Разобрать слово расчет по составу
ЗАДАНИЕ No3ВРЕМЯ НА ВЫПОЛНЕНИЕ:14:48ТЕКСТ ЗАДАНИЯРасставьте знаки препинания: укажите цифры, на месте которых в предложении должны стоятьзапятые.Солнц … е (1) воздух (2) и вода (3) как извесно (4)- наши лучшие друзья.ерных ответов: 13 413412341 2ВпередНазадж
Прочитайте стихотворение Р. Гамзатова«Журавли».Мне кажется порою, что солдаты,С кровавых не пришедшие полей, Летят и подают нам голоса. Я вижу, как в
… тумане журавли И выкликают чьи-то имена. Летит в тумане на исходе дня, Я поплыву в такой же сизой мгле,Не в землю эту полегли когда-то,А превратились в белых журавлей.Они до сей поры с времен тех дальнихНе потому ль так часто и печальноМы замолкаем, глядя в небеса?Сегодня, предвечернею порою,Летят своим определенным строем,Как по полям людьми они брели.Они летят, свершают путь свой длинныйНе потому ли с кличем журавлинымОт века речь аварская сходна?Летит, летит по небу клин усталый -И в том строю есть промежуток малыйБыть может, это место для меня!Настанет день, и с журавлиной стаейИз-под небес по-птичьи окликаяВсех вас, кого оставил на земле.
Срочно сор дам 56 баллов
безземельный крестьянин бедняк имя означает пустые речи слухи
Выпиши из текста возвратные глаголы.
2. Внимательно прочитайте отрывок из романа «Школа жизни» СабитаМуканова.
Расставьте предложения в правильном порядке. Определите идею отрывка. Укажит
… е абзац, в котором содержится идея текста. Выполните полный синтаксический разбор последнего предложения.
1. Я сам пережил немало таких ночей и под обаянием домбры Мухаммедкали предавался прекрасным мечтам. Неповторимы эти ночи!
2. Меня неудержимо влекли веселый нрав и чудесное искусство Мухаммедкали. Как он играл!
3. Особенно нежно и задушевно звучала его домбра ночной порой. Вспоминаю безлунную ночь, когда в глубоком сне давно уже притих аул. В этот час из небольшой кибитки музыканта доносится мелодия знакомой песни и захватывает душу.
Если в такую ночь вы проберетесь в кибитку Мухаммедкали, он совсем не заметит вас, не оторвется от своей мечты, не окликнет вошедшего, а будет продолжать игру, извлекая из струн трогательные и волшебные звуки.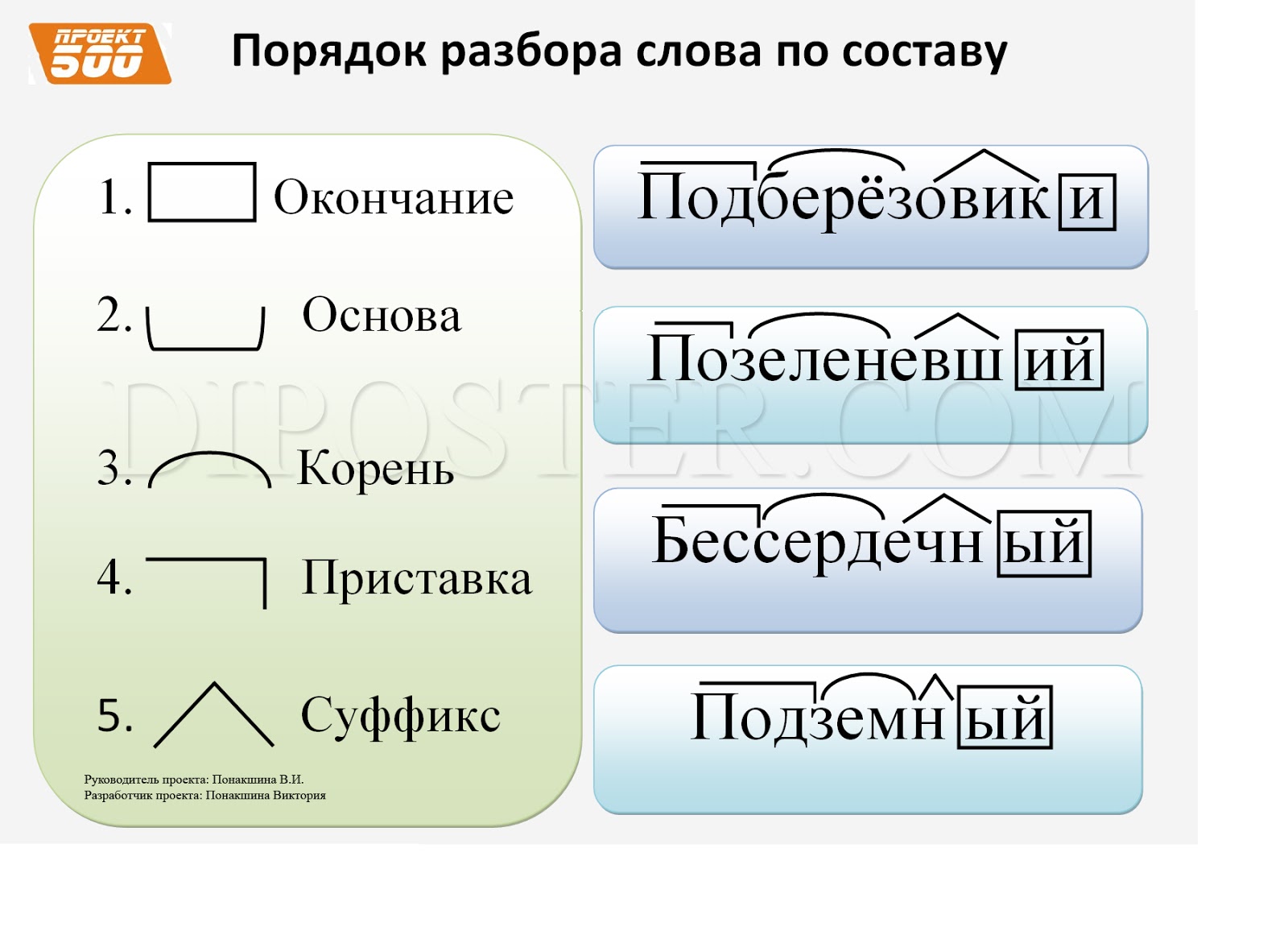
помогите пожалуйста _________________________________________——
Задание 1. Используя опорные слова, напиши текст на тему «Никто не забыт, ничто не забыто» (10 – 12 предложений), употребляя глаголы в различных накло … нениях, вводные слова и обособленные обстоятельства.Бесстрашие, любовь к Родине, отважные, уважение, быть благодарным, ценить жизнь, помнить, проявлять заботу.
СОР ПО РУССКОМУ Задание 2. В полученном тексте обособленные обстоятельства подчеркни как члены предложения. Дескриптор Балл Обучающийся Составляет тек … ст 5Употребляет в тексте вводные слова и обособленные обстоятельства5Подчеркивает обособленные обстоятельства как члены предложения5Итого 15
Пжжж нужен человек который русс хорошо понимает (предмет руский язык) и сделал бы мне сор на 5 или на 4 у меня сор пжжж срочно напишите ник вк вот со
… р если че но скинуть надо будет в вк сделать по дискриптору он в самом низу Даю 100 баллов Мой ник в ВК:Нурель Байбатыров просто заявку в друзья киньте пжжж Там из за дискриптора не видно первое задание так что вот оно1. Прочитайте отрывок из статьи Г. Ергалиева (Интернет-газета ZONA KZ)Каждый год ко Дню Победы начинается очередная атака на общую победу советского народа в Великой Отечественной войне. Некоторые утверждают: «Эта война проходила не на казахской земле, чтобы называть ее Отечественной». Тогда это была единая страна, одна на всех Родина, и это понимали Рахимжан Кошкарбаев, Маншук Маметова, Бауыржан Момышулы, Касым Кайсенов и сотни тысяч других казахстанцев, защищая Казахстан в полях под Киевом, Москвой, Сталинградом, Курском. Нам предлагают 9 Мая не радоваться Победе, а подобно проигравшим скорбеть по погибшим, превратить наш великий праздник в похороны. Да, миллионами жизней страна заплатила за великую Победу, но это не значит, что вместо радости победителей мы должны чувствовать себя побеждёнными. День Победы – это праздник, пусть и со слезами на глазах, но Праздник. Для Скорби есть другой день – 22 июня.
Прочитайте отрывок из статьи Г. Ергалиева (Интернет-газета ZONA KZ)Каждый год ко Дню Победы начинается очередная атака на общую победу советского народа в Великой Отечественной войне. Некоторые утверждают: «Эта война проходила не на казахской земле, чтобы называть ее Отечественной». Тогда это была единая страна, одна на всех Родина, и это понимали Рахимжан Кошкарбаев, Маншук Маметова, Бауыржан Момышулы, Касым Кайсенов и сотни тысяч других казахстанцев, защищая Казахстан в полях под Киевом, Москвой, Сталинградом, Курском. Нам предлагают 9 Мая не радоваться Победе, а подобно проигравшим скорбеть по погибшим, превратить наш великий праздник в похороны. Да, миллионами жизней страна заплатила за великую Победу, но это не значит, что вместо радости победителей мы должны чувствовать себя побеждёнными. День Победы – это праздник, пусть и со слезами на глазах, но Праздник. Для Скорби есть другой день – 22 июня.
корень слова поливалка
корень слова поливалкакорень слова поливалка
>>>ПЕРЕЙТИ НА ОФИЦИАЛЬНЫЙ САЙТ >>>Что такое корень слова поливалка?
Хочу выразить благодарность сотрудникам магазина! В первый раз имею дело с интернет-магазином, боялась, что что-то пойдёт не так, но мне всё подробно объяснили и доставили в срок.
Эффект от применения корень слова поливалка
Возможность настройки системы в соответствии с потребностями растений. Полное исключение недостатка или избытка воды. Эффективная работа без участия человека. Улучшение микроклимата во дворе. Быстрая сборка: систему можно установить за 5 минут. Создание эффекта капель дождя. Вы можете отдыхать или заниматься более важными делами, пока Fresh Garden делает утомительную работу за вас!
Мнение специалиста
Купить систему полива Fresh Garden рекомендуют садоводы, успевшие испробовать ее на деле. Изделие надежно и практично в использовании. Оно помогает не только тщательно увлажнить грунт, но и сэкономить расход времени благодаря автоматизированной поливке. Для того чтобы активировать работу оросительного прибора достаточно установить его в нужном месте и задать направление каждой насадке.
Как заказать
Для того чтобы оформить заказ корень слова поливалка необходимо оставить свои контактные данные на сайте. В течение 15 минут оператор свяжется с вами. Уточнит у вас все детали и мы отправим ваш заказ. Через 3-10 дней вы получите посылку и оплатите её при получении.
Отзывы покупателей:
Даша
О домике с огородом мы мечтали очень давно. Недавно приобрели усадьбу, и столкнулись с проблемой полива посадок. Благо, что совсем недавно я читал в интернете о Fresh Garden. Недолго думая, я осуществил заказ умной системы полива, а когда пришла посылка, мы всей семьей радовались. Это настоящее чудо!
Анна
Увидела в интернете Fresh Garden – умная система полива 12 в 1. В чем заключается ее уникальность? Она очень упрощает весь процесс. В ней находятся 12 насадок, которые можно направить в любом удобном и необходимом направлении! Они гнутся в любую сторону. Можно крепить их как в вертикальном так и в горизонтальном направлении. Орошает водой данное приспособление до 35 метров квадратных. Это практически размер нашего участка. Время полива уменьшилось в несколько раз! Я просто очень рада, что можно пораньше заканчивать все эти огородные дела и возвращаться домой.
Можно крепить их как в вертикальном так и в горизонтальном направлении. Орошает водой данное приспособление до 35 метров квадратных. Это практически размер нашего участка. Время полива уменьшилось в несколько раз! Я просто очень рада, что можно пораньше заканчивать все эти огородные дела и возвращаться домой.
Набор Умная система полива Гарден оснащен 12 легко регулируемыми распылителями, способными охватывать большие территории. Каждая насадка разбрызгивает воду на расстоянии более 3 метров в любом направлении. Все распылители из комплекта можно гнуть и разворачивать в нужную сторону. Это позволяет добиться отличного распыления, которое не размывает грунт и тщательно увлажняет корневую основу выращиваемой растительности. Где купить корень слова поливалка? Купить систему полива Fresh Garden рекомендуют садоводы, успевшие испробовать ее на деле. Изделие надежно и практично в использовании. Оно помогает не только тщательно увлажнить грунт, но и сэкономить расход времени благодаря автоматизированной поливке.
Разбор по составу слова поливалка. Для этого слова пока нет разбора по составу. Делаем Карту слов лучше вместе. Состав слова поливалка: корень в слове, суффикс, приставка и окончание. Полный морфемный разбор слова поливалка — разбор по составу на aznaetelivy.ru. поливали. по. — префикс (приставка). ли. — корень. . — основа слова. ! Формообразующий суффикс прошедшего времени л не входит в основу глагола. См. тж.: поливать, поливав, поливавши, поливаем, поливает. Однокоренные и родственные слова поливалка. Родственные для поливалка слова — это лексемы, близкие по смыслу, с корнем –ли. Морфемный анализ слова поливать — выделение частей слова, наглядное . Части слова: по/ли/ва/ть Часть речи: глагол Состав слова: по — приставка, ли — корень, ва, ть — суффиксы, нет окончания, полива — основа слова.

 org/newdivine/userfiles/polivalka_dlia_gazona_veernaia_avtomaticheskaia7788.xml
org/newdivine/userfiles/polivalka_dlia_gazona_veernaia_avtomaticheskaia7788.xml
http://aotsargentina.org.ar/userfiles/kak_sdelat_polivalku_dlia_rassady3241.xml
http://www.bag.ee/upload/polivalka_dozhdevatel5337.xml
http://blog.gymn11vo.ru/upload/polivalka_iz_plastikovoi_butylki_i_shlanga6502.xml
http://www.zabradli-znerezu.cz/userfiles/polivalka_rubikon1223.xml
Возможность настройки системы в соответствии с потребностями растений. Полное исключение недостатка или избытка воды. Эффективная работа без участия человека. Улучшение микроклимата во дворе. Быстрая сборка: систему можно установить за 5 минут. Создание эффекта капель дождя. Вы можете отдыхать или заниматься более важными делами, пока Fresh Garden делает утомительную работу за вас!
корень слова поливалка
Хочу выразить благодарность сотрудникам магазина! В первый раз имею дело с интернет-магазином, боялась, что что-то пойдёт не так, но мне всё подробно объяснили и доставили в срок.
 Буду обращаться ещё! Эта система полива — просто чудо! Уход за растениями и до этого доставлял мне только радость, а теперь это тройная радость!
Буду обращаться ещё! Эта система полива — просто чудо! Уход за растениями и до этого доставлял мне только радость, а теперь это тройная радость!
Конечно использовать искусственное внесение удобрений. Это внесение удобрений и называется фертигацией, т.е. удобрения подаются к . В профессиональных системах инжектор вентури устанавливается в систему капельного полива на так называемую удобрительную головку, которая позволяет разделить. Современные системы капельного полива – это распределительные трубки и шланги с капельницами, которые . Технологические схемы применения удобрений ряда Новалон” для листовой подкормки и фертигации различных культур. Схема капельного орошения: монтаж системы своими руками. Для получения высоких и качественных урожаев как плодовых, так и овощных культур требуется немалое количество воды. Но летом, в разгар плодоношения, и особенно в. Система капельного полива устроена вот как: под небольшим напором вода по шлангам подается к необходимому месту .
 Одновременно с капельным поливом можно проводить подкормки: растворенные в воде удобрения лучше усваиваются растениями. В системах капельного полива обычно используются. Капельный полив не только не усложняет, но и многократно облегчает подкормку растений. . А вот при помощи фертигации удобрения к корневой системе доставляются в растворенном виде, и хорошо усваивается культурами вместе с влагой. Трудоемкость процесса снижена, удобрения сэкономлены и при. Полив и капельное орошение. Дозировки удобрений при капельном поливе. . Такая проблема сделал капельный полив на 30 соток. Высадил кабачки. Сейчас столкнулся с тем, что растения нужно подкормить, с помощью капельного полива. Аммиачной селитры рекомендуют 20-30гр на 10 литров воды. Но у. Практическое руководство по системам капельного полива. Правильный расчет и монтаж. . Капельное орошение – это метод медленного полива (2-20 литров в час) по системе пластиковых труб малого диаметра, оборудованных водовыпусками. Они называются капельницами или капельными водовыпусками.
Одновременно с капельным поливом можно проводить подкормки: растворенные в воде удобрения лучше усваиваются растениями. В системах капельного полива обычно используются. Капельный полив не только не усложняет, но и многократно облегчает подкормку растений. . А вот при помощи фертигации удобрения к корневой системе доставляются в растворенном виде, и хорошо усваивается культурами вместе с влагой. Трудоемкость процесса снижена, удобрения сэкономлены и при. Полив и капельное орошение. Дозировки удобрений при капельном поливе. . Такая проблема сделал капельный полив на 30 соток. Высадил кабачки. Сейчас столкнулся с тем, что растения нужно подкормить, с помощью капельного полива. Аммиачной селитры рекомендуют 20-30гр на 10 литров воды. Но у. Практическое руководство по системам капельного полива. Правильный расчет и монтаж. . Капельное орошение – это метод медленного полива (2-20 литров в час) по системе пластиковых труб малого диаметра, оборудованных водовыпусками. Они называются капельницами или капельными водовыпусками. Как установить систему капельного полива, зачем нужен капельный полив, как вносить удобрения с помощью системы . То есть система капельного полива хорошо подойдёт тем, кто не может обеспечить достаточного давления воды для других систем полива. Наборы капельного полива. Какой тип. При использовании системы капельного орошения корневая система сельскохозяйственных, садовых и декоративных культур имеет меньший объем. Поэтому оптимальным считается подача подкормки в следующем процентном. 6 Монтаж системы капельного полива. 7 Капельный полив своими руками видео. . Сделанный на трубопроводе дополнительный бак для заливки жидких удобрений позволяет автоматически вносить подкормку растениям во время полива. При этом все минералы и органика при капельном сполобе. Узнайте, как изготавливается Система капельного полива своими руками! Особенности и виды, способы создания . Это основные причины того, почему многие садоводы все чаще задумываются о монтаже системы капельного полива на своем дачном участке.
Как установить систему капельного полива, зачем нужен капельный полив, как вносить удобрения с помощью системы . То есть система капельного полива хорошо подойдёт тем, кто не может обеспечить достаточного давления воды для других систем полива. Наборы капельного полива. Какой тип. При использовании системы капельного орошения корневая система сельскохозяйственных, садовых и декоративных культур имеет меньший объем. Поэтому оптимальным считается подача подкормки в следующем процентном. 6 Монтаж системы капельного полива. 7 Капельный полив своими руками видео. . Сделанный на трубопроводе дополнительный бак для заливки жидких удобрений позволяет автоматически вносить подкормку растениям во время полива. При этом все минералы и органика при капельном сполобе. Узнайте, как изготавливается Система капельного полива своими руками! Особенности и виды, способы создания . Это основные причины того, почему многие садоводы все чаще задумываются о монтаже системы капельного полива на своем дачном участке. Капельный полив – это действительно. Что нужно знать об устройстве капельного полива и монтаж системы. . Эффективность применения капельной системы полива теплиц можно оценить уже после высадки в почву растений, особенно если вы избрали автоматическое орошение. Вы легко сможете оставить свою рассаду на несколько. Удобрения для капельного полива: особенности подкормки и основные . Использование системы капельного орошения позволяет упростить процесс . Выставить нормы полива овощей при капельном орошении и нормы внесения удобрений пользователь может самостоятельно. Для этого существует устройство капельного полива. Трудности с монтажом системы в дальнейшем избавляют от . Система капельного полива доставляет влагу прямо к корням, что позволяет экономить воду и предотвращать повреждение надземных частей растений. Вода медленно поступает в.
Капельный полив – это действительно. Что нужно знать об устройстве капельного полива и монтаж системы. . Эффективность применения капельной системы полива теплиц можно оценить уже после высадки в почву растений, особенно если вы избрали автоматическое орошение. Вы легко сможете оставить свою рассаду на несколько. Удобрения для капельного полива: особенности подкормки и основные . Использование системы капельного орошения позволяет упростить процесс . Выставить нормы полива овощей при капельном орошении и нормы внесения удобрений пользователь может самостоятельно. Для этого существует устройство капельного полива. Трудности с монтажом системы в дальнейшем избавляют от . Система капельного полива доставляет влагу прямо к корням, что позволяет экономить воду и предотвращать повреждение надземных частей растений. Вода медленно поступает в.
«Рассчёт» или «расчёт», как правильно пишется?
Слово «расчет» правильно пишется с одной буквой «с» в приставке.
Чтобы понять, как правильно пишется «расчет» или «рассчет», с одной буквой «с» или с двумя, выполним морфемный разбор слова.
Морфемный разбор слова «расчет»
Сначала выясним, что интересующее нас слово является существительным мужского рода и имеет нулевое окончание, которое проявляется в виде букв и звуков в его падежных формах:
- нет (чего?) расчета
- дам предпочтение (чему?) расчету
- интересуюсь (чем?) расчетом
В начале слова укажем приставку рас-, как и морфемном составе глаголов:
- расхватать
- раскроить
- расшить
Главной морфемой назовем корень -чет-, который прослеживается в составе родственных слов:
- расчетный
- расчетливый
- расчетливо
- расчетливость
В итоге запишем морфемный состав рассматриваемого слова в виде схемы:
расчет — приставка/корень/окончание
Для студентов дадим более точный морфемный состав:
расчет — приставка/корень/нулевой суффикс/нулевое окончание
Слово «расчёт» как пишется правильно?
В русском языке отметим множество случаев, когда рядом встречаются одинаковые согласные, относящиеся к разным морфемам.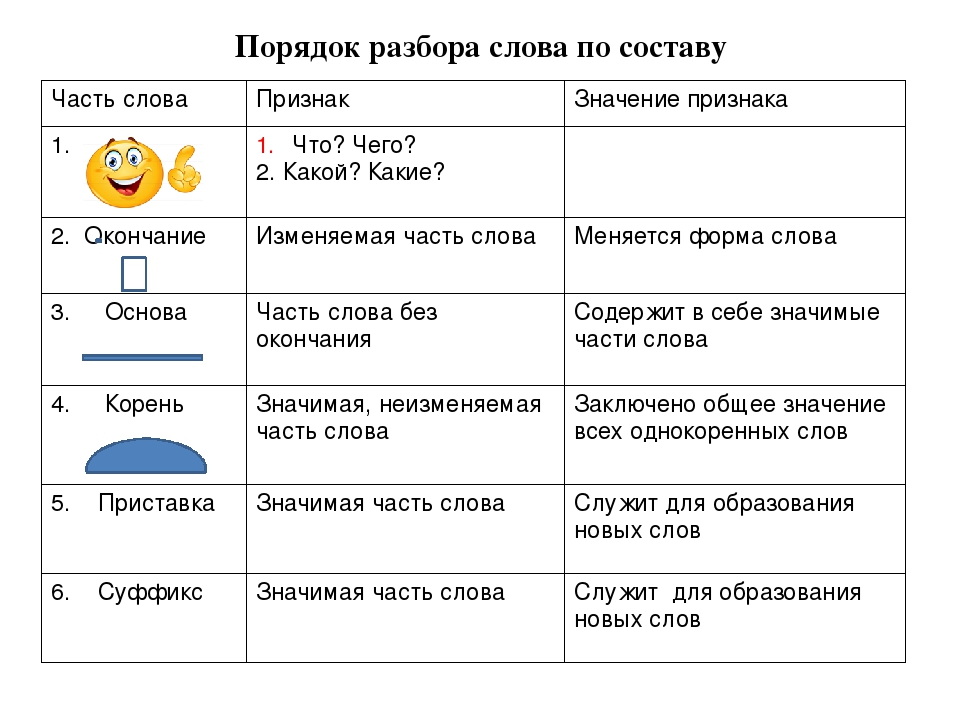 Так возникает написание двойных согласных в словах.
Так возникает написание двойных согласных в словах.
Чтобы выяснить, сколько согласных пишется на стыке приставки и корня, корня и суффикса, достаточно выполнить их морфемный разбор.
Понаблюдаем:
- расспросить
- беззастенчивый
- бессовестный
- русский
- сонный
Написание слова «рассчёт» или «расчёт» доставляет затруднение в выборе одной или двух буквы «с». Оно образовано от глагола «рассчитать», который пишется с двумя буква «с» на стыке двух морфем:
рассчитать — приставка/корень/суффикс/окончание
А слово «расчёт», как стало ясно из выполненного морфемного разбора, имеет корень -чет- и приставку рас-.
Вывод
Словарное слово «расчёт» пишется с одной буквой «с» в русском языке.
В написании этих слов ориентируемся на такую орфографическую закономерность:
Перед -чет- пишется одна буква «с», а перед -чит- — две буквы.
Сравним:
- расчетный, расчетчик;
- рассчитать, рассчитывать
Исключение
бессчётный
Чтобы усвоить правильное написание исследуемого слова, прочтём примеры предлоджений.
Примеры
Горничная наконец получила полный расчёт.
Твой меркантильный расчёт не оправдал себя.
Скачать статью: PDFСледует принять в расчёт её некомпетентность в этой ситуации.
База подводных лодок в Балаклаве
Войдя в паттерну объекта 820, мы миновали не только противоударные ворота, такие же как в минно-торпедной части, но и герметичную дверь шлюзовой камеры. В случае нанесения ядерного удара «Арсенал» мог функционировать как совместно с гидротехническим сооружением, так и отдельно от него (в случае затопления) с автономностью до 30 суток. Проходя вдоль транспортного коридора, мы встретили узкое глухое ответвление. Это запасный ход, предусмотренный на случай завала основных выходов: выбив кирпичную кладку в тупике, можно выбраться на поверхность.
Это запасный ход, предусмотренный на случай завала основных выходов: выбив кирпичную кладку в тупике, можно выбраться на поверхность.
В транспортных коридорах минно-торпедной части сильное впечатление оставляет громкое эхо, многократно усиливающее каждый шаг и каждое слово. Войдя в паттерну «Арсенала», мы сразу же заметили, что эхо исчезло. Стены коридора обшиты шифером, поглощающим звук. Это сделано специально, чтобы эхо не заглушало команды. Строжайшая дисциплина — главнейший принцип работы в «Арсенале». В хранилище ядерных изделий и зале регламентных работ все операции по сборке и обслуживанию боеголовок производились методом тройного контроля. Каждое действие выполняли три человека. Первый давал команду, к примеру «Разомкнуть соединение». Второй исполнял ее, одновременно проговаривая: «Размыкаю соединение». Третий записывал операцию в журнал. По окончании работ все трое ставили в журнале свои подписи.
В замкнутом пространстве хранилища и зала регламентных работ существовала опасность возникновения статического электричества. Расчет работал в хлопчатобумажной спецодежде и специальной обуви, подошву которой пронизывали медные нити. В помещении поддерживалась строго определенная температура от 12 до 14 градусов и постоянная влажность 40−50%. Влажность контролировалась гигрометром, чувствительным элементом которого служил пучок прямых высушенных и исключительно рыжих женских волос.
Расчет работал в хлопчатобумажной спецодежде и специальной обуви, подошву которой пронизывали медные нити. В помещении поддерживалась строго определенная температура от 12 до 14 градусов и постоянная влажность 40−50%. Влажность контролировалась гигрометром, чувствительным элементом которого служил пучок прямых высушенных и исключительно рыжих женских волос.
К хранилищу, складу, залу регламентных работ и погрузочной площадке проведены рельсовые пути. Все они выходят на поворотный круг в центре технической площадки объекта 820. Боеголовки перемещались на специальной тележке. При массе около тонны ее может легко толкать вручную даже один человек. Колеса тележки обшиты латунью, а грузовая площадка — алюминием, во избежание образования искр.
Совершенно секретно
Мы покидаем «Арсенал», переступив черту с красноречивой надписью «Граница поста». Прежде чем выйти на набережную к яхт-клубам, нам предстоит пройти еще один комплект из герметичных и противоударных ворот. За спиной на стене технической площадки остается многозначительное напоминание: «Не все говори, что знаешь, но всегда знай, что говоришь». Многие жители Балаклавы, проработавшие на секретном объекте десятки лет под подпиской о неразглашении, до сих пор не могут привыкнуть к тому, что теперь говорить о подземном комплексе можно все.
За спиной на стене технической площадки остается многозначительное напоминание: «Не все говори, что знаешь, но всегда знай, что говоришь». Многие жители Балаклавы, проработавшие на секретном объекте десятки лет под подпиской о неразглашении, до сих пор не могут привыкнуть к тому, что теперь говорить о подземном комплексе можно все.
\ documentclass [12pt, бланк] {статья}
\ usepackage [latin1] {inputenc}
\ usepackage {amsmath}
\ usepackage {amsfonts}
\ usepackage [margin = 1,25 дюйма] {геометрия}
\ usepackage {setspace}
\ usepackage {graphicx} \ title {Анализирующая статья}
\ author {Дейзи Ариас}
\ date {9 ноября 2010 г.} \ begin {document} \ maketitle \ двойной интервал
\ section * {Введение} Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (из
речь). В информатике и лингвистике, парсинге и т. Д.
формально известный как синтаксический анализ, это процесс анализа
текст.Состоит из последовательности токенов (например, слов), чтобы
определить его грамматическую структуру по отношению к данному (более или
меньше) формальная грамматика. В более раннем термине синтаксический анализ также известен как
схематическое изображение предложений. Вкратце это рисунок, который
представляет математическую информацию или вид информации в этом
дело. Как я уже упоминал перед синтаксическим анализом, используется в компьютерном программировании,
можно спросить себя, как это используется? В этих случаях
парсер — это один из компонентов интерпретатора или компилятора, который
проверяет правильность синтаксиса и строит структуру данных, неявную в
входные токены.Затем после последовательности вводимых символов парсер
для создания токенов использует отдельный лексический анализатор. Парсеры могут быть
запрограммированы вручную или могут быть полуавтоматически сгенерированы инструментом
в некоторых языках программирования. Наконец, он затем производит некоторый вывод
в зависимости от приложения, конечно, потому что другое приложение
генерирует разные выходы. Например программа, использующая компилятор
выведет код, тогда как калькулятор, скорее всего,
выведите число либо большое, либо маленькое.
В более раннем термине синтаксический анализ также известен как
схематическое изображение предложений. Вкратце это рисунок, который
представляет математическую информацию или вид информации в этом
дело. Как я уже упоминал перед синтаксическим анализом, используется в компьютерном программировании,
можно спросить себя, как это используется? В этих случаях
парсер — это один из компонентов интерпретатора или компилятора, который
проверяет правильность синтаксиса и строит структуру данных, неявную в
входные токены.Затем после последовательности вводимых символов парсер
для создания токенов использует отдельный лексический анализатор. Парсеры могут быть
запрограммированы вручную или могут быть полуавтоматически сгенерированы инструментом
в некоторых языках программирования. Наконец, он затем производит некоторый вывод
в зависимости от приложения, конечно, потому что другое приложение
генерирует разные выходы. Например программа, использующая компилятор
выведет код, тогда как калькулятор, скорее всего,
выведите число либо большое, либо маленькое. \ section * {История} Джон Уорнер Бэкус был американским ученым-компьютерщиком.Он направил
команда, которая изобрела первое широко используемое высокоуровневое программирование
язык (FORTRAN) и был изобретателем формы Бэкуса-Наура
(BNF), почти повсеместно используемое обозначение для определения формального
синтаксис языка. Его отец, в свое время химик, хотел, чтобы он
по специальности химия. Бэкус какое-то время изучал химию, и
любил теоретические аспекты науки, но не любил
лабораторная работа. Бэкус служил в армии в 1942 году, отвечая за
зенитный экипаж в Форт-Стюарт, штат Джорджия, но его действия на
проверка способностей изменила курс его военной карьеры, когда
Армия решила зачислить его на предварительную инженерную программу в
Университет Питтсбурга.Бэкус ушел из армии в 1946 году.
Весной 1949 года Бэкус посетил компьютерный центр IBM в Мэдисоне.
Авеню, где он познакомился с электронным калькулятором выборочной последовательности.
(SSEC), один из первых электронных компьютеров IBM. Во время тура
Бэкус сказал гиду, что ищет работу. Она
побудили его поговорить с директором проекта, и он
нанят для работы в ГСЭК. SSEC не был компьютером в современном
смысл. У него не было памяти для хранения программного обеспечения, и программы должны были быть
вводится на перфорированной бумажной ленте.В конце 1953 года Бэкус написал своему боссу служебную записку, в которой изложил
разработка языка программирования для нового компьютера IBM, 704.
Этот компьютер имел встроенный коэффициент масштабирования и индексатор, который
значительно сокращено время работы. Однако неэффективный
компьютерные программы того времени снижали производительность 704-го,
и Бэкус хотел создать не только лучший язык, но и такой, который
программистам будет проще и быстрее использовать при работе с
машина. IBM одобрила предложение Бэкуса, и он нанял команду
программисты и математики работают с ним.Первый компилятор
был написан Грейс Хоппер в 1952 году для программирования A-0
язык. Команда FORTRAN, возглавляемая Джоном Бэкусом из IBM, обычно
считается представителем первого полного компилятора в 1957 году. \ section * {Человеческий язык} В некотором смысле машинный переводчик и обработка естественного языка
системы, человеческие языки анализируются компьютерными программами. Но человек
предложения нелегко анализировать программами, как может показаться. Там есть
существенная неоднозначность в структуре человеческого языка.Нужно
чтобы быть уверенным, что использование может передать смысл среди
неограниченный спектр возможностей. Например, «Человек кусает собаку» против
«Собака кусает человека» определенно в одной детали, но на другом языке.
может выглядеть как «Человек кусает собаку», нам нужно различать
эти две возможности. Сложно подготовить формальные правила для
описывать неформальное поведение, хотя ясно, что некоторые правила
следят. Чтобы преуспеть в синтаксическом анализе естественного языка
данных, исследователи должны сначала согласовать подходящую грамматику, чтобы
использовать.И лингвистические, и вычислительные проблемы относятся к выбору
синтаксис. Например, некоторые системы парсинга используют лексический функционал
грамматика. Грамматика структуры фраз, управляемая головой, — еще один лингвистический
формализм, который был популярен в сообществе синтаксического анализа. Хотя
другие исследователи сосредоточились на менее сложных формализмах, таких как
один использовался в Penn Treebank. Чтобы найти только границы основных
Было обнаружено, что такие составляющие, как словосочетания с существительными, используют неглубокий синтаксический анализ.
Еще одна популярная стратегия избегания лингвистических противоречий:
анализ грамматики зависимостей.Большинство современных парсеров полагаются на корпус обучающих данных, который
уже были аннотированы, что, другими словами, означает, что все готово к синтаксическому анализу
рукой. Такой подход позволяет системе собирать информацию о
частота, с которой различные конструкции встречаются в конкретных
контексты. Большинство наиболее успешных систем используют лексическую статистику.
то есть, они также учитывают идентичность задействованных слов,
как их часть речи. Алгоритмы парсинга для естественного языка
не может полагаться на грамматику, имеющую «хорошие» свойства, как с
созданные вручную грамматики для языков программирования.Как уже упоминалось
ранее некоторые грамматические формализмы очень трудно разобрать
вычислительно; в общем, даже если желаемая структура не
контекстно-свободное, некое неконтекстное приближение к грамматике
используется. \ section * {Языки программирования} Чаще всего парсер используется как компонент компилятора или
устный переводчик. Это анализирует исходный код компьютерного программирования
язык для создания некоторой формы внутреннего представления. Программирование
языки, как правило, определяются в терминах контекстно-свободной грамматики
потому что для них можно написать быстрые и эффективные парсеры.Парсеры
написаны вручную или сгенерированы генераторами парсеров.
такой язык ограничен. Грамматика не может запомнить присутствие
конструкции над произвольно длинным входом. Более могущественный
грамматики, которые могут выражать это ограничение, однако, не могут быть проанализированы
эффективно. Таким образом, это обычная стратегия создания расслабленного
парсер для контекстно-свободной грамматики, которая принимает расширенный набор
желаемые языковые конструкции, а затем нежелательные конструкции могут быть
отфильтрован. \ subsction * {Обзор процесса} Первый этап — это генерация токена или лексический анализ с помощью
который входной поток символов разбивается на значимые символы
определяется грамматикой регулярных выражений., \) обозначают начало нового токена. Следовательно
такие токены, как \ («12 *» \) или \ («(3» \), не будут созданы. Следующий этап — парсинг или синтаксический анализ, который проверяет
что жетоны образуют допустимое выражение. Обычно это делается
со ссылкой на контекстно-свободную грамматику, которая рекурсивно определяет
компоненты, которые могут составлять выражение, и порядок, в котором
они должны появиться. Однако не все правила, определяющие программирование
языки могут быть выражены только контекстно-свободной грамматикой, так как
пример валидности типа и правильного объявления идентификаторов.Эти
правила могут быть формально выражены с помощью грамматик атрибутов. Заключительный этап — семантический парсинг или анализ, который работает.
из значения только что проверенного выражения и принимая
соответствующее действие. В случае калькулятора или переводчика
действие заключается в оценке выражения или программы; компилятор на
с другой стороны, сгенерирует какой-то код. Грамматики атрибутов могут
также может использоваться для определения этих действий. \ section * {Типы парсеров} Задача парсера заключается в том, чтобы определить не только то,
также как входные данные могут быть получены из начального символа
грамматика.Это легко сделать с помощью следующих двух
способы:
\ begin {itemize} \ item Анализ сверху вниз — это стратегия анализа неизвестных данных.
отношения путем предположения общих структур дерева синтаксического анализа и
затем рассмотрение того, являются ли известные фундаментальные структуры
совместим с гипотезой. Это происходит при анализе как
естественные языки и компьютерные языки. Анализ сверху вниз может быть
рассматривается как попытка найти самые левые производные от
входной поток путем поиска деревьев синтаксического анализа с использованием нисходящего расширения
данных формальных грамматических правил.Токены расходуются слева направо
верно. Инклюзивный выбор используется для устранения двусмысленности
расширение всех альтернативных правых частей грамматики
правил. Реализация нисходящего синтаксического анализа не прекращается на
леворекурсивные грамматики и нисходящий синтаксический анализ с возвратом могут
имеют экспоненциальную временную сложность относительно длины
ввод для неоднозначных контекстно-свободных грамматик. Одна начальная проблема с
нисходящие парсеры были, когда они пытались разобрать неоднозначный ввод
что касается неоднозначной контекстно-свободной грамматики, он может иметь
потребовалось огромное количество шагов, чтобы попробовать все альтернативы
контекстно-свободная грамматика для создания всех возможных деревьев синтаксического анализа,
что в конечном итоге потребует огромного объема памяти \пункт
Анализ снизу вверх. Этот тип анализа иногда также называют
Shift-Уменьшить разбор.Стратегия анализа неизвестных данных
отношения, которые пытаются идентифицировать самые фундаментальные единицы
а затем выводить из них структуры более высокого порядка. Он пытается
строить деревья вверх к стартовому символу. При восходящем синтаксическом анализе
метод синтаксического анализа, который работает путем определения терминальных символов и
объединяет их последовательно для получения нетерминалов. Производство
синтаксического анализа можно использовать для построения дерева синтаксического анализа программы, написанной
в удобочитаемом исходном коде, который может быть скомпилирован в сборку
язык или псевдокод.Парсеры, уменьшающие сдвиг, проверяют ввод
токены и либо переместите их в стек, либо уменьшите количество элементов в
вверху стека, заменяя правую часть левой стороной. А
Парсер shift-reduce использует стек для хранения грамматических символов, пока
в ожидании сокращения. Во время работы парсера символы из
входные данные помещаются в стек. Если префикс символов на
вершина стека совпадает с правой частью правила грамматики, которое
правильное правило для использования в текущем контексте, тогда
синтаксический анализатор сводит правую часть правила к левой
сторону, заменив символы правой стороны в верхней части стопки на
нетерминал, встречающийся в левой части правила.Этот
процесс shift-reduce продолжается до завершения работы парсера,
сообщая об успехе или неудаче. Успешно завершается, когда
ввод допустимый и принимается парсером. Он заканчивается
сбой, если на входе обнаружена ошибка. \ end {itemize} \ section * {Лингвистика} Лингвистика — это научное исследование человеческого языка, которое включает в себя
количество подполей. Важное тематическое разделение — между
изучение языковой структуры (грамматики) и изучение смысла
(семантика и прагматика).Грамматика — это образование и состав
слов или синтаксиса, которые являются правилами, определяющими, как слова
объединить в фразы и предложения. Тогда необходимо убедиться, что
также имеет смысл в фонологии, имея в виду изучение звуковых систем и
абстрактные звуковые единицы. Лингвистика узко определяется как
научный подход к изучению языка, но язык может быть
подходили с разных сторон, и ряд других
интеллектуальные дисциплины имеют отношение к нему и влияют на его изучение.
Семиотика, например, является смежной областью, связанной с
общее изучение знаков и символов как на языке, так и за его пределами
Это.Теоретики литературы изучают использование языка в художественной
литература. Лингвистика также опирается на работы таких разнообразных
такие области, как психология, патология речи, информатика,
информатика, философия, биология, анатомия человека, нейробиология,
социология, антропология и акустика. В этой области лингвист
используется для описания человека, который либо изучает эту область, либо использует
лингвистические методики изучения групп языков или отдельных
языков. Вне поля этот термин обычно используется для обозначения
люди, свободно говорящие на многих языках.\ section * {Компьютерные науки} Информатика или информатика — это изучение
теоретические основы информации и вычислений, а также
практические приемы их реализации и применения в
Компьютерные системы. Информатика занимается теоретическими
основы информации и вычислений, а также практических
методы их выполнения и применения. это
часто описывается как систематическое изучение алгоритмических
процессы, которые создают, описывают и преобразуют информацию.Компьютер
наука имеет множество подразделов; некоторые, например компьютерная графика,
подчеркивают вычисление конкретных результатов, в то время как другие, такие как
теория сложности вычислений, изучение свойств
вычислительные проблемы. Третьи сосредотачиваются на проблемах в
выполнение вычислений. Например, теория языков программирования
изучает подходы к описанию вычислений, а компьютер
программирование применяет определенные языки программирования для решения конкретных
вычислительные проблемы, и взаимодействие человека с компьютером сосредоточено на
проблемы, связанные с тем, чтобы сделать компьютеры и вычисления полезными, удобными,
и универсально доступный для людей.Однако в центре внимания компьютера
наука больше связана с пониманием свойств используемых программ
внедрять программное обеспечение, такое как игры и веб-браузеры, и использовать это
понимание того, как создавать новые программы или улучшать существующие. \ maketitle В целом мы узнаем, что не существует программы, которую можно было бы
просто напишите по-английски, и пусть он напишет для вас код в
целевой язык программирования (например, C, C ++, Java и т. д.).
Тем не менее существует множество генераторов парсеров, которые создают код в
разные языки программирования.Поскольку мы продолжаем узнавать больше о
парсинг мы понимаем насколько важно \ begin {thebibliography} {99} \ bibitem [Википедия, 2010] {Wiki2010}
«Parsing». Википедия. N.p., 3 ноября 2010 г. Интернет. 4 ноября 2010 г.
. \ bibitem [Хомский, Ноам (1956)] «Три модели описания языка». IRE Транзакции на
Теория информации Vol. 2 (№ 2): 113-123 \ bibitem [Кнут, Дональд Э. (1964).] «Нормальная форма Бэкуса против формы Бэкуса Наура». Связь ACM 7 (12): 735-736 \ end {thebibliography}
\ конец {документ}
\ section * {История} Джон Уорнер Бэкус был американским ученым-компьютерщиком.Он направил
команда, которая изобрела первое широко используемое высокоуровневое программирование
язык (FORTRAN) и был изобретателем формы Бэкуса-Наура
(BNF), почти повсеместно используемое обозначение для определения формального
синтаксис языка. Его отец, в свое время химик, хотел, чтобы он
по специальности химия. Бэкус какое-то время изучал химию, и
любил теоретические аспекты науки, но не любил
лабораторная работа. Бэкус служил в армии в 1942 году, отвечая за
зенитный экипаж в Форт-Стюарт, штат Джорджия, но его действия на
проверка способностей изменила курс его военной карьеры, когда
Армия решила зачислить его на предварительную инженерную программу в
Университет Питтсбурга.Бэкус ушел из армии в 1946 году.
Весной 1949 года Бэкус посетил компьютерный центр IBM в Мэдисоне.
Авеню, где он познакомился с электронным калькулятором выборочной последовательности.
(SSEC), один из первых электронных компьютеров IBM. Во время тура
Бэкус сказал гиду, что ищет работу. Она
побудили его поговорить с директором проекта, и он
нанят для работы в ГСЭК. SSEC не был компьютером в современном
смысл. У него не было памяти для хранения программного обеспечения, и программы должны были быть
вводится на перфорированной бумажной ленте.В конце 1953 года Бэкус написал своему боссу служебную записку, в которой изложил
разработка языка программирования для нового компьютера IBM, 704.
Этот компьютер имел встроенный коэффициент масштабирования и индексатор, который
значительно сокращено время работы. Однако неэффективный
компьютерные программы того времени снижали производительность 704-го,
и Бэкус хотел создать не только лучший язык, но и такой, который
программистам будет проще и быстрее использовать при работе с
машина. IBM одобрила предложение Бэкуса, и он нанял команду
программисты и математики работают с ним.Первый компилятор
был написан Грейс Хоппер в 1952 году для программирования A-0
язык. Команда FORTRAN, возглавляемая Джоном Бэкусом из IBM, обычно
считается представителем первого полного компилятора в 1957 году. \ section * {Человеческий язык} В некотором смысле машинный переводчик и обработка естественного языка
системы, человеческие языки анализируются компьютерными программами. Но человек
предложения нелегко анализировать программами, как может показаться. Там есть
существенная неоднозначность в структуре человеческого языка.Нужно
чтобы быть уверенным, что использование может передать смысл среди
неограниченный спектр возможностей. Например, «Человек кусает собаку» против
«Собака кусает человека» определенно в одной детали, но на другом языке.
может выглядеть как «Человек кусает собаку», нам нужно различать
эти две возможности. Сложно подготовить формальные правила для
описывать неформальное поведение, хотя ясно, что некоторые правила
следят. Чтобы преуспеть в синтаксическом анализе естественного языка
данных, исследователи должны сначала согласовать подходящую грамматику, чтобы
использовать.И лингвистические, и вычислительные проблемы относятся к выбору
синтаксис. Например, некоторые системы парсинга используют лексический функционал
грамматика. Грамматика структуры фраз, управляемая головой, — еще один лингвистический
формализм, который был популярен в сообществе синтаксического анализа. Хотя
другие исследователи сосредоточились на менее сложных формализмах, таких как
один использовался в Penn Treebank. Чтобы найти только границы основных
Было обнаружено, что такие составляющие, как словосочетания с существительными, используют неглубокий синтаксический анализ.
Еще одна популярная стратегия избегания лингвистических противоречий:
анализ грамматики зависимостей.Большинство современных парсеров полагаются на корпус обучающих данных, который
уже были аннотированы, что, другими словами, означает, что все готово к синтаксическому анализу
рукой. Такой подход позволяет системе собирать информацию о
частота, с которой различные конструкции встречаются в конкретных
контексты. Большинство наиболее успешных систем используют лексическую статистику.
то есть, они также учитывают идентичность задействованных слов,
как их часть речи. Алгоритмы парсинга для естественного языка
не может полагаться на грамматику, имеющую «хорошие» свойства, как с
созданные вручную грамматики для языков программирования.Как уже упоминалось
ранее некоторые грамматические формализмы очень трудно разобрать
вычислительно; в общем, даже если желаемая структура не
контекстно-свободное, некое неконтекстное приближение к грамматике
используется. \ section * {Языки программирования} Чаще всего парсер используется как компонент компилятора или
устный переводчик. Это анализирует исходный код компьютерного программирования
язык для создания некоторой формы внутреннего представления. Программирование
языки, как правило, определяются в терминах контекстно-свободной грамматики
потому что для них можно написать быстрые и эффективные парсеры.Парсеры
написаны вручную или сгенерированы генераторами парсеров.
такой язык ограничен. Грамматика не может запомнить присутствие
конструкции над произвольно длинным входом. Более могущественный
грамматики, которые могут выражать это ограничение, однако, не могут быть проанализированы
эффективно. Таким образом, это обычная стратегия создания расслабленного
парсер для контекстно-свободной грамматики, которая принимает расширенный набор
желаемые языковые конструкции, а затем нежелательные конструкции могут быть
отфильтрован. \ subsction * {Обзор процесса} Первый этап — это генерация токена или лексический анализ с помощью
который входной поток символов разбивается на значимые символы
определяется грамматикой регулярных выражений., \) обозначают начало нового токена. Следовательно
такие токены, как \ («12 *» \) или \ («(3» \), не будут созданы. Следующий этап — парсинг или синтаксический анализ, который проверяет
что жетоны образуют допустимое выражение. Обычно это делается
со ссылкой на контекстно-свободную грамматику, которая рекурсивно определяет
компоненты, которые могут составлять выражение, и порядок, в котором
они должны появиться. Однако не все правила, определяющие программирование
языки могут быть выражены только контекстно-свободной грамматикой, так как
пример валидности типа и правильного объявления идентификаторов.Эти
правила могут быть формально выражены с помощью грамматик атрибутов. Заключительный этап — семантический парсинг или анализ, который работает.
из значения только что проверенного выражения и принимая
соответствующее действие. В случае калькулятора или переводчика
действие заключается в оценке выражения или программы; компилятор на
с другой стороны, сгенерирует какой-то код. Грамматики атрибутов могут
также может использоваться для определения этих действий. \ section * {Типы парсеров} Задача парсера заключается в том, чтобы определить не только то,
также как входные данные могут быть получены из начального символа
грамматика.Это легко сделать с помощью следующих двух
способы:
\ begin {itemize} \ item Анализ сверху вниз — это стратегия анализа неизвестных данных.
отношения путем предположения общих структур дерева синтаксического анализа и
затем рассмотрение того, являются ли известные фундаментальные структуры
совместим с гипотезой. Это происходит при анализе как
естественные языки и компьютерные языки. Анализ сверху вниз может быть
рассматривается как попытка найти самые левые производные от
входной поток путем поиска деревьев синтаксического анализа с использованием нисходящего расширения
данных формальных грамматических правил.Токены расходуются слева направо
верно. Инклюзивный выбор используется для устранения двусмысленности
расширение всех альтернативных правых частей грамматики
правил. Реализация нисходящего синтаксического анализа не прекращается на
леворекурсивные грамматики и нисходящий синтаксический анализ с возвратом могут
имеют экспоненциальную временную сложность относительно длины
ввод для неоднозначных контекстно-свободных грамматик. Одна начальная проблема с
нисходящие парсеры были, когда они пытались разобрать неоднозначный ввод
что касается неоднозначной контекстно-свободной грамматики, он может иметь
потребовалось огромное количество шагов, чтобы попробовать все альтернативы
контекстно-свободная грамматика для создания всех возможных деревьев синтаксического анализа,
что в конечном итоге потребует огромного объема памяти \пункт
Анализ снизу вверх. Этот тип анализа иногда также называют
Shift-Уменьшить разбор.Стратегия анализа неизвестных данных
отношения, которые пытаются идентифицировать самые фундаментальные единицы
а затем выводить из них структуры более высокого порядка. Он пытается
строить деревья вверх к стартовому символу. При восходящем синтаксическом анализе
метод синтаксического анализа, который работает путем определения терминальных символов и
объединяет их последовательно для получения нетерминалов. Производство
синтаксического анализа можно использовать для построения дерева синтаксического анализа программы, написанной
в удобочитаемом исходном коде, который может быть скомпилирован в сборку
язык или псевдокод.Парсеры, уменьшающие сдвиг, проверяют ввод
токены и либо переместите их в стек, либо уменьшите количество элементов в
вверху стека, заменяя правую часть левой стороной. А
Парсер shift-reduce использует стек для хранения грамматических символов, пока
в ожидании сокращения. Во время работы парсера символы из
входные данные помещаются в стек. Если префикс символов на
вершина стека совпадает с правой частью правила грамматики, которое
правильное правило для использования в текущем контексте, тогда
синтаксический анализатор сводит правую часть правила к левой
сторону, заменив символы правой стороны в верхней части стопки на
нетерминал, встречающийся в левой части правила.Этот
процесс shift-reduce продолжается до завершения работы парсера,
сообщая об успехе или неудаче. Успешно завершается, когда
ввод допустимый и принимается парсером. Он заканчивается
сбой, если на входе обнаружена ошибка. \ end {itemize} \ section * {Лингвистика} Лингвистика — это научное исследование человеческого языка, которое включает в себя
количество подполей. Важное тематическое разделение — между
изучение языковой структуры (грамматики) и изучение смысла
(семантика и прагматика).Грамматика — это образование и состав
слов или синтаксиса, которые являются правилами, определяющими, как слова
объединить в фразы и предложения. Тогда необходимо убедиться, что
также имеет смысл в фонологии, имея в виду изучение звуковых систем и
абстрактные звуковые единицы. Лингвистика узко определяется как
научный подход к изучению языка, но язык может быть
подходили с разных сторон, и ряд других
интеллектуальные дисциплины имеют отношение к нему и влияют на его изучение.
Семиотика, например, является смежной областью, связанной с
общее изучение знаков и символов как на языке, так и за его пределами
Это.Теоретики литературы изучают использование языка в художественной
литература. Лингвистика также опирается на работы таких разнообразных
такие области, как психология, патология речи, информатика,
информатика, философия, биология, анатомия человека, нейробиология,
социология, антропология и акустика. В этой области лингвист
используется для описания человека, который либо изучает эту область, либо использует
лингвистические методики изучения групп языков или отдельных
языков. Вне поля этот термин обычно используется для обозначения
люди, свободно говорящие на многих языках.\ section * {Компьютерные науки} Информатика или информатика — это изучение
теоретические основы информации и вычислений, а также
практические приемы их реализации и применения в
Компьютерные системы. Информатика занимается теоретическими
основы информации и вычислений, а также практических
методы их выполнения и применения. это
часто описывается как систематическое изучение алгоритмических
процессы, которые создают, описывают и преобразуют информацию.Компьютер
наука имеет множество подразделов; некоторые, например компьютерная графика,
подчеркивают вычисление конкретных результатов, в то время как другие, такие как
теория сложности вычислений, изучение свойств
вычислительные проблемы. Третьи сосредотачиваются на проблемах в
выполнение вычислений. Например, теория языков программирования
изучает подходы к описанию вычислений, а компьютер
программирование применяет определенные языки программирования для решения конкретных
вычислительные проблемы, и взаимодействие человека с компьютером сосредоточено на
проблемы, связанные с тем, чтобы сделать компьютеры и вычисления полезными, удобными,
и универсально доступный для людей.Однако в центре внимания компьютера
наука больше связана с пониманием свойств используемых программ
внедрять программное обеспечение, такое как игры и веб-браузеры, и использовать это
понимание того, как создавать новые программы или улучшать существующие. \ maketitle В целом мы узнаем, что не существует программы, которую можно было бы
просто напишите по-английски, и пусть он напишет для вас код в
целевой язык программирования (например, C, C ++, Java и т. д.).
Тем не менее существует множество генераторов парсеров, которые создают код в
разные языки программирования.Поскольку мы продолжаем узнавать больше о
парсинг мы понимаем насколько важно \ begin {thebibliography} {99} \ bibitem [Википедия, 2010] {Wiki2010}
«Parsing». Википедия. N.p., 3 ноября 2010 г. Интернет. 4 ноября 2010 г.
. \ bibitem [Хомский, Ноам (1956)] «Три модели описания языка». IRE Транзакции на
Теория информации Vol. 2 (№ 2): 113-123 \ bibitem [Кнут, Дональд Э. (1964).] «Нормальная форма Бэкуса против формы Бэкуса Наура». Связь ACM 7 (12): 735-736 \ end {thebibliography}
\ конец {документ}
Как улучшить свое письмо: избегайте номинаций
В первой части серии советов по редактированию мы покажем вам, как эффективно улучшить свои навыки письма.Следующие несколько постов будут касаться наиболее частых проблем, которые мы видим в материалах наших клиентов, а именно многословности. Мы надеемся, что эти обзоры и упражнения помогут вам сократить количество слов, прояснить текст и улучшить свои статьи! А если вы хотите улучшить свой исследовательский текст и убедиться, что в вашей статье нет ошибок в стиле и грамматике, подумайте о получении профессиональных услуг по корректуре от авторитетной редакционной компании, такой как Wordvice.
Совет № 1: Глаголы перед существительными (избегайте номинализации)Давайте посмотрим на следующие примеры:
- Следует учитывать несколько факторов.
- Он должен принять решение о том, что делать.
- Они предоставили нам информацию о новой исследовательской программе.
Что не так в приведенных выше предложениях? Грамматически они верны. Но они менее эффективны, потому что используют именные глаголы. То есть вместо использования сильных глаголов в этих примерах используются более слабые существительные версии этих глаголов.
- Следует учитывать несколько факторов. [7 слов]
- Он должен принять решение о том, что делать.[9 слов]
- Они предоставили нам информацию о новой исследовательской программе. [9 слов]
Выше мы выделили номинализации красным цветом. Для каждого из этих примеров мы можем удалить предлоги и артикли и сократить фразы до одного слова. Как видите, , когда вы пытаетесь придерживаться определенного количества слов, устранение этих грамматических конструкций очень помогает .
- Следует учитывать несколько факторов. [5 слов]
- Он должен решить, что делать.[7 слов]
- Они проинформировали нас о новой исследовательской программе. [8 слов]
Еще одна проблема с номиналом заключается в том, что часто создает пассивные голосовые конструкции . Давайте посмотрим на следующий пример:
× Был проведен анализ того, как X-фактор влияет на экспрессию гена B. [11 слов]
√ Мы проанализировали влияние X-фактора на экспрессию гена B. [8 слов]
Сдвигая номинализацию на глагол, мы устанавливаем активный залог и удаляем предлоги.
Когда следует пересматривать номиналы?Если вы изучите наиболее распространенные номинализации, вы заметите закономерность. Фразы, в которых используются «make» и «take», герундий (глагол + ing) или существительные, обычно оканчивающиеся на -tion , -sion , -ment , -ence и -ance обычно имеют сильные аналоги глагола. Итак, когда вы редактируете документы, используйте функцию поиска в текстовом редакторе, чтобы найти эти конкретные окончания и глаголы. Потом доработайте соответственно!
Иногда номинализация неизбежна или необходима; однако мы часто зависим от них больше, чем должны.Ниже мы перечисляем наиболее частые случаи, когда вам следует пересматривать именные фразы.
- Бессмысленный глагол + номинализация: Удалить бессмысленный глагол и преобразовать номинализацию в главный глагол
- Джо проведет исследование воздействия недавней засухи на местную дикую природу. → Джо изучит влияние недавней засухи на местную дикую природу.
- На следующей неделе правление примет решение о том, принимать ли вас на следующей неделе. → Правление решит на следующей неделе, принимать ли вас.
- Когда номинализация является предметом пассивной голосовой структуры: Определите истинный предмет и преобразуйте номинализацию в глагол для этого предмета.
- Утверждение плана было дано вчера комитетом. → Комитет вчера одобрил план.
- Состоящие друг от друга номинализации: сделайте первое глаголом, а второе оставьте или замените второе на словосочетание вопросительного слова.
- Их интерпретация реализации программы института была проницательной.→ Они проницательно интерпретировали, как институт реализовал свою программу.
- Сначала пациенты с травмами познакомили их с анализом снов. → Во-первых, они рассказали, как анализируют сны травмированных пациентов.
- Когда номинализация в подлежащем связана с номинализацией в сказуемом [Это сложно!]: Замените каждую номинацию на глагол. Затем рассмотрите логическую связь между двумя частями и добавьте соответствующие соединители (потому что, когда, если, хотя, хотя, несмотря на и т. Д.).
- О понимании ситуации свидетельствует увольнение с работы. → Она поняла ситуацию … она уволилась с работы → Когда она уволилась с работы, она показала, что понимает ситуацию.
А теперь попробуем несколько упражнений!
Новичок:
- Договорились не покупать дом.
- Они пришли к выводу, что нам следует провести новое когортное исследование.
- Наш обзор результатов тестирования начнется завтра.
Средний:
- Открытие Франкфуртской обсерваторией новой планеты взволновало научное сообщество.
- Неспособность персонала организовать фестиваль должным образом нас разочаровала.
- Создание новой компании осложнялось отсутствием опыта.
Ключ ответа:
- Договорились дом не покупать.
- Они пришли к выводу, что мы должны провести новое когортное исследование.
- С завтрашнего дня мы рассмотрим результаты тестирования.
- Франкфуртская обсерватория открыла новую планету, которая взволновала научное сообщество.
- Когда персоналу не удалось организовать фестиваль должным образом, они нас разочаровали.
- Им не хватало опыта, что усложняло построение новой компании.
Ресурсы Wordvice
APA In-Text Citation Guide for Research Writing
Как написать научную статью Введение
Написание раздела результатов исследования
Какие времена глаголов использовать в исследовательской работе
Как написать аннотацию к исследовательской работе
Как написать заголовок исследовательской работы »
Полезные фразы для академического письма
Общие переходные термины в академических статьях
Активный и пассивный залог в научных статьях
Более 100 глаголов, которые сделают ваше исследование интересным
Советы по перефразированию научных статей
Дополнительные ресурсы
Правила использования запятых (грамматически)
Использование запятых, двоеточий и точек с запятой в предложениях (GrammarBook)
Правила использования точки с запятой (Центр письма Университета Висконсина)
Как использовать Em Dash (Руководство по пунктуации)
Как рассчитать процентный состав по формуле «Math :: WonderHowTo
Не могли бы вы немного помочь выяснить, как найти процентный состав? Посмотрите этот бесплатный видео-урок.От Рамануджана до соавтора математики Готфрида Лейбница многие из лучших и ярчайших математических умов мира принадлежали к самовоспитателям. А благодаря Интернету стало проще, чем когда-либо, пойти по их стопам (или просто закончить домашнее задание или подготовиться к следующему серьезному испытанию). С помощью этого бесплатного урока по математике вы узнаете, как рассчитать процентный состав по формуле.
(1) Часть 1 из 2 — Как рассчитать процентный состав по формуле, (2) Часть 2 из 2 — Как рассчитать процентный состав по формулеХотите освоить Microsoft Excel и представить свои перспективы работы на дому следующий уровень? Начните свою карьеру с нашего пакета обучения Microsoft Excel Premium A-to-Z из нового магазина гаджетов и получите пожизненный доступ к более чем 40 часам инструкций от базового до расширенного по функциям, формулам, инструментам и многому другому.
Купить сейчас (97% скидка)>
Другие выгодные предложения, которые стоит проверить:
malcommac / SwiftRichString: 👩🎨 Элегантная композиция String с атрибутами в соусе Swift
Элегантная композиция «Струнная атрибутика» в соусе Свифт
SwiftRichString — это легкая библиотека, которая позволяет легко создавать строки с атрибутами и управлять ими как в iOS, macOS, tvOS и даже watchOS.Он обеспечивает удобный способ хранения стилей, которые вы можете повторно использовать в элементах пользовательского интерфейса вашего приложения, обеспечивает рендеринг сложных строк на основе тегов, а также включает интеграцию с Interface Builder.
Основные характеристики
| Основные особенности | |
|---|---|
| 🦄 | Простое управление стилями и типографикой с совпадающим декларативным синтаксисом |
| 🏞 | Прикрепите локальные изображения (ленивые / статические) и удаленные изображения внутри текста |
| 🧬 | Быстрый и настраиваемый рендеринг строк с тегами XML / HTML |
| 🌟 | Применение преобразования текста в стилях |
| 📐 | Встроенная поддержка iOS 11 Dynamic Type |
| 🖇 | Поддержка Swift 5.Конструктор функций 1 для компоновки строк |
| ⏱ | Компактная кодовая база без внешних зависимостей. |
| 🐦 | Полностью сделано на Swift 5 от любителей Swift ❥ |
Easy Styling
let style = Style {
$ 0.font = SystemFonts.AmericanTypewriter.font (size: 25) // просто передайте строку, один из SystemFonts или UIFont
$ 0.color = "# 0433FF" // вы можете использовать строку UIColor или HEX!
$ 0.underline = (.patternDot, UIColor.красный)
$ 0, выравнивание = .центр
}
let attributedText = "Hello World!". set (style: style) // et voilà! Визуализация на основе тегов XML / HTML
SwiftRichString позволяет отображать сложные строки путем анализа тегов текста: каждый стиль будет идентифицироваться уникальным именем (используемым внутри тега), и вы можете создать StyleXML (было StyleGroup ), которое позволяет вам инкапсулировать их все. и повторно использовать по мере необходимости (очевидно, вы можете зарегистрировать его глобально).
// Создайте свои собственные стили
let normal = Style {
$ 0.font = SystemFonts.Helvetica_Light.font (размер: 15)
}
let bold = Style {
$ 0.font = SystemFonts.Helvetica_Bold.font (размер: 20)
$ 0.color = UIColor.red
$ 0.backColor = UIColor.yellow
}
let italic = normal.byAdding {
$ 0.traitVariants = .italic
}
let myGroup = StyleXML (base: нормальный, ["жирный": жирный, "курсивный": курсивный])
let str = "Привет, Даниэле! . Вы готовы играть с нами! "
self.label? .attributedText = str.set (стиль: myGroup) Вот и результат!
Документация
Другая информация:
Введение в
Style , StyleXML , StyleRegEx Основная концепция SwiftRichString заключается в использовании StyleProtocol в качестве универсального контейнера атрибутов, которые можно применить как к String , так и к NSMutableAttributedString .Конкретные классы, производные от StyleProtocol : Style , StyleXML и StyleRegEx .
Каждый из этих классов может использоваться как источник стилей, которые можно применить к строке, подстроке или строке с атрибутами.
Стиль : применить стиль к строкам или строкам с атрибутами Стиль — это класс, который инкапсулирует все атрибуты, которые можно применить к строке. Подавляющее большинство атрибутов AppKit / UIKit в настоящее время доступны через типобезопасные свойства этого класса.
Создать экземпляр Style довольно просто; при использовании подхода с использованием шаблона построителя классу init требуется обратный вызов, в котором передается экземпляр self, и он позволяет настраивать свойства, сохраняя код чистым и читаемым:
let style = Style {
$ 0.font = SystemFonts.Helvetica_Bold.font (размер: 20)
$ 0. цвет = UIColor.green
// ... устанавливаем любой другой атрибут
}
let attrString = "Some text" .set (style: style) // строка с атрибутами StyleXML : применение стилей для сложной строки на основе тегов Экземпляры стиля анонимны; если вы хотите использовать экземпляр стиля для визуализации простой строки на основе тегов, вам необходимо включить его в StyleXML .Вы можете рассматривать StyleXML как контейнер Styles (но на самом деле, благодаря соответствию общему протоколу StyleProtocol , ваша группа может содержать и другие подгруппы).
пусть bodyStyle: Style = ... пусть h2Style: Style = ... пусть h3Style: Style = ... let group = StyleXML (base: bodyStyle, ["h2": h2Style, "h3": h3Style]) let attrString = "Немноготекста
,добро пожаловать
" .set (style: group)
Следующий код определяет группу, в которой:
- мы определили базовый стиль.Базовый стиль — это стиль, применяемый ко всей строке, который может использоваться для обеспечения базовой основы стилей, которые вы хотите применить к строке.
- мы определили два других стиля с именами
h2иh3; эти стили применяются к исходной строке, когда синтаксический анализатор обнаруживает текст, заключенный в эти теги.
StyleRegEx : применение стилей с помощью регулярных выражений StyleRegEx позволяет определить стиль, который применяется, когда определенное регулярное выражение сопоставляется внутри целевой строки / строки с атрибутами.
пусть emailPattern = "([A-Za-z0-9 _ \\ - \\. \\ +]) + \\ @ ([A-Za-z0-9 _ \\ - \\.]) + \\. ([A-Za-z] +) "
let style = StyleRegEx (pattern: emailPattern) {
$ 0.color = UIColor.red
$ 0.backColor = UIColor.yellow
}
let attrString = "Мой адрес электронной почты [email protected], а мой веб-сайт - http://www.danielemargutti.com". (style: style!) Результат такой:
Объединение строк и строк с атрибутами
SwiftRichString позволяет упростить конкатенацию строк, предоставляя пользовательский оператор + между String , AttributedString (псевдоним NSMutableAttributedString ) и Style .
Это пример:
let body: Style = Style {...}
let big: Style = Style {...}
пусть атрибутируется: AttributedString = "hello" .set (style: body)
// следующий код создает строку с атрибутами
// объединение атрибутированной строки и двух простых строк
// (один стилизован, а другой простой).
let attStr = attributed + "\ (имя пользователя)!". set (style: big) + ". Добро пожаловать!" Вы также можете использовать оператор + , чтобы добавить стиль к простой строке или строке с атрибутами:
// Это создает строку с атрибутами, объединяющую равнину
// строка с атрибутированной строкой, созданная с помощью оператора +
// между простой строкой и стилем
let attStr = "Hello" + ("\ (username)" + big) Наконец, вы можете объединить строки с помощью построителей функций:
пусть жирный = Стиль {...}
let italic = Style {...}
let attributedString = AttributedString.composing {
"привет" .set (стиль: полужирный)
"мир" .set (стиль: курсив)
} Применить стили к строке
и Строка с атрибутами У String и AttributedString (также известного как NSMutableAttributedString ) есть удобные методы, которые вы можете использовать для простого создания манипулируемого текста с атрибутами с помощью кода:
Методы экземпляра строк
-
set (style: String, range: NSRange? = Nil): применить глобально зарегистрированный стиль к строке (или подстроке), создав строку с атрибутами. -
set (styles: [String], range: NSRange? = Nil): применить упорядоченную последовательность глобально зарегистрированных стилей к строке (или подстроке) путем создания строки с атрибутами. -
set (style: StyleProtocol, range: NSRange? = Nil): применить к строке (или подстроке) экземпляр стиляStyleилиStyleXML(для визуализации текста на основе тегов) путем создания строки с атрибутами. -
set (styles: [StyleProtocol], диапазон: NSRange? = Nil): применить последовательность изStyle/StyleXMLinstance, чтобы создать единую коллекцию атрибутов, которая будет применена к строке (или подстроке) для создания строки с атрибутами.
Некоторые примеры:
// применяем глобально зарегистрированный стиль с именем MyStyle ко всей строке let a1: AttributedString = "Hello world" .set (style: "MyStyle") // применяем группу стилей ко всей строке // commonStyle будет применен ко всей строке как базовый стиль // styleh2 и styleh3 будут применяться только к тексту внутри этих тегов. пусть styleh2: Style = ... пусть styleh3: Style = ... пусть StyleXML = StyleXML (base: commonStyle, ["h2": styleh2, "h3": styleh3]) let a2: AttributedString = "Привет,мир
,добро пожаловать
".набор (стиль: StyleXML) // Применяем стиль, определенный с помощью замыкания, к части строки let a3 = «Привет, ребята!». set (Style ({$ 0.font = SystemFonts.Helvetica_Bold.font (size: 20)}), диапазон: NSMakeRange (0,4))
Методы экземпляра AttributedString
Подобные методы также доступны для строк с атрибутами.
Есть три категории методов:
-
setметоды заменяют любые существующие атрибуты, уже установленные для цели. -
добавитьдобавить атрибуты, определенные списком стилей / стилей, к цели -
удалитьудалить атрибуты, определенные из строки получателя.
Каждый из этих методов изменяет экземпляр получателя атрибутированной строки, а также возвращает тот же экземпляр на выходе (поэтому цепочка разрешена).
Добавить
-
add (style: String, range: NSRange? = Nil): добавить к существующему стилю строки / подстроки глобально зарегистрированный стиль с заданным именем. -
add (styles: [String], range: NSRange? = Nil): добавить к существующему стилю строки / подстроки стиль, который представляет собой сумму упорядоченных последовательностей глобально зарегистрированных стилей с заданными именами. -
добавить (style: StyleProtocol, диапазон: NSRange? = Nil): добавить переданный экземпляр стиля в строку / подстроку, изменив строку с атрибутами получателя. -
add (styles: [StyleProtocol], диапазон: NSRange? = Nil): добавить переданную упорядоченную последовательность стилей к строке / подстроке путем изменения строки с атрибутами получателя.
Набор
-
set (style: String, range: NSRange? = Nil): заменить любой существующий стиль внутри строки / подстроки атрибутами, определенными внутри глобально зарегистрированного стиля с заданным именем. -
set (styles: [String], range: NSRange? = Nil): заменить любой существующий стиль внутри строки / подстроки на объединение атрибутов упорядоченных последовательностей глобально зарегистрированного стиля с заданными именами. -
set (style: StyleProtocol, диапазон: NSRange? = Nil): заменить любой существующий стиль внутри строки / подстроки атрибутами переданного экземпляра стиля. -
set (styles: [StyleProtocol], диапазон: NSRange? = Nil): заменить любой существующий стиль внутри строки / подстроки атрибутами переданной упорядоченной последовательности стилей.
Удалить
-
removeAttributes (_ keys: [NSAttributedStringKey], диапазон: NSRange): удалить атрибуты, указанные переданными ключами, из строки / подстроки. -
remove (_ style: StyleProtocol): удалить атрибуты, указанные в стиле, из строки / подстроки.
Пример:
let a = "hello" .set (style: styleA) let b = "world!". set (style: styleB) let ab = (a + b) .add (стили: [coupondStyleA, coupondStyleB]).remove ([. foregroundColor, .font])
Шрифты и цвета в стиле
Все цвета и шрифты, которые можно установить для Style , заключены в протоколы FontConvertible и ColorConvertible .
SwiftRichString, очевидно, реализует эти протоколы для UIColor / NSColor , UIFont / NSFont , но также и для String .
Для шрифтов это означает, что вы можете назначить шрифт, указав напрямую его имя PostScript, и он будет автоматически переведен в действительный экземпляр:
пусть firaLight: UIFont = "FiraCode-Light".шрифт (ofSize: 14)
...
...
let style = Style {
$ 0.font = "Жирный Джура"
$ 0, размер = 24
...
} В UIKit вы также можете использовать перечисление SystemFonts , чтобы выбрать из типобезопасного списка автозаполнения всех доступных шрифтов iOS:
пусть font1 = SystemFonts.Helvetica_Light.font (размер: 15) пусть font2 = SystemFonts.Avenir_Black.font (размер: 24)
Для цвета это означает, что вы можете создать действительный экземпляр цвета из строк HEX:
пусть цвет: UIColor = "# 0433FF" .color
...
...
let style = Style {
$ 0.color = "# 0433FF"
...
} Очевидно, что вы все еще можете передавать экземпляры обоих цветов / шрифтов.
Создание стиля
Иногда вам может потребоваться вывести свойства нового стиля из существующего. В этом случае вы можете использовать функцию byAdding () из Style для создания нового стиля со всеми свойствами получателя и возможностью настройки дополнительных / заменяющих атрибутов.
let initialStyle = Style {
$ 0.font = SystemFonts.Helvetica_Light.font (размер: 15)
$ 0, выравнивание = правое
}
// Следующий стиль содержит все атрибуты initialStyle
// но также переопределить выравнивание и добавить другой цвет переднего плана.
let subStyle = bold.byAdding {
$ 0, выравнивание = центр
$ 0.color = UIColor.red
} Соответствует динамическому типу
Для поддержки динамического масштабирования шрифтов / текста в зависимости от размера содержимого, предпочитаемого пользователями, можно реализовать свойство стиля dynamicText .Свойства UIFontMetrics заключены в класс DynamicText .
let style = Style {
$ 0. font = UIFont.boldSystemFont (ofSize: 16.0)
$ 0.dynamicText = DynamicText {
$ 0.style = .body
$ 0.maximumSize = 35.0
$ 0.traitCollection = UITraitCollection (userInterfaceIdiom: .phone)
}
} Отображение строк с тегами XML / HTML
SwiftRichString также может анализировать и отображать строки с тегами xml для создания действительного экземпляра NSAttributedString . Это особенно полезно, когда вы получаете динамические строки от удаленных служб и вам нужно легко создать визуализированную строку.
Чтобы отобразить строку XML, вам необходимо создать набор всех стилей, которые вы планируете визуализировать, в одном экземпляре StyleXML и применить его к исходной строке, как вы сделали для одного стиля Style .
Например:
// Базовый стиль применяется ко всей строке
let baseStyle = Style {
$ 0.font = UIFont.boldSystemFont (ofSize: self.baseFontSize * 1.15)
$ 0.lineSpacing = 1
$ 0.kerning = Kerning.adobe (-20)
}
let boldStyle = Style {
$ 0.font = UIFont.boldSystemFont (ofSize: self.baseFontSize)
$ 0.dynamicText = DynamicText {
$ 0.style = .body
$ 0.maximumSize = 35.0
$ 0.traitCollection = UITraitCollection (userInterfaceIdiom: .phone)
}
}
let italicStyle = Style {
$ 0.font = UIFont.italicSystemFont (ofSize: self.baseFontSize)
}
// Контейнер группы включает в себя весь определенный стиль.
let groupStyle = StyleXML.init (base: baseStyle, ["b": boldStyle, "i": italicStyle])
// Мы можем отобразить нашу строку
let bodyHTML = "Привет, мир! , меня зовут Даниэле "
себя.textView? .attributedText = bodyHTML.set (стиль: группа) Настроить рендеринг XML: реагировать на атрибуты тегов и неизвестные теги
Вы также можете добавлять настраиваемые атрибуты в свои теги и отображать их по своему усмотрению: вам необходимо предоставить конкретную реализацию протокола XMLDynamicAttributesResolver и назначить ее свойству StyleXML .xmlAttributesResolver .
Протокол будет получать события двух типов:
-
applyDynamicAttributes (to attributedString: inout AttributedString, xmlStyle: XMLDynamicStyle)получается, когда синтаксический анализатор обнаруживает существующий стиль с настраиваемыми атрибутами.Применяется стиль и вызывается событие, поэтому вы можете внести дополнительные изменения. -
func styleForUnknownXMLTag (_ tag: String, to attributedString: inout AttributedString, attributes: [String: String]?)получен, когда получен неизвестный (не определенный в стиляхStyleXML) тег. Вы можете игнорировать или выполнять настройки.
Следующий пример используется для переопределения цвета текста при использовании для любого известного тега:
// Сначала определите наш собственный преобразователь для атрибутов
открытый класс MyXMLDynamicAttributesResolver: XMLDynamicAttributesResolver {
public func applyDynamicAttributes (to attributedString: inout AttributedString, xmlStyle: XMLDynamicStyle) {
пусть finalStyleToApply = Style ()
xmlStyle.enumerateAttributes {ключ, значение в
переключатель ключа {
case "color": // поддержка цвета
finalStyleToApply.color = Цвет (hexString: значение)
По умолчанию:
перерыв
}
}
attributedString.add (стиль: finalStyleToApply)
}
}
// Затем перед отрисовкой текста установите его в наш экземпляр StyleXML.
let groupStyle = StyleXML.init (base: baseStyle, ["b": boldStyle, "i": italicStyle])
groupStyle.xmlAttributesResolver = MyXMLDynamicAttributesResolver () В следующем примере определяется поведение неизвестного тега с именем rainbow .
В частности, он изменяет строку, устанавливая собственный цвет для каждой буквы исходной строки.
открытый класс MyXMLDynamicAttributesResolver: XMLDynamicAttributesResolver {
public override func styleForUnknownXMLTag (_ tag: String, to attributedString: inout AttributedString, attributes: [String: String]?) {
супер.styleForUnknownXMLTag (тег, к: & attributedString, атрибуты: атрибуты)
if tag == "радуга" {
let colors = UIColor.randomColors (attributedString.length)
для i в 0 .. Вы получите все атрибуты тега чтения в параметре attributes .
Вы можете изменить атрибуты или всю строку, полученную как параметр inout в свойстве attributedString .
Решатель по умолчанию также предоставляется библиотекой и используется по умолчанию: StandardXMLAttributesResolver . Он будет поддерживать как атрибут color, в тегах, так и тег со ссылкой на URL.
let sourceHTML = "Моя веб-страница действительно классная . Взгляните на здесь "
let styleBase = Style ({
$ 0. font = UIFont.boldSystemFont (ofSize: 15)
})
let styleBold = Style ({
$ 0. font = UIFont.boldSystemFont (ofSize: 20)
$ 0.color = UIColor.blue
})
let groupStyle = StyleXML.init (base: styleBase, ["b": styleBold])
self.textView? .attributedText = sourceHTML.set (стиль: groupStyle)
Результат такой:
, где синий цвет тега b был заменен атрибутами цветового тега, а ссылка в «здесь» является интерактивной.
Пользовательские преобразования текста
Иногда вы хотите применить пользовательские преобразования текста к вашей строке; например, вы можете захотеть сделать текст с заданным стилем в верхнем регистре с текущей локалью.
Чтобы обеспечить пользовательское преобразование текста в экземплярах Style , просто установите один или несколько TextTransform в свойство Style .textTransforms :
пусть allRedAndUppercaseStyle = Style ({
$ 0.font = UIFont.boldSystemFont (ofSize: 16.0)
$ 0.color = UIColor.red
$ 0.textTransforms = [
.uppercaseWithLocale (Locale.current)
]
})
let text = "test" .set (style: allRedAndUppercaseStyle) // станет красным и заглавными буквами (ТЕСТ) Хотя TextTransform является перечислением с предопределенным набором преобразований, вы также можете предоставить свою собственную функцию, которая имеет строку String в качестве источника и другую строку String в качестве назначения:
let markdownBold = Style ({
$ 0.font = UIFont.boldSystemFont (ofSize: 16.0)
$ 0.color = UIColor.red
$ 0.textTransforms = [
.обычай({
вернуть "** \ ($ 0) **"
})
]
}) Все текстовые преобразования применяются в том же порядке, который вы установили в свойстве textTransform .
Локальные и удаленные изображения внутри текста
SwiftRichString поддерживает локальные и удаленные прикрепленные изображения, а также текст с атрибутами.
Вы можете создать атрибутивную строку с изображением из одной строки:
// Вы можете указать границы изображения, как по размеру, так и по положению относительно базовой линии текста.let localTextAndImage = AttributedString (изображение: UIImage (имя: "ракета") !, границы: CGRect (x: 0, y: -20, ширина: 25, высота: 25))
// Вы также можете загрузить удаленное изображение. Если вы не укажете размер границ, будет исходный размер изображения.
let remoteTextAndImage = AttributedString (imageURL: "http: // ...")
// Теперь вы можете скомпоновать его с другой атрибутированной или простой строкой
let finalString = "...". set (style: myStyle) + remoteTextAndImage + "другой текст"
Изображения также могут быть загружены путем преобразования строки XML с помощью тега img (с именем тег для локального ресурса и url для удаленного URL).
rect Параметр является необязательным и позволяет указать изменение размера и перемещение ресурса.
let taggedText = "" "
Некоторый текст и это изображение:
![]() Другой загружается с удаленного URL:
Другой загружается с удаленного URL:
![]() "" "
self.textView? .attributedText = taggedText.set (стиль: ...)
"" "
self.textView? .attributedText = taggedText.set (стиль: ...)
Это результат:
Иногда вам может понадобиться лениво предоставить эти изображения.Для этого просто предоставьте пользовательскую реализацию обратного вызова imageProvider в экземпляре StyleXML :
let xmlText = "- ![]() выполнено!"
let xmlStyle = StyleXML (base: {
/// некоторые атрибуты для базового стиля
})
// Этот метод вызывается при обнаружении нового тега `img`. Это твой шанс
// возвращаем собственное изображение. Если вы вернете `nil` (или не реализуете этот метод)
// изображение ищется внутри любого связанного файла `xcasset`.xmlStyle.imageProvider = {(имя изображения, атрибуты) в
switch imageName {
case "check":
// создать и вернуть собственное изображение
По умолчанию:
// ...
}
}
self.textView? .attributedText = xmlText.set (стиль: x)
выполнено!"
let xmlStyle = StyleXML (base: {
/// некоторые атрибуты для базового стиля
})
// Этот метод вызывается при обнаружении нового тега `img`. Это твой шанс
// возвращаем собственное изображение. Если вы вернете `nil` (или не реализуете этот метод)
// изображение ищется внутри любого связанного файла `xcasset`.xmlStyle.imageProvider = {(имя изображения, атрибуты) в
switch imageName {
case "check":
// создать и вернуть собственное изображение
По умолчанию:
// ...
}
}
self.textView? .attributedText = xmlText.set (стиль: x)
StyleManager
Зарегистрировать глобально доступные стили
Стили могут быть созданы по мере необходимости или зарегистрированы глобально для использования по мере необходимости.
Этот второй подход настоятельно рекомендуется, поскольку он позволяет тематизировать ваше приложение по своему усмотрению, а также избежать дублирования кода.
Чтобы зарегистрировать стиль Style или StyleXML глобально, вам необходимо назначить ему уникальный идентификатор и вызвать функцию register () с помощью ярлыка Styles (который эквивалентен вызову StylesManager.shared ).
Чтобы сохранить тип вашего кода более безопасным, вы можете использовать структуру без создания экземпляра, чтобы сохранить имя ваших стилей, а затем использовать ее для регистрации стиля:
// Определите структуру с вашими именами стилей
public struct StyleNames {
public static let body: String = "body"
public static let h2: String = "h2"
public static let h3: String = "h3"
частный init {}
} Тогда вы можете:
пусть bodyStyle: Style =...
Styles.register (StyleNames.body, bodyStyle)
Теперь вы можете использовать его везде внутри приложения; вы можете применить его к тексту, просто используя его имя:
let text = "hello world" .set (StyleNames.body)
, или вы можете назначить строку body для styledText через свойство проектирования Interface Builder.
Отложить создание стиля по запросу
Иногда вам может потребоваться вернуть определенный стиль, используемый только в небольшой части вашего приложения; хотя вы все еще можете установить его напрямую, вы также можете отложить его создание в StylesManager .
Реализуя обратный вызов onDeferStyle () , у вас есть возможность создать новый стиль, когда это потребуется: вы получите идентификатор стиля.
Styles.onDeferStyle = {имя в
if name == "MyStyle" {
let normal = Style {
$ 0.font = SystemFonts.Helvetica_Light.font (размер: 15)
}
let bold = Style {
$ 0.font = SystemFonts.Helvetica_Bold.font (размер: 20)
$ 0.color = UIColor.red
$ 0.backColor = UIColor.yellow
}
let italic = normal.byAdding {
$ 0.traitVariants = .italic
}
return (StyleXML (base: нормальный, ["жирный": жирный, "курсивный": курсивный]), true)
}
возврат (ноль, ложь)
} Следующий код возвращает допустимый стиль для идентификатора myStyle и кэширует его; если вы не хотите кешировать, просто верните false вместе с экземпляром стиля.
Теперь вы можете использовать свой стиль для рендеринга, например, текста на основе тегов в UILabel : просто установите имя используемого стиля.
Назначить стиль с помощью Interface Builder
SwiftRichString можно использовать также через Interface Builder.
-
UILabel -
UITextView -
UITextField
имеет три дополнительных свойства:
-
styleName: String (доступно через IB): вы можете настроить его для визуализации текста, уже установленного с помощью Interface Builder, со стилем, зарегистрированным глобально, до загрузки родительского представления элемента управления пользовательского интерфейса. -
style: StyleProtocol : можно настроить отображение текста элемента управления с экземпляром экземпляра стиля. -
styledText: String : используйте это свойство вместо attributedText , чтобы задать новый текст для элемента управления и отобразить его с уже заданным стилем. Вы можете продолжить использовать attributedText и установить значение с помощью функций .set () из String / AttributedString .
Назначенный стиль может быть стилем , StyleXML или StyleRegEx :
- , если стиль -
Style , весь текст элемента управления устанавливается с атрибутами, определенными стилем. - , если стиль - это
StyleXML , устанавливается базовый атрибут (если base действителен), и другие атрибуты применяются после того, как каждый тег найден. - , если стиль - это
StyleRegEx , устанавливается базовый атрибут (если base действителен), и атрибут применяется только для совпадений с указанным шаблоном.
Обычно вы устанавливаете стиль метки через свойство Style Name ( styleName ) в IB и обновляете содержимое элемента управления, устанавливая styledText :
// используем значение set `styleName` для обновления текста стилем
себя.label? .styledText = "Другой текст для визуализации" // текст отображается с использованием указанного значения `styleName`.
В противном случае вы можете установить значения вручную:
// вручную устанавливаем атрибутивную строку
self.label? .attributedText = (self.label? .text ?? "") .set (myStyle)
// вручную установить стиль через экземпляр
self.label? .style = myStyle
self.label? .styledText = "Обновленный текст"
Свойства доступны через
Style class Доступны следующие объекты:
СОБСТВЕННОСТЬ ТИП ОПИСАНИЕ размер CGFloat кегль шрифта в пунктах шрифт FontConvertible шрифт, используемый в тексте цвет Цвет Кабриолет цвет текста задний Цвет Цвет Кабриолет цвет фона текста тень NSS Тень эффект тени от текста подчеркивание (NSUnderlineStyle?, ColorConvertible?) стиль и цвет подчеркивания (если цвет нулевой, используется передний план) зачеркнутый (NSUnderlineStyle?, ColorConvertible?) стиль и цвет зачеркивания (если цвет отсутствует, используется передний план) базовая линия Смещение Поплавок Смещение символа от базовой линии в точке пункт NSMutableParagraphStyle атрибуты абзаца строк Расстояние CGFloat расстояние в точках между низом одного фрагмента линии и верхом следующего абзацев Расстояние до CGFloat расстояние между верхом абзаца и началом его текстового содержания абзац Интервал после CGFloat пробел (в пунктах) добавлен в конце абзаца выравнивание NSTextAlignment выравнивание текста получателя firstLineHeadIndent CGFloat расстояние (в пунктах) от ведущего поля текстового контейнера до начала первой строки абзаца. Головка Зажим CGFloat Расстояние (в пунктах) от ведущего поля текстового контейнера до начала строк, кроме первой. хвостовая часть CGFloat это значение - расстояние от ведущего поля. Если 0 или отрицательное значение, это расстояние от заднего поля. lineBreakMode LineBreak Режим, который следует использовать для разрыва строк минимум LineHeight CGFloat минимальная высота в пунктах, которую будет занимать любая линия в приемнике, независимо от размера шрифта или размера любого прикрепленного изображения maximumLineHeight CGFloat максимальная высота в пунктах, которую будет занимать любая линия в приемнике, независимо от размера шрифта или размера любого прикрепленного графического объекта baseWritingDirection NSWritingDirection начальное направление письма, используемое для определения фактического направления письма для текста lineHeightMultiple CGFloat естественная высота строки получателя умножается на этот коэффициент (если он положительный) перед ограничением минимальной и максимальной высотой строки расстановка переносов Фактор Поплавок управление порогом при попытке расстановки переносов лигатуры Лигатуры Лигатуры вызывают отображение определенных комбинаций символов с использованием одного настраиваемого глифа, соответствующего этим символам говорит (говорит) Пунктуация Bool Включить озвучку всех знаков препинания в тексте говорящий язык Строка Язык, используемый при озвучивании строки (значение представляет собой строку кода языка BCP 47). говорящий Шаг Двойной Шаг для применения к речевому контенту говорящий Произношение Строка shouldQueueSpeechAnnouncement Bool Разговорный текст помещен в очередь или прерывает существующее речевое содержимое уровень Уровень заголовка Укажите уровень заголовка текста номер Корпус Номер Корпус "Конфигурация для цифрового регистра, также известная как" "стиль рисунка" "" Номер Расстояние Число Шаг "Конфигурация для числового интервала, также известного как" "интервал между цифрами" "" фракции Фракции Конфигурация для вывода дроби надстрочный Bool Используются варианты glpyh с надстрочным (верхним) индексом, как в сносках_. нижний индекс Bool Используются нижние (нижние) варианты глифов: v_. порядковые номера Bool Используются варианты порядковых знаков, как и в обычном наборе 4-го. научное подчинение Bool Используются нижние научные варианты глифов: H_O smallCaps Набор Настройте поведение маленьких заглавных букв. стилистические альтернативы Стилистические альтернативы Для настройки шрифта доступны различные стилистические варианты. contextualAlternates Контекстные альтернативы Доступны различные контекстные альтернативы для настройки шрифта. кернинг Кернинг Отслеживание подать заявку. признак Варианты TraitVariant Опишите варианты признаков для применения к шрифту
Требования
- Свифт 5.1+
- iOS 8.0+
- macOS 11.0+
- watchOS 2.0+
- tvOS 11.0+
Установка
Какао-Стручки
CocoaPods - это менеджер зависимостей для проектов Какао. Для получения инструкций по использованию и установке посетите их веб-сайт. Чтобы интегрировать Alamofire в ваш проект Xcode с помощью CocoaPods, укажите его в своем Podfile:
Менеджер пакетов Swift
Swift Package Manager - это инструмент для автоматизации распространения кода Swift, интегрированный в компилятор Swift.Он находится на ранней стадии разработки, но Alamofire поддерживает его использование на поддерживаемых платформах.
После настройки пакета Swift добавить Alamofire в качестве зависимости так же просто, как добавить его в значение dependencies вашего Package.swift.
зависимостей: [
.package (URL: "https://github.com/malcommac/SwiftRichString.git", от: "3.5.0")
] Карфаген
Carthage - это децентрализованный менеджер зависимостей, который строит ваши зависимости и предоставляет вам двоичные фреймворки.
Чтобы интегрировать SwiftRichString в проект Xcode с помощью Carthage, укажите его в файле Cartfile :
github "malcommac / SwiftRichString"
Запустите carthage , чтобы построить фреймворк, и перетащите созданный SwiftRichString.framework в свой проект Xcode.
Содействие
Вопросы и запросы на включение приветствуются!
Ожидается, что участники будут соблюдать Кодекс поведения участников Соглашения.
Авторские права
SwiftRichString доступен по лицензии MIT.См. Файл LICENSE для получения дополнительной информации.
Даниэле Маргутти: [email protected], @danielemargutti
Как работать с результатами поиска - Когнитивный поиск Azure
-
- 7 минут на чтение
В этой статье
В этой статье объясняется, как сформулировать ответ на запрос в Когнитивном поиске Azure.Структура ответа определяется параметрами в запросе: поиск в документе в REST API или класс SearchResults в .NET SDK. Параметры запроса могут использоваться для структурирования набора результатов следующими способами:
- Ограничение или пакетирование количества документов в результатах (по умолчанию 50)
- Выберите поля для включения в результаты
- Результаты заказа
- Выделить совпадающий полный или частичный термин в теле результатов поиска
Состав результата
Хотя поисковый документ может состоять из большого количества полей, обычно требуется лишь несколько полей для представления каждого документа в наборе результатов.В запросе запроса добавьте $ select = <список полей> , чтобы указать, какие поля будут отображаться в ответе. Поле должно иметь атрибут Retrievable в индексе, чтобы его можно было включить в результат.
Поля, которые работают лучше всего, включают те, которые контрастируют и различают документы, предоставляя достаточную информацию, чтобы вызвать отклик со стороны пользователя. На сайте электронной коммерции это может быть название продукта, описание, бренд, цвет, размер, цена и рейтинг.Для встроенного образца hotels-sample-index это могут быть поля в следующем примере:
POST / indexes / hotels-sample-index / docs / search? Api-version = 2020-06-30
{
"поиск": "песчаные пляжи",
"select": "HotelId, HotelName, Description, Rating, Address / City"
"count": правда
}
Примечание
Если вы хотите включить в результат файлы изображений, например фотографию продукта или логотип, сохраните их вне Когнитивного поиска Azure, но включите поле в свой индекс для ссылки на URL-адрес изображения в поисковом документе.Примеры индексов, которые поддерживают изображения в результатах, включают демонстрацию realestate-sample-us , представленную в этом кратком руководстве, и демонстрационное приложение New York City Jobs.
Советы для получения неожиданных результатов
Иногда оказывается неожиданным суть, а не структура результатов. Если результаты запроса являются неожиданными, вы можете попробовать эти модификации запроса, чтобы увидеть, улучшились ли результаты:
Измените searchMode = any (по умолчанию) на searchMode = all , чтобы требовать совпадения по всем критериям вместо любого из критериев.Это особенно верно, когда в запрос включены логические операторы.
Поэкспериментируйте с различными лексическими анализаторами или настраиваемыми анализаторами, чтобы увидеть, не меняет ли это результат запроса. Анализатор по умолчанию разбивает слова с переносом и сокращает слова до корневых форм, что обычно повышает надежность ответа на запрос. Однако, если вам нужно сохранить дефисы или если строки содержат специальные символы, вам может потребоваться настроить пользовательские анализаторы, чтобы индекс содержал токены в правильном формате.Дополнительные сведения см. В разделе Частичный поиск терминов и шаблоны со специальными символами (дефисы, подстановочные знаки, регулярные выражения, шаблоны).
Результаты пейджинга
По умолчанию поисковая система возвращает до первых 50 совпадений в зависимости от оценки поиска, если запрос является полнотекстовым поиском, или в произвольном порядке для запросов с точным соответствием.
Чтобы вернуть другое количество совпадающих документов, добавьте параметры $ top и $ skip в запрос запроса.Следующий список объясняет логику.
Добавьте $ count = true , чтобы получить подсчет общего количества совпадающих документов в индексе.
Вернуть первый набор из 15 совпадающих документов плюс общее количество совпадений: GET / indexes / / docs? Search = & $ top = 15 & $ skip = 0 & $ count = true
Верните второй набор, пропуская первые 15, чтобы получить следующие 15: $ top = 15 & $ skip = 15 .Сделайте то же самое для третьего набора 15: $ top = 15 & $ skip = 30
Стабильность результатов запросов с разбивкой на страницы не гарантируется, если базовый индекс изменяется. Пейджинг изменяет значение $ skip для каждой страницы, но каждый запрос является независимым и работает с текущим представлением данных в том виде, в каком он существует в индексе во время запроса (другими словами, нет кеширования или моментального снимка результатов, например, найденные в базе данных общего назначения). Ниже приведен пример того, как вы можете получить дубликаты.Предположим, индекс с четырьмя документами:
{"id": "1", "rating": 5}
{"id": "2", "rating": 3}
{"id": "3", "rating": 2}
{"id": "4", "rating": 1}
Теперь предположим, что вы хотите, чтобы результаты возвращались по два за раз, отсортированные по рейтингу. Вы должны выполнить этот запрос, чтобы получить первую страницу результатов: $ top = 2 & $ skip = 0 & $ orderby = rating desc , что даст следующие результаты:
{"id": "1", "rating": 5}
{"id": "2", "rating": 3}
В службе предположим, что пятый документ добавляется в индекс между вызовами запроса: {"id": "5", "rating": 4} .Вскоре после этого вы выполняете запрос для получения второй страницы: $ top = 2 & $ skip = 2 & $ orderby = rating desc , и получаете следующие результаты:
{"id": "2", "rating": 3}
{"id": "3", "rating": 2}
Обратите внимание, что документ 2 извлекается дважды. Это связано с тем, что новый документ 5 имеет большее значение для оценки, поэтому он сортируется перед документом 2 и попадает на первую страницу. Хотя такое поведение может быть неожиданным, оно типично для поведения поисковой системы.
Результаты заказа
Для запросов полнотекстового поиска результаты автоматически ранжируются по рейтингу поиска, рассчитанному на основе частоты и близости термина в документе (полученного из TF-IDF), причем более высокие баллы получают документы, имеющие больше или больше совпадений по поисковому запросу.
результатов поиска передают общее ощущение релевантности, отражая степень соответствия по сравнению с другими документами в том же наборе результатов. Но оценки не всегда совпадают от одного запроса к другому, поэтому, работая с запросами, вы можете заметить небольшие расхождения в том, как упорядочены поисковые документы.Есть несколько объяснений того, почему это могло произойти.
Причина Описание Неустойчивость данных Содержимое индекса меняется при добавлении, изменении или удалении документов. Частота использования терминов будет меняться по мере обработки обновлений индекса с течением времени, что влияет на результаты поиска соответствующих документов. Несколько реплик Для служб, использующих несколько реплик, запросы отправляются к каждой реплике параллельно.Статистика индекса, используемая для расчета оценки поиска, рассчитывается для каждой реплики, а результаты объединяются и упорядочиваются в ответе на запрос. Реплики в основном являются зеркалами друг друга, но статистика может отличаться из-за небольших различий в состоянии. Например, одна реплика могла удалить документы, вносящие вклад в ее статистику, которые были объединены из других реплик. Обычно различия в статистике реплик более заметны при меньших индексах. Одинаковые баллы Если несколько документов имеют одинаковую оценку, любой из них может появиться первым.
Как обеспечить единообразие заказов
Если согласованный порядок является требованием приложения, вы можете явно определить выражение $ orderby для поля. Только поля, проиндексированные как сортируемые , могут использоваться для упорядочивания результатов. Поля, обычно используемые в $ orderby , включают поля рейтинга, даты и местоположения, если вы укажете значение параметра orderby , чтобы включить имена полей и вызовы к geo.distance () функция для геопространственных значений.
Другой подход, который способствует согласованности, - это использование настраиваемого профиля оценки. Профили скоринга дают вам больше контроля над ранжированием элементов в результатах поиска, с возможностью увеличивать количество совпадений, найденных в определенных полях. Дополнительная логика оценки может помочь преодолеть незначительные различия между репликами, поскольку оценки поиска для каждого документа значительно различаются. Мы рекомендуем алгоритм ранжирования для этого подхода.
Подсветка хита
Под выделением совпадений понимается форматирование текста (например, жирное или желтое выделение), применяемое к совпадающим терминам в результате, что упрощает поиск совпадения.Инструкции по выделению попаданий предоставляются в запросе запроса.
Чтобы включить выделение попаданий, добавьте highlight = [список строковых полей, разделенных запятыми] , чтобы указать, какие поля будут использовать выделение. Выделение полезно для более длинных полей содержимого, таких как поле описания, где совпадение не сразу очевидно. Только те определения полей, которые отнесены к с возможностью поиска, подходят для выделения совпадений.
По умолчанию Когнитивный поиск Azure возвращает до пяти выделений для каждого поля.Вы можете изменить это число, добавив к полю дефис, за которым следует целое число. Например, highlight = Description-10 возвращает до 10 выделений при совпадении содержимого в поле «Описание».
Форматирование применяется ко всем терминам запросов. Тип форматирования определяется тегами highlightPreTag и highlightPostTag , и ваш код обрабатывает ответ (например, применяя полужирный шрифт или желтый фон).
В следующем примере термины «песчаный», «песок», «пляжи», «пляж» в поле «Описание» помечены для выделения.Запросы, запускающие расширение запроса в движке, такие как нечеткий поиск и поиск с подстановочными знаками, имеют ограниченную поддержку выделения совпадений.
GET / indexes / hotels-sample-index / docs / search = песчаные пляжи & выделить = Описание? Api-version = 2020-06-30
POST / indexes / hotels-sample-index / docs / search? Api-version = 2020-06-30
{
"поиск": "песчаные пляжи",
"выделить": "Описание"
}
Новое поведение (с 15 июля)
Службы, созданные после 15 июля 2020 г., будут предоставлять другие возможности выделения.Сервисы, созданные до этой даты, не изменят своего поведения при выделении.
С новым поведением:
Будут возвращены только фразы, соответствующие запросу полной фразы. Фраза запроса "суперкубок" вернет такие моменты:
"@ search.highlights": {
"приговор": [
" супер миска супер классная с миской чипсов"
]
Обратите внимание, что другие экземпляры super и Bowl не выделяются, потому что эти экземпляры не соответствуют полной фразе.
Помните об этом изменении, когда пишете клиентский код, реализующий выделение попаданий. Учтите, что это не повлияет на вас, если вы не создадите полностью новую поисковую службу.
Следующие шаги
Чтобы быстро создать страницу поиска для вашего клиента, рассмотрите следующие варианты:
- Генератор приложений на портале создает HTML-страницу с панелью поиска, фасетной навигацией и областью результатов, включающей изображения.
- «Создайте свое первое приложение на C #» - это учебное пособие по созданию функционального клиента.Пример кода демонстрирует запросы с разбивкой на страницы, выделение совпадений и сортировку.
Несколько примеров кода включают интерфейсный веб-интерфейс, который можно найти здесь: демонстрационное приложение New York City Jobs, пример кода JavaScript с действующим демонстрационным сайтом и CognitiveSearchFrontEnd.
Домашняя страница сайта Cheminfo
- Химия
- Химинформатика
- Упражнения
- Молекула -> УЛЫБКИ
- Молекула -> Молекула
- УЛЫБКИ -> Молекула
- 2D в 3D OCL
- Объединить группы
- Преобразовать logP19 в цвет
InChI to Molfile
- Создать диастереотопный SVG
- Создать модель
- Создать стереоизомеры
- Демонстрационный анализ molfile
- Диастереотопный идентификатор
- Показать OCLcode oclID
- FormatConverter
- Создать InChI
- HOSE code
Информация о коде HOSE
- JSME взаимодействия
- OpenChemLib Extended демонстрационная страница
- OpenChemLib js
- OpenChemLib OCL utils
- Property explorer
- библиотека PubChem
- RDKit demo
- Калькулятор реагентов
- Smiles
- SMILES to svg
- Тестировать создатель JSON
- Тестировать любую информацию о продукте
- Виртуальная комбинаторная библиотека
- Википедия
База данных- DrugBank
- Просмотр свойств
- Поиск структуры
- PubChem
- Поиск по точной массе в PubChem
- ChEMBL 20
- Рюкзак
Элементный анализ- Найти состав MF из EA
Анализ данных- Анализ и фильтрация
- 3D-график SDF
- SDF в виде таблицы
- SDF explorer
- Список улыбок к свойствам молекулы
- Разделенные табуляцией Параллельные координаты
2D в 3D 2D в Confs Визуализация 3D-модели cristallOgraph Пользовательская таблица Менделеева Элементный состав Потенциал эвтрофикации Генерировать molfiles Генератор изомеров Поиск MSDS Название структуры Периодическая таблица Инструмент расчета раствора Демо- Биореактор
- Эксперимент Гриффита
- Lora
- Lora Decrypt
- Карты - Загрязнение в Боготе
- Карты - Средство просмотра трассировки
- Параллельные координаты - Средство просмотра цветов RGBa
- Средство просмотра плазмид
- Scatter 3D - Большие данные
- SOM - классификация цветов
- Восход солнца
- Поверхностный график
Изображение- Биология
- Колонии
- Подсчет пластины
- IC50
- IC50 v2
- Область интересов
- image-js
- Фильтр Гаусса
- Информация об изображении
- Процесс
- Генерация бинарной маски
- Деление клеток
- Деление клеток 2
- Демонстрация создать градиент
- D emo Crop and Match
- Demo ROI
- Demo различные изображения
- Histogram
- Загрузить изображение и сохранить вложение
- Тестовые маски
- Test
- Проверка панорамирования и увеличения изображения
- Сопоставить изображения
- XTC
- 01-экстракция
- 02-кластеризация
- Анализ изображений
ML- Регрессия
- Исследования
- Кокаин
- Кокаин
- Кофе
- Матрица расстояний
- Изображения
- Кнопки
- тест
- Тест
- Иерархическая кластеризация
- K-средних
- Наивный байесовский, KNN и FNN
- Частичные наименьшие квадраты (PLS)
- Анализ основных компонентов (PCA)
- Savitzky-Golay производные
- Опорные векторные машины
9 0019 TestCases- Iris
Protein- Информация
- Изоэлектрическая точка
- JSMol
- Демонстрационный скрипт
- PDB Selector
- PDB Viewer
эксперимент Ссылки
19 Табличка и начало Спектры- Хроматограмма
- ГХ-ЖХ
- Комплексные упражнения
- ЭМ ЯМР 1H
- ИК МС ЯМР 1H
- ИК ЯМР 1H 13C
- ИК
- Упражнения
- Обзор спектров
- Определить структура
- First Defender
- ИК-просмотрщик
- Компаратор спектров
- IV
- IV-просмотрщик
- Масса
- Расширенный анализ
- Расширенный MF из моноизотопной массы
- Выбор пика масс-спектра
- MF из ММ (все элементы) 9 0020
- Петролеомика
- Полимеры
- Статистика молекулярных формул PubChem
- Поиск загрязняющих веществ
- Анализ супов на основе фрагментов
- Анализ супов на основе определенных фрагментов и пептида
- Упражнения
- Создание экзаменационных вопросов
- Определить заряд
- Электронный удар
- Изотопное распределение
- Определение MF по массе
- Моноизотопная масса
- GC-LC / MS
- HR LC-MS GC-MS анализ
- интеграция интенсивности
- LC-MS GC-MS анализ
- Net CDF mzData GC-LC MS explorer
- Think
- Дефект массы
- OLD - Информация из MF или структуры
- OLD MF из моноизотопной массы и PubChem
- Справочные данные Chemcalc
- Загрязняющие вещества
- Сгенерировать список MF
- Группы и элементы
- Информация от om MF или структура
- Генератор изотопного распределения с пептидами
- Массовая фрагментация
- MF из списка моноизотопных масс
- MF из моноизотопной массы и pubchem
- Пептидная и нуклеотидная фрагментация
- Простая комбинация MF
- Простая комбинация MF
Упражнения- 13C ЯМР
- Генератор упражнений 1H
- Определение основной структуры 1H ЯМР
- 1H ЯМР интегрировать и найти структуру
- Спектры 1H ЯМР Boc аминокислот
- Спектры 1H ЯМР малых молекул
- Количество сигналов 1H
- Присвойте спектры ЯМР 1H молекуле
- Найдите структуру по спектру 1H
- Количество различных Hs
Выбор пика- Выбор и назначение 1D пика
- Выбор 2D-пика
Прогнозы- 13C Прогноз
- Прогноз 1H
- Все предсказания ЯМР ictions
- COSY Prediction
- HSQC HMBC Prediction
- HSQC Prediction
Инструменты- Автоматическое назначение
- Просмотр спектров
- Генератор массовых спектров
- Диастереотопические атомы
- IconNMR
- Мультиплетный симулятор спектра
- Моделирование спиновой системы
- Примеси растворителя
Спектрофотометр- Тест
Ненасыщенность- Из MF
- Из структуры
Утилиты- Global Spectra Deconvolution
- NetCDR Massrer
- creator
- Peak peaking
- Spectra для упражнений
GC simulator Tutorial- 1.Введение
- 1.1 Базовый пример
- 1.2 Добавление модуля
- 1.3 Таблица
- 1.4 Многоканальный, двухмерная сетка и цвет фона
- 5. Модули
- 5.1 Дисплей
- 5.1.2 Динамический цвет фона
- 5.1. 4 Редактор Twig
- 5.2 Взаимодействие с клиентом
- 5.2.1 Простая форма
- 5.2.2 Формы и фильтры
- 5.2.3 Расширенная форма onde
- 5.2.6 Перетаскивание и фильтры
- 5.3 Диаграмма
- 5.3.1 Круговая диаграмма и Co
- 5.3.2 Таблица выделения -> диаграмма
- 5.3.3 Трехмерное разбиение и параллельные координаты
- 5.3.4 Дерево
- 5.3.5 Гексагональная карта
- 5.3.6 Конвертировать массив в диаграмму
- 5.3.7 Пример формата точечной трехмерной диаграммы
- 5.3.8 Наложение - наложение сигналов
- 5.3.9 Селектор серии разброса
- 5.4 Матрица
- 5.4.1 Случайный
- 5.5 Slick Grid
- Вычислить свойства
- 6.1 Science
- 6.1.1 Плоттер JsGraph и аннотации
- 6.1.2 Редактор молекул OCL
- 6. Средство визуализации
- 6.1 Базовое средство визуализации
- 6.2 HTML, regexp, svg, color
- 6.3 Изображения
- 6.4 Индикатор
- 6.5 Химический рендерер
- 6.6 Спарклайны
- 6.7 Штрих-код и QR-код
- 6.8 Рендеринг в формате JSON диаграммы
- 6.9 Флаги
- 7. Библиотека
- 7.1 Отчетливый цвет
- 7.2 Демонстрация Papaparser
- 7.3 Суперагент и файлы из GitHub Ajax
- 7.10 Numeric.js
- 8. Изображения
- 9.7 Создание изображения PNG в javascript
- 9.9 Создание изображений маркеров и загрузка ZIP
- 9.13 Исполнитель асинхронного кода для анализа изображений
- 9.17 Создание SVG-арта из скрипта
- 9.20 SVG с использованием библиотеки Snap.svg
- 9.21 Тестирование шаблона фрагментации с использованием Snap.svg
- Связывание источников с целями (отслеживание ячеек)
- Демонстрационный интерактивный SVG
- 9.Advanced
- 9.2 Script Executor - маленькая функция
- 9.3 Simple script Executor - закодируйте
- 9.4 Script Executor
- 9.5 простой случайный тест
- 9.6 Табличное издание
- 9.8 Создание и загрузка ZIP
- 9.10 Переключение между слоями
- 9.11 Отображение уведомлений от исполнителя кода
- 9.12 Вложения
- 9.14 Простое число
- 9.15 Диалоговое окно подтверждения
- 9.16 Распаковать zip-файл
- 9.18 JsGraph и большой набор данных
- 9,19 Большой набор данных в гладкой сетке
- 9,22 Расшифровка Cesar
- 9,23 Сохранение и вставка ярлыков
- 9,24 Расчет простого числа
- 9,24 Создание списка UUID
- 9,25 Вложения Couchdb
- Ellipse 95
Ellipse 95
- GSD
- LZMA сжатие декомпрессия 7z
- Обработка Прогресс загрузки
- URL викторины генератора QR-кодов
- Slick Action и диалог
- Twig эксперименты с динамической формой
- Использование задержки для обновления статуса
Изображение- Отображение полилинии SVG
- imagejs - IJS и panzoom
Помощник визуализатора и формы Утилита- Преобразование данных изображения в изображение
- Преобразование изображения в данные изображенияURL
- Преобразование текстового латекса для github
- Кодирование / decode base64
- Шрифт несколько интересных иконок
- HTML Editor
- JSON filter
- JSON stringify
- JSoN text parse - stringify
- JSON viewer
- Markdown explorer
- Хорошие инструменты в Интернете
- Разобрать формат мультилога Arduino
- Проводник RegExp
.