What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Частини слова 3 клас — crystal-zvon.ru
Скачать частини слова 3 клас rtf
Состав слова. Предложения состоят из слов, но и у слов есть свои составные части. Если разобрать слово по составу, можно многое понять о его происхождении и значении. Изучение состава слова – тема 3 класса русского языка – помогает лучше понять правила правописания и родной язык в целом.
Из каких частей состоит слово и зачем они нужны? Есть четыре вида “кирпичиков”, из которых состоят слова. Два из них есть в слове всегда – это корень и окончание.
Приставка и суффикс используются во многих словах, но это не обязательные части. Корень – это то, что выражает значение слова, его главная часть. Разбор слова по составу (2). Предварительный сбор учащихся состоится 30 августа в 10 часов в 16 кабинете. Можно принести цветы (из класса), за которыми ухаживали дома и квитанции об оплате питания за сентябрь. Спиши слова. Обозначь над словами части речи.
Сапог, белизна, писать, ты, в, линейка, она, рисовать, читать, по, на. Карточка 2. Спиши слова. Обозначь над словами части речи. Дерево, книга, за, у, я, Читать еще. 3 класс. дифференцированные карточки (русский язык). Задание на «3». Вставь пропущенную букву, подбери и запиши проверочное слово. Много тр.вы — _. Гулять в л.су _. Отметь основу слова (это часть слова без окончания). 2. Объясни значение слова с помощью слова-родственника, подбери ещё одно-два однокоренных, выдели их общую часть – корень.
3. Определи и укажи часть слова перед корнем – приставку, постарайся объяснить её работу. 4. Определи и укажи часть слова после корня перед окончанием – суффикс, подумай о его работе.
5. Проверь, все ли части слова выделены. Части слова. 3 класс. Кожевникова Ирина Герольфовна. 26 Окт презентация, документ. Урок русского языка 3 класс «Части слова.
Суффикс». Тороп Ольга Петровна. 3 Апр разное. тест по русскому языку «Части слова» 3 класс. Сторожева Елена Ивановна. 20 Мар документ. Тест по русскому языку по теме «Части слова». (3 класс). Слиткова Галина Анатольевна. 31 Мар
Розробки уроків — Українська мова 3 клас. Урок № Основа слова. Частини основи: корінь, префікс, суфікс. Тема: Основа слова. Частини основи: корінь, префікс, суфікс. Мета: формувати в учнів поняття про основу слова; вчити виділяти змінну частину, визначати основу в словах; розвивати мовлення; виховувати любов до природи.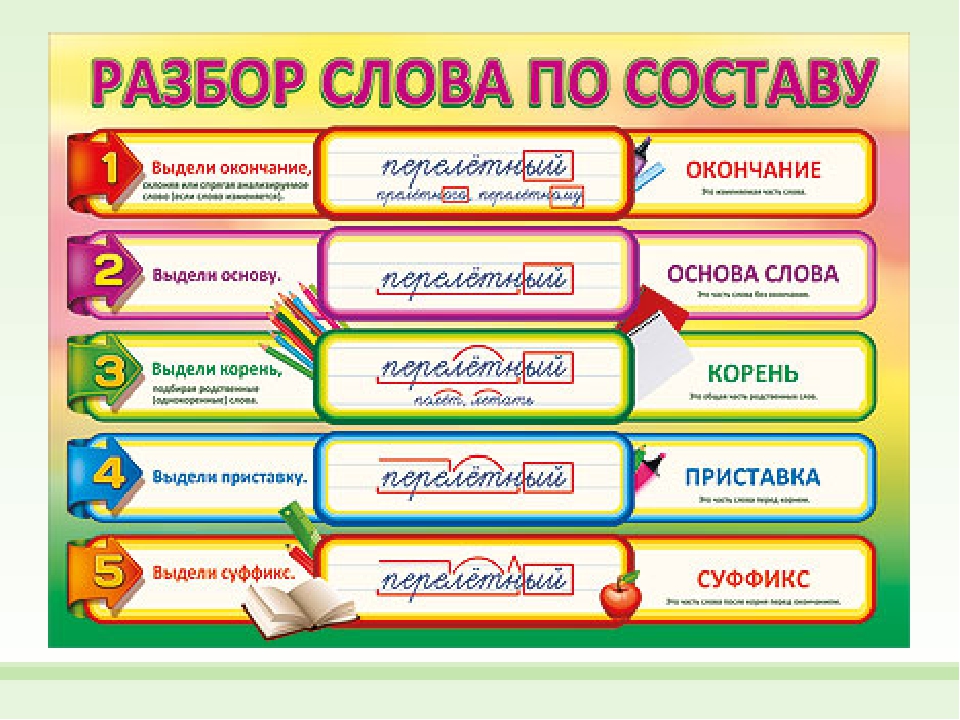
Тип уроку: урок засвоєння нових знань (формування мовної компетенції). Обладнання: підручник, зошит. Учебник №1. Проверь себя с. Home. Канакина. 3 класс. Учебник №1. Проверь себя с. 3. Находим корень слова, для этого подбираем однокоренные слова (за/пис/ка — пис/ать, под/пис/ать, пере/пис/ать; под/окон/ник — окн/а, окон/ная). 4. Находим приставку. Для этого подбираем однокоренные слова без приставки или с другой приставкой.
Основа слова — Будова слова. Орфографія. Обзор самых популярных ГДЗ в 5-м классе. Княгиня Ольга: происхождение, крещение, месть древлянам т. Слух и ухо
fb2, fb2, fb2, fb2Похожее:
Морфологический разбор слова корунд онлайн
Слово ‘корунд’
Слово корунд является Именем существительным
(это самостоятельная, склоняемая часть речи). Оно неодушевленное и употребляется в мужском роде. Разряд по значению:конкретное. Второе склонение (т.к. в им. падеже, в мужском роде окончание нулевое или в среднем роде окончания: ‘о’ или ‘е’). Относится к Нарицательным именам существительным. Множественная форма слова ‘корунд’ является ‘корунды’- В Именительном падеже, слово корунд(корунды) отвечает на вопросы: кто? что?
- Родительный падеж (Кого? Чего?) — корунда(корундов)
- Дательный падеж (Кому? Чему?) — Дать корунду(корундам)
- Винительный падеж (Кого? Что?) — Винить корунд(корунды)
- Творительный падеж (Кем? Чем?) — Доволен корундом(корундами)
- Предложный падеж (О ком? О чём?) — Думать о корунде(о корундах)
- Твердый минерал — кристаллический глинозем с примесью железа, хрома, титана.


Слово «корунд» является Именем существительным
Слово «корунд» — неодушевленное
корУнд
Ударение падает на слог с буквой У. На четвертую букву в слове.
Слово «корунд» — мужской
Слово «корунд» — конкретное
Слово «корунд» — 2 склонение
Слово «корунд» — нарицательное
Единственное числоМножественное число
Именительный п.
Корунд был просто необыкновенным по составу.
Я никогда не встречал ещё корунда.
К корунду было приковано внимание многих учёных — он содержал много иридия и титана.
Винительный п.
Это вы нашли корунд?
Творительный п.
О корунде такого размера я ещё не слышал.
- трагик
- пыжик
- селянка
- слюнотечение
- мантия
- отповедь
- золото
- дистрофик
- боеспособность
- инфекция
%d0%bc%d0%be%d1%80%d1%84%d0%b5%d0%bc%d0%bd%d1%8b%d0%b9+%d0%b0%d0%bd%d0%b0%d0%bb%d0%b8%d0%b7+%d1%81%d0%bb%d0%be%d0%b2%d0%b0 — со всех языков на все языки
Все языкиАнглийскийРусскийКитайскийНемецкийФранцузскийИспанскийШведскийИтальянскийЛатинскийФинскийКазахскийГреческийУзбекскийВаллийскийАрабскийБелорусскийСуахилиИвритНорвежскийПортугальскийВенгерскийТурецкийИндонезийскийПольскийКомиЭстонскийЛатышскийНидерландскийДатскийАлбанскийХорватскийНауатльАрмянскийУкраинскийЯпонскийСанскритТайскийИрландскийТатарскийСловацкийСловенскийТувинскийУрдуФарерскийИдишМакедонскийКаталанскийБашкирскийЧешскийКорейскийГрузинскийРумынский, МолдавскийЯкутскийКиргизскийТибетскийИсландскийБолгарскийСербскийВьетнамскийАзербайджанскийБаскскийХиндиМаориКечуаАканАймараГаитянскийМонгольскийПалиМайяЛитовскийШорскийКрымскотатарскийЭсперантоИнгушскийСеверносаамскийВерхнелужицкийЧеченскийШумерскийГэльскийОсетинскийЧеркесскийАдыгейскийПерсидскийАйнский языкКхмерскийДревнерусский языкЦерковнославянский (Старославянский)МикенскийКвеньяЮпийскийАфрикаансПапьяментоПенджабскийТагальскийМокшанскийКриВарайскийКурдскийЭльзасскийАбхазскийАрагонскийАрумынскийАстурийскийЭрзянскийКомиМарийскийЧувашскийСефардскийУдмурдскийВепсскийАлтайскийДолганскийКарачаевскийКумыкскийНогайскийОсманскийТофаларскийТуркменскийУйгурскийУрумскийМаньчжурскийБурятскийОрокскийЭвенкийскийГуараниТаджикскийИнупиакМалайскийТвиЛингалаБагобоЙорубаСилезскийЛюксембургскийЧерокиШайенскогоКлингонский
Все языкиРусскийАнглийскийДатскийТатарскийНемецкийЛатинскийКазахскийУкраинскийВенгерскийТурецкийТаджикскийПерсидскийИспанскийИвритНорвежскийКитайскийФранцузскийИтальянскийПортугальскийАрабскийПольскийСуахилиНидерландскийХорватскийКаталанскийГалисийскийГрузинскийБелорусскийАлбанскийКурдскийГреческийСловенскийИндонезийскийБолгарскийВьетнамскийМаориТагальскийУрдуИсландскийХиндиИрландскийФарерскийЛатышскийЛитовскийФинскийМонгольскийШведскийТайскийПалиЯпонскийМакедонскийКорейскийЭстонскийРумынский, МолдавскийЧеченскийКарачаевскийСловацкийЧешскийСербскийАрмянскийАзербайджанскийУзбекскийКечуаГаитянскийМайяАймараШорскийЭсперантоКрымскотатарскийОсетинскийАдыгейскийЯкутскийАйнский языкКхмерскийДревнерусский языкЦерковнославянский (Старославянский)ТамильскийКвеньяАварскийАфрикаансПапьяментоМокшанскийЙорубаЭльзасскийИдишАбхазскийЭрзянскийИнгушскийИжорскийМарийскийЧувашскийУдмурдскийВодскийВепсскийАлтайскийКумыкскийТуркменскийУйгурскийУрумскийЭвенкийскийЛожбанБашкирскийМалайскийМальтийскийЛингалаПенджабскийЧерокиЧаморроКлингонскийБаскскийПушту
Урок 28.
 от полимеров природных к полимерам синтетическим — Естествознание — 11 класс
от полимеров природных к полимерам синтетическим — Естествознание — 11 классЕстествознание, 11 класс
Урок 28. От полимеров природных к полимерам синтетическим
Перечень вопросов, рассматриваемых в теме: Какой смысл вкладывают в понятия «полимер», «мономер», «элементарное звено»? Как полимеры классифицируют по происхождению, способам получения и свойствам? Каковы свойства искусственных и синтетических полимеров, их преимущества и недостатки? Какие можно привести примеры полимеров и области их применения?
Глоссарий по теме:
Полимеры представляют собой аморфные и кристаллические, неорганические и органические вещества, общим признаком которых является то, что их структура состоит из «мономерных звеньев», соединённых в макромолекулы.
Мономер – элементарное звено полимера, группа атомов, повторяющаяся в структуре полимера.
Степень полимеризации – число мономерных звеньев – отдельных элементов в структуре полимера.
Эластичность – это способность полимеров к обратимым деформациям высокой степени при небольшой нагрузке (например, каучуки, резина).
Органические полимеры – это полимеры, которые содержат органические звенья.
Элементоорганические полимеры – это полимеры, которые содержат в цепи органических мономеров отдельные неорганические атомы. Не встречаются в природе.
Неорганические полимеры не содержат углерод-углеродных связей в повторяющемся звене, могут содержать отдельные органические радикалы, в качестве боковых атомов.
Основная и дополнительная литература по теме урока:
1. Естествознание. 11 класс: учебник для общеобразоват. организаций: базовый уровень / И.Ю. Алексашина, К.В. Галактионов, И.С. Дмитриев, А.В. Ляпцев и др. / под ред. И.Ю. Алексашиной. – 3-е изд., испр. – М.: Просвещение, 2017. – С. 135-140.
– С. 135-140.
2. Тагер А. А., Физико-химия полимеров. – М.: Научный мир, 2007. – С. 347-356.
Открытые электронные ресурсы по теме урока:
Электронный технический словарь / Раздел: полимеры, природные, синтетические. URL: http://www.ai08.org/index.php/term/%D0%A2%D0%B5%D1%85%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9+%D1%81%D0%BB%D0%BE%D0%B2%D0%B0%D1%80%D1%8C+%D0%A2%D0%BE%D0%BC+V,4157-sinteticheskie-prirodnye-polimer.xhtml
Теоретический материал для самостоятельного изучения
Современный этап человеческой цивилизации – это одновременно и этап активного развития химических веществ и различных материалов. Многие из современных материалов, созданных человеком, разработаны по аналогии и на основе природных структур. В число таких соединений, наиболее часто используемых в повседневной жизни человеком, входят высокомолекулярные соединения – полимеры.
Полимеры представляют собой аморфные и кристаллические, неорганические и органические вещества, общим признаком которых является то, что их структура состоит из «мономерных звеньев», соединённых в макромолекулы.
Число мономерных звеньев – отдельных элементов в структуре полимера называют степенью полимеризации. Степень полимеризации должна быть достаточно высокой, в противном случае соединение называют олигомером. В большинстве случаев, полимеры – это вещества, молекулярная масса которых составляет от нескольких тысяч до нескольких миллионов.
По пространственному расположению мономерных звеньев выделяют линейные полимеры, в которых звенья соединены в цепочку (например, такую структуру имеет целлюлоза) и разветвлённые, в том числе и с трёхмерными пространственными структурами.
В строении всех полимеров присутствует повторяющийся структурный фрагмент – мономерное звено, включающий несколько атомов. Полимеры, молекулы которых содержат не одну, а несколько видов повторяющихся групп, называют гетерополимерами. Полимер формируется из мономеров в ходе реакций полимеризации или поликонденсации.
По происхождению полимеры делят на природные и синтетические. Природные полимеры возникают естественным путём. Например, к их числу относятся нуклеиновые кислоты (ДНК, РНК), а также белки, полисахариды. В большинстве случаев природные полимеры – это органические соединения, но существуют и природные неорганические полимеры.
Синтетические полимеры получают искусственным путём из низкомолекулярных соединений с помощью реакций полимеризации или поликонденсации. Химические названия полимеров формируют из названия мономера и приставки «поли-», например, полипропилен, полиэтилен, поливинилацетат и т. п.
За счет того, что полимеры обладают рядом важных для хозяйственной деятельности характеристик, их используют в промышленности и быту.
Основными характеристиками полимеров являются следующие:
1. Эластичность – это способность полимерам к обратимым деформациям высокой степени при небольшой нагрузке (например, каучуки, резина).
2. Малая хрупкость кристаллических и стекловидных полимеров (например, органическое стекло, пластмассы).
3. Способность макромолекул полимеров к ориентации в пространстве под действием механического поля. Эта характеристика полимеров применяется при промышленном изготовлении плёнок и волокон.
Важными для хозяйственной деятельности человека являются и свойства растворов полимеров, в частности:
1. Значительная вязкость раствора при сравнительно небольшой концентрации полимера.
2. Образование раствора полимера через стадию набухания.
Кроме того, полимеры могут резко менять свои физико-механические свойства под влиянием небольших количеств реагента (это свойство полимера используется при вулканизации каучука, в процессе дубления кож и т. п.).
Свойства полимеров обусловлены как их большой молекулярной массой, так и цепным строением и гибкостью молекул. В промышленности полимеры используют в качестве композитных материалов.
По химическому составу полимеры классифицируют на органические, неорганические и элементоорганические.
Органические полимеры содержат органические звенья, например, это полипептиды, которые содержат пептидную группу из атомов кислорода, азота, углерода, водорода (О=С-N-Н). Пептидная связь – основа белков.
Элементоорганические полимеры не встречаются в природе и являются синтетическими. Элементоорганические полимеры содержат в цепи органических мономеров отдельные неорганические атомы (например, кремний, алюминий). Искусственно полученное вещество, которое можно отнести к данной группе – это кремнийорганические соединения.
Неорганические полимеры не содержат углерод-углеродных связей в повторяющемся звене, могут содержать отдельные органические радикалы, в качестве боковых атомов.
По форме и пространственной ориентации макромолекул полимеры разделяют на линейные, разветвлённые, плоские, ленточные, гребнеобразные, сеточные и т.д.
Кроме того, полимеры классифицируют по полярности, которая влияет на растворимость полимера. Полярность отдельных мономерных звеньев полимера определяется присутствием диполей в их составе – молекул с разобщенными положительными и отрицательными зарядами.
У гидрофильных полимеров звенья обладают высокой полярностью, эти полимеры хорошо растворяются в воде. Полимеры с неполярными звеньями являются гидрофобными, они, напротив, плохо растворяются или не растворяются в воде, но при этом могут быть растворимы в маслах или иных жидкостях (например, в бензине). Полимеры, которые содержат полярные и неполярные звенья, являются амфифильными.
Полимеры, по реакции на нагревание разделяют на термореактивные и термопластичные. Термопластичные полимеры (к которым относится полипропилен, полиэтилен, полистирол) при нагреве обратимо плавятся, а при охлаждении затвердевают. Термореактивные полимеры при нагреве разрушаются без плавления и необратимо.
Природные полимеры формируются в живых организмах. Ключевыми для жизни из них являются белки, полисахариды и нуклеиновые кислоты. Решающим этапом возникновения жизни на Земле стало формирование из простых органических молекул высокомолекулярных соединений.
Человек изначально использовал природные полимеры в своей жизни. Например, это кожа, шерсть, меха, шёлк, в их состав входят природные биополимеры. Промышленное производство полимеров началось в первой четверти XX века. Промышленное производство полимеров практически сразу развивалось в двух направлениях – это переработка полимеров природного происхождения и синтез искусственных полимеров.
Производство синтетических полимеров начато в 1906 году, когда Лео Бакеланд создал бакелитовую смолу – путем конденсации фенола и формальдегида, который при нагревании превратился в трёхмерный полимер. В течение десятилетий этот полимер использовали для изготовления аккумуляторов, корпусов электрических приборов, телевизоров, электрических розеток.
Благодаря своим физическим и химическим свойствам полимеры используются в машиностроении, сельском хозяйстве, текстильной промышленности, медицине, авиастроении и широко применимы в быту (пластик, посуда, резина, клей и лаки). Все живые ткани живых организмов – это также высокомолекулярные соединения.
Наука о полимерах с 30-х годов XX века развивается как самостоятельная область знаний. Эта наука тесно связана с физикой, коллоидной, физической и органической химией. Сегодня выделяют и отдельные области знаний – например, химия полимеров, физика полимеров.
Выводы:
Полимеры представляют собой аморфные и кристаллические, неорганические и органические вещества, общим признаком которых является то, что их структура состоит из «мономерных звеньев», соединённых в макромолекулы.
Число мономерных звеньев – отдельных элементов в структуре полимера называют степенью полимеризации. Степень полимеризации должна быть достаточно высокой, в противном случае соединение называют олигомером. В большинстве случаев, полимеры – это вещества, молекулярная масса которых составляет от нескольких тысяч до нескольких миллионов.
По пространственному расположению мономерных звеньев выделяют линейные полимеры, в которых звенья соединены в цепочку (например, такую структуру имеет целлюлоза) и разветвлённые, в том числе и с трёхмерными пространственными структурами.
Примеры и разбор решения заданий тренировочного модуля:
1. Аморфные и кристаллические, неорганические и органические вещества, общим признаком которых является то, что их структура состоит из «мономерных звеньев», соединённых в макромолекулы, это:
1. Полимеры.
2. Мономеры.
3. Молекулы.
Правильный ответ: 1. Полимеры.
2. Вставьте пропущенные слова в текст:
«У __________ полимеров звенья обладают высокой полярностью, эти полимеры хорошо растворяются в воде. Полимеры с неполярными звеньями являются _________, они, напротив, плохо растворяются или не растворяются в воде, но при этом могут быть растворимы в маслах или иных жидкостях (например, в бензине)».
Правильный ответ: гидрофильные; гидрофобные.
Sh5dowehhh против аналитиков Sports.ru: первые прогнозы зашли у всех! — Sports.ru x Parimatch — Блоги
Спор трех дотеров о топ-матчах и ставках.
Sports.ru и Parimatch запускают новый проект: три эксперта по Доте собираются раз в неделю и обсуждают топ-матчи, чтобы предсказать победителя и найти выгодные ставки. Вот кто будет в течение всей DPC-лиги разбирать будущие серии:
1. Евгений «Sh5dowehhh» Алексеев – стример, аналитик, бывший игрок, тренер и просто кич.
2. Роман Галеев – киберспортивный журналист, автор раздела Доты на Sports.ru.
3. Владислав «Kozak» Лазуренко – профессиональный каппер, главный по ставкам на Sports.ru.
Вот они слева направо:
На первой неделе нас ждет сразу три крутых матча, мимо которых сложно пройти.
Virtus.pro – короли онлайна?
Роман Галеев: «Мы посмотрели коэффициенты на эту встречу и считаем их неправильными. Нам кажется, что серию заберет Gambit, потому что выступление VP на мейджоре очень не понравилось. При этом Гамбит показали хорошие драфты в тяжелом уайлд-карде, где пришлось играть с LGD и Vici. В групповом этапе мейджора «Монако» не отлетела бы как Alliance и что-нибудь да показала.
Все еще не понятно, что с пулом у Virtus.pro: мы видели, как на лане все банили Тимбера от DM, из-за чего он чувствовал себя крайне неуверенно. Save в послематчевых интервью говорил, что команде нужно расширять пул для конкуренции с мировыми топами. Смогли ли расширить за две недели?
Итого: нам больше нравится игра, драфты и персонажи Gambit. К тому же, вышел патч и он хорошо подходит для Дрима: мета Дровки и прочих его сигнатурок возвращается».
Kozak: «Мы видели на мейджоре игру Virtus.pro с печальными пиками Энчи и Кункки. Мягко говоря, на турнире у VP все шло не очень: после падения в нижнюю сетку отдали Виспа американцам из Quincy Crew и были близки к вылету с турнира. Прошли дальше, попали на Тандер, снова показали слабую игру и посредственные пики, закономерно покинули чемпионат.
Не думаю, что VP будут в тильте после мейджора, но ребятам явно дали понять, что к тир-1 Доте на LAN-турнире они не готовы. А вот Gambit в уайлд-карде дали бой и LGD, и Vici, даже обыграли Liquid, хоть и зарофлили в решающем матче за выход в групповой этап с Барой.
Вышел новый патч, поэтому фактор андердога сглаживается, и номинально все находятся в равных условиях. Если брать во внимание коэффициент 2,8 на Gambit, то шансы, по моему мнению, неплохие. Как отметил Роман, мета нового патча располагает к возвращению старых героев от игроков «Монако»: Дум, Дровка, Некрофос и прочие удобные для них персонажи воскресли.
Sh5dowehhh: «Смотрите, мне кажется, что Virtus.pro – команда, которая показывает максимальный уровень игры именно на буткемпе. В своей стандартной комфортной обстановке, под кальянчик, они вечером отдыхают и комфортно себя чувствуют. А когда приезжают на LAN – все по-другому. Понятное дело, ведь у Сэйва, ДМа и Эпилептика на троих статистика на мейджорах 0:15 (DM в Chaos 0:5 сыграл по картам в свое время, и у этих двух парней было по 0:5 в старых VP). На мейджоре они были в заведомо некомфортной обстановке. Судить форму DMа по провалу на лане странно, такое ведь уже не впервой.
Судить форму DMа по провалу на лане странно, такое ведь уже не впервой.
Очевидно, что Gambit комфортнее чувствуют себя на лане. Sonneiko, AfterLife и No[o]ne – опытнейшие игроки, которые выступали на мейджорах и Интах, Immersion на свой сигнатурной Земле раньше разваливал на лане 7-0-20. Эти парни просто опытнее, понятно, что они смотрелись лучше в условиях LAN-турнира.
Сейчас они вернулись домой, и у «Монако» такая ситуация, что Нун с команды вышел и вернулся. У тиммейтов состояние максимально странное: они были на грани, возможно, уже искали нового мидера. Явно некомфортная ситуация, где вы вынуждены терпеть игрока, который ливнул, потому что нет выбора. И наоборот: Нун показал, что не хочет играть с этими парнями, но вынужден, ведь другого варианта у него нет.
Вы правильно сказали, что многое будет зависеть от адаптации к патчу. Но, как я уже отмечал, Virtus.pro в интернете, которые себе уже очередной кальянчик забивают, максимально настроены на игру с Гамбит. Не скажу, что это будет уверенный разгром 2:0, но серию у «Монако» отжать должны. Gambit могут удивить неожиданными драфтами, Афтерлайф может подсмотреть неожиданную стратегию из Китая и забрать карту, но ставить на них я бы не стал».
Предикты
Команда Sports.ru сошлась на победе Gambit минимум на одной карте (фора +1.5) за 1,6.
Sh5dowehhh считает, что Virtus.pro победит с точным счетом 2:1. Кэф на такой исход – 3,15.
Spirit – NAVI (Коэффициенты на Parimatch: 2.15 и 1.65)
Кэф на Spirit завышен?
Роман Галеев: «Здесь я совсем не понимаю, почему такие коэффициенты. Spirit – на коне. Они только что выиграли D2CL, где расправились с Vikin.gg и Unique со счетом 2:0 и отдали лишь одну карту HCE, и то они, по-хорошему, должны были ее закрывать, ведя в один момент 8 тысяч золота.
Насколько я помню, на первой лиге Spirit обыграли NAVI 2-1. Более того, у NAVI непонятно, что с моралью – Айсберга де-факто кикнули, а потом вернули. Непонятно, с каким пулом героев придет Ramzes на оффлейн, т.к. последнее время он играл на керри. В общем, уверенность вселяет только V-Tune.
Более того, у NAVI непонятно, что с моралью – Айсберга де-факто кикнули, а потом вернули. Непонятно, с каким пулом героев придет Ramzes на оффлейн, т.к. последнее время он играл на керри. В общем, уверенность вселяет только V-Tune.
Мы часто говорили раньше об узком пуле героев у Spirit, но я посмотрел – за последний месяц (17 игр) ни у кого нет меньше семи героев в пуле. У TORONTOTOKYO их вообще 12. А Collapse достал Акса, разнес HCE 14-1-11, и у него 40 игр уже в карьере на нем. Так что я не понимаю, почему Spirit здесь считаются такими андердогами».
Sh5dowehhh: «Ну здесь не прямо суперандердогами. 2,15 – не андердоги, когда 2,5 – это другой разговор».
Kozak: «Когда букмекеры только открыли линию на матч, на Spirit было 2,5 – очевидно прибыльная ставка. Сейчас коэффициенты подравнялись, но мы все еще считаем, что нужно брать Spirit – у них виден прогресс, а у NAVI – один большой знак вопроса».
Sh5dowehhh: «Spirit неплохо жмут кнопки, и их тренер, Silent, явно не афк сидит. Постоянно видно, что у них есть тренировочный процесс, и он успешный. Мипошка вон на Аппарате с KDA 25 бегает. Проиграли карту HCE? Бывает.
Но NAVI есть что доказывать. У них слишком большая мотивация победить конкретно первую встречу, особенно против Team Spirit. Если они смогут, весь негатив, выпавший на них в последние время, спадет, так что NAVI будут максимально потеть.
А если вы смотрите на то, что они проиграли Spirit на первой лиге, так они считали, что матч для них ничего не значит (NAVI шли со статистикой 5:0) – решала лишь встреча с VP. В последний момент Valve выкатывает правила, по котором этот матч что-то значил. Если кто-то помнит, там Alwayswannafly все три карты на Crystal Maiden играл, хотя в пуле был Phoenix. NAVI пытались запутать VP пиками, забайтить на бан какой-то. Как вы думаете, можно судить по этой серии?
Kozak: «Я помню эту серию и согласен, что на первых двух картах NAVI расслаблено играли – брали Ликана, которым не играют.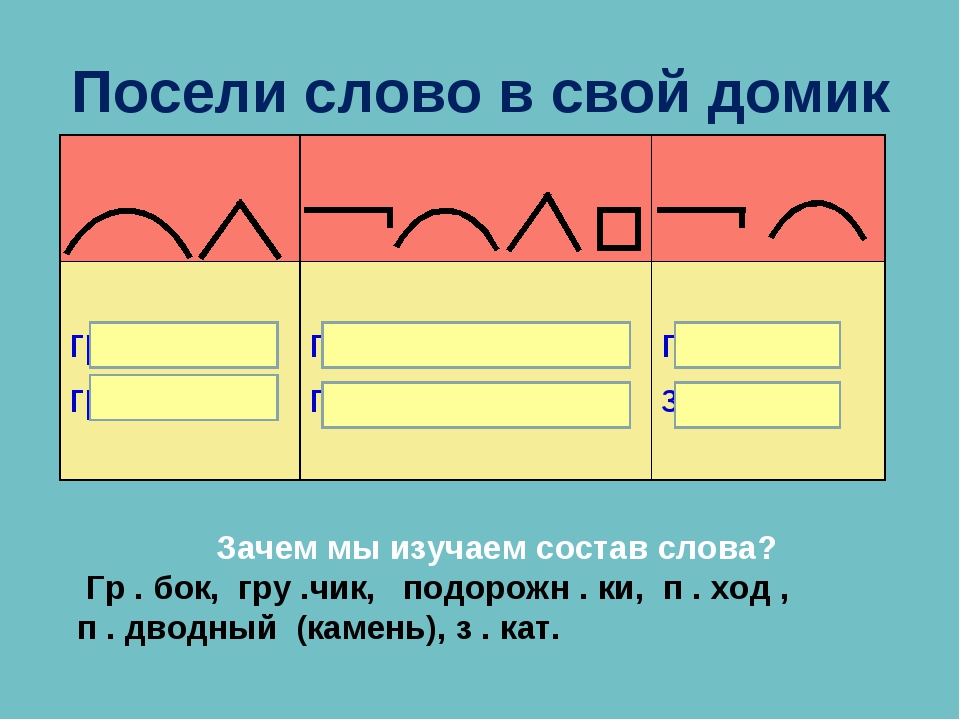 А на третьей уже был сигнатурный пик: взяли страту под Чена, как будто реально хотели выиграть, но не смогли. Spirit переломили ход карты, буквально на классе переиграли, дали бой. К тому же, у меня инсайд такой есть, что Спирит решили не собираться на буткемп на первые матчи против аутсайдеров – проиграли в итоге Empire и NoTechies (обе вылетели во второй дивизион), и из-за этого не попали на мейджор.
А на третьей уже был сигнатурный пик: взяли страту под Чена, как будто реально хотели выиграть, но не смогли. Spirit переломили ход карты, буквально на классе переиграли, дали бой. К тому же, у меня инсайд такой есть, что Спирит решили не собираться на буткемп на первые матчи против аутсайдеров – проиграли в итоге Empire и NoTechies (обе вылетели во второй дивизион), и из-за этого не попали на мейджор.
Итог: у Spirit мы видим явный прогресс, а у NAVI – непонятно что».
Sh5dowehhh: «Не стоит забывать, что вышел новый патч, а в NAVI игроки опытные. Я немного общался с игроками NAVI, у них вроде бы что-то получается, они что-то понимают.
А насчет буткемпа – они и под конец не собрались вместе. Yatoro из Украины, он не смог приехать, и Miroslaw тоже. У них поменялись результаты, потому что они кикнули So Bad. К тому же оказалось, что Miroslaw вообще их друг, им комфортно с ним играть. Korb3n в одном из интервью говорил, что Сайлент и Со Бэд не стакались, так что на первых картах у них даже тренера не было.
Любым кровью и потом нужно NAVI забирать эту игру. Я бы дал коэффициент на эту игру 1,87 – 1,87, но уверен, что NAVI должны серию забрать».
ПредиктыКоманда Sports.ru считает успешной ставку на победу Spirit за 2,15.
Sh5dowehhh верит в NAVI и их мотивацию и берет победу Natus Vincere в серии за 1,65.
Secret – Nigma (Коэффициенты на Parimatch: 1,15 и 5)
Первый матч ИЛТВ в команде Куроки.
Роман Галеев: «У нас здесь разошлись мнения, потому что мы диаметрально противоположно думаем об этом матче. Parimatch дает на Secret коэффициент 1.15 и 5 на Nigma. Здесь я согласен с коэффициентами, потому что веры в Нигму против Secret у меня никакой нет.
После патча я бы даже больше поверил в состав с w33, чем в текущий, потому после глобального апдейта максимально ценны игроки с сигнатурками в виде Висажа, Лон Друида или Мипо, как у Макса «Qojqva» Брокера. Помню послепатчевый матч Nigma – Alliance, когда никто не знал, что брать, а Виха выкатился на своем Мипаре и закончил за 20 минут. Именно такой фактор w33 мог помочь Нигме.
Помню послепатчевый матч Nigma – Alliance, когда никто не знал, что брать, а Виха выкатился на своем Мипаре и закончил за 20 минут. Именно такой фактор w33 мог помочь Нигме.
Но Пуппей после солидной пощечины всегда возвращался очень сильно. И конкурентов для Secret в Европе нет, поэтому мы и видим их всегда в топе, как в своем регионе, так и в мире».
Sh5dowehhh: «Если взять выборку в последние 10 личных встреч Secret и Nigma с Вихой, то сколько раз победила Нигма? Думаю, больше половины, потому что очень часто и в финалах турниров они давали Сикретам бой. Даже если Nigma с W33 проигрывала слабым командам, то против Secret на Бетрайдере, которого Пуппей никогда не банил, они стабильно могли побеждать даже 2:0.
По новому составу: да, Миракл постоянно хорошо играет на высоком уровне, но Ниша может его просто перефармить, начиная с линий».
Роман Галеев: «Я тоже себе это отмечал: Nisha не играет в стиле Йопажа с кучей килов на лейнинге, он просто стабильно выигрывает в фарме и ластхитах. Поэтому здесь будет интересно посмотреть за мидом, ведь для Миракла центральный коридор все еще непривычен».
Kozak: «Я наоборот считаю, что коэффициент на Secret смешной. 1,15 против пяти на Нигму – не совсем адекватно. Это все вера в прошлые результаты Secret, а на мейджоре мы видели, что у них тоже есть проблемы против сильной иностранной Доты. Те же Neon их сильно пинали и могли спокойно забирать серию, а IG вообще разгромили 2:0.
Женя правильно отметил, что у Нигмы всегда неплохо шло в матчах с Secret: и на Mad Moon от WePlay! камбэк с 0:2 до 3:2 в Bo5 и на других европейских лигах были аутплеи чисто на сигнатурках и скилле.
Сейчас Nigma подписала iLTW. Я считаю, что для них это позитивный трансфер, который принесет коллективу больше стабильности. К тому же, хороший патч для Игоря, где он разваливает пабы на керри-Гирокоптере.
Кэф 5 на Нигму это слишком много, такого быть объективно не должно. Возможно, 3,5 или 3, окей, но не 5. Условного говоря, на 2:0 от Secret дают 1,55, но если хоть на одной из карт Nigma с линий поведет тысячу золота, то уже на конкретную карту будет выше, чем до этого мы брали бы на 2:0».
Возможно, 3,5 или 3, окей, но не 5. Условного говоря, на 2:0 от Secret дают 1,55, но если хоть на одной из карт Nigma с линий поведет тысячу золота, то уже на конкретную карту будет выше, чем до этого мы брали бы на 2:0».
Sh5dowehhh: «Знаете, у Нигмы есть проблема в том, что Mind_Control выпадал из-за ковида. Не понятно, играл ли он в Доту все это время, когда в составе выступал Rmn. Адекватно оценить форму Nigma мы не можем – только на рандом. Мы можем только предположить, что они, условно, подготовились к патчу, наберут своих сигнатурок, Миракл удивит Тинкером, к которому допикают БХ, и так далее.
Я согласен, что ставить в таких матчах на Secret на 2:0 это глупо. Мы все знаем, что Пуппей любит надрафтить так, что в начале игры в лайве коэффицент уже будет 1.87 – 1.87, а потом Secret выиграют после чудесного камбэка.
Secret именно так команда, против которой букмекеры боятся равнять коэффициенты, потому что они часто камбэкают. Но Nigma именно те ребята, в которыхх можно поверить. Я уверен, что в лайве тут будут исходы, куда можно поставить лучше, чем на 2:0 до старта. Но это не говорит о вере в победу Нигмы, на этот матч надо смотреть вживую».
Kozak: «Да, подписываюсь под твоими словами, хороший матч для лайва. Зачем играть в рулетку и брать 2:0 за такой низкий кэф? Это бредовое решение».
Sh5dowehhh: «100%. За 1,55, когда уже на пиках Пуппей может отдать Виспа с Аббадоном и у тебя начинает седеть голова… Никакого смысла ставить на 1,55, когда капитан на мейджоре берет себе Бейна и отдает Виспа. С большой вероятностью Secret победят, потому что у ILTW явно могут быть проблемы с коммуникацией на таком уровне – он банально может не успевать за темпом. Первая официалка, к сожалению для нового состава Нигмы, выпала против Secret, а не условных Викингов. В общем, нужно ловить в лайве на Secret».
ПредиктыМнения у двойки Sports.ru разделились: Галеев пропускает матч из-за нерентабельного кэфа на Secret, а Лазуренко берет победу Нигмы хотя бы на одной карте (фора +1. 5) за 2,35.
5) за 2,35.
Sh5dowehhh считает текущие кэфы на Secret низкими, но хочет ставить на них в лайве, где оценка букмекера будет более рентабельной.
Ставки на неделю
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем не хватает многих типов слов / лемм (определителей, местоимений, сокращений и многого другого). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания.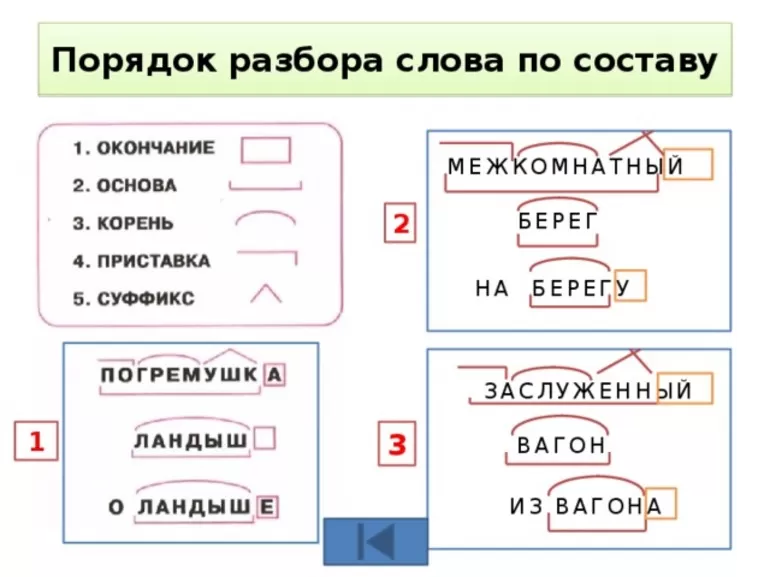 Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
voximity / pars3k: Библиотека комбинатора синтаксического анализатора Crystal
pars3k (parsec / parse 3000) — это библиотека для Crystal, добавляющая поддержку синтаксических анализаторов комбинаторов.
Структура в значительной степени вдохновлена Parsec из Haskell. Он также вдохновлен кристально-парсек .
Пояснение
Комбинаторный синтаксический анализатор — это система синтаксического анализа, которая позволяет создавать небольшие «синтаксические анализаторы»,
объект, который принимает String и имеет небольшую вычислительную логику, применяемую для извлечения
более глубокий смысл, такой как парсинг через JSON и преобразование в пригодный для использования Hash .
Идея синтаксического анализатора комбинатора — это концепция буквального комбинирования синтаксических анализаторов. Маленькие парсеры можно комбинировать с логикой (например, ИЛИ, И и т. д.) для создания более крупных и значимых синтаксических анализаторов.В конечном итоге у вас должен получиться один большой синтаксический анализатор.
Приложение
Как упоминалось ранее, этот стиль синтаксического анализатора может использоваться для создания интерпретируемых языков программирования, декодирование языков разметки, чтение из файлов разных форматов и т.д. более гибкий и надежный стиль синтаксического анализа, чем, скажем, регулярные выражения. Следующая категория будет содержат некоторые варианты использования с использованием pars3k.
Использование
требуется "pars3k" включают Pars3k
Примечание: ВЫСОКО рекомендую включить Pars3k
Все синтаксические анализаторы относятся к типу Parser (T) , где T — это конечный тип, возвращаемый анализатором.Одним из примеров примитивного синтаксического анализатора является Parser (Char) , который можно создать с помощью Parse.char (Char) .
Метод дает Parser (Char) , который при синтаксическом анализе ищет определенный символ, как указано.
Примитивные парсеры
char_a = Parse.char ('а')
помещает char_a.parse "abc" # => a В этом примере создается Parser (Char) из Parse.char и анализируется на нем строка «abc» . В
синтаксический анализатор просматривает начало строки и ищет первый символ.Если
первый символ соответствует символу, изначально предоставленному синтаксическому анализатору ( Parse.char 'a' ), затем
синтаксический анализ будет успешным, и результат синтаксического анализа вернет совпавший символ.
помещает char_a.parse "bca" # => ожидалось 'a', получилось 'b'
В этом примере используется тот же анализатор char_a , но на нем анализируется строка «bca» . Потому что не запускается
с исходным требованием 'a' , синтаксический анализ завершается неудачно и возвращает ParseError . ParseError — это
структура, содержащая сообщение об ошибке синтаксического анализа, которое можно получить с помощью ParseError # message .
Таким образом, тип возврата Parser (T) #parse является типом объединения (T | ParseError) , так как он может возвращать любой.
str_cat = Синтаксический анализ строки "кошка" помещает str_cat.parse "cat" # => cat помещает str_cat.parse "коты классные" # => кот помещает str_cat.parse "dog" # => ожидал 'cat', получил 'd'
В этом примере создается новый примитивный синтаксический анализатор, Parser (String) , созданный Parse.строка (String) . Он ожидает
точная копия предоставленной строки. В этом примере используется текст «кошка» .
Анализаторы амальгамы
char_a = Parse.char 'a' char_b = Parse.char 'b' parse_ab = char_a | char_b помещает parse_ab.parse "abc" # => a помещает parse_ab.parse "bca" # => b помещает parse_ab.parse "cab" # => ожидал 'b', получил 'c'
В этом примере создаются три парсера:
- синтаксический анализатор
(Char), который ожидает символ'a', - — синтаксический анализатор
(Char), который ожидает символ'b'и - a
Parser (Char), созданный с использованием|, который сначала пробует левый синтаксический анализатор, затем правый и использует успешный парсер.
Как видно на | Оператор позволяет создавать синтаксические анализаторы амальгамы, используя логику ИЛИ. Сначала он пробует парсер
слева, затем справа. Если оба потерпят неудачу, он выдаст ParseError , выданный крайним правым синтаксическим анализатором.
Этот процесс утомителен для большого количества символов, например, если вы хотите принять все буквы
алфавит. Для этого существует Parser (Char) , который можно создать с помощью Parse.one_char_of (String) ,
который принимает String как список символов и позволяет анализировать символ, который находится в этом списке.
parse_alphabet = Parse.one_char_of "abcdefghijklmnopqrstuvwxyz" помещает parse_alphabet.parse "abc" # => a помещает parse_alphabet.parse "bca" # => b помещает parse_alphabet.parse "xyz" # => x помещает parse_alphabet.parse "yzx" # => y помещает parse_alphabet.parse "123" # => ожидалось 'z', получилось '1'
В этом примере создается синтаксический анализатор, который принимает символ из предоставленного списка. Как видно, буквенные символы разобрать успешно, но числовые символы нет, так как они не были в исходной строке алфавит.
Кроме того, это определение parse_alphabet доступно из Parse.alphabet , которое также принимает прописные буквы. Parse.alphabet_lower принимает только строчные буквы.
Повторяющиеся синтаксические анализаторы
Мы можем создавать синтаксические анализаторы, которые будут повторяться до тех пор, пока они не перестанут анализировать, используя Parse.many_of (Parser (T)) . Этот парсер
принимает любой вид Parser (T) и выводит пригодный для использования синтаксический анализатор типа Parser (Array (T)) . Он будет соответствовать строке
непрерывно, пока он больше не сможет, и сгруппируйте все проанализированные значения в массив.
Дополнительное примечание: Parse.one_or_more_of (Parser (T)) также существует, действует аналогично, но с ошибкой, если хотя бы один синтаксический анализ
не разбирается успешно.
word = Parse.many_of Parse.alphabet помещает word.parse "hello world" # => ['h', 'e', 'l', 'l', 'o'] помещает word.parse "abc" # => ['a', 'b', 'c'] помещает word.parse "123" # => []
Есть явная проблема с результатом синтаксического анализа: он возвращает список символов. Если мы хотим преобразовать
это в пригодную для использования String , мы должны преобразовать синтаксический анализатор.
Преобразование парсеров
Существующие синтаксические анализаторы можно «преобразовать» для создания новых синтаксических анализаторов с новой логикой. Преобразование парсеров очень полезно.
Чтобы преобразовать синтаксический анализатор, используйте метод Parser (T) #transform (T -> B) , который принимает блок, который получает
результирующее значение синтаксического анализа в качестве параметра и выводит преобразованное / преобразованное значение.
Например, если вы создали парсер, который принимает числа:
цифра = Parse.one_char_of "0123456789"
После анализа он выдаст символы в случае успеха:
пут (цифра.синтаксический анализ "1"). class # => Char
, мы находим, что результатом является Char , а не какая-либо форма Number ! Чтобы решить эту проблему, мы можем преобразовать парсер:
цифра = (Parse.one_char_of "0123456789"). Transform {| char | char.to_i}
помещает digit.parse "1" # => 1
помещает (digit.parse "1"). class # => Int32 Успех! Теперь проанализированное значение нашего парсера имеет правильный тип: Int32 .
Возвращаясь к проблеме, которую мы обнаружили в парсере слов из предыдущего раздела, мы можем преобразовать массив (Char) в Строка .
word = (Parse.many_of Parse.alphabet) .transform & .reduce ("") {| value, char | значение + символ}
помещает word.parse "hello world" # => hello
помещает word.parse "abc" # => abc
помещает word.parse "" # => Это преобразование принимает символов , массив (Char) и преобразует его с помощью метода уменьшения, который выполняет итерацию
через все символы в массиве и добавляет их в пустую строку.
Кроме того, этот идентичный анализатор слов доступен как Parse.слово ( Parser (String) ).
Операторы парсера
| Оператор (OR) уже обсуждался. Есть еще пара операторов, например:
-
A >> Bсоздает новый синтаксический анализатор, который обеспечивает последовательный синтаксический анализ как A, так и B, но в результате принимает значение B. -
A << Bсоздает новый синтаксический анализатор, который обеспечивает последовательный синтаксический анализ как A, так и B, но результат со значением A.
буква = Разобрать.алфавит digit = Parse.one_char_of "0123456789" parser_take_digit = буква >> цифра parser_take_letter = буква << цифра помещает parser_take_digit.parse "a1" # => 1 помещает parser_take_digit.parse "b2" # => 2 помещает parser_take_letter.parse "a1" # => a помещает parser_take_letter.parse "b2" # => b
В этом примере создаются два парсера, букв и цифр , которые являются просто синтаксическими анализаторами амальгамы, которые позволяют
алфавитный символ или любой цифровой символ, соответственно.Затем создаются два новых парсера с использованием >> и << операторов. Первый анализирует оба последовательно, но дает результат цифр , а второй выполняет
то же самое, но результат со значением , буква . После их анализа два парсера должны работать последовательно, но
возвращает только результат синтаксического анализа, на который указывает оператор.
Списки синтаксического анализа
Parse имеет специальный синтаксический анализатор, который может анализировать список анализируемых элементов с помощью синтаксического анализатора A , ограниченного синтаксическим анализатором B .Используя это, мы можем создать синтаксический анализатор, который анализирует список слов (используя Parser.word ), разделенных
парсер амальгамы, использующий запятые. Он вызывается из Parse.delimited_list (Parser (A), Parser (B)): Parser (Array (A)) .
word = Parser.word optional_whitespace = Parser.many_of Parser.char '' запятая = (Parser.char ',') << optional_whitespace list_parser = Parse.delimited_list слово, запятая помещает list_parser.parse "привет, мир" # => ["привет", "мир"] помещает list_parser.parse "как, вы, вы" # => ["как", "есть", "вы"] помещает list_parser.parse "123, 456" # => [] помещает list_parser.parse "привет, мир, как дела" # => ["привет"]
Сложные последовательные парсеры
Если вам нужно создать сложные последовательные парсеры, вы можете использовать Parser (T) #sequence . Последовательность method - это метод, который принимает блок, который получает вывод Parser (T) в качестве значения, и должен возвращать
новый Parser любого типа, или Parser (B) .Мы можем воссоздать parser_take_digit и parser_take_letter парсеры, использующие эту функциональность:
буква = Parse.alphabet
digit = Parse.one_char_of "0123456789"
parser_take_digit = letter.sequence do | char_result |
digit.sequence do | digit_result |
Анализировать.constant digit_result
конец
конец Исходные два синтаксических анализатора представляют собой последовательность d друг в друге, и в конечном итоге возвращается синтаксический анализатор Parse.constant .
Парсер Parse.constant - это синтаксический анализатор, который принимает любое значение типа T .При анализе он ВСЕГДА возвращает
значение типа T . В этом случае мы создаем его с результатом Char из цифры .
parser_letter_digit = letter.sequence do | char_result |
digit.sequence do | digit_result |
Parse.constant ({char_result, digit_result}) # синтаксический анализатор констант с `Tuple (Char, Char)`
конец
конец Этот синтаксический анализатор будет анализировать такие строки, как a1 , b2 , c3 и т. Д., Но возвращать оба полученных значения как кортеж .
результат = parser_letter_digit.parse "a1" помещает результат [0] # => a помещает результат [1] # => 1
Эта форма упорядочивания синтаксического анализатора может быстро стать утомительной. В результате в библиотеке появился специальный макрос
вдохновленный заявлением Haskell do . Он позволяет объединять парсеры в цепочку, как указано выше, но в гораздо более линейном
и организованно. Вот самый последний последовательный парсер parser_letter_digit с использованием do_parse :
parser_letter_digit = do_parse ({
char_result <= письмо,
digit_result <= цифра,
Разобрать.константа ({char_result, digit_result})
}) Тело макроса do_parse - это список действий, разделенных запятыми. Последний элемент этого списка
ДОЛЖНО быть выражением, которое в конечном итоге возвращается через новый синтаксический анализатор.
Для каждого из других элементов в списке они должны быть либо результатами синтаксического анализа, либо локальными переменными.
- Результаты синтаксического анализа выглядят как
имя_результатной_переменной <= parser,. В этом случае результат парсераимя_результатной_переменной. - Локальные переменные - это просто
имя_переменной = значение,. В этом случаеимя_переменнойустанавливается равным, значение.
Используя наши знания о pars3k, мы можем создавать такие парсеры:
word = Parse.word
whitespace = Parse.many_of Parse.char ''
равно = пробел >> (Parse.char '=') << пробел
key_value_pair = do_parse ({
ключ <= слово,
eq <= равно,
значение <= слово,
Parse.constant ({ключ, значение})
})
запятая = (Разобрать.char ',') << пробел
key_value_list = Parse.delimited_list key_value_pair, запятая
помещает key_value_list.parse "hello = world" # => [{"hello", "world"}]
помещает key_value_list.parse "how = are, you = sir" # => [{"how", "are"}, {"you", "sir"}]
помещает key_value_list.parse "all = sorts, of = supported, white = space" # => [{"all", "sorts"}, {"of", "supported"}, {"white", "пробелы"} ] Пользовательские парсеры
Пользовательские парсеры могут быть созданы с использованием пользовательской логики. Иногда это необходимо, если существующие примитивные парсеры не могут быть объединены достаточно эффективно, чтобы выполнить задачу.
def char_parser (символ)
Parser (Char) .new do | context |
если context.position> = context.parsing.size
ParseResult (Char) .error "Ожидается '# {char}', получен конец строки", контекст
elsif context.parsing [context.position] == char
ParseResult (Char) .new char, context.next
еще
ParseResult (Char) .error "ожидался '# {char}', получил '# {context.parsing [context.position]}", context
конец
конец
конец -
контекст- этоParseContext -
контекст.parsing- это анализируемая строка -
context.position- позиция в анализируемой строке -
ParseResult (T)- результат синтаксического анализа типаT, такой же, как и ожидаемый синтаксический анализатор -
ParseResult (T) .new result, new_context_after_shiftдолжен использоваться для получения проанализированных значений -
ParseResult (T) .error message, original_contextдолжен использоваться для выдачи ошибок синтаксического анализа
Это определяет char_parser (Char) , который создает синтаксический анализатор, который ожидает указанный символ.Эта реализация
совпадает с внутренней реализацией Parse.char (Char) . См. Исходный код, чтобы узнать о других приложениях
Парсеры, производные от блоков.
Документы
Создание документов с помощью Crystal docs .
(PDF) CRYSTAL: Создание концептуального словаря
заданных определений пришлось отбросить вручную)
Система PALKA [Moldovan and Kim, 1992,
Moldovan et al, 1993], используемая ЛАО, включает в себя индукцию
itep simdar в CRYSTAL PALKA кон-
формирует начальную «структуру шаблона Frame-Phrasal»
(FP-структуру) из каждого примерного предложения, которое было помечено как
как имеющее информацию для извлечения. Структура FP-
включает ограничение на корневая форма глагола
и семантические ограничения для групп существительных, кроме
для предложных фраз без маркированной информации
PALKA обобщает семантические ограничения, перемещаясь вверх по семантической иерархии
и специализируется, перемещаясь вниз
вниз пока FP-структура не закодирует все прикладные
положительных обучающих примера и ни один из отрицательных
PALKA не является допустимым. шума в обучающих данных, и
один отрицательный экземпляр может блокировать в противном случае g & od
обобщение
CRYSTAL допускает более выразительные шаблоны извлечения
, чем AutoSlog или PALKA, тогда как AutoSlog требует точного ограничения слов для триггерное слово или
слов, которые были изначально определены из одного экземпляра
, CRYSTAL допускает точное ограничение слов для
любых слов, которые он узнает как значимые, а также может выучить
определений CN без ограничений слов PALKA FP
структур ограничивают корневую форму глагола, но не позволяют
никаких других ограничений точного слова В отличие от AutoSlog и
PALKA, CRYSTAL не принимает априорного решения о том, какие
составляющих должны быть включены в его определения CN
Индуктивная концепция обучение в CRYSTAL аналогично
описанному алгоритму индуктивного обучения по Mitchell
[1982], поиск на основе данных «от конкретного к общему», чтобы найти
наиболее конкретное обобщение, которое охватывает все положительные
и никаких отрицательных случаев. CRYSTAI преследует ту же цель,
, но использует жадное объединение аналогичных экземпляров, а не поиска в ширину
Это не гарантирует, что
CRYSTAL всегда найдет оптимальный словарь, но
на практике словари CRYSTAL кажутся близкими к
оптимальным
Еще один обзор индуктивного изучения концепций, by
Михальски [1983] описывает «звездную методологию» 1, которая
очень похожа на алгоритм CRYSTAL. Эта методология
способна изучить набор множественных обобщений
, чтобы охватить положительные примеры, сохраняя только лучшие
объединение, а не ветвление по всем возможным искоренениям поколения
Михальский рассматривает эту методологию в терминах
алгоритма покрытия набора с целью объединения
обобщений для нахождения минимального набора, охватывающего все
положительных обучающих примеров, избегая отрицательных значений
позиций. Это и есть цель CRYSTAL
8 Выводы
CRYSTAL - одна из первых систем, которая автоматически
выводит концептуальный словарь из учебного корпуса,
и представляет собой улучшение по сравнению с предыдущими попытками
вывести правила анализа текста из обучающих примеров. Цель
CRYSTAL - найти минимальный набор общих
обобщенных определений CN, которые охватывают все положительные
обучающих экземпляров и проверяют каждое предложенное определение
на тренировочном корпусе, чтобы гарантировать, что частота ошибок
находится в пределах предопределенного допуска CRYSTAL'S error toler-
Параметрance также позволяет пользователю управлять отзывом -
ion компромисс
Требования CRYSTAL - это анализатор предложений
lyzer, семантический лексикон, который отображает отдельные слова в классы
в семантической иерархии, и набор аннотированных
обучающих текстов Подход, принятый CRYSTAL Fa-
упрощает систему извлечения информации «под ключ», что
не требует знания технологий обработки языка.
технологий со стороны конечного пользователя, который создает аннотационный учебный корпус
CRYSTAL, а затем использует обучение
для создания системы обучения. полностью функциональный концептуальный словарь, который
не требует дополнительной разработки знаний
Ссылки
[Granger, 1977] R Granger FOUL-UP Программа, которая
определяет значения слов из контекста В
Proceeding * Пятой международной конференции
по искусственному интеллекту, страницы 172-178 Морган
Кауфманн, 1977
900 02 [Lehnert et al, 1993] W Uhnert, J McCarthy,S Soderland, E. RilofT, C. Cardie, J. Peterson, Feng,
C Dolan, and S. Goldman University of
Massachusetts / Hughes Описание CIRCUS
Система, используемая для MUC-5 В ходе работы * пятой конференции по пониманию сообщений
(MUC 5), страницы
277-290, 1993
[Lehnert, 1991] W Lehnert Symbobc / iubBymbolic
Анализ предложений Эксплуатация лучшее из двух миров In
J Barnden и J Pollack, редакторы, Advances in
Connectiontst and Neural Computing Theory, Vol 1
pages 135-164 Ablex Publishers, Norwood, NJ, 1991
[Lindberg et al, 1993 ] D Lindberg B Humphreys и
A McCray Unified medical language systems Методы
информации в медицине, 32 (4) 281-291, 1993
[Михальски, 1983] Теория RS Михальски и методология индуктивного обучения
Искусственный интеллект,
20 111-161, 1983
[Mitchell, 1982] TM Mitchell Generahzation as search
\ r искусственный интеллект, 18 203-226, 1982
[Moldovan and Kim, 1992] D Moldovan и J Kim
PALKA Система для получения хнгутатических знаний
Технический отчет PKPL 92-8, USC Department of
Electrical Engineering Systema, 1992
[Moldovan et al, 1993] D Moldovan, S. 1 Procee звонки Пятого.Сообщение
Understanding Conference (MUC 5), San Mateo, CA,
August 1993 Morgan Kaufmann
[RilofT, 1993] E RilofT Автоматическое построение словаря
для задач извлечения информации В
Proceedings of the Eleventh National Conference on
Искусственный интеллект, страницы 811-816, Вашингтон, округ Колумбия,
Июль 1993 г. AAAI Press / MIT Press
[Zernik, 199l] U Zenuk Lexical Acquisition Использование
Интернет-ресурсов для создания словаря Лоуренс
Erlbaum Associates, Хиллсдейл, Нью-Джерси, 1991
SODERLAND, ETAL 1319
Кристалл о множественности английского языка
Дэвид Кристал исследует заметный рост английского языка и обсуждает различия в формальных и неформальных письменных и устных словах, которые формируют идентичность и социальные отношения во всем мире.
[T] литературный язык не является однородным явлением, внутренне непротиворечивым в том, как он использует произношение, орфографию, грамматику, лексику и образцы речи. Общее впечатление, что такая последовательность существует в англоязычном сообществе, происходит из того факта, что большая часть письменного английского языка, который мы видим вокруг себя, имеет формальных и характеров. Это английский в своем лучшем поведении. Когда люди составляют книги, статьи, брошюры, вывески, плакаты и все другие печатные издания на английском языке, они пытаются «сделать это правильно», часто нанимая персонал (например, редакторы копий) или руководства (например, руководства по домашнему стилю). ), чтобы гарантировать соответствие языка стандарту.То же самое относится к людям, которые профессионально говорят на этом стандарте, например дикторам радио, политическим представителям, профессорам университетов и юристам в зале суда. Чем ближе они смогут привести свой устный стиль к письменному стандарту, тем меньше они будут подвергаться критике за "небрежность", "лень" или "небрежность". Таким образом, общественный язык, который мы слышим и читаем, обычно находится в формальном конце спектра.И спектр там есть, в пределах стандартного английского языка. Вариации везде.Даже в формальной сфере существует разнообразие. Юристы, священнослужители, политики, врачи, доноры, дикторы радио, ученые и другие, даже когда общаются настолько осторожно, насколько это возможно, не все говорят и пишут одинаково….
[На] другом конце спектра неформальным стандартным английским сильно пренебрегали. Что происходит с выступлением дикторов радио в столовой BBC? Как разговаривают политики, когда встречаются, чтобы выпить? Используют ли преподаватели университетов в поездке за границу на том же языке в своих открытках или электронных письмах домой, что и в своих лекциях и статьях? Разве неработающие редакторы никогда не разделяют инфинитивы? Как только мы начинаем задавать такие вопросы, становится ясно, что здесь есть другой мир, ожидающий своего исследования.…
Чем больше у нас возможностей в формально-неформальном диапазоне, тем больше мы чувствуем себя готовыми удовлетворить потребности сложного, многогранного общества. Что касается одежды, разнообразный гардероб позволяет нам одеваться по случаю; То же самое и с языком. Чем больше у нас языкового выбора, тем больше мы способны действовать надлежащим образом при переходе от одного социального события к другому. Очевидно, что любой, кто не умеет выражать по-английски формально, с контролем и точностью, находится в серьезном невыгодном положении в современном обществе.Но верно и обратное: любой, кто не способен справиться с неформальным диапазоном использования английского языка, также находится в серьезном невыгодном положении. …
Иметь только один стиль в нашем распоряжении или не иметь чувства уместности в стилистическом использовании - это бессильно и беспокоит общество. Мы не только больше не контролируем ситуацию, в которой находимся, но и вскоре обнаруживаем, что стилистическая несостоятельность - это первый шаг на пути к социальной изоляции. …
Это относится ко всем культурам и ко всем языкам, но это особенно актуально в случае такого языка, как английский, который развил так много нюансов формальности и неформальности в ходе своего долгого, социально разнообразного, технологического влияния и все более глобальная история.Чем больше мы понимаем эти нюансы, тем лучше, чтобы мы могли использовать их надлежащим образом при случае, а также соответствующим образом реагировать, когда их используют другие. Контроль также означает, что мы можем переключаться с одного стиля на другой, чтобы передать определенный эффект. …
Ни одно описание истории английского языка не должно игнорировать весь диапазон формальности языка, но неформальные уровни были серьезно недопредставлены в традиционных описаниях, отчасти потому, что они были так сильно связаны с региональной диалектной речью.На протяжении веков языковой педагогики формальный английский был превознесен, а неформальный английский - маргинализирован - часто наказывался, используя такие ярлыки, как «небрежный» или «неправильный». Но чем больше мы ищем неформальности в истории английского языка, тем больше мы находим ее, и тем более в контекстах, имеющих однозначную литературную родословную. Это еще одна история, которую предстоит рассказать. …
Одной из наиболее важных тенденций в эволюции английского языка во второй половине двадцатого века действительно было появление новых стандартных употреблений в англоязычных сообществах мира, а также новых разновидностей нестандартного английского языка в этих сообществах, многие из которых из них говорят представители этнических меньшинств.В то же время более старые региональные сорта, которые ранее не привлекали особого внимания за пределами страны их происхождения, такие как карибские англичане, Южная Африка или Индия, получили международную известность, особенно благодаря творческой литературе. Их истории тоже важны, потому что они рассказывают о зарождающейся идентичности. …
Идентичность, конечно, гораздо большее понятие, чем география. Ответ на вопрос «Кто вы?» Нельзя свести к «Откуда вы?», Хотя это измерение, несомненно, имеет решающее значение.Есть много возможных ответов, таких как «Я врач», «Я сикх», «Я подросток» или «Я женщина», и каждая из этих идентичностей влияет на то, как говорящий использует язык - или использовал язык в прошлом. Новые стандарты, нестандартность, неформальность и идентичность ... настоящих английских историй, которые никогда не были рассказаны полностью.
Кристалл, Дэвид. Истории английского языка . Лондон: Penguin Books, 2004, стр. 7-11, 13-14.|| Амазонка || WorldCat
Дэвид Кристал, Кембриджская энциклопедия английского языка (третье издание)
1Эта обширная энциклопедия состоит из 506 страниц, включает в себя предисловие, вводную главу и еще 24 главы, разделенные на шесть частей, касающихся различных тем: история английского языка, его словарный запас, грамматика, устные и письменные разновидности, использование и усвоение языка. Он дополняется полезной веб-графикой и важным разделом для дальнейшего чтения для каждого раздела книги, что позволяет углубить любой из предметов.Кроме того, он содержит три указателя по лингвистическим предметам, авторам и темам соответственно.
2 Книга представляет собой уникальный справочник по текущим знаниям английского языка и включает в себя представление различных аспектов каждого подполя вместе с иллюстрациями, таблицами данных, картами, диаграммами и отдельными панелями, которые включают анекдотические или конкретные случаи, иллюстрирующие и предоставить более глубокое понимание рассматриваемой темы. Некоторые главы даже включают упражнения с ответами на боковой странице, что добавляет интерактивный компонент к работе.
3Почти каждая страница из 25 глав содержит хотя бы один из этих пунктов, что обеспечивает педагогическую цель этой амбициозной работы. Регулярное распространение теоретического содержания, тематических исследований и анекдотических статей делает работу всеобъемлющей и легкой для понимания. Как пишут авторы в предисловии, он стремился к «балансу между разговором о языке и предоставлением языку возможности говорить сам за себя», следуя модели его предыдущей работы Кембриджская энциклопедия языка .
4 Педагогический характер этой книги делает ее подходящей для разных категорий читателей. Студенты, изучающие английский язык, английскую лингвистику или общее языкознание, найдут единый отчет о многочисленных темах, которые включены в изучение языка в целом и английского языка в частности. Кроме того, благодаря структурированному отчету и сочетанию научной информации с иллюстрациями и небольшими независимыми статьями, читатели, не являющиеся академическими, интересующиеся английским языком, также найдут полезные идеи по любому аспекту предмета, будь то в форме конкретной информации или иллюстративного материала. Примеры.
5Первая глава «Моделирование английского языка» состоит из короткой вводной диаграммы, показывающей отношения между различными аспектами изучения языка, раскрытыми в основной части работы, в соответствии с классической дихотомией: структура и использование. Следующие главы сгруппированы в вышеупомянутые шесть тематических частей, каждая из которых содержит переменное количество глав от двух до шести, каждая из которых посвящена основным областям изучения конкретного подполя.Эти шесть глав также различаются по длине: 120 страниц посвящены Части 1 ( The History of English ), а 178 - Части 5 ( Using English ), а остальные части составляют от 30 до 75 страниц.
6В первой части, «История английского языка», представлены первые семь глав в хронологическом порядке: «Истоки английского», «Древнеанглийский», «Среднеанглийский», «Ранний современный английский», «Современный английский» и, наконец, «Мировой английский», расширяющий эту традиционную классификацию.Для каждой главы автор предлагает отчет об основных осях синхронного описания: орфография, звуки, грамматика и лексика, а также другие аспекты, такие как существующие корпуса и основные вехи в истории языка для каждого периода, такие как The Anglo- Саксонские хроники , Чосер, Шекспир и др.
7 Как мы уже упоминали, работа Кристал полезна и восхитительна как для студентов, изучающих лингвистику, так и для людей, интересующихся английским языком. Тем не менее, некоторые части работы более доступны, чем другие, вследствие рассматриваемой темы.Например, часть 1 содержит большое количество данных, часть из которых (например, описание древнеанглийского языка) является каким-то образом специализированным, что делает ее менее доступной для тех, кто не имеет лингвистической подготовки. Напротив, часть 2 посвящена более знакомому предмету для читателя, не знакомого с лингвистикой: лексике, и поэтому она более доступна для читателей, не имеющих предварительных знаний в лингвистике.
8Грамматика является предметом Части 3, поэтому отчет обязательно неполный.Он представляет собой выбор основных тем, с тем преимуществом, что не используется какая-либо техническая терминология. Таким образом, эта часть почти полностью состоит из панелей, содержащих примеры грамматических особенностей. Часть 4 предлагает описание двух технических аспектов описания английского языка: фонетики и письма. Как следствие, он состоит из меньшего количества иллюстраций, анекдотов и примеров и поэтому менее образовательный, но в нем удается представить схематическое изложение основ английской фонологии, фонетики и письма на нескольких страницах.Завершая работу, в Части 5 добавлены некоторые темы по изучению и изучению английского языка. Представлено лишь небольшое количество явлений, но они точно проиллюстрированы совокупными данными и диаграммами.
9 Рассмотрев это содержание, можно удивиться интересу объединения истории английского языка в один том (Часть 2), его грамматики (Части 3 и 4), а также изучения и изучения (Части 5). Включение диахронического описания (часть 2) и синхронного описания (части 3 и 4) кажется амбициозным, но логичным в энциклопедическом труде такого рода.Однако последняя часть нарушает его тематическую согласованность, поскольку затрагивает темы, связанные не с самим английским языком, а с его изучением. Тем не менее, эта часть, несомненно, обогащает описание описания английского языка новыми параметрами анализа; Было бы жаль опускать данные об овладении языком и о свойствах английского языка, выдвинутые корпусными исследованиями. Это характерная черта работы Кристалла: она направлена на включение основных ссылок на все области изучения английского языка, включая самые последние тенденции.
10Глава 2, «Истоки английского языка», представляет собой краткое введение, представляющее мифическое и историческое происхождение английского языка, предшествующее главе 3 о древнеанглийском языке. Наряду с основным описанием языка в этой главе рассматривается ряд вопросов: руны, ранняя литература и ее устройства, фонетические изменения, различные источники словарного запаса, такие как латинский и древнескандинавский, влияние скандинавских народов и появление диалектов. Еще одним ценным активом главы является количество иллюстрированных примеров ранних письменных работ, часто сопровождаемых их транскрипцией и переводом, что может быть особенно полезно как для студентов, так и для дилетантов.Точно так же наличие карт важно для понимания зарождения древнеанглийских диалектов.
11 В главе 4, посвященной среднеанглийскому языку, представлена преемственность английского языка через исторические события и их влияние на трансформацию языка, а также обсуждаются такие темы, как изменение и преемственность литературных традиций, творчество Чосера, норманнский и французский языки. влияние и изменения в различных аспектах языка: звуковой системе, орфографии, грамматике, морфологии и лексике.Особое внимание обращается также на развитие среднеанглийских диалектов и происхождение стандартной разновидности. Все это содержание представлено в ясной и краткой форме. Как и в предыдущей главе, содержание панелей имеет большую ценность: изображения различных литературных произведений сопровождаются их транскрипцией, а использование карт и диаграмм является важным вкладом в понимание рассказа Кристал.
12 В главе 5 представлено синхронное описание раннего современного английского языка, примерно между 1400 и 1800 гг. Нашей эры, и основное внимание уделяется ряду вопросов: появлению книгопечатания в Англии, основным текстам, таким как различные версии Библии, авторам, таким как Шекспир, изменениям. в грамматике и звуке, стабилизация языка (под влиянием регуляризации орфографии или пунктуации) и публикация словаря Джонсона.Опять же, иллюстрации позволяют получить визуальное изображение главных героев и справочных работ, а панели предлагают несколько примеров каждого пункта.
13Глава 6 содержит обзор некоторых интересных тем современного английского языка, таких как грамматические изменения в начале этого периода, влияние предписывающей грамматики, современные разновидности английского языка, американская языковая идентичность и современные тенденции в лексическом творчестве. В некоторых таблицах содержатся конкретные данные по этим вопросам, например об эволюции создания научной лексики и предпочтительном произношении некоторых терминов.Кроме того, благодаря многочисленным изображениям, он представляет и иллюстрирует ряд литературных личностей, которые внесли свой вклад в языковую идентичность современного английского языка, таких как Чарльз Диккенс.
14Глава 7 посвящена разновидностям английского языка во всем мире, таких как Австралия, Новая Зеландия, Южная Африка, Южная и Юго-Восточная Азия, Колониальная Африка и южная часть Тихого океана, уделяя особое внимание синхронному и диахроническому описанию разновидностей в США. Хотя такое масштабное освещение обязательно схематично, карты и диаграммы позволяют нам связать их с производными британского или американского английского языка.В нем также представлены интересные данные об использовании английского языка как L1 и L2 во всем мире, а также группировка этих разновидностей в соответствии с различными стандартами английского языка.
15 Вторая часть книги, объединяющая главы с 8 по 12, посвящена лексике и исследует ее природу, ее источники, этимологию, структуру и ряд лексико-семантических понятий, таких как табу и клише. Глава 8 вводит эту часть, затрагивая тему размера словаря и некоторых видов элементов, входящих в его состав, таких как сокращения и имена собственные.В главе 9 рассматривается тема, представляя источники английской лексики и некоторые правила словообразования, такие как составные слова или неологизмы, предоставляя забавные иллюстрированные примеры популярной и литературной культуры.
16Глава 10, посвященная этимологии, рассматривает традиционные темы семантических изменений и народной этимологии и развивает более оригинальный вопрос о собственных именах для мест, людей или предметов. Названия мест проиллюстрированы несколькими картами, на которых представлены источники географических названий в Англии, США и Канаде, а имена людей анализируются на предмет их типа, вариаций и использования во времени.
17Глава 11 исследует структуру лексики, обращаясь к таким предметам, как семантические поля, тезаурусы, синтагматические и парадигматические отношения, словосочетания, лексикализация и семантические отношения, такие как синонимия и гипонимия. Использование панелей для диаграмм и примеров представляет собой важный инструмент в этой главе, чтобы проиллюстрировать структурные взаимосвязи в лексиконе. Глава 12 обогащает это повествование включением коннотативных аспектов: табу, ругани, жаргона, сленга, двусмысленности, политкорректности и архаизмов, среди прочего.
18Часть 3 посвящена грамматике английского языка, затрагивая ряд тем: определение синтаксиса, морфологии, частей речи и структуры предложения в главах 13, 14, 15 и 16 соответственно. В главе 13 проводится различие между понятиями грамматических знаний и предписывающей грамматики, а также вводятся основные понятия, которые позволят нелингвистам легко понять следующие главы. В главе 14 представлены некоторые характерные особенности английской грамматики, такие как суффиксирование числа существительных и система падежей и времени глагола.Примеры очень конкретны, но доступны благодаря их схематическому расположению. Здесь, как и в остальной работе, доступность предпочтительнее глубины.
19 Глава 15 продолжает это техническое описание, имея дело с частями речи и их подклассами в соответствии с их особыми семантическими, морфологическими или синтаксическими свойствами. Опять же, синоптическое представление позволяет читателю получить быстрый обзор основных единиц анализа. Аналогичным образом, описание структуры предложения в главе 16 содержит множество структурированных тем, таких как типы и функции предложений, элементы предложения, фразы, вербальные свойства (такие как аспект, голос и время), информационная структура и текстовая связность.Этот общий обзор особенно полезен для знакомства с одной из этих конкретных тем, но он менее явным в отношении взаимосвязи между этими различными аспектами грамматики.
20 Часть 4 короче других частей и состоит только из двух глав, 17 и 18, которые касаются устной и письменной речи соответственно. Первый представляет основы фонологической и фонетической системы английского языка, уделяя особое внимание описанию наиболее сложных аспектов, таких как гласные и дифтонги, и уделяя особое внимание месту и манере артикуляции, структуре слогов, связанной речи, просодии и звуку. символизм.За исключением последней темы, эта глава обязательно носит технический характер, но достаточно ясна, чтобы дать базовые знания любому читателю, не имеющему лингвистического образования.
21Глава 18 посвящена теме письма и состоит из двух разных частей. Первый представляет собой описание элементов латинского алфавита с его происхождением и вариантами, как синхронными (верхний регистр против нижнего регистра), так и диахроническим, и заканчивается парой концепций текстометрии: частотой и распределением.Вторая часть продолжает техническое описание и включает некоторый педагогический материал для работы с различными разнородными темами: графемические символы и разнообразие, графология, орфография и пунктуация.
22 Раздел 5 работы завершает описание английского языка, данное в предыдущих главах, добавляя другую перспективу. Если в частях 2–4 рассматриваются различные аспекты английского языка как абстрактной системы, в части 5 описывается способ использования английского языка и, в частности, различные оси вариации в соответствии с классическим анализом.Эти оси включают диатопические, диастратические и диафазные различия, но работа Кристал включает также более инновационные рамки, такие как особенности различных текстовых гендеров и использование английского языка в интернет-сфере.
23Глава 19 расширяет описание использования языка, принимая во внимание использование предложений в реальном дискурсе. Особое внимание уделяется текущим тенденциям в изучении языков, таким как разговоры, и представлены некоторые существующие модели анализа, охватывающие как монологические, так и диалогические различия.Он также содержит интересное описание языковых вариаций в типах текста и речевых носителях, включая недавние типы текста, рожденные интернет-революцией.
24Глава 20 обогащает описание использования английского языка представлением региональных вариаций, в основном за счет демонстрации и комментирования отрывков из газет по двум основным моделям использования языка, американскому и британскому английскому. Он отображает некоторые из наиболее заметных различий в произношении, грамматике и словарном запасе.Он также широко использует карты и диалектные атласы для учета внутренних вариаций этих двух моделей, предоставляя подробные данные, включая британские разновидности английского языка, такие как шотландский, ирландский и валлийский английский, и мировые разновидности, такие как канадский, карибский, австралийский, новый Зеландия, южноафриканский и южноазиатский английский. Это описание обязательно схематично, но позволяет читателю уловить общее представление об особенностях английского языка во всем мире.
25Глава 21 посвящена социальным вариациям, включая такие темы, как прескриптивизм и гендерно-уважительное использование, но большая часть ее сосредоточена на особенностях английского языка в различных профессиональных областях, таких как наука, право и политика, а также в типах СМИ: журнал, радиовещание, спорт, реклама и т. д.Точно так же глава 21 объединяет данные последних тенденций в корпусной лингвистике, которые стремятся охватить максимальное разнообразие использования языков. Стремясь к полноте, он также включает очень специфические способы использования языка, такие как шахматы, геральдика и книги рецептов.
26Глава 22 идет еще дальше в описании языковых вариаций; Если глава 21 направлена на охват широкого круга случаев использования определенного языка в целях общения, в этой главе исследуются возможности языковых вариаций для других целей, например, для игры, создания социальной дистанции, юмора и выражения литературной или личной идентичности.Особое внимание уделяется юмору и выражению идентичности, детализируя их особенности на разных уровнях языка: фонетике, синтаксисе, морфологии, лексике и письме. Он завершается ссылкой на судебную лингвистику, которая анализирует личные различия для создания научных отчетов, используемых в юридических вопросах.
27 Под заголовком «Электронный вариант» Глава 23 завершает Часть 5, в которой представлены конкретные применения в цифровых медиа и различные характеристики различных типов текста: текстовые сообщения, электронная почта, группы чата, блоги и т., а также особое использование языка в юмористических целях. Что еще более интересно, в нем схематично представлены отличительные черты английского языка в электронно-опосредованном общении (EMC) или netspeak. В главе анализируются особенности словообразования, графологии (орфография, заглавные буквы, интервалы и т. Д.), Пунктуации, грамматики, дискурса и прагматики.
Изложение в работе последних тем в электронно-опосредованной коммуникации может быть преимуществом, поскольку оно информирует о последних тенденциях по этой теме, как это делают немногие книги, и недостатком, поскольку эти данные скоро устареют из-за быстрого развития технологий и его (лингвистические) практики.В любом случае, всеобъемлющий характер работы делает необходимым включение этой главы, которая останется свидетельством состояния электронных коммуникаций в конце 2010-х годов.
28Последний раздел работы знакомит с некоторыми темами, касающимися приобретения и изучения языка с использованием новейших инструментов. В главе 24 приводится ряд примеров, которые дают общее представление о том, как дети усваивают язык, а также об использовании ими звуков, слов, морфологии и синтаксиса на ранних этапах обучения.В нем также упоминаются некоторые недостатки в речевой деятельности, например, вызванные афазией, заиканием или задержкой речевого развития.
29 Наконец, глава 25 касается использования цифровых инструментов для анализа английского языка, таких как корпусные и электронные словари. В нем представлена типология корпуса, некоторые примеры наиболее важных из них и некоторые методы анализа данных корпуса, такие как теги и структурирование. Однако он не касается более специализированных методов, таких как синтаксический анализ.Точно так же в описании электронных словарей упоминаются новые системы классификации слов, такие как деревья слов, но не упоминаются другие важные, такие как создание лексико-семантических онтологий. В этом смысле эта глава менее глубока, чем остальные, несомненно, из-за того, что цель работы - отдать предпочтение доступности над глубиной.
30С учетом всего этого в этой книге читатель не найдет ответов на вопросы о грамматических правилах или произношении описательного или предписывающего характера того или иного элемента языка.Это не учебник по грамматике, и как таковой он описывает не то, как работает английский язык как частный язык, а как он работает как образец естественного языка, как макросистема. Тем не менее, исчерпывающий охват этого описания делает его уникальным по количеству предметов, рассматриваемых в унифицированной и структурированной манере.
31 Таким образом, энциклопедия Crystal Encyclopedia предоставляет подробный и удобный отчет почти обо всех аспектах английского языка, которые могут быть интересны неспециалисту.С одной стороны, иллюстрации, примеры и простой язык делают его доступным для всех читателей; с другой стороны, специфика данных и широкий охват предметов делают его также интересным инструментом для лингвистов. Кроме того, благодаря простой и понятной структуре работы читатель может легко найти ответ, пример или развитие на любой конкретный вопрос о лингвистическом описании английского языка, кроме грамматических правил.
32 Тем не менее, читатель должен иметь в виду, что это справочник, посвященный основным вопросам научной дисциплины лингвистики, а не руководство, которое можно легко прочитать от начала до конца.Действительно, подробный отчет о предметах, затронутых в книге, делает ее настолько насыщенной информацией, что читать ее от корки до корки было бы ошеломляюще. Степень охвата этой работы можно проиллюстрировать, сравнив ее с программой университетского учебного плана по английской лингвистике: части 2–4 могут предоставить материал для самостоятельных предметов на первом году обучения.
Краткое содержание Think on my words Crystal
Предупреждение: TT: undefined function: 32 Предупреждение: TT: неопределенная функция: 32
«Думай моими словами»
Изучение Шекспира
Язык
Дэвид Кристал
1 «Вы говорите на языке, которого я не понимаю»:
мифы и реалии
Идея о том, что английский во времена Шекспира живет в сельской местности и хорошо в наше время - это удивительно стойкий миф.я слышу кто-нибудь выступит с этим по радио или в прессе, каждые несколько месяцы. Это миф, рожденный незнанием основных фактов о пути языковые изменения. И главная проблема в приближении к языку Шекспира, на мой взгляд, состоит в том, что целая паутина мифов выросли вокруг него, и его нужно смахнуть, чтобы наши возможная языковая встреча с чем-то реальным.
МИФ О КОЛИЧЕСТВЕ
«У Шекспира был самый большой словарный запас среди всех английских писателей.’
Как мы увидим, у него определенно был обширный словарный запас для своего времени, но ... «Самый крупный из всех английских писателей»? Конечно, это не так. Любой современный писатель использует гораздо больше слов, чем Шекспир.
Причина в том, как увеличился словарный запас английского языка за последние 400
года.
к концу XVI века в английском языке было около 150 000 различных слов. век. Сегодня полный Оксфордский словарь английского языка содержит более 600, разные слова.
Итак, сколько из этих слов мы используем?
Большинство из нас используют не менее 50 000 слов. То есть мы знаем как минимум половину слов в словарь.
Обычно объем словаря Шекспира составляет
.около 20 000 разных слов.
Недостаточно количества. Дело не столько в количестве слов, сколько в том, что мы делаем те слова, которые делают разницу между обычным и обычным блестящее использование языка.
Также важна наша способность выбирать наиболее эффективные слова из языковых словарный запас, чтобы выразить наши намерения.
если словарный запас не содержит нужных нам слов, мы должны быть готовы к изобретать новые, чтобы восполнить недостаток, и использовать старые в беспрецедентными способами.
Шекспир, как мы увидим в главе 7, превосходен во всем этом. Больше, чем что-нибудь еще, он показывает нам, как быть смелым с языком.
Форматы Quarto и Folio
Существовало два формата публикации произведений Шекспира: кварт и фолио. Разница между ними заключалась в размере.Страница кварто была около 9,5 дюймов в ширину. и высотой 12 дюймов; страница фолио была намного больше: 12 дюймов в ширину и 19 дюймов высокая.
В Библии используется всего около 6000 различных слов. Шекспир использует более трех раз больше слов.
Почему у Шекспира такой большой словарный запас? Отчасти потому, что он так много писал, но в основном из-за того, о чем он писал. Это разница между людьми, ситуации и предмет, который порождает различные виды словарного запаса, и Шекспир признан непревзойденным в сфере его творчества. персонажи, настройки и темы.
МИФ СТИЛЯ
Это самая легкая фраза в мире: «стиль Шекспира».
Как только мы попытаемся идентифицировать этот стиль применительно к определенному языковому особенности, понятие начинает распадаться.
Стиль всегда меняется в двух измерениях: диахроническом, во времени, по мере роста людей. старшая; и синхронно, в любой момент времени, когда люди адаптируют свое письмо для разных типов тематики.
С писательской карьерой продолжительностью около двадцати пяти лет и различными профессиями. контент, простирающийся от высокой трагедии до низкой комедии, мы должны ожидать стилистического вариация, а не однородность.
Под стилем я подразумеваю набор лингвистических особенностей, которые, вместе взятые, уникально идентифицировать пользователя языка.
Словарь предлагает наибольшее количество вариантов: почти всегда место для выбора, когда мы выбираем слово. В лингвистике, лексике является частью предмета семантики.
English предлагает нам множество вариантов изменения длины предложений, структура предложения, порядок слов и структура слов - все искусство исследования грамматики.
Фонологический выбор: звуки (отраженные в орфографии) составляют треть измерение, позволяющее нам создавать модели гласных, согласные, слоги, ритмы и мелодии, а также генерирующие эффекты, которые традиционно описываются с использованием таких понятий, как аллитерация, рифма и метр. В лингвистике орфографическая сторона рассматривается под заголовком графология и произношения в разделе фонология.
Pragmatic Choices: варианты нашего взаимодействия, когда мы стихотворные или прозаические диалоги друг с другом.Вариантов здесь больше гибкость, включая широкий спектр понятий, например, как мы задаем вопросы и отвечать друг другу, перебивать, повторять, менять тему или выражать свои мысли вежливо или грубо. Выбор между тобой и тобой - особенно интересная переменная под этим заголовком, которую часто называют прагматика.
Учитывая необычайный диапазон характера и содержания Шекспира, а также период времени (более двадцати лет), в течение которого он писал, действительный стилистический обобщения, вероятно, невозможны.
7 «Подумай о моих словах»:
Шекспировский словарь
Словарь - это область языка, наименее подверженная обобщениям. в отличие от грамматика, просодия и дискурсивные модели языка, которые подлежат общие правила, которые можно полностью изучить за относительно короткий период времени, изучение словарного запаса в основном носит произвольный характер и имеет неопределенную продолжительность.
Составители глоссариев концентрируются, как и должны, на трудных словах, с помощью которых обычно означало слова, используемые в Шекспире, которые отличаются от используемых сегодня.
Есть, во-первых, несколько сложных слов, не отличающихся употреблением таких имен. поскольку Феб и Фаэтон представляют трудности. Но это энциклопедия, а не лингвистическая проблема.
Во-вторых, есть много разных слов, которые несложны. Фактически, понятие слова «сложность» представляют широкий спектр. С одной стороны, есть слова, которые вряд ли нужно замалчивать. С другой стороны, есть слова где невозможно вывести из их формы, что они могут означать, и глянец обязателен.
8 «Обсуждение существительного и глагола»:
Шекспировская грамматика
Грамматика имеет смысл языка. Вот для чего это нужно. Слова сами по себе не имеет смысла. Отдельные слова слишком неоднозначны, потому что их несколько значения конкурируют за наше внимание. Таблица, например, имеет полдюжины значений в раннем современном английском языке, и единственный способ определить, какой из них есть, наблюдение за тем, как это слово используется в контексте.
Если мы хотим «разобраться» в Шекспире, мы должны обратиться к его грамматике.Как и в случае со словарным запасом (см. Главу 7), грамматические правила английского языка изменились. очень мало за последние 400 лет: около 90% порядков слов и слов формации, используемые Шекспиром, используются до сих пор.
Грамматический анализ этого отрывка выявил бы более ста пунктов предложение, предложение, фраза и структура слова. Все они присутствуют в модерне Английский. Тем не менее, широко распространено впечатление, что шекспировская
Книга вопросов и ответов с Деборой Калб: вопросы и ответы с Дэвидом Кристал
Q: Как вы впервые заинтересовались лингвистикой?
A: Интерес к языкам всегда на первом месте, и в моем случай, возникший из-за того, что вырос в двуязычном сообществе в Уэльсе, и развивается любопытство, почему люди говорят по-другому.Позже подпитывается хороший выбор языков в школе.
Затем отличный курс английского языка в университете. Лондонский колледж, сочетающий в себе язык и литературу, включает в себя ряд родственные языки (такие как древнескандинавский и готический), и познакомил меня с фонетика.
Вопрос: Как бы вы сказали, что преподавание грамматики изменилось в последние десятилетия?
A: Значительно, хотя и с большим разнообразием среди страны. Ни разу с конца XVIII века не было так много изменения в обучении грамматике, которые я пережил.
В 1950-х годах мы стали свидетелями последних лет формального старого стиля. подход (синтаксический анализ) с его сильной прескриптивной предвзятостью 18-го века. 1960-е годы увидел исчезновение этого этоса, но ничто не заменило его, кроме очень общий подход «используемый язык», в результате школьники, которым вообще не преподавали грамматику.
Такое положение дел продолжалось до 1990-х годов, когда новый Национальная учебная программа привнесла более сбалансированный и проницательный подход, который включила грамматику в очень мотивирующую перспективу значения и использования.
Многие учителя в Великобритании стали действительно опытными в постановке этот подход на практике, поэтому найти часы стало для меня неприятным шоком. был возвращен несколько лет спустя, когда Майкл Гоув был секретарем для образовательных учреждений, и возвращение старого образца в форме тестов. на уровне начальной школы.
Я надеюсь, что выводы из более раннего периода не будут быть потерянным, и это была одна из причин, по которой я написал свою книгу.
Q: Какая связь между грамматикой и гламуром?
A: Помимо той же этимологии - способность читать и писать когда-то считалось очень загадочным, почти волшебным умение - связь через значение и использование.В техническом плане: семантика (изучение смысла) и прагматика (изучение выбора, который мы сделать, когда мы используем язык).
Показывая, что разные части грамматики означают, и как и почему они используются в повседневной жизни, мы делаем их актуальными для задача повседневного общения и - если мы будем искать контексты, которые интересно, захватывающе и действительно гламурно - мы можем оживить их.
Для одного 10-летнего ребенка самая гламурная вещь в мире уметь писать, как Терри Пратчетт.Показывая ей некоторые способы Терри ловко манипулирует порядком слов - например, ставит строки прилагательных после существительного добавить атмосферу («Он видел отблеск десяти тысяч глаз, зеленый, красный и белый »), она написала свой рассказ в его стиле и исполнила свое желание.
Вопрос: Насколько английская грамматика развивалась за столетия? и какие примеры особенно интересны, когда дело доходит до к изменениям?
A: Ну, в огромной степени, конечно, если взглянуть на древнеанглийский язык. показывает сразу, потому что тогда мы видим все окончания слов и незнакомые слова заказы - временами очень похожие на немецкие - английский с тех пор утратил.С другой со стороны, есть несколько конструкций, которые вообще не изменились.
На мой взгляд, одним из самых интересных изменений стал период Средневековья, когда мы утратили контраст между «ты» и «ты» в повседневная речь. Это было еще во времена Шекспира, и мы исследовали, как переключение между местоимениями всегда меняет температуру отношения между ораторами в его пьесах действительно завораживают.
Что изменение местоимений говорит нам об изменении отношения между Макбетом и леди Макбет, Гамлетом и Офелией или Отелло и Дездемона? Мы начинаем с грамматики, но заканчиваем драматизмом.
Вопрос: Что вы видите в будущем, когда дело доходит до эволюция - и преподавание - грамматики английского языка?
О: Грамматика английского языка продолжит меняться, как и всегда. сделано, но медленно. Невозможно предсказать будущее, но я бы ожидал изменения, которые мы наблюдаем сегодня, продолжаются, например, постоянное увеличение использования прогрессивных форм с глаголами, которые раньше не принимали его, как когда люди сказать, что я люблю это, а не люблю (как в лозунге McDonald’s).
Что касается обучения ... одно хорошее следствие разногласий По сравнению с текущим тестированием маленьких детей в Великобритании, оно принесло грамматика снова вниманию широкой публики.
Опять же, предсказывать будущее невозможно, особенно когда решения находятся в руках политиков, которые разбираются в лингвистических проблемах. обычно примитивен или наивно предписывает.
Помогал бы хорошо осведомленный в лингвистическом отношении министр. Без это зависит от самих учителей - конечно, при поддержке людей писать книги и предлагать курсы повышения квалификации по этой теме - показать родителям, практикующих и сильных мира сего, как заставить грамматику ожить и действительно помогают в развитии у молодежи грамотности и грамотности.