Разобрать слово по составу (корень, суффикс, приставка, окончание)
Русский язык, 19.05.2019 11:20, rouberuplay
Посмотреть ответы
Другие вопросы по: Русский язык
При электролизе расплава хлорида калия на аноде выделился газ объемом 22,4л(н. составьте схему электролиза расплава соли. определите кол-во вещ-ва соли, которая подверглась электро…
Опубликовано: 27.02.2019 11:50
Ответов: 3
.(Общая масса сома, щуки и карася- 4,43кг. масса щуки в 1,6 раза больше массы карася, а масса сома на 0,86кг больше массы щуки. найти массу каждой из рыб.)….
Опубликовано: 27.02.2019 12:00
Ответов: 3
Як ви розумієте значення прислів я кожному птаху своє гніздо миле…
Опубликовано: 27.02.2019 16:00
Ответов: 1
.(При отправлении телеграммы оплата производится так за подачу 18руб и доп. слово 1,1.построй формулу зависимости с телеграммы от числа n слов в ней.)….
слово 1,1.построй формулу зависимости с телеграммы от числа n слов в ней.)….
Опубликовано: 27.02.2019 16:50
Ответов: 1
1701: 27 4176: 58 3984: 83 2241: 27 1755: 39 1272: 53 4368: 84 3078: 38 3948: 42 3528: 84 2847: 39 2590: 35 1536: 32 1824: 57 3168: 44 4176: 58 3984: 48 3432: 44 3354: 34 1536: 32…
Опубликовано: 28.02.2019 21:10
Ответов: 3
Какое из слов: золотой, серебряный, медный ,стеклянный-может быть нарицательным существительным?…
Опубликовано: 01.03.2019 04:30
Ответов: 2
Знаешь правильный ответ?
Разобрать слово по составу (корень, суффикс, приставка, окончание) пригнать и приединить…
Популярные вопросы
Виюне прошлого года количество солнечных дней в петербурге составляло 25% от количества пасмурных, а количество тёплых дней 20% от количества прохладных. только 3 дня в июне были т…
Опубликовано: 27. 02.2019 17:10
02.2019 17:10
Ответов: 1
h3s04 + 2naoh = na2s04 + 2н20 рассчитайте массу гидроксида натрия, необходимого для полной нейтрализации раствора, содержащего 24,5 г серной кислоты….
Опубликовано: 28.02.2019 02:40
Ответов: 2
.(На первой стоянке в 4 раза меньше машин. чем на второй. после того как на первую приехали 35 машин, а со второй уехали 25 машин, машин стало поровну. сколько машин было на каждой…
Опубликовано: 28.02.2019 02:40
Ответов: 1
:разгадайте ребус: нарисована стена»чашка. что это может значить?…
Опубликовано: 28.02.2019 20:40
Ответов: 3
Расчитайте массу водорода, который веделился при взаимодействии магния с 98г раствора с массовой долей серной кислоты 10%….
Опубликовано: 28.02.2019 22:10
Ответов: 3
Из 523 цыплят, выведенных в инкубаторе, петушков оказалось на 25 меньше, чем курочек. сколко курочек и сколько петушков было выведено в инкубаторе?…
сколко курочек и сколько петушков было выведено в инкубаторе?…
Опубликовано: 01.03.2019 05:40
Ответов: 1
:найти основы в предложениях и подчеркнуть. недвижный камыш. не трепещет осока. глубокая тишь. безглагольность покоя. луга убегают далёко-далёко. во всем утомленье — глухое, немое….
Опубликовано: 01.03.2019 19:00
Ответов: 3
Впервый день тракторная бригада вспахала 3/8 участка, во второй день-2/5 остатка, а в третий день-остальные 216 га. определите площадь участка….
Опубликовано: 01.03.2019 20:40
Ответов: 3
Сравните клетки, находящиеся в интерфазе и в фазах митоза. в чем заключаеться разница между ними?…
Опубликовано: 01.03.2019 22:10
Ответов: 1
Дано ав=13см, вс=20см, вд-высота трейгольника, вд=12 см, вычислите длины проекций строн ав, вс на прямую ас и длину сторон ас.. .
.
Опубликовано: 02.03.2019 07:20
Ответов: 3
Больше вопросов по предмету: Русский язык Случайные вопросы
Справочник по построению дерева — документация Lark
Lark автоматически строит дерево на основе структуры грамматики, где каждое совпадающее правило становится ветвью (узлом) в дереве, а его дочерние элементы являются его совпадениями в порядке совпадения.
Например, узел правила : child1 child2 создаст узел дерева с двумя дочерними элементами. Если он соответствует как часть другого правила (т. е. если он не является корнем), узел дерева нового правила станет его родителем.
Использование item+ или item* приведет к созданию списка элементов, эквивалентного записи item item item .. .
Используете элемент ? вернет элемент, если он совпал, или ничего.
Если may_placeholders=True (по умолчанию), то использование [item] вернет элемент, если он совпал, или значение None , если нет.
Если may_placeholders=False , то [] ведет себя как ()? .
Клеммы
Терминалы всегда являются значениями в дереве, а не ветвями.Lark по умолчанию отфильтровывает определенные типы терминалов, учитывая их пунктуацию:
Терминалы, которые не отображаются в дереве:
Терминалы, которые будут отображаться в дереве:
Примечание. Терминалы, состоящие из литералов и других терминалов, всегда включают полное совпадение без фильтрации какой-либо части.
Пример:
начало: PNAME pname
ПИМЯ: "("ИМЯ")"
pname: "("ИМЯ")"
ИМЯ: /\w+/
%игнорировать /\s+/
Lark проанализирует «(Hello) (World)» как:
начало
(Привет)
псевдоним Мир
Правила с префиксом ! сохранит все свои литералы в любом случае.
Пример:
выражение: "(" выражение ")"
| ИМЯ+
ИМЯ: /\w+/
%игнорировать " "
Lark разберет «((hello world))» как:
выражение
выражение
выражение
"привет"
"Мир"
Скобки не отображаются в дереве по умолчанию. Слова появляются, потому что им соответствует именованный терминал.
Слова появляются, потому что им соответствует именованный терминал.
Формирование дерева
Пользователи могут изменить автоматическое построение дерева, используя набор грамматических функций.
Пример:
начало: "("_приветствовать")"
_greet: /\w+/ /\w+/
Lark будет анализировать «(hello world)» как:
начало
"привет"
"Мир"
Пример:
начало: приветствие приветствие
?приветствовать: "(" /\w+/ ")"
| /\ш+/ /\ш+/
Lark будет анализировать «hello world (planet)» как:
начало
приветствовать
"привет"
"Мир"
"планета"
!выражение: "("выражение ")"
| ИМЯ+
ИМЯ: /\w+/
%игнорировать " "
Будет разбирать «((hello world))» как:
выражение
(
выражение
(
выражение
привет
Мир
)
)
Использование ! Префикс обычно является «запахом кода» и может указывать на недостаток в вашем дизайне грамматики.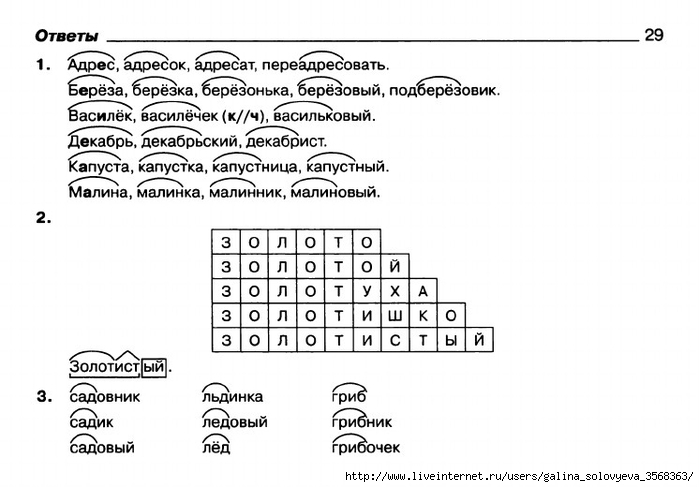
Пример:
начало: приветствие приветствие
приветствовать: "привет"
| "мир" -> планета
Lark будет анализировать «hello world» как:
начало
приветствовать
планета
Составление моделей леса решений и нейронных сетей
| Посмотреть на TensorFlow.org | Запустить в Google Colab | Посмотреть на GitHub | Скачать блокнот | Функциональный API Кераса |
Введение
Добро пожаловать в учебник
Возможно, вы захотите составить модели вместе, чтобы повысить эффективность прогнозирования
(ансамблирование), чтобы получить лучшее от различных технологий моделирования (гетерогенное
сборка модели) для обучения разных частей модели на разных наборах данных
(например, предварительное обучение) или для создания многоуровневой модели (например, модель
оперирует предсказаниями другой модели).
В этом руководстве рассматривается расширенный вариант использования композиции модели с использованием Функциональный API. Вы можете найти примеры для более простых сценариев композиции модели в разделе «Предварительная обработка функций» этого руководства и в разделе «использование предварительно обученного встраивания текста» этого руководство.
Вот структура модели, которую вы создадите:
!pip install graphviz -U --quiet
из источника импорта graphviz
Источник("""
орграф G {
raw_data [label="Входные характеристики"];
preprocess_data [label="Обучаемая предварительная обработка NN", shape=rect];
необработанные_данные -> предварительные_данные
подграф кластер_0 {
цвет=серый;
a1[label="NN layer", shape=rect];
b1[label="Слой NN", shape=прямоугольник];
а1 -> б1;
label = "Модель №1";
}
подграф кластер_1 {
цвет=серый;
a2[label="NN layer", shape=rect];
b2[label="NN layer", shape=rect];
а2 -> б2;
label = "Модель №2";
}
подграф кластер_2 {
цвет=серый;
a3[label="Лес решений", shape=rect];
label = "Модель №3";
}
подграф кластер_3 {
цвет=серый;
a4[label="Лес решений", shape=rect];
label = "Модель №4";
}
предварительные_данные -> а1;
предварительные_данные -> а2;
предварительные_данные -> а3;
предварительные_данные -> а4;
b1 -> аггр;
b2 -> аггр;
а3 -> аггр;
а4 -> аггр;
aggr [label="Агрегация (среднее)", shape=rect]
аггр -> прогнозы
}
""")
Составленная модель состоит из трех этапов:
- Первый этап — это слой предварительной обработки, состоящий из нейронной сети и
общие для всех моделей на следующем этапе.
 На практике такой
слой предварительной обработки может быть либо предварительно обученным встраиванием для точной настройки, либо
случайно инициализированная нейронная сеть.
На практике такой
слой предварительной обработки может быть либо предварительно обученным встраиванием для точной настройки, либо
случайно инициализированная нейронная сеть. - Второй этап представляет собой ансамбль из двух лесов решений и двух нейронных сетевые модели.
- На последнем этапе усредняются прогнозы моделей на втором этапе. Он не содержит обучаемых весов.
 На практике такой
слой предварительной обработки может быть либо предварительно обученным встраиванием для точной настройки, либо
случайно инициализированная нейронная сеть.
На практике такой
слой предварительной обработки может быть либо предварительно обученным встраиванием для точной настройки, либо
случайно инициализированная нейронная сеть.Нейронные сети обучаются с помощью алгоритм обратного распространения и градиентный спуск. Этот алгоритм имеет два важных свойства: (1) Слой нейронной сети можно обучить, если она получает градиент потерь (подробнее именно, градиент потерь в соответствии с выходом слоя), и (2) алгоритм «передает» градиент потерь с выхода слоя на вход слоя (это «цепное правило»). По этим двум причинам обратное распространение может обучать вместе несколько слоев нейронных сетей, расположенных поверх каждого Другой.
В этом примере леса решений обучаются с помощью
Случайный лес
(РЧ) алгоритм. В отличие от Backpropagation, обучение RF не «передает»
градиент потерь от выхода к входу. По этим причинам
классический RF-алгоритм нельзя использовать для обучения или тонкой настройки нейронной сети
под. Другими словами, этапы «леса решений» нельзя использовать для обучения
«Обучаемый блок предварительной обработки NN».
По этим причинам
классический RF-алгоритм нельзя использовать для обучения или тонкой настройки нейронной сети
под. Другими словами, этапы «леса решений» нельзя использовать для обучения
«Обучаемый блок предварительной обработки NN».
- Обучение этапа препроцессинга и нейронных сетей.
- Тренируйте этапы леса принятия решений.
Установите TensorFlow Decision Forests
Установите TF-DF, запустив следующую ячейку.
pip установить tensorflow_decision_forests -U --quiet
Wurlitzer необходим для отображения
подробные журналы обучения в Colabs (при использовании verbose=2 в конструкторе модели).
pip install wurlitzer -U --quiet
Импорт библиотек
импорт tensorflow_decision_forests как tfdf импорт ОС импортировать numpy как np импортировать панд как pd импортировать тензорный поток как tf импортировать математику импортировать matplotlib.
 pyplot как plt
pyplot как plt
2022-10-19 11:34:33.433593: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Не удалось зарегистрировать фабрику cuBLAS: Попытка зарегистрировать factory для плагина cuBLAS, когда он уже зарегистрирован 2022-10-19 11:34:34.158152: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Не удалось загрузить динамическую библиотеку «libnvinfer.so.7»; ошибка & двоеточие; libnvinfer.so.7: не удается открыть общий объектный файл: Данный файл или каталог отсутствует 2022-10-1911:34:34.158263: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Не удалось загрузить динамическую библиотеку «libnvinfer_plugin.so.7»; ошибка & двоеточие; libnvinfer_plugin.so.7: не удается открыть общий объектный файл: Данный файл или каталог отсутствует 2022-10-19 11:34:34.158275: W tensorflow/compiler/tf2tensorrt/utils/py_utils.
 cc:38] Предупреждение TF-TRT: Не удается открыть некоторые библиотеки TensorRT. Если вы хотите использовать графический процессор Nvidia с TensorRT, убедитесь, что отсутствующие библиотеки, упомянутые выше, установлены правильно.
cc:38] Предупреждение TF-TRT: Не удается открыть некоторые библиотеки TensorRT. Если вы хотите использовать графический процессор Nvidia с TensorRT, убедитесь, что отсутствующие библиотеки, упомянутые выше, установлены правильно.
Набор данных
В этом руководстве вы будете использовать простой синтетический набор данных, чтобы упростить интерпретировать окончательную модель.
определение make_dataset (num_examples, num_features, seed = 1234):
np.random.seed (семя)
функции = np.random.uniform (-1, 1, размер = (num_examples, num_features))
шум = np.random.uniform (размер = (num_examples))
left_side = np.sqrt(
np.sum (np.multiply (np.square (функции [:, 0: 2]), [1, 2]), ось = 1))
right_side = features[:, 2] * 0,7 + np.sin(
характеристики[:, 3] * 10) * 0,5 + шум * 0,0 + 0,5
метки = левая_сторона <= правая_сторона
возвращаемые функции, labels.astype(int)
Создать несколько примеров:
make_dataset(num_examples=5, num_features=4)
(массив([[-0,6169611, 0,24421754, -0,12454452, 0,57071717],
[0,55995162, -0,45481479, -0,44707149, 0,60374436],
[0,91627871, 0,75186527, -0,28436546, 0,00199025],
[0,36692587, 0,42540405, -0,25949849, 0,12239237],
[0,00616633, -0,9724631, 0,54565324, 0,76528238]]),
массив ([0, 0, 0, 1, 0]))
Вы также можете нарисовать их, чтобы получить представление о синтетическом шаблоне:
plot_features, plot_label = make_dataset (num_examples = 50000, num_features = 4) plt.
 rcParams["figure.figsize"] = [8, 8]
common_args = dict (c = plot_label, s = 1,0, альфа = 0,5)
plt.subplot(2, 2, 1)
plt.scatter(функции_графика[:, 0], функции_графика[:, 1], **общие_аргументы)
plt.subplot(2, 2, 2)
plt.scatter(функции_графика[:, 1], функции_графика[:, 2], **общие_аргументы)
plt.subplot(2, 2, 3)
plt.scatter(функции_графика[:, 0], функции_графика[:, 2], **общие_аргументы)
plt.subplot(2, 2, 4)
plt.scatter(функции_графика[:, 0], функции_графика[:, 3], **общие_аргументы)
rcParams["figure.figsize"] = [8, 8]
common_args = dict (c = plot_label, s = 1,0, альфа = 0,5)
plt.subplot(2, 2, 1)
plt.scatter(функции_графика[:, 0], функции_графика[:, 1], **общие_аргументы)
plt.subplot(2, 2, 2)
plt.scatter(функции_графика[:, 1], функции_графика[:, 2], **общие_аргументы)
plt.subplot(2, 2, 3)
plt.scatter(функции_графика[:, 0], функции_графика[:, 2], **общие_аргументы)
plt.subplot(2, 2, 4)
plt.scatter(функции_графика[:, 0], функции_графика[:, 3], **общие_аргументы)
Обратите внимание, что этот шаблон сглажен и не выровнен по оси. Это даст преимущество моделям нейронных сетей. Это связано с тем, что для нейронной сети проще, чем для дерева решений, иметь круглые и не выровненные границы решений.
С другой стороны, мы будем обучать модель на небольшом наборе данных с 2500 примерами. Это даст преимущество модели леса решения. Это связано с тем, что леса решений намного эффективнее, используя всю доступную информацию из примеров (леса решений «эффективны по выборке»).
Наш ансамбль нейронных сетей и лесов решений будет использовать лучшее из обоих миров.
Давайте создадим поезд и протестируем tf.data.Dataset :
def make_tf_dataset(batch_size=64, **args):
функции, метки = make_dataset(**args)
вернуть tf.data.Dataset.from_tensor_slices(
(функции, метки)).batch(batch_size)
количество_функций = 10
train_dataset = make_tf_dataset(
num_examples=2500, num_features=num_features, batch_size=100, seed=1234)
test_dataset = make_tf_dataset(
num_examples=10000, num_features=num_features, batch_size=100, seed=5678)
Структура модели
Определите структуру модели следующим образом:
# Входные объекты. raw_features = tf.keras.layers.Input (shape = (num_features,)) # Этап 1 # ======= # Обычная обучаемая предварительная обработка препроцессор = tf.keras.layers.Dense(10, активация=tf.
 nn.relu6)
preprocess_features = препроцессор (raw_features)
# Этап 2
# =======
# Модель №1: НН
m1_z1 = tf.keras.layers.Dense(5, активация=tf.nn.relu6)(preprocess_features)
m1_pred = tf.keras.layers.Dense (1, активация = tf.nn.sigmoid) (m1_z1)
# Модель №2: НН
m2_z1 = tf.keras.layers.Dense(5, активация=tf.nn.relu6)(preprocess_features)
m2_pred = tf.keras.layers.Dense (1, активация = tf.nn.sigmoid) (m2_z1)
# Модель №3: ДФ
model_3 = tfdf.keras.RandomForestModel (num_trees = 1000, random_seed = 1234)
m3_pred = model_3 (предварительные_функции)
# Модель №4: ДФ
model_4 = tfdf.keras.RandomForestModel(
количество_деревьев=1000,
#split_axis="SPARSE_OBLIQUE", # Раскомментируйте эту строку, чтобы повысить качество этой модели
random_seed=4567)
m4_pred = model_4 (предварительные_функции)
# Так как TF-DF использует детерминированные алгоритмы обучения, вы должны установить модель
# обучаем seed различным значениям, иначе оба
# `tfdf.keras.RandomForestModel` будет точно таким же.
# Этап 3
# =======
mean_nn_only = tf.
nn.relu6)
preprocess_features = препроцессор (raw_features)
# Этап 2
# =======
# Модель №1: НН
m1_z1 = tf.keras.layers.Dense(5, активация=tf.nn.relu6)(preprocess_features)
m1_pred = tf.keras.layers.Dense (1, активация = tf.nn.sigmoid) (m1_z1)
# Модель №2: НН
m2_z1 = tf.keras.layers.Dense(5, активация=tf.nn.relu6)(preprocess_features)
m2_pred = tf.keras.layers.Dense (1, активация = tf.nn.sigmoid) (m2_z1)
# Модель №3: ДФ
model_3 = tfdf.keras.RandomForestModel (num_trees = 1000, random_seed = 1234)
m3_pred = model_3 (предварительные_функции)
# Модель №4: ДФ
model_4 = tfdf.keras.RandomForestModel(
количество_деревьев=1000,
#split_axis="SPARSE_OBLIQUE", # Раскомментируйте эту строку, чтобы повысить качество этой модели
random_seed=4567)
m4_pred = model_4 (предварительные_функции)
# Так как TF-DF использует детерминированные алгоритмы обучения, вы должны установить модель
# обучаем seed различным значениям, иначе оба
# `tfdf.keras.RandomForestModel` будет точно таким же.
# Этап 3
# =======
mean_nn_only = tf. reduce_mean(tf.stack([m1_pred, m2_pred], ось = 0), ось = 0)
mean_nn_and_df = tf.reduce_mean(
tf.stack([m1_pred, m2_pred, m3_pred, m4_pred], ось=0), ось=0)
# Модели Керас
# =============
ансамбль_nn_only = tf.keras.models.Model (raw_features, mean_nn_only)
ансамбль_nn_and_df = tf.keras.models.Model (raw_features, mean_nn_and_df)
reduce_mean(tf.stack([m1_pred, m2_pred], ось = 0), ось = 0)
mean_nn_and_df = tf.reduce_mean(
tf.stack([m1_pred, m2_pred, m3_pred, m4_pred], ось=0), ось=0)
# Модели Керас
# =============
ансамбль_nn_only = tf.keras.models.Model (raw_features, mean_nn_only)
ансамбль_nn_and_df = tf.keras.models.Model (raw_features, mean_nn_and_df)
Предупреждение&двоеточие; Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров. ПРЕДУПРЕЖДЕНИЕ:absl:Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров. Используйте /tmpfs/tmp/tmputxnmu4_ в качестве временного учебного каталога. Предупреждение&двоеточие; Модель вызывалась напрямую (т. е. с использованием `model(data)` вместо `model.
 predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
ПРЕДУПРЕЖДЕНИЕ:absl:Модель была вызвана напрямую (т.е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
Предупреждение&двоеточие; Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров.
ПРЕДУПРЕЖДЕНИЕ:absl:Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров.
Используйте /tmpfs/tmp/tmpwcs1i6ci в качестве временного учебного каталога.
predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
ПРЕДУПРЕЖДЕНИЕ:absl:Модель была вызвана напрямую (т.е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
Предупреждение&двоеточие; Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров.
ПРЕДУПРЕЖДЕНИЕ:absl:Аргумент конструктора `num_threads` не задан, а количество процессоров равно os.cpu_count()=32 > 32. Установка num_threads на 32. Установите num_threads вручную, чтобы использовать более 32 процессоров.
Используйте /tmpfs/tmp/tmpwcs1i6ci в качестве временного учебного каталога. Предупреждение&двоеточие; Модель вызывалась напрямую (т. е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
ПРЕДУПРЕЖДЕНИЕ:absl:Модель была вызвана напрямую (т.е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
Предупреждение&двоеточие; Модель вызывалась напрямую (т. е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
ПРЕДУПРЕЖДЕНИЕ:absl:Модель была вызвана напрямую (т.е. с использованием `model(data)` вместо `model.predict(data)`) перед обучением. Модель будет возвращать только нули, пока не будет обучена. Форма вывода может измениться после обучения Tensor("inputs:0", shape=(None, 10), dtype=float32)
Перед обучением модели вы можете построить ее, чтобы проверить, похожа ли она на начальная схема.
из keras.utils.vis_utils импорта plot_model plot_model(ensemble_nn_and_df, to_file="/tmp/model.png", show_shapes=True)
Обучение модели
Сначала обучите предварительную обработку и два слоя нейронной сети, используя
алгоритм обратного распространения.
%%время
ансамбль_nn_only.compile(
оптимизатор=tf.keras.optimizers.Adam(),
потеря=tf.keras.losses.BinaryCrossentropy(),
метрики=["точность"])
ансамбль_nn_only.fit (train_dataset, эпохи = 20, validation_data = test_dataset)
Эпоха 1/20 25/25 [===============================] - 1 с 17 мс/шаг - потеря&двоеточие; 0,6390 - точность&двоеточие; 0,6864 - val_loss: 0.6222 - val_accuracy: 0,7074 Эпоха 2/20 25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,6028 - точность&двоеточие; 0,7424 - val_loss: 0.5907 - val_accuracy: 0,7336 Эпоха 3/20 25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,5724 - точность&двоеточие; 0,7468 - val_loss: 0,5646 - val_accuracy: 0,7392 Эпоха 4/20 25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,5470 - точность&двоеточие; 0.7500 - val_loss: 0,5437 - val_accuracy: 0,7392 Эпоха 5/20 25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,5264 - точность&двоеточие; 0.
 7500 - val_loss: 0,5277 - val_accuracy: 0,7392
Эпоха 6/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,5104 - точность&двоеточие; 0.7500 - val_loss: 0,5153 - val_accuracy: 0,7392
Эпоха 7/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4976 - точность&двоеточие; 0.7500 - val_loss: 0,5052 - val_accuracy: 0,7392
Эпоха 8/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4869 - точность&двоеточие; 0.7500 - val_loss: 0,4961 - val_accuracy: 0,7396
Эпоха 9/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4774 - точность&двоеточие; 0.7500 - val_loss: 0,4877 - val_accuracy: 0,7401
Эпоха 10/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4688 - точность&двоеточие; 0,7516 - val_loss: 0.4800 - val_accuracy: 0,7427
Эпоха 11/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4612 - точность&двоеточие; 0,7588 - val_loss: 0.
7500 - val_loss: 0,5277 - val_accuracy: 0,7392
Эпоха 6/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,5104 - точность&двоеточие; 0.7500 - val_loss: 0,5153 - val_accuracy: 0,7392
Эпоха 7/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4976 - точность&двоеточие; 0.7500 - val_loss: 0,5052 - val_accuracy: 0,7392
Эпоха 8/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4869 - точность&двоеточие; 0.7500 - val_loss: 0,4961 - val_accuracy: 0,7396
Эпоха 9/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4774 - точность&двоеточие; 0.7500 - val_loss: 0,4877 - val_accuracy: 0,7401
Эпоха 10/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4688 - точность&двоеточие; 0,7516 - val_loss: 0.4800 - val_accuracy: 0,7427
Эпоха 11/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4612 - точность&двоеточие; 0,7588 - val_loss: 0. 4732 - val_accuracy: 0,7487
Эпоха 12/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4546 - точность&двоеточие; 0,7664 - val_loss: 0,4674 - val_accuracy: 0,7554
Эпоха 13/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4491 - точность&двоеточие; 0,7736 - val_loss: 0,4624 - val_accuracy: 0,7636
Эпоха 14/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4446 - точность&двоеточие; 0.7808 - val_loss: 0.4584 - val_accuracy: 0,7683
Эпоха 15/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4409 - точность&двоеточие; 0,7844 - val_loss: 0,4551 - val_accuracy: 0,7716
Эпоха 16/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4377 - точность&двоеточие; 0,7908 - val_loss: 0,4524 - val_accuracy: 0,7751
Эпоха 17/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4351 - точность&двоеточие; 0,7956 - val_loss: 0.
4732 - val_accuracy: 0,7487
Эпоха 12/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4546 - точность&двоеточие; 0,7664 - val_loss: 0,4674 - val_accuracy: 0,7554
Эпоха 13/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4491 - точность&двоеточие; 0,7736 - val_loss: 0,4624 - val_accuracy: 0,7636
Эпоха 14/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4446 - точность&двоеточие; 0.7808 - val_loss: 0.4584 - val_accuracy: 0,7683
Эпоха 15/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4409 - точность&двоеточие; 0,7844 - val_loss: 0,4551 - val_accuracy: 0,7716
Эпоха 16/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4377 - точность&двоеточие; 0,7908 - val_loss: 0,4524 - val_accuracy: 0,7751
Эпоха 17/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4351 - точность&двоеточие; 0,7956 - val_loss: 0. 4502 - val_accuracy: 0,7770
Эпоха 18/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4328 - точность&двоеточие; 0,8016 - val_loss: 0,4483 - val_accuracy: 0,7792
Эпоха 19/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4308 - точность&двоеточие; 0.8032 - val_loss: 0,4466 - val_accuracy: 0,7806
Эпоха 20/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4291 - точность&двоеточие; 0,8024 - val_loss: 0.4452 - val_accuracy: 0,7825
Время ЦП&колон; пользователь 7,83 с, sys: 1,63 с, всего&двоеточие; 9,46 с
Время стены&колон; 5,95 с
4502 - val_accuracy: 0,7770
Эпоха 18/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4328 - точность&двоеточие; 0,8016 - val_loss: 0,4483 - val_accuracy: 0,7792
Эпоха 19/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4308 - точность&двоеточие; 0.8032 - val_loss: 0,4466 - val_accuracy: 0,7806
Эпоха 20/20
25/25 [===============================] - 0 с 10 мс/шаг - потеря&двоеточие; 0,4291 - точность&двоеточие; 0,8024 - val_loss: 0.4452 - val_accuracy: 0,7825
Время ЦП&колон; пользователь 7,83 с, sys: 1,63 с, всего&двоеточие; 9,46 с
Время стены&колон; 5,95 с
Давайте оценим предварительную обработку и часть только с двумя нейронными сетями:
оценка_nn_only = ансамбль_nn_only.evaluate(test_dataset, return_dict=True)
print("Точность (только NN №1 и №2): ", Assessment_nn_only["точность"])
print("Потери (только NN #1 и #2): ", Assessment_nn_only["потеря"])
100/100 [===============================] - 0 с 2 мс/шаг - потеря&двоеточие; 0,4452 - точность&двоеточие; 0,7825 Точность (только NN #1 и #2): 0,7825000286102295 Потери (только NN № 1 и № 2): 0,4451720118522644
Давайте обучим два компонента леса решений (один за другим).
%%время train_dataset_with_preprocessing = train_dataset.map (лямбда x, y: (препроцессор (x), y)) test_dataset_with_preprocessing = test_dataset.map (лямбда x, y: (препроцессор (x), y)) model_3.fit(train_dataset_with_preprocessing) model_4.fit(train_dataset_with_preprocessing)
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать <функция <лямбда> по адресу 0x7fcaccdb35e0> и будет выполняться как есть. Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fcaccdb35e0>: среди кандидатов не найдено подходящего AST: Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert. ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать <функция <лямбда> по адресу 0x7fcaccdb35e0> и будет выполняться как есть. Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fcaccdb35e0>: среди кандидатов не найдено подходящего AST: Чтобы отключить это предупреждение, украсьте функцию @tf.в 0x7fc9cc0ebc10> и запустит его как есть. Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fc9cc0ebc10>: среди кандидатов не найдено подходящего AST: Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert. ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать <функция <лямбда> по адресу 0x7fc9cc0ebc10> и будет выполняться как есть. Причина&колон; не удалось разобрать исходный код <функции <лямбда> по адресу 0x7fc9cc0ebc10>: среди кандидатов не найдено подходящего AST: Чтобы отключить это предупреждение, украсьте функцию @tf. и запустит его как есть. и запустит его как есть. Пожалуйста, сообщите об этом команде TensorFlow. При регистрации ошибки установите уровень детализации на 10 (в Linux `export AUTOGRAPH_VERBOSITY=10`) и прикрепите полный вывод. Причина&колон; не удалось получить исходный код Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert. ПРЕДУПРЕЖДЕНИЕ&двоеточие; AutoGraph не смог преобразовать и запустит ее как есть. Пожалуйста, сообщите об этом команде TensorFlow.
 autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ&двоеточие; AutoGraph не смог преобразовать <функция <лямбда> по адресу 0x7fcaccdb35e0> и запустит ее как есть.
Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fcaccdb35e0>: среди кандидатов не найдено подходящего AST:
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать
autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ&двоеточие; AutoGraph не смог преобразовать <функция <лямбда> по адресу 0x7fcaccdb35e0> и запустит ее как есть.
Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fcaccdb35e0>: среди кандидатов не найдено подходящего AST:
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать  autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ&двоеточие; AutoGraph не смог преобразовать <функция <лямбда> по адресу 0x7fc9cc0ebc10> и запустит ее как есть.
Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fc9cc0ebc10>: среди кандидатов не найдено подходящего AST:
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
Чтение обучающего набора данных...
Набор обучающих данных читается в 0:00:03.004224. Найдено 2500 примеров.
Учебная модель...
[INFO kernel.cc:1176] Загрузка модели из пути /tmpfs/tmp/tmputxnmu4_/model/ с префиксом f49e46e27a3247f2
Модель обучена в 0:00:02.101842
Компиляция модели...
[INFO abstract_model.cc:1248] Создан движок "RandomForestOptPred".
[INFO kernel.cc:1022] Использовать быстрый универсальный движок
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не смог преобразовать
autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ&двоеточие; AutoGraph не смог преобразовать <функция <лямбда> по адресу 0x7fc9cc0ebc10> и запустит ее как есть.
Причина&колон; не удалось проанализировать исходный код <функции <лямбда> по адресу 0x7fc9cc0ebc10>: среди кандидатов не найдено подходящего AST:
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
Чтение обучающего набора данных...
Набор обучающих данных читается в 0:00:03.004224. Найдено 2500 примеров.
Учебная модель...
[INFO kernel.cc:1176] Загрузка модели из пути /tmpfs/tmp/tmputxnmu4_/model/ с префиксом f49e46e27a3247f2
Модель обучена в 0:00:02.101842
Компиляция модели...
[INFO abstract_model.cc:1248] Создан движок "RandomForestOptPred".
[INFO kernel.cc:1022] Использовать быстрый универсальный движок
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не смог преобразовать  Пожалуйста, сообщите об этом команде TensorFlow. При регистрации ошибки установите уровень детализации на 10 (в Linux `export AUTOGRAPH_VERBOSITY=10`) и прикрепите полный вывод.
Причина&колон; не удалось получить исходный код
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать
Пожалуйста, сообщите об этом команде TensorFlow. При регистрации ошибки установите уровень детализации на 10 (в Linux `export AUTOGRAPH_VERBOSITY=10`) и прикрепите полный вывод.
Причина&колон; не удалось получить исходный код
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
ПРЕДУПРЕЖДЕНИЕ:tensorflow:AutoGraph не удалось преобразовать  При регистрации ошибки установите уровень детализации на 10 (в Linux `export AUTOGRAPH_VERBOSITY=10`) и прикрепите полный вывод.
Причина&колон; не удалось получить исходный код
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
Модель собрана.
Чтение обучающего набора данных...
Набор обучающих данных, прочитанный в 0:00:00.213698. Найдено 2500 примеров.
Учебная модель...
[INFO kernel.cc:1176] Загрузка модели из пути /tmpfs/tmp/tmpwcs1i6ci/model/ с префиксом 6a19b75110c14264
Модель обучена в 0:00:01.951841
Компиляция модели...
[INFO kernel.cc:1022] Использовать быстрый универсальный движок
Модель собрана.
Время ЦП&колон; пользователь 22,4 с, sys: 1,67 с, всего&двоеточие; 24,1 с
Время стены&колон; 8,79 с
При регистрации ошибки установите уровень детализации на 10 (в Linux `export AUTOGRAPH_VERBOSITY=10`) и прикрепите полный вывод.
Причина&колон; не удалось получить исходный код
Чтобы отключить это предупреждение, украсьте функцию @tf.autograph.experimental.do_not_convert.
Модель собрана.
Чтение обучающего набора данных...
Набор обучающих данных, прочитанный в 0:00:00.213698. Найдено 2500 примеров.
Учебная модель...
[INFO kernel.cc:1176] Загрузка модели из пути /tmpfs/tmp/tmpwcs1i6ci/model/ с префиксом 6a19b75110c14264
Модель обучена в 0:00:01.951841
Компиляция модели...
[INFO kernel.cc:1022] Использовать быстрый универсальный движок
Модель собрана.
Время ЦП&колон; пользователь 22,4 с, sys: 1,67 с, всего&двоеточие; 24,1 с
Время стены&колон; 8,79 с
И давайте оценим леса решений по отдельности.
model_3.compile(["точность"]) model_4.compile(["точность"]) оценка_df3_only = модель_3.
 оценить(
test_dataset_with_preprocessing, return_dict = True)
оценка_df4_only = модель_4.оценить(
test_dataset_with_preprocessing, return_dict = True)
print("Точность (только DF #3): ", Assessment_df3_only["точность"])
print("Точность (только DF #4): ", Assessment_df4_only["точность"])
оценить(
test_dataset_with_preprocessing, return_dict = True)
оценка_df4_only = модель_4.оценить(
test_dataset_with_preprocessing, return_dict = True)
print("Точность (только DF #3): ", Assessment_df3_only["точность"])
print("Точность (только DF #4): ", Assessment_df4_only["точность"])
100/100 [===============================] - 1 с 11 мс/шаг - потери&двоеточие; 0.0000e+00 - точность&двоеточие; 0,7866 100/100 [===============================] - 1 с 11 мс/шаг - потери&двоеточие; 0.0000e+00 - точность&двоеточие; 0,7865 Точность (только DF #3): 0,7865999937057495 Точность (только DF #4): 0,7864999771118164
Оценим весь состав модели:
ансамбль_nn_and_df.compile(
потеря=tf.keras.losses.BinaryCrossentropy(), метрика=["точность"])
оценка_nn_and_df = ансамбль_nn_and_df.evaluate(
test_dataset, return_dict = Истина)
print("Точность (2xNN и 2xDF): ", Assessment_nn_and_df["точность"])
print("Потери (2xNN и 2xDF): ", Assessment_nn_and_df["потери"])
100/100 [===============================] - 1 с 11 мс/шаг - потери&двоеточие; 0,4361 - точность&двоеточие; 0,7863 Точность (2xNN и 2xDF): 0,786300003528595 Потери (2xNN и 2xDF): 0,43608152866363525
Чтобы закончить, давайте еще немного настроим слой нейронной сети. Обратите внимание, что мы делаем
не настраивать предварительно обученное встраивание, так как от него зависят модели DF (если только мы
также переучил бы их после).
Обратите внимание, что мы делаем
не настраивать предварительно обученное встраивание, так как от него зависят модели DF (если только мы
также переучил бы их после).
Таким образом, у вас есть:
print(f"Точность (только NN #1 и #2):\t{evaluation_nn_only['accuracy']:.6f}")
print(f"Точность (только DF #3):\t\t{evaluation_df3_only['accuracy']:.6f}")
print(f"Точность (только DF #4):\t\t{evaluation_df4_only['accuracy']:.6f}")
Распечатать("----------------------------------------")
print(f"Точность (2xNN и 2xDF):\t{evaluation_nn_and_df['точность']:.6f}")
def delta_percent (src_eval, ключ):
src_acc = src_eval["точность"]
final_acc = оценка_nn_and_df["точность"]
увеличение = final_acc - src_acc
print(f"\t\t\t\t {увеличение:+.6f} над {ключом}")
delta_percent(evaluation_nn_only, "Только NN #1 и #2")
delta_percent(evaluation_df3_only, "только DF #3")
delta_percent(evaluation_df4_only, "только DF #4")
Точность (только NN #1 и #2): 0,782500
Точность (только DF #3): 0,786600
Точность (только DF #4): 0,786500
----------------------------------------
Точность (2xNN и 2xDF): 0,786300
+0,003800 только для NN #1 и #2
-0,000300 только для DF #3
-0,000200 только для DF #4
Здесь вы можете видеть, что составная модель работает лучше, чем отдельная
части.