О заводе НПП «Cпецкабель» Эксперты, в ОКБ Кабельной отрасли в 70-90-ых годах, имевшие практический опыт испытаний специальных кабелей для военного оборудования, в 1997 году образовали научно-производственное предприятие «Спецкабель». Сегодня же предприятие располагает научно-техническими и испытательными базисами, специализированным кабельным производством. Благодаря существующей системе подготовки технического персонала, постоянно растет численность кадров. Огнестойкие силовые кабели КУНРС для электроустановок (НОВИНКА) Кабели огнестойкие для электрических установок на напряжение до 450/750 В включительно серии КУНРС в исполнении нг(А)-FRLS и нг(А)-FRHF марок:
Кабели предназначены для работы в цепях питания мощных электроприемников в системах противопожарной защиты, а также в других системах энергоснабжения на объектах повышенной пожарной опасности. Кабели изготавливаются серийно по ТУ 16.К99-043-2011. Кабели соответствуют ГОСТ Р 53768-2010, также соответствуют требованиям нормативных документов «Технического регламента о пожарной безопасности», в том числе установленным в ГОСТ Р 53315-2009 (п.5.3, ПРГП 1б) по нераспространению горения при групповой прокладке (категория А), а также в ГОСТ Р 53315-2009 (п.5.8, ПО 1) по огнестойкости (в течение 180 минут). Кабели успешно прошли все сертификационные испытания Кабели могут эксплуатироваться внутри и вне помещений, при условии защиты от прямого воздействия солнечного излучения и атмосферных осадков, а кабели с оболочкой чёрного цвета – внутри и вне помещений без какой-либо защиты. Вся информация Хиты продаж
Весь каталог Новые огнестойкие кабели
Огнестойкие кабели промышленного интерфейса для систем безопасности
О компании ООО «СпецЭнергоКабель» Компания ООО «СпецЭнергоКабель» является официальным дилером завода НПП «Спецкабель».
Новости
Все новости Новости сайта 26. Патентные ведомства Китая и Турции выдали кабельному заводу «Спецкабель» патент на симметричный огнестойкий кабель. Напомним, что ранее в 2014 году данная разработка была запатентована на территории Российской Федерации.
Симметричные огнестойкие кабели используются для передачи высокочастотных сигналов в системах связи, системах промышленной автоматизации и системах пожароохранной сигнализации на атомных станциях, в частности, внутри гермозоны. Кабель содержит, по крайней мере, одну симметричную пару токопроводящих жил, изолированных огнестойкой кремнийорганической резиной и полиимидной пленкой, покрывающей каждую из изолированных жил, и разделяющей их одним слоем. При этом пленка скрепляет изолированные жилы между собой, обеспечивая постоянство симметрии пары по длине кабеля.
Разработчикам кабеля удалось добиться следующих результатов: повышена надежность, увеличен срок службы кабеля в условиях работы внутри гермозоны атомных станций при обеспечении минимального уровня потерь и сохранении нормируемых параметров. 21.07.18 Кабельный завод «Спецкабель» получил положительные отзывы об огнестойкой кабельной линии (ОКЛ) систем противопожарной защиты «Спецкаблайн-К» от компании «Пожстройсервис», которая занимается ее монтажом на арене «Лужники». По мнению специалистов компании, данная кабельная линия значительно дешевле, проще в монтаже и имеет весомое преимущество — возможность оперативно изменять комбинацию прокладываемых кабелей путем добавления или исключения их в линии без применения монтажных коробок. По достоинству была оценена ещё одна возможность этой ОКЛ – прокладка в ограниченных пространствах. Таким образом, проводить монтаж данной линии быстро, удобно и легко даже в труднодоступных местах. 18.07.18 В настоящее время на электротехническом рынке РФ сложилась ситуация, когда производители кабельно-проводниковой продукции стали часто сталкиваться с фальсифицированной продукцией. Недобросовестные компании изготавливают и поставляют потребителям продукцию с заведомо заниженными характеристиками, без указания необходимых маркировок и с прочими нарушениями. 14.07.18 На нашем сайте можно ознакомиться с новым каталогом кабелей оборонного назначения. 27.06.18 На кабельном заводе «Спецкабель» 22 июня Межведомственная комиссия в составе представителей ОАО «ВНИИКП», АО «Атомэнергопроект», ФГУП ВО «Безопасность» и НИЦ «Курчатовский институт» по результатам приёмочных испытаний одобрила применение кабелей серии СПЕЦЛАН для структурированных кабельных систем категорий 5е, 6, 6А, 7, 7А в исполнении «нг(А)-HF» (ТУ 16. 21.06.18 Кабельный завод «Спецкабель» совместно с НПП «МЕТА» провели семинар для проектных организаций.
В ходе семинара были подняты вопросы, связанные с особенностями конструкции и применения продукции производства «Спецкабель» и «МЕТА». Все новости сайта | ||||||||||||||||||||||||||||||||||||
 Кабели КУНРС могут применяться во взрывоопасных зонах, температура эксплуатации от -50 град. до +80 град. (для исполнения нг(А)-FRHF) или от -40 град. до +60 град. (для исполнения нг(А)- FRLS), срок службы не менее 30 лет. Допускается прокладка бронированных кабелей в грунтах категорий I–III.В сравнении с кабелями с ПВХ изоляцией жил и огнестойким барьером в виде слюдосодержащей ленты, например, марки ВВГнг(А)-FRLS и ППГнг(А)-FRHF, кабели серии КУНРС более удобны при монтаже и разделке кабеля. Кроме того, кабели серии КУНРС более устойчивы к перегрузкам и могут иметь более высокие допустимые длительные токи.
Кабели КУНРС могут применяться во взрывоопасных зонах, температура эксплуатации от -50 град. до +80 град. (для исполнения нг(А)-FRHF) или от -40 град. до +60 град. (для исполнения нг(А)- FRLS), срок службы не менее 30 лет. Допускается прокладка бронированных кабелей в грунтах категорий I–III.В сравнении с кабелями с ПВХ изоляцией жил и огнестойким барьером в виде слюдосодержащей ленты, например, марки ВВГнг(А)-FRLS и ППГнг(А)-FRHF, кабели серии КУНРС более удобны при монтаже и разделке кабеля. Кроме того, кабели серии КУНРС более устойчивы к перегрузкам и могут иметь более высокие допустимые длительные токи.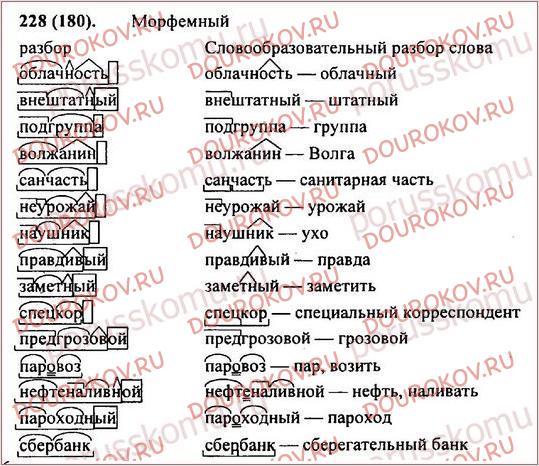 К99-036-2007
К99-036-2007

 К99-037-2009
К99-037-2009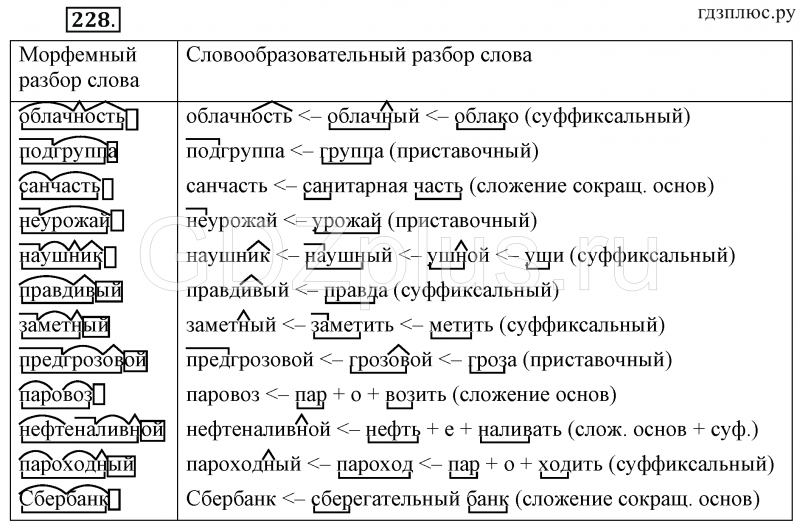
 По мнению специалистов компании, данная кабельная линия значительно дешевле, проще в монтаже и имеет весомое преимущество — возможность оперативно изменять комбинацию прокладываемых кабелей путем добавления или исключения их в линии без применения монтажных коробок. По достоинству была оценена ещё одна возможность этой ОКЛ – прокладка в ограниченных пространствах.
Таким образом, проводить монтаж данной линии быстро, удобно и легко даже в труднодоступных местах.
По мнению специалистов компании, данная кабельная линия значительно дешевле, проще в монтаже и имеет весомое преимущество — возможность оперативно изменять комбинацию прокладываемых кабелей путем добавления или исключения их в линии без применения монтажных коробок. По достоинству была оценена ещё одна возможность этой ОКЛ – прокладка в ограниченных пространствах.
Таким образом, проводить монтаж данной линии быстро, удобно и легко даже в труднодоступных местах.
 spcable.ru/catalog/pdf/spcable_catalog_mil.pdf.
Для заказа печатного экземпляра необходимо отправить запрос на электронный адрес [email protected] или позвонить по телефону 8 (495) 134-2-134.
spcable.ru/catalog/pdf/spcable_catalog_mil.pdf.
Для заказа печатного экземпляра необходимо отправить запрос на электронный адрес [email protected] или позвонить по телефону 8 (495) 134-2-134. Кабели СПЕЦЛАН используются при строительстве атомных электростанций Нововоронежская АЭС-2, Белорусская АЭС, ЛАЭС-2.
Кабели СПЕЦЛАН используются при строительстве атомных электростанций Нововоронежская АЭС-2, Белорусская АЭС, ЛАЭС-2. 07.18
07.18
 Такая ситуация наносит реальный вред всем участникам рынка – конечным потребителям, продавцам и дистрибьюторам.
Кабельный завод «Спецкабель» совместно с другими организациями, осуществляющими деятельность на рынке кабельной продукции, подписал Совместное заявление об этике работы на электротехническом рынке РФ в сегменте кабельно-проводниковой продукции.
Совместная инициатива реализуется в рамках проекта «Кабель без опасности». Организации, подписавшие заявление, разработали способы взаимного контроля, направленного на противодействие незаконному обороту кабельной продукции, обеспечение её качества и воздействие на недобросовестных производителей и поставщиков.
Организации, подписавшие Совместное заявление, выражают уверенность, что усилиями производителей, дистрибьюторов и потребителей кабельной продукции будет поставлен надёжный барьер обороту фальсифицированной и контрафактной продукции.
Такая ситуация наносит реальный вред всем участникам рынка – конечным потребителям, продавцам и дистрибьюторам.
Кабельный завод «Спецкабель» совместно с другими организациями, осуществляющими деятельность на рынке кабельной продукции, подписал Совместное заявление об этике работы на электротехническом рынке РФ в сегменте кабельно-проводниковой продукции.
Совместная инициатива реализуется в рамках проекта «Кабель без опасности». Организации, подписавшие заявление, разработали способы взаимного контроля, направленного на противодействие незаконному обороту кабельной продукции, обеспечение её качества и воздействие на недобросовестных производителей и поставщиков.
Организации, подписавшие Совместное заявление, выражают уверенность, что усилиями производителей, дистрибьюторов и потребителей кабельной продукции будет поставлен надёжный барьер обороту фальсифицированной и контрафактной продукции. Все кабели включены в ограничительные перечни Минпромторга и Минобороны России. В каталог вошли последние разработки компании:
• Кабели симметричные для цифровых систем передачи данных и структурированных кабельных систем категории 5, 5е, 6 и 6А;
• Симметричные судовые кабели для передачи цифровых сигналов;
• Кабели судовые на номинальное напряжение до 0,6/1,0 кВ;
• Кабели судовые огнестойкие на номинальное напряжение до 0,6/1,0 кВ;
• Кабели судовые герметизированные на напряжение до 0,6/1,0 кВ;
Каталог можно скачать по ссылке http://www.spcable.ru/catalog/pdf/spcable_catalog_mil.pdf.
Для заказа печатного экземпляра необходимо отправить запрос на электронный адрес [email protected] или позвонить по телефону 8 (495) 134-2-134.
Все кабели включены в ограничительные перечни Минпромторга и Минобороны России. В каталог вошли последние разработки компании:
• Кабели симметричные для цифровых систем передачи данных и структурированных кабельных систем категории 5, 5е, 6 и 6А;
• Симметричные судовые кабели для передачи цифровых сигналов;
• Кабели судовые на номинальное напряжение до 0,6/1,0 кВ;
• Кабели судовые огнестойкие на номинальное напряжение до 0,6/1,0 кВ;
• Кабели судовые герметизированные на напряжение до 0,6/1,0 кВ;
Каталог можно скачать по ссылке http://www.spcable.ru/catalog/pdf/spcable_catalog_mil.pdf.
Для заказа печатного экземпляра необходимо отправить запрос на электронный адрес [email protected] или позвонить по телефону 8 (495) 134-2-134. К99-058-2014) для нужд Росатома.
На заводе «Спецкабель» разработаны и серийно производятся более 150 видов кабелей для СКС: от категории 5е (со скоростью передачи 100 Мбит/с) до категории 7А (со скоростью до 10 Гбит/с). Разнообразие конструкций позволяет найти оптимальное решение для построения СКС на любом объекте.
Кабели в безгалогенном исполнении «нг(А)-HF» обладают стойкостью к дезактивирующим растворам, плесневым грибам, горюче-смазочным материалам, солнечному излучению и прочим воздействиям, а также сроком эксплуатации 40 лет при температуре 50 С°, что позволяет применять их на атомных станций, вне гермозоны, в системах класса безопасности 3 (НП-001-15).
Кабели СПЕЦЛАН используются при строительстве атомных электростанций Нововоронежская АЭС-2, Белорусская АЭС, ЛАЭС-2.
К99-058-2014) для нужд Росатома.
На заводе «Спецкабель» разработаны и серийно производятся более 150 видов кабелей для СКС: от категории 5е (со скоростью передачи 100 Мбит/с) до категории 7А (со скоростью до 10 Гбит/с). Разнообразие конструкций позволяет найти оптимальное решение для построения СКС на любом объекте.
Кабели в безгалогенном исполнении «нг(А)-HF» обладают стойкостью к дезактивирующим растворам, плесневым грибам, горюче-смазочным материалам, солнечному излучению и прочим воздействиям, а также сроком эксплуатации 40 лет при температуре 50 С°, что позволяет применять их на атомных станций, вне гермозоны, в системах класса безопасности 3 (НП-001-15).
Кабели СПЕЦЛАН используются при строительстве атомных электростанций Нововоронежская АЭС-2, Белорусская АЭС, ЛАЭС-2. Повышенный интерес аудитории вызвала вопрос применения огнестойких кабельных линий для систем ПС и СОУЭ, а также недавние изменения в Федеральном законе №123 «Технический регламент о требованиях пожарной безопасности».
Специалисты компании «Спецкабель» разъясняли особенности и способы применения огнестойких кабельных линий «Спецкаблайн», в том числе с монтажными коробками производства НПП «МЕТА».
Выражаем благодарность всем специалистам, посетившим данное мероприятие, и надеемся, что информация, полученная в ходе семинара, окажется полезной в дальнейшей работе.
Повышенный интерес аудитории вызвала вопрос применения огнестойких кабельных линий для систем ПС и СОУЭ, а также недавние изменения в Федеральном законе №123 «Технический регламент о требованиях пожарной безопасности».
Специалисты компании «Спецкабель» разъясняли особенности и способы применения огнестойких кабельных линий «Спецкаблайн», в том числе с монтажными коробками производства НПП «МЕТА».
Выражаем благодарность всем специалистам, посетившим данное мероприятие, и надеемся, что информация, полученная в ходе семинара, окажется полезной в дальнейшей работе.[PDF] Онлайн-сбор неизвестных морфем японского языка с использованием морфологических ограничений
- title={Онлайн-сбор неизвестных японских морфем с использованием морфологических ограничений},
автор={Юго Мураваки и Садао Курохаши},
booktitle={EMNLP},
год = {2008}
}
- Юго Мураваки, С.
 Курохаши
Курохаши - Опубликовано в EMNLP 25 октября 2008 г.
- Лингвистика
Мы предлагаем новый модуль сбора словарного запаса, который работает совместно с морфологическим анализатором и может работать в онлайн-режиме. Каждый раз, когда анализируется предложение, он обнаруживает неизвестные морфемы, перечисляет кандидатов и выбирает лучших кандидатов, сравнивая несколько примеров, хранящихся в хранилище. Когда морфема выбрана однозначно, сборщик лексики обновляет словарь анализатора, и она будет использоваться в последующем анализе. Мы используем ограничения японской морфологии…
Посмотреть на ACL
DL.ACM.ORGонлайн японский неизвестный обнаружение морфема с использованием орфографических вариаций
- Yugo Murawaki, S. Kurohashi
Linguistics
LREC
- 20109
- Юго Мураваки, С.
СРЕДНЯЯ СРЕДИ представлена проблема морфологического анализа японского языка, использование орфографических вариаций японского языка в предположении, что орфографические варианты ведут себя одинаково, и каждый кандидат сверхсегментации проверяется на соответствие своим аналогам.
Семантическая классификация автоматически приобретенных существительных с использованием лексико-синтаксических подсказок
- Yugo Murawaki, S. Kurohashi
Лингвистика
Коленинг
- 2010
. текст с назначенными им полными тегами POS и исследует лексико-синтаксические подсказки, которые извлекаются из автоматически анализируемого текста, и исследуют их влияние.
Простой подход к обработке неизвестных текстов в японском морфологическом анализе
- Рёхей Сасано, С. Курохаши, М. Окумура
Информатика
IJCNLP
- 2013
слова, которые являются производными от слов в заранее определенном словаре…
Составление и разложение японских морфем катаканы и кандзи для индукции правил принятия решений из патентных документов
- Мичико Ясукава, Х. Йокоо
Лингвистика
- 2010
Мы предлагаем новый метод построения списка слов для индукции правил из японских патентных документов.
Для сегментации слов в японском языке статистические морфологические анализаторы использовались во многих…Непараметрическая байесовская сегментация японских словосочетаний существительных
- Юго Мураваки, С. Курохаши
Информатика
EMNLP
0011 2011
Предложена новая процедура блочной выборки, называемая выборкой на основе гибридного типа, которая позволяет напрямую избежать локального оптимума, не слишком удаленного от глобального оптимума, и эффективно исправляет начальную сегментацию, заданную морфологическим анализатором.
Модальность разговорного испанского и японского языков: корпусное исследование и автоматическая аннотация
- Карлос Эрреро Зорита
Лингвистика
- 2017
Основная цель этой диссертации состоит в том, чтобы автоматически находить и классифицировать элементы, сигнализирующие о модальности в испанских и японских предложениях, принимая во внимание как теоретическую, так и эмпирическую информацию. В…
В…
Японский морфологический анализ книг с картинками
- S. Fujita, Hirotoshi Taira, Tessei Kobayashi, Takaaki Tanaka
Environment Science
- 2014
Picture Books имеет знаменитость на норве на норве на норве на норве на номинациях. Однако предложения в книжках с картинками трудно анализировать автоматически. Поэтому для повышения точности…
Может ли заземление символов улучшить НЛП низкого уровня? Сегментация слов как пример
- Хиротака Камеко, Шинсуке Мори, Ёсимаса Цуруока
Информатика
EMNLP
- 2015
A словарь терминов в три этапа путем создания псевдостохастически сегментированного корпуса и его фильтрации в соответствии с оценками заземления.
О определении японского слова
- Yugo Murawaki
Лингвистика
ARXIV
- 2019
Эта работа утверждает, что короткие слова универсальных зависимостей не являются синтаксическими словами в соответствии с указаниями в соответствии с указаниями в соответствии с указаниями ANNOTATES, и не являются синтаксическими словами. обсуждаются затраты и выгоды от принятия довольно незнакомых критериев.
Понимание неизвестного: неподтвержденная обработка входных данных на естественном языке
В статье описывается нечеткий подход к проблеме в рамках смысловой обработки естественного языка в отношении семантической и синтаксической приемлемости предложения.
SHOWING 1-10 OF 18 REFERENCES
SORT BYRelevanceMost Influenced PapersRecency
Overview of Morpho Challenge in CLEF 2007
- M. Kurimo, Mathias Creutz, V. Turunen
Computer Science
CLEF
- 2007
Результаты показывают, что анализ морфем оказывает существенное влияние на эффективность IR на всех языках и что эффективность лучших неконтролируемых методов может быть выше, чем контрольных эталонных методов.
Неконтролируемая сегментация слов в Morphemes — Challenge 2005, Отчет о введении и оценке
- M. Kurimo, Mathias Creutz, Matti Varjokallio, E. Arisoy, M. Saraçlar
Lingistics, Computer Science
- 2007
Lingistics, Computer Science
1111119.
Разработан статистический алгоритм машинного обучения, который сегментирует слова на мельчайшие смысловые единицы языка, морфемы. В идеале это базовые словарные единицы, подходящие для различных задач, таких как понимание речи и текста, машинный перевод, поиск информации и статистический язык. моделирование.
Японская неизвестная идентификация слов по персонажам на основе персонажа
- Masayuki Asahara, Yuji Matsumoto
Компьютерная наука
Coling
- 2004
На основе Чунки на основе характерной идентификации. при разбиении на фрагменты на основе SVM с использованием символьной n-граммы и окружающего контекста n-лучших кандидатов на сегментацию слов из статистического морфологического анализа в качестве признаков.
Неизвестная проблема слов: морфологический анализ японцев с использованием максимальной энтропии с поддержкой словаря
- Kiyotaka Uchimoto, S. Sekine, H. Isahara
Computer Science
ЭМНЛП
- 2001 9007
- Masaaki Nagata
Компьютерная наука
ACL
- 1999
- Shinsuke Mori, M. Nagao
Компьютерная наука
Coling
- 1996
- Masayuki Asahara, Yuji Matsumoto
Коллекционер
Coling
- 2000
- T. Nakagawa, Yuji Matsumoto
Компьютерная наука
ACL
- 2006
- Дайсуке Кавахара, С. Курохаши
Информатика
LREC
- 2006
Парсер: входные данные передаются парсеру, и он обобщает синтаксическую структуру (в форме дерева разбора)
Семантический интерпретатор: затем семантический интерпретатор улавливает его семантические детали, создает его более глубокую структуру.
Правила преобразования: правила преобразования принимают эту глубокую структуру предложения и делают ее совместимой с точки зрения хранения базы данных.
Обработчик базы данных: над ней работает обработчик базы данных, генерирующий обработанную форму с точки зрения хранения.
Ланугае форма
Значение языка
Язык в контексте
распознаватель
Генератор
Переводчик
Риэлтор
Автоматы с конечным числом состояний Пример морфологии приведен ниже
Пример:
Лексический анализ. В информатике лексический анализ — это процесс преобразования последовательности символов в последовательность токенов. Программа или функция, выполняющая лексический анализ, называется лексическим анализатором, лексером или сканером. Лексикон означает словарь. Это набор всех возможных допустимых слов языка вместе с их значением. Идентификация (глагол, существительное и местоимение в ближайшее время).
Пример: рассмотрим это выражение на языке программирования C:
Сумма=8+5;
Лексема
Тип токена
сумма
Идентификатор
=
Оператор присваивания
8
Номер
+
Оператор сложения
5
Номер
;
Конец оператора
общая грамматика, используемая синтаксическим анализом для естественного языка, является контекстно-свободной грамматикой, также называемой структурой фразы и грамматикой определенного предложения.
Типы методов парсера —
Разбор сверху вниз
анализ снизу вверх
Статистический
Коннекционист
Гибрид. Оценка НЛП:
Оптическое распознавание символов
Поиск информации
Извлечение информации (IE)
Распознавание речи
Упрощение текста
Вопрос-Ответ
Обобщение
Машинный перевод
Диалоговые системы Автоматическое суммирование
Маркировка части речи
Машинный перевод
Распознавание именованных объектов
Генерация естественного языка
Система разговорного диалога
Преобразование текста в речь
Это метод. модель, которая может не только обращаться к словарю с большим объемом лексической информации, но также может идентифицировать неизвестные слова, изучая определенные характеристики, что может решить проблему неизвестного слова.
Часть метода оценки речи для японских неизвестных слов с использованием статистической модели морфологии и контекста
Статистическая модель статистической модели Японского Университетского Состояния Состояние Состояние известных слов. набор моделей длины и правописания, классифицированных по типам символов, составляющих слово, представлен для повышения точности сегментации слов и точности тегирования частей речи.
Извлечение слов из Corpora и его часть речи с использованием распределительного анализа
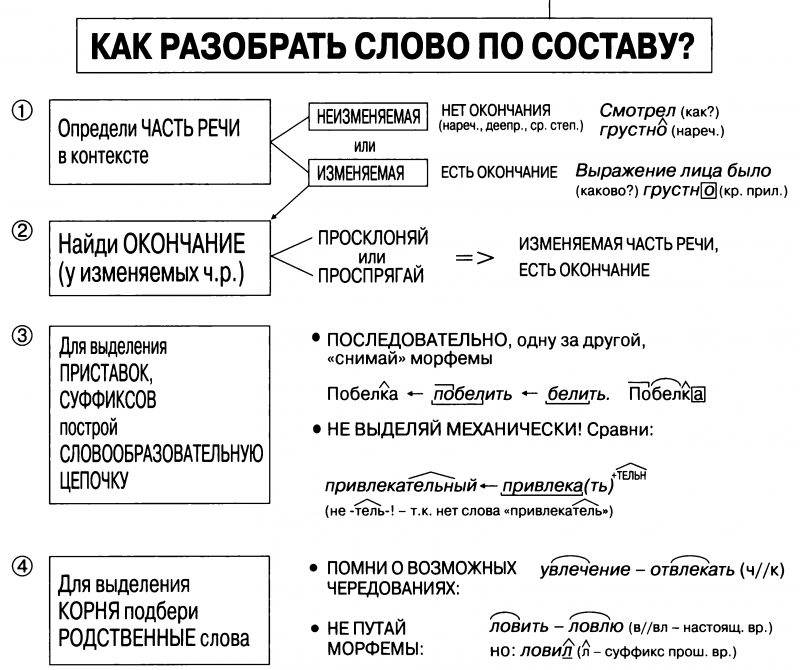
Эта работа предлагает метод, чтобы извлечь слова из извлечения слов из извлечения слов. корпус и оценить вероятность того, что каждое слово принадлежит заданным частям речи (POSs), используя дистрибутивного анализа, и показывает, что этот метод эффективен для вывода POS неизвестных слов.
Расширенные модели и инструменты для высокоэффективной части речи
. вводится концепция позиционной группировки, при которой набор тегов разбивается на разные классы эквивалентности в каждой позиции условных вероятностей в марковской модели.
Сегментация китайского языка и обнаружение новых слов с использованием условных случайных полей ) для выполнения надежной и точной сегментации китайских слов, предоставляя принципиальную структуру, которая легко поддерживает интеграцию знаний предметной области в виде нескольких словарей символов и слов.
Угадание отчиков отчики неизвестных слов с использованием глобальной информации
Возратчивая модели для догадки по вспомогательству, с использованием глобальных слов, с использованием глобальных слов, с использованием глобальных слов, с использованием глобальных слов, с использованием глобальных слов. Попущающая информационная информация, использующая глобальные слова, используя глобальные слова, с использованием глобальных слов. а также предлагается локальная информация, а ее параметры оцениваются с помощью выборки Гиббса.
Сбор кадров из Интернета с использованием высокопроизводительных вычислений
Создан огромный текстовый корпус из Интернета, а из него созданы фреймы прецедентов, которые содержат большинство примеров обычного использования и готов к применению во многих анализах и приложениях НЛП.
Подходы к обработке естественного языка, применение и ограничения — IJERT
Подходы к обработке естественного языка, применение и ограничения
Г-жа Риджука Патхак Г-н Биджу Тханкачан
M Tech (CSE) 4-й сем. Доцент C.S.E.
Д.И.М.А.Т. Райпур Д.И.М.А.Т. Raipur
РЕФЕРАТ
Естественный язык — это язык, который используется или на котором говорит человек. Этими языками являются хинди, английский, французский, маратхи, бенгальский, гуджрати и т. д. И обработка естественного языка является областью искусственного интеллекта, а естественная обработка основана на создании системы, с помощью которой человек может без проблем взаимодействовать с компьютером на своем родном языке. В этой статье мы сосредоточимся на концепции обработки естественного языка, ее подходах, ее типы и приложение для обработки естественного языка.
ВВЕДЕНИЕ
Обработка естественного языка состоит из трех разных слов 1.натуральный: естественный означает не искусственный, который не создан машиной, что вещи называются естественными.
2. Язык: язык в основном является средством общения, с помощью которого мы заставляем людей понимать наши мысли и передавать сообщения.Когда мы объединяем эти два слова, в результате мы получаем естественный язык, поэтому естественный язык — это язык, который генерируется автоматически
не создается машиной, в отличие от машинного языка, используемого в компьютере, c, c++, java и т. д. Примерами естественных языков являются хинди
, английский, марти, гуджрати, немецкий и т. д.
И третье слово обрабатывает текущую форму процесса, который в основном выполняется на компьютере. Таким образом, обработка естественного языка — это обработка естественного языка с помощью компьютера, которая называется обработкой естественного языка (НЛП). NLP в основном относится к области искусственного интеллекта, в основном используемого для создания переводчика языка, машинного перевода (MT) и так далее.
На рис.1.1 показана концепция естественного языка. Процесс НЛП разделен на две части: понимание и генерация.
Подобласть искусственного интеллекта (ИИ) и его новые и различные разработки в НЛП приведены ниже:2.1 Первая эра (1940-1950)
В этот период работа в основном опирается на две основополагающие парадигмы; а именно автоматизация и использование вероятностных моделей. автоматизация началась в 1950-е годы с моделью алгоритмических вычислений Тьюринга. Пробуждение Тьюринга привело сначала к развитию нейронов Питтса MC Culloch, которые сделали упрощенную модель нейрона как своего рода вычислительного элемента, который можно было описать в терминах логики высказываний, а затем к работе Клинса. по конечной автоматизации и регулярным выражениям. Шеннон применил вероятностные модели дискретных марковских процессов для автоматизации языковой обработки. Хомский впервые рассмотрел конечный автомат как способ охарактеризовать грамматику и определить язык с конечным состоянием, порожденный грамматикой с конечным состоянием, эта модель привела к области теории формальных языков, в которой алгебра и теория множеств используются для определения формального языка как символов последовательности.
Сюда входит контекстно-свободная грамматика, впервые определенная Хомским.[1]2.1 Вторая эпоха (1957-1970)
Во вторую эпоху языковая обработка распадается на две парадигмы: символическую и стохастическую. Символическая работа началась с двух направлений работы. первой была работа Хомского, а другая — по формальной теории языка и генеративному синтаксису, а также работа многих лингвистов и компьютерных ученых по алгоритмам синтаксического анализа, сначала с использованием подходов «сверху вниз» и «снизу вверх», а затем с помощью динамического программирования. Вторым направлением исследований стала новая область искусственного интеллекта. Это была простая система, которая работала в одном домене, в основном за счет сочетания сопоставления с образцом и поиска по ключевым словам с простой эвристикой для рассуждений и ответов на вопросы. Десятилетие 19В 60 году также появилась первая тестируемая модель обработки человеческого языка, основанная на грамматике преобразования, а также на онлайн-корпусах.
Коричневый корпус американского английского представлял собой коллекцию из 1 миллиона образцов из 500 письменных текстов разных жанров, которая была собрана в Университете Брауна в 1963-64 годах[1].2.3 Третья эра (1970-1993)
В эту эру произошел взрыв исследований в области языковой обработки. Успех SHRDUL показал, что синтаксический анализ был достаточно хорошо понят, чтобы начать фокусироваться на семантике и моделях дискурса. Роджер Шэнк и его коллеги создали серию программ для понимания языка, ориентированных на концептуальные знания человека, такие как сценарии, планы и цели, а также на организацию человеческой памяти
Парадигмы, основанные на логике и понимании естественного языка, были объединены в системах, которые использовали логику предикатов в качестве семантического представления. LUNAR является примером такой системы.
Парадигма моделирования дискурса была сосредоточена на четырех ключевых анализах дискурса.[1]
2.4 Четвертая эра (с 1993 г.
по настоящее время)В этом случае использование вероятностных моделей и моделей, управляемых данными, стало вполне стандартным при обработке естественного языка. Алгоритмы синтаксического анализа, маркировки частей речи, ссылок и дискурса — все они начали включать вероятности
и использовать стратегии оценки, заимствованные из распознавания речи и поиска информации.
3. Система НЛП
Как мы знаем, НЛП состоит из двух частей: понимание (обработка входных данных) и генерация (обработка выходных данных). Мы также знаем, что для НЛП нам нужен естественный язык в качестве входных данных и получение другого естественного языка в качестве выходных данных, для этого нам нужна общая система НЛП, которая выполняет несколько шагов, которые показаны на рис. № 2 и рис. № 3 для входной стороны и другой для стороны генерации. соответственно.
Вводится ввод, и отсюда начинаются шаги
А для стороны генерации нам нужно выполнить обратные шаги обработки стороны ввода.
4. Лингвистические структуры
Лингвистика – это научное изучение человеческого языка. Лингвистика может быть разделена на три категории или подобласти исследования:
Языковая форма: языковая форма, или языковая структура, или грамматика. Основное внимание уделяется системным правилам, которым следует говорящий на языке. Он включает в себя: морфологию (образование и состав слова), синтаксис (образование и состав синтаксического разбора и предложения из этих слов) и фонологию (звуковую систему), а фонетика является родственной отраслью лингвистики, занимающейся фактическими свойствами речи.
звук и неречевой звук, а также то, как они производятся и воспринимаются.Значение языка: значение языка связано с тем, как язык использует логические структуры и ссылки на реальный мир для передачи, обработки и присвоения значения, а также устранения двусмысленности. Это подполе охватывает
семантику (как значение выводится из слов и понятий) и прагматика (как значение выводится из контекста).
Лингвистика в ее более широком контексте включает эволюционную лингвистику, которая рассматривает происхождение языка; историческая лингвистика, изучающая языковые изменения, социолингвистика
, в котором рассматривается связь между языковыми вариациями и социальной структурой; психолингвистика, изучающая представление и функции языка в уме, нейролингвистика, изучающая обработку языка в мозгу; овладение языком
, как дети или взрослые осваивают язык; и анализ дискурса; который включает в себя структуру текстов и разговоров.
5. Этапы обработки естественного языка
Обработка естественного языка состоит из шести этапов: фонологический анализ, морфологический анализ, лексический анализ, семантический анализ, прагматический анализ, дискурсивный анализ.
Все они кратко обсуждаются ниже-Фонологический анализ: фонология является отраслью языкознания. это анализ разговорной речи. Распознавание и генерация речи
1) фонетические правила для звуков в словах;
2) фонематические правила для вариантов произношения, когда слова произносятся вместе, и;
3) Просодические правила изменения ударения и интонации в предложении. В системе НЛП, которая принимает голосовой ввод, звуковые волны анализируются и кодируются в оцифрованный сигнал для интерпретации по различным правилам.
Морфологический анализ: Это самая элементарная фаза НЛП. Он касается словообразования в этой области, отдельные слова анализируются в соответствии с их компонентами, называемыми морфемами. Морфемы — это не что иное, как основной грамматический строительный блок, из которого состоят слова. Или, другими словами, структура называется морфологией. Вычислительные средства для выполнения морфологического разбора представляют собой преобразователь с конечным состоянием.
Преобразователь: Преобразователь выполняет это путем сопоставления двух наборов символов, а преобразователь с конечным состоянием делает это с конечной автоматизацией.
Преобразователь обычно состоит из четырех частей:
например: Дерево синтаксического анализа для предложения- john ate apple
s- NP VP VP- V NP NP-NAME NP-ART N
NAME-john V-ate
ART-the N-apple
Синтаксический анализ
В компьютерных науках синтаксический анализ или, более формально, синтаксический анализ — это процесс анализа текста, состоящего из последовательности токенов, для определения его грамматической структуры по отношению к заданной формальной грамматике. Самый
Семантический анализ
Семантика имеет дело со значением предложения на естественном языке. На этом этапе понимается смысл предложения. Если компьютер хочет передать средства
естественного языка, для фиксации смысла требуется вычислительное представление этих предложений.
Прагматический анализ: прагматический анализ — это изучение отношений между языком и контекстом использования.
Следовательно, прагматический анализ включает анализ того, как язык используется для обозначения людей и вещей.Анализ дискурса: дискурс представляет собой набор предложений, но произвольный набор нескольких предложений не образует дискурс. в речи предложение должно быть связным
Подходы: Подходы к обработке естественного языка делятся примерно на четыре категории: 1. Символические: символические подходы, также известные как рационалистические, предполагают, что значительная часть знаний в человеческом уме не выводится органами чувств, а фиксируется заранее, предположительно путем генетического наследования. .
Внутренняя оценка: система внутренней оценки основана на концепции измерения производительности изолированной системы НЛП, и этот тип и этот тип системы характеризовали свою производительность в основном в отношении результата золотого стандарта, заранее определенного оценщиками.
Внешняя оценка: она также известна как оценка в процессе использования. Она рассматривает систему НЛП в более сложных условиях либо как встроенную, либо как обслуживающую, а затем характеризуется с точки зрения ее полезности по отношению к общей задаче сложной системы или человеческий пользователь.
Оценка «черного ящика»: для оценки «черного ящика» требуется запустить систему НЛП на заданном наборе данных и измерить ряд параметров, связанных с качеством процесса и, что наиболее важно, с результатом.
Оценка стеклянного ящика: рассматривается дизайн системы, алгоритмы, реализующие используемые ею лингвистические ресурсы и т. д.
Автоматическая оценка: можно определить автоматические процедуры для оценки системы НЛП путем сравнения ее результатов с золотым стандартом.
Ручная оценка: ручная оценка выполняется судьями-людьми, которым поручено оценить качество системы и, чаще всего, выборки ее результатов на основе ряда критериев.
Применение: Обработка естественного языка предоставляет как теорию, так и реализации для ряда
приложений.
Наиболее частые приложения, использующие НЛП, включают следующее:.
Ограничение: критической проблемой при обработке естественного языка является неоднозначность, связанная с более чем одним значением.
Несколько типов неоднозначности:
Лексическая неоднозначность: когда одно слово может иметь несколько разных значений, результирующая неоднозначность называется лексической.
Синтаксическая двусмысленность: иногда предложения могут быть проанализированы более чем одним способом, то есть фразы могут быть составлены по-разному.
Референтная двусмысленность: использование местоимения и других анафор может вызвать референциальную двусмысленность
Прагматическая двусмысленность: эта двусмысленность подчеркивает смысл предложения, возникает из-за различных намерений говорящего.
Other are-
Фразовое присоединение Союз
Структура группы существительных
Семантическая двусмысленность Анафорическая двусмысленность Небуквальная речь Многоточие и т.д.
Заключение. На протяжении всего документа мы видели важность НЛП в том, как оно помогает в переводе, поиске информации, понимании разных языков, машинном переводе, извлечении информации, поскольку НЛП имеет множество применений, в то же время у него есть некоторые проблемы, а также двусмысленность. в этой области было проведено множество исследований, но двусмысленность по-прежнему остается серьезной проблемой в НЛП.