Раздаточный материал «Разбор слов по составу»
Морфемный разбор слова
(по составу)
1. Времена, перевязь, глазной, гнёздышко, глоток, горный, давний, далёкий, подарок, денёк, детёныш, длинный, дождливый, вздох, дочурка, дровишки, дроздовый, еловый, жарища, желток.
2. Зелёный, зеркальный, позолота, ловец, замазка, игривый, игрушка, качка, козлёнок, конина, котёнок, красивый, лесник, крикливый, кровинка, ледник, летучий, ловушка, овчина, парник, перина, мировая, низина, новизна, носишко.
3. Ночник, выпечка, плечистый, плясун, пчелиный, пятнашки, робкий, садовый, свинина, свисток, божок, бочар, больной, силач, синева, ходули, подсказка, скворушка, снежинка, хитрый, травинка, тропинка, сосновый, соринка.
4. Столовая,
теплица, тростник, похвала, храбрец, хлопушка, часовой, чернота, читка, богиня,
боковой, бодрый, болячка, большой, бодрый, верхушка, веснушки, ветвистый,
вечерок, винтовой, водяной, волевой, водный, глотка, детки, заварка.
5. Вековой, дождевик, закладка, жаркое, желтуха, зеркальщик, золотистый, пляска, почтовый, пятнистый, свинья, тепло, тростинка, травяной, выхлоп, глазёнки, дочка, дроздёнок, желтоватый, катушка, качели, медовый, козлиный.
6. Загадка, запах, парное, восход, бессмыслица, вывоз, довесок, закат, изгиб, наплечник, надпись, обрезок, отзыв, перелесок, побег, безволосый, зарубежный, наземный, надводный, подбородок, красота, испарение.
7. Безвкусица, вылет, вытяжка, поход, заокеанский, настольный, договор, догрузка, запись, наушник, роспись, придорожный, развесёлый, надстройка, осмотр, перегородка, подзеркальник, пригород, прожилка, бестолковый.
Морфемный разбор слова
(по составу)
8. Пододеяльник,
перечница, березняк, золотко, колечко, огрызок, замочек, гордость, доброта,
матушка, звёздочка, крикун, газетчик, барабанщик, пустыня, брёвнышко, дырявый,
вдумчивый, градусник, спутник, ведёрко, дворовый.
9. Вестник, известняк, бабушка, хвастун, бодрость, чистота, дружок, переписчик, глазастый, бородатый, кудрявый, графиня, воробышек, гнёздышко, миленький, плохонький, красивый, братский, белить, голодать, угощает, вредный, голубиный.
10. Болотистый, вязкий, ленивый, скалистый, бережливый, нижний,
солёный, вырезной, хвастливый, душевный, высокий, обедают, завязать, доходчивый, земляк, обезвредить, дуплянка, пустяк, рыбак, коровник, резак, малинник, солить.
11. Мельница, гористый, крепкий, улов, правдивый, добренький, голосистый, орлиный, аленький, комариный, бегун, драчливый, ближний, дарёный, плясун, шумливый, хлопотливый, виновный, защитник, рассадник, быстрота, список.
12. Хлебушко, болтун, волюшка, стрелок,
работница, выдумщик, спутница, влетел, близость, подлечить, погладим, вбежать,
выбелить, оковать, изрезать, морюшко, колокольчик, беготня, хрипота, голосок,
полюшко, грузчик, парочка, заползти.
13. Ворчун, косточка, счётчик, молодняк, задачник, дубняк, шутник, предсказал, притащил, привязывают, просидишь, разгрузишь, продумаешь, прошипят, протекает, моряк, заползти, червяк, кивнуть, свистнуть, рогатый, крикнуть.
Морфемный разбор слова
(по составу)
14. Колючий, детский, широкий, колышек, пёрышко, монахиня, сигнальщик, игрок, деревянный, кожаный, оловянный, полотняный, клыкастый, пятнышко, косматый, горластый, стеклышко, хвостатый, донышко, гладкий, фальшивый, усатый.
15. Гордыня, чубатый, работник, цветник, ванночка, стаканчик, помощник, гусиный, ветвистый, гулкий, баловница, волнистый, журавлиный, короткий, смолистый, пугливый, липкий, стыдливый, ястребиный, дождливый.
16.
Болтливый, звонкий, громкий, в горных, говорливый, скользкий, серебристый,
ноский, совестливый, сухонький, на водном, сонливый, жилистый, талантливый,
трескотня, торопливый, визготня, мускулистый, счастливый, землистый.
17. Слезливый, вдовушка, дремота, вечерний, мороженый, плачевный, трусливый, верхний, весеннее, дальняя, зимнего, крайнюю, тоскливого, спорные, декабрьская, разрезная, покупные, с гневными, прихлопывают, гусак, скрипач, музыкант.
18. Поварёшка, бородач, сухарь, резец, семечко, братец, билетёр, словарь, арестант, рубец, лифтёр, рыбёшка, шахтёр, вратарь, морозец, силач, гусёныш, холодец, боксёр, времечко, глупец, темечко, дикарь, мордашка, букварь.
19. Контролёр, гонец, кавказец, жареного, услужливая, развесной, раненый, щекотливую, учёное, сушёный, подводный, почасовая, взлетает, горец, взбегают, подземная, оговориться, ослышаться, предобрым, старец, сибиряк, гречанка.
Морфемный разбор слова
(по составу)
20.
Синяк, озеленить, обвязывают, накипело, насахарить, наигрывает, пришкольный,
излучает, залепить, отбросить, насвистывать, отужинаю, добудиться, доверять,
весна, вершина, извиняет, подбодрить, опериться, свиной, припекает.
21. Выпарить, выпрямить, вырезать, гадаю, засоряешь, черника, устареть, овчарня, связываю, угостить, угадываем, дохнуть, зеваю, искоренить, абрикосовый, авторский, глубокий, окунёвый, голодную, преградить, повизгиваешь, бродячий.
22. Горючий, ползучий, берёзовый, продуктовый, далёкий, кипучий, стукнуть, дубовый, лежачий, трескучий, июньский, геройский, свинцовый, капитанский, шипучий, флотский, пассажирский, чистка, задумчивый.
23. Усидчивому, устойчивую, шагнуть, хлопнуть, очистить, скользить, блекнуть, добреть, зябнуть, запугать, крепнуть, канавка, мокнуть, рассыпчатый, прыгнуть, волосинка, пушинку, пылинкой, о братишке, с сынишкой, голосишко.
24. Белизна, царапина, старина, баранина, новизна, впадина, у баяниста, с журналистом, о связисте, изгибина, ножка, арбузище, бородища, задвижка, грузин, пепелище, орлица, изюмина, волчица, прибежище, толщина, варка, распутица.
25.
Домишко, горошина, вещица, кожица, пожарище, сестрица, осетрина, воришка,
желтизна, домина, выскочка, москвич, морщина, головка, соринка, дорожка, пскович,
ручища, в городишке, лепёшка, бревенчатый, местечко, зверёныш, голосище,
горчинка, кройка, кислинка.
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н. , Ожегов С.И., Рацибурская Л.В.
, Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
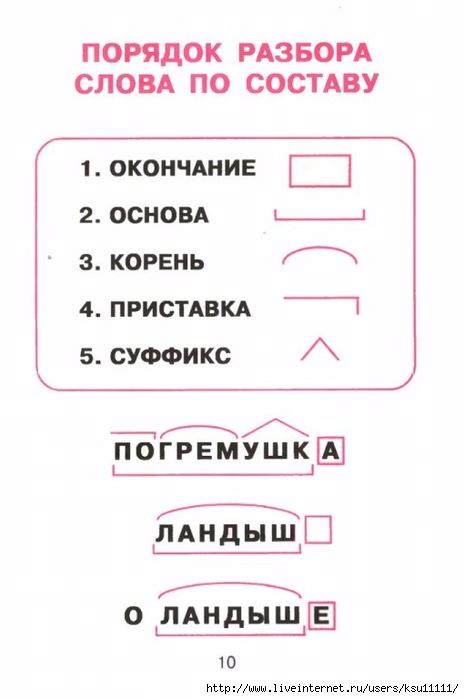
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться.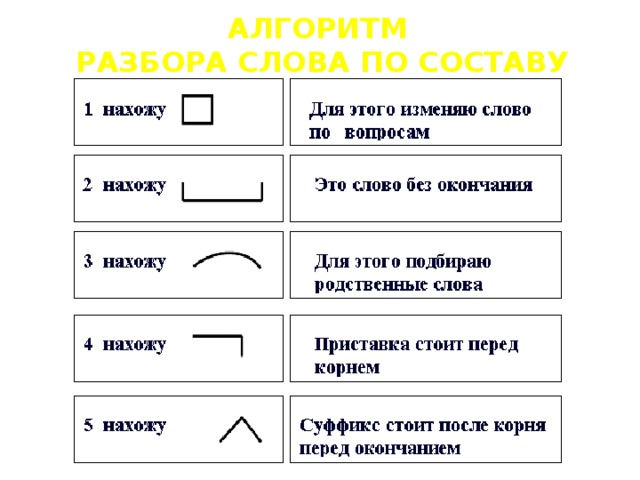 Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
| Вопрос 1 из 20 Роман датского писателя 20 в. Ханса Кирка «… и сыновья» | |
| клитгор | коридор |
| квантор | квестор |
Только что искали: сттаьнсоч сейчас к а т е р сейчас пвтроосу 1 секунда назад оферта 1 секунда назад п ц ы е л я ь 1 секунда назад в р е м я н к а 1 секунда назад миндаль 1 секунда назад н ч а и л е р 1 секунда назад калсев 1 секунда назад пошита 1 секунда назад р н ж и у а д 1 секунда назад тенимр 2 секунды назад мхрноа 2 секунды назад п о в а р и х а 2 секунды назад делитонее 2 секунды назад
Grok | Ссылка на Logstash [8.
 5]
5] - Версия плагина: v4.4.3
- Дата выпуска: 28 октября 2022 г.
- Список изменений
Другие версии см. Версия документации плагина.
Получение Helpedit
По вопросам о плагине открывайте тему на форуме обсуждения. Для ошибок или запросов функций, откройте проблему в Github. Список поддерживаемых Elastic плагинов см. в Матрице поддержки Elastic.
Descriptionedit
Разбирать произвольный текст и структурировать его.
Grok — отличный способ преобразовать неструктурированные данные журнала во что-то структурированное и доступное для запросов.
Этот инструмент идеально подходит для журналов syslog, apache и других журналов веб-сервера, mysql журналы и вообще любой формат журналов, который обычно пишется для людей а не потребление компьютера.
Logstash по умолчанию содержит около 120 шаблонов. Вы можете найти их здесь:
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns. Можете добавить
свое банально. (см.
Можете добавить
свое банально. (см. Patterns_dir настройка)
Если вам нужна помощь в построении шаблонов, соответствующих вашим журналам, вы найдете Приложения http://grokdebug.herokuapp.com и http://grokconstructor.appspot.com/ весьма полезны!
Грок или рассечение? Или оба?редактировать
Плагин фильтра dissect — это еще один способ извлечь неструктурированные данные о событиях в поля с помощью разделителей.
Dissect отличается от Grok тем, что не использует регулярные выражения и работает быстрее. Dissect работает хорошо, когда данные надежно повторяются. Grok — лучший выбор, когда структура вашего текста меняется от строки к строке.
Вы можете использовать как Dissect, так и Grok для гибридного варианта использования, когда раздел
строка достоверно повторяется, но не вся строка. Фильтр рассечения может
деконструировать часть строки, которая повторяется. Фильтр Grok может обрабатывать
остальные значения поля с большей предсказуемостью регулярных выражений.
Grok Basicsedit
Grok работает, комбинируя текстовые шаблоны во что-то, что соответствует вашим журналы.
Синтаксис шаблона grok: %{SYNTAX:SEMANTIC}
СИНТАКСИС — это имя шаблона, который будет соответствовать вашему тексту. За
например, 3.44 будет соответствовать шаблону НОМЕР , а 55.3.244.1 будет
соответствовать шаблону IP . Синтаксис — это то, как вы соответствуете.
SEMANTIC — это идентификатор, который вы даете совпадающему фрагменту текста.
Например, 3,44 может быть продолжительностью события, поэтому вы можете назвать его
просто продолжительность . Кроме того, строка 55.3.244.1 может идентифицировать клиента .
сделать запрос.
В приведенном выше примере ваш фильтр grok будет выглядеть примерно так:
%{ЧИСЛО:длительность} %{IP:клиент} При желании вы можете добавить преобразование типа данных в свой шаблон grok. По умолчанию
вся семантика сохраняется в виде строк. Если вы хотите преобразовать тип данных семантики,
например, измените строку на целое число, а затем добавьте к ней суффикс целевого типа данных.
Например
По умолчанию
вся семантика сохраняется в виде строк. Если вы хотите преобразовать тип данных семантики,
например, измените строку на целое число, а затем добавьте к ней суффикс целевого типа данных.
Например %{NUMBER:num:int} , который преобразует семантику num из строки в
целое число. В настоящее время поддерживаются только следующие преобразования: int и float .
Примеры: Имея представление о синтаксисе и семантике, мы можем извлечь полезные поля из пример журнала, подобный этому вымышленному журналу http-запросов:
55.3.244.1 GET /index.html 15824 0.043
Шаблон для этого может быть:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{ЧИСЛО:байт} %{ЧИСЛО:продолжительность} Более реалистичный пример, давайте прочитаем эти журналы из файла:
input {
файл {
путь => "/var/log/http.log"
}
}
фильтр {
грок {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
} После фильтра grok в событии будет несколько дополнительных полей:
-
клиент: 55. 3.244.1
3.244.1 - Метод
: ПОЛУЧИТЬ -
запрос: /index.html -
байт: 15824 -
продолжительность: 0,043
 3.244.1
3.244.1 Регулярные выраженияedit
Grok находится поверх регулярных выражений, поэтому допустимы любые регулярные выражения в гроке тоже. Библиотека регулярных выражений называется Oniguruma, и вы можете увидеть полный поддерживаемый синтаксис регулярных выражений на Oniguruma сайт.
Custom Patternsedit
Иногда в logstash нет нужного шаблона. Для этого у вас есть несколько вариантов.
Во-первых, вы можете использовать синтаксис Oniguruma для именованного захвата, который позволяет сопоставить фрагмент текста и сохранить его как поле:
(?шаблон здесь)
Например, журналы postfix имеют идентификатор очереди , который представляет собой 10 или 11 символов
шестнадцатеричное значение. Я могу легко зафиксировать это следующим образом:
Я могу легко зафиксировать это следующим образом:
(?[0-9A-F]{10,11})
Кроме того, вы можете создать файл пользовательских шаблонов.
- Создайте каталог с именем
узоровс файлом в нем под названиемextra(название файла не имеет значения, но назовите его осмысленно для себя) - В этом файле напишите нужный шаблон в качестве имени шаблона, пробел, затем регулярное выражение для этого шаблона.
Например, выполнение примера идентификатора очереди постфикса, как указано выше:
# содержимое ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11} Затем используйте параметр Patterns_dir в этом плагине, чтобы сообщить logstash, где
каталог ваших пользовательских шаблонов. Вот полный пример с образцом журнала:
1 января 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>
filter {
грок {
Patterns_dir => [". /patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}  /patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
/patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
} Приведенное выше совпадет и даст следующие поля:
-
метка времени: 1 января 06:25:43 -
источник журнала: mailserver14 -
программа: постфикс/очистка -
идентификатор: 21403 -
идентификатор_очереди: BEF25A72965 -
syslog_message: message-id=<[email protected]>
Поля timestamp , logsource , program и pid поступают из Шаблон SYSLOGBASE , который сам определяется другими шаблонами.
Другим вариантом является определение шаблонов в строке в фильтре с использованием pattern_definitions .
Это в основном для удобства и позволяет пользователю определить шаблон, который можно использовать только в этом случае. фильтр. Эти вновь определенные шаблоны в
фильтр. Эти вновь определенные шаблоны в pattern_definitions не будут доступны за пределами этого конкретного фильтра grok .
Переход на Elastic Common Schema (ECS)edit
Чтобы облегчить переход на Elastic Common Schema (ECS), фильтр плагин предлагает новый набор шаблонов, совместимых с ECS, в дополнение к существующим узоры. Новые определения шаблонов ECS фиксируют имена полей событий, которые соответствует схеме.
Набор шаблонов ECS содержит все определения шаблонов из устаревшего набора и
сменная замена. Используйте ecs_compatibility настройка переключения режимов.
В файлы, совместимые с ECS, будут добавлены новые функции и улучшения. устаревшие шаблоны могут по-прежнему получать исправления ошибок, которые обратно совместимы.
Параметры конфигурации фильтра Grokedit
Этот подключаемый модуль поддерживает следующие параметры конфигурации, а также общие параметры, описанные ниже.
Также см. Общие параметры для списка параметров, поддерживаемых всеми фильтрующие плагины.
break_on_match редактировать- Тип значения — логический.
- Значение по умолчанию:
, правда.
Перерыв на первом совпадении. Первый успешный матч от grok приведет к фильтр заканчивается. Если вы хотите, чтобы грок попробовал все шаблоны (возможно, вы разбор разных вещей), затем установите для этого параметра значение false.
ecs_compatibility edit Управляет совместимостью этого плагина с Elastic Common Schema (ECS).
Значение этого параметра влияет на имена извлеченных полей событий при совпадении составного шаблона (например, HTTPD_COMMONLOG ).
keep_empty_captures редактировать- Тип значения — логический.
- Значение по умолчанию:
, ложь.
Если верно , оставить пустые захваты в качестве полей событий.
совпадение изменить- Тип значения — хеш
- Значение по умолчанию:
{}.
Хэш, определяющий сопоставление , где искать и с какими шаблонами.
Например, следующее будет соответствовать существующему значению в поле сообщения для заданного шаблона, и если совпадение будет найдено, к событию с захваченным значением будет добавлено поле длительность :
filter {
грок {
совпадение => {
"message" => "Продолжительность: %{NUMBER:duration}"
}
}
} Если вам нужно сопоставить несколько шаблонов с одним полем, значение может быть массивом шаблонов:
filter {
грок {
совпадение => {
"сообщение" => [
"Продолжительность: %{ЧИСЛО:длительность}",
"Скорость: %{ЧИСЛО:скорость}"
]
}
}
} Чтобы выполнить сопоставление нескольких полей, просто используйте несколько записей в хэше match :
filter {
грок {
совпадение => {
"скорость" => "Скорость: %{ЧИСЛО:скорость}"
"duration" => "Продолжительность: %{NUMBER:duration}"
}
}
} Однако, если один шаблон зависит от поля, созданного предыдущим шаблоном, разделите их на два отдельных фильтра grok:
filter {
грок {
совпадение => {
"message" => "Привет, остальная часть сообщения: %{GREEDYDATA:остальные}"
}
}
грок {
совпадение => {
"остальное" => "число %{ЧИСЛО:число} и слово %{СЛОВО:слово}"
}
}
} named_captures_only изменить- Тип значения — логический.
- Значение по умолчанию:
, правда.

Если true , сохранять только именованные захваты из grok.
перезаписать изменить- Тип значения — массив
- Значение по умолчанию:
[].
Поля для перезаписи.
Позволяет перезаписать значение в уже существующем поле.
Например, если у вас есть строка системного журнала в поле сообщения , вы можете
перезаписать поле сообщения с частью совпадения, например:
filter {
грок {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
перезаписать => [ "сообщение" ]
}
} В данном случае строка вида 29 мая 16:37:11 печальный регистратор: привет мир будет проанализировано, и hello world перезапишет исходное сообщение.
Если вы используете ссылку на поле в перезаписать , вы должны использовать поле
ссылка в шаблоне. Пример:
Пример:
фильтр {
грок {
match => { "somefield" => "%{NUMBER} %{GREEDYDATA:[вложенные][поле][тест]}" }
перезаписать => [ "[вложенное] [поле] [тест]" ]
}
} pattern_definitions редактировать- Тип значения — хеш
- Значение по умолчанию:
{}.
Хэш имени шаблона и кортежей шаблонов, определяющих пользовательские шаблоны, которые будут использоваться текущий фильтр. Шаблоны, совпадающие с существующими именами, переопределяют ранее существовавшие. определение. Думайте об этом как о встроенных шаблонах, доступных только для этого определения грок
Patterns_dir редактировать- Тип значения — массив
- Значение по умолчанию:
[].
Logstash по умолчанию поставляется с набором шаблонов, поэтому вам не нужно
обязательно нужно определить это самостоятельно, если вы не добавляете дополнительные
узоры. С помощью этого параметра вы можете указать несколько каталогов шаблонов.
Обратите внимание, что Grok будет читать все файлы в каталоге, соответствующем шаблонам_файлов_глоба.
и предположим, что это файл шаблона (включая любые файлы резервных копий с тильдой).
С помощью этого параметра вы можете указать несколько каталогов шаблонов.
Обратите внимание, что Grok будет читать все файлы в каталоге, соответствующем шаблонам_файлов_глоба.
и предположим, что это файл шаблона (включая любые файлы резервных копий с тильдой).
Patterns_dir => ["/opt/logstash/patterns", "/opt/logstash/extra_patterns"]
Файлы шаблонов представляют собой обычный текст в формате:
ШАБЛОН НАЗВАНИЯ
Например:
НОМЕР \d+ 3 3 Шаблоны загружаются при создании конвейера.
Patterns_files_globредактировать
- Тип значения — строка
-
Значение по умолчанию:
"*"
Общий шаблон, используемый для выбора файлов шаблонов в каталогах указанный pattern_dir
tag_on_failure редактировать - Тип значения — массив
-
Значение по умолчанию:
["_grokparsefailure"].
Добавление значений в поле tags , когда не было
успешное совпадение
tag_on_timeout изменить - Тип значения — строка
-
Значение по умолчанию:
"_groktimeout".

Тег, применяемый в случае истечения времени ожидания регулярного выражения grok.
цель изменить - Тип значения — строка
- Для этого параметра нет значения по умолчанию
Определить целевое пространство имен для размещения совпадений.
timeout_millis редактировать - Тип значения — число
-
Значение по умолчанию:
30000.
Попытка завершить регулярные выражения по истечении этого времени. Это относится к шаблону, если применяется несколько шаблонов. Это никогда не истечет время ожидания раньше, но может занять немного больше времени. Фактическое время ожидания является приблизительным, основанным на квантовании 250 мс. Установите 0, чтобы отключить тайм-ауты
timeout_scope редактировать - Тип значения — строка
-
Значение по умолчанию:
"шаблон" -
Поддерживаемые значения:
"шаблон"и"событие".

Если несколько шаблонов предоставлены для соответствия ,
тайм-аут исторически применялся к каждому шаблону , вызывая накладные расходы
для каждого испробованного шаблона; когда грок фильтр
настроено с timeout_scope => событие , плагин вместо этого применяет
единый тайм-аут для всех попыток совпадений в событии, поэтому он может
добиться аналогичной защиты от неуправляемых совпадений со значительно
меньше накладных расходов.
Обычно лучше ограничить время ожидания для всего события.
Common Optionsedit
Следующие параметры конфигурации поддерживаются всеми плагинами фильтров:
add_field edit - Тип значения — хеш
- Значение по умолчанию – 9.0029 {}
Если этот фильтр прошел успешно, добавьте к этому событию любые произвольные поля.
Имена полей могут быть динамическими и включать части события с использованием %{field} .
Пример:
фильтр {
грок {
add_field => { "foo_%{somefield}" => "Привет, мир, от %{host}" }
}
} # Вы также можете добавить сразу несколько полей:
фильтр {
грок {
add_field => {
"foo_%{somefield}" => "Привет, мир, от %{host}"
"новое_поле" => "новое_статическое_значение"
}
}
} Если в событии есть поле "somefield" == "hello" этот фильтр, в случае успеха,
добавил бы поле foo_hello , если оно присутствует, с
значение выше, а часть %{host} заменена этим значением из
мероприятие. Во втором примере также будет добавлено жестко заданное поле.
add_tag редактировать- Тип значения — массив
- Значение по умолчанию:
[].
Если этот фильтр прошел успешно, добавьте к событию произвольные теги.
Теги могут быть динамическими и включать в себя части события с помощью %{поле} синтаксис.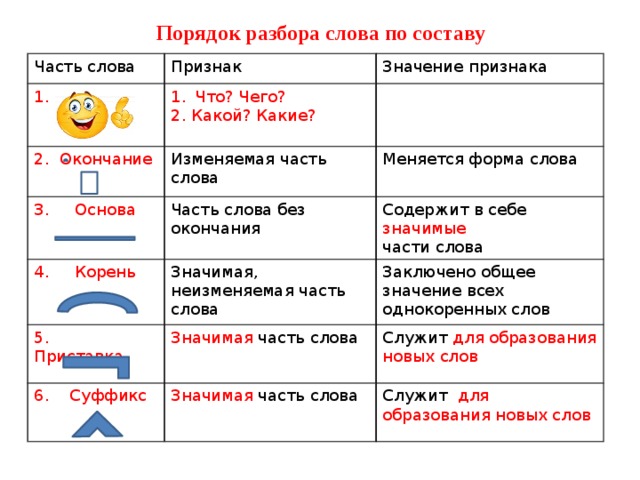
Пример:
фильтр {
грок {
add_tag => [ "foo_%{somefield}" ]
}
} # Вы также можете добавить сразу несколько тегов:
фильтр {
грок {
add_tag => [ "foo_%{somefield}", "taggedy_tag"]
}
} Если в событии есть поле "somefield" == "hello" этот фильтр, в случае успеха,
добавил бы тег foo_hello (и во втором примере, конечно, добавил бы тег taggedy_tag 9тег 0030).
enable_metric изменить- Тип значения — логический.
- Значение по умолчанию:
, правда.
Отключить или включить ведение журнала метрик для этого конкретного экземпляра подключаемого модуля. По умолчанию мы записываем все метрики, которые можем, но вы можете отключить сбор метрик для конкретного плагина.
идентификатор редактировать- Тип значения — строка
- Для этого параметра нет значения по умолчанию.
Добавить уникальный ID в конфигурацию плагина. Если идентификатор не указан, Logstash сгенерирует его.
Настоятельно рекомендуется установить этот идентификатор в вашей конфигурации. Это особенно полезно
когда у вас есть два и более плагина одного типа, например, если у вас 2 фильтра grok.
Добавление именованного идентификатора в этом случае поможет в мониторинге Logstash при использовании API-интерфейсов мониторинга.
фильтр {
грок {
идентификатор => "Азбука"
}
} Подстановка переменных в 9Поле 0029 id поддерживает только переменные среды и не поддерживает использование значений из хранилища секретов.
Periodic_flush редактировать- Тип значения — логический.
- Значение по умолчанию:
, ложь.
Вызывать метод промывки фильтра через регулярные промежутки времени. По желанию.
удалить_поле редактировать- Тип значения — массив
- Значение по умолчанию:
[].
Если этот фильтр прошел успешно, удалить произвольные поля из этого события. Имена полей могут быть динамическими и включать части события с помощью %{field} Пример:
фильтр {
грок {
remove_field => [ "foo_%{somefield}" ]
}
} # Вы также можете удалить сразу несколько полей:
фильтр {
грок {
remove_field => [ "foo_%{somefield}", "my_extraneous_field" ]
}
} Если в событии есть поле "somefield" == "hello" этот фильтр, в случае успеха,
удалит поле с именем foo_hello , если оно присутствует. Секунда
пример удалит дополнительное нединамическое поле.
remove_tag редактировать- Тип значения — массив
- Значение по умолчанию:
[].
Если этот фильтр прошел успешно, удалить произвольные теги из события.
Теги могут быть динамическими и включать в себя части события, используя %{поле} синтаксис.
Пример:
фильтр {
грок {
remove_tag => [ "foo_%{somefield}" ]
}
} # Вы также можете удалить сразу несколько тегов:
фильтр {
грок {
remove_tag => [ "foo_%{somefield}", "sad_unwanted_tag"]
}
} Если в событии есть поле "somefield" == "hello" этот фильтр, в случае успеха,
удалит тег foo_hello , если он присутствует. Второй пример
также удалит грустный, нежелательный тег.
[PDF] Новый банк деревьев или перепрофилирование? О возможности межъязыкового анализа романских языков с универсальными зависимостями†
- title={Новый банк деревьев или перепрофилированный? О возможности межъязыкового анализа романских языков с универсальными зависимостями†},
автор = {Маркос Гарсия и Карлос Г {\ 'о} мез-Родр {\ 'и} Гес и Мигель А. Алонсо},
journal={Инженерия естественного языка},
год = {2017},
объем = {24},
страницы={91–122}
}
- Marcos Garcia, Carlos Gómez-Rodríguez, Miguel A. Alonso
- Published 6 October 2017
- Computer Science
- Natural Language Engineering
) между романскими языками, анализируя его производительность по сравнению с использованием аннотированных вручную ресурсов целевых языков. Несколько экспериментов учитывают такие факторы, как лексическое расстояние между исходным и целевым разнообразием, влияние делексикализации, сочетание различных исходных деревьев или адаптация ресурсов к целевому языку, среди…
Посмотреть на Cambridge Press
ruc.udc.esМногоязычный анализ зависимостей: представление слов и совместное обучение синтаксическому анализу. (Распокация En Dépendances Multistingue: Representation de Mots et Apprentissage Suit Pour L’-Analyze Syntakique)
- Mathieu dehouck
Компьютерная наука, лингвистика
- 2019
. морфологии в данном корпусе как функция предпочтительного прикрепления головы, и показано, что это очень помогает языкам с небольшими ресурсами, но также полезно для языков с лучшими ресурсами, когда их генеалогическое древо хорошо заполнено.
Разбор в отсутствие родственных языков: оценка анализаторов с низким ресурсом на тагальском языке
- Angelica M. Aquino, F. D. De Leon
Компьютерная наука, лингвистика
UDW
- 2020
это показывают, что это показано, что это показано, что это показано, что это показано, что это показано, что это показывают, что это показывают, что это показывают, что это показывает, что это показывает, что это показано. одноязычная модель, разработанная на основе минимальных данных о целевом языке, последовательно превосходит все межъязыковые и многоязычные модели, когда не существует тесно связанных источников для языка с низким уровнем ресурсов.
LiRo: эталон и таблица лидеров для заданий на румынском языке
LiRo, платформа для сравнительного анализа моделей румынского языка по девяти стандартным задачам: классификация текста, распознавание именованных объектов, машинный перевод, анализ тональности, тегирование POS, анализ зависимостей, языковое моделирование, ответы на вопросы и семантическое сходство текста.
предложенный.LiRo: эталон и таблица лидеров для заданий на румынском языке
- С. Думитреску, Петру Ребежа, Себастьян Рудер
Информатика
- 2021
Предлагается платформа LiRo, платформа для сравнительного анализа моделей румынского языка по девяти стандартным задачам: классификация текста, распознавание именованных сущностей, машинный перевод, анализ настроений, теги POS, анализ зависимостей, языковое моделирование, ответы на вопросы и семантическое текстовое сходство.
Не все линеаризации одинаково требовательны к данным при анализе маркировки последовательностей
- Alberto Muñoz-Ortiz, Michalina Strzyz, David Vilares
Информатика
RANLP
- 2021
Результаты показывают, что кодирование с выбором головы более эффективно с точки зрения данных и работает лучше в идеальной (золотой) структуре, но это преимущество значительно снижается в пользу форматов брекетинга при выполнении установка напоминает реальную конфигурацию с низким уровнем ресурсов.
Юбилейная статья: Тогда и сейчас: 25 лет прогресса в инженерии естественного языка является растущее преобладание SM и ML.
Bertinho: Галисийский представитель BERT
- Давид Виларес, Маркос Гарсия, Карлос Гомес-Родригес
Информатика
Proces. дель Ленг. Natural
- 2021
В этом документе представлены две одноязычные галисийские модели BERT, построенные с использованием 6 и 12 слоев преобразователя соответственно; обучение с ограниченными ресурсами (~45 миллионов токенов на одном графическом процессоре 24 ГБ).
Как анализировать языки с ограниченными ресурсами: межъязыковой анализ, аннотации на целевом языке или и то, и другое?
- AILSA MEECHAN-MADDON, JOAKIM NIVRE
Лингвистика, компьютерная наука
Труды Пятой Международной конференции по лингвистике зависимости (истощение, синтаксис 2019) -Языковой синтаксический анализ, аннотация на целевом языке или и то, и другое?
Bertinho: Галисийский представитель BERT Bertinho: Представительство BERT para el gallego
- David Vilares, M. García, Carlos Gómez-Rodŕıguez
Информатика
- 2021
В этом документе представлены две одноязычные галисийские модели BERT, построенные с использованием 6 и 12 слоев преобразователя соответственно; обучение с ограниченными ресурсами (~45 миллионов токенов на одном графическом процессоре 24 ГБ).
Грубо-зернистая по сравнению с мелкозернистыми литовскими зависимостью.0011
SORT BYRelevanceMost Influenced PapersRecency
Synthetic Treebanking for Cross-Lingual Dependency Parsing
В этом вкладе рассматривается межъязыковая точка зрения на статистический анализ зависимостей, в которой делается попытка использовать богатые ресурсами древовидные банки исходного языка для построения и адаптации моделей для целевых языков с ограниченными ресурсами.
Перевод Treebank для индукции межъязыкового парсера
- J. Tiedemann, Zeljko Agic, Joakim Nivre
Информатика
CoNLL
- 2014
Этот подход опирается на проецирование аннотаций, но избегает использования зашумленных аннотаций на стороне источника несвязанного параллельного корпуса и вместо этого полагается на ручное аннотирование дерева в сочетании со статистическим машинным переводом, что позволяет обучать полностью лексикализованные парсеры.
Анализ межъязыковых зависимостей на основе распределенных представлений
- Jiang Guo, Wanxiang Che, David Yarowsky, Haifeng Wang, Ting Liu
Компьютерные науки, лингвистика
ACL
- 2015
В этой статье представлены два алгоритма для создания межъязыковых распределенных представлений слов, которые отображают словари из двух разных языков в общее векторное пространство и устраняют разрыв в лексических характеристиках. с помощью распределенных представлений признаков и их композиции.
Улучшение межъязыковой проекции синтаксических зависимостей
- Дж. Тидеманн
Информатика
NODALIDA
- 2015
В данной статье представлены несколько модификаций стандартного алгоритма проецирования аннотаций для синтаксических структур при разборе межъязыковых зависимостей. Наш подход уменьшает проекционный шум и…
Межъязыковые кластеры слов для прямой передачи лингвистической структуры
- Оскар Тэкстрем, Райан Т. Макдональд, Якоб Ушкорейт
Информатика, лингвистика
NAACL
- 2012
Показано, что, дополняя системы прямого переноса функциями межъязыкового кластера, относительная погрешность делексикализованных синтаксических анализаторов зависимостей, обученных на английских банках деревьев и переведенных на иностранные языки, может быть уменьшена до до 13%.
Выборочный обмен для анализа многоязычных зависимостей
- Тахира Назим, Р. Барзилай, А. Глоберсон
Информатика, лингвистика
ACL
- 2012
Мы представляем новый алгоритм анализа многоязычных зависимостей, который использует аннотации из различных наборов исходных языков для анализа нового языка без аннотаций. Наша мотивация — расширить…
Coling 2008: Материалы семинара по межплатформенной и междоменной оценке синтаксического анализатора
- Йохан Бос, Э. Бриско, Йи Чжан
Информатика
COLING
2008 2008
- David Vilares, M.
Синтаксический анализ с широким охватом достиг точки, когда разные подходы могут предложить (на первый взгляд) сопоставимую производительность, но современные синтаксические анализаторы банка деревьев по-прежнему ограничиваются только подмножеством аннотаций PTB; остается неизвестным, насколько метрика ParsEval может сообщить разработчикам приложений НЛП; и анализы в стиле PTB оставляют желать лучшего с точки зрения лингвистической информации.
Анализ межъязыковых зависимостей родственных языков с богатыми морфосинтаксическими наборами тегов
- Zeljko Agic, J. Tiedemann, Danijela Merkler, Simon Krek, K. Dobrovoljc, Sara Moze
Лингвистика, компьютерная наука
EMNLP 2014
- 2014
. межъязыковый синтаксический анализ и эмпирически подтверждают утверждение, демонстрируя значительные улучшения по сравнению с бедным представлением общих признаков в форме сокращенного набора тегов части речи.
Анализ зависимостей с нулевыми ресурсами: ускорение делексикализованной межъязыковой передачи с помощью лингвистических знаний
- Lauriane Aufrant, Guillaume Wisniewski, François Yvon
Информатика, лингвистика
COLING
- 2016
целевому языку и противопоставить подход, основанный на данных, подходу, основанному на лингвистически мотивированных правилах, автоматически извлекаемых из Всемирного атласа языковых структур.
- Marcos Garcia, Carlos Gómez-Rodríguez, Miguel A.