Разбор слова по составу — Ушакова О.Д.
К сожалению, возможность скачать бесплатно полный вариант книги заблокирована.
Название: Разбор слова по составу.
Автор: Ушакова О.Д.
2008.
Разбор слова по составу — достаточно трудный и вместе с тем очень важный вид работы на уроках русского языка. Надеемся, что с помощью нашей практической тетрадки дети, как говорится, набьют руку в данном виде разбора и приобретут все необходимые для этого навыки и умения.
Слова размещены в алфавитном порядке.
Специальными значками обозначены морфемы, выделяющиеся в слове, а также основа слова. Морфема — это минимальная значимая часть слова. Главная морфема слова-корень; дополнительное — служебное — значение несут остальные морфемы: префикс (приставка), суффикс, окончание. Основа включает в себя все морфемы слова, креме окончания.
Подчеркиванием (для наглядности-под основой) выделяются разделительный твердый знак между приставкой и корнем и соединительная гласная между корнями сложного слова (например, в слове прямоугольник). Нулевые окончания (например, в слове перелёт □) не указываются.
Купить.
По кнопкам выше и ниже «Купить бумажную книгу» и по ссылке «Купить» можно купить эту книгу с доставкой по всей России и похожие книги по самой лучшей цене в бумажном виде на сайтах официальных интернет магазинов Лабиринт, Озон, Буквоед, Читай-город, Литрес, My-shop, Book24, Books.
По кнопке «Купить и скачать электронную книгу» можно купить эту книгу в электронном виде в официальном интернет магазине «ЛитРес», и потом ее скачать на сайте Литреса.
По кнопке «Найти похожие материалы на других сайтах» можно найти похожие материалы на других сайтах.
On the buttons above and below you can buy the book in official online stores Labirint, Ozon and others. Also you can search related and similar materials on other sites.
Дата публикации:
Теги: скачать словарь русского языка бесплатно :: русский язык :: словарь :: Ушакова :: разбор слова
Смотрите также учебники, книги и учебные материалы:
Следующие учебники и книги:
Предыдущие статьи:
наихудшая ситуация — Ким Чен Ын признал ущерб от пандемии — ИноТВ
Выступая перед своими сторонниками, руководитель Северной Кореи рассказал, что пандемия серьёзно сказалась на экономике страны, пишет на своём сайте Sky News. По словам корейского лидера, сейчас ситуация наихудшая. Но он призвал членов партии приложить усилия для её нормализации.
Лидер Северной Кореи Ким Чен Ын заявил, что его страна находится в наихудшей ситуации за все времена, поскольку экономика сильно пострадала от пандемии, пишет на своём сайте Sky News. Такие заявления он сделал, выступая перед тысячами своих сторонников во время политической конференции партийных ячеек в Пхеньяне.
Он также призвал секретарей ячеек партии внести свой вклад в то, чтобы ситуация исправилась. «Улучшение стандартов жизни людей… даже в наихудшей ситуации, в которой нам нужно преодолевать беспрецедентное множество вызовов, зависит от роли, которую играют партийные ячейки, первичные организации партии», — приводит его слова автор статьи. Ячейки численностью от 5 до 30 человек — самое мелкое подразделение партии КНДР.
Как пишет журналист, возможно, это самый сложный момент для Кима за всю историю его правления. И до этого экономика страны была не в лучшем состоянии, в том числе из-за американских санкций. Но особенно на ней сказались пандемия и карантин.
И до этого экономика страны была не в лучшем состоянии, в том числе из-за американских санкций. Но особенно на ней сказались пандемия и карантин.
Sky News отмечает, что Ким Чен Ын снова продемонстрировал необычайную открытость, как в январе, когда признал, что его планы по переустройству экономики не работают. Он призвал участников конференции воплощать в жизнь принятые решения, в частности, укреплять ядерное сдерживание перед лицом США и исполнять пятилетний план развития. При этом он раскритиковал партийные ячейки за некую недостачу, которую, по его словам, необходимо незамедлительно скорректировать.
Автор статьи отмечает, что Ким недавно отверг предложение администрации Байдена о переговорах и возобновил свои испытания баллистических ракет. Кроме того, КНДР отказалась от участия в Олимпийских играх из опасений пандемии, пишет Sky News.
ГДЗ по русскому языку 7 класс Шмелев, Флоренская Решебник
Русский язык может считаться самым важным предметом из тех, что активно изучаются в современных школах Российской Федерации. Для большинства детей-школьников русский является родным, однако некоторые учащиеся (например, многочисленные представители национальных меньшинств нашей необъятной родины) проходят его в качестве второго. Как бы то ни было, предмет занимает существенное время ребенка и требует значительных инвестиций внимания и прочих положительных качеств.
Авторы-методисты А.Д. Шмелев, Э.А. Флоренская, Л.О.Савчук, Е.Я. Шмелева предложили совершенно новый учебно-методический комплекс по курсу родной речи для учеников седьмого класса. Он был написан с учетом самого передового преподавательского опыта ведущих учителей нашей страны. Издателем выступила компания «Вентана-Граф» с 2016 по 2019 годы. УМК включает собственно учебник, вспомогательные материалы, а также решебник. По нему можно проверять правильность выполнения упражнений.
Чем ГДЗ по русскому Шмелевой может понравится семиклассникам
Популярность учебных пособий обусловлена их четкостью и ясностью, а также непременным удобством использования. На виртуальных страницах сборника можно найти практически всё: разбор слова по составу, правила пунктуации, фонетику, нормы и особенности языковых традиций в контексте культуры речи. Пособие на страницах нашего сайта, выделяется следующими особенностями:
На виртуальных страницах сборника можно найти практически всё: разбор слова по составу, правила пунктуации, фонетику, нормы и особенности языковых традиций в контексте культуры речи. Пособие на страницах нашего сайта, выделяется следующими особенностями:
- легко искать упражнения, так как есть интуитивный и актуальный указатель;
- приведены исключительно наиболее современные версии, которые утверждены ведущими методистами страны;
- уделено много внимания творческим заданиям для самых увлеченных учащихся;
- наш сайт доступен со всех популярных электронных устройств (планшетов, телефонов и прочих).
ГДЗ для 7 класса, авторы которого Шмелев, Флоренская, Савчук не только приводит ответы, но, прежде всего, показывает пример. Поэтому такой труд не утомляет подростка. Пособие учитывает психофизиологические особенности. Оно мотивирует к самостоятельной работе. Не составит труда подготовиться к ответам на уроках, контрольным, тестовым и проверочным работам.
Главные темы в онлайн-решебнике Шмелевой, Флоренской для 7 класса
Большая часть параграфов была посвящена изучению новых правил правописания. Тем не менее, внимание уделено и качественному повторению ранее пройденного материала. Такой подход просто необходим, ведь ученики к концу года частично забывают некоторые важные сведения и правила. Авторы дают массу полезных знаний, которые удовлетворяют федеральным образовательным стандартам (ФГОС) РФ.
Книга учит новым подходам, позволяет развить интуитивную грамотность. Основные темы в текущем году:
- правила пунктуации;
- причастный и деепричастный обороты, их роль в предложении;
- выделение запятыми вводных слов, обращений;
- развитие культурной книжной (письменной) речи, написание сочинений.
Сборник, созданный Шмелевым соответствует минимальным требованиям официальных документов. Он может быть частью авторских рабочих программ преподавателей. С помощью ГДЗ очень удобно учиться самостоятельно, если не получается по болезни постоянно посещать учебное заведение.
С помощью ГДЗ очень удобно учиться самостоятельно, если не получается по болезни постоянно посещать учебное заведение.
(PDF) Разбор GLR с несколькими грамматиками для запросов естественного языка
Разбор GLR с несколькими грамматиками для запросов естественного языка • 143
Транзакции ACM по обработке информации на азиатских языках, Vol. 1, No. 2, June 2002.
оперирует соответствующим субпарсером. Мы объединяем выходные данные субпарсеров
вместе, чтобы сформировать общий синтаксический анализ входной строки. Наши экспериментальные результаты показывают, что разбиение грамматики
может уменьшить общий размер таблицы синтаксического анализа на порядок,
по сравнению с использованием одной контекстно-свободной грамматики, полученной из обучающих наборов ATIS
.Полное покрытие синтаксическим анализом одного синтаксического анализатора GLR такое же, как подходы к синтаксическому анализатору
. Однако композиция синтаксического анализатора может производить частичный синтаксический анализ, и, таким образом,
достигает более высокой точности понимания. Мы также сравнили две стратегии составления синтаксического анализатора
: каскадное и прогнозирующее сокращение. Каскадирование применяет субпарсеры в каждой позиции
во входной строке (или решетке) в порядке, указанном вызывающим графом коллекции субграмматик
.Мы использовали алгоритм кратчайшего пути, чтобы найти лучший путь
через несколько выходов субпараметра, чтобы охватить всю входную строку. Predictive
pruning следует ограничениям предсказания левого угла при вызове различных подпараметров
и, следовательно, более эффективен с точки зрения вычислений, чем каскадирование. Дополнительные
вычислений в каскаде (по сравнению с прогнозирующим сокращением) расходуются на производство
большего количества частичных синтаксических анализов, поскольку каскадирование позволяет синтаксическим деревьям начинаться и заканчиваться во всех
входных местах предложения. Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
, встроенного в архитектуру мультипарсера, которая может составлять
различных синтаксических анализаторов (синтаксический анализатор GLR, синтаксический анализатор Эрли и т. Д.). для замены ручного процесса, а также
, поскольку включает вероятности ранжирования альтернативных деревьев синтаксического анализа в выходных данных данных WSJ
в Penn Treebank.
БЛАГОДАРНОСТЬ
Мы хотели бы поблагодарить нескольких анонимных рецензентов за их комментарии и предложения.
СПИСОК ЛИТЕРАТУРЫ
ЭБНИ, С. 1991. Разбор по частям. В «Принципиальный синтаксический анализ: вычисления и психолингвистика», R. C.
Berwick et al., Eds. Kluwer Academic Publishers, 1991.
AHO, A., SETHI, I., R. и ULLMAN, J. 1986. Компиляторы: принципы, методы и инструменты. Addison-Wesley,
Reading, MA: 1986.
AMTRUP, J. 1995. Параллельный синтаксический анализ: различные схемы распределения для диаграмм. В материалах 4-го Международного семинара
по технологиям синтаксического анализа (ACL / SIGPARSE, сентябрь.1995), 12-13.
EARLEY, J. 1968. Эффективный контекстно-свободный алгоритм синтаксического анализа. Кандидат наук. диссертация, Университет Карнеги-Меллона,
Питтсбург, Пенсильвания, 1968.
ХИЛЛИЕР, Ф. С. и ЛИБЕРМАН, Дж. Дж. 1995. Введение в исследования операций. 6-е изд. McGraw-Hill, 1995.
JOHNSON, S.C 1975. YACC: еще один компилятор компилятора. Tech. Rep. CSTR 32, Bell Laboratories,
Murray Hill, NJ., 1975.
KITA, K., MORIMOTO, T. и SAGAYAMA, S. 1993. Анализ LR с тестом достижимости категорий, примененный к распознаванию речи
.IEICE Trans. Инф. Syst. Е 76-Д, 1 (1993), 23-28.
KITA, K., TAKEZAWA, T., HOSAKA, J., EHARA, T. и MORIMOTO, T. 1990. Распознавание непрерывной речи
с использованием двухуровневого LR-синтаксического анализа. В материалах Международной конференции по разговорному языку
Processing, 21.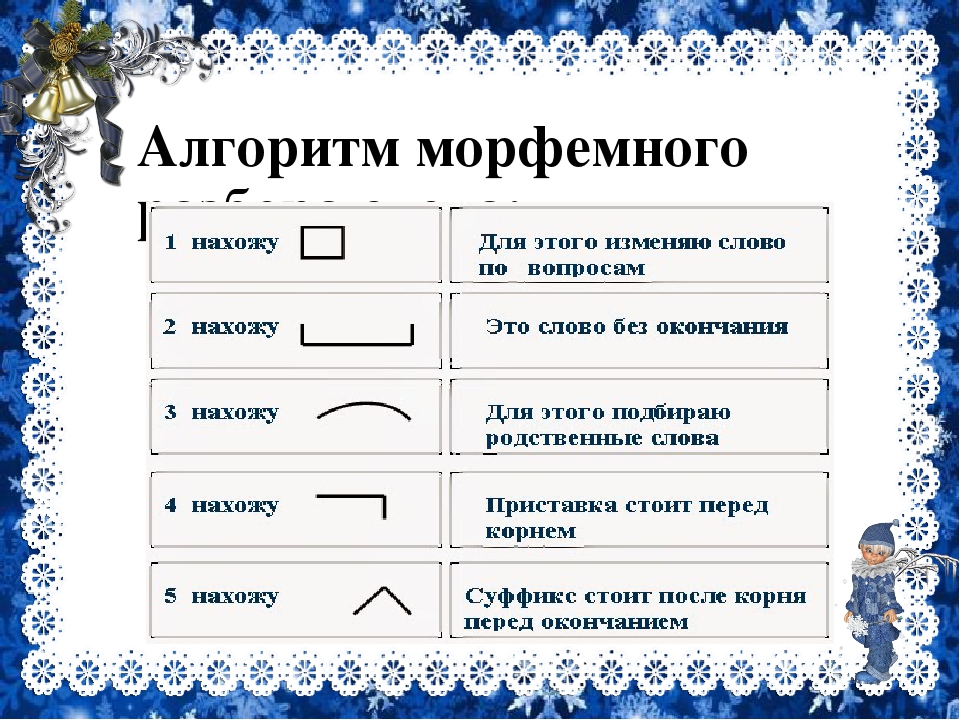 3.1, 905-908.
3.1, 905-908.
КИТА, К., ТАКЕЗАВА, Т. и МОРИМОТО, Т. 1991. Распознавание непрерывной речи с использованием двухуровневого анализа LR.
IEICE Trans. Е 74, 7 (1991), 1806-1810.
КОРЕНЯК, А.1969. Практический метод построения LR (k). Commun. ACM 12, 11 (ноябрь 1969).
LUK, P. C., MENG, H. и WENG, F. 2000. Грамматическое разбиение и состав синтаксического анализатора для понимания естественного языка.
. В материалах Международной конференции по обработке разговорной речи (Пекин,
2000).
Границы | Доказательства морфологического состава сложных слов с использованием MEG
1. Введение
Некоторые слова простые, а некоторые нет.Поначалу это звучит как очень банальная тавтология, но споры о том, хранятся ли мультиморфемные слова просто в виде целой словоформы (Butterworth, 1983; Giraudo and Grainger, 2001) или всегда строятся из их морфемных частей (Taft, 2004). ) был развлекательным, провокационным и спорным в области лексической обработки в течение последних 40 лет. Комплексная модель того, как слова сохраняются и извлекаются, требует понимания того, как связаны форма и значение и как эта связь разворачивается во времени в естественной речи.
Потенциальный контраст между хранением целого слова и хранением морфем впервые обсуждался в классической модели удаления аффиксов (Taft and Forster, 1975), которая предполагала, что лексический доступ включает доступ к основе морфологически сложных слов. Это исследование показало, что псевдосложные слова с реальными основами (например, de- juvenate ) требовали больше времени для отклонения в задаче лексического решения (и часто выбирались неверно как слова), чем псевдосложные слова с реальными префиксами и несуществующие. стебли (e.г., де- , пертуар ). Это было воспринято как доказательство того, что к морфемам обращались до лексического доступа, и они способствуют поиску лексического элемента в памяти. При использовании различных парадигм прайминга накопились доказательства в пользу доступности морфем во время лексического доступа (Marslen-Wilson et al.
Один из способов взглянуть на лексическую обработку сложных слов — посмотреть, может ли активация морфологической структуры модулировать доступность сложного слова. Некоторые исследования кросс-модального прайминга (Marslen-Wilson et al., 1994) показали, что прайминг в лексическом решении между словами, имеющими общий корень, происходил только тогда, когда простое число и цель имели связанные значения (например, отправление началось с от , но от департамента нет), в то время как другие исследования (Zwitserlood, 1994) ) с использованием прайминга с частичным повторением обнаружил, что прайминг не зависит от семантических отношений между простым и целевым. Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, в котором простому слову предшествует прямая маска и за ним следует целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al., 2003; Растл и др., 2004; Фиорентино и Поппель, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например, бордел ). Было обнаружено более быстрое время лексического решения для сложных слов, которые могут быть сегментированы на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как угол-кукуруза и бутлег-ботинок , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Однако исследования с использованием замаскированного прайминга, парадигмы сублиминального прайминга, в котором простому слову предшествует прямая маска и за ним следует целевое слово (Forster and Davis, 1984), обнаружили, что при манипулировании семантической прозрачностью эффекты облегчения возникали для сложных слов независимо от имеют ли прайм и мишень один и тот же морфологический корень (Longtin et al., 2003; Растл и др., 2004; Фиорентино и Поппель, 2007; McCormick et al., 2008). Эти эффекты не проявлялись для морфологически простых слов (например, бордел ). Было обнаружено более быстрое время лексического решения для сложных слов, которые могут быть сегментированы на существующие морфемы, что означает, что замаскированные простые / немаскированные целевые пары без семантических отношений, такие как угол-кукуруза и бутлег-ботинок , показали ускоренное распознавание целевых слов с помощью величины, неотличимые от пар с семантическими отношениями, такими как очиститель-очиститель и чашка-чай .
Поскольку общепринято, что морфологическая декомпозиция выполняется для каждого сложного слова, которое может быть исчерпывающим образом разобрано на существующие морфемы, исследования визуального распознавания слов должны сместить акцент с декомпозиции на последующие механизмы, задействованные для активации фактического значения сложного целевого слова. . Менье и Лонгтин (2007) предположили, что активация слова вступает в игру поэтапно, которые включают по крайней мере одну раннюю стадию морфологической декомпозиции и более позднюю стадию семантической интеграции морфологических частей.Fiorentino et al. (2014) представили доказательства основанного на морфемах пути активации слова, который включает разложение на морфологические составляющие и комбинаторные процессы, действующие на эти представления. Поскольку предыдущие исследования показали, что ранняя декомпозиция, вызванная морфологической структурой, происходит автоматически для прозрачных и непрозрачных слов, разница между этими двумя типами слов может проявиться на более позднем этапе комбинаторных операций.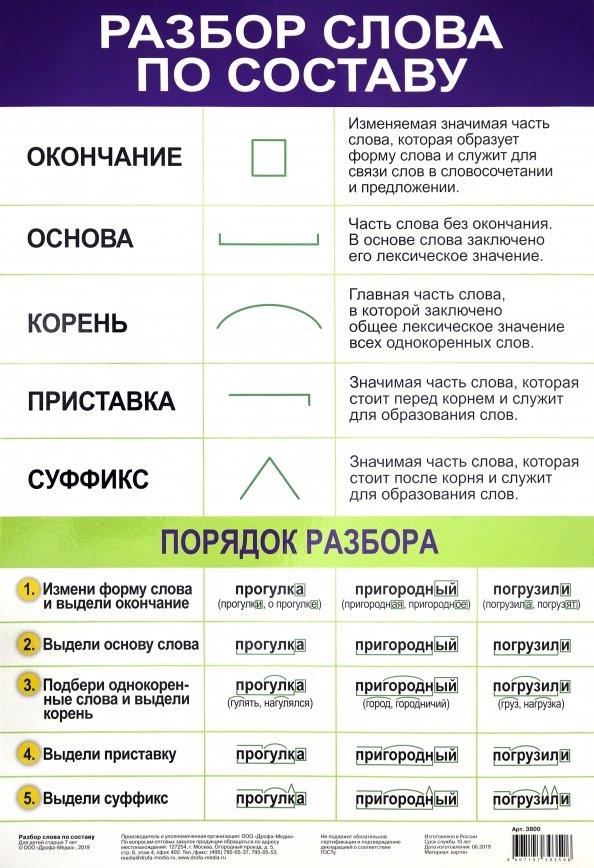
Другой способ взглянуть на лексическую обработку сложных слов — это посмотреть, как форма отображается на значение.Это очень важно при обработке морфологически сложных слов, чтобы отделить то, как мозг воспринимает прозрачные слова от того, как он воспринимает непрозрачные. Это можно исследовать, посмотрев, как значения морфем складываются в мозгу. Существуют модели общего механизма связывания в построении предложений (Friederici et al., 2000) и в базовой композиции именных фраз (Bemis and Pylkkänen, 2011), которые вовлекают левую переднюю височную долю (LATL) в состав слов во фразы. .В парадигме минимальной композиции Bemis и Pylkkänen (2011) обнаружили, что два составных элемента во фразе прилагательное-существительное (например, красная лодка ) вызывают большую активацию в левой передней височной доле, LATL, примерно на 225 мс, чем два. несоставные элементы (например, лодка xkq , случайная последовательность букв и слово). Это было воспринято как доказательство того, что базовая комбинаторная обработка данных поддерживается LATL. Внутри сложных слов есть специальный подкласс слов, которые имеют структуру, параллельную именным фразам, известным как составные слова.Сложные слова обладают уникальным свойством состоять только из свободных морфем (отдельных слов). Сложные слова также различаются по измерению семантической прозрачности , степени, в которой комбинация значений морфем соответствует общему значению слова. Это означает, что мы можем варьировать вклад морфем в композицию значения. Эти свойства делают составные слова отличным кандидатом для исследования морфологического состава сложных слов, поскольку они могут обеспечивать аналогичную структуру для работы, выполняемой на уровне фразы.Эти параллели приводят к тому, что LATL является кандидатом на композицию в пределах слова, и это обеспечивает интересную основу для изучения эффектов внутрилексической семантической композиции как аналога композиции на уровне фразы.
Таким образом, семантически прозрачные составные слова (например, почтовый ящик) должны вызывать большую активность в этой области, чем простые слова, поскольку их значения происходят из состава их морфемических частей, тогда как семантически непрозрачные составные слова (например,, бутлег) не должны вызывать большей активности, поскольку между их частями и значениями нет связи.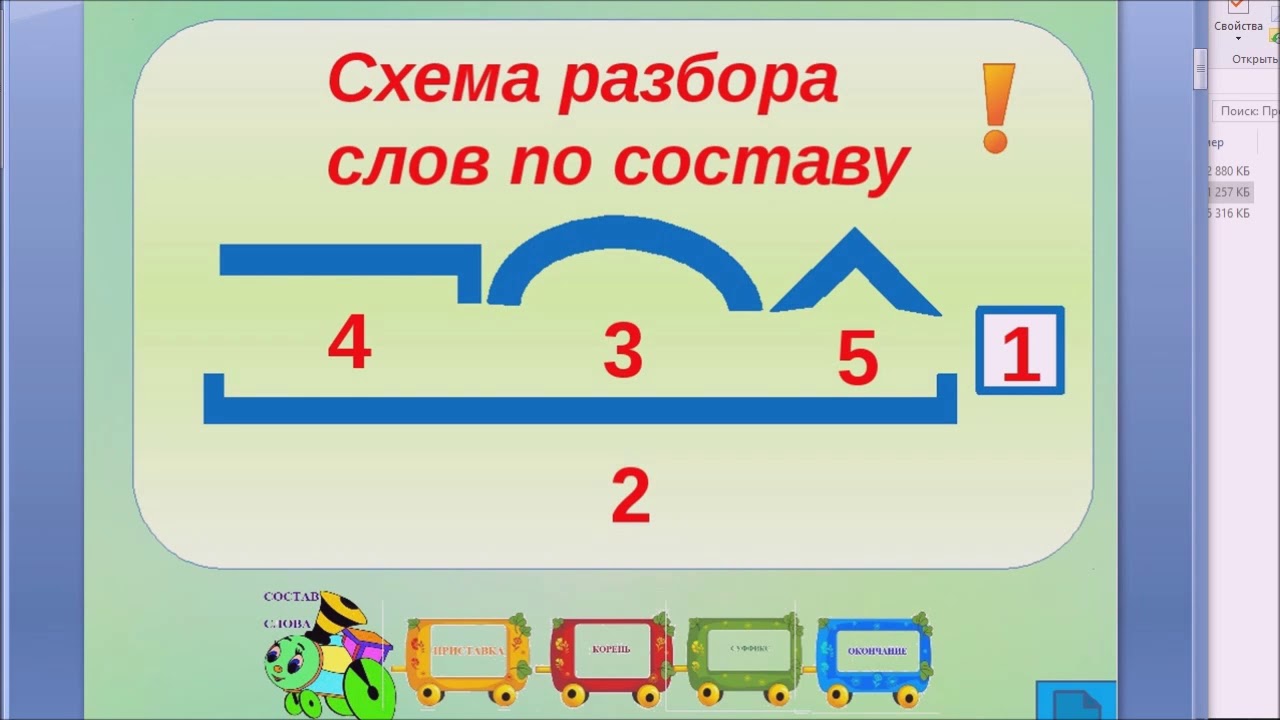 В общем, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и грунтовка с полным повторением (например,g., ROADSIDE-roadside), которые будут использованы для исследования композиционных эффектов их морфем. Штрихи условия повторения прайминга использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов, связанных с лексической обработкой, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробного заполнения.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов.
В общем, модель сложного распознавания слов потребует, по крайней мере, этих двух этапов обработки: разбора на базовые единицы (декомпозиция) и композиции этих словоформ в сложное значение. Чтобы распаковать эти этапы, мы предлагаем использовать два типа парадигм грунтования: грунтовку с частичным повторением (например, ДОРОГА-обочина), аналогичные парадигмам, используемым в исследованиях замаскированного грунтования, которые будут использоваться для исследования эффектов разложения в соединениях, и грунтовка с полным повторением (например,g., ROADSIDE-roadside), которые будут использованы для исследования композиционных эффектов их морфем. Штрихи условия повторения прайминга использовали для оценки эффекта композиции в отсутствие поведенческой реакции. В этом отношении метод анализа аналогичен принятому Zweig и Pylkkänen (2009), в котором авторы напрямую сравнивают сложные (производные) слова, таким образом стремясь найти эффекты разложения, которые не зависят от прайминга. В этом исследовании используется задача создания именования слов для изучения этих этапов, связанных с лексической обработкой, поскольку она обеспечивает сопоставимые эффекты с задачами лексического принятия решений (Neely, 1991) и не требует пробного заполнения.Эта задача была выполнена, пока активность мозга регистрировалась с помощью МЭГ, чтобы исследовать, есть ли в левой височной доле область, отвечающая за морфологический состав. Это исследование вносит свой вклад в работу по характеристике нейронных основ лексической обработки сложных слов, предоставляя доказательства композиции в составных словах и связывая их с их нейронными коррелятами. Учитывая предшествующую литературу, мы ожидаем найти доказательства разложения для сложных слов, но не для симплексных слов.Это открытие согласуется с литературой по визуальному распознаванию слов, особенно с литературой по замаскированному праймингу, где есть облегчающие эффекты при прайминге морфологически сложных слов, но не морфологически простых слов. Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
Однако мы не ожидаем увидеть это общее преимущество морфологической сложности в составе. Поскольку состав смысла регулируется семантически, мы ожидаем обнаружить влияние композиции на активность мозга только для прозрачных соединений.
2.Материалы и методы
2,1 Участники
Восемнадцать правшей, носителей английского языка в возрасте от 18 до 30 лет, с нормальным или исправленным зрением, все дали информированное согласие и приняли участие в этом эксперименте. Исследование было одобрено Университетским комитетом по деятельности с участием людей (UCAIHS) Нью-Йоркского университета. Данные MEG от трех участников были исключены из-за большого количества отказов от испытаний, вызванных шумовыми помехами (> 25%). Подробности отказа описаны в процедуре.
2.2. Материал
Все стимулы состояли из английских би-морфемных соединений (например, чашка) и морфологически простых существительных (например, шпинат), сопоставленных по длине и поверхностной частоте. Мы манипулировали семантической прозрачностью, включая полностью семантически прозрачные (например, чайная чашка) слова, в которых обе составляющие морфемы имеют семантическое отношение к значению всего соединения, и полностью семантически непрозрачные слова (например, фигня), в которых ни один из составляющих морфемы имеют семантическое отношение к составному значению.
311 английских словосочетаний было собрано из предыдущих исследований (Juhasz et al., 2003; Fiorentino and Poeppel, 2007; Fiorentino and Fund-Reznicek, 2009; Drieghe et al., 2010) и классифицировано с точки зрения семантической прозрачности с помощью семантики. задача на соответствие, выполняемая с помощью инструмента Amazon Mechanical Turk. В этом задании 20 участникам было предложено оценить по шкале от 1 до 7, насколько каждый компонент соединения относится к целому слову. По шкале 1 соответствует несвязанному, а 7 — очень близкому.Каждому участнику случайным образом представили один из компонентов каждого соединения. Соединения классифицировались как семантически непрозрачные (далее непрозрачные ), если сумма баллов их составляющих находилась в интервале 2–6, и как семантически прозрачные (далее прозрачные ), если сумма находилась в интервале 10–14. Например, непрозрачный состав крайний срок получил суммарный рейтинг 3,76 с мертвым , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же сложный кукольный домик получил суммарную оценку 11,79, где кукла дала оценку прозрачности 6,47, а дом дала оценку 5,32. Для каждого типа слова было выбрано шестьдесят словосочетаний. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Простые слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
Соединения классифицировались как семантически непрозрачные (далее непрозрачные ), если сумма баллов их составляющих находилась в интервале 2–6, и как семантически прозрачные (далее прозрачные ), если сумма находилась в интервале 10–14. Например, непрозрачный состав крайний срок получил суммарный рейтинг 3,76 с мертвым , что дает рейтинг прозрачности 1.44 и строка дает рейтинг 2.32. Точно так же сложный кукольный домик получил суммарную оценку 11,79, где кукла дала оценку прозрачности 6,47, а дом дала оценку 5,32. Для каждого типа слова было выбрано шестьдесят словосочетаний. Этот метод нормирования семантической прозрачности соответствовал методам, использованным в упомянутых предыдущих исследованиях. Морфологически простые слова (далее simplex : например, шпинат) были объединены из Rastle et al.(2004) и English Lexicon Project отбирали слова, закодированные на наличие только одной морфемы (Balota et al., 2007). Простые слова (например, бордел ) были выбраны так, чтобы они имели неморфологическую связь формы с их простыми числами (например, бульон ). Кроме того, эти слова были ограничены и выбраны таким образом, чтобы простое слово нельзя было разбить на более мелкие части без создания недопустимых морфем.
2.3. Типовой проект дома
Три разных типа слов были сопоставлены в двух условиях прайминга: полное повторение и частичное (составляющее) повторение (см. Таблицу 1).Для условия повторного праймирования в качестве прайма и мишени использовали одно и то же соединение (например, чашка TEACUP). Для прайминга с частичным повторением мы использовали первый компонент соединения в качестве праймера (например, чайную чашку TEA). Для симплексного условия неморфологическая родственная форма использовалась в качестве составляющей в условии частичного повторения прайминга (например, SPIN-шпинат). Эти два условия прайминга были объединены для управления условиями, в которых прайм не имел семантического отношения к цели (например,г. , DOORBELL-чашка; ДВЕРЬ-чашка).
, DOORBELL-чашка; ДВЕРЬ-чашка).
Таблица 1. Матрица расчета .
2.4. Процедура
Все участники прочитали все элементы во всех условиях (всего 720), которые были разделены на три списка по 240 слов и рандомизированы в каждом списке. Порядок представления списков был сбалансирован между испытуемыми. Экспериментальной задачей было наименование слов: испытуемым предлагались пары слов, и их просили прочитать вслух второе слово каждой пары.Стимулы были представлены белым шрифтом Courier размером 30 пунктов на сером фоне с помощью PsychToolbox (Brainard, 1997). Каждое испытание начиналось с предъявления фиксирующего креста, затем штриховки, затем мишени. Каждая из этих визуальных презентаций была представлена в течение 300 мс с последующим пропуском 300 мс (см. Рисунок 1). Мы записали начальную латентность речи и высказывания каждого испытуемого для поведенческого анализа.
Рис. 1. Структура эксперимента .
Перед экспериментом форма головы каждого участника была оцифрована с использованием системы Polhemus Fastscan вместе с пятью точками индикатора положения головы, которые используются для совместной регистрации положения головы относительно датчиков MEG во время сбора данных.Электромагниты, прикрепленные к этим точкам, локализуются после того, как участники лежат внутри массива датчиков МЭГ, что обеспечивает совместную регистрацию систем координат головы и датчика. Форма головы используется во время анализа для совместной регистрации головы на МРТ участников. Половине участников МРТ не проводились; поэтому мы масштабировали общий эталонный мозг, который предоставляется в FreeSurfer, чтобы он соответствовал размеру голов этих участников.
Во время эксперимента участники оставались лежать в комнате с магнитным экраном, а реакцию их мозга контролировали градиентометры MEG.Экспериментальные элементы проецировались на экран, чтобы участник мог прочитать и выполнить задание.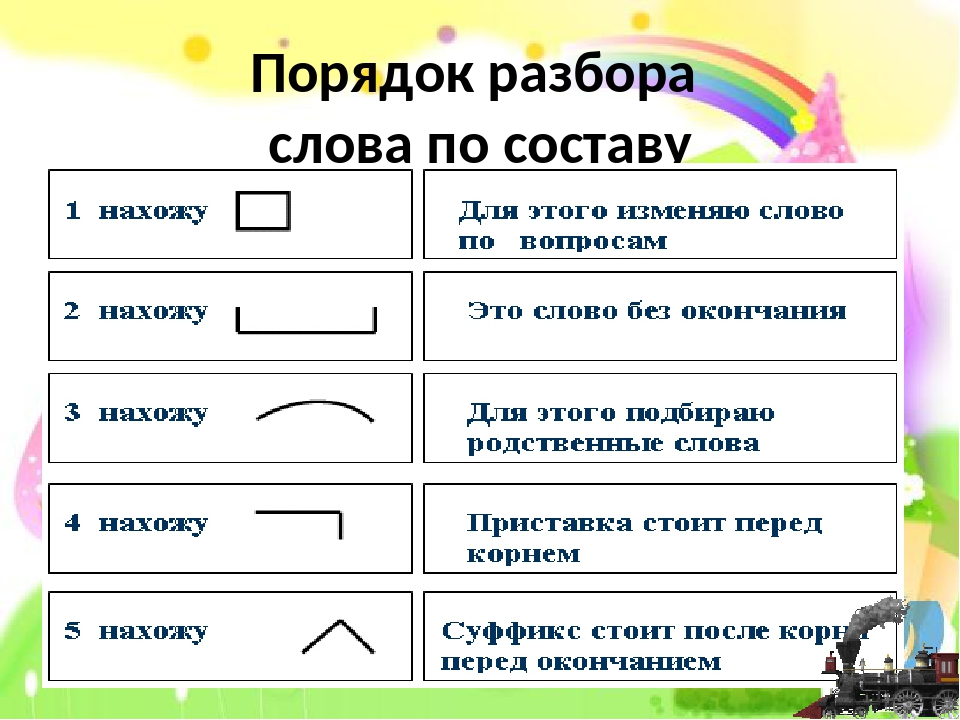 Данные МЭГ были собраны с использованием аксиальной системы градиентометра для всей головки со 157 каналами и тремя опорными каналами (Технологический институт Канадзавы, Ноноичи, Япония). Запись проводилась в режиме постоянного тока, то есть без фильтра верхних частот, с фильтром нижних частот 300 Гц и режекторным фильтром 60 Гц.
Данные МЭГ были собраны с использованием аксиальной системы градиентометра для всей головки со 157 каналами и тремя опорными каналами (Технологический институт Канадзавы, Ноноичи, Япония). Запись проводилась в режиме постоянного тока, то есть без фильтра верхних частот, с фильтром нижних частот 300 Гц и режекторным фильтром 60 Гц.
2,5. Анализ
Мы исследовали латентность начала, время реакции на наименование слова, чтобы оценить эффекты морфологического разложения на основе Fiorentino and Poeppel (2007).Поскольку время реакции чувствительно к лексическим свойствам слов (Fiorentino and Poeppel, 2007), составные слова должны обрабатываться быстрее при праймировании, чем симплексные слова из-за остаточной активации ранее активированных морфем. Недекомпозиционный счет не предсказывает никаких различий из-за структуры слова, если слова правильно сопоставлены для соответствующих свойств всего слова. Таким образом, начальная задержка может использоваться, чтобы понять, есть ли эффект разложения. Поведенческие данные были проанализированы с использованием традиционного дисперсионного анализа для типа слова с помощью модели взаимодействия с частичным повторением.Прайминг с частичным повторением в задачах лексического решения использовался, чтобы продемонстрировать доступность морфем в сложных словах (Rastle et al., 2004). Подобные поведенческие эффекты были также обнаружены при использовании именования слов (см. Neely, 1991 для сравнительного обзора лексического решения и именования слов). Таким образом, доказательства эффектов разложения можно наблюдать во время реакции, чтобы говорить, , задержка начала . Предыдущие исследования привели к предсказанию, что должен быть стимулирующий эффект более короткой задержки начала из-за прайминга для соединений по сравнению с их эквивалентами из симплексных слов, поскольку сегментация на морфемы приводит к более быстрому доступу к сложному слову.
После сбора данных мозга мы применили метод непрерывно скорректированных наименьших квадратов (Adachi et al. , 2001), процедуру снижения шума в программном обеспечении MEG160 (Yokogawa Electric Corporation и Eagle Technology Corporation, Токио, Япония), которая вычитает шум из Градиометры МЭГ основаны на измерениях шума в опорных каналах, удаленных от головы. Данные подвергались полосовой фильтрации в диапазоне 1–40 Гц с использованием БИХ-фильтра. Запись всего эксперимента была разделена на представляющие интерес эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
, 2001), процедуру снижения шума в программном обеспечении MEG160 (Yokogawa Electric Corporation и Eagle Technology Corporation, Токио, Япония), которая вычитает шум из Градиометры МЭГ основаны на измерениях шума в опорных каналах, удаленных от головы. Данные подвергались полосовой фильтрации в диапазоне 1–40 Гц с использованием БИХ-фильтра. Запись всего эксперимента была разделена на представляющие интерес эпохи, от -200 мс до до 600 мс после визуального отображения основного слова.Мы отклонили испытания, в которых максимальная амплитуда размаха превышала предел 4000fT, и уравняли испытания, чтобы иметь равное количество испытаний для каждого условия и для каждого типа слова для правильного сравнения. Средний процент отклоненных испытаний среди субъектов составлял 1,9%, а для каждого типа слова: 1,3% для непрозрачных, 2,2% для симплексных, 1,8% для прозрачных. Каналы датчиков были отмечены как плохие и отбрасывались для каждого испытуемого, если полное отклонение канала превышало 10%.
Матрица ковариации шума была вычислена для каждого участника с использованием процедуры автоматического выбора модели (Engemann and Gramfort, 2015) на случайном выборе базовых эпох (120 эпох) от -200 мс до начала представления креста фиксации.Для участников с МРТ кортикальные реконструкции были сгенерированы с помощью FreeSurfer, в результате чего пространство источника составляло 5124 вершины (CorTechs Labs Inc., Ла-Хойя, Калифорния и MGH / HMS / MIT Центр биомедицинской визуализации Athinoula A. Martinos, Чарльстон, Массачусетс). Метод модели граничных элементов (БЭМ) использовался для моделирования активности в каждой вершине для расчета прямого решения. Обратное решение было сгенерировано с использованием этой прямой модели и матрицы ковариации шума и вычислено с ограничением фиксированной ориентации, требующим, чтобы дипольные источники были перпендикулярны кортикальной поверхности.Затем данные датчиков для каждого испытуемого проецировались в их индивидуальное исходное пространство с использованием оценки минимальной нормы с корковыми ограничениями (все анализы проводились с использованием MNE-Python: Gramfort et al.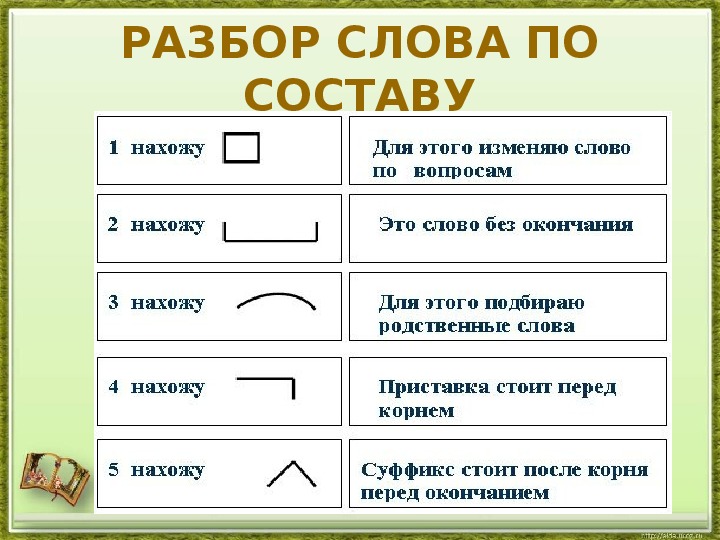 , 2013, 2014), в результате чего получались нормализованные по шуму карты динамических статистических параметров. (dSPM: Dale et al., 2000).
, 2013, 2014), в результате чего получались нормализованные по шуму карты динамических статистических параметров. (dSPM: Dale et al., 2000).
Для этого анализа наш план (таблица 2) сводится к простому сравнению между составными (например, TEACUP) и симплексными словами (например, SPINACH) одного и того же размера, которые служили простыми числами в условии повторения (например,g., TEACUP-teacup), описанный выше в разделе «Дизайн». Поскольку для этого анализа мы используем нейрофизиологические данные, относящиеся к молчаливому чтению слов, которые служили простыми числами, поведенческих данных для этих слов нет. Таким образом, мы также избегаем артефактов, связанных с произвольными движениями, которые могут поставить под угрозу анализ эффектов, представляющих интерес для исследования (Hansen et al., 2010).
Таблица 2. Анализ простых чисел .
Мы исследовали нервную активность, локализованную во всей левой височной доле.Этот регион был выбран на основе композиционных эффектов, обнаруженных в предложениях (Friederici et al., 2000) или фразах прилагательное-существительное (Bemis and Pylkkänen, 2011). Чтобы проверить, была ли повышена активность соединений в этой области, был проведен t -тест на остаточную активацию типа составного слова (непрозрачный, прозрачный) после удаления активации из симплексного контрольного слова от 100 до 600. мс после появления стимула. Карта значений p мозга была сгенерирована для временных рядов, и пространственно-временные кластеры были идентифицированы для смежных пространственно-временных кластеров, которые имели значение p меньше 0.05 и длительностью не менее 10 мс. Значения t были суммированы для тех точек в кластере, которые соответствовали этим критериям. Затем сначала был выполнен тест непараметрической перестановки путем перетасовки меток типов слов, а затем вычисления кластеров, образованных новыми метками. Распределение, сгенерированное из 10 000 перестановок, было вычислено путем вычисления значимых уровней наблюдаемого кластера. Скорректированное значение p было определено из процента кластеров, которые были больше, чем исходный вычисленный кластер (Maris and Oostenveld, 2007).Эти тесты были рассчитаны с использованием пакета статистического анализа данных MEG, Eelbrain (https://pythonhosted.org/eelbrain/).
Скорректированное значение p было определено из процента кластеров, которые были больше, чем исходный вычисленный кластер (Maris and Oostenveld, 2007).Эти тесты были рассчитаны с использованием пакета статистического анализа данных MEG, Eelbrain (https://pythonhosted.org/eelbrain/).
3. Результаты
3.1. Морфологическая декомпозиция
С точки зрения поведения мы обнаружили значительный эффект прайминга с частичным повторением [ F (1, 17) = 25,91, p <0,001], но, что наиболее важно, взаимодействие типа слова с помощью прайминга [ F ( 2, 17) = 9,24, p <0,001] (рисунок 2).Этот эффект показывает, что именование составных слов облегчается в большей степени, чем для морфологически простых слов, если они начислены. В запланированных сравнениях были обнаружены достоверные различия между непрозрачными соединениями и симплексными словами [ F (1, 17) = 5,93, p <0,03] и прозрачными соединениями и симплексными словами [ F (1, 17) = 14,46, p <0,005], но не между прозрачными и непрозрачными соединениями [ F (1, 17) = 2.84, p. > 0,1]. Эти результаты показывают, что даже в словообразовании существует чувствительность к морфологической структуре помимо орфографического и фонологического перекрытия, но этот этап обработки нечувствителен к значению морфем по отношению к составному слову, что согласуется с предыдущим литература по морфологическому разложению (Rastle et al., 2004; McCormick et al., 2008).
Рис. 2. Средство разницы задержки начала частичного повторения прайминга .
3.2. Морфологический состав
Результаты показывают надежные эффекты большей активации прозрачных соединений по сравнению с их симплексными контролями в височной доле. С этим различием связаны два значимых кластера: первый кластер был локализован в передней средней височной извилине от 250 до 470 мс ( t = 4552,3, p <0,05, рисунок 3), а второй кластер активности был локализуется в задней верхней височной извилине от 430 до 600 мс (∑ t = 5654, p <0.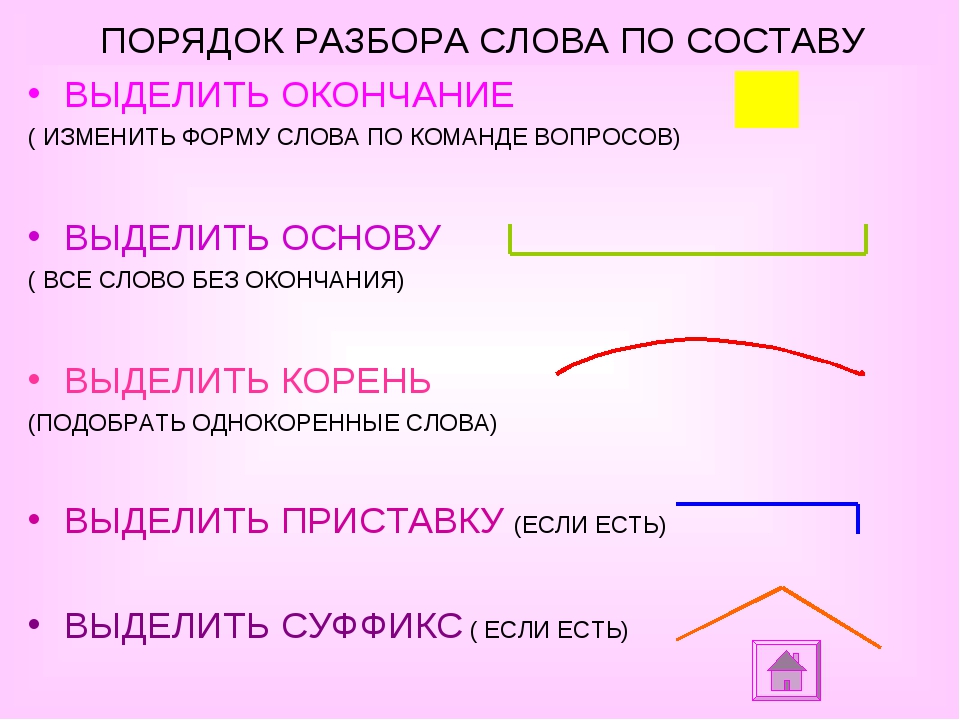 05, рисунок 4). Однако не было обнаружено надежных кластеров для различия непрозрачных соединений и симплексных слов в височной доле.
05, рисунок 4). Однако не было обнаружено надежных кластеров для различия непрозрачных соединений и симплексных слов в височной доле.
Рис. 3. Разница между прозрачностью и симплексом в левой передней височной доле (LATL) .
Рис. 4. Разница между прозрачностью и симплексом в задней верхней височной мышце (pSTG) .
4. Обсуждение
Анализ разных типов слов по отдельности выявил очень последовательные доказательства того, что существует разница в том, как простые и сложные слова обрабатываются в мозгу.Поведенческие результаты подтвердили, что существует стадия лексического доступа, которая чувствительна к морфологическим формам в сложных словах, и продемонстрировали, что эти эффекты также могут наблюдаться в других модальностях тестирования, а именно, в именовании слов. Эффект начального латентного взаимодействия, когда составные слова создавались быстрее, чем морфологически простые слова, когда они начинались с их составной морфемы, в значительной степени согласуется с результатами в литературе по замаскированному праймингу по распознаванию слов и дает дополнительные доказательства того, что в лексическом доступе есть стадия декомпозиции. где сложные слова разбираются на свои морфемы (Rastle et al., 2004; Тафт, 2004; Моррис и др., 2007; Маккормик и др., 2008; Fiorentino и Fund-Reznicek, 2009). Операция синтаксического анализа происходит независимо от семантических отношений между составляющими морфемами и их сложным словом. Поскольку ранняя активация составляющих посредством морфологического разложения происходит независимо от семантической прозрачности, то, что отличает прозрачное и непрозрачное соединение, должно происходить, таким образом, на более поздней стадии морфемного состава. Повышенная активность прозрачных соединений в передней височной доле с 250 до 470 мс свидетельствует о стадии лексического доступа, на которой значения морфемы играют роль в доступе к общему значению слова. Bemis и Pylkkänen (2011) показывают комбинаторные эффекты в LATL для прилагательных слов примерно через 225 мс после предъявления критического слова. Разницу во времени можно объяснить разными моментами времени, когда мы фиксируем начало действия стимула. В Bemis and Pylkkänen (2011) начало совпадает с началом существительного лодка во фразе красная лодка , тогда как в нашем исследовании критическим стимулом является весь составной парусник .
Bemis и Pylkkänen (2011) показывают комбинаторные эффекты в LATL для прилагательных слов примерно через 225 мс после предъявления критического слова. Разницу во времени можно объяснить разными моментами времени, когда мы фиксируем начало действия стимула. В Bemis and Pylkkänen (2011) начало совпадает с началом существительного лодка во фразе красная лодка , тогда как в нашем исследовании критическим стимулом является весь составной парусник .
Повышенная активация в задней височной доле прозрачных соединений с 430 до 600 мс, которая следует за активностью в LATL, согласуется с тем фактом, что эта область участвует в лексическом поиске (Hickok and Poeppel, 2007; Lau et al., 2008). Lau et al. (2008) предположили, что задняя область височной доли является лучшим кандидатом для лексического хранения слов. Поскольку LATL отвечает за составление значения составляющих морфем, задняя височная доля будет отвечать за извлечение информации из хранимого в ней лексико-семантического представления. Эта область также участвует в преобразовании звука в значение (Binder et al., 2000), которое включает поиск фонологической информации. Это исследование согласуется с моделями декомпозиции из литературы по визуальному распознаванию слов и обеспечивает нейронную основу для этапа лексического доступа, участвующего в композиции значения в составных словах, тем самым помогая распутать когнитивные процессы, которые нечеткие, когда время реакции является единственной мерой. .Объединяя результаты психолингвистических исследований с записями МЭГ активности мозга, полученные результаты предполагают, что распознавание соединений включает в себя различные стадии: стадию декомпозиции, которая не зависит от семантики, и стадию композиции, которая регулируется семантикой. Мы показали, что ход активации различается по сложности слова и семантической прозрачности.
Авторские взносы
Авторы TB и DC являются первыми авторами, поскольку оба они в равной степени внесли свой вклад в работу.
Финансирование
Эта работа поддержана Национальным научным фондом в рамках гранта № BCS-0843969 и Исследовательским советом Нью-Йоркского университета в Абу-Даби в рамках гранта № G1001 Института NYUAD Нью-Йоркского университета Абу-Даби. Работа по туберкулезу была поддержана исследовательской стипендией Национального научного фонда под номером DGE-1342536. Работа DC была поддержана Координацией по совершенствованию кадров высшего образования и Комиссией Фулбрайта в соответствии с Законом о взаимном образовательном обмене, спонсируемой Государственным департаментом Соединенных Штатов Америки, Бюро по вопросам образования и культуры.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить Алека Маранца за его поддержку и руководство этим проектом. Мы также хотели бы поблагодарить Машу Вестерлунд и Фиби Гастон за критические отзывы для этой статьи. Мы также хотели бы поблагодарить Джеффа Уокера из NYU MEG Lab за его помощь во время тестирования участников.
Список литературы
Адачи Ю., Шимогавара М., Хигучи М., Харута Ю. и Очиаи М. (2001). Снижение непериодического магнитного шума окружающей среды при измерении МЭГ методом наименьших квадратов с постоянной корректировкой. Заявл. Сверхпроводимость. IEEE Trans . 11: 669–672. DOI: 10.1109 / 77.919433
CrossRef Полный текст | Google Scholar
Балота Д. А., Яп М. Дж., Кортезе М. Дж., Хатчисон К. А., Кесслер Б., Лофтис Б. и др. (2007). Проект английской лексики. Behav. Res. Методы 39, 445–459. DOI: 10.3758 / BF03193014
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Бемис, Д. К., и Пюлкканен, Л. (2011). Простая композиция: магнитоэнцефалографическое исследование понимания минимальных языковых фраз. Дж. Neurosci . 31, 2801–2814. DOI: 10.1523 / JNEUROSCI.5003-10.2011
Дж. Neurosci . 31, 2801–2814. DOI: 10.1523 / JNEUROSCI.5003-10.2011
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Биндер, Дж.R., Frost, J. A., Hammeke, T. A., Bellgowan, P. S., Springer, J. A., Kaufman, J. N., et al. (2000). Активация височной доли человека речью и неречевыми звуками. Cereb. Cortex 10, 512–528. DOI: 10.1093 / cercor / 10.5.512
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Баттерворт, Б. (1983). «Лексическое представление», in Language Production , Vol. 2, изд Б. Баттерворт (Лондон: Academic Press), 257–294.
Дейл, А.М., Лю, А. К., Фишл, Б. Р., Бакнер, Р. Л., Белливо, Дж. У., Левин, Дж. Д. и др. (2000). Динамическое статистическое параметрическое картирование: комбинирование ФМРТ и МЭГ для получения изображений корковой активности с высоким разрешением. Neuron 26, 55–67. DOI: 10.1016 / S0896-6273 (00) 81138-1
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Фунд-Резничек, Э. (2009). Маскированная морфологическая грунтовка составных компонентов. Ment. Lexicon 4, 159–193.DOI: 10,1075 / мл. 4.2.01fio
CrossRef Полный текст | Google Scholar
Фиорентино, Р., Найто-Биллен, Ю., Бост, Дж., И Фунд-Резничек, Э. (2014). Электрофизиологические доказательства комбинаторной обработки английских соединений на основе морфем. Cogn. Neuropsychol . 31, 123–146. DOI: 10.1080 / 02643294.2013.855633
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Фиорентино, Р., Поппель, Д. (2007). Сложные слова и структура в лексике. Lang. Cogn. Процесс . 22, 953–1000. DOI: 10.1080 / 016909607011
CrossRef Полный текст | Google Scholar
Форстер К. И. и Дэвис К. (1984). Прайминг повторения и ослабление частоты в лексическом доступе. J. Exp. Psychol. Учить. Mem. Cogn . 10, 680–698. DOI: 10.1037 / 0278-7393.10.4.680
DOI: 10.1037 / 0278-7393.10.4.680
CrossRef Полный текст | Google Scholar
Friederici, A. D., Wang, Y., Herrmann, C. S., Maess, B., and Oertel, U. (2000). Локализация ранних синтаксических процессов в лобных и височных областях коры: магнитоэнцефалографическое исследование. Hum. Brain Mapp . 11, 1–11. DOI: 10.1002 / 1097-0193 (200009) 11: 1 <1 :: AID-HBM10> 3.0.CO; 2-B
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Грамфорт А., Луесси М., Ларсон Э., Энгеманн Д. А., Штромайер Д., Бродбек К. и др. (2013). Анализ данных МЭГ и ЭЭГ с помощью MNE-python. Фронт. Neurosci . 7: 267. DOI: 10.3389 / fnins.2013.00267
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Грамфорт, А., Луесси, М., Ларсон, Э., Энгеманн, Д. А., Стромайер, Д., Бродбек, К. и др. (2014). Программное обеспечение МНЭ для обработки данных МЭГ и ЭЭГ. Neuroimage 86, 446–460. DOI: 10.1016 / j.neuroimage.2013.10.027
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Хансен, П. К., Крингельбах, М. Л., и Салмелин, Р. (2010). MEG: Введение в методы . Нью-Йорк, Нью-Йорк: Издательство Оксфордского университета.
Google Scholar
Юхас, Б.Дж., Старр, М. С., Инхофф, А. В., и Плак, Л. (2003). Влияние морфологии на обработку составных слов: свидетельства от именования, лексических решений и фиксации взгляда. Br. Дж. Психол . 94, 223–244. DOI: 10.1348 / 000712603321661903
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Longtin, C.-M., Segui, J., and Hallé, P.A. (2003). Морфологическая грунтовка без морфологической связи. Lang. Cogn. Процесс . 18, 313–334.DOI: 10.1080 / 01690960244000036
CrossRef Полный текст | Google Scholar
Марслен-Уилсон, В., Тайлер, Л. К., Вакслер, Р., и Олдер, Л. (1994). Морфология и значение в английской ментальной лексике. Psychol. Ред. . 101, 3–33. DOI: 10.1037 / 0033-295X.101.1.3
Psychol. Ред. . 101, 3–33. DOI: 10.1037 / 0033-295X.101.1.3
CrossRef Полный текст | Google Scholar
Маккормик, С. Ф., Растл, К., и Дэвис, М. Х. (2008). Есть ли в слове «фетиш» праздник? влияние орфографической непрозрачности на морфо-орфографическую сегментацию при визуальном распознавании слов. J. Mem. Lang . 58, 307–326. DOI: 10.1016 / j.jml.2007.05.006
PubMed Аннотация | Полный текст | CrossRef Полный текст | Google Scholar
Нили, Дж. Х. (1991). «Эффекты семантического прайминга в визуальном распознавании слов: выборочный обзор текущих открытий и теорий», в Basic Processes in Reading: Visual Word Recognition , eds D. Besner and GW Humphreys (Hillsdale, NJ: L. Erlbaum Associates), 264 –336.
Google Scholar
Растл, К.и Дэвис М. Х. (2003). Чтение морфологически сложных слов . Нью-Йорк, Нью-Йорк: Психология Пресс.
Google Scholar
Тафт, М., и Форстер, К. И. (1975). Лексическое хранение и поиск слов с префиксом. J. Verb. Учить. Глагол. Поведение . 14, 638–647. DOI: 10.1016 / S0022-5371 (75) 80051-X
CrossRef Полный текст | Google Scholar
Цвейг, Э., и Пюлкканен, Л. (2009). Визуальный эффект m170 морфологической сложности. Lang.Cogn. Процесс . 24, 412–439. DOI: 10.1080 / 01690960802180420
CrossRef Полный текст | Google Scholar
Zwitserlood, P. (1994). Роль семантической прозрачности в обработке и представлении нидерландских словосочетаний. Lang. Cogn. Процесс . 9, 341–368. DOI: 10.1080 / 01690969408402123
CrossRef Полный текст | Google Scholar
Рекурсивная композиция поддерева при разборе зависимостей на основе LSTM
Мы используем UUParser, вариант синтаксического анализатора на основе переходов K&G, который использует систему перехода дуги-гибрида из Kuhlmann et al.(2011) расширился с помощью перехода Swap и статико-динамического оракула, как описано в de Lhoneux et al.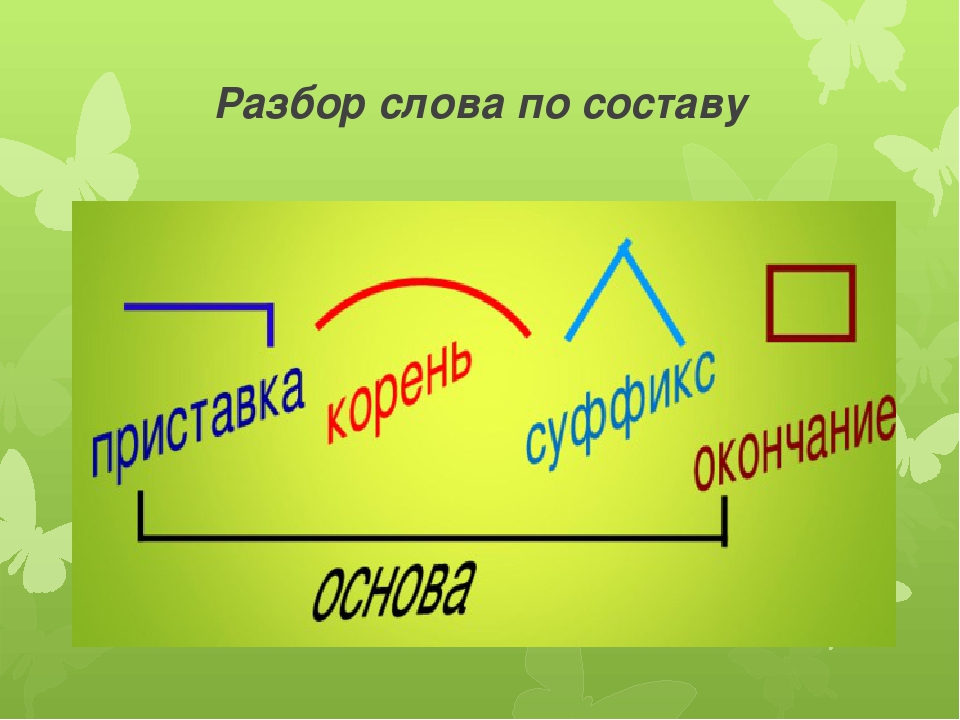 (2017b) . Переход Swap используется для создания непроективных деревьев зависимостей (Nivre, 2009)
(2017b) . Переход Swap используется для создания непроективных деревьев зависимостей (Nivre, 2009)
. Мы используем гиперпараметры по умолчанию. При использовании тегов POS мы используем универсальные теги POS из древовидных структур UD, которые являются крупнозернистыми и единообразными для разных языков. Эти теги POS предсказываются UDPipe
(Straka et al., 2016) как для обучения, так и для анализа.Этот синтаксический анализатор получил 7-е место в среднем по шкале LAS в общей задаче CoNLL 2018 (Zeman et al., 2018) , что примерно на 2,5 балла LAS ниже лучшей системы, которая использует ансамблевую систему, а также встраивания ELMo, как представил Peters et al. (2018) . Обратите внимание, однако, что мы используем немного урезанную версию модели, используемой для совместной задачи, которая описана в Smith et al. (2018a) : мы используем менее точный POS-теггер (UDPipe) и не используем модели с несколькими банками деревьев.Кроме того, Smith et al. (2018a) использует три верхних элемента стека, а также первый элемент буфера для представления конфигурации, в то время как мы используем только два верхних элемента стека и первый элемент буфера. Smith et al. (2018a) также используют расширенный набор функций, представленный Kiperwasser и Goldberg (2016b), где они также используют крайние правые и крайние левые дочерние элементы элементов стека и буфера, которые они рассматривают. Мы не используем этот расширенный набор функций.Это сделано для того, чтобы настройки парсера были как можно более простыми и не добавляли мешающих факторов. Это все еще модель, близкая к SOTA. Мы оцениваем модели синтаксического анализа на наборах разработки и сообщаем среднее из 5 лучших результатов за 30 эпох и 5 прогонов с различными случайными начальными числами.
% PDF-1.5 % 4 0 obj > эндобдж 7 0 объект (Вступление) эндобдж 8 0 объект > эндобдж 11 0 объект (Результаты этой работы) эндобдж 12 0 объект > эндобдж 15 0 объект (Краткое содержание диссертации) эндобдж 16 0 объект > эндобдж 19 0 объект (Комбинированная категориальная грамматика) эндобдж 20 0 объект > эндобдж 23 0 объект (Категории) эндобдж 24 0 объект > эндобдж 27 0 объект (Исчисление Ламбека) эндобдж 28 0 объект > эндобдж 31 0 объект (Комбинаторные правила CCG) эндобдж 32 0 объект > эндобдж 35 0 объект (Заявление) эндобдж 36 0 объект > эндобдж 39 0 объект (Состав) эндобдж 40 0 объект > эндобдж 43 0 объект (Наборный) эндобдж 44 0 объект > эндобдж 47 0 объект (Обозначение: ассоциативность косой черты) эндобдж 48 0 объект > эндобдж 51 0 объект (Семантика CCG) эндобдж 52 0 объект > эндобдж 55 0 объект (Лямбда-исчисление) эндобдж 56 0 объект > эндобдж 59 0 объект (Система типов) эндобдж 60 0 объект > эндобдж 63 0 объект (Исчисление Ламбека с лямбда-членами) эндобдж 64 0 объект > эндобдж 67 0 объект (Правила CCG с семантикой) эндобдж 68 0 объект > эндобдж 71 0 объект (Пример вывода с семантикой) эндобдж 72 0 объект > эндобдж 75 0 объект (Замечание по терминологии) эндобдж 76 0 объект > эндобдж 79 0 объект (PL-CCG, формализм для польского языка) эндобдж 80 0 объект > эндобдж 83 0 объект (Синтаксические особенности) эндобдж 84 0 объект > эндобдж 87 0 объект (Свободный порядок слов) эндобдж 88 0 объект > эндобдж 91 0 объект (Multiset-CCG) эндобдж 92 0 объект > эндобдж 95 0 объект (Модификаторы предложения) эндобдж 96 0 объект > эндобдж 99 0 объект (Состав мультимножества) эндобдж 100 0 объект > эндобдж 103 0 объект (Модификаторы как аргументы) эндобдж 104 0 объект > эндобдж 107 0 объект (Правила PL-CCG) эндобдж 108 0 объект > эндобдж 111 0 объект (Семантика PL-CCG) эндобдж 112 0 объект > эндобдж 115 0 объект (Лямбда-исчисление мультимножества) эндобдж 116 0 объект > эндобдж 119 0 объект (Система типов) эндобдж 120 0 объект > эндобдж 123 0 объект (Переупорядочивание аргументов) эндобдж 124 0 объект > эндобдж 127 0 объект (Правила PL-CCG с семантикой) эндобдж 128 0 объект > эндобдж 131 0 объект (Деревья контента) эндобдж 132 0 объект > эндобдж 135 0 объект (Мотивация) эндобдж 136 0 объект > эндобдж 139 0 объект (Определение дерева содержимого) эндобдж 140 0 объект > эндобдж 143 0 объект (Алгоритм извлечения зависимостей) эндобдж 144 0 объект > эндобдж 147 0 объект (Деревья содержимого в лямбда-исчислении) эндобдж 148 0 объект > эндобдж 151 0 объект (Примеры) эндобдж 152 0 объект > эндобдж 155 0 объект (Древовидный банк PL-CCG) эндобдж 156 0 объект > эндобдж 159 0 объект (CCGbank) эндобдж 160 0 объект > эндобдж 163 0 объект (Польский берег деревьев \ (Sk \ 233adnica \)) эндобдж 164 0 объект > эндобдж 167 0 объект (Алгоритм преобразования) эндобдж 168 0 объект > эндобдж 171 0 объект (Классификация узловых элементов) эндобдж 172 0 объект > эндобдж 175 0 объект (Построение деривации) эндобдж 176 0 объект > эндобдж 179 0 объект (Извлечение зависимостей) эндобдж 180 0 объект > эндобдж 183 0 объект (Построение семантического представления) эндобдж 184 0 объект > эндобдж 187 0 объект (Пример вывода алгоритма) эндобдж 188 0 объект > эндобдж 191 0 объект (Оценка) эндобдж 192 0 объект > эндобдж 195 0 объект (Версии словаря) эндобдж 196 0 объект > эндобдж 199 0 объект (Количественная оценка) эндобдж 200 0 объект > эндобдж 203 0 объект (Парсер) эндобдж 204 0 объект > эндобдж 207 0 объект (Методология) эндобдж 208 0 объект > эндобдж 211 0 объект (Полученные результаты) эндобдж 212 0 объект > эндобдж 215 0 объект (Обсуждение лексики) эндобдж 216 0 объект > эндобдж 219 0 объект (Обычная версия) эндобдж 220 0 объект > эндобдж 223 0 объект (Другие версии) эндобдж 224 0 объект > эндобдж 227 0 объект (Заключение) эндобдж 228 0 объект > эндобдж 231 0 объект (Список функций, используемых польским банком деревьев) эндобдж 232 0 объект > эндобдж 235 0 объект (Библиография) эндобдж 236 0 объект > эндобдж 239 0 объектов> поток x څ Ko0aK (bT @ 40O0
;> » 5? yyl%, () wDX˕TĀ. 7ܒ OC4t} z2i
9I}}) / P ֜ fpeg3ja ~ U4] ۥ o & od]). +! Rg (] + \ c
EVJ ǵX
7ܒ OC4t} z2i
9I}}) / P ֜ fpeg3ja ~ U4] ۥ o & od]). +! Rg (] + \ c
EVJ ǵX
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, выше приведено достаточно информации, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов. Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. А так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется слишком много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа. Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его переносом в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа. Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс.