Государственное казенное учреждение социального обслуживания Ростовской области центр помощи детям, оставшимся без попечения родителей, "РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7"
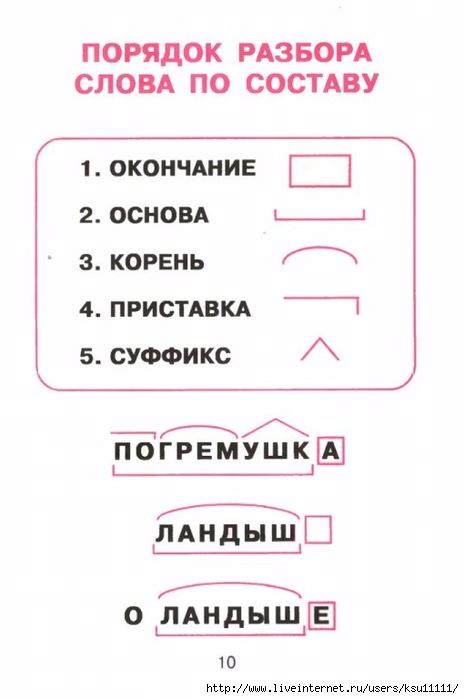
Разобрать слово по составу проход: «проход» — корень слова, разбор по составу (морфемный разбор слова)
Зубило №8. Записки чайника, Владимир Иванович Данилушкин
4
И задний немецкий танк перестал пятиться, будто раздумал, но развернул орудие в сторону холма и выстрелил.
Вечный зов. Том 2, Анатолий Иванов, 1976г.
5
Через задний угол была протянута дырявая простыня.
Преступление и наказание, Федор Достоевский, 1866г.
Найти еще примеры предложений со словом ЗАДНИЙ
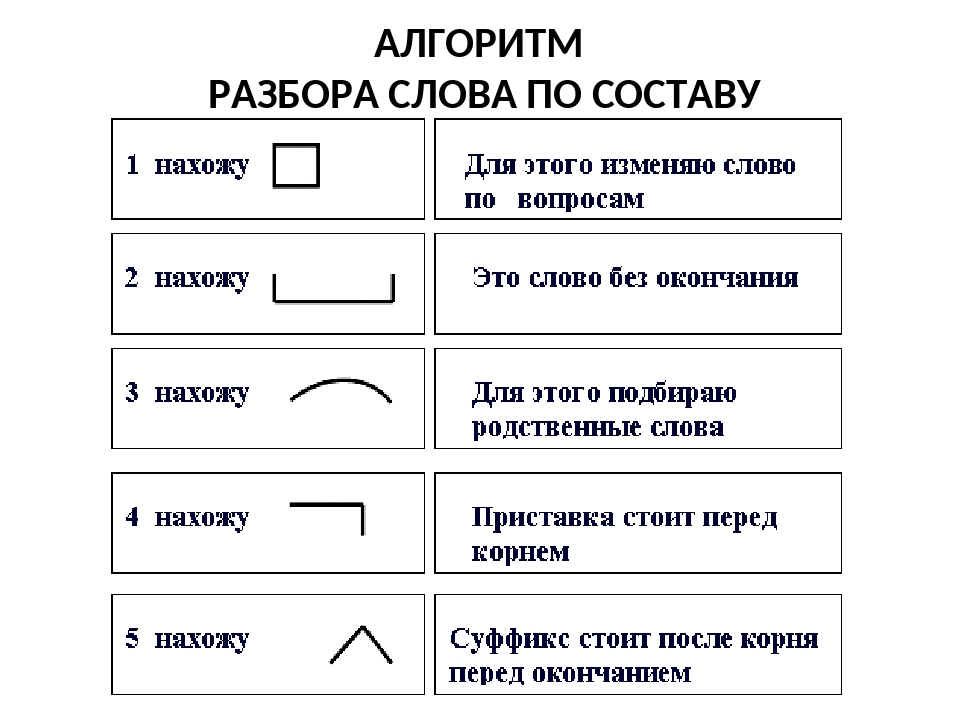
Конспект урока русского языка на тему «Удвоенные согласные»
-Добрый день!
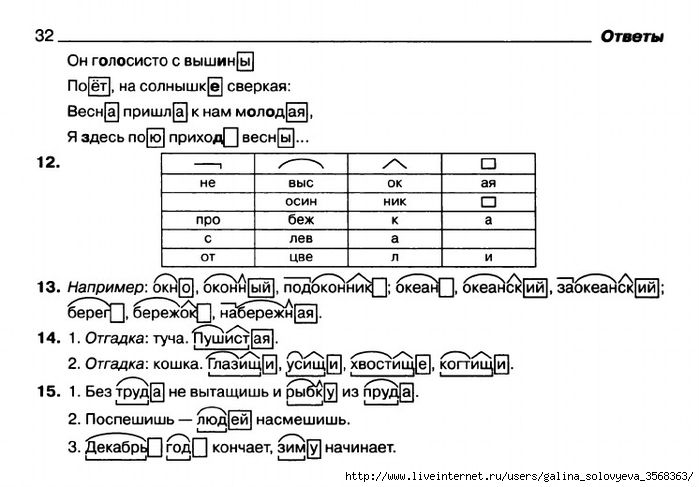
-Дети, вам тепло? (Да!)
В классе светло? (Да!)
Прозвенел уже звонок? (Да!)
Уже закончился урок? (Нет!)—
Только начался урок? (Да!)
А хотите ли вы учиться? (Да!)
Значит можно всем садиться!
-Начинаем урок русского языка.
— Рассказать секреты слова Я для вас всегда готова. Но на уроке будь готов
Сам раскрыть секреты слов.
— Ребята, вы готовы сделать новые открытия? Тогда приступаем к работе.
ор ох еф ел ес
Ребята, посмотрите на доску и скажите, что написано у меня? (соединения букв)
— соединения каких букв написаны?
— давайте сейчас пропишем эти буквы я на доске, а вы в воздухе. Руку поставили на локоток, я пишу, вы вместе со мной.
Давайте посмотрим, что у нас дано во второй строке? (слова)
— прочитайте эти слова (огнетушитель, пищеварение)
Сейчас вам нужно будет эти слова записать. Но сначала давайте подготовим наши пальчики к работе:
Большой пальчик мы потрем,
Указательным пожмем,
Средний с вами мы погладим,
Безымянный – пощипаем,
А мизинчик разотрем
Кистью дружно мы встряхнем
И писать уже начнем.
Откройте тетрадочки, запишите дату, классная работа. А сейчас запишите соединения букв, каждое по 2 раза, и затем запишите слова, которые записаны у меня на доске.
Следим за посадкой, спинку держим прямо, голову не наклоняем сильно, ноги под прямым углом. Соблюдаем наклон тетради. Стараемся писать.
Встаньте те ребята, которых я погладила по голове. Эти ребята молодцы! Она очень красиво, правильно написали соединения и слова. Присаживайтесь.
Ребята, откройте свои маленькие тетрадочки, сейчас проведем словарную работу. Я вам диктую слова, вы записываете, ставите ударение в слове и подчеркиваете орфограмму.
Слова: столица, класс, завод, город, кровать, праздник, мороз, молоток, народ, осина, пятница, растение.
Я думаю, что все написали словарную работу только на 5, я проверю и поставлю вам оценки, и я надеюсь, что сегодня каждый из вас заработал буковки на обложку своей тетрадочки.
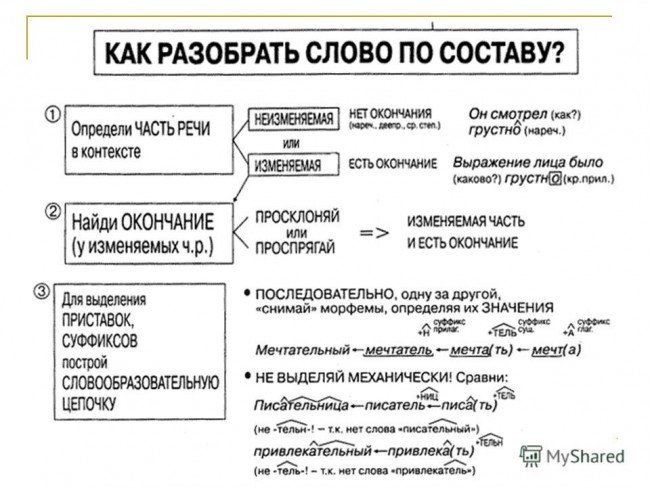
Сегодня на уроке нам предстоит сделать большое открытие, познакомиться со сложными словами, узнать, что это за слова, как они пишутся. Познакомимся с новым способом образования слов. Будьте активны, хорошо работайте, внимательно слушайте мои вопросы и правильно на них отвечайте.
Ребята, отгадайте загадку.
Раз в горах я побывал,
Видел там камней обвал.
Перевал весь завалило.
Отгадай, что это было? (камнепад)
Посмотрите на это слово, прочитайте его еще раз и скажите, что это слово обозначает? (обвал, падение камней)
— от каких слов образовано это слово? (камни падают)
— давайте разберем это слово по составу (камнепад)
— сколько у нас в слове корней? (2)
— назовите эти корни (камн, пад)
— посмотрите внимательно на это слово, скажите, какая гласная соединяет два корня? (е)
— как мы такую гласную можем назвать, если она соединяет два корня? (соединительной гласной)
— скажите, как назвать животного, у которого на носу рог? (носорог)
— как от слова нос и рог образовано слово носорог? (с помощью соединительной гласной о)
— как одним словом назвать ферму, на которой разводят птиц? (птицеферма)
— объясните, как от слов птица и ферма образовано слово птицеферма? (с помощью соединительной гласной е)
— как одним словом назвать корабль, который колет лед? (ледокол)
— объясните, как от слов лед и колет образовано новое слово ледокол? (с помощью соединительной гласной о)
Сейчас запишите слова, образованные от двух корней, разберите эти слова по составу. Выполняете задание в тетрадях, а Данил идет к доске.
Носорог, птицеферма, ледокол.
Смотрим следующее упражнение 88. Читаем задание. Итак, давайте объясним, от каких слов образованы данные слова:
— паровоз – пар возит.
— корнеплод – плод в корне.
— лесовоз – лес возит.
— пылесос – пыль сосет.
— скажите, какие гласные стоят между двумя корнями? (о, е)
— вам нужно записать эти слова, разобрать их по составу.
Сейчас записываете в тетрадях эти слова, а Кристина идет к доске, выполняет упражнение на доске.
Паровоз, корнеплод, лесовоз, пылесос.
Давайте, ребята, проверим, все ли верно выполнила Кристина?
— скажите, сколько корней в каждом слове? (2)
— какая гласная соединяет эти корни? (о, е)
Прочитайте правило, которое находится под упражнением про себя. Сейчас прочитаем правило вслух.
В составе сложного слова может быть несколько корней. Это сложные слова. В них используется соединительная гласная о или е.
— сколько корней может быть в составе сложного слова? (несколько)
— как называются слова, в которых несколько корней? (сложные)
— какие гласные в них используются? (соединительные о или е)
Всего, ребята, существует две соединительных гласных о и е. Других не бывает. Запомните это навсегда.
Давайте повторим правило еще раз. А сейчас расскажите мне это правило.
Мы ногами топ-топ, Мы руками хлоп-хлоп, А потом прыг-скок И ещё разок. А потом вприсядку, А потом вприсядку, А потом вприсядку, И снова — по порядку. Побежим мы по дорожке Раз, два, три! И похлопаем в ладошки Раз, два, три! И покрутим головами Раз, два, три! Все танцуйте вместе с нами Раз, два, три!
Сейчас у нас тихонечко сядет первый ряд, еще тише сядет второй ряд, и третий ряд садятся как мышки – тихо-тихо.
Смотрим упражнение 89. Читаем задание.
Давайте посмотрим, от каких корней или корня образованы данные слова?
Проход – образовано от корня ход, это слово простое, в нем приставка про-.
Пароход – образовано от 2 корней пар, ход.
— как соединены два корня между собой? (с помощью соединительной гласной о, это сложное слово)
Мореход – образовано от 2 корней море, ход, слово имеет 2 корня, это сложное слово)
— как соединены между собой два корня? (в данном случае соединены целое слово море и корень ход, соединительной гласной в этом слове нет)
Походка – слово образовано от корня ход, есть приставка по, суффикс к-, это простое слово, так как в нем 1 корень)
Сейчас мы запишем эти слова к себе в тетрадь, а Кирилл идет к доске. Записываете слова, разбираете их по составу.
Проход, пароход, мореход, походка.
— какие слова состоят из двух корней? (пароход и мореход)
— какая соединительная гласная использована для соединения двух корней? (о, е)
Следующее упражнение 90. Читаем задание.
Вам нужно списать данные слова и разобрать их по составу. Давайте посмотрим на слова и попробуем объяснить, от каких слов образованы данные слова.
Мясорубка – мясо рубит.
Водокачка – воду качает
Мышеловка – мышей ловит
Хлеборезка – хлеб режет
Газопровод – газовый провод
Водопроводчик — воду проводит.
Записываем эти слова в тетрадь, разбираем их по составу, а Дима Золотников идет к доске.
— как образованы данные слова? (с помощью двух основ)
-как вы думаете, какими двумя способами могут соединяться основы в сложных словах? (1. Чаще всего сложные слова образуются при помощи соединительных гласных о и е. 2. Могут образовываться путем соединения целых слов без соединительных гласных.)
Давайте прочитаем с вами сведение о языке, которое находится ниже упражнения 90.
Читаем про себя. Читаем вслух.
Новые слова могут быть образованы не только при помощи приставок и суффиксов, но и сложением двух основ.
Выполняем упражнение 91. Читаем задание. Что нам нужно сделать? (от слов бумага, снимок, кружок образовать новые сложные слова со словом фото)
— какие слова мы образуем? (фотобумага, фотоснимок, фотокружок)
— давайте запишем эти слова в тетрадь и разберем их по составу. Ваня идет к доске выполнять данное упражнение.
Фотобумага, фотоснимок, фотокружок.
— скажите, понадобились нам при образовании новых слов соединительные гласные о или е? (нет)
— почему? (так как в данном случае образование слов происходит путем соединения целых слов без соединительных гласных)
— с какими словами мы познакомились на уроке?
— какие слова называются сложными?
— как образуются сложные слова?
— какими двумя способами могут соединяться основы в сложных словах?
— какие соединительные гласные вы знаете?
Дома вам нужно выполнить упражнение 93. Откройте это упражнение. Посмотрите на него. Вам нужно записать слова, разобрать их по составу, подчеркнуть соединительную гласную и устно объяснить, как эти слова образованы. Открываем дневники, записываем с. 41 упр. 93.
Ребята, у вас на партах лежат цветочки. На доске висят две вазы. «Если вам понравилось на уроке, и вы узнали что-то новое, то прикрепите цветок к вазе «Я доволен», если не понравилось, то прикрепите цветок к вазе «»Не доволен».
Встали все. Урок окончен.
go — Оптимизация композиции html/шаблона
спросил
Изменено
8 лет, 6 месяцев назад
Просмотрено
4к раз
Я ищу лучший (более быстрый и организованный) способ разделить мои шаблоны в Go. Я настоятельно предпочитаю придерживаться html/template (или его оболочки), так как доверяю его модели безопасности.
Прямо сейчас я использую template.ParseGlob для анализа всех моих файлов шаблонов в пределах init() .
Я применяю template.Funcs к полученным шаблонам
Я установил $title в каждом шаблоне (например, listing_payment.tmpl ) и передал его в шаблон контента.
Я понимаю, что html/template кэширует шаблоны в памяти после анализа
Мои обработчики вызывают только t. ExecuteTemplate(w, "name.tmpl", map[string]interface{}) и не делать глупый разбор каждого запроса.
Я составляю шаблоны из нескольких частей (и это часть, которую я нахожу неуклюжей), как показано ниже:
Является ли это производительным, или несколько тегов {{ template "name" }} приводят к потенциальному снижению производительности для каждого запроса? Я вижу много ошибок write-breaked pipe при стресс-тестировании более тяжелых страниц. Это может быть просто из-за тайм-аутов сокета (т. е. закрытия сокета до того, как писатель сможет закончить), а не из-за какой-то композиции для каждого запроса (исправьте меня, если это не так!)
Есть ли лучший способ сделать это в рамках ограничений пакета html/template? Первый пример в документах шаблона Django подходит к тому, что мне нужно. Расширьте базовый макет и замените заголовок, боковую панель и блоки контента по мере необходимости.
Несколько косвенно: когда template.ExecuteTemplate возвращает ошибку во время запроса, есть ли идиоматический способ ее обработки? Если я передаю средство записи обработчику ошибок, я получаю суп на странице (потому что он просто продолжает писать), но перенаправление не похоже на идиоматический HTTP.
С некоторой помощью на Reddit мне удалось разработать довольно разумный (и производительный) подход к этому, который позволяет:
Создание макетов с блоками контента
Создание шаблонов, эффективно «расширяющих» эти макеты
Заполнение блоков (скрипты, сайдбары и т.п.) другими шаблонами
{{ определить "название"}}Индексная страница{{ end }}
// Мы должны определить каждый блок в базовом макете.
{{ определите "скрипты" }} {{ конец }}
{{ определите "боковую панель" }}
// У нас есть боковая панель, состоящая из двух частей, которая меняется в зависимости от страницы
{{ шаблон "sidebar_index" }}
{{ шаблон "sidebar_base" }}
{{ конец }}
{{ определить "контент" }}
{{ шаблон "listings_table" . }}
{{ конец }}
… и наш код Go, который использует подход map[string]*template.Template , описанный в этом ответе SO:
var templates map[string]*template.Template
var ErrTemplateDoesNotExist = errors.New("Шаблон не существует.")
// Загружаем шаблоны при инициализации программы
функция инициализации () {
если шаблоны == ноль {
шаблоны = сделать (карта [строка] * шаблон. Шаблон)
}
templates["index.html"] = template.Must(template. ParseFiles("index.tmpl", "sidebar_index.tmpl", "sidebar_base.tmpl", "listings_table.tmpl", "base.tmpl"))
...
}
// renderTemplate — это оболочка вокруг template.ExecuteTemplate.
func renderTemplate(w http.ResponseWriter, строка имени, карта данных[строка]интерфейс{}) ошибка {
// Убедитесь, что шаблон существует на карте.
tmpl, хорошо := шаблоны[имя]
если! хорошо {
вернуть ErrTemplateDoesNotExist
}
w.Header().Set("Content-Type", "text/html; charset=utf-8")
tmpl.ExecuteTemplate(w, "база", данные)
вернуть ноль
}
Судя по первоначальным тестам (с использованием wrk ), он кажется немного более производительным, когда дело доходит до большой нагрузки, вероятно, из-за того, что мы не передаем все ParseGlob шаблонов при каждом запросе. Это также значительно упрощает разработку самих шаблонов.
6
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Патент США на систему и способ анализа документа Патент (Патент № 8,327,265, выданный 4 декабря 2012 г.
)
ПРИТЯЗАНИЕ НА ПРИОРИТЕТ
Настоящая заявка испрашивает приоритет в соответствии с 35 USC §120 и является продолжением в части из, заявка на патент США Ser. № 09/288,994, поданной 9 апреля 1999 г., в настоящее время патент США. 6424982, полное содержание которого включено сюда в качестве ссылки.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Настоящее изобретение в целом относится к системе и способу обработки документа и, в частности, к системе и способу идентификации множества фраз в документе, которые указывают контекст документа.
Различные факторы способствовали обширному хранению и поиску текстовой информации с использованием компьютерных баз данных. Факторами были резкое увеличение емкости жестких дисков в сочетании со снижением стоимости жестких дисков компьютеров и увеличением скорости передачи компьютерных сообщений. Кроме того, факторами были повышенная скорость обработки компьютеров и расширение компьютерных коммуникационных сетей, таких как доска объявлений или Интернет. Таким образом, люди имеют доступ к большим объемам текстовых данных, хранящихся в этих базах данных. Однако, хотя технология облегчает хранение больших объемов текстовых данных и доступ к ним, возникают новые проблемы, связанные с большим объемом доступных сейчас текстовых данных.
В частности, человек, пытающийся получить доступ к текстовым данным в компьютерной базе данных, имеющей большой объем данных, нуждается в системе для анализа данных, чтобы быстро и эффективно извлекать нужную информацию без извлечения посторонней информации. Кроме того, пользователю системы нужна эффективная система для сжатия каждого большого документа во множество фраз (одно или несколько слов), которые характеризуют документ, чтобы пользователь системы мог понять документ, фактически не просматривая весь документ. Система для сжатия каждого документа во множество ключевых фраз известна как система синтаксического анализа или синтаксический анализатор.
В одном типичном синтаксическом анализаторе анализатор пытается идентифицировать фразы, которые часто повторяются в документе, и идентифицирует эти фразы как ключевые фразы, характеризующие документ. Проблема такой системы в том, что она очень медленная, поскольку должна подсчитывать повторения каждой фразы в документе. Также требуется большой объем памяти. По мере увеличения объема анализируемых данных низкая скорость этого анализатора становится неприемлемой. Другой типичный синтаксический анализатор выполняет трехэтапный процесс для определения ключевых фраз. Во-первых, каждому слову в документе присваивается тег, основанный на части речи слова (например, существительное, прилагательное, наречие, глагол и т. д.), и определенные части речи, такие как артикль или прилагательное, могут быть удалены из списка словосочетаний, характеризующих документ. Затем можно использовать одну или несколько последовательностей слов (шаблонов) для идентификации и удаления фраз, которые не добавляют никакого понимания к документу. Наконец, в качестве ключевой фразы, характеризующей документ, принимается любая фраза, являющаяся подходящей частью речи и не попадающая ни в один из шаблонов. Однако этот обычный синтаксический анализатор также работает медленно, что неприемлемо, поскольку объем данных, подлежащих анализу, увеличивается.
Во всех этих традиционных системах синтаксического анализа синтаксический анализатор пытается разбить документ на более мелкие части на основе характеристик (частоты повторения или части речи) конкретных слов в документе. Проблема в том, что язык обычно не так легко классифицировать, и поэтому обычный синтаксический анализатор не точно анализирует документ или требует много времени для анализа документа. Кроме того, традиционные системы синтаксического анализа очень медленные, поскольку все они пытаются использовать сложные характеристики языка в качестве метода анализа ключевых фраз из документа. Эти проблемы с обычными синтаксическими анализаторами становятся более серьезными по мере увеличения количества документов, которые необходимо проанализировать. Сегодня количество документов, которые необходимо проанализировать, неуклонно растет огромными темпами, в том числе благодаря Интернету и всемирной паутине. Поэтому эти обычные синтаксические анализаторы неприемлемы. Таким образом, желательно предоставить систему и способ синтаксического анализа, которые решают вышеуказанные проблемы и ограничения с помощью обычных систем синтаксического анализа, и именно на это направлено настоящее изобретение.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Предлагаются система и способ синтаксического анализатора в соответствии с изобретением, в которых символы разрыва внутри предложения или абзаца используются для синтаксического анализа документа на множество ключевых фраз. Система синтаксического анализатора в соответствии с изобретением является очень быстрой и не жертвует большой точностью ради скорости. Символы разрыва в документе могут включать знаки препинания, определенные стоп-слова и определенные типы слов, например глаголы и артикли. Система синтаксического анализатора может включать в себя буфер, который принимает одно или несколько слов до получения символа разрыва. Когда буфер получает символ разрыва, синтаксический анализатор может определить, сохраняется ли фраза перед символом разрыва на основе типа символа разрыва. В частности, если символ разрыва является знаком препинания, синтаксический анализатор может сохранить одно или несколько слов перед символом разрыва в качестве ключевой фразы. Если символ разрыва является символом другого типа, фраза перед символом разрыва может быть сохранена, а может и не быть сохранена. Как только судьба фразы определена, буфер очищается, и следующая последовательность из одного или нескольких слов считывается в буфер, чтобы ее также можно было проанализировать. Таким образом, множество фраз в документе может быть быстро извлечено из документа на основе символов разрыва в предложениях и абзацах документа.
Система синтаксического анализатора в соответствии с изобретением может также использоваться для синтаксического анализа различных иностранных языков на фразы при условии, что база данных правил включает правила, применимые к конкретному иностранному языку. В частности, каждый иностранный язык может иметь немного. другой синтаксис или символы (например, в случае азиатских языков или арабского языка), поэтому правила должны отражать эти синтаксические и характерные различия.
Таким образом, в соответствии с изобретением предлагается система для разбора фрагмента текста на одну или несколько фраз, характеризующих документ. Система содержит буфер для считывания одного или нескольких слов из фрагмента текста в буфер и синтаксический анализатор для идентификации фразы, содержащейся в буфере, причем фраза представляет собой последовательность из двух или более слов между символами разрыва. Анализатор дополнительно содержит средство для определения типа символа разрыва, который следует за идентифицированной фразой, и средство для сохранения ключевой фразы из буфера на основе определенного типа символа разрыва. Ключевые фразы хранятся в базе данных.
В соответствии с другим аспектом изобретения метод синтаксического анализа может включать двухэтапный процесс, в котором фразы извлекаются из фрагмента текста, как описано выше. Во время второго прохода извлекаются все вхождения извлеченных фраз в фрагменте текста. Второй проход гарантирует, что фразы, которые не были извлечены в каждом месте фрагмента текста, все еще могут быть извлечены.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
РИС. 1 представлена блок-схема системы обработки текста;
РИС. 2 — блок-схема системы синтаксического анализа в соответствии с изобретением;
РИС. 3А представляет собой блок-схему, иллюстрирующую двухпроходный способ синтаксического анализа в соответствии с изобретением;
РИС. 3B представляет собой блок-схему, иллюстрирующую более подробную информацию об этапе извлечения фраз способа синтаксического анализа, показанного на фиг. 3А;
РИС. 4 — пример документа, который должен быть проанализирован системой синтаксического анализа в соответствии с изобретением;
РИС. 5A-5L представляют собой схемы, иллюстрирующие работу буфера синтаксического анализа в соответствии с изобретением в документе, показанном на фиг. 4;
РИС. 6 представляет собой схему, иллюстрирующую фрагмент японского текста; и
РИС. 7 представляет собой схему, иллюстрирующую японские фразы, извлеченные из японского текста на фиг. 6 в соответствии с изобретением.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНОГО ВАРИАНТА ВОПЛОЩЕНИЯ
Изобретение особенно применимо к системе анализа документов на английском языке, и именно в этом контексте изобретение будет описано. Однако следует понимать, что система и способ в соответствии с изобретением имеют большую полезность, например, для других языков и различных фрагментов текстовых данных. Чтобы лучше понять изобретение, теперь будет описана система обработки текста.
РИС. 1 представлена блок-схема системы 10 обработки текста. Система 10 обработки текста может включать в себя систему 12 анализатора, кластеризатор 14 , генератор карт 16 и базу данных (БД) 18 . Система обработки текста может получать один или несколько фрагментов текста, таких как статьи, пресс-релизы или документы, и может генерировать карту, графически показывающую отношения между ключевыми фразами в документе. Каждый фрагмент текста может быть получен системой синтаксического анализатора 9.0073 12 , который обрабатывает каждый фрагмент входящего текста и генерирует одну или несколько ключевых фраз для каждого фрагмента текста, характеризующих фрагмент текста. Ключевые фразы могут храниться в базе данных 18 . Подробности системы синтаксического анализатора будут описаны ниже со ссылкой на фиг. 2-5. Как только ключевые фразы извлечены из каждого фрагмента текста, кластеризатор 14 может сгенерировать один или несколько кластеров ключевых фраз на основе взаимосвязей между фразами. Сгенерированные кластеры также могут храниться в базе данных 9.0073 18 . Генератор карт 16 может использовать сгенерированные кластеры для фрагментов текста в базе данных, чтобы сгенерировать графическую карту, показывающую отношения ключевых фраз в различных фрагментах текста в базе данных друг к другу, чтобы пользователь система может легко осуществлять поиск по базе данных, просматривая ключевые фразы фрагментов текста. Более подробная информация о кластеризаторе и генераторе карт раскрыта в одновременно находящейся на рассмотрении заявке на патент США Ser. № 08/801,970, которая принадлежит правопреемнику настоящего изобретения и включена сюда посредством ссылки. Система обработки текста может быть реализована различными способами, включая компьютерную систему клиент-серверного типа, в которой компьютеры-клиенты получают доступ к серверу через общедоступную компьютерную сеть, такую как Интернет. Синтаксический анализатор, кластеризатор и генератор карт могут быть программными приложениями, выполняемыми центральным процессором (не показан) системы 10 обработки текста. Теперь система парсера 12 в соответствии с изобретением будет описан более подробно.
РИС. 2 представлена блок-схема системы синтаксического анализа 12 в соответствии с изобретением. Система 12 синтаксического анализа может включать в себя буфер 20 , синтаксический анализатор 22 и базу данных правил (БД правил) 24 . В буфере может храниться одно или несколько слов входящего фрагмента текста, которым может быть документ, которые анализируются синтаксическим анализатором 22 с использованием правил, содержащихся в БД правил 24 . Выход системы синтаксического анализатора 12 представляет собой одну или несколько фраз (каждая фраза содержит одно или несколько слов), которые характеризуют анализируемый документ. В частности, синтаксический анализатор может разделять фразы в документе на основе символов разрыва внутри документа в соответствии с изобретением. Более подробно, одно или несколько слов могут считываться в буфер из документа до тех пор, пока не будет идентифицирован символ разрыва. Таким образом, система анализатора 12 идентифицирует фразы, которые находятся между символами разрыва. Затем, в зависимости от типа символа разрыва, фраза может быть сохранена как ключевая фраза или удалена. Система парсера 12 , например, могут быть реализованы как одна или несколько частей программного обеспечения, выполняемых микропроцессором (не показан) серверного компьютера, доступ к которому может осуществляться множеством клиентских компьютеров через компьютерную сеть, такую как Интернет, локальная сеть или глобальная сеть. Синтаксический анализатор 22 предпочтительно быстро извлекает ключевые фразы из фрагмента текста, используя символы разрыва. Теперь будут описаны символы разрыва в соответствии с изобретением.
Символы разрыва могут включать явный разрыв, например знак препинания, числа, слова, содержащие числа, и стоп-слова. Стоп-слова могут быть дополнительно классифицированы как мягкие стоп-слова или жесткие стоп-слова. Далее будет описан каждый из этих различных символов разрыва. Явные символы разрыва могут включать в себя различные знаки препинания, такие как точка, запятая, точка с запятой, двоеточие, восклицательный знак, правая или левая круглая скобка, левая или правая квадратная скобка, левая или правая фигурная скобка, символ возврата или символ перевода строки. Стоп-символы могут быть сгенерированным списком или могут включать косую черту (/) и символ амперсанда (@). Разделителем могут быть цифры, буквы, иностранные символы, символы разрыва, апострофы, дефисы и другие стоп-символы. Различные слова в фрагменте текста могут быть классифицированы как артикли, соединители, символы твердой и плавной остановки, лингвистические индикаторы, синтаксические категории, такие как существительные, глаголы, неправильные глаголы, прилагательные и наречия.
При анализе символов фрагмента текста к фразе всегда можно добавить разделители. Апостроф или тире в начале слова рассматриваются как символы разрыва (см. ниже), апостроф или тире в конце слова также рассматриваются как символы разрыва, а слова с апострофом или тире в середине слово добавляется к фразе в буфере. Все стоп-символы и разрывы рассматриваются как стоп-символы и разрывы, как описано ниже. На уровне слова синтаксического анализа имена собственные сохраняются путем проверки на заглавную букву в первом символе слова. Кроме того, в буфере сохраняются все слова, содержащие только буквы верхнего регистра и числовые слова. Необязательно числовая строка может быть классифицирована и обработана как стоп-символ. Ниже приведены обязательные правила синтаксического анализа на уровне слов. Во-первых, слово, следующее за притяжательным «s», может быть удалено. Например, как предложение «У кошки лапа мокрая». анализируется в соответствии с изобретением, «the» удаляется, а «cat» помещается в буфер, а затем удаляется при обнаружении символа разрыва (апострофа). Апостроф удаляется, потому что это знак препинания, тогда следующим символом для разбора является притяжательная буква «s» после апострофа, который удаляется вместе со словом «лапа», поскольку оно следует за притяжательной буквой «s». Соединительные слова, появляющиеся в начале фразы, также удаляются, хотя соединительное слово, за которым следует «The», сохраняется в буфере. Для символа жесткой остановки удаляется последняя фраза, связанная с символом жесткой остановки, и обрабатывается оставшийся буфер. Символ плавной остановки может рассматриваться как символ разрыва. Повторяющийся символ рассматривается как стоп-символ.
Для дальнейшего удаления нежелательных слов для разбора. могут использоваться некоторые необязательные правила синтаксического анализа на уровне фраз. В частности, могут быть удалены фразы длиннее заданной длины, такие как шесть слов, может быть удалена фраза со всеми словами в верхнем регистре и может быть удалена фраза со всеми числовыми словами. Все вышеперечисленные правила синтаксического анализа могут быть сохранены в базе данных , 24, правил синтаксического анализа, показанной на фиг. 2. Подробности системы анализатора 12 теперь будут описаны со ссылкой на фиг. 3А и 3В.
РИС. 3A представляет собой блок-схему, иллюстрирующую двухпроходный процесс 30 синтаксического анализа в соответствии с изобретением. В частности, во время первого прохода 40 одна или несколько фраз извлекаются из фрагмента текста с использованием жестких и мягких стоп-слов, как описано ниже со ссылкой на фиг. 3Б. Таким образом, первый проход извлекает словосочетания с существительными. Например, если часть текста включает в себя «Большая лягушка и кенгуру прыгают вниз», при первом проходе извлекается фраза «большая лягушка», но не «прыгает кенгуру», как описано ниже. Во время второго прохода 41 , все извлеченные фразы извлекаются из фрагмента текста. В частности, появление каждой извлеченной фразы в фрагменте текста может быть извлечено из фрагмента текста. Например, предположим, что фрагмент текста содержит фрагменты «Программные ошибки в . . . » и «программные ошибки . . . ». Синтаксический анализатор на первом этапе отбрасывает первое вхождение термина «ошибки программного обеспечения», поскольку за ним следует жесткая остановка, но сохраняет второе вхождение, поскольку за ним следует мягкая остановка. Чтобы синтаксический анализатор не отбрасывал фразы с хорошими существительными, такие как первое вхождение термина «ошибки программного обеспечения», второй проход извлекает все вхождения извлеченных фраз из фрагмента текста, так что, например, оба вхождения термина « программные ошибки». Теперь более подробно будет описан первый проход метода.
РИС. 3B представляет собой блок-схему, иллюстрирующую дополнительные детали этапа , 40, извлечения фразы для синтаксического анализа документа в соответствии с изобретением. Способ начинается с загрузки первого слова документа в буфер из базы данных документов или памяти сервера на этапе 42 . Затем синтаксический анализатор определяет, является ли слово символом разрыва на шаге 44 . Синтаксический анализатор также может удалять определенные символы или слова на этом этапе процесса синтаксического анализа. Если слово не является символом разрыва, метод возвращается к шагу 9.0073 42 и следующее слово документа считывается в буфер. Этот процесс чтения слова в буфер повторяется до тех пор, пока не встретится символ разрыва, так что буфер будет содержать последовательность слов (фразу), которая имеет символ разрыва перед последовательностью слов и символ разрыва после последовательности слов. Таким образом, документ разбивается на фразы, которые отделяются друг от друга символами разрыва.
Если встречается символ разрыва, синтаксический анализатор может определить, является ли символ разрыва явным символом разрыва на шаге 9.0073 46 , удалите символ разрыва и извлеките фразу, содержащуюся в буфере, если на шаге 48 существует явный символ разрыва. Фраза, извлеченная из буфера, может быть сохранена в базе данных для использования в будущем. Затем, на этапе 50 , буфер может быть очищен для очистки слов из буфера, и буфер может начать загрузку новых слов в буфер на этапах 42 и 44 до тех пор, пока не будет идентифицирован другой символ разрыва. Возврат к шагу 46 , если символ разрыва не является явным символом разрыва, синтаксический анализатор определяет, является ли символ разрыва стоп-словом на шаге 52 . Если символ прерывания представляет собой мягкое стоп-слово, то мягкое стоп-слово удаляется, а фраза в буфере сохраняется в базе данных на шаге 54 , буфер сбрасывается на шаге 50 и буфер снова заполняется новыми слова из документа. Если символ разрыва не является стоп-словом (т. е. символ разрыва не является стоп-словом), то стоп-слово и фраза в буфере удаляются на шаге 9.0073 56 буфер очищается на шаге 50 и пополняется новыми словами из документа на шагах 42 и 44 . Таким образом, фразы из документа извлекаются в соответствии с изобретением с использованием символов разрыва и типа символа разрыва, чтобы отделить фразы друг от друга и определить, какие фразы будут сохранены в базе данных. Синтаксический анализатор в соответствии с изобретением не пытается анализировать каждое слово документа для идентификации ключевых фраз, как в обычных системах, а извлекает фразы из документа быстрее, чем обычные синтаксические анализаторы, и с такой же точностью, как обычные синтаксические анализаторы. Теперь пример работы синтаксического анализатора в соответствии с изобретением будет описан со ссылкой на фиг. 4 и 5 A- 5 L.
РИС. 4 показан пример документа 60 , анализируемого системой анализа в соответствии с изобретением, а на фиг. 5A-5L иллюстрируют работу буфера во время синтаксического анализа документа 60 , показанного на фиг. 4. В этом примере документ представляет собой короткую электронную новость, но синтаксический анализатор может также извлекать фразы из любого другого фрагмента текста. Фактически синтаксический анализатор в соответствии с изобретением может извлекать фразы из различных типов документов со скоростью до 1 Мбайт данных в секунду. Показанная конкретная история описывает нового «змееподобного» робота, разработанного NEC. ФИГ. 5A-5L иллюстрируют в таблице 68 , работа буфера в соответствии с изобретением по приведенной выше истории. В частности, первый столбец 70 таблицы содержит текущее считываемое в буфер слово, второй столбец 72 содержит определение типа слова синтаксическим анализатором в соответствии с изобретением, третий столбец 74 содержит содержимое буфера в определенное время, четвертый столбец 76 содержит индекс слова (т. е. фразы, которые извлекаются из документа) и пятый столбец 78 содержит комментарии о процессе синтаксического анализа.
Как показано на РИС. 5А, первое слово, считанное в буфер, представляет собой последовательность звездочек в начале рассказа, которые анализатор классифицирует как слово прерывания (пунктуация) и удаляет из буфера. Следующее слово «Компьютер» вводится в буфер, так как оно не является разбивочным словом, а следующее слово «Выбор» также вводится в буфер, так как оно также не является разбивочным словом. Таким образом, буфер содержит фразу «Выбор компьютера», как показано в ячейке 9.0073 80 . Следующее слово в документе — это запятая, которую синтаксический анализатор классифицирует как символ разрыва. Поскольку символ разрыва является пунктуацией (явный разрыв), слова в буфере сохраняются в базе данных, как показано в столбце индекса слов 76 , и буфер очищается. Теперь новые слова считываются в буфер и анализируются. Следующее слово в буфере — «Октябрь», которое является жестким стоп-словом, поскольку оно относится к дате и удаляется. Следующее слово, полученное буфером, это «1995», который является символом разрыва, поскольку это число, и он также удаляется. Следующее слово, полученное буфером, — «COPYRIGHT», которое идентифицируется как стоп-слово, поскольку оно состоит из заглавных букв и удаляется. Следующее слово — «Newsbytes», которое не является символом разрыва и поэтому сохраняется в буфере. Следующее слово — «Inc». который также хранится в буфере. Следующее слово — это точка, которая является символом разрыва, так что буфер содержит «Newsbytes Inc.». сохраняются в базе данных, как показано в столбце Word Index, символ разрыва удаляется, а буфер очищается.
Следующие два слова, полученные буфером, а именно «1995» и последовательность звездочек, являются словами прерывания, которые удаляются. Следующие два слова, полученные буфером, — это «Newsbytes» и «Newsbytes», которые оба хранятся в буфере. Следующим полученным словом является «август», которое является стоп-словом, так что содержимое буфера и стоп-слово удаляются. Следующие три слова, полученные буфером, представляют собой все символы разрыва (т. е. числа или знаки препинания), которые удаляются. Следующее слово — это слово, содержащее число в ячейке 82 , который сохраняется в буфере, но затем удаляется, когда следующим символом является символ разрыва, поскольку буфер содержит только одно слово. Как видно на фиг. 5B-5L, процесс синтаксического анализа продолжается для всего документа, так что список ключевых фраз, как показано в столбце 76 индекса Word, извлекается из документа и сохраняется в базе данных.
Таким образом, фразы, которые характеризуют документ или фрагмент текста, могут быть быстро извлечены из документа в соответствии с изобретением. Изобретение использует символы разрыва в документе или фрагменте текста, чтобы отделить фразы друг от друга и извлечь ключевые фразы для документа. В приведенном выше примере извлеченные фразы, такие как «Newsbytes Inc.», «змееподобный робот», «Корпорация NEC», «роботизированная электронная змея», «работа по оказанию помощи при стихийных бедствиях» и «первый в мире активный универсальный шарнир» позволяют человек, просматривающий только ключевые фразы, чтобы понять контекст документа, не просматривая весь документ. Система синтаксического анализа в соответствии с изобретением выполняет извлечение ключевых фраз быстрее, чем любые другие традиционные системы синтаксического анализа, что важно, поскольку общий объем текстовых данных и документов, доступных для синтаксического анализа, увеличивается с экспоненциальной скоростью, отчасти из-за взрыв пользователя интернета.
Синтаксический анализатор в соответствии с изобретением может использоваться для анализа документов на различных иностранных языках с незначительными модификациями базы данных правил для отражения изменений в символах и изменений в синтаксисе языка.




 Выполняете задание в тетрадях, а Данил идет к доске.
Выполняете задание в тетрадях, а Данил идет к доске.

 Ваня идет к доске выполнять данное упражнение.
Ваня идет к доске выполнять данное упражнение.
 ExecuteTemplate(w, "name.tmpl", map[string]interface{})
ExecuteTemplate(w, "name.tmpl", map[string]interface{})  ExecuteTemplate(w, "name.tmpl", map[string]interface{})
ExecuteTemplate(w, "name.tmpl", map[string]interface{})  Расширьте базовый макет и замените заголовок, боковую панель и блоки контента по мере необходимости.
Расширьте базовый макет и замените заголовок, боковую панель и блоки контента по мере необходимости.
 ParseFiles("index.tmpl", "sidebar_index.tmpl", "sidebar_base.tmpl", "listings_table.tmpl", "base.tmpl"))
...
}
// renderTemplate — это оболочка вокруг template.ExecuteTemplate.
func renderTemplate(w http.ResponseWriter, строка имени, карта данных[строка]интерфейс{}) ошибка {
// Убедитесь, что шаблон существует на карте.
tmpl, хорошо := шаблоны[имя]
если! хорошо {
вернуть ErrTemplateDoesNotExist
}
w.Header().Set("Content-Type", "text/html; charset=utf-8")
tmpl.ExecuteTemplate(w, "база", данные)
вернуть ноль
}
ParseFiles("index.tmpl", "sidebar_index.tmpl", "sidebar_base.tmpl", "listings_table.tmpl", "base.tmpl"))
...
}
// renderTemplate — это оболочка вокруг template.ExecuteTemplate.
func renderTemplate(w http.ResponseWriter, строка имени, карта данных[строка]интерфейс{}) ошибка {
// Убедитесь, что шаблон существует на карте.
tmpl, хорошо := шаблоны[имя]
если! хорошо {
вернуть ErrTemplateDoesNotExist
}
w.Header().Set("Content-Type", "text/html; charset=utf-8")
tmpl.ExecuteTemplate(w, "база", данные)
вернуть ноль
}
 )
) Таким образом, люди имеют доступ к большим объемам текстовых данных, хранящихся в этих базах данных. Однако, хотя технология облегчает хранение больших объемов текстовых данных и доступ к ним, возникают новые проблемы, связанные с большим объемом доступных сейчас текстовых данных.
Таким образом, люди имеют доступ к большим объемам текстовых данных, хранящихся в этих базах данных. Однако, хотя технология облегчает хранение больших объемов текстовых данных и доступ к ним, возникают новые проблемы, связанные с большим объемом доступных сейчас текстовых данных. Проблема такой системы в том, что она очень медленная, поскольку должна подсчитывать повторения каждой фразы в документе. Также требуется большой объем памяти. По мере увеличения объема анализируемых данных низкая скорость этого анализатора становится неприемлемой. Другой типичный синтаксический анализатор выполняет трехэтапный процесс для определения ключевых фраз. Во-первых, каждому слову в документе присваивается тег, основанный на части речи слова (например, существительное, прилагательное, наречие, глагол и т. д.), и определенные части речи, такие как артикль или прилагательное, могут быть удалены из списка словосочетаний, характеризующих документ. Затем можно использовать одну или несколько последовательностей слов (шаблонов) для идентификации и удаления фраз, которые не добавляют никакого понимания к документу. Наконец, в качестве ключевой фразы, характеризующей документ, принимается любая фраза, являющаяся подходящей частью речи и не попадающая ни в один из шаблонов. Однако этот обычный синтаксический анализатор также работает медленно, что неприемлемо, поскольку объем данных, подлежащих анализу, увеличивается.
Проблема такой системы в том, что она очень медленная, поскольку должна подсчитывать повторения каждой фразы в документе. Также требуется большой объем памяти. По мере увеличения объема анализируемых данных низкая скорость этого анализатора становится неприемлемой. Другой типичный синтаксический анализатор выполняет трехэтапный процесс для определения ключевых фраз. Во-первых, каждому слову в документе присваивается тег, основанный на части речи слова (например, существительное, прилагательное, наречие, глагол и т. д.), и определенные части речи, такие как артикль или прилагательное, могут быть удалены из списка словосочетаний, характеризующих документ. Затем можно использовать одну или несколько последовательностей слов (шаблонов) для идентификации и удаления фраз, которые не добавляют никакого понимания к документу. Наконец, в качестве ключевой фразы, характеризующей документ, принимается любая фраза, являющаяся подходящей частью речи и не попадающая ни в один из шаблонов. Однако этот обычный синтаксический анализатор также работает медленно, что неприемлемо, поскольку объем данных, подлежащих анализу, увеличивается.
 Таким образом, желательно предоставить систему и способ синтаксического анализа, которые решают вышеуказанные проблемы и ограничения с помощью обычных систем синтаксического анализа, и именно на это направлено настоящее изобретение.
Таким образом, желательно предоставить систему и способ синтаксического анализа, которые решают вышеуказанные проблемы и ограничения с помощью обычных систем синтаксического анализа, и именно на это направлено настоящее изобретение. В частности, если символ разрыва является знаком препинания, синтаксический анализатор может сохранить одно или несколько слов перед символом разрыва в качестве ключевой фразы. Если символ разрыва является символом другого типа, фраза перед символом разрыва может быть сохранена, а может и не быть сохранена. Как только судьба фразы определена, буфер очищается, и следующая последовательность из одного или нескольких слов считывается в буфер, чтобы ее также можно было проанализировать. Таким образом, множество фраз в документе может быть быстро извлечено из документа на основе символов разрыва в предложениях и абзацах документа.
В частности, если символ разрыва является знаком препинания, синтаксический анализатор может сохранить одно или несколько слов перед символом разрыва в качестве ключевой фразы. Если символ разрыва является символом другого типа, фраза перед символом разрыва может быть сохранена, а может и не быть сохранена. Как только судьба фразы определена, буфер очищается, и следующая последовательность из одного или нескольких слов считывается в буфер, чтобы ее также можно было проанализировать. Таким образом, множество фраз в документе может быть быстро извлечено из документа на основе символов разрыва в предложениях и абзацах документа.

 7 представляет собой схему, иллюстрирующую японские фразы, извлеченные из японского текста на фиг. 6 в соответствии с изобретением.
7 представляет собой схему, иллюстрирующую японские фразы, извлеченные из японского текста на фиг. 6 в соответствии с изобретением.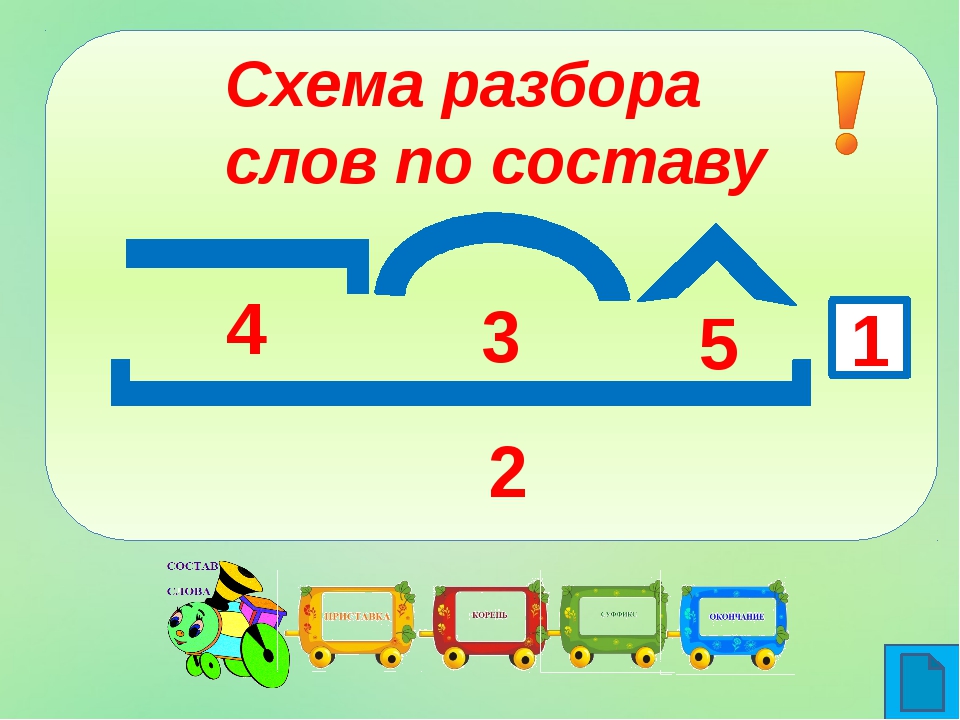 Каждый фрагмент текста может быть получен системой синтаксического анализатора 9.0073 12 , который обрабатывает каждый фрагмент входящего текста и генерирует одну или несколько ключевых фраз для каждого фрагмента текста, характеризующих фрагмент текста. Ключевые фразы могут храниться в базе данных 18 . Подробности системы синтаксического анализатора будут описаны ниже со ссылкой на фиг. 2-5. Как только ключевые фразы извлечены из каждого фрагмента текста, кластеризатор 14 может сгенерировать один или несколько кластеров ключевых фраз на основе взаимосвязей между фразами. Сгенерированные кластеры также могут храниться в базе данных 9.0073 18 . Генератор карт 16 может использовать сгенерированные кластеры для фрагментов текста в базе данных, чтобы сгенерировать графическую карту, показывающую отношения ключевых фраз в различных фрагментах текста в базе данных друг к другу, чтобы пользователь система может легко осуществлять поиск по базе данных, просматривая ключевые фразы фрагментов текста.
Каждый фрагмент текста может быть получен системой синтаксического анализатора 9.0073 12 , который обрабатывает каждый фрагмент входящего текста и генерирует одну или несколько ключевых фраз для каждого фрагмента текста, характеризующих фрагмент текста. Ключевые фразы могут храниться в базе данных 18 . Подробности системы синтаксического анализатора будут описаны ниже со ссылкой на фиг. 2-5. Как только ключевые фразы извлечены из каждого фрагмента текста, кластеризатор 14 может сгенерировать один или несколько кластеров ключевых фраз на основе взаимосвязей между фразами. Сгенерированные кластеры также могут храниться в базе данных 9.0073 18 . Генератор карт 16 может использовать сгенерированные кластеры для фрагментов текста в базе данных, чтобы сгенерировать графическую карту, показывающую отношения ключевых фраз в различных фрагментах текста в базе данных друг к другу, чтобы пользователь система может легко осуществлять поиск по базе данных, просматривая ключевые фразы фрагментов текста. Более подробная информация о кластеризаторе и генераторе карт раскрыта в одновременно находящейся на рассмотрении заявке на патент США Ser. № 08/801,970, которая принадлежит правопреемнику настоящего изобретения и включена сюда посредством ссылки. Система обработки текста может быть реализована различными способами, включая компьютерную систему клиент-серверного типа, в которой компьютеры-клиенты получают доступ к серверу через общедоступную компьютерную сеть, такую как Интернет. Синтаксический анализатор, кластеризатор и генератор карт могут быть программными приложениями, выполняемыми центральным процессором (не показан) системы 10 обработки текста. Теперь система парсера 12 в соответствии с изобретением будет описан более подробно.
Более подробная информация о кластеризаторе и генераторе карт раскрыта в одновременно находящейся на рассмотрении заявке на патент США Ser. № 08/801,970, которая принадлежит правопреемнику настоящего изобретения и включена сюда посредством ссылки. Система обработки текста может быть реализована различными способами, включая компьютерную систему клиент-серверного типа, в которой компьютеры-клиенты получают доступ к серверу через общедоступную компьютерную сеть, такую как Интернет. Синтаксический анализатор, кластеризатор и генератор карт могут быть программными приложениями, выполняемыми центральным процессором (не показан) системы 10 обработки текста. Теперь система парсера 12 в соответствии с изобретением будет описан более подробно. В буфере может храниться одно или несколько слов входящего фрагмента текста, которым может быть документ, которые анализируются синтаксическим анализатором 22 с использованием правил, содержащихся в БД правил 24 . Выход системы синтаксического анализатора 12 представляет собой одну или несколько фраз (каждая фраза содержит одно или несколько слов), которые характеризуют анализируемый документ. В частности, синтаксический анализатор может разделять фразы в документе на основе символов разрыва внутри документа в соответствии с изобретением. Более подробно, одно или несколько слов могут считываться в буфер из документа до тех пор, пока не будет идентифицирован символ разрыва. Таким образом, система анализатора 12 идентифицирует фразы, которые находятся между символами разрыва. Затем, в зависимости от типа символа разрыва, фраза может быть сохранена как ключевая фраза или удалена. Система парсера 12 , например, могут быть реализованы как одна или несколько частей программного обеспечения, выполняемых микропроцессором (не показан) серверного компьютера, доступ к которому может осуществляться множеством клиентских компьютеров через компьютерную сеть, такую как Интернет, локальная сеть или глобальная сеть.
В буфере может храниться одно или несколько слов входящего фрагмента текста, которым может быть документ, которые анализируются синтаксическим анализатором 22 с использованием правил, содержащихся в БД правил 24 . Выход системы синтаксического анализатора 12 представляет собой одну или несколько фраз (каждая фраза содержит одно или несколько слов), которые характеризуют анализируемый документ. В частности, синтаксический анализатор может разделять фразы в документе на основе символов разрыва внутри документа в соответствии с изобретением. Более подробно, одно или несколько слов могут считываться в буфер из документа до тех пор, пока не будет идентифицирован символ разрыва. Таким образом, система анализатора 12 идентифицирует фразы, которые находятся между символами разрыва. Затем, в зависимости от типа символа разрыва, фраза может быть сохранена как ключевая фраза или удалена. Система парсера 12 , например, могут быть реализованы как одна или несколько частей программного обеспечения, выполняемых микропроцессором (не показан) серверного компьютера, доступ к которому может осуществляться множеством клиентских компьютеров через компьютерную сеть, такую как Интернет, локальная сеть или глобальная сеть. Синтаксический анализатор 22 предпочтительно быстро извлекает ключевые фразы из фрагмента текста, используя символы разрыва. Теперь будут описаны символы разрыва в соответствии с изобретением.
Синтаксический анализатор 22 предпочтительно быстро извлекает ключевые фразы из фрагмента текста, используя символы разрыва. Теперь будут описаны символы разрыва в соответствии с изобретением. Различные слова в фрагменте текста могут быть классифицированы как артикли, соединители, символы твердой и плавной остановки, лингвистические индикаторы, синтаксические категории, такие как существительные, глаголы, неправильные глаголы, прилагательные и наречия.
Различные слова в фрагменте текста могут быть классифицированы как артикли, соединители, символы твердой и плавной остановки, лингвистические индикаторы, синтаксические категории, такие как существительные, глаголы, неправильные глаголы, прилагательные и наречия. Ниже приведены обязательные правила синтаксического анализа на уровне слов. Во-первых, слово, следующее за притяжательным «s», может быть удалено. Например, как предложение «У кошки лапа мокрая». анализируется в соответствии с изобретением, «the» удаляется, а «cat» помещается в буфер, а затем удаляется при обнаружении символа разрыва (апострофа). Апостроф удаляется, потому что это знак препинания, тогда следующим символом для разбора является притяжательная буква «s» после апострофа, который удаляется вместе со словом «лапа», поскольку оно следует за притяжательной буквой «s». Соединительные слова, появляющиеся в начале фразы, также удаляются, хотя соединительное слово, за которым следует «The», сохраняется в буфере. Для символа жесткой остановки удаляется последняя фраза, связанная с символом жесткой остановки, и обрабатывается оставшийся буфер. Символ плавной остановки может рассматриваться как символ разрыва. Повторяющийся символ рассматривается как стоп-символ.
Ниже приведены обязательные правила синтаксического анализа на уровне слов. Во-первых, слово, следующее за притяжательным «s», может быть удалено. Например, как предложение «У кошки лапа мокрая». анализируется в соответствии с изобретением, «the» удаляется, а «cat» помещается в буфер, а затем удаляется при обнаружении символа разрыва (апострофа). Апостроф удаляется, потому что это знак препинания, тогда следующим символом для разбора является притяжательная буква «s» после апострофа, который удаляется вместе со словом «лапа», поскольку оно следует за притяжательной буквой «s». Соединительные слова, появляющиеся в начале фразы, также удаляются, хотя соединительное слово, за которым следует «The», сохраняется в буфере. Для символа жесткой остановки удаляется последняя фраза, связанная с символом жесткой остановки, и обрабатывается оставшийся буфер. Символ плавной остановки может рассматриваться как символ разрыва. Повторяющийся символ рассматривается как стоп-символ. могут использоваться некоторые необязательные правила синтаксического анализа на уровне фраз. В частности, могут быть удалены фразы длиннее заданной длины, такие как шесть слов, может быть удалена фраза со всеми словами в верхнем регистре и может быть удалена фраза со всеми числовыми словами. Все вышеперечисленные правила синтаксического анализа могут быть сохранены в базе данных , 24, правил синтаксического анализа, показанной на фиг. 2. Подробности системы анализатора 12 теперь будут описаны со ссылкой на фиг. 3А и 3В.
могут использоваться некоторые необязательные правила синтаксического анализа на уровне фраз. В частности, могут быть удалены фразы длиннее заданной длины, такие как шесть слов, может быть удалена фраза со всеми словами в верхнем регистре и может быть удалена фраза со всеми числовыми словами. Все вышеперечисленные правила синтаксического анализа могут быть сохранены в базе данных , 24, правил синтаксического анализа, показанной на фиг. 2. Подробности системы анализатора 12 теперь будут описаны со ссылкой на фиг. 3А и 3В. Например, если часть текста включает в себя «Большая лягушка и кенгуру прыгают вниз», при первом проходе извлекается фраза «большая лягушка», но не «прыгает кенгуру», как описано ниже. Во время второго прохода 41 , все извлеченные фразы извлекаются из фрагмента текста. В частности, появление каждой извлеченной фразы в фрагменте текста может быть извлечено из фрагмента текста. Например, предположим, что фрагмент текста содержит фрагменты «Программные ошибки в . . . » и «программные ошибки . . . ». Синтаксический анализатор на первом этапе отбрасывает первое вхождение термина «ошибки программного обеспечения», поскольку за ним следует жесткая остановка, но сохраняет второе вхождение, поскольку за ним следует мягкая остановка. Чтобы синтаксический анализатор не отбрасывал фразы с хорошими существительными, такие как первое вхождение термина «ошибки программного обеспечения», второй проход извлекает все вхождения извлеченных фраз из фрагмента текста, так что, например, оба вхождения термина « программные ошибки».
Например, если часть текста включает в себя «Большая лягушка и кенгуру прыгают вниз», при первом проходе извлекается фраза «большая лягушка», но не «прыгает кенгуру», как описано ниже. Во время второго прохода 41 , все извлеченные фразы извлекаются из фрагмента текста. В частности, появление каждой извлеченной фразы в фрагменте текста может быть извлечено из фрагмента текста. Например, предположим, что фрагмент текста содержит фрагменты «Программные ошибки в . . . » и «программные ошибки . . . ». Синтаксический анализатор на первом этапе отбрасывает первое вхождение термина «ошибки программного обеспечения», поскольку за ним следует жесткая остановка, но сохраняет второе вхождение, поскольку за ним следует мягкая остановка. Чтобы синтаксический анализатор не отбрасывал фразы с хорошими существительными, такие как первое вхождение термина «ошибки программного обеспечения», второй проход извлекает все вхождения извлеченных фраз из фрагмента текста, так что, например, оба вхождения термина « программные ошибки». Теперь более подробно будет описан первый проход метода.
Теперь более подробно будет описан первый проход метода. Таким образом, документ разбивается на фразы, которые отделяются друг от друга символами разрыва.
Таким образом, документ разбивается на фразы, которые отделяются друг от друга символами разрыва. Если символ разрыва не является стоп-словом (т. е. символ разрыва не является стоп-словом), то стоп-слово и фраза в буфере удаляются на шаге 9.0073 56 буфер очищается на шаге 50 и пополняется новыми словами из документа на шагах 42 и 44 . Таким образом, фразы из документа извлекаются в соответствии с изобретением с использованием символов разрыва и типа символа разрыва, чтобы отделить фразы друг от друга и определить, какие фразы будут сохранены в базе данных. Синтаксический анализатор в соответствии с изобретением не пытается анализировать каждое слово документа для идентификации ключевых фраз, как в обычных системах, а извлекает фразы из документа быстрее, чем обычные синтаксические анализаторы, и с такой же точностью, как обычные синтаксические анализаторы. Теперь пример работы синтаксического анализатора в соответствии с изобретением будет описан со ссылкой на фиг. 4 и 5 A- 5 L.
Если символ разрыва не является стоп-словом (т. е. символ разрыва не является стоп-словом), то стоп-слово и фраза в буфере удаляются на шаге 9.0073 56 буфер очищается на шаге 50 и пополняется новыми словами из документа на шагах 42 и 44 . Таким образом, фразы из документа извлекаются в соответствии с изобретением с использованием символов разрыва и типа символа разрыва, чтобы отделить фразы друг от друга и определить, какие фразы будут сохранены в базе данных. Синтаксический анализатор в соответствии с изобретением не пытается анализировать каждое слово документа для идентификации ключевых фраз, как в обычных системах, а извлекает фразы из документа быстрее, чем обычные синтаксические анализаторы, и с такой же точностью, как обычные синтаксические анализаторы. Теперь пример работы синтаксического анализатора в соответствии с изобретением будет описан со ссылкой на фиг. 4 и 5 A- 5 L.
 е. фразы, которые извлекаются из документа) и пятый столбец 78 содержит комментарии о процессе синтаксического анализа.
е. фразы, которые извлекаются из документа) и пятый столбец 78 содержит комментарии о процессе синтаксического анализа. Следующее слово в буфере — «Октябрь», которое является жестким стоп-словом, поскольку оно относится к дате и удаляется. Следующее слово, полученное буфером, это «1995», который является символом разрыва, поскольку это число, и он также удаляется. Следующее слово, полученное буфером, — «COPYRIGHT», которое идентифицируется как стоп-слово, поскольку оно состоит из заглавных букв и удаляется. Следующее слово — «Newsbytes», которое не является символом разрыва и поэтому сохраняется в буфере. Следующее слово — «Inc». который также хранится в буфере. Следующее слово — это точка, которая является символом разрыва, так что буфер содержит «Newsbytes Inc.». сохраняются в базе данных, как показано в столбце Word Index, символ разрыва удаляется, а буфер очищается.
Следующее слово в буфере — «Октябрь», которое является жестким стоп-словом, поскольку оно относится к дате и удаляется. Следующее слово, полученное буфером, это «1995», который является символом разрыва, поскольку это число, и он также удаляется. Следующее слово, полученное буфером, — «COPYRIGHT», которое идентифицируется как стоп-слово, поскольку оно состоит из заглавных букв и удаляется. Следующее слово — «Newsbytes», которое не является символом разрыва и поэтому сохраняется в буфере. Следующее слово — «Inc». который также хранится в буфере. Следующее слово — это точка, которая является символом разрыва, так что буфер содержит «Newsbytes Inc.». сохраняются в базе данных, как показано в столбце Word Index, символ разрыва удаляется, а буфер очищается. Следующим полученным словом является «август», которое является стоп-словом, так что содержимое буфера и стоп-слово удаляются. Следующие три слова, полученные буфером, представляют собой все символы разрыва (т. е. числа или знаки препинания), которые удаляются. Следующее слово — это слово, содержащее число в ячейке 82 , который сохраняется в буфере, но затем удаляется, когда следующим символом является символ разрыва, поскольку буфер содержит только одно слово. Как видно на фиг. 5B-5L, процесс синтаксического анализа продолжается для всего документа, так что список ключевых фраз, как показано в столбце 76 индекса Word, извлекается из документа и сохраняется в базе данных.
Следующим полученным словом является «август», которое является стоп-словом, так что содержимое буфера и стоп-слово удаляются. Следующие три слова, полученные буфером, представляют собой все символы разрыва (т. е. числа или знаки препинания), которые удаляются. Следующее слово — это слово, содержащее число в ячейке 82 , который сохраняется в буфере, но затем удаляется, когда следующим символом является символ разрыва, поскольку буфер содержит только одно слово. Как видно на фиг. 5B-5L, процесс синтаксического анализа продолжается для всего документа, так что список ключевых фраз, как показано в столбце 76 индекса Word, извлекается из документа и сохраняется в базе данных. В приведенном выше примере извлеченные фразы, такие как «Newsbytes Inc.», «змееподобный робот», «Корпорация NEC», «роботизированная электронная змея», «работа по оказанию помощи при стихийных бедствиях» и «первый в мире активный универсальный шарнир» позволяют человек, просматривающий только ключевые фразы, чтобы понять контекст документа, не просматривая весь документ. Система синтаксического анализа в соответствии с изобретением выполняет извлечение ключевых фраз быстрее, чем любые другие традиционные системы синтаксического анализа, что важно, поскольку общий объем текстовых данных и документов, доступных для синтаксического анализа, увеличивается с экспоненциальной скоростью, отчасти из-за взрыв пользователя интернета.
В приведенном выше примере извлеченные фразы, такие как «Newsbytes Inc.», «змееподобный робот», «Корпорация NEC», «роботизированная электронная змея», «работа по оказанию помощи при стихийных бедствиях» и «первый в мире активный универсальный шарнир» позволяют человек, просматривающий только ключевые фразы, чтобы понять контекст документа, не просматривая весь документ. Система синтаксического анализа в соответствии с изобретением выполняет извлечение ключевых фраз быстрее, чем любые другие традиционные системы синтаксического анализа, что важно, поскольку общий объем текстовых данных и документов, доступных для синтаксического анализа, увеличивается с экспоненциальной скоростью, отчасти из-за взрыв пользователя интернета.