морфемный разбор — Как правильно разобрать по составу слово «соловей»?
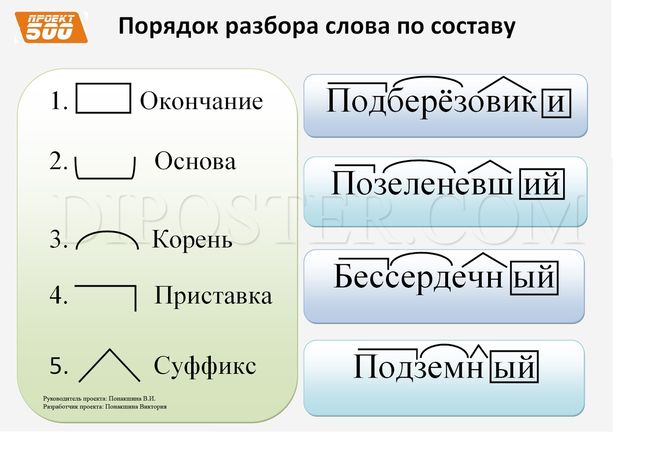
Как правильно разобрать по составу слово «соловей»?
1) Я бы сделала разбор таким:
соловей — изменяемое существительное (кого? соловь-я, кому? соловь-ю), соответственно – ей – окончание;
-солов- выделила бы корнем (и основой), т.к. однокоренное слово -солов ушка.
2) Но есть и другие варианты разбора слова по составу:
а) Панов и Текучев считают, что окончание у данного слова нулевое.
Корнем слова является — «солов-«.
Суффикс у слова — «-ей-«.
Основа слова — «соловей».
б) У Тихонова соловей — корень,
нет суффикса,
нулевое окончание,
соловей — основа слова.
Или (для начальной школы) допустимы все три варианта? Ученик разобрал как в первом варианте, учитель исправил как в 2(б)
- морфемный-разбор
1
Единственного «правильного» пути нет. Ваш вариант (1) хоть и не вполне корректен, но может иметь место в тетради ученика начальной школы, и ужасно, если учитель, ничего не объяснив, снижает за это оценку.
Комментарии
-ей- считается суффиксом, ср.: грамота — грамот-ей-0, ворожа — ворож-ей-0 и т. п., в словах воробей, соловей выделяется он же (этимологически были основы, от которых с помощью суффикса -ий, перешедшего впоследствии в -ей, и образовались названия птиц). Окончание нулевое. В косвенных падежах от суффикса -ей остается лишь йот, который прячется в окончании (вернее, в буквах, которые обозначают йотированные звуки): солов-j-а, солов-j-ами и т. д.
а) см. выше.
б) Тихонов, видимо, считает, что на синхронном уровне исторический суффикс -ей (-ий), выделять не следует.
5
Зарегистрируйтесь или войдите
Регистрация через GoogleРегистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Страница не найдена
wordmap
Данная страница не найдена или была удалена.
Только что искали:
термос 1 секунда назад
до состояния эмульсии 1 секунда назад
благословению 1 секунда назад
замшейте 1 секунда назад
оппортунистам 1 секунда назад
пахтальщице 3 секунды назад
тпоиахнр 4 секунды назад
ареначчпя 6 секунд назад
по вознесении господа 7 секунд назад
жертва продольной пилы 8 секунд назад
дисрнкте 9 секунд назад
в районе паха 9 секунд назад
рбтоаек 14 секунд назад
глацииап 15 секунд назад
хоровом 16 секунд назад
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Откуда | |
|---|---|---|---|---|
| Игрок 1 | отгребальщик | 150 слов | 95.29.162.251 | |
| Игрок 2 | отгребальщик | 105 слов | 91. 132.23.36 132.23.36 |
|
| Игрок 3 | бесцеремонность | 70 слов | 95.29.162.251 | |
| Игрок 4 | передача | 19 слов | 95.29.162.251 | |
| Игрок 5 | изафет | 7 слов | 87.167.30.38 | |
| Игрок 6 | слон | 0 слов | 85.249.22.7 | |
| Чукча | бесцеремонность | 17 слов | 176.59.111.116 | |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | кивок | 9:12 | 178.35.16.46 | |
| Игрок 2 | аплит | 46:53 | 176.59. 170.202 170.202 |
|
| Игрок 3 | сотня | 49:49 | 178.35.16.46 | |
| Игрок 4 | топор | 41:50 | 188.0.169.200 | |
| Игрок 5 | налипание | 209:210 | 194.85.193.56 | |
| Игрок 6 | обрат | 55:53 | 89.113.143.52 | |
| Игрок 7 | фалда | 0:0 | 89.113.143.52 | |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| О | На одного | 5 вопросов | 176.59.199.162 | |
| Лелкк | На одного | 10 вопросов | 176.59.199.162 | |
| Ева | На одного | 10 вопросов | 176. 59.104.31 59.104.31 |
|
| Максим | На одного | 10 вопросов | 46.160.248.62 | |
| Akki | На одного | 10 вопросов | 94.158.173.2 | |
| Лол | На одного | 5 вопросов | 89.0.251.114 | |
| Каролина | На одного | 20 вопросов | 85.249.169.75 | |
| Играть в Чепуху! | ||||
Word2Vec для фраз — изучение встраивания более чем одного слова | Моше Хазум
Фото Александры на UnsplashКогда дело доходит до семантики, мы все знаем и любим знаменитый алгоритм Word2Vec [1] для создания вложений слов с помощью распределенных семантических представлений во многих приложениях НЛП, таких как NER, семантический анализ, классификация текста и многое другое.
Однако ограничением текущей реализации алгоритма Word2Vec является естественное поведение униграмм . В Word2Vec мы пытаемся предсказать данное слово на основе его контекста (CBOW) или предсказать окружающий контекст на основе данного слова (Skip-Gram). Но что, если мы хотим использовать термин «American Airlines» целиком? В этом посте я объясню, как создавать вложения для более чем униграмм, используя неконтролируемый текстовый корпус. Если вы знакомы с алгоритмом Word2Vec и встраиванием слов, вы можете пропустить первую часть этого поста.
В Word2Vec мы пытаемся предсказать данное слово на основе его контекста (CBOW) или предсказать окружающий контекст на основе данного слова (Skip-Gram). Но что, если мы хотим использовать термин «American Airlines» целиком? В этом посте я объясню, как создавать вложения для более чем униграмм, используя неконтролируемый текстовый корпус. Если вы знакомы с алгоритмом Word2Vec и встраиванием слов, вы можете пропустить первую часть этого поста.
В частности, мы рассмотрим:
- Введение в представление слов в задачах НЛП.
- Гипотеза распределения [2] и алгоритм Word2Vec.
- Изучение фраз из текста без присмотра.
- Как извлечь фразы, похожие на заданную фразу.
Компания Amenity Analytics, в которой я сейчас работаю, создает продукты Text Analytics, уделяя особое внимание области финансов. Это помогает предприятиям получать полезную информацию в огромных масштабах. Недавно мы выпустили новую поисковую систему на основе Elastic Search, чтобы помочь нашим клиентам получить более точное и целенаправленное представление своих данных. Изучив запросы пользователей в поисковой системе, мы заметили, что многие клиенты ищут финансовые термины, а наивного выполнения полнотекстового поиска по запросу недостаточно. Например, один термин, который много раз встречался в поисковых запросах пользователей, — это «точка перегиба».
Изучив запросы пользователей в поисковой системе, мы заметили, что многие клиенты ищут финансовые термины, а наивного выполнения полнотекстового поиска по запросу недостаточно. Например, один термин, который много раз встречался в поисковых запросах пользователей, — это «точка перегиба».
Найдите определение «точки перегиба» в Investopedia:
«Точка перегиба — это событие, которое приводит к значительным изменениям в развитии компании, отрасли, сектора, экономики или геополитической ситуации и может считаться поворотным точка, после которой ожидается резкое изменение с положительными или отрицательными результатами»
Наши клиенты хотят видеть важные события в компаниях, за которыми они следят, поэтому нам нужно искать больше терминов с тем же значением, что и « Точка перегиба», например «Поворотный момент», «Переломный момент» и т. д.
Представление слов
Наиболее гранулированными объектами языка являются символы, из которых формируются слова или токены. Слова (и символы) дискретны и символичны. Невозможно сказать, что «лабрадор» и «собака» каким-то образом связаны друг с другом, просто взглянув на слова как есть или взглянув на характеры, которые их составляют.
Слова (и символы) дискретны и символичны. Невозможно сказать, что «лабрадор» и «собака» каким-то образом связаны друг с другом, просто взглянув на слова как есть или взглянув на характеры, которые их составляют.
Мешок слов (BOW)
Наиболее распространенным методом извлечения признаков для задач НЛП является метод набора слов (BOW). В пакете слов мы смотрим на гистограмму вхождений слов в данном корпусе без учета порядка. Часто мы ищем не только одно слово, но и биграммы («хочу»), триграммы («хочу») или n-граммы в общем случае. Это распространенный подход к нормализации счетчиков для каждого слова, потому что документы могут различаться по длине (в большинстве случаев).
Нормализованный ЛУК.Один из основных недостатков представления BOW заключается в том, что оно дискретно и не может отражать семантическую связь между словами.
Частота термина — обратная частота документа (TF-IDF)
Одним из результатов представления BOW является то, что оно дает оценку словам, которые встречались много раз, но многие из них не дают никакой значимой информации, например «к и от». Мы хотим различать слова, которые встречаются много раз и являются общими словами, от слов, которые встречаются много раз, но дают информацию о конкретном документе. Взвешивание векторов BOW является обычной практикой, и одним из наиболее часто используемых подходов к взвешиванию является TF-IDF (Manning et al., 2008).
Мы хотим различать слова, которые встречаются много раз и являются общими словами, от слов, которые встречаются много раз, но дают информацию о конкретном документе. Взвешивание векторов BOW является обычной практикой, и одним из наиболее часто используемых подходов к взвешиванию является TF-IDF (Manning et al., 2008).
Однако и BOW, и TF-IDF не могут фиксировать семантическое значение слов, поскольку они представляют слова или n-граммы дискретным образом.
Гипотеза распределения заключается в том, что слова, встречающиеся в одном и том же контексте, обычно имеют сходные значения [2]. Это основа семантического анализа текста. Идея, лежащая в основе этой гипотезы, заключается в том, что мы можем узнать значение слов, глядя на контекст, в котором они появляются. Легко заметить, что слово «играть» в предложении «Мальчик любит играть на улице» имеет другое значение, чем слово «играть» в предложении «Пьеса была фантастической». В целом слова, близкие к целевому слову, более информативны, но в некоторых случаях в предложениях существуют длительные зависимости между целевым словом и словами, которые «далеки» от него. За прошедшие годы было разработано множество подходов к изучению слова из его контекста, в том числе знаменитый Word2Vec, о котором пойдет речь в этом посте из-за его огромной популярности как в академических кругах, так и в отрасли.
В целом слова, близкие к целевому слову, более информативны, но в некоторых случаях в предложениях существуют длительные зависимости между целевым словом и словами, которые «далеки» от него. За прошедшие годы было разработано множество подходов к изучению слова из его контекста, в том числе знаменитый Word2Vec, о котором пойдет речь в этом посте из-за его огромной популярности как в академических кругах, так и в отрасли.
Word2Vec
Гипотеза распределения является основной идеей Word2Vec. В Word2Vec у нас есть большой неконтролируемый корпус, и для каждого слова в корпусе мы пытаемся предсказать его по заданному контексту (CBOW) или пытаемся предсказать контекст по конкретному слову (Skip-Gram). Word2Vec — это (неглубокая) нейронная сеть с одним скрытым слоем (с размерностью d) и функцией оптимизации Negative-Sampling или Hierarchical Softmax (подробнее можно прочитать в этой статье). На этапе обучения мы перебираем токены в корпусе (целевое слово) и смотрим на окно размером k (k слов с каждой стороны целевого слова, обычно со значениями от 2 до 10).
В конце обучения мы получим из сети следующую матрицу встраивания:
Матрица встраивания после обучения Word2Vec Теперь каждое слово будет представлено не дискретным и разреженным вектором, а d-размерностью непрерывный вектор, и значение каждого слова будет отражаться его отношением к другим словам [5]. Причина этого заключается в том, что во время обучения, если два целевых слова имеют общий контекст, интуитивно вес сети для этих двух целевых слов будет близок друг к другу и, следовательно, к их совпадающим векторам. Таким образом, мы получаем представление распределения для каждого слова в корпусе, в отличие от подходов, основанных на подсчете (таких как BOW и TF-IDF). Из-за поведения распределения конкретное измерение в векторе не дает никакой ценной информации, но, рассматривая (распределительный) вектор в целом, можно выполнить множество задач подобия. Например, мы получаем, что V(«Король»)-V(«Мужчина»)+V(«Женщина) ~= V(«Королева») и V(«Париж»)-V(«Франция)+V(» Испания») ~= V(«Мадрид»). Кроме того, мы можем выполнить меры сходства, такие как косинус-сходство, между векторами и получить, что вектор слова «президент» будет близок к «Обаме», «Трамп», «генеральный директор», «председатель» и т. д.
Кроме того, мы можем выполнить меры сходства, такие как косинус-сходство, между векторами и получить, что вектор слова «президент» будет близок к «Обаме», «Трамп», «генеральный директор», «председатель» и т. д.
Как показано выше, мы можем выполнять множество задач на сходство слов, используя Word2Vec. Но, как мы упоминали выше, мы хотим сделать то же самое для более чем одного слова.
Мы можем легко создавать биграммы с нашим неконтролируемым корпусом и использовать их в качестве входных данных для Word2Vec. Например, предложение «Я шел сегодня в парк» будет преобразовано в «Я_шел_шел_сегодня_сегодня_в_парк», и каждая биграмма будет рассматриваться как униграмма в обучающей фразе Word2Vec. Это будет работать, но есть некоторые проблемы с этим подходом:
- Он выучит эмбеддинги только для биграмм, при этом многие из этих биграмм не имеют особого смысла (например, «walked_today») и мы пропустим эмбеддинги для униграмм, вроде «гулял» и « сегодня».

- Работа только с биграммами создает очень разреженный корпус. Подумайте, например, о приведенном выше предложении «Сегодня я ходил в парк». Допустим, целевое слово — «walked_today», этот термин не очень распространен в корпусе, и у нас не будет много контекстных примеров, чтобы изучить репрезентативный вектор для этого термина.
Итак, как решить эту проблему? как мы извлекаем только значимые термины, сохраняя слова как униграммы, если их взаимная информация достаточно сильна? Как всегда ответ внутри вопроса — взаимная информация .
Взаимная информация (МИ)
Взаимная информация между двумя случайными величинами X и Y является мерой зависимости между X и Y. Формально:
Взаимная информация (МИ) случайных величин X и Y.В нашем случае , X и Y представляют все биграммы в корпусе, такие что y идет сразу после x.
Точечная взаимная информация (PMI)
PMI — это мера зависимости между конкретным появлением x и y. Например: x=прошел, y=сегодня. Формально:
Например: x=прошел, y=сегодня. Формально:
Легко видеть, что когда два слова x и y встречаются вместе много раз, но не поодиночке, PMI(x;y) будет иметь высокое значение, а значение 0, если x и y полностью независимы.
Нормализованная поточечная взаимная информация (NPMI)
Хотя PMI является мерой зависимости появления x и y, у нас нет верхней границы его значений [3]. Нам нужна мера, которую можно сравнивать между всеми биграммами, поэтому мы можем выбирать только биграммы выше определенного порога. Мы хотим, чтобы показатель PMI имел максимальное значение 1 для идеально коррелированных слов x и y. Формально:
Нормализованная поточечная взаимная информация x и y.Подход на основе данных
Другой способ извлечения фраз из текста — использование следующей формулы [4], которая учитывает количество униграмм и биграмм и коэффициент дисконтирования для предотвращения создания биграмм слишком редких слов. Формально:
Формально:
Теперь, когда у нас есть способ извлекать значимые биграммы из большого неконтролируемого корпуса, мы можем заменить биграммы с NPMI выше определенного порога на одну униграмму, например: «точка перегиба» будет преобразована в « точка_перегиба». Легко создать триграммы, используя преобразованный корпус с биграммами и снова запустив процесс (с более низким порогом) для триграмм форм. Точно так же мы можем продолжить этот процесс до n-грамм с уменьшающимся порогом.
Наш корпус состоит примерно из 60 миллионов предложений, содержащих в общей сложности 1,6 миллиарда слов. Нам потребовался 1 час, чтобы построить биграммы с использованием подхода, управляемого данными. Наилучшие результаты достигаются при пороговом значении 7 и минимальном количестве сроков 5.
Мы измерили результаты, используя набор оценок, который содержит важные биграммы, которые мы хотим идентифицировать, например, финансовые термины, имена людей (в основном генеральные и финансовые директора). города, страны и т. д. Используемая нами метрика — это простой отзыв: из наших извлеченных биграмм, каково покрытие в оценочном тесте. В этой конкретной задаче нас больше заботит отзыв, а не точность, поэтому мы позволили себе использовать относительно небольшой порог при извлечении биграмм. Мы принимаем во внимание, что наша точность может ухудшиться при снижении порога, и, в свою очередь, мы можем извлечь биграммы, которые не очень ценны, но это предпочтительнее, чем пропустить важные биграммы, при выполнении задачи расширения запроса.
города, страны и т. д. Используемая нами метрика — это простой отзыв: из наших извлеченных биграмм, каково покрытие в оценочном тесте. В этой конкретной задаче нас больше заботит отзыв, а не точность, поэтому мы позволили себе использовать относительно небольшой порог при извлечении биграмм. Мы принимаем во внимание, что наша точность может ухудшиться при снижении порога, и, в свою очередь, мы можем извлечь биграммы, которые не очень ценны, но это предпочтительнее, чем пропустить важные биграммы, при выполнении задачи расширения запроса.
Код примера
Чтение корпуса строка за строкой (мы предполагаем, что каждая строка содержит одно предложение) с эффективным использованием памяти: not line:
break
yield line
Очистите предложения, обрезав начальные и конечные пробелы, строчные буквы, удалив знаки препинания, удалив ненужные символы и сократив повторяющиеся пробелы в один пробел (обратите внимание, что это не обязательно, потому что позже мы будем токенизировать наше предложение через пробел): 9a-z0-9\s]’, », предложение)
return re. sub(r’\s{2,}’, ‘ ‘, предложение)
sub(r’\s{2,}’, ‘ ‘, предложение)
Маркировать каждую строку простым разделителем пробелов (более продвинутые методы для токенизации существуют, но токенизация с помощью простого пробела дала нам хорошие результаты и хорошо работает на практике), а также удалить стоп-слова. Удаление стоп-слов зависит от задачи, и в некоторых задачах НЛП сохранение стоп-слов дает лучшие результаты. Следует оценивать оба подхода. Для этой задачи мы использовали набор стоп-слов Spacy.
из spacy.lang.en.stop_words import STOP_WORDSdef tokenize(sentence):
вернуть [токен для токена в предложении.split(), если токен не в STOP_WORDS]
Теперь, когда у нас есть представления наших предложений в виде двумерной матрицы очищенных токенов, мы можем строить биграммы. Мы будем использовать библиотеку Gensim, которая действительно рекомендуется для семантических задач НЛП. К счастью, в Genim есть реализация для извлечения фраз, как с NPMI, так и с описанным выше подходом Миколова и др. на основе данных. Можно легко управлять гиперпараметрами, такими как определение минимального количества терминов, порога и оценки («по умолчанию» для подхода, основанного на данных, и «npmi» для NPMI). Обратите внимание, что значения различаются между двумя подходами, и это необходимо учитывать.
на основе данных. Можно легко управлять гиперпараметрами, такими как определение минимального количества терминов, порога и оценки («по умолчанию» для подхода, основанного на данных, и «npmi» для NPMI). Обратите внимание, что значения различаются между двумя подходами, и это необходимо учитывать.
из gensim.models.phrases import Phrases, Phraserdef build_phrases(sentences):
фразы = фразы(предложения,
min_count=5,
threshold=7,
progress_per=1000)
return Phraser(phrases)
После завершения создав модель фраз, мы можем легко сохранить ее и загрузить позже: может использовать его для извлечения биграмм для данного предложения:
def offer_to_bi_grams(phrases_model, предложение):
return ' '.join(phrases_model[sentence])
Мы хотим создать на основе нашего корпуса новый корпус со значимыми биграммами, объединенными вместе для последующего использования:
def Offerings_to_bi_grams(n_grams, input_file_name, output_file_name):
с open(input_file_name, 'r') as input_file_pointer:
с open(output_file_name, 'w+') as out_file:
для предложения в get_sentences(input_file_pointer):
clean_sentence = clean_sentence( предложение)
tokenized_sentence = tokenize(cleaned_sentence)
parsed_sentence = Offering_to_bi_grams(n_grams, tokenized_sentence)
out_file.
 write(parsed_sentence + '\n')
write(parsed_sentence + '\n') возможно, потребуется изменить гиперпараметры), как и раньше. Обучающая фраза будет рассматривать «точку перегиба» как одно слово и выучит распределенный d-мерный вектор, который будет близок к векторам таких терминов, как «точка перегиба» или «перегиб», что и является нашей целью!
В нашем корпусе из 1,6 миллиарда слов нам потребовался 1 час для построения биграмм и еще 2 часа для обучения Word2Vec (с пакетным Skip-Gram, размерностью 300, 10 эпохами, контекстом k=5, отрицательной выборкой 5, скорость обучения 0,01 и минимальное количество слов 5) на машине с 16 ЦП и 64 ОЗУ с использованием сервиса AWS Sagemaker. Отличный пример использования сервиса AWS Sagemaker для обучения Word2Vec в блокноте можно найти здесь.
Можно также использовать библиотеку Gensim для обучения модели Word2Vec, например здесь.
Например, при задании термина «точка перегиба» мы получаем следующие связанные термины, упорядоченные по их показателю косинусного сходства с их представленным вектором и вектором «точка_перегиба»:
«terms»: [
{
"term": "перегиб",
"score": 0,741
},
{
"term": "tipping_point",
"score": 0,667
},
{
"term": "inflexion_point",
"score": 0,637
},
{
"term": "hit_inflection",
"score": 0,624
},
{
"term": "точки перегиба",
"score": 0,606
},
{
"term": "достигнутый_перегиб",
"score": 0,583
},
{
"term": "вершина",
"оценка": 0,567
},
{
"термин": "достижение_изменения",
"оценка": 0,546
},
{
"термин": "достижение_опрокидывания",
"оценка": 0,518
},
{
"term": "hitting_inflection",
"score": 0,501
}
]
Некоторые из наших клиентов хотели увидеть влияние Черной пятницы на продажи компаний, поэтому, давая термин «Черная пятница Пятница» получаем:
"terms": [
{
"term": "cyber_monday",
"score": 0,815
},
{
"term": "thanksgiving_weekend",
"score": 0,679
},
{
"term": "праздничный_сезон",
"score": 0,645
},
{
"term": "thanksgiving_holiday",
"score": 0,643
},
{
"term": "valentine_day",
" оценка": 0,628
},
{
"термин": "день_матери",
"оценка": 0,628
},
{
"термин": "рождество",
"оценка": 0,627
},
{
"term": "shopping_cyber",
"score": 0,612
},
{
"term": "holiday_shopping",
"score": 0,608
},
{
"term": "праздник",
"счет": 0,605
}
]
Круто, не правда ли?
В этом посте мы рассмотрели различные подходы к представлению слов в задачах NLP (BOW, TF-IDF и Word Embeddings), узнали, как изучать представление слов из их контекста с помощью Word2Vec, увидели, как мы можем извлекать значимые фразы из заданного корпуса ( NPMI и подход, основанный на данных), и как преобразовать данный корпус, чтобы выучить похожие термины/слова для каждого из извлеченных терминов/слов с использованием алгоритма Word2Vec. Результаты этого процесса можно использовать в последующих задачах, таких как расширение запроса в задачах извлечения информации, классификация документов, кластеризация, ответы на вопросы и многие другие.
Результаты этого процесса можно использовать в последующих задачах, таких как расширение запроса в задачах извлечения информации, классификация документов, кластеризация, ответы на вопросы и многие другие.
Спасибо за внимание!
[1] Миколов, Т., Чен, К., Коррадо, Г.С., и Дин, Дж. (2013). Эффективная оценка представлений слов в векторном пространстве. CoRR, абс/1301.3781 .
[2] Харрис, З. (1954). Распределительная структура. Слово , 10 (23): 146–162.
[3] Баума, Г. (2009). Нормализованная (точечная) взаимная информация при извлечении словосочетаний.
[4] Миколов Т., Суцкевер И., Чен К., Коррадо Г.С. и Дин Дж. (2013). Распределенные представления слов и фраз и их композиционность. НИПС .
[5] Голдберг Ю., Херст Г., Лю Ю. и Чжан М. (2017). Нейросетевые методы обработки естественного языка. Компьютерная лингвистика, 44 , 193–195.
10 вещей, которые следует учитывать при выборе места проведения мероприятия
by Whova | Последнее обновление: 2 декабря 2021 г.
При организации мероприятия вы сталкиваетесь со многими решениями, но выбор правильного места и местоположения — это решение, которое окажет наибольшее влияние на ваше мероприятие. Все, от даты мероприятия, составов докладчиков, вариантов питания и опыта участников, зависит от места проведения мероприятия и места, которое вы выберете.
Звучит немного пугающе? Вы не должны так себя чувствовать. Вот несколько советов о том, когда принимать решение, что учитывать и как сделать лучше.
Когда начинать искать место проведения
Чем раньше, тем лучше. Как только вы хорошо разберетесь в следующих 3 факторах, вы можете начать поиск места проведения: бюджет, предполагаемый размер мероприятия и требования к площади.
Забронируйте место как минимум за 8 месяцев, чтобы у вас было достаточно времени для планирования других важных вещей, таких как поиск лучших докладчиков, создание программы мероприятия и веб-сайта, начало продажи билетов, общение с посетителями и многое другое.
Советы по теме: : 8 Программное обеспечение для управления и планирования мероприятий, которое сэкономит ваше время
На что обратить внимание при поиске места проведения
1. Местоположение
Возможно, вы уже обдумывали это. Для местного мероприятия вы можете искать место на разумном расстоянии от домов или мест работы большинства участников. Если многие участники будут приезжать из другого города, место проведения рядом с аэропортом или их отелями будет выгодно. В любом случае не забудьте рассмотреть пробки, транспорт и варианты парковки.
Если вы хотите уменьшить вероятность опоздания ваших посетителей, предоставьте им мобильное приложение для мероприятий, которое в наши дни является стандартом. С картами, схемами проезда и информацией о парковке/шаттле у них под рукой ваши посетители будут чувствовать себя уверенно и спокойно, отправляясь на мероприятие. Если место проведения находится в большом кампусе или институте, использование карт с закрепленными местоположениями может очень помочь. Для мероприятий с выставками, афишами или параллельными сессиями интерактивные карты помещений помогут посетителям удобно ориентироваться.
Для мероприятий с выставками, афишами или параллельными сессиями интерактивные карты помещений помогут посетителям удобно ориентироваться.
Взгляните, например, на Whova. Whova получила множество наград, в том числе приз зрительских симпатий на церемонии вручения наград Event Technology Awards (также известной как «Оскар» в области технологий для мероприятий).
2. Парковка
- Зарезервируйте близлежащие парковочные места для своих посетителей и либо включите стоимость в стоимость билетов, либо заставьте участников платить за парковку.
- Взгляните на скидки Uber и Lyft, предлагаемые для мероприятий. Вы можете договориться с ними, чтобы настроить это и распространить промо-код среди своих посетителей.
- Предоставьте участникам возможность разделить поездку или такси друг с другом. Для них также будет хорошим шансом пообщаться друг с другом. Приложение для конференций, такое как Whova, предоставляет доску сообщества и функцию группового чата, чтобы помочь в этом. Получите больше информации здесь.
- Предлагайте услугу парковки на время мероприятия, даже если место его проведения не предоставляет. Предоставление камердинера может быть важным, если событие является высококлассным событием, таким как гала-концерт.

Дополнительные советы: Руководство для начинающих по Event Communication : Стратегия, план и инструменты
3. Вместимость и минимумы
- Какова емкость? Вам необходимо знать вместимость помещений по нескольким причинам. Во-первых, 500 человек (если это предполагаемый размер вашего мероприятия) не могут комфортно разместиться в зале на 250 человек. А во-вторых, есть правила пожарной безопасности, которые должны соблюдаться на объекте.
- Каковы минимальные требования к еде и напиткам?
- Как внести коррективы на основе отзывов посетителей? Важно иметь возможность сделать обоснованную корректировку размера комнаты или еды и напитков прямо перед или во время вашего мероприятия. Вы можете легко подсчитать количество сотрудников или получить мгновенную обратную связь с помощью живого опроса в приложении для мероприятий, что сэкономит ваше время и деньги. Вот 64 вопроса для опроса о событиях в готовых к использованию шаблонах.

 Вот 64 вопроса для опроса о событиях в готовых к использованию шаблонах.
Вот 64 вопроса для опроса о событиях в готовых к использованию шаблонах.4. Гибкость контракта и форс-мажор
«Заключение официального контракта с организатором мероприятия является обязательным, потому что изменение места проведения мероприятия — это, вероятно, последнее, что вы хотите увидеть», — говорит основатель SoftwareHow, который организовал отраслевая конференция с 300 участниками.
Тем не менее, в связи с большой неопределенностью пандемии рекомендуется договориться о гибких условиях контракта с вашим заведением, поскольку ваше мероприятие может быть отложено или отменено из-за непредвиденных факторов. Например, из-за карантина или стихийного бедствия люди не смогут посетить ваше мероприятие, даже если они зарегистрировались. Если место проведения включает пункт о форс-мажоре, вы можете проверить, могут ли они добавить пункт, связанный с COVID, который защитит вас от потери всего вашего депозита.
5. Услуги и удобства
- Есть ли в заведении кухня и может ли она обеспечить питание для вашего мероприятия? Если да, то часто место проведения отказывается от платы за помещение и взимает только авансовый платеж вместе со стоимостью еды для каждого посетителя. Места без кухни могут иметь партнерские отношения с поставщиком продуктов питания, которым вы должны пользоваться, поэтому вы можете заранее проверить их еду. Убедитесь, что выбрали место, где подают вкусную еду или где вы можете пригласить сторонних продавцов еды для лучшего впечатления посетителей.
- Есть ли столы, стулья и постельное белье, которые можно использовать? Если в заведении есть эти предметы, вы можете сэкономить много денег и усилий, используя то, что у них есть, при условии, что это соответствует вашей теме и атмосфере.
- Есть ли бригада по установке/очистке? Если вы нашли место, где есть команда по установке и уборке, радуйтесь! Это не всегда так. Если эти услуги недоступны, вам необходимо создать команду для проведения мероприятий или найти волонтеров.
- Есть ли у него возможности AV? В некоторых местах есть встроенное аудио-визуальное оборудование, которое вы можете использовать, а в других вам нужно будет привезти его с собой.
 Места без кухни могут иметь партнерские отношения с поставщиком продуктов питания, которым вы должны пользоваться, поэтому вы можете заранее проверить их еду. Убедитесь, что выбрали место, где подают вкусную еду или где вы можете пригласить сторонних продавцов еды для лучшего впечатления посетителей.
Места без кухни могут иметь партнерские отношения с поставщиком продуктов питания, которым вы должны пользоваться, поэтому вы можете заранее проверить их еду. Убедитесь, что выбрали место, где подают вкусную еду или где вы можете пригласить сторонних продавцов еды для лучшего впечатления посетителей.
Советы по теме: Не разбираетесь в технологиях? Создание и управление программой мероприятия в Интернете и на мобильных устройствах без каких-либо технических навыков
6. Планировка
типы мероприятий, которые вы будете включать, удобства, которые вам потребуются, а также потребности вашей команды и посетителей.
Сократив свой выбор, получите иллюстрированный план каждого помещения и просмотрите понравившиеся места хотя бы один раз, отметив важные моменты, например, где находятся розетки и где находится или может быть расположено аудио-видео оборудование.
Расположение и план помещения сильно повлияют на несколько различных аспектов вашего мероприятия:
- Поток трафика Подумайте о потоке трафика на вашем мероприятии. Тип потока, который вам нужен, будет разным для каждого события. В каких зонах будет высокий трафик на мероприятии? Постановка на учет? Двери зрительного зала? Имейте это в виду при выборе места проведения, понимая, что то, как вы расположите столы и декор, также сильно повлияет на это.
- Мероприятия Если вы хотите, чтобы на вашем мероприятии были основные докладчики, вам понадобится либо сцена, либо место для размещения арендованной сцены. Вам нужна демо-зона? Будет ли бар?

Дополнительные советы: Как создать бейджи с именами участников за 5 минут
7. Страховка
Согласно BizBash, некоторые заведения даже не будут иметь с вами дело, если у вас нет страховки. Эми Холлквист-Хамрик, президент страхового агентства Hallquist, согласна с BizBash. «Есть несколько мест, которые требуют определенной ответственности, а также они названы дополнительными застрахованными для мероприятия», — говорит Холлквист. «Как правило, вы можете попросить своего агента по страхованию гражданской ответственности получить это одобрение для вашего мероприятия. Также рекомендуется НАЧАТЬ РАНЬШЕ, планируя добавить это, а также иметь все необходимые формулировки, адрес и т. д. до начала мероприятия. связаться с вашим агентом».
8. Атмосфера и доступность
Обратите особое внимание на существующий декор внутри помещения. В каком стиле построена архитектура и что передает интерьер здания? Если вы проводите гала-концерт, вам, скорее всего, понадобятся другие помещения, чем для выставки. Чем меньше атмосфера соответствует желаемому ощущению вашего мероприятия (высококлассное, высокотехнологичное и т. д.), тем больше декораций вам нужно будет сделать, чтобы компенсировать это.
В каком стиле построена архитектура и что передает интерьер здания? Если вы проводите гала-концерт, вам, скорее всего, понадобятся другие помещения, чем для выставки. Чем меньше атмосфера соответствует желаемому ощущению вашего мероприятия (высококлассное, высокотехнологичное и т. д.), тем больше декораций вам нужно будет сделать, чтобы компенсировать это.
Доступность означает возможность того, что каждый, особенно люди с особыми потребностями, может получить доступ к зданию и его удобствам. Прежде чем вы сможете ответить на этот вопрос, вам нужно понять, кто ваши посетители и каковы их потребности.
Возможно, вы знаете, будут ли в вашем заведении дети, но вы можете не знать, будут ли там люди с особыми потребностями. В этой ситуации обзор последних мероприятий, организованных вашей организацией, может дать вам представление об этом.
9. Акустика
Приходилось ли вам когда-нибудь присутствовать на мероприятии, которое было настолько громким, что было трудно слышать других, из-за чего вы напрягали слух и теряли голос за одну ночь? Это часто вызвано плохой акустикой помещения или тем, как звук распространяется по залу. Низкий потолок сделает помещение уютным, но сделает его громче, если будет многолюдно. В качестве альтернативы, большое помещение в стиле склада приведет к эху, или тому, что архитекторы называют «реверберацией».
Низкий потолок сделает помещение уютным, но сделает его громче, если будет многолюдно. В качестве альтернативы, большое помещение в стиле склада приведет к эху, или тому, что архитекторы называют «реверберацией».
Хотя акустика не обязательно будет иметь решающее значение при выборе места проведения концерта, есть несколько способов его улучшить, например, использование патио за пределами места проведения мероприятия. В своей статье для Американского института архитекторов компания Armstrong Ceilings предлагает использовать акустические облака или навесы для улучшения акустики помещения.
10. Гибкость в дате мероприятия
Гибкость в дате мероприятия может быть отличным способом вести переговоры с местами проведения. У них могут быть свободные даты в календаре, которые они хотят заполнить. Предоставив 2-3 варианта даты, вы, скорее всего, получите скидку.
Советы по теме: 8 шагов для создания отличного маркетингового плана для вашего мероприятия
Как найти место проведения
Поиск подходящего места для вашего мероприятия может занять немало времени. К счастью, есть несколько сокращенных номеров, которые помогут вам сэкономить время:
К счастью, есть несколько сокращенных номеров, которые помогут вам сэкономить время:
- Свяжитесь с местным бюро конференций и посетителей, чтобы узнать о местах, которые лучше всего соответствуют вашим потребностям.
- На веб-сайтах со списками событий, таких как 10times, eventful и т. д., найдите местные мероприятия, похожие на ваши, и посмотрите, где они проводятся.
- Используйте онлайн-инструмент, например Peerspace, Unique Venues, EventUp. Они помогут вам проанализировать множество мест, чтобы найти то, что подходит именно вам.
Как видите, при выборе места проведения мероприятия нужно учитывать многое. Однако, если вы примете во внимание вышеизложенное при проведении своего исследования, вы найдете идеальное место для вашего мероприятия.
После того, как дата и место проведения мероприятия определены, пришло время создать веб-сайты и планы мероприятий, продвигать ваше мероприятие, продавать билеты и привлекать посетителей. Хотели бы вы узнать, как сделать своих посетителей счастливыми, сэкономив при этом свое время от утомительных задач по управлению мероприятиями? Посмотрите, как Whova может помочь.