What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information.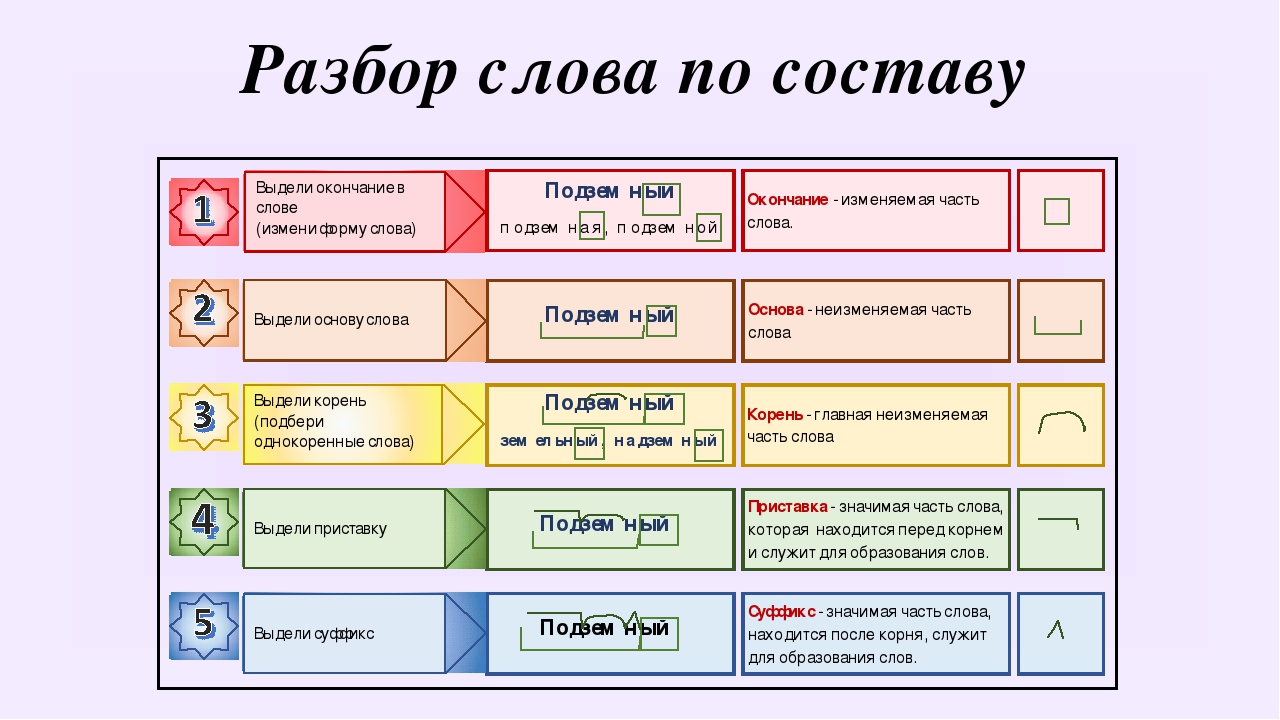 The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.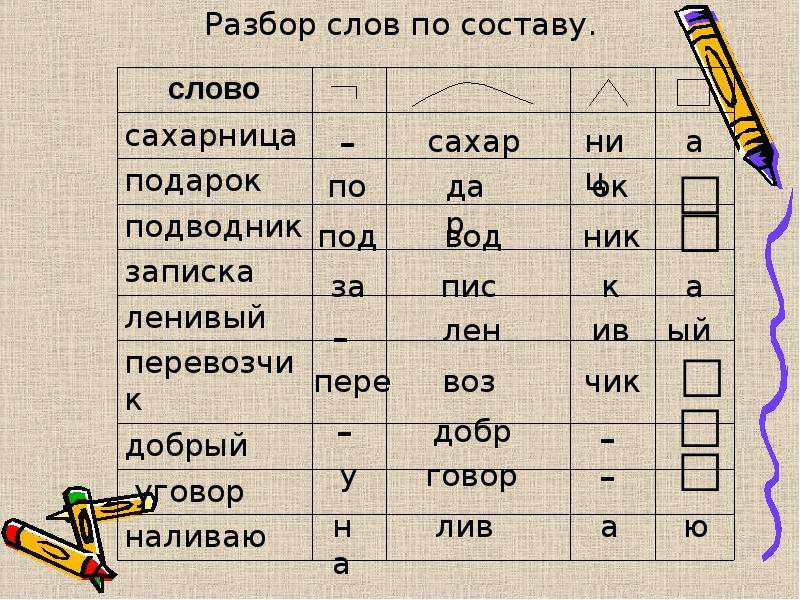
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data.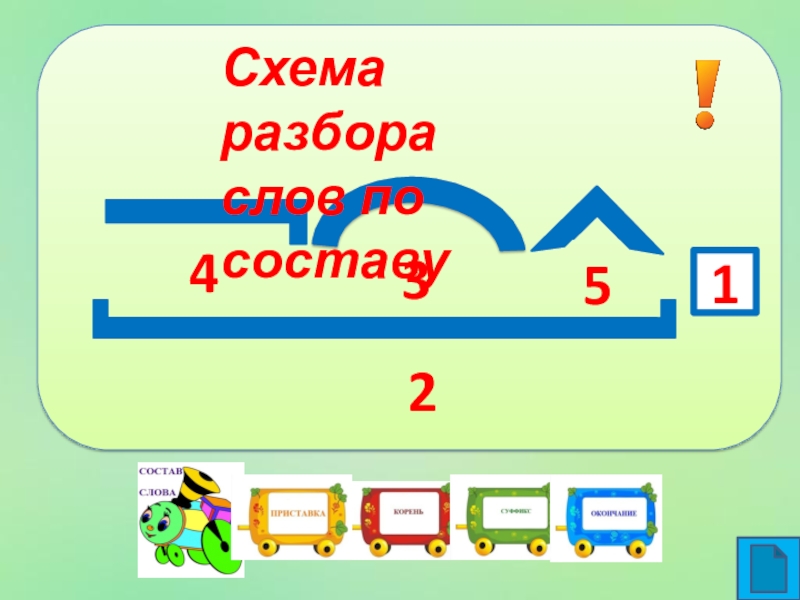 My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.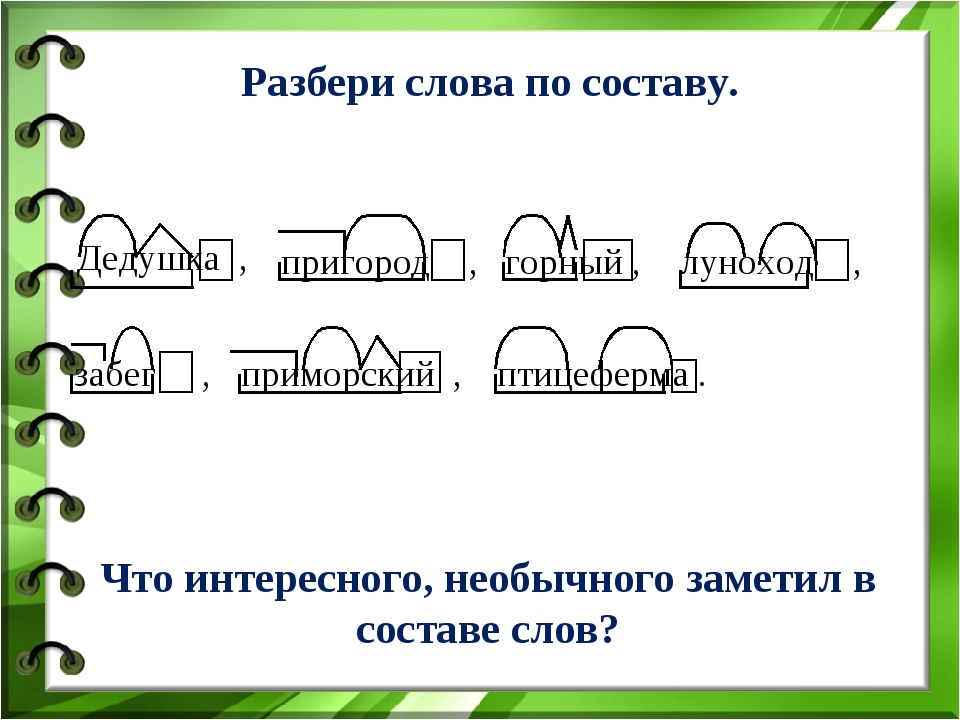
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфемный разбор (разбор слова по составу) шпора по языковедению
Морфемный разбор (разбор слова по составу) Литневская Е. И. При морфемном разборе слова (разборе слова по составу) сначала в слове выделяется окончание и формообразующий суффикс (если они есть), подчеркивается основа. После этого основа слова разбивается на морфемы. Как в школьной, так и в научной грамматике представлены два противоположных подхода к морфемному членению основы: формально-структурный и формально-смысловой. Суть формально-структурного морфемного разбора состоит в том, что в основе в первую очередь выделяется корень как общая часть родственных слов. Затем то, что идет до корня, должно быть осознано как приставка (приставки) в соответствии с представлениями ученика о том, встречались ли ему подобные элементы в других словах. Аналогично с суффиксами. Иначе говоря, главным при разборе становится эффект узнаваемости учеником морфем, внешнее сходство каких-то частей разных слов. И это способно привести к массовым ошибкам, причина которых — игнорирование того факта, что морфема является значимой языковой единицей. Формально-структурному подходу противопоставлен подход формально-смысловой (формально-семантический). Главная установка данного подхода и алгоритм морфемного разбора выходят из трудов Г. О. Винокура и состоят в неразрывности морфемного членения и словообразовательного разбора. О том, что этот подход является целесообразным и даже единственно возможным, писали многие ученые и методисты на протяжении многих десятилетий. Алгоритм морфемного разбора основы состоит в построении словообразовательной цепочки «наоборот»: со слова как бы «снимаются» приставки и суффиксы, корень же выделяется в последнюю очередь.
Затем то, что идет до корня, должно быть осознано как приставка (приставки) в соответствии с представлениями ученика о том, встречались ли ему подобные элементы в других словах. Аналогично с суффиксами. Иначе говоря, главным при разборе становится эффект узнаваемости учеником морфем, внешнее сходство каких-то частей разных слов. И это способно привести к массовым ошибкам, причина которых — игнорирование того факта, что морфема является значимой языковой единицей. Формально-структурному подходу противопоставлен подход формально-смысловой (формально-семантический). Главная установка данного подхода и алгоритм морфемного разбора выходят из трудов Г. О. Винокура и состоят в неразрывности морфемного членения и словообразовательного разбора. О том, что этот подход является целесообразным и даже единственно возможным, писали многие ученые и методисты на протяжении многих десятилетий. Алгоритм морфемного разбора основы состоит в построении словообразовательной цепочки «наоборот»: со слова как бы «снимаются» приставки и суффиксы, корень же выделяется в последнюю очередь.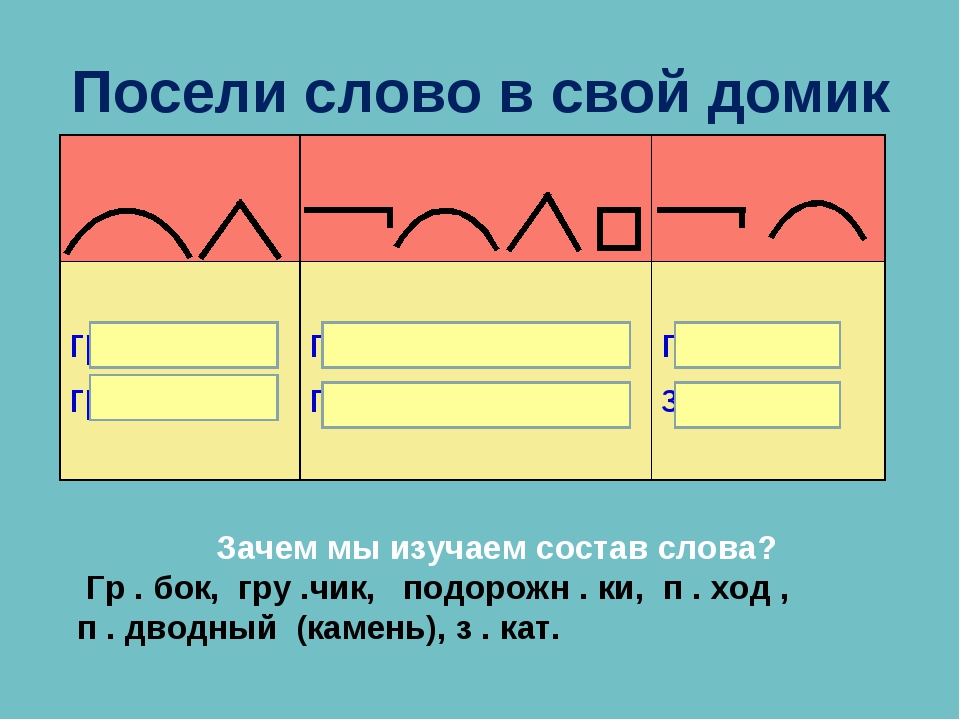 При разборе постоянно необходимо соотнесение значения производного и значения его производящего; производящая основа в современном русском языке — основа мотивирующая. Если между значением производного и значением производящего (в нашем представлении) слова нет отношения мотивированности, производящее выбрано неверно. Таким образом, порядок разбора слова по составу таков: 1) выделить окончание и/или, формообразующий суффикс (если они есть), 2) выделить основу слова — часть слова без флексий, 3) выделить в основе слова приставку и/или суффикс через построение словообразовательной цепочки, 4) выделить в слове корень. Приведем пример разбора по составу словоформы обновлением. Образец рассуждения: Окончание словоформы обновлением — ем, оно выражает грамматические значения Т.п. ед. числа. Основа — обновлениj-. Существительное обновление обозначает то же действие, что и глагол обновить, формально образовано от этого глагола и мотивировано им по значению. При образовании слова обновление от глагола обновить использован суффикс -ениj.
При разборе постоянно необходимо соотнесение значения производного и значения его производящего; производящая основа в современном русском языке — основа мотивирующая. Если между значением производного и значением производящего (в нашем представлении) слова нет отношения мотивированности, производящее выбрано неверно. Таким образом, порядок разбора слова по составу таков: 1) выделить окончание и/или, формообразующий суффикс (если они есть), 2) выделить основу слова — часть слова без флексий, 3) выделить в основе слова приставку и/или суффикс через построение словообразовательной цепочки, 4) выделить в слове корень. Приведем пример разбора по составу словоформы обновлением. Образец рассуждения: Окончание словоформы обновлением — ем, оно выражает грамматические значения Т.п. ед. числа. Основа — обновлениj-. Существительное обновление обозначает то же действие, что и глагол обновить, формально образовано от этого глагола и мотивировано им по значению. При образовании слова обновление от глагола обновить использован суффикс -ениj. Глагол обновить образован приставкой об- и суффиксом -и от прилагательного новый; суффикс -и при образовании от этого глагола существительного обновление усекается. Корень слова обновление — новл; сочетание вл возникло как результат чередования с в перед суффиксом -ениj.
Глагол обновить образован приставкой об- и суффиксом -и от прилагательного новый; суффикс -и при образовании от этого глагола существительного обновление усекается. Корень слова обновление — новл; сочетание вл возникло как результат чередования с в перед суффиксом -ениj.
Как убивали Кеннеди | Публикации
Винтовка, гильзы и паспорт Ли Харви Освальда. Свое оружие Ли приобрел по объявлению в газете за 12 долларов 78 центов
Что касается второй пули, ранившей Коннэлли и найденной потом криминалистами, то она действительно была выпущена из винтовки Освальда, что подтвердила баллистическая экспертиза. Но, судя по всему, это был единственный выстрел, который сделал бывший морпех: эксперты обратили внимание на то, что лишь на одной из трех гильз, найденных на месте засады Освальда, имелись характерные микроскопические отметины от затвора его винтовки. Значит, и третий выстрел, поразивший президента в голову, был сделан не из «манлихера-каркано». Комиссия же утверждала, что третья пуля попала в голову Кеннеди тоже сзади, хотя входного отверстия найти так и не удалось — почти вся правая сторона черепа президента была снесена. Но на пленке Запрудера видно, что после третьего выстрела голова президента совершила резкий рывок назад и влево, из чего можно сделать вывод, что стрелявший находился впереди и справа. Нейтронно-радиоактивный анализ, проведенный в 1970-е годы, установил, что химический состав осколков, извлеченных из головы президента, не соответствует составу пуль, которыми стрелял Освальд. Стрелявший занял позицию за деревянной оградой на травяном склоне по правую сторону от Элм-стрит.
Но на пленке Запрудера видно, что после третьего выстрела голова президента совершила резкий рывок назад и влево, из чего можно сделать вывод, что стрелявший находился впереди и справа. Нейтронно-радиоактивный анализ, проведенный в 1970-е годы, установил, что химический состав осколков, извлеченных из головы президента, не соответствует составу пуль, которыми стрелял Освальд. Стрелявший занял позицию за деревянной оградой на травяном склоне по правую сторону от Элм-стрит.
О том, что стрельба велась оттуда, говорили многие свидетели, но члены Комиссии Уоррена не придали им особого значения.
Очевидно, что гипотеза Комиссии Уоррена об убийце-одиночке трещит по швам. У Освальда были сообщники, а значит, имела место тщательно спланированная акция. Но, похоже, перед Уорреном изначально поставили задачу всеми силами доказать, что Освальд действовал один. Значит, спецслужбам США было что скрывать. Но что именно: что они проворонили у себя под носом заговор или что сами имели к нему отношение?
ПЕРВЫЕ ПОДОЗРЕВАЕМЫЕ: СПЕЦСЛУЖБЫ И ПЕНТАГОН
Написаны десятки книг, авторы которых утверждают, что за убийством Джона Кеннеди стоят ФБР, ЦРУ или Пентагон. Но прямых доказательств этому нигде не приводится, все сводится к наличию мотивов. Так, ни для кого не секрет, что между президентом США и директором ФБР Эдгаром Гувером существовала глубокая личная неприязнь. Кеннеди давно бы уволил главу секретного ведомства, но у того имелся компромат на хозяина Белого дома: сведения о его любовной связи с Джудит Кэмпбелл. Что касается ЦРУ и Пентагона, то в их руководстве было немало недовольных внешней политикой Кеннеди. Ему ставили в вину, что он сорвал высадку десанта антикастровцев на Кубу в апреле 1961 года, запретив посылать на помощь повстанцам авиацию, пошел на компромисс с Москвой во время Карибского и Берлинского кризисов (1961, 1962) и собирался вывести американские войска из Вьетнама. Но достаточно ли этих фактов, чтобы доказать причастность силовиков к устранению Кеннеди? Конечно, нет.
Но прямых доказательств этому нигде не приводится, все сводится к наличию мотивов. Так, ни для кого не секрет, что между президентом США и директором ФБР Эдгаром Гувером существовала глубокая личная неприязнь. Кеннеди давно бы уволил главу секретного ведомства, но у того имелся компромат на хозяина Белого дома: сведения о его любовной связи с Джудит Кэмпбелл. Что касается ЦРУ и Пентагона, то в их руководстве было немало недовольных внешней политикой Кеннеди. Ему ставили в вину, что он сорвал высадку десанта антикастровцев на Кубу в апреле 1961 года, запретив посылать на помощь повстанцам авиацию, пошел на компромисс с Москвой во время Карибского и Берлинского кризисов (1961, 1962) и собирался вывести американские войска из Вьетнама. Но достаточно ли этих фактов, чтобы доказать причастность силовиков к устранению Кеннеди? Конечно, нет.
СПЕЦСЛУЖБЫ НЕ ПРИЧЕМ
Зато существует одно важное обстоятельство, которое свидетельствует о том, что спецслужбы здесь ни при чем. Даже если бы какое-либо из этих ведомств и замыслило убрать президента, оно ни за что не стало бы связываться с Ли Харви Освальдом. В разное время (конец 1950-х — начало 1960-х) его пытались завербовать и военная разведка, и ЦРУ, и ФБР. Но безуспешно. Дело в том, что Освальд страдал вялотекущей шизофренией, был неуживчив , вспыльчив, некоммуникабелен и к тому же не имел даже среднего образования . Конструктивно работать с ним не представлялось никакой возможности, поэтому спецслужбам он казался бесполезным. Неужели такому человеку доверили бы участвовать в операции против президента?
В разное время (конец 1950-х — начало 1960-х) его пытались завербовать и военная разведка, и ЦРУ, и ФБР. Но безуспешно. Дело в том, что Освальд страдал вялотекущей шизофренией, был неуживчив , вспыльчив, некоммуникабелен и к тому же не имел даже среднего образования . Конструктивно работать с ним не представлялось никакой возможности, поэтому спецслужбам он казался бесполезным. Неужели такому человеку доверили бы участвовать в операции против президента?
Кроме того, стоит согласиться с мнением историка Игоря Ефимова, автора книги «Кто убил президента Кеннеди?», считающего, что «внутри таких организаций, как ЦРУ, ФБР, Пентагон и пр., — система взаимного контроля так интенсивна, что никакой крупный заговор не может не остаться нераскрытым».
ВТОРОЙ ПОДОЗРЕВАЕМЫЙ: КУБИНСКИЙ ДИКТАТОР
Graph-to-Graph Transformer для анализа зависимостей на основе переходов
Если вам нужна модель Transformer , которая дополнительно вводит или выводит любую структуру графа и работает с BERT , тогда вы в нужном месте. В этом блоге вы узнаете:
В этом блоге вы узнаете:
- Кодирование графиков и последовательностей в одном общем преобразователе
- Произвести требуемый выходной график
- Достижение современных результатов анализа зависимостей на основе переходов
Давайте рассмотрим наше предложение, которое принято к результатам EMNLP 2020 (будет представлено на 4-м семинаре по структурированному прогнозированию для NLP).
Введение
Мы предлагаем архитектуру Graph-to-Graph Transformer , которая сочетает в себе основанный на внимании механизм Transformer для кондиционирования графов с подобным вниманию механизмом для прогнозирования графов. Теперь вы можете кодировать обе последовательности
В нашей архитектуре каждая голова внимания может легко научиться обращать внимание только на токены в данном отношении, но она также может изучать другие структуры в сочетании с другими входными данными. Это дает смещение в сторону весов внимания, которые учитывают локальность во входном графе, но не жестко кодируют какие-либо конкретные веса внимания.
Это дает смещение в сторону весов внимания, которые учитывают локальность во входном графе, но не жестко кодируют какие-либо конкретные веса внимания.
Мы также демонстрируем, что, несмотря на измененные механизмы ввода, эта архитектура Graph3Graph Transformer может быть эффективно инициализирована с помощью стандартных предварительно обученных моделей Transformer. Инициализация анализатора Graph3Graph Transformer с предварительно обученными параметрами BERT приводит к существенным улучшениям.
В этой статье мы применяем нашу архитектуру к , основанному на переходах, синтаксическому анализу зависимостей со стандартной системой arc (плюс операция SWAP для непроективных деревьев).
Математическое описание
Graph3Graph Transformer расширяет архитектуру Transformer, чтобы принимать любой произвольный граф в качестве входных данных. Мы добавляем второй член в уравнения Transformer, теперь представления значений могут быть получены как:
А веса внимания можно рассчитать с помощью Softmax более:
Где — это горячий вектор, используемый для определения отношения между токеном и.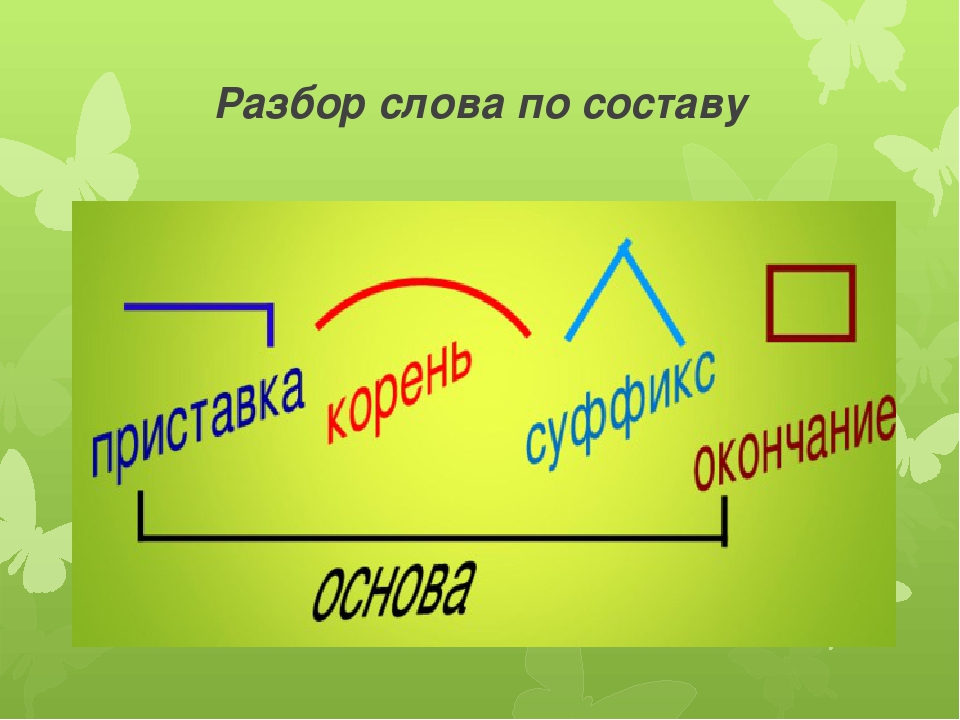 и являются изученными параметрами. В этой статье мы рассматриваем немаркированный граф зависимостей, поэтому он может быть
и являются изученными параметрами. В этой статье мы рассматриваем немаркированный граф зависимостей, поэтому он может быть
Мы добавили метки зависимости к соответствующим вложениям зависимых слов.
Механизм вывода графа Graph3Graph Transformer предсказывает каждое помеченное ребро графа, используя выходные вложения токенов, которые связаны этим ребром. В этой работе ребра графа обозначены как отношения зависимости, которые предсказываются как часть действий анализатора зависимостей на основе переходов. В частности, классификатор Relation использует выходные вложения двух верхних элементов в стеке и предсказывает метку их отношения зависимости в зависимости от его направления.Существует также классификатор Exist, который использует выходные вложения двух верхних элементов в стеке и передней части буфера для прогнозирования типа действия синтаксического анализатора, SHIFT , SWAP , RIGHT-ARC или ВЛЕВО-ARC .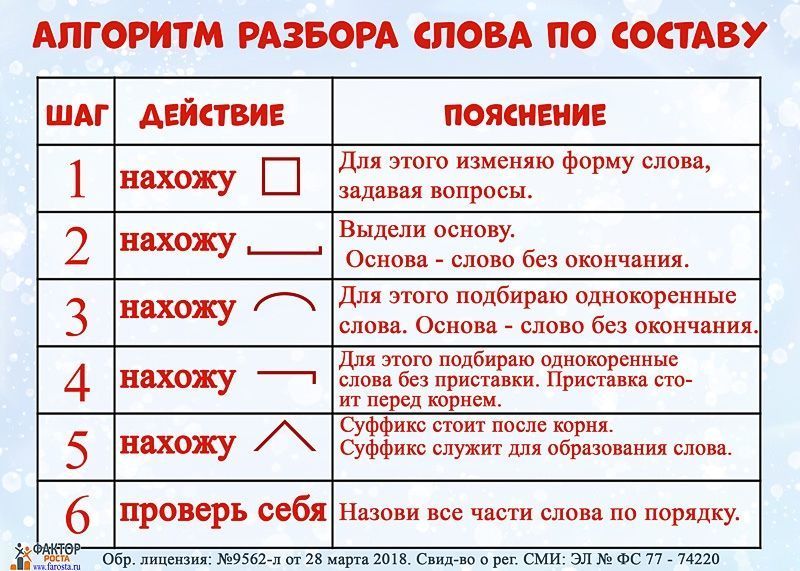
где, и — выходные вложения двух верхних токенов в стеке и передней части буфера, соответственно. Классификаторы $ \ operatorname {Exist} $ и $ \ operatorname {Relation} $ — это MLP с одним скрытым слоем.
Приложения
Наша архитектура может быть легко применена ко многим задачам НЛП, которые взаимодействуют с разными графами. Вам просто нужно построить на основе структуры вашего графа. Вот потенциальные приложения:
- Задачи NLP, требующие создания графа, такие как синтаксический анализ, маркировка семантических ролей и…
- Задачи NLP, которые используют структуру графов в качестве дополнительных входных данных для поиска лучших представлений, таких как MT, NLI и задачи классификации.
Модели анализа

Государственный трансформатор
Мы напрямую используем состояние анализатора, то есть элементы стека и буфера, в качестве входных данных для модели Transformer. Мы дополнительно включаем компоненты, зарекомендовавшие себя в StackLSTM paper.
Последовательность входных токенов начинается с символа CLS , затем включает токены в стеке снизу вверх. Затем идет символ SEP , за которым следуют маркеры в буфере спереди назад, так что они находятся в том же порядке, в котором они появились в предложении. Учитывая эту входную последовательность, модель вычисляет последовательность векторов, которые вводятся в сеть трансформатора. Каждый вектор представляет собой сумму нескольких вложений, которые определены ниже.
Встраивание входных токенов : Встраивание каждого токена определяется как:
, где это предварительно обученное вложение BERT первого подслова каждого слова, и мы отбрасываем вложения не первых подслов из-за эффективности обучения. — это вложение POS, которое инициализируется случайным образом.
— это вложение POS, которое инициализируется случайным образом.
Модель композиции : В качестве альтернативы предлагаемому нами методу ввода графа предыдущая работа показала, что сложные фразы могут быть введены в нейронную сеть с помощью рекурсивных нейронных сетей для рекурсивного составления вложений подфраз.Мы расширяем предложенную композиционную модель \ newcite {dyer-etal-2015-transition}, применяя однослойную нейронную сеть с прямой связью в качестве модели композиции и добавляя пропускаемые соединения к каждому рекурсивному шагу. Вот один пример кодирования частично построенного графа:
Всего внедрений ввода : общее количество внедрений каждого токена можно рассчитать как:
, где — результат составной модели, — встраивание позиций и — встраивание сегментов для различения токенов в стеке и буфере.t $ исторической модели вычисляется следующим образом:
, где и — предыдущий переход и связанная с ним метка зависимости, а и — предыдущий выходной вектор и состояние ячейки модели истории. Выходные данные модели истории вводятся непосредственно в классификаторы действий синтаксического анализатора.
Выходные данные модели истории вводятся непосредственно в классификаторы действий синтаксического анализатора.
Преобразователь предложений
В этой базовой линии мы напрямую вводим начальное предложение в Transformer, а затем выбираем требуемые выходные вложения на основе состояния анализатора.Более конкретно, токены входных предложений вычисляются с помощью маркера BERT, а следующий переход прогнозируется на основе внедрений первых подслов двух верхних элементов стека и переднего элемента буфера.
Общее количество вложений входных данных — это сумма предварительно обученных встраиваний токенов BERT, рандомизированных вложений POS и позиционных вложений.
Интеграция базовых показателей с помощью Graph3Graph Transformer
Мы вычисляем новый частично построенный граф авторегрессивным способом следующим образом:
, где — текущий частично заданный граф, — это последовательность встраивания выходных токенов кодировщика, — это состояние анализатора и — это вновь спрогнозированный частичный граф. , и — механизмы ввода и вывода графа. Функция выбирает из токенов, встраиваемых в два верхних элемента в стеке и перед буфером, в зависимости от состояния анализатора.
, и — механизмы ввода и вывода графа. Функция выбирает из токенов, встраиваемых в два верхних элемента в стеке и перед буфером, в зависимости от состояния анализатора.
Мы дополнительно добавляем третий список на вход State Transformer, чтобы отслеживать слова, которые были удалены из списка стека. Кроме того, мы исключаем композиционную модель из State Transformer, когда интегрируем ее с Graph3Graph Transformer.
Результаты
Мы оцениваем наши модели на английском WSJ Penn Treebank и Universal Dependency Treebank.Чтобы показать эффективность нашей модели, мы определяем новую вариацию нашей модели, которая использует внедрение CLS для действий синтаксического анализатора прогнозов и меток вместо механизма вывода графа. Вот подробные результаты:
WSJ Penn Treebank
Для преобразователя состояний замена модели композиции (StateTr) нашим механизмом ввода графа (StateTr + G2GTr) приводит к уменьшению относительной ошибки LAS (RER) на 9,97%, 11,66% без / с инициализацией BERT, что демонстрирует ее эффективность.
Удаление механизма вывода графа (StateCLSTr, StateTr + G2CLSTr) приводит к ошибке 12.Относительное падение производительности на 28%, 10,53% для моделей StateTr и StateTr + G2GTr соответственно, что демонстрирует важность нашего механизма вывода графиков.
Если мы рассматриваем оба механизма ввода и вывода графа вместе, добавление их обоих (BERT StateTr + G2GTr) к BERT StateCLSTr достигает 21,33% снижения относительной ошибки LAS, что показывает синергию использования обоих механизмов вместе.
Для преобразователя предложений синергия между его кодировщиком и BERT приводит к отличной производительности даже для базовой модели. Тем не менее, добавление G2GTr приводит к значительному улучшению (4,62% LAS RER), что еще раз демонстрирует эффективность архитектуры Graph3Graph Transformer.
Наконец, мы также оцениваем модель BERT SentTr + G2GTr с семью слоями самовнимания вместо 6, что дает 2,19% LAS RER, что мотивирует будущую работу над более крупными моделями Graph3Graph Transformer.
UD Treebanks
Мы сравниваем нашу модель BERT SentTr + G2GTr с предыдущей работой, основанной на LAS. В качестве основы мы используем оценки модели на основе переходов, предложенной Kulmizev et al, 2019, которая использует глубоко контекстуализированные представления слов BERT и ELMo в качестве дополнительных входных данных для их моделей анализа. Модель BERT SentTr + G2GTr работает значительно лучше базовой на всех языках, что подтверждает эффективность нашей архитектуры Graph3Graph Transformer для захвата разнообразных типов структур из корпусов различных размеров.
Модель BERT SentTr + G2GTr работает значительно лучше базовой на всех языках, что подтверждает эффективность нашей архитектуры Graph3Graph Transformer для захвата разнообразных типов структур из корпусов различных размеров.
Анализ ошибок
Чтобы проанализировать эффективность предлагаемых механизмов ввода и вывода графа в вариациях нашей модели StateTr, предварительно обученной с помощью BERT, мы измеряем их точность как функцию длины зависимости, расстояния до корня, длины предложения и типа зависимости. Результаты показывают, что большая часть улучшений модели StateTr + G2GTr по сравнению с другими вариантами происходит из сложных случаев, которые требуют более глобального взгляда на предложение.
Длина зависимости : интегрированные модели G2GTr превосходят другие модели по более длинным (более сложным) зависимостям, что демонстрирует преимущество добавления частичного дерева зависимостей в модель самовнимания, которая обеспечивает глобальное представление предложения, когда модель учитывает длинные зависимости.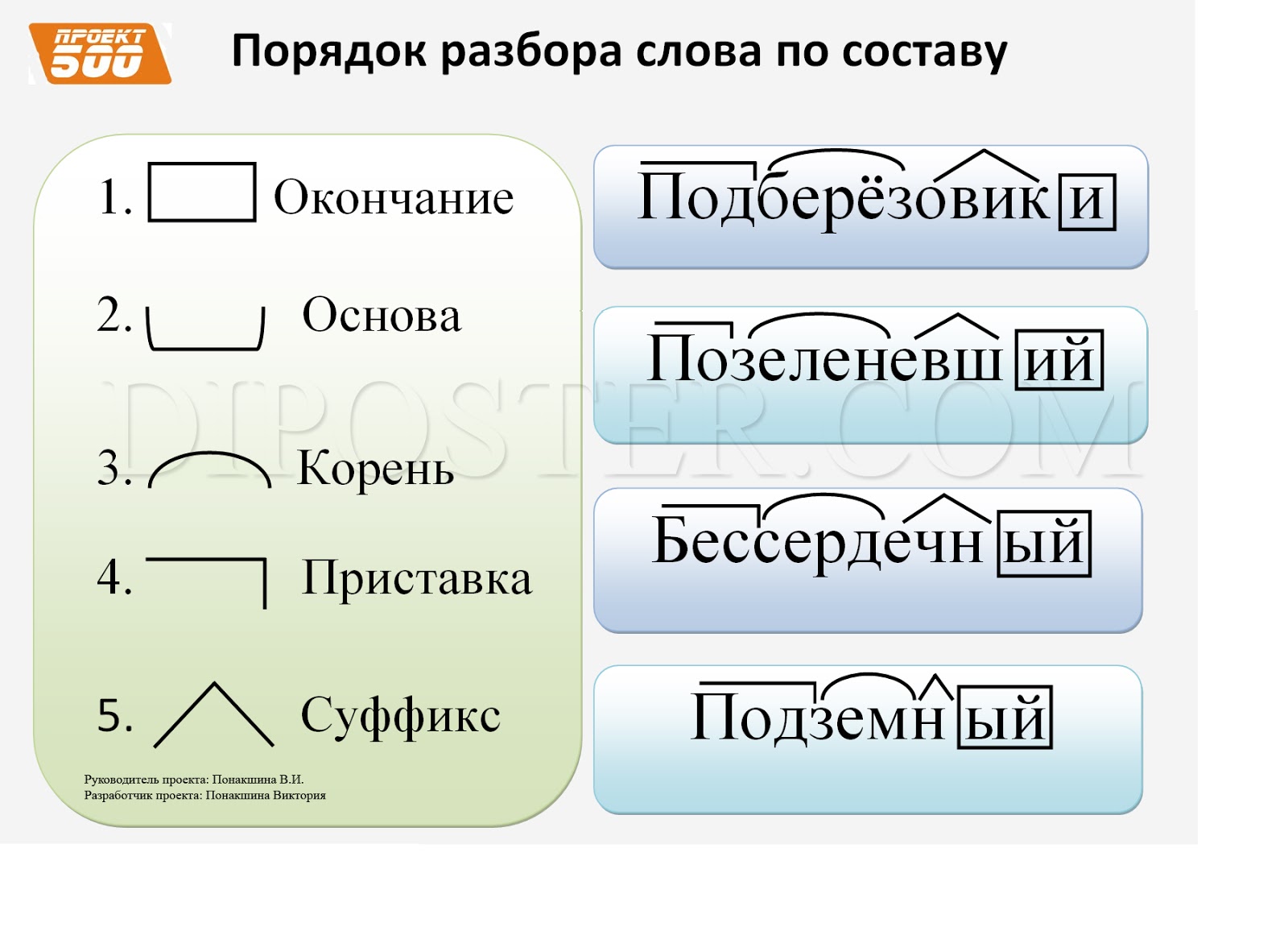 Исключение механизма вывода графа также приводит к падению производительности, особенно при длинных зависимостях.
Исключение механизма вывода графа также приводит к падению производительности, особенно при длинных зависимостях.
Расстояние до корня : модели StateTr + G2GTr превосходят базовые модели на узлах средней глубины, которые, как правило, не находятся ни около корня, ни рядом с листьями, и, следовательно, требуют более глобальной информации, а также более глубоких узлов.
Длина предложения : Относительная стабильность модели StateTr + G2GTr при различных длинах предложений снова показывает эффективность модели Graph3Graph Transformer в более сложных случаях.Отказ от использования метода вывода графика показывает особенно плохую производительность для длинных предложений, как и сохранение модели композиции.
Реализация
Вы можете найти реализацию нашего предложения по синтаксическому анализу зависимостей на основе переходов в репозитории G2GTr. Чтобы использовать Graph3Graph Transformer для вашей задачи NLP, вам следует обратиться к репозиторию g2g-transformer. Вот пример использования:
Вот пример использования:
# Загрузка BertGraphModel и инициализация ее доступными моделями BERT.импортный фонарик
из parser.utils.graph import initialize_bertgraph, BertGraphModel
# ввод графика без метки с размером метки 5 и нормализацией слоя ключа
# вы также можете загрузить другие предварительно обученные модели BERT.
encoder = initialize_bertgraph ('bert-base-cased', layernorm_key = True, layernorm_value = False,
input_label_graph = Ложь, input_unlabel_graph = True, label_size = 5)
#sample input
input = torch.tensor ([[1,2], [3,4]])
граф = torch.tensor ([[[1,0], [0,1]], [[0,1], [1,0]]])
graph_rel = torch.tensor ([[0,1], [3,4]])
output = encoder (input_ids = input, graph_arc = graph, graph_rel = graph_rel)
печать (вывод [0].форма)
## torch.Size ([2, 2, 768])
# ввод помеченного графика
encoder = initialize_bertgraph ('bert-base-cased', layernorm_key = True, layernorm_value = False,
input_label_graph = True, input_unlabel_graph = False, label_size = 5)
#sample input
input = torch. tensor ([[1,2], [3,4]])
граф = torch.tensor ([[[2,0], [0,3]], [[0,1], [4,0]]])
output = encoder (input_ids = input, graph_arc = график,)
печать (вывод [0]. форма)
## torch.Size ([2, 2, 768])
tensor ([[1,2], [3,4]])
граф = torch.tensor ([[[2,0], [0,3]], [[0,1], [4,0]]])
output = encoder (input_ids = input, graph_arc = график,)
печать (вывод [0]. форма)
## torch.Size ([2, 2, 768])
 tensor ([[1,2], [3,4]])
граф = torch.tensor ([[[2,0], [0,3]], [[0,1], [4,0]]])
output = encoder (input_ids = input, graph_arc = график,)
печать (вывод [0]. форма)
## torch.Size ([2, 2, 768])
tensor ([[1,2], [3,4]])
граф = torch.tensor ([[[2,0], [0,3]], [[0,1], [4,0]]])
output = encoder (input_ids = input, graph_arc = график,)
печать (вывод [0]. форма)
## torch.Size ([2, 2, 768])
Если вы просто хотите использовать BertGraphModel в своем исследовании, вы можете просто импортировать его
из нашего репозитория:
из парсера.utils.graph импорт BertGraphModel, BertGraphConfig
config = BertGraphConfig (ВАША-КОНФИГУРАЦИЯ)
config.add_graph_par (ГРАФИЧЕСКАЯ КОНФИГУРАЦИЯ)
Encoder = BertGraphModel (конфигурация)
Следующая статья представляет собой рекурсивную неавторегрессивную версию G2G Transformer, которая используется для уточнения графиков:
Поделиться: Tweet
Разборки парсерав загоне Уолл-стрит: эмпирическое исследование типов ошибок в выходных данных парсера
Совместное извлечение аппозиций с синтаксическими и семантическими ограничениями,
Уилл Рэдфорд, Джеймс Р. Курран, ACL, 2013
Курран, ACL, 2013
Анализ с помощью композиционных векторных грамматик,
Ричард Сочер, Джон Бауэр, Кристофер Д. Мэннинг, Эндрю Й. Нг, ACL, 2013
Словарь с дополнениями к глаголам на иврите,
Ханна Фадида, Алон Итаи, Шули Винтнер, LREC, 2013
Об элементах точной системы машинного перевода дерева в строку,
Грэм Нойбиг, Кевин Дух, ACL, 2014
Оценка парсера с использованием деревьев деривации: дополнение к evalb,
Сет Кулик, Энн Биис, Джастин Мотт, Энтони Крох, Марк Либерман, Беатрис Санторини, ACL, 2014
Совместный жадный анализ на основе RNN и композиция слов,
Джоэл Легран, Ронан Коллобер, ICLR, 2015
Изучение композиционных архитектур и векторных представлений слов для присоединения предложных фраз,
Йонатан Белинков, Тао Лей, Регина Барзилай, Амир Глоберсон, TACL, 2014 г.
Выявление каскадных ошибок с использованием ограничений в синтаксическом анализе зависимостей,
Доминик Нг, Джеймс Р.Курран, ACL, 2015
Это зависит от: Сравнение анализатора зависимостей с помощью веб-инструмента оценки,
Джинхо Д. Чой, Джоэл Тетро, Аманда Стент, ACL, 2015
Анализ нейронных составляющих на основе переходов,
Таро Ватанабэ, Эйитиро Сумита, ACL, 2015
Что сложно в универсальном синтаксическом анализе зависимостей ?,
Анжелика Кирилина, Янник Верслея, СПМРЛ, 2015
Протокол для аннотации различий парсеров,
Джеймс В.Бруно, Аойф Кэхилл, Бинод Гьявали, ETS Research Reports, 2016
Прогнозирование производительности синтаксического анализа с помощью машин ссылочного перевода,
Эргун Бичичи, Пражский вестник математической лингвистики, 2016 г.
Оценка устойчивости синтаксического анализатора для нетрадиционных предложений,
Дом Б. Хашеми, Ребекка Хва, EMNLP, 2016
Детальный параллелизм в вероятностном парсинге с Habanero Java,
Мэтью Фрэнсис-Ландау, Бинг Сюэ, Джейсон Эйснер, Вивек Саркар, Семинар по нестандартным приложениям: архитектуры и алгоритмы, 2016 г.
Старая школа vs.Новая школа: Сравнение парсеров на основе переходов с улучшением нейронной сети и без нее,
Мириам де Лонё, Сара Стимн, Йоаким Нивр, Международный семинар по береговым покровам деревьев и лингвистическим теориям, 2017 г.
Приложение PP: Где мы находимся ?,
Даниэль де Кок, Цзяньцян Ма, Корина Дима, Эрхард Хинрихс, EACL, 2017
Разметка глубинных семантических ролей: что работает и что дальше,
Лухенг Хе, Кентон Ли, Майк Льюис, Люк Зеттлемойер, ACL, 2017
Нарушение {НЛП}: {Использование} {Морфосинтаксис}, {Семантика}, {Прагматика} и {Мир} {Знание} для {Дурака} {Сантимента} {Анализ} {Системы},
Тейлор Малер, Вилли Чунг, Мика Элснер, Дэвид Кинг, Мари-Катрин де Марнефф, Кори Шейн, Саймон Стивенс-Гилль, Майкл Уайт, {EMNLP} 2017 {Workshop} по {Building} {Linguistically} {Generalizable} {NLP} {Systems}, 2017 г.
Простой метод уточнения предложений с координационной неоднозначностью,
Майкл Уайт, Манджуан Дуан, Дэвид Л.Король, INLG, 2017
Обучает ли String-Based Neural MT синтаксис исходного кода ?,
Син Ши, Ункит Падхи, Кевин Найт, EMNLP, 2016
Прикрепление предложной фразы к продуктам для встраивания слов,
Пранава Сваруп Мадхьястха, Ксавье Каррерас, Ариадна Кваттони, IWPT, 2017
Улучшение синтаксического анализа постоянных групп
Лемао Лю, Мухуа Чжу, Шумин Ши, AAAI, 2018
Расширение синтаксического анализатора до удаленных доменов с помощью нескольких десятков частично аннотированных примеров
Видур Джоши, Мэтью Питерс, Марк Хопкинс, ACL, 2018
Безумно неоднозначный: игра для изучения структурной неоднозначности и того, почему это сложно для компьютеров,
Ажда Гекчен, Итан Хилл, Майкл Уайт, NAACL (Демонстрация), 2018 г.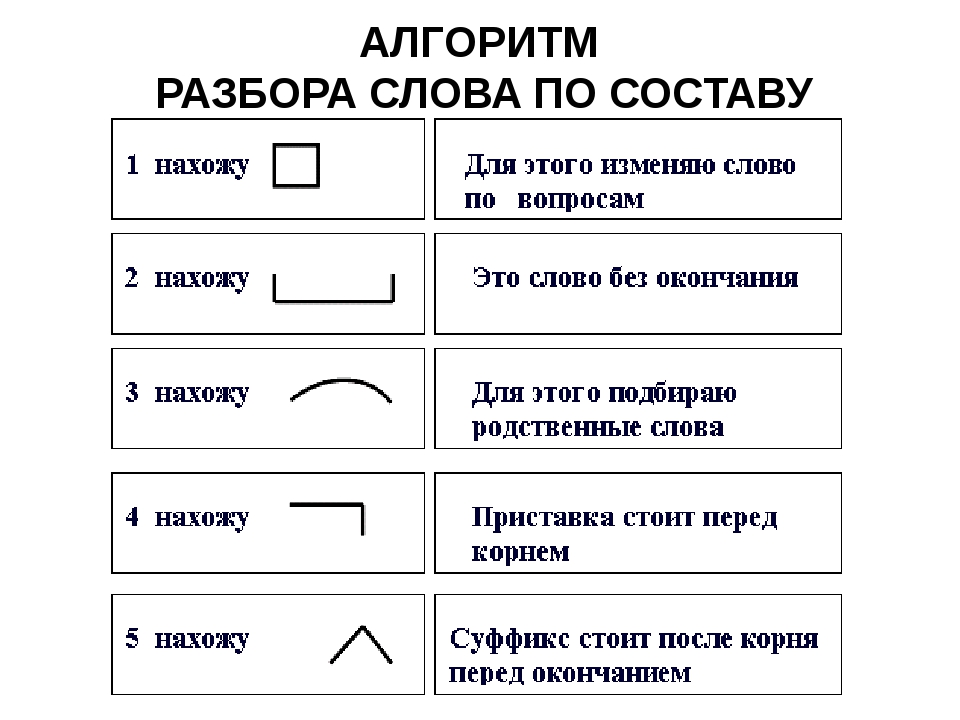
Анализ речи: нейронный подход к интеграции лексической и акустико-просодической информации,
Транг Тран, Шубхам Тошнивал, Мохит Бансал, Кевин Гимпел, Карен Ливеску, Мари Остендорф, NAACL, 2018
Автоматическое извлечение семантических юридических метаданных с использованием обработки естественного языка,
Амин Слейми, Николя Санье, Мехрдад Сабетзаде, Лайонел Бриан, Джон Данн, 26-я Международная конференция по разработке требований IEEE, 2018 г.
Эмпирическое исследование типов ошибок во вьетнамском синтаксическом анализе,
Куи Т.Нгуен, Юсуке Мияо, Хироши Нодзи, Нхунг Т. Нгуен, CoLing, 2018 г.
Приведение в порядок деревьев — Обнаружение ошибок в деревьях,
Инес Ребейн, Йозеф Руппенхофер, CoLing, 2018
Анализ естественного языка: успехи и проблемы,
Карлос Гомес-Родригес, Boletin de Estadistica e Investigacion Operativa, 2018
Составной синтаксический анализ как маркировка последовательности,
Карлос Гомес-Родригес, Давид Виларес, ЕМНЛП, 2018 г.
Статус служебных слов в грамматике зависимостей: критика универсальных зависимостей (UD),
Тимоти Осборн, Ким Гердес, Glossa, 2019
Визуальное устранение неоднозначности вложения предложных фраз: мультимодальное машинное обучение для коррекции синтаксического анализа
Себастьян Делекраз, Леонор Бесерра-Бонаш, Алексис Наср, Фредерик Беше, Бенуа Фавр, Достижения в области вычислительного интеллекта, 2019
О роли стиля в анализе речи с помощью нейронных моделей
Транг Тран, Цзяхонг Юань, Ян Лю, Мари Остендорф, Interspeech, 2019
Интеграция многоязычного компонента предварительного заказа в коммерческую платформу SMT
Анита Рамм, Риккардо Супербо, Димитар Штерионов, Тони О’Дауд, Александр Фрейзер, Пражский бюллетень математической лингвистики, 2017
Использование Prosody для улучшения анализа зависимостей
Хусейн Гали, Майкл Мандель, Международная конференция по речевой просодии, 2020 г.
Travatar: движок машинного перевода леса в строку, основанный на преобразователях деревьев,
Грэм Нойбиг, ACL, 2013
Поведенческий анализ моделей NLI: выявление влияния трех факторов на надежность,
Висенте Иван Санчес Кармона, Джефф Митчелл, Себастьян Ридель, NAACL, 2018
Лучшие, быстрые и надежные парсеры с тегами последовательностей,
Давид Виларес, Мостафа Абду, Андерс Согаард, NAACL, 2019
Полу-контролируемое извлечение отношений из одноязычного словаря для русского WordNet
Даниил Алексеевский, CICLing, 2017
Новый инструмент для сравнительного анализа и оценки синтаксических синтаксических анализаторов арабского языка
Юнес Джаафар Автор электронной почты Карим Бузубаа, ICALP: Обработка арабского языка: от теории к практике, 2017
Улучшение синтаксического анализа структуры фраз с уменьшением сдвига с помощью информации о границах составляющих
Вэньлян Чен, Мухуа Чжу, Мин Чжан, Юэ Чжан, Цзинбо Чжу, Computational Intelligence, 2016
Нелексикализованный прерывистый анализ на основе переходов,
Максимин Коаву, Бенуа Краббе, Шэй Б. Коэн, TACL, 2019 г.
Коэн, TACL, 2019 г.
Нейронное перераспределение повышает субъективное качество машинного перевода: NAIST на WAT2015
Грэм Нойбиг, Макото Моришита, Сатоши Накамура, WAT, 2015
Моделирование предпочтений выбора глаголов и существительных в машинном переводе «строка-дерево»,
Мария Нэдейде, Александра Берч, Филипп Коэн, CMT, 2016
На пути к воспроизводимости при синтаксическом разборе,
Дэниел Дакота, Сандра Киблер, РАНЛП, 2017 г.
Автоматизированная генерация наборов тестов для анализа ошибок систем распознавания концепций,
Тудор Гроза, Карин Верспур, ALTA, 2014
Регуляризация лексикона на основе графов для PCFG со скрытыми аннотациями
Сяодун Цзэн, Дерек Ф.Вонг, Лидия С. Чао, Изабель Транкосо, Транзакции IEEE / ACM по обработке звука, речи и языка, 2015 г.
Встраивание синтаксиса и семантики предлогов с помощью тензорной декомпозиции,
Hongyu Gong, Suma Bhat, Pramod Viswanath, NAACL, 2018 г.
Разбор зависимостей с расширенной валентностью,
Тианце Ши, Лилиан Ли, ЕМНЛП, 2018 г.
Распределительные закономерности глаголов и глагольных прилагательных: свидетельства Treebank и более широкий смысл,
Даниэль де Кок, Патрисия Фишер, Корина Дима, Эрхард Хинрикс, IWTLT, 2017
Une note sur l’analyse du constituant pour le francais
Парк Чонъёль, ТАЛН, 2018
Эмпирическое исследование предварительного обучения местного упорядочивания для структурированного прогнозирования,
Чжисун Чжан, Сян Конг, Лори Левин, Эдуард Хови, Результаты EMNLP, 2020
Неконтролируемый синтаксический анализ с S-DIORA: кодирование одного дерева для рекурсивных автоэнкодеров с глубоким внутренним и внешним видом
Эндрю Дроздов, Субендху Ронгал, Йи-Пей Чен, Тим О’Горман, Мохит Айер, Эндрю МакКаллум, EMNLP, 2020
Сильно инкрементный анализ аудитории с графическими нейронными сетями
Кайю Ян, Цзя Дэн, NeurIPS, 2020
Замечание о составном синтаксическом анализе для корейского языка
Миджа Ким, Парк Джунгёль, инженерия естественного языка, 2020
Синтаксические анализаторы знают лучше: новое вложение немецкого PP
Bich-Ngoc Do, Инес Ребейн, CoLing, 2020
Глобальные оценки синтаксического согласования в высказываниях взрослых и детей во время взаимодействия: оценки НЛП на основе нескольких корпусов
Кларенс Грин, Хе Сан, Языковые науки, 2021 г.
На пути к более детальному и надежному прогнозированию производительности НЛП
Zihuiwen Ye, Pengfei Liu, Jinlan Fu, Graham Neubig, EACL, 2021 г.
Что в промежутке? Оценка творческих способностей парсера нейронных групп на основе диапазона
Даниэль Дакота, Сандра Кюблер, Труды Общества вычислений в лингвистике, 2021 г.
| Инкрементальная интерпретация категориальной грамматики * | |
| Дэвид Милвард | |
| Центр когнитивных наук | |
| Эдинбургский университет | |
| 2 Buccleuch Place, Эдинбург, EH8 9LW, Великобритания | |
davidm @ cogsci. ed.ac.uk ed.ac.uk | |
| Аннотация | |
| В статье описан парсер для Catego- | .|
| rial Грамматика, полностью содержащая слово | |
| поэтапная инкрементальная интерпретация. Модель | |
| Парсеру | не требуются фрагменты sen- |
| имеет тенденцию образовывать составляющие, и, таким образом, | |
| позволяет избежать проблем с ложной двусмысленностью. | |
| В статье кратко обсуждается | |
| отношения между основным Catego- | |
| риал Грамматика и другие формализмы, такие как | |
| как HPSG, Dependency Grammar и | |
Исчисление Ламбека. Также включает Также включает | |
| обсуждение некоторых вопросов, которые | |
| возникают при разборе лексикализованных грамматик, | |
| и возможности использования статистического | |
| приемов настройки на конкретный лан- | |
| манометров. | |
| 1 Введение | |
| Существует большое количество психолингвистических свидетельств | |
| , что предполагает, что значение может быть извлечено следующим образом: | |
| перед концом предложения и перед концом | |
| фразовых составляющих (например, Marslen-Wilson 1973, | |
Tanenhaus et al. 1990). Также есть недавние evi- 1990). Также есть недавние evi- | |
| , следовательно, предполагая, что во время обработки речи | |
| частичных интерпретаций могут быть построены предельно ra- | |
| pidly, даже до того, как слова будут завершены (Spivey- | |
| Knowlton et al. 1994) 1. Есть еще потенциал | |
| вычислительных приложений для инкрементального взаимодействия | |
| pretation, включая фильтрацию раннего синтаксического анализа с использованием sta- | |
| статистик, основанных на правдоподобии логической формы, а in- | |
| интерпретация фрагментов диалогов (опрос | |
| предоставлено Milward and Cooper, 1994, следовательно — | |
далее именуется M&C). | |
| В текущих вычислительных и психолингвистических | |
| В литературных источниках существует два основных подхода к | |
| пошаговое построение логических форм. Один | |
| подход заключается в использовании грамматики с «нестандартным» | |
| * Это исследование было поддержано UK Science | |
| и Совет по инженерным исследованиям, грант RR30718. | |
| Я благодарен Патрику Стерту, Карлу Фогелю и сотрудникам | |
| рецензентов за комментарии к более ранней версии. | |
1Spivey-Knowlton et al.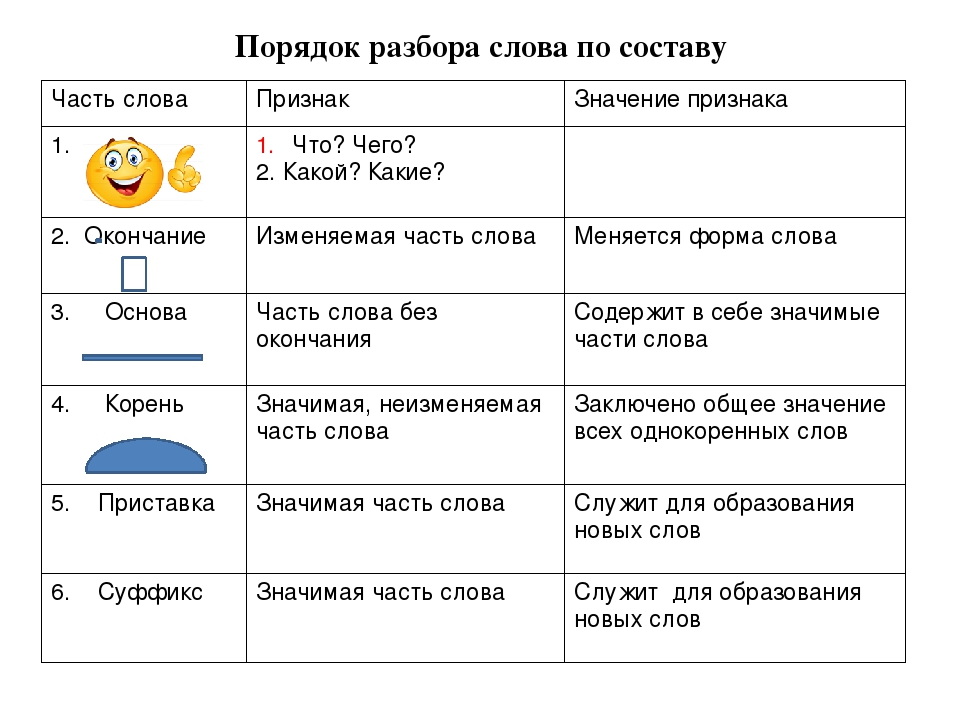 сообщил о 3 экспериментах. сообщил о 3 экспериментах. | |
| Один показывал эффекты до конца слова, когда | |
| не было другого подходящего слова с таким же | |
| начальная фонология.Другой показал on-line эффекты | |
| от прилагательных и определителей в составе именной группы | |
| обработки. | |
| Округа | , так что исходный фрагмент сообщения |
| tence, как любит Джон, может рассматриваться как кон- | |
| , и, следовательно, ему будет присвоен тип и se- | |
| мантика.Примером такого подхода является Com- | .|
| бинарная категориальная грамматика, CCG (Steedman | |
| 1991), который берет базовую компьютерную графику только с приложением — | |
| tion, и добавляет различные новые способы комбинирования ele- | |
| элементов вместе 2. Может инкрементальная интерпретация | |
| затем можно получить с помощью стандартного восходящего сдвига | |
| уменьшить парсер, работая слева направо по | |
| приговор.Альтернативный подход, пример | |
| найден в результате работы Stabler по нисходящему синтаксическому анализу | |
| (Stabler 1991) и Пульман при разборе левого угла | |
| (Pulman 1986) напрямую связывает семантику | |
| с частичными структурами, образованными во время топки- | |
анализирует нижний или левый угол. Например, синтаксис Например, синтаксис | |
| В дереве отсутствует существительная фраза, например, следующая | |
| с / \ | |
| нп вп | |
| Джон / \ | |
| в нп « | |
| классов | |
| может быть задана семантика как функция из enti- | |
| связей с ценностями истины i.е. Топор. любит (john, x), с- | |
| , говоря, что Джон любит, является составной частью. | |
| Ни один из подходов не обходится без проблем. Если | |
| Грамматика | дополнена операциями |
| достаточно мощный, чтобы сделать большинство начальных фрагментов | |
| составляющих, тогда могут быть нежелательные интер- | |
| действий с остальной грамматикой (примеры | |
| из них в случае CCG и Lambek Cal- | |
кулус приведены в разделе 2). Добавление Добавление | |
| дополнительных операций также означает, что для любого данного | |
| чтение предложения обычно будет много | |
| различных возможных производных (так называемые «ложные» | |
| двусмысленность), делая простые стратегии синтаксического анализа, такие как | |
| как сдвиг-понижение крайне неэффективно. | |
| Ограничения подходов к синтаксическому анализу be- | |
| становится очевидным, если мы рассмотрим грамматики с | |
| левая рекурсия. В таких случаях простой сверху вниз | |
| Синтаксический анализатор | будет неполным, а синтаксический анализатор левого угла |
| прибегнет к буферизации ввода (поэтому не будет полностью | |
| 2 Обратите внимание, что CCG не предоставляет тип для всех в- | |
исходных фрагментов предложений. Например, он дает Например, он дает | |
| типа, чтобы Джон думает Мэри, но не Джон думает каждый. | |
| В отличие от исчисления Ламбека (Lambek 1958) pro- | |
| предлагает бесконечное количество типов для любого начального сообщения. | |
| фрагмент тенсе. | |
| 119 | |
| дословно).M&C иллюстрирует проблему | |
| рассматривая фрагмент, Мэри думает, что Джон. Это | |
| имеет небольшое количество возможных семантических представлений. | |
| отправлений (точное количество зависит от | |
| грамматика) например | |
), П.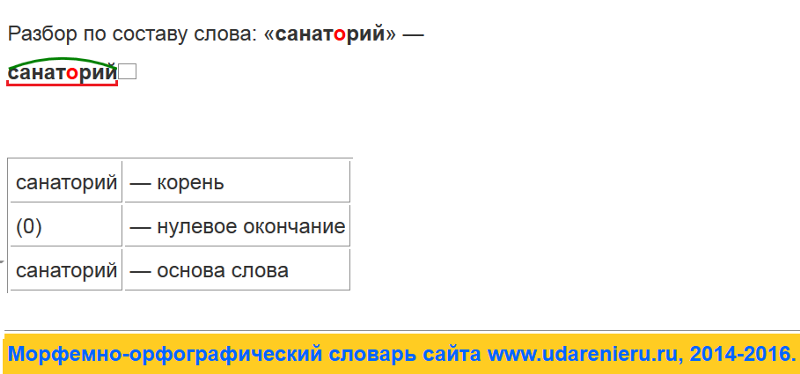 думает (Мэри, П. (Джон)) думает (Мэри, П. (Джон)) | |
| AP.AQ. Q (думает (Мэри, П (Джон))) | |
| ), P.AR. (R (Ax. Думает (x, P (john)))) (Мэри) | |
| Второе представление подходит, если | |
| предложение оканчивается модификатором предложения. Модель | |
| третий позволяет использовать модификатор глагольной фразы. | |
| Если семантическое представление должно быть считано | |
| синтаксическая структура, тогда синтаксический анализатор должен предоставить | |
| одно синтаксическое дерево (возможно, с пустыми узлами). | |
| Однако на самом деле таких | |
| синтаксических деревьев, соответствующих, например, | |
| первое семантическое представление, поскольку np и | |
| с могут быть произвольно удалены друг от друга. Следующее дерево — | |
| подходит для предложения, которое Мэри считает, что Джон бреет | |
| , но не для e. | |
| Иоанна | |
| M&C предлагает различные варианты упаковки | |
| частичных синтаксических деревьев, включая использование Tree Adjoi- | |
| Грамматика нин (Джоши, 1987) или теория описания | |
| (Маркус и др., 1983). Еще одна возможность — | |
| выберите одно синтаксическое дерево, а для использования деструктивного | |
| операций с деревом позже в синтаксическом анализе a. | |
| Подход, который мы здесь примем, основан на | |
| по Милварду (1992, 1994). Частичные синтаксические деревья могут | |
| можно рассматривать как исполнение двух основных ролей. Модель | |
| во-первых, чтобы предоставить синтаксическую информацию, которая gui- | |
| как можно интегрировать остальную часть предложения | |
| в дерево.Второй — заложить основу для | |
| семантическое представление. Первая роль может быть кепкой — | |
| с использованием синтаксических типов, где каждый тип соответствует | |
| относится к потенциально бесконечному количеству частичных | |
| синтаксических деревьев. Вторую роль может захватить | |
| синтаксический анализатор, конструирующий семантические представления | |
| напрямую.Таким образом, общая модель обработки | |
| состоит из переходов вида: | |
| Синтаксический тип i — + Синтаксический тип i + 1 | |
| Семантическое сообщение Семантическое сообщение + 1 | |
| 3 Это может оказаться похоже на одно изображение | |
| Грамматика, прилегающая к дереву, где присоединение складывается в | |
| — это уже существующая хорошо сформированная древовидная структура.Это тоже | |
| ближе к некоторым методам инкрементальной адаптации | |
| структур дискурса, где разрешены дополнения к | |
| правая граница древовидной структуры (например, Polanyi и | |
| Scha 1984). Однако есть проблемы с этим | |
| вид подхода, когда рассматриваются особенности (см. | |
| e.грамм. Виджай-Шанкер 1992). | |
| Это обеспечивает переход между состояниями или динамическую модель | |
| обработки, при этом каждое состояние представляет собой пару | |
| синтаксический тип и семантическое значение. | |
| Основное отличие нашего подхода от | |
| , что Милвард (1992, 1994) состоит в том, что он основан на | |
| о более выразительном грамматическом формализме, Appli- | |
| cative Категориальная грамматика, в отличие от Lexi- | |
| калиброванная грамматика зависимостей.Аппликативный Cate- | |
| грамматики gorial позволяют категориям иметь аргументы- | |
| элементов, которые сами по себе являются функциями (например, очень | |
| можно рассматривать как функцию от функции, а gi- | |
| ven тип (n / n) / (n / n) при использовании в качестве прилагательного- | |
| модификатор тивал). Умение разобраться с функциями | |
| функций имеет преимущества в обеспечении большего количества элементов | |
| лингвистических описаний, а в предоставлении одного | |
| вид надежного синтаксического анализа: синтаксический анализатор никогда не дает сбоев до | |
| последнее слово, так как всегда могло быть последнее | |
| слово, которое является функцией всех составляющих | |
| На данный момент сформировано | .Однако есть соответствующий |
| проблема гораздо большего недетерминизма, причем даже | |
| однозначных слов, допускающих много возможных тран- | |
| секций. Поэтому становится критически важным либо пер- | |
| образуют некую упаковку неоднозначности, или язык | |
| тюнинг. Это будет обсуждаться в заключительном разделе | .|
| статьи. | |
| 2 Аппликативная категориальная грамматика | |
| Аппликативно-категориальная грамматика самая плохая | |
| sic форма категориальной грамматики, всего с одним | |
| комбинированное правило, соответствующее функции appli- | |
| Катион | . Впервые он был применен к лингвистическому описанию — |
| ция Аджукевичем и Бар-Гиллелем в 1950-х гг. | |
| Хотя он все еще используется для лингвистического описания | |
| (например, Bouma and van Noord, 1994), это было | |
| несколько омрачен в последние годы HPSG | |
| (Pollard and Sag 1994), а также Lambek Cate — | |
| gorial Grammars (Lambek 1958). Следовательно, | |
| стоит дать несколько кратких указаний о том, как он подходит к | |
| в связи с этими разработками. | |
| Была предложена первая направленная Аппликативная CG | |
| Бар-Гиллеля (1953). Функциональные типы включали | |
| список аргументов слева и список аргументов | |
| мент. Вправо. Перевод примечания Бар-Гиллеля | |
| в обозначение на основе функций, аналогичное | |
| в HPSG (Pollard and Sag 1994), мы получаем | |
| следующая категория для переходного глагола, такого как | |
| поставить: | |
| r s \] Unp> | |
| L r (np, pp> | )|
| Список аргументов слева собран до | |
| der, l, и те, что справа, an np | |
| и стр. В указанном порядке под элементом r. | |
| Bar-Hillel использовал правило одного приложения, | |
| , что соответствует следующему: | |
| 120 | |
| ix 1 L ~ … L1 I (L1 .. • Ln) R1. .. Rn ~ X r (R1 … R ~> | |
| В результате получилась система, очень близкая к | .|
| формализованные грамматики зависимостей Гайфмана | |
| (1965) и Hays (1964).Единственная реальная разница | |
| состоит в том, что Бар-Гиллель разрешил аргументы самим себе. | |
| функций. Например, наречие | |
| медленно можно было дать тип 4 | |
| LrO | |
| Неудачный аспект первой системы Бар-Гиллеля | |
| заключалось в том, что правило приложения всегда приводило только к | |
| в примитивном виде.Следовательно, аргументы с удовольствием — | |
| тематических типов должны были соответствовать единственному лексическому | |
| элементов: не было возможности сформировать тип np \ s ~ | |
| для нелексической глагольной фразы, например, любит Мэри. | |
| Вместо того, чтобы адаптировать Правило приложения к | |
| позволяет применять функции к одному аргументу в | |
| Время | , вторая система Бар-Гиллеля (часто называемая AB |
| Категориальная грамматика, или Аджукевич / Бар-Гиллель | |
| CG, Bar-Hillel 1964) принята нота «Карри» — | |
| , и это было принято большинством CG | |
| с.Для представления функции, требующей | |
| Слева | нп, справа нп и пп, |
| можно выбрать один из следующих трех типов, используя | |
| Обозначение по Карри: | |
| нп \ ((с / пп) / нп) | |
| (np \ (s / pp)) / np | |
| ((np \ s) / pp) / np | |
| Большинство компьютерных групп выбирают третью из них (чтобы получить | |
| структура vp), или включить правило ассоциативности | |
| , что означает, что типы взаимозаменяемы | |
| (в исчислении Ламбека ассоциативность является следствием | |
| расчет исчисления, а не конкретизация | |
| отдельно). | |
| Основной стимул к изменению Applicative CG | |
| — результат работы Адеса и Стидмана (1982). | |
| Адес и Стидман отметили, что использование функции | |
| Состав | позволяет компьютерным группам иметь дело с неограниченными |
| конструкций зависимостей. Функциональный состав | |
| позволяет применить функцию к своему аргументу, | |
| , даже если этот аргумент неполный e.грамм. | |
| s / pp + pp / np — + s / np | |
| Это позволяет периферийное извлечение, где «зазор» | |
| находится в начале или в конце, например относительное предложение. | |
| Предложены варианты правила композиции | |
| для устранения непериферических экстрактов, | |
| 4 Переформулировка здесь не совсем совпадает с формулировкой | |
| Бар-Гиллель, использовавший слегка проблемный дубль | |
| слэш — обозначение функций функций. | |
| 5 Обозначения Ламбека (Lambek 1958). | |
| , но это привело к нежелательным эффектам в других местах в | |
| грамматики (Баума, 1987). Последующие процедуры | |
| непериферической экстракции на основе Lambek | |
| Исчисление (в него встроена стандартная композиция: | |
| это правило, которое подтверждается расчетом. | |
| lus) либо представили альтернативу | |
| прямая и обратная косая черта i.е. / и \ для nor- | |
| ошибочных аргументов,? для wh-args (Moortgat 1988) или | |
| ввел так называемые модальные операторы на WH- | |
| Аргумент | (Моррилл и др., 1990). Обе техники |
| можно рассматривать как маркировку wh-arguments как | |
| , требующие особого обращения, и поэтому не | |
| приводит к нежелательным эффектам в другом месте грамма — | |
| мар. | |
| Однако есть проблемы с наличием только | |
| состав, самый основной из неприменимых | |
| операций. В CG, которые содержат функции | |
| функций (например, очень или медленно), добавление | |
| Состав | добавляет оба новых анализа предложений, |
| и новые строки к языку.Это связано с | |
| факт, что композицию можно использовать для образования | |
| Функция | , которую затем можно использовать в качестве аргумента |
| в функцию функции. Например, если | |
| два типа, n / n и n / n, составляют | |
| типа n / n, тогда это может быть изменено прилагательным- | |
| модификатор тивального типа (n / n) / (n / n).Таким образом, | |
| существительное очень старая ветхая машина может получить unac- | |
| приемлемый брекетинг, \ [\ [очень \ [старая ветхая \] \] машина \]. | |
| Ассоциативная компьютерная графика с композицией, или Лампа- | |
| bek Calculus также позволяет использовать строки, такие как мальчик с | |
| получить тип n / n предсказывающий очень мальчик | |
| с автомобилем, чтобы быть приемлемым существительным.Хотя | |
| отдельных примеров могли бы исключить | |
| используя соответствующие функции, трудно увидеть, как | |
| , чтобы сделать это в целом, сохраняя при этом исчисление | |
| подходит для инкрементной интерпретации. | |
| Если требуется особая обработка белых аргументов | |
| в любом случае (для устранения непериферической экстракции), | |
| , а если состав, как правило, является проблемным- | |
| matic, это говорит о том, что нам, возможно, следует вернуться к | |
| грамматик, использующих только Application в качестве гена — | |
| ral операции, но имеют особую обработку для | |
| белых аргументов.Использование нотации не Карри | |
| Bar-Hillel, естественнее использовать отдельный | |
| wh-list, чем отмечать белые аргументы индивидуально. | |
| Например, категория, соответствующая родственнику | |
| предложений с пробелом в именной фразе будут: | |
| lO |,: o / | |
| Затем можно указать операции, которые действуют | |
| как чисто аппликативные операции по отношению к | |
| списки левых и правых аргументов, но больше похоже на | |
| Состав | по белому списку.Это |
| очень похож на механизм WH- | |
| рассматривается в GPSG (Газдар и др., 1985) и | |
| HPSG, где wh-аргументы обрабатываются с помощью | |
| Механизмы косой черты или принципы наследования признаков | |
| 121 | |
| , которые близко соответствуют функциональному составу. | |
| Учитывая, что наши аргументы привели к категории | |
| грамматика gorial, которая очень похожа на HPSG, | |
| почему бы не использовать HPSG, а не Applicative CG? | |
| Основная причина в том, что Applicative CG очень сильно | |
| более простой формализм, который может быть очень упрощен- | |
| Интерфейс семантики простого синтаксиса, с функцией ap- | |
| Пликация в отображении синтаксиса в приложение-функцию- | |
| ция в семантике 6’7.Это, в свою очередь, делает его относительным. | |
| очень легко предоставить доказательства надежности и надежности | |
| Полнота | для алгоритма инкрементного синтаксического анализа. |
| В конечном итоге, некоторые из разработанных здесь методик | |
| можно расширить до более сложных | |
| формализмов, таких как HPSG. | |
| 3 AB Категориальная грамматика с | |
| Ассоциативность (AACG) | |
| В этом разделе мы определяем грамматику, аналогичную Bar- | .|
| Первая грамматика Гиллеля. Однако, в отличие от Бар-Гилеля, | |
| мы позволяем поглощать по одному аргументу за раз. | |
| Полученная грамматика эквивалентна AB Cate- | .|
| gorial Грамматика плюс ассоциативность. | |
| Категории грамматики определены как | |
| следует: | |
| 1. Если X — синтаксический тип (например, s, np), то | |
| 10 — это категория. | |
| r0 | |
| 2. Если X — синтаксический тип, а L и R — списки | |
| категорий, затем | |
| Приложение справа определяется правилом S: | |
| 6 Одна область, в которой применяются подходы к | |
| семантическая комбинация выигрывает в простоте по сравнению с унификацией | |
| Подходы, основанные на | , заключаются в предоставлении семантики для |
| функций функций.Мур (1989) предлагает угощение — | |
| мент функций функций в унификации на основе | |
| , но только путем явного включения лямбда | |
| выражений. Поллард и Саг (1994) имеют дело с примерно | |
| функций функций, таких как непересекающееся adjec- | |
| тивов, явным построением множества. | |
| 7 Как уже говорилось выше, для белого движения требуется немного- | |
| вещь больше похожа на состав, чем на аппликацию. Сим- | |
| Интерфейс семантики синтаксиса | может быть сохранен, если |
| одинаковая операция используется как в синтаксисе, так и в семантике. | |
| Wh-аргументы можно рассматривать как аналогичные другим ar- | |
| гументов i.е. как лямбда, абстрагированная в семантике. | |
| Например, фрагмент: Иоанн нашел женщину, которая | |
| Мэри можно дать семантику, kP.3x. женщина (x) | |
| &: found (john, x) g ~ P (mary, x), где P — забава- | |
| ction из левого аргумента Мэри типа e и WH- | |
| аргумент, также типа e. | |
| s,., Это объединение списков, например (np) — (s) равно (np, s). | |
| к j | |
| Приложение слева определяется правилом: | |
| L = R \ [= RJ | |
| Базовая грамматика содержит некоторые ложные данные. | |
| vations, так как такие предложения, как John, любят Мэри | |
| можно заключить в квадратные скобки ((Джон любит) Мэри) | |
| или (Джон (любит Мэри)).Однако мы увидим | |
| , что эти ложные выводы не переводят | |
| в ложную двусмысленность в синтаксическом анализаторе, который отображает | |
| из строк слов непосредственно в семантическое представление | |
| отправлений. | |
| 4 Добавочный синтаксический анализатор | |
| Большинство парсеров, которые работают слева направо по | |
| Строка ввода | может быть описана в терминах состояния |
| переходов i.е. по правилам, которые говорят, как текущий | |
| состояние анализа (например, стопка категорий или диаграмма) | |
| может быть преобразовано следующим словом в новое | |
| гос. Здесь это будет особенно ясно, | |
| с парсером, описанным всего двумя правилами | |
| , которые принимают состояние, новое слово и создают новое | |
| состояние 9.Есть две необычные особенности. Во-первых, | |
| нет ничего эквивалентного механизму стека: | |
| во все времена состояние характеризуется одним | |
| Синтаксический тип | и одно семантическое значение, а не |
| некоторым стеком семантических значений или синтаксических деревьев | |
| , которые ждут соединения.Se- | |
| соответственно, все переходы между состояниями происходят на | |
| ввод нового слова: нет «пустых» тран- | |
| секций (например, шаг уменьшения сдвига-уменьшения | |
| парсер). | |
| Два правила, которые показаны на рисунке 1 t °, это | |
| трудно понять в самом общем виде. | |
| Здесь мы будем работать по правилам постепенно, по кон- | |
| sidering, какие правила нам могут понадобиться в пар. | |
| особей. Рассмотрим следующую пару | |
| фрагментов предложений с их простейшими возможными | |
| Тип CG: | |
| Мэри думает: s / s | |
| Мэри думает, что Джон: s / (np \ s) | |
| Мэри думает, что Джон любит: s / np | |
| Мэри думает, что Джону нравится Сью: s | |
| Теперь рассмотрим каждый тип как описание | |
| состояние, в котором синтаксический анализатор находится после поглощения | |
| фрагмент.Получаем последовательность переходов как | |
| следует: | |
| 9 Этот подход более подробно описан в Mil- | .|
| ward (1994), где синтаксические анализаторы формально указаны в | |
| единиц их динамики. | |
| l ° Li, Ri, Hi — списки категорий, li и ri — списки | |
| переменных той же длины, что и соответствующие | |
| Ли и Ри. | |
| 122 | |
| Государственная заявка: | |
| Y | |
| 1 <> | |
| 1Ло). R2 r (\ [rP ~ o | |
| hHo | |
| ч <> | |
| F | |
| Прогноз состояния: | |
| Y | |
| 10 | |
| ILI «Lo | |
| r | |
| hL1, Ho | |
| hO | |
| F | |
| ¢ {W ~ __} rRI «R2 | |
| ч <> | |
| Ar ~.Ф (Г (г,)) | |
| Y | |
| I <> | |
| Х | |
| rR1 • | |
| hO | |
| ~ rl. (Ah. F (all. (H (ar (((G rl) r) ll))))) | |
| Рисунок h Правила перехода | |
| • L0 | |
| >.R2 | |
| .H0 | |
| где W: | |
| где W: | |
| 1Xo | |
| рРИ «Ро | |
| ч <> | |
| G | |
| ИЗЛИ ,, Л | |
| rR1.R | |
| h0 | |
| G | |
| «Джон …. любит …. Сью» s / s — ~ s / (np \ s) — ~ s / np — ~ s | |
| Если встроенному предложению, например John, нравится Sue | |
| — это отображение s / s на s, это предполагает | |
| , что все предложения можно рассматривать как | |
| отображение из некоторой категории с ожиданием s на | |
| эта категория i.е. от X / s до X. Аналогично все | |
| словосочетаний с существительными могут рассматриваться как сопоставления из | .|
| от X / np к X. | |
| Теперь рассмотрим отдельные переходы. Сим- | |
| . Самый последний из них — это тип аргумента, например, | |
| , определяемое состоянием, соответствует следующему слову | |
| и.е. | |
| «Sue» s / np — ~ s где: Sue: np | |
| Это можно обобщить до следующего правила: | |
| , который аналогичен приложению функции в стандарте | |
| Дард CG 11 | |
| X / Y «~» X где: W: Y | |
| Аналогичный переход происходит и для лайков.Здесь np \ s | |
| ожидалось, но отметка «Нравится» дает только часть этого: | |
| nit отличается тем, что не является правилом грамматики: здесь | |
| функтор — это категория состояния, а аргумент — это | |
| лексическая категория. В стандартном приложении функции компьютерной графики: | |
| функтор и аргумент могут соответствовать слову | |
| или фразу. | |
| требуется np справа для формирования np \ s. | |
| Таким образом, после того, как лайки будут поглощены, статус категории будет | |
| нужно ожидать np. Требуется аналогичное правило | |
| в функциональную композицию в CG, т. Е. | |
| , {W ~ X / Y ~ X / Z где: W: Y / Z | |
| Рассматривая это неформально с точки зрения древовидной структуры — | |
| тур, происходит замена | |
| пустой узел в частичном дереве вторым частичным | |
| дерево i. | |
| Указанные до сих пор два правила должны быть дополнительными | |
| обобщено, чтобы учесть случай, когда лексический | |
| Элемент | имеет более одного аргумента (например, если мы повторно — |
| поместите лайки с помощью ди-переходного элемента, такого как дает или | |
| трипереходные, такие как ставки). Это относительно три- | |
| с обозначением без карри, аналогичным | |
| используется для AACG.Получается единственное правило | .|
| Гос.Приложения, что соответствует заявке- | |
| катион, когда список аргументов R1 пуст, | |
| для функциональной композиции, когда R1 имеет длину один, | |
| и n-арному составу, когда R1 имеет длину n. | |
| Единственное изменение, необходимое для нотации AACG: | |
| 123 | |
| 8 | |
| I (> | |
| г (8> | |
| ч (> | |
| AQ.Q | |
| «Джон» — + | |
| S | |
| I <> | |
| л (np> r | |
| L h | |
| h0 | |
| хиджры. (n (john ‘)) | |
| лайков RS 1 1 <> | r (np> | |
| т чО | |
| AY.любит ‘(john’, Y) | |
| Рисунок 2: Возможные переходы между состояниями | |
| i <> | |
| г (> | | |
| ч <> J | |
| лайков ‘(john’, sue ‘) | |
| включение дополнительного списка функций, h list, | |
| , в котором хранится информация о том, какие аргументы | |
| ждут головы (причин для этого будет | |
| объяснено позже).Лексика идентична той, что | |
| для стандартного AACG, за исключением h-списков | |
| , которые всегда пусты. | |
| Теперь рассмотрим первый переход. Вот сен- | |
| тенсе ожидалось, но что встретилось | |
| было существительным, Джон. Соответствующее правило | |
| в нотации CG будет: | |
| «W» X / Y — + X / (Z \ Y) где: W: Z | |
| Это правило гласит, что если искать Y и получить | |
| Z, затем найдите Y, в котором отсутствует Z.+ Z => U Y | |
| / \ | |
| z zkY ~ | |
| Правило прогнозирования состояния получается дальнейшими | |
| обобщение, чтобы позволить лексическому элементу иметь неправильный- | |
| аргументов, а для ожидаемого аргумента — | |
| У | отсутствуют аргументы. |
| State-Application and State-Prediction to- | |
| вместе обеспечивают основу звука и целостности | |
| синтаксический анализатор 12. Разбор предложений осуществляется звездочкой- | |
| в состоянии ожидания приговора и подать заявление — | |
| правил недетерминированно, как каждое слово | |
| вводится.Успешный разбор достигается, если fi- | |
| окончательное государство больше не ожидает аргументов. Как бывший | |
| достаточно, пересмотрите строку, которую Джон любит Сью. Модель | |
| последовательность переходов, соответствующая Иоанну li- | |
| kes Sue — приговор, приведенный на рисунке 2. | |
| Переход при встрече с Джоном определен — | |
| stic: State-Application не может применяться, State- | |
| Прогноз может быть создан только в одном направлении.Модель | |
| Результатом | является новое состояние, ожидающее аргумента, который, |
| для np может дать s, то есть np \ s. | |
| 12 Синтаксический анализатор принимает те же строки, что и грам- | |
| mar и присваивает им одинаковые семантические значения. Это | |
| немного отличается от стандартного понятия так- | |
| неполнота и полнота парсера, где par- | |
| ser принимает те же строки, что и грамматика, и as- | |
| подписывает им одинаковые синтаксические деревья. | |
| Переход на ввод лайков не | |
| детерминированный. Государственная заявка может подавать, как в | |
| Рис. 2. Однако State-Prediction также может | |
| слоями и могут быть созданы четырьмя способами (эти | |
| соответствуют различным способам нарезки | |
| левая и правая подкатегории списков le- | |
| xical entry, лайки, я.е. как (np> • 0 или 0 • (np>). | |
| Одна возможность соответствует предсказанию | |
| модификатор s \ s, секунда до предсказания | |
| (np \ s) \ (np \ s) модификатор (т. Е. Глагольная фраза тоже — | |
| различаются), третья — существует функция, которая | |
| принимает подлежащее и глагол как отдельные аргументы. | |
| ments, а четвертый соответствует | |
| , для которой требуется аргумент s / np.Модель | |
| второй из них, пожалуй, самый интересный, | |
| и приведен на рисунке 3. Это выбор этого | |
| конкретный переход на этом этапе, который позволяет | |
| Модификация глагольной фразы | , и, следовательно, предполагая, что |
| следующее слово — Сью, неявная скобка | |
| фрагмент строки как (Джон (любит Сью)).Обратите внимание, что | |
| , если выбрано Государственное приложение, или первый из | |
| Возможности прогнозирования состояния, фрагмент Иоанна | |
| нравится, что Сью сохраняет плоскую структуру. Если есть до | |
| быть без модификации глагольной фразы, без глагола | |
| Введена структура фразы | . Это относится к |
| отсутствие ложной двусмысленности: каждый вариант | |
| переход имеет смысловые последствия; каждый выбор | |
| влияет на то, является ли определенная часть семантики | |
| должен быть изменен или нет. | |
| Напоследок стоит отметить, зачем нужно | |
| используют h-списки. Они нужны, чтобы различать bet- | |
| различных случаев действительных функциональных аргументов (из функции | |
| функций) и функций, формируемых государством — | |
| Прогноз. Рассмотрим следующие деревья, где | |
| узел np \ s пуст. | |
| Оба дерева имеют одинаковый синтаксический тип, однако | |
| в первом случае мы хотим допустить, чтобы было | |
| модификатор s \ s нижнего s, но не в se- | |
| пров. В возглавляемом списке проводится различие между | |
| два корпуса, причем только первый имеет np на своем | |
| 124 | |
| S | |
| i0 | |
| л (np> | |
| r ! | |
| L h | |
| hO | |
| хиджры.(H (Джон)) | |
| «lik_ ~ s» | |
| «Ю | |
| 1 <> | |
| S | |
| л (нп) | |
| 1 (/ rO, вверх>! | |
| L h0 r (np,) | |
| г <) | |
| 1 (нп) | |
| ч (/ rO, np>! | |
| л чО | |
| ч (> | |
| AY.АК. (K (AX.likes ‘(X, Y))) (Джон) | |
| где W: | |
| Рисунок 3: Пример реализации прогнозирования состояния | |
| 8 | |
| л (np> | |
| | r (np> | |
| Lh <> | |
| AY.AX.Iikes ‘(X, Y) | |
| список заголовков, позволяющий прогнозировать модификатор s. | |
| 5 Анализ лексикализованных грамматик | |
| Когда мы рассматриваем полную обработку предложения, см. Op- | |
| для инкрементальной обработки, использование lexi- | |
| калиброванных грамматик имеет большое преимущество перед | |
| использование более стандартных грамматик, основанных на правилах. В | г.|
| обработка предложения с использованием лексикализованного формализма | |
| не надо смотреть на грамматику в целом, | |
| , но только по грамматической информации с индексом | |
| каждым из слов.При этом увеличивается в размере | |
| грамматики не обязательно влияют на эффективность | |
| обработки, при условии увеличения размера за счет | |
| добавление новых слов, а не увеличение | |
| лексическая двусмысленность. Сразу полный комплект возможен le- | |
| Собрано | хикальных записей для предложения, они могут, |
| , если требуется, затем преобразовать обратно в набор из | |
| правил структуры фраз (которым должно соответствовать | |
| к небольшому подмножеству формализма, основанного на правилах, equi- | |
| валент на всю лексикализованную грамматику), перед | |
| обрабатывается стандартным алгоритмом, например | |
| Эрли (Earley 1970). | |
| При инкрементном синтаксическом анализе мы не можем предсказать, какой из | |
| В предложении будет | слов, поэтому нельзя использовать |
| та же техника. Однако, если мы хотим основать | |
| по приведенным выше правилам, казалось бы, | |
| приобретаем дальше. Вместо грамматической информации- | |
| ция локализуется к предложению в целом, она | |
| локализован для определенного слова в его конкретном | |
| контекст: нет необходимости рассматривать пп как | |
| начало предложения, если оно встречается в конце, даже если | |
| есть глагол с записью, которая допускает | |
| тема стр. | |
| Однако есть серьезная проблема. Как мы уже отметили | |
| в последнем абзаце, это характер парсинга | |
| постепенно, что мы не знаем, какие слова | |
| Следующим будет | . Но тут парсер даже не |
| используйте информацию о том, что слова должны появиться | |
| из словаря определенного языка.Для бывшего | |
| достаточно, при вводе 3 nps синтаксический анализатор выполнит | |
| успешно создает состояние, ожидающее 3 nps слева. | |
| Это может быть вероятным состоянием, скажем, для финала | |
| язык, но маловероятное состояние для такого языка | |
| на английском языке. Обратите внимание, что инкрементальная интерпретация | |
| здесь бесполезен, поскольку семантическое представление | |
| не должно быть более или менее правдоподобным в | |
| разных языков.Практически наивный ин- | |
| реализация параллельного терактивного пролога на текущем | |
| аренда рабочей станции не может быть интерактивной в реальном | |
| смысл примерно после 8 слов 13. | |
| Вроде нужен какой-то язык | |
| Настройка возраста | 14. Это могло быть в характере исправленного |
| ограничения к правилам e.грамм. для английского мы можем | |
| исключает использование предсказания, когда существительная фраза — | |
| Обнаружено | , и два уже существуют в левом списке. |
| Более привлекательная альтернатива — базовая настройка | |
| по статистическим методам. Этого можно добиться с помощью | |
| запускает синтаксический анализатор по корпусам для обеспечения pro- | |
| вероятностей отдельных переходов с учетом конкретных | |
| слов.Эти переходы захватили бы | |
| вероятность того, что слово имеет определенную часть | |
| речи, и вероятность конкретного перехода — | |
| ция выполняется с этой частью речи. | |
| 13 Однако этот результат следует обработать некоторыми | |
| предостережение: в этой реализации не было попытки | |
| для выполнения любой упаковки различных возможных транзит- | |
| ед., А алгоритм имеет экспоненциальную сложность.В | г.|
| контраст, упакованный распознаватель на основе аналогичного, но | |
| — намного более простой инкрементный синтаксический анализатор для Lexicalised De- | |
| Pendency Грамматика имеет O (n a) временную сложность (Mil- | |
| ward 1994) и хорошими практическими характеристиками, взяв | |
| пары секунд на предложения из 30 слов. | |
| 14 Термин «настройка языка» употребляется, вероятно, | |
| здесь шире, чем его использование в психолингвистической литературе- | |
| rature для обозначения различных структурных предпочтений bet- | |
| языков, например для высокого и низкого крепления | |
| (Митчелл и др., 1992). | |
| 125 | |
| На | уже была проделана некоторая ранняя работа.|
| , обеспечивающий статистический анализ с использованием транзистора | |
| связей между рекурсивно структурированным синтаксическим ок. | |
| тегов (Tugwell 1995) 15.В отличие от простого Маркова | |
| существует потенциально бесконечное число | |
| , поэтому неизбежно возникает проблема нехватки | |
| данных. Поэтому необходимо производить различные | |
| обобщений по состояниям, например ig- | |
| занесение в списки R2. | |
| Модель полной обработки может быть либо | |
| Серийный номер | , исследуя наиболее высоко оцененные транзиты- |
| в первую очередь (но с возможностью возврата, если семан- | |
| Тик правдоподобия нынешней интерпретации падает | |
| слишком низко) или ранжируется параллельно, исследуя только n | |
| путей с наивысшим рейтингом согласно переходу | |
| вероятностей и смыслового правдоподобия. | |
| 6 Заключение | |
| Tim paper представил метод предоставления | |
| дословных толкований для основной категории | |
| Грамматика. Заключительный раздел противопоставлен синтаксическому анализу | |
| с лексикализованной и основанной на правилах грамматикой, и ar- | |
| указывает на то, что статистическая настройка языка особенно важна. | |
| в основном подходит для инкрементального лексикализованного синтаксического анализа | |
| стратегий. | |
| Список литературы | |
| Ades, A. ga Steedman, M .: 1972, ‘По приказу | |
| слов, Linguistics ~ d Philosophy 4, 517-558. | |
| Bar-Hillel, Y .: 1953, ‘Квазиарифметическая запись | |
| для синтаксического описания », Язык 29, 47-58. | |
| Bar-Hillel, Y.: 1964, Язык ~ d Информация: | |
| Избранные очерки их теории ~ 4 приложения, | |
| Эддисон-Уэсли. | |
| Баума, Г .: 1987, ‘Основанный на унификации анализ | |
| Неограниченные зависимости », in Proceedings of the | |
| 6-й Амстердамский коллоквиум, ITLI, Университет | |
| Амстердам. | |
| Bouma, G. & van Noord, G .: 1994, ‘Constraint-Based | |
| Категориальная грамматика ‘, в трудах 32-го, | |
| ACL, Лас-Крусес, США | |
| Эрли, Дж .: 1970, «Эффективный контекстно-свободный синтаксический анализ» | |
| Алгоритм ‘, ACM Communications 13 (2), 94-102. | |
| Гайфман, Х.: 1965, ‘Системы зависимости. L: Фраза | |
| Structure Systems ‘, Информация ~ Контроль 8: 304- | |
| 337. | |
| Gazdar, G., Klein, E., Pullum, G.K., & Sag, | |
| I.A .: 1985, Обобщенная структура фраз — | |
| мар, Блэквелл, Оксфорд. | |
| Хейс, Д.Г .: 1964, «Теория зависимости: форма- | ».|
| lism ~ z Some Observations ‘, Language 40, 511-525. | |
| Джоши А.К .: 1987, «Знакомство с деревом, прилегающим к дереву» | |
| Grammars ‘, в Manaster-Ramer (ed.), Mathema- | |
| тики языка, Джон Бенджаминс, Амстердам. | |
| l ~ подход Tugwell, однако, отличается тем, что | |
| переходы между состояниями не ограничиваются правилами State- | |
| Прогнозирование и применение состояний.Это имеет преимущество | |
| ges в разрешении грамматике изучать такие явления | |
| как тяжелый сдвиг НП, но имеет недостаток суф- | |
| из-за больших проблем с разреженными данными. А compro- | |
| система mise использует правила здесь, но разрешает переупорядочивать- | |
| кольцо r-списков может быть предпочтительнее. | |
| Ламбек, Дж .: 1958, «Математика предложения | ».|
| Структура ‘, American Mathematical Monthly 65, | |
| 154-169. | |
| Маркус, М., Хиндл, Д., и Флек, М .: 1983, ‘D- | |
| Теория: Говоря о разговорах о деревьях », в | |
| Протоколы 21-й ACL, Кембридж, Массачусетс. | |
| Marslen-Wilson, W .: 1973, Linguistic Structure & | |
| Затенение речи при очень коротких задержках », Na- | |
| туре 244, 522-523. | |
| Milward, D .: 1992, ‘Dynamics, Dependency Gram- | |
| mar & Incremental Interpretation ‘, in Proceedings | |
| из COLING 92, Нант, том 4, 1095-1099. | |
| Milward, D. & Cooper, R .: 1994, ‘Incremental Inter- | |
| pretation: Applications, Theory &; Отношение к | |
| Dynamic Semantics ‘, in Proceedings of COLING | |
| 93, Киото, Япония, 748-754. | |
| Milward, D .: 1994, «Грамматика динамических зависимостей», | |
| , чтобы появиться в Linguistics ~ d Philosophy 17, 561-605. | |
| Mitchell, D.C., Cuetos, F., & = Corley, M.M.B .: 1992, | |
| ‘Статистические и лингвистические детерминанты par- | |
| предвзятость пения: кросс-лингвистические данные ». Бумага презен- | |
| на 5-й ежегодной конференции CUNY по Hu- | |
| Обработка приговоров | человек, Нью-Йорк. |
| Мур, Р.С .: 1989, ‘Семантический журнал на основе унификации — | |
| толкование ‘, в материалах 27-й ACL, Ван- | |
| couver. | |
| Moortgat, M .: 1988, Категориальные исследования: Logi- | |
| называется лингвистические аспекты исчисления Ламбека, | |
| Форис, Дордрехт. | |
| Моррилл, Г., Лесли, Н., Хеппл, М. и Барри, Г .: 1990, | .|
| ‘Категориальные вычеты ~ z Структурные операции’, | |
| в Barry, G. ~ z Morrill, G. (ред.), Исследования в Ca- | |
| тегориальная грамматика, Эдинбургские рабочие документы в | |
| Когнитивная наука, 5. | |
| Polanyi, L. & Scha, R .: 1984, ‘Синтаксический подход | |
| to Discourse Semantics », in Proceedings of CO- | .|
| LING 8 ~, Стэнфорд, 413-419. | |
| Pollard, C. &: Sag, I.A .: 1994, Head-Driven Phrase | |
| Структурная грамматика, Издательство Чикагского университета | |
| &: CSLI Publications, Чикаго. | |
| Пулман, С.Г .: 1986, ‘Грамматики, синтаксические анализаторы, ~ z Память | |
| Ограничения ‘, Языковые когнитивные процессы 1 (3), | |
| 197-225. | |
| Спайви-Ноултон, М., Седиви, Дж., Эберхард, К., & Та- | |
| nenhaus, М .: 1994, Психолингвистическое исследование | |
| Взаимодействие между языком и зрением », в Pro- | |
| заседаний 12-й Национальной конференции по ИИ, | |
| AAAI-9 ~. | |
| Стейблер, Э.П .: 1991, «Избегайте парадокса пешехода», | .|
| , Бервик, Р. К. и другие. (ред.), Основанный на принципах Par- | |
| Sing: Computing ~ d Psyeholinguistics, Kluwer, | |
| Нидерланды, 199-237. | |
| Steedman, M.J .: 1991, Type-Raising 8z Direction- | |
| Литература по комбинаторной грамматике ‘, в трудах | |
| 29-я ACL, Беркли, U.S.A. | |
| Таненхаус, М.К., Гарнси, С., ~ Боланд, Дж .: 1990, | |
| ‘Комбинированная лексическая информация &: Язык | |
| Понимание », в Altmann, G.T.M. Когнитивный | |
| Модели обработки речи, MIT Press, Cam- | |
| мост Ма. | |
| Тагвелл, Д.: 1995, «Грамматика перехода между состояниями для | ».|
| Data-Oriented Parsing ‘, in Proceedings of the 7th | |
| Конференция европейских ACL, EACL-95, Dub- | |
| лин, этот объем. | |
| Виджай-Шанкер, К .: 1992, ‘Использование описаний деревьев | |
| в дереве, примыкающем к грамматике ‘, Computational | |
| Языкознание 18 (4), 481-517. | |
| 126 |
NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики (Книга)
Hausser, R. NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики . США: Н. П., 1986.
Интернет.
Хауссер, Р. NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики . Соединенные Штаты.
Хауссер, Р. Ср.
«NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики». Соединенные Штаты.
@article {osti_6721611,
title = {NEWCAT: Анализ естественного языка с использованием левоассоциативной грамматики},
author = {Hausser, R},
abstractNote = {Эта книга показывает, что анализ структурных составляющих порождает нерегулярный порядок линейной композиции, что является прямой причиной крайней вычислительной неэффективности.Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на наращивании и отмене валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа дублирует лингвистический анализ. Левоассоциативная грамматика проиллюстрирована двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.},
doi = {},
url = {https: // www.osti.gov/biblio/6721611},
журнал = {},
номер =,
объем =,
place = {United States},
год = {1986},
месяц = {1}
}
Глава 3 Морфологический анализ конечного состояния Глава 3 Морфологический анализ конечного состояния 4 апреля 2011 г.
Глава 3 Конечный морфологический синтаксический анализ
4 апреля 2011 г.
Обзор
• Праймер для морфологии • Использование FSA для морфологического распознавания
сложных слов • FST (определение, каскадирование, композиция) • FST для морфологического анализа • В следующий раз: подробнее о FST, морфологических Анализ
и демонстрация XFST
Праймер по морфологии
• Слова состоят из основы и аффиксов.• Аффиксы могут быть префиксами, суффиксами, циркумфиксами.
или инфиксы. Примеры?
• (Также: морфология корня и рисунка) Примеры?
• Иногда могут применяться фонологические процессы сочетаниям морфем.
Фонология на границах морфем Примеры:
английский испанский Единственное число Множественное число Единственное число Множественное число [kæt] ‘Кот’
[kæts] «Кошки»
[ниндзё] Англ .: «мальчик»
[ниндзё]
[дг] ‘собака’
[dgz] «Собаки»
[fɪnʧ] «Зяблик»
[fɪnʧəәz] «Зяблики»
[kaɾakol] Англ .: «улитка»
[kaɾakoles]
/ s / / s /
Подробнее о морфологии
• Языки различаются по разнообразию морфологические системы.
• Языки также различаются по степени фонологические процессы применяются в (и иногда размывают) границы морфем.
• В английском языке относительно мало флективных морфология, но довольно богатая (если не идеально продуктивная) деривационная морфология.
• Турецкий язык насчитывает более 200 миллиардов словоформ.
Вопросы
• Еще примеры сложных морфем? • Какие основные представления мы можем
хотите? • Зачем нам обращаться к базовым
представительства? • Как все меняется, когда мы рассматриваем
орфографические правила, а не фонологические правила?
Морфологический анализ
• Синтаксический анализ: создание лингвистической структуры для Вход.
• Примеры морфологического анализа: –Разделение слов на основы / корни и аффиксы
например, ввод: коты анализируют вывод: cat + s –Марфирование морфем с помощью меток категорий.
например, ввод: коты анализируют вывод: cat + N + PL ate eat + V + PAST
Перечислить в модельный словарь • Как насчет использования большого списка в качестве словаря?
а, трубкозуб,… … Выпечка, выпечка, пекарня, выпечка, выпечка, выпечка,… … Кот, кататоник, коты, катапульта,… … Собака, упорный, собаки,… … Знакомый, знакомство, знакомство, семья,…
• Проблема?
Использование FSA для распознавания морфологически сложные слова
• Создание FSA для классов основ слов (слово списки).
• Создайте FSA для аффиксов, используя классы слов как заменители списков основных слов.
• Объединить FSA для стволов с FSA для аффиксы.
Пример FSA с использованием классов Word
Определение выбора и упорядочивания морфем для английские существительные в единственном и множественном числе:
Текст J&M, рис. 3.3
Вариант с некоторыми словами:
Примечание. Орфографические проблемы не решаются.
Другие обобщения
… оформить, оформить, оформить,… … Окаменелости, окаменелости, окаменелости,… • Они представляют собой наборы связанных слов.• Новые формы построены с добавлением
деривационная морфология. –ADJ + -ity СУЩЕСТВЕННОЕ –ADJ или NOUN + -ize ГЛАГОЛ
Правила образования
Примечание: Какую строку это распознает? Это правда что мы хотим?
Текст J&M, рис. 3.7
Морфологический анализ
• Задача синтаксического анализа: –Распознавать строку –Вывести информацию о стержне и аффиксах
строка • Что-то вроде этого: — Сырьё: кошки –Выход: cat + N + PL
• Мы будем использовать датчики с конечным числом состояний для выполнить это.
Конечный преобразователь (FST) FST: (формальное определение см. В тексте на стр. 58) • похож на FSA, но определяет регулярные отношения, а не
обычных языка • имеет два набора алфавита • имеет функцию перехода, связывающую входные данные с состояниями • имеет функцию вывода, связывающую состояние и ввод с
выход • может использоваться для распознавания, создания, перевода или
связанные наборы
Визуализация FTS
• FST можно рассматривать как верхнюю ленту. и нижняя лента (выходная).
Текст J&M, рис. 3.12
Регулярные отношения
• Обычный язык: набор строк • Регулярное отношение: набор пар строк. • Например, регулярное отношение = {a: 1, b: 2, c: 2}
Ввод Σ = {a, b, c} Выход = {1, 2} FST: a: 1
к: 2 q0 q1
b: 2
Условные обозначения FST такси
q0 q1
в
q0 q1 ab
с: с
q0 q1
в
q0 q1
Сложный входной элемент Разделен на верхний и нижний
Пара по умолчанию Пара по умолчанию — ярлык c: ϵ
q0 q1 c сверху, ничего снизу
=
=
FST: не только модные FSA
• Обычные языки закрыты по разнице, дополнение и пересечение; обычный отношения (как правило) нет.
• Обычные языки и регулярные отношения оба закрыты под союзом.
• Но регулярные отношения закрываются композиция и инверсия; не определено для обычные языки.
инверсия
• FST закрываются при инверсии, т.е. инверсия FST — это FST.
• Инверсия просто переключает вход и выход этикетки. например, если T1 отображает «a» в «1», то T1-1 отображает «1» в «a»
• Следовательно, FST, разработанный как синтаксический анализатор, может легко заменяется на генератор.
Состав
• Можно выполнить ввод через несколько FST с использованием вывода одного FST в качестве ввод следующего. Это называется каскадированием.
• Композиция эквивалентна каскадированию. но объединяет два FST и создает новый, более сложный FST.
• T1 ∘ T2 = T2 (T1 (s)) где s — входная строка
Пример композиции
• Очень простой пример: T1 = {a: 1} T2 = {1: один} T1∘ T2 = {a: one} T2 (T1 (a)) = один • Обратите внимание, что порядок имеет значение: T1 (T2 (a)) ≠ один • Составление будет полезно для добавления
орфографические правила.= граница морфемы
# = граница слова
Текст J&M, рис. 3.13
Каковы преимущества этого FST по сравнению с предыдущим FSA? Что такое входной алфавит? Как выглядит результат?
От лексического до среднего уровня
Обзор
• Праймер для морфологии • Использование FSA для морфологического распознавания
сложных слов • FST (определение, каскадирование, композиция) • FST для морфологического анализа • В следующий раз: подробнее о FST, морфологических Анализ
и демонстрация XFST
Примечание: FSA как генератор • В качестве распознавателя можно использовать не только FSA —
он также может генерировать.Вернемся к овечьему языку:
0 1 3 2 4
б а а! а
• Начать с начального состояния (0). • Вывести каждую метку дуги. • Примеры вывода: baa! баааа! бааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааа!
Конечные преобразователи: Мили машины
• Q: конечный набор состояний q0, q1,…, qN • Σ: конечный алфавит комплексных символов i: o
такие, что i ∈ I и o ∈ O. Σ ⊆ I x O. I и O каждый может включать ϵ.
• q0: начальное состояние • F: множество конечных состояний, F ⊆ Q • δ (q, i: o): матрица перехода.
Регулярные отношения: неязыковые пример
• Отец родственника: {〈Ларри, Дэвид〉, 〈Эд, Кора〉, 〈Дэвид, Генри〉, 〈Дэвид, Саймон〉}
• Родительские отношения: {〈Ларри, Дэвид〉, 〈Эд, Кора〉, 〈Дэвид, Генри〉, 〈Дэвид, Саймон〉, 〈Андреа, Дэвид〉, 〈Джери, Кора〉, 〈Кора, Генри〉, 〈Кора, Саймон〉}
• Дедушка по родственникам: {〈Ларри, Генри〉, 〈Ларри, Саймон〉, 〈Эд, Генри〉, 〈Эд, Саймон〉}
• Родство по отцу и деду: {〈Ларри, Генри〉, 〈Ларри, Саймон〉}