What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «зевать», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ЗЕВАТЬ, аю, аешь; несов.
1. Глубоко, с открытым ртом непроизвольно вдыхать и сразу резко выдыхать воздух (при желании спать, при усталости). Во весь рот зевает кто-н. (широко открывая рот).
Во весь рот зевает кто-н. (широко открывая рот).
2. Глядеть, наблюдать из праздного любопытства (разг.). З. по сторонам.
3. что. Упускать благоприятный момент, случай, лишаться чего-н. по оплошности (разг.).
| сов. прозевать
| однокр. зевнуть, ну, нёшь (к 1 и 3 знач.).
| сущ. зевание, я, ср.
| прил. зевательный, ая, ое (к 1 знач.; спец.). Зевательные движения.
Фонетический (звуко-буквенный) разбор
зева́ть
зевать — слово из 2 слогов: зе-вать. Ударение падает на 2-й слог.
Транскрипция слова: [з’иват’]
з — [з’] — согласный, звонкий парный, мягкий (парный)
е — [и] — гласный, безударный
в — [в] — согласный, звонкий парный, твёрдый (парный)
а — [а] — гласный, ударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 6 букв и 5 звуков.
Цветовая схема: зевать
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «зевать» по составу
зевать (программа института)
Части слова «зевать»: зев/а/ть
Часть речи: глагол
Состав слова:
зев — корень,
а, ть — суффиксы,
нет окончания,
зева — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Зев, зевать, зиять | Сайт учителя русского языка и литературы
Зев, зевать, зиять. Очень остро и тонко применяется Пушкиным «Шишковский» принцип включения в русские лексемы церковнославянских значений. Обычно этот процесс также предполагает общность живых этимологических связей и отношений между русизмами и церковнославянизмами. Но здесь церковнославянская семантика вливается в русскую лексику. Например, просторечный глагол зевать находится в живом взаимодействии с церковно-книжным словом зев. Ср. употребление слова
Например, просторечный глагол зевать находится в живом взаимодействии с церковно-книжным словом зев. Ср. употребление слова
Там мрак божественному гневу
Подвергнул грады и полки
На жертву алчной смерти зеву
(Ода на прибытие Елизаветы Петровны).
У Державина:
Бездны разверзают зевы.
Бог преступников казнит
(Целен. Саула, 223).
У Жуковского:
И смерть отвсюду им: открыт
Пред ними зев пучины жадной…
(Уллин и его дочь).
Но ср. у Пушкина в «Осени» (1833) сближение слов зев и зеванье:
На смерть осуждена,
Бедняжка клонится без ропота, без гнева,
Улыбка на устах увянувших видна;
Могильной пропасти она не слышит зева.
Поэтому Пушкин семантически сливает глагол зевать с церковнославянским зиять.
В «Фаусте»:
И всяк зевает да живет,
И всех вас гроб, зевая, ждет.
Зевай и ты.
В стихотворении «Когда за городом, задумчив, я брожу»:
Могилы склизкие, которы также тут,
Зеваючи жильцов к себе на утро ждут.
Ср. у епископа Порфирия в «Книге бытия моего»: «Может быть, он просто зевал на нас, как зевает гроб, ожидая своего жильца» (ср. сл. Грота–Шахматова, 2, с. 2947).
Ср. также совмещение церковно-славянских и русских значений в слове обольстительный:
И тем ее вернее губим
Средь обольстительных сетей…
(Евгений Онегин, 4, 7)
и др.
(Виноградов. Язык Пушкина, с. 183–184).
Презентация к уроку русского языка по теме «Состав слова» (обобщение)
Урок подготовила
Учитель начальных классов
МБОУ «Старокрымский УВК №3
«Школа-лицей»
Казакова Татьяна Леонидовна
Урок русского языка 3 класс Обобщение знаний по теме «Состав слова»
Прозвенел звонок
Начинается урок.
На уроке не зевать,
А работать и писать.
Начинаем урок!
Урок-
путешествие
Урок – игра по русскому языку
Состав слова
Части слова
Приставка
Корень основа Суффикс
Окончание
Гавань Грамотеев
Словообразование
– это наука, которая изучает
строение слова.
Пиратский Остров
От данных слов образуй с помощью указанных суффиксов однокоренные слова
I гр. II гр. III гр.
глаз сад лес
-к-
-ик-
— ник
-ик-
-ов-
— очк-
-н-
-н-
-ник-
Река Испытаний
Найдите и подчеркните лишнее слово
Золото, позолота, зола
Семя, семечко, семья
Часовщик, часть, час
Вдруг, подруга, друзья
Носильщик, нос, носатый
Горный, горка, городок
Вода, водяной, водитель
Бухта Спокойствия
Выполни упр.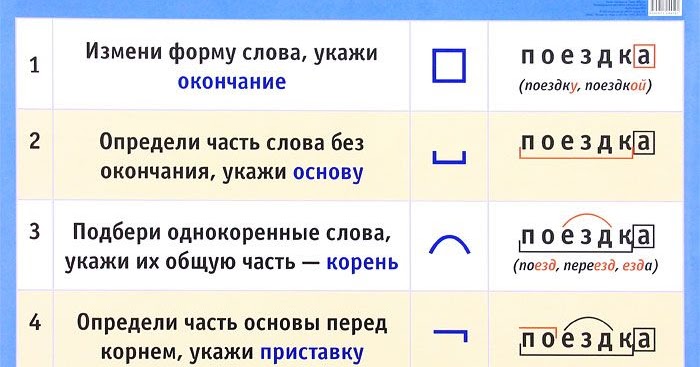 183 (учебник)
183 (учебник)
звездочка
подсвечник
оленята
пришкольный
почки
зернышко
подорожник
заморозки
облако
кормушка
дочка
поездка
Море Задач
1
2
3
11
5
8
7
13
4
9
10
12
6
Страна Знаний
ГОРОД
М
О
И
Н
А
Ч
Е
К
Н
О
И
П
С
Т
В
А
Р
К
А
С
И
К
С
Ф
Ф
У
Е
К
Р
О
Н
Ь
М
- Морфемы – это части слов, которые мы сегодня выделяли.
 А разбор слова по составу называется морфемным разбором .
А разбор слова по составу называется морфемным разбором .
 А разбор слова по составу называется морфемным разбором .
А разбор слова по составу называется морфемным разбором .Шарада
Корень мой находится в цене
В очерке найди приставку мне
Суффикс мой в тетрадке все встречали
Вся же – в дневнике и в журнале
оценка
Домашнее задание
Учебник с. 98, упр. 189.
Вам нужно списать словосочетания и найти в каждом неизменяемое слово. Выделить в этих словах основу
Берег Трудолюбия
Мудрый совет
Доброго
пути!
описывающих слов — Найдите прилагательные для описания вещей
слов для описания ~ термин ~
Как вы, наверное, заметили, прилагательные к слову «термин» перечислены выше. Надеюсь, сгенерированный выше список слов для описания термина соответствует вашим потребностям.
Если вы получаете странные результаты, возможно, ваш запрос не совсем в правильном формате. В поле поиска должно быть простое слово или фраза, например «тигр» или «голубые глаза». Поиск слов, описывающих «людей с голубыми глазами», скорее всего, не даст результатов.Поэтому, если вы не получаете идеальных результатов, проверьте, не вводит ли ваш поисковый запрос «термин» в заблуждение таким образом.
В поле поиска должно быть простое слово или фраза, например «тигр» или «голубые глаза». Поиск слов, описывающих «людей с голубыми глазами», скорее всего, не даст результатов.Поэтому, если вы не получаете идеальных результатов, проверьте, не вводит ли ваш поисковый запрос «термин» в заблуждение таким образом.
Обратите также внимание на то, что если терминов-прилагательных не так много или их совсем нет, возможно, в вашем поисковом запросе содержится значительная часть речи. Например, слово «синий» может быть как существительным, так и прилагательным. Это сбивает двигатель с толку, и поэтому вы можете не встретить много прилагательных, описывающих его. Возможно, я исправлю это в будущем. Вам также может быть интересно: что за слово ~ термин ~?
Описание слов
Идея движка Describing Words возникла, когда я создавал движок для связанных слов (он похож на тезаурус, но дает вам гораздо более широкий набор из связанных слов, а не только синонимов). Играя с векторами слов и API «HasProperty» концептуальной сети, я немного повеселился, пытаясь найти прилагательные, которые обычно описывают слово. В конце концов я понял, что есть гораздо лучший способ сделать это: разбирать книги!
Играя с векторами слов и API «HasProperty» концептуальной сети, я немного повеселился, пытаясь найти прилагательные, которые обычно описывают слово. В конце концов я понял, что есть гораздо лучший способ сделать это: разбирать книги!
Project Gutenberg был первоначальным корпусом, но синтаксический анализатор стал более жадным и жадным, и в итоге я скармливал ему где-то около 100 гигабайт текстовых файлов — в основном художественной литературы, в том числе многих современных работ. Парсер просто просматривает каждую книгу и вытаскивает различные описания существительных.
Надеюсь, это больше, чем просто новинка, и некоторые люди действительно сочтут его полезным для написания и мозгового штурма, но стоит попробовать сравнить два существительных, которые похожи, но отличаются в некотором значении — например, интересен пол: «женщина» против «мужчины» и «мальчик» против «девочки». При первоначальном быстром анализе кажется, что авторы художественной литературы как минимум в 4 раза чаще описывают женщин (в отличие от мужчин), используя термины, связанные с красотой (в отношении их веса, черт лица и общей привлекательности).
Голубая окраска результатов отражает их относительную частоту. Вы можете навести курсор на элемент на секунду, и должна появиться оценка частоты.Сортировка по «уникальности» используется по умолчанию, и благодаря моему сложному алгоритму ™ она упорядочивает их по уникальности прилагательных к этому конкретному существительному относительно других существительных (на самом деле это довольно просто). Как и следовало ожидать, вы можете нажать кнопку «Сортировать по частоте использования», чтобы выбрать прилагательные по частоте их использования для этого существительного.
Особая благодарность разработчикам mongodb с открытым исходным кодом, который использовался в этом проекте.
Обратите внимание, что Describing Words использует сторонние скрипты (такие как Google Analytics и рекламные объявления), которые используют файлы cookie.Чтобы узнать больше, см. Политику конфиденциальности.
Определение зевоты по Merriam-Webster
\ ˈYȯn , ˈYän \непереходный глагол
2 : , чтобы широко открыть рот и сделать глубокий вдох, как правило, в качестве непроизвольной реакции на усталость или скуку.
переходный глагол
2 : для достижения или побуждения зевотой его зевнули внуки — Л.Л. Кинг 2 : Широкое открывание рта при глубоком вдохе, часто являющееся непроизвольной реакцией на усталость или скуку. также : реакция, напоминающая зевок.
… успех в прокате, но вызвал только зевок критиков — Текущая биография
также : реакция, напоминающая зевок.
… успех в прокате, но вызвал только зевок критиков — Текущая биография
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов. Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели.У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется слишком много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа. Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое).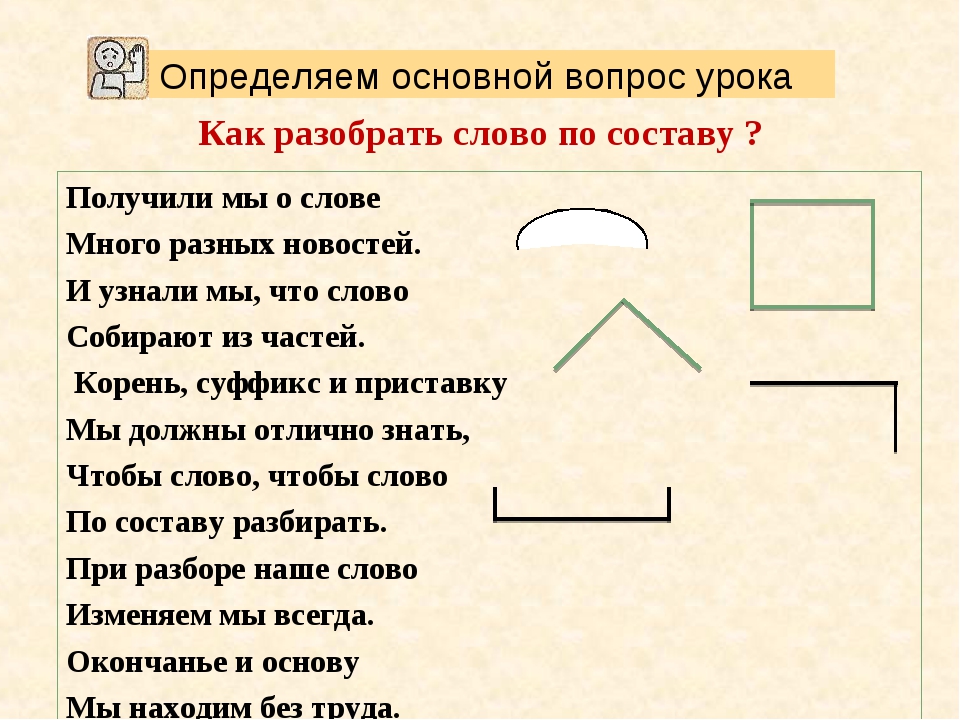 Это побудило меня исследовать «Словарь Вебстера» 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Это побудило меня исследовать «Словарь Вебстера» 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа. Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания.Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express. js.
js.
В настоящее время это основано на версии викисловаря, которой несколько лет.Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Движений глаз при чтении слов и предложений
В общении люди не придают одинаковую информативную ценность различным элементам, составляющим высказывание. Следовательно, люди не только принимают во внимание то, что они хотят сообщить, но и принимают во внимание психическое состояние адресата. Они организуют дискурс определенным образом, чтобы генерировать релевантный мнимый стимул, который может быть успешно интегрирован адресатом в общую основу (ср.Sperber and Wilson 1995 [1986], Lambrecht 1994: XIII, Krifka 2008: 245, Portolés 2010: 283-284). Таким образом, также можно предположить, что не все высказывания представляют собой одинаковое усилие обработки. Следовательно, в языках есть элементы, которые позволяют регулировать это когнитивное усилие. Элементы с процедурным значением, такие как операторы фокуса, могут точно выполнять этот эффект регулирования. Они ограничивают процессы вывода в доступном контексте из-за своих морфосинтаксических, семантических и прагматических свойств и направляют адресата к предполагаемому сообщаемому предположению, оптимизируя при этом усилия по обработке (см.Sperber and Wilson 1995 [1986], Blakemore 1987, 2002, Portolés 2001 [1998], Wilson and Sperber 2002). Из-за своего процедурного значения испанский оператор инклюзивного фокуса incluso вызывает определенную информационную структуру и тем самым регулирует усилия по обработке высказываний: он информативно выделяет элемент парадигмы как наиболее важный элемент в конкретном и доступном контексте. Инструкция оператора фокуса обычно запускает контрастное отношение между фокусом и альтернативой и приводит к интерпретации скалярной импликатуры (ср.Rooth 1985, 1996, König 1991: 10, Portolés 2007, 2010, 2011, DPDE онлайн) Цель экспериментального исследования, представленного в этой диссертации, состоит в том, чтобы изучить, вызывают ли разные фокусирующие структуры (отмеченные испанским оператором фокуса incluso) разные когнитивные паттерны.
Элементы с процедурным значением, такие как операторы фокуса, могут точно выполнять этот эффект регулирования. Они ограничивают процессы вывода в доступном контексте из-за своих морфосинтаксических, семантических и прагматических свойств и направляют адресата к предполагаемому сообщаемому предположению, оптимизируя при этом усилия по обработке (см.Sperber and Wilson 1995 [1986], Blakemore 1987, 2002, Portolés 2001 [1998], Wilson and Sperber 2002). Из-за своего процедурного значения испанский оператор инклюзивного фокуса incluso вызывает определенную информационную структуру и тем самым регулирует усилия по обработке высказываний: он информативно выделяет элемент парадигмы как наиболее важный элемент в конкретном и доступном контексте. Инструкция оператора фокуса обычно запускает контрастное отношение между фокусом и альтернативой и приводит к интерпретации скалярной импликатуры (ср.Rooth 1985, 1996, König 1991: 10, Portolés 2007, 2010, 2011, DPDE онлайн) Цель экспериментального исследования, представленного в этой диссертации, состоит в том, чтобы изучить, вызывают ли разные фокусирующие структуры (отмеченные испанским оператором фокуса incluso) разные когнитивные паттерны. во время обработки (с помощью онлайн-исследования слежения за глазами) и запускают ли они различные стратегии понимания (с помощью автономного теста на понимание). В частности, исследование было направлено на анализ: а) существуют ли корреляции между морфосинтаксическими, семантическими и прагматическими свойствами оператора фокуса incluso и информативной структурой высказывания, б) как оператор фокуса влияет на задействованные элементы операции фокусировки. и c) в какой степени наличие инклюзии определяет восстановление выводов.Таким образом, рассматриваются различные лингвистические переменные, которые позволяют анализировать, в какой степени различаются модели обработки и стратегии понимания, присутствует или отсутствует оператор фокуса в высказывании, если положение оператора фокуса является предложным или постпозиционным по отношению к элементу фокуса. , или если концептуальное значение и процедурное значение совпадают или антиориентированы по отношению к общей основе читателя. Кроме того, эти три лингвистические переменные анализируются в трех различных информационных структурах относительно альтернативной информации: неявная альтернатива, явная единственная альтернатива и явная комплексная альтернатива.
во время обработки (с помощью онлайн-исследования слежения за глазами) и запускают ли они различные стратегии понимания (с помощью автономного теста на понимание). В частности, исследование было направлено на анализ: а) существуют ли корреляции между морфосинтаксическими, семантическими и прагматическими свойствами оператора фокуса incluso и информативной структурой высказывания, б) как оператор фокуса влияет на задействованные элементы операции фокусировки. и c) в какой степени наличие инклюзии определяет восстановление выводов.Таким образом, рассматриваются различные лингвистические переменные, которые позволяют анализировать, в какой степени различаются модели обработки и стратегии понимания, присутствует или отсутствует оператор фокуса в высказывании, если положение оператора фокуса является предложным или постпозиционным по отношению к элементу фокуса. , или если концептуальное значение и процедурное значение совпадают или антиориентированы по отношению к общей основе читателя. Кроме того, эти три лингвистические переменные анализируются в трех различных информационных структурах относительно альтернативной информации: неявная альтернатива, явная единственная альтернатива и явная комплексная альтернатива. В соответствии с результатами исследования можно утверждать, что различные синтаксические, семантические и информативные изменения порождают разные структуры обработки. Что касается маркировки фокуса, общие результаты отражают, что отмеченная структура фокусировки никогда не требует больших усилий по обработке, чем то же высказывание без процедурного устройства. Кроме того, положение оператора фокуса относительно элемента фокуса строго коррелирует с обработкой фокусирующих структур. В связи с этим утверждается, что чем более распространенным и частым является положение оператора фокусировки, тем меньше затраты на обработку.Наконец, степень информативности оказывает влияние на обработку данных типов структур. Совместная ориентация концептуальной и процедурной информации относительно общей основы ускоряет обработку. Любой конфликт между двумя значениями приводит к стратегии разрешения конфликта, в которой предпринимается попытка приспособления. С точки зрения понимания, можно сделать вывод, что жесткость процедурной метки приводит к интерпретации обычной скалярной импликатуры и что оператор фокуса становится незаменимым для построения контрастных отношений.
В соответствии с результатами исследования можно утверждать, что различные синтаксические, семантические и информативные изменения порождают разные структуры обработки. Что касается маркировки фокуса, общие результаты отражают, что отмеченная структура фокусировки никогда не требует больших усилий по обработке, чем то же высказывание без процедурного устройства. Кроме того, положение оператора фокуса относительно элемента фокуса строго коррелирует с обработкой фокусирующих структур. В связи с этим утверждается, что чем более распространенным и частым является положение оператора фокусировки, тем меньше затраты на обработку.Наконец, степень информативности оказывает влияние на обработку данных типов структур. Совместная ориентация концептуальной и процедурной информации относительно общей основы ускоряет обработку. Любой конфликт между двумя значениями приводит к стратегии разрешения конфликта, в которой предпринимается попытка приспособления. С точки зрения понимания, можно сделать вывод, что жесткость процедурной метки приводит к интерпретации обычной скалярной импликатуры и что оператор фокуса становится незаменимым для построения контрастных отношений.
ВПТЗ США: изобретения, касающиеся составов программного обеспечения, не подлежат патенту в соответствии с §101, если они явно не отрицают, что механизм хранения является переходной волной или сигналом
Деннис Крауч
Ex parte Mewherter (PTAB 2013)
ВПТЗ США недавно назначило Ex parte Mewherter в качестве прецедентного решения в отношении обработки отказов в соответствии с 35 USC. § 101. Мнение в основном состоит в том, что стандартные формулы Beauregard (машиночитаемые носители информации) не подлежат патенту, поскольку они могут охватывать временные сигналы, которые не подлежат патентованию в соответствии с решением Федерального округа Nuijten.
Патентная заявка IBM с серийным номером 10/685192 направлена на «систему преобразования презентаций слайд-шоу», которая преобразует каждый слайд в «растровые изображения», а затем извлекает контекстные данные (например, заголовки) и помещает их «в непосредственной близости от растра». образы «. Речь идет о претензии 16, которая написана следующим образом:
образы «. Речь идет о претензии 16, которая написана следующим образом:
16. Машиночитаемый носитель данных, на котором хранится компьютерная программа для преобразования презентации слайд-шоу для использования с приложением без презентации, причем компьютерная программа содержит процедуру установки инструкций, заставляющих машину выполнять следующие шаги:
Извлечение заголовка слайда для первого слайда в презентации слайд-шоу, созданной приложением презентации слайд-шоу, выполняющимся в памяти компьютера;
Преобразование первого слайда с заголовком слайда в растровое изображение;
размещение как упомянутого заголовка слайда, так и упомянутого растрового изображения упомянутого слайда в документе на языке разметки; и
Повторение упомянутых этапов извлечения, преобразования и удаления для выбранной группы других слайдов в презентации слайд-шоу.

Эксперт отклонил иск в соответствии с 35 U.S.C. § 101 как требование неуставного предмета. В частности, исследователь указал, что инструкции могут быть встроены в сигнал или волну и, следовательно, не подлежат патентованию в соответствии с In re Nuijten (Fed. Cir. 2007). В своей апелляции к PTAB IBM утверждала, что заявленный ею «машиночитаемый носитель данных » достаточно закреплен, чтобы избежать временных проблем, выраженных Федеральным округом в Nuijten .В апелляции, однако, PTAB подтвердил отказ эксперта, установив, что при «самом широком разумном толковании» «машиночитаемый носитель информации» по-прежнему включает непатентованные временные сигналы. Здесь спецификация конкретно не определяет термин претензии, и IBM не дала никаких обещаний, что претензия ограничивается энергонезависимыми сигналами.
В ходе подготовки к экзаменам 2012 года ВПТЗ США предложило параллельное руководство:
Если в спецификации ничего не говорится (в исходном раскрытии нет специального определения CRM):
— Допустимо изменить формулу изобретения, чтобы исключить вариант воплощения сигнала, добавив «энергонезависимый» для модификации машиночитаемого носителя.

— См. «Соответствие предмета содержания компьютерно-читаемых носителей» (январь 2010 г.)
«Не временный» — это не требование, а просто один из вариантов.
— Заявитель может выбрать другие способы изменения претензии в соответствии с первоначальным раскрытием.
— Недопустимо просто добавлять «физический» или «материальный»
— Неподходящие сигналы Nuijten были физическими и материальными.
— Недопустимо добавлять «хранилище» при отсутствии поддержки в первоначальном раскрытии, потому что самая широкая разумная интерпретация машиночитаемых носителей информации, основанная на обычном использовании, охватывает сигналы / несущие волны.
Суть в том, что заявители на патенты теперь должны специально отказываться от преходящих волн или сигналов в качестве их композиционного носителя любых заявлений о программном обеспечении.
Скажи, что? Рот и горло обезьяны приспособлены для речи
Если бы вы могли изменить способ организации мозга обезьяны или обезьяны, это животное было бы способно воспроизводить совершенно разборчивую речь.
Это заключение исследования, в котором с помощью рентгеновских лучей тщательно отслеживались движения рта и глотки обезьяны, чтобы понять весь потенциал ее голосового тракта.
Затем исследователи использовали эту информацию для создания компьютерной модели того, как было бы звучать, если бы обезьяна могла произносить такие фразы, как «счастливых праздников».
Открытие ставит под сомнение давние предположения о том, как люди развили свою уникальную способность использовать разговорный язык.
«В учебниках вы найдете то, что обезьяны не могут говорить, потому что у них нет для этого соответствующего голосового тракта», — говорит Текумсе Фитч, когнитивный биолог из Венского университета.«Это, я думаю, миф. Мы с коллегами очень устали видеть это. Но вы видите это во всех учебниках. Многие популярные книги, а также научные книги об эволюции языка предполагают, что для того, чтобы чтобы развить речь, мы должны были произвести огромные изменения в нашем речевом тракте ».
Но вы видите это во всех учебниках. Многие популярные книги, а также научные книги об эволюции языка предполагают, что для того, чтобы чтобы развить речь, мы должны были произвести огромные изменения в нашем речевом тракте ».
В прошлом ученые смотрели на мертвых животных, чтобы оценить, на что способны их речевые тракты. Но Fitch говорит, что это заставило людей сильно недооценить гибкость нечеловеческих млекопитающих.
Он и его коллеги наблюдали за длиннохвостой макакой по имени Эмилиано, когда он делал множество различных жестов и звуков, включая чмоканье губами, зевание, жевание, воркование и ворчание.Их специальное оборудование сделало серию быстрых рентгеновских снимков, что позволило им запечатлеть полный диапазон движений голосового тракта обезьяны. Затем они использовали компьютерные модели, чтобы изучить его способность генерировать речь.
Пятница, в журнале Science Advances , его команда сообщает, что обезьяны будут физически способны воспроизводить пять различимых гласных — наиболее распространенное количество гласных в языках мира.
Люди-слушатели могли ясно понимать фразы, которые они создавали с помощью синтезированной обезьяньей речи, включая предложение руки и сердца.
Суть в том, что, по мнению Fitch, ограничения речи обезьяны обусловлены особенностями организации ее мозга.
«Как только у вас появился мозг, который был готов управлять голосовым трактом, — говорит Fitch, — голосовой тракт обезьяны или нечеловеческого примата был бы идеально подходит для произнесения множества слов».
Настоящая проблема в том, что мозг обезьян не имеет прямых связей с нейронами, контролирующими гортань и язык, говорит он. Более того, у обезьян нет критических связей внутри самого мозга, между слуховой корой и моторной корой, что делает их неспособными имитировать то, что они слышат, так, как это делают люди.
Восстание планеты обезьян , научно-фантастический фильм 2011 года, действительно имеет правильную идею, отмечает Fitch. В этом фильме после того, как лабораторный шимпанзе по имени Цезарь претерпевает изменения в мозгу, он в конечном итоге может говорить такие слова, как «Нет».
«Новый Planet of the Apes — довольно точное представление о том, что, по нашему мнению, происходит», — говорит Fitch.
СКОТТ САЙМОН, ВЕДУЩИЙ:
Люди могут говорить.Я не всегда лучшая реклама для этого. Но мы можем. Обезьяны и обезьяны не могут разговаривать. Но что, если бы они могли? Нелл Гринфилдбойс из NPR сообщает о новом исследовании, в котором изучали, как бы звучал голос обезьян, если бы у них был человеческий мозг, помогающий им говорить.
НЕЛЛ ГРИНФИЛДБОЙС, ФИЛЬМ: Вы когда-нибудь смотрели фильм под названием «Восстание планеты обезьян»?
(ЗВУК ИЗ ФИЛЬМА «ВОСХОД ПЛАНЕТЫ ОБЕЗЕЙ»)
ГРИНФИЛДБОЙС: Он вышел несколько лет назад. И в нем шимпанзе по имени Цезарь подвергается воздействию препарата, улучшающего мозг.Позже он сбегает из клетки и борется с охранником, который говорит ему убираться.
(ЗВУК ИЗ ФИЛЬМА «ВОСХОД ПЛАНЕТЫ ОБЕЗЬЯН»)
НЕИЗВЕСТНЫЙ АКТЕР: (Как охранник) Убери от меня свою вонючую лапу, проклятая грязная обезьяна.
ЭНДИ СЕРКИС: (В роли Цезаря) №
ГРИНФИЛДБОЙС: Это шокирует. Цезарь может говорить. Он может сказать нет. И все, что для этого потребовалось, — это изменения в мозгу. Tecumseh Fitch считает, что это действительно может быть правдой. Он когнитивный биолог Венского университета.И он говорит, что давно существует предположение, что эволюция речи потребовала серьезных изменений в голосовом тракте. Но он на это не покупается.
TECUMSEH FITCH: В учебниках вы найдете то, что обезьяны не могут разговаривать, потому что у них нет для этого соответствующего голосового тракта. Я думаю, это миф.
ГРИНФИЛДБОЙС: Он говорит, что обезьяны обычно издают всевозможные звуки и шлепки губами.
ФИТЧ: Значит, они издают хрюканье, реплики. У них есть эти звуки угрозы, которые вроде как, хех, когда они действительно широко открывают рот.Они кричали бы, если бы им было больно.
ГРИНФИЛДБОЙС: Он и некоторые его коллеги недавно использовали специальное рентгеновское оборудование для наблюдения за длиннохвостой макакой по имени Эмилиано. Когда машина издает звуковой сигнал, вы можете услышать воркование обезьяны.
Когда машина издает звуковой сигнал, вы можете услышать воркование обезьяны.
(ЗВУК ОБЕЗЬЯНЫ)
ГРИНФИЛДБОЙС: Исследователи внимательно отслеживали движения его губ, языка и гортани.
FITCH: Итак, нас интересовало, какие возможные формы может принимать голосовой тракт обезьяны?
ГРИНФИЛДБОЙС: С помощью этой информации и компьютерных моделей они могли выяснить, какие аспекты речи были бы физически возможны для обезьяны.Оказывается, обезьяны могут на многое. Они могли произвести пять гласных. А пять гласных — это довольно стандартно для человеческих языков.
ФИТЧ: Итак, мы обнаружили, что они могут очень, очень четко — а, ага, а, мм, ах — все эти гласные находятся в пределах досягаемости обезьяны.
ГРИНФИЛДБОЙС: Затем исследователи использовали компьютер, чтобы смоделировать, как это будет звучать, если бы обезьяна заговорила. Допустим, обезьяна прониклась духом сезона и сказала: «Счастливых праздников».
ГОЛОС №1, ГЕНЕРИРУЕМЫЙ КОМПЬЮТЕРОМ: С праздником.
ГРИНФИЛДБОЙС: А что, если обезьяна попросит вас выйти за вас?
ГОЛОС №2, ГЕНЕРИРУЕМЫЙ КОМПЬЮТЕРОМ: Ты выйдешь за меня замуж?
ГРИНФИЛДБОЙС: Они выбрали эту фразу, потому что в ней много гласных. Но Fitch говорит, что обезьяны тоже могут произносить много согласных. Все, что нужно, чтобы говорить, — это правильный мозг.
Фитч: Как только у вас появится мозг, который будет готов управлять голосовым трактом, голосовой тракт обезьяны или любого другого нечеловеческого примата будет идеально подходит для создания множества слов.
GREENFIELDBOYCE: Работа опубликована в журнале Science Advances. И Fitch надеется, что это раз и навсегда избавит от мысли о том, что анатомия голоса обезьян не способна говорить. Нелл Гринфилдбойс, Новости NPR.
(ЗВУК КОМПОЗИЦИИ ПАТРИКА ДОЙЛА, «LOFTY SWING») Стенограмма предоставлена NPR, авторское право NPR.
Смысловая композиция в пейзажном письме Гертруды Стайн
Об этой книге
Введение
Эта книга предлагает смелый критический метод прочтения работы Гертруды Стайн на ее собственных условиях, отказавшись от традиционных объяснений и приняв радикальный подход Стейн к значению и знанию. Вдохновленная имманентностью пейзажа, как Прованса, куда она побывала в 1920-х годах, так и пространственными отношениями пейзажной живописи, Штейн представляет новую модель смысла, согласно которой осмысление — это деятельность, распределенная в тексте и между последовательными текстами. От любовной поэзии до пьес и портретов Линда Ворис предлагает внимательное прочтение наиболее антологизированных и менее известных произведений Штейна в тематическом исследовании нового метода интерпретации. Практикуя новаторские способы осмысления Штейна, Ворис раскрывает волнение своих открытий и их поразительное значение для знаний, идентичности и близости.
Вдохновленная имманентностью пейзажа, как Прованса, куда она побывала в 1920-х годах, так и пространственными отношениями пейзажной живописи, Штейн представляет новую модель смысла, согласно которой осмысление — это деятельность, распределенная в тексте и между последовательными текстами. От любовной поэзии до пьес и портретов Линда Ворис предлагает внимательное прочтение наиболее антологизированных и менее известных произведений Штейна в тематическом исследовании нового метода интерпретации. Практикуя новаторские способы осмысления Штейна, Ворис раскрывает волнение своих открытий и их поразительное значение для знаний, идентичности и близости.
Ключевые слова
Гертруда Стайн Пейзаж Письмо Философия Модернизм Американская литература
Авторы и аффилированные лица
 org/Organization»> 1. Американский университет Вашингтон, округ Колумбия, США
org/Organization»> 1. Американский университет Вашингтон, округ Колумбия, СШАОб авторах
Линда Ворис — адъюнкт-профессор литературы в Американском университете в Вашингтоне, округ Колумбия.С., США. Ее публикации появились в журналах Modernism / modernity , Studies in American Fiction и American Women Poets in the 21st-Century .Библиографическая информация
Обзоры
«Композиция смысла в сочинении пейзажной живописи Гертруды Стайн Линды Ворис просто меняет правила игры для стипендии Штейн.