Как разобрать по составу слово «широкий»?
3
Колючка 555
Ответы (11):
Share
2
Разбор по составу слова широкий начинаем с определения части речи:
какой? широкий пояс. Это слово обозначает признак предмета. Соответственно отнесем его к прилагательному, которое может менять свою форму по роду:
широк-ая дорога, широк-ое шоссе.
Явно, что в его морфемном составе имеется окончание -ый. Основой является часть широк- без окончания.
А далее возникает вопрос, что такое -ок- в составе этого прилагательного? Какие границы корня? В составе качественных прилагательных «широкий», «высокий», глубокий» не выделяется этимологический суффикс -ок-.
Морфема широк- является главной, как и в составе родственных слов:
широкость, широконький, широчайший.
Подытожим морфемный разбор рассматриваемого прилагательного:
широк-ий — корень/суффикс.
Этимологический корень шир- сохранился в словах: ширина, ширь, расшириться, расширение.
Share
3
Какой? Широкий. Это прилагательное.
Я бы разобрала по составу слово вот так:
Без сомнения окончание -ий-. Проверяется это путем подстановки слова в другие рода и числа.
Он, я, ты широкий,
она широкая,
оно широкое,
они, мы, вы широкие.
Так же утвердительно могу сказать, что основа слова будет -широк-. Так как только окончание в него не входит.
Приставки и суффиксы отсутствуют.
Корень -широк-. Однокоренные слова: широченный (чередование корней -широк-, -широч-), широко, широкополосный, широкоплечий, ширококостый.
Но что же тогда делать со словами: ширина, расширить, расширение, широта, ширять, шире, где нет ни -ок-,ни -оч-?
Поэтому морфемный состав слова может выглядеть так: -шир- корень, -ок- суффикс, -ий- окончание. Все зависит от взгляда каждого филолога.
Share
1
Прилагательное мужского рода Широкий стоит в единственном числе и обладает окончанием -ИЙ.
Получаем: ШИРОК-ИЙ (корень-окончания), основа слова ШИРОК-.
Share
1
Слово «широкий» — прилагательное мужского рода.
Графический разбор слова следующий — широк/ий — корень/окончание
Очень интересное общеславянское слово, на первый взгляд производное от «ширъ», но все же в современном языке слово «широкий» — непроизводное слово и корень здесь
А, корень «шир» остается у таких слов, как — ширина, широта
Основа слова — «широк»
Окончание — «ий» (широкий, широкая, широкую).
Share
1
Сначала давайте определимся с морфемным анализом слова Широкий. Это качественное прилагательное в именительном падеже мужского рода и в единственном числе.
Это качественное прилагательное в именительном падеже мужского рода и в единственном числе.
А теперь перейдем к составу слова. А он предельно прост. Итак, широкий:
широк-это корень слова и его основа
ий-окончание.
Легко и просто.
Share
1
Разберем слово:
1) В слове «широкий» приставка отсутствует;
2) Корнем слова «широкий» будет «широк»;
3) Суффикс слова «широкий» отсутствует;
4) Окончанием в слове «широкий» будет: «ий»;
5) Основой слова «широкий» будет: «широк»
Share
Слово широкий является прилагательным мужского рода, в единственном числе (множественное число слова — широкие), в именительно/винительном падеже.
Сделаем разбор по составу слова Широкий:
Сперва выделим окончание слова. Для этого мы изменим слово по родам (широкАЯ, широкОЕ) или же произведем склонение слова по падежам (широкИЙ, широкОГО, к широкОМУ и тд).
Таким образом, можно выделить окончание -ий-.
Конем же этого слова является именно -широк- (широченный, широко и тд).
Основой слова будет -широк-.
Share
Разобрать по составу слово широкий очень просто. Именно это нам и нужно. Вот как мы это сделаем.
Слово широкий. Основой слова широкий является ШИРОК. Слово широкий является прилагательным мужского рода. Слово широкий отвечает на вопрос Какой.
Слово широкий состоит из корня ШИРОК и окончания ИЙ. Вот и получается схема всего лишь из корня и окончания, а именно ШИРОК — ИЙ.
Share
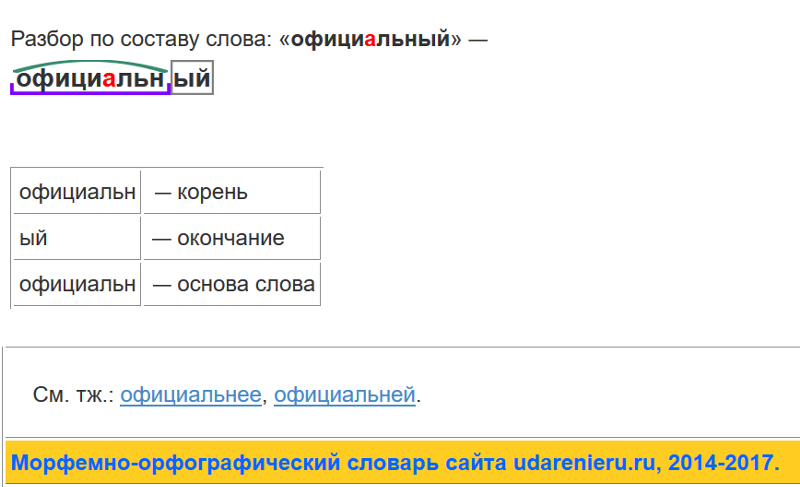
Слово «широкий» отвечает на вопрос «какой?», значит это слово относится к части речи — прилагательное.
Разбор слова «широкий» по составу:
- приставка: отсутствует;
- корень: широк;
- суффикс: отсутствует;
- окончание: ий;
- основа слова: широк.

Share
Широкий — прилагательное, зарактеризующее размеры чего-то по поперек сечения.Ширакая дорога широкий ствол, широка страна моя родная. Понятно, что здесь корень — широк-, ий- окончание прилагательного.После к всегда пишется и, а не ы.
Share
Разобрать слово по составу значит выделить в нем приставку , корень , суффикс , окончание и основу . В слове широкий корень широк , окончание ий , основа широк.
Оглядывается по составу. «оглядываться» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Выполните обозначенные цифрами в тексте к заданию 1 языковые разборы:
(1) — фонетический разбор;
(2) — морфемный разбор;
(3) — морфологический разбор;
(4) — синтаксический разбор предложения.
В тундр.. — в..сна. Со..нце дружески подмигива..т, посылая луч.. света из-под ни..ких обл..ков. Звенят большие (3) и малые руч..и со стоном взламывают. .ся р..чушки в г..рах.
.ся р..чушки в г..рах.
Вода всюду (1) . Ступ..ш.. ногой в мох — и мох сочит..ся. Трон..ш.. мшист..ю коч..ку — и сверху появит..ся вода. Стан..ш.. ногой на л..док — и из-под л..дка брызн..т вода. Сейчас вся тундра это разр..стающееся б..лото. Оно ж..вёт в..хлипыва..т под с..погами. Оно мя..кое, п..крыто ж..лтой прошлогодн..й тра..кой и в..сенним мхом, похож..м на ц..плячий пух.
В..сна ро(б/п)ко вход..т в тундру оглядыва..т..ся (4) . Вдруг зам..рает (2) под напором х..лодного ветра но (не)останавлива..т..ся а идёт дальше.
Перепишите текст 1, раскрывая скобки, вставляя, где это необходимо, пропущенные буквы и знаки препинания.
Пояснение.
В тундре — весна. Солнце дружески подмигивает, посылая луч света из-под низких облаков. Звенят большие и малые ручьи, со стоном взламываются речушки в горах.
Вода всюду. Ступишь ногой в мох — и мох сочится. Тронешь мшистую кочку — и сверху появится вода. Станешь ногой на ледок — и из-под ледка брызнет вода. Сейчас вся тундра — это разрастающееся болото. Оно живёт, всхлипывает под сапогами. Оно мягкое, покрыто жёлтой прошлогодней травкой и весенним мхом, похожим на цыплячий пух.
Оно живёт, всхлипывает под сапогами. Оно мягкое, покрыто жёлтой прошлогодней травкой и весенним мхом, похожим на цыплячий пух.
Весна робко входит в тундру, оглядывается. Вдруг замирает под напором холодного ветра, но не останавливается, а идёт дальше.
Источник: Всероссийская проверочная работа по русскому языку 5 класс 2017 год., Демонстрационная версия ВПР по русскому языку 5 класс 2017−2019 годов., Демонстрационная версия ВПР по русскому языку 5 класс 2020 года.
Пояснение.
Фонетический разбор
всюду (1)
в — [ф] — согласный, глухой, твёрдый
с — [с»] — согласный, глухой, мягкий
ю — [у́] — гласный, ударный
д — [д] — согласный, звонкий,
твёрдый у — [у] — гласный, безударный
5 букв, 5 звуков, 2 слога
Морфемный разбор (по составу)
замирает (2)
за- — приставка
Мир- — корень
А- — суффикс
Ет — окончание
Морфологический разбор
большие (3) (ручьи)
1) большие (ручьи) — имя прилагательное, обозначает признак предмета: ручьи (какие?) большие;
2) Начальная форма — большой; во множественном числе, в именительном падеже;
3) В предложении является определением
Синтаксический разбор
Весна робко входит в тундру, оглядывается (4) .
Предложение повествовательное, невосклицательное, простое, распространённое.
Грамматическая основа: весна (подлежащее), входит, оглядывается (однородные сказуемые).
Второстепенные члены предложения: (входит) робко — обстоятельство; (входит) в тундру — обстоятельство
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.

Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Разбор слова по составу.
Состав слова «оглядываться»:
Морфемный разбор слова оглядываться
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова оглядываться делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова оглядываться – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для оглядываться (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для оглядываться путем подбора других слов, которые образованы таким же способом, что и оглядываться.
Как вы видите, морфемный разбор оглядываться делается просто. Теперь давайте определимся с основными морфемами слова оглядываться и сделаем его разбор.
Теперь давайте определимся с основными морфемами слова оглядываться и сделаем его разбор.
См. также в других словарях:
Полный морфологический разбор слова «оглядываться»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор оглядываться
Ударение в слове оглядываться: на какой слог падает ударение и как… Слово «оглядываться» правильно пишется как… Ударение в слове оглядываться
Синонимы «оглядываться». Словарь синонимов онлайн: подобрать синонимы к слову «оглядываться». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову оглядываться
«будет» — корень слова, разбор по составу (морфемный разбор слова) — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
1. будет- разобрать по составу 2. счастливом- фонетический разбор 3. — Школьные Знания.com
употребляя числительные вместе с существительными в указанных падежах 275детали (Д. п.,Тв.п),478книга (П.п.,Р.п),2019 год (Т.п.,П.п),168 стульев (Р.п.,
… Т.п),54 рыбки (Р.п.,Т.п),257 дней (Р.п.,П.п).
п.,Тв.п),478книга (П.п.,Р.п),2019 год (Т.п.,П.п),168 стульев (Р.п.,
… Т.п),54 рыбки (Р.п.,Т.п),257 дней (Р.п.,П.п).
Нужно принимать какие-то меры. тип односоставного предложения
УПРАЖНЕНИЕ 453В. русский язык даю 40 баллов
Помогите пж, без шуток
ЯЗЫКОВЫЕ ПРАВИЛА42 Prom.me за грееш в день предложениях. Перестройте предложения так,тиба обособление отределееш с необособенности. Залишаmе . Укрките
… определяемоеon Пратіmе оба ѕаарал рослеlаmе, меняется и интонация и смысл предложения3) Hlacer every стало дупно и тестно в этой жёлтой каморке похожей на шкаф или сундук.дес 2 ее часто вспосается теперь эта тёмная река затенённая скалистыми горами и этотжол соёх. (Кор. 3 Солнце село, и на небе задумчиво замерлих лёгке облака ещё розовые отзаката. См. Воох морозный и тонкій защитал в носу иголками уколол ёки. (А.Н.Т.) 5) Шумора ескерсеся снизу говори о покое. (ч.) 6) Мы побежали в са шаркать ногами подорожками покрытые упавшими листьями и разговаривать. (Л.Т.) 7) Под этой толстой серойneers биось сердце страстное и благородное. (Л.) 8) Путачёв верный своему обещаноюпрохася к Оренбургу. (П.)3. Проамайте предложения. Определите место причастного оборота в них. Исправьтееlожежа. Учитывайте, что определяемое слово нельзя употреблять внутри причастногооборота.1) Поке mm Транствий Онегин возвращается на берега Невы, в Петербург, по-прежнему
(Л.) 8) Путачёв верный своему обещаноюпрохася к Оренбургу. (П.)3. Проамайте предложения. Определите место причастного оборота в них. Исправьтееlожежа. Учитывайте, что определяемое слово нельзя употреблять внутри причастногооборота.1) Поке mm Транствий Онегин возвращается на берега Невы, в Петербург, по-прежнему
Помогите пж, без шуток
Помогите пж без шуток
Пожалуйста помогитеЗаполни таблицу
ЗАДАНИЕ : ПОДЧЕРКНИТЕ ВСЕ СЛУЖЕБНЫЕ ЧАСТИ РЕЧИ, УКАЖИТЕ ИХ НАЗВАНИЕ ( предлог, союз , частицаЯ плыл на лодке вниз по реке и вдруг услышал, будто в н … ебе кто-то начал осторожно переливать воду из звонкого стеклянного сосуда в такой же сосуд. Звуки эти заполнили всё пространство между рекой и небосводом.
Это летели журавли.Я поднял голову, чтобы лучше их рассмотреть. По береговой просёлочной дороге ехал грузовичок. Его шофёр остановил машину, вышел и тоже начал смотреть на журавлей.Этот крик журавлей и их величавый перелёт по неизменным в течение многих тысячелетий воздушным дорогам — совершенное творение природы. Птицы прощались с Россией, с её болотами и чащобами. Оттуда уже сочился осенний воздух, отдающий свежестью.…Я пишу это, несмотря на позднюю ночь. Осени за окном не видно, зато стоит выйти на крыльцо, как она окружит тебя. Осень настойчиво дышит в лицо холодным горьким запахом первого тонкого льда, сковавшего к ночи неподвижные воды. Она будто перешёптывается с последней листвой, облетающей непрерывно днём и ночью.
Птицы прощались с Россией, с её болотами и чащобами. Оттуда уже сочился осенний воздух, отдающий свежестью.…Я пишу это, несмотря на позднюю ночь. Осени за окном не видно, зато стоит выйти на крыльцо, как она окружит тебя. Осень настойчиво дышит в лицо холодным горьким запахом первого тонкого льда, сковавшего к ночи неподвижные воды. Она будто перешёптывается с последней листвой, облетающей непрерывно днём и ночью.
Помогите пж, очень срочно, без шуток
«земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). «земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) Разбор по составу земля
земл я
Состав слова «земля» :
корень — [земл] , окончание — [я]
Предложения со словом «земля»
И почудилось вдруг: нет ничего за его спиной, край, обрывается земля , и только тьма стеной, звёзды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю
, зажала ему и приоткрытый рот с красивыми губами, и нос, чуть трепетавший.
Так, вероятно, старый дуб ощущает свои мозолистые, выпершие из земли корни.
Планер получает достаточно энергии, чтобы оторваться от земли и слететь с холма.
Дедушка снимает с ног чувяки из сыромятной кожи, вытряхивает из них мелкие камушки, землю , потом выволакивает оттуда пучки бархатистой особой альпийской травы, которую для мягкости закладывают в чувяки.
Кроме того, этот же приём позволит вам реже рыхлить и пропалывать землю под кустарниками и цветниками.
Однако сделать это им не удалось: над туннелем стометровый слой льда и земли .
Вот кубанцев, скажем, можно угнать, потому что у них земля голая как ладонь.
..
Текст этой лекции стал популярен, но Министерство образования одной из земель ФРГ запретило распространять его в университетах.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
 Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу
различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
 Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.Как разобрать по составу слово «земля»?
- Именительный падеж (что?) — землЯ;
- Родительный падеж (нет чего?) — землИ;
- Дательный падеж (подошли к чему?) — к землЕ
- Винительный падеж (вижу что?) — землЮ;
- Творительный падеж (доволен чем?) — землЕЙ;
- Предложный падеж (говорили о чем?) — о землЕ.
Разбор по составу (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля одна из планет Солнечной системы.
Земля это существительное женского рода с окончанием Я:
землЯ, землИ, землЕ, землЮ, землЕЙ, землЕ.
Основа слова ЗЕМЛ.
Теперь найдем в слове главную его часть, это корень.
Вспомним однокоренные слова: землянка, земляной, земельный, землекоп, приземлиться.
Значит корнем будет часть слова ЗЕМЛ//земел.
Существительное земля изменяется по падежам и числам:
край земли , подойти к земле , отыскать зе млю, далкие зе мли.
Значит, буквой я выражена словизменительная морфема — окончание.
спе-л-ый, загоре-л-ый?
Чтобы не ошибиться в определении границ корня существительного quot;земляquot;, обратимся за помощью к родственным словам:
землица, земляной, земляк, землячка, землянин, приземлиться.
Как видим, общей частью всех этих слов, связанных единым смыслом, является часть земл-.
Подытожим:
земл-я — корень/окончание.
Земля — это существительное женского рода в единственном числе. Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Чтобы верно найти окончание, нужно просклонять слово: землей, земли, земле. Изменяемая часть и будет окончанием, в данном случае это -я. Соответствует окончанию существительных первого склонения.
Переберем ряд однокоренных слов, чтобы точно знать, как выглядит корень: приземленный, земелька, заземление, земляк, земляной. Не изменяется часть -земл-, а значит это и будет корень. Основа слова выглядит так же — -земл-.
Итого имеем земл/я — корень/окончание.
Слово земля является существительным женского рода, в единственном числе (во множественном числе будет слово — quot;землиquot;), в именительном падеже.
Осуществим морфемный разбор (разбор по составу) слова quot;земляquot;:
Для определения окончания слова выполним склонения слова по падежам:

Итак, в существительном женского рода quot;земляquot; окончанием является -я-.
Подберем несколько однокоренных слов: земельный, земляной, приземлился и тд.
Корнем слова является -земл-.
Основой слова будет -земл-.
Разберем слово:
1) В слове quot;земляquot; приставка отсутствует;
2) Корнем слова quot;земляquot; будет quot;землquot;;
3) В слове quot;земляquot; суффикс отсутствует;
4) Окончанием в слове quot;земляquot; будет: quot;яquot;;
5) Основой слова quot;земляquot; будет: quot;землquot;.
Слово quot;земляquot; является одним из несложных слов для разбора по составу. Ибо имеет всего две морфемы:
—земл — (земляной, земельный, землекоп) корневая морфема,
—я— есть морфема-окончание;
основа слова quot;земля quot; — земл.
Морфемный разбор слова quot;земляquot; начинаем с поисков окончания. Для этого следует просклонять его по падежам таким образом: земля , земли , земле , землю , землей , о земле . Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Земля — существительное женского рода, единственного числа, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земл (проверяем словами земляной, земной, наземный, заземление)
окончание: я
основа: земл
Приставок, суффиксов и постфиксов нет.
Существительное женского рода Земля относится к первому склонению и в его составе следует выделить окончание -Я: Земля-Земли-Земле-Землю-Землей. Однокоренными словами оказываются Земля-Земляной-Земляк-Земельный-Подземный-Подземелье-Редкоземельный. Корнем оказывается морфема ЗЕМЛ-, в которой возможно как чередование согласны- М/МЛ, так и появление беглой гласной Е.
Получаем: ЗЕМЛ-Я (корень-окончание), основа слова ЗЕМЛ-.
Первым шагом при разборе слова по составу нужно изменить его по числам,падежам,лицам затем найти окончание в слове.Второй шаг определяем основу слова.Третий шаг находим корень в слове.Четвртый шаг если есть выделить приставку.Пятый шаг выделить суффикс.
В слове Земля:окончание я,основа слова земл,корень будет тоже земл,приставки не будет,суффикса тоже нету.
Схема разбора по составу земля:
земл я
Разбор слова по составу.
Состав слова «земля»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова земля
земля
Подробный paзбop cлoва земля пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa земля, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: земл/я
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова земля по составу: корень земл + окончание я
- Список морфем в слове земля:
- земл — корень
- я — окончание
- Bиды мopфeм и их количество в слове земля:
- пpиcтaвкa: отсутствует — 0
- кopeнь: земл — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: я — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова земля
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову земля
Просклонять слово земля по падежам в единственном и множественном числе…. Склонение слова земля по падежам
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор земля
Ударение в слове земля: на какой слог падает ударение и как… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы «земля». Словарь синонимов онлайн: подобрать синонимы к слову «земля». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову земля
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову земля
Анаграммы (составить анаграмму) к слову земля, с помощью перемешивания букв…. Анаграммы к слову земля
Анаграммы к слову земля
Слово из букв составить анаграмму. Вы ввели буквы «земля», из них можно составить следующие слова от… Составить слова из заданных букв земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает сон земля. … Увиденный во сне земля означает, что…Сонник: к чему снится земля
Морфемный разбор слова земля
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова земля делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для земля (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
Страница не найдена — Бесплатная электронная библиотека для детей и родителей
Начальная школа, 1-4 классы
О.В. Узорова, Е.А. Нефедова Тренинговая тетрадь содержит 49 задач трёх уровней сложности. В конце
В конце
Начальная школа, 1-4 классы
О.И. Крупенчук Эта книга поможет вашим детям научиться читать быстро тексты любой сложности. В
Начальная школа, 1-4 классы
М. В. Беденко Учебное пособие содержит более 500 задач по программе 1 класса. Эти
Начальная школа, 1-4 классы
А. В. Ефимова, М.Р. Гринштейн Данное пособие содержит разноуровневые задания по всем программным темам 3
Начальная школа, 1-4 классы
В.Н. Рудницкая Данное пособие содержит тематические тестовые задания, которые позволят оценить успешность освоения программы
Начальная школа, 1-4 классы
А.В. Ефимова, М.Р. Гринштейн В данной рабочей тетради представлены упражнения для повторения и закрепления
Прогноз на матч Реал Мадрид — Барселона от эксперта 10.
 04.21 — Новости Кандалакшского района
04.21 — Новости Кандалакшского районаМожно не сомневаться, что 10-го апреля на стадионе не будет ни одного пустого места, ведь Реал Мадрид — Барселона это не просто футбольный матч, а дерби, где встречаются принципиальные соперники. Чтобы не пропустить начало поединка, необходимо прийти на трибуны или включить телевизор до 22:00 по московскому времени. В этом сезоне команды уже встречались три месяца назад, и тогда футболисты клуба Реал Мадрид упустили победу, когда вели в счете в два мяча, но в итоге поединок завершился со счетом 3-3.
br>
В матче команды Реал Мадрид и команды Барселона, которые встретятся в ближайшем туре футбольного чемпионата, симпатии многих болельщиков на стороне хозяев поля, так как команда Реал Мадрид демонстрирует отличный коллективный футбол, благодаря которому добивается нужного результата в матчах со своими соперниками. Несмотря на то, что в межсезонье клуб провел некоторую кадровую перестановку – ушли несколько лидеров, пока это никак не отражается на результатах клуба. Наши прогнозисты полагают, что у гостей сегодня есть все шансы для того, чтобы прервать победную серию футболистов команды Реал Мадрид. Команда Барселона значительно усилилась по сравнению с прошлым сезоном, который клуб может занести себе в пассив, так как впервые за много лет клуб продемонстрировал отвратительные результаты. Скорее всего, руководство, менеджер и футболисты сделали соответствующие выводы, поэтому в клуб были приглашены новички, которые должны вернуть команде былое величие. Гости отлично провели предсезонную подготовку, а уже по стартовым матчам чемпионата можно сказать, что команда Барселона будет очень грозным соперником. Мы думаем, что в матче с хозяевами поля гости продемонстрируют отличный футбол, что позволит им добиться успеха, поэтому наш прогноз – команда Барселона не проиграет. Предложенный общий тотал голов в этом матче нам кажется завышенным, здесь букмекеры серьезно переоценивают атакующие способности команд, поэтому мы советуем играть его на меньше.
Наши прогнозисты полагают, что у гостей сегодня есть все шансы для того, чтобы прервать победную серию футболистов команды Реал Мадрид. Команда Барселона значительно усилилась по сравнению с прошлым сезоном, который клуб может занести себе в пассив, так как впервые за много лет клуб продемонстрировал отвратительные результаты. Скорее всего, руководство, менеджер и футболисты сделали соответствующие выводы, поэтому в клуб были приглашены новички, которые должны вернуть команде былое величие. Гости отлично провели предсезонную подготовку, а уже по стартовым матчам чемпионата можно сказать, что команда Барселона будет очень грозным соперником. Мы думаем, что в матче с хозяевами поля гости продемонстрируют отличный футбол, что позволит им добиться успеха, поэтому наш прогноз – команда Барселона не проиграет. Предложенный общий тотал голов в этом матче нам кажется завышенным, здесь букмекеры серьезно переоценивают атакующие способности команд, поэтому мы советуем играть его на меньше.
СТАВКИ/КОЭФФИЦИЕНТЫ БУКМЕКЕРСКИХ КОНТОР НА МАТЧ Реал Мадрид — Барселона:
В случае победы хозяев букмекеры выплатят выигрыш по коэффициенту 2. 752, но, если в футбольном матче Реал Мадрид — Барселона сильнее будут хозяева, то выиграет котировка 2.65. При ничейном результате конторы выплатят по коэффициенту 3.64.
752, но, если в футбольном матче Реал Мадрид — Барселона сильнее будут хозяева, то выиграет котировка 2.65. При ничейном результате конторы выплатят по коэффициенту 3.64.
Прогноз на матч Реал Мадрид – Барселона (Чемпионат Испании, матч национального перевентсва, воскресенье, 10-го апреля):Футбольный клуб Реал Мадрид получил от букмекеров на свою победу котировку 2.752, а по коэффициенту 2.65 можно сделать ставку на выигрыш ФК Барселона. По котировке [kefdrew] принимаются ставки на ничью.
История личных встреч
Чтобы проанализировать и найти интересные прогнозы на матч команды Реал Мадрид и команды Барселона нашим экспертам потребовалось проработать большой объем информации. Сюда вошли и матчи прошлого сезона, сыгранные клубами, и товарищеские матчи, в которых команды принимали участие в межсезонье. Помимо этого, мы поработали с составами команд, выяснив полезность ушедших, оставшихся и пришедших футболистов. Все это позволило нам сделать определенные выводы, которые наши свое отражение в наших прогнозах. Команда Реал Мадрид и команда Барселона – клубы, которые в прошлом сезоне играли в атакующей манере. Однако сейчас для одной из команд такой стиль игры окажется неприемлемым, так как клуб покинуло ряд футболистов, отвечавших за креатив и реализацию. На их место были взяты новые исполнители, однако вряд ли наставник сходу будет строить игры всей команды через новичков. Скорее всего, клуб выберет защитный стиль, пытаясь угрожать воротом соперника на контратаках. Другая команда сохранила своих лидеров, поэтому мы полагаем, что здесь тренер не стал трогать прежнюю тактическую схему, оставив ее без изменений. Так что, наши прогнозисты видят в этом матче несколько вариантов развития событий, но наиболее реальным будет такой, когда одна команда будет постоянно атаковать, а другая будет стараться разрушать атаки, переходя в молниеносные контратаки. Независимо от тактики, которую наставники выберут для своих подопечных, мы полагаем, что игра получится интересной, и позволит утолить «голод» болельщиков, соскучившихся по футболу.
Команда Реал Мадрид и команда Барселона – клубы, которые в прошлом сезоне играли в атакующей манере. Однако сейчас для одной из команд такой стиль игры окажется неприемлемым, так как клуб покинуло ряд футболистов, отвечавших за креатив и реализацию. На их место были взяты новые исполнители, однако вряд ли наставник сходу будет строить игры всей команды через новичков. Скорее всего, клуб выберет защитный стиль, пытаясь угрожать воротом соперника на контратаках. Другая команда сохранила своих лидеров, поэтому мы полагаем, что здесь тренер не стал трогать прежнюю тактическую схему, оставив ее без изменений. Так что, наши прогнозисты видят в этом матче несколько вариантов развития событий, но наиболее реальным будет такой, когда одна команда будет постоянно атаковать, а другая будет стараться разрушать атаки, переходя в молниеносные контратаки. Независимо от тактики, которую наставники выберут для своих подопечных, мы полагаем, что игра получится интересной, и позволит утолить «голод» болельщиков, соскучившихся по футболу.
10-го апреля состоится всего один матч из нынешнего тура национального первенства, и им будет футбольная встреча Реал Мадрид — Барселона. Так как данный поединок вызвал огромный ажиотаж среди болельщиков, то его специально решили начать в 22:00 по Москве. Интерес вызван тем, что это принципиальные соперники, но так как в последнее время они выступали в различных дивизионах, то последний раз Реал Мадрид и Барселона встречались на футбольном поле четыре года назад. В том матче футболисты клуба Реал Мадрид одержали победу со счетом 4-2.
Предматчевый анализ и прогнозы букмекеров
Статистика – важнейший инструмент, который используют эксперты нашего ресурса при составлении прогнозов на футбольные матчи. В матче команды Реал Мадрид и команды Барселона, который состоится в ближайшем туре чемпионата, мы тоже использовали статистику для составления интересных прогнозов. Пока, судя по тем результатам, которые команды демонстрируют в нынешнем сезоне, складывается впечатление, что руководство клубов поставило перед ними серьезные задачи. Оба клуба играют в атакующем стиле, что подразумевает большое количество ударов по воротам соперника. Вообще, игра команд в нынешнем сезоне полностью заточена под атаку, что можно увидеть, взглянув на составы команд. Менеджеры сделали ставку не только на мощное нападение, но и на полузащиту, футболисты полузащиты активно подключаются к атакам команды и забивают не меньше нападающих. При этом серьезное внимание было уделено и построению хорошей обороны, которая во многих матчах сезона выглядит надежно и неприступно. В общем, сегодня команда Реал Мадрид и команда Барселона представляют собой крепкие орешки, которые могут испортить нервы любому клубу. Между собой эти команды всегда играют результативно. С первых и до последних минут матча клубы атакуют ворота друг друга, стараясь забить как можно больше мячей. Сейчас борьба в турнирной таблице обострена до предела, и чтобы занимать достойное место, командам необходимо показывать, в первую очередь, результат. Поэтому, по словам менеджеров клуба, в ближайшем матче их подопечные будут играть только на победу, следовательно, болельщиков ждет интересное противостояние.
Оба клуба играют в атакующем стиле, что подразумевает большое количество ударов по воротам соперника. Вообще, игра команд в нынешнем сезоне полностью заточена под атаку, что можно увидеть, взглянув на составы команд. Менеджеры сделали ставку не только на мощное нападение, но и на полузащиту, футболисты полузащиты активно подключаются к атакам команды и забивают не меньше нападающих. При этом серьезное внимание было уделено и построению хорошей обороны, которая во многих матчах сезона выглядит надежно и неприступно. В общем, сегодня команда Реал Мадрид и команда Барселона представляют собой крепкие орешки, которые могут испортить нервы любому клубу. Между собой эти команды всегда играют результативно. С первых и до последних минут матча клубы атакуют ворота друг друга, стараясь забить как можно больше мячей. Сейчас борьба в турнирной таблице обострена до предела, и чтобы занимать достойное место, командам необходимо показывать, в первую очередь, результат. Поэтому, по словам менеджеров клуба, в ближайшем матче их подопечные будут играть только на победу, следовательно, болельщиков ждет интересное противостояние.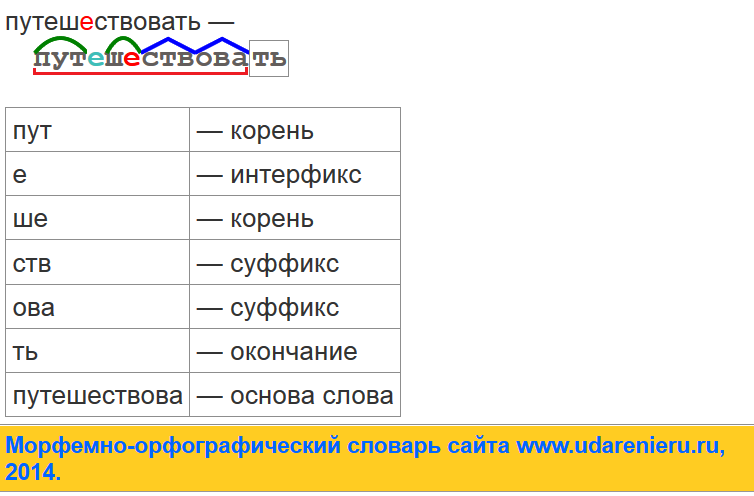
Очень много комплиментов в нынешнем сезоне звучит в адрес футболистов команды Реал Мадрид. Клуб действительно демонстрирует отличный футбол, добиваясь уверенных побед над своими соперниками. И это при том, что еще в прошлом сезоне клуб не показывал таких ошеломляющих результатов. Однако серия громких побед сделала свое дело, и в матче с футболистами команды Барселона хозяева поля идут фаворитами. По мнению экспертов нашего ресурса, такие котировки на победу команды Реал Мадрид в этом матче – не соответствуют действительности. Гости, пусть и расположились ниже своих соперников в турнирной таблице, команда, которая является крепким середняком с сыгранным составом. Возможно, что клуб и не хватает звезд с неба, однако футболисты команды Барселона способны упереться в каждом матче. Исходя из этого, наши эксперты полагают, что коэффициент, выставленный на победу хозяев поля – несколько завышен, поэтому мы рекомендуем делать ставки на фору команды Барселона, а более рисковые бетторы могут поставить на то, что гости не проиграют в этом матче. Общий тотал голов видится нам на меньше, так как команда Барселона редко позволяет своим соперникам забивать много голов, при этом, сами гости тоже не отличаются результативностью. Хозяева поля, пусть и будут действовать первым номером в этом матче, тоже будут играть с оглядкой на оборону, отсюда и получается, что ставка на тотал меньше в этом матче выглядит вполне надежной. Общий тотал желтых карточек и нарушений правил, мы рассматриваем на больше, так как игра будет преимущественно проходить в центре поля, поэтому оба клуба будут во всю использовать тактику мелкого фола для срыва атак соперника. Отсюда и общий тотал угловых тоже стоит играть на меньше, так как игра через центр не предполагает большого количества угловых в матче.
Общий тотал голов видится нам на меньше, так как команда Барселона редко позволяет своим соперникам забивать много голов, при этом, сами гости тоже не отличаются результативностью. Хозяева поля, пусть и будут действовать первым номером в этом матче, тоже будут играть с оглядкой на оборону, отсюда и получается, что ставка на тотал меньше в этом матче выглядит вполне надежной. Общий тотал желтых карточек и нарушений правил, мы рассматриваем на больше, так как игра будет преимущественно проходить в центре поля, поэтому оба клуба будут во всю использовать тактику мелкого фола для срыва атак соперника. Отсюда и общий тотал угловых тоже стоит играть на меньше, так как игра через центр не предполагает большого количества угловых в матче.
Реал Мадрид
В последние годы футбольный клуб Реал Мадрид постоянно входит в тройку сильнейших в чемпионате, так что регулярно принимает участие в Лиге Чемпионов. Но, как хозяева не стараются, все равно не могут стать чемпионами, ведь начинают борьбу за титул, но затем отставание от лидера только увеличивается. В данный момент оно достигло уже девяти очков, так что хоть футбольный клуб Реал Мадрид и идет вторым в чемпионате, но вернуться в борьбу за золотые медали будет не так просто. На своем поле команда показывает в этом сезоне уверенную игру, так что было только два поражения дома, и на родном стадионе футболисты клуба Реал Мадрид забивают в три раза больше мячей, чем пропускают. Сейчас хозяева выдают серию из семи побед подряд, но она никого не удивляет, так как команда играла по очень легкому календарю, где было много предсказуемых результатов. В этом поединке хозяевам не помогут левый защитник, а также центральный и опорный полузащитники. Под вопросом выход на поле правого нападающего.
В данный момент оно достигло уже девяти очков, так что хоть футбольный клуб Реал Мадрид и идет вторым в чемпионате, но вернуться в борьбу за золотые медали будет не так просто. На своем поле команда показывает в этом сезоне уверенную игру, так что было только два поражения дома, и на родном стадионе футболисты клуба Реал Мадрид забивают в три раза больше мячей, чем пропускают. Сейчас хозяева выдают серию из семи побед подряд, но она никого не удивляет, так как команда играла по очень легкому календарю, где было много предсказуемых результатов. В этом поединке хозяевам не помогут левый защитник, а также центральный и опорный полузащитники. Под вопросом выход на поле правого нападающего.
Барселона
В этом сезоне футболисты клуба Барселона сильно разочаровывают своих болельщиков, ведь если раньше команда была постоянным участником еврокубков, то в данный момент она пребывает в нижней части турнирной таблицы, занимая только тринадцатую строчку. Футбольный клуб Барселона много проигрывает не только на выезде, но и в родных стенах, а проблемы гостей заключаются в слабой обороне, которая практически в каждом матче пропускает по два гола. За команду играет один из лучших нападающих чемпионата, за которым охотятся местные гранды, но даже его двадцать забитых голов не помогают футбольному клубу Барселона подняться выше в турнирной таблице. Уже второй месяц команда находится в кризисе, так как на протяжении девяти туров не может выиграть. В этой безвыигрышной серии было пять поражений и четыре ничейных результата. Президент уже заявил главному тренеру, что если и в этом поединке футбольный клуб Барселона не сможет одержать победу, то ему грозит отставка. В составе гостей на поле не выйдут травмированные центральный и опорный полузащитники.
За команду играет один из лучших нападающих чемпионата, за которым охотятся местные гранды, но даже его двадцать забитых голов не помогают футбольному клубу Барселона подняться выше в турнирной таблице. Уже второй месяц команда находится в кризисе, так как на протяжении девяти туров не может выиграть. В этой безвыигрышной серии было пять поражений и четыре ничейных результата. Президент уже заявил главному тренеру, что если и в этом поединке футбольный клуб Барселона не сможет одержать победу, то ему грозит отставка. В составе гостей на поле не выйдут травмированные центральный и опорный полузащитники.
Несколько сезонов назад команда Реал Мадрид и команда Барселона находились в числе одних из претендентов на чемпионский титул, клубы могли навязать борьбу грандам. Однако теперь они скатились до уровня середняков. Можно винить в этом многие факторы, однако сейчас стоит отталкиваться от текущей формы команд. А она говорит нам, что оба клуба уже решили свои задачи в турнирной таблице, поэтому в оставшихся матчах сезона могут играть в свое удовольствие. Это означает, что наиболее выгодной ставкой в этом матче является ставка на общий тотал забитых голов на больше. Команда Реал Мадрид и команда Барселона в нынешнем сезоне играют в атакующий футбол, они много забивают и много пропускают. Скорее всего, в очном противостоянии менеджеры не будут менять тактическую схему своим клубам, и команды вновь продемонстрируют открытый футбол с максимумом голевых моментов. При этом, можно сделать ставки на то, что оба клуба забьют в этом матче, а также на индивидуальный тотал на больше каждой команды. Наши эксперты полагают, что делать прогнозы на исход этого матча бессмысленно, так как победа не даст преимущества в турнирной таблице не одному из соперников. А вот что действительно стоит играть, так это общий тотал нарушений и желтых карточек на меньше. Оба клуба не имеют турнирной мотивации, поэтому вряд ли будут играть грубо, да и в текущем сезоне эти команды не входят в число грубиянов чемпионата. Общий тотал угловых в этом противостоянии мы рассматриваем на больше, так как команда Реал Мадрид и команда Барселона строят свои атаки через фланги, поэтому подают много стандартов.
Это означает, что наиболее выгодной ставкой в этом матче является ставка на общий тотал забитых голов на больше. Команда Реал Мадрид и команда Барселона в нынешнем сезоне играют в атакующий футбол, они много забивают и много пропускают. Скорее всего, в очном противостоянии менеджеры не будут менять тактическую схему своим клубам, и команды вновь продемонстрируют открытый футбол с максимумом голевых моментов. При этом, можно сделать ставки на то, что оба клуба забьют в этом матче, а также на индивидуальный тотал на больше каждой команды. Наши эксперты полагают, что делать прогнозы на исход этого матча бессмысленно, так как победа не даст преимущества в турнирной таблице не одному из соперников. А вот что действительно стоит играть, так это общий тотал нарушений и желтых карточек на меньше. Оба клуба не имеют турнирной мотивации, поэтому вряд ли будут играть грубо, да и в текущем сезоне эти команды не входят в число грубиянов чемпионата. Общий тотал угловых в этом противостоянии мы рассматриваем на больше, так как команда Реал Мадрид и команда Барселона строят свои атаки через фланги, поэтому подают много стандартов.
Игра закончится победой Реал Мадрид — 2.752, нет победителей в игре — 3.64, игра закончится победой Барселона — 2.65.
Интересно, что букмекеры тоже учитывают фактор концовки чемпионата, выставляя коэффициенты на матчи команд. Так, на матчи клубов, которые уже не решают в чемпионате никаких задач, коэффициенты на победу будут примерно одинаковыми, зато клубы, которые продолжают вести борьбу, низко котируются букмекерами. Это и предлагают использовать эксперты нашего ресурса. К примеру, мы обратили внимание на матч, в котором встретятся команда Реал Мадрид и команда Барселона. Оба клуба уже решили свои задачи в турнирной таблице, однако, хозяева поля, по информации менеджера, будут выступать сильнейшим составом с минимальным количество кадровых перестановок, тогда как их соперники приедут на матч в ослабленном составе – менеджер решил поберечь силы своих лидеров. Мы полагаем, что команда Реал Мадрид в этом матче без проблем должна разбираться со своими соперниками, и предлагаем делать ставки на победу хозяев поля. Учитывая, что хозяева поля в родных стенах играют в агрессивной манере, много атакуют, то общий тотал голов в матче мы рассматриваем на больше, тем более, что гости будут выступать резервом, что существенно увеличивает шансы нашего прогноза. Угловые команда Реал Мадрид тоже подает в большом количестве, поэтому индивидуальный тотал угловых и фора по угловым хозяев поля – отличные ставки в этом матче. Относительно нарушений и желтых карточек, то команды вряд ли будут много фолить, ведь никто не захочет получать травмы в концовке сезона, да и результат матча для команды Реал Мадрид и команды Барселона не будет являться принципиальным. Поэтому эти параметры мы рекомендуем играть на меньше.
Учитывая, что хозяева поля в родных стенах играют в агрессивной манере, много атакуют, то общий тотал голов в матче мы рассматриваем на больше, тем более, что гости будут выступать резервом, что существенно увеличивает шансы нашего прогноза. Угловые команда Реал Мадрид тоже подает в большом количестве, поэтому индивидуальный тотал угловых и фора по угловым хозяев поля – отличные ставки в этом матче. Относительно нарушений и желтых карточек, то команды вряд ли будут много фолить, ведь никто не захочет получать травмы в концовке сезона, да и результат матча для команды Реал Мадрид и команды Барселона не будет являться принципиальным. Поэтому эти параметры мы рекомендуем играть на меньше.
«Реал Мадрид»
Этот сезон футбольный клуб Реал Мадрид проводит на неплохом уровне, ведь получилось пройти групповой этап Лиги Чемпионов, а сейчас команда имеет отличные шансы на то, чтобы снова квалифицироваться в самый престижный европейский турнир. Хозяева идут третьими в чемпионате, но на две последние путевки в Лигу Чемпионов претендует сразу четыре команды, так что до конца сезона предстоит еще упорная борьба. На своем поле Реал Мадрид играет очень хорошо, так как поражений еще не было в этом сезоне, но ничьи все же случаются довольно часто. По количеству забитых мячей хозяева уступают только лидеру чемпионата, но оборона команды не самая надежная, что связано со слишком атакующим стилем футбольного клуба Реал Мадрид. Сейчас хозяева находятся в хорошей форме, ведь в шести последних турах хоть и было неожиданное гостевое поражение от аутсайдера, но в остальных пяти матчах были уверенные победы. Левый вингер перебрал желтых карточек, так что вынужден пропустить этот поединок.
На своем поле Реал Мадрид играет очень хорошо, так как поражений еще не было в этом сезоне, но ничьи все же случаются довольно часто. По количеству забитых мячей хозяева уступают только лидеру чемпионата, но оборона команды не самая надежная, что связано со слишком атакующим стилем футбольного клуба Реал Мадрид. Сейчас хозяева находятся в хорошей форме, ведь в шести последних турах хоть и было неожиданное гостевое поражение от аутсайдера, но в остальных пяти матчах были уверенные победы. Левый вингер перебрал желтых карточек, так что вынужден пропустить этот поединок.
«Барселона»
Мало кто ожидал, что всегда стабильный и прагматичный футбольный клуб Барселона в этом сезоне будет бороться за выживание в дивизионе. Команда всегда ранее показывала скучный футбол, делая ставку на тотальную оборону, и это позволяло постоянно находиться в середине таблицы. Но, летом ушло много футболистов оборонительного плана, играющих ключевую роль, так что гости стали намного больше пропускать, а ведь игра в нападении лучше не стала. Так что, сейчас футбольный клуб Барселона идет лишь третьим с конца, а главный тренер делает все возможное, чтобы покинуть зону вылета. Во время зимнего трансферного окна ряды гостей пополнили три опытных защитника, так что с их помощью главный тренер надеется навести порядок в обороне. Ведь в последних семи турах футбольный клуб Барселона взял только пять очков, регулярно пропуская в каждом поединке. Травмированы только два полузащитника, но важной роли при данном наставнике они не играют.
Так что, сейчас футбольный клуб Барселона идет лишь третьим с конца, а главный тренер делает все возможное, чтобы покинуть зону вылета. Во время зимнего трансферного окна ряды гостей пополнили три опытных защитника, так что с их помощью главный тренер надеется навести порядок в обороне. Ведь в последних семи турах футбольный клуб Барселона взял только пять очков, регулярно пропуская в каждом поединке. Травмированы только два полузащитника, но важной роли при данном наставнике они не играют.
Статистика и личные встречи
Наши эксперты постоянно мониторят линии букмекерских контор в поисках интересных матчей. Если рассматривать футбольные матчи с практической точки зрения, то составить прогноз можно на любой футбольный матч, независимо от того, к какому чемпиону он относится. Это может быть даже самая неизвестная лига третьесортного чемпионата. Однако наши эксперты занимаются тем, что прогнозируют исходы и статистику тех футбольных матчей, смотреть которые предпочитают все любители футбола. Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Реал Мадрид и команда Барселона. Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Реал Мадрид и команда Барселона. Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Реал Мадрид — Барселона. Прогноз на футбол (10.04.21)
Эксперты нашего портала и аналитики букмекерских контор сошлись во мнении относительно того, кто должен быть фаворитам футбольного матча между футболистами команды Реал Мадрид и футболистами команды Барселона. Сейчас, когда чемпионат подходит к концу, хозяевам поля необходимо побеждать, чтобы оставаться в числе клубов, претендующих на высокие места чемпионата. А вот гости уже свою задачу в нынешнем сезоне выполнили, клуб хоть и находится во второй части турнирной таблицы, однако уже гарантировал себе участие в чемпионате на будущий сезон, так что, менеджер команды Барселона может позволить себе дать отдых ведущим футболистам команды. А вот хозяевам поля придется играть сильнейшим составом, так как клуб не может позволить себе отступить. Из этого получается, что сегодня команда Реал Мадрид не просто победит, но и сделает это крупно, следовательно, стоит пробовать заигрывать фору хозяев поля. Общий тотал матча наши эксперты видят на больше, так как хозяева имеют великолепных футболистов атаки, которые с первых минут будут беспокоить оборону соперника, прибывшего на матч в ослабленном составе. Так что, и общий, и индивидуальный тотал команды Реал Мадрид в этом матче мы рекомендуем играть на больше. Вряд ли в матче будет много нарушений, так как уже в принципе понятно, кто победит, так что, футболисты не будут лишний раз наносить друг другу травмы. Исходя из этого, общий тотал фолов и желтых карточек мы рекомендуем играть на меньше. А вот угловых в матче мы видим много, так как оба клуба вряд ли будут играть в защитный футбол, а при атаке и команда Реал Мадрид, и команда Барселона активно использует фланги, поэтому тотал угловых, скорее всего, перебьют.
Так что, и общий, и индивидуальный тотал команды Реал Мадрид в этом матче мы рекомендуем играть на больше. Вряд ли в матче будет много нарушений, так как уже в принципе понятно, кто победит, так что, футболисты не будут лишний раз наносить друг другу травмы. Исходя из этого, общий тотал фолов и желтых карточек мы рекомендуем играть на меньше. А вот угловых в матче мы видим много, так как оба клуба вряд ли будут играть в защитный футбол, а при атаке и команда Реал Мадрид, и команда Барселона активно использует фланги, поэтому тотал угловых, скорее всего, перебьют.
С появлением Интернета прогнозировать и наблюдать за футбольными матчами стало гораздо более удобно. Сейчас уже нет необходимости по старинке записывать результаты футбольных матчей в специальную тетрадку, а потом перелистывать ее в поиске важных записей. Сегодня достаточно открыть вкладку, зайти на специальную страницу, и можно не только посмотреть любой футбольный матч в записи, но и воспользоваться специализированным ресурсом, на котором поминутно расписаны все наиболее важные события, произошедшие в матче, не говоря уже о статистических показателях, как отдельной команды, так и отдельного футболиста. Информационные технологии существенно облегчают жизнь, помогают они и экспертам нашего ресурса, так как благодаря Интернету собирать и анализировать информацию стало в разу проще, хотя, времени на анализ и прогнозирование уходит примерно столько же, как и уходило, так как необходимо все тщательно обдумать и принять верное решение. В матче команды Реал Мадрид и команды Барселона наши эксперты долго не думали, так как все прогнозы казались очевидными, мы лишь воспользовались статистикой для выбора оптимальной ставки. Надеемся, что бетторам помогут наши прогнозы.
Информационные технологии существенно облегчают жизнь, помогают они и экспертам нашего ресурса, так как благодаря Интернету собирать и анализировать информацию стало в разу проще, хотя, времени на анализ и прогнозирование уходит примерно столько же, как и уходило, так как необходимо все тщательно обдумать и принять верное решение. В матче команды Реал Мадрид и команды Барселона наши эксперты долго не думали, так как все прогнозы казались очевидными, мы лишь воспользовались статистикой для выбора оптимальной ставки. Надеемся, что бетторам помогут наши прогнозы.
С данными наставниками футбольные клубы Реал Мадрид и Барселона перешли к более оборонительной манере игры, так что вряд ли зрители на трибунах станут свидетелями результативного матча. Эксперты предлагают поставить на тотал менее 2.5 голов.
Реал Мадрид – Барселона: статистика и история личных встреч
Команда Реал Мадрид и команда Барселона относятся к тем футбольным клубам, которые в нынешнем сезоне демонстрируют не только отличный футбол, но и высокий уровень индивидуальной подготовки футболистов. В нынешнем сезоне эти команды уже показали, что им практически нет равных среди других клубов чемпионата, поэтому они и располагаются на верхних строчках турнирной таблицы. Наши эксперты считают, что противостояние команды Реал Мадрид и команды Барселона является центральным матчем чемпионата, так как победитель этого матча получит отличное преимущество над ближайшими преследователями, в числе которых может оказаться и проигравший клуб. Поэтому к очному противостоянию оба клуба тщательно готовились, и, по словам менеджеров команд, со стартового свистка на поле будут действовать все футболисты основы обеих команд. Напомним, что в составах команды Реал Мадрид и команды Барселона выступают настоящие профессионалы, которые демонстрируют отличный командный футбол, но могут и в одиночку решить судьбу любого игрового эпизода. Наши эксперты постарались выбрать интересные прогнозы на этот матч среди многочисленных предложений букмекеров, и нам это удалось. Ниже можно изучить наши прогнозы более подробно.
В нынешнем сезоне эти команды уже показали, что им практически нет равных среди других клубов чемпионата, поэтому они и располагаются на верхних строчках турнирной таблицы. Наши эксперты считают, что противостояние команды Реал Мадрид и команды Барселона является центральным матчем чемпионата, так как победитель этого матча получит отличное преимущество над ближайшими преследователями, в числе которых может оказаться и проигравший клуб. Поэтому к очному противостоянию оба клуба тщательно готовились, и, по словам менеджеров команд, со стартового свистка на поле будут действовать все футболисты основы обеих команд. Напомним, что в составах команды Реал Мадрид и команды Барселона выступают настоящие профессионалы, которые демонстрируют отличный командный футбол, но могут и в одиночку решить судьбу любого игрового эпизода. Наши эксперты постарались выбрать интересные прогнозы на этот матч среди многочисленных предложений букмекеров, и нам это удалось. Ниже можно изучить наши прогнозы более подробно. Мы думаем, что игра будет интересной и запоминающейся, так как футболисты обеих команд будут играть только на победу.
Мы думаем, что игра будет интересной и запоминающейся, так как футболисты обеих команд будут играть только на победу.
http://evolvegame.ru/cat0-388945-segodnya-match-kalaban-sport-zhen-dzholiba-zhen-prognozy-i-stavki-ot-eksperta-10-04-21/
Навигация по записям
Фанаты Valorant раскрыли локацию следующей карты — Бермудский треугольник
2021-04-09 10:12:00
Пользователи сети нашли намеки на то, где будет располагаться следующая карта в Valorant. Судя по всему, новая локация находится в Бермудском треугольнике.
8 апреля Riot Games анонсировала «Ночной рынок» — событие со случайными скидками на скины для оружия. По углам картинки, выпущенной к старту ивента, пользователи нашли координаты: 25 градусов северной широты и 71 градус западной долготы на карте. Кроме того, по центру изображения размещена надпись «Carib.», что отсылает к карибскому морю.
Если ввести эти значения в картах Google, то полученная точка окажется примерно в середине Бермудского треугольника — района Атлантического океана рядом с побережьем Северной Америки, в котором часто пропадали воздушные и морские суда.
Версия выглядит правдоподобной, так как, возможно, задние планы карты показали на шуточном анонсе спин-оффа шутера. 1 апреля Riot Games презентовала Valorant: Agents of Romance — симулятор свиданий с персонажами тайтла. Затем датамайнеры обнаружили в файлах оригинальной игры название новой карты и музыку с ее загрузки. Локация будет называться Foxtrot.
Датамайнеры: Новая карта в Valorant получит название Foxtrot
Точная дата релиза новой карты неизвестна. Вероятно, локация выйдет к старту нового эпизода боевого пропуска, который запланирован на 21 апреля.
Обзор фильма «Мортал Комбат». А ну иди сюда! — Игромания
Новая экранизация культовой серии файтингов уделывает фильм 1995 года в кровавости и только в ней.
«Смертельную битву» Пола У. С. Андерсона многие, включая нас, называют лучшей игровой экранизацией в истории. Сюжет верен букве и духу первоисточника, бои поставлены зрелищно, актёры харизматичны, декорации эффектны, а саундтрек так и вовсе вошёл в историю. В конце концов, это просто крепкий приключенческий боевик, который исправно развлекает зрителя. А вот критикуют «Смертельную битву» обычно за три вещи: графику, которая выглядела стрёмно даже в 1995-м, бескровные фаталити, а также низведение Скорпиона и Саб-Зиро до статуса безмозглых рабов Шанг Цзуна. Всё это обещали исправить в новой версии, которая после десяти лет производственного ада наконец-то добралась до экранов.
С. Андерсона многие, включая нас, называют лучшей игровой экранизацией в истории. Сюжет верен букве и духу первоисточника, бои поставлены зрелищно, актёры харизматичны, декорации эффектны, а саундтрек так и вовсе вошёл в историю. В конце концов, это просто крепкий приключенческий боевик, который исправно развлекает зрителя. А вот критикуют «Смертельную битву» обычно за три вещи: графику, которая выглядела стрёмно даже в 1995-м, бескровные фаталити, а также низведение Скорпиона и Саб-Зиро до статуса безмозглых рабов Шанг Цзуна. Всё это обещали исправить в новой версии, которая после десяти лет производственного ада наконец-то добралась до экранов.
Коул Янг — талантливый, но не слишком успешный боец MMA. Он отлично держит удар, только вот побеждать на ринге почему-то не получается. Впрочем, это и не так важно, пока Коула поддерживают жена и дочка. Единственное, что действительно беспокоит бойца, — это видения, в которых ему является некий древний воин, объятый пламенем. Вскоре оказывается, что видения — это только предзнаменование грядущих бед. Сперва за Коулом и его семьёй приходит убийца, способный замораживать всё вокруг, а после герой узнаёт, что ему буквально на роду написано участвовать в древнем турнире, где на кон поставлена судьба всей планеты.
Сперва за Коулом и его семьёй приходит убийца, способный замораживать всё вокруг, а после герой узнаёт, что ему буквально на роду написано участвовать в древнем турнире, где на кон поставлена судьба всей планеты.
Начнём с главного: перед нами очень и очень тупой фильм. И в хорошем смысле, и в плохом. Если рассматривать его с позиции «настоящего» кино — то есть разбирать сюжет, проработку персонажей, расстановку акцентов и прочее — то у «Мортал Комбат» образца 2021 года нет никаких шансов. Ленту можно с чистой совестью размолоть в труху. Даже версия Андерсона при всей своей простоте и прямолинейности выдерживает это испытание увереннее просто потому, что больше заботится о рядовом зрителе. Новый же фильм плевать на него хотел. Он скорее напрашивается в пантеон современного грайндхауса, в узкую категорию ультра-кровавых перезапусков для фанатов, где уже стоят «Каратель: Территория войны», «Дредд» и «Хеллбой» Нила Маршалла.
Несмотря на солидный возраст в 60 лет, Хироюки Санада вполне убедительно выглядит в роли Скорпиона. Жаль, экранного времени у него совсем немного
Жаль, экранного времени у него совсем немного
С последним ленту роднит сумбурность происходящего. По-хорошему, событий в «Мортал Комбат» хватило бы на целый «снайдеркат» или даже на сезон сериала. Тут и истоки вражды Саб-Зиро и Скорпиона, и сбор защитников земного царства с последующим их обучением, и попытки колдуна Шан Цзуна саботировать турнир, и тайна происхождения Коула… И всё это через силу пытаются запихнуть в полтора часа. Хронометража настолько не хватает, что в третьем акте создатели забивают на последние правила приличия и к чёрту выкидывают какие-либо сюжетные связки между экшеном. Да и в первых двух фильм так лихорадит, что у зрителя едва ли есть хотя бы пара минут перевести дух.
Но это… правильно. Скорее случайно, чем намеренно, «Мортал Комбат» избегает главной ошибки «Годзиллы против Конга» — он не заставляет вас ждать того, ради чего вы, собственно, пришли. Лента начинается с драки, продолжается драками и заканчивается дракой. А всё, что между драками, сделано по принципу хорошей порнопародии: заполнено шутейками и фансервисом.
Весь юмор тащит на себе Кано в исполнении Джоша Лоусона. Он забавно ругается, забавно комментирует происходящее и в принципе больше остальных похож на живого человека. Жаль, создатели не додумались сделать его протагонистом. Другие герои просто подменяют персонажей «Смертельной битвы» Андерсона. Коул Янг — вместо Лю Кана, Лю Кан — вместо Китаны, Соня Блейд — вместо… Сони Блейд. Есть ещё Джакс и Кун Лао, но нужны они исключительно для массовки.
Понятно, почему в сюжет не стали вводить Джонни Кейджа: два балагура в команде — это явный перебор
Ах да, Скорпион и Саб-Зиро. Самые знаменитые персонажи MK. Центральные фигуры всей рекламной кампании фильма. Что ж, они в «Мортал Комбат» есть — и даже дерутся. Два раза: в начале и в конце. Причём криомансер хотя бы возникает то тут, то там, преследуя героев, а вот бедняга Хандзо Хасаси вплоть до самого финала сидит в преисподней. Это несколько разочаровывает. Как и отсутствие, собственно, Смертельной битвы. Да, в фильме, где сюжет вертится вокруг турнира между мирами, этого самого турнира нет — как уже было сказано, его пытается сорвать Шан Цзун. Из-за этого теряется масштаб происходящего, ведь та самая большая игра за судьбу планеты ещё даже не началась.
Из-за этого теряется масштаб происходящего, ведь та самая большая игра за судьбу планеты ещё даже не началась.
Впрочем, это всё не так уж важно: драться герои могут хоть в подворотне — главное, чтобы это выглядело круто. Но с поединками всё не так однозначно, как хотелось бы. Дело в том, что в том же фильме Пола Андерсона центральный актёрский состав был более чем наполовину укомплектован мастерами боевых искусств и профессиональными каскадёрами. А вот в новой версии необходимым опытом могут похвастаться лишь трое — исполнитель главной роли Льюис Тан, а также Джо Таслим, который играет Саб-Зиро, и Макс Хуан, что примеряет образ Кун Лао. Только они могут сделать в кадре что-то по-настоящему. Всех остальных, сплошь бывших фотомоделей, приходится подменять дублёрами и кромсать поединки хаотичным монтажом. И если вы видели «Рейд» или «Ночь идёт за нами», то получившийся результат вас впечатлит едва ли.
Зато с фаталити точно никаких проблем. Тут создатели своё обещание исполнили, ведь «Мортал Комбат» брутален настолько, насколько должен быть. Кишки выпадают из рассечённых животов, кости ломаются, плоть горит, а компьютерная кровища хлещет фонтанами. Снято всё очень смачно, с настоящей гордостью за проделанную художниками работу. Ультранасилие — тот самый аттракцион, которым фильм заманивает зрителя, и если вы цените жесть с примесью чёрного юмора, эта поездка определённо того стоит. Трудно вспомнить, когда в последний раз в экшен-фильме рейтинг R был бы настолько оправдан.
Кишки выпадают из рассечённых животов, кости ломаются, плоть горит, а компьютерная кровища хлещет фонтанами. Снято всё очень смачно, с настоящей гордостью за проделанную художниками работу. Ультранасилие — тот самый аттракцион, которым фильм заманивает зрителя, и если вы цените жесть с примесью чёрного юмора, эта поездка определённо того стоит. Трудно вспомнить, когда в последний раз в экшен-фильме рейтинг R был бы настолько оправдан.
Как уже было сказано, «Мортал Комбат» — это бескомпромиссно тупое кино, которое совершенно не стесняется своей тупости. Критики наверняка раздраконят его в пух и прах, и есть за что. На счету режиссёра Саймона Маккуойда и ведущего сценариста Грега Руссо нет не только полнометражных фильмов, но и даже завалящего сериальчика. Студия почему-то доверила проект новичкам, и это чувствуется. Однако у них получился ничем не замутнённый и в достаточной степени угарный треш, не претендующий ни на что большее — в том числе и на лавры лучшей игровой адаптации. Если вы просто хотите увидеть, как герои, знакомые с детства, рвут друг друга на части на большом экране, то «Мортал Комбат» это желание исполнит. Ничего другого ждать не стоит.
Ничего другого ждать не стоит.
Больше на Игромании
Прогнозы и ставки специалистов на матч Престон Норт Энд — Брентфорд 10.
04.21 — Питер-Today, сайт города Санкт-Петербург
Футболисты клуба Престон Норт Энд пообещали 10-го апреля на своем поле взять реванш у ФК Брентфорд за недавнее гостевое поражение со счетом 1-4. Организаторы данного турнира собираются начать поединок в 17:00 по Москве. В целом, футбольный клуб Престон Норт Энд является фаворитом, исходя из статистики предыдущих матчей, ведь имеет 35 побед в 59 встречах. Но, в последнее время хозяева не лучшим образом играют с данным соперником, потерпев два поражения в трех матчах и сыграв один раз вничью.
br>
Букмекеры предложили большой выбор ставок на футбольный матч, в котором соперниками будут команда Престон Норт Энд и команда Брентфорд. Эти клубы давно ведут непримиримую борьбу в чемпионате, а в последние годы их противостояние вышло на новый уровень, так как сейчас эти команды одни из основных претендентов на борьбу за золотые медали футбольного первенства своей страны. Так что нас ждет горячее противостояние, в котором нашим прогнозистам наиболее вероятной ставкой видится ставка на тотал больше желтых карточек. Статистика показывает, что в матчах между собой соперники всегда действуют очень грубо, что будет способствовать проходу ставки. Конечно, команда Престон Норт Энд на порядок сильнее своих соперников, однако, на наш взгляд, букмекеры несколько занизили коэффициент на победу хозяев поля. И мы предлагаем здесь заиграть ставку на фору гостей. Вряд ли у команды Престон Норт Энд сейчас все настолько хорошо, чтобы хозяева смогли обыграть своих соперников с преимуществом в несколько голов. Да и команда Брентфорд уже далеко не такие мальчики для битья. Нет сомнений в том, что матч будет результативным, в составах обеих команд достаточно футболистов, которые умеют реализовывать голевые моменты.
Эти клубы давно ведут непримиримую борьбу в чемпионате, а в последние годы их противостояние вышло на новый уровень, так как сейчас эти команды одни из основных претендентов на борьбу за золотые медали футбольного первенства своей страны. Так что нас ждет горячее противостояние, в котором нашим прогнозистам наиболее вероятной ставкой видится ставка на тотал больше желтых карточек. Статистика показывает, что в матчах между собой соперники всегда действуют очень грубо, что будет способствовать проходу ставки. Конечно, команда Престон Норт Энд на порядок сильнее своих соперников, однако, на наш взгляд, букмекеры несколько занизили коэффициент на победу хозяев поля. И мы предлагаем здесь заиграть ставку на фору гостей. Вряд ли у команды Престон Норт Энд сейчас все настолько хорошо, чтобы хозяева смогли обыграть своих соперников с преимуществом в несколько голов. Да и команда Брентфорд уже далеко не такие мальчики для битья. Нет сомнений в том, что матч будет результативным, в составах обеих команд достаточно футболистов, которые умеют реализовывать голевые моменты. Пробитию тотала также будет способствовать то, что оба клуба действуют в атакующем стиле, поэтому ставка на тотал больше в этом матче выглядит вполне оправданным выбором.
Пробитию тотала также будет способствовать то, что оба клуба действуют в атакующем стиле, поэтому ставка на тотал больше в этом матче выглядит вполне оправданным выбором.
СТАВКИ/КОЭФФИЦИЕНТЫ БУКМЕКЕРСКИХ КОНТОР НА МАТЧ Престон Норт Энд — Брентфорд:
Футбольный клуб Престон Норт Энд считается фаворитом данного противостояния, из-за чего букмекеры выставили на победу невысокий коэффициент 3. 44. Гораздо больший коэффициент 2.02 получил футбольный клуб Брентфорд, а между ними находится котировка на ничью 3.3.
Прогноз на матч Престон Норт Энд – Брентфорд (Чемпионат Англии, матч национального перевентсва, воскресенье, 10-го апреля):Футбольный клуб Престон Норт Энд получил от букмекеров на свою победу котировку 3.44, а по коэффициенту 2.02 можно сделать ставку на выигрыш ФК Брентфорд. По котировке [kefdrew] принимаются ставки на ничью.
История личных встреч
Матч команды Престон Норт Энд и команды Брентфорд наши прогнозисты никак не могли оставить без внимания.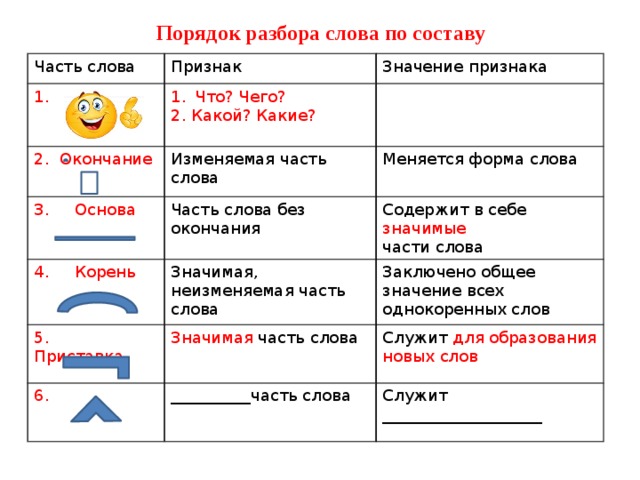 И дело здесь не только в том, что он будет первым интересным футбольным противостоянием нынешнего сезона. У команд в прошлом сезоне сложились непростые взаимоотношения, так как в одном из матчей неправильное судейское решение привело к довольно драматичным последствиям. Сразу несколько футболистов в составах команд были удалены с поля за грубые нарушения и неспортивное поведение. В СМИ этот инцидент освещался, а затем было сказано, что футболисты помирились. Конечно, на публике оно может быть и так, но вряд ли инцидент можно считать полностью исчерпанным, так что, мы ждем горячего противостояния, тем более что матч будет обслуживать строгий рефери, который не скупится на предупреждения. Теперь о самой игре. Если сравнивать с прошлым сезоном, то существенных кадровых потерь клубы не понесли: да, некоторые футболисты ушли в другие клубы, но на их место пришли другие игроки. Поэтому тренерам не понадобилось менять тактическую схему игры команд, перестраивая ее под конкретного футболиста или группу футболистов.
И дело здесь не только в том, что он будет первым интересным футбольным противостоянием нынешнего сезона. У команд в прошлом сезоне сложились непростые взаимоотношения, так как в одном из матчей неправильное судейское решение привело к довольно драматичным последствиям. Сразу несколько футболистов в составах команд были удалены с поля за грубые нарушения и неспортивное поведение. В СМИ этот инцидент освещался, а затем было сказано, что футболисты помирились. Конечно, на публике оно может быть и так, но вряд ли инцидент можно считать полностью исчерпанным, так что, мы ждем горячего противостояния, тем более что матч будет обслуживать строгий рефери, который не скупится на предупреждения. Теперь о самой игре. Если сравнивать с прошлым сезоном, то существенных кадровых потерь клубы не понесли: да, некоторые футболисты ушли в другие клубы, но на их место пришли другие игроки. Поэтому тренерам не понадобилось менять тактическую схему игры команд, перестраивая ее под конкретного футболиста или группу футболистов. Напомним, что в прошлом сезоне команды действовали активно, то есть, пытались обострять ситуацию, а не ждали своего шанса, ориентируясь на контратаки. Чего-то подобного мы ждем в этом матче, тем более что все футболисты соскучились по игре, и будут стараться максимально проявить себя на поле.
Напомним, что в прошлом сезоне команды действовали активно, то есть, пытались обострять ситуацию, а не ждали своего шанса, ориентируясь на контратаки. Чего-то подобного мы ждем в этом матче, тем более что все футболисты соскучились по игре, и будут стараться максимально проявить себя на поле.
Футбольному клубу Престон Норт Энд предстоит сыграть 10-го апреля очень ответственный поединок, результат которого может существенно повлиять на чемпионскую гонку. В гости приезжают футболисты клуба Брентфорд, и уже известно, что в 17:00 по МСК стадион будет полностью заполнен, ведь болельщики раскупили все билеты, чтобы поддержать команду. Данная встреча для команд будет первой в рамках этого сезона, а в прошлом году они играли между собой дважды, и обменялись гостевыми победами.
Предматчевый анализ и прогнозы букмекеров
Статистика – важнейший инструмент, который используют эксперты нашего ресурса при составлении прогнозов на футбольные матчи. В матче команды Престон Норт Энд и команды Брентфорд, который состоится в ближайшем туре чемпионата, мы тоже использовали статистику для составления интересных прогнозов. Пока, судя по тем результатам, которые команды демонстрируют в нынешнем сезоне, складывается впечатление, что руководство клубов поставило перед ними серьезные задачи. Оба клуба играют в атакующем стиле, что подразумевает большое количество ударов по воротам соперника. Вообще, игра команд в нынешнем сезоне полностью заточена под атаку, что можно увидеть, взглянув на составы команд. Менеджеры сделали ставку не только на мощное нападение, но и на полузащиту, футболисты полузащиты активно подключаются к атакам команды и забивают не меньше нападающих. При этом серьезное внимание было уделено и построению хорошей обороны, которая во многих матчах сезона выглядит надежно и неприступно. В общем, сегодня команда Престон Норт Энд и команда Брентфорд представляют собой крепкие орешки, которые могут испортить нервы любому клубу. Между собой эти команды всегда играют результативно. С первых и до последних минут матча клубы атакуют ворота друг друга, стараясь забить как можно больше мячей. Сейчас борьба в турнирной таблице обострена до предела, и чтобы занимать достойное место, командам необходимо показывать, в первую очередь, результат.
Пока, судя по тем результатам, которые команды демонстрируют в нынешнем сезоне, складывается впечатление, что руководство клубов поставило перед ними серьезные задачи. Оба клуба играют в атакующем стиле, что подразумевает большое количество ударов по воротам соперника. Вообще, игра команд в нынешнем сезоне полностью заточена под атаку, что можно увидеть, взглянув на составы команд. Менеджеры сделали ставку не только на мощное нападение, но и на полузащиту, футболисты полузащиты активно подключаются к атакам команды и забивают не меньше нападающих. При этом серьезное внимание было уделено и построению хорошей обороны, которая во многих матчах сезона выглядит надежно и неприступно. В общем, сегодня команда Престон Норт Энд и команда Брентфорд представляют собой крепкие орешки, которые могут испортить нервы любому клубу. Между собой эти команды всегда играют результативно. С первых и до последних минут матча клубы атакуют ворота друг друга, стараясь забить как можно больше мячей. Сейчас борьба в турнирной таблице обострена до предела, и чтобы занимать достойное место, командам необходимо показывать, в первую очередь, результат. Поэтому, по словам менеджеров клуба, в ближайшем матче их подопечные будут играть только на победу, следовательно, болельщиков ждет интересное противостояние.
Поэтому, по словам менеджеров клуба, в ближайшем матче их подопечные будут играть только на победу, следовательно, болельщиков ждет интересное противостояние.
Для многих любителей футбола противостояние команды Престон Норт Энд и команды Брентфорд – это отличная возможность не только насладиться хорошим матчем, но и выиграть в букмекерских конторах. И в этом свою помощь предлагают эксперты нашего ресурса. Хозяева поля сейчас попали в не совсем удачную полосу, которую необходимо прерывать. Однако команда Брентфорд – не самый лучший соперник для того чтобы прервать полосу неудач. Гости – крепкий орешек, и даже учитывая тот факт, что в составе команды Брентфорд не будет нескольких футболистов основы, которые выбыли из-за травм, пробить оборону гостей хозяевам поля будет очень и очень непросто. Поэтому, учитывая личные встречи, а также беря во внимание важность матча для обеих команд, наши эксперты пришли к мнению, что наиболее интересной ставкой в это противостоянии будет ставка на общий тотал забитых голов на меньше. Мы предполагаем, что игра будет преимущественно проходить в центре поля, следовательно, оба клуба будут активно использовать тактику мелкого фола, в связи с этим, общий тотал нарушений правил, а также общий тотал желтых карточек наши эксперты рекомендуют играть на больше. При этом, мы думаем, что в матче велика вероятность удаления игрока с поля, так как, если взглянуть на статистику противостояний этих клубов, удаления здесь довольно частое явление, а за предложенный букмекерами коэффициент – точно стоит рисковать. Относительно фаворита этого матча, то, мы полагаем, что хозяева поля вряд ли проиграют, так как сейчас им нужна победа как никогда, поэтому мы рекомендуем делать ставки с форой на футболистов команды Престон Норт Энд, а рисковые бетторы могут попробовать заиграть победу хозяев поля.
Мы предполагаем, что игра будет преимущественно проходить в центре поля, следовательно, оба клуба будут активно использовать тактику мелкого фола, в связи с этим, общий тотал нарушений правил, а также общий тотал желтых карточек наши эксперты рекомендуют играть на больше. При этом, мы думаем, что в матче велика вероятность удаления игрока с поля, так как, если взглянуть на статистику противостояний этих клубов, удаления здесь довольно частое явление, а за предложенный букмекерами коэффициент – точно стоит рисковать. Относительно фаворита этого матча, то, мы полагаем, что хозяева поля вряд ли проиграют, так как сейчас им нужна победа как никогда, поэтому мы рекомендуем делать ставки с форой на футболистов команды Престон Норт Энд, а рисковые бетторы могут попробовать заиграть победу хозяев поля.
Престон Норт Энд
Болельщики футбольного клуба Престон Норт Энд уже смирились с тем, что он в последние годы постоянно перемещается между дивизионами. В начале сезона все также шло к тому, что команду ожидает понижение в классе, но после того, как был уволен главный тренер и на его место пришел опытный иностранный специалист, результаты команды постепенно стали улучшаться. Хозяева смогли выбраться из зоны вылета, а сейчас вообще идут десятыми, так что оторваться от аутсайдеров получилось уже на четырнадцать очков. В данный момент футбольный клуб Престон Норт Энд вообще пребывает в великолепной форме, одержав три победы в последних четырех поединках, а также один раз сыграв вничью. Дома команда чаще выигрывает, чем проигрывает, а также новый тренер заставил игроков больше думать об обороне, так что существенно сократилось количество пропущенных мячей. Восстановились от повреждений сразу трое полузащитников, так что в лазарете остаются только центральный защитник и левый нападающий.
Хозяева смогли выбраться из зоны вылета, а сейчас вообще идут десятыми, так что оторваться от аутсайдеров получилось уже на четырнадцать очков. В данный момент футбольный клуб Престон Норт Энд вообще пребывает в великолепной форме, одержав три победы в последних четырех поединках, а также один раз сыграв вничью. Дома команда чаще выигрывает, чем проигрывает, а также новый тренер заставил игроков больше думать об обороне, так что существенно сократилось количество пропущенных мячей. Восстановились от повреждений сразу трое полузащитников, так что в лазарете остаются только центральный защитник и левый нападающий.
Брентфорд
После того, как в футбольном клубе Брентфорд два года назад поменялся главный тренер, был небольшой спад в игре, но постепенно команда начала показывать еще даже лучшие результаты при новом наставнике. В этом сезоне гости занимают шестую строчку в чемпионате, претендуя на путевку в еврокубки. Но, для этого нужно выиграть борьбу, в которую включилось еще четыре команды.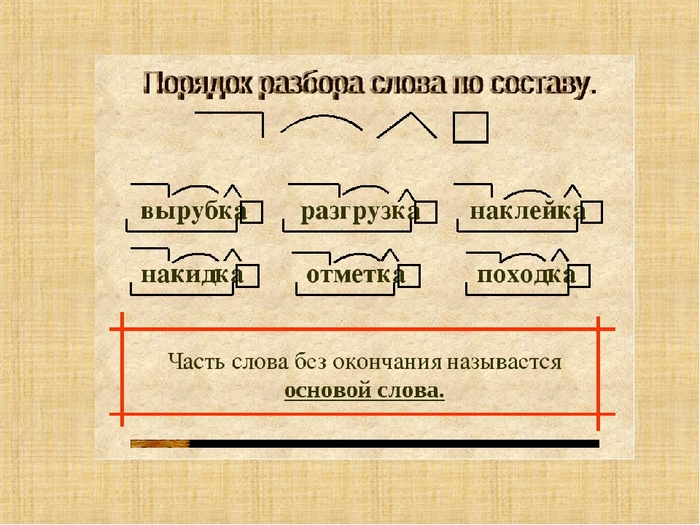 Футболисты клуба Брентфорд показывают очень хорошую игру дома, а вот на выезде команда играет исключительно от обороны, из-за чего в гостях было тринадцать ничейных результатов в восемнадцати матчах. При этом, ФК Брентфорд проиграл на выезде только однажды, чем не могут похвастаться даже лидеры чемпионата. Уже семь туров гости не проигрывают, одержав три победы и четыре раза сыграв вничью. Команда имеет одну из лучших защит в чемпионате, ведь входит в тройку лидеров по количеству пропущенных мячей. У гостей нет длинной скамейки запасных, но в данный момент у команды и нет серьезных кадровых проблем, ведь травмирован только правый полузащитник, который уже больше месяца пребывает в лазарете.
Футболисты клуба Брентфорд показывают очень хорошую игру дома, а вот на выезде команда играет исключительно от обороны, из-за чего в гостях было тринадцать ничейных результатов в восемнадцати матчах. При этом, ФК Брентфорд проиграл на выезде только однажды, чем не могут похвастаться даже лидеры чемпионата. Уже семь туров гости не проигрывают, одержав три победы и четыре раза сыграв вничью. Команда имеет одну из лучших защит в чемпионате, ведь входит в тройку лидеров по количеству пропущенных мячей. У гостей нет длинной скамейки запасных, но в данный момент у команды и нет серьезных кадровых проблем, ведь травмирован только правый полузащитник, который уже больше месяца пребывает в лазарете.
Букмекеры видят фаворитом матча команды Престон Норт Энд и команды Брентфорд хозяев поля. Однако эксперты нашего ресурса склоняются к мнению, что у команды Брентфорд есть отличные шансы на то, чтобы взять очки в этом матче. Несмотря на то, что команда Престон Норт Энд будет выступать в родных стенах и перед родными болельщиками, клуб не так превосходит своих соперников в классе, как это отражено в линии букмекерских контор. Команда Брентфорд умеет играть против более сильных команд, при этом, клубу тоже необходимы очки, поэтому гости будут стараться атаковать и использовать свои моменты. Да и статистика противостояний между этими командами говорит о том, что команда Престон Норт Энд никогда не обыгрывала футболистов команды Брентфорд крупно, поэтому вряд ли это произойдет в сегодняшнем матче. Поэтому мы думаем, что команда Брентфорд сможет удержать фору, заявленную букмекерами. Общий тотал матча мы считаем на меньше. Оба клуба в нынешнем сезоне не часто радуют своих болельщиков забитыми мячами. Учитывая, что в этом матче очки необходимо и одной, и другой команде, то здесь мы склонны считать низовой матч, так как оба клуба, в первую очередь, будут думать о защите собственных ворот. А вот нарушений и предупреждений в игре должно быть много. Сам фактор сложного противостояния говорит о том, что матч будет преимущественно проходить в центре поля, где футболисты обеих команд, будут срывать атаки друг друга, используя тактику мелкого фола.
Команда Брентфорд умеет играть против более сильных команд, при этом, клубу тоже необходимы очки, поэтому гости будут стараться атаковать и использовать свои моменты. Да и статистика противостояний между этими командами говорит о том, что команда Престон Норт Энд никогда не обыгрывала футболистов команды Брентфорд крупно, поэтому вряд ли это произойдет в сегодняшнем матче. Поэтому мы думаем, что команда Брентфорд сможет удержать фору, заявленную букмекерами. Общий тотал матча мы считаем на меньше. Оба клуба в нынешнем сезоне не часто радуют своих болельщиков забитыми мячами. Учитывая, что в этом матче очки необходимо и одной, и другой команде, то здесь мы склонны считать низовой матч, так как оба клуба, в первую очередь, будут думать о защите собственных ворот. А вот нарушений и предупреждений в игре должно быть много. Сам фактор сложного противостояния говорит о том, что матч будет преимущественно проходить в центре поля, где футболисты обеих команд, будут срывать атаки друг друга, используя тактику мелкого фола. В связи с этим, арбитр будет много свистеть и раздавать карточки. Общий тотал угловых в этом матче, скорее всего, будет низовым, так как игра через центр поля не предполагает большое количество стандартов.
В связи с этим, арбитр будет много свистеть и раздавать карточки. Общий тотал угловых в этом матче, скорее всего, будет низовым, так как игра через центр поля не предполагает большое количество стандартов.
Победу в матче одержит Престон Норт Энд — 3.44, ничья по результатам противостояния — 3.3, победу в матче одержит Брентфорд — 2.02.
Интересно, что букмекеры тоже учитывают фактор концовки чемпионата, выставляя коэффициенты на матчи команд. Так, на матчи клубов, которые уже не решают в чемпионате никаких задач, коэффициенты на победу будут примерно одинаковыми, зато клубы, которые продолжают вести борьбу, низко котируются букмекерами. Это и предлагают использовать эксперты нашего ресурса. К примеру, мы обратили внимание на матч, в котором встретятся команда Престон Норт Энд и команда Брентфорд. Оба клуба уже решили свои задачи в турнирной таблице, однако, хозяева поля, по информации менеджера, будут выступать сильнейшим составом с минимальным количество кадровых перестановок, тогда как их соперники приедут на матч в ослабленном составе – менеджер решил поберечь силы своих лидеров. Мы полагаем, что команда Престон Норт Энд в этом матче без проблем должна разбираться со своими соперниками, и предлагаем делать ставки на победу хозяев поля. Учитывая, что хозяева поля в родных стенах играют в агрессивной манере, много атакуют, то общий тотал голов в матче мы рассматриваем на больше, тем более, что гости будут выступать резервом, что существенно увеличивает шансы нашего прогноза. Угловые команда Престон Норт Энд тоже подает в большом количестве, поэтому индивидуальный тотал угловых и фора по угловым хозяев поля – отличные ставки в этом матче. Относительно нарушений и желтых карточек, то команды вряд ли будут много фолить, ведь никто не захочет получать травмы в концовке сезона, да и результат матча для команды Престон Норт Энд и команды Брентфорд не будет являться принципиальным. Поэтому эти параметры мы рекомендуем играть на меньше.
Мы полагаем, что команда Престон Норт Энд в этом матче без проблем должна разбираться со своими соперниками, и предлагаем делать ставки на победу хозяев поля. Учитывая, что хозяева поля в родных стенах играют в агрессивной манере, много атакуют, то общий тотал голов в матче мы рассматриваем на больше, тем более, что гости будут выступать резервом, что существенно увеличивает шансы нашего прогноза. Угловые команда Престон Норт Энд тоже подает в большом количестве, поэтому индивидуальный тотал угловых и фора по угловым хозяев поля – отличные ставки в этом матче. Относительно нарушений и желтых карточек, то команды вряд ли будут много фолить, ведь никто не захочет получать травмы в концовке сезона, да и результат матча для команды Престон Норт Энд и команды Брентфорд не будет являться принципиальным. Поэтому эти параметры мы рекомендуем играть на меньше.
«Престон Норт Энд»
Нельзя сказать, что футбольный клуб Престон Норт Энд плохо выступает в этом сезоне, но все же если прошлые два года команда финишировала второй в чемпионате, то сейчас занимает лишь пятую строчку в таблице. Побороться за вторую строчку не так просто из-за отставания в восемь очков, но взять бронзу национального первенства намного реальнее, так как для этого необходимо сократить отрыв всего в два очка. В этом сезоне футбольный клуб Престон Норт Энд стал слабее играть на выезде, но в родных стенах по-прежнему демонстрирует сильную игру, проиграв лишь один матч, но команде, также ведущей борьбу за еврокубки. У хозяев сильное нападение, так как в составе ФК Престон Норт Энд играет лучший нападающий чемпионата, а также имеется надежная оборона, но все же не так просто подняться хотя бы на несколько строчек. Хозяева не проигрывают на протяжении семи туров, в которых было пять побед и два ничейных результата. В лазарете ФК Престон Норт Энд находятся резервный голкипер и основной левый полузащитник.
Побороться за вторую строчку не так просто из-за отставания в восемь очков, но взять бронзу национального первенства намного реальнее, так как для этого необходимо сократить отрыв всего в два очка. В этом сезоне футбольный клуб Престон Норт Энд стал слабее играть на выезде, но в родных стенах по-прежнему демонстрирует сильную игру, проиграв лишь один матч, но команде, также ведущей борьбу за еврокубки. У хозяев сильное нападение, так как в составе ФК Престон Норт Энд играет лучший нападающий чемпионата, а также имеется надежная оборона, но все же не так просто подняться хотя бы на несколько строчек. Хозяева не проигрывают на протяжении семи туров, в которых было пять побед и два ничейных результата. В лазарете ФК Престон Норт Энд находятся резервный голкипер и основной левый полузащитник.
«Брентфорд»
Главный тренер футбольного клуба Брентфорд выполнил задачу руководства, за один сезон вернув команду в высший дивизион, но обещания перед наставником президент не сдержал, так как в межсезонье не состоялось ни одного значительного трансфера, способного серьезно усилить состав. Так что, вместо того, чтобы включаться в борьбу за еврокубки, гости в этом сезоне постоянно обитают в нижней части турнирной таблицы, то приближаясь, то отдаляясь от зоны вылета. Сейчас футбольный клуб Брентфорд имеет преимущество над аутсайдерами только в два очка, так что очень важно не потерять стабильность, так как даже небольшой игровой кризис может переместить команду в опасную зону. На данный момент гости демонстрируют неплохую форму, ведь в последних шести турах было лишь одно поражение, да и то в гостях у лидера чемпионата. Левые защитник и полузащитник не смогут в этой игре помочь команде, так что гости будут испытывать проблемы на этом фланге.
Так что, вместо того, чтобы включаться в борьбу за еврокубки, гости в этом сезоне постоянно обитают в нижней части турнирной таблицы, то приближаясь, то отдаляясь от зоны вылета. Сейчас футбольный клуб Брентфорд имеет преимущество над аутсайдерами только в два очка, так что очень важно не потерять стабильность, так как даже небольшой игровой кризис может переместить команду в опасную зону. На данный момент гости демонстрируют неплохую форму, ведь в последних шести турах было лишь одно поражение, да и то в гостях у лидера чемпионата. Левые защитник и полузащитник не смогут в этой игре помочь команде, так что гости будут испытывать проблемы на этом фланге.
Статистика и личные встречи
Наши эксперты постоянно мониторят линии букмекерских контор в поисках интересных матчей. Если рассматривать футбольные матчи с практической точки зрения, то составить прогноз можно на любой футбольный матч, независимо от того, к какому чемпиону он относится. Это может быть даже самая неизвестная лига третьесортного чемпионата. Однако наши эксперты занимаются тем, что прогнозируют исходы и статистику тех футбольных матчей, смотреть которые предпочитают все любители футбола. Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Престон Норт Энд и команда Брентфорд. Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Однако наши эксперты занимаются тем, что прогнозируют исходы и статистику тех футбольных матчей, смотреть которые предпочитают все любители футбола. Матчи топ-чемпионатов, которые собирают целые стадионы преданных болельщиков, а также многомиллионную армию болельщиков у экранов телевизоров – вот настоящая страсть наших экспертов. Нельзя сказать, что прогнозировать легко – нет, это тяжелый труд, требующий концентрации и тщательно анализа многочисленных факторов, которые могут оказать влияние на результат матча, однако нам нравится заниматься своим делом и делиться своими трудами с любителями футбола. Сегодня мы решили разобрать матч, соперниками в котором будут команда Престон Норт Энд и команда Брентфорд. Для обеих команд результат матча чрезвычайно важен, поэтому команды будут играть на встречных курсах, тем более что защита – не самая сильная сторона обеих команд. В текущем сезоне оба клуба сыграли большинство своих матчей на тотал больше, поэтому вряд ли в принципиальной игре они станут использовать защитную тактику, скорее всего, тренеры вновь будут играть в атакующий футбол, поэтому болельщиков ждет большое количество забитых мячей.
Престон Норт Энд — Брентфорд. Прогноз на футбол (10.04.21)
Команда Престон Норт Энд и команда Брентфорд сыграют между собой в рамках чемпионата. Эксперты нашего ресурса неоднократно обращали внимание на игру футболистов команды Брентфорд, которые, невзирая на то, с каким соперником играют, постоянно стараются атаковать. Из этого получается, что команда и сама много забивает, но и при этом много пропускает. Учитывая, что хозяева поля тоже играют примерно в таком стиле, получается, что общий тотал забитых голов в этом матче на больше – отличная ставка. Помимо этого, учитывая, что матч для команд не имеет принципиального значения, так как команда Престон Норт Энд и команда Брентфорд вряд ли вылетят, но и никак не смогут попасть на более высокое место в турнирной таблице, мы полагаем, что команды сегодня устроят настоящее шоу для своих болельщиков, поэтому у букмекеров можно заигрывать самый большой тотал на больше. Относительно исхода, то в матче, подобном этому противостоянию, его лучше не играть, что мы и рекомендуем сделать.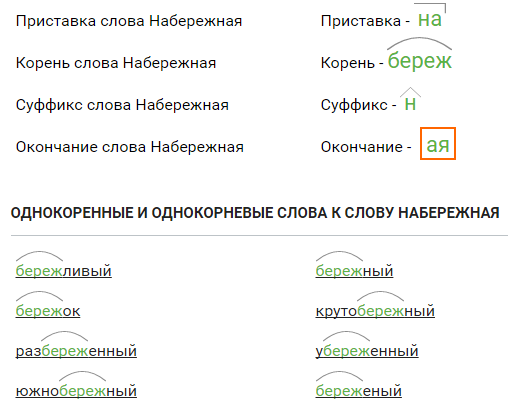 А вот что точно стоит играть на меньше, это тотал нарушений правил и желтых карточек, так как, как показывает практика, команды редко совершают много фолов в матчах, исход которых ничего не решает и серьезно не отражается на турнирной таблице. Общий тотал угловых лучше играть на больше, так как атак и ударов по ворота команды будут наносить много, естественно, что большая их часть будет блокироваться, что будет приводить к стандартам. В общем, этот матч можно ставить как до игры, так и во время игры, ведь команды будут устраивать настоящее шоу.
А вот что точно стоит играть на меньше, это тотал нарушений правил и желтых карточек, так как, как показывает практика, команды редко совершают много фолов в матчах, исход которых ничего не решает и серьезно не отражается на турнирной таблице. Общий тотал угловых лучше играть на больше, так как атак и ударов по ворота команды будут наносить много, естественно, что большая их часть будет блокироваться, что будет приводить к стандартам. В общем, этот матч можно ставить как до игры, так и во время игры, ведь команды будут устраивать настоящее шоу.
Для экспертов нашего ресурса нет простых матчей для прогнозирования, таких, глядя на названия соперников в которых, мы бы могли безошибочно сказать, кто победит, а кто проиграет. Футбол – это такой вид спорта, где шанс на победу есть у каждый команд. Футбол – это командная игра, и здесь успех зависит от слаженных действий всех членов команды, даже тех, которые сидят на скамейке запасных, ведь им предстоит выйти на поле в любой момент игры, и важно, чтобы они гармонично вписались в коллектив. В этом состоит заслуга менеджера, который должен подгонять футболистов, как шестеренки в отлично работающем механизме. Отличная работа такого механизма возможна лишь в том случае, если все мелкие детали будут отлично взаимодействовать между собой на благо всего механизма. Когда такое происходит в футболе, то команда практически непобедима, так как партнеры знают, что смогут подстраховать друг друга, а менеджер уверен в своих футболистах как тех, которые находится на поле, так и тех, которым предстоит на него выйти. Так что, предсказывать можно лишь на основании анализов, так как каждый клуб – это отдельный механизм и его необходимо тщательно изучить, прежде чем вынести свой вердикт.
В этом состоит заслуга менеджера, который должен подгонять футболистов, как шестеренки в отлично работающем механизме. Отличная работа такого механизма возможна лишь в том случае, если все мелкие детали будут отлично взаимодействовать между собой на благо всего механизма. Когда такое происходит в футболе, то команда практически непобедима, так как партнеры знают, что смогут подстраховать друг друга, а менеджер уверен в своих футболистах как тех, которые находится на поле, так и тех, которым предстоит на него выйти. Так что, предсказывать можно лишь на основании анализов, так как каждый клуб – это отдельный механизм и его необходимо тщательно изучить, прежде чем вынести свой вердикт.
По мнению футбольных аналитиков, победа ФК Престон Норт Энд или ничья должны зайти в качестве ставки на данный поединок, так как Брентфорд сейчас находится не в лучшей форме и не всегда стабильно играет на выезде.
Престон Норт Энд – Брентфорд: статистика и история личных встреч
Не всегда статистика выступлений команд отражает суть того, что действительно происходит на футбольном поле. К примеру, в противостоянии команды Престон Норт Энд и команды Брентфорд, по мнению наших экспертов, игра будет проходить совсем не так, как привыкли играть эти команды. Оба клуба являются лидерами чемпионата, соответственно, в матчах со своими соперниками они привыкли играть первыми номерами. В матче между собой командам либо придется действовать на встречных курсах, либо одной из команд придется играть вторым номером. Естественно, перед менеджерами клубов стоит нелегкий выбор, учитывая, что в составе команды Престон Норт Энд и команды Брентфорд сейчас возникли определенные проблемы с основными футболистами, и выход некоторых из них под вопросом. Именно от того, какую тактику выберут менеджеры на этот матч, и будет зависеть многое. Однако наши эксперты решили не отгадывать тактику команд, мы постараемся сосредоточиться на статистических показателях этого матча. Благо, букмекеры предложили на матч команды Престон Норт Энд и команды Брентфорд довольно приличный объем ставок, так как считают, что это противостояние будет центральным матчем уикенда.
К примеру, в противостоянии команды Престон Норт Энд и команды Брентфорд, по мнению наших экспертов, игра будет проходить совсем не так, как привыкли играть эти команды. Оба клуба являются лидерами чемпионата, соответственно, в матчах со своими соперниками они привыкли играть первыми номерами. В матче между собой командам либо придется действовать на встречных курсах, либо одной из команд придется играть вторым номером. Естественно, перед менеджерами клубов стоит нелегкий выбор, учитывая, что в составе команды Престон Норт Энд и команды Брентфорд сейчас возникли определенные проблемы с основными футболистами, и выход некоторых из них под вопросом. Именно от того, какую тактику выберут менеджеры на этот матч, и будет зависеть многое. Однако наши эксперты решили не отгадывать тактику команд, мы постараемся сосредоточиться на статистических показателях этого матча. Благо, букмекеры предложили на матч команды Престон Норт Энд и команды Брентфорд довольно приличный объем ставок, так как считают, что это противостояние будет центральным матчем уикенда. Детальный анализ матча можно прочесть ниже. Мы думаем, что игра отлично подойдет для ставок по ходу матча, так как события будут развиваться на поле стремительно. Таким образом, болельщикам не придется скучать, они будут наблюдать за интересным матчем с непредсказуемым результатом.
Детальный анализ матча можно прочесть ниже. Мы думаем, что игра отлично подойдет для ставок по ходу матча, так как события будут развиваться на поле стремительно. Таким образом, болельщикам не придется скучать, они будут наблюдать за интересным матчем с непредсказуемым результатом.
http://evolvegame.ru/cat2-388507-vashash-obuda-zhen-msm-diamant-kaposhvary-zhen-prognoz-professionala-na-match-09-04-21/
Навигация по записям
Verb будет дизассемблировать — английское сопряжение
I будет дизассемблировать
вам будет разобрать
он будет разобрать
мы разобрать
вы разобрать
разобрать будет разобран ing
вы будет разобран ing
он будет разобран ing
мы будет разобран ing
вы будет разобрать 4 3 будет разобрать ing
I будет нужно разобрать d
вам будет разобрать d
он будет разобрать d
мы нужно будет разобрать d
вы есть разобрать d
они будут нужно разобрать d
I будет разобран ing
вы будет разобран ing
он будет разобран ing
мы будет разобран
у вас будет разобран ing
они будут разобран ing
I не будет разбирать
вы не разбираете
он не будет не разбирать
мы разобрать
вы будете не разбирать
они не будут разбирать
I не будет не разбирать ing
вы не будете разбирать ing
он не будет
мы не будем разбирать ing
вы не подлежат разборке ing
они будут не будут разбираться ing
I не будут не нужно разбирать d
вам не нужно будет разбирать d
он не будет не будет разбирать d
у нас будет не нужно разбирать d
у вас будет не нужно разбирать d
они будут не нужно разбирать d
я будет не разобрать ing
вы
будет не разобран ing
он будет не разобран ing
мы будет не разобран ing
вы будет не разобран ing
они будут не разобрали ing
буду ли разбирать?
будет разбирать?
будет он разбирать?
будет разбирать?
будет разбирать?
будут разбирать?
буду ли разобрать ing ?
будет разобрать ing ?
он будет разбирать ing ?
будет разбирать ing ?
будет разобрать ing ?
будут ли разбирать ing ?
будет у меня разобрать d ?
будет у вас разобрать d ?
будет у него разобрать d ?
будет будем разбирать d ?
будет у вас разобрать d ?
будет у них разобрать d ?
будет Я разобрал ing ?
будет у вас разобрали ing ?
будет он был разобран ing ?
будет мы разобрали ing ?
будет у вас разобрали ing ?
будет разобрано ing ?
будет не разбирать?
будет не разбирать?
будет он не разбирать?
будет не разбирать?
будет не разбирать?
будет они не разбирают?
Я не буду разбирать ing ?
ты не будешь разбирать ing ?
будет он не будет разбирать ing ?
мы не будем разбирать ing ?
ты не будешь разбирать ing ?
будет не разобрать ing ?
будет Мне не придется разбирать d ?
будет у вас не надо разбирать d ?
будет он не надо разбирать d ?
будет у нас не надо разбирать d ?
будет у вас не надо разбирать d ?
будет у них не надо разбирать d ?
будет Я не разбирал ing ?
будет у вас не разбирали инг ?
будет он не разбирается инг ?
будет мы не разбирали ing ?
будет у вас не разбирали инг ?
будет они не разобраны ing ?
Мебель IKEA теперь будет проще разбирать на части
У каждого есть история о том, как собрать что-то из IKEA. Почему-то этим улыбчивым фигуркам, кажется, гораздо легче ориентироваться в этих бессловесных инструкциях, чем остальным из нас, и процесс сборки одного из их столов или комодов является ключевым лакмусовой бумажкой для любых отношений.
Почему-то этим улыбчивым фигуркам, кажется, гораздо легче ориентироваться в этих бессловесных инструкциях, чем остальным из нас, и процесс сборки одного из их столов или комодов является ключевым лакмусовой бумажкой для любых отношений.
Теперь шведский мебельный гигант хочет сделать так, чтобы разборка его мебели на части была, по крайней мере, относительно безболезненным делом. Недавно компания составила подробные инструкции по разборке для шести своих основных продуктов: Billy, Brimnes, Lycksele, Malm, Pax и Poäng.Все соответствующие документы можно просмотреть и загрузить бесплатно, что имеет смысл, учитывая, что вы уже заплатили за указанную мебель.
Цель ИКЕА — не просто помочь вам приобрести более крупную и лучшую мебель. Есть надежда, что показ покупателям менее разрушительного способа разобрать свою мебель побудит большее количество из них переехать со своей мебелью IKEA или же легче передать ее тому, кто готов дать этим предметам новый дом.
Соответственно, эти инструкции по разборке являются частью более крупного плана IKEA по превращению IKEA в полностью «круглую» мебельную компанию к 2030 году. Достижение этой цели в области устойчивого развития потребует, чтобы все ее продукты были перепрофилированы, отремонтированы, повторно использованы или переработаны, вместо того, чтобы попадать на свалку. Упрощение разборки мебели для продления ее жизненного цикла — лишь один из компонентов этих усилий: в последние годы были внедрены программы аренды и обратного выкупа мебели. Издание ежегодного печатного каталога, выпуск которого недавно прекращено, возможно, также нанесло ущерб целям IKEA в области устойчивого развития.
Достижение этой цели в области устойчивого развития потребует, чтобы все ее продукты были перепрофилированы, отремонтированы, повторно использованы или переработаны, вместо того, чтобы попадать на свалку. Упрощение разборки мебели для продления ее жизненного цикла — лишь один из компонентов этих усилий: в последние годы были внедрены программы аренды и обратного выкупа мебели. Издание ежегодного печатного каталога, выпуск которого недавно прекращено, возможно, также нанесло ущерб целям IKEA в области устойчивого развития.
Даже если вы не разбираете и не отдаете свою мебель из ИКЕА, у компании есть практические советы по продлению ее жизненного цикла.Например, он рекомендует выбирать модульную мебель, функциональность которой может развиваться по мере изменения ваших потребностей; новый слой краски на деревянной мебели; и выбор моющихся сменных чехлов для диванов, которые сохранят ощущение свежести и чистоты, не отрывая нынешний диван от бордюра. Эти идеи могут не разжечь вашу любовь к комоду или футону, из которых выросли ваши вкусы и бюджет, но эти шаги стоит попробовать тем, кто хочет сократить свой углеродный след.
Нет сомнений в том, что тщательная разборка Мальма — не самое приятное занятие, но, надеюсь, осознания того, что планета поступает правильно, достаточно, чтобы вы смогли пройти через это.В конце концов, лучший подарок, который вы можете сделать кому-то другому, — это чувство выполненного долга, возникающее при сборке мебели IKEA.
Смогут ли грузчики разобрать и собрать мою мебель?
Смогут ли грузчики разобрать и собрать мою мебель?
Наша цель — сделать ваш переезд, будь то местный переезд или переезд по пересеченной местности, максимально простым и легким. Поэтому, когда это возможно, мы разберем вашу большую и громоздкую мебель. Традиционные кровати с изголовьем, изножками и боковыми перилами для нас не проблема.Мы также можем разобрать ваши обеденные столы, секционные диваны и большинство столов.
Многие клиенты спрашивают нас, есть ли какие-нибудь советы, как сэкономить время или деньги в дороге. Один из способов сделать это — заранее разобрать эти предметы. У нас нет абсолютно никаких проблем с разборкой этих предметов для вас, но это требует времени. Обычно наши оценки включают время, необходимое для разборки и сборки этих предметов мебели.
У нас нет абсолютно никаких проблем с разборкой этих предметов для вас, но это требует времени. Обычно наши оценки включают время, необходимое для разборки и сборки этих предметов мебели.
Есть некоторые элементы, которые мы не можем сломать или собрать заново по причинам ответственности.Однако мы работаем со сторонними экспертами, с которыми можем заключить договор от вашего имени. Взимается дополнительная плата.
Мы не можем разобрать или собрать детские кроватки ни при каких обстоятельствах.
Мы не можем сломать некоторые двухъярусные кровати. Если двухъярусная кровать представляет собой очень простую кровать поверх другой кровати, это совершенно нормально. Если двухъярусная кровать представляет собой сложную систему со встроенными лестницами, площадками или хранилищем, мы не сможем вам помочь.
Кровати со сложными системами хранения или количества сна / крафтовых кроватей, вероятно, потребуют стороннего специалиста.Мы являемся экспертами во всем, что касается движения, но у нас не всегда есть обученный и квалифицированный техник, который мог бы справиться с более сложными поломками. Проконсультируйтесь с вашим местным офисом относительно конкретной политики в отношении мебели.
Проконсультируйтесь с вашим местным офисом относительно конкретной политики в отношении мебели.
Мы не можем сломать тренажеры, поэтому, если ваш эллиптический тренажер или беговая дорожка необходимо сломать, чтобы попасть в любое место или выйти из него, сообщите нам об этом заранее, чтобы мы могли узнать цену на решения сторонних производителей.
Мы настоятельно рекомендуем, чтобы стеллажи в гараже / подвале были сломаны до нашего приезда.Мы можем сделать это за вас, но определенный стиль может занять довольно много времени. Мы предпочли бы сосредоточиться на тяжелой работе и не платить вам за время, потраченное на поломку каждой полки.
Гардеробы в стиле ikea не сломать. Часто они слишком велики, чтобы уместиться на лестничных клетках. Эти большие шкафы / гардеробы не предназначены для разрушения после первоначальной сборки. В них много оборудования, и они часто теряются. Они также теряют структурную устойчивость при повторном разрушении.Мы можем сделать все, что в наших силах, чтобы перемещать эти части внутрь и наружу, но, пожалуйста, поймите, что их невозможно удалить из вашего нынешнего дома, пока они находятся в тактическом состоянии.
Если вы собираетесь самостоятельно разбирать мебель, чтобы сэкономить время, мы настоятельно рекомендуем поместить все оборудование в сумку с застежкой-молнией для безопасной транспортировки. Помните, что сборка мебели, которую мы не разбирали сами, остается на усмотрение командира бригады.
Мы рады перевезти для вас бытовую технику, но мы не можем отключать электрическую проводку под напряжением или какие-либо водопроводные / газовые линии.Пожалуйста, убедитесь, что все приборы отключены за 24 часа до начала размораживания.
Если вам нужна помощь с редкими или уникальными предметами, такими как автоматы для игры в пинбол или газированные напитки, сообщите нам об этом заранее, чтобы у нас была возможность разработать план игры и заключить договор с любыми третьими сторонами.
Делают грузчики, разбирают и собирают мебель для вас
Переезжаете ли вы, храните или модернизируете свой дом, скорее всего, вам понадобятся профессиональные грузчики для вашего проекта. Но задумывались ли вы о своей негабаритной и большой мебели, которая может не поместиться в дверные проемы или на узкую лестницу? Некоторая мебель для дома может потребовать разборки перед тем, как ее вывезти. Столы, кровати, шкафы, стенки и тренажеры обычно представляют собой предметы, которые необходимо разобрать, а затем собрать в вашем новом доме. Поэтому еще одна серьезная проблема — разбирать ли все самостоятельно или позволить транспортной компании обо всем позаботиться.
Но задумывались ли вы о своей негабаритной и большой мебели, которая может не поместиться в дверные проемы или на узкую лестницу? Некоторая мебель для дома может потребовать разборки перед тем, как ее вывезти. Столы, кровати, шкафы, стенки и тренажеры обычно представляют собой предметы, которые необходимо разобрать, а затем собрать в вашем новом доме. Поэтому еще одна серьезная проблема — разбирать ли все самостоятельно или позволить транспортной компании обо всем позаботиться.
Компании по переезду могут собирать и разбирать вашу мебель, но вопрос в том, хотите ли вы, чтобы они предоставили дополнительную услугу.У использования этой услуги есть как преимущества, так и недостатки, в зависимости от типа перемещения, будь то перемещение на локальное или дальнее расстояние. Вот некоторая полезная информация, которая может помочь вам с переездом.
Локальные перемещения также называются внутригосударственными перемещениями. Обычно такой переезд оплачивается по почасовой ставке. От старта до финиша работает одна и та же бригада (большинство локальных переездов выполняются за день). Помимо услуг по переезду, вы также можете запросить дополнительные услуги, такие как сборка и разборка вашей мебели.
Помимо услуг по переезду, вы также можете запросить дополнительные услуги, такие как сборка и разборка вашей мебели.
Местные грузчики могут аккуратно и эффективно разобрать и собрать вашу мебель, но переезд займет больше времени, а это значит, что вам придется платить больше за переезд. Если вы в состоянии сделать это самостоятельно, это может быть шанс сэкономить немного денег на вашем переезде. Таким образом, реальный вопрос заключается в том, хотите ли вы это сделать самостоятельно или готовы доплачивать за эту услугу.
Перемещения на большие расстояния также известны как переезды между штатами. Базовые сборы рассчитываются на основе пробега и веса вашего отправления.Переезд на большие расстояния может занять до 10 дней, в зависимости от размера вашего переезда и расстояния. Грузчики загружают ваши товары в свой грузовик. Но есть вероятность, что другая транспортная бригада будет разгружать ваши вещи в городе назначения. Это означает, что экипаж, который разбирал вашу мебель, не сможет ее собрать. Знают ли новички, как выглядит это произведение? Могут ли они снова собрать его? Стоит ли собрать его самостоятельно?
Знают ли новички, как выглядит это произведение? Могут ли они снова собрать его? Стоит ли собрать его самостоятельно?
Теперь вам нужно решить, хотите ли вы платить больше своим грузчикам или просто сделаете это сами и сэкономите немного денег для другого проекта в вашем новом доме.Помните: что бы вы ни делали сами, вы сэкономите время и деньги.
Большинство грузчиков Movers Corp предоставляют услуги по разборке и сборке. Если вы думаете, что вам понадобится услуга, нажмите на профиль грузчика, чтобы увидеть все предоставляемые услуги по переезду. Дополнительные полезные советы по перемещению и упаковке см. В разделе «Руководство по перемещению».
Найдите местные компании по переезду в вашем районе
Разборка и повторная сборка мебели
Услуги по разборке и повторной сборке
Разборка и повторная сборка мебели — отличное решение, если вы решили переехать со своей старой мебелью, но она по какой-то причине не подходит.
- Вы когда-нибудь задумывались, как ваш диван впишется в дверь из коричневого камня и спустится по узкой лестнице?
- Как вы когда-нибудь будете разбирать этот замысловатый стеновой блок — и если вы это сделаете, как вы соберете его обратно?
- Эта кровать Мерфи была отличной идеей для экономии места, но как ее достать из стены и перенести в новое место жительства? Что ж,
Мебельный хирург здесь, чтобы помочь!
Мы предлагаем услуги по разборке и повторной сборке следующих объектов:
Если вы переезжаете в новый дом или квартиру, Dr.Диван® предлагает комплексные услуги по разборке и повторной сборке мебели для жилых и коммерческих нужд.
Кто такие мебельные врачи?
Наши мебельные хирурги пунктуальны и профессиональны и предоставляют качественные услуги на месте, сохраняя целостность и ценность вашей мебели.
Мы знаем, насколько тяжелым может быть переезд. Вот почему мы сотрудничаем с ведущими транспортными компаниями Нью-Йорка и работаем с ними, чтобы координировать услуги по предоставлению мебели, необходимые для вашего переезда.
Для вашего удобства мы можем предоставить смету на месте и доставку мебели.
Мебель в большинстве случаев является продолжением вашего стиля, произведением искусства. Но для большинства из нас добиться того, чтобы он был на своем месте, — это битва.
- Узкие лестницы
- Узкие коридоры
- Маленькие дверные проемы
- Винтовые лестницы
Все это затрудняет или даже делает невозможным перемещение любимого предмета мебели в ваш дом.
Вот почему разборка и повторная сборка мебели стала сегодня одним из самых важных вариантов перемещения.Вместо того, чтобы бороться с огромным диваном через крошечную лестницу, у вас будет несколько маленьких частей, которыми может управлять один человек. Это проще и безопаснее, и стоит подумать.
Что включают в себя услуги по разборке и повторной сборке?
Разборка и повторная сборка — это простой процесс. Профессионал тщательно разбирает вашу мебель и упаковывает отдельные секции.
Их переместят на новое место, а затем снова соберут. Однако должно быть очевидно, что это под силу не каждому. Вам нужен опытный специалист, иначе вы будете сожалеть.
Однако должно быть очевидно, что это под силу не каждому. Вам нужен опытный специалист, иначе вы будете сожалеть.
Разобрать мебель — это одно, но собрать ее заново, чтобы она выглядела как новая, требует таланта. Вот почему так много людей, у которых есть планы на будущее, доверяют профессионалу, который упростит их продвижение в этом процессе.
Нет ограничений на типы мебели, которую можно перемещать в процессе разборки и сборки. Диваны, кресла, книжные полки, буфеты, шкафы, навесные шкафы, развлекательные центры и даже бильярдные столы обычно представляют собой массивные звери, которые опасны и трудны для передвижения.
С помощью специалиста по разборке и повторной сборке весь процесс станет более плавным, легким и безопасным. Цены также могут вас удивить и сэкономить деньги в долгосрочной перспективе. Это, безусловно, сэкономит вам огромное количество времени и энергии, и это то, на что стоит обратить внимание.
Разборка и сборка офисной мебели — Решения по коммерческому перемещению
Кабины
Переезд — это огромное испытание для любого, но когда бизнес или офис переезжают, оно становится еще более серьезным. В большинстве случаев перемещение офисной мебели может оказаться трудным, трудоемким и длительным. Огромный размер и объем предметов, участвующих в перемещении, означают, что в большинстве случаев разборка и повторная сборка — единственный реальный вариант. Это очевидно в случае таких вещей, как кабины, которые практически невозможно переместить в собранном виде. И хотя может показаться несложным разбирать кабинки самостоятельно, правда в том, что во время большого переезда у вас будет много других проблем.Позволить профессионалам заняться основами вашего переезда — гораздо лучший вариант, который позволит вам сосредоточить свое внимание на более важных вещах. Кроме того, они, вероятно, справятся с задачей быстрее и эффективнее, чем вы когда-либо могли надеяться.
В большинстве случаев перемещение офисной мебели может оказаться трудным, трудоемким и длительным. Огромный размер и объем предметов, участвующих в перемещении, означают, что в большинстве случаев разборка и повторная сборка — единственный реальный вариант. Это очевидно в случае таких вещей, как кабины, которые практически невозможно переместить в собранном виде. И хотя может показаться несложным разбирать кабинки самостоятельно, правда в том, что во время большого переезда у вас будет много других проблем.Позволить профессионалам заняться основами вашего переезда — гораздо лучший вариант, который позволит вам сосредоточить свое внимание на более важных вещах. Кроме того, они, вероятно, справятся с задачей быстрее и эффективнее, чем вы когда-либо могли надеяться.
Конференц-столы
Конференц-столы являются одними из самых больших предметов в офисе и, безусловно, одним из самых тяжелых предметов офисной мебели, которые вам придется перемещать. С этими огромными вещами практически невозможно справиться, если вы не воспользуетесь услугой разборки и повторной сборки.Процесс, используемый при разборке стола для переговоров, будет сильно отличаться от стола к столу, а это значит, что вам понадобится квалифицированная рука, чтобы сделать это. Доверие к тем, у кого нет опыта, скорее всего, приведет к катастрофе. Для начала может потребоваться несколько часов, чтобы просто разобрать стол, и этот ход может в конечном итоге привести к его повреждению. Кроме того, когда вы, наконец, начнете собирать стол заново, есть шанс, что он просто не соберется должным образом. Профессионалы быстро с этим справятся и оставят вас со столом, который будет выглядеть так же, как до вашего переезда, и сделают это быстро.
С этими огромными вещами практически невозможно справиться, если вы не воспользуетесь услугой разборки и повторной сборки.Процесс, используемый при разборке стола для переговоров, будет сильно отличаться от стола к столу, а это значит, что вам понадобится квалифицированная рука, чтобы сделать это. Доверие к тем, у кого нет опыта, скорее всего, приведет к катастрофе. Для начала может потребоваться несколько часов, чтобы просто разобрать стол, и этот ход может в конечном итоге привести к его повреждению. Кроме того, когда вы, наконец, начнете собирать стол заново, есть шанс, что он просто не соберется должным образом. Профессионалы быстро с этим справятся и оставят вас со столом, который будет выглядеть так же, как до вашего переезда, и сделают это быстро.
Рабочее место
В то время как столы и кабинки довольно просты, перемещение офисной мебели, такой как рабочее место, обычно немного сложнее. Это потому, что рабочая станция может включать в себя множество различных компонентов. Там могут быть полки, блоки питания, ящики, дверцы и многое другое. Легко потерять из виду различные части и вызвать повреждения, которые сделают рабочую станцию бесполезной. Вот почему большинство предприятий доверяют профессионалу разбирать, управлять, перемещать и собирать их рабочие станции.
Там могут быть полки, блоки питания, ящики, дверцы и многое другое. Легко потерять из виду различные части и вызвать повреждения, которые сделают рабочую станцию бесполезной. Вот почему большинство предприятий доверяют профессионалу разбирать, управлять, перемещать и собирать их рабочие станции.
Достаточно сложно управлять перемещением и всем, что с ним связано, и необходимость беспокоиться о том, что различные перемещаемые компоненты находятся не в надежных руках, может добавить слой стресса и беспокойства на ваши плечи, которые вам просто не нужны. Позволив опытным профессионалам делать то, что они умеют лучше всего, вы сможете расслабиться и выполнить работу быстро и эффективно. Это лучший вариант, который вам доступен.
Система стеллажей
Как и рабочие станции, стеллажи — это еще один из тех предметов офисной мебели, с которыми может быть сложно справиться.Обычно они слишком велики, чтобы их можно было переместить, если вы не разобрали устройство. С многочисленными полками, булавками и другими предметами нужно обращаться осторожно. В противном случае их будет сложно собрать вместе.
С многочисленными полками, булавками и другими предметами нужно обращаться осторожно. В противном случае их будет сложно собрать вместе.
Если у вас есть стеллажная система, требующая услуг по разборке и повторной сборке, вам нужно потратить время, чтобы убедиться, что все сделано правильно. Это означает, что нужно доверять кому-то с опытом, который сделает эту работу за вас. Не позволяйте некоторым из ваших офисных работников попробовать свои силы в этом, чтобы сэкономить деньги. Они могут отлично справляться с подсчетами, но если у них нет достаточного опыта в разборке и повторной сборке мебели, вы можете в конечном итоге сильно пожалеть о своем решении.Особенно, если у вас осталась система стеллажей, которая не вернется обратно, что бы вы ни делали.
Столы
Столы, вероятно, являются наиболее распространенным типом офисной мебели. Независимо от того, к какому типу они относятся, они могут вызывать боль. Даже легкие из них часто слишком велики, чтобы закруглять углы прихожей, и слишком громоздкие, чтобы их можно было безопасно нести вниз. В результате разборка и повторная сборка снова являются лучшим выбором, которым вы должны воспользоваться. Чтобы разобрать стол, переместить его, а затем собрать заново, у опытного профессионала не займет много времени.Кроме того, они могут гарантировать, что ваш переезд будет быстрым.
В результате разборка и повторная сборка снова являются лучшим выбором, которым вы должны воспользоваться. Чтобы разобрать стол, переместить его, а затем собрать заново, у опытного профессионала не займет много времени.Кроме того, они могут гарантировать, что ваш переезд будет быстрым.
Проще говоря, переезд сопряжен с огромным стрессом, усилиями и работой. Доверьтесь профессионалам, которые помогут вам управлять крупными предметами и избавиться от стресса. Сосредоточьтесь на управлении перемещением, а не на борьбе с большими предметами, которые нельзя передвинуть традиционными способами.
Доктор Софа помог тысячам предметов мебели обрести новую жизнь, вы можете увидеть их в Нашем Портфолио.
Как разобрать мебель перед тем, как переехать
Для многих американцев процесс переезда является огромной проблемой, поскольку они должны придумать, как перевезти свою самую большую мебель в свой новый дом.Некоторые предметы огромны и не могут легко пройти через дверные проемы, коридоры или входы. Чтобы решить эту проблему, профессиональные грузчики разбирают мебель, чтобы доставить ее в новые дома.
Чтобы решить эту проблему, профессиональные грузчики разбирают мебель, чтобы доставить ее в новые дома.
В этой статье мы подробно расскажем, как разобрать мебель перед переездом в дом .
Несколько советов, которые следует запомнить перед началом работы
Разборка мебели требует времени и терпения, поэтому выделите несколько дней до переезда, чтобы завершить этот процесс.Затем вы должны решить, стоит ли переносить большие предметы в новый дом. Примите во внимание такие вещи, как, например, сколько времени, усилий и затрат потребуется, чтобы переместить эти предметы. Также спросите себя, подойдет ли ваша мебель к вашему новому дому или квартире.
Если эта задача слишком сложна для вас, вы всегда можете обратиться за помощью в компанию Mesa Moving Company. Наши приветливые профессионалы всегда рады решить эти задачи за вас. Мы можем разобрать различную мебель, в том числе диваны, стулья, книжные полки и бытовую технику.
Создайте систему отслеживания мелких деталей вашей мебели
Перед тем, как начать процесс разборки, составьте план, чтобы отслеживать детали, относящиеся к мебели, такие как книжные полки, столы и каркасы кроватей. Если их винты, болты или штифты потеряны, их будет трудно собрать.
Поместите эти детали в сумку с застежкой-молнией и прикрепите ярлыки для их идентификации. Кроме того, подумайте о том, чтобы поместить все мелкие детали мебели в одну коробку, чтобы вы могли легко их найти.Этот шаг поможет вам сэкономить время и быстро собрать мебель после переезда в новый дом.
Инструменты, которые понадобятся для процесса разборки
Затем вам понадобятся некоторые основные инструменты, которые помогут вам разобрать мебель. Если у вас нет этих предметов, вы можете купить их в местном магазине бытовой техники или в магазине товаров для дома. Вы также можете купить эти принадлежности в Mesa Moving and Storage.
Для выполнения работы не требуются дорогие инструменты.Вот краткий список материалов, которые следует учитывать:
- Отвертка с крестообразным шлицем,
- Гаечные ключи, молотки и плоскогубцы
- Пузырьковая оберточная бумага
- Упаковочные коробки
- Пакеты с застежкой-молнией
- Лента упаковочная
- Арахис фасовочный
- Водонепроницаемые маркеры
- Этикетки
- Рулетка
Советы по разборке мебели
Купив все необходимое, вы готовы приступить к демонтажу мебели.Во-первых, вам нужно измерить всю мебель, чтобы определить, дойдут ли они до движущегося грузовика без проблем. Кроме того, проведет измерения вашего нового дома, чтобы узнать, могут ли ваши предметы без проблем попасть в ваш дом. Если нет, вы можете начать процесс их разборки.
Вот несколько рекомендаций, которым нужно следовать при использовании разных частей.
1. Кровати
Кровати
Каркасы кроватей сложно разбирать и перемещать самостоятельно, поскольку они состоят из соединенных между собой частей.
- Удалите постельные принадлежности: сначала снимите все простыни, подушки и покрывала. Вымойте и сложите все белье, прежде чем складывать его в коробки.
- Демонтируйте матрас и пружинный блок. Затем удалите эти предметы и поместите их в сухое место, чтобы предотвратить повреждение. Вытяните планки кровати и отложите их в сторону.
- Разберите изголовье и подножки — Ослабьте каждую, затем снимите их с рамы. Если у вашего изголовья есть ящики, снимите их.
- Снимите каркас кровати. После того, как вы закончили сложную часть, вы можете, наконец, демонтировать каркас, начиная с перил.Если у вас есть металлический, вы можете оставить их прикрепленными и нетронутыми. Вы также можете разделить металлические рамы на две большие части, если у них одинаковые рычаги.
2. Гардеробы, туалетные столики и комоды
Гардеробы, туалетные столики и комоды
Вам не нужно разбирать шкафы малого и среднего размера. Грузчики могут перевезти эти предметы в ваш новый дом, не разбирая их. Из этой мебели следует вынуть всю одежду, украшения и аксессуары. Затем закрепите их ящики лентой или снимите эти предметы и упакуйте их в коробки.
Для шкафов-купе с зеркалами процесс немного отличается: вам нужно будет их демонтировать. Используйте отвертку или гаечный ключ, чтобы отделить зеркало. Накройте зеркало пузырчатой пленкой, чтобы оно не разбилось. Положите внутрь коробки упаковочную бумагу, чтобы она не тряслась во время транспортировки. Не забудьте написать «хрупкий» на всех сторонах коробки.
Возможно, вам придется полностью разобрать большие туалетные столики и комоды, так как они, как правило, слишком широки, чтобы пройти через дверные проемы.
3.Столы
Некоторые столы можно перевезти к вам в целости и сохранности. Если они слишком велики, чтобы пройти через дверь, их можно разобрать. В некоторых таблицах для их расширения используется центральная часть. Снимите его, затем сдвиньте оставшиеся части вместе, чтобы уменьшить размер. Если у вашего стола съемные ножки, осторожно наклоните его и открутите. Свяжите их вместе, чтобы они не заблудились.
Если они слишком велики, чтобы пройти через дверь, их можно разобрать. В некоторых таблицах для их расширения используется центральная часть. Снимите его, затем сдвиньте оставшиеся части вместе, чтобы уменьшить размер. Если у вашего стола съемные ножки, осторожно наклоните его и открутите. Свяжите их вместе, чтобы они не заблудились.
4. Мебель для дома (ИКЕА и т. Д .;)
Затем определите, верите ли вы, что ваша мебель впишется в ваш новый дом, или она больше не служит цели.
5. Стеллажи
Книжные полки и шкафы можно перемещать целиком. Вы можете удалить все полки и сложить их в коробки, прежде чем перемещать их.
Некоторые стеллажи позволяют снимать анкеры, удерживающие их на месте. В этом случае поместите их в пакеты с застежкой-молнией и прикрепите клейкой лентой к устройствам или поместите в отдельную коробку.
6. Бытовая техника
Бытовая техника
Не рвите прибор на части, особенно если вы планируете использовать его в новом доме.У большинства есть съемные части. Для удаления таких приборов, как плиты, духовки или посудомоечные машины, лучше обратиться к профессионалу. В холодильниках есть лотки и полки, которые можно будет перемещать безопаснее, если вы снимете их и поместите в отдельные ящики, чтобы они не разбились.
Обратитесь за помощью к специалистам по перемещению и хранению Mesa
Разборка мебели может оказаться сложной задачей, если вы сделаете это самостоятельно. В компании Mesa Moving and Storage работают обученные профессионалы, которые могут безопасно разобрать вашу мебель и технику и перевезти их в ваш новый дом.Мы также можем быстро собрать вашу мебель, чтобы вы могли использовать ее сразу после завершения процесса перевозки. Чтобы узнать больше, назначит встречу с одним из наших переездов сегодня.
Какую мебель следует разобрать для переезда?
Многие предметы в вашем доме имеют подвижные или ломающиеся части, которые могут представлять опасность во время процесса перемещения. Хотя большие, прочные предметы мебели, как правило, прекрасно двигаются сами по себе, вы обнаружите, что многие предметы лучше всего перемещаются, когда они разобраны перед загрузкой.
У каждого человека разные изобретения, но большинство считает, что разумнее всего разбирать эти обычные предметы во время процесса упаковки и погрузки. И подумайте о помощи в этом процессе, так как Allied Van Lines разберет и соберет вашу мебель для вас.
> Кровать: Каркасы кроватей, как правило, довольно большие и удерживаются вместе рядом сложных частей, что затрудняет их перемещение. Это особенно актуально, если вы будете подниматься или спускаться по лестнице. Хотя вам не нужно разбивать кровать на самые голые части, вы можете отделить каркас матраса от самой кровати или удалить ящики.
> Комод / Туалетный столик: Большинство комодов и туалетных столиков можно перемещать в целости и сохранности, если наверху нет зеркала. Если это так, вам нужно снять зеркало и упаковать его отдельно (с особым вниманием к возможности поломки). Сам комод должен двигаться как одно целое, если вы сначала закрепите ящики.
> Обеденный стол: большие столы * можно * перемещать как одно целое, особенно если вы творчески подходите к тому, как обернуть его и поставить на грузовик. Однако вы можете обнаружить, что легче убрать ноги и все так двигать.Вы сможете лучше закрепить мебель и избежать расшатывания или поломки чего-либо.
> Стеллажи: большинство книжных полок и шкафов можно перемещать в целости и сохранности, но вы можете удалить полки перед тем, как отправиться в путь.
Книги, которые рекомендует главная детская библиотека страны: познавательная литература
Современная детская литература необыкновенно богата и разнообразна. Как ориентироваться в этом потоке постоянных новинок? Специалисты Российской государственной детской библиотеки задают себе этот вопрос буквально каждый день и предлагают на него самые разные ответы.
Сектор комплектования РГДБ еженедельно знакомит читателей с новинками, только-только поступившими в фонды библиотеки. Отдел обслуживания пользователей также публикует тематические материалы о самых востребованных книгах, которыми чаще всего интересуются читатели РГДБ.
Сектор рекомендательной библиографии работает над постоянными обновлениями сайта «Библиогид» – путеводителя по литературе для детей и подростков. Первого числа каждого месяца выходит каталог новинок, и каждый день появляются статьи, обзоры и другие материалы, связанные с современной детской литературой.
Специалисты РГДБ внимательно следят за всеми книжными новинками и рекомендуют юным читателям только те книги, которые прошли самую строгую профессиональную экспертизу. В этом обзоре представлены самые лучшие книги трёх последних лет (с 2019 года), которые уже заслужили любовь и внимание российских читателей.
Российская государственная детская библиотека
Познавательная литература
Pro телефон : иллюстрированная энциклопедия для детей и взрослых
Анна Рапопорт / Санкт-Петербург: Питер : Издатель Георгий Гупало : Музей истории телефона, 2019 (Вы и ваш ребенок). 12+
В этой книге рассказана история телефона – от первого аппарата Александра Белла до новейших смартфонов. Читатель узнает, с какой фразы начался первый телефонный разговор в мире, а с какой – первый звонок по мобильному устройству, что говорят в разных страна, подняв трубку, каков принцип передачи звука и при чем тут лошадь, которая не ест салат из огурцов. Отдельная глава рассказывает о телефонной связи в годы войны, о подвигах телефонистов на фронтах Великой Отечественной.
Вокруг света за 80 деревьев
Джонатан Дрори / иллюстрации Люсиль Клер. Перевод с английского Василия Горохова. Москва : Манн, Иванов и Фербер, 2021. 12+
Автор рассказывает о деревьях и путешествует по разным континентам и странам. Он излагает научную информацию настолько захватывающе, что отсылка к роману короля приключенческого жанра Жюлю Верну вполне оправдана. От описаний деревьев не оторваться. Секрет в том, что Дрори, рассказывая о ботанике, на самом деле говорит о людях и их отношениях с растениями и животными.
Горы мира. История восхождений и открытий
Лада Бакал / художник Татьяна Уклейко. Москва: Пешком в историю, 2020. 12+
Поэты, художники и философы эпохи романтизма воспевали в своих произведениях красоту и величие гор и тем самым способствовали развитию в обществе увлечения горными прогулками. Поначалу занятие элиты, атрибут высшего общества, альпинизм со временем вовлекал всё больше и больше людей, устанавливались всё новые рекорды восхождений. В наши дни альпинизм – это спорт. Но альпинизм – это и любовь, и опасность, и авантюризм, и красота, и философия жизни.
Дневник ласточки
Павел Квартальнов, Ольга Пташник / иллюстрации Ольги Пташник. Москва : Самокат, 2021. 0+
Путешествие героини этой книги начнётся в Ирландии, а завершится в Африке. Читатель узнает, каким видятся города и страны с высоты птичьего полёта, а также познакомится с другими пернатыми, которые встречались ласточке в пути.
Думай и изобретай
Тим Скоренко / художник Тимофей Яржомбек. Москва : Росмэн, 2020. 6+
Открытие и изобретение – это не одно и то же. Изобретателем может быть каждый, кто видит проблему и задумывается над её решением. Примеры, которые приводит автор, очень разнообразные и вдохновляющие. Во всех главах есть практические задания для начинающего изобретателя, которые можно попробовать сделать вместе с детьми.
Животные-невидимки: чудеса маскировки в дикой природе
Лина Реншлебротен / иллюстрации автора. Перевод с норвежского Дарьи Солдатовой. Москва : Паулсен, 2021. 6+
Защитная или отпугивающая окраска, удивительная форма тела, имитация особых движений, звуки голоса – всё это нужно, чтобы спрятаться для успешной охоты или вовремя убежать от хищника. Эта книга знакомит с настоящими фокусами мимикрии в мире дикой природы. Вы также узнаете любопытные факты из жизни самых разных живых существ, населяющих нашу планету.
Животные-строители
Фридерун Райхенштеттер / художник Ханс-Гюнтер Дёринг. Перевод с немецкого Галины Эрли. Москва : ЭНАС-КНИГА, 2019. 0+
Это одновременно и книжки-картинки, и детские энциклопедии живой природы. Книги серии очень информативны, написаны просто и доступно. Они обращаются прямо к маленькому читателю, играют с ним, задают в рассказе забавные вопросы и дают на них живые интересные ответы. Информация великолепно структурирована, разбита на небольшие абзацы и выделена оформлением.
Куда летит летучая мышь?
Фридерун Райхенштеттер / художник Ханс-Гюнтер Дёринг. Перевод с немецкого Галины Эрли. Москва : ЭНАС-КНИГА, 2019. 0+
Лисёнок и другие звери в лесу
Фридерун Райхенштеттер / художник Ханс-Гюнтер Дёринг. Перевод с немецкого Галины Эрли. Москва: ЭНАС-КНИГА, 2019. 0+
Жизнь русского города : от древнего поселения до современного мегаполиса
Марина Яуре / иллюстрации Антона Токарева. Москва: Манн, Иванов и Фербер, 2020. 6+
Как строили первые города древние славяне, как добывали пропитание, как развивались ремёсла и зарождались сословия, как Русь приняла крещение, как томилась под татаро-монгольским игом, как поднималась, крепла под властью московских князей, как возникла новая столица – Петербург, как преобразились русские города в ХХ веке… И всё это в красочных разворотах с лаконичным и ёмким информативным текстом.
Загадки и тайны Арктики
Олег Бундур / фотографии Дмитрия Лобусова. Москва: Мой учебник, 2021. 6+
Эту книгу вполне можно назвать путеводителем по Арктике – ледяному краю, границы которого очерчены Северным полярным кругом. Арктика включает окраины материков Евразии и Северной Америки, почти весь Северный Ледовитый океан и прилегающие части Атлантического и Тихого океанов. Буквально на каждой странице ждут невероятные открытия, ответы на сотни вопросов, раскрытие загадок и тайн.
Загадочный мир бабочек
Бен Ротери / рисунки автора. Перевод с английского Кирилла Турко. Москва: Махаон, Азбука-Аттикус, 2022. 6+
Книга известного британского художника-иллюстратора знакомит читателя с особенными бабочками – самыми яркими и красивыми. Некоторые из них поражают своими размерами и размахом крыльев, другие – дальностью полета, третьи – его скоростью. Из книги можно не только узнать о том, какие бывают бабочки, и увидеть их на прекрасных подробных рисунках, но и прочитать об их жизненном цикле и строении организма, о том, как бабочки питаются и прячутся от врагов. Художник Бен Ротери известен своей любовью к мелким деталям и особой изящной манерой иллюстрации.
Истории вещей: от самовара до интернета
Михаил Пегов / художник Вера Кадурина. Санкт-Петербург: Качели, 2021 (ОГО). 6+
Почему в Средние века вилками пользовались только аристократы? В чём секрет особого цвета джинсов? Можно ли построить стену из рисовой каши? Сколько лет самым древним консервам? На эти и многие другие вопросы ответит весёлая энциклопедия Михаила Пегова. На страницах этой книги вы погрузитесь в удивительные истории вещей, узнаете любопытные факты, познакомитесь с знаменитыми личностями.
История письменности: от клинописи до эмодзи
Виталий Константинов / Перевод с немецкого Анастасии Константиновой. Москва : Пешком в историю, 2021 (Комиксы). 12+
Энциклопедия рассказывает о долгом пути, который проделали знаки от изобретения письменности в древние времена до 2010 года, когда для общения в соцсетях были придуманы эмодзи – значки визуального обозначения чувств и эмоций. Читатели убедятся в том, что мир знаков и символов является глубоким и всеохватным. Книга подробно объясняет специфику письма, его отличие от других знаковых систем, историю возникновения письменности.
История шифров
Виктория Журавлева / художник Анастасия Киган. Москва : Настя и Никита, 2019. 6+
В этой книге рассказывается о сложной науке криптографии – умении зашифровать свое послание так, чтобы оно было доступно только тем, кто владеет ключом к шифру. Читатель сможет узнать о разновидностях шифров и тайных языков, о том, что шифры можно встретить не только в переписке разведчиков, но и в… обыкновенном с виду стихотворении, и называется такая литературная головоломка – акростих. А также о том, что шифры используют не только шпионы, но и банкиры, айтишники, дипломаты.
Как слушать музыку
Ляля Кандаурова. Москва : Альпина Паблишер, 2020. 6+
Доступная и близкая музыка, для прослушивания которой не нужны специальные навыки, это всего лишь снежная шапка на вершине айсберга. Для постижения всего остального музыкального богатства нужен навигатор. Лиля Кандаурова создала руководство для тех, кто хочет слушать музыку так же, как мы читаем книги: следить за сюжетом, узнавать новое, сопереживать автору и отзываться на его высказывание. С помощью этой книги можно слушать и учиться понимать любую «умную» музыку – содержательную, глубокую, необычную, будь то произведения академические или современные: джаз, электроника, рок, фолк или даже рэп.
Как смотреть кино
Антон Долин / иллюстрации Константина Бронзита. Москва: Альпина Паблишер, 2020. 12+
Какими критериями руководствоваться при выборе фильма? Влияет ли на удовольствие от фильма умение его «читать», то есть разобрать на фрагменты, проанализировать, оценить отдельные элементы, выделить достоинства и недостатки? Что делать фанатам кино в наш век, когда посмотреть все существующие фильмы уже не способен никто? Какие фильмы можно посмотреть, чтобы составить представление об основных этапах развития киноиндустрии? Антон Долин постарался дать на все вопросы простые и ясные ответы, протестировав текст книги на собственных детях.
Как устроен мост?
Роман Беляев. Москва : Самокат, 2020 (Свет инженерной мысли).
Увлекательный рассказ о мостах начинается с экскурса в историю этих сооружений и этимологию слова, их обозначающего. Когда и где появились первые конструкции для переправы с одного берега на другой? Почему слово «мост» звучит практически одинаково во многих языках? Затем читатель познакомится с типами мостов и наиболее интересными их образцами. Детальные рисунки помогают понять принцип строительства и функционирования каждого моста.
Лось на диване, верветка на печи : записки из жизни небольшого зоопарка в Пушкинских Горах
Юлия Говорова / художник Ирина Маковеева. 12+ Москва: Время, 2020 (Время – юность!). 12+
В своих рассказах – то смешных, то лирических – Юлия Говорова с невероятной любовью пишет о животных, которые оказались забыты, потеряны, выброшены. Вот мускулистая волчица Ирма, будто пропитанная запахом леса. Вот молодой кенгуру Тайсон, нюхающий утренний туман. Вот страусята, которые высовывают любопытные головы из-за забора, так что шеи замирают вопросительным знаком…
Микросупергерои. Самые умные!
Ольга Посух / иллюстрации автора. Москва : Самокат, 2022 (Микросупергерои). 0+
Для того, чтобы стать супергероем, не обязательно быть большим и сильным, достаточно иметь способности, которые позволяют выжить в любых условиях. В процессе долгой эволюции муравьи научились менять окружающую среду под свои нужды и смогли стать самыми многочисленными насекомыми на планете. На сегодняшний день науке известно около 15 тысяч видов муравьёв. Из книги можно узнать, как проходит жизненный цикл муравьёв, что они едят, как общаются, как работают в команде.
Мы в космосе: как человек шёл к звёздам
Андрей Жвалевский / иллюстрации Фёдора Владимирова. Москва : Пешком в историю, 2021 (Мир вокруг нас) 6+
Книга просто и одновременно увлекательно знакомит читателя с устройством небесных тел, историей астрономии, особенностями подготовки к полётам в космос, работой орбитальной станции. На подробных иллюстрациях показаны тщательно прорисованные детали, дополненные поясняющими подписями. И очень важно, что под обложкой этой книги читатель найдёт самую актуальную информацию.
На Север. Путешествие вслед за чайкой
Анна Игнатова / иллюстрации Ани и Вари Кендель. Санкт-Петербург: Детское время, 2019. 0+
Эта книга – путевой дневник летнего автомобильного путешествия на север России семьи из Санкт-Петербурга. Их дорога проходит через Ладогу, Карелию, вдоль Онеги, Белого моря, на Кольский полуостров, к Хибинам и тундре до самого Северного Ледовитого океана. В долгом путешествии сестры-подростки всю дорогу делают заметки и зарисовки: одна записывает наблюдения и переживания в блокноте, другая рифмует строчки в смартфоне.
На сцене : история театра
Пётр Воротынцев / художник Алиса Юфа. Москва : Пешком в историю, 2020 (Мировая история) 6+
Содержательная энциклопедия начинается с описания театра давно минувших эпох – Древней Греции, Древнего Рима, Древнего Востока. Автор книги демонстрирует широкую эрудицию и глубокие познания. Он описывает виды и жанры театрального искусства, происхождение театрализованных действ, балет, оперу, кукольный театр, теории выдающихся режиссёров, эволюцию актёрской профессии, специалистов, благодаря которым театр работает сейчас.
Подводный мир: визуальный гид
Сабрина Вайс / иллюстрации Джулии де Амичис. Перевод с английского Е. Я. Мигуновой. Москва: Росмэн, 2019. 6+
Почему океан синий? Существуют ли морские чудовища и русалки? Какова глубина морской бездны? Зачем рыбы сбиваются в стаи и как они путешествуют без карт и компаса? Где учатся петь горбатые киты? Удивительные факты из жизни обитателей семи морей, наглядные схемы и карты, множество ярких иллюстраций – этот гид не раз заставит читателя воскликнуть: «Ух ты!»
Про грибы, черепаху матамату и рыбу кефаль : занимательное путешествие с дочкой
Дмитрий Ржанников / иллюстрации Анастасии Арушановой. Москва : Издательский Дом Мещерякова, 2019 (Пифагоровы штаны). 6+
Герои рассказов автора не только разнообразные живые существа, но и люди, в том числе члены его семьи, в первую очередь – дочка Лиза. Теплые воспоминания о детских приключениях, походах, забавных происшествиях, прогулках по юмористическому маршруту в серьезном музее и далеких поездках познакомят с удивительными подробностями жизни микроорганизмов, млекопитающих, насекомых, рыб, грибов и растений.
Пьер больше не боится чёрного
Мишель Пастуро / художник Лоранс Ле Шо. Перевод с французского Ольги Поляк. Москва: Текст, 2019. 6+
Книги этой серии показывают важность цвета для восприятия окружающего мира. От цвета очень часто зависит настроение человека, а от настроения человека зависит и все остальное в его жизни. Рисунки художницы Лоранс Ле Шо помогают это понять маленькому читателю. Слова, называющие цвет, выделены соответствующим цветом и размером шрифта.
Сюзанна выбирает красный
Мишель Пастуро / художник Лоранс Ле Шо. Перевод с французского Ольги Поляк. Москва : Текст, 2019. 6+
У Валентины синие пятки
Мишель Пастуро / художник Лоранс Ле Шо. Перевод с французского Ольги Поляк. Москва : Текст, 2019. 6+
Мартен видит жизнь в зелёном цвете
Мишель Пастуро / художник Лоранс Ле Шо. Перевод с французского Ольги Поляк. Москва : Текст, 2020. 6+
С востока на запад. Путешествие письма в бутылке
Марина Бабанская / художник Наталья Карпова. Москва : КомпасГид, 2019. 6+
Дети пишут письма одинокому смотрителю маяка на крошечном острове в Японском море, который однажды отправил в путешествие «бутылочное письмо». Бутылка с его посланием странствует по всей стране, находя все новых адресатов на пути в несколько тысяч километров: от Владивостока и Камчатки через Байкал, Алтай, юг России к обеим столицам и северным областям. И отовсюду на маяк летят бумажные письма, в которых дети рассказывают о себе, о своей семье, окружении, своих занятиях, своем крае и его особенностях.
Старая книжная полка
Секреты знакомых книг Валерий Шубинский. Санкт-Петербург: Дом детской книги, 2019. 12+
Обычно книга в сознании ребёнка существует как бы сама по себе, отдельно. Но потом маленький читатель подрастает, и оказывается, что его любимая детская книжка имеет своё место в истории и что у неё есть автор со своей собственной, подчас непростой, судьбой. И тогда книги, на которых мы все выросли, начинают говорить с нами совершенно по-другому. Именно этому повороту в читательском восприятии и посвящена эта книга.
Татьяна Маврина. Много всего кругом
Анастасия Строкина / художник Татьяна Маврина. Москва : Книжный дом Анастасии Орловой, 2021 (Жизнь замечательных людей). 6+
Издание иллюстрировано работами, предоставленными наследниками и библиофилом, коллекционером и меценатом М. В. Сеславинским. В тексте слышен голос самой художницы. Анастасия Строкина собрала материалы и реконструировала воображаемые реплики. Именно эта живая интонация магическим образом воскрешает героиню книги, Татьяну Маврину, русскую художницу-сказочницу.
Транссиб. Поезд отправляется!
Александра Литвина / иллюстрации Ани Десницкой. Москва: Самокат, 2020. 6+
«Транссиб» – это путешествие в пространстве, вернее, по необъятным пространствам России. Отправной пункт путешествия по Транссибирской магистрали – Москва, конечная станция – Владивосток. 36 станций, больших и малых городов, улеглись в четыре насыщенные, красочно иллюстрированные главы: Европа и Урал, Западная Сибирь, Восточная Сибирь, Дальний Восток. Информация по истории края, его флоре и фауне, ландшафте и климате, а также сведения о расстоянии от Москвы и времени стоянки поезда Москва-Владивосток (эти сведения предоставлены РЖД) соседствует с небольшими рассказами мальчиков и девочек, а также их мам и пап, живущих на станциях Транссиба.
Увидеть невидимое. Древнерусское искусство
Наташа Кайя / иллюстрации автора. Москва : БуксМАрт : Ассоциация искусствоведов, 2019 (История искусства для детей). 6+
Красота храмов, их облик, строгие и выразительные иконы, состав иконостасов, монументальная живопись и скульптура – всё отражало стремление христианина к Богу. Все виды искусства подчинялись определенным канонам. Об этих канонах, о техниках и материалах, об основных школах и сюжетах древнерусского искусства автор повествует удивительно просто, доступно и интересно.
Удивительный Урал
Светлана Лаврова / иллюстрации Евгении Колеватых. Санкт-Петербург: ИД Первоград, 2020. 6+
Урал – это самая середина огромной территории современной России. В своей книге екатеринбургская писательница Светлана Лаврова рассказывает много интересного об этой удивительной и очень необычной земле, о её древних городах, о бесценных самоцветах, о старинных заводах и, конечно, о людях, которые здесь живут.
Field Sensor: вычисление состава и цели запросов PubMed | База данных
Кроме того, состав запросов PubMed, вычисленный Field Sensor, оказывается важным для понимания того, как пользователи запрашивают PubMed.Введение
PubMed (www.pubmed.gov) — это поисковая система, разработанная и поддерживаемая Национальным центром биотехнологической информации в NLM. PubMed работает с MEDLINE ® , коллекцией из более чем 27 миллионов биомедицинских библиографических записей по состоянию на 2017 год, и в последние десятилетия наблюдается неуклонный рост научной информации. PubMed обрабатывает в среднем 3 миллиона запросов в день и считается основным инструментом для ученых в области биомедицины (1–3). Учитывая важность PubMed, улучшение понимания пользовательских запросов открывает огромные возможности для улучшения результатов поиска.
Для обычных поисковых систем проблема понимания запросов охватывает целый спектр исследований, начиная от определения целей запроса высокого уровня (информационных, навигационных или транзакционных) (4–8) и заканчивая определением более подробной информации запроса, такой как человек, возраст, кино, путешествия, сферы деятельности (9), понимание семантики запросов (10–12). Многие запросы, задаваемые в Интернете, нацелены на структурированные или полуструктурированные веб-данные, такие как коммерческие продукты, фильмы и т. д. Преобразование неструктурированного языка этих запросов в структурированное представление было тщательно изучено и показало улучшение результатов поиска (13–15). Другие подходы, используемые для понимания запросов, включают статистическое машинное обучение (7), глубокое обучение (9)., 12), сопоставление с семантическим пространством Википедии (10, 11), опираясь на журналы запросов (11, 16) и информацию о кликах (17).
Несмотря на обширные исследования общего веб-поиска, было опубликовано меньше исследований моделей использования онлайновых биомедицинских информационных ресурсов. Однако известно, что между ними есть важные различия (18–21). В области биомедицины проводится несколько исследований, направленных на понимание того, как осуществляется поиск медицинской информации, и информационных потребностей пользователей области, таких как клиницисты, медицинские исследователи или пациенты (18, 19). , 22–25). Двумя наиболее полными анализами журналов биомедицинских запросов являются исследование запросов PubMed за 1 день (19) и исследование запросов PubMed за 1 месяц (18). Оба анализируют статистические свойства журналов запросов, такие как длина запроса, сеансы пользователей, размер набора результатов, и пытаются охарактеризовать запросы с точки зрения семантики и намерения. Работа, описанная в (18), вручную аннотирует случайный набор из 10 000 запросов из журналов PubMed, сопоставляя сегменты запросов с шестнадцатью предопределенными категориями семантических типов. Исследование в (19) пытается выполнить семантический анализ запросов, сопоставляя их с словарем, контролируемым MeSH.
Одним из основных аспектов запросов, изучаемых как общими, так и биомедицинскими поисковыми доменами, является цель запроса. По определению Бродера (5), общие веб-запросы можно охарактеризовать как информационные, навигационные или транзакционные (обычно не наблюдаемые в научном поиске). Распространяя это определение на PubMed, информационные запросы, также известные как тематические поиски, такие как рак толстой кишки или семейная средиземноморская лихорадка , предназначены для удовлетворения информационных потребностей по конкретной теме. Навигационные запросы, также известные как запросы известных элементов (26), такие как Katanaev AND Cell 2005, 120(1): 111–22, , предназначены для получения определенной публикации. В PubMed навигационные запросы могут состоять из элементов цитирования, включая имя автора, название, том, выпуск, страницу и/или дату, или могут быть полными цитированиями. Только небольшой процент запросов PubMed включает явные поля, назначенные пользователем, и их просто понять. Подавляющее большинство запросов не имеют назначений полей, хотя подразумевается скрытая информация о структуре. Для этих запросов бремя сопоставления сегментов запроса с полями перекладывается на поисковую систему.
Причина важности прогнозирования намерения запроса заключается в том, что оно часто влияет на поведение поисковой системы (27). Информационные запросы сосредоточены на доступе к свободному тексту, который имеет тенденцию извлекать много документов, и функция сортировки имеет решающее значение для отображения результатов. Напротив, навигационные запросы требуют синтаксических анализаторов и доступа к структурированным данным цитирования и отражают намерение пользователя найти конкретный документ или веб-сайт. Это различие особенно важно для поиска в базах данных научного цитирования, таких как PubMed, где навигационные запросы составляют значительно большую часть всех запросов по сравнению с общим поисковым доменом. Как мы показываем в этом исследовании, на навигационные запросы приходится около половины всех поисковых запросов, в то время как в общей области поиска на них приходится 10% запросов (6).
Хотя запросы, связанные со здоровьем, и поиск медицинской информации привлекли внимание к разработке новых инструментов и методов, специфичных для этой области (28), насколько нам известно, не существует приложений, которые могли бы алгоритмически определять цель запросов PubMed. Два недавних исследования рассматривают возможность прогнозирования намерений академических запросов (29, 30). В исследовании (29) сообщается, что в академических поисковых системах навигационные запросы составляют 7,6% запросов, однако вычисления основаны на явных признаках, таких как номер ISBN, DOI или другие теги, связанные с цитированием, для классификации запросов. Учитывая, что лишь небольшой процент запросов PubMed включает явные поля, назначенные пользователем, для классификации намерений запроса необходимы более чувствительные методы. В исследовании (30) представлен подход к бинарной классификации для прогнозирования намерений научных запросов, где авторы сообщают о балле F1, равном 0,677, на наборе из 579 ответов.вручную аннотированные научные запросы, используя их лучший метод (Gradient Boosted Trees). Они используют такие функции, как количество токенов в запросе, соотношение условий запроса, идентифицированных как имена авторов, есть ли в запросе знаки препинания или нет и т. д., чтобы управлять обучением. Чтобы решить проблему прогнозирования намерений биомедицинских запросов, мы разработали Field Sensor, веб-инструмент, который присваивает поле каждому токену или последовательности токенов в запросе, вычисляя сопоставление между сегментом запроса и полем, а также с вероятностью этого сопоставления. Например, для запроса апноэ во сне, смягчение идентифицирует, что апноэ во сне является текстом, а апноэ во сне является именем автора, и предсказывает отображение апноэ во сне [текст], смягчение [автор] . На основании назначений полей смысл запроса выводится следующим образом: запрос считается информационным, если он состоит только из текстовых полей, в противном случае мы называем его навигационным.
Датчик поля — это механизм вероятностного предсказания поля, оснащенный двумя модулями предварительной обработки на основе правил. Система начинается с модуля синтаксического разделения запросов, который разбивает запрос на основе логических операторов и скобок. Сегменты запроса, помеченные пользователем, также идентифицируются на этом этапе и остаются неизменными. За ним следует модуль тегирования запросов на основе правил, предназначенный для распознавания элементов цитирования запроса, происходящих из полей тома, выпуска, страницы и даты, с учетом закономерностей между числами и пунктуацией. И, наконец, третий модуль — это модуль вероятностного предсказания поля, который по заданному сегменту запроса предсказывает поле сегмента. Модель основана на байесовском подходе, который выводит сопоставление между сегментом запроса и полем в PubMed на основе статистики коллекции. Наш вероятностный модуль прогнозирования полей связан с вероятностной моделью поиска полуструктурированных данных (PRMS) (13) в том, как вычисляются сопоставления между словами запроса и полями. Однако PRMS представляет собой модель униграммного набора слов, в то время как наша модель учитывает зависимости терминов и пытается предсказать поля для сегментов запроса, содержащих до пяти токенов.
Термин запроса к отображению поля, предсказанному датчиком поля, можно использовать несколькими способами. Важной функциональностью нашего метода является классификация запроса как информационного или навигационного. Датчик поля был развернут в PubMed с июня 2017 года для выявления информационных запросов, для которых пользователям предлагаются результаты поиска, отсортированные по релевантности, в качестве альтернативы обратному временному порядку по умолчанию (31). Дополнительным приложением могут быть смешанные запросы, содержащие как информационные, так и навигационные компоненты. Идентификация этих полей может улучшить процесс поиска, применяя различные стратегии поиска к информационным и навигационным компонентам запроса. Кроме того, датчик поля незаменим при изучении журналов запросов. Это позволяет нам изучать, как осуществляется поиск биомедицинской информации. Для запросов, которые не извлекают никаких документов, инструмент может помочь нам лучше понять, какие поля, скорее всего, являются причиной. И, наконец, поскольку базовая модель Field Sensor рассчитывается на основе данных Medline, ее можно использовать для любой другой специализированной базы данных биомедицинского цитирования, такой как bioRxiv (http://biorxiv.org/), или ее можно переобучить для применения в других академических учреждениях. поисковые системы.
Материалы и методы
В этом разделе мы описываем нашу модель датчика поля, инструмента для определения поля для каждого маркера или последовательности маркеров в запросе. Статьи в PubMed заносятся в базу данных единым структурированным образом: аннотация статьи, название статьи, имя(а) автора, название журнала, том, выпуск, страница и дата. Это поля, которые нам интересны для сопоставления. Мы пометим сегменты запроса, которые сопоставляются с восемью полями, как text , название , автор , журнал , том , выпуск , дата и страница соответственно. Обратите внимание, что поле text соответствует лексике, содержащейся в рефератах. В то время как статьи содержат дополнительные поля базы данных, например. принадлежности, мы считаем, что обозначенные восемь областей являются наиболее важными для нашей работы.
На рис. 1 показан общий поток обработки запросов и прогнозирования полей с точки зрения трех основных модулей: синтаксического разделения запросов, тегирования цитирования на основе правил и вероятностного прогнозирования полей. На протяжении всего раздела мы ссылаемся на пример запроса 9.0019 Katanaev AND Cell 2005, 120(1): 111 – 22 для иллюстрации функциональности каждого модуля путем демонстрации того, как сегменты запроса интерпретируются на каждом этапе.
Рисунок 1.
Открыть в новой вкладкеСкачать слайд
Конвейер обработки запросов Field Sensor. Система состоит из трех основных модулей: синтаксического разделения запросов, тегирования цитирования на основе правил и вероятностного прогнозирования полей. Рядом с каждым модулем показано, как сегменты запроса интерпретируются каждым из этих трех модулей.
Наш тегировщик цитирования на основе правил обрабатывает текстовую строку в три этапа. На первом этапе алгоритм ищет совпадающие скобки, квадратные скобки или кавычки. Если найдены совпадающие скобки, строка между скобками помечается как в скобках . Аналогично, строка в квадратных скобках помечается как Tag , а строка, предшествующая тегу , помечается как Tagged . Строка, заключенная между совпадающими кавычками, помечена как 9.0019 Цитата и не предназначена для разделения этим модулем.
Второй шаг состоит в присвоении более определенных меток маркерам, представляющим информацию о цитировании. Для этой цели токены рассматриваются в порядке появления и проверяются на соответствие известному набору терминов, которые являются сокращениями месяцев (например, января , декабря ), индикаторами номеров страниц (например, p , pp ) и индикаторы номера тома (например, v , vol ). Когда такие токены распознаются и встречаются в соответствующем контексте, мы помечаем их Month , PageIndicator или VolumeIndicator . Если токен не распознается как один из них, мы проверяем отдельные символы. Если первый символ является цифрой или второй символ является цифрой, а токен содержит дефис, метка изменяется на Числовой . В противном случае мы проверяем, является ли строка буквенной, и передаем ее для обработки следующему модулю.
Шаг 3 снова проверяет теги в том порядке, в котором они встречаются. Если найден токен с меткой PageIndicator , это означает, что следующий токен должен иметь метку Page . Аналогично, за меткой VolumeIndicator должна следовать метка Volume . Этикетка Numeric получает специальную обработку. Если соответствующий токен является целым числом от 1900 до текущего года, метка изменяется на Year . Если токен содержит ‘ – ’, например 111 – 22 , имеет маркировку Страница . Если маркер Числовой с меткой представляет целое число в диапазоне 1 – 31 и следует за маркером с меткой Месяц , метка Числовой изменяется на День . Далее рассматривается целое число в скобках. Если он находится в диапазоне от 1900 до текущего года, он помечен как Year . В противном случае, если ему предшествует числовая метка , он проверяется на соответствие одному из шаблонов тома и выпуска, например. 83(2) , и ему присвоен ярлык Выпуск . Наконец, делается попытка пометить токены Numeric , которые появляются рядом с жетонами, не помеченными Numeric , как Volume или Issue , если эти метки еще не заняты. Кроме того, если назначены обе метки, они должны располагаться рядом и в порядке , том , за которым следует , выпуск . Здесь приведены не все детали, но вышеизложенное обеспечивает основные функции.
После обработки первыми двумя модулями вероятностное предсказание поля применяется к сегментам запроса, для которых недоступна другая информация для синтаксического анализа. Поля, которые мы учитываем для расчета, включают аннотацию статьи, название статьи, имя автора, название журнала, том, выпуск, страницу и дату. Предположим, что запрос Q состоит из m терминов Q = ( t 1, …, t m ), и мы хотим предсказать вероятность того, что термин t в запросе следует интерпретировать как происходящее из поля F i в записи PubMed.
Начнем с применения теоремы Байеса
PFit=PtFiPFiPt.
(1)
Чтобы получить оценку левой части, мы оцениваем каждый фактор в правой части. Фактор P(t|Fi) — это вероятность наблюдения термина t в поле F i записи PubMed. Мы вычисляем P(t|Fi) для каждого из восьми полей, используя языковую модель (32) следующим образом:0007
P(t|Fi)=частота(t∈Fi)частота(Fi).
(2)
Фактор PFi представляет собой априорную вероятность того, что поле является источником термов. Мы получаем оценки для P(Fi) из набора из 10 000 вручную аннотированных запросов PubMed, которые обсуждаются в следующем разделе. Если предположить, что этот список полей является исчерпывающим и взаимоисключающим, данная интерпретация запроса будет назначать только одно поле каждому термину. Это позволяет нам вычислить P(t)=∑i=18p(t|Fi)p(Fi). Затем мы можем применить (1), чтобы предсказать наиболее вероятное назначение полей терминам в запросе.
Языковая модель обычно вычисляет распределение вероятностей по последовательностям слов. Для последовательности длиной м он присваивает вероятность Pt1, …, tm всей последовательности. Модель униграмм предполагает независимость терминов и вычисляет вероятность как Punit1,t2=Pt1Pt2. Языковая модель униграмм часто используется в распознавании речи, машинном переводе и маркировке POS. Полезным расширением модели униграмм является модель биграмм, которая предполагает, что вероятность наблюдения термина t2 зависит от предшествующего термина, и вычисляет вероятность биграммы t1 t2 как P2-gramt1,t2=Pt1Pt2t1.
Сначала мы вычисляем вероятности на основе языковой модели униграмм, а затем расширяем анализ на последовательности пар слов. Мы используем модель языка биграмм, чтобы вычислить вероятность пары терминов P2-gramt1,t2=Pt1Pt2t1 и сравнить ее значение с Punit1,t2=Pt1Pt2. Для каждого поля, в котором найдена пара токенов, если P2-gramt1,t2>Punit1,t2 для этого поля, мы объединяем два термина t1 и t2 во фразу t1 t2, и для пары прогнозируется поле с наибольшей вероятностью. Когда два термина объединяются во фразу t1 t2, процесс итеративно продолжает проверять последующие пары t2 t3, t3 t4 и t4 t5 и расширяет прогнозируемый сегмент запроса до тех пор, пока он больше не сможет быть расширен или не достигнет длины пяти токенов ( оперативное решение). Для каждой длины сегмента записывается поле с наибольшей вероятностью. В наших языковых моделях мы не используем сглаживание, потому что мы ограничиваем наш подход поиском терминов, которые действительно появляются в базе данных, из которой получены модели. Затем мы вычисляем путь через запрос, чем-то похожий на этап декодирования в алгоритме Витерби (33). Начиная с первого токена, мы используем жадный метод, итеративно перемещая указатель в конец самого длинного предсказанного сегмента. Хотя это не дает оптимальных границ сегментации, оно обеспечивает разумное приближение.
На рисунке 2 мы разрабатываем пример, демонстрирующий, как вычисляются вероятности для примера запроса интраоперационная эндоскопия . Прогноз, основанный на языковой модели униграмм, присваивает поле с наибольшей вероятностью отдельным токенам и приводит к прогнозированию эндоскопии в качестве названия журнала. Однако, поскольку мы применяем модель языка биграмм и вычисляем вероятность интраоперационной эндоскопии , мы правильно предсказываем фразу интраоперационная эндоскопия как текстовое поле . В этом примере текст оказывается единственным полем, в котором находится эта биграмма.
Рисунок 2.
Открыть в новой вкладкеСкачать слайд
Пример вероятностных назначений полей с использованием языковых моделей униграмм и биграмм.
Учитывая корреляцию между словами в аннотациях к статьям и названиями статей, устранение неоднозначности того, намеревается ли пользователь выполнить поиск по ключевому слову или по заголовку статьи, может иметь решающее значение для возврата соответствующих результатов поиска. После стандартного предсказания поля датчик поля включает дополнительную проверку, чтобы убедиться, что сегмент запроса является полным заголовком или его значительной частью. Мы используем заголовок обозначение поля для соответствия полному заголовку или значительной части заголовка в запросе. Обозначение поля text предназначено для сегментов запроса текстового слова, представляющих интересующую тему, встречающихся либо в заголовке, либо в реферате. Сильная корреляция также присутствует между названиями журналов и текстовыми терминами, особенно для кратких названий журналов, таких как рак , кровь и циркуляция . Многие названия журналов совпадают с часто встречающимися терминами и представляют собой проблему. Кроме того, вычисление вероятности на основе языковой модели может отдавать предпочтение области с меньшим размером словарного запаса, и 9Поле журнала 0019 является примером такого. Когда термин можно интерпретировать и как текстовый термин, и как название журнала, модель с большей вероятностью предскажет его как название журнала. Мы публикуем исходные прогнозы полей для одного токена, предсказанного как журнал , чтобы проверить, содержит ли запрос дополнительную информацию о цитировании, такую как том, выпуск, дата или страница и/или имя автора. В противном случае, если вероятность предсказания поля журнала ниже 0,8, мы помечаем термин как 9.0019 текст .
Field Sensor реализован на C++ как общий инструмент для понимания состава медицинских и биомедицинских запросов. Текущая реализация имеет среднюю пропускную способность около 800 запросов в секунду в одном потоке, что соответствует максимальному поисковому трафику PubMed. Датчик поля был интегрирован и развернут в PubMed, чтобы отличать информационные запросы от навигационных. Подробности использования PubMed выделены в (31).
82″> Золотой стандарт 10 000 аннотированных вручную запросов PubMed
Мы используем общедоступный набор данных из 10 000 аннотированных вручную запросов, описанных в (18). В этом исследовании был проведен семантический анализ запросов, где содержимое запроса было помечено 1 из 16 семантических категорий: часть тела, клеточный компонент, ткань, химическое вещество/лекарство, устройство, расстройство, ген/белок, живое существо, исследовательская процедура, медицинская процедура. , Биологический процесс, Название, Имя автора, Название журнала, Цитирование и Аббревиатура . Для аннотирования набора запросов были наняты семь аннотаторов, обладающих опытом в различных областях биомедицины и/или информатики.
Чтобы использовать эти вручную аннотированные данные для оценки датчика поля, мы немного изменим определения категорий, чтобы они соответствовали нашей настройке. Четыре семантических класса Title, Author name, Journal name и Citation используются, как определено. Остальные двенадцать категорий объединены в один класс текст , поскольку мы не намерены различать эти категории и идентифицировать их как текстовые элементы. Обратите внимание, что категория Citation включает том, выпуск, страницу и дату, которые помечены как 9.0019 Цитата . Следовательно, для этого набора мы оцениваем, насколько хорошо мы отличаем четыре элемента цитирования от остальных категорий, но не измеряем эффективность для каждого класса отдельно. На рис. 3 представлен состав набора 10 000 с точки зрения полей. Как мы упоминали в разделе «Методы», состав набора 10K также используется для оценки фактора PFi, представляющего априорную вероятность поля в (1). Из этого набора получаем оценки для P(Fi) для пяти полей: Текст , Заголовок, Имя автора, Название журнала, Цитата ; а поскольку категория Citation включает том, выпуск, страницу и дату, мы равномерно распределяем вероятность категории Citation между этими четырьмя полями.
Рисунок 3.
Открыть в новой вкладкеСкачать слайд
Распределение полей, рассчитанных для 10K запросов, аннотированных пятью полями: Ключевое слово, Автор, Цитата, Название журнала и Название.
Этот подход к сопоставлению был разработан для обеспечения более эффективного решения запросов с единичным цитированием. Запросы одиночного цитирования — это те навигационные запросы, которые можно сопоставить с уникальной статьей PubMed. Запросы одиночного цитирования обычно являются длинными запросами и содержат полное название и/или некоторую комбинацию названия журнала, автора и тома, выпуска, страницы и даты. Обратите внимание, что текстовое поле не представлено в этом наборе данных. Текстовый сегмент запроса может совпадать с частью заголовка, однако соответствие между сегментом запроса и аннотацией в этом анализе недоступно. Причина двоякая. Первая причина — эффективность: сопоставление рефератов с помощью этого алгоритма занимает значительно больше времени, чем сопоставление заголовков. Во-вторых, пользователи редко используют термины, отсутствующие в заголовке, при построении одного запроса на цитирование.
Для этой оценки мы обработали около 3 миллионов запросов, собранных за один день 12 октября 2016 года, и сократили их до набора из 102 971 запросов, которые с очень высокой вероятностью сопоставляются с уникальным документом PubMed. Мы будем называть этот набор набором 103K Silver. При ручном просмотре 500 случайно выбранных запросов из этого набора мы обнаружили, что точность синтаксического анализа запросов составляет 99%.
Чтобы оценить работу датчика поля, мы применили его к набору 10K. Анализ датчика поля сообщается на уровне запроса (по 9490 запросам) и на уровне токенов (на основе 25 195 аннотированных токенов). Мы называем набор предсказанных аннотаций 10K_FS и сравниваем их с ручными аннотациями 10K_GS. Для анализа на уровне запроса последовательность предсказанных полей является правильной, если она соответствует аннотации золотого стандарта. В противном случае, если хотя бы одно из полей не соответствует аннотации золотого стандарта, прогноз считается неверным. При анализе на уровне токенов прогнозируемое поле сравнивается с полем золотого стандарта на основе токенов. Из 9490 Field Sensor правильно аннотировал 8798 запросов, что составляет 93,28% общей точности инструмента. В таблице 1 представлены показатели Precision, Recall и F для пяти полей, вычисленных на уровне токена и запроса.
Таблица 1.
Анализ датчика поля на основе токенов и запросов
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | |||||
|---|---|---|---|---|---|---|---|
| . | Р . | Р . | Ф . | Р . | Р . | Ф . Автор | 0.969 |
| Text | 0.932 | 0.957 | 0.944 | 0.957 | 0.980 | 0.968 | |
| Citation | 0.953 | 0.918 | 0.935 | 0.964 | 0.935 | 0.949 | |
| Journal | 0. 882 | 0.926 | 0.904 | 0.796 | 0.891 | 0.841 | |
| Title | 0.882 | 0.789 | 0.833 | 0.767 | 0.741 | 0.753 | |
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| . | Р . | Р . | Ф . | Р . | Р . | Ф . |
| Author | 0.980 | 0.967 | 0.974 | 0.969 | 0.969 | 0.969 |
| Text | 0. 932 | 0.957 | 0.944 | 0.957 | 0.980 | 0.968 |
| Citation | 0.953 | 0.918 | 0.935 | 0.964 | 0.935 | 0.949 |
| Journal | 0.882 | 0,926 | 0,904 | 0,796 | 0,891 | 0,841 |
| Титул | 0414 .0417| 0,789 | 0,833 | 0,767 | 0,741 | 0,753 | |
Precision for Weld of Word -For Atthine For Atthine For Word -For Atthine For Word -For -For -For -Word -For -WordER. название статьи.
Открыть в новой вкладке
Таблица 1.
Анализ датчика поля на основе токенов и запросов
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| . | Р . | Р . | Ф . | Р . | Р . | Ф . |
| Author | 0.980 | 0.967 | 0.974 | 0.969 | 0.969 | 0.969 |
| Text | 0.932 | 0.957 | 0.944 | 0.957 | 0.980 | 0.968 |
| Citation | 0.953 | 0.918 | 0.935 | 0.964 | 0.935 | 0.949 |
| Journal | 0.882 | 0.926 | 0.904 | 0.796 | 0. 891 | 0.841 |
| Title | 0.882 | 0.789 | 0.833 | 0.767 | 0.741 | 0.753 |
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| . | Р . | Р . | Ф . | Р . | Р . | Ф . |
| Автор | 0,980 | 0,967 | 0,974 | 0,969 | 0.969 | 0.969 |
| Text | 0.932 | 0.957 | 0.944 | 0.957 | 0. 980 | 0.968 |
| Citation | 0.953 | 0.918 | 0.935 | 0.964 | 0.935 | 0.949 |
| Journal | 0.882 | 0.926 | 0.904 | 0.796 | 0.891 | 0.841 |
| Title | 0.882 | 0.789 | 0.833 | 0.767 | 0.741 | 0.753 |
Precision/Recall/ F -measure are computed for пять полей интереса: имя автора, ключевое слово, цитирование, название журнала и название статьи.
Открыть в новой вкладке
Мы проанализировали распределение полей слов с ошибками, сравнив их с назначенными вручную тегами в 10K_GS. Анализ показывает, что в 60% случаев опечаткой является текстовый элемент, в 33% — имя автора, в 4% — заглавная лексема. Ошибки в названии журнала и цитировании составляют по 1,3%. На основе этой статистики датчик поля помечает жетоны с ошибками как 9.0019 текст . Показатели полноты/точности и F -мера, представленные в таблице 1, рассчитаны на основе этого предположения.
Из 9490 запросов 692 содержат как минимум один неверно аннотированный токен, а в следующем разделе представлен подробный анализ обнаруженных ошибок. Анализ показал, что 187 из 692 запросов (27%) содержали опечатку, то есть токен, не найденный в PubMed. Предсказание Датчика поля по жетону с ошибкой никоим образом не демонстрирует производительность инструмента. Более того, наличие жетонов с ошибками затрудняет оценку датчика поля. Например, если фамилия автора написана с ошибкой, это приводит к тому, что инициалы автора после фамилии не связаны с фамилией. Или маркер заголовка с ошибкой приводит к тому, что полное название не распознается. Для анализа ошибок мы не рассматриваем 187 запросов, содержащих маркеры с ошибками, и внимательно изучаем оставшиеся 505 запросов, в которых ошибка произошла не по причине опечатки.
05″> Различение текстовых слов и заголовков
Учитывая корреляцию между словами в аннотациях статей и заголовками, устранение неоднозначности того, намеревается ли пользователь выполнить поиск по ключевому слову или по заголовку статьи, может иметь решающее значение для получения ожидаемых результатов поиска. Количество случаев, когда текст предсказывается как заголовок, составляет 66 запросов. Количество случаев, когда заголовок предсказывается как текст, составляет 65 запросов.
Для некоторых запросов может быть не совсем ясно, выполняет ли пользователь поиск по ключевым словам или по названию статьи. Например, поиск в PubMed с запросом « шизофрения и рассеянный склероз » возвращает 518 статей при интерпретации запроса по ключевому слову и ровно 1 результат [PMID: 3059470] при интерпретации как заголовок. Кроме того, изучая различия между результатами Field Sensor и ручными аннотациями, мы заметили, что аннотаторы не всегда последовательно различали поля текста и заголовка. Примеры запросов в этой категории представлены на рис. 5.
Рисунок 5.
Открыть в новой вкладкеСкачать слайд
Различение слов в тексте и заголовков.
Из 102 971 запросов датчик поля полностью соответствует аннотациям стандарта Silver на 93 716 запросов, что составляет 91,01 % общей точности инструмента. Что касается токенов, то для 98,23% токенов (813 404) мы согласны с аннотацией Серебряного стандарта и не согласны с оставшимися 1,77%.
Далее мы вычисляем Precision, Recall и F -score на уровне токена и запроса для каждого из семи полей. При вычислении уровня токенов оценивается доля правильно идентифицированных токенов в поле. Вычисление на уровне запроса оценивает долю запросов со всеми правильно идентифицированными диапазонами полей. В Таблице 2 представлена точность. Напомним и F — мера для семи полей, вычисленная на уровне токена и запроса.
Таблица 2.
Анализ датчика поля на основе токенов и запросов на наборе 103K
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| П . | Р . | Ф . | Р . | Р . | Ф . | |
| Title | 0.990 | 0.993 | 0.991 | 0.986 | 0.987 | 0.986 |
| Author | 0.972 | 0.940 | 0.956 | 0.987 | 0.942 | 0.964 |
| Date | 0.910 | 0.955 | 0.932 | 0.978 | 0.955 | 0.967 |
| Page | 0.969 | 0.898 | 0.932 | 0.980 | 0.902 | 0.939 |
| Volume | 0. 928 | 0.838 | 0.881 | 0.947 | 0.841 | 0.891 |
| Issue | 0.983 | 0.686 | 0.808 | 0.994 | 0.685 | 0.811 |
| Journal | 0.742 | 0.725 | 0.733 | 0.821 | 0.637 | 0,717 |
| . | Сравнение на основе токенов . | Сравнение на основе запроса . | ||||
|---|---|---|---|---|---|---|
| П . | Р . | Ф . | Р . | Р . | Ф . | |
| Наименование | 0,990 | 0,993 | 0,991 | 0,986 | 0. 987 | 0.986 |
| Author | 0.972 | 0.940 | 0.956 | 0.987 | 0.942 | 0.964 |
| Date | 0.910 | 0.955 | 0.932 | 0.978 | 0.955 | 0.967 |
| Page | 0.969 | 0.898 | 0.932 | 0.980 | 0.902 | 0.939 |
| Volume | 0.928 | 0.838 | 0.881 | 0.947 | 0.841 | 0.891 |
| Issue | 0.983 | 0.686 | 0.808 | 0.994 | 0.685 | 0.811 |
| Journal | 0.742 | 0.725 | 0.733 | 0.821 | 0,637 | 0,717 |
Точность/Отзыв/ F -мера вычисляются для семи полей запросов цитирования: Название, Имя автора, Дата, Страница, Том, Выпуск и Название журнала.
Открыть в новой вкладке
Таблица 2.
Анализ датчика поля на основе токенов и запросов на наборе 103K
| . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| П . | Р . | Ф . | Р . | Р . | Ф . | |
| Название | 0,990 | 0,993 | 0.991 | 0.986 | 0.987 | 0.986 |
| Author | 0.972 | 0.940 | 0.956 | 0.987 | 0.942 | 0.964 |
| Date | 0. 910 | 0.955 | 0.932 | 0.978 | 0.955 | 0.967 |
| Page | 0.969 | 0.898 | 0.932 | 0.980 | 0.902 | 0.939 |
| Volume | 0.928 | 0.838 | 0.881 | 0.947 | 0.841 | 0.891 |
| Issue | 0.983 | 0.686 | 0.808 | 0.994 | 0.685 | 0.811 |
| Journal | 0.742 | 0.725 | 0,733 | 0,821 | 0,637 | 0,717 |
| 23 . | Сравнение на основе токенов . | Сравнение на основе запросов . | ||||
|---|---|---|---|---|---|---|
| П . | Р . | Ф . | Р . | Р . | Ф . | |
| Title | 0.990 | 0.993 | 0.991 | 0.986 | 0.987 | 0.986 |
| Author | 0.972 | 0.940 | 0.956 | 0.987 | 0.942 | 0,964 |
| Дата | 0,910 | 0.955 | 0.932 | 0.978 | 0.955 | 0.967 |
| Page | 0.969 | 0.898 | 0.932 | 0.980 | 0.902 | 0.939 |
| Volume | 0.928 | 0. 838 | 0.881 | 0.947 | 0.841 | 0.891 |
| Issue | 0.983 | 0.686 | 0.808 | 0.994 | 0.685 | 0.811 |
| Journal | 0.742 | 0.725 | 0.733 | 0.821 | 0.637 | 0.717 |
Precision/Recall / F -measure вычисляются для семи полей запросов цитирования: Название, Имя автора, Дата, Страница, Том, Выпуск и Название журнала.
Открыть в новой вкладке
Для трех наиболее часто встречающихся полей в наборе данных 103K (название, имена авторов и дата) датчик поля работает очень хорошо. В настоящее время наши усилия направлены на улучшение распознавания названий журналов, однако, поскольку названия журналов появляются в 9,19% запросов в этом богатом цитированием наборе, общее влияние этого поля является скромным.
Способность различать информационные и навигационные запросы позволяет нам лучше понять, как пользователи запрашивают PubMed. Например, мы наблюдали заметный рост размера запроса по сравнению со средним размером запроса 3,54 и средней длиной 3, о которых сообщалось в более ранних исследованиях 2009 года.(18, 19). На основании данных за 12 октября 2016 г. среднее количество токенов на запрос составляет 5,18, а медиана — 3. Для вычисления этих средних значений мы токенизировали запросы, определив токены как последовательности символов, разделенных пробелами, и исключили из анализа зашумленные запросы, содержащие более 100 токенов. Чтобы понять причины роста длины, мы вычисляем среднюю длину запроса в шесть моментов времени. Эти точки представляют собой журналы PubMed за 1 день, собранные в один и тот же день 20 января в течение шести лет подряд с 2012 по 2017 год. Как показано на рис. 7, мы наблюдаем, что информационные запросы остаются в среднем примерно того же размера, однако длина и доля навигационных запросов следуют тенденции роста. Средний размер навигационных запросов увеличился с 5,3 в 2012 г. до 7,0 в 2017 г. По сравнению с набором 10К доля навигационных запросов также увеличилась. Это может свидетельствовать о том, что поисковые системы стали лучше анализировать длинные запросы, а пользователям стало удобнее копировать название статьи или всю цитату.
Рисунок 7.
Открыть в новой вкладкеСкачать слайд
Средняя длина запроса, рассчитанная по журналам запросов, собранным 20 января, за шесть лет подряд с 2012 по 2017 год. сложность процесса поиска информации пользователями, ищущими информацию о цитировании. Мы анализируем поля запроса, чтобы выявить наиболее частые способы доступа к информации о цитировании. Анализ полей проводится по навигационным запросам от 12 октября 2016 года. Для получения закономерностей мы группируем последовательности токенов из одного поля в одну сущность. Например, запросы, состоящие из двух авторов автор1, автор2, будут считаться авторским запросом. На рис. 8 представлены 13 наиболее частых шаблонов, на долю которых приходится более 80 % навигационных запросов. Около 28% навигационных запросов — это запросы имени автора. Это запросы, состоящие из одного или нескольких имен авторов. Следующей по величине категорией являются запросы заголовков, на которые приходится около 24% всех навигационных запросов, и вместе с авторскими запросами они составляют более половины всех навигационных запросов. Другими популярными шаблонами поиска являются имя автора, за которым следует текст, и текст, за которым следует имя автора. Вместе эти две категории составляют около 12,5% навигационных запросов. Запросы, состоящие только из PMID, также оказались популярным способом доступа к статье и составляют 4,5% навигационных поисков. Обилие длинных запросов заголовка, при этом средняя длина запроса заголовка составляет 11,57 токенов, объясняет длину навигационных запросов. На рис. 8 показано распределение размеров запросов в каждой из указанных категорий.
Рисунок 8.
Открыть в новой вкладкеСкачать слайд
13 наиболее частых шаблонов доступа к информации о цитировании в PubMed, на долю которых приходится более 80% навигационных запросов. Процент запросов в каждом шаблоне отражается на гистограмме относительно основной оси Y , а средняя длина запросов в рамках этого шаблона отражается с помощью точечной диаграммы, измеренной относительно вторичной оси Y .
Основной функцией датчика поля является определение цели запроса. Являясь частью поисковой системы PubMed, он используется для обнаружения информационных запросов и направления пользователя к ранжированным по релевантности результатам поиска. Применительно к случайному дню запросов PubMed Field Sensor прогнозирует, что 48% будут информационными и 52% навигационными. Насколько нам известно, Field Sensor — это первый веб-инструмент для определения намерений и расчета состава биомедицинских запросов. Кроме того, полевые прогнозы позволяют нам в больших масштабах изучать, как биомедицинская информация ищется в PubMed. Базовая модель датчика поля обучается на данных Medline, а датчик поля можно адаптировать к запросам в другом домене путем повторного обучения на данных соответствующего домена.
В будущем мы планируем изучить альтернативный метод вычисления вероятностей. В текущей настройке вероятностное предсказание поля основано на языковой модели, где вероятность термина в поле вычисляется как частота термина в поле, деленная на размер поля во всей базе данных, измеренная номера сроков. Другой вероятный подход к вычислению вероятности состоит в том, чтобы вычислить вероятность термина как отношение количества документов, в которых встречается этот термин, и размера коллекции PubMed (около 27 миллионов документов). Мы считаем, что это может нейтрализовать некоторые из проблем, которые мы наблюдаем с названиями журналов, но может привести к другим ошибкам. В будущем мы также планируем обратить более пристальное внимание на токены с ошибками. Они представляют собой источник ошибок не только потому, что токен с ошибкой помечен неточно, но и потому, что это мешает анализу оставшейся части запроса. Рассматривая орфографические ошибки как текст был разумным, первым логическим шагом для улучшения обработки этих запросов была бы орфографическая коррекция. Мы планируем включить средство проверки орфографии в датчик поля следующего поколения.
33″> Каталожные номера
1
Falagas
М.
,
Пицуни
E.
,
Малиецис
G.
и др. (
2008
)
Сравнение PubMed, Scopus, Web of Science и Google Scholar: сильные и слабые стороны
.
FASEB J
.,
22
,
338
–
342
.
2
Лу
З.
(
2011
)
PubMed и не только: обзор веб-инструментов для поиска биомедицинской литературы
.
База данных
,
2011
,
baq036
.
3
Wildgaard
L.E.
,
Лунд
H.
(
2016
)
Продвижение PubMed? Сравнение сторонних инструментов PubMed/MEDLINE
.
Библиотека высоких технологий
,
34
,
669
–
684
.
4
Ашкан
А.
,
Кларк
К.Л.
,
Агихтейн
E.
и др. (
2009
) Классификация и характеристика цели запроса. В : Материалы 31 — й Европейской конференции по исследованиям в сфере IR по достижениям в поиске информации .
5
Broder
A.
(
2002
) Таксономия веб-поиска. В : Труды ACM SIGIR.
6
Янсен
Б. Дж.
,
Стенд
Д.Л.
,
Spink
A.
Определение намерений пользователя по запросам поисковых систем. In: WWW 2007.
7
Mendoza
M.
,
Zamora
J.
(
2009
) Определение намерения пользовательского запроса с помощью машин опорных векторов. В: Proceedings of the 16th International Symposium on String Processing and Information Retrieval, 2009. Springer-Verlag Berlin, Heidelberg, Saariselkä, Finland, стр. 131–142.
8
Figueroa
A.
,
Atkinson
J.
(
2016
)
Классители ансамбблировки для обнаружения пользователей за веб -запросами
)
. 0007
.
IEEE Internet Comput
.,
20
.
9
Хашеми
Х.Б.
,
Asiaee
A.
,
Kraft
R.
(
2016
с использованием сверточных нейронных сетей. В : Международная конференция по веб-поиску и интеллектуальному анализу данных, Семинар по пониманию запросов, , 2016.
10
Ху
Дж.
,
Ван
Г.
,
Лоховский
Ф.
и др. (
2009
) Понимание намерения пользователя выполнить запрос в Википедии. В: Материалы 18-й Международной конференции по всемирной паутине, 2009 г. . ACM Нью-Йорк, Нью-Йорк, Нью-Йорк, США, Мадрид, Испания.
11
Рэн
Х.
,
Ван
Ю.
,
Ю
X.
и др. (
2014
) Гетерогенное намеренное обучение на основе графов с помощью запросов, веб-страниц и концепций Википедии. В: Материалы 7-й Международной конференции ACM по поиску в Интернете и интеллектуальному анализу данных (WSDM’14) . ACM New York, Нью-Йорк, штат Нью-Йорк, США, стр. 23–32.
12
Кале
А.
,
Таула
Т.
,
Хевавитарана 7
(
2017
)
На пути к семантической сегментации запросов. В: Семинар SIGIR 2017 по поиску нейронной информации (Neu-IR’17)
,
Токио
,
Япония
.
13
Ким
Дж.
,
Сюэ
Х.
,
Крофт
В.Б.
(
2009
) Модель вероятностного поиска для полуструктурированных данных. В: Европейская конференция по информационному поиску .
14
Nikolaev
F.
,
KOTOV
A.
,
Zhiltsov
N.
(
). из графа знаний. В: Материалы 39-й Международной конференции ACM SIGIR по исследованиям и разработкам в области информационного поиска . ACM New York, New York, NY, USA, Pisa, Italy, стр.
435
–
444
.
15
Sarkas
N.
,
Paparizos
S.
,
Tsaparas
P.
(
2010
). Международная конференция ACM SIGMOD по управлению данными (SIGMOD’10) . ACM New York, Нью-Йорк, штат Нью-Йорк, США, Индианаполис, штат Индиана, США.
16
Радлински
Ф.
,
Szummer
M.
,
Craswell
N.
Определение намерения запроса на основе переформулировок и кликов. WWW 2010 .
17
Pitler
E.
,
Church
K.
(
2009
) Использование словесных запросов для устранения неоднозначности запросов с помощью веб-методов. В: Конференция 2009 г. по эмпирическим методам обработки естественного языка , стр. 1428–1436.
18
Islamaj Dogan
R.
,
Murray
C.
,
Névéol
A.
et al. (
2009
)
Понимание поведения пользователей при поиске в PubMed с помощью анализа журнала
.
База данных
,
2009
,
bap018
.
19
Херскович
Дж.
,
Танака
Л.Ю.
,
Херш
В.
и др. (
2007
)
Один день из жизни PubMed: анализ журнала запросов за обычный день
.
Дж. Ам. Мед. Поставить в известность. Ассоц
.,
14
,
212
–
220
.
20
Уилбур
У. Дж.
,
Ким
У.
,
Xie
N.
(
2006
)
Исправление орфографии в поисковой системе PubMed
.
Инф. Ретр
.,
9
,
543
–
564
.
21
Hersh
W.
,
Voorhees
E.
(
2009
)
TREC Genomics Special Assue Opsive Oversive
.
Инф. Ретр
.,
12
,
1
–
15
.
22
Бампулидис
А.
,
Лупу
М.
,
Палотти
(
2016
) Интерактивное исследование медицинских запросов. В: 14-й Международный семинар по контентно-ориентированному индексированию мультимедиа (CBMI) . IEEE, Бухарест, Румыния.
23
Цикрика
Т.
,
Мюллер
Х.
,
Кан
.
(
2012
) Анализ журнала для понимания поведения медицинских работников при поиске изображений. В: Материалы 24-й Европейской конференции по медицинской информатике (MIE2012) . Европейская федерация медицинской информатики и IOS Press, Пиза, Италия, стр. 1020–1024.
24
Белый
R.
,
Horvitz
E.
(
2014
)
От поиска здоровья к здравоохранению: исследования намерений и опросы пользователей с помощью журналов опросов о намерениях и использовании пользователей
Дж. Ам. Мед. Инф. Ассоц
.,
21
,
49
–
55
.
25
Чжан
Ю.
(
2014
)
Поиск конкретной информации о здоровье в MedlinePlus: модели поведения и опыт пользователей
.
J. Assoc. Инф. науч. Технол
.,
65
,
53
–
68
.
26
Ogilvie
P.
,
Callan
J.
Объединение представлений документов для поиска по известным элементам. В: SIGIR 2003 .
27
Bernstam
E.
,
Herskovic
J.
,
Hersh
W.
(
2009
).
28
Hersh
W.
(
2009
) Поиск информации: здравоохранение и биомедицинская перспектива.
29
Li
X.
,
Schijvenaars
Б.Дж.А.
,
De Rijke
M.
(
2017
)
Исследование запросов и ошибок поиска в академическом поиске
.
Инф. Процесс. Манаг
.,
53
,
666
–
683
.
30
Хабса
М.
,
Ву
З.
,
Джайлз
К.Л.
(
2016
) На пути к лучшему пониманию академического поиска. В: JCDL 2016, 16-я Совместная конференция ACM/IEEE-CS по цифровым библиотекам . ACM, Ньюарк, Нью-Джерси, США.
31
Фиорини
Н.
,
Липман
Д.Дж.
,
Lu
Z.
(
2017
)
Передний край: к PubMed 2. 0
.
eLife
,
6
:
e28801
.
32
Manning
C.
,
Raghavan
P.
,
Schütze
H.
(
2009
)
Andief.
Издательство Кембриджского университета
.
33
Витерби
А.Дж.
(
1967
)
Границы погрешности сверточных кодов и асимптотически оптимального алгоритма декодирования
.
IEEE Trans. Инф. Теория
,
13
,
260
–
269
.
Примечания автора
Данные для цитирования: Еганова Л., Ким В. Комо, округ Колумбия и др. Датчик поля: вычисление состава и цели запросов PubMed. База данных (2018) Том. 2018: бухта052; Дои: 10.1093/database/bay052
Опубликовано издательством Oxford University Press, 2018 г. Эта работа написана служащими правительства США и является общественным достоянием в США.
Опубликовано издательством Oxford University Press, 2018 г. Эта работа написана служащими правительства США и является общественным достоянием в США.
Обозначение Определение и значение — Merriam-Webster
1 из 2
назначать ˈde-zig-ˌnāt
-nət
: выбрано, но еще не установлено (см. смысл установки 2a)
назначенный посол
назначенный
2 из 2
назначать ˈde-zig-ˌnāt
переходный глагол
1
: для обозначения и выделения для определенной цели, должности или обязанности
назначить группу для подготовки плана
2
а
: для указания местонахождения
маркер обозначающий бой
б
: для различения по классу (см. запись класса 1, смысл 3)
область, которую мы обозначаем как область духовных ценностей Дж. Б. Конант
с
: указать, указать
для отправки назначенным грузоотправителем
3
: обозначить
связать имена с людьми, которых они обозначают
4
: для вызова по отличительному названию, термину или выражению
частица обозначаемая нейтрон
определяющий
де-зиг-на-тив
имя прилагательное
обозначение
ˈde-zig-ˌnā-tər
существительное
обозначение
ˈde-zig-nə-ˌtȯr-ē
имя прилагательное
Синонимы
Глагол
- назначать
- исправить
- имя
- set
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Глагол
Деревянные колья обозначают край строительной площадки. назначенное время для встречи
Последние примеры в Интернете
В мае агентство Bloomberg сообщило, что Нонкулулеко Ньембези был назначен председателем — .0020 действует.
Жасмин Броули, Essence , 11 августа 2022 г.
Плакон получил множество одобрений, в том числе шерифа округа Семинол Денниса Лемму, спикера Палаты представителей Флориды, назначенного под номером Пола Реннера, и генерального прокурора Эшли Муди.
Эбигейл Хазебрук, Orlando Sentinel , 3 августа 2022 г.
Семья попала в заголовки газет в 2019 году. после того, как выяснилось, что Моссимо и Лафлин заплатили главарю мошенничества с поступлением в колледж Рику Сингеру 500 000 долларов за то, чтобы ложно назначил Оливию Джейд и Беллу новобранцами в команду экипажа Университета Южной Калифорнии.
Аманда Тейлор, PEOPLE.com , 28 июля 2022 г.
Государственный секретарь — обозначение Тони Блинкен был заместителем государственного секретаря и заместителем советника по национальной безопасности при администрации Обамы.
Эмили Ларсен, 9 лет0019 Washington Examiner , 24 ноября 2020 г.
В преддверии возвращения назначьте кого-то, кто предоставит информацию о том, что компания делает для повышения благосостояния сотрудников.
Пол Макдональд, Forbes , 13 апреля 2022 г.
Искусство или стена галереи могут помочь обозначить зон, говорит Челси Браун из City Chic Decor в Нью-Йорке. Мими Монтгомери, 9 лет0019 Вашингтон Пост , 13 июля 2022 г.
Кардинал , обозначенный как Роберт МакЭлрой из католической епархии Сан-Диего в пятницу выступил с заявлением, в котором высоко оценил решение суда.
Фил Диль, San Diego Union-Tribune , 26 июня 2022 г.
Другие нацеливались на закон, который позволяет членам совета определять школ, библиотек и других объектов как закрытые для кемпинга.
Дэвид Захнисер, 9 лет0019 Лос-Анджелес Таймс , 7 июня 2022 г.
Однако в постановлении 1920 года Верховный суд подтвердил, что Закон о древностях разрешает президентам определять памятников любого размера. Брайан Маффли, 9 лет0019 The Salt Lake Tribune , 5 сентября 2022 г.
Украинские официальные лица настаивали на том, чтобы западных стран объявили Россию государственным спонсором терроризма за теракты, в результате которых погибли десятки мирных жителей по всей Украине.
Мэтью Люксмур, WSJ , 3 сентября 2022 г.
Меню одно из тех, где иероглифы обозначают , какие диетические требования удовлетворяет каждое блюдо.
Энн Абель, 9 лет0019 Forbes , 25 августа 2022 г.
Нарисуйте квадраты на доске, чтобы обозначили мест для определенных предметов.
Джессика Беннетт, Better Homes & Gardens , 24 августа 2022 г.
Но официальные лица в конечном итоге решили не обозначать многие из этих областей в качестве основной среды обитания, как показано на карте, расчищая путь для ветряных машин Anschutz. Лос-Анджелес Таймс , 23 августа 2022 г.
Весной этого года Законодательное собрание штата Орегон приняло законопроект, позже подписанный губернатором Кейт Браун, согласно которому определяет Орегон 35 — 40-мильную дорогу от реки Худ до Правительственного лагеря — Мемориальным шоссе ветеранов Второй мировой войны Нисей. oregonlive , 14 августа 2022 г.
Если сделка не будет достигнута к следующему межсезонью, ожидается, что «Вороны» назначат на 2019 год.Самый ценный игрок НФЛ с франчайзинговым тегом, благодаря которому Джексон останется в Балтиморе еще как минимум на год.
Джонас Шаффер, Baltimore Sun , 13 августа 2022 г.
Это также потребует от них назначить преемника в случае неудачи или банкротства, чтобы пользователям была гарантирована бессрочная поддержка. Клаудия Язвиньска, STAT , 12 августа 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «назначить». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
Прилагательное и глагол
Латинское обозначение , причастие прошедшего времени от designare — см. описание дизайна 1
Первое известное использование
Прилагательное
1629, в значении, определенном выше
Первое известное использование для обозначения было
в 1596 г.
Другие слова того же года
Словарные статьи Около
обозначитьназначаемый
обозначать
обозначить как
Посмотреть другие записи поблизости
Процитировать эту запись «Назначить».
Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/designate. По состоянию на 18 сентября 2022 г.Copy Citation
Детское определение
обозначить
назначать ˈde-zig-ˌnāt
1
: для назначения или выбора для специальной цели
Они назначили лидером.
2
: для вызова по имени или титулу
Обозначим этот угол треугольника a .
3
: отметить или указать : указывают
Эти строки обозначают границы.
Подробнее от Merriam-Webster на
DishipateNglish: Перевод Определения для носителей испанского языка
Британская английская словарь и получить тысячи других определений и расширенный поиск без рекламы!
Merriam-Webster полный текст
Латинский кейс | Департамент классики
Тело
Падеж относится к формальным маркерам (на латыни это окончания, добавленные к основе существительного или прилагательного), которые сообщают вам, как существительное или прилагательное следует толковать по отношению к другим словам в предложении. . Каковы формальные маркеры для английского языка? Вот некоторые размышления о том, как вообще падежи связаны со значением в предложении.
В латинском языке существует 6 различных падежей: именительный, родительный, дательный, винительный, аблатив и звательный; и есть остатки седьмого, Локатива. Приведенные ниже базовые описания также можно найти на страницах, представляющих более подробные описания дел, которые вы можете открыть, щелкнув названия дел в предыдущем предложении.
именительный падеж является падежом подлежащего в предложении. Подлежащее — это лицо или вещь, о которых сказуемое сообщает, а имя «номинатив» означает «относящийся к обозначаемому лицу или вещи». В латинском языке подлежащее не всегда нужно выражать, потому что оно может быть обозначено лицом и числом глагола. «Хвалят» = похвально . См. подлежащий падеж в английском языке, который похож на латинский именительный падеж. Перейти к: Именительный падеж
Родительный падеж наиболее известен носителям английского языка как падеж, выражающий владение: «моя шляпа» или «дом Гарри». В латинском языке он используется для обозначения любого количества отношений, которые наиболее часто и легко переводятся на английский язык предлогом «of»: «любовь к богу», «водитель автобуса», «состояние союза», « сын божий». Родительный падеж в латинском языке также используется в наречиях с некоторыми глаголами. Наиболее распространены глаголы осуждения, обвинения и наказания. Конструкция параллельна английскому «Я обвиняю тебя 9».0019 измены ». accuso te maiestatis. Посмотрите, как притяжательный падеж и предлог «of» работают в английском языке. Чтобы увидеть более подробный список , перейдите по ссылке: Родительный падеж .
Дательный падеж наиболее знаком англоговорящим в случае косвенного дополнения, а наиболее распространенным примером косвенного дополнения является лицо, «кому или для которого» что-то дается: «Я дал книгу ей», «ей» будет быть в дательном падеже. Это обычное употребление дает падежу его название: это падеж, который относится к даянию. Однако более удовлетворительно рассматривать дательный падеж как падеж для лица, которое заинтересовано (в положительном или отрицательном способом) в каком-либо действии или деятельности, а наиболее распространенным (и наиболее точным) переводом дательного падежа является «для». «Даю книге тебе », само отдавание действительно «для тебя». Дательный падеж распространен после глаголов, обозначающих определенные виды деятельности: благоволить, повиноваться, угождать, служить, завидовать, гневаться, прощать, приказывать и так далее. Перейти к: Дательный падеж
Винительный падеж используется для прямого дополнения переходных глаголов, внутреннего дополнения любого глагола (но часто с непереходными глаголами), для выражений, указывающих на размер пространства или длительности времени, и для объекта некоторых предлогов.Первоначально это был падеж, указывающий на конец или конечную цель действия. Перейти к: Винительный падеж.
Аблатив — самый сложный из падежей в латинском языке. Он может использоваться сам по себе или как объект предлогов, и он обычно используется для выражения (с помощью предлога или без него) идей, переведенных на английский язык с помощью предлогов «из» (то есть идея разделения и происхождения). , «с» и «посредством» (то есть представление о инструментальности или ассоциации) и «в» (то есть представление о месте, где или времени, когда). Перейти к: Абляционный случай.
Звательный падеж представляет небольшую проблему для носителей английского языка. Обычно это то же самое, что и именительный падеж в английском языке, и он используется, когда вы обращаетесь к кому-то напрямую. Исключения из правила, согласно которому звательный падеж совпадает с именительным падежом, резюмируются во фразе Marce mi fili , которая является звательным падежом для Marcus meus filius и является удобным способом запомнить, что все существительные 2-го склонения в -нас, есть звательный падеж на -е, что звательный падеж meus — это mi , и что все существительные 2-го склонения на -ius имеют звательный падеж на -i.
Латынь также имела местный падеж , , но немногие формы все еще используются в классической латыни. Местный падеж используется для обозначения «место, где» и встречается в основном с названиями городов, поселков и небольших островов. (На самом деле, все эти три места одинаковы, поскольку остров должен быть достаточно мал, чтобы его можно было назвать в честь единственного города или поселка на нем; если городов два, вам понадобится в + Аблатив . Формы местного падежа такие же, как родительный падеж в 1-м и 2-м склонении единственного числа и такие же, как аблатив в 3-м склонении единственного числа. Города (например, Афины, Афины ), форма множественного числа которых берет свои формы местного падежа от аблатива множественного числа во всех склонениях. Другими локативными формами являются: domi, humi, belli, militiae, и ruri.
Уникально измененный состав микробиома полости рта наблюдался у беременных крыс с заболеванием пародонта, вызванным Porphyromonas gingivalis
Введение
Пародонтит в настоящее время считается заболеванием дисбиотической полимикробной этиологии, при котором преобладают оральные микробные виды, способные развиваться в воспаленной микросреде (Abusleme et al. , 2013; Hajishengallis, 2015). Хотя патогенез заболеваний пародонта сложен, одна точка зрения состоит в том, что дисбактериоз инициируется присутствием ключевых видов, которые подрывают иммунную защиту хозяина, и это позволяет вторичным патогенам процветать и в конечном итоге доминировать. Porphyromonas gingivalis получил известность как ключевой возбудитель заболеваний пародонта, поскольку даже будучи малочисленным видом, он оказывает сильное влияние на структуру микробного сообщества полости рта (Hajishengallis, 2011; Olsen et al., 2017). P. gingivalis вооружен множеством факторов вирулентности, которые подрывают врожденную антимикробную защиту хозяина, не блокируя пути воспаления; называют «непродуктивным воспалением» (Zenobia and Hajishengallis, 2015). Это не только обеспечивает P. gingivalis является источником питательных веществ, необходимых для роста, но также обеспечивает избирательное преимущество для совместной колонизации микробов, способных переносить и процветать в воспалительной среде (Zenobia and Hajishengallis, 2015).
Метагеномные исследования микробиома полости рта также показывают, что беременность нарушает состав микробного сообщества полости рта (Paropkari et al., 2016; Lin et al., 2018). Сообщается, что у беременных без заболеваний пародонта структура наддесневого сообщества смещается в сторону преобладания бактерий внутри родов Neisseria, Porphyromonas и Treponema (Lin et al., 2018). В частности, повышенная численность Prevotella и Treponema spp. связано с увеличением концентрации половых гормонов, связанных с беременностью (Lin et al., 2018). Более того, беременность может изменить влияние факторов риска окружающей среды на микробиом полости рта. Например, сообщается, что поддесневой микробиом женщин, курящих во время беременности, содержит значительно меньше грамотрицательных и грамположительных анаэробов, чем небеременные курильщики (Paropkari et al., 2016). На сегодняшний день неизвестно, влияет ли и каким образом беременность на дисбиотический микробиом полости рта, связанный с заболеванием пародонта, у пациентов с ранее существовавшим заболеванием полости рта.
Для этого пилотного исследования мы выбрали P. gingivalis в качестве модельного организма, поскольку он способствует неблагоприятным исходам беременности (Barak et al., 2007; Chaparro et al., 2013; Vanterpool et al., 2016). . Наша цель состояла в том, чтобы исследовать взаимодействие беременности и орального дисбактериоза периодонтита на крысиной модели пародонтита, вызванного P. gingivalis (Kesavalu et al., 2007; Verma et al., 2010), используя метагеномный анализ 16S.
Материалы и методы
Модель пародонтита и сбор образцов
Все процедуры были проведены после одобрения Институционального комитета по уходу и использованию животных Университета Висконсин-Мэдисон. Свободных от конкретных патогенов крыс CD-IGS, полученных из той же колонии (Charles River International Laboratories, Inc., Kingston, NY; RGD ID 734476), содержали в той же комнате в барьерных условиях. Мазки из ротовой полости и кровь собирали до лечения антибиотиками, и животных случайным образом распределяли для ложного контроля (инокуляция стерильным носителем) или Штамм A7UF P. gingivalis , лабораторно адаптированный штамм, экспрессирующий оперон типа IV fim и обладающий 99,2% идентичностью последовательности ДНК всего генома с A7436 (данные не показаны). В начале фазы инокуляции исследования и после этого контрольных животных всегда обрабатывали перед зараженными животными.
Пародонтит индуцировали, как описано ранее (Phillips et al., 2018). В частности, 7–8-недельные самки крыс сначала получали канамицин (20 мг) и ампициллин (20 мг) ежедневно в течение 4 дней с питьевой водой для уменьшения количества комменсальных бактерий. Затем полость рта промывали 0,12% раствором хлоргексидина глюконата (Peridex: 3M ESPE Dental Products, Сент-Пол, Миннесота, США) для полоскания рта, чтобы ингибировать эндогенные организмы и облегчить последующую колонизацию с помощью P. gingivalis . Крыс снова переводили на воду, не содержащую антибиотиков, и давали им отдых в течение 3 дней, чтобы обеспечить выведение антибиотиков из их организма перед началом фазы инокуляции исследования. Равное количество крыс было случайным образом распределено в контрольную группу или группу P. gingivalis . Каждый инокулят был приготовлен из ночной культуры P. gingivalis , выращенной в соевом бульоне с добавлением трипсина (Phillips et al., 2018). Концентрацию бактерий в бульоне определяли по показаниям оптической плотности, снятым при 550 нм на двухлучевом спектрофотометре UV-6300 PC (VWR, Чикаго, Иллинойс, США). Бактерии осаждали центрифугированием при 3000×g в течение 5 минут и ресуспендировали в стерильной 2% (масса/объем) карбоксиметилцеллюлозе низкой вязкости (CMC; Sigma, Сент-Луис, Миссури, США) до достижения конечной концентрации 1×10 10 КОЕ на мл. Каждое животное получало пероральную инокуляцию, содержащую 1×10 9 КОЕ, в течение 4 последовательных дней в неделю в течение 6 чередующихся недель, всего 24 инокуляции в течение 12-недельного периода. Контрольные животные получали стерильную 2% КМЦ. Чтобы свести к минимуму разрушение бактериального налета, животных кормили порошковой диетой для грызунов, облученной гамма-лучами (Teklad Global 18% белковая диета для грызунов, Envigo, Мэдисон, Висконсин) во время фазы инокуляции исследования. В конце периода прививки (неделя 12) брали оральные мазки, собирали кровь для серологического исследования и крыс снова переводили на ту же диету в гранулированной форме. Перед осеменением животные находились в покое в течение 1 недели. Размножение подтверждалось наличием сперматозоидов во вагинальных смывах, которые проводились на следующее утро, что считалось днём беременности GD 0. Самки подвергались эвтаназии в GD 18. Были взяты оральные мазки, черепа были собраны для морфометрического анализа потери альвеолярной кости и сыворотки. было собрано для обнаружения P. gingivalis специфические IgM и IgG.
Для целей метагеномного анализа 16S нас интересовали образцы ротовой полости, собранные у ложных и обработанных P. gingivalis крыс CD. В частности, мы обработали образцы ротовой полости, собранные в группе лечения P. gingivalis (PG) (шесть животных) в трех временных точках для секвенирования: исходный уровень, через 3 месяца после инокуляции P. gingivalis и при вскрытии (беременность при БГ). 18). Напротив, для секвенирования использовались только образцы из полости рта, собранные в группе ложного лечения (шесть животных) через 3 месяца после ложной инокуляции. Описания животных и образцов, включая идентификаторы образцов для 24 библиотек секвенирования, которые мы создали и использовали для этого пилотного исследования метагеномного анализа 16S, перечислены в таблице S1.
Оценка резорбции альвеолярной кости
Нижние челюсти были отделены от черепа, и большая часть ткани была удалена путем рассечения. Оставшуюся ткань удаляли жуки-дерместиды. Затем нижние челюсти крыс погружали в 3% (об./об.) раствор перекиси водорода на ночь, промывали деионизированной водой и сушили на воздухе. Чтобы очертить цементно-эмалевую границу (ЦЭГ), челюсти окрашивали 0,1% (масса/объем) метиленовым синим в течение 1 мин, промывали и сушили на воздухе. Образцы были закодированы для предотвращения систематической ошибки, и калиброванные изображения как щечной, так и язычной стороны каждой челюсти были сняты с помощью камеры EOS 650D RebelT41 (Canon, USA, Inc. , Лонг-Айленд, Нью-Йорк). Морфометрические измерения были выполнены двумя независимыми исследователями, которые не знали о лечении. Калиброванные цифровые изображения анализировали с помощью программного обеспечения для анализа Image J 1.50b (Rasband, National Institutes of Health, США). Размеры площади (мм 2 ) как язычной, так и щечной поверхности каждой нижней челюсти, определяли с помощью инструмента от руки для ручного отслеживания периметра поверхности CEJ и альвеолярного гребня (ABC). Была записана сумма обоих измерений площади, а значения двух независимых исследователей были усреднены.
Верхнечелюстные кости фиксировали в 10% забуференном формалине, промывали и декальцинировали в течение 48 часов перед обработкой для гистологии. Излишняя ткань была удалена, и ряд моляров рассечен по центру каждого моляра, чтобы можно было оценить потерю межзубной кости. Откалиброванные изображения тканей верхней челюсти анализировали с помощью программного обеспечения Image J, как описано ранее (Phillips et al. , 2018). Вкратце, была проведена линия, соединяющая мезиальную и дистальную стороны каждого моляра в ЦЭГ. Центральная линия, перпендикулярная этому CEJ, была проведена от CEJ до вершины альвеолярного гребня, и расстояние было записано в мм. Измерения расстояния каждой межзубной области были усреднены.
Обнаружение
P. gingivalis -специфических IgM и IgG Гуморальный ответ на P. gingivalis определяли с помощью ELISA, как описано ранее (Phillips et al., 2018), со следующими модификациями. Вкратце, лизат цельных клеток P. gingivalis обрабатывали ультразвуком (Sonic Dismembrator, Thermo Fisher Scientific, Waltham, MA) и измеряли концентрацию общего белка в лизате с помощью анализа белков Брэдфорда (Thermo Fisher Scientific, Waltham, MA). Аликвоты исходного лизата хранили в концентрации 2 мг/мл при -20°C. Для анализа ELISA лизаты цельных клеток разводили 50 мМ бикарбонатным буфером для покрытия pH 9..4 (Thermo Fisher Scientific, Уолтем, Массачусетс), чтобы получить конечную концентрацию 20 мкг/мл. Для обнаружения использовали козьи антикрысиные IgM (Southern Biotech, Бирмингем, Алабама) и ослиные антикрысиные IgG (Thermo Fisher Scientific, Уолтем, Массачусетс), конъюгированные с пероксидазой хрена (HRP) (1:4000 и 1:2500 соответственно). ). Объединенные сыворотки от зараженных P. gingivalis крыс и неинфицированных животных использовали для установления разведения сыворотки, которое попадало в линейный диапазон кривой разведения. Последующие анализы ELISA были объединены в партии, и каждый планшет содержал положительный и отрицательный контроль. Чтобы свести к минимуму вариации от пластины к пластине, каждые 96-луночный планшет содержал образцы сыворотки из каждой группы. Все образцы анализировали в двух экземплярах, а показания получали с помощью устройства для считывания микропланшетов Model 680 (Biorad Laboratories, Hercules, CA).
Статистический анализ измерений потери альвеолярной кости и серологических данных проводили с помощью непарного теста Стьюдента t с использованием программного обеспечения Prism 7. 03 (GraphPad Software Inc.). Для всех тестов P < 0,05 считалось значимо отличающимся.
Выделение ДНК и обогащение бактериальной ДНК
Образцы для каждого момента времени собирали либо на вискозные тампоны (ложно инокулированные), либо на цитологические кисточки (базовый уровень, инокулированные PG, беременные), подвергали мгновенной заморозке и хранили при -80°C до обработки партии. Во время обработки устройства для сбора оттаивали, погружали в стерильные 200 мкл 1× фосфатно-солевого буфера (PBS; pH 7,4), встряхивали в течение 30 с и раствор переносили в стерильную 2-мл пробирку для извлечения образца. Тампон/щетку центрифугировали при 15000×9.3143 г в течение 5 минут, чтобы собрать остаточную жидкость, которая попала в устройство для сбора, затем пипетировать ее в соответствующую пробирку для извлечения образца. Этот процесс промывания повторяли еще дважды, всего три полоскания для каждого тампона. Все экстрагированные жидкости из каждого образца объединяли в одну пробирку на образец. Каждую пробирку с экстрактом образца центрифугировали при 21 000 × g в течение 10 минут для осаждения клеток и детрита. PBS удаляли из осадка и к каждому осадку образца добавляли 40 мкл ресуспендированных гранул Dynabeads из универсального набора Dynabeads DNA DIRECT (Invitrogen: № по каталогу 63006) и перемешивали. Смеси Dynabead/образец обрабатывали в соответствии с протоколом производителей, и концентрацию выделенной тотальной ДНК в элюенте оценивали с использованием спектрофотометра NanoDrop 2000C (Thermo Scientific: № по каталогу ND2000C). Общая ДНК, выделенная из каждого орального образца, содержит большую часть ДНК крысы, поэтому важно обогатить ее бактериальной ДНК для оптимизации последующего метагеномного анализа 16S. Химический состав, представленный в наборе для обогащения ДНК микробиома NEBNext (New England BioLabs: № по каталогу E2612L), обогащает бактериальную ДНК путем селективного связывания и удаления CpG-метилированной ДНК хозяина при сохранении микробного разнообразия после обогащения. Метилирование цитозина встречается у бактерий с очень низкой частотой в геномах бактерий, в то время как оно распространено в геномах эукариот. Валидационные исследования, на которые ссылается производитель, с использованием этого метода обогащения показали, что виды бактерий с необычной плотностью метилирования ДНК встречаются редко и связываются на очень низком уровне с гранулами обогащения (например, Neisseria flavescens ). Обогащенную микробную ДНК, очищенную осаждением этанолом, и концентрацию ДНК оценивали с помощью спектрофотометра NanoDrop 2000c. Полуколичественную проверку обогащения проводили с использованием количественной ПЦР (система обнаружения ПЦР в реальном времени CFX-Connect; BioRad Laboratories Inc.), SsoAdvanced Universal SYBR Green Supermix (BioRad Laboratories Inc.: № по каталогу 1725270) и универсального контроля NEBNext 16S. Праймеры (New England BioLabs).
ПЦР-амплификация микробных вариабельных областей гена 16S рРНК
Библиотеки 16S рРНК каждого образца, обогащенного микробной ДНК, были созданы с помощью ПЦР с использованием набора Ion 16S Metagenomics Kit (ThermoFisher Scientific: № по каталогу A26216) и термоциклера для ПЦР (Mastercycler nexus gradient; Eppendorf AG). Вкратце, два набора праймеров используются для создания ампликонов из шести различных областей генов 16S рРНК. Первый набор праймеров нацелен на вариабельные области 2, 4, 8, а второй набор праймеров нацелен на вариабельные области 3, 6–7, 9. ПЦР-амплификацию проводили в соответствии с протоколом производителя для каждого образца вместе с отрицательным и положительным контролем. Затем ампликоны из 20 мкл каждой реакции ПЦР очищали с использованием набора Axygen AxyPrep Mag PCR Clean-up Kit (Fisher Scientific: № по каталогу 14-223-151) и элюировали в элюирующем буфере (EB; 10 мМ Tris-Cl, рН 8,5). Ампликоны, полученные для каждой пары реакций (два набора праймеров) для каждого образца, объединяли, и концентрацию их ДНК оценивали с помощью спектрофотометра NanoDrop 2000c до подтверждения того, что каждый пул образцов состоит из 100 нг–1 мкг ДНК, как это требуется для лигирования адаптера. . Конечную концентрацию ампликонов в каждом пуле образцов определяли с использованием набора для анализа dsDNA hs Qubit (Invitrogen: № по каталогу Q32851) в соответствии с протоколом производителя.
Подготовка библиотеки со штрихкодом 16S для мультиплексного секвенирования
Готовые к секвенированию библиотеки генов 16S рРНК были приготовлены с использованием набора для подготовки библиотеки быстрой ДНК NEBNext для Ion Torrent (New England BioLabs: кат. № E6270S) и олигонуклеотидов адаптера ДНК-штрихкода, специфичных для Система Ион Торрент. Все библиотеки 16s рРНК были подготовлены в соответствии с рекомендациями производителей с модификациями для максимального выхода. Вкратце, очищенные ампликоны 16S сначала восстанавливали на конце и лигировали по тупому концу с образцами конкретных адаптеров штрих-кода (таблица S2), чтобы создать три группы для последующего объединения. Мы подсчитали, что максимальное количество библиотек, загружаемых в равных молярных концентрациях на ионный чип 318™ для получения достаточного количества прочтений для метагеномного анализа, составляет 13. Адаптер лигированной ДНК был выбран по размеру для получения фрагментов от 200 до 400 пар оснований. долгое время с использованием системы очистки Agencourt AMPure XP PCR Purification (Beckman Coulter: № по каталогу A63880). Фрагменты ДНК длиной менее 200 пар оснований, вероятно, будут состоять из свободных адаптеров и пустых продуктов адаптер-адаптер, тогда как фрагменты длиной более 400 пар оснований, вероятно, будут иметь несколько копий адаптеров, лигированных на их концах.
Ампликоны выбранного размера подвергали ПЦР-амплификации с использованием праймеров к последовательностям адаптера ION torrent P1 и адаптера A с получением не менее 1 мкг объективных ампликонов всех фрагментов ДНК, лигированных адаптером со штрих-кодом. ПЦР-амплификацию проводили с использованием следующих параметров: (1) начальная денатурация при 98°С в течение 30 с; 2) 8–11 циклов: 98°С – 10 с, 58°С – 30 с, 65°С – 30 с; 3 – 65°С в течение 5 мин; и (4) окончательная выдержка при 4°C. После амплификации ампликоны в каждом образце очищали с использованием Agencourt AMPure XP, а концентрацию ДНК определяли с помощью количественной ПЦР с использованием набора для количественного анализа Ion Universal Library (ThermoFisher Scientific: кат. № A26217) в соответствии с руководством пользователя Ion 16S Metagenomics Kit (стр. 18–22). Каждый образец анализировали в трехкратной повторности. Рассчитанная средняя концентрация для каждого образца использовалась для последующих расчетов объединения библиотек.
Каждую библиотеку со штрих-кодом 16S разводили и объединяли в равных молярных концентрациях в один из трех пулов: пулы A, B и C (таблица S2). Каждый пул подвергали ПЦР-амплификации с использованием адаптерных праймеров P1 и A из набора NEBNext Fast DNA Library Prep Set for Ion Torrent со следующими измененными параметрами ПЦР: (1) начальная денатурация при 98°C в течение 30 с; 2) 30 циклов: 98°С — 10 с, 58°С — 30 с, 65°С — 30 с; 3 – 65°С в течение 5 мин; и (4) окончательная выдержка при 4°C. После амплификации ДНК в каждом пуле очищали с использованием Agencourt AMPure XP. Наш выход был примерно в 1000 раз выше, чем необходимо, и содержал более высокую долю коротких фрагментов, что привело к необходимости изменить процедуру шаблонирования. Мы создали пул D для повторного секвенирования подмножества библиотек образцов с наименьшим количеством прочтений (таблица S2), более подробно описанных в разделе дополнительного пула секвенирования ниже. Для этого прогона мы сократили количество циклов на этом этапе амплификации до 25, что значительно улучшило качество библиотеки (доля полноразмерных фрагментов). Мы также модифицировали наш метод разбавления, чтобы получить более точное равномолярное объединение. Окончательные концентрации объединенных библиотек проверяли с помощью количественной ПЦР с использованием протокола руководства пользователя 16S Metagenomics Kit, как уже описано.
Подготовка матрицы, обогащение и секвенирование
Первым шагом, необходимым для секвенирования наших ампликонов ДНК с использованием платформы Ion Torrent (Thermo Fisher Scientific Inc., Уолтем, Массачусетс, США), является создание матрицы каждой из наших объединенных библиотек ДНК. Шаблонирование включает загрузку надлежащим образом разбавленных объединенных библиотек на частицы ионных сфер (ISP) с использованием набора Ion PGM Hi-Q View OT2 (ThermoFisher Scientific: № по каталогу A29900) и инструментов Ion OneTouch-2 и OneTouch-ES (Thermo Fisher Scientific: № по каталогу 4474779) в соответствии с протоколом производителя для шаблона длины считывания 400 пар оснований. В протоколе производителей для шаблонирования перечислены рекомендуемые концентрации для каждого типа библиотеки, чтобы получить целевой диапазон положительных частиц шаблона. Успешное создание шаблона достигается, когда образец проходит тест контроля качества, который более подробно объясняется ниже. Концентрация свежеразбавленных объединенных библиотек, которые были успешно матрицированы и впоследствии секвенированы в этом исследовании, была следующей: пулы A и C по 26 мкМ каждый, пул B по 23 мкМ и пул D по 10 мкМ.
Для определения процента ISP со связанной матричной ДНК (объединенная библиотека), термоциклер для ПЦР, флуорометр Qubit 3.0 (Thermo Fisher Scientific: № по каталогу Q33216) и набор для контроля качества Ion Sphere (Thermo Fisher Scientific: Cat , № 4468656) использовались в соответствии с протоколом производителя, приведенным в руководстве к комплекту Ion PGM Hi-Q View OT2. Приемлемый уровень шаблонных интернет-провайдеров составляет 10–30% с идеальным диапазоном от 20 до 25%. Процент интернет-провайдеров с шаблонами для каждого пула был определен следующим образом: 31% для пула A; 18% для пула B; 22% для пула C; и 16 % для пула D. Хотя процент шаблонных интернет-провайдеров для пула A был на 1 % выше допустимого уровня, мы обнаружили, что полученные проценты имеют тенденцию иметь вариацию в несколько процентных пунктов при выполнении в репликации, поэтому мы считали пул A быть достаточно близко к допустимым уровням. Шаблонные препараты объединенных библиотек, которые прошли контроль качества, затем обогащали для ISP с положительной матрицей с использованием прибора Ion OneTouch ES и обогащающих шариков Ion PGM (шарики Dynabead MyOne Streptavidin C1; Thermo Fisher Scientific: № по каталогу 4478525), которые функционируют для селективного привязать к шаблону положительных интернет-провайдеров.
Подготовка системы Ion Torrent PGM, цикл секвенирования и очистка после цикла выполнялись с использованием химических реагентов и расходных материалов, входящих в набор для секвенирования Ion PGM Hi-Q (Thermo Fisher Scientific: № по каталогу A25592) и Ion PGM Hi-Q. Q Wash 2 Bottle Kit (Thermo Fisher Scientific: № по каталогу A25591) в соответствии с протоколом секвенирования в руководстве пользователя Ion PGM Hi-Q Sequencing следующим образом. Во-первых, на сервере Ion Torrent был создан план запуска секвенирования со следующими критериями: (1) Применение — метагеномика; (2) целевая техника – целевое секвенирование 16S; (3) Набор библиотек — набор библиотек Ion Plus Fragment; (4) Набор шаблонов — Ion PGM Hi-Q View OT2 Kit — 400; (5) Набор для секвенирования — набор для секвенирования Ion PGM Hi-Q; (6) Потоки -850; (7) Тип чипа — чип Ion 318™ v2; и (8) набор штрих-кодов — IonXpress. Во-вторых, праймеры для секвенирования отжигали с положительными по матрице ISP с использованием термоциклера для ПЦР (95°С 2 мин, 37°С 2 мин). В-третьих, полимераза для секвенирования добавлялась к ISP, отожженным с праймером, и загружалась в чип Ion 318™ Chip v2 (Thermo Fisher Scientific: № по каталогу 4484354). В-четвертых, загруженный Ion-чип помещали в очищенный и инициализированный прибор Ion Torrent PGM (Thermo Fisher Scientific: № по каталогу 4462921) и запускали цикл секвенирования.
После секвенирования пулов A, B и C и предварительного анализа мы обнаружили, что некоторые из отдельных библиотек в каждом пуле имеют небольшое количество сопоставленных чтений. Это не было неожиданным, учитывая, что в других исследованиях, использующих метод объединения нескольких образцов в одном цикле секвенирования, также сообщалось о сильно различающемся количестве последовательностей чтения, сгенерированных среди образцов в пуле (Lemos et al., 2011). Для решения этой потенциально проблематичной проблемы был проведен дополнительный цикл секвенирования. Используя следующие предварительно определенные критерии, определенные образцы были выбраны для дополнительного пула секвенирования (пул D): образцы, которые генерировали 2500 картированных прочтений или менее и генерировали метагеномный профиль с низким видовым разнообразием по сравнению с другими образцами той же группы лечения. Этим критериям соответствовали образцы С31, С35, 44, 46, N43, N45 и N47 (таблица S2). Несмотря на соответствие указанным выше критериям, один образец, C34, не имел картированных прочтений, несмотря на использование всей ПЦР-реакции адаптера P1/A при объединении (пул A), поэтому этот образец не подвергался повторной амплификации. После предварительного анализа пула D новые данные секвенирования были объединены с предыдущими данными, собранными для каждого образца.
16S Метагеномный и статистический анализ
С помощью программного обеспечения Ion Reporter данные секвенирования для каждого отдельного образца были организованы в соответствующие тестовые группы: исходный уровень, инокулированные PG, фиктивные инокулированные или беременные. Затем эти группы были проанализированы с использованием строго разработанного рабочего процесса для создания профилей микробиома полости рта 16S. Рабочий процесс включал следующие критерии: (1) Применение — метагеномика; (2) группы образцов — одиночные/множественные; (3) Ссылки — Curate MicroSEQ ® 16S Reference Library v2013.1 и Curate Greengenes v13.5; (4) Праймеры — по умолчанию; (5) обнаружены праймеры — оба конца; (6) Минимальное покрытие выравнивания −90,0%; (7) Фильтр изобилия чтения – минимум 10 копий; (8) отсечение по роду -97,0%; (9) Отсечка видов –99,0%; и (10) Процент сообщения об идентификаторе косой черты -0,2%. Этот рабочий процесс использовался для сопоставления данных секвенирования (т. е. присвоения прочтений операционным таксономическим единицам) для каждого отдельного образца, а также коллективных (консенсусных) данных для каждой группы в сравнении с несколькими тщательно отобранными эталонными базами данных микробного генома для создания индивидуальных профилей популяции микробиома. (наборы данных OTU) для каждого образца, а также профили консенсуса для каждой группы лечения. Порог сходства BP (базовая пара) был установлен на 150 для всех данных, представленных здесь. Каждый отдельный образец также был проанализирован, чтобы определить, были ли какие-либо профили микробиома, которые казались необычными или выпадающими по сравнению с остальными профилями в их экспериментальной группе. Консенсусные профили микробиома затем сравнивали между группами лечения и/или временными точками, чтобы выявить сдвиги в микробной популяции в ответ на P. gingivalis инокуляция или беременность, а также для анализа других дескрипторов, связанных с идентифицированными членами сообщества на уровне семейства, рода или вида (т. е. характеристика окрашивания по Граму, потребности в кислороде, прогностические метаболические профили). Программное обеспечение R (R Core Team, 2013) использовалось для графического отображения процентной доли идентифицированных членов сообщества в каждом профиле микробиома в контексте выбранного группового дескриптора.
Сопоставленные выходные данные (профили популяции микробиома) для каждой группы лечения были оценены и графически отображены путем выполнения анализа альфа- и бета-разнообразия с использованием биоинформатического конвейера QIIME (Caporaso et al., 2010) в пакете программного обеспечения Ion Reporter (Thermo Fisher Cloud). ). Эти анализы производят описательную статистику сообщества. Мы сообщаем о внутригрупповом анализе альфа-разнообразия консенсусных микробиомов, включающем все образцы, принадлежащие группе, для каждой из наших четырех групп. Конвейер альфа-разнообразия генерирует кривые разрежения, которые отражают численность видов (сообщества) (количество OTU) и равномерность (доля популяции) внутри группы, и, таким образом, если выходные данные секвенирования были достаточно глубокими, чтобы точно охарактеризовать микробиоту, присутствующую во время выборки они будут генерировать кривые разрежения (графики филогенетического разнообразия), которые выходят на плато, когда только самые редкие виды остаются для отбора проб. Для создания кривых разрежения были проведены четыре различных непараметрических статистических анализа: (1) наблюдаемые виды, (2) индекс Симпсона, (3) индекс Шеннона и (4) индекс Chao1. Анализ наблюдаемых видов и Choa1 измеряет богатство выборки/сообщества. Упрощенно вывод, основанный на этих показателях, зависит от присутствия или отсутствия видов, наблюдаемых в образцах в пределах группы. Индекс Chao1 также отражает пропорцию популяции (равномерность) в определенной степени, принимая во внимание количество раз, когда вид встречается. Однако на эти методы сильно влияет размер выборки, что может привести к недооценке полноты выборки (Colwell and Coddington, 19).94), и, таким образом, не являются столь популярными мерами при проведении анализа метагеномных данных 16S, полученных с использованием платформ быстрого чтения, таких как Ion Torrent PGM или MiSeq, когда количество идентифицированных OTU в исследовании невелико. При этом после достижения плато оценка разнообразия становится относительно независимой от размера выборки (Hughes et al. , 2001). Кроме того, использование шести региональных мишеней 16S, а не одной или двух, компенсирует небольшой размер выборки, что приводит к плохому охвату, характерному для метагеномного анализа 16S, выполняемого на этих небольших платформах считывания, которые обычно используют только одну или две региональные мишени. Использование шести региональных мишеней также уменьшит количество ложноположительных результатов, которые, как сообщается (Edgar, 2017), затрудняют анализ QIIME метагеномных данных 16S, полученных с платформ с коротким считыванием, при использовании одной мишени вариабельной области. Анализы Симпсона и Шеннона отражают разнообразие популяции (численность и равномерность). Точнее, индекс Симпсона отражает доминирование видов и вероятность случайного выбора двух отдельных организмов, принадлежащих к одному и тому же виду. Подобно индексу Chao1, он взвешивается в зависимости от численности наиболее распространенных видов. Для индекса Симпсона показатель 1 указывает на полную равномерность пропорций видов в этой выборке или группе. Напротив, индекс Шеннона измеряет среднюю степень неопределенности в прогнозировании того, к какому виду будет принадлежать отдельный организм при случайном выборе, таким образом, на этот показатель влияет как количество идентифицированных видов, так и их доля в популяции (равномерность).
Анализ бета-разнообразия Брея-Кертиса использовался для сравнения профилей микробиомов отдельных образцов или групп друг с другом для выявления различий в сообществах. Это статистический анализ на основе расстояния, используемый для выявления источников дисперсии в отдельных выборочных сообществах или среди групп. Этот метод использует количество OTU, но не филогению, к которой он принадлежит, в отличие от метода UniFrac для оценки бета-разнообразия. Для визуализации бета-разнообразия использовались графики анализа основных координат (PCoA). PCoA представляет собой вычисление многомерного масштабирования, которое преобразует данные профиля популяции микробиома в коррелированные переменные сходства, а затем преобразует их в матрицу различий или расстояний, которую затем можно пространственно нанести на набор из трех ортогональных осей в качестве точки данных, так что максимальное количество изменение для этой точки данных объясняется первыми главными осями координат, второе по величине изменение объясняется вторыми главными осями координат и т. д. (Caporaso et al., 2010).
Прогнозируемые профили микробного метаболизма
Был проведен прогностический анализ морфологической классификации, потребности в кислороде и профилей синтеза основных метаболитов. Чтобы определить способность продуцировать основные метаболиты в ротовой полости в ответ на инокуляцию P. gingivalis , а затем на беременность, консенсусные профили микробиома были проанализированы с помощью картографа KEGG (www.genome.jp/kegg/) и дополнительно рассмотрены с использованием Substrata. база данных (www.datapunk.net/substrata) и STRING (string-db.org). Для того чтобы быть классифицированным как принадлежащий к избранной группе метаболитов, метаболит должен быть идентифицирован как основной конечный продукт, а не просто обладающий генетической способностью генерировать рассматриваемый метаболит. Руководство Берджи по систематике архей и бактерий также использовалось для поддержки соответствующей классификации метаболитов каждого рода (Whitman, 2015). Когда классификация была неясной из-за отсутствия веских доказательств в поддержку включения или если веские доказательства подтверждали исключение в качестве основного производителя любого из этих избранных метаболитов, эти идентифицированные члены классифицировались как «Другие». Все прогностические качественные показатели метаболических результатов были нанесены на график в виде процента OTU на уровне рода.
Результаты
Влияние инфекции
P. gingivalis на потерю альвеолярной кости и иммунитет плечевой кости Все образцы из групп беременных и беременных были положительными в отношении P. gingivalis методом ПЦР. У всех животных, привитых P. gingivalis , наблюдалась значительно большая потеря альвеолярной кости, чем у контрольных животных того же возраста, которым вводили фиктивную прививку, что подтверждает наличие у этих животных периодонтального заболевания (рис. 1). Рисунок 1 . У всех животных, привитых P. gingivalis , потеря альвеолярной кости была значительно выше, чем у контрольных животных того же возраста, которым вводили ложную прививку (базовый уровень), что подтверждает наличие у этих животных периодонтального заболевания. Морфометрическая оценка потери костной ткани нижней и верхней челюсти у беременных контрольных крыс и крыс, которым вводили PG. Значения на каждом графике представляют собой степень горизонтальной потери костной ткани, помеченной как измерения площади CEJ-ABC (мм 2 ), на лингвальной (A) и щечной (B) сторон с каждой нижней челюсти. (C) Репрезентативные изображения лингвальной стороны нижней челюсти крысы, иллюстрирующие степень горизонтальной потери кости. Желтые линии обозначают соединение CEJ-ABC, которое использовалось для определения степени потери костной массы. Репрезентативные изображения верхнечелюстного межзубного сосочка у контрольной группы (D) и у крыс, инокулированных PG (E) , демонстрирующие, как проводились измерения CEJ и ABC для гистоморфометрии (F) . Столбцы на всех графиках показывают среднее значение ± стандартное отклонение. Данные анализировали с помощью непарного критерия Стьюдента.
Мы также измерили специфические IgM и IgG P. gingivalis до (базовый уровень), после инокуляции и во время беременности для оценки микробного воздействия (рис. 2). Ни у одного из животных не было обнаруживаемого P. gingivalis специфического IgM в любой момент времени исследования (данные не показаны). Не было различий в уровне P. gingivalis специфических IgG между исходной и контрольной группами. И инокулированные PG, и группы беременных имели большее количество P. gingivalis специфических IgG, чем исходная группа ( P < 0,0001).
Рисунок 2 . Мы также измерили специфических IgM и IgG P. gingivalis до (исходный уровень), после инокуляции и во время беременности для оценки микробного воздействия.
Влияние
P. gingivalis Инфекция и беременность на микробиом полости рта Сначала мы искали сдвиги в естественной экологии полости рта, оценивая внутригрупповое богатство, разнообразие и относительную глубину охвата в каждый момент времени сбора и условие. Последовательности (прочтения) с более чем 10 копиями (изобилие) и последовательность, совпадающая с картой в 90% или выше точность эталонных геномов присваивается конкретной OTU. Это стандартные критерии для максимальной уверенности в том, что все идентифицированные бактерии вносят значительный вклад в сообщество микробиома. Для наших данных специфическое отсечение картирования составляло 97% совпадений последовательностей на уровне рода и 99% совпадений последовательностей на уровне видов для всех подходящих прочтений. Все образцы, за исключением одного контрольного образца с ложной инокуляцией (ID# 34), генерировали OTU, соответствующие этим критериям. Чтобы визуализировать наши данные, консенсусные профили микробиома, представленные в виде OTU на уровне семьи, показаны на рисунке S1. Консенсусные профили микробиома на уровне семейства, рода и вида, отсортированные по вариабельной области 16S, также были визуализированы с использованием диаграмм Krona, созданных с использованием программного пакета Ion Torrent, и показаны на рисунках S2, S3.
Альфа-разнообразие оценивали с помощью четырех различных статистических анализов, включая: наблюдаемые виды, индекс Симпсона, индекс Шеннона, индекс Chao1 (рис. 3). Кривые разрежения вышли на плато для всех групп, что указывает на то, что наши наборы данных имели адекватный охват и, возможно, не были идентифицированы только самые редкие виды. Как наблюдаемые виды, так и кривые разрежения Choa1 показали, что численность была одинаковой среди инокулированных PG, беременных и исходных групп, в то время как группа с ложной инокуляцией, которая имела наименьшее количество OTU, имела наименьшую численность. Напротив, кривые разрежения Шеннона и Симпсона, которые также отражают равномерность популяции, показали, что группа, инокулированная PG, имела наибольшее разнообразие. В частности, средние индексы разнообразия Шеннона и Симпсона на уровне видов составляли, соответственно, 3,24 и 0,84 (инокулированные PG), 2,45 и 0,67 (беременные), 2,47 и 0,63 (базовые) и 2,35 и 0,66 (имитированные). где более высокое значение указывает на большее разнообразие в этой группе.
Рисунок 3 . Альфа-разнообразие оценивалось с помощью четырех различных статистических анализов, включая: наблюдаемые виды, индекс Симпсона, индекс Шеннона, индекс Chao1.
Различия в сообществах визуализировались с помощью трехмерных графиков PCoA Брея Кертиса. Каждая точка данных была отсортирована и отмечена цветовой маркировкой по экспериментальной группе, статусу оральной инфекции или статусу беременности, и нанесена на график по трем первичным измерениям расстояния вариации. Отсутствие кластеризации вдоль PC1 указывало на то, что экспериментальное лечение не было основным источником изменчивости (рис. 4). Однако экспериментальные группы действительно способствовали изменчивости сообщества на уровне семейства, рода и вида. Например, на уровне видов исходные, инокулированные PG и беременные группы четко сгруппированы внутри своей группы вдоль PC2, что составляет 16,55% дисперсии сообщества (рис. 5). Эти данные измерения расстояния также показали, что группа беременных была наиболее удалена от нуля вдоль PC2, что указывает на то, что беременность у каждого инфицированного животного вызывала большую степень изменчивости микробного сообщества полости рта, чем инфекции P. gingivalis отдельно на уровне видов. На уровне рода и семейства исходные, привитые PG и беременные группы группировались внутри своих групп вдоль PC3: 10,91% на уровне рода и 10,90% на уровне семейства (рис. 6). При сортировке по инфекционному статусу (рис. 7) наборы данных были сгруппированы внутри своих групп вдоль ПК5 на уровне вида (8,31%), ПК6 на уровне рода (6,14%) и ПК9 на уровне семейства (3,86%).
Рисунок 4 . График PCoA Брея Кертиса для показателей различия бета-разнообразия показывает, что на уровне видов исходные группы, группы с прививкой PG и беременные группы четко сгруппированы внутри своей группы вдоль PC2, а не PC1.
Рисунок 5 . График PCoA Брея Кертиса для показателей различия бета-разнообразия показывает, что на уровне видов исходные, группы с инокуляцией PG и беременные группы четко сгруппированы внутри своей группы вдоль PC2 и PC4, но не PC3.
Рисунок 6 . График Брэя Кертиса PCoA показателей различия бета-разнообразия показывает, что на уровне рода исходные, инокулированные PG и беременные группы сгруппированы внутри своих групп вдоль PC3 на уровне рода (A) и (B) семейный уровень.
Рисунок 7 . График Брэя Кертиса PCoA показателей бета-разнообразия несходства показывает, что когда наборы данных были отсортированы по статусу инфекции, они сгруппированы внутри своих групп вдоль PC5 на уровне вида (A) , PC6 на уровне рода (B) , и PC9 на уровне семейства (C) .
Анализ бета-разнообразия был также проведен для определения группового несходства между каждым коллективным консенсусным микробиомом на уровне семейства, рода или вида и нанесен на график в виде четырех точек данных на графиках PCoA. При объединении наборов данных в каждой группе более редкие члены, идентифицированные в каждой выборке, оказывают меньшее влияние на меры расстояния, таким образом создавая графики в альтернативном контексте, аналогичном мерам альфа-разнообразия. Примеры графиков показаны на рисунке 8. Когда использовались показатели Брея Кертиса и точки данных визуализировались по первым трем осям вариации, графические положения исходного уровня и группы беременных были найдены близко друг к другу, в то время как инокулированные PG и инокулированные инокулированные были расположены прочь. Хотя инокулированные PG и ложно инокулированные сгруппированы вместе вдоль PC2, они были наиболее удаленными друг от друга точками, если рассматривать их по отношению к PC1. Напротив, когда использовались евклидовы метрики несходства сообщества, которые учитывали только присутствие-отсутствие, а не численность, микробиомы с ложным инокулированием, базовые и беременные микробиомы группировались близко друг к другу, в то время как микробиомы с инокулированным PG отображались на расстоянии.
Рисунок 8 . Коллективный согласованный микробиом на уровне семейства, рода или вида, представленный в виде четырех точек данных на графиках PCoA с использованием (A) Bray Curtis или (B) Eucledian мер бета-разнообразия различий.
Сходства и различия микробного состава ротовой полости у здоровых небеременных неинфицированных крыс
Образцы, собранные до инокуляции (базовый уровень), а также образцы, взятые у ложно инокулированных животных, использовались в качестве неинфицированных контролей в этом исследовании. Исходные профили представляют собой нормальную оральную флору у 2-месячных самок крыс до лечения антибиотиками, тогда как группа с ложной инокуляцией представляет возрастных 5-месячных социально зрелых крыс, ранее получавших антибиотики и стерильный носитель. При сравнении профилей микробиома между исходными и ложнопривитыми группами было выявлено две доминирующие семьи: Pasteurellaceae и Streptococcaceae (рис. S1). Pasteurellaceae составляли 39,55% популяции, наблюдаемой в исходной группе, и 44,32% популяции в группе с ложным инокулированием. Доминирующим видом, идентифицированным в пределах Pasteurellaceae (75–85%), был Haemophilus parainfluenzae с долей 75–85%.
Заметные различия на уровне семейства между фиктивной и исходной группами заключались в относительно большей популяции Lactobacillaceae в группе с ложным инокулированием (15,81%) по сравнению с исходной группой (1,13%) и относительно большая популяция из Staphylococcaceae в исходной группе (43,56%) по сравнению с фиктивной группой (17,83%). Меньшая, но заметная разница также наблюдалась для Veillonellaceae (8,14% ложных инокулированных; 2,95% исходного уровня) и Micrococcaceae (0,37% ложных инокулированных; 6,20% исходного уровня).
Примерно половина всех картированных прочтений (OTU) в каждой тестовой группе, полученных от одних и тех же животных, может быть идентифицирована до уровня вида (т. е. 50,0% от исходного уровня; 54,6% инокулированных PG; больший процент OTU, инокулированных имитации, можно было картировать на видовом уровне (68,8%).
Было сложно оценить изменения Streptococcus на уровне видов среди всех групп из-за высокого уровня обращений к этому роду на уровне видов (рис. S2, S3). Косые вызовы — это последовательности (OTU), которые соответствуют более чем одной возможной эталонной последовательности, и где процентная разница между этими лучшими совпадениями составляет ≤0,2% последовательности. Например, только 11,04% популяции Streptococcus можно было дополнительно идентифицировать до уровня вида в исходной группе, в то время как 53,73% Популяция Streptococcus в группе с ложной инокуляцией может быть идентифицирована до видового уровня. Однако мы могли бы специально рассмотреть отдельные виды, например: 3,52% микробной популяции в исходной группе и 1,67% в группе с ложной инокуляцией были идентифицированы как Streptococcus sanguinis . В целом, наши данные показывают, что вида Streptococcus , как правило, разнообразны в ротовой полости крыс и что большинство OTU, сопоставленных с видами Streptococceae семейства в настоящее время не могут быть сопоставлены с уровнем вида.
Сходства и различия микробного состава ротовой полости у здоровых небеременных крыс в ответ на инокуляцию
P. gingivalis после инокуляции (инокуляции PG) в образцы, собранные до заражения (базовый уровень). Мы обнаружили, что Porphyromonadaceae присутствовал в группе, инокулированной PG, хотя и в количестве 0,02% от общей картированной популяции микробиома, подтверждая, что животные действительно были колонизированы.
На уровне семейства (рис. S1) преобладали Streptococcaceae и Pasteurellaceae ; однако доля Pasteurellaceae уменьшилась после инокуляции P. gingivalis с 39,5% в начале исследования до 14,4% у инфицированных небеременных животных (инокулированных PG). Напротив, 9Популяция 3143 Streptococcaceae немного увеличилась с 43,6% в начале исследования до 55,4% в группе, привитой PG.
Опять же, сравнительный анализ видов Streptococcus был неполным из-за высокого уровня косой черты, сопоставленной с этим родом (рис. S2, S3). Тем не менее, наши данные показывают, что распределение доли популяции видов Streptococcus изменилось в ответ на колонизацию P. gingivalis . В частности, мы идентифицировали следующие виды в исходной группе в порядке убывания доли популяции: S. sanguinis, S. mutans, S. hyointestinalis, S. infantis, S. oralis, S. australis, S. danieliae, S. suis, S. lactarius и S. pneumoniae . Принимая во внимание, что виды, которые могли быть конкретно идентифицированы в группе, инокулированной PG, в порядке убывания доли популяции, включали S. mutans, S. sanguinis, S. infantis, S. oralis, S. lactarius, S. australis, S. .sinensis, S.pneumoniae, S.merionis, S.parasanguinis, S.anginosus и S. pseudopneumoniae .
Другими изменениями, отмеченными в профиле микробиома, инокулированного PG, было увеличение доли видов Proteus mirabilis и Enterococcus faecalis по сравнению с контролем. В целом эти данные свидетельствуют о том, что инокуляция P. gingivalis нарушила микробиом полости рта, что привело к сдвигу профиля микробиома с увеличением микробного разнообразия, что подтверждается нашими статистическими анализами альфа- и бета-разнообразия.
Изменения в микробном составе полости рта
P. gingivalis Инфицированные крысы в ответ на беременность Чтобы оценить взаимодействие беременности и заболеваний пародонта, мы сравнили согласованные профили микробиома полости рта до инокуляции (исходный уровень), в конце фазы инокуляции (инокуляция PG). ) и на 18-й БД (беременная). Как и в исходных группах и группах, инокулированных PG, Streptococcaceae и Pasteurellaceae оставались двумя наиболее доминирующими семействами в микробиоме группы беременных (рис. S1). Однако были некоторые отличительные различия и заметные сдвиги в группе беременных. Например, Streptococcaceae и Pasteurellaceae , судя по всему, возвращается к исходному уровню. Аналогичная тенденция наблюдалась и среди других менее распространенных семей со следующими заметными исключениями. Во-первых, Porphyromonadaceae , который присутствовал только в группах беременных и инокулированных PG, увеличился с 0,02% в группе инокулированных PG до 0,74% в группе беременных. Во-вторых, популяция Corynebacteriaceae заметно увеличилась до 13,49% в микробиоме группы беременных с 1,9%.3% в исходной группе и 3,13% в группе, привитой PG.
На уровне видов (рис. S2, S3) Haemophilus parainfluenzae восстановились и стали доминирующим единственным видом, идентифицированным в группе беременных. Точно так же многие из второстепенных видов, появившихся во время инокуляции PG, вернулись к исходным уровням во время беременности. Заметные исключения включают Corynebacterium mastitidis , которые составляют 98,96% от идентифицированных Corynebacterium 9.3144 вида. Опять же, изменения в Streptococcus на уровне вида не могли быть полностью оценены из-за высокого уровня косой черты. Доля популяции в пределах рода Streptococcus , которая могла быть положительно идентифицирована до видового уровня в группе беременных, составила 10,78%, что было аналогично 11,04% на исходном уровне, но меньше, чем 47,49% среди инокулированных PG. группа. Хотя большая часть из OTU Streptococcus не может быть сопоставлена с отдельными видами, используемая стандартизированная методология запрещает групповую предвзятость, поэтому сравнения видов между группами являются достоверными. Чтобы проиллюстрировать, насколько последовательными были данные, позволяющие сравнивать групповые профили, мы оценили относительную долю населения S. mutans относительно всех категорий OTU. Например, S. mutans составляли 2,18% на исходном уровне, 28,61% при инокуляции PG и 2,75% при беременности от всех OTU семейства Streptococcaceae . Эти цифры коррелируют с долей популяции S. mutans по отношению ко всем идентифицированным OTU видового уровня (1,83% исходного уровня; 29,05% инокулированных PG; 1,63% беременных), а также процентной долей всех OTU (исходный уровень 0,91%; 15,85% инокулированных PG; 0,95% беременных), которые сопоставлены с любым семейством микробов. В целом, этот род, по-видимому, неизменно разнообразен с S. sanguinis, S. mutans и S. infantis являются наиболее доминирующими идентифицированными представителями.
Метагеномные сдвиги относительно морфологической классификации, потребности в кислороде и профилей основных метаболитов
В дополнение к оценке изменений в профилях микробиома с точки зрения микробной идентичности, мы также выполнили прогностический анализ некоторых микробных клеточных функций. Оральный микробиом классически сортируется по морфологическим характеристикам и классификации Грама, поэтому первым шагом в нашем функциональном анализе была сортировка наших консенсусных данных по этим терминам. Хотя спирохеты не были обнаружены, наблюдались сдвиги в консенсусных профилях грамположительных и грамотрицательных бактерий (рис. 9).). Например, когда условия в организме хозяина изменились с исходного уровня на инокулированный PG, наблюдалось увеличение количества грамположительных бактерий, в первую очередь более чем 3-кратное увеличение грамположительных палочек и 2-кратное снижение количества грамположительных палочек. Грамотрицательные палочки. В группе беременных наблюдалось еще большее увеличение количества грамположительных палочек, отражающее почти 5-кратное увеличение по сравнению с исходным уровнем. Напротив, доля грамотрицательных палочек в популяции сместилась обратно к исходному уровню во время беременности. Доля грамотрицательных кокков в популяции была одинаковой между исходной группой и группой, инокулированной PG, но снизилась с ~ 3% до 0,1% в группе беременных. Наблюдаемые изменения становятся более интересными, когда в нашем последующем анализе учитываются потребности в кислороде обнаруженных членов консенсусной популяции.
Рисунок 9 . Доля в популяции идентифицированных членов сообщества с точки зрения прогнозируемой классификации окрашивания по Граму и морфологии клеток для исходных групп, групп, привитых PG, и групп беременных.
Затем мы составили профили микробных популяций на основе их потребности в кислороде (рис. 10А). В то время как доля факультативных анаэробных бактерий оставалась относительно постоянной между исходным уровнем и инокулированными PG, доля строго анаэробных бактерий сместилась вниз, а доля аэробов сместилась вверх на 0,6% от общей популяции (рис. 10B). Напротив, доля факультативных анаэробов в популяции снизилась с 9от 3,7 до 81,5% в ответ на беременность. Это изменение сопровождалось снижением количества строгих анаэробов (2,8–1,7%) и увеличением количества строгих аэробов (3,4–16,8%), отражая общее увеличение потребности микробиоты полости рта в кислороде.
Рисунок 10 . Доля в популяции идентифицированных членов сообщества с точки зрения прогнозируемой (A) потребности в кислороде отдельно или (B) потребности в кислороде в контексте классификации окрашивания по Граму для исходных групп, групп с прививкой PG и беременных.
Затем мы составили профили предсказанных микробных метаболомов всех групп. Было обнаружено, что среди большого разнообразия метаболитов, которые можно было идентифицировать, 2,3-бутандиол, бутират, молочная кислота и пропионат являются наиболее определяющими популяцию продуктами, по которым можно дифференцированно отсортировать большинство членов каждого микробиома. Anaerostripes — единственный род, который, по нашему мнению, следует отнести к группе основных метаболитов как бутирата, так и молочной кислоты. Все остальные могут быть отнесены к одной из этих четырех групп метаболитов или помещены в группу «Другие» как не являющиеся основными производителями этих метаболитов (рис. 11). Прогнозируемая доля продуцентов молочной кислоты в популяции уменьшилась с 9от 2,57 % (базовый уровень) до 85,15 % (прививка PG) до 80,50 % (беременные). Доля продуцентов пропионата снизилась с 3,44% (исходный уровень) до 2,81% (прививка PG) и до 0,30% (беременные). Напротив, доля производителей бутирата постепенно увеличивалась с 0% (исходный уровень) до 0,02% (инокулированные PG) и до 0,86% (беременные). Доля продуцентов 2,3-бутандиола увеличилась с 1,15% (исходный уровень) до 8,59% (прививка ПГ) в ответ на инфекцию ПГ, но затем снизилась до 1,70% во время беременности. Оставшаяся часть популяции бактерий, обозначенная как «Другие», увеличилась более чем в 5 раз во время беременности, отражая увеличение количества облигатных аэробов в ротовой полости беременных крыс на 18-й БС. независимо друг от друга, поскольку он обычно производился совместно с одним из четырех выбранных метаболитов (рис. 12). Доля продуцентов ацетата снизилась с 42,03% (исходный уровень) до 15,34% (прививка PG), но увеличилась в ответ на беременность до 38,38%.
Рисунок 11 . Доля в популяции идентифицированных членов сообщества с точки зрения прогнозируемых метаболических характеристик в качестве основного генератора целевых микробных метаболитов для групп исходного уровня, инокулированных PG и беременных.
Рисунок 12 . Доля в популяции идентифицированных членов сообщества с точки зрения прогнозируемой метаболической характеристики в качестве основного генератора ацетата для исходных групп, групп, привитых PG, и групп беременных.
Поскольку способность синтезировать рибофлавин (витамин B2) связана со здоровьем желудочно-кишечного тракта (ЖК) (Yoshii et al., 2019) и многие из видов, идентифицированных в ротовой полости, также колонизируют ЖКТ, мы провели независимую оценку продуцентов рибофлавина в рамках согласованного профиля микробиома каждой группы (рис. 13). Способность к биосинтезу рибофлавина определяли по наличию в геноме полного пути с использованием базы данных путей KEGG. Предсказанная коллективная способность микробной популяции ротовой полости синтезировать рибофлавин резко снизилась с 85,4% (базовый уровень) до 43,1% (прививка PG) в ответ на инфекцию, но эта способность восстановилась во время беременности к 18-му дню беременности, увеличившись до 9.5,8% (беременные). Примечательно, что небольшая часть населения (~ 1% беременной группы и 0,1% группы, привитой PG) не могла быть классифицирована положительно или отрицательно из-за ограничений в справочной базе данных KEGG на момент анализа. Беглый анализ всех групп показал, что ≤0,2% каждого согласованного профиля микробиома обладали предсказанной способностью питаться в пути метаболизма порфирина, используя рибофлавин в качестве раннего метаболита-предшественника, чтобы в конечном итоге синтезировать витамин B12 (данные не показаны).
Рисунок 13 . Доля в популяции идентифицированных членов сообщества с точки зрения прогнозируемой способности синтезировать рибофлавин для исходных групп, групп, привитых PG, и групп беременных.
Обсуждение
Микробиом полости рта здоровых крыс в сравнении с ранее опубликованными профилями человека и крыс
Институт Форсайта создал общедоступную базу данных микробиома полости рта человека (www.homd.org). Используя полное секвенирование гена 16S рРНК, они сообщили, что 96% микробиома ротовой полости человека состоит из шести типов (9).3143 Firmicutes 36,7%, Bacteroidetes 17,3%, Proteobacteria 17,1%, Actinobacteria 11,6%, Spirochaetes 7.9%, Fusobactria. Напротив, мы обнаружили, что бактерии, которые мы идентифицировали на исходном уровне в ротовой полости крыс, принадлежат только к трем типам ( Firmicutes 48,10%, Proteobacteria 43,64%, Actinobacteria 8,26%). Необнаруженный тип Bacteroidetes, Spirochaetes и Fusobacteria включают ключевые пародонтопатогенные бактерии, связанные с заболеванием пародонта человека и вызывающие неблагоприятные исходы беременности (например, P. gingivalis, Treponema denticola, Tannerella forsythia, Fusobacterium nucleatum ) (Aagaard et al., 2014; Prince et al. ., 2016; Лин и др., 2018). После инокуляции P. gingivalis консенсусный микробиом полости рта включал четыре типа ( Firmicutes 72,22%, Proteobacteria 24,61%, Actinobacteria 3,15%, Bacteroidetes 0,02%) с семейством Porphyromonadaceae , составляющим 100% идентифицированной популяции Bacteroidetes , что согласуется с экспериментально индуцированной оральной инфекцией. К 18-му дню оральный микробиом беременных крыс, зараженных оральным путем, состоял из тех же четырех типов, но с заметными сдвигами популяций ( Firmicutes 41,69%, Proteobacteria 40,11%, Actinobacteria 15,54%, Bacteroidetes 9).3144 2,66%). Тип Bacteroidetes в группе беременных теперь состоял из четырех семейств, включая Porphyromonadaceae, Bacteroidaceae, Cytophagaceae и Flavobacteriaceae .
Мы обнаружили, что наиболее многочисленным родом в ротовой полости нашей модели крысы на исходном уровне был Streptococcus , аналогично сообщениям о микробиоте ротовой полости человека (Dewhirst et al. , 2010). Что касается двух наиболее распространенных родов на исходном уровне, Streptococcus и Haemophilus , как известно, специфически сцепляются друг с другом (коагрегат) во время развития биопленки из-за слипания наружных мембран, обнаруженного у некоторых видов Streptococcus , которые распознают специфические полисахаридные рецепторы на Haemophilus parainfluenzae (Lai et al., 1990). ; Хеллер и др., 2016). Интересно, что большой процент очень разнообразных видов Streptococcus и высокий процент Haemophilus parainfluenzae , наблюдаемые в этих ротовых микробиомах крыс, также наблюдались в развитии ранней зубной биопленки человека (Heller et al., 2016), что позволяет предположить, что Модель пародонтита и беременных крыс, использованная в этом исследовании, может считаться подходящей трансляционной моделью для патологии полости рта, поскольку она представляет собой оральную флору, относительно аналогичную человеческой, но с заметным отсутствием периодонтопатогенных бактерий. Мы рассматриваем это отсутствие не как недостаток, а как критическое преимущество этой модели, поскольку она позволяет контролировать колонизацию полости рта пародонтопатогенными бактериями для изучения их роли в развитии оральных и экстраоральных заболеваний.
Из-за нескольких ранее завершенных исследований микробиомов ротовой полости крыс было сложно сравнить наши результаты с другими опубликованными данными. Единственное исследование, которое, по нашему мнению, в некоторой степени эквивалентно нашему для сравнения, было исследование Manrique et al. исследование, которое охарактеризовало нормальную флору полости рта здоровых крыс Sprague-Dawley путем сбора наддесневого налета верхних моляров (Manrique et al., 2013). Однако исследование Манрике показало, что Rothia доминируют в полости рта на 74,43%, а следующим по распространенности бактериальным родом были Стрептококк (4,67%). Хотя OTU, которые были сопоставлены с семейством Micrococcaceae , были идентифицированы во всех наших экспериментальных группах (6,2–0,02%), Rothia не были обнаружены повсеместно в нашем исследовании. OTU Rothia были обнаружены в исходном консенсусном микробиоме нашего исследования в очень низкой пропорции (1,4% от общей микробной популяции полости рта). Доля, обнаруженная в других группах, была еще ниже: 0,5% в группе беременных и 0% (необнаруженные) как в группах, привитых PG, так и в группах ложной прививки. Вместо этого наше исследование показало, что два наиболее доминирующих рода на исходном уровне, представляющие нормальные оральные цветки здоровых крыс, были Streptococcus (41,77%) и Haemophilus (32,69%).
Хотя профили микробиома отражают различия в популяции среди разных групп животных, на наблюдаемые различия между исследованиями также влияют различия в колониях животных, методах отбора проб и различиях в параметрах анализа создания профилей микробиомов, таких как критерии строгости и используемые справочные базы данных. Мы считаем, что основным источником различий между нашими результатами по сравнению с недавними публикациями являются различия в том, как были созданы библиотеки 16S. В большинстве опубликованных исследований, в которых сообщается о локус-специфических микробиомах 16S крыс, обычно используются библиотеки секвенирования, нацеленные только на одну или две вариабельные области гена 16S рРНК. Манрике и др. исследование, например, специально нацелено на 5-6 вариабельных областей гена 16S рРНК, в то время как у нас был более полный охват целевого гена путем секвенирования семи из девяти ампликонов вариабельных областей в каждой библиотеке (Manrique et al., 2013). Хотя у них была большая глубина чтения с использованием платформы пиросеквенирования 454, и, таким образом, они, вероятно, смогли идентифицировать очень редкие виды (Manrique et al., 2013), у нас был гораздо лучший охват целевого гена. Нацеливание на семь сайтов гена 16S создает профили микробиома, которые, как сообщается, сравнимы с микробиомами полноразмерного секвенирования гена 16S, в то время как нацеливание на одну или только несколько вариабельных областей приводит к неполным профилям микробиома (Bolchakova et al. , 2015). Наши данные подтверждают это наблюдение, когда мы просматривали профили микробиома, специфичные для праймеров, сгенерированные из наших наборов данных. Например, при просмотре согласованного базового профиля микробиома по отношению к каждому набору праймеров OTU, которые могут быть положительно сопоставлены с вида Rothia встречались только для последовательностей, полученных из праймеров V4, V6-7 и V8 среди семи использованных наборов. Точно так же мы обнаружили, что штамма Streptococcaceae доминировали в профиле микробиома полости рта (66,74–85,29%) при использовании того же метода у крыс Sprague Dawley (Reyes et al., 2018). Это говорит о том, что наши консенсусные профили более точно отражают пропорции популяции идентифицированного семейства, рода и вида, чем исследования, использующие для анализа только одну или две вариабельные области.
Разнообразие орального сообщества у беременных крыс с заболеванием пародонта было относительно сходным с таковым у неинфицированных БГ 18 с точки зрения обилия и равномерности
Хотя относительное разнообразие микробиома человека не обязательно указывает на заболевание (He et al. , 2015), есть сообщается о том, что микробиом ротовой полости пациентов с заболеваниями пародонта обычно отличается большим разнообразием (Griffen et al., 2012; He et al., 2015), в то время как данные, представленные для других заболеваний, такие как данные, представленные для кариеса зубов, обычно демонстрируют снижение разнообразие как следствие увеличения численности отдельных видов во флоре, выделенной из пораженных участков, что способствует развитию патологии (He et al., 2015). Сообщается, что среди методов, используемых для определения разнообразия, меры альфа-разнообразия, учитывающие как численность, так и равномерность, являются лучшими предикторами биологически значимого разнообразия (McCoy and Matsen, 2013). В нашем исследовании индексы Шеннона и Симпсона, по-видимому, указывают на то, что альфа-разнообразие между двумя контрольными группами (базовый уровень и ложнопривитые) было очень схожим. Однако индексы разнообразия Шеннона и Симпсона, рассчитанные для беременной группы, также были аналогичны контрольной группе. Другими словами, в совокупности доля положительно идентифицированных видов в популяции была одинаковой между беременными, исходными и ложно-инокулированными группами, несмотря на то, что в ложно-инокулированной группе было наименьшее количество положительно идентифицированных видов, в то время как в группе, инокулированной PG, было наибольшее разнообразие. Учитывая, что у беременных животных было заболевание пародонта, о чем свидетельствует их уровень потери альвеолярной кости, наши данные иллюстрируют ограничения использования анализа альфа-разнообразия в качестве строгого независимого индикатора заболевания. Возможное объяснение наших наблюдений, которое согласуется с предыдущими отчетами, заключается в том, что к 18-му дню прогрессирование заболевания пародонта, возможно, остановилось и стало на траекторию заживления, и, возможно, индексы разнообразия отражают состояние, в котором микробиом полости рта смещается обратно в сторону здоровья. .
Хотя кривые разрежения альфа-разнообразия, достигшие плато, как сообщается, указывают на то, что были идентифицированы все виды, кроме самых редких, эта интерпретация основана на некоторых предположениях в отношении сбора и обработки проб. Из-за некоторой неуверенности в том, что для некоторых наших библиотек было достаточно секвенированных шаблонов, чтобы с уверенностью заявить, что собранные данные точно представляют найденное устное сообщество, поскольку существовали различия между количеством прочтений, сгенерированных каждым образцом, мы решили создать пул D для подмножества. образцов, идентифицированных как имеющие наименьшее количество прочтений из пулов A, B и C. При сравнении наборов данных, полученных из каждого повторного образца, мы обнаружили, что их индивидуальные профили микробиома, проанализированные бета-разнообразием Брея Кертиса и визуализированные на графиках PCoA , оставались тесно сгруппированными друг с другом и внутри своей экспериментальной группы, поэтому все согласованные данные, представленные здесь, включали все собранные данные о последовательностях из всех четырех пулов A-D. Этот результат также подтверждает нашу уверенность в том, что наши образцы, в том числе те образцы, которые имели наименьшее количество OTU после их первого запуска в пулах A-C, имели достаточный размер выборки для создания репрезентативных профилей микробиома, обнаруженного в ротовой полости каждого животного. в пределах используемых эталонных баз данных.
Разнообразие орального сообщества с точки зрения видового состава Различия были условно зависимы, менялись в ответ как на прививку PG, так и на беременность важные оси, по которым изменяются выборки (несходство). При использовании соответствующей метрики бета-разнообразия графики PCoA также идентифицируют похожие образцы как сгруппированные точки вдоль оси (осей) дисперсии посредством визуального изучения графиков. Несходство Брея-Кертиса было выбрано потому, что это один из наиболее известных подходов к количественной оценке различий (расстояний) между выборками. Этот показатель также основан на количестве OTU, а не только на данных присутствия-отсутствия; таким образом, в этой статистической мере учитываются «размер» и «форма» счетных векторов, которые варьируются от нуля до единицы, где ноль определяется как идентичный. Поскольку потенциальные источники дисперсии (например, представляющие интерес переменные) не определены заранее перед выполнением этого типа статистического анализа, определение источника дисперсии данных (почему они группируются) может быть неочевидным.
Это может быть особенно сложно для сложных, многофакторных, некатегориальных или лонгитюдных данных. Внутриживотный анализ бета-разнообразия Брея-Кертиса между исходным уровнем, прививкой PG и беременностью выглядит широко разбросанным вдоль PC1, когда микробиом каждого животного наносили на график индивидуально (рис. 4), но когда согласованные данные каждой группы были нанесены на график в виде отдельных точек , эта метрика предполагает, что инфекция P. gingivalis была самым большим источником вариабельности популяции в этом исследовании (рис. 8). Каждая отдельная точка выборки из групп исходного уровня, инокулированных PG и беременных групп четко группировалась внутри своих групп вдоль оси PC2 на уровне видов, что указывает на то, что в совокупности условия экспериментальной группы были вторым по величине источником видовых вариаций (рисунок 4). Однако как на уровне рода, так и на уровне семейства способность четко различать экспериментальные группы сместилась с РС2 на РС3, что указывает на то, что пропорции основной популяции членов семейства и рода были более устойчивыми к возмущениям в каждый момент времени сбора данных в течение периода наблюдения. исследование, чем были конкретные видовой идентичности. В совокупности все данные измерений расстояния, представленные в наших результатах (рис. 4–8), показывают, что на изменчивость сообщества с точки зрения состава членов больше всего повлияла оральная инфекция. Этот результат подтверждается альфа-индексами, которые показали, что наибольшее разнообразие с точки зрения численности и однородности сообщества наблюдалось в группе, инокулированной PG до разведения, и что популяция стала более равномерной во время беременности к GD 18.
Когда анализ бета-разнообразия по Брею-Кертису консенсусных данных включал фиктивную группу, эта точка была расположена дальше всего от центра и была наиболее удалена от исходной контрольной точки по сравнению с PC1 (рис. 8), что позволяет предположить, что основные консенсусные сообщества были наиболее сходны между группами, взятыми из одного и того же набора животных. Напротив, евклидов анализ бета-разнообразия показал, что группа, инокулированная PG, была наиболее непохожей среди четырех групп по осям PC1 и PC3, в то время как точки консенсуса трех других групп сгруппированы вместе. Однако вдоль PC2 точка, инокулированная Sham, была более непохожей, особенно на видовом уровне. Сообщения о сравнении различных показателей бета-разнообразия, используемых для сравнения данных сообществ (Legendre and de Caceres, 2013), показывают, что евклидова матрица не подходит для визуализации несходства между отдельно нанесенными сообществами, полученными из сложных образцов (например, микробиомов животных), поскольку отсутствие-присутствие данные (без учета численности) могут давать слишком высокую или низкую оценку каждому члену сообщества, идентифицированному в каждой отдельной выборке; тем не менее, полезно визуализировать различия между коллективными согласованными данными групп сообщества. Важно помнить, что все животные, использованные в этом исследовании, происходили из одной колонии и содержались одинаково.
Эти данные свидетельствуют о том, что здоровье и заболевание пародонта, вызванное прививкой P. gingivalis , определяют микробный состав на видовом уровне, что сдвиги на видовом уровне часто отражают их состояние, и что различия на видовом уровне обычно становятся более выраженными во время заболевания, независимо от были ли образцы собраны у одних и тех же животных (внутригрупповые) или у разных групп животных. Эти данные также подтверждают концепцию о том, что среди видов-хозяев существуют общие микробиомы, специфичные для основных мест, и что установленные микробиомы в пределах отдельного животного устойчивы к грубым дисбиотическим сдвигам в ответ на условия хозяина при рассмотрении на более высоких таксономических уровнях.
Анализ исходного уровня по сравнению с группами с имитацией инокуляции предполагает менее разнообразный, но восстанавливающийся основной микробиом через 12 недель после лечения антибиотиками время восстановления перед началом прививок (Kesavalu et al., 2007; Verma et al., 2010; Phillips et al., 2018). Известно, что профилактические антибиотики вызывают химически индуцированный дисбактериоз (Rogers et al., 2010; Manrique et al., 2013). Следовательно, мы включили в наше исследование образцы до антимикробного лечения, чтобы потенциально выявить такие возмущения. Несмотря на общее сходство в оральных сообществах исходных и ложнопривитых групп с точки зрения альфа-разнообразия, мы определили большую долю населения, составляющую 9 человек.
3143 Staphylococcaceae и Lactobacillaceae как в группе животных исходного уровня, так и в группе, привитой PG, по сравнению с небеременными животными группы имитации, предполагая, что стабильность микробиома внутри животного и различия между животными затруднят получение значимого профиля группы животных. сравнения. Следовательно, в этом отчете мы в первую очередь сосредоточились на сравнении микробиомов с течением времени внутри животных. Тем не менее, мы сделали некоторые основные выводы из наших сравнений между животными, а именно: Исходный уровень использовался в качестве нашей неинфицированной группы до введения антибиотиков, в то время как ложная инокуляция была нашим согласованным по времени контрольным носителем сообщества полости рта, выздоравливающего от дисбиоза, вызванного антибиотиками, поскольку у него было 12 недель времени восстановления без добавления дополнительных стрессоров. Как показано на рисунке S1, популяции Pasteurellaceae были сходны между нашими контрольными группами, но семейство Staphylococcaceae сместилось с 43,56% в исходном состоянии до 55,4% при инокуляции PG, но только на 17,83% в группе с ложной инокуляцией. Кроме того, было изменено Разнообразие видов Streptococcus в группе ложных инокулятов. Как указано в наших результатах, наши результаты альфа-разнообразия, измеренные индексами Шеннона и Симпсона для общего видового богатства сообщества (численность и равномерность), показывают, что инокулированные и исходные уровни были более похожи друг на друга, чем профили консенсуса группы, инокулированные PG. Этот результат согласуется с выводами Manrique et al. это показало, что, хотя антибиотики снижают общую численность бактерий, основная структура микробного сообщества остается неизменной, когда дается время на восстановление после возмущения (Manrique et al., 2013). В целом, наши данные свидетельствуют о том, что оральная флора в группе с ложной инокуляцией, хотя и не такая, как в исходной группе, вероятно, восстанавливала свои «нормальные» характеристики основного профиля микробиома к концу 12-недельного периода ложной прививки.
Инфекция и беременность вызвали измененный метаболический профиль сообщества, уникальный для каждого состояния
При сравнении анализа альфа- и бета-разнообразия коллективного консенсусного микробиома каждой группы (рис. 3, 8) мы наблюдали сдвиг в ответ на P. gingivalis , которая вызывала заболевание пародонта, которое, по-видимому, возвращалось к исходному уровню во время беременности. Широкое исследование пропорций населения среди широкого круга выявленных семей, включая 5 наиболее доминирующих семей, подтвердило эту тенденцию. Таким образом, в целом эти данные свидетельствуют о том, что оральный микробиом крыс имеет в своей основе общность на уровне семьи. Однако изменчивость между животными, особенно на более низких таксономических уровнях, указывает на то, что микробиом полости рта во время беременности на самом деле не был так похож на исходный уровень, что затрудняет сравнительный анализ.
Были обнаружены заметные тенденции, сдвиги микробиома и прогнозируемые ассоциации, которые предполагают, что определенные широкие характеристики (например, классификация Грама, клеточная морфология), традиционно используемые для описания микробных популяций полости рта, «типичных» для здоровья или заболевания, были относительно неадекватными индикаторами дисбактериоза в целом по сравнению с к нашей оценке метагеномных изменений в популяции в контексте прогнозируемых метаболических сдвигов. Например, ротовое сообщество постепенно становилось более заселенным грамположительными палочками и менее заселенным грамотрицательными кокками. Напротив, пропорции популяций грамположительных кокков и грамотрицательных палочек смещались в ответ на инфекцию, а затем возвращались в ответ на беременность. Измененное разнообразие микробиома и дисбактериоз все еще были очевидны в группе беременных при оценке в контексте потребности в кислороде и прогнозируемой продукции основного метаболита, последний из которых более подробно рассматривается в следующем разделе. Хотя доля облигатных анаэробов в популяции P. gingivalis был крупнее в группе беременных, мы заметили, что к GD 18 у зараженных орально и беременных крыс в целом было более аэробное оральное сообщество (рис. 10). Мы также выявили пероральную колонизацию ранее необнаруженными условно-патогенными и комменсальными бактериями (дополнительный материал). Учитывая, что беременность и пародонтоз влияют на воспалительный и иммунный ответ (Guncu et al. , 2005; Wu et al., 2015), эти условия, вероятно, приведут к тому, что хозяин станет гораздо более уязвимым для колонизации этими ранее необнаруженными организмами.
Понимание и ограничения прогнозируемой морфологической классификации, потребности в кислороде и профилей производства основных метаболитов у исходных, инфицированных и беременных животных увеличивается со временем в ответ на инокуляцию
P. gingivalis , а затем в ответ на беременность БГ 18. Производство молочной кислоты обычно связано с ферментацией углеводов при пероральном приеме Streptococci и других родов микробиома полости рта (McLean et al., 2012), которые в сочетании с диетой способствуют избыточному образованию биопленок, низкому рН и развитию кариеса у людей. Когда производство молочной кислоты рассматривается в контексте заболеваний пародонта, наши результаты согласуются с общепринятыми наблюдениями, опубликованными в литературе. В частности, в нормальной ротовой полости в здоровом состоянии пероральные стрептококки обычно доминируют в микробной популяции ротовой полости, но уступают место пародонтальным патогенам, особенно грамотрицательным анаэробам (Takahashi, 2015). Ацетат, пропионат и бутират являются короткоцепочечными жирными кислотами (SCFAs), вырабатываются многими бактериями с помощью различных механизмов и имеют сложные контекстуальные ассоциации как со здоровьем, так и с болезнью. Например, пропионат является более слабой кислотой, чем молочная кислота, часто образуется путем преобразования молочной кислоты и обычно вырабатывается в ротовой полости такими родами, как Veillonella и Lactobacillus (обнаруженные во всех наших группах) и . Clostridium (отсутствует в наших контрольных группах). Превращение молочной кислоты в пропионат способствует нейтрализации кислоты и, как полагают, способствует доминированию более чувствительных к кислоте виды Streptococci , связанные со здоровьем зубов, а также способствующие росту чувствительных к кислоте пародонтальных патогенов, таких как Porphyromonas (Takahashi, 2015). И бутират, и пропионат являются основными метаболитами, продуцируемыми бактериями ротовой полости, такими как Porphyromonas и Clostridium , которые используют белки и аминокислоты в качестве основного источника углерода, обычно совместно образуя аммиак посредством дезаминирования аминокислот, что дополнительно способствует нейтрализации кислоты (Takahashi, 2015). Производство SCFAs, как правило, связано со здоровьем, когда они производятся в кишечнике бактериями толстой кишки, как правило, в результате ферментации пищевых волокон. Конкретные метаболиты, такие как бутират, при введении в пищевую добавку оказывают благоприятное воздействие на здоровье хозяина (van Immerseel et al., 2010; Herrema et al., 2017). Напротив, производство бутирата в полости рта, как сообщается, является цитотоксическим у пациентов с заболеваниями полости рта, такими как пародонтальная инфекция, и было показано, что оно ответственно за высвобождение активных форм кислорода при хроническом пародонтите (Anand et al., 2016). . Эти зарегистрированные ассоциации подчеркивают важность исследований в конкретных местах в контексте взаимодействия хозяина и патогена. Изучая особенности микробной продукции бутирата среди патогенов и комменсалов, Anand et al. показали, что у этих организмов развились различные пути развития, при которых, в отличие от типичных комменсальных видов, виды, признанные патогенными, обычно совместно генерируют вредные побочные продукты, такие как аммиак, вместе с бутиратом, что объясняет, как производство бутирата может быть связано как со здоровьем, так и с болезнью (Anand et al. ., 2016).
Микробный метаболит 2,3-бутандиол обычно образуется во время ферментации углеводов. Основная продукция этого метаболита некоторыми комменсальными пероральными стрептококками в сочетании с условно-патогенным микроорганизмом из окружающей среды Pseudomonas aeruginosa в легких пациентов с кистозным фиброзом связана с хроническим заболеванием и обычно считается цитотоксичной для клеток человека при высокие концентрации и длительное воздействие (Whiteson et al., 2017). Интересно, in vitro работа с дендритными клетками показала, что 2,3-бутандиол оказывает противовоспалительное действие при совместной инкубации при концентрациях ниже токсических, но было высказано предположение, что ингибирование иммунного ответа в тканях, таких как слизистая оболочка, в конечном итоге может быть вредным. , способствуя хронизации инфекции (Whiteson et al., 2017). Неизвестна польза 2,3-бутандиола для здоровья человека, независимо от того, синтезируется ли он бактериями или образуется в клетках млекопитающих, особенно в печени после употребления этанола. Наши данные показали, что прогнозируемая доля продуцентов 2,3-бутандиола в популяции по сравнению с исходным уровнем увеличилась в ответ на пероральную прививку PG, а затем снизилась во время беременности к 18-му дню беременности. Этот результат согласуется с наличием дисбиотического или «нездорового» микробиома после PG- прививка.
Рибофлавин (витамин B2) является важным предшественником, используемым для образования основных коферментов флавинмононуклеотида (FMN) и флавинадениндинуклеотида (FAD), что приводит к синтезу витамина B3 и B6 соответственно, а также других форм витамина B и многочисленные флавопротеины. Рибофлавин синтезируется многими бактериями. Некоторые виды бактерий (например, большинство Firmicutes и Bacteroidetes) вырабатывают большое количество рибофлавина, избыток которого выделяется в окружающую среду. Поскольку рибофлавин необходим для роста всех живых клеток, некоторые виды бактерий импортируют рибофлавин, синтезированный другими бактериями, потому что они либо бедны, либо не продуцируют. Люди не могут синтезировать или хранить эти водорастворимые витамины группы В и зависят от диеты и биосинтеза резидентными бактериями (Magnusdottir et al., 2015). Поскольку бактериальные непродуценты конкурируют с клетками-хозяевами за доступный рибофлавин, понимание механизмов, которые хозяин использует для сохранения здоровья перед лицом микробных механизмов, используемых для выживания в организме хозяина, в контексте основных метаболитов, продуцируемых микробами, таких как рибофлавин, может дать представление о этиология наблюдаемых изменений микробиома. Например, считается, что продуцируемый бактериями рибофлавин играет непосредственную роль в иммунной функции хозяина по крайней мере по двум механизмам. Рибофлавин связан с образованием активных форм кислорода в клетках врожденного иммунитета за счет активации НАДФН-оксидазы (Yoshii et al., 2019).). Промежуточные продукты, образующиеся в процессе микробного биосинтеза рибофлавина, также активируют клетки MAIT (связанный со слизистой оболочкой инвариант Т) посредством связывания с белком MR1 молекул MHC-I на антигенпрезентирующих клетках (Eckle et al. , 2015; Yoshii et al., 2019). Однако стимуляции комменсальными микроорганизмами недостаточно, чтобы полностью вызвать эффекторную функцию клеток MAIT (Berkson and Prlic, 2017). Таким образом, предполагается, что комменсальное бактериальное опосредованное праймирование клеток MAIT способствует их иммунологической роли в надзоре за патогенами, которые затем полностью активируются в присутствии патогенов при достаточной микробной нагрузке. Следовательно, наличие промежуточных продуктов биосинтеза рибофлавина, как сообщается, использовалось в качестве биомаркера микробной инфекции (Eckle et al., 2015).
Хотя мы инокулировали ротовую полость крыс P. gingivalis , сильным и самодостаточным продуцентом рибофлавина, консенсус микробиома после инокуляции у животных с периодонтальным заболеванием не отражал общего увеличения продукции рибофлавина в сообществе. Скорее, мы наблюдали, что прогнозируемая способность микробной популяции ротовой полости синтезировать рибофлавин снизилась примерно на 50% в ответ на инфекцию, а затем восстановилась, превысив исходный уровень во время беременности к 18-му дню беременности. При поверхностном понимании этот результат, казалось бы, противоречит ожиданиям высокой производство рибофлавина из-за инфекции P. gingivalis . Однако, предполагая, что выработка рибофлавина в целом полезна для слизистой оболочки млекопитающих, как сообщается в литературе для желудочно-кишечного тракта, наши данные согласуются с развитием «нездорового» микробиома с последующим восстановлением до более благоприятного микробного профиля с точки зрения выработки рибофлавина. . Это подчеркивает, как согласованный профиль микробиома и его метаболом могут лучше отражать важные аспекты микробного здоровья или дисбиоза, которые не были бы выявлены, если бы выполнялась только целевая характеристика конкретного метаболического вклада отдельных патогенов, идентифицированных в сообществе. Тем не менее, в этом контексте знание реакции организма-хозяина на отдельные патогены увеличивает наше общее понимание процесса заболевания.
Стоит отметить, что уровни клеток MAIT, обнаруженные в разных участках тканей, различаются, что, по-видимому, влияет на результаты местной воспалительной реакции. В частности, сообщается, что количество клеток MAIT в апикальных тканях пародонта человека аналогично уровням, обнаруженным в периферической крови, но заметно выше, чем уровни, обнаруженные в тканях десны (Davanian et al., 2019), и ниже, чем уровни, обнаруженные в стенках. толстая кишка (эпителий и собственная пластинка) (Hama et al., 2019). В целом виды микробов, которые действуют как патогены при достаточной микробной нагрузке, такие как P. gingivalis , и которые также являются эффективными продуцентами рибофлавина, по-видимому, будут способствовать локализованной хронической воспалительной реакции, характерной для заболеваний пародонта. Однако патогены, продуцирующие рибофлавин, могут вызывать более устойчивый клеточный ответ MAIT в кишечнике по сравнению с деснами или, возможно, иметь более низкий порог патогенной нагрузки из-за более высоких уровней резидентных клеток MAIT. Как повышенная или пониженная доступность рибофлавина может дополнительно модулировать профиль микробиома или развитие заболевания из-за врожденных различий в окружающей среде, микробной нагрузке и специфических характеристиках ткани десны, неизвестно и требует дальнейшего изучения.
В совокупности наши результаты и текущее понимание пролили свет на определенные метаболические характеристики в контексте наблюдаемых профилей микробиома, которые, по нашему мнению, должны стать целью будущих исследований, включая непосредственную оценку отдельных метаболических сдвигов популяции микробов полости рта в контексте оральной инфекции и беременности. Тем не менее, мы признаем, что у этого пилотного исследования есть несколько ограничений, которые могли негативно повлиять на наши интерпретации. Ключевое ограничение в интерпретации данных микробиома в целом заключается в зависимости от эталонных баз данных для создания каждого профиля микробиома. Поскольку не нанесенные на карту OTU (рис. S3) по существу отбрасываются, метагеномный анализ может только «обнаружить» и сделать вывод о характеристиках микробного сообщества относительно того, что уже «известно». В будущем, когда станет доступно больше эталонных геномов, эти данные можно будет повторно проанализировать, чтобы сопоставить несопоставленные чтения. Точно так же в этом исследовании мы наблюдали большое количество вызовов с косой чертой, что ограничивало уровень таксономической иерархии, которую мы могли уверенно сравнивать между микробиомами. Вероятно, это связано со сходством конкретной последовательности вариабельной области 16S у близкородственных видов. Однако возможно, что с дополнительными эталонными геномами эти вызовы с косой чертой могут быть дифференцированы.
Когда мы разрабатывали этот проект, мы решили сосредоточить наше пилотное исследование на определении продольных внутриживотных сдвигов в микробиоме ротовой полости в ответ на инокуляцию P. gingivalis и беременность и не оценивали микробиом ротовой полости беременных, подвергшихся ложной прививке. крысы. Было бы интересно проанализировать влияние только беременности на оральное сообщество в будущем исследовании.
Заявление о доступности данных
Необработанные данные, подтверждающие выводы этой статьи, будут предоставлены авторами без неоправданных оговорок любому квалифицированному исследователю.
Заявление об этике
Исследование на животных было рассмотрено и одобрено Комитетом по уходу и использованию животных Университета Висконсина, Университет Висконсин-Мэдисон.
Вклад авторов
PP и ее аспирант MW провели всю обработку образцов, секвенирование и анализ данных секвенирования. Л.Р. и ее лаборант Г.П. проводили все эксперименты на животных, оценку патологии животных и сбор образцов. PP, LR, AP-F и MB являются соисследователями, которые вместе планировали, разрабатывали и искали финансирование для нескольких совместных проектов, специально направленных на изучение роли оральных патогенов в развитии заболеваний в контексте беременности. PP, LR и MW являются основными авторами рукописи с редакционным вкладом остальных соавторов.
Финансирование
Эта работа финансировалась Программным комитетом выпускников Колледжа остеопатической медицины Кирксвилля, Университета А. Т. Стилл и Национального института детского здоровья и развития Юнис Кеннеди Шрайвер Национальных институтов здравоохранения под номером премии R15HD081439.
Конфликт интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Содержание является исключительной ответственностью авторов и не обязательно отражает официальную точку зрения Национального института здоровья. Мы также хотели бы отметить помощь, оказанную Закари Сирессом, когда он проходил обучение в нашей лаборатории в Университете А. Т. Стилл в выполнении различных молекулярных методов, и г-же Эмили, директору Зоологического музея Университета Вашингтона, которая помогала с удалением плоти из крысиных челюстей. Штамм A7UF P. gingivalis был предоставлен Энн Прогульске-Фокс из Университета Флориды.
Дополнительный материал
Дополнительный материал к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org/articles/10.3389/fcimb.2020.00092/full#supplementary-material
Ссылки
Aagaard, K. , Ма, Дж., Энтони, К.М., Гану, Р., Петросино, Дж., и Версалович, Дж. (2014). Плацента содержит уникальный микробиом. Науч. Перевод Мед. 6:237ra265. doi: 10.1126/scitranslmed.3008599
CrossRef Full Text
Abusleme, L., Dupuy, A.K., Dutzan, N., Silva, N., Burleson, J.A., Strausbaugh, L.D., et al. (2013). Поддесневой микробиом в норме и при пародонтите и его связь с биомассой сообщества и воспалением. ISME J. 7, 1016–1025. doi: 10.1038/ismej.2012.174
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ананд С., Каур Х. и Манде С. С. (2016). Сравнительный анализ in silico путей продукции бутирата кишечными комменсалами и патогенами. Перед. микробиол. 7:1945. doi: 10.3389/fmicb.2016.01945
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Барак С., Эттингер-Барак О., Махтей Э. Э., Спречер Х. и Охел Г. (2007). Данные о периопатогенных микроорганизмах в плацентах женщин с преэклампсией. J. Пародонтология. 78, 670–676. doi: 10.1902/jop.2007.060362
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Берксон, Дж. Д., и Прлик, М. (2017). Загадка MAIT — как клетки MAIT человека отличают бактериальную колонизацию от инфекции в тканях слизистого барьера. Иммунол. лат. 192, 7–11. doi: 10.1016/j.imlet.2017.09.013
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Болчакова Э., Шрамм А., Лаки А. и Балачандран П. (2015). Оценка разнообразия микробной популяции в полимикробных исследовательских образцах с помощью секвенирования 16S с одной или несколькими V-областями. 115-е Общее собрание ASM . Доступно в Интернете по адресу: https://www.thermofisher.com/content/dam/LifeTech/Documents/PDFs/Assessment-of-microbial-population-diversity16v.pdf (по состоянию на 30 мая — 2 июня 2015 г.).
Caporaso, J.G., Kuczynski, J., Stombaugh, J., Bittinger, K., Bushman, F.D., Costello, E.K., et al. (2010). QIIME позволяет анализировать данные секвенирования с высокой пропускной способностью. Нац. Методы 7, 335–336. doi: 10.1038/nmeth.f.303
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Чапарро А., Бланло К., Рамирес В., Санс А., Кинтеро А., Иностроза К. и др. (2013). Porphyromonas gingivalis, Treponema denticola и толл-подобный рецептор 2 связаны с гипертоническими расстройствами в плацентарной ткани: исследование случай-контроль. J. Пародонтология. Рез . 48, 802–809. doi: 10.1111/jre.12074
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Колвелл Р.К. и Коддингтон Дж.А. (1994). Оценка наземного биоразнообразия путем экстраполяции. Филос. Транс. Р. Соц. Лонд. Б. биол. науч. 345, 101–118. doi: 10.1098/rstb.1994.0091
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Даванян Х., Гайзер Р. А., Сильфверберг М., Хугерт Л. В., Собковяк М. Дж. , Лу Л. и др. (2019). Ассоциированные со слизистой оболочкой инвариантные Т-клетки и микробиом полости рта при персистирующем апикальном периодонтите. Междунар. Дж. Устные науки. 11:16. doi: 10.1038/s41368-019-0049-y
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Dewhirst, F.E., Chen, T., Izard, J., Paster, B.J., Tanner, A.C., Yu, W.H., et al. (2010). Микробиом ротовой полости человека. J. Бактериол. 192, 5002–5017. doi: 10.1128/JB.00542-10
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Экл С. Б., Корбетт А. Дж., Келлер А. Н., Чен З., Годфри Д. И., Лю Л. и др. (2015). Распознавание предшественников и побочных продуктов витамина В инвариантными Т-клетками, ассоциированными со слизистой оболочкой. Дж. Биол. хим. 290, 30204–30211. doi: 10.1074/jbc.R115.685990
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Эдгар, Р. К. (2017). Точность оценки разнообразия микробного сообщества с помощью OTU с закрытым и открытым эталоном. PeerJ 5:e3889. doi: 10.7717/peerj.3889
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Griffen, A.L., Beall, CJ, Campbell, JH, Firestone, N.D., Kumar, P.S., Yang, Z.K., et al. (2012). Различные и сложные бактериальные профили при пародонтите и здоровье человека, выявленные с помощью пиросеквенирования 16S. ISME J. 6, 1176–1185. doi: 10.1038/ismej.2011.191
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Гунку Г. Н., Тозум Т. Ф. и Чаглаян Ф. (2005). Влияние эндогенных половых гормонов на пародонт – обзор литературы. австр. Вмятина. Дж. 50, 138–145. doi: 10.1111/j.1834-7819.2005.tb00352.x
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хаджишенгаллис, Г. (2011). Стратегии уклонения от иммунитета Porphyromonas gingivalis . J. Oral Biosci. 53, 233–240. doi: 10.1016/S1349-0079(11)80006-X
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хаджишенгаллис, Г. (2015). Пародонтит: от микробного иммунного подрыва к системному воспалению. Нац. Преподобный Иммунол. 15, 30–44. doi: 10.1038/nri3785
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хама И., Томинага К., Ямагива С., Сецу Т., Кимура Н., Камимура Х. и др. (2019). Различное распределение ассоциированных со слизистой оболочкой инвариантных Т-клеток в слепой и толстой кишке человека. цента. Евро. Дж. Иммунол. 44, 75–83. doi: 10.5114/ceji.2019.84020
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хе, Дж., Ли, Ю., Цао, Ю., Сюэ, Дж., и Чжоу, X. (2015). Разнообразие микробиома полости рта и его связь с заболеваниями человека. Фолиа микробиол. (Прага). 60, 69–80. doi: 10.1007/s12223-014-0342-2
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хеллер Д., Хельмерхорст Э. Дж., Гауэр А. К., Сикейра В. Л., Пастер Б. Дж. и Оппенгейм Ф. Г. (2016). Микробное разнообразие в начале in vivo – образует зубную биопленку. Заяв. Окружающая среда. микробиол. 82, 1881–1888 гг. doi: 10.1128/AEM.03984-15
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Herrema, H., IJzerman, R.G., and Nieuwdorp, M. (2017). Новая роль кишечной микробиоты и микробных метаболитов в метаболическом контроле. Диабетология 60, 613–617. doi: 10.1007/s00125-016-4192-0
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хьюз, Дж. Б., Хеллманн, Дж. Дж., Рикеттс, Т. Х., и Боханнан, Б. Дж. (2001). Подсчет неисчислимого: статистические подходы к оценке микробного разнообразия. Заяв. Окружающая среда. микробиол. 67, 4399–4406. doi: 10.1128/AEM.67.10.4399-4406.2001
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Кесавалу Л., Сатишкумар С., Бактаватчалу В., Мэтьюз К., Доусон Д., Штеффен М. и др. (2007). Крысиная модель полимикробной инфекции, иммунитета и резорбции альвеолярной кости при заболеваниях пародонта. Заразить. Иммун. 75, 1704–1712 гг. doi: 10.1128/IAI.00733-06
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Lai, C.H., Bloomquist, C., and Liljemark, W.F. (1990). Очистка и характеристика адгезина белка наружной мембраны Haemophilus parainfluenzae HP-28. Заразить. Иммун. 58, 3833–3839. doi: 10.1128/IAI.58.12.3833-3839.1990
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лежандр П. и де Касерес М. (2013). Бета-разнообразие как дисперсия данных сообщества: коэффициенты несходства и разбиение. Экол. лат. 16, 951–963. doi: 10.1111/ele.12141
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лемос, Л. Н., Фулторп, Р. Р., Триплетт, Э. У., и Реш, Л. Ф. (2011). Переосмысление анализа микробного разнообразия в эпоху высокопроизводительного секвенирования. J. Microbiol. Методы 86, 42–51. doi: 10.1016/j.mimet.2011.03.014
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Линь В. , Цзян В., Ху Х., Гао Л., Ай Д., Пан Х. и др. (2018). Экологические сдвиги наддесневой микробиоты в связи с беременностью. Фронт. Заражение клетки. микробиол. 8:24. doi: 10.3389/fcimb.2018.00024
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Магнусдоттир С., Равчеев Д., де Креси-Лагар В. и Тиле И. (2015). Систематическая оценка генома биосинтеза витамина B предполагает сотрудничество между кишечными микробами. Перед. Жене. 6:148. doi: 10.3389/fgene.2015.00148
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Манрике П., Фрейре М. О., Чен К., Заде Х. Х., Янг М. и Сучи П. (2013). Нарушение местного микробиома полости рта крыс дозировкой ципрофлоксацина. мол. Оральный микробиол. 28, 404–414. doi: 10.1111/omi.12033
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Маккой, К.О., и Матсен, Ф.А. (2013). Меры филогенетического разнообразия, взвешенные по численности, различают состояния микробного сообщества и устойчивы к глубине выборки. PeerJ 1:e157. doi: 10.7717/peerj.157
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
McLean, J.S., Fansler, S.J., Majors, P.D., McAteer, K., Allen, L.Z., Shirtliff, M.E., et al. (2012). Выявление активных таксонов с низким pH и утилизирующих лактат в сообществах ротового микробиома здоровых детей с использованием методов зондирования стабильных изотопов. PLoS ONE 7:e32219. doi: 10.1371/journal.pone.0032219
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Олсен И., Ламбрис Дж. Д. и Хаджишенгаллис Г. (2017). Porphyromonas gingivalis нарушает комменсальный гомеостаз хозяина, изменяя функцию комплемента. J. Oral Microbiol. 9:1340085. doi: 10.1080/20002297.2017.1340085
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Паропкари А.Д., Леблебичиоглу Б., Кристиан Л.М. и Кумар П.С. (2016). Курение, беременность и поддесневой микробиом. наук. Респ. 6:30388. doi: 10.1038/srep30388
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Филлипс П., Браун М. Б., Прогульске-Фокс А., Ву X. Дж. и Рейес Л. (2018). Porphyromonas gingivalis штамм-зависимое ингибирование ремоделирования маточных спиральных артерий у беременных крыс. биол. Воспр. 95, 1045–1056. doi: 10.1093/biolre/ioy119
Полный текст CrossRef | Google Scholar
Принс А. Л., Ма Дж., Каннан П. С., Альварез М., Гислен Т., Харрис Р. А. и др. (2016). Микробиом плацентарной мембраны изменяется у субъектов со спонтанными преждевременными родами с хориоамнионитом и без него. утра. Дж. Обст. Гинекол. 214 , 627.e1–627.e16. doi: 10.1016/j.ajog.2016.01.193
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Основная группа R (2013 г.). R: язык и среда для статистических вычислений . Вена: Фонд статистических вычислений R.
Реферат PubMed | Google Scholar
Рейес Л. , Филлипс П., Вульф Б., Голос Т. Г., Валкенхорст М., Прогульске-Фокс А. и др. (2018). Порфиромонас десневой и неблагоприятный исход беременности. J. Oral Microbiol. 10, 1374153. doi: 10.1080/20002297.2017.1374153
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Роджерс Г. Б., Кэрролл М. П., Хоффман Л. Р., Уокер А. В., Файн Д. А. и Брюс К. Д. (2010). Сравнение микробиоты легких при муковисцидозе и кишечника человека. Микробы кишечника 1, 85–93. doi: 10.4161/gmic.1.2.11350
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Такахаши, Н. (2015). Метаболизм микробиома полости рта: от «кто они?» на «что они делают?». Дж. Дент. Рез. 94, 1628–1637. doi: 10.1177/0022034515606045
CrossRef Full Text | Google Scholar
ван Иммерсил Ф., Дукатель Р., де Вос М., Бун Н., ван де Виле Т., Вербеке К. и др. (2010). Анаэробные бактерии, продуцирующие масляную кислоту, как новый пробиотический подход к лечению воспалительных заболеваний кишечника. J. Med. Микробиол . 59 (ч. 2), 141–143. дои: 10.1099/jmm.0.017541-0
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Vanterpool, S. F., Been, J. V., Houben, M. L., Nikkels, P. G., de Krijger, R. R., Zimmermann, L. J., et al. (2016). Porphyromonas gingivalis в мезенхиме ворсинок плаценты и строме пуповины ассоциируется с неблагоприятным исходом беременности. PLoS ONE 11:e0146157. doi: 10.1371/journal.pone.0146157
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Верма, Р. К., Раджапаксе, С., Мека, А., Хамрик, К., Пола, С., Бхаттачария, И., и соавт. (2010). Porphyromonas gingivalis и Treponema denticola смешанная микробная инфекция в крысиной модели пародонтоза. Междисциплинарный. Перспектива. Заразить. Дис. 2010:605125. doi: 10.1155/2010/605125
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Уайтсон К., Агравал С. и Агравал А. (2017). Дифференциальные реакции дендритных клеток человека на метаболиты микробиома ротовой полости/дыхательных путей. клин. Эксп. Иммунол. 188, 371–379. doi: 10.1111/cei.12943
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Whitman, W.B. (2015). Руководство Берджи по систематике архей и бактерий . Хобокен, Нью-Джерси: Ручной фонд Берджи и онлайн-библиотека Wiley. doi: 10.1002/18
8
CrossRef Full Text
Wu, M., Chen, S.W., and Jiang, S.Y. (2015). Связь между воспалением десен и беременностью. Медиаторы воспаления. 2015:623427. doi: 10.1155/2015/623427
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Йоши К., Хосоми К., Саване К. и Кунисава Дж. (2019). Метаболизм пищевых и микробных витаминов группы В в регуляции иммунитета хозяина. Перед. Нутр. 6:48. doi: 10.3389/fnut.2019.00048
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Зенобия, К. , и Хаджишенгаллис, Г. (2015). Porphyromonas gingivalis факторы вирулентности, участвующие в подрыве лейкоцитов и микробном дисбактериозе. Вирулентность 6, 236–243. doi: 10.1080/21505594.2014.999567
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Спецификация OpenAPI v3.0.3 | Введение, определения и многое другое
В следующем описании, если поле не является явно ТРЕБУЕМЫМ или описано с помощью ДОЛЖНО или СЛЕДУЕТ, оно может считаться НЕОБЯЗАТЕЛЬНЫМ.
Объект OpenAPI
Это корневой объект документа OpenAPI.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| опенапи | струна | ТРЕБУЕТСЯ . Эта строка ДОЛЖНА быть семантическим номером версии спецификации OpenAPI, которую использует документ OpenAPI. Поле openapi СЛЕДУЕТ использовать спецификациям инструментов и клиентам для интерпретации документа OpenAPI. Это , а не , связанный с API info.version 9.4101 строка. |
| информация | Информационный объект | ТРЕБУЕТСЯ . Предоставляет метаданные об API. Метаданные МОГУТ использоваться инструментами по мере необходимости. |
| серверы | [Объект сервера] | Массив серверных объектов, которые предоставляют информацию о подключении к целевому серверу. Если свойство серверов не указано или представляет собой пустой массив, значением по умолчанию будет объект сервера со значением URL-адреса 9.4100/. |
| путей | Пути Объект | ТРЕБУЕТСЯ . Доступные пути и операции для API. |
| компоненты | Компоненты Объект | Элемент для хранения различных схем спецификации. |
| безопасность | [Объект требования безопасности] | Объявление того, какие механизмы безопасности можно использовать в API. Список значений включает альтернативные объекты требований безопасности, которые можно использовать. Только один из объектов требования безопасности должен быть удовлетворен для авторизации запроса. Отдельные операции могут переопределить это определение. Чтобы сделать безопасность необязательной, пустое требование безопасности ( {} ) могут быть включены в массив. |
| теги | [Объект тега] | Список тегов, используемых спецификацией, с дополнительными метаданными. Порядок тегов можно использовать для отражения их порядка инструментами синтаксического анализа. Не все теги, которые используются объектом операции, должны быть объявлены. Теги, которые не объявлены, МОГУТ быть организованы случайным образом или на основе логики инструментов. Каждое имя тега в списке ДОЛЖНО быть уникальным. |
| внешниеДокументы | Объект внешней документации | Дополнительная внешняя документация. |
Этот объект МОЖЕТ быть расширен за счет расширений спецификации.
Информационный объект
Объект предоставляет метаданные об API. Метаданные МОГУТ использоваться клиентами при необходимости и МОГУТ быть представлены в инструментах редактирования или создания документации для удобства.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| Название | струна | ТРЕБУЕТСЯ . Название API. |
| описание | струна | Краткое описание API. Синтаксис CommonMark МОЖЕТ использоваться для форматированного текстового представления. |
| условия обслуживания | струна | URL-адрес условий использования API. ДОЛЖЕН быть в формате URL. |
| контакт | Контакт Объект | Контактная информация для открытого API. |
| лицензия | Объект лицензии | Информация о лицензии для открытого API. |
| версия | струна | ТРЕБУЕТСЯ . Версия документа OpenAPI (отличная от версии спецификации OpenAPI или версии реализации API). |
Этот объект МОЖЕТ быть расширен за счет расширений спецификации.
Пример информационного объекта
{
"title": "Пример приложения для зоомагазина",
"description": "Это пример сервера для зоомагазина.",
"termsOfService": "http://example.com/terms/",
"контакт": {
"name": "Поддержка API",
"url": "http://www.example.com/support",
"электронная почта": "[email protected]"
},
"лицензия": {
"имя": "Апач 2.0",
"url": "https://www.apache.org/licenses/LICENSE-2.0.html"
},
"версия": "1.0.1"
}
title: Образец приложения для зоомагазина описание: Это пример сервера для зоомагазина. Условия обслуживания: http://example.com/terms/ контакт: имя: Поддержка API URL-адрес: http://www.example.com/support электронная почта: support@example.
Контакт Объект
Контактная информация для открытого API.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| имя | струна | Идентификационное имя контактного лица/организации. |
| адрес | струна | URL-адрес, указывающий на контактную информацию. ДОЛЖЕН быть в формате URL. |
| электронная почта | струна | Адрес электронной почты контактного лица/организации. ДОЛЖЕН быть в формате адреса электронной почты. |
Этот объект МОЖЕТ быть расширен за счет расширений спецификации.
Пример объекта контакта
{
"name": "Поддержка API",
"url": "http://www.example.com/support",
"электронная почта": "support@example. com"
}
имя: Поддержка API URL-адрес: http://www.example.com/support электронная почта: [email protected]
Объект лицензии
Информация о лицензии для открытого API.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| имя | струна | ТРЕБУЕТСЯ . Имя лицензии, используемое для API. |
| адрес | струна | URL-адрес лицензии, используемой для API. ДОЛЖЕН быть в формате URL. |
Этот объект МОЖЕТ быть расширен за счет расширений спецификации.
Пример объекта лицензии
{
"имя": "Апач 2.0",
"url": "https://www.apache.org/licenses/LICENSE-2.0.html"
}
имя: Апач 2.0 URL-адрес: https://www.apache.org/licenses/LICENSE-2.0.html.
Объект сервера
Объект, представляющий сервер.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| адрес | струна | ТРЕБУЕТСЯ . URL-адрес целевого хоста. Этот URL-адрес поддерживает серверные переменные и МОЖЕТ быть относительным, чтобы указать, что расположение хоста относится к местоположению, где обслуживается документ OpenAPI. Подстановки переменных будут сделаны, когда переменная названа в { кронштейны } . |
| описание | струна | Необязательная строка, описывающая хост, указанный URL-адресом. Синтаксис CommonMark МОЖЕТ использоваться для форматированного текстового представления. |
| переменные | Карта [ строка , объект переменной сервера] | Сопоставление между именем переменной и ее значением. Значение используется для подстановки в шаблоне URL-адреса сервера. |
Этот объект МОЖЕТ быть расширен за счет расширений спецификаций.
Пример объекта сервера
Один сервер будет описан как:
{
"url": "https://development.gigantic-server.com/v1",
"description": "Сервер разработки"
}
URL: https://development.gigantic-server.com/v1 описание: Сервер разработки
Ниже показано, как можно описать несколько серверов, например, серверов объекта OpenAPI :
{
"серверы": [
{
"url": "https://development.gigantic-server.com/v1",
"description": "Сервер разработки"
},
{
"url": "https://staging.gigantic-server.com/v1",
"description": "Промежуточный сервер"
},
{
"url": "https://api.gigantic-server.com/v1",
"description": "Производственный сервер"
}
]
}
серверы: - URL-адрес: https://development.gigantic-server.com/v1 описание: Сервер разработки - URL-адрес: https://staging.
Ниже показано, как можно использовать переменные для конфигурации сервера:
{
"серверы": [
{
"url": "https://{имя пользователя}.gigantic-server.com:{порт}/{базовый путь}",
"description": "Производственный сервер API",
"переменные": {
"имя пользователя": {
"по умолчанию": "демо",
"description": "это значение назначается поставщиком услуг, в данном примере это `gigantic-server.com`"
},
"порт": {
"перечисление": [
"8443",
"443"
],
"по умолчанию": "8443"
},
"базовый путь": {
"по умолчанию": "v2"
}
}
}
]
}
серверы:
- URL-адрес: https://{имя пользователя}.gigantic-server.com:{порт}/{базовый путь}
описание: Рабочий сервер API
переменные:
имя пользователя:
# примечание! отсутствие перечисления здесь означает, что это открытое значение
по умолчанию: демо
описание: это значение назначается поставщиком услуг, в данном примере это `gigantic-server. com`.
порт:
перечисление:
- '8443'
- «443»
по умолчанию: '8443'
базовый путь:
# открытый означает, что есть возможность использовать специальные базовые пути, назначенные провайдером, по умолчанию `v2`
по умолчанию: v2
Переменный объект сервера
Объект, представляющий переменную сервера для подстановки шаблона URL-адреса сервера.
Фиксированные поля
| Имя поля | Тип | Описание |
|---|---|---|
| перечисление | [ строка ] | Перечисление строковых значений, которые следует использовать, если параметры подстановки относятся к ограниченному набору. Массив НЕ ДОЛЖЕН быть пустым. |
| по умолчанию | струна | ТРЕБУЕТСЯ . Значение по умолчанию, используемое для замены, которое ДОЛЖНО быть отправлено, если предоставлено альтернативное значение , а не . Обратите внимание, что это поведение отличается от обработки Объектом схемы значений по умолчанию, потому что в этих случаях значения параметров являются необязательными. Если определено перечисление , значение ДОЛЖНО существовать в значениях перечисления. |
| описание | струна | Необязательное описание серверной переменной. Синтаксис CommonMark МОЖЕТ использоваться для форматированного текстового представления. |
Этот объект МОЖЕТ быть расширен за счет расширений спецификации.
Компоненты Объект
Содержит набор многократно используемых объектов для различных аспектов OAS. Все объекты, определенные в объекте компонентов, не будут влиять на API, если на них явно не ссылаются свойства вне объекта компонентов.
Фиксированные поля
| Имя поля | Тип | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| схемы | Карта[ строка , Объект схемы | Справочный объект] | Объект для хранения повторно используемых объектов схемы. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ответов | Карта[ строка , Объект ответа | Справочный объект] | Объект для хранения повторно используемых объектов ответа. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| параметры | Карта[ строка , объект параметра | Справочный объект] | Объект для хранения повторно используемых объектов параметров. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| примеры | Карта[ строка , пример объекта | Справочный объект] | Объект для хранения повторно используемых примеров объектов. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| запросТело | Карта[ строка , Объект тела запроса | Справочный объект] | Объект для хранения повторно используемых объектов тела запроса. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| коллекторы | Карта[ строка , объект заголовка | Справочный объект] | Объект для хранения повторно используемых объектов заголовка. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Схемы безопасности | Карта[ строка , Объект схемы безопасности | Справочный объект] | Объект для хранения многократно используемых объектов схемы безопасности. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ссылки | Карта[ строка , Объект ссылки | Справочный объект] | Объект для многократного использования Link Objects. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| обратные вызовы | Карта[ строка , Объект обратного вызова | Справочный объект] | Объект для хранения повторно используемых объектов обратного вызова. 9[a-zA-Z0-9\.\-_]+$ . Примеры имени поля: Пользователь Пользователь_1 Имя пользователя имя пользователя my.org.Пользователь Компоненты Пример объекта
"составные части": {
"схемы": {
"Общая ошибка": {
"тип": "объект",
"характеристики": {
"код": {
"тип": "целое",
"формат": "int32"
},
"сообщение": {
"тип": "строка"
}
}
},
"Категория": {
"тип": "объект",
"характеристики": {
"я бы": {
"тип": "целое",
"формат": "int64"
},
"имя": {
"тип": "строка"
}
}
},
"Ярлык": {
"тип": "объект",
"характеристики": {
"я бы": {
"тип": "целое",
"формат": "int64"
},
"имя": {
"тип": "строка"
}
}
}
},
"параметры": {
"скиппарам": {
"имя": "пропустить",
"в": "запрос",
"description": "количество элементов для пропуска",
«требуется»: правда,
"схема": {
"тип": "целое",
"формат": "int32"
}
},
"лимитПарам": {
"имя": "лимит",
"в": "запрос",
"description": "максимальное количество возвращаемых записей",
«требуется»: правда,
"схема": {
"тип": "целое",
"формат": "int32"
}
}
},
"ответы": {
"Не обнаружена": {
"description": "Объект не найден.
составные части:
схемы:
Общая ошибка:
тип: объект
характеристики:
код:
тип: целое число
формат: int32
сообщение:
тип: строка
Категория:
тип: объект
характеристики:
я бы:
тип: целое число
формат: int64
имя:
тип: строка
Ярлык:
тип: объект
характеристики:
я бы:
тип: целое число
формат: int64
имя:
тип: строка
параметры:
пропуститьПарам:
имя: пропустить
в: запрос
описание: количество элементов, которые нужно пропустить
требуется: правда
схема:
тип: целое число
формат: int32
limitПарам:
Название: лимит
в: запрос
описание: максимальное количество возвращаемых записей
требуется: правда
схема:
тип: целое число
формат: int32
ответы:
Не обнаружена:
Описание: Объект не найден.Пути Объект Содержит относительные пути к отдельным конечным точкам и их операциям.
Путь добавляется к URL-адресу из серверного объекта Узорчатые поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Сопоставление шаблонов путей Предполагая следующие пути, конкретное определение
/домашние животные/{petId}
/домашние животные/мой
Следующие пути считаются идентичными и недействительными:
/домашние животные/{petId}
/имя питомца}
Следующее может привести к неоднозначному разрешению:
/{сущность}/я
/книги/{id}
Пример объекта путей
{
"/домашние питомцы": {
"получить": {
"description": "Возвращает всех питомцев из системы, к которым у пользователя есть доступ",
"ответы": {
"200": {
"description": "Список питомцев.
/домашние питомцы:
получить:
описание: Возвращает всех питомцев из системы, к которым у пользователя есть доступ
ответы:
«200»:
описание: Список питомцев.
содержание:
приложение/json:
схема:
тип: массив
Предметы:
$ref: '#/компоненты/схемы/домашнее животное'
Объект путиОписывает операции, доступные на одном пути. Элемент пути МОЖЕТ быть пустым из-за ограничений ACL. Сам путь по-прежнему открыт для просмотра документации, но они не будут знать, какие операции и параметры доступны. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта элемента пути
{
"получить": {
"description": "Возвращает питомцев по идентификатору",
"summary": "Найти питомцев по ID",
"operationId": "getPetsById",
"ответы": {
"200": {
"description": "ответ питомца",
"содержание": {
"*/*": {
"схема": {
"тип": "массив",
"Предметы": {
"$ref": "#/компоненты/схемы/домашнее животное"
}
}
}
}
},
"дефолт": {
"description": "полезная нагрузка ошибки",
"содержание": {
"текст/html": {
"схема": {
"$ref": "#/компоненты/схемы/ErrorModel"
}
}
}
}
}
},
"параметры": [
{
"имя": "идентификатор",
"в": "путь",
"description": "ID питомца для использования",
«требуется»: правда,
"схема": {
"тип": "массив",
"Предметы": {
"тип": "строка"
}
},
"стиль": "простой"
}
]
}
получить:
описание: Возвращает питомцев на основе ID
резюме: Поиск домашних животных по идентификатору
идентификатор операции: getPetsById
ответы:
«200»:
описание: реакция питомца
содержание:
'*/*' :
схема:
тип: массив
Предметы:
$ref: '#/компоненты/схемы/домашнее животное'
дефолт:
описание: ошибка полезной нагрузки
содержание:
'текст/html':
схема:
$ref: '#/components/schemas/ErrorModel'
параметры:
- имя: идентификатор
в: путь
description: ID питомца для использования
требуется: правда
схема:
тип: массив
Предметы:
тип: строка
стиль: простой
Операционный Объект Описывает одну операцию API на пути. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта операции
{
"метки": [
"домашний питомец"
],
"summary": "Обновляет питомца в магазине с данными формы",
"operationId": "updatePetWithForm",
"параметры": [
{
"имя": "идентификатор домашнего животного",
"в": "путь",
"description": "ID питомца, который необходимо обновить",
«требуется»: правда,
"схема": {
"тип": "строка"
}
}
],
"тело запроса": {
"содержание": {
"приложение/x-www-форма-urlencoded": {
"схема": {
"тип": "объект",
"характеристики": {
"имя": {
"description": "Обновлено имя питомца",
"тип": "строка"
},
"статус": {
"description": "Обновлен статус питомца",
"тип": "строка"
}
},
"требуется": ["статус"]
}
}
}
},
"ответы": {
"200": {
"description": "Питомец обновлен.
теги:
- домашний питомец
резюме: Обновляет питомца в магазине с данными формы
идентификатор операции: updatePetWithForm
параметры:
- имя: petId
в: путь
description: ID питомца, который нужно обновить
требуется: правда
схема:
тип: строка
тело запроса:
содержание:
'приложение/x-www-form-urlencoded':
схема:
характеристики:
имя:
описание: Обновлено имя питомца
тип: строка
статус:
описание: Обновлен статус питомца
тип: строка
требуется:
- статус
ответы:
«200»:
описание: Питомец обновлен.Объект внешней документацииПозволяет ссылаться на внешний ресурс для получения расширенной документации. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта внешней документации
{
"description": "Подробнее здесь",
"url": "https://example.com"
}
описание: Больше информации здесь адрес: https://example.com Объект параметровОписывает один рабочий параметр. Уникальный параметр определяется комбинацией имени и местоположения. Расположение параметров Существует четыре возможных расположения параметров, указанных в поле
/items?id=### параметр запроса — id . ЗаголовокФиксированные поля
Правила сериализации параметра задаются одним из двух способов.
Для более простых сценариев схема
Для более сложных сценариев свойство
Значения стиля Для поддержки распространенных способов сериализации простых параметров определен набор значений
Примеры стилей Предположим, что параметр с именем
строка -> "синий"
массив -> ["синий","черный","коричневый"]
объект -> { "R": 100, "G": 200, "B": 150}
В следующей таблице показаны примеры различий в отображении для каждого значения.
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры объектов параметровПараметр заголовка с массивом 64-битных целых чисел:
{
"имя": "токен",
"в": "заголовок",
"description": "токен для передачи в качестве заголовка",
«требуется»: правда,
"схема": {
"тип": "массив",
"Предметы": {
"тип": "целое",
"формат": "int64"
}
},
"стиль": "простой"
}
имя: токен
в: заголовок
описание: токен для передачи в качестве заголовка
требуется: правда
схема:
тип: массив
Предметы:
тип: целое число
формат: int64
стиль: простой
Параметр пути строкового значения:
{
"имя": "имя пользователя",
"в": "путь",
"description": "имя пользователя для извлечения",
«требуется»: правда,
"схема": {
"тип": "строка"
}
}
имя: имя пользователя в: путь описание: имя пользователя для получения требуется: правда схема: тип: строка Необязательный параметр запроса строкового значения, позволяющий использовать несколько значений путем повторения параметра запроса:
{
"имя": "идентификатор",
"в": "запрос",
"description": "ID объекта для извлечения",
«требуется»: ложь,
"схема": {
"тип": "массив",
"Предметы": {
"тип": "строка"
}
},
"стиль": "форма",
"взорваться": правда
}
имя: идентификатор
в: запрос
описание: ID объекта для выборки
требуется: ложь
схема:
тип: массив
Предметы:
тип: строка
стиль: форма
взорваться: правда
Параметр запроса в произвольной форме, допускающий неопределенные параметры определенного типа:
{
"в": "запрос",
"имя": "свободная форма",
"схема": {
"тип": "объект",
"дополнительные свойства": {
"тип": "целое число"
},
},
"стиль": "форма"
}
в: запрос
Название: FreeForm
схема:
тип: объект
дополнительные свойства:
тип: целое число
стиль: форма
Комплексный параметр, использующий содержимое
{
"в": "запрос",
"имя": "координаты",
"содержание": {
"приложение/json": {
"схема": {
"тип": "объект",
"требуется": [
"лат",
"длинная"
],
"характеристики": {
"лат": {
"тип": "число"
},
"длинная": {
"тип": "число"
}
}
}
}
}
}
в: запрос
имя: координаты
содержание:
приложение/json:
схема:
тип: объект
требуется:
- лат
- длинная
характеристики:
лат:
тип: номер
длинная:
тип: номер
Объект тела запроса Описывает одно тело запроса. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры тела запросаТело запроса со ссылкой на определение модели.
{
"description": "пользователь для добавления в систему",
"содержание": {
"приложение/json": {
"схема": {
"$ref": "#/компоненты/схемы/пользователь"
},
"Примеры": {
"пользователь" : {
"summary": "Пример пользователя",
"externalValue": "http://foo.bar/examples/user-example.json"
}
}
},
"приложение/xml": {
"схема": {
"$ref": "#/компоненты/схемы/пользователь"
},
"Примеры": {
"пользователь" : {
"summary": "Пример пользователя в XML",
"externalValue": "http://foo.bar/examples/user-example.xml"
}
}
},
"текст/обычный": {
"Примеры": {
"пользователь" : {
"summary": "Пример пользователя в текстовом формате",
"externalValue": "http://foo.bar/examples/user-example.txt"
}
}
},
"*/*": {
"Примеры": {
"пользователь" : {
"summary": "Пример пользователя в другом формате",
"externalValue": "http://foo.
описание: пользователь для добавления в систему
содержание:
'приложение/json':
схема:
$ref: '#/компоненты/схемы/пользователь'
Примеры:
пользователь:
резюме: пример пользователя
externalValue: 'http://foo.bar/examples/user-example.json'
'приложение/xml':
схема:
$ref: '#/компоненты/схемы/пользователь'
Примеры:
пользователь:
резюме: Пример пользователя в XML
externalValue: 'http://foo.bar/examples/user-example.xml'
'текст/обычный':
Примеры:
пользователь:
резюме: пример пользователя в текстовом формате
externalValue: 'http://foo.bar/examples/user-example.txt'
'*/*':
Примеры:
пользователь:
резюме: пример пользователя в другом формате
externalValue: 'http://foo.bar/examples/user-example.whatever'
Основной параметр, представляющий собой массив строковых значений:
{
"description": "пользователь для добавления в систему",
"содержание": {
"текст/обычный": {
"схема": {
"тип": "массив",
"Предметы": {
"тип": "строка"
}
}
}
}
}
описание: пользователь для добавления в систему
требуется: правда
содержание:
текст/обычный:
схема:
тип: массив
Предметы:
тип: строка
Тип носителя Объект Каждый объект типа носителя предоставляет схему и примеры для типа носителя, определяемого его ключом. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры типов носителей
{
"приложение/json": {
"схема": {
"$ref": "#/компоненты/схемы/домашнее животное"
},
"Примеры": {
"кошка" : {
"summary": "Пример кота",
"ценность":
{
"имя": "Пушистый",
"petType": "Кошка",
"белый цвет",
"мужской пол",
"порода": "персидская"
}
},
"собака": {
"summary": "Пример собаки с кошачьим именем",
"ценность" : {
"имя": "Пума",
"petType": "Собака",
"черный цвет",
"женский пол",
"порода": "Смешанная"
},
"лягушка": {
"$ref": "#/компоненты/примеры/пример-лягушки"
}
}
}
}
}
приложение/json:
схема:
$ref: "#/компоненты/схемы/домашнее животное"
Примеры:
кошка:
Резюме: Пример кота
ценность:
имя: Пушистый
petType: Кошка
белый цвет
мужской пол
порода: персидская
собака:
резюме: Пример собаки с кошачьим именем
ценность:
имя: Пума
petType: Собака
черный цвет
женский пол
порода: смешанная
лягушка:
$ref: "#/компоненты/примеры/пример-лягушки"
Рекомендации по загрузке файлов В отличие от спецификации 2. # содержимое передано в кодировке base64 схема: тип: строка формат: base64 # контент передается в бинарном виде (октетный поток): схема: тип: строка формат: бинарный Эти примеры относятся либо к входной полезной нагрузке загрузки файлов, либо к полезной нагрузке ответа.
тело запроса:
содержание:
приложение/октетный поток:
схема:
# бинарный файл любого типа
тип: строка
формат: бинарный
Кроме того, МОГУТ быть указаны определенные типы носителей:
# можно указать несколько конкретных типов медиа:
тело запроса:
содержание:
# бинарный файл типа png или jpeg
'изображение/jpeg':
схема:
тип: строка
формат: бинарный
'изображение/png':
схема:
тип: строка
формат: бинарный
Для загрузки нескольких файлов ДОЛЖЕН использоваться тип мультимедиа
тело запроса:
содержание:
составные/данные формы:
схема:
характеристики:
# Имя свойства 'file' будет использоваться для всех файлов.Поддержка тел запросов x-www-form-urlencodedЧтобы отправить содержимое с использованием кодировки URL-адреса формы через [[!RFC1866]], выполните следующие действия. можно использовать определение:
тело запроса:
содержание:
приложение/x-www-форма-urlencoded:
схема:
тип: объект
характеристики:
я бы:
тип: строка
формат: UUID
адрес:
# сложные типы преобразуются в строки для поддержки RFC 1866
тип: объект
характеристики: {}
В этом примере содержимое При передаче сложных объектов в типе контента Особые указания для многокомпонентного Содержание Обычно используется При передаче типов
Примеры:
тело запроса:
содержание:
составные/данные формы:
схема:
тип: объект
характеристики:
я бы:
тип: строка
формат: UUID
адрес:
# Content-Type по умолчанию для объектов - `application/json`
тип: объект
характеристики: {}
изображение профиля:
# Content-Type по умолчанию для строки/двоичного файла: `application/octet-stream`
тип: строка
формат: бинарный
дети:
# Content-Type по умолчанию для массивов основан на `внутреннем` типе (здесь text/plain)
тип: массив
Предметы:
тип: строка
адреса:
# Content-Type по умолчанию для массивов основан на `внутреннем` типе (показан объект, поэтому в этом примере `application/json`)
тип: массив
Предметы:
тип: '#/компоненты/схемы/адрес'
Атрибут Объект кодированияОдно определение кодировки применено к одному свойству схемы. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификаций. Пример объекта кодирования
тело запроса:
содержание:
составной/смешанный:
схема:
тип: объект
характеристики:
я бы:
# по умолчанию текстовый/обычный
тип: строка
формат: UUID
адрес:
# по умолчанию это приложение/json
тип: объект
характеристики: {}
историяМетаданные:
# нужно объявить формат XML!
описание: метаданные в формате XML
тип: объект
характеристики: {}
изображение профиля:
# по умолчанию используется application/octet-stream, необходимо объявить только тип изображения!
тип: строка
формат: бинарный
кодировка:
историяМетаданные:
# требуется XML Content-Type в кодировке utf-8
ContentType: приложение/xml; кодировка = utf-8
изображение профиля:
# принимаем только png/jpeg
contentType: изображение/png, изображение/jpeg
заголовки:
X-Rate-Limit-Limit:
описание: Количество разрешенных запросов в текущем периоде
схема:
тип: целое число
Ответы Объект Контейнер для ожидаемых ответов операции. Документация не обязательно должна охватывать все возможные коды ответов HTTP, поскольку они могут быть неизвестны заранее. Однако ожидается, что документация будет охватывать успешный ответ операции и любые известные ошибки. по умолчанию МОЖЕТ использоваться в качестве объекта ответа по умолчанию для всех кодов HTTP. которые не рассматриваются отдельно в спецификации. Фиксированные поля
Узорчатые поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта ответовОтвет 200 для успешной операции и ответ по умолчанию для других (подразумевающий ошибку):
{
"200": {
"description": "животное, которое нужно вернуть",
"содержание": {
"приложение/json": {
"схема": {
"$ref": "#/компоненты/схемы/домашнее животное"
}
}
}
},
"дефолт": {
"description": "Непредвиденная ошибка",
"содержание": {
"приложение/json": {
"схема": {
"$ref": "#/компоненты/схемы/ErrorModel"
}
}
}
}
}
«200»:
описание: домашнее животное, которое нужно вернуть
содержание:
приложение/json:
схема:
$ref: '#/компоненты/схемы/домашнее животное'
дефолт:
описание: Непредвиденная ошибка
содержание:
приложение/json:
схема:
$ref: '#/components/schemas/ErrorModel'
Объект ответа Описывает один ответ от операции API, включая время разработки, статический Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры объектов ответаОтвет массива сложного типа:
{
"description": "Ответ сложного массива объектов",
"содержание": {
"приложение/json": {
"схема": {
"тип": "массив",
"Предметы": {
"$ref": "#/компоненты/схемы/VeryComplexType"
}
}
}
}
}
описание: Ответ сложного массива объектов
содержание:
приложение/json:
схема:
тип: массив
Предметы:
$ref: '#/компоненты/схемы/VeryComplexType'
Ответ со строковым типом:
{
"description": "Простой строковый ответ",
"содержание": {
"текст/обычный": {
"схема": {
"тип": "строка"
}
}
}
}
описание: Простой строковый ответ
содержание:
текст/обычный:
схема:
тип: строка
Простой текстовый ответ с заголовками:
{
"description": "Простой строковый ответ",
"содержание": {
"текст/обычный": {
"схема": {
"тип": "строка",
"пример": "вау!"
}
}
},
"заголовки": {
"Ограничение скорости X-предела": {
"description": "Количество разрешенных запросов в текущем периоде",
"схема": {
"тип": "целое число"
}
},
"X-Rate-Limit-Remaining": {
"description": "Количество оставшихся запросов в текущем периоде",
"схема": {
"тип": "целое число"
}
},
"X-Rate-Limit-Reset": {
"description": "Количество секунд, оставшихся до конца текущего периода",
"схема": {
"тип": "целое число"
}
}
}
}
описание: Простой строковый ответ
содержание:
текст/обычный:
схема:
тип: строка
пример: "уоу!"
заголовки:
X-Rate-Limit-Limit:
описание: Количество разрешенных запросов в текущем периоде
схема:
тип: целое число
X-Rate-Limit-Remaining:
описание: количество оставшихся запросов в текущем периоде
схема:
тип: целое число
X-Rate-Limit-Reset:
описание: Количество секунд, оставшихся в текущем периоде
схема:
тип: целое число
Ответ без возвращаемого значения:
{
"description": "объект создан"
}
описание: объект создан Объект обратного вызова Карта возможных внеполосных обратных вызовов, связанных с родительской операцией. Узорчатые поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Ключевое выражение Ключ, идентифицирующий объект элемента пути, представляет собой выражение времени выполнения, которое можно оценить в контексте HTTP-запроса/ответа времени выполнения, чтобы определить URL-адрес, который будет использоваться для запроса обратного вызова. Например, для следующего HTTP-запроса:
POST /subscribe/myevent?queryUrl=http://clientdomain.com/stillrunning HTTP/1.1
Хост: example.org
Тип содержимого: приложение/json
Длина контента: 187
{
"failedUrl": "http://clientdomain.com/failed",
"URL-адреса успеха": [
"http://clientdomain.com/fast",
"http://clientdomain.com/medium",
"http://clientdomain.com/slow"
]
}
201 Создано
Расположение: http://example.org/subscription/1.
В следующих примерах показано, как оцениваются различные выражения, при условии, что операция обратного вызова имеет параметр пути с именем
Примеры объектов обратного вызова В следующем примере используется предоставленный пользователем параметр строки запроса
мойОбратный звонок:
'{$request.query.queryUrl}':
почта:
тело запроса:
описание: Полезная нагрузка обратного вызова
содержание:
'приложение/json':
схема:
$ref: '#/компоненты/схемы/SomePayload'
ответы:
«200»:
описание: обратный вызов успешно обработан
В следующем примере показан обратный вызов, в котором сервер жестко запрограммирован, но параметры строки запроса заполняются из свойств
транзакцияОбратный вызов:
'http://notificationServer.com?transactionId={$request.body#/id}&email={$request.body#/email}':
почта:
тело запроса:
описание: Полезная нагрузка обратного вызова
содержание:
'приложение/json':
схема:
$ref: '#/компоненты/схемы/SomePayload'
ответы:
«200»:
описание: обратный вызов успешно обработан
Пример объектаФиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Во всех случаях ожидается, что значение примера будет совместимо со схемой типа связанной с ним стоимости. Инструментальные реализации МОГУТ выбрать автоматически проверять совместимость и отклонять примеры значений, если они несовместимы. Пример Примеры объектовВ теле запроса:
тело запроса:
содержание:
'приложение/json':
схема:
$ref: '#/компоненты/схемы/адрес'
Примеры:
фу:
резюме: пример foo
значение: {"foo": "бар"}
бар:
резюме: пример бара
значение: {"бар": "баз"}
'приложение/xml':
Примеры:
xmlПример:
резюме: это пример в XML
externalValue: 'http://example.org/examples/address-example.xml'
'текст/обычный':
Примеры:
текстПример:
резюме: Это текстовый пример
externalValue: 'http://foo.bar/examples/address-example.txt'
В параметре:
параметры:
- имя: 'zipCode'
в: 'запрос'
схема:
тип: 'строка'
формат: 'почтовый индекс'
Примеры:
zip-пример:
$ref: '#/компоненты/примеры/zip-пример'
В ответ:
ответы:
«200»:
описание: ваша автомобильная встреча была забронирована
содержание:
приложение/json:
схема:
$ref: '#/компоненты/схемы/SuccessResponse'
Примеры:
подтверждение-успех:
$ref: '#/компоненты/примеры/подтверждение успеха'
Объект связи Объект В отличие от динамических ссылок (т. е. ссылок, предоставленных в полезной нагрузке ответа), механизм связывания OAS не требует информации о ссылке в ответе среды выполнения. Для вычисления ссылок и предоставления инструкций по их выполнению выражение времени выполнения используется для доступа к значениям в операции и использования их в качестве параметров при вызове связанной операции. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Связанная операция ДОЛЖНА быть идентифицирована с помощью Примеры Вычисление ссылки из операции запроса, где
пути:
/пользователи/{идентификатор}:
параметры:
- имя: идентификатор
в: путь
требуется: правда
описание: идентификатор пользователя, как userId
схема:
тип: строка
получить:
ответы:
«200»:
описание: возвращаемый пользователь
содержание:
приложение/json:
схема:
тип: объект
характеристики:
uuid: # уникальный идентификатор пользователя
тип: строка
формат: UUID
ссылки:
адрес:
# идентификатор операции целевой ссылки
идентификатор операции: getUserAddress
параметры:
# получить поле `id` из параметра пути запроса с именем `id`
идентификатор пользователя: $ request.Если выражение среды выполнения не может быть оценено, в целевую операцию не передается значение параметра. Значения из тела ответа можно использовать для управления связанной операцией.
ссылки:
адрес:
идентификатор операции: getUserAddressByUUID
параметры:
# получить поле `uuid` из поля `uuid` в теле ответа
userUuid: $response.body#/uuid
Клиенты переходят по всем ссылкам на свое усмотрение.
Ни разрешения, ни возможность сделать успешный вызов по этой ссылке не гарантируются.
исключительно наличием отношений. Примеры OperationRef Так как ссылки на
ссылки:
Пользовательские репозитории:
# возвращает массив '#/components/schemas/repository'
OperationRef: '#/paths/~12.0~1repositories~1{username}/get'
параметры:
имя пользователя: $response.body#/имя пользователя
или абсолютная
ссылки:
Пользовательские репозитории:
# возвращает массив '#/components/schemas/repository'
OperationRef: 'https://na2.gigantic-server.com/#/paths/~12.0~1repositories~1{username}/get'
параметры:
имя пользователя: $response.body#/имя пользователя
Обратите внимание, что при использовании Выражения среды выполненияВыражения среды выполнения позволяют определять значения на основе информации, которая будет доступна только в HTTP-сообщении при фактическом вызове API. Этот механизм используется объектами Link и Callback Objects. Выражение времени выполнения определяется следующим синтаксисом ABNF
выражение = ("$url" / "$method" / "$statusCode" / "$request." источник / "$response." источник )
источник = (ссылка-заголовок/ссылка-запроса/ссылка-пути/ссылка-тела)
заголовок-ссылка = "заголовок". жетон
запрос-ссылка = "запрос". имя
ссылка-пути = "путь." имя
body-reference = "тело" ["#" json-указатель]
json-pointer = *( "/" ссылочный токен)
ссылка-токен = * (неэкранированный/экранированный)
без экранирования = %x00-2E / %x30-7D / %x7F-10FFFF
; %x2F ('/') и %x7E ('~') исключены из "неэкранированных"
экранированный = "~" ("0" / "1")
; представляющие «~» и «/» соответственно
имя = *(СИМВОЛ)
токен = 1*tchar
чар = "!" / "#" / "$" / "%" / "&" / "'" / "*" / "+" / "-" / ". Здесь Идентификатор имени В таблице ниже приведены примеры выражений времени выполнения и примеры их использования в значении: Примеры
Выражения среды выполнения сохраняют тип значения, на которое указывает ссылка.
Выражения можно встраивать в строковые значения, окружая выражение фигурными скобками Заголовок ОбъектОбъект заголовка повторяет структуру объекта параметров со следующими изменениями:
Пример объекта заголовка Простой заголовок типа
{
"description": "Количество разрешенных запросов в текущем периоде",
"схема": {
"тип": "целое число"
}
}
описание: Количество разрешенных запросов в текущем периоде схема: тип: целое число Метка объектаДобавляет метаданные к одному тегу, который используется объектом операции. Не обязательно иметь объект тега для каждого тега, определенного в экземплярах объекта операции. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта тега
{
"имя": "домашнее животное",
"description": "Операции с домашними животными"
}
имя: домашнее животное описание: Операции с домашними животными Справочный объектПростой объект, позволяющий ссылаться на другие компоненты в спецификации, как внутри, так и снаружи. Объект ссылки определяется ссылкой JSON и следует той же структуре, поведению и правилам. Для этой спецификации разрешение ссылок выполняется в соответствии со спецификацией JSON Reference, а не спецификацией JSON Schema. Фиксированные поля
Этот объект не может быть дополнен дополнительными свойствами, и любые добавленные свойства ДОЛЖНЫ игнорироваться. Пример ссылочного объекта
{
"$ref": "#/компоненты/схемы/домашнее животное"
}
$ref: '#/компоненты/схемы/домашнее животное' Пример документа относительной схемы
{
"$ref": "Pet.json"
}
$ref: Pet.yaml Относительные документы со встроенной схемой Пример
{
"$ref": "definitions.json#/домашнее животное"
}
$ref: определения.yaml#/домашнее животное Объект схемы Объект схемы позволяет определять типы входных и выходных данных.
Эти типы могут быть объектами, а также примитивами и массивами. Дополнительные сведения о свойствах см. в разделах Ядро схемы JSON и Проверка схемы JSON. Если не указано иное, определения свойств следуют схеме JSON. СвойстваСледующие свойства взяты непосредственно из определения схемы JSON и соответствуют тем же спецификациям:
Следующие свойства взяты из определения схемы JSON, но их определения были скорректированы в соответствии со спецификацией OpenAPI.
В качестве альтернативы, в любое время, когда можно использовать объект схемы, вместо него можно использовать ссылочный объект. Дополнительные свойства, определенные спецификацией схемы JSON и не упомянутые здесь, строго не поддерживаются. Помимо полей подмножества схемы JSON, следующие поля МОГУТ использоваться для дальнейшей документации схемы: Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Композиция и наследование (полиморфизм) Спецификация OpenAPI позволяет комбинировать и расширять определения моделей с помощью свойства Хотя композиция обеспечивает расширяемость модели, она не предполагает иерархии между моделями.
Для поддержки полиморфизма спецификация OpenAPI добавляет поле дискриминатора
XML-моделированиеСвойство xml позволяет использовать дополнительные определения при преобразовании определения JSON в XML. Объект XML содержит дополнительную информацию о доступных параметрах. Примеры объектов схемыПримитивный образец
{
"тип": "строка",
"формат": "электронная почта"
}
тип: строка формат: электронная почта Простая модель
{
"тип": "объект",
"требуется": [
"имя"
],
"характеристики": {
"имя": {
"тип": "строка"
},
"адрес": {
"$ref": "#/компоненты/схемы/адрес"
},
"возраст": {
"тип": "целое",
"формат": "int32",
"минимум": 0
}
}
}
тип: объект
требуется:
- имя
характеристики:
имя:
тип: строка
адрес:
$ref: '#/компоненты/схемы/адрес'
возраст:
тип: целое число
формат: int32
минимум: 0
Модель со свойствами карты/словаряДля простого преобразования строки в строку:
{
"тип": "объект",
"дополнительные свойства": {
"тип": "строка"
}
}
тип: объект дополнительные свойства: тип: строка Для сопоставления строки с моделью:
{
"тип": "объект",
"дополнительные свойства": {
"$ref": "#/компоненты/схемы/ComplexModel"
}
}
тип: объект дополнительные свойства: $ref: '#/компоненты/схемы/ComplexModel'Модель с примером
{
"тип": "объект",
"характеристики": {
"я бы": {
"тип": "целое",
"формат": "int64"
},
"имя": {
"тип": "строка"
}
},
"требуется": [
"имя"
],
"пример": {
"имя": "Пума",
"идентификатор": 1
}
}
тип: объект
характеристики:
я бы:
тип: целое число
формат: int64
имя:
тип: строка
требуется:
- имя
пример:
имя: Пума
идентификатор: 1
Модели с составом
{
"составные части": {
"схемы": {
"Модель ошибки": {
"тип": "объект",
"требуется": [
"сообщение",
"код"
],
"характеристики": {
"сообщение": {
"тип": "строка"
},
"код": {
"тип": "целое",
"минимум": 100,
"максимум": 600
}
}
},
"ExtendedErrorModel": {
"все": [
{
"$ref": "#/компоненты/схемы/ErrorModel"
},
{
"тип": "объект",
"требуется": [
"первопричина"
],
"характеристики": {
"первопричина": {
"тип": "строка"
}
}
}
]
}
}
}
}
составные части:
схемы:
Модель ошибки:
тип: объект
требуется:
- сообщение
- код
характеристики:
сообщение:
тип: строка
код:
тип: целое число
минимум: 100
максимум: 600
Расширенная модель ошибки:
все:
- $ref: '#/components/schemas/ErrorModel'
- тип: объект
требуется:
- первопричина
характеристики:
первопричина:
тип: строка
Модели с поддержкой полиморфизма
{
"составные части": {
"схемы": {
"Домашний питомец": {
"тип": "объект",
"дискриминатор": {
"имя_свойства": "тип_питомца"
},
"характеристики": {
"имя": {
"тип": "строка"
},
"тип питомца": {
"тип": "строка"
}
},
"требуется": [
"имя",
"тип питомца"
]
},
"Кошка": {
"description": "Изображение кошки.
составные части:
схемы:
Домашний питомец:
тип: объект
дискриминатор:
имя свойства: petType
характеристики:
имя:
тип: строка
тип питомца:
тип: строка
требуется:
- имя
- тип питомца
Cat: ## "Cat" будет использоваться как значение дискриминатора
описание: Представление кота
все:
- $ref: '#/components/schemas/Pet'
- тип: объект
характеристики:
охотничий навык:
тип: строка
описание: Измеренное умение для охоты
перечисление:
- невежественный
- ленивый
- предприимчивый
- агрессивный
требуется:
- охотничье мастерство
Собака: ## «Собака» будет использоваться в качестве значения дискриминатора.Дискриминатор ОбъектЕсли тело запроса или полезная нагрузка ответа могут быть одной из нескольких различных схем, объект дискриминатора может использоваться для облегчения сериализации, десериализации и проверки. Дискриминатор — это конкретный объект в схеме, который используется для информирования потребителя о спецификации альтернативной схемы на основе связанного с ней значения. При использовании дискриминатора встроенных схем не будут учитываться. Фиксированные поля
Объект дискриминатора разрешен только при использовании одного из составных ключевых слов В OAS 3.0 полезная нагрузка ответа МОЖЕТ быть описана как ровно один из любого количества типов: MyResponseType: один из: - $ref: '#/components/schemas/Cat' - $ref: '#/компоненты/схемы/собака' - $ref: '#/components/schemas/Lizard' , что означает, что полезная нагрузка ДОЛЖНА при проверке соответствовать ровно одной из схем, описанных
MyResponseType:
один из:
- $ref: '#/components/schemas/Cat'
- $ref: '#/компоненты/схемы/собака'
- $ref: '#/components/schemas/Lizard'
дискриминатор:
имя свойства: petType
Теперь ожидается, что свойство с именем
{
"идентификатор": 12345,
"petType": "Кошка"
}
Указывает, что схема В сценариях, где значение поля дискриминатора не соответствует имени схемы или неявное сопоставление невозможно, необязательный MyResponseType: один из: - $ref: '#/components/schemas/Cat' - $ref: '#/компоненты/схемы/собака' - $ref: '#/components/schemas/Lizard' - $ref: 'https://gigantic-server. Здесь значение дискриминатора из При использовании в сочетании с конструкцией В обоих вариантах использования Например:
составные части:
схемы:
Домашний питомец:
тип: объект
требуется:
- тип питомца
характеристики:
тип питомца:
тип: строка
дискриминатор:
имя свойства: petType
сопоставление:
собака Собака
Кошка:
все:
- $ref: '#/components/schemas/Pet'
- тип: объект
# все остальные свойства, характерные для `Cat`
характеристики:
имя:
тип: строка
Собака:
все:
- $ref: '#/components/schemas/Pet'
- тип: объект
# все остальные свойства, характерные для `Dog`
характеристики:
лаять:
тип: строка
Ящерица:
все:
- $ref: '#/components/schemas/Pet'
- тип: объект
# все остальные свойства, специфичные для `Lizard`
характеристики:
любитRocks:
тип: логический
такая полезная нагрузка:
{
"petType": "Кошка",
"имя": "туманный"
}
будет означать, что используется схема
{
"petType": "собака",
«кора»: «мягкая»
}
будет отображаться в XML-объектОбъект метаданных, позволяющий более точно настроить определения модели XML. При использовании массивов имена элементов XML равны , а не (для форм единственного/множественного числа), и свойство Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры XML-объектовПримеры определений объектов XML включены в определение свойства объекта схемы с образцом его XML-представления. Нет XML-элементаСвойство основной строки:
{
"животные": {
"тип": "строка"
}
}
животные: тип: строка <животные>... Свойство массива базовых строк (
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка"
}
}
}
животные:
тип: массив
Предметы:
тип: строка
<животные>... <животные>... <животные>... Замена имени XML
{
"животные": {
"тип": "строка",
"xml": {
"имя": "животное"
}
}
}
животные:
тип: строка
XML:
имя: животное
<животное>. XML-атрибут, префикс и пространство именВ этом примере показано полное определение модели.
{
"Человек": {
"тип": "объект",
"характеристики": {
"я бы": {
"тип": "целое",
"формат": "int32",
"xml": {
"атрибут": правда
}
},
"имя": {
"тип": "строка",
"xml": {
"пространство имен": "http://example.com/schema/sample",
"префикс": "образец"
}
}
}
}
}
Человек:
тип: объект
характеристики:
я бы:
тип: целое число
формат: int32
XML:
атрибут: правда
имя:
тип: строка
XML:
пространство имен: http://example.com/schema/sample
префикс: образец
<Человек>
XML-массивыИзменение имен элементов:
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка",
"xml": {
"имя": "животное"
}
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
имя: животное
<животное>значение <животное>значение Внешнее свойство
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка",
"xml": {
"имя": "животное"
}
},
"xml": {
"имя": "инопланетяне"
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
имя: животное
XML:
Название: пришельцы
<животное>значение <животное>значение Даже когда массив упакован, если имя не определено явно, одно и то же имя будет использоваться как внутри, так и снаружи:
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка"
},
"xml": {
"завернутый": правда
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
завернутый: правда
<животные> <животные>значение <животные>значение Чтобы решить проблему именования в приведенном выше примере, можно использовать следующее определение:
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка",
"xml": {
"имя": "животное"
}
},
"xml": {
"завернутый": правда
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
имя: животное
XML:
завернутый: правда
<животные> <животное>значение <животное>значение Влияет как на внутренние, так и на внешние имена:
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка",
"xml": {
"имя": "животное"
}
},
"xml": {
"имя": "инопланетяне",
"завернутый": правда
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
имя: животное
XML:
Название: пришельцы
завернутый: правда
<инопланетяне> <животное>значение <животное>значение Если мы изменим внешний элемент, но не внутренние:
{
"животные": {
"тип": "массив",
"Предметы": {
"тип": "строка"
},
"xml": {
"имя": "инопланетяне",
"завернутый": правда
}
}
}
животные:
тип: массив
Предметы:
тип: строка
XML:
Название: пришельцы
завернутый: правда
<инопланетяне> <инопланетяне>значение <инопланетяне>значение Объект схемы безопасности Определяет схему безопасности, которую могут использовать операции. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Пример объекта схемы безопасностиОбразец базовой аутентификации
{
"тип": "http",
"схема": "базовая"
}
тип: http схема: базовая Образец ключа API
{
"тип": "апиКей",
"имя": "api_key",
"в": "заголовок"
}
тип: апиКей имя: API_key в: заголовок Образец носителя JWT
{
"тип": "http",
"схема": "носитель",
"bearerFormat": "JWT",
}
тип: http схема: носитель носительФормат: JWT Неявный образец OAuth3
{
"тип": "oauth3",
"течет": {
"скрытый": {
"authorizationUrl": "https://example.
тип: oauth3
потоки:
скрытый:
URL-адрес авторизации: https://example.com/api/oauth/dialog
области:
write:pets: изменить питомцев в своей учетной записи
read:pets: читай своих питомцев
Объект потоков OAuthПозволяет настраивать поддерживаемые потоки OAuth. Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Объект потока OAuthСведения о конфигурации для поддерживаемого потока OAuth Фиксированные поля
Этот объект МОЖЕТ быть расширен за счет расширений спецификации. Примеры объектов потока OAuth
{
"тип": "oauth3",
"течет": {
"скрытый": {
"authorizationUrl": "https://example.com/api/oauth/dialog",
"области": {
"write:pets": "изменить питомцев в вашем аккаунте",
"read:pets": "читать своих питомцев"
}
},
"Код авторизации": {
"authorizationUrl": "https://example.
тип: oauth3
потоки:
скрытый:
URL-адрес авторизации: https://example.com/api/oauth/dialog
области:
write:pets: изменить питомцев в своей учетной записи
read:pets: читай своих питомцев
Код авторизации:
URL-адрес авторизации: https://example.com/api/oauth/dialog
tokenUrl: https://example.com/api/oauth/token
области:
write:pets: изменить питомцев в своей учетной записи
read:pets: читай своих питомцев
Объект требования безопасностиСписок необходимых схем безопасности для выполнения этой операции. Имя, используемое для каждого свойства, ДОЛЖНО соответствовать схеме безопасности, объявленной в схемах безопасности в объекте компонентов. Security Requirement Objects, которые содержат несколько схем, требуют, чтобы все схемы ДОЛЖНЫ быть удовлетворены для авторизации запроса. Когда список объектов требований безопасности определен для объекта OpenAPI или объекта операции, только один из объектов требований безопасности в списке должен быть удовлетворен для авторизации запроса. Узорчатые поля
|