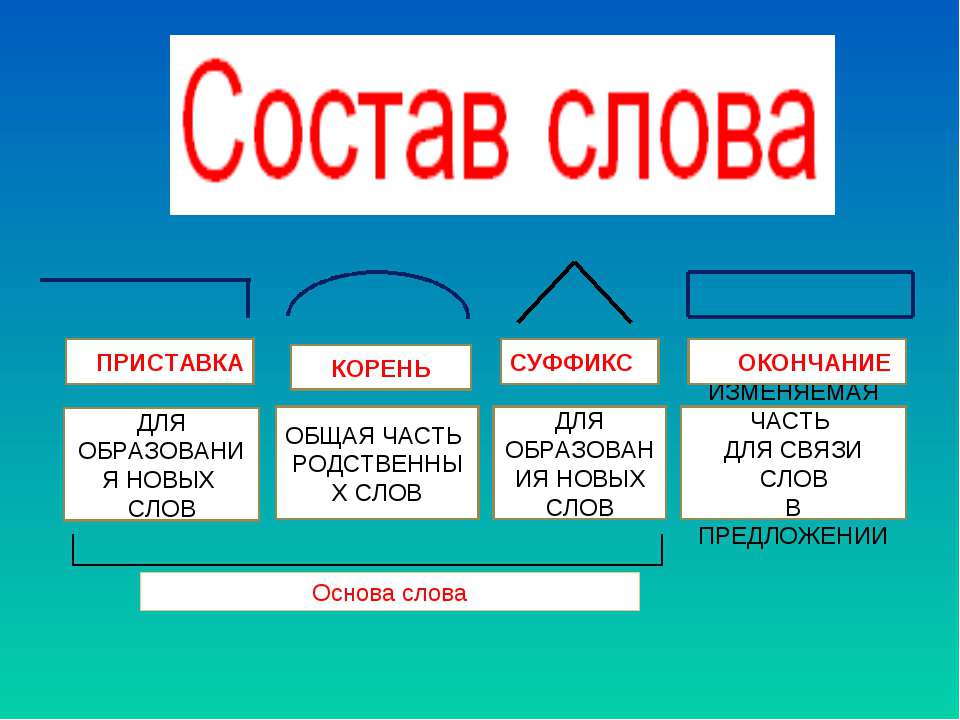
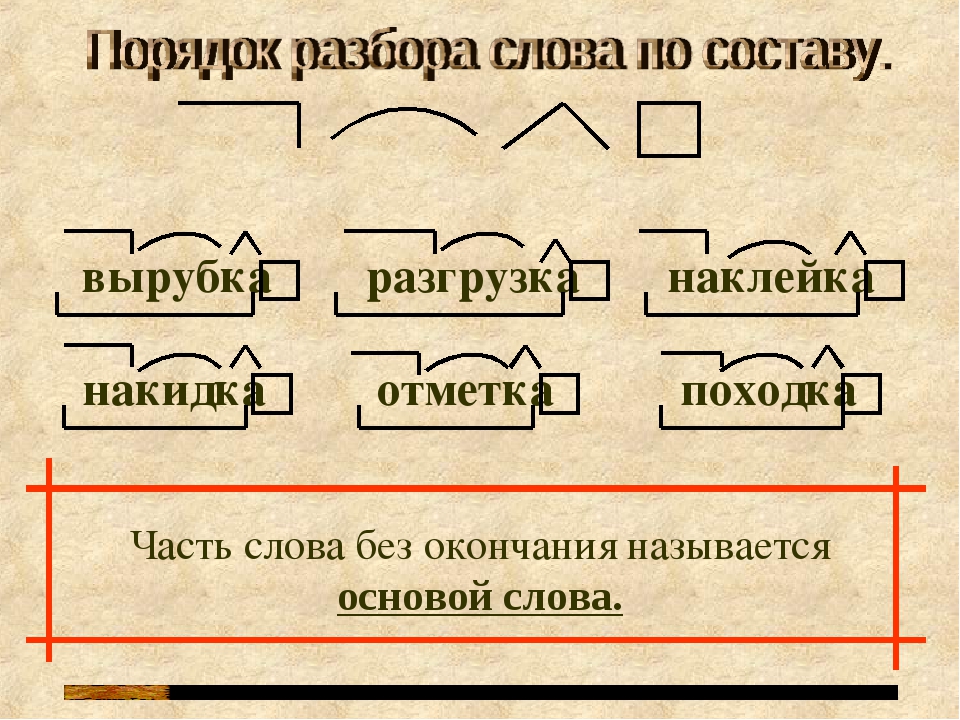
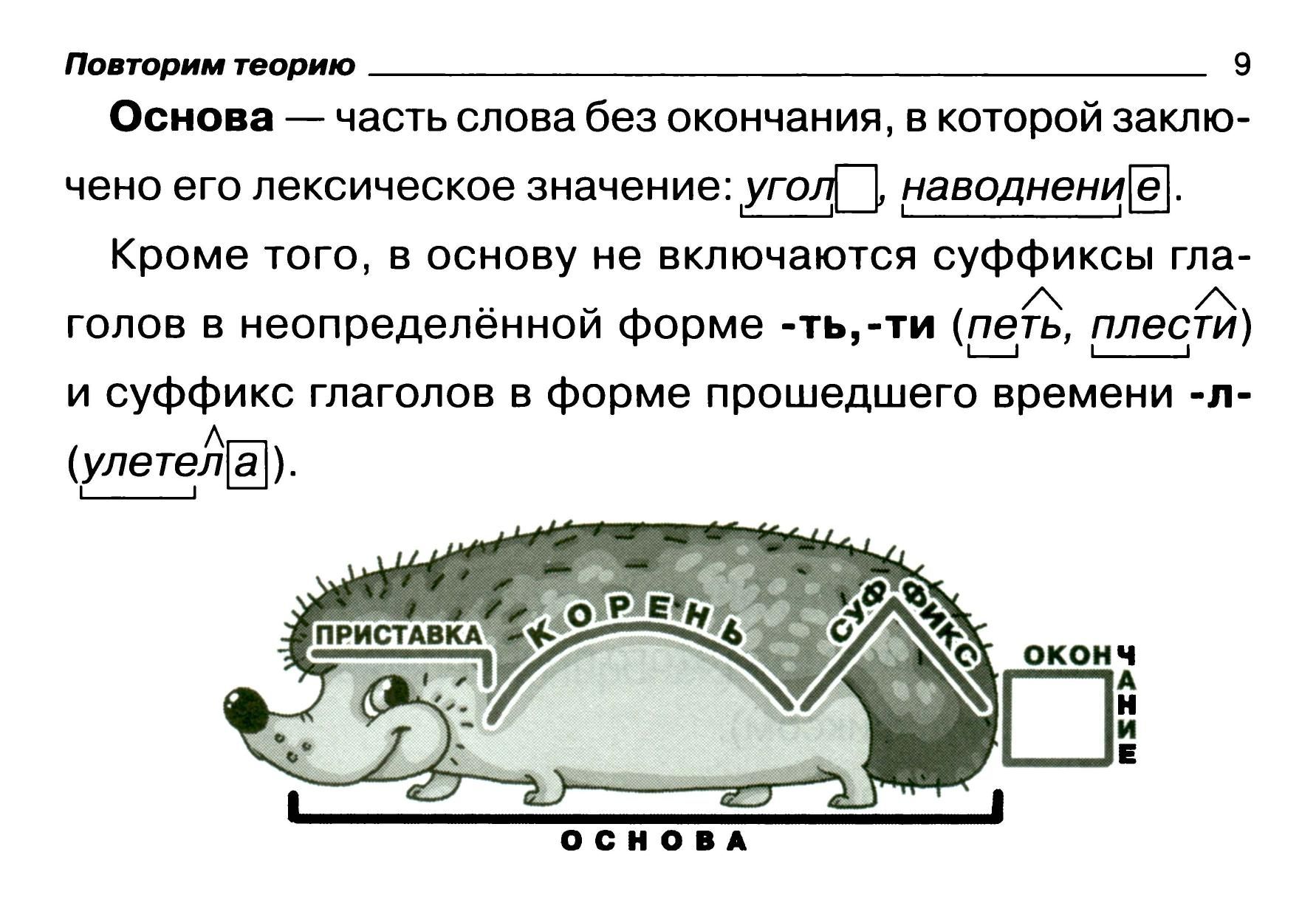
Состав слова. Основа слова. Части основы.
Тема: Состав слова. Основа слова. Части основы.
Цель: дать ученикам общее представление об основе слова, из каких частей может состоять основа слова, продолжать формировать понятия родственные слова, словообразование. Учить разбирать слова по строению, подбирать однокоренные слова.
развивающая: развивать связную речь, логическое мышление, умение доказывать свое мнение. Пополнять словарный запас , развивать в новых ситуациях креативное мышление учащихся; умение применять понятия в новых ситуациях.
воспитательная : воспитывать аккуратность, трудолюбие, внимание к слову, его значение, интерес к знаниям.
Планируемые образовательные результаты:
Предметные: научатся называть части слова, выделять корень в родственных словах с опорой на смысловую связь однокоренных слов и общность написания корней;
получат возможность формировать представление о слове как объединении морфем, стоящих в определённом порядке и имеющих определённое значение; разбирать слово по составу, опираясь на знание морфем, и выделять графически; учиться понимать учебную задачу урока и стремиться ее выполнять; работать в паре, используя представленную информацию для получения новых знаний; отвечать на вопросы; овладеть логическими действиями сравнения, анализа и синтеза.
Метапредметные: использовать знаково-символические средства для решения учебных задач; формировать умение планировать, контролировать и оценивать учебные действия в соответствии с поставленной задачей и условиями её реализации; определять наиболее эффективные способы достижения результата; сотрудничать со сверстниками в процессе выполнения парной и групповой работы
Личностные: применение навыков культурного поведения при общении; формирование уважительного отношения к иному мнению; принятие и освоение социальной роли обучающегося; развитие мотивов учебной деятельности и личностного смысла учения; готовность слушать собеседника и вести диалог, признавать возможность существования различных точек зрения и права каждого иметь свою, излагать своё мнение и аргументировать свою точку зрения и оценку событий.Получат возможность развивать личностные качества в процессе общения (внимание к собеседнику, терпение, использование «вежливых» слов и т. п.).
Оборудование: таблички, презентация, проектор, карточки для рефлексии — смайлики.
Тип урока: Урок усвоения новых умений и навыков.
Ход урока
I. Организационная часть
II. Мотивация учебной деятельности
Слайд 1
1. Проверка домашнего задания
Дети, сегодня у нас с вами необычный урок. Скажите, пожалуйста,
Кто из вас был на телевидении? Кто принимал участие в съемках детской передачи? А сегодня каждый из вас будет участником детской телепередачи «Телепазлики» .
Скажите, дети, изучение какой темы мы начали на предыдущем уроке?
С какой частью языка мы познакомились?
Что такое окончание?
Слайд 2
1. Пазлик «Вопросики»
Работа в групах.
(Каждой группе нужно придумать вопрос об окончании)
Что такое окончание?
Как определять окончание?
Как обозначается окончание?
-Молодцы, дети. Я считаю, что лучшая была … группа.
Открыли тетради, записали число, классная работа.
Слайд 3, 4
Пазлик «Загадочный диктант».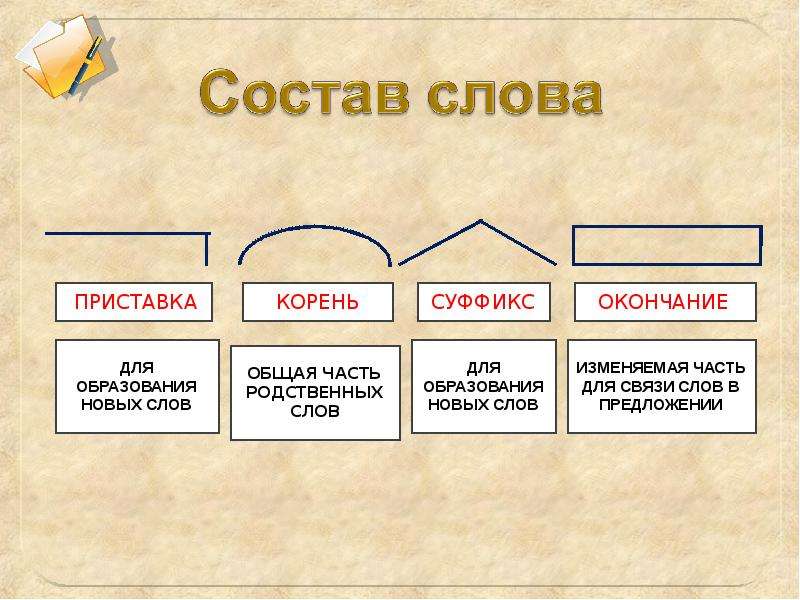
— Вы, наверное, догадались, почему он так называется.
Я буду читать загадки, а вы будете записывать слова — отгадки.
1 ученик у доски
(Дети записывают слова – отгадки и выделяют окончания).
Если в изменяемом слове нет окончания в какой-то его форме, то говорим, что в этом слове нулевое окончание и обозначаем пустой клеткой.
III Объявление темы и цели урока
— Итак, мы научилиись изменять слово по вопросам, а теперь можем определить его другую часть, которая всегда остается неизменной.
Кто из вас знает, как она называется? (Основой)
IV Работа над новой темой
Слайд 5, 6, 7
Игра «Исследователи»
(На слайде записаны слова: вода, водяной, подводный, надводный).
— Давайте попробуем определить общую часть в этих словах. Правильно, общая часть этих слов: вод. Общая часть в этих слов является корнем.
Найдите часть слова, которая стоит перед корнем? Эта часть приставка.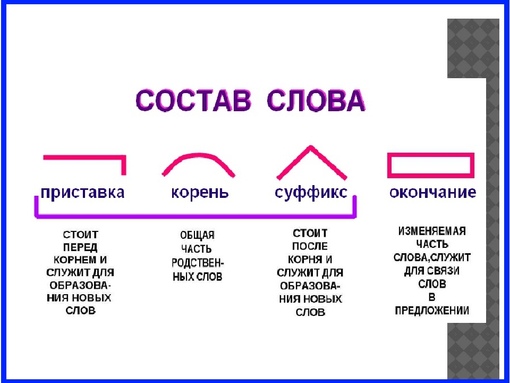
Назовите часть, которая после корня (суффикс).
У каждого на парте таблички-подсказки с частями слова.
Слайд 8, 9
Пазлик » Запоминайка»
Итак запомните правило .
Слайд 10
Физкультминутка (проводит ученик).
V. Закрепление изученного материала.
А теперь открыли учебники
Слайд 11
Следующий Пазлик «Дружного шепота»
— Читаем правило на с. 75.
-Выполняем упражнение 132.
-Назовите слова, в которых есть одинаковый корень.
Слайд 12
Словарная работа Пазлик » Друзья энциклопедии»
Столица – главный город страны.
Пазлик «Творческая остановка»
Упр.130 Работа в парах. Самостоятельная работа. Самопроверка.
Какова цель этого текста?
Когда и где происходило событие?
Что увидел автор?
VІ І. Итог урока. Рефлексия.
Что изучали на уроке?
Что для вас было новым?
Что понравилось?
Что было сложным?
При помощи смайликов оцените свою работу на уроке.
Слайд 13
— Посмотрите, какой рисунок мы сложили из наших пазлов: ВЫ-МОЛОДЦЫ!
VII Домашнее задание:
Подобрать однокоренные слова к слову море или снег. Разобрать их по составу.
Использование — документация pymatgen 2023.5.10
Эта страница предоставляет новым пользователям кодовой базы pymatgen краткий обзор кодовая база pymatgen. Следует также указать, что существует страница примеров со многими примерами ноутбуков ipython с фактический код, демонстрирующий использование кода. Учимся на этих примерах это самый быстрый способ начать работу.
Pymatgen имеет высокую объектно-ориентированную структуру. Почти все (Элемент, Сайт, Структура и т. д.) — это объект. В настоящее время код сильно склонен к изображению и манипулированию кристаллами с периодическими граничные условия, хотя для молекул предусмотрена гибкость.
Основные модули находятся в (да, вы уже догадались) пакете pymatgen.core. Учитывая значение этого пакета для общего функционирования кода, мы имеем предоставил краткий обзор различных модулей здесь:
pymatgen. core.periodic_table
core.periodic_table pymatgen.core.lattice: Этот модуль определяет объект Lattice, который по существу определяет векторы решетки в трех измерениях. Решетка объект предоставляет удобные методы для преобразования дробного в декартово координаты и наоборот, вычисление параметров решетки и углов и т. д.pymatgen.core.sites: определяет объекты Site и PeriodicSite. А Сайт, по сути, представляет собой координатную точку, содержащую элемент или вид. А PeriodicSite также содержит решетку.
Структура и молекула — это просто список периодических сайтов и сайтов. соответственно.pymatgen.core.structure: Определяет объекты структуры и молекулы.pymatgen.core.composition: Композиция — это просто отображение Элемент/вид в суммы.
 core.periodic_table
core.periodic_table 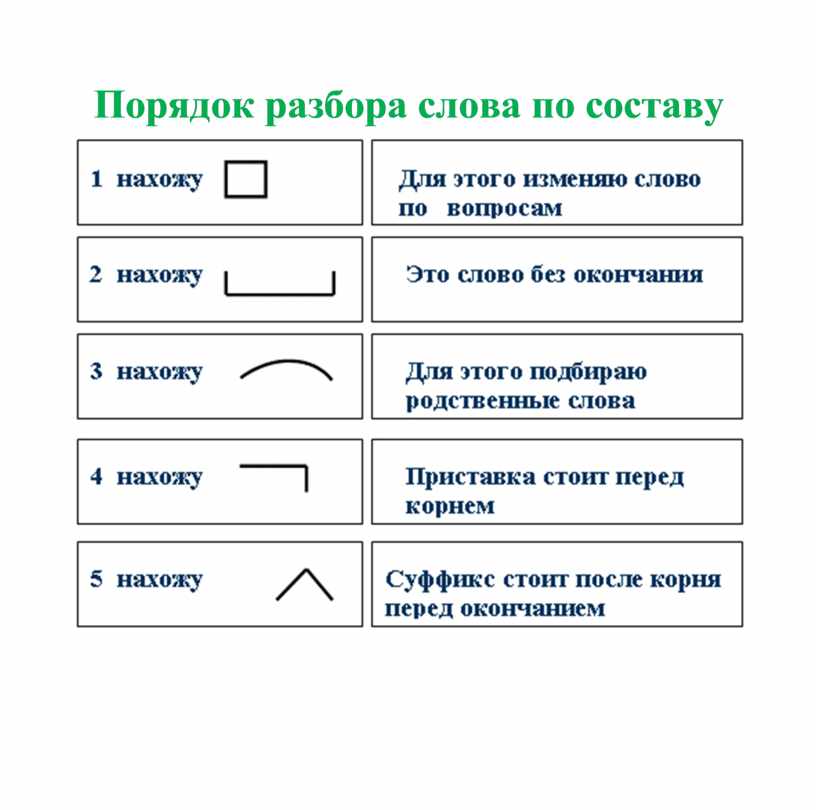
Обычно считается, что все единицы pymatgen выражены в атомных единицах, т. е. ангстремы для длин, эВ для энергий и т. д. Однако большинство объектов не принять любые единицы как таковые, и это должно быть совершенно нормально по большей части нет независимо от того, какие единицы измерения используются, главное, чтобы они использовались последовательно.
Примечание: as_dict / from_dict
Изучая код, вы можете заметить, что многие объекты имеют атрибут as_dict.
реализован метод и статический метод from_dict. Для большинства неосновных
объекты, мы разработали pymatgen таким образом, чтобы можно было легко сохранять объекты для
последующее использование. В то время как python обеспечивает функциональность травления, pickle имеет тенденцию
быть чрезвычайно хрупким по отношению к изменениям кода.
Выходные данные метода as_dict всегда сериализуемы в json/yaml. Итак, если вы хотите сохранить структуру, вы можете сделать следующее:
с файлом open('structure.json', 'w'):
json.dump(structure.as_dict(), файл)
Точно так же, чтобы получить структуру обратно из json, вы можете сделать следующее, чтобы восстановить структуру (или любой объект с методом as_dict) из json как следует:
с файлом open('structure.json'):
dct = json.load(файл)
структура = Структура.from_dict(dct)
Вы можете заменить любую из вышеуказанных команд json на yaml в пакете PyYAML. вместо этого создать файл yaml. Существуют определенные компромиссы между двумя
выбор. JSON намного эффективнее как формат, с чрезвычайно быстрым
скорость чтения/записи, но гораздо менее читаемый. YAML на порядок
или более медленный с точки зрения синтаксического анализа, но более удобочитаемый.
вместо этого создать файл yaml. Существуют определенные компромиссы между двумя
выбор. JSON намного эффективнее как формат, с чрезвычайно быстрым
скорость чтения/записи, но гораздо менее читаемый. YAML на порядок
или более медленный с точки зрения синтаксического анализа, но более удобочитаемый.
Монтиэнкодер/декодер
Расширения стандартного Python JSONEncoder и JSONDecoder были
реализован для поддержки объектов pymatgen. MontyEncoder использует as_dict
API pymatgen для генерации необходимого dict для преобразования в json. К
используйте MontyEncoder, просто добавьте его как
json.dumps(объект, cls=MontyEncoder)
MontyDecoder зависит от нахождения ключа «@module» и «@class» в словаре для декодирования необходимого объекта Python. В общем, MontyEncoder будет добавьте эти ключи, если они отсутствуют, но для лучшей долгосрочной стабильности (например, могут быть ситуации, когда to_dict вызывается напрямую, а не через энкодер), проще всего добавить в любой to_dict следующее свойство:
d["@module"] = тип(я).
 __модуль__
d["@class"] = type(self).__name__
__модуль__
d["@class"] = type(self).__name__
Чтобы использовать MontyDecoder, просто укажите его как cls kwarg при использовании json. нагрузка, например:
json.loads(json_string, cls=MontyDecoder)
Декодер написан таким образом, что он поддерживает вложенный список и словарь пиматген объекты. При прохождении иерархии вложенности декодер будет найдите указанные имена модулей/классов самого высокого уровня и преобразуйте их в пиматген объекты.
MontyEncoder/Decoder также поддерживает массивы datetime и numpy из коробки.
Структуры и молекулы
Для большинства приложений вы будете создавать и управлять Объекты структуры/молекулы. Есть несколько способов создания этих объектов:
Создание структуры вручную
Это вообще самый болезненный метод. Хотя иногда это необходимо, редко тот метод, который вы бы использовали. Пример создания базового кремния Кристалл представлен ниже:
из импорта pymatgen.
 core Решетка, структура, молекула
координаты = [[0, 0, 0], [0,75,0,5,0,75]]
решетка = Lattice.from_parameters (a = 3,84, b = 3,84, c = 3,84, альфа = 120,
бета=90, гамма=60)
struct = Структура (решетка, ["Si", "Si"], координаты)
координаты = [[0,000000, 0,000000, 0,000000],
[0,000000, 0,000000, 1,089000],
[1,026719, 0,000000, -0,363000],
[-0,513360, -0,889165, -0,363000],
[-0,513360, 0,889165, -0,363000]]
метан = молекула (["C", "H", "H", "H", "H"], координаты)
core Решетка, структура, молекула
координаты = [[0, 0, 0], [0,75,0,5,0,75]]
решетка = Lattice.from_parameters (a = 3,84, b = 3,84, c = 3,84, альфа = 120,
бета=90, гамма=60)
struct = Структура (решетка, ["Si", "Si"], координаты)
координаты = [[0,000000, 0,000000, 0,000000],
[0,000000, 0,000000, 1,089000],
[1,026719, 0,000000, -0,363000],
[-0,513360, -0,889165, -0,363000],
[-0,513360, 0,889165, -0,363000]]
метан = молекула (["C", "H", "H", "H", "H"], координаты)
Обратите внимание, что и элементы, и виды (элементы со степенями окисления) поддерживается. Таким образом, и «Fe», и «Fe2+» являются действительными спецификациями.
Чтение и запись структур/молекул
Чаще всего у вас уже есть структура/молекула в одном из многих типичные используемые форматы (например, Cystallographic Information Format (CIF), ввод/вывод кода электронной структуры, xyz, mol и т.д.).
Pymatgen обеспечивает удобный способ считывания структур и молекул с помощью методы from_file и to:
# Чтение POSCAR и запись в CIF.
 структура = Структура.из_файла("POSCAR")
структура.to(имя файла="CsCl.cif")
# Чтение файла xyz и запись во входной файл Gaussian.
метан = Молекула.из_файла("метан.xyz")
метан.к(имя файла="метан.gjf")
структура = Структура.из_файла("POSCAR")
структура.to(имя файла="CsCl.cif")
# Чтение файла xyz и запись во входной файл Gaussian.
метан = Молекула.из_файла("метан.xyz")
метан.к(имя файла="метан.gjf")
Формат определяется автоматически по имени файла.
Для более точного контроля над тем, какой синтаксический анализ использовать, вы можете указать конкретные пакеты ввода-вывода. Например, чтобы создать структуру из cif:
из pymatgen.io.cif импорт CifParser
синтаксический анализатор = CifParser("mycif.cif")
структура = parser.get_structures () [0]
Другой пример создания структуры из файла VASP POSCAR/CONTCAR:
из pymatgen.io.vasp импорт Poscar
poscar = Poscar.from_file("POSCAR")
структура = poscar.structure
Многие из этих пакетов ввода-вывода также предоставляют средства для записи структуры в
различные форматы вывода, например. CifWriter в pymatgen.io.cif . В
в частности, pymatgen.io.vasp.sets
 В общем,
большинство преобразований форматов файлов можно выполнить с помощью нескольких быстрых строк кода. Для
например, чтобы прочитать POSCAR и написать cif:
В общем,
большинство преобразований форматов файлов можно выполнить с помощью нескольких быстрых строк кода. Для
например, чтобы прочитать POSCAR и написать cif: из pymatgen.io.vasp импорт Poscar
из pymatgen.io.cif импорт CifWriter
p = Poscar.from_file('POSCAR')
w = CifWriter(p.структура)
w.write_file('mystructure.cif')
Для молекул pymatgen имеет встроенную поддержку ввода XYZ и Гаусса и
выходные файлы через pymatgen.io.xyz и pymatgen.io.gaussian соответственно:
из pymatgen.io.xyz импортировать XYZ
из pymatgen.io.gaussian импорт GaussianInput
xyz = XYZ.from_file('метан.xyz')
gau = GaussianInput (xyz.molecule,
route_parameters={'SP': "", "SCF": "Tight"})
gau.write_file('метан.inp')
Также поддерживается более 100 типов файлов через OpenBabel. интерфейс. Но для этого вам нужно установить openbabel с привязками Python. Пожалуйста, ознакомьтесь с руководством по установке.
Что можно делать со структурами
Этот раздел находится в стадии разработки. Но просто для того, чтобы дать общее представление о том,
анализ вы можете сделать:
Но просто для того, чтобы дать общее представление о том,
анализ вы можете сделать:
Модифицируйте структуры напрямую или даже лучше, используя pymatgen
.трансформациииpymatgen.alchemy 9Пакеты 0012.Анализ структур. Например, вычислите сумму Эвальда, используя
pymatgen.analysis.ewaldpackage, сравните две структуры для сходство с использованиемpymatgen.analysis.structure_matcher.
Следует отметить, что Структура и Молекула предназначены для изменения. В на самом деле они являются самыми основными изменяемыми единицами (все, что ниже в классе иерархии, такие как Element, Specie, Site, PeriodicSite, Lattice, неизменяемы). Если вам нужны гарантии неизменности структуры/молекулы, вместо этого вы должны использовать классы IStructure и IMolecule.
Модификация структур или молекул
Pymatgen поддерживает высокоуровневый интерфейс Python для изменения структур и
Молекулы. Например, вы можете изменить любой сайт просто с помощью:
Например, вы можете изменить любой сайт просто с помощью:
# Замените частицу в позиции 1 на атом фтора.
структура [1] = "F"
молекула [1] = "F"
# Изменить виды и координаты (дробные для структур,
# Декартово для молекул)
структура [1] = "Cl", [0,51, 0,51, 0,51]
молекула [1] = "F", [1.34, 2, 3]
# Structure/Molecule также поддерживает типичные списочные операторы,
# например, реверс, расширение, поп, индекс, подсчет.
структура.обратная()
молекула.обратная()
Structure.append("F", [0,9, 0,9, 0,9])
molecule.append("F", [2.1, 3,.2 4.3])
Есть также много типичных преобразований, которые вы можете делать со структурами. Вот некоторые примеры:
# Сделать суперячейку структура.make_supercell([2, 2, 2]) # Получить примитивную версию структуры структура.get_primitive_structure() # Интерполировать между двумя структурами, чтобы получить 10 структур (обычно для # Расчеты НЭБ. структура.интерполировать (другая_структура, изображения = 10)
Выше приведены лишь некоторые примеры типичных вариантов использования. Возможно гораздо больше
и вы можете изучить актуальную документацию API для структурных и молекулярных классов.
Возможно гораздо больше
и вы можете изучить актуальную документацию API для структурных и молекулярных классов.
Записи - Блок базового анализа
За пределами основных объектов Element, Site и Structure, большинство анализов в пределах
pymatgen (например, создание PhaseDiagram) выполняются с использованием объектов Entry. Ан
Запись в своей самой основной форме содержит рассчитанную энергию и состав,
и может дополнительно содержать другие входные или расчетные данные. В большинстве случаев
вы будете использовать объекты ComputedEntry или ComputedStructureEntry, определенные в pymatgen.entries.computed_entries . Объекты ComputedEntry могут быть созданы
либо путем ручного разбора расчетов расчетных данных, либо с помощью
9Пакет 0011 pymatgen.apps.borg .
— одновременное использование GGA и GGA+U
Группа Ceder разработала схему, в которой расчеты GGA и GGA+U могут
быть «смешанным», чтобы анализы могли выполняться с использованием типа расчета
наиболее подходящий для каждой записи. Например, для создания фазы Fe-PO
диаграмме наиболее подходящим образом моделируются металлические фазы, такие как Fe и FexPy.
с использованием стандартного GGA, в то время как Хаббард U должен применяться для оксидов, таких как
как FexOy и FexPyOz.
Например, для создания фазы Fe-PO
диаграмме наиболее подходящим образом моделируются металлические фазы, такие как Fe и FexPy.
с использованием стандартного GGA, в то время как Хаббард U должен применяться для оксидов, таких как
как FexOy и FexPyOz.
В модуле pymatgen.io.vasp.sets предопределенные наборы параметров имеют
был закодирован, чтобы позволить пользователям генерировать входные файлы VASP, которые непротиворечивы
с входными параметрами, совместимыми с данными проекта материалов.
Пользователи, которые хотят выполнить анализ, используя прогоны, рассчитанные с использованием этих
параметры должны обрабатывать записи, сгенерированные из этих прогонов, с помощью
соответствующая совместимость. Например, если пользователь хочет сгенерировать фазу
диаграмма из списка записей, сгенерированных из запусков Fe-P-O vasp,
он должен использовать следующую процедуру:
из импорта pymatgen.entries.compatibility MaterialsProjectCompatibility из pymatgen.analysis.
 phase_diagram импортировать PhaseDiagram, PDPlotter
# Получить unprocessed_entries с помощью pymatgen.borg или других средств.
# Обработать записи для совместимости
compat = МатериалыПроектСовместимость()
обработанные_записи = compat.process_entries (необработанные_записи)
# Эти несколько строк создают фазовую диаграмму с использованием ComputedEntries.
pd = PhaseDiagram (обработанные_записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
phase_diagram импортировать PhaseDiagram, PDPlotter
# Получить unprocessed_entries с помощью pymatgen.borg или других средств.
# Обработать записи для совместимости
compat = МатериалыПроектСовместимость()
обработанные_записи = compat.process_entries (необработанные_записи)
# Эти несколько строк создают фазовую диаграмму с использованием ComputedEntries.
pd = PhaseDiagram (обработанные_записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
pymatgen.io — управление вводом и выводом вычислений
Модуль pymatgen.io содержит классы для облегчения записи входных файлов
и разбор выходных файлов из различных вычислительных кодов, включая VASP,
Q-Chem, LAMMPS, CP2K, AbInit и многие другие.
Основным классом для управления вводом является InputSet . Объект InputSet содержит
все данные, необходимые для записи одного или нескольких входных файлов для расчета.
В частности, каждые InputSet имеет метод write_input() , который записывает все
необходимые файлы в указанное вами место. Также есть классы
Также есть классы InputGenerator которые дают InputSet с настройками, адаптированными к конкретным типам вычислений (например,
структурная релаксация). Вы можете думать о классах InputGenerator как о «рецептах» для
выполнение конкретных вычислительных задач, в то время как InputSet содержат эти рецепты
применяется к конкретной системе или структуре.
Пользовательские настройки могут быть предоставлены InputGenerator при создании экземпляра. Например,
построить InputSet для упаковки молекул воды в коробку с помощью Packmol
код при изменении допуска упаковки с 2,0 (по умолчанию) на 3,0:
из импорта pymatgen.io.packmol PackmolBoxGen
input_gen = PackmolBoxGen (допуск = 3,0)
packmol_set = input_gen.get_input_set({"имя": "вода",
"число": 500,
"координаты": "/path/to/input/file.xyz"})
packmol_set.write_input('/path/to/calc/directory')
Вы также можете использовать InputSet. from_directory() для создания pymatgen
from_directory() для создания pymatgen InputSet из каталога, содержащего входные данные для расчета.
Многие коды также содержат классы для разбора выходных файлов в объекты pymatgen, которые
наследуется от InputFile , который предоставляет стандартный интерфейс для чтения и
запись отдельных файлов.
Использование классов InputFile , InputSet и InputGenerator запрещено.
еще не полностью реализовано всеми кодами, поддерживаемыми pymatgen, поэтому см.
соответствующую документацию модуля для каждого кода для более подробной информации.
pymatgen.borg — Усвоение данных с высокой пропускной способностью
Пакет borg все еще находится в стадии разработки, но с его помощью уже можно многое сделать.
это. Основная концепция заключается в предоставлении удобных средств для
ассимилировать большие объемы данных в структуре каталогов. На данный момент основной
приложение представляет собой ассимиляцию целых структур каталогов VASP
вычисления в полезные записи pymatgen, которые затем можно использовать для фазы
схемы и другие анализы. Схема того, как это работает, выглядит следующим образом:
Схема того, как это работает, выглядит следующим образом:
Дроны определены в модуле
pymatgen.apps.borg.hive. Дрон по сути является объектом, который определяет, как каталог анализируется в объект пиматген. Например, VaspToComputedEntryDrone определяет, как каталог, содержащий запуск vasp (с файлом vasprun.xml), преобразуется в ComputedEntry.Объект BorgQueen в модуле
pymatgen.apps.borg.queenиспользует дроны ассимилировать всю структуру подкаталогов. Параллельная обработка по возможности используется для ускорения процесса.
Простой пример — создание фазовой диаграммы
Допустим, вы хотите построить фазовую диаграмму Li-O. Вы все рассчитали Соединения Li, O и Li-O, которые вас интересуют, и прогоны находятся в каталог «Li-O_runs». Затем вы можете создать фазовую диаграмму, используя следующие несколько строк кода:
из импорта pymatgen.borg.hive VaspToComputedEntryDrone из pymatgen.
 borg.queen импортировать BorgQueen
из pymatgen.analysis.phase_diagram импортировать PhaseDiagram, PDPlotter
# Эти три строки ассимилируют данные в ComputedEntries.
дрон = VaspToComputedEntryDrone()
королева = BorgQueen(трутень, "Li-O_runs", 2)
записи = королева.get_data()
# Рекомендуется выполнить save_data, особенно если вы только что ассимилировали
# большое количество данных, что заняло некоторое время. Это позволяет перезагружать
# данные, использующие BorgQueen, инициализируются только аргументом drone и
# вызов queen.load_data("Li-O_entries.json")
queen.save_data("Li-O_entries.json")
# Эти несколько строк создают фазовую диаграмму с использованием ComputedEntries.
pd = Фазовая диаграмма (записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
borg.queen импортировать BorgQueen
из pymatgen.analysis.phase_diagram импортировать PhaseDiagram, PDPlotter
# Эти три строки ассимилируют данные в ComputedEntries.
дрон = VaspToComputedEntryDrone()
королева = BorgQueen(трутень, "Li-O_runs", 2)
записи = королева.get_data()
# Рекомендуется выполнить save_data, особенно если вы только что ассимилировали
# большое количество данных, что заняло некоторое время. Это позволяет перезагружать
# данные, использующие BorgQueen, инициализируются только аргументом drone и
# вызов queen.load_data("Li-O_entries.json")
queen.save_data("Li-O_entries.json")
# Эти несколько строк создают фазовую диаграмму с использованием ComputedEntries.
pd = Фазовая диаграмма (записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
В этом примере ни Li, ни O не требуют U Хаббарда. Однако, если вы
создание фазовой диаграммы из набора записей GGA и GGA+U, вам может понадобиться
постобработка ассимилированных записей с помощью объекта совместимости перед
запуск кода фазовой диаграммы. См. предыдущий раздел о записях и
совместимость.
См. предыдущий раздел о записях и
совместимость.
Другой пример — Расчет энергий реакции
Еще один пример интересной вещи, которую вы можете сделать с загруженными записями, — рассчитать энергию реакции. Например, повторное использование сохраненных нами данных Li-O. на предыдущем шаге:
из pymatgen.apps.borg.hive import VaspToComputedEntryDrone
из pymatgen.apps.borg.queen импортировать BorgQueen
из pymatgen.analysis.reaction_calculator импортировать ComputedReaction
# Эти три строки ассимилируют данные в ComputedEntries.
дрон = VaspToComputedEntryDrone()
королева = BorgQueen (трутень)
queen.load_data("Li-O_entries.json")
записи = королева.get_data()
#Извлеките правильные записи и вычислите реакцию.
rcts = filter(лямбда e: e.composition.reduced_formula в ["Li", "O2"], записи)
prods = filter(лямбда e: e.composition.reduced_formula == "Li2O", записи)
rxn = ComputedReaction(rcts, prods)
распечатать rxn
распечатать rxn.calculated_reaction_energy
pymatgen.
 transformations
transformations Пакет pymatgen.transformations является стандартным пакетом для
выполнение преобразований структур. Многие преобразования уже
поддерживается сегодня, от простых преобразований, таких как добавление и удаление
сайты и замена видов в структуре на более продвинутые «один ко многим».
преобразования, такие как частичное удаление части определенного вида
из конструкции с использованием критерия электростатической энергии. Трансформация
классы следуют строгому API. Типичное использование выглядит следующим образом:
из pymatgen.io.cif импорт CifParser
из импорта pymatgen.transformations.standard_transformations RemoveSpecieTransformations
# Чтение структуры LiFePO4 из cif.
парсер = CifParser('LiFePO4.cif')
структура = parser.get_structures () [0]
t = RemoveSpeciesTransformation(["Li"])
модифицированная_структура = t.apply_transformation (структура)
pymatgen.alchemy — Высокопроизводительные преобразования
Пакет pymatgen. представляет собой основу для выполнения
высокопроизводительные (HT) структурные преобразования. Например, он позволяет пользователю
определить серию преобразований, которые будут применяться к набору структур,
создание новых структур в процессе. Каркас также предназначен для
обеспечить надлежащую регистрацию всех изменений, выполненных в конструкциях,
с бесконечной отменой. Основные классы: alchemy
alchemy
pymatgen.alchemy.materials.TransformedStructure— Стандартный объект представляющий TransformedStructure. Принимает входную структуру и список преобразований в качестве входных данных. Также может быть сгенерирован из cif и POSCAR.pymatgen.alchemy.transmuters.StandardTransmuter— Пример класс Transmuter, который принимает список структур и применяет последовательность преобразований на всех них.
Пример использования — замена Fe на Mn и удаление всего Li во всех структурах:
из pymatgen.
 alchemy.transmuters импорт CifTransmuter
из pymatgen.transformations.standard_transformations импортировать SubstitutionTransformation, RemoveSpeciesTransformation
транс = []
trans.append(SubstitutionTransformation({"Fe":"Mn"}))
trans.append (УдалитьSpecieTransformation (["Lu"]))
transmuter = CifTransmuter.from_filenames(["MultiStructure.cif"], транс)
структуры = преобразователь.transformed_structures
alchemy.transmuters импорт CifTransmuter
из pymatgen.transformations.standard_transformations импортировать SubstitutionTransformation, RemoveSpeciesTransformation
транс = []
trans.append(SubstitutionTransformation({"Fe":"Mn"}))
trans.append (УдалитьSpecieTransformation (["Lu"]))
transmuter = CifTransmuter.from_filenames(["MultiStructure.cif"], транс)
структуры = преобразователь.transformed_structures
pymatgen.matproj.rest — Интеграция с проектом материалов REST API
В версии 2.0.0 pymatgen мы представили один из самых мощных и полезных tools еще — адаптер к REST API Materials Project. Проект материалов REST API (просто Materials API) был введен, чтобы предоставить средства для пользователям программно запрашивать данные о материалах. Это позволяет пользователям эффективно выполнять структурные манипуляции и анализы, не проходя через веб-интерфейс.
Параллельно мы закодировали в модуле pymatgen.ext.matproj a
MPRester, удобный высокоуровневый интерфейс к Materials API для получения
полезные объекты pymatgen для дальнейшего анализа. Чтобы использовать API материалов,
вам необходимо сначала зарегистрироваться в Materials Project и создать свой API
на панели инструментов по адресу https://www.materialsproject.org/dashboard. в
В приведенных ниже примерах пользовательский ключ Materials API обозначен как «USER_API_KEY».
Чтобы использовать API материалов,
вам необходимо сначала зарегистрироваться в Materials Project и создать свой API
на панели инструментов по адресу https://www.materialsproject.org/dashboard. в
В приведенных ниже примерах пользовательский ключ Materials API обозначен как «USER_API_KEY».
MPRester предоставляет множество удобных методов, но мы только выделим несколько ключевых методов здесь.
Чтобы получить информацию о материале с идентификатором проекта материалов «mp-1234», можно использовать следующее:
из pymatgen.ext.matproj импортировать MPRester
с MPRester("USER_API_KEY") как m:
# Структура идентификатора материала
структура = m.get_structure_by_material_id ("mp-1234")
# Dos для идентификатора материала
душ = m.get_dos_by_material_id ("mp-1234")
# Структура полосы для идентификатора материала
структура полосы = m.get_bandstructure_by_material_id ("mp-1234")
API материалов также позволяет запрашивать данные по формулам:
# Чтобы получить список данных для всех записей, имеющих формулу Fe2O3 данные = m.
 get_data("Fe2O3")
# Чтобы получить энергии всех элементов, имеющих формулу Fe2O3
энергии = m.get_data("Fe2O3", "энергия")
get_data("Fe2O3")
# Чтобы получить энергии всех элементов, имеющих формулу Fe2O3
энергии = m.get_data("Fe2O3", "энергия")
Наконец, MPRester предоставляет методы для получения всех записей в химическая система. В сочетании с фреймворком borg это обеспечивает особенно мощный способ объединить собственные расчеты с Материалами Данные проекта для анализа. Код ниже демонстрирует фазовую стабильность можно определить новый расчетный материал:
из pymatgen.ext.matproj импортировать MPRester из pymatgen.apps.borg.hive импортировать VaspToComputedEntryDrone из pymatgen.apps.borg.queen импортировать BorgQueen из pymatgen.entries.compatibility импортировать MaterialsProjectCompatibility из pymatgen.analysis.phase_diagram импортировать PhaseDiagram, PDPlotter # Ассимиляция вычислений VASP в объект ComputedEntry. Предположим, что # расчеты для серии новых фаз LixFeyOz, которые мы хотим # знать фазовую стабильность. дрон = VaspToComputedEntryDrone() королева = BorgQueen(трутень, rootpath=".
 ")
записи = королева.get_data()
# Получить все существующие фазы Li-Fe-O с помощью REST API Materials Project.
с MPRester("USER_API_KEY") как m:
mp_entries = m.get_entries_in_chemsys(["Li", "Fe", "O"])
# Комбинированная запись из рассчитанного прогона с записями проекта материалов
записи.extend(mp_entries)
# Обработка записей с помощью MaterialsProjectCompatibility
compat = МатериалыПроектСовместимость()
записи = compat.process_entries (записи)
# Создать и построить фазовую диаграмму Li-Fe-O
pd = Фазовая диаграмма (записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
")
записи = королева.get_data()
# Получить все существующие фазы Li-Fe-O с помощью REST API Materials Project.
с MPRester("USER_API_KEY") как m:
mp_entries = m.get_entries_in_chemsys(["Li", "Fe", "O"])
# Комбинированная запись из рассчитанного прогона с записями проекта материалов
записи.extend(mp_entries)
# Обработка записей с помощью MaterialsProjectCompatibility
compat = МатериалыПроектСовместимость()
записи = compat.process_entries (записи)
# Создать и построить фазовую диаграмму Li-Fe-O
pd = Фазовая диаграмма (записи)
плоттер = PDPlotter(pd)
плоттер.шоу()
Метод запроса
Для большей гибкости вы также можете использовать метод запросов MPRester. Этот метод позволяет выполнять любой запрос монго к материалам. База данных проекта. Он также поддерживает простой синтаксис строк с подстановочными знаками. Примеры приведены ниже:
из pymatgen.ext.matproj импортировать MPRester
с MPRester("USER_API_KEY") как m:
# Получить все энергии материалов по формуле "*2O".
результаты = m.query("*2O", ['энергия'])
# Получить формулы и энергии материалов с material_id mp-1234
# или с формулой FeO.
results = m.query("FeO mp-1234", ['pretty_formula', 'energy'])
# Получить все соединения вида ABO3
результаты = m.query("**O3", ['pretty_formula', 'энергия'])
 результаты = m.query("*2O", ['энергия'])
# Получить формулы и энергии материалов с material_id mp-1234
# или с формулой FeO.
results = m.query("FeO mp-1234", ['pretty_formula', 'energy'])
# Получить все соединения вида ABO3
результаты = m.query("**O3", ['pretty_formula', 'энергия'])
результаты = m.query("*2O", ['энергия'])
# Получить формулы и энергии материалов с material_id mp-1234
# или с формулой FeO.
results = m.query("FeO mp-1234", ['pretty_formula', 'energy'])
# Получить все соединения вида ABO3
результаты = m.query("**O3", ['pretty_formula', 'энергия'])
Настоятельно рекомендуется ознакомиться с документацией по Materials API по адресу http://bit.ly/materialsapi, где содержится исчерпывающее объяснение схема документа, используемая в проекте материалов, и как лучше всего запросить актуальная информация, которая вам нужна.
Установка PMG_MAPI_KEY в файле конфигурации
MPRester также может считывать ключ API через конфигурационный файл pymatgen. Просто запустите:
pmg config --добавить PMG_MAPI_KEY
, чтобы добавить это к .pmgrc.yaml , и теперь вы можете вызывать MPRester без каких-либо
аргументы. Это значительно упрощает работу опытных пользователей Materials API. использовать MPRester без необходимости постоянно вставлять свой ключ API в скрипты.
использовать MPRester без необходимости постоянно вставлять свой ключ API в скрипты.
Об Aadhaar Paperless Offline e-kyc — Уникальном органе идентификации Индии
Введение
UIDAI запустила Aadhaar Paperless Offline e-KYC Verification, позволяющую владельцам номеров Aadhaar добровольно использовать ее для установления своей личности в различных приложениях в безбумажной и электронной форме. , сохраняя при этом конфиденциальность, безопасность и инклюзивность.
Почему Aadhaar безбумажный оффлайн e-KYC?
UIDAI предоставляет механизм для проверки личности владельца номера Aadhaar с помощью электронной онлайн-службы KYC. Услуга e-KYC обеспечивает аутентифицированную мгновенную проверку личности и значительно снижает стоимость бумажной проверки и KYC. Однако этот метод онлайн-e-KYC доступен не для всех агентств и может не подходить по некоторым из следующих причин;
- Online e-KYC требует надежного подключения
- У агентства должна быть техническая инфраструктура для вызова онлайн-сервиса e-KYC и развертывания устройств (при необходимости)
- Резиденту может потребоваться предоставить биометрические данные для онлайн-проверки e-KYC
- UIDAI ведет запись запроса KYC для целей аудита
Преимущества Aadhaar Paperless Offline e-KYC
- Конфиденциальность:
- Данные KYC могут быть переданы держателем номера Aadhaarnumber напрямую без ведома UIDAI.
- Номер Aadhaar резидента не раскрывается, вместо этого передается только идентификационный номер.
- Для такой проверки не требуются основные биометрические данные (отпечатки пальцев или радужная оболочка глаза)
- Владелец номера Aadhaar может выбрать, какие данные (среди демографических данных и фотографий) будут переданы.
- Данные KYC могут быть переданы держателем номера Aadhaarnumber напрямую без ведома UIDAI.
- Безопасность:
- Данные Aadhaar KYC, загружаемые держателем номера Aadhaar, имеют цифровую подпись UIDAI для проверки подлинности и обнаружения любого вмешательства.
- Агентство может проверять данные с помощью собственной OTP/аутентификации по лицу. Данные
- KYC зашифрованы фразой, предоставленной держателем номера Aadhaar, что позволяет жителям контролировать свои данные.
- Включено:
- Aadhaar Paperless Offline e-KYC является добровольным и управляется держателем номера Aadhaar.
- Любое агентство, работающее с людьми, может использовать его с согласия владельца номера Aadhaar, допускающего широкое использование.

Как это работает?
Aadhaar Безбумажный оффлайн e-KYC устраняет необходимость для резидента предоставлять фотокопию письма Aadhaar, и вместо этого резидент может загрузить KYC XML и предоставить то же самое агентствам, желающим получить его/ее KYC. Агентство может проверить данные KYC, предоставленные резидентом, в порядке, описанном в следующих разделах. Детали KYC находятся в машиночитаемом формате XML, который имеет цифровую подпись UIDAI, что позволяет агентству проверять его подлинность и обнаруживать любое вмешательство. Агентство также может аутентифицировать пользователя с помощью собственных механизмов аутентификации OTP/Face.
Как получить данные Aadhaar Paperless Offline e-KYC
Владельцы номеров Aadhaar могут получить данные Aadhaar Безбумажный оффлайн e-KYC по следующим каналам: .uidai.gov.in)
- Приложение mAadhaarmobile на зарегистрированный номер телефона
- Входящие SMS с использованием зарегистрированного номера телефона
- Адхаар Кендра использует биометрическую аутентификацию
Какие данные включены в e-KYC
При загрузке/получении данных e-KYC в автономном режиме в XML включаются следующие поля.
- Имя резидента
- Загрузить ссылочный номер
- Адрес
- Фото
- Пол
- Д/Б
- Номер мобильного телефона (в хешированном виде)
- Электронная почта (в хешированном виде)
Aadhaar Безбумажные офлайн-данные e-KYC шифруются с использованием «Фразы обмена», предоставленной держателем номера Aadhaar во время загрузки, которую необходимо передать агентствам для чтения данных KYC.
Как поделиться данными Aadhaar Offline e-KYC
Безбумажные офлайн-данные Aadhaar e-KYC могут быть предоставлены проверяющему агентству держателем номера Aadhaar в цифровом или физическом формате вместе с общей фразой:
- Цифровой формат: XML /PDF
- Этот формат предпочтителен, когда требуется фотография высокого качества
- Печатный формат: QR-код
- Когда резиденту удобнее использовать печатный формат
- Фото низкого разрешения только для визуального осмотра
Технические аспекты Aadhaar Paperless Offline e-KYC
Следующая информация поможет жителям лучше понять технические аспекты Aadhaar Paperless Offline e-KYC.
Формат данных XML
Автономный безбумажный e-KYC при загрузке имеет следующий XML:
<Алгоритм метода канонизации ="http://www.w3.org/TR/2001/REC-xml-c14n-20010315" />
Сведения об элементе
Элемент :
OfflinePaperlessKyc : – Контейнер для хранения резидентных данных KYC.
Атрибуты:
версия — Версия: – теперь значение будет 1.0.
Имя — Имя: – Представлено в виде обычного текста.
referenceId — Справочный номер: — это композиция из последних 4 цифр номера Aadhaar, за которой следует отметка времени в формате ГГГГММДДЧЧММССммм.
Пример:
Номер Aadhaar: XXXX XXXX 3632
Отметка времени: 20181001134543123
Справочный номер: r=”363220181001134543123”
доб — доб /YoB: – Представлено в виде обычного текста в формате ДДММГГГГ или ГГГГ
e — EmailID: – Представлено в виде хэша со следующей логикой.
Логика хеширования для идентификатора электронной почты:
Sha256(Sha256(Email+SharePhrase))*количество повторений последней цифры номера Aadhaar
(поле Ref ID содержит последние 4 цифры).
Пример:
Электронная почта: Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
Номер Aadhaar: XXXX XXXX 3632
Пароль: Lock@487
Хэш: Sha256(Sha256(Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для его просмотра.
@487))*2
Если номер Aadhaar заканчивается на ноль, мы будем хэшировать один раз.
m — Мобильный номер: – это представлено в виде хеша со следующей логикой.
Логика хеширования для номера мобильного телефона:
Sha256(Sha256(Mobile+SharePhrase))*количество повторений последней цифры номера Aadhaar
(поле Ref ID содержит последние 4 цифры).
Пример:
Мобильный: 1234567890
Номер Aadhaar: XXXX XXXX 3632
Пароль: Lock@487
Хэш: Sha256(Sha256(1234567890Lock@487))*2 9 0471 Если номер Aadhaar заканчивается на ноль, мы будем хэшировать единицу время.
пол — Пол: – это либо «M» (мужской), либо «F» (женский), либо «T» (трансгендерный).
Poa — Адрес: – Адрес появится под тегом
Care Of- Care Of- Care of like «s/o»
Country- Название страны вроде «India»
Dist- Will содержит название округа
House- will содержит номер дома
loc- Locality
pc-Pincode
po- Название почтового отделения
штат- Название штата
улица-Название улицы
subdist- Название подрайона
vtc — Название VTC
подпись — Подпись: — это будет 344-символьная цифровая подпись данных, представленных в загруженном XML. Это можно проверить с помощью открытого ключа UIDAI, который будет присутствовать в стандартном подписанном xml.
Шаги для проверки подписи:
1. Прочитайте весь XML.
2. Получить подпись из xml
3. Получить сертификат отсюда.
4. Если вы скачали Offline XML до 7 июня 2020 г., то получите сертификат отсюда
5.