Морфологический разбор слова «устойчивый»
Часть речи: Прилагательное
УСТОЙЧИВЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «УСТОЙЧИВЫЙ»
| Слово | Морфологические признаки |
|---|---|
| УСТОЙЧИВЫЙ |
|
| УСТОЙЧИВЫЙ |
|
Все формы слова УСТОЙЧИВЫЙ
УСТОЙЧИВЫЙ, УСТОЙЧИВОГО, УСТОЙЧИВОМУ, УСТОЙЧИВЫМ, УСТОЙЧИВОМ, УСТОЙЧИВАЯ, УСТОЙЧИВОЙ, УСТОЙЧИВУЮ, УСТОЙЧИВОЮ, УСТОЙЧИВОЕ, УСТОЙЧИВЫЕ, УСТОЙЧИВЫХ, УСТОЙЧИВЫМИ, УСТОЙЧИВ, УСТОЙЧИВА, УСТОЙЧИВО, УСТОЙЧИВЫ, УСТОЙЧИВЕЕ, УСТОЙЧИВЕЙ, ПОУСТОЙЧИВЕЕ, ПОУСТОЙЧИВЕЙ, УСТОЙЧИВЕЙШИЙ, УСТОЙЧИВЕЙШЕГО, УСТОЙЧИВЕЙШЕМУ, УСТОЙЧИВЕЙШИМ, УСТОЙЧИВЕЙШЕМ, УСТОЙЧИВЕЙШАЯ, УСТОЙЧИВЕЙШЕЙ, УСТОЙЧИВЕЙШУЮ, УСТОЙЧИВЕЙШЕЮ, УСТОЙЧИВЕЙШЕЕ, УСТОЙЧИВЕЙШИЕ, УСТОЙЧИВЕЙШИХ, УСТОЙЧИВЕЙШИМИ
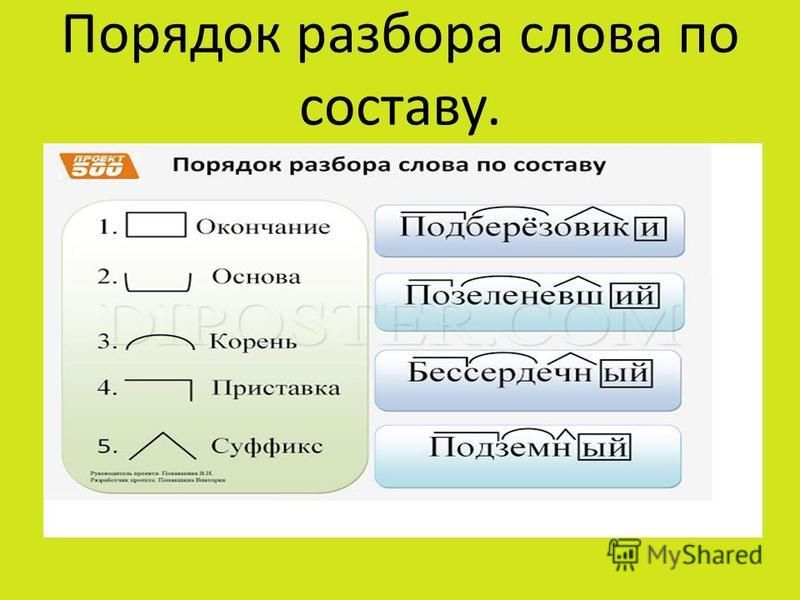
Разбор слова по составу устойчивый
устойчив
ый
| Основа слова | устойчив |
|---|---|
| Приставка | у |
| Корень | стой |
| Суффикс | чив |
| Окончание | ый |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «УСТОЙЧИВЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «устойчивый»
Примеры предложений со словом «устойчивый»
1
Устойчивый наклон, как ходят в атаку.
Красное колесо. Узел 2. Октябрь Шестнадцатого. Книга 2, Александр Солженицын
2
И он поступил мудро – дал объявление нонпарелью (тем шрифтом, какой никогда не пропустит устойчивый читатель): «Собака Черное Ухо – поймана.
Белый Бим Черное ухо (сборник), Гавриил Троепольский
3
Ширококостый, массивный, как медведь, приземистый и устойчивый, он умел за себя постоять.
За три моря. Путешествие Афанасия Никитина, Константин Ильич Кунин
4
Этот ясный, устойчивый мир таил в себе необходимые для новой России, во многом забытые прочные духовные ориентиры.
Война и мир. Том 1, Лев Толстой, 1863–1869г.
5
Но одновременно у меня почему-то существовал устойчивый интерес к древнеиндийскому эпосу Махабхарата…
Повести и рассказы, Лев Толстой, 1885–1903г.
Найти еще примеры предложений со словом УСТОЙЧИВЫЙ
Слова «устойчивее» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «устойчивее» на слоги для переноса.
 ru поможет: фонетический и морфологический разобрать слово «устойчивее» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «устойчивее».
ru поможет: фонетический и морфологический разобрать слово «устойчивее» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «устойчивее».Содержимое:
- 1 Как перенести слово «устойчивее»
- 2 Морфологический разбор слова «устойчивее»
- 3 Разбор слова «устойчивее» по составу
- 4 Сходные по морфемному строению слова «устойчивее»
- 5 Синонимы слова «устойчивее»
- 6 Антонимы слова «устойчивее»
- 7 Ударение в слове «устойчивее»
- 8 Фонетическая транскрипция слова «устойчивее»
- 9 Фонетический разбор слова «устойчивее» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «устойчивее»
- 11 Сочетаемость слова «устойчивее»
- 12 Значение слова «устойчивее»
- 13 Как правильно пишется слово «устойчивее»
- 14 Ассоциации к слову «устойчивее»
Как перенести слово «устойчивее»
ус—тойчивее
устой—чивее
устойчи—вее
Морфологический разбор слова «устойчивее»
Часть речи:
Компаратив
Грамматика:
часть речи: компаратив;
остальные признаки: качественное, сравнительная степень на по-;
отвечает на вопрос: Как?
Начальная форма:
устойчивее
Разбор слова «устойчивее» по составу
| у | приставка |
| стой | корень |
| чив | суффикс |
| ый | окончание |
устойчивый
Сходные по морфемному строению слова «устойчивее»
Сходные по морфемному строению слова
Синонимы слова «устойчивее»
1. стабильный
стабильный
2. прочный
3. солидный
4. надежный
5. безопасный
6. безошибочный
7. верный
8. доказанный
9. достоверный
10. испытанный
11. крепкий
12. кредитоспособный
13. обеспеченный
14. твердый
15. фундаментальный
16. безубыточный
17. основательный
18. стойкий
19. ультраустойчивый
20. мультиустойчивый
21. многоустойчивый
22. константный
23. неизменный
24. постоянный
25. неизмененный
26. живучий
27. незыблемый
28. стабилизированный
29. персистентный
30. фундированный
31. высокоустойчивый
Антонимы слова «устойчивее»
1. опасный
2. податливый
3. поверхностный
4. сомнительный
5. ненадёжный
6. хлипкий
7. колеблющийся
8. слабый
9. изменчивый
10. непрочный
11. нестабильный
12. непостоянный
Ударение в слове «устойчивее»
усто́йчивее — ударение падает на 2-й слог
Фонетическая транскрипция слова «устойчивее»
[уст`ой’ч’ив’ий’э]
Фонетический разбор слова «устойчивее» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| у | [у] | гласный, безударный | у |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| о | [`о] | гласный, ударный | о |
| й | [й’] | согласный, звонкий непарный (сонорный), мягкий | й |
| ч | [ч’] | согласный, глухой непарный, мягкий, шипящий | ч |
| и | [и] | гласный, безударный | и |
| в | [в’] | согласный, звонкий парный, мягкий | в |
| е | [и] | гласный, безударный | е |
| е | [й’] | согласный, звонкий непарный (сонорный), мягкий | е |
| [э] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 10 букв и 11 звуков.
Буквы: 5 гласных букв, 5 согласных букв.
Звуки: 5 гласных звуков, 6 согласных звуков.
Предложения со словом «устойчивее»
Теперь, когда ваше тело занимает стабильное и устойчивое положение, вы полностью готовы к медитации.
Источник: Чой Сунг Мо, Специальные методы самообороны в практике боевых искусств.
Мы быстро начинаем осознавать, что устойчивое развитие означает жизнь в мире с постоянным памятованием о наших взаимоотношениях с его реалиями.
Источник: Мэрилин Хэмилтон, Интегральный город. Эволюционные интеллекты человеческого улья, 2008.
Микророботы могут образовывать
Источник: А. Л. Ливадный, Призрачный Сервер. Изгой, 2015.
Л. Ливадный, Призрачный Сервер. Изгой, 2015.
Сочетаемость слова «устойчивее»
1. устойчивое развитие
2. устойчивое положение
3. устойчивая связь
4. концепция устойчивого развития
5. устойчивое положение тела
6. устойчивое развитие сельских территорий
7. становится всё более устойчивым
8. оказаться устойчивым
9. является устойчивым
10. (полная таблица сочетаемости)
Значение слова «устойчивее»
УСТО́ЙЧИВЫЙ , -ая, -ое; -чив, -а, -о. 1. Способный твердо стоять, держаться, не колеблясь, не падая. Устойчивая лодка. Устойчивая стремянка. (Малый академический словарь, МАС)
Как правильно пишется слово «устойчивее»
Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «устойчивее» в прямом и обратном порядке:
Ассоциации к слову «устойчивее»
Стереотип
Психика
Функционирование
Антибиотик
Устойчивость
Тенденция
Радиосвязь
Популяция
Стабильность
Спрос
Общность
Развитие
Покров
Воздействие
Индивид
Конфигурация
Валюта
Бактерия
Совокупность
Засуха
Сорт
Загрязнение
Энергетик
Обеспечение
Равновесие
Экология
Уклад
Иммунитет
Температура
Качка
Мутация
Древесина
Радиация
Атом
Снижение
Структура
Сохранение
Раствор
Среда
Внедрение
Экономика
Бриз
Кислота
Алгоритм
Электрон
Поддержание
Молекула
Углерод
Интеграция
Формирование
Концепция
Рефлекс
Мировоззрение
Целостность
Компонент
Фактор
Сформироваться
Сохраняться
Характеризоваться
Обеспечивать
Обеспечиваться
Разрушаться
Формироваться
Уравновесить
Достигаться
Разлагаться
Ассоциироваться
Поддерживаться
Морально
Исторически
Более-менее
Наименее
Мирьям де Лоно — Антология ACL
2022
pdf
нагрудник
абс
Поиск структурных знаний в мультимодальном BERT
Виктор Милевски
|
Мирьям де Лоно
|
Мари-Франсин Моэнс
Материалы 60-го ежегодного собрания Ассоциации компьютерной лингвистики (Том 1: Длинные статьи)
В этой работе мы исследуем знания, полученные при встраивании мультимодальных моделей BERT. В частности, мы исследуем их способность сохранять грамматическую структуру лингвистических данных и структуру, изученную над объектами в визуальных данных. Чтобы достичь этой цели, мы сначала делаем неотъемлемую структуру языка и визуальных образов явной с помощью разбора зависимостей предложений, описывающих изображение, и зависимостей между областями объекта в изображении соответственно. Мы называем эту явную визуальную структуру деревом сцены, основанным на дереве зависимостей описания языка. Обширные эксперименты по зондированию показывают, что мультимодальные модели BERT не кодируют эти деревья сцен.
В частности, мы исследуем их способность сохранять грамматическую структуру лингвистических данных и структуру, изученную над объектами в визуальных данных. Чтобы достичь этой цели, мы сначала делаем неотъемлемую структуру языка и визуальных образов явной с помощью разбора зависимостей предложений, описывающих изображение, и зависимостей между областями объекта в изображении соответственно. Мы называем эту явную визуальную структуру деревом сцены, основанным на дереве зависимостей описания языка. Обширные эксперименты по зондированию показывают, что мультимодальные модели BERT не кодируют эти деревья сцен.
pdf
нагрудник
абс
Проблемы и стратегии межкультурного НЛП
Дэниел Хершкович
|
Стелла Франк
|
Хизер Лент
|
Мирьям де Лоно
|
Мостафа Абду
|
Стефани Брандл
|
Эмануэле Бульярелло
|
Лаура Кабельо Пикерас
|
Илиас Халкидис
|
Жуйсян Цуй
|
Констанца Фьерро
|
Катерина Маргатина
|
Филипп Руст
|
Anders Søgaard
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
В сообществе обработки естественного языка (NLP) были предприняты различные усилия, чтобы учесть языковое разнообразие и обслуживать носителей разных языков. Однако важно признать, что говорящие и контент, который они производят и требуют, различаются не только в зависимости от языка, но и в зависимости от культуры. Хотя язык и культура тесно связаны между собой, между ними есть важные различия. По аналогии с межъязыковым и многоязычным НЛП, межкультурное и мультикультурное НЛП учитывает эти различия, чтобы лучше обслуживать пользователей систем НЛП. Мы предлагаем принципиальную основу для этих усилий и проводим обзор существующих и потенциальных стратегий.
Однако важно признать, что говорящие и контент, который они производят и требуют, различаются не только в зависимости от языка, но и в зависимости от культуры. Хотя язык и культура тесно связаны между собой, между ними есть важные различия. По аналогии с межъязыковым и многоязычным НЛП, межкультурное и мультикультурное НЛП учитывает эти различия, чтобы лучше обслуживать пользователей систем НЛП. Мы предлагаем принципиальную основу для этих усилий и проводим обзор существующих и потенциальных стратегий.
pdf
нагрудник
абс
Анализ зависимостей Zero-Shot с автоматическим изучением учебных программ с учетом наихудших случаев
Мирьям де Лоно
|
Шэн Чжан
|
Anders Søgaard
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Большие многоязычные предварительно обученные языковые модели, такие как mBERT и XLM-RoBERTa, оказались удивительно эффективными для межъязыковой передачи синтаксических разбор моделей Ву и Дредзе (2019), но только между родственными языками. Однако исходный язык и язык обучения редко связаны между собой при разборе действительно малоресурсных языков. Чтобы восполнить этот пробел, мы используем метод многозадачного обучения, основанный на автоматизированном изучении учебной программы, для динамической оптимизации производительности синтаксического анализа на языках с выбросами . Мы показываем, что этот подход значительно лучше, чем однородная и пропорциональная размеру выборка в условиях нулевого выстрела.
Однако исходный язык и язык обучения редко связаны между собой при разборе действительно малоресурсных языков. Чтобы восполнить этот пробел, мы используем метод многозадачного обучения, основанный на автоматизированном изучении учебной программы, для динамической оптимизации производительности синтаксического анализа на языках с выбросами . Мы показываем, что этот подход значительно лучше, чем однородная и пропорциональная размеру выборка в условиях нулевого выстрела.
pdf
нагрудник
abs
Лингвистическая аннотация неолатинских математических текстов: экспериментальное исследование по улучшению автоматического разбора Archimedes Latinus
Маргарита Фантоли
|
Мириам де Лоно
Материалы второго семинара по языковым технологиям для исторических и древних языков
В этой статье описывается процесс синтаксического анализа латинского перевода Якопо да Сан Кассиано греческого математического труда «Спирали Архимеда». Принят формализм универсальных зависимостей. Во-первых, мы вводим историческую и лингвистическую важность перевода Якопо да Сан-Кассиано. Далее мы опишем глубокий парсер Biaffine, использованный в этом пилотном исследовании. В частности, мы мотивируем выбор использования техники встраивания деревьев в свете характеристик математических текстов. Затем в документе подробно описывается процесс создания обучающих и тестовых данных, выделяя наиболее привлекательные лингвистические особенности текста и варианты выбора, реализованные в текущей версии банка деревьев. Наконец, результаты синтаксического анализа обсуждаются в сравнении с исходным состоянием, а также обсуждаются наиболее заметные ошибки. В целом, документ показывает дополнительную ценность создания конкретных обучающих данных и использования целевых стратегий (в виде вложений деревьев) для использования существующих аннотированных корпусов при сохранении особенностей одного конкретного текста при выполнении синтаксического анализа.
Во-первых, мы вводим историческую и лингвистическую важность перевода Якопо да Сан-Кассиано. Далее мы опишем глубокий парсер Biaffine, использованный в этом пилотном исследовании. В частности, мы мотивируем выбор использования техники встраивания деревьев в свете характеристик математических текстов. Затем в документе подробно описывается процесс создания обучающих и тестовых данных, выделяя наиболее привлекательные лингвистические особенности текста и варианты выбора, реализованные в текущей версии банка деревьев. Наконец, результаты синтаксического анализа обсуждаются в сравнении с исходным состоянием, а также обсуждаются наиболее заметные ошибки. В целом, документ показывает дополнительную ценность создания конкретных обучающих данных и использования целевых стратегий (в виде вложений деревьев) для использования существующих аннотированных корпусов при сохранении особенностей одного конкретного текста при выполнении синтаксического анализа.
pdf
нагрудник
abs
Чего хочет креолка, что нужно креолке
Хизер Лент
|
Келечи Огуеджи
|
Мирьям де Лоно
|
Ореваогене Ахия
|
Anders Søgaard
Proceedings of the Thirteenth Language Resources and Evaluation Conference
В последние годы сообщество по обработке естественного языка (NLP) уделяло повышенное внимание несоответствию усилий, направленных на языки с высокими ресурсами по сравнению с языками с низкими ресурсами. Усилия по исправлению этой дельты часто начинаются с перевода существующих английских наборов данных на другие языки. Однако этот подход игнорирует тот факт, что разные языковые сообщества имеют разные потребности. Мы рассматриваем группу малоресурсных языков, креольские языки. Креольские языки в значительной степени отсутствуют в литературе по НЛП, а также часто игнорируются обществом в целом из-за стигмы, несмотря на то, что эти языки имеют значительные и активные сообщества. Благодаря беседам с экспертами по креольскому языку и опросам креолоязычных сообществ мы демонстрируем, как вещи, необходимые для языковых технологий, могут резко меняться от одного языка к другому, даже если языки считаются очень похожими друг на друга, как в случае с креольскими языками. Мы обсуждаем важные темы, возникающие в ходе этих бесед, и в конечном итоге демонстрируем, что полезные языковые технологии не могут быть созданы без участия соответствующего сообщества.
Усилия по исправлению этой дельты часто начинаются с перевода существующих английских наборов данных на другие языки. Однако этот подход игнорирует тот факт, что разные языковые сообщества имеют разные потребности. Мы рассматриваем группу малоресурсных языков, креольские языки. Креольские языки в значительной степени отсутствуют в литературе по НЛП, а также часто игнорируются обществом в целом из-за стигмы, несмотря на то, что эти языки имеют значительные и активные сообщества. Благодаря беседам с экспертами по креольскому языку и опросам креолоязычных сообществ мы демонстрируем, как вещи, необходимые для языковых технологий, могут резко меняться от одного языка к другому, даже если языки считаются очень похожими друг на друга, как в случае с креольскими языками. Мы обсуждаем важные темы, возникающие в ходе этих бесед, и в конечном итоге демонстрируем, что полезные языковые технологии не могут быть созданы без участия соответствующего сообщества.
2021
pdf
bib
Синтаксический анализ с использованием предварительно обученных языковых моделей, нескольких наборов данных и встраивания наборов данных
Роб ван дер Гут
|
Мириам де Лоно
Материалы 20-го Международного семинара по банкам деревьев и лингвистическим теориям (TLT, SyntaxFest 2021)
pdf
bib
Proceedings of the Fifth Workshop on Universal Dependencies (UDW, SyntaxFest 2021)
Miryam de Lhoneux
|
Реут Царфати
Материалы пятого семинара по универсальным зависимостям (UDW, SyntaxFest 2021)
pdf
нагрудник
abs
Itihasa: Крупномасштабный корпус переводов с санскрита на английский язык
Rahul Aralikatte
|
Мирьям де Лоно
|
Ануп Кунчукуттан
|
Anders Søgaard
Proceedings of the 8th Workshop on Asian Translation (WAT2021)
Эта работа знакомит с Itihasa, крупномасштабным набором переводческих данных, содержащим 93 000 пар санскритских шлок и их английские переводы. Шлоки взяты из двух индийских эпосов: «Рамаяна» и «Махабхарата». Сначала мы опишем мотивы, лежащие в основе курирования такого набора данных, а затем проведем эмпирический анализ, чтобы выявить его нюансы. Затем мы сравним производительность стандартных моделей перевода в этом корпусе и покажем, что даже самые современные архитектуры преобразования работают плохо, подчеркнув сложность набора данных.
Шлоки взяты из двух индийских эпосов: «Рамаяна» и «Махабхарата». Сначала мы опишем мотивы, лежащие в основе курирования такого набора данных, а затем проведем эмпирический анализ, чтобы выявить его нюансы. Затем мы сравним производительность стандартных моделей перевода в этом корпусе и покажем, что даже самые современные архитектуры преобразования работают плохо, подчеркнув сложность набора данных.
pdf
нагрудник
abs
Как далеко мы можем зайти с одним GPU за 100 часов? COAStaL в MultiIndicMT Shared Task
Рахул Араликатте
|
Эктор Рикардо Муррьета Белло
|
Мирьям де Лоно
|
Дэниел Хершкович
|
Марсель Больманн
|
Anders Søgaard
Proceedings of the 8th Workshop on Asian Translation (WAT2021)
Эта работа показывает, что конкурентоспособные результаты перевода могут быть получены в условиях ограниченных условий путем включения последних достижений в области оптимизации памяти и вычислений. Мы обучаем и оцениваем большие многоязычные модели перевода с использованием одного графического процессора в течение максимум 100 часов и получаем в пределах 4-5 баллов BLEU от лучших представлений в таблице лидеров. Мы также сопоставляем стандартные базовые показатели с корпусом PMI и повторно обнаруживаем хорошо известные недостатки систем перевода и показателей.
Мы также сопоставляем стандартные базовые показатели с корпусом PMI и повторно обнаруживаем хорошо известные недостатки систем перевода и показателей.
pdf
нагрудник
abs
Моисей и случайная болтовня на основе персонажей
|
Рахул Араликатте
|
Эктор Мурьета Белло
|
Дэниел Хершкович
|
Мирьям де Лоно
|
Anders Søgaard
Материалы первого семинара по обработке естественного языка для языков коренных народов Северной и Южной Америки
Мы оценили ряд методов нейронного машинного перевода, разработанных специально для сценариев с ограниченными ресурсами. Неудачно. В итоге мы представили два прогона: (i) стандартную модель, основанную на фразах, и (ii) базовый уровень случайного бормотания с использованием триграмм символов. Мы обнаружили, что превзойти (i) на удивление сложно, несмотря на то, что эта модель теоретически плохо подходит для полисинтетических языков; и что еще более интересно, эта (ii) была лучше, чем некоторые из представленных систем, подчеркивая, насколько сложным является машинный перевод с низкими ресурсами для полисинтетических языков.
pdf
нагрудник
абс
О языковых моделях для креолов
Хизер Лент
|
Эмануэле Бульярелло
|
Мирьям де Лоно
|
Чен Цю
|
Anders Søgaard
Proceedings of the 25th Conference on Computational Natural Language Learning
Креольские языки, такие как нигерийский пиджин-инглиш и гаитянский креольский, недостаточно обеспечены ресурсами и в значительной степени игнорируются в литературе по НЛП. Креольские языки обычно возникают в результате слияния иностранного языка с несколькими местными языками, и то, какие грамматические и лексические особенности переносятся на креольский, представляет собой сложный процесс. Хотя креолы в целом стабильны, некоторые черты могут быть намного сильнее выражены в определенных демографических или языковых ситуациях. В этом документе делается несколько вкладов: мы собираем существующие корпуса и выпускаем модели для гаитянского креольского, нигерийского пиджин-английского и сингапурского разговорного английского. Мы оцениваем эти модели на внутренних и внешних задачах. Руководствуясь приведенной выше литературой, мы сравнили модели стандартного языка с моделями, устойчивыми к распределению, и обнаружили, что несколько неожиданно, модели стандартного языка превосходят модели, устойчивые к распределению. Мы исследуем, является ли это следствием чрезмерной параметризации или относительной стабильности распределения, и обнаруживаем, что разница сохраняется при отсутствии чрезмерной параметризации и что дрейф ограничен, что подтверждает относительную стабильность креольских языков.
Руководствуясь приведенной выше литературой, мы сравнили модели стандартного языка с моделями, устойчивыми к распределению, и обнаружили, что несколько неожиданно, модели стандартного языка превосходят модели, устойчивые к распределению. Мы исследуем, является ли это следствием чрезмерной параметризации или относительной стабильности распределения, и обнаруживаем, что разница сохраняется при отсутствии чрезмерной параметризации и что дрейф ограничен, что подтверждает относительную стабильность креольских языков.
pdf
нагрудник
абс
Многоязычный тест для проверки понимания отрицания с помощью минимальных пар
Марейке Хартманн
|
Мирьям де Лоно
|
Дэниел Хершкович
|
Йова Кеменчеджиева
|
Лукас Нильсен
|
Чен Цю
|
Anders Søgaard
Proceedings of the 25th Conference on Computational Natural Language Learning
Отрицание является одним из самых фундаментальных понятий человеческого познания и языка, и несколько зондов естественного языка (NLI) были разработаны для исследования способности предварительно обученных языковых моделей обнаруживать и рассуждать с отрицанием. Однако существующие наборы данных проверки ограничены только английским языком и не позволяют контролировать производительность при отсутствии или наличии отрицания. В ответ мы представляем многоязычную (английский, болгарский, немецкий, французский и китайский) контрольную коллекцию примеров NLI, которые грамматически правильно обозначены в результате ручной проверки и переформулировки. Мы используем эталонный тест, чтобы исследовать способность многоязычных языковых моделей распознавать отрицание и обнаруживаем, что модели, которые правильно предсказывают примеры с сигналами отрицания, часто не могут правильно предсказать свои контрпримеры без сигналов отрицания, даже когда сигналы не имеют отношения к семантическому выводу.
Однако существующие наборы данных проверки ограничены только английским языком и не позволяют контролировать производительность при отсутствии или наличии отрицания. В ответ мы представляем многоязычную (английский, болгарский, немецкий, французский и китайский) контрольную коллекцию примеров NLI, которые грамматически правильно обозначены в результате ручной проверки и переформулировки. Мы используем эталонный тест, чтобы исследовать способность многоязычных языковых моделей распознавать отрицание и обнаруживаем, что модели, которые правильно предсказывают примеры с сигналами отрицания, часто не могут правильно предсказать свои контрпримеры без сигналов отрицания, даже когда сигналы не имеют отношения к семантическому выводу.
2020
pdf
нагрудник
абс
Копсала: анализ графов на основе переходов с помощью эффективного обучения и эффективного кодирования
Дэниел Хершкович
|
Мирьям де Лоно
|
Артур Кульмизев
|
Эльхам Педжхан
|
Joakim Nivre
Материалы 16-й Международной конференции по технологиям синтаксического анализа и общая задача IWPT 2020 по анализу расширенных универсальных зависимостей
Мы представляем Køpsala, систему Копенгаген-Уппсала для совместной задачи расширенных универсальных зависимостей на IWPT 2020. Наша система представляет собой конвейер, состоящий из готовых моделей для всего, кроме расширенного анализа графов, а для последнего — анализатор графов на основе переходов, адаптированный из Che et al. (2019). Мы обучаем одну расширенную модель синтаксического анализатора для каждого языка, используя золотое разделение предложений и токенизацию для обучения, и полагаемся только на токенизированные поверхностные формы и многоязычный BERT для кодирования. В то время как ошибка, внесенная непосредственно перед отправкой, привела к серьезному падению точности, ее исправление после отправки вывело бы нас на 4-е место в официальном рейтинге, согласно среднему ELAS. Наш синтаксический анализатор демонстрирует, что унифицированный конвейер эффективен как для синтаксического анализа представления значений, так и для расширенных универсальных зависимостей.
Наша система представляет собой конвейер, состоящий из готовых моделей для всего, кроме расширенного анализа графов, а для последнего — анализатор графов на основе переходов, адаптированный из Che et al. (2019). Мы обучаем одну расширенную модель синтаксического анализатора для каждого языка, используя золотое разделение предложений и токенизацию для обучения, и полагаемся только на токенизированные поверхностные формы и многоязычный BERT для кодирования. В то время как ошибка, внесенная непосредственно перед отправкой, привела к серьезному падению точности, ее исправление после отправки вывело бы нас на 4-е место в официальном рейтинге, согласно среднему ELAS. Наш синтаксический анализатор демонстрирует, что унифицированный конвейер эффективен как для синтаксического анализа представления значений, так и для расширенных универсальных зависимостей.
pdf
нагрудник
abs
Сравнение путем преобразования: обратный инжиниринг UCCA из синтаксиса и лексической семантики
Дэниел Хершкович
|
Натан Шнайдер
|
Дотан Двир
|
Джейкоб Пранге
|
Мирьям де Лоно
|
Омри Абенд
Материалы 28-й Международной конференции по компьютерной лингвистике
Создание надежных систем понимания естественного языка потребует четкой характеристики того, дополняют ли друг друга различные представления лингвистических значений и каким образом. Чтобы выполнить систематический сравнительный анализ, мы оцениваем сопоставление между представлениями значения из разных структур, используя два дополнительных метода: (i) преобразователь на основе правил и (ii) контролируемый делексикализованный синтаксический анализатор, который анализирует одну структуру, используя только информацию из другой. как особенности. Мы применяем эти методы для преобразования корпуса STREUSLE (с синтаксическими и лексико-семантическими аннотациями) в UCCA (представление значения полного предложения в графической структуре). Оба метода дают удивительно точные целевые представления, близкие к полностью контролируемому качеству синтаксического анализатора UCCA, что указывает на то, что аннотации UCCA частично избыточны с аннотациями STREUSLE. Несмотря на это существенное сходство между фреймворками, мы обнаруживаем несколько важных областей расхождения.
Чтобы выполнить систематический сравнительный анализ, мы оцениваем сопоставление между представлениями значения из разных структур, используя два дополнительных метода: (i) преобразователь на основе правил и (ii) контролируемый делексикализованный синтаксический анализатор, который анализирует одну структуру, используя только информацию из другой. как особенности. Мы применяем эти методы для преобразования корпуса STREUSLE (с синтаксическими и лексико-семантическими аннотациями) в UCCA (представление значения полного предложения в графической структуре). Оба метода дают удивительно точные целевые представления, близкие к полностью контролируемому качеству синтаксического анализатора UCCA, что указывает на то, что аннотации UCCA частично избыточны с аннотациями STREUSLE. Несмотря на это существенное сходство между фреймворками, мы обнаруживаем несколько важных областей расхождения.
pdf
bib
Материалы четвертого семинара по универсальным зависимостям (UDW 2020)
Мари-Катрин де Марнефф
|
Мирьям де Лоно
|
Жоаким Нивр
|
Себастьян Шустер
Материалы четвертого семинара по универсальным зависимостям (UDW 2020)
pdf
нагрудник
абс
Что должны/делают/могут изучить LSTM при разборе конструкций вспомогательных глаголов?
Мирьям де Лоно
|
Сара Стимн
|
Йоаким Нивр
Компьютерная лингвистика, том 46, выпуск 4 — декабрь 2020 г.
Растет интерес к изучению того, что нейронные модели НЛП узнают о языке. Видным открытым вопросом является вопрос о том, необходимо ли моделировать иерархическую структуру. Мы представляем лингвистическое исследование нейронного синтаксического анализатора, добавляющее понимание этого вопроса. Мы смотрим на информацию о переходности и согласовании конструкций вспомогательных глаголов (AVC) по сравнению с конечными основными глаголами (FMV). Это сравнение мотивировано теоретической работой по грамматике зависимостей и, в частности, работой Теньера (1959), где AVC и FMV являются экземплярами ядра, основной единицы синтаксиса. AVC представляет собой диссоциированное ядро; он состоит как минимум из двух слов, а FMV является его недиссоциированным аналогом, состоящим ровно из одного слова. Мы предлагаем, чтобы представление AVC и FMV отражало одинаковую информацию. Мы используем диагностические классификаторы для проверки согласованности и информации о транзитивности в векторах, изученных нейронным синтаксическим анализатором на основе переходов на четырех типологически разных языках. Мы обнаружили, что синтаксический анализатор получает разную информацию об AVC и FMV, если в архитектуре используются только последовательные модели (BiLSTM), но аналогичную информацию, когда используется рекурсивный уровень. Мы находим объяснения тому, почему это так, внимательно изучая, как информация усваивается в сети, и глядя на то, что происходит с различными представлениями зависимостей AVC. Мы пришли к выводу, что использование рекурсивного слоя при разборе зависимостей может быть полезным, и что мы еще не нашли лучший способ интегрировать его в наши анализаторы.
Мы обнаружили, что синтаксический анализатор получает разную информацию об AVC и FMV, если в архитектуре используются только последовательные модели (BiLSTM), но аналогичную информацию, когда используется рекурсивный уровень. Мы находим объяснения тому, почему это так, внимательно изучая, как информация усваивается в сети, и глядя на то, что происходит с различными представлениями зависимостей AVC. Мы пришли к выводу, что использование рекурсивного слоя при разборе зависимостей может быть полезным, и что мы еще не нашли лучший способ интегрировать его в наши анализаторы.
2019
pdf
нагрудник
абс
Рекурсивная композиция поддерева в анализе зависимостей на основе LSTM
Мирьям де Лонью
|
Мигель Бальестерос
|
Joakim Nivre
Материалы конференции 2019 года Североамериканского отделения Ассоциации вычислительной лингвистики: технологии человеческого языка, том 1 (длинные и короткие статьи)
Необходимость моделирования древовидной структуры в дополнение к моделированию последовательностей является открытым вопросом в анализ нейронных зависимостей. Мы исследуем влияние добавления слоя дерева поверх последовательной модели путем рекурсивного составления представлений поддеревьев (композиции) в синтаксическом анализаторе на основе переходов, который использует функции, извлеченные с помощью BiLSTM. Композиция кажется излишней для такой модели, предполагая, что BiLSTM собирают информацию о поддеревьях. Мы выполняем модельную абляцию, чтобы выявить условия, при которых композиция помогает. При удалении обратного LSTM производительность падает, а композиция не восстанавливает большую часть разрыва. При удалении прямого LSTM производительность падает менее резко, а композиция восстанавливает значительную часть пробела, что указывает на то, что прямой LSTM и композиция собирают аналогичную информацию. Мы считаем, что обратный LSTM связан с функциями просмотра вперед, а прямой LSTM — с функциями, основанными на богатой истории, и обе они имеют решающее значение для синтаксических анализаторов на основе переходов. Для сбора информации, основанной на истории, композиция лучше, чем прямая LSTM сама по себе, но еще лучше иметь прямую LSTM как часть BiLSTM.
Мы исследуем влияние добавления слоя дерева поверх последовательной модели путем рекурсивного составления представлений поддеревьев (композиции) в синтаксическом анализаторе на основе переходов, который использует функции, извлеченные с помощью BiLSTM. Композиция кажется излишней для такой модели, предполагая, что BiLSTM собирают информацию о поддеревьях. Мы выполняем модельную абляцию, чтобы выявить условия, при которых композиция помогает. При удалении обратного LSTM производительность падает, а композиция не восстанавливает большую часть разрыва. При удалении прямого LSTM производительность падает менее резко, а композиция восстанавливает значительную часть пробела, что указывает на то, что прямой LSTM и композиция собирают аналогичную информацию. Мы считаем, что обратный LSTM связан с функциями просмотра вперед, а прямой LSTM — с функциями, основанными на богатой истории, и обе они имеют решающее значение для синтаксических анализаторов на основе переходов. Для сбора информации, основанной на истории, композиция лучше, чем прямая LSTM сама по себе, но еще лучше иметь прямую LSTM как часть BiLSTM.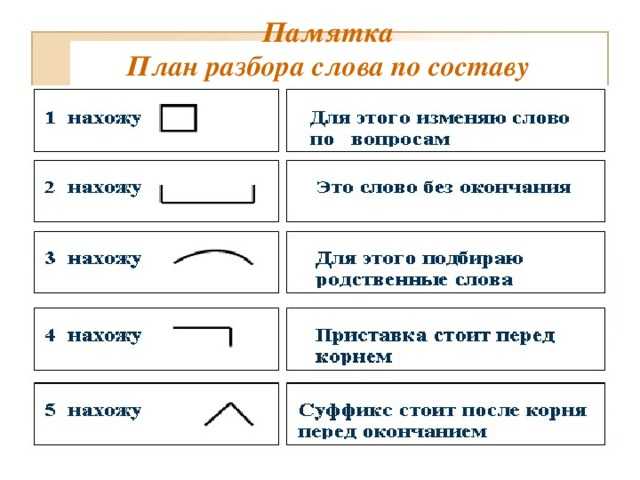 Мы сопоставляем результаты со свойствами языка, показывая, что улучшенный просмотр назад обратного LSTM особенно важен для языков с окончанием головы.
Мы сопоставляем результаты со свойствами языка, показывая, что улучшенный просмотр назад обратного LSTM особенно важен для языков с окончанием головы.
pdf
нагрудник
абс
Глубокие контекстуализированные вложения слов в синтаксическом анализе зависимостей на основе переходов и графов — история о двух синтаксических анализаторах снова
Артур Кульмизев
|
Мирьям де Лоно
|
Йоханнес Гонтрум
|
Елена Фано
|
Joakim Nivre
Материалы конференции 2019 года по эмпирическим методам обработки естественного языка и 9-й Международной объединенной конференции по обработке естественного языка (EMNLP-IJCNLP)
Ранее было показано, что анализаторы зависимостей на основе переходов и графов обладают взаимодополняющими преимуществами и Слабые стороны: синтаксические анализаторы на основе переходов используют богатые структурные функции, но страдают от распространения ошибок, в то время как синтаксические анализаторы на основе графов выигрывают от глобальной оптимизации, но имеют ограниченный набор функций. В этой статье мы показываем, что, несмотря на то, что некоторые детали картины изменились после перехода на нейронные сети и непрерывные представления, основной компромисс между богатыми функциями и глобальной оптимизацией остается практически тем же. Более того, мы показываем, что глубокие контекстуализированные вложения слов, которые позволяют синтаксическим анализаторам упаковывать информацию о глобальной структуре предложения в локальные представления признаков, приносят больше пользы синтаксическим анализаторам на основе переходов, чем синтаксическим анализаторам на основе графа, что делает два подхода практически эквивалентными с точки зрения как точности, так и ошибки. профиль. Мы утверждаем, что причина в том, что эти представления помогают предотвратить ошибки поиска и тем самым позволяют синтаксическим анализаторам на основе переходов лучше использовать присущую им способность принимать точные локальные решения. Мы подкрепляем это объяснение анализом ошибок экспериментов по синтаксическому анализу на 13 языках.
В этой статье мы показываем, что, несмотря на то, что некоторые детали картины изменились после перехода на нейронные сети и непрерывные представления, основной компромисс между богатыми функциями и глобальной оптимизацией остается практически тем же. Более того, мы показываем, что глубокие контекстуализированные вложения слов, которые позволяют синтаксическим анализаторам упаковывать информацию о глобальной структуре предложения в локальные представления признаков, приносят больше пользы синтаксическим анализаторам на основе переходов, чем синтаксическим анализаторам на основе графа, что делает два подхода практически эквивалентными с точки зрения как точности, так и ошибки. профиль. Мы утверждаем, что причина в том, что эти представления помогают предотвратить ошибки поиска и тем самым позволяют синтаксическим анализаторам на основе переходов лучше использовать присущую им способность принимать точные локальные решения. Мы подкрепляем это объяснение анализом ошибок экспериментов по синтаксическому анализу на 13 языках.
2018
pdf
нагрудник
abs
82 банка деревьев, 34 модели: Универсальный анализ зависимостей с помощью моделей с несколькими банками деревьев
Аарон Смит
|
Бернд Бонет
|
Мирьям де Лоно
|
Жоаким Нивр
|
Ян Шао
|
Sara Stymne
Материалы общей задачи CoNLL 2018: многоязычный анализ от необработанного текста к универсальным зависимостям
Мы представляем систему Uppsala для общей задачи CoNLL 2018 по универсальному анализу зависимостей. Наша система представляет собой конвейер, состоящий из трех компонентов: первый выполняет совместную сегментацию слов и предложений; второй предсказывает части речи теги и морфологические признаки; третий предсказывает деревья зависимостей от слов и тегов. Вместо обучения одной модели синтаксического анализа для каждого банка деревьев мы обучали модели с несколькими банками деревьев для одного языка или близкородственных языков, что значительно сократило количество моделей. В официальном тестовом прогоне мы заняли 7-е место из 27 команд по показателям LAS и MLAS. Наша система получила самые высокие оценки за сегментацию слов, универсальные теги POS и морфологические признаки.
Наша система получила самые высокие оценки за сегментацию слов, универсальные теги POS и морфологические признаки.
pdf
нагрудник
abs
Кошмар во время тестирования: как пунктуация мешает синтаксическим анализаторам обобщать
Anders Søgaard
|
Мирьям де Лоно
|
Isabelle Augenstein
Proceedings of the EMNLP Workshop 2018 BlackboxNLP: анализ и интерпретация нейронных сетей для NLP
Пунктуация является сильным индикатором синтаксической структуры, и синтаксические анализаторы, обученные на тексте с пунктуацией, часто сильно полагаются на этот сигнал. Однако пунктуация является отвлечением, поскольку обработка человеческого языка не зависит от пунктуации в такой же степени, и поэтому в неформальных текстах мы часто опускаем пунктуацию. Мы также используем знаки препинания неграмотно, в выразительных или творческих целях или просто по ошибке. Мы показываем, что (а) парсеры зависимостей чувствительны к и отсутствие знаков препинания и альтернативное использование; (б) нейронные парсеры, как правило, более чувствительны, чем старые парсеры; (c) обучение нейронных синтаксических анализаторов без знаков препинания превосходит все стандартные синтаксические анализаторы во всех сценариях, где пунктуация отличается от стандартной пунктуации. Наши основные эксперименты проводятся на синтетически искаженных данных, чтобы изучить влияние знаков препинания в отдельности и избежать возможных путаниц, но мы также показываем влияние на данные вне предметной области.
Наши основные эксперименты проводятся на синтетически искаженных данных, чтобы изучить влияние знаков препинания в отдельности и избежать возможных путаниц, но мы также показываем влияние на данные вне предметной области.
pdf
нагрудник
пресс
Обучение синтаксическому анализатору с гетерогенными банками деревьев
Сара Стимн
|
Мирьям де Лоно
|
Аарон Смит
|
Joakim Nivre
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Вопрос о том, как максимально использовать несколько разнородных банков деревьев при обучении одноязычного синтаксического анализатора зависимостей, остается открытым. Мы начнем с изучения ранее предложенных, но мало оцененных стратегий использования нескольких банков деревьев на основе объединения обучающих наборов с тонкой настройкой или без нее. Далее мы предлагаем новый метод, основанный на встраивании деревьев. Мы проводим эксперименты для нескольких языков и показываем, что во многих случаях точная настройка и встраивание банков деревьев приводят к существенным улучшениям по сравнению с одиночными банками деревьев или конкатенацией со средним выигрышем в 2,0–3,5 балла LAS. Мы утверждаем, что вложения деревьев следует предпочесть из-за их концептуальной простоты, гибкости и расширяемости.
Мы утверждаем, что вложения деревьев следует предпочесть из-за их концептуальной простоты, гибкости и расширяемости.
pdf
нагрудник
abs
Исследование взаимодействий между предварительно обученными вложениями слов, моделями символов и POS-тегами при разборе зависимостей
Аарон Смит
|
Мирьям де Лоно
|
Сара Стимн
|
Йоаким Нивре
Материалы конференции 2018 года по эмпирическим методам обработки естественного языка
Мы предоставляем всесторонний анализ взаимодействия между предварительно обученными вложениями слов, моделями символов и POS-тегами в синтаксическом анализаторе зависимостей на основе переходов. В то время как предыдущие исследования показали, что информация POS менее важна при наличии моделей персонажей, мы показываем, что на самом деле между всеми тремя методами существует сложное взаимодействие. По отдельности каждая из них дает большие улучшения по сравнению с базовой системой, использующей только случайно инициализированные вложения слов, но их объединение быстро приводит к уменьшению отдачи. Мы классифицируем слова по частоте, тегу POS и языку, чтобы систематически исследовать, как каждый из методов влияет на качество синтаксического анализа. Для многих категорий слов применение любых двух из трех методов почти так же хорошо, как и полная комбинированная система. Модели символов имеют тенденцию быть более важными для низкочастотных слов открытого класса, особенно в морфологически богатых языках, в то время как теги POS могут помочь устранить неоднозначность высокочастотных служебных слов. Мы также показываем, что большие размеры встраивания символов помогают даже для языков с небольшим набором символов, особенно в морфологически богатых языках.
Мы классифицируем слова по частоте, тегу POS и языку, чтобы систематически исследовать, как каждый из методов влияет на качество синтаксического анализа. Для многих категорий слов применение любых двух из трех методов почти так же хорошо, как и полная комбинированная система. Модели символов имеют тенденцию быть более важными для низкочастотных слов открытого класса, особенно в морфологически богатых языках, в то время как теги POS могут помочь устранить неоднозначность высокочастотных служебных слов. Мы также показываем, что большие размеры встраивания символов помогают даже для языков с небольшим набором символов, особенно в морфологически богатых языках.
pdf
нагрудник
абс
Совместное использование параметров между анализаторами зависимостей для родственных языков
Мирьям де Лоно
|
Йоханнес Бьерва
|
Изабель Огенштейн
|
Anders Søgaard
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Предыдущая работа предполагала, что совместное использование параметров между анализаторами нейронных зависимостей на основе переходов для связанных языков может привести к повышению производительности, но нет единого мнения о том, какие параметры следует использовать совместно. . Мы представляем оценку 27 различных стратегий совместного использования параметров на 10 языках, представляющих пять пар родственных языков, каждая пара из другой языковой семьи. Мы обнаружили, что совместное использование параметров классификатора перехода всегда помогает, тогда как полезность совместного использования параметров слова и/или символа LSTM варьируется. Основываясь на этом результате, мы предлагаем архитектуру, в которой классификатор перехода является общим, а совместное использование параметров слова и символа контролируется параметром, который можно настроить на данных проверки. Эта модель лингвистически мотивирована и дает значительные улучшения по сравнению с базовым уровнем обучения на одном языке. Мы также обнаружили, что совместное использование параметров классификатора перехода помогает при обучении синтаксического анализатора на несвязанных языковых парах, но мы обнаружили, что в случае несвязанных языков совместное использование слишком большого количества параметров не помогает.
. Мы представляем оценку 27 различных стратегий совместного использования параметров на 10 языках, представляющих пять пар родственных языков, каждая пара из другой языковой семьи. Мы обнаружили, что совместное использование параметров классификатора перехода всегда помогает, тогда как полезность совместного использования параметров слова и/или символа LSTM варьируется. Основываясь на этом результате, мы предлагаем архитектуру, в которой классификатор перехода является общим, а совместное использование параметров слова и символа контролируется параметром, который можно настроить на данных проверки. Эта модель лингвистически мотивирована и дает значительные улучшения по сравнению с базовым уровнем обучения на одном языке. Мы также обнаружили, что совместное использование параметров классификатора перехода помогает при обучении синтаксического анализатора на несвязанных языковых парах, но мы обнаружили, что в случае несвязанных языков совместное использование слишком большого количества параметров не помогает.
2017
pdf
нагрудник
абс
Arc-Hybrid Non-Projective Dependency Parsing with the Static-Dynamic Oracle
Miryam de Lhoneux
|
Сара Стимн
|
Joakim Nivre
Proceedings of the 15th International Conference on Parsing Technologies
В этой статье мы расширяем дуговую гибридную систему для синтаксического анализа на основе переходов с переходом подкачки, который позволяет переупорядочивать слова и строить непроективные деревья. Хотя это расширение нарушает декомпозируемость дуги переходной системы, мы показываем, как существующий динамический оракул для этой системы может быть изменен и объединен со статическим оракулом только для перехода подкачки. Эксперименты на 5 языках показывают, что новая система дает конкурентоспособную точность и значительно лучше, чем система, обученная с помощью чисто статического оракула.
pdf
нагрудник
абс
От необработанного текста к универсальным зависимостям — смотрите, без тегов!
Мирьям де Лоно
|
Ян Шао
|
Али Басират
|
Элиягу Кипервассер
|
Сара Стимн
|
Йоав Голдберг
|
Joakim Nivre
Материалы общей задачи CoNLL 2017: многоязычный анализ от необработанного текста к универсальным зависимостям
Мы представляем представление Уппсалы к общей задаче CoNLL 2017 по разбору от необработанного текста до универсальных зависимостей.