Морфологический разбор слова язык онлайн
Слово язык является Именем существительным (это самостоятельная, склоняемая часть речи). Оно неодушевленное и употребляется в мужском роде. Разряд по значению:конкретное. Второе склонение (т.к. в им. падеже, в мужском роде окончание нулевое или в среднем роде окончания: ‘о’ или ‘е’). Относится к Нарицательным именам существительным. Множественная форма слова ‘язык’ является ‘языки’
- В Именительном падеже, слово язык(языки) отвечает на вопросы: кто? что?
- Родительный падеж (Кого? Чего?) — языка(языков)
- Дательный падеж (Кому? Чему?) — Дать языку(языкам)
- Винительный падеж (Кого? Что?) — Винить язык(языки)
- Творительный падеж (Кем? Чем?) — Доволен языком(языками)
- Предложный падеж (О ком? О чём?) — Думать о языке(о языках)
- Орган в полости рта в виде подвижного мягкого выроста.

- Система фонетических, лексических и грамматических средств, являющаяся орудием выражения мыслей, чувств, волеизъявлений и служащая важнейшим средством общения людей.
- Пленный.
- .Способность говорить, выражать словесно свои мысли.
Слово «язык» является Именем существительным
Слово «язык» — неодушевленное
язЫк
Ударение падает на слог с буквой Ы. На третью букву в слове.
Слово «язык» — мужской
Слово «язык» — конкретное
Слово «язык» — 2 склонениеСлово «язык» — нарицательное
Единственное число
Множественное число
Именительный п.
Родительный п.
Полость языка была воспалена.
Приложи к языку лёд.
Винительный п.
Покажите язык.
Творительный п.
Не трепи языком.
Врач осмотрел налёт на языке.
- хохотун
- конница
- крестный
- синус
- фугас
- мина
- холера
- сотник
- эколог
- евстахиев
%d1%84%d0%be%d0%bd%d0%b5%d1%82%d0%b8%d1%87%d0%b5%d1%81%d0%ba%d0%b8%d0%b9%20%d1%80%d0%b0%d0%b7%d0%b1%d0%be%d1%80%20%d1%81%d0%bb%d0%be%d0%b2%d0%b0 — со всех языков на все языки
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАканАлтайскийАрагонскийАрабскийАстурийскийАймараАзербайджанскийБашкирскийБагобоБелорусскийБолгарскийТибетскийБурятскийКаталанскийЧеченскийШорскийЧерокиШайенскогоКриЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийВаллийскийДатскийНемецкийДолганскийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГэльскийГуараниКлингонскийЭльзасскийИвритХиндиХорватскийВерхнелужицкийГаитянскийВенгерскийАрмянскийИндонезийскийИнупиакИнгушскийИсландскийИтальянскийЯпонскийГрузинскийКарачаевскийЧеркесскийКазахскийКхмерскийКорейскийКумыкскийКурдскийКомиКиргизскийЛатинскийЛюксембургскийСефардскийЛингалаЛитовскийЛатышскийМаньчжурскийМикенскийМокшанскийМаориМарийскийМакедонскийКомиМонгольскийМалайскийМайяЭрзянскийНидерландскийНорвежскийНауатльОрокскийНогайскийОсетинскийОсманскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПортугальскийКечуаКвеньяРумынский, МолдавскийАрумынскийРусскийСанскритСеверносаамскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиШумерскийСилезскийТофаларскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийТувинскийТвиУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВьетнамскийВепсскийВарайскийЮпийскийИдишЙорубаКитайский
Все языкиАбхазскийАдыгейскийАфрикаансАйнский языкАлтайскийАрабскийАварскийАймараАзербайджанскийБашкирскийБелорусскийБолгарскийКаталанскийЧеченскийЧаморроШорскийЧерокиЧешскийКрымскотатарскийЦерковнославянский (Старославянский)ЧувашскийДатскийНемецкийГреческийАнглийскийЭсперантоИспанскийЭстонскийБаскскийЭвенкийскийПерсидскийФинскийФарерскийФранцузскийИрландскийГалисийскийКлингонскийЭльзасскийИвритХиндиХорватскийГаитянскийВенгерскийАрмянскийИндонезийскийИнгушскийИсландскийИтальянскийИжорскийЯпонскийЛожбанГрузинскийКарачаевскийКазахскийКхмерскийКорейскийКумыкскийКурдскийЛатинскийЛингалаЛитовскийЛатышскийМокшанскийМаориМарийскийМакедонскийМонгольскийМалайскийМальтийскийМайяЭрзянскийНидерландскийНорвежскийОсетинскийПенджабскийПалиПольскийПапьяментоДревнерусский языкПуштуПортугальскийКечуаКвеньяРумынский, МолдавскийРусскийЯкутскийСловацкийСловенскийАлбанскийСербскийШведскийСуахилиТамильскийТаджикскийТайскийТуркменскийТагальскийТурецкийТатарскийУдмурдскийУйгурскийУкраинскийУрдуУрумскийУзбекскийВодскийВьетнамскийВепсскийИдишЙорубаКитайский
ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА СЛОВА 1.Пишу слово, ставлю ударение, делю его на слоги, количество гласных и согласных. 2. Фонетическая транскрипция слова. 3. Характеристика звуков по порядку: — согласный, звонкий – глухой, твёрдый – мягкий -гласный , ударный- бзударный; 4. Пишу количество букв и звуков. ОБРАЗЕЦ: Морковь – 2 слога, 2 гл., 4 согл. м — [м] — согл., зв., тв.; о — [а] – гласн., безуд.; р — [р ] – согл., зв., тв.; к — [к ] – согл., глух., тв.; о — [о ] – гл., уд.; в — [ф’] – согл., глух., мягк.; ь — [-] ________________ 7 букв, 6 звуков. | ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА СЛОВА 1.Пишу слово, ставлю ударение, делю его на слоги, количество гласных и согласных. 2. Фонетическая транскрипция слова. 3. Характеристика звуков по порядку: — согласный, звонкий – глухой, твёрдый – мягкий -гласный , ударный- бзударный; 4. ОБРАЗЕЦ: Морковь – 2 слога, 2 гл., 4 согл. м — [м] — согл., зв., тв.; о — [а] – гласн., безуд.; р — [р ] – согл., зв., тв.; к — [к ] – согл., глух., тв.; о — [о ] – гл., уд.; в — [ф’] – согл., глух., мягк.; ь — [-] ________________ 7 букв, 6 звуков. | ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА СЛОВА 1.Пишу слово, ставлю ударение, делю его на слоги, количество гласных и согласных. 2. Фонетическая транскрипция слова. 3. Характеристика звуков по порядку: — согласный, звонкий – глухой, твёрдый – мягкий -гласный , ударный- бзударный; 4. Пишу количество букв и звуков. ОБРАЗЕЦ: Морковь – 2 слога, 2 гл., 4 согл. м — [м] — согл., зв., тв.; о — [а] – гласн., безуд.; р — [р ] – согл., зв., тв.; к — [к ] – согл., глух., тв.; о — [о ] – гл., уд.; в — [ф’] – согл., глух., мягк.; ь — [-] ________________ 7 букв, 6 звуков. | ПЛАН ФОНЕТИЧЕСКОГО РАЗБОРА СЛОВА 1.Пишу слово, ставлю ударение, делю его на слоги, количество гласных и согласных. 2. Фонетическая транскрипция слова. 3. Характеристика звуков по порядку: — согласный, звонкий – глухой, твёрдый – мягкий -гласный , ударный- бзударный; 4. Пишу количество букв и звуков. ОБРАЗЕЦ: Морковь – 2 слога, 2 гл., 4 согл. м — [м] — согл., зв., тв.; о — [а] – гласн., безуд.; р — [р ] – согл., зв., тв.; к — [к ] – согл., глух., тв.; о — [о ] – гл., уд.; в — [ф’] – согл., глух., мягк.; ь — [-] ________________ 7 букв, 6 звуков. |
 Перспектива. | Учебно-методический материал по русскому языку (2 класс) на тему:
Перспектива. | Учебно-методический материал по русскому языку (2 класс) на тему: Пишу количество букв и звуков.
Пишу количество букв и звуков.
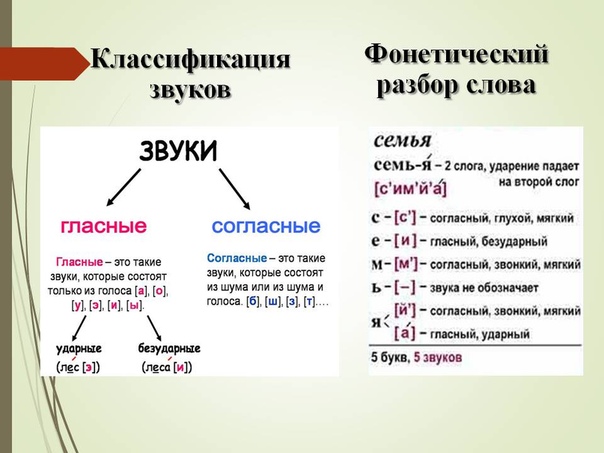
Фонетический разбор слова
Из звуков состоят слова устной речи. Среди звуков есть гласные и согласные. Первые так называются потому, что произносятся с голосом. Когда мы их произносим, воздух не встречает преграды.
Вторые в речи присоединяются к гласным, потому так и называются: согласные. При произнесении этих звуков воздух всегда встречает преграду.
При произнесении этих звуков воздух всегда встречает преграду.
Среди гласных звуков один ударный, а остальные, если есть, безударные.
Гласных звуков 6: [а], [о], [у], [э], [и], [ы].
Согласные звуки бывают твёрдые и мягкие. Большая их часть составляет пары по твёрдости-мягкости. Например: б-б’, м-м’, в-в’. У некоторых пары нет.
Всегда твёрдые согласные звуки: [ж], [ш], [ц]
Всегда мягкие согласные звуки: [щ’], [ч’], [й’]
Помогут запомнить эти согласные звуки предложения: Жонглёр жонглирует шарами и цветами. Щука, чайка.
Учёные придумали, как можно обозначать звуки нашей речи.
Они договорились использовать буквы, но ставить их в особые квадратные скобки. Чтобы показать, что согласный звук мягкий, используют значок, похожий на запятую.
Ещё согласные бывают звонкие и глухие. Многие из них объединяются в пары по звонкости-глухости. Например, б-п, в-ф, г-к, д-т, ж-ш, з-с.
Но есть и такие, которые не имеют глухой или звонкой пары. Например, непарные звонкие: [л], [м], [н], [р], [й’], непарные глухие: [х], [ч’], [ц], [щ’].
На письме звуки обозначаются буквами.
Русский алфавит включает в себя 33 буквы: 10 из них обозначают гласные звуки, 21 – согласные, а также ъ и ь (эти буквы звуков не обозначают).
Буквы гласных: а-я, о-ё, у-ю, ы-и, э-е.
12 букв обозначают парные по звонкости-глухости согласные звуки.
Буквы согласных парных по звонкости-глухости: б-п, в-ф, г-к, д-т, ж-ш, з-с.
Буквы л, м, н, р, й обозначают непарные звонкие согласные звуки.
Буквы х, ч, ц, щ обозначают непарные глухие согласные звуки.
Какие буквы указывают на твёрдость или мягкость согласного:
Произнесём слово «люк».
Перед вами транскрипция слова (передача звуков речи на письме с помощью специальных знаков): [л’ у к]
Услышали первый звук [л’] мягкий согласный? Напишем первую букву л.
Ещё раз послушаем себя: [л’у. Второй звук гласный [у].
Какую букву надо выбрать? Напишем букву у. Получится у нас «лук». Нужна буква ю.
Буквы согласных сами не показывают твёрдость или мягкость своих звуков. За них это делают буквы гласных звуков. Одни указывают на твёрдость, другие на мягкость согласного.
Слышу твёрдый согласный – после него на месте гласного пишу буквы а, о, у, ы, э.
Слышу мягкий согласный – после него на месте гласного пишу буквы я, ё, ю, и, е.
Произносим слова и записываем их буквами:
[н о с] – после твёрдого согласного [н] звук [о] обозначаем буквой о.
[н’ о с] – после мягкого согласного [н’] звук [о] обозначаем буквой ё.
Запишите слова буквами.
[у т’ а΄ т а] – утята Буква я обозначает мягкость предыдущего согласного [и] звук [а] [с’ о΄ с т р ы] – сёстры Буква ё обозначает мягкость предыдущего согласного [и] звук [о] [д’ эʹ н’] – день Буква е обозначает мягкость предыдущего согласного [и] звук [э]
Буква ь обозначает мягкость согласного.
О чём напоминает таблица?
[ж ыʹ] – жѝ [ч΄á] – чá [ч’ ý] – чý
[ш ы΄] – шѝ [щʹá] – щá [щ’ý] – щý
Сочетания жи – ши пишутся с буквой и, а слышим звук [ы]. Сочетания ча – ща пишутся с буквой а, и звук слышим [а].
Ошибочно подменять звук [а] буквой я в звуковой схеме.
Сочетания чу – щу пишутся с буквой у, и звук слышим у].
Ошибочно подменять звук [у] буквой ю в звуковой схеме.
Вот так составили транскрипции к словам с данными орфограммами:
[ж ы т’] – жить [щ’ у к а] – щука [ч’ а ш к а] – чашка [ч’ у л а н] – чулан
Ошибочно подменять звуки [э, о, у, а] буквами е, ё, ю, я в транскрипции.
Произнесём эти буквы:
е – [й’ э], ё – [й’ о], ю – [й’ у], я – [й’ а].
Эти буквы могут обозначать два звука.
Два звука они обозначают в начале слова, после гласных, после разделительных ъ и ь знаков.
яма [й’ аʹ м а]
ель [й’ э л’]
Буквы я, е обозначают два звука, так как стоят в начале слова.
даёт [д а й’ о΄ т]
приятный [п р’и й’ аʹ т н ы й’]
Буквы ё, я обозначают два звука, так как стоят после гласных.
вьюга [в’ й’ у΄ г а]
въеду [в й’ эʹ д у]
Буквы ю, е обозначают два звука, так как стоят после разделительных ъ и ь знаков.
Звук [й’] передаётся буквой й и сочетанием букв ьи.
[л’ и΄ с’ й’ и] – лисьи
[п т’ иʹч’ й’ и] – птичьи
[м у р а в’ й’ и] – муравьи
Правила произношения слов с парными согласными
В словах есть орфограммы, например безударных гласных и парных по глухости и звонкости согласных.
Чтобы не ошибиться в фонетическом разборе слова, обязательно произносите слова вслух, обращая внимание на звучание гласных и согласных.
1. На конце слова и перед глухими согласными на месте букв звонких согласных произносятся парные глухие согласные:
На конце слова и перед глухими согласными на месте букв звонких согласных произносятся парные глухие согласные:
гла [с] (глаз), зага [т] ка (загадка), ро [п] кий (робкий), кни [ш] ка (книжка)
2. Перед звонкими парными (кроме [в]) на месте букв глухих согласных звучат парные звонкие:
Про [з’] ба (просьба), э [г] замен (экзамен), фу [д] бол (футбол).
Как произносятся безударные гласные
Определим, какой безударный гласный звук произносится на месте пропуска.
Звонόк, колόть, бежáть, вязáть.
Зв нόк, к лόть, б жáть, в зáть.
Зв [а] нόк, к [а] лόть, б [и] жáть, в [и] зáть.
С помощью значка транскрипции покажите, какой звук обозначает подчёркнутая в слове буква.
ошѝбка – [а] ши [п] ка
моркόвь – м [а] рко [ф’]
леснѝк л – [и] сни [к]
сдéлать – [з] делать
Как выполнить звуко — буквенный разбор?
1. Послушай слово и запиши его (в столбик) значками звуков, укажи ударение (если не один слог).
2. Дай характеристику каждого звука:
- гласный или согласный;
- гласный: ударный или безударный;
- согласный: твёрдый или мягкий;
- звонкий или глухой.
3. Обозначь звуки буквами.
4. Укажи количество слогов, звуков и букв.
5. Запиши слово в строчку. Если есть орфограммы, отметь их.
Выполняем звуко-буквенный разбор:
Послушай слово: [й’ о ш]. Запишем его значками звуков.
Запишем его значками звуков.
[й’] – согласный, звонкий, мягкий ё
[о] – гласный
[ш] – согласный, глухой, твёрдый ж
3 звука, 2 буквы, 1 слог
ёж
Обозначим звуки буквами.
Два звука [й’о] обозначаются буквой ё, она стоит в начале слова.
Глухой звук ш в конце слова обозначаем буквой ж.
Проверить парный согласный можно словом ежи.
Произнесём слово тетрадь.
[т’] – согласный, глухой, мягкий т
[и] – гласный, безударный е
[т] – согласный, глухой, твёрдый т
[р] – согласный, звонкий, твёрдый р
[á] – гласный, ударный а
[т’] – согласный, глухой, мягкий дь
6 звуков, 7 букв, 2 слога
Тетрáдь
Букв больше, так как мягкий знак звука не обозначает.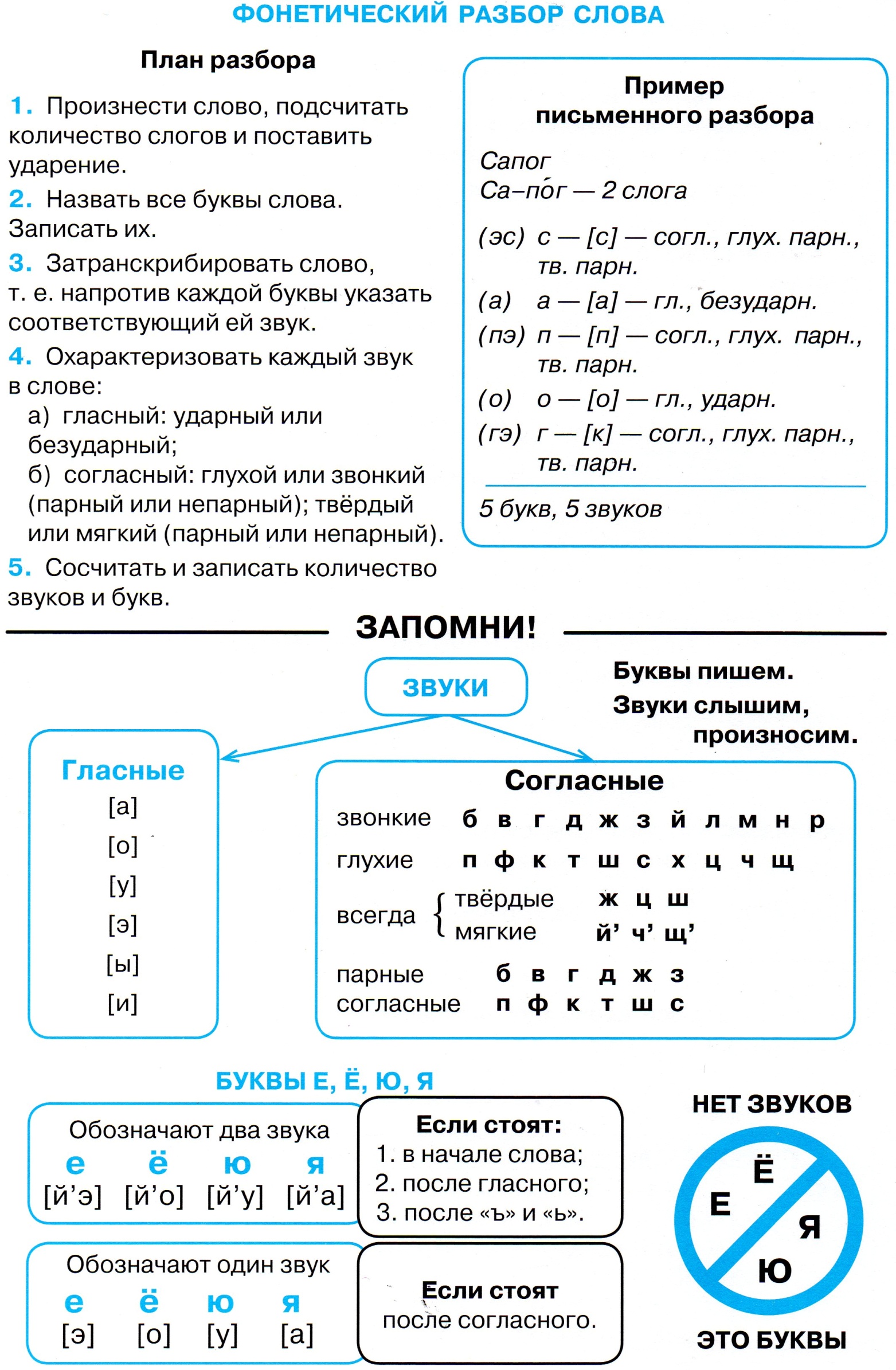
вернуться на страницу «Русский язык 3 класс» >>>
Если Вам понравилось — поделитесь с друзьями :
Присоединяйтесь к нам в Facebook!
Разговорный русский — Real Language Club
Смотрите также:
Подготовка к экзаменам по русскому языку:
Мы рекомендуем:
Самое необходимое из теории:
Предлагаем пройти тесты онлайн:
Рекомендуемые статьи и видео:
Ещё статьи >>>
Русский язык с репетиторами онлайн
Практичные советы по изучению русского языка
Мы в соцсетях:Конспект урока по русскому языку на тему «Фонетический разбор слова.
 » (3 класс)
» (3 класс)«Ташебинская начальная общеобразовательная школа»
Предмет: Русский язык.Тема: «Фонетический разбор слова».
Дата: 06.09.2016 г.
Цель: повторить правила переноса слов; научить применять алгоритм выполнения фонетического анализа слова.
УУД:
Предметные: знают языковые единицы: звук, буква; находят, сравнивают и классифицируют буквы и звуки. Особенности различия звуков и букв. Анализ слова.
Личностные: имеют желание учиться, адекватное представление о поведении, выражают положительное отношение к процессу познания
Метапредметные:
Регулятивные: принимают и сохраняют учебную задачу планируют своё действие в соответствии с поставленной задачей и условиями её реализации.
Познавательные: умеют самостоятельно выделять и формулировать познавательную цель, проверяют написанное, ориентируются в учебнике, находят ответы на вопросы, осуществляют анализ, делают выводы, находят способы решения проблемной задачи.
Коммуникативные: строят высказывание в устной форме владеют способами совместной деятельности.
Тип урока: изучение нового материала.
Оборудование: учебник, карточки со словами.
Ход урока:
-Здравствуйте, ребята. Я желаю вам хорошего настроения. Повернитесь друг к другу, улыбнитесь и пожелайте хорошего настроения на уроке.— Проверьте все ли у вас готово к уроку.
Приветствуют учителя.
Проверяют готовность к уроку.
2
Актуализация знаний.
Минутка чистописания.
ци цы // щи щи //
цирк, птицы, щипцы ///
Повторение правила переноса и деления слов на слоги.

– Вы уже знаете, что слова делятся на слоги.
– Как узнать, сколько слогов в слове?
– Как разделить слова на слоги?
На доске записаны слова:
Ли-са, ма-ли-на, ма-й, те-тра-дь, ли-мон, и-ва, въ-езд, я-ма,
пять, ю-ла.
— Найдите слова, которые неправильно разделены на слоги. Объясните причину ошибки. Разделите эти слова на слоги правильно, запишите в тетради. По окончании работы выполните взаимопроверку.
— К нам за помощью обратился первоклассник. Послушайте его рассказ и определите, какое правило он не усвоил? Помогите ему правильно перенести слова.
РАССКАЗ ПЕРВОКЛАССНИКА
Мы изучаем перенос,
Вот как слова я перенёс:
Едва я перенёс:
Е-
Два, –
Так получил за это «два».
Укол я перенёс:
У—
Кол –
И получил за это «кол».
Опять я перенёс:
О—
Пять –
Теперь, наверно, будет «пять».
– А вы как думаете, ребята?
— Помогите первокласснику правильно перенести слова, расскажите правило переноса слов.
Выполняют чистописание в тетради.
— Сколько гласных, столько и слогов.
— При произношении слова согласные звуки «тянутся» к гласным, образуя вместе с гласными слог. Поэтому слово нужно пропеть.
Выполняют задание.
— Нет.
— Слова переносятся по слогам. Нельзя переносить одну букву. Нельзя переносить две одинаковые буквы. При переносе буква Й переносится с гласной. Слова с Ъ и Ь переносятся с буквой после которой они написаны.
3
Постановка темы и цели занятия.
— Вы знаете, что слова можно записывать по-разному: буквами, с помощью транскрипций и с помощью звуковых моделей.
— Посмотрите на доску.
Лимон – [л’имон]
— Как вы думаете, какая тема сегодняшнего урока? Цель урока?
— Верно. На сегодняшнем уроке нам предстоит учиться проводить фонетический анализ слова устно, а затем записывать его.
— Фонетический разбор слова.
4
Изучение новой темы.
1. Чтение алгоритма «Как выполнять фонетический анализ слова».
Учебник с.9.
Физкультминутка
2. Проведение фонетического анализа слов по алгоритму.
1) Запишем слово, разделим на слоги, запишем его с помощью транскрипции: Ракета, ра-ке—та, [рак’э́та].
2) Запишем слово по буквам в столбик и рядом транскрипцию [ ] звука.
3) Дадим характеристику звукам.
4) Подсчитаем количество букв и звуков.
р – [р] – согласный, твердый, непарный.
a – [а] – гласный, безударный.
к – [к’] – согласный, глухой, парный ([г]).
е – [э] – гласный, ударный.
т – [т] – согласный, глухой, парный ([д]).
а – [а] – гласный, безударный.
6 б., 6 зв.
— Как вы думаете, для чего надо уметь выполнять фонетический разбор слов?
Учащиеся, выполняют фонетический анализ слова, рассуждают и действуют последовательно, согласно указаниям алгоритма:
Учащиеся делают фонетический анализ слова луна.
Слова различаются правописанием и произношением. И редко, когда произношение и написание совпадают, чаще всего они различаются. Для того, чтобы правильно писать слова, надо уметь различать их на слух, охарактеризовывать звуки, знать их буквенное обозначение и еще очень многое, что нам предстоит изучать на уроках русского языка.
5
Итог урока.
Рефлексия.
— Какую учебную задачу поставили перед собой на уроке? Мы достигли её?
— Чему мы научились?
— Кому было трудно?
— Что не получилось? Что нужно сделать, чтобы в дальнейшем избежать ошибок?
— Где вам пригодятся эти знания?
— Оцените свою работу на уроке. Встаньте те, кто считает, что он работал вот так:
— Все получилось;
— были затруднения;
— ничего не получилось.
— Почему вы так думаете?
— Да, вы молодцы. Я с вами полностью согласна.
— Спасибо за урок.
6
Домашнее задание
Выучить алгоритм фонетического разбора.
Учебник с. 4, упр. 4
ма-ли-на, |
те-тра-дь, |
ли-мон, |
и-ва, въ-езд, |
пять, ю-ла. я-ма, |
Урок 59. закрепление по разделу «звуки и буквы» — Русский язык — 2 класс
Русский язык. 2 класс.
Урок 59. Закрепление знаний в разделе «Звуки и буквы»
Цель:
- систематизировать и обобщить знания о звуках и буквах русского языка, об изученных орфограммах.

Задачи:
- закрепить знания об отличиях звука от буквы, гласного звука от согласного звука;
- упражняться в характеристике звуков речи;
- подбирать примеры слов с изученными орфограммами;
- сопоставлять приём проверки написания гласных и согласных в корне слова;
- работать с памяткой «Как провести звуко-буквенный разбор слова».
На уроке
мы узнаем:
- об отличиях буквы от звука, а также гласного звука от согласного;
мы научимся:
- характеризовать звуки русской речи;
мы сможем:
- провести звуко-буквенный разбор слова.
Тезаурус
Звук – это наименьшая единица звучащей речи.
Буква – это знак для отражения звука на письме.
Гласные звуки образуются только при помощи голоса.
Согласные звуки образуются при помощи шума и голоса.
Основная и дополнительная литература по теме урока
Канакина В. П., Горецкий В. Г. Русский язык. Учебник. 2 класс. В 2 ч. Ч. 2. — М.: Просвещение, 2018. – С. 31 – 38.
П., Горецкий В. Г. Русский язык. Учебник. 2 класс. В 2 ч. Ч. 2. — М.: Просвещение, 2018. – С. 31 – 38.
Канакина В.П. Русский язык. Рабочая тетрадь. 2 класс. В 2 ч. Ч. 2. — М.: Просвещение, 2018. – С. 19-22.
Канакина В.П., Щеголёва Г.С. Русский язык. 2 класс. Контрольные работы. В 2 ч. Ч. 2. – М.: Просвещение, 2018. — С. 41 — 45.
Канакина В.П. Русский язык. 2 класс. Тетрадь учебных достижений. – М.: Просвещение, 2017. – С. 50 — 51.
Канакина В.П. Русский язык. Раздаточный материал. Пособие для учащихся. 2 класс. – М.: Просвещение, 2018. — С. 41.
Тихомирова Е.М. Тренажёр по русскому языку к учебнику В.П. Канакиной, В.Г. Горецкого «Русский язык. 2 класс. В 2 ч.» ФГОС (к новому учебнику) – М.: Издательство «Экзамен», 2018. — С.61-64.
Тихомирова Е.М. Тесты по русскому языку. 2 класс. В 2 ч. Ч. 2: к учебнику В.П. Канакиной, В. Г. Горецкого «Русский язык. 2 класс. В 2 ч. Ч. 1.» ФГОС (к новому учебнику) – М.: Издательство «Экзамен», 2017. — С. 22 — 29.
Русский язык: предварительный контроль: текущий контроль: итоговый контроль: 2 класс: учебное пособие для общеобразовательных организаций / О. Е. Курлыгина, О.О. Харченко. – М.: Просвещение: УчЛит, 2018. — С. 64-68.
Е. Курлыгина, О.О. Харченко. – М.: Просвещение: УчЛит, 2018. — С. 64-68.
Открытые электронные ресурсы по теме урока
Канакина В.П. и др. Русский язык. 2 класс. Электронное приложение. — М.: Просвещение, 2011. Ссылка для скачивания: http://catalog.prosv.ru/attachment/ca950bac-d794-11e0-acba-001018890642.iso
Теоретический материал для самостоятельного изучения.
Мы живём в мире, наполненном разнообразными звуками. Звучит всё: вода и солнце, птицы, животные… И человек тоже в некотором смысле звучит. Только звуки речи человека отличаются от всех других звуков тем, что они образуют слова.
Звук является наименьшей звучащей и слышимой единицей любого языка. Отдельно взятый звук не имеет никакого смысла. Но когда звуки сливаются в слова, они создают слова. С помощью звуков речи можно превратить одно слово в другое: сук -лук — тук — ток — том – ром — рот … При изменении только одного звука появляется новое слово с присущим ему значением.
Звуки образуются во время выдоха от колебаний струи воздуха с помощью работы речевого аппарата. Речевой аппарат – это гортань с голосовыми связками, ротовая и носовая полости, нёбо, язык, губы и зубы.
Речевой аппарат – это гортань с голосовыми связками, ротовая и носовая полости, нёбо, язык, губы и зубы.
В звуках речи мы можем различить голос и шум. Голос образуется от того, что выдыхаемый воздух проходит через напряженные голосовые связки. А шум образуется тогда, когда выдыхаемый воздух преодолевает препятствия, которые создают губы, зубы или язык.
Когда выдыхаемый воздух без препятствий проходит через ротовую полость, образуются гласные звуки. Они состоят только из голоса! Гласные звуки — самые звучные. Если приложить палец к гортани и произнести гласные звуки [а], [о], [у], [и], [ы], [э], то можно почувствовать, как дрожат голосовые связки.
В русском языке всего 6 гласных звуков: [а], [о], [у], [ы], [э], [и].
Слова делятся на слоги. В состав слога обязательно входит гласный звук, поэтому в слове столько слогов, сколько гласных звуков.
Если слово состоит из нескольких слогов, то один из них звучит с большей силой, более чётко, чем остальные. Это ударный слог. Гласный звук в ударном слоге является ударным звуком. Гласные звуки в безударных слогах являются безударными гласным звуками. Все ударные гласные звуки произносятся отчётливо. Безударные гласные произносятся ослаблено, более кратко и нечётко.
Гласный звук в ударном слоге является ударным звуком. Гласные звуки в безударных слогах являются безударными гласным звуками. Все ударные гласные звуки произносятся отчётливо. Безударные гласные произносятся ослаблено, более кратко и нечётко.
Часто безударный звук не соответствует букве, которая написана в слове. Безударные гласные — это орфограмма.
В звучащей речи человека есть звуки, которые образуются через преодоление выдыхаемым воздухом препятствий в виде губ, зубов и языка. Из-за этого мы слышим шум. Это согласные звуки.
Из шума состоят все согласные звуки. Но в образовании некоторых согласных звуков кроме шума участвует и голос. Поэтому различают звонкие и глухие согласные звуки.
Согласные звуки, в образовании которых участвуют и голос, и шум, называют звонкими. Голосовые связки при их произнесении напряжены и дрожат. Это звуки [б], [в], [г], [д], [ж], [з], [б’], [в’], [г’], [д’], [ж’], [з’], [м], [н], [л], [р], [м’], [н’], [л’], [р’], [й’]
Согласные звуки, которые создаются только одним шумом и без голоса, называются глухими. При образовании таких звуков голосовые связки расслаблены и не дрожат. Это звуки п, п’, ф, ф’, ш, с, с’, к, к’, т, т’, ч’, щ’, х, х’, ц, ц’.
При образовании таких звуков голосовые связки расслаблены и не дрожат. Это звуки п, п’, ф, ф’, ш, с, с’, к, к’, т, т’, ч’, щ’, х, х’, ц, ц’.
В русском языке при произношении части согласных звуков речевой аппарат работает совершенно одинаково. Например, Б – П. Различаются эти звуки только участием голоса. Такие звуки образуют пары по глухости-звонкости и их называют парными. Это звуки [б], п, [б’], п′, [в], ф, [в’], ф’, [г], к, [г’], к’, [д], т, [д’], т’, [ж], ш, [з], с, [з’], с’.
Другая часть согласных звуков такой пары не имеет. Их назвали непарными. Это звуки [м], [м’], [н], [н’], [л], [л’], [р], [р’], х, х’, ц, [й’], ч’, щ’. Непарных по глухости-звонкости звуков меньше, чем парных.
У согласных звуков есть и ещё одна особенность: некоторые из них мы произносим с особой интонацией: по-доброму, мягко. Как будто разговариваем с малышами.
При произнесении таких звуков кончик языка упирается в нижние передние зубы, а его спинка выгибается к нёбу. Такие звуки назвали мягкими. Остальные согласные звуки стали называть твёрдыми.
Такие звуки назвали мягкими. Остальные согласные звуки стали называть твёрдыми.
Очень большая группа мягких и твёрдых согласных звуков, также как звонкие и глухие, тоже образуют пары, только уже по мягкости-твёрдости. Вот они: [б], [б’], [в], [в’], [г], [г’], [д], [д’], [з], [з’], [к], [к’], [л], [л’], [м], [м’], [н], [н’], [п], [п’], [р], [р’], [с], [с’], [т], [т’], [ф], [ф’], [х], [х’]. И совсем незначительная часть согласных звуков не имеет пары по мягкости-твёрдости. Это звуки мягкие [й’], [ч’], [щ’] и твёрдые [ж], [ш], [ц].
В русском языке всего 42 звука. Из них 6 гласных звуков и 36 согласных.
Но звуки неуловимы. Их нельзя потрогать, поймать и подержать в руках. И человек придумал самое величайшее изобретение — буквы! И тут же свершилось невероятное – невидимый звучащий мир стал видимым! Человек поймал неуловимое – звук!
В русском языке 33 буквы: 10 гласных букв и 21 согласная буква. Буквы называют гласными или согласными потому, что ими обозначают гласные или согласные звуки.
Гласные буквы – а, у, о, ы, и, э, я, ю, ё, е. Согласные буквы — это б, в, г, д, ж, з, й, к, л, м, н, п, р, с, т, ф, х, ц, ч, ш, щ. А две буквы в русском алфавите не обозначают никаких звуков. Они так и называются – знаки — твёрдый (Ъ) и мягкий (Ь).
Нужно помнить, что звуки мы произносим и слышим, а буквы — видим и пишем.
В слове все звуки могут соответствовать своей букве. Например, стол [стол].
Но часто одна буква в разных словах может обозначать разные звуки. Например, в словах плод [плот], плоды [пладЫ]. Буква О обозначает и звук [о], и звук [а], а буква Д — и звук [т], и звук [д]. Иногда одна буква может обозначать одновременно два звука. Например, буквы Е, Ё, Ю, Я в начале слова, после разделительных мягкого и твёрдого знаков, после гласных букв обозначают по два звука: [й’э], [й’о], [й’у], [й’а].
Большинство согласных букв в разных ситуациях могут обозначать два разных звука – парные по мягкости-твердости. Например, в словах мел — мол буква М в одном случае обозначает звук м’, а в другом — м.
В словах русского языка часто звучание не совпадает с написанием. Поэтому существует множество «опасных мест» — орфограмм.
Самая часто встречающаяся в словах русского языка орфограмма, связанная с правописанием гласных букв, это безударная гласная в корне слова.
Вспомните правило! Чтобы правильно написать букву в корне слова, нужно подобрать такое однокоренное слово, чтобы безударный звук стал ударным. Например, лесник – лес.
С согласными буквами тоже связана часто встречающаяся орфограмма «правописание парных согласных на конце и середине слова».
Вспомните правило! Чтобы правильно написать букву согласного звука на конце и в середине слова, нужно подобрать такое однокоренное слово, чтобы после проверяемого согласного звука слышался гласный звук или непарные звонкие согласные звуки н, н’, л, л’, м, м’, р, р’. Например, дуб – дубок.
В русском языке для правописания букв, которые не обозначают никаких звуков, тоже есть правила. Вспомните! Первое — о мягком знаке – показателе мягкости. Мягкость согласного звука на конце и в середине слова перед согласными звуками обозначается мягким знаком. Например, «львы», «конь». Второе — о разделительном мягком знаке. Разделительный мягкий знак пишется в корне слова после согласных перед гласными буквами Е, Ё, Ю, Я, И. Например, «вьюга», «колье».
Мягкость согласного звука на конце и в середине слова перед согласными звуками обозначается мягким знаком. Например, «львы», «конь». Второе — о разделительном мягком знаке. Разделительный мягкий знак пишется в корне слова после согласных перед гласными буквами Е, Ё, Ю, Я, И. Например, «вьюга», «колье».
Таким образом, запись буквами часто неточно передаёт звучание слова.
Но люди придумали точную запись звуков речи, назвали её транскрипцией и стали обозначать квадратными скобками […]. В транскрипции каждый звук записывается отдельной буквой, ставится знак ударения и знак мягкости [’]. Например, малина — [мал’ина].
Для составления более полной картины звуков слова применяется звуко-буквенный анализ слова. Для его проведения необходимо пользоваться Памяткой «Как провести звуко-буквенный разбор слова». Вы можете увидеть её в учебнике В.П. Канакиной и В.Г. Горецкого «Русский язык. 2 класс», часть 2, на страницах 130- 131.
Правил о правописании и гласных, и согласных букв, в русском языке множество. Во 2 классе вы познакомитесь только с некоторыми из них.
Во 2 классе вы познакомитесь только с некоторыми из них.
Но если сейчас хорошо выучить эти орфограммы, то в дальнейшем будет легче осваивать и другие.
На добрый путь всегда готовым будь!
Примеры заданий и разбор их решения. Тренировочный модуль
Задание. Выделите цветом.
Прочитайте группы слов с орфограммой на безударные гласные в корне слова. В каждой группе определи проверяемые и проверочные слова. Выделите красным цветом проверяемые слова, а зелёным – проверочные.
Ветвь, ветвистый, веточка.
Глазной, глазик, глазищи.
Ледяной, лёд, подлёдный.
Крик, крикливый, кричат.
Трава, травка, травушка.
Сосновый, сосны, сосенка.
Воздушный, воздух.
Подсказка: Вспомните правописание безударных гласных в корне слова.
Правильный ответ:
Ветвь, ветвистый, веточка.
Глазной, глазик, глазищи.
Ледяной, лёд, подлёдный.
Крик, крикливый, кричат.
Трава, травка, травушка.
Сосновый, сосны, сосенка.
Воздушный, воздух.
Задание. Выполни звуко-буквенный разбор.
Выполните звуко-буквенный разбор слова ПТИЧЬЯ
Подсказка: Используйте памятку «Как провести звуко-буквенный разбор слова» в учебнике В.П. Канакиной и В.Г. Горецкого «Русский язык. 2 класс», часть 2 на странице 130- 131.
Правильный ответ:
Птичья – 2 слога, 6 букв, 6 звуков.
п — согласный, глухой парный, твёрдый парный.
т’ — согласный, глухой парный, мягкий парный.
и – гласный, ударный.
ч’ — согласный, глухой непарный, мягкий непарный.
й’ — согласный, звонкий непарный, мягкий непарный.
а – гласный, безударный.
Синонимайзер текста онлайн с корректировкой
Синонимайзер текста (уникализатор) — отличный помощник для более быстрого рерайта текста.
Для синонимизации
текста введите текст в текстовое поле и нажмите кнопку синонимизировать.
Как синонимайзер работает без потери смысла в тексте?
Синонимайзер разбивает весь текст по словам и предложениям, далее ставит слова в правильную
форму, затем подбирает синоним к слову и пробует поставить его в ту
форму
в котором оно было изначально, тем самым, смысл текста и предложений сохраняется.
Оцените нашу программу ниже, оставляйте комментарии, мы обязательно ответим.
Синонимайзер на английском языке
Несколько слов о нашем инструменте
Синонимайзер разработан с использованием передовых методов, чтобы он мог эффективно помогать
пользователям в работе. Вы можете использовать его онлайн с любого устройства, все что вам
нужно,
это
подключение к интернету, чтобы использовать уникализатор текста.
Чем полезен сервис синонимизации текста?
В первую очередь сервис будет полезен тем кто занимается рерайтом, чтобы облегчить свой труд в написании уникального текста. Для блоггера, который должен ежедневно публиковать несколько блогов, им сложно писать уникальный контент, особенно при написании на одни и те же темы. В этом случае можно использовать синонимайзер, чтобы избежать самоплагиата и повысить уникальность текста в блоге. Наш инструмент может автоматически исправлять синонимы, но так же вы можете выбрать наиболее подходящий синоним вручную.
Будет ли 100% уникальный текст?
Поскольку перефразирование текста онлайн это автоматический процесс, существует небольшая
вероятность того, что какая-то
часть
текста станет плагиатом. Чтобы проверить уникальность вашего текста, вы можете использовать
инструмент
проверки плагиата. Также перед тем, как выложить статью в просторы интернета, не забудьте
проверить
грамматику вашего контента.
Чтобы проверить уникальность вашего текста, вы можете использовать
инструмент
проверки плагиата. Также перед тем, как выложить статью в просторы интернета, не забудьте
проверить
грамматику вашего контента.
Использования API
Если вы хотите автоматизировать процесс уникализации текста, вы можете использовать наш апи.
На странице API описаны методы, если у
вас есть
вопросы
или
пожелания можете обратиться к нам по почте
admin@rustxt. ru
ru
Приложение доступно в Google Play
Функция корректировки текста
По умолчанию функция отключена. Чтобы слова отображались с вариантами синонимов включите функцию корректировка текста, синонимы будут подсвечены красным цветом, при клике на слово появится раскрывающийся список из которых вы можете выбрать слово и отредактировать его в нужную форму.
Функция подсветка слов
По умолчанию функция включена.
Чтобы легче было понимать какие слова были заменены, синонимы будут подсвечены красным
цветом. Если вам нужен чистый текст, отключите все функции.
Если вам нужен чистый текст, отключите все функции.
Функция выбора словарей
По умолчанию выбраны все словари. Чем меньше вы выберите словарь, тем качественнее будет рерайт текста.
(PDF) Проблемы с синтаксическим анализом и тегами POS гибридного языка
Шаг 6: Результатом является дерево синтаксического анализа формального предложения на хинди
языка.
Шаг 7: Если требуется вывод в виде предложения на английском языке
, выполняется преобразование
всей лексики хинди в лексику английского языка
.
Шаг 8: Разметка POS выполняется для преобразования всех
английских лексиконов в соответствии с английской грамматикой
.
Шаг 9: Семантический анализатор создает дерево синтаксического анализа для
предложения на английском формальном языке в порядке
SVO
Шаг 10: Результатом является дерево синтаксического анализа предложения на английском формальном языке
.
IV. POS TAGGING
POS tagging — это задача классификации каждого слова
в предложении с его подходящей синтаксической категорией
, называемой частью речи [4]. Маркировка POS включает лингвистическое правило
, стохастическую модель и комбинацию
обоих [9]. Основной мотивацией для тегирования
POS на хинди был лексикон или словарь
, который состоял из допустимых слов, корневой словарь
, который состоял из всех допустимых корневых слов
и набор соответствующих лексических категорий, таких как существительное,
глагол, союз, послелог, прилагательное, наречие,
род, число, лицо и т. д.Функция POS-тегов
языка хинди определила лексическую категорию
каждого слова в предложении на основе
его контекста, а также таких функций, как суффикс и префикс
для всех слов.
Термин «префикс / суффикс» представляет собой последовательность первых / последних
нескольких символов слова, которая может не иметь лингвистического значения
[4, 10]. Например, в слове
Например, в слове
слово «Ladkiyan», корень слова — «Ladki», суффикс
— «ян», пол — «женский», число
— «множественное число», человек — «третий», а категория
— «Существительное».
A. Проблемы с тегами POS:
Основной проблемой тегов POS было расположение статей, вспомогательных глаголов
и морфологические несоответствия
в корневом слове, например
, добавление или удаление суффиксов или префиксов.
Другой проблемой был выбор вспомогательных глаголов
, которые должны были использоваться, и где их нужно было корректировать синтаксически
между подлежащим и предикатом предложения
.
Гибрид
Вход
День рождения Tum ki party kis restaurant
mein doge?
Хинди
Вывод
Тум джанамдин ка бходж кис бходжналье
майн дож?
Английский
Выходные
В каком ресторане вы подарите день рождения
?
В вышеупомянутом вводе вспомогательный глагол «ki»
был переведен на вспомогательный глагол «ka» для вывода на хинди
, а в английском переводе добавлен POS
, такой как «will», «the», «of ”И их правильное расположение
между подлежащим, объектом и глаголом
вызывало озабоченность
B. Различные подходы к тегированию POS:
Различные подходы к тегированию POS:
Ниже приведены три наиболее широко используемых метода тегирования POS
:
a) Тегеры на основе правил: набор тегов, присваиваемых
словам на основе лексикона и морфологического анализа
. Первоначально известные слова
помечаются наиболее часто используемым тегом из словаря
, а неизвестные слова — произвольно тегами
[1]. Что касается языка хинди, требуется большое количество правил
, поэтому статистический подход
(HMM и т. Д.) Является полезным.
b) HMM Tagging: Скрытые Марковские модели — это стандартные тегеры
из-за их точности и
из-за того, что их можно обучить из
неаннотированного текста [1]. Модель Маркова имеет
порядковых биграмм, которые используют текущий и
предыдущих тегов для определения следующего тега.
Аналогично, трехграммный порядок использует предыдущие
два тега для тегирования, и это лучший подход
из-за свободного порядка слов.
c) Методы обработки неизвестных слов:
Обработка неизвестных слов — очень важная проблема
в тегах POS. Неизвестно
слов — это слова, которые имеют такие особенности, как
суффикс / префикс. Чтобы узнать корень слова, суффикс / префикс
должен быть удален по лингвистическим правилам
, а затем выполняется поиск в лингвистическом корпусе
для аутентификации с помощью корня
слова. Например, слово «Китабен» — неизвестное
слово.Чтобы определить суффикс или префикс
, выполните следующие действия:
Начните удаление отдельных символов с конца строки слов
и найдите в корпусе
наличие этого слова как «Китабэ + n (удалено).
и так далее.
Когда оно становится «Китаб», которое является корневым словом, оно
будет отображено в словаре, и
соответствующие детали, такие как категория, номер,
пол и т. Д., Будут идентифицированы, и неизвестное
слово будет распознано как известное слово.
V. РЕЗУЛЬТАТЫ И ОБСУЖДЕНИЕ
Случай 1: «Ram library gaya hai», рис. 4, было
гибридным предложением, в котором «библиотека» была нечетной
. Двуязычные слова и грамматические структуры
, включая времена, формы, числа, род и т. Д.,
могут быть дифференцированы и проанализированы для перевода с помощью двуязычного корпуса, таблица 1. В этом предложении
слова хинди были «Рам »И« Gaya »
, а английское слово было« Library »
Языки программирования: синтаксический анализ
Языки программирования: синтаксический анализCOS 441 — синтаксический анализ — 8 февраля 1996 г.
Абстрактный синтаксис
Абстрактный синтаксис — это представление программы, которая:
- абстрагирует ненужные детали конкретного синтаксиса;
- сохраняет только достаточно информации, чтобы мы могли назначить значение (семантика) терминов; а также
- соответствует структуре BNF языка.

Анализ означает интерпретацию входного потока как термины на доступном языке. Напомним, что мы рассматриваем языковые синтаксис состоит из трех уровней: лексические элементы, контекстно-свободный синтаксис, и контекстно-зависимый синтаксис. Следовательно, мы проанализируем язык рассматривая эти три слоя по отдельности.
Лексический анализатор или токенизатор принимает входной поток символов и разбивает на жетоны. Для этого курса мы будем использовать Scheme’s tokenizer, чтобы сделать это за нас.
Парсер берет поток токенов, созданный лексическим анализатором, и создает представление абстрактного синтаксиса программы, называемое абстрактное синтаксическое дерево или дерево синтаксического анализа . Как видите, термин синтаксический анализ часто используется для обозначения простой интерпретации поток токенов в контекстно-свободный синтаксис.
Вернемся к примеру запроса. Запрос:
query :: = Word
| НЕ запрос
| (запрос И запрос)
Чтобы разобрать запросы, мы должны исправить представление для токенов
и представление для запросов, т. е. для абстрактного
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
е. для абстрактного
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
Слово - символ
НЕ НЕ
И И
(- "("
) - ")"
Предположим, что у нас есть функция tokenize : ввод -> список токенов
который преобразует входной поток в список таких токенов.Предположим, что функции make-Word, make-Not и make-And
строить соответствующие представления запросов.Теперь мы можем написать функцию parse для анализа запросов. Эта функция примет на вход список токенов и вернет пара абстрактного запроса и оставшаяся часть ввода.
(определить синтаксический анализ
(лямбда (ввод)
(cond ((равно? 'НЕ (ввод автомобиля))
(пусть * ((r (parse (cdr input)))
(д (автомобиль г))
(отдых (cdr r)))
(минусы (make-Not q) отдыхают)))
((символ? (ввод автомобиля))
(минусы (make-Word (ввод автомобиля)) (ввод cdr)))
((равно? "(" (ввод автомобиля))
(пусть * ((r1 (parse (вход cdr)))
(q1 (автомобиль r1))
(rest1 (cdr r1))
(rest2 (cdr rest1)); пропустить "И"
(r2 (синтаксический анализ rest2))
(q2 (автомобиль r2))
(rest3 (cdr r2))
(rest4 (cdr rest3))); пропускать ")"
(минусы (make-а q1 q2) rest4)))
(else (ошибка «Неверный ввод»)))))
Это довольно просто, потому что грамматика запросов — LL0. Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme для языка, называемого s-выражения .
S-выражения определяются следующим образом:
Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme для языка, называемого s-выражения .
S-выражения определяются следующим образом:
sexp :: = #t | #f | номер | char | символ | () | нить
| (sexp. sexp) | # (sexp *) | (sexp *)
S-выражение формы (sexp. Sexp) пара; s-выражение в форме # (sexp *) является
вектор; и (sexp *) — это список. Списки
представлены парами и нулем.S-выражения построены
от читать и (цитата sexp) ,
сокращенно 'sexp .Если мы теперь немного изменим синтаксис запросов, чтобы запросы являются подмножеством s-выражений, мы можем использовать s-выражение parser, который сделает за нас часть синтаксического анализа. Давайте переопределим запросы следующим образом:
q :: = слово | (НЕ q) | (И q q)Обратите внимание на круглые скобки, которые теперь требуются вокруг запроса NOT. Наша новая функция синтаксического анализа принимает список токенов и возвращает просто проанализированный запрос:
(определить синтаксический анализ
(лямбда (sexp)
(cond ((symbol? sexp) (make-Word sexp))
((пара? sexp)
(cond ((равно? 'NOT (car sexp))
(make-Not (parse (cadr sexp))))
((равно? 'И (автомобиль sexp))
(make-And (parse (cadr sexp)) (parse (caddr sexp))))
(else (ошибка «Неверный ввод»))))
(else (ошибка «Неверный ввод»)))))
Давайте теперь создадим синтаксический анализатор для подмножества Scheme. Мы рассмотрим
следующее подмножество:
Мы рассмотрим
следующее подмножество:
e :: = #t | #f | () | номер | ...
| Икс
| (лямбда (x *) e)
| (если e e e)
| (cond (e e) * [(else e)])
| (e e *)
Мы будем представлять токены точно так, как их представляет Схема в
s-выражения. Мы используем запись определения средство для построения представлений абстрактного синтаксиса:(константа определения-записи (значение)) (определить-запись Var (имя)) (определение-запись Лам (формальное тело)) (определить-запись Если (проверить, затем еще)) (определение-запись Cond (пункты else)) (определение-запись Ap (забавные аргументы))Каждые
(определение-запись Foo (field1... fieldN)) выражение
строит следующие процедуры: make-Foo , Фу? , и Foo-> field1 через Foo-> fieldN .
Они называются конструктором, предикатом и селекторами (или аксессорами).
для данных типа Foo .
Будут действовать следующие тождества:(Фу? (Make-Фу v1 .для значений
 .. vN)) = #t
(Foo-> fieldM (make-Foo v1 ... vN)) = vM
.. vN)) = #t
(Foo-> fieldM (make-Foo v1 ... vN)) = vM
v1 ... vN . Теперь разберем Scheme.
(определить синтаксический анализ
(лямбда (sexp)
(cond ((член sexp '(#t #f ()))
(make-Const sexp))
((или (число? sexp) (строка? sexp) (char? sexp))
(make-Const sexp))
((символ? sexp)
(make-Var sexp))
((пара? sexp)
(cond ((равно? 'lambda (car sexp))
(make-Lam (cadr sexp) (parse (caddr sexp))))
((равно? 'if (car sexp))
(make-If (cadr sexp) (caddr sexp) (cadddr sexp)))
((равно? 'cond (автомобиль sexp))
... ...)
(еще
(make-Ap (parse (car sexp)) (map parse (cdr sexp)))))))))
Чтение
- Опытный интриган, Главы 11, 12, 13
- EOPL Глава 2
Как ограничения синтаксического анализа в реальном времени влияют на усвоение грамматики
Чтобы интерпретировать устную речь, слушатели должны назначать предварительный структурный анализ высказываниям в реальном времени, когда они их слышат; то есть они должны быстро классифицировать разворачивающиеся звуковые события на фонемы-кандидаты, слоги, слова и фразы с помощью какого-то механизма синтаксического анализа языка. Тем не менее, для тех, кто изучает язык, будь то ребенок, изучающий свой первый язык, или взрослый, изучающий дополнительные языки, специфические для языка правила категоризации частично или полностью неизвестны, даже несмотря на то, что эти правила являются теми же самыми, которые в конечном итоге допускают успешную интерпретацию. . Эта картина еще больше усложняется тем фактом, что предварительные структурные задания учащихся используются не только для целей интерпретации, но и в качестве исходных данных для самой процедуры обучения.Например, сейчас хорошо известно, что маленькие дети, изучающие свой первый язык — и взрослые, изучающие второй язык — будут использовать свою гипотезу о синтаксической структуре предложения, чтобы ограничить гипотезы о значениях неизвестных слов и неизвестных морфем в этом предложении. в процессе, известном как «синтаксическая загрузка» (например, Landau & Gleitman, 1985; Gillette, Gleitman, Gleitman, & Lederer, 1999; Gleitman, 1990; Naigles, 1990; Gleitman, Cassidy, Nappa, Papafragou, & Trueswell, 2005; Snedeker & Gleitman, 2004).
Тем не менее, для тех, кто изучает язык, будь то ребенок, изучающий свой первый язык, или взрослый, изучающий дополнительные языки, специфические для языка правила категоризации частично или полностью неизвестны, даже несмотря на то, что эти правила являются теми же самыми, которые в конечном итоге допускают успешную интерпретацию. . Эта картина еще больше усложняется тем фактом, что предварительные структурные задания учащихся используются не только для целей интерпретации, но и в качестве исходных данных для самой процедуры обучения.Например, сейчас хорошо известно, что маленькие дети, изучающие свой первый язык — и взрослые, изучающие второй язык — будут использовать свою гипотезу о синтаксической структуре предложения, чтобы ограничить гипотезы о значениях неизвестных слов и неизвестных морфем в этом предложении. в процессе, известном как «синтаксическая загрузка» (например, Landau & Gleitman, 1985; Gillette, Gleitman, Gleitman, & Lederer, 1999; Gleitman, 1990; Naigles, 1990; Gleitman, Cassidy, Nappa, Papafragou, & Trueswell, 2005; Snedeker & Gleitman, 2004).
Тогда кажется, что сам механизм построения структуры (то есть синтаксический анализатор в реальном времени) будет играть центральную роль в процессе усвоения языка. Тем не менее, относительно мало известно о том, как проблемы и ограничения синтаксического анализа в реальном времени у изучающих язык, такие как их задокументированные трудности с проверкой синтаксического анализа (например, Trueswell, Sekerina, Hill & Logrip, 1999), формируют траектории приобретения или как анализ сам процесс «отрывается от земли» в первую очередь из-за отсутствия специфических для языка грамматических знаний.Ниже мы начинаем исследовать эти две взаимосвязанные проблемы. Мы утверждаем, что в начале процесса обучения сопоставление высказываний со значением определяется универсальными предубеждениями, которые постепенно сопровождаются или вытесняются специфическими для языка грамматическими знаниями, которые более точно направляют синтаксический анализ и интерпретацию (для связанных представлений на первом языке). литературу по приобретению см. Fisher, Gertner, Scott, Yuan, 2010; Gertner & Fisher, 2012; Lidz, Gleitman & Gleitman, 2003; Gleitman et al.2005; о приобретении второго языка см. Van Patten, 1996). В рамках этой точки зрения мы исследуем новую гипотезу о том, что переход от универсальных предубеждений к использованию специфичных для языка знаний определяется не только достоверностью и надежностью специфичных для языка сигналов к структуре и значению (Bates & MacWhinney, 1982; Bates & MacWhinney, 1989; MacWhinney, Bates, & Kliegl, 1984; Slobin & Bever, 1982), но также и из-за присущих проблем, связанных с инкрементальной природой самой обработки предложений в реальном времени, таких как сложность пересмотра первоначального структурного анализа и интерпретации . 1
литературу по приобретению см. Fisher, Gertner, Scott, Yuan, 2010; Gertner & Fisher, 2012; Lidz, Gleitman & Gleitman, 2003; Gleitman et al.2005; о приобретении второго языка см. Van Patten, 1996). В рамках этой точки зрения мы исследуем новую гипотезу о том, что переход от универсальных предубеждений к использованию специфичных для языка знаний определяется не только достоверностью и надежностью специфичных для языка сигналов к структуре и значению (Bates & MacWhinney, 1982; Bates & MacWhinney, 1989; MacWhinney, Bates, & Kliegl, 1984; Slobin & Bever, 1982), но также и из-за присущих проблем, связанных с инкрементальной природой самой обработки предложений в реальном времени, таких как сложность пересмотра первоначального структурного анализа и интерпретации . 1
1.1. Анализируемость и обучаемость
Согласно теории синтаксической начальной загрузки, дети открывают значения слов не только путем наблюдения за миром и отслеживания случайностей слов в мире, но также за счет использования преимуществ лингвистических контекстов, в которых появляются слова (Landau & Глейтман, 1985; Глейтман, 1990). Способность детей использовать лингвистический контекст во время изучения слов проявляется в раннем развитии. Например, в своих первых классических исследованиях эффектов обучения имплицитного синтаксического анализа Найглз (1990) показала, что 25-месячные дети выводят аспекты значения нового глагола из синтаксического контекста, в котором глагол появился.Знакомство детей с новым глаголом в переходном предложении («Утка прославляет кролика») привело детей к мысли, что новый предикат обозначает причинное событие с двумя участниками, а не некаузальное событие с одним участником. Услышание нового глагола в непереходном предложении («Утка и кролик радуются») вызвало противоположное предпочтение, указывая на то, что дети понимали новый предикат как обозначение некаузального события с одним участником. С тех пор многочисленные исследования продемонстрировали аналогичные синтаксические эффекты при обучении глаголам (например,г., Аруначалам и Ваксман, 2010; Фишер, Холл, Раковиц и Глейтман, 1994; Ли и Найглз, 2008; Наппа, Уэссел, МакЭлдун, Глейтман и Трюсвелл, 2009 г .
Способность детей использовать лингвистический контекст во время изучения слов проявляется в раннем развитии. Например, в своих первых классических исследованиях эффектов обучения имплицитного синтаксического анализа Найглз (1990) показала, что 25-месячные дети выводят аспекты значения нового глагола из синтаксического контекста, в котором глагол появился.Знакомство детей с новым глаголом в переходном предложении («Утка прославляет кролика») привело детей к мысли, что новый предикат обозначает причинное событие с двумя участниками, а не некаузальное событие с одним участником. Услышание нового глагола в непереходном предложении («Утка и кролик радуются») вызвало противоположное предпочтение, указывая на то, что дети понимали новый предикат как обозначение некаузального события с одним участником. С тех пор многочисленные исследования продемонстрировали аналогичные синтаксические эффекты при обучении глаголам (например,г., Аруначалам и Ваксман, 2010; Фишер, Холл, Раковиц и Глейтман, 1994; Ли и Найглз, 2008; Наппа, Уэссел, МакЭлдун, Глейтман и Трюсвелл, 2009 г . ; Скотт и Фишер, 2009 г .; Юань и Фишер, 2009; Yuan, Fisher & Snedeker, 2012), и подобное использование лингвистических данных наблюдалось для изучения существительных (например, Brown, 1957; Katz, Baker, & Macnamara, 1974; Hall, Lee, & Belanger, 2001; Smith, Jones, & Landau, 1992; Liittschwager & Markman, 1993).
; Скотт и Фишер, 2009 г .; Юань и Фишер, 2009; Yuan, Fisher & Snedeker, 2012), и подобное использование лингвистических данных наблюдалось для изучения существительных (например, Brown, 1957; Katz, Baker, & Macnamara, 1974; Hall, Lee, & Belanger, 2001; Smith, Jones, & Landau, 1992; Liittschwager & Markman, 1993).
Возьмем один особенно уместный пример: 19-месячные, которые услышали новое слово «tiv» во время просмотра сцены, в которой тряпкой протирали блок, придали ему другое значение в зависимости от того, использовалось ли новое слово в качестве дополнение глагола (как в (1)) или как дополнение предлога (как в (2)).
(1) Кроткий тив
(2) Кроткий с тив
Детские образы, на самом деле, указывают на то, что они интерпретировали «тив» для обозначения блока, если они слышали, что он использовался как дополнение глагола (как в (1)), но для ткани, если они слышали, что оно использовалось как дополнение к предлогу (как в (2), см. White, Baier, & Lidz, 2011; Lidz, Baier & White , Отправлено).
White, Baier, & Lidz, 2011; Lidz, Baier & White , Отправлено).
Способность использовать структурные подсказки для сочетания новых слов с намеченными референтами часто зависит от наличия некоторых подробных языковых знаний.В предыдущем примере результативность, подобная целевой, зависит от того, усвоил ребенок ряд фактов об английской лексике и грамматике, включая структурные свойства и значение предлога «с». Итак, как учащиеся сопоставляют структуру со значениями в начале процесса изучения языка, когда языковых знаний еще нет?
Согласно теории синтаксической самозагрузки, дети первоначально выполняют эту задачу, используя преимущества универсальных, необученных предубеждений для сопоставления структуры значения (Fisher, 1996; Gleitman, 1990; Gleitman et al., 2005; Lidz, Gleitman, & Gleitman, 2003). В начале процесса обучения, когда языковые знания еще не сформированы, предполагается, что учащиеся полагаются на невыученные предубеждения для построения частичных, недооцененных структурных представлений предложений, которые сопоставляются с событиями в мире. Обратите внимание, что с точки зрения обработки эти предубеждения можно рассматривать как универсальные эвристики синтаксического анализа, которые, скорее всего, используются ребенком в режиме реального времени, когда каждое высказывание воспринимается 2 .По мере того как ребенок начинает усваивать специфические для языка подсказки к структуре и значению, они также входят в процесс изучения слов в качестве дополнительных структурных ограничений для интерпретации.
Обратите внимание, что с точки зрения обработки эти предубеждения можно рассматривать как универсальные эвристики синтаксического анализа, которые, скорее всего, используются ребенком в режиме реального времени, когда каждое высказывание воспринимается 2 .По мере того как ребенок начинает усваивать специфические для языка подсказки к структуре и значению, они также входят в процесс изучения слов в качестве дополнительных структурных ограничений для интерпретации.
Одно из таких универсальных предубеждений (полученное из критерия Theta Хомского, 1981) — это тенденция ожидать прозрачного однозначного соответствия между количеством аргументов в предложении (грубо говоря, именными фразами, NPs) и количество тематических ролей (ориентировочно, участников) в мероприятии. Дети в возрасте 21 месяца используют количество НП в предложении как показатель количества участников, в результате чего они неверно истолковывают предложения, в которых количество НП не совпадает с количеством участников. Например, Гертнер и Фишер (2012) обнаружили, что младшие (21-месячные) дети имеют тенденцию неверно истолковывать непереходные предложения с соединенным подлежащим (например, предложение Найглза, 1990, «Утка и кролик радуются») как транзитивные предложения SOV, отчасти потому, что они еще не знают, как специфические для языка реплики союза «и» и множественного числа от «есть» отображаются на правильный структурный анализ (хотя см. также Noble, Theakston & Lieven, 2010, и Pozzan, Gleitman, & Trueswell, в прессе, о других проблемах, связанных с этой структурой).Дети также более охотно, чем взрослые, изменяют значение знакомых глаголов, чтобы соответствовать контекстам NP, в которых они слышны: дети, но не взрослые, разыгрывают причинные интерпретации для знакомого непереходного глагола go , когда он представлен в двух -NP транзитивный контекст, такой как «Ной идет на слоне в ковчег» (Naigles, Fowler, & Helm, 1992; Naigles, Gleitman, & Gleitman, 1993). 3
Например, Гертнер и Фишер (2012) обнаружили, что младшие (21-месячные) дети имеют тенденцию неверно истолковывать непереходные предложения с соединенным подлежащим (например, предложение Найглза, 1990, «Утка и кролик радуются») как транзитивные предложения SOV, отчасти потому, что они еще не знают, как специфические для языка реплики союза «и» и множественного числа от «есть» отображаются на правильный структурный анализ (хотя см. также Noble, Theakston & Lieven, 2010, и Pozzan, Gleitman, & Trueswell, в прессе, о других проблемах, связанных с этой структурой).Дети также более охотно, чем взрослые, изменяют значение знакомых глаголов, чтобы соответствовать контекстам NP, в которых они слышны: дети, но не взрослые, разыгрывают причинные интерпретации для знакомого непереходного глагола go , когда он представлен в двух -NP транзитивный контекст, такой как «Ной идет на слоне в ковчег» (Naigles, Fowler, & Helm, 1992; Naigles, Gleitman, & Gleitman, 1993). 3
Предвзятость детей ожидать, что в предложении столько же участников события, сколько НП, было обнаружено даже для языков, в которых часто пропускаются аргументы (например,г. , китайский, см. Lee & Naigles, 2008; Каннада, см. Lidz, Gleitman, & Gleitman, 2003). Лидз и его коллеги изучили, как дети выполняют задание на понимание предложения на каннаде, языке, в котором вербальная морфология является надежным предиктором структуры аргументов, но из-за частого пропускания аргументов количество NPs — нет. Дети, изучающие этот язык, последовательно сопоставляли предложения с одним NP с событиями с одним участником и предложения с двумя NP с событиями с двумя участниками, игнорируя наличие противоречивой морфологической информации.В отличие от взрослых, дети имели тенденцию приписывать одну и ту же (не причинную) интерпретацию предложениям с одним NP, независимо от наличия (3) или отсутствия (4) причинной морфологии, которая идеально предсказывает причинную интерпретацию с двумя участниками.
, китайский, см. Lee & Naigles, 2008; Каннада, см. Lidz, Gleitman, & Gleitman, 2003). Лидз и его коллеги изучили, как дети выполняют задание на понимание предложения на каннаде, языке, в котором вербальная морфология является надежным предиктором структуры аргументов, но из-за частого пропускания аргументов количество NPs — нет. Дети, изучающие этот язык, последовательно сопоставляли предложения с одним NP с событиями с одним участником и предложения с двумя NP с событиями с двумя участниками, игнорируя наличие противоречивой морфологической информации.В отличие от взрослых, дети имели тенденцию приписывать одну и ту же (не причинную) интерпретацию предложениям с одним NP, независимо от наличия (3) или отсутствия (4) причинной морфологии, которая идеально предсказывает причинную интерпретацию с двумя участниками.
Возвращаясь к нашему примеру в (2), включающему предлог «с», только что приведенное описание предсказывает, что учащийся, который еще не усвоил значение и структурные свойства предлога «с», мог бы истолковать новый NP «the tiv» как аргумент глагола и отвести ему тематическую роль «пациент»; полагаясь на универсальные предубеждения сопоставления структуры и значения, учащийся не только неверно истолкует сообщение, но и сопоставит новое существительное с неправильным референтом (т. е., чтобы соединить его с блоком как в (1), так и (2)). В той степени, в которой это правда, становится критически важным понять механизмы и доказательства, которые учащиеся используют для замены универсальных предубеждений сопоставления структуры и значения полноценными синтаксическими и семантическими правилами, специфичными для языка, так что структуры, не соответствующие универсальные тенденции (например, предложения с опущенными аргументами) или к большинству шаблонов в языке (например, пассивные предложения на английском языке), но, тем не менее, разрешены грамматикой языка, могут быть успешно проанализированы и интерпретированы.
е., чтобы соединить его с блоком как в (1), так и (2)). В той степени, в которой это правда, становится критически важным понять механизмы и доказательства, которые учащиеся используют для замены универсальных предубеждений сопоставления структуры и значения полноценными синтаксическими и семантическими правилами, специфичными для языка, так что структуры, не соответствующие универсальные тенденции (например, предложения с опущенными аргументами) или к большинству шаблонов в языке (например, пассивные предложения на английском языке), но, тем не менее, разрешены грамматикой языка, могут быть успешно проанализированы и интерпретированы.
Возможно, реальный мир может предоставить учащимся доказательства, которые они могут использовать для обнаружения возможных несоответствий между своими интерпретациями и положением дел в мире и соответствующим образом обновить свои текущие гипотезы (см. Chang, Dell, & Bock, 2006, для модель получения на основе ошибок, в которой несоответствия между прогнозом модели и фактическими входными данными используются для обновления абстрактных знаний модели, или вариационная модель , предложенная Янгом, например, Yang, 2002, 2004, 2012, в которой возможные грамматики награждаются или наказываются в зависимости от их способности анализировать ввод). Например, предположим, что учащийся, который игнорирует функцию и структурные свойства предлога «с», услышал его в сентенциальном контексте вроде (5), в котором были известны все другие словарные элементы, во время просмотра сцены, в которой была девушка. есть торт ложкой:
Например, предположим, что учащийся, который игнорирует функцию и структурные свойства предлога «с», услышал его в сентенциальном контексте вроде (5), в котором были известны все другие словарные элементы, во время просмотра сцены, в которой была девушка. есть торт ложкой:
Здесь универсальные предубеждения, описанные выше, не только привели бы к неправдоподобной интерпретации (девушка ест ложку), но и к несоответствию между гипотезой учащегося и сопутствующим событием в мире.В принципе, учащийся может использовать это несоответствие, чтобы отвергнуть свой текущий грамматический анализ и использовать свойства наблюдаемого события, чтобы сформировать новую гипотезу (то есть «с» объединяется с NP; NP, с которым оно сочетается, имеет тематическое отношение «инструмент»). Эта новая гипотеза может быть использована для анализа следующего высказывания, содержащего целевую структуру, а дополнительные лингвистические и реальные свидетельства могут быть использованы для дальнейшего уточнения этой гипотезы.
В этой статье мы предполагаем, что этот процесс обучения, который позволяет учащимся интегрировать или заменять универсальные предубеждения знанием языка, зависит от ограничений и ограничений (развивающего) синтаксического анализатора.Наше предположение состоит в том, что специфичные для языка подсказки к структуре и значению легче получить и использовать в режиме реального времени, если информация, которую они предоставляют, может быть использована для предотвращения совершения синтаксическим анализатором неверных интерпретаций, которые, возможно, потребуется пересмотреть на основе поздно поступающих доказательств. в том же предложении. Эта гипотеза проистекает из хорошо известного факта, что для учащихся сложно пересмотреть первоначальные обязательства по интерпретации (о приобретении L1 у детей, включая языки, отличные от английского, см. Choi, & Trueswell, 2010; Hurewitz, Brown-Schmidt, Thorpe, Gleitman, Trueswell, 2000; Omaki, & Lidz, 2014; Omaki, Davidson White, Goro, Lidz, & Phillips, 2013; Huang, Zheng, Meng, & Snedeker, 2013; Trueswell et al. , 1999; Weighall, 2008; а о приобретении L2 у взрослых см. Pozzan, & Trueswell, 2013; Уильямс, Мебиус и Ким, 2001).
, 1999; Weighall, 2008; а о приобретении L2 у взрослых см. Pozzan, & Trueswell, 2013; Уильямс, Мебиус и Ким, 2001).
Чтобы проиллюстрировать более подробно, рассмотрим гипотетический случай учащегося, который использовал несоответствие между реальным миром и своей интерпретацией (5), чтобы вывести предварительное целевое значение слова «с». Предполагая, что эта гипотеза доступна учащемуся при следующей встрече со словом «с», он будет ожидать, что за ней последует НП, который будет правильно интерпретирован как инструмент:
Текущая гипотеза учащегося относительно значения слова «с» будет подкреплена в этом случае при условии, что фактические данные подтверждают (или, по крайней мере, не противоречат) эту интерпретацию.
Но что, если бы вместо английского наш учащийся овладел одним из многих языков мира, в которых слова, передающие эту информацию, появляются пост-номинально (например, как пост-позиции или суффиксы), как в (7), а не предварительно, как в (6)?
Мы прогнозируем, что в этом случае, встретив NP «ткань», синтаксический анализатор (реального времени) сначала проанализирует ее как прямой объект глагола «clean» и неправильно интерпретирует как пациент сказуемого. Для правильной интерпретации (7) эту интерпретацию необходимо будет пересмотреть после того, как прозвучит «с».То есть, даже когда существует гипотеза целевого значения для «с», эту гипотезу можно использовать только для пересмотра предварительной структуры и частичной интерпретации («очистить ткань») после обработки «с». Но пересмотр исходных интерпретаций — это именно то, что разрабатывающий синтаксический анализатор часто не может сделать; Интерпретации, согласующиеся с неспособностью пересмотреть, на самом деле, составляют в среднем 50-60% детской интерпретации временно неоднозначных предложений (например, Trueswell et al, 1999). Таким образом, с точки зрения вероятности, дети с меньшей вероятностью обнаружат предполагаемый синтаксический анализ этого предложения, что приведет к задержке усвоения значения слова «с».
Для правильной интерпретации (7) эту интерпретацию необходимо будет пересмотреть после того, как прозвучит «с».То есть, даже когда существует гипотеза целевого значения для «с», эту гипотезу можно использовать только для пересмотра предварительной структуры и частичной интерпретации («очистить ткань») после обработки «с». Но пересмотр исходных интерпретаций — это именно то, что разрабатывающий синтаксический анализатор часто не может сделать; Интерпретации, согласующиеся с неспособностью пересмотреть, на самом деле, составляют в среднем 50-60% детской интерпретации временно неоднозначных предложений (например, Trueswell et al, 1999). Таким образом, с точки зрения вероятности, дети с меньшей вероятностью обнаружат предполагаемый синтаксический анализ этого предложения, что приведет к задержке усвоения значения слова «с».
Таким образом, предложения, в которых информация, устраняющая неоднозначность, прибывает в точку, в которой она уже не может быть легко интегрирована с предыдущим материалом, не только будут неправильно истолкованы новичком, но также могут не предоставить учащемуся доказательств для обновления их синтаксиса и семантические гипотезы, потенциально задерживающие процесс приобретения. Важным следствием этой гипотезы является то, что усвоение может происходить медленнее в языках, в которых функциональные слова и морфемы, несущие устраняющую неоднозначность грамматическую информацию, становятся доступными в момент, когда синтаксический анализатор уже допустил неправильную интерпретацию.Фактически, есть некоторые убедительные доказательства, подтверждающие это утверждение: дети, изучающие тагальский язык, язык с начальным глаголом, в котором упущение аргументов широко распространено, но вербальная морфология является надежным предиктором структуры аргументов, проявляют большую чувствительность к причинной морфологии, чем дети, изучающие каннада, язык с окончанием глагола и конечной морфологией, возможно потому, что глагольная морфология может использоваться для управления синтаксическим анализом в языках с начальным глаголом, но только для подтверждения или пересмотра интерпретативных обязательств в языках с окончанием глагола (Trueswell, Kaufman, Hafri, & Lidz, 2012).
Важным следствием этой гипотезы является то, что усвоение может происходить медленнее в языках, в которых функциональные слова и морфемы, несущие устраняющую неоднозначность грамматическую информацию, становятся доступными в момент, когда синтаксический анализатор уже допустил неправильную интерпретацию.Фактически, есть некоторые убедительные доказательства, подтверждающие это утверждение: дети, изучающие тагальский язык, язык с начальным глаголом, в котором упущение аргументов широко распространено, но вербальная морфология является надежным предиктором структуры аргументов, проявляют большую чувствительность к причинной морфологии, чем дети, изучающие каннада, язык с окончанием глагола и конечной морфологией, возможно потому, что глагольная морфология может использоваться для управления синтаксическим анализом в языках с начальным глаголом, но только для подтверждения или пересмотра интерпретативных обязательств в языках с окончанием глагола (Trueswell, Kaufman, Hafri, & Lidz, 2012). О подобных трудностях с причинной морфологией у детей сообщалось и для других языков с окончанием глагола (например, турецкий: Göksun, Küntay, & Naigles, 2008; японский: Murasugi, & Hasimoto, 2004).
О подобных трудностях с причинной морфологией у детей сообщалось и для других языков с окончанием глагола (например, турецкий: Göksun, Küntay, & Naigles, 2008; японский: Murasugi, & Hasimoto, 2004).
К сожалению, прямое кросс-лингвистическое сравнение Trueswell et al. (2012) далеко от окончательного. Во-первых, у тагальского языка и каннада очень разные грамматические и морфологические системы, что оставляет открытой возможность того, что превосходная успеваемость детей, говорящих на тагальском языке, была обусловлена другими грамматическими различиями.Во-вторых, изучалось понимание, а не производство морфологии детьми, что оставило открытым возможность того, что проблемы, наблюдаемые у детей, говорящих на каннада, по сравнению с детьми, говорящими на тагалоге, отражают их трудности с пересмотром первоначальных интерпретаций, а не эти трудности, влияющие на усвоение самой морфологии. . Другими словами, результаты согласуются с альтернативной гипотезой о том, что дети, говорящие на каннада, знали функцию причинной морфологии в языке, но не могли применить это знание в предложениях с тропинками.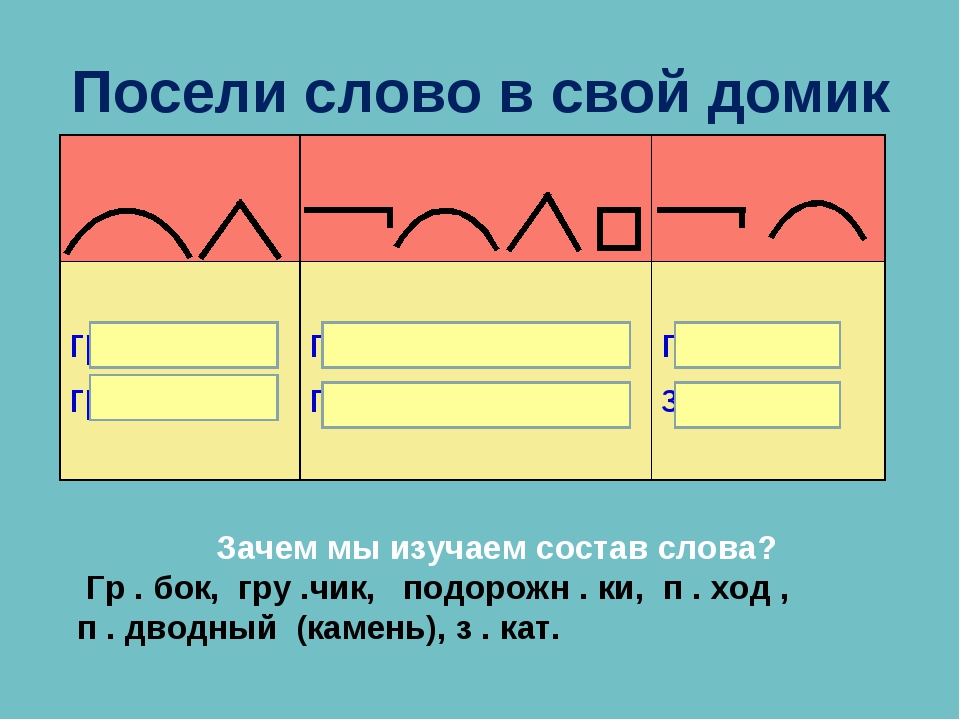 Более важный вопрос заключается в том, задерживают ли такие трудности усвоение значения морфологии и тем самым задерживают использование, даже если пересмотр не требуется, например, при составлении предложений.
Более важный вопрос заключается в том, задерживают ли такие трудности усвоение значения морфологии и тем самым задерживают использование, даже если пересмотр не требуется, например, при составлении предложений.
Поскольку маловероятно, что мы сможем сравнить профили освоения на двух естественных языках, которые различаются только в отношениях, имеющих отношение к нашему исследовательскому вопросу, мы выбрали следующий лучший вариант: изучение искусственного языка, в котором учащиеся пытаются определить, как Структура предложения связана с событиями и действиями, воспринимаемыми в сопутствующем референтном мире (например,г., Хадсон Кам и Ньюпорт, 2005; 2009; Воннакотт, Ньюпорт и Таненхаус, 2008 г.). В рамках этого метода мы можем почти идеально сопоставить грамматики нескольких языков, назначить их разным учащимся и параметрически управлять тем, доступны ли специфичные для языка подсказки к структуре языка в начале предложения и, следовательно, могут служить ориентиром для интерпретации или доступны. только в конце предложения и, следовательно, подтверждают или пересматривают интерпретации. Учитывая растущее количество свидетельств, показывающих, что эту методологию можно успешно использовать для исследования усвоения учащимися и предпочтений различных грамматических шаблонов, подтвержденных на мировых языках (например,г., Калбертсон, Смоленский и Лежандр, 2012; Fedzechkina, Jaeger, & Newport, 2012), кажется, что изучение искусственного языка можно использовать в качестве мощного дополнения к кросс-лингвистическим исследованиям для изучения предпочтений и предубеждений при овладении языком в лаборатории.
только в конце предложения и, следовательно, подтверждают или пересматривают интерпретации. Учитывая растущее количество свидетельств, показывающих, что эту методологию можно успешно использовать для исследования усвоения учащимися и предпочтений различных грамматических шаблонов, подтвержденных на мировых языках (например,г., Калбертсон, Смоленский и Лежандр, 2012; Fedzechkina, Jaeger, & Newport, 2012), кажется, что изучение искусственного языка можно использовать в качестве мощного дополнения к кросс-лингвистическим исследованиям для изучения предпочтений и предубеждений при овладении языком в лаборатории.
Настоящая работа посвящена успеваемости взрослых учащихся 4 ; будущая работа будет изучать детей. Однако есть веские причины полагать, что на усвоение грамматики детьми и взрослыми могут одинаковым образом повлиять предпочтения и ограничения обработки.Например, даже взрослые носители языка иногда не могут пересмотреть первоначальные обязательства по синтаксическому анализу (Trueswell et al. , 1999; Novick, Thompson-Schill, & Trueswell, 2008) и полагаются на «достаточно хорошие» интерпретации предложений при определенных обстоятельствах (например, Кристиансон, Уильямс, Закс и Феррейра, 2006; Феррейра, Ферраро и Бейли, 2002; Феррейра и Патсон, 2007). Более того, последствия ограничений обработки могут быть преувеличены у взрослых, изучающих второй язык, в популяции, у которой также были обнаружены особые трудности с пересмотром первоначальных интерпретаций (например,г., Джуффс и Харрингтон, 1996; Джуффс, 2004 г .; Pozzan & Trueswell, 2013; Робертс и Фелсер, 2011; Williams et al., 2001). Все эти проблемы, как у детей, так и у взрослых, на самом деле могут возникать из-за трудностей с развертыванием управляющих функций / когнитивного контроля, которые недостаточно развиты у детей (Zelazo & Frye, 1998), и могут потребовать особого налогообложения при обработке неродных языков ( Абуталеби, 2008). Мы вернемся к этому вопросу в общем обсуждении.
, 1999; Novick, Thompson-Schill, & Trueswell, 2008) и полагаются на «достаточно хорошие» интерпретации предложений при определенных обстоятельствах (например, Кристиансон, Уильямс, Закс и Феррейра, 2006; Феррейра, Ферраро и Бейли, 2002; Феррейра и Патсон, 2007). Более того, последствия ограничений обработки могут быть преувеличены у взрослых, изучающих второй язык, в популяции, у которой также были обнаружены особые трудности с пересмотром первоначальных интерпретаций (например,г., Джуффс и Харрингтон, 1996; Джуффс, 2004 г .; Pozzan & Trueswell, 2013; Робертс и Фелсер, 2011; Williams et al., 2001). Все эти проблемы, как у детей, так и у взрослых, на самом деле могут возникать из-за трудностей с развертыванием управляющих функций / когнитивного контроля, которые недостаточно развиты у детей (Zelazo & Frye, 1998), и могут потребовать особого налогообложения при обработке неродных языков ( Абуталеби, 2008). Мы вернемся к этому вопросу в общем обсуждении.
Взрослые, изучающие второй язык (в данном случае искусственный язык), конечно, вероятно, будут в чем-то отличаться от детей, изучающих первый язык. Например, знание взрослыми своего родного языка, в первую очередь их знание языковых грамматических тенденций и процедур синтаксического анализа, вероятно, будет перенесено на их второй язык (обзоры см. В Gass & Selinker, 1992; Pienemann, Di Biase, Кавагути и Хоканссон, 2005 г.). Но, как мы обсудим ниже, сравнение нескольких вариантов искусственного языка позволяет нам идентифицировать такие языковые стратегии, если они существуют в нашем исследовании.
Например, знание взрослыми своего родного языка, в первую очередь их знание языковых грамматических тенденций и процедур синтаксического анализа, вероятно, будет перенесено на их второй язык (обзоры см. В Gass & Selinker, 1992; Pienemann, Di Biase, Кавагути и Хоканссон, 2005 г.). Но, как мы обсудим ниже, сравнение нескольких вариантов искусственного языка позволяет нам идентифицировать такие языковые стратегии, если они существуют в нашем исследовании.
Анализ морфологически богатых языков: введение в специальный выпуск | Компьютерная лингвистика
Синтаксический анализ — это центральная задача в обработке естественного языка, когда система принимает предложение на естественном языке в качестве входных данных и обеспечивает синтаксическое представление сущностей и грамматических отношений в предложении в качестве выходных данных.Входные предложения для синтаксического анализатора отражают специфичные для языка свойства (с точки зрения порядка слов, словоформ, лексических элементов и т.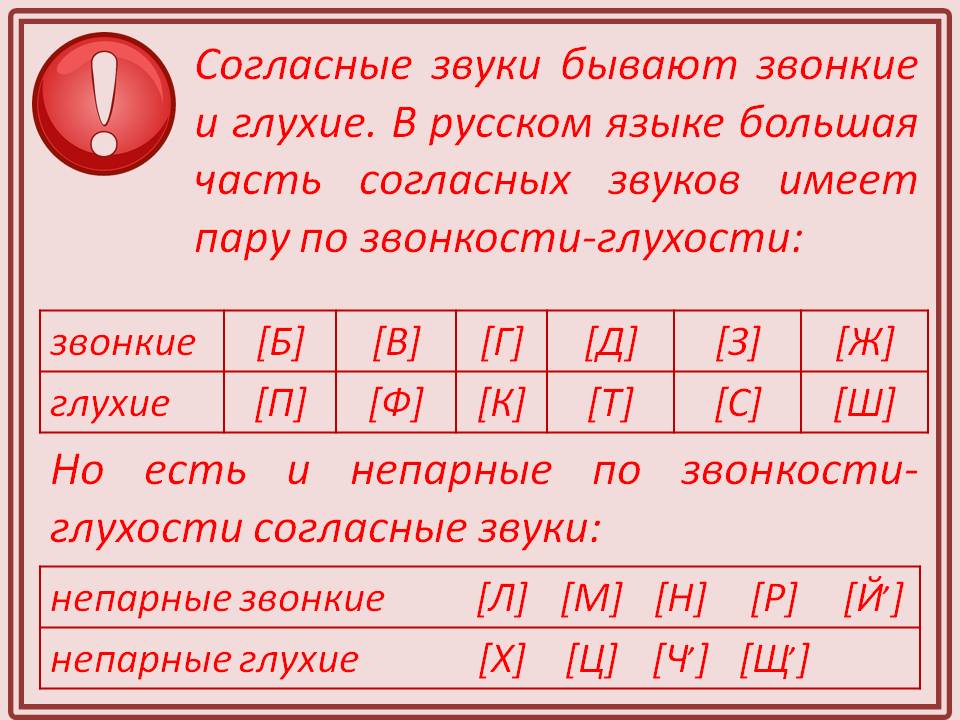 Д.), Тогда как выходные данные абстрагируются от этих свойств, чтобы получить структурированное формальное представление. который отражает функции различных элементов в предложении.
Д.), Тогда как выходные данные абстрагируются от этих свойств, чтобы получить структурированное формальное представление. который отражает функции различных элементов в предложении.
Лучшие на сегодняшний день системы синтаксического анализа с широким охватом используют статистические модели, возможно, в сочетании с грамматиками, созданными вручную.Они используют методы машинного обучения, которые позволяют системе обобщать синтаксические шаблоны, характеризующие данные. Эти методы машинного обучения обучаются на банке деревьев, то есть наборе предложений на естественном языке, снабженных аннотациями с их правильным синтаксическим анализом. На основе паттернов и частот, наблюдаемых в банке деревьев, алгоритмы синтаксического анализа предназначены для предложения и оценки новых анализов невидимых предложений и поиска наиболее вероятного анализа.
Выпуск крупномасштабного аннотированного корпуса для английского языка, Wall Street Journal Penn Treebank (PTB) (Marcus, Santorini, and Marcinkiewicz 1993), привел к значительному скачку в производительности статистического анализа для английского языка (Magerman 1995). ; Коллинз 1997; Чарняк 2000; Чарняк, Джонсон 2005; Петров и др.2006; Huang 2008; Финкель, Климан и Мэннинг, 2008 г .; Каррерас, Коллинз и Ку, 2008 г.). На момент публикации каждая из этих моделей улучшила современное состояние синтаксического анализа английского языка, доведя производительность синтаксического анализа на основе избирательных округов в стандартном тестовом наборе PTB до уровня 92% F 1 — оценка с использованием показателей оценки ParsEval (Black et al. 1991).
; Коллинз 1997; Чарняк 2000; Чарняк, Джонсон 2005; Петров и др.2006; Huang 2008; Финкель, Климан и Мэннинг, 2008 г .; Каррерас, Коллинз и Ку, 2008 г.). На момент публикации каждая из этих моделей улучшила современное состояние синтаксического анализа английского языка, доведя производительность синтаксического анализа на основе избирательных округов в стандартном тестовом наборе PTB до уровня 92% F 1 — оценка с использованием показателей оценки ParsEval (Black et al. 1991).
В последнее десятилетие были разработаны крупномасштабные аннотированные группы деревьев для таких языков, как арабский (Maamouri et al.2004), французском (Abeillé, Clément, and Toussenel 2003), немецком (Uszkoreit 1987; Skut et al. 1997), иврите (Sima’an et al. 2001), шведском (Nivre and Megyesi 2007) и других. Наличие синтаксически аннотированных корпусов для этих языков изначально породило надежду на достижение того же уровня производительности синтаксического анализа на этих языках путем простого переноса существующих моделей на новые доступные корпуса.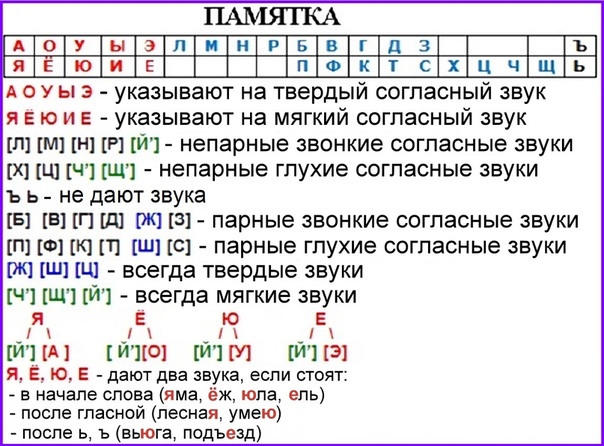
Ранние попытки применить вышеупомянутые модели синтаксического анализа на основе избирательных округов к другим языкам продемонстрировали, что успех этих подходов был довольно ограниченным.Это наблюдение было подтверждено для отдельных языков, таких как чешский (Collins et al. 1999), немецкий (Dubey and Keller 2003), итальянский (Corazza et al. 2004), французский (Arun and Keller 2005), современный стандартный арабский язык (Kulick, Gabbard , и Маркус, 2006), современный иврит (Царфати и Сима’ан, 2007) и многие другие (Царфати и др., 2010).
То же наблюдение было независимо подтверждено параллельными исследованиями по синтаксическому анализу на основе зависимостей на основе данных (Kübler, McDonald, and Nivre 2009).Результаты, полученные в результате кампаний по оценке многоязычного синтаксического анализа, таких как общие задачи CoNLL по синтаксическому анализу многоязычных зависимостей, показали значительные различия в результатах одних и тех же моделей, примененных к ряду типологически различных языков. В частности, эти результаты продемонстрировали, что морфологически богатая природа некоторых из этих языков затрудняет их синтаксический анализ независимо от используемой техники синтаксического анализа (Buchholz and Marsi 2006; Nivre et al. 2007a).
В частности, эти результаты продемонстрировали, что морфологически богатая природа некоторых из этих языков затрудняет их синтаксический анализ независимо от используемой техники синтаксического анализа (Buchholz and Marsi 2006; Nivre et al. 2007a).
Морфологически богатые языки (MRL) выражают несколько уровней информации уже на уровне слов.Лексическая информация для каждой словоформы в MRL может быть дополнена информацией, касающейся грамматической функции слова в предложении, его грамматических отношений с другими словами, местоименных клитиков, флективных аффиксов и так далее. В английском языке многие из этих понятий неявно выражаются порядком слов и смежностью: например, прямой объект обычно является первым NP после глагола и, таким образом, не обязательно требует явной маркировки. Морфологическое выражение такой функциональной информации допускает высокую степень вариации порядка слов, поскольку грамматические функции больше не обязательно должны быть сильно связаны с синтаксическими позициями. Кроме того, лексические элементы, появляющиеся в разных синтаксических контекстах, могут быть реализованы в разных формах. Это приводит к высокому уровню вариативности словоформ и затрудняет лексическое усвоение из небольших корпусов.
Кроме того, лексические элементы, появляющиеся в разных синтаксических контекстах, могут быть реализованы в разных формах. Это приводит к высокому уровню вариативности словоформ и затрудняет лексическое усвоение из небольших корпусов.
Было показано, что сложность лингвистических паттернов, обнаруженных в MRL, во многих отношениях затрудняет синтаксический анализ. Например, стандартные модели предполагают, что слово всегда соответствует уникальному терминалу в дереве синтаксического анализа.На арабском, иврите, турецком и других языках входной токен слова может соответствовать нескольким терминалам. Кроме того, модели, разработанные в первую очередь для синтаксического анализа английского языка, делают существенные выводы на основе шаблонов порядка слов. Анализ неконфигурационных языков, таких как венгерский, может потребовать использования морфологической информации для вывода эквивалентных функций. Разбор чешского или немецкого языка дополнительно осложняется синкретизмом падежа, который исключает детерминированную корреляцию между морфологическим падежом и грамматическими функциями.В таких языках, как венгерский или финский, разнообразие словоформ приводит к высокому уровню слов вне словарного запаса, невидимых в аннотированных данных. Таким образом, синтаксический анализ MRL часто связан с повышенной разреженностью лексических данных. Парсер MRL требует надежных статистических методов для анализа таких явлений.
Разбор чешского или немецкого языка дополнительно осложняется синкретизмом падежа, который исключает детерминированную корреляцию между морфологическим падежом и грамматическими функциями.В таких языках, как венгерский или финский, разнообразие словоформ приводит к высокому уровню слов вне словарного запаса, невидимых в аннотированных данных. Таким образом, синтаксический анализ MRL часто связан с повышенной разреженностью лексических данных. Парсер MRL требует надежных статистических методов для анализа таких явлений.
Вслед за Царфати и др. (2010) мы выделяем три всеобъемлющие проблемы, связанные с анализом MRL.
(i) Архитектурный вызов. В отличие от английского языка, где входной сигнал однозначно определяет последовательность терминалов дерева, словоформы в MRL могут содержать несколько единиц информации (морфем). Эти морфемы необходимо сегментировать, чтобы выявить основные единицы анализа. Кроме того, морфологический анализ слов MRL может быть весьма неоднозначным, а морфологическая сегментация может быть нетривиальной задачей для некоторых языков.Следовательно, архитектура синтаксического анализа для MRL должна содержать, по крайней мере, морфологический компонент для сегментации и синтаксический компонент для синтаксического анализа. Таким образом, задача состоит в том, чтобы определить, как эти две модели должны быть объединены в общую архитектуру синтаксического анализа: следует ли предположить конвейерную архитектуру, в которой морфологическая сегментация устраняется перед синтаксическим анализом? Или мы должны построить совместную архитектуру, в которой модель выбирает дерево синтаксического анализа и сегментацию одновременно?
Эти морфемы необходимо сегментировать, чтобы выявить основные единицы анализа. Кроме того, морфологический анализ слов MRL может быть весьма неоднозначным, а морфологическая сегментация может быть нетривиальной задачей для некоторых языков.Следовательно, архитектура синтаксического анализа для MRL должна содержать, по крайней мере, морфологический компонент для сегментации и синтаксический компонент для синтаксического анализа. Таким образом, задача состоит в том, чтобы определить, как эти две модели должны быть объединены в общую архитектуру синтаксического анализа: следует ли предположить конвейерную архитектуру, в которой морфологическая сегментация устраняется перед синтаксическим анализом? Или мы должны построить совместную архитектуру, в которой модель выбирает дерево синтаксического анализа и сегментацию одновременно?
(ii) Задача моделирования. Дизайн модели статистического анализа требует определения трех формальных элементов: формального представления выходных данных, событий, которые можно наблюдать в данных, и предположений о независимости между этими событиями. Для MRL сложные морфосинтаксические взаимодействия могут накладывать ограничения на форму событий и на их возможные комбинации. В таких случаях нам может потребоваться явное включение морфологической информации в синтаксическую модель. Как следует трактовать морфологическую информацию в синтаксической модели: как явное украшение дерева, как скрытые переменные или как самостоятельные сложные объекты? Какие морфологические признаки следует явно кодировать? Где отмечать морфологические признаки: на уровне части речи, на уровне фразы, на дугах зависимости? Как взаимодействуют морфологические и синтаксические события, и как мы можем использовать эти взаимодействия для вывода правильных общих структур?
Для MRL сложные морфосинтаксические взаимодействия могут накладывать ограничения на форму событий и на их возможные комбинации. В таких случаях нам может потребоваться явное включение морфологической информации в синтаксическую модель. Как следует трактовать морфологическую информацию в синтаксической модели: как явное украшение дерева, как скрытые переменные или как самостоятельные сложные объекты? Какие морфологические признаки следует явно кодировать? Где отмечать морфологические признаки: на уровне части речи, на уровне фразы, на дугах зависимости? Как взаимодействуют морфологические и синтаксические события, и как мы можем использовать эти взаимодействия для вывода правильных общих структур?
(iii) Лексический вызов. Модель анализа MRL требует распознавания морфологической информации в каждой словоформе. Однако из-за высокого уровня морфологической изменчивости системы, управляемые данными, не гарантируют соблюдение всех морфологических вариантов словоформы в данном аннотированном корпусе. Как мы можем присвоить правильные морфологические сигнатуры лексическим элементам в условиях такой крайней недостаточности данных? При разработке модели для синтаксического анализа MRL может потребоваться использовать любые дополнительные ресурсы, к которым у него есть доступ — морфологические анализаторы, немаркированные данные и лексика, — чтобы расширить охват анализатора и получить надежные и точные прогнозы.
Как мы можем присвоить правильные морфологические сигнатуры лексическим элементам в условиях такой крайней недостаточности данных? При разработке модели для синтаксического анализа MRL может потребоваться использовать любые дополнительные ресурсы, к которым у него есть доступ — морфологические анализаторы, немаркированные данные и лексика, — чтобы расширить охват анализатора и получить надежные и точные прогнозы.
Этот специальный выпуск привлекает внимание к различным способам, с помощью которых исследователи, работающие над анализом MRL, решают описанные здесь проблемы. Он содержит шесть исследований, в которых обсуждаются результаты синтаксического анализа для шести языков, с использованием как основанных на группах интересов, так и основанных на зависимостях фреймворков (см. Таблицу 1). Первые три исследования (Seeker and Kuhn; Fraser et al .; Kallmeyer and Maier) сосредоточены на анализе европейских языков и имеют дело с явлениями, которые лежат в их гибком порядке фраз и богатой морфологии, включая проблемы, связанные с синкретизмом падежей. В следующих двух статьях (Голдберг и Эльхадад; Мартон и др.) Основное внимание уделяется семитским языкам и изучается применение универсальных алгоритмов синтаксического анализа (на основе групп и зависимостей, соответственно) для анализа таких данных. Они эмпирически показывают разрывы в производительности между различными архитектурами (конвейер против совместной, золото против машинно-предсказанного ввода), выбор функций и методы увеличения лексического охвата анализатора. Последняя статья (Грин и др.) Представляет собой сравнительное исследование распознавания многословных выражений (MWE) с помощью двух специализированных моделей синтаксического анализа, применяемых как к французскому, так и к современному стандартному арабскому языку.Давайте кратко обрисуем индивидуальный вклад каждой статьи в этом специальном выпуске.
В следующих двух статьях (Голдберг и Эльхадад; Мартон и др.) Основное внимание уделяется семитским языкам и изучается применение универсальных алгоритмов синтаксического анализа (на основе групп и зависимостей, соответственно) для анализа таких данных. Они эмпирически показывают разрывы в производительности между различными архитектурами (конвейер против совместной, золото против машинно-предсказанного ввода), выбор функций и методы увеличения лексического охвата анализатора. Последняя статья (Грин и др.) Представляет собой сравнительное исследование распознавания многословных выражений (MWE) с помощью двух специализированных моделей синтаксического анализа, применяемых как к французскому, так и к современному стандартному арабскому языку.Давайте кратко обрисуем индивидуальный вклад каждой статьи в этом специальном выпуске.
Вклад в специальный выпуск CL по синтаксическому анализу морфологически богатых языков (CL-PMRL).
. | По округам . | На основе зависимостей . | ||
|---|---|---|---|---|
| Арабский | Грин, де Марнефф и Мэннинг 2013 | Мартон, Хабаш и Рамбоу 2013 | ||
| Чехия | 9045 9045 9045 Kuhn47 | Грин, де Марнеф и Мэннинг 2013 | ||
| Немецкий | Каллмейер и Майер 2013 | Искер и Кун 2013 | ||
| Fraser et al.2013 | ||||
| Иврит | Голдберг и Эльхадад 2013 | |||
| Венгерский | Искатель и Кун 2013 | По округам . | На основе зависимостей .  | |
| Арабский | Грин, де Марнефф и Мэннинг 2013 | Мартон, Хабаш и Рамбоу 2013 | ||
| Чехия | 9045 9045 9045 Kuhn47 | Грин, де Марнеф и Мэннинг 2013 | ||
| Немецкий | Каллмейер и Майер 2013 | Искер и Кун 2013 | ||
| Fraser et al.2013 | ||||
| Иврит | Голдберг и Эльхадад 2013 | |||
| Венгерский | Искатель и Кун 2013 |
 Венгерский язык агглютинирует, то есть морфологические маркеры венгерского языка однозначны и легко распознаются. Немецкий и чешский языки слияния с разными типами падежного синкретизма. Seeker и Kuhn используют Bohnet Parser (Bohnet 2010) для синтаксического анализа всех этих языков и показывают, что не использование морфологической информации в статистической модели признаков наносит ущерб.Использование золотой морфологии значительно улучшает результаты для всех этих языков, тогда как автоматически предсказываемая морфология приводит к меньшим улучшениям для языков слияния по сравнению с агглютинирующим. Чтобы бороться с этой потерей производительности, они добавляют к декодеру лингвистические ограничения, ограничивая возможные структуры. Они показывают, что алгоритм декодирования, который отфильтровывает анализ зависимостей, не подчиняющийся ограничениям предиката-аргумента, позволяет авторам получать более существенные выгоды от морфологии.
Венгерский язык агглютинирует, то есть морфологические маркеры венгерского языка однозначны и легко распознаются. Немецкий и чешский языки слияния с разными типами падежного синкретизма. Seeker и Kuhn используют Bohnet Parser (Bohnet 2010) для синтаксического анализа всех этих языков и показывают, что не использование морфологической информации в статистической модели признаков наносит ущерб.Использование золотой морфологии значительно улучшает результаты для всех этих языков, тогда как автоматически предсказываемая морфология приводит к меньшим улучшениям для языков слияния по сравнению с агглютинирующим. Чтобы бороться с этой потерей производительности, они добавляют к декодеру лингвистические ограничения, ограничивая возможные структуры. Они показывают, что алгоритм декодирования, который отфильтровывает анализ зависимостей, не подчиняющийся ограничениям предиката-аргумента, позволяет авторам получать более существенные выгоды от морфологии. также сосредоточьтесь на синтаксическом анализе немецкого языка, хотя и в настройке на основе округа. Они используют основанный на PCFG синтаксический анализатор нелексикализованных диаграмм (Schmid 2004) вместе с набором ручных аннотаций банка деревьев, которые доводят производительность грамматики банка деревьев до уровня автоматически предсказываемых состояний, изученных Петровым и др. (2006). Как и в предыдущем исследовании, синкретизм вызывает неоднозначность, которая снижает производительность синтаксического анализа.Чтобы избежать этой дополнительной неоднозначности, они используют внешние источники информации. В частности, они показывают различные способы использования информации из одноязычных и двуязычных наборов данных в структуре повторного ранжирования для повышения точности синтаксического анализа. Двуязычный подход основан на исследованиях машинного перевода и использует различия в обозначении одних и тех же грамматических функций по-разному в разных языках для повышения уверенности в решении разрешения неоднозначности на одном языке, наблюдая параллельную однозначную структуру на другом.
также сосредоточьтесь на синтаксическом анализе немецкого языка, хотя и в настройке на основе округа. Они используют основанный на PCFG синтаксический анализатор нелексикализованных диаграмм (Schmid 2004) вместе с набором ручных аннотаций банка деревьев, которые доводят производительность грамматики банка деревьев до уровня автоматически предсказываемых состояний, изученных Петровым и др. (2006). Как и в предыдущем исследовании, синкретизм вызывает неоднозначность, которая снижает производительность синтаксического анализа.Чтобы избежать этой дополнительной неоднозначности, они используют внешние источники информации. В частности, они показывают различные способы использования информации из одноязычных и двуязычных наборов данных в структуре повторного ранжирования для повышения точности синтаксического анализа. Двуязычный подход основан на исследованиях машинного перевода и использует различия в обозначении одних и тех же грамматических функций по-разному в разных языках для повышения уверенности в решении разрешения неоднозначности на одном языке, наблюдая параллельную однозначную структуру на другом.
 Поскольку PLCFRS представляет собой мощный формализм, синтаксический анализатор необходимо настроить на скорость. Авторы представляют несколько допустимых эвристик, которые способствуют более быстрому синтаксическому анализу A *.Авторы представляют результаты синтаксического анализа, которые конкурируют с анализом немецкого языка на основе избирательных округов, в то же время предоставляя бесценную информацию о прерывистых составляющих и зависимостях на большом расстоянии.
Поскольку PLCFRS представляет собой мощный формализм, синтаксический анализатор необходимо настроить на скорость. Авторы представляют несколько допустимых эвристик, которые способствуют более быстрому синтаксическому анализу A *.Авторы представляют результаты синтаксического анализа, которые конкурируют с анализом немецкого языка на основе избирательных округов, в то же время предоставляя бесценную информацию о прерывистых составляющих и зависимостях на большом расстоянии. Чтобы решить проблему сегментации слов (архитектурный вызов), они расширяют возможности графического декодера Петрова и др. с решетчатым декодером. Чтобы справиться с паттернами морфологической разметки (задача моделирования), они уточняют начальный банк деревьев с помощью целенаправленных разделений состояний и добавляют набор лингвистических ограничений, которые действуют как фильтр, исключающий деревья, нарушающие соглашение.Наконец, они добавляют информацию из внешнего лексикона с широким охватом, чтобы бороться с лексической разреженностью (лексическая проблема). Они показывают, что вклад этих различных методов является кумулятивным, что дает самые современные результаты по синтаксическому анализу иврита.
Чтобы решить проблему сегментации слов (архитектурный вызов), они расширяют возможности графического декодера Петрова и др. с решетчатым декодером. Чтобы справиться с паттернами морфологической разметки (задача моделирования), они уточняют начальный банк деревьев с помощью целенаправленных разделений состояний и добавляют набор лингвистических ограничений, которые действуют как фильтр, исключающий деревья, нарушающие соглашение.Наконец, они добавляют информацию из внешнего лексикона с широким охватом, чтобы бороться с лексической разреженностью (лексическая проблема). Они показывают, что вклад этих различных методов является кумулятивным, что дает самые современные результаты по синтаксическому анализу иврита. 2007b) и EasyFirst (Goldberg and Elhadad 2010), управление выбором архитектуры и моделирования приводит к аналогичным эффектам. Например, при сравнении производительности синтаксического анализа для золотых и прогнозируемых машиной входных условий они показывают, что богатые информативные наборы тегов предпочтительны в золотых условиях, но меньшие наборы тегов предпочтительнее в условиях, прогнозируемых машиной. Они дополнительно выделяют набор морфологических признаков, который приводит к значительным улучшениям в условиях, прогнозируемых машиной, для обеих структур.Они также показывают, что морфологические особенности, основанные на функциях, более информативны, чем особенности, основанные на поверхности, и что потеря производительности из-за ошибок в тегах части речи может быть восстановлена путем обучения модели на объединенном наборе деревьев, кодирующих золотые теги. и прогнозируемые машиной теги. В то же время неориентированный синтаксический анализ EasyFirst показывает лучшую точность, возможно, из-за гибкости порядка фраз.
2007b) и EasyFirst (Goldberg and Elhadad 2010), управление выбором архитектуры и моделирования приводит к аналогичным эффектам. Например, при сравнении производительности синтаксического анализа для золотых и прогнозируемых машиной входных условий они показывают, что богатые информативные наборы тегов предпочтительны в золотых условиях, но меньшие наборы тегов предпочтительнее в условиях, прогнозируемых машиной. Они дополнительно выделяют набор морфологических признаков, который приводит к значительным улучшениям в условиях, прогнозируемых машиной, для обеих структур.Они также показывают, что морфологические особенности, основанные на функциях, более информативны, чем особенности, основанные на поверхности, и что потеря производительности из-за ошибок в тегах части речи может быть восстановлена путем обучения модели на объединенном наборе деревьев, кодирующих золотые теги. и прогнозируемые машиной теги. В то же время неориентированный синтаксический анализ EasyFirst показывает лучшую точность, возможно, из-за гибкости порядка фраз. Появляется понимание того, что настройка морфологической информации внутри систем синтаксического анализа общего назначения имеет решающее значение для достижения конкурентоспособной производительности.
Появляется понимание того, что настройка морфологической информации внутри систем синтаксического анализа общего назначения имеет решающее значение для достижения конкурентоспособной производительности. Последний может быть грубо описан как анализ, ориентированный на данные (Bod 1992; Bod, Scha и Sima’an 2003) в байесовской структуре, расширенный за счет включения определенных функций, которые упрощают извлечение фрагментов дерева, соответствующих MWE.Интересно, что эти очень разные модели действительно обеспечивают одинаковый диапазон производительности при столкновении с предсказанной входной морфологией. Дополнительные важные проблемы, которые раскрываются в контексте этого исследования, касаются разработки экспериментов для кросс-лингвистического сравнения в условиях тонкой асимметрии между наборами данных на французском и арабском языках.
Последний может быть грубо описан как анализ, ориентированный на данные (Bod 1992; Bod, Scha и Sima’an 2003) в байесовской структуре, расширенный за счет включения определенных функций, которые упрощают извлечение фрагментов дерева, соответствующих MWE.Интересно, что эти очень разные модели действительно обеспечивают одинаковый диапазон производительности при столкновении с предсказанной входной морфологией. Дополнительные важные проблемы, которые раскрываются в контексте этого исследования, касаются разработки экспериментов для кросс-лингвистического сравнения в условиях тонкой асимметрии между наборами данных на французском и арабском языках. Сценарий совместной архитектуры синтаксического анализа и сегментации может быть решен путем расширения универсального декодера CKY до декодера на основе решетки. Проблема моделирования может быть решена путем явной маркировки морфологических признаков как синтаксических разбиений состояний, непосредственного моделирования разрывов в формальном синтаксическом представлении, включения жестко закодированных лингвистических ограничений в качестве фильтров и т. Д.Лексическая проблема может быть решена за счет использования внешних ресурсов, таких как лексика с широким охватом для анализа неизвестных слов, а также использования дополнительных одноязычных и двуязычных данных для получения надежных статистических данных в условиях крайней разреженности.
Сценарий совместной архитектуры синтаксического анализа и сегментации может быть решен путем расширения универсального декодера CKY до декодера на основе решетки. Проблема моделирования может быть решена путем явной маркировки морфологических признаков как синтаксических разбиений состояний, непосредственного моделирования разрывов в формальном синтаксическом представлении, включения жестко закодированных лингвистических ограничений в качестве фильтров и т. Д.Лексическая проблема может быть решена за счет использования внешних ресурсов, таких как лексика с широким охватом для анализа неизвестных слов, а также использования дополнительных одноязычных и двуязычных данных для получения надежных статистических данных в условиях крайней разреженности. Некоторые языки имеют более богатую морфологию, чем другие; некоторые языки обладают более гибким порядком слов, чем другие; некоторые языки слияния демонстрируют синкретизм (грубозернистые недоопределенные маркеры), тогда как другие используют большой набор мелкозернистых и однозначных морфологических маркеров. Следующая задача будет заключаться в том, чтобы охватить эти вариации и исследовать, могут ли типологические свойства языков дать нам более непосредственную информацию об адекватных методах, которые можно использовать для их эффективного анализа.
Некоторые языки имеют более богатую морфологию, чем другие; некоторые языки обладают более гибким порядком слов, чем другие; некоторые языки слияния демонстрируют синкретизм (грубозернистые недоопределенные маркеры), тогда как другие используют большой набор мелкозернистых и однозначных морфологических маркеров. Следующая задача будет заключаться в том, чтобы охватить эти вариации и исследовать, могут ли типологические свойства языков дать нам более непосредственную информацию об адекватных методах, которые можно использовать для их эффективного анализа. Более того, настало время для еще одной кампании по оценке многоязычного синтаксического анализатора, которая подтолкнет сообщество к разработке систем синтаксического анализа, которые можно легко перенести с одного типа языка на другой.Собирая эти недавние статьи, мы надеемся не только поощрять разработку новых систем для анализа индивидуальных MRL, но и способствовать поиску более надежных, универсальных кросс-лингвистических решений.
Более того, настало время для еще одной кампании по оценке многоязычного синтаксического анализатора, которая подтолкнет сообщество к разработке систем синтаксического анализа, которые можно легко перенести с одного типа языка на другой.Собирая эти недавние статьи, мы надеемся не только поощрять разработку новых систем для анализа индивидуальных MRL, но и способствовать поиску более надежных, универсальных кросс-лингвистических решений. Наконец, мы хотим выразить нашу благодарность Роберту Дейлу и Сьюзи Хоулетт за их неоценимую поддержку на протяжении всего редакционного процесса.
Наконец, мы хотим выразить нашу благодарность Роберту Дейлу и Сьюзи Хоулетт за их неоценимую поддержку на протяжении всего редакционного процесса. g., eat + s = ест
g., eat + s = ест  У каждого правила есть левая
сторона, которая определяет синтаксическую категорию, и правую часть,
который определяет его альтернативные составные части, читая слева направо.
У каждого правила есть левая
сторона, которая определяет синтаксическую категорию, и правую часть,
который определяет его альтернативные составные части, читая слева направо. На рисунке 1 показано дерево синтаксического анализа для предложения.
«жираф мечтает». Обратите внимание на
На рисунке 1 показано дерево синтаксического анализа для предложения.
«жираф мечтает». Обратите внимание на  Запретить «жираф ест яблоко» (рис. 1)
Запретить «жираф ест яблоко» (рис. 1)| | НЛП | PLP |
| область дискурса | широкий: что можно выразить | узкий: что можно вычислить |
| словарь | большой / сложный | малый / простой |
| грамматические конструкции | много и разнообразно — декларативный — вопросительный — фрагменты и т.  Д. Д. | несколько — декларативная — императивная |
| значения выражения | многие | одна |
| инструменты и методы | морфологический анализ синтаксический анализ семантический анализ интеграция мировых знаний | лексический анализ контекстно-свободный синтаксический анализ генерация / компиляция кода интерпретация |
Список литературы
- Мэтьюз, Клайв, Введение в обработку естественного языка через Пролог , Лонгман, 1998.
- Аллен, Джеймс, Понимание естественного языка 2e, Бенджамин Каммингс, 1995.
- Уилкс, Йорик, «Обработка естественного языка», Сообщения ACM 39, 1 (январь 1996 г. ),
60-62.
- Ковингтон, Майкл, Обработка естественного языка для программистов на прологе , Прентис Холл, 1994.
- Мэннинг, К. и Х. Шутце, Основы статистической
Обработка естественного языка , MIT Press, 1999.
 ),
60-62.
),
60-62.пролог — Анализ изменяемых языков без порядка слов (например, Latin)
Взяв пример из Введения в латинское Викиверситет, рассмотрим предложение:
матрос дает девушке деньги
Мы можем довольно элегантно справиться с этим в Прологе с помощью DCG с помощью этой кучи правил:
предложение (s (NP, VP)) -> существительное_фраза (NP), глагольная_фраза (VP).noun_phrase (Существительное) -> det, noun (Существительное).
noun_phrase (Существительное) -> существительное (Существительное).
verb_phrase (vp (Глагол, DO, IO)) -> глагол (Глагол), noun_phrase (IO), noun_phrase (DO).
det -> [the].
существительное (X) -> [X], {член (X, [моряк, девушка, деньги])}.
глагол (дает) -> [дает].
 глагол (дает) -> [дает].
глагол (дает) -> [дает].
И мы видим, что это работает:
? - фраза (предложение (S), [матрос, дает, девушка, деньги]).
S = s (моряк, вп (дает, деньги, девушка));
Мне кажется, что DCG действительно оптимизирован для работы с языками с порядком слов.Я совершенно не понимаю, как обращаться с этим латинским предложением:
. nauta dat pecuniam puellae
Это означает то же самое (моряк дает девушке деньги), но порядок слов совершенно свободный: все эти перестановки также означают одно и то же:
nauta dat puellae pecuniam
nauta puellae pecuniam dat
puellae pecuniam dat nauta
puellae pecuniam nauta dat
dat pecuniam nauta puellae
Первое, что приходит в голову, это перечислить перестановки:
предложение (s (NP, VP)) -> существительное_фраза (NP), глагольная_фраза (VP).предложение (s (NP, VP)) -> глагольная_фраза (VP), существительная_фраза (NP).

, но это не годится, потому что в то время как nauta принадлежит именной фразе подлежащего, puellae , которая принадлежит объектной именной фразе, подчиняется глаголу, но может предшествовать ему. Интересно, стоит ли мне подойти к этому, сначала построив какой-то список с атрибутами, например:
? - приписать ([nauta, dat, pecuniam, puellae], приписать)
Атрибут = [существительное (nauta, nom), глагол (do, 3, s), существительное (pecunia, acc), существительное (puella, dat)]
Похоже, это окажется необходимым (и я не вижу хорошего способа сделать это), но грамматически это толкает еду по моей тарелке.Может быть, я мог бы написать парсер с какой-нибудь ужасающей штуковиной, не относящейся к DCG, например:
синтаксический анализ (s (NounPhrase, VerbPhrase), Attributed): -
parse (subject_noun_phrase (NounPhrase, Атрибут)),
синтаксический анализ (глагольная_фраза (VerbPhrase, Атрибут)).
parse (subject_noun_phrase (Существительное), Атрибут): -
член (существительное (Noun, nom), Приписанный).
parse (object_noun_phrase (Существительное), Атрибут): -
member (имя существительное (существительное, соотв.), приписано)
 parse (subject_noun_phrase (Существительное), Атрибут): -
член (существительное (Noun, nom), Приписанный).
parse (object_noun_phrase (Существительное), Атрибут): -
member (имя существительное (существительное, соотв.), приписано)
parse (subject_noun_phrase (Существительное), Атрибут): -
член (существительное (Noun, nom), Приписанный).
parse (object_noun_phrase (Существительное), Атрибут): -
member (имя существительное (существительное, соотв.), приписано)
Похоже, это сработает, но только до тех пор, пока у меня нет рекурсии; как только я введу придаточное предложение, я собираюсь повторно использовать темы нездоровым образом.
Я просто не понимаю, как перейти от предложения без порядка слов к дереву синтаксического анализа. Есть ли книга, в которой это обсуждается? Спасибо.
Поиск информации на малаялам с использованием обработки естественного языка
Поиск информации на малаялам с использованием обработки естественного языкаМеждународный журнал научных и инженерных исследований, том 5, выпуск 6, июнь 2014 г. 56
ISSN 2229-5518
Поиск информации на малаялам с использованием
Обработка естественного языка
Мерлин Раджан, Ринку Т. S, Варунакши Бходжане
S, Варунакши Бходжане
Аннотация. В этой статье объясняется поиск информации с использованием обработки естественного языка для языка малаялам в таких основных вещах, как типы поиска информации, связь обработки естественного языка с поиском информации.
Индексные термины — кластеризация, поиск информации, малаялам, синтаксический анализ, синтаксический анализатор текста с тегами, триммер суффикса слов, просмотр текста.
—————————— ——————————
Малаялам — это язык, на котором говорят в Индии, преимущественно в штате Керала.Это один из 22 запланированных языков Индии и был признан классическим языком в Индии в 2013 году. Самым ранним сценарием, который использовался для написания малаялам, был сценарий Ваттелутту, а затем и Колежутту, производный от него. Самыми древними литературными произведениями на малаялам, отличными от тамильской традиции, являются народные песни Paattus , датируемые между 9 и 11 веками. Буквы сценария Grantha были приняты для написания заимствованных слов на санскрите, что привело к созданию современного сценария малаялам.
Информационный поиск (IR) — это поиск материала (обычно документов) неструктурированного характера (обычно текста), который удовлетворяет потребность в информации из больших коллекций (обычно хранящихся на компьютерах). Раньше поиском информации занимались лишь немногие: библиотекари-справочники, параюристы и аналогичные профессиональные поисковики.
Мерлин Раджан
Отделение информационных технологий, Университет Мумбаи
Идентификатор электронной почты: merlintharakan @ gmail.com
Rinku TS
Департамент информационных технологий, Университет Мумбаи
Идентификатор электронной почты: [email protected]
Варунакши Бходжане
Компьютерный факультет, Университет Мумбаи
Идентификатор электронной почты: [email protected] Сейчас
Мир изменился, и сотни миллионов людей ежедневно занимаются поиском информации, когда они используют поисковую систему или ищут в своей электронной почте. Поиск информации быстро становится доминирующей формой доступа к информации, опережая традиционный поиск в базе данных.Задача поиска информации заключается в выборе документов из базы данных в ответ на запрос пользователя и ранжировании этих документов по релевантности.широко распространено мнение, что автоматизированное НЛП может не подходить для
IR.
Эти трудности включали неэффективность, ограниченный охват и непомерную стоимость ручных усилий, необходимых для создания лексиконов и баз знаний для каждой новой текстовой области. С другой стороны, хотя многочисленные эксперименты не подтвердили полезность НЛП, их нельзя считать окончательными из-за их очень ограниченного масштаба
.Способы преодоления плохого статистического поведения
синтаксических фраз привели к различным методам кластеризации, которые сгруппировали синонимичные или почти синонимичные фразы в «кластеры» и заменили их отдельными «метатермами».
Методы кластеризации, тем не менее, были в некоторой степени успешными в повышении общей производительности системы, но их эффективность снижалась часто из-за низкого качества синтаксического анализа. Информационно-поисковые системы также можно различать по масштабу, в котором они работают: 1) веб-поиск, 2) поиск личной информации, 3) корпоративный, институциональный и предметный поиск.
Типичная задача поиска информации (IR) заключается в выборе документов из базы данных в ответ на запрос пользователя и ранжировании этих документов в соответствии с релевантностью. Обычно это достигается с использованием статистических методов (часто в сочетании с ручным кодированием), которые (а) выбирают термины (слова, фразы и другие единицы) из документов, которые считаются наилучшим образом отражающими их содержание, и (б) создают файл инвертированного индекса. (или файлы), которые обеспечивают легкий доступ к документам, содержащим эти условия.Последующий процесс поиска будет пытаться сопоставить предварительно обработанный пользовательский запрос (или запросы) с основанными на терминах представлениями документов, в каждом случае определяя степень релевантности между ними, которая зависит от количества и типов совпадающих терминов.
IJSER © 2014 http://www.ijser.org
Международный журнал научных и инженерных исследований, том 5, выпуск 6, июнь 2014 г. 57
ISSN 2229-5518
Информационно-поисковая система (IR) направлена на извлекать соответствующие документы по запросу пользователя, где запрос представляет собой набор ключевых слов.CLIR включает поиск документов на языке, отличном от языка запросов. Поскольку язык запроса и документы, которые необходимо перевести в CLIR. Но этот перевод приводит к снижению быстродействия CLIR по сравнению с одноязычной системой IR. Основная причина такого снижения производительности — отсутствие заданного словаря, отсутствие общих терминов и неправильный перевод из-за двусмысленности. С появлением Интернета поиск информации становится все более актуальным и исследуемым.Сейчас большинство людей ежедневно используют какую-либо современную систему поиска информации, будь то Google или какая-то специально созданная система для библиотек. Это связано с заданием вопроса на одном языке и поиском документов на одном или нескольких разных языках. Вариантами IR являются BLIR, CLIR и MLIR [2]. CLIR занимается заданием вопросов на одном языке и поиском документов на другом языке. MLIR занимается заданием вопросов на одном или нескольких языках и поиском документов на одном или нескольких языках.
НЛП — это отрасль информатики, сфокусированная на разработке систем, которые позволяют компьютерам общаться с людьми, используя повседневный язык. Также называется компьютерной лингвистикой. Также касается того, как вычислительные методы могут помочь в понимании человеческого языка. Исследование НЛП преследует неуловимый вопрос о том, как мы понимаем значение предложения или документа. Обработка естественного языка (NLP) — это разработка систем, которые обрабатывают или анализируют письменный или устный естественный язык.
3.1 Подходы в NLP
3.1.1) Статистический подход
Статистическая обработка естественного языка представляет собой классическую модель информационно-поисковых систем и характеризуется набором ключевых слов каждого документа
3.1.2) Лингвистическая направленность
Этот подход основан на применении различных методов и правил, которые явно кодируют лингвистические знания. Документы анализируются на разных лингвистических уровнях.
Синтаксический анализ — это процесс анализа строки символов на естественном языке или
на компьютерных языках в соответствии с правилами формальной грамматики.
4.1 Быстрый синтаксический анализ с помощью анализатора TTP
TTP (Tagged Text Parser) [1], [3] — это синтаксический анализатор английского языка сверху вниз, специально разработанный для быстрой и надежной обработки больших объемов текста. Синтаксический анализатор работает с тегами ввода, где каждое слово помечено тегом, указывающим синтаксическую категорию: часть речи.Синтаксический анализ сверху вниз — это стратегия синтаксического анализа, при которой сначала просматривается самый высокий уровень дерева синтаксического анализа и выполняется работа вниз по дереву синтаксического анализа, используя правила перезаписи формальной грамматики.
В информатике при синтаксическом анализе выявляется грамматическая структура текста линейного ввода, что является первым шагом в выяснении его значения. Анализ снизу вверх сначала идентифицирует и обрабатывает мелкие детали самого нижнего уровня текста, а затем его структуры среднего уровня, оставляя общую структуру самого высокого уровня на потом.TTP — это полный грамматический синтаксический анализатор, и изначально он пытается произвести полный анализ каждого предложения. Однако, в отличие от обычного синтаксического анализатора, он имеет встроенный таймер, который регулирует время, отведенное на синтаксический анализ любого одного предложения. Если синтаксический анализ не возвращается до истечения отведенного времени, синтаксический анализатор переходит в режим пропуска и соответствия, в котором он будет пытаться «подогнать» синтаксический анализ. Находясь в режиме пропуска и подгонки, синтаксический анализатор будет пытаться принудительно сократить количество неполных составляющих, возможно, пропуская части ввода, чтобы перезапустить обработку следующего непроверенного компонента.
Обрезка суффикса [1] выполняет, по существу, две задачи:
(1) Он сокращает изменяемые словоформы до их корневых форм, как указано в словаре
.
(2) Он преобразует именные формы глаголов (например,
«реализация», «хранение») в корневые формы соответствующих глаголов (например, «реализовывать», «хранить»). Это достигается удалением стандартного суффикса, например. «stor + age», заменив его стандартным корневым окончанием («+ e») и проверив вновь созданное слово по словарю.Часто производительность системы поиска информации будет улучшена, если группы терминов, такие как эта, объединить в один термин. Это можно сделать, удалив различные суффиксы -ED, -ING, -ION, -IONS, чтобы оставить единственный термин. Кроме того, процесс удаления суффиксов уменьшит общее количество терминов в системе и, следовательно, уменьшит размер и сложность данных в системе, что всегда является преимуществом. В литературе сообщалось о многих стратегиях удаления суффиксов.Характер задачи будет значительно варьироваться в зависимости от того, используется ли основной словарь, используется ли список суффиксов и, конечно же, от цели, для которой выполняется удаление суффиксов.
IJSER © 2014 http://www.ijser.org
Международный журнал научных и инженерных исследований, том 5, выпуск 6, июнь 2014 г. 58
ISSN 2229-5518
правила удаления суффикса будут задано в виде (условии) S1 S2.Это означает, что если слово заканчивается суффиксом S1 и основа перед S1 удовлетворяет заданному условию, S1 заменяется на S2.
Тестовое сканирование: [5] Частичный синтаксический анализ может использоваться для создания как можно более полного файла a. представление введенного текста, в то время как при просмотре текста цель состоит в том, чтобы извлечь конкретную часть информации или искать только новую информацию. Эта стратегия практична при чтении пересказа уже прочитанной новости или беглого просмотра текста, чтобы найти ответ на конкретный вопрос.
Полный анализ.: [5] Если область приложения сильно ограничена, а база знаний системы обширна, можно обработать каждое слово в тексте и найти его место в интерпретации значения входных данных. Такой подход может быть практичным при чтении сводок погоды, технических рефератов и некоторых других ограниченных приложений.
Частичный синтаксический анализ: [5] В большинстве приложений невозможно, используя современные технологии естественного языка, распознать каждое слово в тексте и учесть его роль во входных данных.Таким образом, большая часть обработки текста основана на подходе «soft fail-soft», когда частично обрабатывается ввод, максимально допуская неизвестные элементы, но в значительной степени полагаясь на знания предметной области, чтобы восполнить пробелы в лингвистических знаниях. Этот подход использовался, например, при чтении новостей.
• Соответствие ожиданиям пользователя.
• Понимание двусмысленности в естественном языке.
• Понимание влияния контекста на значение.
• Понимание референтов таких фраз, как he
(аван), она (аваль) и оно (атху).
• Скорость и эффективность интерфейса.
• Распознавать релевантные данные, игнорируя нерелевантные данные, такие как возраст, пол.
Основные проблемы, которые необходимо решить: Понимание значения одного слова, Понимание значения этого слова в связи с другими словами в синтаксисе и, наконец, понимание обоих этих значений в контексте, в котором они произносятся
Таким образом, в данной статье объясняется различные типы поиска информации с использованием обработки естественного языка.Язык Малаялам — это язык, очень зависимый от контекста, и поэтому он сопряжен со многими трудностями при поиске информации. Он также объясняет методы синтаксического анализа, такие как верхний нижний и нижний верхний, а также триммер суффикса слова. Обработка естественного языка на человеческом уровне — это полная проблема ИИ. То есть это эквивалентно решению центральной проблемы искусственного интеллекта — созданию компьютеров такими же умными, как люди, или сильному ИИ. Таким образом, будущее НЛП тесно связано с развитием ИИ в целом.
По мере улучшения понимания естественного языка компьютеры смогут учиться на основе информации в Интернете и применять полученные знания в реальном мире. В сочетании с генерацией естественного языка компьютеры станут все более и более способными получать и отдавать инструкции.
В будущем людям может не понадобиться кодировать программы, но они будут диктовать компьютеру свой естественный язык, и компьютер будет понимать инструкции и действовать в соответствии с ними.
ССЫЛКИ
[1] Томек Стшалковски и Барбара Воти, «ПОЛУЧЕНИЕ ИНФОРМАЦИИ С ИСПОЛЬЗОВАНИЕМ НАДЕЖНОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА», Институт математических наук Куранта, Нью-Йоркский университет, 715 Broadway, rm. 704 New York, NY 10003 [email protected]
[2] N. Swapna1, N.Hareen kumar2, B. Padmaja Rani3 ОБНОВЛЕНИЕ ИНФОРМАЦИИ НА ИНДИЙСКИХ ЯЗЫКАХ: ПРАКТИЧЕСКОЕ ИССЛЕДОВАНИЕ МЕЖЯЗЫЧНЫХ И МНОГОЯЗЫЧНЫХ ЯЗЫКОВ
,
1.Научный сотрудник отдела CSE, JNTU College ofEngineering, Хайдарабад, AP.
2. Студент бакалавра технических наук, SRIT, входящий в JNTUH. 3. Отдел
CSE, Инженерный колледж JNTU, Хайдарабад, AP.
[3] Томек Стшалковски и Барбара Вотхи, БЫСТРАЯ ОБРАБОТКА ТЕКСТА ДЛЯ ПОЛУЧЕНИЯ ИНФОРМАЦИИ, Институт математических наук Куранта, Нью-Йоркский университет, 251 Mercer Street New York, NY 10012
{tomek, vauthey} @cs.ню.еду.
[4] Джагадиш С. Каллимани *, К.Г. Сриниваса **, Эсвара Редди Б. ***, ОБОБЩЕНИЕ СТАТЕЙ ИЗ НОВОСТЕЙ: ЭКСПЕРИМЕНТЫ С ОНТОЛОГИЧЕСКИМИ — ОСНОВАННЫЕ НА ОСНОВЕ ОНТОЛОГИИ, ИНДИВИДУАЛЬНЫЕ, ЭКСТРАКТИВНЫЕ ТЕКСТОВЫЕ РЕЗЮМЕ, * Исследовательский анализ Департамент компьютерных наук и инженерии, Джавахарлал Неру
Технологический университет, Какинада, Андра-Прадеш, Индия
** Департамент компьютерных наук и инженерии, MS Ramaiah
Технологический институт, Бангалор, Индия
*** Департамент компьютеров Наука и техника, Технологический университет Джавахарлала Неру, Анантапур, Андра-Прадеш, Индия. Электронная почта: jsk_msrit @ rediffmail.com [email protected] [email protected]
IJSER © 2014 http://www.ijser.org
Международный журнал научных и инженерных исследований, том 5, выпуск 6, июнь 2014 г. 59
ISSN 2229-5518
[5] PaulS. Джейкобс и Лиза Ф. Рау, ПРИЕМЫ ЕСТЕСТВЕННОГО ЯЗЫКА ДЛЯ ПОЛУЧЕНИЯ ИНТЕЛЛЕКТУАЛЬНОЙ ИНФОРМАЦИИ, PaulS.