Дизассемблирование языков высокого уровня [КОНТЕНТ БЕСПЛАТНОГО КУРСА]
Этот материал взят из нашего курса «Обратное проектирование программного обеспечения». В этом уроке вы узнаете, как заниматься дизассемблированием языков высокого уровня на простом примере. Это сложная задача, которую невозможно полностью изучить с помощью одной статьи, но это отличное место для начала!
Каждый двоичный файл, который есть в вашей системе, обычно был написан на языке высокого уровня, но вы не всегда знаете этот язык. Иногда можно вернуть или декомпилировать ваш двоичный файл в исходный исходный код. Разборка — непростая задача; с некоторыми специфическими кодами это можно сделать, но вы не будете знать названия переменных или комментарии внутри кода (например). Но вы всегда можете просмотреть двоичный код, преобразовать его в шестнадцатеричный, а затем интерпретировать каждый байт или группу байтов как инструкцию (как вы узнали из предыдущего раздела). Вы можете сделать это вручную или использовать специальный инструмент для дизассемблирования.
В таблице 21 приведен список инструментов, которые можно использовать для дизассемблирования кода x86:
Таблица 21 – Некоторые дизассемблеры для x86.
| Инструмент | Архитектура X86 | Операционная система |
| Интерактивный дизассемблер (IDA) | 32 и 64 | Linux / Win |
| ОллиДбг | 32 | Win |
| Взломать | 16 | ДОС/Выигрыш |
| НДИСАСМ | 32 и 64 | DOS/Win/Mac/Linux |
Конечно, это намного больше, вы можете посмотреть в Интернете и проверить некоторые бесплатные, открытые и коммерческие инструменты дизассемблирования, которые вы можете использовать для этой цели. В этом курсе большую часть времени мы будем использовать OllyDbg или IDA (32-битная бесплатная версия), поскольку они бесплатны и просты в использовании.
Анализ программы
Есть много вещей, о которых вы должны подумать, прежде чем приступать к обратному проектированию двоичной программы. Обычно вы хотите что-то изменить, например удалить сообщение, которое появляется в определенный момент.
Иногда вы просто хотите изменить значение константы или переменной, в других случаях вам может потребоваться исправить ошибку в старом устаревшем коде.
Реверс-инжиниринг всего кода действительно сложно и недоказуемо, потому что бинарник обычно закодирован на языке высокого уровня, и когда вы попытаетесь дизассемблировать код, у вас будет намного больше строк на языке ассемблера по сравнению с оригиналом исходный код на языке высокого уровня.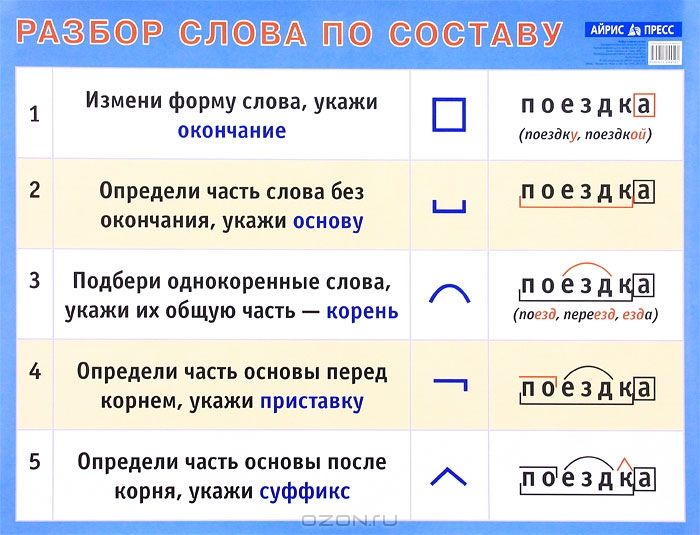
Одним из хороших примеров, поясняющих это, является мышление в ЦИКЛЕ, закодированном на языке высокого уровня. Предположим, что у вас есть код C, подобный следующему (рис. 4):
for (i = 0; i < 0x1212; i++)
{
}
Приведенный выше код действительно прост; как видите, он ничего не делает, просто повторяется 1212 раз (0x указывает шестнадцатеричное значение). Просто запомните синтаксис цикла for: первый параметр (i = 0) — это начальное условие; второй параметр (i < 0x1212) — это условие остановки, а третий параметр — приращение (в данном случае то же самое, что i = i + 1). Чтобы понять, что происходит с кодером после его компиляции, мы выполнили процесс компиляции в двух разных средах. Первый был сделан на старом Borland Turbo C (3.0).
После компиляции и компоновки исходного кода мы получили бинарный файл. Таким образом, можно было разобрать бинарник и проанализировать ассемблерный код.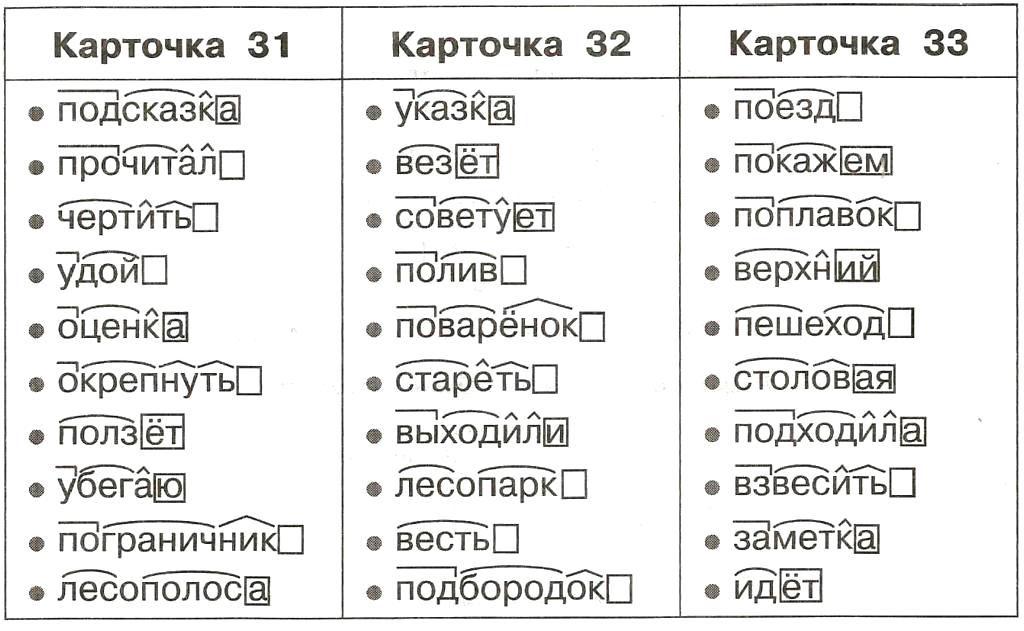 Давайте посмотрим на рисунок 5.
Давайте посмотрим на рисунок 5.
XOR SI, SI
JMP SHORT loc_1029A
loc_10299:
INC SI loc_1029A:
CMP SI, 1212h
JL SHORT loc_10299
Рисунок 5 – Разборка бинарного цикла, скомпилированного в Turbo C 3.
Для дизассемблирования кода использовал IDA Free на 32 бита. Как вы думаете, вы можете понять связь между исходным кодом C и дизассемблированным кодом? Давайте немного объясним вам.
Инструкцию XOR SI, SI можно понимать как «i = 0» (первый параметр из исходного кода C). Откуда нам это знать? Это просто: когда вы используете XOR (исключающее ИЛИ), используя одно и то же значение для обоих параметров, вы получите в результате ноль (если вы не знаете, как работает XOR, посмотрите ссылки).
Перейдем к инструкции INC SI. Это означает третий параметр, который равен «i++». Это действительно легко идентифицировать, потому что ассемблерная инструкция INC просто увеличивает один регистр, который вы указываете. В данном случае мы используем регистр указателя SI, который ранее был запущен с нуля.
В данном случае мы используем регистр указателя SI, который ранее был запущен с нуля.
Вернувшись ко второму параметру («i < 0x1212») и просмотрев его разборку, вы заметите, что у нас есть более одной ассемблерной инструкции для его представления: JMP SHORT loc_1029A, CMP SI, 1212h и JL SHORT loc_10299. Первая ассемблерная инструкция (JMP SHORT loc_1029A) представляет собой безусловный цикл, просто означающий, что код перейдет к указанной метке (обратите внимание, что метка — это просто ссылка на адрес памяти, но дизассемблер IDA помог нам, поставив имя на это).
Когда код перейдет к «loc_1029A», вы увидите, что у нас есть инструкция CMP SI, 1212h (наша вторая ассемблерная инструкция, связанная с «i < 0x1212»). Это инструкция ALU, которая сравнивает регистр SI с 1212h и устанавливает флаговые биты в регистре флагов (раздел 2.1.4). Фактически инструкция CMP действует как SUB (вычесть), с той лишь разницей, что инструкция CMP не сохраняет результат, а только меняет флаги. Теперь, когда у нас обновлены флаги, мы можем проанализировать их, используя условный переход, в данном случае JL. Как видите, в третьей инструкции, связанной с «i < 0x1212», у нас есть JL SHORT loc_1029.9, что означает «прыгать, если меньше», ссылаясь на символ «<», изначально присутствующий в нашем коде C.
Теперь, когда у нас обновлены флаги, мы можем проанализировать их, используя условный переход, в данном случае JL. Как видите, в третьей инструкции, связанной с «i < 0x1212», у нас есть JL SHORT loc_1029.9, что означает «прыгать, если меньше», ссылаясь на символ «<», изначально присутствующий в нашем коде C.
Обратите внимание, что было очень быстро и легко проанализировать параметры один и три из нашего цикла «for», представленного в исходном коде C, только параметр номер два требует времени, чтобы понять логику, но это также легко.
Теперь давайте посмотрим, что мы получим, если скомпилируем тот же код C с помощью компилятора «gcc» (рис. 6).
КОРОТКИЙ JMP loc_401354
loc_401350:
INC [ESP+10h+var_4]
loc_401354:
CMP [ESP+10h+var_4], 1211h JLE SHORT loc _401350
Рисунок 6 – Разборка бинарного цикла, скомпилированного в GCC .
Как видите, ассемблерный код не одинаков, есть много разных решений, принятых компилятором, которые привели к другой комбинации OPCODE (которую мы видим здесь как ассемблерные инструкции).
Давайте начнем думать о параметрах нашего цикла: i = 0, i < 0x1212 и i++. Что случилось с первым параметром (i = 0)? Ну, тут сложно разглядеть, но компилятор «gcc» решил работать с переменной «напрямую», не перемещая ее в регистр указателя (например, SI, как мы видели ранее). Чтобы прояснить эту ситуацию, давайте снова перейдем к третьему параметру (i++), который также поможет нам объяснить первый. Инструкция ассемблера INC [ESP+10h+var_4] отвечает за увеличение переменной таблицы «i», которая изначально управляет циклом. Первое, на что следует обратить внимание, это тот факт, что компилятор генерирует 32-битный код, как мы можем видеть в регистре ESP (раздел 2.1.2). Другое дело, что скобки «[ ]» указывают на то, что мы хотим, чтобы адрес указывал «ESP+10h+var4», что означает, что это место, где находится исходная переменная «i» (что отвечает на наш вопрос о первый параметр: «i = 0»).
Третий параметр, «i<0x1212», еще раз следует проанализировать как подмножество инструкций по сборке: JMP SHORT loc_401354, CMP [ESP+10h+var4], 1211h и JLE SHORT loc_401350. Первая инструкция сборки (JMP SHORT loc_401354) имеет ту же цель, о которой говорилось ранее, просто перейдите к метке и выполните вторую инструкцию сборки (CMP [ESP+10h+var4], 1211h). Как вы можете видеть в этой инструкции, мы снова смотрим в адресную точку по [ESP+10h+var4], чтобы увидеть значение переменной. Здесь интересно то, что мы сравниваем переменную «i» с 1211h. Почему это происходит? В нашем исходном коде C мы сравнили переменную с 1212h. Что ж, компилятор «решил» изменить значение и, чтобы разобраться с этим изменением, он также изменил следующую инструкцию. В третьей инструкции (JLE SHORT loc_401350) вместо упомянутого ранее JL у нас есть JLE, что означает «перейти, если меньше или равно». Вот как компилятор поступил со сравнением, сделанным второй инструкцией. Вместо сравнения с 0x1212 и «прыгать, если меньше», было решено сравнивать с 0x1211 и «прыгать, если меньше или равно», что в итоге означает «то же самое».
Первая инструкция сборки (JMP SHORT loc_401354) имеет ту же цель, о которой говорилось ранее, просто перейдите к метке и выполните вторую инструкцию сборки (CMP [ESP+10h+var4], 1211h). Как вы можете видеть в этой инструкции, мы снова смотрим в адресную точку по [ESP+10h+var4], чтобы увидеть значение переменной. Здесь интересно то, что мы сравниваем переменную «i» с 1211h. Почему это происходит? В нашем исходном коде C мы сравнили переменную с 1212h. Что ж, компилятор «решил» изменить значение и, чтобы разобраться с этим изменением, он также изменил следующую инструкцию. В третьей инструкции (JLE SHORT loc_401350) вместо упомянутого ранее JL у нас есть JLE, что означает «перейти, если меньше или равно». Вот как компилятор поступил со сравнением, сделанным второй инструкцией. Вместо сравнения с 0x1212 и «прыгать, если меньше», было решено сравнивать с 0x1211 и «прыгать, если меньше или равно», что в итоге означает «то же самое».
Изменение двоичного кода
Предположим, вы хотите изменить некоторый двоичный код, который вы уже нашли, например, сравнение, которое вы нашли ранее (раздел 4. 1). Как мы знаем, цикл сравнения будет продолжаться до тех пор, пока второе условие не станет ложным (i<0x1212).
1). Как мы знаем, цикл сравнения будет продолжаться до тех пор, пока второе условие не станет ложным (i<0x1212).
Представьте, что вы больше не хотите входить в этот цикл, но у вас нет исходного кода для этого, тогда вам нужно что-то делать с бинарником. Один из самых простых способов — изменить адрес безусловного перехода (JMP) на следующую инструкцию сразу после условного перехода (JL или JLE).
Другой возможностью является изменение значения переменной перед выполнением сравнения (CMP). В коде, скомпилированном с помощью «gcc», вам придется изменить значение, указанное [ESP+10h+var4].
В некоторых случаях мы можем захотеть удалить появившееся сообщение или окно. В этих случаях у нас обычно есть CALL (инструкция по ассемблеру для вызова подпрограммы), которую мы должны «удалить». На самом деле нам нужно будет перейти на другую инструкцию, как мы увидим в следующем подразделе.
Количество байтов
Когда мы хотим что-то изменить в нашем двоичном файле, мы должны обратить внимание на то, что мы не можем изменить количество байтов. Это один из механизмов безопасности, связанных с бинарными файлами, но мы не собираемся обсуждать его здесь.
Это один из механизмов безопасности, связанных с бинарными файлами, но мы не собираемся обсуждать его здесь.
Дело в том, что мы должны обратить на это внимание, если хотим внести постоянные изменения в наш бинарник. В разделе 4.2 мы упомянули пример JUMP. В данном случае это очень просто, потому что мы просто перейдем к следующей «метке» или инструкции.
Но когда мы хотим опустить CALL, мы должны что-то там поместить, чтобы заменить старые байты. Нам нужно поместить туда что-то, что не изменит поведение других частей нашей программы. Таким образом, очень полезно использовать инструкцию NOP, которая ничего не делает! Эта инструкция имеет один байт (0x90), и мы можем поместить столько, сколько нам нужно, не изменяя количество байтов нашего исходного файла.
Предположим, что исходный CALL имеет три байта, мы просто заменим эти три байта тремя 0x90, что означает выполнение НЕ три раза.
Сумма байтов
Другая проблема, с которой нам иногда приходится сталкиваться, заключается в том, что некоторые двоичные файлы имеют механизм, называемый КОНТРОЛЬНАЯ СУММА. Такого рода вещи действительно распространены, например, в протоколах компьютерных сетей.
Такого рода вещи действительно распространены, например, в протоколах компьютерных сетей.
КОНТРОЛЬНАЯ СУММА представляет собой сумму всех байтов двоичного файла, но с ограничением в несколько байтов (например, 2 байта). Предположим, у нас есть код со следующими байтами: 0x10, 0x22, 0x35. В этом случае КОНТРОЛЬНАЯ СУММА будет 0x0067 (2 байта).
Обычно это поле находится где-то в конце бинарного файла, и если вы измените один из своих байтов (например, 0x10 на 0x11), то вам также придется изменить поле CHECKSUM на новое значение, в данном случае 0x0068 .
[custom-related-posts title="Связанный контент:" none_text="Ничего не найдено" order_by="title" order="ASC"]
23 сентября 2020 г.
Автор
- [СОТРУДНИК]
Последние статьи
разборка - На каком языке написан БИОС?
спросил
Изменено 7 лет, 5 месяцев назад
Просмотрено 5к раз
Насколько я понимаю, код/битовый поток BIOS, хранящийся в ПЗУ, должен быть общим (работать вместе с несколькими типами процессоров или ISA). Кроме того, я видел в Интернете упоминания о том, что у них есть возможность выгрузить свой код (и ' разобрать ' это).
Кроме того, я видел в Интернете упоминания о том, что у них есть возможность выгрузить свой код (и ' разобрать ' это).
Итак, на каком языке, наборе инструкций или машинном коде это написано? Разве ему не нужен какой-либо процессор для выполнения своих операций? Если так, я предполагаю, что он будет использовать внешний процессор, то как он узнает конкретный набор инструкций используемого?
Может у него внутренний процессор?
- разборка
- сброс
- биос
Итак, на каком языке, наборе инструкций или машинном коде он написан?
Он написан на языке, который может быть скомпилирован в машинный код, который может выполняться процессором (ЦП). Как правило, это комбинация языка C и ассемблера.
Разве ему не нужен процессор для выполнения своих операций?
Да, код BIOS выполняется на процессоре.
Если да, то я предполагаю, что он будет использовать внешний ЦП
Правильно.
тогда откуда он знает конкретный набор команд используемого?
Нет. Вот почему, когда вы покупаете материнскую плату, вам необходимо убедиться, что она совместима с процессором, который вы планируете использовать с ней. См., например, список материнских плат ASUS. У них есть материнские платы, предназначенные для процессоров Intel, материнские платы, предназначенные для процессоров AMD, и т. д. И если вы углубитесь в спецификации для данной материнской платы, вы увидите, с какими конкретными процессорами она предназначена для работы:
8В качестве дополнительного ответа, BIOS раньше писался на ассемблере (теперь это в основном код ANSI C), который компилируется в
https://sites.google.com/site/pcdosretro/ibmpcbios и старую книгу Готфрида на ассемблере для ПК IBM).
b) Байт-код UEFI для EFI в настоящее время (замена BIOS).
В качестве доказательства взгляните на https://en.