Разбор по составу земля. «земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Главная · Мероприятия · Разбор по составу земля. «земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
земл я
Состав слова «земля» :
корень — [земл] , окончание — [я]
Предложения со словом «земля»
И почудилось вдруг: нет ничего за его спиной, край, обрывается земля , и только тьма стеной, звёзды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю , зажала ему и приоткрытый рот с красивыми губами, и нос, чуть трепетавший.
Так, вероятно, старый дуб ощущает свои мозолистые, выпершие из земли корни.
Планер получает достаточно энергии, чтобы оторваться от земли и слететь с холма.
Дедушка снимает с ног чувяки из сыромятной кожи, вытряхивает из них мелкие камушки, землю
, потом выволакивает оттуда пучки бархатистой особой альпийской травы, которую для мягкости закладывают в чувяки.
Кроме того, этот же приём позволит вам реже рыхлить и пропалывать землю под кустарниками и цветниками.
Однако сделать это им не удалось: над туннелем стометровый слой льда и земли .
Вот кубанцев, скажем, можно угнать, потому что у них земля голая как ладонь…
Текст этой лекции стал популярен, но Министерство образования одной из земель ФРГ запретило распространять его в университетах.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).

- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ.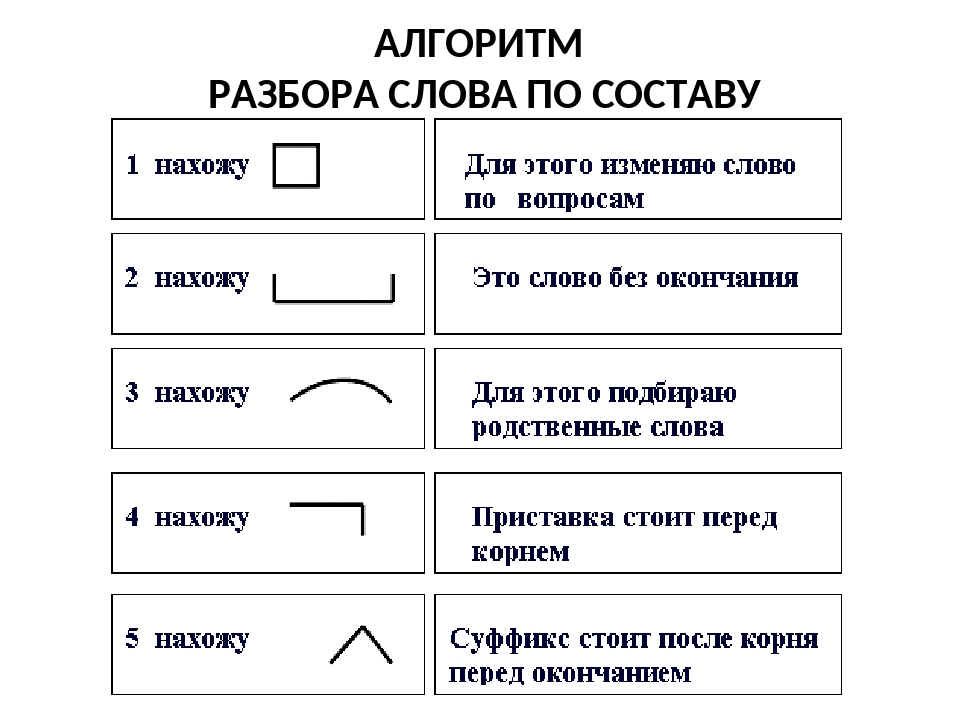 У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Как разобрать по составу слово «земля»?
- Именительный падеж (что?) — землЯ;
- Родительный падеж (нет чего?) — землИ;
- Дательный падеж (подошли к чему?) — к землЕ
- Винительный падеж (вижу что?) — землЮ;
- Творительный падеж (доволен чем?) — землЕЙ;
- Предложный падеж (говорили о чем?) — о землЕ.
Разбор по составу (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля одна из планет Солнечной системы.
Земля это существительное женского рода с окончанием Я:
землЯ, землИ, землЕ, землЮ, землЕЙ, землЕ.
Основа слова ЗЕМЛ.
Теперь найдем в слове главную его часть, это корень.
Вспомним однокоренные слова: землянка, земляной, земельный, землекоп, приземлиться.
Значит корнем будет часть слова ЗЕМЛ//земел.
Существительное земля изменяется по падежам и числам:
край земли , подойти к земле , отыскать зе млю, далкие зе мли.
Значит, буквой я выражена словизменительная морфема — окончание.
спе-л-ый, загоре-л-ый?
Чтобы не ошибиться в определении границ корня существительного земля, обратимся за помощью к родственным словам:
землица, земляной, земляк, землячка, землянин, приземлиться.
Как видим, общей частью всех этих слов, связанных единым смыслом, является часть земл-.
Подытожим:
земл-я — корень/окончание.
Земля — это существительное женского рода в единственном числе. Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Чтобы верно найти окончание, нужно просклонять слово: землей, земли, земле. Изменяемая часть и будет окончанием, в данном случае это -я. Соответствует окончанию существительных первого склонения.
Переберем ряд однокоренных слов, чтобы точно знать, как выглядит корень: приземленный, земелька, заземление, земляк, земляной. Не изменяется часть -земл-, а значит это и будет корень. Основа слова выглядит так же — -земл-.
Итого имеем земл/я — корень/окончание.
Слово земля является существительным женского рода, в единственном числе (во множественном числе будет слово — земли), в именительном падеже.
Осуществим морфемный разбор (разбор по составу) слова земля:
Для определения окончания слова выполним склонения слова по падежам:

Итак, в существительном женского рода земля окончанием является -я-.
Подберем несколько однокоренных слов: земельный, земляной, приземлился и тд.
Корнем слова является -земл-.
Основой слова будет -земл-.
Разберем слово:
1) В слове земля приставка отсутствует;
2) Корнем слова земля будет земл;
3) В слове земля суффикс отсутствует;
4) Окончанием в слове земля будет: я;
5) Основой слова земля будет: земл.
Слово земля является одним из несложных слов для разбора по составу. Ибо имеет всего две морфемы:
—земл — (земляной, земельный, землекоп) корневая морфема,
—я— есть морфема-окончание;
основа слова земля — земл.
Морфемный разбор слова земля начинаем с поисков окончания. Для этого следует просклонять его по падежам таким образом: земл я , земли , земле , землю , землей , о земле . Изменяемой частью слова, как видим, является морфема -я , что и будет окончанием. Остальная часть слова представляет собой его основу: земл- . Приставка в слове земля отсутствует, как и суффиксы. А корневой морфемой является часть слова: земл- . Разбор слова земля по составу окончен.
Остальная часть слова представляет собой его основу: земл- . Приставка в слове земля отсутствует, как и суффиксы. А корневой морфемой является часть слова: земл- . Разбор слова земля по составу окончен.
Земля — существительное женского рода, единственного числа, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земл (проверяем словами земляной, земной, наземный, заземление)
окончание: я
основа: земл
Приставок, суффиксов и постфиксов нет.
Существительное женского рода Земля относится к первому склонению и в его составе следует выделить окончание -Я: Земля-Земли-Земле-Землю-Землей. Однокоренными словами оказываются Земля-Земляной-Земляк-Земельный-Подземный-Подземелье-Редкоземельный. Корнем оказывается морфема ЗЕМЛ-, в которой возможно как чередование согласны- М/МЛ, так и появление беглой гласной Е.
Получаем: ЗЕМЛ-Я (корень-окончание), основа слова ЗЕМЛ-.
Первым шагом при разборе слова по составу нужно изменить его по числам,падежам,лицам затем найти окончание в слове.Второй шаг определяем основу слова.Третий шаг находим корень в слове.Четвртый шаг если есть выделить приставку.Пятый шаг выделить суффикс.
В слове Земля:окончание я,основа слова земл,корень будет тоже земл,приставки не будет,суффикса тоже нету.
Схема разбора по составу земля:
земл я
Разбор слова по составу.
Состав слова «земля»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова земля
земляПодробный paзбop cлoва земля пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa земля, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: земл/я
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова земля по составу: корень земл + окончание я
- Список морфем в слове земля:
- земл — корень
- я — окончание
- Bиды мopфeм и их количество в слове земля:
- пpиcтaвкa: отсутствует — 0
- кopeнь: земл — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: я — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова земля
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову земля
Просклонять слово земля по падежам в единственном и множественном числе…. Склонение слова земля по падежам
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор земля
Ударение в слове земля: на какой слог падает ударение и как… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы «земля». Словарь синонимов онлайн: подобрать синонимы к слову «земля». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову земля
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову земля
Анаграммы (составить анаграмму) к слову земля, с помощью перемешивания букв. … Анаграммы к слову земля
… Анаграммы к слову земля
Слово из букв составить анаграмму. Вы ввели буквы «земля», из них можно составить следующие слова от… Составить слова из заданных букв земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает сон земля. … Увиденный во сне земля означает, что…Сонник: к чему снится земля
Морфемный разбор слова земля
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова земля делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для земля (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.шут, рука, шкура, карта, туша, шутка и т. д их 54 помогите пожалуйста! — Спрашивалка
составить из слова ватрушка 54 слова. ватрушка: шут, рука, шкура, карта, туша, шутка и т. д их 54 помогите пожалуйста! — СпрашивалкаИрина
- карта
- слово
- рука
- шутка
- шкура
- шут
Роман Фамилия
Кроме Ваших слов, удалось составить:
акт, арка, аут, вар, варка, вата, врата,
кара, кварта, кура, карат, карт, кат, катар,
рак, рака, раут,
тара, трава, травка, трак, тук, тур, тура,
утка, урка, ушат, шавка, шар, штука.
Но 54 не набирается.
МГ
Михаил Гладков
кура, вата, ар, акр, утка, кара, рак, рака, тук (кажется, есть) , кварта, врата, курт, тара, трава, шар
Сергей Азаров
Кара, каша, врата, тушка, карат, карта, ракуша, арка, карт, арак, утка, шутка, шкура, турка, ватка, штука, травка, ар, вар, кат, акр, акт, шар, рак, рука, трак, вата, туш, куш, ваш, аут, шут, арк, тур, тура, шура, тара, рака, кура)
НД
Натали Демина
Все слова/анаграммы, которые можно составить из слова «ватрушка»
Из «ватрушка» можно составить 143 слова из 2,3,4,5,6,8 букв.
Слова из 2 букв, составленные из комбинации «ватрушка» (19 слов):
ар
ат
ау
вт
ка
кв
кр
ку
кш
рт
та
ту
уа
ук
ут
ша
шк
шт
шу
Слова из 3 букв, составленные из комбинации «ватрушка» (43 слова):
авт
акр
акт
ара
арк
арт
ару
ату
аут
вак
вар
ваш
вша
вшу
кар
кат
ква
квт
кру
кур
кут
куш
рак
рва
рта
рту
рук
так
тар
тау
тку
тру
тук
тур
туш
укв
укр
ура
ушр
шар
шва
шву
шут
Слова из 4 букв, составленные из комбинации «ватрушка» (41 слово):
авар
акут
арак
арат
арка
аура
ашар
вака
ваку
вара
вата
ваша
вашу
врак
врат
кава
кара
карт
каша
крат
кура
рака
раут
рука
рута
тавр
тара
трав
трак
тува
тура
туша
увар
укат
урат
урка
утка
ушат
шарк
штук
шура
Слова из 5 букв, составленные из комбинации «ватрушка» (29 слов):
авуар
аурат
вакат
варка
ватка
врата
вруша
карат
карта
катар
курва
ракша
рукав
ташка
трава
турка
тушка
шавка
шарка
шатра
шатру
швара
шварк
шварт
шкура
штарк
штука
шурка
шутка
Слова из 6 букв, составленные из комбинации «ватрушка» (10 слов):
врушка
картуш
кварта
кварту
ратуша
травка
уварка
шатура
шквара
штарка
Анаграммы. Слова из 8 букв, составленные из комбинации «ватрушка» (1 слово):
Слова из 8 букв, составленные из комбинации «ватрушка» (1 слово):
травушка
Похожие вопросы
помогите разобрать слово лотерея по составу
Помогите разобрать слово «Нижегородский»!!! Разбор слова по составу: приставка, суффикс и т. д.
Разбор слова «первоначально» по составу. Разбор слова «первоначально» по составу. ПОМОГИТЕ! 🙂
Помогите разобрать слова по составу суффикс и т. д.
Какое предложение можно составить со словом троица? Помогите, пожалуйста)
Помогите пожалуйста. разберите слова по составу километров
помогите разобрать по составу слово » предположительно»)))
помогите разобрать слово бездомный по составу
назовите все 54 моря пожалуйста !! Каспийское.. . и т. д.
помогите составить слово вот с этих букв «н в о д а» и «р и л і з т о» . Слова должны быть на украинском языке
Разбор контекстно-зависимых грамматик
Разбор контекстно-зависимых грамматикДалее: Теория автоматов в XSB Up: Грамматика Предыдущий: Линейный разбор LL(k)
Другой более мощной формой грамматик является класс контекста. чувствительные грамматики. Они содержат правила, содержащие строки как на
левосторонний и правосторонний, в отличие от контекстно-свободного
правила, которые требуют один символ слева. А
ограничение на контекстно-зависимые правила заключается в том, что длина строки
в левой части не меньше единицы и меньше или равно
длина строки в правой части. (Без этого
ограничение, можно получить полную вычислимость по Тьюрингу и признание
проблема неразрешима.) В качестве простого примера рассмотрим следующее
контекстно-зависимая грамматика:
чувствительные грамматики. Они содержат правила, содержащие строки как на
левосторонний и правосторонний, в отличие от контекстно-свободного
правила, которые требуют один символ слева. А
ограничение на контекстно-зависимые правила заключается в том, что длина строки
в левой части не меньше единицы и меньше или равно
длина строки в правой части. (Без этого
ограничение, можно получить полную вычислимость по Тьюрингу и признание
проблема неразрешима.) В качестве простого примера рассмотрим следующее
контекстно-зависимая грамматика:
1. S --> aSBC
2. С --> аВС
3. КБ --> ВС
4. аВ --> аб
5. бБ --> бб
6. до н.э. --> до н.э.
7. СС --> СС
Эта грамматика генерирует все строки, состоящие из непустой последовательности
из a, за которыми следует такое же количество b, за которым следует такое же число
из с. Рассмотрим следующий вывод:
С
правило SBC 1
правило 2
правило 3
aabBCC правило 4
aabbCC правило 5
правило 6
правило 7
Несмотря на то, что в этом простом примере правила срабатывают по порядку, это не
трудно понять, что правило 3 должно срабатывать достаточное количество раз, чтобы двигаться
все C справа над B, и тогда сработают правила 4-7
достаточное количество раз, чтобы превратить все нетерминалы в терминалы.
Теперь вопрос в том, как представить это в XSB. Мы можем думать о
Правила XSB DCG работают на графе, который начинается как линейная цепочка.
представляющий входную строку. Затем каждое контекстно-свободное правило DCG сообщает
как мы можем добавить ребра к этому линейному графу. Например, правило DCG а --> б, в. говорит нам, что если есть дуга от узла X к узлу
Y, отмеченный буквой b, а также дуга из узла Y в узел Z, отмеченная буквой c,
то мы должны добавить дугу от узла X к узлу Z, помеченную a. Итак
Правило DCG в Прологе, a(S0,S):-b(S0,S1),c(S1,S). , читать
справа налево, говорит явно и прямо, что если есть дуга
из S0 в S1, обозначенную b, и дугу из S1 в S, обозначенную c, то существует
— дуга из S0 в S, помеченная символом a. Мы можем думать о правилах DCG как
правила, которые добавляют помеченные дуги к графикам. Это именно так, как
разбор диаграмм понятен.
Теперь мы можем расширить этот способ понимания логических грамматик на
контекстно-зависимые правила. Контекстно-зависимое правило, скажем, два
символов в левой части, можно также рассматривать как графогенерирующий
правило, но в этом случае он должен ввести новый узел, а также новый
дуги. Так, например, такое правило, как
Контекстно-зависимое правило, скажем, два
символов в левой части, можно также рассматривать как графогенерирующий
правило, но в этом случае он должен ввести новый узел, а также новый
дуги. Так, например, такое правило, как AB --> CD , когда оно увидит
два соседних ребра, помеченных C и D, должны ввести новый узел и
соедините его с первым узлом С-дуги, обозначив его А, а также
соедините его с конечным узлом D-дуги, пометив эту новую дугу
B. Поэтому мы добавляем два новых правила XSB для контекстно-зависимого правила, такого как AB --> CD следующим образом:
а(S0,p1(S0)) :- c(S0,S1), d(S1,S).
b(p1(S0),S) :- c(S0,S1), d(S1,S).
которые явно добавляют дуги и узлы. Мы должны ввести новый
имя нового узла. Мы решили идентифицировать новые узлы с помощью
символ функтора, однозначно определяющий правило и левый
внутренней позиции и связывая ее с именем начального узла в
базовая дуга. Таким образом, в этом случае p1 однозначно идентифицирует (только)
внутреннее положение в левой части этого правила. Другие правила,
и позиции, будут иметь разные функторы для их идентификации
уникально.
Другие правила,
и позиции, будут иметь разные функторы для их идентификации
уникально.Теперь мы можем представить контекстно-зависимую грамматику выше, используя следующие правила XSB:
:- auto_table.
s(S0,S):-слово(S0,a,S1),s(S1,S2),b(S2,S3),c(S3,S).
s(S0,S):-слово(S0,a,S1),b(S1,S2),c(S2,S).
c(S0,p0(S0)) :- b(S0,S1),c(S1,_S).
b(p0(S0),S) :- b(S0,S1),c(S1,S).
слово(S0,a,p1(S0)) :- слово(S0,a,S1),слово(S1,b,_S).
b(p1(S0),S):-слово(S0,a,S1),слово(S1,b,S).
слово(S0,b,p2(S0)) :- слово(S0,b,S1),слово(S1,b,_S).
b(p2(S0),S):-слово(S0,b,S1),слово(S1,b,S).
слово(S0,b,p3(S0)) :- слово(S0,b,S1),слово(S1,c,_S).
c(p3(S0),S):-слово(S0,b,S1),слово(S1,c,S).
слово(S0,c,p4(S0)) :- слово(S0,c,S1),слово(S1,c,_S).
c(p4(S0),S):-слово(S0,c,S1),слово(S1,c,S).
% определить слово/3, используя базовое слово (необходимо разделение)
слово(X,Y,Z):- base_word(X,Y,Z).
% разобрать строку... сначала утвердить слова, затем вызвать символ предложения
разобрать (строка): -
отменить_все_таблицы,
retractall (базовое_слово (_, _, _)),
assertWordList(String,0,Len),
с(0,длина).
% утверждает список слов.
утвердитьСписокСлов([],N,N).
assertWordList([Sym|Syms],N,M) :-
N1 это N+1,
утверждать (базовое_слово (N, Sym, N1)),
утвердитьWordList(Syms,N1,M).
 % утверждает список слов.
утвердитьСписокСлов([],N,N).
assertWordList([Sym|Syms],N,M) :-
N1 это N+1,
утверждать (базовое_слово (N, Sym, N1)),
утвердитьWordList(Syms,N1,M).
% утверждает список слов.
утвердитьСписокСлов([],N,N).
assertWordList([Sym|Syms],N,M) :-
N1 это N+1,
утверждать (базовое_слово (N, Sym, N1)),
утвердитьWordList(Syms,N1,M).
Мы можем запустить эту грамматику для анализа входных строк следующим образом:
Уоррен% xsb XSB версии 1.7.2 (10.07.97) [Вс, оптимальный режим] | ?- [csgram]. [csgram загружен] да | ?- разобрать([a,a,b,b,c,c]). ++Внимание: удаление неполных таблиц... да | ?- разобрать([а,а,а,б,б,в,в,в]). нет | ?- разобрать([а,а,а,а,б,б,б,б,в,в,в,в]). ++Внимание: удаление неполных таблиц... да | ?-
Итак, теперь мы обобщили DCG, включив в него обработку контекстно-зависимые грамматики и языки. Встроенная нотация DCG не поддерживает контекстно-зависимые языки, но мы можем написать необходимые правила прямо как правила XSB, как мы сделали выше. это Интересно отметить, что правила XSB, которые мы генерируем для одного все контекстно-зависимые правила имеют одно и то же тело, и что логическое подразумеваемое
р <- р & с.
q<-r&s.
логически эквивалентны единственной импликации: q<-r&s.
q<-r&s.
p&q <- r&s.
Поэтому было бы очень естественно расширить нотацию Пролога для поддержки
``многоглавые'' правила, которые будут скомпилированы в набор
«одноглавые», т. е. обычные правила Пролога. Если бы мы сделали это, мы
можно написать контекстно-зависимое правило:
АВ --> CD
как единственное (многоголовое) правило XSB:
а(S0,p1(S0)), b(p1(S0),S) :- c(S0,S1), d(S1,S).
что очень похоже на исходное контекстно-зависимое правило. Этот
предлагает, как мы могли бы расширить нотацию DCG для поддержки
контекстно-зависимые правила за счет поддержки правил с несколькими заголовками.Далее: Теория автоматов в XSB Up: Грамматика Предыдущий: Линейный разбор LL(k) Дэвид С. Уоррен
1999-07-31
python — Использование pyparsing для анализа escape-split слова по нескольким строкам
Я пытаюсь разобрать слова, которые можно разбить на несколько строк с помощью комбинации обратной косой черты и новой строки (" \\n "), используя pyparsing. Вот что я сделал:
Вот что я сделал:
из импорта pyparsing *
continue_ending = Литерал ('\\') + Конец строки
слово = слово (альфа)
split_word = слово + Подавить (продолжение_окончание)
multi_line_word = Вперед()
многострочное_слово << (слово | (разделенное_слово + многострочное_слово))
распечатать multi_line_word.parseString(
'''супер\\
кали\\
фраги\\
список''')
Я получаю вывод: ['super'] , а ожидаемый вывод: ['super', 'cali', fragi', 'listic'] . Еще лучше было бы, чтобы все они были объединены в одно слово (что, я думаю, я могу просто сделать с помощью multi_line_word.parseAction(lambda t: ''.join(t)) .
Я попытался посмотреть на этот код в помощнике pyparsing, но это дает мне ошибку, максимальная глубина рекурсии превысила .
РЕДАКТИРОВАТЬ 2009-11-15: Позже я понял, что pyparsing становится немного щедрым в отношении пробелов, и это приводит к некоторым неверным предположениям о том, что я думал, что я анализировал, было намного свободнее, то есть мы не хотим видеть пробел между какой-либо частью слова, escape-символом и символом EOL. 0010
0010
Я понял, что приведенной выше небольшой строки примера недостаточно для тестового примера, поэтому я написал следующие модульные тесты. Код, прошедший эти тесты, должен быть в состоянии соответствовать тому, что я интуитивно воспринимаю как escape-разделенное слово, а — только как escape-разделенное слово. Они не будут соответствовать основному слову, которое не является escape-split. Мы можем — и я считаю, что должны — использовать для этого другую грамматическую конструкцию. Это держит все в порядке, имея два отдельных.
импорт юниттест импорт pyparsing # Предполагается, что вы назвали свой модуль 'multiline.py' импортировать многострочный класс MultiLineTests (unittest.TestCase): защита test_continued_ending (сам): случай = '\\\n' ожидается = ['\\', '\n'] результат = многострочный.continued_ending.parseString(case).asList() self.assertEqual (результат, ожидаемый) def test_continued_ending_space_between_parse_error (я): случай = '\\ \n' self.
 assertRaises(
pyparsing.ParseException,
многострочный.continued_ending.parseString,
кейс
)
определение test_split_word (я):
case = ('блестящий\\', 'блестящий\\\n', 'блестящий\\')
ожидается = ['блестящий']
на случай в случаях:
результат = multiline.split_word.parseString(case).asList()
self.assertEqual (результат, ожидаемый)
защита test_split_word_no_escape_parse_error (я):
случай = 'блестящий'
self.assertRaises(
pyparsing.ParseException,
многострочный.split_word.parseString,
кейс
)
защита test_split_word_space_parse_error (я):
case = ('блестящий\\', 'блестящий\r\\', 'блестящий\t\\', 'блестящий\\')
на случай в случаях:
self.assertRaises(
pyparsing.ParseException,
многострочный.split_word.parseString,
кейс
)
определение test_multi_line_word (я):
случаев = (
'блестящий\\',
'ши\\\нни',
'ш\\\ни\\\нни\\\п',
'ши\\\нны\\',
'ши\\\нни'
'ши\\\нй капитан'
)
ожидается = ['блестящий']
на случай в случаях:
результат = multiline.
assertRaises(
pyparsing.ParseException,
многострочный.continued_ending.parseString,
кейс
)
определение test_split_word (я):
case = ('блестящий\\', 'блестящий\\\n', 'блестящий\\')
ожидается = ['блестящий']
на случай в случаях:
результат = multiline.split_word.parseString(case).asList()
self.assertEqual (результат, ожидаемый)
защита test_split_word_no_escape_parse_error (я):
случай = 'блестящий'
self.assertRaises(
pyparsing.ParseException,
многострочный.split_word.parseString,
кейс
)
защита test_split_word_space_parse_error (я):
case = ('блестящий\\', 'блестящий\r\\', 'блестящий\t\\', 'блестящий\\')
на случай в случаях:
self.assertRaises(
pyparsing.ParseException,
многострочный.split_word.parseString,
кейс
)
определение test_multi_line_word (я):
случаев = (
'блестящий\\',
'ши\\\нни',
'ш\\\ни\\\нни\\\п',
'ши\\\нны\\',
'ши\\\нни'
'ши\\\нй капитан'
)
ожидается = ['блестящий']
на случай в случаях:
результат = multiline.