Введение в регулярные выражения Tableau (REGEX)
Введение
Есть Вы когда-нибудь задумывались, что представляют собой все эти функции Tableau, начинающиеся с REGEXP? о? Всегда хотел сделать что-то, что мог бы можно обработать с помощью функции SPLIT(), но это не совсем так, как вы ожидал? Или, возможно, поверьте, что эти функции REGEXP немного пугают. (иногда они выглядят как египетские иероглифы!!)?
Да, Я был там во всех этих случаях. Итак, я с вами. Как немного предыстория, я не программист, никогда не писал ни строчки кода (кроме Расчет таблицы или два), я знаю и понимаю синтаксис SQL и систем уровня предприятия достаточно, чтобы быть опасными.
Да,
Я в основном непрофессионал с базовым пониманием структуры данных, данных
анализ и сопутствующие инструменты для очистки и изменения формы данных… так что эта серия предназначена для
все мы, кто хотел бы понять немного больше, что это за функции
о. И когда/как их использовать!
И когда/как их использовать!
I думаю, одна из причин, по которой я склонился к изучению выражений REGEX, заключается в том, что они следовать шаблонам. Собственно, именно этим они и занимаются — помогают тянуть извлекать (извлекать) или сопоставлять шаблоны в строках данных. В начале моего квест, чтобы изучить REGEX, все это выглядело как куча тарабарщины. Полностью непонятно. Теперь я могу читать и строить эти иероглифы с большим уверенность и понимание, и я собираюсь использовать эту серию блогов, чтобы помочь вам понять и написать их, а также.
Воля
эта серия решает все ваши вопросы по обработке данных REGEX? Возможно нет.
Но это будет хорошей отправной точкой на вашем пути, чтобы начать использовать их в Tableau.
Мы предоставим некоторые связанные ссылки и онлайн-инструменты по пути, а также некоторые
соответствующие ссылки на разделы справки Tableau. Самое главное, что многие из
примеры — от основного до
от среднего до более продвинутого — будут использовать фактические решения, найденные в
Сообщество Табло
Форумы.
История Регулярные выражения
Регулярные выражения Выражения , часто сокращенно обозначаемые как REGEX или REGEXP , существуют с тех пор, как 1980-е годы. Они были продуктом регулярного языка, разработанного в 1950-х годах. который использовался в основном в системах на основе UNIX для обработки текста. Синтаксис немного отличается от системы к системе, поэтому я поделюсь здесь сосредоточился на Tableau.
основной вариант использования регулярных выражений — извлечение определенных данных
элемент из строки данных. Регулярные выражения обычно используются веб-сайтом
и разработчики приложений, чтобы проверить, соответствует ли пользовательский ввод
требуемая структура элемента данных. Пример, с которым мы сталкиваемся почти
ежедневно — это адрес электронной почты. Адреса электронной почты, например, требуют, чтобы пользователь
имя, за которым следует знак @, за которым следует домен (имя-пользователя@имя-домена.
Как сделать Обычный Выражения работают?
Хорошо, Итак, мы знаем, что такое регулярные выражения, но как они работают? Ну как любой «язык» или формат, существуют компоненты, помогающие построить синтаксис или составление выражения, очень похожее на построение вычисления в Tableau с использованием Синтаксис типа ЕСЛИ-ЭТО-ТО-ТО. При правильном построении базовый алгоритм в Tableau переведет шаблон и предоставит совпадение или извлечет данные. Всякий раз, когда нет совпадения с входным шаблоном, Tableau возвращает Нуль .
Тот означает, что нам нужно понять, что строит/поддерживает синтаксис. Другими словами, что означают эти иероглифы?
Коротко о
предупреждение: этот раздел может показаться немного запутанным, так как большая часть терминологии
и определения будут вам чужды. Но это нормально, пожалуйста, не
слишком много беспокойтесь об этом. Мне просто нужно покрыть некоторые из этих основных зданий
блоков, прежде чем показать вам, как регулярные выражения работают на практике.
Но это нормально, пожалуйста, не
слишком много беспокойтесь об этом. Мне просто нужно покрыть некоторые из этих основных зданий
блоков, прежде чем показать вам, как регулярные выражения работают на практике.
А регулярное выражение может содержать 3 отдельные части. Примечание. Не для всех выражений требуются все три, это зависит от требование.
1) метасимволов регулярных выражений Классы
2) Операторы/квантификаторы регулярных выражений – используются для уточнить узор. Например, как много раз должно повторяться совпадение с образцом.
3) Набор выражений (классы символов) — используются для
помогите определить конкретные символы, которые мы хотим сопоставить.
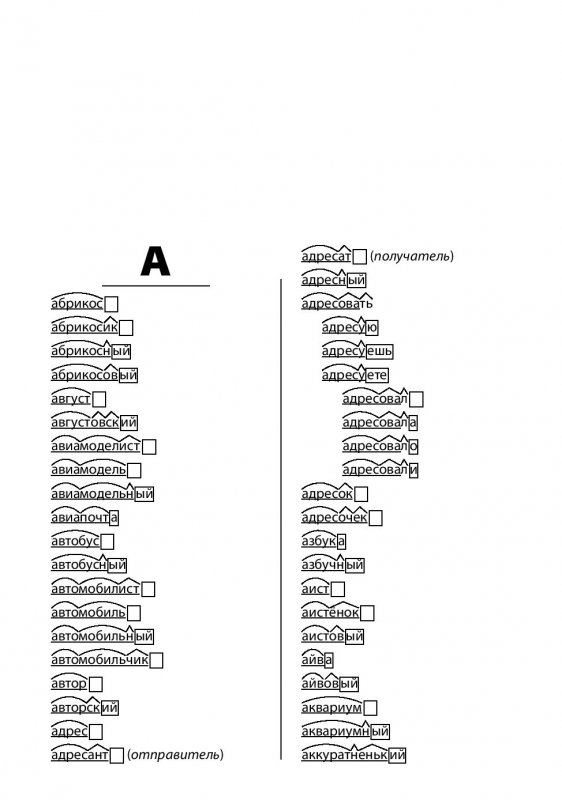
Регулярное выражение Метасимволы Классы
В обычном выражения, используя обратную косую черту с определенными буквами заставляет определенных персонажей что-то делать. Заглавная буква будет другое значение и действие, чем у нижнего регистра:
Символ | Описание |
\б | Матч если текущая позиция является границей слова. Границы возникают на переходы между словесными (\w) и несловесными (\W) символами с комбинированием отметки игнорируются. |
\В | Матч если текущая позиция не является границей слова. |
\д | Матч любой символ с общей категорией Unicode Nd (число, десятичный цифра) |
\Д | Матч
любой символ, не являющийся десятичной цифрой. |
\ш | Матч символ слова. |
\Вт | 9$ | \ .|
\ | Цитаты следующий персонаж. Символы, которые должны быть заключены в кавычки, чтобы рассматриваться как литералы: [ ] \ Символы, которые могут потребоваться в кавычках, в зависимости от контекст — & |
Обычный Операторы выражения/квантификаторы
Функция операторов/квантификаторов отличается от их буквальные значения. Для Например, знак + обычно означал бы добавление к нам, но в регулярных выражениях он может означать сделать что-нибудь —в В этом случае выполните одно или несколько повторений матча. Ниже приведен неполный список:
Оператор | Описание | |
| | Чередование. | |
* | Совпадение 0 или более раз. Совпадение как можно больше раз. | |
+ | Совпадение 1 или более раз. Совпадение как можно больше раз. | |
? | Совпадение ноль или один раз. Предпочитаю один. | |
{н} | Совпадение ровно n раз | |
{н,} | Совпадение не менее n раз. Совпадение как можно больше раз. | |
{н,м} | Совпадение от n до m раз. Совпадение как можно больше раз,
но не более м. | |
*? | Совпадение 0 или более раз. Совпадение как можно меньше раз. | |
+? | Совпадение 1 или более раз. Совпадение как можно меньше раз. | |
?? | Совпадение ноль или один раз. Лучше ноль. | |
{н}? | Совпадение ровно n раз. | |
{н,}? | Совпадение не менее n раз, но не более, чем требуется для общего результата соответствие шаблону. | |
{н,м}? | Совпадение от n до m раз. Совпадение как можно меньше раз, но
не менее н. | Отрицание — соответствует любому символу, кроме a, b или c. |
[А-М] | Диапазон — соответствует любому символу от A до M. |
 A|B соответствует либо A, либо B.
A|B соответствует либо A, либо B.
 9азбука]
9азбука]
Как Например, на приведенном ниже рисунке показан синтаксис/схема всех трех частей. который можно использовать для проверки или сопоставления номера социального страхования:
ОК, это немного, чтобы принять и понять, на данный момент. Но прежде чем перейти к следующий раздел, пожалуйста, найдите минутку, чтобы действительно посмотреть на эти символы и на то, что они могли бы сделать с набором данных. Помните, что регулярные выражения вполне буквальным/явным, пока мы не добавим определенные операторы, метасимволы или набор выражений.
Примечание. Если вы
хотел бы увидеть все три таблицы, они основаны на International
Компоненты для Unicode (ICU) Обычный
Библиотеки выражений.
Обычный Выражения в таблице
Сейчас что вы понимаете историю регулярных выражений и их основные строительные блоки, давайте поговорим о том, как их создать в Tableau. Таблица имеет четыре различные функции REGEXP, которые либо сопоставляются, либо извлекаются, либо заменяются строки внутри большей строки данных. Если это не имеет смысла, наберитесь терпения так как я скоро поделюсь некоторыми примерами.
REGEXP_EXTRACT (нитка, узор) – Ищет конкретный шаблон в строке или подстроке и извлекает этот элемент данных.
REGEXP_EXTRACT_NTH (строка, шаблон, индекс) — Ищет определенный шаблон в строке или подстроке, начиная с n-й позиции в строке, и извлекает этот элемент данных.
REGEXP_MATCH (нитка, узор) – Ищет определенный шаблон в строке или подстроке и возвращает TRUE если есть точное совпадение с .
REGEXP_REPLACE
(строка, шаблон, замена) — ищет определенный шаблон
внутри строки или подстроки и заменяет этот элемент данных с другим элементом данных.
Таблица регулярные выражения также могут быть «вложенными», то есть вы можете использовать Функция REGEXP_REPLACE() внутри другой функции REGEXP_REPLACE(), очень похоже на вы можете сделать это с помощью обычной функции REPLACE(). Вложенность позволяет сделать несколько проходов по данным, чтобы вам не нужно было зубрить все ваши логика в одно выражение. Но не будем забегать вперед… или слишком перегруженный!
Примеры таблиц
Давайте теперь посмотрите на некоторые примеры регулярных выражений. Мы собираемся начать с несколько относительно простых примеров, чтобы облегчить его.
Мы начнем с нескольких простых примеров, которые затем будут становиться все более сложно, когда мы движемся вперед. Я использую термин «простой», но для новичков для регулярных выражений они могут показаться совсем не простыми. Пожалуйста, не получайте ошеломлены, когда вы работаете с ними — они могут быть сложными для понимания вокруг, но со временем, практикой и временем вы станете постоянным мастер выражений!
Запомнить
примеры таблиц метасимволов, операторов и наборов? Мы будем работать с этими различными символами
из этих таблиц для поддержки наших усилий по сопоставлению и извлечению шаблонов. К
сохраняйте базовые вещи, как сопоставление с образцом номера социального страхования, мы будем
использовать упрощенный метод, который опирается на все три таблицы для нашего первого
пример.
К
сохраняйте базовые вещи, как сопоставление с образцом номера социального страхования, мы будем
использовать упрощенный метод, который опирается на все три таблицы для нашего первого
пример.
Для В этом примере давайте воспользуемся следующим простым набором данных о курсах студентов:
Текст |
Смит, Пол изучает английский язык, студенческий билет: ABC123 . |
Джонс, Мэри изучает математику, студенческий билет: DEF345 . |
Ли, Салли учится на факультете экономики, номер студента: GHI678 . |
Браун, Сэм учится на музыкальном факультете, ID студента: ABC345 |
Черный, Келли изучает бизнес, студенческий билет: ABC123 . |
Просто скопируйте эти строки в Excel или Google Sheets, затем используйте Tableau Desktop или Tableau Prep для подключения к электронной таблице.
Мы установит всего 2 цели для сопоставления по этим данным:
1) Получить фамилию человека.
2) Узнайте имя человека.
Мы будет использовать REGEXP_EXTRACT для извлечения каждого из этих различных компонентов, используя следующий синтаксис:
REGEXP_EXTRACT ([Text], ‘( )’)
После
первую запятую мы ставим открывающую скобку и закрывающую скобку
внутри кавычек. Почему? Ну, кавычки обязательный синтаксис, но скобки
это совсем другое. Мне потребовалось некоторое время, чтобы понять, что в
почти в каждом случае, набор закрывающих скобок необходим для создания
то, что известно как «группа захвата». Другими словами, какие конкретные ценности мы
хотите выйти из шаблона? Tableau очень, очень любит группы захвата. Итак, я всегда начинаю с этого начального синтаксиса, а затем строю свой шаблон — те
иероглифы — внутри и/или вокруг
этот набор скобок.
Итак, я всегда начинаю с этого начального синтаксиса, а затем строю свой шаблон — те
иероглифы — внутри и/или вокруг
этот набор скобок.
Последний Имя
Давайте поработайте над первой постановкой задачи получения фамилии человека. В нашем данные, фамилия всегда является первым «словом» в тексте, поэтому простейшее Синтаксис для захвата группы и ее извлечения будет следующим:
REGEXP_EXTRACT ([Text], ‘(\w+)’)
,
9 Итак, 9 что здесь происходит на самом деле? Мы знаем что скобки — это наша «группа захвата», данные, которые мы пытаемся извлечь или сопоставить. Эта начальная обратная косая черта считается нашей вводной или отправной точкой того, что мы пытаемся захватить. Обратная косая черта сама по себе будет означать начало здесь или, скорее, начните с этого следующего символа. Маленькая буква «w» = совпадение со словом характер. Он также будет соответствовать буквенно-цифровым значениям . Комбинированное использование обратной косой черты в REGEXP
с маленькой буквой «w» заставляет эту маленькую букву w больше не быть буквальной буквой «w», а
стать действием по совершению чего-либо. Когда следует
знак + вызывает совпадение всех последующих символов, но только один раз. Значение,
он остановит процесс сопоставления, когда встретит следующий символ, который не
словесный (буквенно-цифровой) символ. В Tableau этот синтаксис вернет
следующие:
Комбинированное использование обратной косой черты в REGEXP
с маленькой буквой «w» заставляет эту маленькую букву w больше не быть буквальной буквой «w», а
стать действием по совершению чего-либо. Когда следует
знак + вызывает совпадение всех последующих символов, но только один раз. Значение,
он остановит процесс сопоставления, когда встретит следующий символ, который не
словесный (буквенно-цифровой) символ. В Tableau этот синтаксис вернет
следующие:
Это именно то, что мы хотим от этого набора данных. Обратите внимание, что он останавливается на запятой поскольку в этом случае выражение REGEXP ищет целое «слово», а не поиск любых дополнительных символов или пробелов. Если бы вы убрали + знак, используя только \w, вы получите следующее совпадение, которое является правильным потому что это совпадение «символа слова» в единственном числе:
См., это было легко!
Первый Имя
Что
о следующей постановке проблемы/цели? Чтобы получить их имя? Он расположен
после пробела и запятой. Это будут наши «якоря», с которых мы будем работать.
Мы будем использовать следующий синтаксис:
Это будут наши «якоря», с которых мы будем работать.
Мы будем использовать следующий синтаксис:
regexp_extract ([текст], ‘, \ s+(\ w+)’)
для В этой ситуации мы выходим за пределы нашей «группы захвата». Почему? Потому что мы нужно указать регулярному выражению начинаться с определенной точки текста — в нашем случае мы нужно смотреть вперед от запятой и пробела. Давайте разберем этот синтаксис на его составные части.
, – Это просто буквальная строка. Мы ищем запятую.
\с – Этот метасимвол означает «пробел». Итак, мы ищем помещение. В сочетании с запятая, теперь мы ищем запятую, за которой следует пробел.
+ – Это означает, что мы собираемся захватить группу захвата слов сразу после матча. команды и пространства.
Может
\s+
быть записано как просто \s? Да, можно, но я
двойной пробел, так что + заставит выражение проверяться на любой
дополнительные пробелы между этой запятой и группой захвата — на всякий случай.
Скоро
I надеюсь, что это было хорошим введением в регулярные выражения, ориентированным на Tableau. Но мы еще не закончили! В следующем блоге из этой серии я поделюсь еще кое-чем практические примеры, которые я регулярно вижу в своей работе и в сообществе Tableau Форумы.
Шаблон регулярного выражения для соответствия, исключая когда… / За исключением случаев между
Ганс, я клюну на приманку и конкретизирую свой предыдущий ответ. Вы сказали, что хотите «что-то более полное», поэтому я надеюсь, что вы не будете возражать против длинного ответа — просто пытаетесь угодить. Начнем с предыстории.
Во-первых, отличный вопрос. Часто возникают вопросы о сопоставлении определенных шаблонов, за исключением определенных контекстов (например, внутри блока кода или внутри круглых скобок). Эти вопросы часто приводят к довольно неудобным решениям. Итак, ваш вопрос о несколько контекстов представляет собой особую проблему.
Сюрприз
Удивительно, но существует по крайней мере одно эффективное решение, которое является общим, простым в реализации и приятным в обслуживании. Он работает со всеми разновидностями регулярных выражений , которые позволяют вам проверять группы захвата в вашем коде. А бывает, чтобы ответить на ряд общих вопросов, которые на первый взгляд могут звучать иначе, чем ваш: «соответствовать всем, кроме пончиков», «заменять все, кроме…», «соответствовать всем словам, кроме тех, что в черном списке моей мамы», «игнорировать tags», «соответствовать температуре, если не выделено курсивом»…
К сожалению, эта методика малоизвестна: по моим оценкам, из двадцати SO-вопросов, в которых ее можно использовать, только один ответ содержит ее упоминание, что означает примерно один из пятидесяти или шестидесяти ответов. Смотрите мой обмен с Коби в комментариях. Этот метод подробно описан в этой статье, которая называет его (оптимистично) «лучшим трюком с регулярными выражениями». Не вдаваясь в подробности, я попытаюсь дать вам четкое представление о том, как работает эта техника. Для получения более подробной информации и образцов кода на разных языках я рекомендую вам обратиться к этому ресурсу.
Не вдаваясь в подробности, я попытаюсь дать вам четкое представление о том, как работает эта техника. Для получения более подробной информации и образцов кода на разных языках я рекомендую вам обратиться к этому ресурсу.
Более известный вариант
Существует вариант, использующий синтаксис, специфичный для Perl и PHP, который выполняет то же самое. Вы увидите его на SO в руках мастеров регулярных выражений, таких как CasimiretHippolyte и HamZa. Я расскажу вам об этом подробнее ниже, но здесь я сосредоточусь на общем решении, которое работает со всеми разновидностями регулярных выражений (при условии, что вы можете проверять группы захвата в своем коде).
Спасибо за предысторию, zx81… А рецепт какой?
Основные факты
Метод возвращает совпадение в захвате группы 1. Это не заботит все об общем матче.
На самом деле, хитрость заключается в том, чтобы сопоставить различные контексты, которые нам не нужны, (объединив эти контексты с помощью | ИЛИ/чередование) , чтобы «нейтрализовать их». После сопоставления всех нежелательных контекстов последняя часть чередования сопоставляется с тем, что мы делаем и собираем в группу 1.
После сопоставления всех нежелательных контекстов последняя часть чередования сопоставляется с тем, что мы делаем и собираем в группу 1.
Общий рецепт:
Not_this_context|Not_this_either|StayAway|(WhatYouWant)
Это будет соответствовать Not_this_context , но в некотором смысле это совпадение отправляется в мусорную корзину, потому что мы не будем смотреть на общие совпадения: мы смотрим только на захваты группы 1.
В вашем случае, с вашими цифрами и тремя вашими контекстами, которые нужно игнорировать, мы можем сделать:
s1|s2|s3|(\b\d+\b)
Обратите внимание: поскольку мы фактически сопоставляем s1, s2 и s3, а не пытаемся избежать их с помощью обхода, отдельные выражения для s1, s2 и s3 могут оставаться ясными как день. (Это подвыражения на каждой стороне 9\)]*\) | ### ИЛИ s3: соответствует любому блоку if(…//endif ### если\(.*?//endif | ### ИЛИ записать цифры в группу 1 ### (\б\д+\б)
Это исключительно легко читать и поддерживать.
Расширение регулярного выражения
Если вы хотите игнорировать больше ситуаций s4 и s5, вы добавляете их слева в большем количестве чередований:
s4|s5|s1|s2|s3|(\b\d+\b)
Как это работает?
Контексты, которые вам не нужны, добавляются в список чередований слева: они будут совпадать, но эти общие совпадения никогда не проверяются, поэтому сопоставление их — это способ поместить их в «мусорную корзину».
Однако содержимое, которое вам нужно, захватывается в группу 1. Затем вы должны программно проверить, что группа 1 установлена и не пуста. Это тривиальная задача программирования (позже мы поговорим о том, как это делается), особенно если учесть, что она оставляет вам простое регулярное выражение, которое вы можете понять с первого взгляда и пересмотреть или расширить по мере необходимости.
Я не всегда являюсь поклонником визуализаций, но эта хорошо показывает, насколько прост этот метод. Каждая «линия» соответствует потенциальному совпадению, но только нижняя строка попадает в группу 1. 9()]*\)|if\(.*?//endif)(*SKIP)(*F)|\b\d+\b
Каждая «линия» соответствует потенциальному совпадению, но только нижняя строка попадает в группу 1. 9()]*\)|if\(.*?//endif)(*SKIP)(*F)|\b\d+\b
Этот вариант немного проще в использовании, поскольку содержимое, совпадающее в контекстах s1, s2 и s3, просто пропускается, поэтому вам не нужно проверять захваты группы 1 (обратите внимание, что круглые скобки удалены). Совпадения содержат только whatYouWant
Обратите внимание, что (*F) , (*FAIL) и (?!) — это одно и то же. Если вы хотите быть более неясным, вы можете использовать демоверсию (*SKIP)(?!)
для этой версии 9.0003
Приложения
Вот некоторые распространенные проблемы, которые этот метод часто может легко решить. Вы заметите, что выбор слов может заставить некоторые из этих проблем звучать по-разному, хотя на самом деле они практически идентичны.
- Как я могу сопоставить foo кроме любого места в теге вроде
 ..>...
..>... - Как я могу сопоставить foo, кроме тега
- Как сопоставить все слова, которых нет в этом черном списке?
- Как я могу игнорировать что-либо внутри блока SUB… END SUB?
- Как сопоставить все, кроме… s1 s2 s3?
Как запрограммировать захват группы 1
Вы не написали код, но для завершения… Код для проверки группы 1, очевидно, будет зависеть от выбранного вами языка. В любом случае он не должен добавлять больше пары строк к коду, который вы будете использовать для проверки совпадений.
Если вы сомневаетесь, я рекомендую вам просмотреть раздел примеров кода в статье, упомянутой ранее, в которой представлен код для нескольких языков.
Альтернативы
В зависимости от сложности вопроса и используемого механизма регулярных выражений существует несколько альтернатив. Вот два, которые могут применяться в большинстве ситуаций, включая несколько условий. На мой взгляд, ни один из них не так привлекателен, как рецепт
На мой взгляд, ни один из них не так привлекателен, как рецепт s1|s2|s3|(whatYouWant) , хотя бы потому, что ясность всегда побеждает.
1. Заменить, а затем совместить.
Хорошее решение, которое звучит банально, но хорошо работает во многих средах, состоит в том, чтобы работать в два этапа. Первое регулярное выражение нейтрализует контекст, который вы хотите игнорировать, заменяя потенциально конфликтующие строки. Если вы хотите только сопоставить, вы можете заменить его пустой строкой, а затем запустить сопоставление на втором шаге. Если вы хотите заменить, вы можете сначала заменить строки, которые будут игнорироваться, чем-то отличительным, например, окружив ваши цифры цепочкой фиксированной ширины из @@@ . После этой замены вы можете заменить то, что вы действительно хотели, тогда вам придется вернуть свои отличительные строки @@@ .
2. Осмотр.
Ваш исходный пост показал, что вы понимаете, как исключить одно условие с помощью поиска. Вы сказали, что C# отлично подходит для этого, и вы правы, но это не единственный вариант. Варианты регулярных выражений .NET, которые можно найти, например, в C#, VB.NET и Visual C++, а также все еще экспериментальные 9)]*\)))(?
Вы сказали, что C# отлично подходит для этого, и вы правы, но это не единственный вариант. Варианты регулярных выражений .NET, которые можно найти, например, в C#, VB.NET и Visual C++, а также все еще экспериментальные 9)]*\)))(?
Но теперь вы знаете, что я не рекомендую это, верно?
Удаление
@HamZa и @Jerry предложили упомянуть дополнительный прием для случаев, когда вы пытаетесь просто удалить WhatYouWant . Вы помните, что рецепт соответствия WhatYouWant (захват его в группу 1) был s1|s2|s3|(WhatYouWant) , верно? Чтобы удалить все экземпляры WhatYouWant , вы меняете регулярное выражение на
(s1|s2|s3)|ЧтоВыХотите
Для замены строки используйте $1 . Здесь происходит следующее: для каждого совпадающего экземпляра s1|s2|s3 замена $1 заменяет этот экземпляр самим собой (на который ссылается $1 ).