Синтаксический разбор:памятка для начал.школы (Эмма Матекина)
Купить офлайн
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на сайте.
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на сайте.
В данной памятке представлен синтаксический разбор предложений в разделе программы школьного курса по русскому языку, предусмотренный программой начальной школы. В па мятке приведены примеры и методические рекомендации по выполнению заданий, которые помогут учащимся правильно в устной и письменной форме производить синтаксический разбор предложений. Пособие может быть использовано в следующих случаях: для объяснения, закрепления и обобщения пройденного материала; для восполнения пробелов в знаниях; в качестве дополнител ьного материала; для подготовки домашних заданий.
.
.Памятка предназначена для учеников начальных классов, учителей, родителей.
Описание
Характеристики
В данной памятке представлен синтаксический разбор предложений в разделе программы школьного курса по русскому языку, предусмотренный программой начальной школы. В па мятке приведены примеры и методические рекомендации по выполнению заданий, которые помогут учащимся правильно в устной и письменной форме производить синтаксический разбор предложений. Пособие может быть использовано в следующих случаях: для объяснения, закрепления и обобщения пройденного материала; для восполнения пробелов в знаниях; в качестве дополнител ьного материала; для подготовки домашних заданий. . .Памятка предназначена для учеников начальных классов, учителей, родителей.
Феникс
На товар пока нет отзывов
Поделитесь своим мнением раньше всех
Как получить бонусы за отзыв о товаре
1
Сделайте заказ в интернет-магазине2
Напишите развёрнутый отзыв от 300 символов только на то, что вы купили3
Дождитесь, пока отзыв опубликуют.
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусовЕсли он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусовКнига «Синтаксический разбор:памятка для начал.школы» есть в наличии в интернет-магазине «Читай-город» по привлекательной цене.
Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом
другом регионе России, вы можете оформить заказ на книгу
Эмма Матекина
«Синтаксический разбор:памятка для начал.
Как синтаксический разбор помогает выздоравливать после тяжелой болезни
Содержимое
- 1 Как тяжелая болезнь может помочь вам лучше понять синтаксический разбор?
- 1.1 Советы по восстановлению после тяжелой болезни
- 1.1.1 Отдыхайте
- 1.1.2 Продумайте свой рацион
- 1.1.3 Занимайтесь физическими упражнениями
- 1.1.4 Поддерживайте связь с близкими
- 1.1.5 Слушайте свое тело
- 1.2 Понимание сложностей в процессе выздоровления от тяжелой болезни
- 1.2.1 Стресс и эмоциональный дисбаланс
- 1.2.2 Физические ограничения и изменение образа жизни
- 1.2.3 Проблемы с питанием и пищеварением
- 1.2.4 Деньги и материальные проблемы
- 1.3 Значимость синтаксического разбора
- 1.3.1 Что такое синтаксический разбор?
- 1.
 3.2 Зачем нужен синтаксический разбор?
3.2 Зачем нужен синтаксический разбор? - 1.3.3 Почему синтаксический разбор так важен?
- 1.3.4 Какие инструменты помогают в синтаксическом разборе?
- 1.4 Проблемы, которые могут возникнуть при нарушении синтаксического разбора
- 1.4.1 1. Неправильное понимание смысла текста
- 1.4.2 2. Ошибки при написании программного кода
- 1.4.3 3. Нежелательные последствия для SEO
- 1.4.4 4. Трудности в обработке естественного языка
- 1.4.5 5. Нарушения в веб-страницах
- 1.5 Причины нарушения синтаксического разбора
- 1.5.1 Несовпадение скобок
- 1.5.2 Ошибки при использовании операторов
- 1.5.3 Нарушение порядка аргументов функций
- 1.5.4 Ошибка в написании ключевых слов
- 1.5.5 Некорректное использование переменных
- 1.6 Оптимизация синтаксического разбора при выздоровлении от тяжелой болезни
- 1.6.1 Выбор оптимального метода синтаксического анализа
- 1.6.2 Автоматическая генерация синтаксического анализатора
- 1. 6.3 Использование машинного обучения
- 1.7 Роль эмоций в процессе синтаксического разбора и выздоровления
- 1.8 Физическое восстановление и его влияние на синтаксический разбор
- 1.8.1 Физическоое восстановление и обучение синтаксическому разбору
- 1.8.2 Виды разбора
- 1.8.3 Преимущества тренировки синтаксического разбора
- 1.9 Влияние питания и режима сна на восстановление и синтаксический разбор
- 1.9.1 Питание
- 1.9.2 Режим сна
- 1.9.3 Заключение
- 1.10 Мнение экспертов о роли синтаксического разбора в процессе выздоровления
- 1.11 Видео по теме:
- 1.12 Вопрос-ответ:
- 1.12.0.1 Что такое синтаксический разбор?
- 1.12.0.2 Как связана тяжелая болезнь с синтаксическим разбором?
- 1.12.0.3 Можно ли восстановить способность к синтаксическому разбору после тяжелой болезни?
- 1.12.0.4 Какие виды болезней могут повлиять на синтаксический разбор?
- 1.12.0.5 Какие проблемы могут возникать при нарушении синтаксического разбора?
- 1. 12.0.6 Какие методы реабилитации используются для восстановления синтаксического разбора?
- 1.1 Советы по восстановлению после тяжелой болезни
 3.2 Зачем нужен синтаксический разбор?
3.2 Зачем нужен синтаксический разбор? 6.3 Использование машинного обучения
6.3 Использование машинного обучения 12.0.6 Какие методы реабилитации используются для восстановления синтаксического разбора?
12.0.6 Какие методы реабилитации используются для восстановления синтаксического разбора?Если вы когда-нибудь переносили тяжелую болезнь и путались в грамматике, узнайте, что такое синтаксический разбор и как он поможет вам восстановить языковые навыки.
Болезни, особенно тяжелые, являются серьезным испытанием для человека. Помимо физических страданий, они могут оставить глубокий след на психике и менталитете человека. Однако, несмотря на все трудности и испытания, выход из тяжелых ситуаций возможен с помощью различных методик и подходов. Один из таких подходов – синтаксический разбор – может стать настоящей помощью в процессе выздоровления.
Синтаксический разбор – это процесс анализа естественных языков на основе грамматических правил. Он используется в лингвистике, программировании и машинном обучении. Однако, немногие знают, что синтаксический разбор можно применять и в медицине.
Таким образом, использование синтаксического разбора во время выздоровления от тяжелой болезни может оказать положительное влияние на наше состояние и ускорить процесс излечения. Для многих людей это может стать открытием и подходом к здоровому образу жизни.
Для многих людей это может стать открытием и подходом к здоровому образу жизни.
Советы по восстановлению после тяжелой болезни
Отдыхайте
Самое главное после болезни – это дать своему организму время отдохнуть. Постарайтесь спать не менее 8 часов в сутки. Не переутомляйтесь и не пытайтесь вернуться к прежнему режиму работы немедленно. Лучше начать с небольших заданий и давать себе время на восстановление.
Продумайте свой рацион
После болезни очень важно правильно питаться. Включите в свой рацион много свежих овощей и фруктов, а также полезных белков и углеводов. Ограничьте употребление жирной и соленой пищи, алкоголя и кофе. Пейте много жидкости, особенно воды и травяных чаев.
Занимайтесь физическими упражнениями
Физические упражнения помогают восстановить силы, но не забывайте, что важно давать своему телу отдых. Начните с простых упражнений, таких как ходьба или йога, и постепенно увеличивайте интенсивность и длительность занятий.
Поддерживайте связь с близкими
Поддержка близких людей – это очень важно для вашего восстановления. Общайтесь с друзьями и родственниками, пусть они помогут вам преодолеть трудности и поправиться после болезни. Обсуждайте свои чувства и проблемы, это поможет вам выразить свои эмоции и чувства.
Общайтесь с друзьями и родственниками, пусть они помогут вам преодолеть трудности и поправиться после болезни. Обсуждайте свои чувства и проблемы, это поможет вам выразить свои эмоции и чувства.
Слушайте свое тело
Самое главное – слушайте свое тело и не стройте на него большие надежды сразу после болезни. Период восстановления может занять достаточно долгое время, и это нормально. Не забывайте отдыхать, питаться правильно и заниматься физическими упражнениями, и скоро вы почувствуете, что ваше тело снова готово к жизни в полную силу.
Понимание сложностей в процессе выздоровления от тяжелой болезни
Стресс и эмоциональный дисбаланс
Восстановление после тяжелой болезни — это долгий и трудный процесс. На пути выздоровления могут возникнуть различные трудности, такие как стресс и эмоциональный дисбаланс. Тяжелое заболевание может оставить ощущение бессилия и безнадежности, что сильно влияет на психологическое состояние человека.
Важно понимать, что процесс выздоровления — это не только физическое восстановление, но и психологическое. Чтобы справиться со стрессом и эмоциональными трудностями, необходимо обратиться к профессионалу, который поможет вам разобраться с своими эмоциями и обрести психологическую поддержку.
Чтобы справиться со стрессом и эмоциональными трудностями, необходимо обратиться к профессионалу, который поможет вам разобраться с своими эмоциями и обрести психологическую поддержку.
Физические ограничения и изменение образа жизни
После тяжелой болезни может понадобиться изменение образа жизни и навсегда отказаться от привычных привычек. Например, если вы страдали от сердечно-сосудистых заболеваний, вам, возможно, придется ограничить употребление жирной и соленой пищи, а также отказаться от курения и алкоголя.
Как правило, при восстановлении после болезни рекомендуется увеличить физическую активность. Но здесь требуется осторожность, чтобы ненароком не навредить своему здоровью. Для этого важно проконсультироваться с врачом и разработать индивидуальный план тренировок.
Проблемы с питанием и пищеварением
После тяжелой болезни могут возникнуть проблемы с питанием и пищеварением. Возможно, организм стал отказываться от определенных продуктов, либо вы потеряли аппетит и не можете нормально питаться. В таких случаях нужно обратиться к диетологу, который поможет вам составить рацион и выбрать продукты, которые будут полезны для вашего здоровья.
В таких случаях нужно обратиться к диетологу, который поможет вам составить рацион и выбрать продукты, которые будут полезны для вашего здоровья.
Кроме того, может возникнуть проблема с пищеварительной системой, особенно после курса антибиотиков. Для того чтобы восстановить микрофлору кишечника, можно принимать пробиотики или ферменты.
Деньги и материальные проблемы
Восстановление после тяжелой болезни может стать дополнительной нагрузкой на ваш бюджет. Оплата лекарств, консультации врачей, процедуры — все это может оказаться немаловажной статьей расходов.
Если вы столкнулись с финансовыми трудностями, попробуйте обратиться за помощью к благотворительным организациям или государственным службам, которые предоставляют материальную поддержку тяжелобольным людям.
Значимость синтаксического разбора
Что такое синтаксический разбор?
Синтаксический разбор — это процесс анализа грамматической структуры предложения, при котором определяется взаимосвязь между словами в предложении. Синтаксический разбор очень важен для понимания значения предложения и его правильного перевода.
Синтаксический разбор очень важен для понимания значения предложения и его правильного перевода.
Зачем нужен синтаксический разбор?
Синтаксический разбор необходим для того, чтобы определить правильный порядок слов в предложении и их функцию в предложении. Без синтаксического разбора предложение может быть понятно неверно или неправильно.
Почему синтаксический разбор так важен?
Синтаксический разбор является критически важным процессом при понимании текста. Он позволяет понять наиболее важные слова и их отношение друг к другу. Это важно не только при чтении, но и при написании текста. Синтаксический разбор помогает избежать грамматических ошибок и улучшает качество текста.
Какие инструменты помогают в синтаксическом разборе?
Синтаксический разбор может быть выполнен вручную или с помощью специальных программ. Существуют онлайн-инструменты, которые могут автоматически выполнить синтаксический разбор текста и указать на ошибки. Также можно использовать программы для автоматического перевода и синтаксического анализа, такие как Google Translate.
- Синтаксический разбор является критически важным процессом при понимании текста.
- Без синтаксического разбора предложение может быть понятно неверно или неправильно.
- Синтаксический разбор помогает избежать грамматических ошибок и улучшает качество текста.
Проблемы, которые могут возникнуть при нарушении синтаксического разбора
1. Неправильное понимание смысла текста
Если при написании текста используются неправильные синтаксические конструкции, то это может привести к неправильному пониманию смысла текста. Например, если вместо союза «или» будет использован пропуск запятой, то предложение может получить двойное значение, которое невозможно правильно понять.
2. Ошибки при написании программного кода
При написании программного кода нарушение синтаксического разбора может привести к тому, что код не будет компилироваться. В этом случае может потребоваться значительное время для выявления ошибок и исправления их.
3.
 Нежелательные последствия для SEO
Нежелательные последствия для SEOНарушения синтаксического разбора могут оказать негативное влияние на оптимизацию контента для поисковых систем. Например, если вы забудете закрыть тег «title» страницы, то это может привести к снижению вашего рейтинга в поисковой системе.
4. Трудности в обработке естественного языка
При обработке естественного языка, например, в компьютерных программных программах, нарушение синтаксического разбора может привести к трудностям в распознавании и понимании текста. Это может привести к ошибкам и неправильным выводам.
5. Нарушения в веб-страницах
На веб-страницах нарушение синтаксического разбора может привести к тому, что страница не будет отображаться правильно. Кроме того, это может привести к проблемам с доступностью и удобством использования сайта, что может отрицательно повлиять на пользовательской опыт в целом.
В итоге, нарушение синтаксического разбора может привести к серьезным проблемам в различных областях, поэтому важно следить за правильным использованием синтаксических конструкций.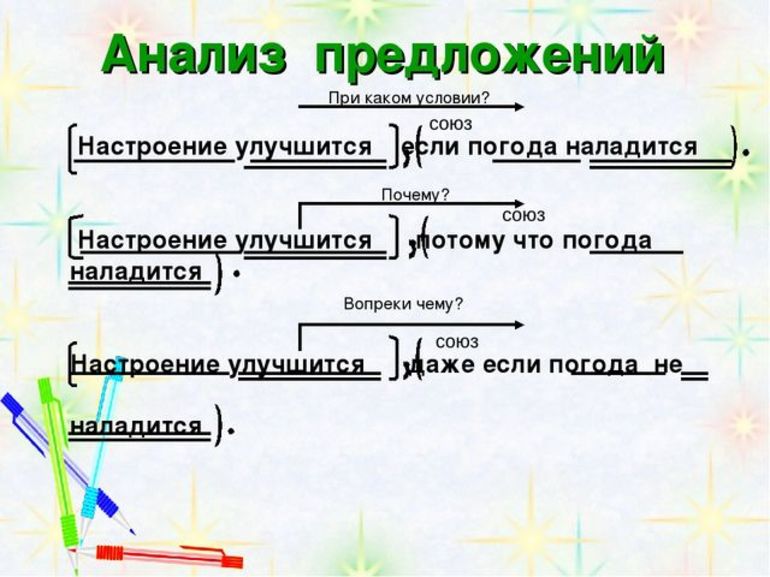
Причины нарушения синтаксического разбора
Несовпадение скобок
Одной из причин нарушения синтаксического разбора может быть несовпадение скобок. Например, если в программе открывающих скобок больше, чем закрывающих, то программа становится невалидной. А если закрывающих скобок больше, чем открывающих, возможно, что программа скомпилируется, но при выполнении может произойти ошибка.
Ошибки при использовании операторов
Еще одной причиной нарушения синтаксического разбора может быть неправильное использование операторов. Если в программе присутствуют недопустимые сочетания операторов или операндов, то произойдет ошибка при компиляции программы.
Нарушение порядка аргументов функций
Некоторые языки программирования предусматривают строгие правила порядка аргументов функций. Если порядок аргументов не соответствует этим правилам, то возможны ошибки при компиляции программы.
Ошибка в написании ключевых слов
Ошибка в написании ключевых слов является одной из частых причин нарушения синтаксического разбора.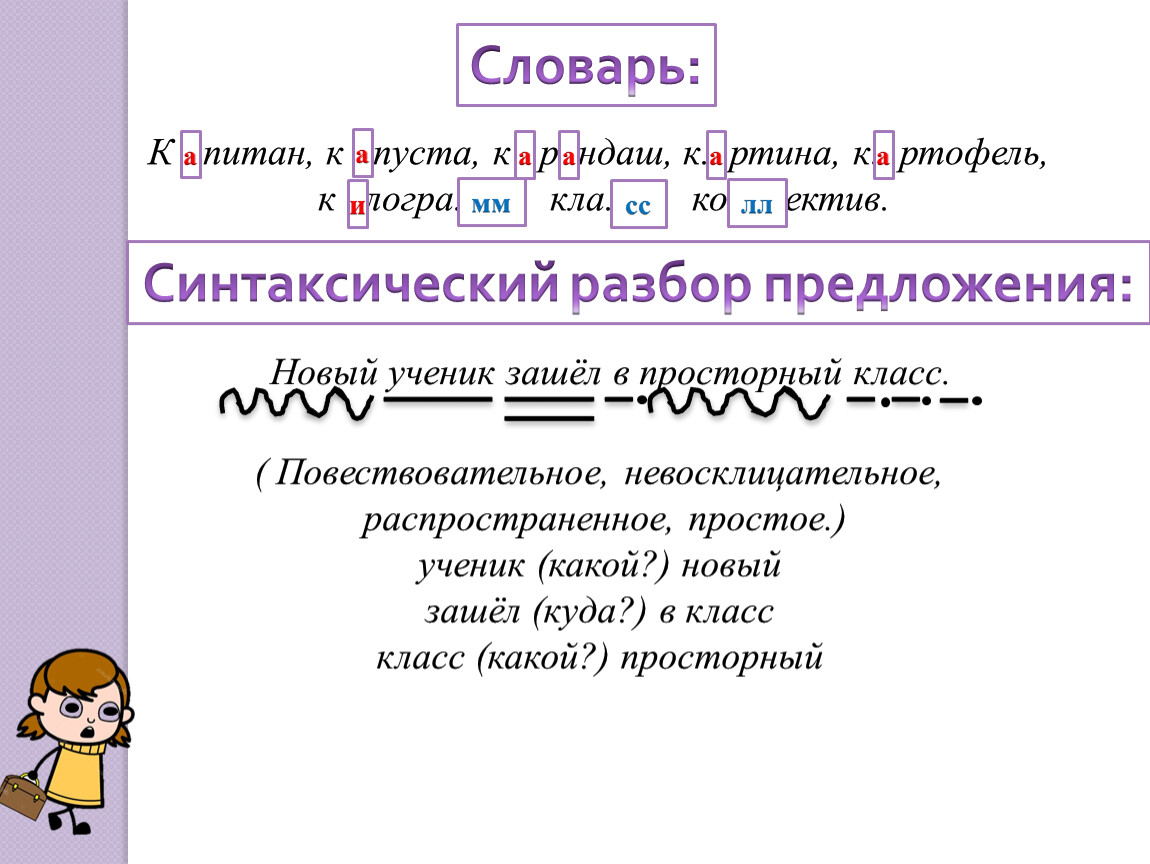 Если в программе написано неправильно ключевое слово, то компилятор не сможет распознать его, что приведет к ошибке.
Если в программе написано неправильно ключевое слово, то компилятор не сможет распознать его, что приведет к ошибке.
Некорректное использование переменных
Некорректное использование переменных также может стать причиной нарушения синтаксического разбора. Например, если переменная используется до ее объявления или если в программе присутствует необъявленная переменная, то компилятор выдаст ошибку.
Оптимизация синтаксического разбора при выздоровлении от тяжелой болезни
Выбор оптимального метода синтаксического анализа
Синтаксический разбор — это процесс анализа текста с целью определения его структуры и формирования синтаксического дерева. Одним из способов оптимизации этого процесса является выбор подходящего метода анализа. Например, метод рекурсивного спуска помогает ускорить процесс разбора на коротких фразах, а метод LR-анализа справляется с более сложными конструкциями.
Автоматическая генерация синтаксического анализатора
Другой способ оптимизации — это использование генератора синтаксических анализаторов. Это позволяет сократить время и усилия при создании конечного автомата, который распознает синтаксический текст. Этот метод особенно полезен при работе с большим объем текста, так как он позволяет синтаксический разбор выполняться более быстро и эффективно.
Это позволяет сократить время и усилия при создании конечного автомата, который распознает синтаксический текст. Этот метод особенно полезен при работе с большим объем текста, так как он позволяет синтаксический разбор выполняться более быстро и эффективно.
Использование машинного обучения
Другой подход — использование методов машинного обучения для определения структуры и помощи в классификации предложений по типам. Например, при обучении нейронной сети на корпусе размеченных текстов можно существенно улучшить точность синтаксического разбора. Такой подход также позволяет осуществлять более точное распознавание контекста и связей между словами в предложении.
- Выбор оптимального метода синтаксического анализа
- Использование генератора синтаксических анализаторов
- Использование методов машинного обучения
Примеры времени выполнения синтаксического разбораМетодыВремя выполнения
| Рекурсивный спуск | до 1 мс на коротких фразах |
| LR-анализ | несколько мс на сложных конструкциях |
| Машинное обучение | от нескольких мс до нескольких секунд в зависимости от объема текста и сложности анализа |
Роль эмоций в процессе синтаксического разбора и выздоровления
Синтаксический разбор является одним из наиболее сложных психологических процессов, которые могут быть затронуты эмоциями. Человек, находящийся в состоянии стресса или аогника, может испытывать трудности в понимании и анализе сложных фраз, что может привести к ошибкам в интерпретации.
Человек, находящийся в состоянии стресса или аогника, может испытывать трудности в понимании и анализе сложных фраз, что может привести к ошибкам в интерпретации.
Следовательно, важно следить за состоянием своих эмоций в период выздоровления от тяжелой болезни, так как это может влиять на процесс синтаксического разбора и, в целом, на скорость и качество восстановления.
- Чтобы улучшить психологическое состояние, можно обратиться за профессиональной помощью психолога или использовать техники медитации и релаксации.
- Можно также попросить помощи у близких или друзей, которые могут поддержать положительный настрой и помочь справиться с негативными эмоциями.
В целом, понимание взаимосвязи между эмоциями и процессом синтаксического разбора может помочь лучше управлять своими эмоциями в период выздоровления, что, в свою очередь, может ускорить процесс восстановления и улучшить его качество.
Физическое восстановление и его влияние на синтаксический разбор
Физическоое восстановление и обучение синтаксическому разбору
Когда мы проходим через тяжелую болезнь, наше физическое функционирование часота меняется. После выздоровления, необходимо постоянное восстановление нашего организма. Как же это влияет на наш разбор языка?
После выздоровления, необходимо постоянное восстановление нашего организма. Как же это влияет на наш разбор языка?
Зрительное восстановление после травмы может занять месяцы, а это может затруднить восприятие и использование языка. Однако, разучивание техники синтаксического разбора может принести значительную пользу в этом процессе. Это потому что работа над синтаксическим разбором дает усиленную тренировку мозга и предоставляет дополнительный способ поддержания его работоспособности.
Виды разбора
Синтаксический разбор — это процесс анализа и интерпретации фразы или предложения, путем разделения его компонентов на элементы грамматической структуры. Это позволяет правильно интерпретировать смысл фразы или предложения.
Есть два вида синтаксического разбора:
- Рекурсивный разбор — этот вид разбора начинается с верхнего уровня грамматики и работает, как дерево.
- Нисходящий анализ — этот вид разбора работает снизу вверх, путем проверки грамматических правил предложения, один за другим.

Преимущества тренировки синтаксического разбора
Тренировка мозга может принести значительные преимущества не только после тяжелой болезни, но и в обычной жизни. Использование технологий, связанных с разбором, может помочь улучшить мышление и фокусировку, улучшить креативность, помочь лучше запоминать и помочь нам стать более производительными. Как говорится, «нет ничего лучше, чем здоровый разум в здоровом теле».
Влияние питания и режима сна на восстановление и синтаксический разбор
Питание
Один из важных факторов восстановления после тяжелой болезни — правильное питание. В период выздоровления необходимо употреблять пищу, богатую витаминами и минералами, которые помогают восстановить иммунитет организма. Также, следует избегать переедания и употребление жирной, слишком сладкой или соленой пищи.
Для быстрого восстановления сил и энергии, в рационе необходимо включать пищу, богатую белками и углеводами, такие как мясо, рыба, яйца, овощи, фрукты. Большое значение имеют также режим питания и частота приема пищи — регулярное питание в малых порциях помогает уменьшить нагрузку на организм и ускорить процесс восстановления.
Большое значение имеют также режим питания и частота приема пищи — регулярное питание в малых порциях помогает уменьшить нагрузку на организм и ускорить процесс восстановления.
Режим сна
Еще один не менее важный фактор, влияющий на восстановление и синтаксический разбор, это правильный режим сна. В период выздоровления необходимо обеспечить своему организму достаточное количество отдыха и сна.
Лучше всего лечь спать в одно и то же время, чтобы организм смог настроиться на определенный режим. Необходимо также обеспечить комфортные условия для сна — тихий и темный номер, удобная кровать и подушки. Для того чтобы хорошо отдохнуть, необходимо также избегать употребления кофеина и алкоголя перед сном.
Заключение
Правильное питание и режим сна — это ключевые факторы восстановления и синтаксического разбора после тяжелой болезни. Необходимо заботиться о своем здоровье, чтобы быстрее вернуться к активной жизни и более успешно восстановить языковые навыки.
Мнение экспертов о роли синтаксического разбора в процессе выздоровления
Синтаксический разбор является важным аспектом развития языковых навыков, который может существенно улучшить способность к общению и пониманию речи, а также помочь в реабилитации после серьезных заболеваний.
По мнению экспертов, систематическое обучение синтаксическому разбору может усилить нейронные связи в головном мозге и повысить качество обработки речи, что сделает процесс выздоровления более эффективным и ускоренным.
Таким образом, синтаксический разбор играет важную роль в процессе выздоровления и восстановления после тяжелой болезни, обеспечивая не только улучшение языковых навыков, но и ускоренный процесс адаптации в окружающей среде.
Видео по теме:
Вопрос-ответ:
Что такое синтаксический разбор?
Синтаксический разбор — это процесс анализа текста с целью определения его грамматической структуры и проверки соответствия правилам языка.
Как связана тяжелая болезнь с синтаксическим разбором?
Тяжелая болезнь может повредить мозг и привести к нарушению языковых навыков, включая способность к синтаксическому разбору.
Можно ли восстановить способность к синтаксическому разбору после тяжелой болезни?
Да, с помощью реабилитации и специальных упражнений можно восстановить способность к синтаксическому разбору.
Какие виды болезней могут повлиять на синтаксический разбор?
Многие заболевания, связанные с нарушением кровообращения в мозге, а также нейродегенеративные заболевания, связанные с постепенным ухудшением функций мозга, могут повлиять на синтаксический разбор.
Какие проблемы могут возникать при нарушении синтаксического разбора?
Нарушение синтаксического разбора может привести к трудностям в понимании и произношении слов, формировании предложений, а также в общении в целом.
Какие методы реабилитации используются для восстановления синтаксического разбора?
Методы реабилитации могут включать упражнения на повторение и распознавание слов и звуков, обучение правилам грамматики, упражнения на формирование правильных предложений и диалогов, а также игры на развитие когнитивных навыков.
моделей обработки предложений | Вычислительные модели чтения. Справочник
. Фильтр поиска панели навигации Oxford AcademicComputational Models of Reading: A HandbookCognitive PsychologyOxford Scholarship OnlineBooksJournals Мобильный телефон Введите поисковый запрос
ЗакрытьФильтр поиска панели навигации Oxford AcademicComputational Models of Reading: A HandbookCognitive PsychologyOxford Scholarship OnlineBooksJournals Введите поисковый запрос
Расширенный поиск
Иконка Цитировать Цитировать
Разрешения
- Делиться
- Фейсбук
- Твиттер
- Электронная почта
Укажите
Райхле, Эрик Д. , «Модели обработки предложений», Computational Models of Reading: A Handbook ( New York , 2021; онлайн-издание, Oxford Academic, 18 февраля 2021 г.), https://doi.org/ 10.1093/oso/9780195370669.003.0004, по состоянию на 5 июля 2023 г.
, «Модели обработки предложений», Computational Models of Reading: A Handbook ( New York , 2021; онлайн-издание, Oxford Academic, 18 февраля 2021 г.), https://doi.org/ 10.1093/oso/9780195370669.003.0004, по состоянию на 5 июля 2023 г.Выберите формат Выберите format.ris (Mendeley, Papers, Zotero).enw (EndNote).bibtex (BibTex).txt (Medlars, RefWorks)
ЗакрытьФильтр поиска панели навигации Oxford AcademicComputational Models of Reading: A HandbookCognitive PsychologyOxford Scholarship OnlineBooksJournals Мобильный телефон Введите поисковый запрос
ЗакрытьФильтр поиска панели навигации Oxford AcademicComputational Models of Reading: A HandbookCognitive PsychologyOxford Scholarship OnlineBooksJournals Введите поисковый запрос
Advanced Search
Abstract
В этой главе сначала описывается то, что было известно о том, как читатели обрабатывают предложения, используя информацию из отдельных слов в сочетании с лингвистическими знаниями для создания более крупных смысловых единиц, соответствующих фразам и предложениям.
Ключевые слова: грамматика, синтаксический анализ, правила построения фраз, семантика, обработка предложений, структурная неоднозначность, синтаксис, тематические роли
Предмет
Когнитивная психологияКоллекция: Оксфордская стипендия онлайн
В настоящее время у вас нет доступа к этой главе.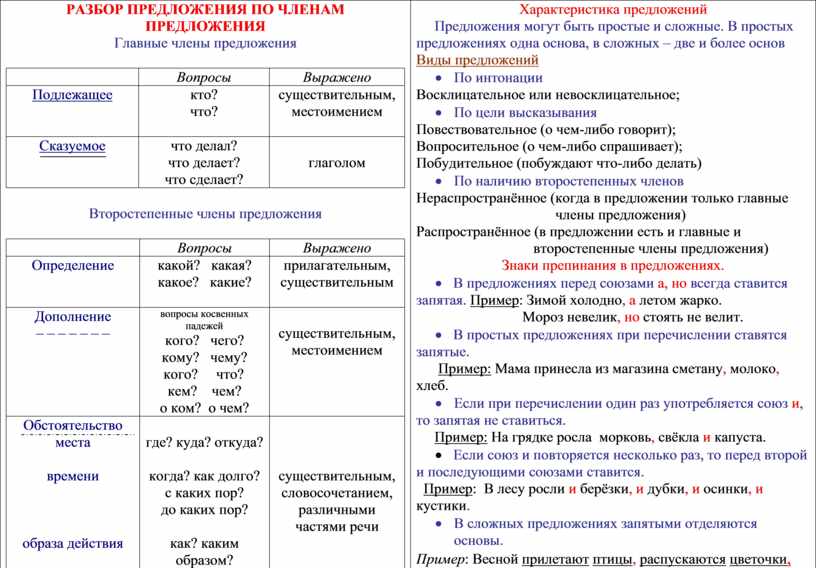
Войти
Получить помощь с доступомПолучить помощь с доступом
Доступ для учреждений
Доступ к контенту в Oxford Academic часто предоставляется посредством институциональных подписок и покупок. Если вы являетесь членом учреждения с активной учетной записью, вы можете получить доступ к контенту одним из следующих способов:Доступ на основе IP
Как правило, доступ предоставляется через институциональную сеть к диапазону IP-адресов. Эта аутентификация происходит автоматически, и невозможно выйти из учетной записи с IP-аутентификацией.
Войдите через свое учреждение
Выберите этот вариант, чтобы получить удаленный доступ за пределами вашего учреждения. Технология Shibboleth/Open Athens используется для обеспечения единого входа между веб-сайтом вашего учебного заведения и Oxford Academic.
- Щелкните Войти через свое учреждение.
- Выберите свое учреждение из предоставленного списка, после чего вы перейдете на веб-сайт вашего учреждения для входа.
- При посещении сайта учреждения используйте учетные данные, предоставленные вашим учреждением. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если вашего учреждения нет в списке или вы не можете войти на веб-сайт своего учреждения, обратитесь к своему библиотекарю или администратору.
Войти с помощью читательского билета
Введите номер своего читательского билета, чтобы войти в систему. Если вы не можете войти в систему, обратитесь к своему библиотекарю.
Члены общества
Доступ члена общества к журналу достигается одним из следующих способов:
Войти через сайт сообщества
Многие общества предлагают единый вход между веб-сайтом общества и Oxford Academic.
- Щелкните Войти через сайт сообщества.
- При посещении сайта общества используйте учетные данные, предоставленные этим обществом. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если у вас нет учетной записи сообщества или вы забыли свое имя пользователя или пароль, обратитесь в свое общество.
Вход через личный кабинет
Некоторые общества используют личные учетные записи Oxford Academic для предоставления доступа своим членам. См. ниже.
Личный кабинет
Личную учетную запись можно использовать для получения оповещений по электронной почте, сохранения результатов поиска, покупки контента и активации подписок.
Некоторые общества используют личные учетные записи Oxford Academic для предоставления доступа своим членам.
Просмотр учетных записей, вошедших в систему
Щелкните значок учетной записи в правом верхнем углу, чтобы:
- Просмотр вашей личной учетной записи и доступ к функциям управления учетной записью.
- Просмотр институциональных учетных записей, предоставляющих доступ.
Выполнен вход, но нет доступа к содержимому
Oxford Academic предлагает широкий ассортимент продукции. Подписка учреждения может не распространяться на контент, к которому вы пытаетесь получить доступ. Если вы считаете, что у вас должен быть доступ к этому контенту, обратитесь к своему библиотекарю.
Ведение счетов учреждения
Для библиотекарей и администраторов ваша личная учетная запись также предоставляет доступ к управлению институциональной учетной записью. Здесь вы найдете параметры для просмотра и активации подписок, управления институциональными настройками и параметрами доступа, доступа к статистике использования и т. д.
д.
Покупка
Наши книги можно приобрести по подписке или приобрести в библиотеках и учреждениях.
Информация о покупкеParser Documentation
На диаграмме выше прямыми линиями показаны фактические выходные данные методов Java. Блоки свободно группируют связанные структуры. Пунктирные линии представляют «наследования», за исключением линии, которая показывает отношения между Прологом и другими компонентами, что означает «консультации». Пунктирные линии означают «чтение/запись файла».
Парсер представляет собой сложную программу, написанную на двух с половиной языках (Java, Prolog и простая разметка самих файлов), поэтому перед внесением каких-либо изменений внимательно прочитайте все файлы.
Первое, что происходит со строкой, поступающей в синтаксический анализатор, — это предварительная обработка. Класс препроцессора — это внутренний класс парсера (вероятно, это плохой дизайн — идите вперед и измените его). Препроцессор отвечает, как минимум, за следующее:
Препроцессор отвечает, как минимум, за следующее:
Препроцессор выполняет некоторые задачи (например, изменение регистра) с помощью вызовов String, но в основном это простой набор регулярных выражений, каждое из которых проверяется последовательно, один и только один раз, на каждой строке ввода. Другими словами, определение двух строк препроцессора, которые изменяют одно и то же, не рекомендуется, и если вы определяете такие строки, важен порядок. Правила препроцессора определяются в файле.
В настоящее время регулярные выражения не компилируются. Я исправлю это (и изменю это примечание в документах, если я помню), когда у меня будет время, но если у меня его нет, пожалуйста, найдите пять минут, чтобы сделать это за меня. Будет полезно, я верю.
Теория X-bar — это теория структуры фраз, которая, похоже, популярна среди специалистов по синтаксису. Приведенное ниже обсуждение в общих чертах следует Синтаксису Эндрю Карни, Генеративному введению , с дополнительным советом профессора Раннера с факультета лингвистики.
Основное обобщение теории X-bar состоит в том, что грамматика естественного языка имеет три основных правила:
Для наших целей не требуются все правила. Английский язык, например, имеет только одно правило дополнения (обычно — см. дальнейшую работу), в котором дополнение находится справа, а головка , элемент X в основании XP, находится слева. Нам также не нужны версии правила дополнения, которые не имеют дополнения, то есть правило X' -> X' . На самом деле определение таких правил сломало бы синтаксический анализатор.
Кроме того, правила спецификатора несколько отличаются. В то время как стандартная грамматика X-bar позволяет любому синтаксическому типу вообще заполнять спецификатор, наше правило ограничено: XP -> XSpec X'/X'. То есть, если категория имеет тип спецификатора, определенный каким-либо другим правилом, она может иметь спецификатор этого типа, но в противном случае ни одна фраза не имеет спецификаторов.
Единственные две фразы со спецификаторами в нашей грамматике — это NP (сочетания существительных) и AuxP (Carnie называет эти TP; это предложения). NP имеют определители в качестве спецификаторов, хотя такой подход не принят в современном синтаксисе (см. Carnie, глава 6). У AuxP есть спецификаторы NP; в частности, подлежащее предложения находится в узле спецификатора над вспомогательным.
Ниже показаны небольшие различия между моим подходом и подходом Карни к простым предложениям. Обратите внимание, что там, где нет явного вспомогательного (или временного) слова, такого как «будет» или, возможно, «ам», в узлах Aux и T ничего нет. В представлении Карни это «ничего» есть непроизносимое слово «нуль [настоящее время]». В моем случае узел не существует.
Написание грамматики
Написать грамматику для этой системы достаточно просто. В системе есть три жестко закодированных буквы, которые она считает «заменяемыми» именами синтаксических категорий: X, Y и Z. (Это было бы неплохо добавить в формат файла.) Первая строка файла объявляет, какие типы вы хотите, чтобы их заменили. Например, чтобы иметь AuxP, VP, NP, AP и PP, вы пишете
(Это было бы неплохо добавить в формат файла.) Первая строка файла объявляет, какие типы вы хотите, чтобы их заменили. Например, чтобы иметь AuxP, VP, NP, AP и PP, вы пишете
Aux V N A P
Затем вы можете начать писать правила. Они содержат следующие детали:
синтаксическая категория @ части @ обязательный список @ код выбора @ код интерпретации (новая строка)
Важно помнить, что единственная новая строка в правиле должна стоять сразу после правила. Это значительно упрощает чтение файла с помощью BufferedReader, хотя и немного запутанно для людей.
Например, пример правила:
Не беспокойтесь слишком о коде интерпретации (или смотрите документы интерпретатора). Мы хотим сосредоточиться на первых четырех частях. Между прочим, символ @ — это просто удобный разделитель, который не имеет смысла в Java или Прологе.
Синтаксическая категория правила сообщает, какого типа будут фразы, создаваемые правилом. Таким образом, правило
Части говорят о том, какие составляющие можно добавить к фразе и в каком порядке. Это правило требует, чтобы один компонент был в категории X. Поскольку X не имеет угловых скобок, по соглашению это одно слово. Это также тот же тип, что и фраза в целом, поскольку X каждый раз заменяется одним и тем же образом. Итак, в NP это N. Следующая часть — это
Список привязки сообщает синтаксическому анализатору, как настроить код для проверки и интерпретации фразы, присваивая каждой составляющей фразы имя. Это имя может быть любым, но оно не должно появляться в коде справа, если только вы не хотите, чтобы оно было заменено названием фразы, заполняющей соответствующий слот. Здесь у нас есть H, обозначающий Голову, и X, обозначающий Неизвестное.
Когда синтаксический анализатор создает фразу с этим правилом, он делает копию кода выбора (и кода интерпретации) и заменяет H именем составной части, заполняющей слот H. Каждая составляющая имеет уникальное имя. У слов есть имена, соответствующие их тексту, плюс индекс их значения, поэтому первое определение «робот» имеет имя «робот0». Фразы имеют имя «phraseXXX», где XXX подсчитывает количество фраз, существовавших ранее. Таким образом, если бы это правило было реализовано как правило VP, заставляющее составляющую «идти в магазин», привязки были бы H = go0, X = фразаFOO, где фразаFOO — это имя «в магазин».
Существует также одна специальная замена в разделах кода, это &. & — это название текущей фразы, которая также является фразойXXX.
Разбор правил осуществляется в Rule.java.
Написание лексикона
После файла грамматики файлы словаря должны выглядеть довольно знакомо. Строка в файле лексикона имеет вид:
(! @) слово @ категория @ код выбора @ код интерпретации (новая строка)
Опять же, вы можете поставить новую строку только в конце. И снова код интерпретации объясняется на странице интерпретатора.
И снова код интерпретации объясняется на странице интерпретатора.
Пример строки lex выглядит так:
динамик @ N @ тип(&, динамик). @предикат(&, [динамик(X)], []).
Слово именно то, на что оно похоже — прямое совпадение с английским текстом токена, возвращенным препроцессором. Он соответствует «динамику» и только «динамику», а не динамикам, говорящим, говорящим, sp3ak3r или чему-то еще.
Категория — это категория, к которой подходит слово, и она должна соответствовать строке в файле грамматики. Все в файле грамматики допустимо — слово может быть , выполняющий преобразование.
Код выбора во многом похож на код выбора правил грамматики, но списка привязки нет; единственная выполняемая привязка выполняется на &, который является именем слова.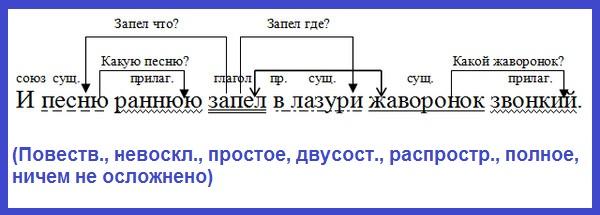
Слова могут быть определены многократно, либо путем создания двух одинаковых слов в разных категориях, либо с добавлением разных кодов, либо и тем, и другим. При сканировании файла класс Lexicon хэширует все слова в таблицу объектов Word, которые отвечают за возврат представляющих их объектов LexItem. То есть слово — это полная словарная статья, например, для 9.0038 прогулка , содержащая:
Прогулка, 1:N, небольшое путешествие пешком. 2: V, идти пешком.Есть два элемента LexItem с именами
walk0 и walk1 , каждый из которых представляет одно такое значение. Так что же делает необязательный ! @ в начале строки делать? Класс Lexicon расширяет слова в определенных категориях морфологически в соответствии с несколькими жестко запрограммированными правилами. Например, динамик @ N генерирует динамик и динамики . Эти правила довольно глупы — они применяются только к Ns и Vs, и они придерживаются окончаний, не задумываясь о фонологии.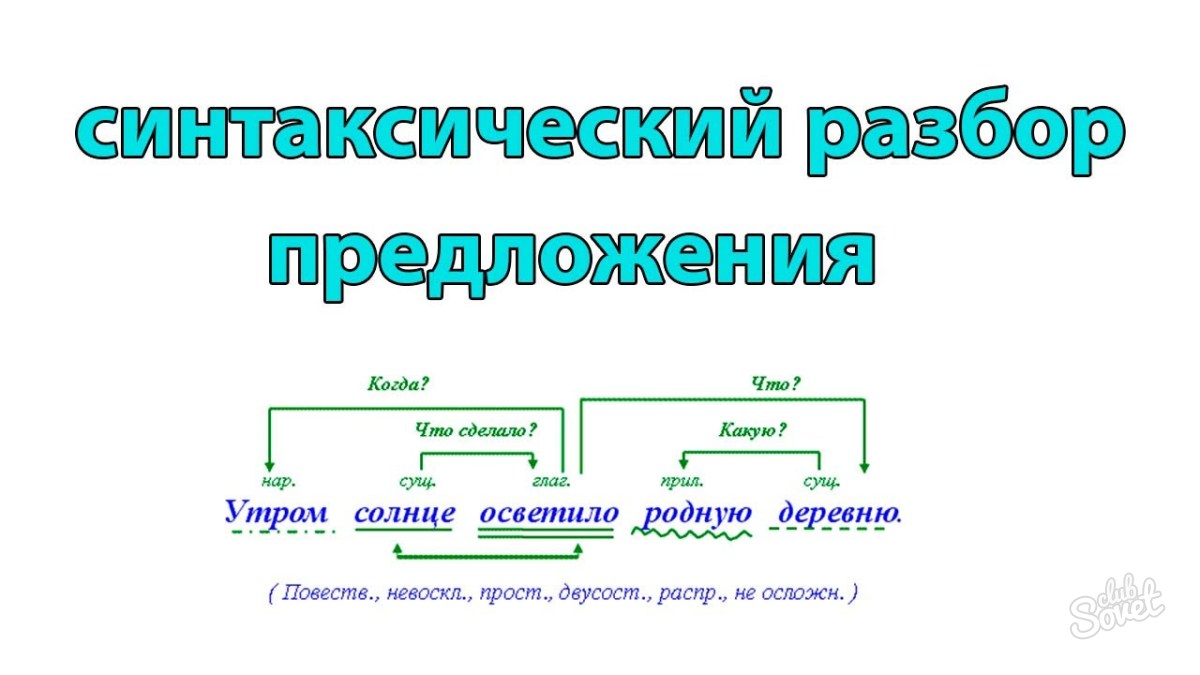 Итак, если бы у вас было
Итак, если бы у вас было , скажем @V , вы бы получили такие вещи, как , скажем и , скажем . Если вы хотите определить правильную форму, сказал , вы можете написать сказал @V , но тогда генератор морфов также даст вам морфы этого. Чтобы избежать этого, вы используете код без морфинга ! @ до твоего правления. Обычно это не важно, но в некоторых случаях неправильное преобразование может привести к плохому определению допустимого слова, и оно всегда без необходимости расширяет словарь пролога. Кстати, обратите внимание, что все произведенные морфы имеют ту же категорию и определение, что и их родительское слово, поэтому, если вы хотите другое определение или категорию для морфа, вы можете должен отключить генерацию морфинга для родителя, иначе вы получите обе копии, что приведет к двусмысленности.
Разбор
Итак, сейчас у всех должен быть животрепещущий вопрос: «Как работает синтаксический анализатор?». Я призываю всех получить жизнь, а также прочитать книгу профессора Аллена, приведенную выше. Но вот краткий экскурс, с особым вниманием к более своеобразным особенностям.
Я призываю всех получить жизнь, а также прочитать книгу профессора Аллена, приведенную выше. Но вот краткий экскурс, с особым вниманием к более своеобразным особенностям.
Основной алгоритм прост. Прочитать токен из строки. Обратитесь к лексикону, чтобы получить все элементы LexItem, связанные со словом. Поместите все эти LexItems в стек, список ключей . Вытащите первый компонент из списка ключей и обработайте его следующим образом:
Для всех правил грамматики создайте новую Дугу и посмотрите, примет ли Дуга Составляющую (то есть может ли правило, на котором основана Дуга, использовать Составляющую в качестве первой части?).
Для всех существующих Дуг проверьте, примут ли они Составляющую (то есть могут ли их правила использовать Составляющую в качестве следующей части?).
Когда Конституант завершает цикл, он сбрасывается из списка ключей на диаграмма , еще один список, который в конечном итоге будет содержать все анализы предложения и его составных частей.
Если в процессе циклирования Дуга может принять Составляющую, Дуга используется для создания новой Дуги, которая содержит Составляющую в качестве своей следующей части. Если новая Дуга не завершена и требует дополнительных частей, она попадает в список дуг , где может проверять новые Составные части по мере их появления. Однако, если новая Арка завершена, она создает Фразу, которая помещается в список ключей.
Когда список ключей пуст, синтаксический анализатор считывает следующий токен и начинает заново. Если токенов больше нет, синтаксический анализ завершается, и синтаксический анализатор может выбрать полный синтаксический анализ на графике.
Однако некоторые фильтры усложняют этот процесс. Первые фильтры — это приемочные фильтры, которые используются, чтобы решить, может ли Составляющая стать следующей частью Дуги. Это разрешено, если:
- Арка не завершена.
- Составляющая еще не находится в Арке или ее дочерних элементах, как и другая Составляющая, которая содержит слова в любой из тех же позиций в предложении.
- Если Составляющая реальна (см. ниже), она начинается там, где находится текущий конец Дуги.
- Учредитель имеет синтаксическую категорию, необходимую для следующего члена Арки.

Выборочная фильтрация
Следующей системой фильтрации является селективный фильтр. Лингвисты различают два типа ограничений на структуры фраз, которые не обсуждаются в теории X-bar. Первая — это подкатегория , которая требует от слова, чтобы его соседи (и обычно, особенно его дополнения) имели различные синтаксические особенности. Например, можно съесть бутерброд или пообедать на бутербродом . Хотя эти две фразы означают примерно одно и то же, * съесть бутерброд или * пообедать бутербродом , потому что это нарушает требования к подкатегориям есть и обедать . (Кстати, лингвисты используют * для обозначения неграмматичности. )
)
Требования к отбору связаны с ролями, которые могут выполнять различные вещи. Например, акт перехода требует (обычно) двух участников, агента и места. Грамматическое предложение с на не должно иметь никакого смысла — у нас может быть Санта-Клаус отправляется в ад , скажем, но для этого нужны правильные аргументы. * Я иду в два часа дня. не является грамматическим (при наших обычных предположениях о Вселенной, а именно, у меня нет машины времени), хотя в обоих предложениях есть слово go с PP[to], потому что two pm is’ т место. * Комната идет на обед имеет аналогичную проблему, где комната не может быть агентом (если вы не живете в проекте будущего дома профессора Мерфи).
Наша программа не различает эти типы фильтров — они оба обрабатываются в Прологе. Всякий раз, когда дуга завершается, она возвращает фразу, которая немедленно (во время построения) ищет связанный с ней код выбора. Он делает все необходимые привязки (на самом деле список привязок разрешается до создания, а & разрешается сразу после). Затем он последовательно вызывает каждую строку (строки в Прологе заканчиваются точками) своего кода выбора. Если последняя строка имеет любые решения, фраза непротиворечива. (Первые строки просто настраиваются — у них может быть любое количество решений, но кроме побочных эффектов на базу данных, таких как утверждения, они игнорируются.) В противном случае фраза устанавливает флаг несогласованности, и синтаксический анализатор отбрасывает его. .
Затем он последовательно вызывает каждую строку (строки в Прологе заканчиваются точками) своего кода выбора. Если последняя строка имеет любые решения, фраза непротиворечива. (Первые строки просто настраиваются — у них может быть любое количество решений, но кроме побочных эффектов на базу данных, таких как утверждения, они игнорируются.) В противном случае фраза устанавливает флаг несогласованности, и синтаксический анализатор отбрасывает его. .
Основой процесса выборочной фильтрации является предикат типа . Если вы посмотрите на лексические статьи, вы увидите, что большинство слов имеют тип. Те немногие, у которых нет списков кодов none , что означает полное отсутствие кода. Некоторые слова имеют несколько типов, но большинство имеют только один. Грамматические правила имеют тенденцию также утверждать некоторые вещи о типе. Типичное утверждение:
assert( ( type(&, Var):- type(H, Var))).
Это означает, что мой тип X тогда и только тогда, когда тип моей головы также X.
Чтобы разобраться во всех утверждениях типов, вам нужно прочитать файл lexical-hierarchy . Первое, что вы увидите, это предикат 9.0177 hтип(X, Y) . htype означает иерархический тип. Это связано с тем, что типы расположены в иерархии наследования, и если слово или фраза имеют тип где-либо в иерархии, они также наследуют все более высокие типы htypes.
Как видите, иерархия довольно безумна. Пунктирные линии представляют собой восходящих наследований, так что фразы с локативными предлогами в некотором смысле являются локациями (а не наоборот). Однако на самом деле не существует циклов, которые бы все сломали, поскольку это позволило бы Прологу доказывать определенные утверждения бесконечными способами (занимающими бесконечное время в процессе). Части имен в скобках показывают фактические задействованные слова, а обычные части показывают их имена в прологе. В том же файле есть менее сложная иерархия глаголов, не показанная здесь.
Грамматические правила обычно выполняют такие проверки, как compOf(H, X) или modOf(H, X) , также определенные в файле lexical-hierarchy . Каждый тип, или htype, имеет различные разрешенные комбинации и модификации, и это тестирование позволяет программе определить, соответствует ли предложенная фраза как с точки зрения подкатегоризации, так и выборочной типизации.
Каждый тип, или htype, имеет различные разрешенные комбинации и модификации, и это тестирование позволяет программе определить, соответствует ли предложенная фраза как с точки зрения подкатегоризации, так и выборочной типизации.
Холдинг
К сожалению, не все предложения попадают в красивую структуру, которую мы определяем с помощью теории X-bar. Два примера, которые часто встречаются в домене информационного сервера, — это перевернутые вопросы «да/нет» и «белые вопросы». Первый производит такие предложения, как:
Вы робот?
а последний производит:
Я знаю где ты живешь
Они также встречаются вместе, например:
Кто ты?
Мы хотим связать их с глубинными структурами Ты робот , Я знаю ты живешь там где и Ты что . Это облегчит их интерпретацию, сделает наш синтаксический анализатор более общим и упростит выборочную проверку.
Следуя подходу, изложенному в главе 4 книги Аллена, синтаксический анализатор содержит избирателей, которые, как мы подозреваем, могли переместиться, поместив их в список задержанных . Компоненты в списке хранения никогда не удаляются, и они продолжают поступать для аудита новыми дугами до конца синтаксического анализа.
Компоненты в списке хранения никогда не удаляются, и они продолжают поступать для аудита новыми дугами до конца синтаксического анализа.
Пролог определяет, какие составляющие хранятся, проверяя предикат hold . Предикат hold утверждается в коде выбора любой структуры, которую предполагается удерживать. В некоторых случаях это само слово ( 9Например, 0038 — это ), но в других случаях это первая фраза над словом (, какая книга ). Пролог отслеживает это с помощью специального типа wh, который утверждается на словах этого типа (очевидно, что они начинаются с wh, хотя это не всегда так). Затем код грамматики при создании XP проверяет, содержит ли он часть wh, и если да, то утверждает, что он держится.
Удерживаемые компоненты не могут быть проверены так же легко, как обычные, поскольку они могут поступать из странных мест в районах вокруг Арки. Дуги, которые начинаются с удерживаемых составляющих, вообще не имеют начала и называются 9. 0169 виртуальный . Один действительно сложный случай — это случай с номером . Ты знаешь, что я люблю роботов? , где синтаксический анализатор должен определить, что do принадлежит первому слоту Aux, Вы же знаете, я люблю роботов , а не второму, Вы знаете, я люблю роботов . Это важно для определения того, какая фраза является вопросом. У синтаксического анализатора есть несколько хаков для этого случая — их легко найти, потому что содержащие их функции устарели.
0169 виртуальный . Один действительно сложный случай — это случай с номером . Ты знаешь, что я люблю роботов? , где синтаксический анализатор должен определить, что do принадлежит первому слоту Aux, Вы же знаете, я люблю роботов , а не второму, Вы знаете, я люблю роботов . Это важно для определения того, какая фраза является вопросом. У синтаксического анализатора есть несколько хаков для этого случая — их легко найти, потому что содержащие их функции устарели.
Разобрать выбор
Парсер завершает работу с набором компонентов на диаграмме. Некоторые из них являются синтаксическими анализами, а некоторые нет. Однако в настоящее время синтаксический анализатор выбирает только один (это можно изменить). Селектор делает следующее:
- Выбросьте все, что не является XP.
- Выбросить все, что не содержит всех слов в строке.
- Если в списке остались AuxP, выберите первый.
- Если нет, выберите первый участник в списке. 93 раза. Ниже приведены некоторые причины, также известные как список моих ошибок.
- Управление снизу вверх — если у нас нет дуг, ищущих в данный момент NP, нам не следует строить их. См. Allen, глава 3, для гибридных синтаксических анализаторов и синтаксических анализаторов с уменьшением сдвига.
- Без слияния. Если у нас есть j разных структур для первых трех слов (поскольку они неоднозначны) и k структур для следующих трех, всего мы имеем j*k структур. Вместо этого одна дуга может обрабатывать все это, говоря: «выберите одну из первой группы, затем одну из второй группы».
- Список удержания. Компоненты в списке удержания остаются навсегда, поэтому предложение что (больше материала) многократно проверяет, приемлемо ли что для всех Арк в списке Арк, даже для Арк, которые уже отвергли его. Это экспоненциально. См. Allen для другого подхода, использующего трассировки.
- Неоднозначности — PP в качестве последней части предложения имеет тенденцию прикрепляться на каждом уровне дерева, удваивая количество деревьев. См. Allen для детерминированных стратегий синтаксического анализа.
Дальнейшая работа
- Усовершенствования предварительной обработки, как указано выше.
- Большой словарь — нам нужен.
- Скомпилируйте файлы Java (Джон говорит, что мы можем это сделать) и файлы Prolog (см. JIPrologRefManual), чтобы ускорить работу.
- Отключите анализатор через TCP, затем найдите большой-большой компьютер для обработки анализа.
- Дополнения NP. См. раздел интерпретатора, чтобы узнать, почему мы не можем использовать нашу обычную семантику, например, для спикера философии 9.0039 . Вместо этого Карни предлагает сделать философия дополнением существительного влево.
- Примыкающие и примыкающие конструкции. X, Y и Z или Привет, как дела? .
- Лучший выбор разбора. Минимизация длины NP может помочь избежать выбора синтаксических анализов, содержащих PP друг в друге, где они обычно не используются.
 93 раза. Ниже приведены некоторые причины, также известные как список моих ошибок.
93 раза. Ниже приведены некоторые причины, также известные как список моих ошибок. См. Allen для детерминированных стратегий синтаксического анализа.
См. Allen для детерминированных стратегий синтаксического анализа.