What is Google Sans Text?
Browse Eckher Glossary and expand your business and technology vocabulary.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa.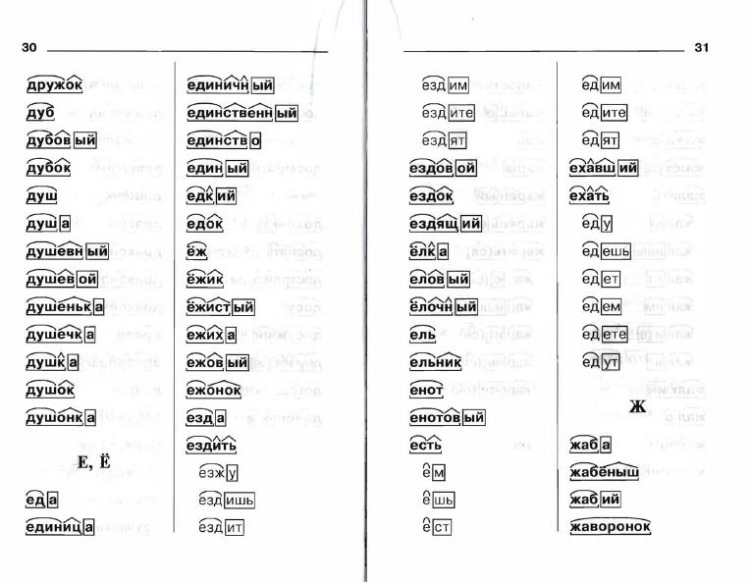 Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «featurize» in English?
How to pronounce «Onehunga» in English?
How to pronounce «Takapuna» in English?
How to pronounce «İzmir» in English?
How to pronounce «Coronaviridae» in English?
How to pronounce «Whanganui» in English?
How to pronounce «Chlöe Swarbrick» in English?
How to pronounce «Kohimarama» in English?
How to pronounce «Tua Tagovailoa» in English?
How to pronounce «Craig Federighi» in English?
How to pronounce «Stefanos Tsitsipas» in English?
How to pronounce «Jacob deGrom» in English?
How to pronounce «myocarditis» in English?
How to pronounce «SZA» in English?
How to pronounce «Cassie Kozyrkov» in English?
Морфемный разбор онлайн, разбор слов по составу, примеры
Разбор слова по составу, или морфемный разбор, — выделение частей, из которых слово состоит. Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах. Надеемся, что сайт поможет вам в подготовке домашних заданий.
План разбора
План разбора слова по составу состоит в следующем:
- Определяем, к какой части речи относится анализируемое слово.

- Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи.
- Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами.
- Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым.
- Обозначем части слова с помощью графических обозначений.

Примеры разборов
Покажем примеры разбора слов разных частей речи с разной комбинацией морфем:
- метро — неизменяемое существительное, нет окончания
- лес — существительное с нулевым окончанием
- пришкольный — прилагательное со всеми основными морфемами: приставкой, корнем, суффиксом, окончанием
- ледокол — существительное с двумя корнями и соединительной гласной
- позвала — глагол с приставкой, окончанием, словооразующим суффиксом а и формобращующим суффиксом л, который не входит в основу
- быстро — наречие с суффиксом, не имеет окончания
Подберите нужные слова с необходимыми частями слова через поиск слов по морфемам.
Особенности разборов
Обратите внимание: морфемные разборы одних и тех же слов могут быть сделаны по-разному в разных словарях, разными учителями и филологами, в школе и в университете. Каждый «источник» аргументирует разбор по-своему и считает свой разбор правильным.
Разные учителя придерживаются разных программ определения морфем в словах. Ярким примером служат инфинитивы глаголов. Например в слове жить: в одних школах ть отмечается как суффикс, в других — как окончание, в третьих — как суффикс с последующим нулевым окончанием. Мы выделяем морфемы по первому варианту.
Образовательные программы школы и университета в части разбора слов могут различаться. В университетах учитывают этимологию слов, выделяют нулевой суффикс (Азов, бег), рассматривают словообразования от нулевого корня и другие сложные примеры. Мы используем программу, ориентированную на школу, и деление на морфемы по словарю А.Н. Тихонова.
Заметим, что есть различия в словаре А.Н. Тихонова и словаре Т.Ф. Ефремовой. Так А.Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т.Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
Тихонова и словаре Т.Ф. Ефремовой. Так А.Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т.Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
При разборе слов следует помнить, что бывают слова, содержащие нулевое окончание (автобус), не имеющие окончания (ателье), имеющие несколько корней (авиапочта) и другие сложные варианты. К сложным вариантам на нашем сайте даны объяснения.
Морфемные словари
Среди печатных изданий словарей морфемных разборов, которые вы найдете в школьной библиотеке, можно выделить следующие:
- Рацибурская Л.В. Словарь уникальных морфем современного русского языка М.: Флинта: Наука, 2009. — 160 с.
- Аванесов Р.И., Ожегов С.И. Морфемно-орфографический словарь Около 100 000 слов / А. Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с.
- Тихонов А.Н. Морфемно-орфографический словарь русского языка, 2002.
- Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с.
 Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с.
Н. Тихонов. — М.: АСТ: Астрель, 2002. — 704 с.В словарях морфемных разборов обычно деление на морфемы делается с помощью слешей: под/вод/н/ый, гор/а и т.д. В словаре Т.Ф. Ефремовой у группы слов с одинаковым корнем исходное слово записано полностью, а в образованных от него словах корневая морфема обозначается через знак V: лес, V-а, V-н-ой и т.д.
«Свист из подворотни». Отклики на статью Путина об Украине
«Визг распоясавшегося пахана» или «победный залп Кремля»? В соцсетях обсуждают статью Путина об Украине и России.
На недавней прямой линии Владимир Путин в очередной раз назвал русских и украинцев «одним народом», пообещав в скором времени опубликовать большую статью с разбором этого тезиса. Спустя две недели президент сдержал свое обещание – текст под названием «Об историческом единстве русских и украинцев» был опубликован на сайте Кремля, на русском и на украинском языках.
Обосновывая свои слова, Путин фактически обращается к советским школьным учебникам 50-летней давности и источникам из школьной программы – например, к «Повести временных лет». Он отмечает, что в середине прошлого тысячелетия название «Украина» использовалось в значении слова «окраина» и утверждает, что жители Киева, левобережья Днепра, Полтавщины, Черниговщины и Запорожья считали себя частью русского православного народа. Современные попытки Украины уйти от влияния Москвы российский президент связывает с внешним давлением Запада, который «всегда стремился к подрыву нашего единства». В статье Путин вводит и употребляет целых 7 раз (!) новый термин – «анти-Россия»: именно в нее, как он читает, условный «Запад» хочет превратить «братскую» Украину.
Украинская тема – одна из самых обсуждаемых в русскоязычных соцсетях на протяжении последних 7 лет, начиная с киевского Майдана, аннексии Крыма и начала войны на востоке Украины. Неудивительно, что и статья Путина породила десятки дискуссий и отзывов – от восторженных до уничижительных.
Неудивительно, что и статья Путина породила десятки дискуссий и отзывов – от восторженных до уничижительных.
Екатерина Барабаш:
Заставила себя прочитать заметку Путина, закинувшись предварительно валерьянкой. Спорить с тезисами этого результата исторической графомании нет никаких сил – не для нас написано. Пусть разбираются те, для кого сигнал послан. Но по тону, по интонации – это типичный свист из подворотни, это визг распоясавшегося пахана, решившего больше не строить из себя хорошего парня.
Сергей Смирнов:
И про статью Путина. Нет сомнений, что лично его историческая тема самого интересует и, думаю, он сам смотрит, что там написано в статье. То есть ближе к Сталину, чем к Брежневу.
Давайте начну с хорошего в статье! Там есть два довольно важных тезиса, которые слегка затерялись за всем остальным. Во-первых, Путин вообще не отрицает существование государства Украина. А исходя из написанных тезисов – должен.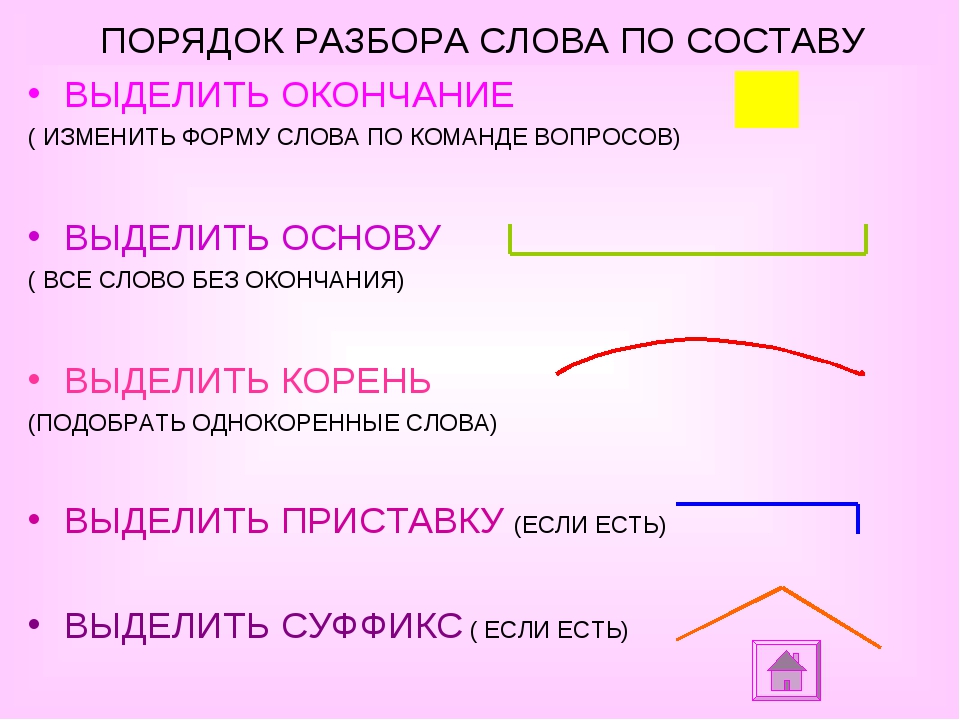 Но нет, вообще не отрицает.
Но нет, вообще не отрицает.
Второй тезис – он пишет, что «Литовская Русь» могла быть основой для объединения земель. Это тоже новый постсоветский взгляд, раньше «Литва» рассматривалась исключительно как инструмент Запада, который должен был помешать объединению русских земель вокруг Москвы. Еще есть довольно резкий выпад на большевиков, но его нет смысла подробно разбирать. Скорее интересно, что он очень резкий, там почти «Ленин – инструмент германской разведки».
А вот остальная часть это буквально советский учебник: параграф «Объединение России и Украины». Даже стилистика аналогичная. Самое грустное – это упоминание семь раз проекта «анти-Россия». Именно так называется серия книг Эксмо про «план Даллеса» и прочие бредни, которые даже в газету «Завтра» не берут. Может быть с названием серии и статьей Путина – это просто совпадение? Не думаю.
Ну и конечно «во всем виноваты поляки и католичество» это вообще тезис 19 века. Чистый Достоевский с Катковым. Тогда к ним еще непременно присоединялись евреи, кажется их в статье Путина явно не хватает.
Илья Крамник:
Статья Владимира Владимировича, уважаемого, про единство народов плоха тем, что ее – с этими обоснованиями – надо было писать 30 лет назад, и, естественно, не ему. А в текущем варианте это чистый плач по прическе после гильотинирования.
Alex Kazharski:
«Я тебя уважаю как самостоятельную женщину, но счастлива ты можешь быть только со мной».
Перевод на гендерный одного историка.
Александр Шмелев:Говорят, великий вождь северокорейского народа Ким Чен Ын написал статью, убедительно доказывающую, что северные корейцы и южные — две части двуединого корейского народа, поэтому КНДР не позволит Южной Корее находиться под внешним управлением и заставит ее присоединиться к идеям чучхе.
ПС: Я сам очень люблю историю и думаю, знаю ее примерно в 100500 раз лучше, чем Путин, однако всегда поражаюсь отсылкам к временам 500-летней давности в разговорах о текущей политике. Неужели правда есть люди, определяющие свои жизненные приоритеты на основании того, о чем — предположительно — думали их прапрапрапрапрапрапрапрапрапрапрапрадедушки и прапрапрапрапрапрапрапрапрапрапрапрабабушки? Реалли? Если же говорить о сегодняшнем дне, то основное различие между современными россиянами и украинцами было сформулировано еще 7 лет назад:
Неужели правда есть люди, определяющие свои жизненные приоритеты на основании того, о чем — предположительно — думали их прапрапрапрапрапрапрапрапрапрапрапрадедушки и прапрапрапрапрапрапрапрапрапрапрапрабабушки? Реалли? Если же говорить о сегодняшнем дне, то основное различие между современными россиянами и украинцами было сформулировано еще 7 лет назад:
«Никогда мы не будем братьями,
У вас царь, у нас демократия,
У вас дома молчанье золото,
А у нас жгут коктейли Молотова».
И понятно, что для любого нормального человека эти различия гораздо важнее чем то, в каких городах 1000 лет назад княжил князь Владимир, или чего хотели казаки Богдана Хмельницкого 400 лет назад.
Сколько ни убеждай южных корейцев, что у них один народ с северными, жрать траву и умирать под ударами палок в концлагерях вряд ли кто-то из них захочет…
Отдельного внимания комментаторов удостоились слова Путина «уходите с чем пришли» – о нелегитимности территориальных приобретений Украины в ХХ веке.
Александр Морозов:
Путин написал статью, смысл которой сводится к денонсации Беловежских соглашений. Интересно, эти его статьи – они обязательны для системы образования или это просто «мнение»? Любопытно, что он – хотя и отрицает существование украинского народа, но признает право украинцев на государство. (Но почему-то – в границах СССР 1922 года). Таким образом, он предъявляет российской и мировой аудитории изощренное сумасшествие: антиукраинским аудиториям в России этот текст не дает основания отвергать украинское государство, при этом текст игнорирует и «карту Европы 1914 года», т.е. «имперскую карту». Фраза «кто с чем пришел, тот с тем и уходите» (т.е. Крым не ваш по состоянию на 1922), ставит вопрос о том, куда же должна идти Молдавия? и какова «территория Беларуси»? не говоря уже о «государственности» в Центральной Азии… В общем, все это муть и сумасшествие. Но Путин ведь настойчиво пытается всем этим фундировать современное российское государство.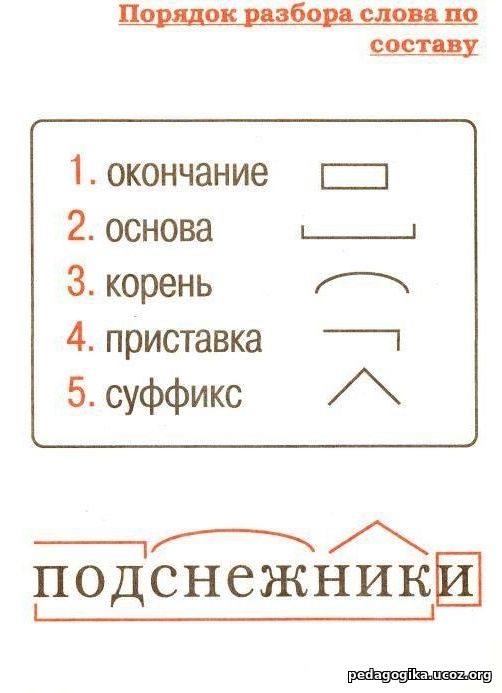
Андрей Мальгин:
Докатились. Путин опубликовал статью, в которой доказывает, что нынешние границы России «необоснованны». Не только с Украиной, но и вообще со всеми бывшими союзными республиками. Если раньше он это подразумевал, то теперь говорит открытым текстом. Это очень опасно. У власти реваншист, сбросивший маску.
«Большевики, – пишет Путин, – относились к русскому народу как неисчерпаемому материалу для социальных экспериментов… Поэтому произвольно нарезали границы, раздавали щедрые территориальные «подарки»…. Очевидно одно: Россия фактически была ограблена».
Ссылается при этом новоявленный исследователь не на Кургиняна какого-нибудь, а на профессора А. Собчака: «Хотите создать собственное государство? Пожалуйста! Но на каких условиях? Напомню здесь оценку, которую дал один из самых ярких политических деятелей новой России, первый мэр Санкт-Петербурга А. Собчак. Как высокопрофессиональный юрист он считал, что любое решение должно быть легитимно, и потому в 1992 году высказал следующее мнение: республики-учредители Союза после того, как они сами же аннулировали Договор 1922 года, должны вернуться в те границы, в которых они вступили в состав Союза. .. Другими словами – уходите с тем, с чем пришли. С такой логикой трудно спорить».
.. Другими словами – уходите с тем, с чем пришли. С такой логикой трудно спорить».
Не знаю, как Собчак, но тут Путин явно лукавит. Потому что если Украина «уйдет с тем, с чем пришла в 1922 году», ей должен отойти, например, Таганрог и еще много-много чего.
Не менее опасно то, что Путин в этой статье пытается обосновать «справедливость» территориальных завоеваний СССР 1939 года, то есть раздел Польши: «…западные земли бывшей Российской империи отошли Польше. В межвоенный период польское правительство развернуло активную переселенческую политику, стремясь изменить этнический состав в «восточных кресах» – так в Польше называли территории нынешней Западной Украины, Западной Белоруссии и части Литвы. Проводилась жёсткая полонизация, местная культура и традиции подавлялись… В 1939 году земли, ранее захваченные Польшей, были возвращены в СССР». Кем возвращены? Гитлером и Сталиным? Польша, значит, захватила, а кто-то неназванный просто взял и вернул, справедливость восторжествовала.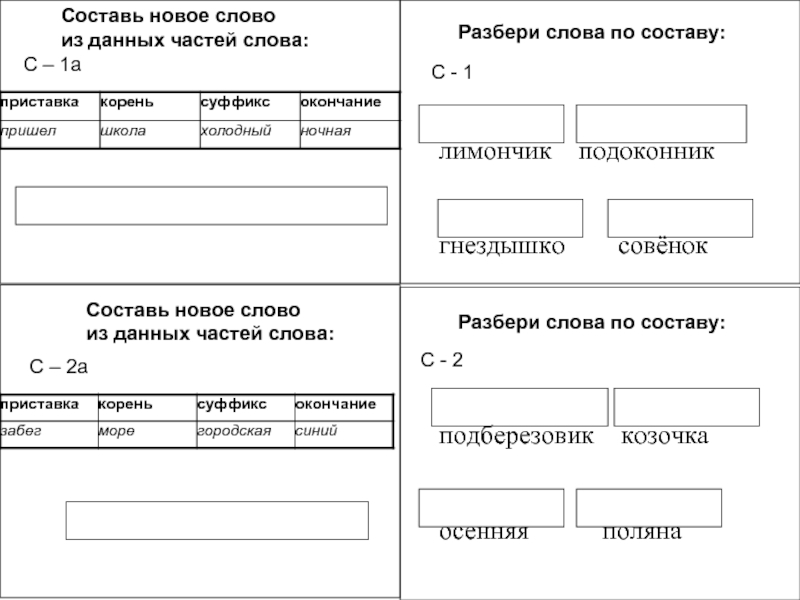
Ну что ж. Интересно, успеют до сентября переписать и издать заново школьные учебники истории?
Не обошлись реакции на новую статью Путина и без всевозможных шуток:
Станислав Шкель:
Весь день думаю над статьёй Путина про русских и украинцев. Пришёл к следующему заключению:
Если украинцы – это ополяченные русские,
То поляки – это онемеченные украинцы.
Немцы – это романизированные готы,
Готы – это оцивилизованные гунны,
Гунны – это мигрировавшие киргизы,
Киргизы – это оказаченные китайцы,
Казахи – это советизированные татары,
Татары – это мусульманские русские,
Русские – это крещённые татары.
Я ничего не упустил?
Сергей Васильев:
Хочу попросить помощи зала. Пожаловаться. Каждый раз, когда я делал инъекцию компонента вакцины «Спутник V», выходила статья Путина.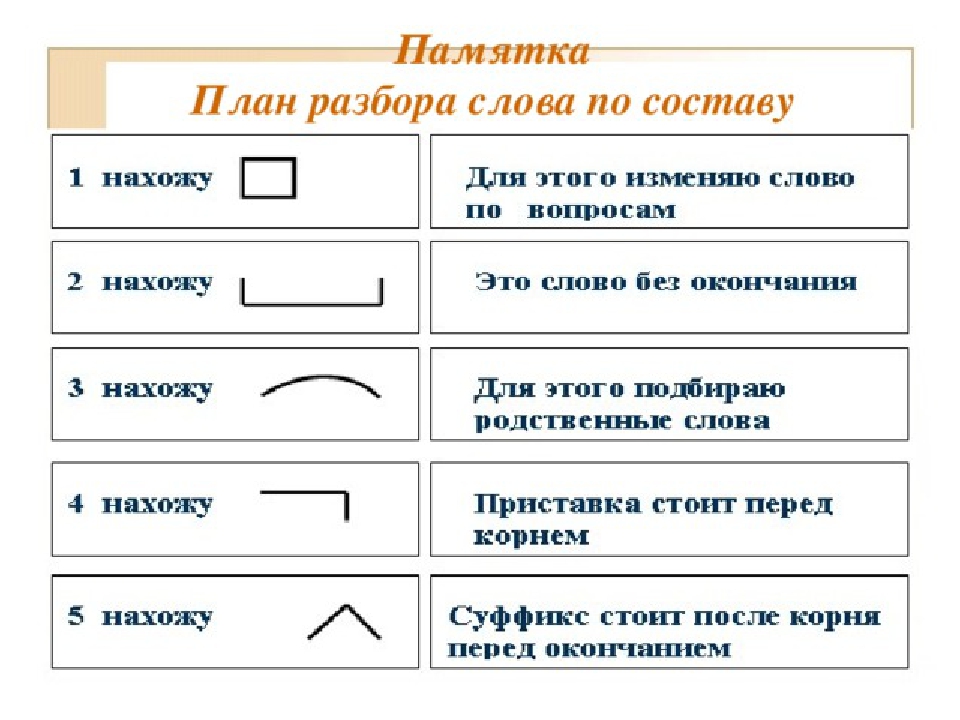 В первый раз про войну, во второй раз – про Украину. А у вас тоже так было?
В первый раз про войну, во второй раз – про Украину. А у вас тоже так было?
(хорошо, что там только два компонента)
За шутками, однако, видны серьезные опасения: многие из прочитавших статью президента увидели в ней между строк готовность Путина и дальше пытаться принуждать Украину к «братству» силой (и не только Украину):
Николай Митрохин:
Кто в последнее время внимательный читатель статей Путина — тот я. Последнюю за занудство видимо уже никуда не взяли, разместили в итоге на сайте. Было очень скучно, но я дочитал. Краткое резюме: фейк-героиня Людмила Павлюченко, всё таки вошла благодаря популярному фильму в канон; Солженицын не зря был у автора во внештатных идеологах; крайне интересно о чем Собчак и Путин толковали между собой в 1992-м году; и в целом, это возможное последнее предупреждение Зеленскому перед следующим шагом по признанию или интеграции в РФ ОРДЛО.
А вообще широко мыслит российский президент в западном направлении. Вплоть до словацкой границы. Всякие там концепты Новороссии и Левобережья его уже не устраивают.
Вплоть до словацкой границы. Всякие там концепты Новороссии и Левобережья его уже не устраивают.
Сергей Абашин:
Интересно, а стремящийся к бессмертию вождь понимает, что его сегодняшняя статья с рассуждениями о «большой русской нации» является типично националистической. Причем, если принять классификацию гражданский/этнический национализмы, озвученная им версия именно этническая, так как апеллирует (точнее даже создаёт мифы) к происхождению, языку, культуре, а не гражданству. Предложенный вождём (его советниками) вид национализма считается имперским, так как он не борется с империей и не стремится отделиться от других народов, а скорее сам себя объявляет официальным/доминирующим и принуждает другие народы ассимилироваться в «большую русскую нацию». Этот вид национализма в Российской империи сформировался во второй половине 19 века и оказался провальным, рухнул сам и заодно похоронил саму империю.
Игорь Эйдман:
Насильно мил не будешь
Путин опубликовал статью «Об историческом единстве русских и украинцев». Ну, история там на уровне учебника для младших школьников сталинских времён. Важнее современность. Он прямо пишет, что Украина – «наша историческая территория» и врагу мы её не отдадим. Для него захват Украины – идея фикс. Он ради этого не остановится и перед большой войной.
Ну, история там на уровне учебника для младших школьников сталинских времён. Важнее современность. Он прямо пишет, что Украина – «наша историческая территория» и врагу мы её не отдадим. Для него захват Украины – идея фикс. Он ради этого не остановится и перед большой войной.
Все это напоминает такую историю. Живут два соседа — нормальный и дурак. Дурак, как напьется, пристает к соседу: «Почему ты меня не любишь, мы же братья практически. А то, что я у тебя огород отжал, так, ты не серчай, какие счёты между братьями». Умный сосед молчит, только на всякий случай калитку закрывает. Тогда алкаш начинает орать: «Ах ты, гад, от меня нос воротишь!». Потом хватает вилы и бросается с ними на соседа.
Но ничего у него не получится. Чем сильнее Путин будет пытаться принудить украинцев к насильственной любви, тем сильнее они будут ненавидеть его и Россию, которую он, к сожалению, представляет. Насильно мил не будешь.
Если многие «либералы» увидели в статье Путина завуалированную, но вполне серьезную угрозу Украине эскалацией насилия, то в лагере «охранителей» (возможно, именно по этой причине) новый текст российского президента предсказуемо вызвал восторг:
Андрей Перла:
Вопрос не в том, готовы ли вы согласиться с Путиным. Вопрос в том, готов ли он сам сделать из своей статьи необходимые практические выводы: а именно отобрать у «Украины» территории, которые У[краинская] советская республика получила в 1922 году. То есть Донбасс и окрестности. От Харькова до Николаева и Одессы.
Вопрос в том, готов ли он сам сделать из своей статьи необходимые практические выводы: а именно отобрать у «Украины» территории, которые У[краинская] советская республика получила в 1922 году. То есть Донбасс и окрестности. От Харькова до Николаева и Одессы.
Егор Холмогоров:
Главное что сделал Путин – это выбросил за борт шелуху про «три братских восточнославянских народа» и прочие советские конструкты (статья вообще белая и единонеделимская) и положил в основу идеологии и, надеюсь, практической политики, принцип единства русского народа, который, в частности, исключает рассмотрение дерусификации как внутреннего дела, исключает «суверенное право быть анти-Россией» и прочее. В общем закопаны все те смысловые ямы, который оставила советски-постсоветская риторика и сам Путин в них регулярно проваливался. Теперь у него есть смысловая шпаргалка для дальнейшего движения. И это прям очень круто.
Сегодня поднимаем бокалы!
Эти восторги не остались незамеченными в противоположном лагере:
Roman Popkov:
Вижу отзывы на «украинскую» статью Путина у наших патриотов–державников и профессиональных русских людей. Визги восторга, прыганье на пятках, победные колыхания жировых масс, распушенные бороды.
Визги восторга, прыганье на пятках, победные колыхания жировых масс, распушенные бороды.
После шести-семи лет фрустрации и разочарований. Уже даже засунув от безысходности одну ногу в стан либеральной оппозиции.
Совсем пропал было русский народ, но тут победный залп сайта кремлин.ру. Государь нас слышит, государево сердце бьется в унисон с нашим.
Тотально необучаемые. Экстремальные кретины. Ничему не научились, выводов из 2014 года – ноль, накопленного опыта ноль. Вот уж действительно, могут повторить, и будут повторять эти прыжки по граблям.
Станислав Белковский:
В. А. Зеленский совершенно логично и закономерно поддерживает публикацию статьи В. В. Путина по украинскому вопросу. Эта статья всячески способствует укреплению внутриполитических позиций президента Украины. И вообще консолидации большинства украинцев на основе неприятия РФ во всех её формах и проявлениях. Путинский Кремль никогда не мог понять, что такое «мягкая сила». Вернее, всегда считал таковой исключительно коррупцию.
Вернее, всегда считал таковой исключительно коррупцию.
Вполне ожидаемым образом отреагировали на статью Путина и в самой Украине:
Денис Казанский:
Путин написал статью об Украине, которая опубликована на сайте Кремля в том числе и на украинском языке. Видимо, постепенно руководство РФ все же принимает неизбежное и начинается считаться с тем, что украинцы имеют свой язык.
Статья в основном является унылым пересказом советского учебника истории, она полна вранья и манипуляций, но больше всего мне понравился этот фрагмент:
«Хотите создать собственное государство? Пожалуйста! Но на каких условиях? Напомню здесь оценку, которую дал один из самых ярких политических деятелей новой России, первый мэр Санкт-Петербурга А. Собчак. Как высокопрофессиональный юрист он считал, что любое решение должно быть легитимно, и потому в 1992 году высказал следующее мнение: республики-учредители Союза после того, как они сами же аннулировали Договор 1922 года, должны вернуться в те границы, в которых они вступили в состав Союза. Все же остальные территориальные приобретения – это предмет для обсуждения, переговоров, потому что аннулировано основание».
Все же остальные территориальные приобретения – это предмет для обсуждения, переговоров, потому что аннулировано основание».
Понятно, что таким образом Путин пытается обосновать аннексию Крыма. Вот только есть один маленький нюанс. В состав СССР Украина в 1922 году входила без Крыма, но зато с Таганрогом, Каменском, Гуково, и значительным куском современной Ростовской области (см. карту). Эта земля тогда входила в состав Донецкой губернии УССР, и была передана в состав РСФСР только в 1924 году.
И если уж «великий историк» решил вспомнить о границах 1922 года, так пусть возвращает Таганрог с Шахтами и Новошахтинском.
Ну а вообще, конечно, весь этот обиженный старческий бубнеж о том, что 30 лет назад что-то не так поделили — не имеет никакого смысла. Украина имеет международное признание в границах 1991 года. И любые территориальные претензии, выдвинутые нам сейчас — есть агрессия и фашизм.
Mustafa Nayyem:
Владимир Путин написал большую статью про Украину.
В тексте много отсылок к истории, которые, как думает автор, должны доказать нам, что не было и нет никакой Украины, украинцев и украинского языка. А если вы думаете иначе, то мы вас, провинциалов любим и такими. Потому что когда-то мы были одним народом. Просто вы были «малороссами» с «окраины», которым посчастливилось говорить и писать на нашем, древнерусском, говорит Владимир Путин.
В целом, хорошая статья. Большая. Но передайте старику, что очень его жаль, и что, на самом деле, это вовсе не статья.
А фантомные боли одержимого неудачника, который по собственной тупости и жадности потерял близкого человека (которого иногда по доброте душевной бил ногами), и теперь, чтобы хоть как-то спасти лицо и облегчить свои муки, пытается доказать себе и миру, что это не он брошенный самодур-недоучка, а тот кто ушел — глупый и неосознанный невротик.
Зачем столько текста, чтобы рассказать нам что-то о нас? Нам вообще все равно, что вы думаете о нас, нашей истории и наших реалиях. Просто живите своей жизнью, перестаньте отравлять жизнь другим и, как говорит Лесь Подервянский, [отстаньте] от нас.
Просто живите своей жизнью, перестаньте отравлять жизнь другим и, как говорит Лесь Подервянский, [отстаньте] от нас.
Статьи он пишет.
Denys Bihunov:
Статья Путина об Украине это мрак: Представьте себе Меркель, которая на пяти листах А4 публикует статью о том, что все народы германской группы (немцы, австрийцы, швейцарцы, голландцы, шведы, норвежцы, датчане) – это немцы, а их обособленная государственность — ошибка истории и недосмотр германского руководства…
Некоторые комментаторы отметили странные особенности стиля статьи – написанной Путиным от первого лица, но со старательным избеганием местоимения «я» и со странным отказом называть украинцев по именам:
Евгений Калюков:
Странное в статье Путина. Одни люди в ней названы полными именами – Андрей Полоцкий, Дмитрий Брянский, Великий князь Московский Дмитрий Иванович, Великий князь Литовский Ольгерд, Великий князь Литовский Ягайло, Иосиф Рутский, Александр Невский, Иван Котляревский, Григорий Сковорода, Тарас Шевченко, Николай Гоголь, Иван Никитович Кожедуб, Людмила Михайловна Павличенко, Сидор Артемьевич Ковпак. .. Других же низводят до инициалов – Б. Хмельницкий (этого хотя бы при первом из пяти упоминаний назвали Богданом, хотя Шевченко и при втором упоминании остаётся Тарасом), П. Скоропадский, С. Петлюра, М. Грушевский, В. Ленин, Н. Хрущёв, Л. Брежнев, А. Собчак или вовсе оставляют без имён (Боброк, Мазепа, Бандера).
.. Других же низводят до инициалов – Б. Хмельницкий (этого хотя бы при первом из пяти упоминаний назвали Богданом, хотя Шевченко и при втором упоминании остаётся Тарасом), П. Скоропадский, С. Петлюра, М. Грушевский, В. Ленин, Н. Хрущёв, Л. Брежнев, А. Собчак или вовсе оставляют без имён (Боброк, Мазепа, Бандера).
Вот это что? Свидетельство того, что статью писали разные люди с разным подходом? Разделение персонажей на отрицательных и положительных или приятных и неприятных лично Путину? И А. Собчак тоже?
Сергей Пархоменко:
Судя по тексту «статьи» Фараона об Украине, старцы запретили ему не одну, а две вещи: называть вслух по имени Алексея Навального, и употреблять в речи местоимение «я».
Очень противно осознавать, что родина находится в руках фанатика, переполненного суевериями и исполненного грубого обрядобесия. Языческая вера в приметы и знамения губит не только его, но и нас.
Статья о единстве украинского и русского народов – далеко не проба пера для российского президента. Год назад, например, Путин вызвал бурю эмоций своим текстом о Второй мировой войне. В соцсетях уже предлагают Владимиру Владимировичу новые темы для публицистических упражнений:
Год назад, например, Путин вызвал бурю эмоций своим текстом о Второй мировой войне. В соцсетях уже предлагают Владимиру Владимировичу новые темы для публицистических упражнений:
Аркадий Янковский:
Его статья «Об историческом единстве КГБ и кооператива «Озеро» была бы более достоверна и ценна!
Что такое морфемы? | SEA
Определение
«Морфема» — это короткий языковой сегмент, отвечающий трем основным критериям:
1. Это слово или часть слова, имеющее значение.
2. Его нельзя разделить на более мелкие значимые сегменты, не изменив его значения или не оставив бессмысленного остатка.
3. Оно имеет относительно одинаковое устойчивое значение в разных вербальных средах.
Свободные и связанные морфемы
Есть два типа морфем без морфем и связанных морфем.«Свободные морфемы» могут иметь особое значение, например, есть , дата , слабый . «Связанные морфемы» не могут оставаться в одиночестве со значением. Морфемы состоят из двух отдельных классов, называемых (а) базовыми (или корнями) и (б) аффиксами.
«Связанные морфемы» не могут оставаться в одиночестве со значением. Морфемы состоят из двух отдельных классов, называемых (а) базовыми (или корнями) и (б) аффиксами.
«Основа» или «корень» — это морфема в слове, придающая этому слову его основное значение. Примером морфемы со «свободным основанием» является женщина в слове женщина . Пример морфемы «связанная основа» — -sent в слове dissent .
Аффиксы
«Аффикс» — это связанная морфема, которая встречается с до или после основания. Аффикс, стоящий перед основанием, называется «префиксом». Некоторые примеры префиксов: ante- , pre- , un- и dis- , как в следующих словах:
до дата
до исторический
un здоровый
dis относительно
Аффикс, идущий после основания, называется суффиксом. «Некоторые примеры суффиксов: -ly , -er , -ism и -ness , как в следующих словах:
«Некоторые примеры суффиксов: -ly , -er , -ism и -ness , как в следующих словах:
Happy ily
сад er
capital ism
kind ness
Производные аффиксы
Аффикс может быть словообразовательным или словоизменительным. «Производные аффиксы» служат для изменения значения слова, опираясь на основу. В приведенных выше примерах слов с префиксами и суффиксами добавление префикса un- к здоровый изменяет значение здорового .Получившееся слово означает «не здоровый». Добавление суффикса -er к сад изменяет значение сад , где растут растения, цветы и т. Д., На слово, которое относится к «человеку, который ухаживает за садом». Следует отметить, что все префиксы на английском языке являются производными.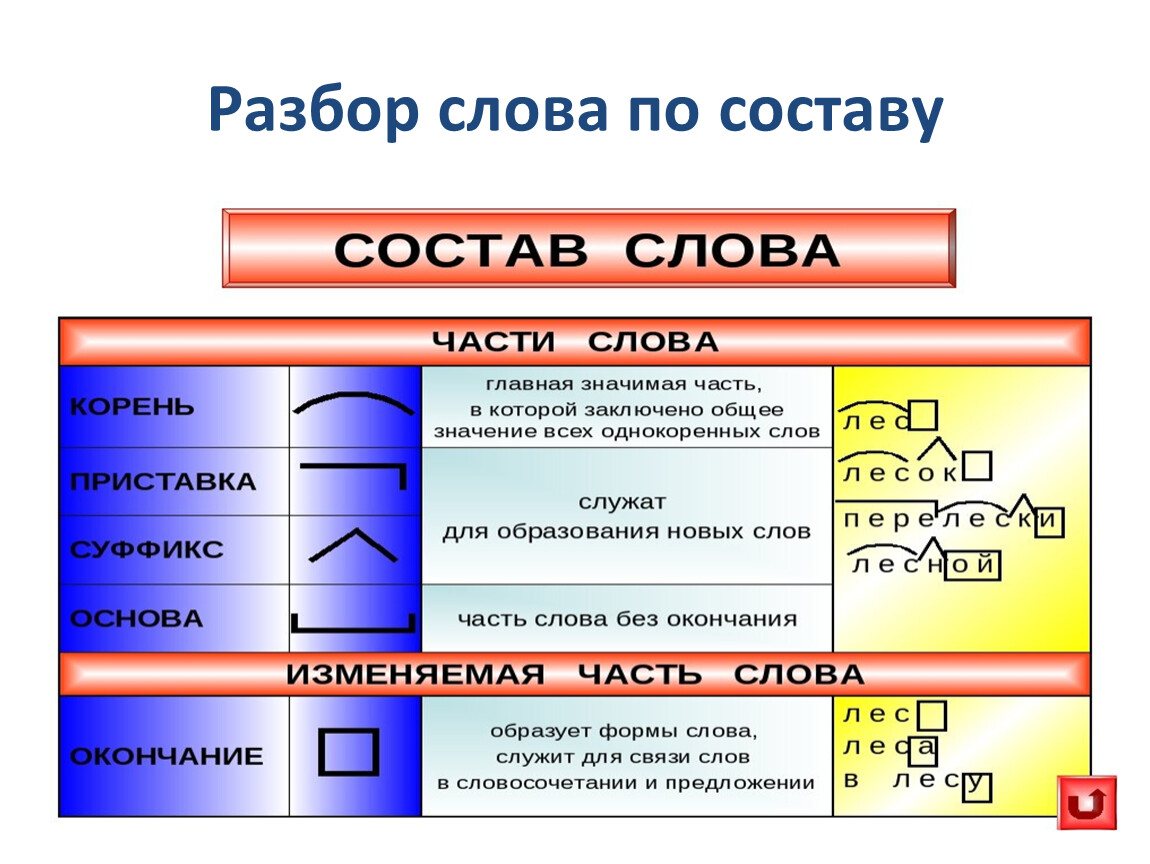 Однако суффиксы могут быть как словообразовательными, так и словоизменительными.
Однако суффиксы могут быть как словообразовательными, так и словоизменительными.
Флективные аффиксы
В английском языке существует большое количество производных аффиксов.Напротив, в английском языке всего восемь «флективных аффиксов», и все это суффиксов . В английском языке есть следующие флективные суффиксы, которые при добавлении к определенным типам слов выполняют множество грамматических функций. Эти грамматические функции показаны справа от каждого суффикса.
-s существительное множественное число
-s существительное притяжательное
-s глагол настоящего времени третье лицо единственного числа
-ing глагол настоящее причастие / герундий
-ed глагол простое прошедшее время
-en глагол прошедшее совершенное причастие
-er прилагательное сравнительное
-est прилагательное превосходная степень
%! PS-Adobe-2.0
%% Создатель: dvipsk 5. 55a Copyright 1986, 1994 Radical Eye Software
%% Заголовок: eisner.acl96.dvi
%% Страниц: 8
%% PageOrder: Ascend
%% BoundingBox: 0 0 612 792
%% EndComments
% DVIPSCommandLine: dvips eisner.acl96.dvi
% DVIPSParameters: dpi = 300, сжато, комментарии удалены
% DVIPS Источник: вывод TeX 2000.05.25: 1844
%% BeginProcSet: texc.pro
/ TeXDict 250 dict def Начало TeXDict / N {def} def / B {привязка def} N / S {exch} N
/ X {S N} B / TR {translate} N / isls false N / vsize 11 72 mul N / hsize 8,5 72
mul N / landplus90 {false} def / @ rigin {isls {[0 landplus90 {1 -1} {- 1 1}
ifelse 0 0 0] concat} if 72 Разрешение div 72 VR Разрешение div neg масштаб
isls {landplus90 {VResolution 72 div vsize mul 0 exch} {Разрешение -72 div
hsize mul 0} ifelse TR}, если разрешение VResolution vsize -72 div 1 add mul
TR [матрица currentmatrix {dup dup round sub abs 0.00001 lt {round} if}
forall round exch round exch] setmatrix} N / @ landscape {/ isls true N} B
/ @ manualfeed {statusdict / manualfeed true put} B / @ копий {/ # копий X} B
/ FMat [1 0 0 -1 0 0] N / FBB [0 0 0 0] N / nn 0 N / IE 0 N / ctr 0 N / df-tail {
/ nn 8 dict N nn begin / FontType 3 N / FontMatrix fntrx N / FontBBox FBB N
строка / базовый массив X / BitMaps X / BuildChar {CharBuilder} N / кодирование IE N
end dup {/ foo setfont} 2 array copy cvx N load 0 nn put / ctr 0 N [} B / df {
/ sf 1 N / fntrx FMat N df-tail} B / dfs {div / sf X / fntrx [sf 0 0 sf neg 0 0]
N df-tail} B / E {pop nn dup definefont setfont} B / ch-width {ch-data dup
длина 5 sub get} B / ch-height {ch-data dup length 4 sub get} B / ch-xoff {
128 ch-data dup length 3 sub get sub} B / ch-yoff {ch-data dup length 2 sub
получить 127 sub} B / ch-dx {ch-data dup length 1 sub get} B / ch-image {ch-data
dup type / stringtype ne {ctr get / ctr ctr 1 add N} if} B / id 0 N / rw 0 N
/ rc 0 N / gp 0 N / cp 0 N / G 0 N / sf 0 N / CharBuilder {save 3 1 ролик S dup
/ base get 2 index get S / BitMaps get S get / ch-data X pop / ctr 0 N ch-dx
0 ch-xoff ch-yoff ch-height sub ch-xoff ch-width добавить ch-yoff
setcachedevice ch-width ch-height true [1 0 0 -1 -.
55a Copyright 1986, 1994 Radical Eye Software
%% Заголовок: eisner.acl96.dvi
%% Страниц: 8
%% PageOrder: Ascend
%% BoundingBox: 0 0 612 792
%% EndComments
% DVIPSCommandLine: dvips eisner.acl96.dvi
% DVIPSParameters: dpi = 300, сжато, комментарии удалены
% DVIPS Источник: вывод TeX 2000.05.25: 1844
%% BeginProcSet: texc.pro
/ TeXDict 250 dict def Начало TeXDict / N {def} def / B {привязка def} N / S {exch} N
/ X {S N} B / TR {translate} N / isls false N / vsize 11 72 mul N / hsize 8,5 72
mul N / landplus90 {false} def / @ rigin {isls {[0 landplus90 {1 -1} {- 1 1}
ifelse 0 0 0] concat} if 72 Разрешение div 72 VR Разрешение div neg масштаб
isls {landplus90 {VResolution 72 div vsize mul 0 exch} {Разрешение -72 div
hsize mul 0} ifelse TR}, если разрешение VResolution vsize -72 div 1 add mul
TR [матрица currentmatrix {dup dup round sub abs 0.00001 lt {round} if}
forall round exch round exch] setmatrix} N / @ landscape {/ isls true N} B
/ @ manualfeed {statusdict / manualfeed true put} B / @ копий {/ # копий X} B
/ FMat [1 0 0 -1 0 0] N / FBB [0 0 0 0] N / nn 0 N / IE 0 N / ctr 0 N / df-tail {
/ nn 8 dict N nn begin / FontType 3 N / FontMatrix fntrx N / FontBBox FBB N
строка / базовый массив X / BitMaps X / BuildChar {CharBuilder} N / кодирование IE N
end dup {/ foo setfont} 2 array copy cvx N load 0 nn put / ctr 0 N [} B / df {
/ sf 1 N / fntrx FMat N df-tail} B / dfs {div / sf X / fntrx [sf 0 0 sf neg 0 0]
N df-tail} B / E {pop nn dup definefont setfont} B / ch-width {ch-data dup
длина 5 sub get} B / ch-height {ch-data dup length 4 sub get} B / ch-xoff {
128 ch-data dup length 3 sub get sub} B / ch-yoff {ch-data dup length 2 sub
получить 127 sub} B / ch-dx {ch-data dup length 1 sub get} B / ch-image {ch-data
dup type / stringtype ne {ctr get / ctr ctr 1 add N} if} B / id 0 N / rw 0 N
/ rc 0 N / gp 0 N / cp 0 N / G 0 N / sf 0 N / CharBuilder {save 3 1 ролик S dup
/ base get 2 index get S / BitMaps get S get / ch-data X pop / ctr 0 N ch-dx
0 ch-xoff ch-yoff ch-height sub ch-xoff ch-width добавить ch-yoff
setcachedevice ch-width ch-height true [1 0 0 -1 -. 1 ч-хофф суб ч-йофф
.1 sub] / id ch-image N / rw ch-width 7 добавить 8 idiv строка N / rc 0 N / gp 0 N
/ cp 0 N {rc 0 ne {rc 1 sub / rc X rw} {G} ifelse} восстановление маски изображения} B / G {{id
gp get / gp gp 1 add N dup 18 mod S 18 idiv pl S get exec} loop} B / adv {cp
add / cp X} B / chg {rw cp id gp 4 index getinterval putinterval dup gp add
/ gp X adv} B / nd {/ cp 0 N rw exit} B / lsh {rw cp 2 copy get dup 0 eq {pop 1} {
dup 255 eq {pop 254} {dup dup add 255 и S 1 и или} ifelse} ifelse положить 1
adv} B / rsh {rw cp 2 copy get dup 0 eq {pop 128} {dup 255 eq {pop 127} {dup 2
idiv S 128 и or} ifelse} ifelse помещает 1 adv} B / clr {rw cp 2 index string
putinterval adv} B / set {rw cp fillstr 0 4 index getinterval putinterval
adv} B / fillstr 18 string 0 1 17 {2 copy 255 put pop} для N / pl [{adv 1 chg}
{adv 1 chg nd} {1 add chg} {1 add chg nd} {adv lsh} {adv lsh nd} {adv rsh} {
adv rsh nd} {1 add adv} {/ rc X nd} {1 add set} {1 add clr} {adv 2 chg} {adv 2
chg nd} {pop nd}] dup {bind pop} forall N / D {/ cc X dup type / stringtype ne {]
} if nn / base get cc ctr put nn / BitMaps get S ctr S sf 1 ne {dup dup
length 1 sub dup 2 index S get sf div put} if put / ctr ctr 1 add N} B / I {
cc 1 add D} B / bop {userdict / bop-hook known {bop-hook} if / SI save N @rigin
0 0 moveto / V matrix currentmatrix dup 1 get dup mul exch 0 get dup mul
Добавлять .
1 ч-хофф суб ч-йофф
.1 sub] / id ch-image N / rw ch-width 7 добавить 8 idiv строка N / rc 0 N / gp 0 N
/ cp 0 N {rc 0 ne {rc 1 sub / rc X rw} {G} ifelse} восстановление маски изображения} B / G {{id
gp get / gp gp 1 add N dup 18 mod S 18 idiv pl S get exec} loop} B / adv {cp
add / cp X} B / chg {rw cp id gp 4 index getinterval putinterval dup gp add
/ gp X adv} B / nd {/ cp 0 N rw exit} B / lsh {rw cp 2 copy get dup 0 eq {pop 1} {
dup 255 eq {pop 254} {dup dup add 255 и S 1 и или} ifelse} ifelse положить 1
adv} B / rsh {rw cp 2 copy get dup 0 eq {pop 128} {dup 255 eq {pop 127} {dup 2
idiv S 128 и or} ifelse} ifelse помещает 1 adv} B / clr {rw cp 2 index string
putinterval adv} B / set {rw cp fillstr 0 4 index getinterval putinterval
adv} B / fillstr 18 string 0 1 17 {2 copy 255 put pop} для N / pl [{adv 1 chg}
{adv 1 chg nd} {1 add chg} {1 add chg nd} {adv lsh} {adv lsh nd} {adv rsh} {
adv rsh nd} {1 add adv} {/ rc X nd} {1 add set} {1 add clr} {adv 2 chg} {adv 2
chg nd} {pop nd}] dup {bind pop} forall N / D {/ cc X dup type / stringtype ne {]
} if nn / base get cc ctr put nn / BitMaps get S ctr S sf 1 ne {dup dup
length 1 sub dup 2 index S get sf div put} if put / ctr ctr 1 add N} B / I {
cc 1 add D} B / bop {userdict / bop-hook known {bop-hook} if / SI save N @rigin
0 0 moveto / V matrix currentmatrix dup 1 get dup mul exch 0 get dup mul
Добавлять . 99 lt {/ QV} {/ RV} ifelse load def pop pop} N / eop {SI восстановить showpage
userdict / eop-hook известный {eop-hook} if} N / @ start {userdict / start-hook
известное {start-hook} if pop / VResolution X / Resolution X 1000 div / DVImag X
/ IE 256 array N 0 1 255 {IE S 1 string dup 0 3 index put cvn put} для
65781,76 дел / размер X 65781,76 дел / размер X} N / p {show} N / RMat [1 0 0 -1 0
0] N / BDot 260 string N / rulex 0 N / ruley 0 N / v {/ ruley X / rulex X V} B / V
{} B / RV statusdict begin / product where {pop product dup length 7 ge {0 7
getinterval dup (Display) eq exch 0 4 getinterval (NeXT) eq или} {pop false}
ifelse} {false} ifelse end {{gsave TR -.1 .1 TR 1 1 шкала rulex ruley false
RMat {BDot} imagemask grestore}} {{gsave TR -.1 .1 TR rulex ruley scale 1 1
false RMat {BDot} imagemask grestore}} ifelse B / QV {gsave newpath transform
round exch round exch itransform moveto rulex 0 rlineto 0 ruley neg
rlineto rulex neg 0 rlinto fill grestore} B / a {moveto} B / delta 0 N / tail
{dup / delta X 0 rmoveto} B / M {S p delta add tail} B / b {S p tail} B / c {-4 M}
B / d {-3 M} B / e {-2 M} B / f {-1 M} B / g {0 M} B / h {1 M} B / i {2 M} B / j {3 M} B / k {
4 M} ч / б {0 rmoveto} B / l {p -4 w} B / m {p -3 w} B / n {p -2 w} B / o {p -1 w} B / q {
p 1 w} B / r {p 2 w} B / s {p 3 w} B / t {p 4 w} B / x {0 S rmoveto} B / y {3 2 рулона p
a} B / bos {/ SS сохранить N} B / eos {SS restore} B конец
%% EndProcSet
%% BeginProcSet: специальный.
99 lt {/ QV} {/ RV} ifelse load def pop pop} N / eop {SI восстановить showpage
userdict / eop-hook известный {eop-hook} if} N / @ start {userdict / start-hook
известное {start-hook} if pop / VResolution X / Resolution X 1000 div / DVImag X
/ IE 256 array N 0 1 255 {IE S 1 string dup 0 3 index put cvn put} для
65781,76 дел / размер X 65781,76 дел / размер X} N / p {show} N / RMat [1 0 0 -1 0
0] N / BDot 260 string N / rulex 0 N / ruley 0 N / v {/ ruley X / rulex X V} B / V
{} B / RV statusdict begin / product where {pop product dup length 7 ge {0 7
getinterval dup (Display) eq exch 0 4 getinterval (NeXT) eq или} {pop false}
ifelse} {false} ifelse end {{gsave TR -.1 .1 TR 1 1 шкала rulex ruley false
RMat {BDot} imagemask grestore}} {{gsave TR -.1 .1 TR rulex ruley scale 1 1
false RMat {BDot} imagemask grestore}} ifelse B / QV {gsave newpath transform
round exch round exch itransform moveto rulex 0 rlineto 0 ruley neg
rlineto rulex neg 0 rlinto fill grestore} B / a {moveto} B / delta 0 N / tail
{dup / delta X 0 rmoveto} B / M {S p delta add tail} B / b {S p tail} B / c {-4 M}
B / d {-3 M} B / e {-2 M} B / f {-1 M} B / g {0 M} B / h {1 M} B / i {2 M} B / j {3 M} B / k {
4 M} ч / б {0 rmoveto} B / l {p -4 w} B / m {p -3 w} B / n {p -2 w} B / o {p -1 w} B / q {
p 1 w} B / r {p 2 w} B / s {p 3 w} B / t {p 4 w} B / x {0 S rmoveto} B / y {3 2 рулона p
a} B / bos {/ SS сохранить N} B / eos {SS restore} B конец
%% EndProcSet
%% BeginProcSet: специальный. профи
TeXDict begin / SDict 200 dict N SDict begin / @ SpecialDefaults {/ hs 612 N
/ vs 792 N / ho 0 N / vo 0 N / hsc 1 N / vsc 1 N / ang 0 N / CLIP 0 N / rwiSeen
false N / rhiSeen false N / letter {} N / note {} N / a4 {} N / legal {} N} B
/ @ scaleunit 100 N / @ hscale {@scaleunit div / hsc X} B / @ vscale {@scaleunit
div / vsc X} B / @ hsize {/ hs X / CLIP 1 N} B / @ vsize {/ vs X / CLIP 1 N} B / @ clip {
/ CLIP 2 N} B / @ hoffset {/ ho X} B / @ voffset {/ vo X} B / @ angle {/ ang X} B / @ rwi {
10 div / rwi X / rwiSeen true N} B / @ rhi {10 div / rhi X / rhiSeen true N} B
/ @ llx {/ llx X} B / @ lly {/ lly X} B / @ urx {/ urx X} B / @ ury {/ ury X} B / magscale
true def end / @ MacSetUp {userdict / md известный {userdict / md тип получения
/ dicttype eq {userdict begin md length 10 add md maxlength ge {/ md md dup
длина 20 add dict copy def} if end md begin / letter {} N / note {} N / Legal {}
N / od {txpose 1 0 mtx defaultmatrix dtransform S atan / pa X newpath
метка обрезки {преобразовать {itransform moveto}} {преобразовать {itransform lineto}
} {6 -2 роликовое преобразование 6 -2 роликовое преобразование 6 -2 роликовое преобразование {
itransform 6 2 roll itransform 6 2 roll itransform 6 2 roll curveto}} {{
closepath}} pathforall newpath counttomark array astore / gc xdf pop ct 39
0 положить 10 fz 0 fs 2 F / | ______ Courier fnt invertflag {PaintBlack} if} N
/ txpose {pxs pys scale ppr aload pop por {noflips {pop S neg S TR pop 1 -1
scale} если xflip yflip и {pop S neg S TR 180 повернуть 1 -1 масштаб ppr 3 получить
ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg TR} if xflip yflip
not и {pop S neg S TR pop 180 rotate ppr 3 get ppr 1 get neg sub neg 0
TR} if yflip xflip not и {ppr 1 get neg ppr 0 get neg TR} if} {noflips {TR
pop pop 270 повернуть масштаб 1 -1} если xflip yflip и {TR pop pop 90 повернуть 1
-1 масштаб ppr 3 get ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg
TR} если xflip yflip not и {TR pop pop 90 rotate ppr 3 get ppr 1 get neg
sub neg 0 TR} если yflip xflip not и {TR pop pop 270 rotate ppr 2 get ppr
0 get neg sub neg 0 S TR} if} ifelse scaleby96 {ppr aload pop 4 -1 roll add
2 дел 3 1 рулон прибавить 2 дел 2 копировать TR.
профи
TeXDict begin / SDict 200 dict N SDict begin / @ SpecialDefaults {/ hs 612 N
/ vs 792 N / ho 0 N / vo 0 N / hsc 1 N / vsc 1 N / ang 0 N / CLIP 0 N / rwiSeen
false N / rhiSeen false N / letter {} N / note {} N / a4 {} N / legal {} N} B
/ @ scaleunit 100 N / @ hscale {@scaleunit div / hsc X} B / @ vscale {@scaleunit
div / vsc X} B / @ hsize {/ hs X / CLIP 1 N} B / @ vsize {/ vs X / CLIP 1 N} B / @ clip {
/ CLIP 2 N} B / @ hoffset {/ ho X} B / @ voffset {/ vo X} B / @ angle {/ ang X} B / @ rwi {
10 div / rwi X / rwiSeen true N} B / @ rhi {10 div / rhi X / rhiSeen true N} B
/ @ llx {/ llx X} B / @ lly {/ lly X} B / @ urx {/ urx X} B / @ ury {/ ury X} B / magscale
true def end / @ MacSetUp {userdict / md известный {userdict / md тип получения
/ dicttype eq {userdict begin md length 10 add md maxlength ge {/ md md dup
длина 20 add dict copy def} if end md begin / letter {} N / note {} N / Legal {}
N / od {txpose 1 0 mtx defaultmatrix dtransform S atan / pa X newpath
метка обрезки {преобразовать {itransform moveto}} {преобразовать {itransform lineto}
} {6 -2 роликовое преобразование 6 -2 роликовое преобразование 6 -2 роликовое преобразование {
itransform 6 2 roll itransform 6 2 roll itransform 6 2 roll curveto}} {{
closepath}} pathforall newpath counttomark array astore / gc xdf pop ct 39
0 положить 10 fz 0 fs 2 F / | ______ Courier fnt invertflag {PaintBlack} if} N
/ txpose {pxs pys scale ppr aload pop por {noflips {pop S neg S TR pop 1 -1
scale} если xflip yflip и {pop S neg S TR 180 повернуть 1 -1 масштаб ppr 3 получить
ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg TR} if xflip yflip
not и {pop S neg S TR pop 180 rotate ppr 3 get ppr 1 get neg sub neg 0
TR} if yflip xflip not и {ppr 1 get neg ppr 0 get neg TR} if} {noflips {TR
pop pop 270 повернуть масштаб 1 -1} если xflip yflip и {TR pop pop 90 повернуть 1
-1 масштаб ppr 3 get ppr 1 get neg sub neg ppr 2 get ppr 0 get neg sub neg
TR} если xflip yflip not и {TR pop pop 90 rotate ppr 3 get ppr 1 get neg
sub neg 0 TR} если yflip xflip not и {TR pop pop 270 rotate ppr 2 get ppr
0 get neg sub neg 0 S TR} if} ifelse scaleby96 {ppr aload pop 4 -1 roll add
2 дел 3 1 рулон прибавить 2 дел 2 копировать TR. 96 dup scale neg S neg S TR} if} N / cp
{pop pop showpage pm restore} N end} if} if} N / normalscale {Разрешение 72
div VResolution 72 div neg scale magscale {DVImag dup scale} if 0 setgray}
N / psfts {S 65781.76 div N} N / startTexFig {/ psf $ SavedState save N userdict
maxlength dict begin / magscale false def normalscale currentpoint TR
/ psf $ ury psfts / psf $ urx psfts / psf $ lly psfts / psf $ llx psfts / psf $ y psfts
/ psf $ x psfts currentpoint / psf $ cy X / psf $ cx X / psf $ sx psf $ x psf $ urx
psf $ llx sub div N / psf $ sy psf $ y psf $ ury psf $ lly sub div N psf $ sx psf $ sy
масштаб psf $ cx psf $ sx div psf $ llx sub psf $ cy psf $ sy div psf $ ury sub TR
/ showpage {} N / erasepage {} N / copypage {} N / p 3 def @MacSetUp} N / doclip {
psf $ llx psf $ lly psf $ urx psf $ ury currentpoint 6 2 roll newpath 4 copy 4 2
рулон moveto 6 -1 рулон S lineto S lineto S lineto closepath clip newpath
moveto} N / endTexFig {end psf $ SavedState restore} N / @ begin special {SDict
begin / SpecialSave save N gsave normalscale currentpoint TR
@SpecialDefaults count / ocount X / dcount countdictstack N} N / @ setspecial
{CLIP 1 eq {newpath 0 0 moveto hs 0 rlineto 0 vs rlineto hs neg 0 rlineto
closepath clip} if ho vo TR hsc vsc scale ang rotate rwiSeen {rwi urx llx
sub div rhiSeen {rhi ury lly sub div} {dup} ifelse scale llx neg lly neg TR
} {rhiSeen {rhi ury lly sub div dup scale llx neg lly neg TR} if} ifelse
CLIP 2 eq {newpath llx lly moveto urx lly lineto urx ury lineto llx ury
lineto closepath clip} if / showpage {} N / erasepage {} N / copypage {} N newpath
} N / @ endpecial {count ocount sub {pop} repeat countdictstack dcount sub {
end} повторить grestore SpecialSave restore end} N / @ defspecial {SDict begin}
N / @ fedspecial {end} B / li {lineto} B / rl {rlineto} B / rc {rcurveto} B / np {
/ SaveX currentpoint / SaveY X N 1 setlinecap newpath} N / st {stroke SaveX
SaveY moveto} N / fil {fill SaveX SaveY moveto} N / эллипс {/ endangle X
/ startangle X / yrad X / xrad X / savematrix matrix currentmatrix N TR xrad
yrad scale 0 0 1 startangle endangle arc savematrix setmatrix} N конец
%% EndProcSet
Начало TeXDict 40258431 52099146 1000 300 300 (eisner.
96 dup scale neg S neg S TR} if} N / cp
{pop pop showpage pm restore} N end} if} if} N / normalscale {Разрешение 72
div VResolution 72 div neg scale magscale {DVImag dup scale} if 0 setgray}
N / psfts {S 65781.76 div N} N / startTexFig {/ psf $ SavedState save N userdict
maxlength dict begin / magscale false def normalscale currentpoint TR
/ psf $ ury psfts / psf $ urx psfts / psf $ lly psfts / psf $ llx psfts / psf $ y psfts
/ psf $ x psfts currentpoint / psf $ cy X / psf $ cx X / psf $ sx psf $ x psf $ urx
psf $ llx sub div N / psf $ sy psf $ y psf $ ury psf $ lly sub div N psf $ sx psf $ sy
масштаб psf $ cx psf $ sx div psf $ llx sub psf $ cy psf $ sy div psf $ ury sub TR
/ showpage {} N / erasepage {} N / copypage {} N / p 3 def @MacSetUp} N / doclip {
psf $ llx psf $ lly psf $ urx psf $ ury currentpoint 6 2 roll newpath 4 copy 4 2
рулон moveto 6 -1 рулон S lineto S lineto S lineto closepath clip newpath
moveto} N / endTexFig {end psf $ SavedState restore} N / @ begin special {SDict
begin / SpecialSave save N gsave normalscale currentpoint TR
@SpecialDefaults count / ocount X / dcount countdictstack N} N / @ setspecial
{CLIP 1 eq {newpath 0 0 moveto hs 0 rlineto 0 vs rlineto hs neg 0 rlineto
closepath clip} if ho vo TR hsc vsc scale ang rotate rwiSeen {rwi urx llx
sub div rhiSeen {rhi ury lly sub div} {dup} ifelse scale llx neg lly neg TR
} {rhiSeen {rhi ury lly sub div dup scale llx neg lly neg TR} if} ifelse
CLIP 2 eq {newpath llx lly moveto urx lly lineto urx ury lineto llx ury
lineto closepath clip} if / showpage {} N / erasepage {} N / copypage {} N newpath
} N / @ endpecial {count ocount sub {pop} repeat countdictstack dcount sub {
end} повторить grestore SpecialSave restore end} N / @ defspecial {SDict begin}
N / @ fedspecial {end} B / li {lineto} B / rl {rlineto} B / rc {rcurveto} B / np {
/ SaveX currentpoint / SaveY X N 1 setlinecap newpath} N / st {stroke SaveX
SaveY moveto} N / fil {fill SaveX SaveY moveto} N / эллипс {/ endangle X
/ startangle X / yrad X / xrad X / savematrix matrix currentmatrix N TR xrad
yrad scale 0 0 1 startangle endangle arc savematrix setmatrix} N конец
%% EndProcSet
Начало TeXDict 40258431 52099146 1000 300 300 (eisner. acl96.dvi)
@start / Fa 1 85 df84 D E / Fb 1111 df110 D E / Fc
12 126 df16 DI26 DI32 DI40
DI122 DIII
E / Fd 6 124 df98 DI102 D111 D
116 D123 D E / Fe 27122 df40 DI44 D48 DI55
D97 DIIIII105
D107 DIIIIIIII
IIII121 D E / Ff 3 111 df0
D32 D110 D E / Fg 14
121 df12 DI21 D58 DIIII81 DII
I110 D120 D E / Fh 13122 df21
D58 D81 DIII102
DII107 D110 D120
DI E / Fi 35 121 df40
DI47
DII60 D62 D65 DIII
IIII76 D78 D80 D83 DI86
D88
D97 DI100 DII108
D110 DI114 DII119 DI
E / Fj 18117 df40 DI47
D49 DI
III78 D80 D83 D101 DI105
D109
DI115 DI
E / Fk 70125 df12 D14 D34 D38 DIII44 DIIIIIIIIIIIIIII61 D63
D65 DI68 D70
DIIIII77 DII83
DII91 DII97 DIIIIIIIIIIIIIIIIIII
IIII124 D E / Fl 2 111 df3 D110
D E / Fm 2 111 df
48 D110 D E / Fn 14 84
df40 DI47 DIIIIII73 D78 DII83 D E / Fo 36121 df12
D38
D42 D45
DI49 DI52
D58 D66 DI69 D76 D78 D83 DI97 D99 DIIIIII108
DIIIII
IIIII120 D E / Fp 53122 df12 D34 D40 DI44
DII50 DI53 D55 DI58 D
65 DIIIIII73 D76 DIIII83 DII92 D97 DIIIIIIII108
DIIIIIIIIIIIII
E / Fq 38123 df11 DII21 D27
DI58 DI
III67 D79 D81 DIII97 D99
DIIIIII107 DIII112 D114 DIII119
DIII
E / Fr 84 128 df11 DII
я
34 D38 DIIIIIIIIIIIIIIIIIIIII61 D63 D65 DIII
IIIIIIIIIIII82 DIIIII89
D91 DII97 DIIIIIIIIIIIIIIIIIIIIIIIIIII127 D E / Fs 13118 df46 D64 D99 DII105 DI108 D110 D112 D114 DI117
D E / Ft 36122 df44 DII48 DIIII54
D56 DI65
D67 DI73 D80 D83 D85 D97 D99
DIII104 DI108
DI
III114 DII
II121 D E / Fu 47122 df12
D34 D49 DIIIIII65
D67
DIIII73
DI78 DII82
DI87 D
92 D97
DII
II
IIII107 DIIIII114 DIIIIIII E / Fv 14 121 df
0 DI3 D15 D20
DI
33 D41
D50
D54 D106 D109 DI120 D E / Fw
23 122 df14 D45
D67 D69 DII78 D80 D97 DII
acl96.dvi)
@start / Fa 1 85 df84 D E / Fb 1111 df110 D E / Fc
12 126 df16 DI26 DI32 DI40
DI122 DIII
E / Fd 6 124 df98 DI102 D111 D
116 D123 D E / Fe 27122 df40 DI44 D48 DI55
D97 DIIIII105
D107 DIIIIIIII
IIII121 D E / Ff 3 111 df0
D32 D110 D E / Fg 14
121 df12 DI21 D58 DIIII81 DII
I110 D120 D E / Fh 13122 df21
D58 D81 DIII102
DII107 D110 D120
DI E / Fi 35 121 df40
DI47
DII60 D62 D65 DIII
IIII76 D78 D80 D83 DI86
D88
D97 DI100 DII108
D110 DI114 DII119 DI
E / Fj 18117 df40 DI47
D49 DI
III78 D80 D83 D101 DI105
D109
DI115 DI
E / Fk 70125 df12 D14 D34 D38 DIII44 DIIIIIIIIIIIIIII61 D63
D65 DI68 D70
DIIIII77 DII83
DII91 DII97 DIIIIIIIIIIIIIIIIIII
IIII124 D E / Fl 2 111 df3 D110
D E / Fm 2 111 df
48 D110 D E / Fn 14 84
df40 DI47 DIIIIII73 D78 DII83 D E / Fo 36121 df12
D38
D42 D45
DI49 DI52
D58 D66 DI69 D76 D78 D83 DI97 D99 DIIIIII108
DIIIII
IIIII120 D E / Fp 53122 df12 D34 D40 DI44
DII50 DI53 D55 DI58 D
65 DIIIIII73 D76 DIIII83 DII92 D97 DIIIIIIII108
DIIIIIIIIIIIII
E / Fq 38123 df11 DII21 D27
DI58 DI
III67 D79 D81 DIII97 D99
DIIIIII107 DIII112 D114 DIII119
DIII
E / Fr 84 128 df11 DII
я
34 D38 DIIIIIIIIIIIIIIIIIIIII61 D63 D65 DIII
IIIIIIIIIIII82 DIIIII89
D91 DII97 DIIIIIIIIIIIIIIIIIIIIIIIIIII127 D E / Fs 13118 df46 D64 D99 DII105 DI108 D110 D112 D114 DI117
D E / Ft 36122 df44 DII48 DIIII54
D56 DI65
D67 DI73 D80 D83 D85 D97 D99
DIII104 DI108
DI
III114 DII
II121 D E / Fu 47122 df12
D34 D49 DIIIIII65
D67
DIIII73
DI78 DII82
DI87 D
92 D97
DII
II
IIII107 DIIIII114 DIIIIIII E / Fv 14 121 df
0 DI3 D15 D20
DI
33 D41
D50
D54 D106 D109 DI120 D E / Fw
23 122 df14 D45
D67 D69 DII78 D80 D97 DII
3.
 2 Визуальных элемента — Основные вещи, которые можно увидеть — Основы графического дизайна и полиграфической продукции
2 Визуальных элемента — Основные вещи, которые можно увидеть — Основы графического дизайна и полиграфической продукцииАлекс Хасс
Рисунок 3.1 Проектирование с использованием точек, линий, плоскостейТочка, линия и плоскость — это строительные блоки дизайна. Из этих элементов дизайнеры создают изображения, значки, текстуры, узоры, диаграммы, анимации и типографские системы. (Lupton & Phillips, 2014, стр.13)
Точка — это точное положение или место на поверхности. Говоря чисто математическим языком, точка отмечает набор координат — у нее вообще нет массы.В этом объективном определении точка — это, по сути, место. Визуально точка — это точка и, следовательно, основной строительный блок каждого варианта линии, текстуры и плоскости.
Субъективно термин точка имеет большую силу. Точка может направлять внимание, быть в центре внимания, создавать акцент и прорезать завуалированную информацию. Композиционный термин focal point объединяет объективное и субъективное, являясь первым местом, куда в композиции обращается взгляд, и обычно содержит наиболее важную часть визуальной коммуникации.
Композиционный термин focal point объединяет объективное и субъективное, являясь первым местом, куда в композиции обращается взгляд, и обычно содержит наиболее важную часть визуальной коммуникации.
Линия — это второй по важности элемент дизайна. Линия представляет собой набор точек, расположенных линейно (см. Рисунок 3.2). Линия соединяет две точки или отслеживает путь движения. Линия может быть реальной или подразумеваемой — например, как композиция из двух или более объектов подряд. Линии в природе действуют как определяющие плоскости — например, горизонт или силуэт леса на фоне неба. Длинные прямые линии не часто встречаются в природе, и поэтому, когда они присутствуют, они, как правило, визуально доминируют в ландшафте.Естественные настройки обычно анализируются глазом на более короткие последовательности изогнутых или прямых линий и органических форм.
При нанесении вручную линия создается штрихом карандаша, пера, кисти или любого другого инструмента для нанесения разметки. Эти линии могут быть тонкими или широкими, выразительными и отчетливыми, отражая текстуру инструмента, с помощью которого они были созданы. Линии могут создавать плоскость (форму), объединяясь вместе или определяя форму. Если линия утолщается, она меняется и становится плоскостью.Когда линии создаются в цифровом виде, они могут приобретать многие из тех же качеств, которыми обладают нарисованные от руки линии, посредством применения эффектов.
Эти линии могут быть тонкими или широкими, выразительными и отчетливыми, отражая текстуру инструмента, с помощью которого они были созданы. Линии могут создавать плоскость (форму), объединяясь вместе или определяя форму. Если линия утолщается, она меняется и становится плоскостью.Когда линии создаются в цифровом виде, они могут приобретать многие из тех же качеств, которыми обладают нарисованные от руки линии, посредством применения эффектов.
. Подобно линиям, плоскости (формы) могут быть выполнены органически или могут быть геометрическими, как в примере, показанном на рис. 3.3. Плоскость — это плоская поверхность с определенными границами. «Линия замыкается и становится формой, ограниченной плоскостью» (Lupton & Phillips, 2014, стр. 38). Плоскости — отличные композиционные инструменты для кластеризации визуальных элементов в визуальные поля.Самолет также может действовать как разделяющее устройство и позволять зрителю видеть, что один раздел информации не связан с другим.
В программном обеспечении для дизайна векторная графика — это форма, созданная путем определения ее параметров с помощью линии и последующего заполнения ее сплошной или текстурированной заливкой. Сетки помогают создавать и определять типографские плоскости, которые плавают или взаимодействуют с твердыми плоскостями изображения, текстуры или цвета. В физическом мире все состоит из двух- или трехмерных форм.То, как вы решите организовать и расположить плоскости на фотографии, иллюстрации или дизайне, будет структурировать композицию и определять не только то, как элементы пересекаются друг с другом, но и то, как зритель взаимодействует с композицией.
Рис. 3.4 ЦветаГрафический дизайн за последние два столетия эволюционировал от ремесла, которое создавало текст и изображения в основном в черно-белом цвете для книг и листов, к ремеслу, которое работает с полноцветными изображениями на аналоговых и цифровых носителях и на всех типах подложек. .Контроль и эффективное использование цвета для поддержки общения сейчас важнее, чем когда-либо. И средства массовой информации, и реклама стали очень изощренными за последние несколько десятилетий и умеют создавать захватывающую, чувственную и энергичную среду, созданную с умелым использованием цвета и текстуры. Публика, в свою очередь, восприняла эти беспрецедентные уровни насыщенности изображений с самыми разными результатами. Один из них — это ожидание, что визуальная палитра будет соответствовать и усилить сообщение.Второй результат — это высокие ожидания сильных и аутентичных изображений мест или объектов. Третий результат — это культурная ностальгия по более ранним образам, созданным с помощью различных устройств. Такие примеры, как 8-битная графика или Kodachrome 1950-х годов, обладают уникальными цветовыми и текстурными палитрами и обладают свойствами, доступными широкой публике. Когда одна из этих ностальгических цветовых палитр применяется к изображению, она добавляет еще один уровень смысла работе, и это значение должно иметь смысл для зрителя.
Бурный рост инструментов для создания и обмена цифровыми фотографиями и графикой также показывает, насколько хорошо широкая публика стала создавать визуальные эффекты с соответствующей атмосферой и текстурой.В наше время планка использования цвета поднялась очень высоко, и понимание основ цвета является абсолютной необходимостью.
Цветовые пространства RBG и CMYK
Учитывая, что дизайн и цвет объединены в каждом проекте, важно понимать, что существуют две цветовые системы, и часто проект должен работать в обеих. Цифровые носители работают в аддитивной цветовой системе, и их основные цвета — красный, зеленый и синий (RGB). В этой системе отсутствие цвета равняется черному, а сочетание всех цветов дает белый цвет.RGB — это цветовая система видимого света (см. Рисунок 3.5). Эта световая система называется аддитивной , потому что три основных цвета вместе создают все оттенки в спектре.
Субтрактивный цвет — это система, необходимая для печатных носителей, и его основные цвета — голубой, пурпурный, желтый и черный (CMYK), как показано на рисунке 3.5. В CMYK отсутствие цвета равняется белому, а при объединении всех цветов получается черный. Обе эти системы имеют много перекрывающихся цветов, но их цветовые сферы не совсем одинаковы.Понимание того, где пересечения существуют, а где нет, жизненно важно для успеха проекта. Если ваши печатные материалы не могут быть воспроизведены на экране, у вас возникнет серьезная проблема дизайна, которую необходимо исправить. Всегда выбирайте цвета, которые будут работать в обеих системах.
Рис. 3.5 Основные цвета для аддитивных и вычитающих цветовых схемОкружающая среда — еще один очень важный аспект выбора цвета. И естественный мир, и мир внутри экрана меняются от момента к моменту, от экрана к экрану.На цвета влияет количество доступного им атмосферного света, а также цвета, соприкасающиеся с просматриваемым объектом. Текстура также меняет наше восприятие цвета, как и яркость или темнота вокруг него.
Как бы дизайнер ни надеялся определить параметры цветовой палитры, всегда будут неизвестные факторы, влияющие на палитру со стороны зрителей. Создайте палитру, которая достаточно сфокусирована для создания правильной атмосферы и уровня энергии для вашего проекта, но не слишком сильно зависит от конкретного цвета.Тщательное и продуманное использование цвета поможет определить сообщение и создать настроение, поддерживающее композицию и концепцию дизайнерской работы. Всегда создавайте палитру, которая будет работать с обеими цветовыми системами, а также будет достаточно надежной, чтобы работать в менее чем оптимальных условиях окружающей среды.
Негативное пространство, которое также называется белым пространством , — это визуально тихая область, которая окружает активную область композиции (см. Рис. 3.6). Его также называют фигурой / фоном, и он играет очень важную роль в композиции, поскольку формирует визуальное восприятие объекта.Без отрицательного пространства нет и положительного — эффект подобен наблюдению белого медведя в метель. Негативное пространство часто считается пассивным и неважным, но активные элементы или «фигура» всегда воспринимаются сознанием зрителя по отношению к своему окружению. Композиция негативного пространства образует и представляет активные элементы в плоской или динамической форме. Если окружающая область занята множеством других элементов, фокус теряет свою силу, потому что все элементы имеют одинаковую визуальную ценность.Работы Густава Климта демонстрируют это качество.
Рисунок 3.6. Пример отрицательного или белого пространстваЕсли, с другой стороны, работа сбалансирована и отрицательное пространство активно, оно приносит энергию форме и ее пространству. Фокусная точка или фигура увеличивает свою визуальную силу, потому что есть контраст для глаза. Еще один способ взглянуть на это — увидеть, что диапазон или палитра зрительной активности увеличивается, и, следовательно, восприятие становится более приятным для глаз.
Когда дизайнеры играют с уменьшением или смешиванием положительного и отрицательного пространства, они создают двусмысленность.Неоднозначность создает напряжение, которое увеличивает интерес к композиции для зрителя, а также увеличивает визуальную энергию дизайна. Есть три типа отношений фигура / фон.
Стабильная фигура / основа — самый распространенный тип. Положительный элемент четко отделен от своего отрицательного пространства. Хорошим примером этого являются текстовые блоки в журналах или книгах.
Двусторонняя фигура / фон является вторым типом и встречается в большинстве работ М.К. Эшер. Как положительное, так и отрицательное пространство доставляют «активную» информацию, которая кажется равной глазу и, следовательно, создает эффект переключения у зрителя. Одна форма воспринимается, в то время как другая действует как ее отрицательное пространство, затем происходит противоположное, и отрицательное пространство становится значимым, а его противоположность становится нейтральным «удерживающим» пространством.
Неопределенная фигура / фон создает сбивающую с толку нехватку фокуса. Глаз ищет доминирующую визуальную «отправную точку» в композиции, но не может ее найти.Часто это создает энергию, и если эффект убедителен, он предлагает зрителю оставаться с работой в течение длительного периода времени, поглощая всю визуальную информацию.
Рис. 3.7 Экспресс-грузовик FedExДизайнеры часто используют рисунок / фон при создании символов, словесных знаков и логотипов из-за его способности создавать смысл с пространством, окружающим знак. Отличным примером рисунка / фона является текстовый знак FedEx (см. Рис. 3.7). Отрицательное пространство, необходимое для определения буквенных форм, также увеличивает их значение, создавая стрелку, указывающую вперед.В полиграфическом дизайне отрицательное пространство также может указывать на то, что находится за пределами кадра, и делает поле страницы или плаката больше, чем оно есть физически. На статическом или движущемся экране негативное пространство может изменять течение времени, создавать разрыв или создавать пространство вокруг важной точки.
Создание сильного натяжения фигуры / земли — отличный навык для дизайнеров любых медиа. Создание белого пространства в конечном итоге становится для дизайнера таким же важным, как и выбор слов и элементов проекта.Составление негативных пространств композиции позволит вам варьировать визуальный акцент элементов, а также контролировать и увеличивать визуальную энергию в целом.
Рисунок 3.8 Пример текстурыТекстура — это визуальное и тактильное качество, с которым работают дизайнеры (см. Рисунок 3.8). Текстура используется как в композиции, так и на печатной подложке или медиа-пространстве. Дизайнеры создают текстуры для своих проектов из всего, что есть под рукой. Текстуру можно создать с помощью типографики, сгенерированной в растровом или векторном программном обеспечении, таком как Photoshop или Adobe Illustrator, или с помощью камеры и захвата элементов в материальном мире.
Продуманное использование текстуры улучшит визуальное восприятие и расширит контекст контента. Часто добавление текстуры добавляет визуальную сложность и некоторую внутреннюю глубину в двухмерный дизайн-проект. Он также может связать один элемент дизайна с другим или стать определяющим элементом бренда или серии коммуникаций.
Тактильный аспект дизайнерской работы играет важную роль в выборе материала для печати. Поверхность может быть гладкой или шероховатой, глянцевой или матовой, толстой или тонкой, полупрозрачной или непрозрачной, бумажной, пластиковой, бетонной, металлической, деревянной или тканевой.Бумага может даже обладать двумя или более из этих качеств, если мы увеличим первоначальный вид бумаги слоями лака, которые обращают тактильный эффект основы. Часто выбор субстрата оказывается наиболее эффективным, если он соответствует концепции и содержанию произведения или контрастирует с ними. Выбор текстуры подложки влияет на то, как зритель воспринимает контент — как физически, так и оптически. Глянцевые подложки часто кажутся сложными, твердыми и холодными. Они обладают чувством точности, потому что чернила ложатся на поверхность бумаги и сохраняют почти всю свою первоначальную целостность.Текстурированная матовая бумага выглядит органичной, доступной и теплой, потому что чернила частично впитываются бумагой, и поэтому на нее влияют ее более мягкие характеристики.
Узор является частью элемента текстуры, но из-за его особой способности удерживать значимый контент и его долгой и важной культурной истории он заслуживает особого упоминания. Все шаблоны могут быть сведены к точкам и линиям и организованы какой-либо сеткой. Их «аромат» — это отражение культуры и времени, из которых они произошли, а также материалов, из которых они созданы.Выкройки могут быть тонким дополнением к содержанию любой дизайнерской работы. Узор может быть создан с использованием соответствующей графики (например, логотипа) или повторяться несколько раз, или он может поддерживать организационные принципы, разработанные дизайнером в декоративной форме; например, если сетка основана на квадрате, а текстура узора также основана на квадрате.
Когда узор рассматривается как единое целое, его отдельные компоненты тают и теряют свою идентичность в более широком поле узора.Эта способность сосредоточиться на узоре несколькими способами создает вторую цель для графического элемента (такого как круг, квадрат, логотип или символ), которые использовал дизайнер. В современной дизайнерской практике узор — это возможность дополнить чистые и простые материальные поверхности, с которыми мы работаем, и украсить страницу или веб-сайт соответствующей текстурой.
Рисунок 3.9 ТипографикаТипографика — среда дизайнеров и самый важный элемент, с которым мы работаем (см. Рисунок 3.9). Типографика не только несет сообщение, но и наполняет сообщение визуальным смыслом, основанным на характере шрифта, его стиле и его композиции.Слова имеют смысл сами по себе, но стиль и состав слов говорят читателю, что вы серьезный, игривый, волнующий или спокойный. Типографика — это тональный эквивалент голоса, который может быть как личным, так и общим по своему вкусу.
Типографика традиционно выполняет две функции в большинстве дизайн-проектов. Одна из функций — привлечь внимание к цели общения или «отобразить» ее. Эта функция называется заголовком или отображением типографики и предназначена для привлечения внимания к себе.Вторая функция — представить подробные сведения о коммуникации в текстовом блоке. Эта функция требует другого типографского подхода — тихого и не привлекающего к себе внимания. Вместо этого он предназначен для того, чтобы сделать контент доступным и легким для чтения.
Категории шрифтов
Есть много способов разбить тип на категории и подкатегории. В этом обзоре обсуждаются семь основных исторических категорий, которые опираются друг на друга. Шрифты с засечками включают четыре из этих категорий: гуманистические, старинные, переходные и современные.Курсив, впервые появившийся в 1500-х годах, превратился в часть «семейства» шрифтов и одно время был отдельной категорией. Первоначально они были разработаны как независимые шрифты для использования в небольших карманных книжках, где пространство было ограничено. Они не воспринимались как текстовые шрифты, но считались ценными для добавления акцента в латинском тексте и поэтому стали частью набора опций и расширений, которыми обладал шрифт. Траектория использования категории без засечек противоположна. Шрифты без засечек исторически использовались только для отображения, но в 20 веке они стали ассоциироваться с современной эстетикой чистого и простого представления и теперь стали очень популярными для дизайна текстовых блоков.Египетские шрифты или шрифты с засечками могут использоваться как отображаемые или как текстовые, в зависимости от характеристик шрифта.
Blackletter
Рисунок 3.10 Пример типа BlackletterBlackletter был средневековой моделью для первых подвижных типов (см. Рисунок 3.10). Он также известен как Block, Gothic, Fraktur или староанглийский. Внешний вид этой категории шрифтов тяжелый и темный. Буквы часто сжимаются и плотно соединяются в текстовый блок, создавая темный цвет (тон) для страницы — от 70% до 80% серого.Чтобы поместить тон в контекст, обычный тон современной текстовой страницы составляет от 55% до 70% серого. Внешний вид букв затрудняет чтение страницы, потому что удобочитаемость не была их первой функцией, как сегодня. Красота шрифта и формы книги были главной целью ранних публикаций. Книги считались предметом богатства и красоты, а не только средством передачи информации.
Гуманист
Рисунок 3.11 Пример шрифта HumanistГуманистические шрифты также называют венецианскими, поскольку они были разработаны в Венеции и ее окрестностях в середине 15 века (см. Рисунок 3.11). Их дизайн был смоделирован на основе более легких букв с открытыми засечками и каллиграфии итальянских писателей-гуманистов. Дизайнеры стремились воспроизвести многие характеристики этого стиля письма, включая несколько вариантов глифа (формы буквы), которыми обладает письменный документ. Например, шрифт может содержать до 10 различных строчных букв «а» для установки страницы. Гуманистические типы были первыми римскими типами. Хотя их было намного легче читать и они светлее на странице, чем блэклетер, они все же создавали визуально темный и тяжелый текстовый блок в отличие от шрифтов, к которым мы привыкли.Гуманистические шрифты имеют небольшой контраст между толстыми и тонкими штрихами — штрихи обычно в целом толстые. Высота гуманистического шрифта по оси x мала по сравнению с современными шрифтами, что препятствует быстрому пониманию и разборчивости. Гуманистические шрифты не часто используются по этим причинам, хотя их хорошо уважают, потому что они являются исходной моделью, на которой основаны многие другие шрифты. Важно помнить, что эти шрифты идеально подходили к самым ранним технологиям печати и что на этих машинах невозможно было напечатать наши легкие и тонкие шрифты.Шрифты развивались вместе с технологическими достижениями полиграфической промышленности.
Примеры гуманистических шрифтов: Jenson, Centaur, Verona, Lutetia, Jersey и Lynton.
Старый стиль
Рисунок 3.12 Пример шрифта старого стиляШрифты старого стиля, также известные как шрифты Garalde, являются следующим шагом в дизайне шрифтов, и их стилистические разработки были обусловлены технологическим прогрессом прессов и улучшенными навыками перфораторов (см. Рисунок 3.12). Дизайнеры шрифтов начали исследовать возможности своего носителя — как металл штампов, так и возможности печатных машин и их бумаги.Формы букв стали более точными, их засечки более отчетливыми. Контрастность штриха также была увеличена, прессы соответствовали дизайну и не искажали его. Целью этих новых шрифтов стало не копирование рукописного текста, а улучшение форм букв для создания более светлого общего тона.
Примеры шрифтов старого стиля: Goudy Old Style, Granjon, Janson, Palatino, Perpetua, Plantin и Sabon.
переходный
Рисунок 3.13 Пример переходного типаНесколько веков спустя дизайн шрифта был снова усовершенствован, и на этот раз импульс исходил от Франции и движения Просвещения. Шрифты создавались по рационалистическим принципам того времени. Штрихи были дополнительно контрастированы с очень толстыми основными штрихами и очень тонкими дополнительными штрихами, а засечки, которые ограничивали штрих, не использовали скобки (округление под пересечением двух штрихов). Буквенные формы приобрели вид, подразумевающий, что они были построены математически и закреплены в сетке.Эти новые шрифты порвали с гуманистическими и старыми традициями стиля и перестали ссылаться на каллиграфию.
Примеры переходных шрифтов: Baskerville, Bookman, Fournier и Joanna (см. Рис. 3.13).
Современное
Рисунок 3.14. Пример современного шрифтаСовременные шрифты также известны как Didones и значительно расширяют контраст, начатый с переходных шрифтов (см. Рисунок 3.14). Bodoni — отличный пример шрифта, поскольку почти каждый может вспомнить чрезвычайный контраст его толстых и тонких штрихов.Француз Дидо и итальянец Бодони первыми представили публике этот дизайнерский стиль. Его основные атрибуты соответствуют эстетике романтического периода.
Романтические буквы могут быть необычайно красивыми, но им не хватает плавного и устойчивого ритма форм эпохи Возрождения. Это тот ритм, который побуждает читателя ввести текст и прочитать. Скульптурные формы романтических писем приглашают читателя встать снаружи и вместо этого взглянуть на буквы. (Брингхерст, 2004, стр.130)
Основными характеристиками современных шрифтов являются резкий контраст между толстыми и тонкими штрихами, чистыми, без скобок, тонкими засечками и полностью вертикальной осью. Эти шрифты имеют почти механический вид из-за их точного, четкого и чистого внешнего вида. Они также обладают элегантностью, которая дополняет период времени, в который они возникли. Современные шрифты часто используются в качестве экранных шрифтов и иногда могут использоваться для текста, хотя и очень осторожно.
Примеры современных шрифтов: Fenice, Zapf Book, New Caledonia, Bodoni и Didot.
Египетский
Рисунок 3.15. Пример египетского шрифтаEgyptian также известен как slab serif, square serif или механический (см. Рисунок 3.15). Эта категория шрифтов была создана в Англии в 1880-х годах — это дизайнерское выражение промышленной революции. Категория была названа египетской из-за популярности всего египетского после возвращения Наполеона из трехлетней египетской экспедиции. Название стиля не имеет ничего общего ни с каким элементом египетской культуры. Первоначально этот стиль создавался для отображения текста, но на протяжении веков такие шрифты, как Clarendon, стали популярными для установки текстовых блоков, поскольку они обладают качеством объективности и все же остаются традиционными.
Примеры египетских шрифтов: Officina Sans и Officina Serif, Clarendon и все шрифты для пишущих машинок.
Без засечек
Рисунок 3.16. Пример шрифта без засечекШрифты без засечек существовали с древних времен, но только в конце 19 века дизайнеры шрифтов начали рассматривать возможность удаления засечек и предоставления буквенным формам стоять самостоятельно (см. Рис. 3.16). Эти шрифты изначально считались подходящими только для целей заголовков и отображения, и стали текстовыми шрифтами только в руках модернистов 20-го века.Первые формы без засечек были созданы на основе каллиграфических форм раннего гуманизма и старого стиля, но в конечном итоге на формы повлияли объективные модернистские принципы и геометрия.
Примеры шрифтов без засечек: Univers, Helvetica и Akzidenz-Grotesk.
Симфония кроссвордов: 12 музыкальных терминов и советы по разгадыванию
В кроссвордах ARCO также может указываться как марка бензина, базирующаяся в Калифорнии.
Возможные подсказки: «С смычком, в музыке», «Инструкция по игре на смычке», «Инструкция для скрипача», «Аналог пиццикато, в музыке», «Газовая марка Западного побережья. ”
Источники: Словарь.OnMusic.org, NYTimes.com, XWordInfo.com
4. ASSAI
«Очень»
«Assai» обычно следует за названием более быстрого темпа, например «allegro», чтобы обозначить, что произведение должно играть очень быстро.
Возможные подсказки: «Очень, в музыке», «Очень, для дирижера», «Аллегро ___ (очень быстро, в музыке)», «Музыкальный усилитель»
Источники: Словарь .OnMusic.org, NYTimes.com, XWordInfo.com
5. A TEMPO
«Скорость возобновления»
Когда скорость музыки изменяется от исходной настройки — обычно с помощью «Accelerando» («играть быстрее») или «ritardando» («играть медленнее ») — обозначение« темп »предписывает игрокам вернуться к исходной скорости.
Возможные подсказки: «Возврат к предыдущей скорости в музыке» «Возобновление скорости в музыкальном плане» «На исходной скорости в музыкальном» «Отменить ритардандо»
Источники: Словарь.OnMusic.org, NYTimes.com, XWordInfo.com
6. LARGO
«Медленно / широко»
«Ларго» — это музыкальный темп, проигрываемый медленнее, чем адажио (40-60 ударов в минуту). Ларго по скорости схож с темпом «ленто» (см. П. 8 ниже), но также обозначает композицию, которую следует играть более широко и эмоционально.
LARGO может также ссылаться на Ки-Ларго, один из островов Флорида-Кис, в разгадке загадки.
Возможные подсказки: «Медленно, в симфониях», «Медленно», «Погребальный темп», «Примерно 40-60 ударов в минуту», «Медленно и достойно», «Флоридский ключ ___»
Источники: Словарь.OnMusic.org, NYTimes.com, XWordInfo.com
7. LEGATO
«Гладкая и связная»
Композиция, мелодия которой плавно перетекает вместе, называется «легато». На нотном стане изогнутые линии, известные как оскорбления, соединяют ноты разной высоты, чтобы обозначить этот стиль игры.
Возможные подсказки: «Плавно, в музыке», «Музыкально связано», «Играется плавно», «Плавно, до солти», «Не стаккато»
Источники: Словарь.OnMusic.org, NYTimes.com, XWordInfo.com
8. LENTO
«Очень медленно»
Как и ларго, «ленто» — это темп, проигрываемый медленнее, чем адажио, и его также можно использовать как существительное для обратитесь к любому кусочку ленто.
Возможные подсказки: «Медленно, в музыке», «Медленно, на балл», «Медленнее, чем адажио», «Указание на медленный поклон, скажем», «Как часто играют в ноктюрн »
Источники: Словарь.OnMusic.org, NYTimes.com, XWordInfo.com
Составление списков в Python — PythonForBeginners.com
Понимание списков обеспечивает краткий способ создания списков.
Он состоит из скобок, содержащих выражение, за которым следует предложение for, затем
ноль или более предложений for или if. Выражения могут быть любыми, то есть вы можете
помещать в списки все виды объектов.
Результатом будет новый список, полученный в результате оценки выражения в контексте
следующих за ним предложений for и if.
Понимание списка всегда возвращает список результатов.
Если раньше так делали:
new_list = []
для i в old_list:
если фильтр (i):
new_list.append (выражения (i))
Вы можете получить то же самое, используя понимание списка. Обратите внимание, что метод добавления исчез!
new_list = [выражение (i) для i в старом_списке, если фильтр (i)]
Синтаксис
Составление списка начинается с « [‘ и ‘]’, квадратных скобок , чтобы помочь вам запомнить, что результатом
будет список.
В основном синтаксисе используются квадратные скобки.
[выражение для элемента в списке при условии]
Это эквивалент:
для позиции в списке:
если условно:
выражение
Давайте разберем это и посмотрим, что он делает.
new_list = [выражение (i) для i в старом_списке, если фильтр (i)]
new_list
Новый список (результат).
выражение (i)
Выражение основано на переменной, используемой для каждого элемента в старом списке.
for i в old_list
Слово for, за которым следует имя переменной для использования, за которым следует слово в старом списке
.
if filter (i)
Примените фильтр с оператором If.
В этом блоге показан пример того, как визуально разбить понимание списка:
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация — DataCamp.
new_range = [i * i for i in range (5) if i% 2 == 0]
Что соответствует:
* результат * = [* преобразование * * итерация * * фильтр *]
Оператор * используется для повторения.Часть фильтра отвечает на вопрос, нужно ли преобразовать элемент
.
Примеры
Теперь, когда мы знаем синтаксис списков, давайте покажем несколько примеров и
, как вы можете его использовать.
Создать простой список
Давайте начнем с простого списка.
x = [i для i в диапазоне (10)]
напечатать x
# Это даст результат:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Вот как можно создать простой список.
Создание списка с использованием циклов и понимания списка
В следующем примере предположим, что мы хотим создать список квадратов.Начните с пустого списка.
# Вы можете использовать циклы:
квадраты = []
для x в диапазоне (10):
squares.append (x ** 2)
печать квадратов
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# Или вы можете использовать списки, чтобы получить тот же результат:
квадраты = [x ** 2 для x в диапазоне (10)]
печать квадратов
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Просто запомните синтаксис: [выражение для элемента в списке при условии]
Умножение частей списка
Умножьте каждую часть списка на три и назначьте ее новому списку.
list1 = [3,4,5]
multiplied = [элемент * 3 для элемента в list1]
печать умноженная
[9,12,15]
Обратите внимание, как элемент * 3 умножает каждую часть на 3.
Показать первую букву каждого слова
Возьмем первую букву каждого слова и составим из нее список.
listOfWords = ["this", "is", "a", "list", "of", "words"]
items = [слово [0] для слова в listOfWords]
распечатать
Результат должен быть: [‘t’, ‘i’, ‘a’, ‘l’, ‘o’, ‘w’]
Преобразователь нижнего / верхнего регистра
Давайте покажем, как легко можно преобразовать строчные / прописные буквы.
>>> [x.lower () для x в ["A", "B", "C"]]
['a', 'b', 'c']
>>> [x.upper () для x в ["a", "b", "c"]]
['A', 'B', 'C']
Печатать числа только из заданной строки
В этом примере показано, как извлечь все числа из строки.
string = "Hello 12345 World"
числа = [x вместо x в строке, если x.isdigit ()]
печатать числа
>> ['1', '2', '3', '4', '5']
Измените x.isdigit () на x.isalpha (), если вам не нужны числа.
Анализ файла с использованием списка
В этом примере мы можем увидеть, как получить определенные строки из текстового файла.
Создайте текстовый файл и введите в него текст.
это строка1
это строка2
это строка3
это строка4
это строка5
Сохраните файл как test.txt
# Затем создайте фильтр, используя понимание списка:
fh = open ("test.txt", "r")
результат = [i для i в fh, если "line3" в i]
результат печати
Вывод: [«это строка 3
«]
Использование понимания списков в функциях
Теперь давайте посмотрим, как мы можем использовать понимание списков в функциях.
# Создайте функцию и назовите ее double:
def double (x):
вернуть x * 2
# Если вы сейчас просто напечатаете эту функцию со значением в ней, она должна выглядеть так:
>>> print double (10)
20
Мы можем легко использовать составление списков для этой функции.
>>> [double (x) для x в диапазоне (10)]
печать двойная
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
# Вы можете поставить условия:
>>> [double (x) для x в диапазоне (10), если x% 2 == 0]
[0, 4, 8, 12, 16]
# Вы можете добавить больше аргументов:
>>> [x + y вместо x в [10,30,50] для y в [20,40,60]]
[30, 50, 70, 50, 70, 90, 70, 90, 110]
Посмотрите, как можно поставить условия и добавить больше аргументов.
Похожие сообщения
Списки Python
Манипуляции со списками в Python
Источники
http://docs.python.org/2/tutorial/datastructures.html
http://www.dalkescientific.com/writings/NBN/list_comps.html
http://effbot.org/zone/python-list.htm
http://blog.cdleary.com/2010/04/learning-python-by-example-list-comprehensions/
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация — DataCamp.
Как автоматически анализировать информацию о композиции и движении в классической музыке
IntroМеня спросили, как я реализую автоматический синтаксический анализ информации для классической музыки, последний раз касался информации о движении и номере движения, поэтому я попытаюсь объясните немного об этом здесь. Я подумал, что будет больше смысла, если я представлю это вместе с полем «Композиция». Я уже говорил о композиции раньше в предыдущем уроке, и он будет охватывать часть той же информации, чтобы быть более связной.
Во-первых, небольшой отказ от ответственности: я считаю, что часть этого проекта находится в стадии разработки. Со временем он развивается, и, хотя композиция хорошо закреплена, информация о движении более сложна и может продолжаться улучшаться. Кроме того, Мэтт работает над некоторыми изменениями в языке выражений, которые я предложил, которые упростят определенные аспекты такого рода вещей, поэтому появятся возможности упростить некоторые выражения, когда эти обновления станут общедоступными.
Итак, для тех, кому интересно, я опишу систему, которую использую.Я думаю, что это хорошая система, и она определенно лучше некоторых альтернатив, но это далеко не единственная система, которая будет работать. Если вы хотите иметь другую систему, вы можете адаптировать то, что я делаю здесь, к вашему стилю работы.
Самое важное, что нужно понять, это то, что у вас должна быть структурированная система именования для вашей классической музыки, и вы должны обеспечить ее соблюдение. Если вы хотите, чтобы ваша информация анализировалась автоматически, ее необходимо систематизировать. Это важно.
Так зачем нам это? Следует понимать, что в популярной / рок / джазовой музыке большинство музыкальных произведений представляют собой одну дорожку, а классическая — другая. Большая часть классической музыки состоит из нескольких треков, которые вместе образуют одно музыкальное произведение — Композицию. Например, 1-й фортепианный концерт Моцарта состоит из 3 частей, каждая из которых представляет собой отдельный трек, и вы можете слушать эти три трека вместе как одну композицию. JRiver изначально не имеет такой концепции композиции, поэтому я ее создал.Часто, хотя и не всегда, когда музыка записывается на компакт-диск, каждое движение композиции является треком. Так что полезно принять эту форму, и ее часто можно использовать для музыкальных произведений, которые не полностью соответствуют структуре, если мы будем осторожны с нашей системой.
Итак, давайте начнем с 1-го фортепианного концерта Моцарта, который будет служить типичным произведением. В нем три трека, и если мы назовем их следующим образом, мы можем увидеть образец:
Концерт № 1 фа мажор, K.37: I. Аллегро
Концерт №1 фа мажор, K.37: II. Andante
Концерт № 1 фа мажор, K.37: III. Allegro
Каждое название трека имеет двоеточие. Все, что находится до двоеточия, является общим для всех треков. Все, что находится после двоеточия, отличает этот трек от других. Этот формат часто используется в онлайн-базах данных; это довольно часто. Если я получаю дорожки, которые не имеют названий в соответствии с этим типом структуры, я использую язык выражений, чтобы настроить их в соответствии с ним. Обеспечение такой последовательности приносит дивиденды.
Композиция
Все, что находится до двоеточия, является Композицией.Все, что находится после двоеточия, является информацией о движении. Итак, в этой системе у нас есть следующее определение:
Имя = Композиция: Часть
Номер части указан в пунктирной нотации в начале части
В приведенном выше примере мы получаем [Композиция] из
Концерт № 1 фа мажор, K.37
Все три трека имеют одинаковое значение.
Этот шаблон позволяет нам автоматически определять Композицию как вычисляемое поле:
ListItem ([Name], 0, :) Самое интересное в этом определении заключается в том, что если вы опустите двоеточие (вы не Если у вас есть отдельные треки, составляющие рок-песню), то [Composition] = [Name] Другими словами, если нет двоеточия, название трека является названием композиции.Итак, если Name = «Лестница в небеса», то композиция = «Лестница в небеса» Легко.
Итак, вы создаете новое поле под названием Composition в Options-> Library & Folders-> Manage Library Fields, и диалоговое окно выглядит следующим образом:
Movement Name
Теперь получить информацию о движении немного сложнее.
Во-первых, MC имеет два встроенных поля: [Movement] и [Movement Number] Поскольку они являются встроенными полями, мы не можем изменить их тип на Calculate Data.
Итак, мы создали два новых поля для использования вместо них: [Movement Name] и [Movement #]
Используйте то же диалоговое окно, что и раньше, для [Composition].
[Название движения] также является расчетными данными, определяемыми следующим образом:
Если (IsEqual ([Состав], [Имя]) ,, ListItem ([Имя], 1, :)) В основном, если Состав отличается от Имени, он принимает все, что стоит после двоеточия. Убедитесь, что у вас не более одного двоеточия.
Для трех треков, которые я показывал вам ранее, будут указаны названия движений:
I..] +)) # /, 1,0)),)
Моя система для [Movement #] ищет два разных паттерна. Во-первых, он ожидает увидеть точку в качестве разделителя. Если точки (точки) нет, то поле [Movement #] будет пустым. Это подходит для отдельных частей трека, у которых нет движений или нескольких частей.
Первый шаблон, который он ищет, — это использование «Нет». в качестве аббревиатуры, что случается так часто, я сделал для нее особый случай. Пример:
«9 Tableaux Etudes Op. 39: No. 1 C minor»
Если он это увидит, он возьмет «No.1 «как Часть №
Второй образец, который он ищет, — это какой-то другой термин, обозначенный точкой, и в этом случае он будет рассматривать все до точки. Некоторые примеры:
Концерт № 1 фа мажор, K .37: II. Анданте [Часть №] = II
Багатели (11) для фортепиано, соч.119: VI. Анданте (соль мажор) [Часть №] = VI
Оркестровая сюита № 1 до мажор, BWV 1066: 1. Ouverture [Movement #] = 1
Этот подход достаточно гибкий, чтобы разумно обрабатывать музыкальные произведения, которые не соответствуют стандартной парадигме записи «1 трек на движение».
Например, 3-я симфония Малера имеет больше оперной структуры, с 6 большими движениями, разделенными на 26 треков. Первая часть 6-й части (дорожка 21) выглядит так:
Симфония № 3: VI-1. Лангсам. Руволл. Empfunden [Movement #] = VI-1
Он также может работать для оперы, в которой технически есть действия и сцены, а не движения. Посмотрите трек из «Травиаты»:
«Травиата: действие 2, сцена III». Альфредо соло [Движение №] = Акт 2 Сцена III
Поскольку он ищет точку, все, что до этой первой точки, будет использоваться как Движение №.Если вам не нужен номер движения, опустите точку.
Как это выглядит
Вы можете увидеть, как все это разыгрывается в представлении:
Мне не нужно вводить какие-либо поля Composition, Movement Name или Movement #. Я проверяю, что мое поле [Имя] фиксируется при копировании или сразу после импорта, а все остальное делается автоматически. Это хорошо работает, потому что я не люблю вводить больше, чем нужно.
Вот как вы можете разбирать информацию.Получив информацию о композиции, вы можете делать просмотры на ее основе, а также собирать сводную статистику, такую как рейтинги и продолжительность. Вот пример:
Надеюсь, JRiver улучшит MC, чтобы обеспечить встроенную поддержку Composition в будущем, чтобы их можно было правильно обрабатывать в плейлистах, смарт-списках и т. Д. Если вы хотите, чтобы это произошло, выразите свою поддержку в поток запроса функции здесь: https://yabb.jriver.com/interact/index.php/topic,128860.0.html
Люди уже какое-то время используют подход [Состав], но поскольку недавно появились дополнительные интерес к информации о движении, я подумал, что выложу это.
В любом случае, я надеюсь, что люди сочтут это полезным, и вы сможете адаптировать методику к своим потребностям …
Важность понимания прочитанного
Хотя многие дети умеют читать, процесс чтения и процесс понимания того, что вы читаете, — это две совершенно разные вещи. Чтение требует беглого разбора и смешивания различных фонетических звуков для создания слов. Понимание чтения, с другой стороны, предполагает обдумывание слов, которые были только что прочитаны, и определение значения только этих слов и текста в целом! Проще говоря, понимание прочитанного — это способность читать, понимать, обрабатывать и вспоминать только что прочитанное.
Понимание прочитанного> «Чтение»
Что ж, без надлежащих навыков понимания учащиеся неспособны понимать то, что они читают. Смысл чтения не в том, чтобы издавать звуки в своем мозгу или вслух, а в том, чтобы понять важных уроков, историй и аргументов. В процессе письма наши предки записали важные знания, которые мы можем понять, просто читая. Понимая то, что мы читаем, мы получаем важную информацию, понимаем научные теории, прошлые мнения и новые рубежи.(С точки зрения непрофессионала, именно благодаря чтению нам больше не нужно «открывать» гравитацию или независимость 182 стран с каждым новым поколением).
Очень важно иметь отличные навыки понимания прочитанного. Это увеличивает удовольствие и эффективность чтения и помогает не только в учебе, но и в профессиональном плане, а также в личной жизни человека. Представьте, например, что ваш начальник дает вам сложный документ: вы можете читать слова, но не можете понять, о чем вам говорится в документе.В чем тогда смысл умения «читать», если оно не может помочь вам двигаться вперед?
Понимание прочитанного есть везде
Многие родители ошибаются, полагая, что понимание прочитанного влияет только на английский язык / языковые навыки. Однако понимание имеет решающее значение для выживания в системе образования. Требование понимать прочитанное в отрывках и задачах со словами присутствует в жизни каждого студента, от урока математики до истории.
Естествознание: Дети читают и изучают многие связанные с наукой темы в течение всего K-12.Правильное понимание прочитанного заставит их читать и понимать факты о животных, растениях, Солнечной системе, научном методе и многом другом.
Математика: Детям по математике часто задают задачи со словами. Без навыков понимания прочитанного детям будет сложно понять, о чем на самом деле спрашивают и говорят.
История: Детей рассказывают о многих значительных лидерах и событиях на протяжении всей истории, таких как Авраам Линкольн, Конституция и Гражданская война в США.Чтобы дети преуспели в чтении истории, они должны понимать, о чем говорится. Понимание чтения поможет им понять и обработать информацию в тексте.
Развитие понимания прочитанного
Вас не устраивают далеко идущие последствия понимания прочитанного? Не будь! Понимание на самом деле построить довольно просто. Тем не менее, это потребует ежедневного активного участия родителей или опекунов, когда вы будете направлять своего ребенка через мыслительные процессы, лежащие в основе понимания любого текста.
- Ежедневная практика чтения: Все дети должны ежедневно проводить не менее получаса за чтением с любимым человеком. Это не только способствует положительному отношению к чтению, но также позволяет моделировать когнитивные шаги, необходимые для понимания прочитанного.
(Серьезно, мы не можем подчеркнуть это достаточно. Исследования бесконечны — каждый ребенок требует ежедневного чтения дома, чтобы добиться успеха). - Проверка понимания: Читаете ли вы или ваш ребенок читает, задает ключевых вопроса на понимание, периодически во время чтения.Это не только поможет вам увидеть, понимают ли они то, что читают, но также научит их, какие вопросы им следует задавать себе во время чтения.
Перед запуском
-Посмотрите на обложку и заголовок! Как вы думаете, о чем будет эта книга?
-Вы что-нибудь знаете по этой теме?
-Какие типы персонажей, по вашему мнению, будут в истории?Во время
— «Что только что произошло?»
Останавливайтесь периодически (каждый абзац или страницу) и спрашивайте:
— «Кто?»
— «Где?»
В ключевых моментах вы также можете спросить: «Как это произошло?» и «Почему это произошло?»По мере прохождения рассказа убедитесь, что ваш ребенок цепляется за рассказ, спрашивая: «Что произошло на данный момент?»
Научите их предсказывать / воображать / выдвигать гипотезы, спрашивая: «Как вы думаете, как персонаж справится с ситуацией?»Кроме того, устраните их сомнения и дайте им возможность высказаться в своей повседневной практике чтения, спросив
«Есть ли что-нибудь, что вам интересно прямо сейчас?» После:
Проверьте, понял ли ваш ребенок текст, спросив
— «Что это было за главное сообщение в рассказе / тексте? »
— «Расскажи мне историю своими словами»
«Какие события в этой истории были наиболее важными?» - Сделайте соединений .Пока вы и ваши дети читаете вслух, поделитесь своим опытом, связанным с этой историей, и попросите их поделиться своим. Это не только вызывает интерес к чтению, но и основывает их на идее, что в процессе чтения есть что-то общее и разделяемое, и вкладывает их в рассказ.
- Создайте визуал . Иногда детям трудно представить себе то, что они только что прочитали. Помогите своим детям визуализировать, описывая сцену, персонажей и сюжет.Вы даже можете спросить их, что они визуализируют, и попросить их нарисовать карандашом, ручкой, маркерами или цветными карандашами. Они будут вовлечены в создание своей собственной истории, которая поможет им получить более четкое представление о том, что происходит.
- Делайте выводы и прогнозы . Выводы и прогнозы идут рука об руку с заданием вопросов. Вывод — это способность брать подсказки и полученные знания из текста и делать выводы о том, что будет дальше. Чтобы помочь им сделать вывод, попросите их предсказать, что может произойти дальше в рассказе
«О чем автор хочет, чтобы вы думали?»
«Как вы думаете, почему персонаж сделал ______?»
«Как вы думаете, что будет дальше?»
«Если бы у истории было продолжение, как вы думаете, о чем она была бы?» - Устраните любую путаницу. Важно вернуться и перечитать , как только ваш ребенок запутается ! Убедитесь, что вы отслеживаете прогресс вашего ребенка в понимании. В тот момент, когда они не могут ответить на один из ваших вопросов, будь то первое предложение или середина, или, может быть, даже в конце, сделайте резервную копию и перечитайте !
Со временем, когда вы с любовью поможете им осознать важность понимания и вместе пролистаете бесконечные истории, вы увидите, как ваш ребенок выучит шаги, необходимые для понимания прочитанного — медленно, а затем все сразу: )
Артикулы:
Монтгомери, Кортни.«Как улучшить понимание прочитанного: 8 советов экспертов». Как улучшить понимание прочитанного: 8 советов экспертов. PrepScholar, 25 июня 2016 г. Web. 10 октября 2017 г.
Осевальт, Джинни. «6 советов, которые помогут вашему ребенку улучшить понимание прочитанного». Понял.org. Интернет. 10 октября 2017 г.
Темы: Фокус, Чтение, Искусство английского языка, Обучение, Дети, Книги, Математический джинн, Родители, Саут-Плейнфилд, грамотность воображение, Понимание прочитанного, Северный Брансуик, Воспитание детей, активные умы, Объем памяти, Концентрация, Английский, Языковые искусства, Грамматика, Лучшее чтение, Книги для детей, Лучшее воспитание, Непрерывное обучение, Детское образование, Потребности ребенка, Продолжение обучения, Критическое мышление, Когнитивное развитие, Самообучение, Фундаментальное обучение, Изучение привычек для детей, Строительные блоки обучения, Детский сад, Pre-k, Выражая чувства, Эмоции, Летнее чтение, Лучше фокус, Интернет-чтение, Содействие обучению, Пища для размышлений, Привычки домашней работы, Печатные книги, Легкое чтение, Полезные привычки, Дети и домашнее задание, Обучающие стратегии, Лучшие привычки в учебе, Морганвилл, Литература, Академический успех, Базовые навыки, Основные навыки, Лучшее образование, Положительное подкрепление, детское развитие, ELA, Родительские навыки, Родительские вехи, Второй класс, Второклассник, Первый класс, Родительско-дочерние отношения, Читающий Джинн, Перед сном, Словарный запас, Растущие умы, Зрение Слова, тяжелая работа, смешивание неврологический, мозг, 2019, что работает в 2020 году, контекст ежедневное чтение, словарь, вывод сборщик слов
.