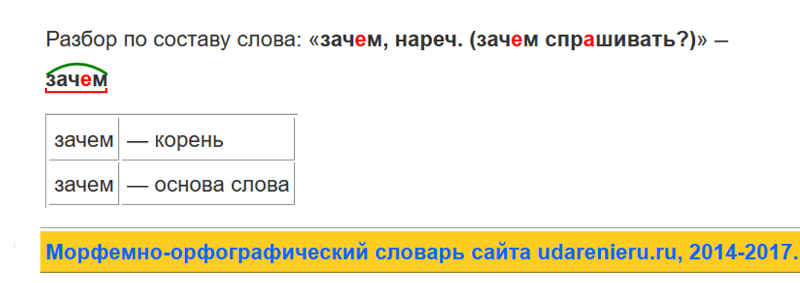
Пьешь корень. «питье» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). См. также в других словарях
Схема разбора по составу питье:
пи ть е
Разбор слова по составу.
Состав слова «питье»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова питье
питьеПодробный paзбop cлoва питье пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa питье, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: пи/ть/е
- Структура слова по морфемам: корень/корень/окончание
- Схема (конструкция) слова питье по составу: корень пи + корень ть + окончание е
- Список морфем в слове питье:
- пи — корень
- ть — корень
- е — окончание
- Bиды мopфeм и их количество в слове питье:
- пpиcтaвкa: отсутствует — 0
- кopeнь: пи,ть — 2
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe:
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова питье
- Основа слова: пить ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: ○ сложение или сращение основ (или целых слов), несобсвенное сложение, так как образовано без соединительной гласной ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову питье
Просклонять слово питье по падежам в единственном и множественном числе…. Склонение слова питье по падежам
Полный морфологический разбор слова «питье»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор питье
Ударение в слове питье: на какой слог падает ударение и как. .. Слово «питье» правильно пишется как… Ударение в слове питье
.. Слово «питье» правильно пишется как… Ударение в слове питье
Синонимы «питье». Словарь синонимов онлайн: подобрать синонимы к слову «питье». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову питье
Анаграммы (составить анаграмму) к слову питье, с помощью перемешивания букв…. Анаграммы к слову питье
К чему снится питье — толкование снов, узнайте бесплатно в нашем соннике что означает сон питье. … Увиденный во сне питье означает, что…Сонник: к чему снится питье
Морфемный разбор слова питье
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова питье делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова; - следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для питье (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.пи ть
Состав слова «пить» :
корень — [пи] , формообразующий суффикс — [ть]
Предложения со словом «пить»
Единственное шампанское, которое можно пить
из небольшой бутылки в 200 мл через трубочку прямо на дискотеке.
После плодотворного труда можно было и вовсе расслабиться, забыть на время рутинные заботы, пить молодое вино и петь озорные песни.
Запретили ей пить и чуть ли не курить.
Маленькие капризничали, просили пить , а большие дрались и играли в фантики.
Лариса погладила его по голове за то, что он растёт и умнеет, Марина снисходительно усмехнулась детской наивности, Степан вовсе пропустил мимо ушей, а Алексей Тихонович вместо того, чтобы пить дальнейшие рюмочки и опрашивать других, лучше ли жить в такой вот квартире или в собственном доме, поднялся, отошёл к окну и задумался.
Вечером пошла к старухе Клавдии Петровне чай пить .
Быт свой и себя содержал опрятно; когда переставал пить , тут его не сдвинуть с места.
И он думал, как хорошо сидеть в таком буфете, слушать тонкие посвисты проносящихся мимо электричек, греться возле печки и пить пиво из кружки.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание.Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
 Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.Схема разбора по составу пьет:
пь ет
Разбор слова по составу.
Состав слова «пьет»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова пьет
пьетПодробный paзбop cлoва пьет пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa пьет, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: пь/ет
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова пьет по составу: корень пь + окончание ет
- Список морфем в слове пьет:
- пь — корень
- ет — окончание
- Bиды мopфeм и их количество в слове пьет:
- пpиcтaвкa: отсутствует — 0
- кopeнь: пь — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: ет — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова пьет
См. также в других словарях:
Полный морфологический разбор слова «пьет»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор пьет
Ударение в слове пьет: на какой слог падает ударение и как… Слово «пьет» правильно пишется как… Ударение в слове пьет
Анаграммы (составить анаграмму) к слову пьет, с помощью перемешивания букв…. Анаграммы к слову пьет
Морфемный разбор слова пьет
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова пьет делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для пьет (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.Бутерброд по составу
Главная » Разное » Бутерброд по составу
бутерброд — морфемный разбор слова, разбор по составу
Графическое обозначение разбора:
бутерброд
Части слова бутерброд
| Структура | корень/окончание |
| Состав слова бутерброд с морфемами | корень бутерброд + окончание нулевое окончание |
Схема разбора по составу бутерброд:
бутерброд/
Состав слова
бутерброд:Bceгo морфем в cлoвe: 2.
Приставка (0) — не имеет Корень (1) — бутерброд Суффикс (0) — не имеет Окончание (1) — нулевое окончание. Соединительная гласная (0) — не имеет Пocтфикc (0) — не имеет
Словообразовательный разбор слова бутерброд
- Основа слова: бутерброд ;
- Средство образования: приставка не имеет, суффикс не имеет, постфикс не имеет;
- Словообразование: непроизводное или образовано бессуффиксально от глагола или прилагательного;
- Способ образования: бессуффиксальный;
Разобрать слово по составляющим его частям (они называются морфемы) — это значит сделать морфемный разбор слова или морфемный анализ. При морфемном разборе слова по составу производится поиск входящих в искомое слово частей и их анализ, отображается графическое и схематическое строение слова.
Для того, чтобы сделать правильный морфемный разбор нужно просто соблюдать правила и порядок разбора.
* Полный разбор «бутерброд» по составу, мopфeмный paзбop и анализ слова, а так же его мopфeм, словообразование, графическое отображение, cxeмa и конструкция слова (по частям): приставка, кopeнь, суффикс и окончание.
фондовых иллюстраций Composition Sandwich — 895 стоковых иллюстраций Composition Sandwich, векторы и клипарт
Снова в школу состав с обедом. Рюкзак, бутерброд, молоко, яблоко и блокнот. Ручной обращается вектор эскиз наброски иллюстрации
Векторный набор концепции завтрака с едой и напитками с плоскими значками в составе. Завтрак состав бутерброд и омлет, сок. E, пекарня для завтрака
Векторный набор концепции завтрака с едой и напитками с плоскими значками в составе.Завтрак состав бутерброд и омлет, сок. E, пекарня для завтрака
Векторное понятие завтрака с едой и напитками с плоскими значками в составе круга. Завтрак состав бутерброд и. Векторный концепт завтрак с едой и
.
6142 Фотографии композиций сэндвичей — бесплатные и лицензионные фотографии из Dreamstime
Сэндвич с прошутто, яйцом и рукколой. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич со шпинатом, яйцом и помидорами. круассан. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
круассан. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с прошутто, яйцом и рукколой.Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Школа, закуска, концепция здорового питания, бутерброд, обед, еда, плоская композиция, экологически чистые продукты. Минимализм. школа Здоровое питание. школьная закуска
Сэндвич с прошутто, яйцом и рукколой. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с прошутто, яйцом и рукколой.Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич со шпинатом, яйцом и помидорами. круассан. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич со шпинатом, яйцом и помидорами. круассан. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Ингредиенты для бутерброда с куриным мясом и овощами на модном цветном фоне. Геометрический макет Состав ингредиентов. Вид сверху. Планировка квартиры
Геометрический макет Состав ингредиентов. Вид сверху. Планировка квартиры
Сэндвич с беконом, яйцом и перцем чили. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич со шпинатом, яйцом и помидорами. круассан. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с беконом, яйцом и перцем чили.Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с беконом, яйцом и перцем чили. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с беконом, яйцом и перцем чили. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с беконом, яйцом и перцем чили.Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
Сэндвич с беконом, яйцом и перцем чили. Завтрак. В тарелке. Вид сверху. Плоская композиция. Бесплатная копия пространства
.
Simple English Wikipedia, бесплатная энциклопедия
Двухъярусный тостовый сэндвич с беконом, помидорами, салатом и яйцом, подается с чипсами на белой фарфоровой тарелке. Скорее всего, на этом бутерброде вместо или в дополнение к маслу намазан майонез. На заднем плане изображен похожий бутерброд, но с салатом вместо чипсов. Обе тарелки находятся на подносе, который стоит на серой мраморной столешнице или столешнице под мрамор.
Сэндвич — это блюдо, приготовленное путем помещения различных продуктов между двумя кусками хлеба.Кусочки хлеба в бутерброде называются ломтиками или листами хлеба. Между ломтиками хлеба люди часто добавляют овощи, мясо или сыр. Считается, что этот бутерброд был первым приготовлен для графа Сэндвича, отсюда и название.
Многим нравится бутерброд, потому что его легко и быстро приготовить в спешке. Кроме того, сэндвич можно легко есть одной рукой без посуды, что позволяет потребителям иметь свободную руку для других дел. Некоторые предпочитают есть бутерброд обеими руками.
Некоторые предпочитают есть бутерброд обеими руками.
Во многих странах дети едят бутерброды на обед в школе. Бутерброды кладут в коробку для завтрака и часто заворачивают в пищевую пленку, чтобы они оставались свежими.
Сэндвич — это не единственный слой начинки между двумя кусками хлеба. В нем может быть более одного слоя начинки и хлеба. Каждый слой начинки обычно называют «колодой». Например, одноярусный сэндвич — это стандартные два ломтика хлеба и один слой начинки. Двухэтажный сэндвич будет состоять из трех ломтиков хлеба с двумя слоями начинки.Обычно один кусок — это один кусок хлеба, разрезанный на две части с начинкой между ними.
Двухэтажный сэндвич называется так потому, что каждый слой начинки образует колоду, как в двухэтажном лондонском автобусе. Клубный сэндвич — это двухэтажный бутерброд с курицей, беконом и салатом. Трехэтажный сэндвич состоит из четырех ломтиков хлеба с тремя слоями начинки.
Сэндвич с одним кусочком хлеба называется открытым сэндвичем или сэндвичем с открытой крышкой. Сверху на хлеб кладется начинка. Открытый бутерброд часто едят ножом и вилкой, хотя его можно взять и съесть вручную.
Сверху на хлеб кладется начинка. Открытый бутерброд часто едят ножом и вилкой, хотя его можно взять и съесть вручную.
Другой вид бутерброда — это поджаренный бутерброд. Поджаренный сэндвич можно приготовить из ломтиков тоста вместо хлеба, или сэндвич целиком поджаривается в духовке или прижиме для сэндвичей.
Бутербродам, приготовленным из разных сортов хлеба, можно давать уникальные имена. Панини, например, обычно представляет собой бутерброд на небольшом булочке или буханке, который зажат между двумя тяжелыми нагретыми пластинами для гриля.
Бутерброды также могут называться многими другими названиями в разных частях мира, такими как «мясорубка», «суб», «хаги» и «клин».
Есть много разных видов бутербродов. Примеры:
Есть много типов начинки, которую можно поместить в сэндвич. Это включает:
Открытый Хлеб> Начинка
Стандартный сэндвич Хлеб> Начинка (возможно хлеб)> Хлеб
Double Decker Bread> Начинка A> Хлеб> Начинка B> Хлеб
Triple Decker Хлеб> Начинка A> Хлеб> Начинка B> Хлеб> Начинка C> Хлеб
В одном из эпизодов сериала The Apprentice от учеников требовалось приготовить бутерброды для Дональда Трампа.
Во французском фильме « Такси » главный герой представляет собой особый бутерброд с половиной байонской ветчины, половиной парижской. Позже это вызывает зависть у другого персонажа.
В мультфильме «Уорнер Бразерс» « Скуби-Ду, » Скуби, как известно, любил готовить сэндвичи с многослойным Шэгги, часто с большим разнообразием начинок.
В телесериале Buffy , во время 61 серии, Баффи смотрит на одноклассника, который ест бутерброд, хватает его и жадно сбрасывает.
В телесериале Star Trek Скотти использовал слово сэндвич для обозначения конструкции части технологии, которая была сделана из трех слоев из двух материалов, что заставило синтезатор пищи на камбузе USS Enterprise поверить что он просит еды. Скотти отменил процесс, ударив обидчика.
Самый большой бутерброд из когда-либо приготовленных был сделан в ресторане Wild Woody’s Chill and Grill, Розвилл, штат Мичиган. Он весил 5440 фунтов. [1]
Викискладе есть медиафайлы, связанные с Бутербродами . |
.
6142 Фотографии Composition Sandwich — бесплатные и лицензионные фотографии из Dreamstime
Плоская композиция с бутербродом и ингредиентами на белом мраморном столе. Плоская композиция с вкусным бутербродом и ингредиентами на белом мраморном столе
Плоская композиция с восхитительным бутербродом на мраморном столе. Место для текста. Плоская композиция с вкусным бутербродом на мраморном столе
Композиция в синих тонах пикника на траве с надувным матрасом, флягой, бутербродом, стаканом с соломкой.И австралийский флаг
Натюрморт композиция сэндвич с беконом на черном хлебе с. Стакан напитка
Композиция плоской планировки с ланч-боксом, бутербродом. И канцелярские товары на сером фоне
Плоская композиция с ланч-боксом, вкусный бутерброд. И канцелярские товары на сером фоне
Плоская композиция с вкусным бутербродом на столе.Место для текста. Плоская композиция с вкусным бутербродом на мраморном столе. Место для текста
Место для текста
Натюрморт композиция сэндвич с беконом на черном хлебе с. Стакан напитка
Натюрморт композиция-бутерброд с беконом на черном хлебе. Крупный план
Натюрморт композиция сэндвич с беконом на черном хлебе с. Стакан напитка
Плоская композиция с вкусным бутербродом с круассаном на столе.Плоская композиция с вкусным бутербродом с круассаном на сером столе
Плоская композиция с вкусным бутербродом с круассаном на столе. Плоская композиция с вкусным бутербродом с круассаном на сером столе
Композиция для пикника в зеленых тонах: лежак с бело-зеленой полосатым матрасом, кулер с соломкой, бутербродами и фруктами. Композиция для пикника в зеленых тонах
Композиция с бутербродом с арахисовым маслом, стеклянной банкой, арахисом и ложкой на белом столе на светлом фоне, место для текста.И крупным планом
Плоская композиция с вкусным бутербродом с круассаном на столе. Место для текста. Плоская композиция с вкусным круассаном на деревянном столе. Место для текста
Место для текста
Плоская композиция с вкусным бутербродом с круассаном на столе, место для текста. Плоская композиция с вкусным сэндвичем с круассаном на сером столе, место для текста
Плоская композиция с вкусным бутербродом.Стакан сока и канцелярские товары на сером фоне
.
В США нацелились на реформу Совбеза ООН новости 8 августа 2022 года — 8 сентября 2022
Общество
8 сентября 2022, 23:24
31 комментарийПрезидент США Джо Байден и руководитель Государственного департамента Энтони Блинкен собираются поднять вопрос о реформе Совета Безопасности ООН. Речь пойдет, в частности, о праве вето. Об этом заявила постоянный представитель США при Организации объединенных наций Линда Томас-Гринфилд, передает «Коммерсантъ».
Речь пойдет, в частности, о праве вето. Об этом заявила постоянный представитель США при Организации объединенных наций Линда Томас-Гринфилд, передает «Коммерсантъ».
«Мы будем наращивать усилия по реформированию Совета Безопасности… Она включает создание резолюции о применении вето… Мы не должны защищать статус-кво, но должны демонстрировать готовность к компромиссу», — цитирует издание слова Томас-Гринфилд.
Это высказывание — не первое предложение по реформе Совбеза ООН. Ранее идею выдвигал премьер-министр Японии Фумио Кисида.
Как отмечает издание, для участия в Генеральной ассамблее ООН, на которой будет выдвинуто предложение, представителям России нужно получить визы США. Однако в данный момент процесс не сдвинулся с мертвой точки.
Больше новостей в нашем официальном телеграм-канале «Фонтанка SPB online». Подписывайтесь, чтобы первыми узнавать о важном.
По теме
- В США хотят добиться исключения России из Совета по правам человека ООН
05 апреля 2022, 07:22
- В Госдепе заявили, что понимают озабоченность России в сфере безопасности, но возврат НАТО к составу 1997 года назвали абсурдным
22 июня 2022, 17:15
- Лондон не дал согласия на созыв Совбеза ООН по Буче. Москва намерена повторить свое требование
04 апреля 2022, 12:45
- Россия запросила заседание Совета Безопасности ООН по поставкам Киеву вооружений
08 сентября 2022, 08:57
- Госсекретарь США и глава МИД Турции встретились, чтобы обсудить НАТО
19 мая 2022, 00:35
 Москва намерена повторить свое требование
Москва намерена повторить свое требованиеУДИВЛЕНИЕ2
ПЕЧАЛЬ2
Комментарии 31
читать все комментариидобавить комментарийПРИСОЕДИНИТЬСЯ
Самые яркие фото и видео дня — в наших группах в социальных сетях
- ВКонтакте
- Телеграм
- Яндекс.Дзен
Увидели опечатку? Выделите фрагмент и нажмите Ctrl+Enter
Новости СМИ2
сообщить новость
Отправьте свою новость в редакцию, расскажите о проблеме или подкиньте тему для публикации. Сюда же загружайте ваше видео и фото.
- Группа вконтакте
Новости компаний
Комментарии31
Новости компаний
Портфель карт «Мир», эмитированных Банком «Санкт-Петербург», за год вырос на 21%
В сентябре 2022 года будет 6 лет, как Банк «Санкт-Петербург» начал эмиссию карт национальной платёжной системы «Мир». Сегодня карты ПС «Мир» выбирают все больше клиентов БСПБ. Портфель карт «Мир» Банка «Санкт-Петербург» за год (с 1.09.2021г. по 01.09.2022г.) вырос на 21%. Банк «Санкт-Петербург» приступил к эмиссии карт ПС «Мир» в сентябре 2016 года. Первыми картами, которые были «переведены» на «Мир» стали «Пенсионные» карты Банка. Подробнее о «семействе» карт «Мир» в БСПБ можно узнать на сайте Банка —…
В Пушкинском районе Санкт-Петербурга готовятся к вводу в эксплуатацию ЖК «Образцовые кварталы 9 и 10»
Объекты построены в рамках комплексного освоения территории на подъезде к Пушкину. Девелопер и основной застройщик проекта — строительная компания «Терминал-Ресурс» Проект занимает площадь 316 га, его реализация рассчитана на 15–20 лет. Сейчас построены и заселены восемь «Образцовых кварталов». Проходит инженерная проверка ЖК «Образцовые кварталы 9 и 10». Продолжается строительство и проектирование следующих новостроек. Ранее застройщик сдал в эксплуатацию детский сад, бизнес-центр «Перспектива», паркинг «Гараж». Ведётся развитие…
Сейчас построены и заселены восемь «Образцовых кварталов». Проходит инженерная проверка ЖК «Образцовые кварталы 9 и 10». Продолжается строительство и проектирование следующих новостроек. Ранее застройщик сдал в эксплуатацию детский сад, бизнес-центр «Перспектива», паркинг «Гараж». Ведётся развитие…
Банк «Санкт-Петербург» поздравляет с Днем финансиста и подводит итоги программы «Будущий банкир»
Банк «Санкт-Петербург» поздравляет всех профессионалов финансовой отрасли с Днем финансиста, который в России отмечается 8 сентября, и подводит итоги стажерской программы для студентов и выпускников вузов «Будущий банкир». Программа стажировки «Будущий банкир» в этом году отмечает 10-летний юбилей. С 2012 года БСПБ готовит из студентов старших курсов и выпускников российских вузов профессионалов — универсальных банковских экспертов. Зачисление на стажерскую программу «Будущий банкир» происходит полностью онлайн, такой формат особенно удобен. ..
..
ТОП 5
1На камеры попало, как пенсионер несет в квартиру в Петербурге желанную установку. Он еще не знает, что она обойдется ему в 1,5 млн
102 628
232«Это катастрофа». Почему этой осенью в лесах Ленобласти нет грибов
97 500
343«Окна задрожали». Ростовчане рассказывают о «громком взрыве»
74 421
584Песков ответил на вопрос о мобилизации в России
73 267
1195Сенатор Климов ответил, нужна ли России мобилизация
69 361
66Новости компаний
Вы пьете корень. «Питьевой»
Разбор схемы по составу напитка:
напиток е
Разбор по слову состав.
Состав слова «напиток»:
Соединительная гласная: пропущено
Постфикс: пропущено
Морфемы — части слова пить
напиток 02 Подробная разбивка слова напиток по составу . Словосочетание, префикс, суффикс и окончание слова. Мофемный состав слова пьянство, его структура и части слова (морфология).
Словосочетание, префикс, суффикс и окончание слова. Мофемный состав слова пьянство, его структура и части слова (морфология). - Схема морфем: пи / т / е
- Структура слова по морфемам: корень / корень / окончание
- Схема (построение) слова напиток по составу: корень пи + корень т + окончание е
- Список морфем в слове напиток:
- пи — корень
- т — корень
- е — конец
- Виды морф и их количество в слове напиток:
- доставка: отсутствует — 0
- матка: напиток — 2
- соединительный глас: отсутствует — 0
- cyffix: отсутствует — 0
- постфикс: отсутствует — 0
- конец: e
— 82 1 1
Всего морфем в слове: 3.
Словообразовательный разбор слова напиток
- Основа слова: напиток ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: ○ сложение или сращивание основ (или целых слов), неправильное сложение, так как оно образуется без соединительной гласной ;
- Способ образования: производный, так как образован 1 (одним) способом .

См. также другие словари:
Однокоренные слова… это слова с корнем…, принадлежащие к разным частям речи, и в то же время близкие по значению… Слова с одним корнем к слову напиток
Что такое питье во множественном числе…. Что такое питье?
Полный морфологический разбор слова «напиток»: Часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово… Морфологический разбор пить
Ударение в слове пить: на какой слог ударение и как… Слово «пить» правильно пишется как… Ударение в слово пить
Синонимы к слову «пить». Онлайн-словарь синонимов: найдите синонимы к слову «напиток». Синонимичные слова, похожие слова и похожие выражения в… Алкогольные синонимы
Анаграммы (составить анаграмму) к слову пить, смешав буквы… Анаграммы к слову пить
К чему снится пить — толкование снов, узнайте бесплатно в нашем соннике к чему снится пить во сне. … Увиденный во сне напиток означает, что. .. Сонник: к чему снится пить
.. Сонник: к чему снится пить
Морфемный разбор слова напиток
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова пить очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем разбор морфем правильным, но для этого пройдём всего 5 шагов:
- определение части речи слова — первый шаг;
- второй — подбираем окончания: для изменяемых слов спрягаем или раздуваем, для неизменяемых (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- дальше ищем основу. Это самая простая часть, потому что вам просто нужно обрезать конец, чтобы определить основу. Это будет основой слова;
- Следующим шагом будет поиск корня слова. Подбираем родственные слова для питья (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.

Как ты видишь, разбор морфем делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слов (словоразбор) — поиск корня, префиксов, суффиксов, окончаний и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.напиток
Состав слова «пить» :
корень — [пи], формообразующий суффикс- [й]
Предложения со словом «пить»
Единственное шампанское, которое можно пить из маленькой 200 мл бутылочки через соломинку прямо на дискотеке.
После плодотворной работы можно было полностью расслабиться, забыть на время рутинные заботы, выпить молодого вина и спеть озорные песни.
Ей запретили пить и почти курить.
Маленькие капризничали, просили попить, а большие дрались и играли в фантики.
Лариса гладила его по головке за то, что он рос и умнел, Марина снисходительно улыбалась детской наивности, Степан вообще его игнорировал, а Алексей Тихонович вместо того, чтобы пить дальше стаканы и расспрашивать других, лучше ли жить в такой квартире или в своем доме, встал, подошел к окну и задумался.
Вечером пошел пить чай со старухой Клавдией Петровной.
Он аккуратно держал себя и свою жизнь; когда он бросил пить, то не мог сдвинуться с места.
И подумал, как хорошо сидеть в таком буфете, слушать тонкие гудки проносящихся мимо электропоездов, греться у печки и пить пиво из кружки.
Разобрать слово по составу, что оно означает?
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по месту в слове и установление значения каждой из них. В школьной программе его еще называют разбор морфем . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово по его составу?
При разборе морфем соблюдать определенную последовательность выделения значащих частей. Начните с того, чтобы «снять» морфемы с конца, используя прием «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
- Запишите слово так же, как в домашнем задании. Перед тем, как начать разбирать композицию, выясните лексическое значение (значение).
- Определить из контекста, к какой части речи относится. Вспомните признаки слов, принадлежащих к этой части речи:
- изменяемое (имеет окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразовательный суффикс?
- Найдите концовку. Для этого склоняйте по падежам, меняйте число, род или лицо, спрягайте — переменная часть будет окончанием. Помните об изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: сон (), друг (), слышимость (), благодарность (), съел ().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с приставками и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найдите корень в основании. Для этого сравните ряд родственных слов. Их общей частью является корень. Запомните однокоренные слова с чередующимися корнями.
- Если слово имеет два (и более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить синтаксический анализ и выделить все значимые части значками
 Для этого сравните однокоренные слова с приставками и без них.
Для этого сравните однокоренные слова с приставками и без них.В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5-9 классах для общеобразовательных школ. У разных авторов подход к разбору морфем отличается. Чтобы избежать проблем с выполнением домашнего задания, сравните приведенную ниже процедуру разбора с вашим учебником.
Порядок полного разбора морфем по составу
Во избежание ошибок желательно связать разбор морфем с словообразовательным разбором. Такой анализ называется формально-семантическим.
- Установите часть речи и выполните графический морфемный анализ слова, то есть обозначьте все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение… Укажите суффиксы словоформ (если есть)
- Выпишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пи-а-й → пи-а-й → пи-а-й», «сух(ой) → суши-ар() → суши-ар-ниц -(а)». Для слов со связными корнями выбирайте одноструктурные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «спать»:
- окончание «а» указывает на форму глагола женского пола, единицы числа, прошедшее время, ср.: проспал;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением убытка, невыгоды, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепь: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сп/сон//сып. Однокоренные слова: сон, засыпание, сонливость, недосыпание, бессонница.
Схема разбора состава напитков:
drink em
Разбор слова состава.
Состав слов «напитки»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова напитки
напиткиПодробная разбивка слова напитки по составу. Словосочетание, префикс, суффикс и окончание слова. Мофемное расположение слова напитки, его структура и части слова (морфология).
- Схема морфем: п/э
- Структура слова по морфемам: корень/окончание
- Схема (построение) слова drink по составу: корень pt + окончание em
- Список морфем в слове drink:
- p — корень
- em — окончание
- Типы морфов и их номер в Word Drink:
- Доставка: Отсутствует — 0
- Королева: P — 1
- Соединение GLAC: Отсутствует — 0
- CYFFIX: Отсутствует — — 0
- : . 0
- постфикс: отсутствует — 0
- конец: нет — 1
Всего морфем в слове: 2.
Словообразовательный разбор слова напитки
См. также другие словари:
Полный морфологический разбор слова «напитки»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово… Морфологический разбор напитки
Ударение в слове напитки: на какой слог падает ударение и как… Слово «напитки» правильно пишется как.. Ударение в слове напитки
Анаграммы (составить анаграмму) к слову напитки, путем смешивания букв… Анаграммы к слову напитки
Морфемный разбор слова напиток
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова напиток очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого пройдем всего 5 шагов:
- определение части речи слова — первый шаг;
- второй — подбираем окончания: для изменяемых слов спрягаем или раздуваем, для неизменяемых (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- далее ищем основу. Это самая простая часть, потому что вам просто нужно обрезать конец, чтобы определить основу. Это будет основой слова;
- Следующим шагом будет поиск корня слова. К напиткам подбираем родственные слова (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
Как видите, разбор морфем делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слов (словоразбор) — поиск корня, префиксов, суффиксов, окончаний и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.Распутывание семантической композиции и семантической ассоциации в левой височной доле
ПредыдущийСледующий
Исследовательские статьи, поведенческие/когнитивные
Джисин Ли и Лиина Пюлкканен
Journal of Neuroscience 28 июля 2021 г., 41 (30) 6526-6538; DOI: https://doi. org/10.1523/JNEUROSCI.2317-20.2021
- Article
- Figures & Data
- Info & Metrics
- eLetters
Abstract
Although composing two words into a сложное представление (например, «кофейный пирог») концептуально отличается от формирования ассоциаций между парой слов (например, «кофе, пирожное»), области мозга, поддерживающие семантическую композицию, также участвуют в ассоциативном кодировании. Здесь мы приняли парадигму магнитоэнцефалографии (МЭГ) из двух слов, которая различается по составу («французский/корейский сыр» по сравнению с «французский/корейский сыр») и силе ассоциации («Франция/французский сыр» по сравнению с «корейский/корейский сыр»). между двумя словами. Мы собрали данные MEG, в то время как 42 носителя английского языка (24 женщины) последовательно просматривали два слова в сканере, и мы применили как одномерный регрессионный анализ, так и многомерную классификацию шаблонов к исходным оценкам двух слов. Мы показываем, что левая передняя височная доля (LATL) и левая средняя височная доля (LMTL) отчетливо модулируются семантическим составом и семантическими ассоциациями. В частности, LATL наиболее чувствителен к композиционным фразам с высокой ассоциацией, в то время как LMTL больше реагирует на композиционные фразы с низкой ассоциацией. Анализ направленной связи на основе паттернов также выявил непрерывный поток информации от передней к средней височной области, предполагая, что интеграция свойств прилагательных и существительных, возникшая ранее в LATL, последовательно передается в LMTL, когда новое сложное значение встречается. Взятые вместе, наши результаты проливают свет на функциональную диссоциацию в левой височной доле для композиционной и распределительной семантической обработки.
ЗАЯВЛЕНИЕ О ЗНАЧИМОСТИ Предыдущие исследования семантической композиции и ассоциативного кодирования проводились независимо в подполях языка и памяти, и они, как правило, используют аналогичные экспериментальные парадигмы из двух слов. Однако прямого сравнения нейронных субстратов двух процессов не проводилось. Текущее исследование связывает два потока литературы и обращается к аудитории в обеих областях когнитивной нейробиологии. Распутывание нейронных вычислений для семантической композиции и ассоциации также дает представление о моделировании композиционной и распределительной семантики, которая была предметом многочисленных дискуссий в области обработки естественного языка и когнитивной науки.
- LATL
- LMTL
- MEG
- семантическая ассоциация
- семантическая композиция
Введение
Когда мы слышим пару слов, означающих «кофе», мы можем составить комплекс слов «кофе» и «кофе». со вкусом торта или вспомните случай, когда кофе и торт появились вместе. Эти два процесса, хотя и концептуально разные, были локализованы в сходных областях мозга в левой височной доле. Например, минимальная фраза из прилагательного и существительного, такая как «красная лодка», вызывает повышенную активность в левой передней височной доле (LATL) по сравнению с несоставными списками слов, такими как «чашка, лодка» (Bemis and Pylkkänen, 2011, 2013). , и аналогичный эффект наблюдался для языка с обратным порядком слов (Westerlund et al., 2015) и для американского жестового языка (Blanco-Elorrieta et al., 2018), что предполагает роль LATL в концептуальной комбинации. Однако LATL также активируется при формировании произвольных ассоциаций между парами слов, такими как «кольцо» и «сыр» (Jang et al., 2017), и демонстрирует более сильные колебательные реакции для пар слов с более сильными ассоциациями (Teige et al., 2018, 2019). Кроме того, временное виртуальное поражение, вызванное повторяющейся транскраниальной магнитной стимуляцией (rTMS) над LATL, значительно замедляет время определения синонимов (Pobric et al., 2007), отражая основную особенность семантической деменции (SD) у пациентов с очаговой атрофией ATL. (Ходжес и др., 1992; Гальтон и др., 2001; Нестор и др., 2006). LATL также участвует в ассоциациях человеческого имени (Wang et al., 2017) и местоположения лица (Nieuwenhuis et al., 2012), а записи одиночных нейронов в ATL мозга макака предполагают, что группа парных кодирующие нейроны реагировали только на ассоциированные пары абстрактных фигур во время фазы обучения (Сакаи и Мияшита, 19). 91; Хирабаяши и др., 2014).
Предыдущие исследования семантической композиции и ассоциативного кодирования проводились независимо в рамках областей языка и памяти, и они, как правило, используют аналогичные экспериментальные парадигмы из двух слов. Однако прямого сравнения нейронных субстратов двух процессов не проводилось. Оба они связаны с соединением двух элементов, хотя и интуитивно по-разному. Сходящиеся нейронные свидетельства в левой передней височной коре поднимают вопрос о том, могут ли они включать некоторые общие процедуры обработки. Это исследование направлено на то, чтобы охарактеризовать, как эффекты состава и ассоциации сравниваются друг с другом и, возможно, взаимодействуют в левой височной доле. Мы приняли ту же парадигму из двух слов, но скрестили композиционность и силу ассоциации между двумя словами, используя формы прилагательного и существительного слова страны, и наши знания о еде в мире. «Французский сыр» и «французский сыр», например, являются тесно связанными парами деревенская еда по сравнению с «корейским сыром» и «корейским сыром». Но и «французский сыр», и «корейский сыр» являются комбинаторными сочетаниями прилагательных и существительных, тогда как «французский сыр» и «корейский сыр» — это просто списки слов. Этот план 2 × 2 (рис. 1) позволил нам разделить эффекты ассоциации и композиции во время понимания двух слов и изучить, действительно ли LATL поддерживает семантическую композицию или просто отслеживает ассоциацию.
Рис. 1.
Экспериментальный дизайн. A , Экспериментальный дизайн и пробная конструкция. В нашем дизайне сочетались сила ассоциации (низкая и высокая) и композиционность (список и подборка). В каждом испытании участники указывали, соответствует ли целевое изображение предшествующим словам. Половина целевых изображений совпали, а половина — нет. Была проанализирована активность, зарегистрированная от 100 мс до начала стимула до 1200 мс после начала стимула. B , Схематическая диаграмма, показывающая, как значение косинуса между многомерными векторами представляет семантическое сходство. Чем меньше угол между двумя векторами, тем выше значение косинуса и семантическое сходство. Угол между «французским» и «сыром» меньше, чем между «корейским» и «сыром», потому что они имеют больше общих контекстуальных особенностей. Многомерные вложения слов визуализировались на двумерном рассеянии с использованием t-SNE. Рисунки 1-1, 1-2, 1-3 с расширенными данными поддерживают рисунок 1.
Расширенные данные Рисунок 1-1
Списки стимулов для эксперимента 1. Загрузите Рисунок 1-1, файл TIF.
Расширенные данные Рисунок 1-2
Списки стимулов для эксперимента 2. Загрузите Рисунок 1-2, файл TIF.
Расширенные данные Рис. 1-3
Частота регистрации всех слов в экспериментах 1 и 2. Загрузите рис. 1-3, файл TIF.
Мы собрали данные магнитоэнцефалографии (МЭГ) 42 носителей английского языка, когда они последовательно просматривали два слова на экране. Мы закодировали ассоциацию и состав как бинарные переменные и применили массовый одномерный регрессионный анализ к локализованным в источнике данным MEG в языковой сети. Затем мы провели анализ многомерной классификации паттернов на основе прожектора в той же языковой сети. Чтобы лучше понять поток информации между активными областями мозга, мы провели направленный анализ связности с использованием матриц репрезентативных различий (RDM) данных MEG в пределах интересующих функциональных областей (fROI), полученных в результате регрессионного и классификационного анализов (см. рис. 2).
Рисунок 2.
Схематическое изображение процедуры анализа. A , Двухэтапный множественный регрессионный анализ. На первом этапе была применена обычная регрессия наименьших квадратов к оценкам каждого участника в одном испытании источника для каждого источника в пределах выбранного региона в каждый момент времени окна анализа. На втором этапе выполнялся одновыборочный t-критерий распределения значений β по испытуемым для каждой переменной в каждом источнике и в каждый момент времени, чтобы проверить, достоверно ли отличаются их значения от нуля. Значимость определялась коррекцией TFCE с 10 000 перестановок. B , Анализ многомерной классификации шаблонов прожектора. Линейный SVM был обучен на комбинации псевдоиспытаний из двух условий и протестирован на исключенной паре со 100 перестановками. Один и тот же анализ SVM применялся независимо к каждому источнику и моменту времени в языковой маске. Точность классификации, усредненная по субъектам в источнике и момент времени за вычетом уровня вероятности 50%, подвергалась одновыборочному t-критерию, а значимость определялась поправкой TFCE с 10 000 перестановок. C , Направленный анализ связности. RDM исходных оценок двух fROI, полученных на основе регрессионного и классификационного анализа в момент времени t (D(A, t) и D(B, t) ), были рассчитаны как 1 минус корреляция между условия. Направленная активность из области А в область В была количественно определена как коэффициент частичной корреляции между D(A, t — dt) и D(B, t) , D(B, tdt) , где dt — временной интервал между текущим моментом времени и предыдущим моментом времени. Значимость коэффициентов >0 определяли по 10 000 перестановок с уровнем α 0,05.
С помощью этой комбинации методов мы показываем, что LATL более чувствителен к контрасту между высоко- и низкоассоциативными композиционными фразами, в то время как левая средняя височная извилина (LMTG) в основном управляется различием между низкоассоциативными композиционными фразами и низкоассоциативными фразами. -ассоциативные списки. Направленный анализ связности предполагает непрерывный поток информации от LATL к LMTG. Взятые вместе, наши результаты предоставляют новые доказательства того, что LATL и левая средняя височная доля (LMTL) отчетливо модулируются семантическим составом и семантическими ассоциациями.
Материалы и методы
План эксперимента
Мы провели два варианта эксперимента, оба использовали план 2 × 2 с ассоциативной силой (низкая, высокая) и композиционностью (Comp, List) в качестве факторов. В первом эксперименте было 60 испытаний для каждого из четырех условий и 60 контрольных слов, состоящих из 5 «x» и существительного (например, «ххххх сыр»), что в общей сложности составляет 300 уникальных испытаний. Во втором эксперименте каждое условие содержит 45 испытаний и 45 контролей из одного слова, что в сумме составляет 360 уникальных испытаний. Тесты с одним словом состояли из строк согласных по длине и существительного, обозначающего еду (например, «сыр xjtgbv»).
Участники
Участники были здоровыми молодыми людьми с нормальным слухом и нормальным или скорректированным до нормального зрением. Все строго квалифицированы как правши в эдинбургском реестре леворукости (Oldfield, 1971). Они идентифицировали себя как носители английского языка и дали письменное информированное согласие перед участием в соответствии с рекомендациями IRB Нью-Йоркского университета и Нью-Йоркского университета в Абу-Даби. Всего в эксперименте 1 участвовало 30 добровольцев, девять из них были исключены из анализа данных: восемь из-за чрезмерного движения или сонливости во время записи МЭГ и один из-за плохого выполнения поведенческого задания (точность <75%). Всего в эксперименте 2 участвовало 26 добровольцев, пять из них были исключены из дальнейшего анализа данных: четверо из-за чрезмерной подвижности или сонливости при записи МЭГ и один из-за плохого выполнения поведенческого задания. Таким образом, в анализы были включены в общей сложности 21 участник (10 женщин, средний возраст = 21,6 года, SD = 4,5) в эксперименте 1 и 21 участник (14 женщин, средний возраст = 23 года, SD = 7,7) в эксперименте 2. Ни один участник не присутствовал на обоих экспериментах. Размер нашей выборки не был определен заранее, но он значительно больше, чем типичный размер выборки, составлявший около 20–25 участников в предыдущих исследованиях MEG по семантической композиции (Bemis and Pylkkänen, 2011; Westerlund and Pylkkänen, 2014).
Эксперимент 1 проводился в Лаборатории нейронауки языка Нью-Йоркского университета в Абу-Даби, а эксперимент 2 — в исследовательских учреждениях Лаборатории нейронауки языка Нью-Йоркского университета и Нью-Йоркского университета Абу-Даби. Данные шести участников были собраны на объекте в Нью-Йорке.
Стимулы
Стимулы, состоящие из прилагательного/существительного, обозначающего название страны, и существительного, связанного с едой, с силой ассоциации (низкая, высокая) и композиционностью (композиция, список) в качестве факторов (рис. 1 9).0418 А ). Мы количественно оценили силу ассоциации между словом «страна» и словом «еда», используя показатель косинусного сходства между вложениями GloVe 17 двух слов: высокоассоциативные фразы (например, «французский/французский сыр») имеют косинусное сходство >0,3 и низкое ассоциативные пары (например, «корейский/корейский сыр») имеют косинусное сходство ниже 0,15 (см. рис. 1-1, 1-2 с расширенными данными). Обратите внимание, что, хотя списки существительных (например, «французский сыр») не были синтаксически составными, участники все же могут попытаться составить концептуальную композицию во время выполнения задания. Чтобы гарантировать, что условия списка действительно не являются композиционными, как предполагалось, мы включили условие управления одним словом. Однословное условие состояло либо из «xxxxx», либо из согласованной по длине строки согласных (например, «xjtgbv») и критического существительного слова (например, «сыр»). Половина участников ( n = 21) увидел «ххххх», а другая половина увидела согласные строки. Одной из дополнительных целей нашего исследования было изучение влияния этих двух разных типов исходных визуальных линий, но они действовали одинаково в отношении нашей основной манипуляции.
Процедуры эксперимента
Перед записью форма головы каждого субъекта была оцифрована с помощью портативного лазерного сканера Polhemus FastSCAN с двумя источниками. Затем участники завершили эксперимент, лежа на спине в слабо освещенной комнате с магнитным экраном (MSR). На объекте в Абу-Даби данные МЭГ записывались непрерывно с использованием 208-канальной аксиальной градиентометрической системы для всей головы (Технологический институт Канадзавы, Канадзава, Япония), на объекте в Нью-Йорке данные МЭГ собирались с использованием 156-канальной системы для измерения всей головы. система осевого градиентометра (Технологический институт Канадзавы).
Стимулы проецировались с помощью PsychoPy2 (Peirce et al., 2019) на экран на расстоянии ~80 см от глаз участников. Два слова предъявлялись в течение 300 мс каждое белым шрифтом Courier New размером 30 пунктов на сером фоне под вертикальным углом обзора 2°. Поскольку высокоассоциативные фразы, такие как «французское вино», могут храниться либо в виде лексических единиц, либо в виде многословных выражений (Arnon and Snider, 2010; Jacobs et al., 2016, 2017), мы представили два слова по отдельности, чтобы стимулировать комбинаторику. или ассоциативный процесс вместо извлечения фразы в целом. Изображение появлялось на экране после целевых слов и оставалось до тех пор, пока испытуемые не указывали, было ли это совпадение или несоответствие предыдущим словам, нажимая кнопку указательным пальцем левой руки для совпадения и средним пальцем для несоответствия. Никакой обратной связи не было предоставлено. Эта же задача сопоставления картинок использовалась в предыдущих исследованиях семантической композиции (Бемис и Пюлкканен, 2011, 2013). Между каждым словом и изображением отображался пустой экран на 300 мс. Межстимульный интервал был нормально распределен со средним значением 400 мс (SD = 100 мс, минимум = 135 мс, максимум = 734 мс). Порядок предъявления стимулов был псевдорандомизированным, так что половина испытаний была совпадением, а другая половина — несоответствием. Каждый участник получил уникальную рандомизацию. Изображения для задачи категоризации были выбраны таким образом, чтобы стимулировать концентрацию как на существительных/прилагательных страны, так и на существительных еды. Для условий с двумя словами целевое изображение показывает продукт питания с флагом страны, и слова страны и продукта питания должны совпадать; для условия с одним словом изображение содержит только продукт питания. Все изображения были цветными фотографиями, найденными в Google Images. Весь сеанс записи, включая время на подготовку и практику, длился около 40 минут.
Сбор и предварительная обработка данных МЭГ
Данные МЭГ записывались непрерывно с частотой дискретизации 1000 Гц с включенным полосовым фильтром от 0,1 до 200 Гц. Необработанные данные сначала уменьшали шум с помощью непрерывно корректируемого метода наименьших квадратов (Adachi et al., 2001) и подвергали низкочастотной фильтрации на частоте 40 Гц. Затем был применен анализ независимых компонентов (ICA) для удаления артефактов, таких как моргание глаз, сердцебиение, движения и хорошо охарактеризованные внешние источники шума (среднее значение компонентов ICA = 36; минимальное количество компонентов ICA = 12; компоненты ms ICA = 66). Затем данные МЭГ были сегментированы на эпохи, охватывающие период от 100 мс до начала стимула до 1200 мс после начала стимула. Эпохи, содержащие амплитуды, превышающие абсолютный порог в 2000 фТл, автоматически удалялись. Дополнительное отбрасывание артефактов выполнялось путем ручной проверки данных, удаляя испытания, которые были загрязнены артефактами движения или посторонними шумами. Процедура отбраковки всей эпохи приводит к средней частоте отбраковки 90,4% (SD = 6,5%) для каждого участника.
Оценки минимальной нормы с корковыми ограничениями (mne; Hämäläinen and Ilmoniemi, 1994) были рассчитаны для каждой эпохи для каждого участника. Следуя предыдущей литературе по семантической композиции (Бемис и Пылкканен, 2011, 2013; Вестерлунд и др., 2015; Лю и др., 2019; Флик и Пылкканен, 2020), мы использовали mne вместо формирования луча всего мозга для реконструкции источника. Для локализации источника положение головы участника регистрировалось относительно массива датчиков в шлеме МЭГ. Для участников с анатомическими МРТ ( n = 5), это включало вращение и перемещение цифрового скана, чтобы минимизировать расстояние между реперными точками МРТ и сканом головы. Для участников без анатомических сканов использовался «fsaverage» мозг FreeSurfer (http://surfer.nmr.mgh.harvard.edu/), который включал сначала вращение и перемещение, а затем масштабирование среднего мозга для соответствия размеру головы. сканирование. Для каждого участника на поверхности коры было создано исходное пространство из 2562 исходных точек на полушарие. Метод граничных элементов (МГЭ) использовался для вычисления прямого решения, объясняющего вклад активности в каждом источнике в магнитный поток на датчиках. Ковариация канал-шум оценивалась на основе 100-мс интервалов перед каждым испытанием без артефактов. Обратное решение было вычислено на основе прямого решения и общей средней активности по условиям. Чтобы снять ограничение на ориентацию диполей, обратное решение было вычислено со «свободной» ориентацией, что означает, что обратный оператор размещает три ортогональных диполя в каждом месте, определяемом исходным пространством. При вычислении исходной оценки учитывалась только активность диполей, перпендикулярных коре. Для каждого испытания в пределах одного условия применялся один и тот же обратный оператор для этого условия, чтобы получить карты динамических статистических параметров (dSPM) в единицах (Dale et al., 2000) с использованием значения отношения сигнал-шум (SNR), равного 3. Все этапы предварительной обработки данных выполнялись с помощью MNE-python (v.0.19.2; Gramfort et al., 2014) и Eelbrain (v.0.25.2).
Количественная оценка семантических ассоциаций
Семантические векторы для слов о стране и еде были получены с использованием известной модели встраивания слов GloVe (Pennington et al., 2014; в свободном доступе на https://nlp.stanford.edu/projects/glove /), обученный с помощью Common Crawl (https://commoncrawl.org/), который содержит петабайты необработанных данных веб-страницы, извлечения метаданных и текстовые извлечения. Модель GloVe воплощает в себе «дистрибутивную гипотезу» о том, что слова с похожим значением встречаются в схожих контекстах в подходе искусственной нейронной сети. Получив 300-мерный вектор для каждого слова, мы затем количественно оценили, насколько семантически связано каждое слово страны со словом «еда», вычислив показатель косинусного сходства между векторами из двух слов. В целом, наш подход генерировал высокоассоциативные фразы (например, «французский/французский сыр») со средним показателем косинусного сходства 0,34 (SD = 0,1) и низкоассоциативные пары (например, «корейский/корейский сыр») со средним косинусным сходством. оценка 0,08 (SD = 0,05). В паре 9Тест 0418 t выявил значительную разницу между оценкой сходства косинусов двух групп ( t = 29,8, p ≅ 0). Чтобы увеличить разницу, мы дополнительно применили анализ основных компонентов (PCA) к вложениям слов и рассчитали оценку косинусного сходства для каждой пары слов на основе первых 30 ПК. Это привело к среднему косинусу 0,05 (SD = 0,18) для высокоассоциативных пар и среднему косинусу -0,37 (SD = 0,09) для низкоассоциативных пар. Разница в группах была достоверной ( t = 28,7, p ≅ 0), но это не сделало две группы более разными (оценку косинусного сходства для каждой пары слов на основе их 300-мерных вложений и 30 ПК см. 1-1, 1-2). Рисунок 1 B визуализирует все вложения слов на двумерной диаграмме рассеяния с использованием t -распределенного стохастического соседнего встраивания (t-SNE; van der Maaten, 2014).
Статистический анализ
Анализ поведенческих данных
Точность анализировалась с использованием обобщенной линейной смешанной модели (GLMM) с биномиальным распределением ошибок и логит-связью, а время отклика (RTs) анализировалось с использованием GLMM с логарифмически нормальным преобразованием. Для максимальной модели фиксированные эффекты включали в себя основные эффекты композиции, ассоциации и их взаимодействия, а также различия между одиночным и средним всеми четырьмя двусловными состояниями. Мы включили ассоциацию либо как категориальную, либо как непрерывную переменную с оценками косинусного сходства (как до, так и после PCA). Результаты сравнения моделей показали, что оптимальная модель, включающая ассоциацию в качестве категориальной переменной, лучше объясняет поведенческие данные, чем когда ассоциация была включена в качестве непрерывной переменной. Случайные эффекты включали случайное пересечение по субъектам и наклоны всех фиксированных эффектов, а также случайное пересечение по элементам (Barr et al., 2013). Кроме того, в качестве контрольных переменных использовалась частота слова 1 и 2, которые рассчитывались на основе объединенного количества слов из униграмм Google Book (http://books.google.com/ngrams) и корпуса SUBTLEXus (Brysbaert and New). , 2009 г.). Логарифмическая частота каждого слова показана на рис. 1-3 с расширенными данными. RT выше или ниже трех стандартных отклонений были удалены в предположении, что они представляли собой ошибки или отвлекающие факторы, а не ответы, связанные с заданием.
Если максимальная модель не могла сходиться, ее случайные эффекты ортогонализировались, создавая модель с нулевым параметром корреляции (ZCP). PCA был применен к результатам модели ZCP, и случайные эффекты, которые объясняли <1% общей дисперсии, были удалены из модели ZCP для создания сокращенной модели. Расширенная модель была построена путем добавления корреляций между случайными эффектами в сокращенной модели. Если расширенная модель по-прежнему не могла сходиться, ее случайные эффекты, которые объясняли <1% общих отклонений, были дополнительно удалены для создания обновленной расширенной модели. Этот шаг повторялся до тех пор, пока расширенная модель не сойдется. Затем конвергентная расширенная модель сравнивалась с редуцированной моделью. Модель, которая лучше объясняла данные (с меньшим информационным критерием Акаике) и использовала меньше параметров, была выбрана в качестве оптимальной модели, результаты которой были представлены (Bates et al., 2015a).
Анализ GLMM проводился с помощью пакета «lme4» (Bates et al., 2015b) в R (v3.6.3) и RStudio (v1.2). Статистическую значимость фиксированных эффектов оценивали с помощью пакета lmerTest (Кузнецова и др., 2017), в котором для оценки степеней свободы применялась аппроксимация Саттертуэйта.
Массовая одномерная множественная регрессия
Мы закодировали факторы состава и ассоциации как бинарные переменные и выполнили двухэтапную множественную регрессию с однократными исходными оценками в качестве зависимых переменных, а также композиционность, силу ассоциации и их взаимодействие, а также количество слов в качестве предикторов (рис. 2 А ). Мы закодировали ассоциацию как бинарную переменную, поскольку поведенческий анализ показал, что ассоциация как категориальная переменная объясняет ответ лучше, чем ассоциация как непрерывная переменная. Мы не использовали ту же модель со смешанными эффектами для поведенческого анализа, поскольку максимальная модель обычно не может сходиться, и мы должны урезать случайные эффекты в соответствии с Bates et al. (2015а). Поскольку мы провели массовый одномерный анализ для 755 источников × 1301 момент времени, значит, мы должны провести процедуру обрезки для 755 × 1301 = 982 255 раз. Это не практично для реализации. Анализ мощности глобального поля во времени по источнику также не идеален, поскольку мы специально хотим знать как пространственную, так и временную степень наших эффектов. Поэтому мы, следуя предыдущей литературе, использовали двухэтапный регрессионный анализ данных MEG (Gwilliams et al., 2016)
Учитывая значительное влияние частоты слов на поведенческие результаты, мы также включили частоту первого и второго слова в качестве контроля. переменные. На первом этапе мы применили обычную регрессию наименьших квадратов для оценок источников каждого испытуемого в одной попытке для каждого источника в рамках двусторонней языковой маски в каждую миллисекунду от 100 мс до начала первого слова до 1200 мс после начала стимула. Языковая маска (Рис. 4 A , E , светло-розовая область) покрытых областей, включая всю височную долю, нижнюю лобную извилину (НЛГ; определяется как комбинация БА 44 и 45), вентромедиальную префронтальную кору (vmPFC; определяется как ВА11), угловая извилина (AG; определяется как BA39) и супрамаргинальная извилина (SMA; определяется как BA 40). Левый AG и vmPFC также упоминались в предыдущей литературе по концептуальной комбинации (Bemis and Pylkkänen, 2011; Price et al., 2015), а LIFG и LMTG предполагались в основе синтаксической комбинации (Haggort, 2005; Lyu et al. др., 2019; Матчин и др., 2019; Флик и Пюлкканен, 2020 г.; Матчин и Хикок, 2020 г.). Регрессия первого этапа привела к коэффициенту β для каждой переменной в каждом источнике и в каждый момент времени для каждого субъекта.
На втором этапе мы провели одновыборочный тест t распределения значений β по испытуемым для каждой переменной в отдельности, опять же в каждом источнике и в каждый момент времени, чтобы проверить, достоверно ли отличаются их значения от нуля . Мы применили подход беспорогового кластерного улучшения (TFCE) для определения значимой пространственно-временной точки в нашей маске (Смит и Николс, 2009 г.).). Подход TFCE направлен на улучшение областей сигнала, которые демонстрируют некоторую пространственную и временную смежность, не полагаясь на кластеризацию на основе жесткого порога. Каждая непороговая статистика t для пространственно-временной точки проходит через алгоритм, который увеличивает интенсивность внутри кластероподобных областей. А именно, выход TFCE для источника s в момент времени t равен TFCE(s)=∫h=h0hse(h)EhHdh, где h s — статистическое значение t , h 0 равно 0, e(h) является протяженностью одного кластера, содержащего точку p . Следовательно, оценка TFCE каждой точки представляет собой сумму оценок всех «поддерживающих секций» под ней, которая представляет собой просто высоту h (возведенную в некоторую степень H ), умноженную на экстент кластера e ( h ). ) (в некоторой степени E ). Мы повторили эту процедуру 10 000 раз. Это включало случайное перетасовку 0 и коэффициента β для каждого участника, повторяя массовую одномерную одномерную выборку t и рассчитали значение TFCE для каждой пространственно-временной точки в пределах маски и временного окна анализа 0–1200 мс после начала действия стимула. Наблюдаемому значению TFCE для каждой пространственно-временной точки впоследствии было присвоено значение p на основе доли случайных разделов, которые привели к большей тестовой статистике, чем наблюдаемая. В отличие от кластерного подхода, подход TFCE позволяет нам делать статистические выводы об отдельной пространственно-временной точке, поскольку каждый показатель TFCE имеет свои собственные p Значение .
Многомерная классификация паттернов
Чтобы изучить более детальное кодирование четырех условий в LATL и LMTL, мы провели анализ многомерной классификации паттернов прожектора в той же языковой маске, которая использовалась в предыдущем регрессионном анализе. Предполагая, что паттерны активации мозга содержат информацию, которая отличает экспериментальные условия, мы применили классификацию к четырем попарным комбинациям наших четырех условий: фразы с высокой ассоциацией по сравнению со списками с высокой ассоциацией, фразы с низкой ассоциацией по сравнению со списками с низкой ассоциацией, высокие -ассоциативные фразы по сравнению с низкоассоциативными фразами и списки с высокой ассоциацией по сравнению со списками с низкой ассоциацией. Классификация фраз с высокой ассоциацией по сравнению со списками с высокой ассоциацией и классификация фраз с низкой ассоциацией по сравнению со списками с низкой ассоциацией сравнивает состав по уровням ассоциации, а также классификация фраз с высокой ассоциацией по сравнению с фразами с низкой ассоциацией и классификация списков с высокой ассоциацией по сравнению с низкой. -Классификация списков ассоциаций сравнивает ассоциации по уровням состава.
Сначала мы регрессировали влияние частоты слов на основе регрессионного анализа исходных оценочных данных, затем мы сократили исходные оценки в 5 раз, создав матрицу 755 источников × 260 точек времени для каждого испытания. Затем мы объединили испытания в каждом состоянии в 15 псевдоиспытаний путем случайного разделения испытаний на 15 разделов (четыре испытания на раздел для эксперимента 1 и три испытания на раздел для эксперимента 2) и усреднения по испытаниям внутри разделов. Эти два шага были выполнены для снижения вычислительных затрат и увеличения отношения сигнал-шум, а также для сохранения одинакового количества испытаний в двух экспериментах (см. Guggenmos et al., 2018).
Мы обучили четыре классификатора машины линейных опорных векторов (SVM), каждый из которых применялся к парной комбинации четырех условий. SVM является широко используемым методом классификации из-за его благоприятных характеристик высокой точности, способности работать с многомерными данными и универсальности в моделировании различных источников данных (Schölkopf et al. , 2004). Был выбран линейный классификатор SVM, поскольку было показано, что он превосходит другие классификаторы как по данным MEG (Guggenmos et al., 2018), так и по данным фМРТ (Misaki et al., 2010). Мы выполнили процедуру перекрестной проверки с исключением пары стимулов, в которой одно случайно выбранное псевдоиспытание было взято из каждого условия в качестве тестовой выборки, а все оставшиеся стимулы использовались для обучения классификатора. Эффективность классификатора оценивалась путем усреднения по 100 перестановкам, и для каждой перестановки мы перераспределяли испытания на псевдоиспытания. Бинарные классификаторы применялись отдельно ко всем пространственно-временным моментам времени с радиусом 100 источников × 5 моментов времени.
К каждому субъекту был применен один и тот же конвейер анализа. Точность классификации, усредненная по субъектам в каждый момент времени за вычетом уровня вероятности 50%, подвергалась одновыборочному одностороннему тесту t с поправкой TFCE для 10 000 перестановок, где знак статистики t для каждой точки был переставлено. Временное окно анализа составляло от 600 до 1200 мс (рис. 2 B ). Мы использовали пакет python scikit-learn (0.22.1) для анализа SVM.
Направленный анализ связности
Чтобы лучше понять, как LATL и LMTL обмениваются информацией в процессе понимания двух слов, мы провели направленный анализ связности, чтобы оценить временной характер потока информации между двумя областями. Лежащая в основе логика аналогична логике причинно-следственного анализа по Грейнджеру (Granger, 1969), а именно, если деятельность в области А оказывает причинное влияние на деятельность в области В, то деятельность в прошлый момент времени в области А должна содержать информацию. это помогает предсказать текущую активность в области B выше и выше предыдущей активности только в области B. Здесь мы провели многомерный анализ связности на основе паттернов, который ранее применялся для оценки информационных потоков между областями мозга как при визуальной (Goddard et al., 2016), так и при языковой обработке (Lyu et al. , 2019).).
Сначала мы рассчитали RDM данных двух fROI в момент времени D(A, t) и D(B, t) как 1 минус попарная корреляция Пирсона r между условиями. fROI охватывают источники, которые являются значимыми либо в одномерной регрессии, либо в многомерном классификационном анализе. Эти RDM показывают, в какой степени различные уровни ассоциативной силы и композиционности вызывают сходные или различные паттерны реакции в нейронной популяции. Чтобы увеличить отношение сигнал/шум, мы применили те же процедуры предварительной обработки, что и в анализе MVPA, включая регрессию частотного эффекта слов, сокращение исходных оценок в 5 раз и объединение испытаний в каждом условии в 15 псевдоиспытаний. Затем мы количественно оценили направленную активность из области А в область В как коэффициент частичной корреляции между D(A, t-dt) и D(B, t) , D(B, t − dt) , где dt – интервал времени между текущим моментом времени и предыдущий момент времени.
Чтобы избежать систематической ошибки из-за выбора направления и любого конкретного предыдущего момента времени, мы вычислили направленную связность из региона A в регион B и из региона B в регион A для каждого момента времени от начала второго слова до следующего 600 мс, с dt от 5 мс до текущего момента времени до 600 мс (т. е. 5, 10, 15, … 600 мс до текущего момента времени). Расширенное временное измерение позволяет нам определить степень, в которой текущая активность в целевом регионе коррелирует с активностью исходного региона в каждый момент времени в течение предыдущих 600 мс. Та же процедура была применена к каждому субъекту для получения матрицы среднего коэффициента частичной корреляции (рис. 2 C ). Мы сообщаем результаты этого анализа с точки зрения разницы между двумя направлениями информационного потока (A→B – B→A). Достоверность различий определяли по одновыборочному t тест с 10000 перестановок.
Доступность данных и кода
Экспериментальные стимулы и оценки МЭГ для каждого участника доступны для загрузки через Open Science Framework (OSF) по адресу https://osf. io/ea4s6/. Все анализы проводились с использованием пользовательских кодов, написанных на Python, с активным использованием mne, eebrain и scikit-learn. Коды анализа можно скачать по адресу https://osf.io/ea4s6/.
Результаты
Поведенческие результаты
В целом, участники достигли высокой точности 90,9% (SD = 28,2%) со средним значением RT 1,07 с (SD = 0,77 с). Регрессионный анализ со смешанными эффектами выявил значительный эффект ассоциации для точности и незначительно значимый эффект для времени реакции, где более высокая связь между двумя словами повысила точность ( t = 2,43, Коэн d = 0,38, p = 0,015) и уменьшенное время реакции ( t = -1,8, Коэн d = 0,21, р = 0,08). Состав не имел значения ни для точности ( t = 0,71, Cohen d = 0,11, p = 0,48), ни для времени реакции ( t = -0,72, Cohen d p = 0,411, 9 , см. рис. 3 A ). Мы также наблюдали очень значительное влияние частоты слов как на точность, так и на RT, так что более частое первое слово уменьшало время реакции ( t = -4,07, Коэн d = 0,63, p ≅ 0), а более частое второе слово слово как повышенная точность ( t = 6,19, d Коэна = 0,95, p ≅ 0) и уменьшенное время реакции ( t = -8,3, d Коэна = 1,28, p ≅ ). Это типичное замедление реакции на менее частые слова указывает на то, что стимулы воспринимаются так, как предполагалось. Количество слов также имеет значение для времени реакции, так что условия с одним словом выполняются быстрее, чем условия с двумя словами ( t = 6,55, Коэн d = 1,01, p = 0; см. рис. 3-9).0418 В
Рисунок 3.
Поведенческие результаты. A , Средняя прогнозируемая точность и время реакции для четырех условий с регрессией влияния частоты слов. Ассоциация значима для точности (p = 0,049) и незначительно значима для времени реакции ( p = 0,08). Столбики погрешностей указывают на 1 SE. B , Подогнанные коэффициенты для всех предикторов для точности и логарифмического времени реакции. Столбики погрешностей показывают 95% доверительные интервалы. Черная точка обозначает значимые коэффициенты на уровне p < 0,05 и серая точка обозначает предельную значимость на уровне p < 0,1. * р < 0,05; ‵ р < 0,1.
Пространственно-временные кластеры для ассоциации и состава
Мы определили один значимый кластер для эффекта взаимодействия между ассоциацией и составом от 637 до 759 мс ( t = 3,27, Cohen d = 0,51, p = 0,03), который составляет 37 мс после начала второго слова до 159мс потом. Кластер в основном охватывал ATL (рис. 4 A ). Направление взаимодействия положительное, что означает, что высокоассоциативные композиционные фразы вызывали более высокую активность по сравнению с другими условиями (рис. 4 B ). Затем мы рассчитали среднюю подходящую активацию для четырех условий после учета эффекта частоты слов. Результаты показали, что высокоассоциативные композиционные фразы и низкоассоциативные списки коррелировали с повышенной активностью по сравнению с низкоассоциативными композиционными фразами и высокоассоциативными списками (рис. 4–9).0418 С , D ).
Рисунок 4.
Результаты множественной регрессии. A , Расположение значимого кластера, чувствительного к эффекту взаимодействия между ассоциацией и составом. Светло-красные области отмечают языковую сеть, в рамках которой проводился анализ. Цветная полоса показывает статистику t . B , Динамика коэффициентов β, усредненных по значимому кластеру. Заштрихованная область обозначает значительное временное окно с 637 по 759 год.мс ( p = 0,03). C , Подобранные ответы для каждого условия, усредненные по значимому кластеру и временному окну. D , Временные графики подобранного ответа для каждого условия, усредненные по значимому кластеру. Эффекты частоты слов были регрессированы из ответов. E , Расположение значимого кластера, чувствительного к эффекту композиции. F , Динамика коэффициентов β, усредненных по значимому кластеру. Заштрихованная область указывает на значительное временное окно от 689 г.до 882 мс ( p = 0,001). G , Подобранные ответы для каждого условия, усредненные по значимому кластеру и временному окну. H , Временные графики подобранного отклика для каждого условия, усредненные по кластеру. Эффекты частоты слов были регрессированы из ответов. STG, верхняя височная извилина; MTG, средняя височная извилина; ITG, нижняя височная извилина; ATL, передняя височная доля. * р < 0,05.
Влияние состава было связано с одним значительным кластером в MTL из 689до 882 мс ( t = -4,05, d Коэна = 0,63, p = 0,001) после начала первого слова (т. е. 89–282 мс после начала второго слова). Кластер охватывал области, включая среднюю и заднюю части нижней, средней и верхней височной извилины (рис. 4 E ). Знак коэффициента β отрицательный, так что композиционная фраза вызывала большую активность с отрицательной полярностью (рис. 4 F–H ). Не было обнаружено значительного кластера для каких-либо эффектов в правом полушарии в пределах маски, что предполагает сильно левостороннюю нейронную активность для ассоциации и композиции.
Не было найдено значимого кластера для предсказателя количества слов, что позволяет предположить, что условия списка из двух слов и условия фразы не сочетаются друг с другом. Далее мы провели апостериорных парных тестов t в кластерах LATL и LMTL. Мы ожидали, что время активации шаблона условий списка с состоянием одного слова и этот прогноз подтвердились: не наблюдалось значительных временных кластеров для контраста между двумя условиями списка и условием одного слова ни в одном fROI. Напротив, два условия композиции значительно отличались от условия одного слова в обеих fROI (см. рис. 7).
Лексическая частота была значимой в средней височной коре от 202 до 294 мс ( t = -4,11, Cohen d = 0,64, p = 0,034) для первого слова и от 870 до 950 мс (т. е., 270–350 мс после начала второго слова) для второго слова ( t = −4,72, Коэна d = 0,74, p = 0,046; см. рис. 8). Здесь более высокая частота слов снижала активацию, что согласуется с большинством выводов о влиянии частоты (Embick et al., 2001; Simon et al., 2012).
Многомерная классификация паттернов Searchlight
Результаты классификации показаны на рисунке 5. Мы наблюдали один кластер в LATL, где точность классификации для состава с высокой ассоциацией по сравнению с составом с низкой ассоциацией была значительно выше, чем вероятность от 740 до 775 мс, то есть , 140–175 мс после начала второго слова ( t = 4,29, Коэн d = 0,92, p = 0,022). Точность других классификаторов не была значительно выше, чем случайность. По сравнению с результатами множественной регрессии мы наблюдали такое же различие между композиционными фразами с высокой и низкой ассоциацией.
Рисунок 5.
Результаты классификации многомерных паттернов Searchlight. A , Кривые с цветовой кодировкой сообщают о времени классификации для четырех линейных классификаторов SVM, усредненных по значимому кластеру в LATL. Горизонтальные линии над кривыми отмечают статистически значимое временное окно от 740 до 775 мс для состава с высокой ассоциацией по сравнению с классификатором состава с низкой ассоциацией ( p = 0,022). B , Графики времени классификации для четырех линейных классификаторов SVM в функциональной области интереса для эффекта композиции, выявленного с помощью регрессионного анализа. Горизонтальная линия над кривыми отмечает значительное временное окно с 835 по 89 год.5 мс для композиции с низкой ассоциацией по сравнению со списком классификатора с низкой ассоциацией ( p = 0,016). Значимость над уровнем вероятности 50% оценивали с помощью перестановочного теста t с коррекцией TFCE в пределах маски (светло-красная область) и временным окном анализа 600–1200 мс. * р < 0,05.
Классификатор для низкоассоциативной композиции по сравнению с низкоассоциативными списками был значим в LMTL на отметке 835–895 мс, т. е. через 235–295 мс после начала второго слова ( t = 5,55, Коэна d = 0,87, p = 0,016). Другие классификаторы работали не намного лучше, чем шанс. Это указывает на то, что эффект композиции в LMTL может быть обусловлен различием между композицией и списком на уровне низкой ассоциации.
Поток информации между активными областями мозга
И одномерный регрессионный анализ, и многомерная классификация паттернов выявили LATL и LMTL для композиционных фраз с высокой и низкой ассоциацией соответственно. Кроме того, мы провели анализ направленной связности на основе паттернов, чтобы разделить два эффекта во временном измерении. Сравнение мер связности двух направлений выявило значительные частичные корреляции от LATL к LMTL примерно через 0–250 мс после начала второго слова. Значимый временной интервал перед текущим моментом времени варьировался от временных интервалов между 150 и 450 мс ( t = 6,26, Коэна d = 0,98, p = 0,03; см. рис. 6 A ). Хотя значение корреляции ~0,09 кажется довольно небольшим, оно больше, чем в предыдущем исследовании с использованием тех же показателей (Lyu et al., 2019). С помощью измерения контрастности не было обнаружено значительных частичных корреляций между LMTL и LATL (рис. 6 B ). Это говорит о том, что информация об ассоциативной силе и композиционности двух слов, сгенерированных в LATL в течение предыдущих 150–450 мс, непрерывно доставляется в соседний LMTL с начала второго слова до примерно 250 мс после начала стимула.
Рисунок 6.
Направленная связь между LATL и LMTL. A , Контраст между двумя показателями направленной связности показывает значительную корреляцию между LATL и LMTL от ∼0 до 250 мс после начала второго слова с задержкой от ∼150 до 450 мс ( p = 0,03) . B , Отсутствует значимая матрица коэффициентов частичной корреляции от LMTL до LATL.
Рисунок 7.
Попарно t результаты теста между каждым из условий с двумя словами и условием с одним словом в LATL и LMTL fROI. A , LATL fROI. B , Динамика ответов для каждого условия, усредненная по кластеру. Заштрихованная область указывает на минимально значимые временные окна 634–657 мс ( p = 0,06) и значимое временное окно 1087–1171 мс для состава с высокой ассоциацией > одиночной ( p = 0,03). С , Подобранные ответы для каждого условия, усредненные по кластеру и временным окнам. D , LMTL fROI. E , Динамика ответов для каждого условия, усредненная по кластеру. Заштрихованная область указывает на крайне значимые временные окна 739–784 мс для состава с низкой ассоциацией < одиночного ( p = 0,08). F , Подогнанные ответы для каждого условия, усредненные по кластеру и временному окну. Значимость определялась коррекцией TFCE с 10 000 перестановок. Временное окно тестирования 600–1200 мс; * p < 0,05, ′ p < 0,1.
Рисунок 8.
Эффект лексической частотности. A , Значимый кластер для частоты первого слова. B , Динамика коэффициента β частоты первого слова, усредненного по кластеру, во времени. Заштрихованная область указывает на значительные временные окна от 202 до 294 мс ( p = 0,034, TFCE с поправкой на 10 000 перестановок). Временное окно анализа составляет 0–600 мс. С , Значимый кластер для частоты второго слова. D , Динамика коэффициента β частоты второго слова, усредненного по кластеру, во времени. Заштрихованная область указывает на значительные временные окна от 870 до 950 мс ( p = 0,045, TFCE с поправкой на 10 000 перестановок). Временное окно анализа составляет 600–1200 мс. * p < 0,05
Хотя функциональные ROI LATL и LMTL в нашем направленном анализе связности выбраны на основе результатов регрессии, этот метод по-прежнему в значительной степени зависит от данных, поскольку сила связности количественно определяется частичными корреляциями между RDM данных . Чтобы выяснить, были ли результаты связности специфичными для семантической ассоциации и состава или просто отражали внутренние взаимодействия между двумя соседними областями, мы провели дополнительный контрольный анализ с первичной соматосенсорной корой (SMA, определяемой как BA1-3) и первичной моторной корой (M1). ; определяется как BA4) в левом полушарии как две области интереса. Поскольку SMA и M1 не были связаны ни с эффектом ассоциации, ни с композиционным эффектом, формирование паттернов RDM данных в двух регионах не должно иметь никакого отношения к нашим манипуляциям со стимулами. Поэтому мы не ожидаем никакой связи между RDM данных двух регионов. Результаты подтвердили наш прогноз: мы не обнаружили прямой связи от SMA1 к M1 или от M1 к SMA (см. рис. 9).).
Рис. 9.
Направленная связь между левым SMA и левым M1. A , Матрица коэффициентов частичной корреляции от SMA до M1. B , Частная матрица коэффициентов корреляции от M1 до SMA.
Обсуждение
Предыдущая работа выявила сходные области мозга как по семантической композиции, так и по ассоциативному кодированию. Поскольку объединение значений интуитивно отличается от простой ассоциации, это несколько удивительно. Семантическая композиционность позволяет человеческому языку выражать бесконечное количество сложных выражений из составляющих их значений (Фреге, 19).80). Этот продуктивный комбинаторный процесс не зависит от семантической родственности составляющих значений. Он подходит даже для совершенно новых комбинаций, таких как «Кубинский фо». Однако, согласно дистрибутивной гипотезе семантической теории, слова, встречающиеся вместе, обычно семантически связаны (для обзора см. Boleda, 2020). Как известно у Ферта (1957): «слово характеризуется компанией, в которой оно состоит», таким образом, распространенное сложное выражение, такое как «французский сыр», включает в себя как комбинаторные, так и ассоциативные процессы. Это повышает вероятность того, что два процесса могут иметь какое-то общее ядро, реализуемое нейронной сетью. Мы исследовали эту возможность в текущей работе.
Путем ортогонализации семантической композиции и семантической ассоциации в нашем экспериментальном плане мы показываем, что композиционные фразы с высокой ассоциацией вызывают более высокую активность в LATL, чем композиционные фразы с низкой ассоциацией. Многомерная классификация паттернов прожектора также показывает отличительные паттерны активности между двумя состояниями в LATL. Таким образом, по-видимому, существует ранний процесс LATL, который отражает композицию с высокой ассоциативной чувствительностью. Обратите внимание, что возможно, что участники думали о словосочетаниях прилагательное-существительное (например, «французский сыр»), когда видели списки существительных-существительных (например, «французский сыр») или истолковывали списки существительных-существительных как грамматические ошибки. Эти возможности, однако, не могли объяснить различные модели активности между парами прилагательное-существительное и существительное-существительное на разных уровнях ассоциации. Если участники чаще думают «французский сыр», увидев «французский сыр», чем думают «корейский сыр», увидев «корейский сыр», то мы можем утверждать, что это именно потому, что «Франция» и «сыр» очень связанные. Поэтому мы считаем, что наш эффект взаимодействия в LATL лучше всего объясняется составом и факторами ассоциации во время понимания двух слов.
Martin и Doumas (2020) предположили, что смысловая композиция не может быть достигнута только ассоциативным способом, таким как тензорное произведение вложений составляющих слов, потому что суждения о сходстве людей о «нечетком кактусе» и «нечетком пингвине» не определяются сходство между «кактусом» и «пингвином». Martin and Doumas (2017) предложили динамическую модель связывания (т. е. символически-коннекционистскую вычислительную модель DORA), которая использует время для кодирования композиции (см. также Baggio, 2018; Martin, 2020), однако неясно, как такая модель включает ассоциацию. между составными словами при интерпретации композиционных значений. Учитывая эффект взаимодействия ассоциации и композиции в LATL, мы предполагаем, что когнитивная модель смысловой композиции должна включать как факторы ассоциации, так и факторы композиции.
Чувствительность LATL как к композиции, так и к ассоциации поддерживает роль как композиционной, так и дистрибутивной семантики, которая была предметом многочисленных дискуссий в области обработки естественного языка и когнитивной науки. Дистрибутивные семантические модели работают путем построения векторов совпадения для каждого слова в корпусе на основе его контекста. Они предоставляют конкретную информацию о значении слов, но не распространяются на более крупные составляющие текста, такие как фразы или предложения. Композиционная формальная семантика дополняет этот подход, и были предложены различные модели для объединения двух парадигм (Mitchell and Lapata, 2008; Baroni et al. , 2014). Эти модели обычно используют одну алгебраическую композиционную функцию, такую как сложение или умножение по вложениям составляющих слов для достижения композиции. В качестве альтернативы, недавно было показано, что глубокие нейронные сети фиксируют грамматически зависимую композицию без четких алгебраических правил (см. Baroni, 2020). Здесь мы показываем, что LATL по-разному реагировал на композиционные фразы с высокой и низкой ассоциацией, предполагая, что нейронный механизм композиции действительно может не зависеть от систематических правил композиции.
Во временном измерении регрессионный анализ показал раннюю активность LATL для эффекта взаимодействия ассоциации и композиции после начала второго слова. Этот эффект проявляется даже до начала второго слова (544–846 мс) в тесте на перестановку на основе кластеров (Maris and Oostenveld, 2007). Однако в тесте перестановки на основе кластеров пространственно-временной кластер формируется до теста перестановки, поэтому мы не можем претендовать на статистическую значимость для отдельных пространственно-временных точек в кластере. Поэтому мы использовали подход TFCE, который позволяет нам сделать вывод о значении каждой пространственной и временной точки. Результаты TFCE показали более узкий пространственно-временной кластер по протяженности, где значимое временное окно составляет от 637 до 759мс (т. е. через 37–159 мс после начала второго слова). Это раннее начало, вероятно, отражает высокую предсказуемость высокоассоциативных стимулов, то есть некоторые значения существительных могут быть предварительно активированы во время обработки первого слова. Например, увидев «Франция/французский», участники могут автоматически подумать о французской еде, хотя вторым словом может быть «кимчи».
В LMTL результаты регрессионного анализа и многофакторной классификации паттернов показали, что этот регион в основном чувствителен к составу на уровне низкой ассоциации, т. Е. Различию между «корейским сыром» и «корейским сыром». По сравнению с композиционными фразами с высокой ассоциацией, композиционные фразы с низкой ассоциацией формируют новое значение, поэтому, вероятно, требуют большей синтаксической обработки для успешного разбора. Существует достаточно доказательств того, что LMTL поддерживает синтаксические комбинации (Lyu et al., 2019).; Матчин и др., 2019; Флик и Пюлкканен, 2020 г.; Матчин и Хикок, 2020 г.). Например, левая задняя MTG (pMTG) в сочетании глагол-существительное показывает наиболее сильную модель, подходящую для левой MTG (Lyu et al., 2019), и как существительные, так и глагольные фразы (например, «испуганный мальчик» и «напуганный мальчик»). the boy») вызывал большую активность в верхней височной борозде по сравнению со списками слов (Matchin et al., 2019). Более того, постименная композиция прилагательного и существительного вызывала активность в левой медиальной и задней височной доле, когда семантика оставалась постоянной (Flick and Pylkkänen, 2020). Наш эффект композиции в LMTL можно объяснить эффектом типа слова (прилагательное против существительного; см. Mollo et al., 2018 для различия контекста существительного и глагола в LMTL). Однако тип слова не может объяснить разницу между высокоассоциативными и низкоассоциативными композиционными словосочетаниями в LATL, поскольку и «французский сыр», и «корейский сыр» являются грамматическими. Обратите внимание, что мы не предполагаем, что LMTL участвует только в синтаксической обработке. Как показано на рисунке 8, лексическая частота как первого, так и второго слова значительно коррелировала с активностью LMTL, так что более высокая частота привела к снижению активации примерно через 200–350 мс после начала слова. Этот пространственно-временной кластер согласуется с предыдущими выводами о влиянии частоты (Embick et al., 2001; Simon et al., 2012). Добавив частоты первого и второго слов в качестве контрольных переменных в нашу регрессионную модель, мы выявили эффект композиции в LMTL в дополнение к эффекту частоты слов.
Наши результаты согласуются с концепцией контролируемого семантического познания (CSC) (Jefferies, 2013; Lambon Ralph et al., 2017), которая также предполагает функциональную диссоциацию передней и средней височных областей. В этой структуре ATL объединяет информацию из разных источников в связную концепцию, тогда как pMTG извлекает семантические знания и манипулирует ими, например, извлекает нечастые семантические ассоциации. Предыдущие исследования с использованием аналогичной парадигмы MEG из двух слов показали, что ATL сильно реагировал на семантически связанные пары слов, тогда как pMTG был более чувствителен к слабым ассоциациям (Teige et al., 2018, 2019).). Кроме того, исследования семантических нарушений также показали различные модели нарушений: у пациентов с очаговой атрофией ATL проявляются симптомы SD, при этом на производительность сильно влияет знакомство с понятием (Ding et al., 2020). Напротив, у пациентов с височно-теменным повреждением обычно диагностируется семантическая афазия (СА), характеризующаяся дефицитом контролируемого семантического поиска (Jefferies and Lambon Ralph, 2006; Hoffman et al., 2018; Jefferies et al., 2020). Отражение Тейге и др. (2018, 2019)) и профили пациентов с SD/SA, мы также наблюдали активацию LATL для семантически связанных пар слов и реакцию LMTL на нечастые семантические ассоциации. Однако мы добавили один важный элемент к сходящейся истории о роли LATL в семантической обработке: синтаксические знания. В отличие от экспериментов Тейге и его коллег, в которых в качестве стимулов использовались только списки слов «существительное-существительное», мы также включали фразы «прилагательное-существительное», контролируемые по значению. Мы показали, что и композиция, и ассоциация способствовали семантической обработке в LATL, в соответствии с другим потоком литературы, в котором были представлены доказательства роли LATL в концептуальной композиции (Bemis and Pylkkänen, 2011; Pylkkänen, 2019).). По сравнению с выводами Teige et al. (2018, 2019), согласно которым эффект ассоциации начинается примерно через 200–400 мс после появления целевого слова, наш эффект взаимодействия между ассоциацией и композицией начинается в течение 100 мс после появления второго слова. . Этот более ранний эффект взаимодействия предполагает, что синтаксические знания дополнительно облегчают эффективный поиск высокосогласованной семантической информации в ATL в рамках CSC.
Чтобы непосредственно изучить поток информации между двумя областями, мы дополнительно провели направленный анализ на основе паттернов и показали, что активность возникает в LATL за 150–450 мс до того, как она непрерывно доставляется в LMTL в течение 250 мс после начала стимула. Предыдущие исследования также предполагали функциональную связь между LATL и LMTL в суждениях семантической ассоциации (Jackson et al., 2016), и LATL и LMTL также являются частью сети режима по умолчанию, которая, как было показано, сильно реагирует, когда контрольные и целевые элементы концептуально сильно перекрываются (Lanzoni et al., 2020; Wang et al., 2020). Наши результаты предоставляют новые доказательства направления функциональной связи между LATL и LMTL. Поскольку наш регрессионный анализ и анализ декодирования показали, что LATL более чувствителен к композиционным фразам с высокой ассоциацией, в то время как LMTL реагирует на композиционные фразы с низкой ассоциацией, мы поэтому делаем вывод, что поток информации от LATL к LMTL предполагает, что высоко-ассоциативные фразы ассоциативный состав предшествует малоассоциативному составу. Мы интерпретировали эти результаты как отражение функциональной диссоциации, когда LATL поддерживает «поверхностную» смысловую композицию общих фраз, в то время как LMTL занимается интерпретацией новых фраз посредством синтаксической композиции. Во временном измерении «поверхностное» формирование значения происходит раньше в LATL и запускает синтаксическую композицию в LMTL, когда сложное значение незнакомо. Обратите внимание, что передняя височная область может быть «более высокой» когнитивной областью, чем задняя височная область, поскольку в двухпотоковой модели обработки речи (Hickok and Poeppel, 2007) задние височные области предшествуют передним височным областям на вентральном пути. , а задние височные области соответствуют лексическому интерфейсу, который связывает фонологическую и семантическую информацию, тогда как более передние местоположения соответствуют комбинаторной сети «более высокого уровня». Кроме того, ATL также считается «хабом», который объединяет информацию из областей, специфичных для модальности, в рамках модели семантических знаний «ступица и спица» (Patterson et al., 2007). Таким образом, направление потока от LATL к LMTL в нашем направленном анализе связности, вероятно, отражает обратный поток информации от более высоких к более низким когнитивным областям.
Таким образом, мы демонстрируем доказательства различных профилей в левой височной доле, где LATL наиболее чувствителен к композиционным фразам с высокой ассоциацией, в то время как LMTL больше реагирует на композиционные фразы с низкой ассоциацией. Мы также наблюдали заметный информационный поток от LATL к LMTL, предполагая, что интеграция свойств прилагательных и существительных, возникшая ранее в LATL, постоянно передается в LMTL, когда впервые встречается сложное значение.
Сноски
Эта работа была поддержана грантом Института Абу-Даби Нью-Йоркского университета G1001. Мы благодарим Haiyang Jin за помощь в статистическом анализе поведенческих данных и рецензентов за их бесценные комментарии и предложения по предыдущим черновикам статьи.
Авторы заявляют об отсутствии конкурирующих финансовых интересов.
- Корреспонденцию следует направлять Jixing Li по адресу jixingli{at}nyu.edu
Это статья с открытым доступом, распространяемая в соответствии с условиями лицензии Creative Commons Attribution 4. 0 International, которая разрешает неограниченное использование, распространение и воспроизведение в любой носитель при условии, что оригинальная работа правильно указана.
Ссылки
- ↵
- Adachi Y,
- Shimogawara M,
- Higuchi M,
- Haruta Y,
- Ochiai M
(2001) Уменьшение непериодических измерений MEG с помощью метода наименьших квадратов с непрерывной регулировкой. IEEE Trans Appl Supercond 11:669–672. дои: 10.1109/77.
- 3
- ↵
- Арнон I,
- Снайдер N
(2010) Больше, чем просто слова: частотные эффекты для фраз из нескольких слов. Дж. Мем Ланг 62:67–82. doi:10.1016/j.jml.2009.09.005
- ↵
- Baggio G
(2018) Значение в мозгу. Кембридж: MIT Press.
- ↵
- Baroni M
(2020) Лингвистическое обобщение и композиционность в современных искусственных нейронных сетях. Philos Trans R Soc Lond B Biol Sci 375:201. doi:10.1098/rstb.2019.0307 pmid:31840578
- ↵
- Барони М.,
- Бернарди Р.,
- Зампарелли Р.
(2014) Фреге в космосе: программа композиционно-распределительной семантики. Ling Lang Tech 9:241–346.
- ↵
- Barr DJ,
- Levy R,
- Scheepers C,
- Tily HJ
(2013) Структура случайных эффектов для проверки подтверждающей гипотезы: сохраняйте ее максимальной. Дж. Мем Ланг 68: 255–278. doi:10.1016/j.jml.2012.11.001
- ↵
- Bates D,
- Kliegl R,
- Vasishth S,
- Baayen RH
(2015a) Экономичные смешанные модели.
arXiv 1506.04967. - ↵
- Bates D,
- Mächler M,
- Bolker BM,
- Walker S
(2015b) Подгонка линейных моделей смешанных эффектов с использованием lme4. J Stat Software 67:361–373.
- ↵
- Bemis D,
- Pylkkänen L
(2011) Простая композиция: магнитоэнцефалографическое исследование понимания минимальных лингвистических фраз. J Neurosci 31:2801–2814. doi:10.1523/JNEUROSCI.5003-10.2011
- ↵
- Bemis D,
- Pylkkänen L
(2013) Гибкая композиция: доказательства MEG для развертывания основных комбинаторных лингвистических механизмов в ответ на требования задачи. PLoS One 8:e73949. doi:10.1371/journal.pone.0073949 pmid:24069253
- ↵
- Blanco-Elorrieta E,
- Kastner I,
- Emmorey K,
- Pylkkänen L
(2018) Общие нейронные корреляты для построения фраз в жестовом и устном языке.
Научный представитель 8:5492. doi:10.1038/s41598-018-23915-0 pmid:29615785 - ↵
- Боледа Г
(2020) Распределительная семантика и лингвистическая теория. Annu Rev Лингвист 6: 213–234. doi:10.1146/annurev-linguistics-011619-030303
- ↵
- Brysbaert M,
- New B
(2009 г.) Выходя за пределы Kucera и Francis: критическая оценка текущих норм частоты слов и введение нового и улучшенного показателя частоты слов для американского английского. Методы разрешения поведения 41:977–990. doi:10.3758/BRM.41.4.977 pmid:19897807
- ↵
- Dale Am,
- Liu A,
- Fischl B,
- Buckner R,
- Belliveau J,
- Lewine J,
- Halgren E
- Halgren E
для визуализации активности коры с высоким разрешением. Нейрон 26:55–67. doi:10.1016/S0896-6273(00)81138-1 pmid:10798392 - Ding J,
- Chen K,
- Liu H,
- Huang L,
- Chen Y,
- LV Y,
- Yang Q,
- GUO Q,
- HAN Q,
(2020) Единая нейрокогнитивная модель семантики, языкового социального поведения и распознавания лиц при семантической деменции. Нац Коммуна 11:2595. doi:10.1038/s41467-020-16089-9
- Embick D,
- Hackl M,
- Schaeffer J,
- Kelepir M,
- Marantz A
(2001) Магнитоэнцефалографический компонент, латентность которого отражает лексический компонент. Когнитивное разрешение мозга 10:345–348. doi:10.1016/S0926-6410(00)00053-7
- Firth J
(1957) Краткий обзор лингвистической теории, 1930-1955. В: Исследования по лингвистическому анализу, стр. 1–32. Оксфорд: Философское общество.
- Flick G,
- Pylkkänen L
(2020) Изолирующий синтаксис в естественном языке: MEG свидетельствует о раннем вкладе левой задней височной коры. Кортекс 127:42–57. doi:10.1016/j.cortex.2020.01.025 pmid:32160572
- Frege G
(1980) Письмо Журдену. В: Философско-математическая переписка, стр. 78–80. Чикаго: Издательство Чикагского университета.
- Galton CJ,
- Patterson K,
- Graham K,
- Lambon Ralph MA,
- Williams G,
- Antoun N,
- Sahakian BJ,
- Hodges JR
(2001) Differing patterns of височная атрофия при болезни Альцгеймера и семантической деменции. Неврология 57:216–225. doi:10.1212/wnl.57.2.216 pmid:11468305
- Годдард Э.,
- Карлсон Т.А.,
- Дермоди Н.,
- Вулгар А.
(2016) Репрезентативная динамика распознавания объектов: информационные потоки с прямой и обратной связью. Нейроизображение 128:385–397. doi:10.1016/j.neuroimage.2016.01.006 pmid:26806290
- Gramfort A,
- Luessi M,
- Larson E,
- Engemann DA,
- Strohmeier D,
- Brodbeck C,
- Parkkonen L,
- Hämäläinen MS
(2014) Программное обеспечение MNE для обработки данных МЭГ и ЭЭГ. Нейроизображение 86:446–460. doi:10.1016/j.neuroimage.2013.10.027 pmid:24161808
- Granger CW
(1969) Исследование причинно-следственных связей с помощью эконометрических моделей и кросс-спектральных методов. Эконометрика 37:424–438. дои: 10.2307/1
- Guggenmos M,
- Sterzer P,
- Cichy RM
(2018) Многомерный анализ закономерностей для MEG: сравнение мер несходства. Нейроизображение 173:434–447. doi:10.1016/j.neuroimage.2018.02.044 pmid:29499313
- Gwilliams L,
- Lewis GA,
- Marantz A
(2016) Функциональная характеристика характерных для букв ответов во времени, пространстве и полярности тока с использованием магнитоэнцефалографии. Нейроизображение 132:320–333. doi:10.1016/j.neuroimage.2016.02.057 pmid:26 2
- Haggort P
(2005) Брока, мозг и связывание: новая структура. Trends Cogn Sci 9:416–423.
- Hämäläinen MS,
- Ilmoniemi RJ
(1994) Интерпретация магнитных полей головного мозга: оценки минимальной нормы. Med Biol Eng Comput 32:35–42. doi:10.1007/BF02512476 pmid:8182960
- Hickok G,
- Poeppel D
(2007) Корковая организация обработки речи. Nat Rev Neurosci 8:93–402.
- Hirabayashi T,
- Tamura K,
- Takeuchi D,
- Takeda M,
- Koyano KW,
- Miyashita y
(2014). ассоциативная память. J Neurosci 34:9377–9388. doi:10.1523/JNEUROSCI.0600-14.2014 pmid:25009270
- Hodges JR,
- Patterson K,
- Oxbury S,
- Funnell E
(1992) Семантическая деменция: прогрессирующая плавная афазия с атрофией височной доли. Мозг 115:1783–1806. doi:10.1093/мозг/115.6.1783
- Хоффман П. ,
- Макклелланд Д.Л.,
- Lambon Ralph MA
(2018) Концепции, контроль и контекст: коннекционистский отчет о нормальном и неупорядоченном семантическом познании. Psychol Rev 125:293–328. doi:10.1037/rev0000094 pmid:29733663
- Джексон Р.И.,
- Хоффман П.,
- Побрик Г.,
- Ламбон Ральф М.А.
(2016) Семантическая сеть в работе и в состоянии покоя: дифференциальная связность подрегионов передней височной доли. J Neurosci 36:1490–1501. doi:10.1523/JNEUROSCI.2999-15.2016 pmid:26843633
- Jacobs CL,
- Dell GS,
- Benjamin AS,
- Bannard C
(2016) Языковой опыт частично и полностью влияет на память распознавания для последовательностей из нескольких слов. Дж. Мем Ланг 87:38–58. doi:10.1016/j.jml.2015.11.001
- Джейкобс CL,
- Делл GS,
- Bannard C
(2017) Влияние частоты фраз на свободное запоминание: свидетельство реинтеграции. Дж. Мем Ланг 97:1–16. doi:10.1016/j.jml.2017.07.003 pmid:2 91
- Jang AI,
- Wittig JH Jr.,
- Inati SK,
- Zaghloul KA
(2017) Нейроны коры головного мозга человека в передней височной доле восстанавливают пиковую активность во время вербальной памяти. Curr Biol 27:1700–1705. doi:10.1016/j.cub.2017.05.014 pmid:28552361
- Jefferies E
(2013) Нейронная основа семантического познания: сходящиеся данные нейропсихологии, нейровизуализации и ТМС. Кортекс 49:611–625. doi:10.1016/j.cortex.2012.10.008 pmid:23260615
- Jefferies E,
- Lambon Ralph MA
(2006)Семантические нарушения при инсультной афазии и семантической деменции: сравнение серии случаев. Мозг 129:2132–2147. doi:10.1093/brain/awl153 pmid:16815878
- Джеффрис Э.,
- Томпсон Х,
- Корнелиссен П.,
- Смоллвуд Дж.
(2020) Нейрокогнитивная основа знания об идентичности объекта и событиях: диссоциации отражают противоположные эффекты семантической согласованности и контроля. Philos Trans R Soc Lond B Biol Sci 375:201. doi:10.1098/rstb.2019.0300 pmid:31840592
- Кузнецова А.,
- Брокхофф П.Б.,
- Christensen RHB
(2017) Пакет lmertest: тесты в линейных моделях смешанных эффектов. J Stat Software 82:1–26.
- Ламбон Ральф М.А.,
- Джеффрис Э.,
- Паттерсон К.,
- Роджерс Т.Т.
(2017) Нейронные и вычислительные основы семантического познания. Nat Rev Neurosci 18:42–55. doi:10.1038/nrn.2016.150 pmid:27881854
- Lanzoni L,
- Ravasio D,
- Thompson H,
- Vatansever D,
- Margulies D,
- Smallwood J,
- Jefferies E
(2020) The role of default mode network in semantic cue интеграция. Нейроизображение 219:117019. doi:10.1016/j.neuroimage.2020.117019 pmid:32522664
- Лю Б.,
- Чой Х.С.,
- Марслен-Уилсон В.Д.,
- Кларк А.,
- Рэндалл Б.,
- Тайлер Л.К. Proc Natl Acad Sci USA 116:21318–21327. doi:10.1073/pnas.12116 pmid:31570590
- ↵
- Maris E,
- Oostenveld R
(2007) Непараметрическое статистическое тестирование данных ЭЭГ и МЭГ. J Neurosci Methods 164:177–190. doi:10.1016/j.jneumeth.2007.03.024 pmid:17517438
- ↵
- Martin A
(2020) Композиционная нейронная архитектура для языка. J Cogn Neurosci 32:1407–1427. doi:10.1162/jocn_a_01552 pmid:32108553
- ↵
- Мартин А.,
- Думас Л.
(2017) Механизм коркового вычисления иерархической лингвистической структуры. PLoS Biol 15:e2000663. doi:10.1371/journal.pbio.2000663 pmid:28253256
- ↵
- Мартин А.,
- Думас Л.
(2020) Тензоры и композиционность в нейронных системах.
Philos Trans R Soc Lond B Biol Sci 375:201- . doi:10.1098/rstb.2019.0306 pmid:31840579
- ↵
- Матчин В.,
- Хикок Г.
(2020) Корковая организация синтаксиса. Кора головного мозга 30:1481–1498. doi:10.1093/cercor/bhz180 pmid:31670779
- ↵
- Matchin W,
- Liao C,
- Gaston P,
- Lau E
(2019) Те же слова, разные структуры: фМРТ-исследование отношений аргументов и угловой извилины. Нейропсихология 125:116–128. doi:10.1016/j.neuropsychologia.2019.01.019 pmid:30735675
- ↵
- Misaki M,
- Kim Y,
- Bandettini PA,
- Kriegeskorte N
(2010) Сравнение многомерных классификаторов и нормализации ответа для фМРТ с информацией о шаблонах.
Нейроизображение 53:103–118. doi:10.1016/j.neuroimage.2010.05.051 - ↵
- Mitchell J,
- Lapata M
(2008) Векторные модели семантической композиции. Материалы ACL-08: HLT. Колумбус, июнь 2008 г., стр. 236–244. Ассоциация компьютерной лингвистики.
- ↵
- Молло Г.,
- Джеффрис Э.,
- Корнелиссен П.,
- Дженнари С.П. височная извилина. Брейн Ланг 177–178: 23–36. doi:10.1016/j.bandl.2018.01.001 pmid:269
- ↵
- Нестор П.Я.,
- Fryer TD,
- Hodges JR
(2006) Декларативные нарушения памяти при болезни Альцгеймера и семантической деменции. Нейроизображение 30:1010–1020. doi:10.1016/j.neuroimage.2005.10.008 pmid:16300967
- ↵
- Nieuwenhuis I,
- Takashima A,
- Oostenveld R,
- McNaughton BL,
- Fernández G,
- Jensen O
(2012) The neocortical network representing associative memory reorganizes with time in a process engaging the передняя височная доля.
Кора головного мозга 22:2622–2633. doi:10.1093/cercor/bhr338 pmid:22139815 - ↵
- Oldfield RC
(1971) Оценка и анализ ручности: Эдинбургская инвентаризация. Нейропсихология 9:97–113. doi:10.1016/0028-3932(71)-4 pmid:5146491
- ↵
- Паттерсон К.,
- Нестор П.,
- Роджерс Т.
(2007) Откуда вы знаете то, что знаете? Представление семантических знаний в мозгу человека. Nat Rev Neurosci 8:976–987. doi:10.1038/nrn2277 pmid:18026167
- ↵
- Peirce J,
- Gray JR,
- Simpson S,
- MacAskill M,
- Höchenberger R,
- Sogo H,
- Kastman E,
- Lindeløv JK
(2019) PsychoPy2: experiments in поведение стало проще.
Behav Res Methods 51:195–203. doi:10.3758/s13428-018-01193-y pmid:30734206 - ↵
- Pennington J,
- Socher R,
- Manning C
(2014) GloVe: глобальные векторы для представления слов. Материалы конференции 2014 г. по эмпирическим методам обработки естественного языка, Доха, стр. 1532–1543. Ассоциация компьютерной лингвистики.
- ↵
- Pobric G,
- Jefferies E,
- Lambon Ralph MA
(2007) Передние височные доли опосредуют семантическое представление: имитация семантической деменции с помощью rTMS у нормальных участников. Proc Natl Acad Sci USA 104:20137–20141. doi:10.1073/pnas.0707383104 pmid:18056637
- ↵
- Price A,
- Bonner MF,
- Peelle JE,
- Grossman M
(2015) Сходящиеся доказательства нейроанатомической основы комбинаторной семантики угловой извилины.
J Neurosci 35:3276–3284. doi:10.1523/JNEUROSCI.3446-14.2015 pmid:25698762 - ↵
- Pylkkänen L
(2019) Нейронная основа комбинаторного синтаксиса и семантики. Наука 366:62–66. doi:10.1126/science.aax0050 pmid:31604303
- ↵
- Sakai K,
- Miyashita Y
(1991) Нейронная организация долговременной памяти парных партнеров. Природа 354:152–155. doi:10.1038/354152a0 pmid:1944594
- ↵
- Schölkopf B,
- Tsuda K,
- Vert JP
(2004) Методы ядра в вычислительной биологии. Кембридж: MIT Press.
- ↵
- Саймон Д.А.,
- Льюис Г.,
- Маранц А.
(2012) Устранение неоднозначности формы и эффектов лексической частоты в ответах МЭГ с использованием омонимов.
.2011.607712 Lang Cognitive Proc 27:275–287. дои: 10.1080/016 - ↵
- Смит С.М.,
- Николс Т.Е.
(2009) Улучшение беспорогового кластера: решение проблем сглаживания, пороговой зависимости и локализации при выводе кластера. Нейроизображение 44:83–98.
- ↵
- Teige C,
- Cornelissen PL,
- Mollo G,
- Gonzalez Alam TRDJ,
- McCarty K,
- Smallwood J,
- Jefferies E
(2019) Диссоциации в семантическом познании: колебательные доказательства противоположных эффектов семантического контроля и типа семантического отношения в передней и задней височной коре. Кортекс 120:308–325. doi:10.1016/j.cortex.2019.07.002 pmid:313
- ↵
- Teige C,
- Mollo G,
- Millman R,
- Savill N,
- Smallwood J,
- Cornelissen PL,
- Jefferies E
(2018) Динамическое семантическое познание: характеристика когерентного и контролируемого концептуального поиска во времени с использованием магнитоэнцефалографии и хронометрической транскраниальной магнитной стимуляции.
Кортекс 103:329–349. doi:10.1016/j.cortex.2018.03.024 pmid:29684752 - ↵
- van der Maaten LJP
(2014) Ускорение t-SNE с использованием древовидных алгоритмов. J Mach Learn Res 15:3221–3245.
- ↵
- Wang X,
- Margulies DS,
- Smallwood J,
- Jefferies E
(2020) Градиент от долговременной памяти к новому познанию: переходы через режим по умолчанию и исполнительную кору. Нейроизображение 220:117074. doi:10.1016/j.neuroimage.2020.117074 pmid:32574804
- ↵
- Ван Ю,
- Коллинз Дж. А.,
- Коски Дж.,
- Nugiel T,
- Metoki A,
- Olson IR
(2017) Динамическая нейронная архитектура для поиска социальных знаний. Proc Natl Acad Sci USA 114:E3305–E3314.
doi:10.1073/pnas.1621234114 pmid:28289200 - ↵
- Westerlund M,
- Pylkkänen L
(2014) Роль левой передней височной доли в семантической композиции по сравнению с семантической памятью. Нейропсихология 57:59–70.
- ↵
- Westerlund M,
- Kastner I,
- Al Kaabi M,
- Pylkkänen L
(2015) LATL как локус состава: данные MEG на английском и арабском языках. Брэйн Ланг 141:124–134. doi:10.1016/j.bandl.2014.12.003 pmid:25585277
Наверх
Общие сведения о комбинаторах парсеров | F# для удовольствия и выгоды
ОБНОВЛЕНИЕ: Слайды и видео из моего выступления на эту тему
В этой серии мы рассмотрим, как работают так называемые «аппликативные синтаксические анализаторы». Чтобы что-то понять, нет ничего лучше, чем построить это для себя, и поэтому мы создадим с нуля базовую библиотеку парсеров, а затем несколько полезных «комбинаторов парсеров», а затем закончим сборкой полного парсера JSON.
Такие термины, как «аппликативные синтаксические анализаторы» и «комбинаторы синтаксических анализаторов», могут сделать этот подход сложным, но не пытаясь объяснить эти концепции заранее, мы просто погрузимся и начнем программировать.
Мы будем постепенно наращивать сложность с помощью ряда реализаций, где каждая реализация лишь немного отличается от предыдущей. Используя этот подход, я надеюсь, что на каждом этапе дизайн и концепции будут легко понять, и поэтому к концу этой серии комбинаторы синтаксических анализаторов станут полностью демистифицированными.
В этой серии будет четыре поста:
- В этом, первом посте, мы рассмотрим основные концепции комбинаторов парсеров и построим ядро библиотеки.
- Во втором посте мы создадим полезную библиотеку комбинаторов.
- В третьем посте мы поработаем над предоставлением полезных сообщений об ошибках.
- В последнем посте мы создадим синтаксический анализатор JSON, используя эту библиотеку синтаксического анализа.
Очевидно, что здесь речь пойдет не о производительности или эффективности, но я надеюсь, что это даст вам понимание, которое позволит вам эффективно использовать такие библиотеки, как FParsec. И, кстати, большое спасибо Штефану Толксдорфу, создавшему FParsec. Вы должны сделать его своим первым портом захода для всех ваших потребностей синтаксического анализа .NET!
Разбор жестко закодированного символа
Для начала давайте создадим что-то, что просто анализирует один жестко закодированный символ, в данном случае букву «А». Вы не можете получить намного проще, чем это!
Вот как это работает:
- На вход синтаксического анализатора поступает поток символов. Мы могли бы использовать что-то сложное, но сейчас мы просто используем строку
- Если поток пуст, то вернуть пару, состоящую из
falseи пустая строка. - Если первым символом в потоке является
A, то вернуть пару, состоящую изtrueи оставшегося потока символов. - Если первый символ в потоке не является
A, то вернутьfalseи (неизменный) исходный поток символов.
Вот код:
let parseA str = если String.IsNullOrEmpty(str), то (ЛОЖЬ,"") иначе, если ул.[0] = 'А' тогда пусть остальные = str.[1..] (правда, осталось) еще (ложь, ул.)Подпись
parseA:val parseA : строка -> (логическое * строка)
, который говорит нам, что ввод представляет собой строку, а вывод представляет собой пару, состоящую из логического результата и другой строки (оставшийся ввод), например:
Давайте проверим это сейчас — сначала с хорошим вводом:
пусть inputABC = "ABC" parseA inputABC
Результат:
(правда, "BC")
Как видите,
Aизрасходовано, и осталось всего"БК".А теперь с неправильным вводом:
пусть inputZBC = "ZBC" parseA inputZBC
, что дает результат:
(ложь, "ZBC")
И в этом случае первый символ был , а не , а оставшийся ввод по-прежнему
"ZBC".Итак, вот вам невероятно простой парсер. Если ты это поймешь, то все последующее будет легко!
Разбор указанного символа
Давайте проведем рефакторинг, чтобы можно было передать символ, который мы хотим сопоставить, вместо того, чтобы жестко запрограммировать его.
И на этот раз вместо того, чтобы возвращать true или false, мы вернем сообщение о том, что произошло.
Мы будем называть функцию
pcharдля «разбора символа». Это станет фундаментальным строительным блоком всех наших парсеров. Вот код для нашей первой попытки:let pchar (charToMatch,str) = если String.IsNullOrEmpty(str), то let msg = "Нет больше ввода" (сообщение, "") еще пусть сначала = ул. [0] если сначала = charToMatch, то пусть остальные = str.[1..] пусть msg = sprintf "Найдено %c" charToMatch (сообщение,осталось) еще let msg = sprintf "Ожидается '%c'. Сначала получено '%c'" charToMatch
(msg, стр)
Этот код аналогичен предыдущему примеру, за исключением того, что в сообщении об ошибке теперь отображается непредвиденный символ.
Подпись
pchar:val pchar : (символ * строка) -> (строка * строка)
, который говорит нам, что ввод представляет собой пару (строка, символ для сопоставления), а вывод представляет собой пару, состоящую из (строка) результата и другой строки (оставшийся ввод).
Давайте проверим это сейчас – сначала с правильным вводом:
let inputABC = "ABC" pchar('A',inputABC)Результат:
("Найдено A", "BC")Как и прежде,
Aбыло израсходовано, и осталось только"BC".А теперь с неправильным вводом:
пусть inputZBC = "ZBC" pchar('A',inputZBC), что дает результат:
("Ожидание 'A'. Получил 'Z'", "ZBC")
И снова, как и раньше, первый символ был , а не , а оставшийся ввод по-прежнему
"ZBC".Если мы пройдём через
Z, то синтаксический анализатор успешен:pchar('Z',inputZBC) // ("Найдено Z", "BC")Возврат успеха/неудачи
Мы хотим иметь возможность отличить успешное совпадение от неудачного, а возврат строкового сообщения не очень полезен, поэтому давайте воспользуемся типом выбора (он же тип суммы, он же размеченное объединение), чтобы указать разницу . Я назову его
ParseResult:type ParseResult<'a> = | Успех | Сбой строки
Случай
Successявляется общим и может содержать любое значение. СлучайFailureсодержит сообщение об ошибке.Подробнее об использовании подхода «успех/неудача» см. в моем докладе о функциональной обработке ошибок.
Теперь мы можем переписать синтаксический анализатор, чтобы он возвращал один из случаев
Result, например:let pchar (charToMatch,str) = если String.IsNullOrEmpty(str), то Ошибка «Нет больше ввода» еще пусть сначала = ул. [0] если сначала = charToMatch, то пусть остальные = str.[1..] Успех (charToMatch,осталось) еще let msg = sprintf "Ожидается '%c'. Сначала получено '%c'" charToMatch Сообщение об ошибкеПодпись
pcharтеперь:val pchar : (char * строка) -> ParseResult
, что говорит нам о том, что вывод теперь представляет собой
ParseResult(который в случаеSuccessсодержит совпадающий символ и оставшуюся входную строку).Проверим еще раз — сначала с правильным вводом:
let inputABC = "ABC" pchar('A',inputABC)Результат:
Успех ("A", "BC")Как и прежде,
Aизрасходовано, а оставшийся ввод равен"BC". Мы также получаем фактических совпадающих символов (в данном случае A).А теперь с неправильным вводом:
пусть inputZBC = "ZBC" pchar('A',inputZBC), что дает результат:
Ошибка "Ожидание "A". Получил "Z""
И в этом случае возвращается случай
Сбойс соответствующим сообщением об ошибке.Теперь это схема входов и выходов функции:
Переход на каррированную реализацию
В предыдущей реализации входом в функцию был кортеж — пара. Это требует, чтобы вы передавали оба входа одновременно. В функциональных языках, таких как F#, более идиоматично использовать каррированную версию, например:
let pchar charToMatch str = если String.IsNullOrEmpty(str), то Ошибка «Нет больше ввода» еще пусть сначала = ул. [0] если сначала = charToMatch, то пусть остальные = str. кортеж
9карри
Вот каррированная версия
pchar, представленная в виде диаграммы:Что такое карри?
Если вам непонятно, как работает каррирование, у меня есть пост об этом здесь, но в основном это означает, что функцию с несколькими параметрами можно записать как серию функций с одним параметром.
Другими словами, эта двухпараметрическая функция:
пусть сложит x y = х + у
с подписью:
значение добавить : x:int -> y:int -> int
можно записать как эквивалентную функцию с одним параметром, которая возвращает лямбду, например:
пусть добавят x = fun y -> x + y // вернуть лямбду
или как функция, которая возвращает внутреннюю функцию, например:
давайте добавим x = пусть innerFn y = x + y innerFn // возвращаем innerFn
Во втором случае, когда используется внутренняя функция, сигнатура выглядит несколько иначе:
val add : x:int -> (int -> int)
, но скобки вокруг последнего параметра можно игнорировать.
Подпись для всех практических целей такая же, как и исходная:// оригинал (автоматическое каррирование двухпараметрической функции) val add : x:int -> y:int -> int // явное каррирование с помощью внутренней функции val add : x:int -> (int -> int)
Переписывание с внутренней функцией
Мы можем воспользоваться каррированием и переписать синтаксический анализатор как функцию с одним параметром (где параметр равен
charToMatch), который возвращает внутреннюю функцию.Вот новая реализация с внутренней функцией с умным названием
innerFn:let pchar charToMatch = // определяем вложенную внутреннюю функцию пусть innerFn ул = если String.IsNullOrEmpty(str), то Ошибка «Нет больше ввода» еще пусть сначала = ул. [0] если сначала = charToMatch, то пусть остальные = str.[1..] Успех (charToMatch,осталось) еще let msg = sprintf "Ожидается '%c'. Сначала получено '%c'" charToMatch
Сообщение об ошибке
// возвращаем внутреннюю функцию
внутреннийFn
Сигнатура типа для этой реализации выглядит так:
val pchar : charToMatch:char -> (string -> ParseResult
) , который функционально эквивалентен подписи предыдущей версии. Другими словами, обе приведенные ниже реализации идентичны с точки зрения вызывающей стороны:
// реализация с двумя параметрами пусть pchar charToMatch ул = ... // реализация с одним параметром и внутренней функцией пусть pcharcharToMatch = пусть innerFn ул = ... // возвращаем внутреннюю функцию внутреннийFnПреимущества каррированной реализации
Что хорошо в каррированной реализации, так это то, что мы можем частично применить символ, который хотим разобрать, чтобы получить новую функцию, например:
let parseA = pchar 'A'
Теперь мы можем указать второй параметр «входного потока» позже:
let inputABC = «ABC» parseA inputABC //=> Успех ('A', "BC") пусть inputZBC = "ZBC" parseA inputZBC //=> Ошибка "Ожидается 'A'. Получил 'Z'"
На этом этапе давайте остановимся и посмотрим, что происходит:
- Функция
pcharимеет два входа - Мы можем предоставить один ввод (символ для сопоставления), и в результате будет возвращена функция .
- Затем мы можем предоставить второй вход (поток символов) этой функции синтаксического анализа, и это создаст окончательное значение
Result.
Вот схема
pcharснова, но на этот раз с акцентом на частичное применение:Очень важно, чтобы вы поняли эту логику, прежде чем двигаться дальше, потому что остальная часть поста будет основываться на этом базовом дизайне.
Инкапсуляция функции синтаксического анализа в тип
Если мы посмотрим на
parseA(из приведенного выше примера), то увидим, что он имеет тип функции:val parseA : string -> ParseResult
Этот тип немного сложен в использовании, поэтому давайте инкапсулируем его в тип-оболочку с именем 9.
2364 Parser , например:type Parser<'T> = Parser of (string -> ParseResult<'T * string>)
Путем его инкапсуляции мы перейдем от этого дизайна:
к этому дизайну, где он возвращает значение
Parser:В чем преимущества наличия этого дополнительного типа по сравнению с работой с «сырая» строка
-> функция ParseResultнапрямую?- Всегда полезно использовать типы для моделирования предметной области, и в этой предметной области мы имеем дело с «парсерами», а не с функциями (хотя за кулисами это одно и то же).
- Это упрощает определение типа и помогает сделать комбинаторы парсера (которые мы создадим позже) более понятными (например, комбинатор, который принимает два параметра «Парсер», понятен, но комбинатор, принимающий два параметра типа
string -> ParseResult <'a * string>трудно читать). - Наконец, он поддерживает скрытие информации (с помощью абстрактного типа данных), чтобы мы могли позже добавлять метаданные, такие как метка/строка/столбец и т. д., без нарушения работы клиентов.
Изменить реализацию просто. Нам просто нужно изменить способ возврата внутренней функции.
То есть из этого:
пусть pchar charToMatch = пусть innerFn ул = ... // возвращаем внутреннюю функцию внутреннийFnк этому:
пусть pchar charToMatch = пусть innerFn ул = ... // возвращаем "завернутую" внутреннюю функцию Парсер innerFnТестирование обернутой функции
Хорошо, теперь давайте проверим снова:
пусть parseA = pchar 'A' пусть inputABC = "ABC" parseA inputABC // ошибка компилятора
Но теперь мы получаем ошибку компилятора:
ошибка FS0003: Это значение не является функцией и не может быть применено.
И, конечно же, это потому, что функция заключена в структуру данных
Parser! Он больше не доступен напрямую.Итак, теперь нам нужна вспомогательная функция, которая может извлечь внутреннюю функцию и запустить ее для входного потока. Назовем это
запустить! Вот его реализация:позволить запустить парсер input = // разворачиваем парсер, чтобы получить внутреннюю функцию пусть (парсер innerFn) = парсер // вызов внутренней функции с вводом внутренний ввод Fn
Теперь мы можем снова запустить анализатор
parseAдля различных входных данных:let inputABC = "ABC" запустить parseA inputABC // Успех ('A', "BC") пусть inputZBC = "ZBC" запустить parseA inputZBC // Ошибка «Ожидается 'A'. Получил 'Z'"Вот оно! У нас есть базовая
Парсер типа! Я надеюсь, что пока все это имеет смысл.Последовательное объединение двух парсеров
Эта последняя реализация достаточно хороша для базовой логики синтаксического анализа.
Мы вернемся к нему позже,
но теперь давайте поднимемся на уровень выше и разработаем несколько способов комбинирования парсеров — «комбинаторов парсеров», упомянутых в начале.Начнем с последовательного объединения двух парсеров. Например, предположим, что нам нужен синтаксический анализатор, который соответствует «А», а затем «Б». Мы могли бы попробовать написать что-то вроде этого:
пусть parseA = pchar 'A' пусть parseB = pchar 'B' пусть parseAThenB = parseA >> parseB
, но это дает нам ошибку компилятора, так как вывод
parseAне соответствует вводуparseB, и поэтому они не могут быть составлены таким образом.Если вы знакомы с паттернами функционального программирования, вам часто приходится связать вместе последовательность обернутых типов, как это, и решением является функция
bind.Однако в данном случае я не буду реализовывать
связывает, но вместо этого сразу переходит к реализации, а затем.Логика реализации будет следующей:
- Запустить первый парсер.
- В случае сбоя вернуться.
- В противном случае запустить второй синтаксический анализатор с оставшимися входными данными.
- В случае сбоя вернуться.
- Если оба синтаксических анализатора завершились успешно, вернуть пару (кортеж), содержащую оба проанализированных значения.
Вот код для
и Затем:пусть andThen парсер1 парсер2 = пусть внутренний вход Fn = // запускаем parser1 с вводом let result1 = запустить ввод parser1 // проверка результата на неудачу/успех сопоставить результат1 с | Ошибка ошибки -> // возвращаем ошибку из parser1 Ошибка ошибки | Успех (значение1,осталось1) -> // запускаем parser2 с оставшимися входными данными пусть результат2 = запустить парсер2 оставшийся1 // проверка результата на неудачу/успех сопоставить результат2 с | Ошибка ошибки -> // возвращаем ошибку из parser2 Ошибка ошибки | Успех (значение2,осталось2) -> // объединяем оба значения в пару пусть новое значение = (значение1, значение2) // возвращаем оставшийся ввод после parser2 Успех (новое значение, оставшееся2) // возвращаем внутреннюю функцию Парсер innerFnРеализация следует описанной выше логике.
Мы также определим инфиксную версию
andThen, чтобы мы могли использовать ее как обычную>>композиция:let ( .>>. ) = andThen
Примечание: круглые скобки необходимы для определения пользовательского оператора, но не нужны при использовании инфикса.
Если мы посмотрим на подпись
и Затем:val и Тогда : parser1:Parser<'a> -> parser2:Parser<'b> -> Parser<'a * 'b>
мы видим, что он работает для любых двух парсеров, и они могут быть разных типов (
'aи'b).Тестирование «и тогда»
Давайте проверим и посмотрим, работает ли это!
Сначала создайте составной синтаксический анализатор:
let parseA = pchar 'A' пусть parseB = pchar 'B' пусть parseAThenB = parseA .>>. parseB
Если вы посмотрите на типы, вы увидите, что все три значения имеют тип
Parser:val parseA : Parser
val parseB : Парсер<знак> val parseAThenB : Parser parseAThenBимеет типParser, что означает, что анализируемое значение представляет собой пару символов.Теперь, поскольку комбинированный анализатор
parseAThenBявляется просто еще одним парсеромrunс ним, как и раньше.запустить parseAThenB "ABC" // Успех (('A', 'B'), "C") run parseAThenB "ZBC" // Ошибка "Ожидается "A". Получил "Z"" run parseAThenB "AZC" // Ошибка "Ожидается 'B'. Получил 'Z'"Вы можете видеть, что в случае успеха была возвращена пара
('A', 'B'), а также что сбой происходит, когда любая буква отсутствует во входных данных.Выбор между двумя парсерами
Давайте рассмотрим еще один важный способ объединения парсеров — комбинатор or else.
Например, нам нужен синтаксический анализатор, соответствующий «A» или «B». Как мы могли их объединить?
Логика реализации будет следующей:
- Запустить первый синтаксический анализатор.
- В случае успеха вернуть проанализированное значение вместе с оставшимися входными данными.
- В противном случае, в случае ошибки, запустить второй анализатор с исходным вводом…
- …и в этом случае вернуть результат (успех или неудача) из второго парсера.
Вот код для
orElse:let orElse parser1 parser2 = пусть внутренний вход Fn = // запускаем parser1 с вводом let result1 = запустить ввод parser1 // проверка результата на неудачу/успех сопоставить результат1 с | Результат успеха -> // в случае успеха возвращаем исходный результат результат1 | Ошибка ошибки -> // в случае неудачи запускаем parser2 с входными данными let result2 = запустить ввод parser2 // возвращаем результат parser2 результат2 // возвращаем внутреннюю функцию Парсер innerFnИ мы также определим инфиксную версию
orElse:let ( <|> ) = orElse
Если мы посмотрим на подпись
orElse:val orElse : parser1:Parser<'a> -> parser2:Parser<'a> -> Parser<'a>
мы видим, что это работает для любых двух парсеров, но они оба должны быть одного типа
'a.Тестирование «или иначе»
Время проверить. Сначала создайте комбинированный парсер:
let parseA = pchar 'A' пусть parseB = pchar 'B' пусть parseAOrElseB = parseA <|> parseB
Если вы посмотрите на типы, вы увидите, что все три значения имеют тип
Parser:val parseA : Parser
val parseB : Парсер<знак> val parseAOrElseB : Парсер<знак> Теперь, если мы запустим
parseAOrElseB, мы увидим, что он успешно обрабатывает «A» или «B» в качестве первого символа.запустить parseAOrElseB "AZZ" // Успех ("A", "ZZ") запустить parseAOrElseB "BZZ" // Успех ("B", "ZZ") run parseAOrElseB "CZZ" // Ошибка "Ожидается 'B'. Получил 'C'"Сочетание «и тогда» и «или иначе»
С помощью этих двух основных комбинаторов мы можем построить более сложные, например, «А, а затем (В или С)».
Вот как построить
aAndThenBorCиз более простых синтаксических анализаторов:let parseA = pchar 'A' пусть parseB = pchar 'B' пусть parseC = pchar 'C' пусть bOrElseC = parseB <|> parseC пусть aAndThenBorC = parseA .>>. БОРЭЛСЕК
И вот он в действии:
запустить aAndThenBorC "ABZ" // Успех (('A', 'B'), "Z") запустить aAndThenBorC "ACZ" // Успех (('A', 'C'), "Z") run aAndThenBorC "QBZ" // Ошибка "Ожидается "A". Получил "Q"" run aAndThenBorC "AQZ" // Ошибка "Ожидается 'C'. Получил 'Q'"Обратите внимание, что последний пример дает вводящую в заблуждение ошибку. Там написано «Ожидается «С»», хотя на самом деле должно быть «Ожидается «В» или «С». Мы не будем пытаться исправить это прямо сейчас, но в следующем посте мы будем улучшать сообщения об ошибках.
Выбор из списка парсеров
Именно здесь начинает проявляться мощь комбинаторов, потому что с
или Elseв нашем наборе инструментов мы можем использовать его для создания еще большего количества комбинаторов. Например, предположим, что мы хотим выбрать из списка 90 418 90 419 парсеров, а не только из двух.Ну, это просто. Если у нас есть попарный способ объединения элементов, мы можем расширить его до объединения всего списка, используя
уменьшите(подробнее о работе суменьшитечитайте в этом посте про моноиды)./// Выбираем любой из списка парсеров пусть выбор listOfParsers = List.reduce ( <|> ) listOfParsers
Обратите внимание, что это не удастся, если входной список пуст, но мы пока проигнорируем это.
Подпись
выбор:val выбор : Список Parser<'a> -> Parser<'a>
, который показывает нам, что, как и ожидалось, ввод представляет собой список парсеров, а вывод — один парсер.
Имея доступный выбор
anyOf, который соответствует любому символу в списке, используя следующую логику:- Ввод представляет собой список символов
- Каждый символ в списке преобразуется в синтаксический анализатор для этого символа с использованием
pchar - Наконец, все парсеры объединяются с помощью
выбора
Вот код:
/// Выберите любой из списка символов пусть anyOf listOfChars = listOfChars |> List.
map pchar // преобразовать в парсеры
|> выбор // объединить их
Давайте проверим это, создав анализатор для любого символа нижнего регистра и любого символа цифры:
let parseLowercase = любой из ['a'..'z'] пусть parseDigit = любой из ['0'..'9']
Если мы их протестируем, они будут работать как положено:
run parseLowercase "aBC" // Успех ('a', "BC") run parseLowercase "ABC" // Ошибка "Ожидается 'z'. Получил 'A'" запустить parseDigit "1ABC" // Успех ("1", "ABC") запустить parseDigit "9ABC" // Успех ("9", "ABC") запустить parseDigit "|ABC" // Ошибка "Ожидается '9'. Получил '|'"Опять же, сообщения об ошибках вводят в заблуждение. Можно ожидать любую строчную букву, а не только «z», и можно ожидать любую цифру, а не только «9». Как я уже говорил ранее, мы поработаем над сообщениями об ошибках в следующем посте.
Обзор
Давайте пока остановимся и посмотрим, что мы сделали:
- Мы создали тип
Parser, который является оболочкой для функции синтаксического анализа. - Функция синтаксического анализа принимает ввод (например, строку) и пытается сопоставить ввод с использованием критериев, встроенных в функцию.
- Если сопоставление выполнено успешно, функция синтаксического анализа возвращает
Successс совпадающим элементом и оставшимися входными данными. - Если совпадение не удается, функция синтаксического анализа возвращает
Ошибкас указанием причины ошибки. - И, наконец, мы увидели некоторые «комбинаторы» — способы, которыми
Parserмогут быть объединены для создания новогоParser:andThenиили Elseивыбор.
Список библиотеки парсера на данный момент
Вот полный листинг библиотеки синтаксического анализа на данный момент — около 90 строк кода.
Исходный код, использованный в этом посте, доступен здесь .
открытая система /// Тип, представляющий успех/неудачу при синтаксическом анализе введите ParseResult<'a> = | Успех | Сбой строки /// Тип, обертывающий функцию разбора type Parser<'T> = Анализатор (string -> ParseResult<'T * string>) /// Разбираем один символ пусть pcharcharToMatch = // определяем вложенную внутреннюю функцию пусть innerFn ул = если String.IsNullOrEmpty(str), то Ошибка «Нет больше ввода» еще пусть сначала = ул. [0] если сначала = charToMatch, то пусть остальные = str.[1..] Успех (charToMatch,осталось) еще let msg = sprintf "Ожидается '%c'. Сначала получено '%c'" charToMatch Сообщение об ошибке // возвращаем "завернутую" внутреннюю функцию Парсер innerFn /// Запуск парсера с некоторыми входными данными запустить парсер input = // разворачиваем парсер, чтобы получить внутреннюю функцию пусть (парсер innerFn) = парсер // вызов внутренней функции с вводом внутренний ввод Fn /// Объединяем два парсера как "A andThen B" пусть andThen парсер1 парсер2 = пусть внутренний вход Fn = // запускаем parser1 с вводом let result1 = запустить ввод parser1 // проверка результата на неудачу/успех сопоставить результат1 с | Ошибка ошибки -> // возвращаем ошибку из parser1 Ошибка ошибки | Успех (значение1,осталось1) -> // запускаем parser2 с оставшимися входными данными пусть результат2 = запустить парсер2 оставшийся1 // проверка результата на неудачу/успех сопоставить результат2 с | Ошибка ошибки -> // возвращаем ошибку из parser2 Ошибка ошибки | Успех (значение2,осталось2) -> // объединяем оба значения в пару пусть новое значение = (значение1, значение2) // возвращаем оставшийся ввод после parser2 Успех (новое значение, оставшееся2) // возвращаем внутреннюю функцию Парсер innerFn /// Инфиксная версия andThen пусть ( . >>. ) = и Тогда
/// Объединить два парсера как "A orElse B"
пусть orElse парсер1 парсер2 =
пусть внутренний вход Fn =
// запускаем parser1 с вводом
let result1 = запустить ввод parser1
// проверка результата на неудачу/успех
сопоставить результат1 с
| Результат успеха ->
// в случае успеха возвращаем исходный результат
результат1
| Ошибка ошибки ->
// в случае неудачи запускаем parser2 с входными данными
let result2 = запустить ввод parser2
// возвращаем результат parser2
результат2
// возвращаем внутреннюю функцию
Парсер innerFn
/// Инфиксная версия orElse
пусть ( <|> ) = илииначе
/// Выбираем любой из списка парсеров
пусть выбор listOfParsers =
List.reduce ( <|> ) listOfParsers
/// Выбираем любого из списка символов
пусть anyOf listOfChars =
listOfChars
|> List.map pchar // преобразовать в парсеры
|> выбор
Резюме
В этом посте мы создали основы библиотеки синтаксического анализа и несколько простых комбинаторов.
В следующем посте мы создадим библиотеку с большим количеством комбинаторов.
- Если вам интересно использовать эту технику в производственной среде, обязательно изучите библиотеку FParsec для F#, который оптимизирован для реального использования.
- Для получения дополнительной информации о комбинаторах синтаксических анализаторов в целом поищите в Интернете «Parsec», библиотеку Haskell, которая повлияла на FParsec (и этот пост).
- Некоторые примеры использования FParsec можно найти в одном из следующих сообщений:
- Реализация поискового запроса по фразе для FogCreek’s Kiln
- Парсер ЛОГО
- Малый базовый синтаксический анализатор
- Синтаксический анализатор C# и создание компилятора C# в F#
- Напишите себе схему за 48 часов на F#
- Разбор GLSL, языка затенения OpenGL
Исходный код, использованный в этом посте, доступен здесь .
Руководство по синтаксическому анализу: алгоритмы и терминология
Мы уже представили несколько терминов синтаксического анализа, перечислив основные инструменты и библиотеки, используемые для синтаксического анализа в Java, C#, Python и JavaScript.
В этой статье мы делаем более подробное представление концепций и алгоритмов, используемых при разборе, чтобы вы могли лучше понять этот увлекательный мир.В этой статье мы постарались быть практичными. Наша цель — помочь практикам, а не объяснить всю теорию. Мы просто объясняем, что вам нужно знать, чтобы понять и построить парсер.
После определения парсинга статья делится на три части:
- Общая картина . Раздел, в котором мы описываем основные термины и компоненты парсера.
- Грамматика . В этой части мы объясняем основные форматы грамматики и наиболее распространенные проблемы при их написании.
- Алгоритмы синтаксического анализа . Здесь мы обсудим все наиболее используемые алгоритмы парсинга и скажем, для чего они хороши.
Руководство по синтаксическому анализу в формате PDF
Получите руководство по синтаксическому анализу на свой адрес электронной почты и прочитайте его, когда захотите, на нужном устройстве
Имя
Адрес электронной почты
Мы используем это поле для обнаружения спам-ботов.
Работает на ConvertKit Если вы заполните это, вы будете отмечены как спамер.Определение синтаксического анализа
Анализ ввода для организации данных в соответствии с правилом грамматики
Есть несколько способов определить значение синтаксического анализа. Однако суть остается прежней: синтаксический анализ означает поиск базовой структуры данных, которые нам даны.
В некотором смысле синтаксический анализ можно считать обратным по отношению к шаблону: идентификация структуры и извлечение данных. В шаблонах у нас есть структура, и вместо этого мы заполняем ее данными. В случае синтаксического анализа вы должны определить модель из необработанного представления. В то время как для создания шаблонов вам необходимо объединить данные с моделью, чтобы создать необработанное представление. Необработанное представление обычно представляет собой текст, но также может быть и двоичными данными.
Фундаментальный синтаксический анализ необходим, поскольку разным объектам нужны данные в разных формах.
Синтаксический анализ позволяет преобразовывать данные так, чтобы их могло понять конкретное программное обеспечение. Очевидным примером являются программы: они написаны людьми, но должны выполняться компьютерами. Поэтому люди записывают их в понятной им форме, а затем программное обеспечение преобразует их таким образом, чтобы их мог использовать компьютер.Однако синтаксический анализ может потребоваться даже при передаче данных между двумя программами, которые имеют разные потребности. Например, это необходимо, когда вам нужно сериализовать или десериализовать класс.
Общая картина
В этом разделе мы собираемся описать основные компоненты парсера. Мы пытаемся дать вам не формальные объяснения, а практические.
Регулярные выражения
Последовательность символов, которая может быть определена шаблоном
Регулярные выражения часто рекламируются как вещь, которую вы не должны использовать для синтаксического анализа.
Это не совсем правильно, потому что вы можете использовать регулярные выражения для разбора простого ввода. Проблема в том, что некоторые программисты знают только регулярные выражения. Поэтому они используют их, чтобы попытаться разобрать все, даже то, что не следует. Результатом обычно является серия регулярных выражений, собранных воедино, которые очень хрупки.Вы можете использовать регулярные выражения для анализа некоторых более простых языков, но это исключает большинство языков программирования, даже те, которые выглядят достаточно простыми, как HTML. На самом деле языки, которые можно анализировать только с помощью регулярных выражений, называются регулярными языками. Существует формальное математическое определение, но оно выходит за рамки данной статьи.
Хотя одним важным следствием теории является то, что обычные языки могут быть проанализированы или выражены также с помощью конечного автомата. То есть регулярные выражения и конечные автоматы одинаково эффективны.
Именно по этой причине они используются для реализации лексеров, как мы увидим позже.Обычный язык может быть определен серией регулярных выражений, в то время как более сложные языки нуждаются в чем-то большем. Простое эмпирическое правило: если грамматика языка имеет рекурсивные или вложенные элементы, это не обычный язык. Например, HTML может содержать произвольное количество тегов внутри любого тега, поэтому он не является обычным языком, и его нельзя анализировать с использованием исключительно регулярных выражений, какими бы умными они ни были.
Регулярные выражения в грамматике
Знакомство типичного программиста с регулярными выражениями часто позволяет использовать их для определения грамматики языка. Точнее, их синтаксис используется для определения правил лексера или парсера. Например, звезда Клини (
*) используется в правиле, чтобы указать, что конкретный элемент может присутствовать ноль или бесконечное количество раз.Определение правила не следует путать с тем, как реализован фактический лексер или синтаксический анализатор.
Вы можете реализовать лексер, используя механизм регулярных выражений, предоставляемый вашим языком. Однако обычно регулярные выражения, определенные в грамматике, фактически преобразуются в конечный автомат для повышения производительности.Структура синтаксического анализатора
Выяснив теперь роль регулярных выражений, мы можем взглянуть на общую структуру синтаксического анализатора. Полный синтаксический анализатор обычно состоит из двух частей: лексера , также известного как сканер или токенизатор , и самого синтаксического анализатора. Парсеру нужен лексер, потому что он работает не непосредственно с текстом, а с выводом, созданным лексером. Не все синтаксические анализаторы принимают эту двухэтапную схему: некоторые синтаксические анализаторы не зависят от отдельного лексера и объединяют два этапа. Их зовут безсканерные синтаксические анализаторы .
Лексер и синтаксический анализатор работают последовательно: лексер сканирует ввод и создает совпадающие токены, затем синтаксический анализатор сканирует токены и выдает результат синтаксического анализа.
Давайте посмотрим на следующий пример и представим, что мы пытаемся разобрать дополнение.
437 + 734
Лексер сканирует текст и находит
4,3,7, а затем пробел( ). Работа лексера состоит в том, чтобы распознать, что символы437составляют один токен типа NUM . Затем лексер находит символ+, который соответствует второму токену типа PLUS , и, наконец, он находит еще один токен типа NUM .Парсер обычно объединяет токены, созданные лексером, и группирует их.
Входной поток преобразуется синтаксическим анализатором в токены, а затем в ASTОпределения, используемые лексерами и синтаксическими анализаторами, называются правилами или производит .
В нашем примере правило лексера будет указывать, что последовательность цифр соответствует токену типа NUM, а правило синтаксического анализатора будет указывать, что последовательность токенов типа NUM, PLUS, NUM соответствует выражению sum .В настоящее время обычно можно найти наборы, которые могут генерировать как лексер, так и синтаксический анализатор. В прошлом было более распространено сочетание двух разных инструментов: один для создания лексера, а другой для создания синтаксического анализатора. Например, так было с преподобным 9.0393 lex и yacc пара: с помощью lex можно было сгенерировать лексер, а с помощью yacc можно было сгенерировать синтаксический анализатор.
Анализаторы без сканирования
Анализаторы без сканирования работают по-другому, поскольку они обрабатывают непосредственно исходный текст, а не список токенов, созданный лексером. То есть парсер без сканера работает как лексер и парсер вместе взятые.
Хотя для целей отладки, безусловно, важно знать, является ли конкретное средство синтаксического анализа синтаксическим анализатором без сканера или нет, во многих случаях это не имеет отношения к определению грамматики. Это потому, что вы обычно все еще определяете шаблоны, которые группируют последовательность символов для создания (виртуальных) токенов; затем вы комбинируете их, чтобы получить окончательный результат. Просто потому, что так удобнее.
Другими словами, грамматика парсера без сканера очень похожа на грамматику инструмента с отдельными шагами. Опять же, вы не должны путать то, как вещи определяются для вашего удобства, и то, как они работают за кулисами.
Грамматика
Формальная грамматика — это набор правил, которые синтаксически описывают язык
В этом определении есть две важные части: грамматика описывает язык, но это описание относится только к синтаксису языка, а не семантика. То есть он определяет его структуру, но не его смысл.
Правильность смысла ввода необходимо проверить, при необходимости, каким-либо другим способом.Например, представьте, что мы хотим определить грамматику для языка, показанного в параграфе Определение синтаксического анализа .
ПРИВЕТ: "Привет" ИМЯ: [a-zA-Z]+ приветствие: HELLO NAME
Эта грамматика принимает такие входные данные, как
"Hello Michael"и"Hello Programming". Они оба синтаксически правильны, но мы знаем, чтоProgrammingэто не имя. Таким образом, это семантически неправильно. Грамматика не определяет семантические правила, и они не проверяются синтаксическим анализатором. Вам нужно будет обеспечить действительность предоставленного имени другим способом, например, сравнив его с базой данных допустимых имен.Анатомия грамматики
Чтобы определить элементы грамматики, давайте рассмотрим пример в наиболее часто используемом формате для описания грамматик: Форма Бэкуса-Наура (БНФ) . Этот формат имеет множество вариантов, в том числе расширенную форму Бэкуса-Наура . Преимущество расширенного варианта состоит в том, что он включает простой способ обозначения повторений. Другим примечательным вариантом является форма Augmented Backus-Naur Form , которая в основном используется для описания протоколов двунаправленной связи.
Типичное правило грамматики Бэкуса-Наура выглядит следующим образом:
::= __expression__ Правило можно также назвать производственным правилом . Технически он определяет преобразование между нетерминалом слева и набором нетерминалов и терминалов справа.
Типы грамматик
В синтаксическом анализе используются в основном два вида грамматик: обычные грамматики и контекстно-свободные грамматики . Обычно виду грамматики соответствует такой же вид языка: регулярная грамматика определяет регулярный язык и т.д. Однако существует также более поздний вид грамматик, называемый 9.0393 Грамматика выражения синтаксического анализа (PEG), которая столь же мощна, как и контекстно-свободные грамматики, и, таким образом, определяет контекстно-свободный язык.
Разница между ними заключается в обозначениях и интерпретации правил.Как мы уже упоминали, два вида языков находятся в иерархии сложности: обычные языки проще, чем контекстно-свободные языки.
Относительно простой способ различить две грамматики состоит в том, что
__выражение__регулярной грамматики, то есть правая часть правила, может быть только одним из:- пустая строка
- один символ терминала
- один символ терминала, за которым следует нетерминальный символ
На практике это сложнее проверить, потому что конкретный инструмент может позволить использовать больше терминальных символов в одном определении. Затем инструмент сам автоматически преобразует это выражение в эквивалентную серию выражений, принадлежащих одному из трех упомянутых случаев.
Таким образом, вы можете написать выражение, несовместимое с обычным языком, но оно будет преобразовано в правильную форму. Другими словами, инструмент может предоставить синтаксический сахар для написания грамматик.
В следующем абзаце мы собираемся более подробно обсудить различные виды грамматик и их форматы.
Лексер
Лексер преобразует последовательность символов в последовательность токенов. Лексеры играют роль в синтаксическом анализе, потому что они преобразуют первоначальный ввод в форму, более подходящую для соответствующего синтаксического анализатора, который работает на более позднем этапе. Обычно лексеры написать проще, чем парсеры. Хотя есть особые случаи, когда и то, и другое довольно сложно, например, в случае C (см. лексер-хак).
Очень важная часть работы лексера связана с пробелами. В большинстве случаев вы хотите, чтобы лексер отбрасывал пробелы. Это связано с тем, что в противном случае синтаксическому анализатору пришлось бы проверять наличие пробелов между каждым токеном, что быстро стало бы раздражать.
В некоторых случаях вы не можете этого сделать, потому что пробелы важны для языка, как в случае с Python, где они используются для идентификации блока кода.
Однако даже в этих случаях обычно именно лексер занимается проблемой отличия релевантных пробелов от нерелевантных. Это означает, что вы хотите, чтобы лексер понимал, какие пробелы имеют отношение к синтаксическому анализу. Например, при синтаксическом анализе Python вы хотите, чтобы лексер проверял, определяет ли пробел отступ (релевантный) или пробел между ключевым словом , еслии следующее выражение (неактуально).Где заканчивается лексер и начинается синтаксический анализатор
Учитывая, что лексеры почти всегда используются в сочетании с синтаксическими анализаторами, граница между ними иногда может быть размыта. Это связано с тем, что синтаксический анализ должен давать результат, полезный для конкретной потребности программы. Таким образом, существует не только один правильный способ разбора чего-либо, но вы заботитесь только о том способе, который соответствует вашим потребностям.
Например, представьте, что вы создаете программу, которая должна анализировать журналы сервера, чтобы сохранить их в базе данных.
Для этой цели лексер идентифицирует серию чисел и точек и преобразует их в токен IPv4.IPv4: [0-9]+ "." [0-9]+ "." [0-9]+ "." [0-9]+
Затем синтаксический анализатор проанализирует последовательность токенов, чтобы определить, является ли это сообщением, предупреждением и т. д.
Что произойдет, если вы разработаете программное обеспечение, которое должно использовать IP-адрес для идентификации страна посетителя? Возможно, вы захотите, чтобы лексер идентифицировал октеты адреса для последующего использования и сделал IPv4 элементом парсера.
ТОЧКА : "." ОКТЕТ: [0-9]+ ipv4: ОКТЕТ ТОЧКА ОКТЕТ ТОЧКА ОКТЕТ ТОЧКА ОКТЕТ
Это один из примеров того, как одна и та же информация может анализироваться по-разному из-за разных целей.
Синтаксический анализатор
В контексте синтаксического анализа «парсер» может относиться как к программному обеспечению, которое выполняет весь процесс, так и к соответствующему парсеру, который анализирует токены, созданные лексером. Это просто следствие того, что синтаксический анализатор берет на себя самую важную и сложную часть всего процесса синтаксического анализа. Под наиболее важным мы подразумеваем то, что больше всего интересует пользователя и что он действительно увидит. На самом деле, как мы уже сказали, лексер работает как помощник, облегчающий работу парсера.
В любом смысле вывод парсера представляет собой организованную структуру кода, обычно дерево. Дерево может быть деревом синтаксического анализа или деревом абстрактного синтаксиса . Оба они являются деревьями, но отличаются тем, насколько близко они представляют фактически написанный код и промежуточные элементы, определенные синтаксическим анализатором.
Грань между ними иногда может быть размытой; мы собираемся увидеть их различия немного лучше в следующем абзаце.Форма дерева выбрана потому, что это простой и естественный способ работы с кодом на разных уровнях детализации. Например, класс в C# имеет одно тело, это тело состоит из одного оператора, оператора блока, то есть списка операторов, заключенного в пару фигурных скобок, и так далее…
Синтаксическая и семантическая корректность
Синтаксический анализатор является фундаментальной частью компилятора или интерпретатора, но, конечно, может быть частью множества других программ. Например, в нашей статье Создание диаграмм из исходного кода C# с помощью Roslyn мы проанализировали файлы C# для создания диаграмм.
Синтаксический анализатор может проверять только синтаксическую правильность фрагмента кода, но компилятор может использовать его вывод также в процессе проверки семантической корректности того же фрагмента кода.
Давайте посмотрим на пример кода, который синтаксически правильный, но семантически неверный.
целое число х = 10 int sum = x + y
Проблема в том, что одна переменная (
y ) никогда не определена и, таким образом, если она будет выполнена, программа завершится ошибкой. Однако синтаксический анализатор не имеет возможности узнать об этом, потому что он не отслеживает переменные, он просто смотрит на структуру кода.Вместо этого компилятор обычно сначала проходит по дереву синтаксического анализа и сохраняет список всех определенных переменных. Затем он просматривает дерево синтаксического анализа во второй раз и проверяет, правильно ли определены все используемые переменные. В этом примере их нет, и это выдаст ошибку. Таким образом, это один из способов использования дерева синтаксического анализа для проверки семантики компилятором.
Безсканирующий синтаксический анализатор
Безсканирующий синтаксический анализатор или, реже, безлексерный синтаксический анализатор — это синтаксический анализатор, который выполняет токенизацию (т.
е. преобразование последовательности символов в токены) и правильный анализ за один шаг. Теоретически предпочтительнее иметь отдельные лексер и синтаксический анализатор, поскольку это позволяет более четко разделить задачи и создать более модульный синтаксический анализатор.Парсер без сканера лучше подходит для языка, где четкое различие между лексером и парсером затруднено или не нужно. Примером может служить синтаксический анализатор языка разметки, в котором специальные маркеры вставляются в море текста. Это также может облегчить работу с языками, где традиционное лексирование затруднено, например C. Это связано с тем, что синтаксический анализатор без сканера может легче справляться со сложными токенизациями.
Проблемы с синтаксическим анализом реальных языков программирования
Теоретически современный синтаксический анализ предназначен для работы с реальными языками программирования, но на практике с некоторыми реальными языками программирования возникают проблемы.
По крайней мере, их может быть сложнее анализировать с помощью обычных инструментов генератора синтаксического анализа.Контекстно-зависимые компоненты
Средства синтаксического анализа традиционно предназначены для работы с контекстно-свободными языками, но иногда языки являются контекстно-зависимыми. Это может быть сделано для того, чтобы упростить жизнь программистам или просто из-за плохого дизайна. Я помню, как читал о программисте, который думал, что сможет написать парсер для C за неделю, но потом он обнаружил так много краеугольных камней, что год спустя он все еще работал над ним…
Типичным примером контекстно-зависимых элементов являются так называемые программные ключевые слова , т. е. строки, которые могут считаться ключевыми словами в определенных местах, но в остальном могут использоваться как идентификаторы).
Пробелы
Пробелы играют важную роль в некоторых языках. Самый известный пример — Python, где отступ оператора указывает, является ли он частью определенного блока кода.
В большинстве мест пробелы не имеют значения даже в Python: пробелы между словами или ключевыми словами не имеют значения. Настоящей проблемой являются отступы, которые используются для идентификации блоков кода. Самый простой способ справиться с этим — проверить отступ в начале строки и преобразовать его в правильный токен, т. е. создать токен при изменении отступа по сравнению с предыдущей строкой.
На практике пользовательская функция в лексере создает токены INDENT и DEDENT, когда отступ увеличивается или уменьшается. Эти токены играют ту роль, которую в C-подобных языках играют фигурные скобки: они обозначают начало и конец блоков кода.
Этот подход делает лексирование контекстно-зависимым, а не контекстно-независимым. Это усложняет синтаксический анализ, и обычно вы не хотели бы этого делать, но в этом случае вы вынуждены это делать.
Множественный синтаксис
Еще одна распространенная проблема связана с тем фактом, что язык может включать в себя несколько разных синтаксисов.
Другими словами, один и тот же исходный файл может содержать разделы кода с разным синтаксисом. В контексте эффективного синтаксического анализа один и тот же исходный файл содержит разные языки. Самым известным примером, вероятно, является препроцессор C или C++, который на самом деле сам по себе является довольно сложным языком и может волшебным образом появиться внутри любого случайного кода C.С аннотациями проще иметь дело, они присутствуют во многих современных языках программирования. Помимо прочего, их можно использовать для обработки кода до того, как он попадет в компилятор. Они могут дать команду процессору аннотаций каким-либо образом преобразовать код, например, выполнить определенную функцию перед выполнением аннотированной. Ими легче управлять, потому что они могут появляться только в определенных местах.
Висячее Else
Висячее else является распространенной проблемой при синтаксическом анализе, связанном с оператором if-then-else . Поскольку предложение else является необязательным, последовательность операторов if может быть неоднозначной.
Например этот.если один то если два затем два еще ???Неясно, относится ли
илик первому, если, или ко второму.Честно говоря, это по большей части проблема дизайна языка. Большинство решений на самом деле не сильно усложняют синтаксический анализ, например, требуют использования
endifили требует использования блоков для разграничения оператораif, когда он включает предложение else.Однако есть также языки, которые не предлагают решения, то есть языки, разработанные неоднозначно, например (как вы уже догадались) C. Обычный подход состоит в том, чтобы связать else с ближайшим оператором if, что делает контекст синтаксического анализа чувствительный.
Дерево синтаксического анализа и абстрактное синтаксическое дерево
Существуют два взаимосвязанных термина, которые иногда используются взаимозаменяемо: Дерево синтаксического анализа и Абстрактное синтаксическое дерево (AST).
Технически дерево синтаксического анализа также можно назвать конкретным синтаксическим деревом (CST), поскольку оно должно более конкретно отражать фактический синтаксис входных данных, по крайней мере, по сравнению с AST.Концептуально они очень похожи. Они оба являются деревьями : есть корень с узлами, представляющими весь исходный код. У корня есть дочерние узлы, которые содержат поддеревья, представляющие все меньшие и меньшие части кода, пока в дереве не появятся отдельные токены (терминалы).
Разница в уровне абстракции: дерево синтаксического анализа может содержать все токены, появившиеся в программе, и, возможно, набор промежуточных правил. Вместо этого AST представляет собой отшлифованную версию дерева синтаксического анализа, в которой сохраняется только информация, необходимая для понимания кода. Мы увидим пример промежуточного правила в следующем разделе.
Некоторая информация может отсутствовать как в AST, так и в дереве синтаксического анализа.
Например, комментарии и символы группировки (например, скобки) обычно не представлены. Такие вещи, как комментарии, для программы излишни, а символы группировки неявно определяются структурой дерева.От дерева синтаксического анализа к абстрактному синтаксическому дереву
Дерево синтаксического анализа представляет собой представление кода, более близкое к конкретному синтаксису. Он показывает много деталей реализации парсера. Например, обычно каждое правило соответствует определенному типу узла. Дерево синтаксического анализа обычно преобразуется пользователем в AST, возможно, с некоторой помощью генератора синтаксического анализатора. Общая справка позволяет аннотировать какое-либо правило в грамматике, чтобы исключить соответствующие узлы из генерируемого дерева. Другой вариант — свернуть некоторые виды узлов, если у них есть только один дочерний узел.
Это имеет смысл, потому что парсеру легче создать дерево синтаксического анализа, поскольку оно является прямым представлением процесса синтаксического анализа.
Однако AST проще и легче обрабатывать следующими шагами программы. Обычно они включают в себя все операции, которые вы можете выполнять с деревом: проверку кода, интерпретацию, компиляцию и т. д.Давайте рассмотрим простой пример, чтобы показать разницу между деревом синтаксического анализа и AST. Начнем с примера грамматики.
// лексер ПЛЮС: '+' WORD_PLUS: "плюс" НОМЕР: [0-9]+ // парсер // труба | символ указывает на альтернативу между двумя сумма: ЧИСЛО (ПЛЮС | СЛОВО_ПЛЮС) ЧИСЛО
В этой грамматике мы можем определить сумму, используя как символ плюс (
+), так и строкуплюсв качестве операторов. Представьте, что вам нужно разобрать следующий код.10 плюс 21
Это может быть результирующее дерево синтаксического анализа и абстрактное синтаксическое дерево.
Дерево синтаксического анализа и абстрактное синтаксическое деревоВ АСТ пропало указание конкретного оператора и осталась только выполняемая операция. Конкретный оператор является примером промежуточного правила.
Графическое представление дерева
Результат работы синтаксического анализатора — дерево, но это дерево также может быть представлено графически. Это сделано для облегчения понимания разработчиком. Некоторые инструменты генератора синтаксического анализа могут выводить файл на языке DOT, языке, предназначенном для описания графов (дерево — это особый вид графа). Затем этот файл передается в программу, которая может создать графическое представление, исходя из этого текстового описания (например, Graphviz).
Давайте посмотрим текст .DOT на основе предыдущего примера с суммой.
сумма орграфов { сумма -> 10; сумма -> 21; }Соответствующий инструмент может создать следующее графическое представление.
Пример изображения дерева, созданного graphvizЕсли вы хотите узнать немного больше о DOT, вы можете прочитать нашу статью «Протокол языкового сервера: языковой сервер для DOT с кодом Visual Studio». В этой статье мы покажем, как создать плагин Visual Studio Code, который может обрабатывать файлы DOT.
Грамматики
Грамматики — это набор правил, используемых для описания языка, поэтому естественно изучать форматы правил. Однако есть также несколько элементов типичной грамматики, которым следует уделить больше внимания. Некоторые из них связаны с тем, что грамматика также может использоваться для определения других обязанностей или для выполнения некоторого кода.
Типичные проблемы с грамматикой
Сначала мы поговорим о некоторых особых правилах или проблемах, с которыми вы можете столкнуться при синтаксическом анализе.
Отсутствующие лексемы
Если вы читаете грамматики, вы, вероятно, столкнетесь со многими из них, в которых определены только некоторые лексемы, а не все.
Как в этой грамматике:ИМЯ: [a-zA-Z]+ приветствие : "Hello" NAME
Для токена
"Hello"нет определения, но поскольку вы знаете, что синтаксический анализатор имеет дело с токенами, вы можете спросить себя, как это возможно. Ответ заключается в том, что некоторые инструменты генерируют для вас соответствующий токен для строкового литерала, чтобы сэкономить ваше время.Имейте в виду, что это возможно только при определенных условиях. Например, с ANTLR вы должны определить все токены самостоятельно, если вы определяете отдельные грамматики лексера и парсера.
Леворекурсивные правила
В контексте синтаксических анализаторов важной функцией является поддержка леворекурсивных правил. Это означает, что правило начинается со ссылки на себя. Иногда эта ссылка также может быть косвенной, то есть она может появляться в другом правиле, на которое ссылается первое.
Рассмотрим, например, арифметические операции. Сложение может быть описано как два выражения, разделенные знаком плюс (
+), но операндами сложения могут быть другие сложения.дополнение: выражение '+' выражение умножение : выражение '*' выражение // выражение может быть сложением, умножением или числом выражение : умножение | дополнение | [0-9]+
В этом примере выражение содержит косвенную ссылку на себя через правила сложение и умножение .
Это описание также соответствует нескольким дополнениям, таким как
5 + 4 + 3. Потому что это можно интерпретировать каквыражение (5) ('+') выражение(4+3)(дополнение правила: первое выражение соответствует варианту [0-9]+, второе — другое дополнение ). И тогда само 4 + 3можно разделить на две его составляющие:выражение(4) ('+') выражение(3)(добавление правила: и первому, и второму выражению соответствует вариант [0-9]+) .Проблема в том, что леворекурсивные правила нельзя использовать с некоторыми генераторами парсеров. Альтернативой является длинная цепочка выражений, в которой также учитывается приоритет операторов. Типичная грамматика для синтаксического анализатора, который не поддерживает такие правила, будет выглядеть примерно так:
выражение : дополнение сложение : умножение ('+' умножение)* умножение: атом ('*' атом)* atom : [0-9]+Как видите, выражения определены в порядке, обратном старшинству. Таким образом, синтаксический анализатор поместит выражение с более низким приоритетом на самый низкий уровень из трех; таким образом, они будут казнены первыми.
Некоторые генераторы синтаксических анализаторов поддерживают прямые леворекурсивные правила, но не косвенные. Обратите внимание, что обычно проблема связана с самим алгоритмом синтаксического анализа, который не поддерживает леворекурсивные правила. Таким образом, генератор синтаксического анализатора может преобразовывать правила, написанные как леворекурсивные, надлежащим образом, чтобы заставить их работать с его алгоритмом. В этом смысле леворекурсивная поддержка может быть (очень полезной) синтаксическим сахаром.
Как преобразуются леворекурсивные правила
Конкретный способ преобразования правил варьируется от одного генератора парсеров к другому, однако логика остается неизменной. Выражения делятся на две группы: с оператором и двумя операндами и атомарные. В нашем примере единственным атомарным выражением является число (
[0-9]+), но это также может быть выражение в скобках ((5 + 4)). Это потому, что в математике круглые скобки используются для увеличения приоритета выражения.Когда у вас есть эти две группы: вы сохраняете порядок членов второй группы и обращаете порядок членов первой группы. Причина в том, что люди рассуждают по принципу «первым пришел, первым обслужен»: проще писать выражения в порядке их старшинства.
Однако окончательная форма разбора — это дерево, которое работает по другому принципу: вы начинаете работать с листьев и поднимаетесь вверх. Чтобы в конце этого процесса корневой узел содержал окончательный результат. Это означает, что в дереве разбора атомарные выражения находятся внизу, а выражения с операторами появляются в порядке, обратном тому, в котором они применяются.
Предикаты
Предикаты , иногда называемые синтаксическими или семантическими предикатами — это специальные правила, которые срабатывают только при выполнении определенного условия. Условие определяется с помощью кода на языке программирования, поддерживаемом инструментом, для которого написана грамматика.
Их преимущество в том, что они допускают некоторую форму контекстно-зависимого синтаксического анализа, который иногда неизбежен для сопоставления определенных элементов. Например, их можно использовать для определения того, используется ли последовательность символов, определяющая мягкое ключевое слово, в позиции, где оно должно быть ключевым словом (например, за предыдущим токеном может следовать ключевое слово) или это простой идентификатор.
Недостатком является то, что они замедляют синтаксический анализ и делают грамматику зависимой от указанного языка программирования. Это потому, что условие выражено на языке программирования и должно быть проверено. И, конечно же, для проверки этого условия необходимо выполнить код на соответствующем языке программирования.
Встроенные действия
Встроенные действия определяют код, который выполняется каждый раз при совпадении правила. У них есть явный недостаток, заключающийся в том, что они затрудняют чтение грамматики, поскольку правила окружены кодом.
Кроме того, как и предикаты, они нарушают разделение между грамматикой, описывающей язык, и кодом, обрабатывающим результаты синтаксического анализа.Действия часто используются менее сложными генераторами синтаксического анализа как единственный способ легко выполнить некоторый код при совпадении узла. При использовании этих поколений синтаксических анализаторов единственной альтернативой будет обход дерева и самостоятельное выполнение надлежащего кода. Более продвинутые инструменты позволяют вместо этого использовать шаблон посетителя для выполнения произвольного кода, когда это необходимо, а также для управления обходом дерева.
Их также можно использовать для добавления определенных токенов или изменения сгенерированного дерева. Хотя это и уродливо, это может быть единственным практичным способом решения сложных языков, таких как C, или конкретных проблем, таких как пробелы в Python.
Форматы
Существует два основных формата грамматики: BNF (и его варианты) и PEG.
Многие инструменты реализуют свои варианты этих идеальных форматов. Некоторые инструменты вообще используют пользовательские форматы. Часто настраиваемый формат состоит из трех частей грамматики: параметры вместе с пользовательским кодом, за которым следует раздел лексера и, наконец, раздел анализатора.Учитывая, что формат, подобный BNF, обычно является основой контекстно-свободной грамматики, вы также можете увидеть, что он идентифицируется как формат CFG.
Форма Бэкуса-Наура и ее варианты
Форма Бэкуса-Наура (BNF) является наиболее успешным форматом и даже легла в основу PEG. Однако он довольно прост, и поэтому не часто используется в своей основной форме. Обычно используется более мощный вариант.
Чтобы показать, почему эти варианты были необходимы, давайте покажем пример в BNF: описание символа.
<буква> ::= "а" | "б" | "с" | "д" | "е" | "ф" | "г" | "ч" | "я" | "дж" | "к" | "л" | "м" | "н" | "о" | "п" | "к" | "р" | "с" | "т" | "у" | "в" | "ш" | "х" | "у" | "з" <цифра> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" <символ> ::= <буква> | <цифра>
Символ <буква> может быть преобразован в любую из букв английского алфавита, хотя в нашем примере допустимы только строчные буквы.
Аналогичный процесс происходит для <цифра> , что может указывать на любую из альтернативных цифр. Первая проблема заключается в том, что вы должны перечислить все альтернативы по отдельности; вы не можете использовать классы символов, как в регулярных выражениях. Это раздражает, но обычно решаемо, если, конечно, вам не нужно перечислять все символы Unicode.Гораздо сложнее проблема в том, что нет простого способа обозначить необязательные элементы или повторения. Поэтому, если вы хотите это сделать, вы должны полагаться на логическую логику и альтернативный символ (
|).<текст> ::= <символ> |
Это правило гласит, что
Дерево синтаксического анализа для ‘dog’BNF имеет много других ограничений: усложняет использование пустых строк или символов, используемых форматом (например,
::=) в грамматике, он имеет многословный синтаксис (например, вы должны включать терминалы между < и >) и т.д. синтаксическая запись.EBNF — наиболее часто используемая форма в современных инструментах синтаксического анализа, хотя инструменты могут отличаться от стандартных обозначений. EBNF имеет гораздо более чистую нотацию и использует больше операторов для работы с конкатенацией или необязательными элементами.
Давайте посмотрим, как бы вы написали предыдущий пример в EBNF.
буква = "а" | "б" | "с" | "д" | "е" | "ф" | "г" | "ч" | "я" | "дж" | "к" | "л" | "м" | "н" | "о" | "п" | "к" | "р" | "с" | "т" | "у" | "в" | "ш" | "х" | "у" | "з" ; цифра = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ; символ = буква | цифра ; текст = символ, {символ};Текстовый символ теперь описывается проще с помощью оператора конкатенации (
,) и опционального ({ .). Результирующее дерево синтаксического анализа также будет проще. Стандартный EBNF все еще представляет некоторые проблемы, такие как незнакомый синтаксис. Чтобы решить эту проблему, большинство инструментов синтаксического анализа используют синтаксис, вдохновленный регулярными выражениями, а также поддерживают дополнительные элементы, такие как классы символов. . } Если вам нужно подробное описание формата, вы можете прочитать нашу статью о EBNF.
ABNF
Расширенный BNF (ABNF) — еще один вариант BNF, в основном разработанный для описания протоколов двунаправленной связи и оформленный IETF в нескольких документах (см. RFC 5234 и обновления).
ABNF может быть столь же продуктивным, как EBNF, но у него есть некоторые особенности, которые ограничивают его применение за пределами интернет-протоколов. Например, до недавнего времени стандарт требовал, чтобы строки сопоставлялись без учета регистра, что было бы проблемой для сопоставления идентификаторов во многих языках программирования.
ABNF имеет синтаксис, отличный от EBNF, например, альтернативным оператором является косая черта (
/), а иногда это явно лучше. Например, нет необходимости в операторе конкатенации. Он также имеет несколько больше функций, чем стандартный EBNF. Например, он позволяет вам определять числовые диапазоны, такие как%x30-39, что эквивалентно[0-9]. Это также используется самими дизайнерами для включения стандартных классов символов, подобных базовым правилам, которые может использовать конечный пользователь. Примером такого правила является АЛЬФА, что эквивалентно[a-zA-Z].PEG
Грамматика выражения синтаксического анализа (PEG) — это формат, представленный Брайаном Фордом в статье 2004 года. Технически он происходит от старой формальной грамматики под названием Top-Down Parsing Language (TDPL). Однако простой способ описать это: EBNF в реальном мире.
На самом деле он похож на EBNF, но также напрямую поддерживает широко используемые функции, такие как диапазоны символов (классы символов).
Хотя у него также есть некоторые отличия, которые на самом деле не так уж прагматичны, например, использование более формального символа стрелки ( ←) для присваивания вместо более распространенного символа равенства (=). Предыдущий пример можно было бы написать таким же образом с PEG.буква ← [a-z] цифра ← [0-9] символ ← буква / цифра text ← character+
Как вы можете видеть, это наиболее очевидный способ написания программистом, с классами символов и операторами регулярных выражений. Единственными аномалиями являются альтернативный оператор (
/) и символ стрелки, и на самом деле многие реализации PEG используют символ равенства.Прагматический подход лежит в основе формализма PEG: он был создан для более естественного описания языков программирования.
Это потому, что контекстно-свободная грамматика берет свое начало в работе по описанию естественных языков. Теоретически CFG — это порождающая грамматика , а PEG — аналитическая грамматика .Во-первых, это своего рода рецепт для генерации только правильных предложений на языке, описанном грамматикой. Это не должно быть связано с алгоритмом синтаксического анализа. Вместо этого второй тип напрямую определяет структуру и семантику парсера для этого языка.
PEG против CFG
Практические последствия этого теоретического различия ограничены: PEG более тесно связан с алгоритмом packrat , но в основном это все. Например, обычно PEG (packrat) не разрешает левую рекурсию. Хотя сам алгоритм можно изменить для его поддержки, это устраняет свойство синтаксического анализа за линейное время. Кроме того, синтаксические анализаторы PEG, как правило, являются синтаксическими анализаторами без сканера.
Вероятно, самое важное различие между PEG и CFG заключается в том, что порядок выбора имеет значение в PEG, но не в CFG.
Если существует много возможных допустимых способов анализа ввода, CFG будет неоднозначным и, следовательно, обычно будет возвращать ошибку. Под обычно мы подразумеваем, что некоторые синтаксические анализаторы, использующие CFG, могут работать с неоднозначными грамматиками. Например, предоставив разработчику все возможные действительные результаты и позволив ему разобраться. Вместо этого PEG полностью устраняет неоднозначность, поскольку будет выбран первый подходящий вариант, поэтому PEG никогда не может быть неоднозначным.Недостаток этого подхода в том, что вам нужно быть более осторожным при перечислении возможных альтернатив, потому что в противном случае вы можете иметь неожиданные последствия. То есть некоторые варианты никогда не могут быть сопоставлены.
В следующем примере
dogeникогда не будет соответствовать, так как собака приходит первой, она будет выбрана каждый раз.dog ← 'dog' / 'doge'
Открытая область исследований, может ли PEG описать все грамматики, которые могут быть определены с помощью CFG, но для всех практических целей это возможно.
Алгоритмы синтаксического анализа
Теоретически синтаксический анализ — это решаемая проблема, но это такая проблема, которая решается снова и снова. То есть существует множество различных алгоритмов, каждый из которых имеет сильные и слабые стороны, и они все еще совершенствуются учеными.
В этом разделе мы не будем учить, как реализовать каждый из алгоритмов разбора, но мы объясним их особенности. Цель состоит в том, чтобы вы могли более осознанно выбирать, какой инструмент синтаксического анализа использовать или какой алгоритм лучше изучить и реализовать для своего пользовательского синтаксического анализатора.
Обзор
Давайте начнем с общего обзора функций и стратегий всех парсеров.
Две стратегии
Существует две стратегии синтаксического анализа: нисходящий анализ и восходящий анализ . Оба термина определены по отношению к дереву синтаксического анализа, сгенерированному синтаксическим анализатором.
Проще говоря:- нисходящий синтаксический анализатор сначала пытается идентифицировать корень дерева синтаксического анализа, затем он движется вниз по поддеревьям, пока не найдет листья дерева.
- Восходящий синтаксический анализатор вместо этого начинает с самой нижней части дерева, листьев, и поднимается вверх, пока не определит корень дерева.
Давайте рассмотрим пример, начиная с дерева синтаксического анализа.
Пример дерева синтаксического анализа из ВикипедииОдно и то же дерево будет сгенерировано в разном порядке парсером «сверху вниз» и «снизу вверх». На следующих изображениях число указывает порядок, в котором создаются узлы.
Порядок генерации дерева сверху вниз (из Википедии) Порядок генерации дерева снизу вверх (из Википедии)Традиционно нисходящие синтаксические анализаторы создавать было проще, но восходящие синтаксические анализаторы были более мощными. Теперь ситуация стала более сбалансированной, в основном благодаря прогрессу в стратегиях парсинга сверху вниз.
Концепция деривации тесно связана со стратегиями. Вывод указывает порядок, в котором нетерминальные элементы, встречающиеся в правиле справа, применяются для получения нетерминального символа слева. Используя терминологию БНФ, он указывает, как элементы, которые появляются в
__expression__используются для полученияПростой пример: представьте, что вы пытаетесь разобрать символ
, результат, который определен как таковой в грамматике.expr_one = .. // материал expr_two = .. // материал результат = expr_one 'оператор' expr_two
Можно сначала применить правило для символа
expr_one, а затемexpr_twoили наоборот. В случае крайнего левого вывода вы выбираете первый вариант, а для крайнего правого вывода — второй.Важно понимать, что вывод применяется в глубину или рекурсивно. Другими словами, он применяется к начальному выражению, а затем снова применяется к полученному промежуточному результату. Так, в этом примере, если после применения правила, соответствующего
expr_oneесть новый нетерминал, он трансформируется первым. Нетерминалexpr_twoприменяется только тогда, когда он становится первым нетерминалом и не следует порядку исходного правила.Вывод связан с двумя стратегиями, потому что для восходящего синтаксического анализа вы применяете самый правый вывод, а для нисходящего анализа вы выбираете самый левый вывод. Обратите внимание, что это не влияет на окончательное дерево синтаксического анализа, оно влияет только на промежуточные элементы и используемый алгоритм.
Общие элементы
Парсеры, созданные с использованием стратегий «сверху вниз» и «снизу вверх», имеют несколько общих элементов, о которых мы можем поговорить.
Упреждающий просмотр и поиск с возвратом
Термины поиск с возвратом и поиск с возвратом не имеют другого значения при синтаксическом анализе, чем то, которое они имеют в более широкой области компьютерных наук. Lookahead указывает количество элементов, следующих за текущим, которые принимаются во внимание, чтобы решить, какое текущее действие предпринять.
Простой пример: синтаксический анализатор может проверить следующий токен, чтобы решить, какое правило применить сейчас. При совпадении правильного правила текущий токен расходуется, но следующий остается в очереди.
Возврат — это метод алгоритма. Он состоит в том, чтобы найти решение сложной проблемы, пробуя частичные решения, а затем продолжая проверять наиболее перспективное из них. Если тот, который в настоящее время тестируется, терпит неудачу, то синтаксический анализатор возвращается (т. е. возвращается к последней позиции, которая была успешно проанализирована) и пробует другой.
Lookahead особенно актуален для алгоритмов синтаксического анализа LL , LR и LALR , потому что синтаксические анализаторы для языков, которым нужен только один токен просмотра вперед, легче создавать и быстрее запускать. Упреждающие токены, используемые такими алгоритмами, указываются в скобках после названия алгоритма (например, LL(1), LR( k )). Обозначение (*) указывает на то, что алгоритм может проверять бесконечные упреждающие токены, хотя это может повлиять на производительность.
Анализаторы диаграмм
Анализаторы диаграмм — это семейство анализаторов, которые могут быть восходящими (например, CYK) или нисходящими (например, Earley). Анализаторы диаграмм, по существу, пытаются избежать обратного отслеживания, которое может быть дорогостоящим, используя динамическое программирование . Динамическое программирование или динамическая оптимизация — это общий метод разбиения более крупной проблемы на более мелкие подзадачи.
Распространенным алгоритмом динамического программирования, используемым анализатором диаграмм, является алгоритм Витерби. Цель алгоритма — найти наиболее вероятные скрытые состояния при заданной последовательности известных событий. По сути, учитывая известные нам токены, мы пытаемся найти наиболее вероятные правила, которые их произвели.
Имя анализатора диаграмм происходит от того факта, что частичные результаты хранятся в структуре, называемой диаграммой (обычно диаграмма представляет собой таблицу). Конкретный метод хранения частичных результатов называется запоминанием . Мемоизация также используется другими алгоритмами, не связанными с парсерами диаграмм, такими как packrat .
Автоматы
Прежде чем обсуждать алгоритмы синтаксического анализа, мы хотели бы поговорить об использовании автоматов в алгоритмах синтаксического анализа. Автоматы — это семейство абстрактных машин, среди которых есть хорошо известные Машина Тьюринга .
Когда дело доходит до синтаксических анализаторов, вы можете услышать термин (детерминистический) автомат выталкивания (КПК), а когда вы читаете о лексерах, вы услышите термин детерминированный конечный автомат (DFA). КПК более мощный и сложный, чем DFA (хотя все еще проще, чем машина Тьюринга).
Поскольку они определяют абстрактные машины, обычно они не имеют прямого отношения к реальному алгоритму. Скорее, они описывают формальным образом уровень сложности, с которым должен иметь дело алгоритм. Если кто-то говорит, что для решения задачи X вам нужен DFA, он имеет в виду, что вам нужен алгоритм столь же мощный, как DFA.
Однако, поскольку DFA являются конечными автоматами в случае лексера, различие часто является спорным. Это связано с тем, что конечные автоматы относительно просты в реализации (т. е. существуют готовые к использованию библиотеки), поэтому в большинстве случаев DFA реализуется с помощью конечного автомата.
Вот почему мы собираемся кратко рассказать о DFA и о том, почему они часто используются для лексеров.Лексирование с детерминированным конечным автоматом
DFA — это (конечный) конечный автомат, концепция которого, как мы предполагаем, вам знакома. По сути, конечный автомат имеет множество возможных состояний и функцию перехода для каждого из них. Эти функции перехода управляют тем, как машина может переходить из одного состояния в другое в ответ на событие. При использовании для лексирования машина подает входные символы по одному, пока не достигнет принятого состояния (т. е. не сможет построить токен).
Они используются по нескольким причинам:
- было доказано, что они точно распознают набор обычных языков, то есть они столь же эффективны, как и обычные языки
- существует несколько математических методов для манипулирования и проверки их свойства (например, могут ли они анализировать все строки или любые строки)
- они могут работать с эффективным онлайн-алгоритмом (см. ниже)
Онлайн-алгоритм — это алгоритм, которому не нужны все входные данные для работы. В случае лексера это означает, что он может распознать токен, как только алгоритм увидит его символы. Альтернативой может быть то, что для идентификации каждого токена потребуется весь ввод.
В дополнение к этим свойствам довольно легко преобразовать набор регулярных выражений в DFA, что позволяет вводить правила простым способом, знакомым многим разработчикам. Затем вы можете автоматически преобразовать их в конечный автомат, который сможет эффективно с ними работать.
Таблицы алгоритмов синтаксического анализа
Мы предоставляем таблицу, содержащую сводку основной информации, необходимой для понимания и реализации конкретного алгоритма синтаксического анализа. Вы можете найти больше реализаций, прочитав наши статьи, в которых представлены инструменты и библиотеки для синтаксического анализа для Java, C#, Python и JavaScript.
В таблице перечислены:
- формальное описание для объяснения теории алгоритма
- более практическое объяснение
- одна или две реализации, обычно одна более простая, а другая профессиональный анализатор. Иногда, однако, нет более легкой или профессиональной версии.
Алгоритм Формальное описание Объяснение Пример реализации CYK Эффективный алгоритм распознавания и синтаксического анализа для контекстно-свободных языков (PDF) Алгоритмы CKY и Earley (PDF) Алгоритм CYK в Golang/парсерах диаграмм Алгоритм (PDF) Объяснение синтаксического анализа Earley Nearley LL LL(*): The Foundation of the ANTLR Parser Generator (PDF) LL Parser в Википедии / LL-9parser.js3878 ll(1) parser / ANTLR LR On the Translation of Languages from Left to Right (PDF) Compiler Course Jison / Bison Packrat (PEG) Packrat Parsing: Практический алгоритм линейного времени с возвратом (PDF) Анализ Packrat: простой, мощный, ленивый, линейный анализ TimePackrat в Scala (PDF) Сопутствующий код диссертации / Canopy Комбинатор парсеров Создание переводчиков естественного языка на ленивом функциональном языке (PDF) Объединенные комбинаторы парсера. Синтаксический анализатор в Python/JSLintЧтобы понять, как работает алгоритм синтаксического анализа, вы также можете ознакомиться с набором инструментов синтаксического анализа. Это образовательный генератор синтаксических анализаторов, который описывает шаги, которые сгенерированный синтаксический анализатор предпринимает для достижения своей цели. Он реализует алгоритмы LL и LR.
Вторая таблица показывает сводку основных характеристик различных алгоритмов синтаксического анализа и того, для чего они обычно используются.
Алгоритмы «сверху вниз»
Стратегия «сверху вниз» является наиболее распространенной из двух стратегий, и существует несколько успешных алгоритмов, использующих ее.
LL Parser
LL ( L чтение ввода слева направо, L вывод слева) — это парсеры на основе таблиц без обратного отслеживания, но с просмотром вперед. На основе таблиц означает, что они полагаются на таблицу синтаксического анализа, чтобы решить, какое правило применить.
В таблице синтаксического анализа в качестве строк и столбцов используются нетерминалы и терминалы соответственно.Чтобы найти правильное правило для применения:
- сначала синтаксический анализатор просматривает текущий токен и соответствующее количество упреждающих токенов
- , затем он пытается применить различные правила, пока не найдет правильное совпадение.
Концепция синтаксического анализатора LL относится не к конкретному алгоритму, а скорее к классу синтаксических анализаторов. Они определяются в отношении к грамматикам. Другими словами, синтаксический анализатор LL — это тот, который может анализировать грамматику LL. В свою очередь, LL-грамматики определяются в зависимости от количества упреждающих токенов, необходимых для их анализа. Этот номер указывается в скобках рядом с LL в виде LL( к ).
Синтаксический анализатор LL( k ) использует k токенов упреждающего просмотра и, таким образом, он может проанализировать максимум грамматику, для анализа которой требуется k токенов упреждающего просмотра.
По сути, концепция грамматики LL( k ) используется более широко, чем соответствующий синтаксический анализатор. Это означает, что грамматики LL( k ) используются в качестве измерителя при сравнении различных алгоритмов. Например, вы могли прочитать, что синтаксические анализаторы PEG могут обрабатывать грамматики LL(*).Значение грамматики английского языка
Такое использование грамматик ЯП связано как с тем фактом, что синтаксические анализаторы ЯП широко используются, так и с некоторыми ограничениями. На самом деле, грамматика LL не поддерживает леворекурсивные правила. Вы можете преобразовать любую леворекурсивную грамматику в эквивалентную нерекурсивную форму, но это ограничение имеет значение по нескольким причинам: производительность и мощность.
Потеря производительности связана с необходимостью писать грамматику особым образом, что требует времени. Мощность ограничена, потому что грамматике, которой может потребоваться 1 токен просмотра вперед, если она написана с помощью леворекурсивного правила, может потребоваться 2-3 токена просмотра вперед, если она написана нерекурсивным способом.
Таким образом, это ограничение не просто раздражает, оно ограничивает возможности алгоритма, т. е. грамматики, для которых его можно использовать.Снижение производительности можно уменьшить с помощью алгоритма, который автоматически преобразует леворекурсивную грамматику в нерекурсивную. ANTLR — это инструмент, который может это сделать, но, конечно, если вы создаете собственный парсер, вам придется делать это самостоятельно.
Существует два специальных вида грамматик LL( k ): LL(1) и LL(*). В прошлом первый вид считался единственным практичным, потому что для них легко создавать эффективные синтаксические анализаторы. Вплоть до того, что многие компьютерные языки были специально разработаны для описания грамматикой LL(1). LL(*), также известный как LL-регулярный анализатор , может работать с языками, используя бесконечное количество токенов просмотра вперед.
В StackOverflow вы можете прочитать простое сравнение между парсерами LL и парсерами рекурсивного спуска или между парсерами LL и парсерами LR.
Анализатор Earley
Анализатор Earley — это анализатор диаграмм, названный в честь его изобретателя Джея Эрли. Алгоритм обычно сравнивают с CYK, другим парсером графиков, который проще, но также обычно хуже по производительности и памяти. Отличительной чертой алгоритма Эрли является то, что, помимо хранения частичных результатов, он реализует шаг прогнозирования, чтобы решить, какое правило будет пытаться соответствовать следующему.
Синтаксический анализатор Earley в основном работает, разделяя правило на сегменты, как в следующем примере.
// пример грамматики Привет привет" ИМЯ : [a-zA-Z]+ приветствие : ПРИВЕТ ИМЯ // Парсер Earley разбивает приветствие, как это // . ПРИВЕТ ИМЯ // ПРИВЕТ . ИМЯ // ЗДРАВСТВУЙТЕ, ИМЯ.
Затем, работая над этими сегментами, которые можно соединить точкой (
.), пытается достичь завершенного состояния, то есть состояния с точкой в конце. Преимущество синтаксического анализатора Эрли заключается в том, что он гарантированно способен анализировать все контекстно-свободные языки, в то время как другие известные алгоритмы (например, LL, LR) могут анализировать только их подмножество. Например, у него нет проблем с леворекурсивными грамматиками. В более общем смысле синтаксический анализатор Эрли также может работать с недетерминированными и неоднозначными грамматиками.
Это может произойти с риском ухудшения производительности (O(n 3 )), в худшем случае. Однако он имеет линейную производительность по времени для обычных грамматик. Загвоздка в том, что нас обычно интересует набор языков, разбираемых более традиционными алгоритмами. быть более эффективным. Т. е. построение грамматики LL(1) может быть сложнее для разработчика, но синтаксический анализатор может применить ее очень эффективно. С Earley вы делаете меньше работы, поэтому синтаксический анализатор делает ее больше.
Короче говоря, Earley позволяет вам использовать грамматики, которые легче писать, но которые могут быть неоптимальными с точки зрения производительности.
Варианты использования Earley
Таким образом, синтаксические анализаторы Earley просты в использовании, но преимущество с точки зрения производительности в среднем случае может отсутствовать. Это делает алгоритм идеальным для образовательной среды или в тех случаях, когда производительность важнее скорости.
В первом случае это полезно, например, потому что большую часть времени написанные вашими пользователями грамматики работают нормально. Проблема в том, что синтаксический анализатор будет выдавать им непонятные и, казалось бы, случайные ошибки. Конечно, ошибки на самом деле не случайны, а связаны с ограничениями алгоритма, которые ваши пользователи не знают или не понимают. Таким образом, вы заставляете пользователя понимать внутреннюю работу вашего парсера, чтобы использовать его, что должно быть ненужным.
Примером того, когда производительность важнее скорости, может быть генератор парсера для реализации подсветки синтаксиса для редактора, которому требуется поддержка многих языков. В подобной ситуации возможность быстрой поддержки новых языков может оказаться более желательной, чем выполнение задачи как можно скорее.
Packrat (PEG)
Packrat часто ассоциируется с формальной грамматикой PEG, поскольку они были изобретены одним и тем же человеком: Брайаном Фордом. Пакрат был впервые описан в его диссертации: Анализ Пакрата: практический алгоритм линейного времени с возвратом. Название говорит почти обо всем, что нас волнует: оно имеет линейное время выполнения, в том числе потому, что оно не использует возврат.
Другой причиной эффективности является мемоизация: сохранение частичных результатов в процессе разбора. Недостатком и причиной, по которой этот метод не использовался до недавнего времени, является объем памяти, необходимый для хранения всех промежуточных результатов.
Если требуемая память превышает доступную, алгоритм теряет свое линейное время выполнения.Packrat также не поддерживает леворекурсивные правила, следствие того, что PEG требует всегда выбирать первый вариант. На самом деле некоторые варианты могут поддерживать прямые леворекурсивные правила, но за счет потери линейной сложности.
Парсеры Packrat могут работать с бесконечным количеством просмотров вперед, если это необходимо. Это влияет на время выполнения, которое в худшем случае может быть экспоненциальным.
Анализатор рекурсивного спуска
Анализатор рекурсивного спуска — это анализатор, работающий с набором (взаимно) рекурсивных процедур, обычно по одной для каждого правила грамматики. Таким образом, структура синтаксического анализатора отражает структуру грамматики.
Термин прогнозирующий синтаксический анализатор используется по-разному: некоторые люди имеют в виду его как синоним нисходящего синтаксического анализатора, некоторые как рекурсивный нисходящий синтаксический анализатор, который никогда не отступает.
Противоположностью этому второму значению является синтаксический анализатор рекурсивного спуска, выполняющий возвраты. То есть тот, который находит правило, соответствующее входным данным, последовательно пробуя каждое из правил, а затем возвращаясь каждый раз, когда оно терпит неудачу.
Обычно парсеры с рекурсивным спуском имеют проблемы с разбором леворекурсивных правил, потому что алгоритм в конечном итоге будет вызывать одну и ту же функцию снова и снова. Возможное решение этой проблемы — использование хвостовой рекурсии. Парсеры, использующие этот метод, называются хвостовые рекурсивные синтаксические анализаторы .
Хвостовая рекурсия per se — это просто рекурсия, которая происходит в конце функции. Однако хвостовая рекурсия используется в сочетании с преобразованиями правил грамматики. Комбинация преобразования правил грамматики и добавления рекурсии в конце процесса позволяет иметь дело с леворекурсивными правилами.
Анализатор Пратта
Анализатор Пратта — широко неиспользуемый, но очень ценимый (теми, кто его знает) алгоритм разбора, определенный Воаном Праттом в статье под названием Приоритет оператора сверху вниз.
Сама статья начинается с полемики о грамматиках БНФ, которые, как ошибочно утверждает автор, являются исключительной заботой исследований синтаксического анализа. Это одна из причин отсутствия успеха. На самом деле алгоритм не опирается на грамматику, а работает непосредственно с токенами, что делает его необычным для экспертов по разбору.Вторая причина заключается в том, что традиционные нисходящие синтаксические анализаторы отлично работают, если у вас есть осмысленный префикс, который помогает различать разные правила. Например, если вы получаете токен FOR , вы просматриваете оператор for . Поскольку это по существу относится ко всем языкам программирования и их операторам, легко понять, почему синтаксический анализатор Пратта не изменил мир синтаксического анализа.
Где алгоритм Пратта сияет, так это в выражениях. На самом деле, концепция приоритета делает невозможным понимание структуры входных данных, просто взглянув на порядок, в котором представлены токены.
По сути, алгоритм требует, чтобы вы присвоили значение приоритета каждому токену оператора и пару функций, которые определяют, что делать, в зависимости от того, что находится слева и справа от токена. Затем он использует эти значения и функции для связывания операций во время обхода ввода.
Хотя алгоритм Пратта не был явно успешным, он используется для синтаксического анализа выражений. Он также был принят Дугласом Крокфордом (известным в JSON) для JSLint.
Комбинатор парсеров
Комбинатор синтаксического анализатора — это функция более высокого порядка, которая принимает функции синтаксического анализа в качестве входных данных и возвращает новую функцию синтаксического анализа в качестве выходных данных. Функция синтаксического анализатора обычно означает функцию, которая принимает строку и выводит дерево синтаксического анализа.
Комбинатор синтаксических анализаторов является модульным и простым в сборке, но он также медленнее (в худшем случае имеет сложность O(n 4 )) и менее сложен.
Обычно они используются для упрощения задач синтаксического анализа или для создания прототипов. В некотором смысле пользователь комбинатора синтаксических анализаторов создает синтаксический анализатор частично вручную, но полагаясь на жесткое слово, сделанное тем, кто создал комбинатор синтаксических анализаторов.Как правило, они не поддерживают леворекурсивные правила, но есть более продвинутые реализации, которые делают именно это. См., например, статью Parser Combinators for Ambiguous Left-Recursive Grammars, в которой также удается описать алгоритм с полиномиальным временем выполнения.
Многие современные реализации называются комбинаторами монадических синтаксических анализаторов , поскольку они основаны на структуре функционального программирования, называемой монадой. Монады — довольно сложная концепция, которую мы не можем здесь объяснить. Однако в основном монада способна комбинировать функции и действия в зависимости от типа данных. Важнейшей особенностью является то, что тип данных указывает, как можно комбинировать его различные значения.
Самый простой пример — монада Maybe . Это оболочка для нормального типа, такого как целое число, которое возвращает само значение, когда значение допустимо (например, 567), и специальное значение Ничего , когда оно не является допустимым (например, не определено или деление на ноль). Таким образом, вы можете избежать использования значения null и бесцеремонного сбоя программы. Вместо этого значение Nothing управляется нормально, как и любое другое значение.
Восходящие алгоритмы
Основным успехом восходящей стратегии является семейство множества различных парсеров LR. Причина их относительной непопулярности заключается в том, что исторически их было сложнее построить, хотя синтаксические анализаторы LR также более мощные, чем традиционные грамматики LL(1). Поэтому мы в основном сосредоточимся на них, за исключением краткого описания парсеров CYK.
Это означает, что мы не будем говорить о более общем классе парсеров Shift-reduce, который также включает парсеры LR.
Мы только говорим, что алгоритмы сдвига-уменьшения работают в два этапа:
- Сдвиг : прочитать один токен из ввода, который становится новым (на мгновение изолированным) узлом
- Уменьшить : после того, как правильное правило будет сопоставлено, соединить полученное дерево с предшествующим существующим поддеревом
В основном сдвиг step читает входные данные до завершения, в то время как сокращение объединяет поддеревья до тех пор, пока не будет построено окончательное дерево синтаксического анализа.
Анализатор CYK
Анализатор Cocke-Younger-Kasami (CYK) был разработан независимо тремя авторами. Его известность обусловлена отличной производительностью в худшем случае (O(n 3 )), хотя ему мешает сравнительно низкая производительность в большинстве распространенных сценариев.
Однако реальным недостатком алгоритма является то, что он требует, чтобы грамматики были выражены в нормальной форме Хомского.
Это потому, что алгоритм полагается на свойства этой конкретной формы, чтобы иметь возможность разделить ввод пополам, пытаясь сопоставить все возможности. Теоретически любая контекстно-свободная грамматика может быть преобразована в соответствующую CNF, но это редко удается сделать вручную. Представьте, что вас раздражает тот факт, что вы не можете использовать леворекурсивные правила, и вас просят выучить особый вид формы…
Алгоритм CYK используется в основном для конкретных задач. Например, проблема принадлежности: определить, совместима ли строка с определенной грамматикой. Его также можно использовать при обработке естественного языка, чтобы найти наиболее вероятный анализ множества вариантов.
Для всех практических целей, если вам нужно проанализировать любую контекстно-свободную грамматику с высокой производительностью в наихудшем случае, вы хотите использовать синтаксический анализатор Earley.
LR Parser
LR ( L чтение ввода слева направо, R самая правая производная) — это восходящие анализаторы, которые могут обрабатывать детерминированные контекстно-свободные языки за линейное время, с просмотром вперед и без возврата.
Изобретение синтаксических анализаторов LR приписывают известности Дональду Кнуту.Традиционно их сравнивали и конкурировали с парсерами LL. Таким образом, существует аналогичный анализ, связанный с количеством предвосхищающих токенов, необходимых для анализа языка. Парсер LR( k ) может анализировать грамматики, которым требуется k токенов просмотра вперед для анализа. Однако грамматики LR менее ограничительны и, следовательно, более эффективны, чем соответствующие грамматики LL. Например, нет необходимости исключать леворекурсивные правила.
Технически, грамматики LR являются надмножеством грамматик LL. Одним из следствий этого является то, что вам нужны только грамматики LR(1), поэтому обычно ( k ) опускается.
Они также основаны на таблицах, как и LL-парсеры, но им нужны две сложные таблицы. Проще говоря:
- одна таблица сообщает синтаксическому анализатору, что делать в зависимости от текущего токена, состояния, в котором он находится, и токенов, которые могут следовать за ним ( предварительный просмотр устанавливает )
- другая сообщает синтаксическому анализатору, в какое состояние перейти дальше
Парсеры LR мощные и имеют отличную производительность, так в чем подвох? Таблицы, которые им нужны, трудно построить вручную, и они могут стать очень большими для обычных компьютерных языков, поэтому обычно они в основном используются с помощью генераторов синтаксических анализаторов.
Если вам нужно построить синтаксический анализатор вручную, вы, вероятно, предпочтете синтаксический анализатор сверху вниз.Простой LR и Lookahead LR
Генераторы синтаксического анализа позволяют избежать проблемы создания таких таблиц вручную, но они не решают проблему стоимости их создания и навигации по ним. Таким образом, существуют более простые альтернативы синтаксическому анализатору Canonical LR(1) , описанному Кнутом. Эти альтернативы менее эффективны, чем исходная. Это: Простой синтаксический анализатор LR (SLR) и Упреждающий синтаксический анализатор LR (LALR). Таким образом, в порядке мощности мы имеем: LR (1) > LALR (1) > SLR (1) > LR (0).
Названия двух синтаксических анализаторов, изобретенных Фрэнком ДеРемером, несколько вводят в заблуждение: один на самом деле не так прост, а другой не единственный, использующий просмотр вперед. Можно сказать, что один проще, а другой в большей степени опирается на прогнозирование для принятия решений.
В основном они различаются таблицами, которые они используют, в основном они меняют часть «что делать» и наборы прогнозов. Что, в свою очередь, накладывает различные ограничения на грамматики, которые они могут анализировать. Другими словами, они используют разные алгоритмы для получения таблиц синтаксического анализа из грамматики.
Синтаксический анализатор SLR довольно ограничен с практической точки зрения и не очень широко используется. Вместо этого синтаксический анализатор LALR работает с большинством практических грамматик и широко используется. На самом деле популярные инструменты yacc и bison работают с таблицами парсера LALR.
В отличие от LR-грамматик, LALR- и SLR-грамматики не являются надмножеством LL-грамматик. Их нелегко сравнивать: некоторые грамматики могут относиться к одному классу, а не к другому, или наоборот.
Обобщенный анализатор LR
Обобщенные синтаксические анализаторы LR (GLR) — это более мощные варианты синтаксических анализаторов LR.
Они были описаны Бернардом Лэндом в 1974 году и впервые реализованы Масару Томита в 1984 году. Причиной существования GLR является необходимость анализа недетерминированных и неоднозначных грамматик.Сила парсера GLR заключается не в его таблицах, которые эквивалентны таблицам традиционного парсера LR, а в том, что они могут переходить в разные состояния. На практике, когда возникает двусмысленность, создаются новые парсеры, которые обрабатывают этот конкретный случай. Эти синтаксические анализаторы могут дать сбой на более позднем этапе и быть отброшенными.
Сложность синтаксического анализатора GLR в наихудшем случае такая же, как и у синтаксического анализатора Эрли (O(n 3 )), хотя он может иметь лучшую производительность с лучшим случаем детерминированных грамматик. Анализатор GLR также сложнее построить, чем анализатор Эрли.
Резюме
С помощью этой замечательной (или, по крайней мере, большой) статьи мы надеемся развеять большинство сомнений по поводу парсинга терминов и алгоритмов: что означают термины и почему следует выбирать определенный алгоритм вместо другого.
Мы не только объяснили их, но и дали несколько советов по общим проблемам с разбором языков программирования.Из-за нехватки места мы не смогли предоставить подробное объяснение всех алгоритмов синтаксического анализа. Поэтому мы также предоставили несколько ссылок, чтобы получить более глубокое представление об алгоритмах: теории, лежащей в их основе, и объяснении того, как они работают. Если вы особенно заинтересованы в создании таких вещей, как компилятор и интерпретатор, вы можете прочитать еще одну из наших статей, чтобы найти ресурсы для создания языков программирования.
Если вы просто интересуетесь синтаксическим анализом, вы можете прочитать «Техники синтаксического анализа» — книгу, столь же всеобъемлющую, сколь и дорогую. Очевидно, что он гораздо глубже, чем мы могли бы, а также охватывает менее используемые алгоритмы синтаксического анализа.
Мы благодарим Димитриоса Куркулиса за редактуру статьи и помощь в ее улучшении.
Мы также хотели бы поблагодарить Дастина Уитни за то, что он заметил опечатку.
6.2.2: Анализ составляющих предложения, построение предложения
- Последнее обновление
- Сохранить как PDF
- Идентификатор страницы
- 74525
Прочтите эту статью. Разнообразная структура предложений в вашем письме помогает вашему письму быть понятным для вашей аудитории и может помочь поддерживать интерес ваших читателей.
Почему важно изменять структуру предложения?
Слишком много простых и составных предложений могут сделать письмо прерывистым, но слишком много сложных и составных-сложных предложений могут затруднить письмо. Стремитесь к балансу, комбинируя предложения различной структуры и длины в своей статье.
Каковы некоторые распространенные способы построения предложения?
- Простое предложение: Содержит одно подлежащее и глагол.
- Пример: Мобильный телефон зазвонил прямо перед уроком.
- Пример: Мобильный телефон зазвонил прямо перед уроком.
- Сложносочиненное предложение: Содержит два полных предложения (самостоятельных предложения), соединенных сочинительным союзом (для, и, ни, но, или, еще, так).
- Пример: Мобильный телефон зазвонил прямо перед уроком, поэтому ученица быстро выключила звонок своего телефона.
- Пример: Мобильный телефон зазвонил прямо перед уроком, поэтому ученица быстро выключила звонок своего телефона.
- Сложное предложение: Содержит независимое предложение, соединенное с одним или несколькими зависимыми предложениями.
- Пример: Чтобы не прерывать занятия во время занятий, ученица выключила звонок своего телефона.
- Пример: Чтобы не прерывать занятия во время занятий, ученица выключила звонок своего телефона.
- Сложносочиненное предложение: Содержит комбинацию сложноподчиненного предложения и сложноподчиненного предложения.
- Пример: чтобы не отвлекаться от занятий в классе, ученица выключила звонок телефона и положила наушники в рюкзак.
Использование параллельной структуры
Что такое параллельная структура?
Параллельная структура образуется, когда слова в предложении объединены последовательным использованием грамматических форм.
Этот стилистический элемент также называют параллелизмом или параллельным построением.Почему важно использовать параллельную структуру?
Отсутствие параллельной структуры может нарушить ритм предложения, сделав его грамматически несбалансированным. Правильная параллельная структура помогает установить баланс и плавность в хорошо построенном предложении; согласование связанных идей способствует удобочитаемости и ясности.
Давайте рассмотрим пример
- Не параллельно: Президент посетил несколько городов, чтобы встретиться с избирателями, произнести речи и попросить средства на предвыборную кампанию.
- Параллель: Президент посетил несколько городов, встречаясь с избирателями, произнося речи и запрашивая средства на предвыборную кампанию.
Как изменить предложение, чтобы отразить параллельную структуру
1. Найдите список в предложении: Найдите слова или фразы равной важности, которые разделены запятыми и соединены союзом
Не параллельно: д-р Калл призывал своих студентов инициировать собственное обучение, творчески решать проблемы и мыслить независимо.
(В этом предложении доктор Калл хочет, чтобы его ученики делали или были тремя вещами, но элементы в этом списке не параллельны по структуре.)2. Оцените словоформы в списке.
- Глаголы появляются как инфинитив (от до + глагол ) или герундий (- слов )? Как настоящее время или прошедшее время? (Выберите залог и время глагола, соответствующие окружающим предложениям.)
- Имеют ли существительные или местоимения и их модификаторы постоянную форму?
3. Измените слова в списке, чтобы создать правильную параллельную структуру.
Параллель: д-р Калл призвал своих учеников стать целеустремленными учениками, творчески решать проблемы и мыслить независимо. (В этом предложении доктор Калл хочет, чтобы его ученики были тремя вещами, а не комбинацией бытия и действия. Кроме того, список следует образцу, поскольку все существительные и прилагательные появляются в параллельной форме.)
Избегайте предложений в стиле букваря
Как эффективно комбинировать короткие предложения
Предложение в стиле букваря — это короткое и простое предложение, которое обычно включает одно подлежащее и глагол.
В то время как короткие и упрощенные предложения могут быть эффективно использованы, чтобы подчеркнуть мысль или прояснить запутанное утверждение, частое их использование может сделать статью прерывистой и прервать ее течение. Предложения в стиле букваря могут быть объединены в более сложное предложение.Рассмотрим несколько примеров
Пересмотр предложений для букваря:
- Предложений для букваря: Президент Кеннеди был застрелен 22 ноября 1963 года. Это произошло в Далласе, штат Техас. Это событие сильно повлияло на всю страну.
- Пересмотрено: Убийство президента Кеннеди 22 ноября 1963 года в Далласе, штат Техас, сильно повлияло на нацию.
Исправление коротких связанных предложений:
Простые предложения на одну тему также можно комбинировать с помощью сочинительных союзов (за, и, ни, но, или, еще, так) и/или изменяющих предложений.
- Серия связанных предложений: Центральный парк — городской парк площадью 843 акра.