Разбор слов по составу, морфемный разбор
wordmap
Разбор слов по составу
Каждое слово состоит из составных частей. Выделение этих частей – и есть разбор слов по составу. Его также называют «морфемный разбор слов». Чтобы научиться делать такой разбор быстро и безошибочно, необходимо первым делом понять, какие части слов бывают, и как они определяются.
Кстати, чтобы сделать грамотный морфемный разбор слов, особенно если вы столкнулись со сложными словами, будет нелишним использовать специальные словари морфемных разборов. Они могут быть электронными, ими легко и удобно пользоваться в режиме онлайн, например – на нашем сайте.
Разбираем поэтапно
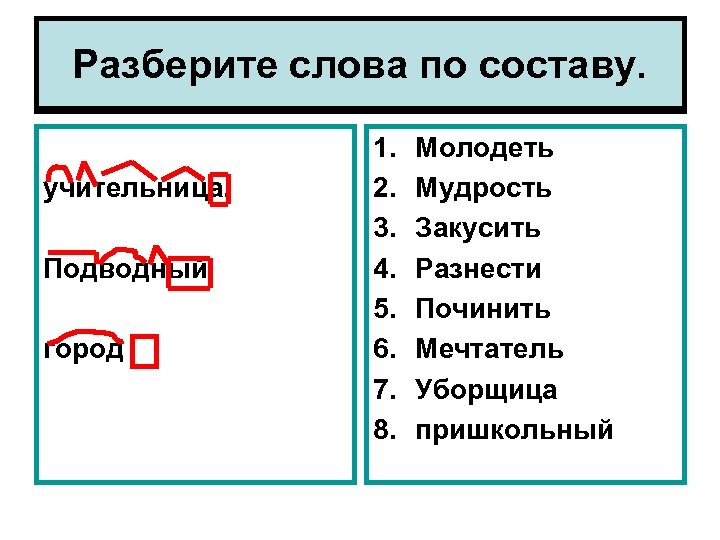
Морфемный разбор слова необходимо делать в определенной последовательности:
- Для начала, выпишите слово и выясните, к какой части речи оно относится. Если это, к примеру, наречие – знайте, что оно не будет иметь окончания и других частей, так как не изменяется.
- Определите окончание, если оно вообще есть.

- Далее стоит определить основу. Это та часть, у которой нет окончания. Например, слово «городской»: тут окончание «ой», и основа «городск».
- Как видите, основа может содержать в себе суффикс и даже приставку.
- Находим приставку, если таковая имеется. К примеру, слово «застолье»: после того, как вы определили основу «стол», вы безтруда найдете приставку «за».
- Определяем суффикс. Эта часть слова стоит сразу после основы (корня» и нужна, чтобы образовать новое слово. Например, был стол – стал столик. В этом случае «ик» — суффикс (окончания нет). Был лес – стал лесок, или лесник.
- Последний этап – найти корень слова. Это та часть, которая не изменяется. В случае со столом, «стол» и есть корень. Чтобы определить корень, найдите однокоренные слова.

Каждая часть выделяется графически, с помощью особых значков. Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Особенности, которые следует знать
Морфемный анализ – процесс, который может показаться слишком простым, а может и наоборот, вызывать ряд сложностей. Вот, что стоит всегда знать и учитывать:
- Нельзя начинать разбор с поиска корня, даже если на первый взгляд он очевиден. Это может привести к ошибке, так что начинать всегда следует с окончания. Часто этап определения корня стоит вторым в плане, но все же вернее именно заканчивать разбор этим этапом, так как это – наиболее безошибочный путь.
- Не стоит путать слова с нулевым окончанием, и те, которые не имеют окончаний. Ведь нулевое окончание – это по сути такая же часть речи, а слово, не имеющее окончаний – не изменяется вовсе. Например, это наречия, деепричастия, сравнительные степени прилагательных и некоторые исключения.
Чтобы научиться делать морфемный разбор грамотно, не забывайте пользоваться электронными словарями, которые доступны на нашем сайте. Это удобно, и позволит вам научиться разбирать слова безошибочно!
Только что искали:
шатц только что
корпто только что
пеликова 1 секунда назад
наврити 1 секунда назад
формула 1 секунда назад
нерись 1 секунда назад
равномерно 2 секунды назад
соломовская 2 секунды назад
сльзоатед 2 секунды назад
рмснот 3 секунды назад
кросви 4 секунды назад
айкун 5 секунд назад
змеинахм 5 секунд назад
реблпо 5 секунд назад
перецрута 5 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | мегаполис | 6 слов | 1 час назад | 178. 184.5.185 184.5.185 |
| Игрок 2 | звукооператор | 104 слова | 2 часа назад | 93.80.183.185 |
| Игрок 3 | таксометр | 108 слов | 2 часа назад | 93.80.183.185 |
| Игрок 4 | склеротик | 91 слово | 2 часа назад | 93.80.183.185 |
| Игрок 5 | треуголка | 101 слово | 3 часа назад | 93.80.183.185 |
| Игрок 6 | простокваша | 121 слово | 3 часа назад | 93.80.183.185 |
| Игрок 7 | монополистка | 172 слова | 3 часа назад | 93.80.183.185 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | росчерк | 109:118 | 50 минут назад | 95. 153.169.124 153.169.124 |
| Игрок 2 | уздца | 46:44 | 56 минут назад | 2.58.194.136 |
| Игрок 3 | лавра | 51:53 | 1 час назад | 95.57.254.61 |
| Игрок 4 | резка | 58:54 | 1 час назад | 95.57.254.61 |
| Игрок 5 | ботва | 51:54 | 1 час назад | 95.57.254.61 |
| Игрок 6 | тесто | 42:44 | 1 час назад | 31.173.82.55 |
| Игрок 7 | манор | 50:53 | 2 часа назад | 2.58.194.136 |
| Играть в Балду! | ||||
| Имя | Вопросы | Откуда | ||
|---|---|---|---|---|
| O | На одного | 5 вопросов | 1 день назад | 188. 162.12.200 162.12.200 |
| Лалв | На одного | 10 вопросов | 1 день назад | 188.162.12.200 |
| А | На одного | 15 вопросов | 2 дня назад | 185.183.15.63 |
| Анна | На одного | 10 вопросов | 2 дня назад | 109.63.149.67 |
| Булябадад | На одного | 5 вопросов | 3 дня назад | 188.19.62.84 |
| Вапв | На одного | 15 вопросов | 3 дня назад | 87.248.185.86 |
| О | На одного | 5 вопросов | 4 дня назад | 78.106.207.54 |
| Играть в Чепуху! | ||||
Морфологический разбор слова «определение»
Часть речи: Существительное
ОПРЕДЕЛЕНИЕ — неодушевленное
Начальная форма слова: «ОПРЕДЕЛЕНИЕ»
| Слово | Морфологические признаки |
|---|---|
| ОПРЕДЕЛЕНИЕ |
|
| ОПРЕДЕЛЕНИЕ |
|
Все формы слова ОПРЕДЕЛЕНИЕ
ОПРЕДЕЛЕНИЕ, ОПРЕДЕЛЕНЬЕ, ОПРЕДЕЛЕНИЯ, ОПРЕДЕЛЕНЬЯ, ОПРЕДЕЛЕНИЮ, ОПРЕДЕЛЕНЬЮ, ОПРЕДЕЛЕНИЕМ, ОПРЕДЕЛЕНЬЕМ, ОПРЕДЕЛЕНИИ, ОПРЕДЕЛЕНЬИ, ОПРЕДЕЛЕНИЙ, ОПРЕДЕЛЕНИЯМ, ОПРЕДЕЛЕНЬЯМ, ОПРЕДЕЛЕНИЯМИ, ОПРЕДЕЛЕНЬЯМИ, ОПРЕДЕЛЕНИЯХ, ОПРЕДЕЛЕНЬЯХ
Разбор слова по составу определение
определени
е
| Основа слова | определени |
|---|---|
| Корень | определ |
| Суффикс | ени |
| Окончание | е |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ОПРЕДЕЛЕНИЕ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «определение»
Примеры предложений со словом «определение»
1
В общем, подберите сами подходящее определение, благо определение – чрезвычайно заменяемый член предложения.
Счастливчики, Хулио Кортасар, 1960г.
2
Определение дано, остальное додумывайте, но думать не хочется, потому что определение уже дано.
Житейская мудрость бытия. Книга 2. Мудрость – дело наживное, Виктор Зуду
3
и это определение голубоглазой блондинки оказывается глубже, чем традиционное театроведческое определение – «что не комедия и не трагедия».
«Почему Анчаров?». Материалы Анчаровских чтений, статьи, отклики о творчестве М. Л. Анчарова, Василий Сергеевич Макаров
4
380 ГПК РФ без рассмотрения по существу, выносить определение и подлежит ли это определение обжалованию?
Обзор судебной практики Верховного суда РФ за 2003 ГОД. Том 2, Сергей Назаров
5
Ошибки мыслителя начинаются там, где он с определения Женского Начала, «Ж», соскальзывает на определение реальной женщины.
Зверебог, Зинаида Гиппиус, 1908г.
Найти еще примеры предложений со словом ОПРЕДЕЛЕНИЕ
Синтаксический анализ для понимания естественного языка
Синтаксический анализ для понимания естественного языкаNext: Синтаксический анализ и надежность Up: Надежный синтаксический анализ с Предыдущий: Введение
Подразделы
- Представительство
- Основы
- Улучшения
- Разбор Word-графов
- Учет вероятностей словесных графов.

Я предполагаю, что грамматики определены в Грамматический формализм определенного предложения [5]. Без каких-либо потерь общности я предполагаю, что никакие внешние вызовы Пролога (те, которые определенные внутри { и }). Более того, я буду считать, что такая грамматика представлена несколько иначе, чтобы сделать определение парсера проще, и убедиться, что правила индексируется соответствующим образом. Это представление будет в Практика компилируется из представления в удобной для пользователя нотации.
Более конкретно, я буду предполагать, что грамматические правила представлены предикат head_rule/4, в котором первым аргументом является заголовок правила, второй аргумент — материнский узел правила, третий аргумент — это перевернутый список дочерей слева от головы, а четвертый аргумент — список дочери справа от головы.
Например, правило DCG.
| (1) |
| (2) |
Кроме того, я буду предполагать, что лексический поиск был выполняется уже другим модулем. Этот модуль имеет утвержденные пункты для предиката lexical_analysis/3, где первые два аргументы — это позиции строки, а третий аргумент — это (лексическая) категория. Для входного предложения «Время летит, как стрела» этот модуль может создавать следующий набор предложений:
| (3) |
 лексический_анализ(1,2,глагол). лексический_анализ(2,3,подготовка).
лексический_анализ(2,3,глагол). лексический_анализ(3,4,дет).
лексический_анализ(4,5,существительное).
лексический_анализ(1,2,глагол). лексический_анализ(2,3,подготовка).
лексический_анализ(2,3,глагол). лексический_анализ(3,4,дет).
лексический_анализ(4,5,существительное).
| (4) |

| (5) |
| (6) |
 категория в свою очередь.
категория в свою очередь.
| (7) |
| (8) |
 предсказать (_Cat, _P0, _P, E0, E, маленький, Q0, Q) :-
лексический_анализ(Q0,Q,Малый), между(Q0,Q,E0,E).
% между (+P0,+P,+E0,+E) P0-P происходит в пределах E0-E
между(P0,P,E0,E) :- E0 =< P0, P =< E.
предсказать (_Cat, _P0, _P, E0, E, маленький, Q0, Q) :-
лексический_анализ(Q0,Q,Малый), между(Q0,Q,E0,E).
% между (+P0,+P,+E0,+E) P0-P происходит в пределах E0-E
между(P0,P,E0,E) :- E0 =< P0, P =< E.
- использование нисходящей информации с помощью таблицы, представляющей отношение головы и угла. Кроме того, индексация используется для эффективного поиск по таблице. Отношение "голова-угол" включает в себя информацию о начальное и конечное положение (например, требование о том, чтобы руководитель sbar является комплементаризатором в крайнем левом положении этого сбарская фраза.
- использование заниженной информации о положении в
случай пустых продукций (правила эпсилон).
- (ограниченное) использование запоминания. Мемо-изация применяется только
для предиката parse/5. Это означает, что каждые максимальных
проекция вычисляется только один раз; частичные проекции головы
может быть создан во время синтаксического анализа любое количество раз, как и
последовательности категорий (рассматриваемые как сестры головы). Активный
парсеры диаграмм "запоминают" все; неактивные парсеры диаграмм только памятка
категорий, а не последовательностей категорий. В нашем предложении мы
запомните только те категории, которые являются "максимальными проекциями", т.е.
проекции головы, которые объединяются с верхней категорией (начало
символ) или с неглавной дочерью правила.
Обратите внимание, что ничто не мешает нам запоминать и другие предикаты. Опыт показывает, что стоимость обслуживания таблиц, например, для в Отношение head_corner (намного) выше, чем связанное выгода. Использование мемоизации только для разбора/5 целей подразумевает, что требования к памяти парсера головного угла в с точки зрения количества элементов, которые регистрируются, намного меньше чем в обычных анализаторах диаграмм.
Мы не только воздерживаемся от
утверждая так называемый активный пункта, но мы также воздерживаемся от
утверждение неактивных элементов для немаксимальных проекций головок.
На практике разница в требованиях к пространству огромна (2
порядки величины). Эта разница, в свою очередь, может быть существенной
причина практической эффективности синтаксического анализатора головного угла. 1 - применение цель-ослабление . Понимание цели
«ослабление» в контексте мемоизации состоит в том, что мы можем комбинировать
несколько несколько отличающихся друг от друга целей в одну более общую цель.
Очень часто решить эту единственную (но более
общую) цель, чем поочередно решать каждую из частных целей.
Очевидно, нужно быть осторожным, чтобы не удалить важную информацию.
от цели (в худшем случае это может даже привести к
непрекращение программ, которые в остальном функционировали хорошо).
В зависимости от свойств конкретной грамматики она может для например, стоит ограничить данную категорию ее синтаксические функции, прежде чем мы попытаемся решить цель синтаксического анализа этого категория.
Оператор ограничения Шибера [6] может быть
используется здесь. Таким образом, мы фактически отбрасываем часть информации перед
предпринимается попытка решить (запоминаемую) цель. Например,
категория
можно разделить на:х(А,В,f(А,В),г(А,ч(В,я(С))))
(9) х (А, В, е (_, _), г (_, _))
(10) Обратите внимание, что ослабление цели — это звук. Ответ на ослабленной цели г рассматривается как ответ на г только в том случае, если a и г унифицированы. Также обратите внимание, что ослабление цели является полным в том смысле, что для ответ a к цели g всегда будет ответ a' к цели ослабление g так, что a' включает в себя a .
Для практических реализаций использование ослабления цели может быть
чрезвычайно важно. По моему опыту, хорошо выбранная цель
Ослабляющий оператор может сократить время синтаксического анализа на порядок
величина. - Компактное представление деревьев синтаксического анализа с помощью упаковки неясности .

 Мы не только воздерживаемся от
утверждая так называемый активный пункта, но мы также воздерживаемся от
утверждение неактивных элементов для немаксимальных проекций головок.
На практике разница в требованиях к пространству огромна (2
порядки величины). Эта разница, в свою очередь, может быть существенной
причина практической эффективности синтаксического анализатора головного угла. 1
Мы не только воздерживаемся от
утверждая так называемый активный пункта, но мы также воздерживаемся от
утверждение неактивных элементов для немаксимальных проекций головок.
На практике разница в требованиях к пространству огромна (2
порядки величины). Эта разница, в свою очередь, может быть существенной
причина практической эффективности синтаксического анализатора головного угла. 1  Оператор ограничения Шибера [6] может быть
используется здесь. Таким образом, мы фактически отбрасываем часть информации перед
предпринимается попытка решить (запоминаемую) цель. Например,
категория
Оператор ограничения Шибера [6] может быть
используется здесь. Таким образом, мы фактически отбрасываем часть информации перед
предпринимается попытка решить (запоминаемую) цель. Например,
категория Для практических реализаций использование ослабления цели может быть
чрезвычайно важно. По моему опыту, хорошо выбранная цель
Ослабляющий оператор может сократить время синтаксического анализа на порядок
величина.
Для практических реализаций использование ослабления цели может быть
чрезвычайно важно. По моему опыту, хорошо выбранная цель
Ослабляющий оператор может сократить время синтаксического анализа на порядок
величина.В этой системе входные данные для синтаксического анализатора — это не просто список слов, а скорее граф слов: ориентированный ациклический граф, в котором состояния являются моментами времени, а ребра помечены словесными гипотезами и соответствующие им вероятности. Таким образом, такие словесные графы ациклические взвешенные автоматы с конечным числом состояний.
При определенных подходах к обработке неправильно сформированного ввода желание
обобщать входные строки на входные автоматы с конечным числом состояний также
явно присутствует. Например, в [3] структура для
описывается неправильно сформированная обработка ввода, в которой некоторые общие
ошибки моделируются как (взвешенные) преобразователи с конечным числом состояний.
составление входного предложения с этими преобразователями производит
(взвешенный) конечный автомат, который затем вводится синтаксическому анализатору.
Например, в [3] структура для
описывается неправильно сформированная обработка ввода, в которой некоторые общие
ошибки моделируются как (взвешенные) преобразователи с конечным числом состояний.
составление входного предложения с этими преобразователями производит
(взвешенный) конечный автомат, который затем вводится синтаксическому анализатору.
Обобщение от строк до взвешенных автоматов вводит по сути два осложнения. Во-первых, мы не можем использовать строковые индексы больше. Во-вторых, нам нужно отслеживать вероятности слова, используемые в определенном производном.
Синтаксический анализ на основе конечного автомата можно рассматривать как
вычисление пересечения этого автомата с грамматикой.
Можно показать, что если грамматика с определенным предложением находится в автономном режиме
разборчив, и если автомат ацикличен, то этот
вычисление может быть гарантированно завершено
[7]. Кроме того, существующие методы анализа на основе
строки можно легко обобщить, используя имена состояний в
автомат вместо обычных строковых индексов.
В синтаксическом анализаторе заголовка это приводит к изменению определения предикат между/4. Вместо простого целого числа сравнения, теперь нам нужно проверить, что вывод из P0 в P может быть расширен до вывода от E0 до E с помощью проверка наличия путей в словесном графе от E0 до P0 и от P до E.
Предикат между/4 реализуется с помощью мемоизации как следует. Предполагается, что имена состояний являются целыми числами; чтобы исключить Для циклических слов-графов мы также требуем, чтобы для всех переходов от P0 к P выполнялось условие P0 < P. Переходы в словесном графе представлены предложениями вида wordgraph:trans(P0,Sym,P,Score), которые указывают на наличие переход из состояния P0 в P с символом Sym и Оценка вероятности.
| (11) |
Next: Синтаксический анализ и надежность Up: Надежный синтаксический анализ с Предыдущий: Введение Норд Г.Дж.М. фургон
1998-09-25
CSCI 131 Spring '18 — Разбор с применением
Инструктор: Майкл Гринберг Класс: TTh 9:35 – 10:50 в Милликене 2099 Часы работы инструктора: четверг с 11:00 до 12:00 в Милликене 2099; 2 среда – 17:00 в Edmunds 225 (или по предварительной записи)
Дом
Учебный план
Пьяцца
Представление
Эта лекция написана на грамотном Haskell; вы можете скачать необработанный исходный код.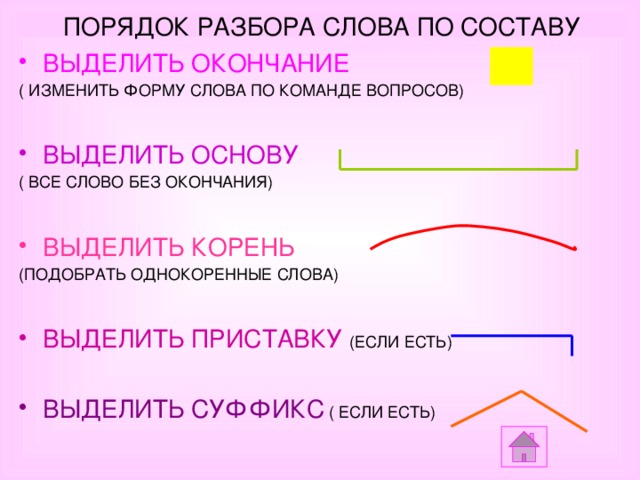
Мы записали простой экземпляр для Может быть и более интересный пример для Либо e :
экземпляр Applicative (Ethere e), где чистый х = правый х, потому что левый х будет плохо напечатан! (Право f) <*> (Право v) = Право $ f v err@(Left e) <*> _ = ошибка _ <*> err@(Left e) = err
Затем мы прошлись по Applicative определениям списков. Было два варианта: декартово произведение…
instance Applicative [] где чистый х = [х] [] <*> _ = [] _ <*> [] = [] (f:fs) <*> xs = map f xs ++ fs <*> xs
…и сжатие:
newtype ZipList a = ZipList { getZipList :: [a] }
вывод (Eq, Show, Functor)
экземпляр Applicative ZipList, где
чистый = ZipList. повторение
ZipList fs <*> ZipList xs = ZipList (zipWith ($) fs xs) Читатели
Мы также определяем экземпляр для читателей… своего рода прелюдия к определению наших парсеров.
экземпляр Прикладной ((->) r), где чистый v р = v frab <*> fra = \r -> frab r (fra r)
Мы смогли использовать этот экземпляр для быстрого и простого построения функций, например:
eogth = (&&) <$> even <*> (> 100) aos = (||) <$> isAlpha <*> isSpace
Первая функция возвращает true для четных чисел и больше ста; последний возвращает true для символов, которые являются буквенными или пробельными.
Соблюдайте законы
Как и Functor , класс типов Applicative регулируется законами.
Идентичность: pure id <*> v = v Состав: pure (.) <*> u <*> v <*> w = u <*> (v <*> w) Гомоморфизм: чистый f <*> чистый x = чистый (f x) Перестановка: u <*> чистый y = чистый ($ y) <*> u
Обратите внимание, что тождество является обобщением id <$> v = v из Functor, поскольку f <$> x = pure f <*> x`.
Мы определили синтаксические анализаторы «классического стиля» с точки зрения лексера ( String -> [Token] ) и синтаксического анализатора ( [Token] -> AST ), но большую часть занятия мы потратили на рассмотрение альтернативной модели: Аппликативный разбор.
импорт Data.Char
импортировать Control.Applicative
Парсер нового типа a = Парсер { parse :: String -> Maybe (a, String) }
буква :: Char -> Parser Char
буква c = парсер $\s ->
дело с
с':с' | c == c' -> Just (c,s')
_ -> Ничего
Letters :: Строка -> Строка парсера
буквы str = Parser $ \s ->
если взять (длина ул) s == ул
затем Just (str,drop (length str) s)
иначе ничего EG parse (буква 'c') "chocolate"
instance Functor Parser где
fmap f p = Парсер $ \s ->
разбор случая p s of
Ничего -> Ничего
Just (v,s') -> Just (f v,s') Обратите внимание, если вы прищуритесь, то увидите, что этот Functor экземпляр Parser представляет собой комбинацию экземпляров для Maybe и для читатели:
instance Functor Может где fmap f Ничего = Ничего fmap f (просто v) = просто (f v) instance Functor ((->) r), где -- (а -> б) -> (г -> а) -> (г -> б) fmap f g x = f (g x)
экземпляр Applicative Parser, где
чистый a = Parser $ \s -> Just (a,s)
f <*> a = Parser $ \s -> -- f :: Parser (a -> b), a :: Parser a
case parse f s of
Ничего -> Ничего
Просто (g,s') -> parse (fmap g a) s' -- g :: a -> b, fmap g a :: Parser b (Наш экземпляр Applicative - это , а также комбинация экземпляров для Возможно и читатель. Можете поверить мне на слово... или проверить сами.)
Можете поверить мне на слово... или проверить сами.)
EG parse ((\x -> [x,x,x]) <$> буква 'c') "шоколад"
буква C = буква 'c' strCH = (\c h -> [c,h]) <$> буква 'c' <*> буква 'h'
EG parse strCH "chocolate"
string :: String -> Parser String строка [] = чистый "" string (c:s) = (:) <$> (буква c) <*> string s
EG parse (string "choco") "chocolate"
EG parse (string "vanilla") "chocolate"
eof :: Парсер () eof = Parser $ \s -> если null s, то просто ((),"") иначе ничего strCH' = (\c h _ -> [c,h]) <$> буква 'c' <*> буква 'h' <*> eof
EG 'parse strCH' "ch" is Just ("ch ",[])`
EG разбор strCH' "шоколад" дает Ничего .
Обратите внимание, что мы проигнорировали значение eof . Мы можем использовать (<*) и (*>) , чтобы избавить себя от некоторых проблем, написав, например,
strCH'' = (\c h -> [c,h]) <$> буква 'c' <*> буква 'h' <* eof
обеспечить :: (a -> Bool) -> Парсер a -> Парсер a
убедитесь, что pred p = Parser $\s ->
разбор случая p s of
Ничего -> Ничего
Just (a,s') -> если пред a, то Just (a,s') else Ничего
удовлетворять :: (Char -> Bool) -> Parser Char
удовлетворять p = Parser f
где f [] = ничего
f (x:xs) = если p x then Just (x,xs) else Nothing Обратите внимание, что буква c эквивалентна удовлетворить (==c) .
просмотр вперед :: Parser (возможно, Char)
просмотр вперед = синтаксический анализатор f
где f [] = Просто (Ничего, [])
f (c:s) = Just (Just c,c:s) Мы могли бы вручную определить целочисленный анализ:
integer :: Parser Int целое число = Парсер $ \s -> let (digits,rest) = span isDigit s in если нулевые цифры, то ничего другого Просто (читать цифры, остальные)
Но будет лучше, если мы определим понятие выбора:
class Applicative f => Alternative f где пустой :: ф а (<|>) :: f a -> f a -> f a многие, некоторые :: Альтернатива f => f a -> f [a] некоторые p = (:) <$> p <*> многие p многие p = некоторые p <|> чистый [] Экземпляр Альтернатива Возможно, где -- пусто :: ф а пусто = ничего -- (<|>) :: f a -> f a -> f a Просто х <|> _ = Просто х Ничего <|> r = r -- пусто <|> f == f -- f <|> пусто == f
экземпляр Альтернативный анализатор, где
пустой = Парсер $ \s -> Ничего
p1 <|> p2 = Парсер $\s ->
разбор случая p1 s of
Просто (а,с') -> Просто (а,с')
Ничего -> разобрать p2 s
integer' :: Строка синтаксического анализатора
целое число' = читать <$> некоторые цифры
где someDigits = (:) <$> удовлетворяет isDigit <*> moreDigits
moreDigits = someDigits <|> чистый []
int :: Парсер Int
int = читать <$> некоторые (удовлетворить isDigit) EG разбор int "8675309"
EG разбор int "5551212zoop"
EG разбор int "KL51212"
threeInts = (\n1 n2 n3 -> [n1,n2,n3]) <$char> ($char> ') <*> (int <* char ',') <*> (убедитесь, что (>0) int)
EG разбор threeInts "1,2,3"
EG разбор threeInts "1,2, 0"
Давайте построим парсер для арифметических выражений.