый приоритет, т.е.
выше, чем A дополнение и S удаление, которые также имеют то же самое
приоритет. Таким образом, 2 * 3-1 дает 5, а не 4, а 2/3-1 равно -1, а не 1. (помните, что при целочисленном делении 2/3=0).
- Операторы с одинаковым приоритетом оцениваются слева направо. Итак, в выражение minute*100/60, сначала происходит умножение, что дает 5900/60, что, в свою очередь, дает 98. Если бы операции оценивались из справа налево, результатом было бы 59*1, то есть 59, то есть неправильный.
 (помните, что при целочисленном делении 2/3=0).
(помните, что при целочисленном делении 2/3=0).2.8. Операции со строками
В общем случае нельзя выполнять математические операции со строками, даже если строки выглядят как числа. Следующее является незаконным (при условии, что сообщение имеет строку типа):
сообщение-1 "Привет"/123 сообщение*"Привет" "15"+2
Интересно, что оператор + работает со строками, хотя и не делать именно то, что вы могли бы ожидать. Для строк оператор + представляет конкатенация , что означает объединение двух операндов путем их связывания концы с концами. Например:
фрукты = "банан" Baked_good = "ореховый хлеб" распечатать фрукты + запеченное_хорошее
Результатом этой программы является бананово-ореховый хлеб. Пробел перед словом
гайка является частью струны и необходима для создания пространства между
объединенные строки.
Пробел перед словом
гайка является частью струны и необходима для создания пространства между
объединенные строки.
Оператор * также работает со строками; он выполняет повторение. Например, «Веселье»*3 — это «Веселье, веселье». Один из операндов должен быть строкой; в другое должно быть целым числом.
С одной стороны, такая интерпретация + и * имеет смысл по аналогии с сложение и умножение. Так как 4*3 эквивалентно 4+4+4, мы ожидайте, что "Веселье"*3 будет таким же, как "Веселье"+"Веселье"+"Веселье", и это так. На с другой стороны, существует важный способ, которым конкатенация строк и повторение отличается от целочисленного сложения и умножения. Не могли бы вы подумайте о свойстве, что сложение и умножение имеют эту строку конкатенация и повторение не делают?
2.9. Вход
В Python есть две встроенные функции для получения ввода с клавиатуры:
n = raw_input("Пожалуйста, введите ваше имя:")
напечатать п
n = input("Введите числовое выражение:")
напечатать п
Пример запуска этого скрипта будет выглядеть примерно так:
$ python tryinput.
 py
Пожалуйста, введите ваше имя: Артур, король бриттов
Артур, король бриттов
Введите числовое выражение: 7 * 3
21
py
Пожалуйста, введите ваше имя: Артур, король бриттов
Артур, король бриттов
Введите числовое выражение: 7 * 3
21
Каждая из этих функций позволяет выдать подсказку функции между скобки.
2.10. Композиция
До сих пор мы рассматривали элементы программы — переменные, выражения, и утверждения — по отдельности, не говоря о том, как их сочетать.
Одной из наиболее полезных особенностей языков программирования является их способность возьмите небольшие строительные блоки и составьте из них . Например, мы знаем, как добавляем цифры и умеем печатать; оказывается, мы можем делать и то, и другое одновременно время:
>>> напечатать 17 + 3 20
На самом деле добавление должно произойти до печати, поэтому действия на самом деле происходят не одновременно. Дело в том, что любое выражение включая числа, строки и переменные, могут использоваться внутри оператора печати. Вы уже видели пример этого:
print "Количество минут с полуночи: ", час*60+минута
Вы также можете помещать произвольные выражения в правую часть присваивания оператор:
процент = (минута * 100) / 60
Сейчас эта способность может показаться не впечатляющей, но вы увидите другие примеры, когда
композиция позволяет четко и понятно выражать сложные вычисления. кратко.
кратко.
Предупреждение. Существуют ограничения на использование определенных выражений. За Например, левая часть оператора присваивания должна быть имя переменной , а не выражение. Итак, незаконно следующее: минута+1 = час.
2.12. Глоссарий
- оператор присваивания
- = оператор присваивания Python, который не следует путать с математическим оператором сравнения, использующим тот же символ.
- оператор присваивания
Оператор, который присваивает значение имени (переменной). Слева от оператор присваивания = является именем. Справа от оператор присваивания — это выражение, которое оценивается Python интерпретатор, а затем присвоено имя. Разница между левая и правая части оператора присваивания часто сбивает с толку новых программистов. В следующем задании:
н = н + 1
n играет совершенно разную роль по обе стороны от =. На справа это значение и составляет часть выражения , которое будет быть оценен интерпретатором Python перед тем, как присвоить его имени налево.
- Информация в программе, предназначенная для других программистов (или кого-либо другого). чтение исходного кода) и не влияет на выполнение программа.
- композиция
- Возможность объединять простые выражения и операторы в составные операторы и выражения для представления сложных вычислений кратко.
- объединить
- Чтобы соединить две строки встык.
- тип данных
- Набор значений. Тип значения определяет, как его можно использовать в выражения. До сих пор типы, которые вы видели, были целыми числами (тип int), числа с плавающей запятой (тип float) и строки (тип ул).
- оценить
- Чтобы упростить выражение, выполняя операции, чтобы дают одно значение.
- выражение
- Комбинация переменных, операторов и значений, представляющая единственное значение результата.
- поплавок
- Тип данных Python, в котором хранится чисел с плавающей запятой.
Числа с плавающей запятой хранятся внутри в двух частях: , базовая и
показатель степени . При печати в стандартном формате они выглядят как
десятичные числа. Остерегайтесь ошибок округления при использовании чисел с плавающей запятой.
и помните, что это только приблизительные значения.
- между
- Тип данных Python, содержащий положительные и отрицательные целые числа.
- целочисленное деление
- Операция деления одного целого числа на другое с получением целого числа. Целочисленное деление дает только целое число раз, которое числитель делится на знаменатель и отбрасывает любой остаток.
- ключевое слово
- Зарезервированное слово, используемое компилятором для разбора программы; ты нельзя использовать ключевые слова вроде if, def и while в качестве переменной имена.
- операнд
- Одно из значений, над которым работает оператор.
- оператор
- Специальный символ, представляющий простое вычисление, такое как сложение, умножение или конкатенация строк.
- правила приоритета
- Набор правил, регулирующих порядок, в котором выражения, включающие
оцениваются несколько операторов и операндов.
- диаграмма состояний
- Графическое представление набора переменных и значений для которые они ссылаются.
- выписка
- Инструкция, которую может выполнить интерпретатор Python. Примеры Операторы включают оператор присваивания и оператор печати.
- ул
- Тип данных Python, содержащий строку символов.
- значение
- Число или строка (или другие элементы, которые будут названы позже), которые можно хранится в переменной или вычисляется в выражении.
- переменная
- Имя, ссылающееся на значение.
- имя переменной
- Имя переменной. Имена переменных в Python состоят из последовательность букв (a..z, A..Z и _) и цифр (0..9), которая начинается с письмом. В передовой практике программирования имена переменных должны быть выбраны так, чтобы они описывали их использование в программе, делая программа самодокументирование .
 При печати в стандартном формате они выглядят как
десятичные числа. Остерегайтесь ошибок округления при использовании чисел с плавающей запятой.
и помните, что это только приблизительные значения.
При печати в стандартном формате они выглядят как
десятичные числа. Остерегайтесь ошибок округления при использовании чисел с плавающей запятой.
и помните, что это только приблизительные значения.
2.13. Упражнения
Запишите, что происходит, когда вы печатаете оператор присваивания:
>>> вывести n = 7
Как насчет этого?
>>> напечатать 7 + 5
Или это?
>>> print 5.
2, "это", 4 - 2, "то", 5/2.0
Можете ли вы придумать общее правило для того, что может следовать за печатью? утверждение? Что возвращает оператор печати?
Возьми предложение: Только работа и отсутствие развлечений делают Джека скучным мальчиком. Сохраните каждое слово в отдельной переменной, затем распечатайте предложение на одну строку с помощью печати.
Добавьте скобки к выражению 6 * 1 - 2, чтобы изменить его значение от 4 до -6.
Поместите комментарий перед строкой кода, которая ранее работала, и запишите, что происходит, когда вы перезапускаете программу.
Разница между input и raw_input заключается в том, что input оценивает входную строку, а raw_input — нет. Попробуйте следующее в интерпретаторе и запишите, что происходит:
>>> х = ввод() 3.14 >>> тип(х)
>>> х = raw_input() 3.14 >>> тип(х)
>>> х = ввод() «Рыцари, которые говорят «ни!» >>> х
Что произойдет, если вы попробуете пример выше без кавычек?
>>> х = ввод() Рыцари, говорящие «ни!» >>> х
>>> х = raw_input() «Рыцари, которые говорят «ни!» >>> х
Опишите и объясните каждый результат.
 2, "это", 4 - 2, "то", 5/2.0
2, "это", 4 - 2, "то", 5/2.0