Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться.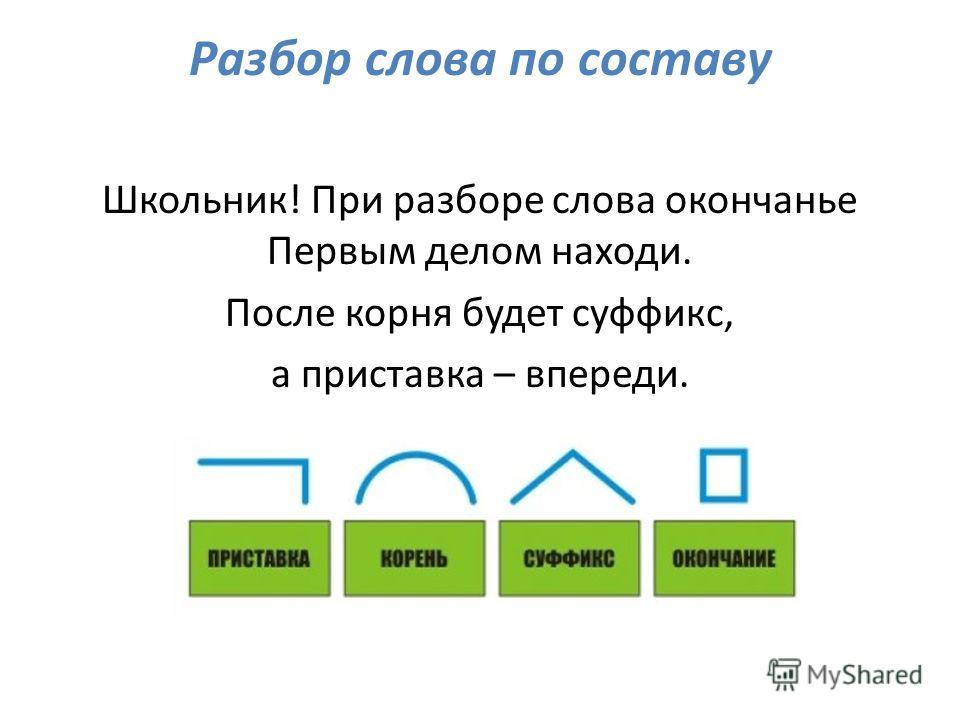 Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: товарищи сейчас випоан 1 секунда назад сиыетбо 1 секунда назад слова на букву б 1 секунда назад куосисн 2 секунды назад нумера 2 секунды назад байдарка 3 секунды назад п о с о л р е 3 секунды назад приступ 3 секунды назад зеворн 3 секунды назад рдоезвьо 3 секунды назад нтвеиль 4 секунды назад б у л а в к а 4 секунды назад кремтюще 4 секунды назад цнраекса 4 секунды назад
Морфологический разбор слова «прямоугольник»
Часть речи: Существительное
ПРЯМОУГОЛЬНИК — неодушевленное
Начальная форма слова: «ПРЯМОУГОЛЬНИК»
| Слово | Морфологические признаки |
|---|---|
| ПРЯМОУГОЛЬНИК |
|
| ПРЯМОУГОЛЬНИК |
|
Все формы слова ПРЯМОУГОЛЬНИК
ПРЯМОУГОЛЬНИК, ПРЯМОУГОЛЬНИКА, ПРЯМОУГОЛЬНИКУ, ПРЯМОУГОЛЬНИКОМ, ПРЯМОУГОЛЬНИКЕ, ПРЯМОУГОЛЬНИКИ, ПРЯМОУГОЛЬНИКОВ, ПРЯМОУГОЛЬНИКАМ, ПРЯМОУГОЛЬНИКАМИ, ПРЯМОУГОЛЬНИКАХ
Разбор слова по составу прямоугольник
прямоугольник
| Основа слова | прямоугольник |
|---|---|
| Корень | прям |
| Соединительная гласная | о |
| Корень | уголь |
| Суффикс | ник |
| Нулевое окончание |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПРЯМОУГОЛЬНИК» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «прямоугольник»
Примеры предложений со словом «прямоугольник»
1
Правда, он нарисовал какие-то геометрические фигурки – кубик, прямоугольник, рядом с ним другой прямоугольник, соединил их какими-то линиями.
Парижанка в Париже, Всеволод Кукушкин, 2014г.
2
Какая-то форма, не больше, – прямоугольник на дне, природа не знает прямоугольников.
Piccola Сицилия, Даниэль Шпек, 2018г.
3
В центре главный прямоугольник
разделен на 48 прямоугольников, пересекающихся белыми линиями, ведущими к центральной точке.
Искусство. Современное. Тетрадь десятая, Вита Хан-Магомедова
4
Центральный прямоугольник на картине, согласно Апатьяри, является лагерем сумчатой крысы, окружающие прямоугольники – норы.
Искусство. Современное. Тетрадь десятая, Вита Хан-Магомедова
5
Сальватичи успел испортить ее, и поручику Джемарджидзе в виде трофея достался деревянный прямоугольник с оборванными шнурами и без штепселей.
Найти еще примеры предложений со словом ПРЯМОУГОЛЬНИК
Простое преобразование PDF в Word с помощью Docparser
От счетов до форм и даже книг PDF-документы используются во всех организациях повсеместно. А иногда вы хотите превратить свои PDF-файлы в редактируемые документы. Сделать это может быть непросто, поскольку формат PDF часто не позволяет вам редактировать содержимое, а иногда даже копировать его. Хотя вы можете найти множество конвертеров PDF в Интернете, они имеют ряд ограничений, от неточностей преобразования до неуверенности в безопасности данных. Если вам нужно редактировать PDF-файлы в Word, это подходящее место для вас. Мы покажем вам, как преобразовать PDF в Word легко с Docparser, приложением для обработки документов, которое помогает автоматизировать ваши рабочие процессы на основе документов.
А иногда вы хотите превратить свои PDF-файлы в редактируемые документы. Сделать это может быть непросто, поскольку формат PDF часто не позволяет вам редактировать содержимое, а иногда даже копировать его. Хотя вы можете найти множество конвертеров PDF в Интернете, они имеют ряд ограничений, от неточностей преобразования до неуверенности в безопасности данных. Если вам нужно редактировать PDF-файлы в Word, это подходящее место для вас. Мы покажем вам, как преобразовать PDF в Word легко с Docparser, приложением для обработки документов, которое помогает автоматизировать ваши рабочие процессы на основе документов.
Содержание
- Как преобразовать PDF в Word с помощью Docparser
- Зачем использовать Docparser для преобразования PDF в Word?
- Почему обычные конвертеры не всегда эффективны
- Часто задаваемые вопросы о Docparser
- Автоматизируйте рабочие процессы на основе документов с помощью Docparser
Начать преобразование PDF-файлов в Wordс помощью Docparser
Экономьте время и деньги, автоматизировав ввод данных.
Кредитная карта не требуется.
Как преобразовать PDF в Word с помощью DocparserЧетыре описанных ниже шага очень просты и не требуют технических знаний. Без лишних слов, вот что вам нужно сделать.
Шаг 1: Создайте свой PDF-файл в Word ParserСначала подпишитесь на бесплатную пробную версию Docparser.
Как только вы это сделаете, Docparser перенесет вас на экран, где вы можете выбрать тип парсера документов (также называемый парсером). Как вы можете видеть на скриншоте ниже, вы можете выбирать из разных категорий документов, таких как заказы на покупку и банковские выписки. Если вы не можете найти нужный тип документа, выберите опцию «Пользовательский шаблон».
После выбора категории введите имя вашего анализатора документов и нажмите «Продолжить».
Шаг 2. Загрузите образец документа Загрузите PDF-файл со своего компьютера (или мобильного устройства) или просто перетащите его.
Другие способы загрузки документа включают в себя подключение поставщика хранилища к Docparser, отправку документа в виде вложения на выделенный адрес электронной почты Docparser и его импорт через REST API Docparser. Где бы ни находился ваш PDF-файл, вы можете легко загрузить его в Docparser.
После загрузки образца документа нажмите «Загрузка завершена», и Docparser перенесет вас на панель инструментов вашей учетной записи.
Шаг 3. Создание правил разбораПравила разбора — это правила, которым алгоритмы Docparser следуют для идентификации и извлечения данных из документов. Вы хотите создать правило синтаксического анализа для каждого поля данных, которое хотите извлечь.
Теперь перейдите в раздел на левой боковой панели, щелкните раздел «Правила», а затем нажмите кнопку «Создать первое правило синтаксического анализа».
В редакторе правил синтаксического анализа вы можете увидеть различные типы правил для различных точек данных, таких как текст, таблицы, даты, номера телефонов, адреса электронной почты и т.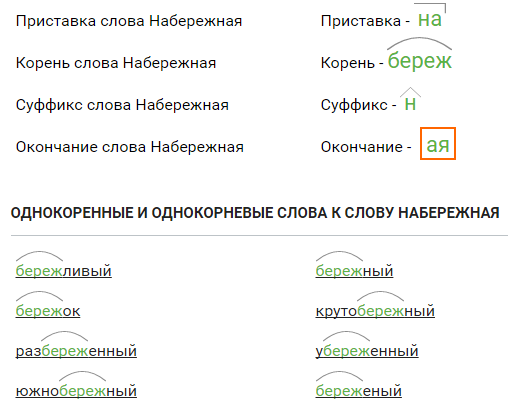 д. Мы собираемся создать первое правило синтаксического анализа.
д. Мы собираемся создать первое правило синтаксического анализа.
Создание первого правила синтаксического анализа
Для этого примера сначала мы хотим извлечь заголовок руководства. Для этого нажмите «Фиксированное положение текста» в разделе «Общие правила».
Теперь нарисуйте прямоугольник вокруг заголовка, затем нажмите «Подтвердить».
Редактор покажет вам предварительно проанализированный текст в машиночитаемом формате. Обратите внимание, что вы можете добавлять различные текстовые фильтры для редактирования или удаления таких частей, как определенные слова или пустые строки.
Если вас устраивает проанализированный текст, нажмите «Сохранить правило синтаксического анализа». Всплывающее диалоговое окно спросит вас, что делать. У нас все еще есть как минимум еще одно правило, которое нужно добавить, поэтому нажмите «Добавить новое правило».
Создайте второе правило синтаксического анализа
Для второго правила синтаксического анализа снова выберите «Фиксированное положение текста». Однако на этот раз обязательно выберите вторую страницу документа. Нарисуйте рамку выбора вокруг содержимого второй страницы и нажмите «Подтвердить».
Однако на этот раз обязательно выберите вторую страницу документа. Нарисуйте рамку выбора вокруг содержимого второй страницы и нажмите «Подтвердить».
Чтобы распространить это правило анализа на остальную часть документа, установите флажок рядом с «Использовать для следующих страниц» в нижней части экрана, и ваше правило будет применяться ко всем оставшимся страницам.
Обратите внимание, что вы всегда можете переключаться между страницами, чтобы убедиться, что поле выбора не пропускает текст ни с одной страницы.
Когда вы закончите, нажмите «Подтвердить» и просмотрите предварительный просмотр результатов синтаксического анализа. Уточните их при необходимости, добавив текстовые фильтры. Как только предварительный просмотр отобразит ваши данные именно так, как вы хотите, нажмите «Сохранить правило синтаксического анализа».
Мы закончили создание правил синтаксического анализа, поэтому во всплывающем диалоговом окне, которое появляется после этого, нажмите «Выход и повторный анализ документов».
Если вы не знаете, как что-то сделать, обязательно изучите нашу базу знаний, в частности, раздел «Правила синтаксического анализа». Не стесняйтесь обращаться также к нашей команде по удовлетворению потребностей клиентов.
Шаг 4. Переместите извлеченные данные в нужное местоПочти готово; последний шаг — выбрать, куда вы хотите отправить извлеченные данные.
Первый вариант — просто скопировать проанализированные данные в новый документ Word и сохранить его.
Второй вариант — связать Docparser с облачным приложением, чтобы всякий раз, когда новые документы импортируются в вашу учетную запись, они автоматически анализировались, а извлеченные данные отправлялись в выбранное вами приложение. Мы называем это «исходящей интеграцией».
Мы рекомендуем вам подключить свою учетную запись к Microsoft Power Automate, где вы можете создавать и редактировать документы Word.
Вы также можете создать исходящую интеграцию с такой платформой, как Zapier, которая позволит вам подключить Docparser к тысячам различных облачных приложений.
Чтобы узнать, как подключить свою учетную запись Docparser к Microsoft Power Automate, прочитайте эту запись в блоге. Это очень простой и быстрый процесс.
После того, как вы настроили интеграцию исходящего трафика, всякий раз, когда в ваш анализатор добавляются новые документы, Docparser автоматически извлекает данные внутри и отправляет их в нужное место в Microsoft Power Automate.
Подключив Docparser к Microsoft Power Automate, вы эффективно создадите автоматизированную систему, которая преобразует ваши PDF-файлы в текст, который затем отправляется в Word. Количество времени, усилий и денег, которые вы сэкономите с течением времени, превзойдет необходимость использовать обычный конвертер вручную для каждого отдельного PDF-файла и тратить время на исправление неточностей впоследствии.
Автоматизируйте рабочий процесс преобразования PDF в Word с помощью Docparser
Экономьте время и деньги, автоматизируя ввод данных.
Кредитная карта не требуется.
Некоторые конвертеры PDF в Word, хотя и достаточно точны в своей обработке, могут дать вам документ Word, полный мелких недостатков, как мы только что упомянули, поэтому вы не сможете чтобы использовать его сразу. Редактирование и корректура этого документа потребует времени, которое может быть стрессовым в зависимости от того, насколько срочно вам нужно использовать его или поделиться им.
Однако с помощью Docparser вы можете настроить конвертер, чтобы получить именно тот результат, который вам нужен. Вы выбираете точные точки данных, которые хотите извлечь, предварительно просматриваете извлеченные данные и уточняете процесс извлечения. Кроме того, вы можете настроить анализатор документов так, чтобы он пропускал те части, которые вам не нужны в документе Word.
После создания собственного конвертера PDF в Word (программирование не требуется) вы сможете извлекать содержимое из всех ваших PDF-файлов, не тратя время на исправление ошибок преобразования.
Кроме того, вы обнаружите, что общее качество данных улучшится, так как вы будете тратить гораздо меньше времени на самостоятельное редактирование и корректуру содержимого документа, что всегда приводит к человеческим ошибкам.
Экономьте время и силыСовременный мир движется слишком быстро, чтобы вы могли вводить информацию вручную. Ваше время и энергию лучше потратить на более важные задачи. Таким образом, вместо того, чтобы тратить часы на копирование и вставку содержимого или просмотр файла Word в поисках и исправлении ошибок преобразования, лучше создать автоматизированную систему, которая извлекает данные из ваших PDF-файлов с почти идеальной точностью.
Docparser позволяет вам построить эту систему. Один пользователь Docparser смог сэкономить до 50 часов работы каждый месяц. Раньше они читали документы, чтобы найти конкретную информацию о клиентах и ввести ее в свою базу данных. С помощью Docparser они не только автоматизировали весь этот процесс ввода данных, но и настроили автоматизированный рабочий процесс, при котором их программное обеспечение для управления недвижимостью получает извлеченные данные и автоматически отправляет оповещения при возникновении проблем.
Бесплатные конвертеры ограничивают количество документов, которые вы можете конвертировать. Например, вам может быть разрешено конвертировать только один документ за раз. Или у вас может быть ограничение в два документа в день.
Это нормально, если у вас есть только один PDF-файл, который нужно время от времени конвертировать. Но если вы получаете несколько документов регулярно, конвертация их по одному, вероятно, займет много времени и усилий. Добавьте к этому время, необходимое для вычитки, и вы можете застрять в этой задаче, возможно, даже столкнувшись с узким местом в своем рабочем процессе.
Docparser, с другой стороны, позволяет конвертировать сразу несколько документов, если они похожи по характеру и структуре (например, книга или руководство).
Если вы получаете PDF-документы в основном по электронной почте, мы рекомендуем вам попробовать Mailparser, наш специальный инструмент для анализа электронной почты.
Хотя большинство PDF-файлов в настоящее время являются исходными документами, некоторые представляют собой отсканированные бумажные документы. В этом случае вам понадобится конвертер, который использует технологию OCR для извлечения текста из отсканированного PDF-файла и преобразования его в машиночитаемый текст, который вы можете копировать и вставлять в Word или другие приложения.
Docparser имеет мощный механизм распознавания текста, который может извлекать данные из отсканированных документов, независимо от того, находятся ли они в формате PDF или изображения.
Преобразование документов PDF в другие форматы Преобразование из PDF в Word — не единственный вариант преобразования, возможный с помощью Docparser; отнюдь не. Например, вы можете конвертировать PDF-документы в форматы электронных таблиц, такие как Excel и CSV, поэтому он идеально подходит для анализа документов, содержащих таблицы, таких как счета-фактуры и банковские выписки.
Еще одним большим преимуществом использования Docparser является то, что вы можете отправлять извлеченные данные в облачное приложение (например, Microsoft Power Automate), где вы можете редактировать содержимое PDF-файла и делиться им. Помимо использования файлов Word, возможности интеграции здесь практически безграничны.
Благодаря этой гибкости вы можете использовать Docparser для нескольких рабочих процессов в вашей организации, от основных бизнес-процессов до бухгалтерского учета, расчета заработной платы и многого другого.
Автоматизируйте рабочий процесс PDF в Word с помощью Docparser
Экономьте время и деньги, автоматизировав ввод данных.
Кредитная карта не требуется.
В Интернете можно легко найти множество конвертеров PDF в Word — даже у Adobe есть собственный конвертер. Эти быстрые и часто бесплатные инструменты могут быть весьма эффективными при извлечении данных вместе с их форматированием из PDF в файл Word.
Однако в некоторых случаях эти преобразователи могут оказаться не самым эффективным методом. Для иллюстрации предположим, что ваш бизнес вращается вокруг продажи контента, на который есть спрос, но который недоступен в собственном цифровом формате. Это может быть:
- Руководства по деталям самолетов, изготовленные компаниями, которые больше не работают , индексирование, разбиение на главы и общую удобочитаемость
Проблемы обычных конвертеров
Если вы попытаетесь использовать бесплатный инструмент для преобразования PDF в Word, вы можете столкнуться со следующими проблемами:
- Вы не можете настроить процесс преобразования : обычные конвертеры попытаются преобразовать PDF-документ целиком. Поэтому, если вы хотите удалить некоторые ненужные разделы из документа Word, вам придется сделать это вручную.
- Несовершенное преобразование : Вы можете получить документ Word, полный ошибок преобразования, таких как слова, разрезанные пополам, символы, которые невозможно распознать, или хаотичное форматирование.
 Контент, который не был точно извлечен, требует дополнительного редактирования и проверки. И тратить время на это, когда у вас много-много документов, просто неэффективно.
Контент, который не был точно извлечен, требует дополнительного редактирования и проверки. И тратить время на это, когда у вас много-много документов, просто неэффективно. - Ограничения использования : Бесплатное использование конвертера имеет ограничения, такие как небольшое количество документов, которые вы можете конвертировать в день, или невозможность конвертировать несколько документов одновременно.
- Безопасность : Не всегда ясно, в какой степени компания, создающая бесплатный конвертер, привержена конфиденциальности и безопасности данных.
 Контент, который не был точно извлечен, требует дополнительного редактирования и проверки. И тратить время на это, когда у вас много-много документов, просто неэффективно.
Контент, который не был точно извлечен, требует дополнительного редактирования и проверки. И тратить время на это, когда у вас много-много документов, просто неэффективно.Поэтому, если вам постоянно нужно конвертировать PDF-документы в Word, вы хотите использовать более надежное решение. Одним из таких решений является Docparser, приложение для обработки документов, которое может быстро и легко извлекать данные из PDF-файлов, резко повышая вашу производительность.
Автоматизируйте рабочий процесс преобразования PDF в Word с помощью Docparser
Экономьте время и деньги, автоматизируя ввод данных.
Кредитная карта не требуется.
Как правило, Docparser анализирует документ за несколько секунд. Тем не менее, количество необходимого времени может варьироваться в зависимости от размера вашего документа и скорости вашего интернет-соединения.
В какие еще форматы может конвертировать Docparser?Вы можете конвертировать PDF в Excel, CSV, JSON и XML. Но это еще не все: вы также можете конвертировать из форматов, отличных от PDF, например Word в Excel или отсканированное изображение в Excel. Docparser очень гибок и позволяет создавать несколько конвертеров для всех ваших потребностей в извлечении данных.
Безопасен ли Docparser? Абсолютно. Мы никогда не будем использовать, передавать или продавать ваши данные третьим лицам. Данные автоматически удаляются после периода хранения от нуля до 180 дней. Чтобы узнать больше, ознакомьтесь с нашей политикой безопасности данных.
Чтобы узнать больше, ознакомьтесь с нашей политикой безопасности данных.
Да! Вы можете подписаться на 21-дневную бесплатную пробную версию. Вы не обязаны предоставлять информацию о своей кредитной карте, поэтому вам не нужно беспокоиться об автоматическом выставлении счетов.
Автоматизируйте рабочие процессы на основе документов с помощью Docparser Несмотря на то, что многие конвертеры действительно могут преобразовать PDF-файл в Word, результаты не всегда удовлетворительны, и в этом случае вам придется потратить много времени на редактирование. Кроме того, вы никогда не знаете, действительно ли ваши данные защищены на их серверах. Эти конвертеры хорошо подходят для случайных нужд, но если вам нужно постоянно конвертировать PDF-файлы в документы Word, лучше инвестировать в решение, которое обеспечивает более настраиваемое и точное извлечение данных. Время и деньги, которые вы сэкономите в долгосрочной перспективе, намного перевешивают инвестиции.
Как только вы начнете использовать Docparser, вы больше не будете терять драгоценное время, самостоятельно вводя информацию в Word. Подпишитесь на бесплатную пробную версию и попробуйте автоматизировать не только процесс преобразования PDF в Word, но и все ваши рабочие процессы на основе документов.
Преобразование PDF-файлов в Word с помощью Docparser за считанные минуты
Экономьте время и деньги за счет автоматизации ввода данных.
Кредитная карта не требуется.
Блог — Artifex
Это вторая статья о возможностях обработки текста в PyMuPDF. Первую статью можно найти здесь. Он касается различных аспектов извлечения текста , и его типичного использования, включая распознавание символов.
Возможности PyMuPDF (и MuPDF) в этой области доступны для всех поддерживаемых типов документов. Таким образом, помимо вездесущего формата PDF, также поддерживаются (Open) XPS, EPUB, HTML, Fiction Book и Comic Book.
В этой статье мы сосредоточимся на некоторых более сложных темах:
- Поиск текстовых строк (все типы документов)
- Выделение текста (только PDF)
- Поиск выделенного текста (только PDF)
- Работа с текстом (только PDF)
Прежде чем мы начнем, позвольте мне суммировать характеристики PyMuPDF .
PyMuPDF …
- — это продукт, принадлежащий и поддерживаемый Artifex. Он доступен под бесплатной лицензией с открытым исходным кодом (GNU AGPL 3.0), а также под коммерческой лицензией.
- — это библиотека программирования Python, которая обеспечивает удобный доступ (привязки Python) к библиотеке C MuPDF, также принадлежащей и поддерживаемой Artifex под той же лицензией моделей,
- имеет свою домашнюю страницу на Github и может быть установлен из PyPI,
- поддерживает многие (если не большинство) функций MuPDF — извлечение текста и манипуляции — лишь одна из множества других функций. Веб-сайт Github даст вам хороший обзор.

Поиск текста
Поиск заданной текстовой строки поддерживается для всех типов документов. Базовый формат метода максимально прост:
result = page.search_for("иглы")
Здесь «страница» — это объект Page , созданный из объекта Document с помощью page = doc.load_page(page_number) .
Метод ищет все вхождения строки «иглы» на странице и возвращает каждое место попадания как элемент в списке Python «результат». «Местоположение» — это прямоугольник, заданный координатами его верхней левой и нижней правой точек.
Не путайте термин «прямоугольник» с одноименным понятием в геометрии: Прямоугольник в управлении документами всегда выровнен по осям: Верхняя и нижняя стороны параллельны оси X, а левая и правая стороны параллельны оси у. Таким образом, прямоугольника с углом поворота 30° относительно оси X не существует. Общие геометрические объекты с четырьмя углами называются в документообороте «четверками» или «четверками».

Чтобы найти все вхождения строки «pymupdf» на **странице 9** документации PyMuPDF, вы можете сделать это:
В [1]: импортировать фитц
В [2]: doc = fitz.open("PyMuPDF.pdf")
В [3]: page = doc[8] # это отсчитывается от 0!
В [4]: page.search_for("pymupdf")
Выход[4]:
[Прямая (72,0, 361,02, 117,38, 375,55),
прямоугольник (93,85, 493,15, 136,48, 506,46),
прямоугольник (72,0, 523,04, 114,63, 536,35),
прямоугольник (72,0, 552,98, 114,63, 566,24),
прямоугольник (72,0, 582,82, 114,63, 596,13),
Прямоугольник(165,44, 618,68, 208,08, 631,99)]
В [5]: # Примечание: числа округлены для удобства чтения
Если «игла» вообще не встречается на странице, будет возвращен пустой список «[]».
Алгоритм поиска нечувствителен к регистру : он найдет «PYMUPDF», «PyMuPDF» и «pymupdf».
Строка «игла» может содержать пробелы и может занимать несколько строк. Встречаются также иглы с дефисом: метод дает два прямоугольника, покрывающих «Py-» соотв. «MuPDF», для иглы «pymupdf», когда эти части текста находятся на отдельных строках.
«MuPDF», для иглы «pymupdf», когда эти части текста находятся на отдельных строках.
Интерпретируйте вывод выше следующим образом:
Первый элемент результата Rect(72.0, 361.02, 117.38, 375.55) является прямоугольником с точками вверху слева = Point(72.0, 361.02) и внизу-справа = Точка(117,38, 375,55) .
Что можно делать с результатами поиска?
Наиболее частое использование, которое мы видели, это либо выделение /подчеркивание мест попадания, либо постоянная замена, соотв. удаление идентифицированного текста.
В следующих разделах объясняется, как это работает.
Выделение текста
Выделение в PDF означает применение визуального эффекта, подобного текстовому маркеру: тексту придается прямоугольный фон какого-либо заметного цвета (желтого, розового и т. д.). Спецификация PDF называет эти объекты маркировки текста «аннотациями».
Опять же, в PyMuPDF эту задачу можно выполнить самым элегантным и интуитивно понятным способом:
В [1]: импортировать фитц
В [2]: doc = fitz.open("PyMuPDF.pdf")
В [3]: страница = документ[8]
В [4]: для прямоугольника в page.search_for("pymupdf"):
...: page.add_highlight_annot (прямая)
В [5]: # ГОТОВО!
Точно так же вы можете подчеркнуть или зачеркнуть текст — просто используйте page.add_underline_annot(rect) соответственно. page.add_strikeout_annot(rect) .
Вы можете заглянуть в репозиторий примеров PyMuPDF, чтобы узнать, как выполнять более сложные случаи маркировки текста.
Поиск выделенного текста
Вы также можете найти и извлечь текст, который уже выделен :
A PyMuPDF Page объект имеет итератор, который проходит через его аннотации, Page.annots() . Для каждой аннотации, полученной этим итератором, возьмите прямоугольник аннотации и извлеките текст, охватываемый им.
В [1]: импортировать фитц
В [2]: doc = fitz.open("PyMuPDF.pdf")
В [3]: страница = документ[8]
В [4]: for r in page.search_for("pymupdf"): # добавить основные моменты демонстрации
...: page.add_highlight_annot(r)
В [5]: for annot in page.annots(): # прочитать текст, отмеченный выделенным цветом
...: если annot.type[0] == fitz.PDF_ANNOT_HIGHLIGHT:
...: печать (f "выделено:
'{page.get_textbox(annot.rect)}'")
выделено: «PyMuPDF»
выделено: 'PyMuPDF'
выделено: «PyMuPDF»
выделено: «PyMuPDF»
выделено: «PyMuPDF»
выделено: «PyMuPDF»
В приведенном выше вы увидите случайные пробелы до или после извлеченного текста. Это вызвано тем, что блики не являются настоящими прямоугольниками: их левая и правая границы являются кривыми, а не прямыми линиями. Таким образом, в зависимости от размера шрифта и положения слова в тексте могут быть извлечены и соседние пробелы.
Редактирование текста
Если ваш PDF-файл содержит конфиденциальную информацию, которая должна быть защищена от несанкционированного доступа (без обязательной блокировки всего документа), PDF «Аннотации редактирования» вступают в игру.
Например, недостаточно просто нарисовать черный прямоугольник над именем правонарушителя в юридическом документе. В этом случае конфиденциальная информация останется в файле: ее все равно можно будет извлечь с помощью такой программы, как PyMuPDF.
Вместо этого конфиденциальная информация должна быть полностью физически удалена из файла. Project x-ray использует PyMuPDF для поиска плохо выполненных анонимизаций в юридических документах. Вот что этот проект говорит о PyMuPDF:
«Под прикрытием xray использует высокопроизводительный проект PyMuPDF для анализа PDF-файлов. Это был замечательный проект для работы».
Физическая замена или удаление нежелательной информации — одно из возможных применений аннотаций редактирования PDF.
Еще раз, реализовать это проще простого, чем с помощью PyMuPDF:
В [1]: импортировать фитц
В [2]: doc = fitz.open("PyMuPDF.pdf")
В [3]: страница = документ[8]
В [4]: # найти и пометить каждое вхождение "pymupdf" как "для удаления"
В [5]: для прямоугольника в page.