Урок русского языка «Значение приставок за-, в-, у-. Разбор по составу» (3 класс)
Тема. Значение пристак за-, в-, у-. Употребление слов с этими приставками. Разбор слов по составу
Цель: учащиеся должны уметь разбирать слова по составу, образовывать новые слова с помощью суффикса и приставки.
Задачи:
1. Создать условия для развития логического мышления, памяти, наблюдательности, умения правильно обобщать данные и делать выводы. Познакомить с приставками за, у, в; учить употреблять слова с приставками в речи; обогащать словарный запас глагольной лексикой с приставками. Познакомить с порядком разбора слов по составу; совершенствовать умения выделять приставки в словах, правильно и уместно использовать слова с приставками в речи.
2. Способствовать развитию познавательного интереса к уроку.
3. Обеспечить условия для воспитания дружеских отношений между учащимися, взаимопомощи, воспитания речевого этикета (умения здороваться, прощаться, просить прощения).
Оборудование: компьютер, презентация Мicrosoft Office Power Point «Разбор слов по составу», задания для групповой работы.
Тип урока. Урок ознакомления с новым материалом.
Ход урока
1. Организационный момент
Прозвенел и смолк звонок,
Начинается урок.
Все сосредоточились,
Работать приготовились.
2. Проверка домашнего задания
— Давайте посмотрим, как вы справились с домашним заданием (упр. 182, с. 114).
Какие слова вы выписали? Как разделили для переноса слово сфотографируй?
3. Чистописание
На доске написаны слова: «гейзер», «йог», «добрый».
Словарная работа.
Гейзер – это горячий источник, периодически выбрасывающий фонтаны горячей воды и пара под давлением.
Йог – это человек, стремящийся познать природные законы и явления.
Прочитайте написанные на доске слова и определите букву, которую мы будем писать на чистописании. Эта буква есть во всех словах, она обозначает непарный согласный мягкий звонкий звук. Какая это буква? («й».)
Определите порядок следования букв в данной последовательности.
уууй ууйй уййй уууй
(Строчные буквы у чередуются со строчными буквами «й». Буква «у» следует в порядке уменьшения на одну. А буквы «й» – в порядке увеличения на одну.)
Напишите цепочку букв в данной последовательности до конца строки.
Пожалуйста, здравствуйте, прощайте, добрый день.
Старайтесь добрыми всегда
И вежливыми быть;
«пожалуйста» не забывать,
«спасибо» говорить.
4. Актуализация знаний.
Выбираем верное утверждение:
1. Слово не может быть без окончания.
Слово не может быть без корня.
Слово не может быть без суффикса.
Слово не может быть без приставки.
2. Окончание – это изменяемая часть слова.
Окончание – это неизменяемая часть слова.
3. Суффикс стоит за корнем.
Суффикс стоит в конце слова.
4. Приставка стоит за корнем.
Приставка стоит перед корнем.
5. Физминутка для глаз.
6. Сообщение темы и целей урока.
Значение приставок за-, в-, у-.
Начать кружиться – закружиться.
Начать зеленеть – зазеленеть.
Начать прыгать – запрыгать.
Начать болеть – заболеть.
Какое значение придает приставка за- словам: начало действия или конец действия?
Ходить – входить. Лететь – влететь. Тащить – втащить.
Какое значение придает приставка в- словам? (Направленность действия)
Ходить – уходить. Лететь – улететь. Тащить – утащить.
Какое значение придает приставка у- словам? (Направленность движения от чего-нибудь в сторону)
7. Образование слов с приставками
Запись одного предложения (по выбору).
8. Разгадывание кроссворда.
А сейчас мы займемся разгадыванием кроссворда. Вы должны догадаться, о каком предмете идет речь.
1. Учебное помещение для занятий. (Класс)
2. Верхняя женская или мужская одежда. (Пальто)
3. Хозяйственная утварь для еды, питья. (Посуда)
4. Защитник Отечества. (Солдат)
5. Лиственное дерево с белым стволом. (Берёза)
6. Красна девица сидит в темнице, а хвост на улице. (Морковь)
Ребята, если вы внимательно посмотрите на слова, то вы найдете «спрятавшееся» слово, которое будет подсказкой для определения темы урока.
Догадались? Состав (чего?) слова. Это слово имеет несколько значений, назовите их. (Состав вещества, офицерский состав, в поезде…).
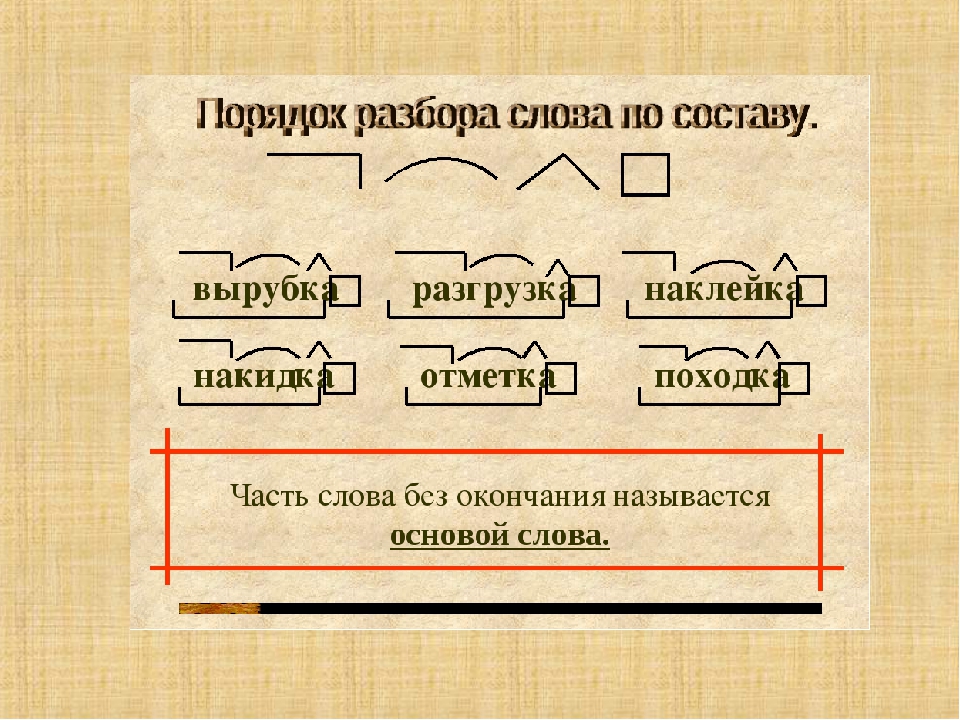
Сегодня вы узнаете, в каком порядке нужно выделять в слове части. Научитесь делать разбор слов по составу.
Научитесь делать разбор слов по составу.
Для чего нужно хорошо знать состав слова? (Чтобы грамотно писать слова, образовывать новые слова, правильно толковать смысл слов.)
9. Музыкальная физминутка.
10. Игра “Угадай, кто я”.
Я читаю загадки, а вы отгадываете.
• Часть я очень главная, в слове я живу. Без меня нет смысла ни розе, ни ежу. (Корень)
• Я и часть, я и предлог. Без меня никто не смог. Я и слово и добавка. Называюсь я … .(Приставка).
• Ну а я частичка. Обозначусь я, как птичка. Только вот наоборот. Это каждый разберёт. (Суффикс)
• Меня в окошко обозначат. Для связи слова я служу, какой смысл в каждом предложении, я всем и сразу расскажу. (Окончание)
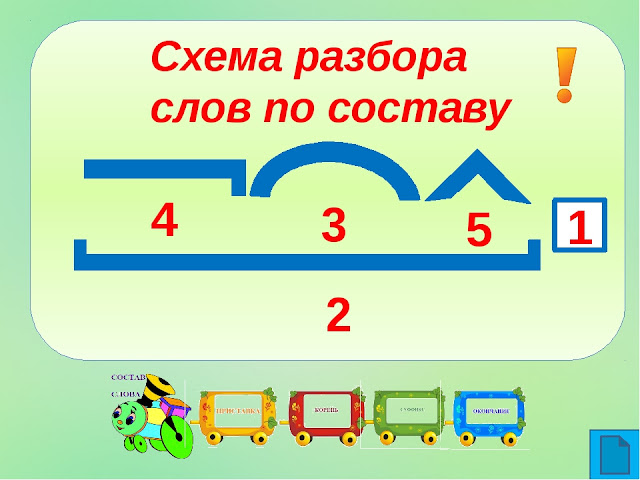
11. Знакомство с алгоритмом разбора слова по составу.
1. Выделяю в слове окончание. Для этого изменяю слово по вопросам.
2. Нахожу корень. Для этого подбираю однокоренные слова и определяю общую часть.
3. Нахожу приставку. Она стоит перед корнем.
4. Нахожу суффикс. Он стоит между корнем и окончанием.
12. Закрепление изученного.
Работа с учебником. Упр. 184.
Как вы считаете, хорошо поступили подружки? Что им сейчас надо сделать?
Помогите подружкам помириться: подскажите волшебные слова, которые люди говорят, чтобы попросить прощения.
Разбор по составу слов подружки, игрушки.
13. Упр. 186. Собери слово. (Загадка) Разобрать слово по составу.
14. Работа в группах. Составь слово.Составьте слова из морфем слов одной строки и запишите их.
1 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Полёт
краски
дочка
лапа
2 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Пришёл
ставить
травка
звезда
3 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Пошёл
слово
лисица
берёза
4 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Догнать
школа
учебник
шарик
5 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Походка
слово
сестрицы
река
6 группа
ПриставкаКорень
Суффикс
Окончание
Новое слово
Расписка
садик
стол
звезда
15. Итог урока. Рефлексия.
Итог урока. Рефлексия.
С чем вы сегодня познакомились?
Что нового узнали?
Что было трудным?
16. Д/з. Упр. 187.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Разбор имён существительных по составу | План-конспект урока по русскому языку (3 класс) по теме:
Тема: «Разбор имен существительных по составу»
Класс: 3
Тип урока: закрепление изученного.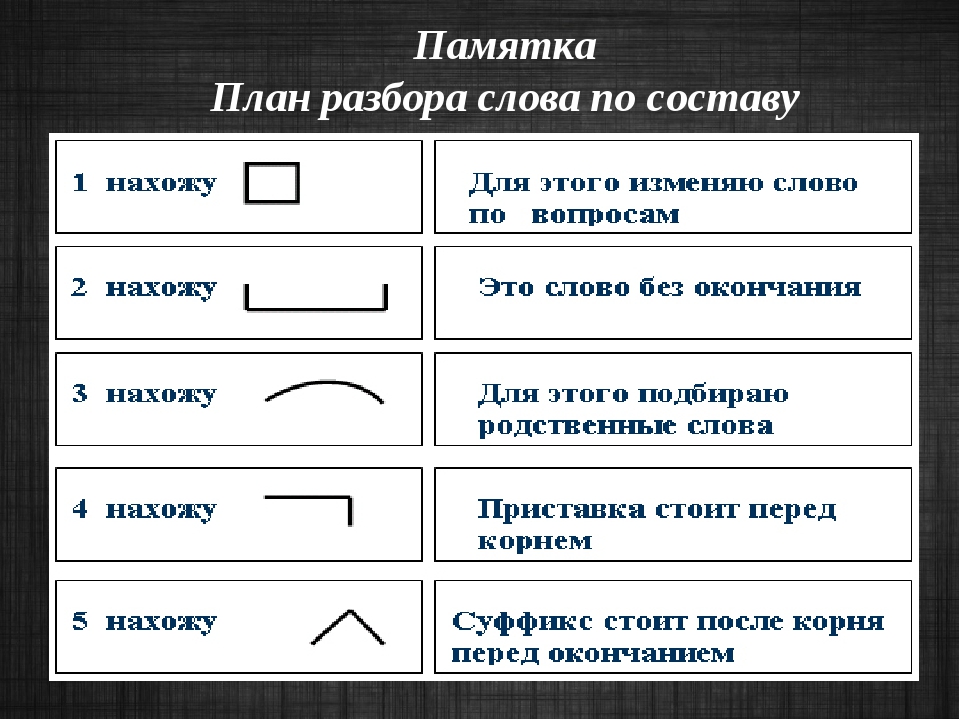
Цель: систематизировать и обобщить знания о словообразовании имен существительных.
Задачи:
Предметные:
- Закрепление умений определять признаки имён существительных;
- Закрепление умений устанавливать способ образования имён существительных.
- Закрепление умения образовывать с помощью суффиксов (-онк-, -оньк-, -еньк, -ок-, -ек-, -ик-, -очк-, -ечк-, -ушк-, -юшк-, -ышк-, -к-, -чик-, -тель-, -ник-, -их-) и употреблять в речи имена существительные (с уменьшительно-ласкательным значением и др.).
- Закрепление умений устного и письменного разбора имён существительных по составу с опорой на смысловые связи слов (на основе словообразовательного анализа), а также соотносить слово со схемой.
Метапредметные:
Познавательные:
- формирование умения выделять и формулировать познавательную цель всего урока и отдельного задания;
- формирование умения осуществлять логические действия анализа, классификации по родовидовым признакам, обобщения, построения рассуждений, отнесения к известным понятиям.
Регулятивные:
- развитие умения следовать учебным действиям;
- развитие умения принимать и сохранять учебную задачу;
- развитие умения контролировать и оценивать учебные действия в соответствии с поставленной задачей и условиями её реализации;
Коммуникативные:
- развитие умения активного использования речевых средств и средств для решения коммуникативных и познавательных задач.
- развитиеготовности слушать собеседника, признавать возможность существования различных точек зрения и права каждого иметь свою, излагать своё мнение и аргументировать свою точку зрения и оценки событий;
- развитие уменийосуществлять взаимный контроль в совместной деятельности, адекватно оценивать собственноеповедение и поведения окружающих.
Личностные:
- формирование познавательной потребности к изучаемой теме;
- развитие мотивов учебной деятельности;
- развитие умения оценивать свою деятельность на уроке.

Оборудование: компьютер; электронная доска; электронная презентация(приложение 1).
КУМО: УМК «Школа 2100», учебник «Русский язык»3 класс (часть 2) — Бунеев Р.Н., Бунеева Е.В., Пронина О.В., 2015;
Ход урока
—
Добрый день, добрый час!
Как я рада видеть вас.
Друг на друга посмотрели
И тихонечко все сели.
— Давайте вместе постараемся, чтобы наше хорошее настроение сохранилось на весь урок.
Приветствие учителя.
Личностные:
формирование познавательной потребности к изучаемой теме;
развитие мотивов учебной деятельности.
Метод слово учителя – (прием стихотворчества).
СЛОВАРНЫЕ СЛОВА.
Кровать, винегрет, салат, стакан, хорошо, синица, малина, огурец, лимон, апельсин, батон, помидор, базар, мечта, осина.
Введение слова багаж.
а) Лексическое значение.
1) Вещи, груз пассажиров.
2) Запас знаний (перенос.).
б) Грамматические признаки.
Багаж (что?) – сущ., неодуш., м.р., ед.ч.
в) Орфографическая работа.
– Запишите слово, обозначьте орфограмму. Образуйте при помощи суффиксов другие имена существительные (багажник), другие части речи (багажное). Запомните написание этих слов.
Части речи.
— Какую тему мы изучаем на уроках русского языка? Какая часть речи называется именем существительным? Перечислите все известные вам части речи.
— С помощью каких суффиксов образуются имена существительные, которые называют самок животных и их детёнышей?
– От основ какой части речи образуются эти существительные? (От основ сущ.)
– Какие вы знаете уменьшительно-ласкательные суффиксы?
– Какое значение у суффикса -очк- в слове мамочка? (Ласкательное.)
II. Формулирование проблемы, планирование деятельности. Открытие знаний.
Учитель называет ключевые слова.
Имя существительное, состав слова, разбор.
– Сформулируйте цель урока. (Учим разбирать имена существительные по составу.)
План.
Учитель вместе с детьми составляет план.
– Что мы сейчас делали? (Формулировали тему урока, составляли план, планировали свою деятельность.)
III. Развитие умений.
1. Работа в учебнике.
Упр. 276 – развивается умение образовывать существительные от названий действий, находить суффикс, определять его значение.
Работа на доске под руководством учителя.
– Назовите однокоренные слова в каждом предложении. Запишите их, укажите части речи:
водить (гл.) – водитель (сущ.)
писать (гл.) – писатель (сущ.) и т.д.
– Какая общая часть есть у всех образованных слов? (Суффикс -тель-.)
– Какое значение вносит он в слово? Сравните с однокоренными глаголами – названиями действий. (Называет человека, который
чем-то занимается.)
– От основ каких частей речи образовались эти существительные? (От основ глагола.)
П. Учитель сообщает, что в словах есть ещё один суффикс глагола а/и, о котором ученики узнают при дальнейшем изучении русского языка в 4-м классе.
Запись:
б) Чтение вывода в рамке на с. 48.
– Как образуются существительные, называющие человека по роду действий, занятий? (От основ глаголов при помощи суффикса -тель.)
– Какое значение будет у суффикса -тель? (Человек по роду действий, занятий.)
в) Тренировочные упражнения в образовании существительных с суффиксом -тель-.
Упр. 277. Выполняется на доске и в тетрадях.
Дети записывают: Мечтатель, житель, отправитель, получатель. Затем отвечают на вопросы после упражнения.
Обобщающий вопрос после текста в рамке.
3. Наблюдение над образованием имён существительных с помощью суффикса -ник-.
а) Упр. 278 – развивается умение образовывать слова от основ существительных и глаголов, находить суффикс, определять его значение.
Дети выписывают слова:
1) мельник, фокусник, помощник, лучник;
2) градусник, чайник, молочник;
3) малинник, осинник, коровник.
3. Упражнение в подборе и записи слов по схемам.
1. Упр. 282.
2–3 схемы ученики анализируют вслух.
Например, по 1-й схеме в упражнении -ник-. В этом слове нулевое окончание, а основа состоит из корня и суффикса -ник-.
К этой схеме подходят слова: кофейник, мельник.
Суффикс -ник- в них имеет разное значение.
Методическая рекомендация: при разборе по составу напоминаем общий порядок: выделяем окончание, затем основу и части внутри основы, начиная с конца, т.е. с суффикса, отмечаем значение суффикса, заканчиваем разбор выделением корня и подбором однокоренных слов.
При разборе существительных во множественном числе следует напомнить, что они обозначают детёнышей (во множественном числе), соотносятся с теми же словами в единственном числе (кукушонок и козлёнок) и образуются заменой суффиксов -онок- (-ёнок-) на -ат-, -ят-.
IV. Итог урока.
– Чему учились на уроке? Было ли интересно? Когда?
– Что было труднее всего? Легче всего?
– Что у вас получалось сегодня лучше всего?
– В чём испытали затруднения?
– Кто сегодня получил отметку в дневник?
– За что?
V. Домашнее задание.
Упр. 5, с. 57.
Подберите к указанным словам однокоренные, чтобы в них обнаружилось чередование гласных и согласных в корне. Дорога, берег, снег, блеск, свет, лицо, испечь, брызгать, собирать, рассмешить, укрепить, любить, холод, искать, вырос.
Выделите основу и окончание в следующих словах. Басенки, засветло, красота, брюки, увлекались, по-осеннему, призываю, настольный, жалко, кенгуру, медвежий, бегун, срочно, духовный, метро, отрезать, заповедник, бегут, испугавшись, хорош, сочнее.
Обозначьте суффиксы в словах. К выделенным словам подберите другие слова с таким же суффиксом (по значению). Студентка, поплавок, геройство, грузинка, медвежонок, сибиряк, доброта, музыкант, дождик, весенний, духовность.
Обозначьте в словах приставку. К выделенным словам подберите другие слова с такой же приставкой (по значению). Взлететь, отрубить, надкусить, безграничный, рассердиться, сверхсрочный, преграда, подбежать, пришкольный.
Сделайте письменный морфемный разбор данных слов. Теснота, воссоединение, верхний, допоздна (читать), недалекий, наслаждение, топленое (молоко), пылесос, съездить, налево (повернуть), ослепительный, льстиво (говорить), неустойчивая (погода), трубопровод, черноморский (флот), вороний (крик), давление, пилотаж. Тест по теме «Морфемика»
2. Какое слово верно разбито на морфемы? 3. Какое слово состоит из пяти морфем?
7. Какое слово состоит из приставки, корня и окончания
8.
9. Отметьте «лишнее» среди родственных.
10. Какое слово не является родственным остальным?
11. Какое слово состоит из приставки, корня, одного суффикса и окончания?
13. В каком ряду все слова родственные?
16. В каком слове нет приставки?
Ответы:
|

 В каком слове нет суффикса?
В каком слове нет суффикса?
Написание сочинения о будущем
Каждая композиция имеет начала, , середину , и концовку . Середина, безусловно, самая длинная, но не менее важны начало и конец.
Если ваша композиция посвящена какой-то прогулке, нет необходимости писать полстраницы о раннем вставании, завтраке, приготовлении обеденной корзины или вывозе машины из гаража. начало должно быть кратким, и нет причин, по которым композиция о прогулке, например, не должна начинаться с фактического места на пляже, в парке, зоопарке, гавани или где бы то ни было.
Точно так же , заканчивающееся , должно закончить Композицию быстро, четко и точно. Это не только завершает вашу историю, но часто может добавить тот «последний штрих», который отличает обычную композицию от хорошей.
Неожиданные концовки придают неожиданный поворот истории, и этот вид завершающего штриха часто используется в творческой композиции. Обычно он содержится не более чем в двух или трех предложениях, которые не длиннее, чем начальный абзац, который устанавливает сцену или приводит историю в движение.
средний Композиции составляет основную часть рассказа или описания и может состоять из трех или четырех абзацев. Он не должен содержать ничего, что не касается конкретной рассказываемой истории, и должен переходить от одного пункта к другому по мере того, как каждый происходит или описывается.
Чтобы избежать ошибок и использовать лучшие слова и фразы, каждое предложение следует тщательно продумать, прежде чем писать пером на бумаге. Старайтесь не писать первое, что приходит вам в голову, но не ждите слишком долго идеи.Как только вы начнете, продолжайте, пока история не закончится. Не делайте фальстартов, вычеркивая или исключая и начиная все сначала.
Старайтесь не писать первое, что приходит вам в голову, но не ждите слишком долго идеи.Как только вы начнете, продолжайте, пока история не закончится. Не делайте фальстартов, вычеркивая или исключая и начиная все сначала.
Когда вы закончите сочинение, прочтите его до конца и посмотрите, как оно звучит для вас. Исправьте грамматические или пунктуационные ошибки. Не бойтесь использовать какое-либо громкое или незнакомое слово просто потому, что вы не умеете писать его по буквам. Используйте свой словарь.
Перепишите свою Композицию после того, как вы ее закончили, где вы можете сказать что-то лучше.Вырежьте части, которые не нужны для вашего рассказа или описания.
Только написание множества Композиций поможет вам в этом преуспеть. Чтение и прослушивание рассказов, замечание в них хороших слов и фраз, их заимствование и использование некоторых хороших идей улучшат вашу способность писать сочинения.
Запомните свои абзацы. Несколько предложений составляют абзац, а несколько абзацев составляют композицию. Подобно тому, как предложение говорит вам определенную сумму и не более того, так и абзац.Когда достигается новая часть истории или описания, начинайте новый абзац.
ПРОШЛОЕ, НАСТОЯЩЕЕ ИЛИ БУДУЩЕЕ
Вот абзац о прошлом :
В прошлом году я ходил в школу каждый день. Я так регулярно посещал занятия, что получил за это сертификат. Я был не только постоянным, но и всегда пунктуальным, ни разу не опаздывая. Я немного гордился этим своим достижением.
Вот абзац о подарке :
Я люблю добираться до школы задолго до того, как прозвенит звонок, чтобы пойти в класс.Я могу поиграть со своими товарищами на детской площадке и пообщаться с ними перед началом уроков. Сейчас мы тренируемся со своими йо-йо и говорим о футболе и крикете в этом году.
Вот абзац о будущем :
В наступающем футбольном сезоне постараюсь попасть в школьную команду. Когда пройдут пробы, я буду настолько хорошо подготовлен, что у меня будут хорошие шансы на продажу
Когда пройдут пробы, я буду настолько хорошо подготовлен, что у меня будут хорошие шансы на продажу
действие. Я начну тренироваться еще до окончания сезона крикета.Сверчок закончится не раньше апреля или мая.
Если вы сложите эти три абзаца, вы получите Композицию, написанную о прошлом, настоящем и будущем. Любая композиция может включать в себя все эти периоды времени. С другой стороны, вы можете написать Композицию, которая все в прошлом, все в настоящем или все в будущем.
Даже в одном абзаце у вас могут быть предложения о разных временах, прошлом, настоящем или будущем. Но никогда не используйте более одного раза в одном предложении.
ПИСЬМО О БУДУЩЕМ
Помните, что ничего не произошло, и — это не , что они происходят; они будут или может произойти , будет происходящим или происходящим, и так далее.
Каким будет мир через сто лет.
Пунктов:
- Больше всего — людей, домов, магазинов, автомобилей, заводов, ферм, плотин, электростанций и так далее.
- Различия в моде — одежда, прически, дизайн автомобилей, строительные конструкции — широкие дороги — надземные пешеходные переходы и пешеходные дорожки на уровне первого этажа высоких зданий в городах и т. Д.
- Новые города и предприятия в стране — новые ирригационные схемы, основанные на новых плотинах и каналах — новые гидроэлектрические системы — больше людей в деревне и более близкие сельскохозяйственные поселения.
- Развитие и продвижение [более бедных] стран [и]… увеличение торговли и путешествий между странами.
- Вещи, которые могут привести к войне и спорам — вещи, которые могут привести к миру и соглашению — общение и переговоры, встречи и игры — богатые страны и бедные — образование, медицина, религии и верования.
Вот еще несколько тем, о которых вы можете писать:
- Что я планирую на следующий отпуск.
- Что сделает папа, если выиграет в лотерею.
- Что сделает мама на вечеринке.
- Что бы мы сделали, если бы пришла война.

Лейк, W.G. ок. 1965 г. Запланированная композиция, книга 3. Сидней: Aidmasta Productions, стр. 3, 13, 18.
Как получить вектор для предложения из word2vec токенов в предложении
Зависит от использования:
1) Если вы хотите получить вектор предложения только для некоторых известных данных.Посмотрите вектор абзаца в этих статьях:
Куок В. Ле и Томаш Миколов. 2014. Распределенные представления приговоров и документов. Eprint Arxiv, 4: 1188–1196.
А. М. Дай, К. Олах и К. В. Ле. 2015. Вложение документов с векторами абзацев. Электронные отпечатки ArXiv, июль.
2) Если вы хотите, чтобы модель оценивала вектор предложений для неизвестных (тестовых) предложений с неконтролируемым подходом:
Вы можете проверить эту статью:
Стивен Ду и Си Чжан.2016. Aicyber на SemEval-2016 Задача 4: представление предложений на основе i-вектора. В материалах 10-го международного семинара по семантической оценке (SemEval 2016), Сан-Диего, США
3) Исследователь также ищет выход определенного уровня в сети RNN или LSTM, недавний пример:
http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12195
4) Для gensim doc2vec многие исследователи не смогли получить хороших результатов, чтобы преодолеть эту проблему, следуя статье с использованием doc2vec на основе предварительно обученных векторов слов.
Джей Хан Лау и Тимоти Болдуин (2016). Эмпирическая оценка doc2vec с практическим пониманием создания встраиваемых документов. В материалах 1-го семинара по репрезентативному обучению для НЛП, 2016.
5) tweet2vec или sent2vec .
Facebook имеет проект SentEval для оценки качества векторов предложений.
https://github.com/facebookresearch/SentEval
6) Более подробная информация содержится в следующем документе:
Модели нейронных сетей для идентификации перефразирования, семантического текстового сходства, вывода естественного языка и ответов на вопросы
А пока вы можете использовать «BERT»:
Google выпускает исходный код, а также предварительно обученные модели.
https://github.com/google-research/bert
А вот пример запуска bert как службы:
https://github.com/hanxiao/bert-as-service
Как автоматически анализировать информацию о композиции и движении в классической музыке
IntroМеня спросили, как я реализую автоматический синтаксический анализ информации для классической музыки, последний раз касался информации о движении и номере движения, поэтому я попытаюсь объясните немного об этом здесь.Я подумал, что будет больше смысла, если я представлю это вместе с полем «Композиция». Я уже говорил о композиции раньше в предыдущем уроке, и это будет охватывать часть той же информации, чтобы быть более связной.
Во-первых, небольшой отказ от ответственности: я считаю, что часть этого проекта еще не завершена. Со временем он развивается, и, хотя композиция хорошо закреплена, информация о движении более сложна и может продолжать улучшаться. Кроме того, Мэтт работает над некоторыми изменениями в языке выражений, которые я предложил, которые упростят определенные аспекты такого рода вещей, поэтому появятся возможности упростить некоторые выражения, когда эти обновления станут общедоступными.
Итак, для тех, кому интересно, я опишу систему, которую использую. Я думаю, что это хорошая система, и она определенно лучше некоторых альтернатив, но это далеко не единственная система, которая будет работать. Если вы хотите иметь другую систему, вы можете адаптировать то, что я делаю здесь, к вашему стилю работы.
Самое важное, что нужно понять, это то, что у вас должна быть структурированная система именования для вашей классической музыки, и вы должны обеспечить ее соблюдение. Если вы хотите, чтобы ваша информация анализировалась автоматически, ее необходимо систематизировать.Это очень важно.
Так зачем нам это? Следует понимать, что в популярной / рок / джазовой музыке большинство музыкальных произведений представляют собой одну дорожку, а классическая — другая. Большая часть классической музыки состоит из нескольких треков, которые вместе образуют одно музыкальное произведение — Композицию. Например, 1-й фортепианный концерт Моцарта состоит из 3 частей, каждая из которых представляет собой отдельный трек, и вы можете слушать эти три трека вместе как одну композицию. JRiver изначально не имеет такой концепции композиции, поэтому я ее создал.Часто, хотя и не всегда, когда музыка записывается на компакт-диск, каждое движение композиции является треком. Так что полезно принять эту форму, и ее часто можно использовать для музыкальных произведений, которые не полностью соответствуют структуре, если мы будем осторожны с нашей системой.
Большая часть классической музыки состоит из нескольких треков, которые вместе образуют одно музыкальное произведение — Композицию. Например, 1-й фортепианный концерт Моцарта состоит из 3 частей, каждая из которых представляет собой отдельный трек, и вы можете слушать эти три трека вместе как одну композицию. JRiver изначально не имеет такой концепции композиции, поэтому я ее создал.Часто, хотя и не всегда, когда музыка записывается на компакт-диск, каждое движение композиции является треком. Так что полезно принять эту форму, и ее часто можно использовать для музыкальных произведений, которые не полностью соответствуют структуре, если мы будем осторожны с нашей системой.
Итак, давайте начнем с 1-го фортепианного концерта Моцарта, который будет служить типичным произведением. В нем три трека, и если мы назовем их следующим образом, мы можем увидеть образец:
Концерт № 1 фа мажор, K.37: I. Аллегро
Концерт №1 фа мажор, K.37: II. Анданте
Концерт № 1 фа мажор, K.37: III. Allegro
Каждое название трека имеет двоеточие. Все, что находится до двоеточия, является общим для всех треков. Все, что находится после двоеточия, отличает эту дорожку от других. Этот формат часто используется в онлайн-базах данных; это довольно часто. Если я получаю треки, которые не имеют названий с таким типом структуры, я использую язык выражений, чтобы настроить их в соответствии с ним. Обеспечение такой последовательности приносит дивиденды.
Композиция
Все, что находится до двоеточия, является Композицией.Все, что находится после двоеточия, является информацией о движении. Итак, в этой системе у нас есть следующее определение:
Имя = Композиция: Движение
Номер Движения обозначен точками в начале Движения
В приведенном выше примере мы получаем [Композиция] из
Концерт № 1 фа мажор, K.37
Все три трека имеют одинаковое значение.
Этот шаблон позволяет нам автоматически определять Composition как вычисляемое поле:
ListItem ([Name], 0, :) В этом определении есть умный смысл в том, что если вы опустите двоеточие (вы не Если у вас есть отдельные треки, составляющие рок-песню), то [Composition] = [Name] Другими словами, если нет двоеточия, название трека является названием композиции.
 Итак, если Name = «Лестница в небеса», то композиция = «Лестница в небеса» Легко.
Итак, если Name = «Лестница в небеса», то композиция = «Лестница в небеса» Легко. Итак, вы создаете новое поле под названием Composition в Options-> Library & Folders-> Manage Library Fields, и диалоговое окно выглядит следующим образом:
Movement Name
Теперь получить информацию о движении немного сложнее.
Во-первых, MC имеет два встроенных поля: [Movement] и [Movement Number] Поскольку они являются встроенными полями, мы не можем изменить их тип на Calculate Data.
Итак, мы создали два новых поля для использования вместо них: [Название движения] и [Номер движения]
Используйте то же диалоговое окно, что и раньше, для [Композиция].
[Название движения] также является расчетными данными, определяемыми следующим образом:
If (IsEqual ([Composition], [Name]) ,, ListItem ([Name], 1, :)) В основном, если Состав отличается от Имени, он принимает все, что стоит после двоеточия. Убедитесь, что у вас не более одного двоеточия.
Для трех треков, которые я показывал вам ранее, будут указаны названия движений:
I..] +)) # /, 1,0)),)
Моя система для [Movement #] ищет два разных паттерна. Во-первых, он ожидает увидеть точку в качестве разделителя. Если точки (точки) нет, то поле [№ движения] будет пустым. Это подходит для отдельных частей трека, у которых нет движений или нескольких частей.
Первый шаблон, который он ищет, — это использование «Нет». в качестве аббревиатуры, что случается так часто, я сделал для нее особый случай. Пример:
«9 Tableaux Etudes Op. 39: No. 1 C minor»
Если он это увидит, он возьмет «No.1 «как Часть №
Второй образец, который он ищет, — это какой-то другой термин, обозначенный точкой, и в этом случае он будет рассматривать все до точки. Некоторые примеры:
Концерт № 1 фа мажор, K .37: II. Анданте [Часть №] = II
Багатели (11) для фортепиано, соч.119: VI. Анданте (соль мажор) [Часть №] = VI
Оркестровая сюита № 1 до мажор, BWV 1066: 1. Ouverture [Movement #] = 1
Ouverture [Movement #] = 1
Этот подход достаточно гибкий, чтобы разумно обрабатывать музыкальные произведения, не соответствующие стандартной парадигме записи «1 трек на движение».
Например, 3-я симфония Малера имеет больше оперной структуры, с 6 большими движениями, разделенными на 26 треков. Первая часть 6-й части (дорожка 21) выглядит так:
Симфония № 3: VI-1. Лангсам. Руволл. Empfunden [Movement #] = VI-1
Он также может работать для оперы, в которой технически есть действия и сцены, а не движения. Посмотрите трек из «Травиаты»:
«Травиата: действие 2, сцена III». Альфредо соло [Движение №] = Акт 2 Сцена III
Поскольку он ищет точку, все, что до этой первой точки, будет использоваться как Движение №.Если вам не нужен номер движения, опустите точку.
Как это выглядит
Вы можете увидеть, как все это разыгрывается в представлении здесь:
Мне не нужно вводить какие-либо поля Composition, Movement Name или Movement #. Я проверяю, что мое поле [Имя] фиксируется при копировании или сразу после импорта, а все остальное делается автоматически. Это хорошо работает, потому что я не люблю вводить больше, чем нужно.
Вот как вы можете разбирать информацию.Получив информацию о композиции, вы можете делать просмотры на ее основе, а также собирать сводную статистику, такую как рейтинги и продолжительность. Вот пример:
Надеюсь, JRiver улучшит MC, чтобы обеспечить встроенную поддержку Composition в будущем, чтобы их можно было правильно обрабатывать в плейлистах, смарт-списках и т. Д. Если вы хотите, чтобы это произошло, выразите свою поддержку в поток запроса функции здесь: https://yabb.jriver.com/interact/index.php/topic,128860.0.html
Люди какое-то время использовали подход [Состав], но поскольку недавно появились дополнительные интерес к информации о движении, я подумал, что выложу это.
В любом случае, я надеюсь, что люди найдут это полезным, и вы сможете адаптировать технику под свои нужды .