Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: с в е к р е а сейчас балетка сейчас отноидясе 1 секунда назад б р о а з е ц 1 секунда назад т к ё с а м е 2 секунды назад тунами 2 секунды назад поленощит 2 секунды назад б и о л о г 2 секунды назад феодализм 2 секунды назад д в р а н ь е 2 секунды назад палетка 2 секунды назад п а н с и о н а т 3 секунды назад знатокч 3 секунды назад гвардия 3 секунды назад т о в с к о 3 секунды назад
ДАВАЙТЕ ЗНАКОМИТЬСЯ
апреля 6, 2022
Меня зовут Лиза и мне 36 лет.
Я русская, но уже давно говорю с грузинским акцентом.
Я счастлива 13 лет жить в Грузии и столько же времени писать о своей грузинской жизни.
За это время я успела выйти замуж за грузина, родить троих детей и создать агентство путешествий по Грузии “MyCityTbilisi».
Мне удивительно и в тоже время приятно читать и слышать, как моя история вдохновляет на приезд и даже переезд.
Грузия подарила мне невероятную жизнь, о которой я всегда мечтала.
Подарила мне саму себя.
И я знаю на своём опыте, какая Грузия теплая, гостеприимная, вкусная и аутентичная.
Я желаю каждому открыть «свою Грузию».
Здесь в блоге я пишу о моей Грузии: особенности менталитета и традиции, грузинская кухня и вино, шоппинг, рекомендую лучшие места, а ещё много пишу о своей грузинской жизни.
Весь мой блог — это признание в любви к Грузии 🇬🇪🤍
Как появилась эта любовь?
На самом деле она передалась на генетическом уровне, ведь моя бабушка второй раз вышла замуж за грузина и 12 лет прожила в Грузии. И даже написала книгу очерков, так что мой блог это тоже в своём роде продолжение семейных традиций✨
За что я люблю Грузию и грузин?
Прежде всего за эмоциональную щедрость✨🤍🇬🇪 за семейственность, приверженность к традициям и корням.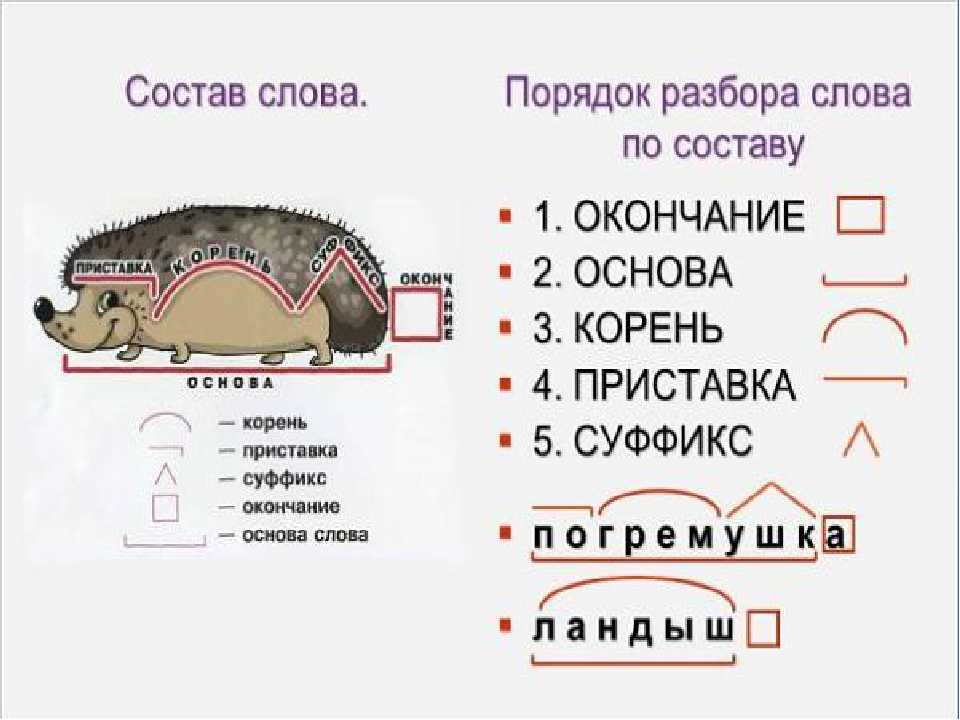 За гордость и за чувство собственного достоинства, за то, как уважают старших и балуют детей. За несгибаемость, принципиальность и за внимание к людям.
За гордость и за чувство собственного достоинства, за то, как уважают старших и балуют детей. За несгибаемость, принципиальность и за внимание к людям.
Грузины приняли христианство в 326 году, одни из первых народов и здесь до сих пор живут по традициям христианского мира. Приведу пример: в Грузии венчаются 90% пар, здесь это обычное дело, люди не решаются и нет этого — «давай через 10 лет, когда будем готовы».
Культ женщин и матерей, уважение к старшим и родственным связям, определённые отношения между женщиной и мужчиной. Да, в Грузии патриархат и мужчина глава семьи. Мужчина зарабатывает деньги, все остальное на женщине, даже если она тоже зарабатывает😎 Вообще в грузинской семье все строится на женщине, и от ее мудрости и деликатности зависит многое.
Конечно, времена меняются и молодежь смотрит на запад, ведь Грузия идёт по европейскому пути развития. Но так как современное поколение живет в традиционных семьях, то существует этот баланс старых традиций и новых веяний.
За 12 лет жизни в Тбилиси могу сказать точно — грузины и русские разные: культура, воспитание, обычаи. Если ты родился в Грузии, то ты все знаешь, все традиции и обычаи впитываются с молоком матери. А когда ты вырос в другом обществе — ты многие вещи просто не знаешь и ошибаешься. Но кто никогда не ошибается, тот ничему не учится. Мудрости учат только ошибки ✨🙏🏽🤍
Грузия — это школа любви ❤️🇬🇪
Грузины очень щедрые на любовь, на хорошие слова. Если человек им нравится, они скажут все и даже больше — это не скрывается и не замалчивается.
Усаживайтесь поудобнее и отправляйтесь в путешествие по удивительной Грузии: гостеприимной, тёплой, вкусной и очень красивой.
Влюбляйтесь в Грузии вместе со мной ♥️??
Где я родилась и как попала в Грузию?
Я родилась в Москве в апреле 1985 году в семьей журналистов, окончила жур-фак МГУ, работала на телевидении. А когда мне исполнилось 23 года в Батуми я встретила свою любовь.
Сталкивалась ли я с трудностями после переезда в Грузию?
Конечно, трудности были. Но я была молодая и очень легкая (я и сейчас не тяжелая), просто смотрела на жизнь и старалась ничего не усложнять. Я впитывала новую для меня культуру, жила по правилам этой страны и была сильно влюблена в свою новую жизнь. Я слушала советы старших и сильно изменилась. Мои подруги шутят, что не узнают меня. А я счастлива этим переменам. Я выросла, стала сильнее и терпимее. Дети рождались друг да другом, у меня тоже не было много времени на рефлексию. Все подчинено заботой о них. Но я стараюсь и о себе не забывать, понимаю как это важно сохранять себя.
Я живу в Тбилиси уже 13 лет, и мне кажется, моя новая жизнь изменила меня. В любую страну, в том числе и в Грузию, нельзя переезжать со своим самоваром.
 Об этом я думаю постоянно: о главном, а не о мелочах. Этому всему меня научила жизнь в Грузии.
Об этом я думаю постоянно: о главном, а не о мелочах. Этому всему меня научила жизнь в Грузии.
Как нашла смелость уехать в другую страну?
Эту смелость я не искала. Я была молодая и влюблённая, и мне была интересна жизнь. Когда мои дети немного подрастут, я обязательно скажу им: пока вы молоды — живите, выходите замуж или женитесь, рожайте детей, ищите работу себе по душе. Делайте как можно больше, пробуйте, ошибайтесь, вставайте и идите дальше. Находите смелость выходить из зоны комфорта, чтобы быть счастливыми.
Чувствую ли я себя частью Грузии?
Конечно, я себя чувствую частью этой необыкновенной страны. Говорят, что нужно чтобы прошло три года для адаптации к жизни в новой стране. А я уже давно говорю с грузинским акцентом, «у нас в Грузии», считаю этот город своим домом и очень люблю все грузинское. Невозможно быть счастливым, если что-то не принимаешь в стране в которой живёшь, я это давно поняла. Нужно научится принятию и поиску тех хороших вещей, которые случаются с нами каждый день.
Все ли на самом деле меня устраивает в жизни в Тбилиси?
Вопрос с подковыркой. Если я скажу, что все устраивает, вы мне не поверите, но это так. Я люблю свою грузинскую жизнь и ничего не хочу менять.
С какого рода трудностями я ежедневно справляюсь?
Самые большие трудности мы устраиваем себе сами. Поэтому я борюсь с собой каждый день…работаю над собой, анализирую, рефлексирую (иногда даже слишком)
Как пережила, когда первое время не было работы и друзей?
Мне повезло, у меня было много друзей и даже родственников в Тбилиси, работы не было, но я быстро родила старшую дочь, так что скучать мне не приходилось.
Как я воспитываю детей, с учётом того, что у русских и у грузин разные подходы?
Возможно я кого-то разочарую, но я грузинская мама. Я достаточно лояльна, я балую их и многое разрешаю. У нас безусловно, есть режим, но иногда мы его вместе и с удовольствием нарушаем, как говорится: порчу любовью. Элене 10 лет и она уже взрослая, мне нравится какой она стала ответственной и любит учиться. Нике 7 лет и он иногда, как и все мальчики, бывает неуправляем, я могу повысить тон и наказать — запретив ему гаджеты. Аннушка 4 года, характер у неё очень сильный. Я так благодарна Богу, что она родилась третьей и я уже натренировалась на старших.
У нас безусловно, есть режим, но иногда мы его вместе и с удовольствием нарушаем, как говорится: порчу любовью. Элене 10 лет и она уже взрослая, мне нравится какой она стала ответственной и любит учиться. Нике 7 лет и он иногда, как и все мальчики, бывает неуправляем, я могу повысить тон и наказать — запретив ему гаджеты. Аннушка 4 года, характер у неё очень сильный. Я так благодарна Богу, что она родилась третьей и я уже натренировалась на старших.
Какие отношение между мужчиной и женщиной в Грузии?
Грузия традиционная страна, в которой правильная система ценностей. Здесь не приняты разводы. Крепкие семьи, много детей, культ матери. Мужчина глава семьи и женщина слушается мужа. А муж обожают свою жену и заботиться о ней. Мужчина добытчик, женщина хранительница домашнего очага. Все также как и было много лет назад. Исключения конечно же нет, но они, как известно, подтверждают эти правила.
Во что я верю?
Очень сложно подобрать слова, когда дело касается темы самоопределения и обретения. И наступает этот момент становления нового «я», переоценки своей жизни, стремлений и приоритетов. И жизнь меняется кардинально, когда человек, преодолевая гордость, перестает жить для себя и начинает жить для ближнего своего…Когда он смиряется, когда перестает себя жалеть, когда перестает требовать и жаловаться.. и, конечно, когда приходит к Богу.
И наступает этот момент становления нового «я», переоценки своей жизни, стремлений и приоритетов. И жизнь меняется кардинально, когда человек, преодолевая гордость, перестает жить для себя и начинает жить для ближнего своего…Когда он смиряется, когда перестает себя жалеть, когда перестает требовать и жаловаться.. и, конечно, когда приходит к Богу.
Жизнь в Грузии — это моя дорога к храму, который стоит на горе, это моя дорога к Богу. Я стараюсь, чтобы меня окружали те люди, которые могут меня чему-то научить. Мои главные учителя — это моя семья и мое ближайшее окружение. Мне абсолютно не страшно признаваться в своих несовершенствах и, наоборот, я чувствую, что, преодолевая их, я двигаюсь вперед. Меня очень поддерживает моя вера, все ответы я нахожу в ней, я знаю, что без веры ничего не получается, да что там…жизнь прожить невозможно.
Если вы спросите меня, что самое главное в жизни и что делает человека по-настоящему счастливым? Я вам отвечу, не задумываясь — это жизнь в любви. Когда живешь не ради себя, а ради близких, когда ставишь потребности человека, которого любишь, выше собственных, когда стараешься жить правильно и быть достойным примером для своих детей…
Когда живешь не ради себя, а ради близких, когда ставишь потребности человека, которого любишь, выше собственных, когда стараешься жить правильно и быть достойным примером для своих детей…
Тут приходят на ум прекрасные слова Ильи Чавчавадзе, известного грузинского писателя и публициста:
«Когда прослыть желаешь человеком, То что ни день чини себе допрос: – Какое сделал я добро сегодня? – Кому сегодня пользу я принес?».
Как изменилась я за последние 10-12 лет? Что для меня стало новой нормой?
- я контролирую что и кому я говорю, понимая, что здесь на все обращают внимание
- я принимаю полностью грузинский менталитет, образ жизни и традиции
- я поняла, что общие ценности это то, на чем держится супружество, дружба и семья
- я могу спокойно выпить воду из под крана и принимаю гостей, не протягивая им тапочки
- если я не могу оплатить сама счёт, я не иду на встречу
- я ни с кем (кроме моей семьи) не обсуждаю политику, в том числе и здесь
- совершая ошибку, я не впадаю в отчаяние (раньше было да), а говорю себе «запомни хорошо и больше не повторяй»
Мои друзья подтвердят, что я и сейчас сохранила оптимистический настрой, но теперь я люблю Грузию, глядя на нее трезво и реалистично. Вообще любовь к стране, можно сравнить с любовью к человеку: сначала ты идеализируешь и видишь только лучшие черты, а потом приходят осознанные чувства, и ты любишь уже вопреки недостаткам. Так что первый семилетний кризис в моих отношениях с Грузией проходит безболезненно. И с моим нынешним реалистичным взглядом, я все равно всей душой люблю эту гостеприимную и теплую страну. Здесь есть то, ради чего сюда стоит переехать.
Чему учит Грузия?
— вы будете приятно удивлены тому, что здесь отношения, верность и честность ценится превыше всего и какой гостеприимный, щедрый и красивый грузинский народ
— грузинская кухня станет одной из ваших любимых и вы всегда будете искать хорошие грузинские рестораны за пределами этой удивительной страны
— вы начнёте радоваться мелочам и убедитесь, что не в деньгах счастье
— вы обязательно выучите пару фраз на грузинском
— у вас появиться близкие друзья в Грузии
— здесь вы почувствуете себя очень счастливым. ..
— И поймете, что Грузия это большая любовь, потому что сюда хочется возвращаться снова и снова
Мои планы на жизнь?
Единственно чего я хочу, чтобы мои дети выросли достойными людьми и мы с мужем всегда были рядом с ними.
Хочу много внуков, большой дом загородом, чтобы там собиралось много друзей, выращивать цветы и ягоды, написать книгу.
Твои любимые грузинские слова?
«Генацвале» — слово принято переводить, как дорогой. Но на самом деле все сложнее: если разобрать по составу, то корень нацвал переводится как вместо кого-то. «Ме шен генацвале» дословно — мне вместо тебя (печали и невзгоды), то есть — Я беру все беды твои на себя.
Прекрасное выражение «Шени чири ме». Здесь шени — твой, чири — несчастье, чума, мор. ме — я, мне. Дословно — мне твои несчастья, то есть Во время испытаний я заменю тебя. Выражение стало настолько крылатым, что чириме пишется уже слитно.
Ещё очень люблю слово «гаихаре» — переводиться как возрадуйся. В ответ на комплимент или доброе слово всегда скажешь «гаихаре». Как легко и просто дарить радость ближнему. Просто словом. В Грузии это данность. Поэтому здесь всегда тепло.
Знакомство с определением и значением — Merriam-Webster
знакомый ə-ˈkwān-təd
1
: личное знание чего-либо : что-то видел или испытал
—+ с
юрист, который хорошо знаком с фактами по этому делу, я не знаком с ее книгами.
2
: встретить : быть знакомым и знать кого-то
два человека, которые еще не знакомы
Весь день они знакомились (друг с другом).
Синонимы
- в ряд
- или курант
- знакомый
- знакомый
- информированный
- знающий
- до
- актуальная
- стих
- well-informed
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Недавние примеры в Интернете
Во время встречи Лопес рассказала, что ее детям недавно исполнилось 9 лет.0013 познакомила со своим бэк-каталогом фильмов. — Гленн Роули, Billboard , 16 января 2023 г.
Когда Истман познакомился с президентом Трампом?
— Los Angeles Times , 19 декабря 2022 г.
Всему виной отсутствие практики, недостаточная командная работа и нехватка времени у игроков для ознакомления с друг с другом.
— Dallas News , 16 января 2022 г.
Когда Истман познакомился с президентом Трампом?
— Los Angeles Times , 19 декабря 2022 г.
Юнион и Уэйд хорошо знакомы с тем, чтобы быть в центре внимания модной индустрии.
— Мишель Ли, Peoplemag , 9 сентября 2022 г.
Удивительно, но появляется куча других людей, и группа становится познакомился с , образовав своего рода сообщество. — Тоби Грей, BGR , 16 сентября 2022 г.
Конечно, в недалеком будущем это станет соревнованием на конференции, поэтому тренерский штаб Алабамы воспользуется этой возможностью, чтобы познакомить с окрестностями Остина.
— Эдди Тиманус, USA TODAY , 3 сентября 2022 г.
Большинство компаний хорошо ознакомил со своими непосредственными поставщиками деталей или материалов.
— New York Times , 22 июня 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «знакомый». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
Среднеанглийский acointet, aqueynted , причастие прошедшего времени от acoynten, aqueynten , «знакомить»
Первое известное использование
13 век, в значении, определенном в смысле 2
Путешественник во времени
2 Первое известное использование
знакомого было в 13 векеПосмотреть другие слова из того же века знакомый
знакомый
ознакомиться с
Посмотреть другие записи поблизости
Процитировать эту запись «Знакомый.
» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/acquainted. По состоянию на 25 января 2023 г.
Последнее обновление: — Обновлены примеры предложенийПодпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
маргиналии
См. Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Модные слова
- Какой из этих предметов назван в честь смертоносного оружия?
- туфли-броги хенли рубашка
- Туфли на шпильке шляпа Федора
Проверьте свой словарный запас с помощью нашей викторины из 10 вопросов!
ПРОЙДИТЕ ТЕСТ
Можете ли вы составить 12 слов из 7 букв?
ИГРАТЬ
Текстовое обучение с помощью scikit-learn | Data Science, Python, Games
Изучение текста с помощью scikit-learn | Наука о данных, Python, Игры| Источник
- Теги :
- машинное обучение
- Удасити
Текстовое обучение — это машинное обучение в широкой области, включающее текст. Многие поисковые гиганты, такие как Google, Yahoo, Baidu, пытались выучить текст из различных поисков. В этом примере мы рассмотрим набор слов, который содержит слова, и по данным подсчитаем частоту появления слова в тексте.
Итак, Bag of Words имеет интересные характеристики:
- Порядок слов не имеет значения. Можно только кинуть текст, без приказа и свалить в мешок (отсюда и название)
- Поскольку это длинные фразы, они фактически дублируют слова и возвращают двойную длину своего вектора.
- Мы можем предложить более сложную модель мешка слов, но на самом деле он просто считает одно слово, поэтому не справляется со сложностью фразы. Когда Google впервые запускается как поисковая система, такие слова, как Chicago Bulls, если вы введете их в поисковую систему, вернет города и животных.
 Теперь их инженеры моделируют сумку достаточной сложности, чтобы уловить фразу.
Теперь их инженеры моделируют сумку достаточной сложности, чтобы уловить фразу.
В sklearn есть модуль для подсчета количества слов в одном предложении, который называется CountVectorizer
В [8]:
%pylab встроенный
Заполнение интерактивного пространства имен из numpy и matplotlib
В [9]:
импортировать numpy
В [1]:
из sklearn.feature_extraction.text import CountVectorizer
В [2]:
векторизатор = CountVectorizer()
In [3]:
string1 = "привет, Кэти, самоуправляемая машина опоздает, лучший Себастьян" string2 = "Привет, Себастьян, машинное обучение будет очень кстати, Кэти"
В [4]:
email_list = [строка1,строка2]
В [5]:
bag_of_words = vectorizer.fit(email_list)
В [6]:
bag_of_words = vectorizer.transform(email_list)
В [13]:
print bag_of_words
(0, 0) 1 (0, 1) 1 (0, 2) 1 (0, 3) 1 (0, 6) 1 (0, 7) 1 (0, 8) 1 (0, 11) 1 (0, 12) 1 (0, 13) 1 (0, 14) 1 (1, 0) 1 (1, 1) 1 (1, 4) 1 (1, 5) 1 (1, 6) 1 (1, 7) 1 (1, 9) 1 (1, 10) 1 (1, 11) 1 (1, 13) 1 (1, 14) 1
В [14]:
print vectorizer.
Некоторые тексты могут быть не важны для включения в алгоритм обучения. Эти слова слишком часто встречаются, и это не очень помогает понять, о чем текст. Стоп-слова, содержащие некоторые ненужные слова, добавление которых только становится шумом, потому что они будут в значительной степени способствовать (потому что они слишком часты) в данных. Почему важно избегать этих слов в качестве предварительной обработки при изучении текста.
Слова также могут быть сжаты из всех доступных расширений слов в только корень для этих слов, например, ответ.
В [16]:
из nltk.stem.snowball import SnowballStemmer
В [17]:
стеммер = SnowballStemmer("english")
В [18]:
stemmer.stem("отзывчивость")
Исходящий[18]:
u'respons'
Входящий [19]:
stemmer.stem("не отвечает")
Выход[19]. Обратите внимание, что основа по-прежнему содержит префикс «un». Иногда мы можем захотеть представить слова, которые только «отвечают» и «не отвечают» могут быть совершенно разными значениями. Мы также могли бы точно настроить эту функцию стебля. Это действительно полезно, поскольку мы можем сократить тысячи функций до одной, имеющей одинаковое значение, что очень полезно для алгоритма.
Это определение основы, предварительное изучение текста, должно быть выполнено до того, как вы начнете использовать набор слов.
TFIDF также является интересным методом изучения текста. В то время как TF похож на набор слов, IDF — это то, насколько редко слово встречается в документе (корпусе). Иногда важно то редкое слово, что если в догадке об авторе фигурирует только один конкретный автор. Это слово будет определять, какой автор пишет документы. И из-за этого редкие слова ранжируются выше.
Мини-проект¶
Как обычно, поскольку этот пост в блоге представляет собой заметку, которую я взял из курса Udacity, здесь я затрагиваю некоторые проблемы, с которыми они столкнулись в своем мини-проекте. Вы можете увидеть ссылку на курс для этой заметки внизу этой страницы.
В начале этого занятия вы идентифицировали электронные письма по их авторам, используя ряд контролируемых алгоритмов классификации. В этих проектах мы выполняли предварительную обработку для вас, преобразовывая входные электронные письма в TfIdf, чтобы их можно было передать в алгоритмы. Теперь вы создадите свою собственную версию этого шага предварительной обработки, чтобы перейти непосредственно от необработанных данных к обработанным функциям.
Вам будут предоставлены два текстовых файла: один содержит адреса всех электронных писем от Сары, а другой содержит электронные письма от Криса. У вас также будет доступ к функции parseOutText(), которая принимает открытое электронное письмо в качестве аргумента и возвращает строку, содержащую все слова в электронном письме.
Вы начнете с разминки, чтобы познакомиться с parseOutText(). Перейдите в каталог инструментов и запустите parse_out_email_text. py, который содержит parseOutText() и тестовое электронное письмо для запуска этой функции.
parseOutText() берет открытое электронное письмо и возвращает только текстовую часть, удаляя все метаданные, которые могут встречаться в начале электронного письма, поэтому остается только текст сообщения. В настоящее время у нас есть этот скрипт, настроенный так, что он будет печатать текст электронной почты на экране. Какой текст вы получите, когда запустите parseOutText()?
В [26]:
%load ../tools/parse_out_email_text.py
В [27]:
#!/usr/bin/python
из nltk.stem.snowball импортировать SnowballStemmer
строка импорта
деф parseOutText (f):
""" учитывая открытый файл электронной почты f, проанализировать весь текст ниже
блок метаданных вверху
(в Части 2 вы также добавите возможности стемпинга)
и вернуть строку, содержащую все слова
в письме (через пробел)
пример использования:
f = открыть ("email_file_name. txt", "r")
текст = parseOutText(f)
"""
f.seek(0) ### вернуться к началу файла (раздражает)
all_text = f.read()
### отделить метаданные
контент = all_text.split("X-FileName:")
слова = ""
если len(содержание) > 1:
### убрать знаки препинания
text_string = content[1].translate(string.maketrans("", ""), string.punctuation)
### часть проекта 2: закомментируйте строку ниже
слова = текстовая_строка
### разбить текстовую строку на отдельные слова, составить основу каждого слова,
### и добавьте слово с основой к словам (убедитесь, что есть один
### пробел между каждым словом, состоящим из корней)
обратные слова
деф основной():
ff = открыть("../text_learning/test_email.txt", "r")
текст = parseOutText(ff)
печатать текст
если __name__ == '__main__':
главный()
Привет всем Если вы можете прочитать это сообщение, вы правильно используете parseOutText Пожалуйста, переходите к следующей части проекта
В parseOutText() закомментируйте следующую строку:
words = text_string
Дополните parseOutText() так, чтобы в возвращаемой строке были все слова, полученные с помощью SnowballStemmer (используйте пакет nltk, некоторые примеры, которые я нашел полезными можно найти здесь: http://www. nltk.org/howto/stem.html). Повторно запустите parse_test.py, который будет использовать вашу обновленную функцию parseOutText() — каков теперь результат?
Подсказка: вам нужно разбить строку на отдельные слова, составить основу каждого слова, а затем снова объединить все слова в одну строку.
В [8]:
%%writefile ../tools/parse_out_email_text.py
из nltk.stem.snowball импортировать SnowballStemmer
строка импорта
деф parseOutText (f):
""" учитывая открытый файл электронной почты f, проанализировать весь текст ниже
блок метаданных вверху
(в Части 2 вы также добавите возможности стемпинга)
и вернуть строку, содержащую все слова
в письме (через пробел)
пример использования:
f = открыть ("email_file_name.txt", "r")
текст = parseOutText(f)
"""
f.seek(0) ### вернуться к началу файла (раздражает)
all_text = f.read()
### отделить метаданные
контент = all_text.split("X-FileName:")
слова = ""
если len(содержание) > 1:
### убрать знаки препинания
text_string = content[1]. translate(string.maketrans("", ""), string.punctuation)
### разбить текстовую строку на отдельные слова, составить основу каждого слова,
### и добавьте слово с основой к словам (убедитесь, что есть один
### пробел между каждым словом, состоящим из корней)
из nltk.stem.snowball импортировать SnowballStemmer
стеммер = SnowballStemmer("английский")
words = ' '.join([stemmer.stem(word) для слова в text_string.split()])
обратные слова
деф основной():
ff = открыть("../text_learning/test_email.txt", "r")
текст = parseOutText(ff)
печатать текст
если __name__ == '__main__':
главный()
Перезапись ../tools/parse_out_email_text.py
В vectorize_text.py вы будете перебирать все электронные письма от Криса и от Сары. Для каждого электронного письма отправьте открытое электронное письмо в функцию parseOutText() и верните текстовую строку с основой. Затем сделайте две вещи:
удалите слова подписи («sara», «shackleton», «chris», «germani» — бонусные баллы, если вы сможете понять, почему это «germani», а не «germani»)
добавьте обновленную текстовую строку к word_data — если электронное письмо от Сары, добавьте 0 (ноль) к from_data или добавьте 1, если электронное письмо написал Крис. После завершения этого шага у вас должно быть два списка: один содержит основной текст каждого электронного письма, а второй должен содержать метки, которые кодируют (через 0 или 1), кто является автором этого электронного письма.
Просмотр всех электронных писем может занять некоторое время (5 минут и более), поэтому мы добавили temp_counter, чтобы обрезать сообщения после первых 200 электронных писем. Конечно, как только все заработает, вы захотите просмотреть весь набор данных.
В поле ниже введите строку, полученную для word_data[152].
В [7]:
%load vectorize_text.py
В [2]:
# %%writefile vectorize_text.py
импортный рассол
импорт системы
импортировать повторно
sys.path.append ("../инструменты/" )
из parse_out_email_text импортировать parseOutText
"""
стартовый код для обработки электронных писем от Сары и Криса для извлечения
особенности и подготовьте документы к классификации
список всех писем от Сары находится в списке from_sara
аналогично для писем от Криса (from_chris)
фактические документы находятся в наборе данных электронной почты Enron, который
вы скачали/распаковали в части 0 первого мини-проекта
данные хранятся в списках и упаковываются в файлы рассола в конце
"""
from_sara = открыть ("from_sara. txt", "r")
from_chris = открыть ("from_chris.txt", "r")
from_data = []
слово_данные = []
### temp_counter — это способ ускорить разработку — есть
### тысячи писем от Сары и Криса, так что пробежались по всем
### может занять много времени
### temp_counter помогает просматривать только первые 200 писем в списке
temp_counter = 0
для имени, from_person in [("sara", from_sara), ("chris", from_chris)]:
для пути в from_person:
### смотреть только первые 200 писем при разработке
### когда все заработает, удалите эту строку, чтобы запустить полный набор данных
# temp_counter += 1
# если temp_counter < 200:
путь = "../"+путь[:-1]
#печать пути
электронная почта = открыть (путь, "r")
### используйте parseOutText для извлечения текста из открытого письма
слова = parseOutText (электронная почта)
### используйте str.replace() для удаления всех вхождений слов
#последние два слова — это выбросы, от которых нужно избавиться в следующем уроке, выбор функции.
#Добавляю это из следующего урока, из будущего. Что?
list_rep = ["Сара", "Шеклтон", "Крис", "Германи"]
# list_rep = ["сара", "шеклтон", "крис", "германи","sshacklensf","cgermannsf"]
для e в list_rep:
слова = слова.заменить(е,"")
### добавить текст в word_data
word_data.append(слова)
### добавьте 0 к from_data, если электронное письмо от Сары, и 1, если электронное письмо от Криса
from_data.append(0, если имя == "Сара", иначе 1)
электронная почта.close()
напечатать "письма обработаны"
from_sara.close()
from_chris.close()
# pickle.dump( word_data, open("your_word_data.pkl", "w"))
# pickle.dump( from_data, open("your_email_authors.pkl", "w"))
вывести word_data[152]
### в части 4 выполните векторизацию TfIdf здесь
электронные письма обработаны tjonesnsf Стефани и Сэму нужен календарь nymex
В [3]:
длина печати (слово_данные)
Преобразуйте word_data в матрицу tf-idf, используя преобразование sklearn TfIdf. Удалить английские стоп-слова.
Вы можете получить доступ к сопоставлению между словами и номерами функций, используя get_feature_names(), которая возвращает список всех слов в словаре. Сколько слов?
Обязательно используйте класс векторизатора tf-idf для преобразования word_data. Не забудьте удалить английские стоп-слова при настройке векторизатора.
В [4]:
из стоп-слов импорта nltk.corpus
В [5]:
sw = stopwords.words("english")
В [6]:
из sklearn.feature_extraction.text import TfidfVectorizer векторизатор = TfidfVectorizer (stop_words = "английский", строчные буквы = True) vectorizer.fit_transform(word_data) # bag_words = vectorizer.transform(word_data) напечатать len(vectorizer.get_feature_names())
Какой номер слова 34597 в вашем TfIdf?
(Просто для ясности: если бы вопрос звучал так: «Что такое слово номер 100», мы бы искали слово, соответствующее vocab_list[100]. Массивы с нулевым индексом иногда так запутывают, чтобы говорить о них.