Примеры исследований на уроках.
Разные формы организации исследовательской деятельности обучающихся на уроках биологии в 8 классе при выполнении лабораторных работ.
Урок «Ткани и органы».
Лабораторная работа «Изучение микроскопического строения тканей».
Инструктивная карточка:
1. Рассмотрите с помощью светового микроскопа клетки из разных групп тканей (эпителиальную и мышечную).
2. Установите особенности строения клеток, их соединение и характер межклеточного вещества.
3. Форма отчета:
А) Зарисуйте клетки, относящиеся к разным группам тканей.
Б) Обозначьте органоиды, видимые в световой микроскоп.
В) Опишите ткани организма человека по плану: ткань, особенности строения и
соединения клеток.
Г) Сделайте вывод: как особенности строения клеток ткани связаны с выполняемыми функциями.
Урок «Строение и функции головного мозга»
Лабораторная работа «Определение безусловных рефлексов различных отделов мозга».
В начале урока ставлю проблемный вопрос «Можно ли утверждать, что чем больше мозг, тем умнее человек?». Для ответа на данный вопрос предлагаю рассмотреть познавательные задания:
1) Вес мозга И.С.Тургенева – 2012 г, Анатоля Франса – 1017г, а у Луи Пастера, как показало вскрытие, после перенесенной болезни вообще не работала половина переднего мозга. Выскажите ваше мнение.
2) У слона самый большой мозг, но он не самое «умное» животное, так как важно соотношение веса мозга к весу тела. У слона оно невысокое, а у дельфина – выше, чем у человека. Но ведь человек держит рыбку, а дельфин за ней прыгает, а не наоборот. Почему? Выскажите ваше мнение.
Учащиеся приходят к выводу, что ответ кроется в строении мозга человека и важно знать функции разных отделов мозга.
Лабораторную работу организую в парах: один ученик – испытуемый, другой – исследователь. Обучающиеся работают по инструктивной карточке, где указаны действия каждого из них (первая и вторая колонки таблицы).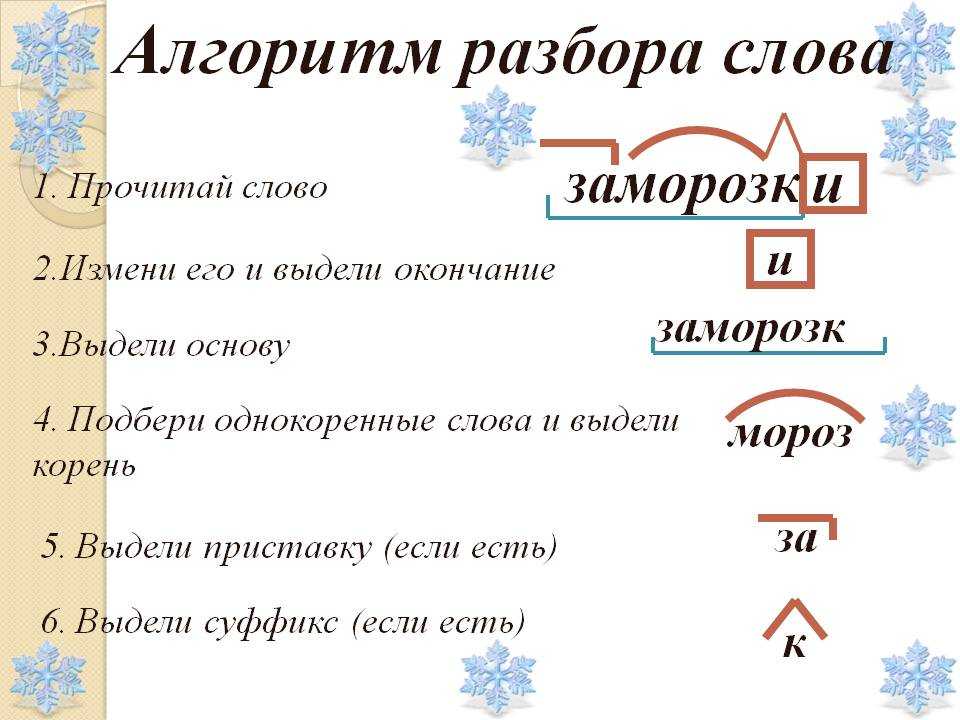
Урок « Кровь, ее состав. Клеточные элементы крови».
Лабораторная работа «Изучение микроскопического строения крови».
Лабораторная работа может проводиться в трех вариантах: иллюстративном, частично-поисковом и исследовательском. На столах обучающихся три вида инструктивных карточек, они сами выбирают вариант работы.
Иллюстративная лабораторная работа
Инструктивная карточка
1. Рассмотрите микропрепараты крови лягушки и человека, найдите доказательства того, что кровь человека в единицу времени единицей объема переносит кислорода больше, чем кровь лягушки (увеличение общей поверхности эритроцитов и относительного содержания гемоглобина).
2. Сравните эритроциты лягушки и человека. По каким признакам можно судить об увеличении поверхности эритроцитов, а по каким – об увеличении относительного содержания гемоглобина в эритроцитах.
По каким признакам можно судить об увеличении поверхности эритроцитов, а по каким – об увеличении относительного содержания гемоглобина в эритроцитах.
3. Запишите вывод:
Кровь человека в единицу времени единицей объема переносит кислорода больше, чем кровь лягушки, так как: 1) увеличивается общая поверхность эритроцитов вследствие…, 2) увеличивается относительное содержание гемоглобина вследствие…
Частично-поисковая лабораторная работа
Инструктивная карточка
1. Рассмотрите микропрепараты крови лягушки и человека.
2. Сравните эритроциты лягушки и человека, обратив внимание на размеры эритроцитов, наличие или отсутствие ядра.
3) Сделайте вывод: чья кровь в единицу времени единицей объема переносит больше кислорода и почему?
Исследовательская лабораторная работа
Инструктивная карточка
1) Исследуйте микроскопическое строение крови лягушки и человека, сравнив их эритроциты.
2) Найдите и проанализируйте факты, доказывающие, что чья-то кровь переносит в единицу времени единицей объема больше кислорода.
3) Сделайте вывод: за основу можете взять рабочую гипотезу: «Перенос кислорода будет зависеть от…, значит необходимо найти доказательства наличия этих причин».
Урок «Регуляция дыхания»
Лабораторная работа «Определение частоты дыхания».
Инструктивная карточка
1) Пронаблюдайте за движениями своей грудной клетки.
3) Объясните разницу полученных данных и запишите вывод.
4) Решите следующие биологические задачи:
А) Сколько воздуха проходит через легкие человека при спокойном дыхании в 1 минуту, в 1 час, в сутки (вдох – 500мл воздуха, частота дыхания – 18 раз в минуту).
Б) Зная, что во вдыхаемом воздухе содержится 20% кислорода, определите, сколько кислорода человек пропускает через легкие в сутки при спокойном дыхании.
Урок «Пищеварение в ротовой полости»
Лабораторная работа «Действие слюны на крахмал»
В начале работы определяем цель эксперимента: доказать, что ферменты слюны расщепляют крахмал и выдвигаем рабочую гипотезу. Затем знакомимся с оборудованием: накрахмаленные картофельным крахмалом салфетки, спички, вата или ватные палочки, йодная вода, химические стаканы или чашки Петри.
Затем знакомимся с оборудованием: накрахмаленные картофельным крахмалом салфетки, спички, вата или ватные палочки, йодная вода, химические стаканы или чашки Петри.
В ходе организационной беседы планируем эксперимент с использованием логической конструкции: «если, то…»
«Если ферменты слюны расщепляют крахмал, то после действия слюны мы не обнаружим крахмал с помощью качественной реакции (йодной воды). То есть если после обработки слюной накрахмаленной салфетки поместить ее в раствор йода, то салфетка не посинеет. Как доказать, что именно слюна, а не вода расщепляет крахмал? Ребята приходят к выводу, что надо провести такой же опыт, но вместо слюны взять воду.
Таким образом, для проведения эксперимента нам необходимо взять две накрахмаленные салфетки и на одну нанести простой рисунок слюной (эксперимент), а на другую водой (контроль). И если наше предположение верно, то на салфетке проявиться белый рисунок.
Далее работа проводится фронтально по инструктивной карточке.
Урок «Пищеварение в желудке».
Лабораторная работа «Воздействие желудочного сока на белки».
Инструктивная карточка
1. Налейте в пробирку 3-4 мл желудочного сока (соляная кислота).
2. Добавьте хлопья белка.
3. Подержите на водяной бане при температуре 38-39 градусов полчаса.
4. Запишите вывод: за основу можете взять рабочую гипотезу: «Если в желудке происходит расщепление белков до аминокислот, то необходимо выяснить условия действия ферментов желудочного сока».
Таким образом, на уроках биологии исследовательская работа может быть организована в процессе выполнения учащимися лабораторных и практических работ. Ряд исследований под руководством учителя учащиеся могут провести вне урока, а результаты сообщить и продемонстрировать на уроке (например, выработка условных рефлексов у аквариумных рыбок, изучение двигательной активности некоторых позвоночных животных – 7 класс). Написание учащимися рефератов – также исследовательская работа, если в ней есть практическая часть с результатами.
Весна. Диктанты для 4 класса
- Опубликовано 07.05.2020
- by Светлана
- в Русский язык, Чётвёртый класс
Обнаружила в своих запасах диктанты для 4 класса на разные темы. Мне кажется, чаще всего попадаются итоговые диктанты на тему «Весна», поэтому я решила их выложить. Все диктанты взяты из открытых источников. К каждому имеется грамматическое задание. Думаю, эти диктанты нужно использовать во время учёбы в 4 классе заранее, в течение года, для подготовки к итоговой аттестации.
Целых 23 штуки!!!
Диктант № 1: «Последние денечки» (76 слов)
Ранним мартовским утром проснулось солнце.
Отдёрнуло оно легкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.
Поглядело светило на эти проказы и стало землю пригревать. Лёд и снег сразу потускнели. По лесной ложбинке побежал весёлый говорливый ручеёк. Он бежал и пел свою песенку о весне.
 Отдёрнуло оно легкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.
Отдёрнуло оно легкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.Грамматическое задание:
- подчеркните главные члены в третьем предложении, над каждым именем существительным укажите падеж;
- разберите по составу слова: побежал, берёзки.
Диктант № 2: «Весеннее утро» (68 слов)
Как хорошо весеннее утро! Из-за синей полоски леса показалось солнце. В его лучах краснеют вершины гигантских сосен. Над рекой золотистым дымком клубится туман. Вот туман пропадает в прозрачном воздухе и открывает синюю гладь реки.
В зеркальной поверхности реки видишь голубое небо и облака.
 На яркой зелени сверкает роса. Лёгкий ветерок покачивает ивовые серёжки. Дрозд на еловой верхушке высвистывает песенку. Свистит и слушает. А в ответ ему удивительная тишина.
На яркой зелени сверкает роса. Лёгкий ветерок покачивает ивовые серёжки. Дрозд на еловой верхушке высвистывает песенку. Свистит и слушает. А в ответ ему удивительная тишина.Грамматическое задание:
- разберите по составу глагол «высвистывает»;
- найдите в тексте глаголы II спряжения и выделите в них окончания;
- образуйте от глагола «покачивает» глагол женского рода в прошедшем времени.
Диктант № 3: «Весеннее солнце» (91 слово)
На небе появилось весеннее солнце. Оно разбудило всех в лесу. Повеселела лесная поляна. Золотые лучи солнца перелетали от тропинки к тропинке. Капельки росы заиграли в каждом цветке, в каждой травинке.
Но вот набежала туча и закрыла всё небо. Загрустила природа. Столб пыли полетел к озеру. От резкого ветра с деревьев посыпались сухие сучья.
Лес грозно зашумел. Крупные капли дождя застучали по земле. На ней появились мокрые пятна. Удары грома оглушили всю местность.
Но гроза быстро прошла. Тишина. Только дятел стучит по коре дуплистой березы. И снова над лесом светит ласковое солнце.

Грамматическое задание:
- подчеркните главные члены четвёртого предложения, над каждым именем существительным укажите падеж.
- разберите по составу слова: загрустила, полетел.
Диктант № 4: «Весна пришла» (75 слов)
Хрупкими хрустальными слезинками заплакали ледяные сосульки. Весёлые солнечные лучи ласково разбудили спящую зимой крепким сном природу. В овражках зажурчали, зазвенели, запели озорные ручейки. На берегу тёмной реки появились первые робкие, но яркие и весёлые первоцветы – мать-и-мачеха. Выбрался из укромного зимнего жилья в корнях старого дуба колючий ёжик. Потянулись к солнышку веточки пушистой вербы. В зарослях сухого валежника проснулся в своей тёплой берлоге косолапый хозяин леса — медведь. Запрыгали по лесной лужайке шустрые зайчишки. Все весне рады!
Грамматическое задание:
- выполните морфологический разбор имени существительного, имени прилагательного и глагола по своему выбору;
- выполните синтаксический разбор первого предложения;
- выполните фонетический разбор слов: сосульки, первые.

Диктант № 5: «Весна в лесу» (88 слов)
Наступила радостная, шумная весна. Тёплые лучи солнца съедают последний снег. Звенят под деревьями весёлые ручьи. Душистой смолой пахнут набухшие почки. С раннего утра до позднего вечера поют на лесной поляне птицы.
Вылезли из своих жилищ жучки, паучки, букашки. Вышел из своего зимнего домика ёжик и осмотрел окрестности. Он не хотел вставать. Холодный ручеек забрался в его сухую постельку и разбудил ежа. Мелькнула серая тень. Это полевая мышь пробежала по узкой тропинке. На макушке ели шумят драчливые вороны. Скоро побегут от кочки к кочке хлопотливые муравьи.
Все рады весне!
Грамматическое задание:
- подчеркните главные члены во втором предложении, над каждым именем существительным укажите падеж;
- разберите по составу слова: пробежала, побегут.
Диктант № 6: «Цветёт черёмуха» (64 слова)
Под лучами майского солнышка всё быстро растёт.
 Отцвели лёгкие белые подснежники. В лугах развернулся пёстрый ковёр из трав и листьев. Налились на черёмухе бутоны. Приятным ароматом повеяло от дерева. Грянули холода. Утренний туман не поднялся колечком с лесной полянки. Он замер и лёг инеем на землю. Тишина в лесу. Птицы молчат. Они боятся застудить горлышко. Одна кукушка кричит с раннего утра до позднего вечера.
Отцвели лёгкие белые подснежники. В лугах развернулся пёстрый ковёр из трав и листьев. Налились на черёмухе бутоны. Приятным ароматом повеяло от дерева. Грянули холода. Утренний туман не поднялся колечком с лесной полянки. Он замер и лёг инеем на землю. Тишина в лесу. Птицы молчат. Они боятся застудить горлышко. Одна кукушка кричит с раннего утра до позднего вечера.Грамматическое задание:
- укажите время большинства использованных в тексте глаголов;
- выпишите из текста глагол из последнего предложения, выполните его морфологический разбор.
Диктант № 7: «Чудесный май» (93 слова)
Стоит чудесный майский день. Как хорошо в эту весеннюю пору! Ласковое солнце осветило всю окрестность. После тёплого дождя покрылись сочной зеленью поля, луга и леса. Синие и жёлтые цветки подняли прелестные головки. Земля надела пёстрый наряд. Вот уже появились душистые кисти на черёмухе, на сирени. У лесного оврага цветут ландыши и земляника.
Спешат домой перелётные птицы. Лес встречает своих певцов. С раннего утра до позднего вечера не смолкают в лесу птичьи голоса. С полей и лесов несутся весенние звуки.
Май – самый нарядный и звонкий месяц года.
 На вершину высокой ели забралась шустрая белочка.
На вершину высокой ели забралась шустрая белочка.Грамматическое задание:
- подчеркните главные члены в девятом предложении, над каждым именем существительным укажите падеж.
- разберите по составу слова: майский, нарядный.
Диктант № 8: «Весенний звон» (76 слов)
Пробудилась земля от долгого зимнего сна. Заблестела молодая травка. Разлилась волна зелёного тумана по широкому лугу. Стоят теплые и тихие вечера. Я прислушался к вечерней тишине. Звенят луга. По земле, по лугам, по оврагам плывет звон. Что это звенит? Вот скатилась капля сладкого сока с берёзовой ветки. Она упала на зеркальную поверхность пруда.
Возвратились из теплого края журавли. Они важно осмотрели родное болото.
 Весело зазвучала их радостная песня. В эти дни мы всюду слышим музыку природы.
Весело зазвучала их радостная песня. В эти дни мы всюду слышим музыку природы.Грамматическое задание:
- разберите по членам первое предложение;
- в девятом предложении определите склонение, падеж и число имён существительных.
- выпишите глаголы настоящего времени, определите их спряжение.
Диктант № 9: «Лягушка» (99 слов)
Весенняя вода разбудила маленькую лягушку. Она выползла из своего укрытия и отправилась в путь.
Ночью шел снег. Следы лягушки легко можно было разобрать на чистом снегу. Мы пошли по следу. В начале пути след был прямой. Он привел нас к болотцу. Потом след начал сбиваться. И вдруг мы увидели лягушку. Она лежала на снегу без признаков жизни.
Мы взяли лягушку и стали отогревать своим дыханием. Но она не оживала. Мы принесли ее домой, налили тёплой воды в кастрюльку и пустили туда малышку. Через час лягушка ожила.
Скоро настали теплые дни. Мы отнесли лягушку к реке и выпустили в воду.

Грамматическое задание:
- разберите по членам второе предложение;
- в предложении «Мы принесли ее домой, налили теплой воды в кастрюльку и пустили туда малышку» определите склонение, падеж и число имён существительных;
- разберите по составу слова: увидели, принесли.
Диктант № 10: «Майское чудо» (83 слова)
Ласковое солнце согревает землю своим теплом.
Ранним утром ты бежишь в ближнюю рощу. В тенистой прохладе ты видишь редкое чудо. В зелени высокой травы белеет прелестный цветок. На тонкой ножке висят жемчужины. Внизу они похожи на крохотные колокольчики. В верхней части еще закрытые цветы напоминают бубенчики. Широкие листья, словно ладони, охраняют хрупкий стебелёк.
Слышишь, как звенят колокольчики весны? Ты вдыхаешь тонкий запах нежного цветка. Прекрасный подарок русского леса!
Догадались, о каком растении идет речь? Ландыш подарила нам весна. Не губи красоту дивной полянки!
Грамматическое задание:
- сделайте синтаксический разбор второго предложения;
- сделайте морфологический разбор глаголов «бежишь, видишь»;
- разберите по составу слова: разбежалась, присмотреть, вдыхаешь, внизу, разъярённый, пронеслось, расписать, засветишь, сверху, слева, объездная.

Диктант № 11: «Скворцы» (83 слова)
Весна. Светит солнце. В саду раздаётся задорная птичья песенка. Это вернулся из далёких стран весёлый скворец. Зимовал он далеко на юге, за тёплым морем. А вернулся в родной домик. Сделали ему скворечник школьники и прикрепили на дереве. Звонкая песня скворца далеко слышна вокруг.
Скворец хорошо подражает разным звукам. В его песне услышишь мальчишеский свист, деревенскую трещотку, кваканье лягушек. Не песня, а целый птичий разговор! Скворец не только распевает песни, но помогает скворчихе строить гнездо. Вот появились скворчата. Родители кормят птенцов червячками и гусеницами.
Грамматическое задание:
- подчеркните главные члены в восьмом предложении, над каждым именем существительным укажите падеж.
- разберите по составу слова: сделали, появились.
Диктант № 12: «Наступление весны» (61 слово)
Весна – самое чарующее время года.
Дни становятся длиннее, и солнце все дольше задерживается на небосводе. Пригретые теплом солнечных лучей, набухают на ветках деревьев почки. Молодая травка робко пробивается сквозь сугробы.
Вернулись грачи. Они – первые вестники весны. Весело звучит их радостная песня.
 Зима еще пытается заявить о себе, сковывая редкие лужи тонким ледком, бросаясь охапками снежинок. Но все явственнее слышится дыхание весны.
Зима еще пытается заявить о себе, сковывая редкие лужи тонким ледком, бросаясь охапками снежинок. Но все явственнее слышится дыхание весны.Грамматическое задание:
- во втором предложении укажите род, число и падеж имен существительных;
- найдите в тексте глагол в неопределенной форме;
- разберите слова по составу: редкие, набухают, вестники.
Диктант № 13: «Чудесный май» (92 слова)
Майскую весну торжественно встречают залпы гроз и тёплые ливни. Чудесная погода
стоит в этом месяце. После грозового дождя ярче светит солнце. На голубом небе расцветает радуга. Первые листочки на сирени, берёзе, тополе сверкают, переливаются на солнышке.
Воздух наполнен могучим запахом весны. Войдите в майский лес. Он весь в зелёном убранстве. Радуют сердце яркие краски весенних цветов. А сколько звуков ты услышишь в весеннем лесу! С раннего утра до позднего вечера распевает пернатое царство. Звонкими голосами поют зяблики, соловьи, певчие дрозды.
 Ты подходишь к ручью и видишь, как он торопливо прокладывает себе дорогу.
Ты подходишь к ручью и видишь, как он торопливо прокладывает себе дорогу.Грамматическое задание:
- в первом предложении укажите род, число и падеж имен существительных;
- сделайте фонетический разбор слов: сколько, сверкают;
- разберите слова по составу слова: подходишь, расцветает.
Диктант № 14: «Ласточки» (71 слово)
Прошли ненастные и хмурые дни. Деревья и кусты освободились от снежного плена. Зазвенела капель. В воздухе чувствуется приближение весны.
Над парком закружилась стайка ласточек. Ласточки – удивительные птицы. Они пьют и охотятся на мошек на лету. Их слабенькие лапки мало приспособлены для хождения по земле.
Ласточки – превосходные пилоты. Длинные остроконечные крылья ласточки похожи на крылья первоклассного истребителя. А их хвост напоминает вилку. Такое строение хвоста помогает ласточке в воздухе выписывать головокружительные виражи.
Грамматическое задание:
- укажите в тексте все падежи слова: ласточка;
- сделайте фонетический разбор слов: слабенькие, пьют;
- проведите грамматический разбор последнего предложения.
Диктант № 15: «Птичье расписание» (77 слов)
Открывает птичье весеннее расписание месяц март. В полях еще лежит снег, но уже появились первые проталины. В это время мы встречаем грачей.
Пришёл апрель. Треснул на речке лед. Это весенний салют в честь прилёта трясогузки. Речка освободилась от ледяного плена. Весело журчит вода. Над ней шумят птичьи крылья. Белые лебеди, серые гуси, дикие утки возвращаются домой из тёплых краёв.
В лесу пылят серёжки осины. Лезет из влажной земли молодая трава.
 В это время можно услышать голос кукушки.
В это время можно услышать голос кукушки.Грамматическое задание:
- укажите в тексте падежи слов в первом предложении;
- сделайте фонетический разбор слов: салют, ледяного;
- определите главные члены в 10 предложении.
Диктант № 16: «Сирень» (90 слов)
Под моим окном расцвёл куст сирени. Тёплый майский ветер ворвался в окно и наполнил комнату чарующим ароматом распустившихся цветов. Его порывы – словно сообщение: весна, весна на улице!
Сирень – удивительное растение. Маленькие цветочки, словно завитушки у модницы, нанизаны на тонкий стебелёк и образуют пышные кисти. Если приглядеться, то можно среди россыпи сиреневых цветков обнаружить тот заветный цветочек с пятью лепестками. Такой цветок по народным поверьям сулит исполнение желаний.
Осторожно-осторожно я склонил ветку сирени и вытянул лапчатый цветок. На моей ладони вспыхнула ярким фиолетовым цветом пятиконечная звёздочка. Теперь надо быстро загадать желание.

Грамматическое задание:
- выполните морфологический разбор имени существительного, имени прилагательного и глагола по своему выбору;
- выполните синтаксический разбор первого предложения;
- выполните фонетический разбор слов: поверьям, заветный.
Диктант № 17: «Начало весны» (88 слов)
Снег заметно стаял. В полной лесной тишине словно сама собой шевелится еловая веточка. А как раз под той ёлкой прикрылся широкими еловыми ветками и спит заяц. В страхе он встаёт и прислушивается. Не может же веточка сама собой шевелиться!
Заяц метнулся, побежал, присел столбиком и слушает. Откуда беда? Куда бежать? Замер заяц на месте, прислушивается к тишине. А перед его носом как выпрямится, как закачается целая берёзка! Как махнет рядом ветка ёлки! И пошло, и пошло. Везде прыгают ветки. Вырываются они из снежного плена. Весь лес кругом шевелится.
Грамматическое задание:
- укажите падежи слов во втором предложении;
- сделайте фонетический разбор слов: тишине, берёзка;
- проведите морфемный разбор слов четвёртого предложения.
Диктант № 18: «Весенняя капель» (105 слов)
Весенняя капель – это первые звуки весны. Еще снежные сугробы толпятся на обочине дороги. Еще подёргиваются тонким ледком лужи. Но уже чувствуется приближение весны.
Яркое солнце появилось на синем небе. Его лучи ласково и нежно обнимают природу. Вот солнечный лучик заиграл на снежной шапке, которая всю зиму безмятежно пролежала на крыше дома. Снег не рад теплу. Тонкие ручейки воды, словно зимние слезы, потянулись к краю крыши. Капли звонко ударяются о землю и разбиваются тысячью брызг.
С каждым днём сосульки становятся все короче и короче. Скоро от них не останется и следа. Затихнет звук капели. Природа, освободившись от снежного плена, зацветет яркими красками. Весна шагает по планете.
Грамматическое задание:
- выполните морфологический разбор имени существительного, имени прилагательного и глагола по своему выбору;
- выполните разбор первого предложения по частям речи;
- выполните фонетический разбор слов: солнечный, ледком.
Диктант № 19: «Приход весны» (79 слов)
На улице весна. Все вокруг радуется её приходу. Горячее ласковое солнце удивительно приятно печёт, но не парит. Ласковый ветерок приносит горьковатый аромат. Неужели это черёмуха? Маленькие бутончики цветов черёмухи только начинают лопаться. Но как пахнет кругом!
Уже на второй день вся черёмуха в цвету. Пчёлы спешат к душистой красавице, запасаются сладким нектаром. Через несколько дней она осыпается. Её мелкие белоснежные лепестки метёт по воде ветер. Он устилает траву нежной белой накидкой. И становится черёмуха незаметной среди деревьев и кустарников.
Грамматическое задание:
- укажите падежи слов в шестом предложении;
- сделайте фонетический разбор слов: черёмуха, несколько;
- проведите морфемный разбор слов четвёртого предложения.
Диктант № 20: «Весеннее расписание» (73 слова)
Весной наши птицы возвращаются на родину из жарких стран.
Важно по проталинке прохаживается грач. Треснул на речке лед. Прилетела трясогузка. В шутку говорят, что она разбила лед своим длинным хвостом. Река освободилась от ледяного плена. Лебеди, гуси, утки возвращаются домой.
А в мае лес развешивает зелёные флажки. Он встречает соловья. Ночью прилетает перепел. Только звёзды освещают его посадочную площадку.
 Открывает птичье весеннее расписание март. В полях лежит снег, но уже показались первые проталины.
Открывает птичье весеннее расписание март. В полях лежит снег, но уже показались первые проталины.Грамматическое задание:
- укажите в тексте падежи слов в первом предложении;
- сделайте фонетический разбор слов: флажки, ночью;
- определите главные члены в последнем предложении.
Диктант № 21: «Весна» (68 слов)
Трудятся на родной земле люди. Нужно успеть выполнить все полевые работы. И тогда зелёными всходами от края до края покроется широкое пшеничное поле. Колокольчиком звенит и льётся с неба звонкая песня жаворонка. Цветёт за окном школьный сад.
Среди зелёных ветвей устроили гнездышко певчие птички. Сразу не заметишь его в густой листве! Скоро появятся птенчики. Птицы накормят их мошками и жирными гусеницами. Много вредных насекомых съедят за лето птенцы.

Грамматическое задание:
- выполните морфологический разбор имени существительного, имени прилагательного и глагола по своему выбору;
- выполните разбор первого предложения по членам;
- выполните фонетический разбор слов: льётся, пшеничным.
Диктант № 22: «Весна в лесу» (94 слова)
Наступила самая мягкая и светлая пора. Весна. Особенно красиво сейчас в лесу, где в каждом шорохе листвы, в каждом дуновении ветра чувствуется пробуждение природы.
Вот сорвалась с листа и звонко ударилась о землю капелька росы. Молодая травка робко пробивается сквозь пласты прошлогодней опавшей хвои. Но уже совсем скоро зелёный ковер покроет всю землю.
Деревья спешат примерить весенние наряды.
Над рекой склонилась ива. Её гибкие ветки украшены забавными серёжками. А узкие листочки трепетно шелестят над водой.
 Стройная сосна выпустила новые иголочки, которые ярко выделяются на фоне старой хвои. На её ветках появляются маленькие душистые шишки.
Стройная сосна выпустила новые иголочки, которые ярко выделяются на фоне старой хвои. На её ветках появляются маленькие душистые шишки.Грамматическое задание:
- укажите в тексте падежи слов в 4 предложении;
- сделайте фонетический разбор слов: выделяются, гибкие;
- сделайте морфемный разбор слов в первом предложении.
Диктант № 23 «Весенний первоцвет» (84 слова)
Ещё в полях лежит снег, а на склонах холмов, сквозь снежные сугробы пробиваются первые весенние цветы. Такие цветы называют первоцветами.
Ранней весной расцветает удивительный цветок. Он похож на маленькое солнышко. Его жёлтые лепесточки, словно тонкие лучики солнца, тянутся к свету. Странное название имеет этот цветок. В народе его окрестили мать-и-мачеха.
Название связано со строением листа. Одна сторона листа мягкая, глянцевая, шелковистая.
А с другой стороны листа поверхность тёплая на ощупь, словно руки родной матери.
 Приложишь листок этой стороной к щеке, и почувствуешь лёгкую прохладу.
Приложишь листок этой стороной к щеке, и почувствуешь лёгкую прохладу.Грамматическое задание:
- выполните морфологический разбор имени существительного, имени прилагательного и глагола по своему выбору;
- выполните разбор второго предложения по членам;
- выполните фонетический разбор слов: глянцевая, строением.
Тэги: 4 класс, весна, диктанты, итоговые, русский язык
О Светлана
Копирайтер. Фрилансер. Мама ребёнка на семейном обучении.
Посмотреть все публикации созданные Светлана →
Новости России и мира — Новостной портал Московский Комсомолец
Самые популярные из свежий материалов
Спецоперация на Украине: онлайн-трансляция
Полномочия компаний, управляющих оборонными предприятиями, которые срывают гособоронзаказ во время военного положения, будут приостанавливаться — над предприятиями будет вводиться внешнее управление, следует из указа президента России Владимира Путина.
Сюжет 9853
Эмма Грибова
Пригожин объяснил, сколько будет продолжаться спецоперация
Сюжет 12688
Эмма Грибова
Shot: в Приморском крае пытались подорвать состав с военной техникой
Сюжет 54090
Эмма Грибова
В небе над всей Великобританией разнесся звук взрыва, дома закачались
36194
Михаил Верный
Украинский комик Щегель сбежал из страны: «Выбор ребят — гибнуть»
Сюжет 13056
Эмма Грибова
Украинскую эскортницу внесли в базу «Миротворца» после награждения за содействие разведке
Сюжет 21976
Карина Алексеева
Народная милиция ДНР показала кадры уничтожения российским снайпером военного ВСУ
Сюжет 1573
Карина Алексеева
Музыкантов группы Виктора Салтыкова отказались сажать в самолёт перед концертом
12296
Россиянка обнаружила мужа сварившимся заживо
3329
Лина Панченко

Капитан 1 ранга рассказал об уничтоженной на острове Майском базе украинских ВМС
В окрестностях Николаева, на острове Майском, российские военные ракетным ударом уничтожили тренировочную базу, где британские инструкторы обучали украинских диверсантов-подводников управлению морскими беспилотниками.
О том, что был уничтожен склад с боеприпасами и затоплено большинство помещений, сообщили николаевские подпольщики, которые и передали координаты базы российской стороне.Эксклюзив Сюжет 9729
Светлана Самоделова
Страна потемкинских деревень: жилой барак «для красоты» закрыли баннером вместе с окнами
Гоголь умер.
Новость, признаем, не первой свежести: случилось это ровно 171 год назад. Но в сочетании вот с этой, совсем свежей, горечь потери ощущается также, как и 4 марта 1852-го — а то и еще острее: аварийный деревянный барак в городе Полысаево (Кемеровская область), давным-давно подлежащий расселению, так и не расселенный, то есть жилой, перед приездом губернатора завесили баннером с изображением нового красивого дома. Ну чье, скажите, перо могло бы лучше описать эту историю?! Эх…4130
Андрей Владимиров
Что происходит в новых регионах России: люди устали от беспредела
С момента начала Специальной военной операции прошел год, а впереди нас ждёт новая круглая дата – близится шесть месяцев с того момента, как Запорожская и Херсонская области, а также ДНР и ЛНР стали частью России.
Вместе с известным политическим экспертом Денисом Денисовым «Московский Комсомолец» обсудил особенности управления и проблемы в новых регионах.Эксклюзив Сюжет 36639
Владимир Михайлов
Сторонники «ЧВК Редан» поставили силовиков Белоруссию на уши: «Отбитое поколение»
Эксклюзив 4712
Ирина Боброва
Медведев заставил Рублева кричать: «Не могу»! И выиграл третий титул подряд
123
Ульяна Урбан
 О том, что был уничтожен склад с боеприпасами и затоплено большинство помещений, сообщили николаевские подпольщики, которые и передали координаты базы российской стороне.
О том, что был уничтожен склад с боеприпасами и затоплено большинство помещений, сообщили николаевские подпольщики, которые и передали координаты базы российской стороне. Новость, признаем, не первой свежести: случилось это ровно 171 год назад. Но в сочетании вот с этой, совсем свежей, горечь потери ощущается также, как и 4 марта 1852-го — а то и еще острее: аварийный деревянный барак в городе Полысаево (Кемеровская область), давным-давно подлежащий расселению, так и не расселенный, то есть жилой, перед приездом губернатора завесили баннером с изображением нового красивого дома. Ну чье, скажите, перо могло бы лучше описать эту историю?! Эх…
Новость, признаем, не первой свежести: случилось это ровно 171 год назад. Но в сочетании вот с этой, совсем свежей, горечь потери ощущается также, как и 4 марта 1852-го — а то и еще острее: аварийный деревянный барак в городе Полысаево (Кемеровская область), давным-давно подлежащий расселению, так и не расселенный, то есть жилой, перед приездом губернатора завесили баннером с изображением нового красивого дома. Ну чье, скажите, перо могло бы лучше описать эту историю?! Эх… Вместе с известным политическим экспертом Денисом Денисовым «Московский Комсомолец» обсудил особенности управления и проблемы в новых регионах.
Вместе с известным политическим экспертом Денисом Денисовым «Московский Комсомолец» обсудил особенности управления и проблемы в новых регионах.Разрушенные дома Луганска: кадры жизни столицы ЛНР
34 Галерея дня 62010
Самая красивая звезда «Динамо» празднует день рождения: лучшие фото
10 4068
Найдена самая горячая экс-волейболистка мира: лучшие фото красотки
10 12397
Валентина Шевченко готовится к очередной защите титула: яркие фото «Пули»
10 3825
Туктамышева готова преподать урок юным фигуристкам в финале Гран-при: фото императрицы
10 10660
Жены и девушки лучших гонщиков «Формулы-1»: спутницы самых быстрых и дерзких
10 13178
Актер Кирилл Канахин и его друзья-нацисты: кадры напавших на Брянскую область террористов
28 1010742
Артисту Сергею Росту исполнилось 58 лет: как менялась жизнь звезды «Модерна»
11 8439
Леджер, Монро, Хоффман, Вуд: галерея звезд, умерших в разгар киносъемок
10 7669
Павел Деревянко появился с молодой спутницей: эффектные фото завидного жениха
14 30665
Умер обладатель 12 премий «Грэмми» Уэйн Шортер: последние фото именитого саксофониста
12 4018
День рождения Анны Семенович: она каталась с Костомаровым и покорила поп-сцену
10 30529
Появилось фото предполагаемого лидера диверсантов, атаковавших Брянскую область: кто такой Денис Никитин
8 590529
Звезда рестлинга пойдет под суд из-за ношения оружия: фото опасной красотки
10 14830
Телеведущая Лариса Вербицкая попала в ДТП: будни 63-летней автоледи
11 20287
Довольного Лукашенко в Китае встретили Си Цзиньпин и караул: кадры торжественных церемоний
18 72605
Вячеславу Зайцеву исполнилось 85 лет: как модельер изменился за последние годы
16 16115
Дэниелу Крейгу исполнилось 55 лет: как «Джеймс Бонд» менялся с годами
19 14397
75-летний Георгий Мартиросян попал в больницу: галерея артиста
11 7654
В театре Гоголя простились с актрисой Светланой Брагарник: скорбные кадры
15 27707
Конфискация авто для СВО, аварийно-опасные ПДД и китайский триумф: итоги недели
Одна на миллион: какие «люксовые» авто купить за «лям» и не пожалеть
Жулики освоили «развод» водителей на деньги с помощью «генератора водорода» в машине
Кадры недели: Ходченкова пришла с новым парнем, Михалков вернулся из Индии
«Вы были мерзкая»: Киркоров назвал имя той, что увела его от Пугачевой
Юлия Савичева: «Он для меня был как второй отец»
Самое читаемое
За неделю За месяц
Путин поменял отношение к СВО: на что намекнул президент в Послании
Эксклюзив Сюжет 283826
«РВ»: «Странные объекты» атакуют Полтавскую область Украины
Сюжет 223182
В Берлине прошла многотысячная акция против поставок оружия Украине
Сюжет 207764
Вблизи подмосковной Коломны произошел взрыв
165009
Немцы завалили выставленный в Берлине подбитый российский танк цветами
Сюжет 153868
Басурин отказался официально вступить в ЧВК «Вагнер»
Сюжет 142709
Самое читаемое:Ещё 3 материала
Гончую застрелили на центральной улице в Подмосковье
Жертвами конфликтного тигра стали более тридцати собак
Ярославский департамент охоты пытается сгладить ущерб от незаконной добычи двадцати лосей
Подпишись на издания «МК»
Подписаться
Российские каршеринги начали массово распродавать «годовалые» машины: в чем засада
Уже скоро в открытую продажу поступят тысячи относительно новых автомобилей ушедших из России в прошлом году марок.
Обслуженных, тщательно отчищенных — но, и в этом нюанс, не менее года проработавших в столичном каршеринге. О такой программе уже открыто заявил один из операторов поминутной аренды, подобные варианты рассматривают и другие участники рынка. Зачем бизнесмены это делают, кого видят в качестве покупателей и стоит ли брать такие авто — выяснил «МК».Эксклюзив 34986
Антон Размахнин
Москвич засудил автотехцентр за вытекшее из двигателя масло
4435
Елена Лелькова
Чаще всего в ДТП попадают дети из района Выхино-Жулебино
2828
Елена Лелькова
Поправки к ПДД сделали электросамокаты изгоями на дорогах
8508
Антон Размахнин
Проблемы с автозапчастями усугубились из-за землетрясения в Турции
16694
Эдуард Раскин
 Обслуженных, тщательно отчищенных — но, и в этом нюанс, не менее года проработавших в столичном каршеринге. О такой программе уже открыто заявил один из операторов поминутной аренды, подобные варианты рассматривают и другие участники рынка. Зачем бизнесмены это делают, кого видят в качестве покупателей и стоит ли брать такие авто — выяснил «МК».
Обслуженных, тщательно отчищенных — но, и в этом нюанс, не менее года проработавших в столичном каршеринге. О такой программе уже открыто заявил один из операторов поминутной аренды, подобные варианты рассматривают и другие участники рынка. Зачем бизнесмены это делают, кого видят в качестве покупателей и стоит ли брать такие авто — выяснил «МК».Авто: ещё 4 материала
Всё! Решила, какую сумочку хочу на 8 Марта. Инкассаторскую!
Инкассаторскую!Последние новости России и мира. На сайте «MK» вы найдете самые свежие новости политики, экономики, общества, культуры, науки, спорта, информацию о происшествиях.
«Московский комсомолец» — это репортажи и комментарии, аналитика и прогнозы экспертов, интервью и публицистика, эксклюзивные сведения, а также актуальные фото и видео.
Журналисты MK.RU — команда, которая всегда в центре событий. Освещаем ярко!
Диктанты 3 класс по Русскому Языку
Категория «Диктанты»
Диктант «Осенний лес»
Октябрь. Деревья давно сбросили желтые листья. В лесу идет дождь, и листва на дорожках не шуршит под ногами. Дрозды кружились над рябиной. Они клевали гроздья сладких ягод. В дубках кричали сойки. Над елью пискнула синичка. Рябчики пролетели в лесную чащу.
Диктанты 3 класс / Диктанты 3 класс 1 четверть / Предложение
Задание
- 228 634
Категория «Диктанты»
Диктант «Любители мастерить»
Ребятишки любят мастерить разные вещицы. Летом они заготовили сосновые и еловые шишки, семена различных растений. Детишки запасли веточки и листочки. И вот открыта мастерская. Она будет выпускать лесные игрушки. Мальчики и девочки делают забавных зверюшек. Вот лесовичок. Какая красивая лисичка-сестричка! Какие чудные ежиха и козлёнок! Кому подарить эти поделки? Ученики отнесли их в детский сад.
Летом они заготовили сосновые и еловые шишки, семена различных растений. Детишки запасли веточки и листочки. И вот открыта мастерская. Она будет выпускать лесные игрушки. Мальчики и девочки делают забавных зверюшек. Вот лесовичок. Какая красивая лисичка-сестричка! Какие чудные ежиха и козлёнок! Кому подарить эти поделки? Ученики отнесли их в детский сад.
Диктанты 3 класс / Диктанты 3 класс 1 четверть / Слово в языке и речи
Задание
- 91 639
Категория «Диктанты»
Диктант «Пернатые друзья»
Серёжа с папой делали кормушку для птиц. Серёжа подавал гвозди и дощечки. Папа их строгал и сколачивал. Зимой каждое утро Серёжа сыпал в кормушку зерно. Воробьи и синички ждали мальчика. Они слетались со всех сторон, спешили позавтракать. В морозные дни Серёжа кормил своих пернатых друзей часто. Сытая птица легко переносит холод.
Диктанты 3 класс / Диктанты 3 класс 1 четверть / Безударные гласные в корне слова
Задание
- 110 715
Категория «Диктанты»
Диктант «Весной»
Весеннее солнце пригрело землю. Зазвенела весенняя капель. У домов галдят крикливые воробьи. С пригорков побежали говорливые ручейки. На полях зазеленели хлеба. Ветки ивы покрылись золотыми шарами. В лесу зацвели голубенькие подснежники. Синички весело перелетали с ветки на ветку. Они искали в складках коры деревьев червячков. Тетерева слетелись на поляны. Птицы чертили по земле крыльями и затевали шумные игры. Скоро прилетят на родину журавли.
Зазвенела весенняя капель. У домов галдят крикливые воробьи. С пригорков побежали говорливые ручейки. На полях зазеленели хлеба. Ветки ивы покрылись золотыми шарами. В лесу зацвели голубенькие подснежники. Синички весело перелетали с ветки на ветку. Они искали в складках коры деревьев червячков. Тетерева слетелись на поляны. Птицы чертили по земле крыльями и затевали шумные игры. Скоро прилетят на родину журавли.
Диктанты 3 класс / Итоговые диктанты за 3 класс
Задание
- 110 586
Категория «Диктанты»
Диктант «Лакомства для зверей»
Бурого медведя считают хозяином смешанных лесов. Он очень любит малину и мёд. Косолапый часто совершает набеги на жилища диких пчёл. Забредает порой на пасеки. Пчёлы мстят медведю. Они жалят его в кончик носа, язык. Зверю приходится спасаться бегством.
Барсук поедает коренья растений, полевых мышей, земляных червей, юрких ящериц, ядовитых змей, болотных лягушек. Его любимое лакомство – виноград. Заяц любит грызть морковь, капусту, репу и петрушку.
Его любимое лакомство – виноград. Заяц любит грызть морковь, капусту, репу и петрушку.
Диктанты 3 класс / Диктанты 3 класс 4 четверть / Глагол
Задание
- 81 764
Категория «Диктанты»
Диктант «Весенняя вода»
Над водой пронеслась стая перелётных птиц. Они радостно встречали весну.
Но много бед жителям леса несёт вода. Солнце растопило снег. Вода хлынула в жилища. Жить там стало опасно. Выбежала из норки полевая мышь. Вот низкий куст. Он широко раскинул ветки. Мышь прыгнула на куст и замерла. Трудно и зайцу. Он жил на островке. Кругом холодная вода. Не переплыть бедняжке это море. Надо ждать.
Диктанты 3 класс / Диктанты 3 класс 4 четверть / Глагол
Задание
- 68 906
Категория «Диктанты»
Контрольный диктант «Луковица с радостью»
Папа привёз мне с юга большую луковицу. Он сказал, что в середине этой луковицы спрятана радость. Я удивилась. В такой серой луковице и вдруг – радость! Мама посадила мою луковицу в горшочек и отнесла в подполье. Прошло много дней. И вот однажды мама подает мне горшочек, а там остренький желтый торчок. Мы поставили горшочек на окно. И перед самым праздником он расцвел. Сколько у него было цветов – синих-синих, душистых-душистых! Как красив был каждый цветок! Папа сказал, что мой цветок зовут гиацинтом. Но я стала называть его Гиней. И я полюбила его больше всех своих игрушек. Игрушки только понарошку живые, а цветок – живой по-настоящему.
Я удивилась. В такой серой луковице и вдруг – радость! Мама посадила мою луковицу в горшочек и отнесла в подполье. Прошло много дней. И вот однажды мама подает мне горшочек, а там остренький желтый торчок. Мы поставили горшочек на окно. И перед самым праздником он расцвел. Сколько у него было цветов – синих-синих, душистых-душистых! Как красив был каждый цветок! Папа сказал, что мой цветок зовут гиацинтом. Но я стала называть его Гиней. И я полюбила его больше всех своих игрушек. Игрушки только понарошку живые, а цветок – живой по-настоящему.
Диктанты 3 класс / Диктанты 3 класс 4 четверть / Местоимение
Задание
- 49 065
Категория «Диктанты»
Контрольный диктант «Май»
Стоит чудесный майский день. Как хорошо в эту весеннюю пору! Горячее солнце осветило всю окрестность. После тёплого дождя появилась зелёная травка4. Синие, жёлтые, красные цветы подняли головки. С каждым днём земля надевает новый пёстрый наряд. Вот уже появились душистые кисти на черёмухе и на сирени.
Вот уже появились душистые кисти на черёмухе и на сирени.
Лёгкий ветерок играет в зелени деревьев. С раннего утра до позднего вечера на разные голоса поют свои песни птицы. Среди них ты легко узнаешь голос1 соловья. Как красиво он поёт! Пришла3 настоящая весна3.
Диктанты 3 класс / Итоговые диктанты за 3 класс
Задание
- 112 011
Категория «Диктанты»
Диктант «Весна»
Наступила ранняя весна. Яркое весеннее солнце освещает землю. Воздух теплый. Затрещал на реке синий лед. Зажурчал в овраге говорливый ручеек. Выглянула нежная травка. Появились клейкие листочки на березках. Уже прилетели шумные грачи. Они поправляют гнезда на деревьях. Детвора радостно встречает пернатых друзей. Ребята мастерят птичьи домики. Скоро в них запоют весёлые скворцы.
Диктанты 3 класс / Диктанты 3 класс 4 четверть
Задание
- 45 273
Категория «Диктанты»
Контрольный диктант «Весеннее утро»
Как хорошо весенним утром в лесу! Вот из-за горизонта выкатилось огромное красное солнце. Вот солнечные лучи попали в густой туман. Он заклубился розовым паром. Открылась водная гладь. На сосенке проснулась крошечная шишечка. Малютка смотрит на широкое поле за рекой. Видит стройные ели с пушистыми ветвями. Слушает радостное пение птиц. Вдыхает аромат лёгкого весеннего воздуха. Вся природа вместе с ней радуется весне.
Вот солнечные лучи попали в густой туман. Он заклубился розовым паром. Открылась водная гладь. На сосенке проснулась крошечная шишечка. Малютка смотрит на широкое поле за рекой. Видит стройные ели с пушистыми ветвями. Слушает радостное пение птиц. Вдыхает аромат лёгкого весеннего воздуха. Вся природа вместе с ней радуется весне.
Диктанты 3 класс / Диктанты 3 класс 3 четверть
Задание
- 139 929
Категория «Диктанты»
Диктант «Друзья»
Мой товарищ Витя гостил летом у брата. Село Юрьево стоит на берегу реки. Заиграет утром луч солнца, а друзья уже у реки. А вот и первая рыбка – ерш. Ловили мальчики и крупную рыбу. Попадался окунь, лещ, сом. Ребята часто ходили в лес за грибами. Однажды они зашли в лесную глушь. Тишина. Только в овраге журчал ключ. Много грибов набрали мальчики в лесной чаще.
Диктанты 3 класс / Диктанты 3 класс 2 четверть / Имя существительное
Задание
- 125 454
Категория «Диктанты»
Диктант «Ранняя весна»
Наступает радостное время года. Ласковое весеннее солнце согревает всё вокруг. Синее небо высокое. По небу плывёт лёгкое облачко. Крепкий лёд на реке потемнел. Сонный лес стоит голый. Пахучие почки уже набухли. На вербах отпали тонкие чешуйки, показались серебряные барашки. На земле лежит прошлогодняя листва, сухие травинки. В вершинах деревьев шумит весенний ветер. Счастливое время!
Ласковое весеннее солнце согревает всё вокруг. Синее небо высокое. По небу плывёт лёгкое облачко. Крепкий лёд на реке потемнел. Сонный лес стоит голый. Пахучие почки уже набухли. На вербах отпали тонкие чешуйки, показались серебряные барашки. На земле лежит прошлогодняя листва, сухие травинки. В вершинах деревьев шумит весенний ветер. Счастливое время!
Диктанты 3 класс / Диктанты 3 класс 3 четверть / Имя прилагательное
Задание
- 110 972
Категория «Диктанты»
Диктант «На речке»
Владимир жил в тайге. Сторожка стояла на берегу реки Краснуха. Кругом тишь. За много лет Вова изучил эту местность. Он хорошо знал всех обитателей. У берегов тихо шуршал камыш. В его зарослях каждую весну строили свои гнёзда утки. Вот появились и первые утята. Рано утром мать выводила их на берег. Малыши щипали нежную травку. Мать была довольна.
Диктанты 3 класс / Диктанты 3 класс 2 четверть / Имя существительное
Задание
- 71 234
Категория «Диктанты»
Диктант «Вокзал»
Вокзал — это большой вход в город. Собрался человек уехать из города. На вокзале ему всё расскажут. Там в справочном бюро дают справки. Когда поезд? Какой это поезд – местный или дальнего следования? Где купить билет? Куда сдать багаж? Где находится багажный вагон? Где можно укрыться от яростного ветра и ненастной погоды? Здесь объявляют приезд и отъезд поездов. Здесь много радостных встреч!
Собрался человек уехать из города. На вокзале ему всё расскажут. Там в справочном бюро дают справки. Когда поезд? Какой это поезд – местный или дальнего следования? Где купить билет? Куда сдать багаж? Где находится багажный вагон? Где можно укрыться от яростного ветра и ненастной погоды? Здесь объявляют приезд и отъезд поездов. Здесь много радостных встреч!
Диктанты 3 класс / Итоговые диктанты за 3 класс
Задание
- 23 834
Категория «Диктанты»
Диктант «Цветочные часы»
По цветам можно узнать время. Раннее летнее утро. К шести часам открыл синий глазок колокольчик. Подняли золотые головки одуванчики. Краснеют нежные цветочки полевой гвоздики. Следом расправляет широкие лепестки шиповник. Вспыхнул яркий огонёк мака. К восьми часам распустились жёлтая кувшинка, белая лилия. Спадает летняя жара. Оживают другие цветы. Распустились душистый табак и луговая дрёма. Посади на клумбах цветочные часы. Они покажут точное время.
Они покажут точное время.
Диктанты 3 класс / Диктанты 3 класс 4 четверть / Глагол
Задание
- 47 382
Категория «Диктанты»
Диктант «Подъём в гору»
Альпинистов часто называют скалолазами. Это смелые, выносливые люди. Им приходится видеть водопады, наблюдать землетрясения, извержения вулканов. Эти спортсмены – умелые пешеходы. Они проходят большие расстояния до горных хребтов, а затем поднимаются вверх. Подъём становится всё круче. Приходится постоянно делать крутые повороты и идти в обход. Отдохнуть можно на бугорке.
Взгляду открылся интересный вид. На утёсе орёл съедал свою добычу. Бедный зайчишка попался ему в лапы. Альпинисты почувствовали жалость к зверьку.
Диктанты 3 класс / Диктанты 3 класс 2 четверть / Состав слова
Задание
- 42 198
Категория «Диктанты»
Диктант «Весна»
Весна долго не открывалась. В апреле стояла ясная морозная погода. Днем под лучами солнца тихо таял снег. Вдруг резко потянуло теплым ветром. Окрестности окутались густым молочным туманом. Мутным потоком полились воды. С яростным треском ломались на реке гигантские льдины. Поздно вечером туман ушел. Небо прояснилось. Утром солнце съело тонкий лед. В теплом весеннем воздухе залились чудным хором жаворонки. Высоко в небе пролетели с радостным криком журавли и гуси. Пришла настоящая весна.
В апреле стояла ясная морозная погода. Днем под лучами солнца тихо таял снег. Вдруг резко потянуло теплым ветром. Окрестности окутались густым молочным туманом. Мутным потоком полились воды. С яростным треском ломались на реке гигантские льдины. Поздно вечером туман ушел. Небо прояснилось. Утром солнце съело тонкий лед. В теплом весеннем воздухе залились чудным хором жаворонки. Высоко в небе пролетели с радостным криком журавли и гуси. Пришла настоящая весна.
Слово в языке и речи / Состав слова
Задание
- 52 112
Категория «Диктанты»
Контрольный диктант «Зимний день»
Стоит чудесный зимний денёк. Под моё окошко летят красивые птички. Смотрю на птиц. Вот они сидят на ветвях кудрявой берёзы. На голове чёрная шапочка. Спина, крылья и хвостик жёлтые. На короткую шейку птичка, словно галстучек повязала. Будто жилет синица надела. Хороша птица! Клювик у птички тоненький. Едят синички вкусное сало. Радостно им.
Радостно им.
Диктанты 3 класс / Диктанты 3 класс 2 четверть
Задание
- 86 044
Категория «Диктанты»
Диктант «Поздняя весна»
Наступила поздняя весна. Погода стоит чудесная. Яркие лучи солнца светят над полями, ласкают землю. Тепло. Из земли показалась молодая травка, первые цветочки. На березах и тополях набухли почки. В лесу запахло березовым соком. Скоро на деревьях зазеленеют листья. Вот уже видны их первые зеленые язычки. Хорошо весной!
Птицы поют свои веселые песни. Радостно чирикают воробьи. Прыгают пушистые синички. Все рады весне!
Диктанты 3 класс / Диктанты 3 класс 3 четверть
Задание
- 44 784
Категория «Диктанты»
Диктант «Осенью»
Мы часто ходим в ближайший лесок. Красив русский лес осенью. Яркие краски радуют глаз. Падают сухие листья. Земля покрылась пёстрым ковром. Шуршит под ногами пожухлая трава. В лесу смолкли птичьи песни. Вода в лесных ручьях чистая. Хорошо дышать свежим воздухом.
Земля покрылась пёстрым ковром. Шуршит под ногами пожухлая трава. В лесу смолкли птичьи песни. Вода в лесных ручьях чистая. Хорошо дышать свежим воздухом.
Диктанты 3 класс / Входной диктант 3 класс
Задание
- 68 638
Категория «Диктанты»
Диктант «Хлеб»
Лежит на столе тёплый душистый хлеб. Кто дарит нам это чудо? Золотые руки людей растят хлеб. Весной они пашут землю, сеют хлеба. Всё лето они ухаживают за посевами. Люди хотят получить хороший урожай. Они хотят подарить всем хлеба побольше.
Диктанты 3 класс / Входной диктант 3 класс
Задание
- 45 562
Категория «Диктанты»
Диктант «Осень в лесу»
Как красив осенний лес! Березки надели золотые платья. Листья клена разрумянились. Густая листва дуба стала как медь. Сосны и ели остались зелеными. Пестрый ковер листьев шуршал под ногами. А сколько грибов в лесу! Душистые рыжики и желтые опята ждут грибников.
А сколько грибов в лесу! Душистые рыжики и желтые опята ждут грибников.
Диктанты 3 класс / Диктанты 3 класс 1 четверть / Предложение
Задание
- 94 215
Категория «Диктанты»
Контрольный диктант «Осенью»
Октябрь. На дворе стоит глубокая осень. Скучная картина! Льют частые дожди. Осенний ветер срывает последние листья с деревьев. Тропинки в лесу укрыл ковёр из пёстрых листьев. Ласточки, соловьи улетели на юг. Сороки, вороны летят к жилью людей. Звери спрятались в тепло. Скоро утренний мороз затянет льдом лужи.
Диктанты 3 класс / Диктанты 3 класс 1 четверть
Задание
- 58 261
Категория «Диктанты»
Диктант «Ноябрь»
В ноябре похолодало. Стоит сырая погода. Весь месяц льют дожди. Дует осенний ветер. Шумят в саду деревья. С берёз и осин листва давно опала. Земля покрыта ковром из листьев. Только на дубах желтеют сухие листья. Тишина в лесу.
Земля покрыта ковром из листьев. Только на дубах желтеют сухие листья. Тишина в лесу.
Вдруг донеслась весёлая песня. Я оглянулся. На берегу речки сидела птичка. Это запела синичка.
Диктанты 3 класс / Диктанты 3 класс 2 четверть / Состав слова
Задание
- 61 454
Категория «Диктанты»
Диктант «Прощание с осенью»
В октябре стоит сырая погода. Весь месяц льют дожди. Дует осенний ветер. Шумят в саду деревья. Ночью перестал дождь. Выпал первый снег. Кругом светло. Всё вокруг стало нарядным. Две вороны сели на берёзу. Посыпался пушистый снежок. Дорога подмёрзла. Хрустят листья и трава на тропе у дома.
Диктанты 3 класс / Диктанты 3 класс 1 четверть
Задание
- 55 117
Яркое определение и значение — Merriam-Webster
1 из 2
британский
1
а
: излучающий или отражающий свет : сияющий, сверкающий
яркий свет
яркие глаза
б
: солнечный
ясный день
также : сияющий от счастья
bright smiling faces
bright moments
2
: illustrious, glorious
brightest star of the opera
3
: beautiful
4
: of high saturation or lightness
яркие цвета
5
а
: живой, веселый
будь ярким и веселым среди своих гостей — Уильям Шекспир
б
: умный, умный
светлая идея
умные дети
6
: благоприятный, многообещающий
светлые перспективы на будущее
3 наречие
ярко наречие
яркий
2 из 2
1
: цвет высокой насыщенности : яркий (см.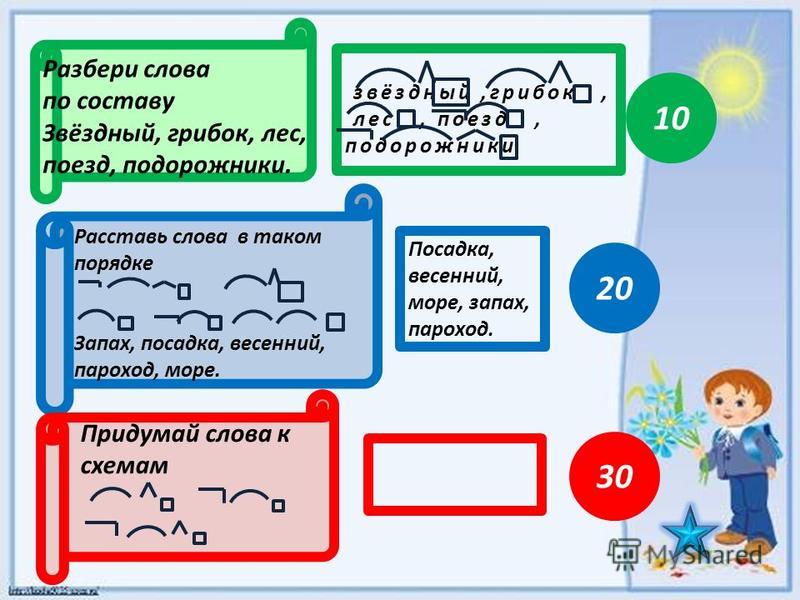 яркий элемент 1 чувство 4) цвет
яркий элемент 1 чувство 4) цвет
— обычно используется во множественном числе
насыщенные земляные тона и четкие яркие цвета — Патрисия Петерсон
2
яркие множественное число : яркая одежда.
Следуйте этим шагам, и вы сможете стирать темную одежду тем же стиральным порошком, который вы используете для стирки белых и ярких вещей. — Мэри Хант
3
яркие множественное число : дальний свет
Не помогало и то, что машина позади нее с включенными фарами, казалось, намеревалась преследовать ее всю дорогу до Феллс-Пойнт. — Лаура Липпман
— Лаура Липпман
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Прилагательное
Освещение было слишком яркий . светлая комната с большим количеством окон
Был яркий солнечный день.
Комната была оформлена в ярких цветов.
светлая комната с большим количеством окон
Был яркий солнечный день.
Комната была оформлена в ярких цветов.
Последние примеры в Интернете
Шестиклассник, убитый в Андовере, запомнился как яркий свет в подготовительной школе Св. Иоанна. Себастьян играл на виолончели в школьном струнном ансамбле и был одаренным писателем, ценившим литературу, говорится в его некрологе.
— Джон Хиллиард, BostonGlobe. com , 18 февраля 2023 г.
Условия выращивания: полная тень и средняя почва. Размер: вьется на 20-30 футов и более. Зоны: 5-8.0175 яркий свет каждый день.
— Рита Пелчар, Better Homes & Gardens , 17 февраля 2023 г.
Тем временем Шак носил солнцезащитные очки с козырьком в качестве стильного щита от ярких огней стадиона.
—Элиз Тейлор, Vogue , 15 февраля 2023 г.
Список лучших практик на месте наблюдения за светлячками включает в себя оставайтесь на тропе и избегайте использования фонариков и других 9 предметов.0175 ярких огней.
— Три Мейнч, Discover Magazine , 15 февраля 2023 г.
Бахарах не был ослеплен яркими огнями Бродвея.
— Лоуренс Маслон, New York Times , 13 февраля 2023 г.
com , 18 февраля 2023 г.
Условия выращивания: полная тень и средняя почва. Размер: вьется на 20-30 футов и более. Зоны: 5-8.0175 яркий свет каждый день.
— Рита Пелчар, Better Homes & Gardens , 17 февраля 2023 г.
Тем временем Шак носил солнцезащитные очки с козырьком в качестве стильного щита от ярких огней стадиона.
—Элиз Тейлор, Vogue , 15 февраля 2023 г.
Список лучших практик на месте наблюдения за светлячками включает в себя оставайтесь на тропе и избегайте использования фонариков и других 9 предметов.0175 ярких огней.
— Три Мейнч, Discover Magazine , 15 февраля 2023 г.
Бахарах не был ослеплен яркими огнями Бродвея.
— Лоуренс Маслон, New York Times , 13 февраля 2023 г. В небольшой лаборатории возле Сената рабочие, одетые в белые халаты и вооруженные специальными красками, кистями и яркими огни освещали многовековой стул из одного из первых зданий палаты.
— Марина Диас, Washington Post , 11 февраля 2023 г.
В зависимости от вашего уровня навыков, выберите простой уход, средний уход или зеленый палец, или ищите по низкой освещенности, яркой слабой или низкой воде.
— Алисса Готьери, Good Housekeeping , 9 февраля 2023 г.
Лиане нравилось быть младше 9 лет0175 ярких сценических огней, и Джона с гордостью наблюдала, как ее не по годам развитый малыш превращается в талантливую девушку.
— Лонгриды , 7 февраля 2023 г.
В небольшой лаборатории возле Сената рабочие, одетые в белые халаты и вооруженные специальными красками, кистями и яркими огни освещали многовековой стул из одного из первых зданий палаты.
— Марина Диас, Washington Post , 11 февраля 2023 г.
В зависимости от вашего уровня навыков, выберите простой уход, средний уход или зеленый палец, или ищите по низкой освещенности, яркой слабой или низкой воде.
— Алисса Готьери, Good Housekeeping , 9 февраля 2023 г.
Лиане нравилось быть младше 9 лет0175 ярких сценических огней, и Джона с гордостью наблюдала, как ее не по годам развитый малыш превращается в талантливую девушку.
— Лонгриды , 7 февраля 2023 г.
Сидя в яркий и воздушный James Oliver Coffee Co. — Линдси К. Грин, Detroit Free Press , 18 декабря 2022 г.
Варианты опунции и граната были сладкими, в то время как манго, клубника и красный апельсин попали в правильные яркие , острые ноты.
— Dallas News , 20 октября 2022 г.
Эти типы цветов могут сделать любую помаду — даже самую ярко-красную — более носибельной и менее вычурной 9.0175 яркий .
— Мишель Ростамян, Allure , 17 октября 2022 г.
Келси Баллерини приносит яркий в студию SiriusXM в Нью-Йорке. 21 сентября.
— People Staff, Peoplemag , 27 сентября 2022 г.
Кевин Харт, Реджина Холл и Марк Уолберг представляют ярких на премьере Me Time в Лос-Анджелесе 23 августа.
— Персонал, Peoplemag , 30 августа 2022 г.
— Линдси К. Грин, Detroit Free Press , 18 декабря 2022 г.
Варианты опунции и граната были сладкими, в то время как манго, клубника и красный апельсин попали в правильные яркие , острые ноты.
— Dallas News , 20 октября 2022 г.
Эти типы цветов могут сделать любую помаду — даже самую ярко-красную — более носибельной и менее вычурной 9.0175 яркий .
— Мишель Ростамян, Allure , 17 октября 2022 г.
Келси Баллерини приносит яркий в студию SiriusXM в Нью-Йорке. 21 сентября.
— People Staff, Peoplemag , 27 сентября 2022 г.
Кевин Харт, Реджина Холл и Марк Уолберг представляют ярких на премьере Me Time в Лос-Анджелесе 23 августа.
— Персонал, Peoplemag , 30 августа 2022 г. Фиолетовый шампунь — это теория цвета в самом простом виде: благодаря временному оттенку все типы светлых и светлых волос выглядят как будто только что из салона ярко .
— Сотрудники Harper’s Bazaar, Harper’s BAZAAR , 30 августа 2022 г.
Теперь большие окна нового светлого и просторного класса Шокли выходят на грязное пространство — там, где раньше была их старая школа.
— Оливия Краут, 9 лет.0175 The Courier-Journal , 10 августа 2022 г.
С камнем , ярким и лентой из розового золота, кому нужны бриллианты?
— Фрэнсис Сола-Сантьяго, , refinery29.com , 10 августа 2022 г.
Узнать больше
Фиолетовый шампунь — это теория цвета в самом простом виде: благодаря временному оттенку все типы светлых и светлых волос выглядят как будто только что из салона ярко .
— Сотрудники Harper’s Bazaar, Harper’s BAZAAR , 30 августа 2022 г.
Теперь большие окна нового светлого и просторного класса Шокли выходят на грязное пространство — там, где раньше была их старая школа.
— Оливия Краут, 9 лет.0175 The Courier-Journal , 10 августа 2022 г.
С камнем , ярким и лентой из розового золота, кому нужны бриллианты?
— Фрэнсис Сола-Сантьяго, , refinery29.com , 10 августа 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «яркий». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
Прилагательное
Среднеанглийский, от древнеанглийского до ; сродни древневерхненемецкому beraht яркому, санскриту bhrājate оно сияет
Существительное
существительное, производное от яркой записи 1
Первое известное употребление
Прилагательное
до 12 века, в значении, определенном в смысле 1a
Существительное
1920, в значении, определенном в смысле 3
Путешественник во времени
Первое известное использование яркого было до 12 века
Посмотреть другие слова из того же века Чай Бригам
яркий
Яркий
Посмотреть другие записи поблизости
Процитировать эту запись «Яркий.
 » Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/bright. По состоянию на 4 марта 2023 г.
» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/bright. По состоянию на 4 марта 2023 г.Ссылка на копию
Детское определение
яркий
Прилагательное
1
: . Выделение или заполнение с большим количеством света
2
: Очень четкий или яркий по цвету
3
: Интеллектуальный смысл 1B, Clever
A Ярко —6666666666666666666666666666666666666666666666666666666666666.
а яркий идея
4
: веселый смысл 1
а яркий улыбка
5
: многообещающий
a яркий будущее
яркий наречие
ярко наречие
яркость существительное
Биографическое определение
Яркий
biographical name
ˈbrīt
John 1811–1889 English orator and statesman
More from Merriam-Webster on
brightNglish: Translation of bright for Spanish Speakers
Britannica English: Translation of bright для носителей арабского языка
Последнее обновление: — Обновлены примеры предложений
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster полный текст
Яркий – определение, значение и синонимы
ярче; самый яркий; Brights
После долгой серой зимы трудно вспомнить, что такое яркий , солнечный день. Яркий означает сияющий светом.
Яркий означает сияющий светом.
Прилагательное яркий подходит для описания всего, что излучает, отражает или наполнено светом — например, яркая луна, яркое небо или яркая, хорошо освещенная комната. Яркий также может означать яркий или яркий — например, ярко-фиолетовый костюм-тройка. Образно говоря, яркая означает «полный надежды или возможности» — как ваше светлое будущее в качестве морского биолога.
Определения яркого
прилагательное
легко излучающие или отражающие свет или в больших количествах
«солнце было яркий и горячий»
«а светлая солнечная комната»
- Синонимы:
- блестящий, блестящий, нитид
яркий с устойчивым, но приглушенным сиянием
- сверкающий, сверкающий, блестящий, светящийся
мягко яркий или сияющий
- блестящий, сверкающий, сверкающий, сверкающий, блестящий, блестящий, блестящий, сверкающий, сверкающий, сверкающий
с краткими блестящими точками или вспышками света
- бусинка, бусинка, пуговица, пуговица
маленький, круглый и блестящий, как блестящая бусина или пуговица
- сияющий, сияющий, сияющий, сияющий, сияющий
излучающий или как бы излучающий свет
- сверкающий, ослепляющий, ослепительный, сверкающий, ослепительный, ослепительный
ярко светит
- яркий как новая копейка
(метафора) ярко сияющий
- блестящий
полный света; ярко светит
- пылкий
светящийся или сияющий, как огонь
- мерцающий
светит мягко и прерывисто
- блестящий, блестящий, блестящий, блестящий, блестящий, блестящий
отражающий свет
- переливающийся, перламутровый, опаловый, опаловый, перламутровый
с игрой блестящих цветов радуги
- зловещий
сияющий неестественным красным светом, словно огонь, видимый сквозь дым
- серебристый
сияющий или светящийся ночью
- атласный, шелковистый, шелковистый, шелковистый, гладкий, лоснящийся
с гладкой блестящей поверхностью, отражающей свет
- самосветящийся
сам по себе обладает свойством излучать свет
- мерцающий
трепетно блестит
- серебристый, серебристый, серебристый
с белым блестящим блеском серебра
- мерцающий
периодически сияющий искрящимся светом
- блестящий, блестящий, нитид
прилагательное
становится гладким и блестящим от трения или как бы от трения; отражающий блеск или свечение
« яркие серебряные подсвечники»
- синонимы: полированный, блестящий, блестящий, блестящий
- полированный
усовершенствованный или сделанный блестящим и гладким
- полированный
прилагательное
не сделать тусклым или менее ярким
- синонимы: незамутненный
прилагательное
с большим количеством естественного или искусственного света
«комната была яркий и воздушный»
«сцена яркий с точечными светильниками
- Синонимы:
- свет
характеризующиеся светом или излучающим свет
- свет
прилагательное
яркий цвет
« яркое платье »
- синонимы: блестящий, яркий
- красочный, красочный
яркий цвет
- красочный, красочный
наречие
с яркостью
«В окнах светилась жемчужина светлый ”
- синонимы: ярко, блестяще
прилагательное
характеризуется быстротой и легкостью в обучении
«некоторые дети ярче в одном объекте, чем в другом»
- синонимы: умный
- разумный
способность мыслить и рассуждать особенно в высокой степени
- разумный
прилагательное
великолепный
« ярких звезд сцены и экрана»
«а яркий момент в истории»
«самый яркий пышный двор»
- Синонимы:
- славный
имеющий, заслуживающий или приносящий славу
- славный
прилагательное
чистый и резкий и звонкий
« яркий звук секции трубы»
- синонимы: блестящий
- реверберирующий
имеющие тенденцию к реверберации или многократному отражению
- реверберирующий
прилагательное
характеризуется счастьем или радостью
« ярких лиц»
- Синонимы:
- счастливый
наслаждение или демонстрация или отмеченные радостью или удовольствием
- счастливый
прилагательное
полный обещаний
«имела светлое будущее издательского дела»
- синонимы: многообещающий, многообещающий
- благоприятный
предвещает благоприятные обстоятельства и удачу
- благоприятный
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: Эти примеры предложений появляются в различных источниках новостей и книгах, чтобы отразить использование слова «яркий» . Мнения, выраженные в примерах, не отражают мнение Vocabulary.com или его редакции.
Отправьте нам отзыв
Мнения, выраженные в примерах, не отражают мнение Vocabulary.com или его редакции.
Отправьте нам отзыв
ВЫБОР РЕДАКЦИИ
Посмотреть
яркий в последний разЗакройте пробелы в словарном запасе с помощью персонализированного обучения, которое фокусируется на обучении слова, которые нужно знать.
Начните изучение словарного запаса
Независимо от того, являетесь ли вы учителем или учеником, Vocabulary.com может направить вас или ваш класс на путь систематического улучшения словарного запаса.
НачатьДобавление языковых анализаторов в строковые поля — Azure Cognitive Search
- Статья
- 4 минуты на чтение
Анализатор языка — это специальный тип анализатора текста, который выполняет лексический анализ с использованием лингвистических правил целевого языка. Каждое строковое поле, доступное для поиска, имеет свойство анализатора . Если ваш контент состоит из переведенных строк, например отдельных полей для английского и китайского текста, вы можете указать языковые анализаторы для каждого поля, чтобы получить доступ к богатым лингвистическим возможностям этих анализаторов.
Каждое строковое поле, доступное для поиска, имеет свойство анализатора . Если ваш контент состоит из переведенных строк, например отдельных полей для английского и китайского текста, вы можете указать языковые анализаторы для каждого поля, чтобы получить доступ к богатым лингвистическим возможностям этих анализаторов.
Когда использовать анализатор языка
Вам следует рассмотреть возможность использования анализатора языка, когда знание структуры слова или предложения повышает ценность разбора текста. Распространенным примером является ассоциация неправильных форм глаголов («принеси» и «принесла») или существительных во множественном числе («мыши» и «мышь»). Без лингвистического понимания эти строки анализируются только по физическим характеристикам, что не позволяет уловить связь. , Так как большие фрагменты текста, скорее всего, будут иметь такое содержание, поля, состоящие из описаний, обзоров или резюме, являются хорошими кандидатами для языкового анализатора.
Вам также следует использовать языковые анализаторы, когда содержимое состоит из строк на незападном языке. Хотя анализатор по умолчанию (Standard Lucene) не зависит от языка, концепция использования пробелов и специальных символов (дефисов и косых черт) для разделения строк больше применима к западным языкам, чем к незападным.
Например, в китайском, японском, корейском (CJK) и других азиатских языках пробел не обязательно является разделителем слов. Рассмотрим следующую японскую строку. Поскольку в нем нет пробелов, анализатор, не зависящий от языка, скорее всего, проанализирует всю строку как один токен, хотя на самом деле строка является фразой.
これは私たちの銀河系の中ではもっとも重く明るいクラスの球状星団です。 (Это самая тяжелая и яркая группа сферических звезд в нашей галактике.)
В приведенном выше примере успешный запрос должен включать полный маркер или частичный маркер с подстановочным знаком суффикса, что приводит к неестественным и ограничивающим возможностям поиска.
Лучше искать отдельные слова: 明るい (Яркий), 私たちの (Наш), 銀河系 (Галактика). Использование одного из японских анализаторов, доступных в Когнитивном поиске, с большей вероятностью разблокирует это поведение, потому что эти анализаторы лучше оснащены для разбиения фрагмента текста на значимые слова на целевом языке.
Использование одного из японских анализаторов, доступных в Когнитивном поиске, с большей вероятностью разблокирует это поведение, потому что эти анализаторы лучше оснащены для разбиения фрагмента текста на значимые слова на целевом языке.
Сравнение Lucene и анализаторов Microsoft
Когнитивный поиск Azure поддерживает 35 языковых анализаторов, поддерживаемых Lucene, и 50 языковых анализаторов, поддерживаемых проприетарной технологией обработки естественного языка Microsoft, используемой в Office и Bing.
Некоторые разработчики могут предпочесть более знакомое, простое решение Lucene с открытым исходным кодом. Анализаторы языка Lucene работают быстрее, но анализаторы Microsoft обладают расширенными возможностями, такими как лемматизация, разложение слов (в таких языках, как немецкий, датский, голландский, шведский, норвежский, эстонский, финский, венгерский, словацкий) и распознавание сущностей (URL-адреса, электронные письма, даты, числа). Если возможно, вам следует провести сравнение анализаторов Microsoft и Lucene, чтобы решить, какой из них лучше подходит. Вы можете использовать Analyze API, чтобы увидеть токены, сгенерированные из заданного текста с помощью определенного анализатора.
Вы можете использовать Analyze API, чтобы увидеть токены, сгенерированные из заданного текста с помощью определенного анализатора.
Индексирование с помощью анализаторов Microsoft в среднем в два-три раза медленнее, чем их эквиваленты Lucene, в зависимости от языка. Производительность поиска не должна существенно снижаться для запросов среднего размера.
Анализаторы английского языка
По умолчанию используется стандартный анализатор Lucene, который хорошо работает с английским языком, но, возможно, не так хорошо, как анализатор английского языка Lucene или анализатор английского языка Microsoft.
Английский анализатор Lucene расширяет стандартный анализатор. Он удаляет из слов притяжательные формы (завершающие ‘s), применяет определение корня в соответствии с алгоритмом выделения корня Портера и удаляет английские стоп-слова.
Анализатор английского языка Microsoft выполняет лемматизацию вместо поиска корней. Это означает, что он может намного лучше обрабатывать флективные и неправильные формы слов, что приводит к более релевантным результатам поиска.

Как указать анализатор языка
Установить анализатор во время создания индекса до его загрузки данными.
В определении поля убедитесь, что поле атрибутировано как «доступное для поиска» и имеет тип Edm.String.
Задайте для свойства «analyzer» один из языковых анализаторов из списка поддерживаемых анализаторов.
Свойство «анализатор» — единственное свойство, которое может принимать анализатор языка, и оно используется как для индексации, так и для запросов. Другие свойства, связанные с анализатором («searchAnalyzer» и «indexAnalyzer»), не будут принимать языковой анализатор.
Анализаторы языка не могут быть настроены. Если анализатор не соответствует вашим требованиям, создайте собственный анализатор с помощью microsoft_language_tokenizer или microsoft_language_stemming_tokenizer, а затем добавьте фильтры для обработки до и после токенизации.
Следующий пример иллюстрирует спецификацию анализатора языка в индексе:
{
"name": "отели-пример-индекса",
"поля": [
{
"имя": "Описание",
"тип": "Эдм. Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "ru.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
{
"имя": "Описание_fr",
"тип": "Эдм.Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "fr.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
 Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "ru.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
{
"имя": "Описание_fr",
"тип": "Эдм.Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "fr.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "ru.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
{
"имя": "Описание_fr",
"тип": "Эдм.Строка",
«извлекаемый»: правда,
"доступный для поиска": правда,
"анализатор": "fr.microsoft",
"indexAnalyzer": ноль,
«Анализатор поиска»: ноль
},
Дополнительные сведения о создании индекса и настройке свойств поля см. в разделе Создание индекса (REST). Дополнительные сведения об анализе текста см. в разделе Анализаторы в Azure Cognitive Search.
Поддерживаемые языковые анализаторы
Ниже приведен список поддерживаемых языков с именами анализаторов Lucene и Microsoft.
| Язык | Имя анализатора Майкрософт | Анализатор Lucene Название |
|---|---|---|
| Арабский | ар. майкрософт | ар.люцен |
| Армянский | ги. люцен люцен | |
| Бангла | млрд. Майкрософт | |
| Баскский | эу.люцен | |
| Болгарский | бг.майкрософт | бг.люцен |
| каталонский | ок. Майкрософт | ка.люцен |
| Китайский упрощенный | ж-ханс.микрософт | ж-ханс.люцен |
| Китайский традиционный | ж-Хант.Microsoft | ж-хант.люцен |
| Хорватский | ч. майкрософт | |
| Чехия | cs.майкрософт | кс.люцен |
| Датский | от Microsoft | da.lucene |
| Голландский | нл.микрософт | нл.люцен |
| Английский | en.Microsoft | эн.люцен |
| Эстонский | и др. Майкрософт | |
| Финский | фи.микрософт | фи.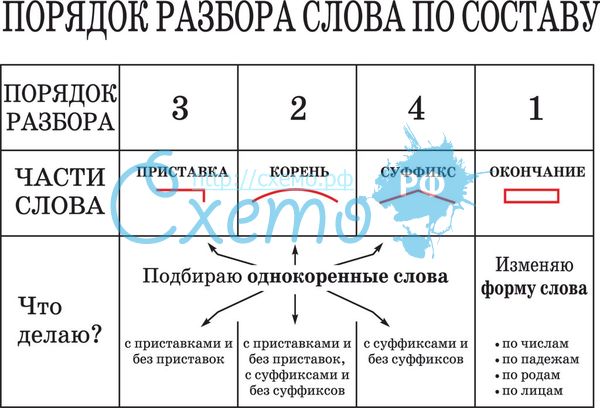 люцен люцен |
| Французский | фр.Microsoft | фр.люцен |
| Галисийский | гл.люцен | |
| немецкий | de.Microsoft | де.люцен |
| Греческий | эл.микрософт | эл.люцен |
| Гуджарати | гу.микрософт | |
| Иврит | он.микрософт | |
| Хинди | привет.Майкрософт | хай.люцен |
| Венгерский | ху.микрософт | hu.lucene |
| Исландский | is.Microsoft | |
| Индонезийский (бахаса) | ID.Майкрософт | ид. люцен |
| Ирландский | га.люцен | |
| итальянский | ит.микрософт | ит.люцен |
| Японский | я. Майкрософт | я.люсен |
| Каннада | кн. Microsoft Microsoft | |
| Корейский | ко.Microsoft | ко.люцен |
| Латвийский | лв.Майкрософт | ур. люцен |
| Литовский | лт. майкрософт | |
| малаялам | мл.Microsoft | |
| Малайский (латиница) | мс.Майкрософт | |
| маратхи | мистер майкрософт | |
| Норвежский | номер майкрософт | № люцена |
| персидский | фа.люцен | |
| польский | пл.Microsoft | пл.люцен |
| Португальский (Бразилия) | пт-Br.Microsoft | pt-Br.lucene |
| Португальский (Португалия) | pt-Pt.Microsoft | pt-Pt.lucene |
| Пенджаби | pa.Майкрософт | |
| Румынский | ро.Майкрософт | ро. люцен люцен |
| Русский | ru.микрософт | ру.lucene |
| Сербский (кириллица) | ср-кириллица.микрософт | |
| Сербский (латиница) | ср-латин.Microsoft | |
| Словацкий | ск.микрософт | |
| Словенский | сл.микрософт | |
| Испанский | es.Microsoft | эс.люцен |
| Шведский | св.микрософт | св.люцен |
| Тамильский | та.микрософт | |
| Телугу | тэ.микрософт | |
| Тайский | т. майкрософт | т. люцен |
| Турецкий | тр. майкрософт | тр.люцен |
| Украинский | Великобритания.Microsoft | |
| Урду | ур.микрософт | |
| Вьетнамский | ви. Майкрософт Майкрософт |
Все анализаторы с именами, помеченными цифрой Lucene работают на основе языковых анализаторов Apache Lucene.
См. также
- Создать индекс
- Создать многоязычный индекс
- Создать индекс (REST API)
- Класс LexicalAnalyzerName (Azure SDK для .NET)
комплиментов, которые могут быть двусмысленными отрицаниями.
Хорошо ли быть «настоящим фейерверком»?Фото Торстена Блэквуда/AFP/Getty Images
Я помню, как впервые кто-то назвал меня «молодой умницей». Я был стажером, ищущим более стабильную работу, и один из моих начальников (отличный парень, которого я очень люблю и уважаю) сказал, что покопается в своей сети, чтобы узнать, есть ли у кого-нибудь вакансия для такого яркого молодого человека, как я. Сначала я был польщен. Но эта фраза также выдвинула на первый план разницу в силе между нами, пожилым мужчиной и молодой женщиной. Эффект был почти такой же, как если бы меня «вежливо» окликнули — я почувствовал себя не серьезным писателем, а светящимся бредом, очаровательным, но тривиальным предметом, которым можно ходить по взрослому столу.
Сначала я был польщен. Но эта фраза также выдвинула на первый план разницу в силе между нами, пожилым мужчиной и молодой женщиной. Эффект был почти такой же, как если бы меня «вежливо» окликнули — я почувствовал себя не серьезным писателем, а светящимся бредом, очаровательным, но тривиальным предметом, которым можно ходить по взрослому столу.
Существует целая категория таких обозначений. Они не совсем неги. Чаще всего они кажутся искренними комплиментами. Но их использование может навязать иерархию, которая тонко подрывает получателя похвалы способами, относящимися к молодежи и, часто, к полу. Яркая молодчина . Умный взмах . Настоящая петарда . Эти описания полны мимолетности — вспышка на сковороде, щелканье кнута, ослепительный свет — и снисходительного зрительного восприятия, которое кажется не относящимся к делу. Их трудно разобрать, сложнее сформулировать последовательную эмоциональную реакцию. В то время как одна часть меня наслаждалась образом себя как гибкого существа, танцующего с лентой в журналистике, другая часть хотела отреагировать на яркая юная штучка комментарий ревущего ХАЛКА РАЗБИВАЕТ, переворачивая стол.
Их трудно разобрать, сложнее сформулировать последовательную эмоциональную реакцию. В то время как одна часть меня наслаждалась образом себя как гибкого существа, танцующего с лентой в журналистике, другая часть хотела отреагировать на яркая юная штучка комментарий ревущего ХАЛКА РАЗБИВАЕТ, переворачивая стол.
Словосочетание «яркая юная штучка» раньше ассоциировалось с представителями определенной общественной жизни Лондона 1920-х годов. Бульварная пресса связывала его с командой богемных светских львиц, которые после Первой мировой войны предавались пьянству, наркотикам, оргиям и роскошным вечеринкам. искусства и моды и благодаря унаследованному богатству. Среди известных BYT были авторы Патрик Бальфур, Эдит Ситуэлл, Энтони Пауэлл и Оливер Мессель; фотограф Сесил Битон; певец Ноэль Кауард; и поэт Джон Бетджеман. Эвелин Во 19 лет30 романов Мерзкие тела описали их подвиги; адаптированный для экрана в 2003 году, его рассказ был переименован (менее язвительно) Bright Young Things . Д.Дж. История Тейлора 2007 года Bright Young People : Потерянное поколение лондонского джазового века также оглядывается на этот период, гламурный всплеск хаоса, зажатый между первой механизированной глобальной войной и глубочайшей финансовой депрессией современности.
Д.Дж. История Тейлора 2007 года Bright Young People : Потерянное поколение лондонского джазового века также оглядывается на этот период, гламурный всплеск хаоса, зажатый между первой механизированной глобальной войной и глубочайшей финансовой депрессией современности.
Но некоторые вещи были яркими и молодыми еще до бурных 20-х. В своем 1869 г.Роман Лорна Дун , Р. Д. Блэкмор создал одобрительный, но покровительственный прецедент для ярких молодых женских вещей: «Мр. Фаггус подмигнул своей кобыле, — писал он, — и она скромно пошла за ним, яркая юная особа, переполненная жизнью, но опускавшая свою душу к высшему и ведомая любовью ко всему, как это принято женщины, когда они знают, что для них лучше». Или попробуйте эту строчку из «Лора Филиппин», позднего рассказа Д. Х. Лоуренса: «Я говорю матери: покажи мне тогда кого-нибудь счастливого! А она показывает мне какого-то парня, или какую-нибудь яркую молодую штучку, и злится, когда я говорю: смотри, хорошенькая обезьянка!» В обоих случаях БЮТ яркий, изящный, но орнаментальный, без настоящей властности и глубины. Г.К. Честертон делает суждение более четким в своем эссе «Дело: почему я католик». «Если смышленую девчонку нельзя просить терпеть ее бабушку, — спрашивает он, — то почему бабушка или мать должны были терпеть смышленую девочку в тот период ее жизни, когда она вовсе не была сообразительна?» Сияние БЮТ Честертон — мимолетное, вторичное состояние, менее актуальное, чем ее кажущийся эгоизм, ее неблагодарность. С 19С по век вплоть до 20-х годов обозначение «яркая молодёжь» ассоциировалось с наивностью и поверхностностью так же, как с харизмой или обещанием.
Г.К. Честертон делает суждение более четким в своем эссе «Дело: почему я католик». «Если смышленую девчонку нельзя просить терпеть ее бабушку, — спрашивает он, — то почему бабушка или мать должны были терпеть смышленую девочку в тот период ее жизни, когда она вовсе не была сообразительна?» Сияние БЮТ Честертон — мимолетное, вторичное состояние, менее актуальное, чем ее кажущийся эгоизм, ее неблагодарность. С 19С по век вплоть до 20-х годов обозначение «яркая молодёжь» ассоциировалось с наивностью и поверхностностью так же, как с харизмой или обещанием.
Распространенность фразы, которая резко возросла в 30-е годы, снизилась в 40-х и 50-х годах и снова начала постепенно расти в середине 60-х. Сегодня вы найдете БЮТ, избавленных от негативных ассоциаций предпринимательской культурой, поклоняющейся молодежи, в дрянных методичках о том, как добиться успеха в бизнесе. («Байтовцев легко распознать — они увлечены тем, кто они есть и чем занимаются… у них любознательный ум во всех видах деятельности, и они неизменно раздражают окружающих, которые по-своему мягко прославляют посредственность, статус-кво. , и быть средним».) Немного другая (гендерная) версия BYT появляется в сексуальных английских переворачивающих страницах: «Эмили — выпускница; яркая молодёжь. У нее нет ни связей, ни обязанностей, ни обязательств. … Когда ее соседка по квартире Люси предложила присоединиться к эскорт-агентству, Эмили рассмеялась и пошутила о том, что это самое большое клише бывшего студента-искусствоведа». (Сюрприз! Эмили присоединяется к эскорт-агентству.) Подобно «симпатичной молодой штучке» Майкла Джексона (PYT), эта BYT излучает следы эротического очарования, может быть, потому, что она Т, вещь, объект для потребления. У Victoria’s Secret даже есть линия нижнего белья «яркая молодёжь» для девочек-подростков.
(«Байтовцев легко распознать — они увлечены тем, кто они есть и чем занимаются… у них любознательный ум во всех видах деятельности, и они неизменно раздражают окружающих, которые по-своему мягко прославляют посредственность, статус-кво. , и быть средним».) Немного другая (гендерная) версия BYT появляется в сексуальных английских переворачивающих страницах: «Эмили — выпускница; яркая молодёжь. У нее нет ни связей, ни обязанностей, ни обязательств. … Когда ее соседка по квартире Люси предложила присоединиться к эскорт-агентству, Эмили рассмеялась и пошутила о том, что это самое большое клише бывшего студента-искусствоведа». (Сюрприз! Эмили присоединяется к эскорт-агентству.) Подобно «симпатичной молодой штучке» Майкла Джексона (PYT), эта BYT излучает следы эротического очарования, может быть, потому, что она Т, вещь, объект для потребления. У Victoria’s Secret даже есть линия нижнего белья «яркая молодёжь» для девочек-подростков.
Тогда есть фейерверк .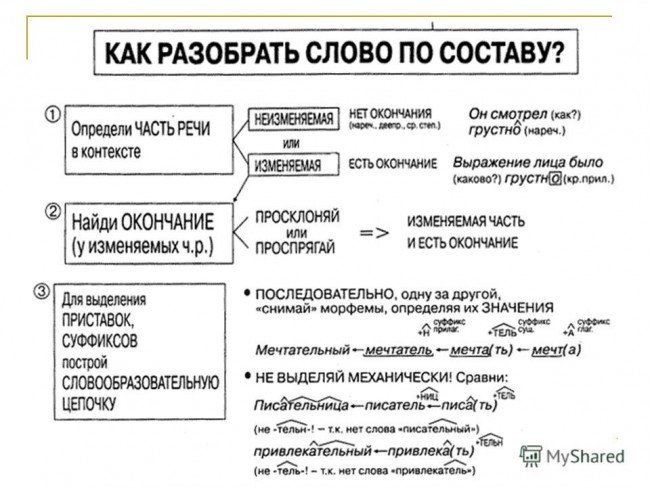 Я думаю, ты хочешь, чтобы тебя называли фейерверком? Если вы женщина, это означает, что говорящий вас одобряет. Он (обычно это он) находит вас дерзкой, энергичной, самоуверенной и честной. Вы также можете быть маленьким, как компактный бумажный цилиндр, начиненный взрывчаткой. Дело в том, что это мило, когда ты кричишь! (Между тем, если вы мужчина и кто-то называет вас фейерверком, вы либо певец Мигель, либо Джон Флетчер, человек-фейерверк, который за годы выступлений зажег от своего тела более 600 000 фейерверков.) мужчин называют «умными кнутом» — в том числе Эндрю Салливана, «умного голоса разума в рэкете блогосферы», Джорджа Клуни и мужской группы OK Go — это слово чаще привязан к представителям второго пола: Эллен Пейдж, Гейл Коллинз, Элизабет Уоррен, Рэйчел Мэддоу, современным мамочкам, остроумной госпоже, Лисбет Саландер. Этот гендерный дисбаланс может иметь какое-то отношение к 19-летнему возрасту Лиз Фейр.94 альбом Whip-Smart , что придало прилагательному стойкий женский блеск.
Я думаю, ты хочешь, чтобы тебя называли фейерверком? Если вы женщина, это означает, что говорящий вас одобряет. Он (обычно это он) находит вас дерзкой, энергичной, самоуверенной и честной. Вы также можете быть маленьким, как компактный бумажный цилиндр, начиненный взрывчаткой. Дело в том, что это мило, когда ты кричишь! (Между тем, если вы мужчина и кто-то называет вас фейерверком, вы либо певец Мигель, либо Джон Флетчер, человек-фейерверк, который за годы выступлений зажег от своего тела более 600 000 фейерверков.) мужчин называют «умными кнутом» — в том числе Эндрю Салливана, «умного голоса разума в рэкете блогосферы», Джорджа Клуни и мужской группы OK Go — это слово чаще привязан к представителям второго пола: Эллен Пейдж, Гейл Коллинз, Элизабет Уоррен, Рэйчел Мэддоу, современным мамочкам, остроумной госпоже, Лисбет Саландер. Этот гендерный дисбаланс может иметь какое-то отношение к 19-летнему возрасту Лиз Фейр.94 альбом Whip-Smart , что придало прилагательному стойкий женский блеск. Но это также может быть связано с тем, что комплимент, хотя и не совсем двусмысленный, предполагает уровень неопытности или нереализованного потенциала, который отсутствует в более мужских терминах, таких как вундеркинд . Остерегайтесь вундеркинда: он гений, и он съест ваш обед. Сообразительный новый сотрудник кажется немного менее опасным — бездоказательным и грубым по краям. Если вундеркинд предполагает, что вы должны поклониться, то умный говорит: «Пока не сбрасывайте со счетов». Она может выглядеть не очень, но, возможно, она окажется больше, чем последняя яркая юная штучка.
Но это также может быть связано с тем, что комплимент, хотя и не совсем двусмысленный, предполагает уровень неопытности или нереализованного потенциала, который отсутствует в более мужских терминах, таких как вундеркинд . Остерегайтесь вундеркинда: он гений, и он съест ваш обед. Сообразительный новый сотрудник кажется немного менее опасным — бездоказательным и грубым по краям. Если вундеркинд предполагает, что вы должны поклониться, то умный говорит: «Пока не сбрасывайте со счетов». Она может выглядеть не очень, но, возможно, она окажется больше, чем последняя яркая юная штучка.
- Язык
- Лексикон Вэлли
Обновление классического бренда — Neenah CLASSIC® Papers — Parse & Parcel
Джилл ДиНиколантонио
По определению, слово «классика» означает «служащий эталоном совершенства: признанной ценностью». Другими словами, то, что выдерживает испытание временем. Бренды Neenah CLASSIC® существуют уже 55 лет. И это говорит о чем-то в отрасли, которая довольно непостоянна, когда речь идет о сортах бумаги с выносливостью. Чтобы дать вам некоторый контекст, я начал работать в индустрии примерно в то же время, когда «Выживший» впервые вышел в эфир. Я видел, как приходит и уходит больше бумаг, чем факелов, потушенных Джеффом Пробстом. Так что да, можно с уверенностью сказать, что CLASSIC® Papers оправдывают свое название. Но как именно бренду, столь культовому и классическому, удается обновиться? Что ж, это был совместный процесс между Neenah Paper и Design Army, на создание которого ушел год. Я говорю, что ожидание того стоило, потому что результаты потрясающие.
После нескольких месяцев исследований и усовершенствований в результате была полностью переосмыслена и реорганизована новая линейка CLASSIC® Papers. Коллекция была упрощена до трех новых каталогов образцов: CLASSIC CREST®, CLASSIC® Linen и CLASSIC® Textures.
Коллекция была упрощена до трех новых каталогов образцов: CLASSIC CREST®, CLASSIC® Linen и CLASSIC® Textures.
КЛАССИЧЕСКАЯ ЦВЕТОВАЯ ПАЛИТРА
Процесс уточнения цветовой палитры не мог быть легким, редактирование никогда не бывает легким. По словам Пума Лефебюра, главного креативного директора Design Army, после рассмотрения нескольких цветовых палитр они сохранили цвета, которые работали больше всего, не были модными и имели стойкость. Имея это в виду, команда выбрала восемь новых цветов, достойных классического статуса:
- Bare White: красивый сбалансированный белый цвет, являющийся переходным мостиком между Avon Brilliant White и Classic Natural White
- Cool Grey: светлый оттенок, соединяющий цвета Antique Grey и Pewter .
- Cadet Grey: Насыщенный серый оттенок дополняет существующий серый цвет .
- Chambray: свежий взгляд на синий деним
- Баклажан: глубокий приятный цвет, похожий на насыщенный фиолетовый цвет свежего баклажана
- Военный: теплый, насыщенный, естественный зеленый цвет
- Кобальт: Актуальный и трендовый ярко-синий
- Imperial Red: Свежий, яркий и модный красный
«Новые цвета мы создавали буквально вручную, смешивая краски в офисе! После того, как восемь новых цветов были усовершенствованы, нам понадобился рецепт, который можно было бы перенести на бумагоделательные машины, — сказал Лефебур. цвета краски. Это был трудоемкий, но очень увлекательный процесс».
цвета краски. Это был трудоемкий, но очень увлекательный процесс».
Этот процесс звучит так, будто мечта этого бумажного фанатика сбылась. Хочу сказать, что цветовая палитра потрясающая. Я абсолютно поражен новым Bare White, и думаю, что дизайнерам, которые ищут белый оттенок с малейшей теплотой, понравится этот вариант.
КЛАССИЧЕСКИЕ ТЕКСТУРЫ
Когда дело доходит до пробуждения эмоций и установления связи с людьми, нет ничего лучше текстуры. Neenah добавила в линейку CLASSIC® Papers два новых тактильных сорта – CLASSIC® Techweave и CLASSIC® Woodgrain. CLASSIC® Techweave — это высококачественный, структурный и модный сорт, который представляет собой ткань тонкого плетения с элементами высоких технологий. В то время как CLASSIC® Woodgrain обладает эстетическим очарованием текстуры дерева, а также экологичным и устойчивым оттенком. Только взгляните, как прекрасно сочетается штамп из фольги с CLASSIC® Woodgrain в новом оттенке Military.
Добавьте эти текстуры к существующим классам CLASSIC® Stipple, CLASSIC® Columns и CLASSIC® Laid, и новая книга образцов CLASSIC® Textures скоро станет незаменимым ресурсом для тех, кто жаждет тактильности в своих печатных проектах.
ДОПОЛНИТЕЛЬНЫЕ ВАРИАНТЫ CLASSIC
Поклонники CLASSIC® Papers будут в восторге, узнав, что в линейку также добавлено шесть новых комбинаций дуплекса, в результате чего общее количество дуплексов для всего бренда достигло 16. Основываясь на отзывах, которые команда получила во время своего исследования, они добавили 64 новых позиции в бумагу, которую они предлагают для цифровой печати, — если вы считаете, что теперь это 237 позиций для всех брендов CLASSIC®.
ДОКАЗАТЕЛЬСТВО В ОБРАЗЦАХ БУМАГИ
Вы же не думали, что я пропущу мою любимую часть, не так ли? Вы можете себе представить, что перезапуск бренда такого масштаба потребует довольно крутых образцов. Увидев каталоги образцов, я ожидала чего-то особенного, но никогда не могла представить, что мне предстоит испытать.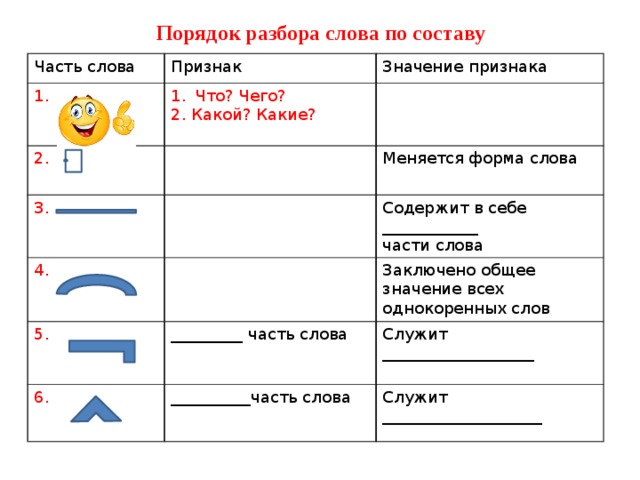 Я был поражен. Я ненавижу даже использовать слово продвижение, потому что это гораздо больше. Это то произведение, к которому вы будете обращаться снова и снова на протяжении всей своей карьеры.
Я был поражен. Я ненавижу даже использовать слово продвижение, потому что это гораздо больше. Это то произведение, к которому вы будете обращаться снова и снова на протяжении всей своей карьеры.
Рекламная акция Think CLASSIC® Papers — это большая, яркая, красивая книга, в которой представлены 64 негабаритных страницы, достойные слюни, наполненные дизайном, искусством, фотографией, типографикой, цифровой печатью, тиснением, тиснением фольгой, металликами, высечками, французскими складки, а цвета и текстуры в изобилии. Каждая страница с остановкой и взглядом демонстрирует разные произведения искусства и разные технологии производства.
Прежде чем вы спросите, это изделие было выпущено в очень ограниченном количестве. Это так редко, что когда я присутствовал на презентации местного класса, мне пришлось поделиться им! Если вам посчастливилось получить собственную копию, не забудьте указать на ней свое имя, иначе она потеряется.
Когда дело доходит до выбора бумаги для печати, проверенная временем вещь очень полезна. Последнее, чего хочет любой дизайнер, — это провал проекта во время печати, потому что бумага не будет делать то, что он от нее ожидает. Но это не значит, что нам нужно довольствоваться обычной белой и яркой бумагой. Нет, вряд ли это можно назвать классикой, особенно когда дело касается бумаги. На самом деле, я бы сказал, что это как раз наоборот. Классический сорт бумаги — это тот, характеристики которого внушают благоговейный трепет: он неподвластен времени по цвету, текстуре и способу применения. Достичь этого тройного успеха в обычных обстоятельствах сложно, но особенно трудно, когда речь идет о бренде, имя которого является синонимом вечности. Я должен сказать, это обновление бренда Neenah CLASSIC® Papers от Design Army достойно пятизвездочного статуса.
Последнее, чего хочет любой дизайнер, — это провал проекта во время печати, потому что бумага не будет делать то, что он от нее ожидает. Но это не значит, что нам нужно довольствоваться обычной белой и яркой бумагой. Нет, вряд ли это можно назвать классикой, особенно когда дело касается бумаги. На самом деле, я бы сказал, что это как раз наоборот. Классический сорт бумаги — это тот, характеристики которого внушают благоговейный трепет: он неподвластен времени по цвету, текстуре и способу применения. Достичь этого тройного успеха в обычных обстоятельствах сложно, но особенно трудно, когда речь идет о бренде, имя которого является синонимом вечности. Я должен сказать, это обновление бренда Neenah CLASSIC® Papers от Design Army достойно пятизвездочного статуса.
О, если вам интересно, новые альбомы образцов и плоские листы CLASSIC® уже в наличии в студии образцов, но они быстро расходятся! И не зря их помощь вдохновляет дизайнеров тактильных трендов, от которых не может нарадоваться.
Лингвистические функции · Документация по использованию spaCy
Интеллектуальная обработка необработанного текста затруднена: большинство слов встречаются редко, и это
обычно для слов, которые выглядят совершенно по-разному, означают почти одно и то же.
Одни и те же слова в другом порядке могут означать совсем другое.
Даже разделение текста на полезные словесные единицы может быть затруднено во многих случаях.
языки. Хотя можно решить некоторые проблемы, начиная только с сырого
символов, обычно лучше использовать лингвистические знания, чтобы добавить полезные
информация. Это именно то, для чего разработан spaCy: вы вводите необработанный текст,
и получить обратно Doc , который поставляется с различными
аннотации.
После токенизации spaCy может анализировать и помечать данный Doc . Это где
появляется обученный конвейер и его статистические модели, которые позволяют spaCy делать прогнозы того, какой тег или метка наиболее вероятно применимы в данном контексте.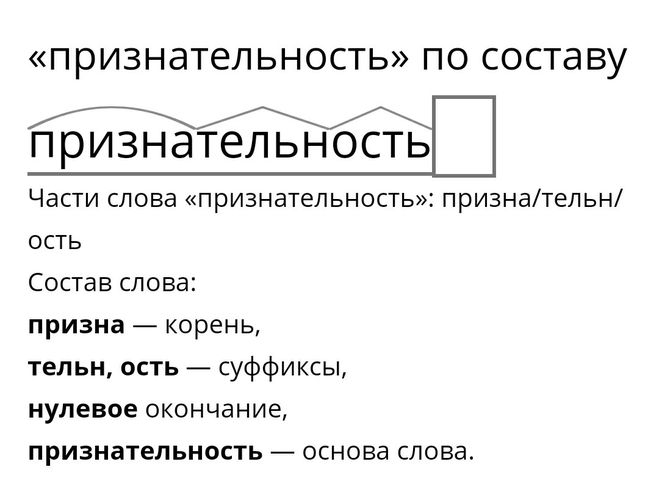 Обученный компонент включает в себя двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Обученный компонент включает в себя двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Токен атрибутов. Как и многие библиотеки НЛП, spaCy кодирует все строки в хэш-значения , чтобы уменьшить использование памяти и улучшить
эффективность. Таким образом, чтобы получить удобочитаемое строковое представление атрибута, мы
нужно добавить подчеркивание _ к его имени:
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
- Текст: Исходный текст слова.
- Лемма: Основная форма слова.
- POS: Простой UPOS тег части речи.
- Тег: Подробный тег части речи.
- Dep: Синтаксическая зависимость, т. е. отношение между токенами.
- Начертание: Начертание слова – заглавные буквы, знаки препинания, цифры.
- is alpha: Является ли токен альфа-символом?
- is stop: Является токеновой частью стоп-листа, т.е. язык?
 е. отношение между токенами.
е. отношение между токенами.| Text | Lemma | POS | Tag | Dep | Shape | alpha | stop | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Apple | apple | PROPN | NNP | nsubj | Xxxxx | True | False | ||||||||||
| is | be | AUX | VBZ | aux | xx | True | True | ||||||||||
| looking | look | VERB | VBG | ROOT | XXXX | True | FALSE | ||||||||||
| AT | AT | 905AT | 905. IN IN | prep | xx | True | True | ||||||||||
| buying | buy | VERB | VBG | pcomp | xxxx | Правда | Ложь | ||||||||||
| Великобритания | Великобритания | ПРОПН | ННП | соединение | X.X. | False | False | ||||||||||
| startup | startup | NOUN | NN | dobj | xxxx | True | False | ||||||||||
| для | для | АДП | В | prep | xxx | True | True | ||||||||||
| $ | $ | SYM | $ | quantmod | $ | False | False | ||||||||||
| 1 | 1 | NUM | CD | compound | d | False | False | ||||||||||
| billion | billion | NUM | CD | pobj | xxxx | True | False |
Совет: что такое теги и метки
Большинство тегов и меток выглядят довольно абстрактно и различаются между
языки.
spacy.explain покажет вам краткое описание — например, spacy.explain("VBZ") возвращает «глагол, 3-е лицо единственного числа, настоящее время».
Используя встроенный в spaCy визуализатор displaCy, вот что наше примерное предложение и его зависимости выглядят так:
📖Схема тегов частей речи
Для получения списка присвоенных тегов детализированных и грубых частей речи моделями spaCy на разных языках, см. задокументированные схемы маркировки в каталоге моделей.
Инфлективная морфология – это процесс, посредством которого корневая форма слова изменен путем добавления префиксов или суффиксов, которые определяют его грамматическую функцию но не меняйте его часть речи. Мы говорим, что лемма (корневая форма) есть измененный (модифицированный/комбинированный) с одним или несколькими морфологическими признаками до создать поверхностную форму. Вот несколько примеров:
| Контекст | Поверхность | Лемма | POS | Морфологические особенности | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Я читал газету | Чтение | Читая | Гломинирование | . | read | VERB | VerbForm=Fin , Mood=Ind , Tense=Pres | |||
| I read the paper yesterday | read | read | VERB | VerbForm=Fin , Mood=Ind , Tense=Past |
 read
read morph
morph 
 pos
pos  Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
получено из WordNet.
Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
получено из WordNet. 

| Text | root.text | root.dep_ | root.head.text |
|---|---|---|---|
| Autonomous cars | cars | nsubj | shift |
| insurance liability | liability | dobj | shift |
| manufacturers | manufacturers | pobj | toward |
Navigating the parse tree
spaCy uses the terms head и ребенок для описания слов связанных
одна дуга в дереве зависимостей. Термин dep используется для дуги
метка, описывающая тип синтаксического отношения, связывающего потомка с
голова. Как и в случае с другими атрибутами, значение .dep — это хеш-значение. Ты можешь
получить строковое значение с
Ты можешь
получить строковое значение с .dep_ .
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
- Текст: Исходный текст токена.
- Dep: Синтаксическое отношение, соединяющее дочерний элемент с головным.
- Текст заголовка: Исходный текст заголовка токена.
- Head POS: Тег части речи головы токена.
- Дочерние элементы: Непосредственные синтаксические зависимости токена.
| Text | Dep | Head text | Head POS | Children |
|---|---|---|---|---|
| Autonomous | amod | cars | NOUN | |
| cars | nsubj | смена | ГЛАГОЛ | Автономный |
| смена | КОРЕНЬ | смена | VERB | cars, liability, toward |
| insurance | compound | liability | NOUN | |
| liability | dobj | shift | VERB | страхование |
| к | подготовка | смена | СУЩЕСТВИТЕЛЬНОЕ | производители |
| производителей | pobj | в направлении | ADP |
Поскольку синтаксические отношения образуют дерево, каждое1 слово имеет ровно одно
голова
. Поэтому вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ согласования дуги
интерес — снизу:
Поэтому вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ согласования дуги
интерес — снизу:Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Если вы попытаетесь сопоставить сверху, вам придется повторить итерацию дважды. Один раз для головы, а потом опять через детей:
Для перебора дочерних элементов используйте атрибут token.children , который
предоставляет последовательность из объектов Token .
Итерация по локальному дереву
Предусмотрено еще несколько удобных атрибутов для итерации по локальному дереву.
дерево из токена. Token.left и
Атрибуты Token.rights предоставляют последовательности синтаксических
дочерние элементы, которые встречаются до и после маркера. Обе последовательности в предложении
заказ. Также есть два атрибута целочисленного типа,
Token.n_lefts и
Token.n_rights , которые дают количество левых и правых
дети.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Вы можете получить целую фразу по ее синтаксическому заголовку, используя Атрибут Token.subtree . Это возвращает заказанный
последовательность жетонов. Вы можете подняться на дерево с Атрибут Token.ancestors и проверьте доминирование с помощью Token.is_ancestor
Проективное и непроективное
Для английских конвейеров по умолчанию дерево синтаксического анализа проективное , что означает отсутствие скрещивающихся скобок. Токены
Таким образом, возвращаемое .subtree гарантированно будет непрерывным. Это не
верно для немецких трубопроводов, у которых много
непроективные зависимости.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
| Текст | Dep | n_lefts | n_rights | ancestors |
|---|---|---|---|---|
| Credit | nmod | 0 | 2 | holders, submit |
| and | cc | 0 | 0 | держатели, подать |
| закладная | соединение | 9 18308 9 38055 | account, Credit, holders, submit | |
| account | conj | 1 | 0 | Credit, holders, submit |
| holders | nsubj | 1 | 0 | submit |
Наконец, особенно полезными могут быть атрибуты . и 9180ge 1.right
потому что они дают вам первый и последний токен поддерева. Это
самый простой способ создать  left_edge
left_edge Объект Span для синтаксической фразы. Обратите внимание, что .right_edge дает токен внутри поддерева — поэтому, если вы используете его как
конечная точка диапазона, не забудьте +1 !
Editable CodespaCy v3.5 · Python 3 · via Binder
| Text | POS | Dep | Head text |
|---|---|---|---|
| Credit and mortgage account holders | NOUN | nsubj | submit |
| must | VERB | aux | submit |
| submit | VERB | ROOT | submit |
| their | ADJ | возможность | запросы |
| запросы | СУЩЕСТВИТЕЛЬНОЕ | 3 dob0 | submit |
Анализ зависимостей может быть полезным инструментом для извлечения информации ,
особенно в сочетании с другими прогнозами, такими как
именованные сущности. В следующем примере извлекаются деньги и
значения валюты, то есть объекты, помеченные как
В следующем примере извлекаются деньги и
значения валюты, то есть объекты, помеченные как MONEY , а затем использует зависимость
проанализируйте, чтобы найти именное словосочетание, на которое они ссылаются, например «Чистый доход» → "9,4 миллиона долларов" .
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
📖Объединение моделей и правил
Дополнительные примеры написания логики извлечения информации на основе правил, использует в своих интересах предсказания модели, сделанные различными компонентами, см. руководство по использованию на сочетание моделей и правил.
Визуализация зависимостей
Лучший способ понять парсер зависимостей spaCy — интерактивный. Делать
это проще, spaCy поставляется с модулем визуализации. Вы можете пройти Doc или
список из Объекты Doc для показа и выполнения displacy.serve для запуска веб-сервера или displacy. для создания необработанной разметки.
Если вы хотите знать, как писать правила, которые подключаются к какому-либо синтаксическому
конструкции, просто подключите предложение к визуализатору и посмотрите, как spaCy
аннотирует его. render
render
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Дополнительные сведения и примеры см. руководство по визуализации spaCy. Вы также можете протестировать DISPLAY в нашей онлайн-демонстрации..
Отключение синтаксического анализатора
В обученных пайплайнах, предоставляемых spaCy, синтаксический анализатор загружается и
включен по умолчанию как часть
стандартный конвейер обработки. Если вам не нужно
любую синтаксическую информацию, вы должны отключить парсер. Отключение
parser заставит spaCy загружаться и работать намного быстрее. Если вы хотите загрузить парсер,
но нужно отключить его для определенных документов, вы также можете контролировать его использование на
объект nlp . Дополнительные сведения см. в руководстве по использованию на
отключение компонентов конвейера.
в руководстве по использованию на
отключение компонентов конвейера.
spaCy имеет чрезвычайно быструю систему распознавания статистических объектов, которая присваивает метки смежным промежуткам токенов. По умолчанию обученные конвейеры могут идентифицировать различные именованные и числовые юридические лица, включая компании, местоположения, организации и продукты. Ты можешь добавить произвольные классы в систему распознавания сущностей и обновить модель с новыми примерами.
Распознавание именованных объектов 101
Именованный объект — это «объект реального мира», которому присвоено имя, например
человек, страна, продукт или название книги. spaCy может распознавать различные
типы именованных сущностей в документе, запрашивая у модели прогноз .
Поскольку модели являются статистическими и сильно зависят от примеров, в которых они были
на обучении, это не всегда работает идеально и может нуждаться в некоторой настройке
позже, в зависимости от вашего варианта использования.
Именованные сущности доступны как свойство ents документа Doc :
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
- Текст: Исходный текст сущности.
- Начало: Индекс начала сущности в
Doc. - Конец: Индекс конца сущности в
Doc. - Метка: Метка сущности, т.е. тип.
| Text | Start | End | Label | Description |
|---|---|---|---|---|
| Apple | 0 | 5 | ORG | Компании, агентства, учреждения. |
| Великобритания | 27 | 31 | GPE | Геополитическая единица, т.е. страны, города, штаты. |
| 1 миллиард долларов | 44 | 54 | ДЕНЬГИ | Денежные суммы, включая ед. |
Используя встроенный в spaCy визуализатор displaCy, вот что наше примерное предложение и его именованные объекты выглядят так:
Доступ к аннотациям и меткам объектов
Стандартным способом доступа к аннотациям объектов является doc.ents свойство, которое создает последовательность из 91 379 объектов Span 91 380. Лицо
тип доступен либо как хеш-значение, либо как строка с использованием атрибутов ent.label и ent.label_ . Объект Span действует как последовательность токенов, поэтому
вы можете перебирать объект или индексировать его. Вы также можете получить текстовую форму
всей сущности, как если бы это был один токен.
Вы также можете получить доступ к аннотациям сущности токена, используя token. и  ent_iob
ent_iob token.ent_type атрибутов. token.ent_iob указывает
независимо от того, начинается ли сущность, продолжается или заканчивается на теге. Если тип объекта не установлен
на токене он вернет пустую строку.
Схема IOB
-
I— Токен находится внутри объекта. -
O– Токен вне сущности. -
B— Токен — это начало объекта.
Схема BILUO
-
B— Токен — это начало объекта с несколькими токенами. -
I— Токен находится внутри объекта с несколькими токенами. -
L— Токен — это последний токен объекта с несколькими токенами. -
U— Токен представляет собой единицу с одним токеном . -
O– Жетон за пределами сущности.

Editable CodespaCy v3.5 · Python 3 · via Binder
| Text | ent_iob | ent_iob_ | ent_type_ | Description |
|---|---|---|---|---|
| San | 3 | B | "GPE" | начало сущности |
| Франциско | 1 | I | "GPE" | inside an entity |
| considers | 2 | O | "" | outside an entity |
| banning | 2 | O | "" | outside an entity |
| sidewalk | 2 | O | "" | outside an entity |
| delivery | 2 | O | "" | outside an entity |
| robots | 2 | O | "" | вне объекта |
Настройка аннотаций объектов
установить аннотации объектов на уровне документа . Однако вы не можете написать
непосредственно к атрибутам
Однако вы не можете написать
непосредственно к атрибутам token.ent_iob или token.ent_type , поэтому проще всего
способ установки объектов - использовать функцию doc.set_ents и создайте новый объект как Span .
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Имейте в виду, что Span инициализируется начальным и конечным токеном индексы, а не смещения символов. Чтобы создать диапазон из смещений символов, используйте Doc.char_span :
Установка аннотаций сущностей из массива
Вы также можете назначать аннотации сущностей с помощью
метод doc.from_array . Для этого следует включить
оба атрибута ENT_TYPE и ENT_IOB в массиве, который вы импортируете
от.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Настройка аннотаций сущностей в Cython
Наконец, вы всегда можете записать в базовую структуру, если компилируете
Цитон функция. Это легко сделать и позволяет
писать эффективный нативный код.
Это легко сделать и позволяет
писать эффективный нативный код.
Очевидно, что если вы будете писать напрямую в массив из структур TokenC* , у вас будет
ответственность за обеспечение того, чтобы данные оставались в непротиворечивом состоянии.
Встроенные типы сущностей
Совет: понимание типов сущностей
Вы также можете использовать spacy.explain() для получения описания строки
представление метки сущности. Например, spacy.explain("ЯЗЫК")
вернет «любой именованный язык».
Схема аннотации
Подробнее о типах сущностей, доступных в обученных конвейерах spaCy, см. разделы «схема маркировки» отдельных моделей в каталог моделей.
Визуализация именованных объектов
дисплей визуализатор ENT
позволяет интерактивно исследовать поведение модели распознавания сущностей. Если вы
обучая модель, очень полезно запустить визуализацию самостоятельно. Помогать
вы делаете это, spaCy поставляется с модулем визуализации. Вы можете пройти
Вы можете пройти Doc или
список объектов Doc для просмотра и выполнения
displacy.serve для запуска веб-сервера или
displacy.render для создания необработанной разметки.
Более подробную информацию и примеры см. руководство по визуализации spaCy.
Пример именованного объекта
Чтобы привязать именованные объекты к «реальному миру», spaCy предоставляет функциональные возможности.
для выполнения связывания сущностей, которое преобразует текстовую сущность в уникальную
идентификатор из базы знаний (КБ). Вы можете создать свой собственный База Знаний и обучить новый EntityLinker с использованием этой пользовательской базы знаний.
Доступ к идентификаторам объектов Требуется модель
Аннотированный идентификатор базы знаний доступен либо как хеш-значение, либо как строка,
используя атрибуты ent.kb_id и ent.kb_id_ Span объект или атрибуты ent_kb_id и ent_kb_id_ объекта Токен объект.
Токенизация — это задача разделения текста на осмысленные сегменты, называемые
токенов . Входные данные для токенизатора представляют собой текст в формате Юникод, а выходные данные —
Объект документа . Для создания объекта Doc вам потребуется
экземпляр Vocab , последовательность из слов строк и, возможно,
последовательность из 91 379 пробелов и 91 380 логических значений, которые позволяют поддерживать выравнивание
токены в исходную строку.
Важное примечание
Токенизация spaCy неразрушающая , что означает, что вы всегда будете
способен восстановить исходный ввод из токенизированного вывода. пробел
информация сохраняется в токенах, никакая информация не добавляется и не удаляется
во время токенизации. Это своего рода основной принцип spaCy’s 9.1379 Объект документа :
doc.text == input_text всегда должно быть верным.
Во время обработки spaCy first токенизирует текст, т. е. сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения должны быть разделены.
– тогда как «Великобритания» должен оставаться один токен. Каждый документ
е. сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения должны быть разделены.
– тогда как «Великобритания» должен оставаться один токен. Каждый документ Doc состоит из отдельных
токены, и мы можем перебрать их:
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Apple | is | looking | at | покупка | Великобритания | запуск | за | $ | 1 | миллиард |
Сначала текст разделен на пробелы, текст разделен на пробелы text. . Затем токенизатор обрабатывает текст слева направо. На
каждой подстроки он выполняет две проверки: split(' ')
split(' ')
Соответствует ли подстрока правилу исключения токенизатора? Например, «нельзя» не содержит пробелов, но должен быть разделен на две лексемы, «делать» и «n’t», а «U.K.» всегда должен оставаться один токен.
Можно ли отделить префикс, суффикс или инфикс? Например, знаки препинания, такие как запятые, точки, дефисы или кавычки.
Если есть совпадение, применяется правило, и токенизатор продолжает свой цикл, начиная с вновь разделенных подстрок. Таким образом, spaCy может разделить комплекс , вложенные токены , такие как комбинации аббревиатур и множественных знаков препинания Метки.
- Исключение Tokenizer: Правило особого случая для разделения строки на несколько
токенов или предотвратить разделение токена при нарушении правил пунктуации. применяемый.
- Префикс: Символ(ы) в начале, напр.
$,(,″,À. - Суффикс: Символ(ы) в конце, напр.
км,),”,!. - Инфикс: Символ(ы) между ними, напр.
-,--,/,….
 применяемый.
применяемый. В то время как правила пунктуации обычно довольно общие, исключения токенизатора
сильно зависят от специфики конкретного языка. Вот почему каждый
доступный язык имеет свой собственный подкласс, например английский или немецкий , который загружает списки жестко закодированных данных и исключений
правила.
spaCy представляет новый алгоритм токенизации, обеспечивающий лучший баланс между производительностью, простотой определения и простотой выравнивания с оригиналом нить.
После употребления префикса или суффикса мы снова обращаемся к особым случаям. Мы хотим
специальные случаи для обработки таких вещей, как «не» в английском языке, и мы хотим того же
правило работать для «(не)!». Мы делаем это, расщепляя открытую скобку, затем
восклицательный знак, затем закрывающая скобка и, наконец, соответствие особому случаю.
Вот реализация алгоритма на Python, оптимизированная для удобочитаемости.
а не производительность:
Мы хотим
специальные случаи для обработки таких вещей, как «не» в английском языке, и мы хотим того же
правило работать для «(не)!». Мы делаем это, расщепляя открытую скобку, затем
восклицательный знак, затем закрывающая скобка и, наконец, соответствие особому случаю.
Вот реализация алгоритма на Python, оптимизированная для удобочитаемости.
а не производительность:
Алгоритм можно обобщить следующим образом:
- Перебор подстрок, разделенных пробелами.
- Проверить, есть ли у нас явно определенный особый случай для этой подстроки. Если мы это сделаем, используйте это.
- Найдите совпадение маркера. Если есть совпадение, остановите обработку и сохраните это токен.
- Проверить, есть ли у нас явно определенный особый случай для этой подстроки. Если мы это сделаем, используйте это.
- В противном случае попытайтесь использовать один префикс. Если мы израсходовали префикс, вернитесь к #3,
чтобы совпадение токена и особые случаи всегда имели приоритет.
- Если мы не использовали префикс, попробуйте использовать суффикс, а затем вернитесь к №3.
- Если мы не можем использовать префикс или суффикс, ищем совпадение URL.
- Если совпадений URL нет, ищите особый случай.
- Найдите «инфиксы» — дефисы и т. д. и разбейте подстроку на токены на всех инфиксах.
- Когда мы больше не сможем потреблять строку, обработайте ее как одиночный токен.
- Сделайте последний проход по тексту, чтобы проверить наличие особых случаев, включающих пробелы или которые были пропущены из-за инкрементальной обработки аффиксов.
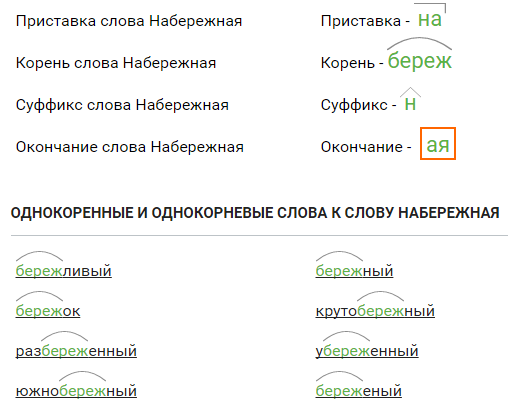
Глобальные и специфичные для языка данные токенизатора предоставляются через язык
данные в spacy/lang . Исключения токенизатора
определить особые случаи, такие как «не» в английском языке, которые необходимо разделить на два
токены: {ИЛИ: "делать"} и {ИЛИ: "не", НОРМ: "не"} . Префиксы, суффиксы
а инфиксы в основном определяют правила пунктуации — например, когда отделяться
точки (в конце предложения) и когда оставлять лексемы, содержащие точки
неповрежденными (аббревиатуры типа «США»).
Правила токенизации, специфичные для одного языка, но могут быть обобщены
на этом языке , в идеале должны жить в языковых данных в
spacy/lang — мы всегда ценим запросы на вытягивание!
Все, что относится к домену или типу текста, например, к финансовой торговле.
аббревиатуры или баварский молодежный сленг – следует добавлять в качестве правила особого случая
к вашему экземпляру токенизатора. Если вы имеете дело с большим количеством настроек, это
может иметь смысл создать полностью настраиваемый подкласс.
Добавление специальных правил токенизации
Большинство доменов имеют как минимум некоторые особенности, требующие специальной токенизации
правила. Это могут быть очень определенные выражения или аббревиатуры, используемые только в
это конкретное поле. Вот как добавить правило особого случая к существующему
Экземпляр Tokenizer :
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Особый случай не обязательно должен соответствовать целой подстроке, разделенной пробелами. Токенизатор будет постепенно отделять знаки препинания и продолжать искать
оставшаяся подстрока. Правила особых случаев также имеют приоритет над
пунктуационное разделение.
Токенизатор будет постепенно отделять знаки препинания и продолжать искать
оставшаяся подстрока. Правила особых случаев также имеют приоритет над
пунктуационное разделение.
Отладка токенизатора
Рабочая реализация приведенного выше псевдокода доступна для отладки как
nlp.tokenizer.explain(текст) . Он возвращает список
кортежи, показывающие, какое правило или шаблон токенизатора соответствует каждому токену.
произведенные токены идентичны nlp.tokenizer() , за исключением токенов с пробелами:
Ожидаемый результат
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Настройка класса токенизатора spaCy
Предположим, вы хотите создать токенизатор для нового языка или определенного домен. Вам может понадобиться определить шесть вещей:
- Словарь особых случаев . Это обрабатывает такие вещи, как сокращения,
единицы измерения, смайлики, некоторые сокращения и т. д.
- Функция
prefix_searchдля обработки предшествующих знаков препинания , таких как open кавычки, открытые скобки и т.д. - Функция
suffix_searchдля обработки после знака препинания , например запятые, точки, закрывающие кавычки и т. д. - Функция
infix_finditerдля обработки непробельных разделителей, таких как дефисы и т.п. - Необязательная логическая функция
token_matchсопоставление строк, которые никогда не должны быть разделены, переопределяя правила инфикса. Полезно для таких вещей, как числа. - Необязательная логическая функция
url_match, аналогичнаяtoken_matchза исключением того, что префиксы и суффиксы удаляются перед применением совпадения.
 д.
д. Обычно не требуется создавать подкласс Tokenizer . Стандартное использование
использовать re.compile() для создания объекта регулярного выражения и передать его . и  search()
search() .finditer() методов:
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
специализируются find_prefix , find_suffix и find_infix .
Важное примечание
При настройке обработки префикса, суффикса и инфикса помните, что вы
передача функций для выполнения spaCy, например. prefix_re.search – нет
просто регулярные выражения. Это означает, что ваши функции также должны определять
как следует применять правила. Например, если вы добавляете собственный префикс
правил, вам нужно убедиться, что они применяются только к символам в начало токена , например. добавив 9 . Точно так же суффиксные правила должны
применяться только в конце токена , поэтому ваше выражение должно заканчиваться $ .
Изменение существующих наборов правил
Во многих случаях вам не обязательно нужны полностью настраиваемые правила. Иногда
вы просто хотите добавить еще один символ к префиксам, суффиксам или инфиксам.
правила префикса, суффикса и инфикса по умолчанию доступны через объект
Иногда
вы просто хотите добавить еще один символ к префиксам, суффиксам или инфиксам.
правила префикса, суффикса и инфикса по умолчанию доступны через объект nlp Значения по умолчанию и токенизатор атрибутов, таких как Tokenizer.suffix_search доступны для записи, поэтому вы можете
перезаписать их скомпилированными объектами регулярных выражений, используя измененное значение по умолчанию
правила. spaCy поставляется с служебными функциями, которые помогут вам скомпилировать обычный
выражения – например, compile_suffix_regex :
Точно так же вы можете удалить символ из суффиксов по умолчанию:
Атрибут Tokenizer.suffix_search должен быть функцией, которая принимает
строка юникода и возвращает регулярное выражение соответствует объекту или Нет . Обычно мы используем
атрибут .search скомпилированного объекта регулярного выражения, но вы можете использовать некоторые другие
функция, которая ведет себя так же.
Важное примечание
Если вы загрузили обученный конвейер, запись в
nlp. По умолчанию или английский. По умолчанию напрямую не будет
работать, так как регулярные выражения считываются из данных конвейера и будут
компилируется при загрузке. Если вы измените nlp.Defaults , вы увидите только
эффект, если вы позвоните spacy.blank . Если вы хотите
изменить токенизатор, загруженный из обученного конвейера, вы должны изменить
nlp.tokenizer напрямую. Если вы тренируете собственный конвейер, вы можете зарегистрироваться
обратные вызовы для изменения nlp
объект перед тренировкой.
Наборы правил префикса, инфикса и суффикса включают не только отдельные символы
но и подробные регулярные выражения, учитывающие окружающий контекст.
счет. Например, существует регулярное выражение, обрабатывающее дефис между
буквы в качестве инфикса. Если вы не хотите, чтобы токенизатор разбивался на дефисы
между буквами вы можете изменить существующее определение инфикса из
lang/punctuation. :  py
py
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Обзор регулярных выражений по умолчанию см. язык/пунктуация.py и
специфические для языка определения, такие как lang/de/punctuation.py для
Немецкий.
Подключение пользовательского токенизатора к конвейеру
Токенизатор — это первый и единственный компонент конвейера обработки
который нельзя заменить записью в nlp.pipeline . Это потому, что он имеет
отличается от всех остальных компонентов: он принимает текст и возвращает Doc , в то время как все остальные компоненты уже должны получить
токенизированный Doc .
Чтобы перезаписать существующий токенизатор, необходимо заменить nlp.tokenizer на
пользовательская функция, которая принимает текст и возвращает Doc .
Создание объекта Doc
Создание объекта Doc вручную требует не менее двух
аргументы: общие Vocab и список слов. По желанию можно пройти
список из 91 379 пробелов 91 380 значений, указывающих, является ли токен в этой позиции
с последующим пробелом (по умолчанию
По желанию можно пройти
список из 91 379 пробелов 91 380 значений, указывающих, является ли токен в этой позиции
с последующим пробелом (по умолчанию True ). См. раздел о
предварительно размеченный текст для получения дополнительной информации.
| Аргумент | Тип | Описание | ||
|---|---|---|---|---|
TEXT | ||||
Текст | TEXT | | | . |
Пример 1. Базовый токенизатор пробелов
Вот пример самого простого токенизатора пробелов. Это занимает общее
vocab, поэтому он может создавать объектов Doc . Когда он вызывается для текста, он возвращает
объект Doc , состоящий из текста, разделенного на один пробел. Мы можем
затем перезапишите атрибут nlp.tokenizer экземпляром нашего пользовательского
токенизатор.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Пример 2: сторонние токенизаторы (элементы слов BERT)
Вы можете использовать тот же подход для подключения любых других сторонних токенизаторов. Твой
пользовательскому вызываемому объекту просто нужно вернуть объект Doc с токенами, созданными
ваш токенизатор. В этом примере оболочка использует фрагмент слова BERT.
токенизатор , предоставленный токенизаторов библиотека. Токены
доступные в объекте Doc , возвращаемом spaCy, теперь соответствуют точным фрагментам слов
производится токенизатором.
💡 Совет: spacy-transformers
Если вы работаете с моделями-трансформерами, такими как BERT, ознакомьтесь с космические трансформеры пакет расширения и документация. Это
включает конвейерный компонент для использования предварительно обученных трансформаторных весов и обучающие модели трансформаторов в spaCy, а так же полезные утилиты для
согласование частей слов с лингвистической токенизацией.
Пользовательский токенизатор слов BERT
Важное примечание о токенизации и моделях
Имейте в виду, что результаты ваших моделей могут быть менее точными, если во время обучения отличается от токенизации во время выполнения. Итак, если вы измените Токенизация обученного конвейера впоследствии может привести к очень разным результатам. предсказания. Поэтому вам следует обучать свой конвейер с помощью того же . токенизатор , который он будет использовать во время выполнения. См. документы на обучение с пользовательской токенизацией для получения подробной информации.
Обучение с пользовательской токенизацией v3.0
Конфигурация обучения spaCy описывает настройки,
гиперпараметры, конвейер и токенизатор, используемые для построения и обучения
трубопровод. 9Блок 1379 [nlp.tokenizer] относится к зарегистрированной функции , которая
принимает объект nlp и возвращает токенизатор. Здесь мы регистрируем
функция с именем
Здесь мы регистрируем
функция с именем whitespace_tokenizer в реестр @tokenizers . Чтобы убедиться, что spaCy знает, как
чтобы создать свой токенизатор во время обучения, вы можете передать свой файл Python,
установка --code functions.py при запуске spacy train .
config.cfg
functions.py
Зарегистрированные функции также могут принимать аргументы, которые затем передаются из
конфиг. Это позволяет быстро изменять и отслеживать различные настройки.
Здесь зарегистрированная функция с именем bert_word_piece_tokenizer занимает два
аргументы: путь к файлу словаря и следует ли переводить текст в нижний регистр.
Подсказки типа Python str и bool гарантируют, что полученные значения имеют
правильный тип.
config.cfg
functions.py
Чтобы избежать жесткого указания локальных путей в файле конфигурации, вы также можете установить
vocab в интерфейсе командной строки с помощью файла --nlp. переопределить, когда вы бежите  tokenizer.vocab_file
tokenizer.vocab_file космический поезд . Дополнительные сведения об использовании зарегистрированных функций см.
см. документы в обучении с пользовательским кодом.
Помните, что зарегистрированная функция всегда должна быть функцией, которую spaCy призывает создать что-то , а не само «что-то». В данном случае это создает функцию , которая принимает объект nlp и возвращает вызываемый объект, который
принимает текст и возвращает Doc .
Использование предварительно размеченного текста
spaCy обычно по умолчанию предполагает, что ваши данные представляют собой необработанный текст . Однако,
иногда ваши данные частично аннотируются, например. с уже существующей токенизацией,
теги частей речи и т. д. Наиболее распространенная ситуация, когда у вас есть предопределенная токенизация . Если у вас есть список строк, вы можете создать Doc возражает напрямую. При желании вы также можете указать список
логические значения, указывающие, следует ли за каждым словом пробел.
При желании вы также можете указать список
логические значения, указывающие, следует ли за каждым словом пробел.
✏️ Что попробовать
- Измените логическое значение в списке
пробелов. Вы должны увидеть его отражение вdoc.textи следует ли за токеном пробел. - Удалить
пробелов=пробеловиз документа - Скопируйте-вставьте случайное предложение из Интернета и вручную создайте
Docссловамиипробелами, чтобыdoc.textсоответствовал оригиналу ввод текста.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Список пробелов, если он предоставлен, должен иметь ту же длину, что и список слов .
список пробелов влияет на doc.text , span.text , token.idx , span.start_char и атрибутов span.. Если вы не укажете последовательность из 91 379 пробелов 91 380, spaCy
будет предполагать, что за всеми словами следует пробел. Как только у вас есть  end_char
end_char Doc , вы можете записать в его атрибуты, чтобы установить
теги частей речи, синтаксические зависимости, именованные сущности и другие
атрибуты.
Выравнивание токенизации
Токенизация spaCy является неразрушающей и использует правила для конкретного языка
оптимизирован для совместимости с аннотациями банка деревьев. Другие инструменты и ресурсы
иногда может токенизировать вещи по-разному — например, "Я" → ["И", "'", "м"] вместо ["И", "м"] .
В подобных ситуациях часто требуется настроить токенизацию так, чтобы
может объединять аннотации из разных источников вместе или брать предсказанные векторы
по
предварительно обученная модель BERT и
применить их к токенам spaCy. SpaCy’s Выравнивание объект позволяет взаимно однозначно отображать индексы токенов в обоих направлениях, как
а также принимая во внимание индексы, в которых несколько токенов выравниваются с одним единственным
токен.
✏️ Что попробовать
- Измените заглавные буквы в одном из списков токенов – например,
"Обама"до"Обама". Вы увидите, что выравнивание нечувствительно к регистру. - Изменить
"подкасты"вother_tokensна"pod", "casts". Тебе следует увидеть что теперь есть две лексемы длины 2 вy2x, одна из которых соответствует «s», а один — «подкасты». - Сделать
other_tokensиspacy_tokensидентичных. Вы увидите, что все жетоны теперь соответствуют 1-к-1.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Вот некоторые сведения из информации о выравнивании, созданной в примере выше:
- Однозначные сопоставления для первых четырех токенов идентичны, что означает
они сопоставляются друг с другом. Это имеет смысл, потому что они также идентичны в
ввод:
"i","прослушал","к"и"обама". - Значение
x2y.data[6]равно5, что означает, чтоother_tokens[6]("подкасты") соответствуетspacy_tokens[5](также"подкасты"). -
x2y.data[4]иx2y.data[5]оба являются4, что означает, что оба токена 4 и 5 изother_tokens("'"и"s") выравниваются с токеном 4 изspacy_tokens("с").

Важное примечание
Текущая реализация алгоритма выравнивания предполагает, что оба
токенизации составляют одну и ту же строку. Например, вы сможете выровнять ["I", "'", "m"] и ["I", "'m"] , которые в сумме дают "I'm" , но не ["Я", "м"] и ["Я", "есть"] .
Менеджер контекста Doc.retokenize позволяет объединять и
разделить токены. Все модификации токенизации хранятся и выполняются на
один раз при выходе из менеджера контекста. Чтобы объединить несколько токенов в один
жетон, пройти
Чтобы объединить несколько токенов в один
жетон, пройти Span to retokenizer.merge . Ан
дополнительный словарь attrs позволяет установить атрибуты, которые будут назначены
объединенный токен — например, лемма, тег части речи или тип объекта. К
по умолчанию объединенный токен получит те же атрибуты, что и объединенный диапазон
корень.
✏️ Что стоит попробовать
- Проверьте атрибут
token.lemma_с настройкой и без установки атрибутов - Перезаписать другие атрибуты, такие как
"ENT_TYPE". Поскольку «Нью-Йорк» также признана именованной организацией, это изменение также будет отражено вдокументов.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Совет: объединение сущностей и словосочетаний
Если вам нужно объединить именованные сущности или фрагменты существительных, воспользуйтесь встроенным merge_entities и merge_noun_chunks конвейер
компоненты. При добавлении в ваш конвейер с использованием
При добавлении в ваш конвейер с использованием nlp.add_pipe , возьмут
позаботьтесь об автоматическом объединении диапазонов.
Если атрибут в attrs является контекстно-зависимым атрибутом маркера, он будет
применяться к базовому токену . Например ЛЕММА , POS или DEP применяются только к слову в контексте, поэтому они являются атрибутами токена. Если
атрибут является контекстно-независимым лексическим атрибутом, он будет применяться к
лежащая в основе лексема , запись в словаре. Например, LOWER или IS_STOP применяются ко всем словам с одинаковым написанием, независимо от
контекст.
Примечание по объединению перекрывающихся отрезков
Если вы пытаетесь объединить перекрывающиеся отрезки, spaCy выдаст ошибку, потому что
непонятно, как должен выглядеть результат. В зависимости от приложения вы можете
хотите найти самый короткий или самый длинный возможный диапазон, поэтому вам решать, как отфильтровать
их. Если вы ищете самый длинный непересекающийся отрезок, вы можете использовать
Если вы ищете самый длинный непересекающийся отрезок, вы можете использовать util.filter_spans helper:
Разделение токенов
Метод retokenizer.split позволяет выполнять разделение
один токен на два или более токенов. Это может быть полезно для случаев, когда
Одних правил токенизации недостаточно. Например, вы можете разделить
«его» в лексемы «это» и «есть» - но не притяжательное местоимение «его». Ты
может написать логику на основе правил, которая может найти только правильное «свое» для разделения, но
на этот раз документ Doc уже будет токенизирован.
Этот процесс разделения токена требует дополнительных настроек, потому что вам нужно
укажите текст отдельных токенов, необязательные атрибуты для каждого токена и способ
токены должны быть присоединены к существующему синтаксическому дереву. Это можно сделать с помощью
предоставление списка из головок — либо токен для прикрепления вновь разделенного токена
to или кортеж (токен, субтокен) , если должен быть присоединен вновь разделенный токен
к другому подтокену. В этом случае «Новый» должен быть присоединен к «Йорку» (т.
второй разделенный подтокен), а «York» должен быть присоединен к «in».
В этом случае «Новый» должен быть присоединен к «Йорку» (т.
второй разделенный подтокен), а «York» должен быть присоединен к «in».
✏️ Что попробовать
- Назначьте субтокенам разные атрибуты и сравните результат.
- Поменяйте головки так, чтобы к "in" было присоединено "New", а к "York" присоединено на «Новый».
- Разбить токен на три токена вместо двух — например,
["Новый", "Йо", "рк"].
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Указание головок в виде списка токенов или (токен, субтокен) кортежей позволяет
присоединение разделенных субтокенов к другим субтокенам без необходимости отслеживать
индексы токенов после разделения.
| Token | Head | Description |
|---|---|---|
"New" | (doc[3], 1) | Attach this token to the second subtoken (index 1 ) что doc[3] будет разделен на, то есть «Йорк». |
"Йорк" | doc[2] | Прикрепите этот токен к doc[1] в исходном Doc , т. е. «in». |
Если вы не заботитесь о головках (например, если вы используете только токенизатор, а не синтаксический анализатор), вы можете прикрепить каждый субтокен к самому себе:
Важное примечание
При разделении токенов тексты подтокенов всегда должны совпадать с оригиналом
текст токена – или, другими словами, "".join(subtokens) == token.text всегда нужен
придерживаться истины. Если бы это было не так, разделение токенов могло бы легко закончиться
приводя к запутанным и неожиданным результатам, которые противоречили бы spaCy.
неразрушающая политика токенизации.
Перезапись атрибутов пользовательского расширения
Если вы зарегистрировали
атрибуты расширения,
вы можете перезаписать их во время токенизации, предоставив словарь
имена атрибутов сопоставляются с новыми значениями как ключ "_" в атрибутах . Для
при слиянии необходимо предоставить один словарь атрибутов для результирующего
объединенный токен. Для разбивки необходимо предоставить список словарей с
настраиваемые атрибуты, по одному на разделенный субтокен.
Для
при слиянии необходимо предоставить один словарь атрибутов для результирующего
объединенный токен. Для разбивки необходимо предоставить список словарей с
настраиваемые атрибуты, по одному на разделенный субтокен.
Важное примечание
Чтобы установить атрибуты расширения во время ретокенизации, атрибуты должны быть
зарегистрировал , используя Token.set_extension
метод, и они должны быть доступны для записи . Это означает, что они должны либо иметь
значение по умолчанию, которое может быть перезаписано, или геттер и сеттер . Метод
расширения или расширения только с геттером вычисляются динамически, поэтому их
значения не могут быть перезаписаны. Для получения более подробной информации см.
документы атрибута расширения.
✏️ Что стоит попробовать
- Добавьте еще одно пользовательское расширение – например,
"music_style"? - и перезаписать. - Измените атрибут расширения, чтобы использовать только функцию получения
- Перепишите код для разделения токена с помощью
retokenizer.split. Помните, что вам необходимо предоставить список значений атрибута расширения как"_"свойство, по одному для каждого разделенного субтокена.
 Вам следует
видите, что spaCy выдает ошибку, потому что атрибут недоступен для записи
больше.
Вам следует
видите, что spaCy выдает ошибку, потому что атрибут недоступен для записи
больше. Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Предложения объекта Doc доступны через Doc.sents свойство. Чтобы просмотреть предложения Doc , вы можете перебрать Doc.sents , a
генератор, который дает Span объектов. Вы можете проверить, соответствует ли Doc имеет границы предложения, называя Doc.has_annotation с именем атрибута "SENT_START" .
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
spaCy предоставляет четыре варианта сегментации предложений:
- Парсер зависимостей: статистический
DependencyParserобеспечивает наиболее точные границы предложений, основанные на анализе полных зависимостей. - Сегментатор статистических предложений: статистический
SentenceRecognizerпроще и быстрее альтернатива синтаксическому анализатору, который только устанавливает границы предложений. - Компонент конвейера на основе правил:
Sentencizerустанавливает границы предложения, используя настраиваемый список знаков препинания в конце предложения. - Пользовательская функция: ваша собственная пользовательская функция добавлена в
конвейер обработки может устанавливать границы предложения, записывая в
Token.is_sent_start.

По умолчанию: Использование синтаксического анализа зависимостей Требует модели
В отличие от других библиотек, spaCy использует синтаксический анализ зависимостей для определения предложения
границы. Обычно это наиболее точный подход, но он требует обученный конвейер , обеспечивающий точные прогнозы. Если ваши тексты
ближе к новостям общего назначения или веб-тексту, это должно хорошо работать из коробки
с обученными пайплайнами, предоставленными spaCy. Для социальных сетей или разговорного текста
которые не следуют тем же правилам, ваше приложение может извлечь выгоду из пользовательского
обученный или основанный на правилах компонент.
Для социальных сетей или разговорного текста
которые не следуют тем же правилам, ваше приложение может извлечь выгоду из пользовательского
обученный или основанный на правилах компонент.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Анализатор зависимостей spaCy учитывает уже установленные границы, поэтому вы можете выполнить предварительную обработку
твой Doc с использованием пользовательских компонентов до анализа. В зависимости от вашего текста,
это также может повысить точность синтаксического анализа, поскольку синтаксический анализатор ограничен предсказанием
анализирует в соответствии с границами предложения.
Статистический сегментатор предложений v3.0 Модель потребностей
SentenceRecognizer представляет собой простой статистический
компонент, который только обеспечивает границы предложения. Наряду с тем, что он быстрее и
меньше парсера, его основное преимущество в том, что его легче обучать
потому что для этого требуются только аннотированные границы предложений, а не полные
разбор зависимостей. Обученные пайплайны spaCy включают в себя парсер
и обученный сегментатор предложений, который
отключен по умолчанию. Если вам нужно только
границ предложения и без синтаксического анализатора, вы можете использовать
Обученные пайплайны spaCy включают в себя парсер
и обученный сегментатор предложений, который
отключен по умолчанию. Если вам нужно только
границ предложения и без синтаксического анализатора, вы можете использовать исключить или отключить аргумент spacy.load для загрузки конвейера
без синтаксического анализатора, а затем явно включить распознаватель предложений с помощью нлп.enable_pipe .
против синтаксического анализатора
Отзыв для отправителя обычно немного ниже, чем для синтаксического анализатора,
который лучше предсказывает границы предложения, когда пунктуация не
подарок.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Компонент конвейера на основе правил
Компонент Sentencizer является
компонент конвейера, который разбивает предложения на
знаки препинания вроде . , ! или ? .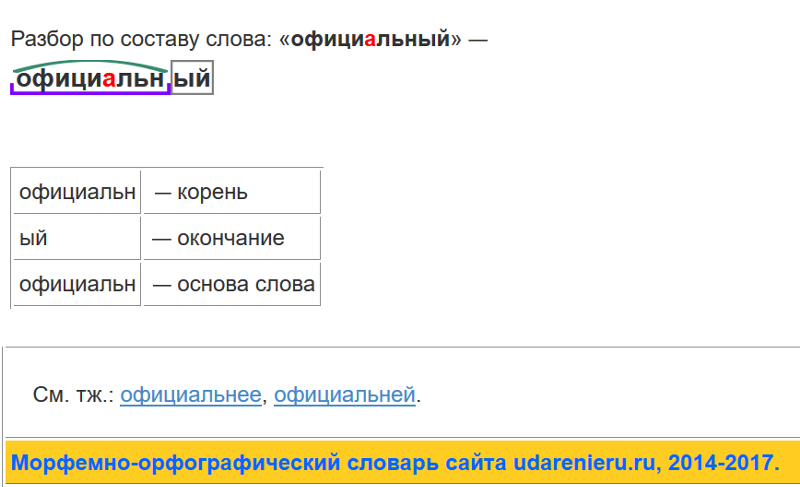 Вы можете подключить его к своему конвейеру, если только
нужны границы предложения без анализа зависимостей.
Вы можете подключить его к своему конвейеру, если только
нужны границы предложения без анализа зависимостей.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Пользовательская стратегия на основе правил
Если вы хотите реализовать собственную стратегию, отличную от стандартной
основанный на правилах подход к разбиению на предложения, вы также можете создать
настраиваемый компонент конвейера, который
берет Doc и устанавливает атрибут Token.is_sent_start для каждого
индивидуальный токен. Если установлено значение False , токен явно помечается как , а не .
начало предложения. Если установлено значение Нет (по умолчанию), оно рассматривается как отсутствующее значение.
и все еще может быть перезаписан синтаксическим анализатором.
Важное примечание
Во избежание несогласованного состояния можно установить границы только до документа.
анализируется (и doc. — это  has_annotation("DEP")
has_annotation("DEP") Ложь ). Чтобы убедиться, что ваш
компонент добавлен в нужном месте, вы можете установить перед = 'parser' или first = True при добавлении в конвейер с помощью nlp.add_pipe .
Вот пример компонента, реализующего правило предварительной обработки для
разбиение на "..." токенов. Компонент добавляется перед парсером, т.е.
затем используется для дальнейшего сегментирования текста. Это возможно, потому что is_sent_start установлено только True для некоторых токенов – все остальные по-прежнему указывают Нет для неустановленных границ предложений. Этот подход может быть полезен, если вы хотите
внедрить дополнительных правил, специфичных для ваших данных, при этом сохраняя возможность
воспользоваться сегментацией предложений на основе зависимостей.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
AttributeRuler управляет сопоставлениями на основе правил и
исключения для всех атрибутов уровня токена. По количеству
компоненты конвейера выросли с spaCy v2 до
v3, обработка правил и исключений в каждом компоненте по отдельности стала
непрактично, поэтому
По количеству
компоненты конвейера выросли с spaCy v2 до
v3, обработка правил и исключений в каждом компоненте по отдельности стала
непрактично, поэтому AttributeRuler представляет собой единый компонент с унифицированным
формат шаблона для всех сопоставлений и исключений атрибутов токена.
AttributeRuler использует Matcher шаблонов для идентификации
токены, а затем присваивает им предоставленные атрибуты. При необходимости
Шаблоны Matcher могут включать контекст вокруг целевого токена.
Например, линейка атрибутов может:
- предоставлять исключения для любых атрибутов токена
- карта мелкозернистые теги от до крупнозернистые теги для языков без
статистические морфологизаторы (замена v2.x
tag_mapв языковые данные) - токен карты форма поверхности + мелкозернистые теги – морфологические признаки (замена v2. x
morph_rulesв языковых данных) - указать теги для токенов пространства (заменив жестко запрограммированное поведение в таггер)
 x
x В следующем примере показано, как тег и POS NNP / PROPN можно указать
для фразы "The Who" , переопределяя теги, предоставленные статистическим
tagger и карту POS-тегов.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Миграция с spaCy v2.x
AttributeRuler может импортировать карту тегов и преобразование
правила в формате v2.x через его встроенные методы или когда компонент
инициализируется перед тренировкой. См.
руководство по миграции для получения подробной информации.
Сходство определяется путем сравнения векторов слов или «вложений слов», многомерные смысловые представления слова. Векторы слов могут быть генерируется по такому алгоритму word2vec и обычно выглядит так:
банан.
 вектор
вектор Важное примечание
Чтобы сделать их компактными и быстрыми, небольшие пакеты пайплайнов spaCy (все
пакеты, оканчивающиеся на sm ) не поставляются с векторами слов и включают только
контекстно-зависимый тензоров . Это означает, что вы все еще можете использовать подобие() методы сравнения документов, спанов и токенов — но результат будет не таким
хорошо, и отдельные токены не будут иметь назначенных векторов. Итак, чтобы использовать реальных векторов слов, вам необходимо загрузить больший пакет конвейера:
Пакеты конвейеров, которые поставляются со встроенными векторами слов, делают их доступными как
атрибут Token.vector .
Doc.vector и Span.vector будет
по умолчанию используется среднее значение их векторов токенов. Вы также можете проверить, есть ли у токена
назначенный вектор и получить норму L2, которую можно использовать для нормализации векторов.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
- Текст : Исходный текст токена.
- имеет вектор : Имеет ли токен векторное представление?
- Норма вектора : Норма L2 вектора токена (квадратный корень из сумма квадратов значений)
- OOV : Вне словаря
Слова «собака», «кошка» и «банан» довольно распространены в английском языке, поэтому они
часть словаря пайплайна и идут с вектором. Слово «afskfsd» на
другая рука встречается гораздо реже и не входит в словарный запас, поэтому ее вектор
представление состоит из 300 измерений 0 , что означает, что это практически
несуществующий. Если ваше приложение выиграет от большого словаря с
больше векторов, вам следует рассмотреть возможность использования одного из более крупных пакетов пайплайна или
загрузка в полный векторный пакет, например, en_core_web_lg , в том числе 685 тыс. уникальных
вектора .
уникальных
вектора .
spaCy может сравнить два объекта и сделать прогноз насколько они похожи они . Прогнозирование сходства полезно для построения рекомендательных систем. или пометка дубликатов. Например, вы можете предложить пользовательский контент, аналогично тому, что они сейчас просматривают, или пометить заявку в службу поддержки как дублировать, если он очень похож на уже существующий.
Каждый Doc , Пролет , Токен и Лексема поставляется с .similarity метод, позволяющий сравнить его с другим объектом и определить
сходство. Конечно, сходство всегда субъективно – будь то два слова, промежутки
или документы похожи, действительно зависит от того, как вы на это смотрите. spaCy’s
реализация подобия обычно предполагает довольно общее определение
сходство.
📝 Что попробовать
- Сравните два разных жетона и попытайтесь найти два самых непохожий токены в текстах с наименьшим показателем сходства (по
векторы).
- Сравните сходство двух объектов
Лексема, записи в словарь. Вы можете получить лексему через атрибут.lexтокена. Вы должны увидеть, что результаты подобия идентичны токену сходство.

Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Чего ожидать от результатов сходства
Вычисление показателей сходства может быть полезным во многих ситуациях, но также важно поддерживать реалистичные ожидания относительно того, какую информацию он может предоставлять. Слова могут быть связаны друг с другом по-разному, поэтому одно Оценка «сходства» всегда будет смесью различных сигналов и векторов. обучение на разных данных может дать очень разные результаты, которые могут не полезно для вашей цели. Вот несколько важных соображений, о которых следует помнить:
- Нет объективного определения подобия. Будь то «я люблю бургеры» и «я
как паста» похож на зависит от вашего приложения . Оба говорят о еде
предпочтения, что делает их очень похожими, но если вы анализируете упоминания
еды, эти предложения довольно непохожи, потому что они говорят об очень
разные продукты.
- Сходство
DocиSpanобъектов по умолчанию к среднему векторов токенов. Это означает, что вектор для «быстрого еда» — это среднее значение векторов «быстро» и «еда», которое не обязательно представитель фразы «фаст-фуд». - Усреднение вектора означает, что вектор нескольких токенов нечувствителен к порядок слов. Два документа, выражающие одно и то же значение с разнородная формулировка вернет более низкую оценку сходства, чем два документа. которые содержат одни и те же слова, но выражают разные значения.
 Оба говорят о еде
предпочтения, что делает их очень похожими, но если вы анализируете упоминания
еды, эти предложения довольно непохожи, потому что они говорят об очень
разные продукты.
Оба говорят о еде
предпочтения, что делает их очень похожими, но если вы анализируете упоминания
еды, эти предложения довольно непохожи, потому что они говорят об очень
разные продукты.💡Совет: проверьте sense2vec
sense2vec — это библиотека, разработанная
нас, который строится на основе spaCy и позволяет вам обучать и запрашивать более интересные и
подробные векторы слов. Он сочетает в себе существительные, такие как «фаст-фуд» или «честная игра».
и включает в себя теги частей речи и метки сущностей. Библиотека также
включает рецепты аннотаций для нашего инструмента аннотаций Prodigy
которые позволяют вам оценивать векторы и создавать списки терминов. Больше подробностей,
загляните в наш блог. К
изучить семантическое сходство во всех комментариях Reddit за 2015 и 2019 годы.,
см. интерактивную демонстрацию.
Он сочетает в себе существительные, такие как «фаст-фуд» или «честная игра».
и включает в себя теги частей речи и метки сущностей. Библиотека также
включает рецепты аннотаций для нашего инструмента аннотаций Prodigy
которые позволяют вам оценивать векторы и создавать списки терминов. Больше подробностей,
загляните в наш блог. К
изучить семантическое сходство во всех комментариях Reddit за 2015 и 2019 годы.,
см. интерактивную демонстрацию.
Добавление векторов слов
Пользовательские векторы слов можно обучать с использованием ряда библиотек с открытым исходным кодом, таких как
как Gensim, FastText,
или оригинал Томаса Миколова
Реализация Word2vec. Большинство
векторные библиотеки слов выводят удобный для чтения текстовый формат, где каждая строка
состоит из слова, за которым следует его вектор. Для повседневного использования мы хотим
преобразовать векторы в двоичный формат, который загружается быстрее и занимает меньше места
место на диске. Самый простой способ сделать это - векторов инициализации утилита командной строки. Это выведет
пустой конвейер spaCy в каталоге
Это выведет
пустой конвейер spaCy в каталоге /tmp/la_vectors_wiki_lg , что дает вам
доступ к некоторым хорошим латинским векторам. Затем вы можете передать путь к каталогу spacy.load или используйте его в [инициализировать] вашей конфигурации, когда вы
обучить модель.
Пример использования
Класс Vectors позволяет отображать несколько ключей от до одинаковых
строка таблицы. Если вы используете
spacy init vectors команда для создания словаря,
обрезка векторов будет выполнена автоматически, если вы установите --prune
флаг. Вы также можете сделать это вручную, выполнив следующие шаги:
- Начните с пакета векторов из слов , который охватывает огромный словарный запас. Для
Например, пакет
en_core_web_lgпредоставляет 300-мерные векторы GloVe для 685 тысяч терминов английского языка. - Если в вашем словаре установлены значения атрибута
Lexeme.prob, лексемы будут отсортированы по убыванию вероятности, чтобы определить, какие векторы обрезать. В противном случае лексемы будут отсортированы по порядку в словаре - Позвоните
Vocab.prune_vectorsс номером векторы, которые вы хотите сохранить.

Vocab.prune_vectors уменьшает текущий вектор
таблицу с заданным количеством уникальных записей и возвращает словарь, содержащий
удаленные слова, сопоставленные с (строка, оценка) кортежей, где строка — это
запись, с которой было сопоставлено удаленное слово, и баллов баллов сходства между
два слова.
Удаленные слова
В приведенном выше примере вектор «Берег» был удален и переназначен на
вектор «побережья», который считается примерно на 73% похожим. «Уход» был переназначен на
вектор «ухода», который идентичен. Если вы используете
Команда
Если вы используете
Команда init vectors , вы можете установить --подрезать возможность легко уменьшить размер векторов при добавлении их в spaCy
pipe:
Это создаст пустой конвейер spaCy с векторами для первых 10 000 слов. в векторах. Все остальные слова в векторах сопоставляются с ближайшим вектором среди сохранившихся.
Добавление векторов по отдельности
Атрибут вектора представляет собой массив numpy или cupy только для чтения (в зависимости от
независимо от того, настроили ли вы spaCy для использования памяти графического процессора), с dtype поплавок32 .
массив доступен только для чтения, так что spaCy может избежать ненужных операций копирования, где
возможный. Вы можете изменить векторы с помощью Vocab или
Векторы табл. Используя
Метод Vocab.set_vector часто является самым простым подходом
если у вас есть векторы в произвольном формате, как вы можете прочитать в векторах с
свою собственную логику и просто установите их с помощью простого цикла. Этот метод, вероятно,
быть медленнее, чем подходы, которые работают сразу со всей таблицей векторов, но
это отличный подход для одноразовых конверсий, прежде чем вы сохраните свои
Этот метод, вероятно,
быть медленнее, чем подходы, которые работают сразу со всей таблицей векторов, но
это отличный подход для одноразовых конверсий, прежде чем вы сохраните свои НЛП
объект на диск.
Добавление векторов
Все языки разные — и обычно полны исключений и специальных
падежи , особенно среди наиболее распространенных слов. Некоторые из этих исключений
общие для разных языков, в то время как другие полностью специфичны — обычно так
что они должны быть жестко запрограммированы.
Модуль lang содержит все данные для конкретного языка,
организованы в простые файлы Python. Это упрощает обновление и расширение данных.
Данные общего языка в корне каталога включают правила, которые можно
обобщены для разных языков — например, правила для основных знаков препинания, эмодзи,
смайлики и однобуквенные сокращения. Индивидуальные языковые данные в
подмодуль содержит правила, которые относятся только к конкретному языку. Это
также позаботится о сборке всех компонентов и создании
Это
также позаботится о сборке всех компонентов и создании Подкласс языка – например, английский или немецкий .
значения определены в Language.Defaults .
| Имя | Описание |
|---|---|
Стоп-слова stop_words.py | ». Соответствующие токены вернут True для is_stop . |
Исключения Tokenizer tokenizer_exceptions.py | Особые правила для токенизатора, например, сокращения типа «can’t» и аббревиатуры со знаками препинания, например «U.K.». |
Правила пунктуации punctuation.py | Регулярные выражения для разделения токенов, например. на знаки препинания или специальные символы, такие как смайлики. Включает правила для префиксов, суффиксов и инфиксов. |
Классы символов char_classes. | Классы символов для использования в регулярных выражениях, например латинские символы, кавычки, дефисы или значки. |
Лексические атрибуты lex_attrs.py | Пользовательские функции для установки лексических атрибутов токенов, например. like_num , который включает специфические для языка слова, такие как «десять» или «сотня». |
Итераторы синтаксиса Syntax_iterators.py | Функции, вычисляющие представления Doc на основе его синтаксиса. На данный момент используется только для фрагментов существительных. |
Lemmatizer lemmatizer.py spacy-lookups-data | Пользовательская реализация лемматизатора и таблицы лемматизации. |
 py
py Создание пользовательского языкового подкласса
Если вы хотите настроить несколько компонентов языковых данных или добавить поддержку
для пользовательского языка или специфичного для предметной области «диалекта» вы также можете реализовать свой
собственный языковой подкласс. Подкласс должен определять два атрибута:
Подкласс должен определять два атрибута: язык (уникальный код языка) и Значения по умолчанию , определяющие языковые данные. Для
обзор доступных атрибутов, которые можно перезаписать, см. Language.Defaults документация.
Редактируемый CodespaCy v3.5 · Python 3 · через Binder
Декоратор @spacy.registry.languages позволяет
зарегистрируйте собственный языковой класс и назначьте ему строковое имя. Это значит, что
вы можете позвонить по номеру spacy.blank с вашим пользовательским
имя языка и даже обучать конвейеры с его помощью и ссылаться на него в своих
тренировочный конфиг.
Использование конфигурации
После регистрации пользовательского языкового класса с использованием реестра языков ,
вы можете обратиться к нему в своей тренировочной конфигурации. Этот
означает, что spaCy будет обучать ваш конвейер, используя пользовательский подкласс.
Чтобы преобразовать "custom_en" в ваш подкласс, зарегистрированная функция
должен быть доступен во время обучения.