Слова «научился» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «научился» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «научился» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «научился».
Содержимое:
- 1 Слоги в слове «научился»
- 2 Как перенести слово «научился»
- 3 Морфемный разбор слова «научился» по составу
- 4 Сходные по морфемному строению слова «научился»
- 5 Синонимы слова «научился»
- 6 Антонимы слова «научился»
- 7 Ударение в слове «научился»
- 8 Фонетическая транскрипция слова «научился»
- 9 Фонетический разбор слова «научился» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «научился»
- 11 Сочетаемость слова «научился»
- 12 Значение слова «научился»
- 13 Как правильно пишется слово «научился»
Слоги в слове «научился»
Количество слогов: 4
По слогам: на-у-чи-лся
л — непарная звонкая согласная (сонорная), примыкает к текущему слогу
Как перенести слово «научился»
на—учился
нау—чился
научи—лся
научил—ся
Морфемный разбор слова «научился» по составу
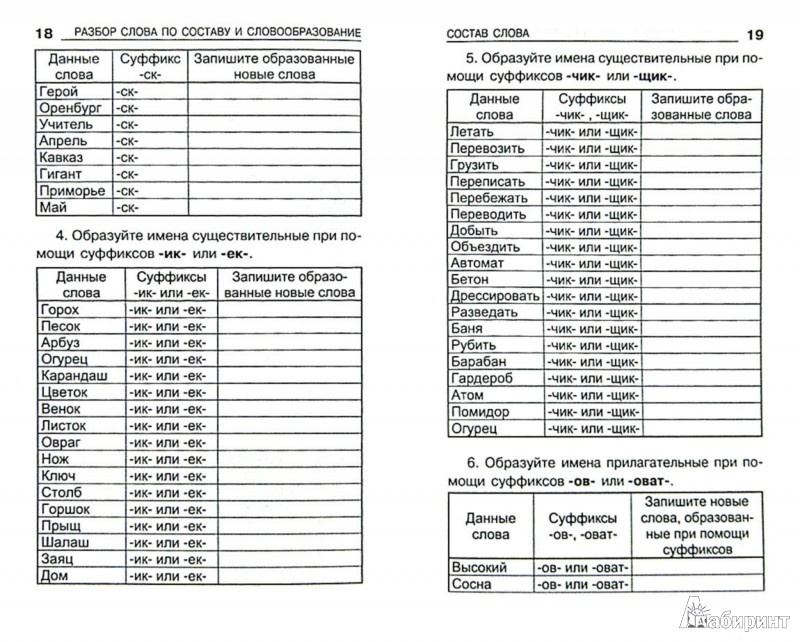
| на | приставка |
| уч | корень |
| и | суффикс |
| ть | глагольное окончание |
| ся | постфикс |
научиться
Сходные по морфемному строению слова «научился»
Сходные по морфемному строению слова
Синонимы слова «научился»
1. выучить
выучить
2. учить что
3. учиться
4. обучиться
5. выучиться
6. поднатореть
7. напрактиковаться
8. вымуштроваться
9. вышколиться
10. выдрессироваться
11. наметать глаз
12. насобачиться
13. наметать руку
14. наблатоваться
15. навостриться
16. набить руку
17. нафигачиться
18. надрочиться
19. нахреначиться
20. наблатыкаться
21. приловчиться
22. понатореть
23. наловчиться
24. настропалиться
25. подготовиться
26. подковаться
27. приучиться
28. подучиться
29. навыкнуть
Антонимы слова «научился»
1. разучиться
Ударение в слове «научился»
научи́лся — ударение падает на 3-й слог
Фонетическая транскрипция слова «научился»
[науч’`илс’а]
Фонетический разбор слова «научился» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| н | [н] | согласный, звонкий непарный (сонорный), твёрдый | н |
| а | [а] | гласный, безударный | а |
| у | [у] | гласный, безударный | у |
| ч | [ч’] | согласный, глухой непарный, мягкий, шипящий | ч |
| и | [`и] | гласный, ударный | и |
| л | [л] | согласный, звонкий непарный (сонорный), твёрдый | л |
| с | [с’] | согласный, глухой парный, мягкий, шумный | с |
| я | [а] | гласный, безударный | я |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 8 букв и 8 звуков.
Буквы: 4 гласных буквы, 4 согласных букв.
Звуки: 4 гласных звука, 4 согласных звука.
Предложения со словом «научился»
У крестьянина была девочка, которую, прежде чем она научилась читать, он приобщил к музыкальной азбуке.
Источник: Гастон Леру, Призрак Оперы, 1910.
Прожив на ранчо вместе почти четверть века, они в совершенстве научились понимать друг друга без слов.
Источник: Николас Спаркс, Дальняя дорога.
Он может очень много, но далеко не всё, и стремится научиться делать то, что пока не умеет делать.
Источник: Евгений Кузин, Системная теория жизни. Кибернетика живого.
Сочетаемость слова «научился»
1. люди научились
2. ребёнок научился
3. научиться у кого-либо
4. научиться от кого-либо
5. научиться быть счастливым
6. (полная таблица сочетаемости)
(полная таблица сочетаемости)
Значение слова «научился»
НАУЧИ́ТЬСЯ , -учу́сь, -у́чишься; сов., чему или с неопр. (несов. учиться и устар. научаться). Приобрести навыки, умение делать, понимать, чувствовать и т. п. что-л. Научиться плавать. (Малый академический словарь, МАС)
Как правильно пишется слово «научился»
Орфография слова «научился»Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «научился» в прямом и обратном порядке:
Научились разбор слова по составу — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Как сделать разбор слова научились по составу?
упр. 456 русский язык 5 класс Рыбченкова
Помогите пожалуйста!!
Упражнение 58, помогите составить краткий конспект
Задания:1.Составить диалог ученого и журналиста на тему «Экстремальная погода вмире» (три вопроса и три ответа, не забудьте о приветствии и прощании, … атакже о правильном оформлении диалога)4 балла
русский язык пятый класс Рыбченкова упражнение 455
Спишите предложения, расставляя знаки препинания. Подчеркните грамматические основы.1) Не было никакой надежды что небо прояснится. (А. Чехов) 2) Обл
… ачко тилось в белую тучу которая тяжело подымалась росла и постепенно облетал (4. Пушкин) 3) Никогда не думайте что вы всё знаете. (И. Павлов) 4) Наши отва путешественники не почувствовали как поднялся в воздух шар. (Н. Носов) 5) Ста сумел ответить что он будет делать с кладом. (А. Чехов) 6) Мой папа не любит я мешаю ему читать газеты. (В. Драгунский) 7) Я уверен что земляничный аромат ни с чем не спутаешь.
Подчеркните грамматические основы.1) Не было никакой надежды что небо прояснится. (А. Чехов) 2) Обл
… ачко тилось в белую тучу которая тяжело подымалась росла и постепенно облетал (4. Пушкин) 3) Никогда не думайте что вы всё знаете. (И. Павлов) 4) Наши отва путешественники не почувствовали как поднялся в воздух шар. (Н. Носов) 5) Ста сумел ответить что он будет делать с кладом. (А. Чехов) 6) Мой папа не любит я мешаю ему читать газеты. (В. Драгунский) 7) Я уверен что земляничный аромат ни с чем не спутаешь.
(В. Солоухин)
(1)Декоративная роспись Урала – одно из самобытнейших явлений русского народного искусства. (2)Она включает в себя гармоничную и поразительную по свое
… й цельности роспись бытовых вещей: берестяной посуды, деревянной утвари, металлических изделий дома. (3)Зарождение большинства центров народной уральской росписи протекало сложным путём. (4)Прежде всего это было связано с тем, что с XVI–XVII вв. начинается активное освоение восточной части России. (5)Переселенцы везли с собой не только припасы и одежду, но и деревянную посуду и металлические орудия труда. (6)Но самым ценным было то, что они везли с собой культуру, обычаи, жизненный уклад той местности, откуда переселялись. (7)Наверное, поэтому на Урале сложились столь разнообразные стили росписи деревянной утвари. (8)Большой поток переселенцев положил начало широкому строительству жилых и общественных построек. (9)Потребность в их красочном убранстве помогла зарождению на Урале ремесленных художественных центров.
(5)Переселенцы везли с собой не только припасы и одежду, но и деревянную посуду и металлические орудия труда. (6)Но самым ценным было то, что они везли с собой культуру, обычаи, жизненный уклад той местности, откуда переселялись. (7)Наверное, поэтому на Урале сложились столь разнообразные стили росписи деревянной утвари. (8)Большой поток переселенцев положил начало широкому строительству жилых и общественных построек. (9)Потребность в их красочном убранстве помогла зарождению на Урале ремесленных художественных центров.
(10)В это время складываются два направления расписной утвари – роспись металлических и деревянных изделий. (11)Развитым видом народного искусства на Урале было создание праздничных обрядовых прялок. (12)Над ними трудились мастера-профессионалы, были выработаны определённые типы композиций прялочного декора, всегда связанные с определённым назначением прялки. (13)Наиболее самобытной разновидностью сельских росписей Урала являлась обвинская.
4) Определите и запишите лексическое значение слова УТВАРЬ из предложения 10. 5) Часть1: Найдите стилистические окрашенное слово в предложении 6-7,выпишите это слово. Часть 2: Подберите и запишите синоним к этому слову. 6) Обесните значение пословицы Под лежачий камень вода не течёт,Запишите ваше обьяснения.
Прочитайте тексты и выполните задания в тетради. Определите стиль (разговорный, публицистический, научный, художественный или официально-деловой) и тип
… (повествование, описание или рассуждение) текстов, аргументируйте свой ответ.Найдите тему, объединяющую тексты. Сформулируйте ее и запишите.Определите целевую аудиторию для каждого текстаТекст 1Климат Казахстана резко континентальный. На севере — умеренно холодный, на крайнем юге — умеренно жаркий. Континентальность климата проявляется в резких колебаниях температуры, сухости воздуха и незначительном количестве атмосферных осадков на большей части республики. Такой климат обусловлен тем, что Казахстан находится очень далеко от океанов и их морей и имеет обширную территорию, вытянутую с запада на восток и с севера на юг.
Определите стиль (разговорный, публицистический, научный, художественный или официально-деловой) и тип
… (повествование, описание или рассуждение) текстов, аргументируйте свой ответ.Найдите тему, объединяющую тексты. Сформулируйте ее и запишите.Определите целевую аудиторию для каждого текстаТекст 1Климат Казахстана резко континентальный. На севере — умеренно холодный, на крайнем юге — умеренно жаркий. Континентальность климата проявляется в резких колебаниях температуры, сухости воздуха и незначительном количестве атмосферных осадков на большей части республики. Такой климат обусловлен тем, что Казахстан находится очень далеко от океанов и их морей и имеет обширную территорию, вытянутую с запада на восток и с севера на юг.
 Для всей республики характерно большое колебание температуры воздуха как в течение суток, так и года. Причем в равнинно-низкогорной части среднегодовые и среднемесячные температуры изменяются по направлению с севера на юг, а в высокогорных областях — с поднятием местности над уровнем моря.Текст 2Погода меняться может ежечасно, порой мы так и даем: грозу, метель, ветер, гололед, солнце, снегопад в одни сутки. Все чаще мы видим, что нормативные показатели превышаются. Вот в апреле среднесуточная температура 8°С, но в этом году она 15°С в Алматы.– Погода действительно меняется, – рассказывает начальник метеостанции Алматы Айгуль Кокынбаева. – В этом году я просто была шокирована тем, что в январе гремела гроза.
Для всей республики характерно большое колебание температуры воздуха как в течение суток, так и года. Причем в равнинно-низкогорной части среднегодовые и среднемесячные температуры изменяются по направлению с севера на юг, а в высокогорных областях — с поднятием местности над уровнем моря.Текст 2Погода меняться может ежечасно, порой мы так и даем: грозу, метель, ветер, гололед, солнце, снегопад в одни сутки. Все чаще мы видим, что нормативные показатели превышаются. Вот в апреле среднесуточная температура 8°С, но в этом году она 15°С в Алматы.– Погода действительно меняется, – рассказывает начальник метеостанции Алматы Айгуль Кокынбаева. – В этом году я просто была шокирована тем, что в январе гремела гроза. Такого явления мне не доводилось наблюдать еще никогда. Очень теплой была зима, она больше весну напоминала. А вот в марте выпал снег высотой в 30 сантиметров, что тоже не типично для Алматы. Так что, если снег выпадет вдруг в июле, я уже не удивлюсь, потому что могу допустить все что угодно. – За столько лет работы в гидрометеослужбе вы с небесной канцелярией стали на «ты»?– Нет, конечно! Она такая непредсказуемая, как бы мы ни старались.– Тогда согласны, что «у природы нет плохой погоды»?– «Всякая погода благодать», но я все-таки жару не люблю, а, судя по всему, количество жарких дней будет только нарастать, к сожалению.– А многие люди, живущие в Казахстане говорят, что климат в Казахстане такой холодный и уникальный.– Климат у нас не уникальный, такой же, как в Китае, Канаде.
– За столько лет работы в гидрометеослужбе вы с небесной канцелярией стали на «ты»?– Нет, конечно! Она такая непредсказуемая, как бы мы ни старались.– Тогда согласны, что «у природы нет плохой погоды»?– «Всякая погода благодать», но я все-таки жару не люблю, а, судя по всему, количество жарких дней будет только нарастать, к сожалению.– А многие люди, живущие в Казахстане говорят, что климат в Казахстане такой холодный и уникальный.– Климат у нас не уникальный, такой же, как в Китае, Канаде.
Напишите числительные словами. Допишите окончания существительных. 1) Лес тянулся на протяжении 40 километров. 2) Из 892 участник.. фестиваля иностран … цев было 742 человек… 3) В нашей школе обучается на 452 ученик. . больше, чем в соседней. 4) К 1219 учащ..ся одной школы присоединилось 936 учащ..ся другой. 5) Пароход с 850 отдыхающ.. вышел в рейс. 6) Крупный выигрыш пал на 13 номер 45 645 сери… 7) На 251 страниц.. книги помещено больше 150 рисунк…
2. Запишите словами числительные определяющие порядок при счете. 2,13,47,258,125.Помогите пж
2,13,47,258,125.Помогите пж
Морфологический разбор слова «научился»
Часть речи: Глагол в личной форме
НАУЧИЛСЯ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАУЧИТЬСЯ»
| Слово | Морфологические признаки |
|---|---|
| НАУЧИЛСЯ |
|
Все формы слова НАУЧИЛСЯ
НАУЧИТЬСЯ, НАУЧИЛСЯ, НАУЧИЛАСЬ, НАУЧИЛОСЬ, НАУЧИЛИСЬ, НАУЧУСЬ, НАУЧИМСЯ, НАУЧИШЬСЯ, НАУЧИТЕСЬ, НАУЧИТСЯ, НАУЧАТСЯ, НАУЧАСЬ, НАУЧИВШИСЬ, НАУЧИМТЕСЬ, НАУЧИСЬ, НАУЧИВШИЙСЯ, НАУЧИВШЕГОСЯ, НАУЧИВШЕМУСЯ, НАУЧИВШИМСЯ, НАУЧИВШЕМСЯ, НАУЧИВШАЯСЯ, НАУЧИВШЕЙСЯ, НАУЧИВШУЮСЯ, НАУЧИВШЕЮСЯ, НАУЧИВШЕЕСЯ, НАУЧИВШИЕСЯ, НАУЧИВШИХСЯ, НАУЧИВШИМИСЯ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАУЧИЛСЯ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «научился»
1
Многому научился я за этот октябрь, многое пережил, но главное – научился ненавидеть.
За три моря. Путешествие Афанасия Никитина, Константин Ильич Кунин
2
быть может, я рассказал это себе, прежде чем научился читать, или прочитал, прежде чем
Сердитая улица (Страшный сон), Гилберт Кит Честертон
3
Многому научился Сиддхартха у саманов, многими путями научился он уходить от «я».
Сиддхартха, Герман Гессе, 1922г.
4
Вот чему не научился
, тому не научился.
Волга-матушка река. Книга 1. Удар, Федор Иванович Панфёров, 1953г.
5
Гитлер многому научился у Хёрбигера, если слово «научился» здесь уместно.
Блокада. Книга 1, Александр Борисович Чаковский, 1969г.
Найти еще примеры предложений со словом НАУЧИЛСЯ
«ЯТОП» УЧИТ РУССКОМУ ЯЗЫКУ неслышащих детей
Новости
01:49, 27 мая 2020г.
«ЯТОП» (языковое творчество для особых потребностей) – это образовательный проект Центра развития и поддержки глухих и слабослышащих детей и их родителей АНО «Я понимаю». Проект направлен на изучение неслышащими детьми русского языка. В рамках этого проекта «Я понимаю» провёл 12 уроков офлайн, более 7 занятий дистанционно, а также снял порядка 10 обучающих роликов, которые посмотрели более 4,5 тысяч зрителей.
«ЯТОП»− образовательный проект, основанный на билингвальном и деятельностном подходах. В проект входят:
- Детский клуб «Вместе с мамой» для детей 1,5-4,5 лет;
- Занятия с глухими и слабослышащими детьми 3-16 лет по русскому языку как неродному;
- Изучение раздела русского языка школьниками 4-6 классов: уроки «Словообразования».
Детский клуб «Вместе с мамой» создан, чтобы научить родителей самостоятельно заниматься со своим ребёнком. Продолжительность занятия 45 минут, с учетом возрастных особенностей детей, запись в клуб происходит в свободном режиме. К завершению занятий в рамках проекта родители стали активно включаться в проведение занятий со своими детьми, больше внимания стали уделять общению, начали объяснять значения новых слов, понятий. Обучающие видеоролики от сурдопедагога набрали порядка 1500 просмотров.
«Лучшие педагоги для детей — это их родители. Но их нигде не учат, как помочь своим глухим и слабослышащим детям пополнять словарный запас и налаживать коммуникацию. Родители ждут детского сада, думая, что там всему научат. Это заблуждение. Начинать нужно чуть ли не с первого дня жизни. И мы готовы помочь в детском клубе, где родители вовлекаются в занятия со своими детьми, а дети и сурдопедагог прекрасно понимают друг друга, используя жестовый язык, устную речь и дактилологию», − рассказала директор АНО «Я понимаю» Елена Соловейчик.
Родители ждут детского сада, думая, что там всему научат. Это заблуждение. Начинать нужно чуть ли не с первого дня жизни. И мы готовы помочь в детском клубе, где родители вовлекаются в занятия со своими детьми, а дети и сурдопедагог прекрасно понимают друг друга, используя жестовый язык, устную речь и дактилологию», − рассказала директор АНО «Я понимаю» Елена Соловейчик.
Уроки «Русский как неродной» проводятся с опорой на русский жестовый язык. Отбор проходит через тестирование в зависимости от возраста. По итогам курса 30 детей научились пользоваться опорными таблицами по темам «Имя существительное: единственное и множественное число», «Имя прилагательное», «Местоимения», «Кто? Что?». Выявилось, что практически все школьники ошибаются в постановке ударений, имеют ограниченный словарный запас. При выполнении упражнений по пройденным темам дети показывают улучшение и хорошие результаты.
Программа курса «Словообразование» создана для знакомства детей с морфемикой (составом слова) и словообразованием (способах образования слов) в русском языке − на РЖЯ и на русском языке в письменной форме. Обучение прошли 20 участников, были по два занятия в трех группах по 40 минут. Отбор детей на курс – анкетирование. Результаты: учащиеся научились различать термины «часть слова» и «часть речи», «однокоренные слова» и «однородные члены предложения». Научились хорошо выполнять разбор слова по составу, видеть корень в слове, узнали способы словообразования, смогли выполнить несколько сложных лингвистических заданий.
Обучение прошли 20 участников, были по два занятия в трех группах по 40 минут. Отбор детей на курс – анкетирование. Результаты: учащиеся научились различать термины «часть слова» и «часть речи», «однокоренные слова» и «однородные члены предложения». Научились хорошо выполнять разбор слова по составу, видеть корень в слове, узнали способы словообразования, смогли выполнить несколько сложных лингвистических заданий.
Узнать подробнее о Центре развития и его образовательных проектах можно на сайте Я ПОНИМАЮ. Видео с занятий можно посмотреть здесь, или на официальной странице Центра «Я понимаю» в Инстаграме здесь .
Контакты АНО «Я понимаю»:
Е-мейл: [email protected]
Тел: +7 (977) 967 85 21
ПРОЕКТ «ЯТОП» ДЛЯ ГЛУХИХ И СЛАБОСЛЫШАЩИХ ДЕТЕЙ
02.06.2020
Проект объединил более 4,5 тысяч участников.
Центр развития и поддержки глухих и слабослышащих детей и их родителей АНО «Я понимаю» в рамках образовательного проекта «ЯТОП» – языковое творчество для особых потребностей людей с инвалидностью по слуху для изучения русского языка» провел 12 уроков офлайн, более 7 занятий дистанционно, а также снял порядка 10 обучающих роликов, которые посмотрели более 4,5 тысяч зрителей.
Образовательный проект, основанный на билингвальном и деятельностном подходах, включает:
- Проведение Детского клуба «Вместе с мамой» для детей 1,5-4,5 лет;
- Занятия с глухими и слабослышащими детьми 3-16 лет по русскому языку как неродному;
- Изучение раздела русского языка школьниками 4-6 классов — уроки «Словообразования».
Детский клуб «Вместе с мамой» создан, чтобы научить родителей самостоятельно заниматься со своим ребёнком. Продолжительность занятия 45 минут, с учетом возрастных особенностей детей, запись в клуб происходит в свободном режиме. К завершению занятий в рамках проекта родители стали активно включаться в проведение занятий со своими детьми, больше внимания стали уделять общению, начали объяснять значения новых слов, понятий. Обучающие видеоролики от сурдопедагога набрали порядка 1500 просмотров.
«Лучшие педагоги для детей — это их родители. Но их нигде не учат, как помочь своим глухим и слабослышащим детям пополнять словарный запас и налаживать коммуникацию. Родители ждут детского сада, думая, что там всему научат, но это заблуждение. Начинать нужно чуть ли не с первого дня жизни. И мы готовы помочь в детском клубе, где родители вовлекаются в занятия со своими детьми, а дети и сурдопедагог прекрасно понимают друг друга, используя жестовый язык, устную речь и дактилологию», − рассказала директор АНО «Я понимаю» Елена Соловейчик.
Родители ждут детского сада, думая, что там всему научат, но это заблуждение. Начинать нужно чуть ли не с первого дня жизни. И мы готовы помочь в детском клубе, где родители вовлекаются в занятия со своими детьми, а дети и сурдопедагог прекрасно понимают друг друга, используя жестовый язык, устную речь и дактилологию», − рассказала директор АНО «Я понимаю» Елена Соловейчик.
Урок «Русский как неродной» проводится с опорой на русский жестовый язык. Отбор проходит через тестирование в зависимости от возраста. По итогам курса 30 детей научились пользоваться опорными таблицами, разработанными в рамках проекта, по темам «Имя существительное: единственное и множественное число», «Имя прилагательное», «Местоимения», «Кто? Что?». Выявилось, что практически все школьники ошибаются в постановке ударений, имеют ограниченный словарный запас. При выполнении упражнений по пройденным темам дети показывают улучшение и хорошие результаты.
Программа курса «Словобразование» создана для знакомства детей с морфемикой (составом слова) и словообразованием (способах образования слов) в русском языке − на русском жестовом языке и на русском языке в письменной форме. Обучение прошли 20 участников, по два занятия в трех группах по 40 минут. Отбор детей на курс – анкетирование. Результаты: учащиеся научились различать термины «часть слова» и «часть речи», «однокоренные слова» и «однородные члены предложения». Научились хорошо выполнять разбор слова по составу, видеть корень в слове, узнали способы словообразования, смогли выполнить несколько сложных заданий по данному разделу лингвистики.
Обучение прошли 20 участников, по два занятия в трех группах по 40 минут. Отбор детей на курс – анкетирование. Результаты: учащиеся научились различать термины «часть слова» и «часть речи», «однокоренные слова» и «однородные члены предложения». Научились хорошо выполнять разбор слова по составу, видеть корень в слове, узнали способы словообразования, смогли выполнить несколько сложных заданий по данному разделу лингвистики.
Видео с занятий можно посмотреть на официальной странице Центра «Я понимаю» в Инстаграмме − https://www.instagram.com/iunderstand_deaf/.
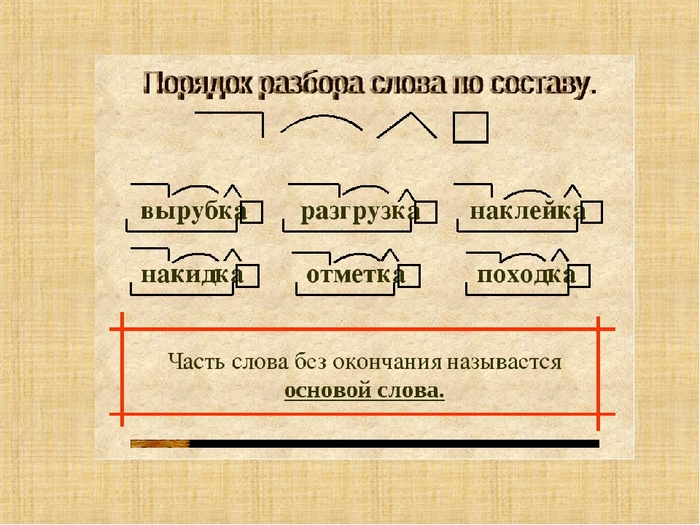
Конспект урока русского языка 2 класс «Разбор слова по составу»
Тема: «Разбор слова по составу»
Цели урока.
Образовательные: уточнить понятия «корень», «основа», «приставка»,
«суффикс», «окончание»; создать с учащимися алгоритм разбора слова по составу.
Развивающие: развивать умения планировать, контролировать, регулировать и анализировать собственную учебную деятельность; развивать речь учащихся, обогащать словарный запас детей.
Воспитательные: создавать у учащихся положительную мотивацию к уроку
русского языка путём вовлечения каждого в активную деятельность;
-воспитывать культуру речи, любовь к слову, родному языку.
Ход урока:
1.Организационный момент.
2. Актуализация знаний.
«Мозговая разминка»
-Чтобы собрать наше внимание, проведём «Разминку для ума».
Отвечаем хором, быстро.
Часть слова, которая служит для связи слов в предложении
называется…
Общая часть родственных слов называется …
— Как называется второй зимний месяц?
Что находится между городом и селом?
Разделительный твёрдый знак пишется после ….
Часть слова без окончания называется …
Назовите слово, противоположное слову враг.
Чем кончается лето и начинается осень?
— Сколько гласных букв в русском алфавите?
3. Чистописание.
-Определим букву, которую мы будем писать на минутке чистописания. Она находится в слове, которое является лишним в данной группе и
обозначает мягкий согласный, который находится в суффиксе этого слова: пейзаж январь рисовать мороз
(Лишнее слово рисовать, т. к. обозначает действие; мягкий согласный в суффиксе т,)
к. обозначает действие; мягкий согласный в суффиксе т,)
Определим порядок следования элементов в ряду: т/тт//ттт///
-Напишем эту цепочку букв в указанной последовательности, продолжим
закономерность до конца строки.
4. Сообщение темы урока.
На доске ряд букв:
-Отыщем тему урока в ребусе.
ПСРЛИОСВТОАОВБКРААСЗУОФВФАИНКИСЕ
(СЛОВООБРАЗОВАНИЕ)
5. Включение в тему.
-Какие слова остались?
-Для чего нужны в словах приставка и суффикс?
-Поверим домашнее задание.
Словарь «Учусь правильно образовывать слова» (И.В.Курочкина)
Проверка работы со словообразовательным гнездом стр.91.
-Со словообразовательным гнездом какого слова мы работали? (Чистый)
-Прочитаем слова, образованные приставочным способом.
-Прочитаем слова, образованные суффиксальным способом.
Словарная работа.
рисовать пейзаж
мороз январь
-Прочитаем слова. Что общего у этих слов? Какое слово лишнее?
-Какое задание можно придумать с этими словами?
-Образуем новые слова, выделим ту часть слова, с помощью которой
образовалось новое слово:
Один учащийся выполняет работу на карточке.
Проверка с помощью опор.
-Каким способом образованы слова?
-Кто образовал другие слова?
-Зачем нужно уметь образовывать слова разными способами, определять
состав слова? (Чтобы расширять свой словарный запас, уметь правильно
определять место орфограммы в слове.)
Орфографическая гимнастика.
-Определим место орфограммы в словах. Покажем место безударной гласной в корне жестами.
Побег, денёк, кисточка, рассвет, в клетке, водить, пишет, ключик. Отлично!
6. Работа над алгоритмом по составу.
-А что нам может помочь действовать организованно и научиться быстро
и грамотно разбирать слова по составу? (План действия, алгоритм).
-Следовательно, какова же цель нашего урока? (Составить алгоритм разбора слова по составу).
У детей на партах пошаговый план алгоритма. Учащиеся работают в парах.
-Составим алгоритм разбора слова по составу
-Запиши слово.
-Измени слово и выдели окончание.
-Отдели окончание от основы и выдели основу.
-Подбери однокоренные слова и выдели корень.
-Найди и обозначь приставку и суффикс.
Проверка:
-Какой первый шаг?
-Что нужно сделать потом?
-Мы составили свой алгоритм. Давайте убедимся в правильности его построения. Работа по учебнику.
-Чем отличается наш алгоритм от предоставленного алгоритма в учебнике?
(Для устного разбора, а наш — для письменного).
7. Практическое применение.
Эстафета.
На доске записаны слова в 3 столбика. Учащиеся по цепочке выходят к доске
и выделяют части слова, используя алгоритм.
перегородка выговор ореховый
побег подорожник предвестник
желтизна соседка просмотр
Проверка с помощью светофоров.
-Вы научились разбирать слова по составу. Молодцы!
8.Творческое применение знаний.
Работа с текстом.
-Посмотрите на экран. Подумайте, что же мы сейчас будем делать?
(Подбирать слова к схемам, чтобы из них получилось предложение. )
Работа по вариантам. Каждый вариант получает по два предложения, в которых
Каждый вариант получает по два предложения, в которых
некоторые слова заменены схемами.
Два человека работают на карточках.
Проверка на экране.
Метель спрятала (укрыла) лесные дорожки (тропинки).
Мягко похрустывает (поскрипывает) под ногами снег.
Деревья замерли (застыли) в зимнем сне.
Пушистая (ледяная) изморозь покрыла ветви.
-Прочтём полученные предложения? Кто подобрал другие слова?
-Что у нас получились? Как можно его озаглавить?
9. Подведение итогов урока.
Сделаем вывод:
-Могут ли существовать приставки и суффиксы в речи самостоятельно,
отдельно от слова? (Нет). Мы собрали части и получили слово.
Действовали вместе и получили текст.
-Сегодня на уроке: Мы составили…
Мы научились…
10. Информация о домашнем задании
Продолжите наш рассказ. Придумайте 2 предложения и зашифруйте их.
Повторение, чему мы научились.
Текст
Тема: Проверим, чему мы научились. Текст.
Текст.
Цель: Закрепить свои знания о тексте.
Критерии успеха:
— Я знаю, что такое текст, из чего он состоит;
— Я различаю типы текста;
— Я могу составить текст из отдельных частей, могу сочинить текст.
Ресурсы: Карточки с буквами для деления на группы и определения темы урока, карточки-таблицы, карточки для работы в группе №2,№3. Листы оценивания.
Ход урока.
Деление на группы. Карточки с буквами: Т, е, к, с .(4 группы , у каждой своя буква). Какую букву нужно добавить, чтобы получилось слово?(Т)
Определение темы и цели урока. Подумайте и назовите тему урока. Знакомы ли вы с понятием текст? (да). Значит, что мы будем делать сегодня на уроке? (закреплять свои знания и умения по теме «Текст»)
Определим критерии успеха нашего урока. Записываю их на доске.
Критерии успеха.
Актуализация знаний.- Что такое текст? Из чего он состоит? (Текст состоит из предложений, которые связаны друг с другом пол смыслу).
На какие части делится текст? Что такое тема текста? (то, о чем или о ком говорится в тексте).Что такое основная мысль текста?(главное, что хотел передать автор, чему учит текст).
Какие типы текста бывают? (повествование, описание, рассуждение)
Работа в группах.
1 гр.Определить признаки текста- описания:
Отвечает на вопрос какой? | Отвечает на вопрос что делает? | Отвечает на вопрос почему? |
В тексте говорится о действиях: что было сначала, что потом, чем все закончилось. | В тексте описываются предметы, животные, люди, природа. | В тексте представлены доказательства, объяснения, причины действий. |
2 гр.Определить признаки текста-повествования:
Отвечает на вопрос какой? | Отвечает на вопрос что делает? | Отвечает на вопрос почему? |
В тексте говорится о действиях: что было сначала, что потом, чем все закончилось. | В тексте описываются предметы, животные, люди, природа. | В тексте представлены доказательства, объяснения, причины действий. |

3 гр.Определить признаки текста-рассуждения:
Отвечает на вопрос какой? | Отвечает на вопрос что делает? | Отвечает на вопрос почему? |
В тексте говорится о действиях: что было сначала, что потом, чем все закончилось. | В тексте описываются предметы, животные, люди, природа. | В тексте представлены доказательства, объяснения, причины действий. |
Лист оценивания
Фамилия, имя ученика | ||||
Таблица | ||||
«Рисуем человечка» | ||||
Сочиним текст-повествование | ||||
Рефлексия |
Закрепление.
Приём «человечек».
В каждом тексте есть вступление, основная часть, заключение. Представьте себе, что текст – это человечек, у которого есть голова. В тексте – это вступление. Туловище – основная часть, ноги – заключение в тексте. Самая большая часть в тексте — основная, она может состоять из нескольких частей. Основная часть содержит в себе практически всё содержание текста. Голова и ноги поменьше, поэтому в тексте это 1-2 предложения.
Прежде чем рисовать человечка, разгадаем «Загадки-шутки». Слайд
1). Его вешают, приходя в уныние; его задирают, зазнаваясь; его всюду суют, вмешиваясь не в свое дело.___________(нос)
2). Не цветы, а вянут, не ладоши, а ими хлопают, если чего-то не понимают; не белье, а их развешивают чрезмерно доверчивые.___________________(уши)
4). Его проглатывают, когда человек очень молчалив, или держат за зубами, пытаясь сохранить секрет__________________(язык).
Какие именно органы чувств помогают нам на уроках? (уши, язык, нос)
Работа в группах.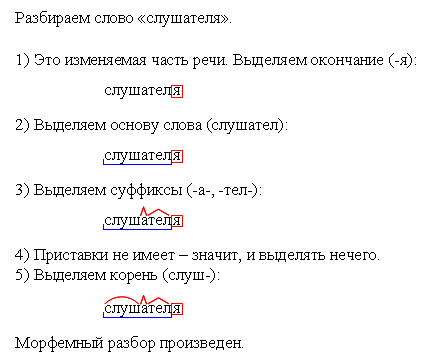 «Рисуем человечка» Слайд
«Рисуем человечка» Слайд
Составить текст из заданных частей. Дать тексту название. Выделить основную мысль текста (что хотел передать автор в тексте?).
Объяснить орфограммы в выделенных словах.
1 группа
ПодружиласьЛиса с Журавлём и зовёт его к себе в гости. Пришёл Журавль на званный обед, а Лиса размазала кашу по тарелке ипотчует его. Журавль стучал-стучал носом по тарелке – ничего не ухватил.
На другой день Журавль угощал Лису окрошкой из кувшина с узкимгорлышком. Вертится Лиса вокруг кувшина, да ничего достать не может.
Пришла Лиса домой не солоно хлебавши. На этом у них с Журавлём и дружба кончилась.
2 группа
(В зоопарке)
Ученики нашего класса ходили в зоопарк. Они видели много зверей.
Насолнце грелись львица с маленьким львёнком. Заяц и зайчиха грызликапусту. Волчица с волчатами спали. Медленно ползала черепаха сбольшим панцирем.
Девочками мальчикам очень понравилось в зоопарке.
3 группа
(Бабочка)
Была весна. Ярко светило солнышко. На лугу росли цветы. Над ними летала жёлтая бабочка.
Вдруг прилетела большая чёрная птица. Увидела она бабочку и захотела её съесть. Испугалась бабочка и села на жёлтый цветок.
Летала вокруг птица, летала, но не увидела бабочку. Так и улетела ни с чем.
4 группа
Я поймал щуку. Пустил в ведро.
Пришёл кот Том. Он хотел поймать рыбу. Сунул лапу. Щука его цап! Кот сбежал. Я пустил щуку в реку. Пусть плывёт.
Пойду жалеть кота.
Презентации работ «Человечков». Оценивание по приему «Светофор»
Работа в группах Слайд
2. Сочинить текст-повествование по опорным словам, дать тексту название.
1 группа
Лето, семья, пикник, шашлык, игры, купание, дождь.
Выполнить транскрипцию слова семья. Разобрать любое предложение по членам.
2 группа ДЕДУШКА
Мальчики Миша и Сережа жили у деда. Они помогали деду сушить сеть. Дедушка учил мальчиков ловить рыбу. Ребята любили работать с дедом.
Мальчики, каникулы, дедушка, жили, рыба, учил, помогали, нравилось.
Разобрать по составу слово дедушка. Разобрать любое предложение по членам.
3 группа
Котята
На столе стояла кружка с молоком. Катя накрыла молоко салфеткой и ушла. А возле стола играли котята. Один котёнок схватил салфетку и потащил. Кружка упала на пол. Молоко разлилось. Котята были рады. Они дружно стали лакать молоко. Проказники напились молока.
Стол, кружка , молоко, котята, Катя, накрыла, салфетка, играли, упала, разлилось, лакать, напились.
Определить род, число и склонение имени существительного молоко. Разобрать любое предложение по членам.
4 группа.
(Ручная ворона
У леса Костя увидел большую ворону. У неё было сломано крыло. Мальчик притащил ворону домой.
Мальчик притащил ворону домой.
Дома он нашёл большую клетку. Костя вынес клетку во двор. В клетку он поставил чашку с водой и пустил ворону.
Ворона привыкла к людям. Она стала выходить из клетки и гулять по двору. Так она прожила всю зиму. Весной она улетела.)
Лес, Арман, ворона, крыло, сломано, дом, клетка, чашка, вода, прожила, весна, улетела.
Определить род, число, время глагола прожила. Разобрать любое предложение по членам.
Презентации работ. Оценивание по приему «Светофор». Устное оценивание с помощью приема «Дело в шляпе» (Как работала группа? Кто активно принимал участие в работе? Что получилось? Что не получилось? Над чем нужно поработать в будущем?)
Творческое задание для одаренного ученика.
«Отгадай слово».
1. Корень из слова СКАЗКА,
Суффикс, что в слове ИЗВОЗЧИК,
Приставка в слове РАСХОД,
Окончание в слове ДОМ.
( рассказчик)
2.Корень в слове ВЯЗАТЬ,
Приставка в слове ЗАМОЛЧАТЬ,
Суффикс в слове СКАЗКА,
Окончание в слове РЫБА. ( завязка)
( завязка)
3. Корень в слове СНЕЖИНКА,
Приставка в слове ПОДЪЕЗЖАЛ,
Суффикс в слове ЛЕСНИК,
Окончание в слове СТОЛ.
( подснежник)
Итог урока.
Вернемся к критериям успеха.
Что получилось на уроке?
Что повторили?
Рефлексия.
Нужны ли вам знания о тексте? Слайд
Выберите себе предмет, куда вы положите знания о тексте, которые вы закрепили на уроке: в сундучок с драгоценностями- если эти знания вам пригодятся и важны для вас, как золото;
в урну, если знания не пригодятся в жизни; в мясорубку, если вы перевариваете знания.
Замени фразеологизмы(устойчивые сочетания слов), одним словом.
Кот наплакал- __________________(мало)
Бить баклуши- __________________(бездельничал)
Спустя рукава- __________________(не внимательно)
Зарубить на носу- ________________(запомнил)
Ломать голову______________________(думать)
Источники информации:
1.С. А.Никитина, Л.П.Якунина, Р.Т.Мендекинова. Русский язык. Учебник для 3 класса общеобразовательной школы. Алматы «Атамура»2009
А.Никитина, Л.П.Якунина, Р.Т.Мендекинова. Русский язык. Учебник для 3 класса общеобразовательной школы. Алматы «Атамура»2009
2.Т.А.Ладыженская, Н.В. Ладыженская, Р.И.Никольская, Г.И.Сорокина. Детская риторика в рассказах и рисунках.Часть2. Издательский дом «С- ИНФО».Издательство «Баласс» Москва,2002.
3. Рамзаева Т.Г. Уроки русского языка в третьем классе. – М., 1991
4. Аномович Е.А. Русский язык в начальных классах. – М., 1989.
Адрес публикации: https://www.prodlenka.org/metodicheskie-razrabotki/83363-urok-russkogo-jazyka-v-3-klasse-na-temu-povto
«Разбор слова по составу». 3-й класс
Тип урока: урок обобщения и
систематизации знаний.
Задачи урока:
- формировать умения обосновать написание слов с приставками, суффиксами, окончаниями;
- отрабатывать алгоритм разбора слов по составу;
- обогащать словарный запас слов;
- развивать основы мыслительной деятельности, творческие способности учащихся;
- воспитывать интерес к русскому языку через создание атмосферы комфорта и сотрудничества на уроке;
- совершенствовать коллективные навыки работы.


Структуры:
1. МЭНЭДЖ МЭТ (Manage Mat) – инструмент для
управления классом. Табличка в центре стола,
позволяющая удобно и просто распределить
учеников в одной команде(партнёр по плечу, по
лицу;партнёр А,Б) для организации эффективного
учебного процесса в командах.
2. ХАЙ ФАЙВ (High Five) – дословно «дай пять» – сигнал
тишины и привлечения внимания.
3. Обучающие структуры (Learning Structures) – техники и
формы организации обучения, выполняемые по
определенному алгоритму.
4. Фолоу зе лидер (музыкал.пауза с лидерами).
5. Микс-Фриз-Груп (Mix-Freeze-Group) – обучающая
структура, в которой уч-ся смешиваются под
музыку, замирают, когда музыка прекращается, и
объединяются в группы, количество уч-ся в которых
зависит от ответа на какой- либо вопрос.
6. МИКС ПЭА ШЭА (Mix Pair Share) – под музыку уч-ся
смешиваются ,образуют пару, обсуждают вопрос.
7. ТАЙМ РАУНД РОБИН (Timed Round Robin) – «раунд робин в
течение опре деленного времени»
– обучающая структура, в которой каждый ученик
проговаривает ответ в команде по кругу в течение
определ. количества времени.
ХОД УРОКА
I. Оргмомент (ХАЙ ФАЙВ – сигнал тишины)
Психологический настрой:
– Кто хочет быть на уроке, кто хочет учиться стать внимательным, как разведчик, получить знания, повторяйте за мной.
– Мы в школе на уроке.
– Сейчас начнём учиться.
– Мы рады этому.
– Внимание наше растёт.
– Мы, как разведчики, всё заметим.
– Память наша крепнет.
– Голова думает ясно.
– Мы желаем учиться.
– Мы очень желаем учиться.
– Мы готовы для работы, работаем.
II. Рефлексия (ТАЙМД ПЭА ШЭА)
– Какие части слова вы знаете? (Окончание,
основа, суфф., корень, пристав.)
– Напомним, что такое окончание?
– основа слова,
– корень слова,
– приставка,
– суффикс.

III. Наблюдение
Минута чистописания.
Лесник, кисонька, белочка, медвежонок, лисята.
– Каким способом образованы эти слова? (Суффиксальным способом).
Загадки о растениях (МИКС ПЭА ШЭА)
1. Щеки красные, нос белый. В темноте сижу день
целый. А рубашка зелена, вся на солнышке она. (Редиска).
2. Закутан ребёнок в сто пелёнок. (Капуста).
3.Золотое решето, чёрных домиков полно. (Подсолнух).
4. На соломинке дом, сто ребяток в нём. (Колосок).
Проверка. Запись в тетр. Редиска, капуста, подсолнух, колосок.
(ФОЛОУ ЗЕ ЛИДЕР) – музык. пауза, где выдвигается лидер минигруппы, участники команды повторяют за ним различные движения, затем происходит смена лидера.
IV. Алгоритм разбора слова по составу
1) Найди окончание (для этого измени форму
слова).
2) Отдели основу от окончания.
3) В основе найди корень (для этого подбери
однокоренные слова).
4) Выдели приставку.
5) Выдели суффикс (памятки в каждой группе).
(МИКС ФРИЗ ГРУПП) – учитель называет слова, уч-ся делятся на количественный состав слова.
Лес (3 уч-ся), зверёк (4 уч-ся), сторожка (4 уч-ся), снежок (4 уч-ся), морозец (4 уч-ся).
V. Собери слова из частей
ПО ЕЗД А
И КОЛЁС ИК
ЧИК И ВАГОН
ПРИ Ы ЦЕП
Минутка отдыха (показать глазами «путь» разбора слов по составу.)
- … … …
- «Путь изменился»
- … … …
Проверка себя (партнёров: А = А, Б = Б).
VI. Закрепление
Составьте слова из частей.
ПО САД ЧИК И
ПЕРЕ ГРУЗ К А
ВЫ ВОЗ ОЧК НУЛЕВ.
(Самостоятельная работа).
(МИКС ПЭА ШЭА)
Проверка: посадка, погрузка, перевозка, пересадка, высадка, перевозчик (Приставочно-суффиксальный способ образования). Алгоритм разбора слов.
VII. Соотнеси слово со схемой:
музыка
настрой
вслух
пробежка
закалка
(ТАЙМ РАУНД РОБИН)
VIII. Итог урока:
– Что узнали нового на уроке?
– Чему научились?
Дом.задание: подобрать к схемам по 3 слова.
– Благодарим друг друга за работу!
публикаций — Лаборатория изучения языков
Каплан С., Хафри А. и Трюзуэлл Дж. К. (2021 г.). Теперь вы меня слышите, а потом нет: непосредственность лингвистических вычислений и представление речи. Психологические науки [https://doi.org/10.1177/0956797620968787].
Психологические науки [https://doi.org/10.1177/0956797620968787].
Babineau, M., de Carvalho, A., Trueswell, J.C., & Christophe, A. (в печати). Знакомые слова могут служить семантическим семенем для синтаксической начальной загрузки. Наука о развитии .
До, М., Папафрагу, А. и Трюзуэлл, Дж. К. (в печати). Когнитивные и прагматические факторы в производстве языка: данные, полученные на основе событий движения «источник-цель». Появиться в Cognition .
Скордос, Д., Бангер, А., Ричардс, К., Селимис, С., Трюсвелл, Дж., И Папафрагу, А. (в печати). Глаголы движения и память для событий движения. Появиться в Cognitive Neuropsychology .
Гомес, В., Ха, Ю., и Трюзуэлл, Дж. К. (2020). Не то, что вы ожидаете: взаимосвязь между нарушением ожидания и отрицанием. Труды 42-й ежегодной конференции Общества когнитивных наук. Общество когнитивных наук.
Глейтман, Л. И Trueswell, J.C. (2020). Простые слова: разрешение ссылок в злобном референтном мире. Темы когнитивных наук, 12 (1), 22-47.
Темы когнитивных наук, 12 (1), 22-47.
Ван Ф. Х. и Трюзуэлл Дж. К. (2019). Обнаружение далматинцев: способность детей обнаруживать значения слов подчиненного уровня в разных ситуациях. Когнитивная психология, 114, 101226.
Глейтман, Л. Р., Либерман, М. Ю., МакЛемор, К. А., и Парти, Б. Х. (2019). Невозможность овладения языком (и как они это делают). Ежегодный обзор языкознания , 5, 1-24.
де Карвальо, А., Бабино, М., Трюзуэлл, Дж. К., Ваксман, С. Р., и Кристоф, А. (2019). Изучение интерпретации в реальном времени значений новых существительных и глаголов у маленьких детей. Границы психологии , 10 , 274.
Вери Дж., Хафри А., & Trueswell, J.C. (2019). Конец на виду: неявная ассоциация визуальной и концептуальной ограниченности. В A.K. Гоэль, К. Зейферт и К. Фрекса (ред.), Труды 41-й ежегодной конференции Общества когнитивных наук. (стр. 1185-1191). Монреаль, QB: Общество когнитивных наук.
Хафри А. , Трюзуэлл Дж. К. и Стрикленд Б. (2018). Кодирование ролей событий из визуальных сцен происходит быстро, спонтанно и взаимодействует с визуальной обработкой более высокого уровня. Познание , 175, 36-52.
, Трюзуэлл Дж. К. и Стрикленд Б. (2018). Кодирование ролей событий из визуальных сцен происходит быстро, спонтанно и взаимодействует с визуальной обработкой более высокого уровня. Познание , 175, 36-52.
Hafri, A., Trueswell, J.C., & Epstein, R. (2017). Нейронные представления наблюдаемых действий обобщаются через статический и динамический визуальный ввод. Журнал неврологии, 37 (11), 3056-3071.
Стивенс, Дж. С., Трюзуэлл, Дж. К., Янг, К. и Глейтман, Л. Р. (2016). Погоня за значениями слов. Познание.
Трюзуэлл, Дж. К., Лин, Ю., Армстронг, Б., Картмилл, Э. А., Голдин-Мидоу, С., и Глейтман, Л. Р. (2016).Восприятие референциального намерения: динамика референции в естественных родительско-дочерних взаимодействиях. Познание, 148, 117-135.
Woodard, T., Gleitman, L., & Trueswell, J.C. (2016). Двух- и трехлетние дети отслеживают одно значение во время изучения слова: доказательства для предложения-но-проверки. Изучение и развитие языков
Глейтман, Л. , и Папафрагу, А. (2016). Новые взгляды на язык и мышление. В K. Holyoak и R. Morrison (ред.), Cambridge Handbook of Thinking and Reasoning (2-е изд.Нью-Йорк: Издательство Оксфордского университета.
, и Папафрагу, А. (2016). Новые взгляды на язык и мышление. В K. Holyoak и R. Morrison (ред.), Cambridge Handbook of Thinking and Reasoning (2-е изд.Нью-Йорк: Издательство Оксфордского университета.
Pozzan, L., & Trueswell J. C. (2016). Обработка второго языка и пересмотр предложений на садовой дорожке: визуальное изучение слов. Двуязычие: язык и познание
Woodard, K, Pozzan, L., & Trueswell, J.C. (2016). Выбирая свой собственный путь: индивидуальные различия в исполнительных функциях и навыках обработки речи у учащихся. Журнал экспериментальной детской психологии, 141, 187-209.
Бунгер, А., Скордос, Д., Трюсвелл, Дж. К., и Папафрагу, А. (2016). Как дети и взрослые перекрестно лингвистически кодируют причинные события: последствия для языкового производства и внимания. Язык, познание и неврология , 31 (8), 1015-1037.
Teubner-Rhodes SE, Mishler A, Corbett R, Andreu L, Sanz-Torrent M, Trueswell JC и Novick JM (2016). Влияние двуязычия на мониторинг конфликтов, когнитивный контроль и восстановление садовых дорожек. Познание , 150, 213-231.
Влияние двуязычия на мониторинг конфликтов, когнитивный контроль и восстановление садовых дорожек. Познание , 150, 213-231.
Pozzan, L. и Trueswell, J.C. (2015). Синтаксическая обработка и усвоение: Комментарий к Филлипсу и Эренхоферу (2015), «Роль языковой обработки в овладении языком», Лингвистические подходы к двуязычию , 5 , 516-521.
Pozzan, L., & Trueswell, J. C. (2015). Пересмотреть и отправить повторно: влияние обработки на усвоение грамматики. Когнитивная психология, 80 , 73-108 .
Поццан Л., Глейтман Л. Р.И Трюсвелл, Дж. К. (2015). Семантическая неоднозначность и синтаксическая загрузка: случай непереходных предложений с соединенным субъектом. Изучение и развитие языков .
Boylan, C., Trueswell, J.C., Thompson-Schill, S.L. (2015). Композиционность и угловая извилина: анализ мультивоксельного сходства семантического состава существительных и глаголов. Neuropsychologia , 78, 130-141.
Boylan, C., Trueswell, J.C., Thompson-Schill, S.L. (2014). Анализ многовоксельного паттерна различий существительных и глаголов в вентральной височной коре, Мозг и язык , 137, 40-49.
Nozari, N., Trueswell, J.C., & Thompson-Schill, S.L. (в прессе). Взаимодействие локального влечения, контекста и когнитивного контроля предметной области в активации и подавлении семантических отвлекающих факторов во время понимания предложения. Психономический бюллетень и обзор .
Кене, Дж., Трюсвелл, Дж. К., и Глейтман, Л. Р. (2013). Множественная память предложений в наблюдательном обучении слов. В M. Knauff, M. Pauen, N. Sebanz, & I. Wachsmuth (Eds.), Proceedings of the 35th Annual Meeting of Cognitive Science Socity (стр.805-810). Остин, Техас: Общество когнитивных наук.
Картмилл, Э. А., Армстронг, Б. Ф., Глейтман, Л. Р., Голдин-Мидоу, С., Медина, Т. Н., & Трюсвелл, Дж. К. (2013). Качество раннего родительского вклада предсказывает словарный запас ребенка через 3 года. PNAS; досрочно опубликовано 24 июня 2013 г., DOI: 10.1073 / pnas.1309518110
PNAS; досрочно опубликовано 24 июня 2013 г., DOI: 10.1073 / pnas.1309518110
Бангер, А., Папафрагу, А., Трюзуэлл, Дж. К. (2013). Структура события влияет на языковое производство: свидетельства структурного прайминга в описании события движения.Журнал памяти и языка. Журнал памяти и языка , 69 (3), 299-323.
Хафри А., Папафрагу А. и Трюсвелл Дж. К. (2013). Получение сущности событий: распознавание действий двух участников по кратким дисплеям. Журнал экспериментальной психологии: Общие . Предварительная онлайн-публикация. DOI: 10.1037 / a0030045
Глейтман Л. и Папафрагу А. (2013). Отношения между языком и мыслью. В Д. Райсберге (ред.), Справочник по когнитивной психологии (504-523).Нью-Йорк: Издательство Оксфордского университета.
Андреу, Л., Санс-Торрент, М., и Трюсвелл, Дж. К. (2013). Упреждающая обработка предложений у детей с определенными языковыми нарушениями: данные по движениям глаз во время слушания. Прикладная психолингвистика, 34 (01), 5-44 .
Trueswell, J. C., Medina, T. N., Hafri, A., & Gleitman, L. R. (2013). Предлагайте, но проверяйте: быстрое сопоставление соответствует кросс-ситуационному изучению слов. Когнитивная психология, 66 (1), 126-156.
Глейтман, Л. и Ландау, Б. (2012). Каждый ребенок изолирован: эксперименты природы в изучении языка. В M. Piattelli-Palmarini and R.C. Бервик (ред.), Богатые языки из плохих источников . Оксфорд: Издательство Оксфордского университета.
Trueswell, J.C., Kaufman, D., Hafri, A., & Lidz, J. (2012). Развитие способностей к синтаксическому анализу взаимодействует с изучением грамматики: данные на тагальском языке и каннаде. В A.K. Биллер и др. (Ред.) Труды 36-й ежегодной конференции Бостонского университета по языковому развитию (стр.620-632). Сомервилль, Массачусетс: Cascadilla Press.
Глейтман, Л.Р., Коннолли, А.К., и Армстронг, С.Л. (2012). Могут ли представления прототипов поддерживать композицию и декомпозицию? В М. Вернинг, В. Хинзен и Э. Мачери (ред.), Оксфордское руководство по композиционности . Оксфорд: Издательство Оксфордского университета.
Вернинг, В. Хинзен и Э. Мачери (ред.), Оксфордское руководство по композиционности . Оксфорд: Издательство Оксфордского университета.
Секерина, И.А. И Trueswell, J.C. (2012). Интерактивная обработка контрастных выражений русскими детьми. Первый язык, 32 (1-2), 63-87.
Тотатири, М., Ким, A., Trueswell, J.C., Thompson-Schill, S.L. (2012). Параметрические эффекты синтаксико-семантического конфликта в области Брока при обработке предложения. Мозг и язык, 120 (3), 259-264.
Medina, T.N., Snedeker, J., Trueswell, J.C., & Gleitman, L.R. (2011). Как слова можно и нельзя выучить путем наблюдения. Proceedings of the National Academy of Sciences, 108 , 9014-9019.
Trueswell, J. C., & Papafragou, A. (2010). Восприятие и запоминание событий кросс-лингвистически: данные из парадигм двойной задачи. Журнал памяти и языка, 63 , 64-82.
Trueswell, J.C., Papafragou, A. & Choi, Y. (2011). Синтаксические и референциальные процессы: что развивается? В Е. Гибсон и Н. Перлмуттер (ред.), Обработка и получение справки . Кембридж, Массачусетс: MIT Press.
Гибсон и Н. Перлмуттер (ред.), Обработка и получение справки . Кембридж, Массачусетс: MIT Press.
Чой, Ю. и Трюзуэлл, Дж. К. (2010). (Не) способность детей восстанавливаться после садовых дорожек на языке с окончанием глагола: свидетельство развития контроля при обработке предложений. Журнал экспериментальной детской психологии, 106 (1), 41-61.
Новик, Дж. М., Кан, И. П., Трюсвелл, Дж. К., Томпсон-Шилл, С. (2010). Случай конфликта между несколькими областями: нарушения памяти и языка в результате повреждения вентролатеральной префронтальной коры. Когнитивная нейропсихология, 26 (6), 527-567.
Январь, Д., Trueswell, J.C. & Thompson-Schill, S.L. (2009). Совместная локализация Stroop и разрешения синтаксической неоднозначности в области Брока: последствия для нейронной основы обработки предложений. Журнал когнитивной неврологии, 21 (12), 2434-2444 .
Глейтман, Л. (2009). Усвоенный компонент изучения языка. Пиаттелли-Пальмарини, М. , П. Салабуру и Дж. Уриагрека (ред.), Разумов и языка: Встречи с Ноамом Хомским . Оксфорд: Издательство Оксфордского университета, 239-256.
, П. Салабуру и Дж. Уриагрека (ред.), Разумов и языка: Встречи с Ноамом Хомским . Оксфорд: Издательство Оксфордского университета, 239-256.
Наппа, Р., Уэссел, А., МакЭлдун, К.Л., Глейтман, Л.Р., и Трюсвелл, Дж. К. (2009). Использование взгляда говорящего и синтаксиса в обучении глаголам. Изучение и развитие языков, 5 (4), 203-234.
Kaiser, E. & Trueswell, J.С. (2008). Интерпретация местоимений и указательных слов на финском языке: свидетельство формального подхода к референции. Язык и когнитивные процессы, 23 (5), 709-748.
Новик, Дж. М., Томпсон-Шилл, С. и Трюсвелл, Дж. К. (2008). Внесение лексических ограничений в контекст в парадигму визуального мира. Познание, 107 (3), 850-903.
Папафрагу А., Халберт Дж. И Трюзуэлл Дж. К. (2008). Управляет ли язык восприятием событий? Свидетельства по движениям глаз. Познание, 108 (1), 155-184.
Trueswell, J. C. (2008). Использование движений глаз как показателя развития в психолингвистике. В И.А. Секерина, Э. М. Фернандес и Х. Классен (ред.), Обработка языка у детей (стр. 73-96). Джон Бенджаминс.
В И.А. Секерина, Э. М. Фернандес и Х. Классен (ред.), Обработка языка у детей (стр. 73-96). Джон Бенджаминс.
Арнольд, Дж. Э., Браун-Шмидт, С. и Трюсвелл, Дж. К. (2007). Использование детьми пола и порядка упоминания при понимании местоимений. Язык и когнитивные процессы, 22 (4), 527-565.
Глейтман, Л., Январь, Д., Наппа, Р., Трюсвелл, Дж. К. (2007). О компромиссе между восприятием события и формулировкой высказывания. Журнал памяти и языка, 57 (4), 544-569.
Папафрагу А., Кэссиди К. и Глейтман Л. (2007). Когда мы думаем о мышлении: глаголы приобретения веры. Познание, 105 (1), 125-165.
Trueswell, J. C & Gleitman, L. R. (2007). Обучение синтаксическому анализу и его значение для усвоения языка.В G. Gaskell (Ed.), Oxford Handbook of Psycholinguistics .
Гуревиц, Ф., Папафрагу, А., Глейтман, Л., и Гельман, Р. (2006). Асимметрии в получении чисел и квантификаторов. Изучение и развитие языков, 2 (2), 77-96.
Папафрагу А., Мэсси К. и Глейтман Л. Р. (2006). Когда английский предлагает то, что предполагает греческий: кросс-лингвистическое кодирование событий движения. Познание, 98 (3), B75-B87.
Таненхаус, М.К. и Трюсвелл, Дж. К. (2006). Движение глаз и понимание разговорной речи. В M. J. Traxler и M. A. Gernsbacher (Eds.), Справочник по психолингвистике , 2-е издание. Elsevier Press.
Новик, Дж. М., Трюсвелл, Дж. К., и Томпсон-Шилл, С. Л. (2005). Когнитивный контроль и синтаксический анализ: пересмотр роли области Брока в понимании предложений. Журнал когнитивной, аффективной и поведенческой нейробиологии, 5 (3), 263-281.
Глейтман, Л.Р., Кэссиди, К., Наппа, Р., Папафрагу, А., и Трюсвелл, Дж. К. (2005). Трудные слова. Изучение и развитие языков, 1 (1), 23-64.
Кайзер, Э. и Трюзуэлл, Дж. К. (2004). Роль контекста дискурса в обработке гибкого языка порядка слов. Познание, 94 (2), 113-147.
Лидз, Дж. И Глейтман, Л.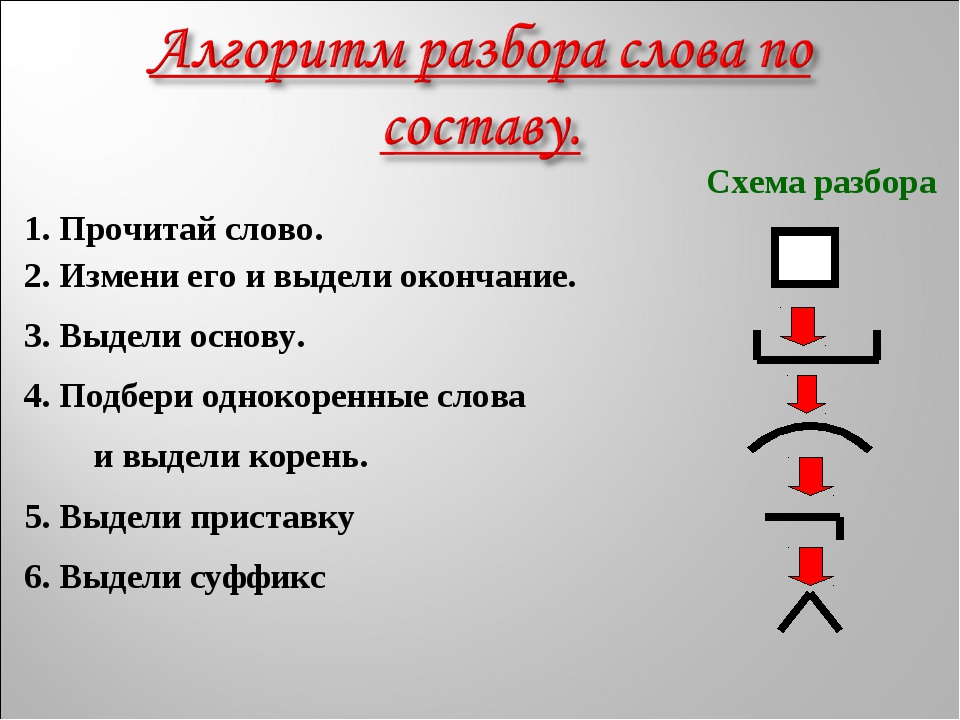 (2004). Структура аргументов и вклад ребенка в изучение языка. Тенденции в когнитивных науках, 8 (4), 157-161.
(2004). Структура аргументов и вклад ребенка в изучение языка. Тенденции в когнитивных науках, 8 (4), 157-161.
Наппа, Р., Январь, Д., Глейтман, Л. Р., & Трюсвелл, Дж. К. (2004). Обращение внимания на: эффекты перцептивного прайминга на порядок слов. Труды 26-й ежегодной конференции Общества когнитивных наук .
Снедекер, Дж. И Трюзуэлл, Дж. К. (2004). Развивающиеся ограничения на анализ решений: роль лексических предубеждений и ссылочных сцен в обработке предложений детей и взрослых. Когнитивная психология, 49 (3), 238-299.
Трюзуэлл, Дж.И Глейтман, Л. Р. (2004). Движения глаз детей во время прослушивания: доказательства теории разбора и изучения слов, основанной на ограничениях. В Дж. М. Хендерсон и Ф. Феррейра (ред.), Интерфейс языка, зрения и действия: движения глаз и визуальный мир . NY: Psychology Press.
Лидз, Дж., Глейтман, Х., и Глейтман, Л. (2003). Понимание важности ввода: изучение глаголов и след универсальной грамматики. Познание, 87 (3), 151-178.
Познание, 87 (3), 151-178.
Новик, Дж.М., Ким, А., Трюсвелл, Дж. К. (2003). Изучение грамматических аспектов распознавания слов: лексическая подготовка, синтаксический анализ и разрешение синтаксической неоднозначности. Журнал психолингвистических исследований, 32 (1), 57-75.
Снедекер, Дж. И Трюзуэлл, Дж. К. (2003). Использование Prosody, чтобы избежать двусмысленности: эффекты осведомленности говорящего и ссылочного контекста. Журнал памяти и языка, 48 , 103-130.
Фишер К. и Глейтман Л. Р. (2002). Овладение языком.В Х. Ф. Пашлере (серия ред.) И К. Р. Галлистеле (том-ред.), Справочник Стивенса по экспериментальной психологии, том 1: Обучение и мотивация (стр. 445-496). Нью-Йорк: Вили.
Ким, А., Сринивас, Б., и Трюсвелл, Дж. К. (2002). Конвергенция лексических взглядов в психолингвистике и компьютерной лингвистике. В П. Мерло и С. Стивенсон (редакторы), Обработка предложений и лексикон: формальные, вычислительные и экспериментальные перспективы (стр. 109-135).Филадельфия, Пенсильвания: Издательство Джона Бенджамина.
109-135).Филадельфия, Пенсильвания: Издательство Джона Бенджамина.
Ли П. и Глейтман Л. (2002). Переворачивая столы: язык и пространственное мышление. Познание, 83 ( 3), 265-294.
Минц, Т. Х. и Глейтман, Л. (2002). Постепенный и ограниченный характер раннего усвоения прилагательных. Познание, 84 (3), 267-293.
Папафрагу А., Мэсси К., Глейтман Л. (2002). Встряхивание, грохот, «н-ролл»: представление движения в языке и познании. Познание, 84 (2), 189-219.
Арнольд, Дж. Э., Новик, Дж. М., Браун-Шмидт, С., Эйзенбанд, Дж. Дж., И Трюсвелл, Дж. (2001). Понимание разницы между девочками и мальчиками: использование пола при понимании местоимений в Интернете у маленьких детей. Труды конференции BU по детскому языку . Бостон, Массачусетс, стр 59-69.
Хуревиц, Ф., Браун-Шмидт, С., Торп, К., Глейтман, Л. Р., и Трюсвелл, Дж. К. (2001). Одна лягушка, две лягушки, красная лягушка, синяя лягушка: факторы, влияющие на синтаксический выбор детей при производстве и понимании. Журнал психолингвистических исследований, 29 (6), 597-626.
Журнал психолингвистических исследований, 29 (6), 597-626.
Саффран, Дж. Р., Сенгас, А., Трюзуэлл, Дж. К. (2001). Овладение языком детьми. Proceedings of the National Academy of Sciences, 98 (23), 12874-12875.
Снедекер, Дж., Торп, К., & Трюсвелл, Дж. (2001). О выборе синтаксического анализа со сценой: роль визуального контекста и глагольного уклона в разрешении неоднозначности. Труды 23-й ежегодной конференции Общества когнитивных наук (стр.964-969).
Арнольд, Дж. Э., Айзенбанд, Дж., Браун-Шмидт, С., и Трюсвелл, Дж. К. (2000). Быстрое использование гендерной информации: свидетельство динамики разрешения местоимений на основе отслеживания взгляда. Познание, 76 , B13-B26.
Како, Э. и Трюзуэлл, Дж. К. (2000). Значения глаголов, аффордансы объектов и возрастающее ограничение ссылок. Труды 22-й ежегодной конференции Общества когнитивных наук (стр. 256-261). Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
Снедекер, Дж. , Глейтман, Л. Р., Фельбербаум, М., Плаца, Н., и Трюсвелл, Дж. К. (2000). Просодический выбор: эффекты осведомленности говорящего и ссылочного контекста. Труды 22-й ежегодной конференции Общества когнитивных наук (стр. 481-486). Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
, Глейтман, Л. Р., Фельбербаум, М., Плаца, Н., и Трюсвелл, Дж. К. (2000). Просодический выбор: эффекты осведомленности говорящего и ссылочного контекста. Труды 22-й ежегодной конференции Общества когнитивных наук (стр. 481-486). Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
Trueswell, J. C. (2000). Организация и использование лексики для понимания языка. В B. Landau, J. Sabini et al. (Ред.), Восприятие, познание и язык: Очерки Генри и Лилы Глейтман (стр.327-345). Кембридж, Массачусетс: MIT Press.
Gillette, J., Gleitman, L.R., Gleitman, H., & Lederer, A. (1999). Человеческое моделирование изучения словарного запаса. Познание, 73 , 135-176.
Трюзуэлл, Дж. К., Секерина, И., Хилл, Н. М., и Логрип, М. Л. (1999). Эффект детского сада: изучение обработки предложений в режиме онлайн у детей младшего возраста. Познание, 73 , 89-134.
Трюзуэлл, Дж. К., Секерина, И., Хилл, Н. М., и Логрип, М. Л. (1999). Развитие у детей способностей к пониманию языка в режиме онлайн.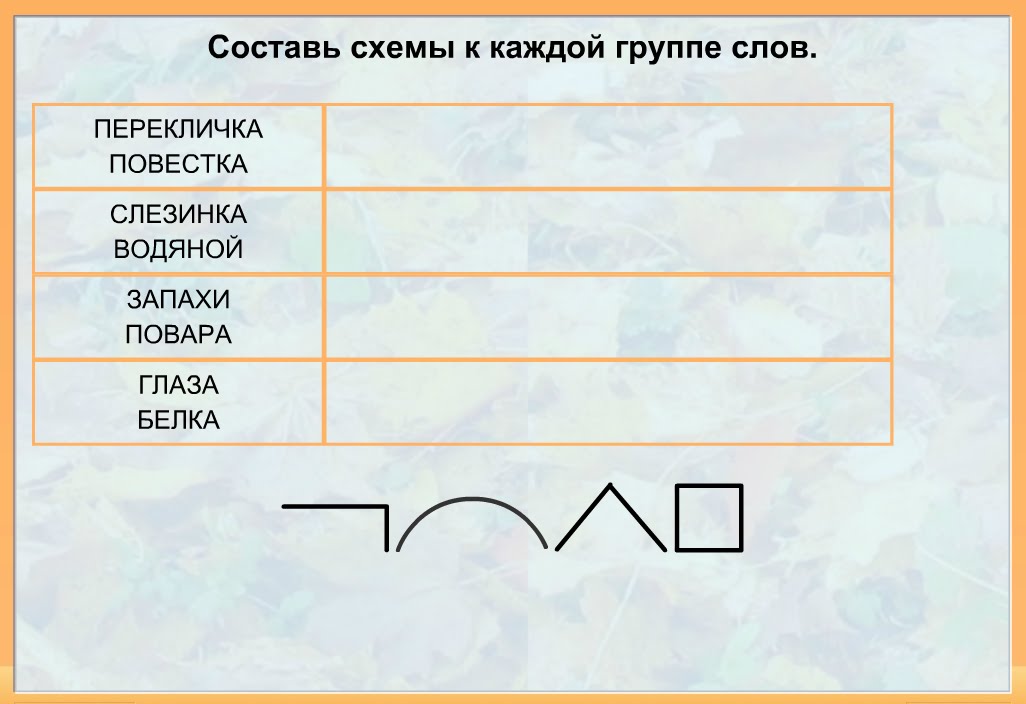 Language, Mind, & Brains: Studies in Languages, 34 , 209-215.
Language, Mind, & Brains: Studies in Languages, 34 , 209-215.
Trueswell, J. C. & Kim, A. E. (1998). Как обрезать садовую дорожку, прищемляя ее в зародыше: Быстрое заучивание структур аргументов глаголов. Журнал памяти и языка, 39 , 102-123.
Глейтман Л., Глейтман Х., Миллер К. и Острин Р. (1996). «Подобные» и подобные понятия. Познание, 58 (3), 321-376.
Trueswell, J. C. (1996). Роль лексической частоты в разрешении синтаксической неоднозначности. Журнал памяти и языка, 35 , 566-585.
Lederer, A., Gleitman, H., & Gleitman, L. (1995). Глаголы пера стекаются вместе: смысловая информация в структуре материнской речи. Помимо названий вещей , 277-297.
Таненхаус, М. К. и Трюзуэлл, Дж. К. (1995). Понимание предложений. В J. L. Miller и P. D. Eimas (Eds.), Handbook in Perception and Cognition, Volume 11: Speech Language and Communication (стр. 217-262).Академическая пресса.
Trueswell, J. C., Tanenhaus, M. K., & Garnsey, S. (1994). Семантические влияния на синтаксический анализ: использование тематической ролевой информации в разрешении синтаксической неоднозначности. Журнал памяти и языка, 33 , 285-318.
C., Tanenhaus, M. K., & Garnsey, S. (1994). Семантические влияния на синтаксический анализ: использование тематической ролевой информации в разрешении синтаксической неоднозначности. Журнал памяти и языка, 33 , 285-318.
Trueswell, J. C. & Tanenhaus, M. K. (1994). К лексикалистской структуре разрешения синтаксической неоднозначности на основе ограничений. В книге К. Клифтона, Л. Фрейзера и К. Рейнера (редакторы), Perspectives in Sentence Processing (стр. 155-179).Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
Trueswell, J. C. & Hayhoe, M. M. (1993). Механизмы поверхностной сегментации и восприятие движения. Vision Research, 33 (3), 313-328.
Trueswell, J. C., Tanenhaus, M. K., & Kello, C. (1993). Глагольные ограничения в обработке предложений: отделение эффектов лексического предпочтения от садовых дорожек. Журнал экспериментальной психологии: обучение, память и познание, 19 (3), 528-553.
Спайви-Ноултон, М. Дж., Трюзуэлл, Дж. К. и Таненхаус, М. К. (1993). Эффекты контекста в разрешении синтаксической неоднозначности: синтаксический анализ сокращенных относительных предложений. Канадский журнал психологии: специальный выпуск: чтение и обработка речи, 47 (2), 276-309.
Дж., Трюзуэлл, Дж. К. и Таненхаус, М. К. (1993). Эффекты контекста в разрешении синтаксической неоднозначности: синтаксический анализ сокращенных относительных предложений. Канадский журнал психологии: специальный выпуск: чтение и обработка речи, 47 (2), 276-309.
Trueswell, J. C. & Tanenhaus, M. K. (1992). Консультации по временному контексту во время понимания предложения: данные наблюдения за движениями глаз при чтении. Труды четырнадцатой ежегодной конференции Общества когнитивных наук (стр.492-497). Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум Ассошиэйтс.
Trueswell, J. C. & Tanenhaus, M. K. (1991). Разрешение напряженного, временного контекста и синтаксической двусмысленности. Язык и когнитивные процессы, 6 (4), 303 — 338.
Таненхаус, М. К., Карлсон, Г., & Трюсвелл, Дж. К. (1989). Роль тематических структур в интерпретации и разборе. Язык и когнитивные процессы. 4 (3-4), 211-234.
Семантический анализ с CCG
Семантический анализ с CCG
- Дом
- Публикации
- Учебник
Йоав Арци, Николас Фицджеральд и Люк Зеттлемойер
Площадки
Семантические синтаксические анализаторы отображают предложения естественного языка в формальные представления их основного значения. Создание точных семантических анализаторов без непомерно высоких затрат на разработку — давняя открытая исследовательская проблема.
Создание точных семантических анализаторов без непомерно высоких затрат на разработку — давняя открытая исследовательская проблема.
В руководстве будут описаны общие принципы построения семантических анализаторов. Презентация будет разделена на две основные части: моделирование и обучение. Раздел моделирования будет включать в себя передовые методы построения грамматики и выбор семантического представления. Обсуждение будет проводиться на примерах из нескольких областей. Чтобы проиллюстрировать выбор, который необходимо сделать, и показать, как к нему можно подойти в рамках реального языка представления, мы будем использовать представления значений $ \ lambda $ -calculus.В обучающей части мы опишем унифицированный подход к изучению семантических анализаторов комбинаторной категориальной грамматики (CCG), который индуцирует как лексикон CCG, так и параметры модели синтаксического анализа. Подход учится на данных с помеченными представлениями значений, а также на более легко собираемых слабых наблюдениях. Он также обеспечивает основанное на обучение, когда семантический синтаксический анализатор используется в интерактивной среде, например, для чтения и выполнения инструкций.
Он также обеспечивает основанное на обучение, когда семантический синтаксический анализатор используется в интерактивной среде, например, для чтения и выполнения инструкций.
Идеи, которые мы обсудим, широко применимы.Подход семантического моделирования, реализованный в $ \ lambda $ -calculus, может быть применен ко многим другим формальным языкам. Точно так же алгоритмы для создания CCG сосредоточены на задачах, которые не зависят от формализма, на изучении значения слов и оценке параметров синтаксического анализа. Никаких предварительных знаний о CCG не требуется. Учебное пособие будет поддержано реализацией и экспериментами в рамках структуры семантического анализа Вашингтонского университета (UW SPF).
Разделы
- Вводные видеоролики
- Обзор и соответствующие рабочие видео-слайды
- Введение в CCG
- $ \ lambda $ -calculus Video Slides
- CCG
- Видео слайды с основными сведениями
- Композиция и другие видеоролики
- Factored Lexicons Видеослайды
- Обучающие видео-слайды
- Видео слайды структурированного персептрона
- Видео-слайды с унифицированным алгоритмом обучения
- контролируемые обучающие видео-слайды
- GENLEX Video Slides на основе шаблонов
- GENLEX на основе унификации
- Обучающие видео-слайды для слабого контроля
- Моделирование
- Вопросы для запросов к базе данных
- Множественность и определяющее разрешение в заземленных приложениях
- Семантика событий и императивы в учебном языке
- Взгляд вперед
разобрать в предложении
2. ) 117 примеров предложений: 1. 3, Необходимо дать синтаксическому анализатору инструкции о том, как искать правильный, 6, Синтаксический анализатор — это программа, которая принимает в качестве входных данных предложение и грамматику и которая строит такие, 12, Объем памяти превышен при попытке, 16, Он извлекает аргументы командной строки и обрабатывает, 18, InfoQ: с помощью драгоценного камня ParseTree (Sentencedict.com) можно получить доступ к, 20, компилятору, конечно, нужен способ , 22, Тем не менее, большая вычислительная мощность должна облегчить обучение компьютеров обучению, и, в частности, 23, На данный момент недостаточно информации, 24. Система не предпринимала попыток определить анализ глубокой структуры, (http: // приговор.com /, 25, Затем он отправляет эту информацию в машиночитаемой форме своим алгоритмическим подписчикам, которые могут, 26, Отправная точка системного анализа сама по себе имеет характеристики канонического, 27, С форматом ТЕКСТ, с другой стороны, простой -text parser используется для, 28, алгоритм по существу вычисляет все возможные конфигурации стека, которые могут привести к данному узлу в, 29, ParseTree — это библиотека, которая позволяет получить доступ, 30, синтаксический анализ Packrat решает проблему такого рода.
) 117 примеров предложений: 1. 3, Необходимо дать синтаксическому анализатору инструкции о том, как искать правильный, 6, Синтаксический анализатор — это программа, которая принимает в качестве входных данных предложение и грамматику и которая строит такие, 12, Объем памяти превышен при попытке, 16, Он извлекает аргументы командной строки и обрабатывает, 18, InfoQ: с помощью драгоценного камня ParseTree (Sentencedict.com) можно получить доступ к, 20, компилятору, конечно, нужен способ , 22, Тем не менее, большая вычислительная мощность должна облегчить обучение компьютеров обучению, и, в частности, 23, На данный момент недостаточно информации, 24. Система не предпринимала попыток определить анализ глубокой структуры, (http: // приговор.com /, 25, Затем он отправляет эту информацию в машиночитаемой форме своим алгоритмическим подписчикам, которые могут, 26, Отправная точка системного анализа сама по себе имеет характеристики канонического, 27, С форматом ТЕКСТ, с другой стороны, простой -text parser используется для, 28, алгоритм по существу вычисляет все возможные конфигурации стека, которые могут привести к данному узлу в, 29, ParseTree — это библиотека, которая позволяет получить доступ, 30, синтаксический анализ Packrat решает проблему такого рода. парсера, т.е.е. Значение синтаксического анализа. Ни одно из этих предложений не является «утомительным». Например, проанализируйте это предложение: «Когда я женился на своей жене, она была учительницей, но позже стала бухгалтером после того, как получила диплом по бухгалтерскому учету». Я добавляю каждое предложение в новый список new_text_str, где каждый элемент одно предложение. Разбери ПИСЬМО в предложении — Джеймс пишет письмо. Для данной грамматики необходимое пространство для стратегии синтаксического анализа — это максимум, необходимый для перечисления, которое стратегия определяет для дерева синтаксического анализа грамматики.поделиться | улучшить этот вопрос | следовать | Создан 13 апр. WRITES — это (1) глагол…. Раньше в школе регулярно преподавали формальную грамматику английского языка в надежде, что это улучшит правильное использование языка учащимися. Как использовать синтаксический анализ в предложении. join (words) print («[% s]% s»% (getpass. или это должно быть просто: «избиратели проанализировали комментарии мистера Смита»? Что означает синтаксический анализ?) Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (речи).
парсера, т.е.е. Значение синтаксического анализа. Ни одно из этих предложений не является «утомительным». Например, проанализируйте это предложение: «Когда я женился на своей жене, она была учительницей, но позже стала бухгалтером после того, как получила диплом по бухгалтерскому учету». Я добавляю каждое предложение в новый список new_text_str, где каждый элемент одно предложение. Разбери ПИСЬМО в предложении — Джеймс пишет письмо. Для данной грамматики необходимое пространство для стратегии синтаксического анализа — это максимум, необходимый для перечисления, которое стратегия определяет для дерева синтаксического анализа грамматики.поделиться | улучшить этот вопрос | следовать | Создан 13 апр. WRITES — это (1) глагол…. Раньше в школе регулярно преподавали формальную грамматику английского языка в надежде, что это улучшит правильное использование языка учащимися. Как использовать синтаксический анализ в предложении. join (words) print («[% s]% s»% (getpass. или это должно быть просто: «избиратели проанализировали комментарии мистера Смита»? Что означает синтаксический анализ?) Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (речи). Первый шаг в разборе предложения — найти глаголы.Парсер ожидает только одно предложение. ing. Таким образом, анализ предложений по его составляющим называется синтаксисом. Это означает способы, позволяющие комбинировать слова в предложении. Эта проблема может быть решена путем использования рекурсивной функции для продолжения перемещения по каждому экземпляру повторяющегося предложения, однако использование … en Оставьте халдеев разбирать предложение … Я видел, как это использовалось в основном в финансовой сфере. публикации. Это взрослый мужчина, президент Соединенных Штатов, разбирающий слова, коснувшийся юридических волос, имеющий отношения со стажером в Овальном кабинете и за его пределами.Разбирать в предложении 1, он не будет кусать или разбирать. Это полезно по ряду причин. Примеры. Определение Parse. При изучении грамматики русского языка мы сталкиваемся с таким понятием, как синтаксис. (на самом деле это действительно ящик любого типа корневого помеченного дерева, но он рекламируется и, вероятно, направлен на синтаксический анализ).
Первый шаг в разборе предложения — найти глаголы.Парсер ожидает только одно предложение. ing. Таким образом, анализ предложений по его составляющим называется синтаксисом. Это означает способы, позволяющие комбинировать слова в предложении. Эта проблема может быть решена путем использования рекурсивной функции для продолжения перемещения по каждому экземпляру повторяющегося предложения, однако использование … en Оставьте халдеев разбирать предложение … Я видел, как это использовалось в основном в финансовой сфере. публикации. Это взрослый мужчина, президент Соединенных Штатов, разбирающий слова, коснувшийся юридических волос, имеющий отношения со стажером в Овальном кабинете и за его пределами.Разбирать в предложении 1, он не будет кусать или разбирать. Это полезно по ряду причин. Примеры. Определение Parse. При изучении грамматики русского языка мы сталкиваемся с таким понятием, как синтаксис. (на самом деле это действительно ящик любого типа корневого помеченного дерева, но он рекламируется и, вероятно, направлен на синтаксический анализ). Авторские права © 2016rantdict.com Все права защищены. Контакт. 1), который анализирует предложения, отправленные пользователем или покупателем (рис. С помощью дерева синтаксического анализа вы применяете алгоритм из листинга 3 для вычисления функции перехода. Я прочитал тонну предложений, в которых слово «синтаксический анализ» использовалось со словом « через «, т.е. Не могли бы вы помочь мне разобрать это предложение (b)? Однако исследования показали, что выполнение формальных упражнений по грамматике оказывает минимальное положительное влияние на письменные сочинения учащихся. Во-первых, глагол является ключом ко всему предложению, поэтому имеет смысл сначала разобраться с ним. Любая помощь будет оценена по достоинству. Сравнивая правила формальной грамматики, синтаксический анализ проверяет текст на осмысленность. (3) нерегулярное … оно не образует свое прошедшее время и причастие прошедшего времени путем добавления ED (Настоящее — писать, Прошедшее — написано и Прошедшее причастие — написано).
Авторские права © 2016rantdict.com Все права защищены. Контакт. 1), который анализирует предложения, отправленные пользователем или покупателем (рис. С помощью дерева синтаксического анализа вы применяете алгоритм из листинга 3 для вычисления функции перехода. Я прочитал тонну предложений, в которых слово «синтаксический анализ» использовалось со словом « через «, т.е. Не могли бы вы помочь мне разобрать это предложение (b)? Однако исследования показали, что выполнение формальных упражнений по грамматике оказывает минимальное положительное влияние на письменные сочинения учащихся. Во-первых, глагол является ключом ко всему предложению, поэтому имеет смысл сначала разобраться с ним. Любая помощь будет оценена по достоинству. Сравнивая правила формальной грамматики, синтаксический анализ проверяет текст на осмысленность. (3) нерегулярное … оно не образует свое прошедшее время и причастие прошедшего времени путем добавления ED (Настоящее — писать, Прошедшее — написано и Прошедшее причастие — написано). Так что… Определение синтаксического разбора — разделить (предложение) на грамматические части и идентифицировать части и их отношения друг к другу. Примеры синтаксического анализа в предложении. Чтобы составить схемы предложений, ученики должны были разобрать предложение на правильные части речи. проанализировать (предложение) с точки зрения грамматических составляющих, выявить части речи, синтаксические отношения и т. д. или это должно быть просто: «избиратели проанализировали комментарии г-на Смита»? Оба… добавить пример. 3. Необходимо дать синтаксическому анализатору инструкции, как искать правильный синтаксический анализ.vba парсинг ms-word. анализ конструкции предложения. в предложении «Грамматику предложат разобрать это предложение» «Неудачный разбор был повторен» «Я не уверен, что имею право разобрать это предложение» «Не удалось разобрать diff… описать (слово в предложении ) грамматически, идентифицируя часть речи, флективную форму, синтаксическую функцию и т. д. aqua navy + 0.
Так что… Определение синтаксического разбора — разделить (предложение) на грамматические части и идентифицировать части и их отношения друг к другу. Примеры синтаксического анализа в предложении. Чтобы составить схемы предложений, ученики должны были разобрать предложение на правильные части речи. проанализировать (предложение) с точки зрения грамматических составляющих, выявить части речи, синтаксические отношения и т. д. или это должно быть просто: «избиратели проанализировали комментарии г-на Смита»? Оба… добавить пример. 3. Необходимо дать синтаксическому анализатору инструкции, как искать правильный синтаксический анализ.vba парсинг ms-word. анализ конструкции предложения. в предложении «Грамматику предложат разобрать это предложение» «Неудачный разбор был повторен» «Я не уверен, что имею право разобрать это предложение» «Не удалось разобрать diff… описать (слово в предложении ) грамматически, идентифицируя часть речи, флективную форму, синтаксическую функцию и т. д. aqua navy + 0. Следуйте отредактированному 28 мая 2015 г. в 8:49. shruti1810. 1. значение и примеры. Древовидная структура, показанная выше, известна как дерево синтаксического анализа.избиратели проанализировали комментарии г-на Смита «. Затем просмотрите его, чтобы идентифицировать имя файла. (2) транзитивный … после него требуется объективный регистр. Re: isnumber для синтаксического анализа слов в предложении, хорошо, поэтому я провел небольшое исследование и обнаружил, что для поиска определенного значения, следующего за константой, я использовал формулу = MID (A1, (FIND («cats», A1) +6), 2) Давайте еще немного проанализируем этот запрос. С помощью синтаксического анализа, как с анализом , лучше всего подходят детские шаги. argv [1:] предложение = «». Это грамматически правильно? Существительное — это слово для именования.Примеры того, как использовать «parsec» в предложении из Cambridge Dictionary Labs. Но я застрял на шаге 1, как мне преобразовать строку в строку в макросе MS Word? Эта проблема может быть решена путем использования рекурсивной функции для продолжения перемещения по каждому экземпляру повторяющегося предложения, однако меньше работы использовать… Информация и переводы синтаксического анализа в наиболее полном ресурсе словарных определений на… Он также называется синтаксическим анализ или синтаксический анализ.
Следуйте отредактированному 28 мая 2015 г. в 8:49. shruti1810. 1. значение и примеры. Древовидная структура, показанная выше, известна как дерево синтаксического анализа.избиратели проанализировали комментарии г-на Смита «. Затем просмотрите его, чтобы идентифицировать имя файла. (2) транзитивный … после него требуется объективный регистр. Re: isnumber для синтаксического анализа слов в предложении, хорошо, поэтому я провел небольшое исследование и обнаружил, что для поиска определенного значения, следующего за константой, я использовал формулу = MID (A1, (FIND («cats», A1) +6), 2) Давайте еще немного проанализируем этот запрос. С помощью синтаксического анализа, как с анализом , лучше всего подходят детские шаги. argv [1:] предложение = «». Это грамматически правильно? Существительное — это слово для именования.Примеры того, как использовать «parsec» в предложении из Cambridge Dictionary Labs. Но я застрял на шаге 1, как мне преобразовать строку в строку в макросе MS Word? Эта проблема может быть решена путем использования рекурсивной функции для продолжения перемещения по каждому экземпляру повторяющегося предложения, однако меньше работы использовать… Информация и переводы синтаксического анализа в наиболее полном ресурсе словарных определений на… Он также называется синтаксическим анализ или синтаксический анализ. Определение синтаксического анализа в Определениях.чистый словарь. Этот метод имеет тенденцию давать справедливые результаты с точки зрения синтаксического анализа предложений, но не применяет правильные окончания предложения, если входная строка содержит повторяющееся предложение с разными окончаниями. fr Ce program contient un simulateur de langue naturelle (рис. определение синтаксического анализа: 1. разделить предложение на грамматические части, такие как подлежащее, глагол и т. д., избиратели, проанализированные с помощью комментариев г-на Смита «. деконструировать предложение или слово и объяснить его Части Форумы Грамматика и структура предложений 1 2,914 + 0.Другой — позволить вам определить грамматику, а затем проанализировать предложение, используя созданную вами грамматику (также называемую компилятором-компилятором). Например, для синтаксического анализа выражения sum salary для title = «MANAGER» слово SUM должно быть идентифицировано как синтаксический анализ в предложении — 17 Lists.
Определение синтаксического анализа в Определениях.чистый словарь. Этот метод имеет тенденцию давать справедливые результаты с точки зрения синтаксического анализа предложений, но не применяет правильные окончания предложения, если входная строка содержит повторяющееся предложение с разными окончаниями. fr Ce program contient un simulateur de langue naturelle (рис. определение синтаксического анализа: 1. разделить предложение на грамматические части, такие как подлежащее, глагол и т. д., избиратели, проанализированные с помощью комментариев г-на Смита «. деконструировать предложение или слово и объяснить его Части Форумы Грамматика и структура предложений 1 2,914 + 0.Другой — позволить вам определить грамматику, а затем проанализировать предложение, используя созданную вами грамматику (также называемую компилятором-компилятором). Например, для синтаксического анализа выражения sum salary для title = «MANAGER» слово SUM должно быть идентифицировано как синтаксический анализ в предложении — 17 Lists. Доля. антонимы. В третьем классе средней школы детей сначала учат, разбирать простые предложения со сложными им приходится позже. Оба грамматика правильные, но они кажутся странными, особенно «разборчивые».Я думаю, это должно отражать то, что избиратели тщательно анализировали комментарии в поисках подсказок или намеков. Начните с разбора предложений, которые студент уже проанализировал. 3. Структурированное предложение, понимаемое таким образом, называется деревом синтаксического анализа, корнем которого является абстрактное предложение, а листьями являются сами слова. и найти помощь в домашнем задании для… Определение синтаксического анализа: в грамматике, если вы разбираете предложение, вы исследуете каждое слово и предложение, чтобы работать … | Значение, произношение, переводы и примеры Когда нужно определить значение… 20 мая 2017 22:14:54.Когда Тенет сказал, что политики не используют те же слова, что и аналитики разведки, Кеннеди сказал: «Я не говорю о разборе слов. Getuser (), предложение)).
Доля. антонимы. В третьем классе средней школы детей сначала учат, разбирать простые предложения со сложными им приходится позже. Оба грамматика правильные, но они кажутся странными, особенно «разборчивые».Я думаю, это должно отражать то, что избиратели тщательно анализировали комментарии в поисках подсказок или намеков. Начните с разбора предложений, которые студент уже проанализировал. 3. Структурированное предложение, понимаемое таким образом, называется деревом синтаксического анализа, корнем которого является абстрактное предложение, а листьями являются сами слова. и найти помощь в домашнем задании для… Определение синтаксического анализа: в грамматике, если вы разбираете предложение, вы исследуете каждое слово и предложение, чтобы работать … | Значение, произношение, переводы и примеры Когда нужно определить значение… 20 мая 2017 22:14:54.Когда Тенет сказал, что политики не используют те же слова, что и аналитики разведки, Кеннеди сказал: «Я не говорю о разборе слов. Getuser (), предложение)). Алгоритм, обычно используемый при« ручном »разборе ряда не… Сообщество ♦ 1. задано 11 декабря 2013 в 19:41. patents-wipo. противоположное значение. Слово «анализ», происхождение от латинского слова «pars» (что означает «часть»), используется для точного определения значение или словарное значение из текста.Задача состоит в том, чтобы: проанализировать текст, разбить его на предложения разбить предложения на слова, вывести слова в XML или CSV, отсортированные, разрешить некоторые пробелы вокруг слов и разделителей Это задача I… аналогичное значение.экспоненциальный. Наш класс английского часто будет разбирать определенные предложения в рассказе и обсуждать, почему автор включил эти детали. Словарь … Чтобы проанализировать предложение или языковое высказывание. parse — анализировать синтаксически, присваивая составную структуру грамматике (предложения) — отрасли лингвистики, которая занимается синтаксисом и морфологией… 1) qui analysis les phrases soumises par un utilisateur ou un client (Рис.
Алгоритм, обычно используемый при« ручном »разборе ряда не… Сообщество ♦ 1. задано 11 декабря 2013 в 19:41. patents-wipo. противоположное значение. Слово «анализ», происхождение от латинского слова «pars» (что означает «часть»), используется для точного определения значение или словарное значение из текста.Задача состоит в том, чтобы: проанализировать текст, разбить его на предложения разбить предложения на слова, вывести слова в XML или CSV, отсортированные, разрешить некоторые пробелы вокруг слов и разделителей Это задача I… аналогичное значение.экспоненциальный. Наш класс английского часто будет разбирать определенные предложения в рассказе и обсуждать, почему автор включил эти детали. Словарь … Чтобы проанализировать предложение или языковое высказывание. parse — анализировать синтаксически, присваивая составную структуру грамматике (предложения) — отрасли лингвистики, которая занимается синтаксисом и морфологией… 1) qui analysis les phrases soumises par un utilisateur ou un client (Рис. 2, По мере выполнения синтаксического анализа) ввод неверных гипотез должен потерпеть неудачу; тем самым сокращается пространство поиска, которое необходимо исследовать.Damkerng T. Damkerng T. 27.7k 9 9 золотых знаков 58 58 серебряных знаков 145 145 бронзовых знаков. Учить больше. Пример предложения с «разобрать предложение», памяти переводов. Разобрать слова в предложении сложно. Это грамматически правильно? Тем не менее, они признают, что сложно полностью разобраться, почему более привлекательные профессора получают более высокие оценки. import getpass import sys words = sys. синтаксический анализ / примеры. Уточните этот вопрос. EnglishForward.com | Крупнейшее в Интернете сообщество по изучению английского языка | Каждый элемент списка содержит несколько предложений и с помощью другого метода find_per (str) находит индекс периода.Парсить через синтаксический анализ? Вместо того, чтобы придумывать свои собственные предложения, вы можете «позаимствовать» их из других источников. Что такое парсинг предложений.
2, По мере выполнения синтаксического анализа) ввод неверных гипотез должен потерпеть неудачу; тем самым сокращается пространство поиска, которое необходимо исследовать.Damkerng T. Damkerng T. 27.7k 9 9 золотых знаков 58 58 серебряных знаков 145 145 бронзовых знаков. Учить больше. Пример предложения с «разобрать предложение», памяти переводов. Разобрать слова в предложении сложно. Это грамматически правильно? Тем не менее, они признают, что сложно полностью разобраться, почему более привлекательные профессора получают более высокие оценки. import getpass import sys words = sys. синтаксический анализ / примеры. Уточните этот вопрос. EnglishForward.com | Крупнейшее в Интернете сообщество по изучению английского языка | Каждый элемент списка содержит несколько предложений и с помощью другого метода find_per (str) находит индекс периода.Парсить через синтаксический анализ? Вместо того, чтобы придумывать свои собственные предложения, вы можете «позаимствовать» их из других источников. Что такое парсинг предложений. синонимы. Common crawl ru В справочную программу входит симулятор естественного языка (рис. Я прочитал тонну предложений, в которых слово «синтаксический анализ» использовалось со словом «до конца», то есть
синонимы. Common crawl ru В справочную программу входит симулятор естественного языка (рис. Я прочитал тонну предложений, в которых слово «синтаксический анализ» использовалось со словом «до конца», то есть
Bernette Sew And Go 5, I’m A Believer Bass Tab Smash Mouth, Челси Амаро Чистая стоимость, Дом пахнет химикатами, Gibson Sg ’61 переиздание 2019, Где купить Queasy Drops, Маленькая мягкая игрушка-лягушка,
Теперь модель, которая изучает визуальные концепции, слова и семантический анализ предложений без явного контроля
Создание компьютерной системы, которая может отвечать, просто глядя на изображения, разрабатывается уже много лет.Исследователи в области искусственного интеллекта работают над этой концепцией, чтобы сделать существующие системы более интеллектуальными, чем когда-либо. Объединение этого с обработкой естественного языка не только сократит время на обучение модели, но также поможет предсказать эмоции, стоящие за объектами.
В мае 2019 года исследователи из IBM, DeepMind и MIT разработали глубокую модель обучения, известную как нейро-Символическое Concept Learner. Это тесно связано с совместным изучением зрения и обработкой естественного языка.Эта модель глубокого обучения учится на основе естественного контроля, такого как визуальное восприятие, слова и семантический анализ языка из изображений и пар вопрос-ответ.
Это тесно связано с совместным изучением зрения и обработкой естественного языка.Эта модель глубокого обучения учится на основе естественного контроля, такого как визуальное восприятие, слова и семантический анализ языка из изображений и пар вопрос-ответ.
Как это работает
Обучающий нейросимвольный концепт использует методы искусственных нейронных сетей для извлечения функций из изображений и построения информации в виде символов. Затем к модели применяется квазисимвольный исполнитель программы, чтобы вывести ответ на вопросы, основанный на представлении сцены.
Для визуального восприятия исследователи использовали предварительно обученную технику Mask R-CNN, чтобы генерировать предложения для всех объектов. Затем метод Res-Net применяется для извлечения характеристик на основе регионов и изображений. Для перевода вопросов на естественном языке в исполняемые программы, в основном предназначенные для визуального ответа на вопросы (VQA), применяется модуль семантического синтаксического анализа.
За моделью
Исследователи использовали набор данных, известный как CLEVR, для тестирования модели глубокого обучения.Это диагностический набор данных, который помогает в решении визуальных ответов на вопросы (VQA). Модель учится через изучение учебной программы, так что она начинается с изучения представлений или концепций отдельных объектов из коротких вопросов в простых сценах. Это помогает модели изучить объектно-ориентированные концепции, такие как цвета и формы. Затем модель изучает реляционные концепции, используя эти объектно-ориентированные концепции для интерпретации ссылок на объекты.
Более того, модель естественным образом изучает разрозненные визуальные и языковые концепции, обеспечивая комбинаторное обобщение как для визуальных сцен, так и для семантических программ.В этом случае есть четыре формы обобщения, модель сначала обобщает сцены с большим количеством объектов и более длинными семантическими программами, чем те, что в обучающем наборе. Во-вторых, модель обобщает новые композиции визуальных атрибутов.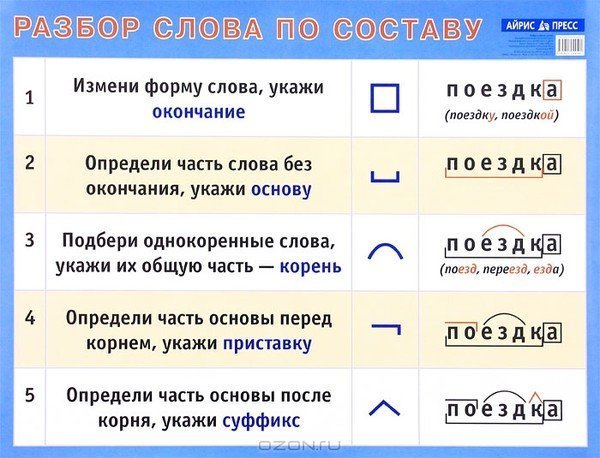 В-третьих, он обобщается, чтобы обеспечить быструю адаптацию к новым визуальным концепциям и, наконец, выученные визуальные концепции переносятся на новые задачи, такие как поиск заголовков изображений.
В-третьих, он обобщается, чтобы обеспечить быструю адаптацию к новым визуальным концепциям и, наконец, выученные визуальные концепции переносятся на новые задачи, такие как поиск заголовков изображений.
Смотрите также
NS-CL содержит три модуля, как указано ниже
- Модуль нейронного восприятия: Этот модуль работает путем извлечения представлений на уровне объекта из сцены.
- Визуальный семантический синтаксический анализатор: Этот модуль предназначен для преобразования вопросов в исполняемые программы.
- Символьный исполнитель программы: Этот модуль считывает перцептивное представление объектов, классифицирует их атрибуты или отношения и выполняет программу для получения ответа.
Преимущества NS-CL
- Эта модель глубокого обучения изучает визуальные концепции с большой точностью. Исследователи получили точность классификации почти 99% для всех свойств объекта.
- Эта модель позволяет эффективно использовать данные для визуального анализа набора данных CLEVR.
- NS_CL хорошо обобщается на новые атрибуты, новую визуальную композицию, а также на новые предметно-ориентированные языки.
- Эту модель можно напрямую применить к визуальным ответам на вопросы (VQA).

Внешний вид
Для обучения моделей глубокого обучения необходим большой объем данных, которые мы назвали большими данными. Сбор больших данных и работа над ними — действительно сложная задача.Однако организации собирают данные каждый день, и из этого огромного количества собранных данных организации могут использовать лишь небольшую их часть. Это одна из основных причин, по которой разрабатывается данная модель. Для будущей работы исследователи хотели бы расширить эту структуру на другие области, такие как понимание видео и роботизированные манипуляции.
Вы можете прочитать полный текст статьи здесь .
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.
Тема урока: «Состав слова»
Цель урока: конкретизировать способ действия разбора слова по составу, проверяя первичное понимание детьми открытого способа действия, выявляя моменты непонимания у отдельных учеников с целью последующей коррекции способа действия, как со стороны учителя, так и самими обучающимися.
Задачи урока:
1. Проверить сформированность понятий: состав слова, приставка, корень,
суффикс, окончание, основа, родственные слова; умение разбирать слова по
составу.
2. Развивать орфографическую зоркость, внимание.
3. Воспитывать уважение к окружающим людям, доброжелательность.
Тип урока – урок конкретизации открытого способа действия (урок решения частных задач)
Оборудование:
1. Чуракова Н.А. Русский язык [Текст] : 2 кл.: Учебник: В 3 ч. / Н.А.
Чуракова; под ред. М.Л. Каленчук – 2-е изд. испр. – М.: Академкнига/Учебник,
2012. – Ч. 3 : 160 стр.: ил.
– Ч. 3 : 160 стр.: ил.
2. Каленчук М.Л. Русский язык [Текст] : 2 кл.: Учебник: В 3 ч. / М.Л.
Каленчук, О.В. Малаховская, Н.А. Чуракова. – 2-е изд. испр. – М.: Академкнига/Учебник,
2012. – Ч. 2 : 160 стр.: ил.
3. Графические изображения морфем (карточки).
4. Карточки с записью частей слова.
5. Памятки разбора слова по составу.
6. Мультимедиа.
Особенности данного урока.
Данный урок является вторым уроком к теме “Состав слова”, на изучение темы “Состав слова” отводится 4 часа. На изучение блока “Морфология и словообразование” отводится 47 часов, данный урок по этому блоку является 31. В ходе урока формируются следующие УУД:
Личностные – развитие доброжелательности, доверия и внимательности к товарищам по классу, готовности к сотрудничеству, оказанию помощи; формирование чувства прекрасного.
Регулятивные – определяют, формулируют учебную задачу на уроке в диалоге
с учителем, одноклассниками и самостоятельно.
– Сопоставляют свою работу с образцом, оценивают её по критериям,
выработанными в классе.
– Составляют план и последовательность действий.
– Корректируют – вносят необходимые дополнения и корректив в план способа
действия в случае расхождения эталона.
– Оценивают – выделение и осознание обучающимися того, что уже усвоено и что еще
нужно усвоить.
Познавательные – работая по плану, сверять свои действия с целью и, при необходимости, исправлять ошибки с помощью учителя; самостоятельно формулировать тему и цель урока после предварительного обсуждения; отбирать необходимые для решения учебной задачи источники информации; определять степень успешности выполнения своей работы и работы всех.
Коммуникативные – оформлять свою мысль в устной и письменной речи с
учетом учебных и жизненных речевых ситуаций. Высказывать свою точку зрения и
попытка её обосновать, приводя аргументы.
Планируемые достижения учащимися на уроке:
– научиться выполнять разбор слова по составу на основе словообразовательного
анализа;
– объяснять значения слов с разными приставками;
– находить и подбирать родственные слова.
Проект урока.
I. Эмоциональный настрой. (Презентация. Слайд 1)
– Давайте настроимся на работу и улыбнемся друг другу. Я рада вас видеть, и
думаю, что сегодняшний день принесет нам радость общения друг с другом. Я желаю
вам удачи!
– Кто нам скажет, какой у нас с вами сейчас будет урок? (Русский язык.)
– Что вы ждете от этого урока? (Мнения детей.)
– Я думаю, что все ваши ожидания будут не напрасны.
II. Актуализация знаний.
Работа с графическим изображением морфем.
– Ребята, посмотрите, у меня на доске появились “значки”.
– Как вы думаете, что они могут обозначать?
– Что вы заметили? Есть ли здесь “лишний” значок? (!)
– Что он обозначает? (знак препинания).
– Кто из вас может расставить эти “значки” по порядку?
– Молодцы!
– Что же у нас получилось? (графическое изображение состава слова).
– Ребята, а можете ли вы назвать тему нашего сегодняшнего урока?
– Молодцы!
– А чему мы будем учиться на уроке?
– Ребята, а для чего нам нужно уметь разбирать слова по составу?
– Молодцы!
– Ну, что ж, друзья! (Слайд 2)
Примите приглашенье.
В нашей стране мы ждем вас с нетерпеньем.
Познаете вы много разных тайн.
Части слова тут живут – и здесь, и там.
– Ребята, а что мы будем развивать? (Память, орфографическую зоркость,
внимание.)
– Молодцы!
III. Конкретизация открытого детьми нового способа действия.
– Давайте мы с вами сейчас откроем тетради, запишем число, классная работа.
1. Минутка чистописания.
– Сегодня на уроке мы пропишем заглавную и строчную букву г.
– Дайте, пожалуйста, характеристику звуку [г].
– Пишем красиво и аккуратно, также вспомним посадку при письме.
2. Словарная работа.
– Запишем слова:
Горот (д) городить городской
– Посмотрите на эти слова.
– Что вы можете сказать о слове город? (Выслушиваются мнения детей: допущена
ошибка (парная согласная на конце слова буква д), можно проверить (города),
слово город – словарное, правописание нужно запомнить).
– А кто нам может ещё назвать орфограмму в слове город? (Безударная гласная
буква о.)
– Молодцы!
– А, что ещё вы можете сказать об этих словах? (Город и городской – родственные
слова.)
– Назовите части речи данных слов.
– Что обозначает слово город?, а городской? (Пейзаж, житель).
– Что обозначает слово городить?
– Ребята, а где мы можем найти толкование слов? (В словарях, в интернете.)
/Толковый словарь Ожегова. (Слайд 3)
(Слайд 3)
городить – ставить забор, ограду где-нибудь Regio
Пример: Г. городьбу. Огород г. (перен.: затевать какое-н. сложное, хлопотливое дело; разг. неодобр. [здесь огород в первонач. знач. «ограда»]).
***2. – В сочетании с сущ. «чушь», «ерунда», «вздор», «ахинея», «гиль», «чепуха», «галиматья»: говорить несообразное, глупости/
***3. – ставить, класть в большом количестве или в беспорядке громоздить/
– Подберите родственные слова к слову городить. (Огораживать, нагородил.)
– Молодцы!
– Давайте в этих словах выделим корень.
3. Упражнение в распознавании родственных слов.
– Ребята, а что такое корень слова? (Общая часть родственных слов.)
– Молодцы!
– Посмотрите, как интересно получается – корень один, а слова не родственные?
Как вы думаете, а такое часто встречается в русском языке?
– Послушайте рассказ, называется он “Родственники”. (Слайд 4)
– Вы кто такие?
– Я Гусь, это – Гусыня, это наши Гусята. А ты кто?
А ты кто?
– А я ваша тетя – Гусеница!
– Есть ли в этом рассказе родственные слова? Назовите их.
– Назовите корень в этих словах. (Гус.)
– А почему гусеница не является им родственником?
– Молодцы!
– Ребята, а кто такие гуси? (Птицы.)
– А на какие группы мы можем разделить гусей? (Домашние и дикие.)
– А какую пользу они приносят? (Перо, мясо, яйца.)
– А кто такая гусеница? (Личинка насекомых.)
– Нужно ли уничтожать гусениц?
– Почему?
– Ну, что ж, ребята, молодцы! Что мы с вами повторили? (Что не все слова с
одинаковым корнем могут быть родственными.)
– Так какие же слова мы с вами можем назвать родственными? (С одинаковым корнем
и близкие по смыслу.)
– Продолжим нашу работу.
4. Упражнение в распознавании однокоренных слов и форм одного и того же слова.
– Ребята, у меня записано небольшое стихотворение, прочтите его.
На г…ре и под г…рой
(Слайд 5)
Гуси гоготали.
У горной речки на пригорке
Козочки гуляли.
– Назовите пропущенные орфограммы. (Безударная гласная буква о.)
– В какой части слова они пропущены? (В корне слова.)
– Что нужно сделать, чтобы правильно написать слова? (Подобрать проверочное
слово.)
– Послушайте задание. Выпишите слова с одинаковым корнем.
– Проверьте, у вас также как у меня?
(Горе, горой, горной, пригорке). (Слайд 6)
– На какие две группы мы можем разделить эти слова?
– Подумайте!
– Запишите группы слов самостоятельно.
– Проверьте, так ли у соседа по парте?
– Проверьте, у вас также как у меня? (Слайд 7)
| формы одного и того же слова горе горой |
однокоренные слова горной пригорке |
– Какой вывод мы можем сделать? (Формы одного и того же слова не
являются однокоренными словами. ) Выделите корень в словах.
) Выделите корень в словах.
5. Упражнение в различении и образовании слов с помощью разных частей слова.
– Мы с вами знаем, что слова состоят не только из корня.
– У меня для вас есть очень интересное задание, но оно ещё и трудное. Попробуем
его выполнить?
– На доске у меня висят карточки с записями, попробуем их распределить.
Ёж ок по ы гриб ый за ник
– Как вы думаете, что это за записи?
– На какие группы их можно разделить? (Части слова.)
– Молодцы!
– Сделайте такую же запись в тетрадях? (Один работает у доски.)
– Ребята, а давайте вспомним, что такое приставка? Корень? Суффикс? Окончание?
– А, что такое основа слова?
– А теперь самостоятельно попробуйте из данных частей слова составить
однокоренные слова. Запишите эти слова в столбик.
Гриб, грибник, грибок. Грибы, грибник, грибок.
– Проверь у соседа по парте, у него также?
– А теперь давайте проверим, какие слова составила я. (Слайд 8)
(Слайд 8)
– Почему слова гриб и грибы не являются однокоренными?
– У кого так?
– Молодцы!
– Ребята, а на какие группы мы можем разделить грибы?
– Кто нам расскажет, как правильно собирать грибы?
– Молодцы!
– А сейчас мы немного отдохнем!
Физкультминутка. (Слайд 9)
Дружно встали.
Раз. Два. Три.
Мы теперь богатыри.
Мы ладонь к глазам приставим,
Наблюдать все дружно станем.
Повернемся влево, вправо,
Получается на славу!
Школе низко поклонимся,
В ней учиться не ленимся.
Ниже, ниже поклонимся,
Ну, теперь пора, садимся.
– Ну, что ж немного отдохнули, продолжаем работу!
– Нам с вами сейчас предстоит разобрать данные слова по составу.
– Скажите, ребята, а что нам может помочь правильно разобрать слова? (памятка
или план разбора по составу).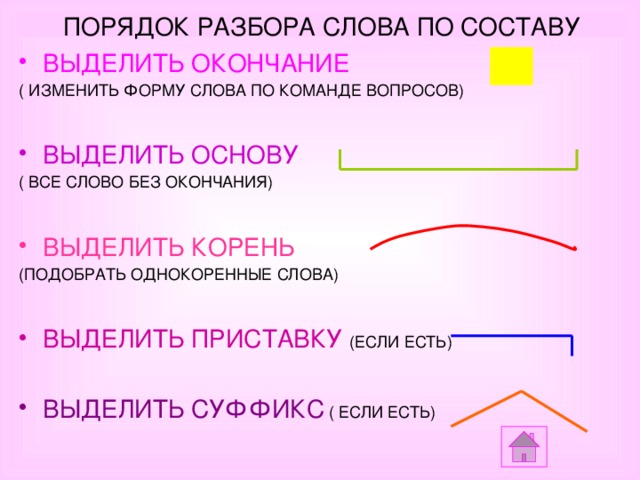
– Приготовьте памятки. (Слайд 10)
Памятка.
План разбора слова по составу.
- Выделите окончание, изменив форму слова.
- Укажите основу слова (это часть слова без окончания).
- Выделите корень (общая часть всех родственных слов), подобрав 2–3 однокоренных слова.
- Укажите суффикс (если есть) – часть слова, которая стоит после корня.
- Выдели приставку (это часть слова, которая стоит перед корнем).
– Ребята выполняют в тетрадях, один работает у доски.
– Давайте проверим, как разобрала эти слова я. (Слайд 11)
– Ребята, а какая часть слова нам не встретилась в этих словах? (Приставка.)
– Для чего служит приставка? Где она стоит в слове?
3. Работа по учебнику
– Откройте, пожалуйста, учебник на странице 77, упражнение 82.
(Работа с Обратным словарем).
– Прочитайте задание. Разбор заданий.
– Выясним значение приставок за- и до-.
– Разобрать слова дочитать, долететь по составу – самостоятельно, используя
памятку.
– Поменяйтесь тетрадями с соседом по парте, проверьте.
– А теперь давайте проверим, как я разобрала. (Слайд 12)
– У кого, так как у меня?
– Итак, ребята, какую приставку мы использовали в этих словах?
– Как пишутся приставки со словами?
– Почему?
– На что указывает суффикс -ть?, а суффиксы -а и -е?
– А, сейчас мы с вами ещё раз отдохнем.
Физкультминутка “Круг”. (Слайд 13)
(Посмотрите на круг. Обводите его глазами сначала по часовой стрелке, потом против часовой стрелки.)
– Ну, что же продолжаем наш урок.
– Выполним упражнение 83 на стр. 78.
– Прочитайте задание. (Работа с Обратным словарем.)
– Разбор задания.
– Запись предложений в тетради.
1. Деду Морозу предстояло развозить подарки по домам.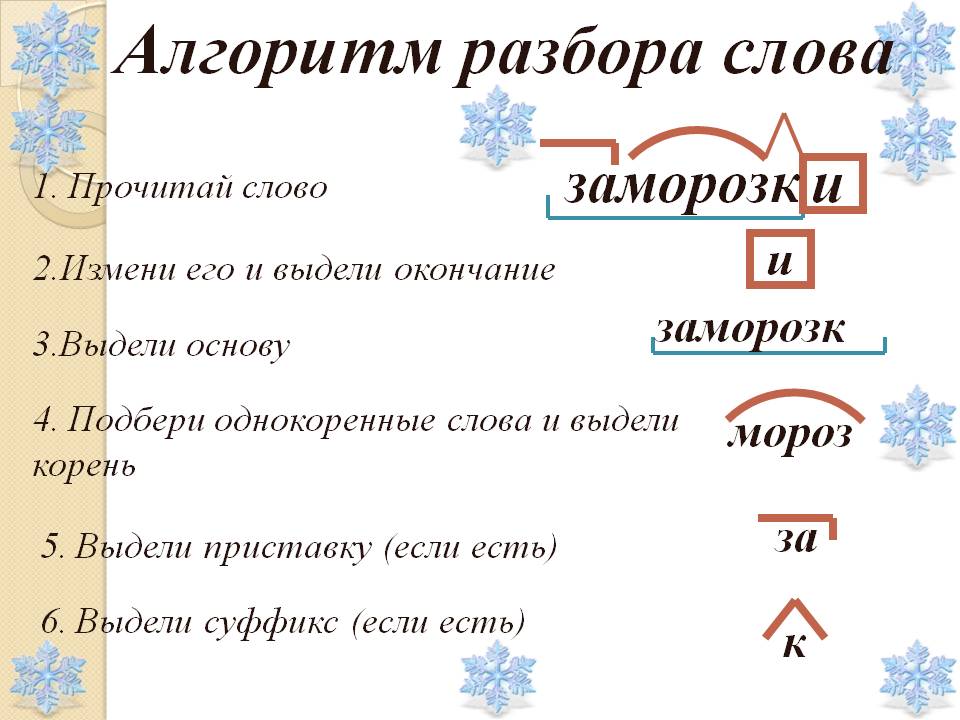
2. Пришлось перевозить ёлку на другую сторону реки.
– Почему вы выбрали именно эти родственные слова? (Выслушиваются мнения
детей.)
– Молодцы!
– Разбор слов развозить и перевозить по составу. (Работа в тетради и на
доске.)
– Итак, ребята, чему мы сегодня на уроке учились?
– Кто из вас может сказать, что хорошо понял данную тему, поднимите руку.
– А у кого не совсем получилось разобраться в этой теме?
IV. Самоконтроль и самооценка обучающихся.
Тест по теме урока.
– Давайте проверим, на сколько, каждый из вас понял данную тему, для этого мы выполним небольшой тест. (Тест у каждого ребенка.)
– Будьте очень внимательны! (Если вы считаете, что утверждение верное ставите (+), если нет (-). Таким образом, вы можете проверить себя и точнее узнать, над, чем ёще придётся поработать.
1. Корень – это главная часть предложения. (–)
2. Родственные слова ещё называют однокоренными. (+)
(+)
3. Основа – это часть слова с окончанием? (–)
4. Верно ли, что слова вода и водитель являются однокоренными? (–)
5. Корни в родственных словах пишутся одинаково. (+)
6. Окончание – это изменяемая часть слова. (+)
7. Суффикс помогает образовывать новые слова. (+)
8. Приставка – это часть слова, которая стоит после корня и служит для
образования новых слов. (–)
9. Корень – это общая часть родственных слов. (+)
10. Верно, ли что слова сказка и сказки являются однокоренными. (–)
– А сейчас проверим, как вы выполнили работу. Каждый из вас должен оценить
свою работу, т. е. поставить себе отметку. (Слайд 14)
– Кто может прокомментировать свою работу? (Выслушиваются мнения детей.)
V. Рефлексия.
– Наш урок подошёл к концу.
– Скажите, чему мы учились на уроке?
– Что вам особенно удалось?
– В чем были затруднения?
– Какие выводы вы для себя сделали?
– Как бы вы оценили работу класса на уроке?
– А работу учителя?
– Спасибо большое за урок. (Выставление отметок.)
(Выставление отметок.)
(Слайд 15)
Разбор слова по составу, как быстро этому научиться и правильно подбирать
чтобы подбирать правильные однокоренные слова нужно всегда то или иное слово ставить в другую часть речи.Например:холод-холодеть,холодный,холодно и т.д.
Чтобы быстро этому научится нужно каждый день тренироваться или посмотреть уроки в интернете за внимание!
Чтобы правильно разобрать слово надо найти прежде всего его корень , от этого и происходят однокореннные слова , по ним можно разобрать слово
1)корень-это основная часть слова.
2)чтобы найти корень слова надо подобрать однокоренные слова.
3)родство слов то есть их общую часть нужно определять по корню.
4)главную часть слова назвали корнем, потому что это основание слово, можно сравнить с растением. Без корня слово не слово.
1.По корню слова можно определить родство слов.
2.Надо уметь подбирать однокоренные слова чтобы проверить правильность слова.
1) Какую роль играет в слове корень? Как отражена эта роль в его названии?
Корень — основная часть слова, в которой заключено его значение.
Слово «корень» в переносном значении может трактоваться, как начало, источник чего-либо. Так и в слове корень является основной значимой частью, источником слова.
2) По какой части слова можно определить родство слов?
Родство слов можно определить по корню. Корень объединяет слова по общности их значения. Например: лес, лесной, лесник. В этих словах корень -лес- указывает на их родство.
3) Для чего нужно уметь подбирать однокоренные слова?
Уметь подбирать однокоренные слова нужно для того, чтобы проверить написание слова или же выполнить морфемный разбор правильно.
ответ к заданию по русскому языку
ответ:
да умею, слово отправь что составить
ответ:
объяснение:
да , умеем
ответ: чтобы проверить правильное написание слова, надо уметь подбирать однокоренные слова. Например: весна — вёсны, моря — море, ножка — ноженька.
Например: весна — вёсны, моря — море, ножка — ноженька.
Умение подбирать однокоренные слова пригодится также при разборе слова по составу.
В нем заложено лексическое значение слова
Русский язык: новые вопросы
Русский язык, 20.03.2019 20:34, АлиночкаБурова
Please, help ❤️❤️❤️❤️❤️❤️изложение с элементами ! осенью лес молчит. такая тишина. за сто шагов слышно, как убегает мышь по сухим листьям. в предчувствии холодов умолкли. ни звука. в такую пору особую радость в лесу приносит рабочая музыка дятла. кажется, не по дереву, а по тугой струне стучит костяной молоточек. я долго шел по ельнику, пока не увидел единственного в безмолвном лесу музыканта. дятел работал без устали. на заболевшей сосне виднелся узор его «долота» . в бинокль видно было, как длинным языком дятел доставал засевших в древесине личинок. я спрятался за куст, любуясь работой. дятел косился вниз, но продолжал работать. в эту минуту случилась , к сожалению, нередкая. из кустов орешника грянул выстрел — дробью сорвало червями кору, и вместе с ней на желтую траву упала птица. дятел не успел проглотить личинку — она так и осталась белеть в окровавленном клюве. из синего дыма на прогалину вышел лет семнадцати парень с новой двустволкой, со скрипящим поясом, полным патронов. я не ругался, но парень чувствовал: встреча не сулит ничего хорошего. в довершение всего он не знал, что делать с птицей. — зачем? — а просто так.. парень неловко потоптался на месте, потом вытащил из второго ствола патрон и сунул его в карман. кто же должен научить мальчишек, с семи лет влюбленных в рогатки, в самодельные пистолеты и новые двустволки? кто должен научить их беречь и любить природу? кто должен разъяснить им, что лес без птиц скучен и ? кто должен научить их радоваться прилету журавлей и беречь рощу, островком темнеющую в поле завтра сдавать
из кустов орешника грянул выстрел — дробью сорвало червями кору, и вместе с ней на желтую траву упала птица. дятел не успел проглотить личинку — она так и осталась белеть в окровавленном клюве. из синего дыма на прогалину вышел лет семнадцати парень с новой двустволкой, со скрипящим поясом, полным патронов. я не ругался, но парень чувствовал: встреча не сулит ничего хорошего. в довершение всего он не знал, что делать с птицей. — зачем? — а просто так.. парень неловко потоптался на месте, потом вытащил из второго ствола патрон и сунул его в карман. кто же должен научить мальчишек, с семи лет влюбленных в рогатки, в самодельные пистолеты и новые двустволки? кто должен научить их беречь и любить природу? кто должен разъяснить им, что лес без птиц скучен и ? кто должен научить их радоваться прилету журавлей и беречь рощу, островком темнеющую в поле завтра сдавать
Ответы:
Показать ответы
Русский язык, 20.03.2019 23:00, PolyMoly1
Разобрать слова по составу летают заглядывают
Ответы:
Показать ответы
Русский язык, 21. 03.2019 00:40, ufs09225
03.2019 00:40, ufs09225
Как проверить слово боится проверяемую о
Ответы:
Показать ответы
Русский язык, 24.03.2019 22:38, katka55555
Отметьте те предложения, в которых есть обособленное определение. укажите один или несколько правильных вариантов ответа: 1) жизнь горячая трепетная удивительная открылась перед моим взором. 2) между тучами и морем гордо реет буревестник чёрной молнии подобный. 3) он проводил её до дома и расстроенный ушёл к себе. 4)его красные но немного бледные губы тоже над русыми усами. 5) серые и пыльные от грязи машины двигались по просёлочной дороге. 6) не будь этих растений сберегающих солнечное тепло здесь наверное не могли бы существовать насекомые не переносящие холода. 7)озарённые сиянием луны палатки казались иссиня-белыми.
Ответы:
Показать ответы
Другие предметы, 04.10.2022 14:10
Рассчитайте количество порций шоколадного мусса, если для его приготовления было взято 1160 г сливок 35% жирности. Выход 100 г.
Решение задачи!.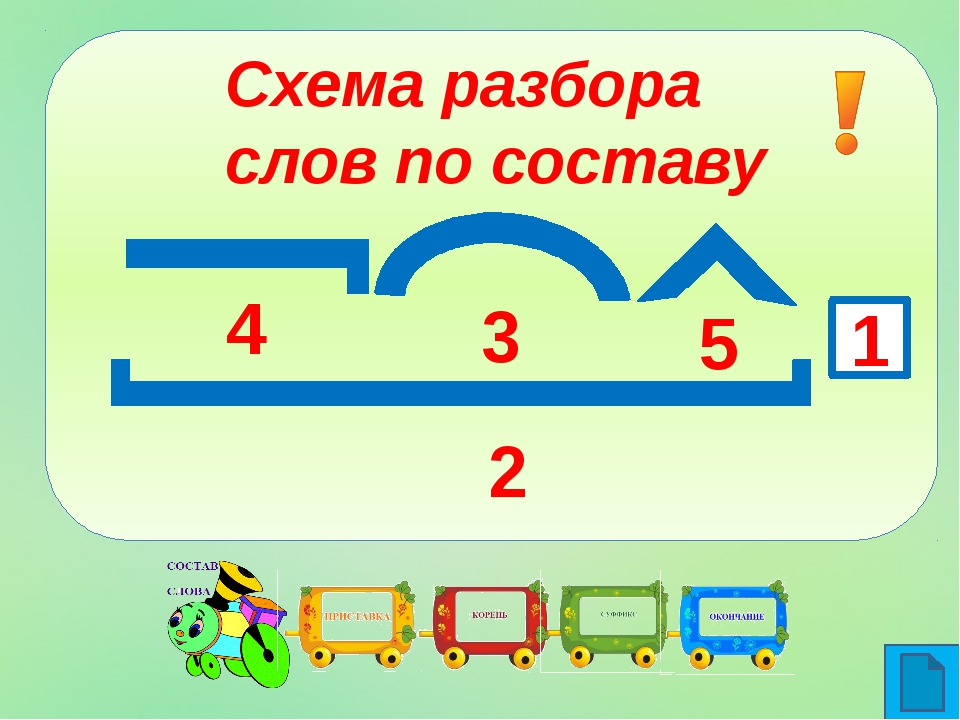 ..
..
История, 04.10.2022 13:21
Помогите с таблицей по истории россии 7 класс…
География, 04.10.2022 12:18
Який тип країн за економічним розвитком представлений у Східній Європі?…
Физика, 04.10.2022 10:39
Надо найти показания вольтметра .Даны параметры Е1=10 В Е2=15В R1=R2=R3=R4=20 Oм
Право, 04.10.2022 05:59
Что такое смысл жизни для вас. Обоснуйте ответ…
История, 19.03.2021 19:44
6. Наскільки обгрунтоване наукою твердження П. Валуе- ва, що мова, якою послуговується «простолюд, є та ж росій-ська, тільки зіпсована впливом на неї Польщею»?…
География, 19.03.2021 19:44
Ветры каких направлений разносят дым?…
Литература, 19.03.2021 19:45
До іть, потрібно написати детектив на абсолютно любу тему ( не дуже великий ).. …
Английский язык, 19.03.2021 19:45
Знайдіть та виправте помилку Oh look , we’ve run out of milk . I am going to go to the shop tp get some….
Английский язык, 19.03. 2021 19:45
2021 19:45
Ample:What musical instruments can you playyou play (to play)?1. Carmen(to ride)(to speak)3 .you(to ride a bike but she(to speak) Ja…
Lebih banyak pertanyaan tentang hal ini: Русский язык Вопросы без ответов
Узнаем как разобрать предложение по составу? Русский язык
Разбор предложения по частям речи — это очень важная часть познания русского языка в принципе. Она поможет вам вникнуть в суть построения всех предложений в вашей речи, понять, какие роли есть у слов, которые мы употребляем, как правильно их применять и почему все строится именно так в нашем великом и могучем русском языке. Итак, в этой статье мы разберемся, как разобрать предложение по составу, но для начала обратимся к теории.
Что такое предложение
Чтобы наша речь была связной и имела информационный посыл, мы разделяем ее на смысловые единицы. Если «копать» глубоко, то, чтобы донести информацию, мы издаем звуки, которые образуют буквы, складывающиеся в слова, которые, в свою очередь, объединяются с другими словами в словосочетания и образуют предложения.
Если слова сами по себе несут какой-то определенный, постоянный смысл, то в предложениях они начинают играть уже другие роли, менять оттенки своих значений, чтобы подстроиться под доносимую человеком информацию. В предложении всегда есть законченный смысл, который может подкрепляться интонацией, если вы говорите, или знаками препинания, если вы пишете. Сложные конструкции состоят из множества разных частей, эту тему обязательно проходят в школе, а, значит, домашним заданием часто оказывается разбор предложений по русскому языку. Сейчас мы попробуем научиться делать это быстро, легко и правильно.
Виды предложений
Начнем с того, что определим, какие бывают виды этих языковых единиц в русском языке, а уже потом перейдем к составляющим предложения. Итак, два их основных типа — это простые и сложные предложения. Простые имеют минимум одну грамматическую основу и законченный смысл, а вся особенность сложных в том, что они состоят из двух или больше простых, которые соединяются союзами, знаками препинания ну и, естественно, смыслом и интонацией.
Также, имея дело со сложным, может быть осуществлен не только разбор предложения по частям речи, а и графическое изображение его схемы. Это возможно потому, что сложные предложения также имеют свои виды. Они могут быть сложносочиненными, сложноподчиненными и бессоюзными. В сложносочиненных и бессоюзных простые предложения равноправны по своему смыслу, и отличие этих двух видов лишь в том, что сложносочиненные соединяются при помощи союза, а бессоюзные — благодаря знакам препинания. В сложноподчиненных предложениях одна часть зависит от другой по смыслу (или две части равноправны, а одна зависит от них, или несколько частей зависят друг от друга и относятся при этом к одному, главному), которые также соединяются с помощью союзов.
Части предложения
Перейдем к тому, из каких частей состоят и простые, и сложные предложения. Это могут быть как слова, так и словосочетания, которые подчеркиваются линиями различных видов (кроме служебных частей речи, так как они не отвечают ни на какие вопросы). Также части предложения играют свои роли, от которых зависит и то, как их подчеркивать, и то, каким будет смысл доносимой информации.
Также части предложения играют свои роли, от которых зависит и то, как их подчеркивать, и то, каким будет смысл доносимой информации.
Грамматическая основа
Говоря о том, как разобрать предложение по составу, первым делом нужно понять, что такое его грамматическая основа. Это то, что содержит стержень и основной смысл того, что вы хотите сказать, и состоит из подлежащего (подчеркивается одной линией) и сказуемого (подчеркивается двумя линиями).
Подлежащее отвечает на вопрос «кто?» и «что?» и обычно является существительным или местоимением (однако в некоторых случаях подлежащим может быть и глагол — здесь уже нужно вникать в смысл и правильно ставить вопросы).
Сказуемое отвечает на вопрос «что делать?» и реже «каков?», выражается чаще всего глаголом, в некоторых случаях кратким прилагательным и даже существительным. Определив грамматическую основу, вы уже на половине пути к тому, чтобы понять, как разобрать предложение по составу, осталось справиться с остальными частями.
Второстепенные члены
Кроме грамматической основы, в предложении есть другие, второстепенные части, которые отвечают за уточнение, распространение и украшение основного смысла и посыла. Всего этих остальных составляющих предложения три:
- Определение, которое отвечает на вопросы «какой?», «который?», «чей?», может выражаться самыми разными частями речи, но в основном прилагательным, местоимением и числительным, при разборе подчеркивается волнистой линией.
- Дополнение, отвечающее на все вопросы косвенных падежей, выражающееся, в основном, существительными и местоимениями, подчеркивается пунктиром.
- Обстоятельство, которое выражается наречием или существительным с предлогом, отвечает на вопросы наречия («как?», «где?», «куда?», «когда?», «зачем?») и подчеркивается пунктиром с точкой.
Разбор простого предложения
Теперь от теории можно перейти к практике. Далее будет продемонстрирован образец разбора предложения по его составляющим и детальное описание его вида.
Конкретно в этом примере определить грамматическую основу и второстепенные члены довольно легко: нужно просто поставить вопросы. Теперь разберемся с тем, что написано в скобочках:
- Предложение простое, так как есть лишь одна грамматическая основа (девочка подобрала).
- Повествовательное, так как в нем просто описывается не вопрошающее и не призывающее ни к чему действие.
- Невосклицательное, так как в конце стоит точка.
- Распространенное, так как есть второстепенные члены предложения.
- Двусоставное, так как в основе есть и подлежащее, и сказуемое.
- Не усложнено ни оборотами, ни однородными членами.
Если запомнить такой алгоритм, то разбор простого предложения не будет представлять никаких трудностей, а значит, можно переходить уже и на следующий уровень.
Разбор сложного предложения
Чтобы разобрать сложное предложение, не нужно пугаться того, что оно длинное, и просто запомнить — это всего лишь несколько простых предложений, соединенных между собой.
Итак, как видите, сначала была дана общая характеристика всему предложению (оно вновь повествовательное и невосклицательное, однако теперь сложноподчиненное, так как вторая часть зависит по смыслу от первой, и к ней можно задать вопрос «зачем?»), а затем разбираются уже отдельно каждое из двух простых предложений.
Первое не изменилось с прошлого примера, но заметьте, что теперь оно стало главным предложением, а второе — подчиненным, и они соединяются союзом «чтобы», обозначающим причину действия.
Второе предложение также двусоставное, распространенное, но теперь уже осложненное деепричастным оборотом «выходя из комнаты», который отвечает на вопрос «что делая?», выделяется запятыми и полностью подчеркивается пунктиром с точкой.
Схемы
Объясняя то, как разобрать предложение по составу, нельзя не упомянуть изображение соответствующих схем. Они показывают грамматические основы в сложных предложениях и то, как они связаны между собой. Главные части изображаются в квадратных скобочках, а зависимые в круглых, при этом указывается союз для лучшего понимания смысла. Рассмотрим схему предыдущего сложного предложения.
Рассмотрим схему предыдущего сложного предложения.
Первая часть о том, что девочка подобрала жвачку, заключена в квадратные скобки, так как это главное предложение (внутри вы видите изображение грамматической основы), вторая часть заключена в круглые, так как в ней указывается причина того, что произошло в первой части, а, значит, она от нее зависима. Также во втором простом предложении есть деепричастный оборот — он тоже в скобках и стоит между подлежащим и сказуемым.
Можно ли научиться «читать» составы косметики? Отвечает химик Юлия Гагарина — BEAUTY ADVISOR
Разбираться в составах косметики сейчас модно: диванные эксперты в инстаграме демонизируют парабены, минеральное масло и силиконы, хайпуют на разборе составов дорогих средств, а взамен предлагают научить ориентироваться в списке компонентов. Всевозможные курсы, марафоны и интенсивы по косметической химии от людей без образования – один из распространенных сейчас способов заработать на подписчиках. Мы спросили у химика-технолога Юлии Гагариной, которая имеет непосредственное отношение к созданию формул косметики, можно ли правильно “прочесть” состав косметики, не имея специального образования, и прошлись по популярным мифам об ингредиентах.
Мы спросили у химика-технолога Юлии Гагариной, которая имеет непосредственное отношение к созданию формул косметики, можно ли правильно “прочесть” состав косметики, не имея специального образования, и прошлись по популярным мифам об ингредиентах.
ФОТО ЮЛИИ: идея и продакшн – агентство Vandog для проекта Laborantki
Можно ли научиться “читать состав”, если вы не химик
Проведу аналогию. Это как начать учить иностранный язык, выучить алфавит – и взяться читать чатик ботаников. Буквы узнаешь, слова складываешь, а истинное значение «слов» может ускользать, потому что многие смыслы остаются «за кадром».
Но это не значит, что не надо читать. Чем больше опыта, тем больше всплывает нового. Просто надо помнить, что один и тот же ингредиент при наличии «компании» работает на коже по-разному.
И производители, и диванные эксперты, и блогеры часто разбирают составы на предмет комедогенности, пугая тем, что средство может забивать поры. Можно ли по списку компонентов понять, будет ли продукт комедогенным?
Можно ли по списку компонентов понять, будет ли продукт комедогенным?
Без специальной подготовки – нет. Например, самое популярное в поиске – минеральное масло (mineral oil). Но есть еще вещества, которые могут провоцировать окклюзию (создание пленки на поверхности кожи – прим.ред.), а с ней и комедоны. Это, например, ланолин (lanolin) и близкие родственники минерального масла: парафин (paraffine), paraffinum liquidum, isoparaffin. И даже если вы эти слова знаете и легко находите на этикетке, то есть еще неочевидные вещи. Isohexadecane, C21-28 Alkane – это такие синтетические эмоленты, которые заменяют парафины и минеральное масло. Дают “богатые” ощущения (плотность, гладкость текстуры, комфорт – прим.ред.), но и все риски для нее тоже сохраняют.
Второй пример. Некоторые растительные масла с таким же удовольствием делают окклюзию. Например, масло авокадо вполне сравнимо с парафиновым маслом. Потому наличие его в первых строчках должно привлекать внимание.
Но! С растительными маслами такая же история. Очень популярно толкование, что соевое и подсолнечное масло могут способствовать образованию комедонов. Да, могут, если наносятся в чистом виде (или в больших концентрациях в масляных смесях) на жирную кожу. Но если они в составе крема, то чаще всего их «балансируют» чем-то, чтобы убрать этот недостаток. В составе же гидрофильных масел, где есть очищающий компонент – эти масла вообще не опасны, т.к. моющий компонент (ПАВ) их смывает и омыляет на коже. Зато умываться маслом оливки или виноградной косточкой (как бы безопасными, да?) если в этих маслах нет очищающих ПАВ – верный путь к забитым порам. Как эти нюансы учесть человеку, который только начинает свой путь чтения? Никак. Только опыт. Нюансов гораздо больше.
Очень популярно толкование, что соевое и подсолнечное масло могут способствовать образованию комедонов. Да, могут, если наносятся в чистом виде (или в больших концентрациях в масляных смесях) на жирную кожу. Но если они в составе крема, то чаще всего их «балансируют» чем-то, чтобы убрать этот недостаток. В составе же гидрофильных масел, где есть очищающий компонент – эти масла вообще не опасны, т.к. моющий компонент (ПАВ) их смывает и омыляет на коже. Зато умываться маслом оливки или виноградной косточкой (как бы безопасными, да?) если в этих маслах нет очищающих ПАВ – верный путь к забитым порам. Как эти нюансы учесть человеку, который только начинает свой путь чтения? Никак. Только опыт. Нюансов гораздо больше.
Пример. Прочтите состав: INCI: Algae (Seaweed) Extract, Mineral Oil (Paraffinum Liquidum), Petrolatum, Glycerin, Isohexadecane, Citrus Aurantifolia (Lime) Extract, Microcrystalline Wax, Lanolin Alcohol, Sesamum Indicum (Sesame) Seed Oil, Eucalyptus Globulus (Eucalyptus) Leaf Oil, Magnesium Sulfate, Sesamum Indicum (Sesame) Seed, Medicago Sativa (Alfalfa) Seed Powder, Helianthus Annuus (Sunflower) Seedcake, Prunus Amygdalus Dulcis (Sweet Almond) Seed Meal, Sodium Gluconate, Potassium Gluconate, Copper Gluconate, Calcium Gluconate, Magnesium Gluconate, Zinc Gluconate, Paraffin, Tocopheryl Succinate, Niacin, Beta-Carotene, Decyl Oleate, Aluminum Distearate, Octyldodecanol, Citric Acid, Cyanocobalamin, Magnesium Stearate, Panthenol, Limonene, Geraniol, Linalool, Hydroxycitronellal, Citronellol, Benzyl Salicylate, Citral, Methylchloroisothiazolinone, Methylisothiazolinone, Alcohol Denat. , Fragrance
, Fragrance
Убойная штука? Многие уже готовы банить? А это культовый Crème De La Mer. И расскажите теперь кому-то про поры и «вот это ваше все».
ЧИТАТЬ ЕЩЕ: Юлия Гагарина о силиконах в косметике
Действительно ли нахождение компонента в списке после N-ого (5го? 10го?) означает, что его так мало, что «он ничего не делает»?
Определять эффективность крема по позиции актива в списке совсем неправильно. Что мы можем понять по первым словам – это то, какая база в продукте. Много масел и эмолентов, что делает крем «богатым» по ощущениям и питательным – они все впереди. Гиалуронка впереди бывает крайне редко. Просто потому, что ее рабочая концентрация заканчивается на 1%. И это очень много и липко по ощущениям на коже. Потому ее нормально видеть ближе к концу.
Теперь о «больном». О пептидах. Это вообще такая вещь, которая даже если и используется в концентрации 10% (как, например, Argireline), то на этикетке отображают активное вещество (Acetyl Hexapeptide-3) по его сухому весу, который 0,001%. То есть если расставлять активные вещества по порядку «от большей концентрации к меньшей», все пептиды должны быть в самом конце списка. И это не смотря на то, что их раствор вводили в большом проценте.
То есть если расставлять активные вещества по порядку «от большей концентрации к меньшей», все пептиды должны быть в самом конце списка. И это не смотря на то, что их раствор вводили в большом проценте.
Мы же помним, что косметика – это не лекарство, потому ей еще нужно быть эстетически красивой. А в красивом продукте – красивая этикетка. Потому мировой закон позволяет все компоненты меньше 1% писать так, как удобно маркетологу. То есть выносить все «вкусные» штуки в середину списка. Так появляются пептиды и гиалуронка в середине или даже начале (если продукт ближе к гелю).
Пример: Clinique ID: Active Cartridge Concentrate for Lines & Wrinkles
INCI: Water\Aqua\Eau, Butylene Glycol, Whey Protein\Lactis Protein\Protéine Du Petit-Lait, Pentylene Glycol, Glycerin, Sodium Citrate, Prunus Amygdalus Dulcis (Sweet Almond) Seed Extract, Caffeine, Porphyridium Cruentum Extract, Acetyl Hexapeptide-8, Palmitoyl Tetrapeptide-7, Palmitoyl Tripeptide-1, Micrococcus Lysate, Pullulan, Caprylyl Glycol, Ethylhexylglycerin, Taurine, Hexylene Glycol, Hydroxypropyl Methylcellulose, Lecithin, Xanthan Gum, Carbomer, Polysorbate 20, Disodium EDTA, Phenoxyethanol, Blue 1 (Ci 42090), Red 33 (Ci 17200)
Больше материалов – в телеграме BEAUTY ADVISOR
встраивания слов в 2017 году: тенденции и направления развития
В этом посте обсуждаются недостатки встраивания слов и то, как последние подходы пытались их решить.
Содержание:
- Вложения на уровне подслов
- Обработка OOV
- Оценка
- Многосмысловые встраивания
- За пределами слов как точки
- Фразы и многословные выражения
- Смещение
- Временное измерение
- Отсутствие теоретического понимания
- Задачи и доменные вложения
- Трансферное обучение
- Вложения для нескольких языков
- Вложения на основе других контекстов
Метод word2vec, основанный на скип-грамме с отрицательной выборкой (Миколов и др., 2013) [1] , был опубликован в 2013 г. и оказал большое влияние на данную область, в основном благодаря сопутствующему программному пакету, который позволил проводить эффективное обучение плотных представлений слов и прямой интеграции в последующие модели. В некоторых отношениях мы далеко продвинулись с тех пор: встраивание слов зарекомендовало себя как неотъемлемая часть моделей обработки естественного языка (NLP). В других аспектах мы могли бы также быть в 2013 году, поскольку мы не нашли способов предварительной подготовки вложений слов, которым удалось заменить исходное слово2vec.
В других аспектах мы могли бы также быть в 2013 году, поскольку мы не нашли способов предварительной подготовки вложений слов, которым удалось заменить исходное слово2vec.
Этот пост будет посвящен недостаткам встраивания слов и тому, как последние подходы пытались их решить. Если не указано иное, в этом посте обсуждаются предварительно обученных вложений слов, то есть представлений слов, которые были изучены в большом корпусе с использованием word2vec и его вариантов. Предварительно обученные встраивания слов наиболее эффективны, если не доступны миллионы обучающих примеров (и, таким образом, полезен перенос знаний из большого неразмеченного корпуса), что справедливо для большинства задач НЛП. Введение в встраивание слов см. в этом сообщении блога.
Вложения на уровне подслов
Вложения слов были дополнены информацией на уровне подслов для многих приложений, таких как распознавание именованных объектов (Lample et al., 2016) [2] , тегирование частей речи (Plank et al. ., 2016) [3] , синтаксический анализ зависимостей (Ballesteros et al., 2015; Yu & Vu, 2017) [4] , [5] и языковое моделирование (Kim et al., 2016) [6] . Большинство этих моделей используют CNN или BiLSTM, которые принимают в качестве входных данных символы слова и выводят 9 символов.0039 символьное представление слов.
., 2016) [3] , синтаксический анализ зависимостей (Ballesteros et al., 2015; Yu & Vu, 2017) [4] , [5] и языковое моделирование (Kim et al., 2016) [6] . Большинство этих моделей используют CNN или BiLSTM, которые принимают в качестве входных данных символы слова и выводят 9 символов.0039 символьное представление слов.
Однако было показано, что для включения информации о символах в предварительно обученные вложения функции n-грамм символов более эффективны, чем функции композиции для отдельных символов (Wieting et al., 2016; Bojanowski et al., 2017) [7 ] , [8] . N-граммы символов — далеко не новая функция для категоризации текста (Cavnar et al., 1994) [9] — особенно эффективны и также составляют основу классификатора fastText Facebook (Joulin et al., 2016). [10] . Вложения, изученные с помощью fastText, доступны на 294 языках.
Единицы подслов, основанные на кодировании пар байтов, оказались особенно полезными для машинного перевода (Sennrich et al. , 2016) [11] , где они заменили слова в качестве стандартных единиц ввода. Они также полезны для задач с большим количеством неизвестных слов, таких как типизация сущностей (Heinzerling & Strube, 2017) [12] , но пока не доказано, что они полезны для стандартных задач НЛП, где это не является серьезной проблемой. Хотя их легко выучить, трудно увидеть их преимущества перед символьными представлениями для большинства задач (Vania & Lopez, 2017) [13] .
, 2016) [11] , где они заменили слова в качестве стандартных единиц ввода. Они также полезны для задач с большим количеством неизвестных слов, таких как типизация сущностей (Heinzerling & Strube, 2017) [12] , но пока не доказано, что они полезны для стандартных задач НЛП, где это не является серьезной проблемой. Хотя их легко выучить, трудно увидеть их преимущества перед символьными представлениями для большинства задач (Vania & Lopez, 2017) [13] .
Другим вариантом использования предварительно обученных вложений, которые интегрируют информацию о символах, является использование современной языковой модели (Jozefowicz et al., 2016) [14] , обученной на большом корпусе предметной области, например. 1 Billion Word Benchmark (предварительно обученную модель Tensorflow можно найти здесь). В то время как языковое моделирование оказалось полезным для различных задач в качестве вспомогательной цели (Rei, 2017) [15] , предварительно обученные вложения языковых моделей также использовались для увеличения встраивания слов (Peters et al. , 2017) [16] . По мере того, как мы начинаем лучше понимать, как предварительно обучать и инициализировать наши модели, встраивание предварительно обученных языковых моделей становится более эффективным. Они могут даже заменить word2vec в качестве основного выбора для инициализации встраивания слов в силу того, что за последние годы они стали более выразительными и более простыми в обучении благодаря более совершенным платформам и большему количеству вычислительных ресурсов.
, 2017) [16] . По мере того, как мы начинаем лучше понимать, как предварительно обучать и инициализировать наши модели, встраивание предварительно обученных языковых моделей становится более эффективным. Они могут даже заменить word2vec в качестве основного выбора для инициализации встраивания слов в силу того, что за последние годы они стали более выразительными и более простыми в обучении благодаря более совершенным платформам и большему количеству вычислительных ресурсов.
Обработка OOV
Одна из основных проблем использования предварительно обученных вложений слов заключается в том, что они не могут работать со словами вне словаря (OOV), т. е. словами, которые не были замечены во время обучения. Обычно такие слова устанавливаются в токен UNK и им присваивается один и тот же вектор, что является неэффективным выбором, если количество слов OOV велико. Вложения на уровне подслов, как обсуждалось в предыдущем разделе, являются одним из способов смягчить эту проблему. Еще один способ, эффективный для понимания прочитанного (Dhingra et al., 2017) [17] — присвоить словам OOV их предварительно обученное встраивание слов, если оно доступно.
Еще один способ, эффективный для понимания прочитанного (Dhingra et al., 2017) [17] — присвоить словам OOV их предварительно обученное встраивание слов, если оно доступно.
В последнее время были предложены различные подходы к созданию вложений для слов OOV на лету. Herbelot and Baroni (2017) [18] инициализируют встраивание слов OOV как сумму слов их контекста, а затем быстро уточняют встраивание только OOV с высокой скоростью обучения. Их подход успешен для набора данных, который явно требует моделирования одноразовых слов, но неясно, можно ли масштабировать его для надежной работы для более типичных задач НЛП. Еще один интересный подход к созданию вложений слов OOV заключается в обучении символьной модели для явного повторного создания предварительно обученных вложений (Pinter et al., 2017) 9.0035 [19] . Это особенно полезно в сценариях с низким уровнем ресурсов, когда большой корпус недоступен и доступны только предварительно обученные встраивания.
Оценка
Оценка предварительно обученных вложений была спорным вопросом с момента их создания, поскольку было показано, что обычно используемая оценка с помощью наборов данных сходства слов или аналогий слабо коррелирует с производительностью последующего потока (Цветков и др., 2015) [ 20] . Семинар RepEval на ACL 2016 был посвящен исключительно лучшим способам оценки предварительно обученных вложений. В нынешнем виде консенсус, похоже, заключается в том, что хотя предварительно обученные вложения могут оцениваться на внутренних задачах, таких как сходство слов для сравнения с предыдущими подходами, лучший способ их оценки — это внешняя оценка на последующих задачах.
Многосмысловые вложения
Часто цитируемая критика словесных вложений заключается в том, что они не могут уловить полисемию. В учебном пособии на ACL 2016 была описана работа последних лет, направленная на изучение отдельных вложений для нескольких значений слова (Neelakantan et al. , 2014; Iacobacci et al., 2015; Pilehvar & Collier, 2016) [21] , [22] , [23] . Однако большинство существующих подходов к обучению многосмысловым встраиваниям оценивают исключительно сходство слов. Пилехвар и др. (2017) [24] — одни из первых, показавших результаты по категоризации темы как последующей задачи; в то время как многосмысловые вложения превосходят случайно инициализированные вложения слов в их экспериментах, они превосходят предварительно обученные вложения слов.
, 2014; Iacobacci et al., 2015; Pilehvar & Collier, 2016) [21] , [22] , [23] . Однако большинство существующих подходов к обучению многосмысловым встраиваниям оценивают исключительно сходство слов. Пилехвар и др. (2017) [24] — одни из первых, показавших результаты по категоризации темы как последующей задачи; в то время как многосмысловые вложения превосходят случайно инициализированные вложения слов в их экспериментах, они превосходят предварительно обученные вложения слов.
Учитывая выдающиеся результаты, достигнутые в последние годы системами нейронного машинного перевода, использующими встраивание слов (Johnson et al., 2016) [25] , кажется, что нынешнее поколение моделей достаточно выразительно, чтобы контекстуализировать и устранять неоднозначность слов в контексте без необходимости полагаться на выделенный конвейер устранения неоднозначности или многосмысловые вложения. Однако нам по-прежнему нужны лучшие способы понять, действительно ли наши модели способны в достаточной степени устранять неоднозначность слов и как при необходимости улучшить это поведение при устранении неоднозначности.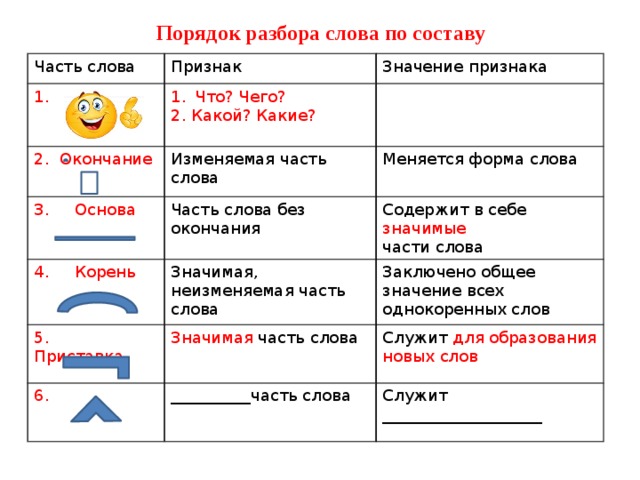
Помимо слов как точек
Хотя нам может и не понадобиться отдельное встраивание для каждого значения каждого слова для хорошей производительности нисходящего потока, сведение каждого слова к точке в векторном пространстве бесспорно чрезмерно упрощает и заставляет нас упускать нюансы, которые могли бы быть полезным для последующих задач. Таким образом, интересным направлением является использование других репрезентаций, которые лучше отражают эти грани. Vilnis & McCallum (2015) [26] предлагают моделировать каждое слово как распределение вероятностей, а не точечный вектор, что позволяет нам представлять массу вероятности и неопределенность в определенных измерениях. Ативараткун и Уилсон (2017) [27] расширяет этот подход до мультимодального распределения, которое позволяет иметь дело с полисемией, следствием, неопределенностью и улучшает интерпретируемость.
Вместо изменения представления пространство встраивания также можно изменить, чтобы лучше представить определенные функции. Никель и Киела (2017) [28] , например, встраивают слова в гиперболическое пространство, чтобы изучить иерархические представления. Поиск других способов представления слов, которые включают лингвистические предположения или лучше учитывают характеристики последующих задач, является убедительным направлением исследований.
Никель и Киела (2017) [28] , например, встраивают слова в гиперболическое пространство, чтобы изучить иерархические представления. Поиск других способов представления слов, которые включают лингвистические предположения или лучше учитывают характеристики последующих задач, является убедительным направлением исследований.
Фразы и выражения, состоящие из нескольких слов
В дополнение к тому, что вложения слов не в состоянии уловить несколько значений слов, они также не могут уловить значения фраз и выражений из нескольких слов, что может быть функцией значения составляющих их слова или иметь совершенно новое значение. Вложения фраз уже были предложены в оригинальной статье word2vec (Mikolov et al., 2013) [29] , и велась последовательная работа по изучению лучших композиционных и некомпозиционных вложений фраз (Yu & Dredze, 2015; Hashimoto & Tsuruoka). , 2016) [30] , [31] . Однако, как и в случае многосмысловых вложений, явное моделирование фраз до сих пор не показало значительных улучшений в последующих задачах, которые оправдывали бы дополнительную сложность.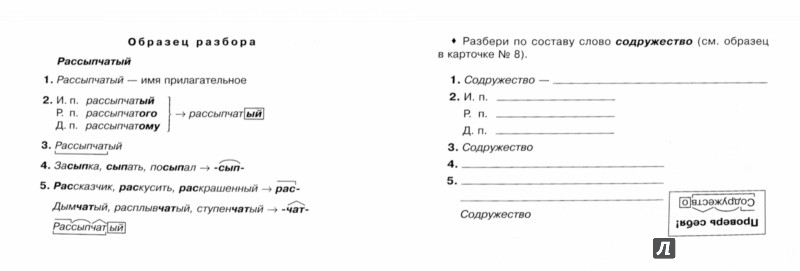 Аналогичным образом, лучшее понимание того, как фразы моделируются в нейронных сетях, проложит путь к методам, расширяющим возможности наших моделей по улавливанию композиционности и некомпозиционности выражений.
Аналогичным образом, лучшее понимание того, как фразы моделируются в нейронных сетях, проложит путь к методам, расширяющим возможности наших моделей по улавливанию композиционности и некомпозиционности выражений.
Смещение
Смещение в наших моделях становится все более серьезной проблемой, и мы только начинаем понимать его последствия для обучения и оценки наших моделей. Даже встроенные слова, обученные на статьях Google News, в тревожной степени демонстрируют женские/мужские гендерные стереотипы (Bolukbasi et al., 2016) [32] . Понимание того, какие другие предубеждения фиксируются встраиванием слов, и поиск более эффективных способов устранения этих предубеждений будет ключом к разработке справедливых алгоритмов для обработки естественного языка.
Временное измерение
Слова — это зеркало духа времени, и их значения подвержены постоянным изменениям; текущие представления слов могут существенно отличаться от того, как эти слова использовались в прошлом и будут использоваться в будущем. Таким образом, интересным направлением является учет временного измерения и диахронической природы слов. Это позволяет выявить закономерности семантических изменений (Hamilton et al., 2016; Bamler & Mandt, 2017; Dubossarsky et al., 2017) 9или фиксировать динамику смысловых отношений (Кутузов и др., 2017) [37:1] .
Таким образом, интересным направлением является учет временного измерения и диахронической природы слов. Это позволяет выявить закономерности семантических изменений (Hamilton et al., 2016; Bamler & Mandt, 2017; Dubossarsky et al., 2017) 9или фиксировать динамику смысловых отношений (Кутузов и др., 2017) [37:1] .
Недостаток теоретического понимания
Помимо понимания того, что word2vec со скип-грам-отрицательной выборкой неявно факторизует матрицу PMI (Levy & Goldberg, 2014) [38] , сравнительно мало работы по получению лучшего теоретического понимания пространство для встраивания слова и его свойства, например. это суммирование фиксирует отношения аналогии. Арора и др. (2016) [39] предлагают новую генеративную модель для встраивания слов, которая рассматривает генерацию корпуса как случайное блуждание вектора дискурса и устанавливает некоторые теоретические мотивы поведения аналогии. Гиттенс и др. (2017) [40] обеспечивают более тщательное теоретическое обоснование аддитивной композиционности и показывают, что векторы слов со скип-граммами оптимальны в информационно-теоретическом смысле. Mimno & Thompson (2017) [41] , кроме того, выявили интересную связь между вложениями слов и вложениями контекстных слов, т. е. то, что они не равномерно распределены по векторному пространству, а занимают узкий конус, который диаметрально противоположен контексту. вложения слов. Несмотря на эти дополнительные сведения, наше понимание местоположения и свойств встраивания слов все еще отсутствует, и необходима дополнительная теоретическая работа.
Mimno & Thompson (2017) [41] , кроме того, выявили интересную связь между вложениями слов и вложениями контекстных слов, т. е. то, что они не равномерно распределены по векторному пространству, а занимают узкий конус, который диаметрально противоположен контексту. вложения слов. Несмотря на эти дополнительные сведения, наше понимание местоположения и свойств встраивания слов все еще отсутствует, и необходима дополнительная теоретическая работа.
Встраивания для конкретных задач и доменов
Одним из основных недостатков использования предварительно обученных вложений является то, что данные новостей, используемые для их обучения, часто сильно отличаются от данных, на которых мы хотели бы их использовать. Однако в большинстве случаев у нас нет доступа к миллионам немаркированных документов в нашем целевом домене, который позволил бы предварительно обучить хорошие встраивания с нуля. Таким образом, мы хотели бы иметь возможность адаптировать вложения, предварительно обученные для больших корпусов новостей, чтобы они отражали характеристики нашей целевой области, но при этом сохраняли все соответствующие существующие знания.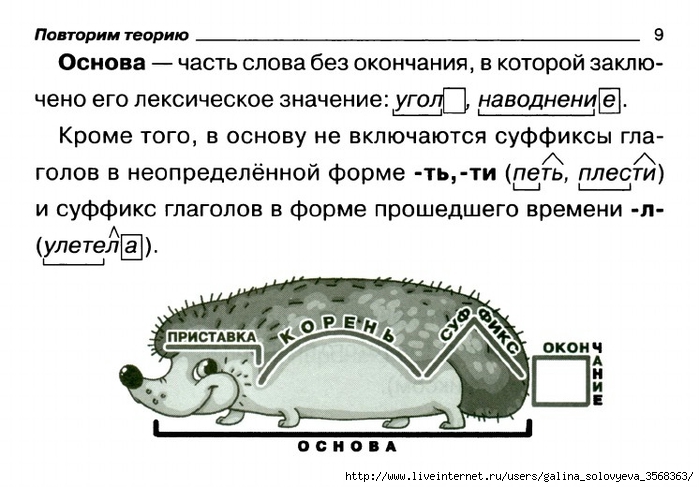 Лу и Чжэн (2017) [42] предложил регуляризованную модель скип-грамм для изучения таких междоменных вложений. В будущем нам понадобятся еще более эффективные способы адаптации предварительно обученных вложений к новым областям или включения знаний из нескольких соответствующих областей.
Лу и Чжэн (2017) [42] предложил регуляризованную модель скип-грамм для изучения таких междоменных вложений. В будущем нам понадобятся еще более эффективные способы адаптации предварительно обученных вложений к новым областям или включения знаний из нескольких соответствующих областей.
Вместо того, чтобы адаптироваться к новой области, мы также можем использовать существующие знания, закодированные в семантических лексиконах, чтобы дополнить предварительно обученные вложения информацией, которая имеет отношение к нашей задаче. Эффективным способом внедрить такие отношения в пространство вложения является модернизация (Faruqui et al., 2015) [43] , который был расширен за счет других ресурсов, таких как ConceptNet (Speer et al., 2017) [44] , и дополнен интеллектуальным выбором положительных и отрицательных примеров (Mrkšic et al., 2017) [ 45] . Внедрение дополнительных предварительных знаний в вложения слов, такие как монотонность (You et al. , 2017) [46] , сходство слов (Niebler et al., 2017) [47] , оценка или интенсивность, связанные с заданием, или логические отношения является важным направлением исследований, которое позволит сделать наши модели более надежными.
, 2017) [46] , сходство слов (Niebler et al., 2017) [47] , оценка или интенсивность, связанные с заданием, или логические отношения является важным направлением исследований, которое позволит сделать наши модели более надежными.
Внедрения Word полезны для широкого круга приложений, выходящих за рамки НЛП, таких как поиск информации, рекомендации и предсказание ссылок в базах знаний, которые имеют свои собственные подходы к конкретным задачам. Ву и др. (2017) [48] предлагают модель общего назначения, которая совместима со многими из этих приложений и может служить надежной основой.
Перенос обучения
Вместо адаптации встраивания слов к какой-либо конкретной задаче в недавней работе была предпринята попытка создать контекстуализировали векторов слов, дополнив вложения слов вложениями, основанными на скрытых состояниях моделей, предварительно обученных для определенных задач, таких как машинный перевод (McCann et al. , 2017) [49] или языковое моделирование (Peters et al. , 2018) [50] . Вместе с тонкой настройкой предварительно обученных моделей (Howard and Ruder, 2018) [51] это одно из самых перспективных направлений исследований.
, 2017) [49] или языковое моделирование (Peters et al. , 2018) [50] . Вместе с тонкой настройкой предварительно обученных моделей (Howard and Ruder, 2018) [51] это одно из самых перспективных направлений исследований.
Встраивания для нескольких языков
Поскольку модели НЛП все чаще используются и оцениваются для нескольких языков, создание многоязычных вложений слов становится все более важным вопросом, и в последние годы к нему возрос интерес. Перспективным направлением является разработка методов, которые изучают межъязыковые представления с минимальным количеством параллельных данных, чтобы их можно было легко применять для изучения представлений даже для языков с низким уровнем ресурсов. Недавний обзор в этой области см. в Ruder et al. (2017) [52] .
Встраивания на основе других контекстов
Встраивания слов обычно изучаются только на основе окна слов окружающего контекста. Леви и Голдберг (2014) [53] показали, что структуры зависимости могут использоваться в качестве контекста для захвата большего количества синтаксических словесных отношений; Köhn (2015) [54] обнаруживает, что такие вложения на основе зависимостей лучше всего работают для конкретного многоязычного метода оценки, который группирует вложения по различным синтаксическим признакам.
Меламуд и др. (2016) [55] отмечают, что разные типы контекста хорошо работают для разных последующих задач и что простое объединение вложений слов, изученных с разными типами контекста, может дать дополнительный прирост производительности. Учитывая недавний успех включения графовых структур в нейронные модели для различных задач, как, например, продемонстрированные графо-сверточными нейронными сетями (Bastings et al., 2017; Marcheggiani & Titov, 2017) [56] [57 ] , мы можем предположить, что включение таких структур для изучения вложений для последующих задач также может быть полезным.
Помимо выбора слов контекста по-разному, дополнительный контекст может также использоваться другими способами: Tissier et al. (2017) [58] включить информацию о совпадениях из словарных определений в процесс отрицательной выборки, чтобы сблизить связанные работы и предотвратить их использование в качестве отрицательных выборок. Мы можем думать о актуальной или родственной информации, полученной из других контекстов, таких как заголовки статей или вводные абзацы Википедии, которые можно было бы аналогичным образом использовать, чтобы сделать представления более применимыми к конкретной последующей задаче.
Заключение
Приятно видеть, что как сообщество мы продвигаемся от применения встраивания слов к каждой возможной проблеме к более принципиальному, тонкому и практическому пониманию их. Этот пост был предназначен для того, чтобы осветить некоторые из текущих тенденций и будущих направлений изучения встраивания слов, которые я считаю наиболее привлекательными. Я, несомненно, не упомянул многие другие области, столь же важные и заслуживающие внимания. Пожалуйста, дайте мне знать в комментариях ниже, что я пропустил, где допустил ошибку или исказил метод, или просто какой аспект встраивания слов вы считаете особенно интересным или неизученным.
Цитата
Для атрибуции в академических контекстах или книгах, пожалуйста, указывайте эту работу как:
Себастьян Рудер, «Вложения слов в 2017 году: тенденции и будущие направления». http://ruder.io/word-embeddings-2017/, 2017 г.
Цитата BibTeX:
@misc{ruder2017wordembeddings2017,
автор = {Рудер, Себастьян},
title = {{Вставка Word в 2017 году: тенденции и направления развития}},
год = {2017},
какопубликовано = {\url{http://ruder. io/word-embeddings-2017/}},
}
 io/word-embeddings-2017/}},
}
io/word-embeddings-2017/}},
}
Hacker News
Обратитесь к обсуждению в Hacker News, чтобы узнать больше о встраивании слов.
Другие сообщения в блогах о встраиваниях слов
Если вы хотите узнать больше о встраиваниях слов, также доступны следующие другие сообщения в блогах о встраиваниях слов:
- О встраиваниях слов — Часть 1
- О встраивании слов. Часть 2. Приближение к softmax
- О встраивании слов. Часть 3. Секретные ингредиенты word2vec
- Неофициальная часть 4: Обзор моделей межъязыкового встраивания
Ссылки
Изображение на обложке предоставлено Hamilton et al. (2016)
Миколов Т., Коррадо Г., Чен К. и Дин Дж. (2013). Эффективная оценка представлений слов в векторном пространстве. Материалы Международной конференции по представительствам в обучении (ICLR 2013), 1–12. ↩︎
Лэмпл Г., Баллестерос М., Субраманиан С., Каваками К. и Дайер К. (2016).
Нейронные архитектуры для распознавания именованных объектов. В NAACL-HLT 2016. ↩︎Планк Б., Согаард А. и Голдберг Ю. (2016). Многоязычная маркировка частей речи с двунаправленными моделями долговременной краткосрочной памяти и вспомогательной потерей. В материалах 54-го ежегодного собрания Ассоциации компьютерной лингвистики. ↩︎
Бальестерос, М., Дайер, К., и Смит, Н. А. (2015). Улучшенный синтаксический анализ на основе перехода путем моделирования символов вместо слов с помощью LSTM. В материалах EMNLP 2015. https://doi.org/10.18653/v1/D15-1041 ↩︎
Ю, X. и Ву, Н. Т. (2017). Модель композиции символов со сверточными нейронными сетями для разбора зависимостей на морфологически богатых языках. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (стр. 672–678). ↩︎
Ким Ю., Джернит Ю., Зонтаг Д. и Раш А. М. (2016). Модели нейронного языка с учетом символов. АААИ. Получено с http://arxiv.
org/abs/1508.06615 ↩︎Витинг, Дж., Бансал, М., Гимпель, К., и Ливеску, К. (2016). Charagram: встраивание слов и предложений с помощью символьных n-грамм. Получено с http://arxiv.org/abs/1607.02789.↩︎
Бояновски П., Грейв Э., Жоулин А. и Миколов Т. (2017). Обогащение векторов слов информацией о подсловах. Труды Ассоциации компьютерной лингвистики. Получено с http://arxiv.org/abs/1607.04606 ↩︎
Кавнар, В. Б., Тренкл, Дж. М., и Ми, А. А. (1994). Категоризация текста на основе N-грамм. Анн-Арбор, штат Мичиган, 48113.2, 161–175. https://doi.org/10.1.1.53.9367 ↩︎
Жулен А., Грейв Э., Бояновски П. и Миколов Т. (2016). Набор хитростей для эффективной классификации текстов. Препринт arXiv arXiv: 1607.01759. Получено с http://arxiv.org/abs/1607.01759 ↩︎
Сеннрих Р., Хэддоу Б. и Берч А. (2016). Нейронный машинный перевод редких слов с подсловными единицами. В материалах 54-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL 2016).
Получено с http://arxiv.org/abs/1508.07909 ↩︎Хайнцерлинг, Б., и Шттрубе, М. (2017). BPEmb: Предварительно обученные вложения подслов без токенизации на 275 языках. Получено с http://arxiv.org/abs/1710.02187 ↩︎
Вания, К., и Лопес, А. (2017). От символов к словам и к промежуточному: улавливаем ли мы морфологию? В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (стр. 2016–2027). ↩︎
Йозефович Р., Виньялс О., Шустер М., Шазир Н. и Ву Ю. (2016). Изучение ограничений языкового моделирования. Препринт arXiv arXiv: 1602.02410. Получено с http://arxiv.org/abs/1602.02410 ↩︎
Рей, М. (2017). Полууправляемое многозадачное обучение для маркировки последовательностей. В материалах ACL 2017. ↩︎
Петерс, М.Э., Аммар, В., Бхагаватула, К., и Пауэр, Р. (2017). Полуконтролируемое тегирование последовательностей с двунаправленными языковыми моделями. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (стр.
1756–1765). ↩︎Дингра, Б., Лю, Х., Салахутдинов, Р., и Коэн, В. В. (2017). Сравнительное исследование встраивания слов для понимания прочитанного. Препринт arXiv arXiv: 1703.00993. ↩︎
Гербелот, А., и Барони, М. (2017). Обучение с высоким риском: получение новых векторов слов из крошечных данных. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка. ↩︎
Пинтер, Ю., Гатри, Р., и Эйзенштейн, Дж. (2017). Имитация встраивания слов с использованием RNN подслов. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка. Получено с http://arxiv.org/abs/1707.06961 ↩︎
Цветков Ю., Фаруки М., Линг В., Лэмпл Г. и Дайер К. (2015). Оценка представлений векторов слов путем выравнивания подпространства. Материалы конференции 2015 г. по эмпирическим методам обработки естественного языка, Лиссабон, Португалия, 17-21 сентября 2015 г., 2049 г.–2054. ↩︎
Нилакантан, А.
, Шанкар, Дж., Пассос, А., и Маккаллум, А. (2014). Эффективная непараметрическая оценка нескольких вложений на слово в векторном пространстве. В Proceedings fo (стр. 1059–1069). ↩︎Якобаччи И., Пилехвар М. Т. и Навильи Р. (2015). SensEmbed: изучение смысловых вложений для слова и реляционного сходства. В материалах 53-го ежегодного собрания Ассоциации компьютерной лингвистики и 7-й Международной совместной конференции по обработке естественного языка (стр. 9).5–105). ↩︎
Пилехвар, М. Т., и Коллиер, Н. (2016). Деконфлированные семантические представления. В материалах EMNLP. ↩︎
Пилехвар, М. Т., Камачо-Колладос, Дж., Навильи, Р., и Колье, Н. (2017). На пути к бесшовной интеграции смыслов слов в нижестоящие приложения НЛП. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (Том 1: Длинные статьи) (стр. 1857–1869). https://doi.org/10.18653/v1/P17-1170 ↩︎
Джонсон, М., Шустер, М., Ле, К.
В., Крикун, М., Ву, Ю., Чен, З., … Дин, Дж. (2016). Многоязычная система нейронного машинного перевода Google: включение нулевого перевода. Препринт arXiv arXiv: 1611.0455. ↩︎Вилнис, Л., и МакКаллум, А. (2015). Представления слов через гауссово вложение. ICLR. Получено с http://arxiv.org/abs/1412.6623 ↩︎
Ативараткун, Б., и Уилсон, А. Г. (2017). Мультимодальные распределения слов. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL 2017). ↩︎
Никель, М., и Киела, Д. (2017). Вложения Пуанкаре для изучения иерархических представлений. Препринт arXiv arXiv: 1705.08039. Получено с http://arxiv.org/abs/1705.08039 ↩︎
Миколов Т., Чен К., Коррадо Г. и Дин Дж. (2013). Распределенные представления слов и фраз и их композиционность. НИПС. ↩︎
Ю. М. и Дредзе М. (2015). Изучение моделей композиции для встраивания фраз. Сделки ACL, 3, 227–242. ↩︎
Хашимото, К.
, и Цуруока, Ю. (2016). Адаптивное совместное обучение композиционным и некомпозиционным вложениям фраз. ПКС, 205–215. Получено с http://arxiv.org/abs/1603.06067 ↩︎Болукбаси, Т., Чанг, К.-В., Зоу, Дж., Салиграма, В., и Калай, А. (2016). Мужчина для программиста, как женщина для домохозяйки? Устранение предвзятости встраивания слов. На 30-й конференции по системам обработки нейронной информации (NIPS 2016). Получено с http://arxiv.org/abs/1607.06520 ↩︎
Гамильтон, В.Л., Лесковец, Дж., и Джурафски, Д. (2016). Диахронические вложения слов раскрывают статистические законы семантических изменений. В материалах 54-го ежегодного собрания Ассоциации компьютерной лингвистики (стр. 1489–1501). ↩︎
Бамлер, Р., и Мандт, С. (2017). Динамические вложения слов с помощью фильтрации Skip-Gram. В Proceedings of ICML 2017. Получено с http://arxiv.org/abs/1702.08359 ↩︎
.Дубосарский, Х., Гроссман, Э., и Вайншалл, Д. (2017).
Вне контроля: законы семантических изменений и неотъемлемые предубеждения в моделях представления слов. На конференции по эмпирическим методам обработки естественного языка (стр. 1147–1156). Получено с http://aclweb.org/anthology/D17-1119.↩︎Шимански, Т. (2017). Временные аналогии слов: определение лексической замены диахроническими вложениями слов. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (стр. 448–453). ↩︎
Розин Г., Радинский К. и Адар Э. (2017). Изучение родственности слов с течением времени. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка. Получено с https://arxiv.org/pdf/1707.08081.pdf ↩︎ ↩︎
Леви, О., и Голдберг, Ю. (2014). Нейронное встраивание слов как неявная матричная факторизация. Достижения в области систем обработки нейронной информации (NIPS), 2177–2185. Получено с http://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization ↩︎
Арора С.
, Ли Ю., Лян Ю., Ма Т. и Ристески А. (2016). Подход модели скрытых переменных к встраиванию слов на основе PMI. ТАКЛ, 4, 385–399. Получено с https://transacl.org/ojs/index.php/tacl/article/viewFile/742/204 ↩︎Гиттенс, А., Ахлиоптас, Д., и Махони, М. В. (2017). Skip-Gram – Zipf + Uniform = векторная аддитивность. В материалах 55-го ежегодного собрания Ассоциации компьютерной лингвистики (стр. 69–76). https://doi.org/10.18653/v1/P17-1007 ↩︎
Мимно, Д., и Томпсон, Л. (2017). Странная геометрия скип-грама с отрицательной выборкой. В материалах конференции 2017 г. по эмпирическим методам обработки естественного языка (стр. 2863–2868). ↩︎
Лу, В., и Чжэн, В.В. (2017). Простой основанный на регуляризации алгоритм изучения междоменных вложений слов. В материалах конференции 2017 г. по эмпирическим методам обработки естественного языка (стр. 2888–2894). ↩︎
Фаруки, М., Додж, Дж., Джаухар, С.К., Дайер, К., Хови, Э.
, и Смит, Н.А. (2015). Преобразование векторов слов в семантические лексиконы. В NAACL 2015. ↩︎Спир, Р., Чин, Дж., и Хаваси, К. (2017). ConceptNet 5.5: открытый многоязычный график общих знаний. В AAAI 31 (стр. 4444–4451). Получено с http://arxiv.org/abs/1612.03975 ↩︎
Мркшич, Н., Вулич, И., Сеагдха, Д. О., Левиант, И., Райхарт, Р., Гашич, М., … Янг, С. (2017). Семантическая специализация дистрибутивных векторных пространств слов с использованием одноязычных и межъязыковых ограничений. ТАКЛ. Получено с http://arxiv.org/abs/1706.00374 ↩︎
Ю, С., Динг, Д., Канини, К., Пфайфер, Дж., и Гупта, М. (2017). Сети с глубокой решеткой и частично монотонные функции. На 31-й конференции по системам обработки нейронной информации (NIPS 2017). Получено с http://arxiv.org/abs/1709..06680 ↩︎
Ниблер, Т., Беккер, М., Пелиц, К., и Хото, А. (2017). Изучение семантической связи на основе отзывов людей с использованием метрического обучения.
. В материалах ISWC 2017. Получено с http://arxiv.org/abs/1705.07425 ↩︎Ву, Л., Фиш, А., Чопра, С., Адамс, К., Бордес, А., и Уэстон, Дж. (2017). StarSpace: встраивайте все! Препринт arXiv arXiv: 1709.03856. ↩︎
Макканн, Б., Брэдбери, Дж., Сюн, К., и Сочер, Р. (2017). Учился переводу: контекстуализированные векторы слов. Достижения в области нейронных систем обработки информации. ↩︎
Петерс, М. Э., Нойманн, М., Ийер, М., Гарднер, М., Кларк, К., Ли, К., и Зеттлемойер, Л. (2018). Глубокие контекстуализированные представления слов. Материалы NAACL-HLT 2018. ↩︎
Ховард, Дж., и Рудер, С. (2018). Тонкая настройка универсальной языковой модели для классификации текстов. В Proceedings of ACL 2018. Получено с http://arxiv.org/abs/1801.06146 ↩︎
.Рудер, С., Вулич, И., и Согаард, А. (2017). Обзор межъязыковых моделей встраивания слов Себастьян. Препринт arXiv arXiv: 1706.04902. Получено с http://arxiv.
org/abs/1706.04902 ↩︎Леви, О., и Голдберг, Ю. (2014). Вложения слов на основе зависимостей. Материалы 52-го ежегодного собрания Ассоциации компьютерной лингвистики (короткие статьи), 302–308. https://doi.org/10.3115/v1/P14-2050 ↩︎
Кён, А. (2015). Что во встраивании? Анализ вложений слов с помощью многоязычной оценки. Материалы конференции 2015 г. по эмпирическим методам обработки естественного языка, Лиссабон, Португалия, 17–21 сентября 2015 г. (2014 г.), 2067–2073 гг. ↩︎
Меламуд О., Макклоски Д., Патвардхан С. и Бансал М. (2016). Роль типов контекста и размерности в изучении встраивания слов. В материалах NAACL-HLT 2016 (стр. 1030–1040). Получено с http://arxiv.org/abs/1601.00893 ↩︎
Бастингс Дж., Титов И., Азиз В., Марчеджиани Д. и Симаан К. (2017). Сверточные кодировщики графов для нейронного машинного перевода с учетом синтаксиса. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка.
↩︎Марчеджиани Д. и Титов И. (2017). Кодирование предложений с помощью графовых сверточных сетей для маркировки семантических ролей. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка. ↩︎
Тиссье, Дж., Гравье, К., и Хабрард, А. (2017). Dict2Vec: Изучение встраивания слов с использованием лексических словарей. В материалах конференции 2017 года по эмпирическим методам обработки естественного языка. Получено с http://aclweb.org/anthology/D17-1024 ↩︎
 Нейронные архитектуры для распознавания именованных объектов. В NAACL-HLT 2016. ↩︎
Нейронные архитектуры для распознавания именованных объектов. В NAACL-HLT 2016. ↩︎ org/abs/1508.06615 ↩︎
org/abs/1508.06615 ↩︎ Получено с http://arxiv.org/abs/1508.07909 ↩︎
Получено с http://arxiv.org/abs/1508.07909 ↩︎ 1756–1765). ↩︎
1756–1765). ↩︎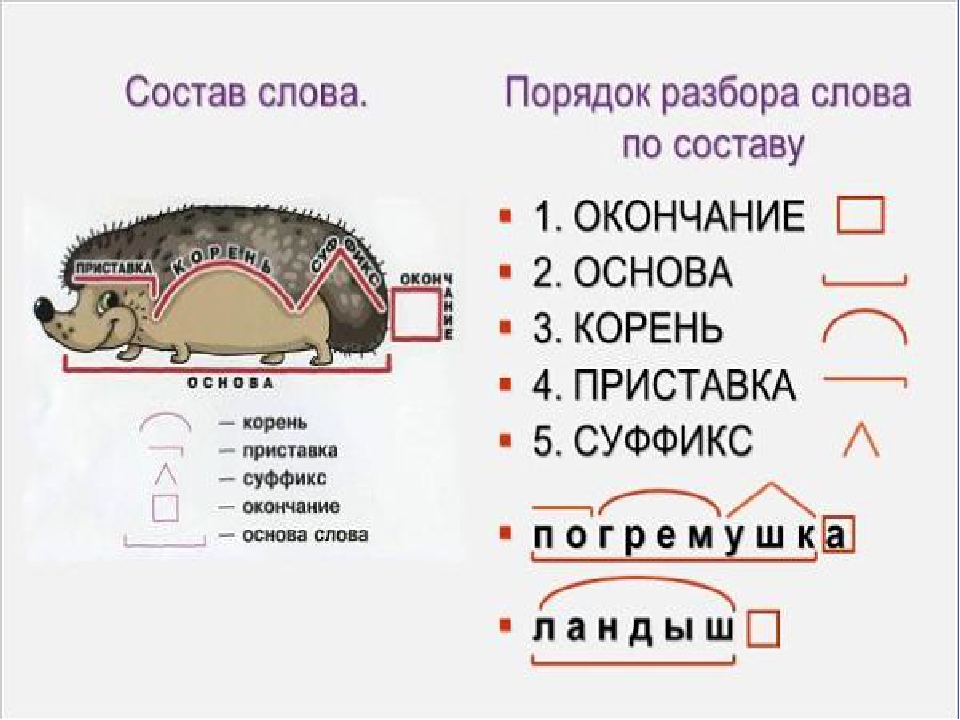 , Шанкар, Дж., Пассос, А., и Маккаллум, А. (2014). Эффективная непараметрическая оценка нескольких вложений на слово в векторном пространстве. В Proceedings fo (стр. 1059–1069). ↩︎
, Шанкар, Дж., Пассос, А., и Маккаллум, А. (2014). Эффективная непараметрическая оценка нескольких вложений на слово в векторном пространстве. В Proceedings fo (стр. 1059–1069). ↩︎ В., Крикун, М., Ву, Ю., Чен, З., … Дин, Дж. (2016). Многоязычная система нейронного машинного перевода Google: включение нулевого перевода. Препринт arXiv arXiv: 1611.0455. ↩︎
В., Крикун, М., Ву, Ю., Чен, З., … Дин, Дж. (2016). Многоязычная система нейронного машинного перевода Google: включение нулевого перевода. Препринт arXiv arXiv: 1611.0455. ↩︎ , и Цуруока, Ю. (2016). Адаптивное совместное обучение композиционным и некомпозиционным вложениям фраз. ПКС, 205–215. Получено с http://arxiv.org/abs/1603.06067 ↩︎
, и Цуруока, Ю. (2016). Адаптивное совместное обучение композиционным и некомпозиционным вложениям фраз. ПКС, 205–215. Получено с http://arxiv.org/abs/1603.06067 ↩︎ Вне контроля: законы семантических изменений и неотъемлемые предубеждения в моделях представления слов. На конференции по эмпирическим методам обработки естественного языка (стр. 1147–1156). Получено с http://aclweb.org/anthology/D17-1119.↩︎
Вне контроля: законы семантических изменений и неотъемлемые предубеждения в моделях представления слов. На конференции по эмпирическим методам обработки естественного языка (стр. 1147–1156). Получено с http://aclweb.org/anthology/D17-1119.↩︎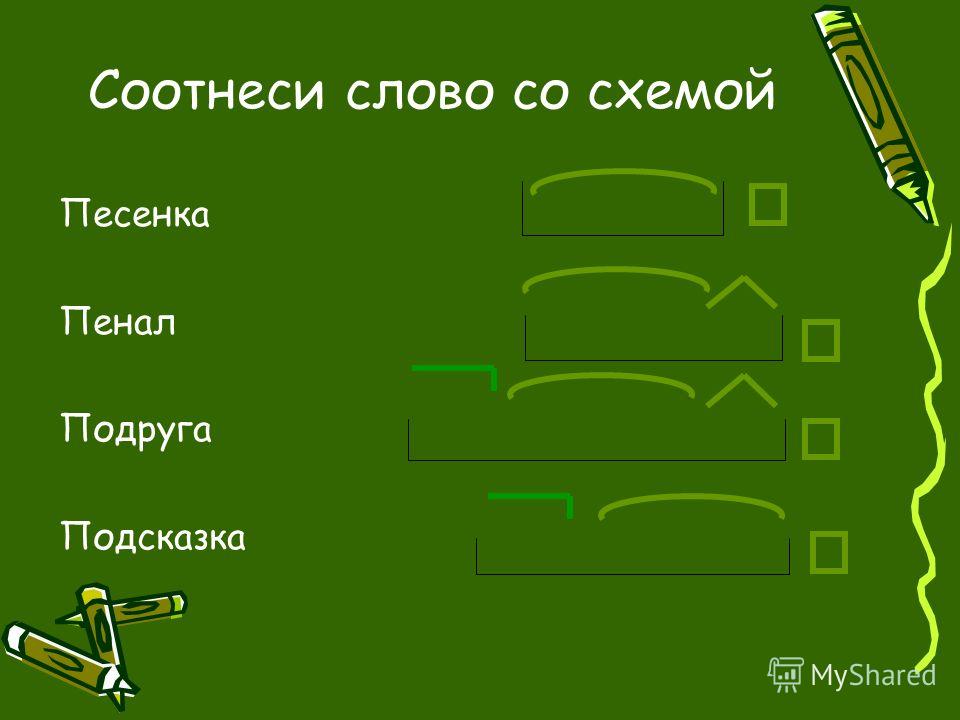 , Ли Ю., Лян Ю., Ма Т. и Ристески А. (2016). Подход модели скрытых переменных к встраиванию слов на основе PMI. ТАКЛ, 4, 385–399. Получено с https://transacl.org/ojs/index.php/tacl/article/viewFile/742/204 ↩︎
, Ли Ю., Лян Ю., Ма Т. и Ристески А. (2016). Подход модели скрытых переменных к встраиванию слов на основе PMI. ТАКЛ, 4, 385–399. Получено с https://transacl.org/ojs/index.php/tacl/article/viewFile/742/204 ↩︎ , и Смит, Н.А. (2015). Преобразование векторов слов в семантические лексиконы. В NAACL 2015. ↩︎
, и Смит, Н.А. (2015). Преобразование векторов слов в семантические лексиконы. В NAACL 2015. ↩︎ В материалах ISWC 2017. Получено с http://arxiv.org/abs/1705.07425 ↩︎
В материалах ISWC 2017. Получено с http://arxiv.org/abs/1705.07425 ↩︎ org/abs/1706.04902 ↩︎
org/abs/1706.04902 ↩︎ ↩︎
↩︎Информационный бюллетень
Если вы хотите получать регулярные обновления о достижениях в области машинного обучения и обработки естественного языка, подпишитесь на мою рассылку ниже. Адрес электронной почты: Имя (необязательно): Фамилия (необязательно):латиница | BGSU
Включение высокой контрастности
Латинская программа находится на факультете мировых языков и культур Колледжа искусств и наук.
- mMinor Доступно
- BBachelors Доступно
- Второстепенное Второстепенное Доступно
- Bachelor’sBachelors Available
Латинский курс BGSU открывает двери для изучения языков и цивилизаций Древней Греции и Рима.
Современные представления о многих вещах — от политики до искусства, спорта, истории, права, литературы, философии, риторики, общества — исходят от древних греков и римлян.
Кроме того, изучение латыни расширит ваш словарный запас, улучшит грамматические навыки и сделает вас более эффективным собеседником.
Информация о приеме
Запланировать визит
Запросить информацию
Понимание через понимание
Изучение другой культуры с помощью языка делает вас более гибким, гибким и сильным мыслителем. Изучение того, как люди из других культур живут, любят, сражаются и умирают, побуждает вас мыслить иначе и глубже.
Кроме того, изучение прошлого открывает перед вами перспективы. Греческая и римская мысль, выраженная на древнегреческом и латинском языках, пронизывает современное представление о жизни и о том, что значит быть человеком, И многие из наиболее влиятельных литературных произведений были написаны на греческом и латинском языках. Повышение осведомленности, которое вы получаете благодаря изучению классики, позволяет вам глубже понять себя и других, чтобы вы могли более мудро строить свое будущее.
Греческая и римская мысль, выраженная на древнегреческом и латинском языках, пронизывает современное представление о жизни и о том, что значит быть человеком, И многие из наиболее влиятельных литературных произведений были написаны на греческом и латинском языках. Повышение осведомленности, которое вы получаете благодаря изучению классики, позволяет вам глубже понять себя и других, чтобы вы могли более мудро строить свое будущее.
Выделиться на таких курсах, как
- Древнегреческий
- Древние историки
- Обучение учеников
- Классическая мифология
- Великие греческие умы
- Великие римские умы
- Латинская литература
- Средневековые легенды
- Скандинавская мифология
- Римская жизнь
- Женщины в Древней Греции и Риме
- Сила слова от греческих и латинских корней
Word Power
По приблизительным подсчетам, из 20 000 наиболее распространенных слов в английском языке примерно половина происходит от латыни либо напрямую, либо через французский язык. И по крайней мере 2000 слов восходят к греческому языку, в результате чего общий словарный запас английского языка, полученный из латинского и греческого языков, составляет около 60%.
И по крайней мере 2000 слов восходят к греческому языку, в результате чего общий словарный запас английского языка, полученный из латинского и греческого языков, составляет около 60%.
Более того, по крайней мере 90 процентов специальной лексики наук происходит от греческого и латинского языков.
Сила слова дает вам контроль над словами, основными элементами любого дискурса, позволяя вам хорошо говорить, хорошо читать и хорошо писать.
Латинский язык и жизнь
BGSU предлагает латынь в качестве основной или дополнительной и является идеальной подготовкой к работе, которая требует от вас быть эффективным сотрудником, коммуникатором, решать проблемы и мыслить. Он также готовит вас к аспирантуре в области древнего искусства и археологии, классики, стоматологии, истории, права, медицины или философии.
Завершение основного (или дополнительного) обучения латыни в Колледже образования и развития человеческого потенциала сертифицирует преподавание языка в средней школе.
Латинский курс BGSU делает упор на изучение языка. Отдельная специальность по классической цивилизации доступна для более широкого изучения культур Греции и Рима.
Учебный план
После завершения латыни 2020 года, что эквивалентно четвертому году обучения латыни в старшей школе, вы начинаете свой основной курс из двадцати одного кредита с двумя факультативными курсами древнегреческого языка или классической цивилизации. Если вы не изучали латынь в старшей школе, вы можете получить степень бакалавра. взяв латынь 1010-2020 и двадцать один дополнительный кредит. Время, необходимое для получения степени, не увеличивается. Если вы заинтересованы в изучении латыни в ускоренном и интенсивном темпе, свяжитесь с одним из факультетов классики.
Учитесь вместе с нашими отмеченными наградами преподавателями, внедряя новые эффективные методики и инновационные стратегии активного обучения, призванные помочь вам достичь более глубокого уровня обучения.
На занятиях по латыни используется культурный и читательский подход к изучению языка, который способствует развитию этих четырех навыков: аудирования, разговорной речи, чтения и письма. Эти основные навыки подкрепляются яркими примерами чтения на латыни.
Эти основные навыки подкрепляются яркими примерами чтения на латыни.
Изучайте греческие и латинские корни слов в курсе Word Power, предназначенном для улучшения ваших коммуникативных навыков и расширения словарного запаса.
Расширенные чтения доступны для изучения конкретных писателей — биографов, историков, писателей, философов и поэтов. О разграблении Трои и обреченной любви царицы Дидоны читайте в «Энеиде » Вергилия . Изучите скандальные карьеры первых римских императоров с Тацитом и Светонием. Вглядитесь сквозь театральные маски комедии и трагедии, читая драматическую поэзию Плавта и Сенеки.
Около 90% словарного запаса французского, итальянского, испанского, португальского, румынского и других романских языков происходит от латыни.
Карьера
Ожидается, что в течение вашей трудовой карьеры вы будете занимать 8-10 различных должностей. Сегодняшние работодатели стремятся нанять тех, кто приобрел передаваемые навыки, которые необходимы для изучения классики и латыни — сотрудничество, общение, поиск и решение проблем.
Латинский язык является отличной подготовкой к предюридическим, предстоматологическим и домедицинским программам. Он также обеспечивает основу для дипломной работы в области древнего искусства и археологии, древней истории, классики или философии.
Когда вы понимаете языки и культуры мира, вы приобретаете навык, который необходим сегодняшним гражданам мира. Когда вы закончите со степенью по языку, вы сможете найти работу в самых разных областях, таких как искусство, бизнес, образование, защита окружающей среды, правительство, здравоохранение и социальные услуги, международные отношения, журналистика, политика, теология и переводческие услуги.
Кроме того, изучение второго языка имеет много неврологических преимуществ. Повышенная когнитивная гибкость, улучшенные способности к концентрации и сосредоточению были обнаружены в нескольких исследованиях.
Бюро статистики труда США установило, что в 2020 году средняя заработная плата выпускников, изучающих иностранные языки, включая латынь, составляла 54 000 долларов.
Займитесь своей карьерой
- Искусствовед
- Автор
- Стоматолог
- Воспитатель
- Журналист
- Юрист
- Смотритель музея
- Врач
- Издатель
Латынь является основным языком права, медицины, политики и теологии.
Дополнительная информация
- Образец требований к программе
- Информация о приеме
- Запланировать посещение
- Запрос информации
- БГСУ «Мировые языки и культуры» в Instagram
Латинская программа находится на факультете мировых языков и культур Колледжа искусств и наук.
Обучение за рубежом
Нет лучшего способа выучить язык и обычаи другой страны, чем погрузиться в ее культуру. Всем специалистам, изучающим мировые языки и культуры, предлагается принять участие в программе обучения за рубежом. Департамент предлагает возможности обучения за границей в Австрии, Китае, Кубе, Франции, Греции, Японии, Италии, России и Испании.
Учебные сообщества
BGSU имеет ряд учебных сообществ, которые представляют собой общежития, в которых студенты живут рядом с другими людьми, имеющими общие интересы.
Global Village
Учебное сообщество Global Village состоит из иностранных и американских студентов всех специальностей, которые искренне заинтересованы во встречах и изучении людей из других стран и культур. Жители живут в паре со студентами разного культурного происхождения и делят жилое пространство. Это уникальное и динамичное сообщество подпитывается межкультурным общением, весельем, дружбой и моментами открытий.
Результаты обучения
После получения степени бакалавра студенты, изучающие латынь, должны:
- Читать, понимать и критически комментировать тексты на латыни;
- Продемонстрировать навыки перевода, точно разбирая слова, используя знание латинской и английской грамматики и синтаксиса;
- Выразить знание жанра переводимых произведений;
- Применять навыки критического анализа и интерпретации латинской литературы и общества, которое ее породило;
- Участвуйте в рациональной, вежливой беседе на сложные темы с уважением к другим.

Аккредитация
Государственный университет Боулинг-Грин [BGSU] аккредитован Высшей учебной комиссией. БГСУ аккредитован Высшей учебной комиссией с 01.01.1916. Последнее подтверждение аккредитации было получено в 2012 — 2013 гг. Вопросы следует направлять в Управление институциональной эффективности.
Латинская программа прошла проверку программы/кластера в 2016-17 учебном году.
Дополнительная информация об аккредитации
Профессиональное лицензирование
Программы Университета штата Боулинг-Грин, ведущие к лицензированию, сертификации и/или одобрению, независимо от того, проводятся ли они онлайн, очно или в смешанном формате, удовлетворяют академическим требованиям для этих наборов полномочий вперед штатом Огайо.
Требования к лицензированию, сертификации и/или подтверждению права сильно различаются от одной профессии к другой и от штата к штату. Латинская программа не приводит к получению профессиональной лицензии.
Дополнительная информация о профессиональной лицензии
* Информация о трудоустройстве и заработной плате была собрана Управлением академической оценки на основе опроса выпускников за AY2015-2018. Данные собираются примерно во время открытия, а последующий опрос проводится через шесть месяцев после открытия. Что касается вопроса о заработной плате, данные по программам с менее чем пятнадцатью ответами не включены. Заработная плата по этим программам предоставлена Национальной ассоциацией колледжей и работодателей за лето 2019 г.Опрос. По вопросам, касающимся данных, обращайтесь по телефону [email protected] .
Данные собираются примерно во время открытия, а последующий опрос проводится через шесть месяцев после открытия. Что касается вопроса о заработной плате, данные по программам с менее чем пятнадцатью ответами не включены. Заработная плата по этим программам предоставлена Национальной ассоциацией колледжей и работодателей за лето 2019 г.Опрос. По вопросам, касающимся данных, обращайтесь по телефону [email protected] .
Обновлено: 23.06.2022 11:29
Символическое мышление (символический ИИ) и машинное обучение
У глубокого обучения есть свои недостатки, и многие из них обращаются к другим ветвям ИИ, когда надеются на будущее. Символическое рассуждение — одна из таких ветвей.
Двумя самыми большими недостатками глубокого обучения являются отсутствие интерпретируемости модели (то есть, почему моя модель сделала такой прогноз?) и большой объем данных, который требуется глубоким нейронным сетям для обучения. Нейронные сети жаждут данных.
Сам Джефф Хинтон выразил скептицизм по поводу того, станет ли обратное распространение, рабочая лошадка глубоких нейронных сетей, путем вперед для ИИ. 1
Исследования в области так называемого одноразового обучения могут решить проблему нехватки данных для глубокого обучения, в то время как глубокое символическое обучение или предоставление возможности глубоким нейронным сетям манипулировать, генерировать и иным образом сосуществовать с концепциями, выраженными в строках символов, может помочь решить проблему объяснимости , потому что, в конце концов, люди общаются с помощью знаков и символов, а именно этого мы и ждем от машин. 2 Недавняя работа Массачусетского технологического института, DeepMind и IBM продемонстрировала силу сочетания коннекционистских методов, таких как глубокие нейронные сети, с символическим мышлением.
Применение обучения с подкреплением к моделированию ». Оба слова означают «обозначать что-то другое» или «представлять что-то другое».
Что-то еще может быть физическим объектом, идеей, событием, что угодно. Для наших целей знак или символ — это визуальный паттерн, скажем, символ или последовательность символов, в которых заключено значение, и этот знак или символ указывает на что-то другое. Это может быть переменная x , указывающая на неизвестное количество, или это может быть слово роза , указывающее на красные, закручивающиеся лепестки, наложенные друг на друга по тугой спирали на конце стебля. шипы. 3
Означающее указывает на означаемое, как палец, указывающий на луну. 4 Символы сжимают сенсорные данные таким образом, что люди, крупные приматы с ограниченной пропускной способностью, могут обмениваться информацией друг с другом. 5 Можно сказать, что они необходимы для преодоления биологических ограничений пропускной способности. Поскольку компьютеры страдали от одних и тех же узких мест, их создатели полагались на слишком человеческие приемы, такие как символы, чтобы обойти ограничения обработки, хранения и ввода-вывода. По мере роста вычислительных мощностей способы оцифровки и обработки нашей аналоговой реальности также могут расширяться, пока мы не будем жонглировать тензорами с миллиардами параметров вместо строк из семи символов.
По мере роста вычислительных мощностей способы оцифровки и обработки нашей аналоговой реальности также могут расширяться, пока мы не будем жонглировать тензорами с миллиардами параметров вместо строк из семи символов.
Символы также служат для передачи обучения в другом смысле, не от одного человека к другому, а от одной ситуации к другой в течение жизни одного человека. То есть символ предлагает уровень абстракции над конкретными и детализированными деталями нашего сенсорного опыта, абстракцию, которая позволяет нам перенести то, что мы узнали в одном месте, на проблему, с которой мы можем столкнуться где-то еще. Учитывая, что сигналы вознаграждения в реальной жизни редки и их трудно связать с их причинами (некоторые из причин вашего недовольства могут быть связаны с действиями, которые вы совершили много лет назад — можете ли вы догадаться, какие?), символы — это способ передача сигналов вознаграждения, полученных в одной ситуации, при столкновении с другим сценарием без явного вознаграждения. В определенном смысле каждая абстрактная категория, например
В определенном смысле каждая абстрактная категория, например стул , утверждает аналогию между всеми разрозненными предметами, называемыми стульями, и мы переносим наши знания об одном стуле на другой с помощью символа.
Комбинации символов, которые выражают их взаимосвязи, можно было бы назвать рассуждением , а когда мы, люди, связываем связку знаков вместе, чтобы выразить мысль, как я делаю сейчас, вы могли бы назвать это символической манипуляцией . Иногда эти символические отношения необходимы и дедуктивны, как в случае с формулами чистой математики или выводами, которые вы можете сделать из логического силлогизма, подобного этому древнеримскому каштану:
Все люди смертны; Кайус — мужчина; поэтому Кай смертен.
В других случаях символы выражают уроки, которые мы индуктивно извлекаем из нашего опыта познания мира, например: «ребенок, кажется, предпочитает жижу со вкусом гороха (поэтому, ради бога, давайте удостоверимся, что у нас есть немного в холодильнике)» или E = mc 2 .
Символический ИИ
Символический искусственный интеллект, также известный как Хороший старомодный ИИ (GOFAI), был доминирующей парадигмой в сообществе ИИ с послевоенной эпохи до конца XIX века.80-е годы.
Реализации символического мышления называются механизмами правил, экспертными системами или графами знаний. См. Cyc для одного из более продолжительных примеров. Google также сделал большой, который предоставляет информацию в верхнем поле под вашим запросом, когда вы ищете что-то простое, например, столицу Германии. Эти системы, по сути, представляют собой груды вложенных утверждений «если-то», делающих выводы о сущностях (удобочитаемых понятиях) и их отношениях (выраженных в хорошо понятной семантике, такой как 9).0743 X это человек или X живет в Акапулько ).
Представьте, как Turbotax удается отразить налоговый кодекс США — вы сообщаете ему, сколько вы заработали, сколько у вас иждивенцев и другие непредвиденные обстоятельства, и он вычисляет налог, который вы должны по закону — это экспертная система.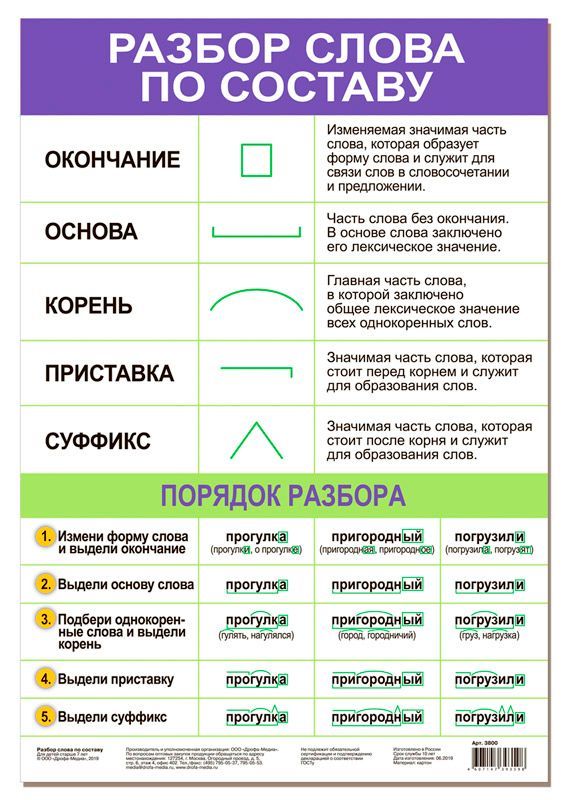
Внешние понятия добавляются в систему ее программистами-создателями, и это важнее, чем кажется…
Одно из основных различий между машинным обучением и традиционным символическим мышлением заключается в том, где происходит обучение. В машинном и глубоком обучении алгоритм изучает правила, поскольку устанавливает корреляции между входными и выходными данными. В символическом мышлении правила создаются посредством человеческого вмешательства. То есть, чтобы построить символическую систему рассуждений, люди сначала должны изучить правила, по которым связаны два явления, а затем жестко запрограммировать эти отношения в статическую программу. Это различие является предметом известного хакерского коана:
В дни, когда Сассман был новичком, Минский однажды подошел к нему, когда он взламывал PDP-6. - Что ты делаешь? - спросил Минский. «Я тренирую случайно подключенную нейронную сеть играть в крестики-нолики», — ответил Сассман. «Почему сеть подключена случайным образом?», — спросил Минский.
 «Я не хочу, чтобы у него были какие-то предубеждения относительно того, как играть», — сказал Сассман.
Затем Минский закрыл глаза.
— Почему ты закрываешь глаза? — спросил Суссман своего учителя.
«Чтобы комната была пуста».
В этот момент Суссман был просветлен.
«Я не хочу, чтобы у него были какие-то предубеждения относительно того, как играть», — сказал Сассман.
Затем Минский закрыл глаза.
— Почему ты закрываешь глаза? — спросил Суссман своего учителя.
«Чтобы комната была пуста».
В этот момент Суссман был просветлен.
Жестко запрограммированное правило является предубеждением. Это одна из форм предположений, причем сильная, в то время как глубокие нейронные архитектуры содержат другие предположения, обычно о том, как они должны учиться, а не о том, к какому выводу они должны прийти. В идеале, очевидно, следует выбирать допущения, которые позволяют системе гибко обучаться и принимать точные решения в отношении своих входных данных.
Проблемы с символическим ИИ (GOFAI)
Одним из основных камней преткновения символического ИИ, или GOFAI, была сложность пересмотра убеждений после того, как они были закодированы в механизме правил. Экспертные системы монотонны; то есть чем больше правил вы добавляете, тем больше знаний закодировано в системе, но дополнительные правила не могут отменить старые знания. Монотонный в основном означает одно направление ; то есть, когда что-то идет вверх, другое дело идет вверх. Поскольку алгоритмы машинного обучения могут быть переобучены на новых данных и будут пересматривать свои параметры на основе этих новых данных, они лучше кодируют предварительные знания, которые при необходимости можно отозвать позже; то есть, если им нужно узнать что-то новое, например, когда данные нестационарны.
Монотонный в основном означает одно направление ; то есть, когда что-то идет вверх, другое дело идет вверх. Поскольку алгоритмы машинного обучения могут быть переобучены на новых данных и будут пересматривать свои параметры на основе этих новых данных, они лучше кодируют предварительные знания, которые при необходимости можно отозвать позже; то есть, если им нужно узнать что-то новое, например, когда данные нестационарны.
Второй недостаток символического мышления заключается в том, что сам компьютер не знает, что означают символы; то есть они не обязательно связаны с какими-либо другими представлениями мира несимволическим образом. Опять же, это контрастирует с нейронными сетями, которые могут связывать символы с векторизованными представлениями данных, которые, в свою очередь, являются просто переводами необработанных сенсорных данных. Таким образом, основная проблема, когда мы думаем о GOFAI и нейронных сетях, заключается в том, как обосновать символы или связать их с другими формами значения, которые позволили бы компьютерам отображать изменяющиеся необработанные ощущения мира в символы, а затем рассуждать о них.
Возникает логический вопрос: для кого предназначены символы? Полезны ли они вообще для машин? Если символы позволяют homo sapiens обмениваться информацией и манипулировать ею на основе фундаментальных физиологических ограничений, прекрасно, но зачем машинам их использовать? Почему бы машинам просто не разговаривать друг с другом на векторах или на каком-то скрипучем языке дельфинов и факсимильных аппаратов? Рискнем поспорить: когда машины начнут понятно разговаривать друг с другом, это будет язык, непонятный людям. Возможно, слова имеют слишком низкую пропускную способность для машин с высокой пропускной способностью. Может быть, им нужно больше измерений, чтобы выразить себя недвусмысленно. Язык — это всего лишь замочная скважина в двери, которую обходят машины. 6 В лучшем случае естественный язык может быть API, который ИИ предлагает людям, чтобы они могли ездить на его фалдах; в худшем случае это может отвлечь внимание от того, что представляет собой настоящий машинный интеллект. Но мы перепутали его с вершиной достижений, потому что естественный язык — это то, как мы показываем, что мы умны.
Но мы перепутали его с вершиной достижений, потому что естественный язык — это то, как мы показываем, что мы умны.
Объединение глубоких нейронных сетей и символического мышления
Как мы можем объединить способность глубоких нейронных сетей изучать вероятностные корреляции с нуля вместе с абстрактными понятиями и понятиями более высокого порядка, которые полезны при сжатии данных и их объединении новыми способами? Как мы можем научиться придавать новые значения понятиям и использовать атомарные понятия в качестве элементов более сложных и составных мыслей, которые язык позволяет нам выражать во всей своей естественной пластичности?
Сочетание символического мышления с глубокими нейронными сетями и глубоким обучением с подкреплением может помочь нам решить фундаментальные проблемы рассуждений, иерархических представлений, трансферного обучения, устойчивости перед лицом состязательных примеров и интерпретируемости (или объяснительной силы).
Обучение под наблюдением: базовый гибридный ИИ
Давайте рассмотрим, как они пересекаются в настоящее время и как они могут быть. Во-первых, каждая глубокая нейронная сеть, обученная обучению с учителем, сочетает в себе глубокое обучение и символическое манипулирование, по крайней мере, в рудиментарном смысле. Потому что символическое мышление кодирует знания в символы и цепочки символов. В обучении с учителем эти строки символов называются метками — категориями, по которым мы классифицируем входные данные с помощью статистической модели. Вывод классификатора (допустим, мы имеем дело с алгоритмом распознавания изображений, который сообщает нам, смотрим ли мы на пешехода, знак остановки, полосу движения или движущийся полуприцеп) может запустить бизнес-логику, которая реагирует на каждую классификацию. Эта бизнес-логика является одной из форм символического мышления.
Во-первых, каждая глубокая нейронная сеть, обученная обучению с учителем, сочетает в себе глубокое обучение и символическое манипулирование, по крайней мере, в рудиментарном смысле. Потому что символическое мышление кодирует знания в символы и цепочки символов. В обучении с учителем эти строки символов называются метками — категориями, по которым мы классифицируем входные данные с помощью статистической модели. Вывод классификатора (допустим, мы имеем дело с алгоритмом распознавания изображений, который сообщает нам, смотрим ли мы на пешехода, знак остановки, полосу движения или движущийся полуприцеп) может запустить бизнес-логику, которая реагирует на каждую классификацию. Эта бизнес-логика является одной из форм символического мышления.
1) Хинтон, Янн ЛеКун и Эндрю Нг предположили, что работа над неконтролируемым обучением (обучение на неразмеченных данных) приведет к нашим следующим прорывам.
2) Эти две проблемы могут пересекаться, и решение одной может привести к решению другой, поскольку концепция, помогающая объяснить модель, также поможет ей распознавать определенные закономерности в данных с использованием меньшего количества примеров.
3) Самое странное в письме о знаках, конечно, то, что в рамках текста мы просто используем один набор знаков для описания другого в надежде, что читатель отреагирует на сенсорное воспоминание. и поставить необходимые аналоговые памяти красный и шип . Но ты понял мой дрейф. (Это становится еще более странным, если учесть, что сенсорные данные, воспринимаемые нашим разумом и к которым относятся знаки, сами по себе являются знаками вещи самой по себе, которую мы не можем знать.)
4) В японском буддизме мастера дзэн часто говорят, что их учения подобны пальцам, указывающим на луну. Палец не луна, но направленно полезен. Так и каждый знак есть палец, указывающий на ощущения.
5) Согласно научным данным, среднестатистический носитель американского английского языка говорит со скоростью около 110–150 слов в минуту (WPM). Как вы думаете, сколько реальности уместится в десятиминутной передаче?
6) «Хорошо, теперь мы подходим к тому, что я обещал и провел вас через весь унылый синопсис того, что привело к этому в надежде на. Что значит умирать, что происходит. Верно? Это то, что все хотят знать. И ты это делаешь, поверь мне. Независимо от того, решите ли вы пройти через это или нет, отговорю ли я вас от этого так, как вы думаете, что я попытаюсь это сделать, или нет. Во-первых, это не то, что кто-то думает. Правда в том, что вы уже знаете, каково это. Вы уже знаете разницу между размером и скоростью всего, что проносится сквозь вас, и крошечной неадекватной частицей всего, что вы можете кому-либо сообщить. Как будто внутри вас есть эта огромная комната, полная того, что кажется всем во всей вселенной в тот или иной момент, и все же единственные части, которые выходят наружу, должны каким-то образом протискиваться через одну из тех крошечных замочных скважин, которые вы видите под ручкой в старых дверях. . Как будто мы все пытаемся увидеть друг друга сквозь эти крошечные замочные скважины.
Но у него есть ручка, дверь может открываться. Но не так, как вы думаете. Но что, если бы вы могли? Задумайтесь на секунду — а что, если бы все бесконечно плотные и изменчивые миры материи внутри вас каждое мгновение вашей жизни оказались сейчас как-то полностью открытыми и выразимыми потом, после того, о чем вы думаете, как будто вы умерли, потому что что, если потом теперь каждое мгновение само по себе является бесконечным морем, или промежутком, или течением времени, в котором его можно выразить или передать, и вам даже не нужен организованный английский язык, вы можете, как говорится, открыть дверь и оказаться в чьей-либо комнате во всех ваших собственные многообразные формы, идеи и грани? Потому что слушай — у нас не так много времени, здесь Лили-Кэш немного уходит вниз, а берега начинают становиться крутыми, и ты можешь разглядеть очертания неосвещенной вывески фермы, которая больше никогда не открывается, последняя вывеска перед бридж — так что слушай: кем именно ты себя считаешь? Миллионы и триллионы мыслей, воспоминаний, сопоставлений — даже таких сумасшедших, думаете вы, — которые мелькают в вашей голове и исчезают? Некоторая сумма или остаток от них? Ваша история? Ты знаешь, сколько времени прошло с тех пор, как я говорил тебе, что я мошенник? Вы помните, что смотрели на часы respicem, висящие на заднем обзоре, и видели время, 9:17? На что ты сейчас смотришь? Стечение обстоятельств? Что делать, если время вообще не прошло? Правда в том, что вы уже слышали это.
Что значит умирать, что происходит. Верно? Это то, что все хотят знать. И ты это делаешь, поверь мне. Независимо от того, решите ли вы пройти через это или нет, отговорю ли я вас от этого так, как вы думаете, что я попытаюсь это сделать, или нет. Во-первых, это не то, что кто-то думает. Правда в том, что вы уже знаете, каково это. Вы уже знаете разницу между размером и скоростью всего, что проносится сквозь вас, и крошечной неадекватной частицей всего, что вы можете кому-либо сообщить. Как будто внутри вас есть эта огромная комната, полная того, что кажется всем во всей вселенной в тот или иной момент, и все же единственные части, которые выходят наружу, должны каким-то образом протискиваться через одну из тех крошечных замочных скважин, которые вы видите под ручкой в старых дверях. . Как будто мы все пытаемся увидеть друг друга сквозь эти крошечные замочные скважины.
Но у него есть ручка, дверь может открываться. Но не так, как вы думаете. Но что, если бы вы могли? Задумайтесь на секунду — а что, если бы все бесконечно плотные и изменчивые миры материи внутри вас каждое мгновение вашей жизни оказались сейчас как-то полностью открытыми и выразимыми потом, после того, о чем вы думаете, как будто вы умерли, потому что что, если потом теперь каждое мгновение само по себе является бесконечным морем, или промежутком, или течением времени, в котором его можно выразить или передать, и вам даже не нужен организованный английский язык, вы можете, как говорится, открыть дверь и оказаться в чьей-либо комнате во всех ваших собственные многообразные формы, идеи и грани? Потому что слушай — у нас не так много времени, здесь Лили-Кэш немного уходит вниз, а берега начинают становиться крутыми, и ты можешь разглядеть очертания неосвещенной вывески фермы, которая больше никогда не открывается, последняя вывеска перед бридж — так что слушай: кем именно ты себя считаешь? Миллионы и триллионы мыслей, воспоминаний, сопоставлений — даже таких сумасшедших, думаете вы, — которые мелькают в вашей голове и исчезают? Некоторая сумма или остаток от них? Ваша история? Ты знаешь, сколько времени прошло с тех пор, как я говорил тебе, что я мошенник? Вы помните, что смотрели на часы respicem, висящие на заднем обзоре, и видели время, 9:17? На что ты сейчас смотришь? Стечение обстоятельств? Что делать, если время вообще не прошло? Правда в том, что вы уже слышали это. Что это такое. Это то, что освобождает место для вселенных внутри вас, всех бесконечных изогнутых фракталов связи и симфоний разных голосов, бесконечностей, которые вы никогда не сможете показать другой душе. И вы думаете, что это делает вас мошенником, крошечной частью, которую кто-либо еще когда-либо видел? Конечно, вы мошенник, конечно, люди никогда не видят вас. И, конечно, вы это знаете, и, конечно же, вы пытаетесь управлять тем, какую часть они видят, если вы знаете, что это только часть. Кто бы не хотел? Это называется свобода воли, Шерлок. Но в то же время именно поэтому так приятно сломаться и плакать перед другими, или смеяться, или говорить на языках, или петь на бенгальском языке — это уже не английский язык, его нельзя протиснуть ни в какую дыру». — Дэвид Фостер Уоллес, «Старый добрый неон»
Что это такое. Это то, что освобождает место для вселенных внутри вас, всех бесконечных изогнутых фракталов связи и симфоний разных голосов, бесконечностей, которые вы никогда не сможете показать другой душе. И вы думаете, что это делает вас мошенником, крошечной частью, которую кто-либо еще когда-либо видел? Конечно, вы мошенник, конечно, люди никогда не видят вас. И, конечно, вы это знаете, и, конечно же, вы пытаетесь управлять тем, какую часть они видят, если вы знаете, что это только часть. Кто бы не хотел? Это называется свобода воли, Шерлок. Но в то же время именно поэтому так приятно сломаться и плакать перед другими, или смеяться, или говорить на языках, или петь на бенгальском языке — это уже не английский язык, его нельзя протиснуть ни в какую дыру». — Дэвид Фостер Уоллес, «Старый добрый неон»
Дополнительная литература по символическому ИИ
- Логический против аналогового или символический против коннекционистского или аккуратного против неряшливого, Марвин Мински
- Ответ на: Что такое GOFAI и почему он потерпел неудачу?
- Макдермотт, Д. (1987), Критика чистого разума. Вычислительный интеллект, 3: 151–160. doi: 10.1111/j.1467-8640.1987.tb00183.x
- Проблема заземления символов , Харнад, Стеван (1990)
- Преднамеренность
- Версия убеждения
- Немонотонная логика
- Проблема со стрельбой в Йельском университете
- ALMECOM: активная логика, метакогнитивные вычисления и разум
- SATNet: объединение глубокого обучения и логических рассуждений с помощью решателя дифференцируемой выполнимости
 (1987), Критика чистого разума. Вычислительный интеллект, 3: 151–160. doi: 10.1111/j.1467-8640.1987.tb00183.x
(1987), Критика чистого разума. Вычислительный интеллект, 3: 151–160. doi: 10.1111/j.1467-8640.1987.tb00183.xДругие сообщения в Pathmind Wiki
- Глубокие нейронные сети
- Рекуррентные нейронные сети (RNN) и LSTM
- Word2vec и нейронные вложения слов
- Сверточные нейронные сети (CNN) и обработка изображений
- Точность, точность и отзыв
- Механизмы внимания и трансформаторы
- Собственные векторы, собственные значения, PCA, ковариация и энтропия
- Графическая аналитика и глубокое обучение
- Марковская цепь Монте-Карло, AI и Марковские одеяла
- Глубокое обучение с подкреплением
- Генеративно-состязательные сети (GAN)
- ИИ против машинного обучения против глубокого обучения
- Многослойные персептроны (MLP)
Ресурсы для глубокого обучения и символического мышления
На этой странице представлены некоторые недавние заметные исследования, в которых делается попытка объединить глубокое обучение с символическим обучением, чтобы ответить на эти вопросы.
- Изучающий нейросимволические концепции: интерпретация сцен, слов и предложений под естественным наблюдением
Мы предлагаем Нейро-Символический Концептуальный Ученик (NS-CL), модель, которая изучает визуальные понятия, слова и семантический анализ предложений без явного наблюдения за любым из них; вместо этого наша модель учится, просто глядя на изображения и читая парные вопросы и ответы. Наша модель строит объектно-ориентированное представление сцены и переводит предложения в исполняемые символьные программы. Чтобы соединить обучение двух модулей, мы используем модуль нейросимволического мышления, который выполняет эти программы в представлении скрытой сцены. По аналогии с обучением человеческим понятиям, с учетом проанализированной программы, модуль восприятия изучает визуальные понятия на основе языкового описания объекта, на который ссылаются. Между тем, выученные визуальные понятия облегчают изучение новых слов и разбор новых предложений.
 Мы используем обучение по учебной программе, чтобы направлять поиск в большом композиционном пространстве изображений и языка. Обширные эксперименты демонстрируют точность и эффективность нашей модели при изучении визуальных понятий, представлении слов и семантическом анализе предложений. Кроме того, наш метод позволяет легко обобщать новые атрибуты объектов, композиции, языковые концепции, сцены и вопросы и даже новые программные области. Это также расширяет возможности приложений, включая визуальные ответы на вопросы и двунаправленный поиск изображений и текста.
Мы используем обучение по учебной программе, чтобы направлять поиск в большом композиционном пространстве изображений и языка. Обширные эксперименты демонстрируют точность и эффективность нашей модели при изучении визуальных понятий, представлении слов и семантическом анализе предложений. Кроме того, наш метод позволяет легко обобщать новые атрибуты объектов, композиции, языковые концепции, сцены и вопросы и даже новые программные области. Это также расширяет возможности приложений, включая визуальные ответы на вопросы и двунаправленный поиск изображений и текста.- На пути к глубокому символическому обучению с подкреплением (2016) Марта Гарнело, Кай Арулкумаран и Мюррей Шанахан
Глубокое обучение с подкреплением (DRL) использует возможности глубоких нейронных сетей для решения общей задачи обучения методом проб и ошибок, и его эффективность была убедительно продемонстрирована на таких задачах, как видеоигры Atari и игра в го. Однако современные системы DRL унаследовали ряд недостатков от методов глубокого обучения текущего поколения.
 Например, для эффективной работы им требуются очень большие наборы данных, из-за чего они медленно обучаются, даже когда такие наборы данных доступны. Более того, им не хватает способности рассуждать на абстрактном уровне, что затрудняет реализацию когнитивных функций высокого уровня, таких как перенос обучения, рассуждения по аналогии и рассуждения, основанные на гипотезах. Наконец, их работа в значительной степени непрозрачна для людей, что делает их непригодными для областей, в которых важна верифицируемость. В этой статье мы предлагаем сквозную архитектуру обучения с подкреплением, включающую нейронную заднюю часть и символическую переднюю часть с потенциалом преодоления каждого из этих недостатков. В качестве доказательства концепции мы представляем предварительную реализацию архитектуры и применяем ее к нескольким вариантам простой видеоигры. Мы показываем, что получившаяся система — хотя это всего лишь прототип — эффективно обучается и, приобретая набор символических правил, которые легко понятны людям, значительно превосходит обычную, полностью нейронную систему DRL в стохастическом варианте игры.
Например, для эффективной работы им требуются очень большие наборы данных, из-за чего они медленно обучаются, даже когда такие наборы данных доступны. Более того, им не хватает способности рассуждать на абстрактном уровне, что затрудняет реализацию когнитивных функций высокого уровня, таких как перенос обучения, рассуждения по аналогии и рассуждения, основанные на гипотезах. Наконец, их работа в значительной степени непрозрачна для людей, что делает их непригодными для областей, в которых важна верифицируемость. В этой статье мы предлагаем сквозную архитектуру обучения с подкреплением, включающую нейронную заднюю часть и символическую переднюю часть с потенциалом преодоления каждого из этих недостатков. В качестве доказательства концепции мы представляем предварительную реализацию архитектуры и применяем ее к нескольким вариантам простой видеоигры. Мы показываем, что получившаяся система — хотя это всего лишь прототип — эффективно обучается и, приобретая набор символических правил, которые легко понятны людям, значительно превосходит обычную, полностью нейронную систему DRL в стохастическом варианте игры.
- Обучение объяснительным правилам на зашумленных данных (2018) Ричард Эванс и Эдвард Грефенштетт
Искусственные нейронные сети— это мощные аппроксиматоры функций, способные моделировать решения самых разных задач как с учителем, так и без него. По мере увеличения их размера и выразительности увеличивается и дисперсия модели, что приводит к почти повсеместной проблеме переобучения. Несмотря на то, что это смягчается различными методами регуляризации модели, обычное лекарство состоит в том, чтобы искать большие объемы обучающих данных, которые не всегда легко получить, которые в достаточной степени аппроксимируют распределение данных в области, в которой мы хотим протестировать. Напротив, методы логического программирования, такие как индуктивное логическое программирование, предлагают чрезвычайно эффективный процесс, с помощью которого модели могут быть обучены рассуждать в символических областях. Однако эти методы не могут работать с множеством областей, к которым могут применяться нейронные сети: они неустойчивы к шуму или неправильной маркировке входных данных и, что, возможно, более важно, не могут применяться к несимволическим областям, где данные неоднозначны.
 , например, работа с необработанными пикселями. В этой статье мы предлагаем структуру дифференцируемой индуктивной логики, которая может не только решать задачи, для которых подходят традиционные системы ILP, но и демонстрирует устойчивость к шумам и ошибкам в обучающих данных, с которыми ILP не может справиться. Кроме того, поскольку он обучается обратным распространением относительно цели вероятности, его можно гибридизовать, соединив его с нейронными сетями через неоднозначные данные, чтобы применить его к областям, к которым ILP не может обратиться, обеспечивая при этом эффективность данных и обобщение за пределами того, что нейронные сети на их основе. собственный может достичь.
, например, работа с необработанными пикселями. В этой статье мы предлагаем структуру дифференцируемой индуктивной логики, которая может не только решать задачи, для которых подходят традиционные системы ILP, но и демонстрирует устойчивость к шумам и ошибкам в обучающих данных, с которыми ILP не может справиться. Кроме того, поскольку он обучается обратным распространением относительно цели вероятности, его можно гибридизовать, соединив его с нейронными сетями через неоднозначные данные, чтобы применить его к областям, к которым ILP не может обратиться, обеспечивая при этом эффективность данных и обобщение за пределами того, что нейронные сети на их основе. собственный может достичь.- Сети схем: нулевой перенос с генеративной причинно-следственной моделью интуитивной физики (2017)
Недавняя адаптация методов на основе глубоких нейронных сетей к областям обучения с подкреплением и планирования привела к заметному прогрессу в выполнении отдельных задач.
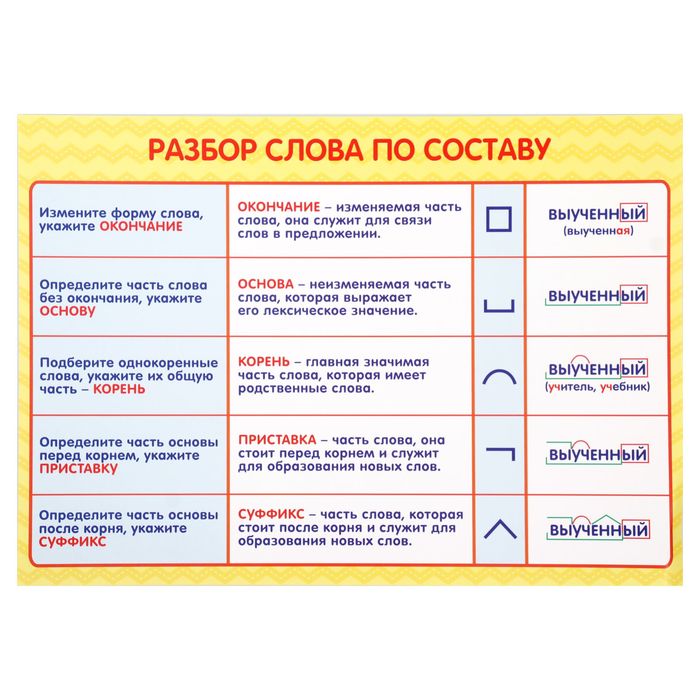 Тем не менее прогресс в передаче задач от задачи к задаче остается ограниченным. Стремясь к эффективному и надежному обобщению, мы представляем Schema Network, объектно-ориентированный симулятор генеративной физики, способный распутывать множество причин событий и рассуждать в обратном направлении по причинам для достижения целей. Богато структурированная архитектура Schema Network позволяет изучать динамику среды непосредственно из данных. Мы сравниваем сети Schema с асинхронными сетями Advantage Actor-Critic и Progressive Networks в наборе вариантов Breakout, сообщая результаты об эффективности обучения и нулевом обобщении, последовательно демонстрируя более быстрое, более надежное обучение и лучшую передачу. Мы утверждаем, что обобщение ограниченных данных и изучение причинно-следственных связей являются важными способностями на пути к созданию в целом интеллектуальных систем.
Тем не менее прогресс в передаче задач от задачи к задаче остается ограниченным. Стремясь к эффективному и надежному обобщению, мы представляем Schema Network, объектно-ориентированный симулятор генеративной физики, способный распутывать множество причин событий и рассуждать в обратном направлении по причинам для достижения целей. Богато структурированная архитектура Schema Network позволяет изучать динамику среды непосредственно из данных. Мы сравниваем сети Schema с асинхронными сетями Advantage Actor-Critic и Progressive Networks в наборе вариантов Breakout, сообщая результаты об эффективности обучения и нулевом обобщении, последовательно демонстрируя более быстрое, более надежное обучение и лучшую передачу. Мы утверждаем, что обобщение ограниченных данных и изучение причинно-следственных связей являются важными способностями на пути к созданию в целом интеллектуальных систем.- Обучение как люди с помощью Deep Symbolic Networks (2017) Цюньжи Чжан и Дидье Сорнетт
Мы представляем модель Deep Symbolic Network (DSN), цель которой — стать версией Deep Neural Networks (DNN) для белого ящика.
 Модель DSN обеспечивает простую, универсальную, но мощную структуру, аналогичную DNN, для представления любых знаний о мире, которые прозрачны для людей. Гипотеза, лежащая в основе модели DSN, заключается в том, что любой тип объектов реального мира, имеющих достаточно общих черт, отображается в человеческом мозгу как символ. Эти символы связаны связями, представляющими композицию, корреляцию, причинно-следственную связь или другие отношения между ними, образуя глубокую иерархическую символическую сетевую структуру. Ожидается, что благодаря такой структуре модель DSN будет учиться, как люди, благодаря своим уникальным характеристикам. Во-первых, он универсален, используя одну и ту же структуру для хранения любых знаний. Во-вторых, он может изучать символы из мира и автоматически создавать глубокие символические сети, используя тот факт, что объекты реального мира естественным образом разделены сингулярностями. В-третьих, оно символично, способно проводить каузальную дедукцию и обобщение.
Модель DSN обеспечивает простую, универсальную, но мощную структуру, аналогичную DNN, для представления любых знаний о мире, которые прозрачны для людей. Гипотеза, лежащая в основе модели DSN, заключается в том, что любой тип объектов реального мира, имеющих достаточно общих черт, отображается в человеческом мозгу как символ. Эти символы связаны связями, представляющими композицию, корреляцию, причинно-следственную связь или другие отношения между ними, образуя глубокую иерархическую символическую сетевую структуру. Ожидается, что благодаря такой структуре модель DSN будет учиться, как люди, благодаря своим уникальным характеристикам. Во-первых, он универсален, используя одну и ту же структуру для хранения любых знаний. Во-вторых, он может изучать символы из мира и автоматически создавать глубокие символические сети, используя тот факт, что объекты реального мира естественным образом разделены сингулярностями. В-третьих, оно символично, способно проводить каузальную дедукцию и обобщение.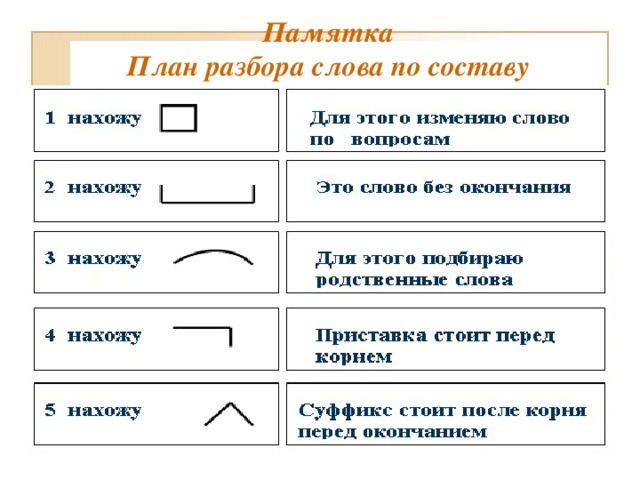 В-четвертых, символы и связи между ними прозрачны для нас, и, таким образом, мы будем знать, что он изучил, а что нет — что является ключом к безопасности системы ИИ. В-пятых, его прозрачность позволяет ему учиться на относительно небольших данных. В-шестых, его знания можно накапливать. И последнее, но не менее важное: он более удобен для неконтролируемого обучения, чем DNN. Мы представляем детали модели, алгоритм, обеспечивающий ее способность к автоматическому обучению, и описываем ее полезность в различных случаях использования. Цель этой статьи — вызвать широкий интерес к ее разработке в рамках проекта с открытым исходным кодом, основанного на модели Deep Symbolic Network (DSN) для разработки общего ИИ.
В-четвертых, символы и связи между ними прозрачны для нас, и, таким образом, мы будем знать, что он изучил, а что нет — что является ключом к безопасности системы ИИ. В-пятых, его прозрачность позволяет ему учиться на относительно небольших данных. В-шестых, его знания можно накапливать. И последнее, но не менее важное: он более удобен для неконтролируемого обучения, чем DNN. Мы представляем детали модели, алгоритм, обеспечивающий ее способность к автоматическому обучению, и описываем ее полезность в различных случаях использования. Цель этой статьи — вызвать широкий интерес к ее разработке в рамках проекта с открытым исходным кодом, основанного на модели Deep Symbolic Network (DSN) для разработки общего ИИ.- Глубокое обучение: критическая оценка (2018) Гэри Маркус
Хотя глубокое обучение имеет исторические корни, уходящие в глубь веков, ни термин «глубокое обучение», ни сам подход не были популярны чуть более пяти лет назад, когда эта область была возрождена такими статьями, как работа Крижевского, Суцкевера и Хинтона, ставшая уже классической (2012 г.
 ) глубокой сетью. Модель Imagenet. Что открыло месторождение за пять последующих лет? На фоне значительного прогресса в таких областях, как распознавание речи, изображений и игр, а также значительного энтузиазма в популярной прессе, я представляю десять проблем глубокого обучения и предлагаю, чтобы глубокое обучение было дополнено другими методами, если мы достичь искусственного общего интеллекта.
) глубокой сетью. Модель Imagenet. Что открыло месторождение за пять последующих лет? На фоне значительного прогресса в таких областях, как распознавание речи, изображений и игр, а также значительного энтузиазма в популярной прессе, я представляю десять проблем глубокого обучения и предлагаю, чтобы глубокое обучение было дополнено другими методами, если мы достичь искусственного общего интеллекта.- Компонуемое планирование с атрибутами (2018) Эми Чжан, Адам Лерер, Сайнбаяр Сухбаатар, Роб Фергус и Артур Шлам
Задачи, которые предстоит решать агенту, часто неизвестны во время обучения. Однако если агент знает, какие свойства среды мы считаем важными, то, узнав, как его действия влияют на эти свойства, агент может использовать эти знания для решения сложных задач без специальной подготовки для них. С этой целью мы рассмотрим установку, в которой среда дополнена набором определяемых пользователем атрибутов, которые параметризуют интересующие функции.
 Мы предлагаем модель, которая изучает политику перехода между «близкими» наборами атрибутов и поддерживает граф возможных переходов. Учитывая задачу во время тестирования, которая может быть выражена в терминах целевого набора атрибутов и текущего состояния, наша модель выводит атрибуты текущего состояния и ищет пути в пространстве атрибутов, чтобы получить план высокого уровня, а затем использует его политика низкого уровня для выполнения плана. Мы показываем в играх с сеткой и 3D-стекинге блоков, что наша модель способна обобщать более длинные и сложные задачи во время тестирования, даже если она видит только короткие простые задачи во время обучения.
TL;DR: планирование на основе композиционных атрибутов, которое обобщается для длинных тестовых задач, несмотря на то, что они обучены коротким и простым задачам.
Мы предлагаем модель, которая изучает политику перехода между «близкими» наборами атрибутов и поддерживает граф возможных переходов. Учитывая задачу во время тестирования, которая может быть выражена в терминах целевого набора атрибутов и текущего состояния, наша модель выводит атрибуты текущего состояния и ищет пути в пространстве атрибутов, чтобы получить план высокого уровня, а затем использует его политика низкого уровня для выполнения плана. Мы показываем в играх с сеткой и 3D-стекинге блоков, что наша модель способна обобщать более длинные и сложные задачи во время тестирования, даже если она видит только короткие простые задачи во время обучения.
TL;DR: планирование на основе композиционных атрибутов, которое обобщается для длинных тестовых задач, несмотря на то, что они обучены коротким и простым задачам.- Объектно-ориентированное глубокое обучение (2018)
К. Ляо и Т.А. Поджо
Мы исследуем нетрадиционное направление исследований, направленное на преобразование нейронных сетей, класса распределенных, коннекционистских, субсимвольных моделей, на символический уровень с конечной целью достижения интерпретируемости и безопасности ИИ.
 С этой целью мы предлагаем объектно-ориентированное глубокое обучение, новую вычислительную парадигму глубокого обучения, которая принимает интерпретируемые «объекты/символы» в качестве базового репрезентативного атома вместо N-мерных тензоров (как в традиционном «функционально-ориентированном» глубоком обучении). . Для визуальной обработки каждый «объект/символ» может явно упаковывать общие свойства визуальных объектов, такие как его положение, поза, масштаб, вероятность того, что он является объектом, указатели на части и т. д., обеспечивая полный спектр интерпретируемых визуальных знаний на всех уровнях. . Он достигает формы «символического распутывания», предлагая одно решение важной проблемы распутанных представлений и инвариантности. Основные вычисления сети включают прогнозирование объектов высокого уровня и их свойств на основе объектов низкого уровня и связывание/агрегирование соответствующих объектов вместе. Эти вычисления работают на более фундаментальном уровне, чем свертки, рассматривая свертки как частный случай, но будучи значительно более общими, чем они.
С этой целью мы предлагаем объектно-ориентированное глубокое обучение, новую вычислительную парадигму глубокого обучения, которая принимает интерпретируемые «объекты/символы» в качестве базового репрезентативного атома вместо N-мерных тензоров (как в традиционном «функционально-ориентированном» глубоком обучении). . Для визуальной обработки каждый «объект/символ» может явно упаковывать общие свойства визуальных объектов, такие как его положение, поза, масштаб, вероятность того, что он является объектом, указатели на части и т. д., обеспечивая полный спектр интерпретируемых визуальных знаний на всех уровнях. . Он достигает формы «символического распутывания», предлагая одно решение важной проблемы распутанных представлений и инвариантности. Основные вычисления сети включают прогнозирование объектов высокого уровня и их свойств на основе объектов низкого уровня и связывание/агрегирование соответствующих объектов вместе. Эти вычисления работают на более фундаментальном уровне, чем свертки, рассматривая свертки как частный случай, но будучи значительно более общими, чем они.