3 способа, чтобы учиться стало легче
В школе и университете ежедневно приходится познавать новое. Это не всегда легко: что-то не запоминается, что-то забывается. Поэтому перед экзаменами школьники и студенты часто испытывают стресс. Наш блогер Таисия Петровичева поделилась своими лайфхаками быстрого и продуктивного обучения: как писать понятные конспекты и сколько раз повторять новый материал.
Обучение ведёт к качественным изменениям — появлению новых навыков. Причём не всегда результат соразмерен затраченным усилиям. Учёба менее эффективная, чем производство на конвейере. Вспомните об этом, когда в следующий раз вам будет казаться, что вы стараетесь-стараетесь, а эффекта нет. Однако, процесс всё-таки можно ускорить. Тут на помощь приходят современные теоретические разработки психологии и практические советы тренеров по личностностному росту.
В посте собраны лайфхаки, которые я использую. Не все из них вас заинтересуют, но живой опыт всегда полезнее, чем безличные топ-5 или топ-10. Для гуманитариев особенно важно при работе с идеями, фактами и языком применять методики, поскольку по сравнению с точными науками их инструменты и так ограничены. Обучение можно разбить на три стадии и попытаться сделать эффективнее каждую из них.
Для гуманитариев особенно важно при работе с идеями, фактами и языком применять методики, поскольку по сравнению с точными науками их инструменты и так ограничены. Обучение можно разбить на три стадии и попытаться сделать эффективнее каждую из них.
1. Восприятие информации
К учёбе надо подготовиться. Сначала вспомните всё, что вы уже знаете по изучаемой теме. Лучше всего это проговорить вслух или про себя. Это очень важный этап. Вы повторяете известное и подготавливаете базу для нового. Да и начинать не с нуля эмоционально легче. Затем взгляните на информацию с позиции исследователя, как будто до вас этого никто никогда не видел: «Что в ней увлекательного?»
Используйте разные подходы и экспериментируйте с форматами, подключая все органы чувств. Это могут быть записи лекций, книги, музыка, фильмы, изображения. На YouTube и других сайтах, выкладывают видеолекции известных специалистов. Открытое образование работает, и оно может помочь заполнить пробелы, оставшиеся после пар.
Большим помощником при обучении станет приложение для аудиозаписи. Сможете попозже переслушать сложную лекцию. Моя знакомая поделилась своим способом подготовки. Она наговаривала конспекты и вопросы к экзамену и слушала их по ходу дня. Это давало возможность возвращаться к своим мыслям, не делая для этого больших усилий. Правда есть минус — наговоривание занимает достаточно много времени.
Научиться слышать и воспринимать живую речь поможет практика расшифровки интервью (или собственного выступления), то есть перевод речи в текст. Во время этого упражнения приходит понимание особенностей построения предложений, разницы между устной и письменной речью. Можно свою написанную работу вставить в онлайн-переводчик, нажать «произнести», и найти ошибки будет легче. Со временем появится навык анализа собственной речи и саморедактирования.
Любители интеллектуальных игр могут развивать скорость работы мозга, слушая аудио в ускоренном режиме. Сразу вспоминается телепередача «Самый умный», где задача была максимально быстро среагировать и дать правильный ответ.
2. Анализ информации
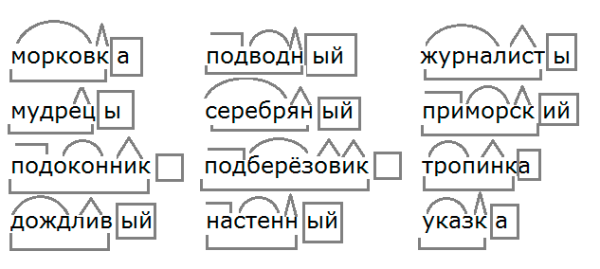
Его цель — привести сложное к простому и понятному, а принцип — пересказать своими словами и встроить новые знания в свою картину мира. Неустаревающая классика — конспекты, но кто сказал, что они должны ограничиваться простой записью слов лектора?
Вот как выглядит конспект по методу Корнелла:
Другой метод конспектирования — нумеровать каждое предложение. Одно из его преимуществ — возможность делать простые отсылки к предыдущим записям. Например, (см. 1).
Для творческих конспектов подойдут интеллект-карты. Их принцип открыт ещё в Древнем Риме. Римляне организовали систему права подобно дереву с большими и маленькими ветвями. Так же создаются и интеллект-карты: в центре пишется тема, от неё отходят ветки с основными положениями, а от них веточки с подробностями. Это даёт не самый подробный конспект, но позволяет разобраться в сложной теме. Удобнее всего составлять интеллект-карты в компьютерных программах, где есть возможность бесконечно вносить изменения и распечатать.
К записям можно добавить систему условных обозначений, например, когда надо записать книгу или сослаться на источник — нарисовать квадратик, если появилась идея — записать под знаком вопроса и тому подобное.
Стоит вспомнить знакомые со школы таблицы. Ведь это, на самом деле, хороший способ рассортировать информацию, выделить и осмыслить различные её стороны. Особенно если объём информации велик. Для сопоставления нескольких текстов можно составлять сводные таблицы, располагая тексты по вертикали, а по горизонтали вопросы для сравнения. Так делали учёные-текстологи. Сейчас такие таблицы удобнее делать в экселе.
Где только возможно дополняйте информацию рисунками, графиками, схемами и визуализируйте примерами. При чтении книг в электронном формате, выделяйте интересные и проблемные куски текста разными цветами, делайте заметки со своими мыслями и критикой.
3. Усвоение
Здесь важно найти в знаниях «белые пятна» и заполнить их. Для лучшего запоминания помогут методы мнемотехник, ассоциаций, пяти повторений и карточек. Обо всем по порядку.
Обо всем по порядку.
1. Мнемотехники
Мозг запоминает новую информацию, если она необходима или вызывает яркие эмоции. На второй особенности построены различные мнемотехники. Например, вам нужно запомнить, что в железном веке на территории Москвы были поселения дьяковской культуры. Для этого вы создаёте в голове яркий образ: стоит дьяк на Красной площади, типичный такой, в чёрной рясе, и держит в руках чёрный металлолом. Чем абсурднее образ, тем вероятнее, что он запомниться.
Отдельная техника для запоминания чисел. Для каждого числа из ряда 0-9 нужно придумать обозначение: персонажа или предмет. Образ для даты битвы на Калке может выглядеть, как колонна с двумя лебедями и картой для проезда на метро «Тройка» (1223). Либо можно сделать проще: разбивать дату на два двухзначных числа. Можно создавать предложения вроде «Каждый Охотник Желает Знать, Где Сидит Фазан» или сочинять рифмованные двустишия. На первый взгляд, кажется, что это слишком трудозатратно, но на практике освоенный метод ускоряет процесс и делает его более творческим.
2. Метод ассоциаций
Он схож с описанными выше, его суть — связать новое с уже знакомым. Можно пойти проторенным путём — выписать вопросы на карточки, а на обратной стороне ответы на них и повторять, пока не запомниться. Чтобы это не превращалось в простую зубрежку, нужно стремиться к пониманию и проговаривать вслух. Если забыли, то лучше восстанавливать ответ, путем рассуждений, а не пытаясь вспомнить, тогда ошибка забывания не закрепиться.
3. Метод пяти повторений
У процесса запоминания есть ещё одно свойство — со временем образы блёкнут. Причём происходит это по определённому принципу: до сна вы помните всё достаточно подробно, затем резко забываете большую часть, а оставшееся сохраняется довольно долго — до полугода. Согласно методу пяти повторений, вы возвращаетесь к информации:
- через несколько часов;
- на следующий день;
- через неделю;
- через месяц;
- через полгода.
Полезное наблюдение я почерпнула из одной книги.
Наконец-то вы усвоили материал — можно забыть об этой проблеме? — не совсем. По моим наблюдениям, есть одно отличие между успешными студентами и не очень. Первые после лекции продолжают обдумывать или обсуждать услышанное, а вторые резко переключаются на что-то другое и забывают тему. Возможно, дело в позитивном подходе к обучению. Подход: «теперь у меня есть мои новые знания; как круто и легко я с ними обращаюсь» лучше, чем «это мучение кончилось».
4. Объяснение материала
Объяснить кому-либо тему — хороший способ самому разобраться в вопросе. Особенно если вы попробуете донести её до ребёнка. Можно поделитесь знаниями в соцсетях.
Подводя итоги, скажу, что сколько людей столько и подходов. Создавайте свою собственную систему обучения, и она заработает, как слаженный механизм. Главное не унывать. Работайте на долгую перспективу, не забывая всё после экзамена. Тогда будет к чему приращивать новые знания. А методики самообразования помогут развить таланты и не переживать, что природа дала мало способностей (хотя, кто знает). Больше практики, целеустремленности, и всё получится!
Вы находитесь в разделе «Блоги». Мнение автора может не совпадать с позицией редакции.
Иллюстрация: Shutterstock (Vectorium)
Предложение со словом «легче»
1
и мне становится легче, легче, легче!
Психоаналитик.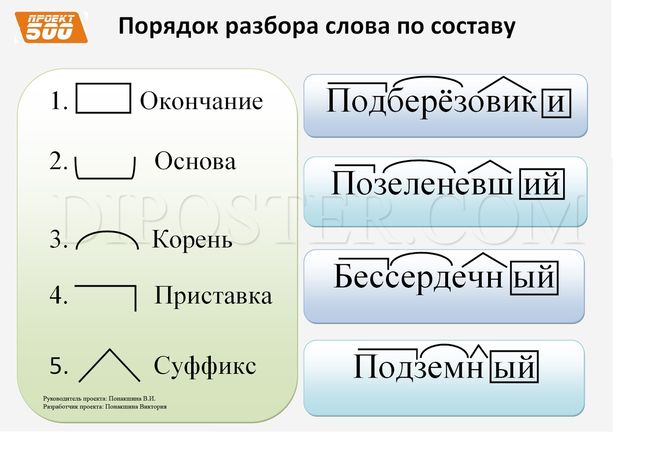 Сборник рассказов, Андрей Огрызко
Сборник рассказов, Андрей Огрызко
2
Легче работалось, легче думалось.
Париж интимный (сборник), Александр Куприн
3
Мне легче, гораздо легче стало.
Анна Каренина, Лев Толстой, 1878г.
4
Следующий номер вам дастся гораздо легче, третий еще легче, а дальше все пойдет, как по маслу.
Рассказы, Аркадий Аверченко
5
Легче, гораздо легче, мое дитятко, милостию Божиею и заступлением его святых угодников.
Димитрий Самозванец, Фаддей Булгарин, 1830г.
6
Легче, легче, и совсем повеселели!
Г. И. Успенский как писатель и человек, Николай Михайловский, 1886г.
7
В душном воздухе делается все легче и легче.
Собрание юмористических рассказов в одном томе, Антон Чехов, 2016г.
8
Во-первых, в Новой Деревне запастись на зиму дровами легче, чем в городе, а во-вторых, легче купить у крестьян картошки.
Вечное возвращение. Книга 1: Повести, Сборник, 2016г.
9
На сердце у Теобальда становилось все легче и легче.
Путь всякой плоти. Роман, Сэмюэл Батлер
10
Многие чувствуют это, и потому им легче умирать, как и мне будет легче умереть, когда я допишу эту историю.
Демиан, Герман Гессе, 1919г.
11
Но таким-то на свете легче, среди людей легче.
Мир госпожи Малиновской, Тадеуш Доленга-Мостович, 1934г.
12
Идти становилось всё легче и легче.
Путешествия Гулливера (в пересказе для детей), Джонатан Свифт, 1722-1725г.
13
Тело становилось все легче и легче, а может быть, наоборот тяжелее, и мгновением позже я погрузилась во тьму.
Список ненависти, Дженнифер Браун, 2009г.
14
Сейчас станет легче, вот сейчас станет легче!“ – убеждал себя он.
Ужасы перистальтики, Глеб Соколов
15
Как только он понял разницу между «ю» и «у», «е» и «о», «я» и «а», ему стало легче, а как только ему стало легче, он – о чудо!
Уроки русского, Елена Девос, 2016г.
16
Я просто решаю задачу по-своему, как легче мне, а не так как объясняли Вы и как, соответственно, Вам легче.
Немеркнущая звезда. Часть вторая, Александр Сергеевич Стрекалов, 2020г.
17
С дипломом легче двинуться по карьерной лестнице, легче, в случае чего, пережить кризис и найти другую работу.
В споре со временем. Доклады, эссе, статьи, Сергей Сметанин
18
Я все слушал, слушал, слушал, а ему становилось все легче и легче и уж совсем полегчало, когда я ему сунул «бумажку под фуражку».
 Сборник рассказов, Андрей Огрызко
Сборник рассказов, Андрей Огрызко19
Становится всё легче и легче сделать шаг в пустоту, навстречу очередной неопределенности.
Ницшеанский сорт, Владимир Дорогин
20
Маленькому Человеку было больно смотреть на это, но вдруг он почувствовал, что с каждой слезой, мальчишке становилось легче и легче.
О небе и земле. Сборник рассказов, Дмитрий Александрович Троцкий
21
Врачи переглядываются, спрашивая каждую минуту, легче или нет, я мотаю головой, что не легче.
Я после, Виктория Сергеевна Дуся, 2020г.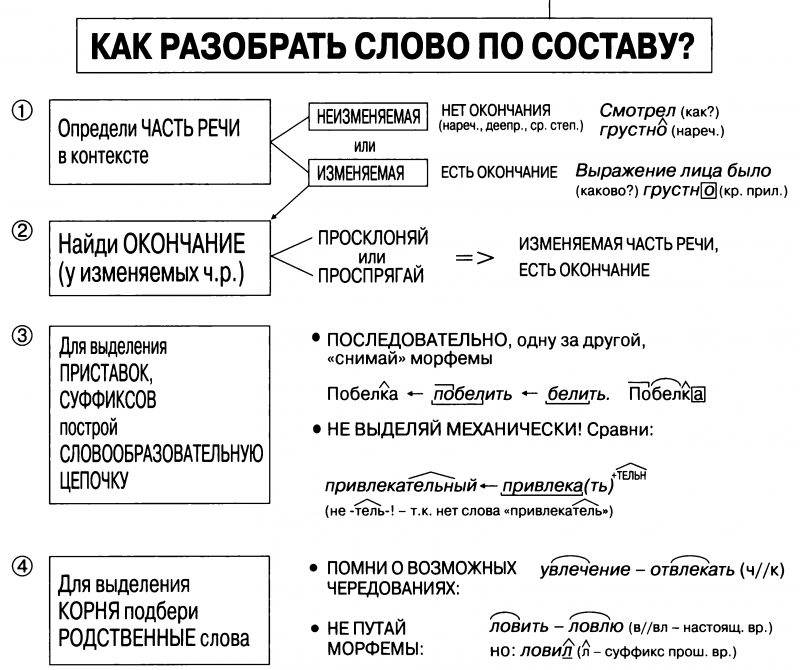
22
Легче, парень, легче, мы тебе голову зашили.
Твой дом там, где я, Кадрия Расиловна Хабибуллина
23
Кажется, я пережила легкий стресс, но мне уже легче…
Шарада, Руслан Каштанов, 2019г.
24
В глазах возникает
Круги от камушка, Нибин Айро
25
Мужчина с женщиной – это всегда легкий бред, – ответила Люда, – это легкий бред, достигший совершенства.
Шаги за спиной, Сергей Герасимов, 1996г.
26
Легкий—легкий такой, на грани оттепели.
Напрямик (сборник), Роман Сенчин, 2016г.
27
Да, она стояла передо мной, – да, сперва по-своему скажу: она была легче тени, ей могла бы позавидовать самая легкая из теней – тень падающего снега;
Зависть (сборник), Юрий Олеша, 2005г.
28
Легчелегкого сказать юной госпоже Тилни, что тебе напомнили сейчас о давнем уговоре и ты просишь ее отложить прогулку до вторника.
Нортенгерское аббатство (сборник), Джейн Остин, 1818, 1817г.
29
Та почувствовала, что спутница на ней почти повисла и что тело ее легчелегкого.
О красоте, Зэди Смит, 2005г.
30
В зале прилета легчелегкого передать кому-нибудь контрабанду в ручной клади, а потом отправиться на таможню за своим законным багажом.
Патрик Мелроуз. Книга 1 (сборник), Эдвард Сент-Обин, 1998г.
31
Назад и в самом деле легчелегкого, потому что садишься на кольце.
Станцуем, красивая?, Алекс Тарн, 2013г.
32
Да с вами бороться легчелегкого, заставив самих уничтожать себе подобных.
Возмездие, Олег Александрович Овсянников
33
Думает, вот хорошо, братова работа легче – легкого, сиди себе, да указанья раздавай, а деньжишь сколь!
Жили или не жили. Старые сказки на новый лад (для взрослых), Наталья Волохина
34
Легчелегкого взять и отмести с порога.
Третий прыжок кенгуру (сборник), Вл. Николаев, 1974, 1988г.
35
Десять лет назад купить дом или землю в Большой Речке было легчелегкого, причем за гроши.
Самая короткая ночь. Эссе, статьи, рассказы, Марина Бойкова-Гальяни
Эссе, статьи, рассказы, Марина Бойкова-Гальяни
36
Все школьные предметы давались мне легчелегкого, но цифры навевали тоску зеленую и желание спасаться бегством.
Бабочка на булавочке, или Блинчик с начинкой. Любовно-иронический роман, Мадам Вилькори
37
Легчелегкого найти стрелочника…
В ожидании августа, ЮРИЙ МИХАЙЛОВ, 2020г.
38
Но в небольшом провинциальном городке за нарушение трудовой дисциплины оказаться за воротами предприятия было легчелегкого.
Поколение А. Выпуск 1, Коллектив авторов, 2020г.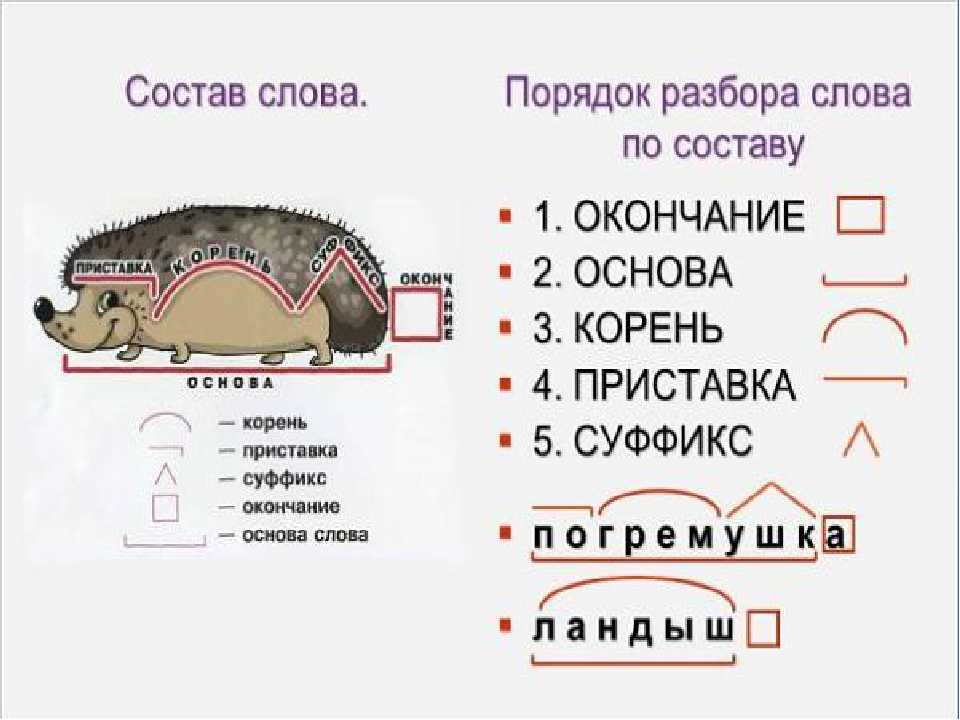
39
Идти хоть было и трудно, но уже легче, намного легче, чем утром.
Белый Бим Черное ухо (сборник), Гавриил Троепольский
40
И легче, сто раз легче бы мне тогда было…
Очарованный странник (сборник), Николай Лесков, 2009г.
41
Легче, пане Голуб, легче, а то можно сбиться с каблука.
Как закалялась сталь, Николай Островский, 2005г.
42
Легче, во сто раз легче мне расстаться с жизнию, чем с тобою, черноокая!
Кавказские повести, Александр Александрович Бестужев-Марлинский
43
В душном воздухе делается всё легче и легче.
Тысяча одна страсть, или Страшная ночь (сборник), Антон Чехов
44
Тогда было все проще в Турции, и погибнуть было легче, но легче и спастись.
Одиссей Полихрониадес, Константин Николаевич Леонтьев
45
Но в гипсе мне работать легче – его можно обрабатывать на всех стадиях и легче набирать из него объёмы.
Переписка художников с журналом «А-Я». 1976-1981. Том 1, Игорь Шелковский
46
Когда я говорил тебе про литографию, то имел в виду, что графику выставить гораздо легче, она быстрее продаётся, её легче транспортировать.
Переписка художников с журналом «А-Я». 1976-1981. Том 1, Игорь Шелковский
47
С каждым днем будет все легче и легче.
Почтамт, Чарльз Буковски, 1971г.
48
Раз установилась линия наименьшего сопротивления, всякое последующее путешествие будет даваться все легче и легче.
Смирительная рубашка. Когда боги смеются (сборник), Джек Лондон
49
Легче организовать восстание, идти в бой, захватить, победить – это легче.
Мятеж, Дмитрий Фурманов, 1924г.
50
Первый матч прошел легче, чем она ожидала, – легче, чем имела право ожидать, – но было бы глупо надеяться, что ей снова так повезет.
Игра на вылет, Лорен Вайсбергер, 2016г.
51
«Я, Гутя, всю бумагу извел, посылая прошения в Москву, – отпустите и меня на ту полосу, где умереть легче, но и жить легче.
Есаулов сад, Борис Черных
52
Чтобы мне было легче думать о том, что ему легче жить с такой женщиной.
Нежный театр, Николай Кононов, 2004г.
Хотите добавить свое предложение к слову «легче»?
Ваше предложение
- Синонимы к слову «легче»
Monadic Parser Combinators: интерактивное учебное пособие по JS (часть 1)
Синтаксический анализ анализирует последовательные данные в структурный результат и является ключевым этапом статического анализа кода и компиляции.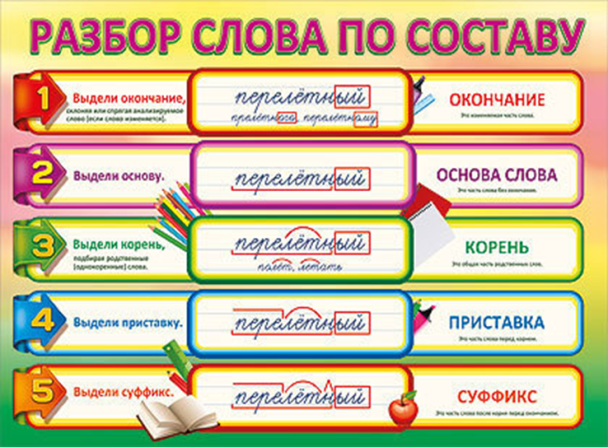 Парсеры также демонстрируют различные функциональные концепции, включая чистоту, композицию и монады.
Парсеры также демонстрируют различные функциональные концепции, включая чистоту, композицию и монады.
В этом интерактивном руководстве мы рассмотрим реализацию простой библиотеки комбинатора парсера. Комбинаторы позволяют программистам легко создавать сложные программы за счет использования небольшого количества совместных служебных функций.
const color = P.either(P.literal('красный'), P.literal('синий'))
const animal = P.either(P.literal('зебра'), P.literal('жираф'))
константные пространства = P.many1 (P.literal (' '))
const highTale =
цвет .цепочка (с =>
space.chain(_ =>
animal.chain(a => P.of(`Был ${c} ${a}.`))))
Войти в полноэкранный режимВыйти из полноэкранного режимаЦель состоит в том, чтобы частично изучить синтаксический анализ и частично изучить функциональное программирование. Предварительный опыт ни в том, ни в другом не предполагается.
Мотивы
Серийные данные, напр. из файла или сетевой нагрузки, часто необходимо преобразовать в результат, прежде чем программа сможет с ним работать.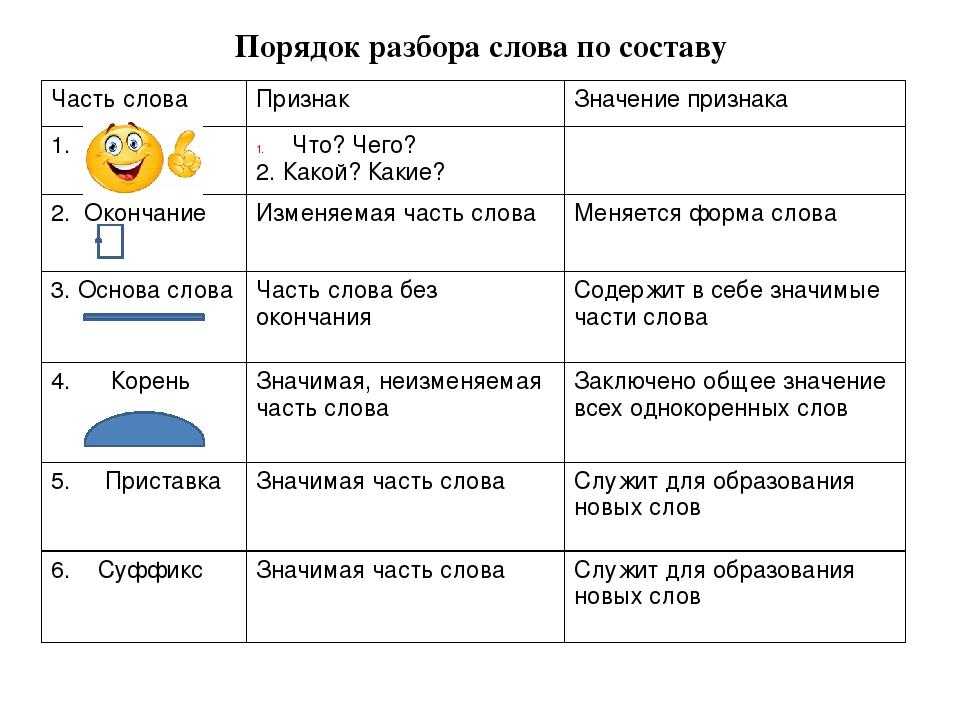 Например:
Например:
- HTML — это строковый формат содержимого страницы. Браузеры анализируют HTML в DOM, дереве узлов в памяти, которые можно запрашивать и манипулировать ими, чтобы влиять на визуализируемую веб-страницу.
- JSON — это строковый формат для вложенных данных, часто используемый для файлов конфигурации или сетевых полезных данных. Программы могут использовать
JSON.parseдля преобразования строки JSON в объект JavaScript, который можно легко читать и обновлять во время выполнения. - ESLint — это инструмент статического анализа кода для обнаружения ошибок и отклонений от стиля. ESLint использует анализатор JavaScript (Espree) для чтения авторской программы (текстового файла) и выявления потенциальных проблем.
Кроме того, класс программ, называемых компиляторами , делает еще один шаг вперед, сворачивая дерево синтаксического анализа обратно в формат преобразованной строки. Таким образом, компиляторы действуют как переводчики между строками одного формального языка и строками другого.
константный кодES2018 = 'число => число + 1'
const codeES5 = compileToES5(codeES2018)
console.log(codeES5) // 'функция (число) {возврат числа + 1}'
Войти в полноэкранный режимВыйти из полноэкранного режима- V8 — это механизм JavaScript, который использует компилятор для преобразования JavaScript в исполняемый машинный код.
- Babel компилирует JavaScript, написанный с использованием современного и/или предметно-ориентированного синтаксиса (например, ES2018 + JSX), в более старый синтаксис (например, ES5).
- Prettier компилирует JavaScript с нестандартным форматированием в JavaScript с согласованным форматированием.
В типичном компиляторе синтаксический анализ называется внешним интерфейсом , а генерация кода называется внутренним интерфейсом .
инфикс FE (парсер) + BE (генератор) постфикс
«2 + 3 * 5» -> / \ -> «2 3 5 * +»
2 *
/ \
3 5
Войти в полноэкранный режимВыйти из полноэкранного режима Однако также возможно генерировать результаты во время шага синтаксического анализа. В этом случае явное дерево не строится, хотя синтаксический анализатор неявно следует древовидной структуре, рекурсивно проходя по входной строке.
В этом случае явное дерево не строится, хотя синтаксический анализатор неявно следует древовидной структуре, рекурсивно проходя по входной строке.
Обычно синтаксический анализатор извлекает структуру из начала некоторого последовательного ввода. Входными данными может быть обычная строка, хотя некоторые синтаксические анализаторы могут ожидать поток (последовательно потребляемый источник, например, генератор или наблюдаемый) из токенов (объектов, записывающих как лингвистический тип, так и лексический контент).
Давайте начнем с простого и рассмотрим парсер как функцию от строки к результату.
// разбор :: Строка -> * константный разбор = s => ?Войти в полноэкранный режимВыйти из полноэкранного режима
Напрашивается вопрос, что выдает наш парсер. Ответ зависит от проблемы. Многие синтаксические анализаторы создают узлы дерева, но синтаксические анализаторы могут быть написаны для получения любого желаемого результата, включая необработанные строки, числа, функции и т. д.
д.
Как справиться с неудачей
А пока давайте просто зафиксируем буквальное строковое значение (или лексема ), которым соответствует наш парсер. Вот (неполный) синтаксический анализатор, предназначенный для сопоставления и получения лексемы «Трицератопс»:
// parseTri :: String -> String const parseTri = s => "Трицератопс"Войти в полноэкранный режимВыйти из полноэкранного режима
К сожалению, этот парсер не работает. Что, если наша строка содержит не того динозавра? Разбор «T. Rex» не должен приводить к «Triceratops». Нам нужен способ сбоя сигнала .
Как бы вы решили эту проблему? Придумать свой собственный подход; ваша функция синтаксического анализа должна иметь возможность принимать следующие строки и либо возвращать «Triceratops», либо указывать (каким-то образом), что ей не удалось выполнить синтаксический анализ.
Сбой сигнализации: может быть?
тип Parser = String -> Возможно StringВойти в полноэкранный режимВыйти из полноэкранного режима
Опытный функциональный программист, скорее всего, воспользуется таким типом суммы, как монада Maybe . Тем не менее, правильное рассмотрение этой концепции сейчас существенно сорвет эту статью, поэтому мы вернемся к
Тем не менее, правильное рассмотрение этой концепции сейчас существенно сорвет эту статью, поэтому мы вернемся к Может быть позже.
Ошибка сигнализации: массив?
тип Parser = String -> [String]Войти в полноэкранный режимВыйти из полноэкранного режима
Функциональные синтаксические анализаторы обычно представляют свои результаты в виде списков. Таким образом, сбой может быть представлен пустым списком [] , а при необходимости может быть зафиксировано несколько успехов (из неоднозначной грамматики). Неоднозначные грамматики выходят за рамки этой статьи, поэтому нам строго не нужны списки.
Ошибка сигнализации: ноль
тип Parser = String -> String | НулевойВойти в полноэкранный режимВыйти из полноэкранного режима
Как Может быть, , так и списки — хорошие способы борьбы с ошибками, но пока мы будем придерживаться метода, с которым знакомы JS-разработчики: null . Значение
Значение null , изобретатель которого Тони Хоар однажды назвал его «ошибкой на миллиард долларов», имеет серьезные подводные камни. Тем не менее, это идиоматично, доступно и на данный момент будет достаточно.
Вот наш новый парсер. Попробуйте на некоторых строках и посмотрите, что получится:
Работа с остатками
Когда мы анализируем результат из строки, в большинстве случаев мы используем только часть ввода. У остатка будут другие значения, которые мы можем проанализировать, а это значит, что нам нужно отслеживать, где возобновить работу. В изменяемой настройке, такой как JavaScript, может возникнуть соблазн создать общее значение index .
пусть индекс = 0
const parseTri = s => {
константный остаток = s.slice(index)
если (остаток.startsWith('Трицератопс')) {
index += 'Трицератопс'.length
вернуть «Трицератопс»
}
вернуть ноль
}
Войти в полноэкранный режимВыйти из полноэкранного режимаЭто прекрасно работает для синтаксического анализа одной строки:
Однако общее изменяемое состояние может быстро вызвать проблемы. Что, если мы хотим впоследствии проанализировать другую строку?
Что, если мы хотим впоследствии проанализировать другую строку?
Конечно, есть решения. Мы могли бы создать класс Parser , экземпляры которого управляют внутренним состоянием, или функцию более высокого порядка makeParser , которая закрывается по состоянию. Оба этих решения хоронят состояние, фактически не устраняя его; отладка такого скрытого состояния иногда даже более сложна.
Чистое потребление токенов
Оказывается, для этой задачи нам на самом деле не нужно изменяемое состояние. В функциональном программировании мы предпочитаем чистых -решений.
Чистые функции — это детерминированные отображения без сохранения состояния от входа к выходу без побочных эффектов. Другими словами, чистые функции имеют выходные данные, но не зависят от внешней вселенной и не изменяют ее. Если вы можете определить свою функцию как (потенциально бесконечную) таблицу входов и выходов, это чисто. Попробуйте вызвать как f1 , f2 и f3 определены ниже:
| f1 в | f1 из | f2 в | f2 из | f3 в | f3 из |
|---|---|---|---|---|---|
привет | 2 | [а, б] | б | 0 | -2 |
"что" | 4 | [0, 9, 1] | 9 | 1 | -1 |
"пау" | 3 | [0] | не определено | 2 | 2 |
"лес" | 6 | [] | не определено | 3 | 7 |
«а» | 1 | [1, 2, 3] | 2 | 4 | 14 |
| 0 | [г, у] | г | 5 | 23 |
| … | … | … | … | … | … |
Если синтаксическому анализатору необходимо указать, где должен начинаться следующий синтаксический анализ, это подразумевает, что оставшийся ввод сам должен быть возвращаемым значением. Итак, наши парсеры вернут две вещи: проанализированный результат и оставшиеся входные данные.
Итак, наши парсеры вернут две вещи: проанализированный результат и оставшиеся входные данные.
тип Parser = String -> String & StringВойти в полноэкранный режимВыйти из полноэкранного режима
Как написать функцию, которая возвращает две вещи? Существует более одного жизнеспособного способа; придумайте свой собственный подход ниже, а затем читайте дальше, чтобы узнать о нашем подходе.
Кортежи и друзья
Поскольку функциональное программирование включает в себя большое количество данных, поступающих и исходящих из функций, функциональные языки часто имеют облегченную структуру данных для объединения значений: кортеж.
-- Хаскелл
myTuple = ("привет", 99) -- 2-кортеж
str = fst myTuple -- "привет"
число = snd myTuple -- 99
Войти в полноэкранный режимВыйти из полноэкранного режима В JavaScript нет кортежей, но есть объекты и массивы (которые на самом деле являются типом объекта). Мы можем достаточно легко эмулировать кортежи:
const myTuple = ['привет', 99] const str = myTuple[0] // 'привет' const num = myTuple[1] // ложьВойти в полноэкранный режимВыйти из полноэкранного режима
const myTuple = {str: 'hello', num: 99 }
const { str } = myTuple // 'привет'
const { число } = myTuple // ложь
Войти в полноэкранный режимВыйти из полноэкранного режима Массивы более лаконичны, но объекты более выразительны. Вы, вероятно, использовали один из них в своем решении выше; мы будем использовать объекты.
Вы, вероятно, использовали один из них в своем решении выше; мы будем использовать объекты.
Боковое примечание: изоморфизмы
n -Tuples и n -element Массивы JS (когда они используются исключительно для хранения данных) на самом деле изоморфны . Наборы A и B изоморфны, если можно определить пару функций a2b и b2a , такую что:
-
a2bсопоставляет все значения вAсо значениями вB -
b2aсопоставляет все значения вBсо значениями вA -
b2a(a2b(a)) = а -
а2б(б2а(б)) = б
Изоморфизмы — богатая тема с некоторыми восхитительными результатами, но в результате приятно знать, когда два типа данных эквивалентны для данного варианта использования.
Загадка для размышлений: почему двузначные объекты , а не могут быть изоморфны 2-el массивам? Какая информация будет потеряна при переводе?
Поточные парсеры
Теперь наш синтаксический анализатор может сообщать, какая часть ввода не была использована, но как мы на самом деле используем эту информацию? Строка, оставшаяся от одного синтаксического анализа, становится входными данными для следующего синтаксического анализа. Заполните приведенный ниже код.
Заполните приведенный ниже код.
Чтобы увидеть наше решение, вы можете войти в скрытую переменную решение .
Обобщение
У нас есть единственный парсер, который умеет парсить «Трицератопсов» — не очень интересно. Напишите несколько парсеров для других динозавров.
Это повторяется. Давайте обобщим и сделаем функцию parseLiteral .
Решение приведенной выше задачи демонстрирует общую функциональную технику. Функции высшего порядка сами принимают и/или возвращают функции; parseLiteral делает последнее. Вместо жесткого кодирования отдельных синтаксических анализаторов для каждой строки, parseLiteral обобщает, сопоставляя строки с синтаксическими анализаторами:
| строка | parseLiteral(string) |
|---|---|
привет | парсер для "привет" |
'лет' | парсер для 'лет' |
"вау" | парсер для "вау" |
| … | … |
Различные типы результатов
Парсеры соответствуют в строках, но они не обязаны давать в них результат . Напишите синтаксические анализаторы для цифровых строк, результатом которых являются числа.
Напишите синтаксические анализаторы для цифровых строк, результатом которых являются числа.
Как только мы начнем использовать наши синтаксические анализаторы для практических целей, будет удобно преобразовывать необработанные лексемы в обработанные результаты, специфичные для нашего варианта использования.
Типы, подписи и псевдонимы
Итак, мы рассмотрели два разных типа синтаксических анализаторов: те, которые возвращают строки, и те, которые возвращают числа.
parseRex :: String -> { результат: String, остаток: String } | Нулевой
parseNum1 :: String -> { результат: число, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Мы пока не обращали особого внимания на эти комментарии, предпочитая учить на собственном примере, но это примеры подписи типа . Подпись типа документирует, к какому набору принадлежит значение. Например, тип Bool представляет собой набор из двух значений: true и false . Вы можете прочитать нотацию
Вы можете прочитать нотацию :: как «имеет тип» или «есть в наборе»:
true::Bool -- `true` находится в наборе `Bool` false :: Bool -- `false` находится в наборе `Bool`Войти в полноэкранный режимВыйти из полноэкранного режима
Функции также относятся к типам. ! (или «нет») функция находится в набор функций, которые сопоставляют значения в Bool со значениями в Bool . Мы обозначаем это как (!) :: Bool -> Bool . Вот ! Функция определена:
| Логический ввод | Логический выход |
|---|---|
правда | ложный |
ложный | правда |
Головоломка: их ровно три другие функции типа Bool -> Bool . Можете ли вы определить их все? Помните, что каждая функция будет таблицей из двух строк.
Функции представляют собой сопоставления от одного типа до другого типа (например, Int -> Bool , String -> String или объект -> String ). Соответственно, функциональные языки часто подчеркивают свою систему типов. Машинное обучение и родственные языки, такие как OCaml, F#, ReasonML, Miranda, Haskell, PureScript, Idris и Elm, являются примерами языков со сложной типизацией, в том числе алгебраические типы данных и полный вывод типа .
JavaScript имеет (иногда печально известную) динамическую систему типов и не имеет официальной нотации типов. Синтаксис здесь заимствован из Haskell и похож на систему, используемую Ramda, служебной библиотекой JS. Это хорошо объясняется как в вики Ramda, так и в документации Fantasy Land.
Мы поднимаем этот вопрос сейчас, потому что становится слишком громоздко записывать весь тип наших парсеров. parseRex и сигнатуры типов parseNum1 различаются только в одном месте, результат :
parseRex :: String -> { результат: String, остаток: String } | Нулевой
parseNum1 :: String -> { результат: число, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Соответственно, с этого момента мы будем использовать Parser a для обозначения «функции разбора, результат которой имеет тип a »:
type Parser a = String -> { result: а, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Этот псевдоним типа — просто сокращение, которое мы будем использовать для целей документации. Это значительно очистит наши комментарии и облегчит обсуждение парсеров. Например, теперь мы можем классифицировать
Это значительно очистит наши комментарии и облегчит обсуждение парсеров. Например, теперь мы можем классифицировать parseRex и parseNum1 более кратко:
parseRex :: Parser String parseNum1 :: Номер парсераВойти в полноэкранный режимВыйти из полноэкранного режима
Попробуйте сами. Упростите наш parseLiteral 9Подпись 0022 с использованием сокращенной записи:
Комбинаторы наконец
Что, если мы хотим сопоставить более одной возможности? Реализуйте следующие парсеры. Существующие синтаксические анализаторы находятся в области действия, используйте их в своем определении:
Опять же, это повторяется. Что делает функциональный программист, когда сталкивается с повторением? Обобщай! Напишите функцию или , которая принимает два парсера и возвращает новый парсер, соответствующий любому из них.
Поздравляем, вы поставили комбинатор .
Комби-кто?
Комбинатор , как и многие термины программирования, перегружен — в разных контекстах он означает разные вещи.
- Комбинаторная логика — это изучение функций, которые действуют на функции. Например, комбинатор
I(x => x) принимает функцию и возвращает ту же функцию. В этом поле «комбинатор» формально означает функцию без свободных (несвязанных) переменных . - Шаблон комбинатора — это стратегия создания гибких библиотек, в которой небольшое количество совместных служебных функций создает богатые результаты (которые, в свою очередь, могут быть новыми входными данными для тех же самых функций).
- Например, "комбинаторы" CSS принимают селекторы CSS и создают новые, более сложные селекторы.
divиh2являются примитивными селекторами; используя комбинатор direct child (>), вы можете создать новыйdiv > h2 9Селектор 0022.
- Например, "комбинаторы" CSS принимают селекторы CSS и создают новые, более сложные селекторы.
Мы определим комбинатор синтаксических анализаторов как функцию, которая принимает один или несколько синтаксических анализаторов и возвращает новый синтаксический анализатор. Некоторые примеры:
Некоторые примеры:
либо :: (парсер a, парсер b) -> парсер (a | b) оба :: (парсер a, парсер b) -> парсер [a, b] любой :: (... Парсер *) -> Парсер * много :: Парсер a -> Парсер [a]Войти в полноэкранный режимВыйти из полноэкранного режима
Вы уже определили либо ; взломай и и любой следующий. Для ручного тестирования parseLiteral и все наши синтаксические анализаторы dino находятся в области действия:
Кроме того, либо находятся в области действия, если хотите:
Это мощная концепция. Вместо ручного кодирования специальных функций парсера для всех мыслимых целей мы можем определить несколько абстрактных комбинаторов. Добавляйте простые синтаксические анализаторы, получайте более мощные синтаксические анализаторы; эти новые мощные синтаксические анализаторы могут, в свою очередь, стать входными данными для тех же комбинаторов. Таким образом, мы можем создать богатое поведение с помощью нескольких простых в использовании инструментов. В этом суть состав – построение комбинацией.
В этом суть состав – построение комбинацией.
Заключение к части 1
Ниже показано текущее состояние нашей библиотеки комбинаторов парсеров.
// анализатор типов a = String -> { результат: a, остаток: строка } | Нулевой
// parseLiteral :: String -> Строка парсера
const parseLiteral = литерал => s => s.startsWith (литерал)
? {результат: литерал, остаток: s.slice(literal.length)}
: нулевой
// либо :: (парсер a, парсер b) -> парсер (a | b)
const либо = (p1, p2) => s => p1(s) || р2(с)
// оба :: (парсер a, парсер b) -> парсер [a, b]
const оба = (p1, p2) => s => {
const r1 = p1(s)
если (!r1) вернуть ноль
const r2 = p2(r1.остаток)
если (!r2) вернуть ноль
возвращаться {
результат: [r1.результат, r2.результат],
остаток: r2.остаток
}
}
// любой :: (...Парсер *) -> Парсер *
const any = (...parsers) => parsers.reduce(любой)
Войти в полноэкранный режимВыйти из полноэкранного режимаВ этой первой части мы рассмотрели:
- что такое синтаксический анализ
- некоторые варианты использования парсеров
- один (нефункциональный) способ устранения сбоя
- один (функциональный) способ устранения состояния
- чистота функции
- с использованием кортежей (или массивов/объектов) в качестве возвращаемых значений
- потоковый синтаксический анализатор последовательно выдает результаты
- типов, сигнатур и псевдонимов
- основных комбинаторов парсера
В предстоящем продолжении этой статьи мы рассмотрим некоторые более сложные вопросы:
- работа с более длинными последовательностями
- по выбору
- функторы и монады
- имитация нотации инфиксной функции
- формальные грамматики и теория синтаксического анализа
- рекурсивный спуск
- лень
Часть 2 будет размещена здесь после публикации.
об авторе
Габриэль Лебек — инструктор Fullstack Academy of Code, интенсивной программы разработки веб-приложений. У него есть степень бакалавра. по математике и студийному искусству, и слишком много увлечений, включая искусствоведческое исследование старинных японских мечей. Вы можете увидеть больше Габриэля на Medium, YouTube, GitHub и Twitter.
Обучение семантическому анализу с использованием методов статистического синтаксического анализа
Обучение семантическому анализу с использованием методов статистического синтаксического анализаРеклама
1 из 90
Верхний обрезанный слайд
Скачать для чтения офлайн
Технологии
Образование
Реклама
Реклама
Обучение семантике синтаксический анализ с использованием методов статистического синтаксического анализа
- 1
Обучение семантическому анализу с использованием
Статистический синтаксический анализ
Техники
Жуйфан Гэ
Кандидат наук.
 Финальная защита
Супервайзер: Рэймонд Дж. Муни
Группа машинного обучения
Департамент компьютерных наук
Техасский университет в Остине
Финальная защита
Супервайзер: Рэймонд Дж. Муни
Группа машинного обучения
Департамент компьютерных наук
Техасский университет в Остине - 2 Семантический анализ Семантический анализ: преобразование естественных языковые (NL) предложения в полностью представления формального значения (MRs) Примеры доменов приложений, в которых MR непосредственно исполняются другим компьютерная система для выполнения какой-либо задачи CLang: язык тренера Robocup Geoquery: приложение для запросов к базе данных
- 3 CLang (язык тренера RoboCup) В соревновании RoboCup Coach команды соревнуются, чтобы тренировать смоделированные игроки Коучинговые инструкции даются на формальном языке называется CLang Имитация футбольного поля Тренер Если у нашего игрока 2 есть мяч, затем позиция наш игрок 5 в полузащита. CLang ((boowner (игрок наш {2})) (делать (игрок наш {5}) (поз. (полузащита)))) Семантический анализ
- 4
GeoQuery: приложение для запросов к базе данных
Приложение запроса для географии США
база данных [Zelle & Mooney, 1996]
Пользователь Какие
реки в Техасе?
Семантический анализ
База ДанныхАнджелина,Анджелина,
Бланко, . .. Бланко, ...
Ответ на запрос (x1, (река (x1), loc (x1, x2),
равно (x2, stateid (техас))))
- 5 Мотивация для семантического Разбор Теоретически это отвечает на вопрос, как люди интерпретируют язык Практические приложения Ответ на вопрос Интерфейс на естественном языке Получение знаний Рассуждение
- 6 Мотивирующий пример Семантический разбор — это композиционный процесс. Структуры предложений необходимы для построения смысловых репрезентаций. ((boowner (игрок наш {2})) (сделай наш {4} (pos (половина нашего)))) Если мяч у нашего игрока 2, наш игрок 4 должен оставаться на нашей половине. Bowner: владелец мяча поз: позиция
- 7 Синтаксические подходы Смысловая композиция следует древовидной структуре синтаксический разбор Составление значения члена из значения его составных частей в синтаксическом разборе Ручные подходы (Вудс, 1970, Уоррен и Перейра, 1982) Изученные подходы Миллер и др. (1996): Концептуально простые предложения. Zettlemoyer & Collins (2005)): Комбинатор ручной сборки Правила шаблона категориальной грамматики (CCG)
- 8 Пример у нашего игрока 2 есть мяч PRP$ NN CD VB ДТ НН НП VPNP С МР: Bowner(игрок(наш,2)) Используйте структуру синтаксического разбора
- 9 у нашего игрока 2 есть мяч PRP$-наш NN-плеер(_,_) CD-2 VB-bowner(_) DT-нуль NN-нуль НП VPNP С Пример МР: Bowner(игрок(наш,2)) Присвойте словам семантические понятия
- 10 у нашего игрока 2 есть мяч PRP$-наш NN-плеер(_,_) CD-2 VB-bowner(_) DT-нуль NN-нуль НП VPNP-плеер(наш,2) С Пример МР: Bowner(игрок(наш,2)) Составьте значение для внутренних узлов
- 11 у нашего игрока 2 есть мяч PRP$-наш NN-плеер(_,_) CD-2 VB-bowner(_) DT-нуль NN-нуль NP-нуль VP-игрок(_)NP-игрок(наш,2) С Пример МР: Bowner(игрок(наш,2)) Составьте значение для внутренних узлов
- 12 у нашего игрока 2 есть мяч PRP$-наш NN-плеер(_,_) CD-2 VB-bowner(_) DT-нуль NN-нуль NP-нуль VP-игрок(_)NP-игрок(наш,2) S-boowner(игрок(наш,2)) Пример МР: Bowner(игрок(наш,2)) Составьте значение для внутренних узлов
- 13
Семантические грамматики
Нетерминалы в семантической грамматике
соответствуют смысловым понятиям в
домены приложений
Ручные подходы (Hendrix et al. , 1978)
Изученные подходы
Тан и Муни (2001), Кейт и Муни (2006), Вонг и
Муни (2006)
- 14 наш игрок 2 имеет мяч наши 2 игрок боунер Пример МР: Bowner(игрок(наш,2)) Bowner → мяч у игрока
- 15 Вклад в диссертацию Ввести два новых синтаксических подходы к семантическому разбору Теоретически хорошо обоснован в вычислительной семантика (Блэкберн и Бос, 2005 г.) Прекрасная возможность: используйте значительные прогресс, достигнутый в статистическом синтаксическом анализе для семантического разбора (Коллинз, 19 лет)97; Чарняк и Джонсон, 2005 г.; Хуан, 2008 г.)
- 16 Вклад в диссертацию НОЖНИЦЫ: новый интегрированный синтаксический семантический парсер SYNSEM: использует существующий синтаксический анализатор для создания деревьев синтаксического анализа с устраненной неоднозначностью, которые управлять композиционным значением композиции Исследуйте, когда знание синтаксиса может помочь
- 17
Представление семантических знаний в
Значение Представление Язык Грамматика
(МРЛГ)
Производственный предикат
СОСТОЯНИЕ →(Bowner PLAYER) P_BOWNER
PLAYER →(player TEAM {UNUM}) P_PLAYER
UNUM → 2 P_UNUM
КОМАНДА → наш P_OUR
Предполагается язык представления значения (MRL)
определяется однозначным контекстно-свободным
грамматика. Каждое продукционное правило вводит один предикат
в МРЛ.
Разбор MR дает его предикат-аргумент
состав.
- 18 Дорожная карта НОЖНИЦЫ СИНСЕМА Будущая работа Выводы
- 19 Семантическая композиция, объединяющая синтаксис и семантика для получения оптимальных представлений Интегрированный синтаксико-семантический анализ Позволяет использовать как синтаксис, так и семантику одновременно для получения точного комбинированного синтаксико-семантический анализ Статистический анализатор используется для создания семантически дополненное дерево синтаксического анализа (SAPT) НОЖНИЦЫ
- 20 Синтаксический разбор PRP$ NN CD VB ДТ НН НП VPNP С у нашего игрока 2 есть мяч
- 21 САПТ PRP$-P_OUR NN-P_PLAYER CD- P_UNUM VB-P_BOWNER DT-NULL NN-NULL NP-НУЛЬ VP-P_BOWNERNP-P_PLAYER S-P_BOWNER у нашего игрока 2 есть мяч Нетерминалы теперь имеют как синтаксические, так и семантические метки. Семантические метки: доминируют предикаты в поддеревьях
- 22 САПТ PRP$-P_OUR NN-P_PLAYER CD- P_UNUM VB-P_BOWNER DT-NULL NN-NULL NP-НУЛЬ VP-P_BOWNERNP-P_PLAYER S-P_BOWNER у нашего игрока 2 есть мяч Г-Н: P_BOWNER(P_PLAYER(P_OUR,P_UNUM))
- 23 НОЖНИЦЫ Обзор Примеры обучения интегрированному семантическому анализатору SAPT ОБУЧЕНИЕ ученик
- 24 Интегрированный семантический парсер САПТ Написать МР МИСТЕР NL Предложение ТЕСТИРОВАНИЕ НОЖНИЦЫ Обзор
- 25 Расширение синтаксиса Коллинза (1997) Модель синтаксического анализа Найдите SAPT с максимальной вероятностью Лексикализованный синтаксический анализ, управляемый головой модель Расширение модели синтаксического анализа для создания семантические метки одновременно с синтаксическими этикетки
- 26 Почему расширение синтаксиса Коллинза (1997) Модель синтаксического анализа Подходит для включения семантических знание Зависимость головы: отношение предикат-аргумент Синтаксическая подкатегория: набор аргументов что предикат появляется с Bikel (2004) реализация: легко расширяемый
- 27 Реализация парсера Контролируемое обучение по аннотированным SAPT просто подсчет частоты Тестирование: вариант стандартной диаграммы CKY- алгоритм разбора Подробности в диссертации
- 28 Сглаживание Каждая метка в SAPT представляет собой комбинацию синтаксическая метка и семантическая метка Увеличивает разреженность данных Разбить параметры Ф(Н | Р, ш) = Ph(Hsyn, Hsem| P, w) = Ph(Hsyn | P, w) × Ph(Hsem| P, w, Hsyn)
- 29
Экспериментальные корпуса
CLang (Кейт, Вонг и Муни, 2005 г. )
300 коучинговых советов
22,52 слова в предложении
Geoquery (Зелле и Муни, 19 лет)96)
880 запросов к базе данных по географии
7,48 слова в предложении
MRL: Пролог и FunQL
- 30 Пролог против FunQL (Вонг, 2007 г.) Пролог: ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Какие реки в Техасе? FunQL: ответ (река (loc_2 (stateid (техас)))) X1: река; x2: техас Логические формы: широко используются в качестве MRL в вычислительная семантика, поддержка рассуждений
- 31 Пролог: ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Какие реки в Техасе? FunQL: ответ (река (loc_2 (stateid (техас)))) Гибкий заказ Строгий порядок Лучшее обобщение на Прологе Пролог против FunQL (Вонг, 2007 г.)
- 32 Экспериментальная методология стандартная 10-кратная перекрестная проверка Правильность CLang: точно соответствует правильному MR Геозапрос: извлекает те же ответы, что и правильный МР Метрики Точность: % правильных возвращенных MR Отзыв: % NL с правильно возвращенными MR F-мера: гармоническое среднее значение точности и полноты
- 33
Сравниваемые системы
КОКТЕЙЛЬ (Танг и Муни, 2001)
Детерминированное, индуктивное логическое программирование
WASP (Вонг и Муни, 2006 г. )
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа
- 34 Сравниваемые системы КОКТЕЙЛЬ (Танг и Муни, 2001) Детерминированное, индуктивное логическое программирование WASP (Вонг и Муни, 2006 г.) Семантическая грамматика, машинный перевод KRISP (Кейт и Муни, 2006 г.) Семантическая грамматика, ядра строк Z&C (Зеттлеймойер и Коллинз, 2007 г.) Основанная на синтаксисе комбинаторная категориальная грамматика (CCG) ЛУ (Лу и др., 2008 г.) Семантическая грамматика, модель генеративного анализа Ручная сборка лексикон для геозапроса Ручная ККИ Правила шаблона
- 35
Сравниваемые системы
КОКТЕЙЛЬ (Танг и Муни, 2001)
Детерминированное, индуктивное логическое программирование
WASP (Вонг и Муни, 2006 г. )
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа
λ-WASP,
обработка логических
формы
- 36 Результаты на CLang Точность отзыва F-мера КОКТЕЙЛЬ - - - НОЖНИЦЫ 89,5 73,7 80,8 ОСАС 88,9 61,9 73,0 КРИСП 85,2 61,9 71,7 Z&C - - - ЛУ 82,4 57,7 67,8 (LU: F-мера после повторного ранжирования составляет 74,4%) Память переполнение Не сообщается
- 37 Результаты на CLang Точность отзыва F-мера НОЖНИЦЫ 89,5 73,7 80,8 ОСАС 88,9 61,9 73,0 КРИСП 85,2 61,9 71,7 ЛУ 82,4 57,7 67,8 (LU: F-мера после повторного ранжирования составляет 74,4%)
- 38 Результаты по геозапросу Точность отзыва F-мера НОЖНИЦЫ 92,1 72,3 81,0 ОСАС 87,2 74,8 80,5 КРИСП 93,3 71,7 81,1 ЛУ 86,2 81,8 84,0 КОКТЕЙЛЬ 89,9 79,4 84,3 λ-WASP 92,0 86,6 89,2 ЗиК 95,5 83,2 88,9 (LU: F-мера после повторного ранжирования составляет 85,2%) Пролог FunQL
- 39 Результаты по геозапросу (FunQL) Точность отзыва F-мера НОЖНИЦЫ 92,1 72,3 81,0 ОСАС 87,2 74,8 80,5 КРИСП 93,3 71,7 81,1 ЛУ 86,2 81,8 84,0 (LU: F-мера после повторного ранжирования составляет 85,2%) конкурентоспособный
- 40 Зачем знать синтаксис не помогает Геозапрос: 7,48 слова в предложении Короткое предложение Структуру предложения можно выучить из NL в паре с MR Выгода от знания синтаксиса по сравнению с потеря гибкости
- 41 Ограничение использования предыдущих Знание синтаксиса Какое состояние самый маленький N1 N2 ответ(наименьший(состояние(все))) Традиционный синтаксический анализ
- 42 Ограничение использования предыдущих Знание синтаксиса Какое состояние самый маленький штат самый маленький N1 Что N2 N1 N2 ответ(наименьший(состояние(все))) ответ(наименьший(состояние(все))) Традиционный синтаксический анализ Семантическая грамматика Изоморфная синтаксическая структура с MR Лучшее обобщение
- 43 Почему предварительное знание Синтаксис не помогает Геозапрос: 7,48 слова в предложении Короткое предложение Структуру предложения можно выучить из NL в паре с MR Выгода от знания синтаксиса по сравнению с потеря гибкости LU против WASP и KRISP Разложенная модель для семантической грамматики
- 44 Подробные результаты Clang на Длина предложения 0-10 (7%) 11-20 (33%) 21-30 (46%) 31-40 (13%) 0-10 (7%) 11-20 (33%) 21-30 (46%) 0-10 (7%) 11-20 (33%) 31-40 (13%) 21-30 (46%) 0-10 (7%) 11-20 (33%)
- 45 НОЖНИЦЫ Резюме Интегрированный синтаксико-семантический анализ подход Изучает точные семантические интерпретации используя аннотации SAPT знание синтаксиса повышает производительность в длинных предложениях
- 46 Дорожная карта НОЖНИЦЫ СИНСЕМА Будущая работа Выводы
- 47 СИНСЕМА Мотивация SCISSOR требует дополнительной аннотации SAPT для обучение Необходимо изучить как синтаксис, так и семантику из тот же ограниченный учебный корпус Высокопроизводительные синтаксические анализаторы имеющиеся, которые обучены на существующих крупных корпусов (Collins, 1997; Charniak & Johnson, 2005)
- 48
SCISSOR требует аннотации SAPT
PRP$-P_OUR NN-P_PLAYER CD- P_UNUM VB-P_BOWNER
DT-NULL NN-NULL
NP-НУЛЬ
VP-P_BOWNERNP-P_PLAYER
S-P_BOWNER
у нашего игрока 2 есть
мяч
Кропотливый. Автоматизируйте это!
- 49 Часть I: Синтаксический анализ PRP$ NN CD VB ДТ НН НП VPNP С у нашего игрока 2 есть мяч Используйте статистический синтаксический анализатор
- 50 Часть II: значения слов P_OUR P_PLAYER P_UNUM P_BOWNER NULL NULL у нашего игрока 2 есть мяч Используйте модель выравнивания слов (Wong and Муни (2006)) у нашего игрока 2 есть мяч P_PLAYERP_BOWNER P_OUR P_UNUM
- 51 Изучение семантической лексики Выравнивание слов IBM Model 5 (GIZA++) 5 лучших сочетаний слов/предикатов для каждого тренинга пример Предполагать выравнивание каждого слова и синтаксический анализ определяет возможный SAPT для составления правильного МИСТЕР
- 52 Введение λvariables в семантические метки для недостающие аргументы (a1: первый аргумент) у нашего игрока 2 есть мяч вице-президент С НП НП P_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ НП
- 53 у нашего игрока 2 есть мяч вице-президент С НП НП P_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ P_BOWNER P_PLAYER P_UNUMP_OUR Часть III: Внутренние семантические метки Как выбрать доминирующие предикаты? НП
- 54 λa1λa2P_PLAYER P_UNUM ? игрок 2 P_BOWNER P_PLAYER P_UNUMP_OUR , a2=c2P_PLAYERλa1λa2PLAYER + P_UNUM λa1 (c2: ребенок 2) Изучение правил семантической композиции
- 55 у нашего игрока 2 есть мяч вице-президент С NPP_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ λa1P_PLAYER ? λa1λa2PLAYER + P_UNUM {λa1P_PLAYER, a2=c2} P_BOWNER P_PLAYER P_UNUMP_OUR Изучение правил семантической композиции
- 56 у нашего игрока 2 есть мяч вице-президент С P_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ λa1P_PLAYER ? P_PLAYER P_OUR +λa1P_PLAYER {P_PLAYER, a1=c1} P_BOWNER P_PLAYER P_UNUMP_OUR Изучение правил семантической композиции
- 57 у нашего игрока 2 есть мяч P_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ λa1P_PLAYER P_PLAYER НУЛЕВОЙ λa1P_BOWNER ? P_BOWNER P_PLAYER P_UNUMP_OUR Изучение правил семантической композиции
- 58 у нашего игрока 2 есть мяч P_OUR λa1λa2P_PLAYER λa1P_BOWNER P_UNUM НУЛЬНУЛЬ λa1P_PLAYER P_PLAYER НУЛЕВОЙ λa1P_BOWNER P_BOWNER P_PLAYER + λa1P_BOWNER {P_BOWNER, a1=c1} P_BOWNER P_PLAYER P_UNUMP_OUR Изучение правил семантической композиции
- 59 Обеспечение смысловой композиции Какое состояние самый маленький N1 N2 ответ(наименьший(состояние(все))) Неизоморфизм
- 60
Обеспечение смысловой композиции
Неизоморфизм между синтаксическим анализом NL и MR
разобрать
Различные языковые явления
Машинный перевод между NL и MRL
Используйте автоматизированный синтаксический анализ
Введите макропредикаты, которые объединяют
несколько предикатов. Убедитесь, что MR может быть составлен с использованием
синтаксический разбор и выравнивание слов
- 61 Однозначная CFG MRL Учебный набор, {(S,T,MR)} Обучение Семантический разбор Анализ входного предложения T Выход MR Тестирование Перед обучением и тестированием тренировочное/тестовое предложение, S Синтаксический парсер синтаксическое дерево синтаксического анализа, T Приобретение семантических знаний Семантическая лексика и правила композиции Оценка параметров Вероятностная модель разбора Обзор СИНСЕМА
- 62 Однозначная CFG MRL Учебный набор, {(S,T,MR)} Обучение Семантический разбор Входное предложение, S Выход MR Тестирование Перед обучением и тестированием тренировочное/тестовое предложение, S Синтаксический парсер синтаксическое дерево синтаксического анализа, T Приобретение семантических знаний Семантическая лексика и правила композиции Оценка параметров Вероятностная модель разбора Обзор СИНСЕМА
- 63
Оценка параметра
• Применять полученные семантические знания ко всему обучению
примеры для создания возможных SAPT
• Используйте стандартную модель максимальной энтропии, подобную этой
Zettlemoyer & Collins (2005) и Wong & Mooney
(2006)
• Обучение находит параметр, который (приблизительно)
максимизирует сумму условного логарифмического правдоподобия
обучающий набор, включая синтаксические разборы
• Неполные данные, поскольку SAPT являются скрытыми переменными.
- 64 Функции Лексические признаки: Особенности Unigram: # что слову присваивается предикат Особенности биграммы: # что слову присваивается сказуемое по предшествующему/последующему слову. Возможности правила: # правило композиции, применяемое в вывод
- 65 ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Какие реки в Техасе? λv1P_ANSWER(x1) λv1P_RIVER(x1) λv1λv2P_LOC(x1,x2) λv1P_EQUAL(x2) Работа с логическими формами Обработка общих логических переменных Использовать лямбда-исчисление (v: переменная)
- 66 Пример пролога ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Какие реки в Техасе? λv1P_ANSWER(x1) (λv1P_RIVER(x1) λv1 λv2P_LOC(x1,x2) λv1P_EQUAL(x2)) Обработка общих логических переменных Использовать лямбда-исчисление (v: переменная)
- 67 Пример пролога ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Какие реки в Техасе? λv1P_ANSWER(x1) (λv1P_RIVER(x1) λv1λv2P_LOC(x1,x2) λv1P_EQUAL(x2)) Обработка общих логических переменных Использовать лямбда-исчисление (v: переменная)
- 68
Пример пролога
Какие реки в Техасе
НП
ПП
В
СБАРК
НП
НП
кв. м.
ВБПВХНП
ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas))))
Начните с
синтаксический разбор
- 69 Пример пролога Какие реки в Техасе ПП СБАРК НП кв.м. λv1λa1P_ANSWER NULL λv1P_RIVER λv1λv2P_LOC λv1P_EQUAL Добавьте предикаты к слова ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas))))
- 70 Пример пролога Какие реки в Техасе СБАРК НП кв.м. λv1λa1P_ANSWER NULL λv1P_RIVER λv1λv2P_LOC λv1P_EQUAL λv1P_LOC ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas)))) Выучите правило с объединение переменных λv1λv2P_LOC(x1,x2) + λv1P_EQUAL(x2) λv1P_LOC
- 71 Результаты эксперимента CLang Геозапрос (Пролог)
- 72 Синтаксические парсеры (Bikel, 2004) Только WSJ CLang(SYN0): F-мера=82,15% Геозапрос (SYN0): F-мера=76,44% WSJ + предложения в домене CLang(SYN20): 20 предложений, F-мера=88,21% Geoquery(SYN40): 40 предложений, F-мера=91,46% Синтаксические анализы золотого стандарта (GOLDSYN)
- 73
Вопросы
Q1. Может ли SYNSEM производить точные семантические
интерпретации?
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры?
В3. Это также улучшает длинные предложения?
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев?
В5. Может ли он обрабатывать синтаксические ошибки?
- 74 Результаты на CLang Точность отзыва F-мера ГОЛДСИН 84,7 74,0 79,0 СИН20 85,4 70,0 76,9SYN0 87,0 67,0 75,7 НОЖНИЦЫ 89,5 73,7 80,8 ОСАС 88,9 61,9 73,0 КРИСП 85,2 61,9 71,7 ЛУ 82,4 57,7 67,8 (LU: F-мера после повторного ранжирования составляет 74,4%) СИНСЕМА САПЦ GOLDSYN > SYN20 > SYN0
- 75 Вопросы Q1. Может ли SynSem производить точные семантические интерпретации? [да] Q2. Могут ли более точные синтаксические парсеры Treebank производить более точные семантические парсеры? [да] В3. Это также улучшает длинные предложения?
- 76 Подробные результаты Clang по длине предложения 31-40 (13%) 21-30 (46%) 0-10 (7%) 11-20 (33%) Прежний Знание Синтаксический ошибка + Гибкость + = ?
- 77
Вопросы
Q1. Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев?
- 78 Результаты на Clang (обучающий размер = 40) Точность отзыва F-мера ГОЛДСИН 61,1 35,7 45,1 СИН20 57,8 31,0 40,4 SYN0 53,5 22,7 31,9 НОЖНИЦЫ 85,0 23,0 36,2 ОСАС 88,0 14,4 24,7 КРИСП 68,35 20,0 31,0 СИНСЕМА САПЦ Качество синтаксического парсера критически важно!
- 79 Вопросы Q1. Может ли SynSem производить точные семантические интерпретации? [да] Q2. Могут ли более точные синтаксические парсеры Treebank производить более точные семантические парсеры? [да] В3. Это также улучшает длинные предложения? [да] Q4. Улучшает ли это ограниченные тренировочные данные из-за к предшествующим знаниям от больших деревьев? [да] В5. Может ли он обрабатывать синтаксические ошибки?
- 80 Обработка синтаксических ошибок Обучение обеспечивает смысловую композицию из синтаксические разборы с ошибками Для тестовых NL, которые генерируют правильные MR, измерьте F-меры их синтаксических разборов SYN0: 85,5% СИН20: 91,2% Если DR2C7 верно тогда игроки 2 , 3 , 7 и 8 должны передать пас игроку 4
- 81
Вопросы
Q1. Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к априорным знаниям о больших банках деревьев? [да]
В5. Является ли он устойчивым к синтаксическим ошибкам? [да]
- 82 Результаты по геозапросу (Пролог) Точность отзыва F-мера ГОЛДСИН 91,9 88,2 90,0 SYN40 90,2 86,9 88,5 SYN0 81,8 79,0 80,4 КОКТЕЙЛЬ 89,9 79,4 84,3 λ-WASP 92,0 86,6 89,2 ЗиК 95,5 83,2 88,9 СИНСЕМА SYN0 работает плохо Все другие современные системы работают конкурентоспособно
- 83 СИНСЕМ Резюме Использует существующий синтаксический анализатор для процесс смысловой композиции Предварительное знание синтаксиса улучшает производительность на длинных предложениях Предварительное знание синтаксиса улучшает производительность на ограниченных обучающих данных Обработка синтаксических ошибок
- 84 Дискриминационный перерейтинг для семантический разбор Адаптировать глобальные функции, используемые для переоценки синтаксический анализ для семантического анализа Улучшение CLang Нет улучшений в Geoquery, где предложения короткие и менее вероятны для глобальные функции, чтобы показать улучшение
- 85 Дорожная карта НОЖНИЦЫ СИНСЕМА Будущая работа Выводы
- 86
Будущая работа
Улучшить НОЖНИЦЫ
Дискриминационные НОЖНИЦЫ (Финкель и др. , 2008 г.)
Работа с логическими формами
НОЖНИЦЫ без дополнительной аннотации (Кляйн и
Мэннинг, 2002, 2004)
Улучшить СИНЕМ
Использование синтаксических анализаторов с повышенной точностью
и в другом синтаксическом формализме
- 87 Будущая работа Использование широкого охвата семантических представления (Curran et al., 2007) Лучшее обобщение синтаксических вариаций Использование семантической маркировки ролей (Gildea и Палмер, 2002 г.) Обеспечивает слой коррелированных семантических информация
- 88 Дорожная карта НОЖНИЦЫ СИНСЕМА Будущая работа Выводы
- 89
Выводы
НОЖНИЦЫ: новый интегрированный синтаксико-семантический
парсер.
SYNSEM: использует существующий синтаксический анализатор для
создавать деревья синтаксического анализа с устраненной неоднозначностью, которые управляют
композиционное значение композиции.
Оба дают точную семантическую интерпретацию.
Использование знаний синтаксиса улучшает
работа над длинными предложениями.
 Финальная защита
Супервайзер: Рэймонд Дж. Муни
Группа машинного обучения
Департамент компьютерных наук
Техасский университет в Остине
Финальная защита
Супервайзер: Рэймонд Дж. Муни
Группа машинного обучения
Департамент компьютерных наук
Техасский университет в Остине .. Бланко, ...
Ответ на запрос (x1, (река (x1), loc (x1, x2),
равно (x2, stateid (техас))))
.. Бланко, ...
Ответ на запрос (x1, (река (x1), loc (x1, x2),
равно (x2, stateid (техас)))) , 1978)
Изученные подходы
Тан и Муни (2001), Кейт и Муни (2006), Вонг и
Муни (2006)
, 1978)
Изученные подходы
Тан и Муни (2001), Кейт и Муни (2006), Вонг и
Муни (2006) Каждое продукционное правило вводит один предикат
в МРЛ.
Разбор MR дает его предикат-аргумент
состав.
Каждое продукционное правило вводит один предикат
в МРЛ.
Разбор MR дает его предикат-аргумент
состав. )
300 коучинговых советов
22,52 слова в предложении
Geoquery (Зелле и Муни, 19 лет)96)
880 запросов к базе данных по географии
7,48 слова в предложении
MRL: Пролог и FunQL
)
300 коучинговых советов
22,52 слова в предложении
Geoquery (Зелле и Муни, 19 лет)96)
880 запросов к базе данных по географии
7,48 слова в предложении
MRL: Пролог и FunQL )
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа
)
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа )
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа
λ-WASP,
обработка логических
формы
)
Семантическая грамматика, машинный перевод
KRISP (Кейт и Муни, 2006 г.)
Семантическая грамматика, ядра строк
Z&C (Зеттлеймойер и Коллинз, 2007 г.)
Основанная на синтаксисе комбинаторная категориальная грамматика (CCG)
ЛУ (Лу и др., 2008 г.)
Семантическая грамматика, модель генеративного анализа
λ-WASP,
обработка логических
формы Автоматизируйте это!
Автоматизируйте это! Убедитесь, что MR может быть составлен с использованием
синтаксический разбор и выравнивание слов
Убедитесь, что MR может быть составлен с использованием
синтаксический разбор и выравнивание слов
 м.
ВБПВХНП
ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas))))
Начните с
синтаксический разбор
м.
ВБПВХНП
ответ(x1, (река(x1), loc(x1,x2), равно(x2,stateid(texas))))
Начните с
синтаксический разбор Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры?
В3. Это также улучшает длинные предложения?
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев?
В5. Может ли он обрабатывать синтаксические ошибки?
Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры?
В3. Это также улучшает длинные предложения?
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев?
В5. Может ли он обрабатывать синтаксические ошибки? Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев?
Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к предшествующим знаниям от больших деревьев? Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к априорным знаниям о больших банках деревьев? [да]
В5. Является ли он устойчивым к синтаксическим ошибкам? [да]
Может ли SynSem производить точные семантические
интерпретации? [да]
Q2. Могут ли более точные синтаксические парсеры Treebank
производить более точные семантические парсеры? [да]
В3. Это также улучшает длинные предложения? [да]
Q4. Улучшает ли это ограниченные тренировочные данные из-за
к априорным знаниям о больших банках деревьев? [да]
В5. Является ли он устойчивым к синтаксическим ошибкам? [да] , 2008 г.)
Работа с логическими формами
НОЖНИЦЫ без дополнительной аннотации (Кляйн и
Мэннинг, 2002, 2004)
Улучшить СИНЕМ
Использование синтаксических анализаторов с повышенной точностью
и в другом синтаксическом формализме
, 2008 г.)
Работа с логическими формами
НОЖНИЦЫ без дополнительной аннотации (Кляйн и
Мэннинг, 2002, 2004)
Улучшить СИНЕМ
Использование синтаксических анализаторов с повышенной точностью
и в другом синтаксическом формализме