«небрежно» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Разбор по составу (морфемный) слова «небрежный Небрежно морфемный
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть).
 Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение. - Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
 Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
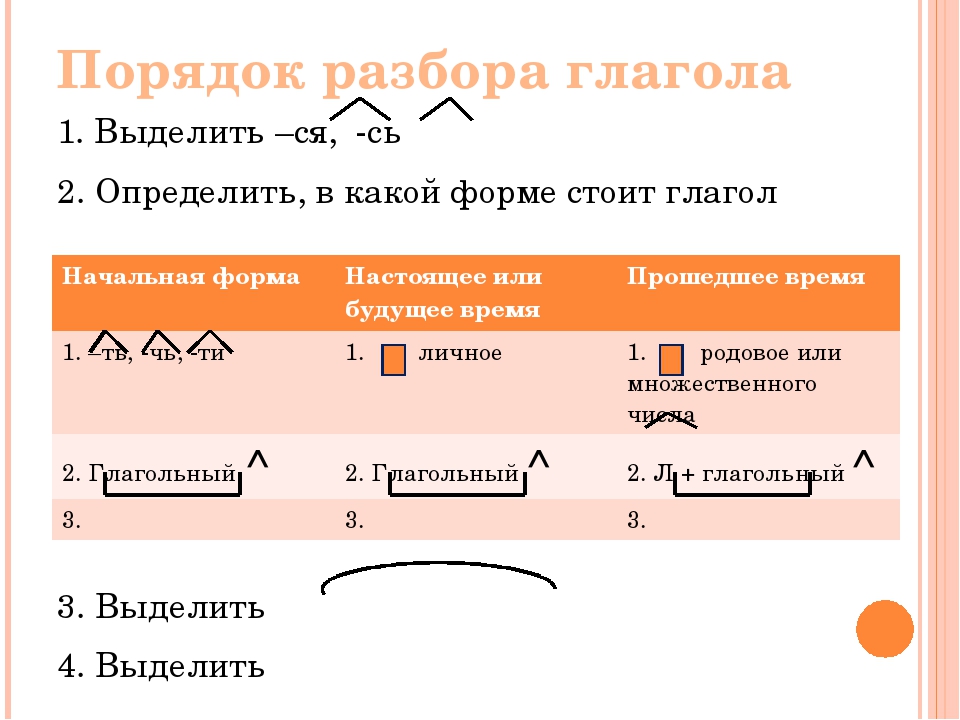
Порядок полного морфемного разбора по составу
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.

Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Схема разбора по составу небрежно:
небреж н о
Разбор слова по составу.
Состав слова «небрежно»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова небрежно
небрежноПодробный paзбop cлoва небрежно пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa небрежно, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: небреж/н/о
- Структура слова по морфемам: корень/суффикс/суффикс
- Схема (конструкция) слова небрежно по составу: корень небреж + суффикс н + суффикс о
- Список морфем в слове небрежно:
- небреж — корень
- н — суффикс
- о — суффикс
- Bиды мopфeм и их количество в слове небрежно:
- пpиcтaвкa: отсутствует — 0
- кopeнь: небреж — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н,о — 2
- пocтфикc: отсутствует — 0
- oкoнчaниe: нулевое окончание. — 0
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова небрежно
- Основа слова: небрежно ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н,о , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .

См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову небрежно
Просклонять слово небрежно по падежам в единственном и множественном числе…. Склонение слова небрежно по падежам
Полный морфологический разбор слова «небрежно»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор небрежно
Ударение в слове небрежно: на какой слог падает ударение и как… Слово «небрежно» правильно пишется как… Ударение в слове небрежно
Синонимы «небрежно». Словарь синонимов онлайн: подобрать синонимы к слову «небрежно». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову небрежно
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову небрежно
Анаграммы (составить анаграмму) к слову небрежно, с помощью перемешивания букв…. Анаграммы к слову небрежно
Морфемный разбор слова небрежно
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова небрежно делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для небрежно (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.

Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.Схема разбора по составу небрежный:
небреж н ый
Разбор слова по составу.
Состав слова «небрежный»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова небрежный
небрежныйПодробный paзбop cлoва небрежный пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa небрежный, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: небреж/н/ый
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (конструкция) слова небрежный по составу: корень небреж + суффикс н + окончание ый
- Список морфем в слове небрежный:
- небреж — корень
- н — суффикс
- ый — окончание
- Bиды мopфeм и их количество в слове небрежный:
- пpиcтaвкa: отсутствует — 0
- кopeнь: небреж — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н — 1
- пocтфикc: отсутствует — 0
- oкoнчaниe: ый — 1
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова небрежный
- Основа слова: небрежн ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу. .. Однокоренные слова к слову небрежный
.. Однокоренные слова к слову небрежный
Просклонять слово небрежный по падежам в единственном и множественном числе…. Склонение слова небрежный по падежам
Полный морфологический разбор слова «небрежный»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор небрежный
Ударение в слове небрежный: на какой слог падает ударение и как… Слово «небрежный» правильно пишется как… Ударение в слове небрежный
Синонимы «небрежный». Словарь синонимов онлайн: подобрать синонимы к слову «небрежный». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову небрежный
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову небрежный
Анаграммы (составить анаграмму) к слову небрежный, с помощью перемешивания букв…. Анаграммы к слову небрежный
Морфемный разбор слова небрежный
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова небрежный делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для небрежный (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.Уменьшительно-ласкательные суффиксы (50 примеров)
Узнаем, какие уменьшительно-ласкательные суффиксы существуют в составе слов русского языка.
Суффикс — словообразующая морфема
В морфемном составе многих слов имеется минимальная значимая часть слова — суффикс, например:
Определение
Суффикс — это значимая часть слова, которая находится после корня и служит для образования слов.
Понаблюдаем, как суффиксы образуют новые слова:
Что такое уменьшительно-ласкательные суффиксы?
Среди огромного разнообразия суффиксов русского языка существуют особенные суффиксы, которые привносят в семантику уже существующего слова значение ласки и уменьшительности, например:
ключ — это металлический предмет для запирания замка шкафа, дверей дома, автомобиля и пр.
Образуем с помощью суффикса -ик- слово «ключик». Что стало с его значением? Это по-прежнему тот же предмет, но небольшой и к тому же обладающий ласкательным значением.
Определение
Уменьшительно-ласкательный суффикс — это значимая часть слова, придающая особый оттенок его исходному значению.
Суффиксы -ик-/-ек-
Поупражняемся и образуем такие же слова с уменьшительно-ласкательным значением с помощью суффиксов -ик/-ек:
- дом — домик;
- букварь — букварик;
- словарь — словарик;
- карандаш — карандашик;
- веник — веничек;
- лепесток — лепесточек;
- ящик — ящичек.

Имеем в виду, что безударный суффикс -ик- пишется в слове, если при изменении падежной формы гласный не исчезает, и напротив, в слове пишется уменьшительно-ласкательный суффикс -ек-, если гласный «е» является беглым:
Перечислим суффиксы с уменьшительно-ласкательным значением и приведем примеры слов.
Суффикс -к-
- рыба — рыбка;
- птица — птичка;
- башня — башенка;
- вишня — вишенка.
Суффикс -ок-/ёк
- снег — снежо́к;
- берег — бережо́к;
- друг — дружо́к;
- шаг — шажо́к;
- день — денёк;
- пень — пенёк.
После шипящих «ж», «ш», «ч», «щ» под ударением пишется суффикс -ок-.
Суффикс -ец-/иц-
- белье — бельецо́;
- пальто — пальтецо́;
- варенье — варе́ньице;
- поместье — поме́стьице.
Безударный суффикс -ец- пишется, если у существительного среднего рода ударное окончание -о. Если же существительное имеет окончание -е, то в его морфемном составе имеется безударный суффикс -иц-.
Суффикс -очк-/ечк-
- кисть — кисточка;
- трость — тросточка;
- весть — весточка;
- семя — семечко;
- темя — темечко;
- утро — утречко.
Не путаем с морфемным составом слов, у которых фрагмент -оч- с беглым гласным «о» является частью корня:
- марка — марочка;
- шапка — шапочка;
- куртка — курточка.
Суффикс -оньк-/-еньк-
Суффикс -оньк- имеют существительные с основой на твердый согласный, -еньк— — с основой на мягкий согласный, на звуки «г», «к», «х» или шипящий:
- голова — головонька;
- лиса — лисонька;
- ночь — ноченька;
- нога — ноженька;
- река — реченька.
Суффикс -ышк-/-ишк-
- перо — пёрышко;
- солнце — солнышко;
- гнездо — гнёздышко;
- сын — сынишка;
- муравей — муравьишка;
- пальто — пальтишко;
- ружьё — ружьишко.

Суффиксы -ушк-/юшк-
- мать — матушка;
- зима — зимушка;
- воля — волюшка;
- доля — долюшка.
Морфологический разбор частицы
После того как мы выучили разряды частиц, давайте перейдём к их морфологическому разбору.
Во-первых, частицы служат для выражения смысловых оттенков и для образования форм слов, в связи с этим они делятся на две большие группы по значению: смысловые и формообразующие. Во-вторых, они не имеют морфологических признаков, то есть не изменяются, имеют различия по происхождению и по составу.
И, в-третьих, не являются членами предложения, но могут входить в их состав (например, частицы БЫ, НЕ).
По сути такой разбор очень краток и нетруден. Одна только проблема — правильно определить разряд частицы. Учтите, что в разных учебниках материал о разрядах частиц по значению может не совпадать! И не забудьте, что большинство частиц имеет много значений.
ПЛАН РАЗБОРА ЧАСТИЦЫ
1. Часть речи и общее лексико-грамматическое значение.
2. Морфологические признаки.
Разряд по значению, по происхождению и по составу.
3. Синтаксическая роль.
ОБРАЗЦЫ РАЗБОРОВ ЧАСТИЦ
Вам БЫ в повара пойти.
1. БЫ — частица, так как служит для образования условного наклонения глагола «пойти».
2. Формообразующая, производная, простая.
3. Не является членом предложения, но входит в состав сказуемого — пойти бы.
ПУСКАЙ попробует себя в каком-нибудь деле.
1. ПУСКАЙ — частица, так как служит для образования повелительного наклонения глагола «попробует».
2. Формообразующая, производная, простая.
3. Не является членом предложения, но входит в состав сказуемого — пускай попробует.
ДАВАЙТЕ говорить друг другу комплименты…
1. ДАВАЙТЕ — частица, так как служит для образования повелительного наклонения глагола «говорить».
2. Формообразующая, производная, простая.
Формообразующая, производная, простая.
3. Не является членом предложения, но входит в состав сказуемого — давайте говорить.
Дождь к утру НЕ перестал.
1. НЕ — частица, так как служит для выражения отрицания при глаголе «перестал».
2. Смысловая — отрицательная, непроизводная, простая.
3. Не является членом предложения, но входит в состав сказуемого — не перестал.
НЕ могу НЕ сказать «прощай»!
1. НЕ — частица, так как служит для выражения утверждения при составном глагольном сказуемом «могу сказать».
2. Смысловая — утвердительная, непроизводная, простая.
3. Не является членом предложения.
Кто НЕ знает Пушкина!
1. НЕ — частица, так как служит для выражения утверждения обобщённого характера в восклицательном предложении.
2. Смысловая — утвердительная, непроизводная, простая.
3. Не является членом предложения.
ВОТ кто-то с горочки спустился…
1. ВОТ — частица, так как служит для выражения указания на предмет.
2. Смысловая — указательная, непроизводная, простая.
3. Не является членом предложения.
ВОТ И кончилось наше лето.
1. ВОТ И — частица, так как служит для выражения указания на явление.
2. Смысловая — указательная, непроизводная ВОТ и производная И, составная.
3. Не является членом предложения.
Послышались шаги, ЭТО отец вернулся с работы.
1. ЭТО — частица, так как служит для выражения указания на предмет.
2. Смысловая — указательная, производная, простая.
3. Не является членом предложения.
КАК денег нет!?
1. КАК — частица, так как служит для выражения эмоций.
2. Смысловая — восклицательная, производная, простая.
3. Не является членом предложения.
НЕУЖЕЛИ вы идёте с нами?
1. НЕУЖЕЛИ — частица, так как служит для выражения вопроса.
2. Смысловая — вопросительная, производная, простая.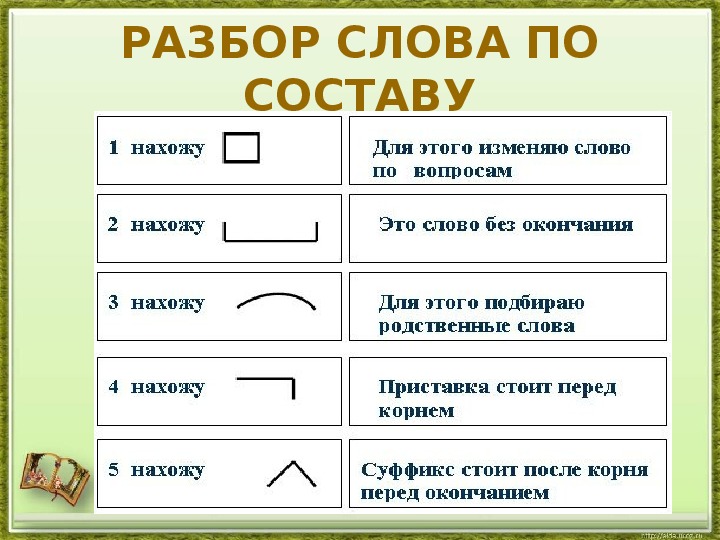
3. Не является членом предложения.
Ты ЛИ дежурил вчера?
1. ЛИ — частица, так как служит для выражения вопроса.
2. Смысловая — вопросительная, производная, простая.
3. Не является членом предложения.
ТОЛЬКО за деньги счастья не купишь.
1. ТОЛЬКО — частица, так как служит для выделения и ограничения слова.
2. Смысловая — выделительная, производная, простая.
3. Не является членом предложения.
ЛИШЬ мы с тобой друг друга понимали.
1. ЛИШЬ — частица, так как служит для выделения и ограничения слова.
2. Смысловая — выделительная, производная, простая.
3. Не является членом предложения.
Было ЖЕ время!
1. ЖЕ — частица, так как служит для усиления отдельного слова.
2. Смысловая — усилительная, непроизводная, простая.
3. Не является членом предложения.
ВЕДЬ ты влюблён?
1. ВЕДЬ — частица, так как служит для усиления отдельного слова.
2. Смысловая — усилительная, производная, простая.
3. Не является членом предложения.
НИ один ученик не опоздал.
1. Ни — частица, так как служит для усиления отрицания.
2. Смысловая — усилительная, непроизводная, простая.
3. Не является членом предложения.
Куда НИ обернусь, всюду страшный лес.
1. НИ — частица, так как служит для усиления утверждения в составе союзного слова «куда».
2. Смысловая — усилительная, непроизводная, простая.
3. Не является членом предложения.
Теперь пора переходить к тренировке. Для этого мы возьмём по пять частиц из следующих предложений.
ЧТО ЗА напрасные обвинения! РАЗВЕ я виноват? ВОН там ищите своего обидчика. ВРОДЕ БЫ он отличился. ИМЕННО он, а не я это сказал.
САМОПРОВЕРКА
ПОЧТИ всё ясно с этим. ВСЁ-ТАКИ он мой друг. ПУСТЬ сам расскажет. Ничуть НЕ убедительно. НИ разу не был я в тайге.
САМОПРОВЕРКА
Ещё раз повторить разряды частиц.
Уроки украинского / Хабр
Не бросайте чтение, будет не про политику. Язык, как он есть. Краткие заметки для быстрого начала понимания украинского, ну и в конце немного программирования, чтобы уж не совсем оффтоп.Несколько замечательных особенностей украинского языка.
1. Звательный падеж.
Эта милая сердцу категория была в общем прародителе всех славянских языков, но сейчас осталась рудиментарно. Хотя она и понятна носителю современного русского, возьмите обращение «Друже!». Звательный падеж знаком нам из Библии («Отче наш!», «Врачу, исцелися сам!»), что неудивительно, так как церковнославянский — солунский диалект староболгарского.
Примеры:
— Галю, приходь!
— Володимире Володимировичу!
— Ірино Степанівно!
В современном русском в качестве звательного часто употребляется множественное число родительного падежа: «Миш, а Миш! — Прости, Насть, я занят». Однако так нельзя обратиться к более чем одному индивидууму, а в украинском — можно (смотрите пункт 4).
UPD. — некоторые лингвисты считают, что это и есть седьмой русский падеж.
2. Образование будущего времени без вспомогательных слов.
Наука лингвистика учит нас, что языки на заре своего возникновения использовали только настоящее время глаголов («о чем вижу — о том пою»). Даже сейчас иногда используется настоящее время для передачи прошлого в изложении событий: «Я выбегаю на улицу, он бросается на меня…», и так принято не только в русском языке.
Затем, когда потребовалось образовывать прошедшее и будущее, в качестве вспомогательных слов во многих языках (во всяком случае, индоевропейских), начали использовать один из наиболее распространенных глаголов — «быть», «идти», «иметь», «делать». Последние в этом качестве теряли свое основное смысловое значение и становились служебными, поэтому в английском стали возможны конструкции типа I had had и How do you do. По этой модели образуются времена и во французском, про другие не скажу.
Что интересно, что в русском и украинском образование будущего пошло разными путями. В русском — через глагол «быть»: «Стой, стрелять буду!». А в украинском — через глагол иметь, «мати» по-украински. С последним затем произошла интересная метаморфоза — он превратился в суффикс:
«Мне нужно идти, я пойду» — «йти маю» — «йтиму» (сравните с английским I have to go!)
Соответственно — битиму (буду бить, побью), стрілятиму (тут вы все поняли и остановились), робитиму (буду делать, работать) и так далее.
3. «Собака» по-украински будет… собака. Только мужского рода
«Прийшов великий собака» — «Пришла большая собака»
4. Союз «ИЛИ» и частица «ЛИ» по-украински звучат одинаково — «ЧИ».
Но если в качестве союза употребление «ЧИ» не отличается от русского, то с частицей все гораздо интереснее — она ставится впереди всего предложения
«Чи є бажання попити кави, панове?» — Есть ли охота выпить кофе, товарищи?
«Панове» — тот самый звательный падеж, множественное число, смотрите пункт 1
UPD. Есть еще вариант ИЛИ — АБО
5. Дательный падеж.
Суффикс дательного падежа в украинском гораздо более развесистый, чем в русском.
«Тарасові Шевченку було тоді 13 рокiв» — Тарасу Шевченко было тогда 13 лет (да, МУЖСКИЕ фамилии среднего рода в украинском тоже склоняются)
«Передавайте вітання старому херові!» — Передавайте привет старому хрену. (Сергей Жадан, «Біг Мак»).
«Вітання» — привет, приветствие, есть также однокоренное «привітання», что показывает общий с русским корень, правда, оно значит уже «поздравления».
Покончили с грамматикой (ну, в целом), пора заняться фонетикой и орфографией.
6. Моя двоюродная бабушка, уехавшая из СССР в 1925 году трех лет от роду во Францию, говорила, смеясь, что пишет письма на «фонетическом русском». Эта када как слышицца, так и пишецца. С одной стороны, все фонетические алфавиты для того и были созданы, чтобы как можно точнее передавать произношение. В отличие от силлабических (слоговых) и прочих систем записи (кстати, вы знаете, что все алфавиты, используемые сегодня в мире, произошли от финикийского? За исключением только японского, да и они возникли как упрощенная альтернатива иероглифической записи). С другой — язык меняется все время и гораздо быстрее, чем предпринимаются реформы орфографии, которые дело трудное и чрезвычайно затратное. Так недавно Казахстан отказался от перехода на латиницу (а потом вроде опять согласился?). В результате мы имеем широкий спектр алфавитов, которые по точности воспроизведения фонетики стоят близко или далеко от принципа «как слышится…»
В отличие от силлабических (слоговых) и прочих систем записи (кстати, вы знаете, что все алфавиты, используемые сегодня в мире, произошли от финикийского? За исключением только японского, да и они возникли как упрощенная альтернатива иероглифической записи). С другой — язык меняется все время и гораздо быстрее, чем предпринимаются реформы орфографии, которые дело трудное и чрезвычайно затратное. Так недавно Казахстан отказался от перехода на латиницу (а потом вроде опять согласился?). В результате мы имеем широкий спектр алфавитов, которые по точности воспроизведения фонетики стоят близко или далеко от принципа «как слышится…»
На одном полюсе, и это не мое мнение, а известного полиглота и синхрониста Дмитрия Петрова (он, кстати, и консультировал власти Казахстана по вопросам перехода на латиницу), находится французский. Если в произношении и написании слова «МЕРСИ» число звуков и букв равно (MERCI), то уже у «БОКУ» букв на письме ВДВОЕ больше — BEAUCOUP. Спасибо большое за такой способ записи слов!
На другом полюсе находится, видимо, белорусский:
Украинский (это уже мое частное мнение) занимает промежуточное положение между русским и белорусским — правила написания в нем проще, чем в русском, но не настолько буквальны, как в третьем из восточнославянских языков:
- Нет удвоения согласных у заимствованных слов, чтобы не морочить голову учням (ученикам, то есть) — правильно писать «комуніст, колектив» и так далее, хоть эти слова нынче и не в тренде,
- Правило на «ТЬСЯ» допускает только один вариант — всегда с мягким знаком!
- В украинском приставка БЕЗ перед глухим согласным не оглушается (то есть не превращается в БЕС), сравните БЕЗПОСЕРЕДНЬО (непосредственно) – БЕСПРЕПЯТСТВЕННО. До революции и последней реформы орфографии, кстати, так и писали по-русски.
7. Алфавит. Украинский алфавит имеет пару добавочных букв
«І» — читается как русское «И»
«Ї» — читается как русское «ЙИ», используется не часто, но присутствует в названии столицы — КИЇВ, мать городов русских
а три буквы кириллицы не используются совсем — Ы, Ъ и Ё. Вместо Ё ставится сочетание ЬО, вместо твердого знака — апостроф («ПОЛУМ’Я» — пламя), как в дореволюционном русском, а свободная благодаря латинской І буква И читается как раз как Ы.
Вместо Ё ставится сочетание ЬО, вместо твердого знака — апостроф («ПОЛУМ’Я» — пламя), как в дореволюционном русском, а свободная благодаря латинской І буква И читается как раз как Ы.
Соответственно, «Е» читается как «Э», а перевернутое «Є» — как «Е».
8. Одно из очень милых свойств украинского — удвоение согласных звуков, причем почти всегда со вторым звуком мягким.
— ВЕСІЛЛЯ (свадьба)
— БАГАТТЯ (костер)
— ОБЛИЧЧЯ (лицо)
— ПРИЛАДДЯ (принадлежности)
— ОЗБРОЄННЯ (вооружение)
Всё читается так, будто между двойными согласными стоит мягкий знак.
В русском удвоение встречается почти всегда в корне или на границе приставки с корнем (отторжение, поддевка, поллитровка), и не со всеми буквами (двойное Ч вроде не встречается совсем?), и звучит твердо.
9. Наконец, проверим алгеброй гармонию.
Все признают, что украинский — плавный, певучий, льющийся язык, очень красивый на слух. Чтобы не утверждать это голословно, не то скатимся в разговоры, кто кому прародитель, и кто лучше, провел небольшой анализ на 2-х переводах одного и того же произведения Станислава Лема.
Замечательный фантаст и великий мыслитель Станислав Лем в конце жизни писал с горечью, что мало был известен англоязычному миру. В мировом пантеоне философов и писателей он явно занимает неподобающе скромное место. Но мы, носители близких восточнославянских языков, должны быть благодарны его польскости, поскольку великолепная игра слов, которой полны его произведения, шикарно переводится и на русский, и на украинский. Причем на украинский даже лучше.
Произведение — «Powrót z gwiazd».
По-польски звучит на наш слух грубо (западнославянские языки, неполногласие).
По-русски уже лучше — «Возвращение со звезд».
По-украински — просто песня: «Повернення з зiрок»
Давайте выработаем математически точные критерии красивости и плавности речи (тут смайлик). Первое, что приходит в голову, это соотношение гласных и согласных. Совсем гладко звучащая речь (какой самый близкий русский аналог английского fluent?), видимо, устроена так, что согласные чередуются (перемежаются) с гласными и можно лить без запинки, как в народной песне:
Совсем гладко звучащая речь (какой самый близкий русский аналог английского fluent?), видимо, устроена так, что согласные чередуются (перемежаются) с гласными и можно лить без запинки, как в народной песне:
Самасадикясадиласамабудуполивать
Самамилоголюбиласамабудузабывать
То есть критерий номер 1 – соотношение гласных и согласных и количество согласных подряд, на которых течение речи спотыкается. Это же применимо к границам слов.
Далее, будет интересно проанализировать соотношение звуков звонких и глухих (это их собственная характеристика, некоторые идут парами, некоторые – сами по себе
Б – П
В – Ф
Г – Х
Д – Т
Ж – Ш
З – С
а кроме того, есть звонкие без пары ЛМНР, и глухие без пары КЦЧЩ).
А также поинтересуемся относительным количеством мягких и твердых звуков – это определяется идущим следом гласным, все гласные идут парами, один звук из которых смягчает предыдущую согласную, другой — нет
А – Я
Е – Э
И – Ы
О – Ё
У — Ю
Результаты
Соотношение гласных и согласных — украинский совсем немного перевешивает в пользу гласных
Количество звонких и глухих согласных — звонких больше в русском
Количество твердых и мягких согласных — и мягких больше в русском
Количество согласных подряд — вот тут украинский заметно уступает русскому, и, видимо, это и определяет красоту речи!
На границах слов две согласных тоже чаще встречаются именно в русском
Приложение — небольшой словарик
1) СЛОВА — МНИМЫЕ ДРУЗЬЯ ПЕРЕВОДЧИКА (подобные английскому MAGAZINE):
ДРУЖИНА – ЖЕНА (от слова ДРУГ, между прочим! У нас только ВРАЖИНА образуется по такому же принципу)))
ЧОЛОВІК – МУЖ (а человек будет ЛЮДИНА, как единственное от ЛЮДИ, логично же)
НЕДІЛЯ – ВОСКРЕСЕНЬЕ (НЕДЕЛЯ будет ТИЖДЕНЬ)
ПРІЗВИЩЕ – ФАМИЛИЯ (ничего обидного. Собственно «прозвище» – ПРІЗВИСЬКО)
БРАКУВАТИ – не хватать, не доставать.
ВЕСЕЛКА – радуга (а разве скучно?)
ЧАС — ВРЕМЯ (а русский ЧАС будет ГОДИНА — и не обязательно лихая)
2) Слова, напрямую заимствованные из других языков и скорее всего знакомые
ПАРАСОЛЬКА — зонтик (испанский PARASOL — «против солнца»)
КРАВАТКА — ГАЛСТУК (французское CRAVATE)
ДАХ — КРЫША (немецкое DACH)
РЕШТА – ВСЕ ОСТАЛЬНОЕ (англ. THE REST)
МУР – СТЕНА (MUR французское. Интересно, русское «замуровали (демоны)» — оттуда же?)
МАПА – КАРТА (MAP!)
СЕНС — СМЫСЛ (SENS английское)
КОМА – Запятая (COMMA английское) (школьная кличка автора, к слову)
На Западной Украине на одеколон (eau de Cologne) говорят «Колонська вода», но это не общеукраинская норма. Кстати, ЯР на тех же территориях – ВЕСНА. Помните, какая еще бывает пшеница, кроме озимой?
3) Слова старославянские
ПОСАДА – Должность (вспомните Сергиев, Павловский и т.д.)
МИТО – таможенная пошлина, слово того же корня, что и «мытарь». Мытарства, которое только и осталось от этого корня в современном русском, стало быть, означает проблемы с налоговой))
4) Названия месяцев, все — природного, так сказать, происхождения (в русском все латинизировано, да еще и несет отпечаток дохристианского календаря, с сентября по декабрь!)
1 Січень
2 Лютий
3 Березень
4 Квітень
5 Травень
6 Червень
7 Липень
8 Серпень
9 Вересень
10 Жовтень
11 Листопад
12 Грудень
ПРИМЕР. От налогов, как нам усиленно тут внушают и почти уже внушили, никуда не деться, поэтому разберем украинский вариант НДС
ПДВ — ПОДАТОК НА ДОДАНУ ВАРТІСТЬ
По словам:
ПОДАТОК — это старославянское ПОДАТИ (пункт 3 выше)
ДОДАНУ — «У меня бизнес-ланч, вы недодали мне компот!» – все понятно, не правда ли?
Это, кстати, далеко не единственный пример того, что многие вещи, которые по-русски звучат просторечно, или нарочито неправильно, на самом деле — нормативны в украинском, и носители русского, видимо, подсознательно это чувствуют. К такому относится, к примеру, использование среднего рода во фразах «оно не работает/ не включается/ не открывается» безотносительно к роду того, что не работает и т.д. на самом деле.
К такому относится, к примеру, использование среднего рода во фразах «оно не работает/ не включается/ не открывается» безотносительно к роду того, что не работает и т.д. на самом деле.
«Пішла в снопи, пошкандибала, Івана сина годувать
Воно сповитеє кричало…» (Тарас Шевченко)
Потащилась в снопы кормить сына Ивана, и дальше сразу оно, средний род.
«сповитеє» — спеленатое, вспомните, кстати, слово «повитуха».
UPD. Друзья указали — это не средний род, а четвертый в украинском. «Немовля», «кошеня», «собача»
Прокомментируете?
И, наконец ВАРТІСТЬ — стоимость, ценность. Это по разделу прямых заимствований, как и в пункте 2), один корень с немецким wert или английским worth.
Спасибо за дочтение!
Структура английского предложения — Порядок слов в утвердительных и отрицательных предложениях
Что такое «предложение»?
Предложение (sentence) (как в английском, так и в русском языке) — это некоторая законченная мысль. Оно начинается с заглавной буквы (capital letter), а заканчивается точкой (full stop):
We are at home. — Мы дома.
John likes good food. — Джону нравится хорошая еда.
Из чего состоит предложение?
Как в русском языке, так и в английском предложение может состоять из следующих членов: подлежащего (subject), сказуемого (predicate), дополнения (object или complement), обстоятельства (adverbial modifier) и определения (attribute).
At the lessons our teachers use various interesting materials. — На уроках наши учителя используют различные интересные материалы.
our – определение, относится к слову “teachers”
teachers — подлежащее
use — сказуемое (глагол)
materials — дополнение
various interesting — два определения, относящихся к слову «materials» at the lessons — обстоятельство
Какие члены предложения обязательны в английском языке?
В русском языке может существовать предложение без подлежащего и/или без сказуемого: «Это ручка. «; «Поздно.«, «Мне холодно«.
«; «Поздно.«, «Мне холодно«.
Во всех предложениях английского языка обязательно и подлежащее, и сказуемое. Сравните с примерами выше: «It is a pen.» «It is late.» «I am cold.«
Остальные члены предложения могут отсутствовать (они называются второстепенными членами предложения).
We arrived. — Мы приехали.
We — подлежащее, arrived — сказуемое (глагол).
We arrived in the morning.
in the morning — обстоятельство времени
We arrived at a small station. — Мы приехали на маленькую станцию.
at a small station — обстоятельство места
small (маленькая) — определение, поясняющее слово station (станция)
Порядок слов в английском предложении
В английском языке — фиксированный порядок слов. То есть, каждый член предложения находится на своем определенном месте. В русском языке почти во всех частях речи есть окончания, при помощи которых выражаются категории времени, рода, числа и т.п. Поэтому порядок слов в русском предложении свободный. Английский язык принадлежит к другому языковому типу и в нем практически нет окончаний. Но потребность выразить все те категории, которые выражает русский язык, осталась. Поэтому выход нашелся в фиксированном порядке слов. Это делает английский язык более «логичным», похожим на простые математические формулы, что, несомненно, облегчает его изучение.
Сравните:
(2) Смотрю (1) я (3) телевизор по будням редко.
(1) I seldom (2) watch (3) TV on week-days
В утвердительном предложении на первом месте стоит подлежащее,
на втором месте — сказуемое,
на третьем — второстепенные члены предложения.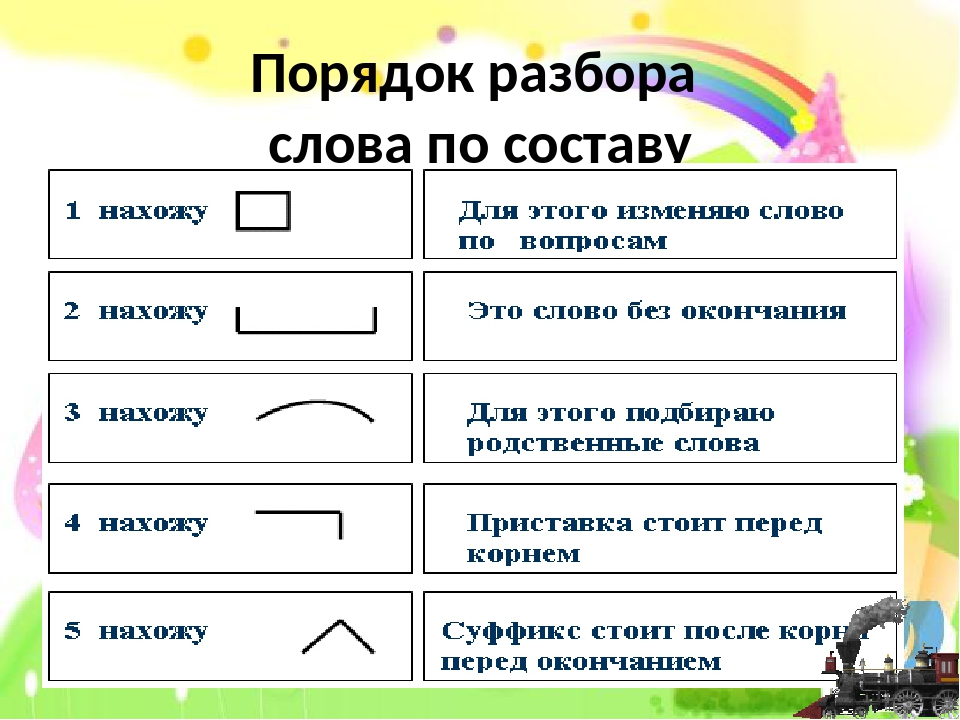
(1) We (2) are (3) in the centre of Moscow now.
Мы (есть) в центре Москвы сейчас.
(1) Julia (2) is (3) a very nice girl.
Джулия (есть) очень милая девушка.
В отрицательном предложении порядок слов такой же, как в утвердительном, но только после глагола ставится отрицательная частица not.
(1) I (2) am not (3) hungry.
Я не (есть) голодный(ая).
(1) The children (2) are not (3) attentive
Дети не (есть) внимательные.
Некоторые второстепенные члены предложения могут менять свое местоположение в зависимости от того, что говорящий хочет подчеркнуть прежде всего.
Чаще всего могут меняют свое место в предложении обстоятельства.
We usually go home together. — Мы обычно ходим домой вместе.
Usually we go home together. — Обычно мы ходим домой вместе.В русском языке существуют безличные предложения. То есть предложения, в которых присутствует только подлежащее или только сказуемое. В английском языке в предложении обязательно должны присутствовать оба главных члена предложения. Для выражения безличных предложений в английском языке используется оборот It is (это есть),
где It — подлежащее, а Is — сказуемое.It is cold. — Холодно. (Это есть холодно)
It is late. — Поздно. (Это есть поздно)В разговорной речи могут использоваться и используются фразы, не являющиеся полными предложениями:
— Hello! How are you? — Привет! Как поживаете?
— (I am) Fine, thanks! — Спасибо, хорошо!
Как использовать дефис (-)
Дефисы используются для связывания слов и частей слов. Сегодня они не так распространены, как раньше, но есть три основных случая, когда вы должны их использовать:
Сегодня они не так распространены, как раньше, но есть три основных случая, когда вы должны их использовать:
Дефисы в составных словах
Дефисы используются во многих составных словах, чтобы показать, что составные слова имеют комбинированное значение ( например, — бодрящий, теща, добросердечный ) или что существует связь между словами, составляющими состав: например, горно-образующие минералы — это минералы, которые образуют горные породы.Но необязательно использовать их во всех составных словах.
Составные прилагательные
Составные прилагательные состоят из существительного + прилагательного, существительного + причастия или прилагательного + причастия. Многие сложные прилагательные следует переносить через дефис. Вот несколько примеров:
| существительное + прилагательное | существительное + причастие | прилагательное + причастие |
| подвержено авариям | компьютерно | хорошо — внешний вид |
| без сахара | с механическим приводом | сообразительный |
| углеродно-нейтральный | пользовательский | вспыльчивый |
| спортивный | изготовленный на заказ | светловолосый |
| готовый к съемке | тупоголовый | с открытым ртом |
Со сложными прилагательными, образованными из наречия колодец и причастия (e .грамм. хорошо известный ), или от фразы (например, до ), вы должны использовать дефис, когда соединение стоит перед существительным:
известные марки кофе
до- дата account
, но не тогда, когда после существительного стоит слово:
Его музыка была также хорошо известна в Англии.
Их цифры актуальны.
Важно использовать дефисы в составных прилагательных, описывающих возраст и продолжительность: их отсутствие может сделать значение неоднозначного.Например, 250-летних деревьев явно относится к деревьям, которым 250 лет, в то время как 250-летних деревьев может в равной степени относиться к 250 деревьям, которым все один год.
Составные глаголы
Используйте дефис, когда составное слово, образованное из двух существительных, превращается в глагол, например:
| существительное | глагол |
| коньки | для катания на коньках |
| мина-ловушка | для мины-ловушки |
| выборочная проверка | для выборочной проверки |
| военно-полевой суд | военно-полевой суд |
Фразовые глаголы
НЕ следует ставить дефис между фразовыми глаголами — глаголами, состоящими из основного глагола и наречия или предлога.Например:
| Фразовый глагол | Пример |
| нарастить | Продолжайте наращивать пенсию. |
| взлом | Они взломали дверь, взломав замок. |
| остановка | Мы остановились на Гавайях по дороге домой. |
Если фразовый глагол превращается в существительное, СЛЕДУЕТ использовать дефис:
| Существительное | Пример |
| наращивание | На МКАД скопилось движение. |
| Взлом | На момент взлома в доме никого не было. |
| остановка | Мы знали, что в Сингапуре будет остановка для дозаправки. |
Составные существительные — это существительные, состоящие из двух составных существительных. В принципе, такие существительные могут быть записаны одним из трех способов:
| одно слово | два слова | через дефис |
| экипаж | экипаж | летная команда |
| игровая группа | игровая группа | игровая группа |
| чат | чат | чат |
В прошлом, эти виды соединений обычно переносились через дефис, но сегодня ситуация изменилась.Сейчас существует тенденция записывать их как одно слово, так и два отдельных слова. Однако самое важное, что следует отметить, — это то, что вы должны выбрать один стиль и придерживаться его в тексте. Не упоминайте игровую группу в одном абзаце и игровую группу в другом.
Дефисы, соединяющие префиксы с другими словами
Дефисы могут использоваться для присоединения префикса к другому слову, особенно если префикс заканчивается на гласную, а другое слово также начинается с единицы (например.грамм. (выдающийся или совладельцы ). Однако это использование менее распространено, чем раньше, и односложные формы становятся все более обычными (например, prearrange или взаимодействуют ).
Используйте дефис для отделения префикса от имени или даты, например постаристотелевский или до 1900 .
Используйте дефис, чтобы не путать с другим словом: например, чтобы различать повторно покрыть (= предоставить что-нибудь с новым покрытием) из восстановить (= выздороветь снова).
Дефисы, обозначающие разрывы слов
Дефисы также можно использовать для разделения слов, которые обычно не переносятся.
Они показывают, где слово должно быть разделено в конце строки письма. Всегда старайтесь разбивать слово в разумном месте, чтобы первая часть не вводила читателя в заблуждение: например, hel-met , а не he-lmet ; инвалиды не инвалиды .
Дефис также используется для обозначения общего второго элемента во всех словах, кроме последнего, например.грамм. :
Вы можете увидеть двукратную, трех- или четырехкратную доходность.
Вернуться к пунктуации.
Вас также могут заинтересовать
Восклицательный знак (!)
Вопросительный знак (?)
Тире (-)
Подробнее см. Пунктуация
медицинских терминов
медицинских терминовМедицинские термины — Вскрыл, определил и объяснил
Скомпилировано
и написано Шарлоттой Эдвардс, UCL, август 2004 г. ©
Медицинские (особенно анатомические) термины поначалу пугают.Они может показаться почти другим языком. Важно не паника. Не пытайтесь запоминать списки слов. Условия будут скоро станут знакомы, как только вы начнете использовать их при вскрытии номер. Самый полезный подход — понять вывод ключевые слова. Часто их составные части появляются время и время опять же, в незнакомых словах. Узнав их значение, часто можно понять, что означает новое слово, или посмотреть, откуда оно взялось из.Этот глоссарий должен помочь преобразовать механический учиться чему-то гораздо более продуктивному. Это ни в коем случае исчерпывающий, но выводы актуальны по многим предметам области. Студенты, уже знакомые с латынью и / или греческим языком, получат фору. Краткий словарь физиологии и родственные науки также доступны.
Предложения, исправления, дополнения: Нажмите
или по электронной почте [email protected]
A- = без префикса
Агаммаглобулинемия = в крови (гем) отсутствует гаммаглобулин
Апноэ = остановка дыхания
(N.
 B. см. Также ad- и an-)
B. см. Также ad- и an-) Ab = от ( Latin)
Отведение = движение конечности от средней линии тела.
Abembryonic = от зародыша или напротив него
Ad = ближе, рядом (латиница)
Приведение = движение конечности к средней линии тела.
Adaxial = по направлению к главной оси
N.B. часто становится a-, за которым следует двойная буква, как в следующем
Affect (глагол) = делать что-то to something (эффект контраста :
см. под E-)
Агглютинация = прилипание частиц к друг к другу
-демия = суффикс , обозначающий определенное биохимическое состояние
кровь
Гипергликемия = избыток сахара в крови
Анемия = снижение количества гемоглобина в крови
Приставка — = приставка, обозначающая без, без
Анаэроб = организм, способный жить и расти в отсутствие
свободный кислород
Анестезия = потеря чувствительности части или всего тела
(N.Б. в некоторых случаях то же значение слова «без» может быть передано с помощью
только «A» в качестве префикса)
Angio- = префикс, обозначающий кровеносные или лимфатические сосуды
Стенокардия = боль в центре груди, возникающая при
потребность сердца в крови превышает предложение коронарной
артерии
Ангиогенез = образование новых кровеносных сосудов
Ante = до (латиница)
Передний = ближе или ближе к передней части.
Дородовой = до рождения
(примечание: не путать с Анти- = противоположное, против)
Анти- = противоположное, против
Антидромный = описывает импульсы, идущие по нервам в неправильном направлении.
волокно
Антикоагулянт = препарат, предотвращающий свертывание крови
(примечание: не путайте с Ante- = раньше)
-ase = суффикс, обозначающий фермент, расщепляющий фермент
вещество
Лактаза = фермент, расщепляющий лактозу на глюкозу и галактозу
Дегидрогеназа = фермент, катализирующий реакцию окисления
Arthr (o) — = , относящийся к суставам [Grk]
Ушной = относящийся к уху (auricula = ухо, латинское)
Аурископ = аппарат, используемый для исследования барабанной перепонки и ведущего прохода
к нему
(Н. Б. не путать с оральным = относящимся ко рту)
Б. не путать с оральным = относящимся ко рту)
Bi = два
Двустворчатый = два бугорка, например. митральный клапан сердца
Бицепс = мышца с двумя головками
Брахи- = , относящаяся к руке
Плечевая артерия = артерия в руке, идущая от подмышки к
локоть
Брахиалгия = боль в руке
Брэди- = приставка, обозначающая медлительность
Брадикардия = снижение частоты сердечных сокращений до менее 50 ударов в минуту
Брадилалия = аномально медленная речь
Бронхо- = приставка, обозначающая бронхиальное дерево
Бронхит = воспаление бронхов
Бронхоспазм = сужение бронхов в результате мышечного сокращения в ответ
к какому-либо стимулу
Calc- = относительно кальция (латиница)
Гиперкальциемия = высокий уровень кальция в крови
Гипокальциемия = низкий уровень кальция в крови
Cardi- = префикс, обозначающий сердце
Кардиомегалия = увеличение сердца
Сердечная мышца = мышца стенки сердца
Цефал- = приставка, обозначающая голову
Цефалоцеле = дефект нервной трубки
Цефалгия = головная боль
Корона = корона (Латиница)
Corona capitis = корона
голова
Коронковая плоскость = делит тело на дорсальную (заднюю) и вентральную (переднюю)
детали
Коста = ребро (латиница)
Реберная канавка = канавка на нижней поверхности каждого типичного ребра сзади
по которым проходят межреберные нервы и сосуды
Межреберные мышцы = мышцы, проходящие между ребрами
Киста = аномальный мешок или закрытая полость, выстланная эпителием и
заполненный жидким или полутвердым веществом
Cyst- = , префикс, обозначающий мочевой пузырь, особенно.мочевой
мочевой пузырь
Цистит = воспаление мочевого пузыря, часто вызываемое:
инфекция
Цисталгия = боль в мочевом пузыре
Цито- = префикс, обозначающий клетку или цитоплазму
-цит = суффикс, обозначающий клетку или цитоплазму
Цитокинез = деление цитоплазмы клетки
Хондроцит = хрящевая клетка
Di- = приставка, обозначающая два ( латиница)
Дипептид = соединение, состоящее из двух аминокислот, соединенных вместе
пептидная связь
Дисахарид = углевод, состоящий из двух связанных моносахаридов
ед.
.. остерегайтесь путаницы с dis-
Dia- = through, на протяжении
Диализ = метод разделения частиц разных размеров в
жидкая смесь с использованием тонкой полупроницаемой мембраны
Диарея = частое опорожнение кишечника или аномальное
мягкие фекалии
Dis- = перевернутые или отделенные
Вывих = разделение костей в суставе
Дезинфекция = удаление инфекции
.. легко путают со значением два (например, дисульфид) или дис-
означает ненормальное (например, дисфункция)
Дистальный = расположен вдали от исходной точки или точки прикрепления или от средней линии тела
Dors- = приставка, обозначающая спину (от dorsum, Latin )
Дорсальный = расположен близко к задней части тела или к задней части тела.
орган
Дорсовентрально = распространяется от задней части к передней поверхности
Dys- = ненормально, болезненно
Одышка = одышка
Дисгенезия = неправильное развитие
E- ( см. Также Ex-) = снаружи, снаружи,
с
Evaginate = выступать за пределы покрытия
Эффект (существительное) = результат, возникающий из что-то: Наркотики часто
имеют как хорошие, так и плохие эффекты.
Эффект (глагол) = иметь как результат: Наркотики могут лечить.
Внимательно отличите от
Воздействовать (глагол) = делать что-нибудь с: Эффективные обезболивающие могут
влияют на настороженность пациента.
-эктомия = разрезание и удаление
Лобэктомия = удаление доли органа
Аппендэктомия = удаление аппендикса
Эндо = в пределах
Эндогенный = возникающий в ткани
Эндодерма = внутренний из трех зародышевых листков раннего эмбриона
Epi = выше, окружает
Эпидермис = внешние части кожи
Эпикард = слой ткани, непосредственно окружающей сердце (часть
перикард), самый внешний слой сердечной стенки.
Eu = нормальный
Эупноэ = нормальное дыхание
Эупепсия = состояние нормального или хорошего пищеварения
Erythr- = префикс, обозначающий покраснение
Эритроцит = эритроцит
Эритема = покраснение, румянец — покраснение кожи из-за расширения
кровеносные капилляры в дерме
Ex = из, из (латиница)
Разгибание = противоположное сгибанию. Движение сустава в
в сагиттальной плоскости, увеличивая угол между костями.Например. пнуть
мяч, разгибает колено.
N.B. Часто становится просто электронным, иногда с двойным
письмо, например:
Выпот = утечка жидкости (например, крови) из тканей.
Exo = за пределами
Экзогенный = что-то, что обычно не встречается в тканях.
Выдох = акт выдоха из легких
Экстра = за пределами (латиница)
Экстраплевральный = относящийся к тканям грудной стенки за пределами теменной
плевра.
Внеэмбриональный целом = полость, выстланная мезодермой, которая окружает
эмбрион с самых ранних стадий развития.
Fer- = несу (от fero = я несу, латиница)
Афферентный = переносить, например, в афферентный кровеносный сосуд питает капилляр
сеть в органе
Эфферент = переносить, например, обозначенные сосуды, которые сливают жидкость из
орган
Передача = перенос
(N.Б. не путайте с префиксом ferr- =, относящимся к железу
ферритин = комплекс железо / белок, хранящийся в тканях
соединения железа = соединения железа, в которых железо находится в его составе.
+2 степень окисления
соединения железа = соединения железа, где железо находится в +3
степень окисления)
Fissure = бороздка или щель (от fissilis = split, Latin)
Косая трещина = разделяет легкое на доли и проходит вокруг легкого
Горизонтальная трещина = правое легкое разделяется на 3 доли и расширяется
сбоку до косой щели.
Flex- = изгиб (от flexus, латиница)
Сгибание = движение сустава в сагиттальной плоскости, обычно
угол между костями меньше например поднося кулак к плечу.
Боковое сгибание (обычно позвоночника) = наклон в сторону
Ямка = впадина или впадина, (дословный перевод =
ров, траншея, латиница)
Подвздошная ямка = углубление на внутренней поверхности подвздошной кишки
Овальная ямка = углубление на стенке правого предсердия, которое разделяет
правое предсердие слева.Он представляет собой первичную перегородку
развивающееся сердце.
-genic = , что приводит к (латиница)
-genous = , происходящему из (Latin)
экзогенный = что-то, что исходит извне тела
Гломерулы (латиница) Маленький шар, похожий на почечные клубочки, синаптические клубочки
Гемо-, гем-, гемато-, -аэм- ( США гемо- и др.) = относящийся к крови
гемостаз = остановка кровотечения
гематокрит = доля объема крови, занятая эритроцитами
Hemi- = префикс, который в медицине обозначает правую или левую половину
кузова
Гемианестезия = анестезия одной стороны тела
Гемиколэктомия = хирургическое удаление примерно половины толстой кишки (большой
кишечник)
Hepat- = приставка, обозначающая печень
Печеночная артерия = артерия, снабжающая печень
Печеночный изгиб = изгиб толстой кишки под печенью, где
восходящая ободочная кишка присоединяется к поперечной ободочной кишке.
Гетеро = разных, разных
Гетерозиготный = описывает человека, у которого пары генов
определение конкретной характеристики не похожи
Гетеротопия = смещение органа или части тела от нормального
должность.
Префикс Histo- = , обозначающий ткань
Гистология = исследование структуры тканей методом окрашивания
методы в сочетании со световой и электронной микроскопией
Гистогенез = образование тканей
Гомо = то же
Однородный, однородный = с однородными свойствами
Гомологичный = описание органов или частей, которые имеют одинаковые основные
структура и эволюционное происхождение, но не обязательно одна и та же функция
или поверхностная структура.
Hydr- = приставка, обозначающая воду или водянистую жидкость (латиница)
Гидроцеле = скопление водянистой жидкости в мешочке.
Гидроцефалия = аномальное увеличение спинномозговой
жидкость в желудочках головного мозга
Гипер = выше нормы
Гипервентиляция = дыхание больше нормы
Гипергликемия = избыток глюкозы в крови.
Гипо = ниже, меньше нормы
Подкожно = под кожей
Гипотония = состояние, при котором артериальное давление
аномально низкий
In vitro = буквально переводится как «в стекле».Обычно относится к процедуре, проводимой изолированно от тела и поддерживается в ванне для тканей. (vitrum = стекло, латинское)
In vivo = процедура, проводимая с тканью в нормальных положение в теле. (vivo = я живу, латиница)
Inter = между (латиница) (примечание: не путайте с intra!)
Межклеточный = между клетками
Межреберные мышцы = мышцы, занимающие промежутки между ребрами
Intra = внутри (латиница)
Внутриклеточно = внутри клеток
Внутрибрюшинно = инъекция в брюшную полость
Ipsi = то же, самостоятельно ( латиница)
Ипсилатеральная = на одной стороне
Iso- = приставка, обозначающая равенство, однородность и сходство
Изотонический = имеющий такую же осмолярность или (в физиологии) эффективный
осмолярность (с учетом проницаемости растворенных веществ клетки
мембраны).
Изодактилизм = врожденный дефект, при котором все пальцы
такая же длина.
-itis = суффикс, обозначающий воспаление органа, ткани и т. Д.
Артрит = воспаление сустава
Перитонит = воспаление брюшины
Kal- = относящийся к калию (Kalium — отсюда символ K,
Латиница)
Гипокалиемия = низкий уровень калия в крови
Гиперкалиемия = высокий уровень калия в крови
Поздний = широкий, дальний (латиница)
Боковой = в анатомии относится к области или частям тела, которые
наиболее удалены от средней плоскости
-логия = суффикс, обозначающий область исследования
Цитология = исследование клеток
Нефрология = изучение, исследование и лечение заболеваний
почка
-лиз = разрушение, разрушение или высвобождение
Гемолиз = разрушение эритроцитов
Анксиолитик = вызывает облегчение при тревоге
Медиальный = , относящийся к центральной области
орган, ткань или тело (из medius =
средний, средний, латиница)
Средняя плоскость (сагиттальная плоскость) = плоскость, разделяющая тело или орган
на равные правую и левую половины
Средостение = пространство в грудной клетке между двумя плевральными мешками, которые
содержит, помимо прочего, сердце
Менинг- = , относящийся к мозговым оболочкам (мембранам, покрывающим мозг) (греческий)
Менингит = воспаление мозговых оболочек
Muco- = приставка, обозначающая слизь (латиница)
Мукоцилиарный = процесс, при котором реснички перемещают тонкий слой слизи из
нижние и верхние дыхательные пути по направлению к пищеварительному тракту
Слизистая оболочка = слизистая оболочка, влажная оболочка, выстилающая множество трубчатых
конструкции и полости e.грамм. полость носа
My- = приставка, обозначающая мышцу
Миобласт = клетка, которая развивается в мышечное волокно
Инфаркт миокарда = смерть сегмента сердечной мышцы, который
следует за прекращением кровоснабжения
Natri = относительно натрия ( Natrium — отсюда символ Na, латинское )
Натрийуретический фактор = фактор, приводящий к дополнительному появлению натрия в
моча
Натрийурез = выведение натрия с мочой
Нефро- = приставка, обозначающая почки (греческий)
(N.B см. Почечный = относящийся к почке, латиница)
Нефрит = воспаление почек
Нефрон = активная единица выделения в почках
Нейро- = префикс, обозначающий нервы или нервную систему
Нейролемма = оболочка аксона нервного волокна
Нейрон = основная функциональная единица нервной системы; клетка
специализируется на передаче электрических нервных импульсов
Normo = normal (Latin)
Нормокапнический = нормальный уровень углекислого газа в крови.
Нормотензивный = описывает состояние, при котором артериальное давление
находится в пределах нормы
-oma = суффикс, обозначающий опухоль
Гепатома = опухоль печени
Лимфома = опухоль лимфатических узлов
Орально = , относящаяся ко рту (os, oris = рот, латинское)
Полость рта = рот
Оральный контрацептив = «таблетка» (принимаемая через рот)
(примечание: не путать с слуховым = относящееся к уху)
Орто- = приставка, обозначающая прямой
Ортодонтия = раздел стоматологии, занимающийся лечением
неровности зубов.
Ортопедия = практика исправления деформаций, вызванных
заболевание или повреждение костей и суставов скелета
-osis = заболевание, поражающее предыдущую часть
слова
например Туберкулез, нефроз
Осте (o) — = , относящийся к кости [Grk]
Параграф = рядом с (латиница)
Паращитовидная железа = железа рядом с щитовидной железой
Параназальный = около носовой полости
Пери = около или около (латиница)
Периневрий = оболочка вокруг нерва.
Перинатальный = примерно во время рождения.
-физ = рост
Гипофиз = отросток под головным мозгом, то есть гипофизом
-plegic = суффикс, обозначающий паралич
Диплегия = паралич обеих сторон тела, особенно ног
Гемиплегия = паралич одной стороны тела
Pneo- = приставка, обозначающая дыхание
Pneumo- = приставка, обозначающая присутствие воздуха или газа
Пневмоторакс = воздух в плевральной полости
Пневмоцефалия = наличие воздуха в черепе
Пневмон- = приставка, обозначающая легкие
Пневмония = воспаление легких, вызванное бактериями, при которых
альвеолы заполняются воспалительными клетками, и легкое становится твердым
Пневмонэктомия = хирургическое удаление легкого
Поли- = префикс, обозначающий множество, множественный
Полисома = группа рибосом, связанных вместе информационной РНК
молекулы, образовавшиеся в процессе трансляции синтеза белка
Полисахарид = углевод, образованный из множества молекул моносахаридов.
соединены в длинные линейные и разветвленные цепи
Стойка = после, сзади (латиница)
Задний = ближний или ближний задний конец или хвост
Задне-передний = сзади вперед
Проксимальный = расположен близко к исходной точке или точке прикрепления
или близко к средней линии тела (от проксимуса =
ближайшая, латиница)
Quadri- = префикс, обозначающий четыре (латиница)
Четырехглавая мышца = большой разгибатель ноги, расположенный в бедре.
и разделен на четыре отдельные части
Квадриплегия = паралич, поражающий все четыре конечности
Почечный = относится к почке (латиница)
(N.Б. см. Нефро- = приставка, обозначающая почку, греч.)
Почечная артерия = любая из двух артерий, выходящих из брюшной полости.
аорта и кровоснабжение почек.
Почечный каналец = тонкая трубчатая часть нефрона, через которую проходит вода и
некоторые растворенные вещества реабсорбируются обратно в кровь.
-rrhage = обозначает чрезмерный или ненормальный поток или выделения из
орган или его часть
кровотечение = чрезмерное кровотечение
меноррагия = чрезмерные менструальные выделения
-ррея = выделения или выделения из органа или части
Диарея = частое опорожнение кишечника или выход аномально мягкого кишечника.
кал.
Ринорея = истечение из носа
Saccharo- = приставка, обозначающая сахар
Дисахарид = углевод, состоящий из двух связанных моносахаридов
ед.
Полисахарид = углевод, образованный из множества молекул моносахаридов.
соединены в длинные линейные и разветвленные цепи
Сагиттальная = анатомическая плоскость, разделяющая тело продольно на левую и правую части, параллельно срединной плоскости.
Стазис = постоянство, прекращение движения (латиница)
Гомеостаз = физиологический процесс, посредством которого внутренние системы
тело поддерживается в равновесии, несмотря на колебания
внешние условия.
-стома = устье
Стома = в хирургии, искусственное отверстие трубки
трахеостомия = искусственное отверстие (рот) в трахее
колостома = искусственное отверстие в толстой кишке, которое
поверхность живота
илеостомия = искусственное отверстие в толстой кишке, которое
поверхность живота
Sub = снизу, снизу (латиница)
Субъязычный = под языком
Подкожно = под кожей
Супер = выше (латиница)
Superior = расположен наверху в теле, связанном с другой структурой.
или поверхность
Поверхностный = расположен на поверхности или близко к ней
Лежа на спине = лежа на спине (часто термин, используемый для описания ленивого человек) (латиница)
Supra = выше (латиница)
Надлобковая область = область, находящаяся над лобковой областью (N.Б. также известен
как подчревная область.)
Надпочечник = над почкой
Тахи- = приставка, обозначающая быстрый, быстрый
Тахипноэ = учащенное дыхание
Тахикардия = учащенное сердцебиение
-термическое = в зависимости от температуры (латиница)
Экзотермический = реакция, при которой выделяется тепло
Терморецептор = сенсорное нервное окончание, которое реагирует на тепло и холод
-томия = разрезание
Лоботомия = рассечение доли органа
Гастротомия = хирургический разрез желудка
Topo- = приставка, обозначающая место, положение и расположение
Местное = местное, используется для пути введения лекарственного средства, которое
наносится непосредственно на обрабатываемую деталь
Топография = изучение различных областей тела, включая то, как
части относятся к окружающим конструкциям
(Н.Б. не путайте ни с тропическим, ни с направлением, ни с
трофический = связанный с питанием, например трофотропный = обращение к пище
Toxi — = приставка, обозначающая ядовитый, токсичный
Токсин = яд, вырабатываемый живым организмом, обычно бактерией
Токсемия = заражение крови, вызванное токсинами, образованными бактериями.
растет в локальном очаге заражения
Trans = через (латиница)
Поперечный = в анатомии, расположен под прямым углом к длинной оси
кузов
Поперечная плоскость (горизонтальная плоскость) = плоскость, разделяющая орган на верхнюю и
нижние половинки
Tri- = префикс, обозначающий три (латиница)
Трехстворчатый клапан = клапан в сердце между правым предсердием и правым
желудочек, состоящий из трех створок
Трицепс = мышца с тремя головками происхождения
-трофическая, -трофия = , относящаяся к питанию (греч.)
Дистрофия = нарушение питания
Атрофия = истощение, уменьшение размера
Гипертрофия = чрезмерное развитие
-тропия, -тропия и т. Д.= привлекает, поворачивается к или влияет. (греческий)
Нейротропный вирус = один поражающий нервы
Фототропизм = ориентация на свет
Uni- = префикс, обозначающий единицу
Односторонний = по анатомии, касается или затрагивает одну сторону тела
или одна сторона органа или другой части
-урез = , относящийся к моче или появляющийся в моче
протеинурез = белок в моче
диурез = дополнительная моча
Вазо — = относительно сосуда, обычно кровеносного сосуда (латиница)
Вазэктомия = удаление части семявыносящего протока
Вазоактивный = влияющий на диаметр кровеносных сосудов
Вентральный = передний (venter = живот, латинское брюшко)
вентро-медиальное = направление вперед и к средней линии
желудочек = заполненная жидкостью камера в сердце / головном мозге (‘ small belly’ )
Дополнительные предложения и фрагменты предложений — Грамматика
Продолжение предложения возникает, когда два или более независимых предложения (также называемых полными предложениями) соединены неправильно.
Пример : Я люблю писать статьи. Я бы писал по одной каждый день, если бы у меня было время.
В приведенном выше примере есть два полных предложения:
Предложение 1 : Я люблю писать статьи.
Предложение 2 : Я бы писал по одному каждый день, если бы у меня было время.
Одним из распространенных типов продолжающихся предложений является соединение запятой . Соединение через запятую происходит, когда два независимых предложения соединяются одной запятой.
Пример соединения запятой: Участники могли выйти из исследования в любой момент, им нужно было указать свои предпочтения.
Предложение 1 : Участники могли покинуть исследование в любое время.
Предложение 2 : Они должны были указать свои предпочтения.
Некоторые соединения запятых возникают, когда писатель пытается использовать переходное выражение в середине предложения.
Пример соединения с запятой: Результаты исследования неубедительны, поэтому необходимо провести дополнительные исследования по этой теме.
Предложение 1 : результаты исследования были неубедительными
Переходное выражение (конъюнктивное наречие): следовательно,
Предложение 2: Необходимо провести дополнительные исследования по теме
Чтобы исправить этот тип соединения запятой, используйте точку с запятой перед переходным выражением и добавьте запятую после него. См. Другие примеры на странице с точкой с запятой.
Редакция: Результаты исследования неубедительны ; следовательно, необходимо провести еще исследование по этой теме.
Вы можете исправить повторное предложение, правильно соединив или разделив его части. Есть несколько простых способов связать независимые предложения.
бесплатный пример кода Swift 5.1
Найдена 31 статья в базе знаний Swift для этой категории.
Как сделать сырые строки в Swift?
Необработанные строки помещают знаки решетки — # — до и после их кавычек и изменяют способ обработки строк в Swift двумя способами…. Продолжить чтение >>
Как вычислить ROT13 строки
ROT13 — это простой алгоритм, который сдвигает буквы в строке вперед на 13 позиций. Очевидно, что он не подходит для какого-либо серьезного шифрования, но очень полезен для сокрытия текста, поэтому его значение неочевидно — например, размещение спойлеров на форуме лучше всего делать с помощью ROT13, чтобы кого-то не раздражать …. Продолжить чтение >>
Как сделать первую букву строки заглавной
Если вы хотите сделать первую букву строки заглавной, не касаясь остальных букв, добавьте это простое расширение String :… Продолжить чтение >>
Как писать слова в строке с заглавной буквы
Swift предлагает несколько способов настройки регистра букв в строке, но если вы ищете регистр букв, то есть текст, где Первая буква каждой строки написана с заглавной буквы — тогда вам нужно использовать свойство с заглавной буквы, например: … Продолжить чтение >>
Как проверить, содержит ли строка какие-либо слова из массива
Вы уже должны знайте, что вы можете проверить, содержит ли строка одно слово вроде этого :… Продолжить чтение >>
Как объединить строки в одну соединенную строку
Swift предлагает три различных способа соединения строк. Первый — это использование оператора + для соединения двух строк для создания третьей: … Продолжить чтение >>
Как преобразовать строку в безопасный формат для заголовков URL и имен файлов
Строки Swift чрезвычайно сложны зверей, позволяя вам свободно смешивать персонажей из любого языка, включая эмодзи.Хотя это действительно важно для отображения текста, это также может вызвать хаос при попытке создать URL-адреса и имена файлов, поэтому, если вам нужно сослаться на строку в этих местах, вы должны сначала преобразовать ее в ярлык …. Продолжить чтение >>
Как преобразовать строку в строчные буквы
Вы можете преобразовать любую строку в нижний регистр, то есть перейти от «HELLO» к «hello», вызвав его метод lowercased () , например: … Продолжить чтение >>
Как преобразовать строку в прописные буквы
Если вы хотите преобразовать строку в верхний регистр, то есть ГДЕ КАЖДОЕ БУКВУ ЯВЛЯЕТСЯ ЗАГЛАВНЫМ, вы должны использовать в верхнем регистре () метод вашей строки, например:.. Продолжить чтение >>
Как определить URL-адрес в строке с помощью NSDataDetector
Класс NSDataDetector позволяет легко обнаруживать URL-адреса внутри строки, используя всего несколько строк кода. В этом примере выполняется цикл по всем URL-адресам в строке, выводя каждый из них: … Продолжить чтение >>
Как отображать разные строки в зависимости от доступного пространства с помощью optionFittingPresentationWidth ()
На удивление легко настроить свой проект с несколькими строки затем пусть он выберет одну во время выполнения в зависимости от доступного пространства…. Продолжить чтение >>
Как получить длину строки
Строки Swift можно рассматривать как массив отдельных символов. Итак, чтобы вернуть длину строки, вы можете использовать yourString.count для подсчета количества элементов в массиве символов …. Продолжить чтение >>
Как получить строки в строке как array
Строки Swift разделены символом \ n , который в операционных системах Unix является разрывом строки.Используя это, а также компонентов (separatorBy :) метод, вы можете получить массив всех строк в строке, например: … Продолжить чтение >>
Как загрузить строку из файла в вашем пакете
Если у вас есть важный текстовый файл, встроенный в ваш пакет приложений, который вы хотите загрузить во время выполнения, String имеет инициализатор только для этой цели. Он называется contentsOfFile , и вот он в действии: … Продолжить чтение >>
Как загрузить строку с веб-сайта URL
Для загрузки содержимого файла требуется всего несколько строк кода Swift. URL-адрес веб-сайта, но есть три вещи, с которыми вам нужно быть осторожными:.. Продолжить чтение >>
Как перебирать буквы в строке
Вы можете перебирать каждый символ в строке, рассматривая его как массив. Благодаря расширенной поддержке Swift для международных языков и эмодзи, это отлично работает независимо от того, какой язык вы используете …. Продолжить чтение >>
Как измерить строку для кода Objective-C
Regular Swift code может обрабатывать строки как другие виды последовательностей, поэтому вы можете использовать его свойство count для чтения количества содержащихся в нем символов :… Продолжить чтение >>
Как разобрать предложение с помощью NSLinguisticTagger
Если вы хотите разобрать естественный язык, введенный пользователем, вы ищете NSLinguisticTagger : он автоматически распознает английские слова (и слова на других языках тоже, если вы спросите) и расскажет, что это за слово. То есть этот волшебный маленький класс различает глаголы, существительные, прилагательные и так далее, поэтому вы можете сосредоточиться на важном: как мне (глагол) это (существительное) ?… Продолжить чтение >>
Как прочитать отдельный символ из строки
Строки Swift хранятся определенным образом, что не позволяет вам легко индексировать их. Фактически, чтение одной буквы от середины строки означает начало с начала строки и подсчет букв до тех пор, пока вы не найдете ту, которая вам нужна, поэтому, если вы попытаетесь прочитать всех символов в строке таким образом, вы могли бы случайно создать очень медленный код…. Продолжить чтение >>
Как удалить префикс из строки
Строка Swift имеет встроенный метод hasPrefix () , который возвращает истину, если строка начинается с определенных букв, но это не так есть способ удалить эти буквы, если они существуют …. Продолжить чтение >>
Как повторить строку
Строки Swift имеют встроенный инициализатор, который позволяет создавать строки, повторяя строку определенное количество раз. раз.Чтобы использовать его, просто укажите строку для повторения и счет в качестве двух ее параметров, например: … Продолжить чтение >>
Как перевернуть строку с помощью reversed ()
Обращение строки в Swift выполнено используя метод reversed () для своих символов, а затем создавая новую строку из результата. Вот код: … Продолжить чтение >>
Как выполнить поиск без учета регистра одной строки внутри другой
Вы можете искать одну строку внутри другой, используя метод диапазона (of :) , например это:… Продолжить чтение >>
Как сохранить строку в файл на диске с помощью записи (в 🙂
Все строки имеют метод записи (в :) , который позволяет сохранить содержимое строки в диск. Вам необходимо указать имя файла для записи, а также еще два параметра: должна ли запись быть атомарной и какую кодировку строки использовать. Второй параметр почти всегда должен быть true , потому что это позволяет избежать проблем параллелизма. Третий параметр почти всегда должен быть String.Encoding.utf8 , который в значительной степени является стандартом для чтения и записи текста …. Продолжить чтение >>
Как указать точность с плавающей запятой в строке
Интерполяция строк Swift упрощает установку чисел с плавающей запятой. точки в строку, но в ней отсутствует возможность указать точность. Например, если число 45,6789, вы можете захотеть показать только две цифры после десятичного разряда …. Продолжить чтение >>
Как разбить строку на массив: components (separatedBy 🙂
You может преобразовать строку в массив, разбив ее на подстроку, используя метод components (separatedBy :) .Например, вы можете разделить строку запятой и пробелом следующим образом: … Продолжить чтение >>
Как проверить локализацию, установив языковой стандарт отладки и псевдоязык двойной длины
Если вы хотите проверить, как ваш приложение работает при запуске на устройствах с другими языками, у вас есть два варианта: вы можете либо указать симулятору использовать определенный язык, на котором у вас есть локализация, либо вы можете использовать специальный «псевдоязык двойной длины», который в основном действует как стресс-тест…. Продолжить чтение >>
Как обрезать пробелы в строке
Убрать пробелы из строки в Swift несложно, но синтаксис немного многословен — или «самоописательный», если вы чувство оптимизма. Вам нужно использовать метод trimmingCharacters (in :) и предоставить список символов, которые вы хотите обрезать. Если вы просто используете пробелы (табуляции, пробелы и новые строки), вы можете использовать предопределенный список символов whitespacesAndNewlines , например :… Продолжить чтение >>
Как использовать строковую интерполяцию для комбинирования строк, целых чисел и чисел двойной точности
Строковая интерполяция — это способ Swift, позволяющий вставлять переменные и константы в строки. Но в то же время вы также можете выполнять простые операции в рамках интерполяции, такие как изменение регистра букв и основные математические операции. Swift также достаточно умен, чтобы понимать , как преобразовывать значения в строки, а это означает, что вы можете использовать другие строки, целые числа и числа с плавающей запятой…. Продолжить чтение >>
NSRegularExpression: Как сопоставить регулярные выражения в строках
Класс NSRegularExpression позволяет находить и заменять подстроки с помощью регулярных выражений, которые представляют собой краткие и гибкие описания текста. Например, если мы хотим вытащить «Тейлор Свифт» из строки «Меня зовут Тейлор Свифт», мы могли бы написать регулярное выражение, которое соответствует тексту «Меня зовут», за которым следует любой текст, а затем передать это в Класс NSRegularExpression …. Продолжить чтение >>
Замена текста в строке с помощью replaceOccurrences (of 🙂
Легко заменить текст внутри строки благодаря методу replaceOccurrences (of :) . Это строковый метод, и вы указываете ему, что искать и чем его заменить, и все готово …. Продолжить чтение >>
О базе знаний Swift
Это часть Swift Knowledge Base, бесплатная коллекция с возможностью поиска решений для общих вопросов iOS, написанная для Swift 5.1.
17 Реверсивные струны | Работа со струнами с R
Введение
Наш первый пример связан с обращением строки символов. Точнее, цель состоит в том, чтобы создать функцию, которая принимает строку и возвращает ее в обратном порядке. Уловка этого упражнения зависит от того, что мы понимаем под термином , обращающимся к . Для некоторых людей реверсирование можно понимать как просто набор из символов в обратном порядке. Для других реверсирование можно понимать как набор из слов в обратном порядке.Вы видите разницу?
Рассмотрим следующие две простые строки:
-
«атмосфера» -
«теория большого взрыва»
Первая строка состоит из одного слова (атмосфера). Вторая строка образована предложением из четырех слов (теория большого взрыва). Если бы мы перевернули обе строки по символам, то получили бы следующие результаты:
-
«эрехпсомта» -
"yroeht gnab gib eht"
И наоборот, если бы мы перевернули строки по словам, мы получили бы следующий результат:
-
«атмосфера» -
"теория взрыва большой"
В этом примере мы реализуем функцию для каждого типа реверсивной операции.
Реверс символов
Первый случай переворота строки — это сделать это на символов . Это означает, что нам нужно разделить данную строку на разные символы, а затем нам нужно объединить их вместе в обратном порядке. Попробуем написать первую функцию:
# функция, переворачивающая строку по символам
reverse_chars <- функция (строка)
{
# разделить строку по символам
string_split = strsplit (строка, split = "")
# обратный порядок
rev_order = nchar (строка): 1
# перевернутый символ
reversed_chars = разделитель_строки [[1]] [rev_order]
# свернуть перевернутый символ
вставить (reversed_chars, collapse = "")
} Давайте проверим нашу функцию реверса с символьным и числовым векторами:
# попробуйте reverse_chars
reverse_chars ("abcdefg")
#> [1] "gfedcba"
# попробуйте ввести несимвольный ввод
reverse_chars (12345)
#> Ошибка в strsplit (string, split = ""): несимвольный аргумент Как видите, reverse_chars () отлично работает, когда ввод находится в "символьном" режиме .Однако он жалуется, когда вводится "несимвольный" . Чтобы сделать нашу функцию более надежной, мы можем принудительно преобразовать входные данные как символы. Результирующий код имеет вид:
# реверсирование строки по символам
reverse_chars <- функция (строка)
{
string_split = strsplit (as.character (строка), split = "")
reversed_split = string_split [[1]] [nchar (строка): 1]
вставить (reversed_split, collapse = "")
} Теперь, если мы попробуем нашу модифицированную функцию, мы получим ожидаемые результаты:
# пример с одним словом
reverse_chars ("атмосфера")
#> [1] "эрехпсомта"
# пример с несколькими словами
reverse_chars ("теория большого взрыва")
#> [1] "yroeht gnab gib eht" Кроме того, он также работает с несимвольным вводом:
# попробуйте reverse_chars
reverse_chars ("abcdefg")
#> [1] "gfedcba"
# попробуйте ввести несимвольный ввод
reverse_chars (12345)
#> [1] "54321" Если мы хотим использовать нашу функцию с вектором (более одного элемента), мы можем объединить ее с функцией lapply () следующим образом:
# обратный вектор (по символам)
lapply (c ("теория большого взрыва", "атмосфера"), reverse_chars)
#> [[1]]
#> [1] "yroeht gnab gib eht"
#>
#> [[2]]
#> [1] "erehpsomta" Обращение слов
Второй тип операции реверса - перевернуть строку на слов .В этом случае процедура включает разбиение строки по словам, их перегруппировку в обратном порядке и вставку обратно в одно предложение. Вот как мы можем определить нашу функцию reverse_words () :
# функция, переворачивающая строку по словам
reverse_words <- функция (строка)
{
# разделить строку пробелами
string_split = strsplit (as.character (строка), split = "")
# сколько разделенных терминов?
длина_строки = длина (разделение_строк [[1]])
# решаем, что делать
if (длина_строки == 1) {
# одно слово (ничего не делать)
reversed_string = строка_split [[1]]
} еще {
# более одного слова (свернуть)
reversed_split = разделение_строки [[1]] [длина_строки: 1]
reversed_string = вставить (reversed_split, collapse = "")
}
# выход
возврат (обратная_строка)
} Первым шагом внутри reverse_words () является разделение строки в соответствии с шаблоном пробела "" .Затем мы подсчитываем количество компонентов, полученных на этапе разделения. Основываясь на этой информации, есть два варианта. Если есть только одно слово, то делать нечего. Если у нас более одного слова, нам нужно переставить их в обратном порядке и свернуть в одну строку.
После того, как мы определили нашу функцию, мы можем попробовать ее на двух примерах строк, чтобы убедиться, что она работает должным образом:
# examples
reverse_words ("атмосфера")
#> [1] "атмосфера"
reverse_words ("теория большого взрыва")
#> [1] "теория взрыва большой" Аналогичным образом, чтобы использовать нашу функцию для вектора с более чем одним элементом, мы должны вызвать ее в функции lapply () следующим образом:
# обратный вектор (по словам)
lapply (c ("теория большого взрыва", "атмосфера"), reverse_words)
#> [[1]]
#> [1] "теория взрыва большой"
#>
#> [[2]]
#> [1] "атмосфера" Сделать пожертвование
Если вы найдете этот ресурс полезным, сделайте одноразовое пожертвование в любой сумме.Ваша поддержка действительно имеет значение.
Представления списков в Python - PythonForBeginners.com
Представления списков обеспечивают краткий способ создания списков.
Он состоит из скобок, содержащих выражение, за которым следует предложение for, затем
ноль или более предложений for или if. Выражения могут быть любыми, то есть вы можете
помещать в списки все виды объектов.
Результатом будет новый список, полученный в результате оценки выражения в контексте
следующих за ним предложений for и if.
Понимание списка всегда возвращает список результатов.
Если раньше так делали:
new_list = []
для i в old_list:
если фильтр (i):
new_list.append (выражения (i))
Вы можете получить то же самое, используя понимание списка. Обратите внимание, что метод добавления исчез!
new_list = [выражение (i) для i в старом_списке, если фильтр (i)]
Синтаксис
Составление списка начинается с « [‘ и ‘]’, квадратных скобок , чтобы помочь вам запомнить, что результатом
будет список.
В основном синтаксисе используются квадратные скобки.
[выражение для элемента в списке при условии]
Это эквивалент:
для позиции в списке:
если условно:
выражение
Давайте разберемся с этим и посмотрим, что он делает.
new_list = [выражение (i) для i в старом_списке, если фильтр (i)]
new_list
Новый список (результат).
выражение (i)
Выражение основано на переменной, используемой для каждого элемента в старом списке.
for i в old_list
Слово for, за которым следует имя переменной для использования, за которым следует слово в старом списке
.
if filter (i)
Примените фильтр с оператором If.
В этом блоге показан пример того, как визуально разбить понимание списка:
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация - DataCamp.
new_range = [i * i for i in range (5) if i% 2 == 0]
Что соответствует:
* результат * = [* преобразование * * итерация * * фильтр *]
Оператор * используется для повторения.Часть фильтра отвечает на вопрос, нужно ли преобразовать элемент
.
Примеры
Теперь, когда мы знаем синтаксис составления списков, давайте покажем несколько примеров и
, как вы можете его использовать.
Создать простой список
Давайте начнем с простого списка.
x = [i для i в диапазоне (10)]
напечатать x
# Это даст результат:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Вот как можно создать простой список.
Создание списка с использованием циклов и понимания списка
В следующем примере предположим, что мы хотим создать список квадратов.Начните с пустого списка.
# Вы можете использовать циклы:
квадраты = []
для x в диапазоне (10):
squares.append (x ** 2)
печать квадратов
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# Или вы можете использовать списки, чтобы получить тот же результат:
квадраты = [x ** 2 для x в диапазоне (10)]
печать квадратов
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Просто запомните синтаксис: [выражение для элемента в списке при условии]
Умножение частей списка
Умножьте каждую часть списка на три и назначьте ее новому списку.
list1 = [3,4,5]
multiplied = [элемент * 3 для элемента в list1]
печать умноженная
[9,12,15]
Обратите внимание, как элемент * 3 умножает каждую часть на 3.
Показывать первую букву каждого слова
Возьмем первую букву каждого слова и составим из нее список.
listOfWords = ["this", "is", "a", "list", "of", "words"]
items = [слово [0] для слова в listOfWords]
распечатать
Результат должен быть: [‘t’, ‘i’, ‘a’, ‘l’, ‘o’, ‘w’]
Преобразователь нижнего / верхнего регистра
Давайте покажем, как легко можно преобразовать строчные / прописные буквы.
>>> [x.lower () для x в ["A", "B", "C"]]
['a', 'b', 'c']
>>> [x.upper () для x в ["a", "b", "c"]]
['A', 'B', 'C']
Печатать числа только из заданной строки
В этом примере показано, как извлечь все числа из строки.
string = "Hello 12345 World"
числа = [x вместо x в строке, если x.isdigit ()]
печатать числа
>> ['1', '2', '3', '4', '5']
Измените x.isdigit () на x.isalpha (), если вам не нужны числа.
Анализ файла с использованием списка
В этом примере мы можем увидеть, как получить определенные строки из текстового файла.
Создайте текстовый файл и введите в него текст.
это строка1
это строка2
это строка3
это строка4
это строка5
Сохраните файл как test.txt
# Затем создайте фильтр, используя понимание списка:
fh = open ("test.txt", "r")
результат = [i для i в fh, если "line3" в i]
результат печати
Вывод: ["это строка 3
"]
Использование понимания списков в функциях
Теперь давайте посмотрим, как мы можем использовать понимание списков в функциях.
# Создайте функцию и назовите ее double:
def double (x):
вернуть x * 2
# Если вы сейчас просто напечатаете эту функцию со значением в ней, она должна выглядеть так:
>>> print double (10)
20
Мы можем легко использовать составление списков для этой функции.
>>> [double (x) для x в диапазоне (10)]
печать двойная
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
# Вы можете поставить условия:
>>> [double (x) для x в диапазоне (10), если x% 2 == 0]
[0, 4, 8, 12, 16]
# Вы можете добавить больше аргументов:
>>> [x + y вместо x в [10,30,50] для y в [20,40,60]]
[30, 50, 70, 50, 70, 90, 70, 90, 110]
Посмотрите, как можно поставить условия и добавить больше аргументов.
Похожие сообщения
Списки Python
Манипуляции со списками в Python
Источники
http://docs.python.org/2/tutorial/datastructures.html
http://www.dalkescientific.com/writings/NBN/list_comps.html
http://effbot.org/zone/python-list.htm
http://blog.cdleary.com/2010/04/learning-python-by-example-list-comprehensions/
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация - DataCamp.
строк и шаблонов - язык конфигурации
Строковые литералы - самый сложный вид литерального выражения в Terraform, а также наиболее часто используемый.
Terraform поддерживает синтаксис в кавычках и синтаксис heredoc для строк. Оба этих синтаксиса поддерживают последовательности шаблонов для интерполяции значений и манипулирование текстом.
» Цитированные строки
Строка в кавычках - это последовательность символов, разделенных прямыми двойными кавычками.
символы ( ").
» Последовательности побега
В строках, заключенных в кавычки, символ обратной косой черты используется как escape последовательность, со следующими символами, выбирающими escape-поведение:
| Последовательность | Замена |
|---|---|
\ п | Новая строка |
\ r | Возврат каретки |
\ т | Вкладка |
\ " | Буквальная кавычка (без завершения строки) |
\ | Буквальная обратная косая черта |
\ uNNNN | Символ Unicode из базовой многоязычной плоскости (NNNN - четыре шестнадцатеричных цифры) |
\ UNNNNNNNN | Символ Юникода из дополнительных плоскостей (NNNNNNNN - восемь шестнадцатеричных цифр) |
Есть также две специальные escape-последовательности, которые не используют обратную косую черту:
| Последовательность | Замена |
|---|---|
$$ { | Литерал $ { без начала интерполяционной последовательности. |
%% { | Литерал % {, без начала последовательности директив шаблона. |
» Heredoc Strings
Terraform также поддерживает "heredoc" стиль строкового литерала, вдохновленный Unix. языки оболочки, которые позволяют более четко выражать многострочные строки.
Строка heredoc состоит из:
- Последовательность открытия, состоящая из:
- Маркер heredoc (
<<или<< -- два знака меньше, с дополнительным дефисом для heredocs с отступом) - Слово-разделитель по вашему выбору
- разрыв строки
- Маркер heredoc (
- Содержимое строки, которая может охватывать любое количество строк.
- Слово-разделитель, которое вы выбрали, в отдельной строке (с отступом, разрешенным для heredocs с отступом)
Маркер << , за которым следует любой идентификатор в конце строки, вводит
последовательность.Затем Terraform обрабатывает следующие строки, пока не найдет ту, которая
полностью состоит из идентификатора, указанного в интродукторе.
В приведенном выше примере EOT - это выбранный идентификатор. Любой идентификатор
разрешено, но обычно этот идентификатор пишется заглавными буквами и начинается с EO , что означает «конец». EOT в данном случае означает «конец текста».
» Heredocs с отступом
Стандартная форма heredoc (показанная выше) рассматривает все символы пробела как буквальные пробелы.Если вы не хотите, чтобы каждая строка начиналась с пробелов, тогда каждая строка должна быть на одном уровне с левым полем, что может быть неудобно для выражений в блок с отступом:
блок {
значение = << EOT
Привет
Мир
EOT
}
Чтобы улучшить это, Terraform также принимает вариант строки heredoc с отступом который вводится последовательностью << - :
блок {
значение = << - EOT
Привет
Мир
EOT
}
В этом случае Terraform анализирует строки в последовательности, чтобы найти с наименьшим количеством начальных пробелов, а затем обрезает это количество пробелов от начала всех строк, что приводит к следующему результату:
» Последовательности побега
Последовательности обратной косой черты не интерпретируются как escape-символы в строке heredoc выражение.Вместо этого символ обратной косой черты интерпретируется буквально.
Heredocs поддерживают две специальные escape-последовательности, которые не используют обратную косую черту:
| Последовательность | Замена |
|---|---|
$$ { | Литерал $ { без начала интерполяционной последовательности. |
%% { | Литерал % {, без начала последовательности директив шаблона. |
» Шаблоны строк
В строковых выражениях в кавычках и heredoc последовательности $ { и % { начинаются матричных последовательностей .Шаблоны позволяют напрямую вставлять выражения в строку
literal, чтобы динамически создавать строки из других значений.
» Интерполяция
Последовательность $ {...} - это интерполяция , , которая вычисляет выражение
задано между маркерами, при необходимости преобразует результат в строку и
затем вставляет его в последнюю строку:
В приведенном выше примере осуществляется доступ к именованному объекту var.name и его значение
вставляется в строку, что дает результат вроде «Привет, Хуан!».
» Директивы
Последовательность % {...} - это директива , которая позволяет использовать условные
результаты и итерация по коллекциям, аналогично условному
и для выражений.
Поддерживаются следующие директивы:
Директива
% {if/} % {else}/% {endif}выбирает между двумя шаблонами на основе от значения выражения типа bool:"Здравствуйте,% {if var.name! = ""} $ {var.name}% {else} безымянный% {endif}! "Часть
elseможет быть опущена, и в этом случае результат будет пустым. строка, если выражение условия возвращаетfalse.Директива
% {для/в } % {endfor}перебирает элементы данной коллекции или структурной ценности и оценивает данную шаблон один раз для каждого элемента, объединяя результаты вместе:<< EOT % {для ip в aws_instance.пример. *. private_ip} сервер $ {ip} % {endfor} EOTИмя, указанное сразу после
для ключевого слова, используется как временное имя переменной, на которое затем можно ссылаться из вложенного шаблона.