Морфологический разбор слова «принесли»
Часть речи: Глагол в личной форме
ПРИНЕСЛИ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПРИНЕСТИ»
| Слово | Морфологические признаки |
|---|---|
| ПРИНЕСЛИ |
|
Все формы слова ПРИНЕСЛИ
ПРИНЕСТИ, ПРИНЕС, ПРИНЕСЛА, ПРИНЕСЛО, ПРИНЕСЛИ, ПРИНЕСУ, ПРИНЕСЕМ, ПРИНЕСЕШЬ, ПРИНЕСЕТЕ, ПРИНЕСЕТ, ПРИНЕСУТ, ПРИНЕСШИ, ПРИНЕСЯ, ПРИНЕСЕМТЕ, ПРИНЕСИ, ПРИНЕСИТЕ, ПРИНЕСШИЙ, ПРИНЕСШЕГО, ПРИНЕСШЕМУ, ПРИНЕСШИМ, ПРИНЕСШЕМ, ПРИНЕСШАЯ, ПРИНЕСШЕЙ, ПРИНЕСШУЮ, ПРИНЕСШЕЮ, ПРИНЕСШЕЕ, ПРИНЕСШИЕ, ПРИНЕСШИХ, ПРИНЕСШИМИ, ПРИНЕСЕННЫЙ, ПРИНЕСЕННОГО, ПРИНЕСЕННОМУ, ПРИНЕСЕННЫМ, ПРИНЕСЕННОМ, ПРИНЕСЕН, ПРИНЕСЕННАЯ, ПРИНЕСЕННОЙ, ПРИНЕСЕННУЮ, ПРИНЕСЕННОЮ, ПРИНЕСЕНА, ПРИНЕСЕННОЕ, ПРИНЕСЕНО, ПРИНЕСЕННЫЕ, ПРИНЕСЕННЫХ, ПРИНЕСЕННЫМИ, ПРИНЕСЕНЫ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПРИНЕСЛИ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «принесли»
1
Вошел офицер, вошел конвой,
Тёмный путь, Николай Вагнер, 1890г.
2
Принесли бельё, принесли чай, мой сосед пропал, я перекусила.
Мой дом на Урале, Татьяна Нелюбина, 2015г.
3
Через четверть часа нам принесли целый десерт из груш, фиг, апельсинов, фиников, принесли засахаренные фрукты, принесли бокалы и шампанское.
Темное дело. Т. 2, Николай Вагнер, 1881-1884г.
4
Очень хотелось мне принести сюда диссертацию, а потом хотелось принести синенькую тетрадку, но сделать этого я не мог.
Звездный билет (сборник), Василий Аксенов
5
А тебе, балабоша, – повернулась она к Крюкову, – принести дрова, растопить печь, принести воду два ведра и…
Жизнь ни за что. Книга первая, Алексей Сухих
Найти еще примеры предложений со словом ПРИНЕСЛИ
Контрольный диктант в 8 классе № 4 | Сборник диктантов по Русскому языку в 8 классе с русским языком обучения
Цель:
проверить знания, умения
и навыки учащихся
на начало учебного
года за курс
5-7 классов.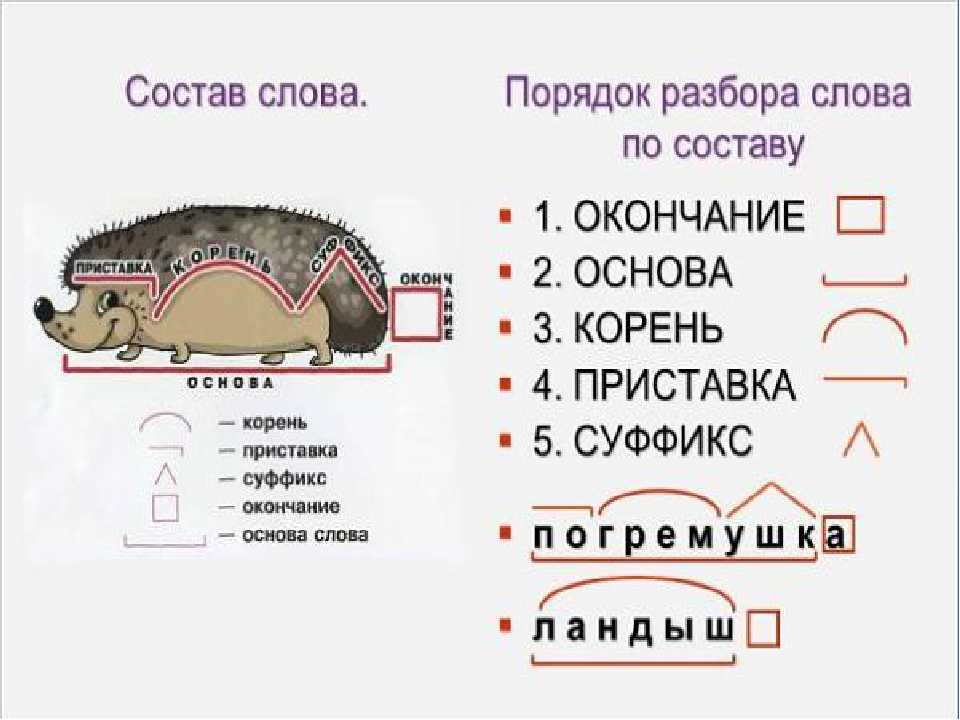
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— н-нн в прилагательных;
— не с прилагательными, наречиями и глаголами;
— написание производных предлогов;
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
— разбора по составу слова;
— умения
подбирать проверочные слова.
Диктант
Однажды нам в подарок принесли берёзку, выкопанную с корнем. Мы посадили её в ящик с землёй и поставили в комнате у окна. Скоро ветки берёзы поднялись, и вся она повеселела.
В саду поселилась осень. Горели пурпуром клёны, порозовел кустарник, и кое-где на берёзках появились жёлтые пряди. Но у нашего деревца мы не замечали никаких признаков увядания.
Ночью пришёл первый заморозок. Я проснулся рано, оделся и вышел в сад. Разгорался рассвет, синева на востоке сменилась багровой мглой. Берёзы за одну ночь пожелтели до самых верхушек, и листья осыпались с них частым печальным дождём.
В комнате при бледном свете зари я увидел, что и наша берёзка стала лимонной. Комнатная теплота не спасла её.
Через день она облетела вся, как будто не хотела отставать от своих подруг.
Последняя память
о лете исчезла.
(127 слов) (По К. Паустовскому)
Грамматические задания
1. Озаглавить текст.
2. Выполнить фонетический разбор слова:
1-й вариант: берёзка 2-й вариант: деревце
3. Разобрать слова по составу:
Выкопанную, горели — 1-й вариант лимонной, посадили — 2-й вариант
4. Объяснить значение:
1-й вариант: желтые пряди 2-й вариант: лимонная берёзка
5. Сделайте синтаксический разбор предложения:
Мы посадили её в ящик с землёй и поставили в комнате у окна
. — 1-й вариантНо у нашего деревца мы не замечали никаких признаков увядания. — 2-й вариант
6. Составить предложение с прямой речью на тему диктанта.
parsing — Как разобрать текстовый файл с помощью C#
Под форматированием текста я имел в виду нечто более сложное.
Сначала я начал вручную добавлять 5000 строк из текстового файла, для которого я задаю этот вопрос, в свой проект.
Текстовый файл содержит 5000 строк разной длины. Например:
1 1 ITEM_ETC_GOLD_01 골드(소) xxx xxx xxx_TT_DESC 0 0 3 3 5 0 180000 3 0 1 0 0 255 1 1 0 0 0 0 0 0 0 -1 0 -1 0 -1 0 -1 0 -1 0 0 0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_money_small.bsr xxx xxx xxx 0 2 0 0 1 0 0.0 0.0 0.0 0.0 0.0 0.0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0 0 0 0 0 0 0 0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 1,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0, 표현할 골드의 양(param1이상) -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх 0 0 1 4 item_etc_hp_potion_01 hp 회복 약초 xxx sn_item_etc_hp_potion_01 sn_item_etc_hp_potion_01_tt_desc 0 0 3 3 1 1 180000 3 0 1 1 255 3 1 0 0 60 0 0 1 21 -1 0 -1 0.0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_bag.bsr item\etc\hp_potion_01.ddj xxx xxx 50 2 0 0 1 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0,0 0,0 0,0 0,0 0,0 0 0 0 0 0 0 0 0 0 0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 120 л.с. 회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 ххх -1 ххх -1 ххх 0 0 1 5 ITEM_ETC_HP_POTION_02 HP 회복약 (소) xxx SN_ITEM_ETC_HP_POTION_02 SN_ITEM_ETC_HP_POTION_02_TT_DESC 0 0 3 3 1 1 180000 3 0 1 1 1 255 3 1 0 3 0 1 0 0 110-1 0 -1 0 -1 0 -1 0 -1 0 0 0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_bag.bsr item\etc\hp_potion_02.ddj xxx xxx 50 2 0 0 2 0 0.0 0.0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0 0 0 0 0 0 0 0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0, 0.0 0.0 0.0 220 HP회복양 0 HP회복양(%) 0 MP회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx - 1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх 0 0

 0 0.0 0.0 220 HP회복양 0 HP회복양(%) 0 MP회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx - 1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх 0 0
0 0.0 0.0 220 HP회복양 0 HP회복양(%) 0 MP회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx - 1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх -1 ххх 0 0
Текст между первым символом (1) и вторым символом (1/4/5) не является пробелом, это табуляция. В этом текстовом файле нет пробелов.
Что я хочу:
Я хочу получить второе целое число (в трех строках, которые я разместил выше, вторые целые числа равны 1,4 и 5) и строку в середине каждой строки, указывающую путь (она начинается с «item\» и заканчивается расширением файла «.ddj»).
Моя проблема:
Когда я гуглю «Форматирование текста на С#» — все, что я получаю, это как открыть текстовый файл и как написать текстовый файл на С#. Я не знаю, как искать текст внутри текстового файла .Также я не могу найти первое целое число, потому что, если это небольшое целое число, как в трех строках, которые я разместил выше, я не смогу найти правильное местоположение, потому что, например, «1» может существовать в другом месте .
Мой вопрос:
Было бы лучше, если бы я написал программу, которая удаляла бы все, кроме того, что мне нужно.
Другим способом, на мой взгляд, является прямой поиск внутри этого файла, но, как я уже упоминал выше, я могу получить неправильное местоположение второго целого числа, если оно слишком низкое.
Подскажите что-нибудь, не могу все это вручную отформатировать.
разбор — Поиск текста в PDF с помощью Python?
спросил
Изменено 2 месяца назад
Просмотрено 137 тысяч раз
Проблема
Я пытаюсь определить, к какому типу относится документ (например, заявление, переписка, повестка в суд и т. д.), выполняя поиск по его тексту, предпочтительно используя Python. Все PDF-файлы доступны для поиска, но я не нашел решения для его анализа с помощью python и применения скрипта для его поиска (если не считать сначала преобразования его в текстовый файл, но это может быть ресурсоемким для n документов).
Все PDF-файлы доступны для поиска, но я не нашел решения для его анализа с помощью python и применения скрипта для его поиска (если не считать сначала преобразования его в текстовый файл, но это может быть ресурсоемким для n документов).
Что я уже сделал
Я изучил документацию по pypdf, pdfminer, Adobe pdf и любые вопросы, которые смог найти (хотя ни один из них, похоже, не помог решить эту проблему напрямую). PDFminer, похоже, обладает наибольшим потенциалом, но после прочтения документации я даже не знаю, с чего начать.
Существует ли простой и эффективный метод чтения PDF-текста по страницам, строкам или всему документу? Или любые другие обходные пути?
- питон
- разбор
- текст
2
Это называется интеллектуальным анализом PDF, и это очень сложно, потому что:
- Формат PDF предназначен для печати, а не для анализа. Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).
- Существует множество программ для создания PDF-файлов, многие из которых неисправны.
 Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).
Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).Такие инструменты, как PDFminer, используют эвристику для повторной группировки букв и слов в зависимости от их положения на странице. Я согласен, интерфейс довольно низкоуровневый, но он имеет больше смысла, когда вы знаете какую проблему они пытаются решить (в конце концов, важно выбрать, насколько близко от соседей должна быть буква/слово/строка, чтобы считаться частью абзаца).
Дорогой альтернативой (с точки зрения времени/мощности компьютера) является создание изображений для каждой страницы и передача их в OCR. Возможно, стоит попробовать, если у вас очень хорошее OCR.
Итак, мой ответ — нет, не существует простого и эффективного метода извлечения текста из PDF-файлов — если ваши документы имеют известную структуру, вы можете точно настроить правила и получить хорошие результаты, но это всегда азартная игра.
Я бы очень хотел оказаться неправым.
[update]
Ответ не изменился, но недавно я участвовал в двух проектах: один из них использует компьютерное зрение для извлечения данных из отсканированных больничных бланков. Другой извлекает данные из судебных протоколов. Что я узнал:
В 2018 году компьютерное зрение станет доступным для простых смертных. Если у вас есть хороший образец уже классифицированных документов, вы можете использовать OpenCV или SciKit-Image для извлечения признаков и обучения классификатора машинного обучения для определения типа документа. является.
Если PDF-файл, который вы анализируете, доступен для поиска, вы можете очень далеко извлечь весь текст, используя программное обеспечение, такое как pdftotext, и байесовский фильтр (алгоритм того же типа, который используется для классификации СПАМ).

Таким образом, не существует надежного и эффективного метода извлечения текста из PDF-файлов, но он может вам и не понадобиться для решения поставленной задачи (классификация типов документов).
4
Я совсем новичок, но у меня работает этот скрипт:
# импортировать пакеты
импортировать PyPDF2
импортировать повторно
#открываем pdf файл
читатель = PyPDF2.PdfReader("test.pdf")
# получить количество страниц
num_pages = len(reader.pages)
# определить ключевые термины
строка = "Социальные сети"
# извлечь текст и выполнить поиск
для страницы в reader.pages:
rext = page.extract_text()
# печать (текст)
res_search = re.search(строка, текст)
печать (res_search)
4
Я написал обширные системы для компании, в которой я работаю, для преобразования PDF-файлов в данные для обработки (счета-фактуры, расчеты, отсканированные билеты и т. д.), и @Paulo Scardine прав — не существует полностью надежного и простого способа сделай это. Тем не менее, самый быстрый, надежный и наименее трудоемкий способ — использовать
д.), и @Paulo Scardine прав — не существует полностью надежного и простого способа сделай это. Тем не менее, самый быстрый, надежный и наименее трудоемкий способ — использовать pdftotext , часть набора инструментов xpdf. Этот инструмент быстро преобразует PDF-файлы с возможностью поиска в текстовый файл, который вы можете читать и анализировать с помощью Python. Подсказка: используйте -макет аргумент. И, кстати, не все PDF-файлы доступны для поиска, а только те, которые содержат текст. Некоторые PDF-файлы содержат только изображения без текста.
4
Недавно я начал использовать ScraperWiki, чтобы делать то, что вы описали.
Вот пример использования ScraperWiki для извлечения данных PDF.
Функция scraperwiki.pdftoxml() возвращает структуру XML.
Затем вы можете использовать BeautifulSoup, чтобы преобразовать его в навигационное дерево.
Вот мой код для —
импорта scraperwiki, urllib2
из bs4 импортировать BeautifulSoup
защита send_Request (url):
#Получить содержимое, независимо от того, является ли файл HTML, XML или PDF
pageContent = urllib2. urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
 urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
Этот код напечатает большую уродливую кучу тегов .
Каждая страница отделена , если вас это утешит.
Если вам нужен контент внутри тегов , который может включать заголовки, заключенные, например, в , используйте line.contents
Если вам нужна только каждая строка текста, не включая теги , используйте line. getText()
getText()
Это грязно и болезненно, но это будет работать для PDF-документов с возможностью поиска. До сих пор я нашел это точным, но болезненным.
2
Вот решение, которое мне показалось удобным для этой проблемы. В переменной text вы получаете текст из PDF для поиска в нем. Но я также сохранил идею выделения текста ключевыми словами, как я нашел на этом сайте: https://medium.com/@rqaiserr/how-to-convert-pdfs-into-searchable-key-words-with-python. -85aab86c544f откуда я взял это решение, хотя сделать nltk было не очень просто, оно может пригодиться для дальнейших целей:
импорт PyPDF2
импортировать текст
из nltk.tokenize импортировать word_tokenize
из nltk.corpus импортировать стоп-слова
def searchInPDF (имя файла, ключ):
вхождения = 0
pdfFileObj = открыть (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
num_pages = pdfReader.numPages
количество = 0
текст = ""
в то время как количество < num_pages:
pageObj = pdfReader. getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
 getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
Я согласен с @Paulo Сбор данных в формате PDF — это огромная проблема. Но вы можете добиться успеха с pdftotext , который является частью бесплатного набора Xpdf:
http://www.foolabs.com/xpdf/download.html
Этого должно быть достаточно для ваших целей, если вы просто поиск отдельных ключевых слов.
pdftotext — это утилита командной строки, но очень простая в использовании. Это даст вам текстовые файлы, с которыми вам будет легче работать.
Это даст вам текстовые файлы, с которыми вам будет легче работать.
Если вы используете bash, есть хороший инструмент под названием pdfgrep, Поскольку это находится в репозитории apt, вы можете установить это с помощью:
sudo apt install pdfgrep
Он хорошо удовлетворил мои требования.
Поиск ключевых слов в PDF-файлах — непростая задача. Я пытался использовать библиотеку pdfminer с очень ограниченным успехом. Это в основном потому, что PDF-файлы являются воплощением столпотворения, когда дело доходит до структуры. Все в PDF может стоять отдельно или быть частью горизонтального или вертикального раздела, назад или вперед. У Pdfminer были проблемы с переводом одной страницы, не распознаванием шрифта, поэтому я попробовал другое направление — оптическое распознавание символов документа. Это сработало почти идеально.
Wand преобразует все отдельные страницы PDF-файла в большие двоичные объекты изображений, после чего вы выполняете распознавание символов для этих двоичных объектов. В качестве объекта BytesIO у меня есть содержимое файла PDF из веб-запроса. BytesIO — это потоковый объект, который имитирует загрузку файла, как если бы объект отрывался от диска, что wand требует в качестве параметра файла. Это позволяет вам просто брать данные в память вместо того, чтобы сначала сохранять файл на диск, а затем загружать его.
В качестве объекта BytesIO у меня есть содержимое файла PDF из веб-запроса. BytesIO — это потоковый объект, который имитирует загрузку файла, как если бы объект отрывался от диска, что wand требует в качестве параметра файла. Это позволяет вам просто брать данные в память вместо того, чтобы сначала сохранять файл на диск, а затем загружать его.
Вот очень простой блок кода, который поможет вам начать работу. Я могу представить себе различные функции, которые будут перебирать разные URL-адреса/файлы, разные поиски по ключевым словам для каждого файла и различные действия, которые необходимо предпринять, возможно, даже для каждого ключевого слова и файла.
# http://docs.wand-py.org/en/0.5.9/ # http://www.imagemagick.org/script/formats.php # brew install freetype imagemagick # варить установить PIL # варить установить tesseract # pip3 установить палочку # pip3 установить pyocr импортировать pyocr.builders запросы на импорт из io импортировать BytesIO из PIL импортировать изображение как PI из wand.
 image импорт изображения
если __name__ == '__main__':
pdf_url = 'https://www.vbgov.com/government/departments/city-clerk/city-council/Documents/CurrentBriefAgenda.pdf'
запрос = запросы.получить(pdf_url)
content_type = req.headers['Content-Type']
модифицированный_дата = req.headers['Последнее изменение']
content_buffer = BytesIO (req.content)
search_text = 'туристическая инвестиционная программа'
если content_type == 'приложение/pdf':
инструмент = pyocr.get_available_tools()[0]
lang = 'eng', если tool.get_available_languages().index('eng') >= 0 иначе нет
image_pdf = изображение (файл = content_buffer, формат = 'pdf', разрешение = 600)
image_jpeg = image_pdf.convert('jpeg')
для img в image_jpeg.sequence:
img_page = изображение (изображение = изображение)
txt = инструмент.image_to_string(
PI.open(BytesIO(img_page.make_blob('jpeg'))),
язык = язык,
строитель=pyocr.
image импорт изображения
если __name__ == '__main__':
pdf_url = 'https://www.vbgov.com/government/departments/city-clerk/city-council/Documents/CurrentBriefAgenda.pdf'
запрос = запросы.получить(pdf_url)
content_type = req.headers['Content-Type']
модифицированный_дата = req.headers['Последнее изменение']
content_buffer = BytesIO (req.content)
search_text = 'туристическая инвестиционная программа'
если content_type == 'приложение/pdf':
инструмент = pyocr.get_available_tools()[0]
lang = 'eng', если tool.get_available_languages().index('eng') >= 0 иначе нет
image_pdf = изображение (файл = content_buffer, формат = 'pdf', разрешение = 600)
image_jpeg = image_pdf.convert('jpeg')
для img в image_jpeg.sequence:
img_page = изображение (изображение = изображение)
txt = инструмент.image_to_string(
PI.open(BytesIO(img_page.make_blob('jpeg'))),
язык = язык,
строитель=pyocr. builders.TextBuilder()
)
если search_text в txt.lower():
print('Предупреждение! {} {} {}'.format(search_text, txt.lower().find(search_text),
дата_изменения))
Закрыть()
builders.TextBuilder()
)
если search_text в txt.lower():
print('Предупреждение! {} {} {}'.format(search_text, txt.lower().find(search_text),
дата_изменения))
Закрыть()
Этот ответ следует за ответом @Emma Yu:
Если вы хотите распечатать все совпадения строкового шаблона на каждой странице.
(Обратите внимание, что код Эммы печатает совпадение на странице):
import PyPDF2
импортировать повторно
pattern = input("Введите шаблон строки для поиска: ")
fileName = input("Введите путь и имя файла: ")
объект = PyPDF2.PdfFileReader (имя файла)
число страниц = объект.getNumPages ()
для i в диапазоне (0, numPages):
pageObj = объект.getPage(i)
текст = pageObj.extractText()
для совпадения в re.finditer(шаблон, текст):
print(f'Номер страницы: {i} | Соответствие: {match}')
Версия, использующая PyMuPDF. Я считаю, что он более надежен, чем PyPDF2.