Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: сджаееоинс сейчас кзаомаи сейчас мяч сейчас топалёк сейчас советйд сейчас лекарька сейчас проссец сейчас т о п ь ч е с сейчас р ю к с у т сейчас с у м е р к и сейчас ракета сейчас монголия сейчас кадафе сейчас боланшс из букв слово сейчас к о у л п сейчас
Разобрать слово работает по составу.
Ответ или решение2
Геннадий
Начинать разбор любого слова по составу следует с поиска окончания. Оставшаяся часть будет основой. Корень, иногда ещё приставки, суффиксы сможем найти в составе основы.
Результат морфемного разбора слова «работает»:
работ — корень,
а — суффикс,
ет — окончание,
работа — основа слова.
Владислав
Разбирая слово по составу, мы делим его на отдельные морфемы: корень, окончание, приставка, суффикс. Схема, облегчающая работу, универсальная для разбора любого слова.
План морфемного состава слова
- Задать вопрос к слову для определения части речи.
- Изменяемая часть — окончание. Для поиска спрягаем или склоняем слово, то есть меняем его.
- Основа — оставшаяся после отделения окончания часть слова. В этой части находим приставку, корень и суффикс.
- Корень — общая часть родственных слов. Ищем максимально возможное количество однокоренных слов для безошибочного выделения корня.
- Приставку найдем перед корнем, в начале слова.
- Суффикс стоит после корня, перед окончанием.
Не обязательно во всех словах найдем все морфемы.
Отсутствующее окончание называется нулевым. В неизменяемых словах, как наречие или деепричастие, нет окончаний.
Много слов без приставки и суффикса, «работа» такое слово. В то же время есть слова с несколькими приставками, суффиксами и даже корнями. Слово «чернорабочий» с двумя корнями. А слова «деревообрабатывающий» с двумя суффиксами. В слове «необработанный» две приставки в составе.
В то же время есть слова с несколькими приставками, суффиксами и даже корнями. Слово «чернорабочий» с двумя корнями. А слова «деревообрабатывающий» с двумя суффиксами. В слове «необработанный» две приставки в составе.
Суффикс «ся»/ «сь» находится в конце слова, после окончания и называется постфикс. Функция суффикса — создание новых слов. Суффикс «л» используют для образования прошедшего времени глагола, он не входит в основу. В слове «сработались» постфикс «сь» располагается в конце слова, после окончания, а суффикс прошедшего времени «л» не включен в состав основы.
Разбираем слово «работает» по составу
- Вопрос, на который отвечает слово «что делает?» — наше слово является глаголом.
- Изменяем слово: «работают», «работать». Таким образом мы определили окончание «ет».
- Основа слова — «работа».
- Однокоренные слова: «работа», «лесопереработка», «заработная», «заработать», «безработный», «наработка», «подработка», «сработаться», «переработка», «переработать», «металлообработка», «недоработка», «деревообработка», «неработоспособный», «переработка».
 В нашем слове «работ» будет корнем.
В нашем слове «работ» будет корнем. - Приставка «под».
- Суффикс «а».
 В нашем слове «работ» будет корнем.
В нашем слове «работ» будет корнем.Знаешь ответ?
Как написать хороший ответ?Как написать хороший ответ?
Будьте внимательны!
- Копировать с других сайтов запрещено. Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
- Публикуются только развернутые объяснения. Ответ не может быть меньше 50 символов!
0 /10000
Сортировка— составление двух функций сравнения?
спросил
Изменено 2 года, 8 месяцев назад
Просмотрено 2к раз
Я хочу отсортировать по одному свойству, а затем по другому (если первое свойство совпадает).
Какой идиоматический способ в Haskell составления двух функций сравнения, т.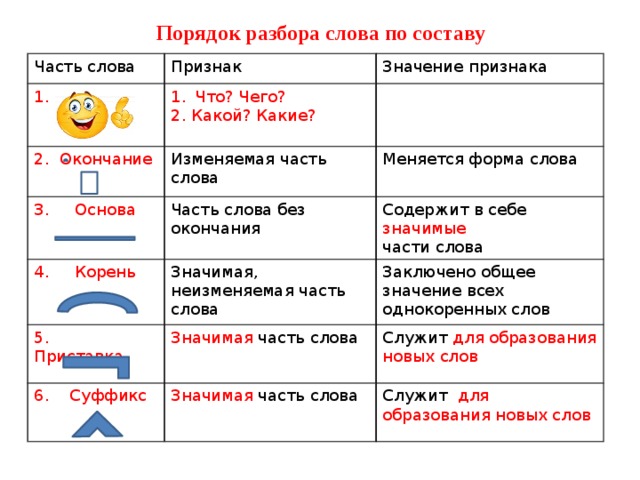
Дано
f :: Орд а => а -> а -> Порядок g :: Ord a => a -> a -> Порядок
составление f и g даст:
h x y = случай v из
Эквалайзер -> г х у
иначе -> v
где v = fxy
- сортировка
- хаскелл
1
vitus указывает на очень крутой экземпляр Monoid для Заказ . Если вы объедините его с instance instance Monoid b => Monoid (a -> b) , окажется, что ваша функция композиции просто (приготовьтесь):
mappend
Проверьте это:
Prelude Data.Monoid> let f a b = EQ Прелюдия Data.Monoid> пусть g a b = LT Прелюдия Data.Monoid> :t f `mappend` g f `mappend` g :: t -> t1 -> Порядок Prelude Data.Monoid> (f `mappend` g) undefined undefined LT Прелюдия Data.Monoid> пусть f a b = GT Prelude Data.Monoid> (f `mappend` g) undefined undefined ГТ
+1 для мощных и простых абстракций
2
Можно использовать оператор <> . В этом примере
В этом примере bigSort сортирует строки по их числовым значениям, сначала сравнивая длину, а затем сравнивая лексикографически.
импорт Data.List (сортировать по) импортировать Data.Ord (сравнивать, сравнивать) bigSort :: [Строка] -> [Строка] bigSort = sortBy $ (сравнение длины) <> сравнить
Пример:
bigSort ["31415926535897932384626433832795", "1", "3", "10", "3", "5"] =
["1","3","3","5","10","31415926535897932384626433832795"]
<> — это псевдоним Data.Monoid (см. ответ jberryman ).
(бесплатная) книга Изучайте Haskell на благо! объясняет, как это работает, в главе 11
экземпляр Monoid Заказ где пустой = эквалайзер LT `mappend` _ = LT EQ `mappend` y = y GT `mappend` _ = GTЭкземпляр настроен следующим образом: когда мы
сопоставляемдва значенияOrdering, одно слева сохраняется, если только значение слева неEQ, и в этом случае правый результат является результатом.EQ.
 Идентификатор
Идентификатор 4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Сравнение наследования и композиции — блог
Как говорится, «Предпочитайте композицию наследованию» — это содержательно и бесспорно.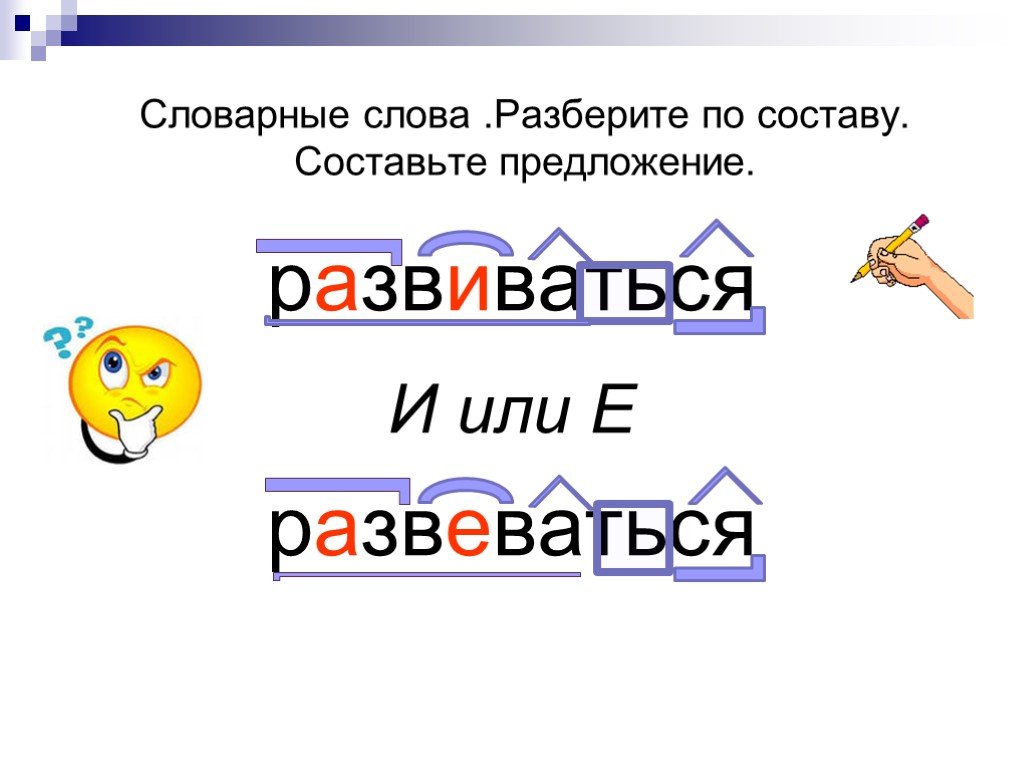 К сожалению, это также не имеет особого смысла, если вы уже не знаете, что это значит. Мы рассмотрим два разных подхода к решению одной и той же проблемы: наследование и композиция. На первый взгляд пример Inheritance выглядит более правильным и немного короче. Я хочу убедить вас, что Композиционный подход более правильный.
К сожалению, это также не имеет особого смысла, если вы уже не знаете, что это значит. Мы рассмотрим два разных подхода к решению одной и той же проблемы: наследование и композиция. На первый взгляд пример Inheritance выглядит более правильным и немного короче. Я хочу убедить вас, что Композиционный подход более правильный.
Что такое композиция? Что такое наследство?
Легче понять на примере, но полезно иметь некоторое представление о том, что вы ищете. Композиция и наследование — это методы, позволяющие опираться на существующий код вместо дублирования логики. Через минуту мы увидим, как это выглядит в коде, но для краткости можно сказать, что
- Наследование используется для моделирования отношения «Является ли», например: «
PoissonRandomNumberGeneratorявляется (конкретным случаем)RandomNumberGenerator» - Композиция используется для моделирования отношения «Имеет-а», например: «
PoissonRandomNumberGeneratorимеет (использует)RandomNumberGenerator»
В примере со случайным числом оправдан любой выбор. Однако поговорка ведет нас к композиции. Возможно, у вас еще нет интуиции, почему это так, но мы доберемся до этого 🙂
Однако поговорка ведет нас к композиции. Возможно, у вас еще нет интуиции, почему это так, но мы доберемся до этого 🙂
Создать: SortedList
Мы хотели бы создать структуру данных SortedList. Сохраняя элементы в отсортированном порядке, мы можем сделать так, чтобы «содержит ли этот список х ? операция очень быстрая . Операции вставки и удаления будут немного медленнее, но мы готовы заплатить эту цену за некоторые варианты использования.
Мы будем использовать модуль bisect из стандартной библиотеки Python, чтобы выполнить большую часть тяжелой работы. Функция bisect сообщает вам, по какому индексу искать элемент, при условии, что список отсортирован. Функция insort (каламбур: «вставить отсортировано») выполняет вставку в отсортированный список в нужном месте, чтобы сохранить его сортировку. Это именно то, что нам нужно! Это означает, что мы можем почти полностью сосредоточиться на различиях между нашими двумя подходами.
Вот как должны вести себя наши отсортированные списки:
sl = СортированныйСписок()
для элемента в (12, 4, 15, 2):
sl.insert(элемент)
print(4 in sl) # Верно
print(18 в sl) # False
print(', '.join(элемент для элемента в sl)) # 2, 4, 12, 15
Вы можете сказать: «Зачем вообще писать класс SortedList ? Разве функции insort и , делящие пополам, не делают то, что нам нужно? Они выполняют правильные действия, но мы как бы кодируем без ограждений, если используем их без класса-оболочки. Помните: эти функции предположим, список отсортирован с самого начала — они его не проверяют! Мы должны быть внимательны к тому, чтобы и случайно не нарушили порядок сортировки в любом коде, используя список, в котором мы хотим использовать пополам и вставить , иначе мы могли бы внести очень сложные ошибки в наш код. Пример того, как это может нас укусить:
из bisect import bisect, insort keep_me_sorted = [] insort(keep_me_sorted, 4) insort(keep_me_sorted, 10) # Опасность! знали ли авторы include_fav_numbers, что они должны # сохранить список в отсортированном порядке? Будут ли они помнить в будущем? include_fav_numbers(keep_me_sorted) # если они забыли, деление пополам и вставка больше не будут работать должным образом в списке
Наш быстрый поиск работает только в том случае, если список отсортирован, что трудно гарантировать одной лишь дисциплиной. Мы могли бы отсортировать список непосредственно перед тем, как использовать
Мы могли бы отсортировать список непосредственно перед тем, как использовать пополам или сортировать . Это сработало бы, но в первую очередь уничтожило бы все преимущества производительности, которые мы получаем от использования пополам ! Вместо этого давайте воспользуемся инкапсуляцией , чтобы защитить список от модификаций, которые нарушили бы наш порядок сортировки.
Реализация InheritanceSortedList
Использование наследования для создания SortedList кажется естественным выбором. A SortedList — это список! Сделано и сделано. Начнем с этого.
из bisect import insort, bisect
класс InheritanceSortedList (список):
деф вставить (я, элемент):
insort (я, элемент)
def __contains__(я, элемент):
"""
__contains__ — это метод, который вызывается, когда
запускается код типа `x в коллекции`. Это где
мы получаем повышение производительности по сравнению с обычным списком.
"""
# Найдите индекс, в котором *может* быть найден elem
ix = bisect(self, elem)
return ix != len(self) и self[ix] == elem
 """
# Найдите индекс, в котором *может* быть найден elem
ix = bisect(self, elem)
return ix != len(self) и self[ix] == elem
"""
# Найдите индекс, в котором *может* быть найден elem
ix = bisect(self, elem)
return ix != len(self) и self[ix] == elem
Итак… мы закончили? Кажется, это делает то, что мы хотим. Этот список подойдет для простых примеров, но позже мы увидим, что он не обеспечивает искомую инкапсуляцию. Во-первых, давайте посмотрим на параметр «Композиция».
Создание списка CompositionSortedList
Чтобы использовать композицию, мы создадим объект, который включает список в качестве скрытого свойства.
из bisect import insort, bisect
класс CompositionSortedList:
защита __init__(сам):
сам._lst = []
деф вставить (я, элемент):
insort(self._lst, элемент)
def __contains__(я, элемент):
ix = bisect(self._lst, elem)
return ix != len(self._lst) и self._lst[ix] == elem
Хорошо, немного длиннее, чем пример с Наследованием, но не так уж плохо. К сожалению, этот не совсем проходит наш тест. В частности,
В частности, (элемент для элемента в sl) завершится ошибкой:
TypeError: итерация по непоследовательности
Подобно магическому методу __contains__ , объекты могут определять, как перебирать их, используя метод __iter__ . Когда мы сделали InheritanceSortedList , мы получили определение __iter__ путем наследования от list . С Composition нам нужно определить один:
класс CompositionSortedList:
# ...
защита __iter__(я):
вернуть iter(self._lst)
К счастью, это не так уж сложно. В основном мы говорим: «Чтобы перебрать CompositionSortedList , просто переберите скрытый бит _lst ». Это настолько распространено, что имеет специальное название. Мы можем сказать, что CompositionSortedList делегирует своему свойству _lst . Позже мы увидим, как сделать это еще лучше.
InheritanceSortedList ломается
Хотели мы того или нет, InheritanceSortedList унаследовал все из поведения списка , включая то, что нам не нужно. Например, у нас есть метод append :
lst = НаследственностьСортированныйСписок() Lst.append(4) Lst.append(5) print(5 in lst) # печатает 'False'
У нас тоже есть __init__ на что мы не рассчитывали:
lst = список сортировки наследования ([5, 3, 2]) print(2 in lst) # печатает 'False'
Методы __init__ и append пришли прямо из родительского класса list . Они не знают , что они должны поддерживать порядок! Они правильно делают инициализацию или добавление к обычному списку , несмотря на то, что это неправильно SortedList .
Мы можем исправить это без особых усилий:
класс InheritanceSortedList (список):
def __init__(я, итерабельный=()):
супер(). __init__(сам)
для элемента в итерации:
self.insert (элемент)
def добавить (я, элемент):
поднять RuntimeError («Добавление к отсортированному списку может нарушить порядок сортировки. Вместо этого используйте вставку»)
def extend(self, iterable):
поднять RuntimeError («расширение отсортированного списка может нарушить порядок сортировки. Вместо этого используйте вставку»)
# ...есть ли другие?
 __init__(сам)
для элемента в итерации:
self.insert (элемент)
def добавить (я, элемент):
поднять RuntimeError («Добавление к отсортированному списку может нарушить порядок сортировки. Вместо этого используйте вставку»)
def extend(self, iterable):
поднять RuntimeError («расширение отсортированного списка может нарушить порядок сортировки. Вместо этого используйте вставку»)
# ...есть ли другие?
__init__(сам)
для элемента в итерации:
self.insert (элемент)
def добавить (я, элемент):
поднять RuntimeError («Добавление к отсортированному списку может нарушить порядок сортировки. Вместо этого используйте вставку»)
def extend(self, iterable):
поднять RuntimeError («расширение отсортированного списка может нарушить порядок сортировки. Вместо этого используйте вставку»)
# ...есть ли другие?
Но мне это кажется хрупким. Мы поймали и исправили все методы, которые могут нарушить порядок сортировки? Даже если у нас есть, может ли будущая версия списка добавить новый? Это иногда называют проблемой хрупкого базового класса, когда изменения в родительском классе ( список ) могут непреднамеренно нарушить производный класс ( InheritedSortedList ).
Кроме того, наличие кучи методов, которые ничего не делают, кроме создания исключений, кажется беспорядочным. Я бы хотел, чтобы мы могли просто пропустить их определение. Давайте посмотрим, как это может работать с Composition.
Давайте посмотрим, как это может работать с Composition.
CompositionSortedList создает
В каком-то смысле CompositionSortedList имеет противоположную проблему. В списке есть множество функций, которые мы хотим, чтобы сделал доступными. Точно так же, как мы сделали с __iter__ , мы можем создать методы, которые делегируют свойство частного списка:
класс CompositionSortedList:
# ...
защита __iter__(я):
вернуть self._lst.__iter__()
защита __len__(я):
вернуть self._lst.__len__()
def __getitem__(я, ix):
вернуть self._lst.__getitem__(ix)
защита __reversed__(я):
вернуть self._lst.__reversed__()
По сравнению с реализацией Inheritance, где нам приходилось отказываться от методов, которые нарушали бы наш порядок сортировки, мы выбираем _in_ поведение, которое мы хотим сделать доступными. Это защищает нас от проблемы хрупкого базового класса!
Это может быть моим личным предпочтением, но я чувствую, что композиция также чище . Мне не нужно копаться в иерархии наследования, чтобы выяснить, где был определен метод. Любая функциональность класса, использующая композицию, равна 9.0073 тут же в определении класса.
Мне не нужно копаться в иерархии наследования, чтобы выяснить, где был определен метод. Любая функциональность класса, использующая композицию, равна 9.0073 тут же в определении класса.
Я начал задаваться вопросом, есть ли более краткий способ написать все эти методы делегата. Они довольно повторяющиеся, и казалось, что от них можно избавиться. Я написал библиотеку под названием superdelegate, которая делает это возможным. Вот как это может выглядеть с суперделегатом
от superdelegate import SuperDelegate, delegate_to
класс CompositionSortedList (SuperDelegate):
# ...
__iter__ = __len__ = __getitem__ = __reversed__ = delegate_to('_lst')
Довольно мило, я думаю!
Когда бы вы использовали наследование?
Композиция безопаснее, понятнее и (с некоторой помощью суперделегата ) почти так же лаконична. Итак, когда вы вообще будете использовать наследование? Наследование уместно в нескольких случаях, которые я могу придумать (пожалуйста, напишите мне, если у вас есть другие рекомендации).