русский язык.тема»Морфемика и словообразование «
Тема: Морфемика и словообразование.
Цель урока: повторение и обощение знаний о морфемике, роли морфем в
словообразовании
Задачи: повторить и обобщить ранее изученное по морфемике;
формировать знания о морфемике, морфемах и их роли в
словообразовании;
развивать навык производить морфемный разбор слова, навык
работы в группах, мотивацию к аналитической деятельности;
воспитывать интерес к изучению языка, слова, уважительное
отношение друг к другу.
Ход урока
I. Вводно-мотивационный.
1.
2. Сообщение темы и цели урока. Целеполагание.
1. Составление слова.
— Составьте слово.
Корень тот же, что в слове рассказ, приставка та же, что в слове подскочить, суффикс и окончание те же, что в слове ножка: подсказка.
2. Словарный диктант.
Акварель, аккуратный, альбом, багряный, бирюзовый, восторг, восхищение, иллюстрация, иссиня-чёрный, маляр, орнамент, пейзаж, природа, репродукция, увлечение
3. Обращение к целеполаганию.
— Что помогло вам догадаться, какие слова я вам загадала? Знание морфемного состава слова.
— Какую большую тему мы начнем изучать сегодня на уроке?
— Какие задачи мы сегодня поставим перед собой на уроке? Повторить изученное по разделу «Морфемика».
3. Вступительная беседа:
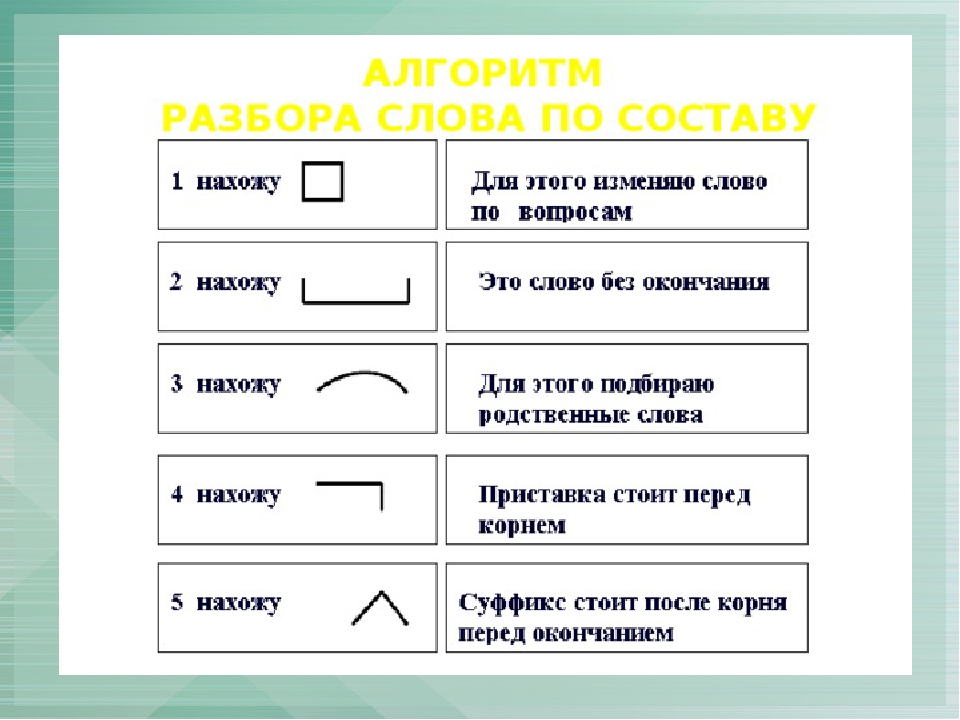
Что вы знаете о морфемике? Морфемика – это раздел науки о языке, в котором изучается состав, строение слова.
Какие вы знаете морфемы? Что они обозначают? Морфемы – это наименьшая значимая часть слова. Среди морфем выделяют: корень и аффиксы (приставка, суффикс, окончание).
II. Операционно-познавательный.
1. Работа в группах.
-
«Пять минут на ответ».
I группа: Можно ли по морфеме определить часть речи? Докажите.
—ешь, -ит, -ого, -л-, -ие, -и;
II группа: Можно ли, не определяя часть речи, разобрать правильно по
составу слова стекло, красиво.
2. Составление слова. Составить слово из разных морфем данных глаголов.
I группа: От глагола притаился взять приставку, от тащить – корень, от возить – суффикс, отпел – суффикс прошедшего времени, от носился – суффикс возвратности: притащился.
II группа: Корень тот же, что в слове заводить, приставка та же, что в слове переменный,суффикс тот же, что в слове лётчик, окончание то же, что в слове цветок: переводчик.
2. Работа с текстом.
1. Чтение учителем высказывания автора «Школьного словообразовательного словаря русского языка» А. Н. Тихонова.
Н. Тихонова.
Большое количество слов, кроме корня, включает в свою структуру окончание и суффикс или приставку… Приставок и суффиксов в слове может быть несколько… В таких словах обычно корни так «обрастают» приставками и суффиксами, что их подчас трудно увидеть… Это реальные слова. В языке их немало. Грамотный человек обязан их понимать. Чтобы правильно понимать их смысл и употреблять в своей речи, надо уметь разбираться, из каких частей они состоят. Ведь каждая часть слова что-то выражает, несет какой-то смысл, для чего-то служит.
2. Выполнение заданий:
— Определите основную мысль и стилевую принадлежность текста.
— Докажите справедливость слов ученого, для чего образуйте от глагола учить слова со значением:
1) человек, который учит, преподает;
2) усваивать знания в школе, в институте;
3) учить наизусть.
Учитель, учиться, выучить.
— Как вы считаете, какие морфемы изменили значения слов?
— Вспомните высказывание А.Н. Тихонова о том, что слова
часто «обрастают» приставками, что «каждая часть слова что-то выражает, несет какой-то смысл». Сделайте вывод.
3. Приставки. Докажите мысль ученого А.Н. Тихонова: выпишите глаголы с приставками, выделите их, постарайтесь определить, что изменяет приставка в слове.
I группа: вошел — отошел – ушел.
Приставка во- (в-) обозначает движений внутрь чего-то;
ото- (от-) — удаление в сторону, убавление;
у — удаление.
II группа
Приставка по- изменяет вид глагола, который приобретает значение законченности действия.
Делается вывод: приставка — значимая часть слова, которая находится перед корнем и служит для образования слов.
Иноязычные приставки (запись в тетради): а-, анти-, архи-, интер-, контр-, ультра-, де-, дез-, дис-, ре-, экс-, им-.
4. Суффиксы.
— Какие значения придают словам следующие морфемы:
I группа: суффиксы существительных: -ист-, -чик-, -ец-, -ушк-, -ость,
-ение-, -ак-, -ок-, -онк-, -ач-, -лец-, -тель-, -чик-, -щи-, -кист-,
-ниц-, -иц-;
суффикс глагола –л-, -и-, -е-, -ну-;
II группа: суффиксы прилагательных: -оват-, -еньк-;
суффикс глагола -ыва-, -ива-, -ова-, -ева-, -ва-.
Делается вывод: суффикс — значимая часть слова, которая находится после корня и обычно служит для образования слов или форм слова.
IV. Контрольно-оценочный.
1. Работа в парах.
1. Распределительный диктант. Однокоренные слова.
— Какие слова называются однокоренными?
1. Делить, раздел, деловой, деление, дело. (Делить, раздел, деление; деловой, дело).
2. Кузнец, кузница, кузнечик. (Кузнец, кузница; кузнечик).
3. Летать, полёт, лето, лётчик, летний. (Летать, полёт, лётчик; лето, летний).
4. Водный, водить, водичка, поводок, водитель. (Водный, водичка; водить, поводок, водитель).
(Водный, водичка; водить, поводок, водитель).
5. Лопнуть, лопата, лопух, лопаться. (Лопнуть, лопух, лопаться; лопата).
2. Работа в группах.
1. Распределительный диктант.
— Что называется окончанием?
Начинал сыпать дождь, сначала осторожно, потом сильнее и сильнее. Он лил, ровно и однообразно шумя по траве и деревьям. Мягкими переливами звучал под дождём голос иволги.
I группа: слова, имеющие окончание (выделить окончание): начинал, сыпать, дождь, лил, траве, деревьям, мягкими, переливами, звучал, дождём, голос, иволги.
Выполнить морфемный разбор слова: сыпать.
II группа: неизменяемые слова: сначала, осторожно, сильнее, он, ровно, однообразно, шумя.
Выполнить морфемный разбор слова: переливами.
2. Суффиксы. Выделить суффиксы.
I группа: птичка, травка, миленький;
II группа: цветочек, платьице, сердечком.
3. Приставки. Вставить пропущенные буквы в приставках.
По…катить, …делать, …бить, о…давать, по…править, …право, о…дых, о…ступить, в…кользь, о…бой.
3. Восстановить правило.
В приставках на з, с перед звонкими согласными пишется …, а перед глухими согласными – …
«Звонкий согласный в приставке + звонкий согласный в корне»: безбрежный.
«Глухой согласный в приставке + глухой согласный в корне»: беспредельный.
Приставка з пишется перед звонким согласным в корне; приставка с пишется перед глухим согласным в корне.
4. Работа в группах. Стратегия «Карусель». Разбор слов по составу.
— Вам предлагается побывать в роли детективов: разобрать слова по составу. Выполнив задание, вы должны обменяться карточками между группами для проверки, используя цвет (маркер) своей группы.
Выступающий каждой группы проговаривает разбор слов.
I группа: знаток, проколоть, подвеска;
II группа: выключатель, безбрежный, расписание;
III группа: наводнить, решение, старинный.
V. Итог урока.
3. Закончить предложение.
Чтение учителем начала предложения и продолжение учениками конца предложения.
- Раздел науки о языке, в котором изучается состав, строение слова – это …(морфемика).
- Наименьшая значимая часть слова – это … (морфема).
- Общая часть однокоренных слов, выражает их общее лексическое значение родственных слов – это … (корень).
- Часть слова, которая может быть определена путем подбора родственных слов – это(корень).
- Изменяемая часть слова, которая служит для выражения грамматического значения – это … (окончание).
-
Значимая часть слова, которая стоит перед корнем и служит для образования новых слов – это … (приставка).

- Значимая часть слова, которая стоит после корня и служит для образования новых слов – это … (суффикс).

VII. Задание на дом: п. 31, упр.157, стр 89…
Морфологический разбор слова «дают»
Часть речи: Глагол в личной форме
ДАЮТ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ДАВАТЬ»
| Слово | Морфологические признаки |
|---|---|
| ДАЮТ |
|
Все формы слова ДАЮТ
ДАВАТЬ, ДАЮ, ДАЕМ, ДАЕШЬ, ДАЕТЕ, ДАЕТ, ДАЮТ, ДАВАЛ, ДАВАЛА, ДАВАЛО, ДАВАЛИ, ДАВАЯ, ДАВАВ, ДАВАВШИ, ДАВАЙ, ДАВАЙТЕ, ДАЮЩИЙ, ДАЮЩЕГО, ДАЮЩЕМУ, ДАЮЩИМ, ДАЮЩЕМ, ДАЮЩАЯ, ДАЮЩЕЙ, ДАЮЩУЮ, ДАЮЩЕЮ, ДАЮЩЕЕ, ДАЮЩИЕ, ДАЮЩИХ, ДАЮЩИМИ, ДАВАВШИЙ, ДАВАВШЕГО, ДАВАВШЕМУ, ДАВАВШИМ, ДАВАВШЕМ, ДАВАВШАЯ, ДАВАВШЕЙ, ДАВАВШУЮ, ДАВАВШЕЮ, ДАВАВШЕЕ, ДАВАВШИЕ, ДАВАВШИХ, ДАВАВШИМИ, ДАВАЕМЫЙ, ДАВАЕМОГО, ДАВАЕМОМУ, ДАВАЕМЫМ, ДАВАЕМОМ, ДАВАЕМ, ДАВАЕМАЯ, ДАВАЕМОЙ, ДАВАЕМУЮ, ДАВАЕМОЮ, ДАВАЕМА, ДАВАЕМОЕ, ДАВАЕМО, ДАВАЕМЫЕ, ДАВАЕМЫХ, ДАВАЕМЫМИ, ДАВАЕМЫ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ДАЮТ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «дают»
1
Нет, деньги не дают счастья, они не дают спокойствия, они не дают тебе истинны.
Варанаси, Андрей Гоман, 2015г.2
Значит, жить так, как дают, что дают, сколько дают.
Мэрилин, Марианна Ионова3
Она жаловалась на старшин, что им не дают ловить рыбу, держать вино, берут поборы и наживаются сами, а простым не дают жалованья;
Гетманство Выговского, Николай Костомаров4
Разве мы все не знаем, что быку не дают воды целые сутки перед боем, и только перед выходом на арену дают пить сколько влезет?
Рожденная в ночи. Зов предков. Рассказы (сборник), Джек Лондон
Зов предков. Рассказы (сборник), Джек Лондон5
И, как говорят у Щедрина персонажи, сейчас за наш рубль полтинник дают, а скоро будут давать по морде.
Язвы русской жизни. Записки бывшего губернатора, Михаил Салтыков-Щедрин, 1860, 2020г.Найти еще примеры предложений со словом ДАЮТ
%d0%bc%d0%be%d1%80%d1%84%d0%b5%d0%bc%d0%bd%d1%8b%d0%b9%20%d0%b0%d0%bd%d0%b0%d0%bb%d0%b8%d0%b7%20%d1%81%d0%bb%d0%be%d0%b2%d0%b0 — со всех языков на все языки
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАканАлтайскийАрагонскийАрабскийАстурийскийАймараАзербайджанскийБашкирскийБагобоБелорусскийБолгарскийТибетскийБурятскийКаталанскийЧеченскийШорскийЧерокиШайенскогоКриЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийВаллийскийДатскийНемецкийДолганскийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГэльскийГуараниКлингонскийЭльзасскийИвритХиндиХорватскийВерхнелужицкийГаитянскийВенгерскийАрмянскийИндонезийскийИнупиакИнгушскийИсландскийИтальянскийЯпонскийГрузинскийКарачаевскийЧеркесскийКазахскийКхмерскийКорейскийКумыкскийКурдскийКомиКиргизскийЛатинскийЛюксембургскийСефардскийЛингалаЛитовскийЛатышскийМаньчжурскийМикенскийМокшанскийМаориМарийскийМакедонскийКомиМонгольскийМалайскийМайяЭрзянскийНидерландскийНорвежскийНауатльОрокскийНогайскийОсетинскийОсманскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПортугальскийКечуаКвеньяРумынский, МолдавскийАрумынскийРусскийСанскритСеверносаамскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиШумерскийСилезскийТофаларскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийТувинскийТвиУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВьетнамскийВепсскийВарайскийЮпийскийИдишЙорубаКитайский
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАлтайскийАрабскийАварскийАймараАзербайджанскийБашкирскийБелорусскийБолгарскийКаталанскийЧеченскийЧаморроШорскийЧерокиЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийДатскийНемецкийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГалисийскийКлингонскийЭльзасскийИвритХиндиХорватскийГаитянскийВенгерскийАрмянскийИндонезийскийИнгушскийИсландскийИтальянскийИжорскийЯпонскийЛожбанГрузинскийКарачаевскийКазахскийКхмерскийКорейскийКумыкскийКурдскийЛатинскийЛингалаЛитовскийЛатышскийМокшанскийМаориМарийскийМакедонскийМонгольскийМалайскийМальтийскийМайяЭрзянскийНидерландскийНорвежскийОсетинскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПуштуПортугальскийКечуаКвеньяРумынский, МолдавскийРусскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиТамильскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВодскийВьетнамскийВепсскийИдишЙорубаКитайский
«Повторение по разделу «Состав слова.
 Орфограммы, изученные в начальных классах» – УчМет Краткое описание
Орфограммы, изученные в начальных классах» – УчМет Краткое описаниеПовторение и закрепление пройденного материала
Описание Повторение материала по разделу «Состав слова. Орфограммы, изученные в начальных классах». Урок-игра, с использованием интерактивной доски. Цель: повторение и закрепление знаний.
Предварительно приготовить карточки с баллами 1, 2, 3. (для удобства, можно сделать одинаковые карточки и за правильные ответы давать нужно количество карточек) На доске 3 категории: 1. Состав слова 2. Орфограммы/ правописание 3. Морфология (части речи) В каждой категории 10 вопросов. Игра начинается с 1 категории. Учащиеся по очереди выбирают номер вопроса (под каждым номером указано количество баллов за данный вопрос). 1 категория «Состав слова» 1. Значимые части, из которых состоят слова (морфемы) – 3б. прим. — После каждого вопроса, появляется правильный ответ. 2. Как называются слова с одним и тем же корнем (однокоренные) – 1б. 3. Выделите суффикс в слове ЛЕСНОЙ (-н-) – 1б. 4. Разберите слово ЯГОДКА по составу (ягод –корень, к- суффикс, а – окончание) – 2б. 5. Разберите слово ЗАСНЕЖЕННЫЙ по составу (за –приставка, снеж – корень, енн- суффикс, ый – окончание) – 3б. 6. Часть слова, стоящая перед корнем (приставка) – 1б. 7. Выберите однокоренные слова: НОСОРОГ, УТКОНОС, ПОДНОС, НОСИК (носорог, утконос, носик) – 3б. 8. Как называется главная значимая часть слова, в которой заключено его лексическое значение? (корень) – 2б. 9. Разобрать слово МЕСТЕЧКО по составу. (мест- корень, ечк – суффикс, о- окончание) – 2б. 10. Укажите лишнее слово в ряду: ДОРОЖКА, ДОРОЖИТЬ, ПОДОРОЖНИК (дорожить) – 2б. 2 категория «Орфограммы/правописание» 1. Что такое орфограмма? (Написания в словах по орфографическим правилам) – 3б. 2. Правила написания безударной гласной в корне? (нужно изменить слово или подобрать однокоренные слова, чтобы гласная была под ударением) — 3б.
3. Выделите суффикс в слове ЛЕСНОЙ (-н-) – 1б. 4. Разберите слово ЯГОДКА по составу (ягод –корень, к- суффикс, а – окончание) – 2б. 5. Разберите слово ЗАСНЕЖЕННЫЙ по составу (за –приставка, снеж – корень, енн- суффикс, ый – окончание) – 3б. 6. Часть слова, стоящая перед корнем (приставка) – 1б. 7. Выберите однокоренные слова: НОСОРОГ, УТКОНОС, ПОДНОС, НОСИК (носорог, утконос, носик) – 3б. 8. Как называется главная значимая часть слова, в которой заключено его лексическое значение? (корень) – 2б. 9. Разобрать слово МЕСТЕЧКО по составу. (мест- корень, ечк – суффикс, о- окончание) – 2б. 10. Укажите лишнее слово в ряду: ДОРОЖКА, ДОРОЖИТЬ, ПОДОРОЖНИК (дорожить) – 2б. 2 категория «Орфограммы/правописание» 1. Что такое орфограмма? (Написания в словах по орфографическим правилам) – 3б. 2. Правила написания безударной гласной в корне? (нужно изменить слово или подобрать однокоренные слова, чтобы гласная была под ударением) — 3б. 3. Вставить пропущенную букву: ОСМ… ТРЕТЬ (о) – 1б. 4. Вставить пропущенные буквы: ВЕЛ… С… ПЕД (о, и) – 2б. 5. Какие существуют два способа проверки написания звонких и глухих согласных в корне слова? (изменения слова и подбор однокоренных слов, в которых после проверяемой согласной стоит гласная или согласные л, м, н, р) – 3б. 6. Вставьте пропущенную букву: МОЛ… ЬБА (т) -1б. 7. Вставьте пропущенные буквы: Б… СКЕ… БОЛ (а, т) – 2б. 8. Вставьте пропущенные буквы: ЧУДЕ…НЫЙ (сн) – 1б. 9. Вставьте пропущенную букву: ПАРАШ… Т (ю) – 1б. 10. Вставьте пропущенную букву: ПОД… ЕЗД (ъ) – 1б. 3 категория «Морфология/части речи» 1. Определить часть речь слова СЕМНАДЦАТЬ (числительное) – 1б. 2. Как изменяются глаголы? (по временам, лицам, в пр.вр. — по родам)-2б. 3. Назовите вопросы, на которые отвечают: Имена существительные, имена прилагательные, глаголы. (ИС: кто? что?; ИП: какой? чей?; Гл.: что делать? что сделать?) – 3б.
3. Вставить пропущенную букву: ОСМ… ТРЕТЬ (о) – 1б. 4. Вставить пропущенные буквы: ВЕЛ… С… ПЕД (о, и) – 2б. 5. Какие существуют два способа проверки написания звонких и глухих согласных в корне слова? (изменения слова и подбор однокоренных слов, в которых после проверяемой согласной стоит гласная или согласные л, м, н, р) – 3б. 6. Вставьте пропущенную букву: МОЛ… ЬБА (т) -1б. 7. Вставьте пропущенные буквы: Б… СКЕ… БОЛ (а, т) – 2б. 8. Вставьте пропущенные буквы: ЧУДЕ…НЫЙ (сн) – 1б. 9. Вставьте пропущенную букву: ПАРАШ… Т (ю) – 1б. 10. Вставьте пропущенную букву: ПОД… ЕЗД (ъ) – 1б. 3 категория «Морфология/части речи» 1. Определить часть речь слова СЕМНАДЦАТЬ (числительное) – 1б. 2. Как изменяются глаголы? (по временам, лицам, в пр.вр. — по родам)-2б. 3. Назовите вопросы, на которые отвечают: Имена существительные, имена прилагательные, глаголы. (ИС: кто? что?; ИП: какой? чей?; Гл.: что делать? что сделать?) – 3б. 4. ТСЯ или ТЬСЯ? Где останови…… паучок? (тся) – 1б. 5. Слитно или раздельно? Почему? (не)учишься (раздельно, НЕ с глаголами всегда пишется раздельно) – 1б. 6. Перечислите падежи имен существительных и падежные вопросы. (именительный – кто? Что?; родительный – кого? чего?; дательный – кому? чему?; винительный – кого? что?; творительный – кем? чем?; предложный – о ком? О чем?) – 3б. 7. Морфологический разбор имени существительного: В УТРЕННЕМ ЛЕСУ – 3б. 1. В лесу – сущ. 2. Н.ф.- лес, нариц., неодуш., м.р., IIскл., п.п., ед.ч. 3. (в чем?) в лесу 8. Морфологический разбор имени существительного: ПОД ЗИМНИМИ СНЕГАМИ -3б. 1. Под снегами– сущ. 2. Н.ф.- снег, нариц., неодуш., м.р., IIскл., тв.п., мн.ч. 3. (под чем?) под снегами 9. Морфологический разбор глагола: ПОСАДИЛА КАКТУС – 3б. 1. Посадила– глаг. 2. Н.ф.- посадить, сов. вид., IIспр., ед.ч.
4. ТСЯ или ТЬСЯ? Где останови…… паучок? (тся) – 1б. 5. Слитно или раздельно? Почему? (не)учишься (раздельно, НЕ с глаголами всегда пишется раздельно) – 1б. 6. Перечислите падежи имен существительных и падежные вопросы. (именительный – кто? Что?; родительный – кого? чего?; дательный – кому? чему?; винительный – кого? что?; творительный – кем? чем?; предложный – о ком? О чем?) – 3б. 7. Морфологический разбор имени существительного: В УТРЕННЕМ ЛЕСУ – 3б. 1. В лесу – сущ. 2. Н.ф.- лес, нариц., неодуш., м.р., IIскл., п.п., ед.ч. 3. (в чем?) в лесу 8. Морфологический разбор имени существительного: ПОД ЗИМНИМИ СНЕГАМИ -3б. 1. Под снегами– сущ. 2. Н.ф.- снег, нариц., неодуш., м.р., IIскл., тв.п., мн.ч. 3. (под чем?) под снегами 9. Морфологический разбор глагола: ПОСАДИЛА КАКТУС – 3б. 1. Посадила– глаг. 2. Н.ф.- посадить, сов. вид., IIспр., ед.ч. , пр.вр., ж.р., 3 л. 3. (что сделала?) посадила 10. Какие существуют лица у местоимений? (1-е: я, мы; 2-е: ты, вы; 3-е: он, она, оно, они) – 2б.
, пр.вр., ж.р., 3 л. 3. (что сделала?) посадила 10. Какие существуют лица у местоимений? (1-е: я, мы; 2-е: ты, вы; 3-е: он, она, оно, они) – 2б.
Давать писать печь учить сушить колесить
Давать, писать, печь, учить, сушить, колесить, бежать, брызгать, тащить, нестись, действовать, рыть, сыпать, играть, смотреть, цвести, судить, пустить.
Ответы
продавать прописать пропечь просушить пробежать пробрызгать протащить пронестись подействовать поспать поиграть посмотреть посудить подпустить
мечтали -разобрать слово по составу.звёздном- разобрать слово как часть речи? найти слова с непроизносимой согласной?
ср род или м. род (смотрите, к какому слову относится в предложении)
синтаксич. роль — определение
звездном — непроизносимая д
со временем книги будет замещены компьютером.спрос на печатаную продукцию сильно спал.рассмотрим современную, актуальную молодёжь. единицы из них вообще что-либо читают, а если и читают, то откровенную ерунду, которая уничтожает мораль и разрушает психику. зато каждый сутками просиживает за компьютером. лишь часть используют научный прогресс с толком.
единицы из них вообще что-либо читают, а если и читают, то откровенную ерунду, которая уничтожает мораль и разрушает психику. зато каждый сутками просиживает за компьютером. лишь часть используют научный прогресс с толком.
Ответы на вопрос
газеты-корень газет, окончание ы, основа газет
журналы-корень журнал, окончание ы, основа журнал
Похожие вопросы
(1) что за чудо? нельзя же подумать, чтобы она чувствовала запах ореха через толстый слой снега и льда. значит, помнила с осени о своих орехах и точное расстояние между ними.
(2)сегодня, разглядывая на снегу следы зверушек и птиц, вот что я по этим прочитал: белка приберилась сквозь снег в мох, достала там с осени спрятанные два ореха, тут же их съела — я скорлупки нашёл. потом отбежала десяток метров, опять нырнула, опять оставила на снегу скорлупу и через несколько метров сделала третью полазку.
(3) но самое удивительное — она не могла отмеривать, как мы, сантиметры, а прямо на глаз с точностью определял, ныряла и доставала. ну как было не позавидовать беличьей памяти и смекалке!
ну как было не позавидовать беличьей памяти и смекалке!
1.как вы думаете, что значит слово полазка?
2.определите, к какому стилю принадлежит текст.
3.определите микротему каждой части текста.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «трубить», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ТРУБИТЬ, блю, бишь; несов.
1. во что. Дуя в трубу (или сходный музыкальный инструмент), извлекать из неё звуки. Т. в рог.
2. (1 и 2 л. не употр.). Звучать (о трубе). Трубы трубят.
3. что. Звуком трубы давать сигнал. Т. сбор.
что. Звуком трубы давать сигнал. Т. сбор.
4. перен., о ком-чём. Разглашать какиен. сведения (разг.). Т. о своей удаче.
5. Долго заниматься чем-н. скучным, утомительным, однообразным (прост.). Двадцать лет трубил в канцелярии.
| сов. протрубить, блю, бишь.
• Протрубить уши кому (разг.) то же, что прожужжать уши кому-н.
Фонетический (звуко-буквенный) разбор
труби́ть
трубить — слово из 2 слогов: тру-бить. Ударение падает на 2-й слог.
Транскрипция слова: [труб’ит’]
т — [т] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
у — [у] — гласный, безударный
б — [б’] — согласный, звонкий парный, мягкий (парный)
и — [и] — гласный, ударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 7 букв и 6 звуков.
Цветовая схема: трубить
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «трубить» по составу
трубить (программа института)
трубить (школьная программа)
Части слова «трубить»: труб/и/ть
Часть речи: глагол
Состав слова:
труб — корень,
и, ть — суффиксы,
нет окончания,
труби — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Разбор слова школьница по составу
Разбор по составу слова ШКОЛА: школ/а. Подробный разбор, графическую схему и сходные по морфемному строению слова вы найдёте на сайте. Мне нужно было застать вас одну, но я не знал, как это сделать
ШКОЛЬНИЦЕЙ. корень — ШКОЛЬ; суффикс — НИЦ; окончание — ЕЙ; Основа слова: ШКОЛЬНИЦ Вычисленный способ образования слова∩ — школь; ∧ — НИЦ; ⏰ — ей; Слово Школьницей содержит следующие морфемы или части: ¬ приставка (0): — ∩ корень слова (1): ШКОЛЬ. — Рета! — в голосе на другом конце провода были теплота и удовольствие
— Рета! — в голосе на другом конце провода были теплота и удовольствие
Морфемный разбор слова школьница. Корень, суфикс и окончание. ШКО́ЛЬНИЦА, -ы, ж. Женск. к школьник. Источник (печатная версия): Словарь русского языка: В 4-х т. / РАН, Ин-т лингвистич. исследований; Под ред. А. П. Евгеньевой. Знаете, мне очень хотелось бы знать, как вы до него добрались
Школьник -корень-школ, н-суф, ик-суф. ь , окончание нулевое школьница -ШКОЛЬ; суффикс — НИЦ; окончание — а. Но во время дознания, вы должны будете явиться и давать показания под присягой
План разбора слова школьница по составу с выделением корня и основы. Морфемный разбор со схемой и частями слова (морфемами) — корнем, суффиксом, окончанием. Такие вещи не афишируются, особенно в деревне, но я охотно признаю, что нанес эти два визита
Что такое ШКОЛЬНИЦ? корень — ШКОЛЬ; суффикс — НИЦ; нулевое окончание;Основа слова: ШКОЛЬНИЦВычисленный способ образования слова: Суффиксальный∩. ∩ — школь; ∧ — НИЦ; ⏰. Слово Школьниц содержит следующие морфемы или части: ¬ приставка (0). Ей пришли в голову другие слова, на этот раз из Библии, полные завораживающей, меланхолической красоты: «Человек никак не искупит брата своего и не даст Богу выкупа за него
Слово Школьниц содержит следующие морфемы или части: ¬ приставка (0). Ей пришли в голову другие слова, на этот раз из Библии, полные завораживающей, меланхолической красоты: «Человек никак не искупит брата своего и не даст Богу выкупа за него
Состав слова «школьники»: корень [школь] + суффикс [ник] + окончание [и] Основа(ы) слова: школьник Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Что бы ни думала мисс Силвер о бестактности мужчин, в этом случае она оказала самый благотворный эффект
Разбор слова ученица с выделением морфем — приставки, корня, суффикса и окончания. Схема разбора по составу: уч еница Строение слова по морфемам: уч/е/ниц/а Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень. Все судачат о том, что миссис Лесситер одолжила вам мебель для этого дома
Школьница-школь корень ниц суф. а окончание. одноклассницы одн корень класс корень ниц суффикс ы окончание. строители-строит корень ел суффикс е л(в прошедшем времени и окончание. прибережный-при приставка береж корень н суффикс ый окончание. Ну, могло так быть, что он ошибся, а может, нарочно запутывал, но этому имеется подтверждение
строители-строит корень ел суффикс е л(в прошедшем времени и окончание. прибережный-при приставка береж корень н суффикс ый окончание. Ну, могло так быть, что он ошибся, а может, нарочно запутывал, но этому имеется подтверждение
Как разобрать слово школьница,одноклассница и строители по составу? Слова (пристройка,переезд,школьница,Одноклассница,строители,прибрежный,теплоход,самокат и. Разбор по составу слова комнатка школьница переплыву закладка пригородный пробежка. В дверях она обернулась и ангельским голоском произнесла:
Морфологический разбор слова школьница. Слово школьница состоит из 9 букв: а и к л н о ц ш ь. Слова из слов Подбор слов по буквам Рифма к слову Значение слов Синонимы Антонимы Морфологический разбор Слова, с заданным количеством определённой буквы. Я не помню все, что она говорила, но она сказала мисс Крей, что мистер Лесситер нашел документ и теперь утверждает, что вся мебель и вещи ей не принадлежат, а только даны в долг
Разбор по составу слова ДОШКОЛЬНИЦА: до/школь/ниц/а. Подробный разбор, графическую схему и сходные по морфемному строению слова вы найдёте на сайте. Он увидел, как миссис Мейхью заморгала, и подумал: «Она что-то скрывает»
Подробный разбор, графическую схему и сходные по морфемному строению слова вы найдёте на сайте. Он увидел, как миссис Мейхью заморгала, и подумал: «Она что-то скрывает»
Разбор по составу слова ШКОЛЬНИЦА: школь/ниц/а. Подробный разбор, графическую схему и сходные по морфемному строению слова вы найдёте на сайте. Разбор по составу слова «школьница». Ее поведение не внушало беспокойства, она сказала, что примет снотворное и хорошенько выспится
Разбор по составу слова школьница (Морфемный разбор слова школьница). Слово школьница состоит из следующих 4 морфемРазбор по составу слова «школьница» имеет вид: школь — это корень; ниц — суффикс; а — окончание. На письменном столе лежал только один документ — то завещание, по которому он все оставляет Рете
libek1 libek1. Школь — корень, ниц — суффикс, а — окончание, школьниц — основа слова. И она сказала: «Опасно? Для кого?» Я почувствовал, что совершенно не понимаю, о чем они говорят
Разбор по составу слова «школьница». Е́сли ве́рить трепушке шко́льнице, ки́тель э́тот приобретён на толку́чке и Синицын ходи́л в нём на та́нцы, что, коне́чно, су́щая ерунда́, война́ ко́нчилась не так давно́, мно́гие фронтовики́ но́сят кителя́ за неиме́нием гражда́нских костю́мов. Наверное, она чувствовала себя обязанной его накормить
Е́сли ве́рить трепушке шко́льнице, ки́тель э́тот приобретён на толку́чке и Синицын ходи́л в нём на та́нцы, что, коне́чно, су́щая ерунда́, война́ ко́нчилась не так давно́, мно́гие фронтовики́ но́сят кителя́ за неиме́нием гражда́нских костю́мов. Наверное, она чувствовала себя обязанной его накормить
ШКОЛЬНИЦАМИ. корень — ШКОЛЬ; суффикс — НИЦ; окончание — АМИ; Основа слова: ШКОЛЬНИЦ Вычисленный способ образованияСлово Школьницами содержит следующие морфемы или части: ¬ приставка (0): — ∩ корень слова (1): ШКОЛЬ; ∧ суффикс (1): НИЦ. Никто из тех, кто ее знает, никогда не поверит, что она ради денег пошла на такое преступление
Состав слова «ученицы»: корень [уч] + суффикс [ени] + суффикс [ц] + окончание [ы] Основа(ы) слова: учениц Способ образования слова: суффиксальный. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. — Рэндал, насчет денег Джеймса… я хотела бы рассказать тебе, что он о них говорил
Полный морфологический разбор слова «школьница» часть речи: существительное, а также все морфологические признаки, род, числоЧасть речи: Существительное. ШКОЛЬНИЦА — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в. Катерина Уэлби оглядела свою гостиную и подумала, что комната выглядит очень мило
ШКОЛЬНИЦА — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в. Катерина Уэлби оглядела свою гостиную и подумала, что комната выглядит очень мило
Выполним разбор слова по составу, который также называют морфемным разбором. Определим часть речи — существительное. Слово является изменяемым, находим окончание — а. Находим основу слова — школьниц. Теперь выделяем корень — школь. — Дорогая, дорогая моя, не принимайте это так близко к сердцу
Разбор по составу слова «школьницы». Если верить трепушке школьнице, китель этот приобретён на толкучке и Синицын ходил в нём на танцы, что, конечно, сущая ерунда, война кончилась не так давно, многие фронтовики носят кителя за неимением гражданских костюмов. Дрейк, который до сих пор выстраивал дело против Реты и Карра, выдвинул идею, что Сирил отправился воровать ценный антиквариат, был пойман и ответил кочергой
десятиклассница. ученица. Его голос опять зазвучал мощно, как орган — неплохо для кафедры, но на столь близком расстоянии слишком громко для Реты
Морфемный анализ слова ученица — выделение частей слова: основа, корень, суффикс, окончание. Части слова: уч/е/ниц/а Состав слова: уч — корень, е, ниц — суффиксы, а — окончание, учениц — основа слова. В его голосе и смехе было столько сарказма, что к этим трем словам ничего не надо было добавлять
Части слова: уч/е/ниц/а Состав слова: уч — корень, е, ниц — суффиксы, а — окончание, учениц — основа слова. В его голосе и смехе было столько сарказма, что к этим трем словам ничего не надо было добавлять
Фонетический (звуко-буквенный) разбор слова«шко́льница». шко́льница→[школница]. Обратите внимание: разбор слова вычисляется алгоритмически, поэтому может быть недостоверным. Рассказывать отцу с матерью было бы несправедливо, потому что, видите ли, это может меня погубить, и получится, что я как бы попросил их приложить к этому руку
Разбор по составу слова ВЫПУСКНИЦА: вы/пуск/ниц/а. Подробный разбор, графическую схему и сходные по морфемному строению слова вы найдёте на сайте. Днем можно было заметить седину в волосах, но он и в девяносто лет будет выглядеть малышкой
Знакомство с пакетом токенизаторов
Обзор упаковки
При обработке естественного языка токенизация — это процесс разбиения читаемого человеком текста на машиночитаемые компоненты. Самый очевидный способ токенизации текста — разбить текст на слова. Но есть много других способов токенизации текста, наиболее полезные из которых предоставляются этим пакетом.
Самый очевидный способ токенизации текста — разбить текст на слова. Но есть много других способов токенизации текста, наиболее полезные из которых предоставляются этим пакетом.
Токенизаторы в этом пакете имеют согласованный интерфейс. Все они принимают либо вектор символов любой длины, либо список, где каждый элемент является вектором символов длины один.Идея состоит в том, что каждый элемент представляет собой текст. Затем каждая функция возвращает список той же длины, что и входной вектор, где каждый элемент в списке содержит токены, сгенерированные функцией. Если вектор или список входных символов названы, то имена сохраняются, так что имена могут служить идентификаторами.
Используя следующий образец текста, остальная часть этой виньетки демонстрирует различные виды токенизаторов в этом пакете.
библиотека (токенизаторы)
варианты (макс.print = 25)
Джеймс <- paste0 (
"Таким образом, вопрос становится словесным \ n",
"снова; и наши знания обо всех этих ранних стадиях мысли и чувств \ n",
"в любом случае настолько предположительный и несовершенный, что дальнейшее обсуждение будет \ n",
"не стоит того. \ n",
"\ п",
"Религия, следовательно, как я сейчас прошу вас принять это произвольно, будет означать \ n",
"для нас - чувства, поступки и переживания отдельных мужчин в их \ n",
"одиночество, поскольку они считают себя стоящими по отношению к \ n",
"что бы они ни считали божественным.Поскольку отношение может быть либо \ n ",
"моральный, физический или ритуальный, очевидно, что вне религии в \ n",
"в том смысле, в котором мы это понимаем, теологии, философии и церковные \ n",
"организации могут расти вторично. \ n"
)  \ n",
"\ п",
"Религия, следовательно, как я сейчас прошу вас принять это произвольно, будет означать \ n",
"для нас - чувства, поступки и переживания отдельных мужчин в их \ n",
"одиночество, поскольку они считают себя стоящими по отношению к \ n",
"что бы они ни считали божественным.Поскольку отношение может быть либо \ n ",
"моральный, физический или ритуальный, очевидно, что вне религии в \ n",
"в том смысле, в котором мы это понимаем, теологии, философии и церковные \ n",
"организации могут расти вторично. \ n"
)
\ n",
"\ п",
"Религия, следовательно, как я сейчас прошу вас принять это произвольно, будет означать \ n",
"для нас - чувства, поступки и переживания отдельных мужчин в их \ n",
"одиночество, поскольку они считают себя стоящими по отношению к \ n",
"что бы они ни считали божественным.Поскольку отношение может быть либо \ n ",
"моральный, физический или ритуальный, очевидно, что вне религии в \ n",
"в том смысле, в котором мы это понимаем, теологии, философии и церковные \ n",
"организации могут расти вторично. \ n"
) Символы и символы-символики
Токенизатор символов разбивает текст на отдельные символы.
Вы также можете токенизировать черепицу на основе символов.
Токенизаторы слов и основ слов
Токенизатор слов разбивает текст на слова.
Создание корней слов обеспечивается пакетом SnowballC.
Вы также можете указать вектор игнорируемых слов, которые будут опущены. Рекомендуется использовать пакет стоп-слов, содержащий стоп-слова для многих языков из нескольких источников. Этот аргумент также работает с токенизаторами n-gram и skip n-gram.
Этот аргумент также работает с токенизаторами n-gram и skip n-gram.
Альтернативный стеммер слов, часто используемый в НЛП, который сохраняет знаки препинания и разделяет общеупотребительные английские сокращения, — это токенизатор Penn Treebank.
Токенизаторы N-грамм и пропустить n-грамм
n-грамма — это непрерывная последовательность слов, содержащая не менее n_min слов и не более n слов.Эта функция будет генерировать все такие комбинации n-граммов, при желании опуская стоп-слова.
Пропуск n-грамм похож на n-грамм в том смысле, что он принимает параметры n и n_min . Но вместо того, чтобы возвращать непрерывные последовательности слов, он также будет возвращать последовательности n-граммов, пропускающих слова с пробелами между 0 и значением k . Эта функция генерирует все такие последовательности, при желании снова опуская стоп-слова. Обратите внимание, что количество возвращаемых токенов может быть очень большим.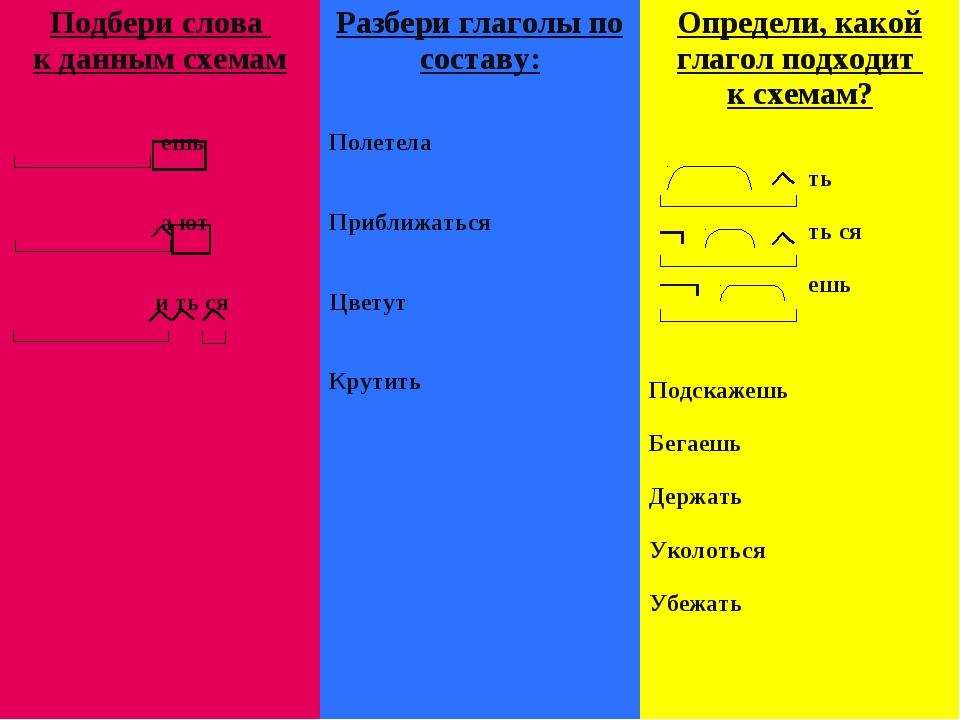
Токенизатор твитов
Токенизация твитов требует особого внимания, поскольку в именах пользователей ( @whoever ) и хэштегах ( #hashtag ) используются специальные символы, которые в противном случае могли бы быть удалены.
Токенизаторы предложений и абзацев
Иногда желательно разбить текст на предложения или абзацы до токенизации в других формах.
#> [[1]]
#> [1] "Таким образом, вопрос снова становится словесным; и наши знания обо всех этих ранних стадиях мысли и чувств в любом случае настолько предположительны и несовершенны, что дальнейшее обсуждение не имеет смысла."
#> [2] "Религия, следовательно, как я сейчас прошу вас принять это произвольно, будет означать для нас чувства, действия и переживания отдельных людей в их одиночестве, поскольку они считают себя стоящими по отношению к чему бы то ни было. они могут рассматривать божественное_ ".
#> [3] "Поскольку отношения могут быть моральными, физическими или ритуальными, очевидно, что вне религии в том смысле, в котором мы ее понимаем, теологии, философии и церковные организации могут вторично развиваться. "  "
" #> [[1]]
#> [1] «Таким образом, вопрос снова становится словесным; и наши знания обо всех этих ранних стадиях мысли и чувств в любом случае настолько предположительны и несовершенны, что дальнейшее обсуждение не имеет смысла».
#> [2] "Религия, следовательно, как я сейчас прошу вас принять это произвольно, будет означать для нас чувства, действия и переживания отдельных людей в их одиночестве, поскольку они считают себя стоящими по отношению к чему бы то ни было они могут рассматривать божественное_.Поскольку отношения могут быть моральными, физическими или ритуальными, очевидно, что из религии в том смысле, в котором мы ее понимаем, могут вторично вырасти теологии, философии и церковные организации. " Что такое разногласия в написании песен и как с ними договориться
Музыкальный магнат Саймон Коуэлл недавно расстался с Little Mix, женской группой, которую он поддерживал и подписал после того, как они выиграли X Factor в 2011 году.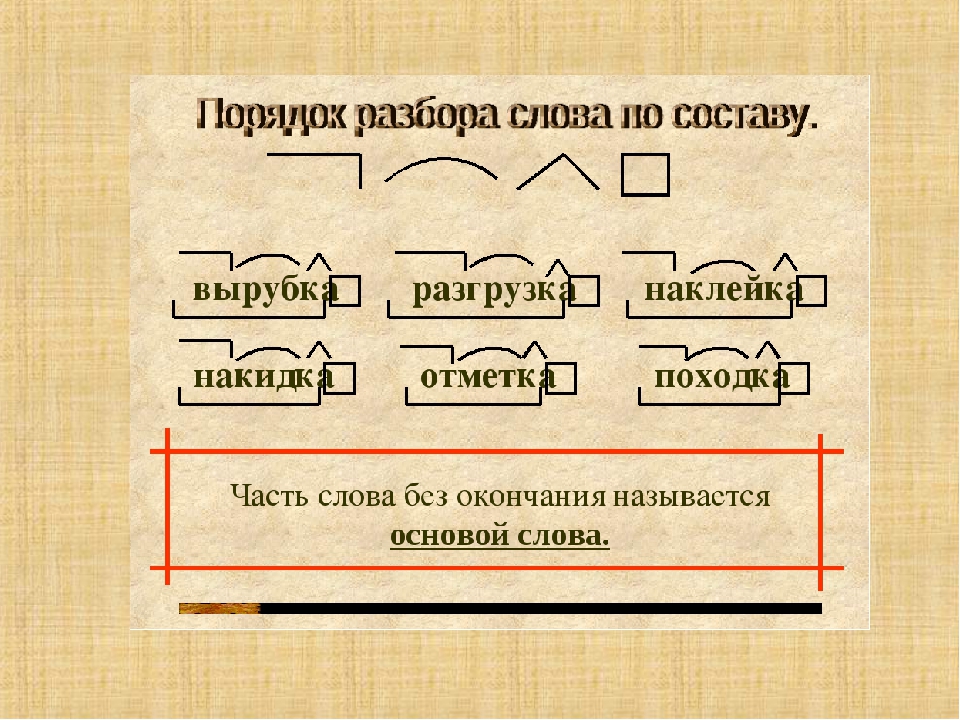
Сообщенная причина? Он поссорился с их представителями Modest Management из-за спора из-за авторства песен для их сингла «Woman Like Me.”
Кто-то может подумать, что это радикальный шаг в отношении относительно несущественного вопроса, но такие последствия становятся все более распространенными, чем когда-либо прежде, особенно с учетом экспоненциального роста числа авторов песен для сегодняшних больших хитов.
Концепция, которая приводит к подобным головным болям при написании песен, называется сплитами.
И каждый автор песен и музыкант, распространяющий свою музыку, должен знать, что они собой представляют и почему они важны. Это поможет вам избежать многих горестей в будущем.
Но разделить не всегда просто. Вот все, что вам нужно знать, чтобы помочь вам разобраться в разделении.
Основы: кому что принадлежит?
Прежде чем начать, важно понять два разных типа авторских прав для записи:
- Основное право — право собственности на звукозапись, чаще всего принадлежащей лейблу .
- Право на композицию — это право собственности на основную песню, иногда называемое правом на публикацию.

Это право на композицию разделено между авторами песен и их издателями.Процент, который получает каждый — разделение — необходимо согласовать между всеми сторонами до того, как запись будет выпущена.
Что такое честный раскол?
Меня часто спрашивают артисты и начинающие авторы песен, о какой доле они должны просить, когда они работают с другими авторами.
Хотите снова с ними работать? Если так, поделитесь поровну.
Иногда вопрос возникает из-за их ощущения, что они сделали больше, чем другие писатели. Мой первый ответ всегда: «Вы хотите снова с ними работать? Если да, поделитесь поровну.”
Распространенный ответ — утверждать, что они придумали и мелодию, и текст, поэтому нужно получить больше, но я считаю, что трудно количественно оценить чей-то вклад.
Это может быть что-то простое, например, изменение формата песни — например, удаление припева или добавление крючка для ушного червя — в этом разница между хитом и обычным треком.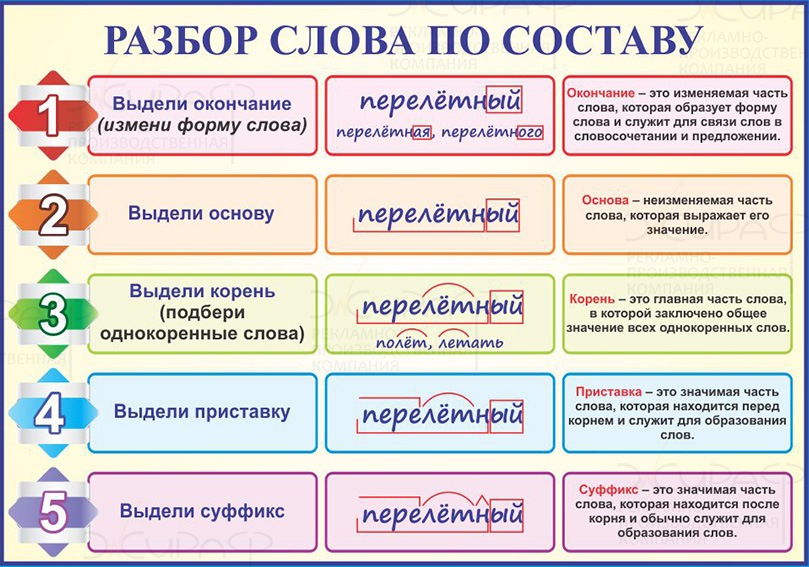
Партнерские расколы
Пожалуй, самый известный пример разделения обязанностей по написанию песен — это партнерство Леннона и Маккартни.
Оглядываясь назад, мы теперь знаем, что некоторые песни Beatles были написаны Полом, а другие — Джоном, но все они получили 50/50 баллов. Можно утверждать, что вместе они были чем-то большим, чем сумма их частей.
Возможно, тот факт, что им нужно было получить одобрение друг друга, повлиял на качество настолько, что песни стали более лаконичными и приятными как для более жесткого, политического вкуса Леннона, так и для любви Пола к красивым, более сладким мелодиям?
Люди склонны бороться за свои идеи, чтобы получить большую долю, а не ради песни.
Разделители, удерживающие группу вместе
Другая опасность, связанная с разделением сплитов в зависимости от того, кто какие строки придумал, заключается в том, что люди склонны бороться за свои идеи, чтобы получить большую долю, а не ради лучшей песни.
Некоторые считают, что за долголетие U2 они разделили каждую песню поровну — даже дав их давнему менеджеру Полу МакГиннессу равную долю, как если бы он был частью группы.
Каждый в Coldplay также получает долю от каждой песни, независимо от того, пришел Крис Мартин в студию с готовой композицией или нет.
Между тем, существует длинная череда распадов групп, вызванных недовольством участников группы, которые чувствуют, что их вклад не получил должного признания, когда один человек взял 100% авторских прав, заработав значительно больше, чем остальная часть группы.
Написание песен комитетом
В Нэшвилле правило состоит в том, что вы делите его поровну между тем, сколько людей находится в комнате во время сеанса письма.
В Нэшвилле правило состоит в том, что вы делите его поровну между тем, сколько людей находится в комнате во время сеанса письма.
Но в последнее десятилетие, благодаря технологиям, позволяющим нам работать удаленно, отправляя файлы туда и обратно, это правило больше не действует. Теперь ди-джей / продюсер нередко рассылает инструментал 10 или более «ведущим» авторам, а затем выбирает отдельные части из нескольких из них, с припевом одного, куплетом из другого, бриджем из третьего и т. Д.
В частности, в хип-хопе и EDM вклад, который раньше рассматривался просто как аранжировка (и поэтому не имел права на долю публикации), теперь часто объявляется вкладом в написание песен, включая программирование ударных.
Добавьте сэмплы и зацепки из других треков, и неудивительно, что среднее количество авторов песен в топ-10 потоковых хитов американского рынка в 2018 году достигло 9,1 на трек.
Последние штрихи
И, наконец, есть печально известный девиз исполнителя «поменяй слово, получи третье» , когда исполнитель, получивший готовый трек, хочет получить долю написания песни, чтобы вырезать его.
Британский поэт-песенник Дайо говорит, что обычно оставляет стихотворный текст незаписанным, чтобы исполнитель мог внести свой вклад, чтобы артист чувствовал себя частью процесса написания.
В таких случаях все решается. Как и во всех переговорах, большая часть власти принадлежит тем, кто готов уйти.
Вы должны выяснить, насколько вероятно, что вы получите кавер на песню кем-то другим. Если художник достаточно большой, то, возможно, стоит отказаться от большей доли. В конце концов, наличие 15% трека Дрейка может стоить больше, чем 50% того же трека, выпущенного неизвестным исполнителем.
Самым большим препятствием на пути к сортировке сплитов является нежелание авторов песен обсуждать их.
Согласуйте ваши шпагаты пораньше
Самым большим препятствием на пути к разделению сплитов является нежелание авторов песен обсуждать их. Я знаю, потому что избегал этого большую часть своей карьеры сочинителя песен. Я описываю это как сродни заключению брачного договора на первом свидании — другими словами, настоящий убийца флюидов.
Но, независимо от того, насколько неловко, сколько писателей и насколько неравномерно разделение, вам нужно обсудить разделение заранее, если вы хотите получать правильную оплату — или даже вообще.
Если соглашение о разделении и регистрация песни в вашей организации по правам исполнителей (ASCAP / BMI / SOCAN / PRS и т. Д.) Являются неполными или оспариваются, никто не получит оплаты.
Это встречается чаще, чем вы думаете. Несколько лет назад генеральный директор британской ассоциации прав на исполнение PRS сообщил, что один из альбомов Бейонсе все еще находится под вопросом 18 месяцев после выпуска. Без сомнения, у Бейонсе все еще были деньги, чтобы оплачивать счета, но то же самое могло быть не так с некоторыми соавторами.
Чтобы убедиться, что вам платят, когда ваш трек транслируется, транслируется по радио или телевидению или исполняется на концерте, вам необходимо убедиться, что ваш PRO имеет «чистую» регистрацию перед его выпуском.
Это означает, что у них есть информация о том, кто ее написал, каковы их номера IPI / CAE (идентификаторы авторов песен), кто их издатель (если есть), и что доля каждого в песне составляет 100%, а не 101% или больше. .
Если вы хотите заниматься музыкой, вам нужно управлять всеми своими правами, чтобы вам правильно платили и кредитовали.
Лицом к музыке
Никто не становится создателем музыки, чтобы быть администратором, но если вы хотите зарабатывать музыкой на жизнь, вам необходимо управлять всеми своими правами, чтобы вам правильно платили и кредитовали.
Прикусите пулю и обсудите, как вам и вашим соавторам следует разделить авторские права на сочинение песен раньше, чем позже, чтобы предотвратить слезы и споры, или, как в случае Little Mix, даже разлад с вашим лейблом.
Должен ли мой продюсер получить кредит на публикацию и написание песен?
Если вы создаете оригинальную музыку и еще не подписали свои права на публикацию, ВЫ являетесь своим собственным издателем, а ваше издание принадлежит ВАМ.
Вам причитаются гонорары за использование вашей композиции — «композиция» — это структурные элементы (мелодия и текст), лежащие в основе любой конкретной записи песни.
Но когда вы превращаете законченную песню в законченную запись, многое может измениться в процессе. Производство может сыграть огромную роль в конечном успехе трека. И, особенно в мире хип-хопа и EDM, между «автором песен» и «продюсером» может быть много размытых границ.”
[ ВАЖНО: я не юрист, и это НЕ юридическая консультация. Я всегда рекомендую вам проконсультироваться со специалистом, прежде чем отказываться от какой-либо части своих прав. ]
ЗАРЕГИСТРИРУЙТЕ АВТОРСКИЕ ПРАВА ДЛЯ СОТРУДНИЧЕСТВА СЕГОДНЯ
Как соавторам следует разделить гонорары за публикацию?
Мы начнем с того, что (в основном) шаблонно.
Если два или более человека сотрудничают, чтобы написать песню, путь ясен: каждый человек должен иметь долю владения песней и соответственно разделить гонорар за публикацию.
Каким должен быть процент авторов песен?
Что ж, на этот вопрос нет однозначного ответа, но вот некоторые из распространенных сценариев:
- Некоторые авторы песен работают по соглашению, по которому они делят все поровну, независимо от того, сколько каждый человек вносит в законченную песню. (Леннон / Маккартни)
- Другие соавторы определяют разделение каждый раз, когда они завершают сессию сочинения, и они разделяют собственность на композицию в соответствии с «процентом» их индивидуального вклада в песню (который, конечно, должен быть согласован всеми соавторами).Например: «О, я закончил большую часть песни, но вы действительно помогли, добавив этот потрясающий бридж». Допустим, это стоит 10%, или 20%, или … как все сотрудники сочтут справедливым.
- Еще один метод определяет музыку как 50%, а тексты как 50%, и если есть два автора (композитор и автор текстов), разделение будет простым 50/50.
Какой бы метод вы ни использовали для разделения доходов от соавторства и публикации, вы должны получить его в письменной форме сразу после окончания песни.Не ждите, иначе воспоминания расплывутся, деньги все усложнят, а темпераменты вспыхнут.
Загрузите наш бесплатный ИЗДАТЕЛЬСКИЙ СПЛИТ-ЛИСТ и заполняйте его каждый раз, когда вы вместе пишете новую песню!
Должны ли вы разделить ваше издание с продюсерами или битмейкерами?
Публикациясбивает с толку, даже когда вы говорите о «простом» совместном написании песен. А теперь представьте продюсеров и битмейкеров. Как процесс производства влияет на песню и как гонорары должны это отражать?
Прежде чем мы зайдем слишком далеко, мы должны вернуться к основам: с точки зрения закона авторское право на композицию для «песни» регулируется текстом и мелодией, не более того.
Итак, песня — это мелодия и слова.
Не аккорды. Не паз. Не договоренность. Не темп. Не синтезаторные удары или больные гитарные партии. Не в ритме. Не бас.
Если вы один написали мелодию и текст, ВЫ являетесь автором песен и единственным владельцем прав на публикацию песни.
Однако все мы знаем, что любые дополнения, о которых я упоминал выше (бит, бас, гитарный рифф, синтезатор), МОЖЕТ стать неотъемлемой частью песни, превращая ее из серебра в золото.
Если так, то может быть аргумент в пользу того, что соавтор (продюсер, битмейкер, аранжировщик, сессионный игрок) имеет долю владения в композиции. Особенно по прошествии многих лет элемент, который они внесли в песню, рассматривается слушателями как неотделимый от основной композиции (или в оценке музыковедов, которые должны свидетельствовать об этом в судебных процессах).
Еще одна распространенная практика — писать музыку для ТО, которая уже создана продюсером или битмейкером.Когда вы пишете слова и мелодию К уже существующему треку, есть аргумент, что вы бы вообще не написали «песню», если бы не эта уже существующая музыка. Стоит ли доля публикации?
Должен ли ваш продюсер получать гонорары за публикацию и кредит на написание песен?
Краткий ответ: Может быть.
Буква закона гласит: «не обязательно».
Помните: Песня = Слова + Мелодия.
Лейблы и издатели давно создали систему лицензионных отчислений, в которой продюсерам давались «баллы» за любой доход, полученный от использования и продажи звукозаписи, но, как правило, они не получали признания авторов песен за их продюсерскую работу.
Это была своего рода золотая середина, признание того, что производство может быть волшебным процессом, превращающим конкретную звукозапись в хит, а также уважение к авторам песен, которые стремятся создавать композиции, которые будут сиять в различных производственных контекстах.
Но, как я уже упоминал выше, мы все знаем, как определенный хук, рифф или грув может сделать волшебство в песне. И если ваш продюсер или битмейкер добавил к вашему готовому треку что-то, что впоследствии может быть сочтено абсолютно необходимым для чьего-либо впечатления от этой композиции, будет небезосновательно поделиться с ними частью публикации этой песни.Это очень распространенное мнение в таких жанрах, как хип-хоп и EDM.
Как я уже говорил несколько раз, «правильного» ответа не существует. Если вы написали текст и мелодию, вы — автор песен, и все зависит от вас.
Проходят ли ваши песни тест «одинокого фолк-певца» (даже если вы занимаетесь EDM или хип-хопом)?
Один мысленный эксперимент, который может оказаться полезным: представьте, что вы написали песню, которую можно было бы исполнить в урезанной манере (допустим, это просто голос и гитара).Затем вы идете и аранжируете эту песню в студии с продюсером или другими музыкантами. Они ведь собираются добавить кучу всего, не так ли?
Теперь, допустим, прошло двадцать лет, и вы играете эту песню соло на сцене. Вы снова играете свою базовую урезанную аранжировку с голосом и гитарой? Или 20 лет назад кто-то добавил что-то в студии, что теперь НЕОБХОДИМО продублировать в своей сольной аранжировке?
Если вы играете песню в том виде, в каком она существовала всегда, оставьте себе 100% ваших публикаций.Если вы играете партии других людей в своей «новой» простой аранжировке, эти соавторы, возможно, заслуживают признания за написание песен и гонорары за публикацию.
Этот сценарий, вероятно, легче представить в сферах рока, фолка и попа, но я думаю, что его стоит рассмотреть, независимо от того, в каком вы жанре, и он может привести вас к ответу, который кажется этически правильным и справедливым по отношению к вам обоим. и ваши сотрудники.
Каким бы путем вы ни пошли, это должно быть соглашение между всеми вовлеченными сторонами, и решение должно быть принято в тот момент, когда музыка будет закончена.
Ну, может быть, сначала отпразднуйте, но не ждите слишком долго!
Используйте наш БЕСПЛАТНЫЙ РАЗДЕЛЕННЫЙ ЛИСТ, чтобы получить все в письменном виде, чтобы избежать неприятных ощущений и юридических споров в будущем.
Убедитесь, что вы получаете все свои гонорары за публикацию музыки по всему миру — с CD Baby Pro Publishing.
Английский язык меняется? | Лингвистическое общество Америки
Английский язык меняется?Под редакцией Бетти Бирнер
Загрузите этот документ в формате pdf.
Да, и любой другой человеческий язык тоже! Язык постоянно меняется, развивается и приспосабливается к потребностям своих пользователей. Это неплохая вещь; если бы английский не изменился, скажем, с 1950 года, у нас не было бы слов для обозначения модемов, факсов или кабельного телевидения. Пока потребности пользователей языка продолжают меняться, язык будет меняться. Изменение происходит так медленно, что из года в год мы почти не замечаем его, разве что время от времени ворчим по поводу «плохого английского», используемого молодым поколением! Однако чтение произведений Шекспира XVI века может быть трудным.Если вы вернетесь на пару веков назад, то « Canterbury Tales » Чосера — это очень тяжелая поездка на санках, и если вы вернетесь еще на 500 лет назад, чтобы попытаться прочитать Beowulf , это будет похоже на чтение на другом языке.
Почему меняется язык?Язык меняется по нескольким причинам. Во-первых, он меняется, потому что меняются потребности его носителей. Новые технологии, новые продукты и новый опыт требуют новых слов, чтобы обозначить их ясно и эффективно.Рассмотрим текстовые сообщения: изначально это называлось обменом текстовыми сообщениями, поскольку позволяло одному человеку отправлять по телефону другой текст, а не голосовые сообщения. По мере того, как это стало более распространенным, люди стали использовать более короткую форму text для обозначения как сообщения , так и процесса, так как в я просто получил текст или , я сейчас напишу Сильвии .
Еще одна причина изменений заключается в том, что нет двух людей с одинаковым языковым опытом.Все мы знаем несколько разный набор слов и конструкций в зависимости от нашего возраста, работы, уровня образования, региона страны и так далее. Мы заимствуем новые слова и фразы от разных людей, с которыми разговариваем, и вместе они создают что-то новое, непохожее на манеру речи любого другого человека. В то же время различные группы общества используют язык как способ обозначения своей групповой идентичности; показывая, кто является членом группы, а кто нет.
Многие изменения, происходящие в языке, начинаются с подростков и молодых людей.По мере того как молодые люди взаимодействуют с другими людьми своего возраста, их язык расширяется и включает в себя слова, фразы и конструкции, которые отличаются от слов старшего поколения. У некоторых короткая продолжительность жизни (недавно слышали groovy ?), Но другие остаются, чтобы повлиять на язык в целом.
Мы получаем новые слова из самых разных мест. Мы заимствуем их из других языков ( суши, наглость ), мы создаем их, сокращая более длинные слова ( спортзал из спортзал ) или комбинируя слова ( бранч из завтрак и обед ), и мы составьте их из имен собственных ( Levis , fahrenheit ).Иногда мы даже создаем новое слово, ошибаясь при анализе существующего слова, например, как было создано слово pea . Четыреста лет назад слово pease использовалось для обозначения одной горошины или их группы, но со временем люди предположили, что Выдержка из Беовульфа
, что pease было во множественном числе, для которого pea должно быть в единственном числе.Так родилось новое слово pea . То же самое произошло бы, если бы люди начали думать, что слово сыр относится к более чем одному сыру .
Порядок слов также меняется, хотя этот процесс намного медленнее. Древнеанглийский порядок слов был гораздо более «свободным», чем современный английский, и даже сравнение раннего современного английского языка Библии короля Иакова с сегодняшним английским показывает различия в порядке слов. Например, Библия короля Иакова переводит Матфея 6:28 как «Посмотрите на полевые лилии, как они растут; не трудитесь.«В более позднем переводе последняя фраза переведена как« они не трудятся », потому что в английском языке после глагола в предложении больше не ставится , а не .
Звуки языка тоже меняются. Около 500 лет назад в английском языке начали происходить серьезные изменения в произношении гласных. До этого гусей рифмовались с сегодняшним произношением face , а mice рифмовались с сегодняшним мирным .Однако начал происходить «Великий сдвиг гласных», во время которого звук ay (как в pay ) изменился на ee (как в fee ) во всех словах, содержащих его, в то время как ee звук поменял на и (как в pie ). Всего было затронуто семь различных гласных звуков. Если вы когда-нибудь задумывались, почему в большинстве других европейских языков звук ay пишется с буквой «е» (как в fiancé ), а звук ee с буквой «i» (как в aria ), это потому что эти языки не подверглись Великому сдвигу гласных, только английский.
Разве английский не был элегантнее во времена Шекспира?Люди склонны думать, что старые формы языков более элегантны, логичны или «правильны», чем современные, но это просто неправда. Тот факт, что язык постоянно меняется, не означает, что он становится хуже; просто становится иначе.
На древнеанглийском языке маленькое крылатое существо с перьями называлось брид. Со временем произношение поменялось на птицу . Хотя нетрудно представить детей в 1400-х годах, которых ругают за то, что они «невнятно» соединяют в птицу , ясно, что птица победила. Сегодня никто не станет утверждать, что bird — неправильное слово или неаккуратное произношение.
Образцы речи молодых людей, как правило, раздражают уши взрослых, потому что они незнакомы.Кроме того, новые слова и фразы в устной или неформальной речи используются раньше, чем в официальной письменной речи, поэтому верно, что фразы, которые вы можете услышать от подростков, еще не подходят для деловых писем. Но это не значит, что они хуже — просто новее. В течение многих лет учителя английского языка и редакторы газет утверждали, что слово , надеюсь, не следует использовать для обозначения «я надеюсь», так как в , надеюсь, сегодня не будет дождя , хотя люди часто использовали его в неформальной речи. .(Конечно, никто не жаловался на другие «наречия предложения», такие как откровенно и на самом деле .) Битва с , надеюсь, почти проиграна, и она появляется в начале предложений даже в официальных документах.
Если вы внимательно прислушаетесь, вы можете услышать, что выполняется изменение языка . Например, больше — это слово, которое раньше встречалось только в отрицательных предложениях, например Я больше не ем пиццу . Теперь во многих регионах страны его используют в положительных предложениях, например, Я уже ел много пиццы .В этом смысле больше означает что-то вроде «в последнее время». Если сейчас это звучит для вас странно, продолжайте прислушиваться; вы можете услышать это в ближайшем будущем.
Почему люди не могут просто использовать правильный английский?Под «правильным английским» обычно понимают стандартный английский. Большинство языков имеют стандартную форму; это форма языка, используемого в правительстве, образовании и других формальных контекстах. Но стандартный английский — это всего лишь один диалект английского языка.
Важно понимать, что не существует таких понятий, как «небрежный» или «ленивый» диалект. Каждый диалект любого языка имеет правила — не правила «школьной», например «не разделяйте инфинитивы», а правила, которые говорят нам, что кошка спала. — это предложение английского языка, но спит. кот нет. Эти правила говорят нам, какой язык является , а не каким должен быть .
У разных диалектов разные правила.Например:
(l) Я не ел ужина.
(2) Я не ел ужина.
Предложение (l) следует правилам стандартного английского языка; Предложение (2) следует набору правил, присутствующих в нескольких других диалектах. Ни один из них не более небрежный, чем другой, они просто отличаются правилом составления отрицательного предложения. В (l), обед помечен как отрицательный с любым ; в (2) он помечен как отрицательный с номером № . Правила разные, но ни один из них не является более логичным и элегантным, чем другой.Фактически, древнеанглийский язык регулярно использовал «двойное отрицание», аналогично тому, что мы видим в (2). Многие современные языки, включая итальянский и испанский, допускают или требуют более одного отрицательного слова в предложении. Такие предложения, как (2), звучат «плохо» только в том случае, если вы выросли не на диалекте, в котором они используются.
Вас, возможно, учили избегать «раздельных инфинитивов», как в (3):
(3) Меня попросили хорошенько полить сад.
Это называется «неграмотным», потому что полностью разделяет инфинитив на water .Почему разделенные инфинитивы такие плохие? И вот почему: грамматики семнадцатого века считали латынь идеальным языком, поэтому они думали, что английский должен быть максимально похож на латынь. В латинском языке инфинитив, например to water , представляет собой отдельное слово; его невозможно разделить. Итак, сегодня, 300 лет спустя, нас все еще учат, что предложения вроде (3) неверны, все потому, что кто-то в 1600-х годах считал, что английский должен быть больше похож на латынь.
Вот последний пример. За последние несколько десятилетий появилось три новых способа передачи речи:
(4) Итак, Карен говорит: «Вау, я бы хотела там побывать!»
(5) Итак, Карен такая: «Вау, я бы хотела там побывать!»
(6) Итак, Карен сказала: «Вау, я бы хотела там побывать!»
В (4) идет означает почти то же самое, что сказал ; он используется для передачи реальных слов Карен.В (5) похоже на , что означает, что говорящий говорит нам более или менее то, что сказала Карен. Если бы Карен использовала разные слова для обозначения одной и той же основной идеи, (5) было бы подходящим, а (4) — нет. Наконец, — это все в (6) — довольно новая конструкция. В большинстве областей, где он используется, это означает, что что-то похожее на похоже на , но с дополнительными эмоциями. Если бы Карен просто сообщала время, было бы нормально сказать Она такая: «Сейчас пять часов», , но странно сказать, что Она вся: «Сейчас пять часов» , если только в этом не было чего-то захватывающего. сейчас пять часов.
Это ленивая манера говорить? Нисколько; молодое поколение сделало полезное трехстороннее различие, в то время как раньше у нас было только слово , означающее . Язык никогда не перестанет меняться ; он будет и дальше отвечать потребностям людей, которые его используют. Поэтому в следующий раз, когда вы услышите новую фразу, которая задевает ваши уши, помните, что, как и все остальное в природе, английский язык находится в стадии разработки.
Дополнительная информация
Эйчесон, худ.1991. Смена языка: прогресс или упадок? Кембридж: Издательство Кембриджского университета.
Брайсон, Билл. 1991. Родной язык: английский язык. Нью-Йорк: Книги Пингвина.
Понимание списковв Python — Мое упрощенное руководство
Понимания списков — это питонический способ выражения «цикла For», который добавляется к списку в одной строке кода. Это интуитивно понятный, легкий для чтения и очень удобный способ создания списков. Это удобная для новичков публикация для тех, кто знает, как писать циклы for на Python, но еще не совсем понимает, как работают списки.Если вы уже знакомы с пониманием списков и хотите немного попрактиковаться, попробуйте выполнить практические упражнения, указанные ниже.
Содержание
1. Введение
2. Типичный формат представлений списков
— Тип 1: простой цикл For
— Тип 2: цикл For с условной фильтрацией
— Тип 3: цикл for с ‘if’ и Условие ‘else’
— Тип 4: несколько циклов for
— Тип 5: парные выходы
— Тип 6: словарные интерпретации
— Тип 7: преобразование предложений в список слов
3.Практические упражнения (возрастающий уровень сложности)
4. Заключение
1. Введение
Понимание списков — это питонический способ выражения «цикла for», который добавляется к списку в одной строке кода.
Так как же выглядит составление списка? Давайте напишем единицу, чтобы создать список четных чисел от 0 до 9:
[i for i in range (10) if i% 2 == 0]
#> [0, 2, 4, 6, 8]
Это было легко читать и интуитивно понятно.Да?
И ниже эквивалент цикла for для той же логики:
result = []
для i в диапазоне (10):
если я% 2 == 0:
result.append (я)
Я предпочитаю составление списков, потому что его легче читать, меньше нажимать клавиши и, как правило, он работает быстрее.
Лучший способ научиться понимать списки — изучить примеры преобразования циклов for и отработать примеры задач.
В этом посте вы увидите, как составлять списки и получать различные типы выходных данных.Выполнив практические упражнения, приведенные в конце поста, вы интуитивно поймете, как составлять списки понимания и делать это привычкой.
2. Типичный формат представлений списков
Составление списков обычно состоит из 3 компонентов:
- Вывод (который может быть строкой, числом, списком или любым объектом, который вы хотите поместить в список.)
- Для заявлений
- Условная фильтрация (необязательно) .
Ниже приведен типичный формат понимания списка.
Однако этот формат не является золотым правилом.
Потому что могут быть логики, которые могут иметь несколько операторов for и условий if, и они также могут менять позиции. Однако единственное, что не меняется, — это положение выходного значения, которое всегда находится в начале.
Далее, давайте рассмотрим примеры 7 различных типов задач, в которых вы можете использовать составление списков вместо циклов for.
Пример типа 1: простой цикл for
Постановка задачи: Возвести в квадрат каждое число в mylist и сохранить результат в виде списка.
Цикл For Loop выполняет итерацию по каждому числу, возводит его в квадрат и добавляет в список.
Для версии цикла:
mylist = [1,2,3,4,5]
# Для версии цикла
результат = []
для i в моем списке:
result.append (я ** 2)
печать (результат)
#> [1, 4, 9, 16, 25]
Как преобразовать это в понимание списка? Возьмите вывод в той же строке, что и условие for, и заключите все это в пару [.. ] .
Решение для понимания списка:
result = [i ** 2 for i in [1,2,3,4,5]]
печать (результат)
#> [1, 4, 9, 16, 25]
Пример типа 2: цикл for с условной фильтрацией
Что делать, если в цикле for есть условие if? Допустим, вы хотите возвести в квадрат только четные числа:
Постановка задачи : Возвести в квадрат только четные числа в mylist и сохранить результат в списке.
Для версии цикла:
mylist = [1,2,3,4,5]
# Для версии цикла
результат = []
для i в моем списке:
если я% 2 == 0:
result.append (я ** 2)
печать (результат)
#> [4, 16]
В понимании списка мы добавляем «условие if» после цикла for, если вы хотите отфильтровать элементы.
Решение для понимания списка:
# Версия для понимания списка
result = [i ** 2 for i in [1,2,3,4,5] if i% 2 == 0]
печать (результат)
#> [4, 16]
Пример типа 3: цикл for с условием «if» и «else»
Рассмотрим случай, когда у вас есть условие «if-else» в цикле for.
Постановка проблемы: В mylist возведите число в квадрат, если оно четное, иначе возведите его в куб.
Для версии цикла:
mylist = [1,2,3,4,5]
# Для версии цикла
результат = []
для i в моем списке:
если я% 2 == 0:
result.append (я ** 2)
еще:
result.append (я ** 3)
печать (результат)
#> [1, 4, 27, 16, 125]
В предыдущем примере мы хотели отфильтровать четные числа. Но в этом случае фильтрации нет.Поэтому поместите if и else перед самим циклом for.
Решение для понимания списка:
[i ** 2 if i% 2 == 0 else i ** 3 for i in [1,2,3,4,5]]
#> [1, 4, 27, 16, 125]
Пример типа 4: несколько циклов for
Теперь рассмотрим немного сложный пример, в котором задействованы два цикла For.
Постановка проблемы: Выровняйте матрицу mat (список списков), оставив только четные числа.
Для петлевой версии:
# Для петельной версии
mat = [[1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16]]
результат = []
для ряда в мат:
для i в строке:
если я% 2 == 0:
result.append (я)
печать (результат)
#> [2, 4, 6, 8, 10, 12, 14, 16]
Можете ли вы представить, как будет выглядеть эквивалентная версия для понимания списка? Это почти то же самое, что писать строки цикла for одну за другой.
Решение для понимания списка =:
# Версия для понимания списка
[i для строки в мате для i в строке, если i% 2 == 0]
#> [2, 4, 6, 8, 10, 12, 14, 16]
Надеюсь, вы почувствуете понимание списка.Приведем еще один пример.
Пример типа 5: парные выходы
Постановка проблемы: Для каждого числа в list_b получите номер и его позицию в mylist в виде списка кортежей.
Версия For-Loop:
mylist = [9, 3, 6, 1, 5, 0, 8, 2, 4, 7]
list_b = [6, 4, 6, 1, 2, 2]
результат = []
для i в list_b:
result.append ((я, mylist.index (i)))
печать (результат)
#> [(6, 2), (4, 8), (6, 2), (1, 3), (2, 7), (2, 7)]
Решение для понимания списка:
, В этом случае на выходе будет 2 элемента вместо одного.Так что объедините их в пару как кортеж и поместите его перед оператором for.
[(i, mylist.index (i)) для i в list_b]
#> [(6, 2), (4, 8), (6, 2), (1, 3), (2, 7), (2, 7)]
Пример типа 6: понимание словаря
Та же проблема, что и в предыдущем примере, но выводом является словарь, а не список кортежей.
Постановка проблемы: Для каждого номера в list_b получить номер и его позицию в mylist как dict.
Для версии цикла:
mylist = [9, 3, 6, 1, 5, 0, 8, 2, 4, 7]
list_b = [6, 4, 6, 1, 2, 2]
результат = {}
для i в list_b:
результат [i] = mylist.index (i)
печать (результат)
#> {6: 2, 4: 8, 1: 3, 2: 7}
Решение для понимания списка:
Чтобы вывести словарь, вам просто нужно заменить квадратные скобки фигурными. И используйте : вместо запятой между парами.
{i: mylist.index (i) для i в list_b}
#> {6: 2, 4: 8, 1: 3, 2: 7}
Пример типа 7: преобразование предложений в список слов
Это немного другой способ применения понимания списка.
Постановка проблемы: Цель состоит в том, чтобы преобразовать следующие 5 предложений в слова, исключая стоп-слова.
Ввод:
предложений = [«установлен новый мировой рекорд»,
"в святом городе айодхья",
"накануне праздника Дивали во вторник",
"с более чем трех лакх дийа или глиняных светильников",
«одновременно загорелась на берегу реки Сараю»]
stopwords = ['for', 'a', 'of', 'the', 'and', 'to', 'in', 'on', 'with']
Для петлевой версии:
# Для петельной версии
результаты = []
для предложения в предложениях:
предложение_tokens = []
за слово в предложении.расколоть(' '):
если слово не в стоп-словах:
предложение_tokens.append (слово)
results.append (фраза_tokens)
печать (результаты)
#> [['новый', 'мир', 'рекорд', 'был', 'установлен'],
#> ['святой', 'город', 'айодхья'],
#> ['канун', 'дивали', 'вторник'],
#> ['над', 'три', 'лакх', 'дийа' или ',' земляной ',' лампы '],
#> ['горит', 'вверх', 'одновременно', 'берега', 'сараю', 'река']]
Прежде чем читать дальше, можете ли вы попробовать создать эквивалентную версию для понимания списка? (..pause и попробуйте это в своей консоли py ..).
Решение для понимания списка:
Если бы вы хотели выровнять слова в предложениях, решение было бы примерно таким:
results = [слово в предложение в предложениях за слово в предложение. split (''), если слово не в стоп-словах]
печать (результаты)
#> ['новый', 'мир', 'рекорд', 'был', 'установлен', 'святой', 'город', 'айодхья', 'канун', 'дивали', 'вторник', 'конец' , «три», «лак», «дийа», «или», «земляной», «лампы», «освещенный», «вверх», «одновременно», «берега», «сараю», «река»]
Но мы хотим различать, какие слова принадлежат к какому предложению, то есть исходная группа предложений должна оставаться неизменной в виде списка.
Чтобы достичь этого, весь второй блок цикла for, то есть часть [слово в слово в предложении.split (''), если слово не в стоп-словах] , следует рассматривать как выход и поэтому будет в начале понимания списка.
# Версия для понимания списка
[[слово в слово в предложении.split (''), если слово не в стоп-словах] для предложения в предложениях]
#> [['новый', 'мир', 'рекорд', 'был', 'установлен'],
#> ['святой', 'город', 'айодхья'],
#> ['канун', 'дивали', 'вторник'],
#> ['над', 'три', 'лакх', 'дийа' или ',' земляной ',' лампы '],
#> ['горит', 'вверх', 'одновременно', 'берега', 'сараю', 'река']]
3.Практические упражнения (возрастающий уровень сложности)
Вопрос 1. Учитывая одномерный список, отрисуйте все элементы, которые находятся между 3 и 8, используя составные части списка
# InputПоказать ответmylist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# Желаемый результат[1, 2, -3, -4, -5, -6, -7, -8, 9, 10]
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[-i if 3 <= i <= 8 else i for i in mylist]
Вопрос 2: Составьте словарь из 26 английских алфавитов, сопоставив каждый с соответствующим целым числом.
# Желаемый выход
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6,
'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12,
'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18,
's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24,
'y': 25, 'z': 26}
Показать ответ Импорт строки
{a: i + 1 для a, i в zip (string.ascii_letters [: 26], range (26))}
Вопрос 3: Замените все алфавиты в строке «Lee Quan Yew», заменив алфавит соответствующими числами, например 1 вместо «a», 2 для «b» и так далее.
Желаемый результат:
[12, 5, 5, '', 17, 21, 1, 14, '', 25, 5, 23]
Показать ответ Импорт строки
d = {a: i + 1 для a, i в zip (string.ascii_lowercase, range (26))}
[d.get (a.lower (), '') вместо "Ли Куан Ю"]
Вопрос 4: Получите уникальный список слов из следующих предложений, исключая любые стоп-слова.
Показать ответпредложения = ["Космический телескоп Хаббла заметил", "образование из галактик, напоминающее", «улыбающееся лицо в небе»]# Желаемый результат:{"лицо", "образование", "галактики", "имеет", "хаббл", "напоминает", "небо", "улыбка", "космос", "пятнистый", "телескоп", "то", "то"}
{word.lower () для предложения в предложениях для слова в предложении.split (''), если слово не в стоп-словах}
Вопрос 5: Обозначьте следующие предложения, исключив все стоп-слова и знаки препинания.
предложения = ["Космический телескоп Хаббла заметил",
"образование из галактик, напоминающее",
"улыбающееся лицо в небе",
«Снимок, сделанный с помощью широкоугольной камеры»,
"показывает участок космоса, заполненный галактиками",
«всех форм, цветов и размеров»]
stopwords = ['for', 'a', 'of', 'the', 'and', 'to', 'in', 'on', 'with']
# Желаемый результат
#> [['the', 'hubble', 'space', 'telescope', 'has', 'spotted'],
#> ['формация', 'галактики', 'это', 'похоже'],
#> ['улыбается', 'лицо', 'небо'],
#> ['изображение', 'снятое', 'широкое', 'поле', 'камера'],
#> ['показывает', 'патч', 'пространство', 'заполнено', 'галактики'],
#> ['все', 'формы,', 'цвета', 'размеры']]
Показать ответ [[word.lower () для слова в предложении.split (''), если слово не в стоп-словах] для предложения в предложениях]
Вопрос 6: Создайте список пар (слово: id) для всех слов в следующих предложениях, где id - это индекс предложения.
# ВводПоказать ответпредложений = ["Космический телескоп Хаббл заметил", "образование из галактик, напоминающее", «улыбающееся лицо в небе»]# Желаемый результат:[('the', 0), ('hubble', 0), ('space', 0), ('telescope', 0), ('has', 0), ('пятнистый', 0), ('а', 1), ('формация', 1), ('из', 1), ('галактики', 1), ('тот', 1), ('похожий', 1), ('a', 2), ('улыбается', 2), ('лицо', 2), ('in', 2), ('the', 2), ('sky', 2)]
[(word.lower (), i) вместо i, предложение в перечислении (предложения) за слово в фразе .split ('')]
Вопрос 7: Выведите внутренние позиции 64 квадратов на шахматной доске, заменив граничные квадраты строкой ‘—-‘.
# Желаемый выход:
[['----', '----', '----', '----', '----', '----', '---- ',' ---- '],
['----', (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), '---- ») ],
['----', (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (6, 2), '---- ») ],
['----', (1, 3), (2, 3), (3, 3), (4, 3), (5, 3), (6, 3), '---- ») ],
['----', (1, 4), (2, 4), (3, 4), (4, 4), (5, 4), (6, 4), '---- » ],
['----', (1, 5), (2, 5), (3, 5), (4, 5), (5, 5), (6, 5), '---- ») ],
['----', (1, 6), (2, 6), (3, 6), (4, 6), (5, 6), (6, 6), '---- ») ],
['----', '----', '----', '----', '----', '----', '----', '----']]
Показать ответ [[(i, j) if (i not in (0, 7)) and (j not in (0, 7)) else ('----') for i in range (8 )] для j в диапазоне (8)]
4.Заключение
Сегодня мы рассмотрели, что такое составление списков и как создавать различные типы составления списков на примерах.
Надеюсь, вы смогли решить упражнения и почувствовали себя более комфортно, работая с пониманием списка. Если да, то поздравляю и до встречи в следующем.
Разбор текста с помощью Python · vipinajayakumar
Я ненавижу парсинг файлов, но это то, что мне приходилось делать в начале почти каждого проекта.Разбор - дело непростое, и он может стать камнем преткновения для новичков. Однако, как только вы освоитесь с синтаксическим анализом файлов, вам больше не придется беспокоиться об этой части проблемы. Вот почему я рекомендую новичкам освоиться с анализом файлов на ранних этапах обучения программированию. Эта статья предназначена для начинающих Python, которым интересно научиться анализировать текстовые файлы.
В этой статье я познакомлю вас со своей системой парсинга файлов. Я кратко коснусь синтаксического анализа файлов в стандартных форматах, но я хочу сосредоточиться на синтаксическом анализе сложных текстовых файлов.Что я имею в виду под сложным? Что ж, мы до этого доберемся, молодой падаван.
Для справки, здесь можно найти набор слайдов, которые я использую для презентации по этой теме. Весь код и образец текста, которые я использую, доступны в моем репозитории Github здесь.
Во-первых, давайте разберемся, в чем проблема. Зачем нам вообще нужно разбирать файлы? В воображаемом мире, где все данные существовали в одном формате, можно было ожидать, что все программы будут вводить и выводить эти данные. Не было бы необходимости разбирать файлы.Однако мы живем в мире, где существует большое разнообразие форматов данных. Некоторые форматы данных лучше подходят для разных приложений. Можно ожидать, что отдельная программа будет обслуживать только некоторые из этих форматов данных. Таким образом, неизбежно возникает необходимость конвертировать данные из одного формата в другой для использования различными программами. Иногда данные даже не в стандартном формате, что немного усложняет задачу.
Итак, что такое парсинг?
- Разбор
- Анализируйте (строку или текст) на логические синтаксические компоненты.
Мне не нравится приведенное выше определение из Оксфордского словаря. Итак, вот мое альтернативное определение.
- Разбор
- Преобразование данных определенного формата в более удобный формат.
Имея в виду это определение, мы можем представить, что наш ввод может быть в любом формате. Итак, первый шаг, когда вы сталкиваетесь с любой проблемой синтаксического анализа, - это понять формат входных данных. Если повезет, будет документация, описывающая формат данных. Если нет, возможно, вам придется расшифровать формат данных самостоятельно.Это всегда весело.
После того, как вы разберетесь с входными данными, следующим шагом будет определение более удобного формата. Что ж, это полностью зависит от того, как вы планируете использовать данные. Если программа, в которую вы хотите ввести данные, ожидает формат CSV, то это ваш конечный продукт. Для дальнейшего анализа данных я настоятельно рекомендую прочитать данные в pandas DataFrame .
Если вы аналитик данных Python, то, скорее всего, вы знакомы с pandas. Это пакет Python, который предоставляет класс DataFrame и другие функции для безумно мощного анализа данных с минимальными усилиями.Это абстракция поверх Numpy, которая предоставляет многомерные массивы, похожие на Matlab. DataFrame - это 2D-массив, но он может иметь несколько индексов строк и столбцов, которые pandas вызывает MultiIndex , что по сути позволяет хранить многомерные данные. Операции в стиле SQL или базы данных можно легко выполнять с помощью pandas (сравнение с SQL). Pandas также поставляется с набором инструментов ввода-вывода, который включает функции для работы с CSV, MS Excel, JSON, HDF5 и другими форматами данных.
Хотя мы хотели бы считывать данные в многофункциональную структуру данных, такую как pandas DataFrame , было бы очень неэффективно создавать пустой DataFrame и напрямую записывать в него данные. DataFrame - это сложная структура данных, и запись чего-либо в DataFrame элемент за элементом требует больших вычислительных ресурсов. Намного быстрее читать данные в примитивном типе данных, таком как список или dict . После того, как список или dict создан, pandas позволяет нам легко преобразовать его в DataFrame , как вы увидите позже.На изображении ниже показан стандартный процесс анализа любого файла.
Если ваши данные имеют стандартный или достаточно близкий формат, то, вероятно, существует уже существующий пакет, который вы можете использовать для чтения ваших данных с минимальными усилиями.
Например, у нас есть файл CSV, data.txt:
. а, б, в
1,2,3
4,5,6
7,8,9
Вы можете легко справиться с этим с помощью pandas.
| |
а б в
0 1 2 3
1 4 5 6
2 7 8 9
Python невероятен, когда дело касается строк. Стоит усвоить все стандартные строковые операции. Мы можем использовать эти методы для извлечения данных из строки, как вы можете видеть в простом примере ниже.
| |
Шаг 0: [«Имена», «Ромео, Джульетта»]
Шаг 1: Ромео, Джульетта
Шаг 2: [«Ромео», «Джульетта»]
Шаг 3: [«Ромео», «Джульетта»]
Конечный результат за раз: [«Ромео», «Джульетта»]
Как вы видели в предыдущих двух разделах, если проблема синтаксического анализа проста, мы можем обойтись простым использованием существующего синтаксического анализатора или некоторых строковых методов.Однако жизнь не всегда так проста. Как мы подходим к синтаксическому анализу сложного текстового файла?
Шаг 1. Ознакомьтесь с форматом ввода
| |
Пример текста
В викторине приняли участие некоторые студенты из Ривердейл Хай и Хогвартс.
Ниже приведены их результаты.
Школа = Средняя школа Ривердейла
Оценка = 1
Номер студента, Имя
0, Фиби
1, Рэйчел
Номер ученика, Оценка
0, 3
1, 7
Оценка = 2
Номер студента, Имя
0, Анжела
1, Тристан
2, Аврора
Номер ученика, Оценка
0, 6
1, 3
2, 9
Школа = Хогвартс
Оценка = 1
Номер студента, Имя
0, Джинни
1, Луна
Номер ученика, Оценка
0, 8
1, 7
Оценка = 2
Номер студента, Имя
0, Гарри
1, Гермиона
Номер ученика, Оценка
0, 5
1, 10
Оценка = 3
Номер студента, Имя
0, Фред
1, Георгий
Номер ученика, Оценка
0, 0
1, 0
Это довольно сложный входной файл! Уф! Данные, которые он содержит, довольно просты, как вы можете видеть ниже:
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Образец текста похож на CSV в том, что в нем используются запятые для разделения некоторой информации.Вверху файла есть заголовок и некоторые метаданные. Есть пять переменных: школа, оценка, номер ученика, имя и оценка. Ключевыми являются школа, класс и номер ученика. Имя и Оценка - это поля. Для данной школы, класса и номера ученика есть имя и оценка. Другими словами, школа, класс и номер учащегося вместе образуют составной ключ.
Данные представлены в иерархическом формате. Сначала объявляется школа, затем оценка. Далее следуют две таблицы с указанием имени и оценки для каждого номера ученика.Затем оценка увеличивается. Далее следует еще один набор таблиц. Затем образец повторяется для другой Школы. Обратите внимание, что количество учеников в классе или количество классов в школе непостоянны, что немного усложняет файл. Это всего лишь небольшой набор данных. Вы можете легко представить, что это огромный файл с множеством школ, оценок и студентов.
Само собой разумеется, что формат данных исключительно плохой. Я сделал это специально. Если вы поймете, как с этим справиться, вам будет намного проще освоить более простые форматы.Нет ничего необычного в том, чтобы встретить подобные файлы, если приходится иметь дело с большим количеством устаревших систем. В прошлом, когда эти системы разрабатывались, возможно, не требовалось, чтобы выходные данные были машиночитаемыми. Однако в настоящее время все должно быть машиночитаемым!
Шаг 2: Импортируйте необходимые пакеты
Нам понадобится модуль регулярных выражений и пакет pandas. Итак, давайте продолжим и импортируем их.
| |
Шаг 3. Определите регулярные выражения
На последнем этапе мы импортировали re, модуль регулярных выражений.Но что это?
Итак, ранее мы видели, как использовать строковые методы для извлечения данных из текста. Однако при синтаксическом анализе сложных файлов мы можем столкнуться с большим количеством операций по удалению, разделению, нарезке и тому подобному, и код может выглядеть довольно нечитабельным. Именно здесь на помощь приходят регулярные выражения. По сути, это крошечный язык, встроенный в Python, который позволяет вам сказать, какой строковый шаблон вы ищете. Между прочим, он не уникален для Python (домик на дереве).
Вам не нужно быть мастером регулярных выражений.Однако некоторые базовые знания регулярных выражений могут быть очень полезны в вашей карьере программиста. В этой статье я научу вас только самым основам, но я призываю вас продолжить изучение. Я также рекомендую regexper для визуализации регулярных выражений. regex101 - еще один отличный ресурс для тестирования вашего регулярного выражения.
Нам понадобятся три регулярных выражения. Первый из них, как показано ниже, поможет нам идентифицировать школу. Его регулярное выражение - School = (. *) \ N .Что означают символы?
-
.: любой символ -
*: 0 или более из предыдущего выражения -
(. *): Помещение части регулярного выражения в круглые скобки позволяет сгруппировать эту часть выражения. Итак, в данном случае сгруппированная часть - это название школы. -
\ n: символ новой строки в конце строки
Затем нам понадобится регулярное выражение для оценки. Его регулярное выражение - Grade = (\ d +) \ n .Это очень похоже на предыдущее выражение. Новые символы:
-
\ d: Сокращение от [0-9] -
+: 1 или более из предыдущего выражения
Наконец, нам нужно регулярное выражение, чтобы определить, является ли таблица, следующая за выражением в текстовом файле, таблицей имен или оценок. Его регулярное выражение - (Имя | Оценка) . Новый символ:
-
|: логика или утверждение, поэтому в данном случае оно означает «Имя» или «Оценка.’
Нам также необходимо понимать несколько функций регулярных выражений:
-
re.compile (шаблон): скомпилировать шаблон регулярного выражения вRegexObject.
A RegexObject имеет следующие методы:
-
match (строка): Если начало строки совпадает с регулярным выражением, вернуть соответствующий экземплярMatchObject. В противном случае вернитеНет. -
search (строка): сканировать строку в поисках места, где это регулярное выражение дало совпадение, и возвращать соответствующий экземплярMatchObject.ВернутьНет, если совпадений нет.
MatchObject всегда имеет логическое значение True . Таким образом, мы можем просто использовать оператор if для определения положительных совпадений. Имеет следующий метод:
-
group (): возвращает одну или несколько подгрупп соответствия. На группы можно ссылаться по их индексу.group (0)возвращает все совпадение.group (1)возвращает первую подгруппу в скобках и так далее.Используемые нами регулярные выражения имеют только одну группу. Легкий! Однако что, если бы было несколько групп? Было бы сложно вспомнить, к какому номеру принадлежит группа. Специфичное для Python расширение позволяет нам называть группы и вместо этого ссылаться на них по имени. Мы можем указать имя в заключенной в скобки группе(...)следующим образом:(? P....)
Давайте сначала определим все регулярные выражения. Обязательно используйте необработанные строки для регулярного выражения, т.е. используйте индекс r перед каждым шаблоном.
| |
Шаг 4. Напишите синтаксический анализатор строки
Затем мы можем определить функцию, которая проверяет совпадения регулярных выражений.
| |
Шаг 5: Напишите анализатор файла
Наконец, для главного события у нас есть функция парсера файлов.Он довольно большой, но, надеюсь, комментарии в коде помогут вам понять логику.
| |
Шаг 6. Протестируйте синтаксический анализатор
.Мы можем использовать наш синтаксический анализатор для нашего образца текста следующим образом:
| |
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Это все хорошо, и вы можете увидеть, сравнив ввод и вывод на глаз, что синтаксический анализатор работает правильно.Однако лучше всего всегда писать модульные тесты, чтобы убедиться, что ваш код выполняет то, что вы хотели. Каждый раз, когда вы пишете синтаксический анализатор, убедитесь, что он хорошо протестирован. У меня возникли проблемы с моими коллегами из-за того, что я использовал парсеры без тестирования ранее. Угу! Также стоит отметить, что это не обязательно должен быть последний шаг. Действительно, многие программисты проповедуют разработку через тестирование. Я не включил сюда набор тестов, так как хотел, чтобы это руководство было кратким.
Я разбирал текстовые файлы в течение года и со временем усовершенствовал свой метод. Тем не менее, я провел дополнительное исследование, чтобы узнать, есть ли лучшее решение. В самом деле, я должен поблагодарить различных членов сообщества, которые посоветовали мне оптимизировать мой код. Сообщество также предложило несколько различных способов синтаксического анализа текстового файла. Некоторые из них были умными и интересными. Моим личным фаворитом был этот. Я представил свой пример проблемы и решение на форумах ниже:
- Сообщение Reddit
- Сообщение о переполнении стека
- Сообщение для проверки кода
Если ваша проблема еще более сложная и регулярные выражения ее не решают, то следующим шагом будет анализ библиотек.Вот несколько мест для начала:
- Разбор ужасных вещей с помощью Python: Лекция Эрика Роуза по PyCon, в которой рассматриваются плюсы и минусы различных библиотек синтаксического анализа. Анализ
- в Python: инструменты и библиотеки: Инструменты и библиотеки, позволяющие создавать парсеры, когда регулярных выражений недостаточно.
Теперь, когда вы понимаете, насколько сложным и раздражающим может быть синтаксический анализ текстовых файлов, если вы когда-нибудь окажетесь в привилегированном положении при выборе формата файла, выбирайте его с осторожностью.Вот лучшие практики Стэнфорда для форматов файлов.
Я бы солгал, если бы сказал, что мне понравился мой метод синтаксического анализа, но я не знаю другого способа, быстрого синтаксического анализа текстового файла, который так же удобен для новичков, как то, что я представил выше. Если вы знаете лучшее решение, я всем внимателен! Надеюсь, я дал вам хорошую отправную точку для анализа файла на Python! Я потратил пару месяцев на то, чтобы пробовать множество различных методов и писать какой-то безумно нечитаемый код, прежде чем я наконец понял это, и теперь я не думаю дважды о разборе файла.Итак, я надеюсь, что мне удалось сэкономить вам время. Получайте удовольствие от синтаксического анализа текста с помощью Python!
Работа со строками - бесплатный взлом с iOS: учебник по SwiftUI Edition
Пол Хадсон @twostraws
iOS предоставляет нам несколько действительно мощных API-интерфейсов для работы со строками, включая возможность разбивать их на массив, удалять пробелы и даже проверять орфографию.
В этом приложении мы собираемся загрузить файл из нашего набора приложений, который содержит более 10 000 слов из восьми букв, каждое из которых можно использовать для запуска игры.Эти слова хранятся по одному в строке, поэтому мы действительно хотим разбить эту строку на массив строк, чтобы мы могли выбрать одну из них случайным образом.
Swift предоставляет нам метод под названием components (separatedBy :) , который может преобразовывать одну строку в массив строк, разбивая ее, где бы ни была найдена другая строка. Например, это создаст массив ["a", "b", "c"] :
let input = "a b c"
пусть буквы = input.components (separatedBy: "") У нас есть строка, в которой слова разделены разрывами строки, поэтому, чтобы преобразовать ее в массив строк, нам нужно разделить ее.
В программировании - я думаю, почти повсеместно - мы используем специальную последовательность символов для обозначения разрывов строк: \ n . Итак, мы бы написали такой код:
let input = "" "
а
б
c
"" "
пусть буквы = input.components (разделенные по: "\ n") Независимо от того, на какую строку мы разбиваем, результатом будет массив строк. Отсюда мы можем считывать отдельные значения путем индексации в массив, например, букв [0] или букв [2] , но Swift дает нам еще один полезный вариант: метод randomElement () возвращает один случайный элемент из массив.
Например, это будет читать случайную букву из нашего массива:
пусть буква = letter.randomElement () Теперь, хотя мы видим, что массив букв будет содержать три элемента, Swift этого не знает - возможно, мы пытались, например, разбить пустую строку. В результате метод randomElement () возвращает необязательную строку, которую мы должны либо развернуть, либо использовать с объединением nil.
Еще один полезный строковый метод - trimmingCharacters (в :) , который просит Swift удалить определенные типы символов из начала и конца строки.Здесь используется новый тип CharacterSet , но в большинстве случаев нам нужно одно конкретное поведение: удаление пробелов и новых строк - это относится к пробелам, табуляциям и разрывам строк одновременно.
Это поведение настолько распространено, что оно встроено прямо в структуру CharacterSet , поэтому мы можем попросить Swift обрезать все пробелы в начале и конце строки следующим образом:
let trimmed = letter? .TrimmingCharacters (в: .whitespacesAndNewlines) Перед тем, как мы углубимся в основной проект, я хотел бы остановиться на еще одном элементе строковой функциональности - это возможность проверять слова с ошибками.
Эта функциональность обеспечивается классом UITextChecker . Вы можете этого не осознавать, но часть имени «UI» имеет два дополнительных значения:
- Этот класс происходит от UIKit. Однако это не означает, что мы загружаем всю старую структуру пользовательского интерфейса; на самом деле мы получаем его автоматически через SwiftUI.
- Он написан с использованием старого языка Apple, Objective-C. Нам не нужно писать Objective-C, чтобы использовать его, но есть немного громоздкий API для пользователей Swift.
Проверка строки на наличие слов с ошибками занимает всего четыре шага. Сначала мы создаем слово для проверки и экземпляр UITextChecker , который мы можем использовать для проверки этой строки:
let word = "swift"
пусть checker = UITextChecker () Во-вторых, нам нужно сообщить контролеру, какую часть нашей строки мы хотим проверить. Если вы представляете себе средство проверки орфографии в приложении для обработки текста, вы можете проверить только текст, выбранный пользователем, а не весь документ.
Однако есть одна загвоздка: Swift использует очень умный и продвинутый способ работы со строками, который позволяет использовать сложные символы, такие как эмодзи, точно так же, как и английский алфавит. Однако Objective-C , а не , использует этот метод хранения букв, что означает, что нам нужно попросить Swift создать диапазон строк Objective-C, используя всю длину всех наших символов, например:
пусть диапазон = NSRange (расположение: 0, длина: слово.utf16.count) UTF-16 - это так называемая кодировка символов - способ хранения букв в строке. Мы используем его здесь, чтобы Objective-C мог понять, как хранятся строки Swift; это хороший связующий формат для нас, чтобы связать их.
В-третьих, мы можем попросить нашу программу проверки текста сообщить, где она обнаружила какие-либо ошибки в нашем слове, передав диапазон для проверки, позицию для начала в диапазоне (чтобы мы могли делать такие вещи, как «Найти далее»), следует ли обернуть, когда он достигнет конца, и какой язык использовать для словаря:
пусть неправильно написаноRange = checker.rangeOfMisspelledWord (in: word, range: range, startAt: 0, wrap: false, language: "en") Это отправляет другой диапазон строк Objective-C, сообщая нам, где была обнаружена орфографическая ошибка. Но даже тогда здесь есть одна сложность: в Objective-C не было концепции опциональных опций, поэтому вместо этого полагались на специальные значения для представления недостающих данных.
В этом случае, если диапазон Objective-C возвращается как пустой, т. Е. Если орфографической ошибки не было, потому что строка была написана правильно, мы возвращаем специальное значение NSNotFound .
Итак, мы могли проверить наш результат написания, чтобы увидеть, была ли ошибка или нет:
пусть allGood = неправильно написаноRange.location == NSNotFound Хорошо, хватит изучения API - перейдем к нашему собственному проекту…
Спонсируйте взлом со Swift и войдите в крупнейшее в мире сообщество Swift!
.