Какой корень в слове повар
Ответ или решение2
Е
Корнем называют одну из морфем русского языка. Как и любую другую морфему, корень мы легко найдем при морфемном разборе слова. Есть схема анализа, облегчающая работу.
Порядок морфемного разбора слова
- Задать вопрос к слову для определения части речи.
- Окончанием является изменяемая часть слова. Для поиска меняем слово: спрягаем или склоняем.
- Основой будет часть, оставшаяся после отделения окончания. В этой части следует искать корень, приставку и суффикс.
- Корнем называют общую часть однокоренных слов. Чтобы корректно выделить ее, нужно найти максимально возможное количество родственных слов.
- Приставку найдем перед корнем, в начале слова.
- Суффикс следует искать после корня, перед окончанием.
Иногда слова содержат не все морфемы.
Отсутствующее в слове окончание, как в нашем слове «повар», называют нулевым. В неизменяемых словах (наречие, деепричастие) нет окончаний.
Встречаются слова с двумя и даже тремя корнями, например, «кофеварка», «скороварка», «пароварка» с двумя корнями.
Много слов без приставки и без суффикса, как слово «вар». Между тем можно найти и с несколькими приставками или суффиксами. «Недоваренный» имеет две приставки и суффикс, «пищеварительный» с тремя суффиксами.
Разбор слова «повар» по морфемам
- Слово отвечает на вопрос «кто?» — существительное перед нами.
- Изменяем слово: «повару», «поваром» — отсутствующее окончание называют «нулевое».
- Основа — слово «повар» полностью.
- Однокоренных слов очень много, некоторые из них: «варить», «взвар», «варенка, «отвар», «заварка», «заваривать», «сварить», «кашеварить», «сварка», «сварочный».
 Корень «вар» легко выделить из этих слов.
Корень «вар» легко выделить из этих слов. - «По» — приставка.
- Суффикса нет.
 Корень «вар» легко выделить из этих слов.
Корень «вар» легко выделить из этих слов.Вывод:
После морфемного разбора «повар» мы нашли корень — это все слово «вар».
Ж
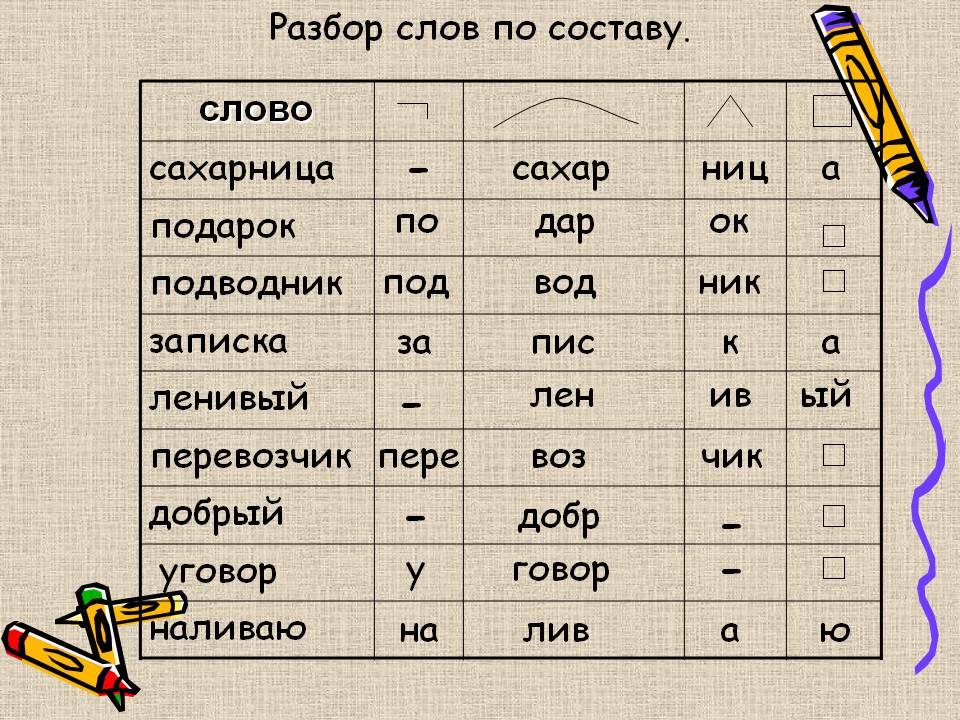
Когда нам нужно найти корень какого-либо слова, мы делаем словообразовательный разбор его.
Начинать следует с отделения окончания. Если не нашли, как у нас в слове, то его называют нулевым. Оставшаяся часть будет основой. Там мы всегда найдем корень, иногда приставки, суффиксы.
Результат разбора слова «повар» по составу:
по — приставка,
вар — корень,
нулевое окончание,
повар — основа слова.
Так мы нашли корень «вар» в слове «повар».
Знаешь ответ?
Как написать хороший ответ?Как написать хороший ответ?
Будьте внимательны!
- Копировать с других сайтов запрещено. Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
- Публикуются только развернутые объяснения.

0 /10000
Использовать простой синтаксис запросов Lucene — Когнитивный поиск Azure
- Статья
- 12 минут на чтение
В Когнитивном поиске Azure простой синтаксис запроса вызывает анализатор запросов по умолчанию для полнотекстового поиска. Синтаксический анализатор работает быстро и обрабатывает распространенные сценарии, включая полнотекстовый поиск, фильтрованный и фасетный поиск, а также поиск по префиксу. В этой статье используются примеры, иллюстрирующие использование простого синтаксиса в запросе поиска документов (REST API).
Примечание
Альтернативным синтаксисом запросов является Full Lucene, поддерживающий более сложные структуры запросов, такие как нечеткий поиск и поиск с использованием подстановочных знаков.
Индекс образцов отелей
Следующие запросы основаны на индексе образцов отелей, который можно создать, следуя инструкциям в этом кратком руководстве.
Примеры запросов сформулированы с использованием REST API и POST-запросов. Вы можете вставить и запустить их в Postman или другом веб-клиенте.
Заголовки запроса должны иметь следующие значения:
| Ключ | Значение |
|---|---|
| Тип содержимого | приложение/json |
| API-ключ | , запрос или ключ администратора |
Параметры URI должны включать конечную точку службы поиска с именем индекса, коллекциями документов, командой поиска и версией API, как в следующем примере:
https://{{service-name}}.search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2020-06-30
Тело запроса должно быть сформировано как действительный JSON:
{
"поиск": "*",
"тип запроса": "простой",
"select": "Идентификатор отеля, Название отеля, Категория, Теги, Описание",
"счет": правда
}
«поиск» установлен на
*— неопределенный запрос, эквивалентный нулевому или пустому поиску. Это не особенно полезно, но это самый простой поиск, который вы можете сделать, и он показывает все извлекаемые поля в индексе со всеми значениями.«queryType» со значением «simple» используется по умолчанию и может быть опущен, но он включен, чтобы еще больше подчеркнуть, что примеры запросов в этой статье выражены в простом синтаксисе.
«выбрать», установленный в список полей, разделенных запятыми, используется для составления результатов поиска, включая только те поля, которые полезны в контексте результатов поиска.
«count» возвращает количество документов, соответствующих критериям поиска. В пустой строке поиска подсчитываются все документы в индексе (50 в случае hotels-sample-index).
 Это не особенно полезно, но это самый простой поиск, который вы можете сделать, и он показывает все извлекаемые поля в индексе со всеми значениями.
Это не особенно полезно, но это самый простой поиск, который вы можете сделать, и он показывает все извлекаемые поля в индексе со всеми значениями.Пример 1: Полнотекстовый поиск
Полнотекстовый поиск может включать любое количество отдельных терминов или фраз, заключенных в кавычки, с логическими операторами или без них.
POST /indexes/hotel-samples-index/docs/search?api-version=2020-06-30
{
"search": "бассейн спа +аэропорт",
«Режим поиска»: любой,
"тип запроса": "простой",
"select": "Идентификатор отеля, Название отеля, Категория, Описание",
"счет": правда
}
Поиск по ключевым словам, состоящий из важных терминов или фраз, работает лучше всего.
Параметр «searchMode» управляет точностью и отзывом. Если вы хотите больше отзывов, используйте значение по умолчанию «любое», которое возвращает результат, если какая-либо часть строки запроса соответствует. Если вы предпочитаете точность, при которой должны совпадать все части строки, измените searchMode на «все». Попробуйте выполнить приведенный выше запрос в обоих направлениях, чтобы увидеть, как searchMode изменяет результат.
Ответ на запрос «pool spa +airport» должен выглядеть примерно так, как показано в следующем примере, но сокращено для краткости.
"@odata.count": 6,
"ценность": [
{
"@search.score": 7.3617697,
«Идентификатор отеля»: «21»,
"HotelName": "Нова Отель и Спа",
"Description": "1 миля от аэропорта. Бесплатный Wi-Fi, открытый бассейн, бесплатный трансфер от/до аэропорта, 9 км от пляжа и 10 км от центра города.",
«Категория»: «Курорт и СПА»,
"Теги": [
"бассейн",
"Континентальный завтрак",
"бесплатная парковка"
]
},
{
"@search.score": 2.5560288,
«Идентификатор отеля»: «25»,
"HotelName": "Скоттиш Инн",
"Description": "Номера с новым дизайном и трансфер до аэропорта. В нескольких минутах от аэропорта, удобства на берегу озера, курортный бассейн и стильные новые номера с интернет-телевизорами.",
«Категория»: «Люкс»,
"Теги": [
"круглосуточная стойка регистрации",
"Континентальный завтрак",
"бесплатный вай-фай"
]
},
{
«@search.score»: 2,2988036, г.
«Идентификатор отеля»: «35»,
"HotelName": "Люкс на площади Бельвю",
"Description": "Роскошный номер в торговом центре. Расположен через дорогу от трамвая до центра города. Бесплатный трансфер до торгового центра и аэропорта.",
«Категория»: «Курорт и СПА»,
"Теги": [
"Континентальный завтрак",
"кондиционирование воздуха",
"круглосуточная стойка регистрации"
]
}
 Бесплатный Wi-Fi, открытый бассейн, бесплатный трансфер от/до аэропорта, 9 км от пляжа и 10 км от центра города.",
«Категория»: «Курорт и СПА»,
"Теги": [
"бассейн",
"Континентальный завтрак",
"бесплатная парковка"
]
},
{
"@search.score": 2.5560288,
«Идентификатор отеля»: «25»,
"HotelName": "Скоттиш Инн",
"Description": "Номера с новым дизайном и трансфер до аэропорта. В нескольких минутах от аэропорта, удобства на берегу озера, курортный бассейн и стильные новые номера с интернет-телевизорами.",
«Категория»: «Люкс»,
"Теги": [
"круглосуточная стойка регистрации",
"Континентальный завтрак",
"бесплатный вай-фай"
]
},
{
«@search.score»: 2,2988036, г.
«Идентификатор отеля»: «35»,
"HotelName": "Люкс на площади Бельвю",
"Description": "Роскошный номер в торговом центре. Расположен через дорогу от трамвая до центра города.
Бесплатный Wi-Fi, открытый бассейн, бесплатный трансфер от/до аэропорта, 9 км от пляжа и 10 км от центра города.",
«Категория»: «Курорт и СПА»,
"Теги": [
"бассейн",
"Континентальный завтрак",
"бесплатная парковка"
]
},
{
"@search.score": 2.5560288,
«Идентификатор отеля»: «25»,
"HotelName": "Скоттиш Инн",
"Description": "Номера с новым дизайном и трансфер до аэропорта. В нескольких минутах от аэропорта, удобства на берегу озера, курортный бассейн и стильные новые номера с интернет-телевизорами.",
«Категория»: «Люкс»,
"Теги": [
"круглосуточная стойка регистрации",
"Континентальный завтрак",
"бесплатный вай-фай"
]
},
{
«@search.score»: 2,2988036, г.
«Идентификатор отеля»: «35»,
"HotelName": "Люкс на площади Бельвю",
"Description": "Роскошный номер в торговом центре. Расположен через дорогу от трамвая до центра города.
Обратите внимание на оценку поиска в ответе. Это показатель релевантности матча. По умолчанию служба поиска возвращает 50 лучших совпадений на основе этой оценки.
Единая оценка «1.0» возникает, когда ранг отсутствует, либо потому, что поиск не был полнотекстовым, либо потому, что критерии не были указаны. Например, при пустом поиске (search= * ) строки возвращаются в произвольном порядке. Когда вы включите фактические критерии, вы увидите, что результаты поиска превращаются в значимые значения.
Пример 2. Поиск по идентификатору
Когда вы возвращаете результаты поиска в запросе, логическим следующим шагом является предоставление страницы сведений, которая включает дополнительные поля из документа. В этом примере показано, как вернуть один документ с помощью функции «Поиск документа», передав идентификатор документа.
В этом примере показано, как вернуть один документ с помощью функции «Поиск документа», передав идентификатор документа.
ПОЛУЧИТЬ /indexes/hotels-sample-index/docs/41?api-version=2020-06-30
Все документы имеют уникальный идентификатор. Если вы используете портал, выберите индекс на вкладке Индексы , а затем просмотрите определения полей, чтобы определить, какое поле является ключевым. Используя REST, вызов Get Index возвращает определение индекса в теле ответа.
Ответ на приведенный выше запрос состоит из документа с ключом 41. Любое поле, помеченное как «извлекаемое» в определении индекса, может быть возвращено в результатах поиска и отображено в вашем приложении.
{
«Идентификатор отеля»: «41»,
"HotelName": "Мотель Ocean Air",
"Description": "Отель на берегу океана с видом на пляж располагает номерами с собственными балконами и 2 крытыми и открытыми бассейнами. Различные магазины и развлекательные заведения находятся на променаде, всего в нескольких шагах от отеля. ",
"Description_fr": "Отель напротив моря с видом на пляж располагает номерами с частным балконом и 2 бассейнами, внутренними и внешними. Разнообразные торговые и художественные анимации, расположенные на набережной, à quelques pas.",
«Категория»: «Бюджет»,
"Теги": [
"бассейн",
"кондиционирование воздуха",
"бар"
],
"ParkingIncluded": правда,
"ДатаПоследнейРеновации": "1951-05-10T00:00:00Z",
«Рейтинг»: 3,5,
"Расположение": {
"тип": "Точка",
"координаты": [
-157,846817,
21.295841
],
"крс": {
"тип": "имя",
"характеристики": {
"имя": "EPSG:4326"
}
}
},
"Адрес": {
"StreetAddress": "1450 бульвар Ала Моана 2238 Ctr Ала Моана",
«Город»: «Гонолулу»,
«ШтатПровинция»: «Привет»,
"Почтовый индекс": "96814",
"Страна": "США"
},
 ",
"Description_fr": "Отель напротив моря с видом на пляж располагает номерами с частным балконом и 2 бассейнами, внутренними и внешними. Разнообразные торговые и художественные анимации, расположенные на набережной, à quelques pas.",
«Категория»: «Бюджет»,
"Теги": [
"бассейн",
"кондиционирование воздуха",
"бар"
],
"ParkingIncluded": правда,
"ДатаПоследнейРеновации": "1951-05-10T00:00:00Z",
«Рейтинг»: 3,5,
"Расположение": {
"тип": "Точка",
"координаты": [
-157,846817,
21.295841
],
"крс": {
"тип": "имя",
"характеристики": {
"имя": "EPSG:4326"
}
}
},
"Адрес": {
"StreetAddress": "1450 бульвар Ала Моана 2238 Ctr Ала Моана",
«Город»: «Гонолулу»,
«ШтатПровинция»: «Привет»,
"Почтовый индекс": "96814",
"Страна": "США"
},
",
"Description_fr": "Отель напротив моря с видом на пляж располагает номерами с частным балконом и 2 бассейнами, внутренними и внешними. Разнообразные торговые и художественные анимации, расположенные на набережной, à quelques pas.",
«Категория»: «Бюджет»,
"Теги": [
"бассейн",
"кондиционирование воздуха",
"бар"
],
"ParkingIncluded": правда,
"ДатаПоследнейРеновации": "1951-05-10T00:00:00Z",
«Рейтинг»: 3,5,
"Расположение": {
"тип": "Точка",
"координаты": [
-157,846817,
21.295841
],
"крс": {
"тип": "имя",
"характеристики": {
"имя": "EPSG:4326"
}
}
},
"Адрес": {
"StreetAddress": "1450 бульвар Ала Моана 2238 Ctr Ала Моана",
«Город»: «Гонолулу»,
«ШтатПровинция»: «Привет»,
"Почтовый индекс": "96814",
"Страна": "США"
},
Пример 3. Фильтр по тексту
Синтаксис фильтра — это выражение OData, которое можно использовать отдельно или с «поиском». При совместном использовании «фильтр» сначала применяется ко всему индексу, а затем поиск выполняется по результатам фильтра. Таким образом, фильтры могут быть полезным методом повышения производительности запросов, поскольку они сокращают набор документов, которые должен обрабатывать поисковый запрос.
При совместном использовании «фильтр» сначала применяется ко всему индексу, а затем поиск выполняется по результатам фильтра. Таким образом, фильтры могут быть полезным методом повышения производительности запросов, поскольку они сокращают набор документов, которые должен обрабатывать поисковый запрос.
Фильтры могут быть определены для любого поля, помеченного как «фильтруемое» в определении индекса. Для hotels-sample-index фильтруемые поля включают категорию, теги, ParkingIncluded, рейтинг и большинство адресных полей.
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "арт-туры",
"тип запроса": "простой",
"filter": "Категория экв. 'Курорт и спа'",
"select": "Идентификатор отеля,Название отеля,Описание,Категория",
"счет": правда
}
Ответ на приведенный выше запрос относится только к тем отелям, которые относятся к категории «Отчет и спа» и содержат термины «искусство» или «туры». В этом случае есть только одно совпадение.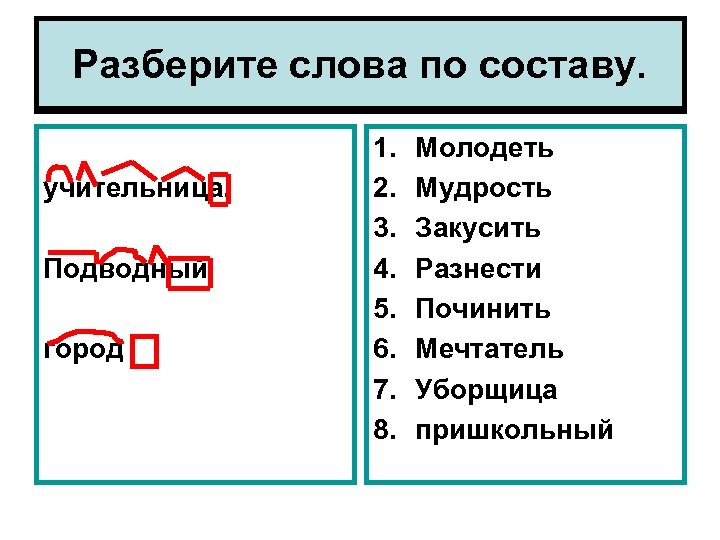
{
"@search.score": 2.8576312,
«Идентификатор отеля»: «31»,
"HotelName": "Остановка в Санта-Фе",
"Description": "Расположен на шести акрах прекрасного ландшафта, в 2 кварталах от торгового центра Plaza. Отдохните в спа-салоне и насладитесь арт-турами по окрестностям.",
«Категория»: «Курорт и спа»
}
Пример 4: Функции фильтра
Выражения фильтра могут включать функции «search.ismatch» и «search.ismatchscoring», позволяющие создавать поисковый запрос внутри фильтра. В этом выражении фильтра используется подстановочный знак бесплатно для выбора удобств, включая бесплатный Wi-Fi, бесплатную парковку и т. д.
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "",
"filter": "search.ismatch('бесплатно*', 'Теги', 'полный', 'любой')",
"select": "Идентификатор отеля, Название отеля, Категория, Описание",
"счет": правда
}
Ответ на приведенный выше запрос соответствует 19 отелям, предлагающим бесплатные удобства. Обратите внимание, что во всех результатах поисковая оценка равна «1,0». Это связано с тем, что выражение поиска имеет значение null или пусто, что приводит к дословным совпадениям фильтра, но не к полнотекстовому поиску. Оценки релевантности возвращаются только при полнотекстовом поиске. Если вы используете фильтры без «поиска», убедитесь, что у вас достаточно сортируемых полей, чтобы вы могли контролировать рейтинг поиска.
Обратите внимание, что во всех результатах поисковая оценка равна «1,0». Это связано с тем, что выражение поиска имеет значение null или пусто, что приводит к дословным совпадениям фильтра, но не к полнотекстовому поиску. Оценки релевантности возвращаются только при полнотекстовом поиске. Если вы используете фильтры без «поиска», убедитесь, что у вас достаточно сортируемых полей, чтобы вы могли контролировать рейтинг поиска.
"@odata.count": 19,
"ценность": [
{
"@search.score": 1,0,
«Идентификатор отеля»: «31»,
"HotelName": "Остановка в Санта-Фе",
"Теги": [
"Посмотреть",
"ресторан",
"бесплатная парковка"
]
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «27»,
"HotelName": "Super Deluxe Inn & Suites",
"Теги": [
"бар",
"бесплатный вай-фай"
]
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «39",
"HotelName": "Уайтфиш Лодж и Сьютс",
"Теги": [
"Континентальный завтрак",
"бесплатная парковка",
"бесплатный вай-фай"
]
},
{
"@search. score": 1,0,
«Идентификатор отеля»: «11»,
"HotelName": "Regal Orb Resort & Spa",
"Теги": [
"бесплатный вай-фай",
"ресторан",
"круглосуточная стойка регистрации"
]
},
 score": 1,0,
«Идентификатор отеля»: «11»,
"HotelName": "Regal Orb Resort & Spa",
"Теги": [
"бесплатный вай-фай",
"ресторан",
"круглосуточная стойка регистрации"
]
},
score": 1,0,
«Идентификатор отеля»: «11»,
"HotelName": "Regal Orb Resort & Spa",
"Теги": [
"бесплатный вай-фай",
"ресторан",
"круглосуточная стойка регистрации"
]
},
Пример 5. Фильтры диапазона
Фильтрация диапазона поддерживается с помощью выражений фильтров для любого типа данных. Следующие примеры иллюстрируют числовые и строковые диапазоны. Типы данных важны в фильтрах диапазона и работают лучше всего, когда числовые данные находятся в числовых полях, а строковые данные — в строковых полях. Числовые данные в строковых полях не подходят для диапазонов, поскольку числовые строки несопоставимы.
Следующий запрос представляет собой числовой диапазон. В hotels-sample-index единственным фильтруемым числовым полем является Rating.
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "*",
"filter": "Рейтинг ge 2 и Рейтинг lt 4",
"select": "Идентификатор отеля, Название отеля, Рейтинг",
"orderby": "Описание рейтинга",
"счет": правда
}
Ответ на этот запрос должен выглядеть так же, как в следующем примере, но сокращенном для краткости.
"@odata.count": 27,
"ценность": [
{
"@search.score": 1,0,
«Идентификатор отеля»: «22»,
"HotelName": "Таверна Каменный Лев",
"Рейтинг": 3,9},
{
"@search.score": 1,0,
«Идентификатор отеля»: «25»,
"HotelName": "Скоттиш Инн",
"Рейтинг": 3,8
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «2»,
"HotelName": "Мотель Твин Доум",
"Рейтинг": 3,6
}
Следующий запрос представляет собой фильтр диапазона по строковому полю (Address/StateProvince):
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "*",
"filter": "Адрес/штатПровинция ge 'A*' и Адрес/штатПровинция lt 'D*'",
"select": "Id Hotel, HotelName, Address/StateProvince",
"счет": правда
}
Ответ на этот запрос должен выглядеть примерно так, как в приведенном ниже примере, но сокращенным для краткости. В этом примере сортировка по StateProvince невозможна, так как поле не атрибутировано как «сортируемое» в определении индекса.
"@odata.count": 9,
"ценность": [
{
"@search.score": 1,0,
«Идентификатор отеля»: «9»,
"HotelName": "Отель Смайл",
"Адрес": {
«ШтатПровинция»: «Калифорния»
}
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «39",
"HotelName": "Уайтфиш Лодж и Сьютс",
"Адрес": {
«ШтатПровинция»: «СО»
}
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «7»,
"HotelName": "Загородный курорт",
"Адрес": {
«ШтатПровинция»: «Калифорния»
}
},
Пример 6: Геопространственный поиск
Пример индекса отелей включает поле Location с координатами широты и долготы. В этом примере используется функция geo.distance, которая фильтрует документы в пределах окружности начальной точки на произвольном расстоянии (в километрах), которое вы указываете. Вы можете настроить последнее значение в запросе (10), чтобы уменьшить или увеличить площадь поверхности запроса.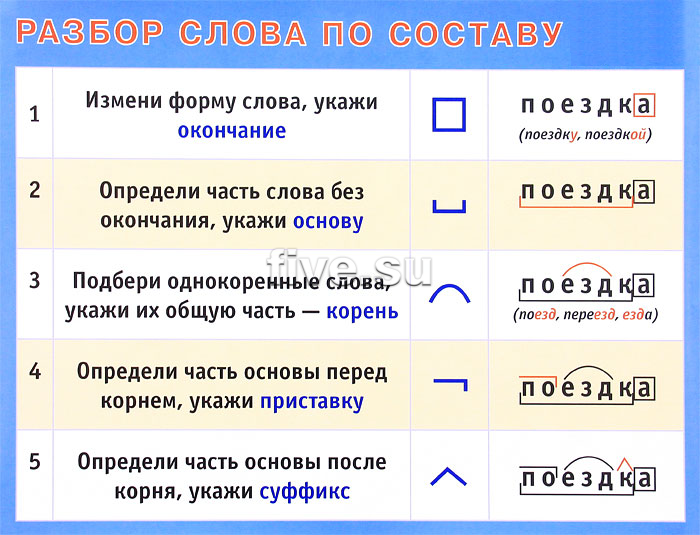
POST /indexes/v/docs/search?api-version=2020-06-30
{
"поиск": "*",
"filter": "geo.distance(Location, geography'POINT(-122.335114 47.612839)') le 10",
"select": "Id Hotel, HotelName, Адрес/Город, Адрес/ШтатПровинция",
"счет": правда
}
Ответ на этот запрос возвращает все отели в пределах 10 километров от указанных координат:
{
"@odata.count": 3,
"ценность": [
{
"@search.score": 1,0,
«Идентификатор отеля»: «45»,
"HotelName": "Аркадия Резорт и Ресторан",
"Адрес": {
«Сити»: «Сиэтл»,
«ШтатПровинция»: «WA»
}
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «24»,
"HotelName": "Gacc Capital",
"Адрес": {
«Сити»: «Сиэтл»,
«ШтатПровинция»: «WA»
}
},
{
"@search.score": 1,0,
«Идентификатор отеля»: «16»,
"HotelName": "Курорт с двумя убежищами",
"Адрес": {
«Сити»: «Сиэтл»,
«ШтатПровинция»: «WA»
}
}
]
}
Пример 7.
 Булевы операторы с режимом поиска
Булевы операторы с режимом поиска Простой синтаксис поддерживает логические операторы в виде символов ( +, -, | ) для поддержки логики запросов И, ИЛИ и НЕ. Логический поиск ведет себя, как и следовало ожидать, за несколькими примечательными исключениями.
В предыдущих примерах параметр «searchMode» был введен как механизм влияния на точность и полноту, при этом «searchMode=any» благоприятствовал отзыву (документ, удовлетворяющий любому из критериев, считается совпадающим), а «searchMode=all » в пользу точности (все критерии должны быть согласованы в документе).
В контексте логического поиска значение по умолчанию «searchMode=any» может сбивать с толку, если вы выполняете запрос с несколькими операторами и получаете более широкие результаты, а не более узкие. Это особенно верно для НЕ, где результаты включают все документы, «не содержащие» определенный термин или фразу.
Следующий пример служит иллюстрацией. Выполнение следующего запроса с режимом поиска (любой) возвращает 42 документа: те, которые содержат термин «ресторан», плюс все документы, в которых нет фразы «кондиционер».
Обратите внимание, что между логическим оператором ( - ) и фразой «кондиционер» нет пробела.
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "ресторан -\"кондиционер\"",
"Режим поиска": "любой",
"searchFields": "Теги",
"select": "Идентификатор отеля, Имя отеля, Теги",
"счет": правда
}
Изменение на «searchMode=all» обеспечивает кумулятивный эффект для критериев и возвращает меньший набор результатов (7 совпадений), состоящий из документов, содержащих термин «ресторан», за вычетом документов, содержащих фразу «кондиционирование воздуха».
Ответ на этот запрос теперь будет похож на следующий пример, обрезанный для краткости.
"@odata.count": 7,
"ценность": [
{
"@search.score": 2.5460577,
«Идентификатор отеля»: «11»,
"HotelName": "Regal Orb Resort & Spa",
"Теги": [
"бесплатный вай-фай",
"ресторан",
"круглосуточная стойка регистрации"
]
},
{
"@search. score": 2.166792,
«Идентификатор отеля»: «10»,
"HotelName": "Загородный отель",
"Теги": [
"круглосуточная стойка регистрации",
"кофе в холле",
"ресторан"
]
},
 score": 2.166792,
«Идентификатор отеля»: «10»,
"HotelName": "Загородный отель",
"Теги": [
"круглосуточная стойка регистрации",
"кофе в холле",
"ресторан"
]
},
score": 2.166792,
«Идентификатор отеля»: «10»,
"HotelName": "Загородный отель",
"Теги": [
"круглосуточная стойка регистрации",
"кофе в холле",
"ресторан"
]
},
Пример 8. Разбивка результатов по страницам
В предыдущих примерах вы узнали о параметрах, влияющих на состав результатов поиска, включая «выбор», который определяет, какие поля будут в результатах, порядок сортировки и как включить количество всех совпадений. Этот пример является продолжением композиции результатов поиска в виде параметров разбивки по страницам, которые позволяют группировать количество результатов, отображаемых на любой заданной странице.
По умолчанию служба поиска возвращает первые 50 совпадений. Чтобы контролировать количество совпадений на каждой странице, используйте «top», чтобы определить размер пакета, а затем используйте «skip», чтобы выбрать последующие пакеты.
В следующем примере используется фильтр и порядок сортировки в поле Рейтинг (Рейтинг можно фильтровать и сортировать), поскольку легче увидеть влияние разбиения на страницы на отсортированных результатах. В обычном полном поисковом запросе лучшие совпадения ранжируются и разбиваются на страницы с помощью «@search.score».
В обычном полном поисковом запросе лучшие совпадения ранжируются и разбиваются на страницы с помощью «@search.score».
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "*",
"filter": "Рейтинг gt 4",
"select": "Название отеля, Рейтинг",
"orderby": "Описание рейтинга",
"Топ-5",
"счет": правда
}
Запрос находит 21 совпадающий документ, но поскольку вы указали «верхний», ответ возвращает только пять лучших совпадений с рейтингом, начинающимся с 4,9 и заканчивающимся на 4,7 с «Леди Озера B & B».
Чтобы получить следующие 5, пропустите первую партию:
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"поиск": "*",
"filter": "Рейтинг gt 4",
"select": "Название отеля, Рейтинг",
"orderby": "Описание рейтинга",
"Топ-5",
"пропустить": "5",
"счет": правда
}
Ответ для второй партии пропускает первые пять совпадений, возвращая следующие пять, начиная с «Pull’r Inn Motel». Чтобы продолжить работу с дополнительными пакетами, вы должны сохранить значение «top» равным 5, а затем увеличивать значение «skip» на 5 при каждом новом запросе (skip = 5, skip = 10, skip = 15 и т. д.).
Чтобы продолжить работу с дополнительными пакетами, вы должны сохранить значение «top» равным 5, а затем увеличивать значение «skip» на 5 при каждом новом запросе (skip = 5, skip = 10, skip = 15 и т. д.).
"значение": [
{
"@search.score": 1,0,
"HotelName": "Мотель Pull'r Inn",
"Рейтинг": 4,7
},
{
"@search.score": 1,0,
"HotelName": "Отель "Великая скала",
"Рейтинг": 4,6
},
{
"@search.score": 1,0,
"HotelName": "Старинный отель",
"Рейтинг": 4,5
},
{
"@search.score": 1,0,
"HotelName": "Мотель Нордика",
"Рейтинг": 4,5
},
{
"@search.score": 1,0,
"HotelName": "Зимний курорт Панорама",
"Рейтинг": 4,5
}
]
Следующие шаги
Теперь, когда вы немного попрактиковались в базовом синтаксисе запросов, попробуйте указать запросы в коде. По следующим ссылкам объясняется, как настроить поисковые запросы с помощью пакетов Azure SDK.
- Запрос вашего индекса с помощью .NET SDK
- Запросите свой индекс с помощью Python SDK .
- Запросите свой индекс с помощью JavaScript SDK
Дополнительные сведения о синтаксисе, архитектуре запросов и примеры можно найти по следующим ссылкам:
- Примеры синтаксических запросов Lucene для создания расширенных запросов
- Как работает полнотекстовый поиск в Когнитивном поиске Azure
- Простой синтаксис запроса
- Полный синтаксис запроса Lucene
- Синтаксис фильтра
[PDF] Композиционно-семантический анализ полуструктурированных таблиц title={Композиционно-семантический анализ полуструктурированных таблиц}, автор={Панупонг Пасупат и Перси Лян}, название книги={ACL}, год = {2015} }
- Панупонг Пасупат, Перси Лян
- Опубликовано в ACL 3 августа 2015 г.
- Информатика
Два важных аспекта семантического анализа для ответа на вопрос — широта источника знаний и глубина логической композиционности. В то время как существующая работа заменяет один аспект другим, эта статья одновременно делает успехи на обоих фронтах благодаря новой задаче: отвечать на сложные вопросы в полуструктурированных таблицах, используя пары вопрос-ответ в качестве наблюдения. Основная проблема возникает из-за двух составных факторов: более широкая область приводит к открытому набору отношений…
В то время как существующая работа заменяет один аспект другим, эта статья одновременно делает успехи на обоих фронтах благодаря новой задаче: отвечать на сложные вопросы в полуструктурированных таблицах, используя пары вопрос-ответ в качестве наблюдения. Основная проблема возникает из-за двух составных факторов: более широкая область приводит к открытому набору отношений…
View on ACL
cs.stanford.eduEvaluating Semantic Parsing against a Simple Web-based Question Answering Model
- Alon Talmor, Mor Geva, Jonathan Berant
Computer Science
*SEMEVAL
- 2017
В этом документе предлагается оценить модели ответов на вопросы, основанные на семантическом анализе, путем сравнения их с базовым уровнем ответов на вопросы, который запрашивает Интернет и извлекает ответ только из веб-фрагментов, без доступа к целевой базе знаний, и обнаруживает, что этот подход обеспечивает разумные производительность.
Neural Semantic Parsing with Type Constraints for Semi-Structured Tables
- J. Krishnamurthy, Pradeep Dasigi, Matt Gardner
Computer Science
EMNLP
- 2017
A new semantic parsing model for answering compositional questions on полуструктурированные таблицы Википедии с современной точностью и ограничениями типов и связыванием сущностей являются ценными компонентами для включения в нейронные семантические парсеры.
Поисково-основанное на поисковом нейронном структурированном обучении для последовательного ответа на вопрос
- Mohit Iyyer, Wen-Tau YIH, Ming-Wei Chang
Компьютерная наука
ACL
- 2017
. Эта работа прополняет новую динамику. Фреймворк, обученный с использованием слабо контролируемого поиска с вознаграждением, который эффективно использует последовательный контекст, чтобы превзойти современные системы контроля качества, предназначенные для ответа на очень сложные вопросы.
Таблицы как полуструктурированные знания для ответов на вопросы
- С. Джаухар, Питер Д. Терни, Э. Хови
Информатика
ACL
- 2016 В этой статье впервые используется структура таблиц 3 руководит созданием набора данных из более чем 9000 вопросов с несколькими вариантами ответов с подробными аннотациями выравнивания, а затем использует эти аннотированные данные для обучения полуструктурированной модели, основанной на функциях, для ответов на вопросы, которая использует таблицы в качестве базы знаний.
- Mohit Iyyer, Wen-tau Yih, Ming-Wei Chang
Computer Science
ArXiv
- 2016
- Kedar Dhamdhere, K. McCurley, Mukund Sundararajan, Ankur Taly
Информатика
ArXiv
- 2017
Информатика
ACL
- 2020
Answering Complicated Question Intents Expressed in Decomposed Question Sequences
This work collects a dataset of 6,066 question sequences которые запрашивают полуструктурированные таблицы из Википедии, всего 17 553 пары вопросов и ответов, и предлагают стратегии для обработки вопросов, которые содержат кореференции к предыдущим вопросам или ответам.
Гибридный семантический подход к анализу таблицы. к SQL-запросам для заданных таблиц, что соответствует трем требованиям реального приложения для анализа данных: междоменное,…
Abductive Matching in Question Answering
Представлен новый способ применения техники семантического машинного анализа, который обеспечивает синтаксический анализ аннотаций. система делает вывод об отсутствии; вся остальная логика синтаксического анализа представлена в виде правил, созданных вручную.
TaPas: анализ таблиц со слабым наблюдением с помощью предварительной подготовки0004
Представлен TaPas, подход к ответам на вопросы по таблицам без создания логических форм, который превосходит или конкурирует с моделями семантического анализа за счет повышения современной точности SQA и работает наравне с современными технологиями WikiSQL и WikiTQ, но с более простой архитектурой модели.
Итеративный поиск для слабо контролируемого семантического анализа
- Прадип Дасиги, Мэтт Гарднер, Шикхар Мурти, Люк Зеттлемойер, Э. Хови
Информатика
NAACL
- 2019
Предлагается новый алгоритм итеративного обучения, который чередуется между поиском непротиворечивых логических форм и максимизацией предельной вероятности извлеченных, тем самым решая проблему ложности.
Ответы на сложные вопросы с использованием извлечения открытой информации
- Тушар Хот, Ашиш Сабхарвал, Питер Кларк
Информатика
ACL
- 2017
В этой работе разрабатывается новая модель вывода для Open IE, которая может эффективно работать с несколькими короткими фактами, шумом и реляционной структурой кортежей и значительно превосходит современный структурированный решатель. по сложным вопросам разной сложности.
ПОКАЗАНЫ 1–10 ИЗ 36 ССЫЛОК
СОРТИРОВАТЬ ПО Релевантности Наиболее влиятельные документы Недавность
Семантический анализ на Freebase из пар вопрос-ответ
- Джонатан Берант, А. Чоу, Рой Фростиг, Перси Лян
Информатика
EMNLP
- 2013
 Чоу, Рой Фростиг, Перси Лян
Чоу, Рой Фростиг, Перси Лянв наборе данных Cai and Yates (2013), несмотря на отсутствие аннотированных логических форм.
Крупномасштабный семантический анализ без пар вопрос-ответ
- Сива Редди, Мирелла Лапата, Марк Стидман
Информатика
TACL
- 2014
В этом документе представлен новый подход к семантическому анализу для запроса Freebase на естественном языке, не требующий ручных аннотаций или пар вопрос-ответ, а также преобразование предложений в семантические графы с использованием CCG и последующее преобразование их в Freebase с использованием обозначений. как форма слабого надзора.
Семантический анализ посредством перефразирования
- Джонатан Берант, Перси Лян
Информатика
ACL
- 2014
В этом документе представлены две простые модели перефразирования, ассоциативную модель и модель векторного пространства, и они обучаются совместно с помощью пар вопрос-ответ, повышая точность двух недавно опубликованных вопросов. — ответные наборы данных.
— ответные наборы данных.
Масштабирование семантических синтаксических анализаторов с сопоставлением онтологий на лету
- Т. Квятковски, Юнсол Чой, Йоав Арци, Люк Зеттлемойер
Информатика
EMNLP
- 2013
Новый подход к семантическому анализу, который учит разрешать онтологические несоответствия, полученный из пар вопрос-ответ, использует вероятностную CCG для построения лингвистически мотивированных представлений значения логической формы и включает модель сопоставления онтологий, которая адаптирует выходные данные. логические формы для каждой целевой онтологии.
Обучение на основе парафраз для ответов на открытые вопросы
- Энтони Фейдер, Люк Зеттлемойер, Орен Эциони
Информатика
ACL
- 2013
Эта работа демонстрирует возможность изучения семантического словаря и функции линейного ранжирования без аннотирования вопросов вручную, автоматического обобщения исходного словаря и включения масштабируемого, распараллеленного параметра персептрона. схема оценки.
схема оценки.
Ответы на вопрос на основе шаблона по данным RDF
- Christina Unger, Lorenz Bühmann, Jens Lehmann, A. N. Ngomo, D. Gerber, P. Cimiano
Информатика
WWW
- 2012
Новый подход, основанный на анализе вопроса для создания шаблона SPARQL, который непосредственно отражает внутреннюю структуру системы ответов на вопросы, которая затем создается с использованием статистической идентификации объектов. и обнаружение предикатов.
Ответы на открытые вопросы по курируемым и извлеченным базам знаний
- Энтони Фейдер, Люк Зеттлемойер, Орен Эциони
Информатика
KDD
- 2014
В этой статье представлен OQA, первый подход к использованию как курируемых, так и извлеченных KB, и демонстрируется, что он обеспечивает вдвое большую точность и полноту по сравнению с текущим состоянием. art Открытая система контроля качества.