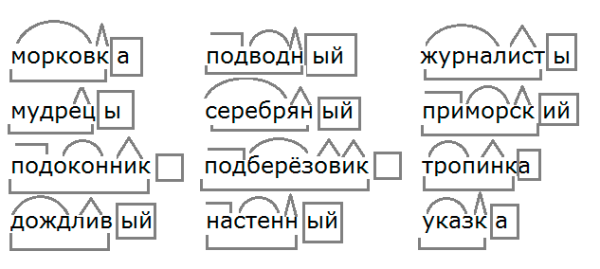
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: в ы з о в сейчас ослатыть сейчас коливуца 1 секунда назад мастерн 1 секунда назад кааелвьр 1 секунда назад пороша 1 секунда назад монтеа 1 секунда назад язычество 1 секунда назад трагенмик 1 секунда назад с ю ф в р а е 1 секунда назад вузчаквб 1 секунда назад м к ш у а 2 секунды назад г о л у б ь 2 секунды назад ц н а г е л 2 секунды назад алегархи 2 секунды назад
Морфологический разбор слова «сохранить»
Часть речи: Инфинитив
СОХРАНИТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «СОХРАНИТЬ»
| Слово | Морфологические признаки |
|---|---|
| СОХРАНИТЬ |
|
Все формы слова СОХРАНИТЬ
СОХРАНИТЬ, СОХРАНИЛ, СОХРАНИЛА, СОХРАНИЛО, СОХРАНИЛИ, СОХРАНЮ, СОХРАНИМ, СОХРАНИШЬ, СОХРАНИТЕ, СОХРАНИТ, СОХРАНЯТ, СОХРАНИВ, СОХРАНИВШИ, СОХРАНЯ, СОХРАНИМТЕ, СОХРАНИ, СОХРАНИВШИЙ, СОХРАНИВШЕГО, СОХРАНИВШЕМУ, СОХРАНИВШИМ, СОХРАНИВШЕМ, СОХРАНИВШАЯ, СОХРАНИВШЕЙ, СОХРАНИВШУЮ, СОХРАНИВШЕЮ, СОХРАНИВШЕЕ, СОХРАНИВШИЕ, СОХРАНИВШИХ, СОХРАНИВШИМИ, СОХРАНЕННЫЙ, СОХРАНЕННОГО, СОХРАНЕННОМУ, СОХРАНЕННЫМ, СОХРАНЕННОМ, СОХРАНЕН, СОХРАНЕННАЯ, СОХРАНЕННОЙ, СОХРАНЕННУЮ, СОХРАНЕННОЮ, СОХРАНЕНА, СОХРАНЕННОЕ, СОХРАНЕНО, СОХРАНЕННЫЕ, СОХРАНЕННЫХ, СОХРАНЕННЫМИ, СОХРАНЕНЫ
Разбор слова по составу сохранить
сохрани
ть
| Основа слова | сохрани |
|---|---|
| Приставка | со |
| Корень | хран |
| Суффикс | и |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «СОХРАНИТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «сохранить»
1
Сохранить свободу – это второстепенно, на первом месте – сохранить жизнь!
Жизнь без слов. Проза писателей из Гуанси (сборник), Коллектив авторов, 2018г.
2
Если мне нельзя сохранить Колина, пожалуйста, помоги мне сохранить дочь, – говорю я, причем, как оказывается, вслух.
Сохраняя веру, Джоди Пиколт, 1999г.
3
У них команда – «сохранить», а у нас – «спасти и сохранить».
Злаки Зодиака, или Ижица-файлы, Игорь Чубаха
4
Чтобы всеми силами сохранить то, что можно сохранить!
Срок для президента (сборник), Михаил Веллер, 2012г.
5
Поэтому важно сохранить то хорошее и нужное, что есть, именно сохранить и приспособить к нуждам новой философии и политики.
Жить за двоих, Владимир Виджай
Найти еще примеры предложений со словом СОХРАНИТЬ
Рисунок 2 из семантического разбора векторного пространства: основа для композиционных моделей векторного пространства title={Семантический анализ векторного пространства: основа для композиционных моделей векторного пространства}, автор={Джайант Кришнамурти и Том Майкл Митчелл}, booktitle={CVSM@ACL}, год = {2013} }
- Джаянт Кришнамурти, Том Майкл Митчелл
- Опубликовано в CVSM@ACL 1 августа 2013 г.
- Информатика
Мы представляем семантический анализ векторного пространства (VSSP), основу для изучения композиционных моделей семантики векторного пространства. Наша структура использует комбинаторную категориальную грамматику (CCG) для определения соответствия между синтаксическими категориями и семантическими представлениями, которые являются векторами и функциями на векторах. Полное соответствие является прямым следствием минимальных предположений о семантических представлениях основных синтаксических категорий (например, существительные являются векторами) и тесной связи CCG…
Наша структура использует комбинаторную категориальную грамматику (CCG) для определения соответствия между синтаксическими категориями и семантическими представлениями, которые являются векторами и функциями на векторах. Полное соответствие является прямым следствием минимальных предположений о семантических представлениях основных синтаксических категорий (например, существительные являются векторами) и тесной связи CCG…
Просмотр в ACL
rtw.ml.cmu.eduИзучение семантической инкрементальности с помощью динамического синтаксиса и семантики векторного пространства
- М. Садрзаде, Мэтью Пурвер, Дж. Хаф, Рут Кемпсон
- 41090 Ariv 9 00167 Информатика
- 2018
Показано, что инкрементному процессу пословного разбора динамического синтаксиса можно присвоить композиционно-распределительную семантику с оператором композиции DS, соответствующим общей операции тензорного сжатия из полилинейной алгебры.
Основанный на зависимости подход к контекстуализации слов с использованием семантики композиционного распределения
- Пабло Гамалло
Информатика
J. Lang. Модель.
- 2019
Мы предлагаем стратегию построения дистрибутивного значения предложений, которая в основном основана на двух типах семантических объектов: контекстных векторах, связанных со словами содержания, и композиционных… Модель
- Пабло Гамалло
Компьютерные науки
Rep4NLP@ACL
- 2017
предпочтения, и избегает проблемных тензорных представлений высокого порядка, определяя лемму и ограничения выбора как тензоры первого порядка.
Композиционная семантика с использованием моделей на основе признаков из WordNet
- Пабло Гамалло, Мартин Перейра-Фаринья
Информатика
- 2017
Эксперименты показывают, что предложенный композиционный метод превосходит современные методы как для непереходного подлежащего-глагола, так и для переходного-субъектного объектные конструкции.
Композиционно-распределительная семантика с синтаксическими зависимостями и селекционными предпочтениями
- Пабло Гамалло
Лингвистика
Прикладные науки
- 2021
Композиционная модель, основанная на синтаксических зависимостях, которая была разработана для построения контекстуализированных векторов слов, следуя лингвистическим принципам, связанным с концепцией выборочных предпочтений, оказывается конкурентоспособной с моделями Transformer.
Обучение семантических синтаксических анализаторов из Entity-Annotated Corpora
- Флориан Шмидт
Информатика
- 2014
В этой диссертации анализируются ограничения существующих подходов к использованию CCGs, взятых из разнородных текстов, таких как openmain. Web и стремится решить эту проблему на основе данных.
Статическая и динамическая векторная семантика для моделей лямбда-исчисления естественного языка
- М. Садрзаде, Р. Мускенс
Философия, информатика
J. Lang. Модель.
- 2018
Векторная семантика для языка, основанная на просто типизированных моделях лямбда-исчисления естественного языка, разработана на основе методов, знакомых по традиции условного определения истинности, и динамической семантики, основанной на форме динамической интерпретации, вдохновленной изменением контекста Хайма. обеспечены потенциалы.
РЕЗЕРНЫЕ размеры тензоров в семантике распределения типа
- T. Polajnar, Luana Fagarasan, S. Clark
Компьютерная наука
EMNLP
- 2014
. Эти бумаги. Категориальная грамматика, в которой слова с определенными грамматическими типами имеют значения, представленные многолинейными картами, и обнаруживает, что матрицы работают так же хорошо, а иногда даже лучше, чем полные тензоры, что позволяет сократить количество параметров, необходимых для моделирования структуры.
Relpron: набор данных о оценке относительной оценки для получения композиции. сложение трудно превзойти — в соответствии с существующей литературой — но реализация категориальной структуры, основанной на модели практической лексической функции, способна соответствовать производительности сложения векторов.
Инкрементный состав в семантике распределения
- Мэтью Пурвер, М. Садрзаде, Рут Кемпсон, Г. Вийнхольдс, Дж. Хоф
Компьютерная наука
Журнал Логики, Язы показывает, как DS может быть присвоена семантика композиционного распределения, которая позволяет постепенно выносить суждения о сходстве и позволяет постепенно устранять неоднозначность языковых конструкций с использованием семантики векторного пространства, и утверждает, что эти результаты закладывают основу для учета недетерминизма лексического содержания.
с показателем 1-10 из 33 ссылок
Сорт Byrelevancemost, повлиявшие на документацию,
Семантическая композиция через рекурсивную матричную векторную пространство
- R.
 Socher, Brody Huval, Christopher D. Manning, A. NG
Socher, Brody Huval, Christopher D. Manning, A. NG - 9009
666666777777777777777777777777777777777777777777777777777777777777777777777777 гг. EMNLP
- 2012
Представлена модель рекурсивной нейронной сети, которая изучает представления композиционных векторов для фраз и предложений произвольного синтаксического типа и длины и может изучать значение операторов в логике высказываний и естественном языке.
Композиционно-распределительная модель значения
- С. Кларк, Б. Коке, Мернуш
Математика
- 2008
- R.
- 2008
 Socher, Brody Huval, Christopher D. Manning, A. NG
Socher, Brody Huval, Christopher D. Manning, A. NGмодели и композиционная теория для грамматических типов, а именно теория Ламбека…
Роль синтаксиса в векторном пространстве Модели композиционной семантики
- К. Германн, П. Блансом
Информатика
ACL
- 2013
Эта модель использует комбинаторные операторы CCG для управления нелинейным преобразованием значения в предложении и используется для изучения многомерных вложений для предложений и их оценки в диапазоне задач, демонстрируя, что включение синтаксиса позволяет краткой модели изучать представления, которые являются одновременно эффективными и общими.
Лексическое обобщение в индукции грамматики CCG для семантического разбора
- T. Kwiatkowski, Luke Zettlemoyer, S. Goldwater, Mark Steedman
Компьютерная наука, лингвистика
EMNLP
- 2011
Algorithm для изучения косолю который включает в себя как лексемы для моделирования значения слов, так и шаблоны для моделирования систематических изменений в использовании слов.
Семантические векторные продукты: некоторые начальные исследования
- D. Widdows
Информатика
- 2008
В этой статье собран список существующих операторов, список типичных операций композиции на естественном языке и описаны два небольших эксперимента, которые начинают исследовать использование некоторых векторных операторов для моделировать те или иные композиционные явления на естественном языке.
Математические основы композиционно-распределительной модели значения
- Б. Коке, М. Садрзаде, С. Кларк
Математика
ArXiv
- 2010
Математическая основа для объединения дистрибутивной теории значения в терминах моделей векторного пространства и композиционной теории для грамматических типов, для которых редукции типов предгрупп повышены до морфизмы в категории, процедура, которая преобразует значения составляющих в значение (хорошо типизированного) целого.
Обучение семантических парсеров со слабым контролем
- Джаянт Кришнамурти, Том Майкл Митчелл
Информатика
EMNLP
- 2012
В этой работе представлен метод обучения семантического синтаксического анализатора без отдельного предложения, с использованием только базы знаний и немаркированного текста и демонстрирует восстановление этой более богатой структуры путем извлечения логических форм из запросов на естественном языке к Freebase.
Композиция в распределительных моделях семантики
- Джефф Митчелл, Мирелла Лапата
Информатика
Cogn. науч.
- 2010
В этой статье предлагается структура для представления значения сочетаний слов в векторном пространстве с точки зрения аддитивных и мультипликативных функций, а также представлен широкий спектр моделей композиции, которые оцениваются эмпирически в задаче на сходство фраз.
От частоты к смыслу: модели векторного пространства семантики
Цель этого обзора — показать широту применения VSM для семантики, дать новый взгляд на VSM и предоставить указатели на литературу для тех, кто менее знаком с этой областью.
Экспериментальная поддержка категориальной композиционной модели распределения значения
- Эдвард Грефенстетт, М. Садрзаде
Компьютерная наука
EMNLP
- 2011
 Садрзаде
СадрзадеАбстрактная категора. (2010) реализован с использованием данных BNC и оценен с общим улучшением результатов за счет увеличения синтаксической сложности, демонстрирующей композиционную мощь модели.
Парсер журналов рулит! Более 50 примеров!
Log Parser — это инструмент, который существует уже довольно давно (фактически, почти шесть лет). Я действительно не могу придумать ничего лучше, чем описание на официальной странице загрузки, так что вот оно: «Синтаксический анализатор журналов — это мощный, универсальный инструмент, который обеспечивает универсальный доступ к запросам к текстовым данным, таким как файлы журналов, файлы XML и CSV. файлы, а также ключевые источники данных в операционной системе Windows, такие как журнал событий, реестр, файловая система и Active Directory».
Log Parser — это инструмент командной строки (да, именно командной строки!), который использует диалект SQL для извлечения информации из источников данных. В частности, я обнаружил, что это бесценно для извлечения информации из журналов веб-серверов сайтов, которыми я управляю и разрабатываю.
В частности, я обнаружил, что это бесценно для извлечения информации из журналов веб-серверов сайтов, которыми я управляю и разрабатываю.
Во-первых, о синтаксисе SQL, который Log Parser использует для запросов к источникам данных… похоже, многие разработчики испытывают естественное отвращение к SQL. Кроме того, многие новые платформы доступа к данным пытаются абстрагировать SQL от разработчика. Тем не менее, я всегда считал, что с SQL легко работать, и считаю, что это важный инструмент, с которым каждый разработчик должен иметь хотя бы практические знания. Все, что необходимо для работы с Log Parser, — это базовое понимание базовой инструкции SQL SELECT, реализованной в Microsoft SQL Server (то есть T-SQL). Это означает, что вы должны быть знакомы со следующими элементами оператора SELECT: TOP, FROM, INTO, WHERE, ORDER BY, GROUP BY. Это все, что вам нужно для выполнения большинства операций Log Parser.
Любопытно, что Log Parser никогда не получал того внимания, которого, по моему мнению, он заслуживает. Помимо шквала внимания, когда он был впервые выпущен, он редко упоминается в официальных сообщениях или блогах Microsoft. Несмотря на это, он остается жизнеспособным и ценным инструментом для анализа не только файлов журнала веб-сервера, но и всех типов структурированных текстовых данных.
В этом посте вместо того, чтобы объяснять, как использовать Log Parser. Приведу несколько примеров его использования. Кроме того, я задокументирую несколько полезных мест в Интернете, где можно найти информацию о Log Parser.
Примеры
Имейте в виду, что большинство примеров, которые я привожу здесь, представляют собой запросы командной строки «все-в-одном» (хотя многие из них переносятся на несколько строк при отображении здесь). Однако запросы также могут выполняться как
.файл синтаксического анализатора: XXXXX.sql
, где XXXXX — это имя файла, содержащего SQL-запрос, удобный для разбора журнала. В следующем списке есть несколько примеров этого.
Приведенные здесь примеры были получены из различных источников, включая документацию, поставляемую с инструментом, блоги и онлайн-документацию, а также мой собственный опыт. К сожалению, у меня нет записей о происхождении каждого отдельного примера, так как я собирал их по частям в течение последних двух или трех лет.
Я надеюсь, что вы найдете здесь что-то полезное и оцените надежность этого инструмента.
1) Все страницы с заданным IP-адресом
logparser «выбрать cs-uri-stem, count(cs-uri-stem) as requestcount из [LogFileName], где c-ip = ‘000.00.00.000’ группировать по cs-uri-stem в порядке количества (cs-uri-stem ) десц»
2) Заходы на определенную страницу по IP-адресу
logparser «выберите c-ip, count(c-ip) as requestcount из [LogFileName], где cs-uri-stem, например ‘/search.aspx%’, группирует по c-ip порядку по количеству (c-ip) desc»
3) Пример ReverseDNS. Это попытка найти домен, связанный с данным IP-адресом.
logparser «выбрать c-ip, REVERSEDNS(c-ip) из [LogFileName], где c-ip = ‘000.00.00.000’ группировать по c-ip»
4) пример CSV. Все обращения к странице записываются в файл CVS.
logparser «выберите * в OUTPUT.CSV из [LogFileName], где cs-uri-stem, например ‘/pagename.aspx’»
5) Пример диаграммы. Все посещения страницы по IP-адресу, отображаемые на графике.
logparser «выберите c-ip, count(c-ip) как requestcount в logparserchart.gif из [LogFileName], где cs-uri-stem, например ‘/pagename.aspx’, группирует по c-ip в порядке количества (c-ip) описание» -o:диаграмма
6) Число обращений в час с определенного IP-адреса
logparser «выберите TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(дата, время), 3600)), count(*) как numberrequests из [LogFileName], где c-ip=’000.000.00.000′ группа по TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(дата,время) ), 3600))»
7) Основной список IP-адресов, генерирующих трафик
logparser «выберите c-ip, count(c-ip) as requestcount из группы [LogFileName] по порядку c-ip по количеству (c-ip) desc»
8) Основной список посещаемых страниц
logparser «выберите cs-uri-stem, count(cs-uri-stem) from [LogFileName], где cs-uri-stem, например «%aspx%», или cs-uri-stem, например, «%ashx%», сгруппируйте по cs- uri-stem порядок по количеству (cs-uri-stem) desc»
9) Основной список посещаемых страниц, включая IP-адреса, с которых происходит обращение
logparser «выберите cs-uri-stem, c-ip, count(cs-uri-stem) из [LogFileName], где cs-uri-stem, например ‘%aspx%’, или cs-uri-stem, например ‘%ashx%’ группировать по cs-uri-stem, c-ip упорядочивать по количеству (cs-uri-stem) desc»
10) Страницы, открываемые после определенной даты и времени
logparser «выберите cs-uri-stem, c-ip, count(cs-uri-stem) из [LogFileName], где cs-uri-stem, например ‘%aspx%’, или cs-uri-stem, например ‘%ashx%’ и date=’2009-06-04′ и время > ’15:00:00′ группируются по cs-uri-stem, порядок c-ip по количеству (cs-uri-stem) desc»
11) Количество посещений страниц ASPX/ASHX по часам с определенного IP-адреса
logparser «выберите TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(date, time), 3600)), count(*) as numberrequests from [LogFileName], где c-ip=’000.
 000.00.00′ и (cs-uri-stem как ‘%aspx %’ или cs-uri-stem как ‘%ashx%’) группа по TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(date,time), 3600))»
000.00.00′ и (cs-uri-stem как ‘%aspx %’ или cs-uri-stem как ‘%ashx%’) группа по TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(date,time), 3600))»12) Количество посещений определенных страниц в час с определенного IP-адреса
logparser «выбрать TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(дата, время), 3600)), cs-uri-stem, count(*) as numberrequests из [LogFileName], где c-ip=’000.000.00.00′ и (cs-uri -stem как ‘%aspx%’ или cs-uri-stem как ‘%ashx%’) группируется по TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(дата,время), 3600)), порядок cs-uri-stem по номеру запросов desc»
13) Популярные браузеры
logparser «Выбрать 50 лучших to_int(mul(100.0,PropCount(*))) как Percent, count(*) как TotalHits, cs(User-Agent) как Browser из группы [LogFileName] по порядку браузера по описанию Totalhits»
14) Почасовая пропускная способность (диаграмма)
logparser «Выберите TO_LOCALTIME(QUANTIZE(TO_TIMESTAMP(дата, время), 3600)) Как час, Div(Сумма(cs-bytes),1024) Как Входящий(K), Div(Сумма(sc-bytes),1024) Как Исходящие (K) в BandwidthByHour.
 gif из группы [LogFileName] по часам»
gif из группы [LogFileName] по часам»15) Запросы по URI
logparser «ВЫБРАТЬ первые 80 QUANTIZE(TO_TIMESTAMP(дата, время), 3600) как час, TO_LOWERCASE(STRCAT(‘/’,EXTRACT_TOKEN(cs-uri-stem,1,’/’))) как URI, COUNT(* ) AS RequestsPerHour, SUM(sc-bytes) AS TotBytesSent, AVG(sc-bytes) AS AvgBytesSent, Max(sc-bytes) AS MaxBytesSent, ADD(1,DIV(Avg(затраченное время),1000)) AS AvgTime, ADD(1,DIV(MAX(time-taken),1000)) AS MaxTime FROM [LogFileName] GROUP BY Hour, URI Имея RequestsPerHour > 10 ORDER BY RequestsPerHour ASC»
16) 10 лучших изображений по размеру
logparser «Выбрать первые 10 StrCat(Extract_Path(TO_Lowercase(cs-uri-stem)),’/’) AS RequestedPath, Extract_filename(To_Lowercase(cs-uri-stem)) As RequestedFile, Count(*) AS Hits, Max( затраченное время) Как MaxTime, Среднее (затраченное время) Как AvgTime, Max(sc-bytes) Как BytesSent From [LogFileName] Где (Extract_Extension(To_Lowercase(cs-uri-stem)) IN (‘gif’;’jpg’ ;’png’)) И (sc-status = 200) Группировать по To_Lowercase(cs-uri-stem) Порядок BytesSent, Hits, MaxTime DESC»
17) 10 самых популярных URL-адресов веб-сайта с указанием общего числа посещений, максимального и среднего времени обслуживания
logparser «Выберите TOP 10 STRCAT (EXTRACT_PATH (cs-uri-stem), ‘/’) AS RequestPath, EXTRACT_FILENAME (cs-uri-stem) AS RequestedFile, COUNT (*) AS TotalHits, Max (затраченное время) AS MaxTime , AVG(time-taken) AS AvgTime, AVG(sc-bytes) AS AvgBytesSent FROM [LogFileName] GROUP BY cs-uri-stem ORDER BY TotalHits DESC»
18) 20 лучших клиентов
logparser «Выберите 20 лучших клиентов c-ip AS, подсчитайте (*) AS Hits INTO Chart.
 gif FROM [LogFileName] GROUP BY c-ip ORDER BY Hits Desc»
gif FROM [LogFileName] GROUP BY c-ip ORDER BY Hits Desc»19) Неработающие ссылки реферера (т. е. внешние ссылки на неработающие ссылки на вашем сайте)
logparser «ВЫБЕРИТЕ РАЗЛИЧНЫЕ cs(Referer) в качестве Referer, cs-uri-stem as Url INTO ReferBrokenLinks.html FROM [LogFileName] WHERE cs(Referer) НЕ NULL AND sc-status = 404 AND (sc-substatus IS NULL OR sc -substatus=0)» -tpl:ReferBrokenLinks.tpl
20) Коды состояния
logparser «ВЫБРАТЬ sc-status как статус, COUNT (*) как число INTO StatusCodes.gif FROM <2> GROUP BY Status ORDER BY Status»
21) Найдите в журнале событий записи журнала W3SVC (IIS) и обозначьте цветом ошибки, предупреждения, информацию. В этом примере выходные данные запроса записываются в файл HTML, созданный с использованием файла шаблона.
logparser «ВЫБЕРИТЕ TimeGenerated,EventTypeName,Strings,Message,CASE EventTypeName КОГДА ‘Событие ошибки’ ТО ‘КРАСНЫЙ’ КОГДА ‘Событие предупреждения’ ТО ‘ЖЕЛТЫЙ’ КОГДА ‘Информационное событие’ ТО ‘БЕЛЫЙ’ ИНАЧЕ ‘СИНИЙ’ КОНЕЦ Цвет В файл .
 html FROM System WHERE SourceName = ‘W3SVC'» -tpl:IISEventLogEntries.tpl
html FROM System WHERE SourceName = ‘W3SVC'» -tpl:IISEventLogEntries.tplГде IISEventLogEntries.tpl — это файл, содержащий следующее:
Новые сообщения W3SVC в журнале системных событий
Время генерации
Тип события
Строки
< TH ALIGN=LEFT BGCOLOR="#C0C0C0">Сообщение
%TimeGenerated%
%EventTypeName%
%Strings%
%Message%
22) Отправка результатов запроса Log Parser непосредственно в таблицу в SQL Server 9. 0017
0017
logparser «выберите * в LogTable из [LogFileName], где cs-uri-stem, например ‘/folder/filename%'» -o:SQL -createTable:ON -server:[DatabaseServer] -database:[Database] -username:[ SqlUser]-пароль: [SqlPassword]
23) Отправлены первые 10 изображений по размеру. Обратите внимание, что в этом примере также показано, как одновременно запрашивать несколько файлов журналов.
logparser «Выбрать первые 10 StrCat(Extract_Path(TO_Lowercase(cs-uri-stem)),’/’) AS RequestedPath, Extract_filename(To_Lowercase(cs-uri-stem)) As RequestedFile, Count(*) AS Hits, Max( затраченное время) Как MaxTime, Среднее (затраченное время) Как AvgTime, Макс. IN (‘gif’;’jpg’;’png’)) И (sc-status = 200) ГРУППИРОВАТЬ ПО To_Lowercase(cs-uri-stem) ORDER BY BytesSent, Hits, MaxTime DESC»
24) Типы браузеров (два разных подхода)
logparser «ВЫБЕРИТЕ отдельные cs (User-Agent), подсчитайте (*) как совпадения INTO useragentsalltypes.
 txt FROM logs\iis\ex*.log GROUP BY cs (user-agent) ORDER BY hits DESC»
txt FROM logs\iis\ex*.log GROUP BY cs (user-agent) ORDER BY hits DESC»logparser «ВЫБРАТЬ TO_INT(MUL(100.0,PROPCOUNT(*)) AS Percent, COUNT(*) AS Hits, cs(User-Agent) as Browser INTO UseragentsHits.txt FROM logs\iis\ex*.log ГРУППИРОВАТЬ ПО браузеру ЗАКАЗАТЬ ПО ОБЪЯВЛЕНИЮ DESC»
25) Уникальных посетителей в день. Для этого нужно два запроса. Первый запрос выбирает из журналов IIS файл CSV, а второй выбирает из этого файла CSV.
logparser «ВЫБЕРИТЕ РАЗЛИЧНЫЕ cs-username, date INTO tempUniqueVisitorsPerDay.csv FROM logs\iis\ex*.log WHERE cs-username <> NULL Group By Date, cs-username»
logparser «ВЫБЕРИТЕ дату, количество (cs-username) как UniqueVisitors в test.txt ИЗ tempUniqueVisitorsPerDay.csv СГРУППИРОВАТЬ ПО дате»
26) 10 самых больших ASPX-страниц.
logparser «Выбрать первые 10 StrCat(Extract_Path(TO_Lowercase(cs-uri-stem)),’/’) AS RequestedPath, Extract_filename(To_Lowercase(cs-uri-stem)) As RequestedFile, Count(*) AS Hits, Max( затраченное время) Как MaxTime, Среднее (затраченное время) Как AvgTime, Max(sc-bytes) Как BytesSent INTO top10pagesbysize.
 txt FROM logs\iis\ex*.log WHERE (Extract_Extension(To_Lowercase(cs-uri-stem)) IN (‘aspx’)) И (sc-status = 200) ГРУППИРОВАТЬ ПО To_Lowercase(cs-uri-stem) ORDER BY BytesSent, Hits, MaxTime DESC»
txt FROM logs\iis\ex*.log WHERE (Extract_Extension(To_Lowercase(cs-uri-stem)) IN (‘aspx’)) И (sc-status = 200) ГРУППИРОВАТЬ ПО To_Lowercase(cs-uri-stem) ORDER BY BytesSent, Hits, MaxTime DESC»27) 10 самых медленных страниц ASPX
logparser «ВЫБЕРИТЕ ТОП 10 cs-uri-stem, максимальное (затраченное время) как MaxTime, среднее (затраченное время) как AvgTime INTO toptimetaken.txt FROM logs\iis\ex*.log ГДЕ Extract_extension(to_lowercase(cs-uri) -stem)) = ‘aspx’ GROUP BY cs-uri-stem ORDER BY MaxTime DESC»
28) 10 самых медленных страниц ASPX в определенный день
logparser «ВЫБЕРИТЕ ТОП 10 cs-uri-stem, максимальное (затраченное время) как MaxTime, среднее (затраченное время) как AvgTime INTO toptimetaken.txt FROM logs\iis\ex*.log ГДЕ Extract_extension(to_lowercase(cs-uri) -stem)) = ‘aspx’ И TO_STRING(To_timestamp(дата, время), ‘MMdd’)=’1003′ ГРУППИРОВАТЬ ПО cs-uri-stem ORDER BY MaxTime DESC»
29) Дневная пропускная способность
logparser «Выберите To_String (To_timestamp (дата, время), ‘MM-dd’) как Day, Div (Sum (cs-bytes), 1024) как Incoming (K), Div (Sum (sc-bytes), 1024) As Outgoing(K) Into BandwidthByDay.
30) Пропускная способность по часам
logparser «ВЫБЕРИТЕ QUANTIZE (TO_TIMESTAMP (дата, время), 3600) AS Hour, SUM (sc-bytes) AS TotalBytesSent INTO BytesSentPerHour.gif FROM logs\iis\ex*.log СГРУППИРОВАТЬ ПО ЧАСАМ ПОРЯДОК ПО ЧАСАМ»
31) Среднее время загрузки страницы на пользователя
logparser «Выберите 20 лучших cs-username AS UserName, AVG (time-taken) AS AvgTime, Count (*) AS Hits INTO AvgTimePerUser.txt FROM logs\iis\ex*.log, ГДЕ cs-username НЕ NULL GROUP BY cs -username ORDER BY AvgTime DESC»
32) Среднее время загрузки страницы для конкретного пользователя
logparser «Выберите cs-username AS UserName, AVG (time-taken) AS AvgTime, Count (*) AS Hits INTO AvgTimeOnSpecificUser.txt FROM logs\iis\ex*.log ГДЕ cs-username = ‘CONTOSO\User1234’ GROUP BY cs-имя пользователя»
33) Тенденции ошибок. Этот запрос довольно длинный, и его легче выразить в текстовом файле, чем в командной строке. Итак, Log Parser читает и выполняет запрос, содержащийся в указанном текстовом файле.
Этот запрос довольно длинный, и его легче выразить в текстовом файле, чем в командной строке. Итак, Log Parser читает и выполняет запрос, содержащийся в указанном текстовом файле.
файл logparser: errortrend.sql
Где errortrend.sql содержит следующее:
ВЫБРАТЬ
TO_STRING(To_timestamp(дата, время), ‘ММдд’) КАК День,
СУММ(c200) КАК 200с,
СУММ(c206) КАК 206с,
СУММ(c301) AS 301s,
СУММ(c302) AS 302s,
СУММ(c304) AS 304s,
СУММ(c400) AS 400s,
СУММ(c401) AS 401s,
3 SUM(c0 4 4 3 SUM(c0 4 4 3) ASUM (c404) AS 404s,
SUM(c500) AS 500s,
SUM(c501) AS 501s,
SUM(c502) AS 502s,
SUM(c503) AS 503s,
) AS 505s
USING
CASE sc-status WHEN 200 THEN 1 ELSE 0 END AS c200,
CASE sc-status WHEN 206 THEN 1 ELSE 0 END AS c206,
CASE sc-статус WHEN 301 THEN 1 Else 0 END AS c301,
CASE sc-статус WHEN 302 THEN 1 ELSE 0 END AS c302,
CASE sc-статус WHEN 304 THEN 1 ELS 0 END AS c304,
CASE sc-статус WHEN 400 THEN 1 ELS 0 END AS c400,
CASE sc-статус WHEN 401 THEN 1 ELS 0 END AS c401,
CASE sc-статус WHEN 403 THEN 1 ELSE 0 END AS c403,
CASE sc-status WHEN 404 THEN 1 ELSE 0 END AS c404,
CASE sc-статус WHEN 500 THEN 1 ELSE 0 END AS c500,
CASE sc-статус WHEN 501 THEN 1 ELS 0 END AS c501,
CASE sc-status WHEN 502 THEN 1 ELSE 0 END AS c502,
CASE sc-статус WHEN 503 THEN 1 ELSE 0 END AS c503,
CASE sc-status WHEN 504 THEN 1 ELSE 0 END AS c504,
CASE sc-status WHEN 505 THEN 1 ELSE 0 END AS c505
INTO ErrorChart.
\iis
\ex*.log
ГРУППА ПО
День
ЗАКАЗ
День
 gif
gif 34) Ошибки Win32
logparser «ВЫБРАТЬ sc-win32-status как ErrorNumber, WIN32_ERROR_DESCRIPTION(sc-win32-status) как ErrorDesc, Count(*) AS Total INTO Win32ErrorNumbers.txt FROM logs\iis\ex*.log ГДЕ sc-win32-status>0 GROUP BY ErrorNumber ORDER BY Total DESC»
35) Коды подстатуса
logparser «ВЫБЕРИТЕ sc-status, sc-substatus, Count(*) AS Total INTO 401subcodes.txt FROM logs\iis\ex*.log WHERE sc-status=401 GROUP BY sc-status, sc-substatus ORDER BY sc- статус, sc-подстатус DESC»
36) Коды подстатуса в день. Это еще один пример выполнения запроса, содержащегося в текстовом файле.
файл logparser: substatusperday.sql
Где substatusperday.sql содержит следующее:
SELECT
TO_STRING(To_timestamp(date, time), ‘MMdd’) AS Day,
SUM(c1) AS 4011,
SUM(c2) AS 4012,
SUM(c3) AS 4013,
SUM(c4) AS 4014 ,
СУММ(с5) КАК 4015,
SUM(c7) AS 4017
USING
CASE sc-подстатус WHEN 1 THEN 1 ELSE 0 END AS c1,
CASE sc-подстатус WHEN 2 THEN 1 ELSE 0 END AS c2,
CASE sc-подстатус WHEN 3 THEN 1 ELSE 0 END AS c3,
CASE sc-подстатус WHEN 4 THEN 1 ELSE 0 END AS c4,
CASE sc-подстатус WHEN 5 THEN 1 ELSE 0 END AS c5,
CASE sc-подстатус WHEN 7 THEN 1 ELSE 0 END AS c7
INTO
401subcodesperday.
ИЗ
logs\iis\ex*.log
ГДЕ
sc-status=401
ГРУППИРОВАТЬ ПО
День
ORDER BY
День
 txt
txt 37) Коды подстатуса на странице
logparser «ВЫБЕРИТЕ ТОП 20 cs-uri-stem, sc-status, sc-substatus, Count(*) AS Total INTO 401Pagedetails.txt FROM logs\iis\ex*.log ГДЕ sc-status=401 СГРУППИРОВАТЬ ПО cs-uri -стебель, sc-статус, sc-подстатус ORDER BY Total»
38) МБ отправлено на код состояния HTTP
logparser «ВЫБЕРИТЕ EXTRACT_EXTENSION (cs-uri-stem) AS PageType, SUM (sc-bytes) как TotalBytesSent, TO_INT (MUL (PROPSUM (sc-bytes), 100,0)) AS PercentBytes INTO PagesWithLargestBytesSent.htm FROM logs\iis\ex *.log СГРУППИРОВАТЬ ПО типу страницы ORDER BY PercentBytes DESC»
39) 500 ошибок на пользователя ASPX и домена
logparser «ВЫБЕРИТЕ cs-username, cs-uri-stem, count(*) as Times INTO 500PagesByUserAndPage.txt FROM logs\iis\ex*.
 log WHERE sc-status=500 GROUP BY cs-username, cs-uri-stem ЗАКАЗАТЬ ПО ВРЕМЕНИ DESC»
log WHERE sc-status=500 GROUP BY cs-username, cs-uri-stem ЗАКАЗАТЬ ПО ВРЕМЕНИ DESC»40) Процент из 500 ошибок, вызванных каждым пользователем
logparser «ВЫБЕРИТЕ cs-username, count(*) as Times, propcount(*) as Percent INTO 500ErrorsByUser.csv FROM logs\iis\ex*.log WHERE sc-status=500 GROUP BY cs-username ORDER BY Times DESC»
41) Определите, какой процент от общего числа отправленных байт приходится на каждый тип страницы
logparser «ВЫБЕРИТЕ EXTRACT_EXTENSION (cs-uri-stem) AS PageType, SUM (sc-bytes) as TotalBytesSent, TO_INT (MUL (PROPSUM (sc-bytes), 100,0)) AS PercentBytes INTO PagesWithLargestBytesSent.txt FROM logs\iis\ex *.log СГРУППИРОВАТЬ ПО типу страницы ORDER BY PercentBytes DESC»
42) 20 первых страниц с определенным кодом возврата HTTP
logparser «ВЫБЕРИТЕ ТОП 20 cs-uri-stem, sc-status, Count(*) AS Total INTO TOP20PagesWith501.txt FROM logs\iis\ex*.
 log WHERE TO_LOWERCASE(cs-uri-stem) LIKE ‘%.aspx’ и sc-status=401 GROUP BY cs-uri-stem, sc-status ORDER BY Total, cs-uri-stem, sc-status DESC»
log WHERE TO_LOWERCASE(cs-uri-stem) LIKE ‘%.aspx’ и sc-status=401 GROUP BY cs-uri-stem, sc-status ORDER BY Total, cs-uri-stem, sc-status DESC»43) Проверить трафик с IP-адресов
logparser «Выберите c-ip AS Client, Div (Sum (cs-bytes), 1024) как IncomingBytes (K), Div (Sum (sc-bytes), 1024) как OutgoingBytes (K), MAX (затраченное время) как MaxTime, AVG(time-taken) как AvgTime, count(*) как совпадения INTO errorsperip.txt FROM logs\iis\ex*.log GROUP BY client ORDER BY Hits DESC»
44) Проверка ошибок по IP-адресу
файл logparser: errorbyip.sql
Где errorbyip.sql содержит следующее:
Выберите
c-ip AS Client,
SUM(c400) AS 400,
sum(c401) AS 401,
SUM(c403) AS 403,
SUM(c404) AS 404,
9048, AS 5008 SUM(c501) AS 501s,
SUM(c502) AS 502s,
SUM(c503) AS 503s,
SUM(c504) AS 504s,
SUM(c505) AS 505s
USING
CASE sc-status WHEN 400 THEN 1 ELSE 0 END AS c400,
CASE sc-status WHEN 401 THEn sc 1 ELSE 9 CASE 0 END AS c401 -status WHEN 403 THEN 1 ELSE 0 END AS c403,
CASE sc-status WHEN 404 THEN 1 ELSE 0 END AS c404,
CASE sc-status WHEN 500 THEN 1 ELSE 0 END AS c500,
CASE sc-status WHEN 501 THEN 1 ELSE 0 END AS c501,
CASE sc-status WHEN 502 THEN 1 ELSE 0 END AS c502,
CASE sc-status WHEN 503 THEN 1 ELSE 0 END AS c503,
CASE sc-status WHEN 504 THEN 1 ELSE 0 END AS c504,
CASE sc-статус WHEN 505 THEN 1 ELSE 0 END AS c505
INTO
FROM
logs\iis\ex*.
WHERE
c-ip=’‘
GROUP BY
client
 log
log 45) Поиск неработающих ссылок
logparser «ВЫБЕРИТЕ РАЗЛИЧНЫЕ cs(Referer) как Referer, cs-uri-stem как Url INTO ReferBrokenLinks.txt FROM logs\iis\ex*.log, ГДЕ cs(Referer) НЕ НУЛЕВОЕ И sc-status=404 AND (sc- подстатус IS NULL ИЛИ sc-substatus=0)»
46) 10 страниц с наибольшим количеством посещений
logparser «Выберите TOP 10 STRCAT (EXTRACT_PATH (cs-uri-stem), ‘/’) AS RequestPath, EXTRACT_FILENAME (cs-uri-stem) AS RequestedFile, COUNT (*) AS TotalHits, Max (затраченное время) AS MaxTime , AVG(занято) AS AvgTime, AVG(sc-bytes) AS AvgBytesSent INTO Top10Urls.txt FROM logs\iis\ex*.log ГРУППИРОВАТЬ ПО cs-uri-stem ORDER BY TotalHits DESC»
47) Уникальные пользователи для каждого типа браузера (требуется два запроса)
logparser «ВЫБЕРИТЕ РАЗЛИЧНЫЕ cs-username, cs(user-agent) INTO UserAgentsUniqueUsers1.
 csv FROM logs\iis\ex*.log WHERE cs-username <> NULL GROUP BY cs-username, cs(user-agent)»
csv FROM logs\iis\ex*.log WHERE cs-username <> NULL GROUP BY cs-username, cs(user-agent)»logparser «ВЫБЕРИТЕ cs (агент пользователя), count (имя пользователя cs) as UniqueUsersPerAgent, TO_INT (MUL (PROPCOUNT (*), 100)) AS Percentage INTO UniqueUsersPerAgent.txt FROM UserAgentsUniqueUsers1.csv СГРУППИРОВАТЬ ПО cs (агент пользователя) ЗАКАЗАТЬ ПО UniqueUsersPerAgent DESC»
48) Количество отправленных байтов на расширение файла
logparser «ВЫБЕРИТЕ EXTRACT_EXTENSION(cs-uri-stem) AS Extension, MUL(PROPSUM(sc-bytes),100.0) AS PercentageOfBytes, Div(Sum(sc-bytes),1024) as AmountOfMbBytes INTO BytesPerExtension.txt FROM logs\iis \ex*.log GROUP BY Extension ORDER BY PercentageOfBytes DESC»
49) Домены, направляющие трафик на ваш сайт
logparser «ВЫБЕРИТЕ EXTRACT_TOKEN (cs (Referer), 2, ‘/’) AS Domain, COUNT (*) AS [Requests] INTO ReferringDomains.txt FROM logs\iis\ex*.
 log СГРУППИРОВАТЬ ПО ДОМЕНУ ORDER BY Requests DESC»
log СГРУППИРОВАТЬ ПО ДОМЕНУ ORDER BY Requests DESC»50) Типы ОС (требуется два запроса)
logparser «ВЫБЕРИТЕ РАЗЛИЧНЫЕ c-ip, cs(user-agent) INTO UserAgentsUniqueUsers.csv FROM logs\iis\ex*.log, ГДЕ c-ip <> NULL GROUP BY c-ip, cs(user-agent)»
файл logparser:getos.sql
Где getos.sql содержит следующее:
ВЫБЕРИТЕ
СУММ (c70) КАК Win7,
СУММ (c60) КАК Vista,
СУММ (c52) КАК Win2003,
СУММ (c51) КАК WinXP,
СУММ (C50) КАК Win2000,
СУММ (W98) КАК Win9
SUM (W95) AS Win95,
SUM (W9x) AS Win9x,
SUM (NT4) AS WinNT4,
SUM (OSX) AS OS-X,
SUM (Mac) AS Mac-,
SUM (PPC) AS Mac-PPC,
SUM (Lnx) AS Linux
USING
CASE strcnt(cs(User-Agent),’Windows+NT+6.1′) WHEN 1 THEN 1 ELSE 0 END AS C70,
CASE strcnt(cs(User-Agent),’Windows+NT+6.0′) WHEN 1 THEN 1 ELSE 0 END AS C60,
CASE strcnt(cs(User-Agent),’Windows+ NT+5.
CASE strcnt(cs(User-Agent),’Windows+NT+5.1′) WHEN 1 THEN 1 ELSE 0 END AS C51,
CASE strcnt(cs(User-Agent),’Windows+NT+5.0′) WHEN 1 THEN 1 ELSE 0 END AS C50,
CASE strcnt(cs(User-Agent),’Win98′) WHEN 1 THEN 1 ELSE 0 END AS W98,
CASE strcnt(cs(User-Agent),’Win95′) WHEN 1 THEN 1 ELSE 0 END AS W95,
CASE strcnt(cs(User-Agent),’Win+9x+4.90′) WHEN 1 THEN 1 ELSE 0 END AS W9x,
CASE strcnt(cs(User-Agent),’Winnt4.0′) WHEN 1 THEN 1 ELSE 0 END AS NT4,
CASE strcnt(cs(User-Agent),’OS+X ‘) WHEN 1 THEN 1 ELSE 0 END ASX,
CASE strcnt(cs(User-Agent),’Mac’) WHEN 1 THEN 1 ELSE 0 END AS Mac,
CASE strcnt(cs(User-Agent),’PPC’) WHEN 1 THEN 1 ELSE 0 END AS PPC,
CASE strcnt(cs(User-Agent),’Linux’) WHEN 1 THEN 1 ELSE 0 END AS Lnx
INTO
GetOSUsed.txt
FROM
UserAgentsUniqueUsers.csv
 2′) WHEN 1 THEN 1 ELSE 0 END AS C52,
2′) WHEN 1 THEN 1 ELSE 0 END AS C52, 51) Получить ошибки тайм-аута из журнала событий сервера. Отображение результатов в таблице данных.
logparser «выберите * из \\имя_сервера\приложение, где сообщение типа «%timeout expired%» -i:EVT -o:datagrid
52) Получить исключения из журнала событий (приложений) сервера
logparser «выберите timegenerated, eventtypename, eventcategoryname, сообщение в webserverlog.csv из \\servername\application, где сообщение типа «%myapplication%exception%»» -i:EVT
Ссылки
Перейдите по приведенным ниже ссылкам, чтобы найти более подробное обсуждение Log Parser, а также еще больше примеров его использования.
- Посетите форумы Log Parser на официальном сайте Microsoft IIS (несмотря на возраст инструмента, эти форумы по-прежнему посещаются)
- Приобретите Microsoft Log Parser Toolkit на Amazon.com (также доступна версия для Kindle)
- Использовать Microsoft Logparser для анализа журналов IIS — статья Log Parser в блоге под названием «Linux Lore»? Странно, но тем не менее это отличная справочная статья.