Морфологический разбор слова «добавка»
Слово можно разобрать в 2 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Существительное
ДОБАВКА — неодушевленное
Начальная форма слова: «ДОБАВКА»
| Слово | Морфологические признаки |
|---|---|
| ДОБАВКА |
|
Все формы слова ДОБАВКА
ДОБАВКА, ДОБАВКИ, ДОБАВКЕ, ДОБАВКУ, ДОБАВКОЙ, ДОБАВКОЮ, ДОБАВОК, ДОБАВКАМ, ДОБАВКАМИ, ДОБАВКАХ
2 вариант разбора
Часть речи: Существительное
ДОБАВКА — неодушевленное
Начальная форма слова: «ДОБАВОК»
| Слово | Морфологические признаки |
|---|---|
| ДОБАВКА |
|
Все формы слова ДОБАВКА
ДОБАВОК, ДОБАВКА, ДОБАВКУ, ДОБАВКОМ, ДОБАВКЕ, ДОБАВКИ, ДОБАВКОВ, ДОБАВКАМ, ДОБАВКАМИ, ДОБАВКАХ
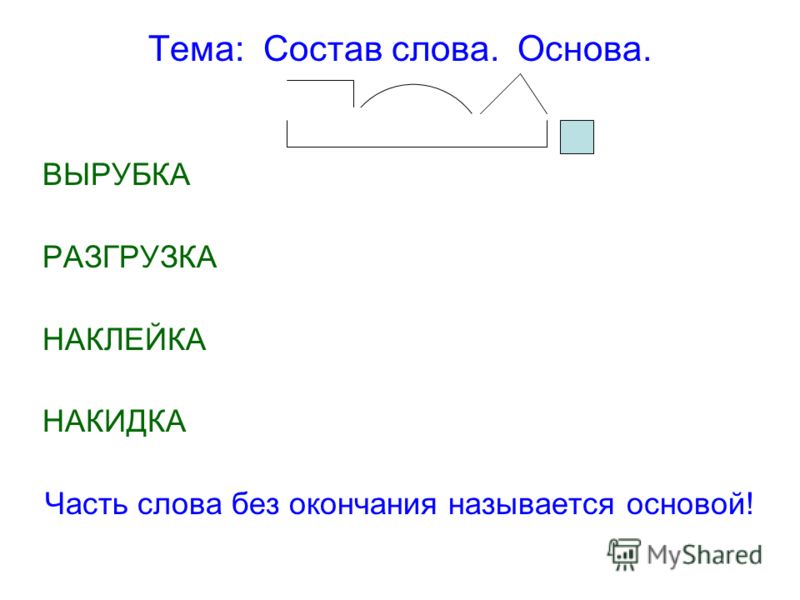
Разбор слова по составу добавка
добавк
а
| Основа слова | добавк |
|---|---|
| Приставка | до |
| Корень | бав |
| Суффикс | к |
| Окончание | а |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ДОБАВКА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «добавка»
Примеры предложений со словом «добавка»
1
Землекопам особая добавка, ситного по фунту на заедку.
Лето Господне, Иван Шмелев, 1944г.
2
Пот потом пригодится, как добавка к росткам дайкона.
Тетрадь кенгуру, Кобо Абэ, 1991г.
3
Если, например, у него будет много детей, такая добавка оказалась бы очень кстати.
Чувство и чувствительность, Джейн Остин, 1811г.
4
У соседей в саду куры: их помёт отличная поверхностная добавка.
Улисс, Джеймс Джойс, 1921г.
5
Теперь ее жизнь – не просто существование, которое принимаешь как должное, а премия, добавка, и каждый предстоящий день сулит радостное приключение.
Собиратели ракушек, Розамунда Пилчер, 1987г.
Найти еще примеры предложений со словом ДОБАВКА
Слова «добавки» морфологический и фонетический разбор
Фонетический морфологический и лексический анализ слова «добавки». Объяснение правил грамматики.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «добавки» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «добавки».
Содержимое:
- 1 Слоги в слове «добавки» деление на слоги
- 2 Как перенести слово «добавки»
- 3 Морфологический разбор слова «добавки»
- 4 Разбор слова «добавки» по составу
- 5 Сходные по морфемному строению слова «добавки»
- 6 Антонимы слова «добавки»
- 7 Ударение в слове «добавки»
- 8 Фонетическая транскрипция слова «добавки»
- 9 Фонетический разбор слова «добавки» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «добавки»
- 11 Сочетаемость слова «добавки»
- 12 Значение слова «добавки»
- 13 Как правильно пишется слово «добавки»
- 14 Ассоциации к слову «добавки»
Слоги в слове «добавки» деление на слоги
Количество слогов: 3
По слогам: до-ба-вки
По правилам школьной программы слово «добавки» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
до-бав-ки
По программе института слоги выделяются на основе восходящей звучности:
до-ба-вки
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
Как перенести слово «добавки»
до—бавки
доба—вки
добав—ки
Морфологический разбор слова «добавки»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: мужской;
число: множественное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
добавок
Разбор слова «добавки» по составу
| до | приставка |
| бав | корень |
| к | суффикс |
| а | окончание |
добавка
Сходные по морфемному строению слова «добавки»
Сходные по морфемному строению слова
Антонимы слова «добавки»
1. сбавка
сбавка
2. скидка
3. удержание
Ударение в слове «добавки»
доба́вки — ударение падает на 2-й слог
Фонетическая транскрипция слова «добавки»
[даб`афк’и]
Фонетический разбор слова «добавки» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| д | [д] | согласный, звонкий парный, твёрдый, шумный | д |
| о | [а] | гласный, безударный | о |
| б | [б] | согласный, звонкий парный, твёрдый, шумный | б |
| а | [`а] | гласный, ударный | а |
| в | [ф] | согласный, глухой парный, твёрдый, шумный | в |
| к | [к’] | согласный, глухой парный, мягкий, шумный | к |
| и | [и] | гласный, безударный | и |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 7 букв и 7 звуков.
Буквы: 3 гласных буквы, 4 согласных буквы.
Звуки: 3 гласных звука, 4 согласных звука. Из них 1 мягкая согласная и 3 твёрдых согласных.
Предложения со словом «добавки»
Кроме остатков удобрений, продукты содержат различные пищевые добавки, консерванты, улучшители вкуса.
Алексей Светлов, Аллергия, 2013.
Каждый раз она очень вежливо просила добавки, за что кухарка дала ей ещё сладких спелых слив.
Энид Блайтон, Тайна пропавшей кошки, 1943.
Сегодня отечественные или импортные биологически активные добавки можно купить в каждой аптеке.
Ирина Зайцева, Лечебное питание при пониженном иммунитете, 2011.
Сочетаемость слова «добавки»
1. пищевые добавки
2. активные добавки
3. витаминные добавки
4. добавки каши
5. за добавкой кофе
6. в тарелку добавки
в тарелку добавки
7. в поисках добавки
8. на кухню за добавкой
9. попросить добавки
10. требовать добавки
11. принимать пищевые добавки
12. (полная таблица сочетаемости)
Значение слова «добавки»
ДОБА́ВКА , -и, ж. Разг. 1. Действие по знач. глаг. добавить—добавлять. (Малый академический словарь, МАС)
Как правильно пишется слово «добавки»
Правописание слова «добавки»
Орфография слова «добавки»
Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «добавки» в прямом и обратном порядке:
Ассоциации к слову «добавки»
Витамин
Рацион
Приправа
Сплав
Специя
Удобрение
Цемент
Компонент
Диета
Медикамент
Пайка
Раствор
Порция
Сироп
Смесь
Паста
Регулятор
Азот
Сырьё
Соус
Желе
Примесь
Кислота
Суп
Пряность
Сахара
Спирт
Каша
Углерод
Вещество
Миска
Блюдо
Сахар
Препарат
Промышленность
Десерт
Очистки
Продукт
Перец
Медь
Питание
Салат
Настой
Пища
Гипс
Тарелка
Порошок
Чеснок
Мёд
Уксус
Соль
Изделие
Аппетит
Рецепт
Пищевой
Минеральный
Питательный
Синтетический
Алкогольный
Лекарственный
Наркотический
Лимонный
Растительный
Химический
Кондитерский
Натуральный
Мясной
Фруктовый
Продуктовый
Кормовой
Растворимый
Пшеничный
Неорганический
Цементный
Травяной
Органический
Жидкий
Молочный
Овощной
Картофельный
Экологический
Шоколадный
Кулинарный
Улучшать
Смесить
Съедать
Изготавливать
Зарегистрировать
Потреблять
Повышать
Солить
Вводиться
Съесть
Применяться
Опустошить
Использоваться
Смешивать
Добавлять
Снижать
Увеличивать
(PDF) Механизм аддитивной композиции (2017) | Ran Tian
Цитаты
Открытый доступ
Подробнее фильтры
Статья •
На пути к универсальному перефрастическому предложению
[. ..]
..]
John Wieting 1
1, Mohit Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal Bansal. , Кевин Гимпел 1 , Карен Ливеску 1 •Учреждения (1)Технологический институт Toyota в Чикаго 1
01.01.2016
Аннотация: Рассматривается задача обучения универсальным вложениям парафрастических предложений на основе наблюдения из базы данных Paraphrase (Ганиткевич и др., 2013). Мы сравниваем шесть композиционных архитектур, оценивая их на аннотированных наборах данных текстового сходства, взятых как из того же распределения, что и обучающие данные, так и из широкого круга других доменов. Мы обнаружили, что самые сложные архитектуры, такие как рекуррентные нейронные сети с долговременной кратковременной памятью (LSTM), лучше всего работают с данными в предметной области. Однако в сценариях вне домена простые архитектуры, такие как усреднение слов, значительно превосходят LSTM. Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика. Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию. Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика. Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию. Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
…читать дальшеЧитать меньше
509 цитирований
Журнальная статья•DOI•
Линейная алгебраическая структура словесных смыслов с приложениями к полисемии
[…]
Юаньчжи Арора 1 1 , Yingyu Liang 1 , Tengyu MA 1 , Andrej Risteski 1 — Покажите меньше +1 больше • Учреждения (1)
Принстонский университет 1
20 Jul 2018 -Transction Компьютерная лингвистика
Аннотация: Встраивания слов повсеместно используются в НЛП и поиске информации, но неясно, что они представляют, когда слово многозначно. Здесь показано, что в линейном супер…
…читать дальшеЧитать меньше
157 цитирований
Журнальная статья•DOI•
Неконтролируемые представления предложений в виде информационных серий слов: Revisiting TF–IDF
[. ..]
..]
Игнасио Арройо-Фернандес 1 , Карлос-Франсиско Мендес-Крус 1 , Херардо Сьерра 1 , Хуан-Мануэль Торрес-Морено 2 , Григорий Сидоров — Показать меньше +1 еще•Учреждения (2)
Национальный автономный университет Мексики 1 , Университет Авиньона 2
0
01 Jul 2019-Компьютерная речь и язык
Аннотация: Представление предложений на семантическом уровне является сложной задачей для обработки естественного языка и искусственного интеллекта. Несмотря на достижения в области встраивания слов (т. е. векторных представлений слов), определение значения предложения остается открытым вопросом из-за сложности семантических взаимодействий между словами. В этой статье мы представляем метод встраивания, который направлен на изучение неконтролируемых представлений предложений из неразмеченного текста. Мы предлагаем неконтролируемый метод, который моделирует предложение как взвешенную серию вложений слов. Вес ряда подобран с использованием взаимной информации Шеннона (MI) среди слов, предложений и корпуса. На самом деле, преобразование Term Frequency-Inverse Document Frequency (TF-IDF) является надежной оценкой такого MI. Наш метод предлагает преимущества по сравнению с существующими: идентифицируемые модули, краткосрочное обучение, онлайн-вывод (невидимых) представлений предложений, а также независимость от предметной области, внешних знаний и ресурсов лингвистических аннотаций. Результаты показали, что наша модель, несмотря на ее конкретность и низкие вычислительные затраты, была конкурентоспособной с современным уровнем техники в известных задачах семантического текстового подобия (STS).
Вес ряда подобран с использованием взаимной информации Шеннона (MI) среди слов, предложений и корпуса. На самом деле, преобразование Term Frequency-Inverse Document Frequency (TF-IDF) является надежной оценкой такого MI. Наш метод предлагает преимущества по сравнению с существующими: идентифицируемые модули, краткосрочное обучение, онлайн-вывод (невидимых) представлений предложений, а также независимость от предметной области, внешних знаний и ресурсов лингвистических аннотаций. Результаты показали, что наша модель, несмотря на ее конкретность и низкие вычислительные затраты, была конкурентоспособной с современным уровнем техники в известных задачах семантического текстового подобия (STS).
…читать дальшеЧитать меньше
35 цитирований
Proceedings Article•DOI•
Использование лексических ресурсов для встраивания обучающихся сущностей в многореляционные данные
[…]
Teng Long, R , Джеки Чи Кит Чеунг 1 , Дойна Прекап 1 • Институты (1)
Университет Макгилла 1
18 мая 2016 г. сосредоточен на объединении реляционной информации, полученной из баз знаний, с информацией о распределении, полученной из больших текстовых корпусов. Мы предлагаем простой подход, который использует описания сущностей или фраз, доступных в лексических ресурсах, в сочетании с семантикой распределения, чтобы получить лучшую инициализацию для обучения реляционных моделей. Применение этой инициализации к модели TransE приводит к значительным новым современным характеристикам в наборе данных WordNet, снижая средний ранг с предыдущего лучшего из 212 до 51. Это также приводит к более быстрой сходимости представлений объектов. Мы обнаружили, что при таком подходе существует компромисс между улучшением среднего ранга и числом попаданий на 10. Это показывает, что многое еще предстоит понять в отношении повышения производительности реляционных моделей.
сосредоточен на объединении реляционной информации, полученной из баз знаний, с информацией о распределении, полученной из больших текстовых корпусов. Мы предлагаем простой подход, который использует описания сущностей или фраз, доступных в лексических ресурсах, в сочетании с семантикой распределения, чтобы получить лучшую инициализацию для обучения реляционных моделей. Применение этой инициализации к модели TransE приводит к значительным новым современным характеристикам в наборе данных WordNet, снижая средний ранг с предыдущего лучшего из 212 до 51. Это также приводит к более быстрой сходимости представлений объектов. Мы обнаружили, что при таком подходе существует компромисс между улучшением среднего ранга и числом попаданий на 10. Это показывает, что многое еще предстоит понять в отношении повышения производительности реляционных моделей.
…читать дальшеЧитать меньше
15 цитирований
Журнальная статья•DOI•
Структурированная модель распределения значения и обработки предложений
[. ..]
..]
Эммануэле Херсонитус 1 Pannitto 2 , Alessandro Lenci 2 , Philippe Blache 3 , Chu-Ren Huang 1 — Показать меньше +2 еще•Учреждения (3)
Гонконгский политехнический университет 1 University of Pisa0020 2 , Экс-Марсельский университет 3
01 июля 2019-Инженерия естественного языка
Аннотация: Большинство композиционно-распределительных семантических моделей представляют значение предложения с помощью одного вектора. В этой статье мы предлагаем структурированную распределительную модель (SDM), которая сочетает встраивание слов с формальной семантикой и основана на предположении, что предложения представляют события и ситуации. Семантическое представление предложения — это формальная структура, полученная из теории репрезентации дискурса и содержащая векторы распределения. Эта структура динамично и поэтапно строится за счет интеграции знаний о событиях и их типичных участниках, поскольку они активизируются лексическими единицами. Знания о событиях моделируются как граф, извлеченный из проанализированных корпусов и кодирующий роли и отношения между участниками, которые представлены в виде векторов распределения. SDM основан на обширных психолингвистических исследованиях, показывающих, что обобщенные знания о событиях, хранящиеся в семантической памяти, играют ключевую роль в понимании предложений. Мы оцениваем два недавно введенных набора данных о композиционности SDMon, и наши результаты показывают, что сочетание простой композиционной модели со знанием событий постоянно улучшает производительность. , даже с разными типами встраивания слов.
Знания о событиях моделируются как граф, извлеченный из проанализированных корпусов и кодирующий роли и отношения между участниками, которые представлены в виде векторов распределения. SDM основан на обширных психолингвистических исследованиях, показывающих, что обобщенные знания о событиях, хранящиеся в семантической памяти, играют ключевую роль в понимании предложений. Мы оцениваем два недавно введенных набора данных о композиционности SDMon, и наши результаты показывают, что сочетание простой композиционной модели со знанием событий постоянно улучшает производительность. , даже с разными типами встраивания слов.
… Прочитайте Moreread Mest
10 Цитации
СПИСОК ЛИТЕРАТУРЫ
Открытый доступ
Подробнее фильтры
. 1 •Institutions (1)
Bell Labs 1
01 января 1995
TL;DR: Постановка задачи обучения Непротиворечивость процессов обучения ограничивает скорость сходимости процессов обучения, контролирующих способность к обобщению построения процесса обучения алгоритмы обучения что важно в теории обучения?
. ..читать дальшечитать меньше
..читать дальшечитать меньше
Аннотация: Постановка задачи обучения непротиворечивость процессов обучения ограничивает скорость сходимости процессов обучения контролируя обобщающую способность процессов обучения строят алгоритмы обучения что важно в теории обучения?.
…читать дальшеЧитать меньше
38 164 цитирования
Материалы статьи•DOI•
Перчатка: глобальные векторы для представления слов
[…]
Джеффри Пеннингтон 1 , Ричард Сохер 2 , Кристофер Д. Мэннинг 1 • Учреждения (2)
Стэнфордский университет 1 , Университет Колорадо Боулдер 2
01 октябрь 2014
; DR: Новая глобальная модель логбилинейной регрессии, которая сочетает в себе преимущества двух основных семейств моделей, описанных в литературе: глобальной матричной факторизации и методов локального контекстного окна, и создает векторное пространство со значимой подструктурой.
…читать дальшечитать меньше
Аннотация: Современные методы изучения представлений слов в векторном пространстве преуспели в захвате мелких семантических и синтаксических закономерностей с помощью векторной арифметики, но происхождение этих закономерностей оставалось неясным. Мы анализируем и определяем свойства модели, необходимые для появления таких закономерностей в векторах слов. Результатом является новая глобальная модель логбилинейной регрессии, которая сочетает в себе преимущества двух основных семейств моделей, описанных в литературе: глобальной матричной факторизации и методов локального контекстного окна. Наша модель эффективно использует статистическую информацию, обучая только ненулевые элементы в матрице совпадения слов, а не всю разреженную матрицу или отдельные контекстные окна в большом корпусе. Модель создает векторное пространство со значимой подструктурой, о чем свидетельствует ее эффективность 75% в недавней задаче аналогии слов. Он также превосходит связанные модели в задачах подобия и распознавании именованных объектов.
Он также превосходит связанные модели в задачах подобия и распознавании именованных объектов.
…читать дальшечитать меньше
23,307 цитирований
«Механизм аддитивного композита…» относится к предыстории или методам в этой статье
…p) := p p. Различные настройки функции F рассматривались в предыдущих исследованиях, и были сделаны предположения о причине семантической аддитивности некоторых векторных представлений. В Пеннингтоне и соавт. (2014) авторы отметили, что логарифм является гомоморфизмом от умножения к сложению, и использовали это свойство для обоснования F(p) := lnp для обучения семантически аддитивных векторов слов, основанных, но на не…
[…]
…GloVe Модель GloVe (Пеннингтон и др., 2014) тренирует уменьшение размерности для векторных представлений с помощью F (x) := lnx….
[.. .]
…В Pennington et al. (2014) авторы отметили, что логарифм является гомоморфизмом от умножения к сложению, и использовали это свойство для обоснования F (x) := lnx для обучения семантически аддитивных векторов слов, основываясь, но на непроверенной гипотезе, что умножения вероятностей совпадения ….
 ..
..[…]
… i +ln(kP-шум (c i )),wi +ln(kP-шум (c i ( ))) Рисунок 3: График функции потерь SGNS с двумя асимптотами (красный) и его предельная кривая при k!+1 с одной асимптотой (синий). GloVe Модель GloVe (Pennington et al., 2014) представляет собой уменьшение размерности векторных представлений, в которых F(p) := lnp. Для Av t= (v i) i и w t = (w i) i функция потерь определяется как L t(v i;w i) = f #(ci;t) (v i w i)2: Другими словами, GloVe использует a..
[…]
…однозначное и единое объяснение аддитивной композиционности нескольких недавно предложенных векторов слов, включая Skip-Gram with Negative Sampling (SGNS) (Mikolov et al., 2013b), модель GloVe (Pennington et al., 2014), Hellinger PCA (Lebret and Collobert, 2014) и модель CCA (Stratos et al., 2 Mechanism of Additive Composition …в процентах от вашего дохода ваша налоговая ставка, как правило, меньше, чем эта… t …
[…]
 ..
..Журнальная статья•DOI• 9(3) 1 , Университет Нью-Мексико 2 , Университет Карнеги-Меллона 3
01 ноября 2009 г. -Siam Review
-Siam Review
TL; DR: В этой работе предлагается принципиальная статистическая основа для выявления и количественной оценки степенного поведения в эмпирических данных с помощью сочетание методов подбора максимального правдоподобия с тестами согласия, основанными на статистике Колмогорова-Смирнова (КС) и отношениях правдоподобия.
…читать дальшечитать меньше
Аннотация: Степенные распределения возникают во многих ситуациях, представляющих научный интерес, и имеют важные последствия для нашего понимания природных и антропогенных явлений. К сожалению, обнаружение и характеристика степенных законов осложняются большими флуктуациями, происходящими в хвосте распределения — частью распределения, представляющей большие, но редкие события, — и трудностью определения диапазона, в котором выполняется степенное поведение. . Обычно используемые методы анализа степенных данных, такие как аппроксимация методом наименьших квадратов, могут давать существенно неточные оценки параметров степенных распределений, и даже в тех случаях, когда такие методы дают точные ответы, они все равно неудовлетворительны, поскольку не дают указаний на подчиняются ли данные вообще степенному закону. Здесь мы представляем принципиальную статистическую основу для выявления и количественной оценки степенного поведения в эмпирических данных. Наш подход сочетает в себе методы подбора максимального правдоподобия с тестами согласия, основанными на статистике Колмогорова-Смирнова (KS) и отношениях правдоподобия. Мы оцениваем эффективность подхода с помощью тестов на синтетических данных и приводим критические сравнения с предыдущими подходами. Мы также применяем предложенные методы к двадцати четырем наборам данных реального мира из ряда различных дисциплин, каждый из которых, как предполагается, подчиняется степенному закону распределения. В некоторых случаях мы обнаруживаем, что эти предположения согласуются с данными, в то время как в других случаях степенной закон исключается.
Здесь мы представляем принципиальную статистическую основу для выявления и количественной оценки степенного поведения в эмпирических данных. Наш подход сочетает в себе методы подбора максимального правдоподобия с тестами согласия, основанными на статистике Колмогорова-Смирнова (KS) и отношениях правдоподобия. Мы оцениваем эффективность подхода с помощью тестов на синтетических данных и приводим критические сравнения с предыдущими подходами. Мы также применяем предложенные методы к двадцати четырем наборам данных реального мира из ряда различных дисциплин, каждый из которых, как предполагается, подчиняется степенному закону распределения. В некоторых случаях мы обнаруживаем, что эти предположения согласуются с данными, в то время как в других случаях степенной закон исключается.
…читать дальшечитать меньше
8065 цитирований
«Механизм аддитивного композита…» относится к предыстории или методам в этой статье
.
..(10)
Для каждого фиксированного Υ мы оцениваем α и m по выборке pΥi,n/pi,n (1 ≤ i ≤ n), используя метод Clauset et al. (2009)….[…]
…Закон Ципфа был тщательно проверен эмпирическим путем в нескольких условиях (Montemurro, 2001; Ha et al., 2002; Clauset et al., 2009).; Corral et al., 2015)….
[…]
…np i;n, n lnn in: (4) Предел np i;n!0 будет подробно изучен в наша теория. Эмпирически закон Ципфа был тщательно проверен в нескольких условиях (Montemurro, 2001; Ha et al., 2002; Clauset et al., 2009; Corral et al., 2015). Замечание 2. Когда цель выбрана случайно, значение вероятности p i;n показывает случайность. Предположение (B1) формализует эту интуицию. Кроме того, (B2) предполагает, что p i;n находится в…
[…]
…dom переменная X подчиняется степенному закону, вероятность xX при условии mX определяется как P(xXjmX) = m x : (10) Для каждого xed мы оцениваем и mиз выборки p i ;n=p i;n(1 дюйм), используя метод Clauset et al.
(2009). А именно, оценивается путем максимизации правдоподобия выборки и не стремится минимизировать статистику Колмогорова-Смирнова, которая измеряет, насколько хорошо теоретическое распределение (10) соответствует эмпирическому…[…]
 ..(10)
Для каждого фиксированного Υ мы оцениваем α и m по выборке pΥi,n/pi,n (1 ≤ i ≤ n), используя метод Clauset et al. (2009)….
..(10)
Для каждого фиксированного Υ мы оцениваем α и m по выборке pΥi,n/pi,n (1 ≤ i ≤ n), используя метод Clauset et al. (2009)…. (2009). А именно, оценивается путем максимизации правдоподобия выборки и не стремится минимизировать статистику Колмогорова-Смирнова, которая измеряет, насколько хорошо теоретическое распределение (10) соответствует эмпирическому…
(2009). А именно, оценивается путем максимизации правдоподобия выборки и не стремится минимизировать статистику Колмогорова-Смирнова, которая измеряет, насколько хорошо теоретическое распределение (10) соответствует эмпирическому…Posted Content•
Distributed Representations of Words and Phrases and their Compositionality
[…]
Tomas Mikolov 1 , Ilya Sutskever 1 , Kai Chen 1 , Greg S. Corrado 1 , Jeffrey Dean 1 — Показать меньше +1 еще•Учреждения (1)
Google 1
16 октября 2013-arXiv: Computation and Language
Резюме. Недавно введенная непрерывная модель Skip-gram является эффективным методом. для изучения высококачественных распределенных векторных представлений, которые охватывают большое количество точных синтаксических и семантических отношений слов. В этой статье мы представляем несколько расширений, улучшающих как качество векторов, так и скорость обучения. Путем подвыборки часто используемых слов мы получаем значительное ускорение, а также изучаем более регулярные представления слов. Мы также описываем простую альтернативу иерархическому softmax, называемую отрицательной выборкой. Неотъемлемым ограничением представлений слов является их безразличие к порядку слов и их неспособность представлять идиоматические фразы. Например, значения «Канада» и «Эйр» не могут быть легко объединены для получения «Эйр Канада». Руководствуясь этим примером, мы представляем простой метод поиска фраз в тексте и показываем, что изучение хороших векторных представлений для миллионов фраз возможно.
В этой статье мы представляем несколько расширений, улучшающих как качество векторов, так и скорость обучения. Путем подвыборки часто используемых слов мы получаем значительное ускорение, а также изучаем более регулярные представления слов. Мы также описываем простую альтернативу иерархическому softmax, называемую отрицательной выборкой. Неотъемлемым ограничением представлений слов является их безразличие к порядку слов и их неспособность представлять идиоматические фразы. Например, значения «Канада» и «Эйр» не могут быть легко объединены для получения «Эйр Канада». Руководствуясь этим примером, мы представляем простой метод поиска фраз в тексте и показываем, что изучение хороших векторных представлений для миллионов фраз возможно.
…читать дальшеЧитать меньше
7 602 цитирования
Журнальная статья•
Методы адаптивного субградиента для онлайн-обучения и стохастической оптимизации
[. ..]
..]
John C. Duchi 9 02 Haladzan 2 1 , Йорам Сингер 3 • Учреждения (3)
Калифорнийский университет, Беркли 1 , Принстонский университет 2 , Google 3
01 февраля 2011 г. Learning Machine Journal0005
TL;DR: В этой работе описывается и анализируется устройство для адаптивного изменения проксимальной функции, которое значительно упрощает настройку скорости обучения и приводит к гарантиям сожаления, которые доказуемо так же хороши, как и лучшие проксимальные функции, которые можно выбрать задним числом.
…читать дальшечитать меньше
Аннотация: Мы представляем новое семейство субградиентных методов, которые динамически включают знания о геометрии данных, наблюдаемых в предыдущих итерациях, для выполнения более информативного обучения на основе градиента. Метафорически адаптация позволяет нам находить иголки в стогах сена в виде очень предсказуемых, но редко встречающихся признаков. Наша парадигма основана на недавних достижениях в области стохастической оптимизации и онлайн-обучения, в которых используются проксимальные функции для управления шагами градиента алгоритма. Мы описываем и анализируем устройство для адаптивного изменения проксимальной функции, которое значительно упрощает настройку скорости обучения и приводит к гарантиям сожаления, которые доказуемо так же хороши, как и лучшая проксимальная функция, которую можно выбрать задним числом. Мы даем несколько эффективных алгоритмов для задач минимизации эмпирического риска с общими и важными функциями регуляризации и ограничениями области. Мы экспериментально изучаем наш теоретический анализ и показываем, что адаптивные субградиентные методы превосходят современные, но неадаптивные субградиентные алгоритмы.
Наша парадигма основана на недавних достижениях в области стохастической оптимизации и онлайн-обучения, в которых используются проксимальные функции для управления шагами градиента алгоритма. Мы описываем и анализируем устройство для адаптивного изменения проксимальной функции, которое значительно упрощает настройку скорости обучения и приводит к гарантиям сожаления, которые доказуемо так же хороши, как и лучшая проксимальная функция, которую можно выбрать задним числом. Мы даем несколько эффективных алгоритмов для задач минимизации эмпирического риска с общими и важными функциями регуляризации и ограничениями области. Мы экспериментально изучаем наш теоретический анализ и показываем, что адаптивные субградиентные методы превосходят современные, но неадаптивные субградиентные алгоритмы.
…читать дальшеЧитать меньше
6,957 цитирований
«Механизм аддитивной композиции…» относится к методам в этой статье
Свернуть
(PDF) Механизм аддитивной композиции (2015) | RAN TIAN
СТАТЬЯ СТАТЬЯ •
На сторону универсального перефрастического приговора вступителей
[. ..]
..]
Джон Витминг 1 , Мохит Бансал 1 , Кевин Гимпел 1 , Karencu 1 1 • Институты 10020 1 , Karencu 1 11 • Институты 10020 1 , Karencu 1 11 • Институты (1 , Karencu 1 11 • Институты (1 , Karencu 1 11 • Институты (1 , Karencu 1 11 • Институты. )
Технологический институт Toyota в Чикаго 1
01 января 2016 г.
Аннотация: Мы рассматриваем задачу изучения вложений парафразных предложений общего назначения на основе наблюдений из базы данных Paraphrase (Ганиткевич и др., 2013). Мы сравниваем шесть композиционных архитектур, оценивая их на аннотированных наборах данных текстового сходства, взятых как из того же распределения, что и обучающие данные, так и из широкого круга других доменов. Мы обнаружили, что самые сложные архитектуры, такие как рекуррентные нейронные сети с долговременной кратковременной памятью (LSTM), лучше всего работают с данными в предметной области. Однако в сценариях вне домена простые архитектуры, такие как усреднение слов, значительно превосходят LSTM. Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика. Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию.
Однако в сценариях вне домена простые архитектуры, такие как усреднение слов, значительно превосходят LSTM. Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика. Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию. Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
…читать дальшеЧитать меньше
509 цитирований
Журнальная статья•DOI•
Линейная алгебраическая структура словесных смыслов с приложениями к полисемии
[…]
Юаньчжи Арора 1 1 , Yingyu Liang 1 , Tengyu MA 1 , Andrej Risteski 1 — Покажите меньше +1 больше • Учреждения (1)
Принстонский университет 1
20 Jul 2018 -Transction Компьютерная лингвистика
Аннотация: Встраивания слов повсеместно используются в НЛП и поиске информации, но неясно, что они представляют, когда слово многозначно. Здесь показано, что в линейном супер…
…читать дальшеЧитать меньше
157 цитат
Размещенный контент•
К универсальным вложениям парафрастических предложений
[. ..]
..]
Джон Витинг 1 , Мохит Бансал 1 , Кевин Гимпел 1 , Карен Ливеску 1 •Учреждения (1)
Технологический институт Toyota в Чикаго 1
25 ноября 2015-arXiv: Computation and Language
TL;DR: В этой работе рассматривается проблема изучения универсальных парафрастических вложений предложений на основе на основе наблюдения из базы данных Paraphrase и сравнивает шесть композиционных архитектур, обнаружив, что наиболее сложные архитектуры, такие как рекуррентные нейронные сети с долгой кратковременной памятью (LSTM), лучше всего работают с данными в предметной области.
…читать дальшечитать меньше
Аннотация: Рассматривается задача обучения эмбеддингам парафразных предложений общего назначения на основе наблюдений из базы данных Paraphrase (Ганиткевич и др., 2013). Мы сравниваем шесть композиционных архитектур, оценивая их на аннотированных наборах данных текстового сходства, взятых как из того же распределения, что и обучающие данные, так и из широкого круга других доменов. Мы обнаружили, что самые сложные архитектуры, такие как рекуррентные нейронные сети с долговременной кратковременной памятью (LSTM), лучше всего работают с данными в предметной области. Однако в сценариях вне домена простые архитектуры, такие как усреднение слов, значительно превосходят LSTM. Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика.
Мы обнаружили, что самые сложные архитектуры, такие как рекуррентные нейронные сети с долговременной кратковременной памятью (LSTM), лучше всего работают с данными в предметной области. Однако в сценариях вне домена простые архитектуры, такие как усреднение слов, значительно превосходят LSTM. Наша простейшая модель усреднения даже конкурентоспособна с системами, настроенными для конкретных задач, а также чрезвычайно эффективна и проста в использовании.
Чтобы лучше понять, как эти архитектуры сравниваются, мы проводим дальнейшие эксперименты над тремя задачами НЛП под наблюдением: сходство предложений, следствие и классификация настроений. Мы снова обнаруживаем, что модели усреднения слов хорошо работают в отношении сходства предложений и следствий, превосходя LSTM. Однако при классификации настроений мы обнаруживаем, что LSTM работает очень хорошо, даже записывая новые современные характеристики в Стэнфордском дереве настроений.
Затем мы демонстрируем, как объединить наши предварительно обученные вложения предложений с этими контролируемыми задачами, используя их как в качестве априорных, так и в качестве экстрактора признаков черного ящика. Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию. Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
Это приводит к производительности, соперничающей с современными задачами SICK по сходству и следствию. Мы предоставляем все наши ресурсы исследовательскому сообществу в надежде, что они могут послужить новой основой для дальнейшей работы над универсальными вложениями предложений.
…читать дальшеЧитать меньше
86 цитирований
Журнальная статья•DOI•
Неконтролируемые представления предложений в виде информационных серий слов: Revisiting TF–IDF
[…]
Ignacio Arndroyo-09 , Carlos-Francisco Méndez-Cruz 1 , Gerardo Sierra 1 , Juan-Manuel Torres-Moreno 2 , Grigori Sidorov — Показать меньше +1 еще•Учреждения (2)
Национальный автономный университет Мексики 1 99020 1 , Григорий Сидоров0021 , Авиньонский университет 2
01 июля 2019 г.-Компьютерная речь и язык
Аннотация: Представление предложений на семантическом уровне является сложной задачей для обработки естественного языка и искусственного интеллекта.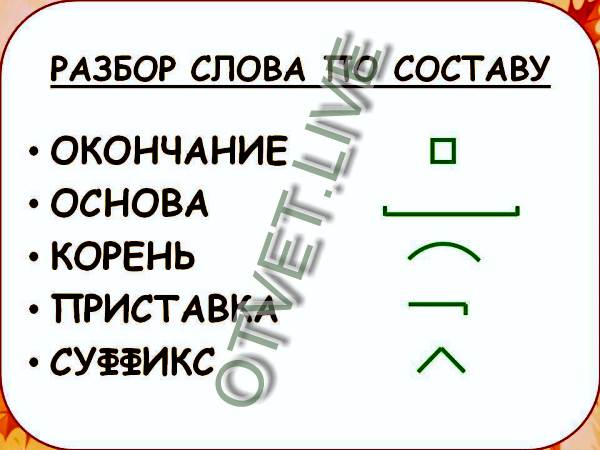 Несмотря на достижения в области встраивания слов (т. е. векторных представлений слов), определение значения предложения остается открытым вопросом из-за сложности семантических взаимодействий между словами. В этой статье мы представляем метод встраивания, который направлен на изучение неконтролируемых представлений предложений из неразмеченного текста. Мы предлагаем неконтролируемый метод, который моделирует предложение как взвешенную серию вложений слов. Вес ряда подобран с использованием взаимной информации Шеннона (MI) среди слов, предложений и корпуса. На самом деле, преобразование Term Frequency-Inverse Document Frequency (TF-IDF) является надежной оценкой такого MI. Наш метод предлагает преимущества по сравнению с существующими: идентифицируемые модули, краткосрочное обучение, онлайн-вывод (невидимых) представлений предложений, а также независимость от предметной области, внешних знаний и ресурсов лингвистических аннотаций. Результаты показали, что наша модель, несмотря на ее конкретность и низкие вычислительные затраты, была конкурентоспособной с современным уровнем техники в известных задачах семантического текстового подобия (STS).
Несмотря на достижения в области встраивания слов (т. е. векторных представлений слов), определение значения предложения остается открытым вопросом из-за сложности семантических взаимодействий между словами. В этой статье мы представляем метод встраивания, который направлен на изучение неконтролируемых представлений предложений из неразмеченного текста. Мы предлагаем неконтролируемый метод, который моделирует предложение как взвешенную серию вложений слов. Вес ряда подобран с использованием взаимной информации Шеннона (MI) среди слов, предложений и корпуса. На самом деле, преобразование Term Frequency-Inverse Document Frequency (TF-IDF) является надежной оценкой такого MI. Наш метод предлагает преимущества по сравнению с существующими: идентифицируемые модули, краткосрочное обучение, онлайн-вывод (невидимых) представлений предложений, а также независимость от предметной области, внешних знаний и ресурсов лингвистических аннотаций. Результаты показали, что наша модель, несмотря на ее конкретность и низкие вычислительные затраты, была конкурентоспособной с современным уровнем техники в известных задачах семантического текстового подобия (STS).
… Прочитайте Moreread Less
35 Цитатов
Статья о разбирательстве • DOI •
Семантически обучающие и аддитивные композиционные распределения
[…]
Ran Tian, Naoaki Okazaki, Kentaro Inui
9000 010 01 август, Наоаки Оказаки, Кентаро. 2016 Аннотация: В этой статье векторная модель композиции связывается с формальной семантикой — композиционной семантикой на основе зависимостей (DCS). Мы приводим теоретические доказательства того, что векторные композиции в нашей модели соответствуют логике DCS. Экспериментально мы показываем, что композиция на основе векторов обеспечивает сильную способность вычислять похожие фразы как похожие векторы, достигая почти современного уровня техники в широком диапазоне задач сходства фраз и классификации отношений; Между тем, DCS может направлять построение векторов для структурированных запросов, которые могут выполняться напрямую.