Слова «всегда» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «всегда» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «всегда» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «всегда».
Содержимое:
- 1 Слоги в слове «всегда»
- 2 Как перенести слово «всегда»
- 3 Морфемный разбор слова «всегда» по составу
- 4 Сходные по морфемному строению слова «всегда»
- 5 Синонимы слова «всегда»
- 6 Антонимы слова «всегда»
- 7 Ударение в слове «всегда»
- 8 Фонетическая транскрипция слова «всегда»
- 9 Фонетический разбор слова «всегда» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «всегда»
- 11 Значение слова «всегда»
- 12 Как правильно пишется слово «всегда»
Слоги в слове «всегда»
Количество слогов: 2
По слогам: все-гда
По правилам школьной программы слово «всегда» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
всег-да
По программе института слоги выделяются на основе восходящей звучности:
все-гда
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
г примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «всегда»
все—гда
всег—да
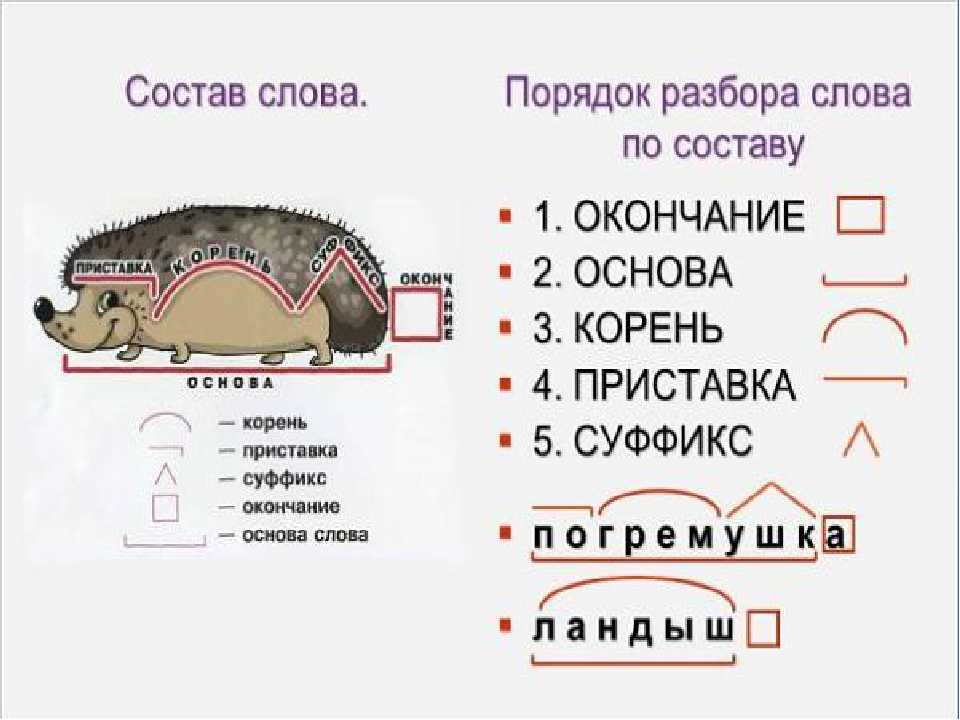
Морфемный разбор слова «всегда» по составу
| всегда | корень |
всегда
Сходные по морфемному строению слова «всегда»
Сходные по морфемному строению слова
Синонимы слова «всегда»
1. вовек
вовек
2. вечно
3. завсегда
4. постоянно
5. издревле
6. ввек
7. навеки
8. навсегда
9. вовеки
10. всечасно
11. неизменно
12. извечно
13. изначала
14. искони
15. завсе
16. извека
17. повсечастно
18. век
19. непрерывно
20. все время
21. вообще
22. повседневно
23. присно
24. выну
25. до скончания времен
26. во веки веков
27. когда угодно
28. во всякое время
29. в любое время
30. в любой момент
31. всякий час
32. бессменно
33. хронически
34. день и ночь
35. круглый год
36. весь век
37. перманентно
38. денно и нощно
39. во все времена
40. как свет стоит
41. от века
42. испокон веков
43. испокон веку
44. спокон веков
45. спокон веку
46. изначально
47. ныне и присно
48. до скончания века
49. до скончания веков
50. до морковкина заговенья
до морковкина заговенья
51. до греческих календ
52. всю жизнь
53. до смерти
54. до самой смерти
55. до гроба
56. до гробовой доски
57. до могилы
58. до самой могилы
59. до последнего вздоха
60. до последнего дыхания
61. до конца дней
62. довеку
63. по гроб жизни
64. всякий раз
65. каждый раз
66. все
67. от века веков
68. веки вечные
69. во всяком случае
70. не переставая
71. ныне и присно и вовеки веков
72. пока бьется сердце
73. безотлыжно
74. бесперечь
Антонимы слова «всегда»
1. никогда
2. случайно
Ударение в слове «всегда»
всегда́ — ударение падает на 2-й слог
Фонетическая транскрипция слова «всегда»
[фс’игда]
Фонетический разбор слова «всегда» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| в | [ф] | согласный, глухой парный, твёрдый, шумный | в |
| с | [с’] | согласный, глухой парный, мягкий, шумный | с |
| е | [и] | гласный, безударный | е |
| г | [г] | согласный, звонкий парный, твёрдый, шумный | г |
| д | [д] | согласный, звонкий парный, твёрдый, шумный | д |
| а | [а] | гласный, ударный | а |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 6 букв и 6 звуков.
Буквы: 2 гласных буквы, 4 согласных букв.
Звуки: 2 гласных звука, 4 согласных звука.
Предложения со словом «всегда»
Снова о нефти, всегда о нефти.
Источник: Энни Уэст, В объятиях незнакомца.
Прислужники отчима всегда разыскивали её и силой возвращали домой.
Источник: Энни Уэст, В объятиях незнакомца.
Ему всегда хорошо удавалось не обращать внимания на ничего не значащие происшествия.
Источник: Энни Уэст, В объятиях незнакомца.
Значение слова «всегда»
ВСЕГДА́ , нареч. Во всякое время, постоянно. (Малый академический словарь, МАС)
Как правильно пишется слово «всегда»
Орфография слова «всегда»
Правильно слово пишется: всегда́
Нумерация букв в слове
Номера букв в слове «всегда» в прямом и обратном порядке:
- 6
в
1 - 5
с
2 - 4
е
3 - 3
г
4 - 2
д
5 - 1
а
6
python — Регулярное выражение для разбора нескольких слов
спросил
Изменено 4 года, 3 месяца назад
Просмотрено 2к раз
У меня есть строки вида ‘Team ScoreA-ScoreB (##%)’
Я ищу метод синтаксического анализа регулярного выражения или строки, который будет анализировать все следующее:
- Команда А 15-10 (30%)
- Команда А 15-10 (45%)
- Те-ам А 30-15 (6%)
- Команда А 10-30 (14%)
- Команда А.
 15-20 (12%)
15-20 (12%)
 15-20 (12%)
15-20 (12%)В основном: {слово/слова/сокращенные слова}{пробел}{числа}{дефис}{числа}{пробел}{(}{числа}{%}{)}
У меня есть: /([ A-Z])\w+\s\d+-\d+\s\(\d+%\)/g , который пока будет захватывать команды из одного слова только с символами.
Это для любительского парсера таблиц. Я также рассматривал попытку разбить строку (однако пробелы означают множественные разделения и соединения) на три части и объединить их, но это кажется неэффективным. 9 — начало строки
(.*?) — Группа 1, соответствующая нулю или более символам, кроме символа новой строки, как можно меньшему числу \s* — ноль или более пробелов (\d+-\d+) — Группа 2 одна или несколько цифр, дефис, одна или несколько цифр \s* \( — буквальное открытие ( (\d+%) — Группа 3, соответствующая 1 или более цифрам + % символ 9(. *?)\s*(\d+-\d+)\s*\((\d+%)\)$’)
s = «Команда А 15-10 (30%)\nКоманда А 15-10 (45%)\nКоманда А 30-15 (6%)\nКоманда А 10-30 (14%)\nКоманда А. 15-20 (12%)»
строки = s.split(«\n»)
для х в строках:
м = п.поиск(х)
если М:
print(«%s, %s, %s»%(м.группа(1),м.группа(2),м.группа(3)))
*?)\s*(\d+-\d+)\s*\((\d+%)\)$’)
s = «Команда А 15-10 (30%)\nКоманда А 15-10 (45%)\nКоманда А 30-15 (6%)\nКоманда А 10-30 (14%)\nКоманда А. 15-20 (12%)»
строки = s.split(«\n»)
для х в строках:
м = п.поиск(х)
если М:
print(«%s, %s, %s»%(м.группа(1),м.группа(2),м.группа(3))) re.findall вернет списки кортежей. Если у вас многострочный ввод, используйте флаг re.MULTILINE при компиляции шаблона.
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Анализ текста с помощью PowerShell (1/3)
Стив Ли
18 января 2019 г. 2 1
2 1
Это первый пост в серии из трех частей.
- Часть 1 :
- Полезные методы класса String
- Введение в регулярные выражения
- Командлет Select-String
- Часть 2:
- Оператор -split
- Оператор -match
- Оператор switch
- Класс регулярных выражений
- Часть 3:
- Реальный мир, полный и немного увеличенный, пример синтаксического анализатора на основе коммутатора
В моем рабочем процессе регулярно возникает задача анализа текста. Это может быть получение маркера из одной строки текста или преобразование текстового вывода собственных инструментов в структурированные объекты, чтобы я мог использовать возможности PowerShell.
Я всегда стремлюсь создать структуру как можно раньше в конвейере, чтобы позже я мог рассуждать о содержимом как о свойствах объектов, а не как тексте по некоторому смещению в строке. Это также помогает при сортировке, поскольку свойства могут иметь правильный тип, поэтому числа, даты и т.
Пользователю PowerShell доступно несколько вариантов, и здесь я привожу обзор наиболее распространенных из них.
Это не текст о том, как создать высокопроизводительный синтаксический анализатор для языка со структурированной грамматикой EBNF. Для этого есть инструменты получше, например ANTLR.
Методы .Net для строки
класса Любая обработка синтаксического анализа строки в PowerShell была бы неполной, если бы в ней не упоминались методы класса строки .
Есть несколько методов, которые я использую чаще других при разборе строк:
| Имя | Описание |
|---|---|
Подстрока (int startIndex) | Извлекает подстроку из этого экземпляра. Подстрока начинается с указанной позиции символа и продолжается до конца строки. |
Подстрока (int startIndex, int length) | Извлекает подстроку из этого экземпляра. Подстрока начинается с указанной позиции символа и имеет указанную длину. Подстрока начинается с указанной позиции символа и имеет указанную длину. |
IndexOf(строковое значение) | Сообщает отсчитываемый от нуля индекс первого вхождения указанной строки в данном экземпляре. |
IndexOf(строковое значение, int startIndex) | Сообщает отсчитываемый от нуля индекс первого вхождения указанной строки в данном экземпляре. Поиск начинается с указанной позиции символа. |
LastIndexOf(строковое значение) | Сообщает отсчитываемый от нуля индекс последнего вхождения указанной строки в данном экземпляре. Часто используется вместе с Substring . |
LastIndexOf (строковое значение, int startIndex) | Сообщает отсчитываемую от нуля позицию индекса последнего вхождения указанной строки в этом экземпляре. Поиск начинается с указанной позиции символа и продолжается в обратном направлении к началу строки. |
Это небольшая часть доступных функций. Возможно, вам стоит потратить время на изучение класса string, так как он очень важен в PowerShell. Документы находятся здесь.
Например, это может быть полезно, когда у нас есть очень большие входные данные, разделенные запятыми, с 15 столбцами, и нас интересует только третий столбец с конца. Если бы мы использовали оператор -split ',' , мы бы создали 15 новых строк и массив для каждой строки. С другой стороны, используя LastIndexOf на входной строке несколько раз, а затем SubString , чтобы получить интересующее значение быстрее и приводит только к одной новой строке.
функция parseThirdFromEnd([string]$line){
$i = $line.LastIndexOf(",") # получить последний разделитель
$i = $line.LastIndexOf(",", $i - 1) # получаем предпоследний разделитель, а также конец интересующего нас столбца
$j = $line.LastIndexOf(",", $i - 1) # получаем разделитель перед нужным столбцом
$j++ # далее вперед после разделителя
$line. SubString($j,$i-$j) # получаем текст искомого столбца
}  SubString($j,$i-$j) # получаем текст искомого столбца
}
SubString($j,$i-$j) # получаем текст искомого столбца
} В этом примере я игнорирую тот факт, что IndexOf и LastIndexOf возвращают -1, если они не могут найти текст для поиска. Из опыта я также знаю, что легко испортить арифметику индекса.
Таким образом, хотя использование этих методов может повысить производительность, они также более подвержены ошибкам и требуют гораздо больше ввода. Я бы прибегал к этому только тогда, когда знаю, что входные данные очень велики, а производительность является проблемой. Так что это не рекомендация и не отправная точка, а то, к чему можно прибегнуть.
В редких случаях я пишу весь синтаксический анализатор на C#. Примером этого является модуль, обертывающий систему контроля версий Perforce, где инструмент командной строки может выводить словари Python. Это двоичный формат, и вариант использования был достаточно сложным, поэтому мне было удобнее использовать язык реализации, проверяемый компилятором.
Регулярные выражения
Почти все параметры синтаксического анализа в PowerShell используют регулярные выражения, поэтому я начну с краткого введения некоторых концепций регулярных выражений, которые будут использоваться позже в этих сообщениях.
Регулярные выражения очень полезно знать при написании простых синтаксических анализаторов, поскольку они позволяют нам выражать интересующие шаблоны и захватывать текст, соответствующий этим шаблонам.
Это очень богатый язык, но вы можете продвинуться довольно далеко, изучив несколько ключевых частей. Я считаю, что сайт Regular-expressions.info является хорошим онлайн-ресурсом для получения дополнительной информации. Он не написан непосредственно для реализации регулярного выражения .net, но большая часть информации действительна для разных реализаций.
| Регулярное выражение | Описание |
|---|---|
* | Ноль или более предшествующих символов. a* соответствует пустой строке, a , aa и т. д., но не b . |
+ | Один или несколько предшествующих символов. a+ соответствует a , aa и т. д., но не пустой строке или д., но не пустой строке или b . |
. | Соответствует любому символу |
[акс1] | Любой из a , x , 1 |
| соответствует любому из a , b , c , d |
\ш | Метасимвол \w используется для поиска символа слова. Словесный символ — это символ от az, AZ, 0-9., включая символ _ (подчеркивание). Он также соответствует вариантам таких символов, как ??? и ??? . |
\Вт | Инверсия \w . Соответствует любому символу, не являющемуся словом |
\с | Метасимвол \s используется для поиска пробела |
\С | Инверсия \s . Соответствует любому непробельному символу Соответствует любому непробельному символу |
\д | Совпадает с цифрами |
\D | Инверсия \d . Соответствует не цифрам |
\б | Соответствует границе слова, то есть положению между словом и пробелом. |
\Б | Инверсия \b . . er\B соответствует er в глаголе , но не # начало строки
\s+ # один или несколько пробелов
(\d+) # захватить одну или несколько цифр в первой группе (индекс 1)
, # запятая
(.+) # захватить один или несколько символов любого типа во второй группе (индекс 2) |
 +)
+)  Matches[0].Groups[1..4].Value # это распространенный способ получения групп вызова select-string
[PSCustomObject] @{
Имя = $ первое
Фамилия = $последняя
Ручка = $ ручка
TwitterFollowers = [число] $followers
}
}
Matches[0].Groups[1..4].Value # это распространенный способ получения групп вызова select-string
[PSCustomObject] @{
Имя = $ первое
Фамилия = $последняя
Ручка = $ ручка
TwitterFollowers = [число] $followers
}
}  -]+) # захватить один или несколько любых символов, кроме `-`, в группу с именем 'last'
- # а '-'
(?
-]+) # захватить один или несколько любых символов, кроме `-`, в группу с именем 'last'
- # а '-'
(?