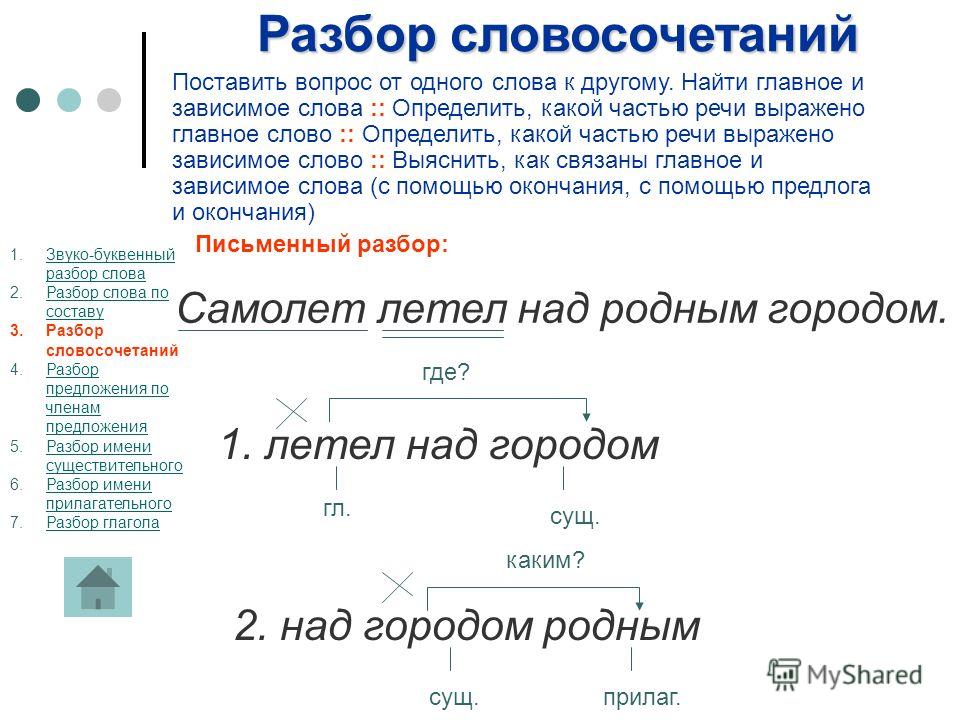
Морфологический разбор глагола «поставили» онлайн. План разбора.
Для слова «поставили» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «поставили» — глагол - Морфологические признаки.
- поставить (инфинитив)
- Постоянные признаки:
- 2-е спряжение
- переходный
- совершенный вид
- изъявительное наклонение
- множественное число
- прошедшее время.
Выхолощенного боевого мека поставили к столу; он не сопротивлялся, оптические сенсоры блестели тускло.
Выполняет роль сказуемого.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи.
 Общее значение
Общее значение - Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)
 Общее значение
Общее значениеПоделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
12 голосов, оценка 4. 750 из 5
750 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «поставили» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
разбор слова поставили — Школьные Знания.com
Надо найти главные члены правления.помтгите пожалуйста.
Расскажите пожалуйста как можно больше о спряжении глагола
3. Запиши по 2 слова:с удвоенной согласнойс непроизносимой согласной в корнес парной согласнойс непроверяемой безударной гласной в корне
морфологический разбор «весеннее» помогите
помогите пожалуйста выполнить найти наречие местоимения союз
морфологический разбор «в лесу» помогите
Придумай рассказ из 5-6 предложений , о том может ли быть на Марсе жизнь?____________________________________________________________________________ … _______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________ПОМОГИТЕ ПЖ СРОЧНО!!!
Задание 1 (5 баллов). Допишите фразу:
В слове «список» количество букв и звуков ____________ (неравное/равное).
В слове «портфель» первый звук _______
… _____ (звонкий/глухой).
Задание 2 (5 баллов).
Напишите количество букв и звуков в словах:
яблоко — ___ букв, ___ звуков;
тетрадь — ___ букв, ___ звуков;
праздник — ___ букв, ___ звуков.
Задание 3 (5 баллов).
Найдите слово, в корне которого пропущена чередующаяся гласная. Запишите в ответ это слово, вставив пропущенную букву:
р…стительность;
лес…ница;
тр…пинка;
ябл…ко.
Ответ: _____________________.
Задание 4 (5 баллов).
Укажите строчку, в которой на месте пропуска везде пишется буква Е:
щипл…т траву, в син…м небе, лежать на полян…;
гон…т гусей, хорош…й друг, закопать в земл…;
стел…т постель, могуч…й лес, убираться в дом…;
вид…шь речку, цепк…м движением, танцевать на площад….
В ответе запишите номер строки.
Ответ: ___________________________
Задание 5 (5 баллов).
Выпишите все служебные части речи из данного предложения:
Если бы можно было сейчас позвонить, прибежать, высказать!
Ответ: ___________________________.
Допишите фразу:
В слове «список» количество букв и звуков ____________ (неравное/равное).
В слове «портфель» первый звук _______
… _____ (звонкий/глухой).
Задание 2 (5 баллов).
Напишите количество букв и звуков в словах:
яблоко — ___ букв, ___ звуков;
тетрадь — ___ букв, ___ звуков;
праздник — ___ букв, ___ звуков.
Задание 3 (5 баллов).
Найдите слово, в корне которого пропущена чередующаяся гласная. Запишите в ответ это слово, вставив пропущенную букву:
р…стительность;
лес…ница;
тр…пинка;
ябл…ко.
Ответ: _____________________.
Задание 4 (5 баллов).
Укажите строчку, в которой на месте пропуска везде пишется буква Е:
щипл…т траву, в син…м небе, лежать на полян…;
гон…т гусей, хорош…й друг, закопать в земл…;
стел…т постель, могуч…й лес, убираться в дом…;
вид…шь речку, цепк…м движением, танцевать на площад….
В ответе запишите номер строки.
Ответ: ___________________________
Задание 5 (5 баллов).
Выпишите все служебные части речи из данного предложения:
Если бы можно было сейчас позвонить, прибежать, высказать!
Ответ: ___________________________.
 (3) Вспомним героиню сказки Г.Х. Андерсена Герду: её друг Кай попал в беду, она отправилась на его поиски, ей пришлось преодолеть множество препятствий. (4) На её пути встречались и злые разбойники, и хитрая колдунья; ей приходилось мёрзнуть и голодать. (5) Но она смогла освободить своего друга из плена Снежной королевы.
1) Определите тип речи, использованный в предложениях 1-5 (повествование, описание, рассуждение, повествование с элементами описания). (5 баллов)
Запишите ответ: ________.
2) Какой заголовок наиболее точно отражает основную мысль текста? (5 баллов)
А. Что такое дружба?
Б. Испытания в дружбе.
В. Преданные друзья.
Г. Судьба Герды.
Ответ: ______________________
3) Среди предложений 1-5 найдите такое, которое связано с предыдущим с помощью союза и личного местоимения. В ответ запишите номер этого предложения. (5 баллов)
Ответ: ______________________.
Задание 12 (35 баллов).
Напишите небольшое сочинение (от 50 слов до 70 слов) на тему «Что такое дружба?».
Паж сделайте четверть закрываю, не успеваю
(3) Вспомним героиню сказки Г.Х. Андерсена Герду: её друг Кай попал в беду, она отправилась на его поиски, ей пришлось преодолеть множество препятствий. (4) На её пути встречались и злые разбойники, и хитрая колдунья; ей приходилось мёрзнуть и голодать. (5) Но она смогла освободить своего друга из плена Снежной королевы.
1) Определите тип речи, использованный в предложениях 1-5 (повествование, описание, рассуждение, повествование с элементами описания). (5 баллов)
Запишите ответ: ________.
2) Какой заголовок наиболее точно отражает основную мысль текста? (5 баллов)
А. Что такое дружба?
Б. Испытания в дружбе.
В. Преданные друзья.
Г. Судьба Герды.
Ответ: ______________________
3) Среди предложений 1-5 найдите такое, которое связано с предыдущим с помощью союза и личного местоимения. В ответ запишите номер этого предложения. (5 баллов)
Ответ: ______________________.
Задание 12 (35 баллов).
Напишите небольшое сочинение (от 50 слов до 70 слов) на тему «Что такое дружба?».
Паж сделайте четверть закрываю, не успеваю ТЕКСТ ЗАДАНИЯ1 задание. Рассмотрите иллюстрации. Выполните одно задание из 2-х предложенных тем.1. Придумайте сказку о священном дереве Байтерек, испол
… ьзуя собственные знания и опыт.Повествование ведите от 1-го лица. Объем письменной работы — 100-150 слов.2. Представьте себя на месте маленькой звездочки и напишите сказку, используя имеющиеся знанияи жизненный опыт. Повествование ведите от 1-го лица. Объем письменной работы — 100-150слов.
Рассмотрите иллюстрации. Выполните одно задание из 2-х предложенных тем.1. Придумайте сказку о священном дереве Байтерек, испол
… ьзуя собственные знания и опыт.Повествование ведите от 1-го лица. Объем письменной работы — 100-150 слов.2. Представьте себя на месте маленькой звездочки и напишите сказку, используя имеющиеся знанияи жизненный опыт. Повествование ведите от 1-го лица. Объем письменной работы — 100-150слов.
Создайте дневниковую запись «Как я провел лето» с элементами художественного и разговорного стилей. Используйте в своей работе предложения, выражающие … различные состояния человека. Правильно пишите безударные падежные окончания (объем 50-60 слов). Сроочно
Морфологический разбор слова дозволить онлайн
Слово ‘дозволить’
 У глагола дозволить есть постоянные признаки:
У глагола дозволить есть постоянные признаки:- Возвратный/Невозвратный — слово ‘дозволить’ является невозвратный;
- Переходный/Непереходный — слово ‘дозволить’ это переходный глагол. ; Глагол ‘дозволить’ относится к несовершенному виду.
- Пример изъявительного наклонения: В наши бумаги поставили какие-то штампы и взмахом руки дозволили продолжать путь.;
- Пример cослагательного наклонения: Дозволил бы мне король пользоваться всеми правами живого – посмертно?;
- Пример повелительного наклонения: Царь-государь! Дозволь тебе сегодня, для радостного дня, замолвить слово. ;
- Род слова определить не возможно потому, что глагол является Инфинитивом.
- Лицо — не определяется в инфинитиве;
- У данного слово время не определяется потому, что слово дозволить является Инфинитивом;
Слово «дозволить» значит:
- Позволить, разрешить.

«ДОЗВОЛИТЬ» — это Глагол. Обозначающая действие предмета и отвечает на вопросы «Что делать?» или «Что сделать?». В предложении обычно выполняет роль сказуемого.
дозвОлить
Ударение падает на слог с буквой
Слово «дозволить» — род не определяется в инфинитиве
Глагол ‘дозволить’ является несовершенным видом.
Переходность глагола «дозволить» — переходный
Лицо у глагола «дозволить» — не определяется в инфинитиве
«ДОЗВОЛИТЬ» — это невозвратный глагол
Пример использования наклонений
Изъявительное В наши бумаги поставили какие-то штампы и взмахом руки дозволили продолжать путь.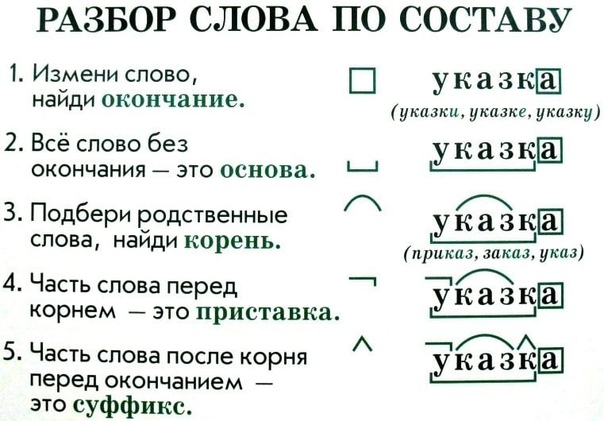
Сослагательное (условное)
Дозволил бы мне король пользоваться всеми правами живого – посмертно?
Повелительное
Время глагола «дозволить» — не определяется в инфинитиве
Слово «дозволить» — относится к Второму спряжению
Глагол в прошедшем времени
Она (ед. число)
число)
Оно (ед. число)
Они (мн. число)
- ссудить
- заспорить
- грохнуть
- оттаптывать
- лечить
- перевести
- сипнуть
- дискриминировать
- пестрить
- ступать
Конспект урока Тема: «Фонетический разбор слова»
Конспект урока
Тема: «Фонетический разбор слова»
Цель: — научить учащихся производить фонетический разбор слова.
Задачи: — развивать умения различать звонкие и глухие, твердые и мягкие, парные и непарные согласные; умения правильно ставить ударение и делить слова на слоги.
Ход урока:
Организационный момент
— Здравствуйте, ребята. Сегодня на урок к нам пришли гости. Поздоровайтесь. Садитесь.
— Открываем тетради, записываем число, классная работа.
Проверка домашнего задания
— Спишите слова с доски, расставьте ударение, запишите транскрипцию.
— Кстати, что такое транскрипция? На каком еще уроке вы работаете с транскрипцией?
Получается:
Землялев
цветок
открыть
мороз
очки
[з,и м л,а]
[л,э ф]
[ц в,и т о к]
[а т к р ы т,]
[м а р о с,]
[а ч,к,и]
— Молодцы! Вы очень хорошо справились с заданием. А теперь в середине новой строки запишем тему нашего урока «Фонетический разбор слова».
А теперь в середине новой строки запишем тему нашего урока «Фонетический разбор слова».
Изучение нового материала
— Итак, тема нашего урока «Фонетический разбор слова».
— Какую цель мы поставили перед собой на этот урок?
— Какие задачи необходимо решить для достижения нашей цели?
Фонетический опрос
— Каждый правильный ответ +5 б., неправильный ответ -5 б.
— Как называется раздел науки о языке изучающий звуки речи? (фонетика)
— На какие группы делятся звуки речи? (гласные, согласные)
— Какие звуки являются гласными? (которые состоят только из голоса)
— Какие звуки являются согласными? (которые состоят из голоса и шума)
— Какими бывают гласные звуки? (ударные и безударные)
— Каким буквам отведена двойная роль? (е, ё, ю, я)
— Сколько букв в русском алфавите?
— Сколько гласных?
— Сколько согласных?
— В чем разница между буквой и звуком?
— Сколько парны согласных по глухости – звонкости?
— Сколько непарных глухих? (4)
— Назовите. [х, ц, ч, щ]
[х, ц, ч, щ]
— Сколько непарных мягких согласных? (3)
— Назовите. [ч,, щ,, й,]
— Сколько непарных твердых согласных? (3)
— Назовите. [ж, ш, ц]
— Сколько глысных звуков? (6)
— Сколько согласных звуков? (36)
— Сколько всего звуков? (42)
— Молодцы, ребята!
Физминутка
— Вышла мышка как-то раз (ходьба на месте). Поглядеть который час (повороты влево, вправо, пальцы «трубочкой» перед глазами).
— Мышки дернули за гири (руки вверх и приседание с опусканием рук). Раз, два, три, четыре (хлопки над головой).
— Вдруг раздался страшный звон (хлопки перед собой).
— Убежали мышки вон (бег на месте).
— Отдохнули. Теперь сел ровно. Спинки выпрямили. Теперь перейдем к изучению нового материала.
Спинки выпрямили. Теперь перейдем к изучению нового материала.
Объяснения учителя
— Открываем учебники на стр. смотрим план фонетического разбора.
— А теперь я покажу вам как надо выполнять фонетический разбор.
— С красной строки, с большой буквы записываем предложение:
На лесной поляне стоял старый пень1.
Пень – 1 слог.
п [п᾽] – согл., парн., глух., мягк..
е [э] – гл., ударн..
н [н᾽] – согл., непарн., сонор., мягк..
ь [-]
- [п, э н,]
— Ребята, кому не понятно, как выполнять фонетический разбор?
IV. Закрепление изученного.
– Разгадать ребусы и выполнить фонетический разбор слов. (учащийся у доски)
воро′та – 3 слога
в [в] – согл. , парн., зв., тв..
, парн., зв., тв..
о [а] – гл., безуд..
р [р] – согл., непарн., сон., тв..
о [о] – гл., ударн..
т [т] – согл., парн., глух., тв..
а [а] – гл., безуд..
- [в а р о т а]
ры′бка – 2 слога
р [р] – согл., парн., сон., тв..
ы [ы] – гл., ударн..
б [п] – согл., парн., глух., тв..
к [к] – согл., парн., глух., тв..
а [а] – гл., безуд..
ты′ква – 2 слога
т [т] — согл., парн., глух., тв..
ы [ы] — гл., ударн..
к [к] — согл., парн., глух., тв..
в [в] — согл., парн., зв., тв..
а [а] — гл., безуд..
камы´ш – 2 слога
к [к] — согл., парн., глух., тв..
а [а] — гл., безуд..
м [м] — согл., непарн., сон., тв..
ы [ы] — гл., ударн..
ш [ш] — согл., парн., глух., тв..
Работа в команде по карточкам
Алфавит, фарфор, каталог, библиотека, красивее, звонит, приговор, договор, средства, километр, свёкла, творог.
Правильно произнесите записанные слова.
Что, чтобы, скучный, конечно, скворечник, яичница, гречневый, пустячный.
— Команда, все члены которого быстро и правильно справились с заданием получаете 20 баллов.
V. Подведение итогов.
VI. Домашнее задание.
— Итак, ребята, наш урок заканчивается.
— Чему мы научились сегодня на уроке?
— Достигли ли мы цели, которую поставили перед собой в начале урока?
— Что на уроке понравилось больше всего?
— Выставили оценки, заработанные вами на уроке.
— Открыли дневники, записываем домашнее задание все, кроме команды С.Боброва, выполнить фонетический разбор слов: ёж, медведь, цирк.
— Команда Семена составит связанный рассказ на тему: «Что я знаю о фонетике?»
Сочетание чн как правило, произносится в соответствии с написанием.
Например: Античный, дачный, качнуть.
Но в некоторых сочетаниях букв чн не так, как пишется, а по-другому [шн], например: коне[ш]но, ску[ш]но, наро[ш]но, праче[ш]ная.
В некоторых словах допускается двоякое произнашение.
Например: булочная, гречневый, сливочный.
В конце XIX – начале XX века многие слова произносились с [шн], а не с [чн]. Произношение [шн] старой московской орфоэпической нормы.
Как разобрать по составу слова: поставили, выполняешь?
Морфемный разбор (по составу) слова ЯВЛЯЕТСЯ
Это глагол в форме 3-го лица единственного числа с личным окончанием ЕТ и основой слова ЯВЛЯ_СЯ.
Корневая морфема (однокоренные слова: явление, являться, явь) ЯВЛ с чередованием в корне согласных в//вл.
Далее выделим постфикс СЯ (указывает на возвратность) и суффикс Я.
явл/я/ет/ся
Прилагательное Вменяемый относится к мужскому роду и потому выделяем в нем окончание -ЫЙ: Вменяемый-Вменяемая-Вменяемые. Однокоренные слова находим: Вменяемый-Вменять-Вменение-Невменяемость-Невменяемый. Корнем слова оказывается ВМЕН-, хотя исторически слово образовано сложением приставки В с слова Менить, в значении рассматривать. Также выделяем суффикс инфинитива -Я- и суффикс прилагательного -ЕМ-.
Получаем: ВМЕН-Я-ЕМ-ЫЙ (корень-суффикс-суффикс-окончание). Основа слова ВМЕНЯЕМ-.
Интересно, что в случае причастия Вменяемый, основа слова будет уже ВМЕНЯ-, поскольку причастие не самостоятельная часть речи, а форма глагола.
Прилагательное «миленький» имеет уменьшительно-ласкательный суффикс -еньк-, придающий ему соответствующую эмоциональную окраску, так же как и следующие слова: чёрненький, свеженький, молоденький, весёленький, коротенький. Главная часть слова — корень — -мил-, как и в слове «милый», от которого приведённое Вами прилагательное образовано суффиксальным способом. Ну а окончание — -ий, в чём легко убедиться, если попробовать изменить форму, например, рода этого прилагательного: миленький — миленькая — миленькое.
Существительное домосед образовано методом сложения и нулевой суффиксацией от слова «дом» и глагола «сидеть». При словообразовании от глагола отсекаются его суффиксы, и остается «голый» корень. При этом образуется другая часть речи — существительное. В словообразовании в таком случае принимает участие нулевой суффикс, поэтому морфемный состав слова «домосед» мне видится вот таким:
дом-, -сед- — корни;
-о- соединительная морфема;
нулевой суффикс, нулевое окончание.
дом/о/сед/нулевой суффикс/нулевое окончание.
В слове вместо видимых трех морфем на самом деле существует целых пять!
Точно такое же строение имеют аналогично образованные существительные: птицелов (птица + ловить), кашевар (каша + варить), паровоз (пар + возить), звездолёт (звезда + летать) и многие другие.
Очень продуктивный способ словообразования.
Слово «зависимость» это имя существительное, отвечает на вопрос «Что?», неодушевлённое, женский род единственное число, винительный падеж.
Разбор по составу слова «зависимость» имеет вид:
корень — завис;
суффикс — им;
суффикс — ость;
нулевое окончание .
Основа слова является — зависимость .
Способ образования слова — суффиксальный.
Пример предложения Всё дело в том, какой характер принимает взаимная зависимость.
Морфологический разбор слова ЗАСПОРИТ: таблица с пояснениями
Сегодня мы будем делать морфологический разбор слова «заспорит».
Это очередной глагол, с которым мы подробно познакомимся. Вот мы и начали делать разбор, так как уже определили, что это глагол.
Как определили? Да очень просто – задали вопрос – что сделает?
Всё, что касается дел, т.е. что-то делать, сделать – это всё глаголы. Такая часть речи.
Когда мы поставили вопрос (что Сделает? – заспорит), то сразу заметили, что начинается он с согласной С – сделает.
По этой согласной мы сразу же может определить вид данного глагола.
Начинается с С, значит, совершенного вида.
Далее будем искать его форму в процессе спряжения по лицам и числам.
| Лицо | Число | Форма глагола (пример в предложении) |
| 1 | Единственное | Я заспорю тебя на эту тему. |
| 2 | Ты заспоришь, как всегда. | |
| 3 | Он (она) заспорит и не выиграет спор. | |
| 1 |
Множественное | Мы заспорим всей командой, если не согласимся. |
| 2 | Вы заспорите любого неудачника. | |
| 3 | Они заспорят, когда поймут, что смогут выиграть викторину. |
Проспрягав глагол, мы видим, что рассматриваемая нами форма находится в ячейке 3 лица единственного числа.
А так как в других лицах и мн.числе форма глагола «заспорит» изменяется, то можно догадаться, что это непостоянный морфологический признак слова.
Поэтому будем это учитывать при заполнении данных разбора.
Для тех, кому эти пояснения показались скучными и долгими, предлагается таблица разбора с указанием всех морфологических признаков слова «заспорит».
Морфологический разбор слова «заспорит»
| Часть речи | глагол, отвечающее на вопрос «что сделает?» |
| Морфологические признаки | Начальная форма: заспорить. Постоянные признаки: 2-е спряжение, непереходный, совершенный вид. Непостоянные признаки: изъявительное наклонение, единственное число, будущее время, 3-е лицо. |
| Синтаксическая роль | сказуемое. |
На сегодня всё. До новых разборов!
Трагедия в Казани и беспомощность властей — разбор «ИрСити»
Как «усиление безопасности в школах» после трагедии в Казани поможет решить психологические проблемы учеников и вообще любого жителя Иркутской области, чем руководствуются власти, когда определяют, какие массовые мероприятия можно проводить в эпоху коронавируса, а какие — нельзя, и почему разработка стратегии развития региона может стать ещё одной нереализованной мечтой, переходящей от одного губернатора к другому, — на эти вопросы редакция «ИрСити» попыталась ответить в очередном разборе минувшей недели.
В обзоре событий недели журналисты «ИрСити» не пытаются определять ключевые информационные поводы прошедших семи дней, а пишут о том, что их больше всего задело.
Зоя Кузнецова: Отгородиться забором, тревожной кнопкой – и забыть
После трагедии в Казани чиновники всей России заговорили о проверке безопасности в школах. Иркутские – тоже. И губернатор Игорь Кобзев, и мэр Иркутска Руслан Болотов высказались про «усилить меры безопасности», проверить работу тревожных кнопок, дополнительные инструктажи, входной контроль, охрану внутреннего и внешнего периметра.
Как будто охранник (вахтёр) на входе в школу сможет остановить человека с ружьём. Как будто тревожная кнопка может помешать нажать на курок. Как будто камеры заставят человека передумать стрелять. Как будто забор вокруг школы может стать препятствием.
Всё внимание – одной самой простой и показательной стороне проблемы. За неделю не было ни одного комментария со стороны министра образования Иркутской области Максима Парфёнова (внезапно я даже забыла, как его зовут, пришлось гуглить — так часто он появляется в публичном поле) или главы минмолодёжи (у Маргариты Цыгановой, судя по Instagram, сейчас главная забота – форум «Байкал» и студфестивали, которые, как известно, решают все проблемы, начиная от митингов).
Ни слова не сказали ни председатель комитета по соцполитике мэрии Виталий Барышников, ни глава городского департамента образования Олег Ивкин, ни руководитель управления по молодёжной политике Дмитрий Абрамович (тут тоже имя пришлось погуглить по аналогичной причине).
Физическая безопасность – важна, кто бы спорил. Только почему-то все делают вид, что она решит проблему насилия и стрельбы в школах. Ни один из иркутских чиновников даже не намекнул, что власти задумались о системе психологической помощи в школах – есть она или нет, доверяют ли дети учителям и психологам, понимают, куда идти, если и дома, и в школе – миллиард проблем, успевают ли учителя посмотреть на детей не в рамках учебной статистики, могут ли тактично поговорить с родителями.
Сколько подростков просто брошены наедине со своими проблемами? С семейными ссорами? С агрессией в школе? С несчастливой первой влюблённостью? С проблемами с учёбой? Сколько могут с этим справится? У скольких есть адекватный взрослый (и не обязательно родитель, а, например, наставник, психолог, руководитель секции), который поможет разобраться, не обвиняя и не унижая? Может быть, самое время и об этом подумать тоже, Игорь Иванович, Руслан Николаевич и все вышеперечисленные?
Потому что если не разбираться с этими вопросами, а потом и с системой психологической помощи для всех вообще, а не только для подростков, тогда надо огородить заборами с колючей проволокой (зачёркнуто), навесить камеры, поставить тревожные кнопки и КПП (зачёркнуто), охранников вообще везде – в больницах, университетах, детсадах, парках, торговых центрах, кинотеатрах, даже на набережных, вокруг жилых комплексов и супермаркетов. Потому что эти места технически мало чем отличаются от школ.
Даниил Конин: Концерты безопаснее карнавала?
Мэрия Иркутска в минувшую пятницу объявила о переносе на сентябрь праздничного шествия в честь 360-летия города. Это произошло из-за ситуации с коронавирусом — в Иркутске ежедневно выявляется от 40 до 50 новых случаев COVID-19. При этом эпидемиологическая ситуация, по задумке властей, не должна помешать провести разнообразные концерты и спортивные мероприятия.
У меня нет морального права обсуждать важность и нужность празднования Дня города в Иркутске. Всё-таки я не иркутянин по рождению, с городом у меня особые отношения. Поэтому я задам другой вопрос: а точно ли сейчас стоит проводить какие-то массовые мероприятия?
Не так давно мы отпраздновали День Победы. Я думаю, что в Иркутске, равно как и во многих других городах страны, это делалось с оглядкой на Москву. До последнего было не очень понятно, будет ли праздноваться 9 Мая в столице и что по этому поводу думает президент. Но тот был настроен решительно, и эта решительность стала негласным «одобрением» для проведения торжеств в других регионах. Хотя Роспотребнадзор был против массовых мероприятий.
Последствия прошедшего праздника мы увидим только через полторы-две недели. Посмотрим, случится ли всплеск заболеваемости. В Иркутской области, к примеру, продолжают держать свободными часть оборудованных коек, хотя до мая прирост новых случаев коронавируса снижался (хотя бы статистически). На федеральном уровне уже заявляют о третьей волне, которая то ли уже началась, то ли вот-вот начнётся.
Тем временем в Иркутске переносят карнавал в честь Дня города, но при этом планируют проводить разные концерты. Обсуждается приезд какой-нибудь «звезды», хотя тут уже не всё так однозначно. Но если «звезда», не дай бог, к нам прилетит, на площади возле здания правительства будет та же ситуация, что и во время 9 Мая. Тогда какой смысл было отменять шествие? Оно чем-то опаснее концертов, где соберётся 100, 200, 500 или больше человек, скучившись на небольшом пятачке? Хотелось бы понять логику происходящего. Пока не очень получается.
В прошлом году День города не проводился (читай, ушёл в онлайн), но я бы не сказал, что жизнь в Иркутске от этого как-то перевернулась. Мне кажется, и сейчас его проводить не стоит. Тем более прошедший День Победы показал, что организовать массовое мероприятие с соблюдением всех противоэпидемических мер нереально.
Ксения Власова: Иркутская область закопалась в стратегии развития
В Иркутской области опять сменился министр экономического развития. Должность эта расстрельная (а какая – нет?), но очень творческая – шутка ли, придумывать, как и куда будет расти Приангарье. Но вот как-то не везёт с министрами. Более того, обычному человеку мало понятно, чем региональный минэк занимается – раньше хоть его делегации разъезжали по городам и весям с «презентацией экономического потенциала Иркутской области», сейчас и этого нет – спасибо коронавирусу.
Сегодня министерство экономразвития больше похоже на информационную службу, которая предоставляет циферки депутатам ЗС и другим членам правительства. Выполнять те же функции для предпринимателей (которые вообще-то должны быть локомотивом региональной экономики, но пока — нет) уже и не надо – создан центр «Мой бизнес», где можно как задать вопросы, так и получить поддержку.
Тема специфичная, на каждом углу об этом не говорят, а эффективность инструментов развития минэк оценивает где-то в глубинах своих глубин и делится этой информацией опять же по отдельному запросу. А вот если бы, например, рассказывал каждый квартал: смотрите, вот такие займы выдали, вот под такие проценты, вот на такие проекты, вот на что эти деньги потратились и вот так в итоге всё вокруг заколосилось? Мечты-мечты.
Новым министром стала Наталья Гершун, которая проработала в правительстве — сначала в комитете экономического анализа и прогнозирования, а потом в минэке – 15 лет. После ещё почти четыре года – в аналогичной структуре Ленинградской области. Видимо, губернатор решил возвращать опытные кадры в регион.
На этой неделе Игорь Кобзев встретился с Натальей Гершун. И первой задачей, которую он поставил перед министром, — держитесь за стулья, а то упадёте и закатитесь от восторга под стол – стала доработка стратегии социально-экономического развития области до 2036 года.
«Необходимо учесть все поступившие предложения. Я уже говорил, что документ должен быть принят до конца года», — написал губернатор на своей странице в Instagram.
Напомню, что свистопляска (а иначе это назвать трудно) со стратегией началась в 2016 году, когда регионом руководил коммунист Сергей Левченко. В феврале 2017-го заксобрание одобрило её в первом чтении, но дальше этого дело не пошло, а обсуждение стратегии превратилось в политическую склоку.
В начале 2020 года губернатор Игорь Кобзев заявил, что его команда создаст новый документ. Как уточнялось на сайте минэка, это связано с тем, что принятый в первом чтении проект уже устарел. С февраля по июнь обновлённая стратегия «широко обсуждалась». Какие изменения она претерпела за 5 месяцев – неизвестно. А в ноябре губернатор внёс документ в ЗС. Тогда предполагалось, что в течение 2021 года региональный парламент приступит к её рассмотрению.
Но что-то пошло не так. Думаю, что без особого расчёта тут не обошлось – возможно, стратегию планируют принять без унизительных публичных разборок, максимально отшлифованную, чтобы коммунисты не смогли вцепиться мёртвой хваткой в недостатки, а критика была бы менее политизированной и болезненной.
Как-то ради интереса я бегло сравнила два документа – Левченко и Кобзева – и не нашла особых различий. Ещё одним глазком я сравнивала проекты со стратегией Красноярского края (принятой ещё в 2018 году) и долго не могла отделаться от чувства тревоги.
У соседей документ оказался очень самокритичным (это притом, что Красноярский край по развитию занимает лидирующие позиции в Сибирском федеральном округе и по многим показателям «бьёт» Приангарье), авторы откровенно указывали на дыры и так же откровенно предлагали, как эти дыры будут перекрывать. В наших стратегиях всё прекрасно: ржится рожь, овёс овсится, чечевица-чечевица (простите, не удержалась).
Спикер заксобрания Приангарья Александр Ведерников в интервью «ИрСити» объяснил, что стратегия Кобзева «была сделана по имеющимся ранее наработкам». Видимо, поэтому она не так сильно отличается от предыдущей стратегии, хотя, безусловно, статистические данные в ней актуализированы.
Ведерников привёл два примера, что не учитывает новый проект. Первое – это взаимоувязка роста туристического потока и решения проблемы антропогенной нагрузки на экосистему озера Байкал.
Второе – газификация.
Может, когда-то она и сулила новые перспективы развития, но сейчас — просто красивое, мощное слово, мечта, далёкая от реализации. На карте «Газпрома» Иркутской области нет, хотя «Газпром» разрабатывает в Приангарье одно из крупнейших в России газоконденсатных месторождений – Ковыктинское. В программу газификации, утверждённую 6 мая премьер-министром Михаилом Мишустиным, Иркутская область вряд ли войдёт – инфраструктуры как таковой нет. И не предвидится.
Но охрана Байкала и газификация — не единственные замечания, которые можно сделать к проекту стратегии, но это такие вечные вопросы, на которые пока что нет ответа. А все ждут.
С самой стратегией может получиться так же – Приангарье просто увязнет в бесконечной доработке документа, как в болоте, а деньги будут выделятся интуитивно, а не в комплексе с проектами, запланированными в стратегии. Последнее – это ноющая зубная боль – ни спать, ни есть, ни говорить.
Получится ли у Гершун создать такую стратегию социально-экономического развития Иркутской области, на которую будет опираться всё наше локальное, региональное мирозданье, а вопросы инвестиционной привлекательности Приангарья будут рассматриваться вне зависимости от исхода политических баталий? Ведь тогда и губернаторская чехарда не будет пугать бизнес, потому что перестанет быть чехардой, а превратится в простую и красивую сменяемость власти.
Не знаю. Мечты-мечты.
Редакция «ИрСити»
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я счастлив, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Соединение— Куда поставить энклитику -ne?
Ваша идея верна.
Льюис-Шорт не очень понятен:
добавляется в прямом вопросе в качестве знака допроса к первому или главному слову статьи
, но, если вы знаете немецкий язык, Джорджес гораздо яснее: ‑n (e) прикреплено к фокусу вопроса, поэтому в основном в начале предложения.
Чтобы полностью ответить на ваш вопрос, очень интересна цитата из Terentius, Phormio, v.851: Sed isne est, quem quaero an non?
- Он показывает ‑ne , приложенное к слову, о котором спрашивают, вместо глагола: это он?
- Это пример того, что может предшествовать слову с пометкой ne в прямых вопросах: связки и тому подобное, а не настоящие составляющие.
- Это напоминает нам, что альтернативы могут быть введены с помощью an; иногда повторяется ‑ne .
Если вы прочтете ссылку Georges, то увидите, что при использовании в качестве союза в косвенных вопросах ‑ne может быть присоединено к словам в любой позиции; однако это не относится к прямым вопросам.
В частности, у меня есть сильные сомнения по поводу вашего cum Marcone: Я не смог найти ни одного примера предложной фразы Prep + Noun + ne, и я бы сказал, что это невозможно: формы, оправданные дошедшим до нас корпусом, Nonne cum Marco? (ожидается подтверждение) или Num cum Marco? (ожидается отказ).
Mecumne loqueris? действительно работает и меня устраивает, даже если бы я мог найти его только в современных тетрадях, но здесь ‑cum работает как суффикс, почти окончание падежа, и это конструкция ближе к mihine , чем к PP выше. Возможно, подойдет даже magnone cum gaudio , но я не смог найти никаких примеров. Я не знаю, что мешает присоединять энклитики к существительным после предлогов : но я готов поспорить, что то же самое верно и для ‑que и ‑ve .
Отличие от финского (я думаю: поправьте меня, если я ошибаюсь) состоит в том, что ‑ko / ‑kö используется исключительно и обязательно в вопросах «да / нет», а ‑ne не является обязательным (по крайней мере, в более поздние периоды) и иногда (редко) могут быть присоединены к вопросительным наречиям и местоимениям: примеры см. по ссылкам выше.
Анализ состояния Союза
Раздел 3 статьи II Конституции США гласит, что Президент
…. время от времени предоставляет Конгрессу информацию о состоянии Союза и рекомендует на его рассмотрение такие меры, которые он сочтет необходимыми и целесообразными; в исключительных случаях он может созвать обе палаты или любую из них …
Джордж Вашингтон произнес свое первое Ежегодное послание 8 января 1790 года. Сегодня вечером, чуть более 214 лет спустя, Джордж Буш выступил со своим пятым Посланием о положении Союза на совместной сессии Конгресса и американского народа.
Несмотря на то, что современные Обращения о состоянии Союза готовятся группами писателей, можно с уверенностью предположить, что заключительные выступления тщательно проверяются и одобряются Президентом, что делает Послание хорошей целью для анализа.Как сказал один друг: «Поскольку очевидно, что речь безжалостно курируется перед презентацией, интересно отметить, как часто и где появляются определенные особенности».
Вместо того, чтобы обсуждать стиль или представление Обращения, я хотел бы провести сравнительный графический анализ двух легко измеряемых характеристик: длины предложения и частоты встречаемости слов.
Длина предложения
В этой таблице показано количество предложений, количество слов и среднее количество слов в предложении в расшифровке стенограммы 1 Джорджа У.Послания Буша о положении в стране, а также его специальное обращение к Конгрессу после терактов 11 сентября:
| | 1-е обращение к совместной сессии Конгресса 27 февраля 2001 г. | Специальное обращение к Конгрессу 20 сентября 2001 г. | Адрес 1 государства Союза 29 января 2002 г. | 2-й адрес 28 января 2003 г. | 3-й адрес 20 января 2004 г. | 4-й адрес 2 февраля 2005 г. |
| Количество слов | 4 385 | 2,992 | 3 841 | 5,361 | 5,203 | 5 063 |
| Количество предложений | 278 | 182 | 214 | 284 | 278 | 236 |
| Среднее количество слов в предложении | 15.8 | 16,4 | 17,9 | 18,9 | 18,7 | 21,4 |
Чтобы поместить эти числа в исторический контекст, на этой диаграмме пятый адрес Буша сравнивается с четырьмя дополнительными адресами в штате Союза:
| | Джордж Вашингтон 5-е ежегодное послание 3 декабря 1793 г. | Авраан Линкольн 1-е годовое послание 3 декабря 1861 г. | Рональд Рейган 4-й адрес 6 февраля 1985 г. | Уильям Дж.Клинтон 5-й адрес 4 февраля 1997 г. | Джордж Буш 4-й адрес 2 февраля 2005 г. |
| Количество слов | 1 971 | 7 038 | 4 248 | 6,793 | 5 063 |
| Количество предложений | 57 | 216 | 305 | 440 | 236 |
| Среднее количество слов в предложении | 34.6 | 32,6 | 13,9 | 15,4 | 21,4 |
Отображение предложений
Один из способов визуального представления каждой речи — рассматривать каждое слово как блок (), а каждое предложение как строку блоков ().
Сгруппированные по вертикали, первые 15 предложений сегодняшнего послания Джорджа Буша к положению перед Союзом выглядят следующим образом:
| Предложение № | |
| | Количество слов |
Используя меньшие блоки для представления каждого слова, вся речь будет выглядеть так:
| Предложение № | |
| | Количество слов |
Распространенность слов
В этой визуальной структуре определенные слова или фразы могут быть представлены как минимум двумя способами: выделением самого слова или выделением всего предложения, в котором оно появляется.На этой диаграмме красным цветом выделены 17 предложений в сегодняшней речи Буша, которые содержат слово «свобода»:
| Предложение № | |
| | Количество слов |
Инструмент для онлайн-анализа
Чтобы найти свои собственные слова или фразы или сравнить появление двух слов в адресах Буша в штате Союза, попробуйте инструмент анализа состояния Союза. Хорошее начало — свобода и свобода.
Выписки
- Первый адрес Джорджа Буша в штате Союза: 2001
- Обращение Джорджа Буша к совместной сессии Конгресса и американского народа: 2001 г.
- Государственные адреса Союза Джорджа Буша: 2002, 2003, 2004, 2005, 2006, 2007, 2008
- Пятое ежегодное послание Джорджа Вашингтона: 1793
- Первое ежегодное послание Авраана Линкольна: 1861
- Четвертый адрес Рональда Рейгана в штате Союза: 1985
(четвертый адрес Рейгана и его первый после переизбрания.) - Пятый адрес государства Союза Уильяма Дж. Клинтона: 1997
Расчеты анализа текста | Расчеты и типы данных
Хотя большинство людей думают о функциях для выполнения сухих вещей, таких как математика в электронной таблице, вы также можете использовать функции в текстовых полях своей базы данных. Так же, как вы можете складывать и вычитать числа с помощью числовых функций, вы можете использовать текстовые функции для нарезки слов в своей базе данных.Например, вы можете получить данные из внешнего источника, который требует серьезной очистки, прежде чем вы сможете их использовать. Эти данные содержат имена и фамилии людей в одном поле; у него даже есть целые сообщения электронной почты, заполненные полевым адресом, темой и телом, тогда как все, что вам нужно, — это адрес электронной почты. Вы можете оборудовать временную базу данных полями и текстовыми вычислениями для анализа (воспринимайте это как просеивание) данных в форме, которую ожидает ваша лучше спроектированная база данных. Совет: Исправление данных таким способом обычно означает, что вы выполняете поиск определенного типа неверных данных, если, скажем, только некоторые записи имеют два адреса электронной почты в одном поле.Используйте вычисление с помощью команды Replace-Field Contents в записях. Сначала выполните поиск, а затем выполните вычисленное «Заменить содержимое поля», которое исправляет ошибку. |
| КЛИНИКА ЭНЕРГОПОЛЬЗОВАТЕЛЕЙ Повторяющиеся поля для нескольких результатов |
Что делать, если одной скидки недостаточно? Предположим, вы хотите предоставить своим клиентам 5-процентную скидку на заказы от пяти и более, 10-процентную скидку на заказы от 10 или более, 15-процентную скидку на заказы от 15 и более и так далее.Вы можете создать больше полей вычислений с небольшими вариациями уже определенных вами вычислений: Если вы хотите семь ценовых разрывов, вы должны определить семь полей. И если вы хотите немного изменить расчет (например, дать дополнительную 2-процентную скидку за перерыв вместо 5-процентной). вам нужно изменить расчет каждого отдельного поля. Этот пример — один из тех случаев, когда могут пригодиться повторяющиеся поля. Когда вы создаете повторяющееся поле расчета, у вас есть только одно вычисление, но вы получаете несколько результатов.Однако с помощью только одного расчета FileMaker не показывает очевидного способа предоставления различных ставок дисконтирования. Секретный ингредиент — это функция Get (Calculation-RepetitionNumber). Он возвращает количество повторений, которое рассчитывается в данный момент. Например, когда FileMaker вычисляет третье значение в повторяющемся поле, эта функция возвращает 3. Имея в виду эту функцию, вы можете разработать единый расчет, в котором используются разные ставки дисконтирования в зависимости от числа повторов: Мин ( Максимум ( Цена * (1 - Получить (CalculationRepetitionNumber) *.5); Стоимость * 1,2 ); Цена ) В этом расчете вы заменяете постоянную ставку дисконтирования выражением: (1 - Получить (CalculatedRepetitionNumber) * .5) Если вы протестируете этот расчет с несколькими числами, вы увидите, что он дает дополнительную 5-процентную скидку за каждое последующее повторение. После того, как вы определили такое поле, многое станет действительно простым: Чтобы добавить больше ценовых разрывов, просто измените количество повторов в диалоговом окне «Указать расчет».
|
10.3.1. Оператор конкатенации
В отличие от большого разнообразия математических операторов для работы с числами, есть только один, который относится именно к тексту — оператор конкатенации. Представленный знаком & (амперсанд), он связывает фрагменты текста вместе.(Когда вам нужно разрезать и разделить текст для его анализа, вы используете функцию вместо оператора, как описано в Разделе 10.3.2.)
Чтобы использовать его, поместите его между блоками текста, как в приведенном ниже выражении:
"Это проверка"
Результат этого расчета: Это тест.
Оператор конкатенации позволяет комбинировать текст из двух разных полей и улучшать их совместную работу. Например, когда вы настраивали макет Jobs в своей базе данных в главе 8, вам пришлось пойти на компромисс.При создании списка значений для всплывающего меню «Клиент» (раздел 8.1) вы могли выбрать только одно поле для отображения вместе со значением идентификатора. В этом примере использовалось поле «Имя», но полное имя сделало бы меню более полезным. Вы можете сделать это с помощью расчетов.
Создайте новое поле, которое показывает то, что вы хотите, в вашем списке значений. Добавьте новое поле расчета в таблицу «Клиенты» под названием «Полное имя». Используйте этот расчет:
Фамилия Имя "
Некоторые результаты могут быть «Гриббл, Дейл» или «Хилл, Генри».«Обратите внимание, что расчет включает запятую и соответствующие пробелы для разделения данных между полями. Теперь вы можете изменить список значений« Все клиенты », чтобы воспользоваться преимуществами нового поля. Просто измените его, чтобы использовать новое поле« Полное имя »вместо« Первое ». Поле имени. Результат показан на рис. 10-3.
|
Совет: Объединение полей отлично подходит для упрощения отображения данных, но у них есть и другое применение. Вместо того, чтобы настраивать сортировку с двумя ключами для сортировки клиентов по фамилии, а затем по имени, теперь вы можете просто сортировать по полю полного имени.Вы также можете создать подсчетную часть (раздел 6.9.4.7), которая будет работать при сортировке по полю «Полное имя».
10.3.2. Типы текстовых функций
Функции обработки текстаFileMaker бывают двух видов: текстовые функции и функции форматирования текста. Текстовые функции обрабатывают такие задачи, как упомянутый выше синтаксический анализ или определение того, встречается ли в поле конкретная строка символов. Вы можете изменить все экземпляры определенных символов в поле или подсчитать длину текста с помощью текстовых функций.
Функции форматирования текста изменяют внешний вид текста, например, выделение части текста в поле жирным и красным шрифтом. Эти функции намного более гибкие, чем просто выделение поля жирным и красным шрифтом на макете, потому что вы можете указать расчету, чтобы он выполнял поиск внутри поля, находя только символы «Продажа пропана!» и сделать их красными, при этом весь окружающий текст останется нетронутым.
10.3.3. Текстовые функции
Многие из текстовых функций существуют, чтобы помочь вам разобрать текст и разбить его на части полезными способами.Иногда одно текстовое значение содержит несколько полезных фрагментов информации, и вам нужно рассматривать их по отдельности. Если вам повезет, информация поступит в форме, которую FileMaker уже понимает. Если вам не повезло, вам придется проделать дополнительную работу, чтобы сообщить FileMaker, как именно разделить текстовое значение.
FileMaker может автоматически разбивать текст тремя способами: по символам, словам или значениям. Когда он выполняет разделение, он дает вам три способа решить, какие части вы хотите: левую, среднюю или правую.
10.3.3.1. Функции символов
Символьный синтаксический анализ удобен, когда у вас есть данные в хорошо известном формате, и вам нужно получить доступ к его частям. Вы можете использовать функции для получения первых трех цифр номера социального страхования, последних четырех цифр номера кредитной карты или кода стиля, скрытого внутри номера продукта.
FileMaker может работать с отдельными символами внутри текстового значения. Первая буква в текстовом значении — это номер один; второй номер два; и так далее.Затем вы можете попросить несколько первых символов, или несколько последних, или только пятый, шестой и седьмой.
Примечание: Каждая буква, цифра, знак препинания, пробел, табуляция, возврат каретки или другой символ считается символом.
| КЛИНИКА ЭНЕРГОПОЛЬЗОВАТЕЛЕЙ Расчет в кнопке |
В главе 5 вы узнали, как создавать кнопки на макете и программировать их для выполнения всех видов функций базы данных одним щелчком мыши (Раздел 6.6.5.3). Единственная проблема в том, что чем больше функций вы даете своей базе данных, тем больше кнопок вам нужно сделать. И некоторым людям, использующим вашу базу данных, нужен совершенно другой набор кнопок, чем другим. К счастью, у большинства команд кнопок есть одна или несколько опций, которые вы можете установить с помощью вычислений. Расчет может регулировать действия кнопки на основе данных поля, информации пользователя, текущей даты или времени и т. Д. Предположим, вам нужен быстрый способ нанести на карту местоположение вашего клиента.Многие веб-сайты предоставляют бесплатные карты, а в FileMaker есть команда кнопки «Открыть URL», которая открывает веб-браузер и перенаправляет вас на указанную веб-страницу. С помощью этой команды и расчета, который дает правильный веб-адрес, вы можете быстро и легко добавить отображение в свою базу данных. Во-первых, вам нужно выяснить, как должен выглядеть URL-адрес. Вы можете принять это решение, перейдя на веб-страницу, похожую на ту, которую вы хотите. Например, этот адрес показывает карту домашней базы FileMaker Inc. с использованием Map Quest: .http: // www.mapquest.com/maps/map. adp? Country = US & addtohistory = & address = 5201 + Patrick + Henry + Drive & city = Santa + Clara & state = CA & zipcode = 95052 & homesubmit = Get + Map Сначала эти строки могут показаться мусором, но если вы присмотритесь, вы увидите там адрес, город, штат и почтовый индекс. Нетрудно сделать текстовый расчет, который дает тот же веб-адрес для клиента, на основе правильных полей:
Теперь вы можете создать расчет. Вероятно, вы захотите вставить веб-адрес, заключить его в кавычки, а затем задать вставку необходимых полей в нужные места.Обязательно завершайте каждый раздел адреса цитатой и используйте оператор & между каждым фрагментом текста и каждым полем. Вот расчет с адреса выше: "http://www.mapquest.com/maps/map. adp? country = США & addtohistory = & address = "& Клиенты :: Адрес и "& city =" & Заказчики :: City & "& state =" & Заказчики :: Государство и "& zipcode =" & Клиенты :: Почтовый индекс и "& homesubmit = Получить + карту" Когда вы закончите, нажмите кнопку «ОК» пару раз, пока не вернетесь к своему макету.Теперь вы можете проверить свою кнопку в режиме просмотра. |
- Функция Left возвращает несколько первых букв текстового значения, удаляя остальные. Вы передаете (то есть сообщаете) расчет фактическому текстовому значению и желаемому количеству букв. Например, чтобы получить инициалы человека, вы можете использовать такой расчет:
Слева (имя; 1) и слева (фамилия; 1)
Чтобы получить первые три цифры номера социального страхования, вы можете использовать следующий расчет:
Левый (SSN; 3)
- Функция Right делает то же самое, но начинается с другого конца текстового значения.Если вы хотите записать последние четыре цифры номера чьей-либо кредитной карты, вы можете сделать это следующим образом:
Справа (номер кредитной карты; 4)
- Если нужной информации нет ни на одном из концов, возможно, вам придется использовать среднюю функцию. Эта функция немного отличается: она ожидает трех параметров. Как и при использовании Left и Right, первым параметром является проверяемое FileMaker текстовое значение. Второй параметр — это стартовая позиция.Наконец, вы указываете FileMaker, сколько символов вам нужно.
Например, предположим, что у вас есть база данных продуктов, в которой используется специальная система кодирования для каждого элемента. Код «SH-112-M» обозначает рубашку фасона 112, среднего размера. Чтобы вывести только номер стиля (112 в середине кода продукта), вы хотите, чтобы при вычислении использовалось три символа из поля «Номер продукта», начиная с четвертого символа.
Средний (номер продукта; 4; 3)
10.3.3.2. Функции слова
FileMaker также понимает понятие слов. С функциями слова вам не нужно беспокоиться о каждом отдельном символе.
В представлении FileMaker слово — это любой отрезок букв, цифр или точек, в котором нет других пробелов или знаков препинания. В большинстве случаев это определение означает, что FileMaker делает именно то, что вы ожидаете: он видит настоящие слова в тексте. Например, каждое из следующих слов — одно слово:
- FileMaker
- ABC123
- Это.is.a.word
Любая последовательность других символов вообще не является частью слова. В каждом из них есть два слова:
- FileMaker Pro
- ABC 123
- A-тест
- Два *** слова
Предупреждение: Если в вашем текстовом значении нет обычных слов (например, длинного URL-адреса), вам, возможно, придется обратить особое внимание на правило букв, цифр и точек, чтобы получить ожидаемые результаты. .
| ЧАСТО ЗАДАВАЕМЫЙ ВОПРОС Срединный путь |
Похоже, вы можете указать функции Middle выделять символы в любом месте текстового поля, просто указав, какие символы нужно считать. Так зачем нам нужны функции Left и Right, если вы можете сделать то же самое с Middle? Как показывает пример из Раздела 10.3.3.2, функция Middle действительно предоставляет все возможности, необходимые для выбора текстовых значений символ за символом.Например, вместо: Слева (номер модели; 3) Вы можете сделать это: Средний (номер модели; 1; 3) Имитировать функцию Right становится немного сложнее, но это возможно. Есть много мест, где одна функция может делать то же самое, что и другая (или несколько других). Например, вы можете использовать Left и Right вместо Middle, если хотите.Расчет: Средний (номер продукта; 4; 3) Можно переписать так: Справа (слева (номер продукта; 7); 3) Хорошая новость в том, что нет правильного ответа. Вы можете писать свои расчеты как хотите, если они работают. Фактически, у разработчиков FileMaker есть великая традиция находить творческие способы делать что-то с меньшим набором текста.Однако имейте в виду, что когда-нибудь в будущем вам, вероятно, придется выяснить, что вы делали в вычислениях, чтобы вы могли их изменить, исправить или использовать в другом месте. Если несколько дополнительных нажатий клавиш облегчат понимание вычислений, они могут того стоить. |
Аналогично функциям символов, FileMaker имеет три функции, ориентированные на слова, которые называются LeftWords, RightWords и MiddleWords. Каждый из них принимает два параметра, включая текстовое значение для проверки, и число или два, чтобы сообщить FileMaker, какие слова вас интересуют.Вы можете использовать функцию LeftWords для анализа имени и отчества человека, если вы когда-нибудь получите файл со всеми тремя именами, бесцеремонно выгруженным в одно поле.
- LeftWords возвращает весь текст до конца указанного слова. Например, эта функция:
LeftWords (Преамбула; 3)
Мы, люди, можем вернуться. Но если преамбула содержала «This *** Is *** a *** Test», вместо этого она вернула бы This *** Is *** A.Другими словами, он не просто возвращает слова. Он возвращает все до конца третьего слова.
- Аналогично, RightWords возвращает все, что находится после начала указанного слова, считая с конца. Этот расчет:
RightWords (Откровения; 1)
Вернет Аминь.
- Что было бы LeftWords и RightWords без MiddleWords? Вы, наверное, догадались, как работает эта функция: вы передаете текстовое значение, начальное слово и количество возвращаемых слов.Затем он возвращает все от начала начального слова до конца конечного слова. Следующий расчет показывает, как это работает; он возвращает «или нет».
MiddleWords («Быть или не быть»; 3; 2)
10.3.3.3. Функции текстового значения
Как текст может иметь значение? Что ж, для FileMaker значения — это то, что содержат поля, поэтому текст поля является его значением. Если поле содержит более одного фрагмента текста, каждый в отдельной строке, FileMaker рассматривает каждый как отдельное значение, отсюда и термин «возвращаемые значения, разделенные».Вы можете думать об этих фрагментах текста как о строках или абзацах. Функции текстового значения позволяют использовать эти разрывы строк для анализа текста. Этот трюк пригодится чаще, чем вы думаете.
Вот простой пример, показывающий, как это работает. Предположим, у вас есть поле Цвета со списками вроде этого:
Красный
Зеленый
Синий
Оранжевый
Желтый
FileMaker сообщает, что это поле содержит пять значений, и вы можете работать с ними, как с символами и словами.Например, эта функция LeftValue возвращает «Красный» и «Зеленый»:
LeftValues (Цвета; 2)
Используйте функцию GetValue, когда вам нужно проанализировать только одно значение из списка. Требуемое значение должно находиться в предсказуемом месте в списке, как в примере с целым электронным письмом в одно поле в начале этого раздела. Допустим, вам пришло письмо с таким адресом:
Электронная почта от
Электронная почта на
Субъект
Кузов
Вы можете получить адрес электронной почты с помощью этой функции:
Получить ценность (электронная почта; 2)
FileMaker также имеет функции RightValues и MiddleValues.Смотрите в рамке ниже идеи о том, как их использовать.
| КЛИНИКА ЭНЕРГОПОЛЬЗОВАТЕЛЕЙ Перехитрите умников |
LeftValues и RightValues полезны, когда вам нужно извлечь некоторые элементы из списка, разделенного возвращаемыми значениями (раздел 6.2.5). Но они также полезны, когда вы хотите защитить свою базу данных от людей, которые знают несколько обходных путей. Допустим, у вас проводится промо-акция, в ходе которой ваши лучшие клиенты могут выбрать одну бесплатную премию из списка из четырех пунктов.Итак, вы создали поле со списком значений и набором переключателей. Всем известно, что вы можете выбрать только один элемент из набора переключателей, верно? По-видимому, нет, потому что у вас есть продавцы, которые знают, что могут превзойти систему, щелкнув Shift, чтобы выбрать несколько переключателей. (Эти люди читают Раздел 6.2.5.) Все, что вам нужно сделать, это добавить рассчитанное автоматически значение в поле «Надбавки». Убедитесь, что вы сняли флажок «Не заменять существующее значение (если есть)».Вот как идет расчет: RightValues (Премии; 1) Теперь ваши сообразительные продавцы могут изнашивать свои клавиши Shift, но они по-прежнему не могут выбрать более одного элемента в поле премиум-класса, потому что ваш расчет удерживает в поле одно значение. С помощью аналогичной техники вы даже можете добавить умные элементы в набор флажков. Сделайте это вычисление: LeftValues (Премии; 2) Пользователи программы не могут установить более двух флажков.FileMaker знает первые два элемента, которые они выбрали, и просто продолжает помещать те же два обратно в поле, независимо от того, сколько флажков пытаются установить продавцы. Для другого поворота измените расчет на: RightValues (Премии; 2) Теперь FileMaker запоминает два последних выбранных элемента и очень ловко отменяет выбор самого старого значения, так что поле всегда содержит два последних элемента, выбранных из набора флажков. |
10.3.3.4. Функции подсчета текста
Другой способ разобрать текст — просто подсчитать его отдельные части. FileMaker имеет три связанные функции для определения количества текста в ваших полях:
- Функция Length возвращает длину текстового значения путем подсчета символов.
- Функция WordCount сообщает вам, сколько слов содержится в текстовом значении.
- Используя функцию ValueCount, вы можете узнать, сколько строк имеет поле.
Эти функции становятся мощными в сочетании с различными функциями Left, Right и Middle. Если поля, которые вы анализируете, содержат разное количество текста, вы можете настроить FileMaker для подсчета каждого из них, поэтому вам не придется это делать. Например, чтобы вернуть все буквы поля, кроме последней, можно использовать следующий расчет:
Слева (Мое поле; Длина (Мое поле) - 1)
Он использует функцию Left, чтобы получить символы из поля, и функцию Length (минус один), чтобы узнать, сколько символов нужно получить.Просто измените число в конце, чтобы убрать любое количество ненужных символов с конца поля. Пожалуйста.
10.3.3.5. Другие функции анализа текста
FileMaker включает в себя десятки текстовых функций, но некоторые из них заслуживают особого упоминания, потому что вы видите их в оставшейся части этого раздела и потому, что они очень полезны для очистки беспорядочных данных.
- Функция замены выполняет поиск и замену в текстовом значении. Например, если вы хотите превратить все крестики в букву «О» в своем любовном письме (возможно, вы чувствовали себя слишком сильно), вы можете сделать это:
Заменитель (Любовное письмо; "X"; "O")
Некоторые функции FileMaker поддерживают специальный синтаксис в квадратных скобках, и Substitute является одной из них.Если вы хотите выполнить несколько замен в фрагменте текста, вы можете сделать это с помощью одной функции Substitute. Каждая пара в скобках представляет одно поисковое значение и его замещающее значение. Вот как вы можете отобразить значение поля без всех гласных. Вы можете это сделать:
Заменить (Мое поле; ["a"; "]; [" e ";" "]; [" i ";" "]; [" o ";" "]; [" u "; ""])
Примечание: Этот пример показывает еще один интересный факт о Substitute: вы можете использовать его для удаления чего-либо.Просто замените его пустыми кавычками: «».РЕМОНТ МАСТЕРСКОЙ
Когда данные не соответствуютИногда текст, который нужно разбить, не состоит из частей, которые FileMaker распознает автоматически, например символов или слов. Например, предположим, что у вас есть путь к файлу:
C: Мои документы Снимки продуктовИнструментыБольшой Hammer.jpg
Необходимо получить имя файла (Large Hammer.jpg) и его родительскую папку (Инструменты). К сожалению, это текстовое значение не делится на символы, слова или значения. Он разделен на компоненты пути, между которыми стоит обратная косая черта.
Когда вы сталкиваетесь с чем-то вроде этого, лучше всего сделать так, чтобы это выглядело так, как если бы FileMaker мог справиться с этим. Если вы можете превратить каждую обратную косую черту в символ новой строки (), то вы можете просто использовать функцию RightValues для извлечения двух последних значений. Другими словами:
Заменить (Путь к файлу; ""; "
«)Результатом этого выражения является список компонентов пути, каждый в отдельной строке:
К:
Мои документы
Фотографии продукта
Инструменты
Большой молот.jpg
Чтобы получить только имя файла, вы можете сделать это:
RightValues (Substitute (Путь к файлу; "" ; «
«); 1)Если ваши данные уже не содержат несколько строк, вы всегда можете использовать функцию Substitute, чтобы превратить любой список с разделителями в список значений. Однако имейте в виду, что функция Substitute чувствительна к регистру. Вы можете узнать больше о чувствительности к регистру в Разделе 11.2.1.2.
- В то время как Substitute может использоваться для изменения или удаления того, что вы указали, Filter может удалить все, что вы не указали. Например, предположим, что вы хотите удалить любые нечисловые символы из номера кредитной карты. Вы можете попытаться подумать обо всех возможных вещах, которые человек может ввести в поле номера кредитной карты (удачи!), Или вместо этого вы можете использовать фильтр:
Фильтр (номер кредитной карты; "0123456789")
Это вычисление указывает FileMaker вернуть содержимое поля «Номер кредитной карты» со всем, кроме удаляемых им цифр.Другими словами, просто введите символы, которые вы хотите сохранить, во втором параметре.
10.3.4. Функции форматирования текста
Обычно, когда вы видите данные в поле вычисления, они отображаются в формате (шрифт, размер, стиль, цвет и т. Д.), Который вы применили в режиме макета. Каждый символ в поле имеет один и тот же формат, если только вы не хотите вручную выполнять поиск по всем своим записям, выбирая слова «Только ограниченное время» в поле «Примечания к продвижению», чтобы вы могли выделять их жирным и красным цветом каждый раз, когда они появляются.Этот метод не только тратит ваше драгоценное время (особенно если вы получаете зарплату), он также разрушает ваш дизайн, когда вы пытаетесь распечатать поле.
Функции форматирования текстаFileMaker позволяют вам точно указать, какой бит текста вы хотите в 18-пунктах, жирным шрифтом, красным шрифтом Verdana. И вам не нужно посещать ни одной записи лично. Вы просто пишете расчет, а FileMaker выполняет всю работу за вас, не изменяя реальных данных.
FileMaker имеет шесть функций форматирования текста, описанных ниже.
Совет: Поскольку в этом большом заголовке выше четко написано «Функции форматирования текста», любой разумный человек может предположить, что это форматирование применяется только к тексту. К счастью, миром правят неразумные люди. Вы можете применить форматирование текста к любому типу данных, как вы увидите далее в этой главе.
10.3.4.1. TextColor и RGB
Функция TextColor принимает два параметра: текст и цвет. Он возвращает текст, который вы отправляете, в правильном цвете.Это текст, который вы указываете с помощью сопутствующей функции RGB. Как и многие компьютерные программы, FileMaker рассматривает цвета в коде RGB, который определяет все цвета как комбинации красного, зеленого и синего, выраженные числовыми значениями.
Эта функция возвращает цвет на основе трех параметров: красный, зеленый и синий. Например, если вы хотите изменить поле «Полное имя», чтобы имя отображалось ярко-красным цветом, а фамилия — ярко-синим цветом, используйте следующий расчет:
TextColor (Имя; RGB (255; 0; 0)) & "" & TextColor (Фамилия; RGB (0; 0; 255))
Совет: Для ускоренного курса по кодам RGB, включая то, как избежать его использования, см. Поле ниже.
| ДО СКОРОСТИ Раскрась мой мир (16 млн цветов) |
FileMaker имеет основной конфликт из-за цвета. В конце концов, это компьютерная программа, которая работает с данными, которые имеют ограниченное количество типов, например текстовое значение, число, дату и время. Итак, какой тип данных представляет собой цвет? Объяснение не очень красочное. FileMaker распознает 16 777 216 различных цветов, каждый из которых слегка отличается от предыдущего, и каждый имеет номера от 0 до 16 777 215.К сожалению, выучить все эти цвета по номерам недоступно даже самому скучающему разработчику. Таким образом, FileMaker использует стандартный (хотя и совершенно не интуитивный) метод определения цвета как смеси компонентных цветов: красного, зеленого и синего с различной интенсивностью. Каждый параметр функции RGB представляет собой число от нуля до 255. Число указывает, насколько интенсивным или ярким должен быть цвет компонента. Ноль в первом параметре означает, что красный цвет вообще не входит в уравнение.255, с другой стороны, означает, что FileMaker должен провернуть красный компонент на максимум. Функция RGB возвращает число, идентифицирующее один из 16 с лишним миллионов вариантов. Чтобы сделать это вдвойне запутанным для тех, кто не имеет степени в области компьютерного программирования или ремонта телевизоров, система RGB использует красный, зеленый и синий в качестве источников света, а не более интуитивно понятные красно-желто-синие основные цвета красок. и пигменты. Когда цветные огни смешиваются (например, эти маленькие пиксели на мониторе), красный и зеленый образуют… желтый.Другими словами, для FileMaker и других экспертов по RGB имеет смысл видеть ярко-желтый цвет следующим образом: RGB (255; 255; 0) Так что же делать человеку? Не используйте коды RGB. Найдите другие инструменты. Если вы используете Mac OS X, у вас есть именно такой инструмент в папке Utilities (в папке Applications). Это называется Цифровой измеритель цвета. Запустите приложение и выберите «RGB как фактическое значение, 8 бит» во всплывающем меню в его окне.Теперь маленькие синие числа показывают правильные значения красного (R), зеленого (G) и синего (B) цвета для любого цвета, на который вы указываете на экране. Например, в области состояния (в режиме макета) откройте меню «Цвет заливки» и наведите указатель на любой из цветов, чтобы увидеть эквивалент RGB. В Microsoft Windows вы можете видеть цвета RGB в стандартном окне выбора цвета. Просто перейдите в режим макета и в области состояния нажмите кнопку «Цвет заливки». Выберите Другой цвет. Когда вы щелкаете цвет, вы видите значения красного, зеленого и синего цветов, перечисленные в правом нижнем углу окна. |
10.3.4.2. Текстовый шрифт
Чтобы изменить шрифт в результате вычисления, используйте функцию TextFont. В простейшем виде эта функция… ну… проста. Вы просто передаете ему текст, который хотите отформатировать, и имя используемого шрифта. FileMaker возвращает тот же текст с примененным шрифтом:
TextFont («Дьюи побеждает Трумэна!»; «Times New Roman»)
TextFont также имеет третий необязательный параметр, называемый fontScript.Большинство людей могут просто проигнорировать этот вариант. Он сообщает FileMaker о том, какой набор символов вас интересует, и о выборе подходящего шрифта. (Набор символов определяет, для каких языков можно использовать шрифт.) FileMaker принимает следующие значения fontScript:
- Роман
- Греческий
- Кириллица
- Центральноевропейская
- ShiftJIS
- Традиционный китайский
- Упрощенный китайский
- OEM
- Символ
- Другое
Примечание: В отличие от имени шрифта, которое представляет собой просто текстовое значение, значение скрипта не должно быть в кавычках.Это не текстовое значение. Вместо этого вы должны указать одно из вышеуказанных значений точно, без кавычек.
Если FileMaker не может найти конкретный шрифт, который вы просили, он выбирает другой шрифт в указанном скрипте, поэтому, если вы используете английскую систему и вам нужно выбрать китайский шрифт, этот параметр может помочь. (Если вы не укажете сценарий, FileMaker автоматически использует сценарий по умолчанию на вашем компьютере. Вот почему вам редко приходится об этом беспокоиться — вы автоматически получаете то, что, вероятно, хотите.)
10.3.4.3. Размер текста
Функция TextSize проста в любом случае. Просто передайте текст и желаемый размер (точно так же, как размеры в меню Формат изображений / U2192.jpg border = 0> Размер в режиме обзора). FileMaker возвращает текст измененного размера.
10.3.4.4. TextStyleAdd и TextStyleRemove
Изменить стили текста (полужирный, курсив и т. Д.) Немного сложнее. В конце концов, кусок текста может иметь только один цвет, один шрифт или один размер, но он может быть полужирным, курсивом и подчеркнутым одновременно.С текстовыми стилями вы не просто меняете один стиль на другой; вам нужно сделать такие вещи, как взять курсивный текст и добавить полужирное форматирование или даже взять текст, зачеркнутый полужирным шрифтом, и снять его, оставив все остальное на месте.
Для решения этих проблем FileMaker предоставляет две функции для работы со стилем: TextStyleAdd и TextStyleRemove. Вы используете первый, чтобы добавить стиль к фрагменту текста:
"Сделайте это с помощью" & TextStyleAdd ("style"; курсив)
Аналогично, функция TextStyleRemove удаляет указанный стиль из текста.
TextStyleRemove (Мое текстовое поле; курсив)
Параметр стиля текста используется в вычислениях без кавычек, как и в приведенных выше примерах. Вы можете использовать любой текстовый стиль в FileMaker: обычный, полужирный, курсив, подчеркивание, сжатие, расширение, зачеркивание, маленькие заглавные буквы, надстрочный, подстрочный, прописные, строчные, заглавные буквы, WordUnderline и DoubleUnderline. А еще есть AllStyles. Когда вы используете параметр AllStyles, он добавляет (или удаляет) все существующие стили.
С помощью этих двух функций и всех этих опций стиля вы можете выполнять любые фантазии форматирования, которые только можно вообразить. Вот несколько рекомендаций:
- Когда вы добавляете стиль к некоторому тексту с помощью TextStyleAdd, он не меняет ни один стиль, который вы уже применили. Новый стиль просто накладывается поверх существующих стилей.
- Простой стиль — заметное исключение из вышеупомянутого пункта. Добавление простого стиля эффективно удаляет любые другие стили. Этот стиль пригодится, когда вам нужно убрать беспорядок в стилях и применить что-то попроще.Допустим, в ваших полях есть слова «Просроченные», выделенные прописными буквами, полужирным шрифтом, курсивом и двойным подчеркиванием, и вы решите, что скромный курсив подойдет. Вложение функции TextStyleAdd с параметром Plain помогает:
TextStyleAdd (TextStyleAdd ("просроченный"; Обычный); Курсив)
Подсказка: Как вы могли догадаться, использование TextStyleRemove с параметром AllStyles делает то же самое, что и TextStyleAdd с Plain.Оба они удаляют существующие стили, но, как вы можете видеть выше, добавляя Plain, вы можете писать более аккуратные выражения. - Когда вы добавляете более одного параметра стиля, FileMaker применяет их все к тексту. Вы можете использовать вложение, как показано в предыдущем пункте, или просто сложить их вместе со знаком +:
TextStyleAdd («ВНИМАНИЕ»; полужирный + курсив)
- Если вы возьмете фрагмент текста, отформатированный с помощью функции форматирования текста, а затем отправите его в другое вычисление в качестве параметра, форматирование будет выполнено вместе с текстом.Например, с помощью функции замены вы можете форматировать текст, который еще даже не был напечатан. Если вы добавите эту функцию в текстовое поле, в которое люди могут вводить письма клиентам, каждое слово «в течение ограниченного времени» заменяется полужирным курсивом.
Заменить (Letter; «на ограниченное время»; TextStyleAdd («на ограниченное время»; Жирный + Курсив)
Фильтр токенов синонимов | Руководство по Elasticsearch [7.12]
Фильтр маркеров синонимов позволяет легко обрабатывать синонимы во время
процесс анализа.Синонимы настраиваются с помощью файла конфигурации.
Вот пример:
PUT / test_index
{
"настройки": {
"индекс": {
"анализ": {
"анализатор": {
"синоним": {
"tokenizer": "пробел",
"фильтр": ["синоним"]
}
},
"filter": {
"синоним": {
"тип": "синоним",
"путь_синонимов": "анализ / синоним.txt"
}
}
}
}
}
} Вышеупомянутое настраивает фильтр синонимов с путем анализ / синоним.txt (относительно расположения config ). В
Синоним Анализатор затем конфигурируется с фильтром.
Этот фильтр токенизует синонимы с любыми токенизаторами и фильтрами токенов. появляются перед ним в цепочке.
Дополнительные настройки:
-
развернуть(по умолчаниюистинно). -
снисходительный(по умолчаниюfalse). Еслиистинно,игнорирует исключения при анализе конфигурации синонима.Это важно Следует отметить, что игнорируются только те правила синонимов, которые не могут быть проанализированы. Например, рассмотрите следующий запрос:
PUT / test_index
{
"настройки": {
"индекс": {
"анализ": {
"анализатор": {
"синоним": {
"tokenizer": "стандартный",
"фильтр": ["my_stop", "синоним"]
}
},
"filter": {
"my_stop": {
"тип": "стоп",
"стоп-слова": ["полоса"]
},
"синоним": {
"тип": "синоним",
"снисходительный": правда,
"синонимы": ["foo, bar => baz"]
}
}
}
}
}
} В приведенном выше запросе слово bar пропускается, но отображение foo => baz все еще добавляется.Однако если отображение
было добавлено foo, baz => bar , ничего не будет добавлено в список синонимов. Это потому, что целевое слово для
Само отображение исключается, потому что оно было стоп-словом. Точно так же, если отображение было «bar, foo, baz» и развернуть было
установлено значение false никакое сопоставление не будет добавлено, так как при expand = false целевое сопоставление является первым словом. Однако если expand = true , тогда добавленные сопоставления будут эквивалентны foo, baz => foo, baz i.e, все отображения, кроме
стоп-слово.
Токенизатор
и ignore_case устарелиправить Параметр токенизатора управляет токенизаторами, которые будут использоваться для
tokenize синоним, этот параметр предназначен для обратной совместимости для индексов, созданных до 6.0.
Параметр ignore_case работает только с параметром токенизатора .
Поддерживаются два формата синонимов: Solr, WordNet.
Solr синонимыправить
Ниже приведен пример формата файла:
# Пустые строки и строки, начинающиеся с решетки, являются комментариями.# Явные сопоставления соответствуют любой последовательности токенов на LHS "=>" # и замените на все альтернативы на правой стороне. Эти типы сопоставлений # игнорировать параметр расширения в схеме. # Примеры: i-pod, i pod => ipod морской бисквит, морской бисквит => морской бисквит # Эквивалентные синонимы можно разделять запятыми и давать # нет явного отображения. В этом случае поведение отображения будет # взяты из параметра расширения в схеме. Это позволяет # один и тот же файл синонимов для использования в разных стратегиях обработки синонимов.# Примеры: ipod, i-pod, i pod настольный футбол, настольный футбол вселенная, космос Смеюсь в голос # Если expand == true, "ipod, i-pod, i pod" эквивалентен # к явному отображению: ipod, i-pod, i pod => ipod, i-pod, i pod # Если expand == false, "ipod, i-pod, i pod" эквивалентен # к явному отображению: ipod, i-pod, i pod => ipod # Объединяются несколько записей сопоставления синонимов. foo => foo bar foo => baz # эквивалентно foo => foo bar, baz
Вы также можете определить синонимы для фильтра прямо в
файл конфигурации (обратите внимание на использование синонимов вместо synonyms_path ):
PUT / test_index
{
"настройки": {
"индекс": {
"анализ": {
"filter": {
"синоним": {
"тип": "синоним",
"синонимы": [
"i-pod, i pod => ipod",
"вселенная, космос"
]
}
}
}
}
}
} Однако рекомендуется определять большие синонимы в файле, используя synonyms_path , потому что указание их inline излишне увеличивает размер кластера.
Синонимы WordNetправить
Синонимы, основанные на формате WordNet, могут быть
заявлен в формате :
PUT / test_index
{
"настройки": {
"индекс": {
"анализ": {
"filter": {
"синоним": {
"тип": "синоним",
"формат": "сеть слов",
"синонимы": [
"s (100000001,1, 'воздержаться', v, 1,0).",
"s (100000001,2, 'воздерживаться', v, 1,0).",
"s (100000001,3, 'отказаться', v, 1,0)."
]
}
}
}
}
}
} Поддерживается использование synonyms_path для определения синонимов WordNet в файле
также.
Разбор файлов синонимовправить
Elasticsearch будет использовать фильтры токенов, предшествующие фильтру синонимов.
в цепочке токенизаторов для анализа записей в файле синонимов. Так, например, если
фильтр синонимов ставится после стеммера, тогда также будет применен стеммер
к синонимам. Поскольку записи в карте синонимов не могут быть сложены
позиции, некоторые фильтры токенов могут вызвать проблемы здесь. Фильтры токенов, которые производят
несколько версий токена могут выбрать, какую версию токена выпускать, когда
парсинг синонимов, e.грамм. asciifolding будет производить только сложенную версию
токен. Другие, например мультиплексор , word_delimiter_graph или ngram выдаст
ошибка.
Если вам нужно построить анализаторы, включающие как мульти-токен-фильтры, так и синонимы фильтры, рассмотрите возможность использования фильтра мультиплексора, с мульти-токеновыми фильтрами в одной ветви и фильтром синонимов в другой.
ресурсов // Текстовый анализ // Репозиторий программного обеспечения для бухгалтерского учета и финансов // University of Notre Dame
- На главную>
- Текстовый анализ>
- Ресурсы
Эта страница содержит инструменты, полезные для текстового анализа в финансовых приложениях, и данные из некоторых связанных с текстами публикаций, которые я имею с Тимом Лафраном.Существенный метод текстового анализа имеет различные ярлыки в других дисциплинах, таких как контент-анализ, обработка естественного языка, поиск информации или компьютерная лингвистика. В растущей литературе обнаруживается значительная взаимосвязь между реакцией цен на акции и настроением выпускаемой информации, измеряемой классификациями слов, например приведенными ниже.
Если вы хотите получать уведомления об обновлениях по электронной почте, пришлите мне электронное письмо, и я внесу вас в список рассылки обновлений.Сборники данных, представленные на этом веб-сайте, предназначены для использования отдельными исследователями. Для получения коммерческих лицензий свяжитесь с нами.
Ресурсы:
- Списки слов настроения Loughran-McDonald — файл Excel, содержащий каждое из слов настроения LM по категориям (отрицательное, положительное, неопределенность, спорное, сильное модальное, слабое модальное, ограничение).
- Главный словарь Loughran-McDonald — словарь, используемый для определения того, какие токены (наборы символов) классифицируются как слова.Также содержит классификацию тональности, подсчет во всех документах и другую полезную информацию о каждом слове.
- Сводные данные файла 10-X Loughran-McDonald — файл, содержащий подсчет настроений, размер файла и другие показатели для всех заявок 10-X за все годы.
- Таблица всех поданных документов SEC EDGAR по типу и году — простой подсчет всех типов документов EDGAR по годам.
- Stopwords — различные списки игнорируемых слов.
Примечание. Мы благодарим Кэма Харви и других, которые предложили некоторые модификации, которые мы включили в эти списки.Списки слов описаны в:
- Тим Лафран и Билл Макдональд, 2011, Когда ответственность не является ответственностью? Текстовый анализ, словари и 10-Ks, Journal of Finance , 66: 1, 35-65. (Доступно в SSRN: http://ssrn.com/abstract=1331573.)
- Андрей Боднарук, Тим Лафран и Билл Макдональд, 2015, Использование текста размером 10 КБ для измерения финансовых ограничений, Журнал финансового и количественного анализа , 50: 4, 1-24. (Доступно в SSRN: http: // ssrn.com / abstract = 2331544.)
- Тим Лафран и Билл Макдональд, 2016, Текстовый анализ в бухгалтерском учете и финансах: обзор, Journal of Accounting Research , 54: 4,1187-1230. (Доступно в SSRN: http://ssrn.com/abstract=2504147.)
Хотя мы предоставляем каждую категорию тональности в таблице ниже, все списки слов содержатся в Основном словаре.
Для пользователей WordStat: WordStat.файлы cat и .NFO
2018 Главный словарь (формат xlsx, формат csv)
Обновлено: март 2019
Получено из версии 4.0 из 2of12inf. Расширен для включения слов, встречающихся в документах 10-K / Q, и звонков о доходах, которых нет в исходном списке слов 2of12inf. Помимо основного списка слов, словарь включает статистику частотности слов во всех 10-K / Q за 1994-2018 гг. (Включая варианты 10-X — см. Подробную документацию).Словарь сообщает о количестве, доле от общего количества, средней доле на документ, стандартном отклонении доли на документ, подсчете документов (т. Е. Количестве документов, содержащих хотя бы одно вхождение слова), восьми идентификаторах категорий тональности, идентификаторе Гарвардского списка слов, количестве слогов и источник каждого слова. Категории настроений: негативное, позитивное, неопределенное, спорное, модальное, сдерживающее. Модальные слова помечены как 1, 2 или 3, где 1 = сильное модальное, 2 = умеренное модальное и 3 = слабое модальное.Остальные эмоциональные слова отмечены числом, указывающим год, в котором они были добавлены в список. Подробная документация представлена здесь.
Как отмечалось выше, в Главном словаре также собраны все списки тональных слов. Каждая строка в электронной таблице главного словаря представляет собой слово. Списки тональных слов идентифицируются по столбцу, а элементы данного набора идентифицируются ненулевыми записями. Ненулевые записи представляют год, в котором слово было добавлено в данный список тональности.
Скачать файл здесь (187MB)
Используя проанализированные файлы Stage One (здесь), создается набор данных, содержащий сводные данные для каждой регистрации. Класс Python для этого модуля доступен здесь. Этот файл содержит запись заголовка с метками и разделен запятыми. Каждая запись сообщает:
- CIK — центральный индексный ключ SEC
- FILING_DATE — дата подачи (ГГГГММДД) для формы
- FYE — конец финансового года, как указано в заявке.
- FORM_TYPE — конкретный тип формы (например, 10-K, 10-K / A, 10-Q405 и т. Д.)
- FILE_NAME — локальное имя файла для подачи
- SIC — четырехзначный SIC, указанный в заголовке заявки. Если этот номер не появляется в заголовке, то основная веб-страница для всех заявок от этой фирмы в EDGAR анализируется в попытке идентифицировать номер SIC. Если все эти методы терпят неудачу, назначается SIC -99.
- FFInd — отраслевая классификация Fama-French 48, основанная на номере SIC.Все отсутствующие коды SIC относятся к разным категориям.
- N_Words — количество всех слов, где слово — это любой токен, встречающийся в главном слове.
- N_Unique — количество слов, хотя бы один раз встречающихся в документе.
- Последовательность подсчетов настроений — отрицательная, положительная, неопределенная, спорная, слабая модальная, умеренная модальная, сильная модальная, ограничивающая.
- N_Negation — количество случаев, когда отрицание происходит в пределах четырех или менее слов от слова, идентифицированного как положительное.Отрицательные слова — это («нет, нет, никто, ни, никогда, никто», см. Gunnel Totie, 1991, Negation in Speech and Writing). Таким образом, чистые положительные слова — это положительное количество слов за вычетом количества отрицательных слов. Хотя этот метод кажется разумным, наиболее важные случаи отрицания достаточно тонки, и большинство алгоритмов их не улавливают.
Статистика, полученная на основе анализа первого этапа
- GrossFileSize — общее количество знаков в исходной папке.
- NetFileSize — общее количество символов в файле после первого этапа синтаксического анализа.
- ASCIIEncodedChars — общее количество символов в кодировке ASCII (например, & amp;)
- HTMLChars — общее количество символов, относящихся к кодировке HTML.
- XBRLChars — общее количество символов, относящихся к кодировке XBRL.
- XMLChars — общее количество символов, относящихся к кодировке XML.
- N_Tables — количество таблиц в архиве.
- N_Exhibits — количество экспонатов в подаче.
1993-2018 гг., Документы SEC по типу / году: анализ основного индекса (нажмите, чтобы загрузить)
Обновлено: январь 2019 г.
Веб-сайт EDGAR SEC индексирует все электронные документы в квартальных мастер-файлах. В этой таблице перечислены все различные документы по годам.
Стоп-слова — это, как правило, слова, которые не считаются добавляющими информацию к рассматриваемому вопросу.Таким образом, универсального списка стоп-слов не существует, поскольку то, что считается неинформативным, зависит от контекста вашего приложения. То, что я помечаю ниже как «общие» стоп-слова, — это такие слова, как «и», «то» или «из». Общий список стоп-слов, который я предоставляю, основан на списке стоп-слов, используемом Python Natural Language Toolkit (NLTK), измененном следующим образом:
- Удалено:
- Все однобуквенные слова («A», «I», «S», «T»). Обычно при анализе деловых документов лучше всего игнорировать однобуквенные слова.«A» и «I» не имеют решающего значения при подсчете слов и могут быть неправильно подсчитаны, поскольку они часто используются для составления списков. Как и все списки слов, ваше приложение может потребовать модификации. (Например, если вы ищете самоатрибуцию генерального директора, «я» становится критическим словом.)
- «ДОН» — скорее название.
- «ВОЛЯ» — компонент нашего «сильного модального» списка настроений
- «ПРОТИВ» — компонент нашего списка «негативных» настроений
- Добавлено: «AMONG»
Обратите внимание, что все списки написаны в верхнем регистре, поэтому вы должны помнить об этом при сравнении эквивалентности.Мы также добавляем комментарии к некоторым словам, используя разделитель вертикальной черты (|), поэтому списки следует читать соответственно.
Как уже говорилось ранее, в Интернете доступно множество списков запрещенных слов. В большинстве случаев мы рекомендуем использовать наш «общий» список. Для полноты мы также предоставляем более длинный список с пометкой «GenericLong». Остальные списки зависят от контекста и не обязательно являются исчерпывающими.
Использование технологий в обучении. Как мы использовали обработку естественного языка… | Баккен и Бэк | Bakken & Bæck
Традиционные алгоритмы исправления орфографии в значительной степени полагаются на словари, чтобы найти правильные слова.
Раньше существовал «норвежский проект по заклинаниям», подход с открытым исходным кодом к созданию норвежских словарей, которые читаются всеми основными программами с открытым исходным кодом, как для букмола, так и для нюнорска, но, к сожалению, он больше не поддерживается и не развивается. Норвежские языковые пакеты, используемые Firefox или Chrome, основаны на этих словарях, но являются устаревшими с точки зрения орфографии. Итак, мы взяли дело в свои руки и собрали нашу собственную обновленную версию.
Национальная библиотека Норвегии — отличный ресурс для поиска корпусов норвежских текстов, аннотированных текстов и списков слов, таких как Norsk Ordbank, отражающих официальную стандартную орфографию как нюнорска, так и букмола.Мы взяли более свежие списки слов и обогатили словари с открытым исходным кодом, чтобы они были актуальными. Затем мы используем великолепную «Hunspell», бесплатную библиотеку средства проверки орфографии и морфологического анализатора, чтобы проверить правильность написания.
Методы, описанные до сих пор, не работают с правильными словами, которых нет в словаре. Чтобы решить эту проблему, мы нашли другой способ обогащения данных — за счет использования предопределенных сущностей. Сущности — это слова или фразы, которые (справедливо) последовательно обозначают некоторый референт.Таким образом, сущность может относиться к человеку, городу, зданию или стране. Составление списка известных сущностей позволило нам еще больше улучшить исправление орфографии в Skrible.
Мы также хотели включить еще один распространенный источник ошибок; составное обнаружение. Германские языки и протоиндоиранские языки, такие как санскрит, допускают (возможно) бесконечное количество составных слов. Скомпилировав упрощенную языковую модель, которая полагается на биграммы для обнаружения возможных композитов, мы помогли себе увидеть эти ошибки.
Skrible предлагает дополнительные функции, чем упомянутые выше. Учителя могут легко оставлять отзывы с помощью функции проверки и общаться со студентами, добавляя комментарии. Вместе с нашими клиентами KF (Kommuneforlaget) и NTB Arkitekst мы стремимся поддерживать студентов и учителей в обучении навыкам понимания, письма и творчества.
С августа 3200 учеников 44 школ в муниципалитете Бурм начали использовать Skrible. Хотите попробовать новый инструмент для письма? Не стесняйтесь обращаться к Ане или Марте из команды Skrible!
Иллюстрации Оливера О’Каллагана.