Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: нтеьолс сейчас в е с о т сейчас л а в р а е сейчас с е о п т ь ч сейчас неблагоприятный исход сейчас н е к в и т ц сейчас жаворонок сейчас угадать 1 секунда назад таверс 1 секунда назад пустяк 1 секунда назад д о ы р л к о 1 секунда назад миноска 1 секунда назад кавалер 1 секунда назад лотерея 1 секунда назад продукт 1 секунда назад
в двадцать лет он её уже закончил
Введите слово или предложение и получите морфологический разбор с указанием части речи, падежа, рода, времени и т.д.
Начальная форма: В
Часть речи: предлог
Грамматика:
Формы: в
Начальная форма: ДВАДЦАТЬ
Часть речи: числительное (количественное)
Грамматика: именительный падеж
Формы: двадцать, двадцати, двадцатью
Начальная форма: ГОД
Часть речи: существительное
Грамматика: множественное число, мужской род, неодушевленное, родительный падеж
Формы: год, года, году, годом, годе, годы, лета, годов, лет, годам, годами, годах, гг
Начальная форма: ЛЁТ
Часть речи
Грамматика: винительный падеж, единственное число, мужской род, неодушевленное
Формы: лёт, лета, лету, лет, летом, лете, леты, летов, летам, летами, летах
Начальная форма: ОН
Часть речи: местоимение-существительное
Грамматика: третье лицо, единственное число, именительный падеж, мужской род
Формы: он, его, него, ему, нему, им, ним, нём
Начальная форма: ОНА
Часть речи: местоимение-существительное
Грамматика: третье лицо, единственное число, женский род, родительный падеж
Формы: она, её, неё, ней, ей, ею, нею
Начальная форма: УЖЕ
Часть речи: наречие
Грамматика:
Формы: уже
Начальная форма: УЖ
Часть речи: существительное
Грамматика: единственное число, мужской род, одушевленное, предложный падеж
Формы: уж, ужа, ужу, ужом, уже, ужи, ужей, ужам, ужами, ужах
Начальная форма: УЗКИЙ
Часть речи: прилагательное
Грамматика: качественное прилагательное, неодушевленное, одушевленное, сравнительная степень (для прилагательных)
Формы: узкий, узкого, узкому, узким, узком, узкая, узкой, узкую, узкою, узкое, узкие, узких, узкими, узок, узка, узко, узки, уже, поуже
Начальная форма: ЗАКОНЧИТЬ
Часть речи: глагол в личной форме
Грамматика: действительный залог, единственное число, мужской род, непереходный, прошедшее время, совершенный вид
Формы: закончить, закончил, закончила, закончило, закончили, закончу, закончим, закончишь, закончите, закончит, закончат, закончив, закончивши, закончимте, закончи, закончивший, закончившего, закончившему, закончившим, закончившем, закончившая, закончившей, закончившую, закончившею, закончившее, закончившие, закончивших, закончившими, законченный, законченного, законченному, законченным, законченном, закончен, законченная, законченной, законченную, законченною, закончена, законченное, закончено, законченные, законченных, законченными, закончены
python — есть ли способ преобразовать числовые слова в целые числа?
Задавать вопрос
спросил
Изменено 5 месяцев назад
Просмотрено 147 тысяч раз
Мне нужно конвертировать один в 1 , два в 2 и так далее.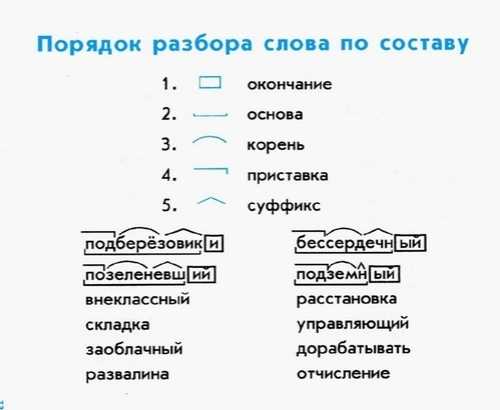
Есть ли способ сделать это с помощью библиотеки, класса или чего-то еще?
- python
- строка
- текст
- целое число
- число
5
Большая часть этого кода предназначена для настройки numwords dict, что делается только при первом вызове.
по определению text2int(textnum, numwords={}):
если не цифры:
единицы = [
«ноль», «один», «два», «три», «четыре», «пять», «шесть», «семь», «восемь»,
«девять», «десять», «одиннадцать», «двенадцать», «тринадцать», «четырнадцать», «пятнадцать»,
«шестнадцать», «семнадцать», «восемнадцать», «девятнадцать»,
]
десятки = ["", "", "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
весы = ["сотня", "тысяча", "миллион", "миллиард", "триллион"]
numwords["и"] = (1, 0)
для idx, слово в enumerate(unit): numwords[word] = (1, idx)
для idx слово в перечислении (десятки): numwords[слово] = (1, idx * 10)
для idx, слово в enumerate(scale): numwords[word] = (10 ** (idx * 3 или 2), 0)
текущий = результат = 0
для слова в textnum.
split():
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
возвращаемый результат + текущий
print text2int("семь миллиардов сто миллионов тридцать одна тысяча триста тридцать семь")
#7100031337

9
Я только что выпустил модуль Python для PyPI под названием word2number именно для этой цели. https://github.com/akshaynagpal/w2n
Установите его, используя:
pip install word2number
убедитесь, что ваш пип обновлен до последней версии.
Использование:
из word2number import w2n
print w2n.word_to_num("два миллиона три тысячи девятьсот восемьдесят четыре")
2003984
5
Мне нужно было что-то немного другое, так как я вводил из преобразования речи в текст, а решение не всегда заключается в суммировании чисел. Например, «мой почтовый индекс один два три четыре пять» не должен преобразовываться в «мой почтовый индекс 15».
Например, «мой почтовый индекс один два три четыре пять» не должен преобразовываться в «мой почтовый индекс 15».
Я взял ответ Эндрю и изменил его, чтобы обработать несколько других случаев, которые люди выделили как ошибки, а также добавил поддержку таких примеров, как почтовый индекс, который я упомянул выше. Некоторые базовые тестовые случаи показаны ниже, но я уверен, что есть еще возможности для улучшения.
по определению is_number(x):
если тип(х) == ул:
х = х.заменить(',', '')
пытаться:
поплавок (х)
кроме:
вернуть ложь
вернуть Истина
def text2int (textnum, numwords={}):
единицы = [
«ноль», «один», «два», «три», «четыре», «пять», «шесть», «семь», «восемь»,
«девять», «десять», «одиннадцать», «двенадцать», «тринадцать», «четырнадцать», «пятнадцать»,
«шестнадцать», «семнадцать», «восемнадцать», «девятнадцать»,
]
десятки = ['', '', "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
весы = ['сотня', 'тысяча', 'миллион', 'миллиард', 'триллион']
ordinal_words = {'первый':1, 'второй':2, 'третий':3, 'пятый':5, 'восьмой':8, 'девятый':9, 'двенадцатый':12}
ordinal_endings = [('ieth', 'y'), ('th', '')]
если не цифры:
числа['и'] = (1, 0)
для idx, слово в enumerate(unit): numwords[word] = (1, idx)
для idx слово в перечислении (десятки): numwords[слово] = (1, idx * 10)
для idx, слово в enumerate(scales): numwords[word] = (10 ** (idx * 3 или 2), 0)
textnum = textnum. replace('-', ' ')
текущий = результат = 0
керстринг = ''
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
определение is_numword(x):
если is_number(x):
вернуть Истина
если слово цифрами:
вернуть Истина
вернуть ложь
определение from_numword(x):
если is_number(x):
масштаб = 0
приращение = int (x.replace (',', ''))
шкала возврата, приращение
вернуть числовые слова[x]
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
ластюнит = Ложь
последняя шкала = Ложь
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если (не is_numword(слово)) или (слово == 'и', а не последняя шкала):
если по номеру:
# Сбросить текущий номер, который мы строим
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
еще:
масштаб, приращение = from_numword(слово)
onnumber = Истина
если последняя единица и (слово не в весах):
# Предположим, что это часть строки отдельных чисел для
# сбрасывать, например, почтовый индекс "один, два, три, четыре, пять"
curstring += repr(результат + текущий)
результат = текущий = 0
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
последняя шкала = Ложь
ластюнит = Ложь
если слово в весах:
последняя шкала = Истина
Элиф слово в единицах:
ластюнит = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
 replace('-', ' ')
текущий = результат = 0
керстринг = ''
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
определение is_numword(x):
если is_number(x):
вернуть Истина
если слово цифрами:
вернуть Истина
вернуть ложь
определение from_numword(x):
если is_number(x):
масштаб = 0
приращение = int (x.replace (',', ''))
шкала возврата, приращение
вернуть числовые слова[x]
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
ластюнит = Ложь
последняя шкала = Ложь
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если (не is_numword(слово)) или (слово == 'и', а не последняя шкала):
если по номеру:
# Сбросить текущий номер, который мы строим
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
еще:
масштаб, приращение = from_numword(слово)
onnumber = Истина
если последняя единица и (слово не в весах):
# Предположим, что это часть строки отдельных чисел для
# сбрасывать, например, почтовый индекс "один, два, три, четыре, пять"
curstring += repr(результат + текущий)
результат = текущий = 0
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
последняя шкала = Ложь
ластюнит = Ложь
если слово в весах:
последняя шкала = Истина
Элиф слово в единицах:
ластюнит = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
replace('-', ' ')
текущий = результат = 0
керстринг = ''
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
определение is_numword(x):
если is_number(x):
вернуть Истина
если слово цифрами:
вернуть Истина
вернуть ложь
определение from_numword(x):
если is_number(x):
масштаб = 0
приращение = int (x.replace (',', ''))
шкала возврата, приращение
вернуть числовые слова[x]
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
ластюнит = Ложь
последняя шкала = Ложь
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если (не is_numword(слово)) или (слово == 'и', а не последняя шкала):
если по номеру:
# Сбросить текущий номер, который мы строим
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
ластюнит = Ложь
последняя шкала = Ложь
еще:
масштаб, приращение = from_numword(слово)
onnumber = Истина
если последняя единица и (слово не в весах):
# Предположим, что это часть строки отдельных чисел для
# сбрасывать, например, почтовый индекс "один, два, три, четыре, пять"
curstring += repr(результат + текущий)
результат = текущий = 0
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
последняя шкала = Ложь
ластюнит = Ложь
если слово в весах:
последняя шкала = Истина
Элиф слово в единицах:
ластюнит = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
Некоторые тесты. ..
..
один два три -> 123 три сорок пять -> 345 три и сорок пять -> 3 и 45 триста сорок пять -> 345 триста -> 300 двадцать пятьсот -> 2500 три тысячи шесть -> 3006 три тысячи шесть -> 3006 девятнадцатый -> 19 двадцатый -> 20 первый -> 1 мой почтовый индекс один два три четыре пять -> мой почтовый индекс 12345 девятнадцать девяносто шесть -> 1996 пятьдесят седьмой -> 57 один миллион -> 1000000 первая сотня -> 100 Я куплю первую тысячу -> Я куплю 1000 # возможно, следует оставить порядковый номер в строке тысяча -> 1000 сто шесть -> 106 1 миллион -> 1000000
3
Если кому-то интересно, я взломал версию, которая поддерживает остальную часть строки (хотя в ней могут быть ошибки, особо не проверял).
по определению text2int (textnum, numwords={}):
если не цифры:
единицы = [
«ноль», «один», «два», «три», «четыре», «пять», «шесть», «семь», «восемь»,
«девять», «десять», «одиннадцать», «двенадцать», «тринадцать», «четырнадцать», «пятнадцать»,
«шестнадцать», «семнадцать», «восемнадцать», «девятнадцать»,
]
десятки = ["", "", "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
весы = ["сотня", "тысяча", "миллион", "миллиард", "триллион"]
numwords["и"] = (1, 0)
для idx, слово в enumerate(unit): numwords[word] = (1, idx)
для idx слово в перечислении (десятки): numwords[слово] = (1, idx * 10)
для idx, слово в enumerate(scales): numwords[word] = (10 ** (idx * 3 или 2), 0)
ordinal_words = {'первый':1, 'второй':2, 'третий':3, 'пятый':5, 'восьмой':8, 'девятый':9, 'двенадцатый':12}
ordinal_endings = [('ieth', 'y'), ('th', '')]
textnum = textnum. replace('-', ' ')
текущий = результат = 0
курс = ""
onnumber = Ложь
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
если по номеру:
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
еще:
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
 replace('-', ' ')
текущий = результат = 0
курс = ""
onnumber = Ложь
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
если по номеру:
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
еще:
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
replace('-', ' ')
текущий = результат = 0
курс = ""
onnumber = Ложь
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
если по номеру:
curstring += repr(результат + текущий) + " "
curstring += слово + " "
результат = текущий = 0
onnumber = Ложь
еще:
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
onnumber = Истина
если по номеру:
curstring += repr(результат + текущий)
возврат
Пример:
>>> text2int("Я хочу пятьдесят пять хот-догов за двести долларов. ")
Я хочу 55 хот-догов за 200 долларов.
 ")
Я хочу 55 хот-догов за 200 долларов.
")
Я хочу 55 хот-догов за 200 долларов.
Могут возникнуть проблемы, если у вас есть, скажем, «200 долларов». Но, это было действительно грубо.
1
Мне нужно было обработать пару дополнительных случаев синтаксического анализа, таких как порядковые слова («первый», «второй»), слова с дефисом («сто») и порядковые слова с дефисом, например («пятьдесят седьмой»), поэтому Я добавил пару строк:
определение text2int(textnum, numwords={}):
если не цифры:
единицы = [
«ноль», «один», «два», «три», «четыре», «пять», «шесть», «семь», «восемь»,
«девять», «десять», «одиннадцать», «двенадцать», «тринадцать», «четырнадцать», «пятнадцать»,
«шестнадцать», «семнадцать», «восемнадцать», «девятнадцать»,
]
десятки = ["", "", "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
весы = ["сотня", "тысяча", "миллион", "миллиард", "триллион"]
numwords["и"] = (1, 0)
для idx, слово в enumerate(unit): numwords[word] = (1, idx)
для idx слово в перечислении (десятки): numwords[слово] = (1, idx * 10)
для idx, слово в enumerate(scales): numwords[word] = (10 ** (idx * 3 или 2), 0)
ordinal_words = {'первый':1, 'второй':2, 'третий':3, 'пятый':5, 'восьмой':8, 'девятый':9, 'двенадцатый':12}
ordinal_endings = [('ieth', 'y'), ('th', '')]
textnum = textnum. replace('-', ' ')
текущий = результат = 0
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
вернуть результат + текущий`
 replace('-', ' ')
текущий = результат = 0
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
вернуть результат + текущий`
replace('-', ' ')
текущий = результат = 0
для слова в textnum.split():
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
вернуть результат + текущий`
2
Вот тривиальный подход:
>>> number = {'one':1,
... 'два':2,
... 'три':3,}
>>>
>>> число['два']
2
Или вы ищете что-то, что может обрабатывать «двенадцать тысяч сто семьдесят два» ?
1
определение parse_int (строка):
ЕДИНИЦЫ = {'ноль': 0,
'один': 1,
'два': 2,
«три»: 3,
«четыре»: 4,
«пять»: 5,
«шесть»: 6,
«семь»: 7,
«восемь»: 8,
«девять»: 9,
«десять»: 10,
«одиннадцать»: 11,
«двенадцать»: 12,
«тринадцать»: 13,
«четырнадцать»: 14,
«пятнадцать»: 15,
«шестнадцать»: 16,
«семнадцать»: 17,
«восемнадцать»: 18,
«девятнадцать»: 19,
«двадцать»: 20,
«тридцать»: 30,
«сорок»: 40,
«пятьдесят»: 50,
«шестьдесят»: 60,
«семьдесят»: 70,
«восемьдесят»: 80,
«девяносто»: 90,
}
числа = []
для токена в string. replace('-', ' ').split(' '):
если токен в ЕДИНИЦАХ:
number.append (ЕДИНИЦЫ [токен])
токен elif == 'сотня':
числа[-1] *= 100
токен elif == 'тысяча':
числа = [x * 1000 для x в числах]
токен elif == 'миллион':
числа = [x * 1000000 для x в числах]
возвращаемая сумма (числа)
 replace('-', ' ').split(' '):
если токен в ЕДИНИЦАХ:
number.append (ЕДИНИЦЫ [токен])
токен elif == 'сотня':
числа[-1] *= 100
токен elif == 'тысяча':
числа = [x * 1000 для x в числах]
токен elif == 'миллион':
числа = [x * 1000000 для x в числах]
возвращаемая сумма (числа)
replace('-', ' ').split(' '):
если токен в ЕДИНИЦАХ:
number.append (ЕДИНИЦЫ [токен])
токен elif == 'сотня':
числа[-1] *= 100
токен elif == 'тысяча':
числа = [x * 1000 для x в числах]
токен elif == 'миллион':
числа = [x * 1000000 для x в числах]
возвращаемая сумма (числа)
Проверено с 700 случайными числами в диапазоне от 1 до миллиона, работает хорошо.
1
Используйте пакет Python: WordToDigits
pip install wordtodigits
Он может находить числа, представленные в словесной форме в предложении, и затем преобразовывать их в правильный числовой формат. Также обрабатывает десятичную часть, если она присутствует. Словарное представление чисел может быть где угодно в отрывке .
Это может быть легко жестко закодировано в словарь, если есть ограниченное количество чисел, которые вы хотите проанализировать.
В несколько более сложных случаях вы, вероятно, захотите создать этот словарь автоматически на основе относительно простой грамматики чисел. Что-то вроде этого (конечно, в обобщенном виде…)
для i в диапазоне (10): myDict[30 + i] = "тридцать-" + singleDigitsDict[i]
Если вам нужно что-то более обширное, похоже, вам понадобятся инструменты для обработки естественного языка. Эта статья может стать хорошей отправной точкой.
Внесены изменения, чтобы text2int(scale) возвращал правильное преобразование. Например, text2int(«сотня») => 100.
импорт повторно
цифры = {}
определение text2int (текстовый номер):
если не цифры:
unit = [ "ноль", "один", "два", "три", "четыре", "пять", "шесть",
«семь», «восемь», «девять», «десять», «одиннадцать», «двенадцать»,
«тринадцать», «четырнадцать», «пятнадцать», «шестнадцать», «семнадцать»,
«восемнадцать», «девятнадцать»]
десятки = ["", "", "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят",
«семьдесят», «восемьдесят», «девяносто»]
весы = ["сотня", "тысяча", "миллион", "миллиард", "триллион",
«квадриллион», «квинтиллион», «сексиллион», «септиллион»,
«октиллион», «нониллион», «дециллион»]
numwords["и"] = (1, 0)
для idx, слово в enumerate(unit): numwords[word] = (1, idx)
для idx слово в перечислении (десятки): numwords[слово] = (1, idx * 10)
для idx, слово в enumerate(scales): numwords[word] = (10 ** (idx * 3 или 2), 0)
ordinal_words = {'первый':1, 'второй':2, 'третий':3, 'пятый':5,
«восьмой»: 8, «девятый»: 9, 'двенадцатый':12}
ordinal_endings = [('ieth', 'y'), ('th', '')]
текущий = результат = 0
токены = re. split(r"[\s-]+", textnum)
для слова в токенах:
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
возвращаемый результат + текущий
 split(r"[\s-]+", textnum)
для слова в токенах:
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
возвращаемый результат + текущий
split(r"[\s-]+", textnum)
для слова в токенах:
если слово в ordinal_words:
масштаб, приращение = (1, порядковые_слова[слово])
еще:
для окончания замена в ordinal_endings:
если word.endswith(окончание):
слово = "%s%s" % (слово[:-len(окончание)], замена)
если слово не цифрами:
поднять исключение ("Недопустимое слово: " + слово)
масштаб, приращение = numwords[слово]
если масштаб > 1:
ток = макс (1, ток)
текущий = текущий * масштаб + приращение
если масштаб > 100:
результат += текущий
ток = 0
возвращаемый результат + текущий
2
Быстрое решение — использовать inflect.py для создания словаря для перевода.
inflect.py имеет функцию number_to_words() , которая преобразует число (например, 2 ) в словоформу (например, 'два' ). К сожалению, его реверс (который позволил бы вам избежать маршрута словаря перевода) не предлагается. Тем не менее, вы можете использовать эту функцию для создания словаря перевода:
К сожалению, его реверс (который позволил бы вам избежать маршрута словаря перевода) не предлагается. Тем не менее, вы можете использовать эту функцию для создания словаря перевода:
>>> изменение импорта
>>> p = inflect.engine()
>>> word_to_number_mapping = {}
>>>
>>> для i в диапазоне (1, 100):
... word_form = p.number_to_words(i) # 1 -> 'один'
... word_to_number_mapping[word_form] = i
...
>>> print word_to_number_mapping['one']
1
>>> print word_to_number_mapping['одиннадцать']
11
>>> print word_to_number_mapping['сорок три']
43
Если вы готовы уделить некоторое время, возможно, вы сможете изучить внутреннюю работу inflect.py number_to_words() и создайте свой собственный код, чтобы сделать это динамически (я не пытался это сделать).
Есть рубиновый драгоценный камень Марка Бернса, который делает это. Недавно я разветвил его, чтобы добавить поддержку в течение многих лет. Вы можете вызвать рубиновый код из python.
требуют «числа_в_словах»
требуется 'числа_в_словах/duck_punch'
nums = ["пятнадцать шестнадцать", "восемьдесят пять шестнадцать", "девятнадцать девяносто шесть",
"сто семьдесят девять", "тринадцатьсот", "девять тысяч двести девяносто семь"]
числа. каждый {|n| р н; p n.in_numbers}
 каждый {|n| р н; p n.in_numbers}
каждый {|n| р н; p n.in_numbers}
результаты:
"пятнадцать шестнадцать"
1516
"восемьдесят пять шестнадцать"
8516
"1996"
1996 г.
"сто семьдесят девять"
179
"тринадцать сотен"
1300
"девять тысяч двести девяносто семь"
9297
7
Я взял логику @recursive и преобразовал ее в Ruby. Я также жестко закодировал таблицу поиска, так что это не так круто, но может помочь новичку понять, что происходит.
WORDNUMS = {"ноль"=> [1,0], "один"=> [1,1], "два"=> [1,2], "три"=> [1,3],
"четыре"=> [1,4], "пять"=> [1,5], "шесть"=> [1,6], "семь"=> [1,7],
"восемь"=> [1,8], "девять"=> [1,9], "десять"=> [1,10],
«одиннадцать» => [1,11], «двенадцать» => [1,12], «тринадцать» => [1,13],
"четырнадцать"=> [1,14], "пятнадцать"=> [1,15], "шестнадцать"=> [1,16],
«семнадцать» => [1,17], «восемнадцать» => [1,18], «девятнадцать» => [1,19],
"двадцать" => [1,20], "тридцать" => [1,30], "сорок" => [1,40],
"пятьдесят" => [1,50], "шестьдесят" => [1,60], "семьдесят" => [1,70],
"восемьдесят" => [1,80], "девяносто" => [1,90],
"сотня" => [100,0], "тысяча" => [1000,0],
"миллион" => [1000000, 0]}
определение text_2_int (строка)
numberWords = string. gsub('-', ' ').split(/ /) - %w{and}
текущий = результат = 0
numberWords.each сделать |слово|
масштаб, приращение = WORDNUMS[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100
результат += текущий
ток = 0
конец
конец
возвращаемый результат + текущий
конец
 gsub('-', ' ').split(/ /) - %w{and}
текущий = результат = 0
numberWords.each сделать |слово|
масштаб, приращение = WORDNUMS[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100
результат += текущий
ток = 0
конец
конец
возвращаемый результат + текущий
конец
gsub('-', ' ').split(/ /) - %w{and}
текущий = результат = 0
numberWords.each сделать |слово|
масштаб, приращение = WORDNUMS[слово]
текущий = текущий * масштаб + приращение
если масштаб > 100
результат += текущий
ток = 0
конец
конец
возвращаемый результат + текущий
конец
Я хотел обрабатывать такие строки, как две тысячи сто сорок шесть
Это обрабатывает числа словами в индийском стиле, некоторые дроби, комбинации чисел и слов, а также сложение.
определение слова_в_число (слова):
числа = {"ноль":0, "а":1, "половина":0,5, "четверть":0,25, "один":1,"два":2,
«три»: 3, «четыре»: 4, «пять»: 5, «шесть»: 6, «семь»: 7, «восемь»: 8,
«девять»: 9, «десять»: 10, «одиннадцать»: 11, «двенадцать»: 12, «тринадцать»: 13,
«четырнадцать»: 14, «пятнадцать»: 15, «шестнадцать»: 16, «семнадцать»: 17,
«восемнадцать»: 18, «девятнадцать»: 19, «двадцать»: 20, «тридцать»: 30, «сорок»: 40,
«пятьдесят»: 50, «шестьдесят»: 60, «семьдесят»: 70, «восемьдесят»: 80, «девяносто»: 90}
группы = {"сотня":100, "тысяча":1_000,
«лак»: 1_00_000, «лакх»: 1_00_000,
"миллион": 1_000_000, "крор": 10**7,
«миллиард»: 10**9, «триллион»: 10**12}
split_at = ["и", "плюс"]
п = 0
пропустить = ложь
массив_слов = слова. split(" ")
для i слово в перечислении (words_array):
если не пропустить:
если слово в группах:
n*= группы[слово]
Элиф слово в цифрах:
n += числа[слово]
слово elif в split_at:
пропустить = Истина
осталось = ' '.join(words_array[i+1:])
n+=words_to_number(оставшееся)
еще:
пытаться:
n += число с плавающей запятой (слово)
кроме ValueError как e:
поднять ValueError(f"Недопустимое слово {слово}") из e
вернуть н
 split(" ")
для i слово в перечислении (words_array):
если не пропустить:
если слово в группах:
n*= группы[слово]
Элиф слово в цифрах:
n += числа[слово]
слово elif в split_at:
пропустить = Истина
осталось = ' '.join(words_array[i+1:])
n+=words_to_number(оставшееся)
еще:
пытаться:
n += число с плавающей запятой (слово)
кроме ValueError как e:
поднять ValueError(f"Недопустимое слово {слово}") из e
вернуть н
split(" ")
для i слово в перечислении (words_array):
если не пропустить:
если слово в группах:
n*= группы[слово]
Элиф слово в цифрах:
n += числа[слово]
слово elif в split_at:
пропустить = Истина
осталось = ' '.join(words_array[i+1:])
n+=words_to_number(оставшееся)
еще:
пытаться:
n += число с плавающей запятой (слово)
кроме ValueError как e:
поднять ValueError(f"Недопустимое слово {слово}") из e
вернуть н
ТЕСТ:
print(words_to_number("миллион и один"))
>> 1000001
print(words_to_number("один крор и один"))
>> 1000 0001
print(words_to_number("0,5 миллиона один"))
>> 500001.0
print(words_to_number("полмиллиона сто"))
>> 500100.0
print(words_to_number("четверть"))
>> 0,25
print(words_to_number("сто плюс один"))
>> 101
1
Этот код работает для серии данных:
импортировать панд как pd mylist = pd.
 Series(['один','два','три'])
мой список1 = []
для x в диапазоне (len (mylist)):
mylist1.append (w2n.word_to_num (мой список [x]))
печать (мой список1)
Series(['один','два','три'])
мой список1 = []
для x в диапазоне (len (mylist)):
mylist1.append (w2n.word_to_num (мой список [x]))
печать (мой список1)
1
Я нахожу более быстрый способ:
Da_Unità_a_Cifre = {'один': 1, 'два': 2, 'три': 3, 'четыре': 4, 'пять': 5, 'шесть': 6, ' семь»: 7, «восемь»: 8, «девять»: 9, «десять»: 10, «одиннадцать»: 11,
«двенадцать»: 12, «тринадцать»: 13, «четырнадцать»: 14, «пятнадцать»: 15, «шестнадцать»: 16, «семнадцать»: 17, «восемнадцать»: 18, «девятнадцать»: 19}
Da_Lettere_a_Decine = {"tw": 20, "th": 30, "fo": 40, "fi": 50, "si": 60, "se": 70, "ei": 80, "ni": 90 , }
elemento = input("вставьте слово:")
Val_Num = 0
пытаться:
elemento.lower()
elemento.strip()
Unità = elemento[elemento.find("ty")+2:] # è uguale alla str: Five
если элементо[-1] == "у":
Val_Num = int(Da_Lettere_a_Decine[элемент[0] + элемент[1]])
печать (Val_Num)
Элиф Элементо == "сто":
Val_Num = 100
печать (Val_Num)
еще:
Cifre_Unità = int(Da_Unità_a_Cifre[Unità])
Cifre_Decine = int(Da_Lettere_a_Decine[элемент[0] + элемент[1]])
Val_Num = int(Cifre_Decine + Cifre_Unità)
печать (Val_Num)
кроме:
распечатать("неверный ввод")
Этот код работает только для чисел до 99. И слово в целое, и целое в слово (для остальных нужно реализовать 10-20 строк кода и простую логику. Это просто простой код для начинающих):
И слово в целое, и целое в слово (для остальных нужно реализовать 10-20 строк кода и простую логику. Это просто простой код для начинающих):
num = input( "Введите число, которое вы хотите конвертировать :")
mydict = {'1': 'Один', '2': 'Два', '3': 'Три', '4': 'Четыре', '5': 'Пять', '6': 'Шесть' , «7»: «Семь», «8»: «Восемь», «9»: «Девять», «10»: «Десять», «11»: «Одиннадцать», «12»: «Двенадцать», « 13 ': «Тринадцать», «14»: «Четырнадцать», «15»: «Пятнадцать», «16»: «Шестнадцать», «17»: «Семнадцать», «18»: «Восемнадцать», «19».': 'Девятнадцать'}
mydict2 = ['', '', 'Двадцать', 'Тридцать', 'Сорок', 'пятьдесят', 'шестьдесят', 'Семьдесят', 'Восемьдесят', 'Девяносто']
если num.isdigit():
если (целое (число) < 20):
print(" :---> " + mydict[число])
еще:
var1 = целое число (число) % 10
переменная2 = целое (число) / 10
print(" :---> " + mydict2[int(var2)] + mydict[str(var1)])
еще:
число = число.нижний()
dict_w = {'один': 1, 'два': 2, 'три': 3, 'четыре': 4, 'пять': 5, 'шесть': 6, 'семь': 7, 'восемь': 8 , «девять»: 9, «десять»: 10, «одиннадцать»: 11, «двенадцать»: 12, «тринадцать»: 13, «четырнадцать»: 14, «пятнадцать»: 15, «шестнадцать»: 16, ' семнадцать»: «17», «восемнадцать»: «18», «девятнадцать»: «19». '}
mydict2 = ['', '', "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
разделить = число[число.найти("ty")+2:]
если число:
если (число в dict_w.keys()):
print(" :---> " + str(dict_w[число]))
Элиф разделить == '' :
для i в диапазоне (0, len (mydict2) -1):
если mydict2[i] == число:
print(" :---> " + ул(i * 10))
еще :
ул3 = 0
str1 = число[число.найти("ty")+2:]
строка2 = число[:-len(str1)]
для i в диапазоне (0, len (mydict2)):
если mydict2[i] == str2:
ул3 = я
если str2 не в mydict2:
print("----->Неверный ввод<-----")
еще:
пытаться:
print(" : ---> " + str((str3*10) + dict_w[str1]))
кроме:
print("----->Неверный ввод<-----")
еще:
print("----->Введите ввод<-----")
 '}
mydict2 = ['', '', "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
разделить = число[число.найти("ty")+2:]
если число:
если (число в dict_w.keys()):
print(" :---> " + str(dict_w[число]))
Элиф разделить == '' :
для i в диапазоне (0, len (mydict2) -1):
если mydict2[i] == число:
print(" :---> " + ул(i * 10))
еще :
ул3 = 0
str1 = число[число.найти("ty")+2:]
строка2 = число[:-len(str1)]
для i в диапазоне (0, len (mydict2)):
если mydict2[i] == str2:
ул3 = я
если str2 не в mydict2:
print("----->Неверный ввод<-----")
еще:
пытаться:
print(" : ---> " + str((str3*10) + dict_w[str1]))
кроме:
print("----->Неверный ввод<-----")
еще:
print("----->Введите ввод<-----")
'}
mydict2 = ['', '', "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"]
разделить = число[число.найти("ty")+2:]
если число:
если (число в dict_w.keys()):
print(" :---> " + str(dict_w[число]))
Элиф разделить == '' :
для i в диапазоне (0, len (mydict2) -1):
если mydict2[i] == число:
print(" :---> " + ул(i * 10))
еще :
ул3 = 0
str1 = число[число.найти("ty")+2:]
строка2 = число[:-len(str1)]
для i в диапазоне (0, len (mydict2)):
если mydict2[i] == str2:
ул3 = я
если str2 не в mydict2:
print("----->Неверный ввод<-----")
еще:
пытаться:
print(" : ---> " + str((str3*10) + dict_w[str1]))
кроме:
print("----->Неверный ввод<-----")
еще:
print("----->Введите ввод<-----")
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Алгоритм- Как читать значения из чисел, записанных словами?
Что ж, я слишком поздно ответил на этот вопрос, но я работал над небольшим тестовым сценарием, который, похоже, сработал для меня очень хорошо. Я использовал (простое, но уродливое и большое) регулярное выражение, чтобы найти все слова для меня. Выражение выглядит следующим образом:
Я использовал (простое, но уродливое и большое) регулярное выражение, чтобы найти все слова для меня. Выражение выглядит следующим образом:
(?<Значение>(?:ноль)|(?:один|первый)|(?:два|второй)|(?:три|третий)|(?:четыре|четвертый)| (?:пять|пятый)|(?:шесть|шестой)|(?:семь|седьмой)|(?:восемь|восьмой)|(?:девять|девятый)| (?:десять|десятая)|(?:одиннадцать|одиннадцатая)|(?:двенадцать|двенадцатая)|(?:тринадцать|тринадцатая)| (?:четырнадцать|четырнадцатый)|(?:пятнадцать|пятнадцатый)|(?:шестнадцать|шестнадцатый)| (?:семнадцать|семнадцатый)|(?:восемнадцать|восемнадцатый)|(?:девятнадцать|девятнадцатый)| (?:двадцать|двадцатый)|(?:тридцать|тридцатый)|(?:сорок|сороковой)|(?:пятьдесят|пятидесятый)| (?:шестьдесят|шестидесятая)|(?:семьдесят|семидесятая)|(?:восемьдесят|восьмидесятая)|(?:девяносто|девяностая)| (?<Величина>(?:сотня|сотая)|(?:тысяча|тысячная)|(?:миллион|миллионная)| (?:миллиард|миллиард)))
Здесь показано с разрывами строк для целей форматирования.
В любом случае, мой метод состоял в том, чтобы выполнить это регулярное выражение с библиотекой, такой как PCRE, а затем прочитать именованные совпадения. И это работало на всех различных примерах, перечисленных в этом вопросе, за исключением типов «Одна половина», поскольку я их не добавлял, но, как вы можете видеть, это было бы несложно сделать. Это решает множество проблем. Например, он касается следующих элементов исходного вопроса и других ответов:
И это работало на всех различных примерах, перечисленных в этом вопросе, за исключением типов «Одна половина», поскольку я их не добавлял, но, как вы можете видеть, это было бы несложно сделать. Это решает множество проблем. Например, он касается следующих элементов исходного вопроса и других ответов:
- кардинальное/номинальное или порядковое: «один» и «первый»
- распространенных орфографических ошибок: «сорок»/«сорок» (Обратите внимание, что это НЕ ЯВНО решается, это было бы то, что вы хотели бы сделать, прежде чем передать строку этому синтаксическому анализатору. Этот синтаксический анализатор видит этот пример как «ЧЕТЫРЕ» ...)
- сотни/тысячи: 2100 -> "двадцать сто", а также "две тысячи сто"
- разделители: "одиннадцатьсот пятьдесят два", а также "одиннадцатьсот пятьдесят два" или "одиннадцатьсот пятьдесят два" и еще много чего
- разговорные выражения: «тридцать с чем-то» (это также НЕ ПОЛНОСТЬЮ адресовано, как что ТАКОЕ «что-то»? Ну, этот код находит это число просто как «30»). **
 **
**Теперь вместо того, чтобы хранить это чудовище регулярного выражения в вашем исходном коде, я рассматривал возможность создания этого регулярного выражения во время выполнения, используя что-то вроде следующего:
char *ones[] = {"zero", "one", " два", "три", "четыре", "пять", "шесть", "семь", "восемь", "девять", "десять", "одиннадцать", "двенадцать",
«тринадцать», «четырнадцать», «пятнадцать», «шестнадцать», «семнадцать», «восемнадцать», «девятнадцать»};
char *tens[] = {"", "", "двадцать", "тридцать", "сорок", "пятьдесят", "шестьдесят", "семьдесят", "восемьдесят", "девяносто"};
char *ordinalones[] = { "", "первый", "второй", "третий", "четвертый", "пятый", "", "", "", "", "", "", "двенадцатый " };
char *ordinaltens[] = { "", "", "двадцатый", "тридцатый", "сороковой", "пятидесятый", "шестидесятый", "семидесятый", "восьмидесятый", "девяностый" };
и так далее...
Самое простое здесь то, что мы сохраняем только те слова, которые имеют значение. В случае с ШЕСТЫМ вы заметите, что для него нет записи, потому что это просто обычный номер с добавленным TH. .. Но такие, как ДВЕНАДЦАТЬ, требуют особого внимания.
.. Но такие, как ДВЕНАДЦАТЬ, требуют особого внимания.
Итак, теперь у нас есть код для создания нашего (уродливого) RegEx, теперь мы просто выполняем его на наших числовых строках.
Одна вещь, которую я бы порекомендовал, это отфильтровать или съесть слово "И". Это не обязательно, и только приводит к другим проблемам.
Итак, что вам нужно сделать, так это настроить функцию, которая передает именованные совпадения для «величины» в функцию, которая просматривает все возможные значения величины и умножает ваш текущий результат на это значение величины. Затем вы создаете функцию, которая просматривает именованные совпадения «Value» и возвращает int (или что-то еще, что вы используете) на основе обнаруженного там значения.
Все совпадения VALUE ДОБАВЛЯЮТСЯ к вашему результату, в то время как совпадения Magnitutde умножают результат на значение mag. Таким образом, Двести пятьдесят тысяч становится "2", затем "2 * 100", затем "200 + 50", затем "250 * 1000", в итоге получается 250000. ..
..
Ради интереса я написал эту версию vbScript, и она отлично работала со всеми предоставленными примерами. Теперь он не поддерживает именованные совпадения, поэтому мне пришлось немного потрудиться, чтобы получить правильный результат, но я его получил. Суть в том, что если это совпадение «ЗНАЧЕНИЕ», добавьте его в свой аккумулятор. Если это совпадение величины, умножьте свой аккумулятор на 100, 1000, 1000000, 1000000000 и т. д. Это даст вам довольно удивительные результаты, и все, что вам нужно сделать, чтобы приспособиться к таким вещам, как «одна половина», это добавить их. к вашему регулярному выражению, поместите для них маркер кода и обработайте их.
Что ж, я надеюсь, что этот пост поможет КТО-НИБУДЬ. Если кто-то хочет, я могу опубликовать псевдокод vbScript, который я использовал для тестирования, однако это не красивый код, а НЕ производственный код.
Если позволите... На каком окончательном языке это будет написано? C++ или что-то вроде скриптового языка? Источник Грега Хьюгилла поможет понять, как все это объединяется.