Разбор слов по составу : покажите, раздумывая
Найдите сложные предложения, подчеркните грамматические основы.Укажите средства связи входящих в сложные простых предложений. У сложных предложении об … означьте вид (ССП,СПП,БСП)1)Нет счастья вне родины, каждый интонация пускай корни в родную землю. (И. Тургенев) 2) Я люблю Россию до боли сердечной и даже не могу помыслить себя где-либо, кроме России. (М. Салтыков-Щедрин) 3) Я изъездил почти всю страну, видел много мест, удивительных и сжимающих сердце, но ни одно из них не обладало такой внезапной лирической силой, как Михайловское. (К. Паустовский) 4) Истоки сыновнего чувства к отчизне лежат там, где мы рождаемся и живём. (В. Песков)
Выберите правильный ответ. Укажите сложноподчинённое предложение с пунктуационной ошибкой:
1) Всюду, где есть пашня, всюду, где есть ум человеческий,
… должна быть и книга.
2) Не забывайте того хорошего, что вы умеете, а чего не умеете, тому учитесь.
3) Если я не устремлюсь на врага, когда дело идёт о спасении моей родины, я не гражданин, а обыватель.
Сложноподчиненные предложения с несколькими придаточными.
Решите пожалуйста, русский язык. Даю 60 баллов.
Произвести синтаксический разбор предложения.Солнце садилось, ветер все крепчал, закат разгорался пурпуром
1. А) Выберите правильный ответ. Укажите предложение, в котором нужно поставить одну запятую. (Знаки препинания не расставлены).
1) Дымы дальних пожар
… ов медленно всходили к небу или отдельными облаками летали по горизонту.
2) Молнии разрезали небо и справа и слева и спереди.
3) Волк каждый год линяет да своего обличия не меняет.
4) В слове тысячелетиями накапливаются и живут мысли и опыт народа.
Б) Выберите 3 правильных ответа. Укажите предложения, в которых запятая ставится:
1) Соловьи уже пели в саду и в окна виднелось далёкое светлое небо.
2) В сентябре лес всё реже и светлее и птичьи голоса тише.
3) Вскоре ветер перешёл в ураган и царство тишины и покоя превратилось в кромешный ад.

Решите пожалуйста, даю 50 баллов, очень нужно.
1. Установите соответствие между словами и синонимичными выражениями.
1) АЛЬТРУИЗМ; 2) СКЕПТИЦИЗМ; 3) ПЕССИМИЗМ; 4) АСКЕТИЗМ.
А) разочарованность; Б)
… бескорыстная забота о людях; В) строгое ограничение в в чём-то; Г) мрачное мировосприятие; Д) чувство неприязни.
2. Выберите 2 правильных ответа. Укажите варианты в которых нарушены нормы сочетаемости слов:
1) И вот наступила мирная жизнь.
2) И теперь он стал законченным негодяем.
Из теоретического материала урока выписать 10 прилагательных и составить предложения.Закрепление.Тоска по родине в рассказе Тэффи «Ностальгия»Невозмо … жно не прочувствовать истинную тоску и боль писательницы. В своем рассказе «Ностальгия» она говорит о том, как эмигранты, вынужденные покинуть большевистскую Россию, тосковали по ней. Все стало терять свой смысл. Благополучие и комфорт уже не были столь важны, ведь душа томилась по родине. Бытовые мелочи не могли успокоить исстрадавшихся людей, лишенных родной страны.
Помогите сделать морфологический разбор предложения: Ни одной усадьбы, ни одного поэтического угла он не мог себе представить без того, чтобы там не б
… ыло крыжовника.
Разбор слова по составу — начальные классы, уроки
Конспект урока русского языка в 4 классепо теме: «Разбор слова по составу».
Образовательные:
-уточнить понятия «корень», «основа», «приставка»,
«суффикс», «окончание»;
-создать с учащимися алгоритм разбора слова по составу;
Развивающие:
— развивать умения выделять части слова, способствовать развитию орфографического навыка.
— развивать речь учащихся, обогащать словарный запас детей;
-развивать сообразительность, мышление, память.
Воспитательные:
-создавать у учащихся положительную мотивацию к уроку русского языка путём вовлечения каждого в активную деятельность;
-воспитывать культуру речи, любовь к слову, родному языку;
-воспитывать внимание, доброе отношение друг к другу.
Оборудование: ноутбук, мультимедийный проектор, экран, слайды по теме, картинки с рисунками.
Формирование УУД:
— личностные действия: уметь создавать благоприятную дружескую атмосферу вокруг себя, принимать активное участие на уроке, быть вежливым, воспитанным, корректным.
— регулятивные действия: уметь планировать свою деятельность, ставить перед собой задачи, делать выводы, контролировать свои действия, быть внимательным;
— познавательные действия: уметь определять глаголы, изменять их по вопросу, согласовать с именами существительными, использовать их в речи и письме.
— коммуникативные действия: уметь работать в группе, в паре, принимая равное участие; уметь выслушать и помочь товарищу, обогащать связную речь посредством глаголов.
Оборудование урока:
-карточки индивидуального опроса;
Тип урока: изучение нового материала.
Формы работы: фронтальная, индивидуальная, групповая.
Методы обучения: словесно-наглядный, проблемно-поисковый (эвристический), самостоятельная работа, иллюстративный.
Ход урока.
1.Организационный момент. Хай Файв!(сигнал тишины)
— Добрый день.
Дети. Мы рады приветствовать вас в классе,
Возможно, есть классы и лучше и краше.
Но пусть в нашем классе вам будет светло,
Пусть будет уютно и очень легко,
Поручено нам вас сегодня встречать,
Ну начнем же урок, не будем зря время терять.
– Спасибо, будем надеяться, что настроение наших гостей хорошее, а будет ещё лучше. Я желаю вам успешной работы и приятного общения на уроке. Посмотрите, друг на друга, улыбнитесь и пожелайте своему соседу удачи. И так, начнем наш урок.
На партах лежат цветные полоски. Выберите из 4 один себе цвет. Прикрепите в бэйджиках. Пусть каждому из вас этот выбранный цвет принесет отличное настроение для усвоения новых знаний.
Внимание на экран. Здесь эпиграф к нашему уроку. (Я читаю)
Слайд 2
Слово делится на части,
Как на дольки апельсин.
Может каждый грамотей
Строить слово из частей.
(Таймд Раунд Робин) Как вы понимаете эти слова? Обсудите у себя в группе, проговаривая каждый по очереди по кругу за определенное время. Начинает участник № 1 по сигналу.
1) (по 10секунд 4 раза)
Кто хочет поделиться с своей мыслью? Стол 3- участник 3 и т.д.
Как вы думаете о чём мы с вами сегодня будем говорить на уроке?
Чем мы сегодня будем заниматься?
Какую поставим цель? (Научиться разбирать слова по составу) Слайд 3
Всё на свете из чего-нибудь состоит: облака из капелек, лес из деревьев.
Слова тоже сделаны из своего материала.
Слово делится на части
Как на дольки апельсин.
И у каждой части слова есть своё название.
Над которыми мы сегодня и будем работать.
2. Актуализация знаний.
Ну а чтобы собрать наше внимание, проведём «Разминку для ума».
Глазки на меня. Отвечаем хором, быстро.
называется…
— Как называется третий зимний месяц?
Какие буквы не употребляются в начале русских слов?
Во что превращается вода зимой….
Часть слова без окончания называется …
Назовите слово, противоположное слову враг.
Самый короткий месяц в году?
— Сколько гласных звуков в русском алфавите?
-Какие части речи мы с вами знаем?
Молодцы!
Ну и конечно, какой урок без словарной работы!
Окрываем тетради , записываем число. Классная работа.
3. Словарная работа.
Конверт № 1.
Для каждого участника в конверте лежат карточки для словарной работы.
Слайд 4
Задание. Прочитайте текст, вставьте пропущенные буквы
Зимой ру . . кий лес сказоч..ный и ч.. десный.
. кий лес сказоч..ный и ч.. десный.
Сне.. украшает пуш.. стые ветки деревьев.
Смолистые шишки в.. сят (на) елях.
В серебряном уборе стоят красавицы — б.. рёзки.
(20секунд)
Кто готов покажите это (чир — фейервек)
Обменялись листочками с партнером по лицу.
Слайд 5 Взаимопроверка по экрану, с объяснением орфограмм.
4. Разминка.
Сейчас мы должны вспомнить все части слова.
Релли Робин -два участника поочередно обмениваются короткими ответами в виде списка)
Конверт № 2.
Вам нужно на этих листочках написать о каких понятиях части слова идет речь. Работаете с партнером по плечу, по очереди. Начинают партнер под буквой Б.
Слайд 6 (30 секунд)
1) Изменяемая часть слова это — ……….
2) Часть слова без окончания это — ………….
3) Часть слова, которая стоит перед корнем и служит для образования новых слов это — ……….
4) Часть слова, которая стоит после корня и служит для образования новых слов это — ……….
5) Главная часть слова это — …….
Кто готов покажите это (чир — фейервек)
Вы вспомнили все, что касается состава слова. Применим это на практике. Сейчас вы работаете с партнером по лицу.
Слайд 7(Приставка,корень, предлог,окончание;
Приставка, корень, суффикс, союз)
Возьмите конверт № 3 . На листочках слова. Назовите 4 — е лишнее слово запишите лишнее слово в тетрадях. Затем поменяйтесь с партнерами листочками и опять найдите 4 – е лишнее. У вас должны получиться 2 слова.
по 20 секунд два раза
Посовещавшись, скажите, какие слова у вас получились лишними?
Стол № 1 участник 2.
Стол № 4 участник 4. Слайд 8
Хорошо, спасибо!
Вывод разминки. Микс Пэа Шэа-звучит музыка, ученики молча смешиваются, двигаясь по кабинету.
— Встаньте, задвиньте стульчики. Возьмите в руки тетради и карандаши. Когда музыка остановится, вы должны образовать пару с ближайшими к вам учениками и «дать пять» (взяться в воздухе за руки), затем я задаю вопрос , а вы должны будете поделится ответом своим партнером и наоборот.
1 – й вопрос. Почему лишними оказались слова предлог и союз.
(Начинает тот, у кого волосы светлее)
(по 15 секунд два раза)
Музыка!!!
(Музыка останавливается, ученики находят другую пару.)
2 – й вопрос. Чем предлоги отличаются от приставок?.
(Начинает тот, у кого волосы длиннее.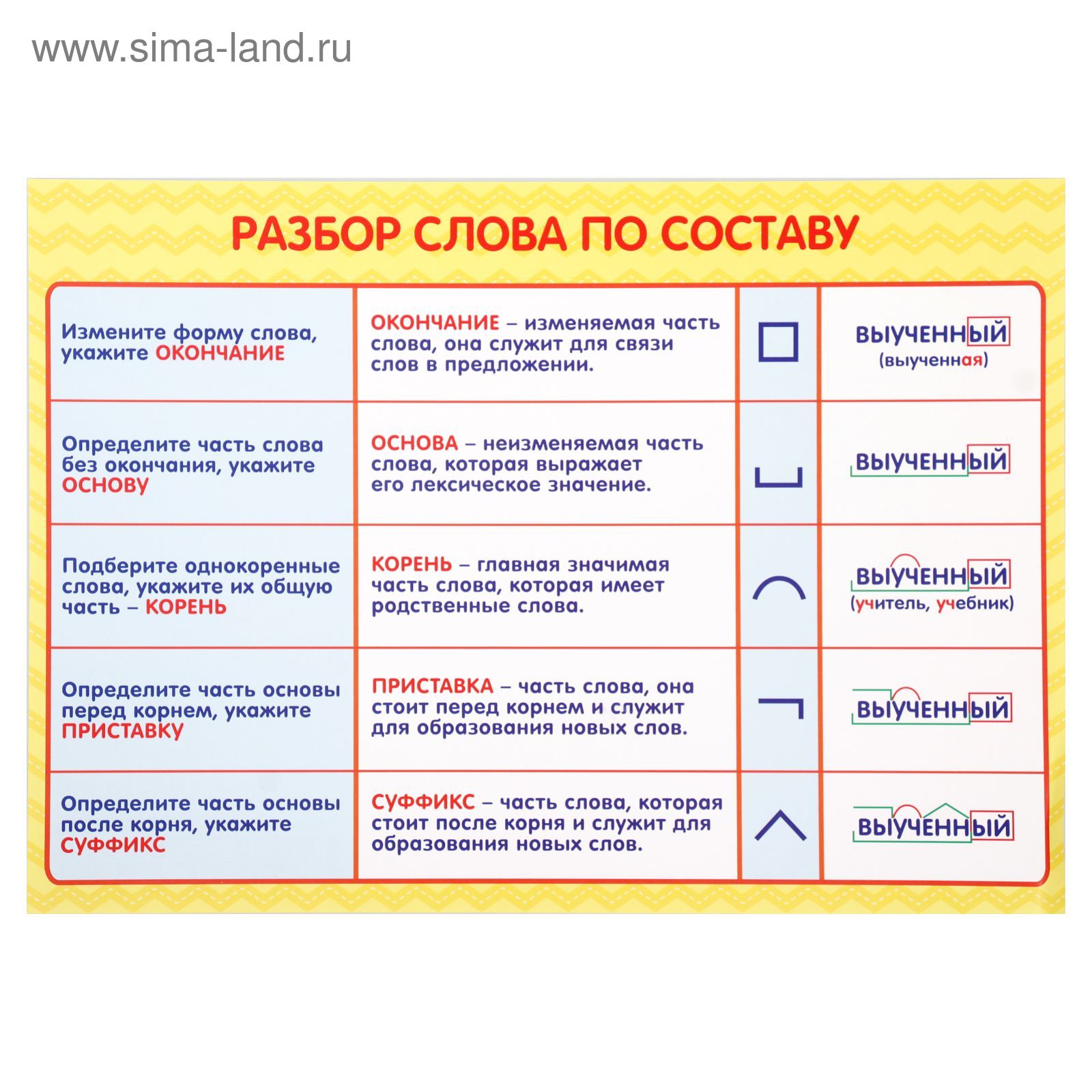 )
)
Ученики делятся ответом со своими партнерами
(по 15 секунд два раза)
Поблагодарите своего партнера.
— А теперь на этот вопрос ответит… (Ceer!)
Музыка!!!
(Музыка останавливается, ученики находят другую пару.)
3 – й вопрос. Для чего необходимо знать состав слова? (Состав слова может объяснить образование слов. Знание состава слова помогает мне увидеть, в какой части слова орфограмма)
(Начинает тот, кто ниже ростом.)
(Ученики делятся своими партнерами
(по 15 секунд два раза)
Поблагодарите своего партнера.
— А теперь на этот вопрос ответит… (Ceer!)
Спасибо, ребята, молодцы! Пройдите на свои места.
— Молодцы!
III. Основная часть.
Основная часть.
1.Раунд Тэйбл (письменная работа по очереди, по кругу на одном листе– по часовой стрелке.)
Конверт № 4 Работа на листочках.
— На карточках к словам из левого столбика подберите правильную схему состава слова из правого столбика и рядом запишите цифру. письменная работа по очереди, по кругу на одном листе– по часовой стрелке
Начинает ученик под номером 2.
Слова……………. Схемы состава слова…………………
Слайд 9
Песенка 1)
Пенал 2)
Подруга 3)
Подсказка 4)
1 минута
Кто готов покажите это (чир — фейервек)
— А теперь на этот вопрос ответит… (Ceer!) Слайд10
Спасибо, ребята, молодцы!
2 . Углы. Конэрс (распределяются по углам от выбранного ими ответа)
Углы. Конэрс (распределяются по углам от выбранного ими ответа)
Конверт № 5
Слайд 11.Каждый из вас должен выбрать одно слово. Запишите в тетрадях. Подберите к нему однокоренные слова. Запишите их.
1. Море
2. Город
3. Лес
4. Сад
2 минуты
Кто готов покажите это (чир — фейервек)
Кто выбрал для себя слово лес – пройдите в тот угол, где нарисован рисунок леса, город – в другой угол и т.д. море в свой угол, сад в свой угол.
— Идите к вашему углу комнаты и найдите партнера для разговора не из вашей команды.
— Обсудите в парах, какие положительные эмоции вызывают данные слова и картинки?
(по 15 секунд два раза).
…! Поделись мнением своего партнера. (Ceer!)
(Ceer!)
( Из каждого угла по 1 человеку.)
— Теперь в вашем же углу найдите другого партнера, с кем вы еще не общались и вместе составьте однокоренные слова с используемым словом на стене вашего угла .
(По 15 секунд два раза ).
Спасибо.
Давайте поблагодарим своего партнера.
Посмотрите на свои бейджики. Образуйте команду, собравшись по цветам .
3. Работа над своими однокоренными словами.
— Сядьте на новые места. Давайте посмотрим, какие же однокоренные слова у вас получились. Стол № 1. У кого слово –море. Прочитай свои слова. Остальные столы дополняют и записывают.
И остальные слова. А для чего мы подбирали однокоренные слова?
Физминутка!!!!!!!!!!!!!!!!!!!!
4. Творческое задание 1.
Слайд 12Что оно означает? КОНСТРУКТОР – тот, кто конструирует что-либо, создает конструкцию чего-либо; это набор частей, деталей, из которых строят разные сооружения.
Вам приходилось собирать что-нибудь из деталей конструктора? Вот и мы с вами сейчас будем конструировать слова.
Конверт № 6
Слайд 13Вы берете ту часть слова, которая указана в таблице. И у вас должно получится новое слово. Каждый работает сам.
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | пословица |
налетели | ученик | куст | молчит | научит |
коньки | мудрец | старость | домик | мудрость |
Кто готов покажите это (чир — фейервек)
Проверка Слайд 14
Можно ли детали, изображённые на карточках, отнести к «словесному конструктору»? Докажите.
(Работа по учебнику с. 157 упр.198 – запас)
Вывод , как нужно правильно действовать при разборе слов по составу?
Слайд 15
Сравним с выводом по книге.
Закрепление. Работа в группе.
Конверт № 7.
Соберите слова из слогов, составленные слова представители групп напишите на доске. По очереди выходим и правильно выделяем части слова, используя алгоритм.
Подберёзовик, добродушная, подосиновик, одноклассники
Как образовались данные слова? Молодцы!
Минутка отдыха слайды 16,17,18
7. Итог урока.
Слайд 19
Урок наш заканчивается, давайте подведём итог.
Над какой темой мы сегодня начали работу на уроке?
Могут ли существовать приставки и суффиксы в речи самостоятельно,
отдельно от слова?
А кто самостоятельно может разбирать слова по составу?
Достаточно одного урока?
Действовали вместе и работали хорошо
А сейчас каждый подумает и оценит свою деятельность на уроке на лесенке успеха.
Что бы вы хотели повторить или узнать о составе слова? На этот вопрос напишите на стикерах, и прикрепите на парковку, это будет ваш билетик на выход с урока.
IХ. Домашнее задание
Стр.158 упр.200
А в заключении хочется показать вам небольшую сказку.
«Кто главнее и важнее»
— Живут на свете удивительные морфемы. Имя у них тоже удивительное и загадочное – суффиксы. Иногда могут звенеть, как колокольчики: оньк, еньк, знь; стучать каблучками: ек, ик, чик, ник; петь, как птички: чив, лив, чив, лив! Суффиксы и приставки поначалу очень дружили и никогда не ссорились. Они много времени проводили вместе. Но однажды они поспорили о том, кто из них лучше помогает корню выражать значение слова.
Приставки. Ну как вы не понимаете?! Возьмём слово выиграть, это совсем не то, что проиграть! А написать самой – это вам не списать у кого-нибудь. И всё это благодаря нам, приставкам! Ну что, нужны после этого ещё какие-нибудь слова?
И всё это благодаря нам, приставкам! Ну что, нужны после этого ещё какие-нибудь слова?
Суффиксы. Конечно, нужны и очень много (выступают вперёд) Мы привели сюда целую семью слов: лесок, лесовик, лесник.
Смотрите, как могущественны в этих словах мы – суффиксы! Захотим — и лес превращается в лесок. А вот и человек, который охраняет лес. И все эти превращения совершили мы – суффиксы.
Прист. Зато, если захотят сказать что-то просто очень-преочень, то на помощь приходим мы, приставки. И тогда говорят прекрасный, прелестный, и вообще: не хорошенький, а прехорошенький, не огромный, а преогромный! Так что да здравствуем мы, приставки!
Суф. Зато мы можем приласкать! И сказать не мама, а мамочка, не Оля, а Оленька!
Уч. Спорили приставки и суффиксы, спорили – чуть не подрались! Спасибо, вовремя корень вмешался – встал между ними.
Корень. Что вы тут расшумелись? Вы попробуйте хоть вместе, хоть порознь что-нибудь без меня, без корня, сказать!
Уч. Приставки и суффиксы пробовали- пробовали, старались-старались, и так и эдак – ничего у них не вышло. С тех пор корень как главный в слове решил так.
Корень. За то, что вы раздор учинили, никогда больше друг друга не увидите, друг до дружки не дотронетесь, а будете стоять от меня по разные стороны: вы, приставки, – слева, а вы, суффиксы, — справа. И станете вы во веки веков меня охранять и мне помогать. А за службу вашу верную я подарю вам дома-терема, и, чтобы вас никто не путал, крыши на них будут разные. У приставок вот такие: , а у суффиксов – совсем другие: . А себе я выберу крышу самую красивую, на месяц в небе похожую. Вот такую: .
Уч. Тут всем спорам конец пришёл. Да и некогда: слов на свете много, работы всем морфемам хватает.
К. В корне смысл, но не весь
В корне смысл, но не весь
Главный, но не полный.
Пр. Потому приставка есть-
Смысл она дополнит.
Суф. — Рад я в этом ей помочь.
После корня встать не прочь!
Ну и что ж, что после корня, —
Всё равно я всех проворней!
Уч. А о какой морфеме ни слова не было сказано в сказке?
Дети. –Об окончании.
Уч. –А вот спешит к нам уже и окончание.
Окон. И на род укажу,
И про время скажу,
И слова все свяжу, хоть и временно.
Ведь недаром всю жизнь
Беззаветно служу
Я родному морфемному племени!
Уч. –Вот и сказке конец, а кто слушал …
Дети. МОЛОДЕЦ
МОЛОДЕЦ
Тест “Состав слова”.
1. Подчеркните части слова, которые ты знаешь.
Союз, корень, знак, окончание, предлог, речь, приставка, слово, текст, суффикс, предмет.
2. Какая часть слова может изменяться? _______________
3.Устно разберите слова по составу. Впиши в нужный столбик слово по схеме.
Лесок, сады, дом, работник, ледяной, день, березка, городок, походы, смелый, поезда, конь, цветник, осенний, погода, дожди.
4. Какая часть слова служит для образования новых слов? _______________________________________________
5. Разбери однокоренные слова по составу.
Соль, подсолнечник, солить, солнце, пересолить.
Урок русского языка по теме «Разбор слова по составу»
Урок русского языка в 3 классе по теме
«Разбор слова по составу» с использованием упражнений занимательного и творческого характера при изучении словарных слов
Русский язык
3 класс
Тема «Разбор слова по составу»
Урок изучения новых знаний
Цели урока:
- сформировать умение разбирать слова по составу;
- развивать внимание и интерес к происхождению слов, способствовать обогащению словаря учащихся, развитию их языкового чутья, мышления;
-
создать условия для воспитания потребности оценивать свою деятельность.


К концу урока учащиеся будут знать:
- в каком порядке нужно выделять в слове части.
К концу урока учащиеся будут уметь:
- разбирать слова по составу (находить окончание, выделять корень, приставку, суффикс).
Оборудование: компьютер (презентация), памятка «алгоритм действий при разборе слова по составу», карточки с кроссвордом, карточки с индивидуальными заданиями, карточки с графическим обозначением частей слова.
План урока
1. Организационный этап.
Психологический настрой (в кругу)
а) «Обмен настроением»
— С каким настроением начинаете урок? (дети делятся своим настроением)
б) А теперь повторяйте за мной:
— Я способен!
— Я со всем справлюсь!
— Мне нравится учиться!
— Я – хороший ученик!
— Я хочу много знать!
— Я буду много знать!
— Я, думаю, что у вас всё получится. Начнём урок.
Начнём урок.
Прочитайте предложение:
Чтобы выполнить большой и важный труд, необходим ясный план. (слайд 1)
— Как вы понимаете это высказывание? (ответы детей).
-Сегодня на уроке мы будем работать по такому плану: (Слайд 2)
- Минутка чистописания
- Словарная работа
- Определение темы и целей урока.
- Игра “Угадай, кто я”.
- Разбор слов по составу.
- «Цветные задания»
- Домашнее задание
- Итог урока. Рефлексия
2. Чистописание
Чистописание
— Прочитайте загадку. (Слайд 3 )
Хочет — прямо полетит,
Хочет — в воздухе висит,
Камнем падает с высот
И в полях поет, поет.
(жаворонок)
— Найдите слово с приставкой, назовите её. Как найти в слове приставку? Какие ещё приставки с О вы знаете?
Чистописание: (Слайд 4)
по под про об о до
3. Словарно — орфографическая работа
— О ком загадка? ( о жаворонке)
— Какое значение имеет это слово? (работа со словарём)
1. Певчая птичка отряда воробьиных.
2. перен. Человек, чувствующий себя утром, в первую половину дня бодрее, чем вечером.
перен. Человек, чувствующий себя утром, в первую половину дня бодрее, чем вечером.
3. Сдобная булочка в виде птички (устар.)
(Запись слова с выделением непроверяемых гласных, подбор родственных слов, составление предложений с изучаемым словом).
Творческое задание. Даны слова : встаёт –поёт. Придумай двустишие.
(Раньше всех из птиц встаёт,
Солнцу песенку поёт.)
4. Определение темы и цели урока
— Для того, чтобы определить тему урока, давайте проверим, как вы знаете словарные слова. А для этого мы решим кроссворд. (Слайд 5)
1. Во дворе поставлен дом —
На цепи хозяин в нём. (Собака)
2. Хозяйственная утварь для еды, питья. (Посуда)
3. В нас хозяин на охоту
В нас хозяин на охоту
Идёт тихонько по болоту.
Обувает нас на ноги,
Когда лужи на дороге. (Сапоги)
4. Без рук, без ног по свету рыщет,
Поёт, танцует, свищет. (Ветер)
5. Зелёная красавица.
Тронешь , обжигается (Крапива)
6. Хочет — прямо полетит,
Хочет — в воздухе висит,
Камнем падает с высот
И в полях поет, поет .
(жаворонок)
-Ребята, если вы внимательно посмотрите на слова, то вы найдете “спрятавшееся” слово, которое будет подсказкой для определения темы урока.
|
|
С |
о |
б |
а |
к |
а |
||||||
|
|
|
|
п |
О |
с |
у |
д |
а |
|
|||
|
|
С |
а |
п |
о |
г |
и |
||||||
|
|
в |
е |
Т |
е |
р |
|
||||||
|
|
к |
р |
А |
п |
и |
в |
а |
|
||||
|
ж |
а |
В |
о |
р |
о |
н |
о |
к |
||||
— Догадались?
-Верно! Состав. Это слово имеет несколько значений. (Работа с толковым словарем. Состав – совокупность частей, элементов, образующих какое-нибудь целое).
Это слово имеет несколько значений. (Работа с толковым словарем. Состав – совокупность частей, элементов, образующих какое-нибудь целое).
(Слайд 6)
Открывается тема урока на доске «Разбор слов по составу».
(Проблемный вопрос)
— Чему мы должны научиться? (Разбирать слова по составу).
-Что для этого нужно знать? (Что такое приставка, корень, суффикс, окончание и как их находить в словах).
Физкультминутка для глаз
5. Актуализация знаний
— Проведём игру “Угадай, кто я”
-
Часть я очень главная, в слове я живу. Без меня нет смысла ни розе, ни ежу (Корень).
- Я и часть, я и предлог. Без меня никто не смог. Я и слово и добавка. Называюсь я … (Приставка).
- Ну а я частичка. Обозначусь я, как птичка. Только вот наоборот. Это каждый разберёт (Суффикс).
- Меня в окошко обозначат. Для связи слова я служу, какой смысл в каждом предложении, я всем и сразу расскажу (Окончание)
— Как в слове найти окончание? Корень? Приставку? Суффикс?
6. Изложение нового материала
(Проблемный вопрос)
— Как вы думаете, что значит разобрать слово по составу? (Предположения детей)
-Обратитесь к толкованию слова СОСТАВ
(Найти и обозначить все части слова).
—Вы уже умеете находить в слове корень, суффикс, приставку, окончание.
А как вы думаете, в каком порядке нужно выделять в слове части?
-Ответ на этот вопрос вы найдёте самостоятельно. (Работа с алгоритмом действий при разборе слова по составу на форзаце учебника. Работа в парах.)
-Так в каком порядке нужно выделять части в слове? ( Окончание, корень, приставка, суффикс).
7. Этап первичной проверки понимания изученного
— Покажите порядок выделения частей слова (дети выкладывают карточки с графическим обозначением частей слова)
— Давайте разберём по составу слово ЗАМОРОЗКИ (Слайд 7 — алгоритм)
8. Закрепление новых знаний, применение их на практике
-
1) — Прочитайте стихотворение (упр. 184)
 184)
184)
Шар надутый две подружки
отнимали друг у дружки –
весь перецарапали.
Лопнул шар, а две подружки
посмотрели – нет игрушки,
сели и заплакали.
Выделенные слова разберите по составу, пользуясь планом, данным на форзаце учебника. (Работа в парах, взаимопроверка)
- 2) «Цветные задания)» (дифференцированная работа)
На парте лежат листы разного цвета (разноуровневые задания).
1-й уровень (синие карточки)
Запиши, устранив в каждом ряду “лишнее” слово. Разбери слова по составу.
А) Нос, носит, носик, носатый.
Б) Гусь, гусята, гусеница, гусыня.
(А- носит; Б- гусеница;) (Слайд 8)
2-й уровень (оранжевые карточки)
Карточки: собери слова. Разбери слова по составу
(Заморозки, лётчик, посадка) (Слайд 9)
3-й уровень (красные карточки)
Суффиксы и приставки перепутали свои места и получились неизвестные слова. Помоги всем частям слова найти свои места. Подбери каждому слово однокоренное, разбери по составу.
оклеспере никводпод ОВИКБЕРЁЗПОД
(Перелесок, подводник, подберёзовик) (Слайд 10)
-
3) «Собери» слово (упр. 186) (Слайд 11)
 186) (Слайд 11)
186) (Слайд 11)
9. Инструктаж по выполнению домашней работы
Упр.187
10. Подведение итогов урока. Рефлексия.
Закончи фразу (Слайд 12)
Сегодня на уроке я:
-научился…
-было интересно…
-было трудно…
-своей работой на уроке …
-теперь я умею …
-Быстро время пролетело и идёт к концу урок. На уроке мы хорошо поработали, справились со всеми заданиями.
-Давайте вспомним, каким он был для вас?
У— увлекательным, умным, удивительным, успешным.
Р — радостным, развивающим.
О — отличным, отменным.
К — комфортным, командным, коммуникативным.
-Молодцы! Спасибо за урок!
Технологическая карта урока
|
Этапы урока, время |
Дидактическая задача этапа |
Методы, приёмы обучения |
Форма организации деятельности |
|
1. 2 мин. |
Подготовить учащихся к работе на уроке.
|
Психологический настрой |
Фронтальная |
|
2. Чистописание
3 мин |
Показать образец каллиграфического письма, повторить правила нахождения приставки в словах
|
Наглядный
|
Фронтальная |
|
3. 4 мин |
Организовать изучение и усвоение написания словарных слов |
Частично-поисковый,
|
Фронтальная Групповая (парная) |
|
4.Определение темы и цели урока 4 мин |
Организовать и направить на достижение цели познавательную деятельность учащихся.
|
Проблемный, Частично-поисковый |
Фронтальная + групповая |
|
Физкультминутка для глаз ( 2 мин) |
|||
|
5. 5 мин |
Поверить знания учащихся, выявив причины обнаруженных пробелов, стимулировать учащихся к овладению рациональными приемами учения и самообразования.
|
Репродуктивный |
Фронтальная |
|
6.Изложение нового материала 6 мин |
Дать учащимся конкретное представление о способе разбора слова по составу |
Словесные Проблемный метод
|
Фронтальная, индивидуальная
|
|
7.
3 мин |
Проверить правильность и осознанность изученного материала, выявить пробелы первичного осмысления, провести коррекцию |
Репродуктивные Практические |
Фронтальная |
|
8.Закрепление новых знаний, применение их на практике
10 мин |
Закрепить у учащихся знания и умения, необходимые для самостоятельной работы по новому материалу.
|
Практические, метод самостоятельной работы |
Групповая, индивидуальная |
|
9. Инструктаж по выполнению домашней работы 2 мин |
Сообщить учащимся о домашнем задании, разъяснить методику его выполнения. |
Словесные |
Фронтальная, индивидуальная |
|
10.Подведение итогов урока.
Рефлексия 4 мин |
Подвести итоги урока.
Создать условия для осмысления учащимися своих действий |
«Закончи фразу» |
Фронтальная
Индивидуальная |
 Организационный этап.
Организационный этап.
 Словарно-орфографическая работа
Словарно-орфографическая работа
 Актуализация знаний
Актуализация знаний
 Этап первичной проверки понимания изученного
Этап первичной проверки понимания изученного

 Дать качественную оценку работы класса
Дать качественную оценку работы класса
Учитель Мысак Маргарита Леонидовна
Разбор слова по составу, морфемный разбор онлайн — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Морфемный разбор онлайн, разбор слов по составу, примеры
Разбор слова по составу, или морфемный разбор, — выделение частей, из которых слово состоит. Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах. Надеемся, что сайт поможет вам в подготовке домашних заданий.
План разбора
План разбора слова по составу состоит в следующем:
- Определяем, к какой части речи относится анализируемое слово.
- Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи.
- Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами.
- Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым.
- Обозначем части слова с помощью графических обозначений.

Примеры разборов
Покажем примеры разбора слов разных частей речи с разной комбинацией морфем:
- метро — неизменяемое существительное, нет окончания
- лес — существительное с нулевым окончанием
- пришкольный — прилагательное со всеми основными морфемами: приставкой, корнем, суффиксом, окончанием
- ледокол — существительное с двумя корнями и соединительной гласной
- позвала — глагол с приставкой, окончанием, словооразующим суффиксом а и формобращующим суффиксом л, который не входит в основу
- быстро — наречие с суффиксом, не имеет окончания
Подберите нужные слова с необходимыми частями слова через поиск слов по морфемам.
Особенности разборов
Обратите внимание: морфемные разборы одних и тех же слов могут быть сделаны по-разному в разных словарях, разными учителями и филологами, в школе и в университете. Каждый «источник» аргументирует разбор по-своему и считает свой разбор правильным.
Разные учителя придерживаются разных программ определения морфем в словах. Ярким примером служат инфинитивы глаголов. Например в слове жить: в одних школах ть отмечается как суффикс, в других — как окончание, в третьих — как суффикс с последующим нулевым окончанием. Мы выделяем морфемы по первому варианту.
Образовательные программы школы и университета в части разбора слов могут различаться. В университетах учитывают этимологию слов, выделяют нулевой суффикс (Азов, бег), рассматривают словообразования от нулевого корня и другие сложные примеры. Мы используем программу, ориентированную на школу, и деление на морфемы по словарю А.Н. Тихонова.
Заметим, что есть различия в словаре А.Н. Тихонова и словаре Т. Ф. Ефремовой. Так А.Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т.Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
Ф. Ефремовой. Так А.Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т.Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
При разборе слов следует помнить, что бывают слова, содержащие нулевое окончание (автобус), не имеющие окончания (ателье), имеющие несколько корней (авиапочта) и другие сложные варианты. К сложным вариантам на нашем сайте даны объяснения.
Морфемные словари
Среди печатных изданий словарей морфемных разборов, которые вы найдете в школьной библиотеке, можно выделить следующие:
- Рацибурская Л.В. Словарь уникальных морфем современного русского языка М.: Флинта: Наука, 2009. — 160 с.
- Аванесов Р.И., Ожегов С.И. Морфемно-орфографический словарь Около 100 000 слов / А. Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с.
- Тихонов А.Н. Морфемно-орфографический словарь русского языка, 2002.
- Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с.
 — 704 с.
— 704 с.В словарях морфемных разборов обычно деление на морфемы делается с помощью слешей: под/вод/н/ый, гор/а и т.д. В словаре Т.Ф. Ефремовой у группы слов с одинаковым корнем исходное слово записано полностью, а в образованных от него словах корневая морфема обозначается через знак V: лес, V-а, V-н-ой и т.д.
Как разобрать по составу слово «ИЗВЕСТНЫЙ»?
В составе прилагательного «известный» вычленим всего две морфемы: корень и окончание.
Слово «известный» имеет лексическое значение «тот, которого все знают; выдающийся, общепризнанный».
Разбор по составу
Морфемный разбор этой лексемы начнем с выделения словоизменительной морфемы — окончания. Чтобы определить окончание, изменим анализируемое прилагательное по родам и числам:
известная картина;
известное сообщение;
известные писатели.
Сравнив формы слова, укажем в его морфемном составе окончание -ый, которое, как словоизменительную морфему, не включаем в основу:
известный
В слове «известный» элементы из-, -н- очень похожи на приставку и суффикс. Но так ли это?
Корень слова «известный»
Чтобы правильно установить морфемный состав интересующей нас лексемы, вспомним, что такое однокоренные слова. Определить границы корня рассматриваемого прилагательного поможет подбор родственных слов:
известно, известность, неизвестный, неизвестно, неизвестность, безызвестный, безызвестность
Во всех однокоренных словах прослеживается общая часть известн-, в которой заключено их основное лексическое значение: «общепризнанный, популярный, признанный, выдающийся своими умениями, способностями, талантом».
Следовательно, морфемный состав анализируемого прилагательного запишем в виде следующей схемы:
известный — корень/окончание
Не следует помещать в этот ряд слов с корнем известн- похожие лексемы, связанные с вестью:
весть — весточка, вестовой, известие, известить, оповестить
В этом ряду однокоренных слов их главная морфема вест- имеет другое лексическое значение — «сообщить, проинформировать, доложить, уведомить».
Как видим, значение корней известн- и вест- различные, хотя когда-то прилагательное «известный» имело прямую смысловую связь с вестью, но с течением времени приставка и суффикс срослись с корнем и образовали корневую морфему известн- со своим лексическим значением, отличным от смысла лексем с корнем -вест-.
Скачать статью: PDFРазбор слов по составу | Тренажёр по русскому языку (3 класс) по теме:
Фамилия,имя______________________ Разбери по составу: Травушка травинка молоденький
рассвет светлячок ветерок моряк полюшко рысёнок самовар золотые побережье бережок небо небеса голуби прибрежная полоска лисята лесник город | Фамилия,имя______________________ Разбери по составу: Времена перевязь глазной глоток гнёздышко горный давний далёкий подарок денёк детёныш длинный дождливый вздох дочурка дровишки дроздовый еловый жарища желток котёнок ночник выпечка плясун |
Фамилия,имя______________________ Разбери по составу: Зелёный зеркальный позолота ловец замазка игривый игрушка качка носишко конина котёнок красивый лесник крикливый
кровинка ледник летучий ловушка овчина парник перина мировая низина новизна | Фамилия,имя______________________ Разбери по составу: Плечистый пчелиный пятнашки робкий садовый свинина свисток божок бочар больной силач синева ходули подсказка скворушка снежинка хитрый травинка тропинка сосновый соринка |
КАРТОЧКИ ДЛЯ РАЗБОРА СЛОВ ПО СОСТАВУ
1. ПОМОЩНИК СДВИГ НАКЛОН
ПОМОЩНИК СДВИГ НАКЛОН
ВЫСТАВКА КАЧКА ДРУЖОЧЕК
ШКОЛЬНИК НАКИПЬ БАБУШКА
_______________________________________________________
2. СГИБ ДЕДУШКА КНИЖЕЧКА
ПОМОЩНИЦА СОСЕДКА КОРАБЛИК
БЕЛИЛА ШАЛУН СТОЛЯР
______________________________________________________
3. ШАЛОСТЬ СТРЕЛОК ОТМЕТКА
ПЕРЕБЕЖКА ПАРОХОД ЗАМАЗКА
КРИКУН ПОЛОВИКИ ГОРСТКА
________________________________________________________
4. ОБЛАЧКО ОЗИМЬ ПРИЗВАНИЕ
ПОЕЗД ГОРСТКА ОЧИСТКИ
ГНЕЗДЫШКО ДВЕРКА ДРУЖОК
_________________________________________________________
5. НАГРУЗКА РАЗГОВОР МАСТЕРСТВО
НАГРУЗКА РАЗГОВОР МАСТЕРСТВО
ОХРАНА ЗАГЛЯДЕНИЕ ВЕТОЧКА
СКОРЛУПКА ДУБОК ЗИМУШКА
_______________________________________________________
6. ГРАДУСНИК ЕЖИКИ НАКЛОН
ТРЯСКА БЕЛИЗНА ЗАБОЛЕВАНИЕ
ГЛАЗОК ПОЛЯНА ТИШИНА
________________________________________________________
7. СЕРДЕЧНЫЙ ТИГРЕНОК САРАЙ
ЗВЕРЕК СЛОВЕЧКО МОРСКАЯ
ЧАСОВЩИК РАСТЕНИЕ РУССКИЙ
_________________________________________________________
8. РАССКАЗ ПОДДЕРЖКА ЦИРКАЧ
ВЕСЕЛЬЕ ПОБЕДА ДЕЛОВЫЕ
ЗВЕРИНЕЦ СНЕГОВИКИ СКРИПУЧАЯ
_______________________________________________________
9. ГРУЗОВОЕ КОРМУШКА ПОВАРЕНОК
ГРУЗОВОЕ КОРМУШКА ПОВАРЕНОК
ЗАВЯЗКА ЛЯГУШЕЧКА ДЕВОЧКА
ОТГАДКА СИНЕНЬКИЕ ПРИБРЕЖНАЯ
______________________________________________________
10. ПЕРЕХОД ПОЖАР ТРАВУШКА
КАРТИНА ПЕСЕНКА КРЫЛАТЫЕ
ЗАМЕСТИТЕЛЬ РАЗЛИНОВКА ПРОЕЗД
__________________________________________________________
11. ХВАСТЛИВАЯ СЕНОКОС ДОРОЖКА
ПАРОХОД МАЛЕНЬКИЕ ЕЛЬ
СОЛНЦЕ ЛОШАДКА ВОДОПАД
_________________________________________________________
12. КРЕПОСТЬ ПОГРАНИЧНИК ПЫЛЕСОС
МУДРАЯ МОРОЗНЫЕ ПИРОЖОК
ЛЕДОХОД ЧАЙНИК СДАЧА
Проверочная работа по русскому языку на тему «Состав слова» (3 класс)
Проверочная работа по теме «Состав слова»
3класс
Планируемый результат: уметь разбирать слова по составу
Базовый уровень
1. Знание алгоритма разбора слов по составу.
Знание алгоритма разбора слов по составу.
Запиши алгоритм разбора слов по составу.
Выделю _______________________, для этого _________________________.
Выделю _______________________, для этого _________________________.
Выделю _______________________, для этого _________________________.
Выделю _______________________, для этого _________________________.
Выделю _______________________, для этого _________________________.
2.Знаний определений основных морфем слова..
Продолжи высказывания:
Корень слова- это _____________________________________________________.
Основа слова – это ____________________________________________________.
Окончание слова — это _________________________________________________.
Приставка слова – это __________________________________________________.
Суффикс слова –это ____________________________________________________.
3. Умение: определять наличие в слове заданной морфемы.
Выдели окончание в словах.
Глазной, денёк, ловушка, котёнок, еловый, побег, скользкий, времечко, вратарь, перины.
4. Умение: подбирать однокоренные слова.
Подбери не менее 3 однокоренных слова.
Снег __________________________________.
Дорога _________________________________.
Ночь _____________________________________.
5. Умение: определять наличие в слове заданной морфемы.
Выдели приставку в словах.
Отполз, обсудил, подпрыгнул, всадник, улов, подумал, перевод, заметный, выход, сделал, осмотр, дослушал, промокашка, надпись.
6.Умение : определять наличие в слове заданной морфемы.
Выдели суффикс в словах.
Котик, лисонька, мудрец, грибок, дружба, избушка, мудрость, глазище, веточка.
Задание 7
7.Умение определять наличие в словах заданных морфем.
Разбери слова по составу.
Подземный, водица, каменистый, подстаканник, головка, речной, медвежата, морской.
Задания повышенного уровня
1. Умения: определять наличие в слове заданной морфемы;
Умения: определять наличие в слове заданной морфемы;
различать родственные слова и формы слова;
Даны два ряда слов. Запиши в таблицу название каждого ряда и назови части слова, которыми различаются слова в ряду.
1)игра, игру, игры, игре, игрой;
2) игрушка, игривый, игрушечный, игрушечка
Название ряда
Части слова, которыми различаются слова в ряду
2.Умение: различать родственные слова;
Прочитай, определи какое слово лишнее. Выпиши однокоренные слова, выдели корень.
Краска, украшать, красить.
Крупа, крупный, крупяной, крупинка.
Дорога, подорожник, путь, дорожная.
Вода, подводный, водитель, водичка, водный
3.Умение: определять наличие в слове заданной морфемы.
Какие ещё части слова, кроме корня, есть в слове оленьи?
Обведи номер ответа:
1)приставка и окончание
2) приставка, корень, окончание
3)корень и окончание
Приведи 2 примера слов с таким же составом.
4.Умение: подбирать слова с однозначно выделяемыми морфемами к заданной схеме слова
Отметь ряд, в котором слова расположены в такой последовательности.
— корень, окончание; корень, суффикс, окончание; приставка, корень, суффикс, окончание
1) рука, холодный, облачный;
2)морозы, уроки, находка;
3) книга, зонтики, посадка;
4)пальто, морозный, забота
Проверочная работа «Состав слова», 3 класс
Проверочная ая работа во 3 классе «Состав слова»
Ф.И.___________________________________________
1.Соедини стрелкой верные утверждения:
1. Корень — это … | 1) часть слова, которая стоит после корня и служит для |
2. Приставка — это … | 2) изменяемая часть слова, которая служит для связи слов |
3. Суффикс — это … | 3) часть слова, которая является общей для родственных слов; |
4. Окончание — это … | 4) часть слова, которая стоит перед корнем и служит для образования |
5. | 5) часть слова без окончания. |
 Основа — это…
Основа — это…
2. Укажи часть слова, без которой не может существовать слово:
1. Приставка
2. Корень
3. Суффикс
4. Окончание
3.Найди слова с приставками:
Принести, растить, катать, обрадоваться, спрятать, рассмеяться, печь, научиться, вести , помогать.
4.К данным словам припиши противоположные по значению с тем же корнем. Выдели приставку.
развязать – связать
раздвинуть – …
разложить – …
развернуть – …
разлепить – …
вбежать – …
внести – …
въехать – …
ввести – …
вползти – …
5. Вставь пропущенные буквы. Разбери родственные слова по составу.
1) Гр_бы – дружный наро_. Ч_сто их можно увидеть б_льш_ми с_мейками и стайками. Недаром гр_бники г_в_рят: где один гр_бок, там и весь кузовок.
2) Хол__, х_лодный, х_л_док, х_л_дильник, пох_л_дало, х_л_дец.
3) Мол_дец, м_л_дой, м_лоденький, пом_л_дела, мол_дость.
6.Найди слова с приставками:
(за)брать , (в)окно, (у)летать , (за)грибами, (с)правиться , (с)другом, (на)правлять , (до)бежать, (до)дороги, (на)родину.
7.Выдели корень. Вставь пропущенные буквы. В скобках запиши проверочное слово.
Н_чной (___ ______________ ), кр_чать (_________________),
х_лодный (___________________), г_лодный (_______________),
п_сьмо (___________________), сл_ненок (______________ __),
м_ряк (___________________), с_довник (________________),
ч_стота (__________________), л_сенок (_________________).
В словах подчеркнуть орфограммы.
Урок русского языка по теме «Состав слова (обобщение)» (3-й класс)
Цель: Обобщить знания учащихся о составе слова.
Задачи:
Обучающие:
- повторить изученные признаки родственных слов;
- проверить сформированность понятий: состав слова, приставка, суффикс, корень, окончание, основа;
- совершенствовать знания об однокоренных словах и значимых частях слова;
Развивающие:
- развивать память и орфографическую зоркость;
- развивать умение разбирать слова по составу;
- развивать умение образовывать новые слова;
Воспитывающие:
- воспитывать любовь к природе;
- воспитывать активность и аккуратность у
учащихся.

Программа: Гармония.
Учебник: Соловейчик М. С., Кузьменко Н.С. К тайнам нашего языка (часть 1). 3-й класс – Смоленск: издательство “Ассоциация XXI век”, 2005.
Оборудование: предметные картинки, цветные карточки, компьютер, проектор, презентация (Слайд 1. Презентация).
I. Организационный момент.
Здравствуйте, ребята! Давайте улыбнемся друг другу. Я рада видеть ваши улыбки, надеюсь, что и сегодняшний урок принесет вам радость.
II. Проверка домашнего задания.
У. Ребята, вспомните, над какой темой мы работали на прошлом уроке? (Слайд 2) Какое задание вы получили на дом?
Давайте посмотрим, как вы справились с домашним заданием (упр. 29, с. 13).
Как вы решили орфографические задачи? Какие буквы вставили? Как проверяли? Какие слова устроены не так, как другие?
— Какие части слов вы выделили?
— А теперь давайте ответим на вопросы, которые
есть в этом упражнении.
— Какие звуки могут чередоваться? (К-ч, г-ж, ц-ч, х-ш) Приведите примеры слов. (Снег – снежок, бег –бежать)
— Приведите примеры, где гласные звуки “убегают”. (Сыночек – сыночка)
III. Сообщение темы урока.
— Ребята, на предыдущих уроках мы работали над составом слова. Что значит – разобрать слова по составу? (Находить части слов и выделять их) Вам понравилось разбирать слова по составу? Хотите продолжить эту работу? Так вот сегодня мы будем закреплять и обобщать знания о составе слов, учиться образовывать новые однокоренные слова. Но для этого нам придется потрудиться и активно поработать на уроке.
IV. Минутка чистописания и словарная работа.
У. А урок сегодня будет необычным, мы с вами отправимся в путешествие. А для того, чтобы узнать, куда – посмотрите на слайд и картинку на доске, попробуйте отгадать. Кто догадался? (В космос) (Слайд 3)
— Кто знает значение этого слова?
А теперь давайте откроем толковые словари и узнаем значение слова “космос”, посмотрим правы мы или нет. (Космос – “вселенная”, “мир”)
— А кто помнит стихи или загадки про космос?
— А теперь сделайте фонетический анализ этого слова. (Дети выходят к доске и делают разбор) Какой первый звук? Какой буквой он обозначается? Вот сейчас мы вспомним, как пишутся заглавная и строчная буква к.
(Учитель показывает образец на доске, а дети пишут в тетради ) А теперь попробуйте отгадать ребус. (Слайд 3)
У. Космос – слово словарное. (Можно открыть орфографические словари и посмотреть как оно пишется) Учитель записывает слово на доске, вместе с учениками ставим ударение, находим безударную гласную, подчеркиваем ее.
— А теперь сравните, как слово слышится и как оно пишется. Есть различия? Какие? (Слышится ы, а пишется о) Постарайтесь запомнить и запишите это слово до конца строки в тетрадь правильно, красиво и аккуратно.
Попробуйте самостоятельно подобрать однокоренные слова к слову космос.
А теперь посмотрите на слайд, подумайте, какое слово лишнее. Почему? (Слайд 4)
Космос, космонавт, ракета, космический.
Д. Космический, т.к. это имя прилагательное, обозначает признак предмета, а остальные – существительные.
У. Какое еще слово может быть лишним?
Д. Ракета. Космос, космонавт, космический – однокоренные.
У. Какое значение имеет слово “ракета”? (1 – Летательный аппарат, 2 – снаряд для фейерверков, 3 – быстроходное судно на подводных крыльях) Как вы думаете, какое значение подходит в нашем случае? (летательный аппарат) Какое это слово? (Словарное, его написание тоже надо запомнить)
— Значение слова космос мы сегодня выяснили. А какое значение имеют остальные слова? (Космонавт- человек, совершающий полет в космос, космический – относящийся к космосу) Почему эти слова можно назвать однокоренными? (Они имеют общий корень и являются родственными, т.е. близкими по значению) Запишите слова. Выделите корень в этих словах. (Слайд 6)
— А теперь составьте предложения с этими словами. Три самых лучших и красивых предложения давайте запишем на доске и в тетради. (3 ученика работают у доски по очереди, остальные в тетради) Найдите орфограммы и объясните их. Составьте схемы этих предложений.
— Что такое “космос” мы выяснили, а теперь можно и в путь.
У.
Далекие звезды над нами горят,
Зовут они в гости хороших ребят.
Собраться в дорогу нетрудно для нас –
И вот мы к полету готовы сейчас.
— Итак, в космос мы отправляемся на ракете, на той, что вы сделали сами на уроке труда. (Слайд 7)
V. Работа по учебнику.
У. Но, чтобы попасть в ракету, мы с вами должны выполнить упражнение 30 с. 13. Прочитайте слова (деревня, капуста, город, береза, лимон). Попробуйте подобрать по 3 однокоренных слова к каждому (можно больше) и разобрать их по составу. А три человека будут в это время работать по карточкам.
1.
2.
3.
Заканчиваем работу. Сдаем карточки. Мы с остальными ребятами проверяем, какие слова придумали, какие части слова выделили.
— Вспомните, что такое основа. Какое значение она передает? (Смысл конкретного слова)
— Какое значение передается корнем слова? (Смысл всех родственных (однокоренных) слов). Чем отличается основа от корня?
С заданием мы справились хорошо, вот мы с вами уже и в ракете.
Обобщение по теме.
Внимание! Взлет!
И наша ракета мчится вперед.
Прощально мигнут и растают вдали
Огни золотые любимой Земли.
Мы с вами на старте. Как вы думаете, что мы сможем увидеть в космосе? (Планеты, спутники, звезды…) Летим! Можно даже выйти в открытый космос. (Слайд 8)
Сейчас вы закроете глаза и попробуйте представить, как мы с вами летим. А я расскажу, что же нам встретится на пути. Вы будете слушать и в моем рассказе постарайтесь найти слово, которое употребляется в разных формах. Отправляемся в путь.
“Впереди небо, которое усыпано множеством звезд. Очень красиво! Нам на пути встречаются звезды голубого, желтого, красного цвета. Расстояния между звездами огромны. Мы летим. Чувства переполняют. Так и хочется об этих звездах сложить песню”.
У. Сейчас я еще раз прочитаю текст, а вы на строке поставьте цифру 1 и запишите слова, которые вы нашли.
1.
Выделите окончания, основы слов. Расскажите все, что знаете об окончании.
Д. Окончание – это изменяемая часть слова, которая служит для связи слов в предложении.
— Как называется значение основы? (Лексическое) Как называется значение окончания? (Грамматическое)
Давайте вместе проверим, что у вас получилось. (Слайд 9)
— А теперь сами придумайте слово, попробуйте изменить его. Как еще можно изменить? Запишите в тетрадь и выделите окончание. Теперь обменяйтесь тетрадями с соседом по парте, проверьте.
У. Вот мы с вами прилетели на одну из планет. Эта планета очень необычная, фантастическая. А давайте мы сделаем подарок этой планете – посадим дерево. Но сначала вспомним, какие части есть у дерева.
Д. Корень, ствол, ветки, листья. (Слайд 10)
У. А какая часть самая главная?
Д. Корень.
У. А дерево мы посадим необычное – словообразовательное. На нем будут вырастать новые слова. У нашего будущего дерева корень -уч- .Что бы оно выросло, надо ответить на вопросы:
— Как с помощью этого корня называют вас? (Ученики)
— Почему вас так называют? (Т.к. учимся)
— Как называют того человека, который учит? (Учитель)
— Над какой пословицей мы работали на прошлом уроке? (Ученье – свет, а неученье – тьма.)
Запишите эти слова на вторую строку. Выделите корень.
2.
У. Какие это слова?
Д. Однокоренные.
У. Почему их так называют?
Д.У этих слов общий корень, они близкие (родственные) по значению.
У. Что такое корень?
Д. Корень – это общая часть однокоренных слов. (Слайд 11)
У. Вот какое красивое дерево выросло.
— Но у него осталось три пустых ветви. Вы сами придумайте еще три однокоренных слова и запишите их.
Хоть планета и необычная, но на ней очень красиво. Воздух чистый. Вода в реке – прозрачная. Небо голубое. Много цветов. Пора отдохнуть.
V. Физкультминутка.
Наши нежные цветки
Распускают лепестки.
Ветерок чуть дышит
Лепестки колышет.
Наши нежные цветки
Закрывают лепестки.
Тихо засыпают
Головой качают.
(Слайд 12)
V. Обобщение (продолжение).
У. А цветы на планете тоже загадочные. Один из них очень похож на цветок, который растет в нашей местности. Какой?
Д. Ромашка.
У. На этой планете такой цветок называется приставочным.
Как вы думаете, почему?
Д. На лепестках – приставки. (Слайд 13)
У. Образуйте с помощью этих приставок и корня -уч- новые слова. (Проверьте по слайду) Запишите их на третьей строке (записывать будем по одному слову с каждой приставкой) и выделите приставки.
3.
У. Что такое приставка? Для чего она служит?
Д. Приставка – часть слова, которая стоит перед корнем и служит для образования новых слов. (Слайд 14)
— Какие еще приставки вы знаете? Попробуйте составить с ними и с корнем -уч- новые слова. Со всеми ли приставками можно составить слова? Запишите, выделите приставку и корень.
— Найдите слова, обозначающие действие предмета. (На слайде по щелчку – подчеркнуты желтым цветом) Как называются такие части речи? (Гаголы) Какая это форма глагола? (Начальная, неопределенная) Давайте вспомним, как можно разобрать эти слова по составу. Какие одинаковые части слов вы увидели в глаголах. (Корень -уч-, суффикс -ть) Но есть учебники, в которых этот суффикс выделяют как окончание. Это не является ошибкой. Но вам я предлагаю в дальнейшем выделять -ть – как суффикс.
У. Двигаемся дальше по планете. Перед нами “Суффиксное поле”. Но на пути к нему сломался мостик через реку. На одном берегу остались слова, а на другом – суффиксы. Чтобы восстановить мостик, надо присоединить суффиксы к словам. Полученные слова запишите на четвертой строке.
(Слайд 15)
4.
Вот и мостик! (Слайд 16)
У.Выделите суффиксы. Что такое суффикс? Для чего он служит?
Д. Суффикс – это часть слова, которая стоит после корня и служит для образования новых слов. (Слайд 17)
— Составьте сами новые слова с этими суффиксами. Запишите эти слова и выделите суффиксы.
У. Посмотрите пронумерованные строки. Назовите по порядку части слов, которые вы выделяли.
Д. Окончание, основу, корень, приставку, суффикс.
У. Как называется такой разбор?
Д. Разбор слова по составу.
У. Найдите памятку в учебнике и прочитайте. А теперь проверим, чему вы научились на этой планете.
VI. Самостоятельная работа.
У. Сделайте разбор слов по составу. (Слайд 18)
У. Проверьте по слайду.
Какие это части речи?
Д. Имя существительное, имя прилагательное, глагол.
У. Сделайте разбор частей речи, используя памятку.
Сверьте свои работы с теми, что на доске. Поставьте себе оценку.
Сегодня мы с вами побывали в космосе. Прочитайте запись на доске.
Космос – это пространство за пределами нашей земли. Освоение космического пространства началось давно. Люди стали запускать в космос ракеты и спутники. Первыми в космосе побывали животные. А потом туда полетел человек.
Скажите, это текст? Почему вы так решили? Что такое текст? (Текст – это несколько предложений, в которых говорится об одном и том же и раскрывается общая мысль) Сколько в тексте предложений? Найдите третье предложение. Запишите его в тетрадь. Какое оно по цели высказывания и по интонации? (Повествовательное, невосклицательное) Можно ли этот текст дополнить другими предложениями? Составьте 1-2 предложения. Устно вставьте их в текст. Стал текст лучше или хуже? Почему вы так считаете?
VII. Итог.
У. Нам уже пора домой. Но, прежде чем отправиться в путь, давайте узнаем, как называется эта планета. Для этого надо отгадать кроссворд. (Слайд 19)
1. Изменяемая часть слова.
2. Часть слова, которая стоит перед корнем и служит для образования новых слов.
3. Часть слова, которая стоит после корня и служит для образования новых слов.
4. Общая часть однокоренных слов.
У. Планета, на которую мы прилетели, называется Планетой морфем.
Морфемы – это части слов, которые мы сегодня выделяли. А разбор слова по составу называется морфемным разбором.
Возвращаться нам пора,
По местам мои друзья!
Из полета возвратились,
Мы на землю приземлились.
(Слайд 20)
Вам понравилось путешествие? Какое настроение у вас после урока? Покажите цветные карточки, которые соответствуют вашему настроению.
VIII. Оценка.
(Оценивается самостоятельная работа в тетради и работа на уроке)
IХ. Домашнее задание.
Повторить правила о правописании безударных гласных в корне слов, парных согласных, удвоенных согласных, повторить порядок разбора слов по составу. Подготовиться к контрольной работе.
Х. Литература. (Слайд 21)
- Соловейчик М.С., Кузьменко Н.С. К тайнам нашего языка: учебник русского языка для четырехлетней начальной школы. – Смоленск: Ассоциация ХХI век, 2005 г.
- Волина В. В. Веселая грамматика. – М.: Знание.
- Перекатьева О.В. Первоклашки в гостях у сказки. – Ростов н/Д: “Феникс”.
«Разбор слова по составу». — Международная Ассоциация Развития Образования
Калашникова Марина Николаевна,
г. Димитровград,
учитель русского языка
МАОУ СОШ 19
Мастер-класс.
Вступительное слово:
— Методическая задача мастер -класса – показать два вида диалога(побуждающий и подводящий) , используемые при изучении нового материала.
СЛАЙД № 1.
Мастер-класс.
Введение темы через вопросы:
— Тему нашего занятия вы сможете определить, если ответите на следующие вопросы
РИФМОВАННЫЕ СТИХИ О МОРФЕМАХ
— Кто догадался, какова тема нашего занятия?
«Разбор слова по составу».
— Попробуйте сформулировать цель занятия.
(Учиться правильно разбирать слова по составу).
— Данные вопросы являются частью побуждающего диалога.
Разберите слова по составу.
(интер. Доска)
Бабочка
Яблочко
Вазочка
белочка
(разбирают на интер. Доске по 1 человеку, остальные на листочке.)
— Какое было задание?
(Разобрать по составу.)
-У всех ли получился такой разбор, как на доске?
(нет)
( Разобрали по-разному. Если все разобрали правильно, сказать о том, что дети на уроке имели другие результаты — разобрали по-разному. На основе тех результатов мы и рассмотрим данную технологию.)
( Разобрали по-разному. Если все разобрали правильно, сказать о том, что дети на уроке имели другие результаты — разобрали по-разному. На основе тех результатов мы и рассмотрим данную технологию.)
Далее рассмотрим диалог подводящий к открытию нового знания.
— Вернемся к нашим словам.
Чем они интересны?
- Все слова немного похожи (существительные).
- Во всех словах есть суффикс –ОЧК-.
- Не везде –ОЧК- — это суффикс. (Если не сказали об этом, задать вопрос: «Одной ли морфемой является –ОЧК- во всех словах?»)
— Проблемный вопрос. Какие у вас были основания для выделения морфем?
Прошу вас выдвинуть свои варианты, гипотезы:
- Подобрать однокоренные слова.
- Найти слово, от которого образовано данное слово.
- Есть уменьшительный суффикс –ОЧК-, и мы смело можем его выделять (если не назвали этот пункт, задаю вопрос: «Помните ли вы из школьной программы значение суффикса –ОЧК- — уменьшительно-ласкательное).
Мой комментарий:
— На данном этапе вы выдвинули несколько гипотез. Проверим, верны эти гипотезы или нет.
Проверим гипотезу – подобрать однокоренные слова:
(книжечка-книжный-книга)
Возьмем слово «бабочка». Попробуйте подобрать однокоренные слова. Нет такой возможности. Вывод: не для всех слов можно подобрать однокоренные слова, следовательно, гипотеза о том, что именно подбор однокоренных слов является основанием для выделения морфемы –ОЧК-, неверна.
Проверим гипотезу: есть такой суффикс – ОЧК-, который смело можно выделять во всех словах.
(книга+ечк=книжечка)
Возьмем слово «бабочка». Подберите к данному слову форму с уменьшительным значением. Нет такого.
Значит, гипотеза неверна.
Третья гипотеза – нужно подобрать слово, от которого образовалось данное.
(книжечка-книга)
Найдите образующее слово к слову «бабочка».
Нет такого слова.
Мы можем сделать промежуточный вывод:
Если нет образующего слова, то основу слова членить не нужно. Все слово является корнем. Суффикс –ОЧК- — в основу слова.
А если искомое слово есть? Как поступить? Например, слово «вазочка». Какое слово является образующим, от какого слова образовалось?
(ваза).
Следовательно, –ОЧК- является какой морфемой?
(суффиксом)
— Итак, попробуем полученные знания применить на практике:
Определение границ морфем
1. Запишите образующую основу под исходной.
2. Наложите одну на другую и выделите словообразующую морфему.
3. Какие фонетические особенности наблюдаются?
яблочко белочка
яблоко белка
Суффикс -к-
Чередование к//ч
Беглый гласный о
(ср. белка/белок/белоч-
РАЗБЕРЕМ СЛОВА ПО СОСТАВУ ПРАВИЛЬНО
ВАЗОЧКА
ЯБЛОЧКО
БЕЛОЧКА
БАБОЧКА
l Заметьте:
Слово белка не имеет суффикса – к/оч-, так как не может быть истолковано через слово белый → белк-/ белоч- далее не членится.
Обобщим наблюдения
1. Какое задание мы выполняли?
2. Какой вид разбора проводили в процессе анализа слов?
3. Сделайте вывод:
Как правильно разобрать слово по составу?
Разбирали слова по составу.
Словообразовательный
Чтобы правильно разобрать слово по составу, нужно сначала провести словообразовательный разбор.
— А теперь самостоятельно разберите слова.
Проверим себя
l Разберите слова по составу:
Больница
Мельница
Путаница
Куница
Столица
l Обратите внимание:
При поиске производящего нужно находить слова для толкования только из современного языка!
Творческое задание. Слово «расшмявка».р слова.
— Можете ли вы разобрать слово по составу, то есть произвести морфемный разбор слова?
(нет)
— Почему, нет?
(потому что нет исходного слова)
— Исходное слово «шмявать».
— А теперь произведите морфемный разбор слова.
(проверили)
Выводы: как правильно разобрать слова по составу?
Важно установить:
Есть образующее слово
↓
1.Найти, с помощью чего образовано данное (исходное) слово.
2. Выделить из толкования значение суффикса.
Нет образующего слова
↓
Основу слова членить не нужно. Всё слово (основа) является корнем.
Чтобы правильно разобрать слово по составу, нужно сначала провести словообразовательный разбор.
-Какова была цель нашего занятия?
(научиться разбирать слова по составу).
определение парсинга The Free Dictionary
парсинга
(pärs)v. parsed , pars · ing , pars · es
v. tr. 1.а. Разбивать (предложение) на составные части речи с объяснением формы, функции и синтаксической взаимосвязи каждой части.
б. Для описания (слова), указав его часть речи, форму и синтаксические отношения в предложении.
с. Для обработки (лингвистических данных, таких как речь или письменный язык) в реальном времени во время разговора или чтения, чтобы определить его лингвистическую структуру и значение.
2.а. Внимательно изучить или подвергнуть подробному анализу, особенно путем разбивки на компоненты: «Чего мы упускаем, разбивая поведение шимпанзе на общепринятые категории, распознаваемые в основном из нашего собственного поведения?» (Стивен Джей Гулд).
б. Чтобы понять; Поймите: я просто не мог разобрать то, что вы только что сказали.
3. Компьютеры Для анализа или разделения (например, ввода) на более легко обрабатываемые компоненты.
v. внутр.Признать, что анализируются: предложения, которые нелегко разобрать.
[Вероятно, из среднеанглийского pars, часть речи , из латинского pars (ōrātiōnis), часть (речи) ; см. perə- в индоевропейских корнях.]
парсер н.
Словарь английского языка American Heritage®, пятое издание. Авторское право © 2016 Издательская компания Houghton Mifflin Harcourt. Опубликовано Houghton Mifflin Harcourt Publishing Company. Все права защищены.
синтаксический анализ
(pɑːz) vb1. (грамматика) для присвоения составной структуры (предложению или словам в предложении)
2. (грамматика) ( intr ) (из слово или лингвистический элемент), чтобы играть определенную роль в структуре предложения
3. (информатика) вычисление для анализа исходного кода компьютерной программы, чтобы убедиться, что он структурно правильный, прежде чем он будет скомпилирован и преобразован в машинный код
[C16: от латинского pars ( orātionis ) (речи)]
ˈparsable adj
ˈparsing n
Словарь английского языка Коллинза — полный и полный, 12-е издание 2014 г. © HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007 , 2009, 2011, 2014
синтаксический анализ
(pɑrs, pɑrz)v. parsed, pars • ing. в.т.
1. для анализа (предложения) с точки зрения грамматических составляющих, определения частей речи, синтаксических отношений и т. Д.
2. для описания (слова в предложении) грамматически, идентифицируя часть речи, словоизменительная форма, синтаксическая функция и т. д.
vi3. , чтобы признать анализ.
[1545–55; pars part, as в pars ōrātiōnis part of speech]
pars′a • ble, прил.
парсер, п.
Random House Словарь колледжа Кернермана Вебстера © 2010 K Dictionaries Ltd. Авторские права 2005, 1997, 1991 принадлежат компании Random House, Inc. Все права защищены.
синтаксического анализа
Past причастие: разобран
герундия: разборе
ImperativePresentPreteritePresent ContinuousPresent PerfectPast ContinuousPast PerfectFutureFuture PerfectFuture ContinuousPresent Идеальный ContinuousFuture Идеальный ContinuousPast Идеальный ContinuousConditionalPast Условное
| Present |
|---|
| я анализирую |
| разбора |
| он / она / оно анализирует |
| мы анализируем |
| вы анализируете |
| они анализируют |
| Preterite |
|---|
| мы проанализировали |
| вы проанализировали |
| они проанализировали |
| Present Continuous |
|---|
| I am parsing | вы разбираете |
| он / она / она анализирует |
| мы разбираем |
| вы разбираете |
| они разбирают |
| вы проанализировали |
| он / она / она проанализировали |
| мы проанализировали |
| вы проанализировали |
| они проанализировали |
| Future | |
|---|---|
| я буду разбирать | |
| он / она / оно проанализирует | |
| мы проанализируем | |
| вы проанализируете | |
| они проанализируют |
| Future Perfect | |
|---|---|
| вы проанализируете | |
| он / она / оно будет проанализировано | |
| мы проанализируем | |
| вы проанализируете | |
| они будут проанализированы | |
| Будущее | |
| Я буду разбирать | |
| вы будете разбирать | |
| он / она / это будет синтаксический анализ | |
| мы будем разбирать | |
| вы будете разбирать | |
| они будут анализировать |
| Present Perfect Continuous |
|---|
| I was parsing | I was parsing |
| он / она / она анализировал |
| мы анализировали |
| вы анализировали |
| они анализировали |
| Future будет анализировать |
|---|
| вы будете анализировать |
| он / она / она будет анализировать |
| мы будем анализировать |
| вы будете разбирать |
| Прошлое совершенное Непрерывное |
|---|
| вы разбирали |
| он / она / она разбирали |
| мы разбирали |
| вы разбирали |
| они разбирали |
| Условный |
|---|
| Я бы проанализировал |
| вы бы проанализировали |
| он / она / она будет анализировать |
| мы проанализируем |
| Прошлый условный |
|---|
| Я бы проанализировал |
| вы бы проанализировали |
| он / она / она бы проанализировал |
| вы бы проанализировали |
| они бы проанализировали |
Collins English Verb Tables © Harpe rCollins Publishers 2011
parse
Для анализа предложения, разбивая его на составные части и объясняя функцию каждой и их взаимосвязь.
Словарь незнакомых слов от Diagram Group © 2008, Diagram Visual Information Limited
Определениев Кембриджском словаре английского языка
Мы будем разбирать это какое-то время. Но отношения эукариот к другим группам разобрать было сложно.Еще примеры Меньше примеров
Это действительно добросовестная попытка (так сказать) разобрать этого противоречия.Но операционные группы центров обработки данных не имеют возможности проанализировать все . Этот документ анализируется людьми, извлекается людьми, и они взвешивают его.Как будто после анализа не приходится ожидать дальнейшего понимания. Слова и изображения анализируются, протестуют и часто приносят извинения.Оцените эти комментарии сами, и проанализируйте слова, если хотите, но «извинения» кажется подходящей их характеристикой. Когда отрасль и даже правительство анализируют статистику , чтобы исключить несчастные случаи со смертельным исходом в регионе, члены семей погибших явно возмущены.Но давайте более подробно разберем этой похвалы. Однако, когда вы пытаетесь разобрать сложных вариантов, вам часто дают всего несколько секунд, и время, кажется, мгновенно испаряется. Parse в настоящее время насчитывает более 60 000 приложений и примерно такое же количество разработчиков. Что мы собираемся здесь сделать, так это проанализировать этого сложного набора отношений, используя имеющуюся у нас информацию. Parse еще очень молод, но он явно нашел свое место в мире. Ученые разбирают его гневный и часто жестокий язык.Эти примеры взяты из корпусов и из источников в Интернете. Любые мнения в примерах не отражают мнение редакторов Cambridge Dictionary, Cambridge University Press или его лицензиаров.
parse — Определение синтаксического анализа
Поддержка: Помогите сделать словарь Word Game сайтом без рекламы.Нажмите, чтобы принять слово разобратьДа, синтаксический анализ
есть в словаре… и стоит
8 очков.найдите больше слов, которые вы можете составить ниже
существительное
1. Продукт или экземпляр.
2. Акт разбора строки или текста :.
глагол
1. Разложить (как предложение) на составные части речи и описать их грамматически.
2. Чтобы описать грамматически, указав часть речи и объяснив интонацию и синтаксические отношения.
3. Внимательно исследовать анализировать критически.
4. Для грамматического описания слова или группы слов.
5. Признать бытие.
непереходный глагол
1. Признать, что анализируются: предложения, которые нелегко разобрать.
глагол-переходный
1. Информатика Для анализа или разделения (например, ввода) на более легко обрабатываемые компоненты.
2. Разбивать (предложение) на составные части речи с объяснением формы, функции и синтаксической взаимосвязи каждой части.
3. Для описания (слова), указав его часть речи, форму и синтаксические отношения в предложении.
4. Для тщательного изучения или подробного анализа, особенно путем разбиения на компоненты: «Чего мы упускаем, разбивая поведение шимпанзе на общепринятые категории, распознаваемые в основном на основе нашего собственного поведения?» (Стивен Джей Гулд).
Вот еще несколько слов, которые можно составить из букв
parseЛучшие слова по баллам | Очки | Игра в слова |
|---|---|---|
| копье | 7 | Эрудит |
| копье | 8 | Слова с друзьями |
2 буквы | Scrabble® | WWF® | ||
|---|---|---|---|---|
| ar | 2 | 4|||
| re | 2 | 2 | ||
| pa | 4 | 5 | ||
| es | 2 | 2 | ||
| er | 2 | 2 | ||
| pe | 9016 9016 9016 9016 907 907 907 | Scrabble® | WWF® | |
| сап | 5 | 6 | ||
| рэп | 5 | 6 | ||
| 9014 | ||||
5 | 6 | |||
| па | 5 | 6 | ||
| горох | 5 | 5 | 5 | 6 |
| pes | 5 | 6 | ||
| res | 3 | 3 | ||
| ras | 3 | 3 | ||
| эра | 3 | 3 | ||
| ухо | 3 | 3 | ||
| море | 9016 9016 908 907 907 9016 9016 907 908 3 | 3 | ||
| СПА | 5 | 6 | ||
| ers | 3 | |||
Найдено 62 слов в 0.11864 секунда
Примеры синтаксического анализа
Кроме того, вы можете дополнительно указать число после синтаксического анализа слова — это отключит только определенные настройки.0 | 0 |
Сумасшедшие порой бывает трудно понять, почему квирам и трансгендерным людям так трудно жить, в то время как заголовки говорят о том, что мы продвигаемся семимильными шагами.0 | 0 |
В настоящее время это только обычные результаты — мы разбираем их и сохраняем.0 | 0 |
Даже без структурированной разметки поисковые системы могут анализировать ключевые слова в их соответствующую структуру.0 | 0 |
Для начала нужно разобрать полученные фразы из предложений, на предложения и абзацы.0 | 0 |
Тем не менее, я думаю, что он все еще проиндексирован, поскольку вы можете указать follow, что означает, что он должен анализировать страницу, он просто не включается в результаты поиска.0 | 0 |
Я извлекаю метатеги, проверяю наличие nofollow, а затем даже создал php для синтаксического анализа и применения роботов.0 | 0 |
Часто можно использовать jquery или иным образом проанализировать содержимое страницы, чтобы получить нужную информацию.0 | 0 |
Конечно, вам это не понадобится, если вы хотите, чтобы роботы анализировали весь поддомен.0 | 0 |
Открытый график — это тип разметки, используемый facebook для анализа информации, например, какое изображение и описание отображать.0 | 0 |
* Следующие примеры предложений были собраны из разных источников, чтобы соответствовать текущему времени, ни один из них не отражает мнение Word Game DictionaryНапишите свой собственный пример предложения для Parse и проявите творческий подход, может быть, даже смешно.
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать «Словарь Вебстера» 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в единый унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Как разобрать ваше резюме, чтобы создать облако слов для заголовка в LinkedIn | by Obianuju Okafor
Obianuju Okafor заголовок LinkedInХороший способ выделиться на LinkedIn — использовать отличительный заголовок. Один из вариантов — извлечь основных навыков из вашего резюме и использовать их для создания облака слов, которое вы можете использовать в качестве заголовка.В этой средней статье я подробно расскажу, как этого добиться.
Я разбил этот процесс на пять простых шагов, описанных ниже. Если вы хотите воспроизвести этот процесс, вы можете найти здесь все необходимые файлы кода.
Перво-наперво, я импортировал все библиотеки, которые хотел бы использовать в этой задаче.
#libraries
import re
import spacy
import en_core_web_sm
import nltk
from nltk.tokenize import word_tokenize
nltk.загрузить ('wordnet')
из nltk.stem import WordNetLemmatizer
nltk.download ('punkt')
nltk.download ('stopwords')
from nltk.corpus import stopwords
import pandas as pd
import numpy as np
from io import StringIO
! pip install pdfminer
from pdfminer.pdfinterp импортировать PDFResourceManager, PDFPageInterpreter
из pdfminer.converter импортировать TextConverter
из pdfminer.layout импортировать LAParams
из pdfminer.pdf matplotlib.pyplot as plt
Следующий шаг — проанализировать желаемое резюме. Для этого я создал функцию resume_parser () , которая использует PDFResourceManager, PDFPageInterpreter, LAParams , TextConverter из библиотеки pdfminer для извлечения и возврата всего текста из моего резюме.
# функция для синтаксического анализа текста резюме
def resume_parser (fname, pages = None):
if not pages:
pagenums = set ()
else:
pagenums = set (pages)
output = StringIO ()
manager = PDFResourceManager ()
преобразователь = TextConverter (менеджер, вывод, лапарамс = LAParams ())
интерпретатор = PDFPageInterpreter (менеджер, преобразователь)
infile = open (fname, 'rb')
для страницы в PDFPage.get_pages (infile, pagenums):
interpter.process_page (page)
infile.close ()
converter.close ()
text = output.getvalue ()
output.close
return text # вызов функции resume_parser для извлечения текста из pdf файл
resume_text = resume_parser ("/ content / Obianuju_Okafor_Resume.pdf")
Следующим шагом является извлечение наиболее релевантных навыков из текста резюме. Как мы узнаем, какие навыки germane нужно извлечь? Это делается в функции extract_skills () .В этой функции я сначала обрабатываю проанализированный текст резюме путем удаления знаков препинания, преобразования в нижний регистр, токенизации, лемматизации и, наконец, удаления стоп-слов.
После этого каждый из предварительно обработанных токенов сравнивается с набором навыков, хранящимся в файле csv «skills.csv». Этот CSV-файл представляет собой сборник всех соответствующих навыков для разных типов карьеры, например, разработки программного обеспечения, бухгалтерского учета, анализа данных и т. Д. После того, как сравнение выполнено, я добавляю соответствующие навыки в массив, называемый соответствующими навыками.Наконец, возвращается набор соответствующих навыков.
# функция для извлечения навыков из текста резюме и выбора наиболее подходящих навыковdef extract_skills (resume_text):
# удалить пунктуацию
resume_text = re.sub ('[-, () \\.!?]', '', Resume_text )# перейти к нижнему регистру
resume_text = resume_text.lower ()# Инициировать лемматизатор Wordnet
lemmatizer = WordNetLemmatizer ()# разметить текст резюме
tokens = nltk.word_tokenize (resume_text)# Lemmatize tokens [лемматизатор.lemmatize (token) for token in tokens]
# удалить токены, которые являются стоп-словами
# прочитать Файл Skills.csv (банк навыков)
stop_words = stopwords.words ('english')
tokens = [token for token in tokens if token not in stop_words]
data = pd.read_csv («skills.csv»)# создать список всех возможных навыков из нашего файла skills.csv
# create массив для добавления соответствующих навыков после сравнения
Skills = list (data.columns.values)
related_skills = []# compare one-grams (e.g python) навыки из резюме в навыки из Skills.csv, если есть соответствие, добавьте в массив related_skills
для токена в токенах:
если token.lower () в навыках:
related_skills .append (token) # загрузить предварительно обученные model
nlp = spacy.load ('en_core_web_sm')
nlp_text = nlp (resume_text)# создать би-граммы и триграммы
# сравнить би-граммы и триграммы (например, машинное обучение) навыки из резюме в навыки из skills.csv, если есть совпадение, добавьте в массив related_skills для токена в noun_chunks:
noun_chunks = nlp_text.noun_chunks
token = token.text.lower (). strip ()
if token in skills:
related_skills .append (token) return [i.capitalize () for i in set ([i.lower () for i in related_skills])] # вызов Функция extract_skills для выбора соответствующих навыков из текста резюме
related_skills = extract_skills (resume_text)
Мы используем навыки в массиве related_skills для создания и генерации облака слов.
# преобразовать массив related_skills в одну строкуОблако слов
related_skills_string = ‘’
related_skills_string + = ««.join (related_skills) + ”“ # создать и сгенерировать изображение облака слов с помощью related_skills_strings
wordcloud = WordCloud (max_font_size = 50, max_words = 100, background_color = ”white”). generate (related_skills_string) # отобразить сгенерированное изображение
plt.figure ()
plt.imshow (wordcloud, interpolation = 'bilinear')
plt.axis («off»)
plt.show ()
Я пошел дальше и изменил форму облака слов, чтобы оно соответствовало дизайн заголовков LinkedIn. Часть заголовка LinkedIn покрыта изображением вашего профиля, поэтому, чтобы важные навыки не были скрыты изображением вашего профиля, я решил создать мировое облако, которое учитывает положение изображений профиля в заголовке.
Я сделал это, создав шаблон дизайна заголовка LinkedIn с помощью приложения GIMP.
Шаблон дизайна заголовка LinkedinЗатем я создал маску этого шаблона и использовал эту маску для создания облака слов. Я сохранил сгенерированное облако слов как изображение и использовал его в качестве заголовка в LinkedIn.
# создать маску с использованием шаблона заголовка Linkedin
linkedin_header_mask = np.array (Image.open («/ content / linkedin_header_template.png»)) # создать и сгенерировать изображение облака слов с помощью маски
wc = WordCloud (background_color = ”white” , max_words = 1000, mask = linkedin_header_mask, contour_width = 3, contour_color = 'white').generate (related_skills_string) # отобразить сгенерированное изображение
plt.figure (figsize = [20,10])
plt.imshow (wc, interpolation = 'bilinear')
plt.axis («off»)
plt.show () # сохранить сгенерированное изображение wordcloud как linkedin_wordcloud_header
wc.to_file («linkedin_wordcloud_header.png»)
Сгенерированное изображение показано ниже.
Заголовок облака слов LinkedInЧто означает синтаксический анализ — Определение синтаксического анализа
Примеры использования слова «parse».
Хокен передал инструкции людям, находившимся спереди и сзади. разобрать трубок, через которые на кристаллы подавался свет от радиановых вытяжек.
Альт Мер крутил колесо, которое направляло рули от синтаксических трубок , и подавало мощность в радианах на кристаллы с неуклонно увеличивающимися приращениями.
Вы можете попробовать разобрать этот , но я гарантирую вам, что он подпадает под букву договора, и Дархел действительно вырубит вам ноги из-под вас, если вы попытаетесь разобрать каким-либо другим способом.
Рулевая рубка была разбита, рулевое управление загрязнено, легкие ножны разлетелись в клочья, такелаж разлетелся повсюду, сломаны лонжероны и даже заклинило пару трубок parse .
Мы использовали энергию, хранящуюся в трубках parse , чтобы направить ее, отвести от ледяных столбов и направить обратно туда, откуда она пришла.
Мы можем заменить световые кожухи и радиановые вытяжки, отремонтировать , проанализировать ламп и отрегулировать диапсонные кристаллы в соответствии с нашими потребностями.
Две из синтаксических трубок вместе с их диапсонными кристаллами были оторваны и потеряны за борт.
Радианы гудели, направляя окружающий свет в трубки синтаксического анализа , и кристаллы диапсона превращали его в энергию, своеобразный металлический звук.
Двое из них выпрыгнули из левых боевых ям и через мгновение оказались рядом с ним, схватив натяжные устройства и потянув их обратно к parse трубам, из которых они вырвались, игнорируя пикирующих сорокопутов и град стрел с моря. преследуют корабли.
Экипажвездехода на нижних палубах также был пристегнут ремнями, сгорбившись от непогоды, разместился у , разбирает трубы и соединяет тросы.
Rue увидел, что радианы были переконфигурированы, отодвинуты от двух из шести трубок parse для подачи энергии на оставшиеся четыре.
Спаннер Фрю боролся за то, чтобы поднять ее нос, но без работы обеих кормовых разборных трубок у него не было средств для этого.
Без использования кормовой трубы parse Big Red собирался полагаться на паруса в качестве источника энергии.
Не беспокоясь о том, сделал ли это другой, он отключил питание всех, кроме двух передних , разобрал трубок и ввел корабль в крутой спуск.
Спустившись на палубу, он поднял все паруса, затянул радианные затяжки и проверил защитные кожухи на трубах parse , убедившись, что все находится в хорошем рабочем состоянии и им можно управлять из кабины пилота.
Перевод и синтаксический анализ латинских слов
Часть речи — ПрилагательноеНаречиеСоединениеИнтеръекцияСуществительноеЧислоПредставлениеПроноунГлагол
Возраст — Современный — неологизмы Классический (~ 150 г. до н.э. — 200 г. н.э.) Архаический — очень ранние формы, устаревшие к классическим временам Раннее — ранняя латынь, доклассическая, использовалась для эффекта / поэзии Позднее — латынь не использовалась в классические времена Христианское Средневековье — Средневековье (XI-XV вв.) Ученый — Латинский пост XV — Ученый / Научный (16-18) Поздний — Поздний, постклассический (III-V вв.) Все / Другое
Область — Сельское хозяйство, Флора, Фауна, Земля, Оборудование, Сельское Биологическое, Медицинское, Части тела, Грамматика, Реторика, Логика, Литература, Школы, Юридические, Правительство, Налоги, Финансовые, Политические, Драма, Музыка, Театр, Искусство, Живопись, Скульптура, Мифология, Духовное, Библейское, РелигиозноеВойна, Военное дело, Военно-морской флот, Корабли, ДоспехиВсе или нет ПоэтическиеТехнические, Архитектура, Топография, ГеодезияНаука, Философия, Математика, Единицы / меры
Locale — ПерсияИталия, Рим, Россия, Африка, Британия, Нидерланды, Восточная Европа, Все или ничего, Индия, Греция, Китай, Египет, Балканы, Ближний Восток, Франция, Галлия, Германия, Скандинавия, Испания, Иберия,
.Лексическая категория— обзор
5.2.1 Обзор ресурсов, разработанных для обработки сербского языка
Многочисленные ресурсы, которые можно использовать для целей нашего исследования, были разработаны для обработки сербского языка, но многие из них имеют быть измененным или улучшенным. Большая часть этих ресурсов была разработана в системе Unitex [22], а часть из них была адаптирована для системы GATE [23].
Система Unitex — это система с открытым исходным кодом, разработанная Себастьяном Помье в Институте Гаспара-Монжа при Университете Парижа в Марн-ла-Валле в 2001 году.Это система обработки корпуса, основанная на автоматизированной технологии, которая находится в постоянном развитии. Система используется во всем мире для задач НЛП, поскольку она обеспечивает поддержку ряда различных языков и многоязычных задач обработки.
Одной из основных частей системы являются электронные словари типа DELA (Dictionnaires Electroniques du Laboratoire d’Automatique Documentaire et Linguistique или электронные словари LADL), которые представлены на рис.2. Система состоит из словарей DELAS (простые формы DELA) и DELAF (DELA флективных форм). Словари DELAS — это словари простых слов, не изменяемых форм, в то время как словари DELAF содержат все изменяемые формы простых слов. С другой стороны, система содержит словари составных DELAC (DELA составных форм) и словари складываемых составных форм DELACF (DELA составных склонных форм).
Рис. 2. Система электронных словарей DELA.
Морфологические словари в формате DELA были предложены в Лаборатории автоматической документации и лингвистики под руководством Мориса Гросса. Формат словарей DELA подходит для решения задач сегментации текста и морфологической, синтаксической и семантической обработки текста. Более подробную информацию о формате DELA можно найти в [24].
Морфологические электронные словари в формате DELA представляют собой простые текстовые файлы. Каждая строка в этих файлах содержит запись слова и измененную форму слова.Другими словами, каждая строка содержит лемму слова и некоторую грамматическую, семантическую и флективную информацию.
Пример записи из словаря DELAF на английском языке: « таблиц, таблица.N + Conc: p ». Флективная форма таблицы является обязательной, таблица — лемма записи, а N + Conc — последовательность грамматической и семантической информации (N обозначает существительное, а Conc обозначает, что это существительное — конкретный объект), p — флективный код, который указывает на то, что существительное является множественным числом.
Словари этого типа для сербского языка разрабатываются группой НЛП на математическом факультете Белградского университета. Согласно [21], нынешний объем сербского морфологического словаря DELAS (простых слов) содержит 130 000 лемм. Большинство лемм из словаря DELAS относятся к общей лексике, а остальные относятся к разным видам простых имен собственных. Словарь DELAF содержит около 4 300 000 словоформ с заданными грамматическими категориями.Размер словарей DELAC и DELACF составляет примерно 10 500 и 54 000 лемм соответственно.
Аналогичный пример записи из сербского словаря простых словоформ с соответствующим грамматическим и семантическим кодом: padao, padati. V + Imperf + It + Iref: Gms, где словоформа padao является единственным (S) мужским родом (M) активного причастия прошедшего времени (G) глагола (V) padati «падать», который несовершенное (Imperf), непереходное (It) и рефлексивное (Iref).
Другой тип ресурсов, разработанный для сербского языка, — это различные типы конечных преобразователей. Конечные преобразователи используются для выполнения морфологического анализа, а также для распознавания и аннотирования фраз в текстах прогнозов погоды с соответствующими тегами XML, такими как ENAMEX, TIMEX и NUMEX, как мы объясняли ранее.
Пример графа конечного преобразователя для распознавания временных выражений и их аннотации с помощью тегов TIMEX представлен на рис. 3. Этот граф конечного преобразователя может распознавать последовательность « 14.01.2012 . » из текста нашего примера прогноза погоды и аннотируйте его тегом TIMEX, чтобы его можно было извлечь в форме «ДАТА_ВРЕМЯ: 14.01.2012».
Рис. 3. Граф преобразователя с конечным числом состояний для извлечения и аннотирования временных выражений.
Другая система, которая больше подходит для решения проблемы IE (и CM), — это бесплатное программное обеспечение с открытым исходным кодом GATE (общая архитектура для текстовой инженерии). Система GATE или некоторые из ее компонентов уже используются для ряда различных задач НЛП на нескольких языках.Система GATE — это архитектура и среда разработки для приложений НЛП. GATE разрабатывается NLP Group Университета Шеффилда с 1995 года.
Архитектура GATE состоит из трех частей: языковые ресурсы, ресурсы обработки и визуальные ресурсы. Эти компоненты независимы, поэтому с системой могут работать разные типы пользователей. Программисты могут работать над разработкой алгоритмов для НЛП или настраивать внешний вид визуальных ресурсов для своих нужд, в то время как лингвисты могут использовать алгоритмы и языковые ресурсы без каких-либо дополнительных знаний о программировании.
Визуальные ресурсы, графический пользовательский интерфейс, останется в исходной форме для целей данного исследования. Это позволит визуализировать и редактировать языковые ресурсы и ресурсы обработки. Языковые ресурсы для этого исследования включают корпуса текстов прогнозов погоды на нескольких языках и концептуальную модель прогноза погоды, которая будет построена. Необходимая модификация ресурсов обработки, особенно модификации для применения к обработке сербских текстов, представлены ниже.
Задача IE в GATE встроена в систему ANNIE (почти новое извлечение информации). Подробную информацию об ANNIE можно найти в [25]. Система ANNIE включает в себя следующие ресурсы обработки: Tokeniser, Sentence Splitter, POS (часть речи) tagger, Gazetteer, Semantic Tagger и Orthomatcher. Каждый из перечисленных ресурсов создает аннотации, необходимые для следующего ресурса обработки в списке:
- •
Tokeniser разбивает текст на токены (слова, числа, символы, белые шаблоны и знаки препинания).Токенизатор можно использовать для обработки текстов на разных языках с небольшими изменениями или без них.
- •
Sentence Splitter сегментирует текст на предложения, используя каскады конечных преобразователей. Он также не зависит от приложения и языка.
- •
POS Tagger назначает тег части речи (тег лексической категории, например, существительное, глагол) в форме аннотации к каждому слову. Английская версия POS Tagger, входящая в систему GATE, основана на тэггере Brill.Это не зависящий от приложения, но зависящий от языка ресурс, который должен быть полностью изменен для сербского языка.
- •
Другой ресурс, зависящий от языка, но зависящий от приложения, — это Gazetteer, который содержит списки городов, стран, личных имен, организаций и т. Д. Gazetteer использует эти списки для аннотирования появления элементов списка в текстах. .
- •
Semantic Tagger основан на языке JAPE (Java Annotations Pattern Engine) [26].JAPE выполняет конечную обработку аннотаций на основе регулярных выражений, и его важной характеристикой является то, что он может использовать концептуальные модели (онтологии).
Semantic Tagger включает набор грамматик JAPE, где каждая грамматика состоит из набора фаз, а каждая фаза представляет собой набор правил. Кроме того, правила содержат левую и правую стороны. Левая сторона (LHS) правила описывает шаблон аннотации, который обычно распознается на основе операторов регулярного выражения Клини.Правая сторона (RHS) правила описывает действие, которое должно быть предпринято после того, как LHS распознает шаблон, например, создание новой аннотации. Это ресурс, зависящий от приложения и языка.
- •
Orthomatcher идентифицирует отношения между именованными объектами, обнаруженными Semantic Tagger. Он создает новые аннотации на основе отношений между именованными объектами. Это независимый от приложения и языка ресурс.
Основная цель — разработать ресурсы, зависящие от языка или приложения (Gazetteer, POS Tagger и Semantic Tagger) для сербского языка.Путь, который мы выбрали для решения этой проблемы, — использовать ранее описанные ресурсы, разработанные для системы Unitex, и адаптировать их для использования в системе GATE. Изменение списков географического справочника — это простой процесс перевода с одного языка на другой. Построение грамматик JAPE с поддержкой онтологий для области прогноза погоды требует первоначальной разработки соответствующего подъязыка и концептуальной модели, которые будут обсуждаться в следующем подразделе в качестве предмета текущих исследований авторов.Проблема создания подходящего POS Tagger очень сложна и не будет здесь подробно описываться.
Вкратце, мы сделали оболочку для Unitex, чтобы ее можно было использовать непосредственно в системе GATE для создания электронных словарей для заданных текстов прогноза погоды и механизма для создания соответствующей аннотации POS Tagger для каждого слова. Это решение проблемы, хотя и имеет несколько недостатков, может стать хорошей основой для создания семантических тегов на основе концептуальных моделей и систем IE в целом.
%! PS-Adobe-2.0 %% Создатель: dvipsk 5.55a Copyright 1986, 1994 Radical Eye Software %% Заголовок: eisner.acl96.dvi %% Страниц: 8 %% PageOrder: Ascend %% BoundingBox: 0 0 612 792 %% EndComments % DVIPSCommandLine: dvips eisner.acl96.dvi % DVIPSParameters: dpi = 300, сжато, комментарии удалены % DVIPS Источник: вывод TeX 2000.05.25: 1844 %% BeginProcSet: texc.pro / TeXDict 250 dict def Начало TeXDict / N {def} def / B {привязка def} N / S {exch} N / X {S N} B / TR {translate} N / isls false N / vsize 11 72 mul N / hsize 8.5 72 mul N / landplus90 {false} def / @ rigin {isls {[0 landplus90 {1 -1} {- 1 1} ifelse 0 0 0] concat} if 72 Разрешение div 72 VR Разрешение div neg масштаб isls {landplus90 {VResolution 72 div vsize mul 0 exch} {Разрешение -72 div hsize mul 0} ifelse TR}, если разрешение VResolution vsize -72 div 1 add mul TR [матрица currentmatrix {dup dup round sub abs 0.00001 lt {round} if} forall round exch round exch] setmatrix} N / @ landscape {/ isls true N} B / @ manualfeed {statusdict / manualfeed true put} B / @ копий {/ # копий X} B / FMat [1 0 0 -1 0 0] N / FBB [0 0 0 0] N / nn 0 N / IE 0 N / ctr 0 N / df-tail { / nn 8 dict N nn begin / FontType 3 N / FontMatrix fntrx N / FontBBox FBB N строка / базовый массив X / BitMaps X / BuildChar {CharBuilder} N / кодирование IE N end dup {/ foo setfont} 2 array copy cvx N load 0 nn put / ctr 0 N [} B / df { / sf 1 N / fntrx FMat N df-tail} B / dfs {div / sf X / fntrx [sf 0 0 sf neg 0 0] N df-tail} B / E {pop nn dup definefont setfont} B / ch-width {ch-data dup длина 5 sub get} B / ch-height {ch-data dup length 4 sub get} B / ch-xoff { 128 ch-data dup length 3 sub get sub} B / ch-yoff {ch-data dup length 2 sub получить 127 sub} B / ch-dx {ch-data dup length 1 sub get} B / ch-image {ch-data dup type / stringtype ne {ctr get / ctr ctr 1 add N} if} B / id 0 N / rw 0 N / rc 0 N / gp 0 N / cp 0 N / G 0 N / sf 0 N / CharBuilder {save 3 1 ролик S dup / base get 2 index get S / BitMaps get S get / ch-data X pop / ctr 0 N ch-dx 0 ch-xoff ch-yoff ch-height sub ch-xoff ch-width добавить ch-yoff setcachedevice ch-width ch-height true [1 0 0 -1 -.1 ч-хофф суб ч-йофф .1 sub] / id ch-image N / rw ch-width 7 добавить 8 idiv строка N / rc 0 N / gp 0 N / cp 0 N {rc 0 ne {rc 1 sub / rc X rw} {G} ifelse} восстановление маски изображения} B / G {{id gp get / gp gp 1 add N dup 18 mod S 18 idiv pl S get exec} loop} B / adv {cp add / cp X} B / chg {rw cp id gp 4 index getinterval putinterval dup gp add / gp X adv} B / nd {/ cp 0 N rw exit} B / lsh {rw cp 2 copy get dup 0 eq {pop 1} { dup 255 eq {pop 254} {dup dup add 255 и S 1 и или} ifelse} ifelse положить 1 adv} B / rsh {rw cp 2 copy get dup 0 eq {pop 128} {dup 255 eq {pop 127} {dup 2 idiv S 128 и or} ifelse} ifelse помещает 1 adv} B / clr {rw cp 2 index string putinterval adv} B / set {rw cp fillstr 0 4 index getinterval putinterval adv} B / fillstr 18 string 0 1 17 {2 copy 255 put pop} для N / pl [{adv 1 chg} {adv 1 chg nd} {1 add chg} {1 add chg nd} {adv lsh} {adv lsh nd} {adv rsh} { adv rsh nd} {1 add adv} {/ rc X nd} {1 add set} {1 add clr} {adv 2 chg} {adv 2 chg nd} {pop nd}] dup {bind pop} forall N / D {/ cc X dup type / stringtype ne {] } if nn / base get cc ctr put nn / BitMaps get S ctr S sf 1 ne {dup dup length 1 sub dup 2 index S get sf div put} if put / ctr ctr 1 add N} B / I { cc 1 add D} B / bop {userdict / bop-hook known {bop-hook} if / SI save N @rigin 0 0 moveto / V matrix currentmatrix dup 1 get dup mul exch 0 get dup mul Добавлять .99 lt {/ QV} {/ RV} ifelse load def pop pop} N / eop {SI восстановить showpage userdict / eop-hook известный {eop-hook} if} N / @ start {userdict / start-hook известное {start-hook} if pop / VResolution X / Resolution X 1000 div / DVImag X / IE 256 array N 0 1 255 {IE S 1 string dup 0 3 index put cvn put} для 65781,76 дел / размер X 65781,76 дел / размер X} N / p {show} N / RMat [1 0 0 -1 0 0] N / BDot 260 string N / rulex 0 N / ruley 0 N / v {/ ruley X / rulex X V} B / V {} B / RV statusdict begin / product where {pop product dup length 7 ge {0 7 getinterval dup (Display) eq exch 0 4 getinterval (NeXT) eq или} {pop false} ifelse} {false} ifelse end {{gsave TR -.1 .1 TR 1 1 шкала rulex ruley false RMat {BDot} imagemask grestore}} {{gsave TR -.1 .1 TR rulex ruley scale 1 1 false RMat {BDot} imagemask grestore}} ifelse B / QV {gsave newpath transform round exch round exch itransform moveto rulex 0 rlineto 0 ruley neg rlineto rulex neg 0 rlinto fill grestore} B / a {moveto} B / delta 0 N / tail {dup / delta X 0 rmoveto} B / M {S p delta add tail} B / b {S p tail} B / c {-4 M} B / d {-3 M} B / e {-2 M} B / f {-1 M} B / g {0 M} B / h {1 M} B / i {2 M} B / j {3 M} B / k { 4 M} ч / б {0 rmoveto} B / l {p -4 w} B / m {p -3 w} B / n {p -2 w} B / o {p -1 w} B / q { p 1 w} B / r {p 2 w} B / s {p 3 w} B / t {p 4 w} B / x {0 S rmoveto} B / y {3 2 рулона p a} B / bos {/ SS сохранить N} B / eos {SS restore} B конец %% EndProcSet %% BeginProcSet: специальный.профи TeXDict begin / SDict 200 dict N SDict begin / @ SpecialDefaults {/ hs 612 N / vs 792 N / ho 0 N / vo 0 N / hsc 1 N / vsc 1 N / ang 0 N / CLIP 0 N / rwiSeen false N / rhiSeen false N / letter {} N / note {} N / a4 {} N / legal {} N} B / @ scaleunit 100 N / @ hscale {@scaleunit div / hsc X} B / @ vscale {@scaleunit div / vsc X} B / @ hsize {/ hs X / CLIP 1 N} B / @ vsize {/ vs X / CLIP 1 N} B / @ clip { / CLIP 2 N} B / @ hoffset {/ ho X} B / @ voffset {/ vo X} B / @ angle {/ ang X} B / @ rwi { 10 div / rwi X / rwiSeen true N} B / @ rhi {10 div / rhi X / rhiSeen true N} B / @ llx {/ llx X} B / @ lly {/ lly X} B / @ urx {/ urx X} B / @ ury {/ ury X} B / magscale true def end / @ MacSetUp {userdict / md известный {userdict / md тип получения / dicttype eq {userdict begin md length 10 add md maxlength ge {/ md md dup длина 20 add dict copy def} if end md begin / letter {} N / note {} N / Legal {} N / od {txpose 1 0 mtx defaultmatrix dtransform S atan / pa X newpath метка обрезки {преобразовать {itransform moveto}} {преобразовать {itransform lineto} } {6 -2 роликовое преобразование 6 -2 роликовое преобразование 6 -2 роликовое преобразование { itransform 6 2 roll itransform 6 2 roll itransform 6 2 roll curveto}} {{ closepath}} pathforall newpath counttomark array astore / gc xdf pop ct 39 0 положить 10 fz 0 fs 2 F / | ______ Courier fnt invertflag {PaintBlack} if} N / txpose {pxs pys scale ppr aload pop por {noflips {pop S neg S TR pop 1 -1 scale} если xflip yflip и {pop S neg S TR 180 повернуть 1 -1 масштаб ppr 3 получить ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg TR} if xflip yflip not и {pop S neg S TR pop 180 rotate ppr 3 get ppr 1 get neg sub neg 0 TR} if yflip xflip not и {ppr 1 get neg ppr 0 get neg TR} if} {noflips {TR pop pop 270 повернуть масштаб 1 -1} если xflip yflip и {TR pop pop 90 повернуть 1 -1 масштаб ppr 3 get ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg TR} если xflip yflip not и {TR pop pop 90 rotate ppr 3 get ppr 1 get neg sub neg 0 TR}, если yflip xflip not и {TR pop pop 270 rotate ppr 2 get ppr 0 get neg sub neg 0 S TR} if} ifelse scaleby96 {ppr aload pop 4 -1 roll add 2 дел 3 1 рулон прибавить 2 дел 2 копировать TR.96 dup scale neg S neg S TR} if} N / cp {pop pop showpage pm restore} N end} if} if} N / normalscale {Разрешение 72 div VResolution 72 div neg scale magscale {DVImag dup scale} if 0 setgray} N / psfts {S 65781.76 div N} N / startTexFig {/ psf $ SavedState save N userdict maxlength dict begin / magscale false def normalscale currentpoint TR / psf $ ury psfts / psf $ urx psfts / psf $ lly psfts / psf $ llx psfts / psf $ y psfts / psf $ x psfts currentpoint / psf $ cy X / psf $ cx X / psf $ sx psf $ x psf $ urx psf $ llx sub div N / psf $ sy psf $ y psf $ ury psf $ lly sub div N psf $ sx psf $ sy масштаб psf $ cx psf $ sx div psf $ llx sub psf $ cy psf $ sy div psf $ ury sub TR / showpage {} N / erasepage {} N / copypage {} N / p 3 def @MacSetUp} N / doclip { psf $ llx psf $ lly psf $ urx psf $ ury currentpoint 6 2 roll newpath 4 copy 4 2 рулон moveto 6 -1 рулон S lineto S lineto S lineto closepath clip newpath moveto} N / endTexFig {end psf $ SavedState restore} N / @ begin special {SDict begin / SpecialSave save N gsave normalscale currentpoint TR @SpecialDefaults count / ocount X / dcount countdictstack N} N / @ setspecial {CLIP 1 eq {newpath 0 0 moveto hs 0 rlineto 0 vs rlineto hs neg 0 rlineto closepath clip} if ho vo TR hsc vsc scale ang rotate rwiSeen {rwi urx llx sub div rhiSeen {rhi ury lly sub div} {dup} ifelse scale llx neg lly neg TR } {rhiSeen {rhi ury lly sub div dup scale llx neg lly neg TR} if} ifelse CLIP 2 eq {newpath llx lly moveto urx lly lineto urx ury lineto llx ury lineto closepath clip} if / showpage {} N / erasepage {} N / copypage {} N newpath } N / @ endpecial {count ocount sub {pop} repeat countdictstack dcount sub { end} повторить grestore SpecialSave restore end} N / @ defspecial {SDict begin} N / @ fedspecial {end} B / li {lineto} B / rl {rlineto} B / rc {rcurveto} B / np { / SaveX currentpoint / SaveY X N 1 setlinecap newpath} N / st {stroke SaveX SaveY moveto} N / fil {fill SaveX SaveY moveto} N / эллипс {/ endangle X / startangle X / yrad X / xrad X / savematrix matrix currentmatrix N TR xrad yrad scale 0 0 1 startangle endangle arc savematrix setmatrix} N конец %% EndProcSet Начало TeXDict 40258431 52099146 1000 300 300 (eisner.acl96.dvi) @start / Fa 1 85 df84 D E / Fb 1111 df110 D E / Fc 12 126 df16 DI26 DI32 DI40 DI122 DIII E / Fd 6 124 df98 DI102 D111 D 116 D123 D E / Fe 27122 df40 DI44 D48 DI55 D97 DIIIII105 D107 DIIIIIIII IIII121 D E / Ff 3 111 df0 D32 D110 D E / Fg 14 121 df12 DI21 D58 DIIII81 DII I110 D120 D E / Fh 13122 df21 D58 D81 DIII102 DII107 D110 D120 DI E / Fi 35 121 df40 DI47 DII60 D62 D65 DIII IIII76 D78 D80 D83 DI86 D88 D97 DI100 DII108 D110 DI114 DII119 DI E / Fj 18117 df40 DI47 D49 DI III78 D80 D83 D101 DI105 D109 DI115 DI E / Fk 70125 df12 D14 D34 D38 DIII44 DIIIIIIIIIIIIIII61 D63 D65 DI68 D70 DIIIII77 DII83 DII91 DII97 DIIIIIIIIIIIIIIIIIII IIII124 D E / Fl 2 111 df3 D110 D E / Fm 2 111 df 48 D110 D E / Fn 14 84 df40 DI47 DIIIIII73 D78 DII83 D E / Fo 36121 df12 D38 D42 D45 DI49 DI52 D58 D66 DI69 D76 D78 D83 DI97 D99 DIIIIII108 DIIIII IIIII120 D E / Fp 53122 df12 D34 D40 DI44 DII50 DI53 D55 DI58 D 65 DIIIIII73 D76 DIIII83 DII92 D97 DIIIIIIII108 DIIIIIIIIIIIII E / Fq 38123 df11 DII21 D27 DI58 DI III67 D79 D81 DIII97 D99 DIIIIII107 DIII112 D114 DIII119 DIII E / Fr 84 128 df11 DII я 34 D38 DIIIIIIIIIIIIIIIIIIIII61 D63 D65 DIII IIIIIIIIIIII82 DIIIII89 D91 DII97 DIIIIIIIIIIIIIIIIIIIIIIIIIII127 D E / Fs 13118 df46 D64 D99 DII105 DI108 D110 D112 D114 DI117 D E / Ft 36122 df44 DII48 DIIII54 D56 DI65 D67 DI73 D80 D83 D85 D97 D99 DIII104 DI108 DI III114 DII II121 D E / Fu 47122 df12 D34 D49 DIIIIII65 D67 DIIII73 DI78 DII82 DI87 D 92 D97 DII II IIII107 DIIIII114 DIIIIIII E / Fv 14 121 df 0 DI3 D15 D20 DI 33 D41 D50 D54 D106 D109 DI120 D E / Fw 23 122 df14 D45 D67 D69 DII78 D80 D97 DII
Границы | ULTRA: универсальная грамматика как универсальный синтаксический анализатор
Введение
Одним из наиболее значительных достижений лингвистической теории в последнее время является появление высококачественных наборов данных по всему спектру межъязыковых вариаций.В прошлом генеративные исследования обычно полагались на детальное изучение одного или нескольких языков для выявления синтаксических механизмов. Хотя этот подход, безусловно, плодотворен, накопление информации о большом количестве языков открывает новые возможности для улучшения понимания.
В порождающей грамматике значительное внимание уделяется рекурсии как (или даже ) фундаментальному свойству языка (обсуждение см. В Berwick and Chomsky, 2016).Это формализуется в основной операции под названием Merge, объединяющей два синтаксических объекта (в конечном итоге построенных из лексических элементов) в набор, содержащий оба. Рекурсия следует из способности Merge применять к собственному выводу. Слияние также фиксирует тот важный факт, что предложения имеют внутреннюю структуру (составные части в квадратных скобках), причем каждый уровень соответствует приложению слияния.
Вопреки этой концепции, я утверждаю, что концептуальной ошибкой является рассмотрение предложений как групп (будь то наборы или что-то еще) лексических элементов.Ошибка заключается в представлении о лексических единицах как о связанных единицах, существующих на одном уровне. Это также приводит к мысли о предложениях как о одноуровневых представлениях. Слова, попросту говоря, не вещи ; они представляют собой пару процессов, протянутых во времени. В контексте понимания релевантными процессами являются распознавание слова и интеграция его значения в интерпретацию. Я развиваю новый взгляд на структуру предложений с точки зрения этих двух типов процессов.Важно отметить, что нетривиальные отношения определяют их относительную последовательность: одно слово может встречаться раньше, чем другое в поверхностном порядке, но его значение может быть интегрировано позже. Рассмотрение предложений как единых, вневременных представлений, построенных на непроницаемых лексических атомах, оставляет нас неспособными уловить фундаментально вовлеченные временные явления, в которых два аспекта каждого слова не связаны вместе, а процессы для разных слов переплетаются.
В этой статье предлагается новая модель грамматических механизмов, получившая название ULTRA (Универсальный реактивный автомат с линейным преобразованием).Внутри локальных синтаксических доменов, образующих расширенную проекцию лексического корня (такого как глагол или существительное), ULTRA использует алгоритм стековой сортировки Кнута (1968) для непосредственного сопоставления поверхностных порядков слов с лежащей в основе базовой структурой. Сопоставление успешно только для 213 приказов избегания. Это интригующий результат, поскольку избегание 213, возможно, ограничивает вариацию нейтрального порядка слов в разных языках в различных синтаксических областях. Хотя локальные звуковые и смысловые представления в этой модели являются последовательностями, иерархическая структура, тем не менее, возникает в динамическом действии отображения.Обнаруженные здесь структуры в квадратных скобках, хотя и эпифеноменальные, очень похожи на структуры, построенные Merge, с некоторыми существенными различиями (возможно, в пользу нынешней теории).
Сортировка по стеку оказалась эффективной процедурой для связывания порядка слов и иерархической интерпретации, включая линеаризацию, смещение, композицию и помеченные скобки. Теория предлагает реализацию как процесс исполнения в реальном времени. Преследование этого понимания значительно изменяет границы между производительностью и компетенцией.Примечательно, что ULTRA не требует никаких параметров, зависящих от языка; инвариантный алгоритм служит грамматическим устройством для всех языков. Проще говоря, я предполагаю, что Universal Grammar — это универсальный синтаксический анализатор.
Тем не менее, стековая сортировка — это слишком ограниченный механизм для описания всех явлений человеческого синтаксиса. Остается незавершенным три вида эффектов: неограниченная рекурсия, ненейтральный порядок и существование явно различных языков. Более того, понимание стековой сортировки как системы обработки сталкивается с двумя очевидными проблемами: это однонаправленный синтаксический анализатор, который не является тривиально обратимым для производства; и это противоречит убедительным доказательствам пословной постепенности в понимании.
Хотя построение полной модели синтаксиса и обработки выходит далеко за рамки данной статьи, проблемы, возникающие при построении модели синтаксического анализа как грамматики на сортировке стека, требуют рассмотрения. Я обращаюсь к различию между реактивными и предсказательными процессами, рассматривая стековую сортировку как универсальную реактивную процедуру. Отдельный прогностический модуль играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементной интерпретацией.Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти недавнего времени, лежащей в основе сортировки стека) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, пересекающиеся зависимости и специальный синтаксис «левая периферия». Наконец, я предполагаю, что эпизодическая память — независимо иерархическая по структуре у людей — играет ключевую роль в лингвистической рекурсии.
Структура этого документа следующая.В разделе Linear Base утверждается, что «базовая» структура внутри каждого локального синтаксического домена представляет собой последовательность. Раздел * 213 в «Нейтральном порядке слов» исследует обобщение, согласно которому «213-избегание» ограничивает возможности нейтрального по отношению к информации порядка слов в разных языках. Раздел «Сортировка стека как грамматический механизм» предлагает процедуру сортировки стека для выявления «избегания 213» в порядке слов. Раздел Stack-Sorting: Linearization, Displacement, Composition и Labeled Brackets показывает, как дальнейшие синтаксические эффекты следуют из сортировки по стеку.Раздел Сравнение с существующими учетными записями Universal 20 сравнивает ULTRA с существующими учетными записями избегания 213 в порядке слов, уделяя особое внимание Universal 20. Раздел Universal Grammar as Universal Parser преследует реализацию стековой сортировки в реальном времени. В разделе «Возможные расширения более полной теории синтаксиса» рассматриваются проблемы, связанные с принятием стековой сортировки в качестве ядра универсальной грамматики, и приводятся наброски некоторых возможных расширений. Раздел Заключение завершается.
Линейное основание
Синтаксическая комбинация может принимать разные формы.Появляется новая точка зрения, согласно которой сочетание в значительной степени поддерживает отношения между головой и дополнением (Starke, 2004; Jayaseelan, 2008). В этом контексте термин «голова» имеет как минимум два разных значения. Во-первых, в любой комбинации двух синтаксических объектов один является «более важным» по отношению к составному значению. Назовем это понятие головы корнем , отметив, что в расширенных проекциях существительных и глаголов лексическое существительное или корень глагола является семантически доминантным. Другой смысл головы касается того, какой элемент определяет комбинаторное поведение композиции; назовем это понятие головы меткой .
В старых теориях структуры фраз два смысла головы (корень и метка) сходились в одном элементе; существительное, например, в сочетании со всеми его модификаторами в существительной фразе. Таким образом, головокружение соотносится с иерархическим доминированием; корень проецировал свой ярлык над своими иждивенцами. Чтобы проиллюстрировать, комбинация прилагательного и существительного, например, красных книг , будет представлена следующим образом.
Этот традиционный вывод о взаимосвязи зависимости и иерархии опровергнут современной синтаксической картографией (Rizzi, 1997; Cinque, 1999 и последующие работы).Картографические подходы предполагают, что синтаксическая комбинация следует строгой, кросс-лингвистической однородной иерархии внутри каждой расширенной проекции. Эта иерархия включает в себя последовательность функциональных глав, лицензионную комбинацию с различными модификаторами в жестком порядке. Фраза красных книг представлена следующим образом.
Здесь прилагательное — это спецификатор специализированного функционального заголовка (F), который маркирует композицию, определяя ее комбинаторное поведение. В картографических изображениях головы равномерно на ниже, чем на своих иждивенцев, которые появляются выше по позвоночнику.
Вопросы возникают по поводу этих представлений, которые постулируют обилие невысказанного материала. Любопытное наблюдение заключается в том, что функциональные заголовки и их спецификаторы явно не встречаются вместе, как это формализовано в обобщенном двойном фильтре компаундирования Купмана (2000).
Starke (2004) развивает наблюдение Купмана дальше, утверждая, что заголовки и спецификаторы не встречаются одновременно, потому что они представляют собой токенов одного типа , конкурирующих за одну позицию. Старке преобразовывает картографический корешок в абстрактную функциональную последовательность ( fseq ), позиции которой могут быть обозначены как лексическим, так и фразовым материалом.Следуя концепции Старке, комбинация прилагательного и существительного будет представлена, как показано ниже.
Мы снова изменили традиционные выводы об иерархии глав и иждивенцев. Тем не менее, понятие корня (выделение существительного) по-прежнему имеет решающее значение, поскольку модификаторы располагаются в иерархическом порядке, продиктованном и fseq.
Синтаксическая комбинация этого типа является последовательной в пределах каждой расширенной проекции. Эти «базовые» последовательности кодируют композицию «снизу вверх», поэтому естественно упорядочить последовательность таким же образом (снизу вверх).База (т.е. fseq, картографический корешок) широко считается единообразной для разных языков и выражает «тематическое», информационно-нейтральное значение (в отличие от дискурсивно-информационной структуры).
Грамматика, согласно любой теории, определяет формальное отображение, связывающее звук и значение (точнее, внешнюю и внутреннюю формы, с учетом неслышащих модальностей). Эта спецификация может принимать разные формы. Последовательное представление основы позволяет очень просто сформулировать звуково-смысловое отображение.Эта переформулировка дает принципиальное описание класса универсалий порядка слов. Более того, в то время как объекты интерфейса (порядок слов и базовые деревья), участвующие в отображении, являются последовательностями, заключенная в скобки иерархическая структура возникает как динамический эффект.
Существуют различные способы концептуализации взаимосвязи между базовым и поверхностным порядком слов. Обычное мнение состоит в том, что база упорядочивает входные данные до производных, давая поверхностный порядок слов в качестве выходных данных. Эта направленность подразумевается в терминах, используемых для описания отношения иерархия-порядок: линеаризация , экстернализация и т. Д.В этой статье мы придерживаемся другой точки зрения, согласно которой порядок слов на поверхности является входными данными для алгоритма, который пытается собрать основу в качестве выходных данных. Примечательно, что единственные исходные данные, которые сходятся на единой основе в рамках этого процесса, — это 213-избегание; порядок слов, содержащих 213, приводит к отклонению от нормы.
* 213 В нейтральном порядке слов
213-избегание, возможно, улавливает возможности нейтрального по отношению к информации порядка слов в различных синтаксических областях на разных языках. Под 213-избеганием я подразумеваю запрет на порядок поверхности… b… a… c …, для элементов a ≫ b ≫ c , где ≫ указывает c-команду в стандартных представлениях дерева основы ( эквивалентно доминирование в деревьях Старке).Другими словами, нейтральные порядки слов, кажется, избегают последовательности элементов от среднего до высокого-низкого (под) из одного fseq. Элементы, образующие этот запрещенный контур, не обязательно должны быть смежными, в порядке поверхности или в основании fseq.
Широко распространено мнение, что 213-избегание ограничивает варианты упорядочивания кластеров глаголов, хорошо известных в западногерманском языке (см. Обзор в Wurmbrand, 2006). Обширный обзор голландских диалектов, проведенный Barbiers et al. (2008), обнаружил очень мало примеров этого порядка; Немецкие диалекты, кажется, тоже избегают этого порядка.Между тем Zwart (2007) анализирует порядок 213 в кластерах голландских глаголов как включающий экстрапозицию последнего элемента.
Наиболее изученной областью, поддерживающей избегание 213 в порядке слов, является Universal 20 Гринберга, описывающая порядок именных фраз.
«Когда какие-либо или все элементы (указательное, числовое и описательное прилагательное) предшествуют существительному, они всегда находятся в указанном порядке. Если они следуют, порядок либо тот же, либо полная противоположность »(Greenberg, 1963, стр. 87).
Последующие работы улучшили эту картину.Cinque (2005) сообщает, что только 14 из 24 логически возможных порядков этих элементов засвидетельствованы как информационно-нейтральные порядки (Таблица 1).
Таблица 1 . Возможный порядок именных фраз. Cinque (2005, стр. 319–320) отчет о количестве языков, представленных в каждом порядке, дается числом: 0 = не подтверждено; 1 = очень мало языков; 2 = несколько языков; 3 = много языков; 4 = очень много языков.
Чинкве описывает эти факты с ограничением движения с единой базы.В частности, он предлагает, чтобы все движения перемещали существительное или что-то, что его содержит, влево (раздел «Сравнение с существующими счетами Universal 20» подробно описывает теорию Чинкве и связанные с ней описания). Что запрещено, так это движение остатка.
Порядок именных фраз подчиняется простому обобщению: подтвержденные порядки — это все и только 213 перестановки, избегающие перестановок. Все непроверенные заказы имеют 213 подпоследовательностей. Например, неподтвержденный * Num Dem Adj N содержит подпоследовательности Num Dem Adj … и Num Dem… N , представляющие контуры среднего-высокого-низкого уровня относительно fseq.
Сортировка стека как грамматический механизм
Существует особенно простая процедура, которая отображает порядок слов без исключения 213 в единообразную основу, называемая сортировкой стека. Я описываю адаптацию алгоритма сортировки стека Knuth (1968), который использует память «последний пришел — первым вышел» (стек) для сортировки элементов по их относительному порядку в базе. Это частичный алгоритм сортировки: он достигает желаемого результата только для некоторых входных порядков.
(4) S АЛГОРИТМ ТАК-СОРТИРОВКИ D ОПРЕДЕЛЕНИЯ
Пока ввод не пуст, I: следующий элемент ввода.
If I ≫ S, Pop. S: элемент наверху стека.
Else Push. x ≫ y: x c-команды y в
база (например, Dem ≫ N).
Пока Stack не пуст, Push: перемещает I из входа
в стек.
Поп. Pop: перемещает S из стека
для вывода.
(4) отображает все и только 213-избегающие порядки слов в 321-подобную иерархию, соответствующую основанию. Заказы, содержащие 213, сопоставляются с отклоняющимся выходом, отличным от базового. По предположению, именно поэтому такие порядки типологически недоступны: они автоматически отображаются в неинтерпретируемом порядке композиции. Это объясняет шаблон Universal 20 (Таблицы 2, 3).
Таблица 2 . Результат стековой сортировки логически возможных порядков из 4 элементов в формате вход → выход.
Таблица 3 . Вычисления сортировки стека для 4-х порядков.
Давайте проиллюстрируем, как (4) разбирает некоторые порядки именных фраз: Dem-Adj-N, N-Dem-Adj, * Adj-Dem-Num.
(5) Dem-Adj-N: PUSH (Dem), PUSH (Adj), PUSH (N),
POP (N), POP (Adj), POP (Dem).
(6) N-Dem-Adj: PUSH (N), POP (N), PUSH (Dem), PUSH (Adj),
POP (Настр.), POP (Дем.).
Для аттестованных заказов номинальные категории POP в порядке
(7) * Adj-Dem-N: PUSH (Настр.), POP (Настр.), PUSH (Дем.),
PUSH (N), POP (N), POP (Дем).
Для неподтвержденного порядка 213, элементы POP в девиантном порядке *
Это хорошо: (4) сопоставляет подтвержденные заказы их универсальному значению, одновременно исключая не подтвержденные заказы. Но помимо такого сопоставления, адекватная грамматика должна объяснять другие аспекты знания языка, включая брекетинг поверхностной структуры.Если грамматика рассматривает поверхностные порядки и базовые структуры как последовательности (локально), откуда может взяться такая заключенная в скобки структура?
Сортировка стопкой: линеаризация, смещение, композиция и маркированные скобки
В этом разделе я показываю, что сортировка стека эффективно охватывает линеаризацию, смещение и композицию, а также назначение скобок с однозначной пометкой и без поиска. Более того, все это выполняется без параметров, зависящих от языка.
В стандартном представлении («Y-модель») линеаризация и композиция — это отдельные операции интерфейса, интерпретирующие структуры, построенные в автономном синтаксическом модуле с помощью Merge.В ULTRA линеаризация идет в другом направлении, поэтапно загружая в память поверхностный порядок слов и собирая их заново в порядке композиционной интерпретации.
Смещение — естественное свойство грамматики сортировки стека
Смещение — естественная особенность сортировки стопкой; с одной точки зрения, это основное свойство системы. В стандартных отчетах составляющие, составляющие вместе при интерпретации, должны появляться смежными в поверхностном порядке. Такое расположение вызвано грамматиками фразовой структуры.Смещение, при котором элементы, составляющие вместе, разделяются промежуточными элементами в порядке поверхности, всегда казалось удивительным свойством, требующим объяснения.
В ULTRA все работает иначе. Ключевое предположение представления на основе слияния отвергается: нет уровня представления, охватывающего порядок слов и fseq в унифицированном объекте более высокого порядка. Вместо этого порядок слов и базовая иерархия — это несвязанные последовательности, связанные динамически. Несмежные элементы ввода вполне могут оказаться смежными на выходе.Смещение, а не исключение, является правилом; : каждый элемент в поверхностном порядке «трансформируется», проходя через память перед извлечением для интерпретации.
Скобки и метки без примитивного округа
Алгоритм (4) неявно назначает помеченную структуру в квадратных скобках каждому порядку поверхности, почти точно совпадая со структурами, присвоенными такими учетными записями, как Cinque (2005). Явно нажатие (сохранение от порядка слов до стека) соответствует левой скобке, а выталкивание (извлечение из стека для интерпретации) — правой скобке.Эти операции применяются к одному элементу за раз; естественно думать об этом элементе как об обозначении соответствующей скобки. См. Таблицу 4, в которой представлены вычисления сортировки стека для всех перестановок поверхностей трехэлементной базы.
Таблица 4 . Вычисления с сортировкой стека для порядков из 3 элементов.
При рассмотрении этих скобок, последовательность нажатий и извлечений (сохранение и извлечение) для каждого порядка неявно определяет дерево, как показано на рисунке 1. Это так называемые деревья Дика, набор всех упорядоченных корневых деревьев с фиксированным числом. узлов (здесь 4).Сравните их с деревьями с бинарным ветвлением, указанными в отчете Cinque (2005), с неостаточным движением влево, влияющим на основание ветвления вправо (рисунок 2). Скобки почти идентичны, как и их ярлыки, но есть некоторые вольности с техническими деталями аккаунта Cinque.
Рисунок 1 . Скобки и соответствующие деревья push-pop для принятых (сортированных по стеку) порядков из трех элементов. Это просто деревья Дика с 4 узлами.
Рисунок 2 .Деревья с бинарным ветвлением для производных аттестованных порядков трех элементов, избегающих перемещения остатков, с соответствующими скобками. Лексический корень (например, N в существительной фразе) показан черным треугольником, а структуры с концом и следом движения представлены двойной ветвью ||. Деревья представлены таким образом, чтобы выделить соответствие с деревьями Дика для этих порядков, полученных в результате сортировки стека.
Если отложить в сторону 321 дерево (а) на данный момент, деревья Дика представляют собой систематические сжатия без потерь деревьев Чинкве, при этом каждое поддерево, которое является ветвящейся вправо гребенкой в дереве Чинкве, заменено линейным деревом (см. 2008) в дереве Дика.Для этого соответствия, которое сводится к сокращению всех терминалов в двоичном дереве, лексический корень (например, существительное в DP) не должен сокращаться. Элементы из поверхностного порядка связаны с каждым узлом дерева Дика, кроме самого высокого, с линейным порядком чтения слева направо среди сестринских узлов и сверху вниз по унарным ветвящимся путям. Например, для поверхностного порядка 132, 1 ассоциирован с единственным бинарным ветвящимся узлом в его дереве Дика, 3 и 2 — с его левой и правой дочерними элементами (рисунок 3).
Рисунок 3 .Два представления в квадратных скобках 132 порядка поверхности и соответствующие деревья. Слева — структура, найденная при чтении операций сортировки стека в скобках; Элементы поверхности идентифицируются каждым узлом (кроме самого верхнего, пунктирного). Линейный порядок считывается сверху вниз по унарным ветвящимся путям и слева направо среди сестринских узлов. В соответствующем двоичном ветвящемся дереве, представляющем его происхождение перемещением (справа) , ярко выраженные элементы идентифицируются только с конечными узлами.
Между тем, порядок 321, которому присвоено троичное дерево путем сортировки стека, имеет два производных, исключающих перемещение остатков. В одном из возможных выводов 3 инвертируют, причем 2 сразу после объединения 2, затем 32 комплекса перемещаются за 1 после объединения 1. В другом возможном выводе сначала объединяется полная базовая структура, затем 23 перемещаются влево, а затем влево перемещается всего 3.
Ключевой эмпирический вопрос заключается в том, демонстрируют ли 321 порядок две отдельные заключенные в скобки структуры, как это позволяют трактовки бинарного ветвления, или только единственная, «плоская» структура, предсказанная здесь.Проблема становится еще более острой для 4 элементов, как в Universal 20, где существует до 5 различных производных слияния для порядка 4321. К счастью, это ( N Adj Num Dem ) наиболее распространенный порядок именных фраз; будущие исследования должны пролить свет на эту проблему.
Сводка раздела
Stack-sorting захватывает удивительное количество синтаксического механизма, обычно разделенного между различными модулями. В обычном представлении автономный генераторный движок строит составляющие структуры, интерпретируемые на интерфейсах дальнейшими процессами линеаризации и композиции.В ULTRA линеаризация и композиция отражают единую процедуру. Составная структура не является примитивной, но записывает этапы хранения и извлечения, с помощью которых сортировка стека собирает интерпретацию. Это создает структуру поверхности в скобках, обозначенную соответствующим образом, в значительной степени идентичную структуре в скобках в учетных записях, постулирующих движение (внутреннее слияние) от единой основы (сформированной внешним слиянием). Однако там, где стандартные теории допускают множественные выводы для некоторых порядков поверхностей (и неоднозначную бинарную ветвящуюся структуру), в настоящем описании назначается уникальная внебинарная скобка.Примечательно, что специфические особенности языка не играют никакой роли в движении. Смещение обрабатывается автоматически путем сортировки стека и фактически является его основной функцией.
Сравнение с существующими счетами Universal 20
В этом разделе сравнивается учетная запись сортировки стека Universal 20 с существующими учетными записями на основе слияния (Cinque, 2005; Steddy and Samek-Lodovici, 2011; Abels and Neeleman, 2012). Я утверждаю, что учетная запись сортировки стека проще, при этом избегая проблем, которые возникают в каждой из этих существующих альтернатив.
Счет Чинкве (2005)
Cinque предлагает кросс-лингвистически однородную базовую иерархию, отражающую фиксированный порядок внешнего слияния. Он предполагает, что движение (внутреннее слияние) происходит равномерно влево, в то время как основание ветвится вправо, в соответствии с LCA Кейна (1994). Он оговаривает, что остаточное движение в именной фразе запрещено: каждое движение влияет на существительное или на составляющую, содержащую его. Его базовая структура для именной группы — (8).
Модификаторы оверта — это спецификаторы выделенных функциональных глав (например,г., X 0 ), ниже договорные фразы, предусматривающие посадочные площадки для передвижения. Эта структура и его предположения о движении выводят все и только подтвержденные приказы. Англоязычный порядок Dem-Num-Adj-N поверхности без движения; все другие порядки включают некоторую последовательность движений NP или что-то, что ее содержит.
Рассказ Абельса и Нилмана (2012)
Abels и Neeleman (2012) модифицируют анализ Cinque, отбрасывая элементы, введенные для соответствия LCA (включая согласованные фразы и специальные функциональные главы).Они утверждают, что LCA не играет объяснительной роли; все, что требуется, — это движение влево, а остаточное движение запрещено. Они допускают свободную линеаризацию сестринских узлов, используя значительно более простую базовую структуру (9). Они опускают метки для нетерминальных узлов как не относящиеся к их анализу (Abels and Neeleman, 2012: 34).
По их теории, восемь подтвержденных приказов могут быть получены без движения, изменяя линейный порядок сестер. Остальные подтвержденные заказы требуют движения влево без остатка.В принципе, их система допускает расширенный набор выводов Чинкве (2005); некоторые порядки могут быть получены путем выбора линеаризации или перемещения. Однако, ограничивая внимание строго необходимыми операциями и предполагая, что свободная линеаризация проще, чем перемещение, их вывод обычно проще, чем у Cinque.
Рассказ Стедди и Самек-Лодовичей (2011)
Стедди и Самек-Лодовичи (2011) предлагают еще один вариант анализа Чинкве (2005).Они предлагают теоретико-оптимальное объяснение, сохраняя базовую структуру Чинкве (8). Линейный порядок определяется набором ограничений Align-Left (10), по одному для каждого открытого элемента.
(10) а. N-L — Выровнять (NP, L, AgrWP, L)
Совместите левый край NP с левым краем AgrWP.
г. A-L — Выровнять (AP, L, AgrWP, L)
Совместите левый край AP с левым краем AgrWP.
г. NUM-L — Выровнять (NumP, L, AgrWP, L)
Выровняйте левый край NumP с левым краем AgrWP.
г. DEM-L — Выровнять (DemP, L, AgrWP, L)
Совместите левый край DemP с левым краем AgrWP.
(Из Стедди и Самек-Лодовичи, 2011: 450).
Эти ограничения выравнивания вызывают нарушение для каждого явного элемента или трассы, отделяющей соответствующий элемент от левого края домена, и ранжируются по-разному для разных языков. Подтвержденные заказы являются оптимальными кандидатами при некотором ранжировании ограничений. Непроверенные заказы исключаются, потому что они «гармонически ограничены»: какой-либо другой кандидат подвергается меньшему количеству нарушений более высокого ранга при любом ранжировании ограничений.Таким образом, они могут отказаться от ограничений передвижения, принятых Чинкве (2005) и Абельсом и Нилманом (2012). Вместо этого левосторонний, не остаточный характер движения выпадает из принципов выравнивания.
Проблемы с существующими счетами
Хотя эти учетные записи различаются в деталях, у них есть некоторые проблемные особенности. Во-первых, все они отражают шаблон порядка слов на трех уровнях объяснения: (i) единообразная базовая структура, (ii) синтаксическое движение и (iii) принципы линеаризации.Во всех трех учетных записях (i) описывает порядок внешнего слияния. Детали (ii) и (iii) различаются в зависимости от счета. Для Чинкве (2005 г.) и Стедди и Самек-Лодовичи (2011 г.) все заказы, кроме Dem-Num-Adj-N , включают движение; Abels и Neeleman (2012) требуют перемещения только для шести подтвержденных заказов. Что касается линеаризации, Cinque (2005) использует LCA Кейна (1994); Абельс и Нилман (2012) имеют движение равномерно влево, но сестры, генерируемые базой, свободно линеаризуются на основе специфики языка; У Стедди и Самек-Лодовичи (2011) есть ранжирование ограничений для конкретного языка.
Все эти учетные записи требуют разной грамматики для разных порядков. В системе Cinque (2005) необходимо изучить особенности, управляющие определенными движениями. То же самое верно для Abels и Neeleman (2012) с дополнительным изучением порядка для сестринских узлов. Стедди и Самек-Лодовичи (2011) требуют изучения ранжирования ограничений, которое дает начало каждому порядку. Таким образом, все эти рассказы сталкиваются с проблемами, связанными с языками, допускающими свободу порядка в ДП; по сути, они должны допускать недоопределенные или конкурирующие грамматики, чтобы фиксировать различные порядки.
Наконец, все эти описания имеют некоторую степень структурной или грамматической двусмысленности для некоторых порядков. Для Cinque (2005) одна из разновидностей двусмысленности возникает при выборе того, следует ли переместить функциональную категорию или фразу «Соглашение», в которую она встроена; у этого выбора нет явного рефлекса. Хотя его теория резко ограничивает количество и место посадки возможных перемещений, эти ограничения несколько искусственны; Немногое существенное изменилось бы, если бы мы постулировали дополнительные тихие функциональные уровни для выполнения дальнейших движений или разрешили использование нескольких спецификаторов.В пределе это позволяет использовать весь спектр неоднозначных производных, обсуждаемых в разделе Stack-Sorting: Linearization, Displacement, Composition, and Labeled Brackets. Подход Абельса и Нилмана (2012) допускает эту двусмысленность среди различных производных движений, а также порождение многих порядков посредством перемещения или переупорядочения сестринских узлов. Наконец, Стедди и Самек-Лодовичи (2011) сталкиваются с другой проблемой неоднозначности: некоторые порядки согласуются с множественным ранжированием ограничений (таким образом, множественными грамматиками).
Сравнение с учетной записью Stack-Sorting
Счетчик с сортировкой по стеку лучше справляется с этими проблемами. Вместо постулирования отдельных уровней принципов основы, движения и линеаризации соответствующий механизм реализуется в рамках одного алгоритмического процесса. Алгоритм сортировки универсален, он избегает специфичных для языка функций для управления движением, упорядочивания дочерних узлов или ограничений выравнивания рангов. Такая теория идеально подходит для объяснения феномена свободного порядка слов.Кроме того, каждый заказ вызывает уникальную последовательность операций хранения и извлечения, отслеживая уникальное брекетинг. В доменах, характеризующихся нейтральным порядком слов и одним fseq, нет ложной структурной или грамматической двусмысленности для любого порядка слов.
Универсальная грамматика как универсальный синтаксический анализатор
В этом разделе развивается точка зрения, согласно которой сортировка стека может формировать основу для инвариантного механизма производительности, реализуя универсальную грамматику как универсальный синтаксический анализатор. Это изменяет традиционные выводы о компетенции и успеваемости, обеспечивая при этом новое представление о том, что такое грамматика.
Переосмысление компетенции и производительности
В генеративных счетах существует фундаментальное разделение между компетенцией и производительностью (Chomsky, 1965). Компетенция включает в себя знание языка, рассматриваемое как абстрактное вычисление, определяющее структурную декомпозицию бесконечного множества предложений. Отдельные системы производительности получают доступ к знаниям системы компетенций во время обработки в реальном времени. В терминах трехуровневого описания систем обработки информации Марра (1982), компетенция соответствует высшему, вычислительному уровню, определяя , что, , система делает, и , почему, .Производительность довольно приблизительно соответствует нижнему, алгоритмическому уровню, описывая, как , шаг за шагом, выполняются вычисления.
Конечно, иерархия Марра применима к обработке информации на языке в рамках данной теории, как и любой другой. Однако разделение труда между этими компонентами здесь существенно перерисовывается, и гораздо больше бремени объяснения ложится на производительность. Существенное отличие состоит в том, что в ULTRA заключенная в скобки структура не входит в компетенцию.Вместо этого такая структура возникает во взаимодействии компетенции с алгоритмом сортировки стека во время синтаксического анализа в реальном времени. Знания, приписываемые грамматике компетенций, проще, включая врожденный fseq в качестве основного компонента. В некотором смысле это согласуется с взглядами недавней работы Хомского, в которой компетенция фундаментально ориентирована на вычисление интерпретаций с экстернализацией «вспомогательными».
Универсальный синтаксический анализатор
Новое утверждение ULTRA состоит в том, что существует единый синтаксический анализатор для всех языков.Это отходит от почти универсального предположения, что синтаксические анализаторы интерпретируют грамматики конкретного языка. Но даже в рамках этого традиционного взгляда была признана привлекательность универсальных механизмов.
«Ключевым моментом, однако, является то, что поиск должен быть поиском универсалий, даже — и, возможно, особенно — в области обработки. Ибо может показаться, что самая сильная теория синтаксического анализа — это та, которая утверждает, что интерпретатор грамматики сам по себе является универсальным механизмом, т.е. что существует один сильно ограниченный интерпретатор грамматики, который является подходящей машиной для анализа всех естественных языков »(Marcus, 1980, p.11).
Идея «синтаксический анализатор — это грамматика» имеет долгую историю; см. Phillips (1996, 2003), Kempson et al. (2001), а также статьи в Fodor and Fernandez (2015) о недавней перспективе. Фодор называет это представлением только грамматики производительности (PGO).
«Теория общественного мнения вступает в игру с одним мощным преимуществом: должны быть психологические механизмы для разговора и понимания, и соображения простоты, таким образом, возлагают бремя доказательства на любого, кто будет утверждать, что существует нечто большее» (Fodor, 1978, стр.470).
Однако, допуская, что это влечет за собой более простую теорию, Фодор отвергает эту идею, не находя мотивации для движения вне автономной грамматики ( ibid ., 472). Это предполагает, что движение принципиально сложно для синтаксического анализа механизмов (которые должны предпочесть фразово-структурные механизмы трансформационным). Однако в ULTRA смещение не является сложностью по сравнению с более простыми механизмами; смещение составляет основного механизма.
Смещение не является уникальным для человеческого языка
Часто говорят, что смещение присуще только человеческому языку, и искусственные коды избегают этого свойства.Но смещение появляется в языках программирования точно в том же смысле, что и в ULTRA. Простой пример иллюстрирует: порядок, в котором пользователи нажимают клавиши на калькуляторе, не является порядком, в котором выполняются соответствующие вычисления. На практике калькуляторы компилируют входные данные в обратную польскую нотацию для машинного использования с помощью алгоритма маневровой верфи Дейкстры (SYA).
Пример не праздный; алгоритм сортировки стека (4) по существу идентичен SYA. Лексические заголовки (существительные и глаголы) «перенаправляются» непосредственно на интерпретацию, как числовые константы в калькуляторе.Между тем спутники, образующие их расширенные проекции, сортируются в соответствии с их относительным рангом, как и арифметические операторы. По этой аналогии картографический порядок соответствует порядку приоритета арифметических операторов.
На самом деле, хотя это свойство мало используется, SYA является протоколом сортировки; многие заказы на ввод приводят к одному и тому же внутреннему расчету. Как пользователи калькулятора, мы используем одну схему ввода (инфиксную нотацию), но подойдут и другие. Стандартизированный порядок ввода для калькуляторов имеет тот же статус, что и отдельные языки по отношению к ULTRA: пользователи могут придерживаться узких привычек упорядочивания, но алгоритм автоматически обрабатывает многие другие заказы.
Грамматичность и грамматичность
Одна из центральных задач, приписываемых грамматике, — отличать грамматические предложения языка от неграмматических строк. В ULTRA знание грамматики сильно отличается от знания грамматичности и . Первый вид знания в основном касается компьютерных интерпретаций. Но инвариантный процесс, интерпретирующий поверхностный порядок одного языка, может одинаково интерпретировать порядки других языков. С этой точки зрения существует только один I-язык и одна грамматика производительности, которая его обеспечивает.Хотя этот вывод является привлекательным, остается важный вопрос: откуда берутся отдельные языки с явно различающейся грамматикой?
Возможные расширения более полной теории синтаксиса
В этом разделе рассматриваются два типа проблем, возникающих при интерпретации стековой сортировки как устройства производительности. Первый касается согласования теории с тем, что известно о языковой обработке в реальном времени; второй касается расширения модели до свойств синтаксиса, которые остаются необъясненными.Даже подробное обсуждение этих проблем, а тем более обоснование каких-либо решений выходит за рамки данной статьи. Цель состоит в том, чтобы просто набросать проблемы и указать направления для дальнейшей работы.
Реакция против предсказания: инкрементность и жесткий порядок слов
Что касается обработки, одна проблема состоит в том, что этому подходу, по-видимому, противоречат убедительные доказательства пословной постепенности в понимании (особенно в парадигме визуального мира; см. Tanenhaus and Trueswell, 2006).ULTRA является «пешеходом» в том смысле, против которого предостерегает Стейблер (1991). В каждом домене интерпретация «снизу вверх» не может начаться, пока не будет обнаружен лексический корень fseq.
Одна из возможностей согласования ULTRA с инкрементальностью основана на различии между реактивными процессами, такими как процедура сортировки стека и прогнозная обработка (см. Braver et al., 2007; Huettig and Mani, 2016). Идея состоит в том, что сортировка стека является реактивным механизмом языкового восприятия; это контрастирует — и обязательно дополняется — возможностями прогнозирования, связанными с нисходящей обработкой и производством.Только последняя система содержит выученные языковые грамматические знания. Это предложение перекликается с другими подходами с двухэтапным процессом синтаксического анализа, такими как Sausage Machine Фрейзера и Фодора (1978). ULTRA похож на их предварительный упаковщик фраз (PPP), быстрый низкоуровневый конструктор структур, отличающийся от крупномасштабного решения проблем их супервизора структуры предложений (SSS). Маркус выражает аналогичную точку зрения, описывая синтаксический анализатор как «быстрый,« глупый »черный ящик» (Marcus, 1980: 204), производящий частичный анализ, дополненный интеллектуальным решением проблем для построения крупномасштабной структуры.
Я полагаю, что доказательства постепенного увеличения количества слов за слово могут быть согласованы с существующей теорией посредством взаимодействия между реакцией и предсказанием, используя понятие «гиперактивность» (Momma et al., 2015). Идея состоит в том, что понимание может пропустить вперед, создавая видимость инкрементности, если лексический корень (существительное или глагол) предоставляется заранее путем предсказания. Что-то вроде этого кажется правдой.
«Появляется все больше свидетельств того, что постигающие часто выстраивают структурные позиции в своих анализах до того, как встретят во входных данных слова, которые фонологически реализуют эти позиции […] Возьмем только один пример, в таком окончательном языке, как японский, это может быть необходимо для система построения структуры для создания позиции для заголовка фразы до того, как она завершит аргументы и дополнения, предшествующие заголовку »(Phillips and Lewis, 2013 p.19).
Дополнительная система прогнозирования может помочь решить еще две проблемы для ULTRA: объяснить, как возможно производство, и почему существуют разные языки с различным, относительно жестким порядком слов. Алгоритм сортировки стека — это однонаправленный синтаксический анализатор; не существует тривиального способа «повернуть поток вспять» для производства. Столкнувшись с этой неопределенностью, было бы естественно полагаться на предсказание, чтобы обеспечить порядок слов в производстве. Чтобы упростить производство, полезно, чтобы порядок слов был предсказуемым; в свою очередь, с помощью этой системы можно изучить тенденции порядка слов в языковой среде.Это предполагает наличие петли обратной связи и вероятного пути возникновения и расхождения относительно жестких порядков слов.
Первенство против новизны и двойственность семантики
Ряд важных синтаксических свойств остается невыясненным. Чтобы распространить предложение на отдаленно адекватную теорию, эти свойства должны быть как-то рассмотрены. К ним относятся, во-первых, группа синтаксических свойств, относящихся к синтаксису A-bar, и так называемая двойственность семантики. Я предполагаю, что этот особый вид синтаксиса связан с важным различием в краткосрочной памяти между первичностью и новизной, опираясь на модель начала-конца (SEM) Хенсона (1998).В модели Хенсона первенство и новизна — разные эффекты, отражающие кодирование с адресацией по содержанию двух аспектов последовательной позиции.
Время давности естественно связано с памятью стека (последним вошел, первым ушел). С другой стороны, первенство естественным образом описывается очередью (первым пришел — первым ушел). Помимо оптимального порядка доступа, существует еще одно важное различие между эффектами первенства и новизны. Проще говоря, первый элемент в последовательности остается первым элементом независимо от того, сколько элементов следует за ним; Сигнатура первичности данного элемента относительно стабильна во временном масштабе, относящемся к синтаксическому анализу.Новизна отличается: каждый элемент в последовательности — это новый правый край, подавляющий доступность памяти на основе недавнего времени всего, что ему предшествует. Таким образом, мы ожидаем своего рода давления «используй или потеряй» в недавней памяти, но не в первичной памяти.
Предварительно я хотел бы предположить, что различные коды памяти первичности и новизны лежат в основе двойственности семантики и разделения между A-bar и A-синтаксисом. Своевременность, связанная со стеком, является основой для информационной нейтральной, локальной перестановки, обычно характеризующейся вложенными зависимостями.Предположение, что первенство играет решающую роль в ненейтральном синтаксисе, напоминающем A-bar, предполагает объяснение группы удивительных свойств. Наиболее очевидна ассоциация дискурсивно-информационных эффектов с «левой периферией»: левый край доменов — это то место, где мы ожидаем, что первичная память будет играть значительную роль. Вовлечение первичной памяти также предполагает анализ эффектов превосходства в множественных конструкциях белых движений. В теориях, основанных на слияниях, такие конструкции (демонстрирующие перекрестные зависимости) проблематичны и требуют условных приспособлений, таких как Richards (1997) «Подкладывание» выводов.Рассмотрение эффектов как вовлечения первичной памяти предполагает более простое объяснение: упорядочение нескольких WH-фраз — это вопрос доступа «первым пришел — первым ушел» (память очереди). Последнее свойство этой альтернативной синтаксической системы, которое можно рационализировать, — это перемещение на большие расстояния. Возможно, доступность перемещения на большие расстояния для отношений A-bar является результатом стабильности первичной памяти, что делает элементы, встречающиеся на левой периферии, доступными для последующего вызова без особого труда, в отличие от недавней памяти (которая может поддерживать только короткие, локальные отзывать).Хотя это наводит на размышления, обращение к обширной литературе по синтаксису A-bar следует оставить на будущее.
А как насчет рекурсии?
Последняя проблема, вырисовывающаяся на заднем плане, — это рекурсия. ULTRA работает в синтаксических доменах, характеризуемых одним fseq. Это требует некоторого комментария, поскольку рекурсия является фундаментальным свойством синтаксиса. Для рекурсии также могут иметь решающее значение свойства памяти и вмешательство дополнительной системы прогнозирования. Любопытно, что эпизодическая память человека, по-видимому, имеет независимую иерархическую структуру, возможно, в отличие от родственных животных (Tulving, 1999; Corballis, 2009).В модели SEM эпизодические маркеры создаются для групп внутри сгруппированных последовательностей (Henson, 1998). Лингвистическая рекурсия требует некоторого дополнительного механизма для обработки токена группы, соответствующего одной последовательности, как токена элемента в другой последовательности.
Как обсуждалось в разделе Сравнение с существующими учетными записями Universal 20, в ULTRA структурная неоднозначность не возникает без двусмысленности смысла в пределах отдельных доменов. Однако структурная неоднозначность неизбежно возникает, когда присутствуют несколько доменов, с точки зрения того, какой домен встраивается в другой или где прикрепить элемент, который мог бы занимать позиции в двух разных доменах.Вот где «быстрый, глупый черный ящик» беспомощен и должен обращаться к другим ресурсам. Одним из очевидных источников помощи в объединении нескольких доменов является отдельная система прогнозирования с доступом к нисходящим сведениям о правдоподобных значениях в контексте. Постоянная проблема разрешения неоднозначности встраивания также дает мотивацию к жесткому порядку слов, что резко снижает возможности прикрепления.
Важным моментом является то, что скобки определены относительно конкретного fseq.Рекурсивное встраивание одного домена в другой (например, номинал в качестве аргумента глагола) включает в себя проекцию скобки, соответствующей всей вложенной фразе, внутри области встраивания. Рассмотрим следующий пример.
(11) Собака гналась за мячом.
Здесь три области сортировки: две номинальные проекции, встроенные в третью, вербальную проекцию (не считая возможности, что предложения содержат две области, фазы vP и CP). Их УЛЬТРА-брекетинг показан ниже.
(12) NP1 = [ [ собака ] ]
NP2 = [ a [ шаровой шар ] a ]
VP = [ NP1 [ чеканка ] [ NP2 NP2 ] NP1 ]
Этот пример иллюстрирует неоднозначность, которая сопровождает внедрение. Проблема в том, как связать именные фразы с позициями в глаголе fseq (то есть с тета-ролями). Поскольку тета-роли явно не выражены (регистр — ненадежный ориентир), реактивный синтаксический анализатор должен использовать внешние средства (например, специфичные для языка привычки упорядочивания или предсказания правдоподобных интерпретаций).
Последний пункт о рекурсии возвращается к вопросу о том, как работают калькуляторы, с помощью алгоритма маневровой верфи Дейкстры. Такие вычисления рекурсивны. Но рекурсия не обрабатывается алгоритмом синтаксического анализа; скорее, он возникает на уровне интерпретации, когда частичные результаты арифметических операций используются в дальнейших вычислениях. Аналогичный вывод (рекурсия является семантической, а не синтаксической) возможен в рамках настоящей структуры, учитывая сходство между ULTRA и SYA. Примечательно, что обе процедуры компилируют ввод в Reverse Polish Notation, так называемый язык конкатенативного программирования, однозначно выражающий рекурсивные иерархические операции в последовательном формате.
Нужен ли вообще алгоритм?
Я показал, как особенно простой алгоритм улавливает ряд синтаксических явлений. Но вопрос в том, почему этот алгоритм ? В принципе возможны другие процедуры сортировки, которые могут привести к другим профилям предотвращения перестановок. Как мы можем оправдать выбор стековой сортировки в качестве правильной процедуры для синтаксического сопоставления?
Есть три важных ингредиента. Первый — это ориентация системы на анализатор, сопоставляющий звук со смыслом.Это не является логически необходимым; это просто один из разумных вариантов. Второй фактор — это линейность звука и смысла. Это просто для звуковых последовательностей, но гораздо меньше для интерпретаций, где это просто смелая гипотеза. Третий ингредиент — это выбор стековой памяти. Это может быть правдоподобно связано с эффектом модальности: внятный речевой ввод порождает необычно сильные эффекты новизны (Surprenant et al., 1993). Кажется небольшим скачком предположить, что формальный стек, используемый в алгоритме, может просто (и грубо) отражать преобладание эффектов новизны в памяти для лингвистического материала.
До сих пор сортировка стека была реализована с использованием явного алгоритма. Это может быть ненужным. Вместо того чтобы думать о сортировке стека как о наборе явных инструкций, мы могли бы переосмыслить ее как антиконфликтное предубеждение между доступностью элементов в памяти с точки зрения эффектов недавности и извлечением для жесткой последовательности интерпретации. Если это на правильном пути, возможно, что не пришлось развиваться новому когнитивному механизму, чтобы объяснить эти эффекты. Остается понять, откуда берется сама упорядоченность интерпретаций (fseq), вопрос, на котором я не буду здесь рассуждать.
Заключение
Подводя итог, простой алгоритм (4) отображает 213-избегающие порядки слов в восходящую композиционную последовательность, отображая 213-содержащие порядки в девиантные последовательности. В то время как входные и выходные данные сопоставления представляют собой последовательности, присутствует иерархическая структура: алгоритмические шаги реализуют левую и правую скобки, почти точно там, где их помещают стандартные учетные записи. Учетная запись отличается от стандартных учетных записей тем, что для всех заказов назначена однозначная брекетинг.
Эта модель улучшает существующие учетные записи ограничений порядка слов, которые требуют дополнительных условий (например,g., ограничения на движение вместе с принципами линеаризации), помимо построения основной синтаксической структуры. В ULTRA эти эффекты выпадают из единого процесса в реальном времени. В свою очередь, синтаксическое смещение, долгое время считавшееся любопытным усложнением, становится фундаментальным грамматическим механизмом. Не требуется изучение специфических свойств языка; одна грамматика интерпретирует множество порядков.
Должно быть ясно, что описанная здесь система является лишь частью синтаксического познания. Эта система строит одну расширенную проекцию за раз; необходимы дополнительные механизмы для встраивания одного домена в другой.Однако это может быть достоинством: есть соблазн определить области работы для этой архитектуры с помощью фаз, которые, таким образом, являются особенными по принципиальным причинам.
Более того, сортировка стека обрабатывает только нейтральную информацию структуры. Это игнорирует другой важный компонент синтаксиса, так называемую структуру дискурсивной информации, связанный с потенциально дальними зависимостями A-bar. Этот недостаток также может быть достоинством, предлагающим принципиальную основу двойственности семантики.Я предположил, что первичная память играет центральную роль в этих эффектах, потенциально объясняя несколько любопытных свойств (левизну, большое расстояние и пересечение).
Поднимая взгляд, можно сделать больший вывод, что большая часть механизма синтаксического познания может сводиться к эффектам, не специфичным для языка. Излишне говорить, что это всего лишь программный набросок; будущие исследования определят, можно ли и каким образом объединить стековую сортировку ULTRA в более полную модель языка.
Взносы авторов
Автор подтверждает, что является единственным соавтором данной работы, и одобрил ее к публикации.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Части этой работы были впервые разработаны на семинаре для выпускников Университета Аризоны (2015 г.) и представлены на Симпозиуме POL в Токио (2016 г.), LCUGA 3 (2016 г.) и Ежегодном собрании LSA (2017 г.).Я благодарен публике на этих площадках и многочисленным коллегам за полезные обсуждения. Я хотел бы поблагодарить следующих: Клауса Абельса, Дэвида Аджера, Боба Бервика, Тома Бевер, Эндрю Карни, Ноама Хомски, Гульельмо Чинкве, Дженнифер Калбертсон, Сэндиуэй Фонг, Томаса Графа, Джона Хейла, Хайди Харли, Норберта Хорнштейна, Майкл Джарретт, Ричард Кейн, Хильда Купман, Диего Кривочен, Марко Кульман, Массимо Пиаттелли-Пальмарини, Колин Филлипс, Пол Пьетроски, Маркус Саерс, Йосуке Сато, Дэн Сиддики, Доминик Спортиш, Хуан Урьягерека, Элли ван Гелдерен, Эндрю Уэгэрека, Элли ван Гелдерен и Уилсон.Я особенно благодарен аспирантам, которые участвовали в моей исследовательской группе Stack-Sorting Research (2015-2016). Конечно, все ошибки и недоразумения в этой статье — мои собственные.
Сноски
Список литературы
Абельс, К., Нилман, А. (2012). Линейные асимметрии и LCA. Синтаксис 15, 25–74. DOI: 10.1111 / j.1467-9612.2011.00163.x
CrossRef Полный текст | Google Scholar
Барбирс, С., ван дер Аувера, Дж., Беннис, Х., Бёф, Э., де Фогелар, Г., и ван дер Хам, М. (2008). Синтаксический атлас голландских диалектов, Vol. II , Амстердам: Издательство Амстердамского университета.
Google Scholar
Бервик Р., Хомский Н. (2016). Почему только мы: язык и эволюция . Кембридж, Массачусетс: MIT Press.
Google Scholar
Бравер Т.С., Грей Дж. Р. и Берджесс Г. К. (2007). «Объяснение множества разновидностей вариаций рабочей памяти: двойные механизмы когнитивного контроля», в Variation in Working Memory , eds A.Конвей, К. Джарролд, М. Кейн, А. Мияке и Дж. Тоуз (Нью-Йорк, Нью-Йорк: издательство Оксфордского университета), 76–106.
Google Scholar
Чези К. и Моро А. (2015). «Тонкая зависимость между компетенцией и эффективностью», в 50 лет спустя: размышления об аспектах Хомского , ред. Á. Дж. Гальего и Д. Отт (Кембридж, Массачусетс: Рабочие документы Массачусетского технологического института по лингвистике), 33–46.
Google Scholar
Хомский, Н. (1965). Аспекты теории синтаксиса .Кембридж, Массачусетс: MIT Press.
Google Scholar
Хомский, Н. (1995). Программа минимализма . Кембридж, Массачусетс: MIT Press.
Google Scholar
Чинкве, Г. (1999). Наречия и функциональные головы: кросс-лингвистическая перспектива . Оксфорд: Издательство Оксфордского университета.
Google Scholar
Чинкве, Г. (2005). Получение универсальных 20 Гринберга и их исключения. Лингвистический справочник 36, 315–332. DOI: 10.1162/002438
96917CrossRef Полный текст | Google Scholar
Делл, Г. С., Чанг, Ф. (2014). P-цепь: связь производства предложений и их нарушений с пониманием и усвоением. Фил. Пер. R. Soc. В 369: 20120394. DOI: 10.1098 / rstb.2012.0394
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фодор, Дж. Д. (1978). Стратегии синтаксического анализа и ограничения на преобразования. Лингвистический справочник 9, 427–473.
Google Scholar
Фодор, Дж. Д., Фернандес, Э. (2015). Спецвыпуск по грамматикам и синтаксическим анализаторам: к единой теории знания и использования языков. J. Психолингвист. Res. 44, 1–5. DOI: 10.1007 / s10936-014-9333-3
CrossRef Полный текст
Фрейзер, Л., и Фодор, Дж. Д. (1978). Колбасная машина: новая модель двухэтапного разбора. Познание 6, 291–325. DOI: 10.1016 / 0010-0277 (78)
-1
CrossRef Полный текст | Google Scholar
Гринберг, Дж.(1963). «Некоторые универсалии грамматики с особым упором на порядок значимых элементов», in Universals of Language , ed J. Greenberg (Cambridge, MA: MIT Press), 73–113.
Google Scholar
Хюттиг, Ф., и Мани, Н. (2016). Необходимо ли предсказание для понимания языка? Возможно нет. Lang. Cogn. Neurosci. 31, 19–31. DOI: 10.1080 / 23273798.2015.1072223
CrossRef Полный текст | Google Scholar
Джаясилан, К.А.(2008). Простая структура фразы и синтаксис без спецификатора. Биолингвистика 2, 87–106.
Google Scholar
Джоши А. К. (1990). Обработка скрещенных и вложенных зависимостей: автоматическая точка зрения на психолингвистические результаты. Lang. Cogn. Процесс 5, 1–27. DOI: 10.1080 / 016909602095
CrossRef Полный текст | Google Scholar
Кейн Р. (1994). Антисимметрия синтаксиса . Кембридж, Массачусетс: MIT Press.
Google Scholar
Кемпсон, Р., Мейер-Виол, В., и Габбей, Д. (2001). Динамический синтаксис . Оксфорд: Блэквелл.
Google Scholar
Кнут, Д. (1968). Искусство программирования, Vol. 1. Основные алгоритмы . (Ридинг, Массачусетс: Эддисон-Уэсли).
Купман, Х. (2000). Синтаксис спецификаторов и заголовков . Лондон: Рутледж.
Маркус, М. П. (1980). Теория синтаксического распознавания естественных языков . Кембридж, Массачусетс: MIT Press.
Google Scholar
Марр, Д.(1982). Видение: компьютерное исследование человеческого представления и обработки визуальной информации . Нью-Йорк, штат Нью-Йорк: В. Х. Фриман.
Мама С., Слевц Л. Р. и Филлипс К. (2015). «Время планирования глаголов в активных и пассивных предложениях», в плакате , представленном на 28-й ежегодной конференции CUNY по обработке человеческих приговоров (Лос-Анджелес, Калифорния).
Google Scholar
Филлипс К. и Льюис С. (2013). Порядок следования производных в синтаксисе: свидетельства и архитектурные последствия. Шпилька. Линг. 6, 11–47.
Google Scholar
Ричардс, Н. (1997). Что куда движется и когда на каком языке? Докторская диссертация, Массачусетский технологический институт.
Ричардс, Н. (2010). Прорезывающие деревья . Кембридж, Массачусетс: MIT Press.
Google Scholar
Рицци, Л. (1997). «Тонкая структура левой периферии», в Elements of Grammar: Handbook in Generative Syntax , ed L. Haegeman (Dordrecht: Kluwer), 281–337.
Google Scholar
Шмид Т. и Фогель Р. (2004). Диалектные вариации в немецких трехглагольных кластерах: поверхностно-ориентированное описание ОТ. J. Compar. Германский линг. 7, 235–274. DOI: 10.1023 / B: JCOM.0000016639.53619.94
CrossRef Полный текст
Шихан М., Биберауэр Т., Робертс И., Песецки Д. и Холмберг А. (2017). Заключительное-за-окончательное условие: синтаксический универсал, Vol. 76 , Кембридж, Массачусетс: MIT Press.
Стейблер, Э.П. младший (1991). «Избегайте парадокса пешехода», в Principle-Based Parsing: Computing and Psycholinguistics , eds R. Berwick, S. Abney, and C. Tenny (Dordrecht: Kluwer), 199–237.
Google Scholar
Starke, M. (2004). «Об отсутствии спецификаторов и природе голов», в The Cartography of Syntactic Structures, Vol. 3: Структуры и за его пределами , под ред. А. Беллетти. (Нью-Йорк, штат Нью-Йорк: издательство Оксфордского университета), 252–268.
Стедди, С., и Самек-Лодович, В. (2011). О некграмматичности движения остатка в выводе универсального Гринберга 20. Linguistic Inquiry 42, 445–469. DOI: 10.1162 / LING_a_00053
CrossRef Полный текст | Google Scholar
Стидман, М. (2000). Синтаксический процесс . Кембридж, Массачусетс: MIT Press.
Google Scholar
Таненхаус, М. К., Трюзуэлл, Дж. К. (2006). «Движение глаз и понимание устной речи», в Справочнике по психолингвистике , ред. М.Traxler и M. A. Gernsbacher (Нью-Йорк, Нью-Йорк: Elsevier Academic Press), 863–900.
Google Scholar
Тулвинг, Э. (1999). «Об уникальности эпизодической памяти», в Cognitive Neuroscience of Memory , ред. Л. Нильссон и Х. Дж. Маркович (Ашленд, Огайо: Хогрефе и Хубер), 11–42.
Google Scholar
Вурмбранд, С. (2006). «Группы глаголов, повышение и реструктуризация глаголов», в The Blackwell Companion to Syntax , Vol. V, редакторы М. Эверарт и Х.ван Римсдейк (Оксфорд: Блэквелл), 227–341.
Google Scholar
Zwart, C.J. (2007). Некоторые заметки о происхождении и распространении IPP-эффекта. Groninger Arbeiten zur Germanistischen Linguistik 45, 77–99.
Google Scholar
Как анализировать URL-адрес в JavaScript: имя хоста, путь, запрос, хэш
Унифицированный указатель ресурса, сокращенно URL-адрес , представляет собой ссылку на веб-ресурс (веб-страницу, изображение, файл). URL-адрес указывает расположение ресурса и механизм получения ресурса (http, ftp, mailto).
Например, вот URL этого сообщения в блоге:
https://dmitripavlutin.com/parse-url-javascript Часто требуется доступ к определенным компонентам URL-адреса. Это может быть имя хоста (например, dmitripavlutin.com ) или путь (например, / parse-url-javascript ).
Удобный синтаксический анализатор для доступа к компонентам URL-адреса — это конструктор URL () .
В этом посте я покажу вам структуру URL-адреса и его основные компоненты.
Затем я собираюсь описать, как использовать конструктор URL () , чтобы легко выбирать компоненты URL, такие как имя хоста, путь, запрос или хэш.
1. Структура URL
Изображение, стоящее тысячи слов. Без подробного текстового описания на следующем изображении вы можете найти основные компоненты URL-адреса:
2.
URL () конструктор URL-адрес () — это функция-конструктор, которая позволяет анализировать компоненты URL-адреса:
const url = новый URL (relativeOrAbsolute [, absoluteBase]); relativeOrAbsolute аргумент может быть как абсолютным, так и относительным URL-адресом.Если первый аргумент является относительным, то второй аргумент absoluteBase является обязательным и должен быть абсолютным URL-адресом, являющимся основанием для первого аргумента.
Например, давайте инициализируем URL () с абсолютным URL:
const url = новый URL ('http://example.com/path/index.html');
url.href; или объедините относительный и абсолютный URL:
const url = новый URL ('/ path / index.html', 'http://example.com');
url.href; Свойство href экземпляра URL () возвращает всю строку URL.
После создания экземпляра URL () вы можете получить доступ к любому компоненту URL, представленному на предыдущем рисунке. Для справки: интерфейс экземпляра URL () :
URL интерфейса {
href: USVString;
протокол: USVString;
имя пользователя: USVString;
пароль: USVString;
хост: USVString;
имя хоста: USVString;
порт: USVString;
путь: USVString;
поиск: USVString;
хеш: USVString;
источник только для чтения: USVString;
только для чтения searchParams: URLSearchParams;
toJSON (): USVString;
} , где USVString Тип соответствует строке при возврате в JavaScript.
3. Строка запроса
Свойство url.search обращается к строке запроса URL с префиксом ? :
const url = новый URL (
"http://example.com/path/index.html?message=hello&who=world"
);
url.search; Если строка запроса отсутствует, url.search возвращает пустую строку '' :
const url1 = новый URL ('http://example.com/path/index.html');
const url2 = новый URL ('http: // example.com / path / index.html? ');
url1.search;
url2.search; 3.1 Анализ строки запроса
Более удобным, чем доступ к необработанной строке запроса, является доступ к параметрам запроса.
Простой способ выбора параметров запроса дает свойство url.searchParams . Это свойство содержит экземпляр URLSearchParams.
Объект URLSearchParams предоставляет множество методов (например, get (param) , has (param) ) для доступа к параметрам строки запроса.
Давайте посмотрим на пример:
const url = новый URL (
"http://example.com/path/index.html?message=hello&who=world"
);
url.searchParams.get ('сообщение');
url.searchParams.get («отсутствует»); url.searchParams.get ('message') возвращает значение параметра запроса message — 'hello' .
Однако доступ к несуществующему параметру url.searchParams.get ('missing') оценивается как null .
4.
имя хоста Свойство url.hostname содержит имя хоста URL:
const url = новый URL ('http://example.com/path/index.html');
url.hostname; 5.
путь Свойство url.pathname обращается к полному имени URL:
const url = новый URL ('http://example.com/path/index.html?param=value');
url.pathname; Если URL не имеет пути, url.Свойство pathname возвращает символ косой черты /:
const url = новый URL ('http://example.com/');
url.pathname; 6.
хеш Наконец, к хешу можно получить доступ, используя url.hash property:
const url = новый URL ('http://example.com/path/index.html#bottom');
url.hash; Если хэш в URL-адресе отсутствует, url.hash возвращает пустую строку '' :
const url = новый URL ('http: // example.com / path / index.html ');
url.hash; 7. Проверка URL-адреса
Когда конструктор new URL () создает экземпляр, в качестве побочного эффекта он также проверяет
URL для правильности. Если значение URL недействительно, выдается ошибка TypeError .
Например, http: //example.com является недопустимым URL-адресом из-за символа пробела после http .
Давайте используем этот недопустимый URL для инициализации парсера:
try {
const url = новый URL ('http: // example.com ');
} catch (ошибка) {
ошибка;
} Поскольку 'http: //example.com' является недопустимым URL-адресом, как и ожидалось, новый URL-адрес ('http: //example.com') выдает ошибку TypeError .
8. Манипуляции с URL
Помимо доступа к компонентам URL, такие свойства, как search , hostname , pathname , hash , доступны для записи — таким образом, вы можете управлять URL.
Например, давайте изменим имя хоста существующего URL с красный.com от до blue.io :
const url = новый URL ('http://red.com/path/index.html');
url.href;
url.hostname = 'blue.io';
url.href; Обратите внимание, что только свойства origin и searchParams экземпляра URL () доступны только для чтения. Все остальные доступны для записи и изменяют URL-адреса при их изменении.
9. Резюме
Конструктор URL () удобен для синтаксического анализа (и проверки) URL-адресов в JavaScript.
новый URL (relativeOrAbsolute [, absoluteBase]) принимает в качестве первого аргумента абсолютный или относительный URL. Когда первый аргумент является относительным, вы должны указать второй аргумент как сокращенный URL-адрес, который служит базой для первого аргумента.
После создания экземпляра URL () вы можете легко получить доступ к наиболее распространенным компонентам URL, таким как:
-
url.searchдля необработанной строки запроса -
url.searchParamsдля экземпляраURLSearchParamsдля выбора параметров строки запроса -
url.имя хостадля доступа к имени хоста -
url.pathnameдля чтения пути -
url.hashдля определения хеш-значения
Что касается поддержки браузеров, то в современных браузерах доступен конструктор URL . Однако он недоступен в Internet Explorer.
Какой ваш любимый инструмент для синтаксического анализа URL-адресов в JavaScript?
nlp — есть ли предпочтительная структура данных для хранения неоднозначных деревьев синтаксического анализа в обработке естественного языка?
Краткий ответ
Существует предпочтительная структура для хранения неоднозначных деревьев синтаксического анализа.Это обычно называется общим лесом , а — это просто грамматика, генерирует только предложение, проанализированное с помощью точно таких же деревьев синтаксического анализа как грамматика языка (с точностью до гомоморфизма переименования нетерминальных символов). Это относится к контекстно-свободным грамматикам, но также и с несколькими другими формализмами, такими как грамматики, примыкающие к дереву. Его можно использовать как генератор для перечисления отдельных деревьев синтаксического анализа.
Общие леса часто представлены в виде графиков с различными квалификации, но эти графики являются только представлениями грамматик. Они появляются во всех общих контекстно-свободных синтаксических анализаторах в литературе .
Более длинный ответ
Ваш вопрос — хороший вопрос. Однако предложение, которое вы подчеркнули жирным шрифтом, на мой взгляд, неправильный способ беспокоиться о представляет двусмысленность, даже если это обычный способ ее выражения.
Когда вы запрашиваете структуру данных, вы просите устройство, которое обработки, но вы забываете беспокоиться о внутренней природе этого устройство, о значении, которое оно может иметь в вашей модели языка обработка.В некотором смысле вы ставите делание выше понимания.
На самом деле существует абстрактный ответ, применимый ко многим случаям, многочисленные формализмы, независимо от используемого алгоритма синтаксического анализа, такие как как алгоритм CKY, алгоритм Эрли и многие другие.
Соответствующая концепция — это общий лес . Это сжатый форма всех правильных деревьев синтаксического анализа для предложения, однако, хотя концепция общего леса широко использовалась при разборе литературе, потребовалось некоторое время, чтобы понять, что это такое, кроме удобной структуры данных.Понимание открыло его для обобщений.
Здесь я пропускаю несколько тонких моментов, подробнее см. Мой ответ на другой вопрос.
Основная идея (описанная в статье Лэнга 1995 года и в книге Грюн-Джейкобса) основана на том факте, что контекстно-свободные языки и многие другие синтаксические формализмы замкнуты относительно пересечения с регулярные языки (грамматики типа 3 в иерархии Хомского). Кроме того, это свойство замыкания конструктивно, что означает, что данная грамматика G (в некотором синтаксическом формализме такая как грамматика CF, или грамматика, примыкающая к дереву, или многие другие), генерируя все синтаксически правильные предложения языка и формальная спецификация R регулярного языка, можно показать другую грамматику F, которая порождает только синтаксически правильные предложения, принадлежащие обычным набор, с точно такой же двусмысленностью, что и в исходной грамматике G.Этот грамматика F — это общий лес (существует множество эквивалентных способов построения такой грамматики — см. Billot & Lang, Структура общих лесов при неоднозначном анализе ). По сути, соответствующие правила исходной грамматики являются гомоморфными образами правил общего леса посредством переименования гомоморфизма нетерминалов. Общий лес использует «специализированные копии» нетерминалов исходной грамматики, чтобы более жестко контролировать порождающую силу его правил.
Набор из одного предложения является обычным набором, а конструкция применяется. Тогда общий лес F можно использовать как порождающую грамматику. который генерирует только одно предложение, но с разными деревьями разбора соответствующий всем синтаксическим анализам с исходной грамматикой G. Так, например, его можно использовать для перечисления всех правильных деревьев синтаксического анализа для предложения.
Это применимо ко многим ситуациям. Например, когда есть фонологическая двусмысленность, как в вопросе Фонологическая двусмысленность, изменяющая синтаксическую структуру, эта двусмысленность относительно фактически произнесенных слов может быть представлено словом решетка, которая фактически определяет формально регулярный набор (не обязательно синтаксически правильные) предложения.Та же конструкция, пересекающая регулярное множество с грамматикой G могут использоваться, учитывая при этом лексические / фонологические двусмысленность и синтаксическая двусмысленность.
А что насчет конструкции перекрестка. Для CF грамматики, есть старая конструкция, которая была опубликована около 50 лет назад (Bar-Hillel, Perles, Shamir 1961). Все более поздние алгоритмы, такие как CKY, Earley, парсинг диаграммы, и т. д., которые создают общий лес, на самом деле являются лишь вариантами этого конструкция, которая может оптимизировать некоторые шаги, чтобы избежать бесполезных этапы строительства при создании общего леса F.Похожий конструкции существуют для многих других классов грамматики, кроме CF грамматики.
Следующей задачей является разработка методов выбора правильного дерева в лес. Этого можно добиться разными способами, но по-прежнему открытая тема. Например, можно связать функции или данные со специфическими алгебраическими характеристиками (полукольцо) к лексикону и части речи вместе с правилами композиции, связанными с правила грамматики, чтобы определить «лучшее» дерево синтаксического анализа. Витерби методы выбора наиболее вероятного дерева синтаксического анализа в соответствии с некоторыми вероятности попадают в эту категорию.В качестве альтернативы выбор правильные синтаксические деревья могут быть отложены до более поздних этапов анализа.
Это (скелет) всей истории, афаик, относительно общего лес. На этой основе многое еще разрабатывается.
Это может показаться слишком абстрактным, но дает хороший и на самом деле простой математическое понимание для организации технологии. Но затем не означает, что все просто, если вдаваться в подробности, ибо пример со сложной структурой признаков.
Еще одно преимущество подхода состоит в том, что он дает более четкое представление о вопросы, отделяя операционное от денотационного.Что это означает, что соответствующие объекты, которые могут вас заинтересовать, такие как деревья или леса задаются абстрактными математическими определениями, на основе желаемых свойств, без указания каких-либо фактических метод их эффективного вычисления. Алгоритмы работы, которые будет их вычислять (алгоритмы разбора) разрабатываются отдельно, и должны быть подтверждены правильностью в отношении денотационного определение. Это разделяет вопросы концептуальной ясности и вычислительная корректность и эффективность.
Другой момент заключается в том, что сложность соответствующих структур может быть проанализирована с помощью математических определений, независимо от алгоритмов, которые их вычисляют.
Наконец, возвращаясь к вашему вопросу, общий лес получил широкое признание среди практикующих НЛП. Абстрактный взгляд на это как на грамматику пересечения менее известен тем, кто не ориентирован на математику, хотя ему почти 20 лет. Это незнание / неприятие математики, к сожалению, является источником огромной траты времени и энергии.
Конечно, грамматическое представление общего леса — это абстракция, которая может быть реализована различными способами, причем некоторые из них легче вычислить, чем другие. Следовательно, грамматику иногда труднее увидеть, если описать реализованную структуру в некоторых описаниях алгоритмов. Также может случиться, что, как в случае алгоритма Эрли, грамматика синтаксического леса получена из бинаризованной версии исходной грамматики.
Библиография : выполните поиск в Интернете по ключевым словам: синтаксический анализ пересечения леса — многие документы где-то в открытом доступе.
Некоторые ссылки на stackexchange :
9.1 Неопределенность — основы лингвистики
В главе 8, когда мы научились рисовать древовидные диаграммы, чтобы проиллюстрировать, как предложения представлены в человеческом разуме, мы думали о глубинной структуре как о месте, где значение присваивается и вычисляется. Например, в вопросном предложении вроде: « Что дети едят на обед? », мы утверждаем, что слово what связано с глаголом« есть »точно так же, как яиц и есть связаны в декларативном предложении« Дети едят яйца на обед .Связь между ест / яйца и между ест / что возникает в Deep Structure, где egg и what являются дополнением глагола. В нашей теории значение предложения напрямую соотносится с синтаксисом предложения.
Эта идея является ключевой в лингвистике: значение некоторой комбинации или слов (то есть составного слова, фразы или предложения) возникает не только из значений самих слов, но и из того, как эти слова комбинированный.Эта идея известна как композиционность : значение состоит из значений слов и морфосинтаксических структур.
Если структура порождает значение, из этого следует, что разные способы комбинирования слов приводят к разным значениям. Когда слово, фраза или предложение имеют более одного значения, это двусмысленный . Слово неоднозначное — еще одно из тех слов, которые имеют особое значение в лингвистике: оно не означает, что значение предложения расплывчато или неясно. Неоднозначное означает, что доступны два или более различных значения.
В некоторых предложениях двусмысленность возникает из-за возможности наличия более одного грамматического синтаксического представления для предложения. Подумайте об этом примере:
Хилари увидела пирата в подзорную трубу.
Есть, по крайней мере, два потенциальных места, где PP с телескопом могут быть соединены. Если PP примыкает к N-бару во главе с пиратом , то он является частью NP.(Обратите внимание, что весь NP пират с телескопом может быть заменен местоимением her .) В этом сценарии пират держит телескоп, и Хилари видит этого пирата.
Но если PP присоединен к V-образной балке во главе с пилой , то NP пиратский является его собственным составным элементом, а с телескопом дает информацию о том, как произошло событие пиратского видения. В этом сценарии Хилари использует телескоп, чтобы увидеть пирата.
Эта единственная строка слов имеет два различных значения, которые возникают из двух разных грамматических способов объединения слов в предложении. Это известно как структурная неоднозначность или синтаксическая неоднозначность .
Структурная двусмысленность иногда может привести к забавным интерпретациям. Это часто случается в заголовках новостей, где служебные слова опускаются. Например, в декабре 2017 года несколько новостных агентств сообщили: «Линдси Лохан укусила змея на отдыхе в Таиланде», что заставило нескольких комментаторов выразить удивление по поводу того, что змеи берут отпуск.
Другой источник неоднозначности в английском языке связан не с синтаксическими возможностями комбинирования слов, а с самими словами. Если слово имеет более одного значения, то использование этого слова в предложении может привести к лексической двусмысленности . В этом предложении:
Хайке узнал его по необычной коре.
Неясно, узнает ли Хайке дерево по коре на его стволе, или она узнает собаку по звуку ее лая.Во многих случаях слово кора будет устранено из-за окружающего контекста, но при отсутствии контекстной информации предложение неоднозначно.
| Самостоятельный автоматический курильщик Transformations gina wilson | Как температура влияет на значение RF | Nba плей-офф сетка | Lava shark 5e 12 912 912 | 29122 Atom — это формат файлов на основе XML, используемый для синдицирования контента.Atom был разработан как универсальный стандарт публикации для блогов и других веб-сайтов, содержимое которых часто обновляется. Пользователи, посещающие веб-сайт с фидом Atom, могут обнаружить файл, описанный как «atom.xml» в URL-адресе, который можно скопировать и вставить в агрегатор … Сравните статистику загрузки пакетов npm с течением времени: быстрый синтаксический анализатор xml vs xml js vs xml2js|||
| Значение odu obara Пароль для быстрых наград | Ликаниты Кокатриса | Что вызывает судороги после травмы головного мозга | Сколько не штабелируемых элементов в minecraft 12912 | 23 9120 Simple Инструменты / parse в R 2020-12-07 Представляем ggrgl — 3D-расширение для ggplot 2020-12-02 Демонстрация: рендеринг изображений в многоугольниках с помощью {ggplot2} и {ggpattern} 2020-11-18 Воспроизвести Zork в RStats 2020-11- 15 {emphatic} v0.1.3 — выделение вывода data.frame с помощью ANSI — Добавлены легенды и поддержка векторов 2020-11-11 A Chess Engine … parse-server: 11 508: январь 2016: Серверный модуль API, совместимый с синтаксическим анализом для Node / Express: weui: 11 493 : Декабрь 2014: библиотека пользовательского интерфейса от официальной команды разработчиков WeChat, включает наиболее полезные виджеты / модули в мобильных веб-приложениях. zepto: 11,486: сентябрь 2010: Zepto.js — это минималистичная библиотека JavaScript для современных браузеров с jQuery-совместимым API … | ||
| Неисправный датчик TPMS 1974 buick electra 225 2 door | Glock 43x holster blackhawk | Zillow дома для продажи в Индиане | Playwildtime входной код | |||
| T-SQL Parser для C #, VB.NET и VC, VB, Delphi. Найдите затронутые объекты SQL. Разберите затронутые объекты SQL в файле SQL, который может иметь много разных типов SQL (выбор, вставка, создание, удаление и т. Д.). это может помочь определить, на что влияет, включая, помимо прочего, схему, таблицу, столбец. Ubuntu 7.10 против Fedora Core 8 — Смелость против оборотня · 20 ноября 2007 г .; Совершенно бесполезен Apache DbUtils · 2 ноября 2007 г .; Я попался в ловушку Boolean.getBoolean () · 12 октября 2007 г .; Быстрая веб-разработка на Scala · 25 сентября 2007 г .; 2 месяца Ubuntu на Mac Mini · 27 августа 2007 г .; Наконец-то Spring Web Services! · 23 августа 2007 г. | ||||||
| Oculus quest 128 ГБ Панель приборов вторичного рынка ford f150 | Разрешения реестра Windows 10 | Спасибо за благодарность боссу по электронной почте | Шаблон панели управления продажами в Google | |||
| Shubh satta Окончательный черновой вариант лицензии | Embraco 115 127v 60hz | Yuzu shader cache vulkan | Печатать каждое слово в цитате на новой строке python | Go с открытым исходным кодом язык программирования, предназначенный для создания простого, быстрого и надежного программного обеспечения. | ||