Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «инъекция», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ИНЪЕКЦИЯ, и, ж. (спец.).
1. Введение лекарственного раствора непосредственно под кожу, в мышцу, в вену.
2. Введение раствора в специально подготовленный канал. И. раствора в шурф.
| прил. инъекционный, ая, ое.
Фонетический (звуко-буквенный) разбор
инъе́кция
инъекция — слово из 4 слогов: инъ-е-кци-я. Ударение падает на 2-й слог.
Транскрипция слова: [инй’экцый’а]
и — [и] — гласный, безударный
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
ъ — не обозначает звука
е — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [э] — гласный, ударный
к — [к] — согласный, глухой парный, твёрдый (парный)
ц — [ц] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
и — [ы] — гласный, безударный
я — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [а] — гласный, безударный
В слове 8 букв и 9 звуков.
При разборе слова используются правила:
- Гласная и после букв ж, ш, ц означает звук [ы]
- Гласная Е после ь, ъ является йотированной и обозначает звук [й’э]
Цветовая схема: инъекция
Разбор слова «инъекция» по составу
инъекция
Части слова «инъекция»: инъек/ци/я
Состав слова:
инъек — корень,
ци — суффикс,
я — окончание,
инъекци — основа слова.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «самосознание», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
САМОСОЗНАНИЕ, я, ср. Полное понимание самого себя, своего значения, роли в жизни, обществе. Классовое с.
Классовое с.
Фонетический (звуко-буквенный) разбор
самосозна́ние
самосознание — слово из 6 слогов: са-мо-со-зна-ни-е. Ударение падает на 4-й слог.
Транскрипция слова: [самасазнан’ий’э]
с — [с] — согласный, глухой парный, твёрдый (парный)
а — [а] — гласный, безударный
м — [м] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
с — [с] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
з — [з] — согласный, звонкий парный, твёрдый (парный)
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, ударный
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
и — [и] — гласный, безударный
е — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [э] — гласный, безударный
В слове 12 букв и 13 звуков.
Цветовая схема: самосознание
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «самосознание» по составу
самосознание
Части слова «самосознание»: сам/о/созна/ни/е
Состав слова:
сам, созна — корни,
о — соединительная гласная,
ни — суффикс,
е — окончание,
самосознани — основа слова.
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).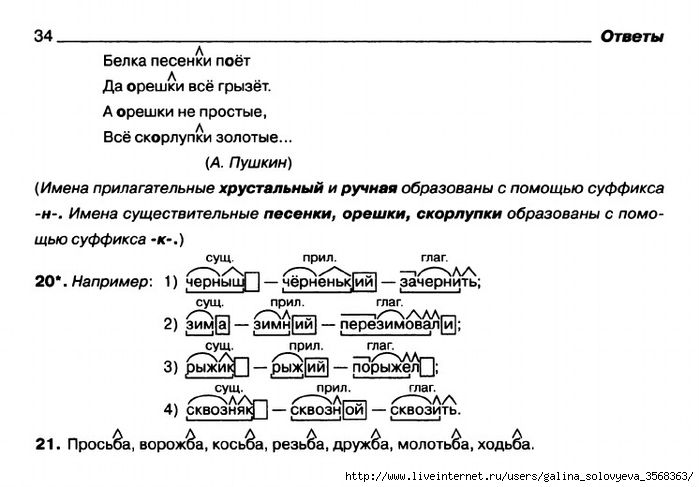
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н., Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Как концептуальная специфика отдельных слов влияет на композицию добавочного предложения: свидетельство MEG
https://doi.org/10.1016/j.bandl.2021.104951Get rights and content
Highlights
- •
модулировать активность LATL для словосочетаний с существительными.
- •
Мы проверили, распространяется ли шаблон в более общем смысле на состав глагол-аргумент.

- •
Аналогичный паттерн модуляции наблюдался в LATL, а также в lmSTC.
- •
Левая АГ не чувствительна к составу глагол-аргумент.
- •
Результаты поддерживают межкатегориальный механизм концептуальной композиции в LATL.

Abstract
В то время как многие исследования были посвящены нейронной основе лексического доступа и композиции лексических элементов в более крупные значения, мало что известно о том, как семантические свойства отдельных слов влияют на состав. Однако исследования комбинаций модификатор-существительное показали, что связанная с композицией активность в левой передней височной доле (LATL) чувствительна к концептуальной специфике составляющих слов.Здесь мы проверили, распространяется ли этот шаблон на комбинации глагол-аргумент в минимальных предложениях субъект-глагол-объект. Если эффекты специфичности LATL распространяются на интеграцию глагол-аргумент, это предполагает общий механизм, который составляет не только концепции сущностей, но также предложения, описывающие события. Результаты показали в целом аналогичную модуляцию за счет концептуальной специфичности в глагольной области, предполагая центральную, независимую от категорий роль LATL как концептуального объединителя. Кроме того, мы наблюдали эффекты специфичности в левой средне-верхней височной коре, но угловая извилина, которую часто предполагали как комбинаторную, не проявляла влияния композиции.
Результаты показали в целом аналогичную модуляцию за счет концептуальной специфичности в глагольной области, предполагая центральную, независимую от категорий роль LATL как концептуального объединителя. Кроме того, мы наблюдали эффекты специфичности в левой средне-верхней височной коре, но угловая извилина, которую часто предполагали как комбинаторную, не проявляла влияния композиции.
ключевых слов
семантика
семантика
Концепции
Концепции
Магнитоэнцефалография
Магнитоэнцефалография
левый передний височный доля
левый угловой долей
. Рекомендуемые изделия из натурального цикла
.
© 2021 Авторы. Опубликовано Elsevier Inc.
Рекомендуемые статьи
Цитирующие статьи
Концептуальная и референциальная аффордансность в концептуальной композиции
Далее мы обрисуем, как механизмы концептуальной и референтной аффордансности могут быть объединены в единую смешанную модель интерпретации (см. Herbelot 2016 за обзор предыдущей работы, сочетающей формальную и распределительную семантику). 16
Herbelot 2016 за обзор предыдущей работы, сочетающей формальную и распределительную семантику). 16
Мы будем использовать теорию репрезентации дискурса (DRT) в качестве основы для нашей семантики. Мы используем DRT, потому что (1) понятие референта дискурса имеет решающее значение для реализации референциальной композиции, и (2) самые последние исследования семантики композиционного распределения еще не смогли показать, как такие модели могут обеспечить эффективный анализ референциального обоснования или динамика дискурса (Бернарди и др., 2015; Садрзаде и Пурвер, 2015). Это последнее положение дел приводит нас к предварительной гипотезе о том, что композиционно-дистрибутивную семантику лучше всего использовать для моделирования только тех частей семантической композиции, которые, с нашей точки зрения, концептуально допустимы.
Из соображений экономии места мы должны предположить базовое знакомство с DRT; читатель упоминается, например. Камп (1981) или Камп и Рейл (1993) для фона. Наша реализация DRT будет полностью стандартной, всего за тремя исключениями. Во-первых, нам нужны средства соединения дистрибутивных семантических представлений со структурами представления дискурса (DRS). Во-вторых, в результате этого мы внесем небольшие изменения в нашу трактовку именных и адъективных предикатов по отношению к тому, что более общепринято.Наконец, нам понадобится способ отличить концептуально предоставленную композицию от референтно предоставленной.
Наша реализация DRT будет полностью стандартной, всего за тремя исключениями. Во-первых, нам нужны средства соединения дистрибутивных семантических представлений со структурами представления дискурса (DRS). Во-вторых, в результате этого мы внесем небольшие изменения в нашу трактовку именных и адъективных предикатов по отношению к тому, что более общепринято.Наконец, нам понадобится способ отличить концептуально предоставленную композицию от референтно предоставленной.
Мы включаем дистрибутивную семантику, основываясь на идее Zamparelli (1995) о том, что существительные (а не только определенные виды общих именных словосочетаний) обозначают карлсоновские виды (Carlson 1977). 17 Решающим шагом является использование дистрибутивных семантических представлений, а не атомарных абстрактных сущностей в качестве моделей для видов. Однако, как и в случае классической трактовки видов как абстрактных объектов, эти представления о распределении будут кодироваться в СРД как константы. Поскольку представления распределения, с математической точки зрения, являются векторами, константы, которые мы используем для них, будут обозначены стрелкой над головой (например, \(\overrightarrow{\mathbf{box}}\)), как отмечалось в предыдущем разделе.
Поскольку представления распределения, с математической точки зрения, являются векторами, константы, которые мы используем для них, будут обозначены стрелкой над головой (например, \(\overrightarrow{\mathbf{box}}\)), как отмечалось в предыдущем разделе.
Мы распространяем идею Зампарелли на прилагательные, также интерпретируя их как векторы (например, \(\overrightarrow{\mathbf{red}}\)). Поскольку предполагается, что прилагательные не обозначают естественные виды, а скорее определяют свойства, это предложение можно рассматривать как обобщение предложения Зампарелли, попутно заменяющее понятия как для видов, так и для свойств.Таким образом, векторы распределения будут служить очень грубыми представлениями понятий. 18 Важнейшим шагом будет позволить дистрибутивным представлениям существительных и прилагательных комбинироваться друг с другом, чтобы получить новые представления того же типа, роль которых в части семантики DRT точно аналогична роли представлений для немодифицированные существительные.
В предыдущем разделе мы кратко описали, как работает композиция двух векторов. Мы предполагаем, что грамматика языка указывает, когда семантическая композиция для определенных фраз включает композицию векторов, в отличие от других видов семантических операций.Композиция векторов происходит за пределами модели DRT, но поскольку результат также является вектором, он может, как и векторы компонентов, быть связан с константой в DRS, которую мы будем представлять, например, как comp (\(\overrightarrow{\mathbf{red}}\), \(\overrightarrow{\mathbf{box}}\)). Другими словами, константы вида \(\overrightarrow{\mathbf{red}}\), \(\overrightarrow{\mathbf{box}}\) и comp (\(\overrightarrow{\mathbf{red }}\), \(\overrightarrow{\mathbf{box}})\) относятся к одному типу.Таким образом, дистрибутивная семантика даст нам относительно конкретную алгебраическую модель для простых и сложных понятий, в которой оба вида понятий имеют фундаментально одинаковую природу, во многом подобно тому, как теоретико-решеточные структуры служат моделями для рассмотрения атомарных сущностей и множеств как фундаментально сходных. типы объектов (Link 1983).
типы объектов (Link 1983).
Следующая часть, которая нам нужна, — это способ использования существительных и прилагательных с такими интерпретациями в DRT, чтобы референты могли быть связаны с понятиями, которые выбирают существительные и прилагательные.Зампарелли использовал отношение реализации Карлсона (1977), которое мы представляем здесь как Реализовать , направлено на это: это отношение сохраняется между объектом и видом только в том случае, если объект представляет собой экземпляр вида. 19 Снова следуя за Зампарелли, мы предполагаем, что отношение Реализовать вводится (возможно, абстрактным) функциональным морфосинтаксисом, который превращает существительное в выражение, обозначающее набор сущностей. Таким образом, в первом приближении мы можем представить референтное выражение, такое как , ящик , как в (8), где u — референт дискурса, введенный фразой, который должен удовлетворять условию, что он является реализацией понятие \(\overrightarrow{\mathbf{box}}\).
Теперь рассмотрим модификацию. До того момента в синтаксисе, где вводится отношение Реализовать , действующие операции композиции будут комбинировать выражения, обозначающие вектор; это соответствует концепции композиции. Мы моделируем концептуально обусловленную композицию как результат компоновки векторов прилагательных и существительных непосредственно в новый вектор, соответствующий сложному концепту, который затем может стоять в отношении к дискурсивному референту, как в (9).
Синтаксические правила языка должны прояснить, когда можно апеллировать к такого рода композиции, а когда нет; интересно, что исследования синтаксиса модификации ясно указывают на то, что синтаксис действительно может кодировать такого рода информацию (см., например, McNally and Boleda 2004 и Bouchard 2005 об ограничениях упорядочения прилагательных на примере реляционных прилагательных).
Теперь рассмотрим референтно-предоставленную композицию понятий. Как упоминалось в разд. 3, это подтверждается только тогда, когда референт имени уже знаком в дискурсе. Таким образом, этот референт играет роль в интерпретации сочетания модификатора и существительного. Мы видим два пути, как это может быть реализовано. Можно было бы использовать референт для модуляции операции композиции, объединяющей векторы прилагательного и существительного. Это может быть представлено как в (10), где нижний индекс u указывает на модуляцию референтом u .
3, это подтверждается только тогда, когда референт имени уже знаком в дискурсе. Таким образом, этот референт играет роль в интерпретации сочетания модификатора и существительного. Мы видим два пути, как это может быть реализовано. Можно было бы использовать референт для модуляции операции композиции, объединяющей векторы прилагательного и существительного. Это может быть представлено как в (10), где нижний индекс u указывает на модуляцию референтом u .
С этой точки зрения понятие, связанное с красным в контексте, было бы точно таким же во всех контекстах, но его взаимодействие с понятием, вносимым существительным, будет варьироваться от одного контекста к другому, например, за счет использования различные веса сумм или произведений векторов.
В качестве альтернативы вектор, соответствующий прилагательному, может быть изменен как функция референта, т. е. переинтерпретирован как ad hoc, опосредованное референтом свойство, как это может быть представлено в (11).
С этой точки зрения операция композиции как таковая никак не изменяется; скорее вход в эту операцию. Другими словами, красный в этом примере будет просто ассоциироваться с другим понятием в рассматриваемом контексте. Потребуются дальнейшие исследования, чтобы определить, какой из этих вариантов представляет собой лучший анализ фактов, и действительно ли они различимы эмпирически.Однако стоит отметить, что этот последний подход очень напоминает индексальную интерпретацию прилагательных, предложенную Бошем (1983) и Ротшильдом и Сигалом (2009), кратко представленную в разд. 2.
Эти анализы не предлагают объяснение того, как контекст вмешивается, чтобы определить референциально предоставленную интерпретацию; в этом, к сожалению, мы находимся в хорошей компании, поскольку ни одна из известных нам теорий не предлагает такого объяснения, а в этой области требуется гораздо больше исследований.
Мы завершаем этот раздел некоторыми очень краткими умозрительными комментариями о том, как предлагаемый анализ соотносится с классическим анализом модификаций прилагательных существительных в рамках формальной семантики.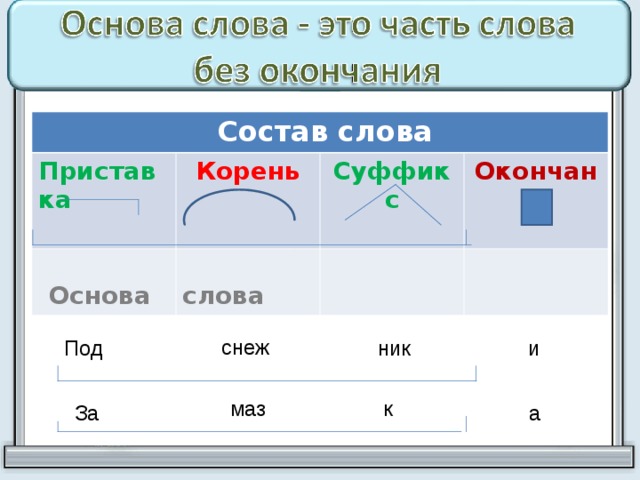 Такая модификация была проанализирована двумя способами: либо рассматривая прилагательное как свойство второго порядка, которое принимает существительное в качестве своего аргумента, либо рассматривая его как свойство первого порядка, которое комбинируется посредством соединения или пересечения множеств с (первое -порядок) свойство, обозначаемое существительным (см.г. Кэмп 1975; Сигел 1976; Larson 1998, среди многих других, за предложения и обсуждение). Последний анализ подходит специально для случаев так называемой интерсективной модификации, когда каждое из адъективных и именных свойств влечет за собой сохранение описываемого индивидуума. Первый является более общим и может использоваться не только для интерсективной модификации, но и для неинтерсективной модификации, а именно субсективной модификации, когда свойство прилагательного не имеет очевидного прямого значения для референта, но свойство существительного имеет место (ср. молекулярный биолог ), и интенсиональная модификация, когда владение номинальным имуществом не подразумевается (или не предполагается владение им) во время или в мире присвоения ( бывший мэр или предполагаемый вор ).
Такая модификация была проанализирована двумя способами: либо рассматривая прилагательное как свойство второго порядка, которое принимает существительное в качестве своего аргумента, либо рассматривая его как свойство первого порядка, которое комбинируется посредством соединения или пересечения множеств с (первое -порядок) свойство, обозначаемое существительным (см.г. Кэмп 1975; Сигел 1976; Larson 1998, среди многих других, за предложения и обсуждение). Последний анализ подходит специально для случаев так называемой интерсективной модификации, когда каждое из адъективных и именных свойств влечет за собой сохранение описываемого индивидуума. Первый является более общим и может использоваться не только для интерсективной модификации, но и для неинтерсективной модификации, а именно субсективной модификации, когда свойство прилагательного не имеет очевидного прямого значения для референта, но свойство существительного имеет место (ср. молекулярный биолог ), и интенсиональная модификация, когда владение номинальным имуществом не подразумевается (или не предполагается владение им) во время или в мире присвоения ( бывший мэр или предполагаемый вор ).
Все вышеописанные реализации композиции понятий являются аналогами неинтерсекционной модификации. Ни в коем случае понятие, вносимое прилагательным, не имеет прямого отношения к референту. Более того, как мы уже установили, наш анализ состава понятий непосредственно улавливает интуицию, развитую в Landman (2001) и Partee (2010), что все сочетания прилагательное-существительное, даже интенсиональные модификации, в некотором смысле субсекциональны, то есть номинальное описание всегда так или иначе используется для идентификации референта, поскольку оно вносит положительный вклад в возможное сложное описание, с которым референт связан через отношение Реализовать .Конечно, остается исследовать, как воспроизвести следствия эффектов мира и временных параметров, которые играли роль в традиционном анализе интенсиональных прилагательных, но мы отмечаем, что один неожиданный результат исследования Boleda et al. (2013) заключалась в том, что интенсиональные прилагательные оказались не более сложными для моделирования в дистрибутивной семантике, чем другие виды прилагательных, поскольку, при прочих равных условиях, композиционно-дистрибутивные семантические методы могли предсказать семантическое представление фраз, содержащих интенсиональные прилагательные из дистрибутивной семантики. репрезентации слов-компонентов так же хорошо, как и фраз, содержащих неинтенсиональные прилагательные (см.4 выше).
репрезентации слов-компонентов так же хорошо, как и фраз, содержащих неинтенсиональные прилагательные (см.4 выше).
70 синонимов КОНЦЕПЦИИ — Merriam-Webster
1 идея или утверждение обо всех членах группы или обо всех случаях ситуации
- попытка изменить общественное представление ночного выпуска новостей
2 что-то воображаемое или изображаемое в уме
- концепт для нового типа автомобиля, который может произвести революцию в отрасли
- абстракция,
- размышления,
- концепция,
- идея,
- изображение,
- впечатление,
- интеллект,
- мысленный взор,
- понятие,
- картина,
- мысль
См. определение в словаре
Часто задаваемые вопросы о концепции
Как существительное
понятие контрастирует со своими синонимами?
Некоторые распространенные синонимы понятия : понятие , идея , впечатление , понятие и мысль . Хотя все эти слова означают «то, что существует в уме как представление (как нечто постигнутое) или как формулировка (как план),» понятие может применяться к идее, образованной путем рассмотрения экземпляров вида или рода. или, шире, к любой идее о том, какой должна быть вещь.
Хотя все эти слова означают «то, что существует в уме как представление (как нечто постигнутое) или как формулировка (как план),» понятие может применяться к идее, образованной путем рассмотрения экземпляров вида или рода. или, шире, к любой идее о том, какой должна быть вещь.
общество без концепции частной собственности
Как
концепция и концепция соотносятся друг с другом?
Концепция часто взаимозаменяема с концепцией ; это может подчеркивать процесс воображения или формулирования, а не результат.
наша меняющаяся концепция того, что представляет собой искусство
Когда целесообразно использовать
идею вместо концепцию ?
Синонимы идея и концепция иногда взаимозаменяемы, но идея может относиться к ментальному образу или формулировке чего-то увиденного, известного или воображаемого, к чистой абстракции или к чему-то предполагаемому или смутно ощущаемому.
инновации идеи
моя идея рая
Когда
впечатлений будут хорошей заменой концепции ?
Слова впечатлений и концепт являются синонимами, но различаются нюансами.В частности,
первое впечатление имеет парящую высоту
Где
понятие может быть разумной альтернативой понятию ?
Слова понятие и понятие могут использоваться в сходных контекстах, но понятие предполагает идею, не очень решаемую анализом или размышлением, и может указывать на причудливую или случайную.
у тебя странные представления
Когда
мысль может быть использована для замены концепции ?
Значения мысли и понятия во многом совпадают; однако думал, что , скорее всего, предполагает результат размышлений, рассуждений или медитаций, а не воображения.
зафиксируйте свои мысли на бумаге
1.Введение
Это исследование основано на методе расширения [11] для разработки инновационного подхода к методу зеленого проектирования для экологически чистых продуктов. Метод расширения — это тип систематического метода, который предоставляет инженерам и проектировщикам некоторые конкретные и эффективные подходы к решению проблем. Эта теория впервые была предложена китайским исследователем Вэнь Цаем [11,58] на основе протяженности вещей. До сих пор он широко применялся во многих областях, включая инженерию, дизайн, экономику, социологию, менеджмент и т. д.[59,60,61,62]. Метод расширения может помочь дизайнерам и инженерам разлагать проблемы, анализировать ряд контекстов, рекомбинировать проблемы и эффективно находить возможные решения. Метод расширения включает в себя четыре основные части: расширение материи-элемента, метод преобразования, метод оценки и метод ромбовидного мышления. Предлагаемый инновационный метод зеленого проектирования был разработан на основе метода расширения и преобразования материи-элемента.
3.2. Модель Материя-Элемент
Понятие материя-элемент лежит в основе экстеники, и все последующие преобразования базируются на понятии материя-элемент. Элемент материи состоит из названия вещи (Имя, N), характеристики (Характеристика, С) и значения (Значение, V). Материя-элемент представлена R или r. Логическое математическое уравнение можно представить следующим образом [11]: R = (N, C, V)(1)
Все в мире может быть построено как модель материи-элемента на основе приведенного выше определения, включая реальные объекты и абстрактные описания.Признаки и соответствующие им величины в модели материи-элемента не ограничиваются одним типом, а также могут быть множественными представлениями.
В этом исследовании используется концепция модели материи-элемента для построения системы декомпозиции продукта или технологии.Любое изделие или технология по своим характеристикам или признакам может быть построено как первый уровень элементно-вещественной модели. По основной функции она делится на подсистемы, а затем устанавливается второй уровень модели материи-элемента. Затем выполняются указанные шаги для установления всех последующих уровней. Процессы работы всего продукта показаны в последовательности на рисунке 1 [11].
Любые проблемы дизайна также могут быть преобразованы в соответствующую модель материи-элемента, чтобы облегчить последующее преобразование материи-элемента и найти наилучшее решение.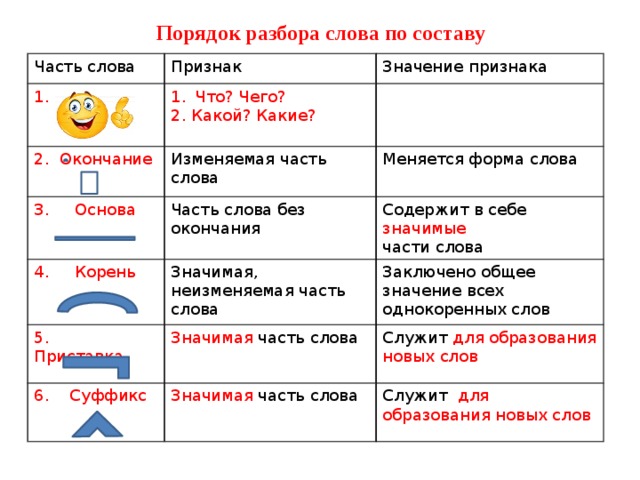 Следовательно, при разработке новых продуктов можно проектировать инновационные, создавая систему декомпозиции на основе модели материя-элемент для нахождения улучшенных частей продуктов.
Следовательно, при разработке новых продуктов можно проектировать инновационные, создавая систему декомпозиции на основе модели материя-элемент для нахождения улучшенных частей продуктов.
3.2.1. Расширяемость материи-элемента
Cai [11] предложил пять расширяемости подхода материя-элемент, включая дивергенцию, сопряжение, корреляцию, импликацию и расширяемость. Исходя из размерностей материй, включая внешнюю, внутреннюю, параллельную, гибкую, комбинирующую и разлагающуюся, можно вывести пути множественных преобразований, которые становятся основой для расширения вещей и решения противоречивых задач [59].
Дивергенция: Одна материя имеет много характеристик, а одна характеристика принадлежит многим материям. Существуют понятия «одна материя, обладающая многими свойствами», «одно свойство, существующее во многих материях», «одно значение, существующее во многих материях», «один элемент, существующий во многих материях».
Эти понятия называются дивергенцией.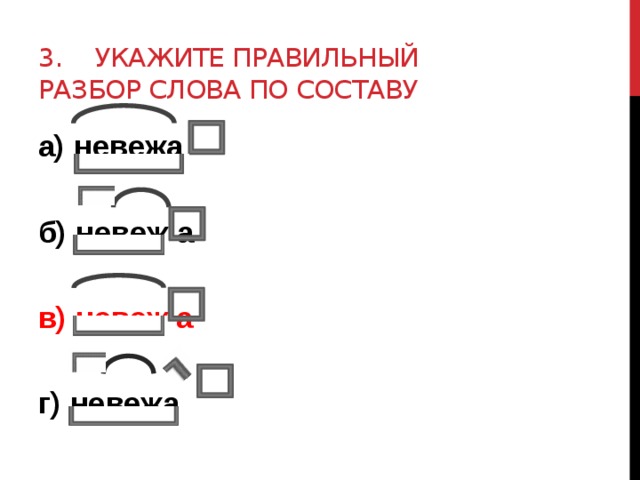 Сопряжение: Внутренняя структура материи — еще один фокус разрешения противоречий. Через изменения внутренней структуры иногда противоречия также могут трансформироваться в совместимости.Одна материя имеет восемь измерений, включая реальное, виртуальное, твердое, мягкое, явное, скрытое, положительное и отрицательное. Вещи могут быть более всесторонне признаны, а инновации могут быть созданы путем анализа восьми сопряженных измерений материи. Корреляция: могут быть зависимые отношения, существующие в вопросах с характеристиками, существующими в одном вопросе, а также в разных вопросах.
Сопряжение: Внутренняя структура материи — еще один фокус разрешения противоречий. Через изменения внутренней структуры иногда противоречия также могут трансформироваться в совместимости.Одна материя имеет восемь измерений, включая реальное, виртуальное, твердое, мягкое, явное, скрытое, положительное и отрицательное. Вещи могут быть более всесторонне признаны, а инновации могут быть созданы путем анализа восьми сопряженных измерений материи. Корреляция: могут быть зависимые отношения, существующие в вопросах с характеристиками, существующими в одном вопросе, а также в разных вопросах.
Значение: если материя А реализована, то должна быть реализована и материя Б. Говорят, что материя А вовлечена в материю Б.
Расширяемость: Дело можно объединить с другими делами в новое дело или разложить на новые дела. Эти новые материи имеют определенные характеристики, которые не принадлежат исходным материям.
3.2.2. Основное преобразование материи в элемент
После создания модели материи в элемент может быть выполнено преобразование материи в элемент. Преобразование материи-элемента — это замена трех элементов (N, C, V) в модели материя-элемент для получения новой материи-элемента.Различные элементы материи могут быть соединены в переплетенную сеть элементов материи посредством преобразования элементов материи. Преобразование материи в элемент — это уникальный способ работы по замене или синтезу различных элементов материи в соответствии с определенной характеристикой или атрибутом. Это модель, которая помогает в развитии идей, основанных на логике, которая может возникнуть в результате человеческого мышления. В данной статье преобразование материи в элемент можно рассматривать как основной инструмент для разрешения проектных противоречий.Его можно использовать для передачи «качества» и «количества» между элементами материи, включая имя объекта. Преобразование основной материи в элемент можно представить в виде математического уравнения следующим образом [58]: (3)T=[NTCT1VT1CT2VT2CT3VT3⋮⋮CTnVTn]=[Преобразование Доминируемая характеристикаVT1Принимаемая характеристикаVT2Преобразующий результатVT3⋮⋮CTnVTn]
где N
Преобразование материи-элемента — это замена трех элементов (N, C, V) в модели материя-элемент для получения новой материи-элемента.Различные элементы материи могут быть соединены в переплетенную сеть элементов материи посредством преобразования элементов материи. Преобразование материи в элемент — это уникальный способ работы по замене или синтезу различных элементов материи в соответствии с определенной характеристикой или атрибутом. Это модель, которая помогает в развитии идей, основанных на логике, которая может возникнуть в результате человеческого мышления. В данной статье преобразование материи в элемент можно рассматривать как основной инструмент для разрешения проектных противоречий.Его можно использовать для передачи «качества» и «количества» между элементами материи, включая имя объекта. Преобразование основной материи в элемент можно представить в виде математического уравнения следующим образом [58]: (3)T=[NTCT1VT1CT2VT2CT3VT3⋮⋮CTnVTn]=[Преобразование Доминируемая характеристикаVT1Принимаемая характеристикаVT2Преобразующий результатVT3⋮⋮CTnVTn]
где N  То есть N T ∈ {замена, разложение/композиция, добавление/удаление, расширение/сжатие}.C Tn обозначает характеристики трансформации, а V Tn указывает значения параметров. V T1 , V T2 и V T3 представляют доминирующую характеристику, принятую характеристику и результат преобразования соответственно. Вышеупомянутый процесс преобразования обычно обозначается аббревиатурой TV T1 = V T3 . Существует четыре типа основных преобразований материи в элемент, включая замену, разложение/сборку, добавление/удаление и расширение/сжатие, а именно [58,59]:
То есть N T ∈ {замена, разложение/композиция, добавление/удаление, расширение/сжатие}.C Tn обозначает характеристики трансформации, а V Tn указывает значения параметров. V T1 , V T2 и V T3 представляют доминирующую характеристику, принятую характеристику и результат преобразования соответственно. Вышеупомянутый процесс преобразования обычно обозначается аббревиатурой TV T1 = V T3 . Существует четыре типа основных преобразований материи в элемент, включая замену, разложение/сборку, добавление/удаление и расширение/сжатие, а именно [58,59]:
(1) Сменная трансформация
Замена: T 1 R = R’,
где (4)T1=[ЗаменаCT1RCT2RCT3R′⋮⋮]
Символ T 1 представляет выполнение замещающего преобразования.R — исходный объект, а R′ обозначает результат после преобразования. R становится R’ замещающим преобразованием. Замещающее преобразование может заменять имя, характеристики и количественную оценку объекта в модели материи-элемента в соответствии с конкретными требованиями.
(2) Разложение и трансформация композиции
Разложение: T 2 R = R′ = {R 1 , R 2 , …, R n }, R 1 ⊕ R 2 9 9 n ⊕0 = 90, ⊕3
где (5)T2=[DecompositionCT1RCT2RCT3{ R1,R2,…,Rn }⋮⋮].
Состав: Т 3 R = R′ = R 1 ⊕ R 2 ⊕…⊕ R n , R = {R 1 , R 2 90, }
где (6)T3=[CompositionCT1RCT2RCT3R1 ⨁ R2 ⨁… ⨁Rn ⋮⋮].
Символы T 2 и T 3 обозначают выполнение декомпозиции или композиционного преобразования. R — это исходный объект, а R’ указывает на результат после преобразования. R становится R’ в результате разложения или преобразования композиции.В теории материи-элемента вещи делятся на «полимеризуемые» или «составные» признаки. «Полимеризуемая» материя-элемент обычно относится к более абстрактному синтезу, тогда как «составная» материя-элемент относится к более конкретной комбинации. Поскольку есть комбинация, есть разложение.
(3) Преобразование добавления/удаления
Дополнение: T 4 R = R′ = R ⊕ R 1 ,
где (7)T4=[ДобавлениеCT1RCT2R1CT3R ⨁ R1⋮⋮].
Удаление: T 4 R = R′ = R ⊖ R 1 ,
где (8)T5=[ДобавлениеCT1RCT2R1CT3R ⊖ R1⋮⋮].
Символы T 4 и T 5 означают выполнение преобразования добавления или удаления. R — это исходный объект, а R’ представляет результат после преобразования. R становится R’ путем преобразования добавления или удаления. Если две (или более) вещи могут быть синтезированы или объединены в соответствии с определенными отношениями, это называется «сложением»; в противном случае это называется «удалением».
(4) Трансформация расширения/сжатия
Расширение: T 6 R = αR = R’,
где (9)T6=[Расширение/СжатиеCT1RCT2αCT3αR⋮⋮].
Аналогично, символ T 6 обозначает выполнение преобразования расширения или сжатия. R — исходный объект. Коэффициент α указывает на увеличение расширения и сжатия. Когда α > 1, это представляет преобразование расширения.В противном случае, когда 0 3.2.3. Набор расширений
Когда α > 1, это представляет преобразование расширения.В противном случае, когда 0 3.2.3. Набор расширений
После определения модели материи-элемента необходимо оценить возможное преобразование материи-элемента. Это делается с помощью набора расширений.Набор расширений можно записать как S˜ = {(x, y) | x∈D, y = f (x) ∈ R}, где D — теоретическая область, R — область действительных чисел (−∞, +∞), а y называется степенью корреляции. По размеру y элементы области можно разделить на три случая, которые принадлежат S˜, не принадлежат S˜ и для которых расширение принадлежит S˜. В качестве домена задать все возможные множества элементов материи, которые могут быть получены преобразованием. Затем установите набор расширений в домене и используйте метод расширения для решения проблемы.Подробное определение набора расширений можно представить следующим образом [63]:
Пусть D — область объектов, а x — общий элемент D; тогда множество расширений S˜ в D определяется как множество следующим образом: (10)S˜={(x,y)|x∈D, y=f (x)∈(−∞,+∞)},
где y = f (x) называется корреляционной функцией множества расширений S˜. Расширенная реляционная функция определена для количественной оценки отношения между элементом и набором. Диапазон расширенной реляционной функции равен (-∞, +∞), что означает, что элемент принадлежит любому множеству с определенной степенью.Множество расширений S˜ в D можно обозначить через
(11)S˜=S+∪H0∪S−,
где
(12)S+={(x,y)|x∈D, y=f(x)>0}, (13)H0={(x,y)|x∈D, y=f(x)=0 },(14)S−={(x,y)|x∈D, y=f(x) 0 (X 0 ∈ D). S− называется отрицательной областью в S˜; он описывает степень, в которой x не принадлежит X 0 . H 0 называется нулевой границей.
Расширенная реляционная функция определена для количественной оценки отношения между элементом и набором. Диапазон расширенной реляционной функции равен (-∞, +∞), что означает, что элемент принадлежит любому множеству с определенной степенью.Множество расширений S˜ в D можно обозначить через
(11)S˜=S+∪H0∪S−,
где
(12)S+={(x,y)|x∈D, y=f(x)>0}, (13)H0={(x,y)|x∈D, y=f(x)=0 },(14)S−={(x,y)|x∈D, y=f(x) 0 (X 0 ∈ D). S− называется отрицательной областью в S˜; он описывает степень, в которой x не принадлежит X 0 . H 0 называется нулевой границей.
3.3. Зеленые ДНК
. Из предшествующей литературы мы можем обнаружить, что в наиболее экологически чистых продуктах используются экологически чистые технологии, экологически чистые материалы и экологически чистое производство для улучшения экологических свойств продуктов. В этом исследовании эти три фактора зеленого дизайна определены как зеленые ДНК (рис. 2). В процессе проектирования продуктов в будущем, если дизайнеры смогут осуществлять свое дизайнерское мышление на основе трех зеленых ДНК, они должны быть в состоянии получить хорошие результаты зеленого дизайна.
3.3.1. Зеленые технологии
К категории зеленых технологий относятся все соответствующие зеленая энергетика и энергосберегающие технологии, включая солнечную энергию, энергию ветра, гидроэнергетику и т. д. Эти зеленые технологии легче всего демонстрируют эффективность зеленых продуктов. Дизайнерам рекомендуется уделять приоритетное внимание дизайну этого зеленого элемента при разработке экологически чистых продуктов.
3.3.2. Зеленый материал
Экологически безопасная концепция 4R (сокращение, повторное использование, переработка, регенерация), отстаиваемая государственными учреждениями и частными экологическими группами, является самым основным определением свойств зеленого материала.Новейшая технология экологически чистых материалов позволила разработать тип биоразлагаемых материалов, которые извлекаются из растительных волокон. Поэтому при выбрасывании таких предметов во внешнюю среду они будут разлагаться микроорганизмами при определенных температурно-влажностных условиях и не причинят вреда окружающей среде. Например, полилактид (PLA) является одним из таких материалов, который широко применяется в дизайне предметов первой необходимости. В будущем дизайнерам рекомендуется уделять первоочередное внимание использованию биоразлагаемых материалов при поиске материалов, подходящих для экологически чистых продуктов.
Например, полилактид (PLA) является одним из таких материалов, который широко применяется в дизайне предметов первой необходимости. В будущем дизайнерам рекомендуется уделять первоочередное внимание использованию биоразлагаемых материалов при поиске материалов, подходящих для экологически чистых продуктов.
3.3.3. Green Manufacture
Ради эстетической привлекательности продукты будут окрашены, покрыты и напечатаны для улучшения эстетического вида. Большинство этих процедур постобработки используют органические растворители и производят вредные токсичные вещества. Если с этими процессами не справиться должным образом, они часто будут вызывать загрязнение окружающей среды и ущерб. Поэтому, если дизайнеры попытаются не применять эти производственные процессы для украшения и украшения продуктов, это значительно уменьшит воздействие их работы на окружающую среду.
Однако эти три Зеленых ДНК не просто представляют значения «Зеленого», они представляют концепцию Зеленой базы данных. В разных отраслях будут применяться различные экологически чистые технологии, экологически чистые материалы и экологически чистые производственные процессы. Детали этого должны быть собраны и изучены дизайнерами для создания специальной базы данных их компании, которая затем может применяться при разработке экологически чистых продуктов в будущем.
В разных отраслях будут применяться различные экологически чистые технологии, экологически чистые материалы и экологически чистые производственные процессы. Детали этого должны быть собраны и изучены дизайнерами для создания специальной базы данных их компании, которая затем может применяться при разработке экологически чистых продуктов в будущем.
3.4. Инновационный метод экологического проектирования
Столкнувшись с экологичным дизайном продукта, генеральные дизайнеры часто не могут уловить точки проектирования или даже не знают, с чего начать.В процессах предварительного анализа продукта и превращения его в экологически чистый продукт, если упомянутые выше три Зеленых ДНК — «зеленая технология», «зеленый материал» и «зеленое производство» — могут быть интегрированы в дизайн-мышление метод расширения (рис. 3), то дизайнеры могут легко уловить точки дизайна и продолжить разработку инновационных экологически чистых продуктов. Интеграция обоих даст дополнительные эффекты дизайна. Поэтому для практического проектирования экологически чистых продуктов предлагается метод «зеленого расширения», основанный на теории расширения и трех концепциях «зеленой ДНК», предложенных в этом исследовании.Предлагаемый инновационный метод зеленого проектирования добавляет три концепции зеленой ДНК в процесс анализа метода расширения. При анализе и преобразовании моделей материи-элемента нового продукта дизайнеры могут импортировать три «зеленых ДНК» в инновационные концепции продуктов для разработки «зеленых» продуктов.
Поэтому для практического проектирования экологически чистых продуктов предлагается метод «зеленого расширения», основанный на теории расширения и трех концепциях «зеленой ДНК», предложенных в этом исследовании.Предлагаемый инновационный метод зеленого проектирования добавляет три концепции зеленой ДНК в процесс анализа метода расширения. При анализе и преобразовании моделей материи-элемента нового продукта дизайнеры могут импортировать три «зеленых ДНК» в инновационные концепции продуктов для разработки «зеленых» продуктов.
Процедуры предлагаемого метода показаны на рисунке 4.
Шаг 1. Произвести декомпозицию и анализ продукта с использованием модели материя-элемент.
Изделие разбирается и анализируется от системы и подсистемы до компонентов, чтобы получить полную информацию о механических и функциональных характеристиках.
Шаг 2. Найдите подсистемы или компоненты с инновационными экологическими ценностями и возможностями.
Три Зеленых ДНК применяются для изучения компонентов и технологий аналитической системы, которая может представить концепции зеленых технологий, зеленых материалов и экологически чистого производства. Это делается для того, чтобы применять различные способы работы для достижения целей эко-дизайна.
Это делается для того, чтобы применять различные способы работы для достижения целей эко-дизайна.
Шаг 3. Примените преобразование материи-элемента, чтобы создать новую модель материи-элемента.
После определения целевых подсистем или компонентов, которые необходимо обновить или улучшить, разрабатывается новая архитектура продукта с преобразованием материи в элемент. Это может создать новые операционные функции или методы для продуктов, даже инновационную концепцию зеленого дизайна, которая полностью отличается от существующих продуктов.
Шаг 4. Внедрить новую модель материи-элемента в практический дизайн продукта.
Практичное проектирование продукта с помощью новой модели материи-элемента, включающей зеленые ДНК.Пункты дизайна будут сосредоточены на интеграции промышленного дизайна, механического дизайна и функций продукта.
Шаг 5. Создайте прототип продукта для проверки концепций экологичного дизайна.
Наконец, на основе практического дизайна создается прототип продукта, который используется для проверки осуществимости и эффективности предлагаемого инновационного дизайна экологически чистого продукта.
Кроме того, этот инновационный метод «зеленого» проектирования может не только побудить дизайнеров рассмотреть три «зеленых» ДНК, но также может дополнительно помочь им в реконструкции инновационного «зеленого» продукта с использованием процесса разложения и перекомпоновки метода расширения.Этот процесс может облегчить строительство экологически чистых модулей и улучшить разборку продукта, тем самым повышая добавленную стоимость за счет вторичной переработки продукта. Это главное нововведение этого метода, которое может помочь окончательному дизайну зеленого продукта получить максимальные устойчивые преимущества и достичь беспроигрышной ситуации для окружающей среды, потребителей и компаний.
Центр письма | Определение общих терминов и концепций письма
Процесс письма
Подсказка по написанию: Инструкции вашего преподавателя для вашего письменного задания.
Мозговой штурм: Упражнения и методы, которые помогут вам найти и систематизировать идеи, аргументы и тезисы для статьи. Чтобы увидеть некоторые примеры, ознакомьтесь с раздаточным материалом Центра письма по методам мозгового штурма.
Чтобы увидеть некоторые примеры, ознакомьтесь с раздаточным материалом Центра письма по методам мозгового штурма.
Фрирайтинг: Форма мозгового штурма, при которой вы пишете без остановки в течение определенного периода времени.
Черновик: Первоначальная версия статьи перед правками и корректурой.
Обратная связь: Комментарии к вашему документу, которые хвалят или дают предложения по улучшению вашего проекта.
Ревизия: Исправление или внесение изменений в тезис, организацию, аргументацию или доказательства статьи.
Вычитка: Исправление структуры предложения, орфографии и других грамматических ошибок в статье. Этот шаг наступает после проверки бумаги.
Семинар по рецензированию: Учащиеся объединяются в пары или группы для написания отзывов и обсуждения улучшений статьи.
Рубрика: Руководство по подсчету баллов, которое учитель использует для оценки вашей работы. Обычно он включает описание того, как может выглядеть отличная, хорошая или плохая оценка. (например, иметь четкую формулировку тезиса, надлежащим образом обращаться к аудитории)
Обычно он включает описание того, как может выглядеть отличная, хорошая или плохая оценка. (например, иметь четкую формулировку тезиса, надлежащим образом обращаться к аудитории)
Элементы бумаги
Введение: Первый абзац или раздел вашей статьи; это дает важную информацию о теме. Он также включает в себя тезис.
Тезис: Четкое изложение основного аргумента в вашей статье.Обычно оно появляется в конце введения.
Основной абзац: Абзац статьи, который не является ни введением, ни заключением. В аргументативной статье основной абзац поддерживает тезис. Он содержит тематические предложения, доказательства и анализ. (см. ниже)
Тема предложения: Четкое изложение основной идеи, которую вы хотите передать в абзаце. Обычно он стоит в начале абзаца.
Доказательства: Любой материал (например,г.: данные или экспертные источники), которые поддерживают или помогают доказать ваш тезис.
Источник: Люди или публикации, предоставляющие доказательства в поддержку вашего тезиса. Примеры могут включать журнальные статьи, книги, интернет-сайты, видео и людей, у которых вы берете интервью. Вы должны ссылаться на свои источники, когда используете их в своей статье.
Анализ: Когда авторы проводят анализ, они объясняют, как их доказательства связаны с их тезисами.
Контраргумент: Аргумент, который не согласен с вашей позицией в статье.Вы должны признавать контраргументы и либо принимать, либо приспосабливаться, либо опровергать их.
Заключение: Последний абзац или раздел эссе; он повторяет тезис и подтверждающие его доказательства. Иногда это также объясняет важность тезиса вне класса.
Жанры письма
Убедительное эссе или Аргументативное эссе: Статья, пытающаяся убедить читателя в том, что одна идея лучше другой. Газета может попытаться предложить своему читателю принять меры в поддержку этой идеи. В некоторых убедительных эссе могут использоваться источники, а в других нет.
Газета может попытаться предложить своему читателю принять меры в поддержку этой идеи. В некоторых убедительных эссе могут использоваться источники, а в других нет.
Исследовательская работа: Эссе, в котором анализируется ряд источников в определенной области, приводятся доводы или интерпретация информации из источников.
Цитаты/ссылки
Это понятия, относящиеся к использованию источников в статье.
Источник: Люди или публикации, предоставляющие доказательства в поддержку вашего тезиса.Некоторыми примерами являются журнальные статьи, книги, веб-сайты в Интернете, видео и люди, у которых вы берете интервью.
Цитирование в тексте: Когда вы ссылаетесь (или «цитируете») источник в основной части своей статьи, эта ссылка является цитированием в тексте. Чтобы увидеть образцы цитат в тексте, обратитесь к руководствам по стилю MLA, APA или Chicago или Purdue OWL.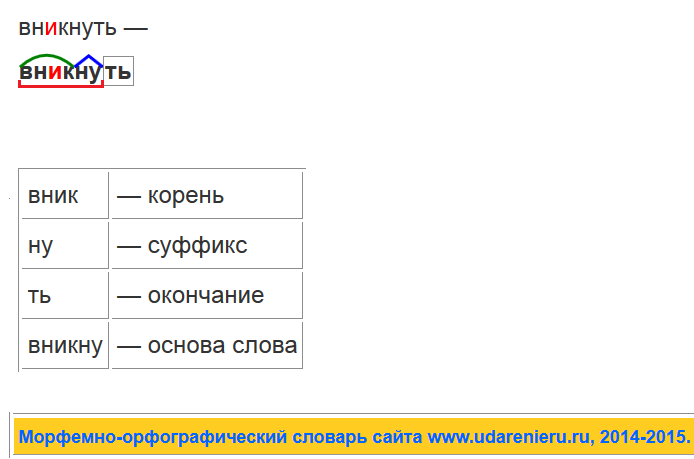
Сигнальная фраза: Фраза, которая ведет к цитате или парафразу. Сигнальная фраза обычно включает имя автора. Обратитесь к MLA, APA или Purdue OWL в чикагском стиле, чтобы узнать, как цитировать предложения с сигнальными фразами.
Цитата: Использование чьих-либо слов в точности так, как они их написали. Цитирование требует кавычек и ссылки в тексте.
Перефразирование: Использование различных слов и предложений для обобщения основной идеи или аргумента источника. Перефразирование требует цитирования в тексте.
Библиография: Находится в конце документа и содержит список всех источников, цитируемых в документе. (Также называется: страница цитируемых работ или ссылка)
Библиографическая ссылка: Каждый источник, использованный в статье, указан в библиографии.Каждая запись источника называется библиографической ссылкой.
Аннотированная библиография: Список источников, которые вы планируете использовать в статье. Каждый источник в списке сопровождается кратким описанием («аннотацией») этого источника и указанием того, как он относится к вашей статье. В аннотации также может оцениваться источник, его точность и качество.
Каждый источник в списке сопровождается кратким описанием («аннотацией») этого источника и указанием того, как он относится к вашей статье. В аннотации также может оцениваться источник, его точность и качество.
Резюме: краткое изложение основных моментов источника.
Определение и примеры морфем в английском языке?
В грамматике и морфологии английского языка морфема — это лингвистическая единица, имеющая определенное значение, которую нельзя разделить на более мелкие части, чтобы при этом они по-прежнему сохраняли смысл. Она состоит из слова, например, dog / собака, или его части, как —s в конце dogs /собаки.
У морфемы есть две стороны, семантическая — содержание, то есть значение, которое мы вкладываем в слово. И фонетическая — непосредственно само слово, которое передает заложенный в него смысл.
Etymology / ЭтимологияТермин “морфема” происходит из французского языка, который в свою очередь заимствовал его от греческого слова “форма”.
- В качестве морфемы может выступать префикс.
What does it mean to pre-board? Do you get on before you get on? (George Carlin) / Что означает предварительная посадка? Вы садитесь прежде, чем сесть? (Джордж Карлин)
- Отдельные слова также могут быть морфемами.
They want to put you in a box, but nobody’s in a box. You’re not in a box. (John Turturro) / Тебя хотят засунуть в ящик, но в ящике — никто. Ты не в ящике. (Джон Туртурро)
- Морфемами могут быть сокращенные слова.
You’re not alone. / Ты не одинок.
Morphs and Allomorphs / Морфы и алломорфыСлово может состоять из одной морфемы (sad / грустный) или двух или более (unluckily / к несчастью), причем каждая обычно имеет определенное значение.
Когда морфема является частью слова, она называется морф. Если морфему можно представить более чем одним морфом, они выступают алломорфами.
Например, префиксы in- (insane / безумный), il- (illegible / неразборчивый), im- (impossible / невозможный), ir- (irregular / неправильный) являются алломорфами одной и той же отрицательной морфемы.
Free and bound morphemes / Свободные и связанные морфемыМорфемы — самые мелкие единицы значения в языке. Они делятся на два типа:
- Free / Свободные
Существуют в виде отдельных слов: eat / есть, date / дата, weak / слабый.
Многие слова в английском состоят из одной свободной морфемы. Например, любое слово в приведенном предложении представляет собой отдельную морфему:
I need to go now, but you can stay. / Мне нужно идти, но ты можешь остаться.
Ни одно из девяти слов в этом предложении не может быть разделено на более мелкие части, так, чтобы они сохраняли смысл.
- Bound / Связанные
Они не могут существовать по отдельности, не теряя смысла. Связанные морфемы состоят из двух отдельных классов:
- Base (root) / Основа (корень)
Основа или корень — это морфема, которая придает слову его основное значение. Примером морфемы со свободной основой является слово woman / женщина в слове womanly / женственный. Примером морфемы со связанной основой является —sent в слове dissent / инакомыслие.
- Affixes / Аффиксы
Аффикс — это связанная морфема, которая стоит до или после основы. Аффикс, который стоит перед базой, называется префиксом. Некоторыми примерами префиксов являются ante—, pre-, un— и dis-, как в следующих словах:
antedate / предвосхищать
prehistoric / доисторический
unhealthy / нездоровый
disregard / невнимание
Аффикс, который идет после базы, называется суффиксом. Примерами суффиксов являются —ly, —er, —ism и —ness, как в следующих словах:
Примерами суффиксов являются —ly, —er, —ism и —ness, как в следующих словах:
happily / счастливо
gardener / садовник
capitalism / капитализм
kindness / доброта
Также при добавлении к определенным типам слов суффиксы выполняют различные грамматические функции:
| -s | Noun plural / существительное во множественном числе | Cats / кошки
|
| -‘s | Noun possessive / притяжательный падеж существительного | Mother’s / мамин (принадлежащий маме) |
| -s | Verb present tense third person singular / глагол настоящего времени третьего лица единственного числа | Has / имеет |
| -ing | Verb present participle, gerund / причастие настоящего времени, герундий | Walking / гуляя, гуляющий |
| -ed | Verb simple past tense / глагол в простом прошедшем времени | Switched / Переключил |
| -en | Verb past perfect participle / причастие прошедшего времени | Having been / будучи |
| -er | Adjective comparative / прилагательное в сравнительной степени | Bigger / Больше |
| -est | Adjective superlative / прилагательное в превосходной степени | Biggest / Самый большой |
Слово не может быть разделено на морфемы просто по слогам и их звучанию. У некоторых морфем, например, у apple / яблока, больше одного слога. Другие, например, окончание —s, не имеют ни одного. Морфема — это форма (последовательность звуков) с узнаваемым смыслом. Если мы знаем историю или этимологию слова, это может оказаться полезным для разделения его на морфемы, но решающим фактором является связь между формой и значением.
У некоторых морфем, например, у apple / яблока, больше одного слога. Другие, например, окончание —s, не имеют ни одного. Морфема — это форма (последовательность звуков) с узнаваемым смыслом. Если мы знаем историю или этимологию слова, это может оказаться полезным для разделения его на морфемы, но решающим фактором является связь между формой и значением.
Морфема может иметь более одного варианта произношения или написания. Например, обычное окончание множественного числа существительного имеет два написания (—s и —es) и три варианта произношения (s-звук, как в backs / спины, z-звук как в bags / мешки, и оглушенный z-звук, как в batches / партии.) Такое изменение типично для морфем английского языка, хотя в написании не отражается.
Знание морфемики позволяет понять, как образуются и усложняются слова. Помогает правильным образом связывать разные понятия в одно. Ведь ежедневно в мире образуются новые словоформы, которые отражают эволюцию мира и развитие технологий, а за этим всегда следуют изменения в языке. Все это естественным образом расширяет лексикон. Вот почему это важная часть обучения, имеющая вполне прикладное значение.
Все это естественным образом расширяет лексикон. Вот почему это важная часть обучения, имеющая вполне прикладное значение.
Состав слова и методика его изучения на уроках русского языка в начальной школе курсовая по педагогике | Дипломная Учебные процессы
Скачай Состав слова и методика его изучения на уроках русского языка в начальной школе курсовая по педагогике и больше Дипломная в PDF из Учебные процессы только в Docsity! ОГЛАВЛЕНИЕ ВВЕДЕНИЕ ГЛАВА I. МОРФЕМНЫЙ СОСТАВ СЛОВА. 1. Понятие морфем. 2. Виды морфем. 3. Значение морфем. ГЛАВА II. МЕТОДИКА ИЗУЧЕНИЯ СОСТАВА СЛОВА В НАЧАЛЬНЫХ КЛАССАХ. 1. Причины трудностей и ошибок младших школьников в разборе слов по составу. 2. Распределение программного материала и содержание работы. 3. Методы и приемы изучения состава слов. ЗАКЛЮЧЕНИЕ ЛИТЕРАТУРА. ПРИЛОЖЕНИЕ. ВВЕДЕНИЕ Тема курсовой работы «Состав слова и методика его изучения в начальной школе на уроках русского языка» значима в современном языкознании, потому что задача пропедевтической работы состоит в подготовке учащихся к пониманию семантической (смысловой) и структурной соотносимости, которая существует в языке между однокоренными словами. Такая задача обусловлена, во-первых, тем, что понимание семантико-структурной соотносимости слов по своей лингвистической сущности является основой усвоения особенностей однокоренных слов и образования слов в русском языке. Во-вторых, указанная задача продиктована трудностями, с которыми сталкиваются младшие школьники при изучении однокоренных слов и морфем. Цель работы: рассмотреть морфемный состав слова и методику изучения в начальных классах. Задачи: — подобрать, изучить и систематизировать литературу по теме; — описать морфемный состав слова в современном русском языке; — рассмотреть методы и приемы работы по изучению состава слова; — изучить опыт работы учителей школ по данной теме. Объект исследования: состав слова. Предмет исследования: методика изучения состава слова в начальной школе, на уроках русского языка. Методы исследования: Теоретические методы: 1) изучение методологических основ; 2) изучение «истории вопроса» и изучение всей литературы по вопросу, анализ всего прошлого опыта, сопоставление прошлого опыта с современным положением дела; Окончания являются носителями сразу нескольких грамматических значений: рода, числа, падежа у имен, лица, числа у глаголов.
Такая задача обусловлена, во-первых, тем, что понимание семантико-структурной соотносимости слов по своей лингвистической сущности является основой усвоения особенностей однокоренных слов и образования слов в русском языке. Во-вторых, указанная задача продиктована трудностями, с которыми сталкиваются младшие школьники при изучении однокоренных слов и морфем. Цель работы: рассмотреть морфемный состав слова и методику изучения в начальных классах. Задачи: — подобрать, изучить и систематизировать литературу по теме; — описать морфемный состав слова в современном русском языке; — рассмотреть методы и приемы работы по изучению состава слова; — изучить опыт работы учителей школ по данной теме. Объект исследования: состав слова. Предмет исследования: методика изучения состава слова в начальной школе, на уроках русского языка. Методы исследования: Теоретические методы: 1) изучение методологических основ; 2) изучение «истории вопроса» и изучение всей литературы по вопросу, анализ всего прошлого опыта, сопоставление прошлого опыта с современным положением дела; Окончания являются носителями сразу нескольких грамматических значений: рода, числа, падежа у имен, лица, числа у глаголов. Носителем лексического значения является только корневая морфема. Синкретические морфемы, совмещающие словообразовательное и грамматическое значения, в языке немногочисленны. Это, главным образом, глагольные приставки. Например, приставки в-/во-, до-, за- и др. в сочетании с глаголом идти, выражая, например, движения (внутрь, к предмету, за предметом и т.д.) в то же время изменяют вид глагола, переводя его из несовершенного вида в совершенный. Два признака морфем – обобщенность и нелинейность (парадигматический характер) – однозначно являются интегральным. Парадигматический характер морфемы проявляется в ее способности входить в сопоставление с единицами, обладающими структурной общностью, но различающимися по смыслу, что подтверждает ее типовой, а следовательно, и обобщенный характер. Это можно показать на примере имен существительных с суффиксом – щик – чик, обозначающими лицо по профессии или занятию: гардероб-щик -, морожен-щик -, прицеп-щик-, обход-чик — , рез-чик — , разнос-чик-, лет-чик — – и т.
Носителем лексического значения является только корневая морфема. Синкретические морфемы, совмещающие словообразовательное и грамматическое значения, в языке немногочисленны. Это, главным образом, глагольные приставки. Например, приставки в-/во-, до-, за- и др. в сочетании с глаголом идти, выражая, например, движения (внутрь, к предмету, за предметом и т.д.) в то же время изменяют вид глагола, переводя его из несовершенного вида в совершенный. Два признака морфем – обобщенность и нелинейность (парадигматический характер) – однозначно являются интегральным. Парадигматический характер морфемы проявляется в ее способности входить в сопоставление с единицами, обладающими структурной общностью, но различающимися по смыслу, что подтверждает ее типовой, а следовательно, и обобщенный характер. Это можно показать на примере имен существительных с суффиксом – щик – чик, обозначающими лицо по профессии или занятию: гардероб-щик -, морожен-щик -, прицеп-щик-, обход-чик — , рез-чик — , разнос-чик-, лет-чик — – и т. д. Что касается слова, то оно изучается в морфемике с грамматической точки зрения. В этом плане наряду с его внутренним строением и членимостью на значимые части рассматриваются особенности его словоизменения и формообразования [1, С. 55]. Кроме интегрально-дифференциальных у морфемы есть и собственно различительные признаки. Наиболее важным из них являются признак ее минимальности, проявляющийся в невозможности дальнейшего членения морфемы на более мелкие части без нарушения ее смысловой целостности. В противном случае образуются незначимые единицы низшего уровня – фонемы. К различительным признакам морфемы относится и ее структурная выделяемость в составе слова, поэтому морфема связана с единицами высшего, синтаксического уровня не прямо, а опосредованно, об этом свидетельствует невозможность выступать в качестве члена предложения и занимать в нем определенную синтаксическую позицию. Что касается признака повторяемости морфемы, то это характерное для нее свойство (большинство морфем употребляются минимум в двух словах одного и того же словообразовательного ряда: учи-тель, писа-тель, ваяя-тель, оформи-тель и т.
д. Что касается слова, то оно изучается в морфемике с грамматической точки зрения. В этом плане наряду с его внутренним строением и членимостью на значимые части рассматриваются особенности его словоизменения и формообразования [1, С. 55]. Кроме интегрально-дифференциальных у морфемы есть и собственно различительные признаки. Наиболее важным из них являются признак ее минимальности, проявляющийся в невозможности дальнейшего членения морфемы на более мелкие части без нарушения ее смысловой целостности. В противном случае образуются незначимые единицы низшего уровня – фонемы. К различительным признакам морфемы относится и ее структурная выделяемость в составе слова, поэтому морфема связана с единицами высшего, синтаксического уровня не прямо, а опосредованно, об этом свидетельствует невозможность выступать в качестве члена предложения и занимать в нем определенную синтаксическую позицию. Что касается признака повторяемости морфемы, то это характерное для нее свойство (большинство морфем употребляются минимум в двух словах одного и того же словообразовательного ряда: учи-тель, писа-тель, ваяя-тель, оформи-тель и т. п.) относится не всеми лингвистами к числу ее обязательных дифференциальных признаков. Таким образом, наиболее предполагаемым понятием морфемы является понятие, в которой говорится, что морфема – это минимально значимая единица языка, у которой план выражения может отсутствовать при сохранении известной смысловой целостности. Морфема – единица двуплановая, обладающая и формой и содержанием. Этим она принципиально отличается от фонемы, не имеющей значения, а также от слога. Морфема – единица воспроизводимая, говорящий не создает морфем в речи, а берет их из хранящегося в памяти «инвентаря» языковых единиц, тогда как предложения относятся к числу единиц, создаваемых говорящим непосредственно в речевом общении. 2. Виды морфем. Корнем, или корневой морфемой, является неделимая общая часть всех родственных слов, содержащая в себе основной элемент их лексического значения. На основе общности значения корневых морфем в словообразовательной системе языка образуются гнезда родственных слов. При этом в составе корня происходят различные чередования как гласных, так и согласных звуков, например к//ч – волк, волч-ий; г//ж – сапог, сапож-н- ый; х//ш, о//нудь звука – мох, за-мш-ел-ый; м//мл – корм-и-ть, кормл-ени-е; и// е – замиро-а-ть, за-мер-е-ть и т.
п.) относится не всеми лингвистами к числу ее обязательных дифференциальных признаков. Таким образом, наиболее предполагаемым понятием морфемы является понятие, в которой говорится, что морфема – это минимально значимая единица языка, у которой план выражения может отсутствовать при сохранении известной смысловой целостности. Морфема – единица двуплановая, обладающая и формой и содержанием. Этим она принципиально отличается от фонемы, не имеющей значения, а также от слога. Морфема – единица воспроизводимая, говорящий не создает морфем в речи, а берет их из хранящегося в памяти «инвентаря» языковых единиц, тогда как предложения относятся к числу единиц, создаваемых говорящим непосредственно в речевом общении. 2. Виды морфем. Корнем, или корневой морфемой, является неделимая общая часть всех родственных слов, содержащая в себе основной элемент их лексического значения. На основе общности значения корневых морфем в словообразовательной системе языка образуются гнезда родственных слов. При этом в составе корня происходят различные чередования как гласных, так и согласных звуков, например к//ч – волк, волч-ий; г//ж – сапог, сапож-н- ый; х//ш, о//нудь звука – мох, за-мш-ел-ый; м//мл – корм-и-ть, кормл-ени-е; и// е – замиро-а-ть, за-мер-е-ть и т.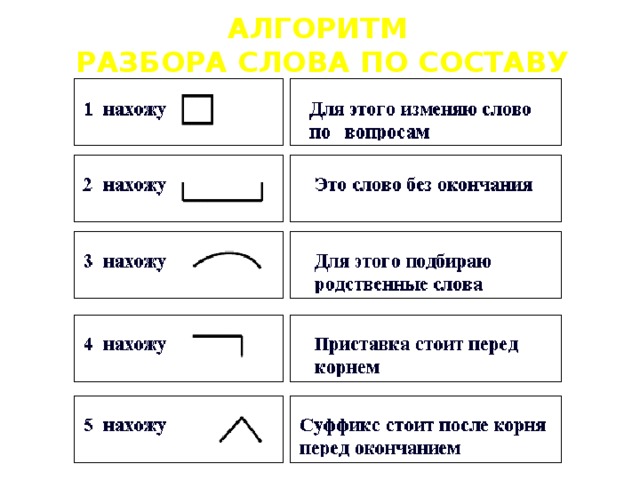 д. Корневые морфемы могут быть свободными (молодой, молодость) и связанными (улица, переулок). Корень это такая минимальная значимая часть, которая противопоставлена всем другим морфемам, т.е. аффиксам: приставкам, суффиксам, окончаниям и некоторым другим. Корень в отличии от аффиксов –обязательная часть в слове. Если слово состоит из одной морфемы, то это корень: тут, и, кино и т.п. Корень составляет основу непроизводных, или по-другому, немотивированных, слов: сын, голова, дом и т.п. Значение таких простых слов «никак не связано с их звуковым обликом, не вытекает из него, о нем нельзя догадаться, его нужно знать. Если вам не известно, что значат сочетания звуков, образующие слова собака, лошадь, стена, дело, окно, яйцо и другие подобные, то вы догадаться об этом не можете. А значение производных слов определяется значением слов простых, мотивировано им, подобно тому, как свойства химических соединений зависят от свойств входящих в них элементов» (4, С. 6). Слова, имеющие общую мотивацию, составляют группы однокоренных слов.
д. Корневые морфемы могут быть свободными (молодой, молодость) и связанными (улица, переулок). Корень это такая минимальная значимая часть, которая противопоставлена всем другим морфемам, т.е. аффиксам: приставкам, суффиксам, окончаниям и некоторым другим. Корень в отличии от аффиксов –обязательная часть в слове. Если слово состоит из одной морфемы, то это корень: тут, и, кино и т.п. Корень составляет основу непроизводных, или по-другому, немотивированных, слов: сын, голова, дом и т.п. Значение таких простых слов «никак не связано с их звуковым обликом, не вытекает из него, о нем нельзя догадаться, его нужно знать. Если вам не известно, что значат сочетания звуков, образующие слова собака, лошадь, стена, дело, окно, яйцо и другие подобные, то вы догадаться об этом не можете. А значение производных слов определяется значением слов простых, мотивировано им, подобно тому, как свойства химических соединений зависят от свойств входящих в них элементов» (4, С. 6). Слова, имеющие общую мотивацию, составляют группы однокоренных слов. То, что в лингвистике трактуется как общая мотивация, в школьной практике называют сходством по смыслу. Однако слово «смысл» нередко для ребенка оказывается лишенным определенного содержания. Если же регулярно показывать, что родственные слова соотносятся с одним и тем же словом, у детей сформируется способ (действие), с помощью которого они будут устанавливать наличие или отсутствие родства слов, и в то же время наполнится конкретным содержанием выражение «сходны по смыслу». Возьмем, например, слова зимовать, зимник, зимовье, зимний. Работая с ними, не следует ограничиваться указанием на то, что эти слова имеют общую часть зим- и сходны по смыслу, нужно проанализировать значение каждого из слов, обратившись к мотивирующему: зимовать – проводить зиму, зимник – дорога для езды зимой, зимовье – помещение, где живут зимой, зимний – относящийся к зиме и т.п. Материал, позволяющий учить детей устанавливать смысловые связи между словами, имеется в учебнике. Это упражнения, где сопоставляются подобное слово, то при этом способе приставка будет найдена безошибочно: выехать, заехать, переехать, объехать и т.
То, что в лингвистике трактуется как общая мотивация, в школьной практике называют сходством по смыслу. Однако слово «смысл» нередко для ребенка оказывается лишенным определенного содержания. Если же регулярно показывать, что родственные слова соотносятся с одним и тем же словом, у детей сформируется способ (действие), с помощью которого они будут устанавливать наличие или отсутствие родства слов, и в то же время наполнится конкретным содержанием выражение «сходны по смыслу». Возьмем, например, слова зимовать, зимник, зимовье, зимний. Работая с ними, не следует ограничиваться указанием на то, что эти слова имеют общую часть зим- и сходны по смыслу, нужно проанализировать значение каждого из слов, обратившись к мотивирующему: зимовать – проводить зиму, зимник – дорога для езды зимой, зимовье – помещение, где живут зимой, зимний – относящийся к зиме и т.п. Материал, позволяющий учить детей устанавливать смысловые связи между словами, имеется в учебнике. Это упражнения, где сопоставляются подобное слово, то при этом способе приставка будет найдена безошибочно: выехать, заехать, переехать, объехать и т. д. Но в словах, о которых говорилось выше, так может быть найдена несуществующая приставка «приез-» или суффикс «ия» в глаголе прошедшего времени и т.п. Вспомним всеобщий способ анализа морфемной структуры слова в лингвистики. Морфема выделяется путем подбора слов, имеющих общий семантический признак и одинаковый по фонемному составу отрезок. Та к, напримет, слово зимний анализиреется в составе трех групп слов: 1-я: зимний, зима, зимушка, зимовье, зимовать, зимовщик и т.д.; 2-я: зимний, теплый, синий, добрый, крепкий и т.д.; 3-я: зимний, умный, летний, пыльный, каменный и т.д. В первый ряд вошли слова, имеющие общую мотивацию: все они объясняются с помощью слова зима. Сравнение буквенного состава слов позволяет выделить общий отрезок зим — — корень. Во втором ряду-слова, имеющие со словом зимний одни и те же грамматические значения; именительный падеж, мужской род, единственное число. Выразителем этих значений служит окончание прилагательных – ий/ый. Если изменить какое-либо из грамматических значений этих слов изменится и буквенный состав окончания.
д. Но в словах, о которых говорилось выше, так может быть найдена несуществующая приставка «приез-» или суффикс «ия» в глаголе прошедшего времени и т.п. Вспомним всеобщий способ анализа морфемной структуры слова в лингвистики. Морфема выделяется путем подбора слов, имеющих общий семантический признак и одинаковый по фонемному составу отрезок. Та к, напримет, слово зимний анализиреется в составе трех групп слов: 1-я: зимний, зима, зимушка, зимовье, зимовать, зимовщик и т.д.; 2-я: зимний, теплый, синий, добрый, крепкий и т.д.; 3-я: зимний, умный, летний, пыльный, каменный и т.д. В первый ряд вошли слова, имеющие общую мотивацию: все они объясняются с помощью слова зима. Сравнение буквенного состава слов позволяет выделить общий отрезок зим — — корень. Во втором ряду-слова, имеющие со словом зимний одни и те же грамматические значения; именительный падеж, мужской род, единственное число. Выразителем этих значений служит окончание прилагательных – ий/ый. Если изменить какое-либо из грамматических значений этих слов изменится и буквенный состав окончания. Наконец, 3 –й ряд. Эти слова обозначают признак, свойственный предмету, названия которого содержится в корне. У всех этих слов есть часть –н-, она находится после корня. Значит, все эти слова образованы с помощью суффикса –н-. Всеобщий способ нахождения в слове морфем, естественно, распространяется на приставки и суффиксы. Отсюда следует, что, проверяя, верно ли выделена приставка или суффикс, нужно подбирать разные слова, имеющие то же дополнительное значение и ту же по фонемному составу часть. Конечно, это не значит, что нельзя использовать подбор однокоренных слов с разными приставками, просто нужно иметь в виду, что этот прием не гарантирует, как и всякий другой частный способ, от ошибок. Всеобщий же способ решения морфемных задач даёт однозначный ответ [11, C. 67]. Кроме того, полезно иметь в виду некоторые особенности приставок и суффиксов, которые подсказывают приемы работы с ними. Так, известно, что приставки как бы «приклеиваются» к слову спереди. Отбрасывая приставку, получаем целое, ни в чем не деформированное слово той же части речи: от глагола – глагол (выбросил — бросил), от прилагательного – прилагательное (подводный — водный) и т.
Наконец, 3 –й ряд. Эти слова обозначают признак, свойственный предмету, названия которого содержится в корне. У всех этих слов есть часть –н-, она находится после корня. Значит, все эти слова образованы с помощью суффикса –н-. Всеобщий способ нахождения в слове морфем, естественно, распространяется на приставки и суффиксы. Отсюда следует, что, проверяя, верно ли выделена приставка или суффикс, нужно подбирать разные слова, имеющие то же дополнительное значение и ту же по фонемному составу часть. Конечно, это не значит, что нельзя использовать подбор однокоренных слов с разными приставками, просто нужно иметь в виду, что этот прием не гарантирует, как и всякий другой частный способ, от ошибок. Всеобщий же способ решения морфемных задач даёт однозначный ответ [11, C. 67]. Кроме того, полезно иметь в виду некоторые особенности приставок и суффиксов, которые подсказывают приемы работы с ними. Так, известно, что приставки как бы «приклеиваются» к слову спереди. Отбрасывая приставку, получаем целое, ни в чем не деформированное слово той же части речи: от глагола – глагол (выбросил — бросил), от прилагательного – прилагательное (подводный — водный) и т. п. Конечно, это не относится к словам, образованным префиксально – суффиксальным способом (подснежник). За то суффиксы часто «переводят» слово из одной части речи в другую: от существительного образуют прилагательное (сон — сонный), от прилагательных – глаголы (белый — белить) и т.п. При чем каждый суффикс сочетается с основой определенного типа. Так, суффикс – тьель- присоединяется к глагольным основам (учить — учитель), а суффикс – щик- к именам существительным (камень-каменщик) и т.п. Подсказывая способы контроля за правильностью выделения приставок и суффиксов, целесообразно обращать внимание детей на эти и другие особенности словообразовательных морфем. С помощью приставок обычно происходит образование новых слов в пределах одной и той же части речи: автор – со-автор., носить – вы-носить, вне-из-вне и т.д. Приставки в русском языке чаще всего используются для словопроизводства глаголов, прилагательных, наречий. Для образования разных форм одного и того же слова пристьавки используются менее активно, чем суффиксы.
п. Конечно, это не относится к словам, образованным префиксально – суффиксальным способом (подснежник). За то суффиксы часто «переводят» слово из одной части речи в другую: от существительного образуют прилагательное (сон — сонный), от прилагательных – глаголы (белый — белить) и т.п. При чем каждый суффикс сочетается с основой определенного типа. Так, суффикс – тьель- присоединяется к глагольным основам (учить — учитель), а суффикс – щик- к именам существительным (камень-каменщик) и т.п. Подсказывая способы контроля за правильностью выделения приставок и суффиксов, целесообразно обращать внимание детей на эти и другие особенности словообразовательных морфем. С помощью приставок обычно происходит образование новых слов в пределах одной и той же части речи: автор – со-автор., носить – вы-носить, вне-из-вне и т.д. Приставки в русском языке чаще всего используются для словопроизводства глаголов, прилагательных, наречий. Для образования разных форм одного и того же слова пристьавки используются менее активно, чем суффиксы.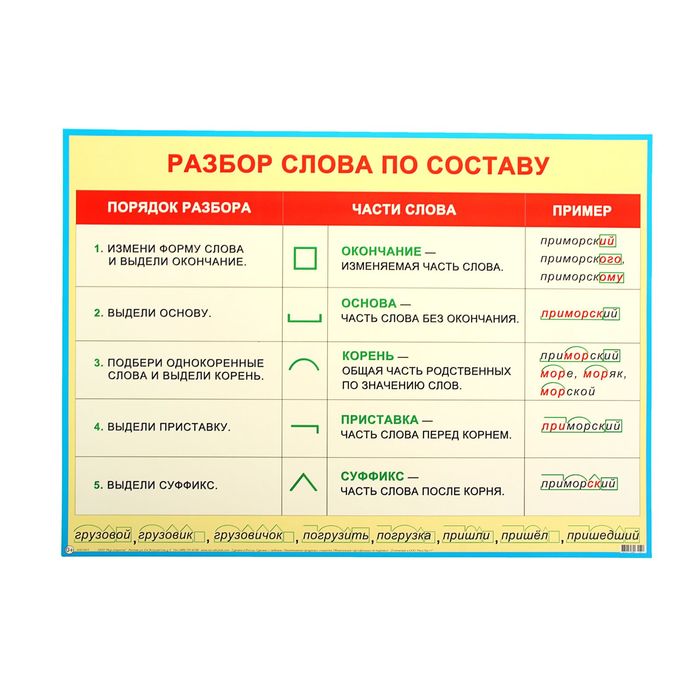 Тем не менее они могут быть и формообразующими: делать – с-делать, бледность – по-бледнеть, слепнуть – о-слепнуть. Приставки русского языка могут присоединяться к словам разных частей речи. Приставкам не свойственна закрепленность за определенными частями речи в связи с большой степенью ответственности и универсальности выражаемых ими значений. Так, приставка со- выражающая значение «совместности», возможна в составе существительных со- товарищ, со-участник; глаголов со-существовать, со-переживать; прилагательных со- звучный, со-предельный и др. Присоединение приставок к основам разных слов не меняет коренным образом их значение. Приставки придают этому значению новые смысловые оттенки. Так, глаголы у-бежать, при-бежать, по существу, обозначают то же действие, что и глагол бежать. Приставки показывают лишь разное направление этого действия. Наречие пре-отлично и прилагательное пре- семпатичный обозначают те же признаки, что и слова отлично и симпатичный, но приставка пре- придает значению данных признаков оттенок высшей степени качества.
Тем не менее они могут быть и формообразующими: делать – с-делать, бледность – по-бледнеть, слепнуть – о-слепнуть. Приставки русского языка могут присоединяться к словам разных частей речи. Приставкам не свойственна закрепленность за определенными частями речи в связи с большой степенью ответственности и универсальности выражаемых ими значений. Так, приставка со- выражающая значение «совместности», возможна в составе существительных со- товарищ, со-участник; глаголов со-существовать, со-переживать; прилагательных со- звучный, со-предельный и др. Присоединение приставок к основам разных слов не меняет коренным образом их значение. Приставки придают этому значению новые смысловые оттенки. Так, глаголы у-бежать, при-бежать, по существу, обозначают то же действие, что и глагол бежать. Приставки показывают лишь разное направление этого действия. Наречие пре-отлично и прилагательное пре- семпатичный обозначают те же признаки, что и слова отлично и симпатичный, но приставка пре- придает значению данных признаков оттенок высшей степени качества. В отличие от приставок суффиксы могут иметь не только широкие и отвлеченные значения, но также и конкретные значения. Суффиксы глаголов и прилагательных отличаются большой широтой и отвлеченностью значения. Так, суффиксы –н-, -ов-, -ск- передают лишь отношение к тому, что обозначено бызовым существительным: книж-н-ый (книга), берез-ов-ый (береза), мор-ск-ой (море). Глагольный суффикс – е- в глаголах типа бел-е-ть, красн-е-ть, имеет широкое значение «становиться, делаться, каким-либо». Суффиксы имен существительных более конкретны, чем у глаголов и прилагатнльных. Они используются для наименования лиц по профессии: столяр, маляр, токарь, пекарь, крановщик; по социальному положению: колхозник, школьник; по качественному признаку: мудрец, гордец, храбрец. Если приставки не имеют закрепленности за определенной частью речи, то суффиксам такая закрепленность свойственна, и они не могут использоваться для образования разных частей речи. С помощью строго определенных суффмксов образуются существительные, прилагательные, глаголы, наречия.
В отличие от приставок суффиксы могут иметь не только широкие и отвлеченные значения, но также и конкретные значения. Суффиксы глаголов и прилагательных отличаются большой широтой и отвлеченностью значения. Так, суффиксы –н-, -ов-, -ск- передают лишь отношение к тому, что обозначено бызовым существительным: книж-н-ый (книга), берез-ов-ый (береза), мор-ск-ой (море). Глагольный суффикс – е- в глаголах типа бел-е-ть, красн-е-ть, имеет широкое значение «становиться, делаться, каким-либо». Суффиксы имен существительных более конкретны, чем у глаголов и прилагатнльных. Они используются для наименования лиц по профессии: столяр, маляр, токарь, пекарь, крановщик; по социальному положению: колхозник, школьник; по качественному признаку: мудрец, гордец, храбрец. Если приставки не имеют закрепленности за определенной частью речи, то суффиксам такая закрепленность свойственна, и они не могут использоваться для образования разных частей речи. С помощью строго определенных суффмксов образуются существительные, прилагательные, глаголы, наречия. Так суффикс –ец- употребляется для образования существительных, суффикс –и- только для образования глаголов (пилить, сулить), суффикс –чив- только для образования прилагательных (разборчивый, настойчивый). В некоторых словах суффиксы не получают своего материального выражения. В этом случае принято говорить о наличии в структуре данных словами. Во 2 классе школьники учат: «Окончание служит для связи слов в предложении». Но в сознании детей в этот период понятие связи слов не выходит за рамки семантических связей, в то время как понятие грамматической связи имеет свое специфическое содержание, которое и 0 0 1 Fдолжно быть раскрыто при анализе слово сочетаний. Например, в словосочетании читает книгу слово, называющее действие, может изменяться «как хочет»: читал книгу, читаю книгу, читаем книгу и т. п., а второе слово ему «подчиняется», выступая в форме определенного падежа: сказать «читает книгой» или «читаю книга» нельзя. И это можно показать детям. Таким образом, даже на самом начальном этапе знакомства с окончанием без употребления каких бы то ни было терминов можно раскрыть роль этой части слова как средства выражения особых, 0 0 1 Fфор мальных (грамматических) связей между словами.
Так суффикс –ец- употребляется для образования существительных, суффикс –и- только для образования глаголов (пилить, сулить), суффикс –чив- только для образования прилагательных (разборчивый, настойчивый). В некоторых словах суффиксы не получают своего материального выражения. В этом случае принято говорить о наличии в структуре данных словами. Во 2 классе школьники учат: «Окончание служит для связи слов в предложении». Но в сознании детей в этот период понятие связи слов не выходит за рамки семантических связей, в то время как понятие грамматической связи имеет свое специфическое содержание, которое и 0 0 1 Fдолжно быть раскрыто при анализе слово сочетаний. Например, в словосочетании читает книгу слово, называющее действие, может изменяться «как хочет»: читал книгу, читаю книгу, читаем книгу и т. п., а второе слово ему «подчиняется», выступая в форме определенного падежа: сказать «читает книгой» или «читаю книга» нельзя. И это можно показать детям. Таким образом, даже на самом начальном этапе знакомства с окончанием без употребления каких бы то ни было терминов можно раскрыть роль этой части слова как средства выражения особых, 0 0 1 Fфор мальных (грамматических) связей между словами.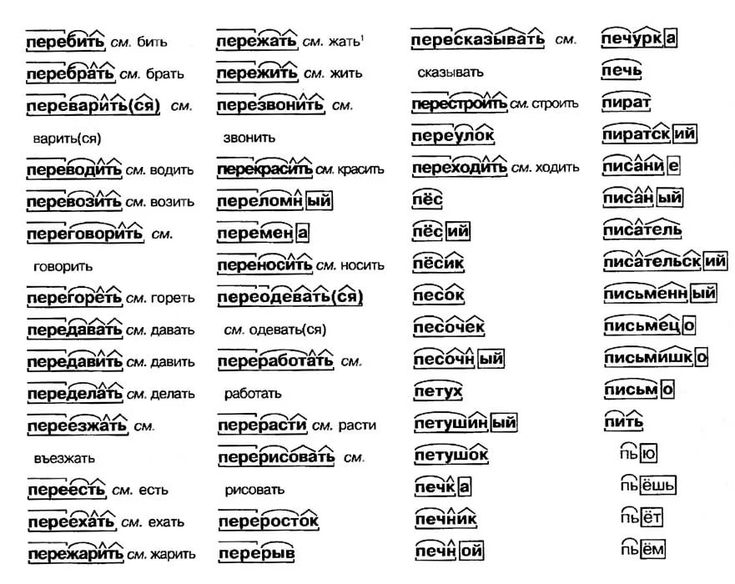 По мере накопления знаний о частях речи углубляются знания 0 0 1 Fучащихся об окончании. В то же время конкретизируются пред ставления о связях между словами и формируется всеобщий способ нахождения в слове этой морфемы: 0 0 1 Fа) изменяется конкрет ное грамматическое значение слова; б) сравниваются исходная и полученная формы слова; в) находится изменившаяся часть. Например, изучается род имен прилагательных. Изменяем 0 0 1 Fпри лагательное по роду: добрый (человек), доброе (дело), добрая (девочка). 0 0 1 FСравниваем полученные словоформы: добрый — доб рое — добрая. Отделяем изменяющиеся части: -ый, -ое, -ая. Это и есть окончание, которое говорит, какого рода прилагательное. Даже если не известно, какой признак называет прилагательное, а известно только, какое у него окончание, мы уже можем об этом прилагательном кое-что сказать. Так, если известно, что у данного прилагательного окончание -ое, то можно сказать, что оно связано с 0 0 1 Fсуществительным среднего рода. И чем больше грамма тических сведений о данной части речи накопит учащийся, тем больше сведений о слове будет 0 0 1 Fсообщать ему окончание: оконча ние -ое сообщит не только о роде данного прилагательного, но и о его числе и падеже.
По мере накопления знаний о частях речи углубляются знания 0 0 1 Fучащихся об окончании. В то же время конкретизируются пред ставления о связях между словами и формируется всеобщий способ нахождения в слове этой морфемы: 0 0 1 Fа) изменяется конкрет ное грамматическое значение слова; б) сравниваются исходная и полученная формы слова; в) находится изменившаяся часть. Например, изучается род имен прилагательных. Изменяем 0 0 1 Fпри лагательное по роду: добрый (человек), доброе (дело), добрая (девочка). 0 0 1 FСравниваем полученные словоформы: добрый — доб рое — добрая. Отделяем изменяющиеся части: -ый, -ое, -ая. Это и есть окончание, которое говорит, какого рода прилагательное. Даже если не известно, какой признак называет прилагательное, а известно только, какое у него окончание, мы уже можем об этом прилагательном кое-что сказать. Так, если известно, что у данного прилагательного окончание -ое, то можно сказать, что оно связано с 0 0 1 Fсуществительным среднего рода. И чем больше грамма тических сведений о данной части речи накопит учащийся, тем больше сведений о слове будет 0 0 1 Fсообщать ему окончание: оконча ние -ое сообщит не только о роде данного прилагательного, но и о его числе и падеже. В то же время будет конкретизироваться общее представление об окончании как двусторонней языковой единице, в которой неразрывно связано ее значение с определенным фонемным (звуковым) составом. Например, окончание – ая говорит о том, что это прилагательное женского рода единственного числа именительного падежа. А окончание – ого того же прилагательного отличается от первого не только по звуковому составу, но и по значению: -ого указывает на мужской или средний род, родительный и винительный падеж единственного числа. Чем содержательнее становится понятие окончания как морфемы, выражающей грамматические значения слова, тем легче учащимся различать слова и словоформы. Появляется формальный признак, опираясь на который можно безошибочно отличать словоформы от разных слов: в слове изменилось только окончание – слово осталось тем же; произошли изменения в той части слова, которая находится перед окончание, — появилось другое слово. Важно, что признак этот действует и тогда, когда значения двух или нескольких слов практически идентичны.
В то же время будет конкретизироваться общее представление об окончании как двусторонней языковой единице, в которой неразрывно связано ее значение с определенным фонемным (звуковым) составом. Например, окончание – ая говорит о том, что это прилагательное женского рода единственного числа именительного падежа. А окончание – ого того же прилагательного отличается от первого не только по звуковому составу, но и по значению: -ого указывает на мужской или средний род, родительный и винительный падеж единственного числа. Чем содержательнее становится понятие окончания как морфемы, выражающей грамматические значения слова, тем легче учащимся различать слова и словоформы. Появляется формальный признак, опираясь на который можно безошибочно отличать словоформы от разных слов: в слове изменилось только окончание – слово осталось тем же; произошли изменения в той части слова, которая находится перед окончание, — появилось другое слово. Важно, что признак этот действует и тогда, когда значения двух или нескольких слов практически идентичны. Например, слова рыбочка и рыбонька, стирать и стирка обозначают одно и то же, но поскольку в той части, которая находится перед окончанием, есть различие, значит, это разные слова. Всеми свойствами обычных окончаний характеризуются и так называемые нулевые окончания. О нулевом окончании говорят, когда грамматическое значение есть, а фонемы, которая бы его выражала, нет. Например, в именительном падеже у существительных 2-го склонения окончание нулевое: стол . А другие падежные окончания выражены звуками: стол-а, стол-у и т.д. на уроках же в начальных классах можно слышать, что стол – слово без окончания. В последствии эта «мелочь» оборачивается тем, что ученик средних классов не отличает слова действительно без окончаний, например, наречия, от слов, которые в одной из своих форм имеют нулевое окончание. Поскольку знакомство с нулевыми окончаниями не предусмотрено действующей программой для начальных классов, учитель должен проявить некоторую изобретательность, чтобы не нарушить принцип научности и не вынуждать детей со временем переучиваться.
Например, слова рыбочка и рыбонька, стирать и стирка обозначают одно и то же, но поскольку в той части, которая находится перед окончанием, есть различие, значит, это разные слова. Всеми свойствами обычных окончаний характеризуются и так называемые нулевые окончания. О нулевом окончании говорят, когда грамматическое значение есть, а фонемы, которая бы его выражала, нет. Например, в именительном падеже у существительных 2-го склонения окончание нулевое: стол . А другие падежные окончания выражены звуками: стол-а, стол-у и т.д. на уроках же в начальных классах можно слышать, что стол – слово без окончания. В последствии эта «мелочь» оборачивается тем, что ученик средних классов не отличает слова действительно без окончаний, например, наречия, от слов, которые в одной из своих форм имеют нулевое окончание. Поскольку знакомство с нулевыми окончаниями не предусмотрено действующей программой для начальных классов, учитель должен проявить некоторую изобретательность, чтобы не нарушить принцип научности и не вынуждать детей со временем переучиваться. Можно, например, воспользоваться какой-нибудь описательной, метафорической конструкцией: «В этом падеже у существительного беззвучное, немое окончание, окончание-неведимка» и т.п.[2, C. 207]. Постфиксом называется значимая часть слова, находящаяся после окончания или суффиксов в глагольных формах и служащая для образования новых слов либо разных форм одного и того же слова. В качестве постфикса в русском языке используется единственная служебная морфема –ся (-сь): катал ся, каталась. Постфикс –ся (сь) употребляется также при образовании формы страдательного залога глаголов: читать — читается, строить – строится и т.д. Постфикс –ся употребляется в структуре причастий, а так же в других глагольных формах, где ему предшествует согласный звук. После гласных звуков во всех глагольных формах, кроме причастий, употребляется – сь. Морфемы в структуре слова следуют друг за другом в строго определенном порядке перемещаться, как правило, не могут [2, С. 301]. Соединительные гласные о/е являются служебными морфемами, которые используются для образования сложных слов путем объединения основ двух слов.
Можно, например, воспользоваться какой-нибудь описательной, метафорической конструкцией: «В этом падеже у существительного беззвучное, немое окончание, окончание-неведимка» и т.п.[2, C. 207]. Постфиксом называется значимая часть слова, находящаяся после окончания или суффиксов в глагольных формах и служащая для образования новых слов либо разных форм одного и того же слова. В качестве постфикса в русском языке используется единственная служебная морфема –ся (-сь): катал ся, каталась. Постфикс –ся (сь) употребляется также при образовании формы страдательного залога глаголов: читать — читается, строить – строится и т.д. Постфикс –ся употребляется в структуре причастий, а так же в других глагольных формах, где ему предшествует согласный звук. После гласных звуков во всех глагольных формах, кроме причастий, употребляется – сь. Морфемы в структуре слова следуют друг за другом в строго определенном порядке перемещаться, как правило, не могут [2, С. 301]. Соединительные гласные о/е являются служебными морфемами, которые используются для образования сложных слов путем объединения основ двух слов. Словообразовательным значением морфем о/е «является соединительное значение, сводящееся к объединению значений, составляющих сложную основу мотивирующих слов в одно целостное сложное значение.» При образовании сложного слова соединительная гласная, находящаяся между основами двух слов, нейтрализует грамматическое значение первого из них и тем самым создает возможность для соединения в одно слово двух различных в грамматическом отношении слов, например: огн-е-упорн-ый. грамматическое значение. Лексическое значение слова «создается» путем взаимодействия и слияний в единое целое значений, присущих отдельным морфемам, составляющим данное слово. Поскольку слияние морфем представляет собой не механическое соединение, а взаимодействие и, кроме того, многие префиксы, корни, суффиксы многозначны, то только по морфемному составу трудно (а иногда и невозможно) определить лексическое значение слова. Тем не менее, лексическое значение многих мотивированных слов определяется его морфемным составом (например, последователь, разведчик, сотрудник, прибрежный, прилуниться и т.
Словообразовательным значением морфем о/е «является соединительное значение, сводящееся к объединению значений, составляющих сложную основу мотивирующих слов в одно целостное сложное значение.» При образовании сложного слова соединительная гласная, находящаяся между основами двух слов, нейтрализует грамматическое значение первого из них и тем самым создает возможность для соединения в одно слово двух различных в грамматическом отношении слов, например: огн-е-упорн-ый. грамматическое значение. Лексическое значение слова «создается» путем взаимодействия и слияний в единое целое значений, присущих отдельным морфемам, составляющим данное слово. Поскольку слияние морфем представляет собой не механическое соединение, а взаимодействие и, кроме того, многие префиксы, корни, суффиксы многозначны, то только по морфемному составу трудно (а иногда и невозможно) определить лексическое значение слова. Тем не менее, лексическое значение многих мотивированных слов определяется его морфемным составом (например, последователь, разведчик, сотрудник, прибрежный, прилуниться и т. д.). Особая роль принадлежит корню как смысловому ядру, создающему семантическую общноть однокоренных слов. Указанная особенность языка является одной из причинг, обусловливающих возможность использования членения слова на морфемы в целях выяснения его смысла. Этой возможностью учащиеся начинают осознанно пользоваться по мере усвоения морфемного состава слов и их образования. Лексическое значение многих производных слов осознается учащимися, когда им «открываются» тайны той связи, на которой основано семантическое родство слов. Итак, значение работы над морфемным составом слов состоит, во- первых, в том, что школьники овладевают одним из ведущих способов раскрытия лексического значения слов. Отсюда вытекает задача учителя – создать оптимальные условия для осознания детьми взаимосвязи, существующей в языке между лексическим значением слова и его морфемным составом, целенаправленно руководить на этой основе уточнением словаря учащихся. Во-вторых, даже элементарные знания об образовании слов очень важны для понимания учащимися основного источника пополнения нашего языка новыми словами, как представлено в трудах многих известных лингвистов (Л.
д.). Особая роль принадлежит корню как смысловому ядру, создающему семантическую общноть однокоренных слов. Указанная особенность языка является одной из причинг, обусловливающих возможность использования членения слова на морфемы в целях выяснения его смысла. Этой возможностью учащиеся начинают осознанно пользоваться по мере усвоения морфемного состава слов и их образования. Лексическое значение многих производных слов осознается учащимися, когда им «открываются» тайны той связи, на которой основано семантическое родство слов. Итак, значение работы над морфемным составом слов состоит, во- первых, в том, что школьники овладевают одним из ведущих способов раскрытия лексического значения слов. Отсюда вытекает задача учителя – создать оптимальные условия для осознания детьми взаимосвязи, существующей в языке между лексическим значением слова и его морфемным составом, целенаправленно руководить на этой основе уточнением словаря учащихся. Во-вторых, даже элементарные знания об образовании слов очень важны для понимания учащимися основного источника пополнения нашего языка новыми словами, как представлено в трудах многих известных лингвистов (Л. А. Булаховский, В.В. Виноградов, Е.М. Галкин-Федорук, Е.А. Земская, Н.М. Шанский и др.), новые слова создаются из тех морфем, из того строительного материала, который уже существует в языке, и по тем моделям, которые исторически сложились и закрепились в системе русского словообразования. Наблюдения над образованием слов оказывают положительное влияние на формирование у учащихся активного отношения к слову, подводят к пониманию закономерности развития языка. В-третьих, ознакомление с основами словообразования способствует обогащению знаний школьников об окружающей их действительности. Слова опосредованно (через понятия) соотносятся с предметами, процессами, явлениями. Установление семантико-структурной связи между словами опирается на связь между соотносительными понятиями (например, слова граница и пограничник семантически и структурно связаны, так как они являются наименованиями соотносимых между собой понятий). Фактически познание школьниками семантико-структурной соотносимости слов означает углубление их представлений о связях между предметами, процессами, имеющих место в окружающей жизни.
А. Булаховский, В.В. Виноградов, Е.М. Галкин-Федорук, Е.А. Земская, Н.М. Шанский и др.), новые слова создаются из тех морфем, из того строительного материала, который уже существует в языке, и по тем моделям, которые исторически сложились и закрепились в системе русского словообразования. Наблюдения над образованием слов оказывают положительное влияние на формирование у учащихся активного отношения к слову, подводят к пониманию закономерности развития языка. В-третьих, ознакомление с основами словообразования способствует обогащению знаний школьников об окружающей их действительности. Слова опосредованно (через понятия) соотносятся с предметами, процессами, явлениями. Установление семантико-структурной связи между словами опирается на связь между соотносительными понятиями (например, слова граница и пограничник семантически и структурно связаны, так как они являются наименованиями соотносимых между собой понятий). Фактически познание школьниками семантико-структурной соотносимости слов означает углубление их представлений о связях между предметами, процессами, имеющих место в окружающей жизни. В-четвертых, осознание роли морфем в слове, а также семантического значения приставок и суффиксов содействует формированию у школьников точности речи. Задача учителя – максимально способствовать не только пониманию учащимися лексического значения слова, но и развитию осознанного употребления в контексте слов с определенными приставками и суффиксами. В-пятых, изучение морфемного состава слова имеет большое значение для формирования орфографических навыков. Обусловлено это тем, что ведущим принципом русского правописания является морфологический. Формирование навыков правописания корня, приставок, суффиксов и окончаний на теоретической основе (а только такое письмо может быть сознательным) требует целенаправленного применения фонетических, словообразовательных и грамматических знаний. Поэтому одной из важных задач изучения морфемного состава слова является создание основы знаний и умений, необходимых для формирования навыков правописания морфем слова, и, прежде всего, корня. Наконец, немаловажен и тот факт, что изучение морфемного состава слова заключает в себе большие возможности для развития умственных способностей учащихся, в частности, для формирования у них специфических умственных умений, без которых невозможно сознательное владение словом как языковой единицей, например, умения абстрагировать семантическое значение корня, приставки и суффикса от лексического значения слова, умения вычленять в слове значимые части (морфемы), умения сравнивать слова в целях установления их семантико-структурной общности или различия и т.
В-четвертых, осознание роли морфем в слове, а также семантического значения приставок и суффиксов содействует формированию у школьников точности речи. Задача учителя – максимально способствовать не только пониманию учащимися лексического значения слова, но и развитию осознанного употребления в контексте слов с определенными приставками и суффиксами. В-пятых, изучение морфемного состава слова имеет большое значение для формирования орфографических навыков. Обусловлено это тем, что ведущим принципом русского правописания является морфологический. Формирование навыков правописания корня, приставок, суффиксов и окончаний на теоретической основе (а только такое письмо может быть сознательным) требует целенаправленного применения фонетических, словообразовательных и грамматических знаний. Поэтому одной из важных задач изучения морфемного состава слова является создание основы знаний и умений, необходимых для формирования навыков правописания морфем слова, и, прежде всего, корня. Наконец, немаловажен и тот факт, что изучение морфемного состава слова заключает в себе большие возможности для развития умственных способностей учащихся, в частности, для формирования у них специфических умственных умений, без которых невозможно сознательное владение словом как языковой единицей, например, умения абстрагировать семантическое значение корня, приставки и суффикса от лексического значения слова, умения вычленять в слове значимые части (морфемы), умения сравнивать слова в целях установления их семантико-структурной общности или различия и т. д. Задача учителя – создать в учебном процессе такие условия, при которых усвоение знаний сочетается с формированием адекватных им умственных действий. В настоящее время, согласно утвержденным программам для 4-летней начальной школы, морфемный состав слова изучается во 2-м и 3-м классах. По мнению методистов и учителей, изучение морфемной структуры слов имеет исключительно важное значение в развитии лингвистических способностей детей и их общем развитии. Невозможно переоценить роль понимания структуры слова в обучении чтению и правописанию. Прежде всего мы узнаем слова при чтении и воссоздаем при письме по их значимым частям – морфемам. Кроме того, изучение состава слова заключает в себе богатейшие возможности для развития интереса детей к миру языка. С восхищением слушают младшие школьники «слово о словах», они искренне удивляются тому, что кто-то не понял, почему словом леонить стали обозначать движения человека в открытом космосе; они хотят знать, что значит и как возникло слово перестройка и т.
д. Задача учителя – создать в учебном процессе такие условия, при которых усвоение знаний сочетается с формированием адекватных им умственных действий. В настоящее время, согласно утвержденным программам для 4-летней начальной школы, морфемный состав слова изучается во 2-м и 3-м классах. По мнению методистов и учителей, изучение морфемной структуры слов имеет исключительно важное значение в развитии лингвистических способностей детей и их общем развитии. Невозможно переоценить роль понимания структуры слова в обучении чтению и правописанию. Прежде всего мы узнаем слова при чтении и воссоздаем при письме по их значимым частям – морфемам. Кроме того, изучение состава слова заключает в себе богатейшие возможности для развития интереса детей к миру языка. С восхищением слушают младшие школьники «слово о словах», они искренне удивляются тому, что кто-то не понял, почему словом леонить стали обозначать движения человека в открытом космосе; они хотят знать, что значит и как возникло слово перестройка и т.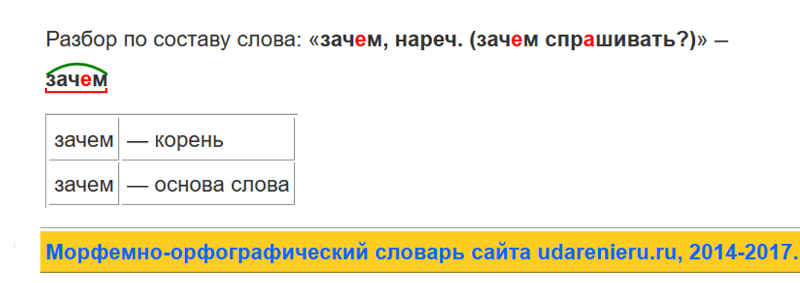 д. Выяснение того, как сделаны слова в русском языке и как они делаются, способствует возникновению мотивации, необходимой для успешного овладения речевой деятельностью, развивает в детях потребность в повышении своей языковой культуры, стремление наиболее точно выразить мысль в слове [7, C. 506]. Особенно, естественно, это заметно на начальном этапе, когда младшие школьники еще не знают всех изменений основных частей речи. Большие затруднения испытывают учащиеся при разборе слов по составу, если у них плохая фонематическая подготовка, а также если они не понимают особенностей русской графики. Так, если школьник не осознает, что в словах рука и земля одно и то же окончание [а], которое после твердого и мягкого согласного передается разными буквами, у него так и не возникает представления о существительных одного склонения как ос словах, имеющих один и тот же набор окончаний. И значит, он будет затрудняться при проверке безударных падежных окончаний по ударным. Источником ошибок довольно часто служит «замаскированная» морфема.
д. Выяснение того, как сделаны слова в русском языке и как они делаются, способствует возникновению мотивации, необходимой для успешного овладения речевой деятельностью, развивает в детях потребность в повышении своей языковой культуры, стремление наиболее точно выразить мысль в слове [7, C. 506]. Особенно, естественно, это заметно на начальном этапе, когда младшие школьники еще не знают всех изменений основных частей речи. Большие затруднения испытывают учащиеся при разборе слов по составу, если у них плохая фонематическая подготовка, а также если они не понимают особенностей русской графики. Так, если школьник не осознает, что в словах рука и земля одно и то же окончание [а], которое после твердого и мягкого согласного передается разными буквами, у него так и не возникает представления о существительных одного склонения как ос словах, имеющих один и тот же набор окончаний. И значит, он будет затрудняться при проверке безударных падежных окончаний по ударным. Источником ошибок довольно часто служит «замаскированная» морфема. Мы имеем в виду в первую очередь своеобразие передачи при письме звука [й]. если младший школьник не понимает, что буква ю в глаголе читаю обозначает не только окончание [у], но и звук [й], который не входит в окончание, то позже, в средних классах, ему уже не понять, как образуются глаголы повелительного наклонения и т.д. и т.п. Разбор слов по составу представляет определенные трудности не только для детей, но и для учителей. На морфемном уровне активнее, чем на других языковых ярусах (например, в морфологии), происходят различные изменения: состав слова упрощается, усложняется и т.п. То, что считалось бесспорным вчера, сегодня подвергается коррекции. Так, например, учителя старшего поколения с трудом склоняются признать, что в слове прекрасный всего две морфемы: корень и окончание (прекрасн-ый), а слова плот и плотник относятся к разнокоренным и т.п. Без систематического обращения к справочной литературе в работе по составу слова учителю не обойтись. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно иметь в виду некоторые важные языковые закономерности.
Мы имеем в виду в первую очередь своеобразие передачи при письме звука [й]. если младший школьник не понимает, что буква ю в глаголе читаю обозначает не только окончание [у], но и звук [й], который не входит в окончание, то позже, в средних классах, ему уже не понять, как образуются глаголы повелительного наклонения и т.д. и т.п. Разбор слов по составу представляет определенные трудности не только для детей, но и для учителей. На морфемном уровне активнее, чем на других языковых ярусах (например, в морфологии), происходят различные изменения: состав слова упрощается, усложняется и т.п. То, что считалось бесспорным вчера, сегодня подвергается коррекции. Так, например, учителя старшего поколения с трудом склоняются признать, что в слове прекрасный всего две морфемы: корень и окончание (прекрасн-ый), а слова плот и плотник относятся к разнокоренным и т.п. Без систематического обращения к справочной литературе в работе по составу слова учителю не обойтись. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно иметь в виду некоторые важные языковые закономерности. Морфема – это минимальная значимая часть слова, которая, как и всякая языковая единица, имеет две неразрывно связанные между собой стороны: внешнюю (звуковой состав) и внутреннюю (значение). Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Например, слова волчонок, медвежонок, козленок имеют одинаковую часть – онок (-енок) и обозначают детенышей животных. Если же мы включим в тот же ряд слова кружок, сахарок, басок и т.п. на том основании, что в них исчезнет второй необходимый признак – общее в значении: о последних трех словах никак нельзя сказать, что они обозначают детенышей. Следовательно, часть –онок не делится на более мелкие отрезки и представляет собой один суффикс[10, С. 111]. Умение устанавливать тождество морфем необходимо для определения сильной позиции фонемы в конкретной морфеме, то есть является обязательным условием правильного решения орфографических задач. Однако установить, действительно ли данные слова (два или больше) имеют в своем составе одну и ту же морфему, далеко не всегда просто.
Морфема – это минимальная значимая часть слова, которая, как и всякая языковая единица, имеет две неразрывно связанные между собой стороны: внешнюю (звуковой состав) и внутреннюю (значение). Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Например, слова волчонок, медвежонок, козленок имеют одинаковую часть – онок (-енок) и обозначают детенышей животных. Если же мы включим в тот же ряд слова кружок, сахарок, басок и т.п. на том основании, что в них исчезнет второй необходимый признак – общее в значении: о последних трех словах никак нельзя сказать, что они обозначают детенышей. Следовательно, часть –онок не делится на более мелкие отрезки и представляет собой один суффикс[10, С. 111]. Умение устанавливать тождество морфем необходимо для определения сильной позиции фонемы в конкретной морфеме, то есть является обязательным условием правильного решения орфографических задач. Однако установить, действительно ли данные слова (два или больше) имеют в своем составе одну и ту же морфему, далеко не всегда просто.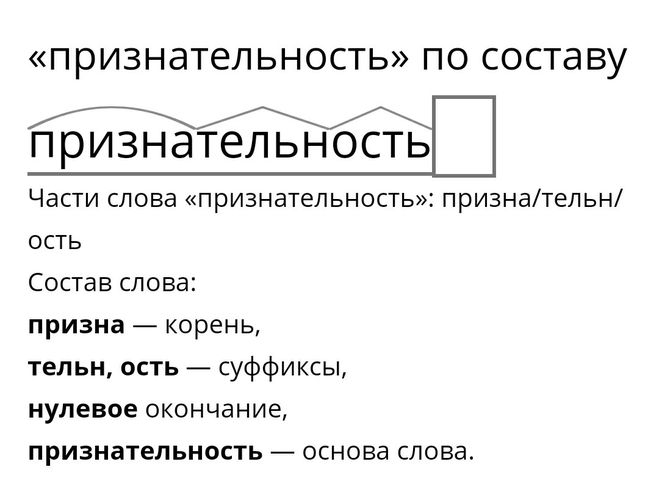 Дело в том, что между морфемами существуют такие же многообразные связи, как и между целыми словами: синонимия, амонимия и т.д. Причем это относится не только к корню, но в равной степени и к аффиксам. Например, корни слов погас и потух – синонимы, то же можно сказать о суффиксах в словах, обозначающих, например, самок животных: -иц- (тигрица), -их- (слониха), -к- (голубка) и т.п. Омонимичными являются корни слов нос и носит, суффиксы в словах чайник и печник, окончания существительных первого склонения в именительном падеже и второго склонения в родительном: рука – стола, окончания –и в трех падежах существительных третьего склонения: тени, приставки в словах закричал – завернул и т.п. Необходимо четко разграничивать один и тот же корень (приставку, суффикс, окончание) и разные корни (приставки, суффиксы, окончания), которые совпали по звуковому (фонемному) составу. Или, напротив, при разном звучании имеют одно только значение. Таким образом, говорить о такой же морфеме можно при совпадении обоих ее признаков.
Дело в том, что между морфемами существуют такие же многообразные связи, как и между целыми словами: синонимия, амонимия и т.д. Причем это относится не только к корню, но в равной степени и к аффиксам. Например, корни слов погас и потух – синонимы, то же можно сказать о суффиксах в словах, обозначающих, например, самок животных: -иц- (тигрица), -их- (слониха), -к- (голубка) и т.п. Омонимичными являются корни слов нос и носит, суффиксы в словах чайник и печник, окончания существительных первого склонения в именительном падеже и второго склонения в родительном: рука – стола, окончания –и в трех падежах существительных третьего склонения: тени, приставки в словах закричал – завернул и т.п. Необходимо четко разграничивать один и тот же корень (приставку, суффикс, окончание) и разные корни (приставки, суффиксы, окончания), которые совпали по звуковому (фонемному) составу. Или, напротив, при разном звучании имеют одно только значение. Таким образом, говорить о такой же морфеме можно при совпадении обоих ее признаков. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы – синонимы, амонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом багаже языка, его безграничных возможностях для выражения всех оттенков мысли. Однако нельзя забывать, что почти каждая морфема имеет свои разновидности, связанные с небольшими различиями в ее фонетическом составе. Конкретные варианты, которыми представлена морфема в речи, называют морфами. Морфы каждой морфемы чередуются в зависимости от грамматической позиции: ходить, но хожу; бродить, но брожу и т.п., то есть перед –ить корень кончается на д, а перед окончанием первого лица д заменяется на ж и т.д. «Чередуются морфы по приказанию следующей морфемы, грамматической единицы. Позиционно чередующиеся морфы, грамматической единицы. Позиционно чередующиеся морфы объединяются в одну морфему. Так, например, морфы ход- и хож- представляют одну и ту же морфему, один и тот же корень» [18, С. 178]. Программа младших классов не предусматривает знакомства учащихся с рассмотренными закономерностями.
Постоянное внимание учителя к тому, что в нашем языке возможны морфемы – синонимы, амонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом багаже языка, его безграничных возможностях для выражения всех оттенков мысли. Однако нельзя забывать, что почти каждая морфема имеет свои разновидности, связанные с небольшими различиями в ее фонетическом составе. Конкретные варианты, которыми представлена морфема в речи, называют морфами. Морфы каждой морфемы чередуются в зависимости от грамматической позиции: ходить, но хожу; бродить, но брожу и т.п., то есть перед –ить корень кончается на д, а перед окончанием первого лица д заменяется на ж и т.д. «Чередуются морфы по приказанию следующей морфемы, грамматической единицы. Позиционно чередующиеся морфы, грамматической единицы. Позиционно чередующиеся морфы объединяются в одну морфему. Так, например, морфы ход- и хож- представляют одну и ту же морфему, один и тот же корень» [18, С. 178]. Программа младших классов не предусматривает знакомства учащихся с рассмотренными закономерностями. Однако важно постоянно иметь их в виду. И если ученики составили группу однокоренных слов снег, снежок, снеговик, снежный, то учитель, уточняя ответы детей, должен сказать: «Эти слова имеют корень снег- (снеж-)». Обойти явление чередования фонем в морфемах даже на начальном этапе изучения состава слова невозможно, так как ему подвержено подавляющее число слов в русском языке. А от более сложных процессов, происходящих в морфемной структуре слов, желательно оградить младших школьников. Имеется в виду явление опрощения и связанные корни. Напомним, что в отличие от свободных корней, которые имеют ясно выраженное лексическое значение, в связанных корнях вещественное значение не поддается объяснению с точки зрения современного языка. Например, что обозначает корень –ня- в словах занять, перенять, отнять и т.п? А корень –ул- в словах улица, переулок, закоулок? Для младших школьников, которые стремятся мыслить конкретно, работа с такими словами затруднительна [11, С. 105]. конечной согласной корня в этих словах.
Однако важно постоянно иметь их в виду. И если ученики составили группу однокоренных слов снег, снежок, снеговик, снежный, то учитель, уточняя ответы детей, должен сказать: «Эти слова имеют корень снег- (снеж-)». Обойти явление чередования фонем в морфемах даже на начальном этапе изучения состава слова невозможно, так как ему подвержено подавляющее число слов в русском языке. А от более сложных процессов, происходящих в морфемной структуре слов, желательно оградить младших школьников. Имеется в виду явление опрощения и связанные корни. Напомним, что в отличие от свободных корней, которые имеют ясно выраженное лексическое значение, в связанных корнях вещественное значение не поддается объяснению с точки зрения современного языка. Например, что обозначает корень –ня- в словах занять, перенять, отнять и т.п? А корень –ул- в словах улица, переулок, закоулок? Для младших школьников, которые стремятся мыслить конкретно, работа с такими словами затруднительна [11, С. 105]. конечной согласной корня в этих словах. Обращается внимание учащихся и на озвончение согласных в середине или оглушение в конце таких слов, как «косьба», «кот» и т.п. [12, С. 143]. Морфемный анализ поддерживает работу над частями речи. Так, еще до изучения склонения имен существительных, прилагательных учащиеся усваивают характерные для этих частей речи окончания (-а, -я, -ая, — яя, -ую, — юю), отдельные суффиксы (-к- травка, канавка, -н- длинный и т.п.). правописание окончаний целесообразно связывать с синтаксическим разбором. Вот почему, планируя материал программы по грамматике, нельзя брать разделы программы последовательно один за другим: «Звуки и буквы», «Слово», «Предложение», «Связная речь». Материал по грамматике, правописанию и развитию речи в начальных классах планируется с таким расчетом, чтобы разные стороны языка выступали на каждом отдельном уроке во взаимосвязи. При этом очень важно учитывать различные стороны речевой культуры учащихся: правильное орфоэпическое произношение, правильное ударение, внимание, внимание к значению слова, умение выбрать нужное слово, правильно и точно отражающую мысль, правильное построение предложений и умение правильно пользоваться монологической речью.
Обращается внимание учащихся и на озвончение согласных в середине или оглушение в конце таких слов, как «косьба», «кот» и т.п. [12, С. 143]. Морфемный анализ поддерживает работу над частями речи. Так, еще до изучения склонения имен существительных, прилагательных учащиеся усваивают характерные для этих частей речи окончания (-а, -я, -ая, — яя, -ую, — юю), отдельные суффиксы (-к- травка, канавка, -н- длинный и т.п.). правописание окончаний целесообразно связывать с синтаксическим разбором. Вот почему, планируя материал программы по грамматике, нельзя брать разделы программы последовательно один за другим: «Звуки и буквы», «Слово», «Предложение», «Связная речь». Материал по грамматике, правописанию и развитию речи в начальных классах планируется с таким расчетом, чтобы разные стороны языка выступали на каждом отдельном уроке во взаимосвязи. При этом очень важно учитывать различные стороны речевой культуры учащихся: правильное орфоэпическое произношение, правильное ударение, внимание, внимание к значению слова, умение выбрать нужное слово, правильно и точно отражающую мысль, правильное построение предложений и умение правильно пользоваться монологической речью. Чтобы обеспечить все перечисленные требования, учитель на каждом уроке русского языка занимается разными сторонами языка. Материал же программы распределяют по учебным четвертям так, чтобы обеспечить возможность разностороннего изучения языка, повторение и взаимосвязь грамматической теории и языковой практики. Таким образом, все сказанное об особенностях планирования по грамматике и правописанию не исключает необходимости выделять центральные, основные темы для работы над ними в определенный период учебного времени. Такие центральные, основные темы имеются в программе каждого их трех начальных классов. Так, например, центральным разделом программы первого класса является раздел «Звуки и буквы». Во втором классе таким центральным, основным разделом является раздел «Слово». В третьем классе главное внимание учащихся на уроках русского языка сосредотачивается на изменение слов в предложениях. Поэтому здесь центральным, основным разделов является изменение и связь слов. 3. Методы и приемы изучения состава слов.
Чтобы обеспечить все перечисленные требования, учитель на каждом уроке русского языка занимается разными сторонами языка. Материал же программы распределяют по учебным четвертям так, чтобы обеспечить возможность разностороннего изучения языка, повторение и взаимосвязь грамматической теории и языковой практики. Таким образом, все сказанное об особенностях планирования по грамматике и правописанию не исключает необходимости выделять центральные, основные темы для работы над ними в определенный период учебного времени. Такие центральные, основные темы имеются в программе каждого их трех начальных классов. Так, например, центральным разделом программы первого класса является раздел «Звуки и буквы». Во втором классе таким центральным, основным разделом является раздел «Слово». В третьем классе главное внимание учащихся на уроках русского языка сосредотачивается на изменение слов в предложениях. Поэтому здесь центральным, основным разделов является изменение и связь слов. 3. Методы и приемы изучения состава слов. Знакомство со значащими частями слова, с морфемным составом слова программа предполагает во втором классе. Дается слово лес, к нему подбираются слова: лесок, лесник, лесной. Вводится термин «корень» и «однокоренные слова»; в понятие «корень» будет входить признак: главная смысловая часть, общая для однокоренных слов; позже, когда дети познакомятся с другими смысловыми частями слова, сюда войдет еще один признак: часть слова, от которой с помощью приставок и суффиксов образуются новые слова. Чтобы у детей не получилось ложного представления о родственных словах как о таких, которые близки или сходны только по звучанию, учитель сопоставляет слова вроде нос и носить. Выясняется, что родственными или однокоренными словами являются только те, которые имеют и общую часть, и общее, близкое значение [20, С. 134]. По своему характеру упражнения по выяснению родственных слов и по выделению корня в них обычно бывают такие: 1) даются ряды однокоренных слов, требуется выделить в них корень; 2) даются предложения и небольшие связные тексты, в которых встречаются родственные слова; 3) проводится работа над осмыслением корней слов; 4) проводится работа по образованию от данного корня однокоренных слов.
Знакомство со значащими частями слова, с морфемным составом слова программа предполагает во втором классе. Дается слово лес, к нему подбираются слова: лесок, лесник, лесной. Вводится термин «корень» и «однокоренные слова»; в понятие «корень» будет входить признак: главная смысловая часть, общая для однокоренных слов; позже, когда дети познакомятся с другими смысловыми частями слова, сюда войдет еще один признак: часть слова, от которой с помощью приставок и суффиксов образуются новые слова. Чтобы у детей не получилось ложного представления о родственных словах как о таких, которые близки или сходны только по звучанию, учитель сопоставляет слова вроде нос и носить. Выясняется, что родственными или однокоренными словами являются только те, которые имеют и общую часть, и общее, близкое значение [20, С. 134]. По своему характеру упражнения по выяснению родственных слов и по выделению корня в них обычно бывают такие: 1) даются ряды однокоренных слов, требуется выделить в них корень; 2) даются предложения и небольшие связные тексты, в которых встречаются родственные слова; 3) проводится работа над осмыслением корней слов; 4) проводится работа по образованию от данного корня однокоренных слов. Так как слова по своему морфемному составу бывают различной степени сложности, и учащиеся знакомятся со всеми частями слова не сразу. Сначала даются слова, состоящие из корня и окончания. Потом дети разбирают слова, состоящие из корня и суффикса. Затем, когда дети познакомятся с приставками, идут слова, состоящие из корня и приставки. Наконец, разбираются смешанные случаи. Основной, наиболее ответственной темой, связанной с изучением состава слова, и в частности, корня, являются тема «Правописание безударных гласных корня». Если в первом классе усвоение правописания безударных гласных развивается на фонетической основе, то дальше формирование навыка писать безударные гласные должно идти иначе. Уже во втором классе совершается переход на морфемную основу. Если ученик верно выделил в слове корень, прочитал его отдельно, обратил внимание на его графический образ, то этим уже в значительной мере обеспечено правильное написание гласной корня. Для усвоения правила правописания безударных гласных большое значение имеют разнообразные упражнения.
Так как слова по своему морфемному составу бывают различной степени сложности, и учащиеся знакомятся со всеми частями слова не сразу. Сначала даются слова, состоящие из корня и окончания. Потом дети разбирают слова, состоящие из корня и суффикса. Затем, когда дети познакомятся с приставками, идут слова, состоящие из корня и приставки. Наконец, разбираются смешанные случаи. Основной, наиболее ответственной темой, связанной с изучением состава слова, и в частности, корня, являются тема «Правописание безударных гласных корня». Если в первом классе усвоение правописания безударных гласных развивается на фонетической основе, то дальше формирование навыка писать безударные гласные должно идти иначе. Уже во втором классе совершается переход на морфемную основу. Если ученик верно выделил в слове корень, прочитал его отдельно, обратил внимание на его графический образ, то этим уже в значительной мере обеспечено правильное написание гласной корня. Для усвоения правила правописания безударных гласных большое значение имеют разнообразные упражнения. Все упражнения сопровождаются дополнительными работами: дети ставят ударения, подчеркивают безударные гласные, иногда выделяют целиком корень, дают устные объяснения. При изучении безударных гласных в корне пользуются разными приемами проверки их правописания в зависимости от характера слов. Такими являются: 1) замена единственного числа множественным: гора – горы; 2) замена множественного числа единственным: дома – дом; 3) образование слов ласкательного значения: трава – травка; 4) нахождение к множественному слову односложного слова: кормушка – корм; 5) замена существительного прилагательным: зима – зимний; 6) замена одной формы глагола другой: пилил – пилят. Не следует добиваться того, чтобы учащиеся запоминали и формулировали эти способы проверки в виде правил. Упражнения, подобные перечисленным, развивают грамматико-орфографическую гибкость, понимание смысловых связей между словами, дети практически усваивают единство написания родственных слов. Имеет некоторое значение и порядок, в котором изучаются безударные гласные; целесообразней всего давать для изучения слова с противопоставляемыми буквами о-а, е-и-я (читаются одинаково, а пишутся 2) окончание противопоставлено по своей роли корню: оно служит для связи слов; 3) окончание изменяется в зависимости от связи с другими словами.
Все упражнения сопровождаются дополнительными работами: дети ставят ударения, подчеркивают безударные гласные, иногда выделяют целиком корень, дают устные объяснения. При изучении безударных гласных в корне пользуются разными приемами проверки их правописания в зависимости от характера слов. Такими являются: 1) замена единственного числа множественным: гора – горы; 2) замена множественного числа единственным: дома – дом; 3) образование слов ласкательного значения: трава – травка; 4) нахождение к множественному слову односложного слова: кормушка – корм; 5) замена существительного прилагательным: зима – зимний; 6) замена одной формы глагола другой: пилил – пилят. Не следует добиваться того, чтобы учащиеся запоминали и формулировали эти способы проверки в виде правил. Упражнения, подобные перечисленным, развивают грамматико-орфографическую гибкость, понимание смысловых связей между словами, дети практически усваивают единство написания родственных слов. Имеет некоторое значение и порядок, в котором изучаются безударные гласные; целесообразней всего давать для изучения слова с противопоставляемыми буквами о-а, е-и-я (читаются одинаково, а пишутся 2) окончание противопоставлено по своей роли корню: оно служит для связи слов; 3) окончание изменяется в зависимости от связи с другими словами.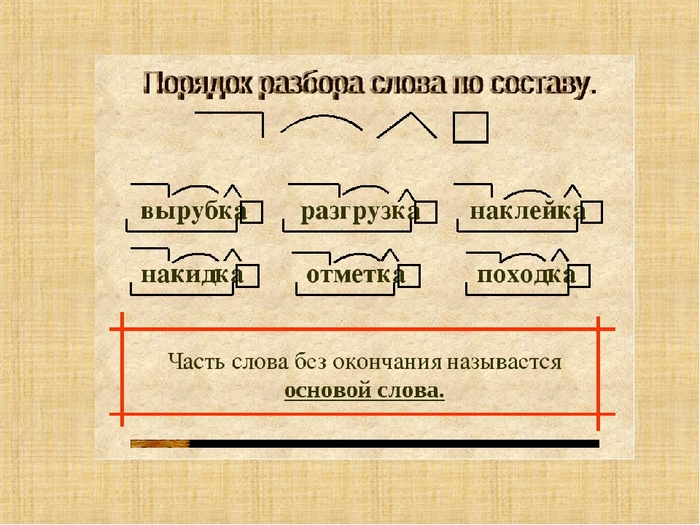 Синтаксический признак окончания очень важен для понимания склонения и спряжения, с которыми дети познакомятся несколько позже; кроме того, понимание синтаксической роли окончания вносит осмысленность в работу по установлению связи между словами при выделении пар слов, чем ученики второго класса должны серьезно заниматься [22, С. 203]. Чтобы учащиеся поняли синтаксическую роль окончаний, рекомендуется для наблюдений брать так называемые деформированные предложения; причем слова в этих предложениях берутся в начальной форме; требуется восстановить предложение, связав слова между собой; для чего, конечно, потребуется изменение окончаний. Работа над разделом «Состав слова» не может сводиться только к анализу слов, она предполагает и синтетические упражнения. Подбор однокоренных, или родственных слов – наиболее распространенный и полезный вид упражнений этого рода. Дается какое-либо слово (существительное, прилагательное, глагол), дети подбирают однокоренные слова. На первых порах ряд этих слов будет небольшим: 2-3 слова, но постепенно он расширяется, например, к слову корм подбираются слова кормушка, кормить, к слову боль – слова больной, болеть, больница, больно, к слову снег – снеговик, снегурочка и даже слово снежок, снежный, к слову лететь – летчик, полет, залететь и т.
Синтаксический признак окончания очень важен для понимания склонения и спряжения, с которыми дети познакомятся несколько позже; кроме того, понимание синтаксической роли окончания вносит осмысленность в работу по установлению связи между словами при выделении пар слов, чем ученики второго класса должны серьезно заниматься [22, С. 203]. Чтобы учащиеся поняли синтаксическую роль окончаний, рекомендуется для наблюдений брать так называемые деформированные предложения; причем слова в этих предложениях берутся в начальной форме; требуется восстановить предложение, связав слова между собой; для чего, конечно, потребуется изменение окончаний. Работа над разделом «Состав слова» не может сводиться только к анализу слов, она предполагает и синтетические упражнения. Подбор однокоренных, или родственных слов – наиболее распространенный и полезный вид упражнений этого рода. Дается какое-либо слово (существительное, прилагательное, глагол), дети подбирают однокоренные слова. На первых порах ряд этих слов будет небольшим: 2-3 слова, но постепенно он расширяется, например, к слову корм подбираются слова кормушка, кормить, к слову боль – слова больной, болеть, больница, больно, к слову снег – снеговик, снегурочка и даже слово снежок, снежный, к слову лететь – летчик, полет, залететь и т. д. Такого рода упражнения очень важны для осмысленного усвоения правописания корней и приставок. Кроме того, они полезны и для развития представлений о смысловых связях слов друг с другом и для систематизации словаря. Очень удобными и полезными являются упражнения в анализе и подборе родственных слов при изучении частей речи, когда от слова, принадлежащего к одной части речи, образуются слова других грамматических разрядов. Вообще следует считать необходимым чуть ли не на каждом уроке проводить подбор однокоренных слов и анализ морфемного состава слов на каждом уроке грамматики и правописания во втором и третьем классах. ЗАКЛЮЧЕНИЕ Профессионализм, любовь к детям, ответственное отношение к их судьбе, к их будущему, постоянное самообразование, поиск, творчество помогут каждому учителю уже при обучении детей составу слов, заложить прочные основы последующих шагов ребенка в овладении богатствами родного языка в развитии и совершенствовании своей речи. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно помнить некоторые важные языковые закономерности.
д. Такого рода упражнения очень важны для осмысленного усвоения правописания корней и приставок. Кроме того, они полезны и для развития представлений о смысловых связях слов друг с другом и для систематизации словаря. Очень удобными и полезными являются упражнения в анализе и подборе родственных слов при изучении частей речи, когда от слова, принадлежащего к одной части речи, образуются слова других грамматических разрядов. Вообще следует считать необходимым чуть ли не на каждом уроке проводить подбор однокоренных слов и анализ морфемного состава слов на каждом уроке грамматики и правописания во втором и третьем классах. ЗАКЛЮЧЕНИЕ Профессионализм, любовь к детям, ответственное отношение к их судьбе, к их будущему, постоянное самообразование, поиск, творчество помогут каждому учителю уже при обучении детей составу слов, заложить прочные основы последующих шагов ребенка в овладении богатствами родного языка в развитии и совершенствовании своей речи. Чтобы правильно вести работу по морфемике, учителю необходимо постоянно помнить некоторые важные языковые закономерности.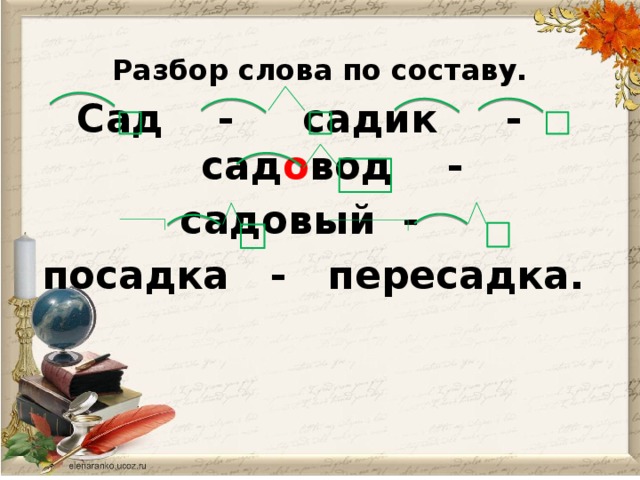 Морфема – это минимальная значимая часть слова, которая, как и всякая другая языковая единица, имеет две неразрывно связанные между собою стороны: внешнюю и внутреннюю. Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы-синонимы, омонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом богатстве языка, его безграничных возможностях для выражения всех оттенков мысли. При разборе слов по составу, так и при звуковом анализе, учитель должен очень внимательно относиться к подбору слов для работы и быть готовым дать правильное объяснение современной структуры слова и его происхождения. Морфемика позволяет получить сведения о строении слова, широко используемые в словообразовании и морфологии. Становление морфемики как особой лингвистической дисциплины стало возможным благодаря исследованиям основателя Казанской лингвистической школы И.
Морфема – это минимальная значимая часть слова, которая, как и всякая другая языковая единица, имеет две неразрывно связанные между собою стороны: внешнюю и внутреннюю. Морфема выделяется в ряду слов, имеющих сходство по указанным двум признакам: общность в значении и фонемном составе. Постоянное внимание учителя к тому, что в нашем языке возможны морфемы-синонимы, омонимичные значимые части и т.п., создает у учащихся представление о неисчерпаемом богатстве языка, его безграничных возможностях для выражения всех оттенков мысли. При разборе слов по составу, так и при звуковом анализе, учитель должен очень внимательно относиться к подбору слов для работы и быть готовым дать правильное объяснение современной структуры слова и его происхождения. Морфемика позволяет получить сведения о строении слова, широко используемые в словообразовании и морфологии. Становление морфемики как особой лингвистической дисциплины стало возможным благодаря исследованиям основателя Казанской лингвистической школы И. А. Бодуэна де Куртенэ, который в 1881 ввел в научный оборот понятие морфемы. ПРИЛОЖЕНИЕ. Конспект урока. Тема урока: разбор слова по составу. Цели урока: 1. Продолжить формирование представлений о том, что значит разобрать слово по составу. 2. развивать навыки разбора слов по составу, орфографическую зоркость учащихся, память, речь,, мышление и воображение. 3. Воспитывать у учащихся любовь к предмету, аккуратность, умение выслушивать ответы детей. Ход урока. I. Организация внимания детей. II. Акутуализация ранее изученного. а) проверка домашнего задания. Словарная работа: прочтите выписанные словарные слова и образованные родственные. б) Минутка чистописания. Прописи, с. 18 — Какие элементы общие в написании данных букв? — На какие две группы можно распределить эти буквы? — По каким признакам? III. Изучение нового материала. — Запишите слова, записанные на доске, отделите в них основу от окончания. На доске и в тетрадях начертить схему этих слов. — Упр. 42. (с. 118) Чтение текста, объяснение значений выделенных слов.
А. Бодуэна де Куртенэ, который в 1881 ввел в научный оборот понятие морфемы. ПРИЛОЖЕНИЕ. Конспект урока. Тема урока: разбор слова по составу. Цели урока: 1. Продолжить формирование представлений о том, что значит разобрать слово по составу. 2. развивать навыки разбора слов по составу, орфографическую зоркость учащихся, память, речь,, мышление и воображение. 3. Воспитывать у учащихся любовь к предмету, аккуратность, умение выслушивать ответы детей. Ход урока. I. Организация внимания детей. II. Акутуализация ранее изученного. а) проверка домашнего задания. Словарная работа: прочтите выписанные словарные слова и образованные родственные. б) Минутка чистописания. Прописи, с. 18 — Какие элементы общие в написании данных букв? — На какие две группы можно распределить эти буквы? — По каким признакам? III. Изучение нового материала. — Запишите слова, записанные на доске, отделите в них основу от окончания. На доске и в тетрадях начертить схему этих слов. — Упр. 42. (с. 118) Чтение текста, объяснение значений выделенных слов. — Конструирование текста по последовательности выполняемых строительных работ. — Комментированная запись текста. — Разобрать по составу выделенные слова. — Чтение сведений о языке на стр. 129. IV. Физкультминутка. V. Продолжение работы по теме урока. — Вспомните, кто произносил такие слова. Глазки, глазки, что вы делали? Ушки, ушки, а вы что делали? Ножки, ножки, а вы что делали? А вы, хвостище, что делали? -Какие здесь использованы предложения по цели высказывания? — Можно ли определить, как герой сказки относился к своим глазам, ушам, ногам, хвосту? Какая часть слова вам в этом помогает? Запишите предложения, имена существительные разберите по составу. — Выпишите из каждого ряда слова с приставками. Разберите их по составу, для этого вспомните алгоритм разбора. Зал, заехал, заря. Долина, долетел, долго, доброта. Изрубить, изба, избить. Полоса, полено, полежал, поле. — Подпишите к словам однокоренные слова с противоположным значением. Используйте приставки от -, у-, вы-. VI. Итог урока.
— Конструирование текста по последовательности выполняемых строительных работ. — Комментированная запись текста. — Разобрать по составу выделенные слова. — Чтение сведений о языке на стр. 129. IV. Физкультминутка. V. Продолжение работы по теме урока. — Вспомните, кто произносил такие слова. Глазки, глазки, что вы делали? Ушки, ушки, а вы что делали? Ножки, ножки, а вы что делали? А вы, хвостище, что делали? -Какие здесь использованы предложения по цели высказывания? — Можно ли определить, как герой сказки относился к своим глазам, ушам, ногам, хвосту? Какая часть слова вам в этом помогает? Запишите предложения, имена существительные разберите по составу. — Выпишите из каждого ряда слова с приставками. Разберите их по составу, для этого вспомните алгоритм разбора. Зал, заехал, заря. Долина, долетел, долго, доброта. Изрубить, изба, избить. Полоса, полено, полежал, поле. — Подпишите к словам однокоренные слова с противоположным значением. Используйте приставки от -, у-, вы-. VI. Итог урока. 1. Обобщение. — Из каких частей может состоять основа слова? — Какая часть должна обязательно входить в основу слова? — При помощи каких частей можно образовать родственные слова? — Что значит разобрать слова по составу? Как это сделать? — Молодцы, ребята. До свидания!
1. Обобщение. — Из каких частей может состоять основа слова? — Какая часть должна обязательно входить в основу слова? — При помощи каких частей можно образовать родственные слова? — Что значит разобрать слова по составу? Как это сделать? — Молодцы, ребята. До свидания!
Понятие морфемы. Морфемный анализ. — МегаЛекции
Значащие части слова: корни, суффиксы, приставки, окончания – называются общим термином морфема. Морфема – это наименьшая (т. е.. далее нечленимая) значащая часть слова. Слово может содержать одну морфему (я, он, где, ах) и несколько морфем (стен-а, стол-ик, по-бел-к-а, по-на-вез-л-и). Для русского языка характерны слова, состоящие из двух-трёх морфем.
Для того чтобы установить состав слова, надо расчленить его на значащие части (морфемы). У изменяемых слов надо прежде всего выделить окончание – путем изменения их формы: учительница, учительницы и т. д. Часть слова, остающаяся за вычетом окончания, называется основой. Чтобы расчленить основу, надо подобрать такие ряды слов, которые имели бы общие формальные части с одним и тем же значением.
Например, чтобы расчленить слово ножка, надо сначала выделить в нём окончание, изменив слово по падежам: ножка– им. п., ножки – род. п., ножке – дат. п. и т. д. Следовательно, в именительном падеже слово ножка имеет окончание -а. Затем подберем слова с тем же корнем: нож-ища, нож-ной. После выделения корня осталась часть -к-; такую же часть мы находим в словах ручка, головка, бумажка, причём эти слова также имеют значение уменьшительности, как и слово ножка. Следовательно, -к- – это суффикс со значением уменьшительности.
Суффикс -к-находим и в других словах, например: москвич-к-а, артист-к-а, румын-к-а; разбор-к-а, раз-вес-к-а. Эти слова, однако, не имеют значения уменьшительности. Следовательно, входящий в них суффикс -к-, хотя он внешне такой же, как в словах ножка, ручка и под., является другим суффиксом – суффиксом со значением «женскости» (москвичка и под. ) и суффиксом со значением действия (разборка и под.).
) и суффиксом со значением действия (разборка и под.).
Определяя состав слов, мы произвели морфемный анализ, т. е. выделили все морфемы, на которые членится слово.
Роль ударения в формообразовании и словообразовании.
Большую, хотя и вспомогательную, роль в образовании слов и их форм играет ударение (см. § 60). В некоторых случаях родственные слова отличаются друг от друга ударением и связанными с местом ударения особенностями произношения гласных звуков (§ 74), например: вéрхом – верхóм, бéгом – бегóм, кр гом – кругóм. То же самое наблюдается и при образовании некоторых форм слов, например: нóги, гóловы – именительный падеж множественного числа; ног , голов – родительный падеж единственного числа.
Основы слов.
Если в какой-нибудь форме слова мы отбросим окончание, то получим основу этой формы: рук-а (основа рук-), вин-тов-к-а (основа винтовк-). Если в слове есть формообразующий суффикс, то основой является часть слова без этого суффикса: у глаголов прошедшего времени (чита-л) и у прилагательных сравнительной степени (умн-ее, шир-е).
Одно и то же слово в разных формах может иметь разные основы: изуча-л (основа изуча-), изучаю (основа изучаj-). Ср.: осты-ть и остын-у; умере-ть, умр-у и умер ит. п.
Если у слова есть окончание, суффиксы стоят между корнем и окончанием; чит-а-ешь (суффикс а + j), при отсутствии окончания суффикс может оказаться на конце слова: сказа-в(суффикс —в).
В русском языке имеется глагольный суффикс-ся (-сь), своеобразие которого заключается в том, что он располагается после окончания: нес-ёт-ся (окончание -ёт), бер-у-сь (окончание -у).
Основа может состоять из одного корня: вод-а (основа вод-), нес-ти (основа нес-), бел-ый (основа бел-). Такая основа называется непроизводной или простой. Кроме корня, основа может включать в свой состав суффиксы и приставки: вод-иц-а (основа вод-иц-), бел-оват-ый (основа бел-оват-), при-нес-л-а (основа при-нес-). Такая основа называется производной.
Такая основа называется производной.
Производящие основы выделяют по соотношению с производными. Каждой производной основе соответствует основа производящая. Производящей называют основу, которая используется при образовании производной. Значение производящей основы мотивирует значение производной, а форма служит базой для построения производной. Обычно производная основа включает в свой состав производящую и какое-либо словообразовательное средство. Сравни:
Производящая основа Производная основа
тигр тигрёнок
паровоз паровозик
писатель писательница
говорить заговорить
Как видно из примеров, сами производящие основы могут быть как непроизводными (тигр, говорить), так и производными (пар-о-воз, писа-тель).
Упражнение 92. Выпишите формы одного и того же слова. Выделите корни.
1) Чернели, чернота, чернеют, черника, чернее, чернела; 2) белый, побелка, белая, белила, белизна, белое, забелить, побелеть; 3) гора, пригорок, гористый, горный, предгорье, горы.
93. Произведите морфемный анализ слов и объясните (устно) на основании значения корня, почему данные предметы и действия так названы.
Образец. 0-пён-ок – гриб; опёнки растут кучками около пней.
Черника, рыжик, рябчик, рогатка, напёрсток, перина, покрывало, мыло, рукавица, плетень, подосиновик, огород, мороженое, замаскироваться, пугало, словарь, голубика.
94. Выпишите однокоренные слова сначала с одним корнем, затем с другим. Корень выделите.
1) Вода, водить, безводный, заводь, заводить, водитель, водица, водиться, водник, наводить, развод, наводнение, переводчик, подводник, наводчик, обводнение, уводить, сводка, обезводить, привод, отводить.
2) Hoc, носить, носильщик, носик, переносица, вынос, носилки, носовой, носитель, разносчик, перенос, занос, нанос.
95. К следующим глаголам подберите родственные приставочные глаголы, противоположные по смыслу данным. Выделите приставки и объясните их значение.
Образец. Выходить из города – входить в город.
Разъединить провода, разобрать винтовку, развязать узел, расплести косу; отступать от города, отклеить марку от конверта, отнести книги, отодвинуть стол; приехать к брату, прилепить пластырь;
въезжать в Москву.
96. К следующим словам подберите родственные слова, постепенно отбрасывая приставки и суффиксы, пока не дойдёте до слова с непроизводной или самой коротой производной основой. Образец. Учительство – учитель-ство – учи-тель – уч-ить (ср.: уч-у, уч-ишь, уч-ат).
Обвинительный, небесспорный, безукоризненный, небезызвестный, рассмотрение, образованность, перевыполнить, переходный, порыбачить, раздаривать, преподносить, преодолевать, попустительствовать, попридержать, обобществить, порассказали, безжизненный, обезвредить, безрассудный.
97. Укажите, в каком классе учащиеся начальной школы знакомятся с составом слова. Установите, как определяются значащие части слова (корень, приставка, суффикс, окончание) в учебниках русского языка для начальной школы.
ЧЕРЕДОВАНИЕ ЗВУКОВ
Воспользуйтесь поиском по сайту:
Корень слова : многокоренные, однокоренные слова
Каждый школьник должен знать, что такое корень слова, чтобы суметь правильно и грамотно писать, а также выполнять морфемный разбор основных речевых единиц. Русский язык очень богат и разнообразен. И на сегодняшний день в нем зарегистрировано более 4000 корней вне зависимости от части речи, рода склонения, падежа и других словесных характеристик.
Содержание
Что собой представляет корень слова
В русском языке есть такое понятие, как морфема. Под ним понимается основные, значимые частицы слова. Выделение этих частей необходимо для определения лексического и грамматического значения речевой единицы. Чтобы определить лексический смысл и выделяется корень слова.
Самая значимая частичка слова – его корень, вычленить корень в слове – значит понять его суть, определить значение. Любая речевая единица может существовать без таких компонентов, как суффиксы, или приставки, но без основы это просто совокупность символов без всякого смысла. Бывают слова, которые содержат в себе несколько таких основ, их может быть две или три, или даже более.
Любая речевая единица может существовать без таких компонентов, как суффиксы, или приставки, но без основы это просто совокупность символов без всякого смысла. Бывают слова, которые содержат в себе несколько таких основ, их может быть две или три, или даже более.
Пример: если взять два слова – небосвод и поднебесье. В данных словах имеются приставка, корень, суффиксы, окончания. Однако основа и в том и в другом случае указывает на основное слово – небо. Если в данных словах опустить корень слова, смысл будет потерян.
Что такое однокоренные слова
Однокоренными в русском языке называются слова, которые имеют единый корень и схожи по смыслу.
Пример 1
Камень-окаменевший-каменный
Данные слова считаются однокоренными, так как главная морфема у всех одинаковая (камен), и смысл примерно одинаковый. Все они описывают предметы или дают им характеристики, которые так или иначе связаны с камнем.
Бывают слова, которые имеют главную морфему, которая одинаково пишется, однако смысл совсем разный.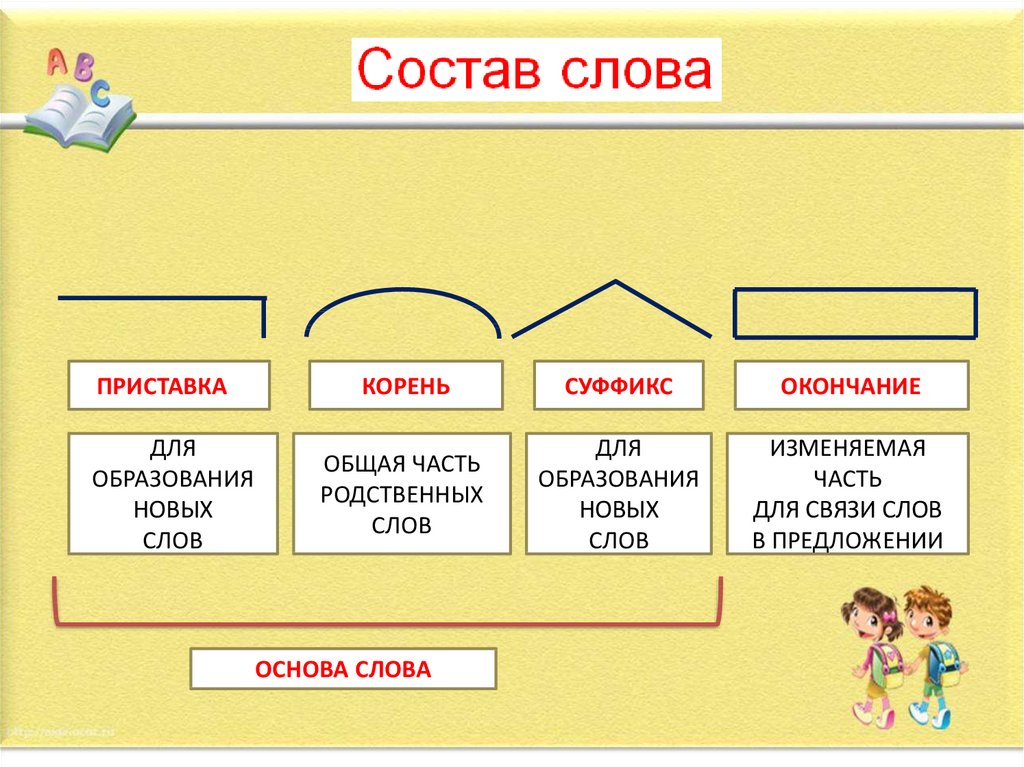 В таких ситуациях нельзя утверждать, что речь идет об однокоренных речевых единицах.
В таких ситуациях нельзя утверждать, что речь идет об однокоренных речевых единицах.
Пример 2
Карточка-картонный.
В данном случае речь идет о совершенно разных предметах, не объединенных общим смыслом.
Как правильно определять корень слова
На самом деле выделять главную морфему в речевых единицах довольно легко. Для этого необходимо выполнить довольно простой алгоритм действий.
Подобрать к исходному слову как можно больше родственных.
При этом необходимо руководствоваться главным критерием – наличие общего смысла.
Например: гриб—грибник-грибной.
Все эти слова связаны не только одинаковой главной морфемой, но и единым смыслом. Прочитав каждое из них можно понять, что речь идет о грибах.
В некоторых словах значение одинаковое, на иногда корень слова несколько разный – одна буква заменяется на другую. Такое явление в русском языке носит название чередования согласных.
Такое явление в русском языке носит название чередования согласных.
Например: видеть-вижу.
Здесь буква «д» замещается буквой «ж». Смысл при этом не меняется, однако корни несколько отличаются. Правильность написания таких чередующихся основ зависит от того, куда падает ударение, в какой части речевой единицы расположена чередующаяся буква, какое лексическое значение несет основная морфема.
Далее в каждом из собранной группы речевых единиц необходимо найти корень — общую часть.
Например: море, морской, мореплаватель.
Данную группу речевых единиц объединяет главная морфема «море».
Обозначить выделенную часть соответствующим значком.
Для обозначения основной морфемы в русском языке принято использовать значок дуги.
Правила русского языка указывают на то, что однокоренные слова могут относиться к различным частям речи, могут быть разного рода, числа и падежа.
Чтобы точно определить данную морфему, необходимо четко определить смысл слова.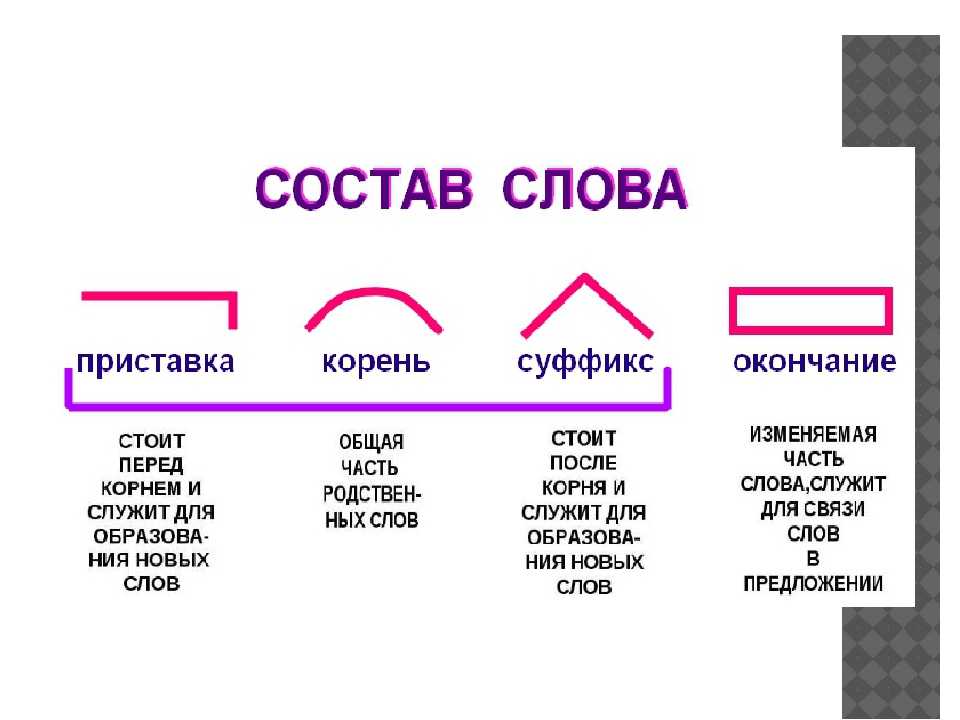 Некоторым для того, чтобы определить морфему слова, проще убрать лишние составляющие – приставки, суффиксы, окончания и выделить оставшуюся основу.
Некоторым для того, чтобы определить морфему слова, проще убрать лишние составляющие – приставки, суффиксы, окончания и выделить оставшуюся основу.
Корень – это морфема, которая совсем не обязательно дополняется другими морфемами – приставками, суффиксами или окончаниями. Она может использоваться как с ними, так и самостоятельно.
Например: вода-водичка-водянистый.
Как правильно сформировать группу однокоренных слов
Главный критерий построения цепочки – единый смысл. При этом однокоренными не будут считаться различные формы и вариации одного и того же слова. Все речевые единицы, собранные в одной группе должны быть разными, но схожими по смыслу. Если сравнить главные морфемы всех составляющих одной группы, они, скорее всего, будут отличаться, но все равно будут считаться однокоренными.
Например: дорога-дорожный—бездорожье.
Чтобы правильно подобрать нужные родственные слова, можно к основной смысловой морфеме добавить приставку, суффикс, либо окончание. В итоге получиться новое слово, которое и будет называться однокоренным исходному.
В итоге получиться новое слово, которое и будет называться однокоренным исходному.
Основные правила построения слов
В русском языке абсолютное большинство речевых единиц построено при помощи комбинации основной морфемы и дополнительных.
Основные виды сочетания морфем
- Корень + суффикс + окончание.
- Приставка + корень + окончание.
- Приставка + корень + суффикс + окончание.
- Приставка + корень + суффикс + суффикс.
Однокоренными не являются речевые единицы, в которых главная морфема представлена идентичным по смыслу основанием, но имеющим разное окончание. Также к родственным словам не относят слова, которые называются омонимами. Это слова, имеющие абсолютно идентичное основание, но совершенно различное значение.
Что такое коренная орфограмма
Орфограммой называют те словесные участки, которые наиболее подвержены допущению ошибок. Несмотря на то, что часто для определения правильности написания подбираются однокоренные проверочные слова, в основе тоже допускаются ошибки.
Именно после подбора проверочных слов легко обнаружить ту часть основы, которую нельзя проверить, если таковая вообще имеется. Для того, чтобы определиться с правильностью написания, рекомендуется гласную букву сделать ударной.
Разновидность основных морфем
Разновидность | Характеристика |
| Свободные | Это разновидность оснований, которые вполне могут использоваться в русском языке, как самостоятельные слова, без суффиксов, окончаний и приставок. |
| Связанные | Основания не могут использоваться как отдельные слова и существовать в русском языке без суффиксов, приставок и окончаний. |
Что такое много коренные слова
Много коренные слова – это речевые единицы, в которых присутствует более чем один корень. В них может два корня, три корня, а иногда и более. Для определения основы в данных словах следует выделить смысловые блоки.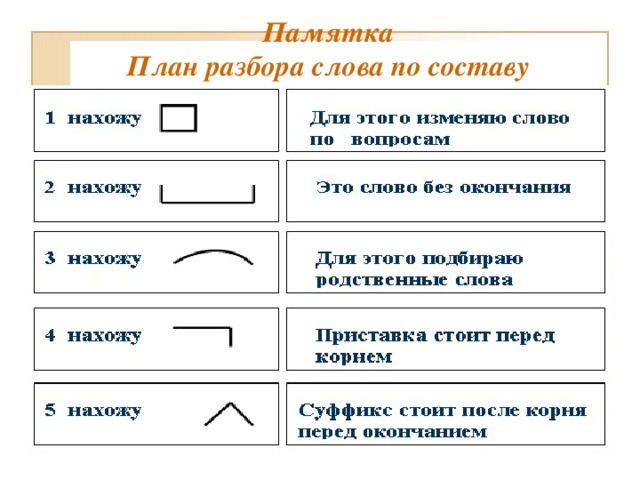 Например: водопад (падает вода), водопровод (проводит воду). После этого легко можно определить корни – они являются смысловыми блоками.
Например: водопад (падает вода), водопровод (проводит воду). После этого легко можно определить корни – они являются смысловыми блоками.
Такое понятие, как корень слова, знакомо всем со школьной скамьи. Это основа речевой единицы, ее суть и смысл. Именно корень заключает в себе лексический смысл. Подбор родственных, однокоренных слов помогает безошибочно определять корень, разбирать на морфемные составляющие. Чаще всего именно словесная основа определяется в последнюю очередь.
Все остальные речевые единицы не могут существовать без корней.
Средний рейтинг 4.2 / 5. Количество оценок: 10
Пока оценок нет. Ваша оценка может стать первой!
Сожалеем, что эта информация вам не пригодилась!
Хотите улучшить информацию?
Расскажите, как мы можем улучшить эту статью?
Конспект урока «Разбор имен существительных по составу»
Тема урока: «Разбор слова по составу»
Цель урока: организовать деятельность учащихся по формированию умения разбирать слова по составу.
Задачи урока:
Уточнить понятия «корень», «приставка», «суффикс», «окончание», «основа»; создать условия для формирования умения разбирать слово по составу с опопрой на алгоритм.
Развивать память, внимание, мышление, связную речь, орфографическую зоркость; развивать умение ставить учебные задачи.
Воспитывать потребность оценивать свою деятельность; воспитывать доброе отношение друг к другу.
Оборудование: компьютер, ноутбук, часы, алгоритм действий при разборе слова по составу, карточки с алгоритмом действий при разборе слова по составу, тесты, карточки с индивидуальными заданиями.
Ход урока.
— Орг. момент.
Здравствуйте, присаживаемся.
Открываем тетради записываем число, классная работа.
Для начала проведем чистописание.
В тетрадь записываем элементы букв, которые представлены на доске.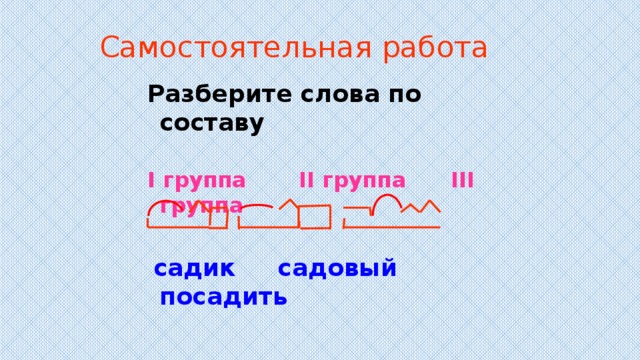
Ваша задача – обратить внимание над правильным соединением букв.
Пишем только одну строчку.
СЛОВАРНАЯ РАБОТА
А сейчас проведем словарную работу.
Под диктовку записываем следующие слова:
Огурцы, помидоры, лимон, апельсины, малину, батон, лесник.
Положили ручки.
Скажите, пожалуйста, какой частью речи являются слова, которые мы с вами записали.
Совершенно верно, все слова являются именем существительным.
— Что вы знаете об имени существительном?
Имя существительное – это часть речи, которая отвечает на вопрос кто, что и обозначает предмет.
— Что еще вы знаете об имени существительном?
(- бывают одушевленные и неодушевленные;
— имеют род: мужской, женский, средний
А также число: единственное и множественное.
Еще имена существительные склоняются по падежам)
— Вспомним, из каких частей состоят имена существительные.
1. А как называется часть слова, которая служит для связи слов в предложении …(окончание)
2.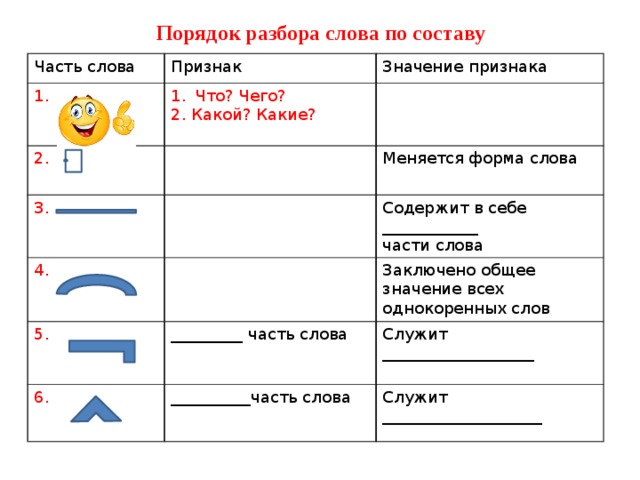 Общая часть однокоренных, родственных слов называется…..(корень)
Общая часть однокоренных, родственных слов называется…..(корень)
3. Часть слова, которая стоит после корня и служит для образования новых слов, называется….(суффикс)
4. Часть слова без окончания называется……(основа)
5. Часть слова, которая стоит перед корнем и служит для образования новых слов, называется….(приставка)
— А как вы думаете, о чем мы сегодня будем говорить? Кто сможет сформулировать тему урока.
— Сегодня мы с вами научимся разбирать имена существительные по частям, т.е. по составу.
И тема нашего урока звучит следующим образом:
Разбор имен существительных по составу.
Пропуская одну строчку после словарной работы, запишем тему урока.
Внимание на доску.
Как правильно произвести разбор имени существительного по составу.
Разберем слово лесник по составу.
А порядок таков:
Первое — пишем слово
лесник
Изменяем слово по падежам и находим окончание.
Им.п. (есть) лесник
Род. п. (нет) лесника
Дат. п. (иду) леснику
Вин.п. (вижу) лесника
Тв.п. (доволен) лесником
П.п. (думаю) о леснике

Что заметили? (меняется окончание). Значит в слове лесник окончание нулевое.
В русском языке окончание обозначается квадратом.
3. Дальше находим основу. Отделяем основу от окончания и выделяем её следующим образом. Смотрим – специальной линией.
4. Затем выделяем части основы. Чтобы выделить корень. Находим однокоренные слова.
Лесник
Однокоренные слова какие?
лес
лесной
Что заметили в однокоренных словах? Одна часть слова остается неизменной. Одна как раз и является корнем и выделяем его в виде дуги.
5. Дальше находим и обозначаем суффикс.
То что стоит после корня, является суффиксом и обозначается галочкой.
6. Нахожу и обозначаю приставку.
В слове лесник перед корнем нет части слова, значит приставка отсутствует .
Вывод. Таким образом.
При разборе слова по составу необходимо:
-выделить окончание
-указать основу слова
-указать части основы. Основа слова состоит из корня суффикса и приставки.
— Чтобы закрепить знания, выполним следующее упражнение.
Открываем учебники на страницу 51., находим упр. 281. .
Читаем внимательно задание.
Попробуйте устно сгруппировать слова по какому-либо признаку.
Какие у вас получились группы слов:
1группа слов, обозначающая род деятельности.
2 группа слов – это слова, имеющие уменьшительно-ласкательные суффиксы.
— разберем слово рябинушка по составу.
1. Запишем слово в тетрадь.
2. разберем слово по составу. Находим окончание, для этого просклоняем имя существительное по падежам.
Какая часть слова меняется? Последняя часть- буква а меняется на разные окончания. Значит окончание А , отмечаем квадратом.
Затем отделяем основу от окончания. Отделили.
Находи корень. Подбираем однокоренные слова. Рябина, рябинка.
Корень – рябин, обозначаем дугой.
Находим суффикс. В данном слове два суффикса- уш и к. обозначаем сверху галочкой.
Приставки в данном слове нет.
-Дальше через запятую выбираем два любых слова и самостоятельно разбираем по составу.
-Проверяем. Даша, что у тебя получилось. Какое слово разобрала.
Выполняем следующее упражнение 282.
Читаем задание.
Делимся на 3 группы.
1 ряд- 1 группа, 2 ряд -2 группа, 3 ряд – 3 группа.
1 группа – в тетради записывает слова, которые по составу походят к 1 схеме, и т.д.
Выполняем.
1 группа какие у вас получились слова, 2 группа- 3 группы.
Открываем дневники и записываем домашнее задание. Упр 286, стр.
Вам необходимо записать слова по группам. .
Рефлексийно-оценочный этап.
-А теперь подведем итог нашего урока
-Какова же тема сегодняшнего урока? (Разбор слова по составу)
-Добились ли мы целей, которые ставили в начале урока?
-Нам получилось вспомнить части слова?
-А какие вы знаете части слова?
-А что мы научились выполнять на уроке? (разбор слова по составу)
— А что нам в этом помогало? (знание алгоритма)
ОЦЕНИВАНИЕ.
Домашнее задание.
-Ребята, я хочу предложить вам на выбор два задания для домашней работы
1. Придумать и записать 7-10 слов, где присутствую все части слова.
2. Упражнение и139.
Спасибо за урок! Желаю вам успехов!
Определение и значение анализа — Merriam-Webster
анализ ·исис ə-ˈna-lə-səs
1
а
: детальное изучение чего-либо сложного с целью понять его природу или определить его существенные черты : тщательное изучение
тщательный анализ проблемы
б
: акт такой экспертизы
2
: разделение целого на составные части
3
а
: идентификация или разделение компонентов вещества
химический анализ почвы
б
: состав смеси
4
математика
а
: доказательство математического утверждения путем предположения результата и вывода действительного утверждения с помощью ряда обратимых шагов
б(1)
: раздел математики, занимающийся главным образом пределами, непрерывностью и бесконечными рядами
(2) Психоанализ а
: философский метод разложения сложных выражений на более простые или более простые
б
: уточнение выражения путем разъяснения его использования в дискурсе
7
лингвистика : использование служебных слов вместо флективных форм в качестве характерного приема языка
Синонимы
- анатомирование
- анатомия
- анализ
- поломка
- деконструкция
- рассечение
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Его анализ выявляет скрытые трещины с ясностью рентгеновского снимка, а его риторическое мастерство, хотя и модулированное в журналистском стиле, во многом обязано четким диалогам Еврипида. Г. В. Бауэрсок, New York Review of Books , 6 ноября 2008 г.
Чтобы математически описать экономические решения, экономисты должны были предположить, что человеческое поведение является одновременно рациональным и предсказуемым. Они представляли себе репрезентативного человека Homo economicus, наделенного устойчивыми предпочтениями, стабильным настроением и завидной способностью принимать только рациональные решения. Эта ловкость рук привела к появлению некоторых теорий, которые имели подлинную прогностическую ценность, но экономисты были вынуждены исключить из своего анализа многие явления, не вписывавшиеся в… рамки, такие как пузыри на фондовом рынке, наркомания и навязчивые покупки.
Джон Кэссиди, 9 лет0115 Житель Нью-Йорка , 18 сентября 2006 г.
Таким образом, чуть более чем за месяц до того, как съезд должен был собраться в Филадельфии, Джеймс Мэдисон провел мощный и всеобъемлющий анализ проблем федерализма и республиканизма.
Г. В. Бауэрсок, New York Review of Books , 6 ноября 2008 г.
Чтобы математически описать экономические решения, экономисты должны были предположить, что человеческое поведение является одновременно рациональным и предсказуемым. Они представляли себе репрезентативного человека Homo economicus, наделенного устойчивыми предпочтениями, стабильным настроением и завидной способностью принимать только рациональные решения. Эта ловкость рук привела к появлению некоторых теорий, которые имели подлинную прогностическую ценность, но экономисты были вынуждены исключить из своего анализа многие явления, не вписывавшиеся в… рамки, такие как пузыри на фондовом рынке, наркомания и навязчивые покупки.
Джон Кэссиди, 9 лет0115 Житель Нью-Йорка , 18 сентября 2006 г.
Таким образом, чуть более чем за месяц до того, как съезд должен был собраться в Филадельфии, Джеймс Мэдисон провел мощный и всеобъемлющий анализ проблем федерализма и республиканизма.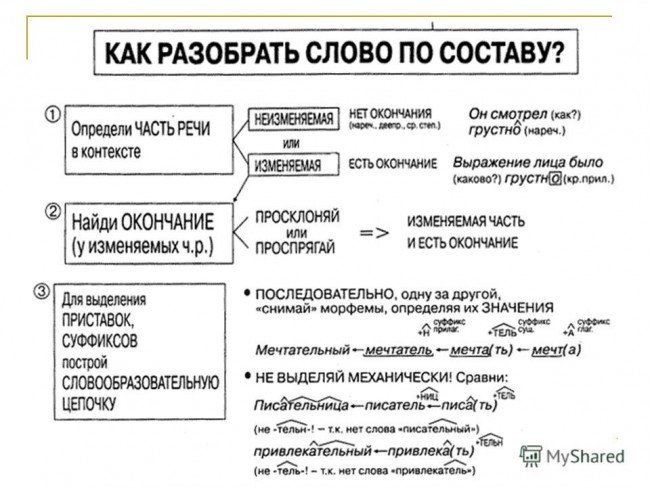 Джек Н. Раков, Original Meanings , 1 996
Благодаря некоторым новаторским исследованиям и растущему количеству изданий, переводов и подробных анализов у нас теперь есть хорошая общая картина духовной культуры позднесредневековых женщин на континенте, особенно в Нидерландах и Германии.
Николас Уотсонс, 9 лет0115 Speculum , июль 1993 г.
Джек Н. Раков, Original Meanings , 1 996
Благодаря некоторым новаторским исследованиям и растущему количеству изданий, переводов и подробных анализов у нас теперь есть хорошая общая картина духовной культуры позднесредневековых женщин на континенте, особенно в Нидерландах и Германии.
Николас Уотсонс, 9 лет0115 Speculum , июль 1993 г.
научный анализ данных
сделать химический анализ почвы
подробный анализ костной структуры лошадей
проведение химического анализа почвы
Газета напечатала анализов позиций каждого кандидата.
Неплохой анализ ситуации.
Это проблема, которая требует тщательного анализа .
Он был в анализе в течение многих лет. Узнать больше
Недавние примеры в Интернете
Американцы, которые зарабатывают менее 75 000 долларов в год, должны получить 60% дополнительных налоговых проверок, ожидаемых в рамках пакета расходов демократов, согласно анализу , опубликованному республиканцами Палаты представителей. Кайл Моррис, Fox News , 12 сентября 2022 г.
Генеральные директора, нанятые извне, уходят из компании в течение трех лет гораздо чаще, чем те, кого продвигают изнутри, согласно исследованию 9.0115 анализ компаний S&P 500, проведенный консультантами по подбору персонала Russell Reynolds Associates.
Хизер Хэддон, WSJ , 12 сентября 2022 г.
Согласно анализу , проведенному BloombergNEF, при пиковой производительности около 6 процентов энергоснабжения приходится на эти разряжающиеся батареи по сравнению с 0,1 процента в 2017 году. ПРОВОДНАЯ , 11 сентября 2022 г.
Габби Ороско ожидает, что съемки будут завершены сразу же, чтобы лучше добавить к анализ .
Хосе Р. Гонсалес, Республика Аризона , 10 сентября 2022 г.
Кайл Моррис, Fox News , 12 сентября 2022 г.
Генеральные директора, нанятые извне, уходят из компании в течение трех лет гораздо чаще, чем те, кого продвигают изнутри, согласно исследованию 9.0115 анализ компаний S&P 500, проведенный консультантами по подбору персонала Russell Reynolds Associates.
Хизер Хэддон, WSJ , 12 сентября 2022 г.
Согласно анализу , проведенному BloombergNEF, при пиковой производительности около 6 процентов энергоснабжения приходится на эти разряжающиеся батареи по сравнению с 0,1 процента в 2017 году. ПРОВОДНАЯ , 11 сентября 2022 г.
Габби Ороско ожидает, что съемки будут завершены сразу же, чтобы лучше добавить к анализ .
Хосе Р. Гонсалес, Республика Аризона , 10 сентября 2022 г. Большинство этих рабочих были белыми; Дэвис, Солт-Лейк-Сити и Эмери были единственными округами, в которых наблюдалось значительное увеличение числа латиноамериканцев трудоспособного возраста, согласно анализу .
Лето Сапунар, The Salt Lake Tribune , 9 сентября 2022 г.
Согласно 9Согласно анализу данных Федерального агентства по охране окружающей среды, проведенному Советом по защите природных ресурсов, электростанции Вирджинии в 2021 году, первом году их участия в RGGI, выбросили на 13 процентов меньше углерода, чем в 2020 году.
Грегори С. Шнайдер, Washington Post , 9 сентября 2022 г.
The Wall Street JournalThe New York Times По данным 9Анализ 0115 , опубликованный в четверг некоммерческой исследовательской организацией Climate Central.
Гарольд Маасс, Неделя , 9 сентября 2022 г.
Большинство этих рабочих были белыми; Дэвис, Солт-Лейк-Сити и Эмери были единственными округами, в которых наблюдалось значительное увеличение числа латиноамериканцев трудоспособного возраста, согласно анализу .
Лето Сапунар, The Salt Lake Tribune , 9 сентября 2022 г.
Согласно 9Согласно анализу данных Федерального агентства по охране окружающей среды, проведенному Советом по защите природных ресурсов, электростанции Вирджинии в 2021 году, первом году их участия в RGGI, выбросили на 13 процентов меньше углерода, чем в 2020 году.
Грегори С. Шнайдер, Washington Post , 9 сентября 2022 г.
The Wall Street JournalThe New York Times По данным 9Анализ 0115 , опубликованный в четверг некоммерческой исследовательской организацией Climate Central.
Гарольд Маасс, Неделя , 9 сентября 2022 г. Согласно анализу гендерного и расового разрыва в оплате труда , проведенному Американской ассоциацией женщин с университетским образованием, средняя американка зарабатывает 83 цента на доллар мужчины.
Джейн Тьер, Fortune , 7 сентября 2022 г.
Узнать больше
Согласно анализу гендерного и расового разрыва в оплате труда , проведенному Американской ассоциацией женщин с университетским образованием, средняя американка зарабатывает 83 цента на доллар мужчины.
Джейн Тьер, Fortune , 7 сентября 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «анализ». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
заимствовано из средневековой латыни, заимствовано из греч. 0115 analýein «ослаблять, разъединять, растворять, разлагать на составные элементы», от ana- ana- + lýein «ослаблять, развязывать» — более подробно
0115 analýein «ослаблять, разъединять, растворять, разлагать на составные элементы», от ana- ana- + lýein «ослаблять, развязывать» — более подробно
Первое известное использование
1581, в значении определяется в смысле 2
Путешественник во времени
Первое известное использование анализа было в 1581 году
Посмотреть другие слова того же года
Словарные статьи рядом с
анализоманализировать
анализ
дисперсионный анализ
Посмотреть другие записи поблизости
Процитировать эту запись «Анализ.»
Словарь Merriam-Webster.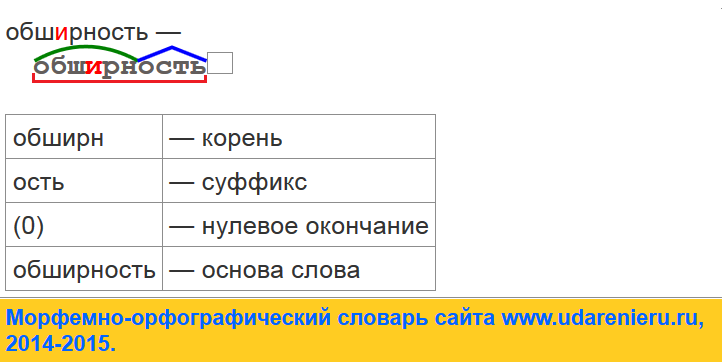 com , Merriam-Webster, https://www.merriam-webster.com/dictionary/analysis. По состоянию на 16 сентября 2022 г.
com , Merriam-Webster, https://www.merriam-webster.com/dictionary/analysis. По состоянию на 16 сентября 2022 г.Копировать цитирование
Детское определение
анализ
анализ ·исис ə-ˈna-lə-səs
1
: изучение чего-либо с целью выяснить, как это сделано, работает или что это такое
химический анализ почвы
2
: объяснение природы и значения чего-либо
анализ новости
Медицинское определение
анализ
анализ ·исис ə-ˈnal-ə-səs
1
: разделение целого на составные части
2
а
: идентификация или разделение ингредиентов вещества
б
: Заявление о компонентах смеси
3
: Психоанализ
Подробнее от Merriam-Webster на
АнализNglish: перевод Анализ для испанских
40004. Перевод анализ для говорящих на арабском языке
Перевод анализ для говорящих на арабском языке
Britannica.com: статья в энциклопедии об анализе
Последнее обновление: 15 сентября 2022 г.
Подпишитесь на крупнейший словарь Америки и получите еще тысячи определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
сливаться
См. Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Сложные слова, которые вы должны знать
- Часто используется для описания «хода времени», что означает неумолимый ?
- Медленный Непредсказуемый
- Стриж Безжалостный
Можете ли вы произнести эти 10 слов, которые часто пишут с ошибками?
ПРОЙДИТЕ ТЕСТ
Ежедневное задание для любителей кроссвордов.
TAKE THE QUIZ
Кембриджский словарь английского языка: значения и определения
Получите четкие определения и звуковое произношение слов, фраз и идиом в британском и американском английском из трех самых популярных кембриджских словарей английского языка с помощью всего одного поиска: the Cambridge Advanced Learner’s Dictionary, Cambridge Academic Content Dictionary и Cambridge Business English Dictionary.
Популярные запросы
- 01 особенность
- 02 уважать
- 03 убеждать
- 04 интерес
- 05 расписание
- 06 предполагать
- 07 подарок
- 08 Работа
- 09 сдача
- 10 тут
Просмотрите английский словарь
0-9 а б с д е ф грамм час я Дж к л м н о п д р с т ты в ж Икс у я
Или просмотрите индекс Кембриджского словаря
Ключевые особенности
Кембриджский словарь английского языка основан на оригинальном исследовании уникального Кембриджского корпуса английского языка и включает все слова уровней A1–C2 по CEFR в профиле английского словаря. Он идеально подходит для тех, кто готовится к кембриджским экзаменам продвинутого уровня или IELTS.
Он идеально подходит для тех, кто готовится к кембриджским экзаменам продвинутого уровня или IELTS.
Получите четкие и простые определения из британского, американского и бизнес-словарей всего за один поиск!
Слушайте слова, произносимые на британском и американском английском
Тысячи реальных примеров показывают, как используются слова.
Указательные слова помогут вам найти точное значение, которое вы ищете. уровни CEFR A2–C2)
На основе Cambridge English Corpus — базы данных, содержащей более 2 миллиардов слов
Благодарности
Словари, которые вы можете искать вместе как английский на этом веб-сайте Cambridge Dictionary:
Кембриджский словарь для продвинутых учащихся, 4-е издание
Купить книгу!
Кембриджский академический словарь
Купить книгу!
Кембриджский словарь делового английского языка
Купить книгу!
Блог
Нестандартное мышление: говорим о творчестве.
Подробнее
Слово дня
Надежда умирает
говорит, когда продолжаешь надеяться, что что-то случится, хотя это кажется маловероятным
Об этом
Новые слова
тихий уход
Больше новых слов
Методология Синонимы: 13 синонимов и антонимов для методологии
См. Определение Методологии на Dictionary.com
- Существительное Методы
СИНОМИССИИ.7 режим
Тезаурус 21 века Роже, третье издание. Copyright © 2013, Philip Lief Group.
Copyright © 2013, Philip Lief Group.
ПОПРОБУЙТЕ ИСПОЛЬЗОВАТЬ методологию
Посмотрите, как выглядит ваше предложение с разными синонимами.
Символы: 0/140
ВИКТОРИНА
Расслабьтесь в шезлонге и пройдите викторину «Слово дня»!
НАЧАТЬ ВИКТОРИНУКак использовать методологию в предложении
В глобальной гонке за вакциной от Covid разные исследователи пробуют различные методологии и платформы.
ИЗМЕНИТ ЛИ ВАКЦИНА ОТ COVID-19 БУДУЩЕЕ МЕДИЦИНСКИХ ИССЛЕДОВАНИЙ? (EP. 430) СТИВЕН Дж. ДУБНЕРА 27 августа 2020 г. ФРИКОНОМИКА
Проблема, добавил он, заключается в том, что у издателей или платформ нет четкой методологии или системы вынесения решений, чтобы оспорить решение Chrome о том, что представляет собой «тяжелую» рекламу.
НОВЫЙ БЛОКИРОВЩИК «ТЯЖЕЛОЙ РЕКЛАМЫ» В GOOGLE CHROME ЗАХВАТИЛ НЕКОТОРЫХ ИЗДАТЕЛЕЙ ОТ SURPRISELARA O’REILLYAGUST 26, 2020DIGIDAY
Firefox был агрессивным сторонником конфиденциальности потребителей и не обязательно был другом цифровых маркетологов, большинство из которых предпочли бы оставаться третьими сторонние файлы cookie и существующие методологии отслеживания и таргетинга без изменений.
STRANGE BEDFELLOWS GOOGLE И FIREFOX ОБНОВЛЯЮТ СВОИ ПАРТНЕРСТВА ПО ПОИСКУ ПО УМОЛЧАНИЮГРЕГ СТЕРЛИНГСТА 17 августа 2020 г. SEARCH ENGINE LAND
Перед тем, как погрузиться в работу, полезно прочитать наше краткое изложение состояния гонки или, по крайней мере, просмотреть наше очень подробное руководство по методологии. .
В НАШЕМ ПРОГНОЗЕ О ВЫБОРАХ НЕ СКАЗАЛОСЬ ТО, ЧТО Я ДУМАЛ, ЧТО ЭТО ПРИГОТОВИТ СЕРЕБРО ([email protected])17 АВГУСТА 2020 г. FIVETHIRTYEIGHT
Мы работаем с Google, чтобы найти самые передовые и эффективные рекламные стратегии, а также новые рекламные функции, и мы раскрываем некоторые из наших новых методологий, которые мы обычно не разделяем.
GOOGLE AND IGNITE VISIBILITY ДЛЯ ПРОВЕДЕНИЯ РАСШИРЕННОГО ПЛАТНОГО МЕДИА-МЕРОПРИЯТИЯ, КОТОРОЕ ВЫ НЕ ХОТИТЕ ПРОПУСТИТЬ упрощают и знакомят клиента со сложностями современной органической оптимизации.
КАК СОЗДАТЬ ВЫИГРЫШНОЕ ПРЕДЛОЖЕНИЕ ПО SEO И ИЗБЕЖАТЬ ПОЛУЧЕНИЯ ТИХОГО КОНТЕНТА «БЕЗ СПОНСОРА»: SEOMONITORAUGUST 3, 2020SEARCH ENGINE LAND
Подробнее о нашей методологии и некоторых ограничениях в данных и, следовательно, в этом анализе см. здесь.
В КАКИХ ГОРОДАХ САМЫЕ БОЛЬШИЕ РАСОВЫЕ РАЗРЫВЫ В ДОСТУПЕ К ТЕСТИРОВАНИЮ НА COVID-19?СУ РИН КИМ 22 ИЮЛЯ 2020 г. FIVETHIRTYEIGHT
Вы можете прочитать наши полные рейтинги и методологию, чтобы лучше понять, как мы рассчитываем оценки.
ПОЛИТИКА ОПРОСОВ И ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ SDHRUMIL MEHTA ([email protected]) 17 ИЮЛЯ 2020 г. FIVETHIRTYEIGHT
Следующие две части содержат обсуждение методологии ведения заметок и не носят непосредственно библиографического характера.
ИСТОРИЯ БИБЛИОГРАФИЙ САРЧЕРА ТЕЙЛОРА
Я объединяю здесь различные исследования, более или менее непосредственно относящиеся к вопросам научной методологии.
THE FOUNDATIONS OF SCIENCE: SCIENCE AND HYPOTHESIS, THE VALUE OF SCIENCE, SCIENCE AND METHODHENRI POINCAR
WORDS RELATED TO METHODOLOGY
- alignment
- assembling
- assembly
- chemistry
- composition
- configuration
- conformation
- constitution
- construction
- coordination
- design
- disposal
- format
- formation
- forming
- formulation
- framework
- grouping
- harmony
- institution
- makeup
- изготовление
- управление
- метод
- методология
- организм
- organizing
- pattern
- plan
- planning
- regulation
- running
- situation
- standard
- standardization
- structure
- structuring
- symmetry
- system
- unity
- whole
- affiliations
- агрегации
- союзы
- ассоциации
- полосы
- тела
- businesses
- cartels
- circles
- cliques
- clubs
- coalitions
- combinations
- combines
- companies
- concerns
- concords
- confederations
- consortiums
- cooperatives
- corporations
- coteries
- экипажи
- учреждения
- федерации
- братства
- гильдии
- houses
- industries
- institutes
- institutions
- leagues
- lodges
- machines
- monopolies
- orders
- outfits
- parties
- professions
- sets
- societies
- sodalities
- sororities
- дружины
- синдикаты
- дружины
- профессии
- труппы
- тресты
- unions
- arrangement
- artifice
- course of action
- custom
- definite plan
- fashion
- logical process
- manner
- methodicalness
- methodology
- mode
- modus
- modus operandi
- операция
- упорядоченность
- упорядоченный процесс
- шаблон
- политика
- практика
- procedure
- proceeding
- process
- regularity
- routine
- scheme
- strategy
- structure
- systematic process
- systematization
- tactics
- technique
- theory
- usage
- way
- wise
Тезаурус 21 века Роже, третье издание. Copyright © 2013, Philip Lief Group.
Copyright © 2013, Philip Lief Group.
Что такое непрерывное производство? Определение и примеры
Непрерывное производство — это метод производства, при котором товары создаются путем комбинирования расходных материалов, ингредиентов или сырья с использованием формулы или рецепта. Он часто используется в отраслях, производящих большие количества товаров, таких как продукты питания, напитки, рафинированное масло, бензин, фармацевтические препараты, химикаты и пластмассы.
Производственный процесс часто требует термической или химической конверсии, например, с использованием тепла, времени или давления. В результате продукт, созданный в процессе непрерывного производства, не может быть разобран на составные части. Например, после производства безалкогольный напиток нельзя разделить на отдельные ингредиенты.
Непрерывное производство основано на последовательности последовательных шагов, при этом завершение одного шага ведет к началу следующего шага. Производители процессов часто полагаются на инструменты и программное обеспечение отслеживания и планирования для поддержания максимальной операционной эффективности.
Процессное производство — это полная противоположность дискретному производству. В то время как процессное производство следует рецептам или формулам и создает продукты, которые нельзя разобрать в конце производственного цикла, дискретное производство использует спецификацию материалов (BOM) и следует инструкциям для создания готовых, собранных товаров. В конце дискретного производственного процесса конечный продукт можно разбить на отдельные части, которые иногда можно перерабатывать. Товары, произведенные посредством дискретного производства, включают автомобили, компьютеры и некоторые игрушки.
Параллельное сравнение процессного и дискретного производстваДискретное производство может быть связано с:
- сборочные линии
- изготовление
- стандартные детали и компоненты
- спецификация
- идентификация деталей по номерам
- измеряется каждой частью или куском
Непрерывное производство может быть связано с:
- рецептов и формул
- смеси и смеси
- переменные ингредиенты
- идентификация деталей по атрибутам
- измерения веса или объема
Процессное производство можно считать более сложным, чем дискретное производство, поскольку оно включает преобразование отдельных сырьевых материалов и технологических входов в конечный продукт. Тем не менее, он также менее ориентирован на дефекты и имеет меньше перерывов и улучшенный контроль качества (КК) на протяжении всего производственного процесса.
В обрабатывающей промышленности помимо процессного и дискретного производства используются различные процессы, чтобы определить, как компания будет производить свою продукцию. Три других распространенных производственных процесса включают:
- серийное производство (REM)
- мастерская по производству работ
- Трехмерная печать
Серийное производство используется для повторяющегося производства с определенной производительностью. Процесс состоит из специальных производственных линий, которые постоянно создают один и тот же продукт или набор продуктов круглый год. Требования к настройке минимальны, а переналадка незначительна, поэтому скорость работы можно регулировать в соответствии с потребностями и требованиями заказчика.
Производство в мастерских использует производственные площади вместо сборочных или производственных линий и фокусируется на производстве небольших объемов нестандартной продукции, включая товары, производимые на заказ (MTO) и на складе (MTS). Если потребительский спрос увеличивается, то операция адаптируется и становится дискретным процессом с заменой отдельных ручных операций автоматизированным оборудованием.
3D-печать , также известная как аддитивное производство, — это новейший производственный процесс. Хотя впервые он был задуман в 1980-х годов, он лишь недавно был введен в производственные циклы. Процесс 3D-печати производит товары из различных композитов и материалов, создавая слои для создания трехмерного твердого объекта из цифровой модели.
Непрерывное производство также можно разделить на два различных метода производства: непрерывное производство и периодическое производство.
Непрерывное процессное производство похоже на серийное производство в том смысле, что оно никогда не заканчивается — оно производит один и тот же продукт или набор продуктов круглый год. С другой стороны, серийное производство зависит от потребительского спроса. Одной партии или определенного количества товаров, произведенных за определенный период времени, может быть достаточно для удовлетворения спроса. Когда партия завершена, оборудование очищается и готовится к производству следующей партии, когда это необходимо.
Поскольку это сложная и часто узкоспециализированная деятельность, большинство производителей используют программные системы планирования ресурсов предприятия (ERP), которые имеют специальные функции для непрерывного производства.
Эти системы производятся различными поставщиками корпоративного программного обеспечения, в том числе:
- САП
- Оракул
- Майкрософт
- Информация
- ИФС
- Мудрец
- СМК
- Системы плекс
- Сиспро
Каждый поставщик может продавать различные системы, предназначенные для предприятий разного размера, от малого и среднего бизнеса (SMB) до крупных предприятий.
Первоначально большинство ERP-систем для непрерывного производства работали локально. Недавно был сделан переход на развертывание большей части программного обеспечения в облаке или в гибридных реализациях.
Примеры непрерывного производстваНекоторые из ведущих рынков непрерывного производства включают:
- продукты питания и напитки
- нефть и газ
- фармацевтические препараты
- средства личной гигиены и косметика
- пластик
- металлы
Пивоварение является одним из примеров непрерывного производства в пищевой промышленности и производстве напитков. Ключевые ингредиенты в производстве пива включают зерно, солод, хмель, дрожжи и сахар; различные рецепты доступны для руководства процессом. Основные шаги включают, во-первых, замачивание зерен в кипящей воде, затем добавление солода вместе с определенным количеством хмеля — в зависимости от типа варящегося пива — и сахара. Эта смесь создает сусло или жидкость, содержащую сахара, которые будут сбраживаться дрожжами для производства спирта. После того, как сусло готово, его добавляют в воду с дрожжами и оставляют для брожения на длительный период. После завершения брожения пиво можно разливать по бутылкам; этот конечный продукт нельзя разложить на составные части.
Лосьоны для рук являются примером продукта, созданного в процессе непрерывного производства для средств личной гигиены и косметической промышленности. Подобно пивоварению, производство лосьона для рук включает в себя смешивание определенных количеств производственных материалов для создания полного соединения, которое нельзя разбить на части в конце.
Последнее обновление: февраль 2020 г.
Продолжить чтение О процессном производстве- Откройте для себя лучшее программное обеспечение ERP для вашей организации
- Почему производители крафтового пива используют ERP для программного обеспечения для крафтовых пивоварен
- 3 способа, которыми технологии изменят производство в 2020 году
- Как ИИ может улучшить планирование производства?
- Какие функции программного обеспечения являются ключевыми для ERP непрерывного производства?
Идти в ногу с различными типами производственных процессов
Автор: Джон Мур
прослеживаемость
Автор: Дайан Дэниел
Дискретное и непрерывное производство: выбор ERP
Автор: Джордж Лоутон
10 вариантов программного обеспечения ERP для непрерывного производства
Автор: Линдси Мур
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная .
.. - Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
SearchDataManagement
- Google упрощает миграцию облачных баз данных, улучшает поток данных
Google хочет упростить переход на новую базу данных AlloyDB для своих пользователей, а также предоставить новую поддержку базы данных …
- Oracle предоставляет сервис облачной базы данных MySQL Heatwave для AWS
Технический гигант запустил новую службу облачной базы данных MySQL, работающую на инфраструктуре AWS, которая будет поддерживать как аналитические, так и .
.. - Соавтор Kafka подробно описывает эволюцию потоковой передачи данных о событиях
Технология потоковой передачи Apache Kafka с открытым исходным кодом и коммерческий поставщик Confluent выросли за последнее десятилетие как …
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение …
- В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю компания SAP вывела бизнес и технологические тренды на вершину индустрии ERP, но сейчас она находится на перепутье …
- Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать .
..
ПоискБизнесАналитика
- Ricoh модернизирует свою аналитику с помощью Qlik
Компания, занимающаяся управлением информацией и цифровыми услугами, начинает развивать культуру данных, и платформа поставщика BI имеет …
- Данные потребителей нуждаются в лучшей защите со стороны правительства
Хотя на рассмотрении Конгресса находится законодательство, касающееся конфиденциальности данных, оно может не устанавливать достаточно четких указаний или не давать отдельным лицам…
- Опасения по поводу конфиденциальности данных растут по мере отставания законодательства
Несмотря на то, что медицинские и финансовые данные защищены федеральным законодательством, частные лица практически не контролируют, как данные о потребителях …
SearchContentManagement
- Как создать контент-стратегию электронной коммерции для увеличения продаж
Стратегия контента, включающая автоматизированную CMS, полезную информацию о продукте и визуальные эффекты, может привлечь внимание клиентов к вашему .
.. - 5 безбумажных офисных программных инструментов, на которые следует обратить внимание
Выбор подходящего безбумажного программного обеспечения для офиса, казалось бы, бесконечный, начинается с понимания того, что …
- Викторина: проверьте свои знания в области управления цифровыми активами
Системы
DAM помогают отделам маркетинга управлять мультимедийным контентом, с которым они работают каждый день. С помощью этого теста проверьте свои знания о …
SearchHRSoftware
- Будущее HR — за Agile большой пятерки.
Принципы Agile-разработки продуктов могут служить руководством по включению мнения сотрудников в процессы и обеспечению …
- Руководители HR преодолевают разрыв между бизнесом и потребностями сотрудников
Во время мероприятия Workday Rising бизнес-лидеры поделились своими трудностями в поиске способа сбалансировать бизнес и сотрудников .
.. - Рабочий день открывает путь к большей взаимосвязанности
Workday Rising предоставил стартовую площадку для новых функций, включая пользовательский интерфейс с малым кодом и без кода для разработки приложений Workday …
Что такое ЧПУ? | Определение, процессы, компоненты и прочее
Обработка с ЧПУ — это термин, широко используемый в производстве и промышленности. Но что такое ЧПУ? А что такое станок с ЧПУ?
Станок с ЧПУ, выполняющий фрезерные операции на заготовке.Изображение предоставлено: Дмитрий Калиновский, Shutterstock
Что такое обработка с ЧПУ?
CNC 101: термин CNC означает «цифровое программное управление», а определение обработки с ЧПУ состоит в том, что это субтрактивный производственный процесс, в котором обычно используются компьютеризированные элементы управления и станки для удаления слоев материала с заготовки, известной как заготовка. или заготовку — и производит деталь по индивидуальному заказу. Этот процесс подходит для широкого спектра материалов, включая металлы, пластмассы, дерево, стекло, пенопласт и композиты, и находит применение в различных отраслях промышленности, таких как крупногабаритная обработка с ЧПУ, обработка деталей и прототипов для телекоммуникаций и ЧПУ. обработка аэрокосмических деталей, для которых требуются более жесткие допуски, чем для других отраслей промышленности. Обратите внимание, что существует разница между определением обработки с ЧПУ и определением станка с ЧПУ: одно представляет собой процесс, а другое — станок. Станок с ЧПУ (иногда неправильно называемый станком C и C) — это программируемый станок, способный автономно выполнять операции обработки с ЧПУ.
CNC-обработка как производственный процесс и услуга доступна по всему миру. Вы можете легко найти услуги по обработке с ЧПУ в Европе, а также в Азии, Северной Америке и других странах мира.
Субтрактивные производственные процессы, такие как обработка с ЧПУ, часто противопоставляются аддитивным производственным процессам, таким как 3D-печать, или формообразующим производственным процессам, таким как жидкостное литье под давлением. В то время как субтрактивные процессы удаляют слои материала с заготовки для создания нестандартных форм и конструкций, аддитивные процессы собирают слои материала для получения желаемой формы, а формирующие процессы деформируют и смещают исходный материал в желаемую форму. Автоматизированный характер обработки с ЧПУ позволяет производить высокоточные и высокоточные, простые детали и рентабельность при выполнении единичных и среднесерийных производственных циклов. Однако, хотя обработка с ЧПУ демонстрирует определенные преимущества по сравнению с другими производственными процессами, степень сложности и запутанности, достижимая для проектирования деталей, и рентабельность производства сложных деталей ограничены.
Несмотря на то, что у каждого типа производственного процесса есть свои преимущества и недостатки, в этой статье основное внимание уделяется процессу обработки с ЧПУ с изложением основ этого процесса, а также различных компонентов и инструментов станка с ЧПУ. Кроме того, в этой статье рассматриваются различные операции механической обработки с ЧПУ и представлены альтернативы процессу обработки с ЧПУ.
Краткое описание этого руководства:
- Обзор процесса обработки с ЧПУ
- Типы операций обработки с ЧПУ
- Обрабатывающее оборудование и компоненты с ЧПУ
- Материалы для ЧПУ
- Рекомендации по размеру ЧПУ
- Альтернативы использованию станка с ЧПУ
- История обработки с ЧПУ
Вы сейчас в перерыве между работами или работодатель ищет новых сотрудников? Мы предоставим вам наши подробные коллекции ресурсов для соискателей работы в промышленности и работодателей, желающих заполнить вакансии. Если у вас есть открытая вакансия, вы также можете заполнить нашу форму, чтобы иметь возможность разместить ее в информационном бюллетене Thomas Monthly Update.
Обзор процесса обработки с ЧПУ
Развиваясь из процесса обработки с числовым программным управлением (ЧПУ), в котором использовались карты с перфолентой, обработка с ЧПУ представляет собой производственный процесс, в котором используются компьютеризированные элементы управления для работы и манипулирования станком и режущими инструментами для придания формы исходному материалу, например, металлу, пластику, дереву, пене, композит и т. д. — в нестандартные детали и конструкции. Хотя процесс обработки с ЧПУ предлагает различные возможности и операции, основные принципы процесса остаются в основном одинаковыми для всех них. Базовый процесс обработки с ЧПУ включает следующие этапы:
- Разработка модели САПР
- Преобразование файла САПР в программу ЧПУ
- Подготовка станка с ЧПУ
- Выполнение операции обработки
Дизайн модели САПР
Процесс обработки с ЧПУ начинается с создания 2D-векторной или 3D-модели твердотельной детали в САПР собственными силами или с помощью компании, предоставляющей услуги по проектированию CAD/CAM. Программное обеспечение для автоматизированного проектирования (САПР) позволяет дизайнерам и производителям создавать модели или визуализации своих деталей и продуктов вместе с необходимыми техническими характеристиками, такими как размеры и геометрия, для производства детали или продукта.
Конструкции деталей, обработанных с ЧПУ, ограничены возможностями (или неспособностью) станка с ЧПУ и инструментов. Например, большинство станков с ЧПУ имеют цилиндрическую форму, поэтому геометрия деталей, возможная в процессе обработки с ЧПУ, ограничена, поскольку инструменты создают изогнутые угловые сечения. Кроме того, свойства обрабатываемого материала, конструкция инструмента и возможности крепления станка дополнительно ограничивают возможности проектирования, такие как минимальная толщина детали, максимальный размер детали, а также включение и сложность внутренних полостей и элементов.
После завершения проекта САПР дизайнер экспортирует его в формат файла, совместимый с ЧПУ, например STEP или IGES.
Таблицы допусков для станков с ЧПУ При заказе деталей для механического цеха важно учитывать все необходимые допуски. Хотя станки с ЧПУ очень точны, они все же оставляют небольшую разницу между дубликатами одной и той же детали, обычно около + или — 0,005 дюйма (0,127 мм), что примерно вдвое превышает ширину человеческого волоса. Чтобы сэкономить на затратах, покупатели должны указывать допуски только в тех областях детали, которые должны быть особенно точными, поскольку они будут соприкасаться с другими деталями. Хотя существуют стандартные допуски для различных уровней обработки (как показано в таблицах ниже), не все допуски одинаковы. Если, например, деталь абсолютно не может быть больше размера, для нее может быть указан допуск +0,0/-0,5, чтобы показать, что она может быть немного меньше, но не больше в этой области.
Таблица 1: Линейные допуски при обработке с ЧПУ
Диапазон размеров (мм) | Тонкая (F) +/- | Средний (М) +/- | Грубая (C) +/- | Очень грубая (V) +/- |
.5-3 | .05 | .1 | .2 | — |
3-6 | .05 | . | .3 | .5 |
6-30 | .1 | .2 | .5 | 1,0 |
30-120 | .15 | .3 | .8 | 1,5 |
120-400 | .2 | .5 | 1,2 | 2,5 |
400-1000 | .3 | .8 | 2,0 | 4,0 |
1000-2000 | .5 | 1,2 | 3,0 | 6,0 |
2000-4000 | — | 2,0 | 4,0 | 8,0 |
Таблица 2: Угловые допуски при обработке с ЧПУ
Диапазон размеров (мм) | Тонкая (F) +/- | Средний (М) +/- | Грубая (C) +/- | Очень грубая (V) +/- |
0-10 | 1 о | 1 или | 1 или 30’ | 3 или |
10-50 | 0 или 30’ | 0 или 30’ | 1 или | 2 или |
50-120 | 0 или 20′ | 0 или 20’ | 0 или 30’ | 1 или |
120-400 | 0 или 10’ | 0 или 10’ | 0 или 15’ | 0 или 30’ |
400 | 0 или 5’ | 0 или 5’ | 0 или 10’ | 0 или 20’ |
Таблица 3: Допуски на радиус и фаску при обработке с ЧПУ
Диапазон размеров (мм) | Тонкая (F) +/- | Средний (М) +/- | Грубая (C) +/- | Очень грубая (V) +/- |
. | .2 | .2 | .4 | .4 |
3-6 | .5 | .5 | 1 | 1 |
6 | 1 | 1 | 2 | 2 |
Преобразование файлов САПР
Отформатированный файл проекта САПР проходит через программу, как правило, программное обеспечение для автоматизированного производства (CAM), для извлечения геометрии детали и создания цифрового программного кода, который будет управлять станком с ЧПУ и манипулировать инструментами для производства детали, разработанной по индивидуальному заказу.
Станки с ЧПУ использовали несколько языков программирования, включая G-код и М-код. Самый известный из языков программирования ЧПУ, общий или геометрический код, называемый G-кодом, контролирует, когда, где и как перемещаются станки — например, когда включать или выключать, как быстро перемещаться в заданную точку. конкретное место, какие пути выбрать и т. д. — по заготовке. Код дополнительных функций, называемый М-кодом, управляет вспомогательными функциями машины, такими как автоматизация снятия и замены кожуха машины в начале и в конце производства соответственно.
После создания программы ЧПУ оператор загружает ее в станок с ЧПУ.
Настройка машины
Прежде чем оператор запустит программу ЧПУ, он должен подготовить станок ЧПУ к работе. Эти подготовительные работы включают в себя крепление заготовки непосредственно к станку, к шпинделям станка, к станочным тискам или аналогичным приспособлениям, а также к прикреплению необходимых инструментов, таких как сверла и концевые фрезы, к соответствующим компонентам станка.
После полной настройки станка оператор может запустить программу ЧПУ.
Выполнение операции обработки
Программа ЧПУ действует как инструкция для станка с ЧПУ; он передает команды станка, определяющие действия и движения инструмента, на встроенный в станок компьютер, который управляет инструментами станка и манипулирует им. Запуск программы предлагает станку с ЧПУ начать процесс обработки с ЧПУ, и программа направляет станок на протяжении всего процесса, поскольку он выполняет необходимые машинные операции для производства детали или продукта, разработанного по индивидуальному заказу.
могут выполняться собственными силами — если компания инвестирует в приобретение и обслуживание собственного оборудования с ЧПУ — или отдаваться на аутсорсинг специализированным поставщикам услуг по обработке с ЧПУ.
Типы операций обработки с ЧПУ
CNC-обработка — это производственный процесс, подходящий для самых разных отраслей, включая автомобильную, авиакосмическую, строительную и сельскохозяйственную, и способный производить ряд продуктов, таких как автомобильные рамы, хирургическое оборудование, авиационные двигатели, шестерни, а также ручные и садовые инструменты. Этот процесс включает в себя несколько различных операций механической обработки, управляемых компьютером, включая механические, химические, электрические и термические процессы, которые удаляют необходимый материал из заготовки для производства детали или продукта, разработанного по индивидуальному заказу. В то время как химические, электрические и термические процессы обработки рассматриваются в следующем разделе, в этом разделе рассматриваются некоторые из наиболее распространенных операций механической обработки с ЧПУ, включая:
- Сверление
- Фрезерование
- Токарная обработка
Сверление с ЧПУ
Сверление — это процесс механической обработки, в котором используются многогранные сверла для создания цилиндрических отверстий в заготовке. При сверлении с ЧПУ, как правило, станок с ЧПУ подает вращающееся сверло перпендикулярно плоскости поверхности заготовки, в результате чего получаются выровненные по вертикали отверстия с диаметром, равным диаметру сверла, используемого для операции сверления. Однако операции углового сверления также могут выполняться с использованием специализированных конфигураций станков и зажимных устройств. Операционные возможности процесса бурения включают зенкерование, зенкерование, развертывание и нарезание резьбы.
Фрезерование с ЧПУ
Фрезерование — это процесс механической обработки, в котором используются вращающиеся многогранные режущие инструменты для удаления материала с заготовки. При фрезеровании с ЧПУ станок с ЧПУ обычно подает заготовку к режущему инструменту в том же направлении, что и вращение режущего инструмента, тогда как при ручном фрезеровании станок подает заготовку в направлении, противоположном вращению режущего инструмента. Операционные возможности процесса фрезерования включают торцевое фрезерование — вырезание в заготовке неглубоких плоских поверхностей и полостей с плоским дном — и периферийное фрезерование — вырезание в заготовке глубоких полостей, таких как пазы и резьба.
Токарная обработка с ЧПУ
Токарная обработка с ЧПУ и многошпиндельная обработкаИзображение предоставлено: Buell Automatics
Токарная обработка — это процесс механической обработки, в котором используются одноточечные режущие инструменты для удаления материала с вращающейся заготовки. При токарной обработке с ЧПУ станок — обычно токарный станок с ЧПУ — подает режущий инструмент линейным движением вдоль поверхности вращающейся заготовки, удаляя материал по окружности до тех пор, пока не будет достигнут желаемый диаметр, для производства цилиндрических деталей с внешними и внутренними элементами. , такие как прорези, конусы и резьба. Операционные возможности процесса токарной обработки включают растачивание, торцевание, нарезание канавок и нарезание резьбы. Когда дело доходит до фрезерного станка с ЧПУ по сравнению с токарным станком, фрезерование с его вращающимися режущими инструментами лучше работает для более сложных деталей. Однако токарные станки с вращающимися заготовками и стационарными режущими инструментами лучше всего подходят для более быстрого и точного создания круглых деталей.
Обработка | Характеристики |
Сверление |
|
Фрезерование |
|
Токарная обработка |
|
Близкие родственники токарных станков, вращающиеся токарные станки с ЧПУ включают токарный набор с заготовкой (металлический лист или труба), которая вращается с высокой скоростью, в то время как металлический вращающийся ролик придает заготовке желаемую форму. В качестве «холодного» процесса формование металла с ЧПУ формирует предварительно сформированный металл — трение вращающегося станка, контактирующего с роликом, создает силу, необходимую для придания формы детали.
Швейцарская обработка, также известная как обработка швейцарским винтом, использует специальный тип токарного станка, который позволяет заготовке двигаться вперед и назад, а также вращаться, чтобы обеспечить более жесткие допуски и лучшую стабильность при резке. Заготовки обрезаются непосредственно рядом с удерживающей их втулкой, а не дальше. Это позволяет снизить нагрузку на изготавливаемую деталь. Швейцарская обработка лучше всего подходит для небольших деталей в больших количествах, таких как часовые винты, а также для приложений с критическими допусками прямолинейности или концентричности. Вы можете узнать больше об этой теме в нашем руководстве о том, как работают станки с швейцарским винтом.
Как работает 5-осевой станок с ЧПУ? 5-осевая обработка с ЧПУ описывает компьютеризированную производственную систему с числовым программным управлением, которая добавляет к традиционным 3-осевым линейным движениям станка (X, Y, Z) две оси вращения, чтобы обеспечить станку доступ к пяти из шести сторон детали в одиночная операция. Добавляя к рабочему столу наклоняющееся вращающееся приспособление (или цапфу), фрезерный станок становится так называемым 3+2, индексным или позиционным станком, что позволяет фрезе приближаться к пяти из шести сторон рабочего стола. призматическая заготовка на 90° без необходимости повторной установки заготовки оператором.
Однако это не совсем 5-осевой фрезерный станок, потому что четвертая и пятая оси не двигаются во время операций обработки. Добавление серводвигателей к дополнительным осям, а также компьютеризированное управление ими — часть с ЧПУ — сделают это единым целым. Такой станок, способный к полной одновременной контурной обработке, иногда называют «непрерывным» или «одновременным» 5-осевым фрезерным станком с ЧПУ. Две дополнительные оси также могут быть встроены в обрабатывающую головку или разделены — одна ось на столе и одна на головке.
Обучение оператора токарного станка с ЧПУ Чтобы работать на токарном станке с ЧПУ, машинист должен выполнить определенный объем курсовых работ и получить соответствующий сертификат от аккредитованной производственной организации по обучению. Программы обучения токарной обработке с ЧПУ обычно включают несколько классов или занятий, предлагая постепенный процесс обучения, разбитый на несколько этапов. Важность соблюдения протоколов безопасности усиливается на протяжении всего тренировочного процесса.
Начальные занятия по токарному станку с ЧПУ могут не включать практический опыт, но они могут включать ознакомление учащихся с кодами команд, перевод файлов САПР, выбор инструмента, последовательности резки и другие области. Курс начинающего токаря с ЧПУ может включать:
- Смазка и планирование технического обслуживания токарных станков
- Перевод инструкций в машиночитаемый формат и загрузка их в токарный станок
- Установление критериев выбора инструмента
- Установка инструментов и деталей для работы с материалом
- Изготовление образцов деталей
Последующее обучение работе на токарном станке с ЧПУ обычно включает реальную работу на токарном станке, а также настройку станка, редактирование программы и разработку нового синтаксиса команд. Обучение работе на токарном станке этого типа может включать курсы по:
- Выяснение того, где необходимы правки, путем сравнения образцов деталей с их спецификациями
- Редактирование программ ЧПУ
- Создание нескольких циклов тестовых компонентов для уточнения результатов правок
- Регулировка подачи охлаждающей жидкости, очистка станка, ремонт и замена инструментов
Прочие операции механической обработки с ЧПУ
Другие механические операции обработки с ЧПУ включают:
- Протяжка
- Пиление
- Шлифовка
- Хонингование
- Притирка
Обрабатывающее оборудование и компоненты с ЧПУ
Как указано выше, существует широкий спектр доступных операций обработки. В зависимости от выполняемой операции обработки в процессе обработки с ЧПУ используются различные программные приложения, машины и станки для получения желаемой формы или дизайна.
Типы программного обеспечения для обработки с ЧПУ
В процессе обработки с ЧПУ используются программные приложения для обеспечения оптимизации, точности и аккуратности изготовленной по индивидуальному заказу детали или продукта. Используемые программные приложения включают:
- CAD
- САМ
- КАЕ
CAD : Программное обеспечение для автоматизированного проектирования (САПР) — это программы, используемые для проектирования и создания 2D-векторных или 3D-моделирования твердотельных деталей и поверхностей, а также необходимой технической документации и спецификаций, связанных с деталью. Конструкции и модели, созданные в программе CAD, обычно используются программой CAM для создания необходимой машинной программы для производства детали с помощью метода обработки с ЧПУ. Программное обеспечение САПР также можно использовать для определения и определения оптимальных свойств деталей, оценки и проверки конструкции деталей, моделирования продуктов без прототипа и предоставления проектных данных производителям и мастерским.
CAM : Программное обеспечение автоматизированного производства (CAM) — это программы, используемые для извлечения технической информации из модели CAD и создания машинной программы, необходимой для запуска станка с ЧПУ и управления инструментами для производства детали, разработанной по индивидуальному заказу. Программное обеспечение CAM позволяет станку с ЧПУ работать без помощи оператора и может помочь автоматизировать оценку готового продукта.
CAE : Программное обеспечение для автоматизированного проектирования (CAE) — это программы, используемые инженерами на этапах предварительной обработки, анализа и последующей обработки процесса разработки. Программное обеспечение CAE используется в качестве вспомогательных средств поддержки в приложениях инженерного анализа, таких как проектирование, моделирование, планирование, производство, диагностика и ремонт, чтобы помочь в оценке и изменении конструкции продукта. Доступные типы программного обеспечения CAE включают программное обеспечение для анализа методом конечных элементов (FEA), вычислительной гидродинамики (CFD) и программного обеспечения для динамики нескольких тел (MDB).
Некоторые программные приложения сочетают в себе все аспекты программного обеспечения CAD, CAM и CAE. Эта интегрированная программа, обычно называемая программным обеспечением CAD/CAM/CAE, позволяет единой программе управлять всем производственным процессом от проектирования до анализа и производства.
Что такое станок с ЧПУ? Типы станков с ЧПУ и станков
В зависимости от выполняемой операции обработки в процессе обработки с ЧПУ используются различные станки и станки с ЧПУ для производства детали или продукта по индивидуальному заказу. В то время как оборудование может различаться по другим параметрам от операции к операции и от приложения к приложению, интеграция компонентов компьютерного числового программного управления и программного обеспечения (как указано выше) остается неизменной для всего оборудования и процессов обработки с ЧПУ.
Сверлильный станок с ЧПУ Сверление использует вращающиеся сверла для создания цилиндрических отверстий в заготовке. Конструкция сверла позволяет металлическим отходам, т. е. стружке, отпадать от заготовки. Существует несколько типов сверл, каждый из которых используется для определенного применения. Доступные типы сверл включают центрирующие сверла (для изготовления неглубоких или направляющих отверстий), сверла с вертикальным сверлением (для уменьшения количества стружки на заготовке), сверла для винтовых станков (для изготовления отверстий без направляющего отверстия) и патронные развертки (для увеличения ранее изготовленные отверстия).
Обычно в процессе сверления с ЧПУ также используются сверлильные станки с ЧПУ, которые специально разработаны для выполнения операции сверления. Однако эту операцию можно выполнять и на токарных, резьбонарезных или фрезерных станках.
Фрезерное оборудование с ЧПУФрезерование использует вращающиеся многогранные режущие инструменты для придания формы заготовке. Фрезерные инструменты ориентированы либо горизонтально, либо вертикально и включают концевые фрезы, винтовые фрезы и фрезы для снятия фасок.
В процессе фрезерования с ЧПУ также используются фрезерные станки с ЧПУ, называемые фрезерными станками или мельницами, которые могут быть горизонтально или вертикально ориентированы. Базовые фрезы способны перемещаться по трем осям, а более продвинутые модели имеют дополнительные оси. Доступные типы мельниц включают ручные фрезерные, простые фрезерные, универсальные фрезерные и универсальные фрезерные станки.
Токарное оборудование с ЧПУ Токарная обработка использует одноточечные режущие инструменты для удаления материала с вращающейся заготовки. Конструкция токарного инструмента варьируется в зависимости от конкретного применения, с инструментами, доступными для черновой, чистовой обработки, торцевания, нарезания резьбы, формовки, подрезки, отрезки и обработки канавок.
В процессе токарной обработки с ЧПУ также используются токарные станки с ЧПУ или токарные станки. Доступные типы токарных станков включают токарные станки с револьверной головкой, токарные станки с двигателями и токарные станки специального назначения.
Что такое настольный станок с ЧПУ? Компании, специализирующиеся на производстве станков с ЧПУ, часто предлагают настольные серии небольших и легких станков. Настольные станки с ЧПУ, хотя и медленнее и менее точны, хорошо обрабатывают мягкие материалы, такие как пластик и пенопласт. Они также лучше подходят для небольших деталей и легкого и среднего производства. Машины, представленные в настольной серии, напоминают более крупный отраслевой стандарт, но их размер и вес делают их более подходящими для небольших приложений. Например, настольный токарный станок с ЧПУ, который имеет две оси и может обрабатывать детали диаметром до шести дюймов, был бы полезен для изготовления ювелирных изделий и форм. Другие распространенные настольные станки с ЧПУ включают лазерные резаки размером с плоттер и фрезерные станки.
При работе с токарными станками меньшего размера важно различать настольный токарный станок с ЧПУ и настольный токарный станок. Настольные токарные станки с ЧПУ, как правило, более доступны по цене, но также меньше по размеру и несколько ограничены в приложениях, с которыми они могут работать. Стандартный настольный токарный станок с ЧПУ обычно включает в себя контроллер движения, кабели и базовое программное обеспечение. Стандартный настольный токарный станок с ЧПУ с аналогичной базовой комплектацией стоит немного дороже.
Материалы для станков с ЧПУ
Процесс обработки с ЧПУ подходит для различных конструкционных материалов, в том числе:
- Металл (например, алюминий, латунь, нержавеющая сталь, легированная сталь и т. д.)
- Пластик (например, PEEK, PTFE, нейлон и т. д.)
- Дерево
- Пена
- Композиты
Выбор оптимального материала для производства с ЧПУ во многом зависит от конкретного производственного приложения и его спецификаций. Большинство материалов можно подвергать механической обработке при условии, что они выдерживают процесс обработки, т. е. обладают достаточной твердостью, прочностью на растяжение, прочностью на сдвиг, химической и температурной стойкостью.
Материал заготовки и его физические свойства используются для определения оптимальной скорости резания, скорости подачи и глубины резания. Измеряемая в поверхностных футах в минуту, скорость резания относится к тому, насколько быстро станок врезается или удаляет материал с заготовки. Скорость подачи, измеряемая в дюймах в минуту, является мерой того, насколько быстро заготовка подается к станку, а глубина резания показывает, насколько глубоко режущий инструмент врезается в заготовку. Как правило, заготовка сначала проходит начальную фазу, на которой она грубо обрабатывается до приблизительных, специально разработанных формы и размеров, а затем проходит чистовую фазу, на которой она испытывает более медленные скорости подачи и меньшую глубину резания для достижения более точных и точных результатов. точные характеристики.
Рекомендации по размеру ЧПУ
Широкий спектр возможностей и операций, предлагаемых процессом обработки с ЧПУ, помогает ему найти применение в различных отраслях промышленности, включая автомобильную, аэрокосмическую, строительную и сельскохозяйственную, и позволяет производить ряд продуктов, таких как гидравлические компоненты, винты и валы. Несмотря на универсальность и настраиваемость процесса, изготовление некоторых деталей, например крупных или тяжелых компонентов, представляет более сложные задачи, чем другие. В таблице 1 ниже представлены некоторые проблемы обработки крупных деталей и тяжелых компонентов.
Таблица 2. Проблемы обработки в зависимости от размера детали Размер детали | Проблемы обработки |
Большая деталь |
|
Тяжелый компонент |
|
Альтернативы использованию станка с ЧПУ
Хотя обработка с ЧПУ демонстрирует преимущества по сравнению с другими производственными процессами, она может не подходить для каждого производственного применения, и другие процессы могут оказаться более подходящими и экономически эффективными. Хотя в этой статье основное внимание уделяется процессам механической обработки с ЧПУ, в которых используются станки для производства детали или продукта, разработанного по индивидуальному заказу, элементы управления ЧПУ могут быть интегрированы в различные станки. Другие процессы механической обработки с ЧПУ включают ультразвуковую обработку, гидроабразивную резку и абразивно-струйную обработку.
Помимо механических процессов, также доступны процессы химической, электрохимической и термической обработки. Процессы химической обработки включают химическое фрезерование, вырубку и гравировку; процессы электрохимической обработки включают электрохимическое удаление заусенцев и шлифование; и процессы термической обработки включают электронно-лучевую обработку, лазерную резку, плазменно-дуговую резку и электроэрозионную обработку (EDM).
История обработки с ЧПУ (Видео)
Резюме
Выше изложены основы процесса обработки с ЧПУ, различные операции обработки с ЧПУ и необходимое для них оборудование, а также некоторые соображения, которые могут приниматься во внимание производителями и механическими мастерскими при принятии решения о том, является ли обработка с ЧПУ наиболее оптимальным решением для их конкретных задач. производственное приложение.
Чтобы найти более подробную информацию о местных коммерческих и промышленных поставщиках услуг и оборудования для производства на заказ, посетите платформу поиска поставщиков Thomas, где вы найдете информацию о более чем 500 000 коммерческих и промышленных поставщиков.
Источники
- Нетрадиционные процессы механической обработки и термической резки
- Обработка пластика с ЧПУ
- Отрасли, использующие высокоточную обработку с ЧПУ
- Токарно-фрезерные услуги с ЧПУ
- Швейцарская токарная обработка по сравнению с традиционной обработкой с ЧПУ
- 7 причин, по которым обработка с ЧПУ превосходит обычную обработку
- Как вращается мир (ЧПУ) — эволюция токарной обработки с ЧПУ
- Типы и преимущества станков с ЧПУ
- Прототипирование с ЧПУ в современном виде
- Преимущества контрактной обработки с ЧПУ
- Все о станках с ЧПУ
- Алюминиевые детали с механической обработкой
- Обработка компонентов огнестрельного оружия
- Советы по отличному дизайну металлического прядения
- Важность деталей и компонентов трансмиссии для внедорожников
- Что такое швейцарская обработка с ЧПУ?
- Что нужно знать о швейцарской токарной обработке
- Авиационная и аэрокосмическая промышленность в Ardel Engineering
- Связь в Ardel Engineering
- Токарно-фрезерные услуги с ЧПУ в Helander
- Обработка пластика с ЧПУ
- Фрезерные станки против. Токарные станки
- Швейцарская обработка с ЧПУ
- Что такое обработка с ЧПУ?
- Руководство по допускам обработки с ЧПУ
- Как указать общие допуски в обрабатываемых деталях
- Обработка с ЧПУ по сравнению с обычной обработкой
Прочие изделия с ЧПУ
- Ведущие сервисные компании с ЧПУ в США
- Типы ЧПУ
- Типы сверл с ЧПУ
- Обработка с ЧПУ Эволюция до обработки с ЧПУ
- Обучение токарному станку с ЧПУ
- Применения для прядения металла с ЧПУ
- Получение образования в области ЧПУ
- Понимание фрезерных станков с ЧПУ
- Что такое настольный станок с ЧПУ?
- Объяснение G-кодов: введение в общие коды G-кода
- Руководство по швейцарскому станку с ЧПУ/швейцарскому винтовому станку
- 10 ведущих производителей станков с ЧПУ в США и мире
- Что означает ЧПУ?
- Нарезание резьбы на токарных станках с ЧПУ
Больше из Изготовление и изготовление на заказ
3.
Некоторые ключевые термины – Деррида: отец деконструкции1. Деконструкция
Деконструкция – это стратегия критического вопрошания, направленная на выявление неоспоримых метафизических допущений и внутренних противоречий в философском и литературном языке. Деконструкция часто включает способ прочтения, связанный с децентрацией — с разоблачением проблематичной природы всех центров. Дальнейшая деконструкция — это форма текстовой практики, заимствованная у Деррида, цель которой — продемонстрировать присущую ненасытность как языка, так и смысла. Он отвергает слово «анализ» или «интерпретация», а также отвергает любое допущение текстов.
2. Бинарные оппозиции
Бинарная оппозиция — это структуралистская идея, признающая человеческую склонность мыслить в терминах оппозиции. Для Соссюра бинарная оппозиция была «средством, посредством которого языковые единицы приобретают значение или значение; каждая единица определяется тем, чем она не является». При такой категоризации термины и понятия имеют тенденцию ассоциироваться с положительным или отрицательным. Например, Разум/Страсть, Мужчина/Женщина, Внутри/Снаружи, Присутствие/Отсутствие, Речь/Письмо и т. д. Деррида утверждал, что эти оппозиции произвольны и неустойчивы по своей сути. Сами структуры начинают перекрываться и конфликтовать, и, в конце концов, эти структуры текста разбираются изнутри текста. В этом смысле деконструкция рассматривается как форум антиструктурализма. Деконструкция отвергает большинство допущений структурализма и более яростно «бинарную оппозицию» на том основании, что такие оппозиции всегда преобладают над одним термином над другим, то есть означаемое над означающим.
3. Различие
В противовес метафизике присутствия деконструкция выдвигает (не)понятие, называемое различием . Деррида использует термин «различие» для описания происхождения присутствия и отсутствия. Различие неопределимо и не может быть объяснено «метафизикой присутствия». Во французском языке глагол «откладывать» означает как «откладывать», так и «отличаться». Таким образом, 90–115 различие может относиться не только к состоянию или качеству отложенности, но и к состоянию или качеству отличия 9.0116 . Различие может быть условием того, что отложено, и может быть условием того, что отличается. Различие может быть условием различия.
Деррида объясняет, что различие есть условие противопоставления присутствия и отсутствия.[1] Различие также является «шарниром» между речью и письмом, а также между внутренним смыслом и внешним представлением. Как только есть смысл, есть и разница.[2]
4. Метафизика присутствия/ логоцентризм
Согласно Деррида, «логоцентризм» — это установка, согласно которой logos (греческий термин, обозначающий речь, мысль, закон или разум) является центральным принципом языка и философии.[3] Логоцентризм — это точка зрения, согласно которой речь, а не письмо, занимает центральное место в языке. Таким образом, « грамматологии » (термин, который Деррида использует для обозначения науки письма) может освободить наши идеи письма от подчинения нашим идеям речи. Грамматология — это метод исследования происхождения языка, который позволяет нашим концепциям письма стать такими же всеобъемлющими, как и наши концепции речи.
Согласно логоцентристской теории, говорит Деррида, речь является изначальным означающим значения, а написанное слово происходит от произнесенного слова. Таким образом, написанное слово является репрезентацией устного слова. Логоцентризм утверждает, что язык возникает как процесс мышления, порождающий речь, а затем эта речь порождает письмо. Логоцентризм — это та характеристика текстов, теорий, способов репрезентации и означающих систем, которая порождает стремление к прямому, непосредственному, заданному удержанию смысла, бытия и знания.[4]
Деррида утверждает, что логоцентризм можно увидеть в теории, согласно которой лингвистический знак состоит из означающего, значение которого определяется обозначаемой идеей или концепцией. Логоцентризм утверждает экстериорность означающего по отношению к означаемому. Письмо концептуализируется как внешнее по отношению к речи, а речь концептуализируется как внешнее по отношению к мышлению. Однако если письмо есть только репрезентация речи, то письмо есть только «означающее означающего». Таким образом, согласно логоцентристской теории, письмо есть просто производная форма языка, черпающая свое значение из речи. Важность речи как центрального элемента развития языка подчеркивается логоцентристской теорией, но важность письма маргинализируется.[5]
Деррида объясняет, что, согласно логоцентристской теории, речь может быть своего рода присутствием, поскольку говорящий одновременно присутствует для слушающего, но письмо может быть своего рода отсутствием, поскольку пишущий не присутствует одновременно для читающего. Письмо может рассматриваться логоцентристской теорией как замена одновременного присутствия писателя и читателя. Если бы читатель и писатель присутствовали одновременно, то писатель общался бы с читателем посредством разговора, а не письма. Таким образом, логоцентризм утверждает, что письмо есть замена речи и что письмо есть попытка восстановить присутствие речи.
Логоцентризм описывается Деррида как «метафизика присутствия», мотивированная стремлением к «трансцендентальному означаемому». превосходит все знаки. «Трансцендентальное означаемое» — это также означаемое понятие или мысль, которая превосходит любое отдельное означающее, но которая подразумевается всеми определениями значения.
Деррида утверждает, что «трансцендентальное означаемое» может быть деконструировано путем исследования допущений, лежащих в основе «метафизики присутствия». Например, если присутствие считается сущностью означаемого, то близость означающего к означаемому может подразумевать, что означающее способно отражать присутствие означаемого. Если присутствие признается сущностью означаемого, то удаленность означающего от означаемого может подразумевать, что означающее неспособно или едва способно отразить присутствие означаемого. Это взаимодействие между близостью и удаленностью является также взаимодействием между присутствием и отсутствием, между внутренним и внешним.
5. След
Идея различия также влечет за собой идею следа. След — это то, от чего отличается/от чего отличается знак. Это отсутствующая часть присутствия знака. Другими словами, теперь мы можем определить след как знак, оставленный отсутствующей вещью после того, как она прошла на сцене своего прежнего присутствия. Каждое настоящее, чтобы познать себя как настоящее, несет на себе определяющий его след отсутствующего. Из этого следует, что первоначальное настоящее должно нести первоначальный след, настоящий след прошлого, которого никогда не было, абсолютное прошлое. Таким образом, полагает Деррида, он достигает положения за пределами абсолютного знания. Согласно Деррида, самого следа не существует, потому что он скромен. То есть, представляя себя, оно стирается. Поскольку все означающие, рассматриваемые как присутствующие в западной мысли, обязательно будут содержать следы других (отсутствующих) означающих, означающее не может быть ни полностью присутствующим, ни полностью отсутствующим.
6. Архе-письмо
Термин «архе-письмо» используется Деррида для описания формы языка, которая не может быть концептуализирована в рамках «метафизики присутствия». язык, не производный от речи. Археписьмо — это форма языка, которой не мешает различие между речью и письмом. «Археписьмо» также является условием игры различия между письменными и неписьменными формами языка.
Деррида противопоставляет понятие «архе-письма» «вульгарному» понятию письма. «Вульгарное» понятие письма, предлагаемое «метафизикой присутствия», деконструируется понятием «архе-письма»[7]. которые рассматривали добавку как «несущественную добавку, добавленную к чему-то законченному». Деррида утверждает, что то, что само по себе завершено, не может быть дополнено, поэтому дополнение может произойти только там, где изначально отсутствует. В любом бинарном наборе терминов можно утверждать, что второй существует для того, чтобы восполнить изначальный недостаток первого.