What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.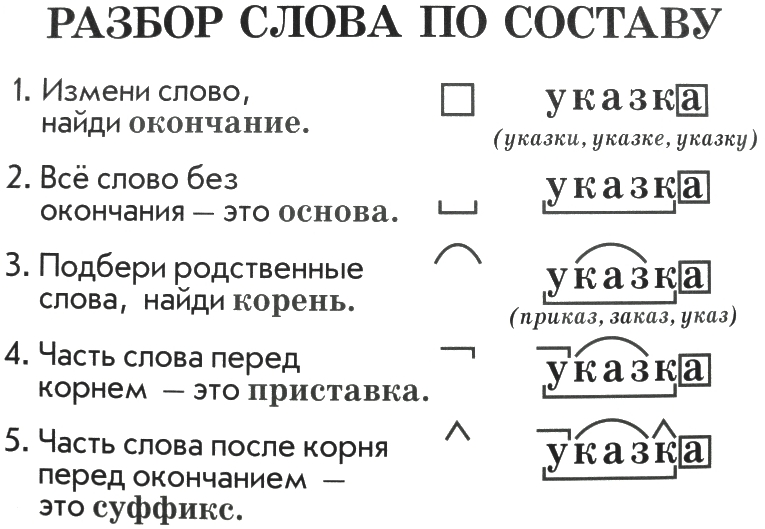
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор слова «начинающий»
Слово можно разобрать в 3 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Прилагательное
НАЧИНАЮЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАЧИНАЮЩИЙ»
| Слово | Морфологические признаки |
|---|---|
| НАЧИНАЮЩИЙ |
|
| НАЧИНАЮЩИЙ |
|
Все формы слова НАЧИНАЮЩИЙ
НАЧИНАЮЩИЙ, НАЧИНАЮЩЕГО, НАЧИНАЮЩЕМУ, НАЧИНАЮЩИМ, НАЧИНАЮЩЕМ, НАЧИНАЮЩАЯ, НАЧИНАЮЩЕЙ, НАЧИНАЮЩУЮ, НАЧИНАЮЩЕЮ, НАЧИНАЮЩЕЕ, НАЧИНАЮЩИЕ, НАЧИНАЮЩИХ, НАЧИНАЮЩИМИ, НАЧИНАЮЩ, НАЧИНАЮЩА, НАЧИНАЮЩЕ, НАЧИНАЮЩИ, ПОНАЧИНАЮЩЕЕ, ПОНАЧИНАЮЩЕЙ
2 вариант разбора
Часть речи: Причастие
НАЧИНАЮЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАЧИНАТЬ»
| Слово | Морфологические признаки |
|---|---|
| НАЧИНАЮЩИЙ |
|
| НАЧИНАЮЩИЙ |
|
Все формы слова НАЧИНАЮЩИЙ
НАЧИНАТЬ, НАЧИНАЮ, НАЧИНАЕМ, НАЧИНАЕШЬ, НАЧИНАЕТЕ, НАЧИНАЕТ, НАЧИНАЮТ, НАЧИНАЛ, НАЧИНАЛА, НАЧИНАЛО, НАЧИНАЛИ, НАЧИНАЯ, НАЧИНАВ, НАЧИНАВШИ, НАЧИНАЙ, НАЧИНАЙТЕ, НАЧИНАЮЩИЙ, НАЧИНАЮЩЕГО, НАЧИНАЮЩЕМУ, НАЧИНАЮЩИМ, НАЧИНАЮЩЕМ, НАЧИНАЮЩАЯ, НАЧИНАЮЩЕЙ, НАЧИНАЮЩУЮ, НАЧИНАЮЩЕЮ, НАЧИНАЮЩЕЕ, НАЧИНАЮЩИЕ, НАЧИНАЮЩИХ, НАЧИНАЮЩИМИ, НАЧИНАВШИЙ, НАЧИНАВШЕГО, НАЧИНАВШЕМУ, НАЧИНАВШИМ, НАЧИНАВШЕМ, НАЧИНАВШАЯ, НАЧИНАВШЕЙ, НАЧИНАВШУЮ, НАЧИНАВШЕЮ, НАЧИНАВШЕЕ, НАЧИНАВШИЕ, НАЧИНАВШИХ, НАЧИНАВШИМИ, НАЧИНАЕМЫЙ, НАЧИНАЕМОГО, НАЧИНАЕМОМУ, НАЧИНАЕМЫМ, НАЧИНАЕМОМ, НАЧИНАЕМАЯ, НАЧИНАЕМОЙ, НАЧИНАЕМУЮ, НАЧИНАЕМОЮ, НАЧИНАЕМА, НАЧИНАЕМОЕ, НАЧИНАЕМО, НАЧИНАЕМЫЕ, НАЧИНАЕМЫХ, НАЧИНАЕМЫМИ, НАЧИНАЕМЫ
3 вариант разбора
Часть речи: Существительное
НАЧИНАЮЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАЧИНАЮЩИЙ»
| Слово | Морфологические признаки |
|---|---|
| НАЧИНАЮЩИЙ |
|
Все формы слова НАЧИНАЮЩИЙ
НАЧИНАЮЩИЙ, НАЧИНАЮЩЕГО, НАЧИНАЮЩЕМУ, НАЧИНАЮЩИМ, НАЧИНАЮЩЕМ, НАЧИНАЮЩИЕ, НАЧИНАЮЩИХ, НАЧИНАЮЩИМИ
Разбор слова по составу начинающий
| Основа слова | начинающ |
|---|---|
| Приставка | на |
| Корень | чин |
| Суффикс | а |
| Суффикс | ющ |
| Окончание | ий |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАЧИНАЮЩИЙ» в конкретном предложении или тексте, то лучше использовать морфологический разбор текста.
Найти синонимы к слову «начинающий»Примеры предложений со словом «начинающий»
1
невысокий, начинающий раздаваться в плечах подросток с уже по-мужицки широкими, крепкими ладонями держал лошадь под уздцы.
Вечный зов. Том 2, Анатолий Иванов, 1976г.2
Начинающий писатель еще не предчувствует в первой радости грядущих мучений.
3
Я ведь не могу не заметить, и юноша тоже заметит, и ребенок, начинающий мальчик, тоже заметит;
Подросток, Федор Достоевский, 1875г.4
5
Мосье Нестор, как начинающий поэт, вероятно, воспоет вас, мадемуазель, звучными стихами, и ему по праву принадлежит финал, апофеоз.
Гоголь-гимназист, Василий Авенариус, 1897г.Найти еще примеры предложений со словом НАЧИНАЮЩИЙ
Ребят помогите Отдыхая(морфологический разбор слова)-деепричастие) Замедлив(разбор слова по составу) Ей трудно было поспеть за стаей, и она летела одна, часто опускаясь на землю и отдыхая от полёта.(синтаксический разбор предложения) Заранее спасибо!)
Сильное впечатление, смешно смеяться, громко плакат, хорошо работать, мудро решение, умное слово, глубоко попал, признался сейчас, ушол в гости, сложно сказать.
Я очень люблю ходить в кино. Больше всего мне нравятся два жанра-ужасы и фантастика.Однажды я сходила на фильм»Бегущий в лабиринте».У меня было отличное настроение.Вот я уже в кинозале.Сначала погас свет,затем началась реклама,а потом начался фильм .Смотреть мне было очень интересно.Картина была о парнишке,который, чудесным образом, попал в неизвестное место. С этого и начались его приключения.Он хотел стать бегуном.В итоге он достиг своей цели.
Больше всего мне нравятся два жанра-ужасы и фантастика.Однажды я сходила на фильм»Бегущий в лабиринте».У меня было отличное настроение.Вот я уже в кинозале.Сначала погас свет,затем началась реклама,а потом начался фильм .Смотреть мне было очень интересно.Картина была о парнишке,который, чудесным образом, попал в неизвестное место. С этого и начались его приключения.Он хотел стать бегуном.В итоге он достиг своей цели.
Мне фильм понравился,теперь я жду его продолжения.
Существо его усугубляется, веселия множатся, и спокойствие упреждает нахмуренность грусти, распложая образы радости в зерцалах воображения.
Лошади меня мчат; извозчик мой затянул песню, по обыкновению заунывную.
Я его оставил в Петербурге, и он намерения не имел оттуда выехать так скоро.
Разум мой вострепетал от сея мысли, и сердце мое далеко ее от себя оттолкнуло.
Ямщик, по обыкновению своему, поскакал во всю лошадиную мочь, и в несколько минут я был уже за городом.
Но упражнения духовные не всегда нас от телесности отвлекают; и для сохранения боков моих пошел я пешком.
Не гоняясь, немало, не десять, не зная, неведомого, незнакомом, не желая, не господин, не сверкали, не ценишь.
Обрывок газеты ( управление), работника заповедника ( управление ), покосившиеся резьба ( согласование), третий день ( согласование), остался здесь ( примыкание), раздается вдали ( примыкание), побледнев от ужаса( управление), вашего друга ( согласование), пятеро друзей ( согласование).
Главные слова выделены.
Надеюсь, что все верно.
Удачи.
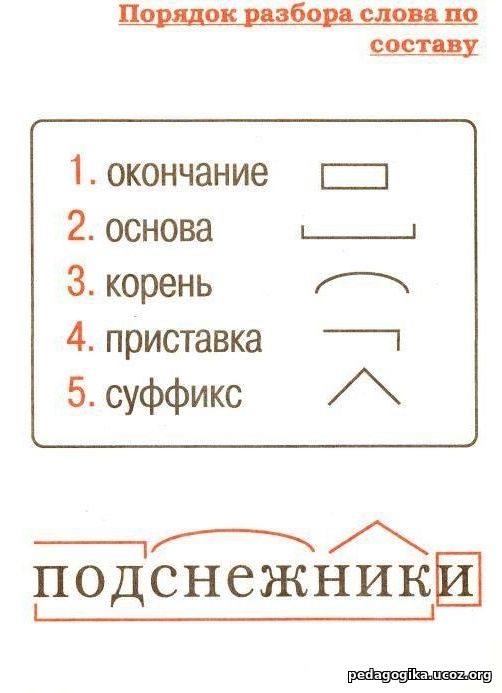
Разбор слова по составу — морфемный разбор, правила, примеры
Алгоритм разбора слова по составу
Алгоритм разбора слова по составу — пошаговая последовательность. Она помогает правильно выполнить работу. Используемый приём сравнения развивает логическое мышление.
Обязательная поэтапность разбора любого слова по составу:
- Выделение окончания
- Определение основы
- Подбор однокоренных слов, выделение корня.
- В последнюю очередь выделение приставок и суффиксов
Чтобы правильно, безошибочно выделить окончание, необходимо образовать другую словоформу. Сопоставить две формы одного и того же слова. Изменившаяся часть слова — окончание. Оставшаяся без изменения — основа.
Особенности определения окончания на примере разных частей речи
Разбор по составу существительного
Например, слово «пеналом». Образуя форму слова, изменяем падеж: «пеналу». Изменилась часть –ом. Значит, это окончание.
Образовывать форму слова необходимо, чтобы не ошибиться в трудных случаях: сравним слова «коров» и «столов». В первом слове окончание нулевое, а –ов — часть корня («корова»), во втором — -ов окончание.
Важно помнить о наречии «домой», где — ой — суффикс: у существительных 2 склонения («дом — 2 склонение») нет окончания –ой. Наречия не изменяются, значит, у него вообще нет окончания. Всё слово — основа.
Имя прилагательное
Слово «волшебными» поставим в форму женского рода единственного числа: «волшебная». Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Сравниваем формы слова, изменяется часть –ыми. Это окончание.
Чтобы правильно выделить корень в слове, обязательно требуется подбирать родственные слова. Важно помнить: приставки, а также суффиксы изменяют лексическое значение. Подбор однокоренных слов помогает без ошибок определить эти морфемы.
Примеры
Бесполезный — то, в чём нет никакой пользы
полезный
польза
Общая часть — корень — польз- . Приставка бес- стоит перед корнем, после него — суффикс –н.
Парашютист — человек, спускающийся с парашютом
парашют
Состав слова: корень, суффикс -ист и нулевое окончание.
Глагол «повторяете» настоящего времени. Попробуем изменить лицо: «повторяют». Вывод: окончание –ете.
«Заставили» — «заставила»: в первом глаголе окончание –и.
Примеры разбора слов по составу
Разбор слова Настенный
- Изменяем форму слова: настенная. Окончание –ый.
- Основа настенн-.
- Подбираем однокоренные слова: стена, пристенок. Находим корень: -стен-
- Сопоставляем все родственные слова: видим приставку на-, суффикс –н-.
- Доказываем наличие этих морфем в других словах: на-поль-н-ый, на-столь-н-ый.
Разбор слова Сползает
- Изменяем форму слова: сползают. Окончание –ет.
- Основа сполза-.
- Подбираем однокоренные слова: ползёт, заползал, ползание. Находим корень: -полз-
- Сопоставляем все однокоренные слова: видим приставку с-, суффикс –а-.
- Доказываем наличие этих морфем в других словах: с-бивают, с-пис-а-ть, прочит-а-ть.
Разбор слова Запевает
- Изменяем форму слова: запеваю. Окончание –ет.
- Основа запева-.
- Подбираем однокоренные слова: петь, пение, запевала. Находим корень: -пе-
- Сопоставляем все родственные слова: видим приставку за-, суффикс –ва-.
Разбор слова Повторяла
- Изменяем форму слова: повторяли.
 Окончание –а.
Окончание –а. - Основа повторя-.
- Подбираем однокоренные слова: вторить, второй. Находим корень: -втор-
- Сопоставляем все однокоренные слова: видим приставку по-, суффикс –я-.
 Окончание –а.
Окончание –а.Разбор слова Преподаватель
- Изменяем форму слова: преподавателю. Окончание нулевое.
- Основа преподаватель.
- Подбираем однокоренные слова: преподавать, подавать, давать (знания), дать. Находим корень: -да-.
- Сопоставляем все родственные слова: видим приставки пре-, по-, суффикс –ва-.
Разбор слова Вверху
- Это наречие. Неизменяемое слово. У неизменяемых слов вообще нет окончания.
- Основа всё слово вверху.
- Подбираем однокоренные слова: наверху, верховный, верх. Находим корень: -верх-.
- Сопоставляем все однокоренные слова: видим приставку в-, суффикс –у.
Разбор слова Разноцветный
- Изменяем форму слова: разноцветное. Окончание -ый.
- Основа разноцветн-.
- Подбираем однокоренные слова: разный, разница, различие, цветной, цвет. Находим два корня: разн-, -цвет-. Это сложное прилагательное.
- Сопоставляем все однокоренные слова: видим соединительную гласную –о-, суффикс –н-.
Изучение состава слова играет значительную роль при формировании орфографической зоркости.
Дети начинают понимать и запоминают: все части слова неизменны в написании и не зависят от произношения.
Трудные случаи при разборе слова по составу
Проводя анализ слов, школьники не всегда обращают внимание на лексическое значение разбираемого слова. Это часто приводит к ошибкам, особенно при выделении суффиксов.
- слова оканчиваются на -чик-, –щик-, -ист, -ушк.
В словах с такими суффиксами подбор однокоренных слов обязателен. (Мяч-ик — мяч, ключ-ик— ключ, рез-чик — резать, ящик, хрящ-ик — хрящ, камен-щик — камень; аист, лист; ушко, нес-ушк-а).
Анализируя состав слова «каменщик», находим существительное, от которого оно образовано: камень; «плащик» — это небольшой плащ. Соответственно видим в словах суффиксы –щик, -ик.
Соответственно видим в словах суффиксы –щик, -ик.
Необходимо обучить детей разграничению понятий «оканчивается на…» и «окончание». Слово «автобус» оканчивается на –бус (-ус, -с), но окончание нулевое.
Непонимание разницы в значениях приводит к частым ошибкам при морфемном анализе глаголов в неопределённой форме.
- элемент –ть (читать, считать)
в учебных пособиях разных авторов рассматриваются или как суффикс, или как окончание. В любом случае предшествующий гласный в эту часть слова не входит.
Рассмотрим –ть как окончание неопределённой формы. Слово «ускорять» оканчивается на –ять (это важно при определении спряжения глагола), здесь –я- — суффикс и окончание –ть. «Побороть» оканчивается на –оть: -о- — суффикс, окончание –ть.
Умение разбирать последовательно слово по составу приобретается при постоянной работе по алгоритму. Нарушение последовательности или игнорирование приводит к ошибкам. Внимание к слову — основа успеха.
тенденций в семантическом анализе — Часть 1 | пользователя Desh Raj | Исследования в области языка и обучения
Встраивание обучающих предложений с использованием глубоких нейронных моделей
Векторная семантика широко использовалась во всех задачах НЛП, особенно после того, как было обнаружено, что вложения слов (Word2Vec, GloVe) хорошо представляют отношения синонимии-антонимии в реальном пространстве.
Подобно встраиванию слов, мы можем попытаться получить плотные векторы для представления предложения, а затем найти способ получить из него формальное представление.Иван Титов (Эдинбургский университет) недавно предложил пару моделей, которые используют LSTM [1] и Graph CNN [2] для задачи SRL на основе зависимостей.
Сначала объясню задачу. Мы работаем с наборами данных, в которых предикаты отмечены в предложении, и цель состоит в том, чтобы идентифицировать и маркировать аргументы, соответствующие каждому предикату. Например, учитывая предложение « Мэри ест яблоко » и предикат, помеченный как EATS, нам нужно пометить слова «Мэри», «an» и «яблоко» как agent , NULL и theme. соответственно.Кроме того, поскольку одно предложение может содержать несколько предикатов, одно и то же слово может иметь разные метки для каждого предиката. По сути, если мы повторяем процесс один раз для каждого предиката, наша задача сводится к проблеме маркировки последовательностей.
Например, учитывая предложение « Мэри ест яблоко » и предикат, помеченный как EATS, нам нужно пометить слова «Мэри», «an» и «яблоко» как agent , NULL и theme. соответственно.Кроме того, поскольку одно предложение может содержать несколько предикатов, одно и то же слово может иметь разные метки для каждого предиката. По сути, если мы повторяем процесс один раз для каждого предиката, наша задача сводится к проблеме маркировки последовательностей.
Подход, основанный на LSTM [1]: LSTM (которые являются типом RNN, которые могут сохранять память) использовались для моделирования последовательностей с момента их появления. В первой модели маркировка последовательностей выполняется следующим образом.
- Векторы получаются из каждого слова путем объединения предварительно обученных вложений (Word2Vec), случайных вложений и случайно инициализированных вложений POS.
- Вектор слова также содержит 1-битовый флаг, чтобы отметить, является ли он предикатом в этом конкретном обучающем экземпляре. Это сделано для того, чтобы сеть обрабатывала каждый предикат по-разному.
- Они загружаются на уровень bi-LSTM для получения контекста слова в предложении.
- Наконец, чтобы пометить любое слово , , мы берем скалярное произведение его скрытого состояния на скрытое состояние предиката и получаем над ним классификатор softmax следующим образом.
- Кроме того, мы можем параметризовать матрицу весов на метке роли r как:
, где векторы в скалярном произведении соответствуют случайно инициализированным вложениям для леммы предиката и роли, соответственно.
Подход на основе GCN [2]: Во второй модели для представления дерева зависимостей для предложения использовались сверточные сети графа (GCN). В очень грубом смысле входной уровень GCN кодирует предложение в матрицу m X n на основе своего дерева зависимостей, так что каждый из n узлов дерева представлен как размерность m вектор. Как только такая матрица получена, мы можем выполнять свертки на ней.
Как только такая матрица получена, мы можем выполнять свертки на ней.
Тогда очевидно, что однослойный GCN может захватывать информацию только о своем непосредственном соседе.Сложив слои GCN, можно включить окрестности более высокой степени. (См. Диаграмму модели на рис. 3 в документе [2].)
GCN и LSTM дополняют друг друга. Почему? LSTM хорошо фиксируют долгосрочные зависимости, но не могут эффективно представлять синтаксис. С другой стороны, GCN строятся непосредственно поверх дерева синтаксических зависимостей, поэтому они хорошо фиксируют синтаксис, но из-за ограничения сверток фиксированного размера диапазон зависимостей ограничен.Следовательно, использование уровня GCN поверх скрытых состояний, полученных из уровня bi-LSTM, теоретически захватило бы лучшее из обоих миров. Эта гипотеза также была подтверждена экспериментальными результатами.
Модель кодера-декодера [3]: В этой статье задача расширяется до формального представления, а не SRL. Если мы рассматриваем формальное представление как другой язык, это похоже на проблему машинного перевода, поскольку как естественные, так и формальные представления означают одно и то же.Таким образом, было бы интересно применить модели, используемые для машинного перевода, к семантическому синтаксическому анализу. [3] делает именно это.
Кодер преобразует входную последовательность в векторное представление, а декодер получает целевую последовательность из этого вектора.
- Кодер использует уровень bi-LSTM, аналогичный предыдущим методам, для получения векторного представления входной последовательности.
- Окончательное скрытое состояние подается на уровень декодера, который снова является bi-LSTM. Скрытые состояния, полученные из этого уровня, используются для прогнозирования соответствующих выходных токенов с помощью функции softmax.
- В качестве альтернативы мы можем иметь иерархический декодер для учета иерархической структуры логических форм. Для этого мы просто вводим нетерминальный токен, скажем
, который указывает начало поддерева. Другие токены могут использоваться для представления начала / конца терминальной последовательности или нетерминальной последовательности. - Чтобы включить древовидную структуру, мы объединяем скрытое состояние родительского нетерминала с каждым дочерним элементом.
- Наконец, на этапе декодирования, чтобы лучше использовать релевантную информацию из входной последовательности, мы используем уровень внимания, где вектор контекста представляет собой взвешенную сумму по скрытым векторам в кодере.
 Для этого мы просто вводим нетерминальный токен, скажем
Для этого мы просто вводим нетерминальный токен, скажем Проектирование BASIC Parser для CALL на JSTOR
AbstractНаписание синтаксического анализатора для синтаксического представления ввода учащихся на BASIC оправдано ограниченным объемом требуемой грамматики и необходимостью интеграции с другими материалами CALL. BAP (BASIC parser) описывается с точки зрения обработки ввода, которая нормализует предложение; сопоставление слов, которое сопоставляет его с ключевыми структурными словами и с его собственным лексиконом; и синтаксический анализ структуры фразы, который исследует составную структуру и особенности подкатегории предложения.Описывается методика, основанная на анализе DCG в PROLOG, который пытается использовать слова предложения по одному по правилу; он проиллюстрирован упрощенными версиями правил разбора типа предложения и именной фразы, а также примерами тестов подкатегории для свойств лексических статей. Предполагается, что такой синтаксический анализатор может стать полезным компонентом во многих действиях CALL.
Информация о журнале Журнал CALICO, основанный в 1983 году, является официальным изданием Консорциума компьютерного обучения языкам (CALICO) и посвящен распространению информации о применении технологий в преподавании языков и изучении языков.Журнал публикуется только в Интернете, полностью реферируется и публикует исследовательские статьи и исследования, а также программное обеспечение и обзоры книг. Ежегодно выходит три выпуска, и обычно один из них представляет собой тематический выпуск, посвященный текущим дискуссиям и разработкам в области компьютерного обучения языкам. Международная редакционная коллегия CALICO и большая группа авторов и рецензентов отражают ее глобальную читательскую аудиторию.
Ежегодно выходит три выпуска, и обычно один из них представляет собой тематический выпуск, посвященный текущим дискуссиям и разработкам в области компьютерного обучения языкам. Международная редакционная коллегия CALICO и большая группа авторов и рецензентов отражают ее глобальную читательскую аудиторию.
Equinox Publishing Ltd., базирующаяся в Шеффилде (Великобритания), была основана в 2003 году и представляет собой независимую академическую прессу, активно публикующую книги и журналы по археологии, лингвистике, популярной музыке и религиоведению.
Следует ли использовать анализ резюме? Вот плюсы и минусы
Когда ваша компания публикует информацию о доступной вакансии, всегда приятно видеть, как множество потенциальных кандидатов проявляют интерес и подают заявки.
Также может быть ошеломляющим знать, что вам придется просеивать и читать каждое резюме и сопроводительное письмо, которое приходит. К счастью, вам не нужно тратить часы своего драгоценного времени, пытаясь найти приложение, которое подходит для работы описание.Вместо этого вы можете воспользоваться синтаксическим анализатором резюме.
Что такое разбор резюме?Синтаксический анализатор резюме — это программа или программное приложение, которое анализирует данные резюме или сопроводительного письма и преобразует их в структурированный формат, чтобы его можно было отсортировать и обработать, чтобы ускорить процесс собеседования и приема на работу.
Как рекрутер или специалист по персоналу, обычно используют программное обеспечение для анализа резюме, которое обычно является частью большинства систем отслеживания кандидатов (ATS), в качестве шага в процессе найма, чтобы создать более простой, удобный и эффективный опыт для всех. кандидаты.
Это не только позволит вам в электронном виде собирать, хранить и систематизировать всю информацию, содержащуюся в резюме и сопроводительных письмах, но и иметь возможность нанять нужного кандидата быстрее, чем без использования синтаксического анализатора.
Как работает возобновление синтаксического анализа?
Задача синтаксического анализатора резюме — находить и извлекать ключевые элементы резюме или сопроводительного письма, такие как имя кандидата, адрес электронной почты, контактная информация, его степень (и) и сертификаты, соответствующие навыки, текущее название компании и прошлое. рабочий стаж.
Некоторые элементы резюме или сопроводительного письма усложняют задачу. Если кандидат решит использовать мягкие цвета шрифта, причудливые гарнитуры или заголовки, созданные во внешних программах, таких как Photoshop, он может исказить то, как синтаксический анализатор резюме может читать текст.
Например, большие заголовки, необычный интервал между символами и неправильный выбор шрифта могут привести к тому, что синтаксический анализатор резюме прочитает мое имя, Мара Калвелло, например:
- Маракальвелло
- Mmaarraa Ccaallvveelloo
- Март Calvello
После того, как инструмент синтаксического анализа завершит работу с документом, вы сможете легко искать данные резюме по определенным ключевым словам или фразам благодаря достижениям в области машинного обучения.Используемая программа также может искать эти термины и работать, чтобы вывести соответствующие резюме и кандидатов в центр внимания при поиске подходящего кандидата.
Вы также можете настроить поля и формы для сбора конкретной информации, которая не всегда включается в традиционные резюме или сопроводительные письма, например о языках, общественных работах или рекомендациях.
250
— это среднее количество резюме, которое получит открытая вакансия.
Источник: Glassdoor
Типы парсеров резюме
Когда дело доходит до возобновления синтаксического анализа, есть три типа подходов, которые вы можете использовать, все с разным уровнем точности и функций.
Анализ на основе ключевых слов
Анализатор резюме на основе ключевых слов идентифицирует слова, шаблоны и фразы в тексте резюме или сопроводительного письма. Он будет использовать свой собственный алгоритм, чтобы найти текст вокруг этих слов, чтобы прочитать его правильно. Это самый простой, но наименее точный тип парсера.
Он будет использовать свой собственный алгоритм, чтобы найти текст вокруг этих слов, чтобы прочитать его правильно. Это самый простой, но наименее точный тип парсера.
С точки зрения точности, вероятно, у вас не будет более 70% точности, потому что он не может добавить дополнительную информацию или данные, не заключенные в определенное ключевое слово.Если вы имеете дело с неоднозначным ключевым словом, например «писатель», они могут неправильно угадать, как оно интерпретирует его.
Примером того, как работает синтаксический анализатор ключевых слов, может быть сканирование чего-то вроде почтового индекса и предположение, что окружающие слова являются адресом. Или он просканирует диапазон дат и предположит, что текст вокруг него — это временная шкала занятости.
Анализ на основе грамматики
При понимании контекста резюме или сопроводительного письма инструмент синтаксического анализа на основе грамматики будет использовать большое количество грамматических правил.Они будут комбинировать определенные слова и фразы вместе, чтобы сформировать сложные структуры, чтобы уловить точное значение каждого предложения в резюме или сопроводительном письме.
С помощью инструмента синтаксического анализа на основе грамматики можно достичь точности до 90%. Тем не менее, для правильного выполнения им требуется большое количество ручного кодирования, выполняемое квалифицированным языковым инженером. Как правило, они сложнее парсеров ключевых слов, но при этом могут улавливать более подробную информацию. Они также могут легко различать разные значения слов и фраз, чтобы лучше понять контекст резюме.
Статистический анализ
Статистический анализатор будет применять числовые модели текста для определения структуры резюме или сопроводительного письма. Подобно синтаксическому анализатору на основе грамматики, они работают, различая контексты одного и того же слова или фразы, как способ захвата определенных элементов, таких как адрес или временная шкала.
С точки зрения точности, они лучше, чем синтаксический анализатор ключевых слов, но не так точны, как синтаксический анализатор грамматики.
Преимущества использования анализа резюме
Независимо от того, являетесь ли вы рекрутером или менеджером по найму, анализируя резюме и сопроводительные письма, вы обнаружите, что это дает некоторые очевидные и очевидные преимущества.
- Экономит время: Выявление и систематизация приложений с соответствующими навыками и информацией и устранение тех, у которых нет, анализ резюме может сэкономить время менеджерам по найму, которые тратятся на ручное чтение каждого резюме и сопроводительного письма, которое попадает на их стол.
- Несколько форматов: Большинство синтаксических анализаторов принимают сопроводительные письма и резюме в различных формах, а это значит, что вам не нужно ничего отказываться. Большинство из них принимают документы в таких форматах, как PDF, TXT, DOC и DOCX.
- Разумный найм: Использование синтаксического анализатора резюме увеличивает вероятность поиска различных квалифицированных кандидатов, которые соответствуют описаниям вакансий в вашей компании. Из-за этого есть вероятность, что вы наймете кандидата, наиболее подходящего для этой должности, исходя из его уникального опыта кандидата.
- Интеграция с ATS: Поскольку большинство анализаторов резюме интегрированы с решениями Системы отслеживания кандидатов, вы сможете получить доступ ко всему, что вам нужно о кандидате в одном месте.
- Устранение предвзятости: Поскольку вы можете настроить синтаксический анализатор резюме так, чтобы он пропускал определенную информацию, вы можете устранить непреднамеренные предубеждения при просмотре резюме или сопроводительного письма. Например, вы можете отключить такие поля, как возраст, пол, название школы или университета, изображение кандидата или снимок в голову, а также дату их рождения.
- Синтаксический анализ социальных сетей: С усовершенствованием технологий синтаксические анализаторы резюме и программное обеспечение ATS могут также анализировать страницу кандидата в социальных сетях, например страницу LinkedIn, в удобный формат.

Проблемы использования анализа резюме
Даже при всех преимуществах использования синтаксического анализатора резюме во всех заявках о приеме на работу, которые ваша компания получает, есть некоторые недостатки, о которых вам также следует помнить.
- Различия в языках: Устный перевод может быть сложным, особенно если учесть, сколько разных способов написать одно и то же. Например, существует несколько способов указать диапазон дат или конкретную должность.Программное обеспечение, которое вы используете, должно понимать эти нюансы.
- Возможность пропустить кандидата: При использовании синтаксического анализатора резюме вы можете пропустить очень квалифицированного кандидата. Хотя у большинства соискателей будут отличные и хорошо написанные резюме и сопроводительные письма, некоторым может чего-то не хватать, и идеальный кандидат может провалиться.
- Стоимость: В зависимости от синтаксического анализатора резюме, который вы выберете, ваша компания может платить от 50 до 200 долларов в месяц.
- Возможное наполнение ключевыми словами: Анализаторы резюме иногда могут быть открыты для манипуляций со стороны определенных кандидатов, которые могут «играть в систему». Если бы кандидат наполнил свое резюме «правильными» ключевыми словами, он мог бы выглядеть более подходящим для этой работы.
Как выбрать парсер резюме
Если вы решили, что хотите использовать синтаксический анализатор резюме в своей компании, есть определенные характеристики и особенности, на которые следует обратить внимание при выборе.
Для начала убедитесь, что он может анализировать резюме и сопроводительные письма во всех популярных форматах, таких как HTML, DOC, DOCX и PDF, чтобы вы не пропустили информацию о потенциальном подходящем кандидате. Как и в случае с популярными форматами, в ваших интересах использовать синтаксический анализатор, поддерживающий синтаксический анализ на нескольких языках.
Как и в случае с популярными форматами, в ваших интересах использовать синтаксический анализатор, поддерживающий синтаксический анализ на нескольких языках.
Самые продвинутые парсеры резюме на рынке используют искусственный интеллект, глубокое обучение и машинное обучение для создания уникального алгоритма для улучшенного извлечения данных и более интеллектуальной идентификации этих данных для улучшения результатов поиска при просмотре приложений-кандидатов.
Как указывалось ранее, вы должны быть уверены, что ваше решение для синтаксического анализа резюме может легко интегрироваться с другими существующими программными приложениями в вашем техническом стеке, такими как ATS.
Это не только поможет рекрутерам и менеджерам по персоналу в одинаковой степени сократить время, затрачиваемое на чтение резюме и проверку потенциальных кандидатов, но также и хранение информации о заявках в одном едином месте. Затем будет создано резюме для каждого кандидата, что поможет вам оценить их навыки и посмотреть, соответствуют ли они описанию должности.
Доказательство в парсере
Нужный кандидат уже есть, и инструмент для анализа резюме поможет вам найти его быстрее. Независимо от того, какие данные анализируются или какой тип работы необходимо заполнить, чувство удовлетворения от поиска лучшего резюме и наиболее квалифицированного приложения не за горами.
Как только на первый взгляд идеальное резюме бросится в глаза, рассмотрите возможность проведения тестирования перед приемом на работу как части процесса собеседования.
Руководство для начинающих по Logstash Grok
Возможность эффективного анализа и запроса данных, отправляемых в стек ELK, зависит от читаемой информации. Это означает, что по мере поступления неструктурированных данных в систему их необходимо преобразовать в структурированные строки сообщений.
Эта неблагодарная, но критическая задача обычно предоставляется Logstash (хотя есть и другие поставщики журналов, см. Наше сравнение Fluentd и Logstash в качестве одного примера).Независимо от источника данных, который вы определяете, извлечение журналов и выполнение некоторых магических действий для их украшения необходимо для обеспечения их правильного анализа перед выводом в Elasticsearch.
Наше сравнение Fluentd и Logstash в качестве одного примера).Независимо от источника данных, который вы определяете, извлечение журналов и выполнение некоторых магических действий для их украшения необходимо для обеспечения их правильного анализа перед выводом в Elasticsearch.
Обработка данных в Logstash осуществляется с помощью плагинов фильтров. В этой статье основное внимание уделяется одному из самых популярных и полезных плагинов фильтров — фильтру Grok Logstash, который используется для преобразования неструктурированных данных в структурированные.
Что такое Grok?
Первоначальный термин на самом деле довольно новый — придуман Робертом А.Хайнлайн в своей книге 1961 года «Незнакомец в чужой стране» — это относится к пониманию чего-либо до уровня, на котором человек фактически погрузился в это. Это подходящее название для языка grok и плагина Logstash Grok, которые изменяют информацию в одном формате, а погружают ее в в другом (в частности, JSON). Уже существует пара сотен шаблонов Grok для журналов.
Хотите сравнить DIY ELK с управляемым ELK?
Как это работает?
Проще говоря, grok — это способ сопоставления строки с регулярным выражением, сопоставления определенных частей строки с выделенными полями и выполнения действий на основе этого сопоставления.
Встроено более 200 шаблонов Logstash для фильтрации таких элементов, как слова, числа и даты, в AWS, Bacula, Bro, Linux-Syslog и других. Если вы не можете найти нужный узор, вы можете написать свой собственный узор. Также есть варианты для нескольких шаблонов соответствия, что упрощает написание выражений для сбора данных журнала.
Вот основной формат синтаксиса для фильтра Grok Logstash:
% {SYNTAX: SEMANTIC} SYNTAX будет обозначать шаблон в тексте каждого журнала.SEMANTIC будет отличительной чертой, которую вы фактически укажете этому синтаксису в проанализированных журналах. Другими словами:
% {PATTERN: FieldName} Это будет соответствовать предопределенному шаблону и сопоставлять его с определенным идентифицирующим полем.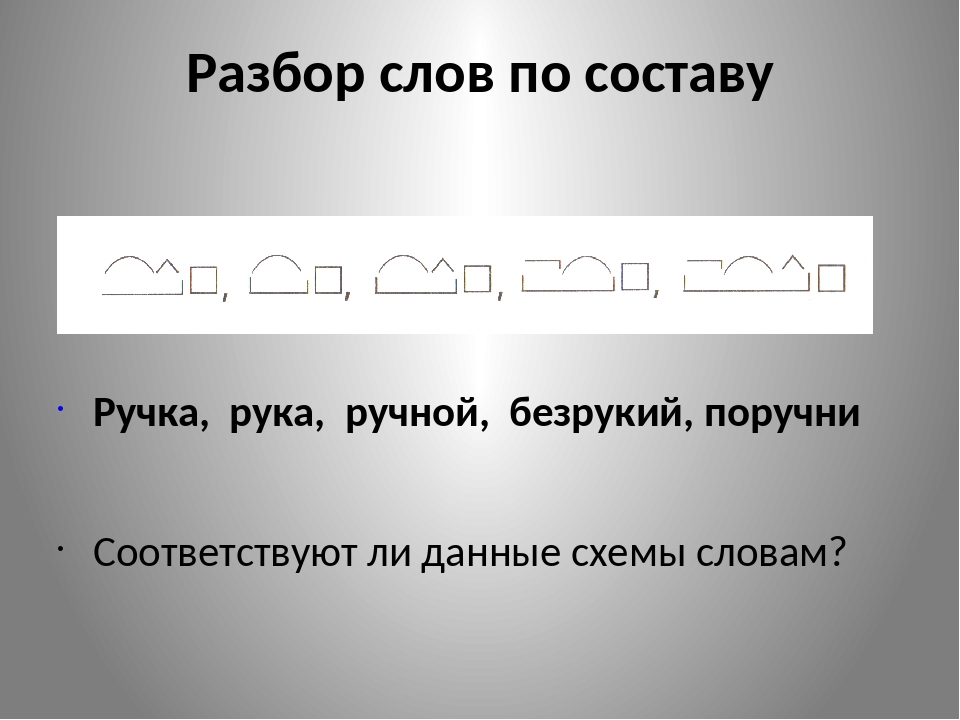
Например, шаблон 127.0.0.1 будет соответствовать шаблону Grok IP, обычно шаблону IPv4.
Grok имеет отдельные шаблоны IPv4 и IPv6, но их можно фильтровать вместе с синтаксисом IP.
Этот стандартный шаблон выглядит следующим образом:
IPV4 (?Притворяясь, что не существует унифицирующего синтаксиса IP, вы бы просто искали оба с одним и тем же именем семантического поля:
% {IPv4: Client IP}% {IPv6: Client IP}Снова используйте синтаксис IP, если по любой причине, по которой вы хотите разделить эти соответствующие адреса в отдельные поля.
Поскольку Grok по существу основан на комбинации регулярных выражений, вы также можете создать свой собственный фильтр Grok на основе регулярных выражений с помощью этого шаблона:
(?настраиваемый шаблон) Например:
(? d \ d- \ d \ d- \ d \ d)Этот шаблон grok будет соответствовать регулярному выражению 22-22-22 (или любой другой цифре) имени поля.
Примеры шаблонов Logstash Grok
Чтобы продемонстрировать, как начать работу с Grokking, я собираюсь использовать следующий журнал приложений:
2016-07-11T23: 56: 42.000 + 00: 00 INFO [MySecretApp.com.Transaction .Manager]: Начальная транзакция для сеанса -464410bf-37bf-475a-afc0-498e0199f008Цель, которую я хочу достичь с помощью фильтра grok, - разбить логлайн на следующие поля: отметка времени, уровень журнала, класс и затем остальная часть сообщения.
Следующий шаблон grok сделает работу:
grok { match => {"message" => "% {TIMESTAMP_ISO8601: timestamp}% {LOGLEVEL: log-level} \ [% {DATA: class} \]:% {GREEDYDATA: message}"} }#NOTE:
GREEDYDATA- это способ, которым Logstash Grok выражает регулярное выражение.Преобразование типа данных Grok
По умолчанию все записи
SEMANTICявляются строками, но вы можете изменить тип данных с помощью простой формулы. В следующем примере Logstash Grok любой синтаксисNUMBER, идентифицированный как семантическоеnum, преобразуется в семантическое число с плавающей запятой,float:% {NUMBER: num: float}Это довольно полезный инструмент, хотя в настоящее время он используется доступно только для преобразований в
_grokparsefailureс плавающей запятойили целые числаint.Это попытается сопоставить входящий журнал с заданным шаблоном grok. В случае совпадения журнал будет разбит на указанные поля в соответствии с определенными шаблонами grok в фильтре. В случае несоответствия Logstash добавит тег под названием
_grokparsefailure.Однако в нашем случае фильтр будет соответствовать и даст следующий результат:
{ "message" => "Начальная транзакция для сеанса -464410bf-37bf-475a-afc0-498e0199f008", "timestamp" => "2016-07-11T23: 56: 42.000 + 00: 00 ", "log-level" => "ИНФОРМАЦИЯ", "class" => "MySecretApp.com.Transaction.Manager" }Управление данными
На основе совпадения вы можете определить дополнительные конфигурации Grok Logstash для управления данными. Например, вы можете заставить Logstash 1) добавлять поля, 2) переопределять поля или 3) удалять поля.
grok { match => {"message" => "% {TIMESTAMP_ISO8601: timestamp}% {LOGLEVEL: log-level} \ [% {DATA: class} \]:% {GREEDYDATA: message}"} overwrite => [«сообщение»] add_tag => ["My_Secret_Tag"] }В нашем случае мы используем действие «перезаписать», чтобы перезаписать поле «сообщение».Таким образом, наше поле «сообщение» не будет отображаться с другими полями, которые мы определили (
метка времени,уровень журналаикласс).Полный список доступных действий, которые вы можете использовать для управления своими журналами, доступен здесь вместе с их типом ввода и значением по умолчанию.
Отладчик Grok
Отличный способ начать создавать фильтры Grok - это инструмент отладки Grok: https: // grokdebug.herokuapp.com/
Этот инструмент позволяет вставлять сообщение журнала и постепенно строить шаблон Grok, непрерывно тестируя компиляцию. Как правило, я рекомендую начать с шаблона
% {GREEDYDATA: message}и постепенно добавлять все новые и новые шаблоны по мере продвижения.В случае приведенного выше примера я бы начал с:
% {GREEDYDATA: message}Затем, чтобы убедиться, что первая часть работает, выполните:
% {TIMESTAMP_ISO8601: timestamp}% {GREEDYDATA : message}Общие примеры Grok в Logstash
Вот несколько примеров, которые помогут вам ознакомиться с тем, как построить Grok-фильтр:
Syslog
Анализ сообщений системного журнала с помощью Grok - одно из наиболее частых требований новых пользователей ,.Также существует несколько различных форматов журналов для системного журнала, поэтому не забывайте писать свои собственные шаблоны Grok. Вот один пример обычного синтаксического анализа системного журнала:
grok { match => {"message" => "% {SYSLOGTIMESTAMP: syslog_timestamp} % {SYSLOGHOST: syslog_hostname} % {DATA: syslog_program} (?: \ [% {POSINT: syslog_pid} \]) ?: % {GREEDYDATA: syslog_message} "} }Если вы используете
rsyslog, вы можете настроить последний для отправки журналов в Logstash.Журналы доступа Apache
grok { match => {"message" => "% {COMBINEDAPACHELOG}"} }Elasticsearch
grok { match => ["message", "\ [% {TIMESTAMP_ISO8601: timestamp} \] \ [% {DATA: loglevel}% {SPACE} \] \ [% {DATA: source}% {SPACE} \]% {SPACE } \ [% {DATA: node} \]% {SPACE} \ [% {DATA: index} \]% {NOTSPACE} \ [% {DATA: updated-type} \] ", "message", "\ [% {TIMESTAMP_ISO8601: timestamp} \] \ [% {DATA: loglevel}% {SPACE} \] \ [% {DATA: source}% {SPACE} \]% {SPACE} \ [% {DATA: node} \] (\ [% {NOTSPACE: Index} \] \ [% {NUMBER: shards} \])?% {GREEDYDATA} » ] }Redis
grok { match => ["redistimestamp", "\ [% {MONTHDAY}% {MONTH}% {TIME}]]", ["redislog", "\ [% {POSINT: pid} \]% {REDISTIMESTAMP: timestamp}"], ["redismonlog", "\ [% {NUMBER: timestamp} \ [% {INT: database}% {IP: client}:% {NUMBER: port} \]"% {WORD: command} "\ s?% { GREEDYDATA: params} "] ] }MongoDB
MONGO_LOG% {SYSLOGTIMESTAMP: timestamp} \ [% {WORD: component} \]% {GREEDYDATA: message} MONGO_QUERY \ {(? <= {).[0-9] +) msMONGO_WORDDASH \ b [\ w -] + \ bMONGO3_SEVERITY \ wMONGO3_COMPONENT% {WORD} | -MONGO3_LOG% {TIMESTAMP_ISO8601: timestamp}% {MONGO3_SEVERITY: severity}% {MONGO3_COMPONENT: context}% {SPACE} {?: } \])? % {GREEDYDATA: message} AWS
ELB_ACCESS_LOG% {TIMESTAMP_ISO8601: timestamp}% {NOTSPACE: elb}% {IP: clientip}:% {INT: clientport: int} (?: (% {IP: backendip}: ?:% {INT: backendport: int}) | -)% {NUMBER: request_processing_time: float}% {NUMBER: backend_processing_time: float}% {NUMBER: response_processing_time: float}% {INT: response: int}% {INT: backend_response: int}% {INT: Received_bytes: int}% {INT: bytes: int} "% {ELB_REQUEST_LINE}" CLOUDFRONT_ACCESS_LOG (?% {YEAR} -% {MONTHNUM} -% {MONTHDAY} \ t% {TIME}) \ t% {WORD: x_edge_location} \ t (?:% {NUMBER: sc_bytes: int} | - ) \ t% {IPORHOST: clientip} \ t% {WORD: cs_method} \ t% {HOSTNAME: cs_host} \ t% {NOTSPACE: cs_uri_stem} \ t% {NUMBER: sc_status: int} \ t% {GREEDYDATA: referrer } \ t% {GREEDYDATA: agent} \ t% {GREEDYDATA: cs_uri_query} \ t% {GREEDYDATA: cookies} \ t% {WORD: x_edge_result_type} \ t% {NOTSPACE: x_edge_request_id} \ t% {HOSTNAME: x_host_header} \ t% {HOSTNAME: x_host_header t% {URIPROTO: cs_protocol} \ t% {INT: cs_bytes: int} \ t% {GREEDYDATA: time_taken: float} \ t% {GREEDYDATA: x_forwarded_for} \ t% {GREEDYDATA: ssl_protocol} \ t% {GREEDYDATA: } \ t% {GREEDYDATA: x_edge_response_result_type} Подводя итог
Logstash Grok - это всего лишь один тип фильтра, который можно применить к вашим журналам перед их отправкой в Elasticsearch.Поскольку он играет такую важную роль в конвейере регистрации, Grok также является одним из наиболее часто используемых фильтров.
Вот список некоторых полезных ресурсов, которые могут помочь вам на пути к гроккингу:
Удачного грокинга!
Хотите сравнить DIY ELK с управляемым ELK?
Разъяснение лингвистического анализа - Приписать
Выяснить, что люди говорят на письменном языке, является сложной задачей. Существует огромное количество литературы, и множество программ пытается достичь этой цели.Суть в том, что мы все еще далеки от того, чтобы компьютеры действительно понимали человеческий язык. Тем не менее, компьютеры могут неплохо справляться с тем, что нам нужно: получением концепций и настроений из текста.
Термин лингвистический анализ охватывает большую территорию. Мы будем использовать его в узком смысле попытки компьютера извлечь значение из текста. Лингвистический анализ - это теория, лежащая в основе того, что делает компьютер. Мы говорим, что компьютер выполняет Обработка естественного языка (НЛП), когда он выполняет анализ, основанный на теории.Лингвистический анализ является основой текстовой аналитики.
Есть этапы лингвистического анализа, которые используются почти во всех попытках компьютера понять текст. Приятно знать некоторые из этих терминов.
Вот несколько общих шагов, которые часто выполняются в таком порядке:
 *
*  Кроме того, мы используем действие «add_tag» для добавления настраиваемого поля тега в журнал.
Кроме того, мы используем действие «add_tag» для добавления настраиваемого поля тега в журнал.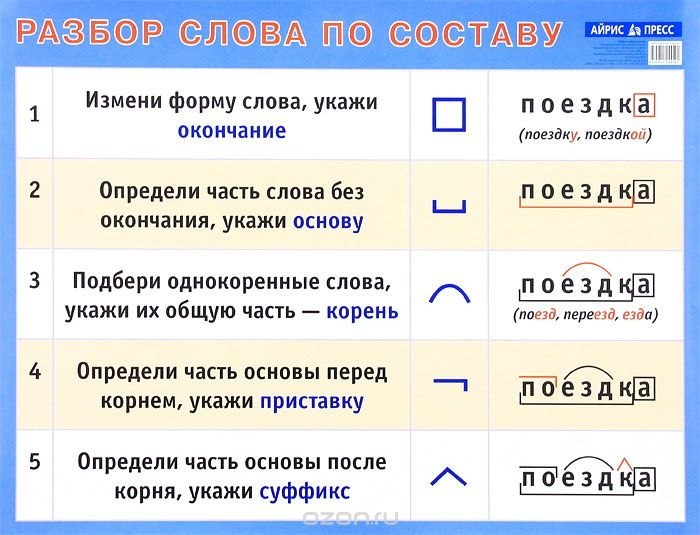 * (? =} ntoreturn :) \} MONGO_SLOWQUERY% {WORD}% {MONGO_WORDDASH: database} \.% {MONGO_WORDDASH: collection}% {WORD}:% {MONGO_QUERY: query}% {WORD}:% {NONNEGINT: ntoreturn }% {WORD}:% {NONNEGINT: ntoskip}% {WORD}:% {NONNEGINT: nscanned}. * Nreturned:% {NONNEGINT: nreturned} .. + (?
* (? =} ntoreturn :) \} MONGO_SLOWQUERY% {WORD}% {MONGO_WORDDASH: database} \.% {MONGO_WORDDASH: collection}% {WORD}:% {MONGO_QUERY: query}% {WORD}:% {NONNEGINT: ntoreturn }% {WORD}:% {NONNEGINT: ntoskip}% {WORD}:% {NONNEGINT: nscanned}. * Nreturned:% {NONNEGINT: nreturned} .. + (? 
- Обнаружение предложений
Здесь компьютер пытается найти предложения в тексте. Многие инструменты лингвистического анализа ограничиваются анализом одного предложения за раз, независимо от других предложений в тексте.Это делает проблему более решаемой для компьютера, но создает проблемы. Джон был моим техником по обслуживанию. Он проделал супер работу. Рассматривая само по себе второе предложение, компьютер может определить, что работа вызывает сильные положительные эмоции. Но если компьютер рассматривает только одно предложение за раз, он не поймет, что это Джон выполнил суперзадачу. - Токенизация
Здесь компьютер разбивает предложение на слова. Опять же, есть много способов сделать это, каждый со своими сильными и слабыми сторонами.Здесь очень важно качество текста. Я действительно сошел с ума, когда техник сказал мне * ваши шины спущены * черт возьми, я знал это. Здесь много проблем с компьютером. Люди видят gotmad и сразу понимают, что там должно было быть место. Компьютеры не очень хороши в этом. Простые токенизаторы просто берут последовательные символы «слова» и отбрасывают все остальное. Здесь это нормально с * спущено → чертовски спущено , но при этом будет удалена информация о том, что * ваши шины спущены * - это цитата, а не часть окружающего предложения.Когда качество текста низкое, такие вещи действительно могут сбить компьютер с толку. - Лемматизация и очистка
Большинство языков допускают использование нескольких форм одного и того же слова, особенно с глаголами. Итак, в английском языке was, is, are, были - все формы глагола должны быть . Лемма - это основная форма слова. Лемма для всех этих слов: - . Существует связанный метод под названием , выделение корня , который пытается найти основную часть слова, например пони → пони .При лемматизации обычно используются таблицы поиска, тогда как при выделении корней обычно используется некоторый алгоритм для таких вещей, как отбрасывание притяжательных и множественных чисел. Лемматизация обычно предпочтительнее стемминга.
Некоторый лингвистический анализ пытается «очистить» токены. Компьютер может попытаться исправить распространенные орфографические ошибки или преобразовать смайлы в соответствующие слова. - Пометка части речи
Когда у нас есть токены (слова), мы можем попытаться вычислить часть речи для каждого из них, например существительное, глагол, прилагательное .Простые таблицы поиска позволяют компьютеру начать с этого, но на самом деле это гораздо более сложная работа, чем эта. Многие слова в английском языке могут быть как существительными, так и глаголами (и другими частями речи). Чтобы понять это правильно, слова нельзя просто рассматривать по одному. Ошибки в части тегов речи часто приводят к досадным ошибкам со стороны компьютера.
 Опять же, есть много способов сделать это, каждый со своими сильными и слабыми сторонами.Здесь очень важно качество текста. Я действительно сошел с ума, когда техник сказал мне * ваши шины спущены * черт возьми, я знал это. Здесь много проблем с компьютером. Люди видят gotmad и сразу понимают, что там должно было быть место. Компьютеры не очень хороши в этом. Простые токенизаторы просто берут последовательные символы «слова» и отбрасывают все остальное. Здесь это нормально с * спущено → чертовски спущено , но при этом будет удалена информация о том, что * ваши шины спущены * - это цитата, а не часть окружающего предложения.Когда качество текста низкое, такие вещи действительно могут сбить компьютер с толку.
Опять же, есть много способов сделать это, каждый со своими сильными и слабыми сторонами.Здесь очень важно качество текста. Я действительно сошел с ума, когда техник сказал мне * ваши шины спущены * черт возьми, я знал это. Здесь много проблем с компьютером. Люди видят gotmad и сразу понимают, что там должно было быть место. Компьютеры не очень хороши в этом. Простые токенизаторы просто берут последовательные символы «слова» и отбрасывают все остальное. Здесь это нормально с * спущено → чертовски спущено , но при этом будет удалена информация о том, что * ваши шины спущены * - это цитата, а не часть окружающего предложения.Когда качество текста низкое, такие вещи действительно могут сбить компьютер с толку. Чтобы понять это правильно, слова нельзя просто рассматривать по одному. Ошибки в части тегов речи часто приводят к досадным ошибкам со стороны компьютера.
Чтобы понять это правильно, слова нельзя просто рассматривать по одному. Ошибки в части тегов речи часто приводят к досадным ошибкам со стороны компьютера.Большинство инструментов лингвистического анализа выполняют указанные выше шаги, прежде чем приступить к работе по выяснению того, что означают токенизированные предложения .На этом этапе различные подходы к лингвистическому анализу расходятся. Мы кратко опишем три наиболее распространенных метода.
Разбор предложений
Ноам Хомски - ключевая фигура в лингвистической теории. Он задумал идею «универсальной грамматики», способа построения речи, который так или иначе понимается всеми людьми и используется во всех культурах. Это наводит на мысль, что если вы сможете выяснить правила, компьютер сможет это сделать и, таким образом, понять человеческую речь и текст.Подход к лингвистическому анализу, основанный на анализе предложений, уходит корнями в эту идею.
Анализатор берет предложение и превращает его во что-то вроде диаграмм предложений, которые вы, вероятно, делали в начальной школе:
Внизу у нас есть жетоны, а над ними классификации, которые группируют жетоны. V = глагол, PP = предложная фраза, S = предложение и т. Д.
После того, как предложение проанализировано, компьютер может делать такие вещи, как выдавать нам все словосочетания с существительными.Таким образом, синтаксический анализ предложений хорошо помогает находить концепции. Но синтаксические анализаторы ожидают, что правильно построенные предложения будут работать. Они плохо справляются с работой при низком качестве текста. Они также плохо разбираются в сантиментах.
Bitext - это пример коммерческого инструмента, использующего синтаксический анализ предложений. Более низкоуровневые инструменты включают Apache OpenNLP , Stanford CoreNLP и GATE .
Анализ на основе правил
Лингвистический анализ на основе правил использует более прагматический подход. При подходе, основанном на правилах, основное внимание уделяется просто достижению желаемых результатов, не пытаясь по-настоящему понять человеческий язык. Анализ на основе правил всегда фокусируется на единственной цели, например, на извлечении концепций. Мы пишем набор правил, которые выполняют извлечение концептов и ничего больше. Сравните это с подходом синтаксического анализа, при котором анализируемое предложение может одинаково хорошо давать концепции (существительные и словосочетания) или сущности (имена собственные).
При подходе, основанном на правилах, основное внимание уделяется просто достижению желаемых результатов, не пытаясь по-настоящему понять человеческий язык. Анализ на основе правил всегда фокусируется на единственной цели, например, на извлечении концепций. Мы пишем набор правил, которые выполняют извлечение концептов и ничего больше. Сравните это с подходом синтаксического анализа, при котором анализируемое предложение может одинаково хорошо давать концепции (существительные и словосочетания) или сущности (имена собственные).
Лингвистический анализ на основе правил обычно имеет сопутствующий компьютерный язык, используемый для написания правил.Это может быть дополнено возможностью использовать язык программирования общего назначения для определенных частей анализа. Платформа GATE предоставляет возможность использовать настраиваемые правила с помощью инструмента, который она называет ANNIE, вместе с языком программирования Java.
Анализ на основе правил также использует списки слов, называемые географическими справочниками . Это списки существительных, глаголов и так далее. Географический справочник также предоставляет что-то вроде лемматизации. Следовательно, справочник глаголов может сгруппировать все формы глагола как под глаголом быть .Но географический справочник может использовать более прямой подход. Для анализа настроений в географическом справочнике может быть запись ужасный с подпунктами ужасный, ужасный, противный. Следовательно, географический справочник может выполнять как лемматизацию, так и группировку синонимов.
Механизмы текстовой аналитики, предлагаемые SAP, основаны на правилах. Они используют язык правил под названием CGUL (Custom Grouper User Language). SAP говорит, что этого языка (выделено мной):
Custom Grouper User Language (CGUL) - это язык на основе предложений, который позволяет выполнять сопоставление с образцом с использованием регулярных выражений на основе символов или токенов в сочетании с лингвистическими атрибутами для определения типов настраиваемых сущностей. Работа с CGUL может быть очень сложной .
Работа с CGUL может быть очень сложной .
Вот пример того, как выглядит правило на языке CGUL:
#subgroup VerbClause: {
(
[CC]
(% (Существительные) *% (NonBeVerbs) +)
| ([OD VB]% (NonBeVerbs) + |% (BeVerbs) [/ OD])
| ([OD VB]% (BeVerbs) + |% (NonBeVerbs) + [/ OD])
[/ CC]
)
| ([OD VB]% (NonBeVerbs) [/ OD])
}
В своей основе CGUL использует регулярные выражения и географические справочники для формирования все более сложных группировок слов.Конечным результатом правил являются готовые группы, например, концепции.
Многие инструменты, основанные на правилах, ожидают, что пользователь свободно владеет языком правил. Предоставление пользователю доступа к языку правил дает пользователю возможность создавать индивидуализированные анализы за счет обучения и разработки правил.
Глубокое обучение и нейронные сети
Третий подход, который мы обсудим, - это машинное обучение. Основная идея машинного обучения состоит в том, чтобы дать компьютеру несколько примеров того, что вы хотите, чтобы он делал, и позволить ему выяснить правила того, как это делать.Эта основная идея существует уже давно и претерпела несколько эволюций. Текущая горячая тема - нейронные сети . Этот подход к машинному обучению естественного языка во многом основан на том, как работает наш мозг. IBM широко рекламирует это с помощью своей технологии Watson. Вы помните, что Ватсон победил лучших игроков в игре Jeopardy. На этом примере мы можем получить представление о технике машинного обучения.
Идея глубокого обучения состоит в том, чтобы строить нейронные сети в несколько слоев, каждый из которых работает над все более широкими частями проблемы.Глубокое обучение - еще одно модное слово, которое часто применяется за пределами области, предназначенной лингвистическими исследователями.
Мы не будем вдаваться в подробности этих методов, а сосредоточимся на их фундаментальных требованиях.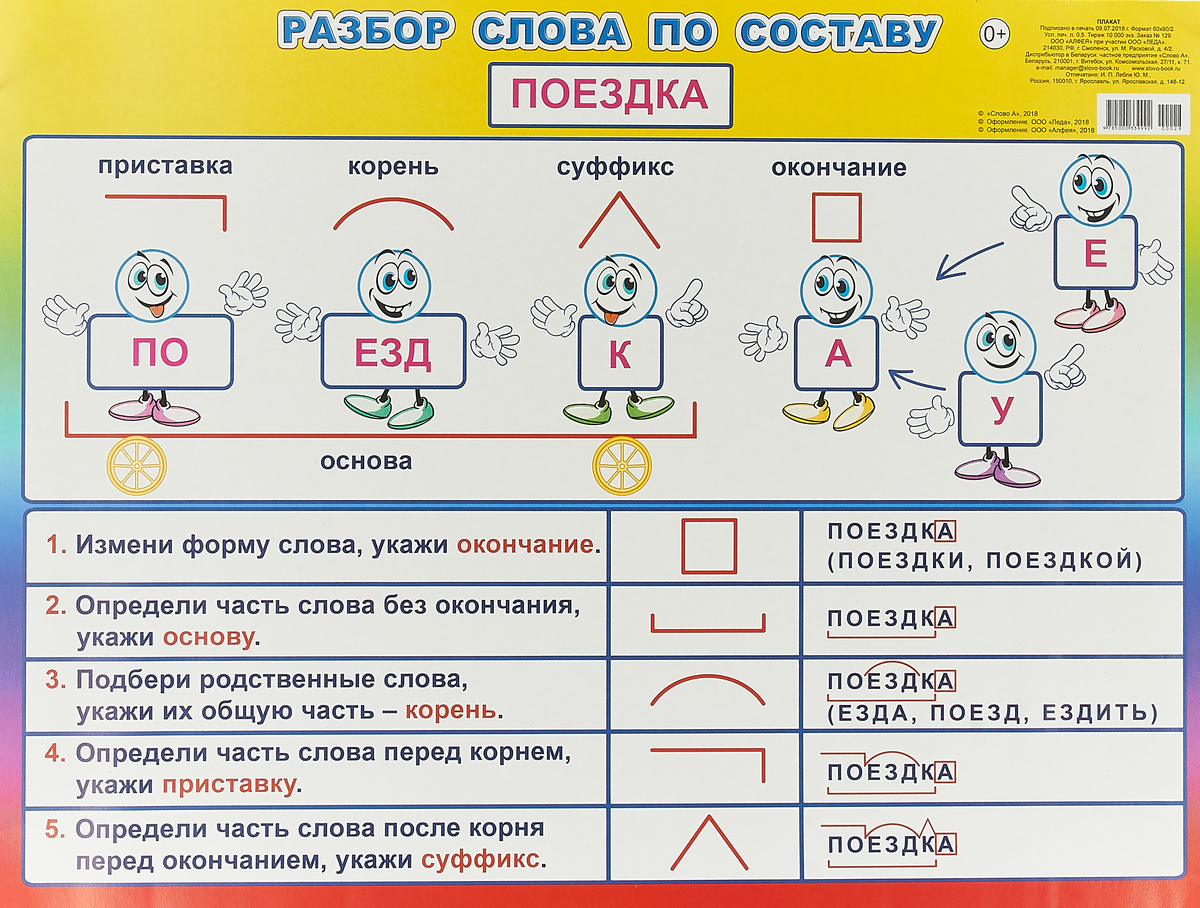 Для работы машинному обучению нужны примеры. Примеров много. Одна из областей, в которой машинное обучение преуспело, - это распознавание изображений. Возможно, вы использовали камеру, которая может находить лица на снимке, который вы делаете. Нетрудно понять, как машинное обучение могло это сделать.Дайте компьютеру много тысяч изображений и скажите ему, где находятся лица. Затем он может выяснить правила поиска лиц. Это действительно хорошо работает.
Для работы машинному обучению нужны примеры. Примеров много. Одна из областей, в которой машинное обучение преуспело, - это распознавание изображений. Возможно, вы использовали камеру, которая может находить лица на снимке, который вы делаете. Нетрудно понять, как машинное обучение могло это сделать.Дайте компьютеру много тысяч изображений и скажите ему, где находятся лица. Затем он может выяснить правила поиска лиц. Это действительно хорошо работает.
Назад к Ватсону. В Jeopardy он отлично поработал. Вы понимаете почему? Игра отлично настроена для машинного обучения. Сначала компьютеру дается ответ. Задача компьютера - вернуть правильный вопрос (в Jeopardy вам дается ответ, и вы должны ответить правильным вопросом). Поскольку в Jeopardy играют уже много лет, у компьютера есть то, с чем он должен работать: масса примеров, настроенных так, как нужно компьютеру.
А что, если мы хотим использовать глубокое обучение для анализа настроений? Где взять примеры? Это не так легко. Люди пытались создать наборы данных, чтобы помочь машинам изучать такие вещи, как сантименты, но на сегодняшний день результаты неутешительны. В проекте Stanford CoreNLP есть инструмент анализа настроений, использующий машинное обучение, но он не пользуется заслуженной популярностью. Сегодня машинное обучение может дать отличные результаты для извлечения концепций, но менее впечатляющие - для анализа настроений.
Сводка
Лингвистический анализ - сложная и быстро развивающаяся наука. Было разработано несколько подходов к лингвистическому анализу, каждый из которых имеет свои сильные и слабые стороны. Для получения наилучших результатов вам следует выбрать подход, обеспечивающий превосходную производительность для нужного вам типа анализа. Например, вы можете выбрать подход машинного обучения для определения тем, подход, основанный на правилах, для анализа тональности и подход синтаксического анализа предложений для определения частей речи и их взаимосвязей.
7 стратегий, которые сделают чтение на иностранном языке самым легким из тех, что вы когда-либо выучили
Если вы читаете это, поздравляем!
Английский - один из самых сложных языков для чтения. От слова к слову одни и те же звуки в английском языке часто пишутся по-разному или одни и те же варианты написания произносятся по-разному. Исследования показали, что англоговорящим детям требуется более чем в два раза больше времени, чтобы научиться читать, чем детям, говорящим на большинстве других европейских языков.
От слова к слову одни и те же звуки в английском языке часто пишутся по-разному или одни и те же варианты написания произносятся по-разному. Исследования показали, что англоговорящим детям требуется более чем в два раза больше времени, чтобы научиться читать, чем детям, говорящим на большинстве других европейских языков.
Но вы читаете эту статью не потому, что хотите насладиться славой умения читать по-английски; вы хотите научиться читать на совершенно другом языке!
Хорошая новость в том, что читать на любом интересующем вас иностранном языке, вероятно, легче, чем читать на английском. Еще лучшая новость заключается в том, что чтение на иностранном языке может быть самым легким, что вы когда-либо выучили. При правильных стратегиях это будет гораздо естественнее, чем усвоение всего этого словарного запаса или оттачивание навыков восприятия на слух.
При правильной технике изучение языка обычно может быть увлекательным, но это еще более верно для обучения чтению на иностранном языке: в основном все, что вам нужно сделать, это читать все, что вы хотите, и вы станете лучше читать.
Конечно, есть несколько приемов, которые вы хотите использовать на этом пути, чтобы сделать ваше «чтение, что вы хотите» максимально эффективным, действенным и безболезненным. Они здесь.
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно.Щелкните здесь, чтобы получить копию. (Скачать)
1. Перенесите свои навыки чтения с родного языка
Если вы умеете читать на одном языке, вы можете читать их все - вроде того. Исследования (подобные этому) показали, что навыки чтения в определенной степени передаются с одного языка на другой.
Другими словами, обучение чтению на иностранном языке частично сводится к тому, чтобы научиться читать на своем родном языке, научиться говорить на иностранном языке, а затем соединить их вместе. Однако загвоздка в том, что ваши навыки чтения начинают серьезно передаваться только после того, как вы достигнете базового уровня владения новым языком.
Однако загвоздка в том, что ваши навыки чтения начинают серьезно передаваться только после того, как вы достигнете базового уровня владения новым языком.
Следовательно, обратная нагрузка на вашу работу по чтению - лучший способ. На ранних этапах изучения языка сосредоточьтесь на знакомстве с языком, расширении словарного запаса и понимании грамматики.
Как только вы усвоите основы, начните более интенсивно практиковаться в чтении. С твердым знанием основ языка и мышцами чтения, уже настроенными за всю жизнь, когда вы терпели письменный английский, вы обнаружите, что не так уж сложно сложить два и два.
2. Разделите время между целенаправленным чтением и расслабленным чтением
Вы можете подумать, что самый быстрый способ научиться читать на иностранном языке - это всегда выбирать самые сложные тексты, которые вы можете найти, и разбирать их со словарем. Однако оказывается, что одним из наиболее важных факторов того, насколько хорошо вы учитесь читать, является просто то, сколько вы читаете. А если вы всегда стараетесь на 110%, у вас не хватит выносливости, чтобы прожорливо жрать книги, чтобы отточить свои навыки чтения.
Обучение чтению на иностранном языке, безусловно, является задачей, к которой применяется золотое правило изучения языка: лень - мать всех эффективных стратегий изучения языка. Если вы слишком много работаете, вы просто не сможете пройти через весь язык .
Итак, уловка состоит в том, чтобы разделить ваше время между интенсивным чтением, скрежещущим зубами и схватившимся за словарь, которое раздвигает пределы ваших способностей, и видом воскресного полуденного бездельничанья. кресло-наслаждаясь-чтением-книгой, которое позволяет вам проводить часы чтения на иностранном языке, хорошо проводя время.
Для целенаправленного чтения выберите материал, который доставит вам хороший вызов, и найдите время, чтобы распутать части, которые вы не понимаете. Для расслабленного чтения главное - читать как можно больше, поэтому выбирайте тексты, которые легче понять и которые посвящены интересующим вас темам.
Для расслабленного чтения главное - читать как можно больше, поэтому выбирайте тексты, которые легче понять и которые посвящены интересующим вас темам.
Вы можете делать и то, и другое на FluentU небольшими порциями благодаря аутентичным видео на разных уровнях сложности.
FluentU берет реальные видео - например, музыкальные видеоклипы, трейлеры к фильмам, новости и вдохновляющие выступления - и превращает их в индивидуальные уроки изучения языка.
С FluentU вы слышите языков в реальном контексте - так, как их на самом деле используют носители языка. Просто беглый взгляд даст вам представление о разнообразии предлагаемых на FluentU видеороликов:
FluentU действительно избавляет от тяжелой работы по изучению языков, оставляя вам только увлекательных, эффективных и результативных занятий. Он уже вручную отобрал для вас лучшие видео и сгруппировал их по уровням и темам. Все, что вам нужно сделать, это выбрать любое видео, которое вам понравится, чтобы начать работу!
Каждое слово в интерактивных субтитрах сопровождается определением, звуком, изображением, примерами предложений и т. Д.
Получите доступ к полной интерактивной расшифровке каждого видео на вкладке Dialogue и легко просматривайте слова и фразы из видео в Vocab.
Вы можете использовать уникальные адаптивные тесты FluentU , чтобы выучить словарный запас и фразы из видео с помощью забавных вопросов и упражнений. Просто проведите пальцем влево или вправо, чтобы увидеть больше примеров изучаемого слова.
Программа даже отслеживает то, что вы изучаете, и сообщает вам, когда именно пришло время для проверки, давая вам 100% персонализированный опыт.
Начните использовать веб-сайт FluentU на своем компьютере или планшете или, что еще лучше, загрузите приложение FluentU из магазина iTunes или магазина Google Play.
Возможно, вы захотите заранее спланировать, как вы собираетесь разделить свое время между целенаправленным чтением и расслабленным чтением. Например, вы можете расслабиться, прочитав в 80% случаев несерьезное чтение, а затем полностью освоить язык, владея карточками и не боясь их использовать, с экземпляром книги «Война». и мир »в остальных 20% случаев.
3. Выполните групповое чтение
Чтение - это весело, но иногда бывает одиноко. В конце концов, недавнее исследование показало, что библиотекари в два раза чаще, чем люди с любым другим занятием, указывают надувные куклы в натуральную величину в качестве своих основных контактных лиц в экстренных случаях. (Шучу.)
Проведение групповых чтений - отличный способ сделать закрытие лица книгой социальным занятием. Просто соберите группу единомышленников (или, по крайней мере, изучающих язык на одном языке) и по очереди читайте вслух, пока все следят за письменным текстом.
Групповое чтение дает два больших преимущества. Во-первых, когда вы слышите, как кто-то читает слова, и в то же время визуально следите за ними, вы связываете вашу слуховую память о том, как слова звучат, с вашим визуальным впечатлением от того, как они выглядят на странице. Во-вторых, вы можете делать паузу примерно каждые несколько страниц и делать групповое резюме или обсуждение (на языке, который вы изучаете!), Охватывая то, что вы прочитали до сих пор.
Если вы хотите подчеркнуть дискуссионную часть вещей, другой вариант этой стратегии - создать книжный клуб.И если вы не знаете, что кто-то изучает ваш язык, не позволяйте этому удерживать вас от создания группы для чтения - наступила эпоха Интернета! Поищите в социальных сетях и местах, где изучающие язык собираются в Интернете, и велика вероятность, что вы найдете людей, заинтересованных в реальной или виртуальной группе чтения.
4. Перечитать заново
Я уже говорил о разделении вашего времени между целенаправленным чтением и расслабленным чтением, но остается вопрос: что именно вы, , делаете , когда делаете сосредоточенное чтение?
Одна из моих любимых стратегий анализа текстов, которые расширяют границы моего понимания прочитанного, - это повторное перечитывание, которое включает в себя четырехкратное чтение текста, каждый раз концентрируясь на разных вещах.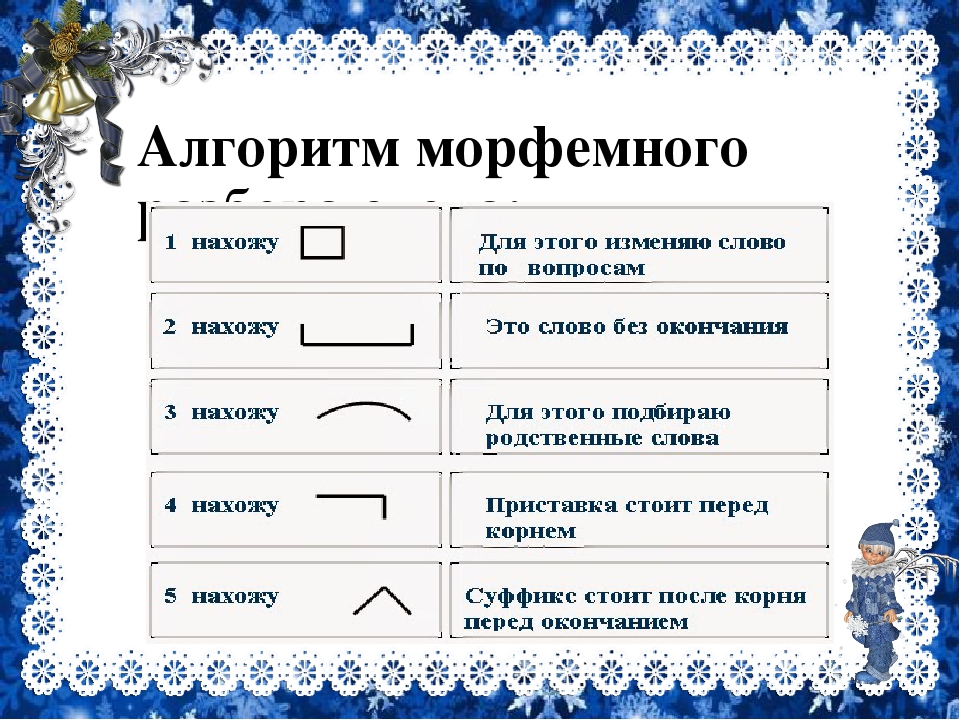 Основная идея состоит в том, чтобы начать чтение с общей картины, затем перейти к деталям, а затем вернуться к общей картине. Вот как это происходит:
Основная идея состоит в том, чтобы начать чтение с общей картины, затем перейти к деталям, а затем вернуться к общей картине. Вот как это происходит:
Раунд 1: понять суть отрывка
При первом проходе прочтите суть. Просто получите представление о том, о чем идет речь, и общее представление о том, что происходит. Не зацикливайтесь на незнакомых словах. Однако, в зависимости от того, насколько непрозрачен отрывок, вам, возможно, придется искать слова здесь и там, даже чтобы понять общее значение.
Раунд 2. Просмотрите более подробно, найдите слова, которых вы не знаете
Второй этап - это раунд «достань-ящик с инструментами и разнеси это на части». Это когда вы, –, хотите зацикливаться на деталях, просматривая все слова, которые вы не знаете, и убедитесь, что понимаете, как работает грамматическая структура текста. Это когда вы разбиваете вещь на части и выясняете, как каждая из этих частей работает.
Раунд 3. Соберите все новые детали, которые вы понимаете
После разбивки отрывка на детали, теперь вы хотите собрать эти детали вместе в единое целое.Этот отрывок из текста предназначен для обобщения всего, что вы узнали на втором шаге о том, что означают отдельные слова и как грамматика сочетается друг с другом.
Вы можете думать об этом этапе как о прочтении сути, как на первом шаге, с одновременным включением всей новой информации из второго шага. Вы хотите читать достаточно быстро, чтобы увидеть весь отрывок с высоты птичьего полета, но у вас должно быть достаточно времени, чтобы интегрировать большую часть новых знаний, которые вы получили на втором шаге.
Раунд 4: Подведите итоги, стремясь к скорости
В четвертом и последнем прогоне текста скорость - это название игры.Теперь, когда вы разбили текст и собрали его снова, идея состоит в том, чтобы как можно быстрее понять смысл. Постарайтесь подтолкнуть себя к этому, как с точки зрения удержания того, что вы узнали на шаге 2, так и с точки зрения прохождения отрывка быстрее, чем вы думали, что могли.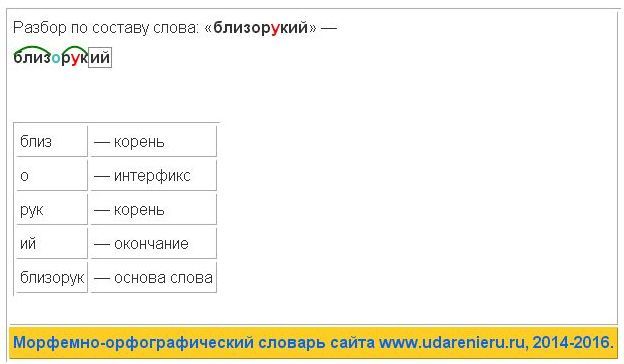
5. Прочтите вслух
При работе над чтением полезно помнить, что чтение на самом деле является лишь продолжением разговорной речи и слушания. Этот факт является ключом к тому, чтобы сделать чтение самым простым занятием при изучении иностранного языка.
Один из способов воспользоваться связью между устным и письменным языком - это действительно говорить и слушать, пока вы читаете. Просто говорите вслух то, что читаете, во время чтения. Когда вы установите связь между слушанием, чтением и речью, все три станут лучше.
6. Делайте «менее медленное» чтение
Если вы хотите держать себя в тонусе и заставить свой мозг быстрее разбирать слова, которые вы читаете, попробуйте несколько заданий по чтению.Скорочтение не обязательно должно быть вашей целью, просто читать медленнее, чем вы привыкли, и устанавливать новые личные рекорды - самое важное.
Вы можете выполнять чтение по времени, установив таймер во время чтения, чтобы вы могли видеть, сколько времени вам нужно, чтобы прочитать заданный текст и вычислить скорость чтения в словах в минуту, или предоставив себе заранее определенное количество времени. завершить отрывок.
Помимо того, что ваш мозг заставляет ваш мозг обрабатывать текст, который вы смотрите, немного быстрее, «менее медленное» чтение добавит немного волнения в вашу практику чтения, что никогда не является плохой идеей, поскольку скука - это смерть от изучения языка.
7. Использование контекста
Context - лучший учитель языка, который у вас когда-либо был. Подумайте об этом: вы выучили свой родной язык исключительно из контекста.
Когда вы читаете, всегда старайтесь максимально использовать контекст. Всякий раз, когда вы находите незнакомое слово, заставьте себя угадывать его значение, прежде чем обращаться к словарю, а затем посмотрите его, чтобы убедиться, что вы правы.
На самом деле это хороший совет для всех аспектов изучения языка, но он особенно важен для упражнений на чтение, когда вы можете инстинктивно тянуться к словарю снова и снова. Заставляя себя угадывать что-то из контекста, изучение языка превращается в своего рода головоломку, и у вас будет более сильная память на слова, которые вы можете правильно угадать из контекста, чем те, которые вам нужно ввести в Google Translate, чтобы понять.
Заставляя себя угадывать что-то из контекста, изучение языка превращается в своего рода головоломку, и у вас будет более сильная память на слова, которые вы можете правильно угадать из контекста, чем те, которые вам нужно ввести в Google Translate, чтобы понять.
Может показаться пугающим столкновение со стеной текста на языке, который вы еще слабо понимаете, но если вы воспользуетесь такими стратегиями, как передача навыков разговорной речи на иностранном языке и навыков чтения на родном языке, уравновешивание расслабленного и сосредоточенного чтения, создание группы чтения , читая вслух, перечитывая заново и пользуясь контекстом, вы увидите, что чтение на иностранном языке - это навык, который, естественно, со временем становится лучше, если вы ему позволите.
И если вы когда-нибудь почувствуете разочарование, просто помните - вы уже научились читать по-английски, вы можете делать все, что угодно!
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно. Щелкните здесь, чтобы получить копию. (Скачать)
Если вам понравился этот пост, что-то подсказывает мне, что вам понравится FluentU, лучший способ изучать языки с помощью реальных видео.
Зарегистрируйтесь бесплатно!
Машинное обучение и анализ текста
Язык - это логическая структура, с которой, в теории, машина должна легко работать. Насколько сложно на самом деле обучить систему анализа текста ML? Давай узнаем сегодня.
Что такое анализ текста в машинном обучении?
Анализ текста - это процесс получения ценных идей из текстов.
ML может работать с различными типами текстовой информации, такой как сообщения в социальных сетях, сообщения и электронные письма.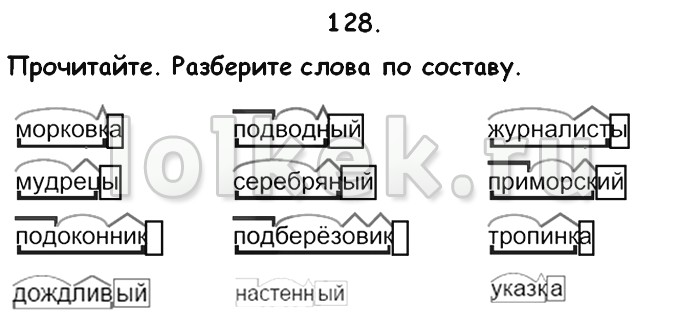 Специальное программное обеспечение помогает предварительно обрабатывать и анализировать эти данные.
Специальное программное обеспечение помогает предварительно обрабатывать и анализировать эти данные.
Анализ текста против интеллектуального анализа текста против анализа текста
Анализ текста и интеллектуальный анализ текста - синонимы. Они описывают один и тот же процесс извлечения смысла из данных путем наблюдения закономерностей.
Однако анализ текста и анализ текста - это немного разные вещи:
- Анализ текста работает с концепциями, смыслом текста. Анализ текста позволяет ответить на следующие вопросы: положительный или отрицательный отзыв? Какая основная тема текста?
- Текстовая аналитика изучает закономерности.Результаты могут быть показаны на графиках, схемах и таблицах. Если вы хотите оценить процент положительных отзывов клиентов, вам понадобится текстовая аналитика.
В этом посте мы поговорим о методах анализа текста ML и сценариях использования.
Почему важен интеллектуальный анализ текста?
Каждый фрагмент контента можно проанализировать на более глубоком уровне, чтобы лучше понять автора или тему текста. Внедряя анализ текста ML, мы можем предоставить пользователям более качественные услуги:
- предоставят ответы на часто задаваемые вопросы;
- перевести на разные языки;
- отслеживает отношение общества к продуктам и услугам;
- упрощает работу с документами за счет кластеризации и классификации документов.
Компании становятся более эффективными в общении со своими клиентами: изучая отзывы клиентов, компания может узнать общественное мнение о своих продуктах. Алгоритмы машинного обучения могут автоматически классифицировать заявки в службу поддержки или обзоры по теме или языку, на котором они написаны.
ML делает текстовый анализ намного быстрее и эффективнее, чем ручная обработка текстов. Это позволяет снизить трудозатраты и ускорить обработку текстов без ущерба для качества.
Как работает анализ текста машинного обучения?
Что вам нужно для создания инструмента анализа текста? Давайте рассмотрим это шаг за шагом.
Соберите данные. Решите, какую информацию вы будете изучать и как вы будете ее собирать. Эти образцы будут использоваться для обучения и тестирования вашей модели. Есть два основных типа источников информации. Если вы заходите на такие ресурсы, как форумы или газеты, то вы собираете внешних данных . Внутренние данные - это то, что каждый человек или компания генерирует каждый день: электронные письма, отчеты, чаты и т. Д.Как внутренние, так и внешние ресурсы могут быть полезны для интеллектуального анализа текста.
Подготовьте данные. Необходимо подготовить или предварительно обработать неструктурированные данные. Иначе программа этого не поймет. В нашем блоге мы уже рассказывали о разных стратегиях предварительной обработки данных.
Примените алгоритм машинного обучения для анализа текста. Вы можете написать свой алгоритм с нуля или использовать библиотеку. Обратите внимание на NLTK, TextBlob и CoreNLP Стэнфорда, если вы ищете что-то легкодоступное для изучения и исследования.
Это методы, используемые для анализа текста ML:
Токенизация
Каждый токен - это значимая единица. Слова и знаки препинания являются токенами, а пробелы - нет. Пример: этот пост посвящен анализу текста. = [«Это», «сообщение», «является», «о», «текст», «анализ», «.»]
Тегирование части речи
Когда вы назначаете грамматическую категорию каждому токену, это тегирование части речи.
Пример: это сообщение об анализе текста.= [«This»: ADJ, «post»: СУЩЕСТВИТЕЛЬНОЕ, «is»: ГЛАГОЛ, «about»: PREP, «text»: NOUN, «analysis»: СУЩЕСТВЕННОЕ, «.»: PUNCT]
Лемматизация
Помещение возвращение слова к его словарной форме (лемма) выполняется для обработки естественного языка. Вы сопоставляете все возможные формы слова с одним «корневым» глаголом, и машина все равно его поймет. «Бытие», «было», «было» согласно лемме «быть».
Вы сопоставляете все возможные формы слова с одним «корневым» глаголом, и машина все равно его поймет. «Бытие», «было», «было» согласно лемме «быть».
Stemming
Удалив аффиксы из слова, вы получите основу, «чистую» форму слова. Google использует стемминг для индексации запросов.Вместо того, чтобы хранить все формы слова, лексикон сокращен до основы. Процесс становится намного быстрее, но менее точен, чем лемматизация. Например, основа или «покупка» - это просто «покупка».
Синтаксический анализ
Существует два вида синтаксического анализа: зависимости и группы интересов. Вы проводите синтаксический анализ, когда хотите понять грамматическую структуру предложения.
Во время синтаксического анализа группы , вы разбиваете текст на подфразы, также называемые составляющими.Это помогает представить структуру предложения. Недостаток: это контекстно-свободная грамматика. В предложении вроде «Посещать родственников может быть скучно» алгоритм не сможет понять двусмысленное значение. Однако это хорошо для проверки грамматики. Например, Grammarly сложно разобрать грамматически неправильное предложение, но, благодаря синтаксическому анализу избирателей, он использует модели того, как должно выглядеть предложение, чтобы найти правильное решение.
Анализ зависимостей идентифицирует основные слова в предложении и находит связанные слова, которые изменяют их значение.Синтаксические отношения помогают понять, что означает предложение, особенно в синтетических языках, таких как славянские языки. Анализ зависимостей также применяется для проверки грамматики и обработки текста, поскольку он может анализировать произвольный порядок слов и фрагментированные предложения.
Для демонстрации мы использовали систему НЛП Аллена, которая автоматически определяет взаимосвязь между словами с помощью нейронной сети, обученной на большом наборе данных текстов.
Методы интеллектуального анализа текста
Теперь давайте рассмотрим некоторые подходы, которые позволяют вам работать с текстовыми данными.
Анализ частоты слов
Этот метод позволяет измерить, как часто слова появляются в тексте.
Именно так люди могут определять тему текста и проводить анализ настроений. Мы знаем, что слово «интересно» обычно относится к положительным впечатлениям. Так что если вы видите это слово в обзоре, значит, клиент доволен. Однако этот метод нечувствителен к сарказму, который может повлиять на общие результаты вашего анализа.
Анализ словосочетания
Два, три или более слов, которые часто используются вместе в речи, называются словосочетаниями. Одно и то же слово в разных словосочетаниях может иметь разные значения. Слово «свободный» означает «освобожденный», как «свободный дух». «Бесплатно» также может означать «бесплатно». Слово «бесплатно» гораздо чаще появляется на веб-сайте интернет-магазина вместе со словом «доставка», чем с словом «дух» или даже отдельно. Учет словосочетаний делает семантический анализ более точным.
Анализ соответствия
Соответствие - это таблица, в которой отображаются разные значения одного и того же слова в разных контекстах. Вот пример из контекстного словаря, показывающий, как разные люди используют слово «согласованность»:
Контекстные словари хороши для изучающих язык, потому что они содержат примеры из реальной жизни, показывающие разные способы использования одного и того же слова. Они так же хороши для систем машинного перевода и генерации речи.
Анализ соответствия и словосочетания полезен для устранения неоднозначности значений ключевых слов.
Используя эти базовые методы, вы можете перейти к более сложным типам анализа текста машинного обучения.
Классификация текста
Алгоритмы машинного обучения обнаруживают различные шаблоны в данных и разбивают текст на кластеры. Поговорим подробнее о типовых задачах классификации текстов.
Анализ настроений
Анализ настроений, или анализ мнений, выявляет и изучает эмоции в тексте.
Эмоции автора важны для понимания текстов. SA позволяет классифицировать полярность мнения о новом продукте или оценить репутацию бренда. Его также можно применять к обзорам, опросам, сообщениям в социальных сетях. Плюс SA в том, что он может эффективно анализировать даже саркастические комментарии.
SA позволяет классифицировать полярность мнения о новом продукте или оценить репутацию бренда. Его также можно применять к обзорам, опросам, сообщениям в социальных сетях. Плюс SA в том, что он может эффективно анализировать даже саркастические комментарии.
Тематический анализ
Тематическое моделирование классифицирует тексты по темам и может облегчить жизнь людей во многих областях. Без него невозможно было бы найти книги в библиотеке, товары в магазине, тикеты в службу поддержки в CRM. Текстовые классификаторы могут быть адаптированы к вашим потребностям.
Теги контента
Студенты и преподаватели, юристы, ученые и лаборанты - все могут извлечь выгоду из использования технологии классификации текста. Поскольку они ежедневно имеют дело с огромными объемами неструктурированных данных, тегирование и классификация текстов по категориям значительно облегчит им жизнь.
С помощью анализа текста можно извлечь ключевые слова, цены, характеристики и другую важную информацию. Маркетолог может провести анализ конкурентов и узнать все об их ценах и специальных предложениях всего за несколько кликов.
Методы, которые помогают идентифицировать ключевые слова и измерять их частоту, полезны для обобщения содержания текстов, поиска ответа на вопрос, индексации данных и создания облаков слов.
Признание сущности
Сущности - это люди, компании или места, упомянутые в тексте. Это может быть полезно при машинном переводе, чтобы программа не переводила фамилии или названия брендов. Более того, признание сущности необходимо для анализа рынка и анализа конкурентов в бизнесе.
Практическое применение анализа текста ML
Каковы практические применения методов анализа текста ML? Мы постарались назвать самые распространенные.
Обработка естественного языка
NLP - это то, что помогает машинам понимать человеческий язык и действовать в соответствии с запросами. Системы NLP используются для чат-ботов, умных помощников и систем безопасности с распознаванием голоса.
Мониторинг социальных сетей
Насколько люди любят ваш бренд? Twitter, Facebook и Instagram - это места, где пользователи делятся своими впечатлениями, оставляют хорошие и плохие отзывы о местах, которые они посетили, и о продуктах, которые они пробовали.Вы можете увидеть, как ваша компания воспринимается в целом, или сосредоточиться на конкретном продукте.
Служба поддержки клиентов
Доверие рутинной работы к ML означает, что сотрудники могут сосредоточиться на задачах, требующих человеческого внимания. Анализ текста машинного обучения помогает маркировать заявки, определять проблему и назначать ее нужному человеку. На основе ключевых слов системы машинного обучения могут определять приоритеты запросов.
Бизнес-аналитика
В BI предпочтение отдается числам. Они отлично подходят для понимания тенденций и статистики.Однако цифры не могут объяснить причины происходящего. Алгоритмы машинного обучения, которые анализируют текстовые данные, могут предоставить ценную информацию, анализируя как внутренние, так и внешние данные.
Продажи и маркетинг
Проанализируйте профили клиентов и конкурентов, проанализировав их данные, и получите более подробное представление о ситуации на рынке. Основываясь на этих данных, вы можете составить более персонализированные предложения по продаже. Анализ текста ML используется для анализа и написания электронных писем, чтобы помочь отделу продаж эффективно общаться с клиентами.
SEO
Инструменты SEO полагаются на машинное обучение при анализе контента на веб-страницах. Если вы хотите, чтобы ваш сайт занимал высокие позиции в результатах поиска, вам следует оптимизировать его для поисковой системы. Вы можете определить темы, о которых пишут другие люди в ваших областях, используя парсеры ключевых слов, и сделать ваш контент более полезным для целевой аудитории.
Если вы хотите, чтобы ваш сайт занимал высокие позиции в результатах поиска, вам следует оптимизировать его для поисковой системы. Вы можете определить темы, о которых пишут другие люди в ваших областях, используя парсеры ключевых слов, и сделать ваш контент более полезным для целевой аудитории.
Программное обеспечение для инвалидов
Анализ текста ML помогает дать голос людям с дефектами речи. Используя технологию преобразования текста в речь, системы машинного обучения озвучивают вводимый текст.Можно сгенерировать оригинальный и уникальный голос для каждого пользователя на основе его собственного голоса (если применимо). Это программное обеспечение позволяет людям с ограниченными возможностями общаться с другими людьми и использовать голосовые интерфейсы.
Робототехника
Роботам необходимо понимать человеческую речь и общаться с ними, что было бы невозможно без анализа текста машинного обучения. Более того, методы анализа настроений позволяют им немного лучше понимать человеческие эмоции и действовать соответственно.Роботы, обученные с использованием моделей анализа текста машинного обучения, могут читать и понимать тексты, то же самое и с данными.
Проблемы анализа текста машинного обучения
Согласно недавнему исследованию, около 80% всех данных, генерируемых на предприятиях, имеют форму текстов. Из этого можно сделать много выводов.
Но текстовый анализ ML также сопряжен с некоторыми проблемами:
- Сложность. Преобразование текста в формат, который может обрабатывать компьютер, требует нескольких шагов.Например, если мы решаем задачу классификации текста, нам необходимо собрать данные, обнаружить в них ключевые слова, определить количество классов, сгруппировать данные по этим классам и описать эти процессы в математических терминах. Это сложно как в интеллектуальном плане, так и с точки зрения человеческих / денежных / временных ресурсов.
- Концептуальная борьба.
