Разбор слова (новая редакция файла)
Разбор слова
Выбери тему:
Фонетический разбор
Состав слова
Пример фонетического разбора
Порядок разбора слова по составу
Проверка знаний (фонетика )
Проверка знаний (состав слова)
Автор – Иванов В.В, МБОУ «СОШ с.Вязовка» Астраханской области Черноярского района, 2017 год
Фонетический разбор слова
РУ — ЖЬЁ
5 звуков, 5 букв, 2 слога
Р [р] – согласный, твёрдый, звонкий
У [у] – гласный, безударный, один звук
Ж [ж] – согласный, твёрдый, звонкий
Ь [ х ] – !
Ё [й`о] – гласный, ударный, два звука
Пример фонетического разбора слова
ТЮЛЬ — ПАН
6 звуков, 7 букв, 2 слога
Т [т`] – согласный, мягкий, глухой
Ю [у] – гласный, безударный, два звука
Л [л`] – согласный, мягкий, звонкий
Ь [ х ] – !
П [п] – согласный, твёрдый, глухой
А [а] – гласный, ударный, один звук
Н [н] – согласный, твёрдый, звонкий
Проверим знания по теме
Дано слово — ВЬЮГА
5 букв
Сколько в слове букв?
Сколько в слове звуков?
5 звуков
Сколько в слове слогов?
2 слога; вью-га
Какой слог — ударный?
Первый, вью — га
Продолжим проверку
Дайте характеристику каждого звука в слове — ВЬЮГА
В
В [в`] – согласный, мягкий, звонкий
Ь [ х ] – нет звука, это — разделитель
Ь
Ю [й`у] – гласный, ударный, два звука
Ю
Г [г] – согласный, твёрдый, звонкий
Г
А
А [а] – гласный, безударный, один звук
Состав слова
Состав слова
Примеры:
1.
2.
двор, дворик , придворный —
слова с общим корнем (однокоренные)
двор , двора, двору , (на) дворе
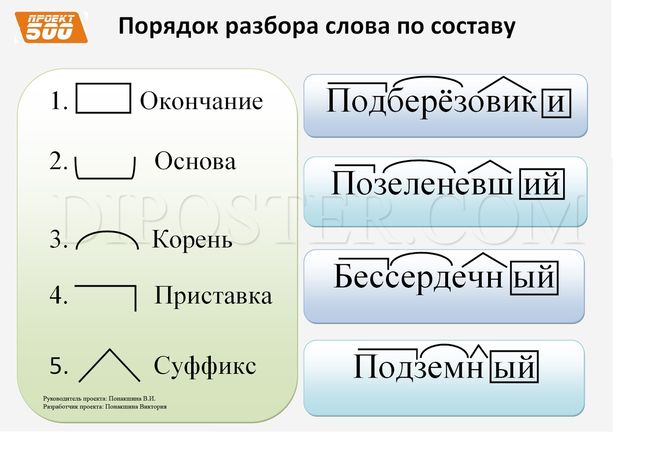
Порядок разбора слова по составу
МЕЖКОМНАТНЫЙ
2
БЕРЕГ
НА БЕРЕГУ
ЗАСЛУЖЕННЫЙ
1
3
ВАГОН
ИЗ ВАГОНА
Проверим знания по теме
Дано слово: БЕЗДЕТНЫЙ
й
ый
ный
Окончание —
бездетн
здетн
бездет
Основа слова —
Корень слова —
дет
детн
здет
безде
Приставка —
без
бе
Суффикс —
ны
тный
н
Проверим знания по теме
Дано слово: ПРИШКОЛЬНАЯ
я
ая
ная
Окончание —
пришкольн
пришколь
Основа слова —
Корень слова —
школьн
школь
школ
пришк
Приставка —
приш
при
Суффикс —
льная
на
н
Проверим знания по теме
Дано слово: ЗАСЛУЖЕННОЕ
ое
нное
ное
Окончание —
заслуженн
служенн
Основа слова —
Корень слова —
служе
служен
служ
засл
Приставка —
за
заслу
Суффикс —
енно
ен
енн
Как правильно разбирать слова по составу / Paulturner-Mitchell.
 com
comАнализ слов по составу (или морфемный — от термина «морфема», обозначающего минимальный значимый компонент слова) является разновидностью лингвистического анализа. Его цель — определить структурный состав лексемы. То есть для правильного анализа слова по составу необходимо найти и выделить все компоненты, из которых строится определенная словоформа. Такой анализ (не путать с морфологическим, когда слово рассматривается с точки зрения принадлежности к определенной части речи) называется морфемным.
Анализ состава следует начинать с установления границ каждой морфемы, то есть необходимо правильно определить приставку, корень, суффикс, окончание, основу. Но стоит помнить, что не каждая словоформа обязательно содержит все существующие морфемы: например, «школа» состоит из корня (-школа-), суффикса (-н-) и окончания (-й). Но, в свою очередь (и это не редкость для современного русского языка), есть слова, включающие в себя несколько корней, приставок или суффиксов. Итак, «пароход» имеет два корня (-парный- и -путь-), один суффикс (-н-) и окончание (-й). «Слушатель» состоит из корня (-слуш-) и двух суффиксов (-а и -тел-), но не имеет префикса, и окончание в этом слове будет нулевым (формально буквами не выражается буквами ).
Итак, «пароход» имеет два корня (-парный- и -путь-), один суффикс (-н-) и окончание (-й). «Слушатель» состоит из корня (-слуш-) и двух суффиксов (-а и -тел-), но не имеет префикса, и окончание в этом слове будет нулевым (формально буквами не выражается буквами ).
Итак, для правильного анализа слова по составу необходимо вспомнить определение всех основных минимальных значимых единиц языка. Основная морфема, несущая лексическое значение (то есть выражающая значение) и являющаяся общей частью всех корневых слов.
Например, в качестве таковых будут выступать следующие родственные серии: «водяной», «водяной», «подводник», «водяной» — будет действовать-вода. Слов без корней в русском языке не существует. Но их много, состоящих только из него: «беговой», «кино», «самый», «лошадка», «дом».
Морфема, стоящая в слове перед корнем, называется приставкой, а суффикс после нее — суффиксом. Понятно, что невозможно придумать токен, который будет содержать только префикс или только суффикс.
Необходимо учитывать порядок определения морфемы, производя морфемный анализ слова по составу. Корень, префикс и суффикс ученые-лингвисты относят к словообразовательным морфемам. То есть к тем, с помощью которых в языке образуются новые слова. Кроме словообразовательных форм выделяют формообразующие. Они существуют для того, чтобы образовывать ряд форм внутри одной лексемы, а также для выражения грамматического значения. К этому виду морфем относятся окончания и некоторые суффиксы.
Окончание является разновидностью морфемы, образующей разные формы одного и того же слова, а также является грамматическим показателем рода, числа, падежа, времени и т. д. Различить его можно только в изменяемых частях речи.
Однако следует различать слова, не имеющие окончания, и с нулевым окончанием. Как уже говорилось, в нем нет тех словоформ, которые не изменяются, — герундий, наречий, несклоняемых существительных, прилагательных, стоящих в сравнительной степени. А нулевое окончание — это формально не выделенный показатель грамматического значения изменяемого слова. Примерами формообразующих суффиксов могут быть -l-, который используется для образования прошедшего времени глаголов (go-ti + суффикс -l), -e-, с помощью которого производятся степени сравнения для наречий и прилагательных (громче — громче) .
Примерами формообразующих суффиксов могут быть -l-, который используется для образования прошедшего времени глаголов (go-ti + суффикс -l), -e-, с помощью которого производятся степени сравнения для наречий и прилагательных (громче — громче) .
И, наконец, у слова есть основа — все его компоненты без окончаний. Выходя за рамки школьной программы, можно определить основу в составе лексемы не только без окончания, но и без формообразующих суффиксов.
Необходимо учитывать порядок определения морфем, производя разбор слова по составу. Примеры морфемного анализа:
«лес»
- Окончание «ой»
- Основа «лес»
- Корень «лес»
- Суффикс «н»
«служащие»
- Окончание «и»
- Основа «служащий»
- Корень «труд»
- Приставка «со»
- Суффикс «прозвище»
Таким образом, подводя итог теме «Разбор слов по составу», следует отметить, что только следуя определенному порядку: найти окончание (если он есть), указать основу, установить, где корень (путем выделения корня слова), выбрать суффикс, приставку (если есть), можно не допускать ошибок.
[PDF] Семантический анализ с комбинаторными категориальными грамматиками
- Идентификатор корпуса: 6349911
@inproceedings{Artzi2013SemanticPW,
title={Семантический анализ с комбинаторными категориальными грамматиками},
автор={Йоав Арци и Николас Фитцджеральд и Люк Зеттлемойер},
booktitle={Ежегодное собрание Ассоциации компьютерной лингвистики},
год = {2013}
} В учебнике будут описаны общие принципы построения семантических парсеров. Презентация будет разделена на две основные части: моделирование и обучение. Раздел моделирования будет включать в себя лучшие практики для разработки грамматики и выбора семантического представления. Обсуждение будет вестись на примерах из нескольких областей. Чтобы проиллюстрировать выбор, который необходимо сделать, и показать, как к нему можно подойти в рамках реального языка представления, мы будем использовать представления значений λ-исчисления.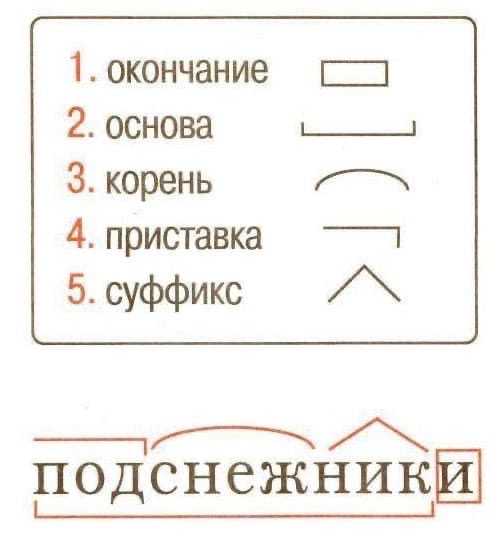
Просмотр в ACL
courses.cs.washington.eduНейросемантический анализ для генерации кода с учетом синтаксиса
- Артур Барановский
Информатика
Thissis Presents 2020 эффективный нейронный семантический анализатор, использующий базовая грамматика логических форм для обеспечения правильно сформированных выражений и показывает, что предложенная модель превосходит стандартную модель кодировщика-декодера для наборов данных и конкурентоспособна с сопоставимыми подходами к семантическому анализу на основе грамматики.- Паван Кумар, Сриканта Дж. Бедатур
Информатика
ArXiv
- 2020 9007a значение этой работы посвящено синтаксическая структура ( Partee, 1975), и (b) способность семантических парсеров обрабатывать лексические вариации в контексте базы знаний (KB).

Обзор семантического анализа
- Коннор Хили, Д. Б. Уилфрид Лорье
Информатика
- 2019
В этом обзоре рассматриваются различные компоненты системы семантического синтаксического анализа и обсуждаются важные работы, начиная от первоначальных методов, основанных на правилах, и заканчивая современными нейронными подходами к синтезу программ.
Обзор по семантическому анализу
- Айшвария Камат, Р. Дас
Информатика
AKBC
- 2019
Этот обзор системы анализа и анализа различных семантических компонентов обсуждает выдающиеся работы, начиная от начального методы, основанные на правилах, к современным нейронным подходам к синтезу программ.
На пути к генерации кода: обзор и уроки семантического анализа
- Селин Ли, Джастин Эмиль Готтшлих, Дэн Рот Intel Labs, U. Pennsylvania
Компьютерные науки
ArXiv
2020 59- Селин Ли, Джастин Эмиль Готтшлих, Д. Рот
Информатика
- 2021
- Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq R. Joty, Xiaoli Li
Информатика
ACL
- 2021
- Haoyu Zhang, Jingjing Cai, Jianjun Xu, J. Wang
Computer Science
ACL
- 2019
- 2019
- Маркус Спайс
Компьютерные науки
- 2015
- Sayontan Ghosh, Amanpreet Singh, Alex Merenstein, S. Smolka, E. Zadok, Niranjan Balasubramanian
Информатика
LREC
- 2022
- Т. Квятковски, Люк Зеттлемойер, С. Голдуотер, Марк Стидман
Информатика, лингвистика
EMNLP
- 2011
- Люк Зеттлемойер, М. Коллинз
Информатика
EMNLP
- 2007
- T. Kwiatkowski, Luke Zettlemoyer, S. Goldwater, Mark Steedman
Информатика
EMNLP
0029 2010
Обзор представлен растущий объем исследований в области семантического анализа с точки зрения эволюции, с конкретным анализом нейросимволических методов, архитектуры и наблюдения.
Обзор семантического анализа для машинного программирования
Представлен обзор растущего числа исследований в области методов семантического анализа естественного языка и извлечения уроков из эволюции семантического анализа. , проводя параллели между современными усилиями в области нейросемантического анализа и синтеза программ.
Платформа условного разделения для эффективного анализа избирательных групп
Общая структура партикулярных условий последовательностей парсинга решения и показывает, что в этой формулировке сегментация дискурса может быть оформлена как частный случай синтаксического анализа, который позволяет нам выполнять синтаксический анализ дискурса, не требуя сегментации в качестве предварительного условия.
Разложение сложных вопросов для семантического анализа
Эта работа предлагает новый метод иерархической семантики множество сложных вопросов для семантического анализа и разрабатывает средство извлечения информации для получения информации о типе и предикате этих вопросов.
На пути к открытой программной архитектуре для чередующихся знаний и обработки естественного языка
SpecNFS: сложный набор данных для извлечения формальных моделей из спецификаций естественного языка
В этой работе разрабатываются и оцениваются системы разбора семантической зависимости для этой задачи с помощью SpecIR, языка представления, представленного для модельных предложений, появляющихся в документах спецификации NFS в виде операторов IF-THEN, и представляет аннотированный набор данных из 1198 предложений.
Лексическое обобщение в индукции грамматики CCG для семантического анализа
Алгоритм изучения факторизованных словарей CCG вместе с вероятностной моделью разбора-выборки слов, которая включает как лексемы для моделирования систематических значений слов, так и шаблоны для моделирования систематических вариаций в значении слов использования представлены.
Онлайн-обучение упрощенным грамматикам CCG для преобразования в логическую форму
Ключевая идея состоит в том, чтобы ввести нестандартные комбинаторы CCG, которые ослабляют определенные части грамматики — например, допускают гибкий порядок слов или вставку лексических единиц — с затратами на обучение.
Индуцирование вероятностных CCG-грамматик из логической формы с помощью унификации высшего порядка
- Люк Зеттлемойер, М. Коллинз
Информатика
UAI
- 2005
- П. Лян, Майкл И. Джордан, Д. Кляйн
Информатика
CL
- 2011
- Дж. Кларк, Дэн Голдвассер, Минг-Вей Чанг, Д. Рот
Информатика
CoNLL
- 800100 статья разрабатывает два новых алгоритма обучения, способных предсказания сложных структур, которые полагаются только на двоичный сигнал обратной связи, основанный на контексте внешнего мира, и переформулирует проблему семантического анализа, чтобы уменьшить зависимость модели от синтаксических шаблонов, что позволяет синтаксическому анализатору лучше масштабироваться с меньшим контролем.
Обучение разбору запросов к базе данных с помощью индуктивного логического программирования
- J. Zelle, R. Mooney
Информатика
AAAI/IAAI, Vol. 2
- 1996
Экспериментальные результаты с полным приложением запросов к базе данных для географии США показывают, что CHILL может изучать синтаксические анализаторы, которые превосходят ранее существовавшие, созданные вручную аналоги, и предоставляют прямое доказательство полезности эмпирического подхода в уровень полного приложения на естественном языке.
Использование конструкторов с несколькими предложениями в индуктивном логическом программировании для семантического анализа
- Лаппун Р. Танг, Р. Муни
Информатика
ECML
- 20010 Предварительные результаты0 70 продемонстрировал, что подход, сочетающий различные методы обучения в индуктивном логическом программировании (ILP), чтобы позволить учащемуся выдвигать более выразительные гипотезы, чем у каждого отдельного учащегося.
Обзор семантического разбора с точки зрения композиционности

 Pennsylvania
Pennsylvania Joty, Xiaoli Li
Joty, Xiaoli Li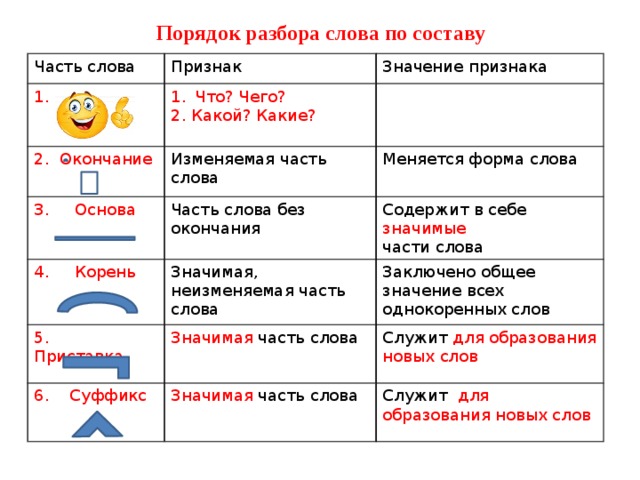

В этой статье используется унификация более высокого порядка для определения пространства гипотез, содержащего все грамматики, согласующиеся с обучающими данными, и разрабатывается алгоритм онлайн-обучения, который эффективно выполняет поиск в этом пространстве, одновременно оценивая параметры логарифмической модели синтаксического анализа.
Обучение преобразованию предложений в логическую форму: структурированная классификация с вероятностной категориальной грамматикой
Описан алгоритм обучения, который принимает в качестве входных данных обучающий набор предложений, помеченных выражениями в лямбда-исчислении, и создает грамматику для задачи вместе с логлинейной моделью, которая представляет собой распределение по синтаксическому и семантическому анализу, обусловленное входным предложением.
Изучение композиционной семантики на основе зависимостей
Разработан новый семантический формализм, композиционная семантика на основе зависимостей (DCS), определено лог-линейное распределение по логическим формам DCS и показано, что система получает сравнимой точности даже с самыми современными системами, которые требуют аннотированных логических форм.
Эффективный статистический анализ с широким охватом с помощью CCG и лог-линейных моделей
В этой статье описывается ряд моделей лог-линейного анализа для автоматически извлекаемой лексикализованной грамматики и разрабатывается новая модель и эффективный алгоритм анализа, который использует все производные, включая CCG. нестандартные производные.

