Состав слова — Русский язык без проблем
Найти:вернуться на главную, на стр. “Морфемика в таблицах“, “Морфемный разбор”
основа — это часть слова, которая выражает его лексическое значение.
корень слова — общая часть родственных слов
аффикс — общее название всех значимых частей слова, за исключением корня.
приставки, или префиксы, — части слова, стоящие перед корнем
суффиксы — части слова, стоящие между корнем и окончанием
постфикс (в применении к аффиксу -ся, -сь)
окончание, или флексия, — это изменяемая часть слова, которая является средством выражения синтаксических свойств слова в предложении. Относится к аффиксам.
В большинстве сложных слов выделяется еще одна часть слова — соединительная гласная (интерфикс)
Морфемный анализ (разбор слова по составу).
При разборе слова по составу мягкий знак относится к той морфеме, мягкость согласного в которой он обозначает. В начальной школе разбор слова по составу будет выглядеть так: стуль-я. Бытует также мнение, что мягкий знак не отражает морфемный состав слова, поэтому отнесение его при разборе слова к той или иной части не является принципиальным. В старших классах при морфемном разборе учитывается звуковой состав слова: стульj-а.
Твердый знак в старых учебниках русского языка было принято выделять вместе с приставкой. В некоторых новых программах начальной школы, например «Перспективная начальная школа» — тоже, например: съ-езд. Твердый знак не обозначает звука речи, и следовательно не должен включаться ни в одну морфему.
Проблемы со знаками ъ и ь связаны с тем, что они не обозначают звуков, а устная речь — первична. Поэтому тенденция к «выключению» знаков, не обозначающих звуки, при морфемном разборе будет усиливаться.
Каждая значимая часть слова — приставка, корень, суффикс, окончание — называется морфемой. В основу входит корень и аффиксы (приставки, словообразовательные суффиксы, постфиксы).
В русском языке 5 постфиксов: 2 глагольных (-ся / -сь, -те: бороться, борюсь, учите) и 3 местоименных (-то, -либо, -нибудь: кто-то, какой-нибудь, чей-либо).
Выше перечисленные аффиксы являются словообразовательными.
Так, постфикс – ся придает глаголам переписываться, ссориться значение взаимности, а местоимения и наречия с постфиксами –то, -либо, -нибудь (кто-то, где-либо, когда-нибудь) имеют значение неопределенности.
Постфикс –ся / -сь выполняет словоизменительную функцию: он используется для образования форм страдательного залога. Например: Рабочие строят дом. – Дом строится рабочими.
Словоизменительный постфикс – те в форме повелительного наклонения глагола выражает грамматическое значение множественного числа: думай — те, запоминай — те.
Постфиксы совмещают в себе признаки приставок и суффиксов. Глаголы остаются глаголами, местоимения – местоимениями (начинать – начинаться, какой – какой-либо).
Формообразующие суффиксы, окончания, интерфиксы в основу не входят. При их наличии основа прерывистая: учи_ся, рисова_ась.
Остались вопросы — задай в обсуждениях https://vk. com/board41801109
com/board41801109
Усвоил тему — поделись с друзьями.
Тесты на тему Морфемика
Тест на тему Морфемный разбор
Тест на тему Схема разбора слова по составу
#обсуждения_русский_язык_без_проблем
вернуться на главную, на стр. “Морфемика в таблицах“, “Морфемный разбор”
Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
, Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: блекало 1 секунда назад о л п и р м е 1 секунда назад таенвра 1 секунда назад с л е т ь п а с а 1 секунда назад т в о р е ц 1 секунда назад р а м ц а т б 2 секунды назад енартхь 2 секунды назад теблфио 2 секунды назад слово из пяти букв у е 2 секунды назад р е ф л о ь с 2 секунды назад сталюр 3 секунды назад е е н е и н м о 3 секунды назад впарао 3 секунды назад т и к д р е 3 секунды назад рутогй 3 секунды назад
Текст: Структурный анализ | Введение в колледж Состав: Cerritos College
Структурный анализ – это процесс разбиения слов на их основные части для определения значения слова. Структурный анализ является мощным словарным инструментом, поскольку знание нескольких частей слова может дать ключ к пониманию значения большого количества слов. Хотя значение, предлагаемое частями слова, может быть неточным, этот процесс часто может помочь вам понять слово достаточно хорошо, чтобы вы могли продолжать чтение без значительных перерывов.
Структурный анализ является мощным словарным инструментом, поскольку знание нескольких частей слова может дать ключ к пониманию значения большого количества слов. Хотя значение, предлагаемое частями слова, может быть неточным, этот процесс часто может помочь вам понять слово достаточно хорошо, чтобы вы могли продолжать чтение без значительных перерывов.
При структурном анализе читатель разбивает слова на основные части:
- Префиксы – части слова, расположенные в начале слова для изменения значения
- Корни – основная значимая часть слова
- Суффиксы – части слова, присоединяемые к концу слова; суффиксы часто изменяют часть речи слова
Например, слово велосипедист можно разбить следующим образом:
- би – префикс, означающий два
- цикл — корень означает колесо
- ist — суффикс существительного, означающий «человек, который»
Таким образом, структурный анализ предполагает, что велосипедист — это человек на двух колесах, что близко к формальному определению слова.
Рассмотрим часть слова –cide. Хотя оно не может стоять как слово само по себе, оно имеет значение: убить . Подумайте о многих словах в нашем языке, в состав которых входит слово -cide. Знание этой части слова дает нам знания о многих словах.
Инфиксы
В английском языке есть только суффиксы и префиксы (часть более крупного класса, называемого аффиксами). В других языках есть вещи, называемые инфиксами. Они идут в середине слова. Piano , pianisimo , pianisisimo, и т. д.
Английский язык имеет только один инфикс:
- «abso-friggin-lutely»
- «соберись-ка черт возьми»
Для дальнейшего развития этого навыка обратитесь к удобному справочному листу «Структурный анализ: общие части слов», где приведен список некоторых распространенных префиксов, корней и суффиксов, а также их значения и примеры слов, в которых они используются.
Приступим к работе
Чтобы попрактиковаться в этом навыке, попробуйте упражнения по структурному анализу от Летбриджского колледжа.
Хотя структурный анализ — это метод, который может использовать каждый, определенно есть определенные дисциплины, в которых он используется более широко.
Медицина, в частности, использует терминологию, основанную на структурном анализе. Посетите следующие сайты, чтобы узнать некоторые общие части слова, встречающиеся в области медицины:
- Построение медицинских терминов: пищеварительная система. Этот сайт поможет вам составить и выучить термины, относящиеся к пищеварительной системе.
- Медицинская терминология от SweetHaven Publishing Services
- Медицинские терминологические системы, шестое издание, аудиоупражнения. Этот сайт поможет вам выучить различные части слова, связанные с медицинской терминологией.
- Ресурсы Medword. Основы медицинской терминологии. Этот сайт содержит списки медицинских префиксов, суффиксов, комбинированных форм, кроссвордов и т. д.
- Медицинская терминология в Sheppard Software
Расчет конструкций | Английский для развития: Введение в композицию колледжа |
Структурный анализ — это процесс разбиения слов на их основные части для определения значения слова.
Структурный анализ является мощным словарным инструментом, поскольку знание нескольких частей слова может дать ключ к пониманию значения большого количества слов. Хотя значение, предлагаемое частями слова, может быть неточным, этот процесс часто может помочь вам понять слово достаточно хорошо, чтобы вы могли продолжать чтение без значительных перерывов.
При использовании структурного анализа читатель разбивает слова на их основные части:
- Префиксы – части слова, расположенные в начале слова для изменения значения
- Корни – основная значимая часть слова
- Суффиксы — части слова, присоединяемые к концу слова; суффиксы часто изменяют часть речи слова
Например, слово «велосипедист» можно разбить следующим образом:
- би — префикс, означающий два
- цикл — корень означает колесо
- ist — суффикс существительного, означающий «человек, который»
Таким образом, структурный анализ предполагает, что велосипедист — это человек на двух колесах, что близко к формальному определению слова.
Рассмотрим часть слова –cide. Хотя оно не может стоять как слово само по себе, оно имеет значение: убить . Подумайте о многих словах в нашем языке, в состав которых входит слово -cide. Знание этой части слова дает нам знания о многих словах.
Инфиксы
В английском языке действительно есть только суффиксы и префиксы (часть более крупного класса, называемого аффиксами). В других языках есть вещи, называемые инфиксами. Они идут в середине слова. Piano , pianisimo , pianisisimo, и т. д.
Английский язык имеет только один инфикс:
- «abso-friggin-lutely»
- «соберись-ка черт возьми»
Для дальнейшего развития этого навыка обратитесь к удобному справочному листу «Структурный анализ: общие части слов», где приведен список некоторых распространенных префиксов, корней и суффиксов, а также их значения и примеры слов, в которых они используются.
Приступайте к работе
Чтобы отработать этот навык, попробуйте упражнения по структурному анализу от Летбриджского колледжа.
Хотя структурный анализ — это метод, который может использовать каждый, определенно есть определенные дисциплины, в которых он используется более широко. Медицина, в частности, использует терминологию, основанную на структурном анализе. Посетите следующие сайты, чтобы узнать о некоторых общих словах, встречающихся в области медицины:
- Построение медицинских терминов: пищеварительная система. Этот сайт поможет вам составить и выучить термины, относящиеся к пищеварительной системе.
- Медицинская терминология от SweetHaven Publishing Services
- Медицинские терминологические системы, шестое издание, аудиоупражнения. Этот сайт поможет вам выучить различные части слова, связанные с медицинской терминологией.
- Ресурсы Medword. Основы медицинской терминологии.
Электронный словарь, способный определять идиомы
Настоящее изобретение относится к электронному словарю, в частности к электронному словарю, способному обрабатывать идиомы.
В течение многих лет люди изучают технологию машинного перевода, которая может переводить письменные или устные выражения с одного языка на другой с помощью компьютеров. Машинный перевод — это своего рода автоматический перевод с одного языка на другой (или многие другие) без помощи человека. На основе лингвистического анализа формы и структуры языка он строит машинную лексику и машинную грамматику с математическим подходом, используя огромные возможности компьютеров для хранения и обработки данных. Чтобы реализовать языковой перевод, система машинного перевода должна иметь функции анализа лексики, синтаксического анализа, анализа грамматики, лексики, словаря идиом, семантического анализа и синтеза целевого языка. Однако до сих пор не существует подходящей системы, поскольку машинный перевод является передовой прикладной наукой, связанной с лингвистикой, компьютерной лингвистикой, информатикой и многими другими предметами. В этой ситуации люди переключились на электронный словарь, который осуществляет перевод на уровне слов и является более практичным. Электронный словарь — это своего рода новый словарь, который хранит и использует данные в электронной форме. Электронный словарь обладает большой гибкостью. Он может организовывать информацию в виде гипермедиа и гипертекста, поддерживать различные методы поиска, предлагать функцию динамического перевода и предоставлять объяснения для найденного слова в виде текста, аудио и изображения.
Электронный словарь — это своего рода новый словарь, который хранит и использует данные в электронной форме. Электронный словарь обладает большой гибкостью. Он может организовывать информацию в виде гипермедиа и гипертекста, поддерживать различные методы поиска, предлагать функцию динамического перевода и предоставлять объяснения для найденного слова в виде текста, аудио и изображения.
Однако большинство существующих электронных словарей могут выполнять перевод только на уровне слов. В случае наличия английского предложения «Он принимает участие в деятельности», существующие электронные словари могут давать китайский перевод для одного слова «принимать», в то время как пользователь не может получить китайское значение слова «принимать участие».
Существуют электронные словари, способные переводить на уровне идиом. Однако у них есть следующие ограничения для пользователей:
Они могут давать перевод, когда пользователь вводит идиому как «принять участие». В случае, если пользователь вводит фразу «принять активное участие», эти электронные словари не смогут идентифицировать идиому «принять участие» и, следовательно, не смогут дать полезный перевод на китайский язык.
Если пользователь не укажет правильное заглавное слово в идиоме, эти словари не дадут перевод на уровне идиомы. В примере «принять участие», если пользователь ищет слово «часть» или «в» в словаре, он не может получить перевод идиомы «принять участие».
Электронный словарь с функцией обработки идиом в соответствии с настоящим изобретением решит указанные выше проблемы.
В одном иллюстративном аспекте изобретения электронный словарь с функцией обработки идиом действует для выполнения метода, который включает:
хранение множества записей в виде электронных данных в памяти, каждая запись состоит из заголовка на первом языке и переведенных выражений на втором языке, соответствующих заголовку, при этом указанные заголовки включают идиомы первого языка;
регистрация новой записи в памяти; и
извлечение записи, соответствующей слову запроса, из памяти;
, в котором указанная операция поиска включает в себя операцию обработки идиом, которая автоматически идентифицирует идиомы, включенные в настоящее предложение, из текста на первом языке и извлекает соответствующие переведенные выражения на втором языке.
Цель, признаки и преимущества настоящего изобретения станут более понятными из приведенного ниже подробного описания, взятого вместе с прилагаемыми чертежами.
РИС. 1 представляет собой общую иллюстрацию электронного словаря согласно настоящему изобретению.
РИС. 2 иллюстрирует последовательность операций средства обработки идиом для электронного словаря.
РИС. 3 иллюстрирует рабочий процесс для сопоставления словаря переноса.
Электронный словарь согласно настоящему изобретению проиллюстрирован на фиг. 1 . Следует понимать, что элементы «средства» на фиг. 1 может быть реализован в компьютере или другом устройстве на базе процессора. Например, средством ввода 100 может быть клавиатура, средством хранения 200 может быть память, связанная с процессором, а средством вывода 500 может быть дисплей. Однако могут быть использованы и другие обычные компьютерные элементы. Кроме того, процессор может использоваться для реализации средства 9 регистрации входа. 0035 300 и средство извлечения входа 400 (и его составные элементы).
0035 300 и средство извлечения входа 400 (и его составные элементы).
Средство ввода 100 используется для ввода строки слов или текста на исходном языке; средство хранения записей , 200, используется для хранения множества записей в виде электронных данных; средство 300 регистрации записей используется для регистрации новых записей в средстве 200 хранения записей; средство поиска записей 400 используется для извлечения записей, соответствующих слову запроса, из средства хранения записей 200 ; средство вывода 500 используется для вывода записей, соответствующих слову запроса.
Как показано на РИС. 1, средство 400 поиска статей в электронном словаре в соответствии с настоящим изобретением содержит средство 600 обработки идиом. Средство обработки идиом 600 состоит из блока 601 захвата текста, блока 602 сегментации предложений, блока 603 синтаксического анализа локальной грамматики и блока 9 сопоставления переводного словаря. 0035 604 .
0035 604 .
РИС. 2 подробно показан состав средства обработки идиом , 600, и его рабочий процесс. Как показано на фиг. 2, когда средство 600 обработки идиом активировано, блок захвата текста 601 захватывает фрагмент текста с экрана, содержащий слово запроса, в то время как слово запроса является словом, на которое указывает пользователь с помощью курсора. Затем блок сегментации предложения 602 идентифицирует предложение, содержащее слово запроса. Блок синтаксического анализа локальной грамматики 603 идентифицирует все возможные грамматические компоненты в предложении. Блок сопоставления словаря переноса 604 будет сопоставлять результат синтаксического анализа с элементами в словаре, каждая совпадающая запись может дать перевод для сегмента в предложении. Те совпадающие записи, которые охватывают слово запроса, образуют набор записей. После ранжирования записей в указанном выше наборе записей в соответствии со степенью соответствия между записью и предложением результат будет отображаться на экране.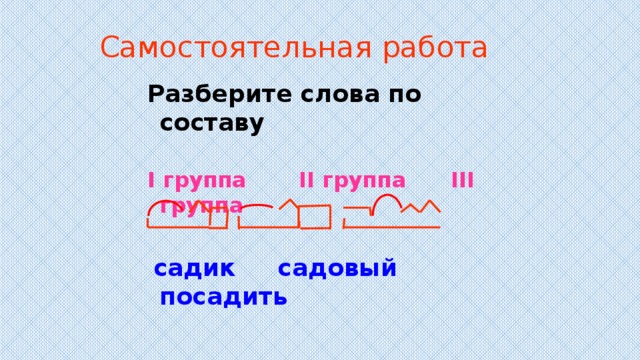
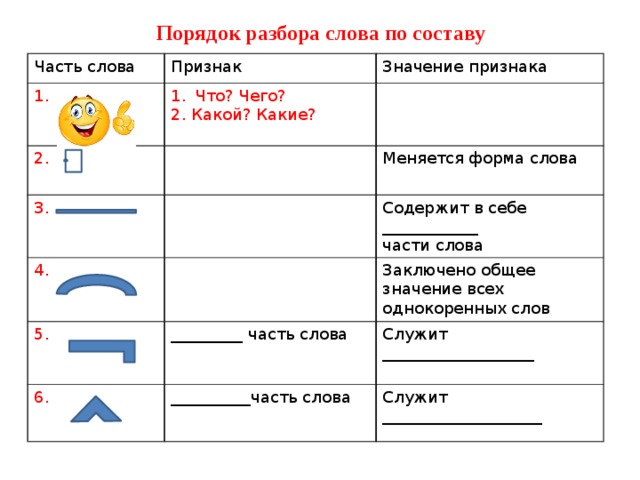
Для англо-китайского электронного словаря блок синтаксического анализа местной грамматики 603 может идентифицировать следующие грамматические компоненты:
1. именная группа,
2. глагольная группа,
3. предлоговая группа,
4. прилагательная группа. ,
5. наречие,
6. одна частица.
Именная группа имеет одну из следующих основных конструкций или комбинацию нескольких основных конструкций:
1.1. одно существительное,
1.2. существительное+существительное,
1.3. существительное+из +существительного,
1.4. существительное существительное,
1.5. прилагательное+существительное,
1.6. артикль+существительное,
1.7. местоимение+существительное,
1.8. числительное + существительное.
Глагольная группа имеет одну из следующих основных конструкций или комбинацию нескольких основных конструкций:
2.1. одиночный глагол,
2.2. быть+глагол,
2. 3. иметь+глагол,
3. иметь+глагол,
2.4. наречие+глагол,
2.5. глагол+нареч.
Фраза с предлогом имеет конструкцию:
3.1. предлог+существительное словосочетание.
Прилагательное словосочетание имеет одну из следующих основных конструкций:
4.1. одно прилагательное,
4.2. больше+прилагательное,
4.3. самый+прилагательное.
Наречная группа имеет одну из следующих основных конструкций:
5.1. одно наречие,
5.2. больше+наречие,
5.3. самый+нареч.
Далее предложение «Он принимает активное участие в деятельности». взят в качестве примера для иллюстрации локальных процедур синтаксического анализа:
Шаг I
he ->существительное
take->глагол
a->артикль
активное действие->прилагательное
часть->существительное
часть->прилагательное
2-000>in-0 ЧастицаThe-> Статья
Activity-> Существительное
Шаг II
HE: Существительное
Взять: глагол
A: Статья
Актив: Прилагательное
Часть: существительное
Часть: Прилагательное
в: предлог
in: частица
the: артикль
действие: существительное
активная часть: прилагательное+существительное->существительное
действие: артикль+существительное->существительное
Шаг III
он: существительное
3 take 9 Глагол
A: Статья
Актив: Прилагательное
Часть: существительное
Часть: Прилагательное
В: Предлог
В: Частица
0002 действие: существительное
активная часть: артикль+существительное->существительное
в действии: предлог+существительное->предлог словосочетание
При выявлении грамматических компонентов в предложении может случиться так, что одно слово принадлежит более чем одни компоненты, которые относятся к совершенно разным частям речи. В приведенном выше предложении слово «часть» может быть как прилагательным, так и существительным, а слово «в» может быть как предлогом, так и частицей. В этом случае результат локального синтаксического анализа сохранит все возможные грамматические компоненты.
В приведенном выше предложении слово «часть» может быть как прилагательным, так и существительным, а слово «в» может быть как предлогом, так и частицей. В этом случае результат локального синтаксического анализа сохранит все возможные грамматические компоненты.
После завершения синтаксического анализа локальной грамматики средство обработки идиом 600 активирует блок сопоставления словаря переноса 604 для выполнения сопоставления между элементами в словаре переноса и результатом синтаксического анализа локальной грамматики.
Ниже представлена структура переводного словаря. Одна статья в лексиконе состоит из трех частей: главы, грамматики и перевода.
| Головка | Grammar | Translation | |
| take v | Obj part comp (p in) | objprep | |
| take v | obj n fin wh comp (pt in) | obj | |
| make sure v | comp(p about of) | objprep | |
| make v | Obj it comp a comp thatc | thatc adj | |
| place n loc | nobj inf | inf | |
The notations in the above table are interpreted as:
| Notation | Interpretation | |
| a | прилагательное. | |
| прил | прилагательное. | |
| комп. | доп. | |
| плавник | конечный глагол. | |
| инфинитив | инфинитив. | |
| п | сущ. | |
| nobj | Объект существительного предшествует ему. | |
| n loc | существительное, обозначающее местоположение. | |
| Obj | объект, возглавляемый указанным словом. | |
| obj | объект, который может быть одним из компонентов грамматики | |
| список после него. | ||
| р | предлог | |
| пт | частица. | |
| thatc | Пункт, возглавляемый словом «это». | |
| v | глагол. | |
| wh | Пункт, возглавляемый словами «кто», «где», «когда» или «что».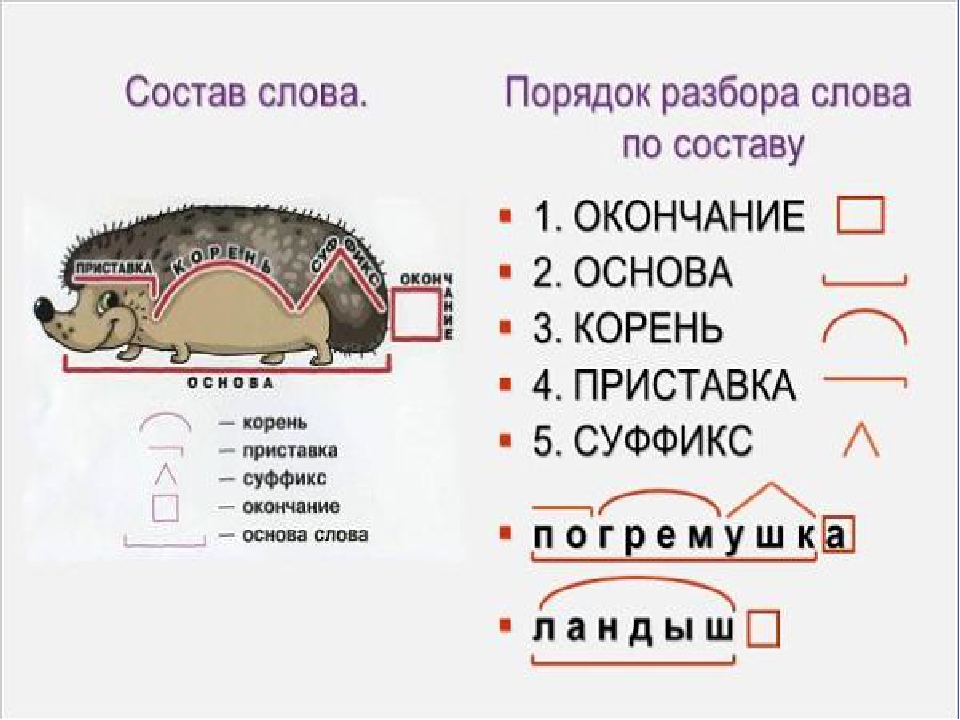 | |
Заголовок записи может состоять из нескольких слов, например:
убедитесь, что В грамматической части статьи первым компонентом является часть речи заглавного слова. Вслед за частью речи идет ряд грамматических компонентов. Компонент грамматики состоит из имени и описания. Он может состоять из нескольких подкомпонентов. В примере obj n fin, который описывает компонент грамматики объекта. Этот объект должен быть существительным, конечным глаголом или предложением, начинающимся с wh. В примере: р об этом описывает фразу с предлогом. Эта фраза с предлогом должна начинаться с «о» или «из». В части перевода есть части грамматики вместе с китайскими словами как перевод английской части записи. РИС. 3 иллюстрирует процедуры сопоставления записей в лексиконе переноса с результатом синтаксического анализа предложения. Первый take Скелетная идиома для этой записи — «принимать участие» (Скелетная идиома — это идиома, которая содержит только необходимые слова). В записи «взять» является заглавным словом. «v» говорит, что это глагольная фраза. «(Obj part)» указывает на то, что глагол «take» должен иметь слово «part» в качестве дополнения. «comp» указывает компонент дополнения после объекта. «(p in)» означает, что дополнение должно быть предлогом, возглавляемым «in». «t(objprep)» показывает, как перевести идиому на китайский язык. «objprep» представляет объект предлога «в». Второй пример: take Основная идиома для этой записи — «take in». В записи «(obj n fin wh)» указывает, что глагол «take» должен иметь объект. Объектом может быть именная группа, конечная глагольная группа или предложение, начинающееся со слов «что», «где», «когда» и т. Сравнивая две приведенные выше записи с результатом анализа «Он принимает активное участие в деятельности», он дает следующие совпадения по частям 1. берет vs. берет 2. активная часть vs. (Obj part) 3. в активности vs. (comp (p in)) и 1. берет vs. берет 2. активная часть vs. (obj n) 3. in vs. (comp (pt in)) В приведенных выше примерах обе записи совпадают с предложением. Если слово запроса «взять» или «в», они оба находятся в наборе поиска по словарю. Однако, если словом запроса является «часть», в наборе словарного поиска находится только запись «принимать участие». Наконец, совпавшие записи ранжируются в соответствии со степенью совпадения между записью и результатом синтаксического анализа. Например, возьмем предложение «Он принимает активное участие в деятельности» и слово-запрос «принимать», доступны три совпадающие записи: «принимать участие», «принимать участие» и «принимать». 1. принять участие: 2. принять участие: 3. взять: Исходя из вышеизложенного, электронный словарь, описанный в данном изобретении, может идентифицировать все идиомы из входного текста, которые содержат слово запроса. Это изобретение реализовало интеллектуальный перевод на уровне идиом. Для специалистов в данной области это изобретение допускает различные модификации и деформации при условии, что сущность и категория этого изобретения остаются неизменными; это изобретение предназначено для защиты всех этих модификаций и деформаций. В этом руководстве будут описаны общие принципы построения семантических синтаксических анализаторов. Презентация будет разделена на две основные части: моделирование и обучение. Раздел моделирования будет включать в себя лучшие практики для разработки грамматики и выбора семантического представления. Обсуждение будет вестись на примерах из нескольких областей. Чтобы проиллюстрировать выбор, который необходимо сделать, и показать, как к нему можно подойти в рамках реального языка представления, мы будем использовать представления значений λ-исчисления. В… Посмотреть на ACL Компьютерная наука 8888888888888 гг. базовая грамматика логических форм для обеспечения правильно сформированных выражений и показывает, что предложенная модель превосходит стандартную модель кодировщика-декодера для наборов данных и конкурентоспособна с сопоставимыми подходами к семантическому анализу на основе грамматики. Компьютерная наука ARXIV 88 88 88 88 889. Partee, 1975), и (b) способность семантических парсеров обрабатывать лексические вариации в контексте базы знаний (KB). Информатика В этом обзоре рассматриваются различные компоненты системы семантического синтаксического анализа и обсуждаются важные работы, начиная от первоначальных методов, основанных на правилах, и заканчивая современными нейронными подходами к синтезу программ. Компьютерная наука AKBC методы, основанные на правилах, к современным нейронным подходам к синтезу программ. Computer Science ArXiv An overview of the представлен растущий объем исследований в области семантического анализа с точки зрения эволюции, с конкретным анализом нейросимволических методов, архитектуры и наблюдения. Информатика Предоставляется обзор растущего объема исследований в области методов семантического анализа естественного языка и извлечения уроков из эволюции семантического анализа. Информатика ACL Общий набор решений партикулярных условий разбора последовательностей, который приводит к разделению партикулярных решений последовательностей парсинга и показывает, что в этой формулировке сегментация дискурса может быть оформлена как частный случай синтаксического анализа, который позволяет нам выполнять синтаксический анализ дискурса, не требуя сегментации в качестве предварительного условия. Компьютерные науки ACL . Информатика В этой статье показана растущая важность чередующихся знаний и языковой обработки в контексте когнитивных вычислений и строительных блоков для открытой архитектуры для приложений глубокого НЛП. вводятся и обсуждаются. Computer Science LREC представляет аннотированный набор данных из 1198 предложений. ПОКАЗАНЫ 1–10 ИЗ 54 ССЫЛОК СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность Computer Science, Linguistics EMNLP An algorithm for learning factored CCG lexicons, along with a probabilistic parse-selection model, который включает в себя как лексемы для моделирования значения слов, так и шаблоны для моделирования систематических изменений в использовании слов. Информатика EMNLP Ключевая идея состоит в том, чтобы ввести нестандартные комбинаторы CCG, которые ослабляют определенные части порядка, или допускают гибкость определенных частей грамматики, например вставка лексических единиц — с выученными затратами. Информатика EMNLP В этой статье используется унификация высшего порядка для определения пространства гипотез, содержащего все грамматики, согласующиеся с обучающими данными, и разрабатывается алгоритм онлайн-обучения, который эффективно выполняет поиск в этом пространстве при одновременной оценке параметры лог-линейной модели синтаксического анализа. Информатика UAI Описан алгоритм обучения, который принимает в качестве входных данных обучающий набор предложений для грамматического исчисления и индукционного исчисления проблема, наряду с логарифмической моделью, которая представляет распределение по синтаксическому и семантическому анализу, обусловленному входным предложением. Информатика NAACL Показано, что WASP работает лучше с точки зрения точности, контроля и охвата, чем существующие методы обучения демонстрирует лучшую устойчивость к изменениям сложности задач и порядка слов. Информатика CL Разработан новый семантический формализм, композиционная семантика на основе зависимостей (DCS), определено лог-линейное распределение по логическим формам DCS и показано, что система получает сопоставимые точность даже для самых современных систем, которые требуют аннотированных логических форм. В этой статье описывается ряд моделей лог-линейного анализа для автоматически извлекаемой лексикализованной грамматики, а также разрабатывается новая модель и эффективный алгоритм анализа, который использует все производные, включая CCG. Компьютерная наука Conll . предсказания сложных структур, которые полагаются только на двоичный сигнал обратной связи, основанный на контексте внешнего мира, и переформулирует проблему семантического анализа, чтобы уменьшить зависимость модели от синтаксических шаблонов, что позволяет синтаксическому анализатору лучше масштабироваться с меньшим контролем. Информатика AAAI/IAAI, Vol. 2 Экспериментальные результаты с полным приложением запросов к базе данных для географии США показывают, что CHILL может изучать синтаксические анализаторы, которые превосходят ранее существовавшие, созданные вручную аналоги, и предоставляют прямое доказательство полезности эмпирического подхода в уровень полного приложения на естественном языке. Ниже приведены два примера записи трансфертного лексикона.
Ниже приведены два примера записи трансфертного лексикона. д. «(pt in)» означает, что дополнением должна быть частица «in».
д. «(pt in)» означает, что дополнением должна быть частица «in». В соответствии с длиной скелетных идиом, т. е. количеством слов в скелетных идиомах, выходные записи ранжируются следующим образом:
В соответствии с длиной скелетных идиом, т. е. количеством слов в скелетных идиомах, выходные записи ранжируются следующим образом: [PDF] Семантический анализ с комбинаторными категориальными грамматиками
@inproceedings{Artzi2013SemanticPW,
title={Семантический анализ с комбинаторными категориальными грамматиками},
автор={Йоав Арци и Николас Фитцджеральд и Люк Зеттлемойер},
название книги={ACL},
год = {2013}
} 
НЕРНАЯ СЕМЕНТИЧЕСКИЙ ПАНЧИНГ ДЛЯ СИНТАКСКОГО КОДОВАНИЯ

Обследование семантического анализа с точки зрения композиции
Обзор семантического анализа

Опрос о семантическом анализе
Toward Code Generation: A Survey and Lessons from Semantic Parsing
Обзор семантического анализа для машинного программирования
 , проводя параллели между современными усилиями в области нейросемантического анализа и синтеза программ.
, проводя параллели между современными усилиями в области нейросемантического анализа и синтеза программ. Платформа условного разделения для эффективного анализа групп
Разложение сложных вопросов для семантического анализа
для семантического анализа и разрабатывает средство извлечения информации для получения информации о типе и предикате этих вопросов. На пути к открытой программной архитектуре для чередующихся знаний и обработки естественного языка
SpecNFS: сложный набор данных для извлечения формальных моделей из спецификаций естественного языка
Лексическое обобщение в индукции грамматики CCG для семантического анализа
 Kwiatkowski, Luke Zettlemoyer, S. Goldwater, Mark Steedman
Kwiatkowski, Luke Zettlemoyer, S. Goldwater, Mark Steedman Онлайн-обучение упрощенным грамматикам CCG для преобразования в логическую форму
Индуцирование вероятностных CCG-грамматик из логической формы с помощью объединения высшего порядка
 Квятковски, Люк Зеттлемойер, С. Голдуотер, Марк Стидман
Квятковски, Люк Зеттлемойер, С. Голдуотер, Марк Стидман Обучение преобразованию предложений в логическую форму: структурированная классификация с вероятностными категориальными грамматиками

Обучение семантическому анализу с помощью статистического машинного перевода
Изучение композиционной семантики на основе зависимостей
Эффективный статистический анализ широкого охвата с CCG и лог-линейными моделями
 нестандартные производные.
нестандартные производные. Семантический анализ вождения с откликом мира
Обучение разбору запросов к базе данных с использованием индуктивного логического программирования
