«Синтаксический разбор предложения » — Яндекс Кью
Ольга Х. · ·
140,4 K
На Кью задали 7 похожих вопросовЭльса М.
Всем трям, то есть здравствуйте. 🙂 Я по жизни… · 22 янв 2019
Чтобы сделать синтаксический разбор предложения, сначала нужно найти и подчеркнуть главные члены (подлежащее и сказуемое). Потом задать от них вопросы к второстепенным членам, узнать, чем они являются и подчеркнуть их. Подписать над каждым словом часть речи.
Определить тип предложения по цели высказывания (повествовательное, вопросительное, побудительное). Указать вид предложения по эмоциональной окраске (восклицательное, невосклицательное). Далее понять, простое предложение или сложное.
Если сложное, то: по грамматическим основам определить количество простых предложений и найти их границы и определить средства связи простых предложений (союзное или безсоюзное).
В конце составить схему предложения.
294 оценили·
140,9 K
Zet .
27 февр 2019
Не помогло
Комментировать ответ…Комментировать…
Кто-то
Человек, который любит помогать. · 22 сент 2021
Чтобы сделать синтаксический разбор предложения, сначала нужно найти и подчеркнуть главные члены (подлежащее и сказуемое). Потом задать от них вопросы к второстепенным членам, узнать, чем они являются и подчеркнуть их… Читать далее
16 оценили·
13,5 K
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
27 ответов скрыто(Почему?)
Ответы на похожие вопросы
Как делается синтаксический разбор предложения? — 11 ответов, задан 056Z»>26 янв 2018
056Z»>26 янв 2018Анастасия BonneFee
Препод-IT-шник. · 12 нояб 2018
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
Для простого:
- Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое).
- Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое.
- Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено.
- Подчеркнуть все члены предложения, указать части речи.
- Составить схему предложения, указав грамматическую основу и осложнение, если оно есть.
Для сложного:
- Указать, какая связь в предложении: союзная или бессоюзная.

- Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы.
- Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП).
- Разобрать каждую часть сложного предложения, как простое (см. выше).

·
146,4 K
Комментировать ответ…Комментировать…
Как делается синтаксический разбор предложения? — 11 ответов, заданВоланд Орле
Люблю сочинять и фотошопить · 12 нояб 2020
Предложение…
Рекомендуется подчеркнуть слова,и подписать часть речи
Подчёркивания
1)Подлежащее-(одной чертой)
2)Сказуемое-(двумя чертами)
3)Обстоятельство-(точка тире,точка тире и т.д.)
4)дополнение-(пунктиром)
5)определение-(волнистой линеей)
Части речи
1)Имя прилогательное
2)Имя существительное
3)Глагол
4)Наречие
5)Числительное
6)Местоимение
7)Предлог
8)Союз
9)Нарецательное
Характеристика(пишиться под предложением)
1. По цели высказывание-вопросительное,повествовательное,побудительное.
По цели высказывание-вопросительное,повествовательное,побудительное.
2.По интонации-восклицательное,невосклицательное.
3.По наличию грамматических основ-простое,сложное.
4.По наличию главных членов предложения-односоставное,двухсоставное.
5.По наличию второстипенных членов-распространённое,нераспростронённое.
6.По граматике-осложнено,несложнено.
7.Схема предложения-[…]
Если чтото непонравилось пишите причину в коментарии
35 оценили·
10,5 K
Комментировать ответ…Комментировать…
Как провести синтаксический разбор предложения? — 1 ответ, заданВера Зобова
Я очень люблю русский язык и попытаюсь ответить… · 4 нояб 2020
1.Охарактеризоватьпредложение по цели высказывания:повествовательное,вопросительное,побудительное.
2.По эмоциональной окраске:восклицательное или невосклицательное.
3.По наличиюграмматических основ:простое,сложное.
4.Затем,в зависимостиот того простое или сложное.
·
2,1 K
Комментировать ответ…Комментировать…
Помогите пожалуйста сделать полный синтаксический разбор предложений🙏 — 1 ответ, заданNas tae
6 окт 2020
1.Правильная речь -это одна из весьма существенных сторон общей культуры человека.
2.Поэт в России-больше чем поэт.
3.Наш дар бесценный-речь.
Заранее ОГРОМНОЕ СПАСИБО!)
·
2,4 K
Комментировать ответ…Комментировать…
Как делается синтаксический разбор предложения? — 11 ответов, заданAM KOLA
22 янв 2020
1) Выделить главные и второстепенные члены предложения 2)по цели высказывания (вопросительное,побудительное,повествовательное. ) 3)по интронации(восклицательное,не восклицательно.) 4)просто или сложное предоложение. 5)распростронёное или не распростронёное
) 3)по интронации(восклицательное,не восклицательно.) 4)просто или сложное предоложение. 5)распростронёное или не распростронёное
·
17,7 K
Комментировать ответ…Комментировать…
Синтаксический разбор предложения 9 класс онлайн-подготовка на Ростелеком Лицей
Тема 1: Повторение изученного в 8 классе
- Видео
- Тренажер
- Теория
Заметили ошибку?
“Знание — сила”
Фрэнсис Бэкон
Тема сегодняшнего урока :»Синтаксический разбор предложения.»
План действий:
-
Найти грамматическую основу предложения.
Грамматическая основа — подлежащее (Кто? Что?) + сказуемое (Что делает предмет? Что с ним происходит? Что он такое? Кто он таков? Каков он?)
-
Дать предложению характеристику.
-
Какое это предложение по цели высказывания: повествовательное, побудительное или вопросительное?
Повествовательное предложение — сообщение, вопросительное — вопрос, побудительное — просьба или приказ.
-
Какое предложение по интонации: восклицательное или невосклицательное?
Восклицательные предложения произносятся с чувствами, в конце такого предложения ставится “!”. Невосклицательное предложение произносится без эмоций, в конце ставится “.” или “?”.
-
Какое предложение по количеству грамматических основ: простое (одна основа) или сложное (несколько основ)?
НО простое предложение может быть осложнённым. Осложнённое предложения содержит знаки препинания.
-
Какое предложение по количеству главных членов: односоставное (либо подлежащее, либо сказуемое) или двусоставное (и подлежащее, и сказуемое)?
Односоставные предложения с подлежащим — назывные.
Односоставные предложения со сказуемым — определённо-личные, неопределённо личные, обобщённо-личные или безличные.
-
Какое предложение по наличию второстепенных членов: нераспространённое (только грамматическая основа) или распространённое (есть второстепенные члены)?
-

 Односоставные предложения со сказуемым — определённо-личные, неопределённо личные, обобщённо-личные или безличные.
Односоставные предложения со сказуемым — определённо-личные, неопределённо личные, обобщённо-личные или безличные.
-
Определить второстепенные члены предложения:
-
относящиеся к подлежащему
-
относящиеся к сказуемому
Определение отвечает на вопросы Какой? Чей?
Дополнение — на вопросы косвенных падежей.
Обстоятельство — на вопросы Где? Куда? Когда? Откуда? Почему? Зачем? Как?
-
Заметили ошибку?
Расскажите нам об ошибке, и мы ее исправим.
[PDF] Разбор дискурса на уровне предложений с использованием синтаксической и лексической информации title={Разбор дискурса на уровне предложения с использованием синтаксической и лексической информации}, автор={Раду Сорикут и Даниэль Марку}, booktitle={Североамериканское отделение Ассоциации компьютерной лингвистики}, год = {2003} }
Мы представляем две вероятностные модели, которые можно использовать для идентификации элементарных единиц дискурса и построения деревьев разбора дискурса на уровне предложений. В моделях используются синтаксические и лексические признаки. Алгоритм синтаксического анализа дискурса, который реализует эти модели, выводит деревья синтаксического анализа дискурса с уменьшением ошибок на 18,8% по сравнению с современным синтаксическим анализатором дискурса, основанным на принятии решений. Ряд эмпирических оценок показывает, что наша модель разбора дискурса достаточно сложна, чтобы генерировать деревья дискурса в…
View on ACL
dl.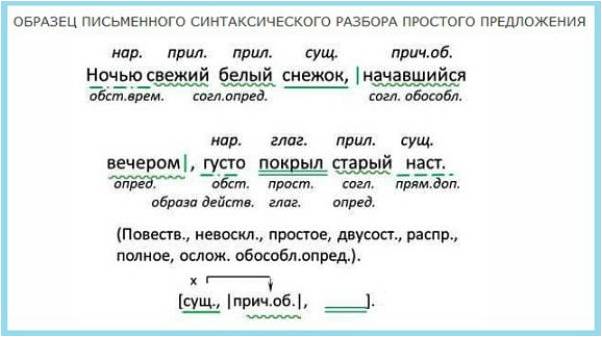 acm.org
acm.orgAn effective Discourse Parser that uses Rich Linguistic Information
- R. Subba, Barbara Maria Di Eugenio
Computer Science
NAACL
- 2009
The modified shift -Модель синтаксического анализа, которая использует авторский классификатор отношений, значительно превосходит базовый уровень с правым разветвлением мажоритарного класса и имеет статистически значимое улучшение в классификации отношений по сравнению с парадигмами обучения атрибут-значение, такими как деревья решений, RIPPER и наивный байесовский алгоритм.
Эксплуатация семантики событий, чтобы проанализировать риторическую структуру текста естественного языка
- R. subba
Компьютерные науки
NAACL
- 2007
Цель этого тезиса — для разоблачения события Semantics в деревья синтаксического анализа (DPT), основанные на информационных риторических отношениях, основанных на классификаторе риторических отношений на основе индуктивного логического программирования.
Анализ дискурса: изучение правил FOL на основе расширенных семантических представлений глаголов для автоматической маркировки риторических отношений
Продемонстрировано, что ILP можно использовать для изучения высокоструктурированных данных естественного языка и что производительность модели анализа дискурса, которая использует только семантическую информацию, сравнима с производительностью современных синтаксических анализаторов дискурса.
Анализ дискурса, автоматический
- Д. Марку
Социология
- 2006
Анализ дискурса на уровне текста с богатыми лингвистическими функциями0004
Социология, информатика
ACL
Разработан анализатор дискурса текстового уровня в стиле RST, основанный на анализаторе дискурса HILDA, который значительно улучшает этап построения дерева за счет включения собственного богатого лингвистического Особенности.
Подход к анализу дискурса, основанный на правилах
- Л. Поланьи, К. Кули, М. В. Д. Берг, Г. Л. Тионе, Дэвид Д. Ан
Социология, информатика
SIGDIAL Workshop
- 2004
Дан обзор последних достижений в области теории дискурса и анализа в рамках лингвистической модели дискурса (LDM), семантической теории структуры дискурса и нового подхода к проблеме сегментации дискурса на основе семантики дискурса. .
Анализ структуры дискурса с помощью синтаксических зависимостей и синтаксического анализа на основе данных Shift-Reduce
- Kenji Sagae
Информатика
IWPT
- 2009
В этой работе применяются алгоритмы сдвига-уменьшения для анализа зависимостей и составляющих для определения синтаксических зависимостей для предложений в документе, а затем дерево теории риторической структуры (RST) для всего документа.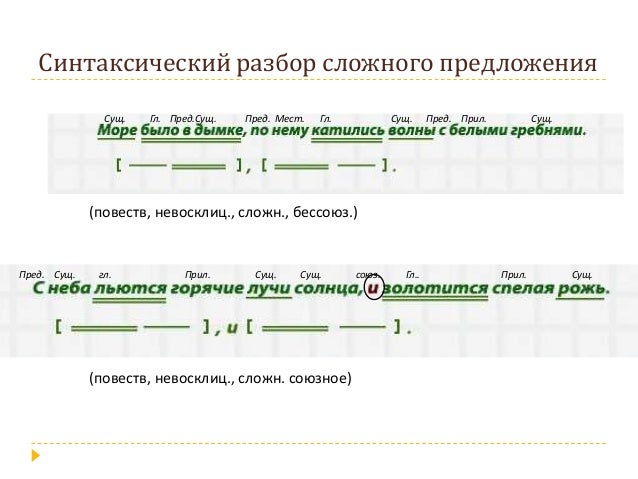
Сегментатор синтаксического и лексического дискурса
- Милан Тофилоски, Джулиан Брук, М. Табоада
Компьютерные науки, социология
ACL
- 20049
В этой работе SLSeg сравнивается с вероятностным сегментатором, показывая, что консервативный подход повышает точность за счет отзыва, сохраняя при этом высокий F-показатель как для официальных, так и для неформальных текстов.
Обработка текстовых технологических ресурсов при анализе дискурса
- Хеннинг Лобин, Х. Люнген, М. Гильберт, Майя Беренфенгер
Социология, информатика
Моделирование, изучение и обработка текстовых технологических структур данных
- 2012
В этой главе описывается тексто-технологический подход к анализу дискурса с целью предоставления структуры дискурса в виде добавления нового слоя аннотации для входных документов, размеченных на нескольких уровнях лингвистической аннотации.
генерирующие дискурсивные структуры для письменных текстов
- H. Lethanh, G. Abeysinghe, C. Huyck
Социология
Coling 2004
- 2004
. это показывает многообещающие результаты в разумном пространстве поиска по сравнению с деревьями дискурса, созданными аналитиками-людьми.
ПОКАЗАНЫ 1–10 ИЗ 18 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Система D-LTAG: анализ дискурса с помощью лексикализованной грамматики, примыкающей к дереву Джоши, Б. Уэббер
Социология
Дж. Лог. Ланг. Инф.
Реализация системы синтаксического анализа дискурса для алексикализованной древовидной грамматики для дискурса, указывающая интеграцию обработки на уровне предложения и дискурса в предположении, что композиционные аспекты семантики на уровне дискурса параллельны аспектам семантики предложения. уровень.
уровень.
Статистические модели применения решений для анализа
- Дэвид М. Магерман
Компьютерная наука
ACL
- 1995
Spatth для каждого предложения и достигает показателей точности намного лучше, чем любой опубликованный результат.
Автоматическая маркировка семантических ролей
- Д. Гилдеа, Дэн Джурафски
Информатика, лингвистика
CL
- 2002
Система для определения семантических отношений или семантических ролей, исполняемых составляющими предложения в семантической структуре, на основе статистических классификаторов, обученных примерно на 50 000 предложений, которые были вручную аннотированы семантическими ролями в рамках проекта семантической маркировки FrameNet.
От TreeBank до PropBank
- Пол Р. Кингсбери, Марта Палмер
Информатика
LREC
- 2002
В этой статье описывается подход к разработке банка предложений, который включает добавление семантической информации в Penn English Treebank и вводит метафреймы как метод обработки похожих фреймов среди близких − синонимичные глаголы.
Дискриминативное повторное ранжирование для синтаксического анализа естественного языка (1998) применяется для анализа банка дерева Wall Street Journal, и утверждается, что этот метод является привлекательной альтернативой — с точки зрения простоты и эффективности — для работы над методами выбора признаков в рамках логарифмически-линейных (максимальной энтропии) моделей.
A Maximum-Entropy-Inspired Parser
- Eugene Charniak
Computer Science
ANLP
- 2000
A new parser for parsing down to Penn tree-bank style parse trees that achieves 90.1% average precision/ представлена полнота для предложений длиной 40 и менее и 89,5% при обучении и тестировании на ранее установленных разделах дерева Wall Street Journal.
Создание большого аннотированного корпуса английского языка: The Penn Treebank
- М. Маркус, Беатрис Санторини, Мэри Энн Марцинкевич
Информатика
CL
- 1993
В результате этого гранта исследователи опубликовали на компакт-диске корпус объемом более 4 миллионов слов. бегущий текст, аннотированный тегами части речи (POS), который включает полностью проанализированную вручную версию классического корпуса Брауна.
бегущий текст, аннотированный тегами части речи (POS), который включает полностью проанализированную вручную версию классического корпуса Брауна.
Построение дискурсивно-тегированного корпуса в рамках теории риторической структуры
- Линн Карлсон, Д. Марку, Мэри Эллен Окуровски
Социология
Семинар SIGDIAL
- 2001
Работа в рамках высокой последовательности, аннотированного ресурса, созданного с использованием теории риторической структуры, четко определенная методология и протокол, позволяющие исследователям разрабатывать эмпирически обоснованные, специфичные для дискурса приложения.
Модели максимальной энтропии для разрешения неоднозначности естественного языка
- А. Ратнапарки, М. Маркус
Информатика
- 1998
Этот тезис демонстрирует, что несколько важных видов неоднозначности естественного языка могут быть разрешены с современной точностью с помощью одного статистического моделирования. метод, основанный на…
метод, основанный на…
Адаптивное многоязычное устранение неоднозначности границ предложений
- Д. Палмер, Марти А. Херст
Информатика
Вычисл. Лингвистика
- 1997
В этой статье представлена эффективная, обучаемая система устранения неоднозначности границ предложений, называемая Satz, которая делает простые оценки частей речи токенов, непосредственно предшествующих и следующих за каждым знаком препинания, и использует эти оценки в качестве входных данных для алгоритм машинного обучения, который затем классифицирует знак препинания.
«Взаимодействие стратегий синтаксического анализа и длины просодической фразы», Назик Динктопал-Дениз
- < Предыдущий
- Далее >
Дата получения степени
10-2014
Тип документа
Диссертация
Название степени
Кандидат наук.
Программа
Лингвистика
Консультант
Джанет Д. Фодор
Тематические категории
Лингвистика
Ключевые слова
Обработка фраз, Синтезирование 9 фраз, Психосентинг, Просодия0011
Abstract
Многие эксперименты показали, что просодия (ритм и мелодия), с которой произносится предложение, может дать слушателю подсказки к его синтаксической структуре (Lehiste, 1973 и далее). Кроме того, в нескольких исследованиях было обнаружено, что неподходящий просодический контур может ввести в заблуждение процедуры синтаксического анализа, что приведет к просодии, вызванной садовой дорожкой. К ним относятся, среди прочего, Speer et al. (1996) и Kjelgaard and Speer (1999) для английского языка. Исследования Speer et al. и Kjelgaard and Speer (SKS) показали, что неуместные просодические сигналы вызывают больше трудностей с обработкой в предложениях с ранним закрытием предложения (синтаксис EC), чем в предложениях с поздним закрытием предложения (синтаксис LC).
Альтернативное объяснение рассматривает возможность того, что составляющие длины могли повлиять на воспринимаемую информативность явных просодических сигналов в этих исследованиях, как это было предложено в гипотезе Rational Speaker Hypothesis Clifton et al. (2002, 2006). Гипотеза рационального говорящего (RSH) утверждает, что просодические разрывы, граничащие с более короткими составляющими, воспринимаются более серьезно как индикаторы синтаксической структуры, чем просодические разрывы, граничащие с более длинными составляющими, потому что первые нельзя оправдать как мотивированные соображениями оптимальной длины. Для проверки этих двух альтернативных гипотез было проведено четыре эксперимента по прослушиванию. Перед экспериментами с прослушиванием был проведен дополнительный эксперимент по чтению, чтобы изучить потенциальные эффекты стратегии позднего закрытия и составных частей при чтении, где нет явной просодии. Во всех случаях целевыми материалами были временно двусмысленные турецкие предложения, которые могли быть морфологически разрешены как синтаксические конструкции LC или EC. Составляющие длины систематически манипулировались во всех целевых материалах, так что оптимальная по длине просодическая фразировка была связана с синтаксисом LC в одном условии и с синтаксисом EC в другом.
В эксперименте 1 использовалось задание на отсутствующие морфемы, разработанное для этого исследования. В задаче на отсутствующие морфемы символы подчеркивания (усредненные по длине) заменили морфемы, устраняющие неоднозначность, и участники должны были вставлять их, когда они читали предложения вслух. Результаты выявили значительное влияние длины фразы на синтаксическую интерпретацию читателей, о чем свидетельствуют вставленные морфемы и произведенные ими просодические разрывы.
В экспериментах 2A и 2B использовалась задача «понять» в конце предложения (Frazier et al., 19).83), в котором участники слушали произносимые предложения и указывали после каждого, поняли они его или нет. Предложения в эксперименте 2А имели распределение длины фраз, аналогичное английским материалам SKS. Эксперимент 2B манипулировал длинами в обратном порядке. Стимулы имели сотрудничающую, конфликтную или нейтральную просодию. Данные о времени отклика подтверждают взаимодействие как синтаксического позднего закрытия, так и RSH. Таким образом, был сделан вывод, что составные длины действительно могут оказывать значительное влияние на решения слушателей по разбору, в дополнение к знакомым синтаксическим искажениям при разборе и просодическим влияниям.
Эксперименты 3A и 3B использовали версию лексического зонда парадигмы восстановления фонемы, использованную Stoyneshka et al.
Результаты экспериментов 3A и 3B показали, что слушатели были очень чувствительны к сентенциальной просодии, о чем свидетельствуют их ответы на восстановление фонемы и данные о времени ответа, подтверждая выводы Стойнешки и др., устанавливающие надежность парадигмы восстановления фонемы при исследовании эффектов просодия в разрешении двусмысленности. Данные о времени отклика показали закономерность, аналогичную той, которую SKS наблюдал для английского языка (за исключением одного условия в эксперименте 3A, с неконгруэнтными пробами): несмотря на изменение длины фразы в эксперименте 3B, не было никакого влияния распределения длины фразы на разрешение неоднозначности. Этому есть естественное объяснение в свете разницы между задачей «получил это» с устранением неоднозначности морфологии внутри стимула предложения и задачей восстановления фонемы, в которой слушатель может спроецировать на глагол любую морфологию, совместимую с услышанной просодией. ЖХ и ЭК одинаково хорошо обрабатывались для конгруэнтных зондов, и было преимущество ЖХ в неконгруэнтных и совместимых зондах.