Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
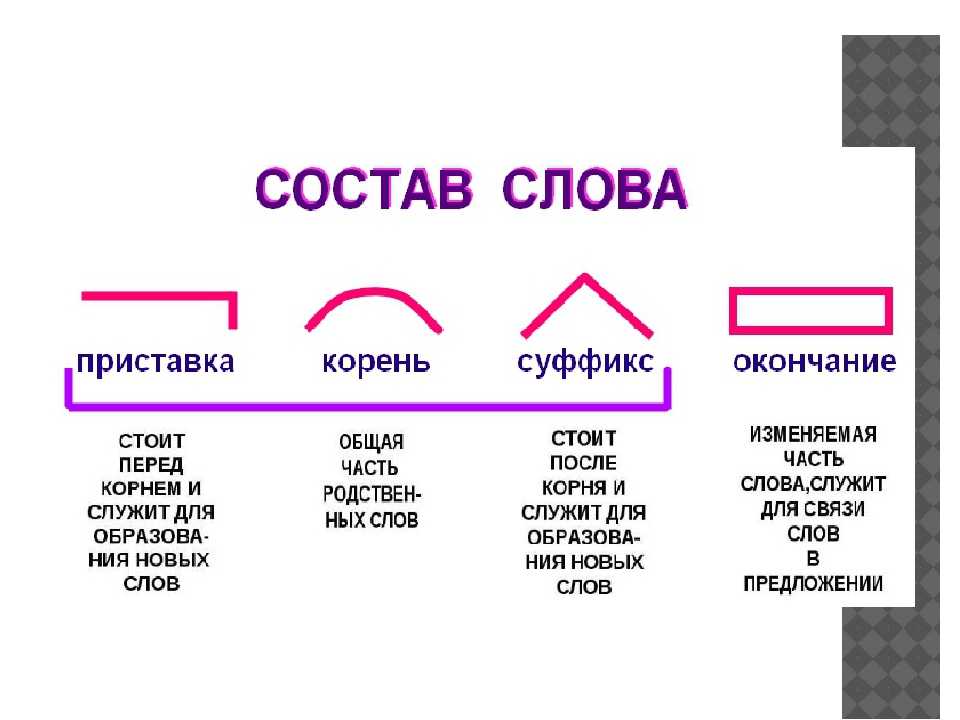
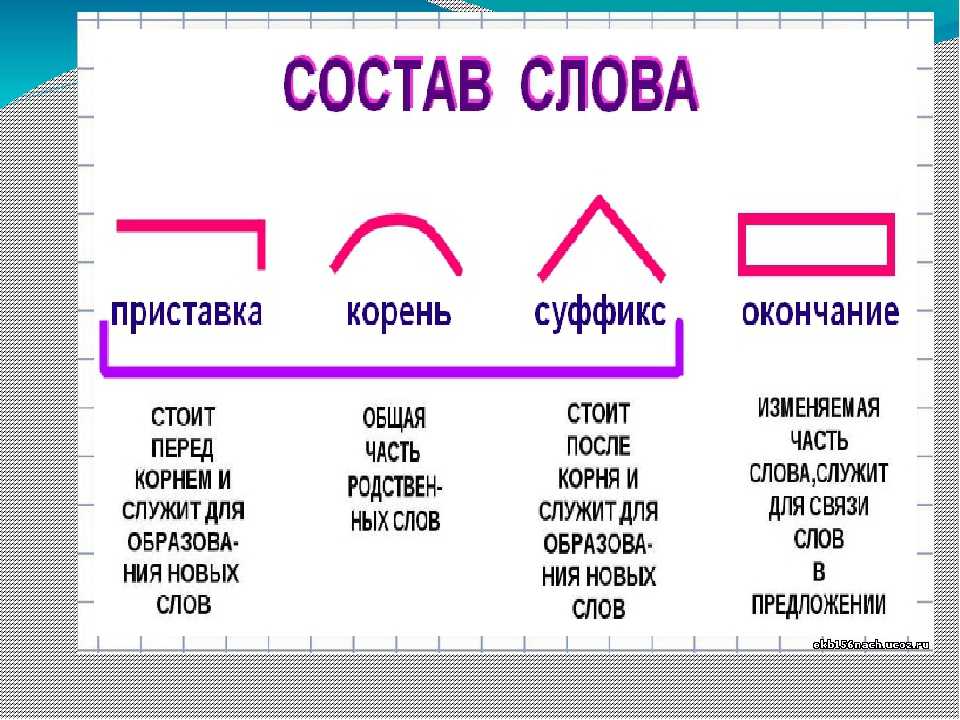
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
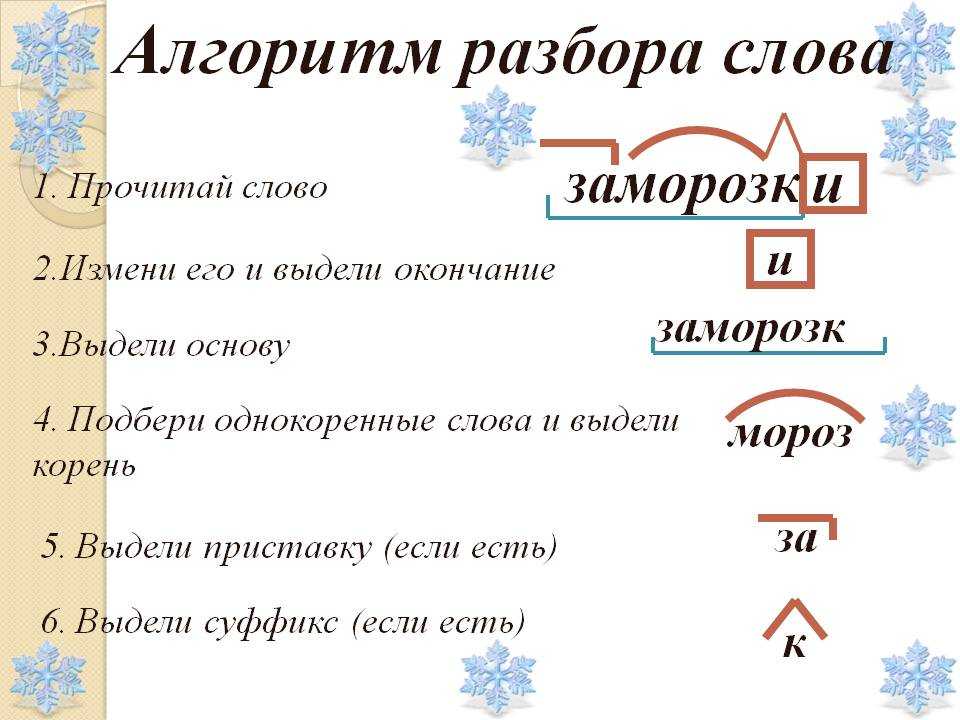
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
| Вопрос 1 из 20 Плохи дела-просто … (разг.) | |
| швах | швец |
| швиц | шваб |
Только что искали: в е р е к а й сейчас теплмца сейчас ееркноч сейчас б р у е ж а к сейчас постланная 1 секунда назад маякпер 1 секунда назад незыблем 1 секунда назад одрвеепки 1 секунда назад мылорав 1 секунда назад занятость 1 секунда назад х а м с т в о 1 секунда назад математика 1 секунда назад кистант 2 секунды назад старжик 2 секунды назад веранда 2 секунды назад
Разбор слов по составу, морфемный разбор
Разбор слов по составу
Каждое слово состоит из составных частей. Выделение этих частей – и есть разбор слов по составу. Его также называют «морфемный разбор слов». Чтобы научиться делать такой разбор быстро и безошибочно, необходимо первым делом понять, какие части слов бывают, и как они определяются.
Выделение этих частей – и есть разбор слов по составу. Его также называют «морфемный разбор слов». Чтобы научиться делать такой разбор быстро и безошибочно, необходимо первым делом понять, какие части слов бывают, и как они определяются.
Кстати, чтобы сделать грамотный морфемный разбор слов, особенно если вы столкнулись со сложными словами, будет нелишним использовать специальные словари морфемных разборов. Они могут быть электронными, ими легко и удобно пользоваться в режиме онлайн, например – на нашем сайте.
Разбираем поэтапно
Морфемный разбор слова необходимо делать в определенной последовательности:
- Для начала, выпишите слово и выясните, к какой части речи оно относится. Если это, к примеру, наречие – знайте, что оно не будет иметь окончания и других частей, так как не изменяется.
- Определите окончание, если оно вообще есть. Для этого просклоняйте слово, произнесите его в разных падежах. Например: стол, стола, к столу… Вот эта изменяемая частичка в конце – и есть окончание.
 Выделяете его в квадратик.
Выделяете его в квадратик. - Далее стоит определить основу. Это та часть, у которой нет окончания. Например, слово «городской»: тут окончание «ой», и основа «городск».
- Как видите, основа может содержать в себе суффикс и даже приставку.
- Находим приставку, если таковая имеется. К примеру, слово «застолье»: после того, как вы определили основу «стол», вы безтруда найдете приставку «за».
- Определяем суффикс. Эта часть слова стоит сразу после основы (корня» и нужна, чтобы образовать новое слово. Например, был стол – стал столик. В этом случае «ик» — суффикс (окончания нет). Был лес – стал лесок, или лесник.
- Последний этап – найти корень слова. Это та часть, которая не изменяется. В случае со столом, «стол» и есть корень. Чтобы определить корень, найдите однокоренные слова.
 Выделяете его в квадратик.
Выделяете его в квадратик.Каждая часть выделяется графически, с помощью особых значков. Корень (или основа» выделяется полукруглой дугой сверху, суффикс – треугольной «галочкой» сверху. Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Приставка похожа на лежащую горизонтально букву «Г» и рисуется над словом, а окончание – это квадрат или прямоугольник, в который заключается часть слова.
Особенности, которые следует знать
Морфемный анализ – процесс, который может показаться слишком простым, а может и наоборот, вызывать ряд сложностей. Вот, что стоит всегда знать и учитывать:
- Нельзя начинать разбор с поиска корня, даже если на первый взгляд он очевиден. Это может привести к ошибке, так что начинать всегда следует с окончания. Часто этап определения корня стоит вторым в плане, но все же вернее именно заканчивать разбор этим этапом, так как это – наиболее безошибочный путь.
- Не стоит путать слова с нулевым окончанием, и те, которые не имеют окончаний. Ведь нулевое окончание – это по сути такая же часть речи, а слово, не имеющее окончаний – не изменяется вовсе. Например, это наречия, деепричастия, сравнительные степени прилагательных и некоторые исключения.
Чтобы научиться делать морфемный разбор грамотно, не забывайте пользоваться электронными словарями, которые доступны на нашем сайте.
Только что искали:
невозможный для осуществления 8 секунд назад
запружалось 13 секунд назад
является солидарной 16 секунд назад
сверь 22 секунды назад
годник 24 секунды назад
енкарт 25 секунд назад
октава 27 секунд назад
в области процентных ставок 27 секунд назад
ипаттека 36 секунд назад
пизмитонг 37 секунд назад
акающему 41 секунда назад
на палубе матросов 47 секунд назад
физическая культура 55 секунд назад
прикликают 1 минута 5 секунд назад
рулко 1 минута 7 секунд назад
parsing.porter — Алгоритм выделения Портера — gensim
Алгоритм выделения Портера Это алгоритм стемминга Портера, перенесенный на Python из версия, закодированная автором в ANSI C. Его можно рассматривать как канонический, поскольку он следует алгоритму, представленному в 1, см. также 2
Автор — Виваке Гупта ([email protected]), оптимизация и очистка кода Ларс Буйтинк.
Примеры
>>> from gensim.parsing.porter import PorterStemmer
>>>
>>> p = PorterStemmer()
>>> p.stem("яблоко")
'приложение'
>>>
>>> p.stem_sentence("Кошки и пони встречаются")
'кошка и пони встретились'
>>>
>>> p.stem_documents(["Кошки и пони", "встреча"])
['кошка и пони', 'познакомились']
- 1
Портер, 1980 г., Алгоритм удаления суффиксов, http://www.cs.odu.edu/~jbollen/IR04/readings/readings5.pdf
- 2
http://www.tartarus.org/~martin/PorterStemmer
- класс gensim.parsing.porter.PorterStemmer
Базы:
объектКласс содержит реализацию алгоритма стемминга Портера.
- б
Буфер, содержащий слово, которое нужно выделить. Буквы в b[0], b[1] … заканчиваются на b[ к ].
- Тип
стр
- к
Регулируется вниз по мере забоя.
- Тип
целое число
- дж
Длина слова.
- Тип
целое число
- шток( с )
Основа слова w .
- Параметры
ш ( стр ) –
- Возвращает
Версия со штоком w .
- Тип возврата
стр
Примеры
>>> из gensim.parsing.porter импортировать PorterStemmer >>> p = PorterStemmer() >>> p.stem("пони") 'пони'
- стволовые_документы ( документов )
Стволовые документы.
- Параметры
документы ( список стр ) – Входные документы
- Возвращает
Стержневые документы.
- Тип возврата
список стр
Примеры
>>> из gensim.parsing.porter импортировать PorterStemmer >>> p = PorterStemmer() >>> p.
stem_documents(["Хороших выходных", "Хороших выходных"])
['приятных выходных', 'приятных выходных']
- стебель_предложение ( тхт )
Сформулируйте предложение txt .
- Параметры
txt ( str ) – Введите предложение.
- Возвращает
Сформулированное предложение.
- Тип возврата
стр
Примеры
>>> из gensim.parsing.porter импортировать PorterStemmer >>> p = PorterStemmer() >>> p.stem_sentence("Вау, очень милая женщина с яблоком") «Вау, очень милая женщина с приложением»

 stem_documents(["Хороших выходных", "Хороших выходных"])
['приятных выходных', 'приятных выходных']
stem_documents(["Хороших выходных", "Хороших выходных"])
['приятных выходных', 'приятных выходных']
Введение в стемминг — GeeksforGeeks
Стемминг — это процесс создания морфологических вариантов корневого/основного слова. Программы стемминга обычно называют алгоритмами стемминга или стеммерами. Алгоритм стемминга сводит слова «шоколад», «шоколад», «шоколад» к корневому слову, «шоколад» и «поиск», «извлеченный», «извлекает» к основе «извлекать». Stemming — важная часть конвейерного процесса обработки естественного языка. Входные данные для стеммера — токенизированные слова. Как мы получаем эти токенизированные слова? Что ж, токенизация включает в себя разбиение документа на разные слова.
Stemming — важная часть конвейерного процесса обработки естественного языка. Входные данные для стеммера — токенизированные слова. Как мы получаем эти токенизированные слова? Что ж, токенизация включает в себя разбиение документа на разные слова.
Стемминг — это метод обработки естественного языка, который используется для приведения слов к их базовой форме, также известной как корневая форма. Процесс стемминга используется для нормализации текста и облегчения его обработки. Это важный шаг в предварительной обработке текста, и он обычно используется в приложениях для поиска информации и интеллектуального анализа текста.
Существует несколько различных алгоритмов для стемминга, включая стеммер Porter, стеммер Snowball и стеммер Lancaster. Стеммер Портера — наиболее широко используемый алгоритм, основанный на наборе эвристик, которые используются для удаления общих суффиксов из слов. Стеммер Snowball — это более продвинутый алгоритм, основанный на стеммере Портера, но он также поддерживает несколько других языков помимо английского. Стеммер Lancaster является более агрессивным и менее точным, чем стеммер Porter и стеммер Snowball.
Стеммер Lancaster является более агрессивным и менее точным, чем стеммер Porter и стеммер Snowball.
Stemming может быть полезен для некоторых задач обработки естественного языка, таких как классификация текста, поиск информации и суммирование текста. Однако определение основы может также иметь некоторые негативные последствия, такие как снижение удобочитаемости текста, и оно не всегда может давать правильную корневую форму слова.
Важно отметить, что стемминг отличается от лемматизации. Лемматизация — это процесс приведения слова к его базовой форме, но, в отличие от стемминга, он принимает во внимание контекст слова и дает правильное слово, в отличие от стемминга, который может давать не-слово в качестве корневой формы.
Примечание: Do должен пройти через концепции «токенизации». -> «нравится» ->»понравилось» -> «вероятно» -> «Любие»
Ошибки при стволете:
В основном есть две ошибки в стволоте-
- ОВСУАЛЬНЫЙ СТИМ
- МОЖЕТ СТАМЕНИЯ
СПАСКА.
Перебор может привести к потере смысла и сделать текст менее читаемым. Например, слово «спорить» может происходить от «argu», которое не является допустимым словом и не передает того же значения, что и исходное слово. Точно так же слово «бег» может происходить от слова «бежать», которое является основной формой слова, но не передает значение исходного слова.
Во избежание чрезмерного стемминга важно использовать парадигматический параграф, соответствующий задаче и языку.
Другой подход к этой проблеме заключается в использовании таких методов, как маркировка семантических ролей, анализ настроений, информация на основе контекста и т. д., которые помогают понять контекст текста и сделать процесс выделения более точным.
Недоформирование происходит, когда два слова происходят от одного и того же корня, но не имеют разных основ. Неполное определение можно интерпретировать как ложноотрицательный результат. Неполное определение основы — это проблема, которая может возникнуть при использовании алгоритмов определения основы при обработке естественного языка. Это относится к ситуации, когда стеммер не производит правильную корневую форму слова или не сводит слово к его базовой форме.
Неполное определение может привести к потере информации и затруднить анализ текста. Например, слова «спорить» и «аргумент» могут быть образованы от «аргу», что не передает значения исходных слов. Точно так же слова «бегущий» и «бегун» могут быть образованы от «бежать», что является базовой формой слова, но не передает значение исходных слов.
Чтобы избежать недооценки, важно использовать парадигматический параграф, соответствующий задаче и языку. Также важно протестировать стеммер на образце текста, чтобы убедиться, что он выдает правильные корневые формы. В некоторых случаях использование лемматизатора вместо стеммера может быть лучшим решением, поскольку он учитывает контекст слова, что делает его менее подверженным ошибкам.
Другой подход к этой проблеме заключается в использовании таких методов, как маркировка семантических ролей, анализ настроений, информация на основе контекста и т.
Применение стемминга:
- Стемминг используется в информационно-поисковых системах, таких как поисковые системы.
- Используется для определения словарей предметной области при анализе предметной области.
- Для отображения результатов поиска путем индексации, когда документы превращаются в числа, и для сопоставления документов с общими темами путем объединения.
- Анализ настроений, который изучает отзывы и комментарии, сделанные разными пользователями о чем-либо, часто используется для анализа продуктов, например, для розничных интернет-магазинов. Перед интерпретацией стемминг принимается в виде средства подготовки текста.
- Метод группового анализа, применяемый к текстовым материалам, называется кластеризацией документов (также известной как группировка текста). Его важные области применения включают извлечение тем, автоматическое структурирование документов и быстрый поиск информации.
Забавный факт : Поиск Google принял слово, берущее свое начало в 2003 году. Раньше поиск по слову «рыба» не выдавал «рыбалка» или «рыбы».
Некоторые алгоритмы стемминга:
- Стеммерный алгоритм Портера
Это один из самых популярных методов стемминга, предложенный в 1980 году. сочетание более мелких и простых суффиксов. Этот стеммер известен своей скоростью и простотой. Основные приложения Porter Stemmer включают интеллектуальный анализ данных и поиск информации. Однако его применение ограничено только английскими словами. Кроме того, группа основ сопоставляется с одной и той же основой, и выходная основа не обязательно является осмысленным словом. Алгоритмы довольно длинные по своей природе и, как известно, являются старейшими стеммерами.
Пример: EED -> EE означает «если в слове есть хотя бы одна гласная и согласная плюс окончание EED, измените окончание на EE», поскольку «согласен» становится «согласен».
Преимущество: Он дает лучший результат по сравнению с другими стеммерами и имеет меньше ошибок. Ограничение: Полученные морфологические варианты не всегда являются настоящими словами.
- Lovins Stemmer
Ловинс предложил в 1968 году удалить самый длинный суффикс из слова, после чего слово записывается для преобразования этой основы в действительные слова.
Пример: сидеть -> сидеть -> сидеть
Преимущество: Это быстро и обрабатывает неправильные формы множественного числа, такие как «зубы» и «зуб» и т. д. Ограничение: Это отнимает много времени и часто не позволяет сформировать слова из основы.
- Стеммер Доусона
Это расширение стеммера Ловинса, в котором суффиксы хранятся в обратном порядке, индексируемом по их длине и последней букве.
Преимущество: Быстр в исполнении и охватывает больше.
- Кровец Стеммер
Предложен в 1993 году Робертом Кровец. Ниже приведены шаги:
1) Преобразование формы множественного числа слова в форму единственного числа.
2) Преобразуйте прошедшее время слова в его настоящее время и удалите суффикс «ing».
Пример: ‘дети’ -> ‘ребенок’
Преимущество: Он легкий по своей природе и может использоваться в качестве предварительного стеммера для других стеммеров. Ограничение: Неэффективно при работе с большими документами.
- Xerox Stemmer
Пример:
- ‘дети’ -> ‘ребенок’
- ‘понял’ -> ‘понял’
- ‘8’ 903 ’92 ‘кто good’
- N-грамм Stemmer
N-грамма — это набор из n последовательных символов, извлеченных из слова, в котором похожие слова будут иметь большую долю общих n-грамм.
Пример: ‘INTRODUCTIONS’ для n=2 становится следующим: *I, IN, NT, TR, RO, OD, DU, UC, CT, TI, IO, ON, NS, S*
Преимущество: Он основан на сравнении строк и зависит от языка. Ограничение: Для создания и индексации n-грамм требуется место, и это неэффективно по времени.
- Snowball Stemmer:
По сравнению со Stemmer Porter, Snowball Stemmer также может отображать неанглийские слова. Поскольку он поддерживает другие языки, Snowball Stemmers можно назвать многоязычным стеммером. Стеммеры Snowball также импортируются из пакета nltk. Этот стеммер основан на языке программирования Snowball, который обрабатывает небольшие строки и является наиболее широко используемым стеммером. Стеммер Snowball более агрессивен, чем стеммер Porter, и его также называют стеммером Porter2. Из-за улучшений, добавленных по сравнению со стеммером Портера, стеммер Snowball имеет более высокую скорость вычислений.
 один и тот же корень из разных стеблей. Чрезмерная выработка также может рассматриваться как ложноположительный результат. Over-stemming — это проблема, которая может возникнуть при использовании алгоритмов стемминга в обработке естественного языка. Это относится к ситуации, когда стеммер создает корневую форму, которая не является допустимым словом или не является правильной корневой формой слова. Это может произойти, когда стеммер слишком агрессивен в удалении суффиксов или когда он не учитывает контекст слова.
один и тот же корень из разных стеблей. Чрезмерная выработка также может рассматриваться как ложноположительный результат. Over-stemming — это проблема, которая может возникнуть при использовании алгоритмов стемминга в обработке естественного языка. Это относится к ситуации, когда стеммер создает корневую форму, которая не является допустимым словом или не является правильной корневой формой слова. Это может произойти, когда стеммер слишком агрессивен в удалении суффиксов или когда он не учитывает контекст слова.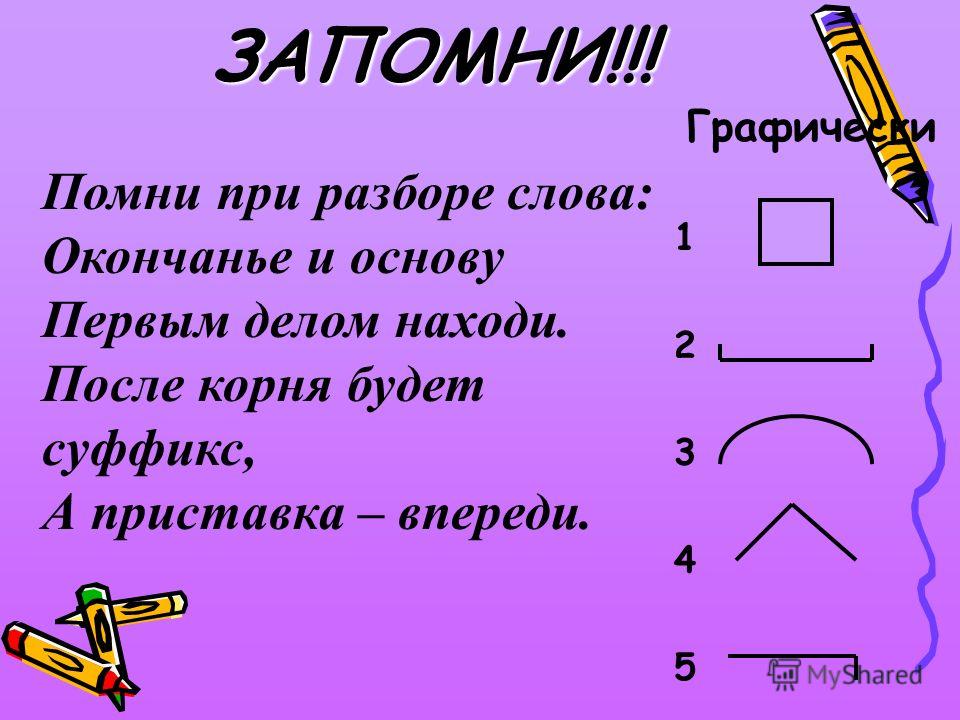 Также важно протестировать стеммер на образце текста, чтобы убедиться, что он создает допустимые корневые формы. В некоторых случаях использование лемматизатора вместо стеммера может быть лучшим решением, поскольку он учитывает контекст слова, что делает его менее подверженным ошибкам.
Также важно протестировать стеммер на образце текста, чтобы убедиться, что он создает допустимые корневые формы. В некоторых случаях использование лемматизатора вместо стеммера может быть лучшим решением, поскольку он учитывает контекст слова, что делает его менее подверженным ошибкам.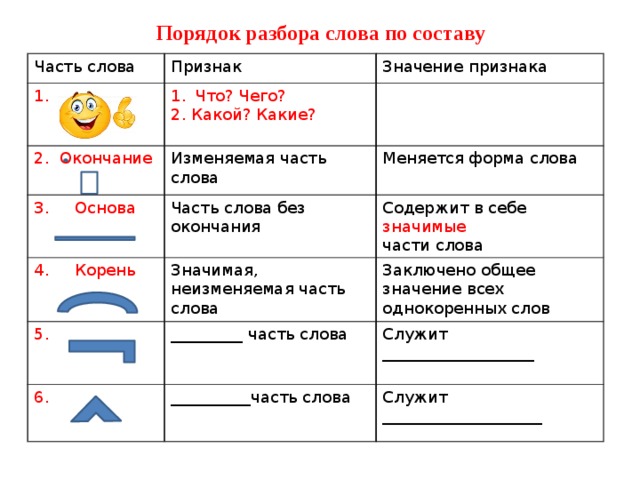 Это может произойти, если стеммер недостаточно агрессивен в удалении суффиксов или когда он не предназначен для конкретной задачи или языка.
Это может произойти, если стеммер недостаточно агрессивен в удалении суффиксов или когда он не предназначен для конкретной задачи или языка. д., которые помогают понять контекст текста и сделать процесс выделения более точным.
д., которые помогают понять контекст текста и сделать процесс выделения более точным.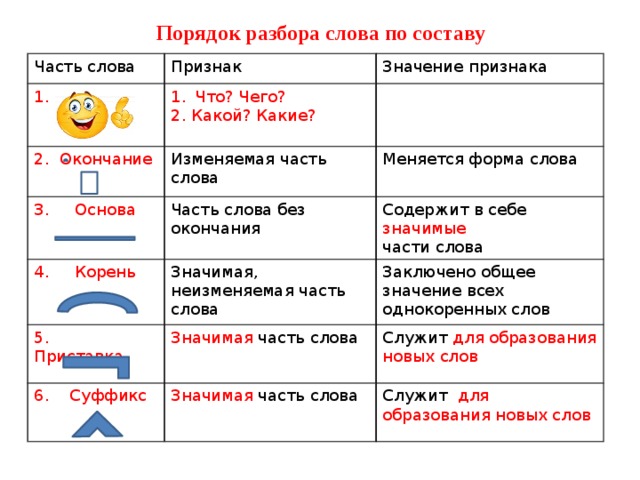
 Ограничение: Очень сложно реализовать.
Ограничение: Очень сложно реализовать.