Начальная школа|Подготовка к школе — Страница 7
Продолжим изучать основные правила русского языка и сегодня вспомним, как разбирать слово по составу.
Разобрать слово по составу – значит сделать его морфемный анализ, или указать, из каких морфем слово состоит. Морфема – минимальная значимая часть слова.
Напомним, на какие части можно разбить слово:
главная значимая часть слова, которую имеют родственные слова.
В русском языке есть слова, которые состоят из одного корня: гриб, метро, перо, остров, погода.
Также, есть слова состоящие из двух корней: теплоход, водопад, самовар.
Из трех корней: водогрязелечебница.
Из четырех корней: электросветоводолечение.
значимая часть слова, которая стоит после корня и предназначенная для образования новых слов.
В некоторых словах может быть два суффикса: подберезовик – суффиксы —ов— и —ик-.
это значимая часть слова, которая находится перед корнем и предназначена для образования новых слов.
Окончаниеэто изменяемая часть слова, она служит для связи слов в предложении.
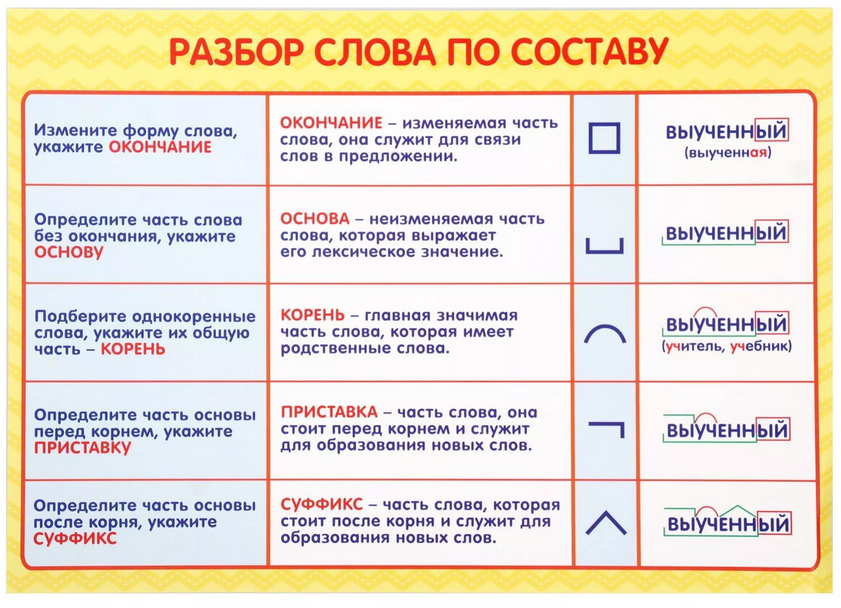
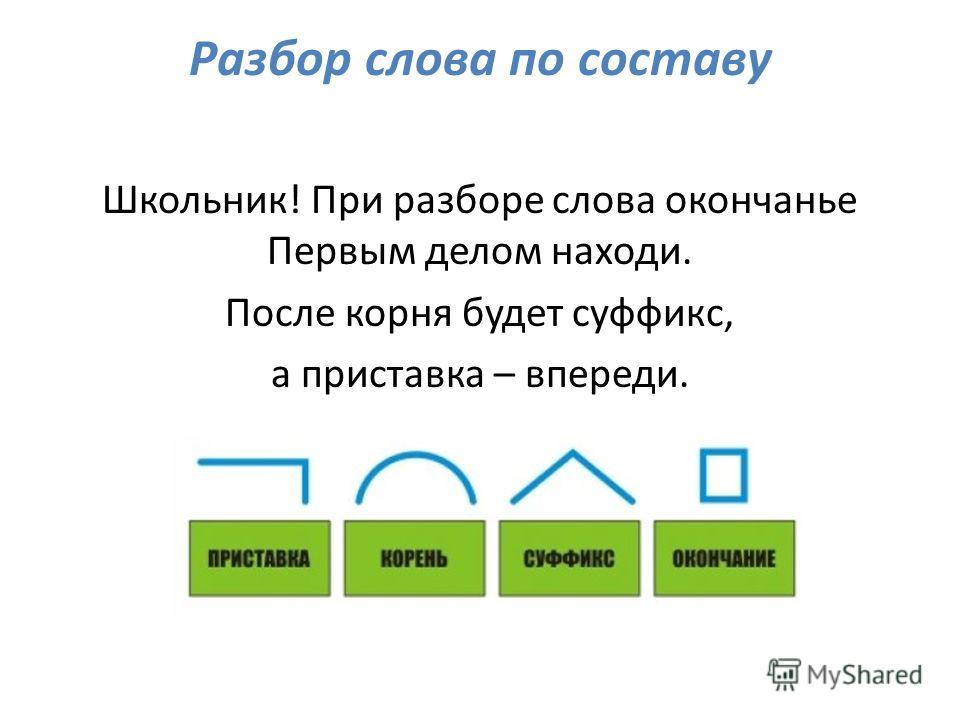
Итак, чтобы разобрать слово по составу надо найти в слове окончание, для чего надо изменить слово.
Например, в слове поездка.
Изменяя слово: поездкой, или поездку, то видно – изменяемая часть – а. Обведем её рамочкой, это окончание.
Далее найдем корень, для этого подберем однокоренное слово – поезд, переезд. Сравнивая эти слова – видим, что не меняется часть слова езд. Это и есть корень.
Затем найдем приставку, для этого надо опять подобрать однокоренные слова – поезд, подъезд.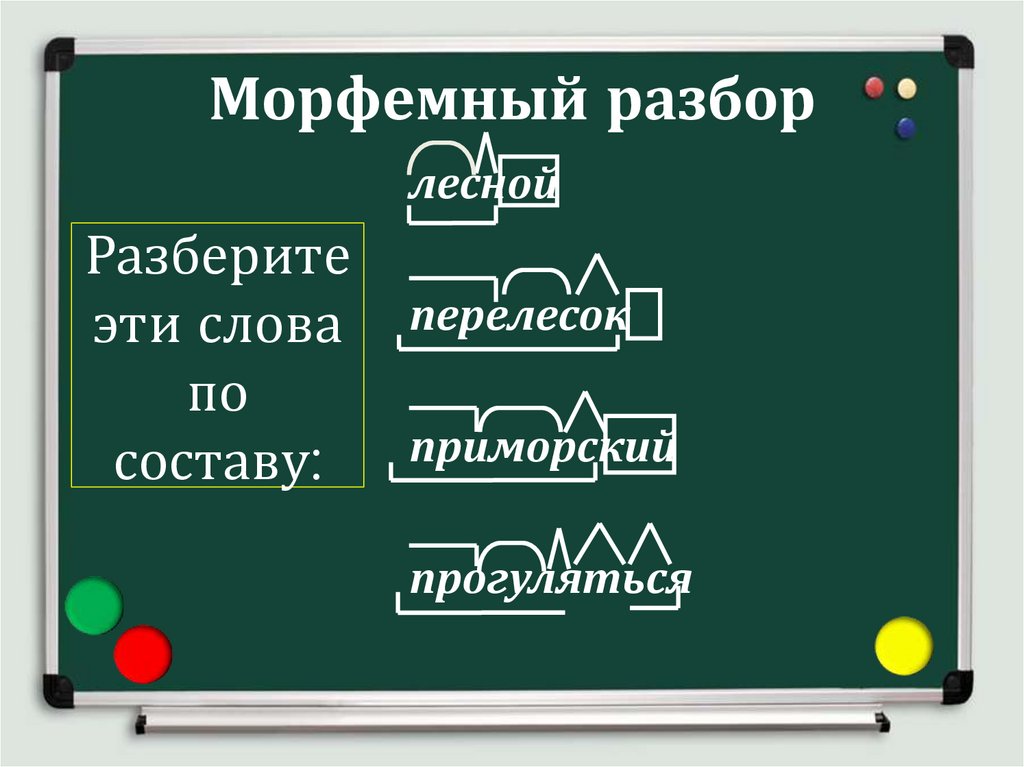 Видно, что приставка стоит перед корнем, т.е. в нашем случае – это часть слова по.
Видно, что приставка стоит перед корнем, т.е. в нашем случае – это часть слова по.
И наконец, найдем суффикс, который стоит после корня и предназначен для образования слова, в нашем случае – это часть слова к.
У нас получилось:
Читать полностью »
Научить ребенка понимать время до семи лет – занятие не из легких. Дело в том, что до школы ребенок еще не может мыслить абстрактно и ему трудно осознать значение времени.
Для ребенка существует только настоящее время, и определить когда произошло то или иное событие ребенок может, только привязав его к какому либо другому, но более яркому событию.
Например, будучи у бабушки летом ребенок провел запоминающийся день, скажем в лесу. Воспоминания ребенка об этом дне не будут привязаны к месяцу в котором это произошло. Он будет вспоминать примерно так: «Помните, как мы здорово гуляли по лесу, когда были у бабушки».
Учить пониманию времени надо с понятий времен года и времени суток. Объясните ребенку, какие бывают времена года и что каждый год они неизменно повторяются. Ребенку легче привязывать времена года к различным событиям.
Объясните ребенку, какие бывают времена года и что каждый год они неизменно повторяются. Ребенку легче привязывать времена года к различным событиям.
Например, зимой мы всегда отмечаем Новый Год, весной появляется зеленая трава, и прилетают птички. Летом ярко светит солнце, в лесу зреют ягоды, можно купаться и загорать. А осенью опять становится холодно, опадают листья, жухнет трава. О смене времен года можно посмотреть видеоурок.
Понятия времени суток можно объяснить, также привязав к событиям. Утром мы просыпаемся, встаем с постели, умываемся и завтракаем. Днем гуляем, занимаемся различными делами, обедаем. Вечером, после ужина, надо готовиться ко сну. А когда мы засыпаем – приходит ночь. А за ночью неизменно придет утро. И так повторяется изо дня в день, из года в год.
Детям, которые спят днем, бывает трудно понять, что после дневного сна не наступает новый день. Они путаются, но с возрастом все встает на свои места.
Когда ребенок справится с этими понятиями, можно приступать к обучению понимания часов. Начнем с часа. Нарисуйте на листе картона круг и разметьте циферблат. Обязательно надпишите часовые деления цифрами. Прикрепите для начала одну стрелку – часовую.
Начнем с часа. Нарисуйте на листе картона круг и разметьте циферблат. Обязательно надпишите часовые деления цифрами. Прикрепите для начала одну стрелку – часовую.
Объясните, что час это не мгновение. Мгновением можно назвать секунду. Похлопайте в ладоши и покажите ребенку, что такое секунда. Объясните, что в часе 60 минут, а в одной минуте 60 секунд, то есть хлопков. То есть час это долго. За час можно хорошо погулять или посмотреть интересный фильм.
Когда часовая стрелка полностью обойдет круг, пройдет целый день. А когда мы спим, стрелка еще раз обходит целый круг. Привяжите время утреннего подъема к определенному времени, например, к восьми часам утра. Обед к двум часам, а прогулку к трем – четырем. Спать в восемь часов. Через несколько дней ребенок уже сам будет подсказывать, что пора обедать или идти гулять.
После того, как ребенок уже уверенно начнет определять часы, можно начинать разбивать часы на части. Прикрепите к нашему циферблату стрелку побольше часовой. Сначала разбейте час на две части по полчаса, затем на четыре по пятнадцать минут и так далее. Не торопите ребенка, он освоит время со временем. Простите за каламбур.
Сначала разбейте час на две части по полчаса, затем на четыре по пятнадцать минут и так далее. Не торопите ребенка, он освоит время со временем. Простите за каламбур.
Удачи вам в обучении ваших деток.
<div><img src=”//mc.yandex.ru/watch/12929171″ style=”position:absolute; left:-9999px;” alt=”” /></div> <p>
Вашему ребенку пять или шесть лет и очень скоро он пойдет в школу. Готовить ребенка надо заранее и если вы этого до сих пор не делали, то самое время этим заняться. Хорошо отправить ребенка на курсы, но можно подготовить ребенка к школе самостоятельно.
Не надо все сваливать на преподавателей в школе, не надо надеяться, что ребенок пойдет в школу и всё само собой образуется. Очень вероятно, что классы будут переполнены, и учитель просто физически не сможет уделить должного внимания вашему (каждому) ребенку.
Посмотрите на своего ребенка и оцените его с точки зрения готовности. Итак, если ребенок плохо выговаривает буквы, то надо пока не поздно обратиться к логопеду. Если часто болеет, то надо посоветоваться с педиатром, как подтянуть его иммунитет. Если ребенок быстро утомляется, то опять же поговорите с педиатром о направлении к конкретным специалистам, чтобы вам поставили правильный диагноз, быть может, вашему ребенку нужен щадящий режим физкультуры. Читать полностью »
Мы уже писали об операционной системе для детей «ДудуЛинукс» (DoudouLinux). Прошло время и благодаря усилиям сообщества ДудуЛинукс и в частности Томского государственного педагогического университета (ТГПУ) на свет появилась новая версия операционной системы – Гиперборея (Hyperborea).
О новой версии ДудуЛинукс и о жизни проекта нам рассказал координатор проекта ДудуЛинукс Сергей Комков:
“ДудуЛинукс (DoudouLinux) – это открытая операционная система, созданная для детей. В состав ДудуЛинукс входят десятки программ, специально подобранных для детей от двух до двенадцати лет. Это удобная и простая среда, с виду похожая на игровую приставку. Для взаимодействия с системой не требуется навыков чтения, нет необходимости знать о том, что такое файл и каталог. Настройки системы сведены к минимуму.
Это удобная и простая среда, с виду похожая на игровую приставку. Для взаимодействия с системой не требуется навыков чтения, нет необходимости знать о том, что такое файл и каталог. Настройки системы сведены к минимуму.
Большое внимание уделено музыке, текстам, картинкам, ссылкам на сайты и другому контенту, который поставляется в составе системы. В состав ДудуЛинукс входит динамический фильтр веб-контента DansGuardian, который оберегает детей от посещения сайтов для взрослых. Используется поисковая система ДакДакГоу (DuckDuckGo) вместо Гугл (Google). Таким образом, обеспечивается безопасность ребенка в сети интернет.
Читать полностью »
Умножение многозначных или многоразрядных чисел удобно производить письменно в столбик, последовательно умножая каждый разряд. Давайте разберем, как это делать. Начнем с умножения многоразрядного числа на одноразрядное число и постепенно увеличим разрядность второго множителя.
Для того чтобы умножить в столбик два числа, разместите их одно под другим, единицы под единицами, десятки под десятками и так далее.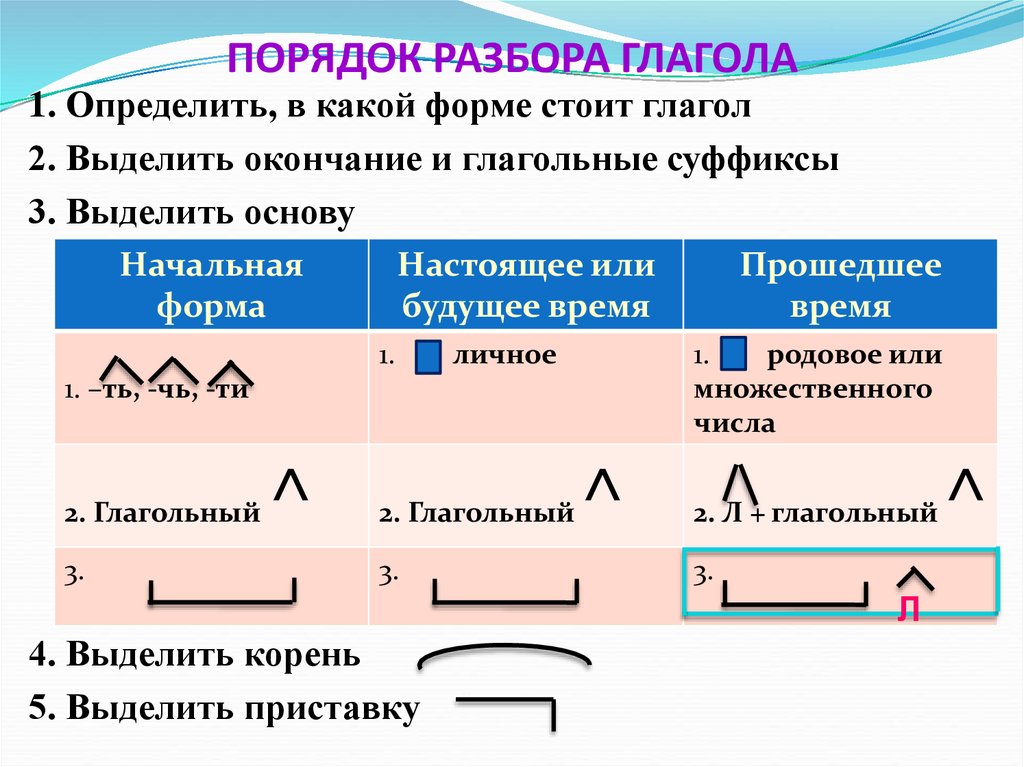 Сравните два множителя и меньший разместите под большим. Затем начинайте умножать каждый разряд второго множителя на все разряды первого множителя.
Сравните два множителя и меньший разместите под большим. Затем начинайте умножать каждый разряд второго множителя на все разряды первого множителя.
Пишем однозначное число под единицами многозначного.
Умножаем 2 последовательно на все разряды первого множителя:
Умножаем на единицы:
8 × 2 = 16
6 пишем под единицами, а 1 десяток запоминаем. Для того, чтобы не забыть пишем 1 над десятками.
Умножаем на десятки:
3 десятка × 2 = 6 десятков + 1 десяток(запоминали) = 7 десятков. Ответ пишем под десятками.
Умножаем на сотни:
4 сотни × 2 = 8 сотен. Ответ пишем под сотнями. В результате получаем:
438 × 2 = 876
Умножим трехзначное число на двухзначное:
924 × 35
Пишем двухзначное число под трехзначным, единицы под единицами, десятки под десятками.
1 этап: находим первое неполное произведение, умножив 924 на 5.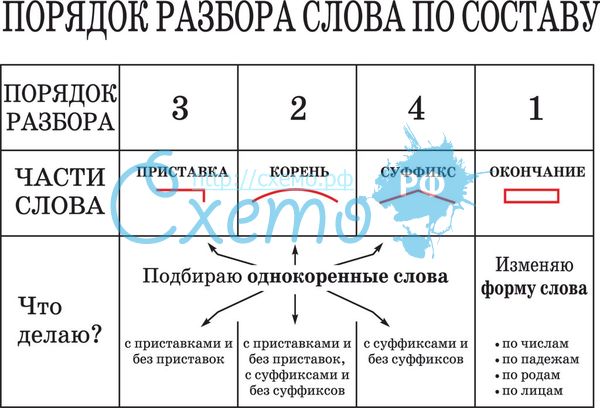
Умножаем 5 последовательно на все разряды первого множителя.
Умножаем на единицы:
4 × 5 = 20 0 пишем под единицами второго множителя, 2 десятка запоминаем.
Умножаем на десятки:
2 десятка × 5 = 10 десятков + 2 десятка (запоминали) = 12 десятков, пишем 2 под десятками второго множителя, 1 запоминаем.
Умножаем на сотни:
9 сотен × 5 = 45 сотен + 1 сотня (запоминали) = 46 сотен, пишем 6 под разрядом сотен, а 4 под разрядом тысяч второго множителя.
924 × 5 = 4620
2 этап: находим второе неполное произведение, умножив 924 на 3.
Умножаем 3 последовательно на все разряды первого множителя. Ответ пишем под ответом первого этапа, сдвинув его на один разряд влево.
Умножаем на единицы:
4 × 3 = 12 2 пишем под разрядом десятков, 1 запоминаем.
Умножаем на десятки:
2 десятка × 3 = 6 десятков + 1 десяток (запоминали) = 7 десятков, пишем 7 под разрядом сотен.
Умножаем на сотни:
9 сотен × 3 = 27 сотен, 7 пишем в разряд тысяч, а 2 в разряд десятков тысяч.
3 этап: складываем оба неполных произведения.
Складываем поразрядно, учитывая сдвиг.
В результате получаем:
924 × 35 = 32340 Читать полностью »
Для того чтобы вычесть одно число из другого, поместим вычитаемое под уменьшаемым, следующим образом: единицы под единицами, десятки под десятками. Для примера, в качестве уменьшаемого возьмем двузначное число, а в качестве вычитаемого – однозначное.
Вычитаем единицы вычитаемого из единиц уменьшаемого:
7 – 5 = 2 результат пишем под единицами.
Теперь вычитаем десятки из десятков, но у вычитаемого нет десятков, поэтому опускаем десяток уменьшаемого в ответ. В результате получаем разность:
27 – 5 = 22
Теперь возьмем оба числа двухзначных:
Вычитаем единицы вычитаемого из единиц уменьшаемого:
6 – 4 = 2 результат пишем под единицами
Теперь вычитаем десятки вычитаемого из десятков уменьшаемого:
8 – 3 = 5 результат пишем под десятками.
В результате получаем разность:
86 – 34 = 52
Давайте попробуем найти разность следующих чисел:
Вычитаем единицы. Из 7 вычесть 9 нельзя, занимаем один десяток из десятков уменьшаемого. Чтобы не забыть ставим точку над десятками.
17 – 9 = 8 результат пишем под единицами.
Теперь вычитаем десятки из десятков. У вычитаемого нет десятков, но мы занимали один десяток у уменьшаемого:
2 десятка – 1 десяток = 1 десяток результат пишем под десятками.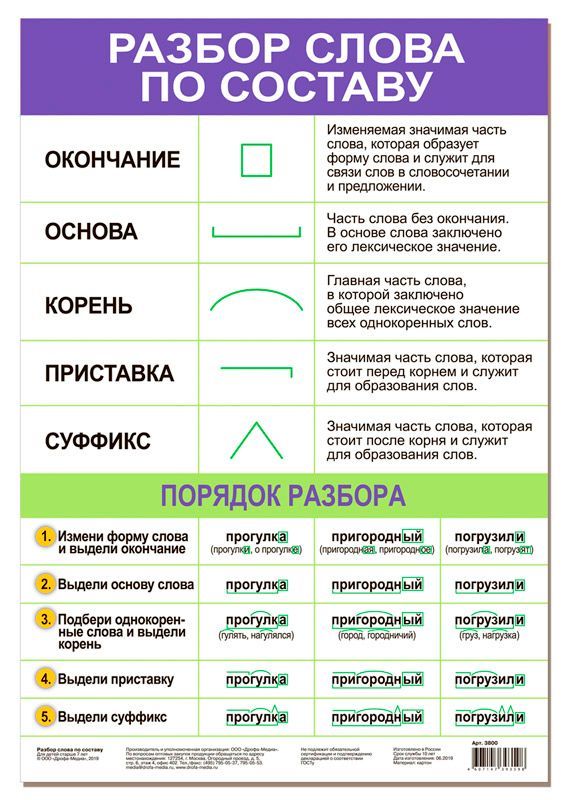
В результате получаем разность:
27 – 9 = 18
Читать полностью »
Легко сложить одноразрядные или однозначные числа. Например, числа 3 и 5:
3 + 5 = 8
Немного сложнее сложить небольшие двухзначное и однозначное числа. Например, 3 и 15. Первое число 3 – однозначное, оно состоит из единиц. Второе число 15 – двухзначное, оно состоит из единиц и десятков.
Для того чтобы сложить двухзначные числа, следует сложить разряды единиц одного числа с разрядами единиц другого числа, затем разряды десятков первого числа с разрядами десятков другого.
Для сложения в столбик разместим одно число под другим, единицы под единицами, а десятки под десятками. Большее число пишем сверху:
Теперь сложим единицы первого и второго числа:
5 + 3 = 8
Запишем ответ под единицами. Теперь надо сложить десятки, но у числа 3 нет десятков и под 1 пустая клетка. В этом случае опускаем 1 в ответ на место десятков. В результате получим ответ:
В этом случае опускаем 1 в ответ на место десятков. В результате получим ответ:
15 + 3 = 18
Попробуем решить еще пару примеров:
Читать полностью »
Мы рады Вам представить детские стихи Любви Степановой.
Колыбельная
Баю – баюшки – баю
Сыну песенку спою.
Ты закроешь глазки
И приснятся сказки:
Кот Матроскин полосатый,
Печкин – почтальон усатый.
Розовый и добрый слон
Пусть приходит тоже в сон.
Спать спокойно до утра
Улеглась вся детвора,
Спи и ты мой мальчик
Как пушистый зайчик.
Читать полностью »
Ранее, мы научились определять спряжения глаголов по их личным окончаниям. Поговорим подробнее о написании личных окончаний глаголов, а также об употреблении мягкого знака после шипящих на конце глагола.
С ударными окончаниями глаголов все понятно.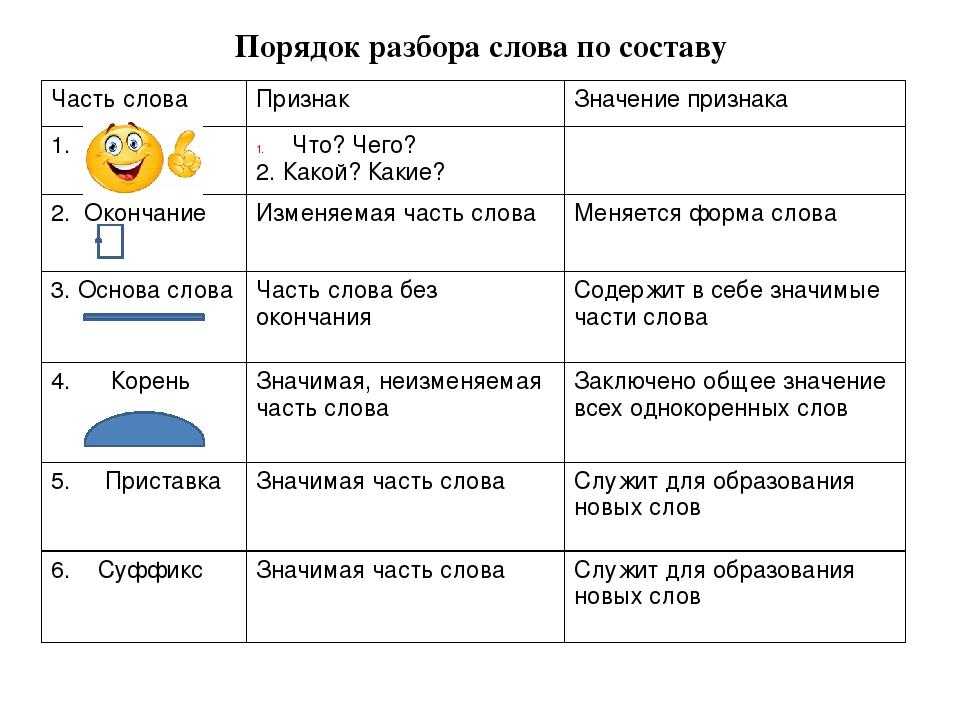 Буква под ударением и является проверочной:
Буква под ударением и является проверочной:
Слова кипеть, кипишь, следишь и так далее – ударные окончания. Они пишутся так же, как произносятся (слышатся).
В безударных окончаниях глаголов правописание букв е и и определяются по неопределенной форме этих глаголов:
Глаголы оканчивающиеся на –ить относятся ко II спряжению: помнить, гладить.
Все остальные глаголы относятся к I спряжению, а именно глаголы в неопределенной форме оканчивающиеся на
-ать, -оть,
-ять, -ыть
-еть, -уть.
Но существуют глаголы – исключения, относящиеся ко II спряжению, которые надо запомнить. Легче всего их запомнить с помощью стишка:
Гнать, держать, смотреть и видеть,
Дышать, слышать, ненавидеть,
И зависеть, и вертеть,
И обидеть, и терпеть,
Вы запомните друзья,
Их на –е спрягать нельзя.


Составим таблицу безударных окончаний глаголов:
I спряжение | II спряжение |
-е- -ут, -ют (в 3-м лице мн.ч) | -и- -ат, -ят (в 3-м лице мн.ч) |
2 глагола – исключения на -ить:
глаголы в неопределенной форме, с окончаниями на -ать, -оть, -уть, -ять, -еть, -ыть колоть и т.д. | глаголы в неопределенной форме на –ить: служить, крушить и т. 7 глаголов – исключений на –еть:
4 глагола – исключения на –ать:
|
 д.
д.
Есть разноспрягаемые глаголы, например, глаголы – бежать и хотеть. Давайте рассмотрим их окончания:
Я хочу, бегу
Ты хочешь, бежишь
он хочет, бежит
Мы хотим, бежим
Вы хотите, бежите
Они хотят, бегут
В русском языке есть глаголы, которые не употребляются в 1-м лице единственного числа.
Например, глагол победить. Вместо первого лица единственного числа, говорят:
Я хочу победить или я постараюсь победить.
Итак, для того, чтобы проверить правильность написания окончания глагола, следует рассуждать следующим образом:
1. Определяем окончание глагола (ударное или безударное).
Определяем окончание глагола (ударное или безударное).
Если ударное, то это и есть проверка. Если безударное, рассуждаем дальше.
2. Ставим глагол в неопределенную форму и проверяем его окончание:
Если глагол оканчивается на –ить, то это глагол II спряжения – пишем в окончании –и, а если глагол в 3 лице множественного числа, то пишем –ат или –ят.
В противном случае рассуждаем дальше:
3. Проверяем, не входит ли глагол в список исключений на –ать и –еть.
Если входит, то это глагол II спряжения, в окончании пишем –и:
ненавидеть – ненавидишь – ненавидит.
Если не входит, то это глагол I спряжения, в окончании пишем –е, а если глагол в 3 лице множественного числа, то пишем –ут или –ют.
Например:
Закрут..шь.
Этот глагол стоит в будущем времени, во 2-м лице и в единственном числе:
- Окончание безударное.
- В неопределенной форме – закрутить – окончание –ить – это II спряжение, в окончании пишем –и: закрутишь.

Завис..т.
Этот глагол в настоящем времени, в 3 лице, множественного числа:
- Окончание безударное.
- В неопределенной форме – зависеть – окончание –еть.
- Глагол входит в список исключений – это II спряжение, глагол в 3 лице, множественного числа, окончание –ят: зависят. Читать полностью »
Второстепенными членами предложения являются члены предложения не входящие в грамматическую основу. Они распространяют главные члены предложения. То есть поясняют и уточняют их.
Например:
Это предложение является распространенным, так как, помимо главных членов, имеет и второстепенные члены предложения.
Второстепенными членами предложения являются определение, дополнение и обстоятельство.
Определение – второстепенный член предложения, который определяет признак предмета. Определение отвечает на вопросы:
- какой?
- чей?
Определение может быть выражено разными частями речи: существительным, прилагательным
или местоимением.
Дополнение – второстепенный член предложения, обозначающий предмет. Дополнение отвечает на вопросы косвенных падежей (всех, кроме именительного), а именно:
- кого? чего?
- кому? чему?
- кого? что?
- кем? чем?
- о ком? о чем?
Дополнение может быть выражено существительным или местоимением. Подчеркивается пунктиром.
Примечание:
Имя существительное, в именительном падеже, в предложениях является подлежащим, а в винительном падеже – это второстепенный член предложения, а именно дополнение.
Котята перевернули миску.
В этом случае существительное миска – в винительном падеже и не является подлежащим, а является дополнением.
Пример дополнения:
Читать полностью »
Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- определить его корректное написание;
- понять, как правильно в нем ставить ударение.
Площадка предлагает ознакомиться с историей возникновения слова.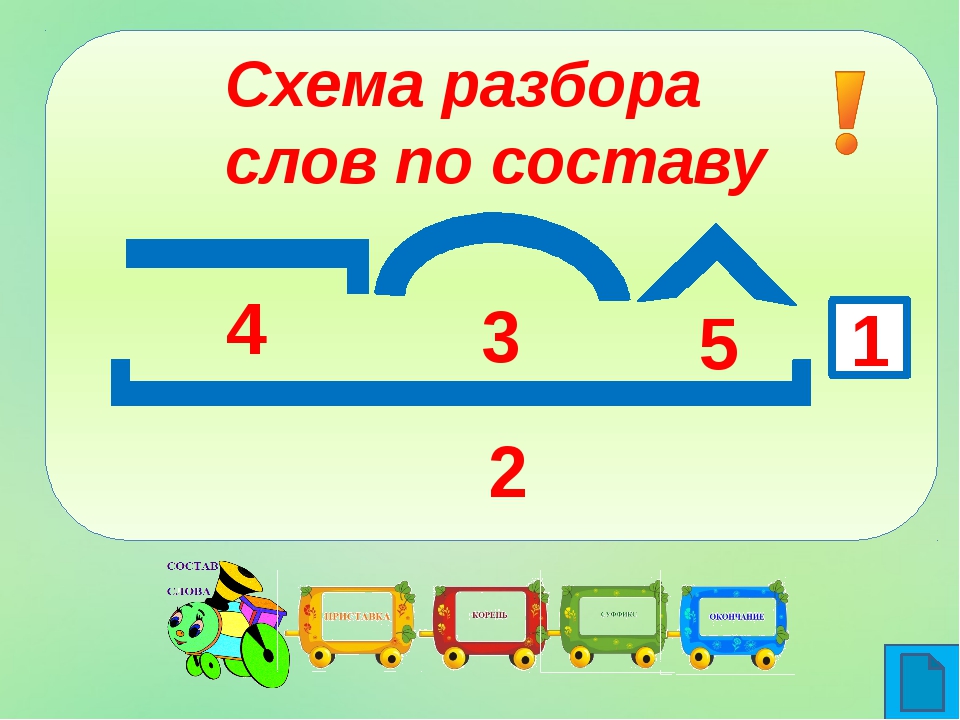 Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
каменный вал 2 секунды назад
сведший счеты 3 секунды назад
в пух и в прах 3 секунды назад
добивавшийся признания за собой 3 секунды назад
желтухино 4 секунды назад
строгие требования 4 секунды назад
возокла 5 секунд назад
ровтацс 5 секунд назад
делоруг 8 секунд назад
песчанка 9 секунд назад
по ветру 10 секунд назад
трлаеь 12 секунд назад
ренимдат 13 секунд назад
игнатин 13 секунд назад
пролепка 15 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | каска | 0 слов | 40 минут назад | 178. 176.166.238 176.166.238 |
| Игрок 2 | сиром | 0 слов | 3 часа назад | 176.60.240.229 |
| Игрок 3 | картофельник | 4 слова | 9 часов назад | 37.214.15.30 |
| Игрок 4 | прозаичность | 99 слов | 11 часов назад | 91.132.23.36 |
| Игрок 5 | ухватливость | 56 слов | 11 часов назад | 91.132.23.36 |
| Игрок 6 | ультрамикроб | 23 слова | 18 часов назад | 94.158.173.2 |
| Игрок 7 | подсаливание | 45 слов | 19 часов назад | 91.132.23.36 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | декан | 55:54 | 5 минут назад | 94. 245.134.239 245.134.239 |
| Игрок 2 | декан | 30:32 | 13 минут назад | 94.245.134.239 |
| Игрок 3 | декан | 5:6 | 14 минут назад | 94.245.134.239 |
| Игрок 4 | декан | 9:10 | 16 минут назад | 94.245.134.239 |
| Игрок 5 | шажок | 52:51 | 21 минута назад | 109.94.10.201 |
| Игрок 6 | рачок | 56:52 | 32 минуты назад | 109.94.10.201 |
| Игрок 7 | систр | 0:0 | 34 минуты назад | 109.94.10.201 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Лол | На одного | 5 вопросов | 15 часов назад | 89. 0.251.114 0.251.114 |
| Каролина | На одного | 20 вопросов | 19 часов назад | 85.249.169.75 |
| Влада | На одного | 20 вопросов | 1 день назад | 178.120.68.219 |
| Писюн | На одного | 10 вопросов | 1 день назад | 83.220.238.3 |
| Е | На одного | 10 вопросов | 1 день назад | 46.8.146.76 |
| Аяна | На двоих | 10 вопросов | 1 день назад | 5.34.95.10 |
| Аяна | На двоих | 5 вопросов | 1 день назад | 5.34.95.10 |
| Играть в Чепуху! | ||||
chempy.util.parsing — документация chempy 0.
 4.1
4.1
# -*- кодировка: utf-8 -*-
""" Функции для химических формул и реакций """
из __future__ import (absolute_import, Division, print_function)
из коллекций импортировать defaultdict
импортировать повторно
предупреждения об импорте
из .pyutil import ChemPyDeprecationWarning, memoize
parsing_library = 'pyparsing' # информация, используемая для выборочного тестирования.
@memoize()
защита _get_formula_parser():
""" Создать прямой анализатор химических формул
BNF для простой химической формулы (без вложения)
целое :: '0'..'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: элемент [целое число]
формула :: срок+
BNF для вложенной химической формулы
целое :: '0'..'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: (элемент | '(' формула ')') [целое число]
формула :: срок+
Примечания
-----
Код этой функции взят из ответа на StackOverflow:
http://stackoverflow.com/a/18555142/790973
написано:
Пол Макгуайр, http://stackoverflow. com/users/165216/paul-mcguire
в ответ на вопрос, сформулированный:
Thales MG, http://stackoverflow.com/users/2708711/thales-mg
код находится под лицензией «CC-WIKI».
(см.: http://blog.stackoverflow.com/2009/06/требуется указание авторства/)
"""
_p = __import__(parsing_library)
Вперед, Группа, Один или несколько = _p.Forward, _p.Group, _p.OneOrMore
Необязательно, ParseResults, Regex = _p.Optional, _p.ParseResults, _p.Regex
Подавить, Word, nums = _p.Suppress, _p.Word, _p.nums
LPAR, RPAR = карта (подавить, "()")
целое число = слово (числа)
# добавить действие синтаксического анализа для преобразования целых чисел в целые, чтобы поддерживать сложение
# и умножение во время разбора
integer.setParseAction (лямбда t: int (t [0]))
# element = Word(alphas.upper(), alphas.lower())
# или, если вы хотите быть более конкретным, используйте это регулярное выражение
элемент = регулярное выражение (
r"A[cglmrstu]|B[aehikr]?|C[adeflmorsu]?|D[bsy]|E[rsu]|F[emr]?|"
"G[ade]|H[efgos]?|I[nr]?|Kr?|L[airu]|M[dgnot]|N[abdeiop]?|"
"Os?|P[abdmortu]?|R[abefghnu]|S[bcegimnr]?|T[abcehilm]|"
"Uu[bhopqst]|U|V|W|Xe|Yb?|Z[nr]")
# вперед объявить 'формулу', чтобы ее можно было использовать в определении 'термина'
формула = Вперед()
термин = Группа((элемент | Группа(LPAR + формула + RPAR)("подгруппа")) +
Необязательно (целое число, по умолчанию = 1) ("несколько"))
# определить содержимое формулы как один или несколько терминов
формула << Один или больше (термин)
# добавить действия парсинга для обработки во время разбора
# действие синтаксического анализа для умножения подгрупп
def multiContents (токены):
т = токены [0]
# если эти токены содержат подгруппу, то используйте множитель для
# увеличить количество всех элементов в подгруппе
если t. подгруппа:
мульт = t.мульт
для срока в т.подгруппе:
термин[1] *= несколько
вернуть t.subgroup
term.setParseAction (умножить содержимое)
# добавить действие синтаксического анализа для суммирования нескольких ссылок на один и тот же элемент
def sumByElement (токены):
elementsList = [t[0] для t в токенах]
# набор конструкций для проверки наличия дубликатов
дубликаты = len (список элементов) > len (набор (список элементов))
# если есть повторяющиеся имена элементов, суммировать по элементам и
# вернуть новый вложенный ParseResults
если дубликаты:
ctr = defaultdict (целое число)
для t в токенах:
ctr[t[0]] += t[1]
вернуть ParseResults([ParseResults([k, v]) для k, v в ctr.items()])
формула.setParseAction (sumByElement)
формула возврата
символы = (
«H», «He», «Li», «Be», «B», «C», «N», «O», «F», «Ne», «Na», «Mg», «Al». ',
«Si», «P», «S», «Cl», «Ar», «K», «Ca», «Sc», «Ti», «V», «Cr», «Mn», «Fe ',
«Co», «Ni», «Cu», «Zn», «Ga», «Ge», «As», «Se», «Br», «Kr», «Rb», «Sr»,
«Y», «Zr», «Nb», «Mo», «Tc», «Ru», «Rh», «Pd», «Ag», «Cd», «In», «Sn»,
«Sb», «Te», «I», «Xe», «Cs», «Ba», «La», «Ce», «Pr», «Nd», «Pm», «Sm»,
«Eu», «Gd», «Tb», «Dy», «Ho», «Er», «Tm», «Yb», «Lu», «Hf», «Ta», «W»,
«Re», «Os», «Ir», «Pt», «Au», «Hg», «Tl», «Pb», «Bi», «Po», «At», «Rn»,
«Fr», «Ra», «Ac», «Th», «Pa», «U», «Np», «Pu», «Am», «Cm», «Bk», «Cf»,
«Es», «Fm», «Md», «No», «Lr», «Rf», «Db», «Sg», «Bh», «Hs», «Mt», «Ds»,
«Rg», «Cn», «Uut», «Fl», «Uup», «Lv», «Uus», «Uuo»
)
имена = (
«Водород», «Гелий», «Литий», «Бериллий»,
«Бор», «Углерод», «Азот», «Кислород», «Фтор», «Неон», «Натрий»,
«Магний», «Алюминий», «Кремний», «Фосфор», «Сера»,
«Хлор», «Аргон», «Калий», «Кальций», «Скандий», «Титан»,
«Ванадий», «Хром», «Марганец», «Железо», «Кобальт», «Никель»,
«Медь», «Цинк», «Галлий», «Германий», «Мышьяк», «Селен»,
«Бром», «Криптон», «Рубидий», «Стронций», «Иттрий», «Цирконий»,
«Ниобий», «Молибден», «Технеций», «Рутений», «Родий»,
«Палладий», «Серебро», «Кадмий», «Индий», «Олово», «Сурьма»,
«Теллур», «Йод», «Ксенон», «Цезий», «Барий», «Лантан»,
«Церий», «Празеодим», «Неодим», «Прометий», «Самарий»,
«Европий», «Гадолиний», «Тербий», «Диспрозий», «Гольмий»,
«Эрбий», «Тулий», «Иттербий», «Лютеций», «Гафний», «Тантал»,
«Вольфрам», «Рений», «Осмий», «Иридий», «Платина», «Золото»,
«Ртуть», «Таллий», «Свинец», «Висмут», «Полоний», «Астатин»,
«Радон», «Франций», «Радий», «Актиний», «Торий», «Протактиний»,
«Уран», «Нептуний», «Плутоний», «Америций», «Кюрий»,
«Берклиум», «Калифорний», «Эйнштейниум», «Фермиум», «Менделевий»,
«Нобелий», «Лавренций», «Резерфордий», «Дубний», «Сиборгий»,
«борий», «хассиум», «мейтнерий», «дармштадтий», «рентгений»,
«Копернициум», «(Унунтриум)», «Флеровиум», «(Унунпентий)»,
'Ливермориум', '(Унунсептиум)', '(Унуноктиум)'
)
lower_names = tuple(n. lower().lstrip('(').rstrip(')') для n в именах)
[документы] def атомный_номер (имя):
пытаться:
возврат символов.индекс (имя) + 1
кроме ValueError:
вернуть нижние_имена.индекс(имя.нижний()) + 1
# Данные в '_relative_atomic_masses' находятся под лицензией CC-SA.
# https://en.wikipedia.org/w/index.php?title=List_of_elements&oldid=700476748
_relative_atomic_masses = (
"1,008 4,002602(2) 6,94 9,0121831(5) 10,81 12,011 14,007 15,999"
" 18,998403163(6) 20,1797(6) 22,98976928(2) 24,305 26,9815385(7) 28,085"
30,973761998(5) 32,06 35,45 39,948(1) 39,0983(1) 40,078(4)"
" 44,955908(5) 47,867(1) 50,9415(1) 51,9961(6) 54,938044(3) 55,845(2)"
" 58,933194(4) 58,6934(4) 63,546(3) 65,38(2) 69,723(1) 72,630(8)"
" 74,921595(6) 78,971(8) 79,904 83,798(2) 85,4678(3) 87,62(1)"
" 88,90584(2) 91,224(2) 92,90637(2) 95,95(1) [98] 101,07(2) 102,90550(2)"
" 106,42(1) 107,8682(2) 112,414(4) 114,818(1) 118,710(7) 121,760(1)"
" 127,60(3) 126,90447(3) 131,293(6) 132,90545196(6) 137,327(7)"
" 138,90547(7) 140,116(1) 140,90766(2) 144. 242(3) [145] 150.36(2)"
" 151,964(1) 157,25(3) 158,92535(2) 162,500(1) 164,93033(2) 167,259(3)"
" 168,93422(2) 173,045(10) 174,9668(1) 178,49(2) 180,94788(2) 183,84(1)"
" 186,207(1) 190,23(3) 192,217(3) 195,084(9) 196,966569(5) 200,592(3)"
" 204,38 207,2(1) 208,98040(1) [209] [210] [222] [223] [226] [227]"
" 232.0377(4) 231.03588(2) 238.02891(3) [237] [244] [243] [247] [247]"
"[251] [252] [257] [258] [259] [266] [267] [268] [269] [270] [269]"
"[278] [281] [282] [285] [286] [289] [289] [293] [294] [294]"
)
защита _get_relative_atomic_masses():
для массы в _relative_atomic_masses.split():
если mass.startswith('[') и mass.endswith(']'):
выход с плавающей запятой (масса [1: -1])
элиф '(' по массе:
выход с плавающей запятой (mass.split ('(') [0])
еще:
доходность (плавающая (масса))
относительные_атомные_массы = кортеж (_get_relative_atomic_masses())
[документы] def mass_from_composition (состав):
""" Расчет молекулярной массы по атомным весам
Параметры
----------
состав: дикт.
Словарь, отображающий int (атомный номер) в int (коэффициент)
Возвращает
-------
плавать
молекулярная масса в атомных единицах массы
Примечания
-----
Атомный номер 0 обозначает заряд или «чистый электронный дефицит».
Примеры
--------
>>> '%.2f' % mass_from_composition({0:-1, 1:1, 8:1})
'17.01'
"""
масса = 0,0
для k, v в композиции.items():
если k == 0: # электрон
масса -= v*5,489е-4
еще:
масса += v*relative_atomic_masses[k-1]
возвратная масса
защита _get_charge (chgstr):
если chgstr == '+':
вернуть 1
Элиф chgstr == '-':
возврат -1
для токена, анти, знака zip('+-', '-+', (1, -1)):
если токен в chgstr:
если анти в chgstr:
поднять ValueError("Неверное описание платежа (+ и - присутствует)")
до, после = chgstr.split(токен)
если len(до) > 0 и len(после) > 0:
поднять ValueError("Значения как до, так и после токена оплаты")
если len(до) > 0:
# will_be_missing_in='0. 5.0'
warnings.warn("'Fe/3+' устарело, используйте, например, 'Fe+3'",
ChemPyDeprecationWarning, уровень стека = 3)
знак возврата * int (1, если раньше == '' еще раньше)
если длина (после) > 0:
знак возврата * int (1, если после == '' еще после)
поднять ValueError("Неверное описание платежа (+ или - отсутствует)")
def _formula_to_parts (формула, префиксы, суффиксы):
# Отбросить префиксы и суффиксы
drop_pref, drop_suff = [], []
для ign в префиксах:
если формула.startswith(ign):
drop_pref.append(ign)
формула = формула[len(ign):]
для ign в суффиксах:
если формула.заканчивается(ign):
drop_suff.append(ign)
формула = формула[:-len(ign)]
# Добыча заряда
если '/' в формуле:
# will_be_missing_in='0.5.0'
warnings.warn("/ depr. (до 0.5.0): используйте 'Fe+3' вместо 'Fe/3+'",
ChemPyDeprecationWarning, уровень стека = 3)
части = формула. split('/')
если «+» в частях [0] или «-» в частях [0]:
поднять ValueError("Заряд необходимо разделить с помощью /")
если parts[1] не None:
wo_pm = части[1].replace('+', '').replace('-', '')
если wo_pm != '' а не str.isdigit(wo_pm):
поднять ValueError("Нецифровой спецификатор заряда")
если len(parts) > 2:
поднять ValueError("В формуле допускается не более одного '/'")
еще:
для токена в «+-»:
если токен в формуле:
если формула.счет(токен) > 1:
поднять ValueError("Несколько токенов: %s" % токен)
части = формула.split(токен)
части[1] = токен + части[1]
перерыв
еще:
части = [формула, нет]
части возврата + [кортеж (drop_pref), кортеж (drop_suff [::-1])]
def _parse_stoich (стоич):
if stich == 'e': # частный случай, электрон не является элементом
возвращаться {}
return {symbols. \d+', s)
если len(m) == 0:
м = 1
Элиф лен(м) == 1:
с = с [лен (м [0]):]
м = интервал (м [0])
еще:
поднять ValueError("Не удалось разобрать: %s" % s)
возврат м, с
[docs]def Formula_to_composition(формула, префиксы=Нет,
суффиксы=('(s)', '(l)', '(g)', '(aq)')):
""" Составление разбора формулы, представляющей химическую формулу
Композиция представлена как отображение словаря int -> int (atomic
число -> кратность). «Атомный номер» 0 представляет собой чистый заряд.
Параметры
----------
формула: ул.
Химическая формула, например «h3O», «Fe+3», «Cl-»
префиксы: итерируемые строки
Префиксы для игнорирования, например. ('.', 'альфа-')
суффиксы: кортеж строк
Суффиксы, которые следует игнорировать, например. ('(г)', '(с)')
Примеры
--------
>>> Formula_to_composition('Nh5+') == {0:1, 1:4, 7:1}
Истинный
>>> Formula_to_composition('.NHO-(водн.)') == {0:-1, 1:1, 7:1, 8:1}
Истинный
>>> Formula_to_composition('Na2CO3. 7h3O') == {11:2, 6:1, 8:10, 1:14}
Истинный
"""
если префиксы None:
префиксы = _latex_mapping.keys()
stoich_tok, chg_tok = _formula_to_parts(формула, префиксы, суффиксы)[:2]
tot_comp = {}
части = stoich_tok.split('.')
для idx, стоич в перечислении (частях):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
comp = _parse_stoich(stoich)
для k, v в comp.items():
если k не в tot_comp:
tot_comp[k] = m*v
еще:
tot_comp[k] += m*v
если chg_tok не None:
tot_comp[0] = _get_charge(chg_tok)
вернуть tot_comp
def _subs (строка, шаблоны):
для patt, repl в Patterns.items():
строка = строка.заменить (patt, repl)
возвращаемая строка
def _parse_multiplicity (строки, essential_keys = нет):
"""
Примеры
--------
>>> _parse_multiplicity(['2 h3O2', 'O2']) == {'h3O2': 2, 'O2': 1}
Истинный
>>> _parse_multiplicity(['2 * h3O2', 'O2']) == {'h3O2': 2, 'O2': 1}
Истинный
>>> _parse_multiplicity(['']) == {}
Истинный
"""
результат = {}
для элементов в [re. split(' \* | ', s) для s в строках]:
если len(items) == 1:
если элементы [0] == '':
продолжать
результат[элементы[0]] = 1
Элиф Лен (предметы) == 2:
результат [предметы [1]] = int (предметы [0])
еще:
поднять ValueError("На много частей в подстроке")
если substant_keys не None:
для k в результате:
если k не в веществе_ключей:
поднять ValueError("Неизвестный ключ_вещества: %s" % k)
вернуть результат
[docs]def to_reaction(line, essential_keys, token, Cls, globals_=None, **kwargs):
""" Разбирает строку на объект реакции и вещества
Reac1 + 2 Reac2 + (2 Reac1) -> Prod1 + Prod2; 10**3,7; ссылка='doi:12/ab'
Reac1 = Prod1; 2.1;
Параметры
----------
строка: ул.
строковое представление для анализа
substant_keys: итерация строк
Допустимые имена, например. ('h3O', 'H+', 'OH-')
жетон: ул.
токен-разделитель между реагентом и продуктом
Класс: класс
например подкласс реакции
globals_: словарь (необязательно)
Глобальные переменные передаются :func:`eval`, когда ``None``:
`chempy. units.default_units` используется с 'chempy'
и дополнительные записи default_units.
Примечания
-----
Эта функция вызывает :func:`eval`, поэтому существуют серьезные проблемы с безопасностью.
с запуском этого на ненадежных данных.
"""
# TODO: добавить обработку юнитов.
если globals_ равен None:
импортный химический
тарифы на импорт от chempy.kinetics
из chempy.units импортировать default_units
globals_ = {k: getattr(rates, k) для k в dir(rates)}
globals_.update({'chempy': chempy, 'default_units': default_units})
если default_units не None:
globals_.update(default_units.as_dict())
пытаться:
stoich, param, kw = map(str.strip, line.rstrip('\n').split(';'))
кроме ValueError:
если ';' в соответствии:
stoich, param = map(str.strip, line.rstrip('\n').split(';'))
еще:
stoich, param = line.strip(), kwargs.pop('param', 'Нет')
еще:
kwargs. update({} если globals_ равно False else eval('dict('+kw+')', globals_))
если isinstance (параметр, строка):
param = None, если globals_ имеет значение False, иначе eval(param, globals_)
если токен не в stich:
поднять ValueError ("Отсутствует токен: %s" % токен)
reac_prod = [[y.strip() для y в x.split(' + ')] для
x в stoich.split(токен)]
действовать, бездействовать = [], []
для стороны в reac_prod:
если сторона[-1].startswith('('):
если не сторона[-1].endswith(')'):
поднять ValueError("Неверный формат (отсутствует закрывающая скобка)")
inact.append(_parse_multiplicity(сторона[-1][1:-1].split(' + '),
вещества_ключи))
act.append(_parse_multiplicity(сторона[:-1],substance_keys))
еще:
inact.append({})
act.append(_parse_multiplicity(сторона, essential_keys))
# stich coeff -> dict
вернуть Cls(действие[0], действие[1], параметр, inact_reac=inact[0],
inact_prod=inact[1], **kwargs)
def _formula_to_format (sub, sup, формула, префиксы = нет,
инфиксы = нет, суффиксы = ('(s)', '(l)', '(g)', '(aq)')):
части = _formula_to_parts (формула, префиксы. ключи(), суффиксы)
стехи = части[0].split('.')
строка = ''
для idx, stoich в перечислении (stoichs):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
строка += _subs('.', инфиксы)
если м != 1:
строка += строка(м)
строка += re.sub(r'([0-9]+)', lambda m: sub(m.group(1)), stoich)
если parts[1] не None:
chg = _get_charge (части [1])
если изменение < 0:
токен = '-' если chg == -1 иначе '%d-' % -chg
если изм > 0:
token = '+', если chg == 1, иначе '%d+' % chg
строка += поддержка (токен)
если len(parts) > 4:
поднять ValueError("Неверная формула")
pre_str = ''.join (карта (лямбда x: _subs (x, префиксы), части [2]))
вернуть pre_str + string + ''.join(parts[3])
[docs]def Formula_to_latex(формула, префиксы=Нет, инфиксы=Нет, **kwargs):
r""" Преобразование строки формулы в латексное представление
Параметры
----------
формула: ул. {%s}' % x,
формула, префиксы, инфиксы, **kwargs) 9{%s}' % str(int(суффикс)) + единица измерения
еще:
возврат с + единица
_unicode_sub = {}
для k, v в enumerate(u"₀₁₂₃₄₅₆₇₈₉"):
_unicode_sub[str(k)] = v
_unicode_sup = {
'+': у'⁺',
'-': у'⁻',
}
для k, v в enumerate(u"⁰¹²³⁴⁵⁶⁷⁸⁹"):
_unicode_sup[str(k)] = v
[docs]def Formula_to_Unicode(формула, префиксы=Нет, инфиксы=Нет, **kwargs):
u""" Преобразование строки формулы в строковое представление Unicode
Параметры
----------
формула: ул.
Химическая формула, например «h3O», «Fe+3», «Cl-»
префиксы: дикт
Префиксные преобразования, по умолчанию: греческие буквы и .
инфиксы: дикт
Инфиксные преобразования, по умолчанию: .
суффиксы: кортеж строк
Суффиксы, которые нужно сохранить, например. ('(г)', '(с)')
Примеры
--------
>>> Formula_to_unicode('Nh5+') == u'NH₄⁺'
Истинный
>>> Formula_to_unicode('Fe(CN)6+2') == u'Fe(CN)₆²⁺'
Истинный
>>> Formula_to_unicode('Fe(CN)6+2(водн. )') == u'Fe(CN)₆²⁺(водн.)'
Истинный
>>> Formula_to_unicode('.NHO-(водн.)') == u'⋅NHO⁻(водн.)'
Истинный
>>> Formula_to_unicode('альфа-FeOOH(s)') == u'α-FeOOH(s)'
Истинный
"""
если префиксы None:
префиксы = _unicode_mapping
если инфиксы равны None:
инфиксы = _unicode_infix_mapping
вернуть _formula_to_format(
лямбда x: ''.join(_unicode_sub[str(_)] для _ в x),
лямбда x: ''.join(_unicode_sup[str(_)] для _ в x),
формула, префиксы, инфиксы, **kwargs)
[docs]def number_to_scientific_unicode(число, fmt='%.3g'):
ты"""
Примеры
--------
>>> number_to_scientific_unicode(3.14) == u'3.14'
Истинный
>>> number_to_scientific_unicode(3.14159265e-7) == u'3.14·10⁻⁷'
Истинный
>>> количество импорта как pq
>>> number_to_scientific_html(2**0,5 * pq.m / pq.s)
«1,41 м/с»
"""
пытаться:
единица измерения = ' ' + число.размерность.юникод
число = число.величина
кроме AttributeError:
единица = ''
s = fmt% число
если 'e' в s:
префикс, суффикс = s. split('e')
возвращаемый префикс + u'·10' + u''.join(map(_unicode_sup.get, str(int(suffix)))) + unit
еще:
возврат с + единица
[docs]def Formula_to_html(формула, префиксы=Нет, инфиксы=Нет, **kwargs):
u""" Преобразование строки формулы в строковое представление html
Параметры
----------
формула: ул.
Химическая формула, например «h3O», «Fe+3», «Cl-»
префиксы: дикт
Префиксные преобразования, по умолчанию: греческие буквы и .
инфиксы: дикт
Инфиксные преобразования, по умолчанию: .
суффиксы: кортеж строк
Суффиксы, которые нужно сохранить, например. ('(г)', '(с)')
Примеры
--------
>>> Formula_to_html('Nh5+')
'NH4+'
>>> Formula_to_html('Fe(CN)6+2')
'Fe(CN)62+'
>>> Formula_to_html('Fe(CN)6+2(водн.)')
'Fe(CN)62+(водн.)'
>>> Formula_to_html('.NHO-(водн.)')
'⋅NHO-(aq)'
>>> Formula_to_html('альфа-FeOOH(s)')
'α-FeOOH(s)'
"""
если префиксы None:
префиксы = _html_mapping
если инфиксы равны None:
инфиксы = _html_infix_mapping
вернуть _formula_to_format(лямбда x: '%s' % x,
лямбда x: '%s' % x,
формула, префиксы, инфиксы, **kwargs)
[docs]def number_to_scientific_html(число, fmt='%. 3g'):
"""
Примеры
--------
>>> number_to_scientific_html(3.14) == '3.14'
Истинный
>>> number_to_scientific_html(3.14159265e-7)
'3,14⋅10-7'
>>> количество импорта как pq
>>> number_to_scientific_html(2**0,5 * pq.m / pq.s)
«1,41 м/с»
"""
пытаться:
unit = ' ' + str(число.размерность)
число = число.величина
кроме AttributeError:
единица = ''
s = fmt% число
если 'e' в s:
префикс, суффикс = s.split('e')
префикс возврата + '⋅10' + str(int(suffix)) + '' + единица измерения
еще:
возврат с + единица
 com/users/165216/paul-mcguire
в ответ на вопрос, сформулированный:
Thales MG, http://stackoverflow.com/users/2708711/thales-mg
код находится под лицензией «CC-WIKI».
(см.: http://blog.stackoverflow.com/2009/06/требуется указание авторства/)
"""
_p = __import__(parsing_library)
Вперед, Группа, Один или несколько = _p.Forward, _p.Group, _p.OneOrMore
Необязательно, ParseResults, Regex = _p.Optional, _p.ParseResults, _p.Regex
Подавить, Word, nums = _p.Suppress, _p.Word, _p.nums
LPAR, RPAR = карта (подавить, "()")
целое число = слово (числа)
# добавить действие синтаксического анализа для преобразования целых чисел в целые, чтобы поддерживать сложение
# и умножение во время разбора
integer.setParseAction (лямбда t: int (t [0]))
# element = Word(alphas.upper(), alphas.lower())
# или, если вы хотите быть более конкретным, используйте это регулярное выражение
элемент = регулярное выражение (
r"A[cglmrstu]|B[aehikr]?|C[adeflmorsu]?|D[bsy]|E[rsu]|F[emr]?|"
"G[ade]|H[efgos]?|I[nr]?|Kr?|L[airu]|M[dgnot]|N[abdeiop]?|"
"Os?|P[abdmortu]?|R[abefghnu]|S[bcegimnr]?|T[abcehilm]|"
"Uu[bhopqst]|U|V|W|Xe|Yb?|Z[nr]")
# вперед объявить 'формулу', чтобы ее можно было использовать в определении 'термина'
формула = Вперед()
термин = Группа((элемент | Группа(LPAR + формула + RPAR)("подгруппа")) +
Необязательно (целое число, по умолчанию = 1) ("несколько"))
# определить содержимое формулы как один или несколько терминов
формула << Один или больше (термин)
# добавить действия парсинга для обработки во время разбора
# действие синтаксического анализа для умножения подгрупп
def multiContents (токены):
т = токены [0]
# если эти токены содержат подгруппу, то используйте множитель для
# увеличить количество всех элементов в подгруппе
если t.
com/users/165216/paul-mcguire
в ответ на вопрос, сформулированный:
Thales MG, http://stackoverflow.com/users/2708711/thales-mg
код находится под лицензией «CC-WIKI».
(см.: http://blog.stackoverflow.com/2009/06/требуется указание авторства/)
"""
_p = __import__(parsing_library)
Вперед, Группа, Один или несколько = _p.Forward, _p.Group, _p.OneOrMore
Необязательно, ParseResults, Regex = _p.Optional, _p.ParseResults, _p.Regex
Подавить, Word, nums = _p.Suppress, _p.Word, _p.nums
LPAR, RPAR = карта (подавить, "()")
целое число = слово (числа)
# добавить действие синтаксического анализа для преобразования целых чисел в целые, чтобы поддерживать сложение
# и умножение во время разбора
integer.setParseAction (лямбда t: int (t [0]))
# element = Word(alphas.upper(), alphas.lower())
# или, если вы хотите быть более конкретным, используйте это регулярное выражение
элемент = регулярное выражение (
r"A[cglmrstu]|B[aehikr]?|C[adeflmorsu]?|D[bsy]|E[rsu]|F[emr]?|"
"G[ade]|H[efgos]?|I[nr]?|Kr?|L[airu]|M[dgnot]|N[abdeiop]?|"
"Os?|P[abdmortu]?|R[abefghnu]|S[bcegimnr]?|T[abcehilm]|"
"Uu[bhopqst]|U|V|W|Xe|Yb?|Z[nr]")
# вперед объявить 'формулу', чтобы ее можно было использовать в определении 'термина'
формула = Вперед()
термин = Группа((элемент | Группа(LPAR + формула + RPAR)("подгруппа")) +
Необязательно (целое число, по умолчанию = 1) ("несколько"))
# определить содержимое формулы как один или несколько терминов
формула << Один или больше (термин)
# добавить действия парсинга для обработки во время разбора
# действие синтаксического анализа для умножения подгрупп
def multiContents (токены):
т = токены [0]
# если эти токены содержат подгруппу, то используйте множитель для
# увеличить количество всех элементов в подгруппе
если t. подгруппа:
мульт = t.мульт
для срока в т.подгруппе:
термин[1] *= несколько
вернуть t.subgroup
term.setParseAction (умножить содержимое)
# добавить действие синтаксического анализа для суммирования нескольких ссылок на один и тот же элемент
def sumByElement (токены):
elementsList = [t[0] для t в токенах]
# набор конструкций для проверки наличия дубликатов
дубликаты = len (список элементов) > len (набор (список элементов))
# если есть повторяющиеся имена элементов, суммировать по элементам и
# вернуть новый вложенный ParseResults
если дубликаты:
ctr = defaultdict (целое число)
для t в токенах:
ctr[t[0]] += t[1]
вернуть ParseResults([ParseResults([k, v]) для k, v в ctr.items()])
формула.setParseAction (sumByElement)
формула возврата
символы = (
«H», «He», «Li», «Be», «B», «C», «N», «O», «F», «Ne», «Na», «Mg», «Al». ',
«Si», «P», «S», «Cl», «Ar», «K», «Ca», «Sc», «Ti», «V», «Cr», «Mn», «Fe ',
«Co», «Ni», «Cu», «Zn», «Ga», «Ge», «As», «Se», «Br», «Kr», «Rb», «Sr»,
«Y», «Zr», «Nb», «Mo», «Tc», «Ru», «Rh», «Pd», «Ag», «Cd», «In», «Sn»,
«Sb», «Te», «I», «Xe», «Cs», «Ba», «La», «Ce», «Pr», «Nd», «Pm», «Sm»,
«Eu», «Gd», «Tb», «Dy», «Ho», «Er», «Tm», «Yb», «Lu», «Hf», «Ta», «W»,
«Re», «Os», «Ir», «Pt», «Au», «Hg», «Tl», «Pb», «Bi», «Po», «At», «Rn»,
«Fr», «Ra», «Ac», «Th», «Pa», «U», «Np», «Pu», «Am», «Cm», «Bk», «Cf»,
«Es», «Fm», «Md», «No», «Lr», «Rf», «Db», «Sg», «Bh», «Hs», «Mt», «Ds»,
«Rg», «Cn», «Uut», «Fl», «Uup», «Lv», «Uus», «Uuo»
)
имена = (
«Водород», «Гелий», «Литий», «Бериллий»,
«Бор», «Углерод», «Азот», «Кислород», «Фтор», «Неон», «Натрий»,
«Магний», «Алюминий», «Кремний», «Фосфор», «Сера»,
«Хлор», «Аргон», «Калий», «Кальций», «Скандий», «Титан»,
«Ванадий», «Хром», «Марганец», «Железо», «Кобальт», «Никель»,
«Медь», «Цинк», «Галлий», «Германий», «Мышьяк», «Селен»,
«Бром», «Криптон», «Рубидий», «Стронций», «Иттрий», «Цирконий»,
«Ниобий», «Молибден», «Технеций», «Рутений», «Родий»,
«Палладий», «Серебро», «Кадмий», «Индий», «Олово», «Сурьма»,
«Теллур», «Йод», «Ксенон», «Цезий», «Барий», «Лантан»,
«Церий», «Празеодим», «Неодим», «Прометий», «Самарий»,
«Европий», «Гадолиний», «Тербий», «Диспрозий», «Гольмий»,
«Эрбий», «Тулий», «Иттербий», «Лютеций», «Гафний», «Тантал»,
«Вольфрам», «Рений», «Осмий», «Иридий», «Платина», «Золото»,
«Ртуть», «Таллий», «Свинец», «Висмут», «Полоний», «Астатин»,
«Радон», «Франций», «Радий», «Актиний», «Торий», «Протактиний»,
«Уран», «Нептуний», «Плутоний», «Америций», «Кюрий»,
«Берклиум», «Калифорний», «Эйнштейниум», «Фермиум», «Менделевий»,
«Нобелий», «Лавренций», «Резерфордий», «Дубний», «Сиборгий»,
«борий», «хассиум», «мейтнерий», «дармштадтий», «рентгений»,
«Копернициум», «(Унунтриум)», «Флеровиум», «(Унунпентий)»,
'Ливермориум', '(Унунсептиум)', '(Унуноктиум)'
)
lower_names = tuple(n.
подгруппа:
мульт = t.мульт
для срока в т.подгруппе:
термин[1] *= несколько
вернуть t.subgroup
term.setParseAction (умножить содержимое)
# добавить действие синтаксического анализа для суммирования нескольких ссылок на один и тот же элемент
def sumByElement (токены):
elementsList = [t[0] для t в токенах]
# набор конструкций для проверки наличия дубликатов
дубликаты = len (список элементов) > len (набор (список элементов))
# если есть повторяющиеся имена элементов, суммировать по элементам и
# вернуть новый вложенный ParseResults
если дубликаты:
ctr = defaultdict (целое число)
для t в токенах:
ctr[t[0]] += t[1]
вернуть ParseResults([ParseResults([k, v]) для k, v в ctr.items()])
формула.setParseAction (sumByElement)
формула возврата
символы = (
«H», «He», «Li», «Be», «B», «C», «N», «O», «F», «Ne», «Na», «Mg», «Al». ',
«Si», «P», «S», «Cl», «Ar», «K», «Ca», «Sc», «Ti», «V», «Cr», «Mn», «Fe ',
«Co», «Ni», «Cu», «Zn», «Ga», «Ge», «As», «Se», «Br», «Kr», «Rb», «Sr»,
«Y», «Zr», «Nb», «Mo», «Tc», «Ru», «Rh», «Pd», «Ag», «Cd», «In», «Sn»,
«Sb», «Te», «I», «Xe», «Cs», «Ba», «La», «Ce», «Pr», «Nd», «Pm», «Sm»,
«Eu», «Gd», «Tb», «Dy», «Ho», «Er», «Tm», «Yb», «Lu», «Hf», «Ta», «W»,
«Re», «Os», «Ir», «Pt», «Au», «Hg», «Tl», «Pb», «Bi», «Po», «At», «Rn»,
«Fr», «Ra», «Ac», «Th», «Pa», «U», «Np», «Pu», «Am», «Cm», «Bk», «Cf»,
«Es», «Fm», «Md», «No», «Lr», «Rf», «Db», «Sg», «Bh», «Hs», «Mt», «Ds»,
«Rg», «Cn», «Uut», «Fl», «Uup», «Lv», «Uus», «Uuo»
)
имена = (
«Водород», «Гелий», «Литий», «Бериллий»,
«Бор», «Углерод», «Азот», «Кислород», «Фтор», «Неон», «Натрий»,
«Магний», «Алюминий», «Кремний», «Фосфор», «Сера»,
«Хлор», «Аргон», «Калий», «Кальций», «Скандий», «Титан»,
«Ванадий», «Хром», «Марганец», «Железо», «Кобальт», «Никель»,
«Медь», «Цинк», «Галлий», «Германий», «Мышьяк», «Селен»,
«Бром», «Криптон», «Рубидий», «Стронций», «Иттрий», «Цирконий»,
«Ниобий», «Молибден», «Технеций», «Рутений», «Родий»,
«Палладий», «Серебро», «Кадмий», «Индий», «Олово», «Сурьма»,
«Теллур», «Йод», «Ксенон», «Цезий», «Барий», «Лантан»,
«Церий», «Празеодим», «Неодим», «Прометий», «Самарий»,
«Европий», «Гадолиний», «Тербий», «Диспрозий», «Гольмий»,
«Эрбий», «Тулий», «Иттербий», «Лютеций», «Гафний», «Тантал»,
«Вольфрам», «Рений», «Осмий», «Иридий», «Платина», «Золото»,
«Ртуть», «Таллий», «Свинец», «Висмут», «Полоний», «Астатин»,
«Радон», «Франций», «Радий», «Актиний», «Торий», «Протактиний»,
«Уран», «Нептуний», «Плутоний», «Америций», «Кюрий»,
«Берклиум», «Калифорний», «Эйнштейниум», «Фермиум», «Менделевий»,
«Нобелий», «Лавренций», «Резерфордий», «Дубний», «Сиборгий»,
«борий», «хассиум», «мейтнерий», «дармштадтий», «рентгений»,
«Копернициум», «(Унунтриум)», «Флеровиум», «(Унунпентий)»,
'Ливермориум', '(Унунсептиум)', '(Унуноктиум)'
)
lower_names = tuple(n. lower().lstrip('(').rstrip(')') для n в именах)
lower().lstrip('(').rstrip(')') для n в именах)
 242(3) [145] 150.36(2)"
" 151,964(1) 157,25(3) 158,92535(2) 162,500(1) 164,93033(2) 167,259(3)"
" 168,93422(2) 173,045(10) 174,9668(1) 178,49(2) 180,94788(2) 183,84(1)"
" 186,207(1) 190,23(3) 192,217(3) 195,084(9) 196,966569(5) 200,592(3)"
" 204,38 207,2(1) 208,98040(1) [209] [210] [222] [223] [226] [227]"
" 232.0377(4) 231.03588(2) 238.02891(3) [237] [244] [243] [247] [247]"
"[251] [252] [257] [258] [259] [266] [267] [268] [269] [270] [269]"
"[278] [281] [282] [285] [286] [289] [289] [293] [294] [294]"
)
защита _get_relative_atomic_masses():
для массы в _relative_atomic_masses.split():
если mass.startswith('[') и mass.endswith(']'):
выход с плавающей запятой (масса [1: -1])
элиф '(' по массе:
выход с плавающей запятой (mass.split ('(') [0])
еще:
доходность (плавающая (масса))
относительные_атомные_массы = кортеж (_get_relative_atomic_masses())
242(3) [145] 150.36(2)"
" 151,964(1) 157,25(3) 158,92535(2) 162,500(1) 164,93033(2) 167,259(3)"
" 168,93422(2) 173,045(10) 174,9668(1) 178,49(2) 180,94788(2) 183,84(1)"
" 186,207(1) 190,23(3) 192,217(3) 195,084(9) 196,966569(5) 200,592(3)"
" 204,38 207,2(1) 208,98040(1) [209] [210] [222] [223] [226] [227]"
" 232.0377(4) 231.03588(2) 238.02891(3) [237] [244] [243] [247] [247]"
"[251] [252] [257] [258] [259] [266] [267] [268] [269] [270] [269]"
"[278] [281] [282] [285] [286] [289] [289] [293] [294] [294]"
)
защита _get_relative_atomic_masses():
для массы в _relative_atomic_masses.split():
если mass.startswith('[') и mass.endswith(']'):
выход с плавающей запятой (масса [1: -1])
элиф '(' по массе:
выход с плавающей запятой (mass.split ('(') [0])
еще:
доходность (плавающая (масса))
относительные_атомные_массы = кортеж (_get_relative_atomic_masses())
 Словарь, отображающий int (атомный номер) в int (коэффициент)
Возвращает
-------
плавать
молекулярная масса в атомных единицах массы
Примечания
-----
Атомный номер 0 обозначает заряд или «чистый электронный дефицит».
Примеры
--------
>>> '%.2f' % mass_from_composition({0:-1, 1:1, 8:1})
'17.01'
"""
масса = 0,0
для k, v в композиции.items():
если k == 0: # электрон
масса -= v*5,489е-4
еще:
масса += v*relative_atomic_masses[k-1]
возвратная масса
Словарь, отображающий int (атомный номер) в int (коэффициент)
Возвращает
-------
плавать
молекулярная масса в атомных единицах массы
Примечания
-----
Атомный номер 0 обозначает заряд или «чистый электронный дефицит».
Примеры
--------
>>> '%.2f' % mass_from_composition({0:-1, 1:1, 8:1})
'17.01'
"""
масса = 0,0
для k, v в композиции.items():
если k == 0: # электрон
масса -= v*5,489е-4
еще:
масса += v*relative_atomic_masses[k-1]
возвратная масса  5.0'
warnings.warn("'Fe/3+' устарело, используйте, например, 'Fe+3'",
ChemPyDeprecationWarning, уровень стека = 3)
знак возврата * int (1, если раньше == '' еще раньше)
если длина (после) > 0:
знак возврата * int (1, если после == '' еще после)
поднять ValueError("Неверное описание платежа (+ или - отсутствует)")
def _formula_to_parts (формула, префиксы, суффиксы):
# Отбросить префиксы и суффиксы
drop_pref, drop_suff = [], []
для ign в префиксах:
если формула.startswith(ign):
drop_pref.append(ign)
формула = формула[len(ign):]
для ign в суффиксах:
если формула.заканчивается(ign):
drop_suff.append(ign)
формула = формула[:-len(ign)]
# Добыча заряда
если '/' в формуле:
# will_be_missing_in='0.5.0'
warnings.warn("/ depr. (до 0.5.0): используйте 'Fe+3' вместо 'Fe/3+'",
ChemPyDeprecationWarning, уровень стека = 3)
части = формула.
5.0'
warnings.warn("'Fe/3+' устарело, используйте, например, 'Fe+3'",
ChemPyDeprecationWarning, уровень стека = 3)
знак возврата * int (1, если раньше == '' еще раньше)
если длина (после) > 0:
знак возврата * int (1, если после == '' еще после)
поднять ValueError("Неверное описание платежа (+ или - отсутствует)")
def _formula_to_parts (формула, префиксы, суффиксы):
# Отбросить префиксы и суффиксы
drop_pref, drop_suff = [], []
для ign в префиксах:
если формула.startswith(ign):
drop_pref.append(ign)
формула = формула[len(ign):]
для ign в суффиксах:
если формула.заканчивается(ign):
drop_suff.append(ign)
формула = формула[:-len(ign)]
# Добыча заряда
если '/' в формуле:
# will_be_missing_in='0.5.0'
warnings.warn("/ depr. (до 0.5.0): используйте 'Fe+3' вместо 'Fe/3+'",
ChemPyDeprecationWarning, уровень стека = 3)
части = формула.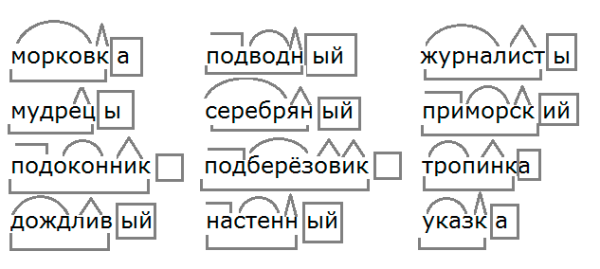 split('/')
если «+» в частях [0] или «-» в частях [0]:
поднять ValueError("Заряд необходимо разделить с помощью /")
если parts[1] не None:
wo_pm = части[1].replace('+', '').replace('-', '')
если wo_pm != '' а не str.isdigit(wo_pm):
поднять ValueError("Нецифровой спецификатор заряда")
если len(parts) > 2:
поднять ValueError("В формуле допускается не более одного '/'")
еще:
для токена в «+-»:
если токен в формуле:
если формула.счет(токен) > 1:
поднять ValueError("Несколько токенов: %s" % токен)
части = формула.split(токен)
части[1] = токен + части[1]
перерыв
еще:
части = [формула, нет]
части возврата + [кортеж (drop_pref), кортеж (drop_suff [::-1])]
def _parse_stoich (стоич):
if stich == 'e': # частный случай, электрон не является элементом
возвращаться {}
return {symbols.
split('/')
если «+» в частях [0] или «-» в частях [0]:
поднять ValueError("Заряд необходимо разделить с помощью /")
если parts[1] не None:
wo_pm = части[1].replace('+', '').replace('-', '')
если wo_pm != '' а не str.isdigit(wo_pm):
поднять ValueError("Нецифровой спецификатор заряда")
если len(parts) > 2:
поднять ValueError("В формуле допускается не более одного '/'")
еще:
для токена в «+-»:
если токен в формуле:
если формула.счет(токен) > 1:
поднять ValueError("Несколько токенов: %s" % токен)
части = формула.split(токен)
части[1] = токен + части[1]
перерыв
еще:
части = [формула, нет]
части возврата + [кортеж (drop_pref), кортеж (drop_suff [::-1])]
def _parse_stoich (стоич):
if stich == 'e': # частный случай, электрон не является элементом
возвращаться {}
return {symbols.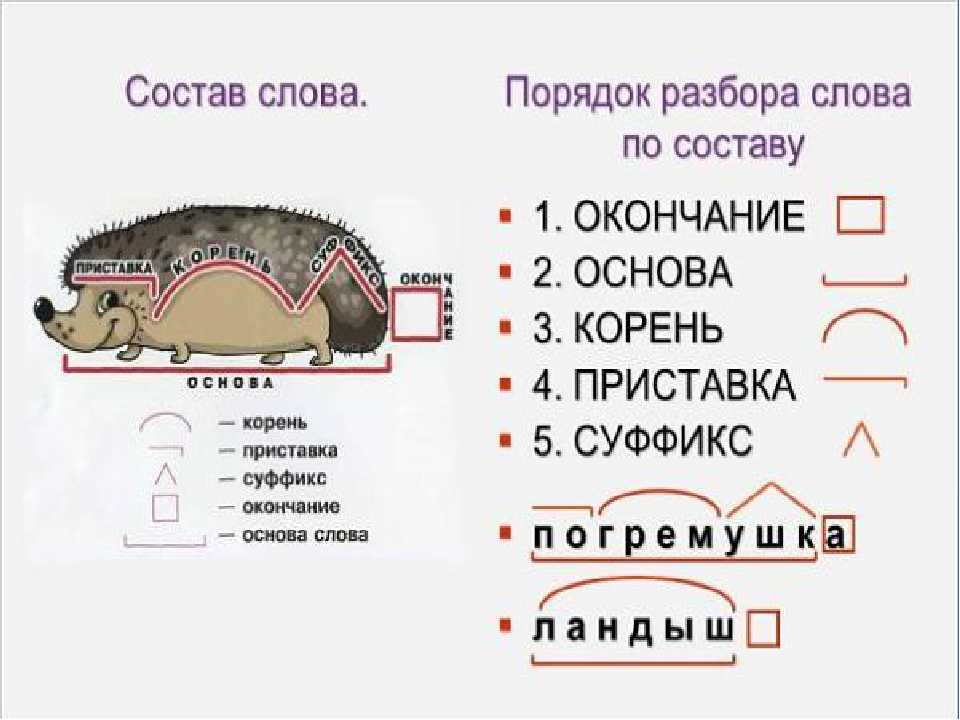 \d+', s)
если len(m) == 0:
м = 1
Элиф лен(м) == 1:
с = с [лен (м [0]):]
м = интервал (м [0])
еще:
поднять ValueError("Не удалось разобрать: %s" % s)
возврат м, с
\d+', s)
если len(m) == 0:
м = 1
Элиф лен(м) == 1:
с = с [лен (м [0]):]
м = интервал (м [0])
еще:
поднять ValueError("Не удалось разобрать: %s" % s)
возврат м, с
 7h3O') == {11:2, 6:1, 8:10, 1:14}
Истинный
"""
если префиксы None:
префиксы = _latex_mapping.keys()
stoich_tok, chg_tok = _formula_to_parts(формула, префиксы, суффиксы)[:2]
tot_comp = {}
части = stoich_tok.split('.')
для idx, стоич в перечислении (частях):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
comp = _parse_stoich(stoich)
для k, v в comp.items():
если k не в tot_comp:
tot_comp[k] = m*v
еще:
tot_comp[k] += m*v
если chg_tok не None:
tot_comp[0] = _get_charge(chg_tok)
вернуть tot_comp
7h3O') == {11:2, 6:1, 8:10, 1:14}
Истинный
"""
если префиксы None:
префиксы = _latex_mapping.keys()
stoich_tok, chg_tok = _formula_to_parts(формула, префиксы, суффиксы)[:2]
tot_comp = {}
части = stoich_tok.split('.')
для idx, стоич в перечислении (частях):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
comp = _parse_stoich(stoich)
для k, v в comp.items():
если k не в tot_comp:
tot_comp[k] = m*v
еще:
tot_comp[k] += m*v
если chg_tok не None:
tot_comp[0] = _get_charge(chg_tok)
вернуть tot_comp  split(' \* | ', s) для s в строках]:
если len(items) == 1:
если элементы [0] == '':
продолжать
результат[элементы[0]] = 1
Элиф Лен (предметы) == 2:
результат [предметы [1]] = int (предметы [0])
еще:
поднять ValueError("На много частей в подстроке")
если substant_keys не None:
для k в результате:
если k не в веществе_ключей:
поднять ValueError("Неизвестный ключ_вещества: %s" % k)
вернуть результат
split(' \* | ', s) для s в строках]:
если len(items) == 1:
если элементы [0] == '':
продолжать
результат[элементы[0]] = 1
Элиф Лен (предметы) == 2:
результат [предметы [1]] = int (предметы [0])
еще:
поднять ValueError("На много частей в подстроке")
если substant_keys не None:
для k в результате:
если k не в веществе_ключей:
поднять ValueError("Неизвестный ключ_вещества: %s" % k)
вернуть результат
 units.default_units` используется с 'chempy'
и дополнительные записи default_units.
Примечания
-----
Эта функция вызывает :func:`eval`, поэтому существуют серьезные проблемы с безопасностью.
с запуском этого на ненадежных данных.
"""
# TODO: добавить обработку юнитов.
если globals_ равен None:
импортный химический
тарифы на импорт от chempy.kinetics
из chempy.units импортировать default_units
globals_ = {k: getattr(rates, k) для k в dir(rates)}
globals_.update({'chempy': chempy, 'default_units': default_units})
если default_units не None:
globals_.update(default_units.as_dict())
пытаться:
stoich, param, kw = map(str.strip, line.rstrip('\n').split(';'))
кроме ValueError:
если ';' в соответствии:
stoich, param = map(str.strip, line.rstrip('\n').split(';'))
еще:
stoich, param = line.strip(), kwargs.pop('param', 'Нет')
еще:
kwargs.
units.default_units` используется с 'chempy'
и дополнительные записи default_units.
Примечания
-----
Эта функция вызывает :func:`eval`, поэтому существуют серьезные проблемы с безопасностью.
с запуском этого на ненадежных данных.
"""
# TODO: добавить обработку юнитов.
если globals_ равен None:
импортный химический
тарифы на импорт от chempy.kinetics
из chempy.units импортировать default_units
globals_ = {k: getattr(rates, k) для k в dir(rates)}
globals_.update({'chempy': chempy, 'default_units': default_units})
если default_units не None:
globals_.update(default_units.as_dict())
пытаться:
stoich, param, kw = map(str.strip, line.rstrip('\n').split(';'))
кроме ValueError:
если ';' в соответствии:
stoich, param = map(str.strip, line.rstrip('\n').split(';'))
еще:
stoich, param = line.strip(), kwargs.pop('param', 'Нет')
еще:
kwargs. update({} если globals_ равно False else eval('dict('+kw+')', globals_))
если isinstance (параметр, строка):
param = None, если globals_ имеет значение False, иначе eval(param, globals_)
если токен не в stich:
поднять ValueError ("Отсутствует токен: %s" % токен)
reac_prod = [[y.strip() для y в x.split(' + ')] для
x в stoich.split(токен)]
действовать, бездействовать = [], []
для стороны в reac_prod:
если сторона[-1].startswith('('):
если не сторона[-1].endswith(')'):
поднять ValueError("Неверный формат (отсутствует закрывающая скобка)")
inact.append(_parse_multiplicity(сторона[-1][1:-1].split(' + '),
вещества_ключи))
act.append(_parse_multiplicity(сторона[:-1],substance_keys))
еще:
inact.append({})
act.append(_parse_multiplicity(сторона, essential_keys))
# stich coeff -> dict
вернуть Cls(действие[0], действие[1], параметр, inact_reac=inact[0],
inact_prod=inact[1], **kwargs)
update({} если globals_ равно False else eval('dict('+kw+')', globals_))
если isinstance (параметр, строка):
param = None, если globals_ имеет значение False, иначе eval(param, globals_)
если токен не в stich:
поднять ValueError ("Отсутствует токен: %s" % токен)
reac_prod = [[y.strip() для y в x.split(' + ')] для
x в stoich.split(токен)]
действовать, бездействовать = [], []
для стороны в reac_prod:
если сторона[-1].startswith('('):
если не сторона[-1].endswith(')'):
поднять ValueError("Неверный формат (отсутствует закрывающая скобка)")
inact.append(_parse_multiplicity(сторона[-1][1:-1].split(' + '),
вещества_ключи))
act.append(_parse_multiplicity(сторона[:-1],substance_keys))
еще:
inact.append({})
act.append(_parse_multiplicity(сторона, essential_keys))
# stich coeff -> dict
вернуть Cls(действие[0], действие[1], параметр, inact_reac=inact[0],
inact_prod=inact[1], **kwargs)  ключи(), суффиксы)
стехи = части[0].split('.')
строка = ''
для idx, stoich в перечислении (stoichs):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
строка += _subs('.', инфиксы)
если м != 1:
строка += строка(м)
строка += re.sub(r'([0-9]+)', lambda m: sub(m.group(1)), stoich)
если parts[1] не None:
chg = _get_charge (части [1])
если изменение < 0:
токен = '-' если chg == -1 иначе '%d-' % -chg
если изм > 0:
token = '+', если chg == 1, иначе '%d+' % chg
строка += поддержка (токен)
если len(parts) > 4:
поднять ValueError("Неверная формула")
pre_str = ''.join (карта (лямбда x: _subs (x, префиксы), части [2]))
вернуть pre_str + string + ''.join(parts[3])
ключи(), суффиксы)
стехи = части[0].split('.')
строка = ''
для idx, stoich в перечислении (stoichs):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
строка += _subs('.', инфиксы)
если м != 1:
строка += строка(м)
строка += re.sub(r'([0-9]+)', lambda m: sub(m.group(1)), stoich)
если parts[1] не None:
chg = _get_charge (части [1])
если изменение < 0:
токен = '-' если chg == -1 иначе '%d-' % -chg
если изм > 0:
token = '+', если chg == 1, иначе '%d+' % chg
строка += поддержка (токен)
если len(parts) > 4:
поднять ValueError("Неверная формула")
pre_str = ''.join (карта (лямбда x: _subs (x, префиксы), части [2]))
вернуть pre_str + string + ''.join(parts[3])
 {%s}' % x,
формула, префиксы, инфиксы, **kwargs) 9{%s}' % str(int(суффикс)) + единица измерения
еще:
возврат с + единица
{%s}' % x,
формула, префиксы, инфиксы, **kwargs) 9{%s}' % str(int(суффикс)) + единица измерения
еще:
возврат с + единица  )') == u'Fe(CN)₆²⁺(водн.)'
Истинный
>>> Formula_to_unicode('.NHO-(водн.)') == u'⋅NHO⁻(водн.)'
Истинный
>>> Formula_to_unicode('альфа-FeOOH(s)') == u'α-FeOOH(s)'
Истинный
"""
если префиксы None:
префиксы = _unicode_mapping
если инфиксы равны None:
инфиксы = _unicode_infix_mapping
вернуть _formula_to_format(
лямбда x: ''.join(_unicode_sub[str(_)] для _ в x),
лямбда x: ''.join(_unicode_sup[str(_)] для _ в x),
формула, префиксы, инфиксы, **kwargs)
)') == u'Fe(CN)₆²⁺(водн.)'
Истинный
>>> Formula_to_unicode('.NHO-(водн.)') == u'⋅NHO⁻(водн.)'
Истинный
>>> Formula_to_unicode('альфа-FeOOH(s)') == u'α-FeOOH(s)'
Истинный
"""
если префиксы None:
префиксы = _unicode_mapping
если инфиксы равны None:
инфиксы = _unicode_infix_mapping
вернуть _formula_to_format(
лямбда x: ''.join(_unicode_sub[str(_)] для _ в x),
лямбда x: ''.join(_unicode_sup[str(_)] для _ в x),
формула, префиксы, инфиксы, **kwargs)  split('e')
возвращаемый префикс + u'·10' + u''.join(map(_unicode_sup.get, str(int(suffix)))) + unit
еще:
возврат с + единица
split('e')
возвращаемый префикс + u'·10' + u''.join(map(_unicode_sup.get, str(int(suffix)))) + unit
еще:
возврат с + единица  3g'):
"""
Примеры
--------
>>> number_to_scientific_html(3.14) == '3.14'
Истинный
>>> number_to_scientific_html(3.14159265e-7)
'3,14⋅10-7'
>>> количество импорта как pq
>>> number_to_scientific_html(2**0,5 * pq.m / pq.s)
«1,41 м/с»
"""
пытаться:
unit = ' ' + str(число.размерность)
число = число.величина
кроме AttributeError:
единица = ''
s = fmt% число
если 'e' в s:
префикс, суффикс = s.split('e')
префикс возврата + '⋅10' + str(int(suffix)) + '' + единица измерения
еще:
возврат с + единица
3g'):
"""
Примеры
--------
>>> number_to_scientific_html(3.14) == '3.14'
Истинный
>>> number_to_scientific_html(3.14159265e-7)
'3,14⋅10-7'
>>> количество импорта как pq
>>> number_to_scientific_html(2**0,5 * pq.m / pq.s)
«1,41 м/с»
"""
пытаться:
unit = ' ' + str(число.размерность)
число = число.величина
кроме AttributeError:
единица = ''
s = fmt% число
если 'e' в s:
префикс, суффикс = s.split('e')
префикс возврата + '⋅10' + str(int(suffix)) + '' + единица измерения
еще:
возврат с + единица car-java — Googlesuche
AlleBilderMapsVideosNewsShoppingBücher
suchoptionen
Tipp: Begrenze diesuche auf deutschsprachige Ergebnisse. Du kannst deinesuchsprache in den Einstellungen ändern.
Примеры кода java для автомобилей — Tabnine
www.tabnine.com › Код › Java
public class Car { class Constants { public final String MAKE; общедоступная окончательная строка REGISTRATION_NUMBER; private Constants(String make, String regNumber) . ..
..
класс концепт-каров в категории java — liveBook · Manning
livebook.manning.com › concept › java › car-class
Листинг 4.2: Класс Car с методами получения и установки … 1. public class Car { 2. private String марка, модель, цвет; 3. частный год; 4. частный двойной миль на галлон; …
Car.java — суть · GitHub
gist.github.com › …
class Car{. целый год;. Строка сделать;. двойная скорость; общественный автомобиль (int y, String m, double s) {. этот.год = г;. это.сделать = м;. это.скорость = с;. }.
Создание класса автомобиля в Java — Qaru Однако в основном классе вы создаете …
Программа класса автомобилей — java
Создание класса автомобилей Java
Как распечатать регистрацию автомобиля в списке на Java?
Массивы и метод addcar — java
Добавлено на stackoverflow.com
Car.java — Теоретическая информатика
www.tcs.ifi.lmu.de › eip › material › graphicswindows › Car. java › view
java › view
Car.java. Hilfsklasse для Test.java. Значок исходного кода Java … Кап 3 @author Martin Hofmann @version 1.0*/ public class Car { private int xLeft; …
4-3 Java: создание класса Car (Java OOP, Objects … — YouTube
www.youtube.com › смотреть
12.12.2014 · Java Software Solutions Foundations of Programming Challenge 4 -3…
Добавлено: 29:52
Прислано: 12.12.2014
Классы и объекты Java — Baeldung
www.baeldung.com › java-classes-objects
03.05.2020 и методы. Давайте рассмотрим пример с использованием простого класса Java, представляющего автомобиль: class Car { …
car-lib/src/android/car/Car.java — platform/packages/services/Car
android.googlesource. com › услуги › Автомобиль › master
import java.util.List;. импортировать java.util.Objects;. /**. * Автомобильный API верхнего уровня для встроенных развертываний Android Auto. * Этот API работает только для устройств с .