Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: сепеакард 1 секунда назад ф а с а р и 1 секунда назад крипичо 1 секунда назад невнстр 1 секунда назад китасног 1 секунда назад ходуаб 1 секунда назад куалтин 1 секунда назад м а р к а 2 секунды назад психология труда 2 секунды назад т е э с о ц н 2 секунды назад с а м о л е т 2 секунды назад обрпа 2 секунды назад футбол 2 секунды назад ша р у м х 2 секунды назад ломнип 3 секунды назад
Урок «Значимые части слова Основа и окончание слова.»
Ноосферный урок русского языка в 6 классе
Тема.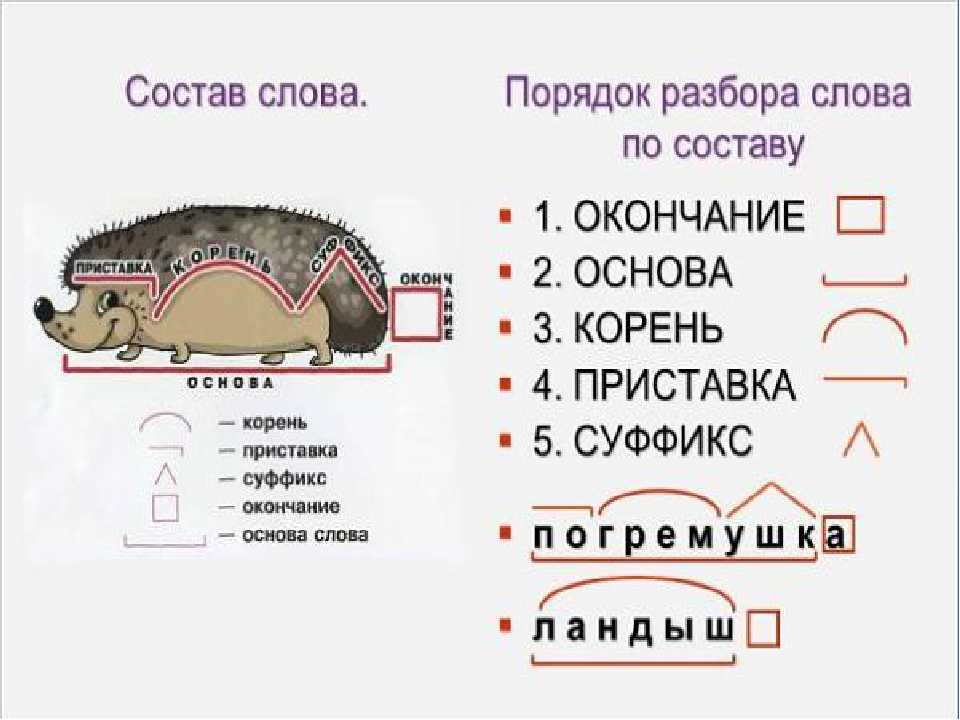 Значимые части слова Основа и окончание слова.
Значимые части слова Основа и окончание слова.
Цель: повторить изученное о частях слова в начальных классах, развивать умение определять родственные слова, выделять значимые части слова, воспитывать бережное отношение к природе.
Оборудование: учебник, ТСО, образон к теме урока.
Ход урока
I. Организационный момент.
- Проверка домашнего задания.
- Релаксация — ТСО.
Займите удобное положение. Расслабьте лицо, шею, плечи, руки, тело, ноги. Представьте, как мышцы лица становятся мягкими, расслабленными. Вы красивы, когда улыбаетесь… представьте, как бы улыбалось все ваше тело…, как бы потянулось оно навстречу солнцу.
Представьте, что вы в горах. Над вами бескрайнее голубое небо, вдали плещется лазурное море. Вы ступаете босыми ногами по теплым камням и чувствуете себя очень спокойно, расслаблено. Вы здесь — абсолютный хозяин…
Вы здесь — абсолютный хозяин…
Представьте звуки и запахи вашего покоя. Вдохните ароматы гор, бросьте с высоты камень и вслушайтесь в далекий отзвук удара его о землю. Прилягте на заросший мхом камень и вглядитесь в движение вокруг вас и вы увидите прямо перед собой необыкновенную ящерицу с короной на голове. Присмотритесь к ящерице повнимательней. Это ни что иное, как слово, состоящее из значимых частей. Голова ящерицы — корень, (в ней заключено основное значение слова), корона — это приставка (она как бы приставлена к голове и стоит всегда перед конем), за головой следует тело с забавными гребешками (это суффиксы — они стоят всегда после корня), а хвост ящерицы — это окончание (изменяемая часть слова). Хотите проверить? Дотроньтесь до ящерицы рукой. Видите, хвостик ящерица сбросила. Это она избавилась от окончания. Все, что осталось, называется основой. Но не переживайте, у ящерицы отрастет новый хвост, ведь окончания изменяемая часть слова.
Вас позабавила встреча с волшебной ящерицей? У вас хорошее настроение. Вы отдохнули, освободились от ненужных забот. Вдохните еще раз чистый воздух гор. Полюбуйтесь на лазурное небо и блестящее на солнце море… и возвращайтесь в класс на урок русского языка.
Вы отдохнули, освободились от ненужных забот. Вдохните еще раз чистый воздух гор. Полюбуйтесь на лазурное небо и блестящее на солнце море… и возвращайтесь в класс на урок русского языка.
- Беседа с учащимися об услышанном.
- Понравилось ли вам в горах?
- Что именно?
- Какие чувства возникли у вас при встрече с волшебной ящерицей?
- Что она собой представляла?
- Какова же тема урока?
(Дети выводят тему урока самостоятельно)
- Нарисуйте увиденный образ на бумаге.
( Работа с образоном, обсуждение, нанесение структурированной информации )
- Работа над новой темой.
- Прочитайте теоретически материал в учебнике и укажите на то, чего вы не увидели во время прогулки в горах (страницы указать).

- Спишите, выделите в словах корень. Являются ли однокоренными слова в каждом ряду?

Новый, новенький, обновка, обновить.
Крик, крикнуть, крикливый.
Борозда, бороздка, бороздить.
— Какие слова называются однокоренными? (слова, имеющие общий корень)
- Игра «Третий — лишний»
(карточки с заданием — на каждой парте)
Выписать из каждой группы только однокоренные слова, обозначить в них корень.
Косилка, косьба, кость;
Вода, водить, провод, водянистый;
Вспахать, запах, пахарь;
Гора, горелка, загорелый, горный;
Истопник, топить, топот.
- Слуховой диктант.
Послушайте текст. Выпишите слово снег с различными окончаниями, поставьте вопросы.
Ранний снег
Пришла Саша домой и принесла на ногах снег.
- Выделите окончания.
- Что такое окончание? (изменяемая часть слова, которая служит для связи слов в предложении и образует слова)
- Какие еще части слова вы знаете?
- Практическое задание.
Разобрать по составу слова:
Травка, подосиновик, пришкольный
Как получить вектор для предложения из word2vec токенов в предложении
спросил
Изменено 3 года, 3 месяца назад
Просмотрено 80 тысяч раз
Я создал векторы для списка токенов из большого документа, используя word2vec. Учитывая предложение, возможно ли получить вектор предложения из вектора токенов в предложении.
Учитывая предложение, возможно ли получить вектор предложения из вектора токенов в предложении.
- word2vec
Существуют разные методы получения векторов предложений:
- Doc2Vec : вы можете обучить свой набор данных с помощью Doc2Vec, а затем использовать векторы предложений.
- Среднее значение векторов Word2Vec : Вы можете просто взять среднее значение всех векторов слов в предложении. Этот средний вектор будет представлять ваш вектор предложений.
- Усреднение векторов Word2Vec с TF-IDF : это один из лучших подходов, который я рекомендую. Просто возьмите векторы слов и умножьте их на их оценки TF-IDF. Просто возьмите среднее значение, и оно будет представлять ваш вектор предложения.
11
Есть несколько способов получить вектор предложения. У каждого подхода есть преимущества и недостатки. Выбор зависит от задачи, которую вы хотите выполнить с вашими векторами.
Во-первых, вы можете просто усреднить векторы из word2vec. По словам Ле и Миколова, этот подход плохо подходит для задач анализа тональности, потому что он «теряет порядок слов так же, как и стандартные модели мешка слов», и «не может распознавать многие сложные лингвистические явления, например сарказм». С другой стороны, по данным Kenter et al. 2016, «простое усреднение словесных вложений всех слов в тексте оказалось надежной основой или функцией для множества задач», таких как задачи на сходство коротких текстов. Вариантом может быть взвешивание векторов слов с их TF-IDF, чтобы уменьшить влияние наиболее распространенных слов.
Более сложный подход, разработанный Socher et al. заключается в объединении векторов слов в порядке, заданном деревом синтаксического анализа предложения, с использованием операций матрицы-вектора. Этот метод работает для анализа настроений предложений, потому что он зависит от синтаксического анализа.
Можно, но не от word2vec. Композиция векторов слов для получения представлений более высокого уровня для предложений (и далее для абзацев и документов) является действительно активной темой исследования. Для этого нет одного лучшего решения, это действительно зависит от того, к какой задаче вы хотите применить эти векторы. Вы можете попробовать конкатенацию, простое суммирование, поточечное умножение, свертку и т. д. Есть несколько публикаций по этому вопросу, из которых вы можете извлечь уроки, но в конечном итоге вам просто нужно поэкспериментировать и посмотреть, что подходит вам лучше всего.
Для этого нет одного лучшего решения, это действительно зависит от того, к какой задаче вы хотите применить эти векторы. Вы можете попробовать конкатенацию, простое суммирование, поточечное умножение, свертку и т. д. Есть несколько публикаций по этому вопросу, из которых вы можете извлечь уроки, но в конечном итоге вам просто нужно поэкспериментировать и посмотреть, что подходит вам лучше всего.
4
Это зависит от использования:
1) Если вы хотите получить вектор предложения только для некоторых известных данных. Взгляните на вектор абзаца в этих газетах:
Куок В. Ле и Томас Миколов. 2014. Распределенные представления приговоров и документов. Эпринт Архив, 4:1188–1196.
А. М. Дай, К. Олах и К. В. Ле. 2015. Встраивание документов с помощью векторов абзацев. Электронные отпечатки ArXiv, июль.
2) Если вы хотите, чтобы модель оценивала вектор предложений для неизвестных (тестовых) предложений с неконтролируемым подходом:
Вы можете проверить эту бумагу:
Стивен Ду и Си Чжан. 2016. Aicyber на SemEval-2016 Задача 4: Представление предложения на основе i-вектора. В материалах 10-го Международного семинара по семантической оценке (SemEval 2016), Сан-Диего, США
2016. Aicyber на SemEval-2016 Задача 4: Представление предложения на основе i-вектора. В материалах 10-го Международного семинара по семантической оценке (SemEval 2016), Сан-Диего, США
3) Исследователи также ищут выходные данные определенного слоя в сети RNN или LSTM, недавний пример:
http://www. .aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12195
4) Для gensim doc2vec многие исследователи не смогли получить хороших результатов, чтобы преодолеть эту проблему, следуя статье с использованием doc2vec на основе предварительно обученные векторы слов.
Джей Хан Лау и Тимоти Болдуин (2016). Эмпирическая оценка doc2vec с практическим пониманием создания встраивания документов. В материалах 1-го семинара по репрезентативному обучению для НЛП, 2016 г.
5) tweet2vec или sent2vec .
У Facebook есть проект SentEval для оценки качества векторов предложений.
https://github.com/facebookresearch/SentEval
6) Дополнительную информацию можно найти в следующем документе:
Модели нейронных сетей для идентификации парафраз, семантического текстового сходства, вывода на естественном языке и ответов на вопросы
А пока вы можете использовать «BERT»:
Google публикует исходный код, а также предварительно обученные модели.
https://github.com/google-research/bert
А вот пример запуска bert как сервиса:
https://github.com/hanxiao/bert-as-service
Вы можете получить векторные представления предложений на этапе обучения (присоединитесь к тесту и обучите предложения в одном файле и запустите код word2vec, полученный по следующей ссылке).
Код для предложения2vec был опубликован Томасом Миколовым здесь. Предполагается, что первое слово строки является идентификатором предложения. Скомпилируйте код, используя
gcc word2vec.c -o word2vec -lm -pthread -O3 -march=native -funroll-loops
и запустите его, используя
./word2vec -train alldata-id.txt -output vectors.txt -cbow 0 -size 100 -window 10 -negative 5 -hs 0 -sample 1e-4 -threads 40 -binary 0 - iter 20 -min-count 1 -sentence-vectors 1
РЕДАКТИРОВАТЬ
В Gensim (разрабатываемая версия), похоже, есть метод для определения векторов новых предложений. Ознакомьтесь с методом model. в https://github.com/gojomo/gensim/blob/develop/gensim/models/doc2vec.py infer_vector(NewDocument)
infer_vector(NewDocument)
У меня были хорошие результаты от:
- Суммирование векторов слов (со взвешиванием tf-idf). Это игнорирует порядок слов, но для многих приложений достаточно (особенно для коротких документов)
- Быстрая отправка
Внедрения Google Universal Sentence Encoder представляют собой обновленное решение этой проблемы. Он не использует Word2vec, но в результате получается конкурирующее решение.
Вот пошаговое руководство по TFHub и Keras.
Сеть глубокого усреднения (DAN) может обеспечивать встраивание предложений, в которых биграммы слов усредняются и передаются через глубокую нейронную сеть с прямой связью (DNN).
Обнаружено, что перенос обучения с использованием встраивания предложений имеет тенденцию превосходить перенос на уровне слов, поскольку он сохраняет семантические отношения.
Вам не нужно начинать обучение с нуля, предварительно обученные модели DAN доступны для ознакомления (проверьте модуль Universal Sentence Encoder в google hub).